Что такое релевантность страниц сайта или поиска?
Возможно, вы когда-нибудь слышали такое слово, как «релевантность». Если вас интересует тема продвижения сайтов, то, скорее всего, да. А знаете ли вы, что такое релевантность страниц сайта? Если нет, то сегодня я, как раз таки напишу, что такое релевантность поиска и страницы сайта.

Релевантность поиска – это степень соответствия найденной информации пользователем, к той, которую он хотел найти.
Например, вы ввели в поисковую систему запрос «скачать музыку». А поисковик вам выдает сайты с информацией «что такое музыка». Так вот, степень соответствия того, что вы хотели получить, к тому, что вы получили, и называется релевантностью поиска. В данном случае, вы получили совсем не то, что хотели ;-), а это значит, что результаты не релевантные поисковому запросу.
Но сейчас поисковики стали достаточно умные и если вы правильно введете поисковый запрос, то, скорее всего, получите на него ответ. Сейчас для улучшения релевантности поисковики используют множество факторов. Это показатель отказов, поведения пользователя на сайте, количество внешних и внутренних ссылок, плотность ключевых слов и т. д.
Если сеошнику получиться обмануть поисковою систему, и вывести в ТОП статью, в которой нет ответа на запрос посетителя, то через несколько дней эта статья будет понижена в выдаче. Поэтому, я всегда говорил, и буду говорить, что самое главное – это написать интересную статью, которая будет решать проблему посетителя, а уже потом, как дополнения, можно использовать и различные seo-методы продвижения. Советую также прочитать статью о том, что такое SEO, SMO и SMM.
Что такое релевантность поиска, думаю, вы поняли, ничего сложного там нет. Теперь давайте поговорим, что такое релевантность страницы или другими словами ее еще называют, техническая релевантность.
Релевантность страниц сайта – это пропорция ключевых слов, содержащихся в тексте или мета-тегах и делающих ее соответствующей поисковым запросам.
Другими словами, чем чаще ключевое слово будет встречаться в тексте и других важных тегах, тем страница будет технически больше релевантная этому запросу.
Но это не значит, что если вставлять ключевое слово в каждом предложении, то статья обязательно выйдет в ТОП ;-). Ключевые фразы нужно вставлять в статью так, чтобы посетителю было приятно ее читать. Если поисковый запрос будет встречаться в каждом предложении, то человек не будет читать такую статью, и таким образом увеличиться показатель отказов этой страницы и соответственно она опуститься вниз. Кроме того, за такой спам ключевыми словами можно получить санкции от поисковиков.
В любом случаи, если вы пишите статью под определеннее ключевое слово, то нужно всегда делать хорошую релевантность этой статьи (желательно 100%). Для этого необходимо придерживаться всего нескольких правил поисковой оптимизации. На самом деле этих правил есть очень много, но сейчас я вам расскажу основные.
1. Ключевая фраза должна присутствовать в теге Title.
Тег Title – это заголовок для поискового робота. Для того, чтобы его сделать, нужно установить плагин All in one seo Pack и делать заголовок записи. О нем, я уже писал в статье «Что такое сниппет и как его сделать для Яндекса и Гугла?» Желательно, чтобы ключевая фраза была в начале заголовка.
2. Поисковый запрос должен быть в заголовке h2.
Это заголовок для посетителя, но он также имеет большой вес. Для примера, заголовок h2 этой статьи вы можете увидеть в самом верху страницы, и звучит он так: «Что такое релевантность страниц сайта? Как сделать релевантность страницы 100%»
Заголовок h2 также должен заинтересовать посетителя, чтобы он захотел прочитать статью до конца. Если вы придумали интересный заголовок, в котором ввели ключевое слово, то можете его прописать в тег Title и h2 одновременно.
3. Ключевая фраза должна присутствовать в основном содержимом статьи.
Многие спрашивают, сколько раз вводить поисковый запрос в статью? Чтобы узнать ответ на этот вопрос, нужно ввести ключевое слово в поисковую систему Яндекс и Гугл. Потом найти сайт, который вышел в топ сразу в два поисковики, и посмотреть сколько раз, на этой странице, присутствует этот запрос. В любом случаи, меньше 2-х раз я бы не советовал вводить :smile:.
Для того, чтобы сделать хорошую плотность ключевых слов на странице, желательно также вводить запрос в каком-нибудь склонении. Если запрос «купить ноутбук в Москве», то можно ввести: «купить хороший ноутбук в Москве», «купить дешево ноутбук в Москве» и т. д.
И еще один совет, старайтесь вводить ключевые слова ближе к началу статьи и в конце. Также можно выделить запрос жирным (тег strong).
4. Ключевая фраза в url.
Для того, чтобы ввести ключевое слове в url страницы, вам сначала нужно настроить ЧПУ. Для этого советую прочитать статью: «Настройка постоянных ссылок (ЧПУ) в WordPress при помощи плагина RusToLat». Там также вы узнаете, как правильно вводить ключевые фразы в название страницы.
5. Ключевая фраза в теге ALT и Title изображений.
Когда вы публикуете какое-нибудь изображения, то к нему есть возможность прописать заголовок (Title) и тег ALT (альтернативный текст). Старайтесь там прописывать ключевые слова. Кстати, в url картинки также можно ввести поисковый запрос :smile:.
6. Ключевая фраза в подзаголовках ( h3, h4, Н4, H5, H6).
Наибольший вес имеет подзаголовок h3, потом h4 и так далее. Старайтесь делать заголовки только там, где это действительно нужно, а не просто так, чтобы ввести ключевое слово. Если вы придержались всех 5 правил, которые я описал выше, то прописывать ключевые фразы в заголовки я бы уже не советовал, поскольку поисковики это могут расценить как спам. А если хотите сделать, то хотя бы в склонении :smile:.
7. Внутренние ссылки.
Для того, чтобы указать поисковому роботу, что страница хорошо релевантная какому-нибудь поисковому запросу, нужно ссылаться с других страниц на эту и в текст ссылки прописывать этот поисковый запрос. Чем больше ссылок будет стоять с других внутренних страниц на продвигаемую, тем больший вес она получит и тем быстрее выйдет в топ.
8. Внешние ссылки.
Внешние ссылки также играют большую роль в продвижении сайта. Но здесь не все так просто. Для покупки ссылок нужно найти хорошие сайты и делать разные анкоры. Поисковые системы против покупки ссылок и если они поймут, что вы их обманываете, то будет очень плохо. На ресурс могут быть наложены различные санкции. Другими словами, покупка внешних ссылок – это тема отдельной статьи, которую я обязательно еще напишу. Не пропустите.
Как проверить релевантность страницы
Для определения релевантности в интернете есть очень много сервисов. Но, я, например, проверяю релевантность на megaindex.ru. Этот сервис указывает, что нужно сделать, чтобы улучшить релевантность страницы.
Для начала вам нужно зарегистрироваться. После регистрации перейдите в аудит сайта и наведите курсор мыши на меню «Еще» и с выпадающего списка выберите «релевантность страницы». (кликабельно)
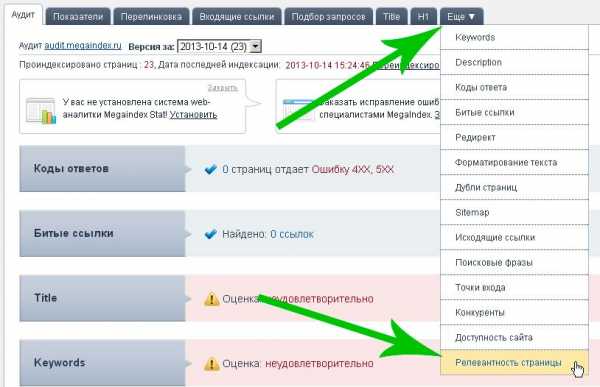
Потом нужно ввести запрос, ссылку на страницу и нажать на кнопку «Проверить».
