Виды и типы баз данных. Структура реляционных БД. Проектирование БД.
Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем рубрику Заметки о MySQL, в которой я уже успел рассмотреть установку и настройку MySQL сервера баз данных, а также рассмотрел способы изменения кодировок сервера MySQL при помощи команды SET NAMES и файла конфигураций my.ini. Сегодня будет краткая и если можно так сказать теоретическая статья, посвященная вопросу — что такое базы данных и какие базы данных бывают.

В этой статье я постараюсь изложить кратко какие виды и типы баз данных бывают и остановлюсь на некоторых из них более подробно. Мы поговорим о структуре иерархических баз данных, уделим внимание структуре сетевых баз данных, и более подробно остановимся на структуре реляционных базах данных, рассмотрим особенности реляционных баз данных
База данных. Математические модели, структура, определение.
Содержание статьи:
Я хоть и не собираюсь на своем блоге подробно рассказывать про математические законы и теории описывающие реляционные базы данных, но принцип того, как они устроены я рассказать должен, если вас заинтересует данная тема, то вы всегда можете посетить специализированный математический ресурс или почитать соответствующую литературу, а можете всегда задать вопрос в комментариях к данной публикации, и я по мере своих возможностей постараюсь вам ответить. Как я уже говорил, тема данной статьи –
Наверное, самое простое определения баз данных, база данных – это упорядоченное хранение какой-либо информации. То есть, информация хранится в упорядоченном или систематизированном виде. Видов систематизации, упорядочивания и хранения информации может быть множество. Каждый из способов хранения информации отвечает каким-либо специфическим требованиям или предназначен для выполнения каких-либо определенных действий. На страницах своего блога я уже писал, про язык XML, данные в XML структурируются в виде дерева с разветвлениями, узлами и корнем. Но это лишь один из множества способов хранения информации. Более подробно обо всем этом читайте в рубрике Заметки о XML и XLST.
Виды и типы баз данных
Как я уже говорил, видов и типов баз данных очень и очень много и описать их все в данной публикации я просто не смогу, но самые распространенные виды хранения информации или виды баз данных я постараюсь описать. Понятно, что база данных хранит в себе информацию о каких-то объектах, например, информацию о товаре в интернет-магазине. Любой товар в базе данных – это объект с какими-то определенными параметрами и свойствами. Перейдем к конкретным примерам.
Иерархическая база данных, структура иерархических баз данных
Иерархическая база данных – каждый объект при таком хранение информации представляется в виде определенной сущности, то есть, у этой сущности могут быть дочерние элементы, родительские элементы, а у тех дочерних могут быть еще дочерние элементы, но есть один объект, с которого все начинается. Получается своеобразное дерево. Примером иерархической базы данных может быть, документ в формате XML или файловая система компьютера, пример с файловой системой компьютера я приводил, когда рассматривал структуру XML документа, в рубрике Заметки о XML.
Следует сказать, что базы данных подобного вида оптимизированы под чтение информации, то есть, базы данных, имеющие иерархическую структуру умеют очень быстро выбирать, запрашиваемую информацию и отдавать ее пользователям. Но такая структура не позволяет столь же быстро перебирать информацию, тут можно привести пример из жизни, компьютер может легко работать с каким-либо конкретным файлом или папкой (которые, по сути являются объектами иерархической структуры) но проверка компьютера антивирусам осуществляется очень долго. Второй пример – реестр Windows.
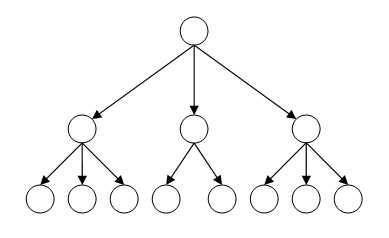
На рисунке вы можете увидеть структуру иерархической базы данных, в самом верху находится родитель или корневой элемент, ниже находятся дочерние элементы, элементы, находящиеся на одном уровне называются братьями, ну или соседними элементами. Соответственно чем ниже уровень элемента, тем вложенность этого элемента больше.
Сетевая база данных, структура сетевых баз данных
Сетевые базы данных, являются своеобразной модификацией иерархических баз данных. Если вы внимательно смотрели на рисунок выше, то наверное обратили внимание, что к каждому нижнему элементу идет только одна стрелочка от верхнего элемента. То есть у иерархических баз данных у каждого дочернего элемента может быть только один потомок. Сетевые базы данных отличаются от иерархических тем, что у дочернего элемента может быть несколько предков, то есть, элементов стоящих выше него. Для большей наглядности и понимания
Стоит заметить, что сетевые базы данных обладают примерно теми же характеристиками, что и иерархические базы данных. Но, в данной рубрике нас не сильно интересуют иерархические и сетевые базы данных, данная тема больше относится к формату XML, и возможно в рубрике посвященной языку расширяемой разметки, я постараюсь более подробно рассмотреть эту тему. А в рубрике посвященной MySQL нас интересуют
Реляционные базы данных, структура реляционных баз данных
Реляционные базы данных получили очень широкое распространение и многие пытаются писать огромные статьи, посвященные вопросу – почему реляционные базы данных получили такое широкое распространение, делают глубокомысленные выводы и замечания. Но на самом деле все очень просто – реляционные базы данных очень легко описываются в математике, то есть, под них очень хорошо написана математика.
Был когда-то такой математик – Эдгар Франк Кодд, умерший в 2003 году, который в восьмидесятых годах очень подробно описал
Особенности реляционных баз данных
Главной особенностью реляционных баз данных является, то, что объекты внутри таких баз данных хранятся в виде набора двумерных таблиц. То есть, таблица состоит из набора столбцов, в котором может указываться: название, тип данных(дата, число, строка, текст и т.д.). Еще одной важной
На самом деле, базы данных – это абстрактное понятие, таблица – это всего лишь способ хранения информации, набор таблиц может быть связан логически и этот набор называют база данных. Поэтому неправильно говорить, что MySQL это база данных, база данных – это хранящаяся информация. А вот такое понятие, как
Самой трудной задачей при работе с реляционными базами данных, является проектирование структуры баз данных. Проектирование структуры базы данных, заключается не только в том, чтобы создать таблицу и указать тип данных и наименование столбцов. На самом деле проектирование – это самый сложный этап при работе с базами данных. Потому что мощности ваших компьютеров ограничены. Пока данных мало, мало таблиц и строк в этих таблицах, машина будет их обрабатывать очень и очень быстро. Но, со временем количество информации будет увеличиваться, и мы получим замедление, которое будет увеличиваться, поскольку машине необходимо время на обработку тех или иных запросов(обработка информации). В прошлой статье я уже писал, что
Проектирование базы данных
Ну что же, мы немного поговорили о достоинствах и недостатках реляционных баз данных
- База данных должна быть как можно более компактна, то есть, неизыбыточна.
- База данных должна быть простой с точки зрения обработки.
И как вы, наверное, поняли, данные требования противоречат друг другу. Проектирование — это самый важный аспект при работе с базами данных. Обычно, проектировщик – это опытный администратор сервера баз данных, либо архитектор баз данных, с большим опытом работы. В серьезных проектах может быть несколько десятков, а то и сотен таблиц, которые связаны между собой самыми замысловатыми способами связи. Конечно, я не собираюсь углубляться в проектирование баз данных, да и не смогу это сделать, но, кое какие основы проектирования баз данных я попытаюсь осветить на страницах своего блога. Прежде чем приступить к проектированию базы данных, нужно понять, а что мы вообще собираемся проектировать. То есть, должны понять, что у нас должно получиться на выходе.
А на выходе мы должны получить так называемую диаграмму или как ее еще называют схема. Диаграмма – это определение: какая информация будет храниться, в какой таблице она будет храниться, в каком столбце какой тип данных, как называется таблица, сколько столбцов в таблице и их тип, как связаны между собой таблицы. Да, типы данных в столбцах могут быть разными, например, номер телефона или индекс можно записать, как с помощью символов, так и с помощью числового типа данных. Но появляется вопрос: какой тип данных лучше для хранения номера телефона или почтового индекса? Чисто интуитивно на этот вопрос чаще всего отвечают правильно – номер телефона в базе данных должен иметь символьный тип, а вот объяснить, почему именно символьный тип могут немногие. Объяснение очень простое, например, нам потребовались все почтовые индексы, начинающиеся на 637 или номера телефонов начинающиеся на 952, так вот, сделать такую выборку из данных имеющих числовой тип задача довольно проблематичная, а сделать такую же выборку из данных символьного типа довольно легко.
