Файл robots txt для сайта на WordPress, Joomla, OpenCart, Bitrix
СОДЕРЖАНИЕ
Файл robots.txt для сайта
Где находится robots.txt на сайте?
Директивы robots.txt
Правило Disallow
Правило Allow
User-agent
Sitemap
Host
Crawl delay
Clean param
Самые частые вопросы
Как в robots.txt запретить индексацию?
Как в robots.txt указать главное зеркало?
Простейший пример правильного robots.txt
Закрытый от индексации сайт – как выглядит robots.txt?
Как указать главное зеркало для сайта на https robots.txt?
Наиболее частые ошибки в robots.txt
Онлайн-проверка файла robots.txt
Готовые решения для самых популярных CMS
robots.txt для WordPress
robots.txt для Joomla
robots.txt Wix
robots.txt для Opencart
robots.txt для Битрикс (Bitrix)
robots.txt для Modx
Выводы
Файл robots.txt для сайта
Robots.txt для сайта – это индексный текстовый файл в кодировке UTF-8.
Индексным его назвали потому, что в нем прописываются рекомендации для поисковых роботов – какие страницы нужно просканировать, а какие не нужно.
Если кодировка файла отличается от UTF-8, то поисковые роботы могут неправильно воспринимать находящуюся в нем информацию.
Файл действителен для протоколов http, https, ftp, а также имеет «силу» только в пределах хоста/протокола/номера порта, на котором размещен.
Где находится robots.txt на сайте?
У файла robots.txt может быть только одно расположение – корневой каталог на хостинге. Выглядит это примерно вот так: http://vash-site.xyz/robots.txt
Директивы файла robots txt для сайта
Обязательными составляющими файла robots.txt для сайта являются правило Disallow и инструкция User-agent. Есть и второстепенные правила.
Правило Disallow
Пример 1 — разрешено индексировать весь сайт:

Пример 2 — полностью запретить индексацию сайта:

Продвижение сайтов в таком случае будет бесполезно. Применение этого примера актуально в том случае, если сайт «закрыт» на доработку (например, неправильно функционирует). В этом случае сайту в поисковой выдаче не место, поэтому его нужно через файл robots txt закрыть от индексации. Разумеется, после того, как сайт будет доработан, запрет на индексирование надо снять, но об этом забывают.
Пример 3 – запрещено сканирование всех документов, находящихся в папке /papka/:

Пример 4 – запретить индексацию страницы с конкретным URL:

Пример 5 – запрещено индексировать конкретный файл (в данном случае – изображение):

Пример 6 – как в robots txt закрыть от индексации файлы конкретного расширения (в данном случае — .gif):

Звездочка перед .gif$ сообщает, что имя файла может быть любым, а знак $ сообщает о конце строки. Т.е. такая «маска» запрещает сканирование вообще всех GIF-файлов.
Правило Allow в robots txt
Правило Allow все делает с точностью до наоборот – разрешает индексирование файла/папки/страницы.
И сразу же конкретный пример:

Мы с вами уже знаем, что с помощью директивы Disallow: / мы можем закрыть сайт от индексации robots txt. В то же время у нас есть правило Allow: /catalog, которое разрешает сканирование папки /catalog. Поэтому комбинацию этих двух правил поисковые роботы будут воспринимать как «запрещено сканировать сайт, за исключением папки /catalog»
Сортировка правил и директив Allow и Disallow производится по возрастанию длины префикса URL и применяется последовательно. Если для одной и той же страницы подходит несколько правил, то робот выбирает последнее подходящее из списка.
Рассмотрим 2 ситуации с двумя правилами, которые противоречат друг другу — одно правило запрещает индексировать папки /content, а другое – разрешает.
В данном случае будет приоритетнее директива Allow, т.к. оно находится ниже по списку:

А вот здесь приоритетным является директива Disallow по тем же причинам (ниже по списку):

User-agent в robots txt
User-agent — правило, являющееся «обращением» к поисковому роботу, мол, «список рекомендаций специально для вас» (к слову, списков в robots.txt может быть несколько – для разных поисковых роботов от Google и Яндекс).
Например, в данном случае мы говорим «Эй, Googlebot, иди сюда, тут для тебя специально подготовленный список рекомендаций», а он такой «ОК, специально для меня – значит специально для меня» и другие списки сканировать не будет.
Правильный robots txt для Google (Googlebot)

Примерно та же история и с поисковым ботом Яндекса. Забегая вперед, список рекомендаций для Яндекса почти в 100% случаев немного отличается от списка для других поисковых роботов (чем – расскажем чуть позже). Но суть та же: «Эй, Яндекс, для тебя отдельный список» — «ОК, сейчас изучим его».

И последний вариант – рекомендации для всех поисковых роботов (кроме тех, у которых отдельные списки). Через «звездочку» было решено сделать по одной простой причине – чтоб не перечислять «поименно» все 300 с чем-то роботов.

Т.е. если в одном и том же robots.txt есть 3 списка с User-agent: *, User-agent: Googlebot и User-agent: Yandex, это значит, первый является «одним для всех», за исключением Googlebot и Яндекс, т.к. для них есть «личные» списки.
Sitemap
Правило Sitemap — расположение файла с XML-картой сайта, в которой содержатся адреса всех страниц, являющихся обязательными к сканированию. Как правило, указывается адрес вида http://site.ua/sitemap.xml.
Т.е. каждый раз поисковый робот будет просматривать карту сайта на предмет появления новых адресов, а затем переходить по ним для дальнейшего сканирования, дабы освежить информацию о сайте в базах данных поисковой системы.
Правило Sitemap должно быть вписано в Robots.txt следующим образом:

Директива Host
Межсекционная директива Host в файле robots.txt так же является обязательной. Она необходима для поискового робота Яндекса — сообщает ему, какое из зеркал сайта нужно учитывать при индексировании. Именно поэтому для Яндекса формируется отдельный список правил, т.к. Google и остальные поисковые системы директиву Host не понимают. Поэтому если у вашего сайта есть копии или же сайт может открываться под разными URL адресами, то добавьте директиву host в файл robots txt, чтобы страницы сайта правильно индексировались.

«Зеркалом сайта» принято называть либо точную, либо почти точную «копию» сайта, которая доступна по другому адресу.
Адрес основного зеркала обязательно должно быть указано следующим образом:
— для сайтов, работающих по http — Host: site.ua или Host: http://site.ua (т.е. http:// пишется по желанию)
— для сайтов, работающих по https – Host: https://site.ua (т.е. https:// прописывается в обязательном порядке)
Пример директивы host в robots txt для сайта на протоколе HTTPS:

Crawl delay
В отличие от предыдущих, параметр Crawl-delay уже не является обязательным. Основная его задача – подсказать поисковому роботу, в течение скольких секунд будут грузиться страницы. Обычно применяется в том случае, если Вы используете слабые сервера. Актуален только для Яндекса.

Clean param
С помощью директивы Clean-param можно бороться с get-параметрами, чтобы не происходило дублирование контента, т.к. один и тот же контент бывает доступен по разным динамическим ссылкам (это те, которые со знаками вопроса). Динамические ссылки могут генерироваться сайтом в том случае, когда используются различные сортировки, применяются идентификаторы сессий и т.д.
Например, один и тот же контент может быть доступен по трем адресам:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
В таком случае директива Clean-param оформляется вот так:

Т.е. после двоеточия прописывается атрибут ref, указывающий на источник ссылки, и только потом указывается ее «хвост» (в данном случае — /catalog/get_phone.ua).
Самые частые вопросы
Как в robots.txt запретить индексацию?
Для этих целей придумано правило Disallow: т.е. копируем ссылку на документ/файл, который нужно закрыть от индексации, вставляем ее после двоеточия:
User-agent: *
Disallow: http://your-site.xyz/privance.html
Disallow: http://your-site.xyz/foord.doc
Disallow: http://your-site.xyz/barcode.jpg
А затем удаляете адрес домена (в данном случае удалить надо вот эту часть — http://your-site.xyz). После удаления у нас останется ровно то, что и должно остаться:
User-agent: *
Disallow: /privance.html
Disallow: /foord.doc
Disallow: /barcode.jpg
Ну а если требуется закрыть от индексирования все файлы с определенным расширением, то правила будут выглядеть следующим образом:
User-agent: *
Disallow: /*.html
Disallow: /*.doc
Disallow: /*.jpg
Как в robots.txt указать главное зеркало?
Для этих целей придумана директива Host. Т.е. если адреса http://your-site.xyz и http://yoursite.com являются «зеркалами» одного и того же сайта, то одно из них необходимо указать в директиве Host. Пусть основным зеркалом будет http://your-site.xyz. В этом случае правильными вариантами будут следующие:
— если сайт работает по https-протоколу, то нужно делать только так:
User-agent: Yandex
Disallow: /privance.html
Disallow: /foord.doc
Disallow: /barcode.jpg
Host: https://your-site.xyz
— если сайт работает по http-протоколу, то оба приведенных ниже варианта будут верными:
User-agent: Yandex
Disallow: /privance.html
Disallow: /foord.doc
Disallow: /barcode.jpg
Host: http://your-site.xyz
User-agent: Yandex
Disallow: /privance.html
Disallow: /foord.doc
Disallow: /barcode.jpg
Host: your-site.xyz
Однако, следует помнить, директива Host является рекомендацией, а не правилом. Т.е. не исключено, что в Host будет указан один домен, а Яндекс посчитает за основное зеркало другой, если у него в панели вебмастера введены соответствующие настройки.
Простейший пример правильного robots.txt
В таком виде файл robots.txt можно разместить практически на любом сайте (с мельчайшими корректировками).