После этого можете посмотреть, какой процент релевантности на вашей странице и почитать рекомендации как его улучшить.
На этом у меня все. Хотел только написать, что такое релевантность сайта, а получилось намного больше :smile:. Но ничего страшного, поисковые системы любят, если на странице много текста ;-).
vachevskiy.ru
Что такое релевантные слова. Что такое релевантность поиска, индекс поисковой системы и ранжирование? Самые удобные ресурсы для проверки релевантности
Когда пользователь хочет найти в интернете информацию, он вбивает в поисковую строку конкретный вопрос и ждёт от системы релевантной выдачи. Но, очень часто этого не происходит. Получается, что страница оказалась не релевантной. Так что такое релевантность?
Понятие релевантности
Релевантность (relevant — относящийся к делу) — соответствие текста требуемым ожиданиям. Другими словами это соответствие искомого и найденного. Значит, релевантная страница это именно то, что ожидал увидеть пользователь, делая запрос в строке поиска. Этот термин стали использовать в современных системах.
Но как же поисковая система определяет эту релевантность, как она решает какую страницу в нужный момент следует предложить? Для этого и существует релевантность поиска, которую каждая система высчитывает с помощью различных алгоритмов. Так что такое релевантность поиска?
Когда пользователь набирает свой запрос в Google или Яндекс, система оценивает документы из своего индекса и выбирает те, которые больше соответствуют запросу. Посетители оценивают работу поисковика по релевантности. Если полученный ответ не удовлетворил пользователя, то он, возможно, больше не захочет пользоваться этой системой.
Поэтому самая главная задача для поисковых систем — найти самые релевантные документы. Это влияет не только на популярность ресурса, но и на его прибыль.
Виды релевантности поиска
- Формальный. При помощи алгоритма происходит сравнивание запроса с видом документа в поисковой машине. В данном способе релевантность высчитывается без участия человека. Всё происходит при помощи поискового робота, по заданной формуле, на основе введенных данных.
- Содержательный. Такой вид применяется в поисковых машинах, но для оценки качества поиска. Специалисты, которых называют асессорами, оценивают результаты поиска, сравнивая их с запросом.
- Пертинентный. К такому виду поиска стремятся все поисковые ресурсы. В данном случае информация полностью удовлетворяет пользователя.
Любая поисковая система работает по собственному алгоритму и каждой системы существует своя фишка, но принцип у всех очень схож:
- Для начала проверяется, насколько часто встречается заданный вопрос или словосочетание на выбранных страницах.
- Идёт проверка промежутка между словами.
- Проверяется количество ссылок на страницу.
- Учитывается, каким текстом набрано словосочетание.
- Проверяется возраст сайта.
Количество информации в сети постоянно увеличивается, поэтому повышение релевантности очень важная задача для каждой системы поиска.
У всех ресурсов существует много страниц, которые соответствуют требованиям запроса. Алгоритм системы поиска предложит самую релевантную страницу. Так что такое релевантность страницы?
Как определяется релевантная страница
Страница сайта — это свой собственный мир в сети. Этот контент содержит текст, изображения. Он перекликается с множеством других страниц. Исходя из этого, получается, что на релевантность влияет, как и содержание текста, так и взаимодействие с другими сайтами.

Внутренняя (содержание текста) релевантность — соответствие содержания текста требованиям системы поиска. Когда при вводе запроса словосочетания на странице будут наиболее употребляемые, то она будет релевантной. У каждого поисковика своя совокупность соотношения вхождений требуемого словосочетания к количеству слов в написанной статье. Чем ближе это число окажется к числу системы, тем выше окажется текст на странице поиска.
Основные параметры оценки страницы
- Несмотря на то, что в каждой системе поиска свой алгоритм, принцип поиска у всех похож. Внутренняя составляющая оценки релевантности:
- Частота употребления нужного словосочетания в написанном тексте. Если общее количество употреблений нужного словосочетания близко к установленному системой, тем выше релевантность страницы.
- Расположение нужных слов в заголовках и подзаголовках. Когда требуемое словосочетание расположено в заголовке текста, то уровень оценки текста повышается.
- Нужные словосочетания находятся в начале страницы. Система начинает поиск с начала страницы, поэтому, чем быстрее встретится заданный запрос, тем выше релевантность.
- Требуемые слова в нужных местах. При наличии нужных слов в заголовках и подзаголовках релевантность повышается.
- Присутствие синонимов. Это важная часть документа. Если в тексте присутствуют синонимы требуемых слов, система сочтёт такой текст полезным и относящимся к заданной теме.
- Количество ссылок, которые ведут на сайт. Это указывает на значимость сайта среди других ресурсов.
- Соответствие сайта требуемым словам. Чем больше количество страниц, отвечающих нужным словосочетаниям, тем выше авторитет.
Конечно, существуют другие технические приемы поисковых машин, по которым они считают одну страницу релевантной, а другую нет. Их достаточно много и раскрывать их не в интересах систем, которые хотят улучшить релевантность для своих пользователей.
- Но как бы не улучшали системы поиска, не стоит забывать несколько важных вещей:
- Полученный результат зависит не только от системы, но и от того насколько удачно и точно был сформулирован запрос, указаны нужные слова.
- У каждого человека свой кругозор, своё восприятие жизни и содержание одной и той же информации будет разной для каждого человека.
У всех поисковых систем:
- Собственные задачи.
- Различные финансовые возможности.
- Сотрудники со своим мировоззрением и кругозором, у всех разный возраст и разное мышление.
Изучив подробно статью, вы найдете ответ на вопрос, что такое релевантность.
Здравствуйте уважаемые друзья. Возможно, вы когда-нибудь слышали такое слово, как «релевантность». Если вас интересует продвижения сайтов, то, скорее всего, да. А знаете ли вы, что такое релевантность страниц сайта? Если нет, то сегодня я, как раз таки напишу, что такое релевантность поиска и страницы сайта.
Релевантность поиска – это степень соответствия найденной информации пользователем, к той, которую он хотел найти.
Например, вы ввели в поисковую систему запрос «скачать музыку». А поисковик вам выдает сайты с информацией «что такое музыка». Так вот, степень соответствия того, что
lab-music.ru
Что такое релевантный запрос и для чего он нужен
В наши дни обычному человеку нет необходимости копаться в библиотеках и архивах в поисках нужной информации. Развитие информационных технологий привело к тому, что практически все необходимое ныне можно найти в интернете. Для облегчения этой задачи существуют специальные поисковые алгоритмы, которые обеспечивают поиск и выдачу информации по запросам пользователей.
Содержание:
Понятие релевантности
В основу работы поисковых систем положен принцип релевантности информации. Релевантность – это одно из важнейших понятий в сфере поисковой оптимизации, уровень соответствия результата выдачи поисковому запросу. То есть, другими словами, насколько отвечает результат поиска потребностям пользователя. Релевантность можно рассмотреть на примерах.
Пользователю срочно понадобилась книга «А», но ни в одном из книжных магазинов он ее не нашел. Пользователь заходит на страницу поисковика и вводит в строку запроса «купить книгу «А». Если, перейдя по предложенным ссылкам, пользователь попадает на страницу книжного интернет-магазина, где ему будет предложена необходимая книга и цена за нее, то такой результат считается релевантным.
У пользователя не включается телефон, он вводит в строчку поиска фразу «сломался телефон». Результатов будет множество, но релевантным будет результат, где описываются возможные причины проблем с телефоном и способы их решения. Нерелевантным является тот результат, где вместо этого просто описываются модели телефонов.
То есть, релевантным результат считается если вы получили на свой запрос конкретный ответ, который вас полностью устраивает или искомую информацию. Тексты, не содержащие никакой конкретики, либо просто содержащие набор фраз релевантными считаться не могут.
