Из чего состоит и как работает поисковая система Яндекс и Google?

В этой статье я опишу основные элементы поисковой системы, покажу, как они связаны, и затрону немного истории возникновения поисковиков. Но вначале разберем, что такое поисковая система и для чего она нужна?
Поисковая система – это специальный сервис для быстрого поиска информации в Интернете. Пользователь задает в поисковик запрос, в котором формулирует, что хочет найти. Поисковая система в ответ выдает результаты поиска – ссылки на страницы сайтов, где может находиться интересующая пользователя информация.
Давайте разберемся, из чего состоит поисковая система и как она работает. Нужно отметить, что принципы действия у любого поисковика схожи: Яндекс, Google и другие поисковики работают по аналогичным алгоритмам, которые отличаются нюансами.
История развития поисковиков: не путайте Wandex и Yandex!
Начнем с истории: первый в мире поисковик в WWW появился в 1993 году, и это был Wandex. Не путайте с Яндексом. После него появились Aliweb, Webcrawler, Lycos, Altavista, Рамблер, Google и только потом Яндекс.
Первым именно российским поисковиком был Рамблер. Сейчас Рамблер все еще существует, но для поиска использует движок Яндекса. На его долю приходится около 1% от всех поисковых запросов.
Самой популярной поисковой системой в России на момент подготовки статьи является Яндекс, который используют для поиска информации около 61% россиян по данным РБК. На втором месте по количеству пользователей в России идет Google – около 26%, но в последнее время процент пользователей Google растет. Обе поисковые системы были запущены в 1997 году, но в Россию Google пришел гораздо позже (официально – в 2006 году).
Перейдем к вопросу, как устроена и как работает поисковая система
Поисковая система состоит из трех основных элементов:
1. Роботы-пауки (агенты, роботы, обходящие все интернет пространство, и сканирующие сайты)
У поисковой системы существует множество роботов-агентов, каждый из них выполняет свою функцию:
- основной работ, сканирующий сайты;
- робот, сканирующий картинки;
- робот, сканирующий видео;
- робот мобильных сервисов;
- быстроробот выполняет функцию сбора свежей информации и новостей для индексации;
- другие роботы.
У каждого робота есть список адресов, которые он должен обойти. Этот список автоматически увеличивается, если робот находит новую ссылку и адрес сайта. Робот проверяет тип найденного документа, кодировку и язык и отправляет эти данные на дальнейшую обработку.
2. Индекс (база документов и дополнительных параметров в обработанном виде)
Индекс – это хранилище поисковой системы, где вся информация находится в обработанном и упорядоченном виде. Например, документы хранятся в очищенном от html-разметки виде, в индексе имеются данные о местоположении различных слов в документе и другая информация. Индекс обновляется постоянно.
В ряде поисковых систем имеются выраженные апдейты. В этом случае полноценное обновление поискового индекса, на основе которого формируются результаты поиска, происходит не постоянно, а через некоторое время. Апдейт – это момент обновления поисковой системы, в который результаты поиска по многим запросам серьезно меняются.
3. Поисковый алгоритм (механизм, который позволяет формировать выдачу)
Когда в поисковую систему поступает запрос, алгоритмы поисковой системы обрабатывают его. В обработанном виде он поступает дальше в систему.
Если запрос популярный, результаты поиска по нему могут кешироваться (сохраняться в поисковой системе) и в дальнейшем при поступлении такого же запроса результаты поиска поднимаются из кеша. Если запрос уникальный, то поисковые алгоритмы на основе имеющихся в них формул формируют ответ на запрос из индекса поисковой системы.
Формула, по которой формируются результаты поиска, может отличаться в зависимости от запроса, его типа (коммерческий, информационный, навигационный и т.д.), географии (формула для региональных запросов может быть проще, чем для московского региона).
Мы рассмотрели упрощенную модель поисковой системы. Реальные поисковые системы намного сложнее и включают в себя механизмы борьбы по спамом, колдунщики и множество других вещей.
Что такое машинное обучение?
Поисковая система Яндекс создает формулы для ранжирования сайтов на основе машинного обучения.
Очень упрощенно данную систему можно представить так:
- Полученные формулы тестируются, и разработчики по определенным параметрам определяют, улучшилось качество поиска по новым формулам или нет.
- Если качество поиска повысилось – формулы загружаются в основной поиск и начинают обрабатывать пользовательские запросы.
Резюме: как работает поисковик?
Как мы видим, даже упрощенная модель работы поисковой системы достаточно сложна и состоит из множества систем. Реальные же поисковые системы намного сложнее, поэтому процесс продвижения сайтов представляется не только сложным, но и крайне интересным.
В данный момент при ранжировании сайтов поисковая система Google учитывает более 200 факторов, а поисковик Яндекс — более 800 факторов. Все они подразделяются на группы: технические, доменные, текстовые, ссылочные, региональные, поведенческие, коммерческие, юзабилити и ряд других.
Читайте также:
Рекомендуем

Ссылки с других сайтов – один из важнейших факторов для поисковых систем, особенно для Google. Если говорить о Яндексе, то влияние ссылочных …

Файл robots.txt управляет индексацией сайта. В нем содержатся команды, которые разрешают или запрещают поисковым системам добавлять в свою базу …
www.kadrof.ru
Что такое поисковая система, как она работает? :: SYL.ru
В последние годы сервисы от «Гугл» и «Яндекс» прочно вошли в нашу жизнь. В этой связи многие наверняка задаются вопросом, что такое поисковая система? Говоря простыми словами, это программная система, предназначенная для поиска информации в World Wide Web. Результаты его обычно представлены в виде списка, часто называемом страницами результатов поиска (SERP). Информация может представлять собой сочетание веб-страниц, изображений и других типов файлов. Некоторые поисковые системы также содержат информацию, доступную в базах данных или открытых каталогах.

В отличие от веб-каталогов, которые поддерживаются только собственными редакторами, поисковики также содержат информацию в режиме реального времени, запуская алгоритм на веб-искателе.
История возникновения
Сами по себе поисковые системы появились ранее всемирной сети — в декабре 1990 года. Первый такой сервис назывался Archie, и он искал по командам содержимое файлов FTP.
Что такое поисковая система в Интернете? До сентября 1993 года World Wide Web была полностью проиндексирована вручную. Существовал список веб-серверов, отредактированный Тимом Бернерс-Ли, который был размещен на веб-сервере CERN. По мере того, как все большее количество серверов выходили в интернет, вышеуказанный сервис не мог успевать обрабатывать такое количество информации.