При проектировании баз данных очень часто встречаются такие задачи и поверьте, от того, как вы будете их решать, будет зависеть, то, насколько быстро будет работать ваша система, в следующей статье я продолжу вопрос проектирования баз данных.
На этом всё, спасибо за внимание, надеюсь, что был хоть чем-то полезен и до скорых встреч на страницах блога для начинающих вебразработчиков и вебмастеров ZametkiNaPolyah.ru
zametkinapolyah.ru
Понятие и назначение базы данных. Примеры и классификация баз данных
 Без баз данных (БД) практически невозможно себе представить работу современных информационных технологий. В этой статье мы рассмотрим назначение и понятие базы данных, поговорим о том, что же такое база данных, и какая база вам лучше подойдёт. Узнаем, какие существуют типы и виды баз данных и какие из них встречаются сегодня чаще. Также поговорим о структуре иерархических баз данных, упомянем сетевые базы данных, уделим пристальное внимание реляционным базам данных.
Без баз данных (БД) практически невозможно себе представить работу современных информационных технологий. В этой статье мы рассмотрим назначение и понятие базы данных, поговорим о том, что же такое база данных, и какая база вам лучше подойдёт. Узнаем, какие существуют типы и виды баз данных и какие из них встречаются сегодня чаще. Также поговорим о структуре иерархических баз данных, упомянем сетевые базы данных, уделим пристальное внимание реляционным базам данных.
Напоследок рассмотрим особенности проектирования БД и их назначение на примере СУБД MySQL, т. к. эта система управления является, по сути, математической моделью реляционных баз данных. Итак, поехали!
База данных: назначение, понятие, классификация
В нашей статье мы не будем углубляться в математические теории и законы, описывающие базы данных, т. к. подробности всегда можно узнать из специализированной литературы. Но принципы работы БД, особенности управления, терминологию, устройство, назначение, а также такое понятие, как классификация баз данных, сегодня должен знать каждый, кто так или иначе сталкивается с ИТ-сферой, а уж тем более в ней работает.
Итак, самое простое определение баз данных звучит следующим образом: база данных — это упорядоченное хранение информации в систематизированном виде. При этом виды упорядочивания, хранения, систематизации и управления могут быть разные. И каждый из них отвечает определённым требованиям либо предназначен для выполнения определённых действий.
Типы и виды баз данных, классификация
Существует достаточно много типов и видов баз данных, поэтому описывать их все в данной публикации мы не будем. Однако самые распространённые всё же упомянем.
Важно понять, что, говоря о данных, мы подразумеваем определенную информацию, например, о товаре в интернет-магазине. И в этих данных содержатся конкретные параметры и свойства. Однако лучше всего рассматривать БД на конкретных примерах.
Иерархическая база данных, структура иерархических данных
Когда речь идёт о хранении иерархических данных, каждый объект хранит информацию в виде определенной сущности, и у каждой сущности могут быть родительские и дочерние элементы, а у дочерних, в свою очередь, тоже могут быть дочерние элементы. Таким образом, можно сказать, что это данные, которые подлежат строгой иерархии (представьте себе своеобразное дерево).
Простой пример иерархических данных — документ в формате XML либо файловая система компьютера.
Нельзя не упомянуть и то, что базы данных этого вида оптимизированы под чтение информации. При такой структуре данные можно быстро выбирать из нужной области, отдавая запрашиваемую информацию пользователям. Например, компьютер легко работает с конкретной папкой либо файлом, которые, по сути, можно назвать объектами структуры иерархических данных. Но когда нужно перебрать всю информацию, это может занять время (если вернуться к вышеописанному примеру, то проверка антивирусом всех уголков нашего компьютера выполняется не так быстро, как хотелось бы). 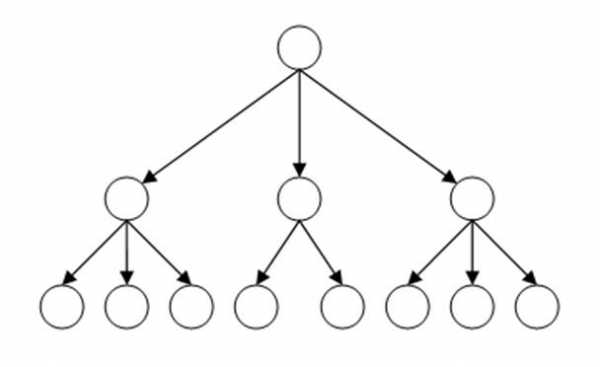 На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
Сетевые базы данных, структура сетевых данных
В каком-то смысле сетевые базы данных — это своеобразная модификация иерархических баз данных. Разница заключается в том, что в структуре иерархических данных у дочернего элемента бывает лишь один потомок (к каждому элементу, расположенному ниже, идёт лишь одна стрелочка с элемента, размещённого выше). А вот в сетевых базах данных у дочернего элемента бывает несколько предков (элементов, находящихся выше него). Для наглядного понимания структуры сетевых данных смотрите очередной рисунок: 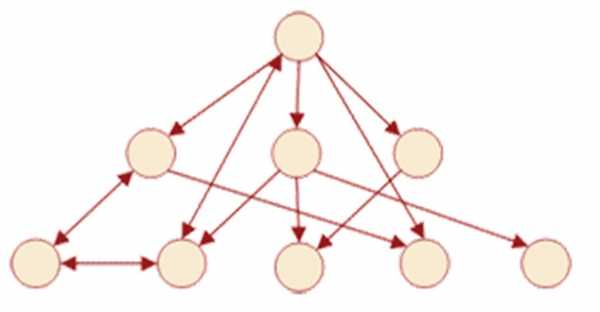 Следует отметить, что сетевые базы данных имеют примерно те же характеристики, что и иерархические данные. Однако в рамках этой статьи мы не будем углубляться в особенности управления сетевыми и иерархическими данными, а лучше подробнее поговорим о реляционных базах данных.
Следует отметить, что сетевые базы данных имеют примерно те же характеристики, что и иерархические данные. Однако в рамках этой статьи мы не будем углубляться в особенности управления сетевыми и иерархическими данными, а лучше подробнее поговорим о реляционных базах данных.
Реляционные базы данных, структура реляционных данных
Реляционные базы данных сегодня распространены очень широко, поэтому в сети можно найти огромное количество материалов на соответствующую тему разного уровня сложности. Кроме того, их проходят на уроках информатики, плюс эти БД хорошо описываются в математике. Структуру данных впервые подробно описал математик Эдгар Франк Кодд (умер в 2003 году), сделав это ещё в 80-х гг. прошлого века. В результате его работ и была создана программная реализация. Реляционные БД стали активно развиваться, поэтому сегодня каждый, кто знаком с базами данных, знает реляционные БД.
Особенности реляционных данных
Главная особенность — все объекты хранятся в виде набора 2-мерных таблиц. Каждая таблица включает в себя набор столбцов, где указываются следующие параметры: — название; — тип данных (число, строка и т. д.).
Вторая важная особенность заключается в том, что число столбцов фиксировано. Это значит, что структура БД известна заранее, при этом количество рядов либо строк данных практически не ограничено. Грубо говоря, строки в реляционных БД — есть объекты, хранимые в базе.
По большему счёту, БД — это абстрактное понятие, а в случае с реляционной структурой таблица — есть не более чем удобный способ хранения информации. Причём набор таблиц превращается в базу данных тогда, когда он связан логически. А чтобы этим всем управлять, используют СУБД. Классический пример СУБД — система управления MySQL. Иными словами, СУБД MySQL — есть программное воплощение математических идей.
