Есть определенный список ошибок, которые могут повлиять на эффективность файла robots.txt, а также вы можете увидеть при проверке файла список определенных рекомендаций. Это вещи, которые могут повлиять на SEO-оптимизацию сайта, и которые нужно исправить. Предупреждения менее критичны, и это просто советы о том, как улучшить ваш сайт robots.txt.
Ошибки, которые вы можете увидеть:
Invalid URL: эта ошибка сообщает о том, что файл robots.txt на сайте отсутствует.
Potential wildcard error: технически это больше предупреждение, чем сообщение об ошибке. Это сообщение обычно означает, что в вашем файле robots.txt содержится символ (*) в поле Disallow (например, Disallow: /*.rss). Это проблема приемлемого использования синтаксиса: Google не запрещает использование символов в поле Disallow, но это не рекомендуется.
Generic and specific user-agents in the same block of code:
Предупреждения, которые вы можете увидеть:
Allow: / : порядок разрешения не повредит и не повлияет на ваш веб-сайт, но это не стандартная практика. Самые крупные поисковые машины, включая Google и Bing, примут эту директиву, но не все программы-кроулеры будут такими же неразборчивыми. Если говорить начистоту, то всегда лучше сделать файл robots.txt совместимым со всеми программами-индексаторами, а не только с самыми популярными.
Field name capitalization: несмотря на то, что имена полей не чувствительны к регистру, некоторые индексаторы могут требовать писать их заглавными буквами, так что хорошей идеей будет делать это по умолчанию — специально для самых привередливых программ.
Sitemap support: во многих файлах robots.txt содержатся данные о карте сайта, но это не считается хорошим решением. Однако, Google и Bing поддерживают эту возможность.
Первым делом необходимо проверить доступность файла robots.txt. Переходим и смотрим его визуально https://robotstxt.ru/robots.txt, открывается ли он.
Дальше нам необходимо проверить его техническую доступность, заходим в сервис проверки ответа сервера Яндекса.
Вводим путь к вашему файлу robots.txt и нажимаем проверить.
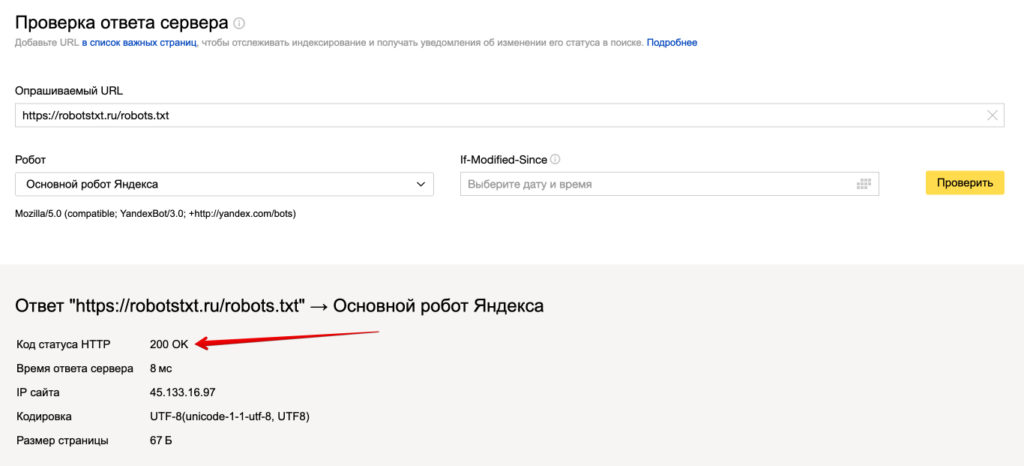
Должен отображаться ответ сервера 200. Если вы видите другие цифры, то значит robots.txt не доступен и поисковая система не сможет его прочитать.
Как проверить в Яндекс?
В разработке…
Как проверить в Google?
Благодаря данному инструменту любой вебмастер и оптимизатор может посмотреть, открыты ли в robots.txt конкретные URL и файлы для индексирования роботами поисковой системы Google?
Допустим, на вашем сайте есть картинка, которую вы не желаете видеть в результатах выдачи Гугла по картинкам. В инструменте Robots Testing Tool вы узнаете, закрыт ли доступ к изображению боту Googlebot-Image.
Здесь нужно прописать URL-адрес, по которому располагается изображение. Далее инструмент обработает robots.txt таким же способом, что и робот Гугла по картинкам, чтобы выяснить, запрещен ли указанный УРЛ для индексирования.
Инструкция по проверке
- Зайдите в Google Search Console и укажите свой сайт.
- Выберите инструмент проверки и проверьте инструкции, прописанные в файле Robots. Любые логические и синтаксические ошибки будут подчеркнуты, а их общее количество можно узнать внизу окна редактирования.
- В самом низу страницы найдите поле, предназначенное для указания необходимого URL-адреса.
- В меню, которое откроется справа, выберите бота.
- Кликните “Проверить”.
- После проверки инструмент покажет статус адреса: “Доступен” либо “Недоступен”. Если статус “Доступен”, значит роботам Гугла не запрещено включать в поиск изображение, а если “Недоступен”, то картинка не будет участвовать в поиске.
- Если нужно, сделайте необходимые исправления в меню и проверьте роботс снова. Имейте ввиду, что все изменения не вносятся в файл robots.txt вашего веб-ресурса автоматически.
- Сделайте копию измененного содержания и вставьте ее в robots на вашем сервере.
Что нужно знать
- Никакие изменения в редакторе не сохраняются на сервере в автоматическом режиме. Нужно скопировать измененный код и внести его в файл роботс.
- Инструмент для проверки Robots показывает результаты только для юзер-агентов Google и роботов данной поисковой системы. При этом сотрудники компании не могут давать никаких гарантий, что роботы других поисковиков будут учитывать содержание файла так же, как и Гугл.
Как отправить измененный robots.txt в Google?
В инструменте проверки роботса есть кнопка “Проверить”, благодаря которой ускоряется обход и включение в индекс нового robots.txt. Для передачи его в поисковую систему Google необходимо:
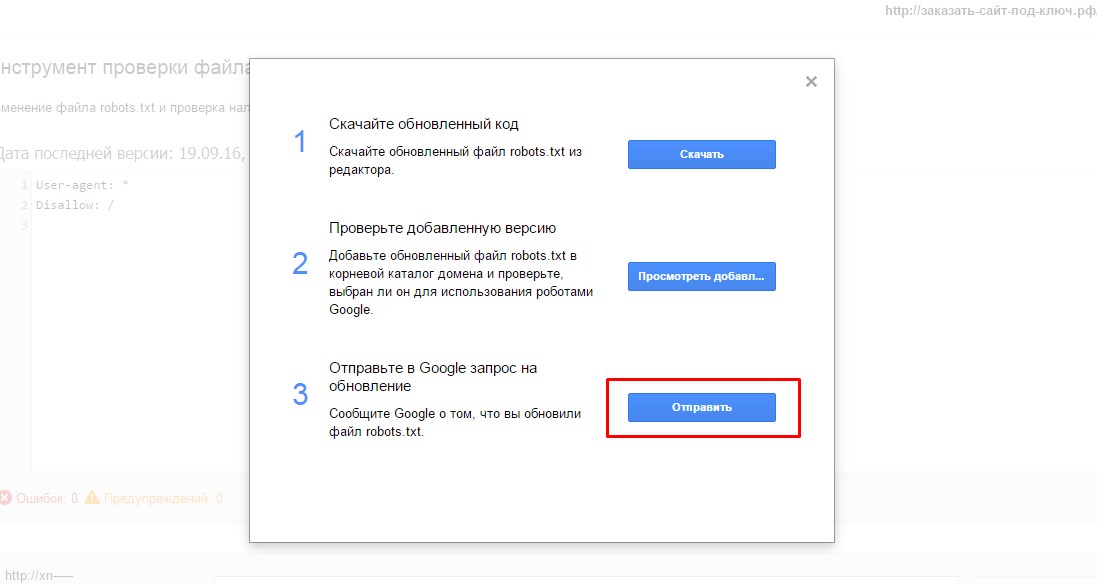
1. В правом нижнем углу редактора файла Robots кликнуть на кнопку “Проверить”. Так вы откроете диалоговое окно передачи.
2. Для выгрузки из инструмента кода файла, который был изменен, нажмите кнопку “Загрузить”.
3. Загрузите новый Robots в корневую папку сайта. Необходимо, чтобы URL файла выглядел следующим образом: /robots.txt.
На заметку. Если у вас нет доступа к админке, из-за чего нет возможности загружать файлы в корневой каталог домена, свяжитесь с его администратором.
Допустим, главная страница вашего веб-ресурса находится по адресу subdomain.site.ru/site/example. Тогда есть вероятность, что вы не сможете обновить файл robots, расположенный по адресу subdomain.site.ru/robots.txt. Тогда напишите владельцу домена с просьбой изменить файл.
4. Нажмите “Проверить”. Так вы узнаете, применяется ли новая версия Robots, которую вы хотите, чтобы роботы просканировали.
5. Кликните “Отправить в Google” для отправки поисковой машине сигнала, что файл был изменен и его необходимо проверить.
6. Удостоверьтесь в том, что измененный файл был успешно проверен роботами. Для этого необходимо обновить страницу “Инструмент проверки файла robots.txt”. После этого обновится окно редактирование, где отобразится новый код файла. В меню, открывающемся над текстовым редактором, вы узнаете, когда Googlebot первый раз увидел актуальную версию роботса.
Заключение
Следуя инструкциям выше, вы будете уверены в том, что настроили Robots.txt правильно и поисковые системы сканируют файл так, как вам нужно.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажите. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Проверка robots.txt на ошибки | Impuls-Web.ru
В одной из прошлых статей мы с вами подробно рассмотрели, как создать файл robots.txt на примере сайта созданного на WordPress.
В этой статье я хотела бы рассмотреть, как осуществить для robots.txt проверку в поисковых системах Яндекс и Google.
Навигация по статье:

Проверка в Яндекс
В яндексе для robots.txt проверка происходит следующим образом:
- 1.Заходим на сервис Яндекс.Вебмастер (https://webmaster.yandex.ru), проходим авторизацию и в верхней панели слева, в раскрывающемся списке, выбираем сайт для которого нужно провести проверку.
- 2.В левом боковом меню выбираем «Инструменты» = > «Анализ robots.txt»
- 3.Попадаем на страницу проверки robots.txt. Если вы не меняли стандартный файл, то увидите следующую картину:
- 4.Если вы еще не добавляли для своего сайта robots.txt, то вам нужно создать этот файл, следуя указаниям, приведенным в моей прошлой статье. После чего, при помощи FTP-клиента загрузить этот файл в корень вашего сайта:
- 5.После этого, в адресной строке «Проверяемый сайт», вводим адрес нашего сайта и нажимаем на кнопку загрузки.
