Типы лексических ошибок — Русский язык без проблем
вернуться на страницу «Культура речи«, «Таблицы«, «Лексика в таблицах«, «Лексический разбор«, на главную
ТИПЫ ЛЕКСИЧЕСКИХ ОШИБОК
Лексическая несочетаемость В спортзале висела треугольная груша (в значение слова груша не входит понятие треугольная).
Неоправданный пропуск слова Никита занял первое место по английскому языку (пропущено слово в олимпиаде).
Многословие
— неоправданный повтор слова Саша сделал хороший доклад. Доклад всем понравился.
— тавтология Начало сессии начинается в конце этого месяца.
— плеоназм Хочу познакомить вас с этим юным вундеркиндом.
Неоправданное употребление антонимов В силу слабости своей позиции ему трудно было защищаться.
Неоправданное употребление заимствованных слов Анакопийская пропасть находится в курортном эпицентре, в Новом Афоне
Неоправданное использование устаревшей лексики, неологизмов, профессиональной и жаргонной лексики, стилистически окрашенных слов 
В продажу поступили беспроводные клавы.
Председатель Законодательного собрания – интересный чувак.
Я признаю необходимость усиления внимания к проблеме.
Неверное использование многозначных лов, омонимов, паронимов Вытянули носочки.
Приносим извинения за предоставленные неудобства.
Смешение понятий С 1 июня самолет будет летать с остановками (с промежуточной посадкой).
РАСПРОСТРАНЕННЫЕ ЛЕКСИЧЕСКИЕ ОШИБКИ
Нарушение лексической сочетаемости слов: Снижается уровень жизни народа (а не ухудшается). Ухудшается состояние/ситуация, а уровень снижается/повышается.
Употребление «роспись и число» вместо «подпись и дата»: Вот такое письмо мы получили, а в конце его подпись и дата» (а не «роспись и число»). Роспись – это живопись на стенах. В документе фиксируется дата
Роспись – это живопись на стенах. В документе фиксируется дата
Употребление слова «обратно» вместо «снова», «опять»: Рижский вокзал надо переименовать снова = опять (а не обратно = назад, в обратном направлении). Наречие «обратно» не является синонимом наречий «снова», «опять».
Лексическая избыточность: Отличившиеся в этой операции получили государственные награды (а не «награждены наградами»). Плеоназм и тавтология — повтор в иной форме ранее сказанного или повторение одного и того же определения другими словами.
Кроме нарушения лексической совместимости, к распространенным лексическим ошибкам относится
— смешение паронимов (роспись — подпись),
— использование слова в несвойственном ему значении («обратно» вместо «опять», «снова»)
— употребление слова иной стилевой окраски
— смешение лексики разных исторических эпох.
Остались вопросы — задай в обсуждениях https://vk. com/board41801109
com/board41801109
Усвоил тему — поделись с друзьями.
Тест на тему Лексические нормы
Тест на тему Использование слова в несвойственном ему значении
Тест на тему Ошибки в сочетаемости слов
Тест на тему Ошибки, связанные с употреблением паронимов
Тест на тему Ошибки тавтология и плеоназм
#обсуждения_русский_язык_без_проблем
вернуться на страницу «Культура речи«, «Таблицы«, «Лексика в таблицах«, «Лексический разбор«, на главную
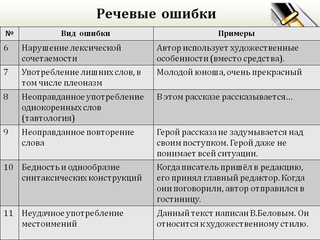
№ | Вид ошибки | Примеры |
Г1 | Ошибочное словообразование. Ошибочное образование форм существительного, прилагательного, числительного, местоимения, глагола (личных форм глаголов, действительных и страдательных причастий, деепричастий) | Благородность, чуда техники, подчерк, надсмехаться; более интереснее, красивше; с пятистами рублями; жонглировал обоими руками, ихнего пафоса, вокруг его ничего нет; сколько нравственных принципов мы лишились из-за утраты духовности; им двигает чувство сострадания; ручейки воды, стекаемые вниз, поразили автора текста; вышев на сцену, певцы поклонились. |
Г2 | Нарушение норм согласования | Я знаком с группой ребят, серьезно увлекающимися джазом. |
Г3 | Нарушение норм управления | Нужно сделать природу более красивую. Все удивлялись его силой. |
Г4 | Нарушение связи между подлежащим и сказуемым или способа выражения сказуемого | Главное, чему теперь я хочу уделить внимание, это художественной стороне произведения. |
Г5 | Ошибки в построении предложения с однородными членами | Страна любила и гордилась поэтом. |
Г6 | Ошибки в построении предложения с деепричастным оборотом | Читая текст, возникает такое чувство сопереживания. |
Г7 | Ошибки в построении предложения с причастным оборотом | Узкая дорожка была покрыта проваливающимся снегом под ногами. |
Г8 | Ошибки в построении сложного предложения | Эта книга научила меня ценить и уважать друзей, которую я прочитал еще в детстве. |
Г9 | Смешение прямой и косвенной речи | Автор сказал, что я не согласен с мнением рецензента. |
Г10 | Нарушение границ предложения | Его не приняли в баскетбольную команду. |
Г11 | Нарушение видовременной соотнесенности глагольных форм | Замирает на мгновение сердце и вдруг застучит вновь. |
Г12 | Пропуск члена предложения (эллипсис) | На собрании было принято (?) провести субботник. |
Г13 | Ошибки, связанные с употреблением частиц: отрыв частицы от того компонента предложения, к которому она относится | Хорошо было бы, если бы на картине стояла бы подпись художника. |
Г14 | Нарушение употребления приложения Г 15 бедность и однообразие синтаксических конструкций Г16 Ошибка в употреблении предлога Г17 нарушение структуры союза не так…, чем вместо не так…, как: | Для атласа «Тайн и загадок» авторами отобрана коллекция цветных иллюстраций к статье об археологических находках в России. Б) Когда писатель пришел в редакцию, его принял главный редактор. Когда они поговорили, писатель отправился в гостиницу. Статья послужила толчком к мыслям. Моя сумка не так красива, чем у подруги |

 Потому что он был невысокого роста.
Потому что он был невысокого роста.
Лексические ошибки и способы их предотвращения
Аннотация: в статье даны методические рекомендации по предотвращению у учащихся лексических ошибок. Продемонстрированы формы работы с разными типами лексических ошибок: как изучаемых, так и не изучаемых в школьной программе. Приведены примеры лексической работы с художественными текстами.
Ключевые слова: русский язык, литература, культура речи, лексическая ошибка, плеоназм, тавтология, фразеология, диалектизм, пароним, ляпалиссиада, хиазм.
Задание на определение лексической ошибки в ЕГЭ было внесено недавно. До этого такие ошибки считались речевыми, а иногда и грамматическими. Наибольшую сложность представляют случаи, когда устойчивые обороты официально-делового стиля искажены и учащемуся необходимо найти «неуместное» слово и заменить правильным. Причем выражения типа «играть роль» и «иметь значение» у детей еще на слуху, а вот «принять ряд решений (вопросов)» и «совершить (сделать) поступок» уже вызывают трудности.
Причем выражения типа «играть роль» и «иметь значение» у детей еще на слуху, а вот «принять ряд решений (вопросов)» и «совершить (сделать) поступок» уже вызывают трудности.
Работу по предотвращению лексических ошибок нужно начинать, конечно, в пятом классе, в основном при изучении темы «Имя прилагательное». Тогда учащиеся знакомятся с понятиями «плеоназм» и «тавтология».
В переводе с древнегреческого слово «плеоназм» — это излишнее употребление ненужных для понимания слов, а «тавтология» — это повторение одного и того же (мысли, причины, описания) в одном предложении (частный случай плеоназма).
Учащиеся сами могут подобрать слова, чтобы получить плеоназм:
• (главная) суть
• (народный) фольклор
• (другая) альтернатива
• (отрицательный) недостаток
• (горячий) кипяток
• (очень) прекрасно
• (впервые) познакомиться
• (бесплатный) подарок
• (светловолосая) блондинка
• (мертвый) труп
При работе с тавтологией можно, например, составить таблицу:
можно | существительное | нельзя |
неуместные | подробности | детальные |
головокружительная | высота | высокая |
свинцовые | белила | белые |
маленькая | зарплата | заработанная |
жизненные | мелочи | маленькие |
страшная | бездна | бездонная |
внезапный | ливень | проливной |
В шестом классе проводится работа по уместному употреблению фразеологизмов.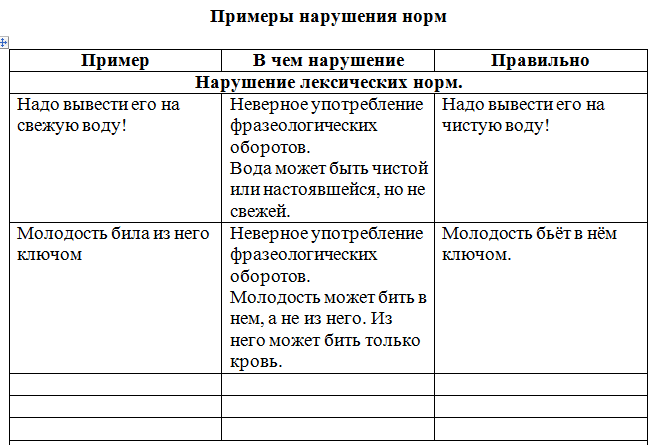 Во-первых, необходимо научить детей определять их стилистическую принадлежность; во-вторых, выработать понимание того, что искажать их нельзя.
Во-первых, необходимо научить детей определять их стилистическую принадлежность; во-вторых, выработать понимание того, что искажать их нельзя.
Работая с фразеологизмами, дети учатся выявлять их источник: Библия, мифология, быт, литературное произведение… Более того, они знакомятся с устаревшими словами:
• остаться с носом (при чем здесь орган дыхания?)
• бить баклуши (что такое баклуши?)
• турусы на колесах (что такое турусы?)
• попасть впросак (куда попасть?)
• во времена оно (это когда?)
В каждом классе проводится лексическая работа по ознакомлению с новыми словами. Примеры таких заданий:
Лексическое значение слова указано неверно в примере (-ах):
I. 1. Плеяда – группа выдающихся людей.
2. Антипатия – чувство неприязни, нерасположения или отвращения к кому-либо или чему-либо.
3. Тоталитаризм – этическая жизненная позиция, утверждающая, что люди имеют право в свободной форме определять смысл и форму своей жизни.
4. Прерогатива – исключительное право, принадлежащее государственному органу или должностному лицу.
II. 1. Глобализация – процесс всемирной экономической, политической, культурной и религиозной интеграции и унификации.
2. Мониторинг – система постоянного наблюдения за явлениями и процессами, проходящими в окружающей среде и обществе.
3. Приватизация – форма преобразования собственности, представляющая собой процесс передачи-продажи (полной или частичной) государственной собственности в частные руки.
4. Референдум – независимость государства во внешних и верховенство государственной власти во внутренних делах.
III. 1. Имидж – совокупность представлений, сложившихся в общественном мнении о том, как должен вести себя человек в соответствии со своим статусом.
2. Букмекер – профессия профессионального спорщика, занимающегося приёмом денежных ставок на различные предстоящие события (чаще всего спортивные).
3. Пирсинг – вид макияжа, который выполняется по принципу татуировки.
4. Айтишник – специалист в сфере информационных технологий.
Знакомство с диалектизмами на уроках русского языка и литературы также очень полезно для предотвращения лексических ошибок.
Например, можно задать детям вопросы:
1. «Кругом всё такие буераки, овраги, а в оврагах всё козюли водятся». (Кого нужно опасаться в оврагах, по мнению Тургенева?)
2. «Не хочу, чтоб и люлька досталась вражьим ляхам». (Какая деталь доказывает патриотизм гоголевского героя?)
3. «Танюшка подошла, а женщина и подает ей ширинку маленькую, концы шёлком шиты». (Что подарили героине Бажова?)
4. «Парни поощряли меня, действуй, мол, и не один калач неси, шанег еще прихвати либо пирог – ничего лишнее не будет». (Что должен принести из дома герой Астафьева?)
5. «Отец нам рассказывал, помнишь, какое это страшное место – Слепая елань, сколько погибло в нем людей и скота». (Куда не советовал ходить отец маленьким героям Пришвина?)
(Куда не советовал ходить отец маленьким героям Пришвина?)
6. «– Куда приехали? – спросил я, протирая глаза. – В умёт. Господь помог, наткнулись прямо на забор». (Куда привез вожатый заблудившихся в буране героев Пушкина?)
7. «Когда любят, то стыдятся. А этот трезвонит ходит по всей деревне…» (За что осуждает героя фильма дед из рассказа Шукшина «Критики»?)
Особое место на уроках во всех классах занимает работа с паронимами. Пример заданий:
Подберите существительные к прилагательным:
• деловой/деловитый
• хамский/хамовитый
• водяной/водный/водянистый
• глиняный/глинистый
• великий/величественный
Найдите ошибку:
доверчивый тон разговора, вдох облегчения, неоглядный мрак, буднее настроение, вековой покой, гордая осанка, действительная помощь, жизненная проблема.
В десятом классе я знакомлю детей с такой формой речевой избыточности, как ляпалиссиады. Этот термин образован от имени французского маркиза Жака де Ля Палиса, на смерть которого была придумана фраза: «Если бы он не был мёртв, он был бы жив». Ляпалиссиады – это неуместные шутки в трагической ситуации, которые могут вызвать комический эффект.
Ляпалиссиады – это неуместные шутки в трагической ситуации, которые могут вызвать комический эффект.
Ещё за четверть часа до своей смерти он был жив.
Если бы он не был мёртв, ему бы всё ещё завидовали.
Я думаю, мы все согласны, что прошлое закончилось. (Буш-младший)
В старших классах также уместно познакомить учащихся с такой фигурой речи, как хиазм. Это риторическая форма, заключающаяся в крестообразном изменении последовательности элементов. В связи с этим мы выясняем, насколько уместен в каждом конкретном случае лексический повтор (однокоренных слов, форм слова).
Примеры хиазмов:
Умейте любить искусство в себе, а не себя в искусстве. (Станиславский)
Кто не знает, чего хочет, должен хотеть того, что знает. (Леонардо да Винчи)
В России две напасти: / Внизу — власть тьмы, / А наверху — тьма власти. (Гиляровский)
Не спрашивай, что твоя страна может сделать для тебя, — спроси себя, что ты можешь сделать для страны. (Джон Ф. Кеннеди)
(Джон Ф. Кеннеди)
Красота — это истина, истина — красота. (Джон Китс)
Учащиеся очень любят составлять хиазмы. Можно предложить несколько блоков тем: философские, бытовые, учебные. В одиннадцатом классе их можно связать с блоками тем экзаменационного сочинения.
Работа по предотвращению лексических ошибок нескончаема, и направлена она, конечно, не столько на выполнение определенных экзаменационных заданий, сколько на формирование культуры речи нашей молодежи. Ведь так приятно слышать красивую, правильную речь!
Список литературы:
1. Красных В.И. Паронимы в русском языке: самый полный толковый словарь. М.: АСТ: Астрель, 2010.
2. Голуб И.Б. Стилистика русского языка: учеб. пособие. М.: Рольф; Айрис-пресс, 1997.
3. Протоиерей Джон Брек. Хиазм в Священном Писании. Μ.: Издательство Общедоступного Православного Университета, 2004.
4. Соловьева Н.Н. Какое слово выбрать? Лексические и грамматические нормы русского литературного языка. М.: Оникс, Мир и Образование, 2008.
М.: Оникс, Мир и Образование, 2008.
Кабачинова Ирина Владимировна,
учитель русского языка и литературы
ГБОУ г. Москвы «Школа им. Н.М. Карамзина»
Мнение редакции может не совпадать с мнением авторов.
Ответственный за размещение информации:
Виктория Разводовская
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Лексические нормы. Лексические ошибки и их исправление. Ошибки в употреблении фразеологических единиц и их исправление | План-конспект урока по русскому языку по теме:
МИНИСТЕРСТВО ОБРАЗОВАНИЯ Нижегородской области
Государственное бюджетное образовательное учреждение
среднего профессионального образования
«Лукояновский педагогический колледж им. А.М.Горького»
(ГБОУ СПО ЛПК)
ОТКРЫТЫЙ УРОК
по ООД Русский язык
(специальность 050144 Дошкольное образование)
Лексические нормы. Лексические ошибки и их исправление. Ошибки в употреблении фразеологических единиц и их исправление
Лексические ошибки и их исправление. Ошибки в употреблении фразеологических единиц и их исправление
Составитель: Аброшнова М.А.,
преподаватель филологических дисциплин
г. Лукоянов 2013 год
Пояснительная записка
Открытый урок по теме «Лексические нормы. Лексические ошибки и их исправление. Ошибки в употреблении фразеологических единиц и их исправление» входит в состав темы 1.2. Лексика. Фразеология ООД Русский язык (специальность 050144 дошкольное образование) и является практическим занятием, на которое по программе отводится два часа. Данный урок проводится в период аттестации на высшую квалификационную категорию преподавателя предметно-цикловой комиссии историко-филологических дисциплин Аброшновой М.А.
Цели:
- Дать обучающимся общие представления о понятии «Лексическая норма русского литературного языка».
- Повторить и обобщить знания по теме «Лексикология»
- Развивать способности к самостоятельному размышлению над поставленными вопросами, поиску ответов на них и аргументации своего мнения.

- Воспитывать познавательную активность, культуру общения, ответственность, интерес и любовь к родному языку.

Оборудование: мультимедийный проектор, толковые и фразеологические словари.
Тип урока: практическое занятие
Ход урока
I. Организационный момент
II. Сообщение темы и целей урока
Слайд 1
Тема сегодняшнего урока: Лексические нормы. Лексические ошибки и их исправление. Ошибки в употреблении фразеологических единиц и их исправление
Данный урок — заключительный в теме «Лексика. Фразеология».
Сегодня мы познакомимся с понятием «лексическая норма русского литературного языка», повторим и обобщим ваши знания по теме «Лексикология», а также будем активно работать над культурой вашей речи.
III. Актуализация знаний
Повторение изученного по теме «Лексикология».
Творческая работа в парах: разгадывание кроссворда Слайд 2
Вопросы к кроссворду:
1. Раздел лингвистики, изучающий лексику. (Лексикология)
2. Словарный запас одного человека. (Лексикон)
Словарный запас одного человека. (Лексикон)
3. Слова, имеющие несколько лексических значений (многозначные)
4. Слова, имеющие одно лексическое значение (однозначные)
5. Антоним к слову «тьма» (свет)
6. Слова схожие по звучанию, но разные по значению (паронимы).
7. Слова, одинаковые по звучанию и написанию, но разные по значению (омонимы)
8. Слова с противоположными значениями (антонимы)
9. Слова, различные по звучанию, но близкие по лексическому значению (синонимы)
10. Лексически неделимые, целостные по значению, воспроизводимые в виде готовых речевых единиц словосочетания (фразеологизмы).
Проверка кроссворда Слайд 3
IV. Работа с эпиграфом. Слайд 4
Итак, тема нашего урока «Лексические нормы»
А эпиграфом нашего урока станут слова Александра Ивановича Куприна: «Язык – это история народа и культуры. Поэтому изучение и сбережение русского языка является не праздным занятием от нечего делать, но насущной необходимостью»
Согласны ли вы с мнением Александра Ивановича Куприна, что изучение языка является необходимостью?
А для чего это нужно?
Чтобы наша речь была правильной, выразительной и чистой.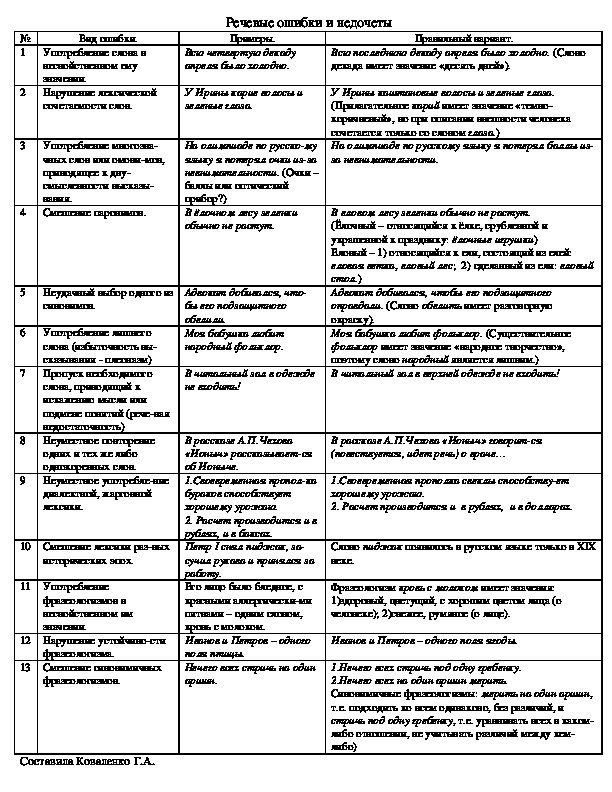
V. Изучение нового материала
Как вы думаете, что такое лексические нормы русского языка и с чем они связаны?
Лексические нормы требуют правильного выбора слова и уместного его употребления в соответствии сего лексическим значением. Значение незнакомого слова мы можем узнать из толкового словаря.
Существуют общие толковые словари, а также словари иностранных слов, специальных терминов, устойчивых выражений (фразеологизмов).
Слайд 5 (Демонстрация слайда с изображением словарей).
Слова, употребление которых ограничено, в словарях обычно имеют соответствующие пометки: «разг.» — разговорное, «прост.» — просторечие, «обл.» — диалектное, «устар.» — устаревшее, а также «книжн.» и «спец.»
Работа с «Толковым словарем» Ожегова
— Пользуясь «Толковым словарем» Ожегова, найдите по 3-5 слов с пометами: «разг.», «обл.», «книжн.» и др., ограничивающими сферу применения этих слов.
В устной и письменной речи необходимо соблюдать лексические нормы.
Слайд 6
- Итак, соблюдение лексических норм достигается в результате:
- Понимания лексического значения слова и употребления слова в соответствии с данным значением.
- Знания лексической сочетаемости слов.
- Учета многозначности либо омонимии слов.
- Учета расслоения лексики на:

— общеупотребительную и сферы ограниченного употребления;
— активно употребляемую и пассивный словарный запас;
— нейтральную и стилистически окрашенную.
Лексическими нормами невозможно овладеть за несколько занятий. Необходимо постоянно обогащать свой словарный запас, систематически обращаться к словарям и справочникам, стремиться изъясняться в соответствии с нормами русского литературного языка не только в официальной, но и в неофициальной обстановке.
При нарушении лексических норм возникают речевые ошибки. Давайте рассмотрим основные речевые ошибки, обусловленные нарушением лексических норм. (Таблица проектируется на экран)
Слайд 7, 8
ВИД ОШИБКИ | ПРИМЕРЫ | ПРАВИЛЬНЫЙ ВАРИАНТ |
1.Употребление слова в несвойственном ему значении. | Всю ЧЕТВЕРТУЮ декаду апреля было холодно. | Всю ПОСЛЕДНЮЮ декаду апреля было холодно. |
2.Нарушение лексической сочетаемости слова. | У Ирины КАРИЕ волосы. | У Ирины КАШТАНОВЫЕ волосы. |
3.Смешение паронимов. | В ЕЛОЧНОМ лесу зеленки обычно не растут. | В ЕЛОВОМ лесу зеленки обычно не растут. |
4.Употребление многозначных слов или омонимов, приводящее к двусмысленности высказывания. | На олимпиаде по русскому языку я потерял ОЧКИ из-за невнимательности. | На олимпиаде по русскому языку я потерял БАЛЛЫ из-за невнимательности. |
5.Неудачный выбор одного из синонимов. | Адвокат добивался, чтобы его подзащитного ОБЕЛИЛИ. | Адвокат добивался, чтобы его подзащитного ОПРАВДАЛИ. |
6.Употребление лишнего слова (речевая избыточность- плеоназм). | Моя бабушка любит НАРОДНЫЙ фольклор. | Моя бабушка любит фольклор (фольклор – «народное творчество»). |
7.Пропуск необходимого слова, приводящий к искажению мысли. | В читальный зал в одежде не входить! | В читальный зал в ВЕРХНЕЙ одежде не входить! |
8.Неуместное повторение одних и тех же либо однокоренных слов (тавтология). | В РАССКАЗЕ А.П.Чехова «ИОНЫЧ» РАССКАЗЫВАЕТСЯ ОБ ИОНЫЧЕ. | В рассказе А.П.Чехова «Ионыч» говорится – (повествуется, идет речь) о враче… |
9.Неуместное употребление диалектной, просторечной лексики. | Своевременная и качественная прополка БУРАКОВ способствует хорошему урожаю. | Своевременная и качественная прополка СВЕКЛЫ способствует хорошему урожаю. |
10.Смешение лексики разных исторических эпох. | Петр Первый снял пиджак, засучил рукава и принялся за работу. | Слово ПИДЖАК появилось в русском языке только в 19 веке. |
11.Двусмысленность высказывания при неудачном использовании местоимений. | Профессор сказал ассистенту, что его предположение оказалось правильным. | Профессор сказал, что предположение ассистента оказалось правильным. |


VI. Закрепление нового материала
Работа в парах с последующей взаимопроверкой.
1. Найдите в данных предложениях слова, употребленные в несвойственном им значении. Объясните лексическое значение этих слов
Слайд 9
1. Этот фильм – настоящий бестселлер.
2. При поездке за границу я не хожу по магазинам и рынкам, а предпочитаю экскурсионный шоп-тур, потому что хочу познакомиться с достопримечательностями страны.
