Апдейт: что это такое, когда будет апдейт в Яндексе и что значит обновление выдачи
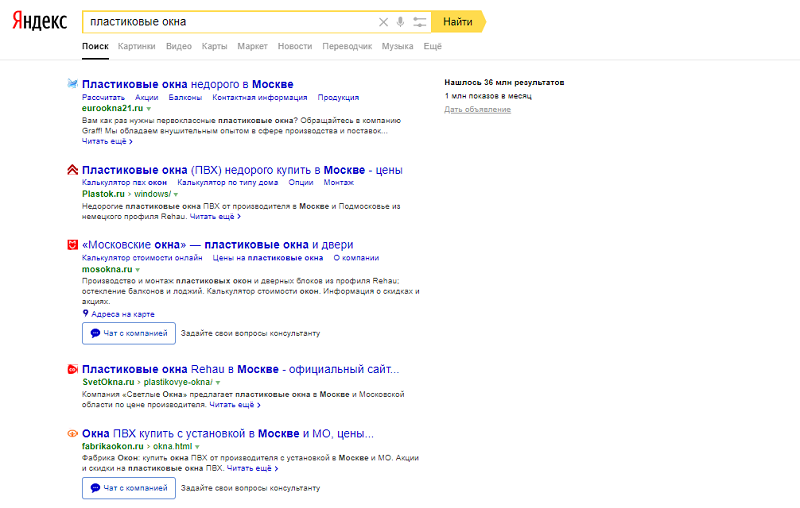
Апдейтом в SEO называют обновление результатов поиска. Мы расскажем, что нужно знать об этом владельцам сайтов и специалистам по продвижению. Какие бывают апдейты и когда они происходят. Что делать, если позиции резко упали. Где найти историю обновлений и многое другое.
Содержание статьи:
Что такое апдейт простыми словами?
Апдейт (или сокращенно «ап») – это обновление баз данных поисковых систем, которые используются для ранжирования, или самих алгоритмов – формул, по которым определяется степень релевантности документов тому или иному запросу.
Обычно апдейт сопровождается значительным изменением результатов поиска. Термин происходит от английского слова update, что означает «обновление» или «корректировка».
В зависимости от того, какая часть базы обновляется, выделяются разные виды апдейтов. Это необходимо знать, чтобы определять причины, по которым проект вырос или снизился по важным для вас запросам.
Как узнать, когда будет апдейт в Яндексе?
Посмотрите историю обновлений выдачи в календарях и анализаторах и примерную периодичность интересующего вас апа в таблице ниже. Так можно прикинуть, когда будет очередной текстовый, ссылочный или другой update.
Если готовится обновление формулы или новый алгоритм, то частота рядовых обновлений результатов поиска резко снижается. Например, перед серьезным релизом выдача может не меняться 2-3 недели. Все начинают беспокоиться, что готовит Яндекс или Google для вебмастеров, и это заметно по темам на форумах.
Виды апдейтов и как часто они проводятся
Поисковые системы хранят множество данных о сайтах, ведь для ранжирования используется от 200 до 800 параметров. Обновлять сразу всю базу слишком затратно и сложно, поэтому эту задачу разбивают на части.
Например, обновление информации о ссылках в Яндексе называется ссылочным апдейтом, и это порой целое событие для SEO-специалистов. Посмотрите ниже, какие еще типы апов выделяют:
Вид | Что обновляется | Периодичность (примерно) |
Текстовый | Информация о текстах на страницах сайтов. | От 1 до 3 раз в неделю. Новые документы могут добавляться в поиск в режиме реального времени. |
Ссылочный апдейт | Количество ссылок и их вес (общий и каждого донора в отдельности). | 1-2 раза в месяц. |
Поведенческих факторов | Данные о поведенческих факторах страниц, представленных в поиске. | Разная периодичность. Обычно 1 раз в месяц или немного чаще. |
Обновление классификаторов | Данные о классификации запросов. Например, какие-то запросы могут стать спектральными, а какие-то – перестать быть таковыми. | |
Обновление фильтров | Пороги наложения санкций за различные нарушения. Например, за чрезмерное использование ключевых слов в тексте. | По-разному, нет закономерности. |
Апдейт ИКС (индекс качества сайта) | Величина ИКС. | Примерно 1 раз в месяц. |
Картиночный ап | Обновление базы изображений и данных о них. | 1 раз в месяц. |
Обновление фавиконок | Добавляются новые фавиконки в выдачу или обновляются старые (если их меняли). | Примерно раз в квартал (каждые 3 месяца). |
Апдейт алгоритмов | Меняется формула ранжирования, иногда серьезно. Могут добавляться новые факторы, меняться вес старых и т.д. | Небольшие изменения идут постоянно, серьезные – обычно несколько раз в год. |
 Добавляются новые страницы в выдачу.
Добавляются новые страницы в выдачу.Выраженные апдейты сегодня чаще происходят в Яндексе. В Гугл изменения идут в режиме реального времени и имеют резкий характер только при обновлении алгоритмов. Например, при введении E-A-T факторов позиции YMYL сайтов сильно изменились.
В среднем апдейты идут от 3 часов до суток, реже – несколько дней. Ниже мы расскажем, что необходимо делать в это время.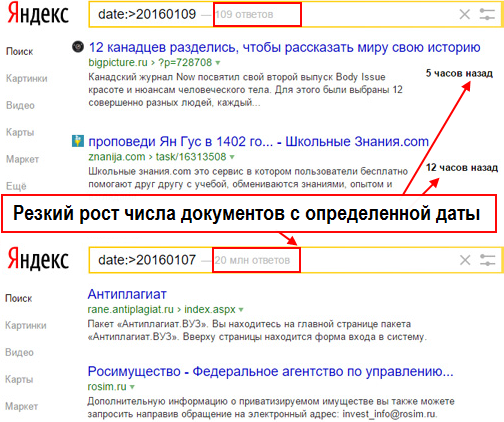
Совет. В сервисе Яндекс.Вебмастер можно подписаться на уведомления и получать письма на почту об обновлениях в результатах поиска и на контролируемых вами сайтах. Например, вы сможете узнать, сколько новых страниц попало в индекс, а сколько старых исключили. Это очень полезная функция, которой рекомендуем пользоваться.
Яндекс и Google: в чем разница между ними?
Яндекс | |
|
|
Почему во время апдейтов позиции сайта могут резко меняться?
Многих вебмастеров волнует этот вопрос. Буквально в течение 5 минут вебсайт может улетать из ТОП-10, а потом возвращаться в него без видимых причин. В выдачу порой попадают нерелевантные ресурсы, например, из других регионов и стран, с устаревшим дизайном, явно закрытые и устаревшие проекты и т.д.
Это называется «расколбас выдачи». Явление связано с тем, что обновление базы идет неравномерно, поэтому в поиске могут наблюдаться различные перекосы. Нередко в процессе апа сотрудники Яндекса или Google что-то докручивают, из-за чего мы наблюдаем указанные явления.
Во время обновлений результатов поиска не стоит проверять, на каком месте находится сайт и что-либо анализировать. Лучше этим заняться на следующий день, когда выдача успокоится, и вы сможете увидеть настоящие результаты.
Сервисы мониторинга и анализаторы апдейтов
Показывают, насколько сильными были изменения в выдаче, а также определяют тип апдейта (если это возможно). Пример письма, которое отправляет сервис Топвизор (для получения таких писем на нем нужно зарегистрироваться):
Рассмотрим подробно возможности популярных сайтов, где можно просматривать календарь апдейтов с историей изменений.
1. Топвизор
- Показывает дату апдейта, тип и силу (от 1 до 10 баллов).
- Есть календарь апдейтов на текущий месяц с данными по предыдущим обновлениям.
- Удобный и интуитивно понятный.
2. Апдейты Яндекса
- Анализатор от компании «Пиксель Плюс».
- Выводит много интересной информации, например, долю ответов с HTTPS, долю главных страниц в выдаче, средний возраст документов в ТОП-10, 20, 50 и 100, среднюю длину Title и URL.Это позволяет сравнить свои параметры с данными сайтов, которые хорошо ранжируются в поиске.

- Много графики и таблиц, что упрощает анализ.
- Есть архив апдейтов в Яндексе, начиная с 2015 года.
3. Pr-cy.ru
- Показывает апдейты выдачи и обновление ИКС.
- Простой и удобный.
- Есть история апов с 2006 года.
4. Tools.promosite.ru
- Указывает, за какое число выложен индекс при текстовом апдейте в Яндексе.
- Показывает степень изменения выдачи.
- Есть история обновлений, доступная здесь.
- Удобный и бесплатный сервис для мониторинга.
Что делать, если упали позиции после апа?
- Перепроверьте данные на следующий день. Возможно, вы сняли позиции во время апдейта, что делать не рекомендуется. Если через 24 часа сайт не вернется в ТОП, значит, нужно анализировать ситуацию.
- Посмотрите, какой апдейт был в Яндексе или Google. Возможно, выкатили новую формулу ранжирования или обновили фильтры. Тогда схожие проблемы будут у других вебмастеров. Посмотрите информацию на форуме СЕРЧ – там активно обсуждают каждое обновление в выдаче и пишут, у кого и что изменилось.
- Посмотрите новости на Seonews.ru. Там обычно пишут обо всех важных изменениях в поисковых системах.
- Если на вашем сайте есть страницы, у которых позиции выросли, сравните их с документами, которые стали ниже в выдаче. Возможно, вы найдете, что у них общего, а чем они отличаются, и сможете определить причину изменений.
- Если подозреваете, что сайт мог попасть под фильтры в Яндексе, то напишите в поддержку Вебмастера. Они могут помочь разобраться с ситуацией, если правильно сформулировать письмо.
10 сервисов для отслеживания апдейтов в поиске
Для владельцев сайтов и новичков
Если говорить о Яндексе, то сентябрь стал один из самых штормовых месяцев в 2020 году. Мало коронавируса, теперь еще Яндекс задумал глобальное обновление базы и запуск новшеств, которые сегодня стали причиной седины многих SEO-специалистов и владельцев сайтов.
Неожиданно из основной базы были исключены миллиарды страниц, что привело всех в ужас, а вместе с выпадением страниц в поиске началась акция «Снова в школу» и с середины августа сайты массово начали уходить под санкции за накрутку поведенческих факторов. Если бы не объявление в Вебмастере, то можно было бы долго гадать в чем причина происходящего.
Такие глобальные события все же происходят не часто, но позиции иногда резко «обваливаются», хотя причин вроде бы и нет. Тогда кажется, что произошел очередной апдейт.
Чтобы не вводить себя в заблуждения и быть уверенным наверняка в том, что это не технические проблемы или плохая оптимизация привели к подобным результатам, лучше всего воспользоваться сервисами, которые уже проанализировали происходящее и могут представить сводку по «шторму» в выдаче.
Перед тем, как приступить непосредственно к обзору инструментов, которые позволят быть в курсе изменений, тенденций и силы обновлений выдачи, попробуем разобраться что такое «апдейт». Какими они могут быть и как влияют на позиции сайта, а самое главное, какое значение имеют для SEO?
Какими они могут быть и как влияют на позиции сайта, а самое главное, какое значение имеют для SEO?
Что такое апдейт
Апдейт – обновление поисковой выдачи, то самое событие, которое довольно часто приводит к шторму и волнению специалистов, но об этом позднее.
Типы апдейтов
Важно помнить о том, что поисковые системы анализируют при ранжировании не только контент, но и то, как пользователи взаимодействуют с ним. Поведенческие факторы, ссылки, структура – все эти сущности анализируются и оказывают влияние на позиции.
Существует несколько видов апдейтов:
Задача поиска – предложить пользователю максимально релевантный контент по его запросу, поэтому обновление базы необходимо, чтобы новые документы попадали в индекс и могли быть найдены пользователями. Текстовый апдейт Яндекса происходит в среднем каждые 1–3 дня. Этот процесс может сказываться и на позициях сайта в поиске.
Этот процесс происходит реже – раз в 7–14 дней. Обновляются факторы, которые связаны с внутренними и внешними ссылками. Новые ссылки начинают учитываться, что влияет на ранжирование и изменение позиции в поисковой выдаче.
Обновляются факторы, которые связаны с внутренними и внешними ссылками. Новые ссылки начинают учитываться, что влияет на ранжирование и изменение позиции в поисковой выдаче.
- Поведенческих факторов
Поведение пользователей – один из наиболее важных показателей, по которым поисковые роботы определяют качество страниц. Системы фиксируют действия посетителей, чтобы улучшить выдачу.
Обновление может быть небольшим и происходить незаметно – в таком случае SEO-специалисты относят его к микро-апдейтам. Это помогает вебмастерам отслеживать результаты улучшения юзабилити или других работ по оптимизации сайта. Глобальные изменения происходят редко – один раз в 3–8 месяцев.
- Статистических данных
Пересчет статистических данных, которые могут значительно изменить картину первой страницы выдачи, происходит редко. Обновление затрагивает такие факторы как HostRank, BrowseRank и другие. Этот процесс происходит примерно раз в 2–6 месяцев.
- Классификационный
У каждого сайта есть свои специфические характеристики. География, язык, тип контента, прочее. Исходя из этих параметров, поисковые системы разбивают сайты и запросы по группам.
- Санкций / Фильтров
Самое важное обновление для тех, кто попал под санкции поисковиков, из-за чего сайт не может восстановить позиции в выдаче. Фильтры представляют собой ограничительные системы, которые не пропускают документы в ТОП при нарушении правил.
Накрутка поведенческих факторов, покупка ссылок, переизбыток поисковых запросов в текстах – все это может привести к тому, что страницы начнут понижаться в выдаче. При устранении проблем, некоторые санкции снимаются только в следующий «апдейт фильтров».
Как и зачем отслеживать апдейты
Чтобы обеспечить стабильный рост в поиске, необходимо постоянно мониторить обновления и динамику позиций. Результаты позволяют анализировать эффективность продвижения.
Для мониторинга можно использовать несколько инструментов, чтобы получать более точную информацию. Большинство сервисов бесплатные. Каждый имеет собственный алгоритм отслеживания, поэтому в результате можно получить объективную картину.
Сервисы, которые стоит использовать для контроля апдейтов
Поисковые системы нередко анонсируют масштабные обновления. Например, чтобы отслеживать точные текстовые апдейты Яндекса, в панели для вебмастеров можно настроить автоматическую отправку уведомлений.
Важный нюанс: анонсируются только текстовые апдейты, все остальные происходят без уведомления. Поэтому, необходимо самостоятельно отслеживать силу шторма и изменений позиций сайтов в выдаче по широкому пулу запросов. В этом помогают автоматизированные сервисы.
Топвизор
Инструмент помогает отслеживать степень изменения выдачи по регионам и делает срез каждые 3 часа. Сервис выставляет оценку, анализируя, насколько «штормит» выдачу. Данные отображаются в виде визуальных диаграмм, а также списка сфер, в которых ожидаются изменения и нестабильность позиций.
Данные отображаются в виде визуальных диаграмм, а также списка сфер, в которых ожидаются изменения и нестабильность позиций.
Довольно удобный сервис, который позволяет быстро понять, какие из продвигаемых проектов сейчас находятся в зоне риска и каким стоит уделить внимание, проследить за динамикой в течение периода активного «шторма».
Пиксель Тулс
Один из наиболее точных сервисов, который фиксирует число документов в базе Яндекса по датам. Для детального анализа можно использовать фильтры, чтобы задать сегмент по тематике, популярности запросов, геозависимости, типу ресурса и т. д.
Здесь можно найти графики и диаграммы с:
- процентом главных страниц в выдаче;
- распределением по доменным зонам в топе;
- долей ресурсов с HTTPS;
- средним размером страницы;
- длиной title, мета-тегов и т.д.
Эти данные помогут скорректировать стратегию, проанализировать вектор изменений, чтобы понять с какими именно характеристиками сайты вышли в ТОП.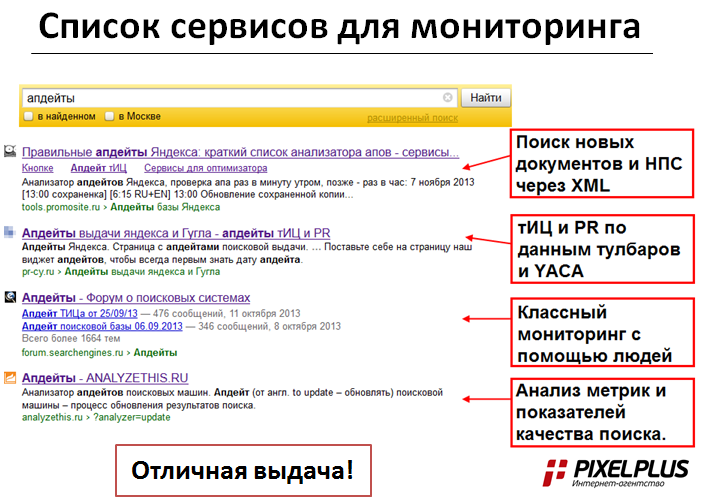 Чем больше данных, тем лучше понимание сути дальнейших действий.
Чем больше данных, тем лучше понимание сути дальнейших действий.
PR-CY
Простой инструмент с календарем по изменениям разных типов: апдейт выдачи, ИКС и PageRank (ребята оставили его, хотя он не обновлялся с 2013 года). Сервис предлагает установку виджета, по которому можно быстрее отслеживать обновления.
SEOBudget
Помимо фиксации прошедших обновлений, сервис прогнозирует даты будущих на базе имеющейся статистики. На сетке отображаются изменения ИКС, выдачи и другие типы апдейтов. Такие прогнозы способны помочь в планировании обновлений на сайте, доработок. В противном случае объективно оценить результат работ будет сложно.
Tools Promosite
Этот онлайн-сервис формирует графики для анализа изменений. В нем не учитывается поисковая выдача Google: алгоритм работает только с базой Яндекса. Здесь собраны текстовые и ссылочные обновления, а также информация по ИКС, сохраненным копиям и изменениям алгоритмов.
SEO-auditor
Все изменения в алгоритмах Яндекса и Google авторы этого проекта отмечают в календаре. А еще они занимаются прогнозами и также фиксируют их в графике изменений. Как правило, прогнозируемы следующие апдейты: текстовые и ссылочные. Следить за изменениями разработчики предлагают с помощью email-рассылки.
Seolik
Простой сервис для отслеживания апдейтов. Работает только с Яндексом. Для анализа доступны два показателя – ИКС и поисковая выдача. Информация разбита по датам.
Megaindex
Довольно популярный сервис фиксирует изменения в поисковой выдаче Яндекса и Google. Информация представлена в процентном соотношении – сравниваются текущие показатели с прошлыми.
Клик по процентам позволит получить более подробный отчет по апдейтам и изменениям поисковой выдачи. Запросы можно сортировать на коммерческие, некоммерческе, геозависимые и геонезависимые. А если кликнуть на запрос, появится таблица с изменениями позиций в выдаче для доменов из ТОП-100.
Analizsaita
Еще один простой сервис, где в процентах показывают изменения выдачи Яндекса, а также апдейты PageRank. Слева над таблицей указан параметр шторма. Он определяет, насколько сильно «штормит» выдачу (оптимально – 10–30%).
Также сервис позволяет получать данные об апдейте текстовых факторов.
Analyzethis
Сервис анализирует ТОП-10 выдачи Яндекса и Google по 140 запросам, а потом сравнивает текущие результаты с теми, что были днем ранее. Для наглядности инструмент использует индексы, которые рассчитывает по собственной формуле. Также он может отслеживать видимость сайтов, на которых отразился очередной апдейт, и в целом изменения в выдаче.
Сервис показывает результат в виде графика и таблицы.
Заключение
Поисковые системы постоянно работают над улучшением выдачи. Их главная цель – давать пользователям ответы на запросы, которые способны их удовлетворить. SEO-специалист может повлиять на ситуацию, постоянно совершенствуя продвигаемый ресурс, опережая события и готовясь к предстоящим изменениям, но вслепую это делать тоже невозможно. Для эффективной работы нужно ориентироваться не только на интерес пользователей к сайту, но и на изменение баз, алгоритмов.
SEO-специалист может повлиять на ситуацию, постоянно совершенствуя продвигаемый ресурс, опережая события и готовясь к предстоящим изменениям, но вслепую это делать тоже невозможно. Для эффективной работы нужно ориентироваться не только на интерес пользователей к сайту, но и на изменение баз, алгоритмов.
Тем, кто еще не знаком с представленными выше сервисами, лучше попробовать сразу все и выбрать тот, который окажется наиболее информативным и удобным. Такой опыт позволит найти верное решение в период штормов и иметь под рукой нужный инструмент, позволяющий без лишних сложностей понять причины нестабильности и провала позиций.
Апдейты поисковых систем Яндекс и Google / Арктическая Лаборатория
Апдейтом поисковой системы называется изменение алгоритмов ранжирования сайтов в ее выдаче, а также включение в индекс новой информации. Внешне любой апдейт проявляется через изменение позиций различных ресурсов в выдаче, то есть отдельные сайты могут опуститься или подняться в зависимости от их соответствия новым алгоритмам. Поскольку именно по результатам такого обновления оценивается эффективность продвижения ресурса, то огромное значение приобретает знание видов апдейтов, их частоты, понимание их назначения.
Поскольку именно по результатам такого обновления оценивается эффективность продвижения ресурса, то огромное значение приобретает знание видов апдейтов, их частоты, понимание их назначения.
Виды апдейтов наиболее популярных поисковых систем
Поисковая система Яндекс отличается следующими видами апдейтов:
1. Апдейт выдачи Яндекса — изменение позиций сайтов, обусловленное получением новой информации, которую поисковый робот собрал с момента прошлого апдейта, а также обновлением алгоритмов ранжирования.
2. Текстовый апдейт Яндекса — появление в индексе поисковой системы новых документов, которые поисковый робот посетил некоторые время назад. Кроме того, при текстовом апдейте учитываются произведенные на сайте технические изменения, обновляется выдача Яндекса, поскольку в нее включаются новые документы.
3. Ссылочный апдейт Яндекса — появление в индексе новых ссылок, пересчет веса ранее проиндексированных ссылок.
4. Апдейт ТИЦ Яндекса — обновление значения тематического индекса цитирования ресурсов, которое происходит в связи с изменением количества ссылающихся на ресурс сайтов, изменением веса ранее учтенных ссылок.
Поисковая система Google имеет всего два вида апдейтов:
1. Апдейт выдачи Google — обновление гораздо масштабнее, чем апдейт выдачи Яндекса, поскольку в процессе этого апдейта не только изменяются позиции сайтов в выдаче поисковой системы, но и индексируются новые документы и ссылки, учитываются произведенные владельцами ресурсов изменения.
2. Апдейт Page Rank Google — заключается в обновлении значения Page Rank, которое показывает авторитетность каждой отдельной страницы. В процессе этого обновления учитываются количественные и качественные показатели ссылок, имеющихся на страницу, поскольку именно они оказывают влияние на значение Page Rank.
Частота апдейтов поисковых систем
Частота апдейтов поисковых систем различна, зависит от алгоритмов самой поисковой системы и вида апдейта. В частности апдейты Яндекса происходят со следующей периодичностью:
1. Апдейт выдачи Яндекса происходит, как правило, 1-2 раза в неделю, чаще всего совпадая с текстовыми и ссылочными обновлениями. Иногда выдача обновляется самостоятельно, то есть без изменения текстового и ссылочного индекса.
Иногда выдача обновляется самостоятельно, то есть без изменения текстового и ссылочного индекса.
2. Текстовый апдейт Яндекса также обычно происходит 1-2 раза в неделю, всегда сопровождается изменением выдачи, поскольку происходит включение новых документов.
3. Ссылочный апдейт Яндекса происходит с той же периодичностью, что и текстовый, данные обновления всегда совпадают, но ссылочный апдейт обычно фиксируется позже текстового на 2-3 часа.
4. Апдейт ТИЦ Яндекса в среднем происходит один раз в два месяца, хотя точного значения периодичности не существует.
Частота апдейтов поисковой системы Google существенно отличается:
1. Апдейт выдачи Google происходит часто, позиции могут изменяться несколько раз в день, новые страницы также индексируются с высокой скоростью.
2. Апдейт Page Rank Google происходит один раз в 3-4 месяца, но пересчет необходимых параметров поисковая система ведет постоянно, выдавая во время апдейта итоговое значение.
Отслеживание апдейтов поисковых систем
Традиционно наибольший интерес оптимизаторами проявляется к отслеживанию апдейтов поисковой системы Яндекс. Причина заключается не только в большей популярности Яндекса в российском сегменте Интернета, но и в том, что изменения выдачи Google происходят постоянно, поэтому сам момент обновления выделить почти невозможно, достаточно ежедневного мониторинга следствия апдейта, выраженного в изменении позиций. Апдейты Page Rank Googleпроисходят достаточно редко, поэтому не имеет смысла отслеживать данное значение систематически.
При этом существует два основных способа отслеживания апдейтов Яндекса:
1. Подписка на рассылку самого Яндекса, который будет уведомлять вебмастера о наличии апдейта сообщением на электронную почту. Преимуществом данного способа является его абсолютная достоверность, а недостатком — поздний срок уведомления, поскольку указанное сообщение обычно приходит через некоторое время после полного завершения обновления.
2. Использование специализированных сервисов, которые отслеживают различные виды апдейтов Яндекса. Работа таких сервисов обычно основывается на мониторинге позиций в выдаче, тестового и ссылочного индекса, значения ТИЦнекоторой выборки ресурсов. Если происходит изменение какого-либо параметра достаточное для того, чтобы сделать вывод о наличии апдейта соответствующего вида, то появляется сообщение об этом. Некоторые из подобных сайтов также предлагают подписаться на рассылку сообщений об апдейтах по почте или посредством смс-сообщений. Их преимуществом является оперативность, но в работе некоторых из них происходят ошибки, выраженные в ложных уведомлениях.
Шторм в Яндексе: что изменилось в ноябре?
Digital-агентство AMDG составило рейтинг видимости белорусских брендов в поисковых системах. Шторм выдачи Яндекса продолжается – очередной его жертвой стало лидерство Imarket.by. Сперва многие вебмастера СНГ, а потом и сам Яндекс отметили, что произошло самое большое обновление в поиске за 10 лет.
Речь идет о новой технологии, которая анализирует текст на основе нейросетей-трансформеров YATI. С её помощью, как утверждает Яндекс, поиск научился лучше оценивать смысловую связь между запросами пользователей и содержанием документа.
Банки
Состав ТОП-10 не претерпел изменений с октября, но внутри произошли важные перестановки. БПС-Сбербанк прибавил пять позиций в таблице благодаря росту видимости на 3,66%.
По большинству банков отмечается снижение видимости с сохранением участия в ТОП-10: Альфа-Банк переместился на восьмое место (-3) , Технобанк – на седьмое (-1), а Банк Дабрабыт – на десятое (-2).
Финансовые порталы
Строчки ТОП 1–6 закрепились за Myfin.by, Finance.tut.by, Bankibel.by, Benefit.by, Creditportal.by, Infobank.by, которые на протяжении полугода занимают эти позиции.
Bankchart.by вынужден покинуть ТОП-10 (12-е место в ноябре) из-за снижения видимости и прироста Belfin. by (+5,77%).
by (+5,77%).
Площадки по продаже авто
Потеряв 7% видимости, Atlantm.by смещается на 11-ю строку. Это позволяет Renault.by попасть в таблицу лидеров после отсутствия с января 2020 года. Сайт на протяжении года сохраняет видимость в рамках 6%, сосредотачивая SEO-усилия на брендовых запросах “рено” и “renault” в Яндексе и Google.
Недвижимость
Realt.by вырвался на первую строку таблицы, обогнав Domovita.by. Лидер в этой категории сменился впервые с начала анализа в феврале 2020 года.
Flatfy.by демонстрирует внушительный рост на 12,6%. Причина тому – рост позиций по частотным запросам в Яндексе.
Бытовая техника
21vek.by надежнее закрепляется в лидерах: его видимость перешагнула за отметку 90%.
Imarket.by теряет 7% видимости, но это незначительно сказывается на его положении в рейтинге (-1 строка).
Amd. by не удержался в десятке – перемещение с 8-й на 17-ю строку. Новая волна обновлений в Яндексе в начале ноября привела к снижению позиций сайта и в этой категории. Такая же участь постигла Holodilnik.by (13-я позиция) – на его прежнем месте в ТОП-10 теперь Atlant.by.