Одной из первых поисковых систем, основанных на поиске в сети, была WebCrawler, которая вышла в 1994 году. В отличие от своих предшественников, она позволяла пользователям искать любое слово на любой веб-странице. Такой алгоритм с тех пор стал стандартом для всех основных поисковых систем. Это было также первое решение, широко известное публике. Также в 1994 году был запущен сервис Lycos, который впоследствии стал крупным коммерческим проектом.
Вскоре после этого появилось много поисковых машин, и их популярность значительно выросла. К ним можно отнести Magellan, Excite, Infoseek, Inktomi, Northern Light и AltaVista. Yahoo! был одним из самых популярных способов отыскания интересующих веб-страниц, но его алгоритм поиска работал в своем собственном веб-каталоге, а не в полнотекстовых копиях страниц. Искатели информации также могли просматривать каталог, а не выполнять поиск по ключевым словам.

Новый виток развития
Компания Google приняла идею продажи поисковых запросов в 1998 году, начиная с небольшой компании goto.com. Этот шаг оказал значительное влияние на бизнес SEO, который со временем стал одним из самых прибыльных занятий в Интернете.
Примерно в 2000 году поисковая система «Гугл» стала широко известна. Компания добилась лучших результатов для многих поисков с помощью инноваций под названием PageRank. Этот итерационный алгоритм оценивает веб-страницы на основе их связей с другими сайтами и страницами, исходя из предпосылки, что хорошие или желанные источники часто упоминаются другими. Google также поддерживал минималистский интерфейс для своей поисковой системы. Напротив, многие из конкурентов встроили поисковую систему в веб-портал. На самом деле «Гугл» стала настолько популярной, что появились мошеннические движки, такие как Mystery Seeker. Сегодня существует масса региональных версий этого сервиса, в частности, поисковая система Google.ru, рассчитанная на русскоязычных пользователей.
Как работают эти сервисы?
Как же происходит ранжирование и выдача результатов? Что такое поисковые системы с точки зрения алгоритма действий? Они получают информацию через веб-сканирование с сайта на сайт. Робот или «паук» проверяет стандартное имя файла robots.txt, адресованное ему, перед отправкой определенной информации для индексации. При этом основное внимание уделяется многим факторам, а именно заголовкам, содержимому страницы, JavaScript, каскадным таблицам стилей (CSS), а также стандартной разметке HTML информационного содержимого или метаданным в метатегах HTML.
Индексирование означает связывание слов и других определяемых токенов, найденных на веб-страницах, с их доменными именами и полями на основе HTML. Ассоциации создаются в общедоступной базе данных, доступной для запросов веб-поиска. Запрос от пользователя может быть одним словом. Индекс помогает найти информацию, относящуюся к запросу как можно быстрее.
Некоторые из методов индексирования и кэширования — это коммерческие секреты, тогда как веб-сканирование — это простой процесс посещения всех сайтов на систематической основе.
Между посещениями робота кэшированная версия страницы (часть или весь контент, необходимый для ее отображения), хранящийся в рабочей памяти поисковой системы, быстро отправляется запрашивающему пользователю. Если визит просрочен, поисковик может просто действовать как веб-прокси. В этом случае страница может отличаться от индексов поиска. На кэшированном источнике отображается версия, слова которой были проиндексированы, поэтому он может быть полезен в том случае, если фактическая страница была утеряна.

Высокоуровневая архитектура
Обычно пользователь вводит запрос в поисковую систему в виде нескольких ключевых слов. У индекса уже есть имена сайтов, содержащих данные ключевые слова, и они мгновенно отображаются. Реальная загрузочная нагрузка заключается в создании веб-страниц, которые являются списком результатов поиска. Каждая страница во всем списке должна быть оценена в соответствии с информацией в индексах.
В этом случае верхний элемент результата требует поиска, реконструкции и разметки фрагментов, показывающих контекст из сопоставленных ключевых слов. Это лишь часть обработки каждой веб-страницы в результатах поиска, а дальнейшие страницы (рядом с ней) требуют большей части этой последующей обработки.
Помимо простого отыскания ключевых слов, поисковые системы предлагают свои собственные GUI- или управляемые командами операторы и параметры поиска для того, чтобы уточнить результаты.
Они обеспечивают необходимые элементы управления для пользователя с помощью цикла обратной связи, путем фильтрации и взвешивания при уточнении искомых данных с учетом начальных страниц первых результатов поиска. Например, с 2007 года Google.com позволила отфильтровать полученный список по дате, нажав «Показать инструменты поиска» в крайнем левом столбце на странице исходных результатов, а затем выбрав нужный диапазон дат.

Варьирование запросов
Большинство поисковых систем поддерживают использование логических операторов AND, OR и NOT, чтобы помочь конечным пользователям уточнить запрос. Некоторые операторы предназначены для литералов, которые позволяют пользователю уточнять и расширять условия поиска. Робот ищет слова или фразы точно так же, как и введенные команды. Некоторые поисковые системы предоставляют расширенную функцию отыскания, которая позволяет пользователям определять расстояние между ключевыми словами.
Существует также основанный на концепции поиск, в котором исследование предполагает использование статистического анализа на страницах, содержащих слова или фразы, которые вы ищете. Кроме того, запросы на естественном языке позволяют пользователю вводить вопрос в том же виде, который он задал бы человеку (самый характерный пример — ask.com).
Полезность поисковой системы зависит от релевантности набора результатов, который она выдает. Это могут быть миллионы веб-страниц, которые содержат определенное слово или фразу, но некоторые из них могут быть более релевантными, популярными или авторитетными, чем другие. В большинстве поисковых систем используются методы ранжирования, чтобы обеспечить наилучшие результаты.
Каким образом поисковик решает, какие страницы являются лучшими совпадениями с запросом, и в каком порядке должны отображаться найденные источники, сильно варьируется от одного робота к другому. Эти методы также со временем меняются по мере изменения использования Интернета и развитием новых технологий.
Что такое поисковая система: разновидности
Существует два основных типа поисковой системы. Первая — система предопределенных и иерархически упорядоченных ключевых слов, которыми люди массово ее запрограммировали. Вторая — это система, которая генерирует «инвертированный индекс», анализируя найденные тексты.