Таким образом, релевантность – это главный критерий успеха. Пользователь, который переходит на страницу сайта из поисковика должен найти именно тот материал, который ищет. В другом случае, страница для него бесполезна, а значит нерелевантная запросу.

Как получить релевантную статью
Раньше, когда сфера поисковой оптимизации только начинала свое развитие, для того чтобы подняться в рейтинге выдачи можно было просто вставить в текст большое количество ключевых слов. Сейчас такой прием не работает. Вернее, сделать такое можно, но после этого гарантировано понижение в рейтинге, вплоть до исключения из индекса.
На сегодняшние день многие пытаются просто вставлять в текст несколько ключевых слов, которые идентичны популярным поисковым запросам. Но релевантной статью это не делает и пользователям такие страницы попросту не интересны. Поисковые системы тоже научились определять релевантность по поведению пользователей, в частности, по времени, проведенному на сайте. Если человек заходит на сайт и сразу же закрывает его, то информация считается не соответствующей запросу. Необходимо чтобы пользователь задержался на странице минимум сорок секунд.
Поисковые системы анализируют сам текст, размещенный на странице на предмет наличия определенных терминов и слов, которые употребляются в статьях подобной тематики.

Другими словами, на данный момент релевантность определяется не по ключевым словам. Несмотря на то что их продолжают использовать, этот метод является устаревшим. В первую очередь необходимо соответствие заявленным темам, это приведет к увеличению количества посетителей, и как следствие, повышению в рейтинге.
С уважением, Евгений Кузьменко.
ekuzmenko.ru
что это такое, поиск и определение их
Тематический трафик – альтернативный подход в продвижении бизнеса

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Релевантные страницы – это те, что максимально точно соответствуют запросу, который пользователь вводит в поисковую строку.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
То есть, если пользователь ищет информацию по запросу «разведение кроликов в условиях Крайнего Севера», то страницы с рекламой кормов для кроликов, пошива шуб из кроликов, описанием кроличьих пород релевантными не будут. А вот та, что рассказывает о сложностях и специфике разведения кроликов в северных регионах – будет.
Чем точнее страница соответствует запросу пользователя, тем выше она будет стоять в выдаче. Учитывая, что пользователи редко просматривают больше первой десятки сайтов в выдаче, повышение релевантности становится хорошим способом продвинуть ваш сайт на более высокие позиции. Однако сделать это непросто. Поисковые системы определяют релевантны ли страницы по определенному набору факторов, например, в Яндекс этих факторов более 400. Более того, стараясь избежать искусственного повышения релевантности, не учитывающего интересы пользователей, и Яндекс, и Google эти факторы тщательно скрывают.
Тем не менее сделать страницы более релевантными можно, надо только разобраться, что на нее влияет.
Внутренняя релевантность
Ее еще называют текстовой. Те страницы, на которых слова, соответствующие поисковому запросу, встречаются многократно, считаются наиболее релевантными. Не так давно было достаточно, чтобы запрос просто встречался в тексте как можно чаще. Это привело к появлению странных текстов с огромным переспамом ключевыми словами. Сегодня поисковые системы рассчитывают соотношение запроса к общему числу слов в тексте, подбирая оптимальное по собственным алгоритмам. Определение релевантных страниц выполняется просмотром ряда параметров:
Количество повторений в тексте слов поискового запроса
Чем ближе частота появления запроса в тексте к идеальному значению, тем более релевантной признается страница. Идеальное значение у каждой системы свое, как оно рассчитывается – неизвестно.
Заголовки и подзаголовки текста должны содержать слова из поискового запроса
Это дает серьезное преимущество в подборе релевантных страниц. В первую очередь это касается слов, оформленных тегом h2. Вхождение слов из запроса в h3 и h4 тоже приветствуется, но уже не так важно.
Расположение ключевого запроса в тексте
Чем ближе запрос к началу страницы, тем лучше, поскольку поисковые роботы систем просматривают текст сверху. Чем раньше робот найдет запрос, тем быстрее он определит релевантные страницы сайта.
Ключевые слова в метаданных
Метатеги title, description и keywords, содержащие ключевой запрос, заметно повышают релевантность страницы.
Использование синонимом ключевых слов
В тексте должны быть использованы не только ключевые слова, но и их синонимы. Использование синонимов сообщает поисковикам, что посадочная страница релевантна запросу и полезна пользователю.
Внешняя релевантность
Она зависит от того, насколько часто на сайт ссылаются. Это та самая ссылочная масса, которую недавно покупали на специальных биржах. С точки зрения поисковых систем, чем чаще на сайт ссылаются, тем он полезней, при этом важно, чтобы ссылки содержали слова из запроса. Чем выше качество текста вокруг ссылки и авторитет ресурса донора (того, что ссылается на ваш сайт), тем лучше. Надо сказать, что покупку ссылок поисковые системы не одобряют, и если вас в ней уличат, то ресурс попадет под фильтры и перестанет появляться в выдаче.
Еще один фактор внешней релевантности — количество релевантных страниц. Возвращаясь к рассмотренному выше примеру сайта о кроликах, отметим, что чем больше на сайте текстов о северных кроликах, тем лучше. Если же страница о кроликах только одна, а остальные о енотах и песцах, системы не воспримут сайт как релевантный. Создавая контент для сайта, учтите, что поиск релевантных страниц – процесс непрерывный, работать над содержанием сайта требуется постоянно.
Ошибки при повышении релевантности
Если поисковые системы сочтут, что вы пытаетесь повысить релевантность не за счет качества контента, а с помощью хитрых приемов, ваш сайт попадет в бан. Поэтому все действия надо выполнять аккуратно и обдуманно. Ниже несколько рекомендаций, как не попасть под фильтры поисковых систем на пути в ТОП.
- Не включайте запрос в заголовок h2 в неизменном виде, измените его, сделайте более интересным и «цепляющим».
- Не старайтесь выделить ключевые слова специальными тегами, например, strong, этот прием уже не работает и приносит больше вреда, чем пользы.
- Размещайте ключи в тексте подальше друг от друга, иначе поисковый робот идентифицирует текст как спам и отправит в конец выдачи.
- Не включайте ключевые фразы в alt и title каждой картинки, это не пойдет на пользу вашему ресурсу.
Если вы не специалист в области SEO, не стоит использовать искусственные приемы для повышения релевантности страниц. Наполняйте сайт хорошим контентом. Это медленный процесс, но он обеспечит постепенный рост позиций сайта.
semantica.in
Как измерить релевантность контента / Rookee.ru corporate blog / Habr
Оценка контента одна из главных составляющих формулы релевантности. Знание текстовых признаков и вклад каждого из них в оценку сайта позволит приблизиться к более профессиональной работе с ресурсом. В данной статье будет рассмотрена модель, позволяющая восстановить формулу ранжирования по каждому конкретному запросу, указана значимость определение тематики сайта при продвижении по определенному запросу, а также проработан вопрос, связанного с определением неестественного текста.Восстановление формулы ранжирования
Если переводить данную задачу в область математики, то входные данные можно представить набором векторов, где каждый вектор – множество характеристик каждого сайта, а координаты в векторе – параметр, по которым оценивается сайт. В описанном векторном пространстве обязательно должна быть задана функция, определяющая отношение порядка двух объектов между собой. Эта функция позволяет ранжировать объекты между собой по принципу «больше — меньше», однако при этом сказать, насколько именно одно больше или меньше другого – нельзя. Такого вида задачи относятся к задачам оценки порядковой регрессии.
