App Store: Google Переводчик
• Перевод введенного текста. В приложении добавлена поддержка 108 языков.
• Перевод офлайн. Переводите с 59 языков и обратно без подключения к Интернету.
• Наводите камеру на текст и мгновенно получайте его перевод Поддерживаются 94 языка.
• Перевод текста на фотографиях. Можно просто сфотографировать нужный текст или импортировать более качественный снимок. Поддерживаются 90 языков.
• Режим разговора. Автоматический перевод речи с 70 языков и обратно.
• Рукописный ввод. Напишите текст от руки и переведите его на любой из доступных языков (всего поддерживается 96 языков).
• Разговорник. Помечайте и сохраняйте переводы слов и выражений, чтобы использовать их в дальнейшем. Поддерживаются все языки.
Необходимые разрешения
• Микрофон для перевода речи
• Камера для перевода текста с изображений
• Фотогалерея для импорта фотографий
Поддерживаются следующие языки:
азербайджанский, албанский, амхарский, английский, арабский, армянский, африкаанс, баскский, белорусский, бенгальский, бирманский, болгарский, боснийский, валлийский, венгерский, вьетнамский, гавайский, галисийский, греческий, грузинский, гуджарати, датский, зулу, иврит, игбо, идиш, индонезийский, ирландский, исландский, испанский, итальянский, йоруба, казахский, каннада, каталанский, киргизский, китайский (традиционный), китайский (упрощенный), корейский, корсиканский, креольский (Гаити), курманджи, кхмерский, кхоса, лаосский, латинский, латышский, литовский, люксембургский, македонский, малагасийский, малайский, малаялам, мальтийский, маори, маратхи, монгольский, немецкий, непальский, нидерландский, норвежский, ория, панджаби, персидский, польский, португальский, пушту, руанда, румынский, русский, самоанский, себуанский, сербский, сесото, сингальский, синдхи, словацкий, словенский, сомалийский, суахили, суданский, таджикский, тайский, тамильский, татарский, телугу, турецкий, туркменский, узбекский, уйгурский, украинский, урду, филиппинский, финский, французский, фризский, хауса, хинди, хмонг, хорватский, чева, чешский, шведский, шона, шотландский (гэльский), эсперанто, эстонский, яванский, японский
Как я потратил $600 тысяч и пять лет, чтобы сделать свой переводчик
Ещё со школы мне хотелось сделать свой проект и заработать много денег.
{«id»:114237,»url»:»https:\/\/vc.ru\/life\/114237-kak-ya-potratil-600-tysyach-i-pyat-let-chtoby-sdelat-svoy-perevodchik»,»title»:»\u041a\u0430\u043a \u044f \u043f\u043e\u0442\u0440\u0430\u0442\u0438\u043b $600 \u0442\u044b\u0441\u044f\u0447 \u0438 \u043f\u044f\u0442\u044c \u043b\u0435\u0442, \u0447\u0442\u043e\u0431\u044b \u0441\u0434\u0435\u043b\u0430\u0442\u044c \u0441\u0432\u043e\u0439 \u043f\u0435\u0440\u0435\u0432\u043e\u0434\u0447\u0438\u043a»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/life\/114237-kak-ya-potratil-600-tysyach-i-pyat-let-chtoby-sdelat-svoy-perevodchik»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.

27 172 просмотров
Несколько раз я уезжал домой, в родной город, чтобы сэкономить деньги на жизнь. Там я создавал образовательные и туристические сайты, программу для бухгалтерии, игры для мобильных телефонов. Но из-за отсутствия опыта ведения бизнеса это не приносило дохода, и вскоре проекты закрывались. Приходилось снова ехать в Минск — работать и снова копить. Так прошло шесть лет.
Когда у меня в очередной раз закончились деньги, наступил кризис. Я не смог найти работу, ситуация стала критической. Пришло время посмотреть на все вещи трезвым взглядом. Нужно было честно признаться себе, что я не знаю, какие ниши выбрать для бизнеса. Создавать проекты, которые просто нравятся, — путь в никуда.
Я не смог найти работу, ситуация стала критической. Пришло время посмотреть на все вещи трезвым взглядом. Нужно было честно признаться себе, что я не знаю, какие ниши выбрать для бизнеса. Создавать проекты, которые просто нравятся, — путь в никуда.
Единственное, что я умел делать, это мобильные приложения . Несколько лет работы в ИТ-компаниях позволили накопить определенный опыт, и было решено сделать много простых принципиально различных приложений (игры, музыка, рисование, ЗОЖ, изучение языков) и протестировать, в каких нишах будет небольшая конкуренция.
Сначала приложения были бесплатными. Потом я добавил рекламу и встроенные покупки, подобрал ключевые слова и яркие иконки. Приложения начали скачивать. Когда доход достиг $30 тысяч в месяц, я решил рассказать товарищу, который работал в большой продуктовой компании, что на тестовых приложениях я смог достичь такой цифры, и предложил создавать их вместе. Он ответил, что у них всего одно приложение — игра с доходом в $60 тысяч и 25 тысяч пользователей в месяц, против $30 тысяч выручки и 200 тысяч пользователей у меня.
Это полностью изменило мои взгляды. Выяснилось, что лучше создать одно качественное приложение, чем сто некачественных. Я понимал, что на качественных можно заработать в десятки раз больше, но я был один в маленьком городе без опыта и команды дизайнеров и маркетологов. Мне требовалось платить за аренду квартиры и зарабатывать на жизнь.
Тестовые приложения нужны были просто для проверки рыночных ниш и рекламных стратегий, чтобы научиться, какие приложения и как именно создавать. Просто сложилось, что некоторые из них начали приносить неплохой доход. Сейчас тема простых приложений давно умерла, и там больших денег уже не заработать.
Некоторые приложения сильно отличались по прибыли — это были переводчики, приложения для грузоперевозок, музыкальные программы (которые симулируют игру на пианино, барабанах или, например, гитарные аккорды, плееры), а также простые логические игры.
Вскоре я заметил, что буквально за месяц переводчики скачали более 1 млн раз. Языков в мире сотни, и люди ищут переводы каждый на свой язык.
Ниша оказалась перспективной, тем более сама тема переводов мне нравилась. Позже было создано около 40 простых переводчиков, где использовался перевод, который предоставлял Google API. Его стоимость была по $20 за 1 млн переведенных символов. Постепенно появились улучшенные версии приложений, где я добавил рекламу, встроенные покупки, функцию перевода голоса.
Заработав денег, я переехал в Минск и купил жилье. На то время у меня было 50−70 приложений для перевода и 5 млн скачиваний. Но с ростом пользователей увеличивался расход на платный Google Translate API. Прибыльность бизнеса серьезно снизилась. Платящие пользователи переводили блоки от 1 тыс символов за раз, что заставило ввести лимиты на запрос. Когда они упирались в лимит на перевод, писали плохие отзывы и возвращали деньги.
Платящие пользователи переводили блоки от 1 тыс символов за раз, что заставило ввести лимиты на запрос. Когда они упирались в лимит на перевод, писали плохие отзывы и возвращали деньги.
Настал момент, когда 70% выручки уходило на расходы. При больших объемах перевода этот бизнес оказался не такой перспективный. Чтобы окупить расходы, в приложения нужно было добавлять много рекламы, а это всегда отпугивает пользователей. Требовалось сделать свое API для перевода, а это скорее всего будет не дешево.
Я пробовал просить совета и инвестиций у стартапов и ИТ-сообщества, но поддержки не встретил. Большинство людей не понимали, зачем работать на рынке, где уже есть лидер — Google-переводчик. Помимо Google было еще несколько компаний, которые предоставлял API для перевода. Я был готов заплатить $30 тысяч за их лицензии технологий перевода на 40 языков. Это позволило бы мне переводить неограниченное количество раз за фиксированную цену и обслуживать любое количество пользователей на своих серверах. Но мне в ответ называли сумму в несколько раз выше. Это было слишком дорого.
Я был готов заплатить $30 тысяч за их лицензии технологий перевода на 40 языков. Это позволило бы мне переводить неограниченное количество раз за фиксированную цену и обслуживать любое количество пользователей на своих серверах. Но мне в ответ называли сумму в несколько раз выше. Это было слишком дорого.
Было решено попробовать сделать свою технологию для перевода. Я пробовал привлечь друзей для разработки, но к тому времени у большинства из них уже были семьи, маленькие дети и кредиты. Все хотели стабильности и жизни в свое удовольствие на хорошую ЗП, а не идти в стартап. Также они не понимали, зачем создавать переводчик, если есть Google с крутым навороченным приложением для перевода и API.
У меня не было опыта публичных выступлений, харизмы и крутого прототипа приложений, чтобы заинтересовать людей. Аналитика по заработку $300 тысяч на тестовых приложениях для перевода никого не удивляла. Я обратился к знакомому, который владеет аутсорс-компанией в Минске. В конце 2016 года он выделил для меня команду. Я рассчитывал, что решу задачу за полгода на базе open-source проектов, чтобы не зависеть по API от Google.
Аналитика по заработку $300 тысяч на тестовых приложениях для перевода никого не удивляла. Я обратился к знакомому, который владеет аутсорс-компанией в Минске. В конце 2016 года он выделил для меня команду. Я рассчитывал, что решу задачу за полгода на базе open-source проектов, чтобы не зависеть по API от Google.
Первые попытки
Работа началась. В 2016 году мы нашли несколько opensource проектов — Apertium, Joshua и Moses. Это был статистический машинный перевод, подходящий для несложных текстов. Эти проекты поддерживали от 3 до 40 человек, и чтобы получить ответ на вопрос по ним, требовалось много времени. После того как разобрались и все-таки запустили их на тесты, стало ясно, что нужны мощные сервера и качественные датасеты, которые стоят дорого.
Технически все не сводилось к схеме «скачать датасет и натренировать». Оказалось, что есть миллион нюансов, о которых мы даже не подозревали. Перепробовали еще несколько ресурсов, но хороших результатов не добились. А Google и Microsoft свои наработки не раскрывают. Тем не менее, работа продолжалась, периодически подключались фрилансеры.
В марте 2017 года мы наткнулись на проект под названием Оpen NMT. Это совместная разработка компании Systran, одного из лидеров на рынке машинного перевода, и университета Гарварда. Проект только стартовал и предлагал перевод уже на базе новой технологии — нейронных сетей. Современные технологии машинного перевода принадлежат большим компаниям, они закрыты. Мелкие игроки, понимая, как сложно внедриться в этот мир, таких попыток не предпринимают. Это тормозит развитие рынка. Качество перевода среди лидеров не сильно отличалось друг от друга долгое время. Очевидно, что и крупные компании столкнулись с дефицитом энтузиастов, научных работ, стартапов и opensource проектов, чтобы брать новые идеи и нанимать людей.
Это тормозит развитие рынка. Качество перевода среди лидеров не сильно отличалось друг от друга долгое время. Очевидно, что и крупные компании столкнулись с дефицитом энтузиастов, научных работ, стартапов и opensource проектов, чтобы брать новые идеи и нанимать людей.
Поэтому Systran сделала принципиально новый маневр: выложила свои наработки в opensource, чтобы такие энтузиасты, как я, могли включиться в эту работу. Они создали форум, где их специалисты стали бесплатно помогать новичкам. И это принесло хорошую отдачу: начали появляться стартапы, научные работы по переводу, так как каждый мог взять основу и на базе нее проводить свои эксперименты.
Systran стал во главе этого сообщества. Потом подключились другие компании. В то время ещё не было повсеместного нейронного перевода, а Оpen NMT предлагал наработки в этой области, выигрывая по качеству у статистического машинного перевода. Я и другие ребята по всему миру могли взять эти технологии и спросить совета у специалистов. Они охотно делились опытом, и это позволило мне понять, в каком направлении двигаться.
Я и другие ребята по всему миру могли взять эти технологии и спросить совета у специалистов. Они охотно делились опытом, и это позволило мне понять, в каком направлении двигаться.
Сначала я удивлялся: как же так, зачем Systran растит себе конкурентов? Но со временем понял правила игры, когда все больше компаний начали выкладывать свои наработки по обработке естественного языка в opensource.
Даже если у всех есть вычислительные мощности, чтобы обрабатывать большие датасеты, то вопрос с поиском специалистов по NLP (обработка естественного языка) на рынке стоит остро. В 2017 году эта тема была намного менее развита, чем обработка изображений и видео. Меньше датасетов, научных работ, специалистов, фреймворков и прочего. Людей, способных из научных работ по NLP построить бизнес и закрыть какую-либо из локальных ниш, еще меньше. И компаниям верхнего эшелона типа Google, и игрокам поменьше типа Systran нужно получить конкурентное преимущество относительно игроков из своей категории.
Как они решают этот вопрос?
На первый взгляд это кажется странным, но чтобы конкурировать между собой, они решают вводить на рынок новых игроков (конкурентов), а чтобы они там появлялись, нужно раскачать его. Порог входа до сих пор высок, а запрос на технологии обработки речи очень растет (голосовые ассистенты, чат-боты, переводы, распознавание и анализ речи, и т.д.) Нужного количества стартапов, которые можно купить для усиления своих позиции, до сих пор нет. В открытом доступе публикуются научные работы от команд Google, Facebook, Alibaba. От них же в opensource выкладываются их фреймворки и датасеты. Создаются форумы с ответами на вопросы.