3. Китайская экономика за последние годы пережила настоящую стагнацию: темпы роста производства были очень высокими.
4. Коттоновые брюки, сшитые из шерстяной ткани, мнутся гораздо меньше льняных.
5. Эмигрант – это иностранец, прибывший в какую-либо страну на постоянное жительство.
Слайд 10
СЛОВАРЬ
БЕСТСЕЛЛЕР – пользующаяся повышенным спросом книга, издаваемая большими тиражами.
ШОП-ТУР – поездка (обычно за границу) с целью приобретения вещей, продуктов и т. п.
СТАГНАЦИЯ – застой в производстве, торговле.
КОТТОНОВЫЙ – хлопчатобумажный.
ЭМИГРАНТ – переселенец из своей страны в какую-либо другую. ИММИГРАНТ – иностранец, прибывший в какую-либо страну на постоянное жительство.
2. Выберите из слов в скобках необходимые (с учетом лексической сочетаемости слов)
Слайд 11
1. (Облокотиться, опереться) спиной, заклятый (друг, враг), вороной (конь, цвет), стоимость (высокая, дорогая), цена (низкая, дешевая), играть (значение, роль), (оказывать, производить) впечатление, отъявленный (лодырь, умница), обречен (на успех, на провал), неминуемый (успех, провал), (наступила, началась) война.
2. Утолить (жажду, голод, печаль, страх), плеяда (талантливых ученых, сквернословящих хулиганов), стая (ворон, зайцев, волков), глубокая (старость, юность, ночь), ранний (вечер, день, утро), оказать (помощь, внимание, содействие), одержать (победу, поражение, успех, удачу).
Проверка
Слайд 12
1. ОПЕРЕТЬСЯ спиной, заклятый ВРАГ, вороной КОНЬ, стоимость ВЫСОКАЯ, цена НИЗКАЯ, играть РОЛЬ, ПРОИЗВОДИТЬ впечатление, отъявленный ЛОДЫРЬ, обречен НА ПРОВАЛ, неминуемый ПРОВАЛ, НАЧАЛАСЬ война.
2. Утолить ЖАЖДУ ( утолить голод), плеяда ТАЛАНТЛИВЫХ УЧЕНЫХ, стая ВОРОН (стая волков), глубокая СТАРОСТЬ (глубокая ночь), оказать ПОМОЩЬ (оказать содействие), одержать ПОБЕДУ
3. Выберите тот из паронимов, который уместен в предложенном словосочетании
Слайд 13
1. Продлить (абонент, абонемент), (архитекторский, архитектурный) коллектив, (будняя, будничная) одежда, (ветреный, ветряной) человек, (впечатлительное, впечатляющее) зрелище, (гарантийная, гарантированная) зарплата, (глинистая, глиняная) ваза, осиное (гнездо, гнездовье).
2. (Голосистые, голосовые) связки, (гречишное, гречневое) поле, (двухгодичный, двухгодовалый) жеребенок, (деревянная, древесная) кора, (лобная, лобовая) атака, (луковичный, луковый) привкус, (луковичная, луковая) форма куполов, (националистический, национальный) костюм, (снискать, сыскать) уважение.
Проверка
Слайд 14
1. Продлить АБОНЕМЕНТ, АРХИТЕКТОРСКИЙ коллектив, БУДНИЧНАЯ одежда, ВЕТРЕНЫЙ человек, ВПЕЧАТЛЯЮЩЕЕ зрелище, ГАРАНТИРОВАННАЯ зарплата, ГЛИНЯНАЯ ваза, осиное ГНЕЗДО.
2. ГОЛОСОВЫЕ связки, ГРЕЧИШНОЕ поле, ДВУХГОДОВАЛЫЙ жеребенок, ДРЕВЕСНАЯ кора, КОРЕННОЕ население, ЛОБОВАЯ атака, ЛУКОВЫЙ привкус, ЛУКОВИЧНАЯ форма куполов, НАЦИОНАЛЬНЫЙ костюм, СНИСКАТЬ уважение.
4. Исправьте предложения, в которых наблюдается речевая избыточность
Слайд 15
1) Я подпрыгнул вверх и сорвал вишню. – Я подпрыгнул и сорвал вишню.
2) От стыда парнишка опустил голову вниз и молчал. – От стыда парнишка опустил голову и молчал.
4) Сергей – настоящий меломан пения и музыки. – Сергей – настоящий меломан.
5) Врач обнаружил нарушение двигательной моторики желудка. – Врач обнаружил нарушение моторики желудка.
6) Он крепко держал в своих руках штурвал руля.
7)Все гости получили памятные сувениры.
Употребление в речи по смыслу и потому логически излишних слов называется ПЛЕОНАЗМОМ
5. Укажите неуместно употребленные однокоренные слова, замените их синонимами
Слайд 16
1) Писатель писал роман в послевоенные годы.
2) Лесник знает в своем лесничестве каждое деревце.
3)Герои-подпольщики вели себя героически.
4)Илюша говорил, что случился этот случай на зимой.
5) Пилот вынужден был совершить вынужденную посадку.
6) Активисты активно участвуют в работе.
Повторение однокоренных слов или одинаковых морфем называется ТАВТОЛОГИЕЙ
6. Вспомните с прошлого урока виды речевых ошибок, связанных с употреблением фразеологизмов.
Слайд 17
Речевые ошибки, связанные с употреблением фразеологизмов
1.Ошибки в усвоении значения фразеологизмов.
2.Ошибки в усвоении формы фразеологизма.
3. Изменение лексической сочетаемости фразеологизма.
4.Изменение лексической сочетаемости фразеологизма
Сейчас потренируемся в употреблении в речи фразеологизмов.
Вспомните фразеологические обороты, начало которых дано в тексте
Слайд 18
На садовом участке ребята работали дружно, старались не ударить …
Бросились искать приезжего. а его и след …
У Сережи с Мишей дружба крепкая: их водой …
Ты всегда преувеличиваешь, делаешь из мухи …
Мы его расспрашиваем, а он словно воды …
Обиделся Петя на замечания товарищей, надулся как …
7. Игра «Узнай фразеологизм»
Слайд 19, 20, 21, 22
8. Слова — паразиты
Слайд 23
Слова — паразиты — это такие слова, которые засоряют речь.
К ним разнообразные частицы, которыми говорящий заполняет вынужденные паузы: вот, ну, это и т.п.; словечки типа: знаете ли, так сказать, вообще, честно говоря и т.п.
Употребление слов — паразитов говорит о бедном словарном запасе человека, поэтому таких слов в нашей речи быть не должно.
VI. Самостоятельная работа
Сейчас вы выступите в роли корректора.
Слайд 24
Исправьте предложения, определите тип речевой ошибки.
1 вариант
1. Два единственных вопроса тревожили жителей города: вода и тепло (единственный — «только один»).
2. Школьный стадион прислонился к старому парку (примыкал).
3. В зале ожидания находилось много командировочных (командированных).
4. Хороший руководитель должен во всем показывать образец своим подчиненным (показывать пример).
2 вариант
1. Проливной ливень заставил нас спрятаться под навес (лишнее слово- проливной).
2. Данный вопрос не играет существенного значения в решении задачи (играть роль).
3. Наши воины свершили много геройских подвигов (героических).
4. Эта выставка обогатит ваш кругозор (расширит).
VII. Вывод по уроку
Слайд 25
На сегодняшнем уроке мы познакомились с лексической нормой русского языка и с правилами ее соблюдения. Какой вывод вы для себя сделаете, исходя из темы нашего урока?
Я вам предлагаю следующий: знание лексической нормы русского языка и ее соблюдение — неотъемлемая часть речевой культуры человека.
Желаю вам быть культурным человеком не только в поведении, но в речи!
Вид ошибки | Условные обозначения ошибки | В чем заключается ошибка | Как исправить ошибку |
| 1.Ошибки в Содержании | С |
|
|
| 2.Речевые ошибки и недочет | Р |
|
|
| 3.Грамматические ошибки. | Г |
|
|
| 4.Орфографические ошибки. | I | Слово написано неправильно. | Сделать работу над ошибками в слове. |
| 5. Пунктуационные ошибки. | V | Неправильно поставлен или отсутствует знак препинания в предложении. | Переписать предложение в исправленном виде, подчеркнуть знак препинания, составить схему предложения, объясняющую постановку знака. |
К вопросу классификации речевых ошибок у иностранных учащихся на начальном этапе
Методика преподавания РКИ выделяет ошибки, связанные с аспектами языка\ фонетические, грамматические, лексические\, и ошибки, связанные с аспектами речи \ неадекватное оформление речи, логические ошибки, нарушение правил литературной нормы, правил речевого этикета и т.п.\.Задача преподавателя –русиста состоит не только в умении вычленить те или иные ошибки, корректируя речь обучаемого, подбирая именно те виды заданий и упражнений, которые максимально эффективно работают на их устранение, но и, классифицируя ошибки, предупреждать их, что, в целом, является составной частью профессиональной компетенции преподавателя РКИ.
В методике РКИ представлено несколько типов классификации ошибок. Рассмотрим некоторые их них. Речевые ошибки — это любые случаи отклонения от действующих речевых норм. Методистами РКИ выделяются, так называемые, нормативные ошибки: «нормативные ошибки представляют собой нарушение образцового, общепризнанного употребления элементов языка\слов, словосочетаний, предложений\, а также нарушение правил использования речевых средств в определенный период развития языка в целом.» \Кан. фил. н.Епихина Е.М. Эмблематические коммуникативные ошибки. – Дисс.: Волгоград, 2014г.\. Сюда можно отнести такие ошибки, как: акцентологические ошибки, грамматические ошибки, а также орфографические, лексические, орфоэпические ошибки. Российский лингвист, проф. С. Н. Цейтлин\Речевые ошибки и их предупреждение. -М.: Просвещение, 1982 -143с\ выделяет ошибки, типичные для устной речи, типичные для письменной речи, а также ошибки, общие для устной и письменной речи, последние называются собственно речевыми. Среди них методисты РКИ выделяют: словообразовательные\видоизменение нормы\, морфологические \ненормативное образование слов и употребление частей речи\, синтаксические\неверное построение словосочетаний, предложений\, лексические\употребление слов в несвойственном им значении, нарушение лексической сочетаемости\, стилистические\нарушение единства стиля речи\ и т.п.
С развитием системы тестирования по русскому языку как иностранному проблема совершенствования классификации типологии ошибок становится все более актуальной. Появилась необходимость различать ошибки с точки зрения степени воздействия их на сам акт коммуникации и, как следствие этого, их значимости в акте коммуникации. Поэтому в методику РКИ в связи с успешностью\неуспешностью коммуникативного акта после МАПРЯЛ 2003 года\ на Х Конгрессе\ было введено определение КЗО\коммуникативно-значимая ошибка\ и КНЗО\ коммуникативно-незначимая ошибка\. По мнению лингвиста О. А. Лазаревой \2011г.\, КЗО – это ошибки нарушения тех или иных норм изучаемого языка, приводящие к нарушению коммуникации, непониманию или неверному пониманию смысла коммуникации при общении, а КНЗО — это ошибки, не влияющие или слабо влияющие на успешный ход коммуникации.
Другими словами, КЗО – это ошибки, нарушающие акт коммуникации, искажающие смысл высказывания, нарушающие диалогическое единство, в результате чего акт коммуникации не может состояться, т.е. смысл высказывания нарушается настолько, что его восстановление не представляется возможным. Например: Он Виктор дал книгу \ непонятно: кто- кому дал книгу, он Виктору или Виктор ему\.
Традиционно к коммуникативно- значимым ошибкам методисты РКИ относят грамматические, типа:
• нарушение согласования: они не изучал физику, вчера мы читал, я купил новый тетрадь;
• нарушение в управлении формами слов: я занимаюсь русский язык, он работает в школа;
• нарушение в видо-временных отношениях: я приехал каждый день, я буду написать, на вечере я пою песню о семье, а Ольга рассказала о сестре;
• неверное употребление возвратных глаголов: я много занимаю, я встречаю с другом;
• нарушение в оформлении прямой и косвенной речи: он говорит, я живу и учусь в Москве, он написал, он изучает русский язык в школе;
• искажение грамматической модели: я надо изучать математику;
• нарушение морфологических норм, ошибки в выборе верной формы сравнительной степени: он написал более хужее, чем вчера;
• нарушение синтаксических связей: я читаю быстрый и др.
А также лексические ошибки –нарушение точности, ясности, логичности словоупотребления, нарушение лексической сочетаемости, однозначности- многозначности, нарушение в выборе слова: мой брат очень дружный\вместо: дружелюбный\, поставьте ручку на стол\вместо: положите\, играет значение\ вместо: имеет значение\, неоправданное повторение слов: Саша писал текст, Саша хороша написал текст, Саша выучил слова, Саша рассказал текст в классе.
А также фонетические ошибки: интонационные, нарушающие орфоэпические нормы, несоблюдение пауз и т.д.: Энтон\ вместо АнтОн\, нарушение ритмической организации слова: говОрил \вместо: говорИл\, звонкости-глухости: бил \вместо: пил\.
К речевым ошибкам относят также ошибки монологического высказывания: нарушения непрерывности речи, последовательности и логичности, отсутствие смысловой законченности. В диалогической речи: неумение инициировать диалог, неумение четко определять свою речевую задачу, неумение адекватно реагировать, скорость \быстрота\ понимания, неумение использования средств речевого этикета.
Одновременно с опытом тестирования появилось необходимость учитывать количество ошибок \их частоту, плотность, степень «загрязненности языка»\ (О.А.Лазарева. Социо- культурная значимость коммуникативно- речевой компетентности. Педагогическое образование в России, 2011г., №3, с. 96-101, статья с сайта: jornals.uspu.ru), автор считает, что КЗО- это ошибки: грубые\полностью искажающие смысл коммуникации\, снимаемые контекстом\изменяющие смысл коммуникации\, а НКЗО-это ошибки, затрудняющие коммуникацию\не ведут к коммуникативной неудаче, вызывающие ее сбой\. Ошибки различаются по принципу: коммуникативная неудача, коммуникативный сбой, затруднение коммуникации, отсутствие нарушения коммуникации. Коммуникативная неудача усматривается в тех случаях, когда «задание не выполнено, цель не достигнута, акт коммуникации не состоялся»\ О.А.Лазарева \, в то время как «коммуникативный сбой — это изменение, искажение намерений говорящего».
Таблица, представленная автором, помогающая произвести подсчет баллов при тестировании в определении КЗО и КНЗО, где первые две\красные строки\ строки КЗО, ошибки, не поддающиеся корректировке, а следующие две строки\зеленые строки\ КНЗО- ошибки, поддающиеся корректировке:
Коммуникативная неудача Минус баллы за все задание
КЗО\Искажение смысла -2
Изменяющие смысл -2
КЗО\Затрудняющие коммуникацию -2
КНЗО\Искажающие коммуникацию -0,5
КНЗО\затрудняющие коммуникацию -0,5
Идеальный речевой продукт Баллы не снимаются
Поэтому при классификации ошибок есть определенная сложность, т.е., с точки зрения коммуникативной значимости, одна и та же ошибка в одном случае может расцениваться как КЗО, а в другом – как КНЗО. Другими словами, интерпретация и разграничение их в какой -то степени процесс субъективный, описанный в методике РКИ недостаточно.
Поэтому нам представляется актуальной попытка определить: какими критериями мы должны руководствоваться при разграничении КЗО и КНЗО и от каких факторов это зависит? По нашему мнению, это зависит от:
• от степени нарушения акта коммуникации: КЗО-это те ошибки, при которых 1) акт коммуникации не состоялся из-за грубейших, не поддающихся исправлению ошибок, 2) состоялся, но искажен до невозможности восстановления, 3) если есть возможность восстановить, но с большим трудом посредством контекста, 4)если двусмысленность неустранима никаким способом;
• от целей коммуникации: если при обучении на данном этапе стоит задача проверить сформированность навыка, так называемые ошибки уровня, т.е. активные лексико- грамматические конструкции, являющиеся целью контроля, а выясняется, что навык не сформирован, то это КЗО, поскольку нарушение произошло на основе уже изученных правил, что свидетельствует о несформированности активного навыка на данном этапе. Например: на элементарном уровне обучаемый должен успешно использовать формы винительного падежа направления и предложного падежа места, поэтому ошибки, типа: он идет в школе\Он был в комнату- на этом уровне- это КЗО, причем на экзамене однотипная ошибка на одно правило засчитывается как одна ошибка \1 правило=1 ошибка\.
КНЗО-это ошибки, при которых на уровне введения в актив и закрепления лексико-грамматических конструкций происходит коммуникативный сбой именно по этим изучаемым темам, поскольку навык еще только в процессе формирования. К ним также относятся, так называемые, ошибки уровня. Если на этапе контроля появляются ошибки уровня, т.е. уровня еще не изученной фонетики, лексики и грамматики, использована грамматика, еще активно не изучавшаяся на этом уровне, то эти ошибки также относятся к КНЗО, например: я написал письма новые друзьям\ а на элементарном уровне слово новым — это прилагательное в дат. п. мн. числа, т.е. та грамматика, которая не изучена в активе, -поэтому эту ошибку относим к КНЗО. Но на первом сертификационном уровне она уже переходит в разряд КЗО. А вот во фразе: я куплю красный ручку\ вместо: красную\ — это КЗО, поскольку это активная грамматика элементарного уровня и ее усвоение контролируется на этом уровне.
При выполнении задачи устранения речевых ошибок необходимо обращать внимание на способы их преодоления, к которым относятся тренинги, различные речевые задания, закрепляющие речевые навыки, обучающие игры, анализ ошибок, который при этом не должен увеличивать боязнь их повтора и не снижать активность процесса говорения, а также обучение самоконтролю.
Лексические нормы (употребление слова), паронимы
Лексические нормы (употребление слова).
Это задание проверяет твое умение различать паронимы.
Паронимы – слова, близкие по звучанию и написанию, но разные по значению.
Лексическими нормами русского языка называются правила употребления слов и словосочетаний в точном соответствии с их значениями. Нарушение лексических норм приводит к тому, что высказывания становятся двусмысленными, а также к серьезным речевым ошибкам. Соблюдение лексических норм русского языка предполагает умение выбрать нужное слово из ряда близких или тождественных по содержанию, т. е. слов-синонимов, а также способность различать слова-паронимы.
Паронимы бывают:
приставочными;
суффиксальными;
различающиеся конечными буквами.
Приставочные паронимы.
В задании А2 они встречаются достаточно редко, поэтому их не так уж и сложно запомнить.
Различай!
| Уплатить — Отдать, внести (деньги) в возмещение чего-либо (чаще всего речь идет крупной сумме денег) | Оплатить — Заплатить за что-нибудь |
| Одеть кого-либо | Надеть на себя |
| Представить — Предъявить, сообщить что-либо кому-либо. Познакомить с кем-либо, дать возможность ознакомиться с чем-либо. Признав достойным чего-либо, ходатайствовать о чём-либо | Предоставить — Отдать кого-что-либо в распоряжение, пользование кому-чему-либо. Дать возможность кому-либо сказать, сделать что-либо, чем-либо распорядиться. |
| Встряхнуть — Приподняв, потрясти с силой. | Стряхнуть — Тряхнув, скинуть, сбросить. |
| Поверка — Сверка в точности. Перекличка с целью проверить наличный состав людей (спец.). | Проверка — Установление правильности чего-либо, соответствия чего-либо чему-либо. |
| Обсудить — Разобрать, обдумать, всесторонне рассмотреть, высказывая свои соображения по поводу чего-либо или о ком-либо. | Осудить — Выразить неодобрение кому-чему-либо, признать дурным. Приговорить к какому-либо наказанию, вынести обвинительный приговор, обвинить. |
| Нетерпимый — такой, с которым нельзя мириться, недопустимый. Не считающийся с чужим мнением, лишённый терпимости. | Нестерпимый — Превышающий терпение, с трудом переносимый. |
| Описка — Ошибка в написании чего-н. по рассеянности. | Отписка — Формальный ответ, не затрагивающий сущности дела. |
Суффиксальные паронимы.
Правило.
Большая часть паронимов связана с различием однокоренных прилагательного и причастия.
Помни!
Суффиксы –УЩ-/-ЮЩ-, -АЩ-/-ЯЩ- относятся к суффиксам причастия и обозначают производителя действия.
КРАСОЧНЫЙ. Отличающийся яркими красками.
КРАСЯЩИЙ. Служащий для окрашивания чего-н., содержащий в себе краску (спец).
Различающиеся конечными буквами.
Различай!
https://5-ege.ru/leksicheskie-normy-paronimy/
| База – Основание, основа. Опора чего-либо; опорный пункт. Склад, складской или снабженческий пункт. | Базис – Совокупность исторически определенных производственных отношений, образующих экономическую структуру общества и определяющих характер надстройки. |
| Абонент – Владелец абонемента (лицо или учреждение). | Абонемент – Право пользования чем-либо в течение определённого срока, а также документ, удостоверяющий это право. |
| Невежа – Грубый, невоспитанный, невежливый человек. | Невежда – Малообразованный человек, неуч; человек, несведущий в какой-либо области знания, профан. |
| Адресат – Тот, кому адресовано почтовое отправление (лицо или учреждение). | Адресант – Тот, кто посылает почтовое или телеграфное отправление (лицо или учреждение) |
| Дипломат – Должностное лицо, занимающееся дипломатической деятельностью, работой в области внешних отношений. | Дипломант – Лицо, награждённое дипломом за успешное выступление на конкурсе, фестивале и т. п. Студент, готовящий выпускную, дипломную работу. |
Помни!
В этой главе представлены не все примеры, которые возможны в задании А2. Чаще всего, тебе придется заглядывать в словарь, чтобы определить значения слов.
Алгоритм действий.
1. Определи, какой частью речи являются слова-паронимы.
2. Внимательно прочитай предложения. Может быть, ты найдешь что-нибудь общее в словах, которые сочетаются с паронимами.
3. Подумай, от какого слова они могут быть образованы. Возможно, различие содержится именно в основах!
4. Посмотри, какой частью слова отличаются слова: приставкой, суффиксом и т.д.
5. Если возможно, вспомни отличия в значении.
Помни! Если вдруг попадутся слова типа абонент – абонемент, этот алгоритм не сработает.
Разбор задания.
В каком предложении вместо слова ВРАЖДЕБНЫЙ нужно употребить слово ВРАЖЕСКИЙ?
1) В качестве ВРАЖДЕБНОЙ силы в сказках иногда выступают животные и растения.
2) Он оказался во ВРАЖДЕБНОМ ему мире.
3) Танковой дивизии удалось сломить ВРАЖДЕБНУЮ оборону противника.
4) Они не были готовы к столь ВРАЖДЕБНОМУ приему местных жителей.
Враждебный и вражеский относятся к паронимам – прилагательным. Попробуем разобраться, от какого слова (слов) они образованы.
Враждебный – вражда (неприязнь, взаимная ненависть, недоброжелательные отношения) + суффикс —ебн-. Значение — выражающий враждебное отношение.
Вражеский – враг (человек, борющийся за иные, противоположные интересы, противник) + суффикс –еск-. Значение — принадлежащий врагу.
Значит, паронимы образованы от разных слов, поэтому и различие следует искать, исходя не столько из суффиксов, сколько из основы слов.
В вариантах № 2, 3, 4 по контексту выражается отношение: враждебный мир, враждебная оборона, враждебный прием. А в варианте №1 по контексту должна указываться принадлежность: вместо враждебные силы нужно говорить вражеские силы.
Таким образом, правильный вариант №1.
Потренируйся.
1. В каком предложении вместо слова ДИПЛОМАТ нужно употребить ДИПЛОМАНТ?
1) Леонида Ивановича считали настоящим ДИПЛОМАТОМ в общении с окружающими людьми.
2) Успех внешней политики государства во многом зависит от опыта и таланта ДИПЛОМАТОВ.
3) Ты говоришь как ДИПЛОМАТ, но дело не идет на лад.
4) ДИПЛОМАТЫ Московского конкурса артистов балета приняли участие в заключительном концерте.
2. В каком предложении вместо слова ВИНОВАТЫЙ нужно употребить ВИНОВНЫЙ?
1) Самым мучительным для Вадима было то, что он все равно ощущал себя ВИНОВАТЫМ, хотя друг с легкостью простил его за эту ложь.
2) Суд признал чиновника ВИНОВАТЫМ в совершении мошенничества.
3) Подросток смотрел на всех испуганным и ВИНОВАТЫМ взглядом.
4) Антонина демонстративно пошла мыть посуду, а он сидел, чувствуя себя ВИНОВАТЫМ в том, что неожиданно нагрянул в гости.
3. В каком предложении вместо слова ДОЖДЕВОЙ нужно употребить ДОЖДЛИВЫЙ?
1) На темной листве блестела одна-единственная ДОЖДЕВАЯ капля.
2) День обещал быть ДОЖДЕВЫМ и ветреным.
3) Сдвигая вековые камни, обрушились вниз ДОЖДЕВЫЕ потоки.
4) Из сада хлынул чистый ДОЖДЕВОЙ воздух, дурманящий запах цветущей липы.
Ответы: 4, 2, 2.
Рекомендуем:
Лексический анализ(анализатор) в дизайне компилятора с примером
Что такое лексический анализ?
Лексический анализ — это самый первый этап в разработке компилятора. Лексер берет модифицированный исходный код, который написан в форме предложений. Другими словами, это помогает вам преобразовать последовательность символов в последовательность токенов. Лексический анализатор разбивает этот синтаксис на серию токенов. Он удаляет лишние пробелы или комментарии, написанные в исходном коде.
