4.5. Организация поиска информации в сети Интернет
4.5. Организация поиска информации в сети Интернет4.5.1. Традиционные поисковые системы Интернета
Для поиска информации используются специальные внешние службы — поисковые серверы: поисковые машины и каталоги.
Поисковые машины — это такие серверы, которые накапливают информацию о содержимом сайтов автоматически, при помощи специальных программ-роботов.
Информацию для серверов-каталогов отбирают люди. В отличие от поисковых машин, информация в каталогах более точно структурирована, причем в вертикальном иерархическом виде.
И поисковые машины, и каталоги являются
внешними службами или, как их еще называют, автономными системами. Особенностью
автономных систем является то, что цикл работы с информацией выполняется полностью
непосредственно на этой системе, начиная с получения информации от первоисточника
и заканчивая предоставлением поискового сервиса конечному пользователю.
Автоматические поисковые системы охватывают больший объем информации, их сведения чаще обновляются и поэтому более актуальны. Однако информация на таких серверах плохо структурирована, потому что оценка содержимого того или иного сайта — трудно формализуемая задача. Чаще всего программа-робот отбирает документы только по наличию искомых слов в тексте документа. Примером поисковой машины является AltaVista (http://www.altavista.com).
В каталогах вся информация имеет четкую вертикальную иерархическую структуру. Причем эта структура строится на основе смыслового содержания. В этом главная ценность каталогов, обрабатываемых людьми: можно найти не множество сайтов, содержащих данные ключевые слова, а множество сайтов, посвященных данной тематике. Примером каталога может служить сервер Yahoo (http://www.yahoo.com).
Каталоги WWW, содержащие большое количество
записей, часто размещают на своих страницах локальные поисковые машины. Реализуемые
в виде традиционных шаблонов, которые мало чем отличаются от шаблонов на автоматических
индексах.
Реализуемые
в виде традиционных шаблонов, которые мало чем отличаются от шаблонов на автоматических
индексах.
Как для поисковых машин, так и для каталогов устанавливается некий принцип отбора информации. Этот принцип закладывается либо в алгоритмы работы поисковых машин, либо в регламент работы людей (для каталогов). В зависимости от того, откуда и какой тип информации накапливается, оценивают две характеристики автономных систем — пространственный масштаб и специализацию.
Пространственный масштаб призван ограничить количество первоисточников информации до некоего конечного предела. Например, поисковая система может быть построена в рамках только одного сайта. Поиск может быть ограничен рамками одного географического домена (например, ru). Такие системы называют региональными.
Существует множество поисковых серверов,
которые не имеют подобных ограничений. Их называют глобальными информационно-поисковыми
системами.
Особенности регионального подхода могут присутствовать и в глобальных системах. Так, система Lycos (http://www.lycos.com) сортирует результаты поиска в зависимости от того, из какого региона поступил запрос.
Наиболее популярные поисковые сервера загружены настолько, что возникает необходимость в создании «зеркал» (mirrors). Зеркала должны содержать точную копию первичной поисковой системы и гарантировать быстрое обслуживание обращений, поступающих из определенной географической зоны.
При обращении к той или иной поисковой
системе следует учитывать, какие сервисы она предоставляет. Например, в отечественной
поисковой машине Яндекс (http://www.yandex.ru)
введен поиск не только страниц, но и серверов. Суть этого метода заключается
в том, что ключевые слова ищутся не по всем страницам, а лишь по их заголовкам
(то, что заключено в HTML между тегами «title»). В зарубежной AltaVista
сделана отдельная служба Real Names, которая содержит перечень всех зарегистрированных
страниц компаний и организаций.
Следующий важный сервис — это специализация поиска. В настоящее время Интернет является хранилищем разных типов информации. Поэтому и поиск информации тоже может быть формализован. Можно искать исключительно графические изображения, можно — мультимедийные записи в формате MP3 и т.д. На многих поисковых серверах можно задать тип искомой информации. кроме того, существуют и серверы, которые специализируются на поиске информации строго определенного типа. FTPSearch (http://ftpsearch.lycos.com) специализируется исключительно на поиске файлов. Он индексирует всевозможные ftp-серверы на предмет находящихся там файлов. Поиск осуществляется непосредственно по наименованию искомого файла. Аналогично MP3Search (http://mp3.box.sk) специализируется на поиске исключительно файлов в формате MP3.
Еще одним важным моментом является то,
какой язык запросов использует та или иная система. Чем сложнее этот язык
— тем более тонкую настройку поиска оказывается возможным провести. В настоящее
время не существует единого унифицированного языка запросов для поисковых
систем. Разработка такого языка сделала бы возможной интеграцию различных
поисковых сервисов в единую сверхсистему поиска. В феврале 1999 был начат
проект SESP (Search Engine Standards Project), в котором участвует 15 крупнейших
поисковых систем Интернета. В задачу проекта входит стандартизация работы
поисковых служб (материалы о нем можно найти по адресу http://www.searchenginewatch.com).
В настоящее
время не существует единого унифицированного языка запросов для поисковых
систем. Разработка такого языка сделала бы возможной интеграцию различных
поисковых сервисов в единую сверхсистему поиска. В феврале 1999 был начат
проект SESP (Search Engine Standards Project), в котором участвует 15 крупнейших
поисковых систем Интернета. В задачу проекта входит стандартизация работы
поисковых служб (материалы о нем можно найти по адресу http://www.searchenginewatch.com).
4.5.2. Метапоисковые системы
Еще одним перспективным направлением развития поисковых сервисов в сети является использование метапоисковых систем. Основа метапоисковых систем — это интерфейс между пользователем и множеством поисковых систем. Метапоисковая система не предназначена для индексирования и накопления информации. назначение ее — чистый поиск и обработка результатов поиска.
Метасистема позволяет, в соответствии
с пожеланиями пользователя, ограничить свой поиск определенными поисковыми
серверами, проверять существование ресурсов, на которые указывают результаты
поиска, осуществлять уточненный поиск в результатах поиска и т.
Примером метапоисковой системы может служить отечественная разработка «ДИСКо Искатель» компании «ДИСКо» (http://www.disco.ru).
Основной чертой метапоисковых систем нового поколения является объединение поисковых серверов различных специализаций. В рамках одного приложения можно осуществлять поиск информации различного типа. При обработке поискового запроса допускается соединение более чем со 100 поисковыми системами (в т.ч. и со специализированными). Результаты поиска дополнительно обрабатываются: ссылки, дублирующие уже найденные, системой исключаются; полученные адреса проверяются на доступность. Есть возможность конфигурации работы с поисковыми серверами (можно выбрать серверы, с которыми будет работать система, указать максимальное число ссылок, получаемых с каждого сервера и т.д.).
Однако и в случае использования метапоисковых
систем не обойтись без знаний о традиционных поисковых серверах — именно они
служат базой для всякого поиска.
Поиск информации в сети Интернет (9 класс). Презентация на тему «способы поиска информации в интернете» Организация поиска информации презентация
Урок «Поиска информации в Интернете»
Цель:
Освоить основные методы поиска в сети; знать способы представления информации в Интернете.
уметь ориентироваться в логических уровнях организации информации
Задачи:
Образовательная – формирование навыков поиска информации в сети Интернет;
Развивающая – развитие у учащихся умения ориентироваться в логических уровнях организации информации.
Воспитательная – воспитание у учащихся ответственности к делу, интереса к информатике.
Скачать:
Предварительный просмотр:
Чтобы пользоваться предварительным просмотром презентаций создайте себе аккаунт (учетную запись) Google и войдите в него: https://accounts.google.com
Подписи к слайдам:
Поиск информации – одна из самых востребованных на практике задач, которую приходится решать любому пользователю Интернета. Существуют три основных способа поиска информации в Интернет: Указание адреса страницы. Передвижение по гиперссылкам. Обращение к поисковой системе (поисковому серверу).
Существуют три основных способа поиска информации в Интернет: Указание адреса страницы. Передвижение по гиперссылкам. Обращение к поисковой системе (поисковому серверу).
Это самый быстрый способ поиска, но его можно использовать только в том случае, если точно известен адрес документа или сайта, где расположен документ.
Это наименее удобный способ, так как с его помощью можно искать документы, только близкие по смыслу текущему документу.
Адреса поисковых серверов хорошо известны всем, кто работает в Интернете. В настоящее время в русскоязычной части Интернет популярны следующие поисковые серверы: Яндекс (yandex.ru), Google (google.ru), Rambler (rambler.ru) и некоторые другие.
Принцип работы поисковой системы. Удобство использования. Сложность языка запросов. Скорость работы.
Индексные поисковые системы, работая в автоматическом режиме обновления своей информации, просматривают в сети Интернет содержимое серверов, индексируют всю информацию, содержащуюся в них и вносят информацию о расположении слов на страницах сайтов в свои базы данных. Каталоговые системы поиска содержат тематически структурированный каталог серверов и чаще всего пополняются вручную.
Каталоговые системы поиска содержат тематически структурированный каталог серверов и чаще всего пополняются вручную.
Информационная потребность – сведения и данные, необходимые пользователю в данный момент. Свойство релевантности – совокупность документов, которая соответствует запросу. Полнота поиска – отражает отношение релевантных откликов к количеству всех возможных документов, удовлетворяющих информационную потребность потребителя. Точность поиска – выражает отношение совокупности релевантных откликов, к количеству всех выданных документов.
Учитывать особенности естественного языка. Не допускать орфографических ошибок. Избегать поиска по одному слову, использовать необходимый и достаточный набор слов. Не писать большими буквами. Исключать из поиска не нужные слова.
Синтаксис языка Значение Пример! Запрет перебора всех словоформ! педагогическая система (из поиска будут исключены слова педагогические системы) + Обязательное присутствие слов в найденных документах Педсовет по+пятница (должны быть выбраны страницы, где встречаются слово не только педсовет) но обязательное условие наличие слова «пятница» & Обязательное вхождение слов в одно предложение Педагогическая & система «» Поиск устойчивых словосочетаний «педагогическая система» (учитывается строгая последовательность слов, слово «система педагогическая» будет исключеная)
– Назовите основные способы поиска информации? – Какие два вида поисковых машин вы знаете? – Назовите наиболее популярные поисковые машины Интернета. – Назовите правила поиска информации? — Для чего используются языки запросов?
– Назовите правила поиска информации? — Для чего используются языки запросов?
Сколько стран и какие входят в Евросоюз? Сколько куполов на соборе Василия Блаженного на красной площади? В каком году изобрели компьютерную мышь? На каком этаже в Эрмитаже висит коллекция гобеленов? Сколько этажей в Главном здании Московского университета? Что означает термин «энтропия» с точки зрения теории информации? Какова максимальная глубина Черного моря?
Предварительный просмотр:
Урок «Поиска информации в Интернете»
Цель:
Освоить основные методы поиска в сети; знать способы представления информации в Интернете.
уметь ориентироваться в логических уровнях организации информации
Задачи:
Образовательная – формирование навыков поиска информации в сети Интернет;
Развивающая – развитие у учащихся умения ориентироваться в логических уровнях организации информации.
Воспитательная
– воспитание у учащихся ответственности к делу, интереса к информатике.
Тип урока:
изучение нового материала.
Формы обучения:
Фронтальная, индивидуальная.
Методы обучения:
Словесный, наглядный, практический, частично-поисковый.
Оборудование:
- Компьютер с выходом в Интернет, мультимедийный проектор, кабинет, оснащённый персональными компьютерами с выходом в Интернет из расчёта 1 ученик – 1 компьютер.
- Презентация к уроку
Краткий план урока:
- Организационный момент, ТБ – 5 мин.
- Технологии поиска информации в сети Интернете – 30 мин.
- Работа в группах по поиску информации в Интернет – 35 мин.
- Сообщения от учащихся результатов поиска – 10 мин.
- Подведение итогов урока – 10 мин.
Ход урока
1. Организационный момент.
Учитель : Добрый день, ребята. Сегодня у нас урок, на котором вы научитесь проводить поиск информации в сети Интернет, узнаете о поисковиках, облегчающих поиск нужной информации. Но для успешного достижения нашей цели давайте ответим на несколько вопросов из изученных вами ранее тем и повторим правила ТБ при работе за компьютером:
- Какие виды компьютерных сетей вам известны?
- Что такое Интернет?
- Какие программы для выхода в Интернет вам известны? Какое общее название у этих программ?
- Почему Интернет так популярен в сегодняшнем мире?
Спасибо за ответы. Молодцы!
Молодцы!
2. Изучение новой темы
Учитель : А сейчас мы поговорим о поиске информации в Интернете (Приложение 1, слайд1).
Очень часто возникает необходимость поиска требуемой информации различной тематики. Для этого можно воспользоваться нужной литературой. Но самым эффективным и быстрым методом является поиск информации в сети Интернет. Но наличие компьютера и выхода в Интернет ещё не гарантирует, что человек сможет найти нужную информацию быстро и полно.
Для поиска в сети Интернет можно пользоваться специализированными сервизными службами, которые позволяют по ключевым словам найти тот или иной документ. Их называют поисковыми системами. Кроме поисковых систем, существую метапоисковые системы. Они не имеют свои поисковые машины, а пользуются возможностями других поисковых систем.
Поисковые системы представлены для пользователей в виде веб-страниц с удобной навигацией. Достаточно ввести адрес системы, и необходимая страница представлена вашим услугам. Другая возможность, встроенная в браузер, представлена на панели в виде кнопки «Поиск»
Скажите какие способы поиска информации вы знаете?
Существуют три способа поиска информации в Интернете (Приложение 1, слайд2 ):
- Указание адреса страницы.

- Передвижение по гиперссылкам.
- Обращение к поисковой системе (поисковому серверу).

Остановимся на каждом из них:
– (Приложение 1, слайд3): Указание адреса страницы – это самый быстрый способ поиска, но его можно использовать только в том случае, если точно известен адрес документа или сайта, где расположен документ.
– (Приложение 1, слайд4) : Передвижение по ссылкам – Это наименее удобный способ, так как с его помощью можно искать документы, только близкие по смыслу текущему документу.
Но этот способ очень простой и подходит для начинающего пользователя.
Пользуясь гипертекстовыми ссылками, можно бесконечно долго путешествовать в информационном пространстве Сети, переходя от одной web-страницы к другой, но если учесть, что в мире созданы многие миллионы web-страниц, то найти на них нужную информацию таким способом вряд ли удастся.
–
(Приложение 1, слайд5):
Здесь на помощь приходят специальные поисковые системы (их еще называют поисковыми машинами). Адреса поисковых серверов хорошо известны всем, кто работает в Интернете. В настоящее время в русскоязычной части Интернета популярны следующие поисковые серверы: Яндекс (yandex.ru), Google (google.ru), Rambler (rambler.ru) и некоторые другие.
Адреса поисковых серверов хорошо известны всем, кто работает в Интернете. В настоящее время в русскоязычной части Интернета популярны следующие поисковые серверы: Яндекс (yandex.ru), Google (google.ru), Rambler (rambler.ru) и некоторые другие.
(Приложение 1, слайд6): Что же такое – поисковая система?
Во всемирной паутине Интернет находится несколько тысяч поисковых систем. У каждой системы свои достоинства и недостатки. Критерием выбора поисковой системы могут служить такие характеристики, как:
- Принцип работы поисковой системы.
- Удобство использования.
- Сложность языка запросов.
- Скорость работы.
(Приложение 1, слайд7): Существуют 2 основных типа поисковых систем Интернет: индексные и классификационные (каталоговые).
Индексные поисковые системы, работая в автоматическом режиме обновления своей информации, просматривают в сети Интернет содержимое серверов, индексируют всю информацию, содержащуюся в них и вносят информацию о расположении слов на страницах сайтов в свои базы данных.
Каталоговые системы поиска содержат тематически структурированный каталог серверов и чаще всего пополняются вручную.
(Приложение 1, слайд8): Основные понятия и характеристики результатов поиска.
Информационная потребность – сведения и данные, необходимые пользователю в данный момент.
Свойство релевантности – совокупность документов, которая соответствует запросу.
Полнота поиска – отражает отношение релевантных откликов к количеству всех возможных документов, удовлетворяющих информационную потребность потребителя.
Точность поиска – выражает отношение совокупности релевантных откликов, к количеству всех выданных документов.
(Приложение 1, слайд9): А теперь давайте попробуем вывести правила поиска информации в сети Интернет?
- Учитывать особенности естественного языка.
- Не допускать орфографических ошибок.
- Избегать поиска по одному слову, использовать необходимый и достаточный набор слов.
- Не писать большими буквами.
- Исключать из поиска не нужные слова.
(Приложение 1, слайд10): Понятие языка запросов.
Синтаксис языка | Значение | Пример |
Запрет перебора всех словоформ | Педагогическая система (из поиска будут исключены слова педагогические системы) | |
Обязательное присутствие слов в найденных документах | Педсовет по+пятница (должны быть выбраны страницы, где встречаются слово не только педсовет) но обязательное условие наличие слова «пятница» | |
Обязательное вхождение слов в одно предложение | Педагогическая & система | |
«» | Поиск устойчивых словосочетаний | «педагогическая система» (учитывается строгая последовательность слов, слово «система педагогическая» будет исключеная) |
А теперь ответим на несколько вопросов (Приложение 1, слайд11):
– Назовите основные способы поиска информации?
– Какие два вида поисковых машин вы знаете?
– Назовите наиболее популярные поисковые машины Интернета.
– Назовите правила поиска информации?
Для чего используются языки запросов?
3. Практическая деятельность за ПК:
Учитель : А теперь рассаживаемся за компьютеры и выполним практическую работу. (Приложение 1, слайд12). Во время выполнения работы учитель контролирует процесс поиска, для того чтобы ученики не увлекались праздным чтением сайтов, так как им необходимо не только найти нужную информацию, но и сравнить поисковые системы; помогает исправить формулировку запроса, если ученик не нашел ни одного желаемого документа.
- Сколько стран и какие входят в Евросоюз?
- Сколько куполов на соборе Василия Блаженного на красной площади?
- В каком году изобрели компьютерную мышь?
- На каком этаже в Эрмитаже висит коллекция гобеленов?
- Сколько этажей в Главном здании Московского университета?
- Что означает термин «энтропия» с точки зрения теории информации?
- Какова максимальная глубина Черного моря?
После выполнения задания учащиеся сообщают результаты поиска информации.
В конце урока учитель подводит его итог, оценивает работу учащихся.
Учитель : Урок окончен. Спасибо за урок!
Поиск информации в Интернете
Компьютерные телекоммуникации
План урока
«Заполни пропуски»
Зачем мы изучаем новую тему?
Способы поиска информации в Интернете.
Типы поисковых систем.
Характеристики популярных поисковых систем.
Домашнее задание.
«Заполни пропуски»
Компьютерная сеть
Электронная почта
Локальные, региональные, глобальные
Локальная
Серверы
Сетевую карту, сетевого кабеля
Глобальная
Кольцо, звезда, шина
www
браузеры
Оценивание
10 ответов – 5
8-9 ответов – 4
6-7 ответов – 3
Способы поиска информации в web
Поиск информации – одна из самых востребованных на практике задач, которую приходится решать любому пользователю Интернета. Существуют три основных способа поиска информации в Интернет:
Указание адреса страницы.
Передвижение по гиперссылкам.
Обращение к поисковой системе (поисковому серверу).
Указание адреса страницы
Передвижение по гиперссылкам
Обращение к поисковой системе
Способ 1: Указание адреса страницы
Это самый быстрый способ поиска, но его можно использовать только в том случае, если точно известен адрес документа или сайта, где расположен документ. Например:
Например:
Способ 3: Обращение к поисковой системе
Пользуясь гипертекстовыми ссылками, можно бесконечно долго путешествовать в информационном пространстве Сети, переходя от одной web-страницы к другой, но если учесть, что в мире созданы многие миллионы web-страниц, то найти на них нужную информацию таким способом вряд ли удастся.
На помощь приходят специальные поисковые системы (их еще называют поисковыми машинами). Адреса поисковых серверов хорошо известны всем, кто работает в Интернете. В настоящее время в русскоязычной части Интернет популярны следующие поисковые серверы: Яндекс (yandex.ru), Google (google.ru) и Rambler (rambler.ru).
Поисковая система
Поисковая система — веб-сайт, предоставляющий возможность поиска информации в Интернете. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp-серверах, товары в интернет-магазинах, а также информацию в группах новостей Usenet. Первой поисковой системой для Всемирной паутины был «Wandex», уже не существующий индекс, разработанный Мэтью Грэйем из Массачусетского технологического института в 1993.
Первой поисковой системой для Всемирной паутины был «Wandex», уже не существующий индекс, разработанный Мэтью Грэйем из Массачусетского технологического института в 1993.
По принципу действия поисковые системы делятся на два типа:
поисковые каталоги
поисковые индексы.
Поисковые каталоги
Поисковые каталоги служат для тематического поиска. Информация на этих серверах структурирована по темам и подтемам. Имея намерение осветить какую-то узкую тему, нетрудно найти список web-страниц, ей посвященных. Катало́г ресурсов в Интернете или каталог интернет-ресурсов или просто интернет-каталог — структурированный набор ссылок на сайты с кратким их описанием.
Каталог в котором ссылки на сайты внутри категорий сортируются по популярности сайтов называется рейтинг (или топ).