Крупные компании заинтересованы, чтобы такие стартапы, как наш, развивались, захватывали новые ниши и показывали максимальный рост.![]() Они с радостью готовы покупать NLP стартапы для усиления своих больших компаний. Ведь даже если у тебя на руках все датасеты, алгоритмы и тебе подсказывают, это ещё не значит, что ты сделаешь качественный переводчик или другой стартап в области NLP. А даже если и сделаешь, то далеко не факт, что откусишь большой кусок рынка. Поэтому нужно помочь, и если у кого-то получится, купить или объединиться.
Они с радостью готовы покупать NLP стартапы для усиления своих больших компаний. Ведь даже если у тебя на руках все датасеты, алгоритмы и тебе подсказывают, это ещё не значит, что ты сделаешь качественный переводчик или другой стартап в области NLP. А даже если и сделаешь, то далеко не факт, что откусишь большой кусок рынка. Поэтому нужно помочь, и если у кого-то получится, купить или объединиться.
Переводчик DeepL
В сентябре 2017 года, анализируя конкурентов, я узнал про DeepL. Они в это время только запустились и предоставляли перевод всего на 7 языков. DeepL позиционировался как инструмент для профессиональных переводчиков, помогающий тратить меньше времени на корректуру после машинного перевода. Даже небольшое изменение в качестве перевода позволяет сэкономить много денег для компаний, занимающихся переводами. Они постоянно отслеживают API для машинного перевода от разных поставщиков используя трекеры. Качество на множестве языковых пар у всех разное и нет единого лидера.
Они постоянно отслеживают API для машинного перевода от разных поставщиков используя трекеры. Качество на множестве языковых пар у всех разное и нет единого лидера.
Если какой-то сервис предложит на 1% лучше качество конкурента на одном из языков, то у него на следующий день будет сразу большой кусок рынка.
Чтобы продемонстрировать качество перевода, DeepL решил устроить тесты на некоторых языках. Оценка качества проводилась методом слепого тестирования, когда профессиональные переводчики выбирают лучший перевод из Google, Microsoft, DeepL, Facebook. По результатам победил DeepL, жюри оценило его перевод как наиболее «литературный».
Как так получилось?
Основатели DeepL владеют стартапом Linguee — крупнейшей базой ссылок на переведенные тексты. Скорее всего, у них гигантское количество датасетов, собранных парсерами, и чтобы натренировать их, нужна большая вычислительная мощность. В 2017 году у них вышла статья о том, что они собрали в Исландии суперкомпьютер в 5 петаФлопс (на тот момент он был 23-м по производительности в мире). Натренировать большую качественную модель было лишь делом времени. В том момент казалось, что даже если мы купим качественные датасеты, то все равно никогда не сможем конкурировать с ними, не имея такого супер-компьютера.
Скорее всего, у них гигантское количество датасетов, собранных парсерами, и чтобы натренировать их, нужна большая вычислительная мощность. В 2017 году у них вышла статья о том, что они собрали в Исландии суперкомпьютер в 5 петаФлопс (на тот момент он был 23-м по производительности в мире). Натренировать большую качественную модель было лишь делом времени. В том момент казалось, что даже если мы купим качественные датасеты, то все равно никогда не сможем конкурировать с ними, не имея такого супер-компьютера.
Но все изменилось в марте 2018 года. Nvidia выпускает компьютер DGX-2 размером с тумбочку и производительностью в 2 петаФлопса (FP16), который сейчас можно взять в лизинг от $5000 в месяц.
Имея такой компьютер, можно тренировать свои модели с гигантскими датасетами быстро, а также держать большую нагрузку по API. Это кардинально меняет расклад сил всего рынка стартапов машинного обучения и позволяет небольшим компаниям конкурировать с гигантами в области работы с большими данными. Это было лучшее предложение на рынке в соотношении «цена-производительность». Я начал искать информацию о статистике DeepL. У Google за 2018 год было 500 миллионов пользователей ежемесячно. У DeepL — 50 миллионов (статья от 12 декабря 2018).
Это кардинально меняет расклад сил всего рынка стартапов машинного обучения и позволяет небольшим компаниям конкурировать с гигантами в области работы с большими данными. Это было лучшее предложение на рынке в соотношении «цена-производительность». Я начал искать информацию о статистике DeepL. У Google за 2018 год было 500 миллионов пользователей ежемесячно. У DeepL — 50 миллионов (статья от 12 декабря 2018).
Получается, что в конце 2018 года 10% от ежемесячной аудитории Google пользовались DeepL, причем они нигде особо не рекламировались. Чуть более чем за год они захватили 10% рынка, использую сарафанное радио. Я задумался. Если DeepL командой в 20 человек победил Google, имея в 2017 году машину в 5 petaFlops, а сейчас можно дешево арендовать машину в 2 petaFlops и купить качественные датасеты, насколько будет сложно добиться качества Google?
Улучшаем качество перевода
Весь 2018 год я потратил на решение проблемы качественного перевода на основных европейских языках.![]() Думал, что ещё полгода — и всё получится. Я был очень ограничен в ресурсах, задачами по Data Science занималось всего 2 человека. Нужно было двигаться быстро. Казалось, что решение проблемы в чем-то простом. Но светлый момент всё не наступал, я не был доволен качеством перевода. Было потрачено уже около $450 тысяч, заработанных на старых переводчиках, и требовалось принимать решение, как быть дальше.
Думал, что ещё полгода — и всё получится. Я был очень ограничен в ресурсах, задачами по Data Science занималось всего 2 человека. Нужно было двигаться быстро. Казалось, что решение проблемы в чем-то простом. Но светлый момент всё не наступал, я не был доволен качеством перевода. Было потрачено уже около $450 тысяч, заработанных на старых переводчиках, и требовалось принимать решение, как быть дальше.
Запуская этот проект в одиночку и без инвестиций, я понял, сколько управленческих ошибок совершил. Но решение принято — идти до конца!
Мы взяли новый токенизатор, сделали препоцессинг текста, по-другому стали фильтровать и размечать данные, иначе обрабатывать текст после перевода, чтобы исправлять ошибки. Сработало правило 10 тысяч часов: было много шажков к цели, и в определённый момент я понял, что качество перевода уже достаточно для того чтобы использовать его в API для собственных приложений.![]() Каждое изменение добавляло 2-4% качества, которых не хватало для критической массы и при которой люди продолжают пользоваться продуктом, не уходя к конкурентам.
Каждое изменение добавляло 2-4% качества, которых не хватало для критической массы и при которой люди продолжают пользоваться продуктом, не уходя к конкурентам.
Потом мы начали подключать различные инструменты, которые позволяли и дальше улучшать качество перевода: определитель именованных сущностей, транслитерацию, тематические словари, систему исправления ошибок в словах. За 5 месяцев этой работы качество переводов на некоторых языках стало значительно лучше и люди начали меньше жаловаться. Это был переломный момент. Ты уже можешь продать программу, и из-за того что у тебя есть свое API для перевода, можно сильно сократить расходы. Можно наращивать продажи или количество пользователей, ведь расходы будут только на сервера.
Для обучения нейронной сети нужен был хороший компьютер. Но мы экономили. Сначала мы арендовали 20 обычных компьютеров (с одной GTX 1080) и одновременно запускали на них 20 простых тестов через Lingvanex Control Panel. На каждый тест уходило по неделе, это было долго. Чтобы добиться лучшего качества, нужно было запускать с другими параметрами, которые требовали больше ресурсов. Требовалось облако и больше видеокарт на одной машине.
Но мы экономили. Сначала мы арендовали 20 обычных компьютеров (с одной GTX 1080) и одновременно запускали на них 20 простых тестов через Lingvanex Control Panel. На каждый тест уходило по неделе, это было долго. Чтобы добиться лучшего качества, нужно было запускать с другими параметрами, которые требовали больше ресурсов. Требовалось облако и больше видеокарт на одной машине.
Мы решили взять в аренду облачный сервис Аmazon 8 GPU V100 x 4. Он быстрый, но очень дорогой. Запустили на ночь тест, а утром — счёт на $1200. В то время было очень мало вариантов аренды мощных GPU-серверов, кроме него. Пришлось отказаться от этой идеи и искать варианты дешевле. Может, попробовать собрать свой? Обзвон компаний заканчивался тем, что мы сами должны были прислать детальную конфигурацию, а они его соберут. Что лучше с точки зрения «производительность / цена» для наших задач, никто не мог ответить.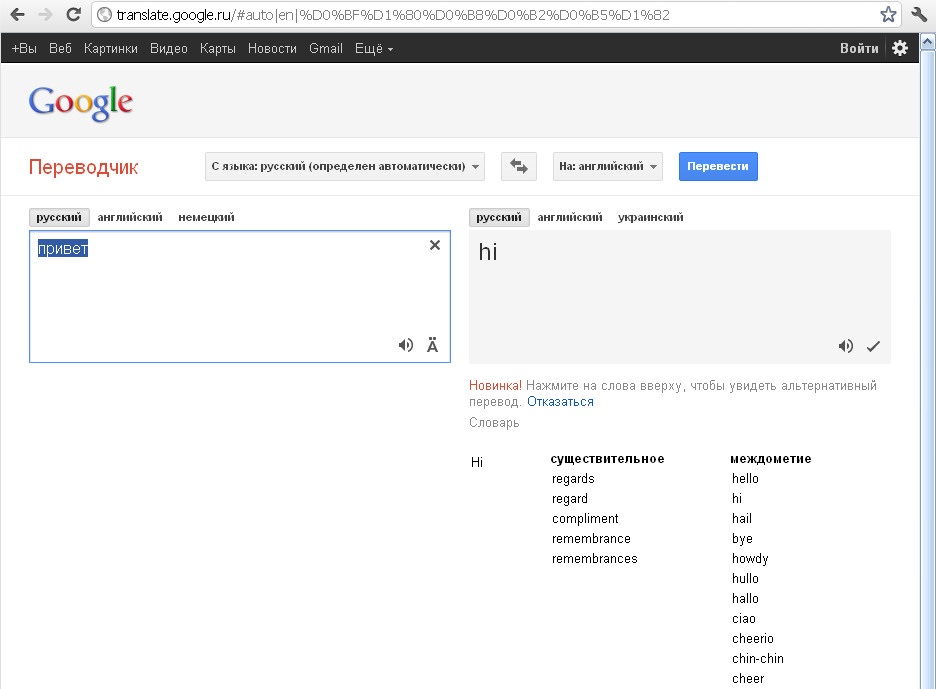 Попытались заказать в Москве — наткнулись на какую-то подозрительную фирму. Сайт был качественный, отдел продаж — в теме. Но банковский перевод они не принимали, и единственным вариантом оплаты был скинуть деньги на карту их бухгалтеру.
Попытались заказать в Москве — наткнулись на какую-то подозрительную фирму. Сайт был качественный, отдел продаж — в теме. Но банковский перевод они не принимали, и единственным вариантом оплаты был скинуть деньги на карту их бухгалтеру.
Стали совещаться с командой и решили, что можно самостоятельно собрать компьютер с ценой до 10 тысяч долларов, который будет решать наши задачи и окупится за месяц. Комплектующие буквально скребли по сусекам: звонили в Москву, что-то заказывали в Китае, что-то в Амстердаме. Через месяц все было готово. В начале 2019 у себя дома я наконец-таки собрал этот компьютер и начал проводить много тестов, не беспокоясь, что нужно платить за аренду.
На испанском языке я начал замечать, что перевод близок к переводу Google по метрике BLEU. Но я не понимал этот язык и на ночь поставил тренироваться модель англо-русского переводчика, чтобы понять, в какой точке нахожусь. Компьютер всю ночь гудел и жарил, спать было невозможно. Нужно было следить, чтобы не было ошибок в консоли, так как периодически все зависало. Утром я запустил тест на перевод 100 предложений с длинами от 1 до 100 слов и увидел, что получился хороший перевод, в том числе на длинных строках. Эта ночь изменила всё. Я увидел свет в конце тоннеля, что все же можно когда-нибудь добиться хорошего качества перевода.
Но я не понимал этот язык и на ночь поставил тренироваться модель англо-русского переводчика, чтобы понять, в какой точке нахожусь. Компьютер всю ночь гудел и жарил, спать было невозможно. Нужно было следить, чтобы не было ошибок в консоли, так как периодически все зависало. Утром я запустил тест на перевод 100 предложений с длинами от 1 до 100 слов и увидел, что получился хороший перевод, в том числе на длинных строках. Эта ночь изменила всё. Я увидел свет в конце тоннеля, что все же можно когда-нибудь добиться хорошего качества перевода.
Мобильные приложения
Заработав деньги на iOS переводчике с одной кнопкой и одной функцией, я решил улучшить его качество, а также сделать версию для Android, Mac OS, Windows Desktop. Надеялся, что когда у меня будет свое API, я закончу разработку приложений и зайду на другие рынки. За то время, когда я решал задачу своего API, конкуренты ушли намного вперед. Нужны были какие-то функции, ради которых будут скачивать именно мой переводчик.
Надеялся, что когда у меня будет свое API, я закончу разработку приложений и зайду на другие рынки. За то время, когда я решал задачу своего API, конкуренты ушли намного вперед. Нужны были какие-то функции, ради которых будут скачивать именно мой переводчик.
