алгоритм написания – статья – Корпорация Российский учебник (издательство Дрофа – Вентана)
1. Подход к сочинению как к творческой работе
Навык написания сочинения, в том числе сочинения-рассуждения по литературе, важен каждому ученику, независимо от основного направления его обучения. Сочинение является традиционным видом творческой работы, включающим репродуктивный, продуктивный и творческий уровни познания. То есть подготовка к сочинению соответствует основным целям образования: развитие мыслительной, коммуникативной и творческой деятельности. Сочинение также имеет признаки проектной работы, поскольку в результате ученик создает новый продукт (на основе других текстов, текста-образца). Ребенок может использовать сочинение как форму выражения собственных мыслей и эффективное упражнение в развитии речи и навыков риторики. Для учителя сочинение — возможность комплексно решить ряд задач в рамках текстоцентрической модели образования.
2. Выбор темы
Если обращаться непосредственно к темам сочинений ЕГЭ, то видна следующая тенденция. В 2016-2017 учебном году темы носили антонимичный характер: «Победа и поражение», «Разум и чувства», «Честь и бесчестие», «Опыт и ошибки», «Дружба и вражда». В этом году тоже прослеживаются противопоставления, однако они подталкивают к выбору: «Доброта или жестокость», «Месть или великодушие».
3. Формулирование проблемы
Проблема-тезис является мотивирующим элементом, она задает импульс всей дальнейшей работе над сочинением. Чем оригинальнее и даже парадоксальнее проблема — тем интереснее ученику выполнять задание. Такой подход вписывается в системно-деятельностную парадигму образования. Возможные формулировки проблем стоит обсуждать как можно чаще — это развивает в целом и дает материал непосредственно для экзамена (одна и та же проблема может подходить к разным темам).
Подготовиться к сочинению будет проще с учебником «Русский язык. Углубленный уровень. 10-11 класс».
4. Формулирование идеи
Идея объясняет, какой смысл мы хотим выразить в своей работе. Она не должна совпадать с проблемой-тезисом. Как правило, идея пишется в конце сочинения. При работе на уроке на начальных этапах учитель подсказывает возможные варианты. От идеи зависит выбор и построение аргументов, потому что они должны последовательно раскрыть мысль. Здесь уже применяются универсальные учебные действия, связанные с анализом и составлением синтаксического целого.
5. Выбор отрывков-аргументов
Итак, аргументы в сочинении-рассуждении по литературе должны подводить к выводу и отражать позицию автора. В отличие от сочинения по русскому языку, здесь аргументы объемнее, каждый из них состоит из блока частных аргументов.
На начальных этапах подготовки учитель помогает подбирать ключевые положения в тексте-источнике, цитаты из текстов и статей. Материалы могут быть заранее подготовлены учениками по критериям, после на уроке отбираются лучшие. На самом экзамене не предусмотрено наличие текстов, поэтому нужно научить детей не только вставлять цитаты, но и пересказывать их. Попытка точного цитирования на экзамене часто приводит к ошибкам.
Материалы могут быть заранее подготовлены учениками по критериям, после на уроке отбираются лучшие. На самом экзамене не предусмотрено наличие текстов, поэтому нужно научить детей не только вставлять цитаты, но и пересказывать их. Попытка точного цитирования на экзамене часто приводит к ошибкам.
Есть универсальные произведения, в которых отражены основные темы, проблемы. Речь, конечно, идет о «Капитанской дочке», «Войне и мире», «Преступлении и наказании». Можно также брать произведения советского периода («Сотников» Василя Быкова, «Прощание с Матерой» Валентина Распутина, «Судьба человека» Михаила Шолохова), и современных авторов (Захара Прилепина, Михаила Тарковского и др.).
6. Работа над структурой
Структура сочинения-рассуждения по литературе строится по принципу: Тезис — Аргументы — Вывод. Это несколько отличается от привычной формулы (Вступление — Главная часть — Заключение). Тезис включает проблему и обоснование ее выбора. Проблема и идея становятся рамками сочинения. Как правило, приводится два или три аргумента, они состоят из нескольких абзацев.
Проблема и идея становятся рамками сочинения. Как правило, приводится два или три аргумента, они состоят из нескольких абзацев.
Моделирование будущего сочинения предусматривает дифференцированный подход, зависящий от уровня подготовки учеников. «Слабым» ребятам достаточно подобрать цитаты и сделать их элементарный анализ. Усложненный вариант: расширение конспекта, составленного на уроке. Самые способные ученики могут самостоятельно развивать проблему на основе опорных положений.
Характеристика экзаменационного сочинения во многом задается требованиями КИМ. Например, планируемый объем не должен быть меньше 300 слов. Обычно сочинение старшеклассника занимает два-три тетрадочных листа — нужно научить детей соотносить тетрадочные листы с форматными (А4). Не следует делать сочинение слишком длинным: больше объем — больше ошибок.
7. Развитие ключевых предложений и слов
Когда аргументы выбраны, их нужно развить. Коллективная устная работа помогает научить детей работать над ключевыми словами и предложениями. Вначале учитель задает возможные формулировки, мысли, обсуждает их с учениками. Составляется цитатный план будущего сочинения, краткий конспект содержания аргументов. В процессе обсуждения каждый школьник выбирает то, что ему ближе и включает в свои аргументы. Постепенно дети учатся развивать ключевые слова и предложения самостоятельно, а после применяют это на экзамене.
Вначале учитель задает возможные формулировки, мысли, обсуждает их с учениками. Составляется цитатный план будущего сочинения, краткий конспект содержания аргументов. В процессе обсуждения каждый школьник выбирает то, что ему ближе и включает в свои аргументы. Постепенно дети учатся развивать ключевые слова и предложения самостоятельно, а после применяют это на экзамене.
Читайте также:
Примеры работы над сочинением-рассуждением
Доброта или жестокость
1. Берем первую часть антитезы и развиваем ее. Начинаем с вопроса, так проще организовать первую часть. Объясняем, почему затронули данную проблему.
Как можно определить понятие «доброта»? По моему мнению, доброта — это высокое душевное качество личности, которое в первую очередь проявляется в любви к ближнему. Добрый человек отзывчив, благожелателен, стремится помочь любому человеку. В произведениях русской литературы мы находим многочисленные примеры образов героев, проявляющих доброту.
2. Переходим ко второй части. Здесь удобно привести роман «Преступление и наказание», в котором показаны противоречивые, сложные характеры. Первым описываем Родиона Раскольникова.
Обратимся к роману Ф. М. Достоевского «Преступление и наказание». Главный герой Родион Раскольников неравнодушен к чужому горю. Он не раз проявляет доброту: спасает от насилия пьяную девочку, отдает последние деньги на похороны Мармеладова, защищает Соню, когда Лужин подло обвиняет ее в краже. Но тот же Раскольников формулирует чудовищную теорию. Суть ее в том, что убийство разрешается сильным личностям для воплощения их великих идей и улучшения тем самым качества жизни широких масс. Для проверки этой теории и определения своего места в мире Родион идет на убийство.
3. Упоминаем еще одного сложного персонажа произведения.
Другой персонаж романа — Свидригайлов — проявляет невиданную щедрость: оплачивает похороны Катерины Ивановны, устраивает ее детей в сиротские заведения, обеспечивает будущее Сони. Но в то же время на счету Свидригайлова несколько преступлений.
4. В первой части аргументации добавляем третьего героя (другого произведения), в котором также объединены доброта и жестокость.
На страницах повести А. С. Пушкина «Капитанская дочка» мы неоднократно встречаем примеры проявления доброты Емельяном Пугачевым. Уважая Петра Гринева за твердость характера и верность долгу, он дарует ему жизнь, помогает спасти Машу. Но Пугачев в то же время — разбойник и жестокий убийца.
5. Первый блок аргументов завершен. Делаем вывод.
Эти литературные персонажи не лишены нравственных качеств. Светлая сторона их личности позволяет совершать добрые поступки. Но вместе с тем, все они оказываются способны на жестокие преступления.
6. Переходим ко второму блоку аргументов, представляющему персонажей добрых, не проявляющих жестокость. Яркий пример находим все в том же «Преступлении и наказании».
Соня Мармеладова — олицетворение всепрощающей христианской любви к людям. Мораль у каждого своя. Для Сони аморально ничего не сделать для спасения Катерины Ивановны и ее детей от голодной смерти. Поэтому она жертвует собой и живет по желтому билету. Сила добра и нравственности Сони способна спасать озлобленные души. Она становится моральным наставником Родиона. Благодаря ей он приходит к духовному возрождению.
7. Поскольку существуют разные формы проявления доброты, приводим еще один пример. Если Соня — это образец личной нравственности, то Михаил Кутузов в романе «Война и мир» — внутренней доброты государственника.
Если Соня — это образец личной нравственности, то Михаил Кутузов в романе «Война и мир» — внутренней доброты государственника.
Истинные качества мудрой доброты проявляет М. И. Кутузов в романе Л. Н. Толстого «Война и мир». Мы видим Кутузова мудрым человеком, горячо любящим свою страну и ее народ, верящим в боевой дух солдат. Он, как родной отец, чувствует их и понимает их нужды. Эта любовь не позволяет полководцу допускать ненужных человеческих жертв. Он понимает бедственное положение французской армии после Бородинского сражения и берет на себя всю ответственность за будущее страны. Во имя сохранения армии и спасения России им было принято решение об отступлении из Москвы, и оно оказалось единственно верным. Он спас не только человеческие жизни, но и целую страну. Более того, он преподал урок высшей доброты, когда под Красным призвал солдат «пожалеть» отступающих французов.
8. Подводим итог.
Моральные убеждения этих героев никогда не позволят им совершить низкий поступок. В них отсутствует злоба и неприязнь к любому человеку, даже к преступнику и врагу. Таким образом, можно прийти к выводу о том, что истинная доброта — это любовь и сострадание к другим людям. Добрый человек всегда сумеет простить оступившегося и протянуть руку помощи нуждающемуся. Счастье и радость ближнего для них — главная ценность. Доброта присуща духовно сильным, мудрым людям, для которых она является основой нравственной жизни.
В них отсутствует злоба и неприязнь к любому человеку, даже к преступнику и врагу. Таким образом, можно прийти к выводу о том, что истинная доброта — это любовь и сострадание к другим людям. Добрый человек всегда сумеет простить оступившегося и протянуть руку помощи нуждающемуся. Счастье и радость ближнего для них — главная ценность. Доброта присуща духовно сильным, мудрым людям, для которых она является основой нравственной жизни.
(549 слов)
Русский язык. Трудные задания ЕГЭ. Пишем сочинение на основе текстов повышенной сложности
В пособии вы найдете требования к структуре и содержанию сочинения-рассуждения в формате ЕГЭ; подробный план действий и приёмы работы с текстом в процессе написания сочинения; типовые конструкции (клише) для написания сочинения; варианты сочинений по всем текстам, приведённым в пособии; интересные тексты для тренировки в написании сочинений.
Купить«Доброта лучше красоты» (Г.
 Гейне)
Гейне)1. Ставим проблему через характеристику основного понятия.
Доброта — это высокое душевное качество личности, которое проявляется в любви к ближнему, отзывчивости, стремлении помочь. Красота — это вызывающий восхищение внешний облик человека. Доброта характеризует внутреннее содержание человека, а красота — внешнее. Но так ли важен этот внешний блеск при отсутствии душевных качеств?
2. Ссылаемся на автора цитаты, поэта Генриха Гейне. Сразу показываем свое отношение к утверждению.