- 6.Произойдет загрузка файла, расположенного по указанному нами адресу и автоматически будет проведена проверка файла на содержание ошибок. Содержимое файла будет показано в поле «Текст robots.txt»
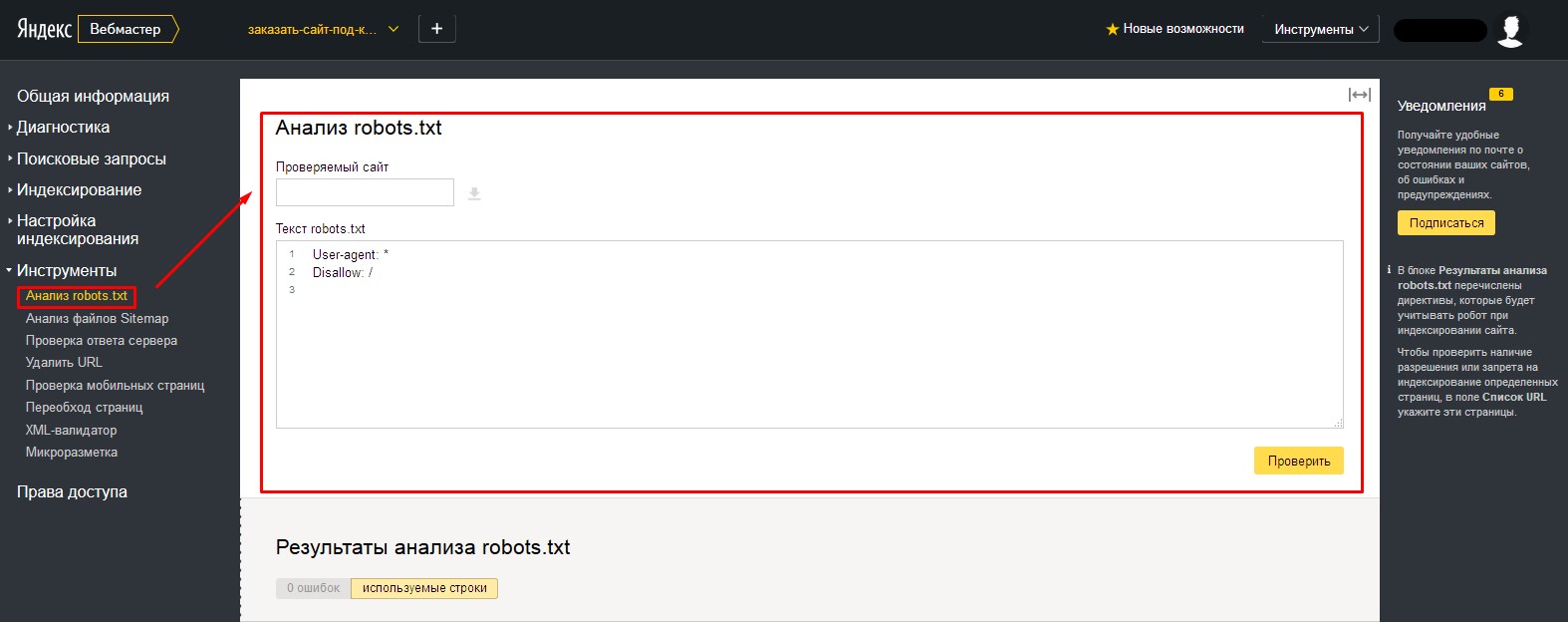

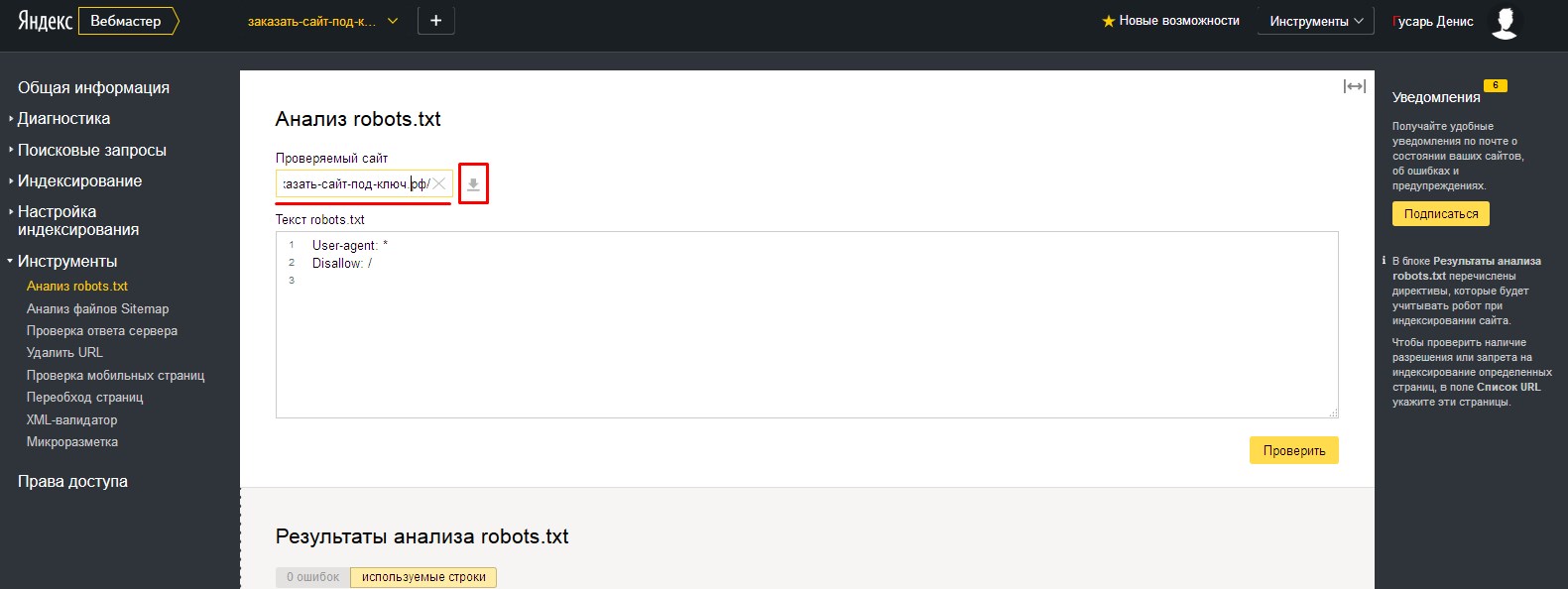
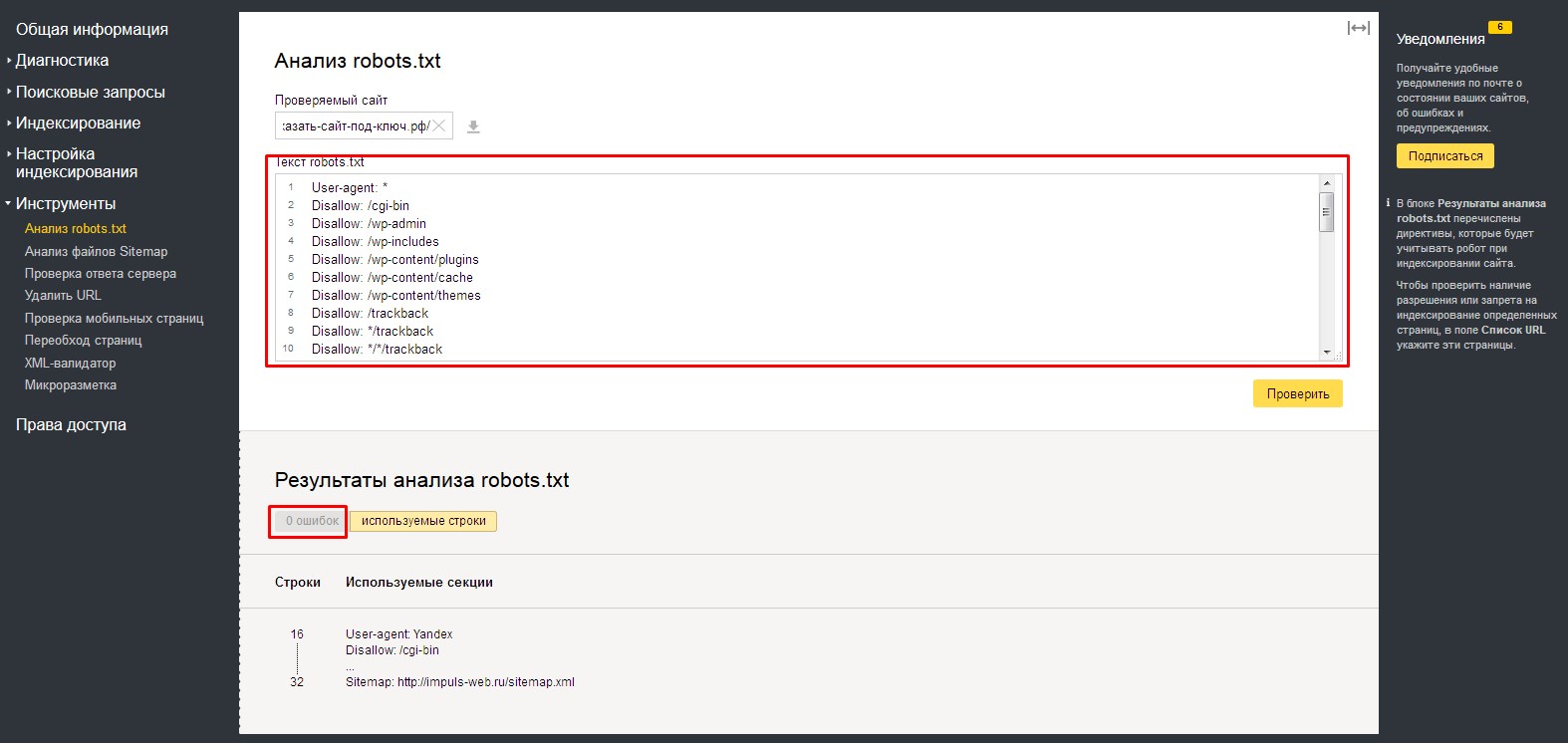
Внизу, в табличке «Результаты анализа robots.txt», вы можете просмотреть количество ошибок в файле.
