Создание базы данных в Microsoft SQL Server – инструкция для новичков | Info-Comp.ru
Приветствую всех на сайте Info-Comp.ru! В этой статье я подробно, специально для начинающих программистов, расскажу о том, как создать базу данных в Microsoft SQL Server, а также о том, что Вы должны знать, перед тем как создавать базу данных.
Сегодняшний материал, как я уже сказал, ориентирован на начинающих программистов, которые хотят научиться работать с Microsoft SQL Server. Поэтому я и буду исходить из того, что Вам нужно создать базу данных для обучения, т.е. основной посыл этой статьи направлен на то, чтобы тот, кто хочет создать базу данных в Microsoft SQL Server, после прочтения статьи четко знал, что ему для этого нужно сделать.
Что нужно, для того чтобы создать базу данных в Microsoft SQL Server?
В данном разделе я представлю своего рода этапы создания базы данных в Microsoft SQL Server, т.е. это как раз то, что Вы должны знать и что у Вас должно быть, для того чтобы создать базу данных:
- У Вас должна быть установлена СУБД Microsoft SQL Server. Для обучения идеально подходит бесплатная редакция Microsoft SQL Server Express. Если Вы еще не установили SQL сервер, то вот подробная видео-инструкция, там я показываю, как установить Microsoft SQL Server 2017 в редакции Express;
- У Вас должна быть установлена среда SQL Server Management Studio (SSMS). SSMS – это основной инструмент, с помощью которого осуществляется разработка баз данных в Microsoft SQL Server. Эта среда бесплатная, если ее у Вас нет, то в вышеупомянутой видео-инструкции я также показываю и установку этой среды;
- Спроектировать базу данных. Перед тем как переходить к созданию базы данных, Вы должны ее спроектировать, т.е. определить все сущности, которые Вы будете хранить, определить характеристики, которыми они будут обладать, а также определить все правила и ограничения, применяемые к данным, в процессе их добавления, хранения и изменения. Иными словами, Вы должны определиться со структурой БД, какие таблицы она будет содержать, какие отношения будут между таблицами, какие столбцы будет содержать каждая из таблиц. В нашем случае, т.е. при обучении, этот этап будет скорей формальным, так как правильно спроектировать БД начинающий не сможет. Но начинающий должен знать, что переходить к созданию базы данных без предварительного проектирования нельзя, так как реализовать БД, не имея четкого представления, как эта БД должна выглядеть в конечном итоге, скорей всего не получится;
- Создать пустую базу данных. В среде SQL Server Management Studio создать базу данных можно двумя способами: первый — с помощью графического интерфейса, второй — с помощью языка T-SQL;
- Создать таблицы в базе данных. К этому этапу у Вас уже будет база данных, но она будет пустая, так как в ней еще нет никаких таблиц. На этом этапе Вам нужно будет создать таблицы и соответствующие ограничения;
- Наполнить БД данными. В базе данных уже есть таблицы, но они пусты, поэтому сейчас уже можно переходить к добавлению данных в таблицы;
- Создать другие объекты базы данных. У Вас уже есть и база данных, и таблицы, и данные, поэтому можно разрабатывать другие объекты БД, такие как: представления, функции, процедуры, триггеры, с помощью которых реализуется бизнес-правила и логика приложения.
Вот это общий план создания базы данных, который Вы должны знать, перед тем как начинать свое знакомство с Microsoft SQL Server и языком T-SQL.
В этой статье мы рассмотрим этап 4, это создание пустой базы данных, будут рассмотрены оба способа создания базы данных: и с помощью графического интерфейса, и с помощью языка T-SQL. Первые три этапа Вы должны уже сделать, т.е. у Вас уже есть установленный SQL Server и среда Management Studio, и примерная структура базы данных, которую Вы хотите реализовать, как я уже сказал, на этапе обучения этот пункт можно пропустить, а в следующих материалах я покажу, как создавать таблицы в Microsoft SQL Server пусть с простой, но с более-менее реальной структурой.
Создание базы данных в SQL Server Management Studio
Первое, что Вам нужно сделать, это запустить среду SQL Server Management Studio и подключиться к SQL серверу.
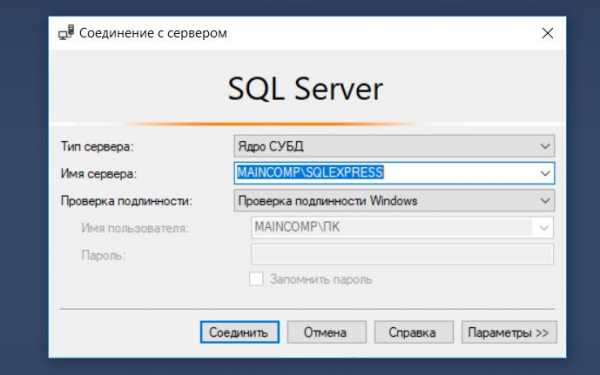
Затем в обозревателе объектов щелкнуть по контейнеру «Базы данных» правой кнопкой мыши и выбрать пункт «Создать базу данных».
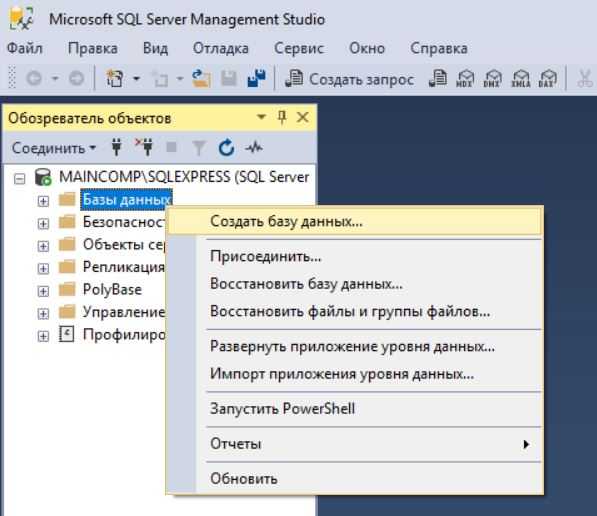
В результате откроется окно «Создание базы данных». Здесь обязательно нужно заполнить только поле «Имя базы данных», остальные параметры настраиваются по необходимости. После того, как Вы ввели имя БД, нажимайте «ОК».
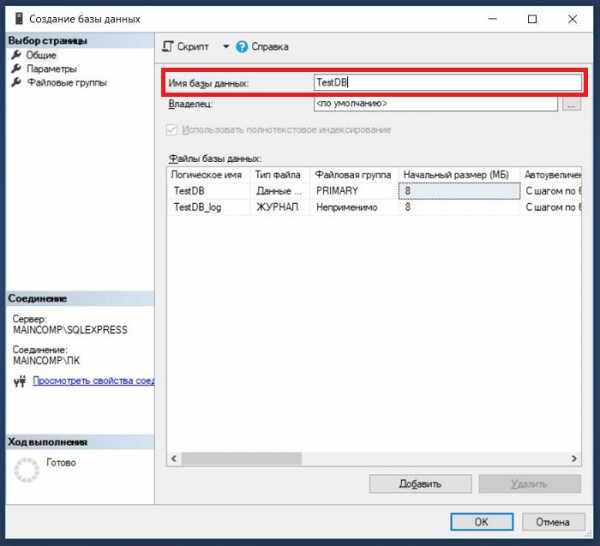
Если БД с таким именем на сервере еще нет, то она будет создана, в обозревателе объектов она сразу отобразится.
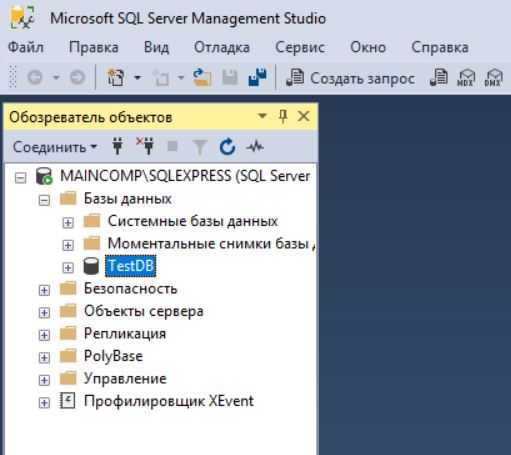
Как видите, база данных создана, и в этом нет ничего сложного.
Создание базы данных на T-SQL (CREATE DATABASE)
Процесс создания базы данных на языке T-SQL, наверное, еще проще, так как для того чтобы создать БД с настройками по умолчанию (как мы это сделали чуть выше), необходимо написать всего три слова в редакторе SQL запросов – инструкцию CREATE DATABASE и название БД.
Сначала открываем редактор SQL запросов, для этого щелкаем на кнопку «Создать запрос» на панели инструментов.
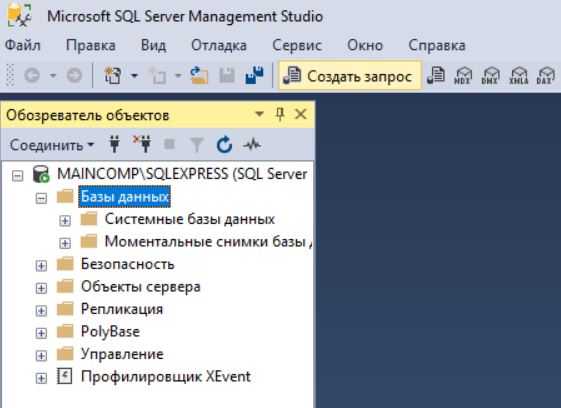
Затем вводим следующую инструкцию, и запускаем ее на выполнение, кнопка «Выполнить».
CREATE DATABASE TestDB;
Где CREATE – это команда языка T-SQL для создания объектов на SQL сервере, командой DATABASE мы указываем, что хотим создать базу данных, а TestDB — это имя новой базы данных.
Конечно же, на данном этапе многие не знают ни Microsoft SQL Server, ни языка T-SQL, многие, наверное, как раз и создают базу данных для того, чтобы начать знакомиться с этой СУБД и начать изучать язык T-SQL. Поэтому чтобы Вам легче было это делать, советую почитать книгу «Путь программиста T-SQL» — это самоучитель по языку Transact-SQL для начинающих, в которой я подробно рассказываю как про основные конструкции, так и про продвинутые конструкции языка T-SQL, и последовательно перехожу от простого к сложному.
С помощью инструкции CREATE DATABASE можно задать абсолютно все параметры, которые отображались у нас в графическом интерфейсе SSMS. Например, если бы мы заменили вышеуказанную инструкцию следующей, то у нас база данных создалась бы в каталоге DataBases на диске D.