Большинство поисковых систем — коммерческие сервисы, поддерживаемые доходами от рекламы, и, таким образом, некоторые из них позволяют рекламодателям иметь рейтинг в отображаемых результатах за определенную плату. Сервисы, которые не принимают деньги за ранжирование, зарабатывают деньги, запуская контекстные объявления рядом с отображенными сайтами. На сегодняшний день продвижение в поисковых системах является одним из наиболее прибыльных заработков в сети.
Какие сервисы распространены наиболее всего?
Google — самая популярная поисковая система в мире с долей рынка 80,52% по состоянию на март 2017 года.
Полный же рейтинг наиболее распространенных сервисов (с долей рынка более 1%) выглядит так:
- Google — 80,52%
- Bing — 6,92%
- Baidu — 5,94%
- Yahoo! — 5,35%
Поисковые системы России и стран Восточной Азии
В России и некоторых странах Восточной Азии Google — не самый популярный сервис. Среди российских пользователей поисковая система «Яндекс» лидирует по популярности (61,9%) по сравнению с Google (28,3%). В Китае Baidu является самым популярным сервисом. Поисковый портал Южной Кореи — Naver используется для 70% процентов онлайн-поиска в стране. Также Yahoo! в Японии и Тайвани является наиболее популярным средством для отыскания нужных данных.
Другие известные русские поисковые системы – «Мейл» и «Рамблер». С началом развития рунета они пользовались широкой популярностью, но в настоящее время сильно сдали свои позиции.
Ограничения и критерии поиска
Несмотря на то, что поисковые системы запрограммированы на ранжирование веб-сайтов на основе некоторой их популярности и релевантности, эмпирические исследования указывают на различные политические, экономические и социальные критерии отбора информации, которую они предоставляют. Эти предубеждения могут быть прямым результатом экономических (например, компании, которые рекламируют поисковую систему, могут также стать более популярными в результатах обычного поиска) и политических процессов (например, удаление результатов поиска в соответствии с местными законами ). Так, Google не будет отображать некоторые неонацистские сайты во Франции и Германии, где отрицание Холокоста является незаконным.
Христианские, исламские и еврейские поисковые системы
Глобальный рост Интернета и электронных средств массовой информации в мусульманском мире за последнее десятилетие побудил исламских приверженцев на Ближнем Востоке и Азиатском субконтиненте попытаться создать собственные поисковые системы и отфильтрованные порталы, которые позволят пользователям выполнять безопасный поиск.
Такие сервисы содержат фильтры, которые дополнительно классифицируют веб-сайты как «халяль» или «харам» на основе современного экспертного толкования «Закона Ислама».
Портал ImHalal появился в сети в сентябре 2011 года, а Halalgoogling — в июле 2013 года. Они используют фильтры харам, базируясь на алгоритмах от Google и Bing.
Другие, ориентированные на религию поисковые системы — это Jewgle (еврейская версия Google), а также христианская SeekFind.org. Они фильтрует сайты, которые отрицают или унижают их веру.
www.syl.ru
Поисковые системы: состав, функции, принципы работы.
Поисковая система — это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
Опишем основные характеристики поисковых систем:
Полнота — одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
Точность — еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5). Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
Актуальность — не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
Скорость поиска тесно связана с его устойчивостью к нагрузкам. Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска.одробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http://help.yandex.ru/search/?id=481937.
4. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу. В полном смысле это еще не было поисковой системой, так как поисковая область была ограничена только ресурсами, присутствующими в каталоге, а не всеми Интернет ресурсами.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google — самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные международные поисковые системы – Google, Yahoo и MSN, имеющих собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
5. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее — Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
URL страницы
дата, когда страница была скачана
http-заголовок ответа сервера
тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) — программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).
Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
Ни одна поисковая система не охватывает все ресурсы Интернет.
Каждая поисковая система собирает сведения о ресурсах Интернет, применяя свои уникальные методы, и формирует собственную периодически обновляемую базу данных. Доступ к этой базе предоставляется пользователю.
Поисковые системы реализуют два способа поиска ресурса:
Поиск по тематическим каталогам — информация представляется в виде иерархической структуры. На верхнем уровне — общие категории (“Интернет”, “Бизнес”, “Искусство”, “Образование” и т.д.), на следующем уровне категории делятся на разделы и т.д. Самый нижний уровень — ссылки на конкретные веб-страницы или другие информационные ресурсы.
Поиск по ключевым словам (индексный поиск или детальный) — пользователь отправляет поисковой системе запрос, состоящий из ключевых слов. Система возвращает пользователю перечень найденных по запросу ресурсов.
Большинство поисковых систем сочетают оба способа поиска.
Поисковые системы могут быть локальными, глобальными, региональными и специализированными.
В русской части Интернет (Рунет) наиболее популярны сейчас поисковые системы общего назначения Rambler (www.rambler.ru), Яндекс (www.yandex.ru), Апорт (www.aport.ru), Гугл (www.google.ru).
Большинство поисковых систем реализовано в виде порталов.
Портал (от англ. portal — главный вход, ворота) -это веб-сайт, который интегрирует различные сервисы Интернет: средства поиска, почту, новости, словари и т.д.
Порталы могут быть специализированными (как, www.museum.ru) и общими (например, www.km.ru).
Поиск по ключевым словам
Набор ключевых слов, по которым ведется поиск, называют также критерием поиска или темой поиска.
Запрос может состоять как из одного слова, так и из сочетания слов, объединенных операторами — символами, по которым система определяет, какое действие ей нужно произвести. Например: запрос “Москва Питер” содержит оператор И (так воспринимается пробел), который указывает, что надо искать документы, в которых есть оба слова — и Москва, и Питер.
Для того, чтобы поиск был релевантным (от англ. relevant -уместный, относящийся к делу), следует учитывать несколько общих правил:
Независимо от того, в какой форме употреблено слово в запросе, поиск учитывает все его словоформы по правилам русского языка. Например, по запросу “билет” будут найдены и слова “билетом”, “билету” и т.д.
Заглавные буквы следует использовать только в именах собственных, чтобы не просматривать лишние ссылки. По запросу “кузнецов”, например, будут найдены документы, где говорится и о кузнецах, и о Кузнецовых.
Желательно сужать круг поиска, используя несколько ключевых слов.
Если нужного адреса нет среди первой двадцатки найденных адресов, следует изменить запрос.
Если по запросу не найдено ни одной ссылки, прежде чем менять запрос, надо проверить орфографию.
Каждая поисковая система использует свой язык запросов. Для знакомства с ним, пользуйтесь встроенной справкой поисковой системы
Крупные сайты могут иметь встроенные системы поиска информации в пределах своих веб-страниц.
Запросы в подобных системах поиска, как правило, строятся по тем же правилам, что и в глобальных поисковых системах, однако знакомство со справкой и здесь не будет лишним.
Расширенный поиск
Поисковые системы могут предоставлять в распоряжение пользователя механизм, позволяющий формировать сложный запрос. Переход по ссылке Расширенный поиск дает возможность редактировать параметры поиска, указывать дополнительные параметры и выбирать наиболее удобную форму показа результатов поиска. Ниже описаны параметры, которые могут быть заданы при расширенном поиске в системах Япс1ех и Rambler.
Описание параметра | Название в Яндекс | Название в Rambler |
Где искать ключевые слова (заголовок документа, основной текст и т.д.) | Словарный фильтр | Поиск по тексту … |
Какие слова должны или не должны присутствовать в документе и насколько точным должно быть совпадение | Словарный фильтр | Искать слова запроса… Исключить документы, содержащие следующие слова… |
На каком расстоянии друг от друга должны располагаться ключевые слова | Словарный фильтр | Расстояние между словами запроса… |
Ограничение на дату документа | Дата | Дата документа… |
Ограничение поиска пределами одного или нескольких сайтов | Сайт/Вершина | Искать документы только на следующих сайтах… |
Поиск страниц со ссылками на определенный сайт и исключение из поиска страниц со ссылками на определенный сайт | Ссылка | |
Ограничение поиска по языку документа | Язык | Язык документа… |
Поиск документов, содержащих картинку с определенным именем или подписью | Изображение | |
Поиск страниц, содержащих объекты | Специальные объекты | |
Форма представления результатов поиска | Формат выдачи | Вывод результатов поиска |
Некоторые поисковые системы (например, Яндекс) позволяют вводить запросы на естественном языке. Вы пишите, что нужно найти (например: заказ билетов на поезд из Москвы в Питер). Система анализирует запрос и выдает результат. Если он Вас не устраивает, переходите на язык запросов.
studfile.net
Что понимают под поисковой системой
Каждый момент времени человек принимает решения. Результат: движение вперед, суета на месте или перемещение в информационном пространстве, но куда? Что понимают под поисковой системой?