Давайте теперь разберем, что тут есть.
- Здесь 2 списка правил – один «персонально» для Яндекса, другой – для всех остальных поисковых роботов.
- Правило Disallow: пустое, а значит никаких запретов на сканирование нет.
- В списке для Яндекса присутствует директива Host с указанием основного зеркала, а также, ссылка на карту сайта.
НО… Это НЕ значит, что нужно оформлять robots.txt именно так. Правила должны быть прописаны строго индивидуально для каждого сайта. Например, нет смысла индексировать «технические» страницы (страницы ввода логина-пароля, либо тестовые страницы, на которых отрабатывается новый дизайн сайта, и т.д.). Правила, кстати, зависят еще и от используемой CMS.
Закрытый от индексации сайт – как выглядит robots.txt?
Даем сразу же готовый код, который позволит запретить индексацию сайта независимо от CMS:

Как указать главное зеркало для сайта на https robots.txt?
Очень просто:
Host: https://your-site.xyz
ВАЖНО!!! Для https-сайтов протокол должен указываться строго обязательно!

Наиболее частые ошибки в robots.txt
Специально для Вас мы приготовили подборку самых распространенных ошибок, допускаемых в robots.txt. Почти все эти ошибки объединяет одно – они допускаются по невнимательности.
1. Перепутанные инструкции:

Правильный вариант:

2. В один Disallow вставляется куча папок:

В такой записи робот может запутаться. Какую папку нельзя индексировать? Первую? Последнюю? Или все? Или как? Или что? Одна папка = одно правило Disallow и никак иначе.

3. Название файла допускается только одно — robots.txt, причем все буквы маленькие. Имена Robots.txt, ROBOTS.TXT и т.п. не допускаются.
4. Правило User-agent запрещено оставлять пустым. Либо указываем имя поискового робота (например, для Яндекса), либо ставим звездочку (для всех остальных).
5. Мусор в файле (лишние слэши, звездочки и т.д.).
6. Добавление в файл полных адресов скрываемых страниц, причем иногда даже без правила Disallow.
Неправильно:
http://mega-site.academy/serrot.html
Тоже неправильно:
Disallow: http://mega-site.academy/serrot.html
Правильно:
Disallow: /serrot.html
Онлайн-проверка файла robots.txt
Существует несколько способов проверки файла robots.txt на соответствие общепринятому в интернете стандарту.
Способ 1. Зарегистрироваться в панелях веб-мастера Яндекс и Google. Единственный минус – придется покопаться, чтоб разобраться с функционалом. Далее вносятся рекомендованные изменения и готовый файл закачивается на хостинг.
Способ 2. Воспользоваться онлайн-сервисами:
— https://services.sl-team.ru/other/robots/

— https://technicalseo.com/seo-tools/robots-txt/

— http://tools.seochat.com/tools/robots-txt-validator/

Итак, robots.txt сформирован. Осталось только проверить его на ошибки. Лучше всего использовать для этого инструменты, предлагаемые самими поисковыми системами.
Google Вебмастерс (Search Console Google): заходим в аккаунт, если в нем сайт не подтвержден – подтверждаем, далее переходим на Сканирование -> Инструмент проверки файла robots.txt.

Здесь можно:
- моментально обнаружить все ошибки и потенциально возможные проблемы,
- сразу же «на месте» внести поправки и проверить на ошибки еще раз (чтоб не перезагружать файл на сайт по 20 раз)
- проверить правильность запретов и разрешений индексирования страниц.
Яндекс Вебмастер (прямая ссылка — http://webmaster.yandex.ru/robots.xml).