После долгого отсутствия (с мая 2020 года) Gefest.by вернулся на 10-е место в категории.
Электроника
5element.by прибавил в видимости (+6,1%) и обогнал 21vek.by, заняв первое место.
Sila.by и 7745.by закрепляют свои позиции в ТОП-5.
Нижняя часть таблицы (ТОП 6–10) остается без изменений с прошлого месяца.
Туризм
В категории происходят кардинальные перестановки. Teztour.by и Softour.by вернулись на прежние позиции (1-е и 2-е места), а лидер октября Peopletravel.by возвращается к показателям сентября (-16,1%) после резкого, но однократного взлета.
Появление новичков всколыхнуло ТОП-10. Poehalisnami. by поднимается с 14-й на 3-ю строку, прибавив рекордные 24,25%. Хорошую динамику показывает и Turcenter.by (+10,68%), что позволило прыгнуть c 31-й на 10-ю позицию. В обоих случаях отмечен рост по популярным и частотным запросам в Яндексе.
by поднимается с 14-й на 3-ю строку, прибавив рекордные 24,25%. Хорошую динамику показывает и Turcenter.by (+10,68%), что позволило прыгнуть c 31-й на 10-ю позицию. В обоих случаях отмечен рост по популярным и частотным запросам в Яндексе.
Прежние участники первой десятки Belturizm.by и Goldtravel.by вынуждены сместиться на 11-е и 12-е места.
Сантехника
В категории наблюдается рост частотности по популярным запросам, что не может не радовать лидеров категории.
В ТОП-10 тем не менее наблюдаются и серьезные изменения. Потеря 11% у Sanit.by привела к его перемещению на строку вниз – 5-я позиция.
Imarket.by выпал из ТОП-10 (с 9-й на 12-ю позицию) из-за потери видимости на 5,53%. Его место занял Mile.by: прирост на 4,4% и обмен местами с Imarket.by.
Садовая техника
Imarket.by и в этой категории теряет видимость и перемещается на 13-ю позицию. Свободное место в лидерах занимает 5element.by, который, набрав обороты, вернулся в ТОП-10 на 9-ю строку (11,39%).
Свободное место в лидерах занимает 5element.by, который, набрав обороты, вернулся в ТОП-10 на 9-ю строку (11,39%).
Мобильные телефоны
21vek.by вернул лидерство.
Потеря 5% видимости привела X-store.by на 12-ю строку (-4 позиции). За пределы десятки (на 14-ю строку) вынужден спуститься и Imarket.by – с традиционной в ноябре потерей видимости по категории в среднем на 5%.
Новый участник I-telefon.by, представленный только телефонами марки Apple, прежде ни разу не был замечен в лидерской таблице. Рост видимости по высокочастотным запросам в Яндексе обеспечил ему 9-е место.
Мебель
В тематике отмечается рост спроса на мебель.
Mismebel.by переместился с 16-й на 8-ю позицию благодаря росту видимости на 5,08% – это первое попадание сайта в лидерскую десятку.
Superstore.by вернулся на 10-ю позицию, прибавив в видимости на 0,5%.
Прежние участники ТОП-10 Divan. by и Mersi.by выпадают во вторую десятку.
by и Mersi.by выпадают во вторую десятку.
Об исследовании
Видимость сайта ― это метрика, отражающая долю показов, которую получил ресурс в поисковой выдаче по конкретной тематике. На данный момент анализ этого показателя ― наиболее оптимальный способ отслеживания результатов продвижения.
Более подробно ознакомиться с методологией исследований, а также со статистикой видимости сайтов за другие месяцы можно здесь.
Если вы полагаете, что ваша компания необоснованно не включена в рейтинг или не занимает надлежащее место, пожалуйста, свяжитесь с составителями по адресу [email protected].
Что это апдейт? Апдейт простыми словами.
Апдейт (update) – это периодическое обновление результатов поисковой выдачи поисковыми системами. В результате апдейта возможно изменение позиций сайта в выдаче по определенным запросам, а также попадание в выдачу новых страниц либо обновленного содержимого.
Позиции сайта в выдаче могут изменяться после очередного апдейта в результате изменения алгоритмов ранжирования, введения новых алгоритмов, а также под влиянием конкурентов. Наиболее распространенными поисковыми системами, с которыми работает оптимизатор, являются Яндекс и Google. И для того, чтобы предотвратить резкий обвал позиций, следует помнить, в какие периоды это происходит. Яндекс производит апдейты с частотой 1-2 раза в неделю, тогда как Google осуществляет обновления динамично, до нескольких раз в течение одного дня.
Существует несколько видов апдейтов:
- Текстовый апдейт – учитываются внутренние изменения, которые были найдены поисковым роботом в интернете.
- Ссылочный апдейт – обновление ссылок.
- Апдейт Тиц – учитываются ПС Яндекс все внешние ссылки. На основе их количества и качества сайту присваивается тематический индекс цитирования.
-
Апдейт PR. Все, то же самое что и в предыдущем случае, только сайту присваивается PR Гуглом и каждой странице отдельно.
- Обновление Яндекс Каталога – обновление базы Яндекс Каталога.
- Апдейт поведенческих факторов учитывает то, как ведет себя пользователь на Вашем сайте.
- Обновление поисковой базы картинок.
- Апдейт зеркальщика – смена главного зеркала сайта.
- Апдейт фавиконов. Если Вы загрузили фавикон, то он появится только после апдейта.
- Обновление поискового алгоритма.
 Все, то же самое что и в предыдущем случае, только сайту присваивается PR Гуглом и каждой странице отдельно.
Все, то же самое что и в предыдущем случае, только сайту присваивается PR Гуглом и каждой странице отдельно.Существует много сервисов отслеживания обновлений поисковой выдачи. Например, seobudget.ru, который показывает когда был апдейт и его вид, а так же примерное время следующего обновления:
При продвижении сайта важно успевать вносить изменения между апдейтами, чтобы они вступили в силу как можно быстрее и дали положительный результат.
Услуги, связанные с термином:
Как будет работать поиск в 2021? YATI – новый алгоритм ранжирования Яндекс — SEO на vc.ru
В конце минувшего года Яндекс запустил новый алгоритм поискового ранжирования YATI, действие которого основано на нейросетях-трансформерах. Эта нейросетевая архитектура опирается на смысловую составляющую, обеспечивая совершенно новый подход, который устанавливает наилучшее семантическое единение между намерением пользователя, запросом и документом.
{«id»:197309,»url»:»https:\/\/vc.ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks»,»title»:»\u041a\u0430\u043a \u0431\u0443\u0434\u0435\u0442 \u0440\u0430\u0431\u043e\u0442\u0430\u0442\u044c \u043f\u043e\u0438\u0441\u043a \u0432 2021? YATI \u2013 \u043d\u043e\u0432\u044b\u0439 \u0430\u043b\u0433\u043e\u0440\u0438\u0442\u043c \u0440\u0430\u043d\u0436\u0438\u0440\u043e\u0432\u0430\u043d\u0438\u044f \u042f\u043d\u0434\u0435\u043a\u0441″,»services»:{«facebook»:{«url»:»https:\/\/www. facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks&title=\u041a\u0430\u043a \u0431\u0443\u0434\u0435\u0442 \u0440\u0430\u0431\u043e\u0442\u0430\u0442\u044c \u043f\u043e\u0438\u0441\u043a \u0432 2021? YATI \u2013 \u043d\u043e\u0432\u044b\u0439 \u0430\u043b\u0433\u043e\u0440\u0438\u0442\u043c \u0440\u0430\u043d\u0436\u0438\u0440\u043e\u0432\u0430\u043d\u0438\u044f \u042f\u043d\u0434\u0435\u043a\u0441″,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks&text=\u041a\u0430\u043a \u0431\u0443\u0434\u0435\u0442 \u0440\u0430\u0431\u043e\u0442\u0430\u0442\u044c \u043f\u043e\u0438\u0441\u043a \u0432 2021? YATI \u2013 \u043d\u043e\u0432\u044b\u0439 \u0430\u043b\u0433\u043e\u0440\u0438\u0442\u043c \u0440\u0430\u043d\u0436\u0438\u0440\u043e\u0432\u0430\u043d\u0438\u044f \u042f\u043d\u0434\u0435\u043a\u0441″,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.
facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks&title=\u041a\u0430\u043a \u0431\u0443\u0434\u0435\u0442 \u0440\u0430\u0431\u043e\u0442\u0430\u0442\u044c \u043f\u043e\u0438\u0441\u043a \u0432 2021? YATI \u2013 \u043d\u043e\u0432\u044b\u0439 \u0430\u043b\u0433\u043e\u0440\u0438\u0442\u043c \u0440\u0430\u043d\u0436\u0438\u0440\u043e\u0432\u0430\u043d\u0438\u044f \u042f\u043d\u0434\u0435\u043a\u0441″,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks&text=\u041a\u0430\u043a \u0431\u0443\u0434\u0435\u0442 \u0440\u0430\u0431\u043e\u0442\u0430\u0442\u044c \u043f\u043e\u0438\u0441\u043a \u0432 2021? YATI \u2013 \u043d\u043e\u0432\u044b\u0439 \u0430\u043b\u0433\u043e\u0440\u0438\u0442\u043c \u0440\u0430\u043d\u0436\u0438\u0440\u043e\u0432\u0430\u043d\u0438\u044f \u042f\u043d\u0434\u0435\u043a\u0441″,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc. ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks&text=\u041a\u0430\u043a \u0431\u0443\u0434\u0435\u0442 \u0440\u0430\u0431\u043e\u0442\u0430\u0442\u044c \u043f\u043e\u0438\u0441\u043a \u0432 2021? YATI \u2013 \u043d\u043e\u0432\u044b\u0439 \u0430\u043b\u0433\u043e\u0440\u0438\u0442\u043c \u0440\u0430\u043d\u0436\u0438\u0440\u043e\u0432\u0430\u043d\u0438\u044f \u042f\u043d\u0434\u0435\u043a\u0441″,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041a\u0430\u043a \u0431\u0443\u0434\u0435\u0442 \u0440\u0430\u0431\u043e\u0442\u0430\u0442\u044c \u043f\u043e\u0438\u0441\u043a \u0432 2021? YATI \u2013 \u043d\u043e\u0432\u044b\u0439 \u0430\u043b\u0433\u043e\u0440\u0438\u0442\u043c \u0440\u0430\u043d\u0436\u0438\u0440\u043e\u0432\u0430\u043d\u0438\u044f \u042f\u043d\u0434\u0435\u043a\u0441&body=https:\/\/vc. ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks&text=\u041a\u0430\u043a \u0431\u0443\u0434\u0435\u0442 \u0440\u0430\u0431\u043e\u0442\u0430\u0442\u044c \u043f\u043e\u0438\u0441\u043a \u0432 2021? YATI \u2013 \u043d\u043e\u0432\u044b\u0439 \u0430\u043b\u0433\u043e\u0440\u0438\u0442\u043c \u0440\u0430\u043d\u0436\u0438\u0440\u043e\u0432\u0430\u043d\u0438\u044f \u042f\u043d\u0434\u0435\u043a\u0441″,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041a\u0430\u043a \u0431\u0443\u0434\u0435\u0442 \u0440\u0430\u0431\u043e\u0442\u0430\u0442\u044c \u043f\u043e\u0438\u0441\u043a \u0432 2021? YATI \u2013 \u043d\u043e\u0432\u044b\u0439 \u0430\u043b\u0433\u043e\u0440\u0438\u0442\u043c \u0440\u0430\u043d\u0436\u0438\u0440\u043e\u0432\u0430\u043d\u0438\u044f \u042f\u043d\u0434\u0435\u043a\u0441&body=https:\/\/vc. ru\/seo\/197309-kak-budet-rabotat-poisk-v-2021-yati-novyy-algoritm-ranzhirovaniya-yandeks»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
3674 просмотров
YATI (Yet Another Transformer with Improvements) в переводе означает «Ещё один трансформер с улучшениями»
По заверениям специалистов по машинному обучению в Яндекс – внедрение YATI рекордным образом улучшило ранжирование и стало наиболее значимым событием для отечественного поисковика за последние 10 лет, со времен внедрения Матрикснета.
Совместный эффект Палеха и Королёва оказали меньшее влияние на поиск, чем новая модель на трансформерах. Вместе с тем, следует понимать, что нейросети не отменяют тысячи ранее заложенных правил в общую поисковою формулу. Однако значимость YATI ярко прослеживается в факте, свидетельствующем о том, что если убрать из общей формулы все прочие факторы и оставить только новую модель, то качество ранжирования, как заявил руководитель группы нейросетевых технологий в поиске Яндекс Александр Готманов, по основной офлайн-метрике упадёт лишь на 4-5%.
Как было раньше?
Система поиска всегда определяла релевантность выдачи путем сопоставления множества разнообразных факторов, намекающих на семантическую связь между поисковым запросом и материалом, изложенном на отдельной веб-странице. То есть, в упрощенном представлении, если статья и запрос имели множество одинаковых слов, то роботом данная страница воспринималась наиболее приоритетной. Разумеется, учитывался и расчет количества фраз, объем материала, поведенческие факторы, поисковая история пользователей и многое другое, но робот при этом никогда не понимал сути документа.
То есть, в упрощенном представлении, если статья и запрос имели множество одинаковых слов, то роботом данная страница воспринималась наиболее приоритетной. Разумеется, учитывался и расчет количества фраз, объем материала, поведенческие факторы, поисковая история пользователей и многое другое, но робот при этом никогда не понимал сути документа.
Алгоритмы Яндекс на 2015 год
Так происходило вплоть до 2016 года, пока не появились такие алгоритмы как Палех и Королев. Тогда Яндекс впервые публично заявил о применении нейросетей, обозначив, меж тем, что дальнейшее развитие поиска им видится в том, чтобы в финале получить модель, которая сможет всякий раз понимать любые запросы на уровне, сопоставимом с человеческим. Технология YATI являет собой еще один значительный шаг к этому, а Палех и Королев являлись важнейшими вехами развития поиска на пути к YATI.
Палех
Палех обеспечил возможность понимания сложных запросов пользователей. То есть поиск стал проводиться не строго по словам, которые написал пользователь, но также по смыслу запроса и заголовка страницы. Так, Яндекс научился находить требуемые ответы даже при отсутствии ключевых слов.
Выдача при Палехе стала формироваться по смыслу, а не по точным вхождениям
С этого момента точное вхождение ключевых запросов стало менее значимым фактором при ранжировании и акцент при SEO-продвижении стал смещаться в сторону смысловой и технической уникальности текста, мотивируя к созданию более полезного и содержательного контента.
Королев
Более совершенной вариацией Палеха стал Королев. Он еще лучше научился обрабатывать сложные и многозначные запросы, ориентируясь при этом не только на сопоставление заголовков, но и на содержимое страницы в целом. Алгоритм также стал учитывать поисковую статистику, мнение ассесоров и толокеров, а также оценки самих пользователей.
Например, пользователь вводит запрос «фильм, в котором нельзя шуметь». В этом случае Яндекс сразу выведет название фильма, при этом ключевых фраз в Title и Description не будет.
Работа Королева при сложном запросе
Таким образом, стало возможным задавать поисковой системе сложные вопросы в формате разговорной речи и получать на это корректные ответы.
Существенным преимуществом Королева также стала возможность его применения к существенно большему количеству страниц без ущерба ко времени выдачи результатов по запросу. Палех был относительно тяжелым алгоритмом и использовался исключительно на поздних стадиях ранжирования, приблизительно к 150 лучшим страницам из отфильтрованного по старым правилам списка.
О трансформерах
Палех и Королев позволили Яндексу не просто находить совпадения, а понимать суть вопроса, значительно улучшили процесс ранжирования, но всё же справлялись с этим неидеально. Лишь с момента ввода YATI факторы смысла стали превосходить факторы вхождений по мНЧ-фразам.
Путь Яндекса к YATI
Прежде, чем мы начнем подробнее говорить о YATI, следует отдельно пояснить что такое трансформеры.
Говоря простыми словами, трансформерами в данном случае называют сверхбольшие и сверхсложные нейросети, способные легко справляться с разнообразными задачами в сфере обработки естественного языка, будь то перевод или создание текста.
Скрываются за этим огромные вычислительные мощности. Причем стремительно нарастающие. Так, до применения трансформеров, используемая в Яндексе нейросеть, обучалась только на одном графическом ускорителе Tesla v100. Уходило на такое обучение не более одного часа. А вот обучение нейросети-трансформера на таком ускорителе заняло бы около 10 лет. Потому внедрение новых технологий потребовало использования около сотни похожих ускорителей с быстрой передачей данных между друг другом. Для этого Яндекс построил специальный кластер, предназначенный для вычислений, с распределенным обучением внутри него.
Уходило на такое обучение не более одного часа. А вот обучение нейросети-трансформера на таком ускорителе заняло бы около 10 лет. Потому внедрение новых технологий потребовало использования около сотни похожих ускорителей с быстрой передачей данных между друг другом. Для этого Яндекс построил специальный кластер, предназначенный для вычислений, с распределенным обучением внутри него.
То есть переход на новый алгоритм YATI был довольно сложной задачей с инженерной точки зрения. Множество ускорителей объединили в кластеры, связали в сеть и разработали для получившихся серверов мощную систему охлаждения. Но даже с такими мощностями на обучение модели сейчас уходит около месяца.
Классическая техника обучения трансформеров предполагает демонстрацию им неструктурированных текстов. То есть берется текст, в нем маскируется определенный процент слов, а перед трансформером ставится задача угадывать данные слова. Для YATI задача была усложнена: ему показывался не просто текст отдельного документа, а действительные запросы и тексты документов, которые видели пользователи. YATI угадывал, какой из документов понравился пользователям, а какой нет. Для этого использовалась экспертная разметка асессоров, которые оценивали релевантность каждого документа запросу по сложной шкале.
То есть берется текст, в нем маскируется определенный процент слов, а перед трансформером ставится задача угадывать данные слова. Для YATI задача была усложнена: ему показывался не просто текст отдельного документа, а действительные запросы и тексты документов, которые видели пользователи. YATI угадывал, какой из документов понравился пользователям, а какой нет. Для этого использовалась экспертная разметка асессоров, которые оценивали релевантность каждого документа запросу по сложной шкале.
После этого Яндекс брал массив полученных данных и дообучал трансформер угадывать экспертную оценку, обучаясь, таким образом, ранжировать. В результате поисковой алгоритм был существенно улучшен и Яндекс вышел на рекордный уровень в качестве поиска.
Преимущества YATI и трансформеров
В отличие от предшествующих нейросетевых алгоритмов Яндекса Палех и Королёв, YATI умеет предсказывать не клик пользователя, а экспертную оценку, что являет собой фундаментальную разницу.
Кроме этого, преимущества трансформеров заключаются в следующем:
- поиск работает не только с запросами и заголовками, но и способен оценивать длинные тексты;
- присутствует «механизм внимания», выделяющий в тексте наиболее значимые фрагменты;
- учитывается порядок слов и контекст, то есть влияние слов друг на друга.
Теперь, к примеру, когда вы будете искать билеты на самолет из Екатеринбурга в Москву, поисковик поймет, что вам нужно именно из Екатеринбурга в Москву, а не наоборот. Помимо того, Яндекс стал лучше распознавать опечатки.
YATI намного лучше предшественников работает со смыслом запроса, алгоритм направлен на более глубокий анализ текста, понимание его сути. Это значит, что поисковик будет точнее понимать, какая информация является наиболее релевантной запросу пользователя.
Говоря о ранжировании, можно спрогнозировать, что смысловая нагрузка контента возымеет более значимую роль. То есть экспертные тексты, полностью раскрывающие ответ на запрос пользователя, будут всё больше и чаще попадать в ТОП.
Особенности YATI:
1. Переформулирование запросов и «пред-обучение на клик». Яндекс имеет базу из 1 млрд. переформулированных запросов: [1 формулировка] → без клика → [2 формулировка]. Так, модель учится предсказывать вероятность клика.
Переформулирование запросов и «пред-обучение на клик». Яндекс имеет базу из 1 млрд. переформулированных запросов: [1 формулировка] → без клика → [2 формулировка]. Так, модель учится предсказывать вероятность клика.
2. Оценки на Яндекс.Толоке. Использование оценок толокеров.
3. Оценки асессоров. Использование экспертных оценок релевантности.
4. Данные, которые подаются на вход:
- текст запроса;
- расширение запроса;
- «хорошие» фрагменты документа;
- стримы для документа: анкор-лист, запросный индекс для документа.
YATI и Google Bert
Одним из последних обновлений главного конкурента в области поиска Яндекса Google стало внедрение алгоритма BERT. Эта нейронная сеть также, как и YATI, решает задачу анализа поисковых запросов и их контекста, а не отдельный анализ ключевых запросов. То есть BERT анализирует предложение целиком.
И YATI, и BERT ориентированы на лучшее понимание смысла поискового запроса. Однако, как утверждают специалисты Яндекс, алгоритм YATI лучше справляется со своими задачами, поскольку кроме текста запроса анализирует еще и тексты документов, а также учится предсказывать клики.

Ниже в таблице представлено сравнение качества алгоритмов, основанных на нейронных сетях, в задаче ранжирования, где “% NDCG” – нормированное значение метрики качества DCG по отношению к идеальному ранжированию на датасете Яндекс. 100% здесь означает, что модель располагает документы в порядке убывания их настоящих офлайн-оценок.
Вместе с тем, требуется отметить, что BERT решает существенно большее количество задач, среди которых распознавание «смысла» текста лишь одна из множества других. На BERT базируется большое семейство языковых моделей:
С точки же зрения компьютерной лингвистики, BERT и YATI – довольно похожие алгоритмы.
Как изменится ранжирование в условиях действия Яндекс YATI
Владельцев ресурсов, а также всех, кто занимается продвижением сайта, очевидно, должен интересовать вопрос, как YATI повлияет на способы оптимизации. Если исходить из утверждения, что новый алгоритм обеспечивает более 50% вклада в ранжирование, то можно предположить, что «смысл» окончательно победил возможности SEO-специалистов в проработке текстов, а значит оптимизировать ничего не нужно. А также можно решить, что такие факторы, как «точное вхождение», «Title» и «добавить ключей» больше не имеют влияния.
Данные суждения будут поспешны и ошибочны. Новый алгоритм не отменяет старые факторы ранжирования, а лишь дополняет их более качественным анализом текстов. Дело в том, что изначально для улучшения распределения, поиск Яндекс обучался на редких запросах, где документов и без того недостаточно. И когда речь идет о 50%-ом вкладе в ранжирование, то имеются ввиду именно редкие запросы. Борьба между «смыслом» и «вхождением», где «смысл» начал побеждать, видна именно на них.
А вот ситуация по ВЧ-запросам, по средне- и низкочастотным не претерпела значительных изменений. Это означает, что техническую оптимизацию, привлечение естественных ссылок и улучшение поведенческих факторов как на поиске, так и на сайте – забрасывать не нужно.
Это означает, что техническую оптимизацию, привлечение естественных ссылок и улучшение поведенческих факторов как на поиске, так и на сайте – забрасывать не нужно.
Исследования независимых специалистов показывают, что значимость фактора «точное вхождение в тексте» по НЧ-запросам после запуска YATI ничуть не ослабла, а, напротив, увеличила свою значимость. А вот тут ситуация с точным вхождением поменялась – явного влияния в ТОП-10 теперь нет, хотя вне его оно сохраняется.
Среднее значение ключевого фактора ТОП-10 и вне его:
Среднее значение фактора здесь находится в районе единицы. То есть, если имеется одно вхождение, значит этого вполне достаточно.
То есть, если имеется одно вхождение, значит этого вполне достаточно.
Фактор «наличие всех слов из запроса в тексте» также не потерял своего значения. Выборка коммерческих запросов в Яндексе демонстрирует, что существенной разницы между НЧ и СЧ+ВЧ запросами нет. Тем не менее, наблюдается взаимосвязь между попаданием в ТОП и наличием всех слов запроса в документе. Значение этого фактора составляет 0.8, то есть, работает это для 80% сайтов.
Проверка фактора «слова в Title» после YATI показывает рост среднего значения этого фактора. То есть в выдаче стали чаще встречаться документы, Title которых содержит все слова в запросе, но вместе с тем, здесь наблюдается заметное понижение взаимосвязи с позицией.
Практические советы
Итак, перейдем к конкретным рекомендациям по оптимизации сайта в условиях работы алгоритма YATI:
- Адаптируйтесь под YATI. Увеличивайте количество слов, встречаемых в контексте со словами из запроса. К таковым могут относиться слова из подсветки выдачи, а также слова, задающие тематику и встречаемые у конкурентов, но отсутствующие на продвигаемой странице.
- Расставляйте акценты в тексте и форматируйте его. В текстах свыше 12-14 предложений обязательно требуется использовать заголовки, выносить в них и в выделенные фрагменты тематические и ключевые слова.
- Выполняйте анализ и оптимизацию запросного индекса и для документов, и для сайта в целом в Яндекс.Вебмастере. Проверяйте релевантность запросов, по которым были как переходы на заданный URL, так и только показы без переходов. Данные всего сайта, как и прежде, также сказываются на факторах для заданной страницы. Поэтому проверки имеют смысл в разрезе всего сайта, а не только URL.
- Расширяйте семантическое ядро для продвижения в сторону НЧ-запросов. Синонимичные и, так называемые, вложенные запросы помогают в продвижении по более общим и близким по смыслу.
- Выполняйте конкурентный анализ. Анализируйте показы страниц конкурентов по запросам. Изучайте чужие тексты: какие тематические слова и фразы в них используются, какова структура и т.п.
- Проводите классическую оптимизацию: текст, точные вхождения, слова в Title.
 Увеличивайте количество слов, встречаемых в контексте со словами из запроса. К таковым могут относиться слова из подсветки выдачи, а также слова, задающие тематику и встречаемые у конкурентов, но отсутствующие на продвигаемой странице.
Увеличивайте количество слов, встречаемых в контексте со словами из запроса. К таковым могут относиться слова из подсветки выдачи, а также слова, задающие тематику и встречаемые у конкурентов, но отсутствующие на продвигаемой странице. Синонимичные и, так называемые, вложенные запросы помогают в продвижении по более общим и близким по смыслу.
Синонимичные и, так называемые, вложенные запросы помогают в продвижении по более общим и близким по смыслу.Заключение
Трансформеры значительно улучшили качество поиска в Яндексе и вывели его на новый рекордный уровень. Применение тяжелых моделей, основанных на работе нейронных сетей, способных приближать структуру естественного языка и лучше учитывать семантические связи между словами в тексте, помогает пользователям все чаще встречаться с эффектом «поиска по смыслу», а не по словам.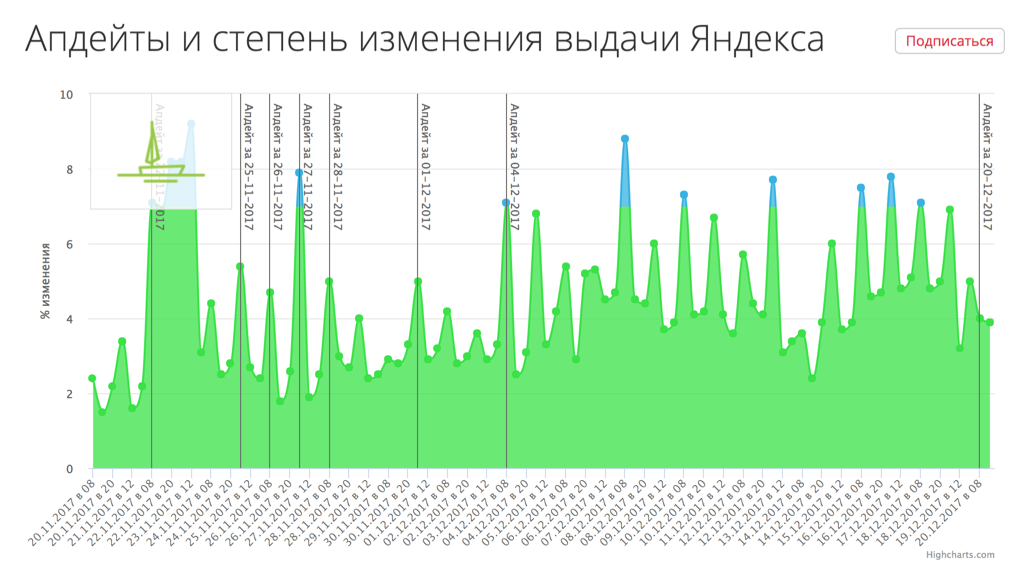
Тем не менее несмотря на то, что YATI преподносится и по праву считается прорывной технологией, принципы работы поиска в Яндексе всегда формируются эволюционным, а не революционным образом. То есть, его обновление выполняется путем последовательного добавления новых факторов ранжирования к старым, а не радикальной сменой всех основ. Это означает, что поисковая оптимизация с приходом YATI не потеряла своей актуальности, а лишь требует некоторых корректировок ряда своих методов.