--Создание БД TestDB
CREATE DATABASE TestDB
ON PRIMARY --Первичный файл
(
NAME = N'TestDB', --Логическое имя файла БД
FILENAME = N'D:\DataBases\TestDB.mdf' --Имя и местоположение файла БД
)
LOG ON --Явно указываем файлы журналов
(
NAME = N'TestDB_log', --Логическое имя файла журнала
FILENAME = N'D:\DataBases\TestDB_log.ldf' --Имя и местоположение файла журнала
)
GO

Удаление базы данных в Microsoft SQL Server
В случае необходимости можно удалить базу данных. В реальности, конечно же, такое редко будет требоваться, но в процессе обучения, может быть, и часто. Это можно сделать также, как с помощью графического интерфейса, так и с помощью языка T-SQL.
В случае с графическим интерфейсом необходимо в обозревателе объектов щелкнуть правой кнопкой мыши по нужной базе данных и выбрать пункт
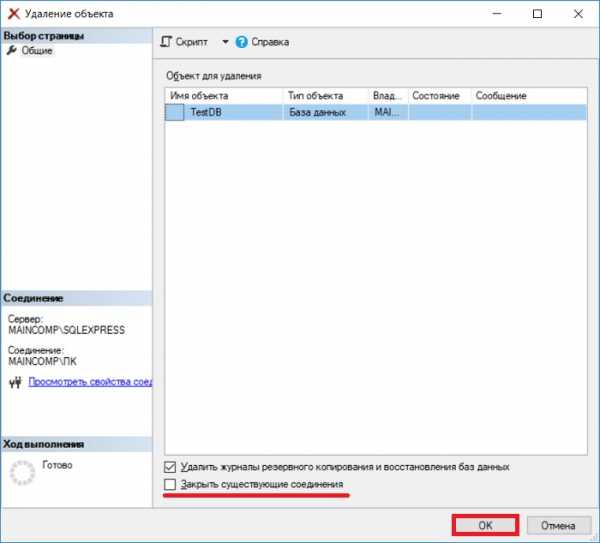
Примечание! Удалить базу данных возможно, только если к ней нет никаких подключений, т.е. в ней никто не работает, даже Ваш собственный контекст подключения в SSMS должен быть настроен на другую БД (например, с помощью команды USE). Поэтому предварительно перед удалением необходимо попросить всех завершить сеансы работы с БД, или в случае с тестовыми базами данных принудительно закрыть все соединения.
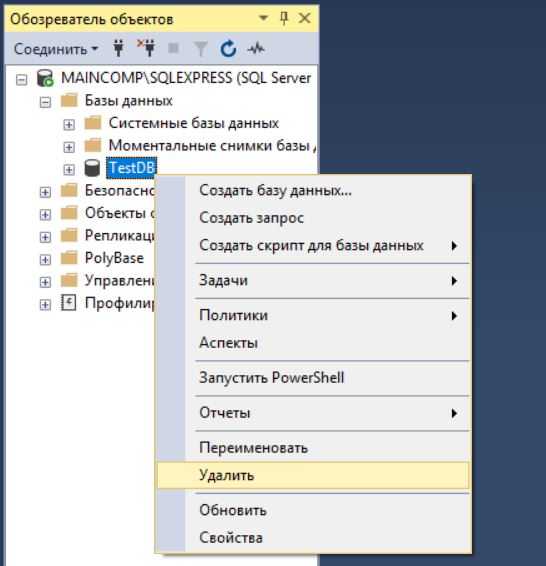
В окне «Удаление объекта» нажимаем «ОК». Для принудительного закрытия существующих подключений к БД можете поставить галочку
В случае с T-SQL, для удаления базы данных достаточно написать следующую инструкцию (в БД также никто не должен работать).
DROP DATABASE TestDB;
Где DROP DATABASE — это инструкция для удаления базы данных, TestDB – имя базы данных. Иными словами, командой DROP объекты на SQL сервере удаляются.
Видео-урок по созданию базы данных в Microsoft SQL Server
На этом наш сегодняшний урок закончен, надеюсь, материал был Вам интересен и полезен, в следующем материале я расскажу про то, как создавать таблицы в Microsoft SQL Server, удачи Вам, пока!
info-comp.ru
SQL или NoSQL — вот в чём вопрос / RUVDS.com corporate blog / Habr
Все мы знаем, что в мире технологий баз данных существует два основных направления: SQL и NoSQL, реляционные и нереляционные базы данных. Различия между ними заключаются в том, как они спроектированы, какие типы данных поддерживают, как хранят информацию.Реляционные БД хранят структурированные данные, которые обычно представляют объекты реального мира. Скажем, это могут быть сведения о человеке, или о содержимом корзины для товаров в магазине, сгруппированные в таблицах, формат которых задан на этапе проектирования хранилища.
Нереляционные БД устроены иначе. Например, документо-ориентированные базы хранят информацию в виде иерархических структур данных. Речь может идти об объектах с произвольным набором атрибутов. То, что в реляционной БД будет разбито на несколько взаимосвязанных таблиц, в нереляционной может храниться в виде целостной сущности.
Внутреннее устройство различных систем управления базами данных влияет на особенности работы с ними. Например, нереляционные базы лучше поддаются масштабированию.

Какую технологию выбрать? Ответ на этот вопрос зависит от особенностей проекта, о котором идёт речь.
О выборе SQL-баз данных
Не существует баз данных, которые подойдут абсолютно всем. Именно поэтому многие компании используют и реляционные, и нереляционные БД для решения различных задач. Хотя NoSQL-базы стали популярными благодаря быстродействию и хорошей масштабируемости, в некоторых ситуациях предпочтительными могут оказаться структурированные SQL-хранилища. Вот две причины, которые могут послужить поводом для выбора SQL-базы:
- Необходимость соответствия базы данных требованиям ACID (Atomicity, Consistency, Isolation, Durability — атомарность, непротиворечивость, изолированность, долговечность). Это позволяет уменьшить вероятность неожиданного поведения системы и обеспечить целостность базы данных. Достигается подобное путём жёсткого определения того, как именно транзакции взаимодействуют с базой данных. Это отличается от подхода, используемого в NoSQL-базах, которые ставят во главу угла гибкость и скорость, а не 100% целостность данных.
- Данные, с которыми вы работаете, структурированы, при этом структура не подвержена частым изменением. Если ваша организация не находится в стадии экспоненциального роста, вероятно, не найдётся убедительных причин использовать БД, которая позволяет достаточно вольно обращаться с типами данных и нацелена на обработку огромных объёмов информации.
О выборе NoSQL-баз данных
Если есть подозрения, что база данных может стать узким местом некоего проекта, основанного на работе с большими объёмами информации, стоит посмотреть в сторону NoSQL-баз, которые позволяют то, чего не умеют реляционные БД.
Вот возможности, которые стали причиной популярности таких NoSQL баз данных, как MongoDB, CouchDB, Cassandra, HBase:
- Хранение больших объёмов неструктурированной информации. База данных NoSQL не накладывает ограничений на типы хранимых данных. Более того, при необходимости в процессе работы можно добавлять новые типы данных.
- Использование облачных вычислений и хранилищ. Облачные хранилища — отличное решение, но они требуют, чтобы данные можно было легко распределить между несколькими серверами для обеспечения масштабирования. Использование, для тестирования и разработки, локального оборудования, а затем перенос системы в облако, где она и работает — это именно то, для чего созданы NoSQL базы данных.
- Быстрая разработка. Если вы разрабатываете систему, используя agile-методы, применение реляционной БД способно замедлить работу. NoSQL базы данных не нуждаются в том же объёме подготовительных действий, которые обычно нужны для реляционных баз.
В следующем разделе рассмотрим некоторые различия между технологиями SQL и NoSQL. А именно, сначала взглянем на простой пример, показывающий фундаментальное различие двух подходов к организации баз данных, потом поговорим о масштабируемости и индексации данных. А в итоге остановимся на примере большой CRM-системы, нуждающейся в высокой производительности хранилища данных.
SQL и NoSQL
Начнём с некоторых ключевых концепций реляционных и нереляционных баз данных. Ниже показана база данных, содержащая сведения о взаимоотношениях людей. Вариант a — это бессхемная структура, построенная в виде графа, характерная для NoSQL-решений. Вариант b показывает, как те же данные можно представить в структурированном виде, типичном для SQL.
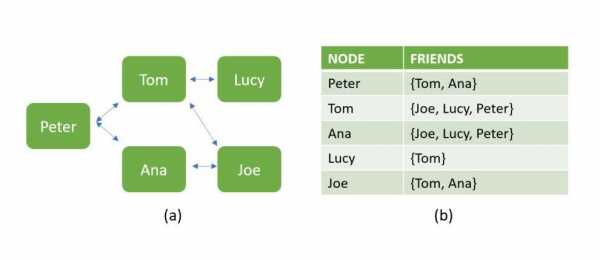
Два варианта представления данных
Бессхемность означает, что два документа в структуре данных NoSQL не должны иметь одинаковые поля и могут хранить данные разных типов. Вот, например, массив объектов, набор полей которых не совпадает.
var cars = [
{ Model: "BMW", Color: "Red", Manufactured: 2016 },
{ Model: "Mercedes", Type: "Coupe", Color: "Black", Manufactured: "1-1-2017" }
];При реляционном подходе данные надо хранить в заранее спроектированной структуре, из которой эти данные потом можно извлекать. Например, используя оператор
JOINпри выборке из двух таблиц:SELECT Orders.OrderID, Customers.Name, Orders.Date
FROM Orders
INNER JOIN Customers
ON Orders.CustID = Customers.CustIDКак более продвинутый пример, для демонстрации того, когда SQL предпочтительнее NoSQL, рассмотрим особенности применения в NoSQL-базах алгоритмов уплотнения. Проблема заключается в том, что в некоторых NoSQL-базах (например, в CouchDB и HBase) постоянно приходится формировать так называемые
sstables — строковые таблицы в формате ключ-значение, отсортированные по ключу. В такие таблицы, которые сохраняются на диск, данные попадают из таблиц, хранящихся в памяти, при их переполнении и в других ситуациях. При интенсивной работе с базой создание таблиц, со временем, приводит к тому, что подсистема ввода-вывода устройства хранения данных становится узким местом для операций чтения данных. Как результат, чтение в NoSQL-базе происходит медленнее, чем запись, что сводит на нет одно из главных преимуществ нереляционных баз данных. Именно для того, чтобы уменьшить этот эффект, системы NoSQL используют, в фоновом режиме, алгоритмы уплотнения данных, пытаясь объединить множество таблиц в одну. Но и сама по себе эта операция весьма ресурсоёмка, система работает под повышенной нагрузкой.Масштабируемость
Одно из основных различий рассматриваемых технологий заключается в том, что NoSQL-базы лучше поддаются масштабированию. Например, в MongoDB имеется встроенная поддержка репликации и шардинга (горизонтального разделения данных) для обеспечения масштабируемости. Хотя масштабирование поддерживается и в SQL-базах, это требует гораздо больших затрат человеческих и аппаратных ресурсов.