Проверка в Google
В Google Search Console для robots.txt проверка делается похожим образом:
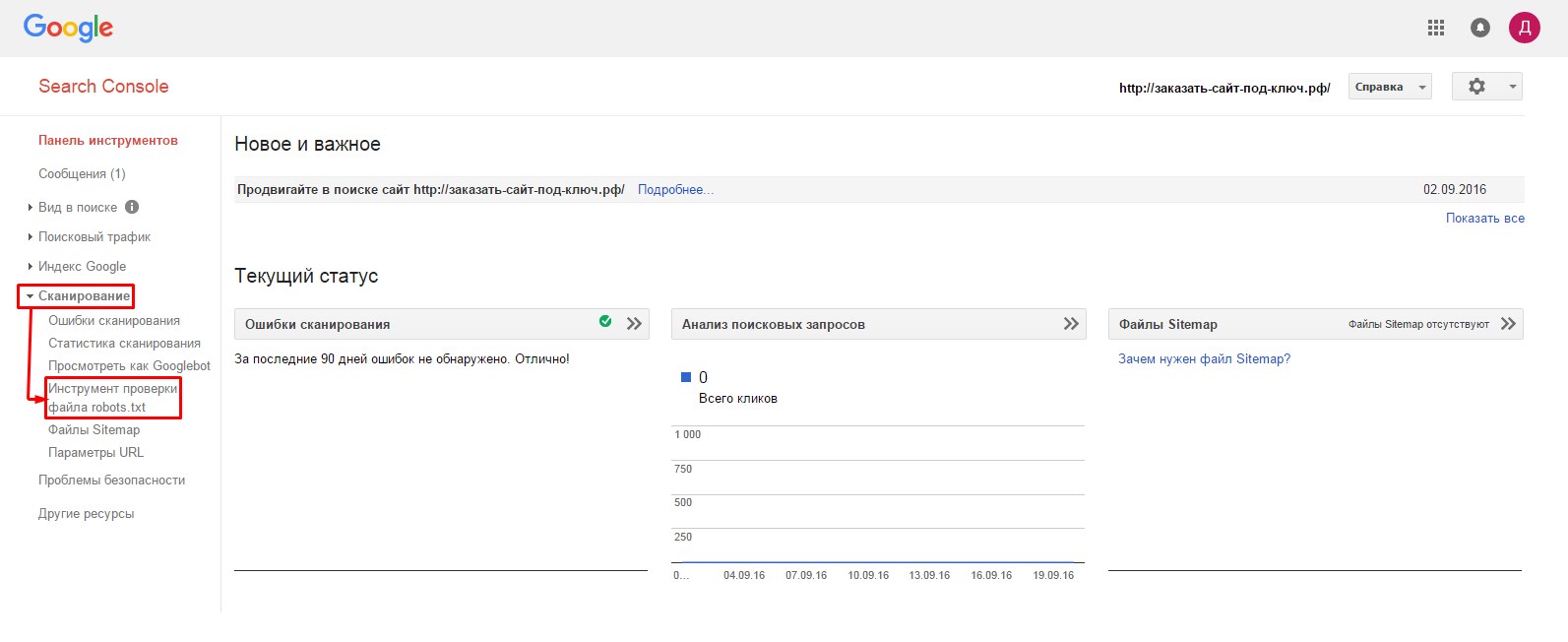
- 1.Заходим на главную страницу сервиса Search Console (//www.google.com/webmasters/tools/dashboard), проходим авторизацию и переходим в раздел
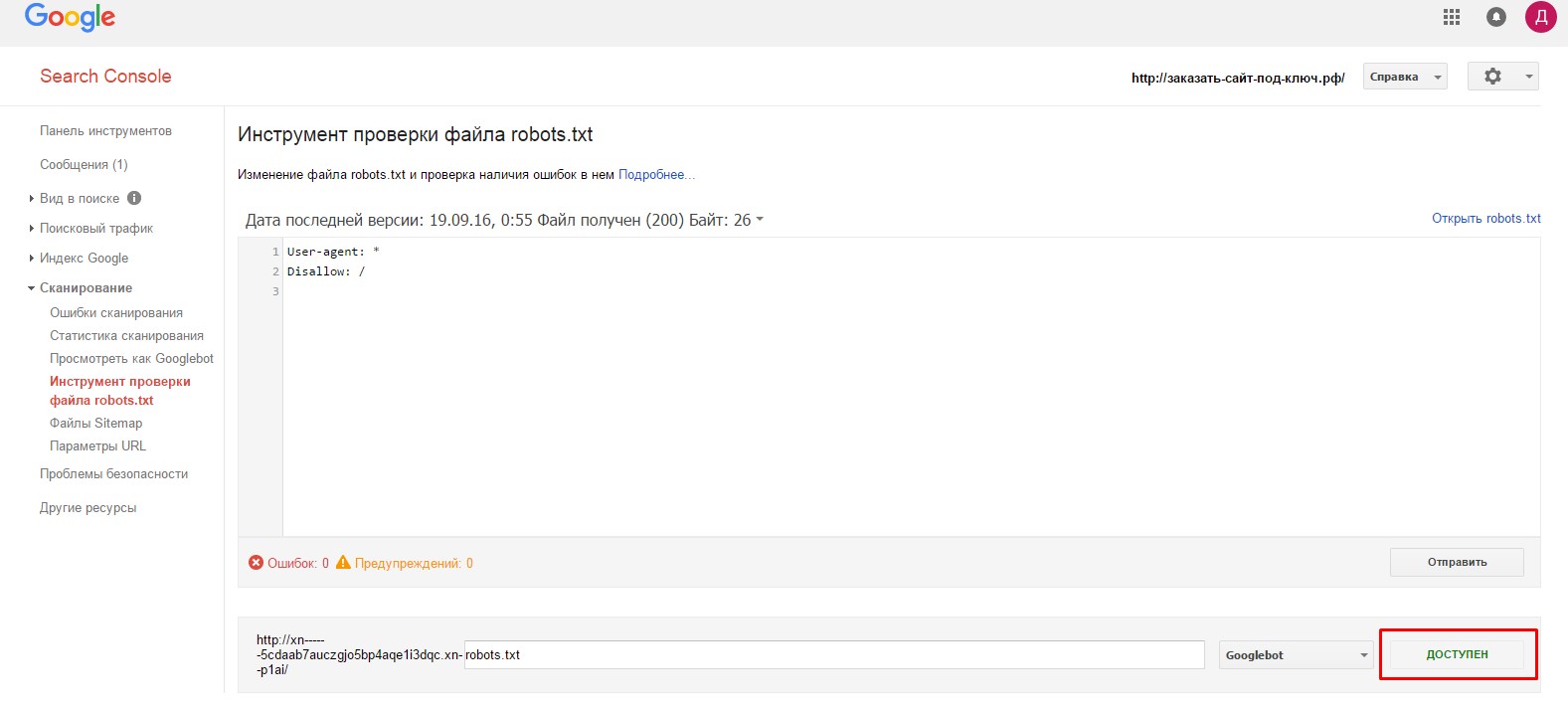
- 2.На следующей странице нам первым делом необходимо удостовериться в доступности файла для гуглбота. В нижней части страницы, в адресной строке вводим путь к нашему файлу robots.txt и нажимаем «Проверить».
- 3.Если все нормально, то красная кнопка замениться на надпись «Доступен».
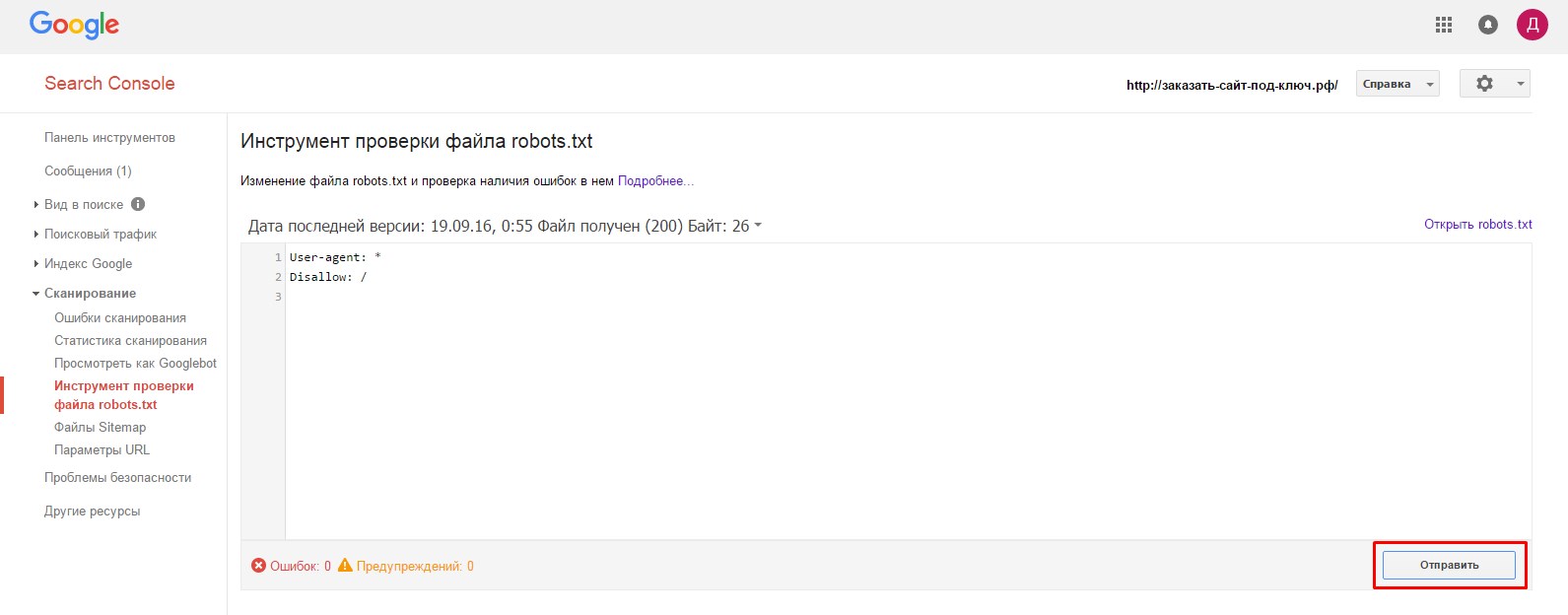
- 4.Далее, нажимаем на кнопку «Отправить».