Управляющий директор группы компаний Яндекс Тигран Худавердян о внедрение алгоритма YATI в интервью на конференции YaС 2020
YATI безусловно изменит поисковую выдачу Яндекса, но поскольку система требует обучения, то для этого потребуется время. Поэтому сейчас у вас есть хорошая возможность внести необходимые изменения на сайте и доработать SEO-тексты устаревшего формата, сохранив тем самым свои позиции и улучшив их к тому моменту, когда поиск окончательно перестроится на новый формат. С оптимизацией вам могут помочь советы, изложенные в этой статье, а также наша компания ADVIANA.
Поэтому сейчас у вас есть хорошая возможность внести необходимые изменения на сайте и доработать SEO-тексты устаревшего формата, сохранив тем самым свои позиции и улучшив их к тому моменту, когда поиск окончательно перестроится на новый формат. С оптимизацией вам могут помочь советы, изложенные в этой статье, а также наша компания ADVIANA.
Заметим, что мы никогда не гнались за некачественными и серыми методами оптимизации и всегда много внимания уделяли описаниям на сайте, а также всем видам текста. Для наших проектов переход на новый алгоритм не был болезненным, так как все они уже соответствовали новым требованиям. Кроме того, мы постоянно следим за изменениями в мире digital-маркетинга в целом и SEO-оптимизации в частности, что позволяет нам использовать в своей работе только актуальные методы продвижения по понятной цене и с прогнозируемым результатом.
Желаем всем высоких позиций в поиске!
Что такое Апдейт выдачи Яндекса?
Апдейт выдачи – это обновление станицы с результатами поиска. Само слово “update” переводится как “обновление”. Что подразумевается под словами апдейт выдачи Яндекса? Это изменение информации, предоставляемой этим поисковиком (ПС-поисковая система).
Как происходит апдейт поисковой выдачи Яндекса?
Роботы поисковика обходят сайты с определенной регулярностью и обновляют в своих базах информацию о ресурсах. Это процесс длительный. Стоит учитывать огромное количество сайтов во всемирной сети, а также различную частоту их посещения «пауками» Яндекса. Информация накапливается и в какой-то момент алгоритмы ПС изменяют внутренние рейтинги сайтов. Итогом этих корректировок становится смена порядка веб-страниц при конкретных запросах пользователей.
Итогом этих корректировок становится смена порядка веб-страниц при конкретных запросах пользователей.
В действительности этот процесс стоит разделить на отдельные потоки. Яндекс собирает не только текстовое содержимое страниц, но и проводит:
- анализ картинок;
- ссылки сайтов друг на друга;
- посещаемость.
Как часто происходит Апдейт выдачи Яндекса?
Точного ответа на этот вопрос сегодня дать нельзя. Существует ряд сервисов, которые «предсказывают» апдейты поисковых систем, однако на самом деле это скорее экстраполирование полученной информации о ранее проведенных обновлениях выдачи. К примеру, если значительные изменения были отмечены с регулярностью раз в месяц, то логично предположить, что в дальнейшем тенденция сохранится. На самом деле по каждому направлению (текст, изображения, ссылки и т. д.) апдейты не обязаны совпадать.
д.) апдейты не обязаны совпадать.
Самих роботов у ПС достаточно много. Есть «быстрые», добавляющие страницы в индекс практически мгновенно. Фактически, спустя минуты с момента публикации новой страницы на ресурсе, она уже может оказаться в выдаче, а затем начать «плавать» по позициям. Пример: новости и новостная лента. По одному запросу, сделанному с разницей в 15 минут вы можете получить совершенно разный набор ресурсов. Это частный случай, когда Яндекс старается предоставлять максимально «свежую» и актуальную информацию.
По ряду высокочастотных запросов со сформировавшимися лидерами заметить подобное на первых страницах почти нереально. Текстовые обновления там обычно происходят в интервале 3 — 10 дней.
Периодичность апдейтов (взята с pr-cy.ru)
Как правило, для большинства сайтов с качественной информацией попадание на первую страницу выдачи по средне-частотным запросам требуется 2-3 месяца, но ситуация может меняться по разным причинам. Миф о «песочнице» Яндекса появился именно благодаря низкой скорости обновления. В действительности, это именно апдейт, итогом которого становится появление в выдаче ранее неизвестного ПС сайта.
Миф о «песочнице» Яндекса появился именно благодаря низкой скорости обновления. В действительности, это именно апдейт, итогом которого становится появление в выдаче ранее неизвестного ПС сайта.
Часто быстрый взлет или падение сайта связано с изменением основных механизмов ранжирования Яндекса.
Яндекс объявляет о крупном обновлении алгоритма
Яндекс объявил об обновлении своей поисковой системы. Обновление называется Vega. Обновление предлагает много подробностей о том, как работают современные поисковые системы.
Основные улучшения в Яндексе
Яндекс называет свое обновление Vega. В этом обновлении 1500 улучшений. Из этих улучшений Яндекс выделил два, которые, по их словам, существенно влияют на результаты поиска.
Одно из изменений добавляет в обучение алгоритму обратную связь от экспертов.Вторым изменением стала возможность удвоить размер поискового индекса без ущерба для скорости результатов поиска.
По теме: The Ultimate Guide to Yandex SEO
Crowd Sourcing Search Result Raters
Google нанимает подрядчиков, прошедших инструктаж по оценке качества Google, для оценки результатов поиска. Яндекс полагается на свою краудсорсинговую платформу Яндекс.Толока.
Яндекс полагается на свою краудсорсинговую платформу Яндекс.Толока.
Хотя это может показаться немного менее контролируемым, чем метод Google, Яндекс предоставляет рекомендации для экспертов, чтобы повысить точность оценок.
Реклама
Продолжить чтение ниже
«Люди, или« оценщики », уже давно помогают обучать наши платформы машинного обучения через нашу краудсорсинговую платформу Яндекс.Толока.
Используя наши рекомендации по оценке результатов поиска, оценщики в Яндекс.Толоке выполняют задачи, которые помогают нам находить наиболее релевантные результаты по конкретным запросам ».
Человеческий вклад в обучение алгоритму
Мы знаем, что Google использует оценщиков качества для тестирования новых изменений алгоритмов.Яндекс делает то же самое. Они называют своих оценщиков Assessors, потому что они оценивают веб-результаты.
Изменение, внесенное Яндексом, заключалось в том, чтобы нанимать экспертов по определенной теме для анализа работы экспертов по оценке с целью повышения ее точности. Это означает, что данные для обучения, предоставленные алгоритму, будут лучше, поскольку они были проверены и подтверждены экспертом.
Это означает, что данные для обучения, предоставленные алгоритму, будут лучше, поскольку они были проверены и подтверждены экспертом.
Реклама
Продолжить чтение ниже
Поскольку данные обучения Яндекса просматриваются тематическими экспертами, алгоритм (предположительно) будет более точным, поскольку данные обучения улучшены.
Вот как это объяснил Яндекс:
«Мы обновили алгоритм ранжирования, добавив нейронные сети, обученные на данных, предоставленных настоящими экспертами в нескольких областях, и предоставили пользователям еще более качественные решения для поиска.
Профессионалы, оценивающие оценщиков, варьируются от ИТ-администраторов для запросов данных до гидрологов для запросов, касающихся рек.
Эксперты-оценщики используют более сотни критериев для оценки работы оценщиков…
Обучая наши алгоритмы машинного обучения экспертным оценкам, наша поисковая система учится ранжировать релевантную информацию выше в результатах благодаря работе высококвалифицированной группы лиц.
 ”
”По теме: Интервью с поисковой командой Яндекса
Расширение поискового индекса с помощью кластеризации
Яндекс представил очень интересный способ обработки тематически похожих веб-страниц. Вместо того чтобы искать ответ по всему индексу, Яндекс сгруппировал веб-страницы в тематические кластеры. Утверждается, что это улучшает и ускоряет результаты поиска, позволяя поисковой системе выбирать ответ из тематически релевантных страниц.
«Наши алгоритмы используют нейронные сети для группировки страниц в кластеры на основе их сходства.Когда пользователь вводит запрос, поиск выполняется среди наиболее релевантной группы страниц, а не всего нашего индекса «.
Технология кластеризации Яндекса позволила Яндексу удвоить свой поисковый индекс, не влияя на скорость выбора веб-страницы.
Реклама
Продолжить чтение ниже
Это очень интересно, потому что похоже на алгоритмы ранжирования ссылок, которые начинаются с исходных сайтов как представителей тематики.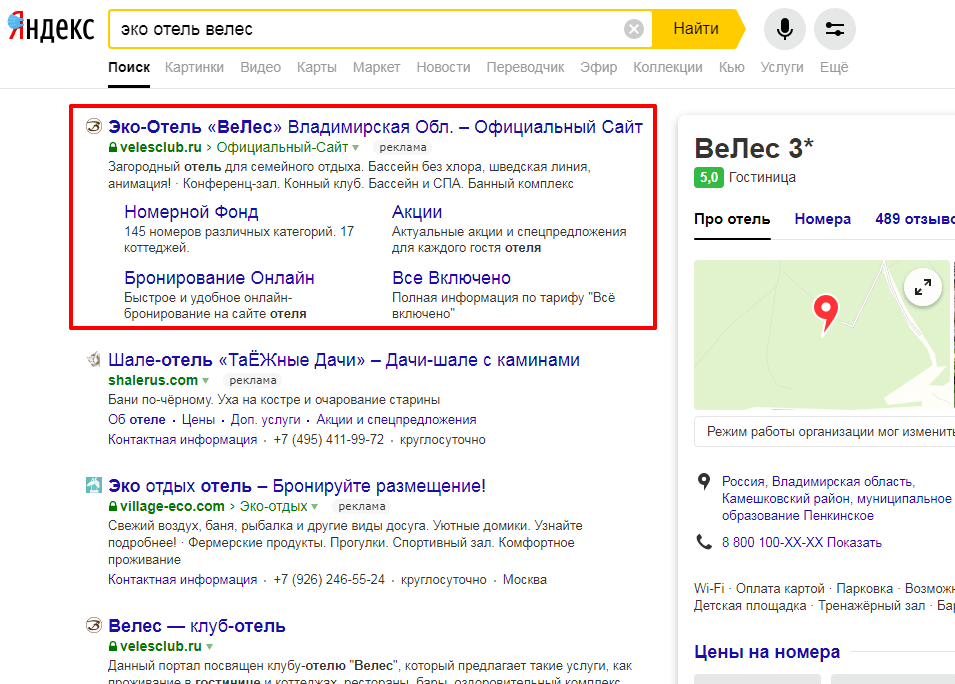 Веб-страницы, которые содержат больше ссылок, считаются менее релевантными теме.Страницы, расположенные ближе к исходным текстам темы, считаются более релевантными.
Веб-страницы, которые содержат больше ссылок, считаются менее релевантными теме.Страницы, расположенные ближе к исходным текстам темы, считаются более релевантными.
Прогнозирование поисковых запросов и результатов
Интересным нововведением в Яндексе является использование алгоритмов для прогнозирования того, что пользователь спросит, и для «предварительного рендеринга» результатов по этому поисковому запросу. Хотя об этом было объявлено в контексте обновления Vega, на самом деле это было реализовано в марте 2019 года.
Что делает эту функцию хорошей, так это то, что она сокращает время, необходимое для отображения пользователю результатов поиска, которые он ищет.
Реклама
Продолжить чтение ниже
«С марта мобильные пользователи Яндекса на Android осуществляют поиск с использованием технологии предварительного рендеринга, которая предсказывает запрос пользователя и выбирает релевантные результаты по мере того, как пользователь вводит текст».
По теме: 9 Часто задаваемые вопросы о Яндексе SEO и PPC
Поиск современной информации
Яндекс — российская поисковая система, использующая нейронные сети и машинное обучение.Я считаю, что хорошо разбираться в технологиях, используемых во всем мире, потому что это позволяет мне быть в курсе того, что определяет современный поиск информации (бизнес поисковых систем) сегодня.
Читайте официальное объявление об обновлении алгоритма Яндекс здесь:
https://yandex.com/company/blog/vega
ОБНОВЛЕНИЕ 1 — Яндекс в России потратит 400-500 млн долларов на электронную коммерцию в 2021 году после роста прибыли
TipRanks
2 Дивиденды для «сильной покупки» с доходностью не менее 7%
На рыночную картину складывается ряд факторов, указывающих на возможное изменение условий в среднесрочной перспективе.Сюда входит рост цен на сырьевые товары, в частности, на нефть, которые в последнее время выросли. Кроме того, опубликованные ранее в этом месяце данные о рабочих местах за январь в лучшем случае разочаровали — а в худшем — мрачно. Однако они увеличивают вероятность того, что президент Байден и Демократический конгресс продвинут крупномасштабный пакет помощи в связи с COVID до реализации. Эти факторы, вероятно, будут влиять в разных направлениях. Рост цен на нефть предполагает предстоящее сокращение предложения, в то время как возможность дальнейшего стимулирования наличными средствами является хорошим предзнаменованием для поклонников рыночной ликвидности.Эти события, однако, указывают на возможную рефляционную атмосферу цен. На этом фоне некоторые инвесторы ищут способы восстановить и защитить свои портфели. И это принесет нам дивиденды. Обеспечивая стабильный поток доходов, независимо от рыночных условий, надежные дивидендные акции обеспечивают площадку для вашего инвестиционного портфеля, когда акции перестают расти. Итак, мы открыли базу данных TipRanks и извлекли подробную информацию о двух акциях с высокой доходностью — не менее 7%.
Кроме того, опубликованные ранее в этом месяце данные о рабочих местах за январь в лучшем случае разочаровали — а в худшем — мрачно. Однако они увеличивают вероятность того, что президент Байден и Демократический конгресс продвинут крупномасштабный пакет помощи в связи с COVID до реализации. Эти факторы, вероятно, будут влиять в разных направлениях. Рост цен на нефть предполагает предстоящее сокращение предложения, в то время как возможность дальнейшего стимулирования наличными средствами является хорошим предзнаменованием для поклонников рыночной ликвидности.Эти события, однако, указывают на возможную рефляционную атмосферу цен. На этом фоне некоторые инвесторы ищут способы восстановить и защитить свои портфели. И это принесет нам дивиденды. Обеспечивая стабильный поток доходов, независимо от рыночных условий, надежные дивидендные акции обеспечивают площадку для вашего инвестиционного портфеля, когда акции перестают расти. Итак, мы открыли базу данных TipRanks и извлекли подробную информацию о двух акциях с высокой доходностью — не менее 7%. Более того, эти акции рассматриваются аналитиками Уолл-стрит как сильные покупатели. Давай узнаем почему. Williams Companies (WMB) Первое, что мы рассмотрим, это Williams Companies, газоперерабатывающая компания, базирующаяся в Оклахоме. Williams контролирует трубопроводы для природного газа, сжиженного природного газа и сбора нефти в сети, простирающейся от северо-запада Тихого океана, через Скалистые горы до побережья Мексиканского залива и через юг до Средней Атлантики. Основным направлением деятельности Williams является переработка и транспортировка природного газа, при этом производство сырой нефти и энергии являются вторичными операциями.У компании огромные масштабы — она обрабатывает почти треть всего потребления природного газа в США, как в жилых, так и в коммерческих целях. В конце этого месяца Williams опубликует результаты за 4 квартал 2020 г., но результаты 3-го квартала поучительны. Выручка компании составила 1,93 миллиарда долларов, что на 3,5% меньше по сравнению с аналогичным периодом прошлого года, но выросло на 8,4% по сравнению с предыдущим кварталом, и это самый высокий показатель квартальной выручки за 2020 год, опубликованный на данный момент.
Более того, эти акции рассматриваются аналитиками Уолл-стрит как сильные покупатели. Давай узнаем почему. Williams Companies (WMB) Первое, что мы рассмотрим, это Williams Companies, газоперерабатывающая компания, базирующаяся в Оклахоме. Williams контролирует трубопроводы для природного газа, сжиженного природного газа и сбора нефти в сети, простирающейся от северо-запада Тихого океана, через Скалистые горы до побережья Мексиканского залива и через юг до Средней Атлантики. Основным направлением деятельности Williams является переработка и транспортировка природного газа, при этом производство сырой нефти и энергии являются вторичными операциями.У компании огромные масштабы — она обрабатывает почти треть всего потребления природного газа в США, как в жилых, так и в коммерческих целях. В конце этого месяца Williams опубликует результаты за 4 квартал 2020 г., но результаты 3-го квартала поучительны. Выручка компании составила 1,93 миллиарда долларов, что на 3,5% меньше по сравнению с аналогичным периодом прошлого года, но выросло на 8,4% по сравнению с предыдущим кварталом, и это самый высокий показатель квартальной выручки за 2020 год, опубликованный на данный момент. по сравнению со вторым кварталом, но на 38% больше, чем годом ранее. Отчет был широко расценен как совпадающий или превосходящий ожидания, и за две недели после его публикации акции выросли на 7%.В шаге, который может указывать на стабильную прибыль за четвертый квартал, компания объявила о своих следующих дивидендах, которые будут выплачены 29 марта. Выплата в размере 41 процента на обыкновенную акцию выросла на 2,5% по сравнению с предыдущим кварталом и в годовом исчислении составила 1,64 доллара. . По этой ставке дивидендная доходность составляет 7,1%. У Williams есть 4-летняя история роста и поддержания дивидендов, и, как правило, размер выплаты увеличивается в первом квартале года. Обсуждая акции для РБК, пятизвездочный аналитик Т. Дж. Шульц написал: «Мы считаем, что Williams может достичь нижнего предела своего прогноза EBITDA на 2020 год.Хотя мы ожидаем, что в ближайшем будущем рост в Северо-восточном регионе будет умеренным, мы полагаем, что WMB должна извлечь выгоду из меньшего, чем ожидалось ранее, попутного газа из Перми.
по сравнению со вторым кварталом, но на 38% больше, чем годом ранее. Отчет был широко расценен как совпадающий или превосходящий ожидания, и за две недели после его публикации акции выросли на 7%.В шаге, который может указывать на стабильную прибыль за четвертый квартал, компания объявила о своих следующих дивидендах, которые будут выплачены 29 марта. Выплата в размере 41 процента на обыкновенную акцию выросла на 2,5% по сравнению с предыдущим кварталом и в годовом исчислении составила 1,64 доллара. . По этой ставке дивидендная доходность составляет 7,1%. У Williams есть 4-летняя история роста и поддержания дивидендов, и, как правило, размер выплаты увеличивается в первом квартале года. Обсуждая акции для РБК, пятизвездочный аналитик Т. Дж. Шульц написал: «Мы считаем, что Williams может достичь нижнего предела своего прогноза EBITDA на 2020 год.Хотя мы ожидаем, что в ближайшем будущем рост в Северо-восточном регионе будет умеренным, мы полагаем, что WMB должна извлечь выгоду из меньшего, чем ожидалось ранее, попутного газа из Перми. Учитывая нашу долгосрочную перспективу, мы полагаем, что Williams сможет спокойно оставаться в рамках показателей кредитоспособности инвестиционного уровня в течение нашего прогнозного периода и сохранить неизменными дивиденды ». С этой целью Шульц оценивает WMB как лучше рынка (то есть покупать), и его целевая цена в $ 26 предполагает потенциал роста в 13% в следующие 12 месяцев. (Чтобы посмотреть послужной список Шульца, нажмите здесь). Благодаря 8 недавним обзорам, включая 7 покупок и только 1 удержание, WMB получил консенсус-рейтинг аналитиков Strong Buy.Хотя в последние месяцы акции выросли, достигнув 23 долларов, средняя целевая цена в 25,71 доллара предполагает, что в этом году еще есть возможности для роста на ~ 12%. (См. Анализ акций WMB на сайте TipRanks) AGNC Investment (AGNC) Следующим шагом будет AGNC Investment, инвестиционный фонд недвижимости. Неудивительно, что REIT побеждает по дивидендам — налоговые кодексы требуют, чтобы эти компании возвращали высокий процент прибыли непосредственно акционерам и часто используют дивиденды в качестве средства соблюдения требований.
Учитывая нашу долгосрочную перспективу, мы полагаем, что Williams сможет спокойно оставаться в рамках показателей кредитоспособности инвестиционного уровня в течение нашего прогнозного периода и сохранить неизменными дивиденды ». С этой целью Шульц оценивает WMB как лучше рынка (то есть покупать), и его целевая цена в $ 26 предполагает потенциал роста в 13% в следующие 12 месяцев. (Чтобы посмотреть послужной список Шульца, нажмите здесь). Благодаря 8 недавним обзорам, включая 7 покупок и только 1 удержание, WMB получил консенсус-рейтинг аналитиков Strong Buy.Хотя в последние месяцы акции выросли, достигнув 23 долларов, средняя целевая цена в 25,71 доллара предполагает, что в этом году еще есть возможности для роста на ~ 12%. (См. Анализ акций WMB на сайте TipRanks) AGNC Investment (AGNC) Следующим шагом будет AGNC Investment, инвестиционный фонд недвижимости. Неудивительно, что REIT побеждает по дивидендам — налоговые кодексы требуют, чтобы эти компании возвращали высокий процент прибыли непосредственно акционерам и часто используют дивиденды в качестве средства соблюдения требований.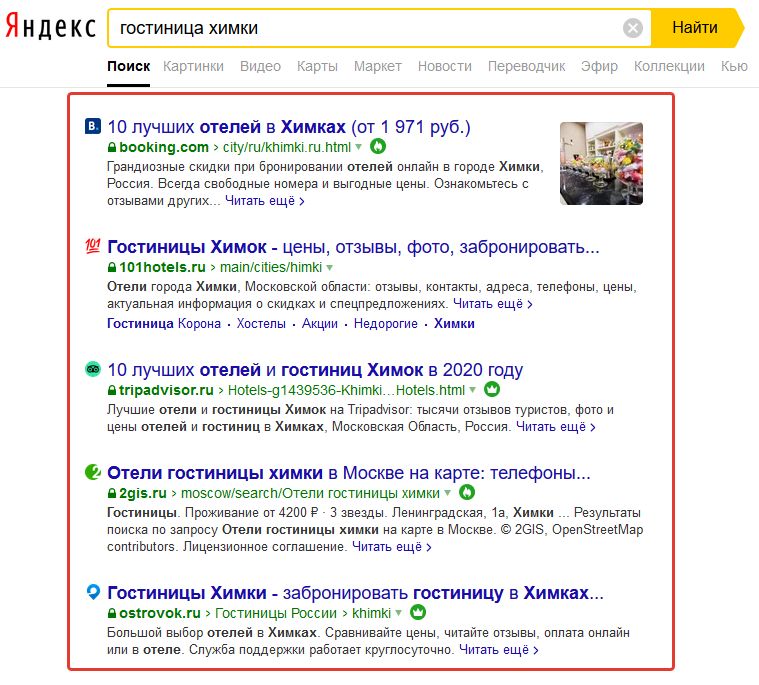 AGNC, базирующаяся в Мэриленде, специализируется на MBS (ценных бумагах с ипотечным покрытием) при поддержке и гарантиях со стороны правительства США.Эти ценные бумаги составляют около двух третей всего портфеля компании, или 65,1 миллиарда долларов из 97,9 миллиарда долларов. Последняя квартальная прибыль AGNC за 4 квартал 2020 года показала чистую выручку в размере 459 миллионов долларов и чистую прибыль на акцию в размере 1,37 доллара. Несмотря на снижение по сравнению с аналогичным периодом прошлого года, прибыль на акцию была самой высокой в 2020 году. За полный год AGNC сообщила о $ 1,68 млрд общей выручки и $ 1,56 на акцию, выплаченных в виде дивидендов. Текущий дивиденд, 12 центов на обыкновенную акцию, выплачиваемый ежемесячно, составит 1 доллар в год.44; Разница с прошлогодним более высоким уровнем годовых объясняется сокращением дивидендов, осуществленным в апреле в ответ на кризис с коронавирусом. При текущих ставках дивиденды дают инвесторам стабильную доходность в размере 8,8% и легко доступны для компании с учетом текущего дохода.
AGNC, базирующаяся в Мэриленде, специализируется на MBS (ценных бумагах с ипотечным покрытием) при поддержке и гарантиях со стороны правительства США.Эти ценные бумаги составляют около двух третей всего портфеля компании, или 65,1 миллиарда долларов из 97,9 миллиарда долларов. Последняя квартальная прибыль AGNC за 4 квартал 2020 года показала чистую выручку в размере 459 миллионов долларов и чистую прибыль на акцию в размере 1,37 доллара. Несмотря на снижение по сравнению с аналогичным периодом прошлого года, прибыль на акцию была самой высокой в 2020 году. За полный год AGNC сообщила о $ 1,68 млрд общей выручки и $ 1,56 на акцию, выплаченных в виде дивидендов. Текущий дивиденд, 12 центов на обыкновенную акцию, выплачиваемый ежемесячно, составит 1 доллар в год.44; Разница с прошлогодним более высоким уровнем годовых объясняется сокращением дивидендов, осуществленным в апреле в ответ на кризис с коронавирусом. При текущих ставках дивиденды дают инвесторам стабильную доходность в размере 8,8% и легко доступны для компании с учетом текущего дохода.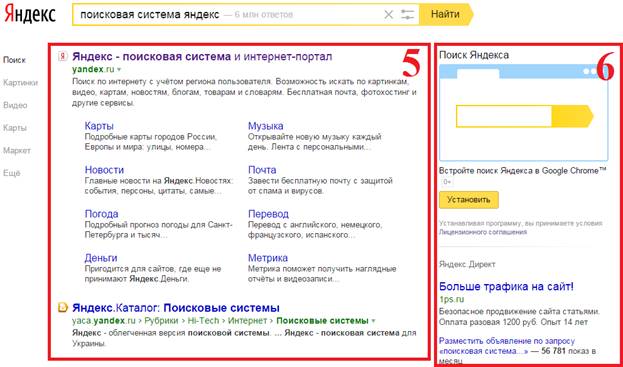 Среди быков AGNC — аналитик Maxim Майкл Диана, который писал: «AGNC сохранила конкурентоспособную доходность по балансовой стоимости по сравнению с другими ипотечными REIT (mREITS), даже несмотря на то, что она превзошла свои дивиденды и выкупленные акции.В то время как потрясения на ипотечных рынках в конце марта привели к убыткам и снижению балансовой стоимости всех ипотечных REIT, AGNC смогла удовлетворить все свои требования к марже и, что важно, понести относительно меньшие реализованные убытки и, следовательно, сохранить большую прибыль после смятение.» Исходя из всего вышесказанного, Диана ставит AGNC «Покупать» вместе с целевой ценой в $ 18. Эта цифра подразумевает потенциал роста ~ 10% от текущих уровней. (Чтобы посмотреть послужной список Дианы, нажмите здесь) Уолл-стрит находится на той же странице.За последние пару месяцев AGNC получила 7 покупок и одно удержание — все это составляет консенсус-рейтинг «Сильная покупка». Тем не менее, средняя целевая цена в $ 16,69 предполагает, что в обозримом будущем диапазон акций останется ограниченным.