| Тип хранилища данных |
Сценарий использования |
Пример |
Рекомендации |
| Хранилище типа ключ-значение |
Подходит для простых приложений, с одним типом объектов, в ситуациях, когда поиск объектов выполняют лишь по одному атрибуту. |
Интерактивное обновление домашней страницы пользователя в Facebook. |
Рекомендовано знакомство с технологией memcached. Если приходится искать объекты по нескольким атрибутам, рассмотрите вариант перехода к хранилищу, ориентированному на документы. |
| Хранилище, ориентированное на документы |
Подходит для хранения объектов различных типов. |
Транспортное приложение, оперирующее данными о водителях и автомобилях, работая с которым надо искать объекты по разным полям, например — имя или дата рождения водителя, номер прав, транспортное средство, которым он владеет. |
Подходит для приложений, в ходе работы с которыми допускается реализация принципа «согласованность в конечном счёте» с ограниченными атомарностью и изоляцией. Рекомендуется применять механизм кворумного чтения для обеспечения своевременной атомарной непротиворечивости. |
| Система хранения данных с расширяемыми записями |
Более высокая пропускная способность и лучшие возможности параллельной обработки данных ценой слегка более высокой сложности, нежели у хранилищ, ориентированных на документы. |
Приложения, похожие на eBay. Вертикальное и горизонтальное разделение данных для хранения информации клиентов. |
Для упрощения разделения данных используются HBase или Hypertable. |
| Масштабируемая RDBMS |
Использование семантики ACID освобождает программистов от необходимости работать на достаточно низком уровне, а именно, отвечать за блокировки и непротиворечивость данных, обрабатывать устаревшие данные, коллизии. |
Приложения, которым не требуются обновления или слияния данных, охватывающие множество узлов. |
Стоит обратить внимание на такие системы, как MySQL Cluster, VoltDB, Clustrix, ориентированные на улучшенное масштабирование. |
Более подробное сравнение SQL и NoSQL можно найти в этом материале. Вот его основные положения. А именно, были проведены испытания трёх основных характеристик систем: параллельная обработка данных, работа с хранилищами информации, репликация данных. Возможности параллельной обработки оценивались путём анализа механизмов блокировки, управления параллельным доступом на основе многоверсионности, и ACID. Тестирование хранилищ охватывало и физические носители, и хранилища использующие оперативную память. Репликацию испытывали в синхронном и асинхронном режимах.
Используя данные, полученные в ходе испытаний, авторы делают выводы о том, что SQL-базы с возможностью кластеризации показали многообещающие результаты производительности в расчёте на один узел, и, кроме того, обладают способностью масштабируемости, что даёт системам RDBMS преимущество перед NoSQL за счёт полного соответствия принципам ACID.
Индексация
В системах RDBMS индексация используется для ускорения операций извлечения данных из баз. Отсутствие индекса означает, что таблица должна быть просмотрена целиком для того, чтобы выполнить запрос на чтение.
И в SQL, и в NoSQL-базах индексы служат одной и той же цели — ускорить и оптимизировать извлечение данных. Но то, как именно они работают — различается из-за разных архитектур баз данных и особенностей хранения информации в базе. В то время, как SQL-индексы представлены в виде B-деревьев, которые отражают иерархическую структуру реляционных данных, в NoSQL базах данных они указывают на документы, или на части документов, между которыми, в основном, нет никаких отношений. Вот подробный материал на эту тему.
CRM-системы
CRM-приложения — это один из лучших примеров систем, для которых характерны огромные объёмы ежедневно обрабатываемых данных и очень большое количество транзакций. Все разработчики таких приложений используют и SQL, и NoSQL базы данных. И, хотя большая часть данных транзакций всё ещё хранится в SQL-базах, применение находят общедоступные системы класса DBaaS (data-base-as-a-service, база данных как сервис), наподобие AWS DynamoDB и Azure DocumentDB, в результате, серьёзная нагрузка по обработке данных может быть перенесена в облачные NoSQL-базы.
В то время, как использование подобных служб освобождает разработчика от решения задач по обслуживанию хранилищ, это, кроме того, область, где NoSQL базы применяются для того, для чего они, в основном, и были созданы, например, для глубинного анализа данных. Объёмы информации, хранимой в огромных CRM-системах финансовых и телекоммуникационных компаний, было бы практически невозможно проанализировать, используя инструменты вроде SAS или R. Это потребовало бы огромных аппаратных ресурсов.
Главное преимущество таких систем — использование неструктурированных данных, похожих на документы. Такие данные могут подаваться на вход статистических моделей, которые дают компаниям возможность выполнять различные виды анализа. CRM-приложения, кроме того, являются весьма удачным примером, в котором две системы баз данных выступают не конкурентами, а существуют в гармонии, играя каждая свою роль в большой архитектуре управления данными.
Итоги
Занимаясь поиском системы управления базами данных, можно выбрать одну технологию, а позже, уточнив требования, переключиться на что-то другое. Однако, разумное планирование позволит сэкономить немало времени и средств.
Вот признаки проектов, для которых идеально подойдут SQL-базы:
- Имеются логические требования к данным, которые могут быть определены заранее.
- Очень важна целостность данных.
- Нужна основанная на устоявшихся стандартах, хорошо зарекомендовавшая себя технология, используя которую можно рассчитывать на большой опыт разработчиков и техническую поддержку.
А вот свойства проектов, для которых подойдёт что-то из сферы NoSQL:
- Требования к данным нечёткие, неопределённые, или развивающиеся с развитием проекта.
- Цель проекта может корректироваться со временем, при этом важна возможность немедленного начала разработки.
- Одни из основных требований к базе данных — скорость обработки данных и масштабируемость.
В итоге хочется сказать, что в современном мире нет противостояния между реляционными и нереляционными базами данных. Вместо этого стоит говорить об их совместном использовании для решения задач, на которых та или иная технология показывает себя лучше всего. Кроме того, всё сильнее наблюдается интеграция этих технологий друг в друга. Например, Microsoft, Oracle и Teradata сейчас предлагают некоторые формы интеграции с Hadoop для подключения аналитических инструментов, основанных на SQL, к миру неструктурированных больших данных.
Уважаемые читатели, а вам приходилось выбирать системы управления базами данных для собственных проектов? Если да — поделитесь пожалуйста опытом, расскажите, что и почему вы в итоге выбрали.
habr.com
Взаимодействие R с базами данных на примере Microsoft SQL Server и других СУБД / Habr
Поскольку львиная доля бизнес информации храниться в базах данных. На каком бы языке программирования вы не писали, вам придётся производить различные действия с ними.
В этой статье я расскажу о двух интерфейса для работы с базами данных в R. Большая часть примеров демонстрируют работу с Microsoft SQL Server, тем не менее все примеры кода будут работать и с другими базами данных, такими как: MySQL, PostgreSQL, SQLite, ClickHouse, Google BigQuery и др.

Для того, что бы повторить все описанные в статье примеры работы с СУБД вам потребуется перечисленное ниже, бесплатное программное обеспечение:
- Язык R;
- Среда разработки RStudio;
- Система Управления Базами Данных, на выбор:
3.1. Microsoft SQL Server
3.2. MySQL
3.3. PostgreSQL
Пакет DBI является наиболее популярным и удобным способом взаимодействия с базами данных в R.
DBI предоставляет вам набор функций, с помощью которых вы можете управлять базами данных. Но для подключения к базам данных требуется установка дополнительных пакетов, которые являются драйверами к различным системам управления базами данных (СУБД).
Список основных функций DBI
dbConnect— подключение к базе данных;dbWriteTable— запись таблицы в базу данных;dbReadTable— загрузка таблицы из базы данных;dbGetQuery— загрузка результата выполнения запроса;dbSendQuery— отправка запроса к базе данных;dbFetch— извлечение элементов из набора результатов;dbExecute— выполнение запросов на обновление / удаление / вставку данных в таблицы;dbGetInfo— запрос информацию о результате запроса или подключении;dbListFields— запрос списка полей таблицы;dbListTables— запрос списка таблиц базы данных;dbExistsTable— проверка наличия таблицы в базе данных;dbRemoveTable— удаление таблицы из базы данных;dbDisconnect— разрыв отсоединения с базы данных.
Подключение к базам данных
Для взаимодействия с базами данных предварительно к ним необходимо подключиться. В зависимости от СУБД с которой вы планируете работать вам потребуется дополнительный пакет, ниже перечень наиболее часто используемых.
odbc— Драйвер для подключения через ODBC интерфейс;RSQLite— Драйвер к SQLite;RMySQL/RMariaDB— Драйвер к СУБД MySQL и MariaDB;RPostgreSQL— Драйвер к PosrtgreSQL;bigrquery— Драйвер к Google BigQuery;RClickhouse/clickhouse— Драйвер к ClickHouse;RMSSQL— Драйвер к Microsoft SQL Server (MS SQL), на момент написания статьи присутствует только на GitHub.
Пакет DBI поставляется с базовой комплектацией R, но пакеты, которые являются драйверами к базам данных необходимо устанавливать с помощью команды install.packages("название драйвера").
Для установки пакетов с GitHub вам также понадобится дополнительный пакет — devtools. Например пакет RMSSQL на данный момент не опубликован в основном репозитории R пакетов, для его установки воспользуйтесь следующим кодом:
install.packages("devtools")
devtools::install_github("bescoto/RMSSQL")Пример подключения к Microsoft SQL Server с помощью пакета odbc
Перед использованием любого пакета в R сессии его предварительно необходимо подключить с помощью функции library("название пакета").
Я неспроста выбрал Microsoft SQL Server в качестве основной СУБД на которой будет приведена большая часть примеров этой статьи. Дело в том, что это достаточно популярная база данных, но при этом она до сих пор не имеет драйвера для подключения из R опубликованного на CRAN.
Но к счастью SQL Server, как и практически любая другая база имеет ODBC (англ. Open Database Connectivity) интерфейс для подключения. Для подключения к СУБД через ODBC интерфейс в R есть ряд пакетов. Первым мы рассмотрим подключение через пакет odbc.
Простое подключение к БД через odbc интерфейс
# установка пакета odbc
install.packages("odbc")
# подключение пакета
library(odbc)
# подключение к MS SQL
con <- dbConnect(drv = odbc(),
Driver = "SQL Server",
Server = "localhost",
Database = "mybase",
UID = "my_username",
PWD = "my_password",
Port = 1433)В функцию dbConnect() вам необходимо первым аргументом drv передать функцию, которая является драйвером для подключения к СУБД (odbc()). Такие функции обычно называются также, как и СУБД, и поставляются с пакетами которые являются драйверами для DBI.