В открывшемся окне нужно нажить на нижнюю кнопку «Отправить»:
- 5.Закрываем окошко и через несколько минут обновляем страницу проверки:
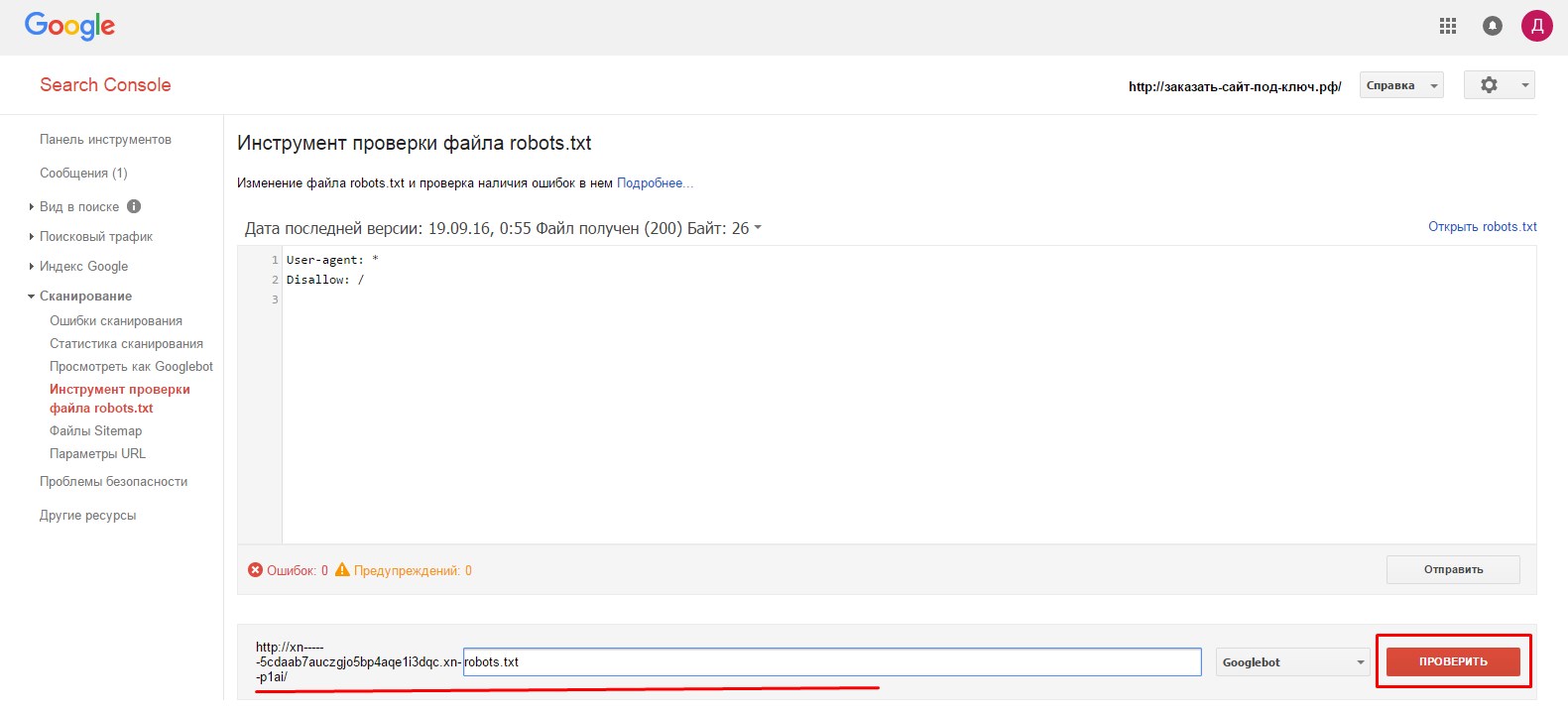
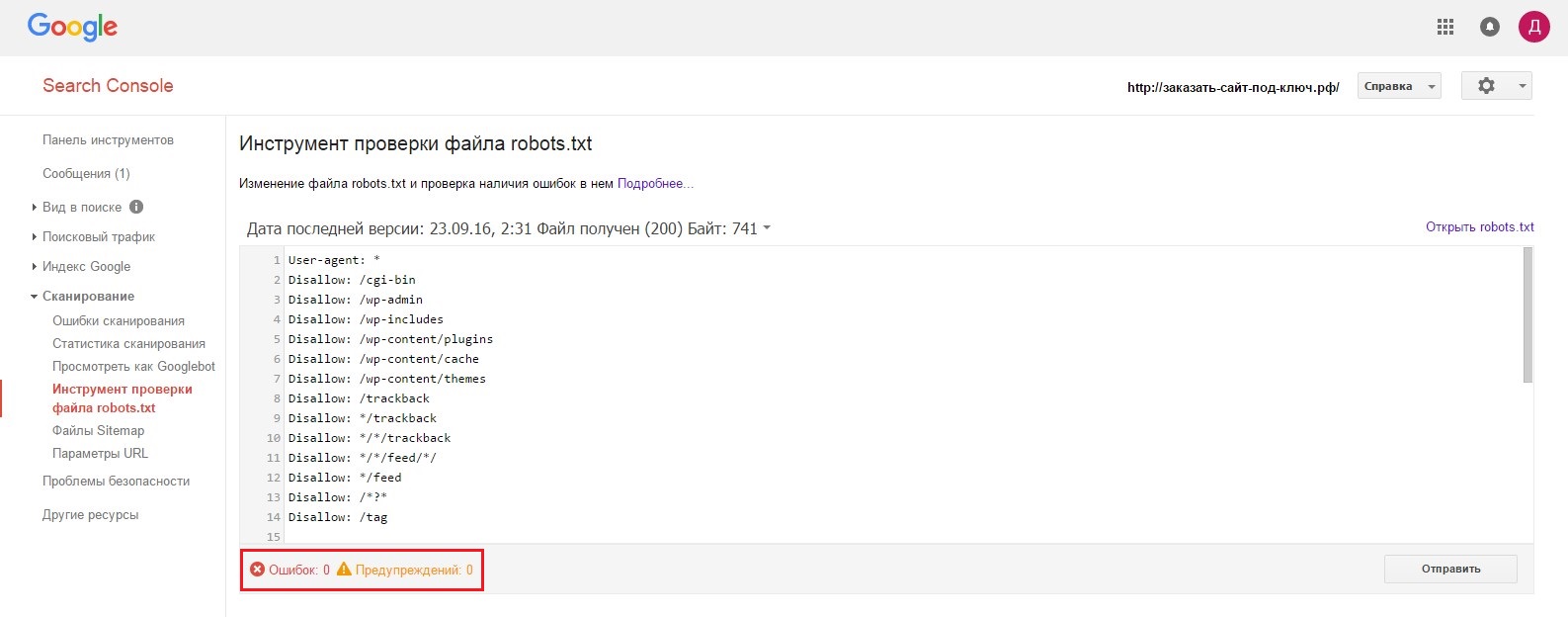
Количество ошибок и предупреждений можно увидеть в нижней части окна.
Как видите, для robots.txt проверка проводится достаточно быстро. Если после проверки у вас найдут какие-то несоответствия, то нужно будет их исправить и повторить процедуру загрузки и проверки файла в той же последовательности.

А на этом у меня сегодня все. Надеюсь, моя статья будет для вас полезна. Думаю, у вас не должно возникнут каких-то сложностей в процессе создания и загрузки файла robots.txt, но если что – пишите мне через форму комментариев. Желаю вам успешной проверки! До встречи в следующих статьях!
С уважением Юлия Гусарь
Файл robots.txt | SEO-портал
Стандарт robots.txt отличается оригинальным синтаксисом. Существуют общие для всех роботов директивы (правила), а также директивы, понятные только роботам определенных поисковых систем.
Стандартные директивы
Директивами для robots.txt называются правила, состоящие из названия и значения (параметра), идущего после знака двоеточия. Например:
# Директива User-agent со значением Yandex: User-agent: Yandex
Регистр символов в названиях директив не учитывается.
Для большинства директив стандарта в качестве значения применяется URL-префикс (часть URL-адреса). Например:
User-agent: Yandex # URL-префикс в качестве значения: Disallow: /admin/
Регистр символов учитывается роботами при обработке URL-префиксов.
Директива User-agent
Правило User-agent указывает, для каких роботов составлены следующие под ним инструкции.
Значения User-agent
В качестве значения директивы User-agent указывается конкретный тип робота или символ *. Например:
# Последовательность инструкций для робота YandexBot: User-agent: YandexBot Disallow: /
Основные типы роботов, указываемые в User-agent:
- Yandex
- Подразумевает всех роботов Яндекса.
- YandexBot
- Основной индексирующий робот Яндекса
- YandexImages
- Робот Яндекса, индексирующий изображения.
- YandexMedia
- Робот Яндекса, индексирующий видео и другие мультимедийные данные.
- Подразумевает всех роботов Google.
- Googlebot
- Основной индексирующий робот Google.
- Googlebot-Image
- Робот Google, индексирующий изображения.
Регистр символов в значениях директивы User-agent не учитывается.
Обработка User-agent
Чтобы указать, что нижеперечисленные инструкции составлены для всех типов роботов, в качестве значения директивы User-agent применяется символ * (звездочка). Например:
# Последовательность инструкций для всех роботов: User-agent: * Disallow: /
Перед каждым последующим набором правил для определённых роботов, которые начинаются с директивы User-agent, следует вставлять пустую строку.
User-agent: * Disallow: / User-agent: Yandex Allow: /
При этом нельзя допускать наличия пустых строк между инструкциями для конкретных роботов, идущими после User-agent:
# Нужно: User-agent: * Disallow: /administrator/ Disallow: /files/ # Нельзя: User-agent: * Disallow: /administrator/ Disallow: /files/
Обязательно следует помнить, что при указании инструкций для конкретного робота, остальные инструкции будут им игнорироваться:
# Инструкции для робота YandexImages: User-agent: YandexImages Disallow: / Allow: /images/ # Инструкции для всех роботов Яндекса, кроме YandexImages User-agent: Yandex Disallow: /images/ # Инструкции для всех роботов, кроме роботов Яндекса User-agent: * Disallow:
Директива Disallow
Правило Disallow применяется для составления исключающих инструкций (запретов) для роботов. В качестве значения директивы указывается URL-префикс. Первый символ / (косая черта) задает начало относительного URL-адреса. Например:
# Запрет сканирования всего сайта: User-agent: * Disallow: / # Запрет сканирования конкретной директории: User-agent: * Disallow: /images/ # Запрет сканирования всех URL-адресов, начинающихся с /images: User-agent: * Disallow: /images
Применение директивы Disallow без значения равносильно отсутствию правила:
# Разрешение сканирования всего сайта: User-agent: * Disallow:
Директива Allow
Правило Allow разрешает доступ и применяется для добавления исключений по отношению к правилам Disallow. Например:
# Запрет сканирования директории, кроме одной её поддиректории: User-agent: * Disallow: /images/ # запрет сканирования директории Allow: /images/icons/ # добавление исключения из правила Disallow для поддиректории
При равных значениях приоритет имеет директива Allow:
User-agent: * Disallow: /images/ # запрет доступа Allow: /images/ # отмена запрета
Директива Sitemap
Добавить ссылку на файл Sitemap в можно с помощью одноименной директивы.
В качестве значения директивы Sitemap в указывается прямой (с указанием протокола) URL-адрес карты сайта:
User-agent: * Disallow: # Директив Sitemap может быть несколько: Sitemap: https://seoportal.net/sitemap-1.xml Sitemap: https://seoportal.net/sitemap-2.xml
Директива Sitemap является межсекционной и может размещаться в любом месте файла. Удобнее всего размещать её в конце файла, отделяя пустой строкой.
Следует учитывать, что файл robots.txt является общедоступным, и благодаря директиве Sitemap злоумышленники могут получить доступ к новым страницам раньше поисковых роботов, что может повлечь за собой воровство контента.
Использование директивы Sitemap в robots.txt может повлечь воровство контента сайта.
Регулярные выражения
В файле robots.txt могут применяться специальные регулярные выражения в URL-префиксах с помощью символов * и $.