Поисковые индексы
Поисковые индексы работают как алфавитные указатели. Клиент задает слово или группу слов, характеризующих его область поиска, — и получает список ссылок на web-страницы, содержащие указанные термины.
Как работает поисковой индекс?
Поисковые индексы автоматически, при помощи специальных программ (веб-пауков), сканируют страницы Интернета и индексируют их, то есть заносят в свою огромную базу данных.
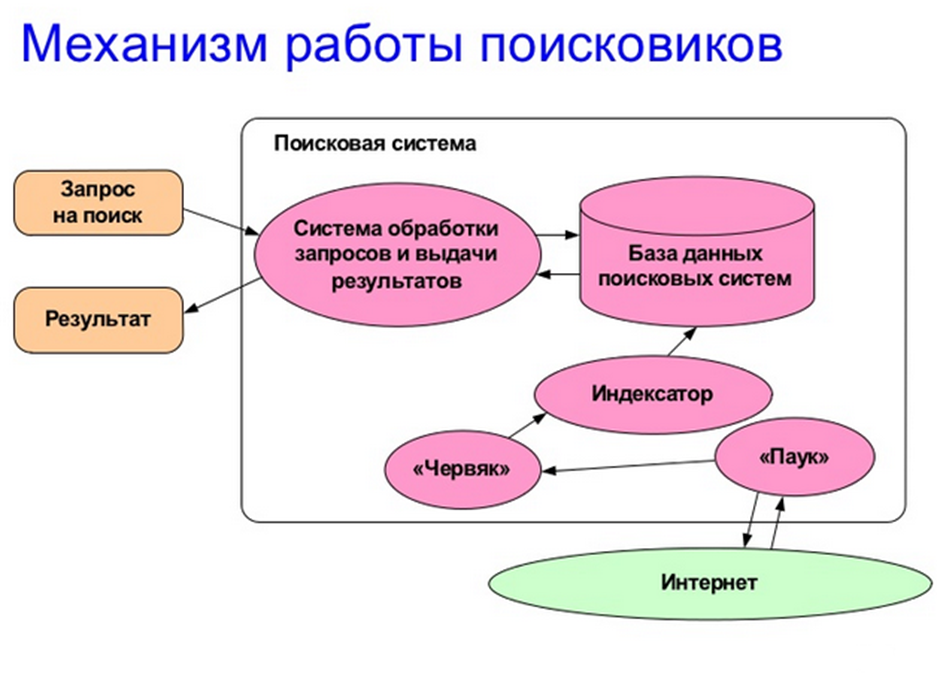
Поиско́вый робот («веб-пау́к») — программа, являющаяся составной частью поисковой системы и предназначенная для обхода страниц Интернета с целью занесения информации о них (ключевые слова) в базу поисковика. По своей сути паук больше всего напоминает обычный браузер. Он сканирует содержимое страницы, забрасывает его на сервер поисковой машины, которой принадлежит и отправляется по ссылкам на следующие страницы. В ответ на запрос, где найти нужную информацию, поисковый сервер возвращает список гиперссылок, ведущих web-страницам, на которых нужная информация имеется или упоминается. Обширность списка может быть любой, в зависимости от содержания запроса.
Золотые правила поиска информации в сети.
Учитывай особенности естественного языка.
Не допускай орфографических ошибок.
Избегай поиска по одному слову.
Не пиши большими буквами.
Исключи из поиска ненужные слова.
Используй возможности расширенного поиска.
Рейтинг поисковых систем в России (по данным SpyLog).
Основные поисковые системы
http://www.yandex.ru/ — 54.8267% http://www.rambler.ru/ — 21.7645% http://www.google.com/ — 15.6207% http://www.mail.ru/ — 4.5466% http://www.aport.ru/ — 1.5788%
http://www.yandex.ru/
Яндекс — российская система поиска в Сети. Сайт компании, Yandex.ru, был открыт 23 сентября 1997 года. Головной офис компании находится в Москве. У компании есть офисы в Санкт-Петербурге, Екатеринбурге, Одессе и Киеве. Слово «Яндекс» (состоящее из буквы «Я» и части слова index; обыгран тот факт, что русское местоимение «Я» соответствует английскому «I») придумал Илья Сегалович, один из основателей Яндекса.
Поиск Яндекса позволяет искать по Рунету документы на русском, украинском, белорусском, румынском, английском, немецком и французском языках с учётом морфологии русского и английского языков и близости слов в предложении. Отличительная особенность Яндекса — возможность точной настройки поискового запроса. Это реализовано за счёт гибкого языка запросов.
По умолчанию Яндекс выводит по 10 ссылок на каждой странице выдачи результатов, в настройках результатов поиска можно увеличить размер страницы до 20, 30 или 50 найденных документов. Время от времени алгоритмы Яндекса, отвечающие за релевантность выдачи, меняются, что приводит к изменениям в результатах поисковых запросов. В частности, эти изменения направлены против поискового спама, приводящего к нерелевантным результатам по некоторым запросам.
http://www.rambler.ru/
Rambler Media Group — интернет-холдинг, включающий в качестве сервисов поисковую систему, рейтинг-классификатор ресурсов российского Интернета, информационный портал.
Rambler создан в 1996 году.
Поисковая система Рамблер понимает и различает слова русского, английского и украинского языков. По умолчанию поиск ведётся по всем формам слова.
http://www.google.ru/
Лидер поисковых машин Интернета, Google занимает более 70 % мирового рынка. Cейчас регистрирует ежедневно около 50 млн поисковых запросов и индексирует более 8 млрд веб-страниц. Google может находить информацию на 115 языках.
По одной из версий, Google — искажённое написание английского слова googol. «Googol (гугол)» – это математический термин, обозначающий единицу со 100 нулями. Этот термин был придуман Милтоном Сироттой, племянником американского математика Эдварда Каснера, и впервые описан в книге Каснера и Джеймса Ньюмена «Математика и воображение» (Mathematics and the Imagination). Использование этого термина компанией Google отражает задачу организовать огромные объемы информации в Интернете.
Интерфейс Google содержит довольно сложный язык запросов, позволяющий ограничить область поиска отдельными доменами, языками, типами файлов и т. д.
Способ поиска Плюсы Минусы Применение
Указание адреса страницы Точное попадание в цель Необходимо знать точный адрес Когда известен точный адрес
Передвижение по гиперссылкам Очевидность поиска Поиск в пределах одной или нескольких страничек Когда нужен ответ на неточный вопрос
Обращение к поисковой системе Всегда есть «положительный» результат Много посторонней информации, сложность формулировки точного запроса Практически в любой ситуации
Для какого способа дана характеристика:
Поиск в пределах сходных страничек Результат содержит много посторонней информации Результат есть всегда Самый точный Самый легкий Самый распространенный Самый лучший
Итоги
Я узнал…
Я научился…
Я буду применять…
Я оцениваю свою работу…
«Поиск научной информации в сети Интернет» Степанова Таня Магистратура 1 курс
В онлайновой работе полезно полагаться на мнение профессионалов, которые ранее уже прошли такой же поисковый путь, проделали черновую работу и составили для коллег советы, руководства, списки полезных страниц и сайтов. Хорошим подспорьем могут быть спец. поисковые системы, отбирающие по заданному алгоритму веб-ресурсы, стоящие внимания.
Основные положительные моменты: Большой каталог доступных химических журналов Есть патентные базы данных Так же есть ссылки на статьи и справочники
Несомненный плюс: быстрая навигация по справочникам Большое разнообразие справочного материала Присутствуют разные разделы по химиии
Windows Live Academic Бета-версия научной поисковой системы от Microsoft. Предназаначена для поиска научных статей как в открытых источниках, так и в архивах изданий с платным доступом. В настоящий момент в систему введены статьи по физике,химии, компьютерным технологиям, электротехнике и смежным дисциплинам.
Chemweb Является крупнейшим он-лайновым химическим порталом в мире. Cодержит информацию по исследованиям в области химии и хим. промышленности. Тематика: аналитическая химия, биохимия, катализ, электрохимия, топливо, неорганическая химия, химические материалы, органическая химия, фармакология, физическая химия, полимеры. Доступ к 350 журналам и базам данных.
Nigma Поисковик по химическим данным Вещества можно записывать как при помощи названий, так и в виде формул. Для введенного вещества система попробует найти реакции с их участием. Кроме молекулярной формулы, система выдает ионную формулу. Система подскажет, почему реакция невозможна
Список используемых ссылок:
2 Способы поиска информации в web Поиск информации – одна из самых востребованных на практике задач, которую приходится решать любому пользователю Интернета. Существуют три основных способа поиска информации в Интернет: 1. Указание адреса страницы. 2. Передвижение по гиперссылкам. 3. Обращение к поисковой системе (поисковому серверу).
3 1: Указание адреса страницы Это самый быстрый способ поиска, но его можно использовать только в том случае, если точно известен адрес документа или сайта, где расположен документ. Не стоит забывать возможность поиска по открытой в окне браузера web-странице (Правка-Найти на этой странице…).
5 3: Обращение к поисковой системе Пользуясь гипертекстовыми ссылками, можно бесконечно долго путешествовать в информационном пространстве Сети, переходя от одной web-страницы к другой, но если учесть, что в мире созданы многие миллионы web-страниц, то найти на них нужную информацию таким способом вряд ли удастся. На помощь приходят специальные поисковые системы (их еще называют поисковыми машинами). Адреса поисковых серверов хорошо известны всем, кто работает в Интернете. В настоящее время в русскоязычной части Интернет популярны следующие поисковые серверы: Яндекс (yandex.ru), Google (google.ru) и Rambler (rambler.ru).
6 Поисковая система Поисковая система веб-сайт, предоставляющий возможность поиска информации в Интернете. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp- серверах, товары в интернет-магазинах, а также информацию в группах новостей Usenet. По принципу действия поисковые системы делятся на два типа: поисковые каталоги и поисковые индексы.
7 Поисковые каталоги Поисковые каталоги служат для тематического поиска. Информация на этих серверах структурирована по темам и подтемам. Имея намерение осветить какую-то узкую тему, нетрудно найти список web-страниц, ей посвященных. Катало́г ресурсов в Интернете или каталог интернет- ресурсов или просто интернет-каталог структурированный набор ссылок на сайты с кратким их описанием. Каталог в котором ссылки на сайты внутри категорий сортируются по популярности сайтов называется рейтинг (или топ).
9 Поисковые индексы Поисковые индексы работают как алфавитные указатели. Клиент задает слово или группу слов, характеризующих его область поиска, и получает список ссылок на web-страницы, содержащие указанные термины. Первой поисковой системой для Всемирной паутины был «Wandex», уже не существующий индекс, разработанный Мэтью Грэйем из Массачусетского технологического института в 1993.
10 Как работает поисковой индекс? Поисковые индексы автоматически, при помощи специальных программ (веб-пауков), сканируют страницы Интернета и индексируют их, то есть заносят в свою огромную базу данных. Поиско́вый робот («веб-пау́к») программа, являющаяся составной частью поисковой системы и предназначенная для обхода страниц Интернета с целью занесения информации о них (ключевые слова) в базу поисковика. По своей сути паук больше всего напоминает обычный браузер. Он сканирует содержимое страницы, забрасывает его на сервер поисковой машины, которой принадлежит и отправляется по ссылкам на следующие страницы. В ответ на запрос, где найти нужную информацию, поисковый сервер возвращает список гиперссылок, ведущих web-страницам, на которых нужная информация имеется или упоминается. Обширность списка может быть любой, в зависимости от содержания запроса.
11 Индекс Яндекс: поиск по запросу «Информатика и ИКТ»
12 Яндекс российская система поиска в Сети. Сайт компании, Yandex.ru, был открыт 23 сентября 1997 года. Головной офис компании находится в Москве. У компании есть офисы в Санкт-Петербурге, Екатеринбурге, Одессе и Киеве. Количество сотрудников превышает 700 человек. Слово «Яндекс» (состоящее из буквы «Я» и части слова index; обыгран тот факт, что русское местоимение «Я» соответствует английскому «I») придумал Илья Сегалович, один из основателей Яндекса, в настоящий момент занимающий должность технического директора компании. Поиск Яндекса позволяет искать по Рунету документы на русском, украинском, белорусском, румынском, английском, немецком и французском языках с учётом морфологии русского и английского языков и близости слов в предложении. Отличительная особенность Яндекса возможность точной настройки поискового запроса. Это реализовано за счёт гибкого языка запросов. По умолчанию Яндекс выводит по 10 ссылок на каждой странице выдачи результатов, в настройках результатов поиска можно увеличить размер страницы до 20, 30 или 50 найденных документов. Время от времени алгоритмы Яндекса, отвечающие за релевантность выдачи, меняются, что приводит к изменениям в результатах поисковых запросов. В частности, эти изменения направлены против поискового спама, приводящего к нерелевантным результатам по некоторым запросам.
13 Лидер поисковых машин Интернета, Google занимает более 70 % мирового рынка. Cейчас регистрирует ежедневно около 50 млн поисковых запросов и индексирует более 8 млрд веб-страниц. Google может находить информацию на 115 языках. По одной из версий, Google искажённое написание английского слова googol. «Googol (гугол)» – это математический термин, обозначающий единицу со 100 нулями. Этот термин был придуман Милтоном Сироттой, племянником американского математика Эдварда Каснера, и впервые описан в книге Каснера и Джеймса Ньюмена «Математика и воображение» (Mathematics and the Imagination). Использование этого термина компанией Google отражает задачу организовать огромные объемы информации в Интернете. Интерфейс Google содержит довольно сложный язык запросов, позволяющий ограничить область поиска отдельными доменами, языками, типами файлов и т. д.
14 Rambler Media Group интернет-холдинг, включающий в качестве сервисов поисковую систему, рейтинг-классификатор ресурсов российского Интернета, информационный портал. Rambler создан в 1996 году. Поисковая система Рамблер понимает и различает слова русского, английского и украинского языков. По умолчанию поиск ведётся по всем формам слова.
15 Вопросы: Назовите основные способы поиска информации в web? В каком случае может возникнуть необходимость поиска по уже открытой в браузере web-странице? Какие два вида поисковых машин вы знаете? Назовите наиболее популярные поисковые машины Интернета.
Поиск
информации в сети
Интернет
Поиск информации в Интернете осуществляется с помощью специальных программ, обрабатывающих запросы — информационно-поисковых систем (ИПС).
Информационно-поисковая система – это прикладная компьютерная среда для обработки, хранения, сортировки, фильтрации и поиска больших массивов структурированной информации.
ИПС бывают двух типов:
1. Документографические . В документографических ИПС все хранимые документы индексируются специальным образом, т. е. каждому документу присваивается индивидуальный код, составляющий поисковый образ. Поиск идет не по самим документам, а по их поисковым образам. Именно так ищут книги в больших библиотеках. Сначала отыскивают карточку в каталоге, а затем по номеру, указанному на ней, отыскивается и сама книга.
2. Фактографические . В фактографичеких ИПС хранятся не документы, а факты, относящиеся к какой-либо предметной области. Поиск осуществляется по образцу факта.
В России наиболее крупными и популярными поисковыми системами являются:
- «Яndex» (www.yandex.ru )
- «Pамблер» (www.rambler.ru )
- «Google» (www.google.ru )
- «Mail» (www . mail . ru )
Веб – сервер — это компьютер, на котором установлено
специальное программное обеспечение.
Веб – сайт — это место на веб — сервере.
В сети Интернет принята числовая система адресации.
Компьютеры предпочитают числа (213.180.204.11 ), а люди – имена (yandex.ru ), так как имена легче запомнить.
Поэтому в Интернете была введена система доменных имен .
educom.spb.ru
Домен третьего уровня,
сообщает название
организации, на
которую зарегистрирован
данный доменный
Домен высшего уровня:
означает, что сайт
Зарегистрирован в РФ
Вся последовательность символов,
используемых в адресе, называется URL
Домен второго уровня,
означает, что сайт
зарегистрирован в
Санкт — Петербурге
Единый указатель ресурсов (URL — Uniform Resource
Locator ) — единообразный локатор (определитель
местонахождения) ресурса.
Ранее назывался Universal Resource Locator —
универсальный локатор ресурса.
URL — это стандартизированный способ записи адреса ресурса
в сети Интернет.
URL был изобретён Тимом Бернерсом-Ли
в 1990 году в стенах Европейского
совета по ядерным исследованиям
в Женеве, Швейцария.
URL стал фундаментальной инновацией
в Интернете.
Изначально URL предназначался для
обозначения мест расположения
ресурсов (чаще всего файлов) во
Всемирной паутине.
Сейчас URL применяется для обозначения адресов почти всех
ресурсов Интернета.
Типы поиска:
- Поиск по адресам URL
- Поисковые системы
Поисковые системы
Поисковые машины — это автоматические системы, опрашивающие серверы, подключенные к глобальной сети, и сохраняющие в своей базе информацию об
имеющихся на серверах данных.
РОБОТ
ИНДЕКС
ПРОГРАММА
ОБРАБОТКИ
ЗАПРОСОВ
Российские поисковые серверы:
- «Яндекс» — www.yandex.ru;
- «Рамблер» — www.rambler.ru;
- «Mail» — www . mail . ru ;
- «Gogo» — www.gogo.ru.
Зарубежные поисковые серверы:
- Alta Vista — www.altavista.com
- Fast Search — www.alltheweb.com
- Northern Light — www.northernlight.com
Технология поиска в
поисковых системах
2. Поиск по ключевым словам
Поиск по ключевым словам
Наиболее простым и результативным поиском является поиск по ключевым словам.
Основной алгоритм поиска следующий:
введите ключевые слова в поле запроса (например, расписание поездов ), нажмите кнопку Найти .
Синтаксис языка запросов
В системе Яндекс существует специальный язык запросов , использовать который более сложно, чем форму расширенного поиска но при его использовании можно получить наилучший результат.
Поисковый запрос вводится в поисковое поле, он может содержать ключевые слова и специальные символы , позволяющие установить взаимосвязи между этими словами и ввести дополнительные параметры. Большинство этих символов представлено в таблице ниже.
Синтаксис языка запросов системы Яндекс
Синтаксис
Что означает оператор
оператора
пробел или &
Логическое И (в пределах предложения)
Пример запроса
лечебная физкультура
Логическое И (в пределах документа)
Логическое ИЛИ
рецепты && (плавленый сыр)
фото | фотография | снимок | фотоизображение
Обязательное наличие слова в найденном документе
Группирование слов
Быть или +не быть
Бинарный оператор И НЕ (в пределах предложения)
~~или_
(технология | изготовление) (сыра | творога)
банки ~ закон
Бинарный оператор И НЕ (в пределах документа)
путеводитель по Парижу ~~ (агентство | тур)
Расстояние в словах (минус (-) — назад, плюс (+) — вперед)
поставщики /2 кофе музыкальное /(-2 4) образование вакансии ~ /+1 студентов
Поиск фразы
&&/(n m)
«красная шапочка» Эквивалентно: красная /+1 шапочка
Расстояние в предложениях (минус (-) — назад, плюс (+) — вперед)
банк && /1 налоги
Специализированные системы поиска информации
В сети Интернет существуют системы поиска по определённым областям это:
Ktotam.ru – поиск сведений о людях
tagoo.ru – поиск музыки
kinopoisk.ru – поиск кинофильмов
ebdb.ru –нахождение книг из электронных библиотек
ulov-umov.ru – поиск работы
Целесообразное использование поисковых систем
- На сегодняшний день молодёжь рассматривает Интернет и компьютеры как средство развлечения.
- Ресурсы Интернета разнообразны. В них есть как полезная информация, так и вредная.
- Информационно-поисковые системы сети Интернет из ресурсов Интернета Имеют возможность найти любую запрашиваемую информацию. Так как поисковые системы осуществляют поиск по ключевым словам.
- Какой запрос задаст пользователь такую информацию он получит.
- Необходимо помнить полученная информация не всегда правдива, полезна и верна.
- Информационно-поисковыми системами необходимо пользоваться только целесообразно.
- Нельзя распространять и пользоваться ложной, безнравственной и компрометирующей информацией
Алгоритм поиска информации в сети Интернет
Введение:
При соединении двух компьютерных сетей возникает межсетевое объединение, которое по-английски называется Internet. В настоящее время в мире насчитываются сотни тысяч больших и малых сетей. Большинство из них уже соединены между собой. Т.о. существует единое информационное поле, состоящее из миллионов взаимосвязанных компьютеров. Его называют единым информационным пространством. Internet – это одна из всемирных компьютерных сетей, которая была основана в 1969 году и называлась тогда ARPANET. (Существуют и другие всемирные сети – Decnet, FIDO и другие).
Что такое Интернет.
Интернет — это многочисленные компьютерные
сети, соединяющие миллионы компьютеров по всему
миру. А Microsoft Internet Explorer — средство подсоединения
к Интернету для получения доступа к гигантскому
хранилищу данных. Internet Explorer как и другие
программы несущие подобные функции называют
Интернет браузерами. Так что же такое Интернет
браузеры?
Интернет браузеры – это специальные программы, позволяющие просматривать содержимое web сайтов.