Далее необходимо перечислить параметры подключения. Для подключения к MS SQL через ODBC необходимо задать следующие параметры:
- Driver — Название ODBC драйвера;
- Server — IP адрес SQL сервера;
- Database — Название базы данных к которой необходимо подключиться;
- UID — Имя пользователя базы данных;
- PWD — Пароль;
- Port — Порт для подключения, у SQL Server по умолчанию порт 1433.
ODBC драйвер для подключения к Microsoft SQL Server включен в комплектацию Windows, но он может иметь и другое название. Посмотреть список установленных драйверов можно в Администраторе источника данных ODBC. Запустить администратор источника данных в Windows 10 можно по следующему пути:
- 32-разрядной версии:
%systemdrive%\Windows\SysWoW64\Odbcad32.exe - 64-разрядной версии:
%systemdrive%\Windows\System32\Odbcad32.exe
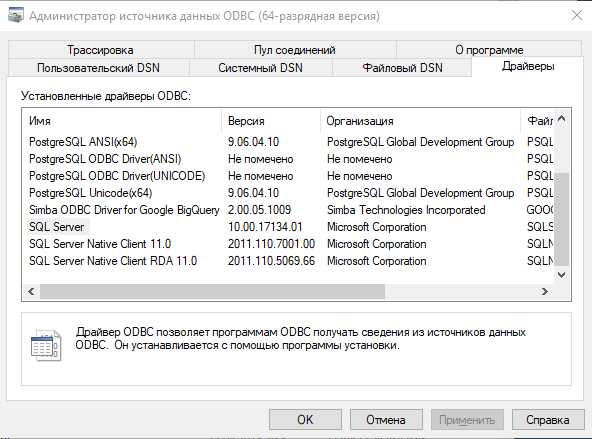
Получить список всех установленных на вашем ПК драйверов также можно с помощью функции odbcListDrivers().
name attribute value
<chr> <chr> <chr>
1 SQL Server APILevel 2
2 SQL Server ConnectFunctions YYY
3 SQL Server CPTimeout 60
4 SQL Server DriverODBCVer 03.50
5 SQL Server FileUsage 0
6 SQL Server SQLLevel 1
7 SQL Server UsageCount 1
8 MySQL ODBC 5.3 ANSI Driver UsageCount 1
9 MySQL ODBC 5.3 Unicode Driver UsageCount 1
10 Simba ODBC Driver for Google BigQuery Description Simba ODBC Driver for Google BigQuery2.0
# ... with 50 more rowsСкачать ODBC драйвера для других СУБД можно по следующим ссылкам:
Для различных СУБД название параметров для подключения могут быть другими, например:
- PostgreSQL / MySQL / MariaDB — user, password, host, port, dbname;
- GoogleBigQuery — project, dataset;
- ClickHouse — user, password, db, port, host;
С помощью администратора источника данных ODBC вы можете запустить мастер для создания ODBC источника данных. Для этого достаточно открыть администратор, перейти на вкладку «Пользовательский DSN» и нажать кнопку «Добавить…».
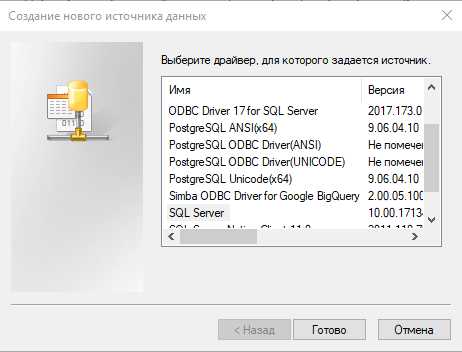
При создании источника данных используя администратор вы присваиваете ему имя, DSN (Data Source Name).
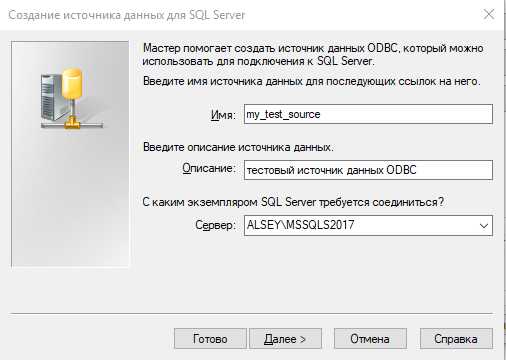
В примере выше мы создали источник данных с DSN «my_test_source». Теперь мы можем использовать этот источник для подключения к Microsoft SQL Server, и не указывать в коде остальные параметры подключения.
Подключение к БД через odbc интерфейс с использованием DSN
# подключение через DSN
con <- dbConnect(odbc(),
DSN = "my_test_source",
UID = "my_username",
PWD = "my_password")Посмотреть имена всех созданных на вашем ПК источников данных ODBC можно с помощью функции odbcListDataSources().
name description
<chr> <chr>
1 BQ Simba ODBC Driver for Google BigQuery
2 BQ_main Simba ODBC Driver for Google BigQuery
3 BQ ODBC Simba ODBC Driver for Google BigQuery
4 OLX Simba ODBC Driver for Google BigQuery
5 Multicharts Simba ODBC Driver for Google BigQuery
6 PostgreSQL35W PostgreSQL Unicode(x64)
7 hillel_bq Simba ODBC Driver for Google BigQuery
8 blog_bq Simba ODBC Driver for Google BigQuery
9 MyClientMSSQL SQL Server
10 local_mssql SQL Server
11 MSSQL_localhost SQL Server
12 my_test_source SQL Server
13 Google BigQuery Simba ODBC Driver for Google BigQueryПример подключения к Microsoft SQL Server с помощью пакета RMSSQL
RMSSQL не опубликован на CRAN, поэтому установить его можно с GitHub с помощью пакета devtools.
install.packages("devtools")
devtools::install_github("bescoto/RMSSQL")Пример подключения с помощью DBI драйвера RMSSQL
# подключение требуемых пакетов
library(RJDBC)
library(RMSSQL)
library(DBI)
# через RMSSQL
con <- dbConnect(MSSQLServer(),
host = 'localhost',
user = 'my_username',
password = 'my_password',
dbname = "mybase")В большинстве случаев, используя для работы с базами данных пакет DBI, вы будете подключаться именно таким способом. Т.е. устанавливать один из требуемых пакетов — драйверов, передавая в качестве значения аргумента drv функции dbConnect, функцию — драйвер для подключения к нужной вам СУБД.
Пример подключения к MySQL, PostgreSQL, SQLite и BigQuery
# подключение к MySQL
library(RMySQL)
con <- dbConnect(MySQL(),
host = 'localhost',
user = 'my_username',
password = 'my_password',
dbname = "mybase",
host = "localhost")
# подключение к PostrgeSQL
library(RPostgreSQL)
con <- dbConnect(PostgreSQL(),
host = 'localhost',
user = 'my_username',
password = 'my_password',
dbname = "mybase",
host = "localhost")
# подключение к PostrgeSQL
library(RPostgreSQL)
con <- dbConnect(PostgreSQL(),
host = 'localhost',
user = 'my_username',
password = 'my_password',
dbname = "mybase",
host = "localhost")
# Подключение к SQLite
library(RSQLite)
# connection or create base
con <- dbConnect(drv = SQLite(),
"localhost.db")
# Подключение к Google BigQuery
library(bigrquery)
con <- dbConnect(drv = bigquery(),
project = "my_proj_id",
dataset = "dataset_name")Как скрыть пароли от базы данных в R скриптах
Выше я привёл несколько примеров которые можно использовать для подключения к любой базе данных но в них есть один минус, в таком виде все доступы к базам данных, включая пароли, хранятся в виде текста в самих скриптах.
Если все ваши скрипты развёрнуты и запускаются исключительно локально на вашем ПК, и он при этом защищён паролем, то скорее всего никакой проблемы в этом не будет. Но если вы совместно с кем то работаете на одном сервере то хранение паролей от баз данных в тексте ваших скриптов не лучшее решение.
В любой операционной системе есть утилита для управления учётными данными. Например, в Windows это диспетчер учетных данных (Credential Manager). Добавить в это хранилище пароль который вы используете для подключения к базе данных можно через пакет keyring. Пакет кроссплатформенный и приведённый пример будет работать в любой операционной системе, как минимум на Windows, MacOS и Linux.
# install.packages("keyring")
# подключаем пакет
library(keyring)
library(RMSSQL)
# создаём ключ
key_set_with_value(service = "mssql",
username = "my_username",
password = "my_password")
# подключение через RMSSQL
con <- dbConnect(MSSQLServer(),
host = 'localhost',
user = 'my_username',
password = key_get("mssql", "my_username"),
dbname = "mybase")Т.е. с помощью функции key_set_with_value() вы добавляете пароль в хранилище учётных данных, а с помощью key_get() запрашиваете его, при этом запросить пароль может только тот пользователь который добавил его в хранилище. С помощью keyring можно хранить пароли не только от баз данных, но и от любых сервисов, а так же авторизационные токены при работе с API.
Создание таблиц и запись в базу данных
Запись в базу данных осуществляется функцией dbWriteTable().
Аргументы функции dbWriteTable():
Жирным шрифтом выделены обязательные аргументы, курсивом — не обязательные
- conn — объект подключения к СУБД, созданный с помощью функции
dbConnect; - name — название таблицы в СУБД, в которую будут записаны данные;
- value — таблица (объект класса data.frame / data.table / tibble_frame) в R, данные из которого будут записаны в СУБД;
- row.names — Добавляет в таблицу столбец row_names, с номерами строк, по умолчанию имеет значение FALSE.
- overwrite — Перезаписывать таблицу, если таблица с именем указанным в аргументе name уже присутвует в СУБД, по умолчанию имеет значение FALSE;
- append — Дописывать данные, если таблица с именем указанным в аргументе name уже присутвует в СУБД, по умолчанию имеет значение FALSE;
- field.types — Принимает на вход именованный вектор, и задаёт тип данных в каждом поле при записи в СУБД, по умолчанию имеет значение NULL;
- temporary — Позволяет создавать временные таблицы в СУБД, которые будут доступны до момента разрыва соединения с базой, по умолчанию имеет значение FALSE.
Пример записи данных в СУБД через DBI
# подключаем пакет
library(odbc)
# соединяемся с базой через DSN
con <- dbConnect(odbc(),
DSN = "my_test_source",
UID = "my_username",
PWD = "my_password")
# создаём в базе таблицу iris, и записываем в неё данные из встроенного в R набора iris
dbWriteTable(conn = con,
name = "iris",
value = iris)
# разрыв соединения с БД
dbDisconnect(con)Для просмотра таблиц в базе данных служит функция dbListTables(), для удаления таблиц dbRemoveTable()
Пример запроса списка таблиц и удаления таблицы из СУБД
# подключение пакета
library(odbc)
# подключение к БД
con <- dbConnect(odbc(),
DSN = "my_test_source",
UID = "my_username",
PWD = "my_password")
# просмотр списка таблиц
dbListTables(con)
# удаление таблицы iris
dbRemoveTable(con, "iris")
# разрыв соединения с БД
dbDisconnect(con)Чтение данных из СУБД
С помощью DBI вы можете запрашивать либо таблицы целиком, либо результат выполнения вашего SQL запроса. Для выполнения этих операций используются функции dbReadTable() и dbGetQuery().