Символ /
Символ / (косая черта) является разделителем URL-префиксов, отражая степень вложенности страниц. Важно понимать, что URL-префикс с символом / на конце и аналогичный префикс, но без косой черты, поисковые роботы могут воспринимать как разные страницы:
# разные запреты: Disallow: /catalog/ # запрет для вложенных URL (/catalog/1), но не для /catalog Disallow: /catalog # запрет для /catalog и всех URL, начинающихся с /catalog, в том числе: # /catalog1 # /catalog1 # /catalog1/2
Символ *
Символ * (звездочка) предполагает любую последовательность символов. Он неявно приписывается к концу каждого URL-префикса директив Disallow и Allow:
User-agent: Googlebot Disallow: /catalog/ # запрет всех URL-адресов, начинающихся с "/catalog/" Disallow: /catalog/* # то же самое
Символ * может применяться в любом месте URL-префикса:
User-agent: Googlebot Disallow: /*catalog/ # запрещает все URL-адреса, содержащие "/catalog/": # /1catalog/ # /necatalog/1 # images/catalog/1 # /catalog/page.htm # и др. # но не /catalog
Символ $
Символ $ (знак доллара) применяется для отмены неявного символа * в окончаниях URL-префиксов:
User-agent: Google Disallow: /*catalog/$ # запрещает все URL-адреса, заканчивающиеся символами "catalog/": # /1/catalog/ # но не: # /necatalog/1 # /necatalog # /catalog
Символ $ (доллар) не отменяет явный символ * в окончаниях URL-префиксов:
User-agent: Googlebot Disallow: /catalog/* # запрет всех URL-адресов, начинающихся с "/catalog/" Disallow: /catalog/*$ # то же самое # Но: Disallow: /catalog/ # запрет всех URL-адресов, начинающихся с "/catalog/" Disallow: /catalog/$ # запрет только URL-адреса "/catalog/"
Директивы Яндекса
Роботы Яндекса способны понимать три специальных директивы:
- Host (устарела),
- Crawl-delay,
- Clean-param.
Директива Host
Директива Host является устаревшей и в настоящее время не учитывается. Вместо неё необходимо настраивать редирект на страницы главного зеркала.
Директива Crawl-delay
Если сервер сильно нагружен и не успевает отрабатывать запросы на загрузку, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
 Яндекс.Помощь
Яндекс.ПомощьПравило Crawl-delay следует размещать в группу правил, которая начинается с директивы User-Agent, но после стандартных для всех роботов директив Disallow и Allow:
User-agent: * Disallow: Crawl-delay: 1 # задержка между посещениями страниц 1 секунда
В качестве значений Crawl-delay могут использоваться дробные числа:
User-agent: * Disallow: Crawl-delay: 2.5 # задержка между посещениями страниц 2.5 секунд
Директива Clean-param
Директива Clean-param помогает роботу Яндекса верно определить страницу для индексации, URL-адрес которой может содержать различные параметры, не влияющие на смысловое содержание страницы.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (например: идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
В качестве значения правила Clean-param указывается параметр и URL-префикс адресов, для которых не следует учитывать данный параметр. Параметр и URL-префикс должны быть разделены пробелом:
User-agent: * Disallow: # Указывает на отсутствие значимости параметра id в URL-адресе с index.htm # (например, в адресе seoportal.net/index.htm?id=1 параметр id не станет учитываться, # а в индекс, вероятно, попадёт страница с URL-адресом seoportal.net/index.htm): Clean-param: id index.htm
Для указания 2-х и более незначительных параметров в одном правиле Clean-param применяется символ &:
User-agent: * Disallow: # Указывает на отсутствие значимости параметров id и num в URL-адресе с index.htm Clean-param: id&num index.htm
Директива Clean-param может быть указана в любом месте файла robots.txt. Все указанные правила Clean-param будут учтены роботом Яндекса:
User-agent: * Allow: / # Для разных страниц с одинаковыми параметрами в URL-адресах: Clean-param: id index Clean-param: id admin
1 сентября 2019 года Google прекратит поддержку нескольких директив в robots.txt. В список попали: noindex, crawl-delay и nofollow. Вместо них рекомендуется использовать:
-
Мета-тег noindex, как наиболее эффективный способ удалить страницу из индекса.
-
404 и 410 коды ответа сервера. В ряде случаев, 410 отрабатывает значительно быстрей для удаления URL из индекса.
-
Защита паролем. Страницы, требующие авторизации, также обычно удаляются из индекса (важно — именно страницы, полностью скрытые под логином, а не часть контента).
-
Временное удаление страницы из индекса с помощью инструмента в Search Console.
-
Disallow в robots.txt.
Тем не менее, robots.txt по-прежнему остаётся одним из главных файлов для SEO-специалиста. Давайте вспомним самые полезные директивы от простых, до менее очевидных.
robots.txt
Это простой текстовый файл, который содержит инструкции для поисковых краулеров — какие страницы сайта не следует посещать, где лежит наш Sitemap.xml и для каких поисковых роботов распространяются правила.
Файл размещается в корневой директории сайта. Например:
Прежде чем начать сканирование сайта, краулеры проверяют наличие robots.txt и находят правила специфичные для их User-Agent, например Googlebot. Если таких нет — следуют общим инструкциям.
Действующие правила robots.txt
User-Agent
У каждой поисковой системы есть свои «агенты пользователя». По сути, это имя краулера, которое помогает дать определённые указания конкретному ему.
Если брать шире, то User-Agent — клиентское приложение на стороне поисковой системы, в некотором смысле имитирующее браузер или, например, мобильное устройство.
Примеры:
-
User-agent: *— символ астериск используются для обозначения сразу же всех краулеров. -
User-agent: Yandex— основной краулер Яндекс-поиска. -
User-agent: Google-Image— робот поиска Google по картинкам. -
User-agent: AhrefsBot— краулер сервиса Ahrefs.
Важно: если в файле указаны правила для конкретных User-Agent, то роботы будут следовать только своим инструкциям, игнорируя общие правила.
В примере ниже краулер DuckDukcGo сможет сканировать папки сайта /api/ и /tmp/, несмотря на астериск («звёздочку»), отвечающий за инструкции всем роботам.
User-agent: *
Disallow: /tmp/
Disallow: /api/
User-agent: DuckDuckBot
Disallow: /duckhunt/Disallow
Директива, которая позволяет блокировать от индексации полностью весь сайт или определённые разделы.
Может быть полезно для закрытия от сканирования служебных, динамических или временных страниц (символ # отвечает за комментарии в коде и игнорируется краулерами).
User-agent: *
# Закрываем раздел /cms и все файлы внутри
Disallow: /cms
# Закрываем папку /images/resized/ (сами изображения разрешены к сканированию)
Disallow: /api/resized/Упростить инструкции помогают операторы:
-
*— любая последовательность символов в URL. По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *. -
$— символ в конце URL-адреса, он используется чтобы отменить использование * на конце правила.
User-agent: *
# Закрываем URL, начинающиеся с /photo после домена. Например:
# /photos
# /photo/overview
Disallow: /photo
# Закрываем все URL, начинающиеся с /blog/ после домена и заканчивающиеся /stats/
Disallow: /blog/*/stats$Важно: в robots.txt не нужно закрывать JS и CSS-файлы, они понадобятся поисковым роботом для правильного отображения (рендеринга) контента.
Allow
С помощью этой директивы можно, напротив, разрешить каталог или конкретный адрес к индексации. В некоторых случаях проще запретить к сканированию весь сайт и с помощью Allow открыть нужные разделы.
User-agent: *
# Блокируем весь раздел /admin
Disallow: /admin
# Кроме файла /admin/css/style.css
Allow: /admin/css/style.css
# Открываем все файлы в папке /admin/js. Например:
# /admin/js/global.js
# /admin/js/ajax/update.js
Allow: /admin/js/Также Allow можно использовать для отдельных User-Agent.
# Запрещаем доступ к сайту всем роботам
User-agent: *
Disallow: /
# Кроме краулера Яндекса
User-agent: Yandex
Allow: /Crawl-delay
Директива, теряющая актуальность в случае Goolge, но полезная для работы с другими поисковиками.
Позволяет замедлить сканирование, если сервер бывает перегружен. Устанавливает интервал времени для обхода страниц в секундах (для Яндекса). Чем выше значение, тем медленнее краулер ходит по сайту.
User-agent: *
Crawl-delay: 5Несмотря на то, что Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Интересно, что китайский Baidu также не обращает внимание на Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт только один раз.
Важно: если установлено высокое значение Crawl-delay, убедитесь, что ваш сайт своевременно индексируется. В сутках 86 400 секунд, при Crawl-delay: 30 будет просканировано не более 2880 страниц в день, что мало для крупных сайтов.
Sitemap
Одно из ключевых применений robots.txt в SEO — указание на расположение карты сайты. Обратите внимание, используется полный URL-адрес (их может быть несколько).
Sitemap: https://www.example.com/sitemap.xml
Sitemap: https://www.example.com/blog-sitemap.xmlНужно иметь в виду:
-
Директива Sitemap указывается с заглавной S.
-
Sitemap не зависит от инструкций User-Agent.
-
Нельзя использовать относительный адрес карты сайта, только полный URL.
-
Файл XML-карты сайта должен располагаться на том же домене.
Также убедитесь, что ссылка возвращает статус 200 OK без редиректов. Проверить можно с помощью инструмента, определяющего ответ сервера или анализа XML-карты сайта.
Типичный robots.txt
Ниже представлены простые и распространенные шаблоны команд для поисковых роботов.
Разрешить полный доступ
Обратите внимание, правило для Disallow в этом случае не заполняется.
Полная блокировка доступа к хосту
User-agent: *
Disallow: /Запрет конкретного раздела сайта
User-agent: *
Disallow: /admin/Запрет сканирования определенного файла
User-agent: *
Disallow: /admin/my-embarrassing-photo.pngРаспространенная ошибка
Установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent, соответствующий краулер будет следовать только тем правилам, что установлены именно для него. Не забывайте дублировать общие директивы для всех User-Agent.
В примере ниже — слегка измененный robots.txt сайта IMDB. Общие правила Disallow не будут распространяться на бот ScoutJet. А вот Crawl-delay, напротив, установлена только для него.
# отредактированная версия robots.txt сайта IMDB
#
# Задержка интервала сканирования для ScouJet
#
User-agent:ScouJet
Crawl-delay: 3
#
#
#
# Все остальные
#
User-agent: *
Disallow: /tvschedule
Disallow: /ActorSearch
Disallow: /ActressSearch
Disallow: /AddRecommendation
Disallow: /ads/
Disallow: /AlternateVersions
Disallow: /AName
Disallow: /Awards
Disallow: /BAgent
Disallow: /Ballot/
#
#
Sitemap: https://www.imdb.com/sitemap_US_index.xml.gzПротиворечия директив
Общее правило — если две директивы противоречат друг другу, приоритетом пользуется та, в которой большее количество символов.
User-agent: *
# /admin/js/global.js разрешён к сканированию
# /admin/js/update.js по-прежнему запрещён
Disallow: /admin
Allow: /admin/js/global.jsМожет показаться, что файл /admin/js/global.js попадает под правило блокировки содержащего его раздела Disallow: /admin/. Тем не менее, он будет доступен для сканирования, в отличие от всех остальных файлов в каталоге.
