ВЧ, СЧ и НЧ запросы в продвижении сайта
Поисковые запросы и их частотность. Как определить частотность запроса?
Поисковой запрос – это тот запрос, который пользователь вводит в поиск:
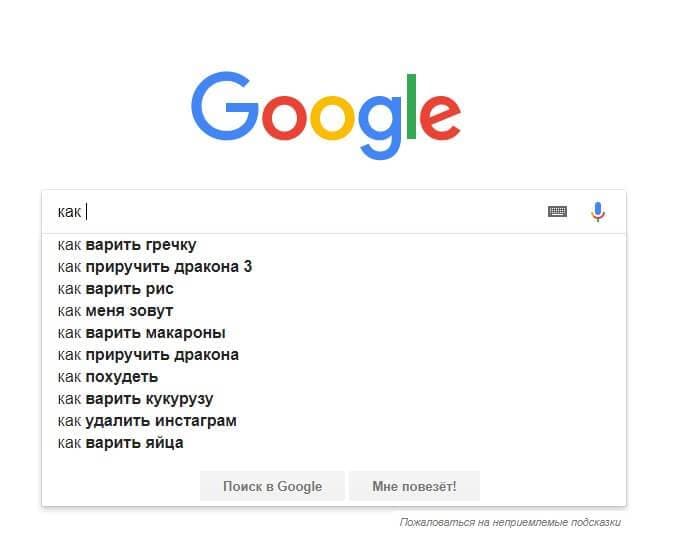
Поисковые подсказки в Google: популярные запросы, начинающиеся на слово «как»
Частотность во многом объясняется тематикой и сферой бизнеса, а также регионом, сезонностью и поисковой системой.
Проверить частотность можно с помощью Яндекс.Вордстата.
Виды поисковых запросов по их частоте
С точки зрения SEO запросы делятся на категории по частотности – параметру, который показывает, насколько часто запрос вводится в поисковик:
- низкочастотные (НЧ) – до 100 показов в месяц;
- среднечастотные (СЧ) – до 1000 показов в месяц;
- высокочастотные (ВЧ) – от 1000 показов в месяц.

Например, вот что покажет Вордстат по теме банкротства физических лиц:
А вот пример для темы инструментов для каллиграфии:
Разница показов огромная. В первом случае все представленные на скриншоте запросы – высокочастотные, во втором – низко- и среднечастотные.
Низкочастотные запросы, их понятие и особенности
Начнем с НЧ: низкочастотные запросы – это сколько? Эти запросы пользователи вводят в поиск редко, реже 100 раз в месяц. Примеры такого запроса – на предыдущем скриншоте (все запросы, за исключением первого).
Тем не менее то, какие запросы считаются низкочастотными, определяется для каждого сайта в отдельности, потому что существуют крайне популярные запросы, по сравнению с которыми и 1000 – это НЧ. Вот, например:
Посмотрите, какие огромные цифры. Разумеется, запросы с 500 показами в месяц для такой ниши – мелочи.
Низкочастотные запросы для продвижения играют одну из важнейших ролей, они самые конкретные и предметные, поэтому как раз по ним правильнее начинать работы по внутренней оптимизации сайта. Поэтому подбор низкочастотных запросов – первый шаг для создания семантического ядра сайта.
- Как подобрать низкочастотные запросы? Берите все, что покажет Вордстат, вплоть до 1 показа в месяц. Чем больше НЧ на старте работ, тем больше трафика будет.
- Как продвигать низкочастотные запросы? Это самые простые и нетребовательные запросы, их не нужно подкреплять ссылками – нужно лишь создавать релевантный контент: писать статьи, новости, карточки товаров, которые максимально содержательно и точно ответят пользователю на его вопрос.
- Трафик по таким запросам начнет расти сразу, но, возможно, медленно: запросы низкоконкурентные, результаты по началу могут не впечатлять, но чем больше таких запросов будет внедрено на сайт, тем выше в итоге будет его посещаемость.

Высококонкурентные НЧ запросы бывают, но редко – преимущественно в узких коммерческих нишах с высокой конкуренцией. То есть людей, которые вводят такие запросы, очень немного, выводить сайт в топ будет нелегко, но если пользователь приходит на ваш сайт, то скорее всего он станет покупателем.
Среднечастотные запросы, их понятие и особенности
Среднечастотные запросы – это сколько? СЧ – это чуть более популярные, чем НЧ. Среднечастотные и низкочастотные запросы – основа продвижения сайта, потому что их больше всего. Используя обе группы запросов, можно достичь оптимальной посещаемости при не самых больших вложениях.
По коммерческим СЧ продвигать сайт сложнее, чем по информационным, и это нужно учитывать: коммерческие запросы – продающие, и конкуренция по ним выше. По среднечастотным запросам количество предложений соответствует уровню спроса: сайтов, которые продвигаются преимущественно по СЧ, действительно немало.
Высокочастотные запросы, их понятие и особенности
Какие запросы считаются высокочастотными? Те, которые пользователи вводят в поиске чаще всего – более 1000 раз в месяц, например:
Высокочастотные запросы – это сколько угодно широкое разнообразие и общее число вариантов: здесь не только информационные и коммерческие, но и брендовые запросы, по которым идет очень большой трафик. Но такие запросы – крайне высококонкурентные, поэтому самые высокочастотные запросы – самые дорогие во всех отношениях.