Пример запроса таблицы iris из СУБД
# подключение пакета
library(odbc)
# подключение к БД
con <- dbConnect(odbc(),
DSN = "my_test_source",
UID = "my_username",
PWD = "my_password")
# загружзка табоицы iris в объект iris
dbiris <- dbReadTable(con, "iris")
# разрыв соединения с БД
dbDisconnect(con)Пример загрузки результата выполнения SQL из СУБД
# подключение пакета
library(odbc)
# подключение к БД
con <- dbConnect(odbc(),
DSN = "my_test_source",
UID = "my_username",
PWD = "my_password")
# Запрашиваем результат выполнения запроса
setosa <- dbGetQuery(con,
"SELECT * FROM iris WHERE Species = 'setosa'")
# разрыв соединения с БД
dbDisconnect(con)Манипулирование данными в СУБД (DML)
Рассмотренная выше функция dbGetQuery() используется исключительно для запросов на выборку данных (SELECT).
Для операций манипуляций с данными, таких как UPDATE, INSERT, DELETE, в DBI существует функция dbExecute().
Пример кода для манипуляции данными в СУБД
# подключение пакета
library(odbc)
# подключение к БД
con <- dbConnect(odbc(),
DSN = "my_test_source",
UID = "my_username",
PWD = "my_password")
# Вставка строк (INSERT)
dbExecute(con,
"INSERT INTO iris (row_names, [Sepal.Length], [Sepal.Width], [Petal.Length], [Petal.Width], [Species])
VALUES (51, 5.0, 3.3, 1.7, 0.3, 'new_values')")
# Обновление данных (UPDATE)
dbExecute(con,
"UPDATE iris
SET [Species] = 'old_value'
WHERE row_names = 51")
# Удаление строк из таблицы (DELETE)
dbExecute(con, "DELETE FROM iris WHERE row_names = 51")
# разрыв соединения с БД
dbDisconnect(con)Транзакции в СУБД
Транзакция это последовательное выполнение операций чтения и записи. Окончанием транзакции может быть либо сохранение изменений (фиксация, commit) либо отмена изменений (откат, rollback). Применительно к БД транзакция это нескольких запросов, которые трактуются как единый запрос.
Цитата из статьи «Транзакции и механизмы их контроля»
Транзакция инкапсулирует несколько операторов SQL в элементарную единицу. В DBI начало транзакции инициируется с помощью dbBegin() и далее либо подтверждается с помощью dbCommit(), либо отменяется с помощью dbRollback(). В любом случае СУБД гарантирует, что: либо все, либо ни одно из утверждений не будут применены к данным.
Для примера, давайте в ходе транзакции добавим в таблицу iris 51 строку, далее изменим значение Sepal.Width в 5 строке, и удалим 43 строку из таблицы.
Пример кода проведения транзакции
# подключение пакета
library(odbc)
# подключение к БД
con <- dbConnect(odbc(),
DSN = "my_test_source",
UID = "my_username",
PWD = "my_password")
# запрашиваем значения до внесения изменений
dbGetQuery(con, "SELECT * FROM iris WHERE row_names IN (5, 43, 51)")
# row_names Sepal.Length Sepal.Width Petal.Length Petal.Width Species
# 1 5 5.0 3.6 1.4 0.2 setosa
# 2 43 4.4 3.2 1.3 0.2 setosa
# 3 51 7.0 3.2 4.7 1.4 versicolor
# инициируем начало транзакции
dbBegin(con)
# добавляе строку
dbExecute(con,
"INSERT INTO iris
(row_names, [Sepal.Length], [Sepal.Width], [Petal.Length], [Petal.Width], [Species])
VALUES (51, 5.0, 3.3, 1.7, 0.3, 'new_values')")
# меняем строку
dbExecute(con,
"UPDATE iris
SET [Sepal.Width] = 8
WHERE row_names = 5")
# удаляем строку 43
dbExecute(con, "DELETE FROM iris WHERE row_names = 43")
# подтверждаем транзакцию
dbCommit(con)
# запрашиваем значения после внесения изменений
dbGetQuery(con, "SELECT * FROM iris WHERE row_names IN (5, 43, 51)")
# row_names Sepal.Length Sepal.Width Petal.Length Petal.Width Species
# 1 5 5 8.0 1.4 0.2 setosa
# 2 51 7 3.2 4.7 1.4 versicolor
# 3 51 5 3.3 1.7 0.3 new_valuesПример кода отмены транзакции
# подключение пакета
library(odbc)
# подключение к БД
con <- dbConnect(odbc(),
DSN = "my_test_source",
UID = "my_username",
PWD = "my_password")
# запрашиваем значения до внесения изменений
dbGetQuery(con, "SELECT * FROM iris WHERE row_names IN (5, 43, 51)")
# row_names Sepal.Length Sepal.Width Petal.Length Petal.Width Species
# 1 5 5.0 3.6 1.4 0.2 setosa
# 2 43 4.4 3.2 1.3 0.2 setosa
# 3 51 7.0 3.2 4.7 1.4 versicolor
# инициируем начало транзакции
dbBegin(con)
# добавляе строку
dbExecute(con,
"INSERT INTO iris
(row_names, [Sepal.Length], [Sepal.Width], [Petal.Length], [Petal.Width], [Species])
VALUES (51, 5.0, 3.3, 1.7, 0.3, 'new_values')")
# меняем строку
dbExecute(con,
"UPDATE iris
SET [Sepal.Width] = 8
WHERE row_names = 5")
# удаляем строку 43
dbExecute(con, "DELETE FROM iris WHERE row_names = 43")
# отменяем транзакцию
dbRollback(con)
# запрашиваем значения после внесения изменений
dbGetQuery(con, "SELECT * FROM iris WHERE row_names IN (5, 43, 51)")
# row_names Sepal.Length Sepal.Width Petal.Length Petal.Width Species
# 1 5 5.0 3.6 1.4 0.2 setosa
# 2 43 4.4 3.2 1.3 0.2 setosa
# 3 51 7.0 3.2 4.7 1.4 versicolorПакет RODBC предоставляет автономный интерфейс для подключения и работы с СУБД через ODBC интерфейс.
RODBC не совместим с DBI, т.е. вы не можете использовать объект подключения созданный с помощью RODBC в функциях предоставляемых пакетом DBI.
Основные функции пакета RODBC
odbcConnect— Подключение к СУБД через DSN;odbcDriverConnect— Подключение к базе через строку подключения;sqlQuery— Отправка запроса в СУБД, и получение результата его выполнения. Поддерживает запросы любого типа: SELECT, UPDATE, INSERT, DELETE.sqlFetch— Получить целиком таблицу из СУБД;sqlTables— Получить список таблиц в базе.sqlSave— Создание новой таблицы в базе данных, или добавление новых данных в уже существующую таблицу;sqlUpdate— Обновление данных в таблице которая уже существует в СУБД;sqlDrop— Удаление таблицы в СУБД;odbcClose— Завершение соединения с СУБД.
Пример работы с RODBC
С моей точки зрения RODBC менее функционален чем DBI, но в нём есть все необходимые функции для работы с СУБД.
Пример взаимодействия с СУБД через RODBC
# подключение пакета
library(RODBC)
# строка подключения
con_string <- odbcDriverConnect(connection = "Driver=SQL Server;Server=localhost;Database=mybase;UID=my_username;PWD=my_password;Port=1433")
# подключение через DSN
con_dsn <- odbcConnect(dsn = "my_test_source",
uid = "my_username",
pwd = "my_password")
# создание таблицы в базе
sqlSave(con_dsn,
dat = iris,
tablename = "iris")
# дописать строки в табдицу iris
sqlSave(con_dsn,
dat = iris,
tablename = "iris",
append = TRUE)
# запрашиваем первые 4 строки
sqlFetch(con_dsn, "iris", rownames = FALSE, max = 4)
# вносим изменение в данные в R
iris[1, 5] <- "virginica"
# обновляем табицу в СУБД
sqlUpdate(con_dsn,
dat = iris,
tablename = "iris")
# запрашиваем первые 4 строки после изменения данных
sqlFetch(con_dsn, "iris", rownames = FALSE, max = 4)
# удаление таблицы
sqlDrop(con_dsn, sqtable = "iris")
# разрыв соеденения с базой
odbcCloseAll()По умолчанию транзакционность в RODBC выключена. Управление транзакциями осуществляется двумя функциями.
odbcSetAutoCommit— Переключение между обычным и транзакционным режимом работы с СУБД;odbcEndTran— Подтверждение или отмена транзакции.
Включение и отключение транзакционного режима осуществляется функцией odbcSetAutoCommit с помощью аргумента autoCommit.
Примре работы в транзакционном режиме в RODBC
# подключение пакета
library(RODBC)
# подключение через DSN
con_dsn <- odbcConnect(dsn = "my_test_source",
uid = "my_username",
pwd = "my_password")
# создание таблицы в базе
sqlSave(con_dsn,
dat = iris,
tablename = "iris")
# включение транзакционного режима
odbcSetAutoCommit(con_dsn, autoCommit = FALSE)
# запрашиваем первые 4 строки
sqlFetch(con_dsn, "iris", rownames = FALSE, max = 4)
# rownames SepalLength SepalWidth PetalLength PetalWidth Species
# 1 1 5.1 3.5 1.4 0.2 setosa
# 2 2 4.9 3.0 1.4 0.2 setosa
# 3 3 4.7 3.2 1.3 0.2 setosa
# 4 4 4.6 3.1 1.5 0.2 setosa
# вносим изменение в данные в R
iris[1, 5] <- "virginica"
# обновляем табицу в СУБД
sqlUpdate(con_dsn,
dat = iris,
tablename = "iris")
# запрашиваем первые 4 строки
sqlFetch(con_dsn, "iris", rownames = FALSE, max = 4)
# rownames SepalLength SepalWidth PetalLength PetalWidth Species
# 1 1 5.1 3.5 1.4 0.2 virginica
# 2 2 4.9 3.0 1.4 0.2 setosa
# 3 3 4.7 3.2 1.3 0.2 setosa
# 4 4 4.6 3.1 1.5 0.2 setosa
# отменяем изменения
odbcEndTran(con_dsn, commit = FALSE)
# запрашиваем первые 4 строки
sqlFetch(con_dsn, "iris", rownames = FALSE, max = 4)
# rownames SepalLength SepalWidth PetalLength PetalWidth Species
# 1 1 5.1 3.5 1.4 0.2 setosa
# 2 2 4.9 3.0 1.4 0.2 setosa
# 3 3 4.7 3.2 1.3 0.2 setosa
# 4 4 4.6 3.1 1.5 0.2 setosa
# обновляем табицу в СУБД
sqlUpdate(con_dsn,
dat = iris,
tablename = "iris")
# применяем изменения
odbcEndTran(con_dsn, commit = TRUE)
# запрашиваем первые 4 строки после изменения данных
sqlFetch(con_dsn, "iris", rownames = FALSE, max = 4)
# rownames SepalLength SepalWidth PetalLength PetalWidth Species
# 1 1 5.1 3.5 1.4 0.2 virginica
# 2 2 4.9 3.0 1.4 0.2 setosa
# 3 3 4.7 3.2 1.3 0.2 setosa
# 4 4 4.6 3.1 1.5 0.2 setosa
# разрыв соеденения с базой
odbcClose(con_dsn)Два описанных в статье метода работы с базами данных на языке R, DBI и RODBC, достаточно универсальны, и будут работать практически с любой СУБД.