Список распространенных User-Agent
| User-Agent | # |
|---|---|
| Googlebot | Основной краулер Google |
| Googlebot-Image | Робот поиска по картинкам |
| Bing | |
| Bingbot | Основной краулер Bing |
| MSNBot | Старый, но всё ещё использующийся краулер Bing |
| MSNBot-Media | Краулер Bing для изображений |
| BingPreview | Отдельный краулер Bing для Snapshot-изображений |
| Яндекс | |
| YandexBot | Основной индексирующий бот Яндекса |
| YandexImages | Бот Яндеса для поиска по изображениям |
| Baidu | |
| Baiduspider | Главный поисковый робот Baidu |
| Baiduspider-image | Бот Baidu для картинок |
| Applebot | Краулер для Apple. Используется для Siri поиска и Spotlight |
| SEO-инструменты | |
| AhrefsBot | Краулер сервиса Ahrefs |
| MJ12Bot | Краулер сервиса Majestic |
| rogerbot | Краулер сервиса MOZ |
| PixelTools | Краулер «Пиксель Тулс» |
| Другое | |
| DuckDuckBot | Бот поисковой системы DuckDuckGo |
Советы по использованию операторов
Как упоминалось выше, широко применяются два оператора: * и $. С их помощью можно:
1. Заблокировать определённые типы файлов.
User-agent: *
# Блокируем любые файлы с расширением .json
Disallow: /*.json$В примере выше астериск * указывает на любые символы в названии файла, а оператор $ гарантирует, что расширение .json находится точно в конце адреса, и правило не затрагивает страницы вроде /locations.json.html (вдруг есть и такие).
2. Заблокировать URL с параметром ?, после которого следуют GET-запросы (метод передачи данных от клиента серверу).
Этот приём активно используется, если у проекта настроено ЧПУ для всех страниц и документы с GET-параметрами точно являются дублями.
User-agent: *
# Блокируем любые URL, содержащие символ ?
Disallow: /*?Заблокировать результаты поиска, но не саму страницу поиска.
User-agent: *
# Блокируем страницу результатов поиска
Disallow: /search.php?query=*Имеет ли значение регистр?
Определённо да. При указании правил Disallow / Allow, URL адреса могут быть относительными, но обязаны сохранять регистр.
User-agent: *
# /users разрешены для сканирования, поскольку регистр разный
Disallow: /UsersНо сами директивы могут объявляться как с заглавной, так и с прописной: Disallow: или disallow: — без разницы. Исключение — Sitemap: всегда указывается с заглавной.
Как проверить robots.txt?
Есть множество сервисов проверки корректности файлов robots.txt, но, пожалуй, самые надёжные: Google Search Console и Яндекс.Вебмастер.
Для мониторинга изменений, как всегда, незаменим «Модуль ведения проектов»:
-
Контроль индексации на вкладке «Аудит» — динамика сканирования страниц сайта в Яндексе и Google.
-
Контроль изменений в файле robots.txt. Теперь точно не упустите, если кто-то из коллег закрыл сайт от индексации (или наоборот).
Держите свои robots.txt в порядке, и пусть в индекс попадает только необходимое!
Как составить robots.txt самостоятельно
Как правильно составить robots.txt и зачем он нужен, как закрыть индексацию через robots.txt и бесплатно проверить robots.txt с помощью онлайн-инструментов.
Как поисковики сканируют страницу
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots.txt.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта — Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI). - Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. - Быстро загружаются.
Проверьте скорость загрузки инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Посмотреть на сайт глазами поискового бота
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt. Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt«, название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами — http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
 Доступная для пользователей ссылка
Доступная для пользователей ссылкаТакой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Как составить robots.txt правильно
Файл можно составить в любом текстовом редакторе и сохранить в формате txt. В нем нужно прописать инструкцию для роботов: указание, каким роботам реагировать, и разрешение или запрет на сканирование файлов.
Инструкции отделяют друг от друга переносом строки.
Символы robots.txt
«*» — означает любую последовательность символов в файле.
«$» — ограничивает действия «*», представляет конец строки.
«/» — показывает, что закрывают для сканирования.
«/catalog/» — закрывают раздел каталога;
«/catalog» — закрывают все ссылки, которые начинаются с «/catalog».
«#» — используют для комментариев, боты игнорируют текст с этим символом.
User-agent: * Disallow: /catalog/ #запрещаем сканировать каталог
Директивы robots.txt
Директивы, которые распознают все краулеры:
User-agent
На первой строчке прописывают правило User-agent — указание того, какой робот должен реагировать на рекомендации. Если запрещающего правила нет, считается, что доступ к файлам открыт.
Для разного типа контента поисковики используют разных ботов:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.Маркета и другие.
Для отдельных ботов можно указать свою директиву, если есть необходимость в рекомендациях по типу контента.
User-agent: * — правило для всех поисковых роботов;
User-agent: Googlebot — только для основного поискового бота Google;
User-agent: YandexBot — только для основного бота Яндекса;
User-agent: Yandex — для всех ботов Яндекса. Если любой из ботов Яндекса обнаружит эту строку, то другие правила User-agent: * учитывать не будет.
Sitemap
Указывает ссылку на карту сайта — файл со структурой сайта, в котором перечислены страницы для индексации:
User-agent: * Sitemap: http://site.com/sitemap.xml
Некоторые веб-мастеры не делают карты сайтов, это не обязательное требование, но лучше составить Sitemap — этот файл краулеры воспринимают как структуру страниц, которые не можно, а нужно индексировать.
Disallow
Правило показывает, какую информацию ботам сканировать не нужно.
Если вы еще работаете над сайтом и не хотите, чтобы он появился в незавершенном виде, можно закрыть от сканирования весь сайт:
User-agent: * Disallow: /
После окончания работы над сайтом не забудьте снять блокировку.
Разрешить всем ботам сканировать весь сайт:
User-agent: * Disallow:
Для этой цели можно оставить robots.txt пустым.
Чтобы запретить одному боту сканировать, нужно только прописать запрет с упоминанием конкретного бота. Для остальных разрешение не нужно, оно идет по умолчанию:
Пользователь-агент: BadBot Disallow: /
Чтобы разрешить одному боту сканировать сайт, нужно прописать разрешение для одного и запрет для остальных:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Запретить ботам сканировать страницу:
User-agent: * Disallow: /page.html
Запретить сканировать конкретную папку с файлами:
User-agent: * Disallow: /name/
Запретить сканировать все файлы, которые заканчиваются на «.pdf»:
User-agent: * Disallow: /*.pdf$
Запретить сканировать раздел http://site.com/about/:
User-agent: * Disallow: /about/
Запись формата «Disallow: /about» без закрывающего «/» запретит доступ и к разделу
http://site.com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с «/about».
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Директива определяет те пути, которые доступны для указанных поисковых ботов. По сути, это Disallow-наоборот — директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл «photo.html» разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.html Disallow: /album1/
Заблокировать доступ к каталогам «site.com/catalog1/» и «site.com/catalog2/» но разрешить к «catalog2/subcatalog1/»:
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
«www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123″
«www.site. com/some_dir/get_book.pl?ref=site_2& book_id=123″
«www.site. com/some_dir/get_book.pl?ref=site_3& book_id=123″
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref/some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
«www.example. com/some_dir/get_book.pl? book_id=123″
Для адресов вида:
«www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df»
«www.example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid/index.php
Для адресов вида
«www.example1. com/forum/showthread.php? s=681498b9648949605&t=8243″
«www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s/forum/showthread.php
Если переходных параметров несколько:
«www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311″
«www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref/forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации. URL нужно писать без «http://» и без закрывающего слэша «/».
User-agent: Yandex Disallow: /about Host: www.site.com
Сейчас эту директиву уже не используют, если в ваших robots.txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
Crawl-delay
Раньше частая загрузка страниц нагружала сервер, поэтому для ботов устанавливали Crawl-delay — время ожидания робота в секундах между загрузками. Эту директиву можно не использовать, мощным серверам она не требуется.
Время ожидания — 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Напомним, что все кириллические ссылки нужно перевести в Punycode с помощью любого конвертера.
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3a
Пример robots.txt
Запись означает, что правило справедливо для всех роботов: запрещено сканировать ссылки из корзины, из встроенного поиска и админки, карта сайта находится по ссылке http://site.com/sitemap, ref не меняет содержание страницы get_book:
User-agent: * Disallow: /bin/ Disallow: /search/ Disallow: /admin/ Sitemap: http://site.com/sitemap Clean-param: ref/some_dir/get_book.pl
Составить robots.txt бесплатно поможет
инструмент для генерации robots.txt от PR-CY, он позволит закрыть или открыть весь сайт для ботов, указать путь к карте сайта, настроить ограничение на посещение страниц, закрыть доступ некоторым роботам и установить задержку:
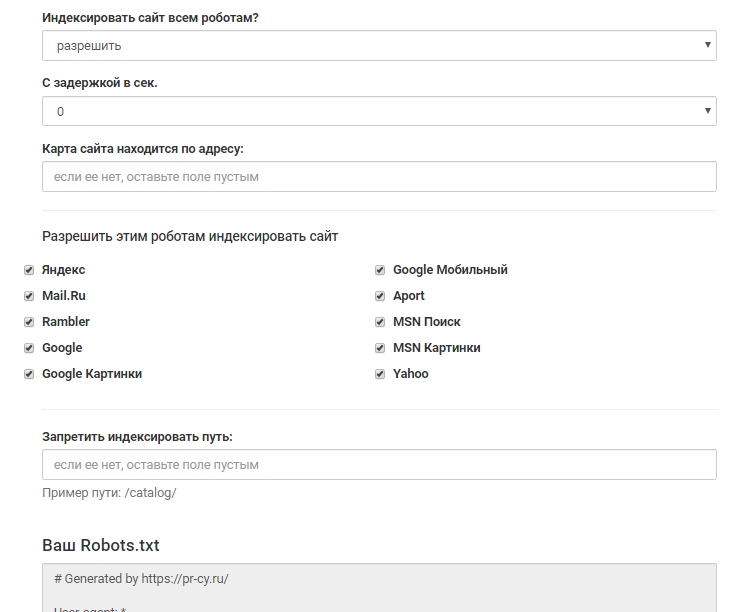 Графы инструмента для заполнения
Графы инструмента для заполненияДля проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Файл robots.txt не подходит для блокировки доступа к приватным файлам, но направляет краулеров к карте сайта и дает рекомендации для быстрого сканирования важных материалов ресурса.
Анализ файлов robots.txt крупнейших сайтов / Хабр
Robots.txt указывает веб-краулерам мира, какие файлы можно или нельзя скачивать с сервера. Он как первый сторож в интернете — не блокирует запросы, а просит не делать их. Интересно, что файлы robots.txt проявляют предположения веб-мастеров, как автоматизированным процессам следует работать с сайтом. Хотя бот легко может их игнорировать, но они указывают идеализированное поведение, как следует действовать краулеру.По существу, это довольно важные файлы. Так что я решил скачать файл robots.txt с каждого из 1 миллиона самых посещаемых сайтов на планете и посмотреть, какие шаблоны удастся обнаружить.