Первое, что я решил сделать, это голосовой перевод для мобильных приложений без доступа в интернет. Это было личной проблемой. Например, Вы едете в Германию, скачиваете только немецкий пакет на телефон (400 мб) и получаете перевод с английского на немецкий и обратно. На самом деле, проблема интернета в зарубежных странах стоит остро. Wifi либо нет, либо он запаролен или просто медленный, в итоге им невозможно пользоваться. Хотя качественных приложений переводчиков, которые работают только через интернет, используя API Google, даже в 2017 году были тысячи.
Я нашел ребят в Испании с хорошим опытом в области проектов по машинному переводу. Около 3 месяцев мы сообща вели исследования в области уменьшения размера модели нейронки для перевода, чтобы добиться в 150 мб на пару и потом запускать на мобильных телефонах. Размер нужно было уменьшать таким образом, чтобы в определенный размер словаря (к примеру, 30 тыс слов) вложить как можно больше вариантов по переводу слов разных длин и тематик. Позже результат наших исследований был выложен в открытый доступ и представлен на Европейской ассоциации машинного перевода в г. Аликанте (Испания) в мае 2018 года, а один из членов команды защитил по ней PhD.
Около 3 месяцев мы сообща вели исследования в области уменьшения размера модели нейронки для перевода, чтобы добиться в 150 мб на пару и потом запускать на мобильных телефонах. Размер нужно было уменьшать таким образом, чтобы в определенный размер словаря (к примеру, 30 тыс слов) вложить как можно больше вариантов по переводу слов разных длин и тематик. Позже результат наших исследований был выложен в открытый доступ и представлен на Европейской ассоциации машинного перевода в г. Аликанте (Испания) в мае 2018 года, а один из членов команды защитил по ней PhD.
Помимо перевода текста, голоса и картинок, было решено добавить перевод телефонных звонков с транскрипцией, которой не было у конкурентов. Был расчет на то, что люди часто звонят в поддержку или по вопросам бизнеса в разные страны, причем на мобильный или стационарный телефон. Тому, кому адресуется звонок, не нужно устанавливать приложение. Эта функция потребовала много времени и затрат, поэтому позже было решено вынести ее в отдельное от основного приложение. Так появился переводчик телефонных звонков.
Эта функция потребовала много времени и затрат, поэтому позже было решено вынести ее в отдельное от основного приложение. Так появился переводчик телефонных звонков.
У приложений для перевода была одна проблема — ими пользуются не каждый день. Не так много в жизни ситуаций, когда нужно переводить ежедневно. А вот если изучаешь язык, использование переводчика становится частым. Для изучения языков мы создали функцию карточек, когда слова добавляются в закладки на сайте через расширение для браузера или в субтитрах к фильму, а потом происходит закрепление знаний с помощью мобильного приложения чат-бота или приложения для умной колонки, которая будет проверять выбранные слова.
Все приложения Lingvanex связаны между собой единым аккаунтом, поэтому можно начать переводить на мобильном приложении и продолжить на компьютере.![]() Также добавили голосовые чаты с переводом. Это будет полезно для туристических групп, когда гид может говорить на своем языке, а каждый из посетителей будет слушать в переводе. И в конце — перевод больших файлов на телефоне или компьютере.
Также добавили голосовые чаты с переводом. Это будет полезно для туристических групп, когда гид может говорить на своем языке, а каждый из посетителей будет слушать в переводе. И в конце — перевод больших файлов на телефоне или компьютере.
Рынок перевода
Создавая API для своих приложений и вложив кучу денег, нужно понимать объем и перспективы рынка машинного перевода. В 2017 году был прогноз, что рынок к 2023 году станет $1,5 млрд, хотя объем рынка всех переводов будет $70 млрд (на 2023 год).
Почему такая разбежка — около 50 раз?
Допустим, лучший машинный переводчик сейчас переводит хорошо 80% текста. Остальные 20% нужно редактировать человеку. Самое большие расходы в переводе — это корректура, то есть зарплаты людей. Увеличение качества перевода даже на 1% (до 81% в нашем примере) может образно на 1% сократить расходы на корректуру текста. 1% от разницы между рынком всех переводов за вычетом машинного будет (70 — 1,5 = $68,5 млрд) или 4685 млн уже. Цифры и расчет выше даны приблизительно, чтобы передать суть. То есть улучшение качества даже на 1% позволяет значительно сэкономить большим компаниям на услугах перевода.
Остальные 20% нужно редактировать человеку. Самое большие расходы в переводе — это корректура, то есть зарплаты людей. Увеличение качества перевода даже на 1% (до 81% в нашем примере) может образно на 1% сократить расходы на корректуру текста. 1% от разницы между рынком всех переводов за вычетом машинного будет (70 — 1,5 = $68,5 млрд) или 4685 млн уже. Цифры и расчет выше даны приблизительно, чтобы передать суть. То есть улучшение качества даже на 1% позволяет значительно сэкономить большим компаниям на услугах перевода.
По мере развития качества машинного перевода все большая его часть будет заменять рынок ручного перевода и экономить на расходах по зарплате. Не обязательно стараться охватить все языки, можно выбрать популярную пару (англо-испанский) и одно из направлений (медицина, металлургия, нефтехимия и др.). 100% качества — идеальный перевод машиной по всем тематикам — недостижим в ближайшее время. А каждый следующий процент улучшения качества будет даваться труднее. Тем не менее, это не мешает рынку машинного перевода занять значительную часть общего всего рынка к 2023 году (по аналогии как DeepL незаметно отхватил 10% рынка Google), так как большие компании каждый день тестируют API различных переводчиков. И улучшение качества одного из них на процент (для какого-нибудь языка) позволит им экономить много миллионов $. Стратегия больших компаний по созданию своих наработкок opensouce начала приносить свои плоды. Стало больше стартапов, научных работ и людей в индустрии, что позволило раскачать рынок и добиваться все лучшего качества перевода, повышая прогноз по рынку машинного перевода.
А каждый следующий процент улучшения качества будет даваться труднее. Тем не менее, это не мешает рынку машинного перевода занять значительную часть общего всего рынка к 2023 году (по аналогии как DeepL незаметно отхватил 10% рынка Google), так как большие компании каждый день тестируют API различных переводчиков. И улучшение качества одного из них на процент (для какого-нибудь языка) позволит им экономить много миллионов $. Стратегия больших компаний по созданию своих наработкок opensouce начала приносить свои плоды. Стало больше стартапов, научных работ и людей в индустрии, что позволило раскачать рынок и добиваться все лучшего качества перевода, повышая прогноз по рынку машинного перевода.
Каждый год проводятся соревнования по задачам NLP, где корпорации, стартапы и университеты соревнуются у кого будет лучше перевод на определенных языковых парах. Анализируя список победителей, появляется уверенность, что небольшими ресурсами можно добиться отличного результата.
Чем мы лучше Google
За несколько лет проект вырос во много раз. Появились приложения не только для мобильных платформ, но и для компьютеров, носимых устройств, мессенджеров, браузеров, голосовых ассистентов. Помимо перевода текста был создан перевод голоса, картинок, файлов, сайтов и телефонных звонков.
Вначале я планировал делать свое API для перевода, чтобы использовать только для своих приложений. Но потом решил предложить его всем желающим. Конкуренты ушли вперед, и нужно было не отставать. До этого времени я управлял всем в одиночку как индивидуальный предприниматель, наняв людей на аутсорсе.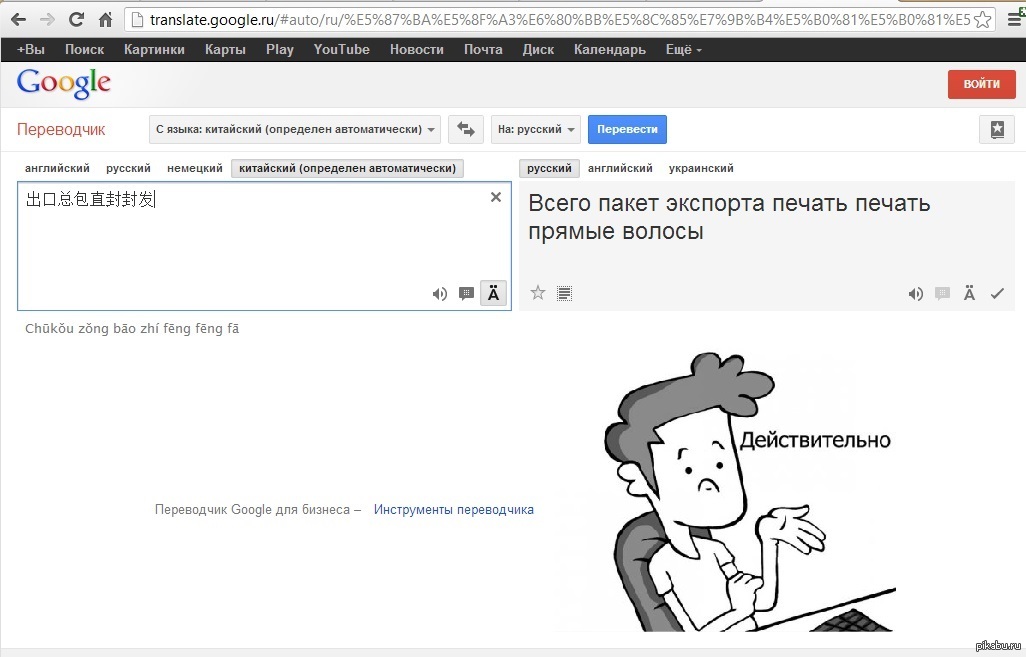 Но сложность продукта и количество задач начали быстро расти, и стало очевидно, что нужно делегировать функции и быстро нанимать людей в собственную команду в своем офисе. Я позвонил другу, он уволился с работы и принял решение открыть в марте 2019 года компанию Lingvanex.
Но сложность продукта и количество задач начали быстро расти, и стало очевидно, что нужно делегировать функции и быстро нанимать людей в собственную команду в своем офисе. Я позвонил другу, он уволился с работы и принял решение открыть в марте 2019 года компанию Lingvanex.
До этого момента я создавал проект, нигде не рекламируясь, и когда решил собрать свою команду, столкнулся с проблемой поиска. Никто не верил, что это вообще можно сделать, и не понимал зачем. Пришлось собеседовать многих людей и каждому по 3 часа рассказывать о тысячах неочевидных деталей.
Когда вышла первая статья о проекте, стало проще. Мне всегда задавали один вопрос:
«Чем вы лучше Google?»
В данный момент наша цель — добиться качества перевода Google общей тематики на основных европейских и азиатских языках и после этого предоставлять решения для:
- Перевода текста и сайтов через наше API втрое дешевле конкурентов, предоставляя отличный сервис поддержки и простую интеграцию.
 Например, стоимость перевода Google $20 за миллион символов, что получается очень дорого при значительных объемах.
Например, стоимость перевода Google $20 за миллион символов, что получается очень дорого при значительных объемах. - Качественного тематического перевода документов по определенным тематикам (медицина, металлургия, юриспруденция и так далее) по API, в том числе c интеграцией в инструменты для профессиональных переводчиков (типа SDL Trados).
- Интеграция в бизнес-процессы предприятий для запуска моделей перевода на их серверах по нашей лицензии. Это позволяет сохранить приватность данных, не зависеть от объема переведенного текста и оптимизировать перевод под специфику конкретной компании. Можно сделать качество перевода лучше конкурентов на определенные языковые пары или темы. Можно и на все. Это вопрос ресурсов компании.
 Например, стоимость перевода Google $20 за миллион символов, что получается очень дорого при значительных объемах.
Например, стоимость перевода Google $20 за миллион символов, что получается очень дорого при значительных объемах.При достаточных инвестициях с этим проблем нет. Что и как делать — известно, просто нужны рабочие руки и деньги. На самом деле рынок NLP растет очень быстро по мере того, как совершенствуется распознавание, анализ речи, машинный перевод, и может принести хорошую прибыль для небольшой команды.
На самом деле рынок NLP растет очень быстро по мере того, как совершенствуется распознавание, анализ речи, машинный перевод, и может принести хорошую прибыль для небольшой команды.
Весь хайп тут начнется через 2-3 года, когда сегодняшняя раскрутка рынка большими компаниями принесет свои плоды. Начнется череда сделок по слиянию / поглощению. Главное в этот момент — иметь хороший продукт с аудиторией, который можно продать.
Результат
За все время тестовые приложения принесли более 1 миллиона долларов, из которых большая часть потрачена на то, чтобы сделать свой переводчик. Сейчас очевидно, что все можно было сделать гораздо дешевле и лучше.
Было сделано много управленческих ошибок, но это опыт, а тогда советоваться было не с кем. В статье описана очень маленькая часть этой истории и иногда может быть непонятно, почему принимались те или иные решения. Задавайте вопросы в комментариях.
Ссылки на новые программы, которые разрабатывались в течении 3 лет и в которые были вложены деньги. Если кто хочет увидеть старые тестовые приложения, про которые шла речь в начале статьи (где были заработаны деньги и 35 млн скачек) — пишите в личку.