Единственная разница в работе между различными СУБД заключается в процессе подключения. Для большинства популярных СУБД существуют отдельные пакеты которые являются драйверами. Для остальных СУБД необходимо настраивать подключение через ODBC интерфейс используя пакеты odbc или RODBC. Все остальные манипуляции, вне зависимости от выбранной вами СУБД, будут неизменны. Исключением является отправка SQL запросов, в зависимости от SQL диалекта который поддерживается СУБД с которой вы работаете.
habr.com
SQL — СУБД Базы данных
Есть много популярных СУБД, доступных для работы. В этом руководстве дается краткий обзор нескольких наиболее популярных СУБД. Это поможет вам сравнить их основные черты.MySQL
MySQL является базой данных SQL с открытым исходным кодом, разработанной шведской компанией MySQL AB. MySQL произносится как “my ess-que-ell,”, в отличие от SQL, произносится как “sequel”. MySQL поддерживает множество различных платформ, включая Microsoft Windows, основных дистрибутивов Linux, UNIX и Mac OS X. MySQL имеет платные и бесплатные версии, в зависимости от его использования (некоммерческих/коммерческих) и функций. MySQL поставляется с очень быстрым, многопоточным, многопользовательским и надежным сервером баз данных SQL.История:
- Разработку вели MySQL Майкл Widenius & David Axmark начиная с 1994 года.
- Первый внутренний релиз 23 мая 1995 года.
- Версия для Windows была выпущена 8 января 1998 года для Windows 95 и NT.
- Версия 3.23: бета с июня 2000 года, релиз производства января 2001.
- Версия 4.0: бета с августа 2002 года, релиз производства марта 2003 года (союзы).
- Версия 4.01: бета с августа 2003 года Джиоти принимает MySQL для отслеживания базы данных.
- Версия 4.1: бета с июня 2004 года, релиз производства октября 2004.
- Версия 5.0: бета с марта 2005 года, релиз производства октября 2005.
- Sun Microsystems приобрела MySQL AB 26 февраля 2008 года.
- Версия 5.1: релиз производства 27 ноября 2008.
Особенности:
- Высокая производительность.
- Высокая доступность.
- Масштабируемость и гибкость запуска
- Надежная поддержка транзакций.
- Web хранилища данных. Сильные стороны
- Сильная защита данных.
- Комплексное развитие приложений.
- Удобное управление.
- Open Source Freedom и 24 х 7 поддержка.
- Самая низкая совокупная стоимость владения.
MS SQL Server
MS SQL Server является реляционной системой управления базами данных, разработанная Microsoft Inc. Ее основные языки запросов:История:
- 1987 – Sybase выпускает SQL Server для UNIX.
- 1988 – Microsoft, Sybase и Aston-Tate порт SQL Server для OS/2.
- 1989 – Microsoft, Sybase и Aston-Tate выпуск SQL Server 1.0 для OS/2.
- 1990 – SQL Server 1.1 выпущен с поддержкой клиентов Windows 3.0.
- Aston – Тейт выпадает из разработки SQL Server.
- 2000 – Microsoft выпускает SQL Server 2000.
- 2001 – Microsoft выпускает XML для SQL Release 1 веб-сервера (скачать).
- 2002 – Microsoft выпускает SQLXML 2.0 (переименован из XML для SQL Server).
- 2002 – Microsoft выпускает SQLXML 3.0.
- 2005 – Microsoft выпускает SQL Server 2005 по 7 ноября 2005 года.
Особенности:
- Высокая производительность.
- Высокая доступность.
- Зеркальное отображение базы данных.
- Моментальные снимки баз данных.
- Интеграция CLR.
- Service Broker.
- DDL триггеры.
- Функции ранжирования.
- Row-версия на основе уровней изоляции.
- XML-интеграция.
- TRY…CATCH.
- Компонент Database Mail.
ORACLE
Это очень большая и управляемая база данных несколькими пользователями системы. Oracle является реляционной системой управления базами данных, разработанная корпорацией “Oracle”. Oracle позволяет эффективно управлять своими ресурсами, информационными базами данных, среди многочисленных клиентов, запрашивающих и отправки данных в сети. Это отличный выбор для сервера баз данных клиент / серверных вычислений. Oracle поддерживает все основные операционные системы для клиентов и серверов, в том числе MSDOS, NetWare, UnixWare, OS / 2 и большинстве разновидностей UNIX.История:
Oracle появилась в 1977 году.- 1977 – Ларри Эллисон, Боб Майнер и Эд Оутс основал лаборатории разработки программного обеспечения для проведения опытно-конструкторских работ.
- 1979 – Версия 2.0 была выпущена Oracle и он стал первым коммерческим реляционная база данных, и в первую базу данных SQL. Компания изменила свое название на Relational Software Inc. (RSI).
- 1981 – RSI начал разрабатывать инструменты для Oracle.
- 1982 – RSI был переименован в корпорации Oracle.
- 1983 – Oracle выпустила версию 3.0, переписан на языке C и побежал на нескольких платформах.
- 1984 – Oracle версия 4.0 была выпущена. В нем содержатся такие функции, как управление параллелизмом – многоверсионную согласованность чтения и т.д.
- 1985 – Oracle версия 4.0 была выпущена. В нем содержатся такие функции, как управление параллелизмом – многоверсионную согласованность чтения и т.д.
- 2007 – Oracle выпустила Oracle11g. Новая версия ориентирована на лучшее разбиение на разделы, легко миграции и т.д.
Особенности:
- Совпадение
- Согласованность чтения
- Механизмы блокировки
- Замораживание базы данных
- Портативность
- Самоуправляемая база данных
- SQL * Plus
- ASM
- Планировщик
- Диспетчер ресурсов
- Хранилище данных
- Материализованные представления
- Битовые индексы
- Сжатие таблиц
- Параллельное выполнение
- Аналитическая SQL
- Сбор данных
- Разметка
MS ACCESS
Это один из самых популярных продуктов Microsoft. Microsoft Access представляет собой программное обеспечение для управления базами данных начального уровня. База данных MS Access не только недорогая, но и мощная база данных для небольших проектов. MS Access использует движок базы данных Jet, который использует конкретный язык SQL диалекта (иногда называют Jet SQL). MS Access поставляется с профессиональным изданием пакета MS Office. MS Access имеет простой в использовании интуитивно понятный графический интерфейс.- 1992 – Access была выпущена версия 1.0.
- 1993 – Access 1.1 выпущен для улучшения совместимости с включением языка программирования Basic Access.
- Наиболее значительный переход был из Access 97 в Access 2000
- 2007 – Access 2007, новый формат базы данных был введен ACCDB, который поддерживает сложные типы данных, такие как многозначного и монтажными полей.
Особенности:
- Пользователи могут создавать таблицы, запросы, формы и отчеты, и соединить их вместе с макросами.
- Импорт и экспорт данных в различных форматах, включая Excel, Outlook, ASCII, Dbase, Paradox, FoxPro, SQL Server, Oracle, ODBC и т.д.
- Существует также формат базы данных Jet (MDB или ACCDB в Access 2007), который может содержать приложения и данные в одном файле. Это делает его очень удобным для распространения всего приложения другому пользователю, который может запустить его в отключенных средах.
- Microsoft Access предлагает параметризованные запросы. Эти запросы и таблицы доступа можно ссылаться из других программ, таких как VB6 и .NET через DAO или ADO.
- На рабочем столе выпуски Microsoft SQL Server можно использовать с доступом в качестве альтернативы к базе данных Jet Engine.
- Microsoft Access является файлом базы данных на основе сервера. В отличие от клиент-серверных реляционных систем управления базами данных (СУБД), Microsoft Access не реализует триггеров базы данных, хранимых процедур или ведение журнала транзакций.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
andreyex.ru
Подборка материалов для изучения баз данных и SQL
Подборка книг, видеокурсов и онлайн-ресурсов для изучения баз данных, основ реляционной теории и языка SQL.

Эта книга — прекрасный выбор для тех, кто стоит в начале тернистого пути изучения SQL. Она не только позволит приобрести необходимую базу начальных знаний, но и расскажет о наиболее популярных тонкостях и мощных средствах языка, которыми пользуются опытные программисты.
Многие пособия, посвященные базам данных, реляционной теории и языку SQL, переполнены скучным изложением теоретических основ. Эта книга является приятным исключением благодаря своему легкому, живому стилю. Автор мастерски преподносит читателю информацию об SQL-выражениях и блоках, типах условий, join-ах, подзапросах и многом другом.
Для закрепления полученных знаний на практике, автор создает учебную базу MySQL и приводит множество практических примеров запросов, охватывающих весь изложенный теоретический материал.

В книге идет речь о версии языка ANSI SQL-92 (SQL2). Подробно рассказывается о способах применения языка запросов для решения соответствующих классов задач по выборке и модификации данных и по работе с объектами структуры базы данных. Все примеры подробно объясняются.
Особое внимание в этом издании уделено различиям диалектов SQL в реализации наиболее распространенных СУБД: MySQL, Oracle, MS SQL Server и PostgreSQL.
Книга предназначена всем, кто желает самостоятельно изучить язык SQL или усовершенствовать свои знания по этой теме.

Данное издание предназначено для тех, кто уже имеет некоторые знания SQL и хочет усовершенствовать свои навыки в этой области. Также оно будет весьма полезно и экспертам в сфере баз данных, так как автор предлагает примеры решения задач в разных СУБД: DB2, Oracle, PostgreSQL, MySQL и SQL Server.
Книга поможет научиться использовать SQL для решения более широкого круга задач: от операций внутри БД до извлечения данных и передачи их по сети в приложения.