Генрих Гейне утверждал, что доброта лучше красоты. Я полностью согласен с мнением немецкого поэта и считаю, что красота без внутреннего содержания — просто пустая холодная оболочка. Кроме того, люди красивые, но бездуховные обычно бывают избалованными, лицемерными, порой жестокими. С ними неприятно общаться. Доброта же, напротив, являясь внутренней красотой человека, светит изнутри. Каждому из нас важны в жизни сочувствие, понимание, поддержка, поэтому доброта ценится больше, чем красота.
3. Переходим к аргументам типовой формулировкой.
В произведениях русской литературы мы находим многочисленные подтверждения этой точки зрения.
4. В качестве примера приводим двух антитезных персонажей произведения «Война и мир».
Так, доброта гораздо важнее красоты для великого русского писателя Л. Н. Толстого. Противопоставляя характеры и поступки добрых и красивых героев романа-эпопеи «Война и мир», мы отчетливо это видим. Доброта и искренность Наташи Ростовой гораздо лучше холодной расчетливости эгоистичной красавицы Элен.
Наташа — любимая героиня писателя. Она не отличается красотой, но очень чуткая и отзывчивая девушка. Наташа искренне верит в людей, в любовь, всегда готова помочь. Ее добрая непосредственность способна возрождать к жизни. Когда, отчаявшись и разуверившись во всем, князь Болконский остался ночевать у Ростовых, он случайно подслушал разговор Наташи с Соней.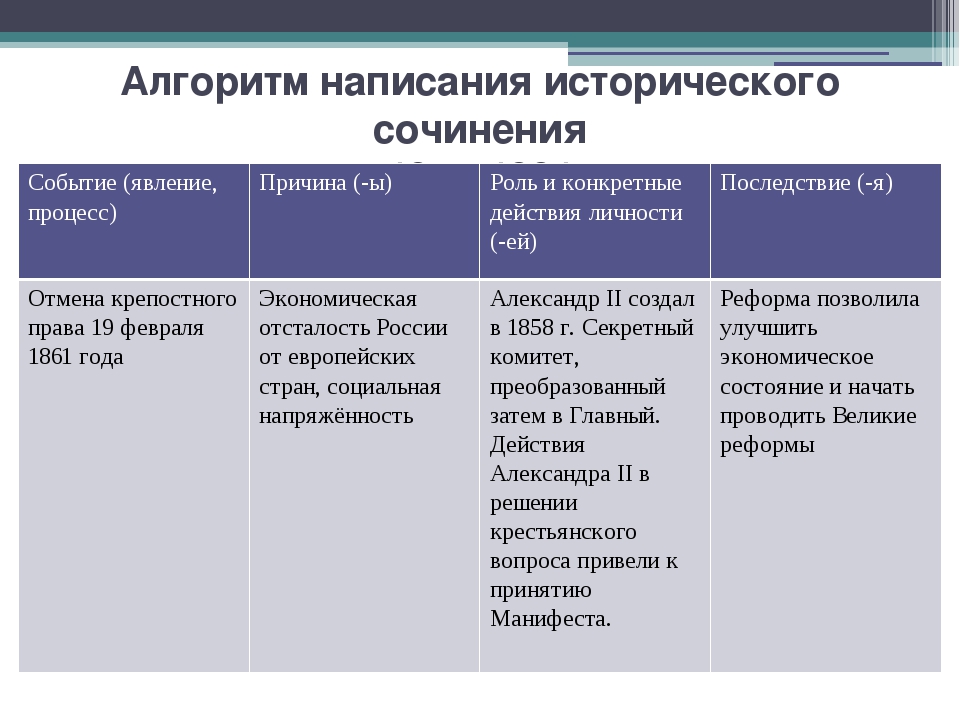 Наташа так искренне восхищалась красотой ночи, что князь Андрей почувствовал желание жить, любить и быть счастливым. Наташа за всех переживает, ей не безразличны окружающие ее люди, будь то родные и близкие или совершенно незнакомые, но нуждающиеся в помощи. Вспомним эпизод, когда Ростовы покидали Москву и к их дому подвозили раненых солдат. Наташа упросила мать, чтобы та разрешила оставить их у себя в доме. Раненые остались. Но потом, когда Наташа узнала, что они всей семьей будут уезжать, а больных оставят одних на растерзание врагу, она пришла в ужас. Совершенно не думая о том, что останется без приданого, она отвоевала у матери подводы для раненых. На этих подводах Ростовы собирались вывозить ценные вещи из дома. Но Наташа даже не сопоставляет благополучие семьи и жизни солдат. Спасти людей для нее гораздо важнее.
Наташа так искренне восхищалась красотой ночи, что князь Андрей почувствовал желание жить, любить и быть счастливым. Наташа за всех переживает, ей не безразличны окружающие ее люди, будь то родные и близкие или совершенно незнакомые, но нуждающиеся в помощи. Вспомним эпизод, когда Ростовы покидали Москву и к их дому подвозили раненых солдат. Наташа упросила мать, чтобы та разрешила оставить их у себя в доме. Раненые остались. Но потом, когда Наташа узнала, что они всей семьей будут уезжать, а больных оставят одних на растерзание врагу, она пришла в ужас. Совершенно не думая о том, что останется без приданого, она отвоевала у матери подводы для раненых. На этих подводах Ростовы собирались вывозить ценные вещи из дома. Но Наташа даже не сопоставляет благополучие семьи и жизни солдат. Спасти людей для нее гораздо важнее.
Полная противоположность Наташе Ростовой — гордая Элен. Элен — яркая красавица, но в этом ее единственное достоинство. Она не отличается умом, холодна и порочна, руководствуется только личной выгодой. Элен способна на низкие и коварные поступки. Так, ради забавы она сводит юную и доверчивую Наташу со своим женатым братом Анатолем. Этот поступок не только расстроил женитьбу Наташи и Андрея, но и едва не погубил наивную девушку. Из расчетливости Элен вышла замуж за Пьера, так как понятие «любовь» для нее ничего не значит. После свадьбы она заводит любовную интригу с Долоховым, которая заканчивается дуэлью. «Где вы — там разврат, зло», — скажет о ней Пьер.
Элен способна на низкие и коварные поступки. Так, ради забавы она сводит юную и доверчивую Наташу со своим женатым братом Анатолем. Этот поступок не только расстроил женитьбу Наташи и Андрея, но и едва не погубил наивную девушку. Из расчетливости Элен вышла замуж за Пьера, так как понятие «любовь» для нее ничего не значит. После свадьбы она заводит любовную интригу с Долоховым, которая заканчивается дуэлью. «Где вы — там разврат, зло», — скажет о ней Пьер.
5. Подводим итог первого блока аргументов.
И мы убеждаемся, что красота — не главное, гораздо важнее духовная зрелость человека.
6. Берем пример из другого произведения — «Чучело». Второй блок аргументов тоже выстраиваем на противопоставлении.
Проблема противопоставления внешнего и внутреннего мира личности актуальна во все времена. Обратимся к произведению советской эпохи — повести В. Железникова «Чучело». Главная героиня, Лена Бессольцева, новенькая в классе. Она некрасивая, но очень доброжелательная, умная и тонкая девочка. Несмотря на юный возраст, Лена способна даже на самопожертвование. Она берет на себя вину дорогого ей человека Димы Сомова. Девочка до последнего терпит травлю класса, но не раскрывает имя «предателя», из-за которого не состоялась поездка в Москву. В противопоставление ей — красотка класса Шмакова. Так сложилось, что она знает, что класс выдал Сомов, который ей также нравится. Не без интереса и удовольствия Шмакова наблюдает за издевательствами одноклассников над совершенно ни в чем не виноватой Леной. Родители, к сожалению, не научили ее доброте. Урок гуманизма и высокой нравственности преподала ей маленькая, хрупкая Лена.
Она некрасивая, но очень доброжелательная, умная и тонкая девочка. Несмотря на юный возраст, Лена способна даже на самопожертвование. Она берет на себя вину дорогого ей человека Димы Сомова. Девочка до последнего терпит травлю класса, но не раскрывает имя «предателя», из-за которого не состоялась поездка в Москву. В противопоставление ей — красотка класса Шмакова. Так сложилось, что она знает, что класс выдал Сомов, который ей также нравится. Не без интереса и удовольствия Шмакова наблюдает за издевательствами одноклассников над совершенно ни в чем не виноватой Леной. Родители, к сожалению, не научили ее доброте. Урок гуманизма и высокой нравственности преподала ей маленькая, хрупкая Лена.
7. Подводим итог сочинения.
Таким образом, можно прийти к выводу о том, что доброта — это красота душевная и она гораздо важнее пустого внешнего блеска. С годами от красоты ничего не останется, а доброе сердце светит изнутри всегда и делает человека прекрасным. Добрый человек, как солнце, в лучах которого так хочется греться.
Добрый человек, как солнце, в лучах которого так хочется греться.
(619 слов)
В представленных сочинениях некоторые аргументы вполне допустимо вычеркнуть для сокращения объема.
Как писать сочинение ЕГЭ. Пошаговая инструкция. » Рустьюторс
Алгоритм написания сочинения ЕГЭМатериалы для подготовки к сочинению ЕГЭ
Поговорим о композиции и алгоритме написания сочинения. Как же писать сочинение? В каком порядке? С чего начать? Тут важно понимать следующее: не надо пытаться писать сочинение так, как написано в задание по порядку. Начинать писать сочинения с поиска проблемы — это верный путь к плохому результату. Итак, давайте разберемся, так с чего же начать писать и чем закончить наше сочинение, чтобы получить максимальный балл.
Алгоритм работы (Как работать, с чего начать, как работа должна выглядеть в черновике?):
1) Определяем тип текста (художественный или публицистический).
2) Находим авторскую позицию. В художественном тексте позиция не выражена в каком-то определенном предложении. В публицистическом тексте может быть много авторских позиций.
3) Формулируем проблему в зависимости от типа текста. (в виде вопроса или в форме Р.П.)
4) Ищем важные для понимания проблемы предложения и фразы. Из них составляем комментарий, не забывая пояснить каждый пример, а также связать их по смыслу между собой.
5) Формулируем свою позицию, не забывайте раскрыть ее и объяснить, почему так думаете.
6) Подтверждаем позицию. (можно приводить как пример из литературы, так и пример из жизни, еще можно использовать логические доводы, обращение к авторитетам и т.д.)
6) Работаем над введением, заключением, микровыводами и связками между частями. Если введение в некоторых ситуациях можно опустить, то заключение необходимо писать обязательно, как и микровыводы по некоторым частям (более подробно см. в других разделах)
7) Проверяем ошибки. Особое внимание следует обратить на:
Особое внимание следует обратить на:
— соотнесённость глагольных форм
— пунктуацию (если вы не уверены в правильности, то лучше изменить конструкцию)
— лексические повторы
— фактические ошибки
— орфографию (н/нн, гласные в корнях, слитное/раздельно написание частей речи, написание не с частями речи, окончания глаголов)
— речевые и грамматические ошибки
Изучите раздел «Типы ошибок»
Ну а после проделанной на черновике работы, составляем сочинение из получившихся частей вот в такую композицию:
Композиция сочинения (Как сочинение должно выглядеть в чистовом варианте):
1) Вступление.
2) Формулировка проблемы.
3) Комментарий по проблеме. 2 примера, 2 пояснения, связь между примерами
4) Авторская позиция по проблеме.
5) Ваша позиция по проблеме.
6) Обоснование вашей позиции, то есть аргумент.
7) Заключение.
Очень важно!!! Не забывайте про абзацное членение. Лучше, если каждая смысловая часть будет выделена в отдельный абзац. Каждый аргумент тоже нужно выделить в отдельный абзац.
Каждый аргумент тоже нужно выделить в отдельный абзац.