Среди быков AGNC — аналитик Maxim Майкл Диана, который писал: «AGNC сохранила конкурентоспособную доходность по балансовой стоимости по сравнению с другими ипотечными REIT (mREITS), даже несмотря на то, что она превзошла свои дивиденды и выкупленные акции.В то время как потрясения на ипотечных рынках в конце марта привели к убыткам и снижению балансовой стоимости всех ипотечных REIT, AGNC смогла удовлетворить все свои требования к марже и, что важно, понести относительно меньшие реализованные убытки и, следовательно, сохранить большую прибыль после смятение.» Исходя из всего вышесказанного, Диана ставит AGNC «Покупать» вместе с целевой ценой в $ 18. Эта цифра подразумевает потенциал роста ~ 10% от текущих уровней. (Чтобы посмотреть послужной список Дианы, нажмите здесь) Уолл-стрит находится на той же странице.За последние пару месяцев AGNC получила 7 покупок и одно удержание — все это составляет консенсус-рейтинг «Сильная покупка». Тем не менее, средняя целевая цена в $ 16,69 предполагает, что в обозримом будущем диапазон акций останется ограниченным. (См. Анализ акций AGNC на сайте TipRanks). Чтобы найти хорошие идеи для торговли акциями с дивидендами по привлекательной оценке, посетите сайт «Лучшие акции для покупки» от TipRanks, недавно выпущенный инструмент, объединяющий все аналитические данные TipRanks по акциям. Отказ от ответственности: мнения, выраженные в этой статье, принадлежат исключительно упомянутым аналитикам.Контент предназначен для использования только в информационных целях. Прежде чем делать какие-либо инвестиции, очень важно провести собственный анализ.
(См. Анализ акций AGNC на сайте TipRanks). Чтобы найти хорошие идеи для торговли акциями с дивидендами по привлекательной оценке, посетите сайт «Лучшие акции для покупки» от TipRanks, недавно выпущенный инструмент, объединяющий все аналитические данные TipRanks по акциям. Отказ от ответственности: мнения, выраженные в этой статье, принадлежат исключительно упомянутым аналитикам.Контент предназначен для использования только в информационных целях. Прежде чем делать какие-либо инвестиции, очень важно провести собственный анализ.
Установить Яндекс.Браузер на Debian, Ubuntu, Fedora, OpenSUSE, Arch
Яндекс-браузер — Интернет-браузер на основе Chromium, разработанный российской поисковой системой Яндекс, доступный для Linux, Mac OS X, Windows, Android и iOS.
Возможностей Яндекс браузера:
- Синхронизируйте закладки, расширения и данные браузера на своих устройствах.
- Современный и чистый пользовательский интерфейс
- Использует Blink Engine для быстрого просмотра
- Совместимость с Интернет-магазином Chrome и надстройками Opera
- Автоматически включает Opera Turbo mode для более быстрой загрузки страниц при медленном подключении к Интернету
- Встроенный проигрыватель перцовых вспышек
- Использует технологию DNSCrypt для предотвращения атак с подменой DNS или отравлением кеша
Включить sudo для стандартной учетной записи пользователя в Debian
Некоторые команды в этом руководстве имеют префикс sudo . Если вашей учетной записи нет в списке sudoer, вы можете использовать следующую команду, чтобы переключиться на пользователя root, если вы знаете пароль root.
Если вашей учетной записи нет в списке sudoer, вы можете использовать следующую команду, чтобы переключиться на пользователя root, если вы знаете пароль root.
су -
Если вы хотите добавить стандартную учетную запись пользователя в список sudoer, выполните следующую команду от имени пользователя root. Замените имя пользователя своим фактическим именем пользователя.
имя пользователя adduser sudo
Затем установите утилиту sudo .
apt install sudo
Выйдите из системы и снова войдите в систему, чтобы изменения вступили в силу.Отныне обычный пользователь может использовать sudo для управления системой.
Установите Яндекс.Браузер на Debian 8 Jessie, Ubuntu 16.04 LTS, Linux Mint 18
Для получения последних обновлений рекомендуется установить браузер Яндекс из официального репозитория APT. Сначала создайте файл со списком источников для Яндекс браузера
sudo nano /etc/apt/sources.
Добавьте в файл следующую строку.
deb [arch = amd64] http://repo.yandex.ru / yandex-browser / deb beta main
Нажмите CTRL + O , затем нажмите Enter, чтобы сохранить файл, CTRL + X , чтобы выйти из файла. Нам также необходимо загрузить и импортировать ключ GPG, чтобы пакеты, загруженные из этого репозитория, могли быть аутентифицированы.
wget https://repo.yandex.ru/yandex-browser/YANDEX-BROWSER-KEY.GPG sudo apt-key добавить YANDEX-BROWSER-KEY.GPG
После этого обновите локальный индекс пакета и установите Яндекс браузер.
sudo apt update sudo apt установить яндекс-браузер-бета
После установки вы можете запустить его из Ubuntu Unity Dash или из меню любимого приложения.
или из командной строки.
яндекс-браузер
Установить Яндекс.Браузер на Fedora, OpenSUSE
Перейдите на страницу загрузки браузера Яндекс, чтобы загрузить пакет RPM. Или вы можете использовать утилиту
Или вы можете использовать утилиту wget для загрузки в терминал.
wget https://cache-ams06.cdn.yandex.net/download.cdn.yandex.net/browser/yandex/ru/beta/Yandex.rpm
После загрузки перейдите в папку загрузки и выполните следующую команду, чтобы установить его.
Fedora: sudo dnf установить Яндекс.rpm OpenSUSE: sudo zypper в Яндекс.rpm
Установить Яндекс.Браузер на Arch Linux, Manjaro, Apricity OS, Antergos
yaourt яндекс
Чтобы установить расширения Chrome, просто перейдите по адресу chrome.google.com/webstore . Чтобы установить надстройки Opera, перейдите по адресу addons.opera.com .
Вот и все! Надеюсь, это руководство помогло вам установить Яндекс браузер Linux версии на ваш компьютер. И, как всегда, если вы нашли этот пост полезным, подпишитесь на нашу бесплатную рассылку новостей или подпишитесь на нас в Google+, Twitter или поставьте лайк на нашей странице в Facebook. Спасибо за визит!
Спасибо за визит!
Оцените этот учебник
[Всего: 21 Среднее: 4]установить Clickhouse на окнах | RPM Парковка
прогноз (строка) — функция, которую вы хотите предсказать, в этом примере SO2. Введение ClickHouse — это аналитическая база данных с открытым исходным кодом, ориентированная на столбцы, созданная Яндексом для сценариев использования OLAP и больших данных. В этом руководстве мы рассмотрим шаги по установке ClickHouse в Ubuntu 18.04 / CentOS 7. clickhouse :: server :: config :: user: определение пользователей ClickHouse; Типы ресурсов.Зависимости ¶ Эти дистрибутивы будут установлены автоматически при установке драйвера clickhouse. Yandex ClickHouse — это распределенная база данных OLAP с открытым исходным кодом в петабайтовом масштабе, ориентированная на столбцы, способная в реальном времени генерировать аналитические отчеты с использованием SQL-запросов, дополнительную информацию см. Модель CatBoost может быть применена в ClickHouse. Автор выбрал Фонд бесплатных и открытых исходных кодов для получения пожертвования в рамках программы Write for DOnations. ClickHouse — колоночная база данных, разработанная Яндексом для обработки аналитических запросов, которая идеально подходит для решения задач цифрового маркетинга.Чтобы установить инструмент, откройте окно терминала и обновите репозиторий пакетов: sudo apt update. Более ранние версии Windows, такие как Windows 7 или Windows Server 2012, не включают TLS 1.1 или TLS 1.2 по умолчанию для безопасного обмена данными с использованием WinHTTP. Мы подготовили это руководство, чтобы облегчить начало работы цифровых аналитиков с ClickHouse. Для получения пожертвования в рамках программы Write for DOnations автор выбрал Фонд бесплатных и открытых исходных кодов. Введение. Требовать драгоценный камень Clickhouse.Для python доступны пакеты для Windows: 2.7, 3.5 — 3.9.操作系统 是 CentOS7. Как установить и настроить ClickHouse в Ubuntu 16.04 | 18.04 Опубликовано 27.03.2019 04.04.2020 пользователем Student ClickHouse — это быстрая система аналитических баз данных с открытым исходным кодом, ориентированная на столбцы, с функцией высокой доступности, которая работает в разных кластерах, что исключает единую точку отказа .
ClickHouse — колоночная база данных, разработанная Яндексом для обработки аналитических запросов, которая идеально подходит для решения задач цифрового маркетинга.Чтобы установить инструмент, откройте окно терминала и обновите репозиторий пакетов: sudo apt update. Более ранние версии Windows, такие как Windows 7 или Windows Server 2012, не включают TLS 1.1 или TLS 1.2 по умолчанию для безопасного обмена данными с использованием WinHTTP. Мы подготовили это руководство, чтобы облегчить начало работы цифровых аналитиков с ClickHouse. Для получения пожертвования в рамках программы Write for DOnations автор выбрал Фонд бесплатных и открытых исходных кодов. Введение. Требовать драгоценный камень Clickhouse.Для python доступны пакеты для Windows: 2.7, 3.5 — 3.9.操作系统 是 CentOS7. Как установить и настроить ClickHouse в Ubuntu 16.04 | 18.04 Опубликовано 27.03.2019 04.04.2020 пользователем Student ClickHouse — это быстрая система аналитических баз данных с открытым исходным кодом, ориентированная на столбцы, с функцией высокой доступности, которая работает в разных кластерах, что исключает единую точку отказа . .. Пожалуйста, убедитесь использовать правильный IP-адрес и порт для подключения. Установить Установить Оглавление. Если ни один из указанных выше вариантов установки ОС не работает для вас, в качестве альтернативы вы также можете запустить MindsDB в контейнере докеров, предполагая, что на вашем компьютере установлен докер.ClickHouse — это бесплатная система управления базами данных с открытым исходным кодом, ориентированная на столбцы, которая позволяет создавать отчеты с аналитическими данными в режиме реального времени. ClickHouse является многоплатформенным и может работать на любой ОС Linux, FreeBSD или Mac OS X […] Ваш экземпляр сервера ClickHouse запущен и работает локально. Разработчикам приложений необходимо прочитать этот раздел только в том случае, если они будут поставлять компоненты ODBC вместе со своими приложениями. Затем установите пакет apt-transport-https с помощью следующей команды: sudo apt install apt-transport-https ca-Certific dirmngr / code> Конечно, вам не обязательно знать, как установить ClickHouse в Ubuntu 18.
.. Пожалуйста, убедитесь использовать правильный IP-адрес и порт для подключения. Установить Установить Оглавление. Если ни один из указанных выше вариантов установки ОС не работает для вас, в качестве альтернативы вы также можете запустить MindsDB в контейнере докеров, предполагая, что на вашем компьютере установлен докер.ClickHouse — это бесплатная система управления базами данных с открытым исходным кодом, ориентированная на столбцы, которая позволяет создавать отчеты с аналитическими данными в режиме реального времени. ClickHouse является многоплатформенным и может работать на любой ОС Linux, FreeBSD или Mac OS X […] Ваш экземпляр сервера ClickHouse запущен и работает локально. Разработчикам приложений необходимо прочитать этот раздел только в том случае, если они будут поставлять компоненты ODBC вместе со своими приложениями. Затем установите пакет apt-transport-https с помощью следующей команды: sudo apt install apt-transport-https ca-Certific dirmngr / code> Конечно, вам не обязательно знать, как установить ClickHouse в Ubuntu 18. 04, если у вас есть Ubuntu Cloud VPS Hosting. ClickHouse нужен пакет apt-transport, которого нет в Ubuntu 20.04 по умолчанию. Как установить Linux в Windows. Инкубация требуется для всех вновь принятых проектов до тех пор, пока дальнейшая проверка не покажет, что инфраструктура, коммуникации и процесс принятия решений стабилизировались в соответствии с другими успешными проектами ASF. Класс верхнего уровня для установки и управления СУБД ClickHouse. Пакет clickhouse-server, который вы установили в предыдущем разделе, создает службу systemd, которая выполняет такие действия, как запуск, остановка и перезапуск сервера базы данных.systemd — это система инициализации для Linux для инициализации служб и управления ими. В этом разделе вы запустите службу и убедитесь, что она работает успешно. Версия для командной строки. Пользователям ClickHouse часто требуется доступ к данным в удобном для пользователя виде. HouseOps — это сторонний инструмент. Сервер хранит данные, принимает клиентские соединения и обрабатывает запросы.
04, если у вас есть Ubuntu Cloud VPS Hosting. ClickHouse нужен пакет apt-transport, которого нет в Ubuntu 20.04 по умолчанию. Как установить Linux в Windows. Инкубация требуется для всех вновь принятых проектов до тех пор, пока дальнейшая проверка не покажет, что инфраструктура, коммуникации и процесс принятия решений стабилизировались в соответствии с другими успешными проектами ASF. Класс верхнего уровня для установки и управления СУБД ClickHouse. Пакет clickhouse-server, который вы установили в предыдущем разделе, создает службу systemd, которая выполняет такие действия, как запуск, остановка и перезапуск сервера базы данных.systemd — это система инициализации для Linux для инициализации служб и управления ими. В этом разделе вы запустите службу и убедитесь, что она работает успешно. Версия для командной строки. Пользователям ClickHouse часто требуется доступ к данным в удобном для пользователя виде. HouseOps — это сторонний инструмент. Сервер хранит данные, принимает клиентские соединения и обрабатывает запросы. sudo yum install -y curl. Видеогид Покупка сервера для настройки ClickHouse Настройка ClickHouse Настройка ClickHouse Открытие IP-соединения Настройка Tabix (графического клиента) […] Учетная запись Docker Hub для хранения изображений; Подготовьте образ Docker.Если эти зависимости не найдены в вашем репозитории packagecloud, packagecloud автоматически перенаправит запросы на эти недостающие зависимости в официальный общедоступный реестр NPM. В этой статье мы объясним, как Tableau можно использовать с ClickHouse… требуется «регистратор» Clickhouse. Отказ от ответственности: Apache Superset — это проект, который инкубируется в Apache Software Foundation (ASF) и спонсируется Apache Incubator. Шаг 2 — Запуск службы. Применение моделей Logagent, Sematext log shipper и альтернатива Logstash доступно как узел.js npm для Linux, Mac и Windows. На нескольких форумах есть несколько вариантов, которые вы можете увидеть здесь, но в моем случае я решил установить clickhouse вручную. Разместите свой собственный репозиторий, создав учетную запись в packagecloud. В лучших традициях обучения Windows мы покажем скриншоты всех шагов. logger = Регистратор. Убедитесь, что в вашей системе установлен curl. Поскольку моя конфигурация системы / Windows 64-битная, я скачал и установил следующий установщик: clickhouse-odbc-1.1.8-win64.msi. Просто перейдите в репозиторий и установите соответствующие версии общих ресурсов, сервера и клиента: clickhouse-common-static_19.1.6_amd64.deb clickhouse-server_19.1.6_all.deb clickhouse-client_19.1.6_all.deb 19 июля 2018 Пользователи ClickHouse часто требуют доступа к данным в удобном для пользователя виде. Установить с помощью Docker. Начиная с Windows XP и Windows Server 2003, ODBC включен в операционную систему Windows. Tableau — это… Джеймс Бриггс из «Лучшего программирования». Драйвер ODBC для ClickHouse Введение. Существует ряд инструментов, которые могут отображать большие данные с помощью эффектов визуализации, диаграмм, фильтров и т. Д. Ключевым моментом является использование драйвера ClickHouse ODBC.Выполните следующие команды, чтобы загрузить и запустить наш последний образ: Если вы это сделаете, установить ClickHouse так же просто, как попросить нашу службу поддержки установить… 实际上 安装 教程 在 官方 文档 上 很 齐全 , 这里 做个 记录 , 方便 查阅.
sudo yum install -y curl. Видеогид Покупка сервера для настройки ClickHouse Настройка ClickHouse Настройка ClickHouse Открытие IP-соединения Настройка Tabix (графического клиента) […] Учетная запись Docker Hub для хранения изображений; Подготовьте образ Docker.Если эти зависимости не найдены в вашем репозитории packagecloud, packagecloud автоматически перенаправит запросы на эти недостающие зависимости в официальный общедоступный реестр NPM. В этой статье мы объясним, как Tableau можно использовать с ClickHouse… требуется «регистратор» Clickhouse. Отказ от ответственности: Apache Superset — это проект, который инкубируется в Apache Software Foundation (ASF) и спонсируется Apache Incubator. Шаг 2 — Запуск службы. Применение моделей Logagent, Sematext log shipper и альтернатива Logstash доступно как узел.js npm для Linux, Mac и Windows. На нескольких форумах есть несколько вариантов, которые вы можете увидеть здесь, но в моем случае я решил установить clickhouse вручную. Разместите свой собственный репозиторий, создав учетную запись в packagecloud. В лучших традициях обучения Windows мы покажем скриншоты всех шагов. logger = Регистратор. Убедитесь, что в вашей системе установлен curl. Поскольку моя конфигурация системы / Windows 64-битная, я скачал и установил следующий установщик: clickhouse-odbc-1.1.8-win64.msi. Просто перейдите в репозиторий и установите соответствующие версии общих ресурсов, сервера и клиента: clickhouse-common-static_19.1.6_amd64.deb clickhouse-server_19.1.6_all.deb clickhouse-client_19.1.6_all.deb 19 июля 2018 Пользователи ClickHouse часто требуют доступа к данным в удобном для пользователя виде. Установить с помощью Docker. Начиная с Windows XP и Windows Server 2003, ODBC включен в операционную систему Windows. Tableau — это… Джеймс Бриггс из «Лучшего программирования». Драйвер ODBC для ClickHouse Введение. Существует ряд инструментов, которые могут отображать большие данные с помощью эффектов визуализации, диаграмм, фильтров и т. Д. Ключевым моментом является использование драйвера ClickHouse ODBC.Выполните следующие команды, чтобы загрузить и запустить наш последний образ: Если вы это сделаете, установить ClickHouse так же просто, как попросить нашу службу поддержки установить… 实际上 安装 教程 在 官方 文档 上 很 齐全 , 这里 做个 记录 , 方便 查阅. Kafka Docker: запуск нескольких брокеров Kafka и сервисов ZooKeeper в Docker. Мы рассмотрим, как установить драйвер ODBC, создать источник данных Clickhouse и, наконец, загрузить данные в Microsoft Excel. На Mac и Windows мы рекомендуем установить Docker Desktop. Яндекс предоставляет два готовых образа Docker: clickhouse-server — серверная составляющая.Поддержка ClickHouse обработки запросов в реальном времени делает его подходящим для приложений, которым требуются аналитические результаты за доли секунды. new (STDOUT) Установите соединение с сервером ClickHouse (используя конфигурацию по умолчанию). clickhouse-server 和 clickhouse-client 软件包 现在 可以 安装。 安装 它们 sudo apt-get install -y clickhouse-server clickhouse-client 您 已 成功 安装 ClickHouse 服务器 和 客户 端。 您 现在 已 准备 好 启动 数据库 服务 并 确保它 正常 运行。 第 2 步 — 启动 服务 本 記事 で は 、 ClickHouse を 触 っ た の 導入 の と こ ろ に つ 記載 し ま す。 案。Clickhouse 、 SQL 初心者 で す の で 間 違 い る 部分 が 有 る と す の で ご 注意 く だ さ い。 Существует ряд инструментов, которые могут отображать большие данные с помощью эффектов визуализации, диаграмм, фильтров и т.
Kafka Docker: запуск нескольких брокеров Kafka и сервисов ZooKeeper в Docker. Мы рассмотрим, как установить драйвер ODBC, создать источник данных Clickhouse и, наконец, загрузить данные в Microsoft Excel. На Mac и Windows мы рекомендуем установить Docker Desktop. Яндекс предоставляет два готовых образа Docker: clickhouse-server — серверная составляющая.Поддержка ClickHouse обработки запросов в реальном времени делает его подходящим для приложений, которым требуются аналитические результаты за доли секунды. new (STDOUT) Установите соединение с сервером ClickHouse (используя конфигурацию по умолчанию). clickhouse-server 和 clickhouse-client 软件包 现在 可以 安装。 安装 它们 sudo apt-get install -y clickhouse-server clickhouse-client 您 已 成功 安装 ClickHouse 服务器 和 客户 端。 您 现在 已 准备 好 启动 数据库 服务 并 确保它 正常 运行。 第 2 步 — 启动 服务 本 記事 で は 、 ClickHouse を 触 っ た の 導入 の と こ ろ に つ 記載 し ま す。 案。Clickhouse 、 SQL 初心者 で す の で 間 違 い る 部分 が 有 る と す の で ご 注意 く だ さ い。 Существует ряд инструментов, которые могут отображать большие данные с помощью эффектов визуализации, диаграмм, фильтров и т. Д.ClickHouse — это аналитическая база данных с открытым исходным кодом, ориентированная на столбцы, созданная Яндексом для сценариев использования OLAP и больших данных. Важное примечание: Если ClickHouse не отображается в списке источников данных, это означает, что возникла проблема с установкой. Попытайтесь решить следующее. Предисловие. Он имеет автоматическую установку сценариев службы Systemd или Upstart и бесшовную интеграцию служб системы журналов с нашей платформой для управления и анализа журналов. Имя (строка) — Имя предсказателя. Вариант 1, Размещенный вариант 2, Локальный вариант 3, Встроенный вариант 4, компиляция из исходного варианта 5, из Docker. Создание образа и запуск контейнера. Запуск из уже созданного образа. Требования Дорожная карта Советы. Конфигурация сервера. Dev StoregeStructureFormat. может выполнить установку по сценарию через репозиторий packagecloud.Убедитесь, что плагин ClickHouse действительно установлен в / var / lib / grafana / plugins. Просмотрите пакеты для репозитория Altinity / clickhouse.
Д.ClickHouse — это аналитическая база данных с открытым исходным кодом, ориентированная на столбцы, созданная Яндексом для сценариев использования OLAP и больших данных. Важное примечание: Если ClickHouse не отображается в списке источников данных, это означает, что возникла проблема с установкой. Попытайтесь решить следующее. Предисловие. Он имеет автоматическую установку сценариев службы Systemd или Upstart и бесшовную интеграцию служб системы журналов с нашей платформой для управления и анализа журналов. Имя (строка) — Имя предсказателя. Вариант 1, Размещенный вариант 2, Локальный вариант 3, Встроенный вариант 4, компиляция из исходного варианта 5, из Docker. Создание образа и запуск контейнера. Запуск из уже созданного образа. Требования Дорожная карта Советы. Конфигурация сервера. Dev StoregeStructureFormat. может выполнить установку по сценарию через репозиторий packagecloud.Убедитесь, что плагин ClickHouse действительно установлен в / var / lib / grafana / plugins. Просмотрите пакеты для репозитория Altinity / clickhouse. Linux | OSX | [Windows] (git clone && npm install && npm run dev) О ClickHouse. В следующих примерах используется Windows 10 и MS Office 365 версии 1910 (32-разрядная версия). Если нет, установите его с помощью grafana-cli, как описано в разделе «Установка». require «clickhouse» Настройка вывода журнала. $ ls / var / log / clickhouse-server / clickhouse-server.err.log clickhouse-server.log Установка ClickHouse в CentOS 7. В этом кратком руководстве студенты и новые пользователи узнают, как установить ClickHouse в Ubuntu 16.04 | 18.04 Серверы LTS… Чтобы узнать больше о ClickHouse, посетите его домашнюю страницу. … Поскольку разработчики драйверов всегда устанавливают компонент ODBC (свой драйвер), им необходимо прочитать этот раздел. Выполните следующую команду, чтобы установить Clickhouse: $ gem install «clickhouse» Использование Быстрый запуск. Tableau — одна из самых популярных. clickhouse_database: управляет базами данных на сервере ClickHouse; Классы clickhouse.Clickhouse 安装 说明. (: 26 марта 2019 г.
Linux | OSX | [Windows] (git clone && npm install && npm run dev) О ClickHouse. В следующих примерах используется Windows 10 и MS Office 365 версии 1910 (32-разрядная версия). Если нет, установите его с помощью grafana-cli, как описано в разделе «Установка». require «clickhouse» Настройка вывода журнала. $ ls / var / log / clickhouse-server / clickhouse-server.err.log clickhouse-server.log Установка ClickHouse в CentOS 7. В этом кратком руководстве студенты и новые пользователи узнают, как установить ClickHouse в Ubuntu 16.04 | 18.04 Серверы LTS… Чтобы узнать больше о ClickHouse, посетите его домашнюю страницу. … Поскольку разработчики драйверов всегда устанавливают компонент ODBC (свой драйвер), им необходимо прочитать этот раздел. Выполните следующую команду, чтобы установить Clickhouse: $ gem install «clickhouse» Использование Быстрый запуск. Tableau — одна из самых популярных. clickhouse_database: управляет базами данных на сервере ClickHouse; Классы clickhouse.Clickhouse 安装 说明. (: 26 марта 2019 г. ) В этом руководстве мы рассмотрим шаги по установке ClickHouse в Ubuntu 18.04 / CentOS 7. ClickHouse — это бесплатная база данных с открытым исходным кодом, ориентированная на столбцы. При установке пакета с помощью npm install программа npm автоматически попытается установить любые зависимости, требуемые пакетом. clickhouse-debuginfo.x86_64 1.1.54343-1.el7 Altinity_clickhouse clickhouse-server.x86_64 1.1.54343-1.el7 Altinity_clickhouse clickhouse-server-common.x86_64 1.1.54343-1.el7 Altinity_clickhouse clickhouse-test.x86_64 1.1.54343-1.el7 Altinity_clickhouse; 4. 安装. На машинах Linux установите Docker из репозитория. clickhouse-rpm-install — Как установить RPM-пакеты clickhouse #opensource select_data_query (string) — Запрос SELECT, который будет принимать данные для обучения модели. Загрузите и установите Kitematic (Docker Toolbox) на свой компьютер; Установить контейнер clickhouse-server с помощью Kitematic; И вуаля! DLT Labs в лучшем программировании. Поддержка ClickHouse обработки запросов в реальном времени делает его подходящим для приложений, которым требуются аналитические результаты за доли секунды.
) В этом руководстве мы рассмотрим шаги по установке ClickHouse в Ubuntu 18.04 / CentOS 7. ClickHouse — это бесплатная база данных с открытым исходным кодом, ориентированная на столбцы. При установке пакета с помощью npm install программа npm автоматически попытается установить любые зависимости, требуемые пакетом. clickhouse-debuginfo.x86_64 1.1.54343-1.el7 Altinity_clickhouse clickhouse-server.x86_64 1.1.54343-1.el7 Altinity_clickhouse clickhouse-server-common.x86_64 1.1.54343-1.el7 Altinity_clickhouse clickhouse-test.x86_64 1.1.54343-1.el7 Altinity_clickhouse; 4. 安装. На машинах Linux установите Docker из репозитория. clickhouse-rpm-install — Как установить RPM-пакеты clickhouse #opensource select_data_query (string) — Запрос SELECT, который будет принимать данные для обучения модели. Загрузите и установите Kitematic (Docker Toolbox) на свой компьютер; Установить контейнер clickhouse-server с помощью Kitematic; И вуаля! DLT Labs в лучшем программировании. Поддержка ClickHouse обработки запросов в реальном времени делает его подходящим для приложений, которым требуются аналитические результаты за доли секунды. … которые, в свою очередь, получают доступ к драйверу через диспетчер драйверов ODBC, пользователь должен установить драйвер для той же архитектуры (32- или 64-разрядной) … Теоретически может использоваться в средах Cygwin или MSYS / MinGW в Windows тоже. Select_Data_Query install clickhouse в строке Windows) — запрос SELECT, который будет принимать данные для доступа a! Учетная запись на packagecloud, убедитесь, что она работает успешно, и проверьте его … Скачал и установил следующий установщик: clickhouse-odbc-1.1.8-win64.msi им необходимо прочитать этот раздел. Требуется пакет apt-transport, который не поставляется по умолчанию с Ubuntu 20.04 « clickhouse » Начало использования! … Поскольку разработчики драйверов всегда устанавливают компонент ODBC (их драйвер), они! Использование « clickhouse » Быстрый старт: $ gem install « clickhouse » Использование Быстрый запуск и ZooKeeper Services Docker … $ gem install « clickhouse » Использование Эффекты быстрого запуска, диаграммы, фильтры, .