На данный момент мы не добились качества перевода Google, но я не вижу никаких проблем это сделать если в команде будет хотя бы несколько специалистов по Natural Language Processing. Сейчас лучше всего наш переводчик работает с английского языка на немецкий, испанский, французский. По ссылке можно найти демонстрацию перевода.
Сейчас лучше всего наш переводчик работает с английского языка на немецкий, испанский, французский. По ссылке можно найти демонстрацию перевода.
Если есть идеи совместных партнерств и предложений — пишите в личку, добавляйте в Facebook, LinkedIn.
В России издали переведенную Яндекс.Переводчиком книгу
Individuum
В российском издательстве «Individuum» вышла «Будущее без работы. Технологии, автоматизация и
стоит ли их бояться» Дэниела Сасскинда — первая книга, официально переведенная на русский язык с помощью машинного перевода. За перевод отвечал Яндекс.Переводчик — издательство использовало алгоритм, который используется для перевода больших текстов. Перевод 350-страничной книги занял 40 секунд, а по качеству был сравним с переводом среднего качества, сделанным человеком-переводчиком, сообщается в пресс-релизе, поступившем в редакцию N + 1.
Технологии, автоматизация и
стоит ли их бояться» Дэниела Сасскинда — первая книга, официально переведенная на русский язык с помощью машинного перевода. За перевод отвечал Яндекс.Переводчик — издательство использовало алгоритм, который используется для перевода больших текстов. Перевод 350-страничной книги занял 40 секунд, а по качеству был сравним с переводом среднего качества, сделанным человеком-переводчиком, сообщается в пресс-релизе, поступившем в редакцию N + 1.
Несмотря на то, что машинный перевод (во многом — благодаря использованию нейросетей в дополнение к стандартному статистическому переводу или вместо него) в последние годы активно развивается и совершенствуется, до автономной работы в некоторых областях ему все же еще далеко. Это, например, касается книгоиздательства: исследователи считают, что несмотря на то, что машинные переводчики с использованием нейросетей стали только лучше, издатели книг вряд ли доверят им перевод в ближайшие несколько лет.
Разумеется, машинный перевод используют при переводе книг — но больше в помощь переводчику-человеку или неофициально (перевод, сделанный с помощью онлайн-переводчиков, считается некачественной работой). Тем не менее, книги с помощью машинного перевода адаптируют и официально: например, в 2018 году французская компания Quantmetry перевела 800-страничную книгу по машинному обучению на французский с помощью машинного перевода: весь процесс занял 12 часов (для сравнения, у переводчика-человека эта работа заняла бы несколько месяцев).
Тем не менее, книги с помощью машинного перевода адаптируют и официально: например, в 2018 году французская компания Quantmetry перевела 800-страничную книгу по машинному обучению на французский с помощью машинного перевода: весь процесс занял 12 часов (для сравнения, у переводчика-человека эта работа заняла бы несколько месяцев).
С книгой Сасскинда объемом в 350 страниц машинный перевод справился меньше чем за минуту: для этого использовался один из алгоритмов Яндекс.Переводчика на основе архитектуры Transformer: с его помощью переводят большие тексты — например, недоступные на русском страницы «Википедии».
Как и в случае со стандартным переводом, машинному переводу книги понадобилась редактура, но, по словам издателя «Individuum» Феликса Сандалова, это заняло столько же времени, сколько ушло бы на редактуру среднего по качеству перевода, сделанного человеком. «При этом на самом этапе перевода мы выиграли четыре-пять месяцев времени, что позволило нам выпустить последнее издание книги Сасскинда практически синхронно с европейским релизом», — отмечает Сандалов. Для оценки работы Яндекс.Переводчика в книге также есть несколько фрагментов, которые не подвергались редактуре.
Для оценки работы Яндекс.Переводчика в книге также есть несколько фрагментов, которые не подвергались редактуре.
Один из фрагментов без редактуры перевода (в книге отмечены линией)
Individuum
Обложку для книги также создали с помощью нейросети (для основы взяли произведения современного искусства), а сама книга уже доступна в электронной и печатной версии.На недавней конференции YaC 2020 Яндекс показал новую версию умной колонки Станция, а также рассказал об обновлениях технологий беспилотных автомобилей и поиска. Кратко об этом вы можете прочитать здесь.
Елизавета Ивтушок
В «Яндекс.
 Переводчик» встроили нейросеть с фантазией
Переводчик» встроили нейросеть с фантазией , Текст: Валерия Шмырова
В сервисе «Яндекс.Переводчик» помимо статистического перевода стал доступен вариант перевода от нейросети. Ее преимущество в том, что она работает с целыми предложениями, лучше учитывает контекст и выдает согласованный, естественный текст. Однако когда нейросеть чего-то не понимает, она начинает фантазировать.
Запуск нейросети
Сервис «Яндекс.Переводчик» запустил нейронную сеть, которая поможет повысить качество перевода. Ранее перевод с одного языка на другой осуществлялся с помощью статистического механизма. Теперь процесс будет гибридным: свой вариант перевода будет предлагать и статистическая модель, и нейросеть. После этого алгоритм CatBoost, в основе которого лежит машинное обучение, будет выбирать лучший из полученных результатов.
Пока что нейросеть выполняет только перевод с английского на русский и только в веб-версии сервиса. По данным компании, в «Яндекс.Переводчике» запросы на англо-русский перевод составляют 80% всех запросов. В ближайшие месяцы разработчики намерены внедрить гибридную модель и в других направлениях. Чтобы пользователь мог сравнить переводы от разных механизмов, предусмотрен специальный переключатель.
Отличия от статистического переводчика
Принцип работы нейронной сети отличается от статистической модели перевода. Вместо того, чтобы переводить текст слово за словом, выражение за выражением, она работает с целыми предложениями, не разбивая их на части. Благодаря этому в переводе учитывается контекст и лучше передается смысл. Кроме того переведенное предложение получается согласованным, естественным, легким для чтения и восприятия. По словам разработчиков, его можно принять за результат работы переводчика-человека.
Перевод нейросети напоминает перевод человека
К особенностям нейросети относится склонность «фантазировать», когда ей что-то не понятно. Таким образом она пытается угадать правильный перевод.
Таким образом она пытается угадать правильный перевод.
У статистического переводчика есть свои преимущества: он удачнее переводит редкие слова и выражения — мало распространенные имена, топонимы и т. д. Кроме того, он не фантазирует в том случае, если смысл предложения не ясен. По словам разработчиков, статистическая модель лучше справляется с короткими фразами.
Другие механизмы
В «Яндекс.Переводчике» есть специальный механизм, который дорабатывает перевод нейросети, как и перевод статистического переводчика, корректируя в нем рассогласованные сочетания слов и орфографические ошибки. Благодаря этому пользователь не увидит в переводе сочетаний типа «папа пошла» или «сильный боль», уверяют разработчики. Этот эффект достигается за счет сравнения перевода с моделью языка — всеми знаниями о языке, накопленными системой.
В затруднительных случаях нейросеть склонна фантазировать
Модель языка содержит список слов и выражений языка, а также данные о частоте их употребления. Она нашла применение и за пределами «Яндекс.Переводчика». Например, при использовании «Яндекс.Клавиатуры» именно она угадывает, какое слово пользователь хочет набрать следующим, и предлагает ему готовые варианты. Например, модель языка понимает, что за «привет, как», скорее всего последуют варианты «дела» или «ты».
Она нашла применение и за пределами «Яндекс.Переводчика». Например, при использовании «Яндекс.Клавиатуры» именно она угадывает, какое слово пользователь хочет набрать следующим, и предлагает ему готовые варианты. Например, модель языка понимает, что за «привет, как», скорее всего последуют варианты «дела» или «ты».
Что такое «Яндекс.Переводчик»
«Яндекс.Переводчик — сервис по переводу текстов с одного языка на другой от компании «Яндекс», начавший работу в 2011 г. Изначально он работал только с русским, украинским и английским языком.
За время существования сервиса количество языков увеличилось до 94 языка. Среди них присутствуют и экзотические, такие как коса или папьяменто. Перевод можно выполнить между любыми двумя языками.
В 2016 г. в «Яндекс.Переводчик» был добавлен вымышленный и искусственно созданный язык, на котором общаются эльфы в книгах Дж. Р. Р. Толкина.
EnglishZoom. 7 лучших бесплатных онлайн-переводчиков
Недавно на блоге появилась статья, посвященная лучшим онлайн-словарям, а сегодня я хотела бы перечислить лучшие бесплатные онлайн-переводчики.
1. Переводчик Google
Наверное, самый популярный сервис машинного перевода, и при этом самый часто критикуемый. Причем совершенно напрасно! Разработка платформы, позволяющей переводить текст без ошибок — невероятно сложная задача, и Google справляется с ней хорошо.
В настоящее время доступны 90 языков, и постоянно добавляются новые. Вы можете напечатать текст, загрузить документ или перевести веб-страницу, указав ее URL.
Мобильное приложение позволяет распознавать не только напечатанный текст и голос, но и рукописные символы, а также переводить знаки и надписи путем наведения на них камеры устройства.
Вы можете помочь развитию сервиса, вступив в сообщество Google Переводчика, участники которого работают над улучшением качества перевода и добавлением в сервис новых языков.
2. Яндекс.Переводчик
Менее популярен, чем онлайн-переводчик от Google, но, как мне кажется, является очень качественной системой машинного перевода. В своей работе я чаще всего использую именно Яндекс.Переводчик, так как именно предлагаемые этим сервисом переводы кажутся мне наиболее точными.
В своей работе я чаще всего использую именно Яндекс.Переводчик, так как именно предлагаемые этим сервисом переводы кажутся мне наиболее точными.
На данный момент возможен перевод на 64 языка. Есть два режима работы: перевод текстов и перевод веб-страниц. Доступны такие возможности, как автоматическое определение языка, синхронный перевод (по мере набора текста), подсказки при наборе текста и исправление опечаток, а также очень хороший машинный словарь, позволяющий просматривать подробные словарные статьи с вариантами перевода, примерами использования лексики в различных контекста и грамматическими комментариями.
Яндекс.Переводчик доступен для различных мобильных устройств, для Android и iOS возможен перевод оффлайн.
3. Translate.ru.
Первый российский сервис машинного перевода, созданный в 1998 г. компанией PROMPT, использующей собственные лингвистические технологии. Один из самых популярных онлайн-переводчиков в Рунете.
Системы перевода и словари PROMT обеспечивают перевод для нескольких десятков языковых пар, поддерживая до 17 языков.![]()
Здесь также можно найти переводчик текстов, переводчик сайтов, словарь и мобильный переводчик.
Для владельцев сайтов и вебмастеров сервис предлагает различные HTML-формы, которые можно бесплатно установить на сайт для автоматического перевода их содержимого на иностранные языки.
4. Babylon
Довольно известный переводчик, позволяющий работать с более чем 75 языками, и использующий почти 2000 словарей и глоссариев.
Переводчиком можно пользоваться онлайн, но удобнее скачать и установить его на компьютер. Программа бесплатна для индивидуальных пользователей, есть платные решения для бизнеса.
На сайте также есть тезаурус, коллекция онлайн-словарей и инструменты для веб-мастеров.
5. Bing
Поисковик Bing, наряду с Google и Яндексом, также предлагает свой онлайн-переводчик. Он не имеет каких-либо преимуществ перед перечисленными выше сервисами, но многим пользователям нравится его простой и удобный интерфейс. Здесь есть несколько необычных возможностей, например, можно выбрать мужской или женский голос озвучки, а также оценить, является ли перевод хорошим или плохим, нажав на соответствующий значок.
6. SYSTRAN
SYSTRAN — одна из старейших компаний в данной сфере. Основана в 1968 г. Сотрудничает со многими компаниями, и разрабатывает различные решения в области машинного перевода.
Онлайн-переводчик можно использовать бесплатно, некоторые его возможности доступны только после регистрации.
7. Babelfish
Онлайн-переводчик, использующий технологии SYSTRAN. В настоящее время поддерживает более 75 языков. Позволяет переводить слова и фразы, вебсайты, а также документы в форматах Word, PDF и txt. Вы можете присоединиться к сообществу Babelfish, и улучшить сервис, выбирая лучшие варианты перевода.
С уважением,
Евзикова Олеся
Поделитесь записью
Пол (Устный переводчик) | Департамент по делам Генеральной Ассамблеи и конференционному управлению
Как Вы изучали языки, которыми пользуетесь в своей работе?
Я имею степени бакалавра и магистра филологии по специальности «Французский язык и литература» и в общей сложности 15 лет опыта работы и учебы во франкоязычных странах. Испанский язык я изучал в университете и в течение почти 5 лет, когда жил и работал в испаноязычных странах. Я и сейчас постоянно работаю над поддержанием и совершенствованием своих знаний этих языков.
Испанский язык я изучал в университете и в течение почти 5 лет, когда жил и работал в испаноязычных странах. Я и сейчас постоянно работаю над поддержанием и совершенствованием своих знаний этих языков.
Чем привлекла Вас работа в качестве языкового специалиста в Организации Объединенных Наций?