Является аналогом предыдущего, за исключением:
- авторизация не обязательна;
- подтверждение прав на сайт не обязательно;
- доступна массовая проверка страниц на доступность;
- можно убедиться, что все правила правильно восприняты Яндексом.
Готовые решения для самых популярных CMS
Правильный robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin # классика жанра
Disallow: /? # любые параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search # поиск
Disallow: /author/ # архив автора
Disallow: *?attachment_id= # страница вложения. Вообще-то на ней редирект…
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */page/ # все виды пагинации
Allow: */uploads # открываем uploads
Allow: /*/*.js # внутри /wp- (/*/ — для приоритета)
Allow: /*/*.css # внутри /wp- (/*/ — для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д.
#Disallow: /wp/ # когда WP установлен в подкаталог wp
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap2.xml # еще один файл
#Sitemap: http://site.ru/sitemap.xml.gz # сжатая версия (.gz)
Host: www.site.ru # для Яндекса и Mail.RU. (межсекционная)
# Версия кода: 1.0
# Не забудьте поменять `site.ru` на ваш сайт.
Давайте разберем код файла robots txt для WordPress CMS:
User-agent: *
Здесь мы указываем, что все правила актуальны для всех поисковых роботов (за исключением тех, для кого составлены «персональные» списки). Если список составляется для какого-то конкретного робота, то * меняется на имя робота:
User-agent: Yandex
User-agent: Googlebot
Allow: */uploads
Здесь мы осознанно даем добро на индексирование ссылок, в которых содержится /uploads. В данном случае это правило является обязательным, т.к. в движке WordPress есть директория /wp-content/uploads (в которой вполне могут содержаться картинки, либо другой «открытый» контент), индексирование которой запрещено правилом Disallow: /wp-. Поэтому с помощью Allow: */uploads мы делаем исключение из правила Disallow: /wp-.
В остальном просто идут запреты на индексирование:
Disallow: /cgi-bin – запрет на индексирование скриптов
Disallow: /feed – запрет на сканирование RSS-фида
Disallow: /trackback – запрет сканирования уведомлений
Disallow: ?s= или Disallow: *?s= — запрет на индексирование страниц внутреннего поиска сайта
Disallow: */page/ — запрет индексирования всех видов пагинации
Правило Sitemap: http://site.ru/sitemap.xml указывает Яндекс-роботу путь к файлу с xml-картой. Путь должен быть прописан полностью. Если таких файлов несколько – прописываем несколько Sitemap-правил (1 файл = 1 правило).
В строке Host: site.ru мы специально для Яндекса прописали основное зеркало сайта. Оно указывается для того, чтоб остальные зеркала индексировались одинаково. Пустая строка перед Host: является обязательной.
Где находится robots txt WordPress вы все наверное знаете — так как и в другие CMS, данный файл должен находится в корневом каталоге сайта.
Файл robots.txt для Joomla
Joomla — почти самый популярный движок у вебмастеров, т.к. не смотря на широчайшие возможности и множества готовых решений, он поставляется бесплатно. Однако, штатный robots.txt всегда имеет смысл подправить, т.к. для индексирования открыто слишком много «мусора», но картинки закрыты (это плохо).
Вот так выглядит правильный robots.txt для Joomla :
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
robots.txt Wix
Платформа Wix автоматически генерирует файлы robots.txt персонально для каждого сайта Wix. Т.е. к Вашему домену добавляете /robots.txt (например: www.domain.com/robots.txt) и можете спокойно изучить содержимое файла robots.txt, находящегося на Вашем сайте.
Отредактировать robots.txt нельзя. Однако с помощью noindex можно закрыть какие-то конкретные страницы от индексирования.
robots.txt для Opencart
Стандартный файл robots.txt для OpenCart:
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
User-agent: Yandex
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*route=product/search
Disallow: /*?page=
Disallow: /*&page=
Clean-param: tracking
Clean-param: filter_name
Clean-param: filter_sub_category
Clean-param: filter_description
Disallow: /wishlist
Disallow: /login
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
Host: Vash_domen
Sitemap: http://Vash_domen/sitemap.xml
robots.txt для Битрикс (Bitrix)
1. Папки /bitrix и /cgi-bin должны быть закрыты, т.к. это чисто технический «хлам», который незачем светить в поисковой выдаче.
Disallow: /bitrix
Disallow: /cgi-bin
2. Папка /search тоже не представляет интереса ни для пользователей, ни для поисковых систем. Да и образование дублей никому не нужно. Поэтому тоже ее закрываем.
3. Про формы PHP-аутентификации и авторизации на сайте тоже забывать нельзя – закрываем.
Disallow: /auth/
Disallow: /auth.php
4. Материалы для печати (например, счета на оплату) тоже нет смысла светить в поисковой выдаче. Закрываем.
Disallow: /*?print=
Disallow: /*&print=
5. Один из жирных плюсов «Битрикса» в том, что он фиксирует всю историю сайта – кто когда залогинился, кто когда сменил пароль, и прочую конфиденциальную информацию, утечка которой не допустима. Поэтому закрываем:
Disallow: /*register=yes
Disallow: /*forgot_password=yes
Disallow: /*change_password=yes
Disallow: /*login=yes
Disallow: /*logout=yes
Disallow: /*auth=yes
6. Back-адреса тоже нет смысла индексировать. Эти адреса могут образовываться, например, при просмотре фотоальбома, когда Вы сначала листаете его «вперед», а потом – «назад». В эти моменты в адресной строке вполне может появиться что-то типа матерного ругательства: ?back_url_ =%2Fbitrix%2F%2F. Ценность таких адресов равна нулю, поэтому их тоже закрываем от индексирования. Ну а в качестве бонуса – избавляемся от потенциальных «дублей» в поисковой выдаче.
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
7. Папку /upload необходимо закрывать строго по обстоятельствам. Если там хранятся фотографии и видеоматериалы, размещенные на страницах, то ее скрывать не нужно, чтоб не срезать дополнительный трафик. Ну а если что-то конфиденциальное – однозначно закрываем:
Готовый файл robots.txt для Битрикс:
User-agent: *
Allow: /map/
Allow: /search/map.php
Allow: /bitrix/templates/
Disallow: */index.php
Disallow: /*action=
Disallow: /*print=
Disallow: /*/gallery/*order=
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*?utm_source=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*arrFilter=
Disallow: /*auth=
Disallow: /*back_url_admin=
Disallow: /*BACK_URL=
Disallow: /*back_url=
Disallow: /*backurl=
Disallow: /*bitrix_*=
Disallow: /*bitrix_include_areas=
Disallow: /*building_directory=
Disallow: /*bxajaxid=
Disallow: /*change_password=
Disallow: /*clear_cache_session=
Disallow: /*clear_cache=
Disallow: /*count=
Disallow: /*COURSE_ID=
Disallow: /*forgot_password=
Disallow: /*ID=
Disallow: /*index.php$
Disallow: /*login=
Disallow: /*logout=
Disallow: /*modern-repair/$
Disallow: /*MUL_MODE=
Disallow: /*ORDER_BY
Disallow: /*PAGE_NAME=
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGEN_
Disallow: /*print_course=
Disallow: /*print=
Disallow: /*q=
Disallow: /*register=
Disallow: /*register=yes
Disallow: /*set_filter=
Disallow: /*show_all=
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: /*SHOWALL_
Disallow: /*sort=
Disallow: /*sphrase_id=
Disallow: /*tags=
Disallow: /access.log
Disallow: /admin
Disallow: /api
Disallow: /auth
Disallow: /auth.php
Disallow: /auto
Disallow: /bitrix
Disallow: /bitrix/
Disallow: /cgi-bin
Disallow: /club/$
Disallow: /club/forum/search/
Disallow: /club/gallery/tags/
Disallow: /club/group/search/
Disallow: /club/log/
Disallow: /club/messages/
Disallow: /club/search/
Disallow: /communication/blog/search.php
Disallow: /communication/forum/search/
Disallow: /communication/forum/user/
Disallow: /content/board/my/
Disallow: /content/links/my/
Disallow: /error
Disallow: /e-store/affiliates/
Disallow: /e-store/paid/detail.php
Disallow: /examples/download/download_private/
Disallow: /examples/my-components/
Disallow: /include
Disallow: /personal
Disallow: /search
Disallow: /temp
Disallow: /tmp
Disallow: /upload
Disallow: /*/*ELEMENT_CODE=
Disallow: /*/*SECTION_CODE=
Disallow: /*/*IBLOCK_CODE
Disallow: /*/*ELEMENT_ID=
Disallow: /*/*SECTION_ID=
Disallow: /*/*IBLOCK_ID=
Disallow: /*/*CODE=
Disallow: /*/*ID=
Disallow: /*/*IBLOCK_EXTERNAL_ID=
Disallow: /*/*SECTION_CODE_PATH=
Disallow: /*/*EXTERNAL_ID=
Disallow: /*/*IBLOCK_TYPE_ID=
Disallow: /*/*SITE_DIR=
Disallow: /*/*SERVER_NAME=
Sitemap: http://site.ru/sitemap_index.xml
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для Modx и Modx Revo
CMS Modx Revo тоже не лишена проблемы дублей. Однако, она не так сильно обострена, как в Битриксе. Теперь о ее решении.
- Включаем ЧПУ в настройках сайта.
- закрываем от индексации:
Disallow: /index.php # т.к. это дубль главной страницы сайта
Disallow: /*? # разом решаем проблему с дублями для всех страниц
Готовый файл robots.txt для Modx и Modx Revo:
User-agent: *
Disallow: /*?
Disallow: /*?id=
Disallow: /assets
Disallow: /assets/cache
Disallow: /assets/components
Disallow: /assets/docs
Disallow: /assets/export
Disallow: /assets/import
Disallow: /assets/modules
Disallow: /assets/plugins
Disallow: /assets/snippets
Disallow: /connectors
Disallow: /core
Disallow: /index.php
Disallow: /install
Disallow: /manager
Disallow: /profile
Disallow: /search
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
Выводы
Без преувеличения файл robots.txt можно назвать «поводырём для поисковых роботов Яндекс и Гугл» (разумеется, если он составлен правильно). Если файл robots txt отсутствует, то его нужно обязательно создать и загрузить на хостинг Вашего сайта. Справка Disallow правил описаны выше в этой статьей и вы можете смело их использоваться в своих целях.
Еще раз резюмируем правила/директивы/инструкции для robots.txt:
- User-agent — указывает, для какого именно поискового робота создан список правил.
- Disallow – «рекомендую вот это не индексировать».
- Sitemap – указывает расположение XML-карты сайта со всеми URL, которые нужно проиндексировать. В большинстве случаев карта расположена по адресу http://[ваш_сайт]/sitemap.xml.
- Crawl-delay — директива, указывающая период (в секундах), через который будет загружена страница сайта.
- Host – показывает Яндексу основное зеркало сайта.
- Allow – «рекомендую вот это проиндексировать, не смотря на то, что это противоречит одному из Disallow-правил».
- Clean-param — помогает в борьбе с get-параметрами, применяется для снижения рисков образования страниц-дублей.
Знаки при составлении robots.txt:
- Знак «$» для «звездочки» является «ограничителем».