Наши сотрудники разработали алгоритм на основе модели линейной регрессии с регулируемой селективностью, который позволил с определенной долей погрешности восстановить ранги сайтов и спрогнозировать изменение выдачи при соответствующих корректировках параметров сайта. Первым шагом алгоритма является обучение модели. В данном случае обучающая выборка представляет собой результаты ранжирования сайтов в рамках одного поискового запроса. Упорядоченность сайтов в рамках поискового запроса фактически означает, что в признаковом пространстве существует некоторое направление, на которое объекты обучающей выборки должны проектироваться в нужном порядке. Это направление и является искомым в задаче восстановления формулы ранжирования. Однако судя по рис.1, таких направлений может быть много.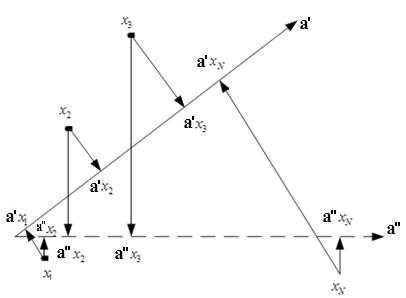
Рис. 1. Выбор направляющего вектора
Для решения данного вопроса был рассмотрен подход, лежащий в основе метода опорных точек, а именно – выбор такого направления, которое будет обеспечивать максимальное удаление объектов друг от друга.
Следующая задача, которая была решена — выбор стратегии обучения. Рассматривалось два варианта – сокращенная стратегия обучения, при которой учитывается порядок двух соответствующих элементов, и полная стратегия, которая учитывает весь порядок объектов. В результате экспериментов была выбрана сокращенная стратегия, которая заключается в решении следующего уравнения:(1)
, где — решение стандартной задачи квадратичного программирования при линейных ограничениях: , где
— симметричная матрица
— вектор коэффициента
— разница векторов характеристик
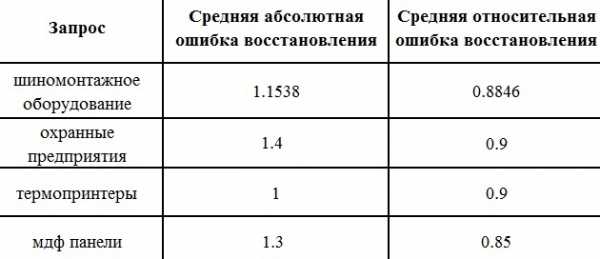
Данный подход на различных выборках (100 признаков и 500 признаков на 20 различных множествах поисковых запросов) показал хорошие результаты (см. табл. 1).
Таблица 1. Результаты сокращенной модели
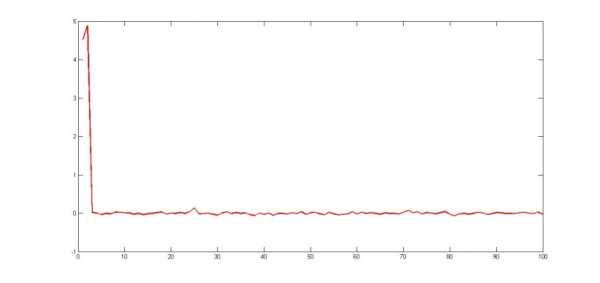
Рис. 2. Восстановленные коэффициенты регрессии при n=100 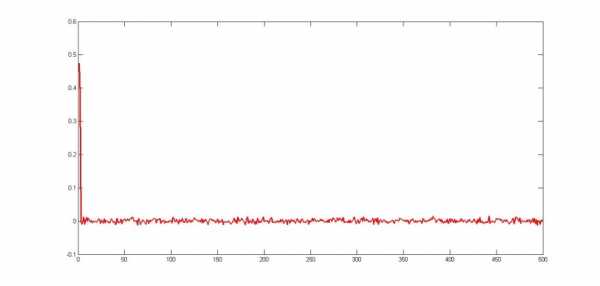
Рис. 3. Восстановленные коэффициенты регрессии при n=500
Если говорить о результатах на конкретных запросах, то проведенные эксперименты дают следующий показатель ошибка
Таблица 2. Ошибки вычислений
При работе над проектом данный подход использовался для прогнозирования позиций при конкретном изменении на сайте. Подобные эксперименты проводились на базе текстовых признаков. Первоначально были собраны данные по сайтам из ТОП20 по рассматриваемому запросу, затем данные подвергались стандартизации с помощью соответствующего алгоритма. После чего выполнялся алгоритм непосредственно по вычислению «релевантности» с помощью метода квадратичного программирования.
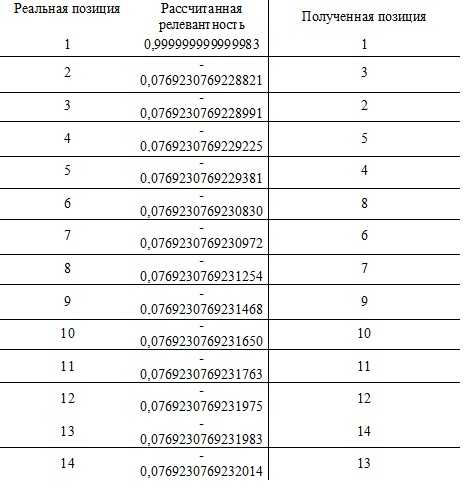
Полученные значения релевантности сайта сортируются и делается вывод о восстановленных позициях.
Таблица 3. Восстановление позиций
Было выявлено, что наибольшее влияние на позиции при ранжировании запроса «шиномонтажное оборудование» вносят признаки: наличие в Яндекс каталоге, вхождение первого слова из запроса «шиномонтажное», вхождение в h2 первого слова запроса «шиномонтажное», вхождение в title страницы второго слова запроса «оборудование».
Были произведены соответствующие корректировки в параметрах сайта и запущена программа. В результате был дан прогноз на соответствующую позицию.
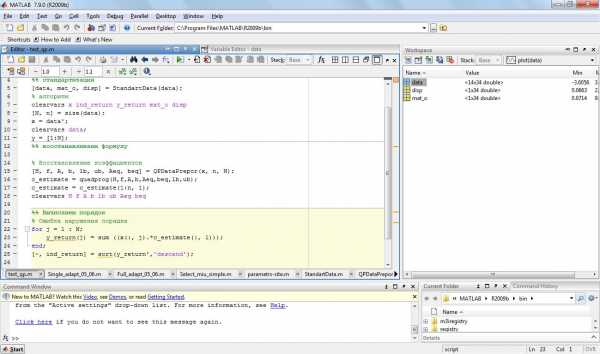
Рис. 4. Программа, восстанавливающая формулу ранжирования
На сайте были произведены все эти изменения, после очередного апдейта сайт занял позиции, близкие к прогнозируемым. Первоначальная позиция была 50, после указанных изменений она составила ТОП20.
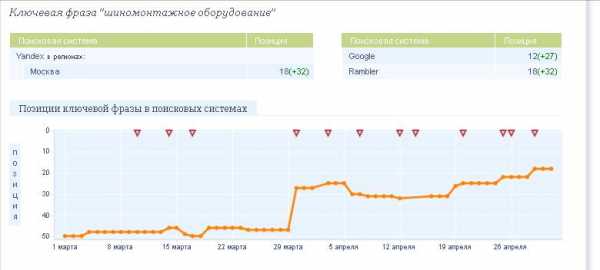
Рис.5. Результаты продвижения запроса «шиномонтажное оборудование»
Измерение тематики текста
В работе с восстановлением формулы ранжирования была подтверждена значимость измерения тематической близости тематики текста по отношению к тематике всего сайта. Подобную метрику можно построить на базе расчета косинуса между векторами соответствующих тематики страницы, релевантной запросу, и всего сайта: (2)
где и соответственно обозначение вектора тематичности сайта и рассматриваемого документа.
N – число слов в словаре коллекции. Вес каждого слова j в документе Di рассчитывается по формуле:(3)
где countij – число вхождений слова в документ, IDFwj — обратная частота слова в коллекции. После расчета веса каждого слова в документе, вектор нормируется:(4)
Аналогичным образом строится вектор и для всего сайта, при этом текст сайта получается объединением текстов всех входящих в него документов.