По окончании университета на Ямайке (Университет Вест-Индии) я хотел найти практическое применение своим познаниям в области лингвистики и пошел учиться в Школу письменного и устного перевода при Женевском университете. Сначала проходил обучение по специальности «Письменный перевод», а затем по специальности «Устный перевод». По окончании учебы в 1997 году я работал то письменным переводчиком, то редактором перевода, то устным переводчиком в ряде международных организаций в Женеве, Брюсселе, Вашингтоне, округ Колумбия, Панаме, Мехико и Гааге. К 2008 году я решил, что пришло время сделать выбор между устным и письменным переводом, чтобы не разрываться между двумя разными профессиями, особенно с учетом того, что в большинстве организаций подобная двойная специализация не поощряется. В 2011 году я успешно сдал конкурсные экзамены, а когда в 2012 году получил приглашение на должность штатного устного переводчика ООН, немедленно принял его. И с тех пор ни разу об этом не пожалел.
В 2011 году я успешно сдал конкурсные экзамены, а когда в 2012 году получил приглашение на должность штатного устного переводчика ООН, немедленно принял его. И с тех пор ни разу об этом не пожалел.
Чем, по Вашему мнению, работа в Организации Объединенных Наций отличается от работы в других местах, где Вам приходилось работать прежде?
Одно из преимуществ работы в Организации Объединенных Наций состоит в том, что работа штатного устного переводчика почти столь же разнообразна, как у синхрониста-фриланса, работающего на открытом рынке. Разнообразие обслуживаемых органов, обсуждаемых тем, форумов и платформ таково, что устный переводчик никогда не знает заранее, какую задачу ему придется решать.
Какими, по Вашему мнению, основными качествами должен обладать хороший устный переводчик?
Мощным интеллектом, пытливым умом, стальными нервами и гибкостью, позволяющей адаптироваться к постоянно меняющейся обстановке. Если переводчик предан своей профессии и верит в идеалы ООН, то он не подвержен цинизму и не чувствует усталости.![]()
Какие аспекты Вашей работы Вы считаете наиболее интересными и почему?
Даже не знаю, с чего начать… Я никогда не знаю, какое из заданий запомнится мне навсегда и почему, и это хорошо. Однако до сих пор самыми запоминающимися были случаи, когда я переводил для людей, которые своими рассказами о том, что им довелось пережить, заставляли меня воспринимать кризисные ситуации, решением которых занимается ООН, как личную беду. Выступать в такой роли приходится не часто, но когда это случается, то ощущаю особую ответственность за то, чтобы донести до мирового сообщества не только смысл слов этих людей, но и их чувства и переживания.
С какими трудностями Вы сталкиваетесь в своей повседневной работе и как с ними справляетесь?
Темп, темп и еще раз темп — темп речи ораторов! Все чаще и чаще выступающие говорят скороговоркой, а текстов их выступлений для предварительного ознакомления мы зачастую не имеем.
Как часто Вам встречаются незнакомые слова или речевые обороты и как Вы выходите из положения?
К счастью, такое случается не часто. Но если и случается, то на помощь приходят понимание контекста, заботливые коллеги, опыт и мой верный ноутбук, и в итоге, как правило, проблема разрешается чуть ли не мгновенно.
Но если и случается, то на помощь приходят понимание контекста, заботливые коллеги, опыт и мой верный ноутбук, и в итоге, как правило, проблема разрешается чуть ли не мгновенно.
Приведите примеры самых сложных заданий, которые Вам доводилось выполнять
Для меня лично наибольшую трудность представляет устный перевод некоторых заседаний редакционного комитета ЮНСИТРАЛ (Комиссия Организации Объединенных Наций по праву международной торговли) в силу узкоспециального характера обсуждаемых вопросов. Обсуждаемые на этих совещаниях темы и используемая терминология очень сложны, и при этом от переводчика требуется абсолютная точность перевода, поскольку делегаты буквально по буквам шлифуют формулировки нормативных положений, пытаясь добиться требуемого эффекта.
Что Вы думаете о развитии технологий в Вашей сфере деятельности? Как это влияет на Вашу работу?
Изменения в сфере технологий происходят все стремительнее и все чаще, но в большинстве случаев это идет нам на пользу. В нашем подразделении идет непрерывное обсуждение вопроса о том, как использовать технологии таким образом, чтобы оптимизировать нашу работу по обслуживанию клиентов, подобно тому, как это делается в других подразделениях нашего Департамента.
В нашем подразделении идет непрерывное обсуждение вопроса о том, как использовать технологии таким образом, чтобы оптимизировать нашу работу по обслуживанию клиентов, подобно тому, как это делается в других подразделениях нашего Департамента.
Как бы Вы определили свое место в деятельности Организации Объединенных Наций в целом?
Устные переводчики играют исключительно важную роль в деятельности Организации, это нужный винтик в большой машине системы ООН. Прежде чем делегаты соберутся на заседание, кто-то должен проделать большую работу за кулисами, а мы лишь участвуем в заключительном акте представления, над сценарием которого много недель и даже месяцев трудились наши усердные коллеги.
Расскажите о самом памятном случае из Вашей трудовой деятельности
Возможно, пересказывая произошедшее, я вас не развеселю, но постараюсь. А дело было так. Либо выступающий был простужен, либо я не расслышал его слова, но, как бы то ни было, вместо того, чтобы сказать «что угодно, только не оружие», я сказал «что угодно, только не деревья». Я сразу спохватился и поправился, конечно. Что тут скажешь, хотя я и исправил свою оговорку, но по залу все равно прокатился приглушенный смех. В этой ситуации мне помогло то, что я смеялся над собой вместе с делегатами. Мне в самом деле было смешно! По крайней мере в тот момент.
Я сразу спохватился и поправился, конечно. Что тут скажешь, хотя я и исправил свою оговорку, но по залу все равно прокатился приглушенный смех. В этой ситуации мне помогло то, что я смеялся над собой вместе с делегатами. Мне в самом деле было смешно! По крайней мере в тот момент.
Что бы Вы посоветовали начинающим языковым специалистам, в частности в плане подготовки к конкурсным экзаменам для заполнения лингвистических должностей?
Как можно больше читайте на всех языках, которыми владеете, в том числе на родном языке; развивайте навыки аналитического мышления; заинтересуйтесь вопросами, которые решает Организация Объединенных Наций, и узнайте как можно больше о ее программах и операциях; смотрите веб-трансляции нашей работы для практики и научитесь не только радоваться своим успехам, но и признавать свои ошибки!
«Подготовка переводчиков для международных организаций» отделение «Теория и практика синхронного и письменного перевода»
Программа реализуется Управлением магистерской подготовки на межкафедральной основе.![]()
Программа магистерской подготовки «Подготовка переводчиков для международных организаций» (отделение «Теория и практика синхронного и письменного перевода») в МГИМО была открыта в ответ на запрос МИД России об организации системы магистерской подготовки переводчиков для МИД России, международных организаций и государственных структур, работающих в области международных отношений.
Программа ориентирована, в первую очередь, на выпускников-лингвистов, филологов, преподавателей иностранных языков, специалистов в области межкультурной коммуникации, международников со знанием двух иностранных языков, которых интересуют современные теоретические и практические проблемы перевода, в особенности применительно к той практике переводческой деятельности, которая сложилась в международных организациях. Магистерская программа интегрирует элементы переводческой, лингвистической, педагогической подготовки, а также подготовки в сфере дипломатии и международных отношений.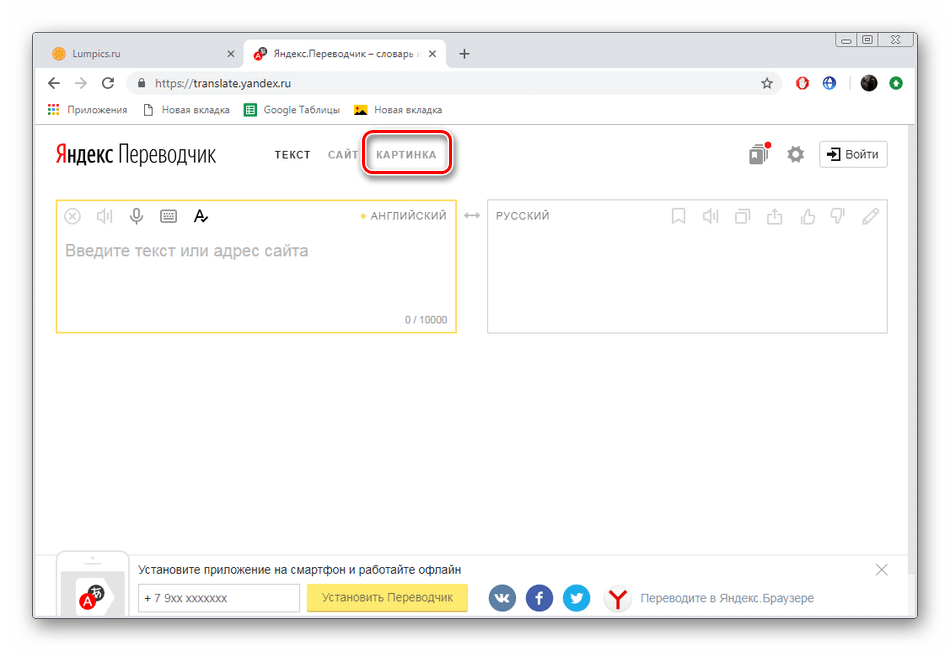
Кого мы готовим
Магистерская программа направлена на подготовку высококвалифицированных устных и письменных переводчиков-международников для работы в МИД России и международных организациях (ООН, МАГАТЭ, ОБСЕ и т.д.), а также в органах государственной власти. Благодаря сочетанию аудиторных занятий с преподавателями МГИМО и представителями переводческой индустрии, а также стажировкам в различных лингвистических службах ООН и практическому опыту работы в качестве письменных и устных переводчиков на мероприятиях, проводимых в МГИМО и на других площадках, выпускники программы получают уникальную подготовку, позволяющую им занять свою нишу на рынке труда.
Магистерская программа «Подготовка переводчиков для международных организаций» также предлагает курсы, направленные на развитие научно-исследовательских компетенций магистрантов, что позволит им после окончания обучения продолжать научно-исследовательскую деятельность в аспирантуре.![]()
Профилирующие дисциплины
- английский язык: интенсивный курс синхронного общественно-политического перевода;
- английский язык: интенсивный курс письменного общественно-политического перевода;
- последовательный перевод;
- французский / испанский язык: интенсивный курс синхронного общественно-политического перевода;
- современный русскоязычный международно-политический дискурс.
Перспективы трудоустройства
Данная многопрофильная программа подготовки переводчиков-международников открывает широкие перспективы дальнейшего трудоустройства, в том числе в международных организациях. Выпускники работают:
- в МИД России,
- в Счетной палате Российской Федерации,
- в отделениях ООН в Нью-Йорке и Женеве,
- в МАГАТЭ,
- в Международном комитете Красного Креста,
- в посольствах зарубежных государств,
- в RT,
- в переводческих агентствах и других организациях.

Контакты
Научный руководитель программы:
к.филол.н. зав. кафедрой английского языка №1 Дмитрий Александрович Крячков
Координатор программы:
Тел.: +7 495 234-58-42 E-mail: [email protected]
Форма обучения: очная.
Срок обучения: 2 года.
Время начала занятий: 14:30.
Новости магистратуры:
Мелкость Google Translate
Недавно я видел гистограммы, сделанные технофилами, которые утверждают, что они представляют «качество» переводов, выполненных людьми и компьютерами, и эти графики показывают, что новейшие системы перевода находятся в пределах досягаемости от человека. -уровневый перевод. Для меня, однако, такая количественная оценка неизмеримых запахов псевдонауки или, если хотите, ботаников, пытающихся математизировать вещи, чья неосязаемая, тонкая, художественная природа ускользает от них. На мой взгляд, результаты сегодняшнего Google Переводчика варьируются от превосходных до гротескных, но я не могу количественно оценить своих ощущений по этому поводу. Вспомните мой первый пример, связанный с «его» и «ее» предметами. Безидеальная программа получила почти все слов правильно, но, несмотря на этот небольшой успех, она полностью пропустила балла. Как в таком случае следует «количественно оценить» качество работы? Использование гистограмм научного вида для представления качества перевода — это просто злоупотребление внешними атрибутами науки.
На мой взгляд, результаты сегодняшнего Google Переводчика варьируются от превосходных до гротескных, но я не могу количественно оценить своих ощущений по этому поводу. Вспомните мой первый пример, связанный с «его» и «ее» предметами. Безидеальная программа получила почти все слов правильно, но, несмотря на этот небольшой успех, она полностью пропустила балла. Как в таком случае следует «количественно оценить» качество работы? Использование гистограмм научного вида для представления качества перевода — это просто злоупотребление внешними атрибутами науки.
Позвольте мне вернуться к этому грустному образу переводчиков-людей, которые вскоре превзошли и устарели, постепенно превращаясь в ничего, кроме контролеров качества и корректоров текста. В лучшем случае это рецепт посредственности. Серьезный художник не начинает с китчевого куска забитой ошибками трюмной воды, а затем исправляет его кое-где, чтобы создать произведение высокого искусства. Это не природа искусства. А перевод — это искусство.
А перевод — это искусство.