А теперь посмотрим на оболочку программы Internet Explorer (вы можете записывать это название сокращенно IE это сокращение принято во всем мире), что же мы там увидим, а первое что вам сразу может бросится в глаза – это панель с кнопками, на которых вы заметите две уже знакомых вам кнопки, это кнопка вперед и назад. Эти кнопки несут такую же функцию как и в окнах Windows. Далее в основной группе кнопок находится кнопка “Остановить”, эта кнопка позволяет остановить действие которое производит IE, например загрузку web страницы. Кнопка “Обновить” позволяет обновить содержимое окна IE в случае необходимости, эта функция особенно полезна когда страница не полностью загрузилась и необходимо произвести ее перезагрузку. Следующая кнопка “Домой” – позволяет перейти нам на страницу, указанной как “домашняя”. Кстати, для функций “Остановить” и функции “Обновить” есть удобные быстрые клавиши, давайте мы их запишем. “Остановить” – Esc, “Обновить” – F5. Ниже панели кнопок вы видите адресную строку.
Виды информации.
Информация – набор символов, графических
образов или звуковых сигналов, несущих
определенную смысловую нагрузку.
Поисковые службы
Поисковая машина представляет собой огромный программно-системный комплекс, в котором различными этапами обработки индексируемой информации занимаются разные системные службы. Некоторые поисковые серверы индексируют страницы, другие занимаются скачиванием интернет страниц, третьи – группировкой индексов в единую базу и т.д. При вводе пользователем
Независимо от того, какую поисковую службу мы используем, информация в них повторяется.
Давайте познакомимся с поисковой службой Google.
Адресация в Интернет.
Адресная строка служит для ввода и отображения адреса Web-страницы. Чтобы перейти к какой-либо странице, вам даже не нужно набирать полностью ее адрес. Просто начните печатать, а средства автозавершения дополнит предполагаемый адрес, основываясь на адресах посещенных вами ранее узлов.
С помощью адресной строки вы можете искать Web-страницы просто набрав команды find, go, или ? и слово, которое вы ищите. Как вы понимаете в адресную строку вводятся адреса Интернета.
Что такое адрес Интернета?
Адрес Интернета (иногда также говорят URL или Uniform Resource Locator) обычно начинается с названия протокола. Затем следует название организации, которая поддерживает данный узел. Суффикс обозначает тип организации. (Протокол – это набор правил и стандартов, который позволяет компьютерам обмениваться данными.)
Например, адрес http://www.msu.ru/ говорит о следующем.
http: Web-сервер использует протокол http.
www Узел находится в Web.
мsu Узел Московского Государственного Университета (МГУ).
.ru Узел (домен) находиться в России.
Обычно, коммерческие узлы имеют суффикс .com, а правительственные .gov.
Если адрес указывает на определенную страницу, то дописываются дополнительные данные, например, имя порта, папка, содержащая страницу и имя файла. Расширения Web-страниц, созданных с использованием языка HTML, обычно оканчиваются на .htm или .html.
Когда вы просматриваете какую-либо Web-страницу, то ее адрес появляется в адресной строке обозревателя.
Давайте с вами рассмотрим домены разных стран:
| at — Австрия au — Австралия ca — Канада ch — Швейцария de — Германия dk — Дания es — Испания fi — Финляндия fr — Франция | it — Италия jp — Япония nl — Нидерланды no — Норвегия nz — Новая Зеландия ru — Россия se — Швеция uk — Украина za — Южная Африка Обучающее видео по поиску информации в сети Интернет: Видео YouTube |
Алгоритм поиска информации в сети Интернет:
2.Двойным щелчком левой кнопки мыши по ярлыку браузера, который установлен на компьютере открыть его (Например, Microsoft Internet Explorer, Mozillla Firefox, Google Chrome).
3. В адресной строке браузера впечатать с клавиатуры адрес поисковика (например, Яндекс.ru, google.ru, mail.ru). Эффективней пользоваться поисковой системой google. (Пример ниже, поисковая система google) Печатать префикс http:// не обязательно
4. В адресной строке поиска впечатать с клавиатуры искомое слово или словосочетание. Например, «Война и мир». Нажать на кнопку поиска
или
Ниже от поля ввода поиска появится адреса и ссылки по найденной информации.
Поисковая служба выводит всю информацию со словосочетанием “Война и мир”.
Необходимо один раз левой кнопкой мыши нажать на понравившуюся ссылку в списке для того, чтобы открыть найденный материал.
Рекомендации по эффективному поиску информации в поисковой строке:
- Если информация очень обширна, то нужно сузить, до более конкретной. Вводим “Война и мир – Толстой”. Теперь поисковая служба находит информацию только по этому словосочетанию. Уменьшим информацию до Параграфа. Введем в строку поиска “Болконский – Война и мир”. Наша информация уменьшилась до конкретной информации.
- Обратите внимание на язык, грамматику, использование различных небуквенных символов:
-Если Вам известна точная фраза из искомых материалов, используйте её как цитату (в кавычках » «)
— чтобы исключить документы, содержащие определенные термины, используйте знак «-» перед каждым таким словом. Например, если Вам нужна информация о различных произведениях Шекспира, кроме трагедии «Гамлет», то введите запрос в виде: «Шекспир-Гамлет»;
— для того чтобы в результаты поиска обязательно включались определенные ссылки, используйте символ «+». Так, чтобы найти ссылки о продаже именно автомобилей, Вам нужен запрос «продажа+автомобиль». Перед знаком “+” должен стоять пробел;
— символ «*» применяют как замещение слов. Пример: спорт* (Google выдаст: Спорт.UA, спорт в новостях, спорт сегодня…).
— фразы, заключенные в кавычки, будут выдаваться поисковиком в точности так, как указано в кавычках. Пример: “Здоровье и спорт” или “Скачать бесплатно фильм ” и т.д.;
— использование логической связки «OR» (или) поможет найти информацию по одному из указанных слов. Пример: Фильмы комедии OR мелодрамы.
Для увеличения эффективности и точности поиска используйте комбинации этих символов.
- Пользуйтесь услугами расширенного поиска. У каждой поисковой системы свое местонахождение кнопки расширенного поиска. Например, у google для того, чтобы воспользоваться услугой расширенного поиска необходимо нажать один раз левой кнопкой мыши на значок «движка» в правом верхнем углу и выбрать раздел «расширенный поиск».
Далее откроется режим расширенного поиска, где можно внести необходимые настройки и нажать на кнопку «найти».
5. Грамотно проводить сортировку найденного материала. Это заметно ускорит последующую обработку материала.
6.
Фиксируйте все интересные для Вас найденные адреса документов в Интернете (например, с помощью программы Блокнот). Затем выбрать среди них нужные для выполнения конкретной работы.Помните, что поисковые системы не производят самостоятельную информацию. Поисковая система – это лишь посредник между обладателем информации (сайтом) и Вами. Базы данных постоянно обновляются, в них вносятся новые адреса, и это нужно учитывать при поиске информации.
Более подробно технология поиска в сети Интернет представлена на сайтах:
http://www.seonews.ru/masterclasses/detail/29812.php
http://blog-reklamista.ru/poleznoe/20-cekretov-poiska-informacii-v-google-video.html
http://www.3dnews.ru/software/internet_search_secrets
http://otherreferats.allbest.ru/programming/00010326_0.html
http://opds.sut.ru/electronic_manuals/pospd/text/4_5.htm
http://dvo.sut.ru/libr/ite/i280levc/3.htm
Всемирная паутина — урок. Информатика, 7 класс.
Свободный доступ к информации, невзирая на границы и расстояния, стал возможен благодаря World Wide Web (WWW, Web) — всемирному хранилищу информации, существующему на технической базе сети Интернет.
WWW, или Всемирная паутина:
— представляет собой множество информационных ресурсов, организованных в единое целое;
— объединяет многочисленные ресурсы, размещённые на компьютерах по всему миру;
— организована так, что в ней информационные ресурсы представлены не в линейной последовательности, а снабжены ссылками (гиперссылками), явно указывающими возможные переходы, связи между ресурсами.
Всемирная паутина — это мощнейшее информационное хранилище; содержащийся в ней объём информации не поддаётся точному измерению. WWW содержит информацию самого разного характера; там можно найти:
- самые свежие новости — политические, экономические, культурные, спортивные;
- научную, техническую, образовательную и справочную информацию абсолютно любого рода;
- рекламу разнообразных товаров и услуг;
- ресурсы для досуга и развлечений — книги, музыку, фильмы, игры и многое другое.
Любой человек, имеющий доступ к Интернету, может разместить в сети свою информацию.
Информация в WWW организована в виде страниц (web-страниц). В свою очередь, страницы могут объединяться в более крупные составляющие — сайты (англ. site — «место, участок»).
Web-сайт — это несколько web-страниц, связанных между собой по содержанию.
Сайты есть у государственных структур, общественных организаций, предприятий, фирм и компаний, музеев и библиотек, газет, образовательных учреждений, в том числе у многих школ.
Каждый сайт и каждая страница имеют свой адрес, по которому к ним можно обратиться. Web-сайты сильно отличаются друг от друга по оформлению, но чаще всего они имеют похожую структуру.
Каждый web-сайт имеет главную страницу, которая аналогична странице с оглавлением в книге. В текстах, размещённых на страницах сайтов, могут быть выделены некоторые слова — гиперссылки, от которых идут гиперсвязи.
Они выделяются цветом или подчёркиванием.
Щёлкнув мышью по такому слову, мы переходим к просмотру другого документа, причём этот документ может находиться на другом компьютере, в другой стране, на другом континенте.
В качестве гиперссылок может использоваться не только текст, но и любое графическое изображение. Такую организацию информации называют гипертекстом.
Перемещаться по Паутине пользователю помогают специальные программы (web-браузеры, англ. browse — «осматривать, изучать»).
Логотипы наиболее распространённых браузеров
На первый взгляд Всемирную паутину можно представить как библиотеку, книги в которой расположены без видимого порядка: нет ни единой системы каталогов, ни библиотекарей. При этом посетители «библиотеки» по собственному усмотрению добавляют новые тома или безвозвратно их забирают. Для того чтобы извлечь полезную информацию из Всемирной паутины, нужно знать, где и как вести поиск, нужен опыт поисковой работы.
Поиск нужного документа в WWW происходит с помощью браузера разными способами:
путём указания адреса документа;
путём перемещения по Паутине гиперсвязей;
путём использования поисковых систем.
Поисковые системы
Все системы поиска информации во Всемирной паутине располагаются на специально выделенных компьютерах с мощными каналами связи. Ежеминутно они обслуживают огромное количество клиентов.
Действие поисковых систем основано на постоянном, последовательном изучении всех страниц всех сайтов Всемирной паутины. Для каждого документа составляется его поисковый образ — набор ключевых слов, отражающих содержание этого документа. В связи с постоянным обновлением информации поисковые системы периодически возвращаются к ранее изученным страницам, чтобы обнаружить и зарегистрировать изменения. Информация о ключевых словах исследованных таким образом страниц сохраняется в поисковой системе.
При поступлении запроса от пользователя поисковая система на основании имеющейся в ней информации формирует список страниц, соответствующих критериям поиска. Найденные документы, как правило, упорядочиваются в зависимости от местоположения ключевых слов (в заголовке, в начале текста), частоты их появления в тексте и других характеристик.
Существует множество поисковых систем. Несмотря на общий принцип работы, поисковые системы различаются по языкам запроса, зонам поиска, глубине поиска внутри документа, методам упорядочивания информации и другим характеристикам. На данный момент самой популярной в мире поисковой системой является Google. Крупнейшие отечественные поисковые системы — Яндекс, Rambler.
Адрес: www.google.com.
Самая быстрая и самая большая поисковая система. Содержит информацию более чем о полутора миллиардах страниц. Имеется возможность выбора языка. Оценивает популярность ресурса по количеству ссылок, ведущих к нему с других страниц.
Адрес: www.yandex.ru.
Мощная отечественная поисковая система. Обеспечивает поиск в основном среди русскоязычных ресурсов, при этом по возможностям не уступает зарубежным системам. Проводит качественный анализ информации с учётом словоформ русского языка.
Адрес: www.rambler.ru.
Одна из первых русских поисковых систем. Кроме стандартных возможностей поиска на сайте имеется рейтинг-каталог ресурсов.
Поисковые запросы
Приступая к поиску, пользователь вводит одно или несколько ключевых слов и выбирает тип поиска.
В большинстве поисковых систем существует три основных типа поиска:
1) поиск по любому из слов — результатом поиска является огромный список всех страниц, содержащих хотя бы одно из ключевых слов; может быть использован, когда пользователь не уверен в ключевых словах;
2) поиск по всем словам — в этом режиме поиска формируется список всех страниц, содержащих все ключевые слова в любом порядке;
3) поиск точно по фразе — в результате поиска составляется список всех страниц, содержащих фразу, точно совпадающую с ключевой (знаки препинания игнорируются).
Если найдено слишком много страниц, то можно добавить ещё одно ключевое слово и повторить поиск. Для этого во многих поисковых системах есть функция поиска среди найденного. Также можно вводить поисковые запросы с использованием логических связок, аналогичных по смыслу союзам «и», «или» и частице «не» русского языка.
Логическая связка | Пример поискового запроса | Комментарий |
| & — логическое «И» | а) канарейки & щеглы | поиск по всем словам |
| | — логическое «ИЛИ» | б) канарейки | щеглы | поиск по любому из слов |
~ — логическое «НЕ» | в) ~ канарейки & щеглы | будут отобраны все страницы, где упоминаются щеглы, но при этом не упоминаются канарейки |
~ — логическое «НЕ» | г) ~ (канарейки | щеглы) | будут отобраны все страницы, где нет упоминаний о щеглах, а также те, где не упоминаются канарейки |
Смысл логических связок становится более понятным, если проиллюстрировать их с помощью графической схемы — кругов Эйлера.
Представим множества документов, в которых присутствуют ключевые слова «канарейки», «щеглы», двумя кругами на плоскости, которые разместим внутри круга, изображающего все документы WWW.
Тогда множества документов, соответствующих нашим запросам, будут представлены закрашенными областями.
Если в результате поиска вы не нашли ни одного подходящего документа, нужно:
- проверить правильность написания ключевых слов;
- проверить правильность использования логических связок;
- подобрать более удачные синонимы;
- изменить логику запроса.
Источники:
Босова, Л. Л. Информатика: учебник для 7 класса / Л. Л. Босова, А. Ю. Босова. — М.: БИНОМ. Лаборатория знаний, 2013.
Используйте ресурсы интернета для поиска информации. Урок «Поиск информации в сети Интернет. Поиск с помощью интернет серфинга
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Подобные документы
Средства поиска информации в сети Интернет. Основные требования и методика поиска информации. Структура и характеристика поисковых сервисов. Глобальные поисковые машины WWW (World Wide Web). Планирование поиска и сбора информации в сети Интернет.
реферат , добавлен 02.11.2010
Характеристика методов поиска информации в Интернете, а именно — с использованием гипертекстовых ссылок, поисковых машин и специальных средств. Анализ новых интернет ресурсов. История возникновения и описание западных и русскоязычных поисковых систем.
реферат , добавлен 12.05.2010
Описание и классификация современных информационно–поисковых систем. Гипертекстовые документы. Обзор и рейтинги основных мировых поисковых систем. Разработка информационно–поисковой системы, демонстрирующей механизм поиска информации в сети Интернет.
дипломная работа , добавлен 16.06.2015
Анализ возможностей поисковых систем Яндекс и Google, их сравнение с точки зрения полезности. История создания поисковых систем, характеристика их интерфейса, поисковых инструментов и алгоритмов. Формирование вопроса и критерий к ответу на него.
реферат , добавлен 07.05.2011
Рассмотрение поисковых систем интернета как программно-аппаратного комплекса с веб-интерфейсом, предоставляющего возможность поиска информации. Виды поисковых систем: Archie, Wandex, Aliweb, WebCrawler, AltaVista, Yahoo!, Google, Яндекс, Bing и Rambler.
реферат , добавлен 10.05.2013
Структура и принципы построения сети Интернет, поиск и сохранение информации в ней. История появления и классификация информационно-поисковых систем. Принцип работы и характеристики поисковых систем Google, Yandex, Rambler, Yahoo. Поиск по адресам URL.
курсовая работа , добавлен 29.03.2013
Сущность и принцип работы глобальной сети Интернет. Поиск информации по параметрам в системе Google. Специализированные системы поиска информации: «КтоТам», «Tagoo», «Truveo», «Kinopoisk», «Улов-Умов». Целесообразное использование поисковых систем.
презентация , добавлен 16.02.2015
Хранение данных в сети Internet. Гипертекстовые документы, виды файлов. Графические файлы, их виды и особенности. Поисковые системы и правила поиска информации. Обзор поисковых систем сети Internet. Все о поисковых системах Yandex, Google, Rambler.
курсовая работа , добавлен 26.03.2011
Общие сведения.
В настоящее время Интернет объединяет сотни миллионов серверов, на которых размещены миллиарды различных сайтов и отдельных файлов, содержащих различного рода информацию. Это гигантское хранилище информации. Существуют различные приемы поиска информации в Интернет.
Поиск по известному адресу. Необходимые адреса берутся из справочников. Зная адрес, достаточно ввести его в адресную строку Браузера.
www.gov.ru — сервер органов государственной власти России.
Конструирование адреса пользователем. Зная систему формирования адреса в Интернет, можно при поискеWeb-сайтов конструировать адреса.
К ключевому слову (названию фирмы, предприятия, организации или простому английскому существительному) необходимо добавить домен тематический или географический, при этом необходимо подключать интуицию.
Адреса коммерческих Web-страниц:
www.cnn.com (всемирные новости CNN),
www.sony.com (фирма SONY),
www.mtv.com (музыкальные новости MTV).
Адреса учебных заведений:
www.ntu.edu (Национальный университет США).
Адреса региональных серверов:
www.poland.net (Польша),
www.israil.net (Израиль).
Поисковые системы Интернет
Для поиска информации в Интернет разработаны специальные информационно-поисковые системы. Поисковые системы имеют обычный адрес и отображаются в виде Web-страницы, содержащей специальные средства для организации поиска (строку для поиска, тематический каталог, ссылки). Для вызова поисковой системы достаточно ввести ее адрес в адресную строку Браузера.
По способу организации информации информационно-поисковые системы делятся на два вида: классификационные (рубрикаторы) и словарные.
Рубрикаторы (классификаторы) — поисковые системы, в которых используется иерархическая (древовидная) организация информации. При поиске информации пользователь просматривает тематические рубрики, постепенно сужая поле поиска (например, если необходимо найти значение какого-то слова, то сначала в классификаторе нужно найти словарь, а затем уже в нем найти нужное слово).
Словарные поисковые системы — это мощные автоматические программно-аппаратные комплексы. С их помощью просматривается (сканируется) информация в Интернет. В специальные справочники-индексы заносятся данные о местонахождении той или иной информации. В ответ на запрос осуществляется поиск в соответствии со строкой запроса. В результате пользователю предлагаются те адреса (URL), на которых в момент сканирования найдены искомые слово или группа слов. Выбрав любой из предложенных адресов-ссылок, можно перейти к найденному документу. Большинство современных поисковых систем являются смешанными.
Наиболее известные и популярные системы поиска:
www.aport.ru www.yahoo.com www.rambler.ru www.yandex.ru www.altavista.com www.google.com
Существуют системы, специализирующиеся на поиске информационных ресурсов по различным направлениям.
Поиск людей в Интернет:
www.whowhere.ru ww. bigfoot.com
Поиск по телеконференциям (Usenet):
www.dejanews.com
Предметные поисковые системы:
Поиск программного обеспечения:
Поиск по файловым архивам:
http://ftpseach. city.ru, http://ftpsearch. licos.com
Каталоги (тематические подборки ссылок с аннотациями):
http://www.atrus.ru
Часто эффективный поиск информации можно провести с помощью региональных каталогов — специализированных серверов, содержащих данные о предприятиях или Web-ресурсах какого-то города или региона. Например, для Санкт-Петербурга такой каталог располагается по адресу http://www.spb.ru.
Список ИПС можно найти на сайте www.monk. newmail.ru
Более подробный перечень поисковых систем и каталогов представлен в табл. 3.2.
Правила выполнения запросов
В каждой поисковой системе в разделе Помощь (Help) можно получить сведения о том, как искать, как составить строку запроса. Ниже приведена информация о типовом, «усредненном» языке запросов.
Простой запрос.
Ввести одно слово, определяющее тему поиска. Например, в поисковой системе Rambler.ru достаточно ввести: автоматика.
Находятся документы, в которых встречаются слова, указанные в запросе. Распознаются все формы слов русского языка, как правило, регистр букв игнорируется.
В запросе можно использовать символ «*» или «?». Знаком «?» в ключевом слове заменяется один символ, на место которого может быть подставлена любая буква, а знаком «*» — последовательность символов.
Например, запрос автомат* позволит найти документы, включающие слова автоматический, автоматика и т.д.
Сложный запрос.
Часто возникает необходимость комбинирования ключевых слов для получения более определенной информации. В этом случае используются дополнительные слова-связки, функции, операторы, символы, комбинации операторов, разделенные скобками.
Например, запрос музыка & (beatles | битлз) означает, что пользователь ищет документы, содержащие слова музыка и beatles или музыка и битлз.
В табл.3.1 приведены правила формирования запросов, принятые в системе Апорт (http://www.aport.ru).