Таким образом, алгоритм определения тематической ценности документа можно представить в следующем виде:
1) Определяется словарь, в котором отсутствуют редкие и стоп-слова, т.е. IDF слов, формирующих словарь, лежит в диапазоне значимых слов.
2) Строится N-мерный вектор тематичности для рассматриваемого документа , используя формулы 3 и 4.
3) Строится N-мерный вектор тематичности для всего сайта , используя формулы 3 и 4.
4) С помощью (2) устанавливается близость векторов и . Чем ближе вектора, тем тематическая ценность документа выше.
На основе данной модели была написана программа, позволяющая определить тематическую схожесть рассматриваемого документа и текстовой составляющей самого сайта. Эксперименты проводились на базе 3 групп сайтов: с одинаковой тематикой, с близкой тематикой, с разной тематикой. Всего было обработано 200 статей. В результате обработки были получены следующие данные по 20 группам «1 тестовый документ / 9 обучающих документов», представленные в таблице.
Таблица 4. Результаты проверки тематической полноты
Из таблицы видно, что предложенный метод определения тематической полноты информационного ресурса работает на практике: проверяемые документы, расположенные на сайтах с более полно раскрывающейся тематикой, имеют более высокие показатели. Однако были выявлены и недочеты разработанной системы. Во-первых, на сайтах часто находятся неинформативные или малоинформативные страницы (формы заказов, обратной связи, контакты и т.п.). Во-вторых, при выборе случайно заданного количества обучающих текстов можно отобрать нетематические страницы. В-третьих, в качестве тестовых текстов могут попасться неспецифический контент, но близкие по тематике, например – правописание того или иного слова. В-четвертых, существуют сайты, которые охватывают разные тематические направления, при этом пересекающихся по смыслу (интернет-магазины, новостные сайты, банки рефератов).
При перечисленных недочетах общая картина позволяет оценить тематическую полноту ресурса. В качестве примера рассмотрим сайт тематики «логистика» с запросами, касающимися оборудования (на сайте присутствует каталог, помимо информации о логистике). Сайт зарегистрирован в Яндекс.Каталоге и имеет рубрику «экспедирование и перевозка грузов»:
Рис. 6. Рубрика, присвоенная в Каталоге.Яндекса
При использовании рассмотренного выше метода был сделан вывод, что тематическая полнота продвигаемых страниц не полная по отношению к запросам тематики «перевозка и доставка из Китая», но достаточная большая по отношению к тематике «оборудование». Соотношение страниц «логистика: оборудование» составляло соответственно «30:200». Соответственно, и позиции, и трафик был лишь у запросов, связанных с оборудованием. При этом приоритетна была «логистика». Для решения проблемы было написано письмо в Яндекс с целью получения развернутой информации. Однако был получен стандартный ответ «Платона» об улучшении и развитии сайта, но в целом все в порядке.
В качестве решения стоял выбор между развитием требуемой тематике на сайте и разнесением двух тематик на разные поддомены. Выиграла необходимость получить быстрый результат. Были составлены ТЗ на перенос направления «оборудование» на поддомен, а на основном сайте сохранена информация по «логистике», а так же на развитие ресурса путем добавления новых релевантных тематике страниц. Результат изменений представлен на рис. Запросы по оборудованию успешно перешли на поддомен и заняли положительные позиции. А после добавления тематических страниц по логистике и запросы по перевозкам, стали показывать положительную динамику.
Рис. 6. Результаты продвижения, после разведения тематик
Таким образом, за счет схемы «поддомен + домен» получилось без потерь разнести тематики и за счет этого повысить релевантность каждой из тематик по-отдельности и добиться положительную динамику по запросам.
Измерение естественности текста
Требования попадания в Яндекс.Каталог ужесточаются. В последнее время приходится сталкиваться с тем, что при проверки сайта, сотрудники яндекса сообщают о некачественном контенте. Выявить данный факт вручную на большом сайте представляется проблемой. Поэтому в настоящий момент ведутся работы по анализу признаков данных текстов. Расскажу о некоторых из них. Можно выделить два основных подхода в получении спам-текста: замена русских букв латинскими и генерация контента, лишенного смысла.
Первый подход вскрывается путем выявления измененных слов с помощью инвертированной частоты и сравнением с установленной эмпирическим путем критической величиной. Слова, образованные заменой русских букв аналогичными латинскими, являются редкими словами с точки зрения статистики употребления. С помощью инвертированной частоты по общей коллекции можно выявить такие слова. Каждому элементу текстового узла , ставится в соответствие значение с помощью функции инвертированной частоты fh:(5)
В качестве функции инвертированной частоты были рассмотрены:(6), (7), (8).
Здесь D – число документов в коллекции, DF – количество документов, в которых встречается лемма, CF – число вхождений леммы в коллекцию, TotalLemms – общее число вхождений всех лемм в коллекции. Из этих вариантов лучший результат в эксперименте, также как и в исследовании Гулина А. показал ICF (7), поэтому где – число вхождений леммы в рассматриваемом тексте, – общее число вхождений всех лемм во множестве.
Чем больше значение функции fh, тем реже слово встречается. Для получения интервала ICF значимых слов была написана программа, на вход которой подавались тексты различного содержания (устранение тематического влияния). Программа обработала порядка 500 МБ текстовой информации. В результате обработки был получен словарь обратных частот слов ICF в нормальной форме. Лемматизация слов была осуществлена с помощью парсера mystem, компании Яндекс. Все элементы словаря были отсортированы в порядке увеличения обратной частоты. В результате анализа данного словаря был получен интервал значимых слов: [500; 191703].
Для установления критерия выявления спам-текстов, также вводится критическая величина Hкрит и производится подсчет Hp процента слов, чья характеристика превышает установленную эмпирическим путем критическую величину Hкрит :(9)
В качестве критической отметки используется процент незначащих слов – 50% (наибольший показатель частоты служебных слов — 37.60%, а придуманных слов автором в среднем — 5.63%). Большой процент употребления в одном тексте таких словообразований Hp будет свидетельствовать о том, что документ является сгенерированным.
Однако сайтов с такими спам-текстами достаточно мало. Второй подход более распространен. Существует класс неестественных текстов, порожденных с помощью генераторов на основе цепей Маркова. На основе исследований Павлова А.С. была предложена модель, позволяющая выявлять такие тексты.
Вся текстовая составляющая B документа D имеет ряд признаков , трудно контролируемых автором. Для построения автоматического классификатора неестественных текстов используются выделенные признаки в машинном обучении. В качестве разрабатываемого подхода лежит алгоритм на основе деревьев решений C4.5. Сам алгоритм определения неестественного текста выглядит следующим образом: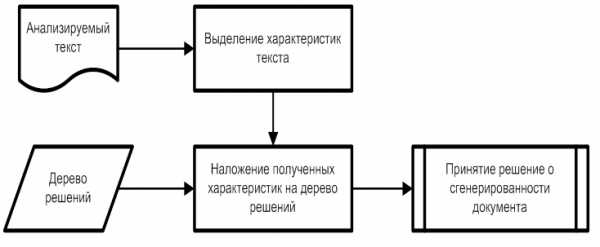
Рис. 7. Алгоритм определения сгенерированного контента
Для получения дерева решений была подготовлена база естественных текстов в размере 2000 и база неестественных текстов объемом также 2000, часть найдена в интернете, часть сгенерирована, остальные получены путем синонимизации документов-образцов или путем перевода с иностранных языков. Исходной коллекцией стала коллекция ROMIP By.Web. Инструменты генерации и синонимизации были найдены в интернете (TextoGEN, Generating The Web 2.2, SeoGenerator и другие).
Полученный набор текстов делился на две равные части. Первая группа использовалась в качестве обучающей выборки, а вторая часть – тестовый набор. Обе выборки имели равное количество документов-образцов и порожденных текстов.