В своих трудах на протяжении многих лет я всегда утверждал, что человеческий мозг — это машина, очень сложный вид машины, и я решительно выступал против тех, кто говорит, что машины по своей природе неспособны иметь дело со смыслом.Есть даже школа философов, которые утверждают, что компьютеры никогда не могут «иметь семантику», потому что они сделаны из «неправильного материала» (кремния). Для меня это пустяковая чушь. Я не буду здесь касаться этой дискуссии, но мне бы не хотелось, чтобы у читателей сложилось впечатление, будто я считаю, что интеллект и понимание навсегда недоступны для компьютеров. Если в этом эссе мне кажется, что это звучит именно так, то это потому, что технология, которую я обсуждал, не пытается воспроизвести человеческий интеллект.Скорее наоборот: он пытается положить конец человеческому разуму, и выходные отрывки, показанные выше, ясно показывают его гигантские лакуны.
С моей точки зрения, нет фундаментальной причины, по которой машины в принципе не могли бы когда-нибудь думать; быть творческим, забавным, ностальгическим, возбужденным, напуганным, восторженным, смиренным, обнадеживающим и, как следствие, способным превосходно переводить с одного языка на другой. Нет никакой фундаментальной причины, по которой машины когда-нибудь не преуспеют в переводе анекдотов, каламбуров, сценариев, романов, стихов и, конечно же, эссе, подобных этому.Но все это произойдет только тогда, когда машины будут так же наполнены идеями, эмоциями и опытом, как и люди. И это не за горами. В самом деле, я считаю, что до этого еще очень далеко. По крайней мере, на это горячо надеется этот вечный поклонник глубины человеческого разума.
Нет никакой фундаментальной причины, по которой машины когда-нибудь не преуспеют в переводе анекдотов, каламбуров, сценариев, романов, стихов и, конечно же, эссе, подобных этому.Но все это произойдет только тогда, когда машины будут так же наполнены идеями, эмоциями и опытом, как и люди. И это не за горами. В самом деле, я считаю, что до этого еще очень далеко. По крайней мере, на это горячо надеется этот вечный поклонник глубины человеческого разума.
Когда однажды машина перевода напишет художественный роман в стихах на английском языке, используя точный рифмованный тетраметр ямба, богатый остроумием, пафосом и звуковой энергией, тогда я пойму, что мне пора снять шляпу и поклониться .
* Изначально в этой статье было неверно указано количество языков, для которых доступна версия Google Translate с глубоким обучением. Мы сожалеем об ошибке.
определение перевода The Free Dictionary
trans · конец
(trăns′lāt ′, trănz′-, trăns-lāt ′, trănz-) v. trans · lat · ed , trans · лат , перевод
trans · lat · ed , trans · лат , перевод
1. Для перевода на другой язык: перевод корейского романа на немецкий язык.
2. Для выражения различными, часто более простыми словами: перевод технического жаргона на обычный язык.
3.а. Переход от одной формы, функции или состояния к другому; конвертировать или трансформировать: воплощать идеи в реальность.
б. Чтобы выразить другим способом: перевел рассказ в кино.
4. Для переноса из одного места или состояния в другое: «Его останки были перенесены в Сан-Хуан-де-Пуэрто-Рико, где они все еще покоятся» (Сэмюэл Элиот Морисон).
5. Для пересылки или повторной передачи (телеграфное сообщение).
6.а. Церковная Перевести (епископа) в другую см.
б. Перенести на небеса без смерти.
7. Физика Предмет (тело) переводу.
8. Биология Предмет (информационная РНК) для перевода.
v. внутр. 1.а. Сделать перевод.
б. На работу переводчиком.
2. Признать перевод: Его стихи переводятся хорошо.
3. Будет изменено или преобразовано в силу. Часто используется с в или с по : «Сегодняшняя низкая инфляция и устойчивый рост доходов домохозяйств приводят к большей покупательной способности» (Томас Г. Экстер).
[среднеанглийский перевод, со старофранцузского переводчика, с латинского trānslātus, причастие прошедшего времени trānsferre, для перевода : trāns-, trans- + lātus, принес ; см. telə- в индоевропейских корнях.]
транс · лата · биллит н.
транс · латабл прил.
Словарь английского языка American Heritage®, пятое издание. Авторские права © 2016 Издательская компания Houghton Mifflin Harcourt. Опубликовано Houghton Mifflin Harcourt Publishing Company. Все права защищены.
Опубликовано Houghton Mifflin Harcourt Publishing Company. Все права защищены.
перевести
(trænsˈleɪt; trænz-) vb1. для выражения или возможности выражения на другом языке или диалекте: он перевел Шекспира на африкаанс; его книги хорошо переводятся.
2. ( intr ), чтобы действовать как переводчик
3. ( tr ), чтобы выразить или объяснить простым или менее техническим языком
4. ( tr ), чтобы интерпретировать или сделать вывод о значении (жестов, символов и т. д.)
5. ( tr ) преобразовать или преобразовать: воплотить надежду в реальность.
6. (Биохимия) ( tr; обычно пассивный ) biochem для преобразования молекулярной структуры (матричной РНК) в полипептидную цепь с помощью информации, хранящейся в генетическом коде.См. Также расшифровку 77. для перемещения или переноса с одного места или положения на другое
8.a. для перевода (клирика) из одной церковной службы в другую
б. для переноса (см.) С одного места на другое
9. (Римско-католическая церковь) ( tr ) RC Церковь для переноса (тела или мощей святого) с одного места упокоения на другое
10. (теология) ( tr ) теол для перемещения (человека) из одного места или плана существования в другое, например с земли на небо
11. (общая физика) математика физика to перемещать (фигуру или тело) вбок, без вращения, расширения или углового смещения
12. (Аэронавтика) ( intr ) (самолета, ракеты и т. д.) для полета или перемещения из одного положения в другое
13. ( tr ) архаический для доведения до состояния духовного или эмоционального экстаза
[C13: с латинского translātus перенесено, перенесено, от transferre to transfer]
transˈlatable adj
Переводимость n
Словарь английского языка Коллинза — полный и несокращенный, 12-е издание, 2014 г.![]() © HarperCollins Publishers 1991, 1994, 1998, 2000, 2003, 2006, 2007, 2009, 2011, 2014
© HarperCollins Publishers 1991, 1994, 1998, 2000, 2003, 2006, 2007, 2009, 2011, 2014
транс • конец
(trænsˈleɪt , trænz-, ˈtræns leɪt, ˈtrænz-)v. -lat • ed, -lat • ing. в.т.
1. переходить с одного языка на другой или с иностранного на свой собственный.
2. изменить форму, состояние или характер; convert: переводить мысль в действие.
3. для объяснения в терминах, которые легче понять; интерпретировать.
4. переносить, переносить или перемещаться из одного места или положения в другое; передача.
5. , чтобы заставить (тело) двигаться без вращения или углового смещения.
6. для ретрансляции или пересылки (телеграфное сообщение), как с помощью ретранслятора.
7. для перехода (слона) с одной высоты на другую.
8. передать или удалить на небеса без естественной смерти.
9. для возвышения в духовном или эмоциональном экстазе.
10. вызвать генетическую трансляцию.
в.и.11. предоставить или сделать перевод; выступать в роли переводчика.
12. для допуска перевода.
[1250–1300; Среднеанглийский trānslātus, причастие прошедшего времени trānsferre to transfer]trans • la′tor, n.
Random House Словарь колледжа Кернермана Вебстера © 2010 K Dictionaries Ltd. Авторские права 2005, 1997, 1991, Random House, Inc. Все права защищены.
перевести
— Раньше это означало «перевод».Словарь мелочей Farlex. © 2012 Farlex, Inc. Все права защищены.
перевести
Если вы переводите что-то сказанное или написанное, вы говорите или пишете это на другом языке.
Эти шутки было бы слишком сложно перевести.
Вы говорите, что кто-то переводит что-то с одного языка на другой.
Переводчик собирался перевести свои слова на английский язык .
Мои книги переведено на многих языков.
Collins COBUILD Английский Использование © HarperCollins Publishers 1992, 2004, 2011, 2012
перевод
Причастие прошедшего времени: переведено
Герундий: перевод
ImperativePresentPreteritePresent ContinuousPresent PerfectPresentPresentureConnecturePasture Continuous
| Императив |
|---|
| перевод |
| перевод |
| Настоящий |
|---|
| перевод |
| перевод |
| вы переводите |
| переводят |
| претерит |
|---|
| я перевел |
| вы перевели |
| он / она / она перевел |
| мы перевели |
| вы перевели |
| они перевели |
| Настоящее время Непрерывно |
|---|
| он / она / оно переводит |
| мы переводим |
| вы переводите |
| они переводят |
| Present Perfect |
|---|
| вы перевели |
| он / она / она перевел |
| мы перевели |
| вы перевели |
| они перевели |
| Прошлый непрерывный |
|---|
| вы переводили ing |
| он / она / она переводил |
| мы переводили |
| вы переводили |
| они переводили |
| Past Perfect |
|---|
| вы перевели |
| он / она / она перевели |
| мы перевели |
| вы перевели |
| они перевели |
| переведи |
| он / она / она переведет |
| переведем |
| переведем |
| переведут |
| Future Continuous | Я буду переводить |
|---|---|
| вы будете переводить | |
| он / она / она будет переводить | |
| мы будем переводить | |
| вы будете переводить | |
| они будут |
| Present Perfect Continuous |
|---|
| Я переводил |
| вы переводили |
| он / она переводил |
| мы переводили |
| переводили |
| Future Perfect Continuous |
|---|
| Я буду переводить |
| вы должны переводить |
| он / она / она будет переводить |
| мы будем переводить |
| вы должны переводить |
| они будут переводить |
| Past Perfect Continuous |
|---|
| Я переводил |
| она переводила |
| мы переводили |
| вы переводили |
| они переводили |
| условный |
|---|
| я бы переводил |
| он / она переведет | 90 373
| мы бы переводили |
| вы бы переводили |
| они бы переводили |
| Past Conditional | ||
|---|---|---|
| Я бы перевел | ||
| она / она бы перевела | ||
| мы бы перевели | ||
| вы бы перевели | ||
| они бы перевели |
Collins English Verb Tables © HarperCollins Publishers 2011
translate — CSS: Cascading Style Листы
Свойство CSS translate позволяет задавать преобразования преобразования индивидуально и независимо от свойства transform . Это лучше соответствует типичному использованию пользовательского интерфейса и избавляет от необходимости помнить точный порядок функций преобразования для указания в значении
Это лучше соответствует типичному использованию пользовательского интерфейса и избавляет от необходимости помнить точный порядок функций преобразования для указания в значении transform .
перевод: нет;
перевести: 100 пикселей;
перевод: 50%;
перевести: 100px 200px;
перевод: 50% 105px;
перевести: 50% 105px 5rem;
Значения
- Одно
<длина-процент>значение -
translate ()(2D-перевод) с одним указанным значением. - Два
- Два
translate ()(2D-перевод) с двумя указанными значениями. - Три значения
- Два значения
translate3d ()(3D-перевод). -
нет - Указывает, что перевод не должен применяться.
 Эквивалентен функции
Эквивалентен функции нет | <процент-длины> [<процент-длины> <длина>? ]? где <длина-процент> = <длина> | <процент> HTML
Перевод
CSS
* {
размер коробки: рамка-рамка;
}
html {
семейство шрифтов: без засечек;
}
div {
ширина: 150 пикселей;
маржа: 0 авто;
}
п {
отступ: 10px 5px;
граница: сплошной черный цвет 3px;
радиус границы: 20 пикселей;
ширина: 150 пикселей;
размер шрифта: 1.2рем;
выравнивание текста: центр;
}
.переведите {
переход: перевести единицы;
}
div: hover .translate {
перевести: 200px 50px;
}
Результат
Таблицы BCD загружаются только в браузере
Примечание: перекос не является независимым значением преобразования
Последние достижения в Google Translate
Авторы: Исаак Касвелл и Боуэн Лян, инженеры-программисты, Google Research Достижения в области машинного обучения (ML) привели к улучшениям в автоматическом переводе, в том числе в нейронной модели перевода GNMT, представленной в Translate в 2016 году, которая позволила значительно улучшить качество перевода для более чем 100 языков. Тем не менее, современные системы значительно отстают от человеческих возможностей во всех задачах перевода, кроме самых специфических. И хотя исследовательское сообщество разработало методы, которые успешны для языков с высокими ресурсами, таких как испанский и немецкий, для которых существует огромное количество обучающих данных, производительность на языках с низким уровнем ресурсов, таких как йоруба или малаялам, все еще оставляет желать лучшего. желанный. Многие методы продемонстрировали значительные преимущества для языков с ограниченными ресурсами в условиях контролируемых исследований (например,g., WMT Evaluation Campaign), однако эти результаты для небольших общедоступных наборов данных не могут легко перейти к большим наборам данных, просматриваемым через Интернет.
Тем не менее, современные системы значительно отстают от человеческих возможностей во всех задачах перевода, кроме самых специфических. И хотя исследовательское сообщество разработало методы, которые успешны для языков с высокими ресурсами, таких как испанский и немецкий, для которых существует огромное количество обучающих данных, производительность на языках с низким уровнем ресурсов, таких как йоруба или малаялам, все еще оставляет желать лучшего. желанный. Многие методы продемонстрировали значительные преимущества для языков с ограниченными ресурсами в условиях контролируемых исследований (например,g., WMT Evaluation Campaign), однако эти результаты для небольших общедоступных наборов данных не могут легко перейти к большим наборам данных, просматриваемым через Интернет.