- После слэша «/» указывается наименование файла/папки/расширения, которую нужно скрыть (в случае с Disallow) или открыть (в случае с Allow) для индексирования.
- Знаком «*» обозначается «любое количество любых символов».
- Знаком «#» отделяются какие-либо комментарии или примечания, оставленные вэб-мастером для себя, либо для кого-то другого. Поисковые роботы их не читают.
stokrat.org
Создаем правильный файл robots.txt — настраиваем индексацию, директивы
- Зачем robots.txt в SEO?
- Создаем robots самостоятельно
- Синтаксис robots.txt
- Обращение к индексирующему роботу
- Запрет индексации Disallow
- Разрешение индексации Allow
- Директива host robots.txt
- Sitemap.xml в robots.txt
- Использование директивы Clean-param
- Использование директивы Crawl-delay
- Комментарии в robots.txt
- Маски в robots.txt
- Как правильно настроить robots.txt?
- Проверяем свой robots.txt
Robots — это обыкновенный текстовой файл (.txt), который располагается в корне сайта наряду c index.php и другими системными файлами. Его можно загрузить через FTP или создать в файловом менеджере у хост-провайдера. Создается данный файл как обыкновенный текстовой документ с самым простым форматом — TXT. Далее файлу присваивается имя ROBOTS. Выглядит это следующим образом:
(robots.txt в корневой папке WordPress)
После создание самого файла нужно убедиться, что он доступен по ссылке ваш домен/robots.txt. Именно по этому адресу поисковая система будет искать данный файл.
В большинстве систем управления сайтами роботс присутствует по умолчанию, однако зачастую он настроен не полностью или совсем пуст. В любом случае, нам придется его править, так как для 95% проектов шаблонный вариант не подойдет.
Зачем robots.txt в SEO?
Первое, на что обращает внимание оптимизатор при анализе/начале продвижения сайта — это роботс. Именно в нем располагаются все главные инструкции, которые касаются действий индексирующего робота. Именно в robots.txt мы исключаем из поиска страницы, прописываем пути к карте сайта, определяем главной зеркало сайта, а так же вносим другие важные инструкции.
Ошибки в директивах могут привести к полному исключению сайта из индекса. Отнестись к настройкам данного файла нужно осознано и очень серьезно, от этого будет зависеть будущий органический трафик.
Создаем robots самостоятельно
Сам процесс создания файла до безобразия прост. Необходимо просто создать текстовой документ, назвав его «robots». После этого, подключившись через FTP соединение, загрузить в корневую папку Вашего сайта. Обязательно проверьте, что бы роботс был доступен по адресу ваш домен/robots.txt. Не допускается наличие вложений, к примеру ваш домен/page/robots.txt.
Если Вы пользуетесь web ftp — файловым менеджером, который доступен в панели управления у любого хост-провайдера, то файл можно создать прямо там.
В итоге, у нас получается пустой роботс. Все инструкции мы будем вписывать вручную. Как это сделать, мы опишем ниже.
Используем online генераторы
Если создание своими руками это не для Вас, то существует множество online генераторов, которые помогут в этом. Но нужно помнить, что никакой генератор не сможет без Вас исключить из поиска весь «мусор» и не добавит главное зеркало, если Вы не знаете какое оно. Данный вариант подойдет лишь тем, кто не хочет писать рутинные повторяющиеся для большинства сайтов инструкции.
Сгенерированный онлайн роботс нужно будет в любом случае править «руками», поэтому без знаний синтаксиса и основ Вам не обойтись и в этом случае.
Используем готовые шаблоны
В Интернете есть множество шаблонов для распространенных CMS, таких как WordPress, Joomla!, MODx и т.д. От онлайн генераторов они отличаются только тем, что сам текстовой файл Вам нужно будет сделать самостоятельно. Шаблон позволяет не писать большинство стандартных директив, однако он не гарантирует правильную и полную настройку для Вашего ресурса. При использовании шаблонов так же нужны знания.
Синтаксис robots.txt
Использование правильного синтаксиса при настройке — это основа всего. Пропущенная запятая, слэш, звездочка или проблем могут «сбить» всю настройку. Безусловно, есть системы проверки файла, однако без знания синтаксиса они все равно не помогу. Мы по порядку рассмотрим все возможные инструкции, которые применяются при настройке robots.txt. Сначала самые популярные.
Обращение к индексирующему роботу
Любой файл robots начинается с директивы User-agent:, которая указывает для какой поисковой системы или для какого робота приведены инструкции ниже. Пример использования:
User-agent: Yandex User-agent: YandexBot User-agent: Googlebot
Строка 1 — Инструкции для всех роботов Яндекса
Строка 2 — Инструкции для основного индексирующего робота Яндекса
Строка 3 — Инструкции для основного индексирующего робота Google
Яндекс и Гугл имеют не один и даже не два робота. Действиями каждого можно управлять в нашем robots.txt. Давайте рассмотрим, какие бывают роботы и зачем они нужны.
Роботы Yandex
| Название | Описание | Предназначение |
| YandexBot | Основной индексирующий робот | Отвечает за основную органическую выдачу Яндекса. |
| YandexDirect | Работ контекстной рекламы | Оценивает сайты с точки зрения расположения на них контекстных объявлений. |
| YandexDirectDyn | Так же робот контекста | Отличается от предыдущего тем, что работает с динамическими баннерами. |
| YandexMedia | Индексация мультимедийных данных. | Отвечает, загружает и оценивает все, что связано с мультимедийными данными. |
| YandexImages | Индексация изображений | Отвечает за раздел Яндекса «Картинки» |
| YaDirectFetcher | Так же робот Яндекс Директ | Его особенность в том, что он интерпретирует файл robots особым образом. Подробнее о нем можно прочесть у Яндекса. |
| YandexBlogs | Индексация блогов | Данный робот отвечает за посты, комментарии, ответы и т.д. |
| YandexNews | Новостной робот | Отвечает за раздел «Новости». Индексирует все, что связано с периодикой. |
| YandexPagechecker | Робот микроразметки | Данный робот отвечает за индексацию и распознание микроразметки сайта. |
| YandexMetrika | Робот Яндекс Метрики | Тут все и так ясно. |
| YandexMarket | Робот Яндекс Маркета | Отвечает за индексацию товаров, описаний, цен и всего того, что относится к Маркету. |
| YandexCalendar | Робот Календаря | Отвечает за индексацию всего, что связано с Яндекс Календарем. |
Роботы Google
| Название | Описание | Предназначение |
| Googlebot | (Googlebot) Основной индексирующий роботом Google. | Индексирует основной текстовой контент страницы. Отвечает за основную органическую выдачу. Запрет приведет к полному отсутствия сайта в поиске. |
| Googlebot-News | (Googlebot News) Новостной робот. | Отвечает за индексирование сайта в новостях. Запрет приведет к отсутствию сайта в разделе «Новости» |
| Googlebot-Image | (Googlebot Images) Индексация изображений. | Отвечает за графический контент сайта. Запрет приведет к отсутствию сайта в выдаче в разделе «Изображения» |
| Googlebot-Video | (Googlebot Video) Индексация видео файлов. | Отвечает за видео контент. Запрет приведет к отсутствию сайта в выдаче в разделе «Видео» |
| Googlebot | (Google Smartphone) Робот для смартфонов. | Основной индексирующий робот для мобильных устройств. |
| Mediapartners-Google | (Google Mobile AdSense) Робот мобильной контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных мобильных объявлений. |
| Mediapartners-Google | (Google AdSense) Робот контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных объявлений. |
| AdsBot-Google | (Google AdsBot) Проверка качества страницы. | Отвечает за качество целевой страницы — контент, скорость загрузки, навигация и т.д. |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений | Сканирование для мобильных приложений. Оценивает качество так же, как и предыдущий робот AdsBot |
Обычно robots.txt настраивается для всех роботов Яндекса и Гугла сразу. Очень редко приходится делать отдельные настройки для каждого конкретного краулера. Однако это возможно.
Другие поисковые системы, такие как Bing, Mail, Rambler, так же индексируют сайт и обращаются к robots.txt, однако мы не будем заострять на них внимание. Про менее популярные поисковики мы напишем отдельную статью.
Запрет индексации Disallow
Без сомнения самая популярная директива. Именно при помощи disallow страницы исключаются из индекса. Disallow — буквально означает запрет на индексацию страницы, раздела, файла или группы страниц (при помощи маски). Рассмотрим пример:
Disallow: /wp-admin Disallow: /wp-content/plugins Disallow: /img/images.jpg Disallow: /dogovor.pdf Disallow: */trackback Disallow: /*my
Строка 1 — запрет на индексацию всего раздела wp-admin
Строка 2 — запрет на индексацию подраздела plugins
Строка 3 — запрет на индексацию изображения в папке img
Строка 4 — запрет индексации документа
Строка 5 — запрет на индексацию trackback в любой папке на 1 уровень
Строка 6 — запрет на индексацию не только /my, но и /folder/my или /foldermy
Данная директива поддерживает маски, о которых мы подробнее напишем ниже.
После Disallow в обязательном порядке ставится пробел, а вот в конце строки пробела быть не должно. Так же, допускается написание комментария в одной строке с директивой через пробел после символа «#», однако это не рекомендуется.
Указание нескольких каталогов в одной инструкции не допускается!
Разрешение индексации Allow
Обратная Disallow директива Allow разрешает индексацию конкретного раздела. Заходить на Ваш сайт или нет решает поисковая система, но данная директива ей это позволяет. Обычно Allow не применяется, так как поисковая система старается индексировать весь материал сайта, который может быть полезен человеку.
Пример использования Allow
Allow: /img/ Allow: /dogovor.pdf Allow: /trackback.html Allow: /*my
Строка 1 — разрешает индексацию всего каталога /img/
Строка 2 — разрешает индексацию документа
Строка 3 — разрешает индексацию страницы
Строка 4 — разрешает индексацию по маске *my
Данная директива поддерживает и подчиняется всем тем же правилам, которые справедливы для Disallow.
Директива host robots.txt
Данная директива позволяет обозначить главное зеркало сайта. Обычно, зеркала отличаются наличием или отсутствием www. Данная директива применяется в каждом robots и учитывается большинством поисковых систем.
Пример использования:
Host: dh-agency.ru
Если вы не пропишите главное зеркало сайта через host, Яндекс сообщит Вам об этом в Вебмастере.
Не знаете главное зеркало сайта? Определить довольно просто. Вбейте в поиск Яндекса адрес своего сайта и посмотрите выдачу. Если перед доменом присутствует www, то значит главное зеркало у вас с www.
Если же сайт еще не участвует в поиске, то в Яндекс Вебмастере в разделе «Переезд сайта» Вы можете задать главное зеркало самостоятельно.