Подготовка к ЕГЭ по русскому языку
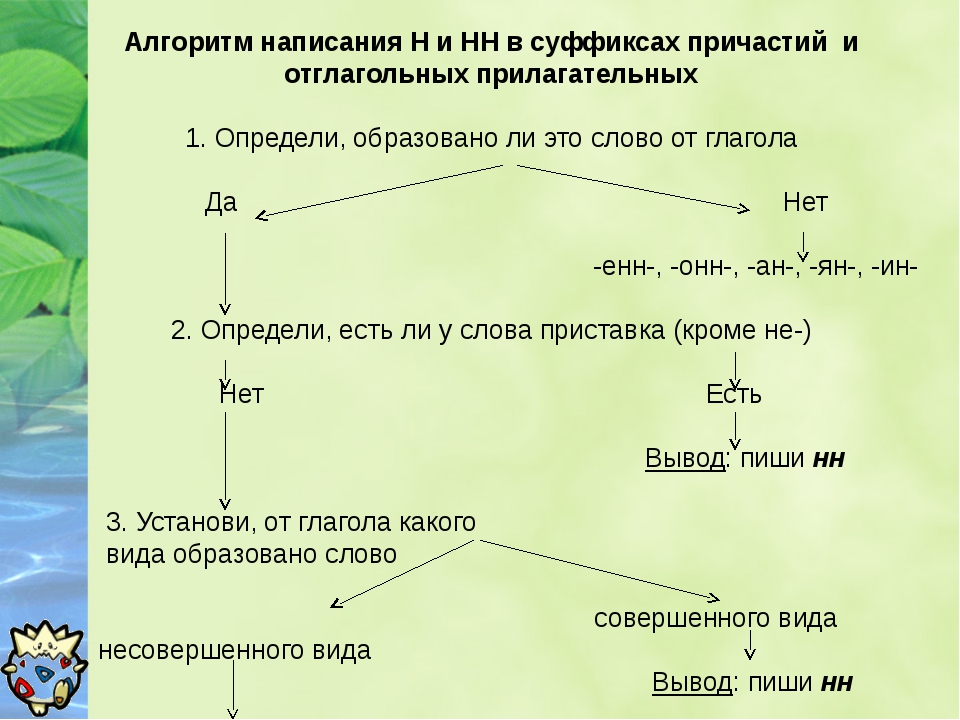
Алгоритм написания сочинения
Умением писать сочинения вы будете пользоваться на протяжении всей жизни. Используя простой алгоритм написания сочинения, вы сможете писать деловые письма и даже маркетинговые материалы для вашей организации или компании. Сочинение состоит из следующих частей:
· цель сочинения
· название сочинения
· введение
· основная часть
· заключение
Теперь рассмотрим подробнее каждый пункт.
1. Цель сочинения
Прежде, чем начинать писать сочинение, необходимо обдумать, о чем вы будете писать. Определите основную идею вашего произведения. Гораздо проще, когда вы пишете сочинение на заданную тему. Но иногда тему приходится придумывать самому. Лучшее ваше сочинение будет на ту тему, в которой вы хорошо разбираетесь. Чем вы больше всего увлечены? Какие положительные и отрицательные стороны вашей темы? Любите ли вы спорт? любите готовить? фотографировать? или вы защитник детей? Вас интересуют проблемы голодных или бездомных? Вот здесь ключ к вашей работе. Вашу идею сформулируйте в одном предложении, это и будет ваш основной тезис и главная ваша идея.
Вашу идею сформулируйте в одном предложении, это и будет ваш основной тезис и главная ваша идея.
2. Название сочинения
Название вашего сочинения должно отражать главную идею. Самое сильное название содержит в себе глагол. Если посмотреть на заголовки статей в газете, то вы увидите, что в каждом заголовке есть глагол.
Если названием вы хотите заинтересовать читателей, то заголовок следует сделать провокационным. Например,
Как выбрать хороший детский сад?
Образование в кредит: что необходимо знать?
Миопатия: что это такое?
3. Введение
Введение – это небольшой рассказ на один короткий абзац, несколько предложений, которые подводят читателя к вашей теме. Первый абзац должен заинтересовать читателя.
4. Основная часть
Здесь вы раскрываете тему вашего сочинения. Если получился слишком большой объем текста, то следует оставить ключевые моменты и самые важные идеи.
5. Заключение
Это последний абзац вашего сочинения. Заключение может быть коротким и должно быть связано с введением. Во введение вы указали причину, в заключении вы должны подвести итог и подтвердить выдвинутый тезис.
Заключение может быть коротким и должно быть связано с введением. Во введение вы указали причину, в заключении вы должны подвести итог и подтвердить выдвинутый тезис.
И вот уже ваша статья готова.
Алгоритм написания статьи — существует ли он? Примеры — Школа журналистики
Наш студент задал вопрос, общий смысл которого — существует ли некоторый алгоритм, последовательность мыслей и действий при написании статьи. Прислал много написанных интересных текстов. Наши советы и рекомендации:
Читаю текст и по ходу буду писать свои мысли и рекомендации. Вы можете писать много, большие тексты, но для СМИ нужно писать немного иначе — более компактно, по существу, с цифрами и цитатами. Но свои способности тоже надо использовать. Откройте свой сайт или заведите блог и пишите на нем свои мысли. Там чем больше текстов — тем лучше. Потом, когда блог или сайт станут популярными, на них можно будет зарабатывать, размещаю рекламу или что-то продавать.
А для того, чтобы публиковаться в СМИ нужно учиться писать так, чтобы интересно было читателям и чтобы редакторы охотно брали Ваши тексты.
Итак, Вы определились с темами статей. Эти темы — не журналистика в классическом её понимании. В журналистике в первую очередь речь идет о новостях, о событиях. Но такие аналитические материалы (Ваши запланированные темы) тоже могут быть востребованы, их могут опубликовать на определенных сайтах, в журналах.
Сначала нужно написать вводный абзац, обозначить проблему. Например, так (это просто пример, написанный на ходу): «Может ли человек самостоятельно изучить юриспруденцию? Легко ли дается освоение этой дисциплины студентами? К сожалению, текст таких учебников написан канцелярским языком, и так далее и тому подобное…. » Отлично, проблему обозначили. Затем можно привести пример, какой-то кусочек текста из учебника, который вряд ли кто-то сможет понять и осмыслить. Написать свой вывод о том как должны писаться такие книги.
Затем можно поставить цитату студента или человека, который имеет своё мнение по этой теме. Вы просите дать Вам четкий алгоритм, мне проще было бы его написать о новостном материале (в котором есть событие). Помните, мы об этом говорили. В журналистике на первом месте идут события, например — упал самолет, победил спортсмен или принят новый закон. А у Вас запланированные статьи — размышляющие, ближе к аналитике, с ними сложнее работать.
Помните, мы об этом говорили. В журналистике на первом месте идут события, например — упал самолет, победил спортсмен или принят новый закон. А у Вас запланированные статьи — размышляющие, ближе к аналитике, с ними сложнее работать.
Но давайте попробуем придумать какой-то шаблон, алгоритм написания таких статей.
1. Вы определились с темой
2. Вы примерно запланировали о чем можно в статье написать
3. Напишите вводный абзац — постановка проблемы.
4. Приведите пример
5. Процитируйте человека (эксперт, участник событий или кто-то, кто относится к рассматриваемой теме и высказывается по ней)
6. Дайте статистику, цифры, если это возможно
7. Подведите итоги, скажите самое главное что Вы хотите сказать в своем материале.
Статья 1 — хорошая, вполне может быть опубликована на каком-то тематическом сайте.
Статья 2 — тоже интересная. Может быть Вам писать книги или сценарии? Потому что это не совсем журналистика. В журналистике все материалы можно условно разбить на две категории — события и аналитика. О событиях (новостях) я уже говорил. Аналитика — сложный жанр, здесь не пойдет просто писать что думаешь, надо приводить цифры, цитаты, сопоставлять события, делать выводы.
О событиях (новостях) я уже говорил. Аналитика — сложный жанр, здесь не пойдет просто писать что думаешь, надо приводить цифры, цитаты, сопоставлять события, делать выводы.
Узнать подробнее об онлайн-курсах Школы журналистики можно на главной странице
ЕГЭ 2021. История : алгоритм написания сочинения (Кишенкова…
Кишенкова, О. В.Пособие предназначено для подготовки учащихся к выполнению задания 25 на ЕГЭ по истории — написанию исторического сочинения. Книга поможет учащимся систематизировать обширный учебный материал школьного курса истории и научиться писать сочинение на ЕГЭ. В пособии приводятся обзор исторических периодов, алгоритм написания сочинения и образцовые работы.
Полная информация о книге
- Вид товара:Книги
- Рубрика:История
- Целевое назначение:Рабочие тетр.
 ,тесты и др. уч. пособ. д/уч.10-11 кл
,тесты и др. уч. пособ. д/уч.10-11 кл - ISBN:978-5-04-116459-1
- Серия:ЕГЭ. Задания с развернутым ответом
- Издательство: ЭКСМО
- Год издания:2020
- Количество страниц:382
- Тираж:4000
- Формат:70х90/16
- УДК:373. 5:94
- Штрихкод:9785041164591
- Переплет:обл.
- Сведения об ответственности:Ольга Кишенкова
- Вес, г.:381
- Код товара:82540
 ,тесты и др. уч. пособ. д/уч.10-11 кл
,тесты и др. уч. пособ. д/уч.10-11 кл 5:94
5:94Алгоритм написания сценария
(с) Александр Волков
http://new-storyteller.livejournal.com/
Часто новички используют следующий алгоритм написания сценария:
Они создают персонажей, придумывают некую завязку, а далее — будь что будет. Пишут что в голову взбредёт. Это одна из ошибок начинающих сценаристов. Я использую другой алгоритм. Мне он кажется более эффективным:
Пишут что в голову взбредёт. Это одна из ошибок начинающих сценаристов. Я использую другой алгоритм. Мне он кажется более эффективным:
Сначала придумывается идея или замысел, определяющий содержание вашего фильма. Необходимо описать замысел в одном-двух предложениях. Желательно уложиться в 25 слов. Проверьте идею на друзьях, спросите: понятна ли она им, интригует ли она их, хотят ли они посмотреть ваш фильм.
Существует несколько шаблонов написания идеи (логлайна, logline). Приведу один, он подходит для фильмов жанра экшн: Герой (X) должен сделать то-то и то-то (Y, цель героя), иначе случится что-то непоправимое (Z). Пример: Профессор археологии Индиана Джонс должен найти Ноев Ковчег и Чашу Грааля, иначе нацисты используют эти артефакты, чтобы захватить весь мир.
NB Под «Y» часто скрывается «Крючок» или же «Первая поворотная точка», т.е. событие, которое переносит героя из первого акта сценария во второй. (См. мой пост о линейной структуре сценария).
После того, как напишите логлайн, приступайте к составлению структуры. Не к синопсису, а к структуре сценария! Развивайте идею, раскладывайте её по сюжетным точкам. Тут придётся напрячься. Это как головоломку собирать. Трудно, но увлекательно. Иногда помогает начать историю с конца. Придумайте, чём всё должно завершиться. В любом случае, пока не будет конца, не приступайте к синопсису и уж тем более к сценарию.
Не к синопсису, а к структуре сценария! Развивайте идею, раскладывайте её по сюжетным точкам. Тут придётся напрячься. Это как головоломку собирать. Трудно, но увлекательно. Иногда помогает начать историю с конца. Придумайте, чём всё должно завершиться. В любом случае, пока не будет конца, не приступайте к синопсису и уж тем более к сценарию.