Программы, выполняющие лексический анализ при разработке компилятора, называются лексическими анализаторами или лексерами. Лексер содержит токенизатор или сканер. Если лексический анализатор обнаруживает, что токен недействителен, он генерирует ошибку. Роль лексического анализатора в конструкции компилятора заключается в чтении символьных потоков из исходного кода, проверке допустимых токенов и передаче данных в анализатор синтаксиса, когда он этого требует.
Пример
Насколько хороша погода?
См. Этот пример лексического анализа; Здесь мы можем легко узнать, что есть пять слов, как приятно, погода, есть.Для нас это очень естественно, поскольку мы можем распознавать разделители, пробелы и знаки препинания.
КАК ПОЛУЧИТЬ ЕЕ?
Теперь посмотрим на этот пример, мы также можем прочитать это. Однако это займет некоторое время, потому что разделители помещены в нечетные места. Это не то, что приходит к вам немедленно.
В этом руководстве вы изучите
Основные термины
Что такое лексема?
Лексема — это последовательность символов, включенных в исходную программу в соответствии с шаблоном соответствия токена.Это не что иное, как экземпляр токена.
Что такое жетон?
Токены в конструкции компилятора — это последовательность символов, которая представляет единицу информации в исходной программе.
Что такое узор?
Шаблон — это описание, которое используется токеном. В случае ключевого слова, которое используется в качестве токена, шаблон представляет собой последовательность символов.
Архитектура лексического анализатора: как распознаются токены
Основная задача лексического анализа — считывать входные символы в коде и производить токены.
Лексический анализатор сканирует весь исходный код программы. Он идентифицирует каждый токен один за другим. Сканеры обычно реализуются для создания токенов только по запросу парсера. Вот как работает распознавание токенов в дизайне компилятора —
Архитектура лексического анализатора
- «Получить следующий токен» — это команда, которая отправляется из парсера в лексический анализатор.
- Получив эту команду, лексический анализатор просматривает ввод, пока не найдет следующий токен.
- Возвращает токен в Parser.
Lexical Analyzer пропускает пробелы и комментарии при создании этих токенов. Если присутствует какая-либо ошибка, то лексический анализатор сопоставит эту ошибку с исходным файлом и номером строки.
Роли лексического анализатора
Лексический анализатор выполняет следующие задачи:
- Помогает идентифицировать токен в таблице символов
- Удаляет пробелы и комментарии из исходной программы
- Сопоставляет сообщения об ошибках с исходной программой
- Помогает вы раскрываете макрос, если он обнаружен в исходной программе
- Прочитать входные символы из исходной программы
Пример лексического анализа, токены, не-токены
Рассмотрим следующий код, который подается в лексический анализатор
# включитьint maximum (int x, int y) { // Это сравнит 2 числа если (x> y) вернуть x; еще { вернуть y; } }
Примеры созданных токенов
| Lexeme | Token |
| int | Ключевое слово |
| максимум | Идентификатор |
| ( | Оператор |
| int | Ключевое слово |
| Идентификатор | |
| , | Оператор |
| int | Ключевое слово |
| Y | Идентификатор |
| ) | Оператор |
| { | Оператор |
| Если | Ключевое слово |
Примеры нетокенов
| Тип | Примеры |
| Комментарий | // Это сравнит 2 числа |
| Директива препроцессора | #include |
| Директива препроцессора | #define NUMS 8,9 |
| Макрос | NUMS |
| Пробел | / n / b / t |
Лексические ошибки
Последовательность символов который невозможно просканировать в какой-либо действительный токен, является лексической ошибкой. Важные факты о лексической ошибке:
- Лексические ошибки не очень распространены, но они должны обрабатываться сканером
- Ошибки в написании идентификаторов, операторов, ключевых слов рассматриваются как лексические ошибки
- Как правило, лексическая ошибка вызвана появление какого-либо нелегального персонажа, чаще всего в начале токена.
Восстановление ошибок в лексическом анализаторе
Вот несколько наиболее распространенных методов восстановления после ошибок:
- Удаляет один символ из оставшегося ввода
- В режиме паники следующие друг за другом символы всегда игнорируются до тех пор, пока мы не дойдем до нужного значения. сформированный токен
- Вставив недостающий символ в оставшийся ввод
- Заменить символ другим символом
- Транспонировать два последовательных символа
Lexical Analyzer vs.Синтаксический анализатор
| Лексический анализатор | Синтаксический анализатор |
| Сканирование Входная программа | Выполнение синтаксического анализа |
| Идентификация токенов | Создание абстрактного представления кода |
| Вставка токенов в таблицу символов | Обновить записи таблицы символов |
| Он генерирует лексические ошибки | Он генерирует дерево синтаксического анализа исходного кода |
Зачем разделять лексический и синтаксический анализаторы?
- Простота дизайна: упрощает процесс лексического анализа и синтаксического анализа за счет устранения нежелательных токенов
- Повышение эффективности компилятора: помогает повысить эффективность компилятора
- Специализация: можно применять специальные методы для улучшения лексического анализа процесс
- Переносимость: для связи с внешним миром требуется только сканер
- Более высокая переносимость: особенности устройства ввода ограничены лексером
Преимущества лексического анализа
- Метод лексического анализатора используется такими программами, как компиляторы, которые может использовать проанализированные данные из кода программиста для создания скомпилированного двоичного исполняемого кода
- Он используется веб-браузерами для форматирования и отображения веб-страницы с помощью проанализированных данных из JavsScript, HTML, CSS
- Помогает отдельный лексический анализатор вы создадите специализированный и потенциально более эффективный процесс сор для задачи
Недостаток лексического анализа
- Вам нужно потратить много времени на чтение исходной программы и ее разбиение на лексемы
- Некоторые регулярные выражения довольно сложно понять по сравнению с правилами PEG или EBNF
- Требуются дополнительные усилия для разработки и отладки лексера и его описаний токенов
- Дополнительные накладные расходы времени выполнения требуются для создания таблиц лексера и построения токенов
Резюме
- Лексический анализ — самый первый этап в разработке компилятора
- Лексемы и токены — это последовательность символов, которые включены в исходную программу в соответствии с шаблоном соответствия токена
- Лексический анализатор реализован для сканирования всего исходного кода программы
- Лексический анализатор помогает идентифицировать токен в таблице символов
- Последовательность символов, которую невозможно сканировать в к любому действительному токену — лексическая ошибка.
- Удаляет один символ из оставшегося ввода. Полезно. Метод исправления ошибок.
- Лексический анализатор сканирует входную программу, пока синтаксический анализатор выполняет анализ синтаксиса. нежелательные токены
- Лексический анализатор используется веб-браузерами для форматирования и отображения веб-страницы с помощью проанализированных данных из JavsScript, HTML, CSS
- Самым большим недостатком использования лексического анализатора является то, что ему требуются дополнительные накладные расходы времени выполнения, необходимые для генерации лексические таблицы и построение токенов
Формат вывода для лексического анализатора
Формат вывода для лексического анализатора Формат вывода для лексического анализатораВаш лексический анализатор должен выводить каждый токен, идентифицированный из введенной программы MINI-L.Каждый токен должен отображаться в отдельной строке вывода, а токены должны отображаться в выводятся в том же порядке, в каком они появляются во введенной программе MINI-L. Чтобы облегчить выставление оценок, токены должны выводиться в формате, описанном в таблице ниже.
Ваш лексический анализатор должен уловить два типа лексических ошибок. Они описаны ниже.
Примечание: на этом этапе проекта даже синтаксически некорректные программы MINI-L все еще могут быть успешно проанализирован в список токенов.На следующем этапе этого проекта будут зафиксированы синтаксические ошибки.
Список токенов
В следующей таблице описаны различные типы токенов, которые может выводить ваш лексический анализатор. Комментарии и пробелы должны игнорироваться вашим лексический анализатор (для них не нужно выводить токены).
| Лексический шаблон во введенной программе MINI-L | Токен, который должен быть выведен |
| Зарезервированные слова | |
| функция | НАЗНАЧЕНИЕ |
| beginparams | BEGIN_PARAMS |
| конечные параметры | END_PARAMS |
| beginlocals | BEGIN_LOCALS |
| endlocals | END_LOCALS |
| начальное тело | BEGIN_BODY |
| торцевой части | END_BODY |
| целое | ЦЕЛОЕ |
| массив | МАССА |
| из | ИЗ |
| если | IF |
| , затем | ТО |
| endif | ENDIF |
| еще | ELSE |
| а | ПРИ |
| до | DO |
| начальный цикл | BEGINLOOP |
| конец петли | ENDLOOP |
| продолжить | ПРОДОЛЖИТЬ |
| читать | ПРОЧИТАТЬ |
| запись | ЗАПИСАТЬ |
| и | И |
| или | ИЛИ |
| не | НЕ |
| правда | ИСТИНА |
| ложный | ЛОЖЬ |
| возврат | ВОЗВРАТ |
| Арифметические операторы | |
| – | ПОД |
| + | ДОБАВИТЬ |
| * | МУЛЬТ |
| / | РАЗД. |
| % | MOD |
| Операторы сравнения | |
| == | EQ |
| <> | NEQ |
| < | LT |
| > | GT |
| <= | LTE |
| > = | GTE |
| Идентификаторы и номера | |
| идентификатор (например,g., «трубкозуб», «BIG_PENGUIN», «fLaMInGo_17», «ot73r») | IDENT XXXX [где XXXX — это сам идентификатор] |
| номер (например, «17», «101», « », «0», «8675309») | НОМЕР XXXX [где XXXX — собственно номер] |
| Прочие специальные символы | |
| ; | СЕМИКОЛОН |
| : | КОЛОНА |
| , | ЗАПЯТАЯ |
| ( | L_PAREN |
| ) | R_PAREN |
| [ | L_SQUARE_BRACKET |
| ] | R_SQUARE_BRACKET |
| : = | НАЗНАЧЕНИЕ |
Лексические ошибки, которые нужно отловить
Ваш лексический анализатор должен улавливать два разных типа лексических ошибок.Если возникнет такая ошибка во время синтаксического анализа программы MINI-L ваш лексический анализатор должен немедленно прекратить работу после сообщения сообщение об ошибке. Сообщение об ошибке должно включать информацию о номере строки и номере позиции столбца в строка токена, связанная с ошибкой. Подробности ниже.
Тип ошибки 1: нераспознанный символ
Ваш лексический анализатор должен сообщить об ошибке и прекратить работу, если обнаружен нераспознанный символ, вне комментария.Например, рассмотрим следующую функцию MINI-L:
01. функциональный тест; 02. beginparams 03. endparams 04. beginlocals 05. n: целое число; 06. endlocals 07. beginbody 08. прочитать n; 09. п: = п + 1? 10. напишите n; 11. конец телаВ приведенной выше программе знак «?» символ в строке 5 (который находится вне комментария) не определен в MINI-L язык. Таким образом, ваш лексический анализатор должен выдавать ошибку «нераспознанный символ», когда он встречает «?» (вместе с информацией о номере строки и номере позиции проблемного символа).Например:
Ошибка в строке 9, столбце 14: нераспознанный символ "?"
Тип ошибки 2: недопустимый идентификатор
Ваш лексический анализатор должен сообщить об ошибке и завершить работу, если обнаружен недопустимый идентификатор. Это может произойти, если идентификатор начинается с цифры или символа подчеркивания, или если идентификатор заканчивается подчеркиванием. Например, рассмотрим следующие две функции MINI-L:
01. function test1; 02. beginparams 03. endparams 04. beginlocals 05.2n: целое число; 06. endlocals 07. beginbody 08. endbody
01. function test2; 02. beginparams 03. endparams 04. beginlocals 05. n_: целое число; 06. endlocals 07. beginprogram 08. конечная программаВ обеих вышеупомянутых функциях идентификатор, объявленный в строке 5, недействителен. Таким образом, в обоих в таких случаях ваш лексический анализатор должен выдавать ошибку «неверный идентификатор», когда он встречает либо «2n», либо «n_». Например, в первой функции выше:
Ошибка в строке 5, столбец 0: идентификатор "2n" должен начинаться с буквы.И во второй функции выше:
Ошибка в строке 5, столбец 0: идентификатор "n_" не может заканчиваться знаком подчеркивания.
Обработка ошибок
в конструкции компилятора
Задачи процесса Обработка ошибок заключаются в том, чтобы обнаружить каждую ошибку, сообщить о ней пользователю, а затем разработать стратегию восстановления и реализовать ее для обработки ошибки.В течение всего этого процесса время обработки программы не должно замедляться.
Функции обработчика ошибок:
- Обнаружение ошибок
- Отчет об ошибках
- Восстановление ошибок
Обработчик ошибок = Обнаружение ошибок + Отчет об ошибках + Восстановление после ошибок.
Ошибка — это пустые записи в таблице символов.
Ошибки в программе должны обнаруживаться и сообщаться анализатором. Всякий раз, когда возникает ошибка, синтаксический анализатор может обработать ее и продолжить синтаксический анализ оставшейся части ввода.Хотя синтаксический анализатор в основном отвечает за проверку на наличие ошибок, ошибки могут возникать на различных этапах процесса компиляции.
Итак, существует много типов ошибок, и некоторые из них:
Типы или Источники ошибок — Есть три типа ошибок: логическая, ошибка времени выполнения и ошибка времени компиляции:
- Логика ошибки возникают, когда программы работают некорректно, но не завершаются аварийно (или не завершаются). Неожиданные или нежелательные выходы или другое поведение могут быть результатом логической ошибки, даже если она не сразу распознается как таковая.
- Ошибка выполнения — это ошибка, которая возникает во время выполнения программы и обычно возникает из-за неблагоприятных системных параметров или неверных входных данных. Примером этого является недостаток памяти для запуска приложения или конфликт памяти с другой программой или логическая ошибка. Логические ошибки возникают, когда исполняемый код не дает ожидаемого результата. Логические ошибки лучше всего устраняются тщательной отладкой программы.
- Ошибки времени компиляции возникают во время компиляции, перед выполнением программы.Примером этого является синтаксическая ошибка или отсутствие ссылки на файл, препятствующие успешной компиляции программы.
Классификация ошибок времени компиляции —
- Лексический : включает орфографические ошибки в идентификаторах, ключевых словах или операторах
- Синтаксические : отсутствие точки с запятой или несбалансированные скобки
005
: несовместимое присвоение значений или несоответствие типов между оператором и операндом - Логический : код недоступен, бесконечный цикл.
Обнаружение ошибки или сообщение об ошибке — Viable-prefix — это свойство синтаксического анализатора, которое позволяет раннее обнаруживать синтаксические ошибки.
- Цель : обнаружение ошибки как можно скорее без дальнейшего использования ненужного ввода
- Как: обнаруживает ошибку, как только префикс ввода не соответствует префиксу какой-либо строки на языке.
Пример: для (; ), будет выдана ошибка, связанная с наличием двух точек с запятой внутри фигурных скобок.
Восстановление после ошибок —
Основное требование для компилятора — просто остановить и выдать сообщение, а также прекратить компиляцию. Вот несколько распространенных методов восстановления.
Ошибки уже обсуждаем. Теперь давайте попробуем понять, как исправить ошибки на каждом этапе компилятора.
1. Восстановление в экстренном режиме:
Это самый простой способ исправления ошибок, а также предотвращает создание бесконечных циклов синтаксического анализатора при восстановлении ошибки.Синтаксический анализатор отбрасывает входной символ по одному, пока не будет найден один из назначенных (например, конец, точка с запятой) набора синхронизирующих токенов (обычно это терминаторы операторов или выражений). Этого достаточно, когда наличие нескольких ошибок в одном и том же операторе редко. Пример: рассмотрим ошибочное выражение — (1 + + 2) + 3. Восстановление в экстренном режиме: переход к следующему целому числу и затем продолжение. Bison: используйте специальный терминал , ошибка , чтобы указать, сколько ввода нужно пропустить.
E-> int | E + E | (E) | error int | (error)
2.Восстановление на фазовом уровне:
При обнаружении ошибки синтаксический анализатор выполняет локальную коррекцию оставшегося входа. Если синтаксический анализатор обнаруживает ошибку, он вносит необходимые исправления в оставшийся ввод, чтобы синтаксический анализатор мог продолжить синтаксический анализ остальной части оператора. Вы можете исправить ошибку, удалив лишние точки с запятой, заменив запятые точками с запятой или повторно введя пропущенные точки с запятой. Чтобы избежать зацикливания во время коррекции, следует проявлять максимальную осторожность.Всякий раз, когда в оставшемся вводе встречается какой-либо префикс, он заменяется некоторой строкой. Таким образом, синтаксический анализатор может продолжить работу над своим выполнением.
3. Производство ошибок:
Использование метода создания ошибок может быть включено, если пользователь знает о типичных ошибках, встречающихся в грамматике, в сочетании с ошибками, приводящими к ошибочным конструкциям. Когда это используется, в процессе синтаксического анализа могут генерироваться сообщения об ошибках, и анализ может продолжаться.Пример: напишите 5x вместо 5 * x
4. Общая коррекция:
Для восстановления после ошибочного ввода синтаксический анализатор анализирует всю программу и пытается найти для нее наиболее близкое совпадение, которое не содержит ошибок. Самое близкое совпадение — это то, что не выполняет много вставок, удалений и изменений токенов. Этот метод непрактичен из-за большой сложности во времени и пространстве.
Следующая статья по теме — Обнаружение и устранение ошибок в компиляторе
Вниманию читателя! Не прекращайте учиться сейчас.Практикуйте экзамен GATE задолго до самого экзамена с помощью предметных и общих викторин, доступных в курсе GATE Test Series .
Изучите все концепции GATE CS с бесплатными живыми классами на нашем канале YouTube.
Лексическая структура и синтаксис в стандартном SQL | BigQuery | Google Cloud
Оператор BigQuery состоит из серии токенов. Токены включают идентификаторы , цитируемые идентификаторы , литералы , ключевые слова , операторы и специальных символа .Вы можете разделить токены пробелами (например, пробел, backspace, вкладка, новая строка) или комментарии.
Идентификаторы
Идентификаторы — это имена, связанные со столбцами, таблицами и другими объекты базы данных. Их можно не цитировать или цитировать.
- Идентификаторы могут использоваться в выражениях пути, которые возвращают
СТРУКТУРА. - Некоторые идентификаторы чувствительны к регистру, а некоторые нет. Подробнее см. Чувствительность к регистру.
- Идентификаторы без кавычек должны начинаться с буквы или символа подчеркивания.Последующие символы могут быть буквами, цифрами или символами подчеркивания.
- Указанные в кавычки идентификаторы должны быть заключены в символы обратной кавычки (`).
- Заключенные в кавычки идентификаторы могут содержать любой символ, например пробелы или символы.
- Указанные в кавычках идентификаторы не могут быть пустыми.
- Указанные в кавычки идентификаторы имеют те же escape-последовательности, что и строковые литералы.
- Зарезервированное ключевое слово должно быть идентификатором в кавычках. если это отдельное ключевое слово или первый компонент выражения пути. Он может не указываться как второй или более поздний компонент выражение пути.
- Идентификаторы имен таблиц имеют дополнительный синтаксис для поддержки дефисов (-)
при ссылке в пунктах
FROMиTABLE.
Примеры
Это действительные идентификаторы:
Клиенты5
`5Клиенты`
поле данных
_dataField1
ADGROUP
`tableName ~`
`ГРУППА`
Эти выражения пути содержат допустимые идентификаторы:
foo.`GROUP`
foo.GROUP
foo (). dataField
список [СМЕЩЕНИЕ (3)]. dataField
список [ORDINAL (3)].поле данных
@ parameter.dataField
Это недопустимые идентификаторы:
5Клиенты
_поле данных!
ГРУППА
5 Для клиентов начинается с цифры, а не с буквы или подчеркивания. _dataField! содержит специальный символ «!» который не является буквой, числом или знаком подчеркивания. ГРУППА — зарезервированное ключевое слово, поэтому не может использоваться в качестве идентификатора.
без обратных кавычек.
Не нужно заключать имена таблиц, содержащие тире. с обратными кавычками.Это эквивалент:
ВЫБРАТЬ * ИЗ данных-клиентов-287.mydatabase.mytable
ВЫБРАТЬ * ИЗ `data-customers-287`.mydatabase.mytable
Литералы
Литерал представляет постоянное значение встроенного типа данных. Некоторые, но не все типы данных могут быть выражены как литералы.
Строковые и байтовые литералы
Строковые и байтовые литералы должны быть в кавычках , либо с одиночным ( '), либо
двойные ( ") кавычки или тройные кавычки с группами по три одиночных
( '' ') или три двойные ( "" ") кавычки.
Цитируемые литералы:
| Буквальный | Примеры | Описание |
|---|---|---|
| Строка в кавычках |
| Строки в кавычках, заключенные в одинарные ( ') кавычки, могут содержать неэкранированные двойные ( ") кавычки, а также обратные.Обратные косые черты ( \ ) вводят escape-последовательности. См. Приведенную ниже таблицу последовательностей эвакуации. Строки в кавычках не могут содержать символы новой строки, даже если им предшествует обратная косая черта ( \ ). |
| Строка в тройных кавычках |
| Допускаются встроенные символы новой строки и кавычки без экранирования — см. Четвертый пример. Обратные косые черты ( \ ) вводят escape-последовательности. См. Таблицу последовательностей выхода ниже. Завершающая неэкранированная обратная косая черта ( \ ) в конце строки не допускается. Завершите строку тремя неэкранированными кавычками подряд, которые соответствуют начальным кавычкам. |
| Сырая струна |
| Заключенные в кавычки или тройные кавычки литералы с префиксом необработанного строкового литерала ( r или R ) интерпретируются как необработанные строки / строки регулярного выражения.Символы обратной косой черты ( \ ) не действуют как escape-символы. Если внутри строкового литерала встречается обратная косая черта, за которой следует другой символ, оба символа сохраняются. Необработанная строка не может заканчиваться нечетным числом обратных косых черт. Необработанные строки полезны для построения регулярных выражений. |
Префиксные символы ( r , R , b , B) являются необязательными для строк в кавычках или тройных кавычках и указывают, что строка является строкой необработанного / регулярного выражения или последовательностью байтов, соответственно .Для
Например, b'abc ' и b' '' abc '' ' оба интерпретируются как байты типа. Символы префикса не чувствительны к регистру.
Цитированные литералы с префиксами:
| Буквальный | Пример | Описание |
|---|---|---|
| байтов |
| Заключенные в кавычки или тройные кавычки литералы с префиксом байтов ( b или B ) интерпретируются как байты. |
| Исходные байты |
| Префиксы r и b можно комбинировать в любом порядке. Например, rb'abc * ' эквивалентно br'abc *' . |
В таблице ниже перечислены все допустимые escape-последовательности для представления не буквенно-цифровых символов в строковых и байтовых литералах.Любая последовательность, отсутствующая в этой таблице, вызывает ошибку.
| Последовательность выхода | Описание |
|---|---|
\ | Белл |
\ б | Backspace |
\ f | Подача формы |
\ п | Новая строка |
\ r | Возврат каретки |
\ т | Вкладка |
\ v | Вертикальный выступ |
\ | Обратная косая черта ( \ ) |
\? | Вопросительный знак (? ) |
\ " | Двойные кавычки ( ") |
\ ' | Одинарное цитирование ( ') |
\ ` | Оборотная сторона ( `) |
\ ooo | Восьмеричный escape-код с ровно 3 цифрами (в диапазоне 0–7).Декодируется до одного символа Юникода (в строковых литералах) или байта (в байтовых литералах). |
\ xhh или \ Xhh | Шестнадцатеричный переход, ровно 2 шестнадцатеричные цифры (0–9 или A – F или a – f). Декодируется до одного символа Юникода (в строковых литералах) или байта (в байтовых литералах). Примеры:
|
\ uhhhh | Escape Unicode со строчной буквой u и ровно 4 шестнадцатеричными цифрами.Действителен только в строковых литералах или идентификаторах. Обратите внимание, что диапазон D800-DFFF не допускается, так как это суррогатные значения Unicode. |
\ Ухххххххх | Escape Unicode с заглавной буквой U и ровно 8 шестнадцатеричных цифр. Действителен только в строковых литералах или идентификаторах. Диапазон D800-DFFF недопустим, поскольку эти значения являются суррогатными значениями Unicode. Также недопустимы значения больше 10FFFF. |
Целочисленные литералы
Целочисленные литералы представляют собой последовательность десятичных цифр (0–9) или шестнадцатеричные числа.
значение с префиксом « 0x » или « 0X ».Целые числа могут иметь префикс « + «.
или « - » для представления положительных и отрицательных значений соответственно.
Примеры:
123
0xABC
-123
Целочисленный литерал интерпретируется как INT64 .
ЧИСЛОВЫЕ литералы
Вы можете создавать числовые литералы, используя NUMERIC ключевое слово, за которым следует значение с плавающей запятой в кавычках.
Примеры:
ВЫБРАТЬ ЦИФР '0';
ВЫБЕРИТЕ НОМЕР '123456';
ВЫБЕРИТЕ ЧИСЛО '-3.14 ';
ВЫБЕРИТЕ ЧИСЛО '-0,54321';
ВЫБЕРИТЕ НОМЕР '1.23456e05';
ВЫБЕРИТЕ ЦИФР '-9.876e-3';
BIGNUMERIC литералы
Вы можете построить BIGNUMERIC литералов, используя ключевое слово BIGNUMERIC , за которым следует
значением с плавающей запятой в кавычках.
Примеры:
ВЫБРАТЬ БИГНУМЕРИЧЕСКИЙ '0';
ВЫБЕРИТЕ BIGNUMERIC '123456';
ВЫБЕРИТЕ BIGNUMERIC '-3.14';
ВЫБЕРИТЕ BIGNUMERIC '-0,54321';
ВЫБЕРИТЕ BIGNUMERIC '1.23456e05';
ВЫБЕРИТЕ BIGNUMERIC '-9.876e-3';
Литералы с плавающей запятой
Варианты синтаксиса:
[+ -] ЦИФРЫ.[ЦИФРЫ] [е [+ -] ЦИФРЫ]
[ЦИФРЫ]. ЦИФРЫ [е [+ -] ЦИФРЫ]
ЦИФРЫ [+ -] ЦИФРЫ
ЦИФРЫ представляет одно или несколько десятичных чисел (от 0 до 9), а e представляет маркер степени (e или E).