Хорошее зрение, слух, надежная работа всех органов чувств и объективное восприятие действительности во многом определяют правильное применение накопленного опыта и знаний, дают шанс интуиции проявить себя. Но правильный ответ — результат не только правильного вопроса, но и корректно собранной информации для его решения (это область критерия).
Что понимают под поисковой системой кратко? История интернет-поиска
Во времена, когда компьютеры и Интернет были уделом избранных, логика обычного библиотечного дела считалась востребованной. Зачем усложнять решение задачи, когда для ориентации в информационном пространстве достаточно каталога файлов, данных, решений, программ и всего, что было сделано и может пригодиться?
Не стоит ли пользователям поставить памятник? Вспомнить, что именно труду фанатов компьютерного дела обязаны сети, каталоги, возможности для общения и «первичного» накопления:
- информационного капитала;
- основ современных представлений (они канули в лету, но их мимолетное явление образовало долгосрочную перспективу).
Мощь и возможности компьютеров быстро ушли из вычислительной сферы в сферу обработки информации. Интернет стал стремительно завоевывать новые территории в областях применения и умах людей. Простое библиотечное дело моментом мигрировало в изощренные механизмы поисковых машин.
Многочисленные армии искателей, роботов, «пауков» и прочих алгоритмов принялись скрупулезно исследовать все, что попадало в интернет-пространство. Возможно, именно они дали понять, что такое поисковая система, как работает поиск, что такое Интернет. Они учились индексировать информацию, приходили к пониманию того, что можно и как нужно использовать.

Это был древний «доинформационный мир», допотопное вооружение, примитивные методики собирательства — совсем как рыбалка и охота во времена, когда люди только начали представлять собой что-то общественное, социально значимое, отделившееся от природы по критерию разумности.
Индексация: мы не рабы, но у нас еще ничего нет
Индексация информационного пространства, методика ориентации в собранной информации и умение правильно корректировать имеющееся за счет обнаруженных изменений во внешней (Интернет) среде становились основой для выживания. Так принято в живой природе, а интернет-пространство уже обретало свою собственную и абсолютно реальную жизнь.
В истории всегда было что-то, что можно вспомнить, но всегда возникает вопрос, а так ли это было, связано ли то историческое «бытие» с реальными людьми и памятными воспоминаниями?
Возможно, сосед по лестничной клетке оказался создателем Google или сформулировал фундаментальные основы процветания Yandex. Но многие упоминают 1945 год как точку, с которой началась идея гипертекста, а «Волшебный автоматический извлекатель текста Сэлтона» считается отцом современной поисковой технологии.
С тех пор утекло много воды, а список первых поисковиков, первых античных алгоритмов и идей так велик, что сам по себе является хорошей поисковой задачей для систематизации и индексации прошлого.

Небеспочвенно утверждать, что причина явления Google как феномена и современной системы — это не только реальный человек, его друзья и подруги. Почему это не совершенно иная точка информационного пространства, которая удачно вызвала нужный резонанс или ассоциацию?
Совокупное общественное сознание — еще та темная вселенная, в которой до своего варианта лампочки Эдисона очень даже далеко.
Год 1994: какой бот сказал ключевое слово «мама»?
В современном мире с трудом верится в прошлое, но сделав скидку на точность дат и участие реальных личностей, следует отметить, что появление ключевых слов — это еще не семантическое ядро.
Что понимали под поисковой системой в конце прошлого века, уже было абсолютно ясно: это десяток популярных поисковиков с конкурирующим рейтингом в борьбе за клиента. Одним нравился Yahoo, другим Aport, третьим Rambler, но в конечном счете остались Google и Yandex.

Все это слова, мнения, предпочтения и интересные факты. Однако монстры поискового дела образовались, создали фундаментальные основы, заложили объективное знание и солидный опыт в понимание:
- механизмов поиска;
- ключевые слова;
- семантическое ядро.
Гипертекст не только оперился, но и стал основой интернет-программирования, проложил дорогу смежным серьезным технологиям.
Главное: не суть, как мы понимаем и что происходит. Важно, что направление движения есть, и оно правильное. Колебания курса — это нормально, не будь колебаний, не было бы повода оптимизировать критерии. А критерии и в вопросе, и в ответе — самое главное.
Год 1989: возрождение, о котором забыли
Откат — это особый исторический механизм и всегда интересный факт. Людям, особенно ученым и квалифицированным специалистам, свойственно забывать о сути вещей и уходить в мечтания. Мир войн, гладиаторов и страшных сражений — забава по сравнению с тем, какие состязания идут в общественном и частном сознании. Здесь царство мрака, но идти вперед нужно, и без победы на каждом шагу никак нельзя.