Для процесса обучения была написана программа, которая по каждому тексту строила вектор, оценивающий параметры, влияющие на определение естественности текста. Согласно исследованию Павлова А.С. наибольший вклад в обучение вносит список параметров, определяющих текстовое разнообразие и частоту использования частей речи. В таблице представлен список наиболее ценных признаков для классификации русскоязычных текстов, для каждого признака указана F-мера и тип признака.
Таблица 5. Наиболее ценные признаки для классификации текстов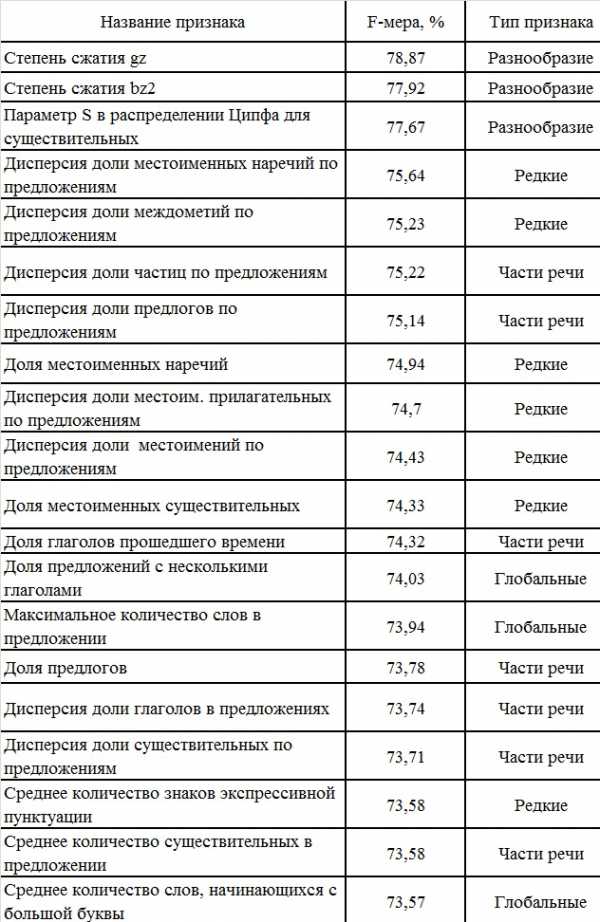
По полученным векторам P каждого из документа D строилось дерево решений. Данная процедура проводилась с помощью аналитической платформы Deductor Studio Academic версии 5.2. В Deductor в основе обработчика «Дерево решений» лежит модифицированный алгоритм C4.5, решающий задачи классификации. В результате было построено дерево со 157 узлами и 79 правилами. На рис. представлена часть полученного дерева. Полученные правила использовались в основной программе при определении спам-текстов сайта.
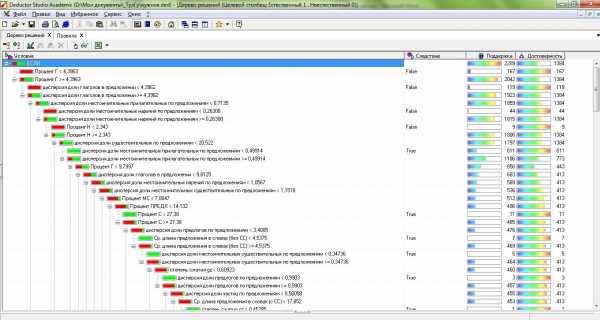
Рис. 8. Дерево решений. Аналитическая платформа Deductor 5.2.
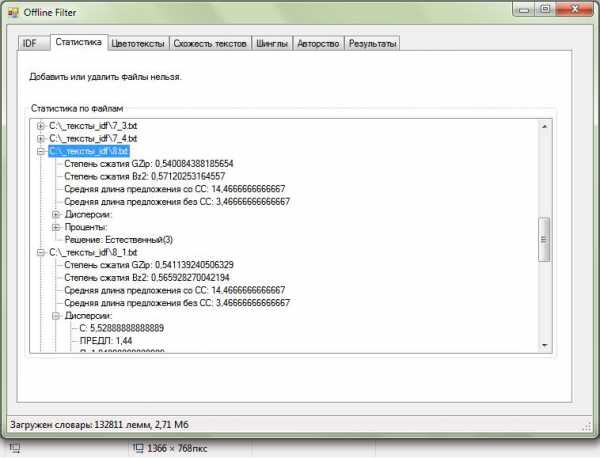
Рис. 9. Результат работы программы по анализу текстов
На практике данный подход помог обнаружить причину отсутствия динамики по запросам. Программа обнаружила сгенерированные тексты на всех страницах категорий сайта. При расследовании было выяснено, что они представляют контент машинного перевода этого же сайта, но английской версии.
Рис. 10. Тексты на страницах категорий
После редактирования данных текстов даже только на продвигаемых страницах, была получена хорошая динамику: запросы из ТОП500 сразу попали в ТОП10 за 9 недель.
Рис. 11. Пример измененного текста.
Рис. 12. Изменение позиций по неделям после выкладки.
В заключение необходимо отметить, что разработка рассмотренных функционалов — не обязательна! Она полезна при глобальных исследованиях поисковых машин. При продвижении сайта достаточно выработать подход, позволяющий точечно работать с запросами на основе анализа ТОПа. Для этого существует много естественных инструментов:
1) Проверьте, сколько по запросу релевантных страниц на сайте и сравните с конкурентами – сможете оценить текстовую полноту сайта
2) Обратите внимание на подсвеченные слова в многословных запросам в сохраненной копии – помощь при составлении текстов, на сколько далеко могут стоять друг от друга слова
3) Используйте язык запросов. Например, анализируя выдачу по точному запросу и без кавычек, можно выявить проблемы с текстовой составляющей
4) Через расширенный поиск ищите запрос по конкретным сайтам и анализируйте, какие страницы и почему выше продвигаемой
5) Результаты Вебмастера.Яндекса и Вебмастера.Гугл, данные метрики и GA также помогут выявить проблемы и провести работу с ними.
Целенаправленная деятельность по запросам всегда дает положительный результат.
Авторы статьи: Неелова Н.В. (к.т.н., руководитель отдела ПП Ingate), Поленова Е.А. (руководитель группы ПП Ingate).
habr.com
Что такое релевантность страниц сайта
Добрый день, друзья! Сегодня очередной пост о самых важных понятиях поискового продвижения для блоггеров и начинающих сеошников. Что такое релевантность страниц сайта — тема этой статьи, из которой вы узнаете определение релевантности, основные ее составляющие и как она оценивается поисковыми системами. Позволю заметить, что это достаточно важный вопрос, на котором строится весь процесс ранжирования сайта при подготовке документов в результат выдачи. От правильного понимания этого термина зависит успешное сео продвижение Вашего сайта в поисковиках. Поэтому предлагаю заглянуть в наш словарик и получить необходимые сведения по центральному элементу ранжирования.
[contents h3 h4]Определение релевантности
Что значит релевантность? Это такой процесс, при котором проверяется схожесть полученного результата от желаемого. Этот термин используется в современных поисковых системах и под ним понимается соответствие полученной информации поисковому запросу, который задал пользователь. Согласно определению, когда посетитель Яндекса или Гугла набирает свой вопрос, поисковая система пытается оценить различные документы из своего индекса и выбрать самые подходящие для ответа. Таким образом, система вычисляет меру соответствия — степень совпадения документа и поискового запроса. Соответственно, если они совпадают, то значение меры самое большое (максимальное), а если же нет — равно нулю.
По степени релевантности документов в результатах выдачи судят об эффективности работы любой поисковой системы. Если пользователь получит на свой запрос абсолютно неподходящий для него ответ, то есть большая вероятность того, что он больше не станет пользоваться таким ресурсом. Поэтому именно подбор самых релевантных документов для свой выдачи — основная задача поисковика. Это влияет и на популярность поисковой системы, и на ее прибыль.