Примеры:
123.456e-67
.1E4
58.
4e2
Числовые литералы, содержащие Предполагается, что либо десятичная точка, либо маркер экспоненты относятся к типу double.
Неявное приведение литералов с плавающей запятой к типу с плавающей запятой возможно, если значение находится в допустимом диапазоне с плавающей запятой.
Нет буквального представление NaN или бесконечности, но следующие строки без учета регистра можно явно преобразовать в float:
- «NaN»
- «инф» или «+ инф»
- «-inf»
Литералы массива
Литералы массива представляют собой списки элементов, разделенных запятыми.
заключены в квадратные скобки. Ключевое слово ARRAY является необязательным, а явное
тип элемента T также является необязательным.
Примеры:
[1, 2, 3]
['x', 'y', 'xy']
МАССИВ [1, 2, 3]
ARRAY <строка> ['x', 'y', 'xy']
ARRAY []
Структурные литералы
Структурный литерал — это структура, все поля которой являются литералами.Структурные литералы могут быть написанным с использованием любого из синтаксисов для построения struct (синтаксис кортежа, синтаксис структуры без типа или типизированный синтаксис структуры).
Обратите внимание, что синтаксис кортежа требует как минимум двух полей, чтобы различать его. из обычного выражения в скобках. Чтобы написать структурный литерал с одиночного поля, используйте синтаксис структуры без типа или синтаксис типизированной структуры.
| Пример | Тип выхода |
|---|---|
(1, 2, 3) | СТРУКТУРА |
(1, 'abc') | СТРУКТУРА |
СТРУКТУРА (1 AS foo, 'abc' AS bar) | STRUCT |
СТРУКТУРА | СТРУКТУРА |
СТРУКТУРА (1) | СТРУКТУРА |
СТРУКТУРА | СТРУКТУРА |
Литералы даты
Синтаксис:
ДАТА 'ГГГГ-М [М] -Д [Д]'
Литералы даты содержат ключевое слово DATE , за которым следует строковый литерал, соответствующий каноническому формату даты, заключенный в одинарные кавычки.Литералы даты поддерживают диапазон между
годы 1 и 9999 включительно. Даты вне этого диапазона недействительны.
Например, следующий литерал даты представляет 27 сентября 2014 г .:
ДАТА '2014-09-27'
Строковые литералы в каноническом формате даты также неявно приводятся к типу DATE при использовании там, где ожидается выражение типа DATE. Например, в запросе
ВЫБРАТЬ * FROM foo WHERE date_col = "2014-09-27"
строковый литерал "2014-09-27" будет преобразован в литерал даты.
Литералы времени
Синтаксис:
ВРЕМЯ '[H] H: [M] M: [S] S [.DDDDDD]]'
Литералы времени содержат ключевое слово TIME и строковый литерал, соответствующий
канонический формат времени, заключенный в одинарные кавычки.
Например, следующее время соответствует 12:30 вечера:
ВРЕМЯ '12: 30: 00.45 '
Литералы даты и времени
Синтаксис:
DATETIME 'ГГГГ- [M] M- [D] D [[H] H: [M] M: [S] S [.DDDDDD]] '
Литералы Datetime содержат ключевое слово DATETIME и строковый литерал, который
соответствует каноническому формату даты и времени, заключенному в одинарные кавычки.
Например, следующая дата и время представляет 12:30 вечера. 27 сентября, 2014:
ДАТА '2014-09-27 12: 30: 00.45'
Литералы Datetime поддерживают диапазон от 1 до 9999 включительно. Даты вне этого диапазона недопустимы.
Строковые литералы с каноническим форматом даты и времени неявно приводят к литерал datetime при использовании там, где ожидается выражение datetime.
Например:
ВЫБРАТЬ * ИЗ foo
ГДЕ datetime_col = "2014-09-27 12: 30: 00.45"
В приведенном выше запросе строковый литерал "2014-09-27 12: 30: 00.45" приводится к
литерал даты и времени.
Литерал datetime может также включать необязательный символ T или t . Этот
является флагом времени и используется как разделитель между датой и временем. Если
вы используете этот символ, пробел не может быть включен до или после него.Действительны:
ДАТА '2014-09-27T12: 30: 00.45'
DATETIME '2014-09-27t12: 30: 00.45'
Литералы отметки времени
Синтаксис:
TIMESTAMP 'ГГГГ- [M] M- [D] D [[H] H: [M] M: [S] S [.DDDDDD] [часовой пояс]] »
Литералы отметок времени содержат ключевое слово TIMESTAMP и строковый литерал,
соответствует каноническому формату отметок времени, заключенных в одинарные кавычки.
поддерживают диапазон от 1 до 9999 включительно.Метки времени вне этого диапазона недействительны.
Литерал отметки времени может включать числовой суффикс для обозначения часового пояса:
TIMESTAMP '2014-09-27 12: 30: 00.45-08'
Если этот суффикс отсутствует, часовой пояс по умолчанию, UTC, используется.
Например, следующая метка времени представляет 12:30 вечера. 27 сентября, 2014 в часовом поясе по умолчанию, UTC:
TIMESTAMP '2014-09-27 12: 30: 00.45'
Для получения дополнительной информации о часовых поясах см. Часовой пояс.
Строковые литералы с каноническим форматом метки времени, в том числе с
имена часовых поясов, неявно приводятся к литералу отметки времени, когда используются, где
ожидается выражение отметки времени. Например, в следующем запросе
строковый литерал "2014-09-27 12: 30: 00.45 America / Los_Angeles" принудительно
к литералу отметки времени.
ВЫБРАТЬ * ИЗ foo
WHERE timestamp_col = "2014-09-27 12: 30: 00.45 America / Los_Angeles"
Литерал отметки времени может включать следующие необязательные символы:
-
Tилиt: Флаг времени.Используйте как разделитель между датой и временем. -
Zилиz: флаг для часового пояса по умолчанию. Это нельзя использовать с[часовой пояс].
Если вы используете один из этих символов, пробел не может быть добавлен до или после него. Действительны:
TIMESTAMP '2017-01-18T12: 34: 56.123456Z'
TIMESTAMP '2017-01-18t12: 34: 56.123456'
TIMESTAMP '2017-01-18 12: 34: 56.123456z'
TIMESTAMP '2017-01-18 12: 34: 56.123456Z'
Часовой пояс
Поскольку литералы отметок времени должны быть сопоставлены с определенным моментом времени, часовой пояс необходимо правильно интерпретировать литерал.Если часовой пояс не указан как часть самого литерала, BigQuery использует часовой пояс по умолчанию значение, которое устанавливает реализация BigQuery.
BigQuery представляет часовые пояса с помощью строк в следующих канонических формат, который представляет собой смещение от всемирного координированного времени (UTC).
Формат:
(+ | -) H [H] [: M [M]]
Примеры:
'-08: 00'
'-8: 15'
'+3: 00'
'+07: 30'
'-7'
Часовые пояса также могут быть выражены с помощью строковых имен часовых поясов из
база данных tz.За меньшее
исчерпывающий, но более простой справочник, см.
Список часовых поясов базы данных tz
в Википедии. Канонические названия часовых поясов имеют формат <континент / [регион /] город> , например America / Los_Angeles .
America / Los_Angeles сообщает то же время, что и UTC-7: 00 во время летнего времени, но сообщает то же время, что и UTC-8: 00 вне летнего времени.Пример:
TIMESTAMP '2014-09-27 12:30:00 America / Los_Angeles'
TIMESTAMP '2014-09-27 12:30:00 Америка / Аргентина / Буэнос-Айрес'
Интервальные литералы
Синтаксис:
ИНТЕРВАЛ 'N' datetime_part
ИНТЕРВАЛ '[Y] - [M] [D] [H]: [M]: [S]. [F]' datetime_part TO datetime_part
datetime_part является одним из YEAR , MONTH , DAY , HOUR , MINUTE или SECOND .
Интервальные литералы бывают двух видов. Первая форма имеет единственную часть даты и времени. Например:
ИНТЕРВАЛ '5' ДЕНЬ
ИНТЕРВАЛ 0,001 СЕКУНДА
Вторая форма допускает несколько последовательных частей даты и времени. Например:
-10 часов, 20 минут, 30 секунд
ИНТЕРВАЛ '10: 20: 30 'ЧАС ДО ВТОРОЙ
- 1 год, 2 месяца
ИНТЕРВАЛ 1-2 ГОДА К МЕСЯЦУ
- 1 месяц, 15 дней
ИНТЕРВАЛ '1 15' МЕСЯЦ ДО ДНЯ
- 1 день 5 часов 30 минут
ИНТЕРВАЛ '1 5:30' ДЕНЬ ДО МИНУТЫ
Чувствительность к регистру
BigQuery следует этим правилам чувствительности к регистру:
| Категория | С учетом регистра? | Банкноты |
|---|---|---|
| Ключевые слова | Нет | |
| Имена встроенных функций | Нет | |
| Имена пользовательских функций | Есть | |
| Названия таблиц | Есть | |
| Имена столбцов | Нет | |
| Строковые значения | Есть | |
| Сравнение строк | Есть | |
| Псевдонимы в запросе | Нет | |
| Соответствие регулярному выражению | См. Примечания | Сопоставление регулярных выражений по умолчанию чувствительно к регистру, если только в самом выражении не указано, что оно должно быть нечувствительным к регистру. |
КАК соответствие | Есть |
Зарезервированные ключевые слова
Ключевые слова — это группа токенов, которые имеют особое значение в BigQuery. язык, и имеют следующие характеристики:
- Ключевые слова нельзя использовать в качестве идентификаторов, если они не заключены в символы обратной кавычки (`).
- Ключевые слова нечувствительны к регистру.
BigQuery имеет следующие зарезервированные ключевые слова.
| ВСЕ И ЛЮБОЙ ARRAY AS ASC ASSERT_ROWS_MODIFIED AT МЕЖДУ BY CASE CAST COLLATE CONTAINS CREATE CROSS CUBEFRED 9034 9034 CUBEFRED 9034 9034 CUBEFECEFE 9034 | ENUM ESCAPE EXCEPT EXCLUDE EXISTS EXTRACT FALSE FETCH FOLLOWING FOR FROM FULL GROUP GROUPING GROUPS HASH INTER IN 9034 9034 IN INTER 9034 9034 IN INTER 9034 9034 IN | IS JOIN LATERAL LEFT LIKE LIMIT LOOKUP RERGE NATURAL NEW NO NOT NULL NULLS OF ON ORDER 9034 PRIT 9034 9034 ORDER EXO | RECURSIVE RESPECT RIGHT ROLLUP ROWS SELECT SET НЕКОТОРЫЕ STRUCT TABLESAMPLE ЗАТЕМ TO TREAT TRUE UNBOUNDED WHE UNION 9034 UNNEST 9034 WHE WITH WINDOWS 9034 |
Завершающая точка с запятой
При желании можно использовать завершающую точку с запятой (; ) при отправке запроса.
строковый оператор через интерфейс прикладного программирования (API).
В запросе, содержащем несколько операторов, вы должны разделять операторы с помощью точки с запятой, но точка с запятой, как правило, не обязательна после последнего утверждения. Некоторые интерактивные инструменты требуют, чтобы в операторах была точка с запятой в конце.
Конечные запятые
При желании можно использовать конечную запятую (, ) в конце списка столбцов в SELECT инструкция. У вас может быть конечная запятая в результате
программное создание списка столбцов.
Пример
ВЫБРАТЬ имя, дата_пуска, ИЗ книг
Параметры запроса
Вы можете использовать параметры запроса для замены произвольных выражений. Однако параметры запроса нельзя использовать для замены идентификаторов, имена столбцов, имена таблиц или другие части самого запроса. Параметры запроса определяются вне оператора запроса.
Клиентские API позволяют связывать имена параметров со значениями; механизм запросов заменяет связанное значение для параметра во время выполнения.
Параметры запроса нельзя использовать в теле этих операторов SQL: CREATE FUNCTION , CREATE VIEW , CREATE MATERIALIZED VIEW и CREATE PROCEDURE .
Именованные параметры запроса
Синтаксис:
@ имя_параметра
Именованный параметр запроса обозначается с помощью идентификатора.
которому предшествует символ @ . Именованный запрос
параметры нельзя использовать вместе с позиционным запросом
параметры.
Пример:
В этом примере возвращаются все строки, в которых LastName равно значению
именованный параметр запроса myparam .
ВЫБРАТЬ * ИЗ реестра ГДЕ Фамилия = @myparam
Позиционные параметры запроса
Параметры позиционного запроса обозначаются с помощью ? персонаж.
Позиционные параметры оцениваются в порядке их передачи.
Параметры позиционного запроса использовать нельзя
вместе с именованными параметрами запроса.
Пример:
Этот запрос возвращает все строки, в которых LastName и FirstName равны
значения, переданные в этот запрос. Порядок, в котором эти значения передаются в
имеет значение. Если сначала передается фамилия, а затем имя,
ожидаемые результаты не будут возвращены.
ВЫБРАТЬ * ИЗ реестра ГДЕ Имя =? и LastName =?
Комментарии — это последовательности символов, которые анализатор игнорирует.BigQuery поддерживает следующие типы комментариев.
Используйте однострочный комментарий, если хотите, чтобы комментарий отображался в отдельной строке.
Примеры
# это однострочный комментарий
ВЫБРАТЬ книгу ИЗ библиотеки;
- это однострочный комментарий
ВЫБРАТЬ книгу ИЗ библиотеки;
/ * это однострочный комментарий * /
ВЫБРАТЬ книгу ИЗ библиотеки;
ВЫБРАТЬ КНИГУ ИЗ библиотеки
/ * это однострочный комментарий * /
ГДЕ book = "Улисс";
Используйте встроенный комментарий, если хотите, чтобы комментарий отображался в той же строке, что и
заявление.Комментарий, перед которым стоит # или –, должен появиться в
право заявления.
Примеры
ВЫБРАТЬ книгу ИЗ библиотеки; # это встроенный комментарий
ВЫБРАТЬ КНИГУ ИЗ библиотеки; - это встроенный комментарий
ВЫБРАТЬ КНИГУ ИЗ библиотеки; / * это встроенный комментарий * /
ВЫБРАТЬ книгу ИЗ библиотеки / * это встроенный комментарий * / WHERE book = "Ulysses";
Используйте многострочный комментарий, если вам нужно, чтобы комментарий занимал несколько строк.Вложенные многострочные комментарии не поддерживаются.
Примеры
ВЫБРАТЬ книгу ИЗ библиотеки
/ *
Это многострочный комментарий
на нескольких строках
* /
ГДЕ book = "Улисс";
ВЫБРАТЬ КНИГУ ИЗ библиотеки
/ * это многострочный комментарий
на двух строках * /
ГДЕ book = "Улисс";
Решение проблемы ошибок отрицательного лексического переноса у студентов чилийских университетов
Введение
Давно признано, что первый язык учащегося (L1) оказывает значительное влияние как на усвоение, так и на использование лексики второго языка (L2) (Swan, 1997).Это влияние часто проявляется в лексических ошибках в устной и письменной речи, которые, по-видимому, трудно устранить учащемуся. Фоссилизация ошибочных лексических форм особенно вероятна, когда учащиеся находятся в одноязычной образовательной среде, поскольку большая часть их воздействия на английский язык происходит от других изучающих язык, которые имеют тот же L1, так что одни и те же ошибки закрепляются и нормализуются.
Эта проблема усугубляется тем фактом, что учебные материалы часто представлены в виде учебников, разработанных для международного рынка и, следовательно, не могут устранять распространенные лексические ошибки, которым подвержены носители одного конкретного L1.Как следствие, учителя могут уделять в классе слишком мало внимания устранению этих ошибок и повышению осведомленности учащихся о том, как L1 может помочь или помешать точному использованию словарного запаса.
студента университетов, для которых английский является неотъемлемой частью программы получения степени, часто необходимо достичь высокого уровня лингвистической компетентности и точности, а это означает, что основные словарные ошибки необходимо минимизировать или, по возможности, устранить. Поэтому я почувствовал явную потребность в том, чтобы этот вопрос каким-либо образом был решен в моем контексте, поскольку, хотя было проведено значительное исследование влияния влияния L1 на усвоение второго языка (SLA), мало было написано о том, как подойти к проблема отрицательной лексической передачи на уроках.
Литература Отзыв
Два основных раздела литературы сыграли важную роль в создании этого исследования. Это влияние L1 на изучение второго языка, особенно в области приобретения и производства словарного запаса, а также намеренное и случайное изучение словарного запаса второго языка.
Чтобы понять, насколько влияние L1 может препятствовать изучению второго языка, нам необходимо иметь четкое понимание этого явления. Однако Джарвис (2000) указывает, что, несмотря на десятилетия исследований в этой области, до сих пор нет общепринятого определения влияния L1 или даже согласия, что такое определение возможно.Возможно, из-за этой фундаментальной проблемы существуют также сильно различающиеся оценки того, сколько ошибок в производстве L2 можно отнести к влиянию L1: некоторые исследования утверждают, что они составляют всего 3%, а другие — 51% (Ellis, 1985). Несмотря на такую неопределенность, Джарвис выбирает определение влияния L1 на SLA как «любой случай данных об учащихся, где существует статистически значимая корреляция. . . показано, что существует между некоторыми особенностями [межъязыковой] успеваемости учащихся и их уровнем L1 »(стр.252).
Джарвис и Павленко (2008) выделяют девять категорий языкового переноса: фонологический, орфографический, лексический, семантический, морфологический, синтаксический, дискурсивный, прагматический и социолингвистический. Большая часть литературы посвящена грамматической структуре, возможно, потому, что именно в ней происходит большинство отрицательных переводов. Например, в одном исследовании испанских старшеклассников Алонсо (1997) обнаружил, что из 138 межъязыковых ошибок 96 были вызваны переносом грамматической структуры.Несмотря на эти выводы, ошибки лексического переноса заслуживают внимания по двум причинам: во-первых, лексический отбор состоит в основном из содержательных слов, и поэтому ошибки этого типа потенциально очень разрушительны, поскольку могут препятствовать общению, в частности, ложатся большим бременем на читателя письменного текста. производство (Hemchua & Schmitt, 2006). Вторая причина заключается в том, что в учебниках по английскому языку в основном рассматриваются типы грамматических ошибок, которые допускают носители испанского языка, поскольку они более универсальны по своей природе, чем конкретная лексика, вызывающая проблемы.
Алонсо (1997) определяет три пути, по которым может происходить негативный лексический перенос с испанского на английский: чрезмерное расширение аналогии (ложные родственные слова), ошибки замещения и межъязыковое / внутриязыковое вмешательство. Ложные родственные слова — это слова, которые имеют идентичные или похожие формы в английском и испанском языках, но имеют разные значения. Типичный пример — испанское слово «разумный», что в переводе с английского означает «чувствительный». Чрезмерное расширение аналогии со стороны испаноговорящих приводит к таким ошибкам, как: «Я не могу много гулять на солнце, так как у меня очень чувствительная кожа».Ошибки замены рассматриваются как те, в которых учащийся использует прямой перевод слова или выражения на испанский язык в контексте, который не подходит для английского языка. Типичный пример — использование слова «знать» в предложении «Я хотел бы знать Францию» (Quiero conocer Francia). Хотя слово conocer может быть выражено словом «знать» во многих контекстах, в данном случае это неуместно. Наконец, межъязыковые / внутриъязыковые интерференционные ошибки относятся к случаям, когда есть различие слов в L2, а в L1 их нет.Примером может служить предложение «Я опоздал, потому что потерял автобус». В английском языке проводится различие между проигрышем и промахом, тогда как в испанском используется только пердер.
Хотя эти ошибки могут повлиять на разборчивость речи для носителей английского языка, они не обязательно могут вызвать проблемы при общении между учащимися L2 в контексте одноязычной аудитории. Это потому, что они кажутся знакомыми, именно потому, что они исходят от L1 учащихся. Знакомство с этими ошибочными формами в моноязычном классе и ознакомление с ними подчеркивается Амара (2015) как одна из причин, почему важно проводить исправление, поскольку «существует опасность того, что, если оставить ошибки без исправления, дефектный язык может служить моделью ввода и быть усвоенной другими учащимися в классе »(стр.61).
L1 часто играет положительную роль в SLA и может объяснить большую часть того, что является правильным в межъязыковой среде учащегося (Swan, 1997). Согласно Hulstijn (2001), «начинающие ученики L2. . . часто кажется, что словоформа L2 напрямую связана с соответствующей словоформой L1 »(стр. 260-261). Таким образом, на ранней стадии обучения L1 может помочь в знании словарного запаса L2. Однако, как указывает Свон (1997), учащиеся будут постоянно делать ошибки со словами, которые они выучили правильно, 1 , особенно если знание определенного языкового элемента не подкрепляется повторным повторением и репетициями.Францен (1998) повторяет эту точку зрения, отмечая, что «даже после того, как учащиеся неоднократно сталкиваются с целевым языковым значением ложных родственных слов, они продолжают злоупотреблять ими в своей речи и письме» (стр. 243). Свон говорит, что при извлечении лексических элементов для повторения учащиеся обычно должны выбирать из ряда возможностей и часто выбирать языковую форму, которая больше всего похожа на аналог в L1, потому что они имеют более полностью автоматизированный контроль над этой формой, чем правильный эквивалент целевого языка .Каваляускене (2009) предполагает, что отрицательные ошибки передачи могут возникать из-за того, что учащимся не хватает способности внимания, чтобы активировать правильную форму L2.
Свон (1997) указывает, что между близкородственными языками существует больше передачи и, следовательно, больше возможностей для ошибок вмешательства, поскольку учащиеся приравнивают формы, которые похожи, но имеют разные значения. Кордер (1983) утверждает, что чем больше воспринимаемое расстояние между изучаемым языком и L1 учащегося, тем меньше вероятность того, что учащийся будет заимствовать из L1, и, следовательно, будет меньше «ошибок заимствования» (стр.27). Однако он предполагает, что наибольшая частота ошибок этого типа будет иметь место на языках, которые «умеренно» похожи, а не на близкородственных. Поскольку английский имеет общий лингвистический корень с испанским, но не так тесно связан с ним, как романские языки, такие как итальянский или португальский, следует ожидать, что частота ошибок передачи L1 у испаноязычных изучающих английский язык будет довольно высокой.
Ряд исследователей считает важным повышение осведомленности учащихся о межъязыковой передаче в целях содействия языковому развитию.Свон (1997) указывает, что улучшенное понимание сходства и различий между L1 и L2 поможет учащимся «принять эффективные стратегии обучения и производства» (стр. 179). Талеби (2014), проводивший исследование межъязыковой осведомленности среди иранских учащихся, считает, что учителя несут ответственность за повышение осведомленности учащихся с помощью материалов, специально разработанных для целей обучения для передачи. Эту точку зрения поддерживают Каваляускене и Каминискиене (2007), чье исследование показывает, что использование перевода в качестве инструмента обучения способствует повышению языковой осведомленности у изучающих английский язык для конкретных целей.
Принимая во внимание проблемы, вызванные негативным лексическим переносом, и сложность устранения застарелых ошибок лексического переноса в одноязычном английском как контексте иностранного языка, важно подумать, как с ними можно справиться в классе. Однако, похоже, что в этой области мало исследований. Поэтому в следующей части моего обзора я более широко сосредоточусь на исследованиях обучения лексике и того, как это влияет на усвоение, поиск и выработку лексики.
Большая часть литературы по освоению словарного запаса посвящена сравнительным преимуществам случайного и преднамеренного изучения словарного запаса. Hulstijn (2001) определяет случайное изучение словарного запаса как «изучение словарного запаса как побочный продукт любой деятельности, явно не связанной с изучением словарного запаса», а намеренное изучение словарного запаса как «любое действие, направленное на сохранение лексической информации в памяти» (стр. 270) . Крашен (1989) утверждал, что учащиеся приобретут весь словарный запас, который им нужен, благодаря углубленному чтению, и поэтому учителя должны поощрять занятия, которые способствуют случайному обучению и препятствуют процедурам намеренного изучения словарного запаса.
Однако позиция о том, что одного раскрытия информации достаточно для обеспечения эффективного изучения словарного запаса, не получила широкой поддержки. Nation (2001) допускает, что большие объемы случайного изучения словарного запаса являются результатом чтения большого количества понятного текста, но придерживается мнения, что некоторые словарные запасы требуют особого внимания, и поэтому учителя должны относиться к ним принципиально и систематически. Он считает, что уделение особого внимания слову или словам, которые он называет «богатой инструкцией», может принести реальную пользу учащемуся L2, особенно при работе с часто встречающимися элементами, которые считаются важными или особенно полезными для студентов, и когда это не в ущерб другим компонентам курса.
Согласно Nation (2001), есть три важных шага, которые способствуют изучению нового словаря: замечание, извлечение и генерация. Замечание может происходить разными способами, но в основном подразумевает деконтекстуализацию, при которой внимание уделяется лексическому элементу как части языка, а не части сообщения; извлечение — это когда учащемуся необходимо выразить значение определенного элемента и он обязан извлечь его устную или письменную форму; а генерация подразумевает производство предмета новыми способами и / или в новом контексте.Для Nation эти процессы необходимы для эффективного обучения.