Проектирование баз данных
Проектирование — самая трудная задача при работе с данными. Оно заключается не только в том, чтобы создать таблицу, указав наименование столбцов и тип данных. Это гораздо более сложный процесс, требующий специализированных знаний и умений. Говоря о типах баз данных в столбцах, подразумевается, например, способ их записи, который бывает символьный (строковый), числовой, календарный, NULL.
Основная сложность заключается в том, что мощность наших компьютеров ограничена. И пока данных мало, таблиц и строк тоже немного, поэтому машина обрабатывает информацию достаточно быстро. Но с течением времени информации становится всё больше, что может стать причиной снижения быстродействия. Работа машины будет замедляться, времени на обработку запросов потребуется всё больше. Добавить новую запись в таблицу не станет проблемой для реляционной СУБД, а вот выборка данных может превратиться в весьма ресурсоёмкую операцию. Хотя, многое будет зависеть и от настроек СУБД.
Требования к проектированию БД
О видах и особенностях реляционных БД мы уже поговорили. Теперь давайте подробнее обсудим сложности их проектирования. В данном случае этот процесс начинается с постановки задач, исходя из нужных требований, особенностей использования, недостатков либо достоинств той либо иной системы управления. В случае с СУБД MySQL необходимо правильно составить общую структуру.
Требования обычно следующие: 1. База данных должна быть относительно простой в плане обработки информации. 2. Она должна быть максимально компактной и неизбыточной настолько, насколько это возможно без ущерба для функциональности.
Возможны и другие требования, причём нередко они противоречат друг другу. Именно поэтому важно найти оптимальный баланс с точки зрения архитектуры, учитывая назначение конечного продукта.
Так как проектирование — важнейший процесс, им занимается проектировщик. Обычно к работе привлекают профессиональных администраторов серверов либо архитекторов БД, имеющих большой практический опыт. Нужно четко понимать, что проектируется и какие результаты должны получиться на выходе. Это бывает непросто, так как, если речь идёт о серьёзных проектах, готовая структура может включать в себя десятки и сотни таблиц, которые бывают связаны друг с другом как простыми, так и замысловатыми способами.
Результат проектирования — диаграмма или схема. Это подробное схематическое описание, в котором указываются, какие данные будут храниться, сколько столбцов в таблице, тип столбцов в таблице, как связаны таблицы между собой и многое другое. При правильном и грамотном проектировании система будет работать стабильно и без сбоев. В обратном случае ожидайте проблем, так как нет ничего хуже, чем ошибиться на этапе построения архитектуры проекта.
Если вы хотите овладеть базами данных на высоком профессиональном уровне, записывайтесь на соответствующий курс в OTUS. Практикующие эксперты научат вас особенностям управления БД и тому, как эффективно взаимодействовать с любой реляционной СУБД, используя для этого язык структурированных запросов SQL.
otus.ru
Базы данных
Понятие о базах данных
Одной из важнейших областей применения компьютеров является переработка и хранение больших объемов информации в различных сферах деятельности человека: в экономике, банковском деле, торговле, транспорте, медицине, науке и т.д.
Существующие современные информационные системы характеризуются огромными объемами хранимых и обрабатываемых данных, сложной организацией, необходимостью удовлетворять разнообразные требования многочисленных пользователей.
Информационная система — это система, которая реализует автоматизированный сбор, обработку и манипулирование данными и включает технические средства обработки данных, программное обеспечение и обслуживающий персонал.
Цель любой информационной системы — обработка данных об объектах реального мира. Основой информационной системы является база данных. В широком смысле слова база данных — это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления его объектами и, в конечном счете, автоматизации, например, предприятие, вуз и т. д.
Создавая базу данных, пользователь стремится упорядочить информацию по различным признакам и быстро производить выборку с произвольным сочетанием признаков. При этом очень важно выбрать правильную модель данных. Модель данных — это формализованное представление основных категорий восприятия реального мира, представленных его объектами, связями, свойствами, а также их взаимодействиями.
База данных — это информационная модель, позволяющая упорядоченно хранить данные о группе объектов, обладающих одинаковым набором свойств.
Информация в базах данных хранится в упорядоченном виде. Так, в записной книжке все записи упорядочены по алфавиту, а в библиотечном каталоге либо по алфавиту (алфавитный каталог), либо в соответствии с областью знания (предметный каталог).
Система программ, позволяющая создавать БД, обновлять хранимую в ней информацию, обеспечивающая удобный доступ к ней с целью просмотра и поиска, называется системой управления базами данных (СУБД).
Типы баз данных
Группу связанных между собой элементов данных называют обычно записью. Известны три основных типа организации данных и связей между ними: иерархический (в виде дерева), сетевой и реляционный.
Иерархическая БД
В иерархической БД существует упорядоченность элементов в записи, один элемент считается главным, остальные — подчиненными. Данные в записи упорядочены в определенную последовательность, как ступеньки лестницы, и поиск данных может осуществляться лишь последовательным «спуском» со ступеньки на ступеньку. Поиск какого-либо элемента данных в такой системе может оказаться довольно трудоемким из-за необходимости последовательно проходить несколько предшествующих иерархических уровней. Иерархическую БД образует каталог файлов, хранимых на диске; дерево каталогов, доступное для просмотра в Norton Соmmander, — наглядная демонстрация структуры такой БД и поиска в ней нужного элемента (при работе в операционной системе МS-DOS). Такой же базой данных является родовое генеалогическое дерево.
Рисунок 1. Иерархическая модель базы данных
Сетевая БД
Эта база данных отличается большей гибкостью, так как в ней существует возможность устанавливать дополнительно к вертикальным иерархическим связям горизонтальные связи. Это облегчает процесс поиска требуемых элементов данных, так как уже не требует обязательного прохождения всех предшествующих ступеней.
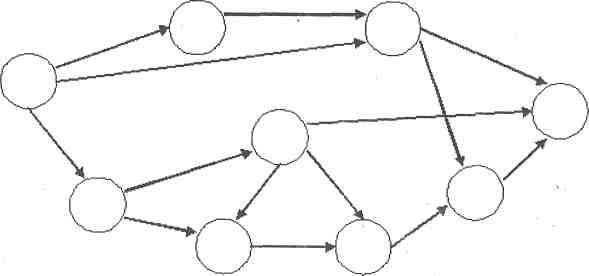
Рисунок 2. Сетевая модель базы данных
Реляционная БД
Наиболее распространенным способом организации данных является третий, к которому можно свести как иерархический, так и сетевой — реляционный (англ. relation — отношение, связь). В реляционной БД под записью понимается строка прямоугольной таблицы. Элементы записи образуют столбцы этой таблицы (поля). Все элементы в столбце имеют одинаковый тип (числовой, символьный), а каждый столбец — неповторяющееся имя. Одинаковые строки в таблице отсутствуют. Преимущество таких БД—наглядность и понятность организации данных, скорость поиска нужной информации. Примером реляционной БД служит таблица на странице классного журнала, в которой записью является строка с данными о конкретном ученике, а имена полей (столбцов) указывают, какие данные о каждом ученике должны быть записаны в ячейках таблицы.
Совокупность БД и программы СУБД образует информационно-поисковую систему, называемую банком данных.
1. По технологии обработки данных базы данных делятся на централизованные и распределенные. Централизованная база данных хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Этот способ использования баз данных часто применяют в локальных сетях ПК. Распределенная база данных состоит из нескольких, возможно, пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД).
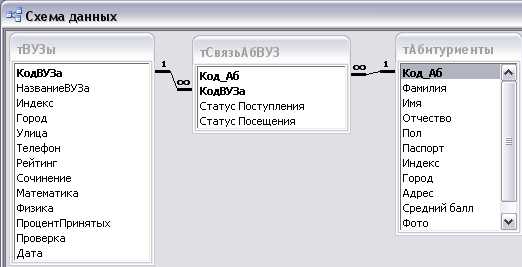
Рис. 3. Реляционная модель базы данных
2. По способу доступа к данным базы данных делятся на базы данных с локальным доступом и базы данных с удаленным (сетевым доступом). Системы централизованных баз данных с сетевым доступом предполагают различные архитектуры таких систем: файл-сервер; клиент-сервер.