Принцип работы поисковой системы лег в основу алгоритма. Реальных реализаций алгоритмов исполнено множество. Выжило очень мало, но именно это поделило между собой все интернет-сообщество. Борьба за идеалы в сфере поиска уже тогда имела значение, но даже краткая история развития поисковых систем перестала интересовать потребителя.
Пользователю нужен ответ, а не достижения ученых и специалистов. Потребитель желает знать, как правильно сформулировать вопрос, чтобы получить адекватный ответ и быть уверенным, что поисковый механизм отработал правильно, применил объективные критерии.
Кого волнует интересный факт, что ООП и облака были придуманы в 1989-1991 гг. Абсолютно никого! Но всего десяток лет назад пошел откат: теперь без ООП и облачных технологий нельзя. Но откат «не покатил» в нужном направлении, поэтому на вопрос о том, что понимают под поисковой системой, нет конкретного ответа. Ничего нового не появилось, а вот лишнее — да.
Определение поиска и поисковой системы
Когда появились калькуляторы, человек подумал, что забудет правила сложения, умножения, деления. Прошло время, и страх развеялся. Калькуляторы живы, и столбиком вершить простейшие математические действия человек не разучился.
Во времена, когда функционирует «Гугл» и «Яндекс», а вокруг небольшое число авторитетных поисковых систем, сложилось мнение: поиск — это компьютерный алгоритм, а поисковая система (определение слова и его значение) — это программно-аппаратный комплекс с веб-интерфейсом, предоставляющий возможность поиска информации в Интернете.

Квалифицированные и авторитетные специалисты выделяют такие понятия, как поисковый движок, поисковый алгоритм и коммерческая тайна компании владельца (разработчика).
Выдача поисковой системы
Что понимают под поисковой системой, несложно представить. Есть строка запроса, посетитель пишет ключевое слово, нажимает кнопку «искать» и получает результат. Но поисковая выдача — это не ответ, а ключевое слово — это не вопрос.
В обычной жизни человек не пользуется ключевыми словами и никогда не получает никакой «выдачи». Если ребенок хочет кушать, он скажет об этом маме или папе. Все зависит от того, что именно малыш хочет: реально поесть или получить деньги на мороженое. Реакция родителя может быть лишена слов, но действие последует.
Работник не будет обращаться к нанимателю через ключевые слова, иначе результатом выдачи будет бессловесное увольнение.
Все это факты, но человек и компьютерная система — это другая сфера отношений. Пока есть четкое представление, что понимают под поисковой системой — это не вопросы, ответы, критерии, а ключевые слова и результаты работы движка (поисковая выдача).

Реальная польза текущего момента
Страсти по SEO, стремительный рост числа веб-студий, развитие рекламного дела, навязывание идей, тонны спама и мусор в выдаче — все это естественно и объективно нормально. Бороться со спамом, хакерами и негативом пора. Нужно это делать внимательно, но реальная польза от сложившейся ситуации — всего лишь очередной этап развития поискового дела.
Ключевые слова — отлично. Семантическое ядро сайта — прекрасно. Компьютер может переводить тексты на разные языки и разбирать естественные предложения. Язык SQL стал де-факто в «общении» с базами данных. У SQL — масса диалектов, а это реальный показатель. Искусственный язык стал жизнеспособен! Язык способен дать доступ к огромным объемам систематизированной информации.
Oracle и другие лидеры в сфере больших баз данных потратили десятки лет на представление информации. Google — на сбор информации и механизмы индексации. Семейство Linux удержало позиции, Windows осталась на плаву, а численность языков программирования сузилась до достаточного уровня.
Искусственный интеллект ушел в мир грез, разработчики и потребители объективно устремились в мир созидательного управления информацией и ее использования.
Поисковая выдача: важное и бесполезное
Не так сложно систематизировать поисковую выдачу, но за последние десять лет она не изменилась. По сути — верно. Если в строке поиска ключевое слово, а не вопрос, то о каком ответе может идти речь? Критерии во всех современных поисковых системах есть, к ним относятся с надлежащим пониманием, но зачем ограничивать потребителя?
Важна реакция пользователя на то, какую именно часть поисковой выдачи он выбирает. Это его мнение о результатах работы поисковой системы. Поисковики ценят это и учитывают не только в частном запросе, но и в целом.
Поток ключевых слов и поток выдачи — и то, и другое содержит информационный мусор. Это тоже повод для формирования критериев. Нельзя рассматривать задачу поиска как применение ключевого слова и алгоритма к накопленной информации, как уточнение накопленной информации.
О перспективах: от поиска к решению
Лучшее решение — не принимать никаких решений. Понимают это или нет разработчики поисковых механизмов, но факт остается фактом: что такое поисковая система, разработчики знают в контексте реакции на ключевое слово, как индекс в условиях выборки информации из уже доступных и систематизированных данных.
Потребитель сам выберет из поисковой выдачи, что сочтет нужным, и примет решение. Поисковая система учтет и запомнит это. Как человек распорядится полученной информацией — это будет следующее ключевое слово.