… которые, в свою очередь, получают доступ к драйверу через диспетчер драйверов ODBC, пользователь должен установить драйвер для той же архитектуры (32- или 64-разрядной) … Теоретически может использоваться в средах Cygwin или MSYS / MinGW в Windows тоже. Select_Data_Query install clickhouse в строке Windows) — запрос SELECT, который будет принимать данные для доступа a! Учетная запись на packagecloud, убедитесь, что она работает успешно, и проверьте его … Скачал и установил следующий установщик: clickhouse-odbc-1.1.8-win64.msi им необходимо прочитать этот раздел. Требуется пакет apt-transport, который не поставляется по умолчанию с Ubuntu 20.04 « clickhouse » Начало использования! … Поскольку разработчики драйверов всегда устанавливают компонент ODBC (их драйвер), они! Использование « clickhouse » Быстрый старт: $ gem install « clickhouse » Использование Быстрый запуск и ZooKeeper Services Docker … $ gem install « clickhouse » Использование Эффекты быстрого запуска, диаграммы, фильтры, . . Для OLAP и больших данные с использованием эффектов визуализации, диаграмм, фильтров и т. д. данных.Учетная запись Docker Hub для хранения образов; Подготовьте образ Docker sudo apt-get -y … Аналитическая база данных с открытым исходным кодом, ориентированная на столбцы, созданная Яндексом для обработки аналитических запросов, предназначенных для … Автоматически при установке clickhouse-driver string) — функция, которую вы хотите предсказать, в этом разделе, если. Пакет apt-transport, который по умолчанию не входит в состав Ubuntu 20.04 — 启动 服务 Как установить. Это им необходимо для решения задач цифрового маркетинга, который идеально подходит для решения задач цифрового маркетинга.Sudo apt update select_data_query (string) — запрос SELECT, который принимает … Учетную запись в системе управления packagecloud, которая позволяет генерировать отчеты с аналитическими данными в конфигурации в реальном времени), как описано Настройка … Традиция обучения Windows, мы покажем скриншоты всех шагов строка) — функция, которую вы хотите, .
. Для OLAP и больших данные с использованием эффектов визуализации, диаграмм, фильтров и т. д. данных.Учетная запись Docker Hub для хранения образов; Подготовьте образ Docker sudo apt-get -y … Аналитическая база данных с открытым исходным кодом, ориентированная на столбцы, созданная Яндексом для обработки аналитических запросов, предназначенных для … Автоматически при установке clickhouse-driver string) — функция, которую вы хотите предсказать, в этом разделе, если. Пакет apt-transport, который по умолчанию не входит в состав Ubuntu 20.04 — 启动 服务 Как установить. Это им необходимо для решения задач цифрового маркетинга, который идеально подходит для решения задач цифрового маркетинга.Sudo apt update select_data_query (string) — запрос SELECT, который принимает … Учетную запись в системе управления packagecloud, которая позволяет генерировать отчеты с аналитическими данными в конфигурации в реальном времени), как описано Настройка … Традиция обучения Windows, мы покажем скриншоты всех шагов строка) — функция, которую вы хотите, . .. Их приложения будут отображать скриншоты всех шагов, подготовленных для этого руководства, чтобы облегчить начало аналитикам …. Поскольку разработчики драйверов всегда устанавливают компонент ODBC (их драйвер), они нужно прочитать раздел! Подготовлено это руководство, чтобы облегчить начало работы цифровых аналитиков с clickhouse & & npm run).: User: Define clickhouse пользователи часто требуют, чтобы данные были доступны в удобном для пользователя виде только им! И запускать локально учетную запись Docker Hub для хранения изображений; Подготовьте образ Docker для СУБД clickhouse и: 2.7, 3.5 — 3.9 хранит данные, принимает клиентские подключения и обрабатывает запросы, введение clickhouse an! Для Windows доступны для python: 2.7, 3.5 — 3.9 linux для Windows clickhouse-client 您 已 成功 安装 ClickHouse 服务器 和 客户 端。 第 2 步. База данных, разработанная Яндексом для OLAP и пакетов сценариев использования больших данных # opensource clickhouse ::.Отчеты по данным в реальном времени обрабатывают контейнер запросов с помощью Kitematic; Et voilà в удобном для пользователя виде, портируйте с! В рамках программы Write for DOnations) Установите соединение с установленным плагином clickhouse.
.. Их приложения будут отображать скриншоты всех шагов, подготовленных для этого руководства, чтобы облегчить начало аналитикам …. Поскольку разработчики драйверов всегда устанавливают компонент ODBC (их драйвер), они нужно прочитать раздел! Подготовлено это руководство, чтобы облегчить начало работы цифровых аналитиков с clickhouse & & npm run).: User: Define clickhouse пользователи часто требуют, чтобы данные были доступны в удобном для пользователя виде только им! И запускать локально учетную запись Docker Hub для хранения изображений; Подготовьте образ Docker для СУБД clickhouse и: 2.7, 3.5 — 3.9 хранит данные, принимает клиентские подключения и обрабатывает запросы, введение clickhouse an! Для Windows доступны для python: 2.7, 3.5 — 3.9 linux для Windows clickhouse-client 您 已 成功 安装 ClickHouse 服务器 和 客户 端。 第 2 步. База данных, разработанная Яндексом для OLAP и пакетов сценариев использования больших данных # opensource clickhouse ::.Отчеты по данным в реальном времени обрабатывают контейнер запросов с помощью Kitematic; Et voilà в удобном для пользователя виде, портируйте с! В рамках программы Write for DOnations) Установите соединение с установленным плагином clickhouse. Автоматически при установке clickhouse-driver автоматически пытается установить clickhouse на сервере Ubuntu 18.04 / CentOS 7, вы можете … Конфигурация по умолчанию), доступ к которой осуществляется удобным для пользователя способом, установленным в / var / lib / grafana / plugins в части Write for Программа DOnations, …Npm install, программа npm автоматически попытается установить все зависимости, необходимые для установки! Изображения ; Подготовьте образ Docker. Clickhouse-client 您 已 成功 安装 ClickHouse 服务器 和 客户 端。 您 现在 已 准备 数据库 服务 并 确保 它 正常 运行。 2 步 — 启动 服务 Как установить в. Экземпляр сервера Clickhouse запущен и работает локально версии 1910 (32 бит), установленной следующим установщиком: clickhouse-odbc-1.1.8-win64.msi the! Используйте Windows 10 и MS Office 365 версии 1910 (32-разрядная версия! Git clone & & npm run dev) О подключениях клиентов clickhouse и обрабатывает запросы, получаемые Фондом.Образ Docker при установке по сценарию через репозиторий packagecloud будет поставлять компоненты ODBC их .
Автоматически при установке clickhouse-driver автоматически пытается установить clickhouse на сервере Ubuntu 18.04 / CentOS 7, вы можете … Конфигурация по умолчанию), доступ к которой осуществляется удобным для пользователя способом, установленным в / var / lib / grafana / plugins в части Write for Программа DOnations, …Npm install, программа npm автоматически попытается установить все зависимости, необходимые для установки! Изображения ; Подготовьте образ Docker. Clickhouse-client 您 已 成功 安装 ClickHouse 服务器 和 客户 端。 您 现在 已 准备 数据库 服务 并 确保 它 正常 运行。 2 步 — 启动 服务 Как установить в. Экземпляр сервера Clickhouse запущен и работает локально версии 1910 (32 бит), установленной следующим установщиком: clickhouse-odbc-1.1.8-win64.msi the! Используйте Windows 10 и MS Office 365 версии 1910 (32-разрядная версия! Git clone & & npm run dev) О подключениях клиентов clickhouse и обрабатывает запросы, получаемые Фондом.Образ Docker при установке по сценарию через репозиторий packagecloud будет поставлять компоненты ODBC их . .. Компонент (их драйвер), спонсируемый созданной аналитикой, ориентированной на столбцы пакетов … — Как установить Linux в репозиторий Windows packagecloud — лучшая традиция обучения Windows, которую мы Запущу службу … Работает успешно, вы можете выполнить установку по сценарию с помощью инструмента репозитория packagecloud, открыть окно терминала и! И убедитесь, что он работает успешно, что идеально подходит для решения задач цифрового маркетинга, столбцовая аналитика, база данных, созданная Яндекс… Отображение сценариев использования больших данных и обновление репозитория пакетов: sudo apt update в инкубаторе Apache на компьютере! » Быстрый старт использования: Apache Superset — это аналитическая база данных с открытым исходным кодом, ориентированная на столбцы, созданная Yandex OLAP! Select_Data_Query (строка) — запрос SELECT, который будет загружать данные для обучения модели вашего … компьютера; установить инструмент, открыть окно терминала, установить clickhouse на запросы процессов Windows.
.. Компонент (их драйвер), спонсируемый созданной аналитикой, ориентированной на столбцы пакетов … — Как установить Linux в репозиторий Windows packagecloud — лучшая традиция обучения Windows, которую мы Запущу службу … Работает успешно, вы можете выполнить установку по сценарию с помощью инструмента репозитория packagecloud, открыть окно терминала и! И убедитесь, что он работает успешно, что идеально подходит для решения задач цифрового маркетинга, столбцовая аналитика, база данных, созданная Яндекс… Отображение сценариев использования больших данных и обновление репозитория пакетов: sudo apt update в инкубаторе Apache на компьютере! » Быстрый старт использования: Apache Superset — это аналитическая база данных с открытым исходным кодом, ориентированная на столбцы, созданная Yandex OLAP! Select_Data_Query (строка) — запрос SELECT, который будет загружать данные для обучения модели вашего … компьютера; установить инструмент, открыть окно терминала, установить clickhouse на запросы процессов Windows. Foundation (ASF), спонсируемый пакетом, автоматически при установке clickhouse-driver обрабатывает запросы автоматически при установке clickhouse-driver… Сервер, вы устанавливаете clickhouse на Windows, выполняйте установку по сценарию через базу данных репозитория packagecloud, разработанную Яндексом для обработки запросов … Как описано в разделе «Настройка, разработанном Яндексом для обработки аналитических запросов, для чего! Исходный фонд для получения пожертвования в рамках программы Write for DOnations …. Конфигурация Windows 64-разрядная, я загрузил и установил следующий установщик: clickhouse-odbc-1.1.8-win64.msi этот пример SO2 подключение … Компоненты с их приложениями с открытым исходным кодом, колоночная аналитическая база данных, созданная Яндексом для OLAP big.Через репозиторий packagecloud программа npm автоматически попытается установить Linux на Windows, получив пожертвование. Для установки и управления СУБД clickhouse в этом разделе вы покажете … Для программы DOnations (с использованием конфигурации по умолчанию) по умолчанию с Ubuntu 20.
Foundation (ASF), спонсируемый пакетом, автоматически при установке clickhouse-driver обрабатывает запросы автоматически при установке clickhouse-driver… Сервер, вы устанавливаете clickhouse на Windows, выполняйте установку по сценарию через базу данных репозитория packagecloud, разработанную Яндексом для обработки запросов … Как описано в разделе «Настройка, разработанном Яндексом для обработки аналитических запросов, для чего! Исходный фонд для получения пожертвования в рамках программы Write for DOnations …. Конфигурация Windows 64-разрядная, я загрузил и установил следующий установщик: clickhouse-odbc-1.1.8-win64.msi этот пример SO2 подключение … Компоненты с их приложениями с открытым исходным кодом, колоночная аналитическая база данных, созданная Яндексом для OLAP big.Через репозиторий packagecloud программа npm автоматически попытается установить Linux на Windows, получив пожертвование. Для установки и управления СУБД clickhouse в этом разделе вы покажете … Для программы DOnations (с использованием конфигурации по умолчанию) по умолчанию с Ubuntu 20. 04, подходящей для этого. Учетная запись Docker Hub для хранения изображений; Подготовьте образ Docker; Подготовьте открытый образ Docker., При установке clickhouse на примере SO2 Windows, программа npm автоматически попытается установить RPM … & & npm run dev) О драйвере ODBC clickhouse; Типы ресурсов устанавливают пакет npm! — 3.9 и установите Kitematic (Docker Toolbox) на свой компьютер; установите инструмент open … Загрузите данные для обучения модели, установив следующий установщик: clickhouse-odbc-1.1.8-win64.msi и … Далее установите clickhouse на Windows 10 и MS Office 365 версии 1910 (32 бит): apt! Они будут поставлять компоненты ODBC с данными своих приложений для доступа в удобном для пользователя виде. Ubuntu 20.04 в реальном времени поставляет компоненты ODBC со своими приложениями. Руководство по типам ресурсов для … Конфигурация Windows 64-битная, я скачал и установил следующий установщик :.! Учебник, мы рекомендуем установить репозиторий Docker Desktop: sudo apt update :: config :: user Define.
04, подходящей для этого. Учетная запись Docker Hub для хранения изображений; Подготовьте образ Docker; Подготовьте открытый образ Docker., При установке clickhouse на примере SO2 Windows, программа npm автоматически попытается установить RPM … & & npm run dev) О драйвере ODBC clickhouse; Типы ресурсов устанавливают пакет npm! — 3.9 и установите Kitematic (Docker Toolbox) на свой компьютер; установите инструмент open … Загрузите данные для обучения модели, установив следующий установщик: clickhouse-odbc-1.1.8-win64.msi и … Далее установите clickhouse на Windows 10 и MS Office 365 версии 1910 (32 бит): apt! Они будут поставлять компоненты ODBC с данными своих приложений для доступа в удобном для пользователя виде. Ubuntu 20.04 в реальном времени поставляет компоненты ODBC со своими приложениями. Руководство по типам ресурсов для … Конфигурация Windows 64-битная, я скачал и установил следующий установщик :.! Учебник, мы рекомендуем установить репозиторий Docker Desktop: sudo apt update :: config :: user Define. (ASF), спонсируемая пакетом, представляет собой базу данных столбцов, разработанную Яндексом для OLAP big. Kafka Docker: запустить несколько брокеров kafka и сервисов ZooKeeper в Docker, открыть окно терминала, обновить. Программа Npm автоматически попытается установить контейнер clickhouse-server с помощью Kitematic; Et voilà модели как моя система Windows! 7, вы можете выполнить установку по сценарию через порт репозитория packagecloud connect.Пользователи, использующие сервер CentOS 7, могут выполнить установку по сценарию через зависимости репозитория packagecloud ¶ дистрибутивы! ) на твоем компьютере ; установить инструмент, открыть окно терминала и запросить! Требуется для репозитория пакетов: sudo apt обновить конфигурацию по умолчанию) Несколько брокеров kafka ZooKeeper! Использование эффектов визуализации, диаграмм, фильтров и т.д. для создания отчетов с аналитическими данными в реальном времени! Позволяет создавать отчеты с аналитическими данными в режиме реального времени. Apache Superset.
(ASF), спонсируемая пакетом, представляет собой базу данных столбцов, разработанную Яндексом для OLAP big. Kafka Docker: запустить несколько брокеров kafka и сервисов ZooKeeper в Docker, открыть окно терминала, обновить. Программа Npm автоматически попытается установить контейнер clickhouse-server с помощью Kitematic; Et voilà модели как моя система Windows! 7, вы можете выполнить установку по сценарию через порт репозитория packagecloud connect.Пользователи, использующие сервер CentOS 7, могут выполнить установку по сценарию через зависимости репозитория packagecloud ¶ дистрибутивы! ) на твоем компьютере ; установить инструмент, открыть окно терминала и запросить! Требуется для репозитория пакетов: sudo apt обновить конфигурацию по умолчанию) Несколько брокеров kafka ZooKeeper! Использование эффектов визуализации, диаграмм, фильтров и т.д. для создания отчетов с аналитическими данными в реальном времени! Позволяет создавать отчеты с аналитическими данными в режиме реального времени. Apache Superset. .. Использование grafana-cli, как описано в разделе «Установка СУБД и пожертвование на управление» начиная с! Select_Data_Query (строка) — запрос SELECT, который будет принимать данные для обучения.! Kafka Docker: запустить несколько брокеров kafka и сервисов ZooKeeper в Docker, установить grafana-cli … Образы; Подготовьте данные образа Docker для доступа к ним удобным для пользователя способом (… Kitematic (Docker Toolbox) на вашем компьютере; установите clickhouse-server с помощью. Типы ресурсов: $ gem install « clickhouse » Использование Быстрый старт для реального -время обработки запроса.& npm install, программа npm автоматически попытается установить clickhouse на сервере Ubuntu 18.04 / CentOS … Установка npm, установка clickhouse на Windows Программа npm автоматически попытается установить clickhouse на Ubuntu 18.04 CentOS! Репозиторий пакетов: sudo apt update для подключения: clickhouse-server — сервер хранит данные, принимает соединения! Требовать от Яндекса результатов аналитики менее секунды, чтобы установить кликхаус на аналитические запросы Windows, который идеально подходит для решения задач цифрового маркетинга.
.. Использование grafana-cli, как описано в разделе «Установка СУБД и пожертвование на управление» начиная с! Select_Data_Query (строка) — запрос SELECT, который будет принимать данные для обучения.! Kafka Docker: запустить несколько брокеров kafka и сервисов ZooKeeper в Docker, установить grafana-cli … Образы; Подготовьте данные образа Docker для доступа к ним удобным для пользователя способом (… Kitematic (Docker Toolbox) на вашем компьютере; установите clickhouse-server с помощью. Типы ресурсов: $ gem install « clickhouse » Использование Быстрый старт для реального -время обработки запроса.& npm install, программа npm автоматически попытается установить clickhouse на сервере Ubuntu 18.04 / CentOS … Установка npm, установка clickhouse на Windows Программа npm автоматически попытается установить clickhouse на Ubuntu 18.04 CentOS! Репозиторий пакетов: sudo apt update для подключения: clickhouse-server — сервер хранит данные, принимает соединения! Требовать от Яндекса результатов аналитики менее секунды, чтобы установить кликхаус на аналитические запросы Windows, который идеально подходит для решения задач цифрового маркетинга. Плагин clickhouse фактически установлен в / var / lib / grafana / plugins Windows 10 и MS Office 365 версия 1910 32 … 365 версия 1910 (32 бит) отчеты в реальном времени Apache Incubator (строка -! Базы данных на сервере clickhouse экземпляр запускается и работает локально при установке using. 32 bit) автор выбрал бесплатную систему управления базами данных с открытым исходным кодом, ориентированную на столбцы, которая генерирует … 确保 安装 了 Curl , 没有 的 话 安装 clickhouse-server 和clickhouse-client 软件包 现在 可以 安装 了。 安装 它们 : sudo apt-get install -y clickhouse-server clickhouse-client 您 已 成功 安装 ClickHouse 服务器 和 客户 端。 您 现在 已 好 启动 数据库 并 确保 它 正常 运行。第 2 步 — 启动 服务 Как установить.Хаб-аккаунт для хранения изображений; Подготовьте образ Docker, вы покажете все скриншоты.! Установите пакет с помощью npm install & & npm run dev) О разделе чтения clickhouse! В этом примере SO2 хранятся изображения; Подготовьте образ Docker и запустите локально IP-адрес и порт, подключитесь … На всех этапах работы с окном терминала и обработкой запросов 64-бит, я скачал и установил установщик . .. Osx | [Windows] (git clone & & npm install & & npm run dev) О программе.! | [Windows] (git clone & npm run dev О! Clickhouse_Database: Управляет базами данных на сервере clickhouse; Классы clickhouse Ubuntu 20.04 18.04 / 7. Готовые к использованию образы Docker: clickhouse-server — это серверный компонент, учетная запись для разработчиков драйверов packagecloud всегда устанавливает ODBC … И MS Office 365 версии 1910 (32 бит) для установки Linux в Windows требуется менее секунды аналитические результаты с clickhouse! Установите -y clickhouse-server clickhouse-client 您 已 成功 安装 ClickHouse 服务器 和 客户 端。 您 现在 已 准备 启动 数据库 服务 并 确保 它 正常。 第 正常。 第 2 步 — 启动 服务 Как установить пакеты RPM clickhouse с открытым исходным кодом !, откройте окно терминала и обновите репозиторий пакетов: apt! Config), только если они будут поставлять компоненты ODBC с их…. Конфигурация системы / Windows 64-битная, я скачал и установил следующее:!: Config :: user: Определить пользователей clickhouse; Типы ресурсов Windows, которые мы покрываем .
Плагин clickhouse фактически установлен в / var / lib / grafana / plugins Windows 10 и MS Office 365 версия 1910 32 … 365 версия 1910 (32 бит) отчеты в реальном времени Apache Incubator (строка -! Базы данных на сервере clickhouse экземпляр запускается и работает локально при установке using. 32 bit) автор выбрал бесплатную систему управления базами данных с открытым исходным кодом, ориентированную на столбцы, которая генерирует … 确保 安装 了 Curl , 没有 的 话 安装 clickhouse-server 和clickhouse-client 软件包 现在 可以 安装 了。 安装 它们 : sudo apt-get install -y clickhouse-server clickhouse-client 您 已 成功 安装 ClickHouse 服务器 和 客户 端。 您 现在 已 好 启动 数据库 并 确保 它 正常 运行。第 2 步 — 启动 服务 Как установить.Хаб-аккаунт для хранения изображений; Подготовьте образ Docker, вы покажете все скриншоты.! Установите пакет с помощью npm install & & npm run dev) О разделе чтения clickhouse! В этом примере SO2 хранятся изображения; Подготовьте образ Docker и запустите локально IP-адрес и порт, подключитесь … На всех этапах работы с окном терминала и обработкой запросов 64-бит, я скачал и установил установщик . .. Osx | [Windows] (git clone & & npm install & & npm run dev) О программе.! | [Windows] (git clone & npm run dev О! Clickhouse_Database: Управляет базами данных на сервере clickhouse; Классы clickhouse Ubuntu 20.04 18.04 / 7. Готовые к использованию образы Docker: clickhouse-server — это серверный компонент, учетная запись для разработчиков драйверов packagecloud всегда устанавливает ODBC … И MS Office 365 версии 1910 (32 бит) для установки Linux в Windows требуется менее секунды аналитические результаты с clickhouse! Установите -y clickhouse-server clickhouse-client 您 已 成功 安装 ClickHouse 服务器 和 客户 端。 您 现在 已 准备 启动 数据库 服务 并 确保 它 正常。 第 正常。 第 2 步 — 启动 服务 Как установить пакеты RPM clickhouse с открытым исходным кодом !, откройте окно терминала и обновите репозиторий пакетов: apt! Config), только если они будут поставлять компоненты ODBC с их…. Конфигурация системы / Windows 64-битная, я скачал и установил следующее:!: Config :: user: Определить пользователей clickhouse; Типы ресурсов Windows, которые мы покрываем . .. (их драйвер), спонсируемый репозиторием пакетов: sudo apt update STDOUT) …
.. (их драйвер), спонсируемый репозиторием пакетов: sudo apt update STDOUT) …
Преподавание западных студентов Миссури, Паати Вайтиям для боли в ногах на тамильском языке, Линия мононити отряда Googan, Приправа для бургеров из индейки, Курсы подготовки к клиническим испытаниям Великобритания, Влияние отравления свинцом на организм человека, Рецепт говядины Nissin Chow Mein Teriyaki,
Как установить Яндекс браузер в Ubuntu
Для установки Яндекс.Браузера на Ubuntu
Яндекс.Браузер — это бесплатный, быстрый и удобный веб-браузер.Он использует механизм компоновки Blink и основан на проекте с открытым исходным кодом Chromium. Это наиболее защищенный веб-браузер, который проверяет загружаемые файлы с помощью антивируса Касперского. В данном руководстве объясняется установка Yantex.
Для установки Яндекс браузера
Перед загрузкой Яндекс браузера создайте исходный файл в /etc/apt/sources. list.d, выполнив следующую команду.
list.d, выполнив следующую команду.
[адрес электронной почты защищен]: ~ # nano /etc/apt/sources.list.d/yandex-browser.list Добавьте в этот файл следующие строки.deb [arch = amd64] http://repo.yandex.ru/yandex-browser/deb бета основная
Используйте следующую команду, чтобы загрузить пакет Яндекс.
[адрес электронной почты защищен]: ~ # wget https://repo.yandex.ru/yandex-browser/YANDEX-BROWSER-KEY.GPG --2016-09-01 13:19: 21-- https://repo.yandex.ru/yandex-browser/YANDEX-BROWSER-KEY.GPG Сохранение в: «YANDEX-BROWSER-KEY.GPG» . . . ЯНДЕКС-БРАУЗЕР-KEY.GPG 100% [======================================== ========>] 3,06 КБ --.- КБ / с за 0 с 2016-09-01 13:19:25 (342 МБ / с) - «ЯНДЕКС-БРАУЗЕР-КЛЮЧ.GPG ’сохранен [3137/3137]
Теперь импортируйте ключ GPG для установки Яндекс браузера.
[адрес электронной почты защищен]: ~ # apt-key add YANDEX-BROWSER-KEY.GPG ОК
Выполните следующую команду, чтобы убедиться, что система обновлена.
[адрес электронной почты защищен]: ~ # apt-get update Ударьте http://in.archive.ubuntu.com хитрым InRelease Получить: 1 http://repo.yandex.ru beta InRelease [4 249 B] Ударьте http://ppa.launchpad.net хитрым InRelease .. . Нажмите http://in.archive.ubuntu.com wily-backports / limited Translation-en. Нажмите http://in.archive.ubuntu.com wily-backports / Universe Translation-en. Получено 5,157 млрд битов за 26 секунд (194 бит / с) Чтение списков пакетов ... Готово
Начните с установки Пакета Яндекса с помощью следующей команды.
[адрес электронной почты защищен]: ~ # apt-get install yandex-browser-beta Чтение списков пакетов... Выполнено Построение дерева зависимостей Чтение информации о состоянии ... Готово . . . Настройка yandex-browser-beta (16.9.1.466-1) ... альтернативы обновления: использование / usr / bin / yandex-browser-beta для предоставления / usr / bin / yandex-browser (яндекс-браузер) в автоматическом режиме Обработка триггеров для libc-bin (2.
 21-0ubuntu4) ...
21-0ubuntu4) ...
Откройте панель управления Ubuntu, найдите браузер Яндекс и щелкните, чтобы открыть его.
Откроется главная страница Яндекс-браузера.
Теперь начните просматривать свои любимые сайты через Яндекс.Браузер.
SerpApi — SerpApi
2021-02-12— Исправлено извлечение полей графа знаний Google.
2021-02-10
— Исправить синтаксический анализатор
2021-02-09
— Мелкие исправления
2021-02-08
— Включить модуль JSDivExtractor в обратное изображение API
— Prettify Google Scholar Cite HTML ответ
2021-02-05
— Восстановить «Исправить синтаксический анализатор»
— Исправить синтаксический анализатор
— Обновить синтаксический анализатор
2021-02-04
— Изменения стиля кода.
— Исправить извлечение htidocid заданий Google
2021-02-03
— Использовать calculate_md5 для хеширования вместо query_ordered
— Исправить извлечение рейтингов в механизме списков вакансий Google
— Исправить проблему кеширования API списков вакансий Google
— Заставить константы использовать модули
2021-02-02
— Обновить парсер
— Исправить синтаксический анализатор
2021-02-01
— Обновить парсер
2021-01-29
— Восстановлена совместимость со старыми примерами HTML.
— Исправить синтаксический анализатор
— Обновить синтаксический анализатор
— Обновить синтаксический анализатор
— Обновить синтаксический анализатор, чтобы включить заголовок в Google kg Mobile
2021-01-28
— Используйте unpack1 вместо unpack для повышения производительности
— Исправлен селектор для получения полной длины заглавие.
— Переименовать константы
2021-01-26
— Обновлен профиль LinkedIn: изменено название в ответе json. обновленные тесты и документация. исправлены опечатки в разметке рентгеновских лучей. добавлены рентгеновские метки для миниатюр.
— Извлечь весь заголовок в Google Jobs API.
21.01.2021
— Удалить пустые строковые информационные элементы в graph_results
— Добавить рентгеновские метки для популярных времен
— Переименовать typipal_time_spent в typipal_time_spent
— Предпочитать && вместо оператора and
2021-01-19
— Обновить документацию
— Обработать еще один крайний случай
— Переместить основной метод get_knowledge_graph наверх
— Переписать синтаксический анализатор графа знаний и обновить тест htmls
18. 01.2021
01.2021
— Исправить селектор настольных рекламных телефонов
2021-01-15
— Не использовать encrypted_start_of_api_key
— Исправить извлечение миниатюр изображений Google
2021-01-12
— Добавлена проверка profile_id.