Таблица 3.1
Операторы для формирования запросов
| Оператор | Синонимы | Комментарий |
| И | AND & | По запросу будут найдены документы, содержащие оба ключевых слова. Его можно и не писать. Например, запрос: информатика и учебник эквивалентен информатика учебник |
| ИЛИ | OR | | Производится поиск тех документов, в которых используется любое из указанных слов или оба слова одновременно |
| НЕ | NOT — ~ | Поиск ограничивается документами, не содержащими слово, указанное после оператора |
| » » | » » | Двойные или одинарные кавычки позволяют находить словосочетание |
| Дата= | дата: date= | Поиск ограничивается документами, попадающими в заданный интервал дат. Пример 1. валюта дата=01/02/2002-01/03/2002. По этому запросу будут выданы документы, содержащие слово «валюта» и имеющие дату от 1 февраля 2002 г. до 1 марта 2002 г. Пример 2. date=01/03/2002 валюта Пример 3. дата: |
Таблица 3.2
Список поисковых серверов и каталогов
| Адрес | Описание |
| www.excite.com | Поисковый сервер с обзорами узлов и путеводителями |
| www.alta-vista.com | Поисковый сервер, имеются возможности расширенного поиска |
| www.hotbot.com | Поисковый сервер |
| www.poland.net www.israil.net | Региональные поисковые серверы Польши, Израиля |
| www.ifoseek.com | Поисковый сервер (простой в использовании) |
| www.ipl.org | Internet Publik library, публичная библиотека, функционирующая в рамках проекта «Всемирная деревня» |
| www.wisewire.com | WiseWire — организация поиска с применением искусственного интеллекта |
| www.webcrawler.com | WebCrawler — поисковый сервер, прост в обращении |
| www.yahoo.com | КаталогWeb и интерфейс для обращения к полнотекстовому поиску на сервере AltaVista |
| www.aport.ru | Апорт — русскоязычный поисковый сервер |
| www.yandex.ru | Яндекс — русскоязычный поисковый сервер |
| www.rambler.ru | Рамблер — русскоязычный поисковый сервер |
| Справочные ресурсы Интернет | |
| www.yellow.com | Желтые страницы Интернет |
| monk. newmail.ru | Поисковые системы различного профиля |
| www.top200.ru | 200 лучшихWeb-сайтов |
| www.allru.net | |
| www.ru | Каталог русских ресурсов Интернет |
| www.allru.net/z09. htm | Образовательные ресурсы |
| www.students.ru | Сервер российского студенчества |
| www.cdo.ru/index_new. asp | Центр дистанционного обучения |
| www.open. ac. uk | Открытый университет Великобритании |
| www.ntu.edu | Национальный университет США |
| www.translate.ru | Электронный переводчик текстов |
| www.pomorsu.ru/guide. library.html | Список ссылок на сетевые библиотеки |
| www.elibrary.ru | Научная электронная библиотека |
| www.citforum.ru | Электронная библиотека |
| www.infamed.com/psy | Психологические тесты |
| www.pokoleniye.ru | Web-сайт Федерации Интернет образования |
| www.metod. narod.ru | Образовательные ресурсы |
| www.spb. osi.ru/ic/distant | Дистанционное обучение в Интернет |
| www.examen.ru | Экзамены и тесты |
| www.kbsu.ru/~book/ | Учебник информатики |
| Mega. km.ru | Энциклопедии и словари |
Поиск информации в Интернете: подводные камни
Проблемы, не лежащие на поверхности, нередко дают о себе знать лишь «задним числом», после того как определенный этап поисковых работ завершен и, возможно, исходя из его результатов уже принято какое-либо решение. Что же мешает сделать ситуацию прозрачной с самого начала эксплуатации той или иной информационно-поисковой системы (ИПС)? Ответ довольно прост: отсутствие исчерпывающей информации подобного рода со стороны разработчика. Прямым следствием этого становятся недостоверность получаемых данных и их неконтролируемая потеря. Редко удается встретить в Сети поисковую систему, которая не обладала бы некоторыми «недокументированными» особенностями. Казалось бы — пользователю необходимо не так уж много сведений, а именно:
как происходит наполнение базы данных ИПС и каков ее объем;
полный спектр возможностей поискового языка системы;
основные особенности представления результатов поиска, прежде всего алгоритма ранжирования записей из списка отклика на поисковый запрос.
Увы, источником подобной информации обычно является не документ, доступный с головной страницы поискового сервера, а разбросанные по Сети, книгам и компьютерным журналам публикации отдельных авторов. К причинам такого положения дел, по-видимому, можно отнести не только небрежность разработчика, но и фактор, именуемый маркетинговой политикой. Проще говоря, предоставление поисковой системой наиболее полной информации о самой себе не всегда положительно сказывается на ее рейтинге. Тем не менее, взять ситуацию под контроль в ряде случаев пользователю оказывается вполне по силам. Выяснить особенности работы избранного поискового сервиса часто удается с помощью тестирования. Построение специальных тестовых запросов, быстро проясняющих именно тот аспект работы системы, который наиболее важен для текущей задачи, во многих случаях оказывается нетривиальным. Тому, как избежать некоторых неприятностей при работе с ИПС, мы и посвятим наше обсуждение. В качестве примеров, иллюстрирующих изложение, будут рассмотрены широко известные поисковые системы Интернета.
16.Поиск информации в интернете
Информация, размещенная во Всемирной сети, исчисляется огромным количеством байт. Для поиска информации во Всемирной сети используются специальные веб-сайты – информационно-поисковые системы. Они позволяют по ключевым словам найти информационные ресурсы, связанные с ключевыми словами. Это может быть текст, содержащий ключевые слова, или графическое изображение одного из ключевых слов. Примерами информационно-поисковых систем являются системы Google и Yandex.
Поиск информации – одна из самых востребованных на практике задач, которую приходится решать любому пользователю Интернета.
Существуют три основных способа поиска информации в Интернет:
1. Указание адреса страницы.
3. Обращение к поисковой системе (поисковому серверу).
Способ 1: Указание адреса страницы
Это самый быстрый способ поиска, но его можно использовать только в том случае, если точно известен адрес документа или сайта, где расположен документ.
Не стоит забывать возможность поиска по открытой в окне браузера web-странице (Правка-Найти на этой странице…).
Это наименее удобный способ, так как с его помощью можно искать документы, только близкие по смыслу текущему документу.
Способ 3: Обращение к поисковой системе
Пользуясь гипертекстовыми ссылками, можно бесконечно долго путешествовать в информационном пространстве Сети, переходя от одной web-страницы к другой, но если учесть, что в мире созданы многие миллионы web-страниц, то найти на них нужную информацию таким способом вряд ли удастся.
На помощь приходят специальные поисковые системы (ихеще называют поисковыми машинами). Адреса поисковых серверов хорошо известны всем, кто работает в Интернете. В настоящее время в русскоязычной части Интернет популярны следующие поисковые серверы:Яндекс (yandex.ru), Google (google.ru) и Rambler (rambler.ru
Поисковая система — веб-сайт, предоставляющий возможность поиска информации в Интернете.
Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp-серверах, товары в интернет-магазинах, а также информацию в группах новостей Usenet.
По принципу действия поисковые системы делятся на два типа: поисковые каталоги и поисковые индексы.
Поисковые каталоги служат для тематического поиска.
Информация на этих серверах структурирована по темам и подтемам. Имея намерение осветить какую-то узкую тему, нетрудно найти список web-страниц, ей посвященных.
Катало́г ресурсов в Интернете или каталог интернет-ресурсов или просто интернет-каталог — структурированный набор ссылок на сайты с кратким их описанием.
Поисковые индексы работают как алфавитные указатели. Клиент задает слово или группу слов, характеризующих его область поиска, — и получает список ссылок на web-страницы, содержащие указанные термины.
Первой поисковой системой для Всемирной паутины был «Wandex», уже не существующий индекс, разработанный Мэтью Грэйем из Массачусетского технологического института в 1993.
Как работает поисковой индекс?
Поисковые индексы автоматически, при помощи специальных программ(веб-пауков), сканируют страницы Интернета и индексируют их, то есть заносят в свою огромную базу данных.
Поисковый робот («веб-паук») — программа, являющаяся составной частью поисковой системы и предназначенная для обхода страниц Интернета с целью занесения информации о них (ключевые слова) в базу поисковика. По своей сути паук больше всего напоминает обычный браузер. Он сканирует содержимое страницы, забрасывает его на сервер поисковой машины, которой принадлежит и отправляется по ссылкам на следующие страницы.
В ответ на запрос, где найти нужную информацию, поисковый сервер возвращает список гиперссылок, ведущих web-страницам, на которых нужная информация имеется или упоминается. Обширность списка может быть любой, в зависимости от содержания запроса.
http://www.yandex.ru/
Яндекс — российская система поиска в Сети. Сайт компании, Yandex.ru, был открыт 23 сентября 1997 года. Головной офис компании находится в Москве. У компании есть офисы в Санкт-Петербурге, Екатеринбурге, Одессе и Киеве. Количество сотрудников превышает 700 человек.
Слово «Яндекс» (состоящее из буквы «Я» и части слова index; обыгран тот факт, что русское местоимение «Я» соответствует английскому «I») придумал Илья Сегалович, один из основателей Яндекса, в настоящий момент занимающий должность технического директора компании.
Поиск Яндекса позволяет искать по Рунету документы на русском, украинском, белорусском, румынском, английском, немецком и французском языках с учётом морфологии русского и английского языков и близости слов в предложении. Отличительная особенность Яндекса — возможность точной настройки поискового запроса. Это реализовано за счёт гибкого языка запросов.
По умолчанию Яндекс выводит по 10 ссылок на каждой странице выдачи результатов, в настройках результатов поиска можно увеличить размер страницы до 20, 30 или 50 найденных документов.
Время от времени алгоритмы Яндекса, отвечающие за релевантность выдачи, меняются, что приводит к изменениям в результатах поисковых запросов. В частности, эти изменения направлены против поискового спама, приводящего к нерелевантным результатам по некоторым запросам.
http://www.google.ru/
Лидер поисковых машин Интернета, Google занимает более 70 % мирового рынка. Cейчас регистрирует ежедневно около 50 млн поисковых запросов и индексирует более 8 млрд веб-страниц. Google может находить информацию на 115 языках.
По одной из версий, Google — искажённое написание английского слова googol. «Googol (гугол)» – это математический термин, обозначающий единицу со 100 нулями. Этот термин был придуман Милтоном Сироттой, племянником американского математика Эдварда Каснера, и впервые описан в книге Каснера и Джеймса Ньюмена «Математика и воображение»(Mathematics and the Imagination). Использование этого термина компанией Google отражает задачу организовать огромные объемы информации в Интернете.
Интерфейс Google содержит довольно сложный язык запросов, позволяющий ограничить область поиска отдельными доменами, языками, типами файлов и т. д.
http://www.rambler.ru/
Rambler Media Group — интернет-холдинг, включающий в качестве сервисов поисковую систему, рейтинг-классификатор ресурсов российского Интернета, информационный портал.
Rambler создан в 1996 году.
Поисковая система Рамблер понимает и различает слова русского, английского и украинского языков. По умолчанию поиск ведётся по всем формам слова.
Переход к информационному обществу XXI века породил беспрецедентный рост объемов и концентрации информации в глобальных компьютерных сетях. Это резко обострило проблему создания информационно-поисковых систем (ИПС) и их эффективного использования.
История автоматизированных информационно-поисковых систем исчисляется полувеком. Типичная ИПС первых лет — это человеко-машинная система, где анализ и описание содержания документов (индексирование) выполняется вручную, а поиски проводятся машиной. Первоначально основу ИПС составляли информационно-поисковые языки (ИПЯ), основным элементом которых являются дескрипторные словари и тезаурусы. Сегодня, однако, большинство работающих ИПС относится к классу вербальных систем бестезаурусного типа, когда индексационные термины выбираются непосредственно из текстов документов. Лавинообразный рост объемов электронной документальной информации, ее видовое, тематическое и языковое разнообразие являются как причиной кризиса современного информационного поиска, так и стимулом его совершенствования.
Проблема поиска ресурсов в сети Интернет была осознана достаточно скоро, и в ответ появились различные системы и программные инструменты для поиска, среди которых следует назвать системы Gopher, Archie, Veronica, WAIS, WHOIS и др. В последнее время на смену этим инструментам пришли «клиенты» и «серверы» всемирной паутины WWW.
Если попытаться дать классификацию ИПС сети Интернет, то можно выделить следующие основные типы:
1. ИПС вербального типа (поисковые системы – search engines)
2. Классификационные ИПС (каталоги – directories)
3. Электронные справочники («желтые» страницы и т.п.)
4. Специализированные ИПС по отдельным видам ресурсов
5. Интеллектуальные агенты.
Глобальный учет всех ресурсов Интернета обеспечивается вербальными и отчасти классификационными системами.
Классификационные ИПС реализуют навигацию в веб-пространстве на основе специальных указателей, представляющих собой тематические «деревья», строящиеся на основе классификаций.
Для решения проблемы максимального охвата ресурсов Интернета создаются системы, называемые метапоисковыми (metasearch engines).
Основным средством поиска информации в сети сегодня следует считать глобальные ИПС вербального типа , индексирующие (по крайней мере, претендующие на это) все Интернет-пространство. К числу главных поисковых систем этого типа (в первую очередь, по объему базы данных) можно отнести Google, Fast (AlltheWeb), AltaVista, HotBot, Inktomi, Teoma, WiseNut, MSN Search. Среди российских систем главными являются три: Яндекс (Yandex), Рамблер (Rambler) и Апорт! (Aport). Как правило, системы с бóльшим объемом базы дают в результате поиска и большее количество документов. Большая, как лингвистическая, так и программная проблема — многоязычие информационного пространства Интернета и многообразие форматов представления данных.
Особенность современных систем — полнотекстовый поиск. Многие вербальные ИПС сети Интернет вычисляют релевантность документов запросам путем сопоставления элементов запроса с полными текстами документов, размещенных в сети. Что касается информационно-поискового языка, то, как правило, в качестве поисковых элементов выступают обычные слова естественных языков. Запросы формулируются через специальный интерфейс, реализуемый в виде экранных форм в программах-броузерах.
В составе любой поисковой системы можно выделить три основные части.
Робот — подсистема, обеспечивающая просмотр (сканирование) Интернета и поддержание инвертированного файла (индексной базы данных) в актуальном состоянии. Этот программный комплекс является основным средством сбора информации о наличии и состоянии информационных ресурсов сети.
Поисковая база данных — так называемый индекс — специальным образом организованная база (англ. index database), включающая, прежде всего, инвертированный файл, который состоит из лексических единиц, взятых из проиндексированных веб-документов, и содержит разнообразную информацию о них (в частности, их позиции в документах), а также о самих документах и сайтах в целом.
Поисковая система — подсистема поиска, обеспечивающая обработку запроса (поискового предписания) пользователя, поиск в базе данных и выдачу результатов поиска пользователю. Поисковая система общается с пользователем через пользовательские интерфейсы — экранные формы программ-броузеров: интерфейс формирования запросов и интерфейс просмотра результатов поиска.
Важным компонентом современных ИПС являются так называемые интерфейсные веб-страницы, т.е. экранные формы, через которые пользователь общается с поисковой системой. Различают два основных типа интерфейсных страниц: страницы запросов и страницы результатов поиска.
Интерфейс выдачи (форма представления результатов) у разных систем включает такие параметры: статистика слов из запроса, количество найденных документов, количество сайтов, средства управления сортировкой документов в выдаче, краткое описание документов и др. Описание каждого документа, в свою очередь, может содержать в своем составе: заглавие документа, URL (адрес в сети), объем документа, дату создания, название кодировки, аннотацию, шрифтовое выделение в аннотации слов из запроса, указание на другие релевантные веб-страницы того же сайта, ссылка на рубрику каталога, к которой относится найденный документ или сайт, коэффициент релевантности, другие возможности поиска (поиск похожих документов, поиск в найденном).
Вопросы для самоконтроля:
- Что собой представляют ИПС?
- Какова классификация ИПС?
- Что собой представляет документальная ИПС?
- Что собой представляет фактографическая ИПС?
- Из каких частей состоит ИПС?
- Какие обеспечивающие подсистемы ИПС имеются?
- Основные понятия информационного поиска.
- Что собой представляют информационно-поисковые языки?
- Какова классификация ИПС в Интернете?
- Основные части любой ИПС.
1. Введение
С каждым годом объемы Интернета увеличиваются в разы, поэтому вероятность найти необходимую информацию резко возрастает. Интернет объединяет миллионы компьютеров, множество разных сетей, число пользователей увеличивается на 15-80% ежегодно. И, тем не менее, все чаще при обращении к Интернет основной проблемой оказывается не отсутствие искомой информации, а возможность ее найти. Как правило, обычный человек в силу разных обстоятельств не может или не хочет тратить на поиск нужного ему ответа больше 15-20 минут. Поэтому особенно актуально правильно и грамотно научиться, казалось бы, простой вещи – где и как искать, чтобы получать ЖЕЛАЕМЫЕ ответы.
Чтобы найти нужную информацию, необходимо найти её адрес. Для этого существуют специализированные поисковые сервера (роботы индексов (поисковые системы), тематические Интернет-каталоги, системы мета-поиска, службы поиска людей и т.д.). В данном мастер-классе раскрываются основные технологии поиска информации в Интернете, предоставляются общие черты поисковых инструментов, рассматриваются структуры поисковых запросов для наиболее популярных русскоязычных и англоязычных поисковых систем.
2. Технологии поиска
Web-технология World Wide Web (WWW) считается специальной технологией подготовки и размещения документов в сети Интернет. В состав WWW входят и web-страницы, и электронные библиотеки, каталоги, и даже виртуальные музеи! При таком обилии информации остро встает вопрос: «Как сориентироваться в столь огромном и масштабном информационном пространстве?»
В решении данной проблемы на помощь приходят поисковые инструменты.
2.1 Поисковые инструменты
Поисковые инструменты — это особое программное обеспечение, основная цель которого – обеспечить наиболее оптимальный и качественный поиск информации для пользователей Интернета. Поисковые инструменты размещаются на специальных веб-серверах, каждый из которых выполняет определенную функцию:
- Анализ веб-страниц и занесение результатов анализа на тот или иной уровень базы данных поискового сервера.
- Поиск информации по запросу пользователя.
- Обеспечение удобного интерфейса для поиска информации и просмотра результата поиска пользователем.
Приемы работы, используемые при работе с теми или другими поисковыми инструментами, практически одинаковы. Перед тем как перейти к их обсуждению, рассмотрим следующие понятия:
- Интерфейс поискового инструмента представлен в виде страницы с гиперссылками, строкой подачи запроса (строкой поиска) и инструментами активизации запроса.
- Индекс поисковой системы – это информационная база, содержащая результат анализа веб-страниц, составленная по определенным правилам.
- Запрос – это ключевое слово или фраза, которую вводит пользователь в строку поиска. Для формирования различных запросов используются специальные символы («», ~), математические символы (*, +, ?).
Схема поиска информации в сети Интернет проста. Пользователь набирает ключевую фразу и активизирует поиск, тем самым получает подборку документов по сформулированному (заданному) запросу. Этот список документов ранжируется по определенным критериям так, чтобы вверху списка оказались те документы, которые наиболее соответствуют запросу пользователя. Каждый из поисковых инструментов использует различные критерии ранжирования документов, как при анализе результатов поиска, так и при формировании индекса (наполнении индексной базы данных web-страниц).
Таким образом, если указать в строке поиска для каждого поискового инструмента одинаковой конструкции запрос, можно получить различные результаты поиска. Для пользователя имеет большое значение, какие документы окажутся в первых двух-трех десятках документов по результатам поиска и на сколько эти документы соответствуют ожиданиям пользователя.
Большинство поисковых инструментов предлагают два способа поиска – simple search (простой поиск) и advanced search (расширенный поиск) с использованием специальной формы запроса и без нее. Рассмотрим оба вида поиска на примере англоязычной поисковой машины.
Например, AltaVista удобно использовать для произвольных запросов, «Something about online degrees in information technology», тогда как поисковый инструмент Yahoo позволяет получать мировые новости, информацию о курсе валют или прогнозе погоды.
Освоение критериев уточнения запроса и приемов расширенного поиска, позволяет увеличивать эффективность поиска и достаточно быстро найти необходимую информацию. Прежде всего, увеличить эффективность поиска Вы можете за счет использования в запросах логических операторов (операций) Or, And, Near, Not, математических и специальных символов. С помощью операторов и/или символов пользователь связывает ключевые слова в нужной последовательности, чтобы получить наиболее адекватный запросу результат поиска. Формы запросов приведены в таблице 1.
Таблица 1
Простой запрос дает некоторое количество ссылок на документы, т.к. в список попадают документы, содержащие одно из слов, введенных при запросе, или простое словосочетание (см. таблицу 1). Оператор and позволяет указать на то, что в содержании документа должны быть включены все ключевые слова. Тем не менее, количество документов может быть все еще велико, и их просмотр займет достаточно времени. Поэтому в ряде случаев гораздо удобнее применить контекстный оператор near, указывающий, что слова должны располагаться в документе в достаточной близости. Использование near значительно уменьшает количество найденных документов. Наличие символа «*» в строке запроса означает, что будет осуществляться поиск слова по его маске. Например, получим список документов, содержащих слова, начинающиеся на «gov», если в строке запроса запишем «gov*». Это могут быть слова government, governor и т.д.