Также важно понимать, что у учащихся отзывчивый и продуктивный словарный запас. Шмитт (2008) утверждает, что, поскольку «продуктивное овладение словарным запасом труднее, чем овладение рецептивным» (стр. 345), нельзя предполагать, что рецептивное воздействие автоматически приведет к продуктивному овладению. Он считает, что слова, полученные в результате случайного обучения, вряд ли будут выучены на продуктивном уровне и что обучение вспоминанию на основе чтения более склонно к забыванию, чем обучение распознаванию.Он приходит к выводу, что для развития продуктивного мастерства учащиеся должны заниматься продуктивными задачами. Для Шмитта идея вовлечения является центральной для эффективности изучения словарного запаса. Это включает в себя ряд факторов, таких как время, потраченное на лексический элемент, внимание, уделяемое ему, повышенное внимание к лексическим элементам, манипулирование целевым элементом и потребность в обучении. Он считает продвижение высокого уровня изучения лексики фундаментальной обязанностью исследователей, авторов материалов, учителей и студентов.
Hulstijn (2001) подчеркивает важность для учащихся быстрого и автоматического доступа к словарю (автоматичность). Он указывает, что для этого недостаточно богатой и сложной обработки, и что частая реактивация лексических форм также важна. Для этого он предлагает выделить достаточно времени в классе для преднамеренной репетиции проблемной лексики и повторного использования ранее увиденных элементов. Шмитт (2008) также подчеркивает важность повышения автоматизма лексического распознавания и производства, отмечая, что «знание лексических единиц имеет ценность только в том случае, если они могут быть распознаны или произведены своевременно, что позволяет использовать язык в реальном времени» (стр. .346).
Основываясь на этой литературе, данное исследование сосредоточено на ряде конкретных областей. Первым из них была необходимость повысить осведомленность учащихся о проблеме отрицательного перевода среди испаноязычных изучающих английский язык. Из-за относительной близости испанской и английской лексики и, следовательно, возможности ошибочного перевода, основное внимание уделялось лексической интерференции. Определение влияния L1, данное Джарвисом (2000), было использовано для обоснования выбора ошибок лексического переноса, проанализированных в исследовании, как и таксономия ошибок L1 Алонсо (1997), поскольку это было получено в результате исследования испаноязычных изучающих.Наконец, исследование было направлено на то, чтобы повысить вовлеченность учащихся в проблемную лексику как способ улучшить их способность к вниманию и автоматизацию. Переводческая деятельность использовалась для повышения осведомленности о различиях и переписке L1 / L2. Кроме того, в рамках лексического анализа и практики использовались три шага Nation (2001): тщательный анализ ошибочного и правильного лексического использования (замечание), упражнения по устному и письменному переводу и контролируемая практика устных дискуссий (поиск) и мини-презентации. и обсуждения пар слов в малых группах (поколение).
Мои исследовательские вопросы были следующими:
- 1. Был бы устойчивый, явный, систематический подход к устранению передачи лексических ошибок L1 уменьшить количество ошибок такого типа студентами?
- 2. Как бы студенты реагировать на устойчивый, четкий, систематический подход к решению перенос лексических ошибок L1?
Метод
Это исследование было проведено в рамках годичной исследовательской программы действий учителей в 2016 году Чилийско-Британского культурного университета (UCBC).UCBC — это небольшой частный университет в Сантьяго, Чили, предлагающий степень бакалавра в области перевода, вторичное обучение английскому языку, а также начальное обучение и обучение в детских садах с особым акцентом на английском языке. Это исследовательский проект, направленный на решение местной проблемы и следующий за циклом планирования, реализации, наблюдения и размышления, чтобы добиться изменений и улучшений на практике (Burns, 2015). В этом разделе я сначала опишу участников, затем дизайн и реализацию этапа реализации и, наконец, сбор и анализ данных.
Мой проект выполнялся с двумя группами студентов UCBC в течение 13 недель в течение первого семестра 2016 года. Обе группы обучались на общих курсах английского языка в рамках своих программ на получение степени. Обзор профиля этих групп можно найти в таблице 1. Одним из этих курсов был Lengua Inglesa 3 (английский язык 3), который студенты изучают в первом семестре второго года обучения, а другим был Competencia Comunicativa 1 (коммуникативный Компетенция 1), которая берется в первом семестре четвертого курса.Первый класс состоял из 25 студентов, обучающихся как по программам перевода, так и по программам повышения квалификации учителей. У них был средний / высокий средний уровень английского языка, и они использовали учебник Cambridge First Certificate in English (FCE) как часть своего учебного материала. Экзамен FCE соответствует уровню B2 Общеевропейских компетенций владения иностранным языком (CEFR). Последний класс состоял из 20 студентов переводческой программы, которые имели продвинутый уровень английского языка и использовали учебник Cambridge Certificate in Advanced English (CAE) (CEFR level C1).
Таблица 1
Группы, участвующие в исследовательском проекте
я преподавал курс Ленгуа 3 с другой учитель, который сосредоточился на грамматике, лексике, аудировании и разговорной речи. Этот компонент занял две трети времени курса. Оставшийся компонент, которую я преподавал, сосредоточился на чтении и письме. На курсе Competencia Comunicativa 1 я был единственным учителем. Студенты в обоих курсах оцениваются посредством письменных тестов, устных тестов / презентаций, и письменные задания в течение семестра (70% от их итоговой оценки) и три выпускные экзамены (владение английским языком и аудирование, чтение и письмо, устные экзамены), иметь вес 30% итоговой оценки.Я решил осуществить проект с двумя группами, чтобы увидеть, насколько это будет полезно для студентов на разных этапах процесса изучения языка. Все участники были чилийцами и носители испанского языка. Их возраст колебался от 20 до 30 лет, но большинство им было чуть за 20.
Моей первоначальной задачей для этого исследовательского проекта было создание банка типичных ошибок L1. Моими основными соображениями при выборе лексических элементов для включения были частота появления ошибок и понятность ошибочной формы для носителя английского языка — разборчивость, потому что такие ошибки являются большими препятствиями для общения, и частота, потому что высокочастотная лексика заслуживает внимания, если студенты стремясь к продуктивному мастерству.Я разработал банк слов на основе своей памяти о типичных ошибках лексического перевода, совершаемых в классе, а также на примерах, которые я нашел примерно на 75 письменных экзаменах студентов второго и третьего курсов за предыдущие годы. Затем этот список был сопоставлен с примерами, предоставленными мне коллегами из университета и другими учителями английского языка, которые были проинформированы о моем проекте. Впоследствии я выбрал 40 элементов для использования во время сеансов ввода, принимая во внимание два упомянутых выше соображения: частота и разборчивость.
Я запрограммировал для вмешательства 13 недель, выделяя от 45 до 60 минут занятий в неделю. На 1-й неделе студентов попросили пройти предварительный тест, чтобы установить степень их знания некоторой целевой лексики, а также предоставить точку сравнения для заключительного теста, который будет использоваться в конце проекта. На второй неделе студентов проинформировали о целях проекта, попросили заполнить анкету и объяснили ключевые концепции, такие как перенос, интерференция L1, родственные связи и т. Д.Наконец, участников попросили прочитать документ о цели и характере исследования и подписать форму согласия, если они хотят участвовать; все студенты согласились сделать это.
Преподавательский ввод и анализ лексических элементов происходили с 3 по 12 недели и принимали две основные формы: действия под руководством учителя, которые включали анализ короткого текста или серии предложений, которые я придумал, и действия под руководством учеников, которые проходили в форме мини-презентаций, за которыми следовали обсуждения в небольших группах.Моя программа позволяла проводить восемь сеансов ввода, в каждой из которых анализировались пять лексических элементов, таким образом охватывая 40 элементов, выбранных из банка слов. Такой подход давал время для тестирования, обратной связи, проверки и викторин (см. Таблицу 2).
Таблица 2
Обзор программы проекта
предварительный тест содержал два типа заданий:
Предметы 1-8 — Перевод: первый набор предметов содержал восемь предложений на испанском языке, части которых студентам задавали перевести на английский.Большинство подчеркнутых разделов содержали слова или выражения в L1, где студенты часто делают ошибки из-за отрицательного перевода (см. рисунок 1, i.).
Предметы 9-16 — Идентификация ошибки. Второй набор предметов это упражнение по исправлению ошибок, в котором учащимся было дано восемь предложений и попросил выявить ошибки. Студентам сказали, что приговоры могут содержат одну, две или нет ошибок. Опять же, эти ошибки были типичной лексикой L2. ошибки, возникающие из-за интерференции L1 (см. рисунок 1, ii.).
фигура 1
Примеры вопросов в предварительном тесте
Перед проведением предварительного тестирования студентов проинформировали, что это был общий диагностический тест, который не имел никакого отношения к оценке их курса, и поэтому они не знали, какой конкретный аспект использования языка оценивается. Моей целью было получить как можно более точное представление о проблемах, которые вызывали эти лексические элементы. Все элементы теста были включены во входные данные в течение следующих недель вместе с другими элементами из моего банка слов.
Первый этап каждого из пяти мероприятий под руководством учителя — «сеансы ввода текстового анализа» (см. Таблицу 2) — состоял из выявления ошибок в коротком тексте или серии вопросов на английском языке. Студентам было дано несколько минут, чтобы прочитать текст / предложения и выявить ошибки. На этом этапе они осознавали, что ищут примеры отрицательного перевода. Затем последовали отзывы всего класса и анализ ошибок, в ходе которого учащимся предлагалось предложить, почему чилийский говорящий по-испански может их допустить.Студентам было предложено записать эти элементы в свои записные книжки, чтобы составить банк слов из элементов помех L1, содержащий примеры неправильного и правильного использования. Заключительный этап — контролируемая практическая деятельность. Это задание обычно выполнялось в виде письменного перевода, когда половине учеников в классе давали один набор предложений, а другой половине — другой набор для перевода на испанский язык. Оба набора содержали изучаемый язык, и ученикам предлагалось использовать естественный испанский язык.Затем они обменялись своими бумагами с кем-то из другой группы и перевели испанские предложения своих одноклассников обратно на английский, стараясь избежать ошибочного перевода L1. В устной форме упражнение включало разделение класса на две группы с разными текстами для перевода на испанский язык. Затем студенты были разделены на пары (по одному от каждой группы), чтобы прочитать свои переводы своему партнеру, который должен был перевести его обратно на английский язык, снова соблюдая осторожность, чтобы избежать вмешательства L1. Пример письменного перевода можно увидеть в Приложении A.
Этот этап перевода не использовался на всех пяти занятиях под руководством учителя. В одном случае этап идентификации ошибки представлял собой серию пар вопросов, таких как те, что показаны на рисунке 2. Каждая пара содержала одно и то же слово, однажды использованное правильно, а однажды ошибочно использованное в результате типичной интерференции L1. В этом случае, после этапов идентификации, анализа и записи, студентов попросили обсудить вопросы в парах. Затем им дали только целевую лексику, изолировали от вопросов на доске и попросили снова обсудить вопросы с новым партнером.
фигура 2
Пример исправления ошибок / контролируемый Практическая деятельность
Мероприятия под руководством студентов представляли собой серию из трех мини-презентаций. В каждом случае четыре или пять добровольцев из каждого класса получали пять пар слов — одну на английском и одну на испанском (см. Приложение B). Каждый из добровольцев подготовил короткую устную презентацию, в которой объяснил использование слов на английском и испанском языках, подчеркнув любые соответствия и различия между ними и приведя примеры.На следующей неделе они представили свои презентации индивидуально в классе группе из пяти студентов. Через 15-20 минут я собрал разные группы в один класс, и мы обсудили их идеи. Я дал классу отзывы и примеры для записи. (На этом этапе и этапе презентации в обсуждении также возникали слова, которых не было в парах слов, например, слова «книжный магазин» и «канцелярские товары», которые возникали при анализе «librería — библиотека»). Затем последовала контролируемая практическая деятельность, в ходе которой студенты использовали целевой словарный запас, чтобы ответить на ряд вопросов-мнений.На заключительном этапе студенты обсуждали вопросы в парах.
Помимо этих презентаций, все ученики четвертого курса подготовили отдельную презентацию продолжительностью от пяти до десяти минут, проводимую парами, в ходе которой они записывали (или находили запись) носителя испанского языка, говорящего на английском языке. Они проанализировали запись и представили ее классу, комментируя любые примеры интерференции L1.
Чтобы ответить на первый вопрос исследования о влиянии вмешательства на лексические ошибки учащихся, были собраны количественные данные в виде результатов двух тестов.Предварительное испытание было подробно описано в разделе выше. Пост-тест проводился на последней неделе (13) исследования. С точки зрения формата, он был таким же, как предварительный тест, и включал многие лексические элементы из этого теста, а также некоторые элементы, которые не были в первоначальном тесте, но были проанализированы в классе в ходе проекта.
Чтобы ответить на второй вопрос исследования, касающийся восприятия учащимися вмешательства, качественные данные были собраны в начале проекта, в середине проекта и в конце: до начала вводных и практических занятий (неделя 2) студенты заполнили анкету и были сделаны аудиозаписи мнений студентов.Мнения студентов также записывались в середине проекта (7-я неделя) и сразу после пост-проектного тестирования (13-я неделя).
Мнения студентов были собраны после завершения проекта в ходе тематических дискуссий с пятью участниками каждого класса. Обсуждения длились около 20 минут каждое и были записаны на звук. Это были полуструктурированные интервью, целью которых было напомнить студентам о целях исследовательского проекта, выяснить, были ли они, по их мнению, достигнуты, и получить общее представление о том, насколько полезным, по их мнению, был проект.Интервью проводились на английском и испанском языках. (Вопросы задавались на английском языке, но студентов поощряли отвечать на испанском, если они чувствовали, что могут более четко выражать свои мысли на этом языке). Эти собеседования проводились сразу после постпроектного тестирования, и я пригласил студентов, которые были более склонны выражать свое мнение в классе, принять участие, чтобы максимально использовать данные, которые я мог бы получить. Аудиозаписи сессий фокус-групп позже были расшифрованы, чтобы их можно было проанализировать более тщательно.
Выводы
Данные, собранные в результате тестов, анкетирования, записанных групповых дискуссий и фокус-групп, представлены и проанализированы здесь со ссылкой на два моих исследовательских вопроса.
Вопрос исследования 1: сможет ли устойчивый, явный, систематический подход к решению проблемы передачи лексических ошибок L1 уменьшить количество ошибок этого типа учащимися?
Не все студенты, прошедшие предварительный тест, прошли последующий тест (см. Таблицу 3).Это было особенно верно в отношении группы Ленгуа 3, низкая посещаемость которой могла быть связана с осознанной потребностью студентов в прохождении тестов по другим предметам в этот период.
Таблица 3
Количество студентов, которые Завершенные пре- и пост-тесты
Как в предварительном, так и в последующем тестировании каждый вопрос помечены как правильные или неправильные. В некоторых случаях ставилась половина баллов (если выражение было неправильно переведено, но без признаков вмешательства L1 в Item 1, и где ошибка была правильно идентифицирована, но не исправлена в п. 2).Хотя выставление полбаллов таким образом несколько субъективно, я стремились сохранить единообразие в маркировке обоих тестов. Оценки за каждый результаты студенческого теста были преобразованы в процентное соотношение, и среднее значение было рассчитан на всю группу.
Таблица 4 показывает, что оба группы улучшили свои оценки как по переводу, так и по исправлению ошибок упражнения. В результаты послетеста в группе четвертого курса примерно на 20-25% выше, чем у результаты дотестирования и второго года обучения составляют около 30-40%. выше.Последний столбец показывает, что почти все, а в одном случае все учащиеся улучшили свои индивидуальные оценки на итоговом тесте.
Таблица 4
Сравнение результатов от Пре- и пост-тесты
a Эти средние значения взяты исключительно из результатов студентов, которые также прошли последующий тест. Средние показатели всех студентов, прошедших предварительный тест незначительно отличается от приведенных средних значений (0% — + 2,5%).
Вопрос исследования 2: Как студенты отреагируют на устойчивый, явный, систематический подход к устранению передачи лексических ошибок L1? 2
Анкета, которую ученикам было предложено заполнить на второй неделе, была на английском языке и требовала от них указать свои имена и возраст.Цели этого инструмента заключались в следующем: получить информацию о том, как учащиеся общаются с носителями английского языка; оценить, насколько они осведомлены о проблеме интерференции L1; чтобы узнать, решалась ли проблема на предыдущих занятиях и каким образом; чтобы выяснить, считают ли они полезным проводить время в классе, систематически анализируя проблему, и получить предложения о том, какие занятия в классе могут облегчить такой анализ. Всего было девять пунктов, два из которых были вопросами с ограниченным ответом, пять — открытыми вопросами, а оставшиеся два — вопросами типа «да / нет» с возможностью предоставить более подробную информацию.
Из анализа этих анкет стало очевидно, что менее половины студентов (в обеих группах) действительно осознавали негативную лексическую передачу. Только шесть студентов (15% от общего числа) упомянули, что ранее рассматривали эту проблему каким-либо систематическим образом, что совпадает с числом, утверждающим, что они предпринимали какие-либо попытки вести учет этих типов ошибок (только трое из которых упомянули, что действительно написание списка слов). Интересно, что один студент заметил, что, по его мнению, проблему с переводом заметят только носители языка (английский), придавая значение тезису, сделанному Амарой (2015) о том, что ученики в одноязычном классе L1 будут изо всех сил пытаться исправить эти ошибки и могут даже у них есть усиленные.Однако все студенты выразили мнение, что проводить время в классе, уделяя особое внимание переводу, было либо очень полезно, либо необходимо.
После заполнения анкет студенты потратили около 15 минут, разбившись на группы по четыре или пять человек, обсуждая некоторые из вопросов, включенных в анкеты, и представитель каждой группы затем суммировал обсужденные мнения. Это резюме было записано. Были выделены следующие основные моменты:
Большой знакомство с английским языком необходимо для устранения ошибок отрицательного передача.
Это естественно, что студенты пытаются адаптировать свою испанскую лексику к английской, если есть это пробел в знаниях.
Ошибка исправление / анализ, переводческая деятельность, больше письменной практики и запись списков слов была бы полезным способом решения проблемы.
Еще одно обсуждение в малых группах было проведено на 7 неделе. Студенты работали в группах по четыре или пять человек и обсуждали пять заранее подготовленных вопросов.Их спросили, насколько уместным они считают время, проведенное в классе над проектом, проанализированные лексические элементы и выполненные нами практические занятия. Им была предоставлена возможность предложить альтернативные способы решения проблемы, и их попросили подумать, чувствуют ли они теперь, что они больше осведомлены о своих собственных лексических ошибках передачи и о проблеме интерференции L1 в целом. Затем представитель каждой группы кратко изложил идеи своей группы. Это обсуждение было записано. Ответы были в основном положительными, хотя студенты, естественно, предпочитали одни занятия другим.Общее впечатление такое, что они оценили участие в проекте и его цели.
В конце проекта была проведена фокус-группа с пятью студентами из каждой группы. На этих встречах студентам было предложено высказать свое мнение по ряду вопросов о проекте. На первый вопрос о том, думали ли они, что занятия, проводимые в классе, помогли им избежать ошибок, связанных с интерференцией L1, ученики были в подавляющем большинстве положительно. Все студенты сказали, что занятия помогли им лучше узнать об этих ошибках, и многие привели конкретные примеры:
Одна ошибка, которую я всегда сделано было «делить время».(Камила, L3)
В письменных заданиях я по-прежнему пишу «привлек мое внимание», а потом думаю: «Нет, погоди! Это «поймал мой внимание'». (Франциско, L3)
Я всегда говорил «приехать» вместо «прибыть». (София, L3)
Я всегда переводил «dar una prueba» и «Practicar un Deporte» неправильно. (Андреа, CC1)
Теперь я гораздо лучше осведомлен этих типов ошибок, и благодаря всему, что мы сделали в классе, я все чаще удается их избегать.(София, L3)
Некоторые студентов четвертого курса (CC1) отметили, что у них уже знал о некоторых ошибках, выявленных во время проекта, но указали, что, тем не менее, они думали, что эти действия были ценный:
Мы знали о большинство [этих ошибок], но мы думаем по-испански, поэтому мы все равно делаем ошибки… так что Я думаю, что практиковать их все же стоит. (Соледад, CC1)
Это комментарий отражает общую оценку того, что проанализированные нами ошибки были трудно устранить, потому что они закрепились.Например, Пабло (L3) указал, что хотя он знал правильные версии лексической предметов, он часто не подозревал, что другая альтернатива (в данном случае пример отрицательного перевода) было неприемлемо. Другие комментарии отражают восприятие учащимися того, насколько важно для них устранить эти ошибок:
Когда мы уйдем отсюда и пойдем уйти и получить работу, мы не сможем совершать такие ошибки, потому что, переводчики и учителя, это повлияет на нашу работу.(Франциско, L3)
студенты также высказались за систематическое лечение отрицательных ошибок передачи за исправление ошибок по мере их возникновения:
Раньше, когда мы делали один из этих ошибок, например, в письменном задании, она была выделена, но мы никогда не делали упражнений, чтобы не повторить ошибку снова, и поэтому мы продолжал их делать. (Соледад, CC1)
Другое студенты выразили мнение, что время, потраченное на анализ этих ошибок, и переводы и обсуждения, которые мы выполняли для отработки правильных форм, помогали им избежать этих ошибок.Дело было в том, что простой рисунок внимание студентов к примерам отрицательной лексической передачи в момент возникшие ошибки не повлияют на осведомленность о проблеме:
Если бы вы только поправили эти ошибки в классе, когда мы их сделали, и упомянули, что они примеры интерференции L1, мы бы не стали уделять этому много внимания. Но поскольку он стал частью класса, нам стало легче их запоминать. (Камила, L3)
я также спросили студентов, считают ли они, что занятия повысили их осведомленность об общей проблеме отрицательной лексической передачи.И снова ответ был положительным. Студенты обеих групп заявили, что они заметили изменения в том, как они думали, когда писали, и, в меньшей степени, степень, говоря. Эта разработка не ограничилась проблемой ложных родственников, поскольку студенты также упомянули, что больше думают о словосочетании и могут ли определенные комбинации слов, используемые в испанском языке, использоваться в так же и на английском.
Раньше я просто сидел вниз и написал, и l1 вмешательство произошло, но теперь я не тороплюсь и думаю о том, что я написал и действительно ли это испанское, и будет ли это понятно.Это был поворотным моментом. (Франциско, L3)
Я понял, что много думать по-испански и дословно переводить с испанского на английский. Теперь я более осознавая, что делаю определенные ошибки, и я спрашиваю себя: «Это сочетание слов работает в английском? » (Висенте, CC1)
Мы намного осторожнее о том, чтобы не делать этих ошибок. Если мы сделаем ошибку, она немедленно исчезнет. звучит неправильно, и мы скажем: «Нет. Это неправильно », особенно с слова, которые мы практиковали, но мы также более осторожны, чтобы не произносить ошибки, которых мы не видели.(Соледад, CC1)
Другой заслуживающий внимания комментарий, сделанный рядом студентов, как во время обсуждения в группах в середине проекта и собрания фокус-групп состояли в том, что мероприятия должны быть включены в программу с первого года обучения. Франциско (L3) резюмировал это просмотр:
Думаю, что вместо будучи всего лишь разовым проектом, он должен быть частью учебной программы, потому что для нас как переводчиков и учителей, нравится нам это или нет, это что-то существенный.
Навстречу в конце проекта я был приятно удивлен, получив письмо от один из студентов второго курса с дополнительными примерами возможных помех L1. Когда попросила рассказать группе о своих размышлениях, она прокомментировала:
Я думал о [Вмешательство L1] на какое-то время, и внезапно я подумал о слове «осознать» и сказал себе: «Я уверен некоторые люди думают, что это означает realizar », и я посмотрел на него. Тогда я подумал о еще один, который был медленным что означает cámara lenta, но люди может перевести это как медленная камера и это было бы неправильно.(Клаудиа, L3)
я считает комментарии этого студента очень обнадеживающими. Мало того, что они предоставили доказательства что она была вовлечена в проблему вмешательства L1 и, возможно, начала думать по-разному о двух языках, на которых она говорила, но также потому, что они показал наглядный пример того, чего я, как учитель, хотел достичь, и что было для студентов более критически относиться к тому, как испанский и английский соответствуют и отличаются.
Обсуждение
Мое первое впечатление о том, как студенты отреагировали на действия, которые мы выполняли во время проекта, заключалось в том, что многие из них были менее способны идентифицировать примеры отрицательной передачи, чем я ожидал.Некоторые из них казались удивленными, узнав, что языковые формы, которые они считали правильными в течение многих лет, на самом деле были неправильными. Однако, как только они признали, что эти ошибки проистекают из L1, а значит, в определенной степени «своих», студенты из обеих групп быстро увлеклись этой проблемой. В целом студенты с энтузиазмом участвовали как в мероприятиях под руководством учителя, так и в мини-презентациях, которые вызвали расширенное и оживленное обсуждение. Студенты стремились получить разъяснения о соответствии и различиях между L1 и L2, и они стали более внимательными к возможным случаям отрицательного перевода.Эти впечатления были подтверждены комментариями, сделанными в обеих фокус-группах.
Как количественные, так и качественные данные этого исследования, по-видимому, подтверждают утверждение, сделанное Nation (2001), Schmitt (2008) и Hulstijn (2001), среди других, что прямое внимание и взаимодействие с определенными лексическими элементами (в этом случай, те, которые вызывают проблемы у чилийских испаноговорящих) помогают учащимся сделать эти элементы частью своего полезного словарного запаса. Кроме того, тип обучения, по-видимому, повысил осведомленность об общей проблеме изучения второго языка: о вмешательстве L1.
Следует отметить, что, несмотря на положительные результаты исследования, некоторые из исправленных ошибок все еще допускались в случаях более свободного производства некоторыми студентами после проекта. Этот момент подчеркивает важность повторного пересмотра в долгосрочной перспективе для обеспечения автоматического отзыва и производства.