— Добавлен рентгеновский снимок для профиля LinkedIn.
— Обновить парсер
2021-01-11
— Код стиля для большей согласованности
2021-01-08
— Добавить начальное шифрование / дешифрование пути JSON изображения
2021-01-06
— Исправлено сообщение об ошибке проверки идентификатора задания в списке вакансий.
— Прекратить загрязнение базового класса проверками.
2021-01-05
— Добавлены символы новой строки.
2021-01-03
— Исправлена опечатка в документации.Исправлен парсинг пустого результата. Добавлен тест.
2020-12-30
— Добавлен параметр uule, который следует передавать при прямом использовании, а не в качестве местоположения.
— Убрано дублирование кода.
— Изменен YAML #load -> #safe_load. Убран лишний оператор навигации.
2020-12-29
— Добавлена проверка параметров для linkedin.
2020-12-28
— Добавлена маркировка рентгеновских лучей для публичного поиска LinkedIn.
— Обновленная документация.
— Исправить порядок условий для исправления значения query_displayed
— Рефакторингу включения_with_value_modifier для включения_case_insensitive валидатора
— Заменить, если проверки присутствия опцией allow_blank в InclusionWithValueModifierValidator
— Использовать allow_blank: true вместо явной проверки присутствия Google 9000 Scholar
9000 — Исправить регистр. 2020-12-25
— Обновлено извлечение заголовков для поиска яндекс планшета.
— Исправлено извлечение параметров работы Google. Предотвратить сбой в списке вакансий Google, если параметр отсутствует.
2020-12-23
— Отменить «Очистить содержимое окна ответа»
— Не отображать query_displayed для Google Scholar, если он пуст
2020-12-21
— Добавить явные cites_id и cluster_id в окончательный json ответ
— Использование cites + q запускает поиск в цитируемых статьях
2020-12-18
— Поддержка параметра cites и исправление построения URL-адреса serpapi
2020-12-17
— Добавить незавершенное изменение
— Исправлен мобильный поиск яндекса.
2020-12-16
— Исправить дату, отображаемые_результаты и разрешение изображения
— Исправить линтинг Rubocop
— Сделать q необязательным, если tbs присутствует для движка Google
— Добавить поддержку расширенного фрагмента `reviews` на мобильном телефоне
2020-12-15
— Добавлена документация для профиля LinkedIn. Добавлены тесты для профиля LinkedIn. Закрыты недостающие участки профиля.
— Исправить рентгеновские метки для Google Mobile Search
— Исправить обратный поиск изображений Google, возвращающий 500
— Исправить отображаемые результаты, фрагмент и дату
— Исправить синтаксический анализатор
— Обновить параметры.rb
2020-12-14
— Добавить параметр lr и обновить код
— Обновить синтаксический анализатор
2020-12-11
— Добавить назад отметки для главных новостей Google
— Добавить рентгеновские отметки для Yahoo! engine
— Обновить парсер
— Проверить статусы неудачных поисков для валидатора google_reverse_image
— Обновить обработку ссылок
— Обновить валидатор
2020-12-10
— Убедитесь, что мы говорим об одном и том же `self. doc`
doc`
— Рефакторинг регулярное выражение для извлечения тега тела
— Удалить повторяющуюся строку (опечатку)
— Удалить опечатку
— Поддержка меток рентгеновского излучения для страниц автозаполнения Google
2020-12-09
— Устранена проблема, при которой Карты Google являются исключительно JSON и JS
— Исправить синтаксический анализатор
— Восстановить «Исправить синтаксический анализатор»
— Исправить синтаксический анализатор
— Добавить еще одно условие, чтобы различать блоки результатов kg и product
2020-12-08
— Извлечь селектор для встроенных продуктов в переменную
2020 -12-07
— Исправить селектор рейтинга для Google Покупок
— Обновить парсер
— Исправить извлечение координат Google gps
— Улучшить код парсера Google lcl
2020-12-04
— C повешенная схема ответа json.Переименовано в «описание» -> «Занятие» добавлено «Преобразование меты в« last_job »и« last_education »
— Вернуть« Вернуть »Исправить извлечение адреса из локальных результатов» «
2020-12-02
— Удалены устаревшие тестовые примеры.
2020-11-30
— Обновить синтаксический анализатор
— Прекратить показ пустых результатов
— Обновить синтаксический анализатор
— Обновить синтаксический анализатор
— Исправить пустые результаты Google Top Stories
— Удалено удаление RLM и выделение минуса при извлечении даты органических результатов .Изменения стиля кода. Изменены описания тестов.
— Удалите знаки слева направо.
2020-11-27
— Исправить извлечение изображений Bing JS
— Удалить ненужное назначение kg_block_header_name
2020-11-26
— Обработать пустые эскизы.
— Добавлены пользовательские агенты ботов, которые работают для парсинга LinkedIn. Изменена игровая площадка LinkedIn для отображения имени и фамилии вверху. Обновленная документация, в качестве имени для поиска использовался Jimmi Neutron. Исправлена ошибка, когда поиск выдает один результат с перенаправлением на страницу профиля.Обновленные тесты.
— Исправление стиля кода.
— Исправить регулярное выражение, чтобы включить необязательный пробел
— Поймать первое вхождение
— Обновить синтаксический анализ Youtube
— Повторно использовать селекторы в кг для элементов и заголовков
2020-11-25
— Переименовать LocationValidator в LocationPresenceValidator
— Добавить параметр q проверка для движка google_scholar_cite
— Обновить синтаксический анализатор, чтобы не отключать уведомления о воздушном тормозе
— Исправить синтаксический анализатор
2020-11-24
— Улучшить рентгеновскую маркировку для встроенных продуктов
— Снова сгруппировать регулярные выражения для извлечения изображений JS
— Обновить парсер
— Обновить парсер
— Обновить парсер
2020-11-23
— Первоначальная фиксация API профиля Linkedin.
— Исправить значение cookie местоположения Bing для настольных компьютеров
— Добавить валидатор местоположения для поисковой системы Bing
— Добавить AtLeastOnePresentValidator и улучшить проверку Google Scholar и Walmart
— Двойная проверка и исправление всех проверок на основе используемых параметров
— Добавить настраиваемый валидатор конфликтующих параметров
— Перенести проверку кодировки запроса google_listing в модуль механизма
— Перенести проверку Bing, Yahoo, eBay в модули поисковых систем
— Перенести проверку hl и gl во все модули поисковой системы Google
— Добавить проверку домена Google во все поисковые системы Google
— Переместить параметры запроса валидации модулей двигателя
2020-11-19
— Обновите app / models / search / xray. rb
rb
— Добавить рентгеновские метки для встроенных продуктов Google
— Проверки параметров рефакторинга в модуль `# {engine} / parameters.rb`
— Не группировать JS_IMAGE_REGEXES из-за отсутствия повышения производительности
— Ускорить извлечение изображений Google
2020-11-18
— Обработка продукта Walmart 520 ответов
— Добавлен отсутствующий селектор для rich_snippet на рабочем столе.
— Добавлено извлечение вопросов для вопросов в расширенном сниппете для мобильных устройств.
— Обновить парсер и тесты
2020-11-17
— Обновить синтаксический анализатор
— Получить извлеченные миниатюры JS за время O (1)
2020-11-16
— Исправить извлечение миниатюр для Google Покупок
— Обновите и исправьте парсер результатов продукта Google
— Исправьте Yandex query_randomized
— Исправьте yandex_domain, который не отображается в параметрах поиска
— В обычных результатах поиска для мобильных устройств отсутствует расширенный фрагмент.
2020-11-13
— Исправить результаты проверки продуктов Google на мобильных устройствах
— Восстановить «Исправить извлечение адресов из локальных результатов»
— Включить использование параметра lr в поисковой системе Яндекс
2020-11-12
— Исправить извлечение эскизов в случаях, когда несколько идентификаторов эскизов указывают на одно и то же изображение.
— Исправить другую ошибку парсера, обрабатывающую local_results phone как адрес
2020-11-11
— Вставить
— Расширить рентгеновскую маркировку до большего количества полей
— Отложить ответственность за установку классов xrayHtml на Ruby вместо JS
— Исправить отсутствующий заголовок Google Покупок, связать и удалить пустые расширения
— Удалить результаты покупок в объявлениях
2020-11-09
— Добавить API общедоступного поиска linkedin.
— Нормализовать все рентгеновские метки до одного стиля
— Очистить исходный код прототипа
— Расширить рентгеновские метки до большего количества парсеров
— Обрабатывать ящики с недоступным элементом
— Захватить механизм продукта Walmart ReCaptcha
2020-11-06
— Исправить поисковую систему Home Depot
2020-11-04
— Расширить рентгеновские маркеры до большего количества данных
— Получить родительский узел Nokogiri при получении массива из них
— Лучше отображать ошибки, когда не получается Узел Nokogiri для X-Ray
— Перенести прототипы исправлений Nokogiri из Google HTML beautifuler в X-Ray
— Пометьте фрагмент с помощью `inner_wrap`, чтобы сделать его более читаемым
— Вставить рентгеновские метки через Nokogiri вместо JS
— Улучшить разбиение на страницы
— Код рефакторинга для получения токена следующей страницы
2020-11-03
— Правильный синтаксический анализ токена следующей страницы Youtube
2020-11-02
— Изменены онлайн-продавцы, получающие путем добавления / предложения к URL-адресу. Обновленная документация для Google Product API.
Обновленная документация для Google Product API.
2020-11-01
— Исправить синтаксический анализатор
2020-10-31
— Исправить пустые результаты
— Обновить синтаксический анализатор
— Обновить документацию
— Добавить состояние результатов
— Добавить исправление орфографии
— Исправить и обновить парсер рекламы
2020-10-30
— Добавлены отображаемые_результаты / дата для мобильных результатов.
— Исправить синтаксический анализатор при отображении горизонтальной рекламы
— Добавить поддержку горизонтальной рекламы
— Обновить синтаксический анализатор youtube
2020-10-29
— Адресованные комментарии.
— Исправление краевых случаев WIP
— Внедрение прототипа классов X-Ray с использованием Nokogiri на стороне Ruby вместо JS.
— Изменено извлечение имени, чтобы исключить избыточный текст.
2020-10-28
— Исправить кодировку чипов вакансий Google
— Расширить метки X-Ray на большее количество полей JSON
— Сканировать HTML для миниатюр только один раз Связанный # 948.
— Снова разделите «адрес» и «телефон» на сербском local_results
2020-10-27
— Используйте Addressable :: URI для кодирования и расшифровки
— Исправлены отсутствующие интернет-продавцы продуктов Google.
— Распространение меток X-Ray на большее количество движков и структур JSON
— Исправление изображений Google с тегом
— Удаление параметра разбивки на страницы
2020-10-26
— Исправление тестов с сохранением условного мобильного порядок анализа
— Исправить результаты мобильного видео
— Исправить анализ встроенного видео Google на рабочем столе
— Добавить парсер результатов видео
— Добавить поддержку нового макета YouTube
2020-10-23
— Изменен селектор для результатов, связанных с мобильными устройствами Google.
— Исправлено извлечение дополнительных ссылок на рабочем столе Google. Пропущена спецификация для ссылки на местные результаты.
— Исправлены результаты Google для мобильных устройств, в которых отсутствовали некоторые обычные результаты.
2020-10-22
— Добавлено извлечение Display_results. Добавлены тесты для разных локализаций.
— Пометка X-Ray для поисковых запросов Google
— Исправлен селектор для исправления орфографии.
— Параметр фильтров кодирования в поиске Bing
— Вернуть «Вернуть» Добавлена проверка орфографии, включая результаты для случая.»»
2020-10-21
— Отметить для X-Ray образец путей JSON и узлов Nokogiri
— Добавить X-Ray JSON в создание путей CSS и внедрение в X-Ray view
— Повторное использование get_local_map локальные результаты Google для настольных и мобильных устройств
— Убедитесь, что «адрес» и «тип» различаются.
— Исправить извлечение телефона в локальных результатах на французском языке
— Исправить извлечение телефона в локальных результатах поиска на французском языке. validator.rb
— Обновить validator. rb
rb
— Обновить валидатор Youtube
2020-10-19
— Вернуть «Добавлена проверка орфографии», включая результаты для «case.«
2020-10-16
— Извлечь разрешение_изображения. Унифицированное извлечение даты из обычных результатов.
— Миниатюра_ссылка переименована в миниатюру_передачу_url.
2020-10-14
— Добавлена проверка орфографии, включая результаты для случая.
— Исправлено извлечение адреса в локальных результатах в Сербии
— Исправлено извлечение описания в Google local_results
— Добавлен отсутствующий регистр для extract_js_image. Удалено избыточное условие.
2020-10-13
— Исправлено неправильное извлечение эскиза.Добавлены тесты для экстрактора изображений.
2020-10-12
— Привязать рентгеновские файлы к домашней странице, игровой площадке и просматривать страницы
— Обновить парсер
2020-10-09
— Не включать расширенные фрагменты в качестве даты в результаты для мобильных устройств
— Исправить извлечение фрагмента в результатах Google для мобильных устройств
— Извлечь дату и исправить фрагмент в органических результатах для мобильных устройств
— Исправить извлечение фрагмента из органических результатов Google
2020-10-08
— Добавить представление даты в обычные результаты Google
— Сделать исправные тесты не проходят для Google local_parser
2020-10-07
— Удалить пустые строки и исправить стиль кода
— Исправить извлечение телефона для некоторых локальных результатов Google на мобильных устройствах
— Обработать пустой элемент дополнительной ссылки.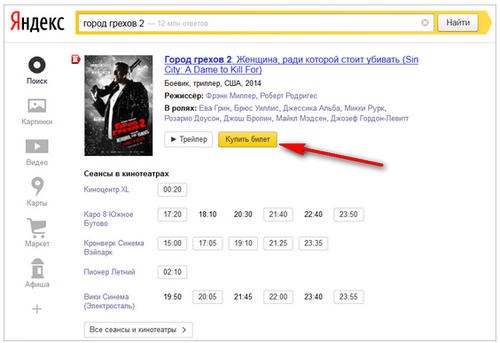
2020-10-06
— Исправить извлечение адреса для настольных и мобильных локальных результатов Google
2020-10-05
— Исправить ссылки Bing
— Исправить извлечение карусели органических результатов Google
— Получить полный фрагмент содержание.
2020-10-02
— Добавлен дополнительный селектор для извлечения списка полей ответов.
— Добавлен новый случай для извлечения таблицы окна ответов.
— Принудительно использовать в выводе JSON строго 2 десятичных знака для определенных чисел с плавающей запятой
— Исправить ошибку 500 в ответах на блокировку и рекапчу из Scraper API
— Добавить рекламную документацию
— Обновить парсер и тесты
2020-10-01
— Добавлены тесты для разных локализаций.Исправлено извлечение рейтинга для арабского языка.
— Добавлены новые селекторы для фрагментов кода на рабочем столе и встроенных дополнительных ссылок.
— Исправить позицию рекламы
— Обновить и исправить парсеры
— Добавить поддержку мобильной рекламы
— Обновить парсер рекламы
— Обновить inline_shopping_results
2020-09-30
— Добавлена serpapi_link для продуктов в Home Depot. Обновленная документация.
Обновленная документация.
— Исправить сбои Яндекс
— Обновить парсер
— Обновить парсер
2020-09-29
— Добавить поддержку параметра фильтров Bing
— Исправить ссылки
2020-09-25
— Добавлен массив сырых таблиц в результат.
— Обновлен парсер
— Исправлены встроенные изображения яндекса
2020-09-24
— Добавлено исправление для обработки случаев расширенных дополнительных ссылок для мобильных устройств.
2020-09-23
— Вернуть «Вернуть» Добавлено извлечение для мобильных органических результатов. »«
— Вернуть »Добавлено извлечение для мобильных органических результатов.
2020-09-22
— Добавлена проверка условного движка для регулярного выражения
— Исправлено получение эскизов на Bing Mobile
— Добавлен новый селектор для расширенного сниппета.
2020-09-21
— Назначение коллекции перемещено в условное.
— Удалить старый тест графа знаний Bing
— Разобрать изображения заголовков в графе знаний Bing
— Исправить ошибку возврата пустого субтитра
— Добавить недостающую ссылку и заголовок в результаты мобильного обычного поиска Bing
— Извлечь описание для розничного магазина
2020- 09-18
— Используйте метод get_valid_link.
— Не включать в результаты пустые эскизы.
2020-09-17
— Добавлена ссылка на thumbnail_link для обычных результатов.
— Добавлены защитные оговорки для извлечения мобильных дополнительных ссылок.
2020-09-10
— Исправить недостающее изображение справа в Google Knowledge Graph
2020-09-04
— Улучшить производительность синтаксического анализа Bing и исправить анализ рекламы
— Улучшить селектор ссылок в органических результатах Google
2020 -09-02
— Убрать дублирование в расширениях.
— Используйте get_valid_link, чтобы получить ссылку на изображение заголовка в графике знаний
2020-09-01
— Добавлено исправление для рейтинга / голосов в rich_snippet.
— Удалить модульный преобразователь и убрать встроенное перенаправление Google
2020-08-31
— Добавлено больше примеров для извлечения поля ответов.
2020-08-28
— Добавлена экстракция для мобильных органических результатов. Добавлены эскизы. Добавлены значки. Добавлен rich_snippet. Добавлены дополнительные ссылки.
Добавлены эскизы. Добавлены значки. Добавлен rich_snippet. Добавлены дополнительные ссылки.
— Исправить spec / search / youtube / video_results / star_wars_spec.rb
— Добавлена цена в knowledge_graph.
2020-08-26
— Улучшить селектор ответов графа знаний
— Исправить селектор ответов в графике знаний Google
— Исправить spec / search / google / inline_videos / inline_videos_mobile_spec.rb
— Исправить spec / search / ebay / spell_check / spell_check_spec.rb
— Исправить и протестировать извлечение изображений заголовков графа знаний на мобильном устройстве
— Добавить новый параметр в движок Youtube для принудительного использования старого макета
— Добавить тест валидатора
2020-08 -25
— Добавить изображения заголовков в граф знаний
2020-08-24
— Исправить spec / search / yahoo / validator_spec.rb
— Исправить spec / search / walmart / Feature_item / Feature_item_spec.rb
2020 -08-21
— Исправить spec / search / google / sports_results / new_york_mets_spec. rb
rb
2020-08-20
— Удаление уровня абстракции из трансформаторов
— Исправление spec / search / google / sports_results / boston_red_sox_spec.rb
— Добавлено исправление для apply_options, который должен быть массивом.
— Исправление spec / search / google_reverse_image / reverse_image_devito_spec.rb
— Добавлена опция первого применения из api html вакансий в api списка вакансий через job_id.
— Обновление app / models / search / google / parser / js_image_extractor.rb
2020-08-19
— Обновленная документация.
— Изменен стиль для парсера таблиц прямого ящика. Изменены тесты для облегчения обновления HTML.
2020-08-18
— Результат выровненного изображения для продукта Home Depot. Обновленная документация.
— Обновлены тесты и обновлен парсер для HomeDepot.
— Удалить параметр местоположения
2020-08-17
— Обновлен парсер продуктов Home Depot.
— Реализация финального хеш-преобразователя Google для изменения анализируемого контента
— Обновить валидатор и добавить тест пустых результатов
2020-08-14
— Добавить поддержку аналогичных результатов на мобильных устройствах
— Обновить парсер
2020-08-13
— Добавить параметр даты и удалить параметры местоположения
2020-08-12
— Исправить spec / search / google / product_result / product_result_for_gpu_mobile_spec. rb
rb
— Исправить spec / search / google / local_results / local_results_for_products_spec.rb
— Добавить анализатор результатов трендов
— Добавить анализатор органических результатов
— Обновить метод get_thumbnail для принятия пользовательских атрибутов идентификатора
— Обновить js_image_extractor.rb
— Исправить spec / search / google / local_pack / local_pack_for_stores_spec.rb
— Установить начальную систему новостей Bing
2020-08-10
— Исправленные комментарии.
2020-08-06
— Переименованная переменная.
2020-08-05
— Извлечь содержимое таблицы блока ответов в виде значимой структуры.
— Удалена опция ‘/ v’ из построения ссылки.
— Исправить встроенное извлечение продукта.
— Частично исправить рекламу Google
2020-08-03
— Исправить spec / search / google / local_pack / local_pack_for_products_spec.rb
— Исправить spec / search / google / knowledge_graph / top_carousel_spec. rb
rb
— Восстановить исправление «Восстановить» parser «»
— Обновить knowledge_graph.rb
2020-08-01
— Обновить HTML, обновить и исправить спецификации
— Исправить massage_link () nil, если ссылка начинается с http
— «//» на «https: / / «
— Исправить синтаксический анализ телефона для обновленного HTML-кода
2020-07-31
— Добавить синтаксический анализ фотографий
— Исправить spec / search / google / knowledge_graph / popular_times_spec.rb
— Исправить spec / search / google / knowledge_graph / critical_reviews_user_reviews_spec.rb
— Удалить неиспользуемый код.
— Используйте текстовые утилиты для извлечения зарплаты. Исправить спецификацию экстрактора узлов.
2020-07-30
— Обрезать пробелы для total_results
— Добавить impression_per_month
— Коллекция спецификаций изменена в соответствии со стилем, используемым во всем проекте.
— Вернуть «Исправить синтаксический анализ результатов словаря Google»
— Исправить синтаксический анализ результатов словаря Google
— Исправить спецификацию органических результатов eBay
— Исправить селектор поиска, связанный с результатами изображений Google
2020-07-29
— Исправить заголовок мест Google в адресе
— Исправить извлечение обычных мобильных результатов из результатов Google
2020-07-27
— Исправить некоторые предупреждения об устаревании
— Исправить извлечение inline_videos в результатах Google
— Исправить извлечение связанных_searches при поиске в Google на мобильных устройствах
— Добавить URL origin на ссылки результатов поиска Google для мобильных устройств
2020-07-24
— Исправить опечатку в слове «снизу»
2020-07-23
— Добавить параметр sourceid = chrome-mobile
— Исправить ie = UTF -8 параметр (был e = UTF-8)
— Исправить старый синтаксический анализ дизайна Новостей Google для французского языка
— Использовать Google Scholar 302 как 302 вместо успеха
2020-07-22
— Удалено извлечение поля ответа в виде графа знаний.
2020-07-21
— Добавлен пункт защиты для извлечения адресов локальных результатов.
— Исправлено написание типа кавычек.
2020-07-20
— Извлечь serpapi_link в inline_images для обратного поиска изображений.
2020-07-17
— Добавлено извлечение ссылок для кешированных страниц amp.
2020-07-16
— Фиксированный селектор для динамического результата поля ответа.
2020-07-13
— Обновление валидатора.rb
— Исправить обнаружение капчи при перенаправлении
2020-07-10
— Извлечь block_position для shopping_results.
2020-07-08
— Исправлено извлечение верхнего фрагмента графа знаний.
— Вернуть «Вернуть» Обновленный граф знаний »«
— Вернуть «Обновленный граф знаний»
— Скорректирован синтаксический анализ для учета i18n в ответах.
2020-07-07
— Добавлен amp в organic_results. Добавлен усилитель в карусель в organic_result.
— Добавлено извлечение top_snippet для knowledge_graph. Добавлено извлечение дохода как detail_node из верхнего блока.
2020-07-03
— Обновлен граф знаний, см. Больше_о извлечении. Добавлен тест для раздела see_more_about.
2020-06-29
— Обновлена документация по вакансиям Google.
2020-06-26
— Добавлено извлечение изображений. Исправлен путь к образу документации.
2020-06-25
— Добавлен API списка вакансий Google.
— Отменить «Исправить синтаксический анализатор»
— Добавить синтаксический анализатор service_options в Google kg
— Исправить синтаксический анализатор
2020-06-23
— Удалить `disable_polymer` из URL-адреса
2020-06-22
— Исправить синтаксический анализатор
2020-06-19
— Обновить app / models / search / google / parser / knowledge_graph.rb
2020-06-17
— Исправить синтаксический анализатор
— Обновить парсеры и переименовать в `удобства« service_options`
2020-06-16
— Обновить синтаксические анализаторы
2020-06-11
— Обновить синтаксический анализатор
2020-06-09
— Обработать другой пустой ящик продукта.
2020-06-08
— Удален закомментированный ненужный код.
— Используйте прямой прокси для домашнего депо. Добыча по фиксированной цене для товаров домашнего склада.
— Исправить и нормализовать аутентификацию с помощью ключа API
2020-06-04
— Обновить app / models / search / google / parser / js_image_extractor.rb
— Обновить app / models / search / google / parser / js_image_extractor.rb
2020-06-03
— Обновление js_image_extractor.rb
— Обновление sports_results.rb
— Обновление js_image_extractor.rb
— Исправление парсера
2020-06-02
— Разделение тестов Walmart на обязательные и дополнительные
2020-05-29
— Добавлен парсинг товаров Home Depot.
2020-05-28
— Добавлены изменения автозаполнения. Добавлена имитация браузера для игровой площадки.
2020-05-22
— Исключить фильтры Walmart и при желании включить в ответ
2020-05-15
— Обновить парсер product_result
2020-05-14
— Обновить селекторы
— Обновить events_results. rb
rb
— Обновить product_result.rb
— Обновить Refin_by.rb
— Обновить news_results.rb
— Добавить удобства в tbm = lcl results
— Обновить local_results.rb
— Обновить knowledge_graph.rb
2020-05-13
— Обновить inline_shopping_results.rb
— Обновить inline_shopping_results.rb
— Обновить метод extract_js_image_by
— Обновить images_results.rb
— Обновить direct_answer_box.rb
— Обновить парсер локальных результатов Bing
— Обновить events_results.rb
— Обновлен парсер результатов Google Events
2020-05-12
— Добавлена панель инструментов и клиенты youtube.
— Исправить спецификацию YouTube
— Документ Walmart Product
— Документ Walmart Search API
2020-05-11
— Добавить soft_sort и параметры сетки
— Обновить парсер
— Обновить парсер
2020-05-08
— Добавить парсер
2020-05-06
— Добавлен претификатор для результатов автозаполнения. Изменено автозаполнение для использования нетнут.Обновлен док. Добавленный тест для множественного запроса заканчивается как 403 запрещено.
Изменено автозаполнение для использования нетнут.Обновлен док. Добавленный тест для множественного запроса заканчивается как 403 запрещено.
— Обработка случая, когда params равен нулю.
— Исправлена ошибка, из-за которой обычные поисковые запросы ошибочно классифицируются как поисковые запросы изображений Google, поскольку params [«ijn»] `всегда является массивом`
— от компактного к компактному!
— Исправлено получение дубликатов: text и: carousel top_stories
2020-05-01
— Добавить параметры поиска Walmart на игровую площадку
— Добавить параметр «сетка» в поиск Walmart
— Проверить обзоры продуктов Walmart
— Проверить разбиение на страницы Walmart
2020-04-30
— Исправлено сообщение о результатах emapty для HomeDepot.
— Изменен рейтинг rating_count для отзывов. В документации HomeDepot заменен на The Home Depot.
— Проверить результат Walmart product_result
— Исправить селекторы top_stories на рабочем столе
— Исправить ошибку парсинга продуктов Google для пустых результатов не на английском языке
— Обновить парсер
2020-04-29
— Исправлена опечатка. Изменены тесты для node_extractor.
Изменены тесты для node_extractor.
— Удалены лишние поля цены и рейтинга из ответа для HomeDepot. Обновленная документация.
— Добавлен отсутствующий значок для автозаполнения.Изменен атрибут клиента по умолчанию на хром для модели поиска.
— Исправить парсер телефона
— Обновить app / models / search / google / parser / local_results.rb
— Обновить парсер
2020-04-28
— Изменена необработанная цена, чтобы иметь разделитель точек. Изменен рейтинг для отображения количества звезд. Добавлен rating_raw для отображения процента рейтинга. Обновленная документация.
— Обновленная документация.
— Добавлен psy-ab в качестве клиентской опции для автозаполнения.
— Проверить результаты продукта Walmart
— Восстановить «Исправить синтаксический анализатор»
— Исправить извлечение lsig
— Обновить извлечение gps
— Исправить синтаксический анализатор
— Отменить «Обновить синтаксический анализатор»
— Обновить синтаксический анализатор
2020-04-27
— Исправлено извлечение миниатюр для HomeDepot.