Не менее популярная поисковая система Rambler ведет статистику посещаемости ссылок из собственной базы данных, поддерживаются те же логические операторы И, ИЛИ, НЕ, метасимвол * (аналогично расширяющему диапазон запроса символу * в AltaVista), коэффициентные символы + и -, для увеличения или уменьшения значимости вводимых в запрос слов.
Давайте рассмотрим наиболее популярные технологии поиска информации в Интернет.
2.2 Поисковые машины (search engines)
Машины веб-поиска — это сервера с огромной базой данных URL-адресов, которые автоматически обращаются к страницам WWW по всем этим адресам, изучают содержимое этих страниц, формируют и прописывают ключевые слова со страниц в свою базу данных (индексирует страницы).
Более того, роботы поисковых систем переходят по встречаемым на страницах ссылкам и переиндексируют их. Так как почти любая страница WWW имеет множество ссылок на другие страницы, то при подобной работе поисковая машина в конечном результате теоретически может обойти все сайты в Интернет.
Именно этот вид поисковых инструментов является наиболее известным и популярным среди всех пользователей сети Интернет. У каждого на слуху названия известных машин веб-поиска (поисковых систем) – Яndex, Rambler, Aport.
Чтобы воспользоваться данным видом поискового инструмента, необходимо зайти на него и набрать в строке поиска интересующее Вас ключевое слово. Далее Вы получите выдачу из ссылок, хранящихся в базе поисковой системы, которые наиболее близки Вашему запросу. Чтобы поиск был наиболее эффективен, заранее обратите внимание на следующие моменты:
- определитесь с темой запроса. Что именно в конечном итоге Вы хотите найти?
- обращайте внимание на язык, грамматику, использование различных небуквенных символов, морфологию.Важно также правильно сформулировать и вписать ключевые слова. Каждая поисковая система имеет свою форму составления запроса — принцип один, но могут различаться используемые символы или операторы. Требуемые формы запроса различаются также в зависимости от сложности программного обеспечения поисковых систем и предоставляемых ими услуг. Так или иначе, каждая поисковая система имеет раздел «Help» («Помощь»), где все синтаксические правила, а также рекомендации и советы по поиску, доступно объясняются (скриншот страничек поисковиков).
- используйте возможности разных поисковых систем. Если не нашли на Яndex, попробуйте на Google. Пользуйтесь услугами расширенного поиска.
- чтобы исключить документы, содержащие определенные термины, используйте знак «-» перед каждым таким словом. Например, если Вам нужна информация о работах Шекспира, за исключением «Гамлета», то введите запрос в виде: «Шекспир-Гамлет». И для того, чтобы, наоборот, в результаты поиска обязательно включались определенные ссылки, используйте символ «+». Так, чтобы найти ссылки о продаже именно автомобилей, Вам нужен запрос «продажа+автомобиль». Для увеличения эффективности и точности поиска, используйте комбинации этих символов.
- каждая ссылка в списке результатов поиска содержит – несколько строчек из найденного документа, среди которых встречаются Ваши ключевые слова. Прежде чем переходить по ссылке, оцените соответсвие сниппета теме запроса. Перейдя по ссылке на определенный сайт, внимательно окиньте взглядом главную страничку. Как правило, первой страницы достаточно, чтобы понять – по адресу Вы пришли или нет. Если да, то дальнейшие поиски нужной информации ведите на выбранном сайте (в разделах сайта), если нет – возвращайтесь к результатам поиска и пробуйте очередную ссылку.
- помните, что поисковые системы не производят самостоятельную информацию (за исключением разъяснений о самих себе). Поисковая система – это лишь посредник между обладателем информации (сайтом) и Вами. Базы данных постоянно обновляются, в них вносятся новые адреса, но отставание от реально существующей в мире информации все равно остается. Просто потому, что поисковые системы не работают со скоростью света.
К наиболее известным машинам веб-поиска относятся Google, Yahoo, Alta Vista, Excite, Hot Bot, Lycos. Среди русскоязычных можно выделить Яndex, Rambler, Апорт.
Поисковые системы являются самыми масштабными и ценными, но далеко не единственными источниками информации в Сети, ведь помимо них существуют и другие способы поиска в Интернете.
2.3 Каталоги (directories)
Каталог Интернет-ресурсов – это постоянно обновляющийся и пополняющийся иерархический каталог, содержащий множество категорий и отдельных web-серверов с кратким описанием их содержимого.Способ поиска по каталогу подразумевает «движение вниз по ступенькам», то есть движение от более общих категорий к более конкретным. Одним из преимуществ тематических каталогов является то, что пояснения к ссылкам дают создатели каталога и полностью отражают его содержание, то есть дает Вам возможность точнее определить, насколько соответствует содержание сервера цели Вашего поиска.
Примером тематического русскоязычного каталога можно назвать ресурс http://www.ulitka.ru/ .
На главной странице данного сайта расположен тематический рубрикатор,
с помощью которого пользователь попадает в рубрику со ссылками на интересующую его продукцию.
Кроме того, некоторые тематические каталоги позволяют искать по ключевым словам. Пользователь вводит необходимое ключевое слово в строку поиска
и получает список ссылок с описаниями сайтов, которые наиболее полно соответствуют его запросу. Стоит отметить, что этот поиск происходит не в содержимом WWW-серверов, а в их кратком описании, хранящихся в каталоге.
В нашем примере в каталоге также имеется возможность сортировки сайтов по количеству посещений, по алфавиту, по дате занесения.
Другие примеры русскоязычных каталогов:
Каталог@Mail.ru
Weblist
Vsego.ru
Cреди англоязычных каталогов можно выделить:
http://www.DMOS.org
http://www.yahoo.com/
http://www.looksmart.com
2.4 Подборки ссылок
Подборки ссылок – это отсортированные по темам ссылки. Они достаточно сильно отличаются друг от друга по наполнению, поэтому чтобы найти подборку, наиболее полно отвечающую Вашим интересам, необходимо ходить по ним самостоятельно, дабы составить собственное мнение.
В качестве примера приведем Подборку ссылок «Сокровища Интернет» АО «Релком»
Пользователь, нажимая на любую из заинтересовавших его рубрик
Автомобилистам
- Астрономия и астрология
- Ваш дом
- Ваши питомцы
- Дети — цветы жизни
- Досуг
- Города в Сети Internet
- Здоровье и медицина
- Информационные агентства и службы
- Краеведческий музей и т.д.,
- Автомобильная электроника.
- Музей автомото старины.
- Коллегия Правовой Защиты Автовладельцев.
- Sportdrive.
Преимуществом такого вида поисковых инструментов является их целенаправленность, обычно подборка включает в себя редкие интернет ресурсы, подобранные конкретным веб-мастером или хозяином интернет странички.
2.5 Базы данных адресов (addresses database)
Базы данных адресов – это специальные поисковые сервера, которые обычно используют классификации по роду деятельности, по выпускаемой продукции и оказываемым услугам, по географическому признаку. Иногда они дополнены поиском по алфавиту. В записях базы данных хранится информация о сайтах, которые предоставляют информацию об электронном адресе, организации и почтовом адресе за определенную плату.
Крупнейшей англоязычной базой данных адресов можно назвать: http://www.lookup.com/ —
Попадая в данные поддиректории, пользователь обнаруживает ссылки на сайты, которые и предлагают интересующую его информацию.
Широко доступных и официальных баз данных адресов в РФ нам неизвестно.
2.6 Поиск в архивах Gopher (Gopher archives)
Gopher – это взаимосвязанная система серверов (Gopher-пространство), распределенная по Интернет.
В пространстве Gopher собрана богатейшая литературная библиотека, однако материалы недоступны для просмотра в удаленном режиме: пользователь может только просматривать иерархически организованное оглавление и выбирать файл по названию. С помощью специальной программы (Veronica) такой поиск можно сделать и автоматически, используя запросы, построенные на ключевых словах.
До 1995 года Gopher являлся самой динамичной технологией Интернет: темпы роста числа соответствующих серверов опережали темпы роста серверов всех других типов Интернет. В сети EUnet/Relcom активного развития серверы Gopher не получили, и сегодня о них практически никто не вспоминает.
2.7 Система поиска FTP файлов (FTP Search)
Система поиска FTP-файлов – это особый тип средств поиска в Internet, который позволяет находить файлы, доступные на «анонимных» FTP-серверах. Протокол FTP предназначен для передачи по сети файлов, и в этом смысле он функционально является своеобразным аналогом Gopher.
Основным критерием поиска является название файла, задаваемое разными способами (точное соответствие, подстрока, регулярное выражение и т.д.). Данный тип поиска, конечно же, не может соперничать по возможностям с поисковыми машинами, так как содержимое файлов никак не учитывается при поиске, а файлам, как известно, можно давать произвольные имена. Тем не менее, если Вам требуется найти какую-нибудь известную программу или описание стандарта, то с большой долей вероятности файл, его содержащий, будет иметь соответствующее имя, и Вы сможете найти его при помощи одного из серверов FTP Search :
FileSearch ищет файлы на FTP-серверах по именам самих файлов и каталогов. Если Вы ищете какую-либо программу или еще что-то, то на WWW-серверах Вы скорее найдете их описание, а с FTP-серверов Вы сможете перекачать их к себе.
2.8 Система поиска в конференциях Usenet News
USENET NEWS – это система телеконференций сообщества сетей Интернет. На Западе этот сервис принято называть новостями. Близким аналогом телеконференций являются и так называемые «эхи» в сети FIDO.
С точки зрения абонента телеконференции, USENET представляют из себя доску объявлений, в которой есть разделы, где можно найти статьи на любую тему — от политики до садоводства. Эта доска объявлений доступна через компьютер, подобно электронной почте. Не отходя от компьютера, можно читать или помещать статьи в ту или иную конференцию, найти полезный совет или вступать в дискуссии. Естественно, статьи занимают место на компьютерах, поэтому не хранятся вечно, а периодически уничтожаются, освобождая место для новых. Во всем мире лучшим сервисом для поиска информации в конференциях Usenet является сервер Google Groups (Google Inc.).
Группы Google – это бесплатное интерактивное сообщество и служба групп обсуждений, которая предлагает самый обширный в Интернете архив сообщений сети Usenet (более миллиарда сообщений).Подробнее ознакомиться с правилами пользования сервисом можно на странице http://groups.google.com/intl/ru/googlegroups/tour/index.html
Среди русскоязычных выделяется сервер Всемирная система USENET и телеконференции Relcom. Точно также как и в других поисковых службах, пользователь набирает строку запроса, а сервер формирует список конференций, содержащих ключевые слова. Далее надо подписаться на отобранные конференции в программе работы с новостями. Также имеет место аналогичный российский сервер FidoNet Online: конференции Fido на WWW.
2.9 Системы мета-поиска
Для быстрого поиска в базах сразу нескольких поисковых систем лучше обратиться к системам мета-поиска.
Системы мета-поиска – это поисковые машины, которые посылают Ваш запрос на огромное количество разных поисковых систем, затем обрабатывают полученные результаты, удаляют повторяющиеся адреса ресурсов и представляют более широкий спектр того, что представлено в сети Интернет.
Наиболее популярная в мире система мета-поиска Search.com .
Объединенный поисковый сервер Search.com компании CNET, Inc. включает в себя почти два десятка поисковых систем, ссылками на которые пестрит весь Интернет.
С помощью данного вида поисковых инструментов пользователь может искать информацию во множестве поисковых систем, однако отрицательной стороной данных систем можно назвать их нестабильность.
2.10 Системы поиска людей
Системы поиска людей – это специальные сервера, которые позволяют осуществлять поиск людей в Интернет, пользователь может указать Ф.И.О. человека и получить его адрес электронной почты и URL-адрес. Однако, следует отметить, что системы поиска людей, в основном, берут информацию об электронных адресах из открытых источников, таких как конференции Usenet. Среди самых известных систем поиска людей можно выделить:
Поиск адресов e-mail
в специальные графы поиска контактные данные (First Name. City, Last Name, Phone number), Вы можете найти интересующую Вас информацию.
Системы поиска людей — это действительно большие сервера, их базы данных содержат порядка 6 000 000 адресов.
3. Заключение
Мы рассмотрели основные технологии поиска информации в Интернет и представили в общих чертах поисковые инструменты, которые существуют на данный момент в Интернете, а также структуру поисковых запросов для наиболее популярных русскоязычных и англоязычных поисковых систем и, подводя итог вышесказанному, хотим отметить, что единой оптимальной схемы поиска информации в Интернет не существует. В зависимости от специфики нужной Вам информации, Вы можете использовать соответствующие поисковые инструменты и службы. А от того, как грамотно будут подобраны поисковые службы, зависит качество результатов поиска.
Как найти в Интернете необходимую информацию: веб-сайты по определенной теме, нужые программы, книги, фильмы, музыку, песни, игры… Да мало ли еще что люди ищут в Интернете! Как, как это можно найти? Конечно же, для поиска информации в Интернете мы пользуемся поисковыми системами, особенно такими наиболее популярными, как , и ! Очень часто, даже совсем ничего не зная о всех правилах и тонкостях поиска, рано или поздно можно найти то, что нужно. Это особенно проявляется, если ищешь что-то распространенное, то, что у всех на слуху, то есть, если ищешь популярную, востребованную среди других пользователей Интернета, информацию. Но как только приходится искать что-то уже менее распространенное, менее популярное, то тут уже с первой попытки, с наскока, так сказать, — уже вряд ли найдешь! И что же в таком случае делать? Искать дальше? И сколько на это понадобится Вам вашего Времени? Нервов? Денег за Интернет? Это зависит от того, насколько Вам повезет в Ваших поисках, насколько будет удача благосклонна к Вам! Но, если Гора упорно не хочет идти к Магомету, то тогда Магомет идет к Горе!
И я предлагаю Вам для начала, на первых порах, так сказать, использовать мои проверенные приемы и секреты эффективного поиска в Интернете. Их заголовки Вы имеете возможность наблюдать в правой части каждой из страниц этого сайта.
Использование только лишь этих приемов и секретов уже поможет Вам искать быстрее и эффективнее! Вы уже будете экономить свои Время, Нервы, и Деньги во время своих поисковых работ!
Но не забывайте, что это – хотя и хорошие, но всего лишь отдельные советы по поиску в Интернете. А вот если Вы еще будете знать и премудрости поиска, о том:
то тогда вообще трудностей, связанных с таким вопросом, как поиск в Интернете, у Вас, не скажу, что не будет вообще возникать, но будет уже ЗНАЧИТЕЛЬНО меньше. И Ваш поиск будет еще БОЛЕЕ эффективным!
Где все это узнать, где всему этому научиться?
Конечно же, можно купить, и даже не одну, книгу по поиску в Интернете. Но в чем недостаток таких книг? Как по мне, это избыточная литературность. Нет четкости, лаконичности, хорошей логической структуры. Кроме того, некотрые авторы, чтобы сделать свою книгу потолще (читай – чтоб продать ее подороже) набивают ее страницы скриншотами (вырезками изображений на мониторе) окон своего браузера с различными веб-страницами. Так же бывает, что в таких книгах много «воды».
Можно также пройти Курсы по поиску информации в Интернете.
Поэтому я предлагаю Вам изучить, или, хотя бы полистать, 🙂 МОЮ КНИГУ по поиску информации в Интернете. Из него Вы узнаете и научитесь всем премудростям поиска. Никто Вас не заставляет сидеть и каптеть над этим руководством, как над каким-то учебником! Даже если Вы будете просто читать, даже не прилагая усилий запомнить и зазубрить, то все равно, у Вас в голове многое останется! А для любителей изучать и учиться (не сомневаюсь, есть в наше пиво-водко-сигаретное время и такие), сразу скажу, что информация подана структурировано, логично, лаконично и удобно. Предлагаемая Вам моя он-лайн книга «Поиск – Всем!!!» абсолютно бесплатна для каждого пользователя Сети Интернет! Ее страницы находятся на сайте www. poisk-vsem.info.
Кстати, на нем же Вы найдете и описанные здесь 28 приемов и секретов эффективного поиска информации в Интернете! Все они вместе находятся в PDF-файле , который можно скачать себе на компьютер и распечатать, а так же в виде электронной книги , которую можно тоже скачать и всегда иметь под рукой у себя на компьютере. Кроме того, Вам предоставляется право распространять эти приемы и секреты в Интернете и в оффлайне. Как в PDF-файле , так и в формате электронной книги , но без изменений, в виде как есть. Так, Вы можете выкладывать их на файлообменники, и дарить своим друзьям и знакомым. А В электронную книгу Вы можете вставить свою рекламу!!! Да и вообще, если лично Вам эти советы, эти приемы и секреты поиска не нужны, то вполне возможно, что они будут полезны Вашим знакомым, друзьям, любимым и близким людям. Почему бы Вам не сделать им подарок, не позаботиться о них?
Кстати, о подарках! Даже если Вам и нафик не нужна вся эта лабуда по поиску, если Вы считаете, что и без нее можете найти информацию развлекательного характера и всякого рода халяву, то даже для таких из Вас там имеется раздел «Бесплатные полезности»!
Но и это еще не все! Для любителей заработать, причем, для тех, кто привык это делать своей ГОЛОВОЙ , а не руками , для таких, достойных всяческой похвалы и уважения людей, я предлагаю (опять же — совершенно бесплатно!) методику заработка (хоть в Интернте, хоть в оффлайне), основанную на применении всех тех знаний и умений, которые изложены в этих приемах и секретах поиска, а так же в бесплатном руководстве по поиску на сайте www.poisk-vsem.info.
И еще есть бонусы на том сайте www.poisk-vsem.info. Для охотников заработать вообще, я там в разделе «Заработать», собираю относительно простые и реальные методики и способы заработка. Как в Интернете, имея свой сайт, или даже без него, так и в оффлайне!
Итак, дорогие друзья, думаю, в любом случае Вы ничего не потеряете, а только приобрете (как много — зависит тлько от Вас!), если вместо отупляющего и пожирающего ваши мозги, время и деньги, бесцельного шастанья по Интернету, займетесь прямо противоположной этому и полезной деятельностью в Сети. Удачи каждому из Вас, удачных поисков, и хороших заработков!!! Внимание! По мере своего времени, сил и накопленного мной или заимствованного из других источников опыта по поиску информации в Интернете, Версии электронной книги «28 приемов и секретов эффективного поиска информации в Интернете!» будут мною обновляться и дополняться новыми приемами и секретами эффективного поиска информации в Интернете! Поэтому, всегда добро пожаловать за обновленной книгой на сайт www.poisk-vsem.info! Также новые премы и секреты поиска и, возможно, и другие материалы по поиску в Интернете, я буду выкладывать на этом сайте, www.poisk-vsem.narod.ru! … | Главная страница сайта. 1. Применение волшебных слов. 2. Английский нам поможет! 3. Запросы в разных вариантах написания — разные результаты. 4. Сленг. 5. Где два, там и третий. 6. А что вверху? 7. Что делать, если постоянно выносит на одни и те же сайты, страницы, документы, файлы. 8. Что может дать название статьи, книги. 9. Как угадать адрес поисковика и адрес сайта. 10. Где получить неофициальную информацию. 11. Как узнать про особенности ИПС. 12. Почему надо искать страницы, написанные на любом языке. 13. Почему надо искать в любой стране. 14. Орфографическая ошибка в запросе – к чему это ведет. 15. Применение синонимов. 16. Удаление слов-паразитов. 17. Поиск в заголовках. 18. Отметьте лучшие ИПС. 19. А какая ИПС самая лучшая? 20. Отвлечься, спокойно подумать и повторять попытки. 21. Поиск по названию файла. 22. Сначала найти специализированную ИПС… 23. «Представьте себе, представьте себе…» 24. Начальный поиск – в каталогах, детальный – в индексах. 25. А правильные ли термины Вы используете? 26. Если какие-то термины Вам не понятны. 27. Поиск среди найденного. 28. Все равно ничего не находится?
|
ОРГАНИЗАЦИЯ ПОЛНОТЕКСТОВОГО ПОИСКА НА ВЕБ-РЕСУРСАХ ORGANIZATION OF FULL-TEXT SEARCH ON WEB RESOURCES
Организация полнотекстового поиска на веб-ресурсах 119
электронных документов. В качестве результата оценено эффективность полнотек-
стового поиска в базах данных.
В работе [3] разработана специальная поисковая машина, работающая на осно-
ве алгоритма Sphinx. Анализируя особенности текстового поиска автор предлагает
учитывать морфологические основы языка. Также работе представлено установки
и конфигурации поисковой машины работающий на основе алгоритма Sphinx. Рас-
сматриваются «базовые» концепции и методы индексирования, которые необходимо
знать и использовать ежедневно при работе со Sphinx.
В статье [4] рассматриваются алгоритмы последовательного и логарифмического
поиска (наихудший и средний случай), дается их анализ, оценивается эффективность
и время выполнения. Приведены образцы выполнения заданий, демонстрационные
примеры.
Диссертация автора [5] фокусируется на проблеме получения текста, допускаю-
щей ошибки, также называемой «приблизительным» сопоставлением строк. Изучено
проблема найти шаблон в тексте, где шаблон и текст могут иметь «ошибки». Реше-
ния этих проблемы разрешила много внимания в последние годы из-за ее применения
во многих областях, таких как информационный поиск, вычислительная биология и
обработка сигналов. Основной целью данной работы является разработка и анализ
новых алгоритмов для решения проблемы поиска текста из источника в различных
условиях, а также лучшее понимание самой проблемы и ее статистического поведе-
ния. В конечном итого автором разработана алгоритм поиска с поддержкой исправ-
ления “ошибочного” запроса.