Заключение
Делая выводы о влиянии этого исследовательского проекта, важно помнить об ограниченном характере исследования.Во-первых, следует признать, что проанализированные ошибки были в некоторой степени искусственными в том смысле, что они не были собраны из образцов бесплатной устной или письменной работы студентов, участвовавших в исследовании. Инструменты, используемые для анализа знаний учащихся по целевым предметам, также не включали бесплатное производство. Кроме того, качественные данные, полученные от студентов на протяжении всего исследования, были собраны в присутствии исследователя, что могло повлиять на ответы и высказанные мнения.Наконец, необходимо также отметить, что из-за краткосрочного характера проекта невозможно было проверить сохранение знаний с течением времени, и поэтому долгосрочное влияние обучения, обсуждения и практики, проводимых в классе, является очень низким. все еще под вопросом.
Тем не менее, результаты исследования, кажется, дают некоторое представление о том, что систематический анализ типичных примеров отрицательного лексического переноса может, по крайней мере, в краткосрочной перспективе, снизить частоту производимых ошибок.Они также указывают на то, что студенты в целом ценили возможность сосредоточиться на типичных лексических ошибках, которые они склонны совершать как говорящие по-испански, и указывают на повышенное понимание участниками лексических ошибок, подразумеваемых наличием l1, имеющего общие корни с L2. учатся.
Этот исследовательский проект выдвинул на первый план область исследования, которой до сих пор пренебрегали или упускали из виду во многих учебных заведениях английского языка. Это связано с тем, что программы курсов во многих школах, институтах и университетах часто тесно связаны с учебниками по общему английскому языку, которые были выпущены для международного рынка и поэтому не могут удовлетворить потребности местных учащихся.Следовательно, необходимость сосредоточиться на конкретных лингвистических проблемах, которые возникают в одноязычных классах, и разработать соответствующие материалы для этой цели — это то, на что должны обратить внимание планировщики курсов не только в Чили, но и во всех контекстах, где вмешательство L1 является значительным. проблема. Участниками этого исследования были студенты университетов, изучающие переводы и преподаватели английского языка. Они выразили мнение, что искоренение некоторых ошибок может помешать достижению языковых навыков, необходимых для их будущей карьеры.Поэтому важно уделять достаточное внимание лексической интерференции L1.
С точки зрения будущих исследований, есть несколько направлений, которые можно было бы изучить дальше. Долгосрочное исследование позволило бы изучить возможное влияние этого типа словарных инструкций на ошибки интерференции L1 в свободном производстве и обеспечить более надежную меру улучшения в долгосрочной перспективе. Другой областью для исследования могло бы стать более конкретное исследование частоты и типа ошибок лексического переноса, совершаемых учащимися разного возраста и уровня и в различных образовательных контекстах, с целью создания и тестирования ряда целевых лексических списков и учебных материалов, которые могут быть включены в учебные планы.
Список литературы
Алонсо, М. Р. (1997). Перенос языка: межъязыковые ошибки у испанских студентов, изучающих английский как иностранный. Revista Alicantina de Estudios Ingleses, 10, 7-14. https://doi.org/10.14198/raei.1997.10.01.
Амара, Н. (2015). Исправление ошибок в обучении иностранному языку. Интернет-журнал «Новые горизонты в образовании», 5 (3), 58-68.
Бернс А. (2015). Перспективы исследования действий. Кембридж, Великобритания: Издательство Кембриджского университета.
Кордер, С.П. (1983). Роль родного языка. В С. М. Гасс и Л. Селинкер (ред.), Перевод языка в изучении языка (стр. 18-31). Амстердам, Нидерланды: Издательство Джона Бенджамина.
Эллис Р. (1985). Понимание приобретения второго языка. Оксфорд, Великобритания: Издательство Оксфордского университета.
Францен Д. (1998). Внутренние и внешние факторы, которые усложняют изучение ложных родственных слов. Анналы иностранных языков, 31 (2), 243-254. https://doi.org/10.1111/j.1944-9720.1998.tb00571.Икс.
Хемчуа, С., & Шмитт, Н. (2006). Анализ лексических ошибок в английских сочинениях изучающих тайский язык. Проспект, 21 (3), 3-25.
Hulstijn, J.H. (2001). Преднамеренное и случайное изучение словарного запаса второго языка: переоценка разработки, репетиции и автоматизма. В П. Робинсоне (ред.), Познание и обучение второму языку (стр. 258-286). Кембридж, Великобритания: Издательство Кембриджского университета. https://doi.org/10.1017/CBO9781139524780.011.
Джарвис, С.(2000). Методологическая строгость в изучении перевода: определение влияния L1 в межъязыковой лексике. Изучение языков, 50 (2), 245-309. https://doi.org/10.1111/0023-8333.00118.
Джарвис, С., и Павленко, А. (2008). Перекрестное языковое влияние на язык и познание. Нью-Йорк, США: Рутледж.
Каваляускене, Г. (2009). Роль родного языка в изучении английского для конкретных целей. Мир ESP, 8 (22), 2-8.
Каваляускене Г., Каминискене Л.(2007). Перевод как средство изучения английского языка для конкретных целей. Калботыра, 57 (3), 132-139. https://doi.org/10.15388/Klbt.2007.7566.
Крашен, С. (1989). Мы приобретаем словарный запас и правописание, читая: Дополнительные доказательства гипотезы ввода. Журнал современного языка, 73 (4), 440-464. https://doi.org/10.1111/j.1540-4781.1989.tb05325.x.
Нация, И. С. П. (2001). Изучение словарного запаса на другом языке. Кембридж, Великобритания: Издательство Кембриджского университета. https://doi.org/10.1017 / CBO9781139524759.
Шмитт, Н. (2008). Инструктаж по изучению словарного запаса второго языка. Исследования в области преподавания языков, 12 (3), 329-363. https://doi.org/10.1177/1362168808089921.
Свон, М. (1997). Влияние родного языка на усвоение и использование лексики на втором языке. В Н. Шмитте и М. Маккарти (ред.), Словарь: Описание, приобретение и педагогика (стр. 156-180). Кембридж, Великобритания: Издательство Кембриджского университета.
Талеби, С. Х. (2014). Межъязыковой перевод среди иранцев, изучающих английский язык как иностранный.Проблемы исследований в области образования, 24 (2), 212-227.
Приложение A: Упражнение по переводу
Студент А
Прочтите предложения ниже и переведите их внизу страницы:
- 1. В Программа, по которой я учусь, рассчитана на пять лет.
- 2. Он почти никогда не ходит на занятия, а когда приходит, то опаздывает.
- 3. Учитель, если я дам вам 50 000 долларов, вы дадите мне 7?
- 4.Его странный акцент привлек мое внимание.
- 5. Если мы собираемся устроить вечеринку, нам нужно подумать о еде.
(При выполнении этого упражнения ученикам предлагалось используйте следующие термины на испанском языке: Carrera, asiste a, ponerme, me llamó la atención, hacer / pensar en, но не ошибочно повторно перевести на английский как: карьера, помогите, поставьте меня, привлеките мое внимание, сделайте / сделайте вечеринка / думаю в)
Приложение B: Инструкции для мини-презентаций
Вы собираетесь сделать короткую презентацию для группы примерно четырех студентов о различиях и сходствах в использовании следующие пары слов, которые могут вызвать проблемы у говорящих по-испански:
- 1.Actualmente — Фактически (нареч.)
- 2. Librería — Библиотека (п.)
- 3. Пердер — Проиграть (v.)
- 4. Recordar — Помните (ст.)
- 5. Revisar — Редакция (v.)
Можно ли перевести любое из этих слов на испанском как слово на английский? Если да, то это единственный способ перевести слово? Если нет, как бы вы перевели слова?
Одинаковы ли они по значению в одних контекстах, а в других нет?
Можете ли вы привести примеры употребления слов?
Банкноты
1 Учащиеся могли узнать лексический элемент правильно в том смысле, что они понимают его правильное использование, но они все равно будут делать ошибки в более свободном производстве из-за влияния L1.Например, испаноязычный ученик, когда его просят объяснить разницу между разумным и чувствительным в английском языке, может быть в состоянии сообщит вам их правильное использование, но может продолжать говорить «разумно» вместо «Чувствительны» в свободном оральном производстве из-за того, что L1 более легко влияет на выбор слов.
2 Цитаты, которые появляются в этом разделе были переведены автором с испанского оригинала и псевдонимы были использованы.
Заметки автора
Пол Энтони Диссингтон учитель английского языка более 25 лет, работает в языковой сфере. институты в Англии, Испании, Португалии, Австралии и Венесуэле. Он сейчас проживает в Чили, где последние 13 лет проработал в разных государственные и частные университеты.
Дополнительная информация
Как
для цитирования этой статьи (APA, 6-е изд.): Dissington, P. A. (2018). Решение проблемы негативных
ошибки лексического переноса у чилийских студентов вузов.Профиль: Проблемы профессионального развития учителей, 20 (1), 25-40. https://doi.org/10.15446/profile.v20n1.64911.
Насколько эффективным может быть «лексический редактор»?
Abstract
Эффект лексического смещения (тенденция фонологических речевых ошибок к созданию слов чаще, чем неслов) обсуждался более 30 лет. Одна учетная запись приписывает эффект лексическому редактору, стратегическому компоненту производственной системы, который проверяет каждую запланированную фонологическую строку и подавляет ее, если это не слово.Альтернативное объяснение состоит в том, что эффект возникает автоматически в результате фонолого-лексической обратной связи. Используя новую парадигму, мы явно попросили участников выполнить лексическое редактирование запланированной речи и сравнили выполнение этой внутренней лексической задачи решения с результатами, полученными из стандартной задачи лексического решения в трех последующих экспериментах. Нашему экспериментально созданному «лексическому редактору» потребовалось 300 мс для распознавания и подавления неслов, что было определено путем сравнения времени реакции, когда редактирование было и не требовалось.Таким образом, мы пришли к выводу, что, хотя стратегическое лексическое редактирование может быть выполнено, любое такое редактирование, которое происходит в повседневной речи, происходит спорадически, если вообще происходит.
Ключевые слова: лексическое смещение, самоконтроль, речевые ошибки, обратная связь
ВВЕДЕНИЕ
Эффект лексического смещения
Прошло более трех десятилетий с тех пор, как эффект лексического смещения впервые проявился в речевых ошибках, но позже все эти годы он по-прежнему находится в центре внимания из-за той решающей роли, которую он играет в формировании моделей языкового производства.По определению, эффект лексического смещения — это тенденция к тому, что фонологические речевые ошибки приводят к реальным словам, а не к несловам с большей частотой, чем можно было бы предсказать (например, Baars, Motley & MacKay, 1975; Dell & Reich, 1981; Hartsuiker, Corley & Martensen, 2005; Humphreys, 2002; Nooteboom, 2005). Например, лексическое смещение должно увеличивать вероятность проскальзывания BARN DOOR до DARN BORE по сравнению с BARN PORCH , проскальзывающего до PARN BORCH .
Первоначальный интерес к эффекту лексического смещения состоял в основном в том, чтобы определить его существование и надежность. Эту проблему рассматривали две группы исследований. Во всех экспериментальных исследованиях использовалась процедура SLIP (Spoonerism of Laboratory Induced Predisposition), впервые разработанная Baars et al. (1975). Этот метод обеспечивает обмен начальными и согласными во время образования пар слов. В задаче SLIP участники будут видеть на экране пары слов, такие как COULD GORE , следующие друг за другом с короткими интервалами между испытаниями.Случайным образом сигнал побуждает участников произнести последнюю пару слов, которую они увидели на экране. Пары целей слово-результат (например, DEEP COT ) могут потенциально проскользнуть в слова (например, KEEP DOT ), в то время как целевые значения, не связанные со словом (например, DEED COP ), могут создать неслова, если их проскользнуть (например, KEED DOP ). Эффект лексического смещения демонстрируется, если промахи лексического результата превышают промахи нелексического результата. Все опубликованные экспериментальные исследования подтвердили, что это действительно так (Baars et al., 1975; Dell, 1986, 1990; Hartsuiker et al., 2005; Hartsuiker et al., 2006; Nooteboom & Quené, 2008; Оппенгейм и Делл, 2008 г.). Во второй группе исследований использовались корпуса естественных речевых ошибок. Эффект был первоначально обнаружен при изучении английского, голландского и немецкого языков (например, Berg, 1983; Dell & Reich, 1981; Stemberger 1984; Nooteboom, 2005), но не на испанском языке (Del Viso, Igoa & Garcia-Alba, 1991). . Маккей (1992), однако, поднимает вопрос о статистической мощности для обнаружения лексической систематической ошибки в испанском исследовании из-за относительной редкости ошибок в этом исследовании (182 ошибки в отличие от, e.г., 363 ошибки в Dell & Reich, 1981). Более того, существование лексической ошибки в испанском языке недавно было подтверждено как анализом данных о естественных ошибках, так и экспериментальным использованием процедуры SLIP (Hartsuiker et al., 2006). В целом, существование эффекта лексического смещения как устойчивого эффекта в отношении речевых ошибок больше не оспаривается. Но по мере того, как эти дебаты прекращаются, открывается новая глава: как создается эффект?
Эффект лексического смещения как ключевая концепция в теориях языкового производства
Любая модель языкового производства должна быть способна объяснить, среди прочего, паттерны ошибок в речи.Следуя принципу экономности, модели выгодно, если она предоставляет естественный механизм для объяснения таких закономерностей, а не апеллирует к апостериорным объяснениям. Эффект лексического смещения оказывается одним из самых интригующих эффектов речевой ошибки в этом отношении, который, согласно Hartsuiker (2006), «разделял литературу по языковому производству на десятилетия».
Модели языкового производства по большей части подпадают под одну из двух категорий в том, что касается их объяснения лежащего в основе механизма, создающего лексическую предвзятость.Первая группа, которая рассматривает производство как последовательность независимых и последовательно упорядоченных стадий (например, Garrett, 1975; Laver, 1980; Levelt, Roelofs, & Meyer, 1999; Roelofs, 2004), рассматривает лексическую предвзятость, а не как возникающий эффект. во время фазы формулировки речи, но как результат мониторинга результатов фазы формулировки на предмет ее лексического статуса. То есть речь, которая сформулирована, но еще не произнесена, оценивается на предмет того, образует ли она слова или нет. Этот предварительный мониторинг лексического статуса — иногда называемый «лексическим редактированием» — был первым предложенным механизмом лексического смещения (Baars et al., 1975), и это объяснение эффекта продолжает оказывать влияние (например, см. Обзор в Nooteboom & Quené, 2008). Вторая группа, которые верят в интерактивные, а не в независимые стадии производства, идентифицируют лексический уклон как автоматическое свойство производственной системы, проистекающее из обратной связи между фонематическим и лексическим уровнями. Другими словами, они видят эффект, возникающий во время формулировки речи, а не на стадии мониторинга после формулировки (например, Dell, 1986). Совсем недавно был предложен смешанный учет эффекта лексического смещения, сочетающий интерактивную обратную связь и мониторинг (Hartsuiker et al., 2005). резюмирует эти три счета, представляя гипотетические коэффициенты ошибок для словесных и несловесных результатов и относя их различия к влияниям, возникающим во время формулировки или редактирования. Обратите внимание, что предполагаемое количество наблюдаемых ошибок одинаково во всех случаях, а разница заключается в количестве сформулированных ошибок. В интерактивной учетной записи обратной связи нет необходимости в процессе мониторинга для объяснения эффекта, и поэтому то, что сформулировано, является тем, что наблюдается. Влияние редактирования является максимальным при чистом мониторинге, потому что вся разница в количестве лексических и нелексических наблюдаемых ошибок приписывается процессу мониторинга, а не формулировке.
Иллюстрация лексической предвзятости, объясняемой тремя разными учетными записями: (а) учетная запись обратной связи, (б) учетная запись мониторинга и (в) смешанная учетная запись. Темные полосы представляют сформулированные ошибки, а светлые полосы — наблюдаемые. Разница между каждыми двумя соседними полосами представляет собой степень редактирования на мониторе. Количество ошибок является гипотетическим и не отражает фактических данных.
В исследовании, описанном в этой статье, мы создаем экспериментальный аналог монитора, который выполняет лексическое редактирование, чтобы оценить, насколько легко сделать производство речи зависимым от лексического статуса.Если это можно сделать быстро и точно, то объяснения по мониторингу можно считать правдоподобными. Если нет, то альтернативные, автоматические учетные записи, такие как обратная связь, повышают доверие. В частности, в нашем основном эксперименте участников просят произносить односложные высказывания. В одном условии они говорят, только если подготовленный слог является словом, то есть они выполняют явное лексическое редактирование. В другом случае они говорят, только если слог не является словом, а в третьем случае они производят слог независимо от его лексического статуса.Сравнивая время отклика, когда требуется лексическое редактирование (или его аналог, «нелексическое редактирование»), с тем, когда оно не требуется, мы можем измерить сложность, связанную с включением монитора, чувствительного к лексическому статусу, в процесс создания речи. Чтобы подготовить почву для сравнения различных аспектов вышеупомянутых учетных записей, мы сначала даем обзор общих учетных записей мониторинга, а затем сосредотачиваемся конкретно на мониторинге лексического статуса и чем этот процесс отличается от интерактивного объяснения лексической предвзятости.
Хотя все сторонники теории мониторинга лексической предвзятости верят в существование монитора, существуют значительные различия во взглядах на природу этого монитора и его свойства. Фраза «самоконтроль в речи» относится к широкому спектру процессов, от обнаружения и исправления ошибок до недопущения произнесения социально неприемлемых материалов до принятия решения переформулировать концепцию более информативным образом при появлении смущения слушателя. Функция мониторинга, имеющая отношение к эффекту лексического смещения, будет представлять собой особый вид монитора, «лексический редактор», который будет заниматься только лексическим статусом потенциальных высказываний.Эта специфика имеет решающее значение для нашей цели, как будет обсуждаться позже, но пока мы сосредоточимся на рассмотрении мониторинга речи и модели мониторинга, которую мы создали в нашем эксперименте.
Самоконтроль производства речи
Ораторы, по-видимому, могут контролировать свою речь как до, так и после того, как она произнесена. Существует достаточно доказательств того, что говорящие имеют доступ к своей «внутренней речи», а также к своей открытой речи и часто перехватывают и исправляют ошибки через этот внутренний канал (Blackmer & Mitton, 1991; Levelt, 1983).Однако точная природа этой внутренней речи осталась неясной. Некоторые полагают, что все промежуточные когнитивные процессы в языковом производстве подлежат такому мониторингу, в то время как другие заключают, что только конечный результат таких процессов доступен для редакционных операций (см. Обзор в Postma 2000). Более того, нет единого мнения о том, как выполняется этот процесс мониторинга.
Наиболее хорошо проработанным способом мониторинга является монитор петли восприятия (Levelt, 1983; Hartsuiker & Kolk, 2001).Эта теория предполагает, что говорящие не имеют доступа к компонентам производственной системы, а только к конечному результату процесса, который оказывается либо внутренней, либо открытой речью (см. Также Bock, 1982). Мониторинг осуществляется посредством анализа потенциального и фактического вывода системой понимания и обработки его, более или менее, как речи, произведенной кем-то другим. Таким образом, теория устраняет необходимость в дополнительном компоненте мониторинга, помимо самой системы понимания.В этой теории есть два важных допущения: во-первых, весь процесс мониторинга является «центральным» процессом, который включает рабочую память и, следовательно, подвержен ее ограничениям. Следствием этого предположения является то, что внимание играет важную роль в этом способе мониторинга. Чтобы прояснить этот момент, Левелт (1989) утверждает, что самоконтроль — это управляемый процесс, который гибко обращает внимание на определенные характеристики речи. Из-за его контролируемой природы можно ожидать, что включение монитора петли восприятия некоторым образом усложнит процесс формирования речи.Конечно, это затруднение компенсируется исправлением ошибок (когда ошибка уже высказана) и предотвращением (когда ошибки в запланированной речи перехватываются).
Второе допущение монитора петли восприятия заключается в существовании двух стадий мониторинга: фазы концептуального мониторинга, на которой с помощью функции сопоставления произносимое сообщение сравнивается с первоначальным намерением говорящего. За этим этапом следует этап, основанный на критериях, на котором запланированная речь на фонетическом или фонологическом уровне оценивается по ряду различных критериев (синтаксис, лексичность, громкость и т. Д.)), и в идеале сигнал об ошибке отправляется в рабочую память, если какой-либо из этих критериев не выполняется (Hartsuiker, 2006). Косвенным следствием этого предположения является то, что монитор только останавливает ошибочное высказывание и посылает системе сигнал перезапуска для выполнения исправления. Следовательно, монитор как таковой не играет активной роли в собственно ремонте.
Пытаясь реализовать экспериментальный монитор, который максимально приближен к описанному в литературе, мы использовали свойства монитора петли восприятия.Первое допущение перцептивного объяснения мониторинга, о котором говорилось выше, заключается в том, что монитор является «сознательным и внимательным» и «более или менее… преднамеренным» (Postma, 2000, стр. 115). Поэтому в нашем эксперименте мы явно попросили человек контролировать свою речь, прежде чем произносить ее.
Во-вторых, мы определили критерий для монитора. Мы поручили нашим участникам следить за лексическим статусом. В следующем разделе мы поговорим более подробно о взглядах на лексическое редактирование и возобновим обсуждение с выбора критерия лексичности, который сделал бы наш экспериментальный монитор лексическим редактором.
Взгляды на особый вид мониторинга: «лексический редактор»
В этом разделе мы описываем, как теории мониторинга и интерактивной (обратной связи) теории объясняют эффект лексического смещения, и обсуждаем, как можно создать наш экспериментальный лексический редактор. В модели Dell (1986, 1988) лексические единицы (морфемы) и фонематические единицы соединяются двусторонними связями. Когда для потенциального слова существует узел морфемы, он может усилить активацию его фонем. Если узел не существует (т. Е. Не слова), фонемы не получают этого усиления.Стоит упомянуть, что учетная запись обратной связи легко объясняет еще один важный вывод об ошибках в данных, эффект семантического смещения (Motley & Baars, 1976), который подчеркивает тот факт, что лексические ошибки имеют тенденцию быть семантически связанными с ранее созданными целями просто потому, что такие узлы уже подготовлены семантическими функциями, которые они разделяют с целевым узлом. Кроме того, обратная связь также была предложена в качестве механизма для повторяющегося эффекта фонем, тенденции фонем перемещаться между словами, которые имеют общие фонемы (Dell, 1984), и для эффектов ошибок на уровне слова, таких как тенденция семантических ошибок к общей фонологии ( е.г., Харлей, 1984; Martin et al., 1996)
В качестве альтернативы учетной записи обратной связи «лексический редактор» может быть интегрирован в компонент мониторинга монитора петли восприятия. Таким образом, в дополнение к контролю того, является ли запланированная речь правильной, социально приемлемой и полностью выражает предполагаемое значение, можно также контролировать по критерию «является ли эта запланированная строка словом?» а затем остановите или отредактируйте строку, если это не так. Фактические механизмы лексического редактирования в модели мониторинга еще не определены, кроме предположений, что он может работать с запланированной речью, что процесс мониторинга требует внимания и что он может гибко изменять свой критерий.Поддержка этой гибкости исходит из демонстрации того, что эффект лексического смещения сокращается, когда говорящие ожидают, что их вывод не будет слов. Такая гибкость была впервые продемонстрирована Baars et al. (1975). Когда большинство целевых строк в процедуре SLIP не были словами, промахи, которые создавали неслова, были примерно так же вероятны, как и те, которые создавали слова, и эти показатели были примерно равны таковым для словесных результатов, когда большинство целей были словами. Следовательно, оказывается, что несловесные исходы подавляются только тогда, когда ожидаются слова — именно то, что можно было бы ожидать от гибкого редактора, который подавляет несловесные исходы, когда говорящий ожидает произнести слова.Hartsuiker et al. (2005), однако, обнаружили, что лексическая предвзятость наблюдается, когда встречаются как словесные, так и несловесные цели, и предположили, что автоматическая обратная связь способствует этому эффекту, потому что, когда ожидаются и слова, и неслова, редактирование лексического статуса не выполняет никакой функции. Однако они также обнаружили, что, когда ожидаются цели без слов, существует тенденция к подавлению результатов слов , эффект гипотетического нелексического редактора . Hartsuiker et al. таким образом, предполагается, что и автоматическая обратная связь, и гибкая возможность контролировать вывод на предмет лексического статуса вносят вклад в лексическое смещение ().
Целью данной статьи является предоставление количественной оценки гипотетического лексического редактора при производстве речи. Как работает такой редактор? Итак, мы представили общую схему нашего экспериментально созданного монитора. Вспомните, что мониторы петли восприятия, примером которых является наш экспериментальный монитор, требуют критерия работы. Итак, чтобы сделать наш монитор лексическим редактором, мы должны выбрать соответствующий критерий, критерий лексичности. Единственный реальный пример явного и гибкого процесса оценки лексического статуса, который у нас есть, — это задача принятия лексических решений, обычно используемая в исследованиях обработки ввода текста.Таким образом, мы принимаем эту задачу в качестве модели лексического редактора и устанавливаем критерий «это то, что я собираюсь сказать слово?» В нашем первом эксперименте участникам предлагается принять лексическое решение относительно запланированного результата и сделать свой результат зависимым от этого решения. Если этот внутренний лексический процесс принятия решения может быть выполнен быстро и точно, то он действительно может происходить в естественной речи и может объяснить, по крайней мере, некоторые компоненты эффекта лексического смещения.