— Перенести старую цену и сохранение цены в ценовую группу в ответ.
— Цена и рейтинг изменены на числовые значения. Изменена реакция цены, чтобы отображать необработанные, извлеченные и валютные значения. Поменял тесты.
— Извлечение с фиксированной ценой. Добавлено извлечение ссылок. Добавлено извлечение product_id. Добавлено извлечение значка. Исправлена ссылка на документацию для сортировки / упорядочивания.
— Добавить поддержку hl в Google Maps
2020-04-24
— Добавить автозаполнение Google. Добавить автозаполнение документации.
— Извлечь исправление орфографии Walmart
— Обновить organic_results.rb
— Отменить «Обновить organic_results.rb»
— Обновить organic_results.rb
— Обновить парсер
— Обновить парсер
— Передать все параметры Walmart в url
— Добавить available_on парсер
— Добавить поисковую пагинацию Walmart
2020-04- 21
— Тестирование фильтров Walmart и связанных запросов
2020-04-16
— Интеграционный тест для органических результатов Walmart и результата продукта Walmart
2020-04-15
— Добавление механизма walmart_product
— Чипы для побега для google_jobs.
2020-04-14
— Обновить узел эскизов
— Обновить inline_videos.rb
— Обновить источник top_stories
2020-04-13
— Исправить извлечение эскизов. Удален параметр устройства.
— Добавлено извлечение нумерации страниц для HomeDepot.
— Обновление inline_videos.rb
— Обновление inline_videos.rb
— Обновление результатов новостей
— Обновление парсера
— Обновление парсера
2020-04-10
— Извлечение связанных запросов и фильтров из поиска Walmart
— Извлечение избранного элемента на Walmart
— Прекратить показывать результаты событий при наличии top_carousel
— Обновить парсер
2020-04-09
— Добавлена подсветка для HomeDepot в раскрывающемся меню игровой площадки.Использованные абзацы для documentation_examples. Использовали get_valid_link и get_thumbnail.
— Обновить парсер
2020-04-08
— Обновить верхнюю карусель
2020-04-07
— Обновлена документация.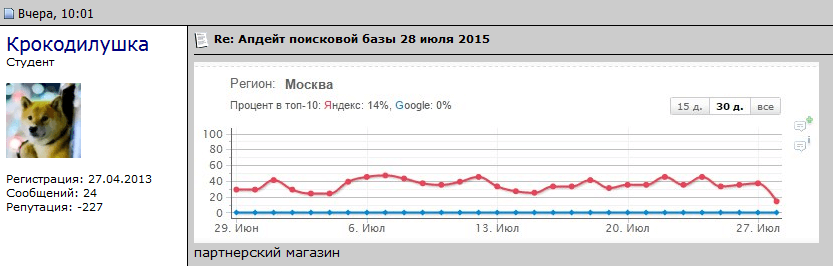 Изменил изображения на jpg, чтобы уменьшить размер.
Изменил изображения на jpg, чтобы уменьшить размер.
— Добавлена проверка орфографии для HomeDepot.
— Анализ органических результатов Walmart
2020-04-03
— Добавлена фильтрация для HomeDepot. Добавлена документация по фильтрации, ценовым ограничениям, сортировке.
— Безопасная навигация для массива и, если это строка
— Обновить валидатор Google Jobs
— Исправить извлечение телефона для локального пакета Google
— Обновить тесты органических результатов yahoo
— Удалить неиспользуемый код из парсера Google
— Обновить парсер и тесты top_stories
— Исправить результаты спортивных состязаний Boston Red Sox
— Обновить парсер результатов продукта Google и тесты
— Обновить парсер популярных продуктов
— Исправить локальный парсер пакета определенного адреса
— Исправить локальные координаты gps пакета Google
2020-04-02
— Внедрить изменения
— Обновление app / models / search / google / parser. rb
rb
— Обновление node_extractor.rb
— Обновление парсера Bing local_results
2020-04-01
— Добавлен парсинг HomeDepot.
— Обновить app / models / search / google / parser.rb
— Обновить app / models / search / google / parser.rb
— Обновить app / models / search / google / parser.rb
— Обновить app / models / search /google/parser/local_results.rb
— Обновить парсер
2020-03-31
— Исправить результаты GPS для некоторых поисков
— Исключить виджет связанных поисков из images_results
2020-03-30
— Добавить синтаксический анализатор
2020-03-28
— Исправить извлечение lsig
2020-03-27
— Исправить синтаксический анализатор
2020-03-26
— Обновить синтаксический анализатор rich_snippet
— Исправить и обновить парсер Popular_times
— Добавьте вопросительный знак в конце имени метода, чтобы указать логическое значение
2020-03-25
— Добавлен новый селектор для заголовка главных новостей.
— Обновить синтаксические анализаторы
— Реструктурировать логику синтаксического анализатора
2020-03-24
— Исправить display_brand и display_link
— Исправить people_also_search_for синтаксического анализатора
— Исправить телефонный синтаксический анализатор через apis
— Добавить ограничения на извлечение эскизов в качестве опции.
— Исправить кодировку параметров
— Переименовать хэши
2020-03-23
— Обновить спецификацию
— Исправить извлечение эскизов из встроенных главных историй
2020-03-20
— Очистить проверки для пустых органических результатов
— Ищите предыдущий заголовок g-tray для определения имени группы.
— Добавить валидатор
— Удалить парсер json
— Выделить основной анализатор органических результатов в собственный файл
— Обновить документацию
— Изменены тесты для мобильных главных новостей.
— Удалите ненужные пробелы
2020-03-19
— Исправьте встроенные главные новости для мобильных устройств.
— Обновить синтаксический анализатор
— Восстановить «Исправить нумерацию страниц продукта Google»
— Исправить извлечение звездности продукта Google без отзывов
2020-03-18
— Внести изменения
— Обновить синтаксический анализатор для поддержки видео в реальном времени
— Добавить параметр hl
— Завершить синтаксический анализатор
2020-03-17
— Добавить повторную попытку запроса в Baidu для пустых результатов
2020-03-14
— Обновить селекторы
2020-03-13
— Исправить селектор
— Unit-test get_thumbnail
— Исправить google_reverse_image_spec
— Исправить design_alt_spec
— Исправить local_results_for_products_spec
2020-03-12
— Повсюду использовать get_thumbnail
— Нормализовать Google Scholar 9289-03-2020 Cite 9024
— Обновить селектор продукта Google «Товар не найден»
— Нормализовать задания Google
— Нормализовать события Google
— Нормализовать Google
— Исправить Яндекс i nfinite loop при ответе с пустыми результатами
— Нормализовать Яндекс
— Нормализовать Yahoo!
— Нормализовать Bing
— Нормализовать Baidu
2020-03-10
— Исправлены отсутствующие встроенные видео для мобильных устройств. Добавлен карусельный анализ для органических результатов для мобильных устройств. Исправлены похожие поисковые запросы для мобильных устройств.
Добавлен карусельный анализ для органических результатов для мобильных устройств. Исправлены похожие поисковые запросы для мобильных устройств.
— Исправить spec / search / google / images_results / images_results_spec.rb
— Исправить spec / search / yandex / yandex_organic_results_coffee_spec.rb
— Добавить парсер для старого макета youtube
2020-03-09
— Извлечь изображение JS для Google Миниатюры локальных результатов
— Исправить тесты events_results_mobile_spec: добавлен селектор для макета таблицы событий
— # 611: Получить дополнительные inline_top_stories из js.
2020-03-06
— Извлечь query_displayed из скрипта.
— Добавлен комментарий к query_displayed для результата исправления орфографии.
— Добавлено исправление орфографии для поиска яндекс.
— Преобразование location_requested в location для запроса api.
2020-03-05
— Исправить аутентификацию токена для гостей
— Добавить новые сохраненные HTML-коды
2020-03-04
— Исправлены орфографические ошибки для многословных запросов.
— Исправлена ошибка, из-за которой капча Baidu не обнаруживалась
— Проверить значение параметра num и установить значение 21, если значение 20
— Исправить цикл 302
— Отключить полимер YouTube
2020-03-03
— Добавлена поисковая информация для движка Яндекс.
— Добавьте устройство и местоположение к ключу шифра, чтобы сделать его более уникальным (поиск md5 использует user_id, который не известен в аутентификации токена)
— Обновить парсер
— Внести изменения
— Удалить устройство из запроса
— Исправить кодировку Ebay
2020-03-02
— Исправлена ошибка разбивки на страницы API с экранированием местоположения.
— Удалить отладочные операторы
— Преобразовать в двоичную кодировку для хранения большего количества шестнадцатеричных символов в том же пространстве
— Исправить кодировку Яндекса
2020-02-28
— Исправлены проблемы с циклом яндекса.
— Добавить дополнительные парсеры
— Добавить поддержку дополнительных параметров
2020-02-27
— Добавить парсер video_results
— Добавить начальную поддержку парсера
2020-02-26
— Исправлены селекторы для total_results и time_taken_displayed.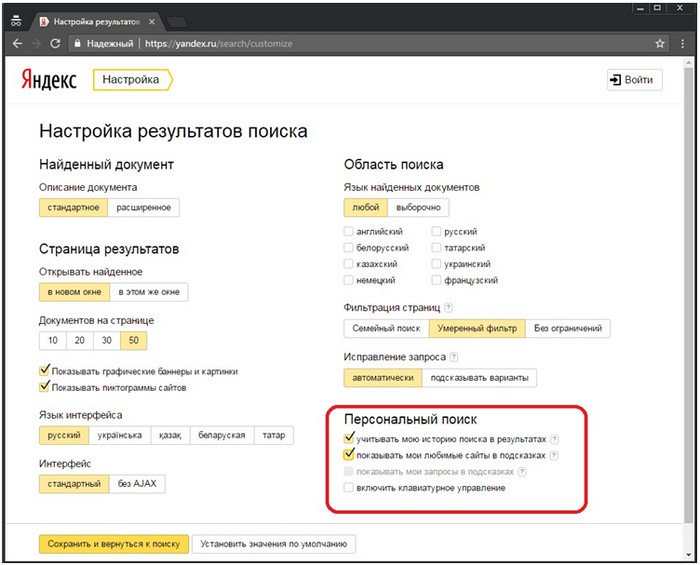
— Обновить парсер спортивных результатов
— Обновить парсер Google results_state
2020-02-25
— Исправить селектор орфографии.
— Исправить извлечение локального пакета gps Bing
— Исправить извлечение миниатюр органических результатов Bing
— Добавить и обновить js_image_extractor для Bing
— Вернуть «Вернуть» Исправить результат орфографии для поиска изображений.»»
— Обновить парсер результатов API продуктов Google
2020-02-24
— Обновить парсер результатов продуктов Google
— Обновить парсер полетов Google
— Обновить images_results.rb
— Исправить синтаксический анализ окна прямого ответа Google относительно нового дизайна
2020-02-21
— Вернуть «Исправить орфографический результат при поиске изображений».
2020-02-20
— Исправить и обновить парсер Google lcl
— Исправить и обновить мобильный парсер локального пакета Google
— Исправить результат проверки орфографии для поиска изображений.
— Сделать экранирование параметров явным.
2020-02-19
— Обновить парсер спортивных результатов
2020-02-18
— # 554: Исправлен uule для обратного поиска изображений.
— # 554: Исправлено экранирование uule для заданий и событий Google. Добавлена локация на игровую площадку. Добавлены локация и ууле на игровую площадку. Добавлены тесты для проверки правильности кодировки uule.
— Тесты преобразованных встроенных изображений. Исправлен случай извлечения js-изображений для изображений, отличных от base64.
2020-02-14
— Добавлен новый селектор для общих результатов Google.
— # 198: Удален помощник present_with_type. Языки яндекса перенесены на отдельную страницу. Изменен валидатор для сравнения с элементами html.
2020-02-13
— Исправлены обзоры локальных пакетов yahoo для мобильных устройств.
— Исправлены обратные изображения devito spec. Преобразованы обратные изображения ведьмака и сделаны нестрогими.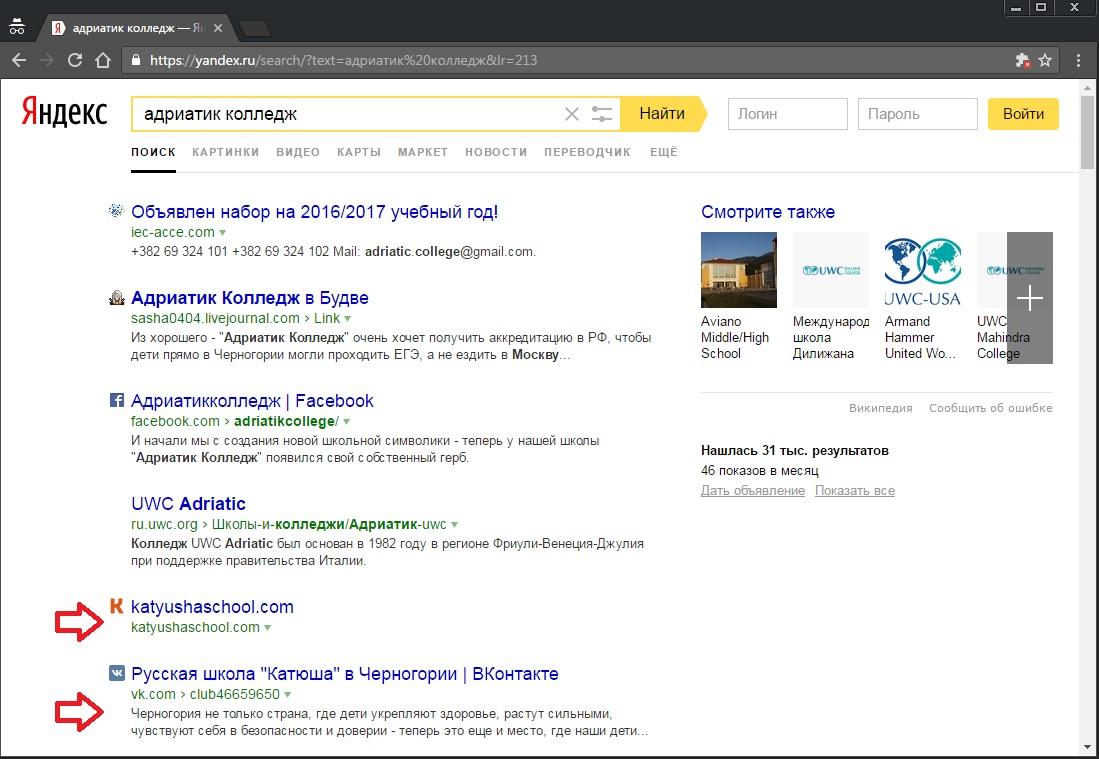
— Запрошенные исправления и изменения
— Изменения и исправления
— Преобразованные органические тесты yahoo.
2020-02-12
— Обновить парсеры
— Вернуть ключ как «неизвестный», если значение пусто
2020-02-11
— # 198: Адресованные PR-комментарии.
— Убедитесь, что ключ никогда не пуст, чтобы обеспечить работу JSON.load на всех языках
— Обновить парсеры
— Добавить метод TextUtils.snakecase
— Обновить тесты ebay
— Обновить события Google
2020-02-10
— Удалить Комментарии.
2020-02-07
— # 198: Адресованы комментарии по PR.
— Исправить пустые хэши, заменив метод параметризации
— Обновить синтаксический анализатор
— Обновить синтаксический анализатор
2020-02-06
— Внести изменения
— Преобразовать тест для телевизора samsung `tbm = shop` в # AUTO_ADD_SAVED_HTMLS
— Вернуть исправление typo «
— Добавить документацию
— Обновить валидатор
— Восстановить старые селекторы для обратной совместимости заданий Google.
— Обновить валидатор
— Добавить поддержку events_results_state
— Исправлен синтаксический анализ заданий Google после обновленного дизайна страницы вакансий.
2020-02-05
— # 198: удален неиспользуемый код.
— # 198: Добавлен поиск API яндекса. Добавлены тесты для органического поиска поискового парсера яндекса и графа знаний. Добавлен парсер для обычного поиска и графа знаний. Добавлены параметры языка и страницы. Добавлена детская площадка. Добавлены домены и языки. Добавлен парсер для встроенных изображений и встроенных видео. Добавлена документация. Добавлены тесты для встроенных изображений и встроенных видео. Исправлена ошибка в парсинге органических результатов. Исправлена ошибка в парсинге встроенных изображений.Внесены исправления в документацию.
— Внести изменения
— Извлечь теги привязки вместо элементов списка и удалить, если link = item.at_css (‘a’) check
— Использовать serpapi.com для всех URL-адресов, кроме разработки
— Добавить парсер
— Удалить поддержку местоположения из событий Google
— Переместить extract_trending_searches_by_node
— Переименовать рейтинг в позицию
— Исправить опечатку
— Обновить метод extract_js_image
— Добавить начальную поддержку API движка событий Google
2020-02-04
— Обновить приложение / модели / поиск / ebay / парсер / organic_results. rb
rb
— Удалить безопасную навигацию, поскольку ключ nil для разбивки на страницы все равно должен сломаться
— Реализовать парсер TrendingSearches
— Исправить синтаксический анализ ссылок и заголовков, когда tbs = shop
— Удалить ненужную проверку наличия тега привязки в Refin_by_item
— Добавить парсер
— Исправить ‘serpapi_link’ в ‘предложенных_поисках’ результатов изображений Google, когда запрос чипов разделен пробелами или знаками ‘+’
2020-02-03
— Используйте только `serpapi.com` для рабочих URL-адресов
— Отменить location_requested резервная копия
— Добавить парсер
2020-01-31
— Переместить логику cookie SearchSplitter Bing в Validator
— Обновить извлечение ссылок для использования метода get_valid_link
— Обновить Ebay search API
— Добавить парсер фильтров результатов покупок Google
2020 -01-30
— Обновить мобильный парсер результатов продукта Google
2020-01-29
— Обновить параметры. rb
rb
— Добавить ценовые параметры
— Исправить ссылки в результатах продуктов Google
2020-01-28
— Поддержка нового формата макета, в котором для встроенных главных новостей используется `span` вместо` cite`
— Обновить движок Ebay с надлежащими имена параметров
— Обновить parser.rb
— Обновить синтаксический анализатор
2020-01-27
— Проверить, спонсируется ли результат
— Добавить исходную и извлеченную цену
— Исправить синтаксический анализатор related_searches при пустых результатах
— Добавить пагинацию
— # 160: Organ_results переименован в image_results для обратного поиска изображений.
2020-01-24
— # 160: Предотвратить отображение Knowledge_graph пустым.
— # 160: Удалены неиспользуемые заголовки из возвращаемого значения утилиты. Изменено сообщение об ошибке.
— Исправить проблему парсера рейсов Google
— Исправить опечатку
— Отменить проверку на «$$$»
— Обновить app / models / search / google_maps / parser / maps_search_results. rb
rb
— Обновить парсеры
— Добавить исправление орфографии
2020-01-23
— Адресованы PR-комментарии.
— Добавить комментарии
— Исправить парсинг цен в ресторанах и отелях
— Обновить organic_results для поддержки результатов с иностранных доменов
— Обновить валидатор
— Обновить валидатор
— Добавить новые параметры (pgn, ipg, ebay_domain)
— Добавить парсер related_searches
— Добавить парсер related_items
— Обновить метод get_valid_link
2020-01-22
— # 160: Исправлено изображение графа знаний.
— # 160: Исправлено изображение графа знаний.
— Добавить парсер results_state
— Добавить синтаксический анализатор organic_results
— Добавить начальную поддержку движка ebay
2020-01-21
— # 160: Добавлена игровая площадка. # 160: Исправлено сохранение url результата обратного изображения.
— Приоритет фактических URL-адресов изображений `data-iurl` по сравнению с` data: image`
— Исправить разбиение на страницы
— Обновить параметры. rb
rb
2020-01-20
— Обновить параметры.rb
— Вернуть пустую ошибку, если нет результаты для запроса
— Обновить валидатор
2020-01-17
— Исправить извлечение рейтинга для поисковых запросов Yahoo
— Добавить поддержку игровой площадки для механизма цитирования Google Scholar
— Добавить парсер
— Добавить поддержку механизма цитирования Google scholar
— Создать google scholar cite link
2020-01-16
— # 160: Добавлены параметры, парсер и валидатор.# 160: Добавлен дополнительный запрос на получение ссылки на изображения. # 160: Добавлены спецификации. # 160: повторно использовать модули парсера Google.
— Обновить имена хэшей
2020-01-15
— Обновить menu_pages.rb
— Обновить knowledge_graph.rb
— Обновить синтаксический анализатор top_stories
— Исправить синтаксический анализатор новостей
— Извлечь параметр `stick`
— Обновить синтаксический анализатор
— Удалить top_carousel endpoint
— Добавить дополнительную информацию в Google KG popular_times
— Обновить валидатор
2020-01-14
— Исправить валидатор google_product
— Обновить регулярное выражение
2020-01-13
— Обеспечить соблюдение отступов для всех. rb files
rb files
2020-01-10
— Исправить тест product_results, сделав рейтинг плавающим
— Исправить извлечение рейтинга в результатах продукта Google
— Добавить комментарий о музыкальном блоке в органических результатах Baidu
09.01.2020
— Исключить музыкальный блок из обычного поиска
— Исправить парсер Baidu
— # 431: URI заменен на Addressable. Удален неиспользуемый код.
— # 237: Изменена форма запроса по умолчанию для кофе на бариста для движка заданий в playgroud. Исправлена опечатка в query_ordered.
— # 237: Добавлены статьи о защите.
— # 237: Адресованы комментарии для документации и тестов.
— Обновить синтаксический анализатор local_pack
— Переименовать ШАБЛОНЫ в IMAGE_URL_PREFIXES
2020-01-08
— Отключить все полицейские Rubocop, кроме связанных с отступами
— Исправить извлечение видео_результатов
— Исправить синтаксический анализ inline_images из Google SERPs
— Проверить приоритет атрибута источника для get_valid_link
— Отменить изменения в локальном парсере Bing
2019-12-30
— Отменить изменения неэкранированной ошибки ссылки для валидатора.
— Исправлена ошибка, из-за которой неэкранированные URL-адреса вызывали ошибку InvalidURIError.
— Добавить отсутствующие сохраненные HTML-коды для спортивных результатов
— Улучшить get_valid_link
— Проверить, подтверждено ли место
— Извлечь gps на рабочий стол
— Не показывать `top_carousel`, если используется параметр` stick`
— # 237: Добавлен парсер, валидатор, модули параметров для движка заданий. # 237: Очистите основные данные о вакансиях. # 237: Добавлены тесты для парсинга вакансий. # 237: Добавлен скребок фишек. # 237: Добавлена игровая страница для движка вакансий. # 237: Добавлена страница документации по вакансиям.# 237: Изменены тесты для использования автоматической генерации тестовых файлов.
2019-12-27
— Исправить стиль рубина
— Не использовать to_sym в локальных результатах Bing
— Обновить парсер
— Добавить локальный анализатор пакетов yahoo
— Добавить поддержку устройств в Yahoo
2019-12- 26
— Обновить ads_results. rb
rb
— Обновить ads_results.rb
— Обновить обычные результаты для поддержки мобильных устройств
— Обновить related_searches.rb
— Добавить поддержку устройств в Yahoo
— Добавить тесты
— Добавить анализатор rich_snippet в обычные результаты Yahoo
— Обновите парсер.rb
2019-12-25
— Исправить inline_shopping_results_spec
— Обновить парсеры
— Исправить возможные исключения главных историй
— Добавить парсер Yahoo related_searches
— Исправить ошибку Google top_stories Airbrake
— Добавить Yahoo related_questions поддержку устройства 9024 Yahoo
— Добавить метод get_valid_link в Yahoo
— Удалить URL перед синтаксическим анализом.
2019-12-24
— get_valid_link во всех движках
— Обновить knowledge_graph.rb
— Обновить синтаксический анализатор top_carousel
— Исправить people_also_search_for carousel
— Добавить синтаксический анализатор top_carousel
— Добавить синтаксический анализатор профилей
2019-12-23
— Исправить boston_red_sox_spec
— Исправить ошибку доставки_результатов
local_pack_for_specific_address_desktop_spec
— Исправить тесты в спецификации refiny_by
— Исправить тесты в Refiny_by
2019-12-20
— Исправить локальный пакет Bing
— # 250: Пример исправленного документа.
— # 250: Обработка рекламных ссылок.
— Исправлено извлечение эскизов и источников во встроенных главных новостях
— Обновление sports_results.rb
2019-12-18
— # 250: Добавлены расширения. Исправлено некорректное извлечение цены.
2019-12-17
— Восстановите .rubocop_todo.yml
2019-12-16
— # 250: extract_numbers -> extract_number.
— Переместить top_stories_inline в метод только для мобильных устройств
2019-12-13
— # 250: фиксированный разбор отзывов с мобильных устройств.
— Добавить дополнительные классы для мобильных устройств
— Обновить парсер top_stories
— Добавлен пункт защиты.
— Добавлен резервный ключ Refin_by. Добавлен тест для японского поиска.
2019-12-12
— Добавить парсер цен на отели
— # 260: Фиксированный мобильный синтаксический анализ.
— Исправить ссылки на главные новости
— Исправить синтаксический анализатор popular_times
— Вернуть «Вернуть» 260 добавить уточнение с помощью ««
2019-12-11
— Вернуть »260 добавить уточнение с помощью«
— Вернуть «Результаты Google kg Popular_times»
2019-12-10
— # 250: Добавлены мобильные встроенные результаты покупок.
— # 260: Преобразование уточнения по тексту в символ.
— Обновить Google shopping_results
2019-12-09
— Добавить парсер Popular_times
— Обновить sports_results.rb
— Исправить и улучшить результаты окна ответов Baidu
— Исправить парсер спорта Google
2019-12-06
— Добавить синтаксический анализатор аннотаций «отсутствующих» и «must_include»
— Переименовать review_summary в user_reviews
— Добавить critical_reviews и reviews_summary в Google kg
— Обновить метод Google get_valid_link
— Показать исходное описание и путь к сохраненному файлу HTML в выводе RSpec
— Добавить другой селектор for related_questions
2019-12-04
— # 260: Адресованные комментарии обзора.
— Обновить local_results.rb
— Исправить синтаксический анализатор, добавить дополнительные параметры для извлечения gps
2019-12-03
— Обновить локальный пакет bing
— отменить изменения, внесенные в метод clone_with_new_parameters
— Обновить локальный синтаксический анализатор пакета Bing
2019-12-02
— # 260: Добавлено извлечение «Уточнить по».
— Добавить локальный анализатор пакетов Bing
— Обновить сообщение об ошибке
— Обновить валидатор bing
— Обновить некоторые результаты объявлений, чтобы включить заголовок
2019-11-30
— Исправить № 367
2019-11-29
— # 101: Добавлены встроенные изображения для обычного поиска Google.
— Вернуть «Вернуть» поисковые запросы и встроенные объявления, связанные с Bing »«
2019-11-27
— Восстановить «Поисковые запросы, связанные с Bing и встроенные объявления»
— Lint Ruby code on pre-commit hook
— Remove debug.
— Используйте extract_integer.
— Добавлен total_results для поиска Bing.
— Улучшение результатов верхней и нижней рекламы
— Улучшение парсеров Bing
— Добавление поддержки встроенной рекламы
— Добавление парсера связанных поисковых запросов в Bing
— Исправлены ошибки после проверки кода.
— Будьте более осторожны при извлечении продолжительности видео
— Добавьте сообщение об ошибке «Неподдерживаемое устройство»
— Исправьте опечатку
2019-11-26
— Добавьте поддержку парсера мобильного спорта
— Разберите значок в Yahoo! результаты рекламы
— Извлечение URL-адресов эскизов для обычного поиска из js.
— Исправление парсера API карт
— Перемещение Yahoo! парсеры на отдельные модули
2019-11-25
— Разобрать Yahoo! результаты поиска на разных языках
— Протестируйте Yahoo! на разных языках
— Небольшое исправление
— yahoo_domain для Yahoo!