Файл-сервер
Архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность такой информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно. Схема обработки информации по принципу файл-сервер изображена на рисунке.
Клиент-сервер
В отличие от предыдущей системы, центральная машина (сервер базы данных), помимо хранения централизованной базы данных, должна обеспечивать выполнение основного объема обработки данных. Запрос на использование данных, выдаваемый клиентом (рабочей станцией), приводит к поиску и извлечению данных на сервере. Извлеченные данные транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент-сервер является использование языка – запросов SQL.
studfile.net
Модели баз данных | Системы управления базами данных
СУБД используют различные модели данных. Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
В иерархической модели элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
Иерархическая модель организует данные в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Рассмотрим в качестве примера иерархической модели данных организацию, хранящую информацию о своём работнике: имя, номер сотрудника, отдел и зарплату. Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. В иерархической базе данных отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Схема иерархической базы данных состоит из нескольких иерархических схем.
В сетевой модели данных у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД. Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Первая модель данных, иерархическая, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Данная публикация представляет собой перевод статьи «Types of Database Models | Database Management System» , подготовленной дружной командой проекта Интернет-технологии.ру
www.internet-technologies.ru
Что такое базы данных и для чего они используются
- Подробности
- декабря 13, 2014
- Просмотров: 28462

База данных представляет собой хранилище данных, в которых данные хранятся в организованном порядке.
Это облегчает функции, такие как извлечение, обновление и добавление новых данных. Базы данных имеют многочисленные применения и преимущества, когда речь идет о больших объемах, данных.
Знаете ли вы что?
«База данных Интеграция» привела к революции в бизнесе, ИТ, и образовательном секторе, предоставляя широкий спектр возможностей для управления и анализа данных.
Структура базы данных
Система базы данных состоит из следующих элементов:
Таблицы: Данные хранятся в строках (записи) и столбцах (поля).
Формы: Формы разработаны с целью ввода новых данных. Чтобы можно было легче и без ошибок добавлять информацию в базу данных через форму, а не вводить данные непосредственно в таблицу.
Запросы: Запросы написаны для извлечения строк и / или столбцов на основе заранее определенного состояния.
Наиболее известные базы данных это: MySQL, SAP, Oracle, IBM DB2 и т.д. СУБД или «система управления базы данных» используется в качестве интерфейса для связи между пользователем и базой данных.
Что такое базы данных и для где они используются?
Хранение данных / Вставка: Начальная фаза (перед вводом данных) включает в себя создание структуры данных, таких как таблицы (с необходимым количеством строк и столбцов). Затем данные вносят в эту структуру.
Восстановление данных: Базы данных используются, когда данные, которые будут храниться в большом количестве нуждаются в постоянном поиске. Это делает процесс извлечения конкретной информации проще.
Данные модификации / Updation: Статические данные не нуждаются в обновлении. Тем не менее, динамические данные нуждаются в постоянной модификации. Рассмотрим возраст сотрудников в организации. Она должна обновляться каждый год (периодическое обновление).
Пример
Рассмотрим развлекательный клуб, который имеет большое количество зарегистрированных людей. Секретарь должен постоянно отслеживать контактные данные всех зарегистрированных пользователей. Если эти записи хранятся в ряде технических описаний или списках, изменение деталей является трудоемкой задачей. Потому что, извлечение и модификация данных должна быть сделана во всех листах, содержащих эти записи в целях сохранения согласованности. Таким образом, целесообразно использовать четко определенную базу данных.
Преимущества баз данных
Емкость хранения: Базы данных хранят большее количество данных по сравнению с другими хранилищами данных. Малогабаритные данные можно вписаться в электронные таблицы или документы. Однако, когда дело доходит до тяжелых данных, базы данных являются лучшим выбором.
Ассоциация данных: записи данных из отдельных таблиц могут быть связаны. Это необходимо, когда определенный фрагмент данных существует в более чем одной таблице. Например, идентификаторы работников могут существовать в таких данных как «Заработная плата», а также «сотрудники». Связь имеет важное значение для того, чтобы иметь единые изменения в нескольких местах и тех же данных.
Несколько пользователей: Разрешения могут быть предоставлены для множественного доступа к базе данных. Это позволяет одновременно нескольким (более одного) пользователям, получить доступ и манипулировать данными.
Удаление данных: Нежелательные требования данных для удаления из базы данных. В таких случаях, записи должны быть удалены из всех связанных таблиц, чтобы избежать каких-либо нарушений данных. Это гораздо проще для удаления записей из базы данных с помощью запросов или форм, а не из других источников данных, таких как таблицы.
Безопасность данных: Файлы данных, хранятся в безопасности, в большинстве случаев. Эта особенность гарантирует, что злоумышленники не получит незаконный доступ к данным, и что их качество поддерживается.
Импорт: Это еще один важный момент в использование баз данных. Он позволяет импортировать внешние объекты (данные из других баз данных). Импорт в основном делается для таблицы или запроса. При вводе, база данных создает копию импортируемого объекта.
Экспорт: В данном случае, таблицы или запросы импортируются другими базами данных.
Связи данных: Это делается для того, чтобы избежать создание копии объекта в базе. Ссылка определяется до требуемого объекта исходной базы данных.
Сортировки данных / Фильтрация: Фильтры могут быть применены к данным, которые имеют одинаковые значения данных. Примером одинаковых данных могут быть имена сотрудников организации с аналогичными фамилиями или именами. Аналогичным образом данные могут быть отсортированы как по возрастанию, так и по убыванию. Это помогает в просмотре или распечатки результатов в требуемом порядке.
Индексация базы данных: Большинство баз данных содержат индекс для хранимых данных, что в конечном итоге повышает время доступа. Тот факт, что линейный поиск данных занимает много времени, делает эту особенность наиболее популярной.
Непрерывные связанные изменения данных: Таблицы с общими данными могут быть связаны с ключами (первичный, вторичный, и т.д.). Ключи очень полезны, потому что изменение общей организации в одной таблице отражается также в связанных таблицах.
Снижает накладные расходы: Передача данных отнимает много времени. Транзакции с помощью запросов очень быстры, таким образом производя более быстрые результаты.
Базы данных упрощают весь смысл хранения и доступа к информации. Тем не менее, предусмотрительность необходима со стороны создателя базы данных, так, чтобы иметь наиболее эффективную базу данных.
Читайте также
juice-health.ru
Реляционные базы данных обречены? / Habr
Примечание переводчика: хоть статья довольно старая (опубликована 2 года назад) и носит громкое название, в ней все же дается хорошее представление о различиях реляционных БД и NoSQL БД, их преимуществах и недостатках, а также приводится краткий обзор нереляционных хранилищ.
В последнее время появилось много нереляционных баз данных. Это говорит о том, что если вам нужна практически неограниченная масштабируемость по требованию, вам нужна нереляционная БД.
Если это правда, значит ли это, что могучие реляционные БД стали уязвимы? Значит ли это, что дни реляционных БД проходят и скоро совсем пройдут? В этой статье мы рассмотрим популярное течение нереляционных баз данных применительно к различным ситуациям и посмотрим, повлияет ли это на будущее реляционных БД.
Реляционные базы данных существуют уже около 30 лет. За это время вспыхивало несколько революций, которые должны были положить конец реляционным хранилищам. Конечно, ни одна из этих революций не состоялась, и одна из них ни на йоту не поколебала позиции реляционных БД.
Начнем с основ
Реляционная база данных представляет собой набор таблиц (сущностей). Таблицы состоят из колонок и строк (кортежей). Внутри таблиц могут быть определены ограничения, между таблицами существуют отношения. При помощи SQL можно выполнять запросы, которые возвращают наборы данных, получаемых из одной или нескольких таблиц. В рамках одного запроса данные получаются из нескольких таблиц путем их соединения (JOIN), чаще всего для соединения используются те же колонки, которые определяют отношения между таблицами. Нормализация — это процесс структурирования модели данных, обеспечивающий связность и отсутствие избыточности в данных.