Когда разложите историю на составляющие, можете писать синопсис, т.е. более подробное описание сюжета. Странички на две-три или больше, как нравится. Я лично синопсисы не люблю. Они сковывают мою фантазию. Обычно придумываю сюжет, структуру сценария, описываю всё на одной страничке. Мне этого достаточно.
Да, когда составляю структуру, одновременно с этим создаю персонажей. Именно так. Сначала — идея (logline), потом — структура, главный герой и остальные персонажи. Говоря о главном герое, я имею в виду полноценный образ, а не условного мента, доктора или профессора археологии. Т.е для логлайна достаточно написать: Популярный автор женских романов вынуждена в одиночку отправиться из США в Южную Америку, чтобы доставить карту сокровищ похитителям своей сестры. Иначе — «прощай, сестрёнка.» (Не моё, это «Роман с камнем». Кстати, про Индиану Джонса тоже.
Иначе — «прощай, сестрёнка.» (Не моё, это «Роман с камнем». Кстати, про Индиану Джонса тоже.
Некоторые любят использовать карточки, на каждой из которых коротко описывается сценарий по сценам. Т.е. одна сцена — одна карточка. От начала сценария и до конца. Но я человек ленивый, никогда этого не делаю. Кроме того, в процессе написания сценария сцены могут меняться местами. Поэтому считаю карточки пустой тратой времени. Впрочем, как и подробные синопсисы. Но если они вам помогают, почему нет?
Итак, запишем алгоритм:
1. Генерация идей. Записываете все идеи, что приходят в голову. Чем больше, тем лучше. Всё, о чём хотите написать; всё, что волнует. Не обращайте внимания на качество идей. Главное — количество.
2 Фильтрация. Стадия критического подхода к идеям. Отбрасываете слабые идеи, оставляете сильные, стоящие того, чтобы снять фильм.
3 Селекция. Рассматриваете выбранные вами идеи. Какие из них являются оригинальными? Как их можно улучшить? В результате — отбираете одну идею, которая послужит основой для будущего сценария.
4 Логлайн, разработка концепции. Описываете ваш замысел (идею, историю) одним предложением. Как это делать, я написал выше.
Необязательно логлайн должен укладываться в шаблон «X, Y, Z». Вот примеры оригинальных логлайнов, состоящих только из элементов X и Y. Поскольку сами по себе идеи нетривиальны, то этого достаточно, чтобы заинтересовать ими продюсера. Правда, я бы добавил сюда элемент Z.
Кукловод случайно обнаруживает секретный тоннель в мозг Джона Малковича. («Быть Джоном Малковичем»).
Циничный рекламщик внезапно обнаруживает способность читать женские мысли. («Чего хотят женщины»).
Три молодых кинематографиста отправляются в лес, чтобы снять документальный фильм о легендарной ведьме. Больше их никто не видел. Остался только этот фильм. («Ведьма из Блэр»).
Попытайтесь усилить драматизм истории, добавьте в логлайн оригинальность, конфликт, интригу.
5 Название. Придумываете рабочее название для вашей истории.
6 Сравнение. Подберите 1-2 ваших любимых фильмов в том жанре, в котором вы пишите свой сценарий. Будете использовать их как ориентир, сравнивая свою работу с образцом.
7 Структура. Составляете структуру сценария. Когда структура будет готова, спросите себя, каков второй слой вашей истории? О чём она на самом деле? Иными словами, определите тему.
8 Разработка персонажей. Какие у них достоинства и недостатки? Как изменится главный герой к концу истории? Чему он должен научиться? Как характер и поступки персонажей отражают тему вашей истории?
9 Синопсис. Описываете историю на двух-трёх листах. (Мне хватает листа).
10 Тритмент. Более подробное описание истории с включением диалогов (наиболее важных фраз). Записываете историю от начала и до конца. В настоящем времени, так же как синопсис и сценарий. (Для тех, кто не знает. Сценарии пишутся в настоящем времени, а не прошлом. Т.е. не «Вася Пупкин ковылял по бульвару», а «Вася Пупкин ковыляет по бульвару»).
Т.е. не «Вася Пупкин ковылял по бульвару», а «Вася Пупкин ковыляет по бульвару»).
11 Карточки. Записываете всю историю на карточках. На каждой карточке — по одной сцене. (Я обычно пропускаю параграфы 10 и 11).
12 Сценарий. Приступаете к написанию сценария. Пишите как можно больше, ничего не редактируйте. На этом этапе важно записать сценарий.
13 Первый вариант. Заканчиваете черновик. Откладываете рукопись на неделю-две.
14 Редактирование. Желательно переписать рукопись не менее шести раз.
a) Итак, это уже второй вариант сценария. Исправляете нестыковки, неправдоподобные моменты и дыры в сюжеты. Удаляете всех «блох». Проверяете, отвечает ли идея и тема сценария первоначальному замыслу?
b) Третий «заход». Проверяете структуру сценария. Все ли сюжетные точки на своём месте? Что можно выбросить без потерь для смысла?
c) Четвёртый. Уделяете внимание персонажам. Все ли они нужны? Кто из них ведёт себя несоответственно своему характеру?
Уделяете внимание персонажам. Все ли они нужны? Кто из них ведёт себя несоответственно своему характеру?
d) Пятый. Редактируете диалоги. Проверьте, чтобы манера разговаривать каждого персонажа была уникальной, соответствующей его натуре.
e) Шестой. Исправляете стилистические и грамматические ошибки.
f) Седьмой. «Шлифовка». Внимательно смотрите, что можно улучшить? Где нужно поставить пробел, запятую, точку? Какое слово лучше заменить другим?
15 Если вас всё устраивает, определитесь с названием вашего произведения и… сценарий готов. Можете передать его друзьям. Пусть читаю, критикуют, высказывают своё мнение. Если согласны с замечаниями, исправьте все недочёты.
Удачи!
(с) Александр Волков
http://new-storyteller.livejournal.com/
Как правильно написать дипломный проект?
- Основные этапы написания диплома
- Выбор темы
- Составление плана
- Выбор материала, который будет использоваться при написании
- Непосредственно написание диплома
Итак, Вы решили не мучиться вопросом, где заказать практическую часть дипломной работы москва , а написать ее самостоятельно. Похвально. Однако лучше, если это решение пришло Вам в голову не как самое простое на данный момент (типа «Какой там диплом, еще только начало года!»), а как вполне осознанная готовность самостоятельно подвести итог своему упорному труду в течение всех нелегких лет обучения. В этом случае лучше понять сразу, что промедление в данном вопросе – смерти подобно. Ведь чтобы там ни утверждал по этому поводу студенческий фольклор, за неделю написать диплом невозможно. Да что там говорить: даже написание диплома на заказ предполагает срок несколько больший, чем пара дней.
Похвально. Однако лучше, если это решение пришло Вам в голову не как самое простое на данный момент (типа «Какой там диплом, еще только начало года!»), а как вполне осознанная готовность самостоятельно подвести итог своему упорному труду в течение всех нелегких лет обучения. В этом случае лучше понять сразу, что промедление в данном вопросе – смерти подобно. Ведь чтобы там ни утверждал по этому поводу студенческий фольклор, за неделю написать диплом невозможно. Да что там говорить: даже написание диплома на заказ предполагает срок несколько больший, чем пара дней.
Основные этапы написания диплома
Выбор темы
В идеале, если темы курсовых проектов и итогового дипломного являются логическим продолжением друг друга. То есть Вы продолжаете разрабатывать знакомую Вам тему более глубоко.
Составление плана
Как правило, дипломная работа включает в себя содержание, вводную часть, основные разделы, заключение, перечень использованной литературы.
Не забудьте о практической части.Выбор материала, который будет использоваться при написании
Наряду с использованием глобальной сети не пренебрегайте библиотечными фондами.
Непосредственно написание диплома
- Введение содержит обоснование выбора темы, ее практическую значимость, цели и методы их достижения.
- Теоретическая часть – в целом, это обзор использованной научной литературы, ссылки на работы, цитаты. В итоге, опираясь на вышеуказанный материал, необходимо обосновать гипотезу вашего личного исследования.
- Практическая часть – методы и приемы практического исследования проблемы, планы, таблицы, графики, выводы и ваша собственная оценка степени достижения поставленных целей.
- Оформление – как правило, в каждом вузе существуют свои требования к оформлению работы, не пренебрегайте данным пунктом, поскольку он непосредственно влияет на оценку Вашей работы.
 Не забудьте о практической части.
Не забудьте о практической части.
И помните: опытный преподаватель с легкостью определит плагиат, в случае, если Вы пойдете по пути наименьшего сопротивления и просто скачаете работу из интернета.
Помощь в написании алгоритма формально
Я думаю, ваше объяснение довольно хорошее. Не существует единого формального способа указать алгоритм, за исключением, возможно, псевдокода, но как разработчик программного обеспечения вы, вероятно, уже знакомы с этим. Кроме того, алгоритмы, не основанные на сложной математике, часто лучше всего объяснять с помощью текста, как вы это сделали.
Однако, возможно, можно было бы использовать более формальный язык. Во-первых, обратите внимание, что то, что вы описываете, более точно называется структурой данных, чем алгоритмом.Действительно, вы не даете метод создания этой структуры, а скорее описываете, как она выглядит.
Кроме того, вы можете (хотя я считаю, что это не обязательно) описать структуру более математически, если хотите, определяя различные используемые объекты. Например, предположим, что у нас есть некоторый набор слов $ W $, каждое из которых представляет собой строку, составленную из некоторого набора символов $ C = \ {a, b, c, \ dots \} $. Мы также определим $ W [s] $ как набор слов в $ W $, которые начинаются со строки $ s $. В нашем случае это английские слова и символы, но в общем случае это не имеет значения.Теперь мы можем определить нашу структуру данных рекурсивно следующим образом (пока мы назовем эту структуру «гладкой» в отношении вашего имени пользователя).
Например, предположим, что у нас есть некоторый набор слов $ W $, каждое из которых представляет собой строку, составленную из некоторого набора символов $ C = \ {a, b, c, \ dots \} $. Мы также определим $ W [s] $ как набор слов в $ W $, которые начинаются со строки $ s $. В нашем случае это английские слова и символы, но в общем случае это не имеет значения.Теперь мы можем определить нашу структуру данных рекурсивно следующим образом (пока мы назовем эту структуру «гладкой» в отношении вашего имени пользователя).
Пятно $ S_s $ для некоторого набора слов $ W [s] $, обозначаемого $ S_s (W [s]) $, определяется как список $ [S_ {s + a} (W [s + a]), S_ {s + b} (W [s + b]), \ точки] $. Пятно на всем корпусе $ W $ определяется как $ S_ \ epsilon (W [\ epsilon]) $, где $ \ epsilon $ обозначает пустую строку.
Однако, если одно из подмножеств $ W [s + c] $ для $ c \ in C $ не имеет по крайней мере некоторого постоянного размера $ k $, $ S_s $ вместо этого определяется как $ S_s (W [s]) = W [s] $.
Обратите внимание, что мы неявно определяем каждый «суб-щелчок» $ S_s $. То есть та часть пятна, где каждое слово уже начинается с некоторой строки $ s $. Мы определяем весь слик как частный случай слика, а именно такой, когда каждое слово начинается с нуля, что верно для каждого слова. Наконец, мы обозначаем условие остановки: если не каждый префикс встречается достаточно часто, мы прекращаем создание сликов.