Вы узнаете, как применять оконные функции и специальные операторы, а также расширенные методы работы с хранилищами данных: создание гистограмм, резюмирование данных в блоки, выполнение агрегации скользящего диапазона значений, формирование текущих сумм и подсумм. Вы сможете разворачивать строки в столбцы и наоборот, упрощать вычисления внутри строки и выполнять двойное разворачивание результирующего множества, выполнять обход строки, что позволяет использовать SQL для синтаксического разбора строки на символы, слова или элементы строки с разделителями. Приемы, предлагаемые автором, позволят оптимизировать код ваших приложений и откроют перед вами новые возможности языка SQL.

Книга уникальна тем, что в каждой главе приводится сравнение реализаций тех или иных запросов на диалектах трех ведущих СУБД. Благодаря этому она представляет собой исчерпывающий и практичный справочник по языку SQL для разработчиков от новичков до гуру, своего рода настольное пособие.
В издании охватываются темы от самых основ до транзакций и блокировок, функций и средств защиты баз данных.
В конце представлено несколько дополнительных тем: интеграция SQL в XML, бизнес-аналитика OLAP и многое другое.
 В книге описаны большинство из современных баз данных с открытым исходным кодом: Redis, Neo4J, CouchDB, MongoDB, HBase, PostgreSQL и Riak. Для каждой базы приведены примеры работы с реальными данными, демонстрирующие основные идеи и сильные стороны.
В книге описаны большинство из современных баз данных с открытым исходным кодом: Redis, Neo4J, CouchDB, MongoDB, HBase, PostgreSQL и Riak. Для каждой базы приведены примеры работы с реальными данными, демонстрирующие основные идеи и сильные стороны.
Эта книга прольет свет на сильные и слабые стороны каждой из семи баз данных и научит вас выбирать ту, которая лучше отвечает требованиям.

Справочное пособие по настройке и масштабированию PostgreSQL. В книге исследуются вопросы по настройке производительности PostgreSQL, репликации и кластеризации. Изобилие реальных примеров позволит как начинающим, так и опытным разработчикам быстро разобраться с особенностями масштабирования PostgreSQL для своих приложений.
Для начинающих:
Для продвинутых:
Для мастеров:
Англоязычный ресурс для интерактивного изучения основ SQL. Курс разделен на 19 тематических уроков, содержащих теоретическую часть и набор упражнений, которые можно выполнять прямо на странице урока в специально предназначенной для этого интерактивной форме.
Еще один полезный ресурс для программистов с достаточным уровнем английского. Представляет собой охватывающий большое количество тем справочник с множеством примеров и упражнений.
Русскоязычный сайт с огромным количеством интерактивных упражнений для оттачивания навыков в написании операторов манипуляции данными языка SQL.
Упражнения начального уровня доступны без регистрации, для выполнения остальных нужно будет зарегистрироваться (регистрация абсолютно бесплатна).
По результатам тестирования на сайте можно заказать сертификат «SQL Data Manipulation Language Specialist», подтверждающий вашу квалификацию. Качество сертификата поддерживается периодической заменой задач и повышением сертификационных требований.
Курс введения в базы данных знакомит слушателей с историей создания систем обработки структурированных данных, подходами к обработке информации, развитием моделей данных и систем управления данными.
Важную часть курса составляет рассмотрение основных этапов проектирования реляционных баз данных, а также аномалий структурированных данных.
5 сайтов для оттачивания навыков написания SQL-запросов
Видеокурс по работе с MySQL
proglib.io
Создание базы данных SQL и таблиц базы данных на примере
Для этого понадобится установленная система управления базами данных (СУБД) DB2. Мы будем использовать диалект языка SQL, который используется именно в этой СУБД.
Первая команда, которую мы будем применять для создании базы данных — это команда CREATE DATABASE. Её синтаксис следующий:
CREATE DATABASE ИМЯ_БАЗЫ ДАННЫХ
Далее для создания таблиц нашей базы данных будем многократно использовать команду CREATE TABLE. Её синтаксис следующий:
CREATE TABLE ИМЯ_ТАБЛИЦЫ (имя_первого_столбца тип данных, …, имя_последнего_столбца тип данных, первичный ключ, ограничения (не обязательно))
Так как наша база данных моделирует сеть аптек, то в ней есть такие сущности, как «Аптека» (таблица Pharmacy в нашем примере создания базы данных), «Препарат» (таблица Preparation в нашем примере создания базы данных), «Доступность (препаратов в аптеке)» (таблица Availability в нашем примере создания базы данных), «Клиент» (таблица Client в нашем примере создания базы данных) и другие, которые здесь подробно и разберём.
Разработке модели «сущность-связь» можно посвятить не одну статью, но если нас прежде всего интересуют команды языка SQL для создания базы данных и таблиц в ней, то условимся считать, что связи между сущностями уже нам понятны. На рисунке ниже приведено представление модели нашей базы данных с атрибутами сущностей (таблиц) и связями между таблицами.
Для увеличения рисунка можно нажать на него левой кнопкой мыши.
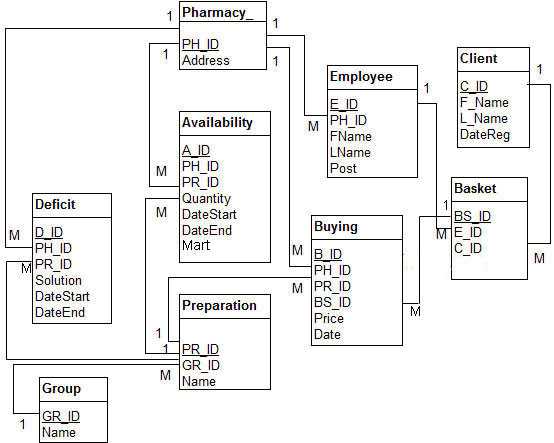
При создании базы данных, в которой таблицы связаны между собой, важно позаботиться о целостности данных. Это означает, например, что если если удалить препарат из таблицы Preparation, то должны удалиться все записи этого препарата в таблице Availability. Ещё пример ограничения целостности: нужно установить запрет на удаление названия группы препарата из таблицы Group, если существует хотя бы один препарат этой группы. Особый случай составляет изменение данных в одной таблице, когда производятся действия с данными в другой таблице. Об этом поговорим в конце статьи. Можно также углубиться в теорию на уроке Реляционная модель данных.
Как уже говорилось, в разбираемом здесь примере создания базы данных использовался вариант языка SQL, который используется в системе управления базами данных (СУБД) DB2. Он является регистронезависимым, то есть не имеет значение, набраны ли команды и отдельные слова в них строчными или прописными буквами. Для иллюстрации этой особенности приведены команды без особой системы набранные строчными и прописными буквами.
Теперь приступим к созданию команд. Первая наша команда SQL создаёт базу данных PHARMNETWORK:
Код SQL
CREATE DATABASE PHARMNETWORK
Описание таблицы PHARMACY (Аптека):
| Имя поля | Тип данных | Описание |
| PH_ID | smallint | Идентификационный номер аптеки |
| Address | varchar(40) | Адрес аптеки |
Пишем команду, которая создаёт таблицу PHARMACY (Аптека), значения первичного ключа PH_ID генерируются автоматически от 1 с шагом 1, вносится проверка на то, чтобы значения атрибута Address в этой таблице были уникальными:
Код SQL
CREATE TABLE PHARMACY(PH_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Address varchar(40) NOT NULL, PRIMARY KEY(PH_ID), CONSTRAINT PH_UNIQ UNIQUE(Address))
Следует обратить внимание на то, что автоматическое генерирование первичного ключа с приращением обеспечено средствами, применяемыми в диалекте SQL для DB2:
Код SQL
PH_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1)
Средства автоматического генерирования первичного ключа с приращением (кратко это называется автоинкрементом) в разных диалектах SQL различаются. Так, в MySQL используется ключевое слово AUTO_INCREMENT и соответствующая часть запроса на создание таблицы выглядит следующим образом:
Код SQL
PH_ID int(4) NOT NULL AUTO_INCREMENT
В SQL Server механизм автоинктемента обеспечивается так:
Код SQL
PH_ID int IDENTITY(1, 1) PRIMARY KEY
Запись (1, 1) здесь означает, что значения первичного ключа должны создаваться начиная с 1 с приращением на 1. Итак, помните о том, что в зависимости от СУБД и диалекта SQL механизмы автоинкремента различаются, а далее для краткости будем приводить запросы на создание таблиц в соответствии с синтаксисом для DB2.
Описание таблицы GROUP (Группа препаратов):
| Имя поля | Тип данных | Описание |
| GR_ID | smallint | Идентификационный номер группы препаратов |
| Name | varchar(40) | Название группы препаратов |
Пишем команду, которая создаёт таблицу Group (Группа препаратов), значения первичного ключа GR_ID генерируются автоматически от 1 с шагом 1, проводится проверка уникальности наименования группы (для этого используется ключевое слово CONSTRAINT):
Код SQL
CREATE TABLE GROUP(GR_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Name varchar(40) NOT NULL, PRIMARY KEY(GR_ID), CONSTRAINT GR_UNIQ UNIQUE(Name))
Описание таблицы PREPARATION (Препарат):
| Имя поля | Тип данных | Описание |
| PR_ID | smallint | Идентификационный номер препарата |
| GR_ID | smallint | Идентификационный номер группы препарата |
| Name | varchar(40) | Название препарата |
Команда, которая создаёт таблицу PREPARATION, значения первичного ключа PR_ID генерируются автоматически от 1 с шагом 1, определяется, что значения внешнего ключа GR_ID (Группа препаратов) не могут принимать значение NULL, определена проверка уникальности значений атрибута Name:
Код SQL
CREATE TABLE PREPARATION(PR_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Name varchar(40) NOT NULL, GR_ID int NOT NULL, PRIMARY KEY(PR_ID), constraint PR_UNIQ UNIQUE(Name))
Теперь самое время создать таблицу AVAILABILITY (Доступность или Наличие препарата в аптеке). Её описание:
| Имя поля | Тип данных | Описание |
| A_ID | smallint | Идентификационный номер записи о доступности |
| PH_ID | smallint | Идентификационный номер аптеки |
| PR_ID | smallint | Идентификационный номер препарата |
| Quantity | int | Количество доступного препарата |
| DateStart | varchar(20) | Дата начала работы аптеки с данным препаратом |
| DateEnd | varchar(20) | Дата окончания работы аптеки с данным препаратом |
| Mart | varchar(3) | Выставлен ли препарат на витрину |
Пишем команду, которая создаёт таблицу AVAILABILITY. Определяются даты начала (не может быть NULL) и окончания (по умолчанию NULL).