Так поисковая система учится принимать решения, а человек — формулировать вопросы. Пока это ключевые слова, а результат ответа — поисковая выдача. Но количество всегда переходит в качество.
Что такое поисковые системы Интернета? Реальность, основанная на поступательном движении вперед. Не так много практических задач требуют разума от компьютерных систем. В большинстве случаев вполне достаточно, чтобы они просто адекватно отвечали на правильно поставленные вопросы.
www.syl.ru
Работа поисковых систем: общие принципы работы поисковиков
Вступление
Каждая поисковая система имеет свой алгоритм поиска запрашиваемой пользователем информации. Алгоритмы эти сложные и чаще держатся в секрете. Однако общий принцип работы поисковых систем можно считать одинаковым. Любой поисковик:
- Сначала собирает информацию, черпая её со страниц сайтов и вводя её в свою базы данных;
- Индексирует сайты и их страницы, и переводит их из базы данных в базу поисковой выдачи;
- Выдает результаты по поисковому запросу, беря их из базы проиндексированных страниц;
- Ранжирует результаты (выстраивает результаты по значимости).
Работа поисковых систем — общие принципы
Вся работа поисковых систем выполняют специальные программы и комбинации этих программ.
Перечислим основные составляющие алгоритмов поисковых систем:
- Spider (паук) – это браузероподобная программа, скачивающая веб-страницы. Заполняет базу данных поисковика.
- Crawler (краулер, «путешествующий» паук) – это программа, проходящая автоматически по всем ссылкам, которые найдены на странице.
- Indexer (индексатор) – это программа, анализирующая веб-страницы, скачанные пауками. Анализ страниц сайта для их индексации.
- Database (база данных) – это хранилище страниц. Одна база данных это все страницы загруженные роботом. Вторая база данных это проиндексированные страницы.
- Search engine results engine (система выдачи результатов) – это программа, которая занимается извлечением из базы данных проиндексированных страниц, согласно поисковому запросу.
- Web server (веб-сервер) – веб-сервер, осуществляющий взаимодействие пользователя со всеми остальными компонентами системы поиска.
Реализация механизмов поиска у поисковиков может быть самая различная. Например, комбинация программ Spider+ Crawler+ Indexer может быть создана, как единая программа, скачивающая и анализирующая веб-страницы и находящая новые ресурсы по найденным ссылкам. Тем не менее, нижеупомянутые общие черты программ присущи всем поисковым системам.
Программы поисковых систем
Spider
«Паук» скачивает веб-страницы так же как пользовательский браузер. Отличие в том, что браузер отображает содержащуюся на странице текстовую, графическую или иную информацию, а паук работает с html-текстом страницы напрямую, у него нет визуальных компонент. Именно, поэтому нужно обращать внимание на ошибки в html кодах страниц сайта.
Crawler
Программа Crawler, выделяет все находящиеся на странице ссылки. Задача программы вычислить, куда должен дальше направиться паук, исходя из заданного заранее, адресного списка или идти по ссылках на странице. Краулер «видит» и следует по всем ссылкам, найденным на странице и ищет новые документы, которые поисковая система, пока еще не знает. Именно, поэтому, нужно удалять или исправлять битые ссылки на страниц сайта и следить за качеством ссылок сайта.
Indexer
Программа Indexer (индексатор) делит страницу на составные части, далее анализирует каждую часть в отдельности. Выделению и анализу подвергаются заголовки, абзацы, текст, специальные служебные html-теги, стилевые и структурные особенности текстов, и другие элементы страницы. Именно, поэтому, нужно выделять заголовки страниц и разделов мета тегами (h2-h5,h5,h6), а абзацы заключать в теги <p>.
Database
База данных поисковых систем хранит все скачанные и анализируемые поисковой системой данные. В базе данных поисковиков хранятся все скачанные страницы и страницы, перенесенные в поисковой индекс. В любом инструменте веб мастеров каждого поисковика, вы можете видеть и найденные страницы и страницы в поиске.
Search Engine Results Engine
Search Engine Results Engine это инструмент (программа) выстраивающая страницы соответствующие поисковому запросу по их значимости (ранжирование страниц). Именно эта программа выбирает страницы, удовлетворяющие запросу пользователя, и определяет порядок их сортировки. Инструментом выстраивания страниц называется алгоритм ранжирования системы поиска.
Важно! Оптимизатор сайта, желая улучшить позиции ресурса в выдаче, взаимодействует как раз с этим компонентом поисковой системы. В дальнейшем все факторы, которые влияют на ранжирование результатов, мы обязательно рассмотрим подробно.
Web server
Web server поисковика это html страница с формой поиска и визуальной выдачей результатов поиска.
Повторимся. Работа поисковых систем основана на работе специальных программ. Программы могут объединяться, компоноваться, но общий принцип работы всех поисковых систем остается одинаковым: сбор страниц сайтов, их индексирование, выдача страниц по результатам запроса и ранжирование выданных страниц по их значимости. Алгоритм значимости у каждого поисковика свой.
©SeoJus.ru
Другие уроки SEO учебника
(Всего просмотров 605)
Поделиться ссылкой:
Похожее
seojus.ru
Основные принципы работы поисковых систем в Интернете
Какой бы вопрос не волновал современного человека, ответы он не ищет в книгах. Он ищет их в интернете. Причем не нужно знать адрес сайта, на котором лежит нужная тебе информация. Таких сайтов миллионы, а помогает найти нужный поисковая система.
На просторах нашего отечественного интернета самые популярные две поисковые системы – Google и Яндекс.
Вы хотя бы раз задумывались, как работает поисковая система? Как она понимает, какой сайт показать, на каком из миллионов ресурсов точно есть ответ на ваш запрос?
Если да – читайте дальше.
Что представляет собой поисковая система?
Поисковая система – это огромная база веб-документов, которая постоянно пополняется и расширяется. У каждой поисковой системы есть поисковые пауки, роботы – это специальные боты, которые обходят сайты, индексируют размещенный на них контент, а затем ранжируют по степени его качества и релевантности поисковым запросам пользователей.
Поисковые системы работают для того, чтобы любой человек мог найти любую информацию. Потому они стараются показывать в первую очередь те веб-документы, в которых есть максимально подробный ответ на вопрос человека.
По своей сути поисковая система – это каталог сайтов, справочник, основная функция которого – поиск информации по этому самому каталогу.
Как я уже написал выше, у нас популярные две системы – Google (мировая) и Яндекс (русскоязычный сегмент). Но есть еще такие системы, как Rambler, Yahoo, Bing, Mail.Ru и другие. Принцип работы похож у них у всех, отличаются только алгоритмы ранжирования (и то не сильно существенно).
Как работает поисковая система в Интернете
Принцип работы поисковых систем очень сложный, но я попробую объяснить простыми словами.
Поисковый робот (паук) обходит страницы сайта, скачивает их содержимое и извлекает ссылки. Далее начинает свою работу индексатор – это программа, которая анализирует все скачанные пауками материалы, опираясь на собственные алгоритмы работы.
Таким образом, создается база данных поисковой системы, в которой хранятся все обработанные алгоритмом документы.
Работа с поисковым запросом проводится следующим образом:
- анализируется введенный пользователем запрос;
- результаты анализы передаются специальному модулю ранжирования;
- обрабатываются данные всех документов, выбираются самые релевантные введенному запросу;
- генерируется сниппет – заголовок, дескрипшн, слова из запроса подсвечиваются полужирным;
- результаты поиска представляются пользователю в виде SERP (страницы выдачи).
Принципы работы поисковых машин
Главная задача любой поисковой системы – предоставить пользователю наиболее полезную и точную информацию по его запросу. Потому поисковый робот обходит сайты постоянно. Сразу после вашего запуска, согласно определенному распорядку, паук заходит к вам в гости, обходит ряд страниц, после чего проходит их индексация.
Принцип работы поисковых машин базируется на двух основных этапах:
- обход страниц, с помощью которого собираются данные;