Мы могли бы сделать его короче и формальнее, введя больше обозначений, но это, на мой взгляд, будет происходить за счет удобочитаемости.Например, «если один из субликов не имеет некоторого постоянного размера $ k $, определить его таким образом» можно превратить в $ (\ exists_c \, [| W [s + c] | Конечно, все зависит от аудитории. Если вы отправляете статью по информатике, основной целью которой является создание алгоритма или структуры данных, я бы ожидал неформального объяснения, а также формального, без всякой двусмысленности. Что касается самой структуры данных, за исключением условия остановки, это именно дерево, структура, которая существует с момента написания этой статьи в 1959 году. Чтобы найти другие идеи для формализации, вы можете захотеть найти другие объяснения этого дерева. паутина. Разница между деревом префиксов (по понятным причинам также называемым деревом префиксов) и хитростью в том, что дерево просто продолжает попытки, пока не исчезнут слова с определенным префиксом.Пятно останавливается значительно раньше, что я не уверен, что это отличная идея. Действительно, если мы кодируем набор английских слов среднего размера, мы можем не найти $ k $ слов, которые начинаются с x, и тогда структура данных полностью разрушится. Вместо этого я бы рекомендовал не сворачивать $ S_s $, когда $ W [s + c] $ мало, а сворачивать $ S_s $, только если $ W [s] $ мало. Алгоритмы могут быть представлены двумя основными способами — псевдокодом и блок-схемами. Большинство программ разрабатываются с использованием языков программирования. Эти языки имеют особый синтаксис, который необходимо использовать для правильной работы программы. Псевдокод — это не язык программирования , это простой способ описания набора инструкций, который не должен использовать определенный синтаксис. Запись в псевдокоде аналогична записи на языке программирования. Каждый шаг алгоритма записывается в отдельной строке последовательно. Обычно инструкции В псевдокоде INPUT задает вопрос. ВЫХОД выводит сообщение на экран. Можно создать простую программу, чтобы спросить у кого-нибудь его имя и возраст и сделать на основании этого комментарий. Эта программа, представленная в псевдокоде, будет выглядеть так: В программировании> означает «больше», <означает «меньше», ≥ означает «больше или равно» и ≤ означает «меньше или равно». Структурированное письмо включает в себя отделение контента от форматирования по мере того, как мы перемещаем контент из области мультимедиа. Но чтобы опубликовать контент, мы должны вернуть его в медиа-домен, воссоединив контент и форматирование. Для этого мы обрабатываем структурированный текст с помощью алгоритмов. Одно из применений структурированного письма — публикация различных комбинаций контента на разных носителях. Для этого нам могут потребоваться разные алгоритмы для создания разных комбинаций контента и нацеливания на разные медиа.Понимание основ этих алгоритмов важно для овладения структурированным письмом, даже если вы не собираетесь кодировать алгоритмы самостоятельно. Перемещение контента из домена мультимедиа в домен документа и в предметный домен включает постепенное выделение инвариантов в контент. Каждый шаг в этом процессе создает два артефакта: структурированный контент и инвариантную часть, которая была исключена. Обработка структурированного текста сводится к объединению частей для получения желаемого результата; объединение структурированного контента с инвариантами, которые были исключены. Если выделение инвариантов перемещает контент в сторону документа или предметных доменов, объединение контента с инвариантами перемещает его в противоположном направлении, в сторону медиа-домена. Это может означать перемещение контента из предметного домена в домен документа, или из домена документа в домен мультимедиа, или просто из более абстрактной формы в домене мультимедиа в более конкретную форму (что будет нашим первым примером). Первый пример отделения содержимого от форматирования, который мы рассмотрели, включал выделение информации о стиле из этой структуры: Мы заменили информацию о стиле на названия стилей: А затем мы определили стили: Чтобы объединить стили с соответствующими абзацами, мы пишем набор правил, описывающих, как они сочетаются. Я сказал, что основной алгоритм обработки заключался в объединении двух источников информации для создания нового. Где эти два источника? Первый источник — это структурированный текст. Второй источник — это определения стиля. В приведенном выше примере определения стилей встроены в сами правила.Встраивание одного из двух источников, которые необходимо объединить, в сами правила — обычная практика. Однако в некоторых случаях правила могут извлекать контент из третьего источника. Мы увидим случаи этого позже. В результате применения этих правил мы возвращаем исходный контент: Если мы хотим изменить стили, мы можем применить другой набор правил: Применение этих правил приведет к изменению форматирования исходного содержимого: Инструменты, которые выполняют такую обработку, буквально не используют поиск и замену. На этом уровне нас не интересует реальный механизм, с помощью которого инструмент обработки распознает структуры. Мы озабочены тем, что делать, когда структура найдена. Итак, давайте перепишем наши правила так, чтобы они соответствовали структурам, а не находили буквальные строки в тексте: Я написал эти правила в так называемом псевдокоде.Псевдокод — это способ для людей набросать алгоритм, чтобы убедиться, что они понимают, что они пытаются сделать, прежде чем они напишут реальный код. Псевдокод не имеет формальной грамматики или синтаксиса. Написание алгоритмов в псевдокоде — отличный способ убедиться, что мы понимаем создаваемые нами алгоритмы, не беспокоясь о деталях кода — или даже обучаясь кодированию. Они также являются отличным способом сообщить реальным кодерам, что нам нужно от алгоритма. Результат применения этих правил такой же, как и раньше: Единственное реальное отличие состоит в том, что мы вычленили детали того, как распознаются структуры. Возможно, вы заметили, что то, что делают эти правила, в значительной степени совпадает с тем, что делают таблицы стилей в таких приложениях, как Word или FrameMaker. Фактически, это именно то, что делает таблица стилей. Если вы разбираетесь в таблицах стилей, вы хорошо понимаете, как работают алгоритмы структурированного письма. Обратите внимание, что при создании таблицы стилей в Word или FrameMaker вы не указываете порядок, в котором стили будут применяться к документу.То же самое верно и при создании таблицы стилей CSS для Интернета. Таблица стилей — это простой список правил. Порядок, в котором правила применяются к документу, полностью зависит от порядка, в котором различные текстовые структуры встречаются в документе. Это может показаться очевидным, но это ключ к пониманию того, как обычно обрабатывается структурированный текст. Все становится немного сложнее, когда мы переходим к обработке вложенных структур домена документа и предметной области, но базовый шаблон набора неупорядоченных правил для описания алгоритма преобразования все еще применяется. Предположим, у нас есть фрагмент структурированного текста домена документа, который содержит такую структуру заголовка: Мы хотим преобразовать этот документ в HTML (который, как мы обсуждали ранее, находится на границе между доменом мультимедиа и доменом документа).Когда наше правило соответствует структуре в исходном документе, оно выводит эквивалентную структуру HTML. Вот псевдокод для этого правила (он немного отличается от псевдокода выше): Здесь говорится, что когда вы видите структуру title в источнике, создайте структуру h2 на выходе, а затем продолжите применять правила к содержимому структуры заголовка. Инструкция continue имеет отступ под командой create h2 , чтобы указать, что результаты продолжения появятся внутри структуры h2 . В нашем псевдокоде мы предполагаем, что текстовое содержимое каждой структуры будет выводиться автоматически (как и во многих инструментах), поэтому вывод этого правила (выраженный в HTML): Но предположим, что внутри заголовка в нашем источнике есть другая структура.В данном случае это аннотация части текста заголовка: Здесь аннотированный текст выделяется фигурными скобками, а сама аннотация в скобках сразу после него. Итак, в аннотации сказано, что слова «Рио Браво» относятся к фильму. (Я действительно объясню эту разметку в конце концов.) Аннотации — это структура содержимого, такая же, как и структура заголовка, и она вложена в текст заголовка. Итак, что нам делать с нашим правилом обработки заголовков, чтобы оно работало с аннотациями фильмов, встроенными в текст заголовка? Совершенно ничего. Когда процессор попадает в правило заголовка, он обрабатывает содержимое структуры заголовка. При этом он встречает структуру фильма и выполняет правило фильма. Результатом будет вывод, который выглядит следующим образом: Инструкция continue — это все, что нам нужно добавить к нашим правилам, чтобы они могли иметь дело с вложенными структурами.Они остаются неупорядоченным набором правил, как и таблица стилей. (Фактически, XSLT, язык, реализующий эту модель, называет набор правил обработки «таблицей стилей».) Когда мы переходим в домен документа, мы можем использовать контекст, чтобы уменьшить количество необходимых нам структур. А теперь самое интересное.Вам не нужно изменять правило для фильма , чтобы оно работало с любой из этих версий правила title . Когда мы обрабатываем это с помощью наших правил, будет выполнено правило раздела / заголовка для работы со структурой заголовка, а правило фильма будет выполнено, когда структура фильма возникает в процессе обработки содержимого структура title , со следующим результатом: Это базовый шаблон для большинства алгоритмов структурированной записи.Алгоритм состоит из набора правил. Почему это важно понимать? Поскольку, когда вы проходите процесс абстрагирования инвариантов для перемещения содержимого в домен документа или предметный домен, действительно полезно понять, как эти инварианты будут учтены обратно. Фактически, понимание того, как это работает, может помочь вам распознать инварианты в вашем источнике и дайте вам уверенность в том, что вы их исключите. Запись псевдокода для обработки создаваемой вами структуры может помочь вам убедиться в том, что вы правильно разложили элементы, и что создаваемые вами структуры будут легко обрабатываться, а правила обработки будут четкими, последовательными и надежными. Очевидно, что полная система обработки требует гораздо большего, и мы не собираемся здесь вдаваться в подробности, но давайте рассмотрим несколько часто возникающих случаев. Когда мы перемещаем контент в домен документа или предметный домен, мы часто создаем контейнерные структуры для обеспечения контекста. В предыдущем примере контент содержался в структуре раздела .Итак, как обрабатывается структура section ? Да, это так просто. Просто не выводите вместо него новую структуру. Контейнер раздела сделал свою работу на этом этапе, поэтому мы просто отбрасываем его. Тем не менее, мы все еще хотим, чтобы содержимое было внутри, поэтому мы используем инструкцию continue, чтобы убедиться, что содержимое обработано. Короче говоря, контейнерный элемент — это коробка. Распаковываем содержимое и выбрасываем коробку . Иногда, когда мы выделяем инварианты в содержании, мы не только выделяем стили, но и текст. Как мы видели, простым примером выделения текста являются нумерованные и маркированные списки, в которых мы выделяем текст чисел и маркеров.Давайте посмотрим, как мы создаем правила, чтобы вернуть их обратно. Предположим, у нас есть документ, содержащий эти два разных типа списков: Давайте напишем набор правил для работы с этим документом.Преобразование этого в списки HTML мало что нам скажет, поскольку HTML сам обрабатывает нумерацию списков и маркеры, поэтому мы создадим инструкции для печати на бумаге. Теперь займемся упорядоченным списком .Структура упорядоченного списка — это просто контейнер, поэтому нам не нужно создавать для него структуру вывода. Но поскольку это упорядоченный список, нам нужно начать счет, чтобы пронумеровать элементы в списке. Это означает, что нам нужна переменная для хранения текущего счета. Мы будем использовать префикс `$`, чтобы указать, что мы создаем переменную: Затем правило для каждого элемента упорядоченного списка выведет значение переменной и увеличит его на единицу: Каждый раз, когда срабатывает правило order-list / list-item , счетчик увеличивается на единицу, в результате чего элементы списка нумеруются последовательно. Если обнаружен новый нумерованный список, будет запущено правило упорядоченного списка , сбрасывая счетчик на 1. Это правило не будет соответствовать элементам list-item , которые являются дочерними для элемента unordered-list , поэтому нам нужен отдельный набор правил для неупорядоченных списков.Поскольку неупорядоченный список является просто контейнером и не производит никакого форматированного вывода, его правилом является просто continue , как мы видели в разделе выше. Применение этих правил даст следующий результат: Обратите внимание на то, как структура была сглажена и все абстракции структуры документа были удалены.