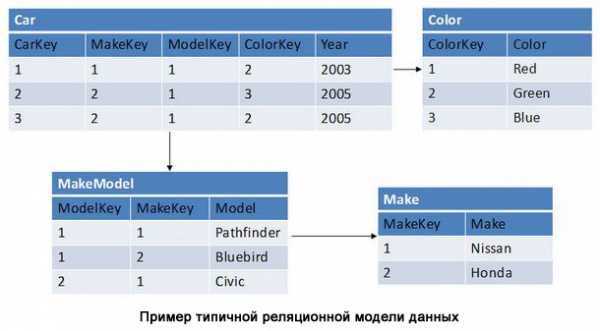
Доступ к реляционным базам данных осуществляется через реляционные системы управления базами данных (РСУБД). Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее.
Причины такого доминирования неочевидны. На протяжении всего существования реляционных БД они постоянно предлагали наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости в сфере управлении данными.
Однако чтобы обеспечить все эти особенности, реляционные хранилища невероятно сложны внутри. Например, простой SELECT запрос может иметь сотни потенциальных путей выполнения, которые оптимизатор оценит непосредственно во время выполнения запроса. Все это скрыто от пользователей, однако внутри РСУБД создает план выполнения, основывающийся на вещах вроде алгоритмов оценки стоимости и наилучшим образом отвечающий запросу.
Проблемы реляционных БД
Хотя реляционные хранилища и обеспечивают наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости, их показатели по каждому из этих пунктов не обязательно выше, чем у аналогичных систем, ориентированных на какую-то одну особенность. Это не являлось большой проблемой, поскольку всеобщее доминирование реляционных СУБД перевешивало какие-либо недочеты. Тем не менее, если обычные РБД не отвечали потребностям, всегда существовали альтернативы.
Сегодня ситуация немного другая. Разнообразие приложений растет, а с ним растет и важность перечисленных особенностей. И с ростом количества баз данных, одна особенность начинает затмевать все другие. Это масштабируемость. Поскольку все больше приложений работают в условиях высокой нагрузки, например, таких как веб-сервисы, их требования к масштабируемости могут очень быстро меняться и сильно расти. Первую проблему может быть очень сложно разрешить, если у вас есть реляционная БД, расположенная на собственном сервере. Предположим, нагрузка на сервер за ночь увеличилась втрое. Как быстро вы сможете проапгрейдить железо? Решение второй проблемы также вызывает трудности в случае использования реляционных БД.
Реляционные БД хорошо масштабируются только в том случае, если располагаются на единственном сервере. Когда ресурсы этого сервера закончатся, вам необходимо будет добавить больше машин и распределить нагрузку между ними. И вот тут сложность реляционных БД начинает играть против масштабируемости. Если вы попробуете увеличить количество серверов не до нескольких штук, а до сотни или тысячи, сложность возрастет на порядок, и характеристики, которые делают реляционные БД такими привлекательными, стремительно снижают к нулю шансы использовать их в качестве платформы для больших распределенных систем.
Чтобы оставаться конкурентоспособными, вендорам облачных сервисов приходится как-то бороться с этим ограничением, потому что какая ж это облачная платформа без масштабируемого хранилища данных. Поэтому у вендоров остается только один вариант, если они хотят предоставлять пользователям масштабируемое место для хранения данных. Нужно применять другие типы баз данных, которые обладают более высокой способностью к масштабированию, пусть и ценой других возможностей, доступных в реляционных БД.
Эти преимущества, а также существующий спрос на них, привел к волне новых систем управления базами данных.
Новая волна
Такой тип баз данных принято называть хранилище типа ключ-значение (key-value store). Фактически, никакого официального названия не существует, поэтому вы можете встретить его в контексте документо-ориентированных, атрибутно-ориентированных, распределенных баз данных (хотя они также могут быть реляционными), шардированных упорядоченных массивов (sharded sorted arrays), распределенных хэш-таблиц и хранилищ типа ключ-значения. И хотя каждое из этих названий указывает на конкретные особенности системы, все они являются вариациями на тему, которую мы будем назвать хранилище типа ключ-значение.
Впрочем, как бы вы его не называли, этот «новый» тип баз данных не такой уж новый и всегда применялся в основном для приложений, для которых использование реляционных БД было бы непригодно. Однако без потребности веба и «облака» в масштабируемости, эти системы оставались не сильно востребованными. Теперь же задача состоит в том, чтобы определить, какой тип хранилища больше подходит для конкретной системы.
Реляционные БД и хранилища типа ключ-значение отличаются коренным образом и предназначены для решения разных задач. Сравнение характеристик позволит всего лишь понять разницу между ними, однако начнем с этого:
Характеристики хранилищ
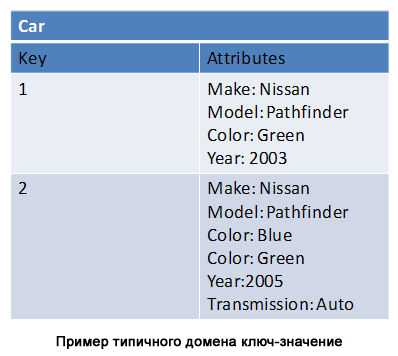
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| База данных состоит из таблиц, таблицы содержат колонки и строки, а строки состоят из значений колонок. Все строки одной таблицы имеют единую структуру. |
Для доменов можно провести аналогию с таблицами, однако в отличие от таблиц для доменов не определяется структура данных. Домен – это такая коробка, в которую вы можете складывать все что угодно. Записи внутри одного домена могут иметь разную структуру. |
| Модель данных1 определена заранее. Является строго типизированной, содержит ограничения и отношения для обеспечения целостности данных. |
Записи идентифицируются по ключу, при этом каждая запись имеет динамический набор атрибутов, связанных с ней. |
| Модель данных основана на естественном представлении содержащихся данных, а не на функциональности приложения. |
В некоторых реализация атрибуты могут быть только строковыми. В других реализациях атрибуты имеют простые типы данных, которые отражают типы, использующиеся в программировании: целые числа, массива строк и списки. |
| Модель данных подвергается нормализации, чтобы избежать дублирования данных. Нормализация порождает отношения между таблицами. Отношения связывают данные разных таблиц. |
Между доменами, также как и внутри одного домена, отношения явно не определены. |
Никаких join’ов
Хранилища типа ключ-значение ориентированы на работу с записями. Это значит, что вся информация, относящаяся к данной записи, хранится вместе с ней. Домен (о котором вы можете думать как о таблице) может содержать бессчетное количество различных записей. Например, домен может содержать информацию о клиентах и о заказах. Это означает, что данные, как правило, дублируются между разными доменами. Это приемлемый подход, поскольку дисковое пространство дешево. Главное, что он позволяет все связанные данные хранить в одном месте, что улучшает масштабируемость, поскольку исчезает необходимость соединять данные из различных таблиц. При использовании реляционной БД, потребовалось бы использовать соединения, чтобы сгруппировать в одном месте нужную информацию.
Хотя для хранения пар ключ-значение потребность в отношения резко падает, отношения все же нужны. Такие отношения обычно существуют между основными сущностями. Например, система заказов имела бы записи, которые содержат данные о покупателях, товарах и заказах. При этом неважно, находятся ли эти данные в одном домене или в нескольких. Суть в том, что когда покупатель размещает заказ, вам скорее всего не захочется хранить информацию о покупателе и о заказе в одной записи.
Вместо этого, запись о заказе должна содержать ключи, которые указывают на соответствующие записи о покупателе и товаре. Поскольку в записях можно хранить любую информацию, а отношения не определены в самой модели данных, система управления базой данных не сможет проконтролировать целостность отношений. Это значит, что вы можете удалять покупателей и товары, которые они заказывали. Обеспечение целостности данных целиком ложится на приложение.