Sitemap.xml в robots.txt
Данную директиву желательно иметь в каждом robots.txt, так как ее используют yandex, google, а так же все основные поисковые системы. Директива представляет из себя ссылку на файл sitemap.xml в котором содержатся все страницы, которые предназначены для индексирования. Так же в sitemap указываются приоритеты и даты изменения.
Пример использования:
Sitemap: http://dh-agency.ru/sitemap.xml
О том, как правильно создавать sitemap.xml мы напишем чуть позже.
Использование директивы Clean-param
Очень полезная, но мало кем применяющаяся директива. Clean-param позволяет описать динамические части URL, которые не меняют содержимое страницы. Такими динамическими частями могут быть:
- Идентификаторы сессий;
- Идентификаторы пользователей;
- Различные индивидуальные префиксы не меняющие содержимое;
- Другие подобные элементы.
Clean-param позволяет поисковым системам не загружать один и тот же материал многократно, что делает обход сайта роботом намного эффективнее.
Объясним на примере. Предположим, что для определения с какого сайта перешел пользователь мы взяли параметр site. Данный параметр будет меняться в зависимости от ресурса, но контент страницы будет одним и тем же.
http://dh-agency.ru/folder/page.php?site=x&r_id=985 http://dh-agency.ru/folder/page.php?site=y&r_id=985 http://dh-agency.ru/folder/page.php?site=z&r_id=985
Все три ссылки разные, но они отдают одинаковое содержимое страницы, поэтому индексирующий робот загрузит 3 копии контента. Что бы этого избежать пропишем следующие директивы:
User-agent: Yandex Disallow: Clean-param: site /folder/page.php
В данном случае робот Яндекса либо сведет все страницы к одному варианту, либо проиндексирует ссылку без параметра. Если такая конечно есть.
Использование директивы Crawl-delay
Довольно редко используемая директива, которая позволяет задать роботу минимальный промежуток между загружаемыми страницами. Crawl-delay применяется, когда сервер нагружен и не успевает отвечать на запросы. Промежуток задается в секундах. К примеру:
User-agent: Yandex Crawl-delay: 3
В данном случае таймаут будет 3 секунды. Кстати, стоит отметить, что Яндекс поддерживает и не целые значения в данной директиве. К примеру, 0.4 секунды.
Комментарии в robots.txt
Хороший robots.txt всегда пишется с комментариями. Это упростит работу Вам и поможет будущим специалистам.
Что бы написать комментарий, который будет игнорировать робот поисковой системы, необходимо поставить символ «#». К примеру:
#мой роботс Disallow: /wp-admin Disallow: /wp-content/plugins
Так же возможно, но не желательно, использовать комментарий в одной строке с инструкцией.
Disallow: /wp-admin #исключаем wp admin Disallow: /wp-content/plugins
На данный момент никаких технических запретов по написанию комментария в одной строке с инструкцией нету, однако это считается плохим тоном.
Маски в robots.txt
Применение масок в robots.txt не только упрощает работу, но зачастую просто необходимо. Напомним, маска — это условная запись, которая содержит в себе имена нескольких файлов или папок. Маски применяются для групповых операций с файлами/папками. Предположим, что у нас есть список файлов в папке /documents/
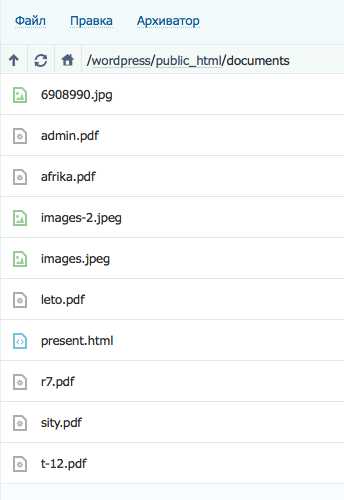
Среди этих файлов есть презентации в формате pdf. Мы не хотим, что бы их сканировал робот, поэтому исключаем из поиска.
Мы можем перечислять все файлы формата .pdf «в ручную»
Disallow: /documents/admin.pdf Disallow: /documents/r7.pdf Disallow: /documents/leto.pdf Disallow: /documents/sity.pdf Disallow: /documents/afrika.pdf Disallow: /documents/t-12.pdf
А можем сделать простую маску *.pdf и скрыть все файлы в одной инструкции.
Disallow: /documents/*.pdf
Удобно, не правда ли?
Маски создаются при помощи спецсимвола «*». Он обозначает любую последовательность символов, в том числе и пробел. Примеры использования:
Disallow: *.pdf Disallow: admin*.pdf Disallow: a*m.pdf Disallow: /img/*.* Disallow: img.* Disallow: &=*
Стоит отметить, что по умолчанию спецсимвол «*» добавляется в конце каждой инструкции, которую Вы прописываете. То есть,
Disallow: /wp-admin # равносильно инструкции ниже Disallow: /wp-admin*
То есть, мы исключаем все, что находится в папке /wp-admin, а так же /wp-admin.html, /wp-admin.pdf и т.д. Для того, что бы этого не происходило необходимо в конце инструкции поставить другой спецсимвол — «$».
Disallow: /wp-admin$ #
В таком случае, мы уже не запрещаем файлы /wp-admin.html, /wp-admin.pdf и т.д
Как правильно настроить robots.txt?
С синтаксисом robots.txt мы разобрались выше, поэтому сейчас напишем как правильно настроить данный файл. Если для популярных CMS, таких как WordPress и Joomla!, уже есть готовые robots, то для самописного движка или редкой СУ Вам придется все настраивать вручную.
(Даже несмотря на наличие готовых robots.txt редактировать и удалять «уникальный мусор» Вам придется и в ВордПресс. Поэтому этот раздел будет полезен и для владельцев сайтов на ТОПовых CMS)
Что нужно исключать из индекса?
А.) В первую очередь из индекса исключаются дубликаты страниц в любом виде. Страница на сайте должна быть доступна только по одному адресу. То есть, при обращении к ресурсу робот должен получать по каждому URL уникальный контент.
Зачастую дубликаты появляются у систем управления сайтом при создании страниц. К примеру, одна и та же страница может быть доступна по техническому адресу /?p=391&preview=true и одновременно с этим иметь ЧПУ. Так же дубли могут возникать при работе с динамическими ссылками.
Всех их необходимо при помощи масок исключать из индекса.
Disallow: /*?* Disallow: /*% Disallow: /index.php Disallow: /*?page= Disallow: /*&page=
Б.) Все страницы, которые имеют не уникальный контент, желательно убрать из индекса еще до того, как это сделает поисковая система.
В.) Из индекса должны быть исключены все страницы, которые используются при работе сценариев. К примеру, страница «Спасибо, сообщение отправлено!».
Г.) Желательно исключить все страницы, которые имеют индикаторы сессий
Disallow: *PHPSESSID= Disallow: *session_id=
Д.) В обязательном порядке из индекса должны быть исключены все файлы вашей cms. Это файлы панели администрации, различных баз, тем, шаблонов и т.д.
Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback
Е.) Пустые страницы и разделы, «не нужный» пользователям контент, результаты поиска и работы калькулятора так же должны быть недоступны роботу.
«Держа в чистоте» Ваш индекс Вы упрощаете жизнь и себе и индексирующему роботу.
Что нужно разрешать индексировать?
Да по сути все, что не запрещено. Есть только один нюанс. Поисковые системы по умолчанию индексируют любой полезный контент Вашего сайта, поэтому использовать директиву Allow в 90% случаев не нужно.
Корректный файл sitemap.xml и качественная перелинковка дадут гарантию, что все «нужные» страницы Вашего сайта будут проиндексированы.
Обязательны ли директивы host и sitemap?
Да, данные директивы обязательны. Прописать их не составит труда, но они гарантируют, что робот точно найдет sitemap.xml, и будет «знать» главное зеркало сайта.
Для каких поисковиков настраивать?
Инструкции файла robots.txt понимают все популярные поисковые системы. Если различий в инструкциях нету, то Вы можете прописать User-agent: * (Все директивы для всех поисковиков).
Однако, если Вы укажите инструкции для конкретного робота, к примеру Yandex, то все другие директивы Яндексом будут проигнорированы.
Нужны ли мне директивы Crawl-delay и Clean-param?
Если Вы используете динамические ссылки или же передаете параметры в URL, то Вам скорее всего понадобиться Clean-param, дабы не вводить робота в заблуждение. Использование данной директивы мы описали выше. Данная директива поможет Вам избежать ненужных дубликатов в поиске, что очень важно.
Использование Crawl-delay зависит исключительно от Вашего хостинга. Если Вы чувствуете, что сервер уже не справляется запросами, то желательно увеличить время межу ними.
Проверяем свой robots.txt
После настройки файла его необходимо проверить. Сделать это возможно через Ваш Вебмастер в разделе «Инструменты» -> «Анализ robots.txt»
Но нужно понимать, что данный онлайн инструмент сможет лишь найти синтаксическую ошибку. Он никак не убережет Вас от лишней исключенной страницы, а так же от мусора в выдаче.
dh-agency.ru
Правильный файл robots.txt для сайта
Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры:
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов.
Спецсимвол $ означает конец строки, символ перед ним последний.
Директива Sitemap
Если вы используете описание структуры сайта с помощью файла Sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все). Пример:
User-agent: Yandex Allow: / sitemap: https://example.com/site_structure/my_sitemaps1.xml sitemap: https://example.com/site_structure/my_sitemaps2.xml
Директива является межсекционной, поэтому будет использоваться роботом вне зависимости от места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки.
Директива Crawl-delay
Директива работает только с роботом Яндекса.
Если сервер сильно нагружен и не успевает отрабатывать запросы робота, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Перед тем, как изменить скорость обхода сайта, выясните к каким именно страницам робот обращается чаще.
- Проанализируйте логи сервера. Обратитесь к сотруднику, ответственному за сайт, или к хостинг-провайдеру.
- Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы).
Если вы обнаружите, что робот обращается к служебным страницам, запретите их индексирование в файле robots.txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота.
Директива Clean-param
Директива работает только с роботом Яндекса.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex
Disallow:
Clean-param: ref /some_dir/get_book.plробот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0[&p1&p2&..&pn] [path]В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Примечание. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.phpозначает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc /forum/showthread.php
Clean-param: sid&sort /forum/*.php
Clean-param: someTrash&otherTrashДиректива HOST
На данный момент Яндекс прекратил поддержку данной директивы.
Правильный robots.txt: настройка
Содержимое файла robots.txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой позволить появляться в поисковой выдаче.
Правильный Robots.txt пример для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads Sitemap: http://site.ru/sitemap.xml # адрес карты сайтаUser-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично
Robots.txt пример для Joomla