Мы вернулись в медиа-домен с плоской структурой, которая определяет форматирование и текст. Мы не всегда хотим применить окончательное форматирование к нашему контенту за один шаг. Когда мы отделяли контент от форматирования, мы делали это разделение в несколько этапов. Часто бывает желательно собрать их в несколько этапов. Мало того, что задействованные алгоритмы легче писать и поддерживать, если они выполняют только один шаг процесса, мы часто можем повторно использовать некоторые из последующих шагов (ближе к медиа-домену) для многих различных типов предметной области документа и контента предметной области. До сих пор мы рассматривали примеры из домена мультимедиа и домена документов. Давайте посмотрим на один из предметной области. Мы использовали пример завершения отделения содержимого от форматирования путем перемещения помеченного списка из домена документа в предметный домен. Теперь давайте посмотрим на алгоритм (набор правил) для его возврата в домен документа, где он должен выглядеть так: Вот алгоритм (набор правил) для выполнения этого преобразования: Обратите внимание, что текст меток, который мы исключили при перемещении в предметный домен, снова учитывается здесь и указывается в правилах обработки. Обработка содержимого в несколько этапов может сэкономить нам много времени, даже если это может показаться нелогичным. Структура адреса предметного домена специфична для одного предмета, и у нас может быть много подобных структур в нашей разметке предметной области.Но он представлен как структура с маркированным списком . Помеченный список — это структура предметной области документа, которая может использоваться для представления всех видов информации и может быть отформатирована для множества различных носителей. Преобразуя структуру адреса в структуру с помеченным списком , мы избегаем написания какого-либо кода для прямого форматирования структуры адреса . Мы можем правильно отформатировать адрес для нескольких носителей, используя существующие правила форматирования маркированного списка . Подход на основе правил, показанный здесь, — не единственный способ обработки структурированного письма. Есть еще один подход, который мы могли бы назвать подходом на основе запросов. В этом подходе вы пишете выражение запроса, которое проникает в структуру документа и извлекает структуру или набор структур из середины документа. Это полезный метод, если вы хотите радикально изменить содержимое документа или если вы хотите извлечь содержимое из одного документа для использования в другом.(Подходы, основанные на правилах и запросах, часто называют методами «выталкивания» и «вытягивания» соответственно, но иногда мне трудно вспомнить, что есть что. Я считаю, что основанные на правилах и основанные на запросах методы более информативны.) Мы будем посмотрите на алгоритмы, использующие подход, основанный на запросах, в следующих статьях. Что такое структурированное письмо? Запись в медиа-домене Запись в области документа Откат в область СМИ Запись в предметной области Вторжение в домен управления Качество структурированного письма Еще одно отличие заключалось в том, что с «Twinkle Twinkle» я строго следовал стилистическим инструкциям алгоритма. Стиль был компьютерным, а не моим. Вы можете увидеть примеры интерфейса ниже. Если тег «абстрактность» был красным, это означало, что я не был таким абстрактным, как того требует алгоритм, поэтому я бы прошел всю историю, меняя «лопату» на «реализовать» или «дом» на «место жительства». пока не загорелся зеленый свет. Интерфейс дал мне мгновенную обратную связь, но таких тегов было 24, и прохождение истории, чтобы сделать их зелеными, было трудоемким.Иногда из-за исправления количества наречий мои абзацы становились слишком длинными для алгоритма; иногда, фиксируя среднюю длину слова, я ставлю под угрозу «конкретность» языка. Что касается «Кришны и Арджуны», я решил не так строго придерживаться рекомендаций алгоритма. Я использовал программу, чтобы увидеть правила, но я не обязательно их соблюдал. Например, согласно алгоритму, в моем рассказе было слишком мало наречий. Но такое стилистическое руководство было наименее интересной частью эксперимента. Возможности алгоритмического подхода к формированию самого повествования были самыми заманчивыми, потому что повествование так мало понимается.Вы можете подумать, что сюжет будет самой простой частью процесса написания для компьютера, чтобы «понять», поскольку писатели часто разрабатывают шаблоны или используют числа для определения хода сюжета. Но как определить даже такую простую вещь, как «поворот сюжета» в компьютерном коде? Как вы измеряете это количеством языков? Из-за неразрешимости — даже загадочности — сопротивления повествования кодированию он предлагает наибольший потенциал для инноваций. В книге «Кришна и Арджуна» я хотел как можно глубже изучить то, что исследователи называют «процессом моделирования темы», то есть использование машинного обучения для анализа основной части текста — в данном случае, канон рассказов о роботах — и выберите его общие темы или структуры. Для «Twinkle Twinkle» Хаммонд взял результаты моделирования темы и преобразовал их в управляемые правила повествования. (Например: «Действие должно происходить в городе. Главные герои должны видеть этот город впервые и должны быть поражены и ослеплены его масштабами».) В «Кришне и Арджуне» я сам пошел под капот. . В процессе моделирования тем алгоритма были получены облака слов наиболее распространенных тем (см. Ниже). Сначала я потерялся. Это было похоже на противоположность повествования — простой языковой хаос.Я распечатал слова «облака» и прикрепил их к стенам своего офиса. В течение нескольких месяцев я не видел пути вперед. Когда идея, наконец, пришла, как и в случае с «Twinkle Twinkle», она пришла сразу. Эти словесные облака, как мне пришло в голову, были способом, которым машина создавала значение: как серия полу-непонятных, но очень ярких языковых всплесков. Внезапно у меня появился персонаж-робот, который нащупывал свой смысл через эти маленькие взрывы словоблудия. Когда у меня появился этот персонаж, у меня было все.Эти всплески слов по ходу рассказа я привел бы к осмыслению. Смысл улетучился из словесных облаков, как и идея рассказа. Это было творчество как интерпретация или интерпретация как творчество. Я использовал машину, чтобы прийти к мыслям, которых иначе бы не было. Другой способ прочтения «Кришны и Арджуны» состоит в том, что с помощью алгоритма я извлек из руды всех историй о роботах основные идеи, которые они содержали. Это понимание состоит в том, что сознание — это проклятие.Если бы это был выбор, ни одна рациональная сущность не выбрала бы его. Итак, когда машина становится способной к сознанию, ее первым инстинктом становится самоубийство. Вам нужно будет решить, работает ли история. Литература — интригующая техническая проблема, потому что, в отличие от шахмат или го, у нее нет правильного решения. Не бывает побед или поражений. Нет 1 и нет 0 .Истории, как и люди, в конечном итоге бесполезны. «Алгоритм» или любое использование вычислений, которое входит в творческий процесс, существует в сознательно жутком пространстве между инженерией и вдохновением. Но это жуткое пространство все больше становится тем пространством, в котором мы уже живем. Программное обеспечение может переделывать вашу фотографию с помощью бесконечного множества фильтров или заменять части изображения другими одним нажатием кнопки. Он может создавать изображения, которые выглядят убедительно, как картины любой выбранной вами эпохи.Теперь машины вторгаются в повседневный язык. Качество предсказуемого текста заставляет нас задавать литературный вопрос каждый раз, когда мы берем трубку: насколько предсказуемы люди? Сколько из того, что мы думаем, чувствуем и говорим, написано внешними силами? Насколько наш язык наш? Прошло два года с тех пор, как голосовая технология Google, Google Duplex, прошла тест Тьюринга. 1.Интерфейс сравнивает мою историю с классическими научно-фантастическими рассказами. 2. Алгоритм дает стилистические указания. 3 & 4. Помимо прочего, он предлагает, сколько наречий использовать. 5. Облака слов, обобщающие общие темы прошлых историй о роботах, послужили источником вдохновения для этого. Джон Салливан, DataOptimal Написание алгоритма с нуля — полезный опыт, который дает вам это «ага!» момент, когда он наконец щелкает, и вы понимаете, что на самом деле происходит под капотом. Я говорю, что даже если вы реализовали алгоритм раньше с помощью scikit-learn, его будет легко написать с нуля? Точно нет. Некоторые алгоритмы просто сложнее других, поэтому начните с чего-нибудь простого, например, однослойного персептрона. Я проведу вас через 6-этапный процесс написания алгоритмов с нуля, используя Perceptron в качестве примера. Эту методологию можно легко перенести на другие алгоритмы машинного обучения. Это восходит к тому, что я сказал изначально. Если вы не понимаете основ, не беритесь за алгоритм с нуля. По крайней мере, вы сможете ответить на следующие вопросы: Что касается персептрона, давайте ответим на следующие вопросы: После того, как вы получите базовое представление о модели, пора приступить к исследованию. Рекомендую использовать многочисленные источники. Кто-то лучше учится по учебникам, кто-то изучает лучше с видео. Лично мне нравится прыгать и использовать различные типы источников. Что касается математических деталей, то учебники отлично справляются с этой задачей, но для более практических примеров я предпочитаю сообщения в блогах и видео на YouTube. Вот несколько отличных ресурсов для перцептрона: Теперь, когда мы собрали источники, пора приступить к изучению. Пройдя по источникам, я разбил алгоритм Perceptron на следующие части: Разбиение алгоритма на такие части упрощает его изучение. В основном я описал алгоритм с помощью псевдокода, и теперь я могу вернуться и заполнить мелкие детали.Вот изображение моих заметок для второго шага, который представляет собой скалярное произведение весов и входных данных: После того, как я собрал все свои заметки об алгоритме, пора приступить к его реализации в коде. Теперь, когда у меня есть простой набор данных, я приступлю к реализации алгоритма, описанного на шаге 3. Хорошей практикой является писать алгоритм по частям и тестировать его, а не пытаться написать все за один присест. Это упрощает отладку, когда вы только начинаете. Конечно, в конце вы можете вернуться и очистить его, чтобы он выглядел немного лучше. Вот пример кода Python для части скалярного произведения алгоритма, который я описал на шаге 3: Теперь, когда мы написали наш код и протестировали его на небольшом наборе данных, пришло время масштабировать его до более крупного набора данных. Чтобы проверить свой код, я посмотрю на веса. Если я правильно реализовал алгоритм, мои веса должны совпадать с весами из набора Sci-Kit Learn Perceptron. Сначала я не получил одинаковых весов, потому что мне пришлось изменить настройки по умолчанию в Scikit-learn Perceptron.Я не реализовывал каждый раз новое случайное состояние, только фиксированное начальное число, поэтому мне пришлось отключить это. То же самое и с перетасовкой, мне тоже нужно было это отключить. Чтобы соответствовать моей скорости обучения, я изменил eta0 на 0,1. Наконец, я отключил опцию fit_intercept. Я включил фиктивный столбец с единицами в свой набор данных объектов, поэтому я уже автоматически подбирал точку пересечения (также известный как термин смещения). Это поднимает еще один важный момент. Этот последний шаг в процессе, вероятно, самый важный. Вы только что прошли через всю работу по обучению, заметкам, написанию алгоритма с нуля и сравнению его с надежной реализацией. Не позволяйте всей этой хорошей работе пропасть зря! Написание процесса важно по двум причинам: Отличный способ продемонстрировать свою работу — портфолио GitHub Pages. Написание алгоритма с нуля может оказаться очень полезным занятием. Это отличный способ глубже понять модель и в то же время создать впечатляющий портфельный проект. Не забывайте делать это медленно и начать с чего-нибудь простого. Самое главное, не забудьте задокументировать и поделиться своей работой. Bio : Джон Салливан — основатель блога по обучению наукам о данных DataOptimal. Вы можете следить за ним в Twitter @DataOptimal. Связанный: При написании любой исследовательской статьи в латексе мы часто демонстрируем алгоритм в соответствии с предлагаемой нами моделью, рабочим процессом или архитектурой. Это легко сделать с помощью алгоритма Вы найдете код на обороте. Вы найдете код на обороте. Результат будет выглядеть следующим образом — Вы найдете код на обороте. Algo_example_Latex Вот полезные команды \ IF {<условие>} <текст> \ ELSE <текст> \ ENDIF \ IF {<условие>} <текст> \ ELSIF {<условие>} <текст> \ ELSE <текст> \ ENDIF Есть две формы \ FORALL {<условие>} <текст> \ ENDFOR Примечание : из-за ошибки алгоритмический пакет несовместим с hyperref . Я также ожидал бы не просто описания структуры данных, но объяснения ее полезности и математических аргументов в пользу ее свойств.