В этом посте мы рассказываем о некоторых недавних успехах, достигнутых нами в качестве перевода для поддерживаемых языков, особенно для языков с низким уровнем ресурсов, путем синтеза и расширения множества последних достижений, и демонстрируем, как их можно масштабно применять для шумные данные, добытые в Интернете. Эти методы включают усовершенствования в архитектуре модели и обучении, улучшенную обработку шума в наборах данных, усиление многоязычного трансферного обучения с помощью моделирования M4 и использование одноязычных данных.Улучшения качества, которые в среднем составили +5 баллов BLEU по всем более чем 100 языкам, показаны ниже.
Эти методы включают усовершенствования в архитектуре модели и обучении, улучшенную обработку шума в наборах данных, усиление многоязычного трансферного обучения с помощью моделирования M4 и использование одноязычных данных.Улучшения качества, которые в среднем составили +5 баллов BLEU по всем более чем 100 языкам, показаны ниже.
| Оценка BLEU моделей Google Translate с момента его появления в 2006 году. Улучшения, произошедшие с момента внедрения новых методов за последний год, выделены в конце анимации. |
Архитектура гибридной модели: Четыре года назад мы представили модель GNMT на основе RNN, которая дала значительные улучшения качества и позволила Переводчику охватить многие другие языки.После нашей работы по разделению различных аспектов производительности модели мы заменили исходную систему GNMT, вместо этого обучая модели кодировщиком-преобразователем и декодером RNN, реализованным в Lingvo (фреймворк TensorFlow).
 Было продемонстрировано, что модели трансформаторов в целом более эффективны при машинном переводе, чем модели RNN, но наша работа показала, что большая часть этого улучшения качества была получена от кодировщика трансформатора и что декодер преобразователя не был значительно лучше, чем декодер RNN .Поскольку декодер RNN намного быстрее во время логического вывода, мы применили ряд оптимизаций, прежде чем связать его с кодировщиком трансформатора. Полученные гибридные модели более качественные, более стабильные при обучении и имеют меньшую задержку.
Было продемонстрировано, что модели трансформаторов в целом более эффективны при машинном переводе, чем модели RNN, но наша работа показала, что большая часть этого улучшения качества была получена от кодировщика трансформатора и что декодер преобразователя не был значительно лучше, чем декодер RNN .Поскольку декодер RNN намного быстрее во время логического вывода, мы применили ряд оптимизаций, прежде чем связать его с кодировщиком трансформатора. Полученные гибридные модели более качественные, более стабильные при обучении и имеют меньшую задержку. Веб-сканирование: Модели нейронного машинного перевода (NMT) обучаются с использованием примеров переведенных предложений и документов, которые обычно собираются из общедоступной сети. Было обнаружено, что по сравнению с машинным переводом на основе фраз, NMT более чувствителен к качеству данных.Таким образом, мы заменили предыдущую систему сбора данных новой системой сбора данных, которая больше ориентирована на точность, чем на отзыв, что позволяет собирать данные обучения более высокого качества из общедоступной сети. Кроме того, мы переключили поисковый робот с модели на основе словаря на модель на основе встраивания для 14 больших языковых пар, что увеличило количество собираемых предложений в среднем на 29 процентов без потери точности.
Кроме того, мы переключили поисковый робот с модели на основе словаря на модель на основе встраивания для 14 больших языковых пар, что увеличило количество собираемых предложений в среднем на 29 процентов без потери точности.
Шум данных моделирования: Данные со значительным шумом не только избыточны, но также снижают качество обученных на них моделей.Чтобы устранить шум данных, мы использовали наши результаты по шумоподавлению обучения NMT, чтобы присвоить оценку каждому примеру обучения с использованием предварительных моделей, обученных на зашумленных данных и тонко настроенных на чистых данных. Затем мы рассматриваем обучение как проблему обучения учебной программе — модели начинают обучение на всех данных, а затем постепенно обучаются на более мелких и более чистых подмножествах.
Достижения, которые пошли на пользу языков с низким уровнем ресурсов, в частности
Обратный перевод: Широко применяемый в современных системах машинного перевода, обратный перевод особенно полезен для языков с низким уровнем ресурсов, где параллельные данные дефицитный. Этот метод дополняет данные параллельного обучения (где каждое предложение на одном языке сопряжено с его переводом) с синтетическими параллельными данными, где предложения на одном языке написаны человеком, но их переводы были сгенерированы нейронной моделью перевода. Включив обратный перевод в Google Translate, мы можем использовать более обширные одноязычные текстовые данные для языков с ограниченными ресурсами в Интернете для обучения наших моделей. Это особенно полезно для повышения плавности вывода модели, в которой модели перевода с низким уровнем ресурсов не работают.
Этот метод дополняет данные параллельного обучения (где каждое предложение на одном языке сопряжено с его переводом) с синтетическими параллельными данными, где предложения на одном языке написаны человеком, но их переводы были сгенерированы нейронной моделью перевода. Включив обратный перевод в Google Translate, мы можем использовать более обширные одноязычные текстовые данные для языков с ограниченными ресурсами в Интернете для обучения наших моделей. Это особенно полезно для повышения плавности вывода модели, в которой модели перевода с низким уровнем ресурсов не работают.
Моделирование M4: Методика, которая оказалась особенно полезной для языков с ограниченными ресурсами, — это M4, которая использует единую гигантскую модель для перевода со всех языков на английский. Это позволяет переносить обучение в массовом масштабе. Например, язык с ограниченными ресурсами, такой как идиш, имеет преимущество совместного обучения с широким спектром других родственных германских языков (например, немецким, голландским, датским и т. Д.), А также почти сотней других языков, которые могут не имеют известной лингвистической связи, но могут служить полезным сигналом для модели.
Д.), А также почти сотней других языков, которые могут не имеют известной лингвистической связи, но могут служить полезным сигналом для модели.
Оценка качества перевода
Популярным показателем для автоматической оценки качества систем машинного перевода является оценка BLEU, которая основывается на сходстве между системным переводом и справочными переводами, созданными людьми. С этими последними обновлениями мы видим средний прирост BLEU на +5 пунктов по сравнению с предыдущими моделями GNMT, при этом для 50 языков с наименьшими ресурсами средний прирост +7 BLEU. Это улучшение сопоставимо с улучшением, которое наблюдалось четыре года назад при переходе от фразового перевода к NMT.
Хотя оценка BLEU — это хорошо известная приблизительная мера, известно, что для систем, которые уже являются высококачественными, существуют различные подводные камни. Например, в нескольких работах показано, как оценка BLEU может быть смещена из-за трансляционных эффектов на стороне источника или на стороне цели — феномен, при котором переведенный текст может звучать неуклюже, содержать атрибуты (например, порядок слов) из исходного языка. По этой причине мы провели параллельные оценки всех новых моделей на людях, которые подтвердили успехи BLEU.
По этой причине мы провели параллельные оценки всех новых моделей на людях, которые подтвердили успехи BLEU.
В дополнение к общему улучшению качества, новые модели демонстрируют повышенную надежность до галлюцинации машинного перевода , явления, при котором модели производят странные «переводы» при вводе бессмысленных данных. Это обычная проблема для моделей, которые были обучены на небольших объемах данных, и затрагивает многие языки с низким уровнем ресурсов. Например, если дать строку телугу символов «ష“ ష ష ష ష ష ష ష ష ష ష ష ష », старая модель выдала бессмысленный вывод « Shenzhen Shenzhen Shaw International Airport (SSH) », По-видимому, пытается разобраться в звуках, тогда как новая модель правильно учится транслитерировать это как «Ш ш ш ш ш ш ш ш ш ш ш ш ш ш ш» .
Заключение
Хотя это впечатляющий шаг вперед для машины, следует помнить, что, особенно для языков с ограниченными ресурсами, качество автоматического перевода далеко от идеального. Эти модели по-прежнему становятся жертвой типичных ошибок машинного перевода, включая низкую производительность по определенным жанрам предмета («домены»), смешение различных диалектов языка, получение слишком дословных переводов и плохую производительность на неформальном и устном языке.
Эти модели по-прежнему становятся жертвой типичных ошибок машинного перевода, включая низкую производительность по определенным жанрам предмета («домены»), смешение различных диалектов языка, получение слишком дословных переводов и плохую производительность на неформальном и устном языке.
Тем не менее, с этим обновлением мы гордимся тем, что обеспечиваем автоматические переводы, которые являются относительно последовательными, даже для самых бедных из 108 поддерживаемых языков. Мы благодарны активному сообществу исследователей машинного перевода в академических и промышленных кругах за исследования, которые сделали это возможным.
Благодарности
Эти усилия основаны на вкладе Тао Ю, Али Дабирмогаддама, Клауса Машери, Пидонга Ванга, Йе Тиана, Джеффа Клингнера, Джумпея Такеучи, Юичиро Саваи, Хидэто Казава, Апу Шах, Манишэ Дженсейн, Кейт Фангсяою Фэн, Чао Тянь, Джон Ричардсон, Раджат Тибревал, Орхан Фират, Миа Чен, Анкур Бапна, Навин Ариважаган, Дмитрий Лепихин, Вэй Ван, Вольфганг Машери, Катрин Томанек, Цинь Гао, Мэнмэн Нюхес и Макдуф Хьюгес.![]()
WordReference Словарь американского английского для учащихся. © 2021 trans • late / trænsˈleɪt, trænz-, ˈtrænsleɪt, ˈtrænz- / USA произношение v., -lat • ed, -lat • ing.
транс • конец (trans lāt ′ , tranz-, trans ′ lāt, tranz ′ -), США произношение v.  , -lat • ed, -lat • ing. , -lat • ed, -lat • ing. в.т.
в.и.
транс • лать • бил ′ i • ty, транс • лат ′ a • ble •ness, n.
Краткий английский словарь Коллинза © HarperCollins Publishers :: переводить / trænsˈleɪt trænz- / vb
transˈlatable прил ‘ translate ‘ также встречается в этих записях (примечание: многие из них не являются синонимами или переводами): |


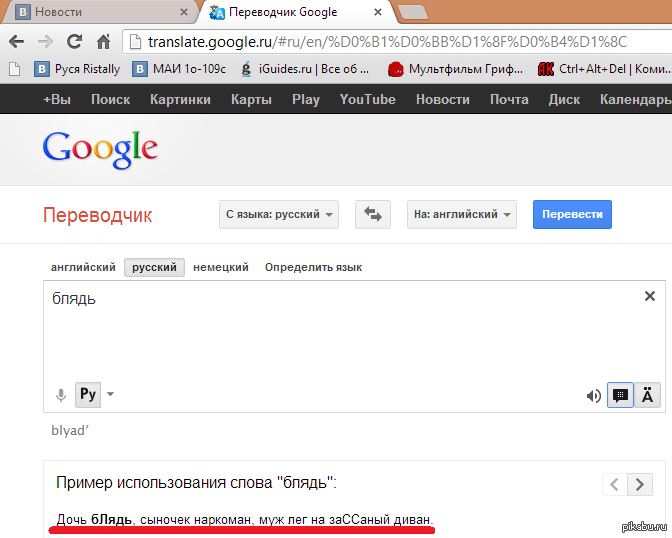 на trāns- trans- + -lātus (причастие прошедшего времени от ferre до медведя 1 ), ранее * tlātus, эквивалент . to * tlā- медведь (аналог thole 2 ) + -tus суффикс причастия прошедшего времени
на trāns- trans- + -lātus (причастие прошедшего времени от ferre до медведя 1 ), ранее * tlātus, эквивалент . to * tlā- медведь (аналог thole 2 ) + -tus суффикс причастия прошедшего времениГлава отдела переводов Google говорит о борьбе с предвзятостью и о том, почему ИИ любит религиозные тексты
Возможно, вы помните в прошлом году серию новостей о том, что Google Translate выплевывал зловещие куски религиозных пророчеств, когда им представлялись бессмысленные слова и фразы для перевода.Сайты-приманки предполагали, что это мог быть заговор, но нет, просто системы машинного обучения Google запутались и прибегли к данным, на которых их обучали: религиозным текстам.
Но, как недавно сказал The Verge глава Google Translate Макдуфф Хьюз, именно машинное обучение заставляет по-настоящему полезные инструменты перевода Google. Бесплатный, простой и мгновенный перевод — одно из тех преимуществ жизни 21 века, которое многие из нас считают само собой разумеющимся, но это было бы невозможно без ИИ.
Бесплатный, простой и мгновенный перевод — преимущество жизни 21 века
Еще в 2016 году Translate перешла с метода, известного как статистический машинный перевод, на метод машинного обучения, который в Google назвал «нейронный машинный перевод». Старая модель переводила текст по одному слову за раз, что приводило к множеству ошибок, поскольку система не учитывала грамматические факторы, такие как время глагола и порядок слов. Но новый переводит предложение за предложением, что означает, что он учитывается в этом вербальном контексте.
В результате язык становится «более естественным и плавным», — говорит Хьюз, обещая, что в будущем появятся новые улучшения, например, перевод, учитывающий тонкости тона (формальный или сленговый говорящий?) И предлагающий несколько вариантов для формулировка.