User-agent: *Disallow: /administrator/Disallow: /cache/Disallow: /includes/Disallow: /installation/Disallow: /language/Disallow: /libraries/Disallow: /media/Disallow: /modules/Disallow: /plugins/Disallow: /templates/Disallow: /tmp/Disallow: /xmlrpc/Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для Bitrix
User-agent: *Disallow: /*index.php$Disallow: /bitrix/Disallow: /auth/Disallow: /personal/Disallow: /upload/Disallow: /search/Disallow: /*/search/Disallow: /*/slide_show/Disallow: /*/gallery/*order=*Disallow: /*?print=Disallow: /*&print=Disallow: /*register=Disallow: /*forgot_password=Disallow: /*change_password=Disallow: /*login=Disallow: /*logout=Disallow: /*auth=Disallow: /*?action=Disallow: /*action=ADD_TO_COMPARE_LISTDisallow: /*action=DELETE_FROM_COMPARE_LISTDisallow: /*action=ADD2BASKETDisallow: /*action=BUYDisallow: /*bitrix_*=Disallow: /*backurl=*Disallow: /*BACKURL=*Disallow: /*back_url=*Disallow: /*BACK_URL=*Disallow: /*back_url_admin=*Disallow: /*print_course=YDisallow: /*COURSE_ID=Disallow: /*?COURSE_ID=Disallow: /*?PAGENDisallow: /*PAGEN_1=Disallow: /*PAGEN_2=Disallow: /*PAGEN_3=Disallow: /*PAGEN_4=Disallow: /*PAGEN_5=Disallow: /*PAGEN_6=Disallow: /*PAGEN_7=Disallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*PAGE_NAME=searchDisallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*SHOWALLDisallow: /*show_all=Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для MODx
User-agent: *Disallow: /assets/cache/Disallow: /assets/docs/Disallow: /assets/export/Disallow: /assets/import/Disallow: /assets/modules/Disallow: /assets/plugins/Disallow: /assets/snippets/Disallow: /install/Disallow: /manager/Sitemap: http://site.ru/sitemap.xml
Robots.txt пример для Drupal
User-agent: *Disallow: /database/Disallow: /includes/Disallow: /misc/Disallow: /modules/Disallow: /sites/Disallow: /themes/Disallow: /scripts/Disallow: /updates/Disallow: /profiles/Disallow: /profileDisallow: /profile/*Disallow: /xmlrpc.phpDisallow: /cron.phpDisallow: /update.phpDisallow: /install.phpDisallow: /index.phpDisallow: /admin/Disallow: /comment/reply/Disallow: /contact/Disallow: /logout/Disallow: /search/Disallow: /user/register/Disallow: /user/password/Disallow: *register*Disallow: *login*Disallow: /top-rated-Disallow: /messages/Disallow: /book/export/Disallow: /user2userpoints/Disallow: /myuserpoints/Disallow: /tagadelic/Disallow: /referral/Disallow: /aggregator/Disallow: /files/pin/Disallow: /your-votesDisallow: /comments/recentDisallow: /*/edit/Disallow: /*/delete/Disallow: /*/export/html/Disallow: /taxonomy/term/*/0$Disallow: /*/edit$Disallow: /*/outline$Disallow: /*/revisions$Disallow: /*/contact$Disallow: /*downloadpipeDisallow: /node$Disallow: /node/*/track$Disallow: /*&Disallow: /*%Disallow: /*?page=0Disallow: /*sectionDisallow: /*orderDisallow: /*?sort*Disallow: /*&sort*Disallow: /*votesupdownDisallow: /*calendarDisallow: /*index.phpAllow: /*?page=Disallow: /*?Sitemap: http://путь к вашей карте XML формата
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, понадобиться закрыть от индексации другие страницы. В зависимости от цели, запрет на индексацию может сниматься или, наоборот, добавляться.
Проверить robots.txt
У каждого поисковика свои требования к оформлению файла robots.txt.
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка robotx.txt для поискового робота Яндекса
Сделать это можно при помощи специального инструмента от Яндекс — Яндекс.Вебмастер, еще и двумя вариантами.
Вариант 1:
Справа вверху выпадающий список — выберите Анализ robots.txt или по ссылке http://webmaster.yandex.ru/robots.xml
Вариант 2:
Этот вариант подразумевает, что ваш сайт добавлен в Яндекс Вебмастер и в корне сайта уже есть robots.txt.
Слева выберите Инструменты — Анализ robots.txt
Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь некоторое время.
Проверка robotx.txt для поискового робота Google
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
- В Google Search Console выберите ваш сайт, перейдите к инструменту проверки и просмотрите содержание файла
robots.txt. Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования. - Внизу на странице интерфейса укажите нужный URL в соответствующем окне.
- В раскрывающемся меню справа выберите робота.
- Нажмите кнопку ПРОВЕРИТЬ.
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН. В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в меню и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененное содержание и добавьте его в файл robots.txt на вашем веб-сервере.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Генераторы robots.txt
- Сервис от SEOlib.ru.С помощью данного инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru.В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл под названием Robots.txt и загрузить в корневой каталог вашего сайта.
webmaster-seo.ru
Правильный robots.txt для популярных CMS
Поисковые роботы индексируют сайт независимо от наличия robots.txt и sitemap.xml, с помощью файла robots.txt можно указать поисковым машинам, что исключить из индекса, и настроить другие важные параметры.
Стоит учесть, что краулеры поисковых машин игнорируют определенные правила, например:
Директивы
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года.
Основные — часто используемые директивы
User-agent: директива, с которой начинается Robots.txt.
Пример:
User-agent: *# указания для всех поисковых роботов.User-agent: Yandex# указания для робота Яндекса.User-agent: GoogleBot# указания для робота Google.Disallow: # запрещающая директива, запрет индексции того, что указанно после /. Allow: # разрешающая директива, для указания на индексацию URL. Disallow: # не работает без спецсимвола /. Allow: / # игнорируются, если после / не указан URL.
Спецсимволы, которые используются в robots.txt /, * , $.
Обратите внимание на символ /, можно допустить крупную ошибку прописав например:
User-agent:* Disallow: / # таким образом можно закрыть весь сайт от индексации.
Спецсимвол * означает любую, в том числе и пустую, последовательность символов, например:
Disallow: /cart/* # закрывает от индексации все страницы после URL: site.ru/cart/
Спецсимвол $ ограничивает действие символа *, дает строгое ограничение:
User-agent:* Disallow: /catalog$ # при таком символе не будет индексироваться catalog, но в индексе будет catalog.html
Директива sitemap — указывает путь к карте сайта и выглядит так:
User-agent:* Allow: / Sitemap: http://www.site.ru/sitemap.xml # ее необходимо указывать с http:// или https://, https:// - указывается если подключён SSL сертификат
Директива Host — указывает главное зеркало сайта с www или без www.
User-agent:* Allow: / Sitemap: http://www.site.ru/sitemap.xml Host: www.site.ru # следует писать путь к домену без http и без слэшей, убедитесь, что домен склеен. Без правильной склейки домена, одна и та же страница может попасть в индекс поисковых систем более одного раза, что может повлечь пессимизацию.
Директива Crow-Delay — ограничивает нагрузку на сервер, задает таймаут для поисковых машин:
User-agent: * Crawl-delay: 2 # задает таймаут в 2 секунды. User-agent: * Disallow: /search Crawl-delay: 4.5 # задает таймаут в 4.5 секунды.
Директива Clean-Param необходима, если адреса страниц сайта содержат динамические параметры, которые не влияют на содержимое, например: идентификаторы сессий, пользователей, рефереров и т. п.
Робот Яндекса, используя значения директивы Clean-Param, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, страницы с таким адресом:
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123 www.site.com/some_dir/get_book.pl?ref=site_2&book_id=123 www.site.com/some_dir/get_book.pl?ref=site_3&book_id=123
Параметр ref используется только для того, чтобы отследить, с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот Яндекса сведет все адреса страницы к одному:
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123,
Также стоит отметить, что для этой директивы есть несколько вариантов настройки
Кириллические символы в robots.txt
Использование символов русского алфавита запрещено в robots.txt, для этого необходимо использовать Punycode (стандартизированный метод преобразования последовательностей Unicode-символов в так называемые ACE-последовательности)
#Неверно: User-agent: * Disallow: /корзина Host: интернет-магазин.рф #Верно: User-agent: * Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0 Host: xn----8sbalhasbh9ahbi6a2ae.xn--p1ai
Рекомендации по тому, что нужно закрывать в файле robots.txt
- Административную панель — но при этом учтите, что путь к вашей административной панели будет известен, убедитесь в надежности пароля в панели управлением сайтом.
- Корзину, форму заказа, и данные по доставке и заказам.
- Страницы с параметрами фильтров, сортировки, сравнения.
Ошибки, которые могут быть в robots.txt
- Пустая строка — недопустимо делать пустую строку в директиве user-agent, которая по правилам robots.txt считается «разделительной» (относительно блоков описаний). Это значит, что спрогнозировать применимость следующих за пустой строкой директив — нельзя.
- При конфликте между двумя директивами с префиксами одинаковой длины, приоритет отдается директиве Allow.
- Для каждого файла robots.txt обрабатывается только одна директива Host. Если в файле указано несколько директив, робот использует первую.
- Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
- Шесть роботов Яндекса не следуют правилам Robots.txt (YaDirectFetcher, YandexCalendar, YandexDirect, YandexDirectDyn, YandexMobileBot, YandexAccessibilityBot). Чтобы запретить им индексацию на сайте, следует сделать отдельные параметры user-agent для каждого из них.
- Директива User-agent всегда должна писаться выше запрещающей директивы.
- Одна строка, для одной директории. Нельзя писать множество директорий на одной строке.
- Имя файла должно быть только таким: robots.txt. Никаких Robots.txt, ROBOTS.txt, и так далее. Только маленькие буквы в названии.
- В директиве host следует писать путь к домену без http и без слешей. Неправильно: Host: http://www.site.ru/, Правильно: Host: www.site.ru (или site.ru)
- При использовании сайтом защищенного протокола https в директиве host (для робота Яндекса) нужно обязательно указывать именно с протоколом, так Host: https://www.site.ru
Проверка ошибок в robots.txt c помощью Лабрики
labrika→в левом меню Технический аудит→в выпадающем меню→Ошибки robots.txt→перепроверить robots.txt
Необходимо учесть, что файл размером больше 32кб считывается как полностью разрешающий, вне зависимости от того, что написано.