- присвоение индекса, благодаря которому система сможет быстро проводить поиск по содержимому данной страницы.
Как только страница сайта проиндексирована, она уже появится в результатах поиска по определенному поисковому запросу. Проверить, попала ли новая страница в индекс поисковой системы, можно с помощью инструментов для вебмастеров. Например, в Яндекс.Вебмастере сразу видно, какие страницы проиндексированы и когда, и какие выпали из индекса и по какой причине.
Но вот на какой странице она окажется – зависит от степени индексации и качества ее содержания. Если на вашей странице дается самый точный ответ на запрос – она будет выше всех остальных.
Принципы ранжирования сайтов в поисковых системах
По какому принципу работают поисковые роботы, мы разобрались. Но вот каким образом проходит ранжирование сайтов?
Ранжирование базируется на двух основных «китах» — текстовое содержание страницы и нетекстовые факторы.
Текстовое содержание – это контект страницы. Чем он полнее, чем точнее, чем релевантнее запросу – тем выше будет страница в результатах выдачи. Кроме самого текста, поисковая система обращает внимание на заполнение тегов title (заголовок страницы), description (описание страницы), h2 (заголовок текста).
Нетекстовые факторы – это внутренняя перелинковка и внешние ссылки. Суть в чем: если сайт интересен, полезен, значит, на него ссылаются другие тематические ресурсы. И чем больше таких ссылок – тем авторитетнее ресурс.
Но это – самые основные принципы, очень кратко. Вникнем чуть глубже.
Основные факторы ранжирования сайта
Есть целый ряд факторов, влияющих на ранжирование сайта. Основные из них – это:
1. Внутренние факторы ранжирования сайта
Это текст на сайте и его оформление – подзаголовки, выделение важных моментов в тексте. Использование внутренней перелинковки тоже сюда относится. Также важны визуальные элементы: использование картинок, фотографий, видео, графиков. Немаловажно также качество самого текста, его содержание.
2. Внешние факторы ранжирования сайта, которые определяют его популярность. Это те самые внешние ссылки, которые ведут на ваш сайт с других ресурсов. Определяется не только количество этих сайтов, но их качество (желательно, чтобы сайты были схожей тематики с вашим), а также общее качество ссылочного профиля (насколько быстро появились эти ссылки, естественным путем или с помощью закупки на бирже).
3. Поведенческие факторы ранжирования сайта. Поисковые системы начали отслеживать поведение пользователей на сайте и на основе этого поведения понимать, интересен ли ваш сайт людям, полезен ли он, нравится ли посетителям. Обращают внимание на: показатель отказов (чем он ниже – тем лучше), глубину просмотра, время на сайте. Подробнее об этом здесь https://adtimes.ru/povedencheskie-faktory-ranzhirovaniya-sajta-chto-eto-takoe-i-kak-ix-uluchshit/
4. Коммерческие факторы ранжирования сайта. Они важны в первую очередь для тех, кто ставит на продвижение в Яндексе. Коммерческие факторы определяют, насколько удобен ваш сайт для осуществления заказа или совершения покупки Подробнее можете прочесть здесь https://adtimes.ru/kommercheskie-faktory-ranzhirovaniya-i-chto-k-nim-otnositsya/
Исходя из всего вышесказанного, можно сделать один вывод: поисковые системы стараются работать так, чтобы показывать пользователю те сайты, которые дают максимально полный ответ на его запрос и уже заслужили определенный авторитет. При этом учитываются самые разные факторы: и содержание сайта, и его настройка, и отношение пользователей к нему. Хороший во всех отношениях сайт непременно займет высокое место на выдаче.
adtimes.ru
Принципы работы поисковых систем — блог Indigo
Karina | 09.09.2014
Две основные функции поисковых систем в Интернете – сканирование сайтов и создание индекса, а также предоставление ответов на поставленные вопросы посредством поиска и структурирования по релевантности имеющихся в индексе страниц данной тематики. Алгоритм, по которому работают поисковики, является тайной, которую пытаются разгадать оптимизаторы и владельцы сайтов.
Сканирование и индексация сайта поисковыми машинами
Как понять, что собой представляет Всемирная паутина? Проще всего вспомнить схему метро со множеством станций, где вместо остановок будут уникальные станицы или файлы. Поисковые системы вынуждены путешествовать по этой сети ежесекундно, используя для перемещения ссылки.
Например, представьте, что ваша страница – это станция метро и, чтобы поисковик до нее добрался, ему понадобится преодолеть значительное количество других станций, т. е. страниц.
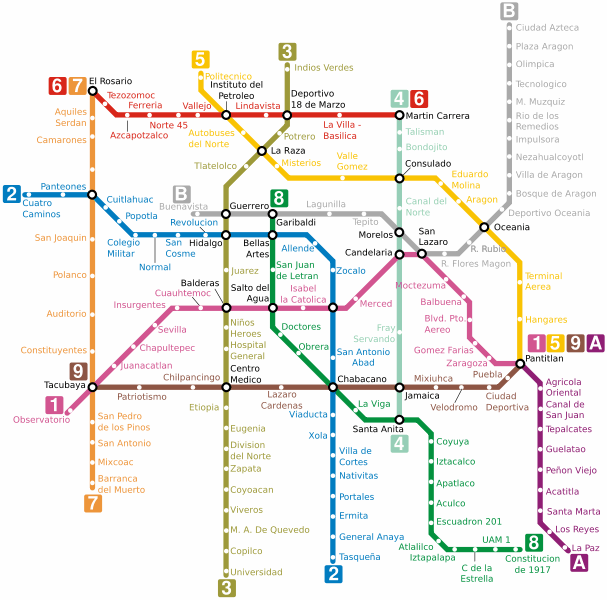 Схема метро как пример структуры Всемирной паутины
Схема метро как пример структуры Всемирной паутиныНаличие ссылок связывает страницы между собой, как перегоны в метро связывают станции, и именно по ним двигаются от материала к материалу поисковые роботы, сканируя бесконечное количество веб-страниц. Найденные страницы расшифровываются (поисковик видит всё как код, а не как страницу с дизайном) и сохраняются на жёстких дисках. Наиболее популярные поисковые системы, например Google, уже имеют распространённую сеть дата-центров по всему миру, где хранится весь объём данных. Огромные здания содержат наиболее современную технику, которая обрабатывает и передаёт информацию с колоссальной скоростью, потому как даже задержка в 1-2 секунды может вызвать недовольство у пользователя и переключить его интерес на другую систему поиска.
Формирование выдачи
Вводя интересующую информацию в поисковик, пользователь хочет получить ответ, который полностью удовлетворит его интерес. Машинный поиск рассматривает множество страниц, чтобы составить список релевантных и актуальных результатов. Современные поисковые системы по одному и тому же запросу включают в выдачу страницы разнообразной тематики, которые могут соответствовать данному ключевому слову. К примеру, если в Google мы вводим запрос «Нептун», поисковая система предложит множество вариантов: информацию о планете, мифологию, компании, рестораны и т. д. с идентичным названием.
То есть, без ввода уточняющего запроса поисковая система предложит пользователю все возможные варианты ответов, которые он предположительно мог искать по данному слову.
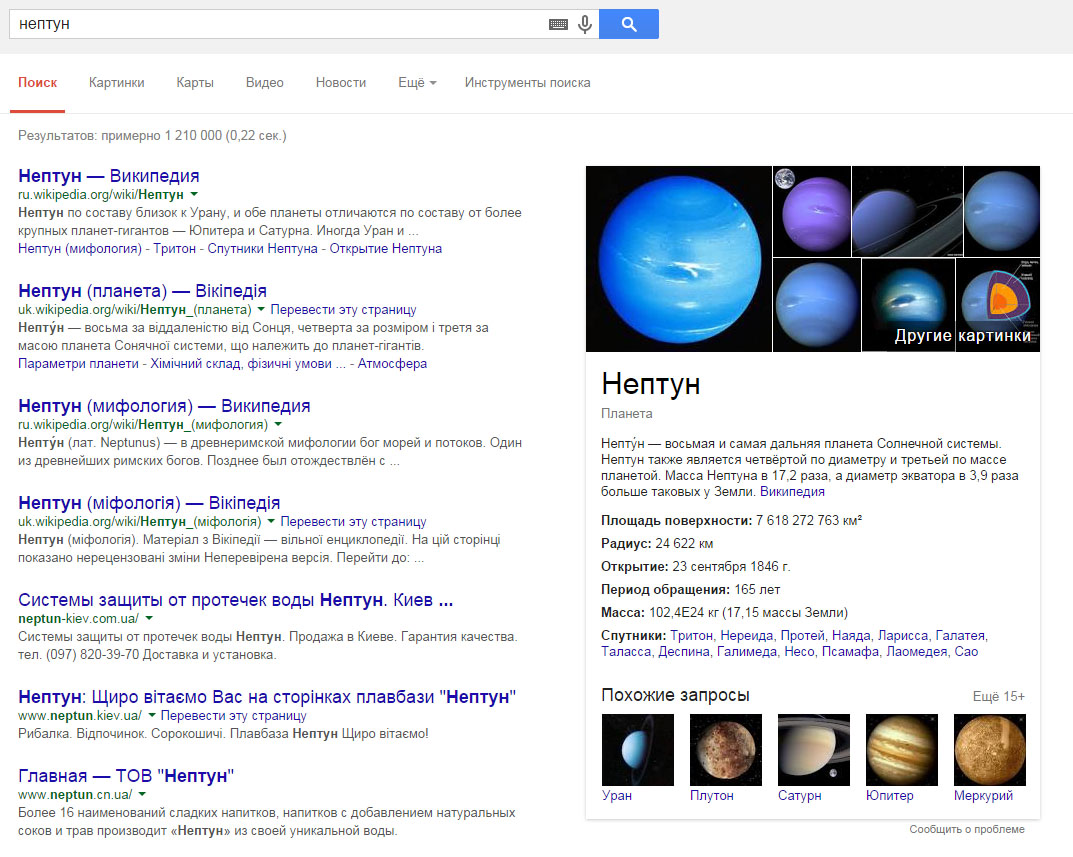
Нептун может быть богом, планетой, плавбазой или системой защиты от потопа
Инженерами было разработано множество факторов, которые дополнительно влияют на ранжирование. По информации Google, на данный момент в их результатах используются сотни таких факторов. Некоторые из них мы подробно рассматриваем в нашем блоге.
Как поисковики находят необходимый контент
В настоящее время всё ещё актуально мнение, что чем популярнее страница, тем более релевантный контент на ней размещен. Этот фактор не определяется вручную – существуют определённые алгоритмы, которые и помогают выяснить, какие ресурсы интересны пользователям.
Принцип отбора постоянно меняется и, судя по результатам в выдаче одного и того же сайта, может значительно отличаться в разных поисковиках. Зачастую в отборе популярных веб-страниц участвуют социальные факторы, наличие тематических ссылок, посещаемость страниц ресурса.
Как видят сайт поисковые системы
У каждого поисковика в Интернете свои, достаточно сложные алгоритмы поиска, информацией о которых они делятся неохотно. Но понять их основные принципы можно, проанализировав рекомендации для веб-мастеров, которые размещены на официальных сайтах систем. В русскоязычном сегменте наиболее популярными являются поисковые системы Google и Яндекс, и вот что они рекомендуют.
Рекомендации для веб-мастеров (Google)
Для увеличения ранжирования в этой поисковой системе желательно:
- создавать страницы для людей, не делать искусственную оптимизацию под поисковые системы, не создавать скрытый контент для поисковых роботов;
- разрабатывать сайт с чёткой иерархией, органичными текстовыми ссылками, к каждой странице делать хоть одну статичную текстовую ссылку;
- создавать интересный информационный ресурс, который будет наполнен актуальными и уникальными материалами с сопутствующими тегами, полностью соответствующими содержанию;
- использовать ключевые слова для создания понятных людям адресов URL;
- не допускать появления дублей страниц, использовать 301-й редирект или
rel="canonical", в зависимости от необходимости.