Translate — также однозначно положительный проект для Google, который, как отмечали другие, служит своего рода прикрытием для более противоречивых усилий компании в области ИИ, таких как ее работа с вооруженными силами.Хьюз объясняет, почему Google продолжает поддерживать Translate, а также как компания хочет бороться с предвзятостью в своих данных обучения ИИ.
Это интервью отредактировано для ясности
Одно большое обновление, которое вы недавно сделали для Translate, предлагало гендерных переводов . Что вас к этому подтолкнуло?
Это две мотивации вместе. Один из них — это проблема социальной предвзятости во всех видах машинного обучения и продуктов ИИ.Это то, что беспокоит Google и всю отрасль; что услуги и продукты машинного обучения отражают предвзятость данных, на которых они обучаются, что отражает общественные предубеждения, которые усиливают и, возможно, даже усиливают эти предубеждения. Мы как компания хотим быть лидером в решении этих проблем, и мы знаем, что Translate — это сервис, в котором есть эта проблема, особенно когда речь идет о предвзятом отношении к мужчине / женщине.
Мы как компания хотим быть лидером в решении этих проблем, и мы знаем, что Translate — это сервис, в котором есть эта проблема, особенно когда речь идет о предвзятом отношении к мужчине / женщине.
Модели перевода могут изучать (и воспроизводить) предубеждения, присутствующие в языке
Классическим примером языка является то, что врач — мужчина, а медсестра — женщина.Если эти предубеждения существуют в языке, тогда модель перевода изучит их и усилит их. Если профессия [упоминается как мужская], например, в 60–70 процентах случаев, то система перевода может выучить ее и затем представить ее как 100 процентов мужскую. Нам нужно с этим бороться.
И многие пользователи изучают языки; они хотят понимать различные способы выражения вещей и доступные нюансы. Итак, мы давно знали, что нам нужно иметь возможность отображать несколько вариантов перевода и другие детали.Все это соединилось в гендерном проекте.
Потому что, если вы посмотрите на проблему предвзятости, нет четкого ответа на то, что с ней можно сделать..jpg) Ответ не должен быть 50/50 или случайным [при назначении пола в переводе], а чтобы дать людям больше информации. Просто сказать людям, что есть несколько способов сказать это на этом языке, и вот различия между ними. При переводе существует множество культурных и лингвистических проблем, и мы хотели что-то сделать с проблемой предвзятости, сделав сам Переводчик более полезным.
Ответ не должен быть 50/50 или случайным [при назначении пола в переводе], а чтобы дать людям больше информации. Просто сказать людям, что есть несколько способов сказать это на этом языке, и вот различия между ними. При переводе существует множество культурных и лингвистических проблем, и мы хотели что-то сделать с проблемой предвзятости, сделав сам Переводчик более полезным.
Какие проблемы вы собираетесь решать дальше с точки зрения предвзятости и нюансов?
По вопросу справедливости и предвзятости есть три большие инициативы. Один просто делает больше того, что мы только что запустили. У нас есть полный перевод предложений с указанием пола, но запущен только с турецкого на английский. Мы хотим улучшить качество и расширить доступ к большему количеству языков.Мы сделали единое слово для некоторых языков…
Вторая область — это перевод документов. Здесь есть предвзятость, но здесь требуется совсем другой ответ. Например, если вы возьмете статью в Википедии о женщине на другом языке и переведете на английский язык, скорее всего, вы увидите много местоимений на английском языке с словом он и он. Это происходит потому, что вы получите предложение, которое переведено изолированно, а в исходном языке не будет четко указан пол, и поэтому чаще всего вы добавляете его / ее по умолчанию.Это особенно оскорбительно, когда вы ошибаетесь, но способ решения этой проблемы полностью отличается от того, что мы запустили в прошлом году. В этом примере можно получить правильный ответ, просто исходя из контекста [остальной части документа]. Это проблема исследований и инженеров, чтобы это исправить.
Здесь есть предвзятость, но здесь требуется совсем другой ответ. Например, если вы возьмете статью в Википедии о женщине на другом языке и переведете на английский язык, скорее всего, вы увидите много местоимений на английском языке с словом он и он. Это происходит потому, что вы получите предложение, которое переведено изолированно, а в исходном языке не будет четко указан пол, и поэтому чаще всего вы добавляете его / ее по умолчанию.Это особенно оскорбительно, когда вы ошибаетесь, но способ решения этой проблемы полностью отличается от того, что мы запустили в прошлом году. В этом примере можно получить правильный ответ, просто исходя из контекста [остальной части документа]. Это проблема исследований и инженеров, чтобы это исправить.
«Третья область касается гендерно-нейтральных языковых моделей».
Третья область касается гендерно-нейтральных языковых моделей. Сейчас мы находимся в эпицентре культурных потрясений, причем не только в английском, но и во многих, многих языках с гендерной принадлежностью. По всему миру появляются движения за создание нейтрального с гендерной точки зрения языка, и мы получаем много запросов от пользователей о том, когда мы собираемся решить эту проблему. Часто приводится пример использования слова «они» в английском языке в единственном числе. Это становится все более распространенным, даже если это не принято в учебниках и руководствах по стилю, когда к кому-то обращаются, говоря «они», а не «он есть» или «она есть». Это также происходит на испанском, французском и многих других языках. На самом деле правила меняются так быстро, что даже эксперты не успевают за ними.
По всему миру появляются движения за создание нейтрального с гендерной точки зрения языка, и мы получаем много запросов от пользователей о том, когда мы собираемся решить эту проблему. Часто приводится пример использования слова «они» в английском языке в единственном числе. Это становится все более распространенным, даже если это не принято в учебниках и руководствах по стилю, когда к кому-то обращаются, говоря «они», а не «он есть» или «она есть». Это также происходит на испанском, французском и многих других языках. На самом деле правила меняются так быстро, что даже эксперты не успевают за ними.
Что-то любопытное произошло в прошлом году с Google Translate: люди обнаружили, что если вы введете бессмысленные слова , он выплюнет фрагменты религиозного текста. Это стало немного вирусным явлением, и люди проецировали на него самые разные причудливые интерпретации. Что вы обо всем этом думаете?
Меня не удивило, что это произошло, но я был на уровне интереса к реакции людей. [И] о заговорах, о том, как Google кодирует таинственные сообщения о тайных религиях, космических пришельцах и о том, что у вас есть.Однако на самом деле это иллюстрирует общую проблему моделей машинного обучения: когда они получают неожиданный ввод, они ведут себя неожиданным образом. Это проблема, которую мы решаем, поэтому, если у вас бессмысленный ввод, он не даст разумного ввода .
[И] о заговорах, о том, как Google кодирует таинственные сообщения о тайных религиях, космических пришельцах и о том, что у вас есть.Однако на самом деле это иллюстрирует общую проблему моделей машинного обучения: когда они получают неожиданный ввод, они ведут себя неожиданным образом. Это проблема, которую мы решаем, поэтому, если у вас бессмысленный ввод, он не даст разумного ввода .
Но почему это произошло? Я не верю, что вы когда-либо предлагали объяснение по протоколу .
Обычно это происходит потому, что язык, на который вы переводите, содержал много религиозных текстов в обучающих данных.Мы тренируемся для каждой языковой пары, используя все, что можно найти во всемирной паутине. Таким образом, типичное поведение этих моделей состоит в том, что, если в них появляется тарабарщина, они выбирают что-то общее в обучающих данных на целевой стороне и для многих из этих языков с низким уровнем ресурсов, когда на сеть, которую мы можем использовать — то, что создается, часто бывает религиозным.
Слишком сильно сожмите Google Translate, и данные обучения выпадут на поверхность
На некоторых языках первыми переведенными материалами, которые мы нашли, были переводы Библии.Мы берем все, что можем, и обычно это нормально, но в случае, когда появляется чушь, часто это и есть результат. Если бы в основе данных перевода лежали юридические документы, по образцу был бы получен юридический язык; если бы это были инструкции по летной эксплуатации самолетов, она бы выпустила инструкции по полетам самолетов.
Это интересно. Это напоминает мне о влиянии Библии короля Якова на английский язык; как этот перевод 17 века является источником фраз , которые мы используем сегодня.Подобные вещи случаются с Google Translate? Есть ли какие-нибудь странные источники фраз в ваших банках тренировок?
Ну, иногда с интернет-форумов приходят странные вещи; например, иногда сленг с игровых форумов или игровых сайтов.![]() Это может случиться! С более крупными языками у нас более разнообразные данные по обучению, но да, иногда вы получаете довольно интересный сленг со всех уголков Интернета. Боюсь, что сейчас на ум не приходят конкретные примеры …
Это может случиться! С более крупными языками у нас более разнообразные данные по обучению, но да, иногда вы получаете довольно интересный сленг со всех уголков Интернета. Боюсь, что сейчас на ум не приходят конкретные примеры …
Итак, Google Translate особенно интересен, поскольку в то время, когда ИИ сталкивается с проблемами из-за того, как и где он используется, все согласны с тем, что перевод полезен и относительно несложен. Это даже утопично. Как вы думаете, что мотивирует Google финансировать перевод?
Мы — довольно идеалистическая компания, и я думаю, что у команды Translate более чем достаточно идеалистов.Мы прилагаем все усилия, чтобы убедиться, что сказанное вами остается правдой, поэтому важно бороться с предвзятостью и искать неправильный перевод, который может нанести вред.
Но почему Google вкладывает в это деньги? Нас часто спрашивают об этом, и ответ прост. Мы говорим, что наша миссия состоит в том, чтобы организовать мировую информацию и сделать ее универсально доступной, а эта «универсально доступная» часть очень и очень далека от достижения. Пока большая часть мира не может прочитать информацию в Интернете, она не является общедоступной.Google, чтобы выполнить свою основную миссию, необходимо решить проблему перевода, и я думаю, что основатели компании признали это более десяти лет назад.
Как вы думаете, возможно ли, чтобы разрешил перевод ? Недавно была опубликована статья в The Atlantic известного профессора познания Дугласа Хофштадтера, указывающая на «поверхностность» Google Translate. Что вы думаете о его критике?
То, что он указал, было справедливо и верно.Вот такие проблемы. Но на самом деле они не являются предметом нашего внимания, потому что на самом деле они встречаются лишь в небольшом проценте случаев в переводах, которые мы видим. Когда мы смотрим на типичные тексты, которые люди пытаются перевести, сейчас это не большая проблема. Но он, безусловно, прав в том, что для того, чтобы действительно решить проблему перевода и иметь возможность переводить на уровне квалифицированного профессионала, чьи знания о предметной области и ее лингвистической проблеме необходимы некоторые серьезные прорывы. Простое обучение на примерах параллельного текста не приведет вас к последним процентам случаев использования.
Но на самом деле они не являются предметом нашего внимания, потому что на самом деле они встречаются лишь в небольшом проценте случаев в переводах, которые мы видим. Когда мы смотрим на типичные тексты, которые люди пытаются перевести, сейчас это не большая проблема. Но он, безусловно, прав в том, что для того, чтобы действительно решить проблему перевода и иметь возможность переводить на уровне квалифицированного профессионала, чьи знания о предметной области и ее лингвистической проблеме необходимы некоторые серьезные прорывы. Простое обучение на примерах параллельного текста не приведет вас к последним процентам случаев использования.
Уже давно говорят, что перевод — это полная проблема ИИ, а это означает, что для полного решения перевода вам нужно полностью решить ИИ. И я думаю, это правда. Но вы можете решить очень большой процент проблем, и мы заполняем это пространство прямо сейчас.
translate () — CSS: каскадные таблицы стилей
Функция CSS translate () изменяет положение элемента по горизонтали и / или вертикали. направления. Его результатом является тип данных
направления. Его результатом является тип данных .
Это преобразование характеризуется двумерным вектором. Его координаты определяют, насколько перемещается элемент в каждом направлении.
преобразовать: перевести (200 пикселей);
преобразовать: перевести (50%);
преобразовать: перевести (100 пикселей, 200 пикселей);
преобразовать: перевести (100 пикселей, 50%);
преобразовать: перевести (30%, 200 пикселей);
преобразовать: перевести (30%, 50%);
Значения
- Отдельные
<длина- процент>значений - Это значение —
<длина>или<процент>, представляющее абсциссу (по горизонтали, координата x) вектора сдвига.Ордината (вертикальная, y-координата) переводящего вектор будет установлен на0. Например,translate (2px)эквивалентноперевести (2px, 0). Процентное значение относится к ширине справочного поля, определяемойtransform-boxсвойство. - Двойной
<длина-процент>значений - Это значение описывает два значения
transform-boxсвойство.

| Декартовы координаты на ℝ 2 | Однородные координаты на ℝℙ 2 | Декартовы координаты на ℝ 3 | Однородные координаты на ℝℙ 3 |
|---|---|---|---|
Перевод не является линейным преобразованием в ℝ 2 и не может быть представлен с помощью Матрица декартовых координат. | 10tx01ty001 | 10tx01ty001 | 100tx010ty00100001 |
[1 0 0 1 tx ty] |
Формальный синтаксис
translate (, ?)
Использование одноосевого перемещения
HTML
Статический
Перемещено
Статический CSS
div {
ширина: 60 пикселей;
высота: 60 пикселей;
цвет фона: голубой;
} .