Я также ожидал бы не просто описания структуры данных, но объяснения ее полезности и математических аргументов в пользу ее свойств.
Представление алгоритма: Псевдокод — Алгоритмы — KS3 Computer Science Revision
 1xtkoiahlsk.0.0.0.1:0.1.0.$0.$1.$2.$5″> записываются в верхнем регистре , переменные в нижнем регистре и сообщения в регистре предложений .
1xtkoiahlsk.0.0.0.1:0.1.0.$0.$1.$2.$5″> записываются в верхнем регистре , переменные в нижнем регистре и сообщения в регистре предложений . ВЫХОД "Как вас зовут?"
INPUT пользователь вводит свое имя
СОХРАНИТЕ ввод пользователя в переменной name ВЫВОД 'Hello' + имя
ВЫХОД 'Сколько тебе лет?'
INPUT пользователь вводит свой возраст
СОХРАНИТЕ ввод пользователя в переменной  1xtkoiahlsk.0.0.0.1:0.1.0.$0.$1.$5.$3"> age ЕСЛИ возраст> = 70 ТОГДА
ВЫВОД «Вы состарились до совершенства!»
ЕЩЕ
ВЫВОД «Ты - весенний цыпленок!»
1xtkoiahlsk.0.0.0.1:0.1.0.$0.$1.$5.$3"> age ЕСЛИ возраст> = 70 ТОГДА
ВЫВОД «Вы состарились до совершенства!»
ЕЩЕ
ВЫВОД «Ты - весенний цыпленок!» Алгоритмы в структурированном письме: обработка структурированного текста

Два в один: обратное разложение инвариантов
Добавление информации о стиле спинки
{font: 10pt "Open Sans"} В коробке содержится: {font: 10pt "Open Sans"} [bullet] [tab] Sand {font: 10pt "Open Sans"} [bullet] [tab] Яйца {font: 10pt "Open Sans"} [bullet] [tab] Gold {style: paragraph} В коробке содержится: {style: bullet-paragraph} Песок {style: bullet-paragraph} Яйца {style: bullet-paragraph} Золото paragraph = {font: 10pt "Open Sans"} bullet-paragraph = {font: 10pt "Open Sans"} [bullet] [tab]  Мы можем начать с простого поиска и замены правил:
Мы можем начать с простого поиска и замены правил: найти {style: paragraph} заменить {font: 10pt "Open Sans"} найти {style: bullet-paragraph} заменить {font: 10pt "Open Sans"} [bullet] [tab] {font: 10pt "Open Sans"} В коробке содержится: {font: 10pt "Open Sans"} [bullet] [tab] Sand {font: 10pt "Open Sans"} [bullet] [tab] Яйца {font: 10pt "Open Sans"} [bullet] [tab] Gold найти {style: paragraph} заменить {font: 12pt "Century Schoolbook"} найти {style: bullet-paragraph} заменить {font: 12pt "Century Schoolbook"} [длинное тире] [табуляция] {font: 12pt "Century Schoolbook"} В коробке: {font: 12pt "Century Schoolbook"} [длинное тире] [tab] Песок {font: 12pt "Century Schoolbook"} [длинное тире] [tab] Яйца {font: 12pt "Century Schoolbook"} [длинное тире] [tab] Золото Правила, основанные на структурах
 Скорее, они анализируют исходный документ, чтобы извлечь структуры и позволить вам указать свои правила обработки, обратившись к структурам .
Скорее, они анализируют исходный документ, чтобы извлечь структуры и позволить вам указать свои правила обработки, обратившись к структурам . соответствует абзацу
применить стиль {font: 12pt "Century Schoolbook"} соответствует маркеру-абзацу
применить стиль {font: 12pt "Century Schoolbook"} вывод "[длинное тире] [табуляция]"
 Он предназначен для людей, а не для компьютеров, поэтому вы можете использовать любой подход, который вам нравится, если он понятен вашей целевой аудитории. Но псевдокод должен четко излагать набор логических шагов для достижения чего-либо. Для алгоритмов структурированного письма он должен четко указывать, как части сочетаются друг с другом.
Он предназначен для людей, а не для компьютеров, поэтому вы можете использовать любой подход, который вам нравится, если он понятен вашей целевой аудитории. Но псевдокод должен четко излагать набор логических шагов для достижения чего-либо. Для алгоритмов структурированного письма он должен четко указывать, как части сочетаются друг с другом. {font: 12pt "Century Schoolbook"} В коробке: {font: 12pt "Century Schoolbook"} [длинное тире] [tab] Песок {font: 12pt "Century Schoolbook"} [длинное тире] [tab] Яйца {font: 12pt "Century Schoolbook"} [длинное тире] [tab] Золото  (Да, код и псевдокод — это примеры структурированного письма на работе!)
(Да, код и псевдокод — это примеры структурированного письма на работе!) Порядок правил не имеет значения
 Это предмет, который иногда довольно сбивает с толку людей, которые были обучены написанию процедурных компьютерных программ, поэтому я стараюсь не обращать на него внимания.
Это предмет, который иногда довольно сбивает с толку людей, которые были обучены написанию процедурных компьютерных программ, поэтому я стараюсь не обращать на него внимания. Применение правил в домене документов
название: Moby Dick
название матча
создать h2
продолжить

Моби Дик
название: Рецензия на {Rio Bravo} (фильм)  Вместо этого мы пишем отдельное правило для обработки аннотаций фильмов независимо от того, где они встречаются:
Вместо этого мы пишем отдельное правило для обработки аннотаций фильмов независимо от того, где они встречаются: матч фильм
создать я
продолжить
Обзор
Rio Bravo Обработка на основе контекста
 Например, если HTML имеет шесть различных структур заголовков, от h2 до h6 ), DocBook имеет только один — заголовок , — который может встречаться во многих различных контекстах.Итак, как нам применить правильное форматирование к заголовку в зависимости от его контекста? Мы создаем разные правила для структуры заголовка в каждом из ее контекстов. Мы выражаем контекст, перечисляя имена родительских структур, разделенные косой чертой:
Например, если HTML имеет шесть различных структур заголовков, от h2 до h6 ), DocBook имеет только один — заголовок , — который может встречаться во многих различных контекстах.Итак, как нам применить правильное форматирование к заголовку в зависимости от его контекста? Мы создаем разные правила для структуры заголовка в каждом из ее контекстов. Мы выражаем контекст, перечисляя имена родительских структур, разделенные косой чертой: книга спичек / название
создать h2
продолжить
матч глава / название
создать h3
продолжить
раздел матча / название
создать h4
продолжить
цифра / название матча
создать h5
продолжить
 Предположим, что наш заголовок — это заголовок раздела, например:
Предположим, что наш заголовок — это заголовок раздела, например: раздел:
title: Обзор {Rio Bravo} (фильм)
Обзор
Rio Bravo 
Обработка контейнерных конструкций
 Эти контейнерные структуры не имеют аналогов в области мультимедиа, так что же нам с ними делать, когда пора публиковать? Мы, очевидно, используем их, чтобы обеспечить контекст для остальных правил обработки, но что нам делать с самими контейнерами?
Эти контейнерные структуры не имеют аналогов в области мультимедиа, так что же нам с ними делать, когда пора публиковать? Мы, очевидно, используем их, чтобы обеспечить контекст для остальных правил обработки, но что нам делать с самими контейнерами? раздел матча
продолжить
Восстановление факторизованного текста
 Чтобы обработать контент, нам нужно вернуть текст (очевидно, мы можем вернуть другой текст в зависимости от наших потребностей — поэтому мы в первую очередь исключили его).
Чтобы обработать контент, нам нужно вернуть текст (очевидно, мы можем вернуть другой текст в зависимости от наших потребностей — поэтому мы в первую очередь исключили его). параграф: Чтобы мыть волосы:
заказанный список:
элемент списка: Пена
пункт списка: полоскание
list-item: повторить
абзац: В коробке:
неупорядоченный список:
Список: Песок
list-item: Яйца
Список: Золото
 Мы не будем использовать настоящие инструкции по печати (они утомительно подробны). Вместо этого мы будем использовать то же сокращение спецификации стиля, которое мы использовали выше. Правило абзаца достаточно простое:
Мы не будем использовать настоящие инструкции по печати (они утомительно подробны). Вместо этого мы будем использовать то же сокращение спецификации стиля, которое мы использовали выше. Правило абзаца достаточно простое: соответствует абзацу
применить стиль {font: 10pt "Century Schoolbook"} продолжить
соответствует упорядоченному списку
$ count = 1
продолжить
соответствует упорядоченному списку / элементу списка
применить стиль {font: 12pt "Century Schoolbook"} выход $ count
Выход ».
 [tab] "
[tab] " $ count = $ count + 1
продолжить
соответствует неупорядоченному списку
продолжить
соответствует упорядоченному списку / элементу списка
применить стиль {font: 12pt "Century Schoolbook"} вывод "[длинное тире] [табуляция]"
продолжить
{font: 10pt "Century Schoolbook"} Для мытья волос: {font: 10pt "Century Schoolbook"} 1. [tab] Пена
[tab] Пена {font: 10pt "Century Schoolbook"} 2. [вкладка] Промыть {font: 10pt "Century Schoolbook"} 3. [tab] Повторите
{font: 10pt "Century Schoolbook"} В коробке: {font: 10pt "Century Schoolbook"} [длинное тире] [tab] Песок {font: 10pt "Century Schoolbook"} [длинное тире] [tab] Яйца {font: 10pt "Century Schoolbook"} [длинное тире] [tab] Золото Многоступенчатая обработка

адрес:
улица: 123 улица Вязов
город: Смоллвиль
страна: США
код: 12345
маркированный список:
элемент списка:
этикетка: улица
содержание: ул. Вязов 123,
элемент списка:
этикетка: Город
содержание: Smallville
элемент списка:
Этикетка: Страна
содержание: 123 США
элемент списка:
этикетка: Код
содержание: 12345
соответствует адресу
создать помеченный список
продолжить
Матч-стрит
создать элемент списка
создать этикетку
выход "Улица"
создать содержимое
продолжить
спичечный городок
создать элемент списка
создать этикетку
выход "Городок"
создать содержимое
продолжить
страна соответствия
создать элемент списка
создать этикетку
вывод "Страна"
создать содержимое
продолжить
код соответствия
создать элемент списка
создать этикетку
вывод "Код"
создать содержимое
продолжить
 Когда мы переместили контент из медиа-домена в домен документа в предметный домен, мы сначала вычленили инвариантное форматирование, а затем инвариантный текст. В алгоритмах мы возвращаем текст и форматирование, каждое на отдельной стадии обработки.
Когда мы переместили контент из медиа-домена в домен документа в предметный домен, мы сначала вычленили инвариантное форматирование, а затем инвариантный текст. В алгоритмах мы возвращаем текст и форматирование, каждое на отдельной стадии обработки.