Код SQL
CREATE TABLE AVAILABILITY(A_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), PH_ID INT NOT NULL, PR_ID INT NOT NULL, DateStart varchar(20) NOT NULL, DateEnd varchar(20) DEFAULT NULL, QUANTITY INT NOT NULL, MART varchar(3) DEFAULT NULL, PRIMARY KEY(A_ID), CONSTRAINT AVA_UNIQ UNIQUE(PH_ID, PR_ID))
Создаём таблицу DEFICIT (Дефицит препарата в аптеке, то есть, неудовлетворённый запрос). Её описание:
| Имя поля | Тип данных | Описание |
| D_ID | smallint | Идентификационный номер записи о дефиците |
| PH_ID | smallint | Идентификационный номер аптеки |
| PR_ID | smallint | Идентификационный номер препарата |
| Solution | varchar(40) | Решение проблемы дефицита |
| DateStart | varchar(20) | Дата появления проблемы |
| DateEnd | varchar(20) | Дата решения проблемы |
Пишем команду, которая создаёт таблицу DEFICIT:
Код SQL
CREATE TABLE DEFICIT(D_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), PH_ID INT NOT NULL, PR_ID INT NOT NULL, Solution varchar(40) NOT NULL, DateStart varchar(20) NOT NULL, DateEnd varchar(20) DEFAULT NULL)
Осталось немного. Мы уже дошли до команды, которая создаёт таблицу Employee (Сотрудник). Её описание:
| Имя поля | Тип данных | Описание |
| E_ID | smallint | Идентификационный номер сотрудника |
| PH_ID | smallint | Идентификационный номер аптеки |
| FName | varchar(40) | Имя сотрудника |
| LName | varchar(40) | Фамилия сотрудника |
| Post | varchar(40) | Должность |
Пишем команду, которая создаёт таблицу Employee (Сотрудник), с первичным ключом, генерируемым по тем же правилам, что и первичные ключи предыдущих таблиц, в которых они существуют. Внешним ключом PH_ID Сотрудник связан с PHARMACY (Аптекой).:
Код SQL
CREATE TABLE EMPLOYEE(E_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), F_Name varchar(40) NOT NULL, L_Name varchar(40) NOT NULL, POST varchar(40) NOT NULL, PH_ID INT NOT NULL, PRIMARY KEY(E_ID))
Очередь дошла до создании таблицы CLIENT (Клиент). Её описание:
| Имя поля | Тип данных | Описание |
| C_ID | smallint | Идентификационный номер клиента |
| FName | varchar(40) | Имя клиента |
| LName | varchar(40) | Фамилия клиента |
| DateReg | varchar(20) | Дата регистрации |
Пишем команду, создающую таблицу CLIENT (Клиент), в отношении первичного ключа которого справедливо предыдущее описание. Особенность этой таблицы в том, что её атрибуты F_Name и L_Name имеют по умолчанию значение NULL. Это связано с тем, что клиенты могут быть как зарегистрированными, так и незарегистрированными. У последних значения имени и фамилии как раз и будут неопределёнными (то есть NULL):
Код SQL
CREATE TABLE CLIENT(C_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), FName varchar(40) DEFAULT NULL, LName varchar(40) DEFAULT NULL, DateReg varchar(20), PRIMARY KEY(C_ID))
Предпоследняя таблица в нашей базе данных — таблица BASKET (Корзина покупок). Её описание:
| Имя поля | Тип данных | Описание |
| BS_ID | smallint | Идентификационный номер корзины покупок |
| E_ID | smallint | Идентификационный номер сотрудника, оформившего корзину |
| C_ID | smallint | Идентификационный номер клиента |
Пишем команду, создающую таблицу BASKET (Корзина покупок), так же с уникальным и инкрементируемым первичным ключом и связанную внешним ключами C_ID и E_ID с Клиентом и Сотрудником соответственно:
Код SQL
CREATE TABLE BASKET(BS_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), C_ID INT NOT NULL, E_ID INT NOT NULL, PRIMARY KEY(BS_ID))
И, наконец, последняя таблица в нашей базе данных — таблица BUYING (покупка). Её описание:
| Имя поля | Тип данных | Описание |
| B_ID | smallint | Идентификационный номер покупки |
| PH_ID | smallint | Идентификационный номер аптеки |
| PR_ID | smallint | Идентификационный номер препарата |
| BS_ID | varchar(40) | Идентификационный номер корзины покупок |
| Price | varchar(20) | Цена |
| Date | varchar(20) | Дата |
Пишем команду, создающую таблицу BUYING (покупка), так же с уникальным и инкрементируемым первичным ключом и связанную внешними ключами BS_ID, PH_ID, PR_ID с Корзиной покупок, Аптекой и Препаратом соответственно:
Код SQL
CREATE TABLE BUYING(B_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), BS_ID INT NOT NULL, PH_ID INT NOT NULL, PR_ID INT NOT NULL, DateB varchar(20) NOT NULL, Price Double NOT NULL, PRIMARY KEY(B_ID))
И совсем уже в завершение темы создания базы данных обещанное отступление о соблюдении ограничений целостности, когда решение — более сложное, чем написание команды. В нашем примере необходимо соблюдать следующее условие: при покупке единицы препарата значение количества этого препарата в таблице AVAILABILITY должно соответственно уменьшиться. Вообще говоря, для таких операций в языке SQL существуют особые средства, называемые триггерами. Но триггеры — вещь капризная: на практике они могут и не сработать или сработать не так, как предусмотрено. Поэтому разработчики по возможности ищут программные средства решения таких задач, пример которых упомянут в этом абзаце.
И действительно, есть программное средство решение обозначенной выше задачи уменьшения значения количества препарата. А именно: в условии добавления соответствующего препарата в таблицу BUYING (Покупка) пишется функция на языке программирования, на котором выполнено приложение, с запросом с ключевым словом UPDATE на замену значения количества этого препарата на единицу меньше в той же аптеке. И таблица BUYING, и таблица AVAILABILITY имеют внешний ключ PH_ID — идентификатор определённой аптеки.
На этом многогранная тема создания баз данных прерывается…
Поделиться с друзьями
Реляционные базы данных и язык SQL
function-x.ru
Получение образца SQL Server баз данных для примеров кода ADO.NET
- Время чтения: 2 мин
В этой статье
Некоторые примеры и пошаговые руководства в LINQ to SQLLINQ to SQL документации используют пример SQL Server баз данных и SQL Server Express.A number of examples and walkthroughs in the LINQ to SQLLINQ to SQL documentation use sample SQL Server databases and SQL Server Express. Эти продукты можно бесплатно загрузить с веб – Майкрософт.You can download these products free of charge from Microsoft.
Получение образца базы данных Northwind для SQL ServerGet the Northwind sample database for SQL Server
Скачайте скрипт instnwnd.sql из следующего репозитория GitHub, чтобы создать и загрузить образец базы данных Northwind для SQL Server:Download the script instnwnd.sql from the following GitHub repository to create and load the Northwind sample database for SQL Server:
Учебные базы данных Northwind и Pubs для Microsoft SQL ServerNorthwind and pubs sample databases for Microsoft SQL Server
Прежде чем можно будет использовать базу данных Northwind, необходимо запустить скачанный instnwnd.sql файл скрипта, чтобы повторно создать базу данных на экземпляре SQL Server с помощью SQL Server Management Studio или аналогичного средства.Before you can use the Northwind database, you have to run the downloaded instnwnd.sql script file to recreate the database on an instance of SQL Server by using SQL Server Management Studio or a similar tool. Следуйте инструкциям в файле сведений в репозитории.Follow the instructions in the Readme file in the repository.
Получение образца базы данных Northwind для Microsoft AccessGet the Northwind sample database for Microsoft Access
Образец базы данных Northwind для Microsoft Access недоступен в центре загрузки Майкрософт.The Northwind sample database for Microsoft Access is not available on the Microsoft Download Center. Чтобы установить Northwind непосредственно из Access, выполните следующие действия.To install Northwind directly from within Access, do the following things:
Откройте Access.Open Access.
В поле Поиск шаблонов в Интернете введите Northwind , а затем нажмите клавишу Ввод.Enter Northwind in the Search for Online Templates box, and then select Enter.
На экране результатов выберите Northwind.On the results screen, select Northwind. Откроется новое окно с описанием базы данных Northwind.A new window opens with a description of the Northwind database.
В новом окне в текстовом поле имя файла укажите имя файла для копии базы данных Northwind.In the new window, in the File Name text box, provide a filename for your copy of the Northwind database.
Нажмите кнопку Создать.Select Create. Access загружает базу данных Northwind и готовит файл.Access downloads the Northwind database and prepares the file.
После завершения этого процесса база данных откроется с экраном приветствия.When this process is complete, the database opens with a Welcome screen.
Получение образца базы данных AdventureWorks для SQL ServerGet the AdventureWorks sample database for SQL Server
Скачайте образец базы данных AdventureWorks для SQL Server из следующего репозитория GitHub:Download the AdventureWorks sample database for SQL Server from the following GitHub repository:
Образцы баз данных AdventureWorksAdventureWorks sample databases
После загрузки одного из файлов резервной копии базы*данных (BAK) восстановите резервную копию на экземпляре SQL Server с помощью SQL Server Management Studio (SSMS).After you download one of the database backup (*.bak) files, restore the backup to an instance of SQL Server by using SQL Server Management Studio (SSMS). См. раздел Get SQL Server Management Studio.See Get SQL Server Management Studio.
Получить SQL Server Management StudioGet SQL Server Management Studio
Если вы хотите просмотреть или изменить загруженную базу данных, можно использовать SQL Server Management Studio (SSMS).If you want to view or modify a database that you’ve downloaded, you can use SQL Server Management Studio (SSMS). Скачайте среду SSMS со следующей страницы:Download SSMS from the following page:
Загрузка SQL Server Management Studio (SSMS)Download SQL Server Management Studio (SSMS)
Вы также можете просматривать базы данных и управлять ими в интегрированной среде разработки Visual Studio (IDE).You can also view and manage databases in the Visual Studio integrated development environment (IDE). В Visual Studioподключитесь к базе данных из Обозреватель объектов SQL Serverили создайте подключение к базе данных в Обозреватель сервера.In Visual Studio, connect to the database from SQL Server Object Explorer, or create a Data Connection to the database in Server Explorer. Откройте эти панели обозревателя в меню вид .Open these explorer panes from the View menu.
Получить SQL Server ExpressGet SQL Server Express
SQL Server Express — это бесплатный выпуск SQL Server, который можно распространять вместе с приложениями.SQL Server Express is a free, entry-level edition of SQL Server that you can redistribute with applications. Скачайте SQL Server Express со следующей страницы:Download SQL Server Express from the following page:
Выпуск SQL Server ExpressSQL Server Express Edition
Если вы используете Visual Studio, SQL Server Express LocalDB входит в бесплатный выпуск сообщества Visual Studio, а также в профессиональный и более поздние версии.If you’re using Visual Studio, SQL Server Express LocalDB is included in the free Community edition of Visual Studio, as well as the Professional and higher editions.
См. такжеSee also
docs.microsoft.com