В работе [6] сделан обзор основных подходы и методы, применяемые для реше-
ния ряда задач информационного поиска по текстовым данным. Данный обзор не
призван охватить и рассмотреть абсолютное большинство задач информационного
поиска, однако, как надеется автор, он будет полезен в качестве общего освещения
методов поиска, применяемых в современных информационно-поисковых системах.
В статье [7] рассматривается задача полнотекстового поиска в корпусе текстов.
Автор для решения предлагает использовать алгоритм с обучением, сочетающий
поиск по словосочетаниям с анализом данных о поведении пользователей. В кон-
це приводятся результаты эксперимента, подтверждающие эффективность данного
алгоритма.
В работе автора [8] рассматриваются задачи поиска фраз и наборов слов в боль-
шом объеме текстов. Основным результатом поиска получение списка документов,
содержащих заданные слова, при этом документы, где слова располагаются ближе
друг к другу, считаются более релевантными. Поскольку эта задача требует сохране-
ния в индексе информации о каждом вхождении каждого слова в текстах, запросы,
включающие часто встречающиеся слова, требуют для своего выполнения длитель-
ного времени. В некоторых поисковых системах предлагается ввести список стоп
слов, которые не учитываются при поиске, но этот подход снижает качество поиска.
В данной работе при поиске обрабатываются все слова и применяются дополнитель-
ные индексы. С помощью дополнительных индексов время выполнения поискового
запроса, включающего часто встречающиеся слова, может быть снижено в десят-
ки раз. Разработан новый вид индекса с трехкомпонентными ключами. Приведены
алгоритмы поиска и результаты экспериментов поиска в сравнении с обычными ин-
дексами. Эксперименты, проведённые автором показывают, что при применении раз-
работанных индексов для определенного класса запросов, состоящих из самых часто
встречающихся слов, скорость поиска возрастает более чем в 90 раз.
Целевая группа интернет-исследований
Обзор
В Целевая группа по интернет-исследованиям (IRTF) фокусируется на долгосрочных исследованиях, связанных с Интернетом. в то время как параллельная организация, Инженерная группа Интернета (IETF), фокусируется на краткосрочных проблемах инженерии и создание стандартов.
IRTF состоит из ряда целенаправленных и долгосрочных Исследовательские группы. Эти группы работают над темами, связанными с интернет-протоколами, приложения, архитектура и технологии.Исследовательские группы имеют стабильное долгосрочное членство, необходимое для содействия развитию исследовательское сотрудничество и командная работа при изучении исследовательских проблем. Участие принимают отдельные участники, а не представители организаций.
IRTF также организует Практический семинар ACM / IRTF по прикладным сетевым исследованиям и Премия за прикладные сетевые исследования поощрять сотрудничество между академическим исследовательским миром и сообщество Интернет-стандартов.
IRTF имеет ограниченное количество гранты на поездки для поддержки посещения аспирантов и начинающих исследователей в наши мероприятия и мастер-классы.
Активные исследовательские группы
Эти 14 исследовательских групп в настоящее время зафрахтованы или предложены для регистрации:
Мастерские и призы
В Практический семинар ACM / IRTF по прикладным сетевым исследованиям это академический семинар, который является форумом для исследователей, поставщиков, операторов сетей и сообщества интернет-стандартов, чтобы представить и обсудить появляющиеся результаты прикладных сетевых исследований. Каждый год он совпадает с летним собранием IETF.
В Премия за прикладные сетевые исследования (ANRP) награжден за последние результаты прикладных сетевых исследований, которые актуальны для перехода на поставку интернет-продуктов и соответствующие усилия по стандартизации.Номинации производятся каждую осень, и победители конкурса выступают с докладами на открытых встречах IRTF. в следующем году.
Дополнительная информация
RFC 7418 дает Учебник IRTF для участников IETF. Он обеспечивает высокоуровневое описание вещей для рассмотрения участниками IETF при внесении предложений о новых исследовательских группах в IRTF, и подчеркивает различия в ожиданиях между двумя организациями.
IRTF управляется Председатель IRTF в консультации с Руководящая группа по интернет-исследованиям (IRSG).В состав IRSG входят председатель IRTF, председатели различные исследовательские группы и другие лица («члены в large ») от исследовательского сообщества, выбранного председателем IRTF.
Управление и работа IRTF описывается различными RFC и другие программные документы. Это включает Правила раскрытия прав интеллектуальной собственности. IETF Политика противодействия преследованию также относится к IRTF.
Премия за прикладные сетевые исследования
О ANRP
Премия прикладных сетевых исследований (ANRP) присуждается за признание лучшие последние результаты в прикладных сетях, интересные новинки исследовательские идеи, потенциально имеющие отношение к Интернет-стандартам сообщества и будущих людей, которые могут повлиять на Интернет-стандарты и технологии, с особым упором на кейсы где эти люди или идеи иначе не получили бы большого внимания или иметь возможность участвовать в обсуждении.
Мы поощряем номинирование исследователей с соответствующими результатами исследований, интересные идеи и новые перспективы. Награда им предложит возможность представить и обсудить свою работу с инженерами, сетевые операторы, политики и ученые, которые участвуют в Инженерная группа Интернета (IETF) и ее исследовательское подразделение, Целевая группа интернет-исследований (IRTF). Как собственные, так и сторонние номинации на эту премию приветствуются.
Приз за прикладные сетевые исследования (ANRP) состоит из:
- денежный приз в размере 1000 долларов США
- Приглашенный доклад на открытом заседании IRTF
- грант на поездку для участия в недельной встрече IETF (авиабилеты, гостиница, регистрация, стипендия)
- признание на пленарном заседании IETF
- приглашение на сопутствующие общественные мероприятия
Кроме того, победителям могут быть предложены дополнительные гранты на поездку в посещать будущие собрания IETF и / или IRTF.Такие гранты выдаются на усмотрение наградного комитета на основании отзывов сообщества, взаимодействие с сообществом и потенциальное влияние в будущем.
Присуждение премии «Прикладные сетевые исследования» вручается один раз за календарь. год с крайним сроком номинации в конце ноября. Каждый год несколько победители будут выбраны и приглашены представить свои работы на одном из три собрания IETF в следующем году.
Как номинировать
Номинации на одноместный автор оригинального рецензируемого журнала, конференции или семинара статья, которая была недавно опубликована или принята к публикации.Номинант должно быть одним из основных авторов номинированной статьи. Оба самовыдвижение (номинирование собственной статьи) и сторонние номинации (номинирование чужой работы с их разрешения) приветствуются.
Номинальная статья должна обеспечить научную основу для возможная будущая инженерная работа в IETF или исследования и экспериментирование в IRTF. Он должен анализировать поведение Интернет-протоколы в оперативном развертывании или на реальных испытательных стендах, внести важный вклад в понимание Интернета масштабируемость, производительность, надежность, безопасность или возможности, или в противном случае иметь отношение к текущим или будущим IETF или IRTF виды деятельности.
Номинации должно Кратко опишите, как номинированная работа связана с этими целями. Они должны описать, как вовлечь кандидата в IETF и IRTF. процесс, и привлечение их к собранию IETF поможет стимулировать перенос результатов и / или идей в новую разработку IETF работать или экспериментировать с IRTF, или иным образом инициировать новые виды деятельности, которые окажет влияние на реальный Интернет.
Цель Премии прикладных сетевых исследований (ANRP) — способствовать развитию превращение результатов исследований в реальные преимущества для интернет.Следовательно, заявители должны указать, что они (или номинант, в случае выдвижения сторонних лиц) доступны для участия по крайней мере, одно собрание IETF в следующем году. Личное присутствие желательно, когда это возможно, но из-за влияние вариантов удаленного участия в связи с пандемией COVID-19 будет быть доступным для победителей ANRP на всех собраниях IETF в 2021 и 2022 годах.
Номинации подаются через сайт подачи и должен включать:
- имя и адрес электронной почты кандидата;
- библиографическая ссылка на опубликованные (или принятые) номинированные бумага;
- PDF-копию номинированной работы;
- заявление, описывающее, как номинированная бумага выполняет цели награды и как номинальный будет взаимодействовать с сообществом IETF и / или IRTF;
- заявление о готовности номинантов представить их работа на собраниях IETF в год награждения;
- заявление о том, что кандидат соглашается с тем, что IRTF Правила раскрытия информации о правах интеллектуальной собственности подадут заявку на премию на открытом заседании IRTF;
- краткая биография или резюме кандидата; а также
- необязательно, любая другая вспомогательная информация (ссылка на веб-сайт кандидата сайт и др.)
Все кандидаты будут уведомлены по электронной почте о решении относительно их выдвижения.
Работы, номинированные на Премию прикладных сетевых исследований (ANRP): не считается вкладом в IETF или IRTF. Однако приглашенные доклады об этих докладах, представленных на открытом заседании IRTF это считаются взносами и правила раскрытия информации о правах интеллектуальной собственности IRTF подать заявление.
Важные даты
| Открытие номинаций: | 18 октября 2021 г. |
| Срок подачи заявок: | 19 ноября 2021 г. |
| Уведомления о наградах: | 5 января 2022 г. |
Наградной комитет
Наградной комитет, состоящий из людей, знающих о IRTF, IETF и более широкое сообщество сетевых исследователей будут оцените представленные материалы по этим критериям отбора.
В комитет по присуждению награды ANRP на 2022 год входят:
- Марк Оллман, ICSI
- Вайбхав Баджпай, TU Мюнхен
- Анна Брунстрем, Карлстадский университет
- Тэджун (Тихай) Чанг, Технологический институт Вирджинии
- Спенсер Докинз, Tencent America
- Ларс Эггерт, NetApp
- Тереза Энгхардт, Netflix
- Мэт Форд, Internet Society
- Стивен Фаррелл, Тринити-колледж Дублина
- Симона Ферлин, Ericsson
- Яна Айенгар, Fastly
- Андра Луту, Telefonica Research
- Велаша Мунсами, Рурский университет, Бохум,
- Кэтлин Мориарти, Dell EMC
- Колин Перкинс, Университет Глазго (председатель)
- Филипп Рихтер, Akamai / MIT
- Мелинда Шор, Быстро
- Анна Сперотто, Университет Твенте
- Стивен Строус, Fastly
- Кристофер Вуд, Cloudflare
- Фрэнсис Ю.Ян, Microsoft Research
Лауреаты прошлых призов
Ранее были присуждены следующие призы в области прикладных сетей:
- В IETF-112, чтобы Томас Виртген за его работу над расширяемостью реализаций BGP и другие протоколы маршрутизации:
- Томас Виртген, Квентин Де Конинк, Рэнди Буш, Лоран Ванбевер и Оливье Бонавентура, «XBGP: Когда вы не можете дождаться IETF и поставщиков», Материалы ACM HotNets, 2020 Слайды
- В IETF-112, чтобы Акса Кашаф за ее работу по изучению эффектов стороннего сервиса зависимости в Интернете
- Акса Кашаф, Вьяс Секар и Юврадж Агарвал, «Анализ зависимостей сторонних сервисов в современных веб-сервисах: извлекли ли мы уроки из инцидента с Mirai-Dyn?», Материалы ACM IMC 2020 Слайды
- В IETF-112, чтобы Кевин Бок за работу о цензуре в Интернете:
- Кевин Бок, Джордж Хьюги, Луи-Анри Мерино, Таня Арья, Даниэль Лисцински, Регина Погосян и Дэйв Левин, «Приходите, как вы есть: помощь немодифицированным клиентам обойти цензуру с обходом на стороне сервера», Материалы ACM SIGCOMM 2020 Слайды
- В IETF-111, чтобы Рюдигер Биркнер за работу по спецификации и верификации сети:
- Рюдигер Биркнер, Дана Драхслер-Коэн, Лоран Ванбевер и Мартин Вечев, «Config2spec: Характеристики сети для майнинга из сетевых конфигураций», Материалы USENIX NSDI 2020.Слайды
- В IETF-111, чтобы Саджад Фулади за работу по потоковому видео с малой задержкой (награжден в 2020 году):
- Саджад Фулади, Джон Эммонс, Эмре Орбей, Кэтрин Ву, Риад С. Вахби и Кейт Винштейн, «Salsify: сетевое видео с низкой задержкой за счет более тесной интеграции видеокодека и транспортного протокола», Материалы USENIX NSDI 2018. Слайды
- В IETF-110, чтобы Фрэнсис Й. Ян за его работу по применению машинного обучения к адаптации скорости передачи видео:
- Фрэнсис Ю.Ян, Хадсон Айерс, Ченжи Чжу, Саджад Фулади, Джеймс Хонг, Кей Чжан, Филип Левис и Кейт Винштейн, «Обучение на месте: рандомизированный эксперимент в потоковом видео», Материалы USENIX NSDI 2020 Слайды
- В IETF-110, чтобы Одри Рэндалл за работу по кэшированию и конфиденциальности DNS:
- Одри Рэндалл, Энце Лю, Гаутам Акивате, Рамакришна Падманабхан, Джеффри М. Фолькер, Стефан Сэвидж и Аарон Шульман, «Trufflehunter: отслеживание кеша редких доменов в больших общедоступных резольверах DNS», Материалы ACM IMC 2020 Слайды
- В IETF-109, чтобы Дебопам Бхаттахерджи за работу по проектированию сетевых топологий для группировок низкоорбитальных спутников:
- Дебопам Бхаттахерджи и Анкит Сингла, «Проектирование топологии сети на скорости 27 000 км / час», Материалы ACM CoNEXT,
Орландо, Флорида, США, декабрь 2019 года.Слайды
- В IETF-109, чтобы Джорджия Фрагкули за ее работу по прозрачности Интернета:
- Джорджия Фрагкули, Катерина Аргираки и Брайан Форд, «MorphIT: Morphing Packet Reports для прозрачности Интернета», Труды по технологиям повышения конфиденциальности, 2019 г. Слайды
- В IETF-109, чтобы Раныша Посуда за ее работу по справедливости контроля за перегрузкой:
- Раниша Уэр, Мэтью К. Мукерджи, Сринивасан Сешан и Жюстин Шерри, «За пределами индекса справедливости Джайна: устанавливая планку для развертывания алгоритмов контроля перегрузки», Труды ACM HotNets,
Принстон, штат Нью-Джерси, США, ноябрь 2019 г.Слайды
- В IETF-108, чтобы Шехар Бано за ее работу по разработке таксономии жизнеспособности Интернет-хостов:
- Шехар Бано, Филипп Рихтер, Мобин Джавед, Срикант Сундаресан, Закир Дурумерик, Стивен Дж. Мердок, Ричард Мортье и Верн Паксон, «Сканирование Интернета на предмет жизнеспособности», ACM Computer Communication Review, апрель 2018 г. Слайды
- В IETF-108, чтобы Чаои Лу за его работу по измерению DNS-over-encryption:
- Чаойи Лу, Баоцзюнь Лю, Чжоу Ли, Шуан Хао, Хайсинь Дуань, Минмин Чжан, Чуньин Ленг, Ин Лю, Цзайфэн Чжан и Цзянь-пин У, «Сквозное крупномасштабное измерение шифрования DNS через шифрование: как далеко мы продвинулись?», Труды конференции ACM Internet Measurement Conference, Амстердам, Нидерланды, октябрь 2019 г.Слайды
- В IETF-108, чтобы Ингмар Поес за работу по организации дорожного движения:
- Энрик Пуйоль, Ингмар Поэс, Йоханнес Зервас, Георгиос Смарагдакис и Аня Фельдманн, «Масштабное управление движением гигантов», Материалы ACM CoNEXT,
Орландо, Флорида, США, декабрь 2019 года. Слайды
- На IETF-107 награды не присуждены из-за пандемии COVID-19.
- В IETF-106, чтобы Weiteng Chen за его работу по безопасности беспроводных сетей:
- Вэйтен Чен и Чжиюнь Цянь Эксплойт Off-Path TCP: как беспроводные маршрутизаторы могут поставить под угрозу ваши секреты, Материалы симпозиума по безопасности USENIX, Балтимор, Мэриленд, США, август 2018 г.
- В IETF-105, чтобы Нета Розен Шифф за ее работу по безопасности NTP:
- Омер Дойч, Нета Розен Шифф, Дэнни Долев и Майкл Шапира, Предотвращение (сетевых) путешествий во времени с помощью Chronos Proc. Симпозиум по безопасности сетей и распределенных систем (NDSS) 2018 г., Сан-Диего, Калифорния, США, февраль 2018 г.
- В IETF-105, чтобы Тэджун Чунг за его работу «Понимание роли регистраторов в развертывании DNSSEC»:
- Тэджун Чунг, Роланд ван Рейсвейк-Дейдж, Дэвид Чоффнес, Дэйв Левин, Брюс М.Мэггс, Алан Мислав и Кристо Уилсон, Понимание роли регистраторов в развертывании DNSSEC Proc. ACM Internet Measurement Conference (IMC), Лондон, Великобритания, ноябрь 2017 года.
- В IETF-104, чтобы Флориан Штрайбельт для демонстрации того, как удаленные стороны могут использовать сообщества BGP для влияния на Интернет-маршрутизацию:
- Флориан Штрайбельт, Франциска Лихтблау, Роберт Беверли, Аня Фельдманн, Кристель Пелссер, Георгиос Смарагдакис и Рэнди Буш. Сообщества BGP: еще больше червей в контейнере маршрутизации.Proc. Конференция ACM Internet Measurement Conference 2018 (IMC ‘18). Бостон, Массачусетс, США, октябрь 2018 г.
- В IETF-104, чтобы Брэндон Шлинкер за представление первого публичного анализа глобального решения доставки контента на основе SDN, обслуживающего более двух миллиардов пользователей, включая измерения производительности в реальном времени:
- Брэндон Шлинкер, Хёджонг Ким, Тимоти Куй, Итан Кац-Бассетт, Харша В. Мадхьястха, Итало Кунха, Джеймс Куинн, Саиф Хасан, Петр Лапухов и Хонги Цзэн. Инженерный выход с Edge Fabric: управление океанами контента в мире.Proc. Конференция ACM SIGCOMM. Лос-Анджелес, Калифорния, США, август 2017 года.
- В IETF-103, чтобы Йоханна Аманн за первое крупномасштабное исследование недавно развернутых функций веб-безопасности, включая их совокупное влияние:
- Дж. Амман, О. Гассер, К. Шейтле, Л. Брент, Г. Карл, Р. Хольц. Миссия выполнена? Безопасность HTTPS после DigiNotar. Proc. 17-я конференция Internet Measurement Conference (IMC’17), ноябрь 2017 г.
- В IETF-103, чтобы Араш Молави Кахки для подробного анализа нескольких версий быстро развивающегося нового транспортного протокола в большом количестве сред:
- Араш Молави Кахки, Самуэль Джеро, Дэвид Чоффнес, Алан Мислав, Кристина Нита-Ротару.Взгляд на QUIC: подход к строгой оценке быстро развивающихся транспортных протоколов. Proc. 17-я конференция Internet Measurement Conference (IMC’17), ноябрь 2017 г.
- В IETF-102, чтобы Мария Апостолаки для подробного анализа влияния атак маршрутизации через Интернет (например, взлома BGP) и злонамеренных интернет-провайдеров (ISP) на криптовалюту Биткойн:
- Мария Апостолаки, Авив Зохар, Лоран Ванбевер. Угон биткойнов: маршрутизация атак на криптовалюты.Proc. Симпозиум IEEE по безопасности и конфиденциальности, 2017 г. Сан-Хосе, Калифорния, США (май 2017 г.).
- В IETF-102, чтобы Панос Пападимитратос для улучшения нашего понимания автомобильной инфраструктуры открытых ключей с точки зрения безопасности, защиты конфиденциальности и эффективности:
- М. Ходай, Х. Джин и П. Пападимитратос. SECMACE: масштабируемая и надежная инфраструктура идентификации и учетных данных в автомобильной связи. IEEE Transactions по интеллектуальным транспортным системам (IEEE ITS), апрель 2018 г.
- В IETF-101, чтобы Моджган Гасеми для подробного анализа производительности коммерческого сервиса потокового видео:
- Моджган Гасеми, Парта Канупарти, Ахмед Манси, Теофил Бенсон, Дженнифер Рексфорд. Характеристика производительности коммерческого сервиса потокового видео. Proc. Конференция по измерениям в Интернете (IMC), 2016 г., Санта-Моника, Калифорния, США, ноябрь 2016 г.
- В IETF-101, чтобы Васпол Руамвибунсук для улучшения взаимодействия веб-клиента и сервера с целью увеличения времени загрузки веб-страницы:
- В.Руамвибунсук, Р. Нетравали, М. Улуйол, Х. Мадхьястха. Vroom: ускорение мобильного Интернета с помощью серверного разрешения зависимостей. Proc. Конференция Специальной группы ACM по передаче данных (SIGCOMM ‘17). ACM, Нью-Йорк, Нью-Йорк, США.
- В IETF-100, чтобы Пауль Эммерих за разработку высокоскоростного генератора пакетов MoonGen:
- Пауль Эммерих, Себастьян Галленмюллер, Даниэль Раумер, Флориан Вольфарт и Георг Карл. MoonGen: скриптовый высокоскоростной генератор пакетов.Proc. Конференция по измерениям в Интернете (IMC), 2015 г., Токио, Япония, октябрь 2015 г.