Избыточное наполнение robots.txt. Начинающие веб-мастера впечатляются статьями, где сказано, что все ненужное необходимо закрыть в robots.txt и начинают закрывать вообще все, кроме текста на строго определенных страницах. Это, мягко говоря, неверно. Во-первых, существует рекомендация Google не закрывать скрипты, CSS и прочее, что может помешать боту увидеть сайт так же, как видит его пользователь. Во-вторых, очень большое количество ошибок связано с тем, что закрывая одно, пользователь закрывает другое тоже. Безусловно, можно и нужно проверять доступность страницы и ее элементов. Как вариант ошибки — путаница с последовательностью Allow и Disallow. Лучше всего закрывать в robots.txt только очевидно ненужные боту вещи, вроде формы регистрации, страницы перенаправления ссылок и т. п., а от дубликатов избавляться с помощью canonical. Обратите внимание: то, что вы поправили robots.txt, совсем не обозначает, что Yandex- bot и Google-bot его сразу перечитают. Для ускорения этого процесса достаточно посмотреть на robots.txt в соответствующем разделе вебмастера.
Примеры правильно настроенного robots.txt для разных CMS:
WordPress
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Disallow: /tag Disallow: /category Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Host: site.ru Sitemap: http://site.ru/sitemap.xml
ModX
User-agent: * Disallow: /manager/ Disallow: /assets/components/ Disallow: /core/ Disallow: /connectors/ Disallow: /index.php Disallow: *? Host: example.ru Sitemap: http://example.ru/sitemap.xml
OpenCart
User-agent: * Disallow: /*route=account/ Disallow: /*route=affiliate/ Disallow: /*route=checkout/ Disallow: /*route=product/search Disallow: /index.php?route=product/product*&manufacturer_id= Disallow: /admin Disallow: /catalog Disallow: /download Disallow: /export Disallow: /system Disallow: /*?sort= Disallow: /*&sort= Disallow: /*?order= Disallow: /*&order= Disallow: /*?limit= Disallow: /*&limit= Disallow: /*?filter_name= Disallow: /*&filter_name= Disallow: /*?filter_sub_category= Disallow: /*&filter_sub_category= Disallow: /*?filter_description= Disallow: /*&filter_description= Disallow: /*?tracking= Disallow: /*&tracking= Disallow: /*?page= Disallow: /*&page= Disallow: /wishlist Disallow: /login Disallow: /index.php?route=product/manufacturer Disallow: /index.php?route=product/compare Disallow: /index.php?route=product/category
Joomla
User-agent:* Allow: /index.php?option=com_xmap&sitemap=1&view=xml Disallow: /administrator/ Disallow: /cache/ Disallow: /components/ Disallow: /go.php Disallow: /images/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /logs/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Disallow: /*com_mailto* Disallow: /*pop=* Disallow: /*lang=ru* Disallow: /*format=* Disallow: /*print=* Disallow: /*task=vote* Disallow: /*=watermark* Disallow: /*=download* Disallow: /*user/* Disallow: /.html Disallow: /index.php? Disallow: /index.html Disallow: /*? Disallow: /*% Disallow: /*& Disallow: /index2.php Disallow: /index.php Disallow: /*tag Disallow: /*print=1 Disallow: /trackback Host: Ваш сайт
Bitrix
User-agent: * Disallow: /*index.php$ Disallow: /bitrix/ Disallow: /auth/ Disallow: /personal/ Disallow: /upload/ Disallow: /search/ Disallow: /*/search/ Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?print= Disallow: /*&print= Disallow: /*register= Disallow: /*forgot_password= Disallow: /*change_password= Disallow: /*login= Disallow: /*logout= Disallow: /*auth= Disallow: /*?action= Disallow: /*action=ADD_TO_COMPARE_LIST Disallow: /*action=DELETE_FROM_COMPARE_LIST Disallow: /*action=ADD2BASKET Disallow: /*action=BUY Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*print_course=Y Disallow: /*COURSE_ID= Disallow: /*?COURSE_ID= Disallow: /*?PAGEN Disallow: /*PAGEN_1= Disallow: /*PAGEN_2= Disallow: /*PAGEN_3= Disallow: /*PAGEN_4= Disallow: /*PAGEN_5= Disallow: /*PAGEN_6= Disallow: /*PAGEN_7= Disallow: /*PAGE_NAME=user_post Disallow: /*PAGE_NAME=detail_slide_show Disallow: /*PAGE_NAME=search Disallow: /*PAGE_NAME=user_post Disallow: /*PAGE_NAME=detail_slide_show Disallow: /*SHOWALL Disallow: /*show_all= Host: sitename.ru Sitemap: http://www.sitename.ru/sitemap.xml
В данных примерах, в указании User-Agent указан параметр * , разрешающий доступ всем поисковым роботам, для настройки robots.txt под отдельные поисковые системы вместо спецсимвола указывается название робота Yandex, GoogleBot, StackRambler, Slurp, MSNBot, ia_archiver.
labrika.ru
Настройка robots.txt для Joomla 3
📅 25-05-2019 | SEO и маркетингРассмотрим как создать для Joomla 3+ правильный файл для поисковых роботов — robots.txt
Этот файл нужен для указания роботам того, что нужно индексировать на вашем сайте и чего НЕ нужно.
Изначально robots.txt имеет такой вид:
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Чтобы понимать суть этого файла, давайте слегка разберём что здесь написано и какие операторы (команды) он поддерживает.
User-agent — это имя робота, для которого предназначена инструкция. По умолчанию в Joomla стоит * (звёздочка) — это означает, что инструкция предназначена для абсолютно всех поисковых роботов.
Наиболее распространённые имена роботов:
- Yandex — все роботы поисковой системы Яндекса
- YandexImages — индексатор изображений
- Googlebot — робот Гугла
- BingBot — робот системы Bing
- YaDirectBot — робот системы контекстной рекламы Яндекса
Использовать отдельные инструкции для каждого робота в большинстве случаем нет необходимости. Если только на каких то специфичных проектах и для особенных задач.
Каждый робот понимает большую часть команд, и только для некотрых, например для робота Яндекса существуют собственные команды.
Поэтому смело можно ставить * (звёздочку) и писать инструкции для всех. Если какой-то робот не поёмёт что-то, он просто проигнорирует эту команду и будет работать дальше.
Disallow — запрещает индексировать содержимое указанной папки или URL.
Пример:
Disallow: /images/ — запрет индексации всего содержимого папки images
Disallow: /index.php* — запрет индексации всех URL адресов, начинающихся с index.php
Allow — наоборот, разрешает индексацию папки или URL.
Пример:
Allow: /index.php?option=com_xmap&sitemap=1&view=xml — разрешает индексацию карты сайта, созданной при помощи Xmap.
Такая директива необходима если у вас стоит запрет на индексацию адресов с index.php, а чтобы робот мог получить доступ к карте сайта, нужно разрешить этот конкретный URL.
Host — указание основного зеркала сайта (с www или без www)
Пример:
Host: www.joomlatown.net — основной адрес этого сайта с www
Sitemap — указание на адрес по которму находиться карта сайта
Пример:
Sitemap: http://www.joomlatown.net/index.php?option=com_xmap&sitemap=1&view=xml
По этому адресу находится карта сайта в формате xml
Clean-param — специальная директива, которая запрещает роботам Яндекса индексировать URL адреса с динамическими параметрами.
Динамические параметры, это различные переменные и цифры, которые подставляются к адресу, например при поиске по сайту.
Пример таких параметров:
http://www.joomlatown.net/poisk?searchword=robots.txt&ordering=newest&searchphrase=all&limit=20
И чтобы Яндекс не учитывал такие служебные страницы, в robots.txt задаётся директива Clean-param.
Всё тот же пример с поиском по сайту:
Clean-param: searchword / — директива запрещает индексировать все URL с параметром ?searchword
Crawl-delay — директива пока знакомая только Яндексу. Она указывает с каким интервалом сканировать страницы, интервал задаётся в секундах.
Может быть полезно если у вас много страниц и достаточно высокая нагрузка на сервер, поскольку каждое обращение робота к странице вашего сайта — это нагрузка на сервер. Робот может сканировать по несколько страниц в секунду и тем самым загрузить серврер.
Пример:
Crawl-delay: 5 — интервал для загрузки страницы — 5 секунд.
Прим: Но с crawl-delay нужно быть осторожнее, он может замедлить индексацию страниц сайта.
Специфичные директивы для Яндекса вы можете посмотреть здесь >>
Все директивы пишутся с новой строки, без пропуска.
Таким образом для Joomla 3, со включенным SEF (красивыми ссылками без index.php) можно вывести такой файл robots.txt
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /index.php*
Allow: /index.php?option=com_xmap&sitemap=1&view=xml
Host: ваш_домен.ru
Sitemap: http://ваш_адрес_карты_сайта
Clean-param: searchword /
Здесь мы запретили индексацию URL адресов с index.php — это можно применить только если у вас включен SEF.
Разрешили индексацию картинок, xml-карты сайта, указали главное зеркало сайта, путь до карты сайта, запретили (очистили) параметр searchword, который используется в поиске Joomla.
Желаю хорошей и быстрой индексации!
joomlatown.net
Самый правильный robots.txt для популярных CMS
Содержание с переходом
Примеры robots.txt
robots.txt – это текстовый файл, лежащий в корне сайта и сообщающий поисковым системам как индексировать сайт. Набор строк сообщает, какие разделы сайта разрешить или запретить от индексации, причем для некоторых поисковых систем, может быть использованы дополнительные параметры обрабатывающий только конкретной поисковой системой.
Подробное руководство по использованию - robots.txt для Яндекс
Для тех, кто долго не любит вникать, как правильно составить robots.txt, привожу сразу список наиболее популярных CMS, и какие чаще всего подойдут для них настройки.
Главное понимать, что эти файлы не гарантируют 100% правильную работу, так как могут не закрыть разделы которые у Вас должны быть закрыты или напротив закрыть то, что не должно быть закрыто. Эти примеры лучше всего использовать, для того чтобы составить самому правильный роботикс тхт для своего сайта и не упустить особенности используемого Вами движка.
Так же не забыть там, где стоит site.ru подставить свой сайт.
Почти во всех случаях будет актуально:
Clean-param: utm_source=* Clean-param: utm_medium=* Clean-param: utm_campaign=* Clean-param: utm_content=* Clean-param: utm_term=* Clean-param: cm_id=* Clean-param: openstat=* Clean-param: ycid=* Clean-param: gcid=* Clean-param: ref=*
Просим не копировать и вставлять в том виде как есть, здесь перечислены лишь популярные элементы и так же требует тонкой настройки.
Если все слишком сложно, то пишите на почту, помогу настроить индексацию сайта.
robots.txt для WordPress
User-agent: * Allow: /wp-content/uploads Disallow: */comment-page-* Disallow: */comments Disallow: */feed Disallow: */trackback Disallow: /*? Disallow: /?feed= Disallow: /?s= Disallow: /author Disallow: /cgi-bin Disallow: /comments Disallow: /page Disallow: /search Disallow: /tag Disallow: /trackback Disallow: /webstat Disallow: /wp-admin Disallow: /wp-comments Disallow: /wp-content/cache Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-feed Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /wp-trackback Disallow: /xmlrpc.php Sitemap: http://site.ru/sitemap.xml Host: site.ru