Как быстро должен работать эффективный лексический редактор? При рассмотрении этого вопроса полезно начать с некоторых фактических оценок, полученных на основе данных.Продолжительность процесса мониторинга для обнаружения ошибок («соответствует ли эта строка целевому слову?» В отличие от «эта строка — слово?») Была оценена Hartsuiker и Kolk (2001) путем моделирования фактического обнаружения и исправления ошибок. данные из образцов речи. Они показали, что для отслеживания каждого потенциального слова на предмет ошибок потребуется не более 150–200 мс, и около 200 мс добавляется для перехвата обнаруженной ошибки, если таковая имеется. Достаточно короткая продолжительность их оценки времени отслеживания для обнаружения ошибок кажется совместимой с беглостью речи.Более того, учитывая, что мониторинг ошибок явно происходит в их речевых данных, мы заключаем, что монитор, который работает в этой временной шкале, действительно совместим с беглостью или, по крайней мере, с беглостью, присутствующей в их данных. Но можно ли в эти сроки провести мониторинг лексического статуса?
Литература по лексическим решениям является полезной отправной точкой для ответа на этот вопрос. Ratcliff et al. (2004) применили диффузионную модель реакций выбора (Ratcliff, 1978) к данным лексического решения, полученным на основе визуальных стимулов, для определения продолжительности «решающего» компонента времени лексической реакции на решение.Это время принятия решения, которое, как можно предположить, соответствует времени мониторинга лексического статуса, оценивается примерно в 165 мс для высокочастотных слов и 225 мс для низкочастотных слов (Ratcliff et al., 2004, эксперимент 9). Таким образом, оценки на основе лексического решения во время обработки ввода в некоторой степени похожи на время отслеживания ошибок Хартсуикера и Колка, и поэтому есть основания ожидать, что лексическое редактирование запланированной речи также может быть связано со временем контроля менее 200 мсек.Мы попытаемся оценить продолжительность и точность процесса лексического редактирования слов и неслов в запланированной речи и посмотреть, обнаруживают ли эти оценки процесс, который столь же эффективен, как этот.
Помимо нашего интереса к оценке правдоподобности лексического редактора в производственной среде, исследование способности людей принимать лексические решения относительно запланированной речи полезно по другой причине. Эмпирическая база когнитивной психологии состоит из исследований ускоренных (обычно с двумя вариантами ответов) реакций на явные стимулы, такие как задача лексического решения.Однако познание — это больше, чем просто явное сопоставление стимулов и реакций. Многие из «стимулов», которые мы должны классифицировать или с которыми иным образом иметь дело, обеспечиваются нашими собственными мыслительными процессами. Языковое производство — яркий тому пример. Повелительного стимула нет. Тем не менее, говорящий должен обрабатывать последовательность внутренне генерируемых элементов. Мы предполагаем, что систематическое исследование принятия решений по таким элементам может выявить полезные свойства познания. В нашем исследовании рассматриваются «лексические решения» для генерируемых и, в последующих экспериментах, явных стимулов.Сравнивая решения в этих ситуациях, можно начать обнаруживать проблемы обработки внутренних представлений. Например, такое представление должно храниться в рабочей памяти в отличие от явного стимула, который остается в поле зрения. Или ему может не хватать деталей, которые присутствуют в явном стимуле. Таким образом, есть основания полагать, что обработка элементов, сгенерированных внутри, может быть более сложной, чем обработка тех, которые находятся прямо перед нами.
Сначала мы представляем эксперимент, в котором участники производят слоги и следят за их лексическим статусом.Затем в следующих трех экспериментах мы сравниваем наши результаты с их эквивалентами в визуальной и слуховой, а также в версии go / nogo лексического решения задачи. В эксперименте 1 участники сначала слышат слуховой слог, состоящий из гласной и согласной (например, / ∧n / ), и сразу видят визуальный слог на экране компьютера (например, GAP ). Их просят объединить первую букву визуального стимула (например, G ) со слуховым слогом и построить новый слог (результат) в их сознании (т.е., ПИСТОЛЕТ ). Именно этот вновь созданный слог будет проверяться на предмет лексического статуса. Визуальные слоги, которые способствуют возникновению построенного слога результата, половину времени представляют собой слова (например, GAP ), а половину времени — несловесные (например, GACK ) (манипулирование лексическим статусом визуального стимула было просто дополнительный механизм контроля, и его не следует путать с критической манипуляцией лексическим статусом отслеживаемых слогов результата).Материал составлен таким образом, что для всех слогов существует четыре комбинации стимула / результата: слово-стимул / слово результата (SWOW), неслово-стимул / слово результата (SNOW), слово-стимул / неслово результата (SWON) и, наконец, неслово-стимул / Результат Неслово (СНОН). В дополнение к этим четырем условиям, основанным на материалах, есть три процессуальных условия. На основе случайного присвоения условию участники должны либо озвучить все новые результаты (базовое условие), либо только словесные результаты (условие Word), либо только результаты без слов (условие Nonword).Сравнивая два последних условия (критические условия) с базовым уровнем, мы можем определить время, необходимое для того, чтобы сделать речь зависимой от лексического статуса.
Эксперимент 1
Метод
Участники
В эксперименте приняли участие двадцать девять англоговорящих студентов Университета Иллинойса в Урбана-Шампейн и двенадцать платных участников. Первая группа получила зачет курса, а вторая группа получила 7 долларов за участие.Систематической разницы между распределением участников по разным условиям не было. Возраст всех участников составлял 18–29 лет.
Материалы
На каждого участника исследования приходилось 160 испытаний. Каждое испытание представляло собой комбинацию слуховой гласной-согласной (слоговой) строки (например, / ∧n / ), за которой следовала визуальная односложная буквенная последовательность, которая могла быть либо словом, либо неслово (например, GAP или ). GACK ). 160 испытаний были организованы в 20 подходов по 8.Каждый набор содержал по два испытания из каждой из четырех комбинаций стимул / результат в эксперименте. Их расположение в наборах по восемь гарантировало, что каждый слуховой слог одинаково участвовал во всех четырех комбинациях и, как правило, чтобы материалы были сопоставлены между комбинациями, как показано на, который представляет собой набор примеров (полный список можно найти в приложении 1):
Таблица 1
Пример набора, использованного в эксперименте 1. Слоги, напечатанные курсивом, — это те слоги, которые участники должны собрать.SWOW = Слово стимула / Слово результата; СНЕГ = Неслово стимула / Слово результата; SWON = Слово-стимул / Неслово Результат; SNON = Стимул-неслово / Неслово-результат.
| Номер и тип испытания | слуховой слог | визуальный стимул | результат | номер и тип испытания | слуховой слог | визуальный стимул | результат |
|---|---|---|---|---|---|---|---|
| 1. SWOW | ∧ n /зазор | пистолет | 5.SWOW | / ∧t∫ / | miss | много | |
| 2. SNOW | / ∧n / | gack | пистолет | 6. SNOW | / ∧t∫ / | мез | много |
| 3. SWON | / ∧t∫ / | зазор | гуч | 7. SWON | / ∧n / | мисс | мун |
| 4. СНОН | / ∧t∫ / | gack | guch | 8.SNON | / ∧n / | mez | mun |
Лексический статус определялся наличием произношения строки в онлайн-словаре Merriam-Webster. Таким образом, / t∧t∫ / является словом независимо от того, понимается ли его написание как «прикосновение» или «туч». Согласно этому правилу, было 40 испытаний лексических результатов (например, GUN ) и 40 нелексических результатов (например, GUCH ), каждое из которых производилось дважды, один раз через словесный стимул (например, GUCH ).g., GUN — GAP ) и однократно через несловесный стимул (например, GUN — GACK ).
Процедура и сбор данных
Участники тестировались индивидуально в тихой комнате. Их усадили перед 17-дюймовым монитором и попросили прочитать инструкции по выполнению задания в удобном для них темпе. В инструкции подчеркивалась как скорость, так и точность. Каждый участник провел 15 испытаний под наблюдением экспериментатора, который предоставил обратную связь.На этапе испытаний испытания следовали друг за другом с фиксированными интервалами между испытаниями. На этапе тестирования обратной связи не поступало. Каждое испытание начиналось с одновременного предъявления на экране цели визуальной фиксации и слухового слога. Громкость регулировалась для каждого участника индивидуально во время первых трех практических испытаний. Все слоги однозначно произнес второй автор, носитель американского английского. Сразу после окончания предъявления слухового слога цель визуальной фиксации была заменена цепочкой букв стимула, которая оставалась на экране в течение 2000 мс, а затем снова была заменена целью фиксации.Время реакции регистрировалось с помощью голосовой клавиши, причем отправной точкой было появление визуального стимула. Участникам было предложено взять первую букву визуального стимула (например, G в GAP или GACK ) и поместить ее в начало слога, который они только что услышали (например, / ∧t∫ / или / ∧n /) и составьте новый слог (например, GUCH или GUN ). С этого момента инструкции различались для разных экспериментальных условий, хотя участники во всех условиях подвергались воздействию одного и того же списка стимулов в рандомизированном порядке.Мы создали три таких условия: базовый уровень (13 участников), в котором участникам было предложено произносить все новые слоги, независимо от их лексического статуса, условие Word (14 участников), в котором участникам было предложено следить за созданными ими слогами для их лексический статус и произносить их вслух, только если это были значащие слова на английском языке. В отличие от последнего условия, было создано условие отсутствия слов (14 участников), чтобы участники могли озвучивать только результаты, не являющиеся словами.В любых условиях участникам предлагалось ответить как можно быстрее и точнее.
В дополнение к сбору задержек ответа с помощью программного обеспечения E-PRIME (программное обеспечение PST, Питтсбург, Пенсильвания, США), ответы участников кодировались на наличие ошибок один раз во время выполнения задачи (онлайн-кодирование) и один раз в автономном режиме с использованием их цифровой записи ответы. Кодирование ошибок производилось следующим образом: для условий Word и Nonword, помимо ошибок неправильного произношения, были определены два типа ошибок.Ошибки пропускания происходили, когда участник не мог произнести слог, который он / она должен был произнести в этом состоянии (например, не сказал GUN в условии Word или GUCH в состоянии Nonword). Комиссионные ошибки кодировались, когда произносился слог, который должен был быть остановлен в определенном состоянии (например, произносится GUCH в состоянии Word или GUN в состоянии Nonword). Целью онлайн-кодирования было в первую очередь проверить, почему возникла ошибка.Как подразумевается, каждый результат будет получен дважды в ходе эксперимента. Если участник однажды допустил ошибку, но в какой-то другой момент эксперимента получил правильный результат, ошибка будет засчитана как ошибка без дальнейшей проверки. Но если участник дважды допустил одну и ту же ошибку в результате (например, не сказал дважды GUN в условии Word), то его / ее попросят объяснить свое решение сразу после завершения эксперимента. Ошибка будет считаться ошибкой только в том случае, если экспериментатор был убежден, что участник правильно построил слог результата и знал о его лексическом статусе за пределами условия теста, но допустил ошибку, правильно обозначив элемент во время теста.Например, если ошибка произошла в слове WRETCH , она будет закодирована как ошибка, только если участник подтвердит, что он / она построил правильный слог и смог описать значение этого слова, но если он / она не знал, что означает, что элемент будет просто выпадать из его / ее пула ответов. В случае участников, свободно владеющих вторым языком (18% участников), все результаты без слов были представлены им после эксперимента, чтобы судить, будут ли такие слоги означать что-либо на их втором языке, и если да, эти испытания были отклонены для тех, кто конкретных участников.4% ответов пришлось отбросить, так как они узнали знакомое слово на другом языке. Для исходного условия ошибки неправильного произношения были исключены из списка времен реакции. Описанные выше проверки не применимы к этому условию.
Результаты
Предварительные сведения
Два набора элементов были исключены из всех анализов, потому что слуховой слог / æθ / часто неверно воспринимался как / εθ / из-за диалектных вариаций. Эти наборы не были включены в последующие эксперименты.
Данные о времени реакции
Для исключения непригодных предметов и участников мы выполнили двухэтапную процедуру. Мы установили очень консервативные критерии исключения, чтобы оставить только те элементы и участников, которые продемонстрировали успешный мониторинг, чтобы мы могли оценить процесс лексического редактирования в его идеальной форме. Шаг 1, процедура исключения проб, использовался для всех трех условий в эксперименте 1. Сначала все испытания с неправильным произношением были отброшены (0,1% для условия Word, 0.3% для условия отсутствия слов и 0,6% для базового условия). Во-вторых, время реакции, превышающее среднее значение ± 2SD распределения времени реакции для каждого участника, было выброшено. С помощью этого метода были исключены 3% ответов в базовом условии, 3,6% из условия Word и 3,8% из условия Nonword.
Шаг 2 включал удаление элементов и участников на основе результатов мониторинга и, следовательно, был выполнен только для условий Word и Nonword. Все комиссионные ошибки были исключены из анализа времени реакции.Первая часть этого шага заключалась в том, чтобы распределить процент ошибок и исключить те элементы, у которых частота ошибок выше, чем на 2SD, выше среднего значения распределения или 30% (в случае, если> 2SD было выше 30%). Во второй части, после отбрасывания непригодных предметов из предыдущей части, та же процедура была проделана для участников вместо предметов. Эти этапы исключения элементов и участников повторялись последовательно до тех пор, пока ни один из элементов или участников не соответствовал критерию исключения.
После выполнения вышеуказанных шагов 14% элементов и 1 из 14 участников из условия Word и 11% элементов и ни один участник из условия Nonword были исключены. Выброшенные предметы из этих двух условий также были исключены из базового условия.
Среднее время реакции для слов и неслов было намного больше в критических условиях, чем их аналоги в базовых условиях. Используя средства участника в качестве единицы анализа, разница между средним временем реакции на слова в условии Word (995 мс, SE = 23 мс) и его базовым аналогом (702 мс, SE = 24 мс) составила 293 мс [F 1 (1,24) = 70.29; 95% ДИ = ± 76 мс]. Используя средства элемента, разница между временем реакции для слов в условии Word (1003 мс, SE = 15 мс) и его базового аналога (699 мс, SE = 6 мс) составила 304 мс [F 2 (1,63 ) = 369,63; 95% ДИ = ± 32 мс; min F ‘(1,34) = 59,06, p <0,01]. В результате анализа участников было получено среднее время реакции 1143 мс (SE = 31 мс) для неслов в условии неслова и 724 мс (SE = 28 мс) для неслов в исходном состоянии с разницей в 419 мс [F 1 ( 1,25) = 98.75; 95% ДИ = ± 91 мс]. Анализ элемента дал 1144 мс (SE = 12 мс) среднего времени реакции для неслов в условии неслова и 718 мс (SE = 11 мс) для среднего времени реакции для неслов в базовом состоянии с разницей в 426 мс [F 2 (1,126) = 1361,78; 95% ДИ = ± 41 мс; min F ‘(1,29) = 92,07, p <0,01].
Эти различия представляют собой основные данные этой статьи, время мониторинга лексического статуса. С этого момента мы берем 304 мс и 426 мс как время контроля для слов (фильтрация неслов) и неслов (фильтрация слов) соответственно.Выбор этих основанных на пунктах различий по сравнению с различиями, полученными в результате анализа участников, оправдан их концептуальным преимуществом. Эти значения представляют собой разности, рассчитанные путем вычитания соответствующих средних базовых значений для каждого элемента из средних значений элемента в критическом состоянии и усреднения разностей. Мы выбрали здесь средства элемента, а не участника, потому что различия Word / baseline-word и Nonword / baseline-nonword являются различиями внутри элемента, но не внутри участников из-за дизайна между участниками Word, Nonword и baseline условия.Однако обратите внимание, что различия на основе элементов и участников в любом случае очень похожи. Хотя наш консервативный метод исключения элементов / участников обеспечивает захват времени мониторинга в идеальных случаях, мы все же рассчитали время мониторинга в 312 мс для слов и 464 мс для не-слов, если бы был завершен только шаг 1 процесса исключения (конечно, ошибки комиссии ни разу не вошел в анализ). Эти результаты вполне согласуются с нашими основными выводами и устраняют сомнения в значительном несоответствии, возникшем в результате очень консервативного процесса исключения.
Другой вывод заключался в том, что не-слова требовалось больше времени, чем слово, как в критических, так и в исходных условиях. В период между критическими условиями производство несловесных слов было на 148 мс дольше, чем производство слов при анализе участников [F 1 (1,25) = 13,29, 95% ДИ = ± 83 мс] и на 141 мс дольше при анализе заданий [F 2 (1,61) = 53,04, 95% ДИ = 39 мс; min F ‘(1,38) = 10,63, p <0,01]. В исходных условиях неслова были на 22 мс длиннее, чем слова с использованием анализа участников [F 1 (1,12) = 7.89, 95% ДИ = 16 мс] и на 19 мс больше с использованием анализа элементов [F 2 (1,61) = 7,28, 95% ДИ = 17 мс; min F ‘(1,42) = 3,79, p> 0,05]. Тем не менее, разница между условиями Word и Nonword была намного больше по сравнению со словом и nonword в исходном состоянии, поскольку значимое взаимодействие между условием (базовое или критическое) и лексическим статусом (word vs. non-word) подразумевает [F 1 (1 , 49) = 5,07, р <0,05; F 2 (1268) = 43,74, p <0,01; min F ′ (1,61) = 4,54, p <0.05].
Наконец, мы обнаружили небольшое взаимодействие между лексическим статусом стимула (например, GAP vs. GAP in) и результатом (например, GUN vs. GUCH in) в критических условиях [ F 1 (1,25) = 23,64, p <0,01; F 2 (1,58) = 8,61, p <0,01; min F '(1,83) = 6,31, p <0,05]. показывает характер этого взаимодействия. Как показано на рисунке, неслова генерировались быстрее в ответ на словесные стимулы, в то время как для слов все было наоборот.Это согласуется с выводами Гордона и Баума (1994) о том, что лексическое простое число облегчает распознавание неслова, но не слова-цели. Обратите внимание, что это взаимодействие не влияет на наши выводы о времени мониторинга, то есть на сравнение условий Word и Nonword и их базовых значений.
Природа взаимодействия в эксперименте 1. Словесные стимулы облегчают произнесение не слов, но не слов.
Данные об ошибке
Как упоминалось ранее, после устранения сомнений в несущественных источниках ошибок (незнание значения определенного слова, принятие бессмысленного слога в английском языке за значимый слог в других языках и т. Д.) мы разделили ошибки на две группы: упущения и упущения. Напомним, что поручения состоят из высказываний, которые должны были быть остановлены в соответствии с лексическим критерием, но не были, в то время как пропуски были испытаниями, в которых слоги не произносились неправильно. Результаты анализа ошибок представлены в. Ошибки комиссии представляют особый интерес, поскольку они показывают, где попытка мониторинга потерпела неудачу. Они были гораздо более вероятны в условии отсутствия слова (16%), чем в условии слова (3%), [(t (26) = 8.19, р <0,01]. Ошибки пропуска показали, что противоположная картина более вероятна в слове «условие» [t (26) = 3,62, p <0,01].
Таблица 2
Частота ошибок в эксперименте 1. Для каждого условия сообщается два типа ошибок. См. Текст для определений.
| Типы ошибок | ||
|---|---|---|
| Состояние | Пропуски | Комиссии |
| Word | 12% | 3% |
| Nonword 900 | 16% | |
Обсуждение
Нашему лексическому редактору потребовалось много времени, чтобы отредактировать как неслова (304 мс), так и слова (426 мс).Давайте посмотрим, как мы определили эти значения. Схема нашего экспериментально созданного процесса мониторинга подробно показана в. Обработка слухового слога не включена в эту схему, так как мы представляем только то, что фактически измеряется в эксперименте, и запись задержки реакции начинается, как только визуальный стимул появляется на экране. Для выполнения задания участникам необходимо было сканировать визуальный стимул на предмет его первой буквы (визуальная обработка). Следующим шагом было объединить эту букву с только что услышанным слогом и составить новый слог (сборка).Для участников условий Word и Nonword следующие два шага (лексическое решение и go / nogo) представляют собой мониторинг; они пропускаются в базовых условиях. Последний шаг состоит в произнесении собранного слога, если это необходимо (ответ). Итак, с базовым временем реакции мы фиксируем три из пяти шагов, отображаемых в. С другой стороны, участники в двух других условиях также должны были завершить фазу мониторинга.
Этапы обработки в сборочном задании эксперимента 1.Обработка слухового слога в эту схему не входит, потому что измерение времени реакции начинается с появления зрительного стимула, когда слуховое предъявление заканчивается.
Таким образом, все пять шагов, показанных выше, отражаются в задержках ответа для условий Word и Nonword. Поскольку нас интересует стоимость мониторинга, мы можем вычислить ее, просто вычтя среднее время отклика для слов и неслов в базовых показателях из их аналогов в условиях Word и Nonword.Это вычитание дает нам разницу в 304 мс для слов и разницу в 426 мс для неслов, которые представляют дополнительное время, необходимое для включения контроля слов и неслов, соответственно, в формирование речи. Другими словами, это оценка стоимости добавления лексического редактора в процесс производства (см.).
Задержки ответа в эксперименте 1. Первый и второй кластеры показывают время реакции на слова и не слова соответственно. Темные полосы представляют условие Word в первом кластере и условие Nonword во втором кластере.Световые полосы — это задержки ответа в базовых группах в сочетании с соответствующими условиями.
Стоимость редактора, полученная с помощью этой процедуры вычитания, не обязательно должна определяться исключительно суммированной длительностью предполагаемого лексического решения и шагов go / nogo. Общие редакционные расходы также могут включать любые задержки при переходе к процессу мониторинга и из него, которые возникают из-за включения редакционных шагов. Можно ожидать, что вставка любого дополнительного процесса в середину другого процесса замедлит исходный процесс около точки вставки.Обратите внимание, что эта «двойная задача» должна применяться к любому неавтоматическому лексическому редактированию, которое происходит при воспроизведении естественной речи, а также в нашем эксперименте. Поскольку мы в значительной степени заинтересованы в определении общей стоимости редактирования неслов (и слов), а не в оценке точной продолжительности отдельных этапов, определение этой стоимости путем вычитания подходит для нашей цели.
В эксперименте 1 мы исследовали модель лексического редактирования, которая напоминает задачу лексического решения в уме говорящего, результат которой определяет процесс производства речи.В следующем разделе мы представим три фактических исследования лексических решений, чтобы изучить два ключевых вывода эксперимента 1: очень длительное время наблюдения и относительную сложность фильтрации слов по сравнению с несловесами. В этих исследованиях исключается часть, в которой говорящий должен мысленно построить целевой слог. Участнику просто даются итоговые слоги, использованные в эксперименте 1, и он выполняет лексическое решение по этим слогам. Три исследования различаются по природе стимула и реакции.Мы начинаем с версии go / nogo задачи лексического решения, которая перекликается с характером go / nogo эксперимента 1, за исключением того, что задача не встроена в процесс производства речи. Затем мы представляем две канонические (два варианта выбора кнопки) лексические задачи принятия решения (по визуальным и слуховым стимулам), которые по сравнению с задачей лексического решения «идти / нет» позволяют оценить процесс принятия решения. В конце концов, мы воспользуемся математической моделью, чтобы извлечь «времена принятия решения» из канонических лексических исследований решений.Напомним, что предыдущие оценки такого времени значительно меньше 200 мс, по крайней мере, для часто используемых слов (например, Ratcliff et al., 2004). Эти времена принятия решения позволят нам оценить легкость наших материалов для лексического решения. Что еще более важно, они будут напрямую сопоставимы с тем, что мы назвали «затраты на мониторинг» в эксперименте 1,
ОБЩЕЕ ОБСУЖДЕНИЕ
Хотя эта статья основана на классическом открытии лексической предвзятости, она уникальна тем, что фокусирует свое исследование на свойствах возможного объяснения этого эффекта, то есть гибкой, требующей внимания системы, которая отслеживает запланированный вывод на предмет лексического статуса.Чтобы определить природу гипотетического лексического редактора, мы ответили на два вопроса: во-первых, если есть лексический редактор, достаточно ли он быстр, чтобы отслеживать каждое слово в нашей повседневной речи? Во-вторых, насколько гибок этот лексический редактор? То есть, можно ли его легко настроить для удаления слов вместо неслов? Пытаясь ответить на эти вопросы, мы использовали производственную парадигму, чтобы активно вовлекать участников в мониторинг их запланированной речи на предмет ее лексического статуса с «иди, если слово» в одном условии и «иди, если не слово» в другом.Мы также добавили базовое условие для оценки времени, необходимого для выполнения задачи без отслеживания требований. Вычитая время реакции для заданий в базовой линии из их аналогов в критических условиях, мы оценили абсолютные затраты на мониторинг слов и неслов в нашей экспериментальной парадигме. Большая продолжительность мониторинга (около 304 мс для не слов и 426 мс для слов) не поддерживает скорость процесса. Обратите внимание, что в этом исследовании мы использовали только односложные слова и неслова, поэтому было бы логично предположить, что время наблюдения за более длинными заданиями может быть даже больше, чем эти оценки.Более того, разница в 122 мс между словом и без слов при гораздо большем количестве ошибок комиссии в условии «Неслово» по сравнению с условием «Слово» (16% против 3%) предполагает, что этот вид явного редактирования имеет сильную тенденцию отфильтровывать неслова, а не слова. По предложению Hartsuiker et al., возможно отфильтровать слова. (2005), но это не предпочтительный критерий.