Доступ к данным
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| Данные создаются, обновляются, удаляются и запрашиваются с использованием языка структурированных запросов (SQL). |
Данные создаются, обновляются, удаляются и запрашиваются с использованием вызова API методов. |
| SQL-запросы могут извлекать данные как из одиночной таблица, так и из нескольких таблиц, используя при этом соединения (join’ы). |
Некоторые реализации предоставляют SQL-подобный синтаксис для задания условий фильтрации. |
| SQL-запросы могут включать агрегации и сложные фильтры. |
Зачастую можно использовать только базовые операторы сравнений (=, !=, <, >, <= и =>). |
| Реляционная БД обычно содержит встроенную логику, такую как триггеры, хранимые процедуры и функции. |
Вся бизнес-логика и логика для поддержки целостности данных содержится в коде приложений. |
Взаимодействие с приложениями
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| Чаще всего используются собственные API, или обобщенные, такие как OLE DB или ODBC. |
Чаще всего используются SOAP и/или REST API, с помощью которых осуществляется доступ к данным. |
| Данные хранятся в формате, который отображает их натуральную структуру, поэтому необходим маппинг структур приложения и реляционных структур базы. |
Данные могут более эффективно отображаться в структуры приложения, нужен только код для записи данных в объекты. |
Хранилища типа ключ-значение: преимущества
Есть два четких преимущества таких систем перед реляционными хранилищами.
Подходят для облачных сервисов
Первое преимущество хранилищ типа ключ-значение состоит в том, что они проще, а значит обладают большей масштабируемостью, чем реляционные БД. Если вы размещаете вместе собственную систему, и планируете разместить дюжину или сотню серверов, которым потребуется справляться с возрастающей нагрузкой, за вашим хранилищем данных, тогда ваш выбор – хранилища типа ключ-значение.
Благодаря тому, что такие хранилища легко и динамически расширяются, они также пригодятся вендорам, которые предоставляют многопользовательскую веб-платформу хранения данных. Такая база представляет относительно дешевое средство хранения данных с большим потенциалом к масштабируемости. Пользователи обычно платят только за то, что они используют, однако их потребности могут вырасти. Вендор сможет динамически и практически без ограничений увеличить размер платформы, исходя из нагрузки.
Более естественная интеграция с кодом
Реляционная модель данных и объектная модель кода обычно строятся по-разному, что ведет к некоторой несовместимости. Разработчики решают эту проблему при помощи написания кода, который отображает реляционную модель в объектную модель. Этот процесс не имеет четкой и быстро достижимой ценности и может занять довольно значительное время, которое могло быть потрачено на разработку самого приложения. Тем временем многие хранилища типа ключ-значение хранят данные в такой структуре, которая отображается в объекты более естественно. Это может существенно уменьшить время разработки.
Другие аргументы в пользу использования хранилищ типа ключ-значение, наподобие «Реляционные базы могут стать неуклюжими» (кстати, я без понятия, что это значит), являются менее убедительными. Но прежде чем стать сторонником таких хранилищ, ознакомьтесь со следующим разделом.
Хранилища типа ключ-значение: недостатки
Ограничения в реляционных БД гарантируют целостность данных на самом низком уровне. Данные, которые не удовлетворяют ограничениям, физически не могут попасть в базу. В хранилищах типа ключ-значение таких ограничений нет, поэтому контроль целостности данных полностью лежит на приложениях. Однако в любом коде есть ошибки. Если ошибки в правильно спроектированной реляционной БД обычно не ведут к проблемам целостности данных, то ошибки в хранилищах типа ключ-значение обычно приводят к таким проблемам.
Другое преимущество реляционных БД заключается в том, что они вынуждают вас пройти через процесс разработки модели данных. Если вы хорошо спроектировали модель, то база данных будет содержать логическую структуру, которая полностью отражает структуру хранимых данных, однако расходится со структурой приложения. Таким образом, данные становятся независимы от приложения. Это значит, что другое приложение сможет использовать те же самые данные и логика приложения может быть изменена без каких-либо изменений в модели базы. Чтобы проделать то же самое с хранилищем типа ключ-значение, попробуйте заменить процесс проектирования реляционной модели проектированием классов, при котором создаются общие классы, основанные на естественной структуре данных.
И не забудьте о совместимости. В отличие от реляционных БД, хранилища, ориентированные на использование в «облаке», имеют гораздо меньше общих стандартов. Хоть концептуально они и не отличаются, они все имеют разные API, интерфейсы запросов и свою специфику. Поэтому вам лучше доверять вашему вендору, потому что в случае чего, вы не сможете легко переключиться на другого поставщика услуг. А учитывая тот факт, что почти все современные хранилища типа ключ-значение находятся в стадии бета-версий2, доверять становится еще рискованнее, чем в случае использования реляционных БД.
Ограниченная аналитика данных
Обычно все облачные хранилища строятся по типу множественной аренды, что означает, что одну и ту же систему использует большое количество пользователей и приложений. Чтобы предотвратить «захват» общей системы, вендоры обычно каким-то образом ограничивают выполнение запросов. Например, в SimpleDB запрос не может выполняться дольше 5 секунд. В Google AppEngine Datastore за один запрос нельзя получить больше, чем 1000 записей3.
Эти ограничения не страшны для простой логики (создание, обновление, удаление и извлечение небольшого количества записей). Но что если ваше приложение становится популярным? Вы получили много новых пользователей и много новых данных, и теперь хотите сделать новые возможности для пользователей или каким-то образом извлечь выгоду из данных. Тут вы можете жестко обломаться с выполнением даже простых запросов для анализа данных. Фичи наподобие отслеживания шаблонов использования приложения или системы рекомендаций, основанной на истории пользователя, в лучшем случае могут оказаться сложны в реализации. А в худшем — просто невозможны.
В таком случае для аналитики лучше сделать отдельную базу данных, которая будет заполняться данными из вашего хранилища типа ключ-значение. Продумайте заранее, каким образом это можно будет сделать. Будете ли вы размещать сервер в облаке или у себя? Не будет ли проблем из-за задержек сигнала между вами и вашим провайдером? Поддерживает ли ваше хранилище такой перенос данных? Если у вас 100 миллионов записей, а за один раз вы можете взять 1000 записей, сколько потребуется на перенос всех данных?
Однако не ставьте масштабируемость превыше всего. Она будет бесполезна, если ваши пользователи решат пользоваться услугами другого сервиса, потому что тот предоставляет больше возможностей и настроек.
Облачные хранилища
Множество поставщиков веб-сервисов предлагают многопользовательские хранилища типа ключ-значение. Большинство из них удовлетворяют критериям, перечисленным выше, однако каждое обладает своими отличительными фичами и отличается от стандартов, описанных выше. Давайте взглянем на конкретные пример хранилищ, такие как SimpleDB, Google AppEngine Datastore и SQL Data Services.
Amazon: SimpleDB
SimpleDB — это атрибутно-ориентированное хранилище типа ключ-значение, входящее в состав Amazon WebServices. SimpleDB находится в стадии бета-версии; пользователи могут пользовать ей бесплатно — до тех пор пока их потребности не превысят определенный предел.
У SimpleDB есть несколько ограничений. Первое — время выполнения запроса ограничено 5-ю секундами. Второе — нет никаких типов данных, кроме строк. Все хранится, извлекается и сравнивается как строка, поэтому для того, чтобы сравнить даты, вам нужно будет преобразовать их в формат ISO8601. Третье — максимальные размер любой строки составляет 1024 байта, что ограничивает размер текста (например, описание товара), который вы можете хранить в качестве атрибута. Однако поскольку структура данных гибкая, вы можете обойти это ограничения, добавляя атрибуты «ОписаниеТовара1», «Описание товара2» и т.д. Но количество атрибутов также ограничено — максимум 256 атрибутов. Пока SimpleDB находится в стадии бета-версии, размер домена ограничен 10-ю гигабайтами, а вся база не может занимать больше 1-го терабайта.
Одной из ключевых особенностей SimpleDB является использование модели конечной констистенции (eventual consistency model). Эта модель подходит для многопоточной работы, однако следует иметь в виду, что после того, как вы изменили значение атрибута в какой-то записи, при последующих операциях чтения эти изменения могут быть не видны. Вероятность такого развития событий достаточно низкая, тем не менее, о ней нужно помнить. Вы же не хотите продать последний билет пяти покупателям только потому, что ваши данные были неконсистентны в момент продажи.