robots.txt для Joomla
User-agent: * Allow: /images Allow: /index.php?option=com_xmap&sitemap=1&view=xml Disallow: /*?action=print Disallow: /*?sl* Disallow: /*atom.html Disallow: /*rss.html Disallow: /administrator Disallow: /bin Disallow: /cache Disallow: /cli Disallow: /component Disallow: /components Disallow: /includes Disallow: /index* Disallow: /index2.php?option=com_content&task=emailform Disallow: /installation Disallow: /language Disallow: /layouts Disallow: /libraries Disallow: /logs Disallow: /media Disallow: /modules Disallow: /plugins Disallow: /templates Disallow: /tmp Disallow: /trackback Disallow: /xmlrpc Sitemap: http://site.ru/sitemap.xml Host: site.ru
robots.txt для MODX
User-agent: * Disallow: /*? Disallow: /*?id= Disallow: /assets Disallow: /assets/cache Disallow: /assets/components Disallow: /assets/docs Disallow: /assets/export Disallow: /assets/import Disallow: /assets/modules Disallow: /assets/plugins Disallow: /assets/snippets Disallow: /connectors Disallow: /core Disallow: /index.php Disallow: /install Disallow: /manager Disallow: /profile Disallow: /search Sitemap: http://site.ru/sitemap.xml Host: site.ru
robots.txt для uCoz
User-agent: * Allow: /*?page Allow: /*?ref= Disallow: /*-*-*-*-987$ Disallow: /*? Disallow: /*_escaped_fragment_= Disallow: /*0-*-0-17$ Disallow: /*0-0- Disallow: /*-0-0- Disallow: /a/ Disallow: /abnl Disallow: /admin Disallow: /index/1 Disallow: /index/2 Disallow: /index/3 Disallow: /index/5 Disallow: /index/7 Disallow: /index/8 Disallow: /index/9 Disallow: /index/sub Disallow: /informer Disallow: /mchat Disallow: /panel Disallow: /poll Disallow: /register Disallow: /search Disallow: /secure Disallow: /shop/checkout Disallow: /shop/user Disallow: /stat Sitemap: http://site.ru/sitemap-forum.xml Sitemap: http://site.ru/sitemap-shop.xml Sitemap: http://site.ru/sitemap.xml Host: site.ru
robots.txt для Drupal
User-agent: * Disallow: *comment* Disallow: *login* Disallow: *register* Disallow: /*&sort* Disallow: /*/delete Disallow: /*/edit Disallow: /*?sort* Disallow: /*calendar Disallow: /*index.php Disallow: /*order Disallow: /*section Disallow: /*votesupdown Disallow: /?q=admin Disallow: /?q=admin/ Disallow: /?q=comment/reply Disallow: /?q=contact Disallow: /?q=filter/tips Disallow: /?q=logout Disallow: /?q=node/add Disallow: /?q=search Disallow: /?q=user/login Disallow: /?q=user/logout Disallow: /?q=user/password Disallow: /?q=user/register Disallow: /admin Disallow: /admin/ Disallow: /archive/ Disallow: /book/export/html Disallow: /CHANGELOG.txt Disallow: /comment Disallow: /comment/reply Disallow: /comments/recent Disallow: /contact Disallow: /cron.php Disallow: /filter/tips Disallow: /forum Disallow: /forum/active Disallow: /forum/unanswered Disallow: /includes Disallow: /INSTALL.mysql.txt Disallow: /INSTALL.pgsql.txt Disallow: /install.php Disallow: /INSTALL.sqlite.txt Disallow: /INSTALL.txt Disallow: /LICENSE.txt Disallow: /logout Disallow: /logout/ Disallow: /MAINTAINERS.txt Disallow: /messages Disallow: /misc Disallow: /modules Disallow: /node Disallow: /node/add Disallow: /print/node Disallow: /profile Disallow: /profiles Disallow: /scripts Disallow: /search Disallow: /taxonomy Disallow: /taxonomy/term*/feed Disallow: /themes Disallow: /update.php Disallow: /UPGRADE.txt Disallow: /user Disallow: /user/ Disallow: /user/login Disallow: /user/logout Disallow: /user/password Disallow: /user/register Disallow: /xmlrpc.php Sitemap: http://site.ru/sitemap.xml Host: site.ru
robots.txt для 1С-Битрикс
User-agent: * Allow: /map/ Allow: /search/map.php Allow: /bitrix/templates/ Disallow: */index.php Disallow: /*action= Disallow: /*print= Disallow: /*/gallery/*order= Disallow: /*/search/ Disallow: /*/slide_show/ Disallow: /*?utm_source= Disallow: /*ADD_TO_COMPARE_LIST Disallow: /*arrFilter= Disallow: /*auth= Disallow: /*back_url_admin= Disallow: /*BACK_URL= Disallow: /*back_url= Disallow: /*backurl= Disallow: /*bitrix_*= Disallow: /*bitrix_include_areas= Disallow: /*building_directory= Disallow: /*bxajaxid= Disallow: /*change_password= Disallow: /*clear_cache_session= Disallow: /*clear_cache= Disallow: /*count= Disallow: /*COURSE_ID= Disallow: /*forgot_password= Disallow: /*ID= Disallow: /*index.php$ Disallow: /*login= Disallow: /*logout= Disallow: /*modern-repair/$ Disallow: /*MUL_MODE= Disallow: /*ORDER_BY Disallow: /*PAGE_NAME= Disallow: /*PAGE_NAME=detail_slide_show Disallow: /*PAGE_NAME=search Disallow: /*PAGE_NAME=user_post Disallow: /*PAGEN_ Disallow: /*print_course= Disallow: /*print= Disallow: /*q= Disallow: /*register= Disallow: /*register=yes Disallow: /*set_filter= Disallow: /*show_all= Disallow: /*show_include_exec_time= Disallow: /*show_page_exec_time= Disallow: /*show_sql_stat= Disallow: /*SHOWALL_ Disallow: /*sort= Disallow: /*sphrase_id= Disallow: /*tags= Disallow: /access.log Disallow: /admin Disallow: /api Disallow: /auth Disallow: /auth.php Disallow: /auto Disallow: /bitrix Disallow: /bitrix/ Disallow: /cgi-bin Disallow: /club/$ Disallow: /club/forum/search/ Disallow: /club/gallery/tags/ Disallow: /club/group/search/ Disallow: /club/log/ Disallow: /club/messages/ Disallow: /club/search/ Disallow: /communication/blog/search.php Disallow: /communication/forum/search/ Disallow: /communication/forum/user/ Disallow: /content/board/my/ Disallow: /content/links/my/ Disallow: /error Disallow: /e-store/affiliates/ Disallow: /e-store/paid/detail.php Disallow: /examples/download/download_private/ Disallow: /examples/my-components/ Disallow: /include Disallow: /personal Disallow: /search Disallow: /temp Disallow: /tmp Disallow: /upload Disallow: /*/*ELEMENT_CODE= Disallow: /*/*SECTION_CODE= Disallow: /*/*IBLOCK_CODE Disallow: /*/*ELEMENT_ID= Disallow: /*/*SECTION_ID= Disallow: /*/*IBLOCK_ID= Disallow: /*/*CODE= Disallow: /*/*ID= Disallow: /*/*IBLOCK_EXTERNAL_ID= Disallow: /*/*SECTION_CODE_PATH= Disallow: /*/*EXTERNAL_ID= Disallow: /*/*IBLOCK_TYPE_ID= Disallow: /*/*SITE_DIR= Disallow: /*/*SERVER_NAME= Sitemap: http://site.ru/sitemap_index.xml Sitemap: http://site.ru/sitemap.xml Host: site.ru
robots.txt для NetCat
User-agent: * Disallow: /*.swf Disallow: /*? Disallow: /eng Disallow: /install Disallow: /js Disallow: /links Disallow: /netcat Disallow: /netcat_cache Disallow: /netcat_dump Disallow: /netcat_files Sitemap: http://site.ru/sitemap.xml Host: site.ru
robots.txt для UMI.CMS
User-agent: * Disallow: /*? Disallow: /? Disallow: /admin Disallow: /emarket/addToCompare Disallow: /emarket/basket Disallow: /files Disallow: /go_out.php Disallow: /images Disallow: /images/lizing Disallow: /images/ntc Disallow: /index.php Disallow: /install-libs Disallow: /install-static Disallow: /install-temp Disallow: /search Disallow: /users Sitemap: http://site.ru/sitemap.xml Host: site.ru
robots.txt для HostCMS
User-agent: * Disallow: /403 Disallow: /404 Disallow: /admin Disallow: /articles/tag Disallow: /captcha.php Disallow: /chmod.sh Disallow: /config.php Disallow: /config_db.php Disallow: /data_templates Disallow: /documents Disallow: /download_file.php Disallow: /glossary/tag Disallow: /hostcmsfiles Disallow: /lib Disallow: /logs Disallow: /main_classes.php Disallow: /modules Disallow: /news/tag Disallow: /search Disallow: /structure Disallow: /templates Disallow: /tmp Disallow: /upload Disallow: /xsl Disallow: captcha.php Disallow: download_file.php Sitemap: http://site.ru/sitemap.xml Host: site.ru
robots.txt для OpenCart
User-agent: * Disallow: /*filter_description= Disallow: /*filter_name= Disallow: /*filter_sub_category= Disallow: /*keyword Disallow: /*limit= Disallow: /*manufacturer Disallow: /*order= Disallow: /*page= Disallow: /*route=account Disallow: /*route=account/login Disallow: /*route=affiliate Disallow: /*route=checkout Disallow: /*route=checkout/cart Disallow: /*route=product/search Disallow: /*sort= Disallow: /*tracking= Disallow: /admin Disallow: /cache Disallow: /cart Disallow: /catalog Disallow: /change-password Disallow: /checkout Disallow: /download Disallow: /export Disallow: /index.php?route=account Disallow: /index.php?route=account/account Disallow: /index.php?route=account/login Disallow: /index.php?route=checkout/cart Disallow: /index.php?route=checkout/shipping Disallow: /index.php?route=common/home Disallow: /index.php?route=product/category Disallow: /index.php?route=product/compare Disallow: /index.php?route=product/manufacturer Disallow: /index.php?route=product/product*&manufacturer_id= Disallow: /index.php?route=product/search Disallow: /login Disallow: /my-account Disallow: /order-history Disallow: /request-return Disallow: /search Disallow: /search?filter_name= Disallow: /search?tag= Disallow: /system Disallow: /vouchers Disallow: /vqmod Disallow: /wishlist Sitemap: http://site.ru/sitemap.xml Host: site.ru
Проверка robots.txt
После вставки проверяем корректность работы файла:
Для Яндекс
– без регистрации, через Яндекс.Вебмастер
Для Google
– инструкция, с регистрацией через Google Вебмастер
В заключении о файле индексации
Если нет Вашей CMS пишите, для Вас составлю бесплатно этот файл и добавлю в список поста.
Так же я старался дать уникальные примеры файлов и редко делю директиву User-agent, как это некоторые любят, по следующим причинам:
- нет смысла делить то, что понимают все поисковые системы, результат создает избыточный размер файла, в крайнем случае, неизвестную директиву проигнорируют
- если мы делим на конкретные ПС, не указывая звездочку, то другие ПС не смогут корректно проиндексировать сайт
- если мы делим на конкретные ПС с указанием звездочки, тогда нет смысла перечислять в двух местах одни и те же директивы, а для других ПС имеет смысл перечислять тоже самое
Подробное руководство по использованию - robots.txt для Яндекс
Для тех, кто долго не любит вникать, как правильно составить robots.txt, привожу сразу список наиболее популярных CMS, и какие чаще всего подойдут для них настройки.
Главное понимать, что эти файлы не гарантируют 100% правильную работу, так как могут не закрыть разделы которые у Вас должны быть закрыты или напротив закрыть то, что не должно быть закрыто. Эти примеры лучше всего использовать, для того чтобы составить самому правильный роботикс тхт для своего сайта и не упустить особенности используемого Вами движка.
Так же не забыть там, где стоит site.ru подставить свой сайт.
Если все слишком сложно, то пишите на почту, помогу настроить индексацию сайта.
www.seoup.su