Насколько релевантен тот или иной документ в сети Интернет, определяется специальным поисковым алгоритмом. У Яндекса он один, у Гугла он другой, но общая схема его работы у них одинаковая. Также и у других поисковиках определние релевантности свое, но имеющее общие корни.
[stextbox id=»info» caption=»Поисковый алгоритм» mode=»css» direction=»ltr» shadow=»true» float=»true» width=»670″ bwidth=»2″ color=»000000″ ccolor=»ff0000″ bcolor=»000000″ bgcolor=»afeeee» cbgcolor=»eee8aa»]Это специальные математические выражения и формулы, по которым поисковые системы выбирают различные сайты в свои результаты поиска. Каждый из этих веб-ресурсов содержит один самый подходящий документ, в котором находится ответ на поисковый запрос пользователя. Принцип работы алгоритма очень прост: сначала выбираются все страницы сайтов, содержащие искомый запрос, а потом идет планомерное отсеивание — отсекаются площадки без четкой информации для пользователя или неразрешенные в связи с использованием запрещенных методов оптимизации (черное seo — клоакинг, дорвеи и т.д.). Выбранные страницы анализируются по контенту документов и принимается решение о том, насколько они соответствуют поисковому запросу. И в зависимости от степени соответствия каждому документу присваивается свой номер в поисковой выдаче. Чем он меньше, тем быстрее его увидит пользователь поисковика.[/stextbox]
Что такое релевантность страниц сайта
Обычно у каждого веб-ресурса есть несколько страниц, которые содержат ответ на запрос пользователя поисковой системы. Задача перед поисковым алгоритмом ставится следующая — выбрать наиболее релевантный документ (страницу сайта или пост блога). Этот вопрос решается следующим образом. На релевантность каждой страницы влияет большое число факторов. Поэтому для оценки соответствия документа веб-ресурса запросу пользователя поисковой системы вычисляется суммарный показатель. Соответственно, страница с максимальным суммарным показателем будет самой подходящей и именно ее поисковая система покажет пользователю. Например, на следующей картинке можно увидеть выборку из поисковой системы Яндекс самых релевантных страниц моего блога по запросу «что такое видимость сайта». Самый первый документ имеет максимальный суммарный показатель.
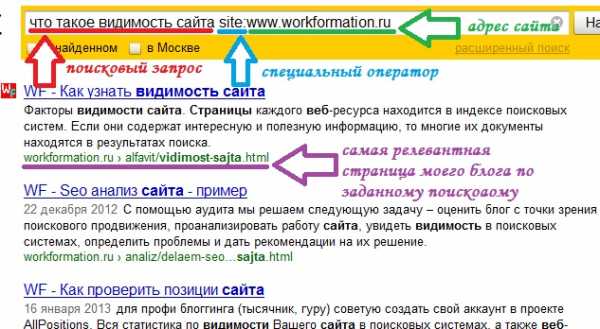
От чего же зависит релевантность страницы? Каждая страница любого сайта — это целый самостоятельный элемент сети Интернет. Он содержит свой контент. В основном он уникален, со своим текстом, картинками и т.д. Этот элемент взаимодействует с другими страницами — от него идут различные ссылки на другие страницы своего сайта или на чужие веб-ресурсы. И по возможности он тоже получает различные внешние ссылки. Поэтому можно сказать, что на релевантность страницы по конкретному поисковому запросу влияют как внутренние параметры, так и внешние. Плюс ко всему еще важен и авторитет этой страницы. Давайте рассмотрим подробнее каждую составляющую.
Внутренняя
Внутренняя или по другому, текстовая релевантность — это степень соответствия внутренних критериев страницы веб-ресурса требованиям поисковых систем. Если при поисковом запросе слова на странице соответствуют его форме и являются наиболее употребляемыми, то этот документ будет считаться самым релевантным. Другими словами можно так сказать — чем ближе до идеального (у каждой системы свое число) соотношение количества вхождений запроса к общему числу всех слов в тексте, тем выше окажется документ в результатах выдачи. Перечислим основные параметры, с помощью которых она оценивается.
- Частота поискового запроса в тексте. Имеется в виду объем и количество повторений ключевого запроса на странице сайта. Чем ближе к идеальному варианту (повторюсь, что у каждой поисковой системы это своя цифра), тем лучше в плане оценки релевантности документа.
- Месторасположение слов в заголовках. Если поисковый запрос находится в заголовке страницы, то повышается вероятность лучшей оценки этого документа, по сравнению с остальными страницами веб-ресурса. То есть тег title должен содержать в своем предложении ключевой запрос, что значительно усилит релевантность страницы.
- Близость к началу страницы. Поисковый робот при сканировании новой страницы идет по коду с самого ее начала. Поэтому чем раньше он встретит поисковый запрос на ней, тем это лучше для оценки релевантности. Поэтому ключевые слова необходимо прописывать как можно раньше в статье сайта или посте блога.
- Наличие ключевых слов в специальных местах документа. В первую очередь это говорится о наличии поисковых запросов в заголовке статьи (обычно в теге h2) и в подзаголовках (в теге h3 — не так важно, как в h2, но наличие приветствуется). Плюс оформление поисковых запросов в тексте в специальные теги (strong и т.д.). И конечно же наличие ключевых слов в мета-тегах Description (описание страницы) и Keywords.
- Наличие синонимов ключевых слов. Очень важный элемент. Наличие синонимов в контенте страницы говорит поисковым системам о том, что данный документ действительно относится к тематике поискового запроса, а значит он будет наиболее полезным для пользователя. Таким образом поисковики чистят результат выдачи — не берутся в расчет страницы, которые содержать ключевые слова как дополнение к другим темам и документы, которые являются площадками для большинства автоматизированных систем продвижения (RooKee, SeoPult и т.д.).
Внешняя (ссылочная)
В основе этой составляющей лежит принцип ссылочной популярности страницы сайта. Здесь в расчет принимается число ссылок с их текстами (анкорами). Чем больше ссылок тем лучше ссылочная релевантность. И если текст ссылки содержит ключевой запрос пользователя, тем значимей становится страница. Поэтому рекомендуется всегда использовать в тексте ссылок поисковый запрос. Причем не важно, внутренняя это ссылка или внешняя — слова анкоров имеют значение. Также оценивается околоанкорный текст ссылки, который содержит внешняя страница другого веб-ресурса. Если он не является тематическим по поисковому запросу, значимость текста ссылки будет меньше.
Авторитетность сайта
Каждый сайт имеет свой специальный рейтинг в поисковых системах, который характеризует его авторитетность. Определение этого рейтинга происходит по ряду основных показателей:
- количество и качество внешних ссылок, ведущих на сайт. Важный показатель, который показывает степень значимости сайта и его страниц среди других веб-ресурсов. Чем качественней внешние ссылки (ключевые слова в анкоре и тематический околоссылочный текст) и чем авторитетней сайт-донор (веб-ресурс, который отдает внешнюю ссылку), тем больший вес может перейти на целевую страницу.
- содержание сайта и соответствие контента поисковым запросам. Чем больше страниц, по которым продвигается сайт, отвечают запросам пользователей поисковых систем, тем выше авторитетность сайта. Поэтому для любого веб-ресурса, который раскручивается в поисковиках наиболее важны два момента — это правильное составление семантического ядра и наличие уникального оптимизированного контента. Даже при наличии огромного числа внешних ссылок невозможно на длительный срок продвинуть целевые страницы сайта в топ-10 без хорошего текста и грамотного набора ключевых слов. Со временем поисковая система пессимизирует эти документы со своей выдачи, уменьшив на порядок их релевантность по причине отсутствия нормального контента с учетом внутренней оптимизации.