Google AppEngine Data Store
Google’s AppEngine Datastore построен на основе BigTable, внутренней системе хранения структурированных данных от Google. AppEngine Datastore не предоставляет прямой доступ к BigTable, но может восприниматься как упрощенный интерфейс взаимодействия с BigTable.
AppEngine Datastore поддерживает большее число типов данных внутри одной записи, нежели SimpleDB. Например, списки, которые могут содержать коллекции внутри записи.
Скорее всего вы будете использовать именно это хранилище данных при разработке с помощью Google AppEngine. Однако в отличии от SimpleDB, вы не сможете использовать AppEngine Datastore (или BigTable) вне веб-сервисов Google.
Microsoft: SQL Data Services
SQL Data Services является частью платформы Microsoft Azure. SQL Data Services является бесплатной, находится в стадии бета-версии и имеет ограничения на размер базы. SQL Data Services представляет собой отдельное приложение — надстройку над множеством SQL серверов, которые и хранят данные. Эти хранилища могут быть реляционными, однако для вас SDS является хранилищем типа ключ-значение, как и описанные выше продукты.
Необлачные хранилища
Существует также ряд хранилищ, которыми вы можете воспользоваться вне облака, установив их у себя. Почти все эти проекты являются молодыми, находятся в стадии альфа- или бета-версии, и имеют открытый код. С открытыми исходниками вы, возможно, будете больше осведомлены о возможных проблемах и ограничениях, нежели в случае использования закрытых продуктов.
CouchDB
CouchDB — это свободно распространяемая документо-ориентированная БД с открытым исходным кодом. В качестве формата хранения данных используется JSON. CouchDB призвана заполнить пробел между документо-ориентированными и реляционными базами данных с помощью «представлений». Такие представления содержат данные из документов в виде, схожим с табличным, и позволяют строить индексы и выполнять запросы.
В настоящее время CouchDB не является по-настоящему распределенной БД. В ней есть функции репликации, позволяющие синхронизировать данные между серверами, однако это не та распределенность, которая нужна для построения высокомасштабируемого окружения. Однако разработчики CouchDB работают над этим.
Проект Voldemort
Проект Voldemort — это распределенная база данных типа ключ-значение, предназначенная для горизонтального масштабирования на большом количестве серверов. Он родилась в процессе разработки LinkedIn и использовалась для нескольких систем, имеющих высокие требования к масштабируемости. В проекте Voldemort также используется модель конечной консистенции.
Mongo
Mongo — это база данных, разрабатываемая в 10gen Гейром Магнуссоном и Дуайтом Меррименом (которого вы можете знать по DoubleClick). Как и CouchDB, Mongo — это документо-ориентированная база данных, хранящая данные в JSON формате. Однако Mongo скорее является объектной базой, нежели чистым хранилищем типа ключ-значение.
Drizzle
Drizzle представляет совсем другой подход к решению проблем, с которыми призваны бороться хранилища типа ключ-значение. Drizzle начинался как одна из веток MySQL 6.0. Позже разработчики удалили ряд функций (включая представления, триггеры, скомпилированные выражения, хранимые процедуры, кэш запросов, ACL, и часть типов данных), с целью создания более простой и быстрой СУБД. Тем не менее, Drizzle все еще можно использовать для хранения реляционных данных. Цель разработчиков — построить полуреляционную платформу, предназначенную для веб-приложений и облачных приложений, работающих на системах с 16-ю и более ядрами.
Решение
В конечном счете, есть четыре причины, по которым вы можете выбрать нереляционное хранилище типа ключ-значение для своего приложения:
- Ваши данные сильно документо-ориентированны, и больше подходят для модели данных ключ-значение, чем для реляционной модели.
- Ваша доменная модель сильно объектно-ориентированна, поэтому использования хранилища типа ключ-значение уменьшит размер дополнительного кода для преобразования данных.
- Хранилище данных дешево и легко интегрируется с веб-сервисами вашего вендора.
- Ваша главная проблема — высокая масштабируемость по запросу.
Однако принимая решение, помните об ограничениях конкретных БД и о рисках, которые вы встретите, пойдя по пути использования нереляционных БД.
Для всех остальных требований лучше выбрать старые добрые реляционные СУБД. Так обречены ли они? Конечно, нет. По крайней мере, пока.
1 — по моему мнению, здесь больше подходит термин «структура данных», однако оставил оригинальное data model.
2 — скорее всего, автор имел в виду, что по своим возможностям нереляционные БД уступают реляционным.
3 — возможно, данные уже устарели, статья датируется февралем 2009 года.
habr.com
Базы данных: основные понятия
База данных— организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупностьданных, характеризующая актуальное состояние некоторойпредметной областии используемая для удовлетворения информационныхпотребностейпользователей.
Централизованная, или сосредоточенная (англ. centralized database): БД, полностью поддерживаемая на одном компьютере.
Распределённая (англ. distributed database): БД, составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
Неоднородная (англ. heterogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД
Однородная (англ. homogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
Фрагментированная, или секционированная (англ. partitioned database): методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
Тиражированная (англ. replicated database): методом распределения данных является тиражирование (репликация).
→ Понятійний словник сторінки
В жизни мы часто сталкиваемся с необходимостью хранить какую-либо информацию, а потому часто имеем дело и с базами данных. Например, мы используем записную книжку для хранения номеров телефонов своих друзей и планирования своего времени. Телефонная книга содержит информацию о людях, живущих в одном городе. Все это своего рода базы данных. Ну а раз это базы данных, то посмотрим, как в них хранятся данные. Например, телефонная книга представляет собой таблицу (табл. 10.1).
В этой таблице данные – это собственно номера телефонов, адреса и ФИО., т.е. строки «Иванов Иван Иванович», «32-43-12» и т.п., а названия столбцов этой таблицы, т.е. строки «ФИО», «Номер телефона» и «Адрес» задают смысл этих данных, их семантику.
Таблица 10.1. Пример базы данных: телефонная книга | ||
ФИО | Номер телефона | Адрес |
Иванов Иван Иванович | 32-43-12 | ул. Ленина, 12, 43 |
Ильин Федор Иванович | 32-32-34 | пр. Маркса, 32, 45 |
Теперь представьте, что записей в этой таблице не две, а две тысячи, вы занимаетесь созданием этого справочника и где-то произошла ошибка (например, опечатка в адресе). Видимо, тяжеловато будет найти и исправить эту ошибку вручную. Нужно воспользоваться какими-то средствами автоматизации. Для управления большим количеством данных программисты (не без помощи математиков) придумали системы управления базами данных (СУБД). По сравнению с текстовыми базами данных электронныеСУБДимеют огромное число преимуществ, от возможности быстрого поиска информации, взаимосвязи данных между собой до использования этих данных в различных прикладных программах и одновременного доступа к данным нескольких пользователей.
Для точности дадим определение базы данных, предлагаемое Глоссарий.ру
База данных– это совокупность связанных данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования, независимая от прикладных программ.База данныхявляется информационной моделью предметной области. Обращение к базам данных осуществляется с помощью системы управления базами данных (СУБД).СУБДобеспечивает поддержку создания баз данных, централизованного управления и организации доступа к ним различных пользователей.
Итак, мы пришли к выводу, что хранить данные независимо от программ, так, что они связаны между собой и организованы по определенным правилам, целесообразно. Но вопрос, как хранить данные, по каким правилам они должны быть организованы, остался открытым. Способов существует множество (кстати, называются они моделями представления или хранения данных). Наиболее популярные – объектная и реляционная модели данных.
Автором реляционной моделисчитается Э. Кодд, который первым предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение) и показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение.
Таким образом, реляционная база данныхпредставляет собой набор таблиц (точно таких же, как приведенная выше), связанных между собой. Строка в таблице соответствует сущности реального мира (в приведенном выше примере это информация о человеке).
Примеры реляционных СУБД: MySql, PostgreSql.