Я взял список 1 млн крупнейших сайтов от Alexa и написал маленькую программу для скачивания файла robots.txt с каждого домена. После скачивания всех данных я пропустил каждый файл через питоновский пакет urllib.robotparser и начал изучать результаты.
Найдено в yangteacher.ru/robots.txt
Среди моих любимых питомцев — сайты, которые позволяют индексировать содержимое только боту Google и банят всех остальных. Например, файл robots.txt сайта Facebook начинается со следующих строк:
Notice: Crawling Facebook is prohibited unless you have express written permission. See: http://www.facebook.com/apps/site_scraping_tos_terms.phphttp://www.facebook.com/apps/site_scraping_tos_terms.php)Это слегка лицемерно, потому что сам Facebook начал работу с краулинга профилей студентов на сайте Гарвардского университета — именно такого рода активность они сейчас запрещают всем остальным.
Требование письменного разрешения перед началом краулинга сайта плюёт в лицо идеалам открытого интернета. Оно препятствует научным исследованиям и ставит барьер для развития новых поисковых систем: например, поисковику DuckDuckGo запрещено скачивать страницы Facebook, а поисковику Google можно.
В донкихотском порыве назвать и посрамить сайты, которые проявляют такое поведение, я написал простой скрипт, который проверяет домены и определяет тех, которые внесли Google в белый список тех, кому разрешено индексировать главную страницу. Вот самые популярные из этих доменов:
(В оригинальной статье указаны также аналогичные списки китайских, французских и немецких доменов — прим. пер.)
Я включил в таблицу пометку, позволяет ли сайт ещё DuckDuckGo индексировать свою заглавную страницу, в попытке показать, насколько тяжело приходится в наши дни новым поисковым системам.
У большинства из доменов в верхней части списка — таких как Facebook, LinkedIn, Quora и Yelp — есть одно общее. Все они размещают созданный пользователями контент, который представляет собой главную ценность их бизнеса. Это один из их главных активов, и компании не хотят отдавать его бесплатно. Впрочем, ради справедливости, такие запреты часто представляются как защита приватности пользователей, как в этом заявлении технического директора Facebook о решении забанить краулеры или глубоко в файле robots.txt от Quora, где объясняется, почему сайт забанил Wayback Machine.
Далее по списку результаты становятся более противоречивыми — например, мне не совсем понятно, почему census.gov позволяет доступ к своему контенту только трём основным поисковым системам, но блокирует DuckDuckGo. Логично предположить, что данные государственных переписей принадлежат народу, а не только Google/Microsoft/Yahoo.
Хотя я не фанат подобного поведения, но вполне могу понять импульсивную попытку внести в белый список только определённые краулеры, если учесть количество плохих ботов вокруг.
Я хотел попробовать ещё кое-что: определить самые плохие веб-краулеры в интернете, с учётом коллективного мнения миллиона файлов robots.txt. Для этого я подсчитал, сколько разных доменов полностью банят конкретный useragent — и отранжировал их по этому показателю:
В списке боты нескольких определённых типов.
Первая группа — краулеры, которые собирают данные для SEO и маркетингового анализа. Эти фирмы хотят получить как можно больше данных для своей аналитики — генерируя заметную нагрузку на многие сервера. Бот Ahrefs даже хвастается: «AhrefsBot — второй самый активный краулер после Googlebot», так что вполне понятно, почему люди хотят заблокировать этих надоедливых ботов. Majestic (MJ12Bot) позиционирует себя как инструмент конкурентной разведки. Это значит, что он скачивает ваш сайт, чтобы снабдить полезной информацией ваших конкурентов — и тоже на главной странице заявляет о «крупнейшем в мире индексе ссылок».
Вторая группа user-agents — от инструментов, которые стремятся быстро скачать веб-сайт для персонального использования в офлайне. Инструменты вроде WebCopier, Webstripper и Teleport — все они быстро скачивают полную копию веб-сайта на ваш жёсткий диск. Проблема в скорости многопоточного скачивания: все эти инструменты очевидно настолько забивают трафик, что сайты достаточно часто их запрещают.
Наконец, есть поисковые системы вроде Baidu (BaiduSpider) и Yandex, которые могут агрессивно индексировать контент, хотя обслуживают только языки/рынки, которые не обязательно очень ценны для определённых сайтов. Лично у меня оба эти краулера генерируют немало трафика, так что я бы не советовал блокировать их.
Это знак времени, что файлы, которые предназначены для чтения роботами, часто содержат объявления о найме на работу разработчиков программного обеспечения — особенно специалистов по SEO.
В каком-то роде это первая в мире (и, наверное, единственная) биржа вакансий, составленная полностью из описаний файлов robots.txt. (В оригинальной статье представлены тексты всех 67 вакансий из файлов robots.txt — прим. пер.).
Есть некоторая ирония в том, что Ahrefs.com, разработчик второго среди самых забаненных ботов, тоже поместила в своём файле robots.txt объявление о поиске SEO-специалиста. А ещё у pricefalls.com объявление о работе в файле robots.txt следует после записи «Предупреждение: краулинг Pricefalls запрещён, если у вас нет письменного разрешения».
Весь код для этой статьи — на GitHub.
Robots.txt средство проверки и тестирования
Файл robots.txt
Файл robots.txt представляет собой простой текстовый файл, используемый для информирования робота Google об областях домена, которые могут быть сканированы поисковым движком, и тех, которые могут не сканироваться. Кроме того, ссылка на карту сайта XML также может быть включена в файл robots.txt. Прежде чем бот поисковой системы начнет индексировать , он сначала ищет в корневом каталоге файл robots.txt и читает приведенные там спецификации.Для этого текстовый файл должен быть сохранен в корневом каталоге домена и иметь имя: robots.txt .
Файл robots.txt можно просто создать с помощью текстового редактора. Каждый файл состоит из двух блоков. Сначала указывается пользовательский агент, к которому должна применяться инструкция, затем следует команда «Запретить», после которой отображаются URL-адреса, подлежащие исключению из сканирования. Пользователь должен всегда проверять правильность работы роботов.TXT-файл перед загрузкой в корневой каталог веб-сайта. Даже малейшая ошибка может привести к тому, что бот будет игнорировать спецификации и, возможно, включать страницы, которые не должны появляться в индексе поисковой системы.
Этот бесплатный инструмент от Ryte позволяет вам протестировать файл robots.txt. Вам нужно только ввести соответствующий URL и выбрать соответствующий пользовательский агент. После нажатия «Начать тест» инструмент проверяет, разрешено ли сканирование по заданному URL-адресу.Вы также можете использовать Ryte FREE, чтобы проверить многие другие факторы на вашем сайте! Вы можете анализировать и оптимизировать до 100 URL-адресов с помощью Ryte FREE. Просто нажмите здесь, чтобы получить бесплатный аккаунт »
Простейшая структура файла robots.txt выглядит следующим образом:
User-agent: * Disallow:
Этот код позволяет роботу Googlebot сканировать все страницы. Чтобы запретить роботу сканировать все веб-присутствие, вы должны добавить следующее в файл robots.txt:
User-agent: * Disallow: /
Пример: Если вы хотите запретить сканирование каталога / info / роботом Googlebot, вам нужно ввести следующую команду в роботах.текстовый файл:
Пользователь-агент: Googlebot Disallow: / info /
Более подробную информацию о файле robots.txt можно найти здесь:
,ТестRobots.txt | SEO Site Checkup
Проверьте, использует ли ваш сайт файл robots.txt. Когда роботы поисковых систем сканируют веб-сайт, они обычно сначала получают доступ к файлу robots.txt сайта. Robots.txt сообщает роботу Googlebot и другим сканерам, что разрешено сканировать на вашем сайте.
Проверьте все факторы Meta Title Test Мета Описание Тест Тест предварительного просмотра результатов поиска Google Тест наиболее распространенных ключевых слов Тест использования ключевых слов Облачный тест ключевых слов Тест по ключевым словам Тест доменов конкурентов Тест заголовков Роботы.Тест TXT Карта сайта Тест SEO Friendly URL Test Изображение Alt Test Встроенный тест CSS Устаревший тест HTML-тегов Тест Google Analytics Тест Фавикон Тест обратных ссылок JS Error Test Тест в социальных сетях Тест размера страницы HTML Сжатие HTML / Тест GZIP Тест скорости загрузки сайта Тест объектов страницы Тест кэширования страницы (кэширование на стороне сервера) Flash-тест Тест использования CDN Тест кэширования изображений Тест кэширования JavaScript CSS Caching Test Тест минификации JavaScript Тест минификации CSS Тест вложенных таблиц Тест Frameset Doctype Test Тест перенаправления URL URL-тест канонизации HTTPS тест Тест безопасного просмотра Тест подписи сервера Тест просмотра каталога Тест текстовых писем Отзывчивый тест медиазапроса Тест мобильного снимка Тест структурированных данных Пользовательский тест страницы ошибки 404 Noindex Tag Test Канонический тест тегов Nofollow Tag Test Запретить директивную проверку SPF Records Test
Чтобы пройти этот тест, вы должны создать и правильно установить роботов .Файл TXT .
Для этого вы можете использовать любую программу, которая создает текстовый файл, или вы можете использовать онлайн-инструмент (эта функция есть в Инструментах Google для веб-мастеров).
Не забудьте использовать все строчные буквы для имени файла: robots.txt , а не ROBOTS.TXT .
Простой файл robots.txt выглядит следующим образом:
Пользователь-агент: * Disallow: / cgi-bin / Disallow: / images / Disallow: /pages/thankyou.html
Это заблокирует все роботы поисковых систем от посещения каталогов «cgi-bin» и «images» и страницы «http: // www.yoursite.com/pages/thankyou.html «
СОВЕТЫ:
- Вам необходима отдельная строка Disallow для каждого префикса URL, который вы хотите исключить
- У вас может не быть пустых строк в записи, поскольку они используются для разделения нескольких записей
- Обратите внимание, что перед командой Disallow у вас есть команда: User-agent: * . Часть User-agent: указывает, какого робота вы хотите заблокировать. Основные известные сканеры: Googlebot (Google), Googlebot-Image (Поиск картинок Google), Baiduspider (Baidu), Bingbot (Bing)
- Важно знать, создаете ли вы свои собственные роботы .Файл txt заключается в том, что хотя в строке User-agent 9002 (что означает «любой робот») используется подстановочный знак (*), он не разрешен в строке Disallow .
- Регулярные выражения не поддерживаются ни в User-agent , ни в Запретить строк
Получив файл robots.txt , вы можете загрузить его в каталог верхнего уровня своего веб-сервера. После этого убедитесь, что вы установили права доступа к файлу, чтобы посетители (например, поисковые системы) могли его прочитать.
,Что такое файл robots.txt и как его создать?
Что такое robots.txt?
 Рисунок: Robots.txt — Автор: Seobility — Лицензия: CC BY-SA 4.0
Рисунок: Robots.txt — Автор: Seobility — Лицензия: CC BY-SA 4.0Robots.txt — это текстовый файл с инструкциями для поисковых роботов. Он определяет, какие области сканерам веб-сайта разрешено искать. Однако они не имеют явного имени в файле robots.txt. Скорее, определенные области не разрешены для поиска. Используя этот простой текстовый файл, вы можете легко исключить из сканирования поисковой системой целые домены, полные каталоги, один или несколько подкаталогов или отдельные файлы.Однако этот файл не защищает от несанкционированного доступа.