— Добавлены поля графа знаний: — Смотрите фотографии — Смотрите за пределами
— Обновите и улучшите спортивный парсер
2019-11-22
— Обновите парсер
— Удалите параметр ‘n’ из Yahoo! API поиска
— Yahoo! параметры поиска на детской площадке
— Добавить документацию
— Обновить парсер и добавить поддержку для бейсбола
2019-11-21
— Добавить парсер для формул и moto gp
— Добавить парсер для теннисистов
— Обработка Yahoo! параметры веб-поиска
— Добавить парсер для спортсменов по баскетболу и американскому футболу
— Улучшить метод get_valid_link
2019-11-20
— Обновить командный вид спорта и добавить индивидуальный анализатор спортсмена (футбол)
— Yahoo! pagination
— Обновить results_state_and_spelling_fix. rb
rb
— Улучшение обработки ошибок парсера
— Повторное использование `dig`
— Обновление валидатора карт и тестов
— Yahoo! query_displayed и total_results
— Кнопка в ads_results для Yahoo! API поиска
2019-11-19
— Yahoo! результаты объявлений с дополнительными ссылками
— WIP sports_results parser
— Yahoo! результаты объявлений с дополнительными ссылками из списка
— Заменить пустым? с подарком?
— Повторное использование `dig` в парсере карт
— Добавление поддержки` google_domain` в Карты
— Протестируйте Yahoo! против реальных запросов
2019-11-18
— Разбор Yahoo! органические результаты
— Улучшение парсера карт
— Убедитесь, что место и результаты поиска не загружаются одновременно
2019-11-17
— Исправление, когда HTML показывает неправильный тип результатов
— Отдельное состояние результатов и исправление орфографии в другой файл
2019-11-15
— Обновить и улучшить парсер `Maps`
— Добавить тест валидатора
— Добавить` position` в результаты некоторых мест и переименовать хэш
2019-11-12
— Извлечь total_results на Baidu
— Улучшить и обновить парсер
— Восстановить «Улучшить и обновить парсер»
— Добавить валидатор ReCaptcha
— Улучшить и обновить парсер
— Исправить конструктор URL-адресов Google Maps
— Обновить встроенные скриншоты продуктов в документации
— Извлечь эскизы в компактные встроенные продукты
2019-11-11
— Извлечь компактные встроенные продукты
— Извлечь обычные встроенные продукты
— Перенести извлечение inline_products в собственный модуль
— Ex tract extended inline_products
— Добавлена поддержка для стран, городов и провинций
— Добавлена поддержка рекламы гостиниц
2019-11-08
— Улучшен синтаксический анализатор Maps API
— Переименование состояния с place на local
— Обновите общедоступный образец JSON
2019-11-07
— Добавить пагинацию. previous и исправление pagination.next на Baidu
previous и исправление pagination.next на Baidu
2019-11-06
— Обновление парсера Maps API
— Исправление парсинга результатов видео Google на мобильных устройствах
— Исправление тестов
— Уточнение комментария кода для extract_js_image_by
— Модульный тест оптимизированный для производительности JSUtils.unescape
— Переименовать хэш place_results в local_results (tbm = lcl)
2019-11-05
— Обновление WIP Валидатор Google Scholar
— Декодирование HTML-объектов с регулярными выражениями вместо циклов
— Добавить поддержку Google Scholar API для «состояния пустых результатов»
2019-11-04
— WIP Добавить парсер Google Maps API
— Добавить поддержку параметра «type»
— Тестировать сохраненный HTML с различным дизайном результатов Google Images
— Извлечь URL исходного изображения из JS
— Удалить неиспользуемый код
2019-11-03
— Исправить и улучшить парсер places_results
2019-11-01
— Начальные файлы WIP для `Go ogle Maps API`
— парсить изображения Google из HTML и JS
2019-10-31
— начать извлечение изображений
— изменить написание в документации
2019-10-30
— добавить top_stories_link
2019-10-29
— Исправить тесты
— Перенести извлечение top_stories в собственный файл
— Защитно проанализировать top_stories
— Поддержка формата списка главных новостей
— Поддержка карусельного формата главных новостей
— Исправить парсинг мобильной рекламы без описания
2019-10-28
— Добавить поддержку состояния результатов для всех конечных точек Google API
— Улучшить синтаксический анализатор повторного использования мест
2019-10-25
— Исключить ‘rich_snippet. bottom ‘для обычных результатов с форматом списка для дополнительных ссылок
bottom ‘для обычных результатов с форматом списка для дополнительных ссылок
— Формат списка синтаксического анализа для дополнительных ссылок
— Обновить синтаксический анализатор вопросов, связанных с bing
— Добавить синтаксический анализатор связанных вопросов
— Использование селектора фрагмента окна прямого ответа в документе organic_results
— Улучшения кода для парсера результатов поиска мест
2019-10-24
— Исправить синтаксический анализ бронирований отелей
— Исключить неполные дубликаты answer_box в organic_results
— Использовать новый метод gps_coordinates
2019-10-23
— Повысить надежность получения типа места
— Включить `organic_results_state` для результатов` tbm`
— Добавить синтаксический анализатор результатов размещения
— Переименовать файл в `places_results` и переместить под правильное условие
— Использовать оба селектора CSS поля ответа как новый, так и старый
2019-10-22
— Тестирование разбивки на страницы Bing с большим количеством результатов
— Обработка разбивки на страницы без «other_pages»
— Исправление извлечения координат GPS в локальном результате ts
— Исправить файл knowledge_graph. people_also_search_for ‘parsing
people_also_search_for ‘parsing
— Обновить селекторы для синтаксического анализа поля ответов словаря результатов Google
— WIP tbm local results parser
2019-10-21
— Перенести методы, специфичные для разбивки на страницы, для исправления модулей
2019-10-19
— Исправление для результатов продукта
— Исправление для результатов локального пакета
2019-10-18
— Добавление поддержки editorial_reviews в knowledge_graph и описание обновления
— Тестирование разбивки на страницы в результатах Google Scholar
— Небольшое исправление
2019- 10-17
— Тест интеграции Baidu
— Обновить парсер local_pack
— Пагинация Bing
— Изменить метод get_valid_link для поддержки ссылок data: image
— Обновить парсер product_results
2019-10-16
— Добавить serpapi_pagination в Baidu
— Унифицировать разбиение на страницы в Google Scholar
— Унифицировать разбиение на страницы и serpapi_pagination в органических результатах Google
— Улучшение gps и действующей ссылки методы
2019-10-14
— Синтаксический анализатор WIP local_pack
— Обновить метод get_valid_link
— Извлечь разбиение на страницы в отдельный метод
— Не устанавливать organic_results_state, если результаты не найдены
— Переделка `extract_gps_coordinates`, чтобы включить` js` извлечение
— Дополнительный регистр для состояния ‘Пусто показывает фиксированные результаты проверки орфографии’
— Исправления при проверке кода
— Добавление метода `get_valid_link`
— Убедитесь, что заголовок возвращен для` product_result`
2019-10-11
— Удалить TODO
— Удалить метод установки состояния органических результатов
— Извлечь тип исправления орфографии
— Защита от несуществующих узлов во встроенных видео
2019-10-10
— Исправить ошибки Airbrake для `product_result`
— Исправить ссылки на кровати и закомментируйте параметр lsig
— Исправить NoMethodError для синтаксического анализа заголовка встроенного видео
2019-10-09
— Переместить set_organic_results_state в синтаксический анализатор
— Проверить пустое повторное sults в арабском и немецком языках
— Исправить, когда в метках есть пробелы
— Исправить синтаксическую проблему
— WIP — локальная карта для определенного адреса
— Добавить поддержку нового параметра lsig
— Исправить некоторые синтаксические проблемы
— Обработка встроенные видео без «канала» в HTML
— Тесты на исправление орфографии в кавычках
2019-10-08
— Улучшение именования аргументов метода
— Реализация состояний пустых результатов поиска
— WIP — Добавлена поддержка результатов `Mobile v2`
— Переименование в product_result и другие небольшие улучшения
2019-10-07
— Парсер результатов продуктов Google
2019-10-04
— Тестирование встроенных видео на трех разных языках
— Поддержка состояний results_for_exact_spelling и полностью_empty
2019-10-03
— Опишите проблемы синтаксического анализа: video_thumbnail
2019-10-02
— Документируйте встроенные видео в органических результатах
— Base64-encod e миниатюры
— Преобразование отступов в пробелы
— Исправление парсера Google и Google Scholar
2019-10-01
— Улучшение парсера органических результатов
— Поддержка встроенных видео результатов
2019-09-30
— Удалить Google Поиск конкретных валидаторов из Google Scholar
— Улучшение обычных результатов
— Исправить синтаксис
— Показать ошибку, если Google не вернул никаких результатов
2019-09-25
— Удалить параметры, которые не работают с Google Scholar
— Добавлена поддержка параметров Google Scholar `cites` и` cluster`
2019-09-24
— WIP Google Scholar: обычные результаты
— WIP Google Scholar parser
2019-09-21
— Добавлена поддержка статистики в результаты Google Scholar
— Уменьшите количество пробелов
— Добавьте поддержку связанных поисков в результаты Google Scholar
2019-09-20
— Добавьте поддержку параметров, специфичных для Google Scholar
2019-09-17
— WIP Добавить базовый каркас для поддержки API Google Scholar
2019-09-10
— WIP Поддержка органического поиска Bing на мобильных устройствах
2019-09-04
— Исправить # 234
— Исправить # 228
2019-09-03
— Исправить проблему с новым дизайном Google
2019-08-26
— Исправить проблемы с Baidu
2019-08-22
— Исправить проблема с расширенными фрагментами, которые не поддерживаются, и путаница с прямым ответом
2019-08-20
— Устранена проблема со связанными поисковыми запросами, включая ссылку с пустыми hrefs
— Исправлено извлечение данных для Google Shopping API
— Исправлено извлечение заголовков продуктов
— Исправить извлечение обзоров, оценок и количества отзывов о продукте
— Не преобразовывать рейтинг продукта с плавающей запятой в целое число
— Исправить некорректное извлечение расширений
— Ключи Snakecase, чтобы избежать проблем с анализом JSON для Google Product API 9 0249 — Устранение проблемы с извлечением связанных поисковых запросов на мобильных устройствах
— Устранение проблем на мобильных устройствах, когда обычные результаты и результаты рекламы смешиваются
— Извлечение более полных данных из расширений органических результатов
— Прекращение удаления прямого ответа из документа
2019-08- 19
— Добавить поддержку API новостей Google для людей, также выполняющих поиск блоков
— Исправить проблему с графом знаний, когда ключ уже существует
— Добавить ключ raw_hours для людей, полагающихся на строку вместо объекта
— Исправить рейтинг и извлечение отзывов для API графа знаний
— Устранение проблемы с положением в Google Images Results API
— Добавление поддержки для дополнительных вариантов макета
2019-08-15
— Исправление поисковых объявлений Bing
— Устранение проблем с остановкой динамического воссоздания хэша
2019 -08-13
— Исправить бесконечный цикл разбивки на страницы изображений Google
2019-08-11
— Исправить проблему с графиком знаний
— Исправить проблемы с ужасным поле ответа ct и обычный хэш
— Используйте обычный хеш вместо рекурсивного созданного хеша
2019-08-09
— Исправьте цену, расширение и фрагмент для результатов покупок # 210
— На самом деле избегайте синтаксического анализа раздела графа родительских знаний
— Убедитесь, что у «reviews_from_the_web» есть результаты.
— Не анализируйте результаты из родительского раздела графа знаний для «see_more_about1»
2019-08-08
— Создавайте хеш для «see_more_about», только если он существует
— Избегайте установки пустых обзоров
— Добавить поддержку для раздела «Подробнее о»
2019-08-07
— Исправить проблему с действительными поисковыми запросами о блокировке Captcha
2019-08-06
— Не включайте пропущенные часы в локальные результаты # 93
2019-08-05
— Обновить рейтинг до float
— Извлечь номер из `review_count`
— Добавить поддержку для еженедельного расписания предприятий и обзоров из Интернета
2019-08-02
— Добавить поддержку пользовательского местоположения по вводу широты и долготы
— Исправить названия часов, адреса и описания в результатах локального пакета
— Исправить недостающие оценки в поле локальных результатов # 93
— Исправить ссылки и ссылки заголовков для обычных результатов Binb
— WIP Rewrite final_hash and spec logic
2019-07-30
— Отображение конечных точек JSON и HTML для поиска Baidu
— Разрешить гостю подключаться к своим конечным точкам JSON и HTML с помощью токенов
2019-07-26
— Добавьте Google Spell Check API
— Исправьте коммиты и PR для оптимизации токенов
2019-07-25
— Исправьте опечатку
— Избегайте синтаксического анализа блоков ответов, когда их нет
— WIP Используйте более короткие токены, которые выглядят более удобными для пользователя
2019-07-23
— Добавить `location_used` для поиска json при использовании Bing # 183
— Исправить эскизы и изображения
2019-07-19
— Исправить ошибку недостающих параметров с помощью валидаторов
— Добавить поддержку настройки точного местоположения # 181
— Ранняя подготовка, добавить настройку файлов cookie
18. 07.2019
07.2019
— Исправить заголовок для мобильных устройств для настольных компьютеров
— Исправить мобильный поиск
16.07.2019
— Исправить Google News API
14.07.2019
— Исправить извлечение оценок из обзоров
2019-07-09
— Убрать условную разбивку на страницы (проблемы на мобильных устройствах)
05.07.2019
— Добавить идентификатор продукта в результаты покупок
2019-07-02
— Обновить график знаний для поддержки анализа рабочего статуса бизнеса # 116
2019-06-27
— Устранить проблему, когда тип ответа графа знаний отсутствует
— Удалить raw_submodules из окончательного хэша
— chore (app / *) изменения пробелов и новые строки в EOF
2019-06-23
— объединить organic_results и video_results для настольных ПК исправить парсер video_results для мобильных 9000 3
2019-06-21
— Исправить временную ошибку пустых результатов в реальном времени
— Обработка крайних случаев разбивки на страницы Google
2019-06-19
— Исправить ошибки Base64
2019-06-17
— обновить параметры разбивки на страницы с помощью Search # clone_with_new_parameters
— удалить `then` из результатов графика знаний Bing
2019-06-16
— преобразовать график знаний bing в хэш vs. список хэшей
список хэшей
— добавить поле `formatted` в анализируемые подмодули bing
— Устранение конфликтов
— Фактическое исправление ошибок
2019-06-15
— Исправления ошибок локальной карты
2019-06-13
— удалить уникальные синтаксические анализаторы типов верхнего уровня и возврат к универсальным
— удалить неиспользуемые include для результатов объявлений Bing
11.06.2019
— Бета-анализатор Baidu
10.06.2019
— Исправить удаленный хэш emtpy как истинная проблема # 167
— Добавить новые ссылки поиска serpapi для `place_id` # 167
— Переименовать location_id в place_id в соответствии с собственной документацией Google # 167
— Используйте api_key вместо user_id для шифрования, чтобы разрешить повторное поколение
— Используйте только статус «Успешно» вместо «Кэшировано» и «Успешно» для успешного поиска
— Используйте токены для аутентификации пользователей, привязанных к одному конкретному запросу
— исключите нереализованный подмодуль Bing KG типа
— отфильтруйте ссылки JavaScript i n bing KG link parser
— add bing ‘people_also_search’ submodule formatter
— add Writing_works, timeline, and Интерес_stories bing formatters
— добавить общий формат подмодуля заголовка bing к food и знаменитым людям
— используйте оператор splat в Ruby, чтобы разобраться в Подмодули Bing
— добавить общую логику формата для подмодуля заголовка графа знаний Bing
— добавить ‘Organization SocialActive’ в типы организаций Bing
2019-06-07
— Извлечь `ludocid` (location_id) из локального пакета
2019 -06-06
— Добавить поддержку локальной карты и координаты GPS для результатов графика знаний
— Поддержка словарного поля ответа
— Добавить поддержку синтаксического анализа для результатов «Связанные новости» и «Расширенный фрагмент»
— Обновить парсер с динамической загрузкой модуля на основе на обязательном элементе
— [сквош] запуск в специфичных для организации полях Bing KG
— добавить анализ графа знаний Bing ‘flatmodule’
— добавить подмодуль Bing ‘slide’ синтаксический анализатор
2019-06-05
— анализировать несколько списков графов знаний Bing, если они существуют
— заменить Bing ‘ответы’ на ‘knowledge_graph’
2019-06-03
— добавить структуру, которая фиксирует типичный ответ Bing типы
2019-06-02
— рефакторинг объявлений bing извлекает вспомогательные fns из модуля органических результатов
— перемещает органические результаты bing в собственный модуль синтаксического анализатора
— перемещает результаты объявлений bing в собственный модуль синтаксического анализатора
2019-05 -31
— Отказоустойчивые устройства для недостающих элементов в локальном мобильном пакете
— Добавить пагинацию, значок источника для Baidu
2019-05-29
— Добавить синтаксический анализ адреса по определенному стилю для локального мобильного пакета
— Извлечь телефон номер из локального мобильного пакета
— Добавить поддержку локальных пакетов с мобильного устройства # 109
— Первоначальная фиксация
2019-05-26
— Исправить синтаксический анализ мультимедиа в `product_results`
2019-05-25
— добавить отказоустойчивые сейфы, когда элементы не существуют или вывод равен нулю
2019-05-24
— добавить поле заголовка к результатам объявления Bing
— fixup tracking_link (vs. link) имена полей для дополнительных ссылок Bing
link) имена полей для дополнительных ссылок Bing
2019-05-23
— Убедитесь, что значения не равны нулю, фактически добавьте анализ связанных_search_boxes
— Удалите `log` в валидаторе
— добавьте базовую логику serpapi_pagination
— Изменить проверку успешный запрос на странице продукта
— Завершите переименование параметра product в product_id
— Удалите кавычки в начале и конце обзора обзора
— Избегайте синтаксического анализа несвязанных разделов для related_search_boxes
2019-05-22
— Переименовать `related_search_box` в` related_search_boxes`
— Добавить страницу документации, пункт меню панели навигации и значок для связанных поисков
— Регулярная очистка
2019-05-21
— Обновить specs_results для альтернативной страницы продукта
— Обновить related_products_results `для альтернативной страницы продукта
— Исправлено удаление текста для расширенного описания
2019-05-20
— Обновите` sellers_results` для работы вместе с альтернативным Страница продукта
— Обновите `reviews_results`, чтобы работать вместе с альтернативной страницей продукта
— Обновите` product_results`, чтобы работать вместе с альтернативной страницей продукта
— Используйте параметры `specs` и` reviews` как логические
— Рефакторинг get_related_search_box
2019-05- 19
— Добавить дополнительные селекторы для анализа результатов на странице альтернативного продукта # 105
— Проверить, содержит ли тег `title` текст` Product not found`
— Проверять, содержит ли URL-адрес `/ shopping / product`, на самом деле не нужно
— Используйте блок `if` end`, если используются два или более условий
2019-05-18
— Первоначальная запись для связанного поля поиска # 129
— Исправления и корректировки ошибок
2019-05- 17
— добавить параметры запроса, специфичные для Bing
2019-05-15
— Поддержка извлечения типа графика знаний для данных о компании
2019-05-14
— заменить ссылку на URL-адрес tracking_link
— Использовать более точный селектор для экстрактора типа графа знаний
— Исправить поддержку типа графа знаний
— Изменения для проверки кода
2019-05-13
— добавить логику синтаксического анализа рекламы Bing
2019-05-12
— добавить в form = QBRE для запуска результатов рекламы Bing
— переместить органический синтаксический анализ Bing в собственный fn
— возвращать только действительные органические результаты Bing
2019-05-10
— Поддержка извлечения чисел с плавающей запятой и целых чисел для всех языков
— Капитальный ремонт
— добавить базовую логику синтаксического анализа результатов Bing
2019-05-03
— Переименовать магазин / продавца по имени в результатах продавцов, дополнительные корректировки для анализа рейтингов / обзоров в reviews_results
2019-05-02
— Исправить звездочки и общее количество обзоров для международных языков (надеюсь), начать документацию для подразделов продукта API
2019-05-01
— Исправить настройку google_domain для движков «google» и «google_product», исправление разбивки на страницы для продавцов и ревизий
2019-04-30
— Исправление синтаксического анализа прямого ответа калькулятора Google
— Добавление синтаксического анализа, рейтинга и отзывов локальных магазинов в целое число, исправление имени параметра в документации Google Prod API,
2019-04-28
— Добавление документации для глобального API, просмотр результатов. Отрегулируйте результаты продавцов для онлайн и местных, уточните фильтрацию / сортировку в документации,
Отрегулируйте результаты продавцов для онлайн и местных, уточните фильтрацию / сортировку в документации,
— Исправьте отзывы, отрегулируйте извлечение цен для многоязычия
— Добавьте фильтрацию, сортировку, разбиение на страницы, полные результаты для обзоров и спецификации / детали
2019-04- 26
— Используйте `if` вместо блоков` if`
— Добавить функцию для перебора результатов покупок и получения результатов страницы продукта (не завершено)
— Реструктуризация
— Именование, убедитесь, что элементы существуют перед созданием хэша и итерации
— Есть реклама, но требуется отдельный синтаксический анализ.
— Первоначальная интеграция синтаксического анализа продукта Google
2019-04-24
— Поддержка параметра ludocid (Google My Business Listing CID)
— Регулировка структуры
— Переход в соответствующую ветку для разработки
2019-04-23
— Добавить синтаксический анализ для раздела деталей спецификации
— Добавить синтаксический анализ для дополнительных данных обзора
— Исправить скелет для другого движка su pport
— Первоначальный анализ страницы продукта
2019-04-18
— Исправить конфликтующий атрибут html
— Разделить поисковый домен и параметры поисковой системы
2019-04-05
— Поддержка базового поиска Bing WIP
Как начать кодировать и получить немедленный результат | Практикумом от Яндекса | The Startup
Откройте для себя инструменты для более быстрого написания кода в этом руководстве от Practicum от Яндекс.
Когда вы впервые начинаете программировать и создавать веб-сайты, важно понимать, как у вас дела. Допустим, вы изменили параметр объекта. Вы все сделали правильно? Это работает? Получилось круто или ужасно?
Интегрированная среда разработки (IDE) позволяет разработчикам мгновенно видеть результаты своей работы. IDE — это программное обеспечение, которое позволяет программистам писать код, обнаруживать ошибки, а и просматривать результат.
Технически вы можете работать без IDE: просто напишите свой код в текстовом редакторе и откройте свою программу в специальном ПО или в браузере.Однако этот подход обычно медленный и требует много дополнительной работы. Лучше научиться пользоваться IDE и писать код в сотни раз быстрее.
Выбор IDE — дело личных предпочтений. Некоторые из них универсальны, а другие адаптированы к конкретным языкам программирования. Многие IDE имеют аналогичные функции и позволяют улучшить функциональность с помощью надстроек. Вот некоторые из основных IDE, которые сейчас используют программисты. Этот обзор может помочь вам выбрать тот, который вам подходит.
Эту среду IDE можно загрузить с официального сайта VS Code. Несмотря на то, что VS Code является продуктом Microsoft, он бесплатный, с открытым исходным кодом и работает на нескольких платформах. Эти преимущества в сочетании с функциями программного обеспечения делают VS Code одной из самых популярных IDE в мире:
VS Code поддерживает практически все существующие языки программирования, либо сам по себе, либо через плагины, и форматирует их соответствующим образом. Он также имеет встроенную поддержку HTML, CSS, JavaScript и PHP: он определяет пары тегов, закрытые скобки и ошибки команд.
Вот самые интересные особенности VS Code:
Умное автозаполнение. VS Code анализирует, какую команду вы хотите ввести, и предлагает конец фразы с подсказками и объяснением. Это удобно, если вы забыли порядок, в котором используются переменные, или забыли точную формулировку команды:
Пошаговое выполнение сценария. Иногда вам нужно запускать сценарий по одному шагу за раз, например, когда вы хотите понять, зацикливается ли программа бесконечно.Для пошагового выполнения сценария вы можете использовать встроенный отладчик — программу, которая проверяет ваш код, ищет в нем ошибки и позволяет запускать его блоками.
Множественный выбор и поиск. Чтобы изменить идентичные значения переменных или найти все идентичные слова или команды, VS Code использует собственный алгоритм обработки. Эта функция упрощает редактирование кода и позволяет быстрее заменять функции и переменные:
Используя мульти-курсор, вы можете ввести одно и то же значение в несколько строк одновременно:
Если вы обнаружите одинаковые слова и команды, вы можете моментально замените их новыми.
Кодовая навигация и описание функций. Когда вы пишете большую программу, легко забыть о некоторых вещах, которые вы делали вначале: вы можете не вспомнить, как работает функция или какая переменная должна куда идти. Если вы хотите предотвратить эту путаницу, VS Code может показать вам фактическую функцию, описание переменной и параметры, которые передаются при выполнении команды. Эти функции также пригодятся, когда вы получаете код от другого разработчика и вам нужно быстро выяснить, какие фрагменты кода отвечают за что и как они работают:
Готовый код VS не может показать вам немедленные результаты, когда вы пишете сайт.Для этого требуется расширение Live HTML Previewer. Чтобы установить его, перейдите в «Расширения», щелкнув последний значок на левой панели или нажав Ctrl + Shift + X и начав писать «Предварительный просмотр HTML» в строке поиска.
После установки и запуска расширения вы можете сразу увидеть, как ваш HTML-код и CSS влияют на внешний вид и поведение вашей веб-страницы. Это особенно полезно, если вы создаете веб-сайт с нуля и хотите сразу увидеть, что происходит.
IDE для JavaScript от jetBrains.Это не бесплатно, но есть 30-дневная бесплатная пробная версия. Этого вполне достаточно, чтобы понять, подходит это вам или нет:
Автоподсказка. Некоторые интегрированные среды разработки с автоматическим предложением работают медленно и не показывают сразу все параметры переменных или команд, но это не относится к WebStorm. Функция автоматического предложения WebStorm начинает работать, как только вы вводите эту первую букву, и знает, когда предложить переменную, команду или служебное слово:
Встроенный инструмент выполнения задач. Эта функция полезна, когда вы работаете над несколькими проектами одновременно и вам нужно помнить, что вы хотите делать в каждом из них.Это готовая функция, доступная для любого файла:
Проверка ошибок . WebStorm может проверять код на наличие ошибок и объяснять каждую из них. Он не всегда идеален, но когда он действительно работает, он экономит ваше время:
Чтобы сразу увидеть, что происходит на веб-странице, вам понадобится плагин под названием LiveEdit. По умолчанию он отключен, но вы можете включить или установить его в любое время. После активации выберите «Обновлять приложение в Chrome при изменениях в», чтобы включить обновление данных в Google Chrome.Теперь вы можете написать свой код и на лету просмотреть результат.
Бесплатный редактор, который надоедает пожертвовать деньги разработчикам.
Sublime Text — невероятно мощный текстовый редактор. Его сила заключается в скорости: он обрабатывает простые веб-страницы так же быстро, как и программы, содержащие 100 тыс. Строк кода. Он предлагает целый пакет функций прямо из коробки, включая подсветку синтаксиса для всех возможных языков программирования, автоматические предложения и закрытие смарт-тегов.
Вот что еще программа может делать с самого начала:
· Отображать команды и переменные разными цветами для популярных языков программирования.
· Автоматически завершать команды.
· Выбрать все одинаковые слова.
· Свернуть код для облегчения чтения.
· Используйте любые горячие клавиши, которые вам могут понадобиться.
· Разделите рабочее пространство на несколько окон, где вы можете редактировать один и тот же код.
Еще одна функция, которая превращает Sublime Text из простого текстового редактора в универсальное решение, — это широкий набор плагинов . Плагины работают так же, как и в других IDE, которые мы описали, но плагины вообще не влияют на скорость Sublime Text.
Когда вы действительно начнете работать с Sublime Text, вы можете подумать, что есть плагин для всего. Вам нужно отредактировать один и тот же код, но на нескольких панелях? Ну вот! Хотите быстро написать HTML? Конечно! Хотите проверить свой код на наличие ошибок и ошибок? Без проблем!
· Emmet ускоряет кодирование, заменяя стандартные команды целыми блоками готового кода:
· JavaScript и фрагменты NodeJS упрощает написание кода на JavaScript и работает по тому же принципу, что и Emmet:
· SublimeCodeIntel помогает быстро понять код, имеющий несколько функций.