В основу объектной моделиположена концепция объектно-ориентированного программирования, в которой данные представляются в виде набора объектов и классов, связанных между собой родственными отношениями, а работа с объектами осуществляется с помощью скрытых (инкапсулированных) в них методов.
Примеры объектных СУБД: Cache, GemStone (от Servio Corporation), ONTOS (ONTOS).
В последнее время производители СУБДстремятся соединить два этих подхода и проповедуют объектно-реляционную модель представления данных. Примеры такихСУБД– IBM DB2 for Common Servers, Oracle8.
Поскольку мы собираемся работать с Mysql, то будем обсуждать аспекты работы только с реляционными базами данных. Нам осталось рассмотреть еще два важных понятия из этой области: ключи и индексирование, после чего мы сможем приступить к изучению языка запросов SQL.
Ключи
Для начала давайте подумаем над таким вопросом: какую информацию нужно дать о человеке, чтобы собеседник точно сказал, что это именно тот человек, сомнений быть не может, второго такого нет? Сообщить фамилию, очевидно, недостаточно, поскольку существуют однофамильцы. Если собеседник человек, то мы можем приблизительно объяснить, о ком речь, например вспомнить поступок, который совершил тот человек, или еще как-то. Компьютер же такого объяснения не поймет, ему нужны четкие правила, как определить, о ком идет речь. В системах управления базами данных для решения такой задачи ввели понятие первичного ключа.
Первичный ключ (primary key, PK) – минимальный набор полей, уникально идентифицирующий запись в таблице. Значит, первичный ключ – это в первую очередь набор полей таблицы, во-вторых, каждый набор значений этих полей должен определять единственную запись (строку) в таблице и, в-третьих, этот набор полей должен быть минимальным из всех обладающих таким же свойством. Поскольку первичный ключ определяет только одну уникальную запись, то никакие две записи таблицы не могут иметь одинаковых значений первичного ключа.
Например, в нашей таблице (см. выше) ФИО и адрес позволяют однозначно выделить запись о человеке. Если же говорить в общем, без связи с решаемой задачей, то такие знания не позволяют точно указать на единственного человека, поскольку существуют однофамильцы, живущие в разных городах по одному адресу. Все дело в границах, которые мы сами себе задаем. Если считаем, что знания ФИО, телефона и адреса без указания города для наших целей достаточно, то все замечательно, тогда поля ФИО и адрес могут образовывать первичный ключ. В любом случае проблема создания первичного ключа ложится на плечи того, кто проектирует базу данных (разрабатывает структуру хранения данных). Решением этой проблемы может стать либо выделение характеристик, которые естественным образом определяют запись в таблице (задание так называемого логического, или естественного, PK), либо создание дополнительного поля, предназначенного именно для однозначной идентификации записей в таблице (задание так называемого суррогатного, или искусственного, PK). Примером логического первичного ключа является номер паспорта в базе данных о паспортных данных жителей или ФИО и адрес в телефонной книге (таблица выше). Для задания суррогатного первичного ключа в нашу таблицу можно добавить поле id (идентификатор), значением которого будет целое число, уникальное для каждой строки таблицы. Использование таких суррогатных ключей имеет смысл, если естественный первичный ключ представляет собой большой набор полей или его выделение нетривиально.
Кроме однозначной идентификации записи, первичные ключи используются для организации связей с другими таблицами.
Например, у нас есть три таблицы: содержащая информацию об исторических личностях (Persons), содержащая информацию об их изобретениях (Artifacts) и содержащая изображения как личностей, так и артефактов (Images) (рис 10.1).
Первичным ключом во всех этих таблицах является поле id (идентификатор). В таблице Artifacts есть поле author, в котором записан идентификатор, присвоенный автору изобретения в таблице Persons. Каждое значение этого поля является внешним ключомдля первичного ключа таблицы Persons. Кроме того, в таблицах Persons и Artifacts есть поле photo, которое ссылается на изображение в таблице Images. Эти поля также являются внешними ключами для первичного ключа таблицы Images и устанавливают однозначную логическую связь Persons-Images и Artifacts-Images. То есть если значение внешнего ключа photo в таблице личности равно 10, то это значит, что фотография этой личности имеет id=10 в таблице изображений. Таким образом,внешние ключииспользуются для организации связей между таблицами базы данных (родительскими и дочерними) и для поддержания ограничений ссылочной целостности данных.
Рис. 10.1.Пример использования первичных ключей для организации связей с другими таблицами
Одна из основных задач, возникающих при работе с базами данных, – это задача поиска. При этом, поскольку информации в базе данных, как правило, содержится много, перед программистами встает задача не просто поиска, а эффективного поиска, т.е. поиска за сравнительно небольшое время и с достаточной точностью. Для этого (для оптимизации производительности запросов) производят индексированиенекоторых полей таблицы. Использовать индексы полезно для быстрого поиска строк с указанным значением одного столбца. Без индекса чтение таблицы осуществляется по всей таблице, начиная с первой записи, пока не будут найдены соответствующие строки. Чем больше таблица, тем больше накладные расходы. Если же таблица содержит индекс по рассматриваемым столбцам, тобаза данныхможет быстро определить позицию для поиска в середине файла данных без просмотра всех данных. Это происходит потому, чтобаза данныхпомещает проиндексированные поля поближе в памяти, так, чтобы можно было побыстрее найти их значения. Для таблицы, содержащей 1000 строк, это будет как минимум в 100 раз быстрее по сравнению с последовательным перебором всех записей. Однако в случае, когда необходим доступ почти ко всем 1000 строкам, быстрее будет последовательное чтение, так как при этом не требуется операций поиска по диску. Так что иногда индексы бывают только помехой. Например, если копируется большой объем данных в таблицу, то лучше не иметь никаких индексов. Однако в некоторых случаях требуется задействовать сразу несколько индексов (например, для обработки запросов к часто используемым таблицам).
Если говорить о MySQL, то там существует три вида индексов: PRIMARY, UNIQUE, и INDEX, а слово ключ (KEY) используется как синоним слова индекс (INDEX). Все индексы хранятся в памяти в виде B-деревьев.
PRIMARY – уникальный индекс (ключ) с ограничением, что все индексированные им поля не могут иметь пустого значения (т.е. они NOT NULL). Таблица может иметь только один первичный индекс, но он может состоять из нескольких полей.
UNIQUE – ключ (индекс), задающий поля, которые могут иметь только уникальные значения.
INDEX – обычный индекс (как мы описали выше). В MySqL, кроме того, можно индексировать строковые поля по заданному числу символов от начала строки.
Компьютеры были созданы для решения вычислительных задач, однако со временем они все чаще стали использоваться для построения систем обработки документов, а точнее, содержащейся в них информации. Такие системы обычно и называют информационными. В качестве примера можно привести систему учета отработанного времени работниками предприятия и расчета заработной платы, систему учета продукции на складе, систему учета книг в библиотеке и т.д. Все вышеперечисленные системы имеют следующие особенности:
Другими словами, информационная система требует создания в памяти ЭВМ динамически обновляемоймодели внешнего мира с использованием единого хранилища —базы данных. Для дальнейшего обсуждения нам необходимо ввести понятие предметной области:
Предметная область— часть реального мира, подлежащая изучению с целью организации управления и, в конечном счете, автоматизации. Предметная область представляется множествомфрагментов, например, предприятие — цехами, дирекцией, бухгалтерией и т.д. Каждый фрагмент предметной области харакетризуется множествомобъектовипроцессов, использующих объекты, а также множествомпользователей, характеризуемых различными взглядами на предметную область.
Словосочетание «динамически обновляемая» означает, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени. При этом одни и те же данные могут быть по-разному представлены в соответствии с потребностями различных групп пользователей.
Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. Независимые от программ пользователя данные обычно называются метаданными. В ряде современных систем метаданные, содержащие также информацию о пользователях, форматы отображения, статистику обращения к данным и др. сведения,хранятся в словаре базы данных.
Таким образом, система управления базой данных(СУБД) — важнейший компонент информационной системы. Для создания и управления информационной системой СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор. Основные функции СУБД:
Обычно современная СУБД содержит следующие компоненты (см. рис.):
studfile.net