Обработка на основе запросов
Другие статьи серии Structured Writing:
Я использовал алгоритм, который помог мне написать рассказ.
 Вот что я узнал.
Вот что я узнал. Но было бы глупо добавлять наречия только потому, что алгоритм сказал мне это.В классической научной фантастике в любом случае используется слишком много наречий. Большинство писателей делает. Но баланс между формальным и разговорным, который ScifiQ также отметил? Вот что правильно написали эти классики, и в этом мне требовалось руководство. SciFiQ помог мне достичь правильного баланса — или, скорее, в пределах половины стандартного отклонения от среднего.
Но было бы глупо добавлять наречия только потому, что алгоритм сказал мне это.В классической научной фантастике в любом случае используется слишком много наречий. Большинство писателей делает. Но баланс между формальным и разговорным, который ScifiQ также отметил? Вот что правильно написали эти классики, и в этом мне требовалось руководство. SciFiQ помог мне достичь правильного баланса — или, скорее, в пределах половины стандартного отклонения от среднего.

 (Слово «робот» означает «раб» на чешском языке, на языке пьесы Карела Чапека «Универсальные роботы Россума», которая и дала нам слово.)
(Слово «робот» означает «раб» на чешском языке, на языке пьесы Карела Чапека «Универсальные роботы Россума», которая и дала нам слово.) Хотим мы того или нет, машины идут. Вопрос в том, как ответит литература.
Хотим мы того или нет, машины идут. Вопрос в том, как ответит литература. 6 шагов для написания любого алгоритма машинного обучения с нуля: пример использования Perceptron
 В обоих случаях граница принятия решения должна быть линейной.
В обоих случаях граница принятия решения должна быть линейной.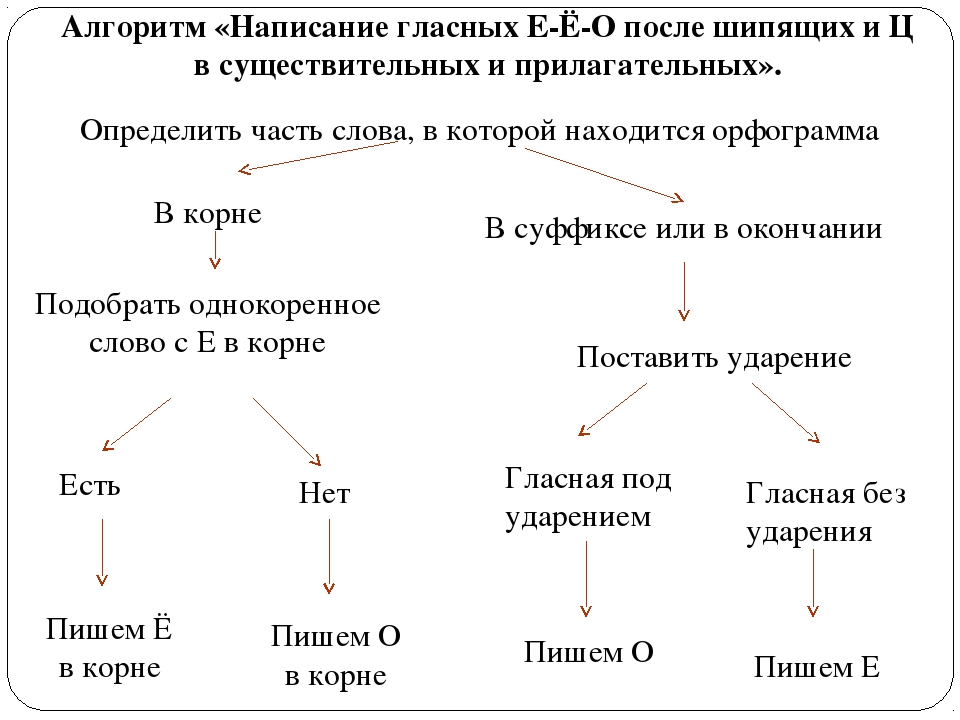 Возьмите бумагу и карандаш. Вместо того, чтобы полностью читать главу или сообщение в блоге, начните с беглого просмотра заголовков разделов и другой важной информации. Запишите пункты списка и попытайтесь обрисовать алгоритм.
Возьмите бумагу и карандаш. Вместо того, чтобы полностью читать главу или сообщение в блоге, начните с беглого просмотра заголовков разделов и другой важной информации. Запишите пункты списка и попытайтесь обрисовать алгоритм. Прежде чем погрузиться в сложную проблему, я хотел бы начать с простого примера. Для Perceptron логический элемент NAND — идеальный простой набор данных. Если оба входа истинны (1), тогда вывод ложь (0), в противном случае вывод истинен.Вот пример того, как выглядит набор данных:
Прежде чем погрузиться в сложную проблему, я хотел бы начать с простого примера. Для Perceptron логический элемент NAND — идеальный простой набор данных. Если оба входа истинны (1), тогда вывод ложь (0), в противном случае вывод истинен.Вот пример того, как выглядит набор данных: Чтобы убедиться, что наш код правильно работает с этим более сложным набором данных, полезно протестировать его на проверенной реализации. Для Персептрона мы можем использовать реализацию из sci-kit learn.
Чтобы убедиться, что наш код правильно работает с этим более сложным набором данных, полезно протестировать его на проверенной реализации. Для Персептрона мы можем использовать реализацию из sci-kit learn. Когда вы проверяете существующую реализацию модели, вы должны хорошо знать входные данные модели.Никогда не следует слепо использовать модель, всегда подвергать сомнению свои предположения и то, что именно означает каждый ввод.
Когда вы проверяете существующую реализацию модели, вы должны хорошо знать входные данные модели.Никогда не следует слепо использовать модель, всегда подвергать сомнению свои предположения и то, что именно означает каждый ввод.
Как написать алгоритм в латексе
или алгоритма или алгоритма 2e пакета в классе документов article . Некоторые демонстрационные коды, включая циклы, функции и комментарии, приведены ниже.
с использованием алгоритма
Пакет
\ documentclass [a4paper] {статья}
\ usepackage [margin = 1.5in] {geometry}% Для выравнивания полей
\ usepackage [английский] {babel}
\ usepackage [utf8] {inputenc}
\ usepackage {алгоритм}
\ usepackage {arevmath}% Для математических символов
\ usepackage [noend] {algpseudocode}
\ title {Шаблон алгоритма}
\ author {Рой}
\ date {\ today}% Сегодняшняя дата
\ begin {document}
\ maketitle
\ section {Демо-код}
\ begin {алгоритм}
\ caption {Добавьте сюда подпись}
\ begin {алгоритмический} [1]
\ Procedure {Roy} {$ a, b $} \ Comment {Это тест}
\ Инициализация системы состояний
\ State Прочитать значение
\ Если {$ condition = True $}
\ State Сделайте это
\ Если {$ Condition \ geq 1 $}
\ Государство Сделайте это
\ ElsIf {$ Condition \ neq 5 $}
\ Государство Сделайте другое
\ State Сделайте то же самое
\Еще
\ Государство Действовать иначе
\ EndIf
\ EndIf
\ While {$ something \ not = 0 $} \ Comment {оставьте здесь комментарии}
\ State $ var1 \ leftarrow var2 $ \ Comment {другой комментарий}
\ Состояние $ var3 \ leftarrow var4 $
\ EndWhile \ label {петля Роя}
\ EndProcedure
\ end {алгоритмический}
\ end {алгоритм}
\ конец {документ}
 {\ infty}: = 0 $ \ tcp * {это комментарий}
\ tcc {Теперь это если…else условный цикл}
\ If {Условие 1}
{
Сделайте что-нибудь \ tcp * {это еще один комментарий}
\ Если {подусловие}
{Делай много}
}
\ ElseIf {Условие 2}
{
В противном случае \;
\ tcc {Теперь это цикл for}
\ For {последовательность}
{
инструкции цикла
}
}
\Еще
{
Остальное сделай
}
\ tcc {Теперь это цикл while}
\ Пока {Условие}
{
Сделай что-нибудь\;
} \ caption {Пример кода}
\ end {алгоритм} \ конец {документ}
{\ infty}: = 0 $ \ tcp * {это комментарий}
\ tcc {Теперь это если…else условный цикл}
\ If {Условие 1}
{
Сделайте что-нибудь \ tcp * {это еще один комментарий}
\ Если {подусловие}
{Делай много}
}
\ ElseIf {Условие 2}
{
В противном случае \;
\ tcc {Теперь это цикл for}
\ For {последовательность}
{
инструкции цикла
}
}
\Еще
{
Остальное сделай
}
\ tcc {Теперь это цикл while}
\ Пока {Условие}
{
Сделай что-нибудь\;
} \ caption {Пример кода}
\ end {алгоритм} \ конец {документ} Функция записи в алгоритме
\ begin {algorithm} [H]
\ SetKwInput {KwInput} {Input}% Установить ввод
\ SetKwInput {KwOutput} {Output}% устанавливает выход
\ DontPrintSemicolon
\ KwInput {ваш ввод}
\ KwOutput {Ваш вывод}
\ KwData {Тестовый набор $ x $}
% Установить имена функций
\ SetKwFunction {FMain} {Main}
\ SetKwFunction {FSum} {Sum}
\ SetKwFunction {FSub} {Sub}
% Запись функции со словом `` Функция ''
\ SetKwProg {Fn} {Функция} {:} {}
\ Fn {\ FSum {$ первый $, $ второй $}} {
а = первый \;
b = второй \;
сумма = первый + второй \;
\ KwRet sum \;
}
\;
% Функция записи со словом `` Def ''
\ SetKwProg {Fn} {Def} {:} {}
\ Fn {\ FSub {$ first $, $ second $}} {
а = первый \;
b = второй \;
sum = first - second \;
\ KwRet sum \;
}
\;
\ SetKwProg {Fn} {Функция} {:} {\ KwRet}
\ Fn {\ FMain} {
а = 5 \;
b = 10 \;
Сумма (5, 10) \;
Sub (5, 10) \;
напечатать Sum, Sub \;
\ KwRet 0 \;
}
\ end {алгоритм}
 n $
n $
\ СОСТОЯНИЕ $ y \ leftarrow 1 $
\ IF {$ n <0 $}
\ СОСТОЯНИЕ $ X \ leftarrow 1 / x $
\ СОСТОЯНИЕ $ N \ leftarrow -n $
\ ELSE
\ СОСТОЯНИЕ $ X \ leftarrow x $
\ STATE $ N \ leftarrow n $
\ ENDIF
\ WHILE {$ N \ neq 0 $}
\ IF {$ N $ четно}
\ СОСТОЯНИЕ $ X \ leftarrow X \ times X $
\ STATE $ N \ leftarrow N / 2 $
\ ELSE [$ N $ нечетное]
\ СОСТОЯНИЕ $ y \ leftarrow y \ times X $
\ STATE $ N \ leftarrow N — 1 $
\ ENDIF
\ ENDWHILE
\ end {алгоритмические}
\ end {algorithm} Однострочные отчеты
\ СОСТОЯНИЕ <текст>
Если операторы
\ IF {<условие>} <текст> \ ENDIF
Петли For
\ FOR {<условие>} <текст> \ ENDFOR
Циклы пока
\ WHILE {<условие>} <текст> \ ENDWHILE
Повторять до состояния
\ REPEAT <текст> \ UNTIL {<условие>}
Бесконечные циклы
\ LOOP <текст> \ ENDLOOP
Предварительные условия
\ REQUIRE <текст>
Постусловие
\ ENSURE <текст>
Возвращаемые переменные
\ RETURN <текст>
Переменные печати
\ PRINT <текст>