Robots.txt хранится в корневом каталоге домена. Таким образом, это первый документ, который сканеры открывают при посещении вашего сайта. Однако файл не только контролирует сканирование. Вы также можете интегрировать ссылку на свою карту сайта, которая дает сканерам поисковых систем обзор всех существующих URL-адресов вашего домена.
Robots.txt Checker
Проверьте файл robots.txt вашего сайта
Как работают роботы.TXT работает
В 1994 году был опубликован протокол под названием REP (Стандартный протокол исключения роботов). Этот протокол предусматривает, что все поисковые роботы (пользовательские агенты) должны сначала найти файл robots.txt в корневом каталоге вашего сайта и прочитать содержащиеся в нем инструкции. Только тогда роботы могут начать индексирование вашей веб-страницы. Файл должен находиться непосредственно в корневом каталоге вашего домена и должен быть написан строчными буквами, поскольку роботы читают файл robots.txt и его инструкции с учетом регистра.К сожалению, не все роботы поисковых систем следуют этим правилам. По крайней мере, файл работает с наиболее важными поисковыми системами, такими как Bing, Yahoo и Google. Их поисковые роботы строго следуют инструкциям REP и robots.txt.
На практике файл robots.txt можно использовать для разных типов файлов. Если вы используете его для файлов изображений, он не позволяет этим файлам появляться в результатах поиска Google. Незначительные файлы ресурсов, такие как файлы сценариев, стилей и изображений, также могут быть легко заблокированы роботами.текст. Кроме того, вы можете исключить динамически генерируемые веб-страницы из сканирования, используя соответствующие команды. Например, страницы результатов внутренней функции поиска, страницы с идентификаторами сеансов или действиями пользователей, такими как корзины покупок, могут быть заблокированы. Вы также можете контролировать доступ сканера к другим файлам, не относящимся к изображениям (веб-страницам), используя текстовый файл. Таким образом, вы можете избежать следующих сценариев:
- поисковые роботы сканируют множество похожих или неважных веб-страниц
- ваш бюджет обхода потрачен впустую без необходимости
- ваш сервер перегружен сканерами
В этом контексте, однако, обратите внимание, что роботы.txt не гарантирует, что ваш сайт или отдельные подстраницы не проиндексированы. Он контролирует только сканирование вашего сайта, но не индексацию. Если веб-страницы не должны быть проиндексированы поисковыми системами, вы должны установить следующий метатег в заголовке вашей веб-страницы:
Однако вы не должны блокировать файлы, которые имеют большое значение для поисковых роботов. Обратите внимание, что файлы CSS и JavaScript также должны быть разблокированы, так как они используются для сканирования, особенно мобильными роботами.
Какие инструкции используются в файле robots.txt?
Ваш robots.txt должен быть сохранен как текстовый файл UTF-8 или ASCII в корневом каталоге вашей веб-страницы. Должен быть только один файл с этим именем. Он содержит один или несколько наборов правил, структурированных в четко читаемом формате. Правила (инструкции) обрабатываются сверху вниз, благодаря чему различаются заглавные и строчные буквы.
В файле robots.txt используются следующие термины:
- user-agent: обозначает имя сканера (имена можно найти в базе данных роботов)
- disallow: предотвращает сканирование определенных файлов, каталогов или веб-страниц
- разрешить: перезаписать запретить и разрешить сканирование файлов, веб-страниц и каталогов Карта сайта
- (необязательно): показывает местоположение карты сайта
- *: обозначает любое количество символов
- $: обозначает конец строки
Инструкции (записи) в роботах.TXT всегда состоит из двух частей. В первой части вы определяете, для каких роботов (пользовательских агентов) применяется следующая инструкция. Вторая часть содержит инструкцию (запретить или разрешить). «user-agent: Google-Bot» и инструкция «disallow: / clients /» означают, что боту Google не разрешен поиск в каталоге / clients /. Если поисковый бот не будет сканировать весь сайт, введите следующую запись: «user-agent: *» с инструкцией «disallow: /». Вы можете использовать знак доллара «$» для блокировки веб-страниц с определенным расширением.Оператор «disallow: / * .doc $» блокирует все URL с расширением .doc. Таким же образом вы можете заблокировать определенные форматы файлов в файле robots.txt: «disallow: /*.jpg$».
Например, файл robots.txt для веб-сайта https://www.example.com/ может выглядеть следующим образом:
Пользователь-агент: * Disallow: / логин / Disallow: / карта / Disallow: / fotos / Disallow: / temp / Disallow: / поиск / Disallow: /*.pdf$ Карта сайта: https://www.example.com/sitemap.xml
Какую роль играет robots.txt в поисковой оптимизации?
Инструкции в роботах.TXT-файл сильно влияет на SEO (поисковая оптимизация), так как файл позволяет вам управлять поисковыми роботами. Однако, если пользовательские агенты слишком ограничены запрещающими инструкциями, это отрицательно влияет на рейтинг вашего сайта. Вы также должны учитывать, что вы не будете ранжироваться с веб-страницами, которые вы исключили, запретив в robots.txt. Если, с другой стороны, нет или почти нет запретных ограничений, может случиться так, что страницы с дублирующимся содержимым будут проиндексированы, что также отрицательно скажется на ранжировании этих страниц.
Прежде чем сохранить файл в корневом каталоге вашего сайта, вы должны проверить синтаксис. Даже незначительные ошибки могут привести к тому, что поисковые роботы будут игнорировать правила запрета и сканировать сайты, которые не следует индексировать. Такие ошибки могут также привести к тому, что страницы больше не будут доступны для поисковых роботов, а целые URL не будут проиндексированы из-за запрета. Вы можете проверить правильность своего robots.txt с помощью Google Search Console. В разделах «Текущее состояние» и «Ошибки сканирования» вы найдете все страницы, заблокированные инструкциями по запрету.
При правильном использовании robots.txt вы можете убедиться, что поисковые роботы сканируют все важные части вашего сайта. Следовательно, все содержимое вашей страницы индексируется Google и другими поисковыми системами.
Ссылки по теме
Похожие статьи
,Веб-страницы роботов
О файле /robots.txt
В двух словах
Владельцы веб-сайтов используют файл /robots.txt, чтобы дать инструкции о их сайт для веб-роботов; это называется Исключение роботов Протокол .
Это работает так: робот хочет просмотреть URL-адрес веб-сайта, скажем, http://www.example.com/welcome.html. Прежде чем он это делает, он первый проверяет http://www.example.com/robots.txt и находит:
Пользователь-агент: * Disallow: /
«User-agent: *» означает, что этот раздел применяется ко всем роботам.«Disallow: /» говорит роботу, что он не должен посещать страницы на сайте.
При использовании /robots.txt необходимо учитывать два важных момента:
- роботы могут игнорировать ваш /robots.txt. Особенно вредоносные роботы, которые сканируют Интернет для уязвимостей безопасности и сборщики адресов электронной почты, используемые спамерами не будет обращать внимания.
- файл /robots.txt является общедоступным файлом. Любой может увидеть, какие разделы вашего сервера вы не хотите использовать роботов.
Поэтому не пытайтесь использовать /robots.txt, чтобы скрыть информацию.
Смотрите также:
Подробности
/Robots.txt является стандартом де-факто и не принадлежит никому орган по стандартизации. Есть два исторических описания:
Кроме того есть внешние ресурсы:
Стандарт /robots.txt активно не разрабатывается. Смотрите Как насчет дальнейшего развития /robots.txt? для дальнейшего обсуждения.
Остальная часть этой страницы дает обзор того, как использовать / роботы.текст на ваш сервер, с некоторыми простыми рецептами. Чтобы узнать больше, смотрите также FAQ.
Как создать файл /robots.txt
Где это поставить
Краткий ответ: в каталоге верхнего уровня вашего веб-сервера.
Чем дольше ответ:
Когда робот ищет файл «/robots.txt» для URL, он удаляет Компонент пути из URL (все, начиная с первой косой черты), и помещает «/robots.txt» на его место.
Например, для «http: // www.example.com/shop/index.html, это будет удалите «/shop/index.html» и замените его «/robots.txt», и в конечном итоге «Http://www.example.com/robots.txt».
Таким образом, как владелец веб-сайта, вы должны поместить его в нужном месте на вашем веб-сервер для этого результирующего URL для работы. Обычно это то же самое место, где вы размещаете главное приветствие index.html вашего сайта стр. Где именно это находится, и как поместить туда файл, зависит от программное обеспечение вашего веб-сервера.
Не забудьте использовать все строчные буквы для имени файла: «роботы.txt «, а не» Robots.TXT.
Смотрите также:
Что положить в него
Файл /robots.txt представляет собой текстовый файл с одной или несколькими записями. Обычно содержит одну запись, похожую на эту:Пользователь-агент: * Disallow: / cgi-bin / Disallow: / tmp / Disallow: / ~ Джо /
В этом примере три каталога исключены.
Обратите внимание, что вам нужна отдельная строка «Disallow» для каждого префикса URL, который вы хотите исключить — вы не можете сказать «Disallow: / cgi-bin / / tmp /» на одна линия.Кроме того, вы можете не иметь пустых строк в записи, так как они используются для разделения нескольких записей.
Обратите внимание, что глобализация и регулярное выражение не поддерживается в User-agent или Disallow линий. ‘*’ В поле User-agent является специальным значением, означающим «любой робот «. В частности, вы не можете иметь такие строки, как» User-agent: * bot * «, «Disallow: / tmp / *» или «Disallow: * .gif».
То, что вы хотите исключить, зависит от вашего сервера. Все, что явно не запрещено, считается справедливым игра для извлечения.Вот несколько примеров:
Чтобы исключить всех роботов из всего сервера
Пользователь-агент: * Disallow: /
Разрешить всем роботам полный доступ
Пользователь-агент: * Disallow:
(или просто создайте пустой файл «/robots.txt», или не используйте его вообще)
Чтобы исключить всех роботов из части сервера
Пользователь-агент: * Disallow: / cgi-bin / Disallow: / tmp / Disallow: / мусор /
Чтобы исключить одного робота
Пользователь-агент: BadBot Disallow: /
Разрешить одного робота
Пользователь-агент: Google Disallow: Пользователь-агент: * Disallow: /
Исключить все файлы, кроме одного
В настоящее время это немного неудобно, так как нет поля «Разрешить». Самый простой способ — поместить все файлы, которые нужно запретить, в отдельный каталог, скажите «вещи», и оставьте один файл на уровне выше этот каталог:Пользователь-агент: * Disallow: / ~ Джо / вещи /В качестве альтернативы вы можете явно запретить все запрещенные страницы:
Пользователь-агент: * Disallow: /~joe/junk.html Disallow: /~joe/foo.html Disallow: /~joe/bar.html,