Важно подчеркнуть, что мы рассматривали мониторинг только для лексического статуса . Следовательно, наша интерпретация этого конкретного подтипа речевого мониторинга никоим образом не может быть обобщена на другие подтипы, такие как мониторинг социальной уместности высказывания или мониторинг того, действительно ли запланированное высказывание соответствует предполагаемому высказыванию.Однако мы считаем, что лексическое редактирование, если оно является частью общей системы контроля речи, должно следовать некоторым общим правилам такой системы. Например, характер отслеживаемой внутренней речи не должен отличаться от одного подтипа мониторинга к другому. В целом, хотя мы верим в общую систему мониторинга , основная цель которой состоит в том, чтобы определить, является ли запланированная или произнесенная строка предполагаемой строкой , существование такой системы не подтверждает автоматически существование лексического редактора, который объясняет лексическую предвзятость.Тот факт, что система контроля речи эффективно выполняет некоторые функции, не означает, что она пригодна и для других функций, если не доказано иное. Следуя этому утверждению, мы посчитали, что было бы очень полезно протестировать именно на эффективность конкретного подтипа мониторинга, который, как предполагается, выполняет лексическое редактирование. Чтобы решить проблему общей эффективности лексического редактирования, мы обсудим абсолютное время мониторинга, полученное в нашем эксперименте 1. Чтобы рассмотреть вопросы, касающиеся гибкости такого редактора, мы объединяем результаты анализа ошибок с разницей между продолжительностью мониторинга. для слов и неслов.
Абсолютное время мониторинга
Мы обнаружили, что редактирование односложных несложных слов требует затрат в 304 мс на время создания произносимых односложных слов. Когда требуется удалить слова, среднее время произнесения произносимых неслов было на 426 мс медленнее, чем базовое значение. Учитывая тот факт, что мы производим 2–3 слова в секунду при беглой речи, каждое слово может произойти от 300 до 500 мс (Levelt, Roelofs, & Meyer, 1999). Если рутинный мониторинг лексического статуса выполняется для каждого слова, которое мы произносим, это будет означать, что у производственной системы остается мало времени для выполнения работы по созданию слова.Конечно, за этим выводом стоят некоторые важные предположения. Во-первых, это предположение, что ведется мониторинг всех слов, подлежащих произнесению. Можно возразить, что некоторые части нашей речи, например служебные слова, не подвергаются контролю, что позволяет системе сэкономить время для отслеживания других слов. Как происходит сбор вишни, если это действительно так, выходит за рамки данной статьи. Здесь мы просто утверждаем, что выполнение функции контроля над каждым словом кажется слишком трудоемким для беглой речи.
Второе предположение состоит в том, что выявленные нами затраты на мониторинг на самом деле вычитаются из наших возможностей выполнять другие компоненты производства — концептуализацию, лингвистическое кодирование и артикуляцию. Это предположение согласуется с утверждениями Levelt (1983) о том, что перцепционный мониторинг является «центральным корректирующим действием» и что само это свойство монитора «делает его предметом обычных ограничений рабочей памяти». Он подкрепляет свое утверждение эмпирическими доказательствами более высокого уровня обнаружения ошибок ближе к концу фраз, принимая это как доказательство того, что обнаружение ошибок конкурирует с производственными процессами, потребность которых в центральных ресурсах имеет тенденцию снижаться к концу разделов (Levelt, 1983). ).Есть также свидетельства в пользу того, что мониторинг является процессом, управляемым стратегией (Postma et al., 1990; Postma & Kolk, 1990, 1992, 1993). Например, Постма и Колк (1990) показали, что отношение нарушений к речевым ошибкам увеличивается, если подчеркивается точность, что является следствием того, что процесс носит стратегический характер и контролируется вниманием. Таким образом, есть основания ожидать, что мониторинг будет конкурировать с производством за ресурсы. Таким образом, ожидается, что большие временные затраты, которые, как мы утверждаем, связаны с мониторингом лексического статуса, серьезно снизят производительность других компонентов производственной системы (см.g., Ferreira & Pashler, 2002 для анализа того, какие компоненты производства могут быть подвержены «центральным узким местам»). Мы подчеркиваем, что для логики этого исследования важно то, что добавление мониторинга в производство обходится дорого. Такие затраты могут возникнуть из-за того, что мониторинг не может происходить одновременно с производственными процессами, то есть они происходят последовательно, или потому, что параллельное включение производства и мониторинга замедляет производство. Таким образом, хотя наши цифры концептуализировали мониторинг как «стадию» производственного процесса, мы не делаем допущения, что его нельзя проводить одновременно с производственными процессами в других частях высказывания.Мы берем на себя только расходы на это.
Третье предположение касается возможности того, что мониторинг может быть осуществим на этапе производства, который менее подвержен центральным узким местам, а именно артикуляции. Levelt (1989) и Hartsuiker and Kolk (2001) предполагают, что слова, которые уже были фонологически закодированы, могут храниться в буфере до их артикуляции. Если аспекты производства, требующие емкости, такие как фонологическое кодирование, происходят со скоростью, превышающей фактическое время, необходимое для озвучивания, будет некоторое «свободное время», доступное для мониторинга, когда производственная система буферизует несколько слов.Если длинная фраза завершила свое фонологическое кодирование и сохраняется в буфере, а артикуляция догоняет, редактор может проверить содержимое буфера. Хотя мы подчеркиваем, что время, возможно, лучше потратить на редактирование для правильности, чем для лексического статуса, вполне возможно, что достаточно времени будет накапливаться в длинных фразах, так что лексическое редактирование возможно, даже с учетом наших оценок того, насколько медленно происходит этот процесс. Однако есть основания сомневаться в том, что во время производства происходит значительная буферизация.Прежде всего, Левелт (1989) исследовал, нужна ли такая буферизация для генерации просодических и фонологических форм, и пришел к выводу, что системе нужно только «заглядывать вперед» к следующему слову в каждом высказывании, чтобы определить форму данного высказывания. слово. Второе свидетельство ограниченного прогнозирования — это анализ фонологических речевых ошибок. Гарретт (1975) показал, что звуковые обмены наиболее распространены в соседних словах или словах, разделенных только одним словом (обычно функциональным словом), с резким падением фонологического обмена в словах, разделенных двумя или более словами.Это открытие предполагает, что буферизация фонологических форм должна быть ограничена не более чем одним или двумя словами за раз.
Последнее, что нужно сделать — это точность редактора. В эксперименте 1, в котором особое внимание уделялось скорости и точности, наши испытуемые в состоянии лексического редактирования (Word) сделали 12% ошибок упущения и 3% ошибок комиссии. Затраты на мониторинг, которые мы определили, вероятно, зависят от этого уровня точности. Если бы мы позволили лексическому редактированию быть менее точным, скажем, обнаруживая только половину неслов, это можно было бы сделать быстрее.Таким образом, возможно более быстрое, но менее точное лексическое редактирование. Но опять же, мы бы поставили под сомнение ценность включения когнитивно требовательного редакционного процесса, который пропускает все ошибки в словах и улавливает только часть ошибок, не связанных со словами. Стоит ли оно того?
Мы действительно не первые, кто подчеркивает, что редактирование должно быть быстрым. Hartsuiker (2006) предположил, что быстрый мониторинг действительно имеет место, и указал на быстрое обнаружение в исследовании Motley, Camden, and Baars (1982). В этом исследовании измерялась эффективность мониторинга социальной уместности (табуированные слова), а не лексического статуса, и средняя задержка ответа составила 800 мс (от сигнала до начала речи) или 1800 мс (от предъявления стимула до начала речи), что является не совсем быстро для рутинной речи, учитывая рассмотренные выше предположения.Если оставить в стороне вопрос о том, является ли данное исследование быстрым или нет мониторингом табунизма, доказательства того, что такой мониторинг выполняется в этой задаче, тем не менее убедительны. Таким образом, хотя кажется, что процесс лексического редактирования занимает так много времени, другие формы мониторинга могут быть более эффективными. Как мы отмечали ранее, Hartsuiker и Kolk (2001) оценили время, необходимое для обнаружения ошибок в речи, не более 200 мс. Вероятно, что мониторинг в целях обнаружения и перехвата ошибок, а также исправления ошибок будет быстрым и эффективным, учитывая его очевидную полезность для связи.Однако, что более важно, мониторинг ошибок подразумевает сравнение между конкретным предполагаемым представлением (например, слова) и представлением, которое было создано для производства. Мониторинг лексического статуса не предполагает такого конкретного сравнения. Спикер просто пытается сказать, будет ли запланированная строка любым словом. В этой связи полезно отметить, что время реакции на лексическое решение составляет около 600 мс, в то время как время реакции при отслеживании слов (соответствует ли этот стимул заданному целевому слову?) Постоянно менее 400 мс (например.г., Фосс и Суинни, 1973). Таким образом, наблюдение за соответствием чего-либо конкретному намерению, вероятно, намного проще и определенно более полезно, чем наблюдение за лексическим статусом. Недавно Nooteboom и Quené (2008) подтвердили этот вывод, показав, что большинство речевых ошибок обнаруживаются на основе сравнения с предполагаемыми словами, а не их лексического статуса. Также вероятно, что мониторинг статуса табу (Motley et al., 1982) или эмоциональной валентности запланированных слов (Slevc & Ferriera, 2006) также является относительно быстрым.Табуны или эмоциональная напряженность могут быть обнаружены с помощью механизмов «натяжной проволоки». Например, если активация узла слова для слова-табу превышает пороговое значение, провод отключается, и требуется какое-то действие, например, остановка производства. Не-слова по определению не имеют конкретных представлений, поэтому путевой провод не может быть. Фактически, это может быть причиной того, что определение лексического статуса строки в стандартном лексическом решении более чем на 200 мс медленнее, чем определение того, что строка является конкретным словом.
Кроме того, относительно более короткие времена контроля в задачах лексического решения в наших экспериментах (143 и 158 мс для слов и 187 и 209 мс для неслов в задачах визуального и слухового лексического решения соответственно), показывают, что мы способны достаточно быстро выполнять лексические решения. мониторинг доступных стимулов с помощью техники нажатия кнопки. Ясно, что эта процедура заметно отличается от контроля лексического статуса в запланированной нами речи. Мы предложили два объяснения, чтобы объяснить разницу между затратами на мониторинг, наблюдаемыми в эксперименте 1, и временем принятия решения в задачах лексического решения.В нашей «гипотезе обеднения внутренней речи», в соответствии с выводами Уилдона и Левелта (1995), мы утверждали, что речевой мониторинг может иметь место на фонологическом уровне из-за гипотетического обедненного характера внутренней речи в отношении фонетических характеристик (Oppenheim & Dell, 2008 г.). Отсутствие некоторых функций (или ключей к лексичности) во внутренней речи, в отличие от фактического стимула, может быть причиной более длительного времени реакции при мониторинге запланированной речи (эксперимент 1) по сравнению с мониторингом доступных стимулов (канонические задачи лексического решения).В качестве второй возможности мы объяснили в нашей «гипотезе прерывания», как мы думаем о мониторинге как о нарушении нормальной обработки потенциального высказывания, после чего восстановление фонологического представления для кодирования в фонетическом плане займет некоторое время. Это не проблема для задач лексического решения, поскольку в этом случае мониторинг не происходит одновременно (и не прерывает) второй процесс, такой как создание языка.
Разница между словами и без слов, гибкость редактора и задача SLIP
В эксперименте 1 наблюдалась разница в 122 мс в пользу более быстрого производства, когда не слова, а не слова, должны быть отфильтрованы.Более того, как в эксперименте 1, так и в задаче лексического решения go / nogo наблюдалось предвзятое отношение к получению слов вместо неслов в ошибках комиссии (эксперимент 1: 16% слов, созданных в условии неслова, по сравнению с 3% неслов, произведенных в условии слова: лексическое решение задачи go / nogo: 12% vs. 5% соответственно). Эти данные имеют отношение к вопросу о гибкости редактора. С одной стороны, мы отмечаем, что участники действительно могут следовать инструкциям по созданию неслов и отфильтровывать слова.Когнитивная система в этом отношении гибка. Однако наш экспериментальный лексический редактор явно работает быстрее, когда критерий — «пропустить слова», а когда он ошибочно пропускает что-то, это чаще всего является словом. Обратите внимание, что любые присущие различия в скорости артикуляции и построения слов и неслов уже были зафиксированы в базовых условиях, и поэтому разница в 122 мс слов и неслов относится только к процессу мониторинга. Этот вывод предполагает, что если лексический редактор должен использоваться, он явно предпочитает отфильтровывать неслова, что действительно является общепринятой целью лексического редактора.
Как упоминалось ранее, гибкость лексического редактора была подтверждена исследованиями с использованием парадигмы SLIP, в которой соотношение словесных и несловесных целей варьировалось (Baars et al., 1975; Hartsuiker et al., 2005). В этих исследованиях эффект лексического смещения изменялся в зависимости от контекста. Точно так же Делл (1986; 1990) показал, что лексическая предвзятость была устранена, когда крайний срок в задаче SLIP был очень быстрым. Хотя Dell интерпретировал зависимость лексического смещения от крайнего срока с точки зрения времени, которое требуется для активации для распространения между фонематическим и лексическим уровнями, можно также приписать эти результаты гибкому лексическому редактору.Когда нет времени на редактирование, возможно, редактор закрывается. Обратите внимание, что есть два отдельных аспекта гибкости: возможность выключить или включить редактор и возможность изменить критерий от фильтрации, скажем, не слов до фильтрации слов. Оба аспекта гибкости освещены в Hartsuiker et al. (2005). Используя процедуру SLIP, Hartsuiker et al. не обнаружил эффекта лексической предвзятости в преимущественно несловесном контексте, в отличие от значимого в смешанном контексте.Они приписали это открытие гибкости редактора, который использует критерий нелексичности в несловесном контексте (отфильтровывает слова), но полностью отказывается от лексического редактирования для смешанного контекста, где лексический статус контекста не информативен. Таким образом, преобладание лексических ошибок на стадии формулировки (приписываемых интерактивной обратной связи) подавляется в несловесном контексте, но остается неизменным в смешанном контексте.
Наши результаты не расходятся с этими выводами.Фактически, наше исследование напоминает условие «смешанного контекста» Хартсуикера и др., В котором они действительно обнаружили больше лексических ошибок. Хотя мы не воспроизводили их несловесно-контекстное состояние (в котором не было обнаружено существенной разницы между лексическими и нелексическими ошибками), мы полагаем, что вывод не будет другим. Хотя отсутствие эффекта лексического смещения в чисто несловом контексте в эксперименте Хартсуикера и др. Предполагает некоторую гибкость редактора, степень гибкости недостаточно высока, чтобы опровергнуть результаты и произвести «нелексическое смещение». эффект».Итак, что касается гибкости редактора, мы рассматриваем наши результаты, а также результаты Hartsuiker et al., Как одобряющие ограниченную гибкость, если лексический редактор будет использоваться при создании речи.
Результаты Hartsuiker et al. (2005) и результаты другого недавнего исследования Nooteboom и Quené (2008) представляют собой сильнейшую поддержку утверждения о том, что, по крайней мере, компонент эффекта лексического смещения происходит из-за гибкого лексического редактора. Nooteboom и Quené, снова используя задачу SLIP, обнаружили различия в эффектах лексического смещения в ошибках обмена завершенными и прерванными фонемами (например,g., keep dot → deep cot, против keep dot → dee… keep dot, соответственно). Ошибки полного обмена показали нормальный эффект лексического смещения, но прерывистые ошибки показали эффект обратного лексического смещения для стимулов, в которых взаимодействующие согласные звуки были разными. Учитывая, что прерывание ошибки, вероятно, является результатом процесса мониторинга, различия во влиянии манипуляции результатом слова и несловесного результата на прерванные и завершенные ошибки позволяют предположить, что мониторинг лексического статуса имеет место.Nooteboom и Quené представили конкретную полиномиальную модель этого процесса и, как и Hartsuiker et al., Пришли к выводу, что мониторинг лексического статуса и автоматическая обратная связь вносят свой вклад в эффект лексического смещения. Важно отметить, что их обнаружение различий в эффекте лексического статуса исходов ошибок между прерванными и завершенными ошибками также присутствовало в исследовании естественных промахов (Nooteboom, 2004), и, следовательно, данные, поддерживающие лексическое редактирование, не ограничиваются Задача SLIP (хотя только экспериментальные данные дают хороший контроль над материалами).
Nooteboom и Quené также считают, что нагрузка на скорость важна для определения характера редактирования, которое может произойти в задаче SLIP. В частности, они утверждают, что есть некоторые свидетельства для мониторинга лексического статуса различий между завершенными и прерванными ошибками в условиях скоростного стресса. Здесь предполагается, что скоростное напряжение поощряет , а не препятствует предварительному редактированию, вызывая быстрые исправления. Мы считаем, что взаимодействие Nooteboom и Quené между лексическим статусом и тем, была ли ошибка прервана или нет, может быть связано с тенденцией к более знакомым двигательным паттернам (.например слова), чтобы его было меньше прерывать. То есть сказать слово более баллистично, чем сказать неслово. Баллистический процесс — это процесс, который после запуска должен завершиться. Следовательно, завершенные ошибки, как правило, будут словами, а прерванные — не словами. Обратите внимание, что это объяснение не предполагает мониторинга лексического статуса, только то, что существует некоторый вид мониторинга и последующий процесс прерывания, который более успешен, когда высказывание не является словом.Более того, открытие Ноотбума и Кене, что эта закономерность особенно проявлялась при стрессе от скорости, согласуется с нашим объяснением. Логан и Коуэн (1984) показывают, как на эффективность остановки выполнения основной задачи влияет время завершения задачи. Учитывая, что сигнал остановки может быть отправлен в артикулятор, как только будет обнаружена ошибка, вероятность прерывания увеличивается при сдвиге вправо распределения времени отклика (т. Е. Более длительном времени отклика).Чем короче задержки отклика (реагирование в сжатые сроки), тем менее успешным будет процесс торможения. Учитывая вышеизложенное обсуждение, результат слова и ударение времени способствуют баллистическому процессу артикуляции, поэтому ожидается, что эффект лексического смещения будет относительно более сильным в случае завершенных, а не прерванных ошибок.
Возможность лексического редактирования, встречающаяся в исследованиях Hartsuiker et al. (2005) и Nooteboom and Quené (2008) поднимают общий вопрос об условиях, при которых лексическое редактирование все еще возможно, учитывая наши результаты.Ясно, что если скорость речи очень низкая, должно быть время, чтобы отредактировать речь для лексического статуса. Однако, если есть время для редактирования лексического статуса, мы бы заявили, что есть время и для более полезного вида редактирования, чтобы проверить, действительно ли запланированное высказывание является целью. Как мы упоминали ранее, исследования показывают, что отслеживание вербального стимула для заранее заданного целевого слова происходит намного быстрее, чем принятие лексического решения в отношении этого стимула. Если да, то зачем редактировать лексический статус, если можно редактировать реальную вещь — цель?
Обеспокоенность нашей моделью лексического редактирования
Психолингвисты говорили о «лексическом редакторе» на протяжении десятилетий, но на сегодняшний день никто не предложил четкого механизма работы такого редактора.В качестве первого шага в разъяснении природы лексического редактора мы создали модель лексического редактирования, которая работает путем принятия лексического решения в отношении мысленно сконструированных стимулов. Мы предоставили доказательства того, что эта модель лексического редактирования, вероятно, слишком медленная и слишком неэффективная, чтобы ее можно было регулярно использовать при производстве речи. Конечно, может быть другой способ лексического редактирования, и этот другой способ может быть довольно быстрым и эффективным.
Мы не утверждаем, что наша модель обязательно соответствует представлениям других о лексическом редакторе, но мы утверждаем, что парадигма, использованная в эксперименте 1, хорошо подходила для нашей модели.Мы признаем, что эта парадигма не отражает всех аспектов нормального речевого образования. Ораторы подготавливают словоформы из значения, а не из слухового слога и визуального стимула. Тем не менее, мы утверждаем, что после того, как подготовленный слог собран, нет никаких оснований полагать, что производственный процесс должен быть каким-то другим. Действительно, многие производственные парадигмы, исследующие фонологическое кодирование (например, процедура SLIP), не включают извлечение слов из значения, либо неявно, либо явно делая допущение, что общие фонологические / фонетические / артикуляционные этапы производства вызываются, когда побуждение к высказыванию исходит от значение, и когда это от фонологического / орфографического ввода.Это совместное использование процессов кодирования словоформ в разных задачах подтверждается исследованиями дефицита продуктивности при афазии, как дефицита в воспроизведении смысла (например, именование изображений), так и в результате затенения слухового ввода (например, Dell, Martin & Schwartz, 2007).
Кроме того, разделение слогов на части считается естественным шагом в фонологическом кодировании (Dell, 1986; Shattuck-Hufnagel, 1987), и эти единицы, скорее всего, являются составными элементами начала и рифмы (Meyer, 1991). Это утверждение имеет особенно сильную поддержку в отношении составляющих начала слова, поскольку многие речевые ошибки связаны с этими частями (Shattuck-Hufnagel, 1987).Наша парадигма следует этому естественному разделению.
Хотя мы не можем с уверенностью обобщить результаты, полученные с помощью этой парадигмы, на рутинную речь, мы все же считаем ее лучшим выбором, чем другие, такие как парадигмы чтения (орфографическая обработка ввода) (см. Bock, 1996). Наши данные ясно показывают, что парадигма чтения с компонентом мониторинга (т. Е. Задача лексического решения go / nogo) сильно отличается от парадигмы производства речи, и поэтому ее результаты не должны восприниматься как отражающие реальные явления, происходящие в процессе производства речи.
Выводы: дань уважения бритве Оккама
Принцип экономии, бритва Оккама, является важным фактором для теорий языкового производства (Levelt et al., 1999). Лексический редактор скуп? Это так в двух отношениях. Во-первых, можно предположить, что он работает с использованием системы понимания, как это предлагается в теории перцептивного цикла мониторинга, поэтому нет необходимости дублировать механизмы, которые извлекают слова из речевого (или потенциального речевого) ввода. Во-вторых, нет сомнений в том, что мы следим за своей речью и запланированной речью, и, следовательно, общее понятие отслеживания того, что мы говорим, хорошо мотивировано.Однако здесь мы утверждали, что эти скупые аспекты лексического редактирования зашли так далеко. Функция системы лексического понимания не состоит в том, чтобы принимать лексическое решение; это распознавать слова. Хотя этот механизм понимания может поддерживать редактора, который реагирует на лексический статус, все же нужно предположить существование процесса лексического принятия решения, который обычно работает во время производства, чтобы объяснить лексическую предвзятость, и это предположение, следовательно, не является скупым. Кроме того, функции мониторинга, которые кажутся ясными и хорошо мотивированными десятилетиями исследований, не касаются мониторинга лексического статуса.Скорее, они включают мониторинг правильности, табуизма и других аспектов социальной целесообразности. Итак, опять же, хотя идея мониторинга хорошо мотивирована, мониторинг лексического статуса — нет. Принимая во внимание эти соображения, мы не считаем описание лексической предвзятости лексическим редактором особенно скупым.
Распространенные синтаксические ошибки SQL и способы их устранения
В SQL Server Management Studio ошибки можно легко отследить с помощью встроенной панели Error List .Эта панель может быть активирована в меню View или с помощью сочетаний клавиш Ctrl + \ и Ctrl + EПанель «Список ошибок» отображает синтаксические и семантические ошибки, обнаруженные в редакторе запросов. Чтобы перейти непосредственно к синтаксической ошибке SQL в редакторе сценариев, дважды щелкните соответствующую ошибку, отображаемую в Списке ошибок
.Ошибки ключевого слова SQL
Ошибки ключевых слов SQL возникают, когда одно из слов, которые язык запросов SQL резервирует для своих команд и предложений, написано с ошибкой.Например, если вы напишите «UPDTE» вместо «UPDATE», это приведет к ошибке
.В этом примере ключевое слово «ТАБЛИЦА» написано с ошибкой:
Как показано на изображении выше, выделено не только слово «TBLE», но и слова вокруг него. На изображении ниже показано, что эта простая ошибка приводит к выделению большого количества слов
.Фактически, всего 49 ошибок было зарегистрировано только из-за неправильного написания одного ключевого слова
Если пользователь хочет исправить все эти сообщенные ошибки, не найдя исходной, то, что начиналось как простая опечатка, становится гораздо большей проблемой
Также возможно, что все ключевые слова SQL написаны правильно, но их расположение не в правильном порядке.Например, инструкция «FROM Table_1 SELECT *» сообщит об ошибке синтаксиса SQL
.Порядок команд
Неправильное расположение ключевых слов обязательно вызовет ошибку, но неправильное расположение команд также может быть проблемой
Если пользователь, например, пытается создать новую схему в существующей базе данных, но сначала хочет проверить, существует ли уже схема с тем же именем, он напишет следующую команду
Однако, несмотря на то, что каждая команда написана правильно и может выполняться отдельно без ошибок, в этой форме возникает ошибка
.Как указано в сообщении об ошибке, команда CREATE SCHEMA должна быть первой заданной командой.Правильный способ выполнения этих команд вместе выглядит так:
В кавычках
Другая распространенная ошибка, возникающая при написании проекта SQL, — использование двойных кавычек вместо одиночных. Для разделения строк используются одинарные кавычки. Например, здесь используются двойные кавычки вместо одинарных, что вызывает ошибку
.Замена кавычек на правильные, устраняет ошибку
Бывают ситуации, когда необходимо использовать двойные кавычки для написания некоторых общих кавычек, например
Как показано в предыдущем примере, это вызовет ошибку.Но это не означает, что нельзя использовать двойные кавычки, они просто должны быть внутри одинарных кавычек. Однако добавление одинарных кавычек в этом примере не решит проблему, но вызовет еще одну
Поскольку внутри этой цитаты есть апостроф, он ошибочно используется как конец строки. Все остальное считается ошибкой
Чтобы иметь возможность использовать апостроф внутри строки, он должен быть «экранирован», чтобы он не считался разделителем строки.Чтобы «избежать» апострофа, необходимо использовать другой апостроф рядом с ним, как показано ниже
Поиск синтаксических ошибок SQL
Поиск синтаксических ошибок SQL может быть сложной задачей, но есть несколько советов, как сделать это немного проще.