- В IETF-100, чтобы Roland van Rijswijk-Deij для анализа влияния криптографии на эллиптических кривых на производительность валидации DNSSEC:
- Роланд ван Рейсвейк-Дей, Каспар Хагеман, Анна Сперотто и Айко Прас. Влияние криптографии с эллиптическими кривыми на производительность при валидации DNSSEC. Proc. Транзакции IEEE / ACM в сети, том 25, выпуск 2, апрель 2017 г.
- На IETF-99, чтобы Стивен Чекоуэй для систематического анализа инцидента Juniper Dual EC:
- Стивен Чековей, Якоб Маскевич, Кристина Гарман, Джошуа Фрид, Шаанан Коуни, Мэтью Грин, Надя Хенингер, Ральф-Филипп Вайнманн, Эрик Рескорла и Ховав Шахам.Систематический анализ инцидента с Juniper Dual EC Proc. Конференция ACM по компьютерной и коммуникационной безопасности, 2016, стр. 468–479. ACM Press, октябрь 2016 г.
- На IETF-99, чтобы Филипп Рихтер для многопрофильного анализа развертывания NAT операторского уровня:
- П. Рихтер, Ф. Вольфарт, Н. Валлина-Родригес, М. Оллман, Р. Буш, А. Фельдманн, К. Крейбич, Н. Уивер и В. Паксон. Многопрофильный анализ развертывания NAT операторского уровня Proc. ACM IMC, Санта-Моника, Калифорния, США, декабрь 2016 г.
- На IETF-98, чтобы Йоси Гилад для расширения «проверка конца пути» к RPKI:
- Авичай Коэн, Йоси Гилад, Амир Херцберг и Майкл Шапира. Быстрый старт безопасности BGP с проверкой конца пути. Proc. ACM SIGCOMM, Флорианополис, Бразилия, август 2016 г.
- На IETF-98, чтобы Алистер Кинг для инфраструктуры, обеспечивающей эффективную обработку больших объемов распределенных и / или живых данных BGP:
- Кьяра Орсини, Алистер Кинг, Данило Джордано, Василиос Джотсас и Альберто Дайнотти.BGPStream: программная платформа для анализа текущих и исторических данных BGP. Proc. ACM IMC, Санта-Моника, Калифорния, США, декабрь 2016 г.
- На IETF-97, чтобы Оливье Тильманс для Фиббинг архитектура, обеспечивающая централизованное управление распределенной маршрутизацией:
- Стефано Виссичкио, Оливье Тилманс, Лоран Ванбевер и Дженнифер Рексфорд. Централизованное управление распределенной маршрутизацией. Proc. ACM SIGCOMM, Лондон, Великобритания, август 2015 года.
- На IETF-97, чтобы Бенджамин Хесманс для обеспечения возможности приложениям управлять передачей данных Multipath TCP:
- Бенджамин Хесманс, Грегори Деталь, Себастьян Барре, Рафаэль Боден и Оливье Бонавентура.SMAPP: на пути к приложениям Smart Multipath с поддержкой TCP. Proc. ACM CoNEXT, Гейдельберг, Германия, декабрь 2015 г.
- На IETF-96, чтобы Самуэль Джеро для анализа безопасности протокола QUIC:
- Роберт Лычев, Самуэль Джеро, Александра Болдырева и Кристина Нита-Ротару. Насколько безопасен и быстр QUIC? Обеспечиваемый анализ безопасности и производительности. Proc. Симпозиум IEEE по безопасности и конфиденциальности, С. 214–231, Сан-Хосе, Калифорния, США, май 2015 г.
- На IETF-96, чтобы Дарио Росси для характеристики принятия и развертывания Anycast в Интернете IPv4:
- Данило Чикалезе, Джордан Оге, Диана Джумблат, Тимур Фридман и Дарио Росси.Характеристика принятия и развертывания Anycast IPv4. Proc. ACM CoNEXT, Гейдельберг, Германия, декабрь 2015 г.
- На IETF-95, чтобы Роя Энсафи за изучение того, как китайский «великий брандмауэр» обнаруживает скрытые серверы обхода:
- Ройя Энсафи, Дэвид Файфилд, Филипп Винтер, Ник Фимстер, Николас Уивер и Верн Паксон. Изучение того, как Великий брандмауэр обнаруживает серверы скрытого обхода. Proc. ACM Internet Measurement Conference (IMC), Токио, Япония, 28-30 октября 2015 г.
- На IETF-95, чтобы Закир Дурумерик для эмпирического анализа безопасности доставки электронной почты:
- Закир Дурумерик, Дэвид Адриан, Ариана Мириан, Джеймс Кастен, Эли Бурштейн, Николас Лидзборски, Курт Томас, Виджей Эранти, Майкл Бейли и Дж. Алекс Халдерман. Ни снега, ни дождя, ни MITM… Эмпирический анализ безопасности доставки электронной почты. Proc. ACM Internet Measurement Conference (IMC), Токио, Япония, 28-30 октября 2015 г.
- На IETF-94, чтобы Сяо София Ван для систематического изучения времени загрузки веб-страниц в SPDY:
- Сяо София Ван, Аруна Баласубраманян, Арвинд Кришнамурти и Дэвид Ветеролл.Насколько Speedy SPDY? Proc. Симпозиум USENIX по проектированию и внедрению сетевых систем (NSDI), Сиэтл, Вашингтон, США, 2-4 апреля 2014 г.
- На IETF-94, чтобы Roland van Rijswijk-Deij для подробного измерения большого набора данных доменов, подписанных DNSSEC:
- Роланд ван Рейсвейк-Дей, Анна Сперотто и Айко Прас. DNSSEC и его потенциал для DDoS-атак: всестороннее исследование. Proc. ACM Internet Measurement Conference (IMC), Ванкувер, Британская Колумбия, Канада, ноябрь 2014 г.
- В IETF-93, чтобы Хайя Шульман для анализа недостатков подходов к конфиденциальности DNS:
- Хайя Шульман. Довольно плохая конфиденциальность: подводные камни DNS-шифрования. Proc. Семинар ACM по конфиденциальности в электронном обществе (WPES), Скоттсдейл, Аризона, США, 3 ноября 2014 г.
- В IETF-93, чтобы Жоау Луиш Собринью для разработки метода агрегации маршрутов, который позволяет фильтровать при соблюдении политик маршрутизации:
- Жоао Луис Собринью, Лоран Ванбевер, Франк Ле и Дженнифер Рексфорд.Распределенное агрегирование маршрутов в глобальной сети. Proc. ACM CoNEXT, Сидней, Австралия, 2-5 декабря 2014 г.
- В IETF-92, чтобы Аарон Гембер-Якобсон для проектирования и оценки уровня управления NFV:
- Аарон Гембер-Якобсон, Раджай Вишванатан, Чайтан Пракаш, Роберт Грандл, Джунаид Халид, Сурав Дас и Адитья Акелла. OpenNF: обеспечение инноваций в управлении сетевыми функциями. Proc. ACM SIGCOMM, Чикаго, штат Иллинойс, США, август 2014 г.
- На IETF-91, чтобы Шэрон Голдберг для обсуждения угроз, когда полномочия BGP RPKI ошибочны, неправильно настроены, скомпрометированы или вынуждены вести себя некорректно:
- Дэнни Купер, Итан Хейлман, Кайл Брогл, Леонид Рейзин и Шэрон Голдберг.О риске ненадлежащего поведения властей РПКИ. Proc. Семинар ACM по горячим темам в сетях (HotNets-XII), Колледж-Парк, Мэриленд, США, ноябрь 2013 г.
- На IETF-91, чтобы Тобиас Флак для разработки новых механизмов восстановления после потерь для TCP, которые минимизируют восстановление по таймауту:
- Тобиас Флач, Нандита Дуккипати, Андреас Терзис, Барат Рагхаван, Нил Кардуэлл, Ючунг Ченг, Анкур Джайн, Шуай Хао, Итан Кац-Бассетт, Рамеш Говиндан. Уменьшение веб-задержки: добродетель мягкой агрессии.Proc. ACM SIGCOMM, Гонконг, Китай, август 2013 г.
- На IETF-91, чтобы Мисба Уддин для разработки сопоставления и ранжирования сетевых поисковых запросов, чтобы оперативные данные были доступны в режиме реального времени для управляющих приложений:
- Мисба Уддин, Рольф Стадлер и Александр Клемм. Масштабируемое сопоставление и рейтинг для поиска в сети. Proc. Международная конференция по управлению сетями и услугами (CNSM), Цюрих, Швейцария, октябрь 2013 г.
- На IETF-90, чтобы Лычев Роберт для изучения преимуществ безопасности, предоставляемых частично развернутым S * BGP:
- Роберт Лычев, Шэрон Голдберг и Майкл Шапира.Безопасность BGP при частичном развертывании. Proc. ACM SIGCOMM, Гонконг, Китай, август 2013 г.
- В IETF-89, чтобы Кенни Патерсон для поиска и документирования новых атак на TLS и DTLS:
- Н. Дж. Аль Фардан и К. Г. Патерсон. Lucky Thirteen: нарушение протоколов записи TLS и DTLS. Proc. Симпозиум IEEE по безопасности и конфиденциальности, С. 526–540, Сан-Франциско, Калифорния, США, май 2013 г.
- В IETF-89, чтобы Кейт Винштейн для разработки транспортного протокола для интерактивных приложений, которым требуется высокая пропускная способность и низкая задержка:
- Кейт Винштейн, Анируд Сивараман и Хари Балакришнан.Стохастические прогнозы обеспечивают высокую пропускную способность и малую задержку в сотовых сетях. Proc. 10-й симпозиум USENIX по проектированию и внедрению сетевых систем (NSDI), Ломбард, Иллинойс, США, апрель 2013 г.
- В IETF-88, чтобы Идилио Драго для характеристики трафика и рабочих нагрузок облачной системы хранения Dropbox:
- Идилио Драго, Марко Меллия, Маурицио М. Мунафо, Анна Сперотто, Рамин Садре и Айко Прас. Внутри Dropbox: общие сведения о службах персонального облачного хранилища.Proc. ACM Internet Measurement Conference (IMC), Бостон, Массачусетс, США, ноябрь 2012 г.
- В IETF-87, чтобы Те-Юань Хуан для понимания трудностей адаптации скорости для потокового видео:
- Те-Юань Хуанг, Нихил Хандигол, Брэндон Хеллер, Ник МакКаун и Рамеш Джохари. Сбитый с толку, робкий и нестабильный: выбрать скорость потокового видео сложно. Proc. ACM Internet Measurement Conference (IMC), Бостон, Массачусетс, США, ноябрь 2012 г.
- В IETF-87, чтобы Лоран Ванбевер за предложение структуры, позволяющей бесшовную реконфигурацию BGP:
- Стефано Виссичкио, Лоран Ванбевер, Кристель Пелссер, Лука Читтадини, Пьер Франсуа и Оливье Бонавентура.Повышение гибкости сети с помощью бесшовных реконфигураций BGP. Proc. Транзакции IEEE / ACM в сети (TON), Том 21, выпуск 3, июнь 2013 г., стр. 990-1002.
- На IETF-86, чтобы Гонка Гюрсун для определения метрики, позволяющей анализировать политики маршрутизации BGP:
- Гонка Гюрсун, Натали Ручански, Эвимария Терци и Марк Кровелла. Расстояние между состояниями маршрутизации: метрика на основе пути для сетевого анализа. Proc. ACM Internet Measurement Conference (IMC), Бостон, Массачусетс, США, ноябрь 2012 г.
- В IETF-85, чтобы Шрикантх Сундаресан за его исследование по измерению производительности канала доступа на домашних шлюзовых устройствах:
- Шрикант Сундаресан, Вальтер де Донато, Ник Фимстер, Рената Тейшейра, Сэм Кроуфорд и Антонио Пескапе. Производительность широкополосного Интернета: взгляд со стороны шлюза. Proc. ACM SIGCOMM, Торонто, Канада, август 2011 г.
- В IETF-85, чтобы Пейман Каземян для разработки общей и независимой от протокола структуры для статической проверки сетевых спецификаций и конфигураций:
- Пейман Каземян, Джордж Варгезе и Ник Маккеун.Анализ пространства заголовков: статическая проверка сетей. Proc. Симпозиум USENIX по проектированию и внедрению сетевых систем (NSDI), Сан-Хосе, Калифорния, США, апрель 2012 г.
- В IETF-84, чтобы Альберто Дайнотти за его исследование нарушений связи в Интернете из-за фильтрации:
- Альберто Дайнотти, Клаудио Скуарселла, Эмиль Абен, К.С. Клаффи, Марко Кьеза, Микеле Руссо и Антонио Пескапе. Анализ сбоев Интернета в масштабах страны, вызванных цензурой. Proc. ACM Internet Measurement Conference (IMC), Берлин, Германия, ноябрь 2011 г.
- (На IETF-83 не было награждено ANRP из-за изменения годового цикла награждения.)
- В IETF-82, чтобы Мичио Хонда за его исследования по определению будущей расширяемости TCP:
- Мичио Хонда, Йошифуми Нисида, Костин Райчиу, Адам Гринхал, Марк Хэндли и Хидеюки Токуда. Можно ли еще расширить TCP? Proc. ACM Internet Measurement Conference (IMC), Берлин, Германия, ноябрь 2011 г.
- В IETF-82, чтобы Насиф Экиз за анализ некорректного поведения TCP-приемников:
- Насиф Экиз, Абутахир Хабиб Рахман и Пол Д.Амер. Неправильное поведение при создании TCP SACK. Обзор компьютерных коммуникаций ACM SIGCOMM, Том 41, выпуск 2, апрель 2011 г.
- На IETF-81, чтобы Маттиа Росси за его исследования по снижению трафика BGP:
- Джефф Хьюстон, Маттиа Росси и Гренвилл Армитаж. Методика уменьшения количества сообщений об обновлениях BGP за счет демпфирования исследования пути. Журнал IEEE по избранным областям коммуникаций (JSAC), Vol. 28, No. 8, pp. 1271–1286, октябрь 2010 г.
- На IETF-81, чтобы Бэйчуань Чжан за его исследования в области «зеленого» дорожного движения:
- Мингуи Чжан, Чэн И, Бинь Лю и Бэйчуань Чжан.GreenTE: энергоэффективная система управления трафиком. Proc. Международная конференция IEEE по сетевым протоколам (ICNP), С. 21–30, октябрь 2010 г.
Краткая история Интернета и связанных сетей
Введение
Винт Серф
В 1973 году Агентство перспективных исследовательских проектов Министерства обороны США (DARPA) инициировало исследовательскую программу по изучению методов и технологий для соединения пакетных сетей различных типов. Задача заключалась в разработке протоколов связи, которые позволили бы компьютерам в сети прозрачно обмениваться данными через несколько связанных пакетных сетей.Это называлось Интернет-проектом, а система сетей, возникшая в результате исследования, была известна как «Интернет». Система протоколов, которая была разработана в ходе этого исследования, стала известна как TCP / IP Protocol Suite после того, как были разработаны два первоначальных протокола: протокол управления передачей (TCP) и Интернет-протокол (IP).
В 1986 году Национальный научный фонд США (NSF) инициировал разработку сети NSFNET, которая в настоящее время обеспечивает основную коммуникационную услугу для Интернета.Обладая возможностями со скоростью 45 мегабит в секунду, NSFNET передает порядка 12 миллиардов пакетов в месяц между сетями, к которым она подключена. Национальное управление по аэронавтике и исследованию космического пространства (НАСА) и Министерство энергетики США предоставили дополнительные магистральные объекты в форме NSINET и ESNET соответственно. В Европе основные международные магистрали, такие как NORDUNET и другие, обеспечивают подключение к более чем ста тысячам компьютеров в большом количестве сетей. Поставщики коммерческих сетей в США.S. и Europe начинают предлагать опорную сеть Интернет и поддержку доступа на конкурсной основе всем заинтересованным сторонам.
«Региональная» поддержка Интернета предоставляется различными сетями консорциума, а «локальная» поддержка предоставляется через каждое из исследовательских и образовательных учреждений. В Соединенных Штатах большая часть этой поддержки поступает от федерального правительства и правительства штатов, но значительный вклад внесла промышленность. В Европе и других странах поддержка обеспечивается совместными международными усилиями и национальными исследовательскими организациями.В ходе своего развития, особенно после 1989 года, Интернет-система начала интегрировать поддержку других наборов протоколов в свою базовую сетевую структуру. В настоящее время акцент в системе делается на многопротокольном взаимодействии и, в частности, на интеграции протоколов взаимодействия открытых систем (OSI) в архитектуру.
Как общественное достояние, так и коммерческие реализации примерно 100 протоколов набора протоколов TCP / IP стали доступны в 1980-х годах.В начале 1990-х годов также стали доступны реализации протокола OSI, и к концу 1991 года Интернет вырос и включил около 5 000 сетей в более чем трех десятках стран, обслуживающих более 700 000 хост-компьютеров, используемых более чем 4 000 000 человек.
Значительную поддержку интернет-сообществу оказывает Федеральное правительство США, поскольку Интернет изначально был частью исследовательской программы, финансируемой из федерального бюджета, а впоследствии стал важной частью исследовательской инфраструктуры США.Однако в конце 1980-х годов количество пользователей Интернета и составляющих сети расширилось на международный уровень и стало включать коммерческие объекты. Действительно, сегодня большая часть системы состоит из частных сетевых объектов в образовательных и исследовательских учреждениях, на предприятиях и в государственных организациях по всему миру.
Координационный комитет межконтинентальных сетей (CCIRN), который был организован Федеральным сетевым советом США (FNC) и European Reseaux Associees pour la Recherche Europeenne (RARE), играет важную роль в координации планов исследований, спонсируемых государством. сети.Усилия CCIRN стали стимулом для поддержки международного сотрудничества в среде Интернета.
Техническая эволюция Интернета
За свою пятнадцатилетнюю историю Интернет функционировал как сотрудничество между сотрудничающими сторонами. Определенные ключевые функции были критическими для его работы, не последней из которых является спецификация протоколов, по которым работают компоненты системы. Изначально они были разработаны в рамках исследовательской программы DARPA, упомянутой выше, но за последние пять или шесть лет эта работа стала более широкой при поддержке правительственных агентств многих стран, промышленности и академического сообщества.Совет по Интернет-активности (IAB) был создан в 1983 году для руководства развитием TCP / IP Protocol Suite и предоставления исследовательских рекомендаций Интернет-сообществу.
За время своего существования IAB несколько раз реорганизовывалась. Теперь он состоит из двух основных компонентов: Инженерная группа Интернета и Целевая группа Интернет-исследований. Первый несет основную ответственность за дальнейшее развитие набора протоколов TCP / IP, его стандартизацию с согласия IAB и интеграцию других протоколов в работу Интернета (например,грамм. протоколы взаимодействия открытых систем). Рабочая группа по интернет-исследованиям продолжает организовывать и изучать передовые концепции сетей под руководством Совета по интернет-активности и при поддержке различных правительственных агентств.
Был создан секретариат для управления повседневной работой Совета по работе в Интернете и Целевой группы по развитию Интернета. IETF собирается три раза в год на пленарных заседаниях, и примерно 50 рабочих групп собираются в промежуточное время с помощью электронной почты, телеконференций и личных встреч.IAB собирается ежеквартально лично или по видеоконференции, а в перерывах — по телефону, электронной почте и на конференциях с использованием компьютера.
Две другие функции имеют решающее значение для работы IAB: публикация документов, описывающих Интернет, и назначение и запись различных идентификаторов, необходимых для работы протокола. На протяжении всего развития Интернета его протоколы и другие аспекты его работы были задокументированы сначала в серии документов, называемых Internet Experiment Notes, а затем в серии документов, называемых запросами на комментарии (RFC).Последние изначально использовались для документирования протоколов первой сети с коммутацией пакетов, разработанной DARPA, ARPANET, начиная с 1969 года, и стали основным архивом информации об Интернете. В настоящее время функцию публикации обеспечивает редактор RFC.
Запись идентификаторов обеспечивается Управлением по присвоению номеров в Интернете (IANA), которое делегировало часть этой ответственности Интернет-реестру, который действует как центральное хранилище информации в Интернете и обеспечивает централизованное распределение идентификаторов сети и автономных систем в некоторые дела — в дочерние реестры, расположенные в разных странах.Интернет-реестр (IR) также обеспечивает централизованное обслуживание корневой базы данных системы доменных имен (DNS), которая указывает на дочерние распределенные DNS-серверы, реплицированные по всему Интернету. Распределенная база данных DNS используется, среди прочего, для связывания имен хостов и сетей с их адресами в Интернете и имеет решающее значение для работы протоколов TCP / IP более высокого уровня, включая электронную почту.
В Интернете есть несколько сетевых информационных центров (NIC), которые предоставляют пользователям документацию, рекомендации, советы и помощь.Поскольку Интернет продолжает расти на международном уровне, потребность в высококачественных функциях сетевых адаптеров возрастает. Хотя первоначальное сообщество пользователей Интернета составляли представители информатики и инженерии, теперь его пользователи охватывают широкий спектр дисциплин в области науки, искусства, литературы, бизнеса, вооруженных сил и государственного управления.