Советы блоггерам
Если блоггер продвигает свой веб-ресурс в поисковых системах, то ему могут быть полезны следующие советы и рекомендации по улучшению релевантности целевых страниц:
- Обязательно перед продвижением целевых страниц правильно подберите семантическое ядро Вашего блога. Если Вы будете продвигать целевые страницы по некачественным поисковым запросам, Ваш блог получит намного меньше целевых посетителей и большее число отказов, что со временем уменьшит качество этих страниц. Проверяйте все параметры ключевых слов (частотности, качество слова, его конкурентность) — это залог получения качественного трафика из поисковых систем.
- Новые страницы проверяйте в результатах выдачи по своему ключевому запросу. Например, Вы продвигаете одну страницу по определенному поисковому запросу. Но после индексации по этому ключевому слову в выдаче поисковой системы находится абсолютно другая страница. Значит Вам необходимо проверить все параметры, по которым рассматривается релевантность целевой страницы. Здесь может быть следующая проблема — документ плохо оптимизирован и/или на него поступает меньшее количество весомых внешних и внутренних ссылок — вес страницы очень мал по сравнению с той, которая висит в выдаче.
- Повышайте авторитет своего блога. Со временем поднятия рейтинга Вашего сайта увеличится и релевантность целевых страниц, по которым продвигается блог. Это все будет идти автоматически с ростом популярности Вашего веб-ресурса. Подымается вИЦ и тИЦ Вашего сайта, растут позиции страниц Вашего сайта в Яндексе (аналогично в других поисковых системах).
На этом мой очередной ликбез закончен. Напоследок просьба к моим читателям — в комментариях этого поста, помимо всего прочего, хотелось бы узнать Ваше мнение по следующим вопросам:
- Как часто Вы проверяете на релевантность Ваши целевые страницы?
- Чего не хватает на Ваш взгляд в моих уроках рубрики продвижения сайта?
- На какую тему Вы бы хотели получить материал в одном из следующих уроков?
Спасибо, друзья! До встречи!
maksimdovzhenko.ru
что такое релевантность страниц сайта и поиска, как проверить релевантность страницы, золотые ссылки
Прежде чем двигаться дальше, давайте разберем, что такое Релевантность вообще. Релевантность это степень соответствия искомого и найденного.
Применительно к SEO, релевантность страницы — это степень соответствия страницы тому запросу, который ввел пользователь в ПС. То есть другими словами, релевантная страница это тот документ, который полностью дает ответ пользователю на его запрос.
Содержание:
1. Релевантность страниц сайта
2. Что такое релевантность поиска
3. Что такое релевантные ссылки
4. Тематические ссылки
5. Золотые ссылки в SEO
6. Как проверить релевантность страницы запросу
Релевантность страниц сайта
Как я сказал выше, релевантные страницы это те страницы, которые отвечают на искомый вопрос. Давайте разберем на примере. Допустим вам надо найти информацию, как составить СЯ.
Вы идете в поисковик, и вбиваете запрос «как составить семантическое ядро». В данном случае релевантной будет страница, которая содержит именно эту информацию, например страница моего блога на которую я поставил ссылку.
То есть, та информация как сделать СЯ самому. А если вы попадете на какую-нибудь контору, которая делает это за деньги, то это уже не то что вы искали, а значит нерелевантная страница. Отсюда вытекает следующее понятие.
Что такое релевантность поиска
Что такое релевантность поиска — это соответствие введенного запроса результатам выдачи. Допустим, пользователь ввел в Яндексе запрос «секреты продвижения сайта».
Если ему Яндекс выдал мой учебник по продвижению сайтов или аналогичный, то это будет релевантный результат поиска. Пользователь ведь и искал именно это.
А если в ТОПе затесался сайт какой-нибудь сео конторы, которая продвигает сайты за деньги, то это уже нерелевантный этому запросу сайт. Я привел упрощенный пример, что бы было понятно.
Поисковики все время стремятся сделать свой поиск наиболее релевантным запросам пользователей. Но не всегда это удается, так сами пользователи не всегда правильно задают свои вопросы. И поисковик точно не знает, что юзер хочет найти.
Отсюда можно сделать вывод, что релевантность поиска зависит от ПС не на 100%. Тут еще есть «человеческий фактор». Вот, например, возьмём запрос «ноутбуки». Что хочет найти пользователь, введя этот запрос в поисковую строку?
Он хочет найти новые модели ноутбуков? Узнать цены и адреса магазинов? Или найти что-то другое… Мне лично не понятно, что он ищет.
Вот и поисковики не всегда могут это определить. Конечно, у них есть много информации об этом юзере (история его поисков, демографические данные и т.д.), но тем не менее, выдать ему релевантный ответ затруднительно.
Что такое релевантные ссылки
Что такое релевантная ссылка — это ссылка, анкор которой соответствует содержимому страницы, на которую ведет ссылка. Либо документ, в котором она стоит, соответствует документу, на который она ведет. Давайте поясню.
В первом случае все должно быть понятно. Если ссылка с анкором, например, «биржа ссылок sape» ведет на страницу, где рассказывается именно про биржу Sape, то это релевантная ссылка.
Во втором случае это может быть ссылка в виде url, т.е. без ключа. Она будет релевантной, если будет идти со страницы, где говорится о ссылках, анкорах и т.д. и вести на страницу со схожей информацией. Соответствено если эти требования нарушены, то ссылка будет нерелевантной.
Тематические ссылки
Кроме релевантных, я еще выделяю тематические ссылки. Тематическая ссылка — это ссылка, ведущая с сайта схожей тематики. Например, наш сайт посвящен продаже ноутбуков.
Если на наш сайт появится ссылка с любого сайта про ноутбуки, информационного или любого другого, то это будет тематическая ссылка. А вот если ссылка будет вести с сайта, который тоже продает ноутбуки, то это будет тематическая релевантная ссылка. Это один самых лучших видов ссылок для сайта.
Но есть ссылки еще круче, это ссылки, по которым есть переходы на сайт. Такие ссылки сейчас работают лучше всего. Такие ссылки получили название золотых. Ссылки, это по сути рекомендации посетить ваш сайт.
Чем больше таких рекомендаций есть на других сайтах, тем он становится ценнее «в глазах» поисковых систем. Логично будет сказать, что чем больше ссылок, тем лучше. Но тут есть очень много нюансов.
Золотые ссылки в SEO
Это понятие появилось совсем недавно, и про них еще практически ни кто не написал в своих SEO-блогах. Так что я фактически первый))). Золотая ссылка — это ссылка, по которой есть постоянные переходы на сайт, на который она ведет.
Такие ссылки сейчас это самый лучший вариант продвижения. Они лучше всего работают на повышение релевантности вашего текста страницы и передают максимальный ссылочный вес. Буквально одна-две таких золотых ссылки могут вытянуть в ТОП10 очень не плохие запросы.
На первый взгляд может показаться, что все просто — купил нужных ссылок и ты в шоколаде. Но на практике все намного сложнее. Мы ведь не знаем, как точно работает алгоритм ПС, мы может только догадываться на основе опыта и наблюдений, делать разные эксперименты. Далее я расскажу вам, как постараться сделать все правильно.
Как проверить релевантность страницы запросу
У нас остался не раскрытым еще один вопрос — как проверить релевантность страницы. Проверить можно в одном из онлайн сервисов. Например, бесплатно это можно сделать в megaindex.ru. Все достаточно просто, заходим «seo сервисы» — «анализ релевантности». Вводим урл страницы и свой запрос. Система выдаст нам данные по странице, возможно, найдет какие-то недоработки по оптимизации и подскажет что исправить.
Как найти наиболее релевантную страницу на сайте. Бывает надо найти на своем сайте страницу релевантную какому-либо запросу. Делается это через расширенный поиск по сайту. Идем в Яндекс, в расширенный поиск, вводим наш запрос и url сайта и жмем найти. Первая страница и будет самой релевантной по версии Яндекса.
Дальше рассмотрим вопрос, что такое анкор ссылки и как их составлять.
Оглавление
Статьи по теме:
Загрузка…seob.info