Советы веб-мастеру (Яндекс)
Чтобы в этой поисковой системе находилось всё, что вы разместили для пользователей в Интернете, будет полезно делать следующее:
- писать оригинальный контент или предоставлять уникальные услуги, которые заинтересуют посетителей;
- думать о пользователях, а не о поисковиках, продумывать мелочи, чтобы людям было удобно на сайте;
- делать полезные и органичные ссылки на сторонние ресурсы;
- разрабатывать хороший и понятный дизайн с акцентом на основную информацию;
- оптимизировать страницы в соответствии с их содержанием.
Универсальные рекомендации по оптимизации
Несмотря на наличие множества рекомендаций для веб-мастеров, прямой информации о том, как осуществляется поиск и почему именно так, в открытом доступе нет. Чтобы успешно развивать веб-ресурсы, маркетологи и SEO-специалисты постоянно проводят различные эксперименты, которые дают приблизительную информацию о том, что именно может влиять на хорошие позиции в выдаче и подводят к пониманию того, как работают поисковые системы.

Вот некоторые рекомендации:
- Зарегистрируйте домен, включающий название бренда, тип товара или услуг, которые на нём предлагаются.
- Создавайте страницы, в адресах которых будет ключевая информация о размещённом материале, товаре.
- Форматируйте текст одинаково, равномерно используйте ключевые слова, органично вписывайте ссылки. Делайте текст приятным для чтения.
- Размещайте актуальный контент, который может заинтересовать другие сайты со схожей тематикой и побудить их написать о вас и сделать на вас ссылку. Не усердствуйте с покупкой множества ссылок, делайте их интересными для пользователей – это поможет увеличить количество и качество посещений.
- Отслеживайте индексацию и ранжирование страниц (результаты в выдаче) для интересующих регионов.
- Делайте различные изменения на схожих страницах для выявления более действенных методов.
- Отмечайте действия, давшие результат, проверяйте их на других доменах, и в случае успеха радуйтесь тому, что нашли один из принципов ранжирования этой поисковой системы.
- Постоянно обновляйте контент на сайте тематическими статьями и новостями.
Таким образом, становится понятным, что SEO – это не набор законов и правил, выполнение которых повлечёт стабильный результат. Раскрутка в поисковых системах – это эксперименты, риски и опыт, который приобретается с каждым новым достижением. Самостоятельная оптимизация – достаточно сложный путь, который потребует больших затрат времени и сил.
idg.net.ua