Родственные сети
В 1980-81 гг. Были начаты два других сетевых проекта, BITNET и CSNET. BITNET принял набор протоколов IBM RSCS и обеспечил прямые соединения по выделенным линиям между участвующими сайтами.Большинство исходных соединений BITNET связывало мэйнфреймы IBM в университетских центрах обработки данных. Это быстро изменилось, поскольку реализации протокола стали доступны для других машин. С самого начала BITNET был многопрофильным по своей природе с пользователями во всех академических областях. Он также предоставил своим пользователям ряд уникальных услуг (например, LISTSERV). Сегодня BITNET и его параллельные сети в других частях мира (например, EARN в Европе) насчитывают несколько тысяч участвующих сайтов. В последние годы BITNET создала магистраль, которая использует протоколы TCP / IP с приложениями на основе RSCS, работающими поверх TCP.
CSNET изначально финансировался Национальным научным фондом (NSF) для создания сетей для университетских, промышленных и государственных исследовательских групп по информатике. CSNET использовала протокол Phonenet MMDF для ретрансляции электронной почты по телефону и, кроме того, впервые применила TCP / IP поверх X.25 с использованием коммерческих общедоступных сетей передачи данных. Сервер имен CSNET предоставил ранний пример службы каталогов белых страниц, и это программное обеспечение до сих пор используется на многих сайтах. На пике популярности CSNET насчитывала около 200 сайтов-участников и международные связи примерно с пятнадцатью странами.
В 1987 году BITNET и CSNET объединились в Корпорацию исследований и образовательных сетей (CREN). Осенью 1991 года служба CSNET была прекращена, так как на раннем этапе она выполнила свою важную роль в предоставлении академических сетевых услуг. Ключевой особенностью CREN является то, что его эксплуатационные расходы полностью покрываются за счет взносов, выплачиваемых организациями-членами.
откуда это все взялось?
С момента основания компании Google более 22 лет назад мы продолжаем выполнять амбициозную миссию по систематизации мировой информации и обеспечению ее универсального доступа и полезности.В то время как мы начинали с организации веб-страниц, наша миссия всегда была гораздо шире. Мы ставили перед собой задачу систематизировать не информацию в Интернете, а всю информацию в мире.
Вскоре компания Google вышла за пределы Интернета и начала искать новые способы понять мир и сделать информацию и знания доступными для большего числа людей. Интернет — и мир — сильно изменились с тех пор, и мы продолжаем улучшать Google Search, чтобы предвосхищать и реагировать на постоянно меняющиеся потребности людей в информации.
Не секрет, что результаты поиска, которые вы видели в 1998 году, выглядят иначе, чем те, которые вы можете найти сегодня. Поэтому мы хотели поделиться обзором того, откуда берется информация в Google, и в другом сообщении о том, как мы подходим к организации постоянно расширяющейся вселенной веб-страниц, изображений, видео, реальных идей и всех других видов информации. там.
Информация из открытого Интернета
Вы, вероятно, знакомы с веб-каталогами в Google — значковыми «синими ссылками», которые ведут на страницы со всего Интернета.Эти списки, наряду со многими другими функциями на странице результатов поиска, ссылаются на страницы в открытом Интернете, которые мы просканировали и проиндексировали, следуя инструкциям, предоставленным самими создателями сайта.
Владельцы сайтов могут указывать нашему веб-сканеру (роботу Google), какие страницы мы должны сканировать и индексировать, и у них даже есть более детальные элементы управления, чтобы указать, какие части страницы должны отображаться в виде текстового фрагмента в поиске Google. Используя наши инструменты для разработчиков, создатели сайтов могут выбирать, хотят ли они быть открытыми через Google, и оптимизировать свои сайты, чтобы улучшить их представление, чтобы получить больше бесплатного трафика от людей, которые ищут информацию и услуги, которые они предлагают.
Поиск в Google — это один из многих способов поиска информации и веб-сайтов. Каждый день мы отправляем миллиарды посетителей на сайты в Интернете, и с тех пор, как Google начал свою работу, ежегодно отправляемый нами трафик рос. Этот трафик направляется на широкий спектр веб-сайтов, помогая людям открывать для себя новые компании, блоги и продукты, а не только самые крупные и хорошо известные сайты в Интернете. Каждый день мы отправляем посетителей на более 100 миллионов различных веб-сайтов.
Общеизвестные и общедоступные источники данных
Создатели, издатели и компании любого размера работают над созданием уникального контента, продуктов и услуг.Но есть также информация, которая попадает в категорию того, что вы могли бы назвать общеизвестным — информация, которая не была создана уникальным образом или не «принадлежит» какому-либо одному человеку, а представляет собой набор широко известных фактов. Подумайте: дата рождения исторической личности, высота самой высокой горы в Южной Америке или даже какой сегодня день.
Мы помогаем людям легко находить такие факты с помощью различных функций поиска Google, таких как панели знаний. Информация поступает из широкого спектра источников с открытой лицензией, таких как Википедия, Энциклопедия жизни, данные CSSE COVID-19 Университета Джона Хопкинса и Data Commons Project, открытая база данных статистических данных, которую мы начали в сотрудничестве с U.S. Census, Бюро статистики труда, Евростат, Всемирный банк и многие другие.
Другой тип общеизвестных знаний — это результат вычислений, и это информация, которую Google часто генерирует напрямую. Поэтому, когда вы ищете преобразование времени («Который час в Лондоне?») Или измерения («Сколько фунтов в метрической тонне?») Или хотите узнать квадратный корень из 348, это фрагменты информации что Google вычисляет. Интересный факт: мы также рассчитываем время восхода и захода солнца для местоположений на основе широты и долготы!
Лицензии и партнерство
Когда дело доходит до организации информации, неструктурированные данные (слова и фразы на веб-страницах) труднее понять нашим автоматизированным системам.Структурированные базы данных, включая общедоступные базы знаний, такие как Викиданные, значительно упрощают нашим системам понимание, систематизацию и представление фактов в полезных функциях и форматах.
Для некоторых специализированных типов данных, таких как спортивные результаты, информация о телешоу и фильмах, а также тексты песен, есть поставщики, которые работают над систематизацией информации в структурированном формате и предлагают технические решения (например, API) для предоставления свежей информации. Мы лицензируем данные от этих компаний, чтобы гарантировать, что провайдеры и создатели (например, музыкальные издатели и артисты) получают компенсацию за свою работу.Когда люди приходят в Google в поисках этой информации, они сразу же получают к ней доступ.
Мы всегда работаем, чтобы предоставлять высококачественную информацию, и для таких тем, как здоровье или гражданское участие, которые влияют на средства к существованию людей, легкий доступ к надежной и авторитетной информации критически важен. По этим темам мы работаем с такими организациями, как местные органы здравоохранения, например CDC в США, и внепартийными некоммерческими организациями, такими как Democracy Works, чтобы сделать достоверную информацию доступной в Google.
Информация, которую предоставляют люди и компании
В мире существует широкий спектр информации, которая в настоящее время недоступна в открытом Интернете, поэтому мы ищем способы помочь людям и предприятиям делиться этими обновлениями, в том числе путем предоставления информации прямо в Google. Местные компании могут заявить о своем профиле компании и поделиться последними новостями с потенциальными клиентами в Поиске, даже если у них нет веб-сайта. Фактически, каждый месяц Google Поиск связывает людей с более чем 120 миллионами компаний, у которых нет веб-сайтов.В среднем местные результаты в поиске обеспечивают более 4 миллиардов контактов для предприятий каждый месяц, в том числе более 2 миллиардов посещений веб-сайтов, а также такие соединения, как телефонные звонки, маршруты, заказ еды и бронирование.
Мы также активно инвестируем в новые методы, чтобы гарантировать, что мы отражаем самую последнюю точную информацию. Это может быть особенно сложно, поскольку местная информация постоянно меняется и не всегда точно отражается в Интернете. Например, после COVID-19 мы использовали нашу двустороннюю переговорную технологию для звонков в компании, помогая обновлять их списки, подтверждая такие детали, как измененные часы работы магазинов или то, предлагают ли они вынос и доставку.С начала этой работы мы сделали более 3 миллионов обновлений для таких предприятий, как аптеки, рестораны и продуктовые магазины, которые были просмотрены в Картах и Поиске более 20 миллиардов раз.
Другие компании, такие как авиакомпании, розничные продавцы и производители, также предоставляют Google и другим сайтам данные о своих товарах и товарах через прямые каналы. Поэтому, когда вы ищете рейс из Боготы в Лиму или хотите узнать больше о характеристиках самых популярных новых наушников, Google может предоставить высококачественную информацию прямо из источника.
Мы также предоставляем возможность людям делиться своими знаниями о местах в более чем 220 странах и территориях. Благодаря миллионам материалов, которые пользователи вносят каждый день — от обзоров и оценок до фотографий, ответов на вопросы, обновлений адресов и т. Д. — люди во всем мире могут найти самую свежую и точную местную информацию в Поиске Google и на Картах.
Недавно созданная информация и идеи из Google
Благодаря достижениям в области искусственного интеллекта и машинного обучения мы разработали инновационные способы извлечения новых идей из окружающего нас мира, предоставляя людям информацию, которая может не только помочь им в их повседневной жизни. но также держите их в безопасности.
В течение многих лет люди обращались к нашей функции Popular Times, чтобы помочь измерить толпы в их любимых местах для позднего завтрака или посетить местный продуктовый магазин, когда он менее загружен. Мы постоянно улучшаем точность и охват этой функции, которая в настоящее время доступна для 20 миллионов мест по всему миру на Картах и в Поиске. Теперь эта технология обслуживает более важные потребности во время COVID. Благодаря расширению нашей функции занятости в реальном времени эти данные Google помогают людям принимать во внимание тесноту, поскольку они покровительствуют предприятиям во время пандемии.
Мы также генерируем новые идеи для помощи в реагировании на кризисы — от карт лесных пожаров на основе спутниковых данных до прогнозирования наводнений с помощью искусственного интеллекта — чтобы помочь людям избежать опасности во время стихийных бедствий.
Организация информации и обеспечение ее доступности и полезности
Недостаточно просто собрать широкий спектр информации. Главное в обеспечении доступности информации — это организация ее таким образом, чтобы люди могли ее реально использовать.
Способы организации информации продолжают развиваться, особенно по мере появления новых форматов информации и контента.Чтобы узнать больше о нашем подходе к предоставлению вам полезных, хорошо организованных страниц результатов поиска, посетите следующий блог из серии «Как работает поиск».Как работают поисковые системы в Интернете?
Объясняет Джавед Мостафа, доцент кафедры информатики Виктора Ингве и директор лаборатории прикладной информатики Университета Индианы в Блумингтоне.Было подсчитано, что объем текстовой информации, доступной через поисковые системы, по крайней мере в 40 раз больше, чем оцифрованное содержание всех книг в Библиотеке Конгресса, крупнейшей в мире библиотеке.Обеспечение доступа к такому большому объему информации является сложной задачей, однако современные поисковые системы замечательно справляются с сортировкой контента и выявлением связанных ссылок на запросы.
В Интернете существует множество поставщиков информации. К ним относятся широко известные и общедоступные источники, такие как Google, InfoSeek, NorthernLight и AltaVista, и это лишь некоторые из них. Вторая группа источников, которую иногда называют «скрытой сетью», по объему предоставляемой информации намного больше, чем общедоступная сеть.В эту последнюю группу входят такие источники, как Lexis-Nexis, Dialog, Ingenta и LoC. Они остаются скрытыми по разным причинам: они могут не разрешать другим поставщикам информации доступ к своему контенту; им может потребоваться подписка; или они могут потребовать плату за доступ. Эта статья посвящена первой группе — общедоступным поисковым веб-службам, которые в совокупности именуются здесь поисковыми системами.
Поисковые системы используют различные методы для ускорения поиска. Некоторые из распространенных методов кратко описаны ниже.
Предварительно обработанные данные
Один из способов сэкономить время поисковыми системами — это предварительная обработка содержимого Интернета. То есть, когда пользователь отправляет запрос, он не отправляется на миллионы веб-сайтов. Вместо этого сопоставление происходит с предварительно обработанными данными, хранящимися на одном сайте. Предварительная обработка выполняется с помощью программы, называемой краулером. Сканер периодически рассылается разработчиками базы данных для сбора веб-страниц. Специализированная компьютерная программа анализирует полученные страницы для извлечения слов.Эти слова затем сохраняются вместе со ссылками на соответствующие страницы в индексном файле. Запросы пользователей сопоставляются с этим индексным файлом, а не с другими веб-сайтами.
Интеллектуальное представление
В этом методе представление индекса тщательно выбирается с целью минимизировать время поиска. Ученые-информатики создали эффективную структуру данных, называемую деревом, которая может гарантировать значительно более короткое общее время поиска по сравнению с поиском, проводимым по последовательному списку ( см. Врезку ).Чтобы удовлетворить запросы, выполняемые множеством пользователей одновременно, и устранить «очереди ожидания», индекс обычно дублируется на нескольких компьютерах поискового сайта.
Приоритизация результатов
URL-адресов или ссылок, созданных в результате поиска, обычно много. Но из-за двусмысленности языка (например, «слепое окно» или «слепое честолюбие») результирующие ссылки, как правило, не будут одинаково релевантны запросу пользователей. Чтобы обеспечить более быстрый доступ к наиболее релевантным записям (и разместить их наверху или рядом с ним), алгоритм поиска применяет различные стратегии ранжирования.Распространенный метод ранжирования, известный как частота-обратная частота-термин-частота документа (TFIDF), рассматривает распределение слов и их частоту и генерирует числовые веса для слов, обозначающих их важность в отдельных документах. Он определяет веса слов, благодаря чему слова, которые очень часто встречаются (например, «или», «к» или «с») и которые встречаются во многих документах, имеют значительно меньший вес, чем слова, которые семантически более релевантны и встречаются в относительно небольшом количестве документов.
Помимо взвешивания терминов, веб-страницы можно взвешивать с помощью других стратегий.Например, анализ ссылок рассматривает характер каждой страницы с точки зрения ее связи с другими страницами, а именно, если это авторитет (количество других страниц, которые указывают на него) или хаб (количество страниц, на которые он указывает). Очень успешная поисковая система Google использует анализ ссылок для улучшения рейтинга результатов поиска.
Контекст и расстояние
Для быстрого определения наиболее релевантных ссылок некоторые поисковые системы сравнивают условия запроса с контекстной информацией, такой как последние запросы, отправленные пользователем.Этот метод иногда называют перехватом запросов и включает в себя сбор слов из недавних запросов и использование этих слов для устранения неоднозначности, уточнения или расширения текущего запроса. Другой способ, которым некоторые поставщики информации могут ускорить доставку результатов поиска, — это использование модели распределенной доставки, при которой копии индекса и связанного контента дублируются и перемещаются в несколько географических местоположений, чтобы сократить сетевое расстояние между пользователями и контентом. Поставщики контента работают со сторонними сервисами, такими как Akamai, для реализации распределенной доставки контента.
Ограничения
Некоторые методы ускорения, описанные выше, связаны с расходами. Отделение организаций, проводящих индексацию, от организаций, которые производят фактический контент, может привести к так называемым гниющим ссылкам, которые указывают на страницы, которые больше не существуют. В качестве альтернативы могут отсутствовать ссылки на новый веб-контент. Как гниющие, так и отсутствующие ссылки могут возникать из-за задержек при сканировании или повторной индексации. Некоторые сканеры получают страницы вслепую, не обращая внимания ни на репутацию, ни на авторитет поставщиков информации.Этот процесс поощряет манипулирование индексированием в злонамеренных целях. Одно из распространенных явлений называется рассылкой спама по индексам. Сайты, желающие искусственно повысить свой рейтинг в результатах поиска, могут размещать на страницах тысячи слов, используя цвета шрифта, соответствующие фону страниц. Эта процедура скрывает слова от зрителей, но делает их доступными для индексов. Наконец, используя преимущества программного обеспечения веб-сервера, поставщики информации могут манипулировать им, чтобы возвращать разные страницы по одному и тому же запросу, сделанному разными хостами.Это привело к взлому страниц, в результате чего сайт может копировать страницу конкурентов, индексировать ее хостом поисковой системы как свою собственную и направлять запросы от других хостов на исходную страницу к альтернативному контенту или сайтам.
Ответ первоначально опубликован 14 октября 2002 г.
Краткая история Интернета
«предыдущая страница 2 из 10 следующая»
Совместное использование ресурсовИнтернет появился в 1960-х годах как способ для государственных исследователей обмениваться информацией.Компьютеры в 60-е годы были большими и неподвижными, и для того, чтобы использовать информацию, хранящуюся на каком-либо одном компьютере, нужно было либо отправиться на компьютер, либо отправить магнитные компьютерные ленты через обычную почтовую систему.
Еще одним катализатором становления Интернета стало разжигание холодной войны. Запуск Советским Союзом спутника Sputnik побудил министерство обороны США рассмотреть способы распространения информации даже после ядерной атаки.В конечном итоге это привело к формированию ARPANET (сети агентств перспективных исследовательских проектов), сети, которая в конечном итоге превратилась в то, что мы теперь знаем как Интернет. ARPANET имела большой успех, но членство было ограничено определенными академическими и исследовательскими организациями, имеющими контракты с Министерством обороны. В ответ на это были созданы другие сети для обмена информацией.
1 января 1983 года считается официальным днем рождения Интернета. До этого различные компьютерные сети не имели стандартного способа связи друг с другом.Был установлен новый протокол связи, названный протоколом управления передачей / межсетевым протоколом (TCP / IP). Это позволяло разным компьютерам в разных сетях «разговаривать» друг с другом. ARPANET и Defense Data Network официально перешли на стандарт TCP / IP 1 января 1983 года, отсюда и зародился Интернет. Теперь все сети можно было соединить универсальным языком.
На изображении выше изображена масштабная модель UNIVAC I (название расшифровывается как Universal Automatic Computer), которая была доставлена в Бюро переписи населения в 1951 году.Он весил около 16000 фунтов, использовал 5000 электронных ламп и мог выполнять около 1000 вычислений в секунду. Это был первый американский коммерческий компьютер, а также первый компьютер, предназначенный для использования в бизнесе. (Бизнес-компьютеры, такие как UNIVAC, обрабатывали данные медленнее, чем машины типа IAS, но были разработаны для быстрого ввода и вывода.) Первые несколько продаж были осуществлены правительственным учреждениям, компании A.C. Nielsen и Prudential Insurance Company. Первый UNIVAC для бизнес-приложений был установлен в подразделении General Electric Appliance для расчета заработной платы в 1954 году.К 1957 году Remington-Rand (купившая в 1950 году Eckert-Mauchly Computer Corporation) продала 46 машин.
«предыдущая страница 2 из 10 следующая»
7 Развитие Интернета и всемирной паутины | Финансирование революции: государственная поддержка компьютерных исследований
документов хранятся на серверных компьютерах и дают каждому документу уникальное имя, которое может использоваться программой браузера для поиска и извлечения документа. Поскольку уникальные имена (называемые универсальными локаторами ресурсов или URL-адресами) длинные, включая DNS-имя хоста, на котором они хранятся, URL-адреса будут представлены в других документах как более короткие гипертекстовые ссылки.Когда пользователь браузера щелкает мышью по ссылке, браузер извлекает и отображает документ, названный по URL-адресу.
Эта идея была реализована Тимоти Бернерс-Ли и Робертом Кайо в ЦЕРНе, лаборатории физики высоких энергий в Женеве, Швейцария, финансируемой правительствами участвующих европейских стран. Бернерс-Ли и Кайо предложили разработать систему связей между различными источниками информации. Определенные части файла будут преобразованы в узлы, которые при вызове будут связывать пользователя с другими связанными файлами.Пара разработала формат документа под названием HYpertext Markup Language (HTML), вариант стандартного обобщенного языка разметки, используемого в издательской индустрии с 1950-х годов. Он был выпущен в ЦЕРН в мае 1991 года. В июле 1992 года был представлен новый Интернет-протокол, протокол передачи гипертекста (HTTP), для повышения эффективности поиска документов. Хотя изначально Интернет был предназначен для улучшения коммуникации в физическом сообществе ЦЕРНа, он, как и электронная почта 20 лет назад, быстро стал новым приложением-убийцей для Интернета.
Идея гипертекста не была новой. Одна из первых демонстраций гипертекстовой системы, в которой пользователь мог щелкнуть мышью по выделенному слову в документе и немедленно получить доступ к другой части документа (или, фактически, к другому документу полностью), произошла осенью 1967 года. Совместная компьютерная конференция в Сан-Франциско. На этой конференции Дуглас Энгельбарт из SRI продемонстрировал потрясающую демонстрацию своей NLS (Engelbart, 1986), которая предоставляет многие из возможностей современных веб-браузеров, хотя и ограничивается одним компьютером.Проект Augment Энгельбарта финансировался НАСА и ARPA. Энгельбарт был награжден премией А. М. Тьюринга Ассоциации вычислительной техники 1997 г. за эту работу. Хотя он так и не стал коммерчески успешным, управляемый мышью пользовательский интерфейс вдохновил исследователей из Xerox PARC, которые занимались разработкой технологии персональных компьютеров.
Широкое распространение Интернета, на которое сейчас приходится наибольший объем Интернет-трафика, ускорилось благодаря разработке в 1993 году графического браузера Mosaic.Это нововведение, разработанное Марком Андрессеном из Национального центра суперкомпьютерных приложений, финансируемого NSF, позволило использовать гиперссылки на видео, аудио и графику, а также на текст.