Другой недостаток высокочастотных запросов в Яндексе и Google – не самая высокая конверсия: непонятно, чего хочет пользователь, вводя в поисковую строку запрос «экран ноутбука». Ему нужна информация по уходу, адреса мастерских, где его можно починить или заменить, или какие-то технические характеристики? И содержимое страницы может оказаться вообще не тем, что он ищет.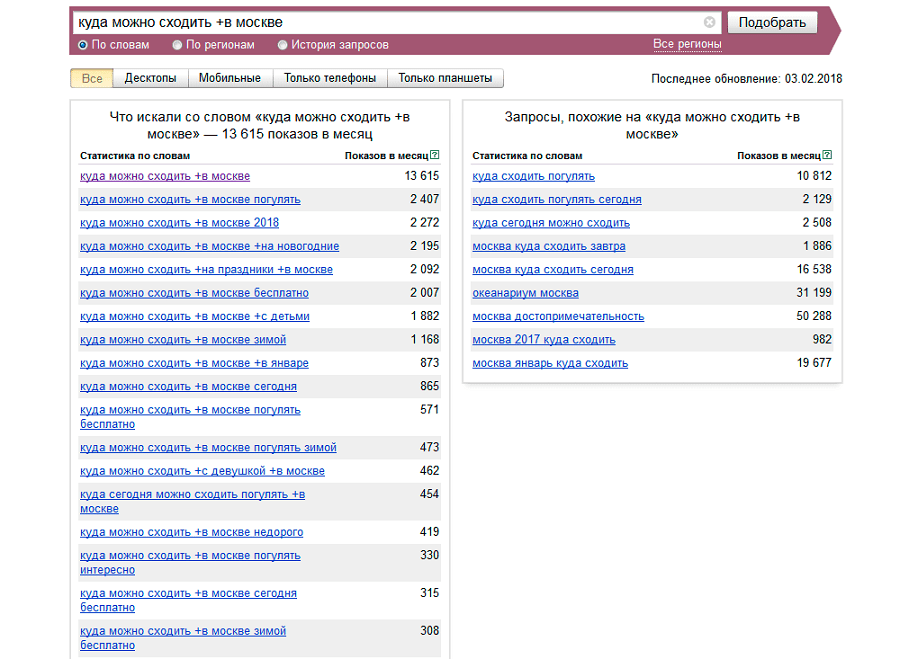
- Как определить высокочастотный запрос или нет? Воспользуйтесь все тем же Яндекс.Вордстатом.
- Как продвигать высокочастотные запросы? Долго и дорого. Чтобы выбраться к вершинам поисковой выдачи, придется долго и упорно работать над сайтом, внушительно вкладываясь в том числе финансово. Нужно учитывать, что в особенности самые высокочастотные запросы (Яндекса или Google – неважно) – это огромный поток аудитории, в том числе нецелевой, и крайне высокая конкуренция.
Какие запросы лучше всего выбирать для продвижения?
Какие запросы – низкочастотные, средне- или высокочастотные – собирать для поисковой оптимизации своей интернет-площадки? Идеальные запросы для продвижения – это низкочастотные и высококонкурентные, но это редко сбывающая мечта оптимизатора и клиента. Поэтому какие запросы лучше выбрать для вашего сайта, зависит собственно от самого сайта.
Если SEO не проводилось ранее, сайт не оптимизирован и вы только в начале пути, то браться нужно сначала за НЧ и работать над ними, подключая постепенно СЧ и ВЧ.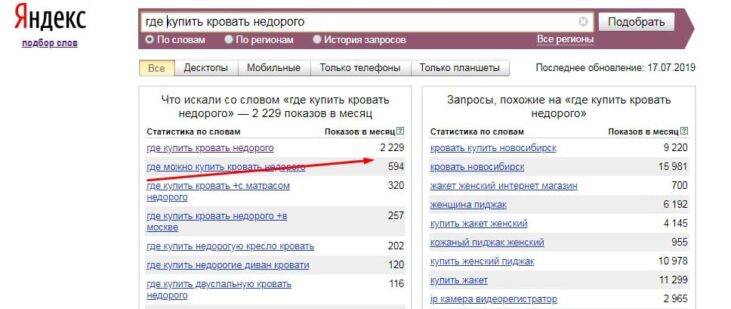
Если сайт максимально оптимизирован под СЧ и НЧ, беритесь за ВЧ.
По вектору оптимизации тоже можно выбирать запросы для продвижения:
- если сайт развивается для спроса по направлению или сфере в целом – используйте ВЧ;
- если нужно привлекать целевых посетителей, которые ищут одну или несколько сфер работы вашей компании – применяйте больше СЧ;
- если нужна высокая конверсия и рост продаж – делайте упор на НЧ.
Высокочастотные, среднечастотные и низкочастотные фразы при продвижении сайтов. Что выбрать?
При продвижении сайтов можно выделить несколько типов или групп поисковых запросов:
- Высокочастотные (ВЧ-запросы) или «информационные» запросы,
- Среднечастотные (СЧ-запросы) или «уточняющие» запросы,
- Низкочастотные (НЧ-запросы) или «товарные/продуктовые» запросы.
В чем отличия между ВЧ-, СЧ- и НЧ-запросами?
Принцип деления поисковых запросов, как это следует из названия, формируется по количеству запросов за месяц, которые делают посетители поисковых систем, а так же по четкости формулирования своей потребности при обращении к поисковой системе.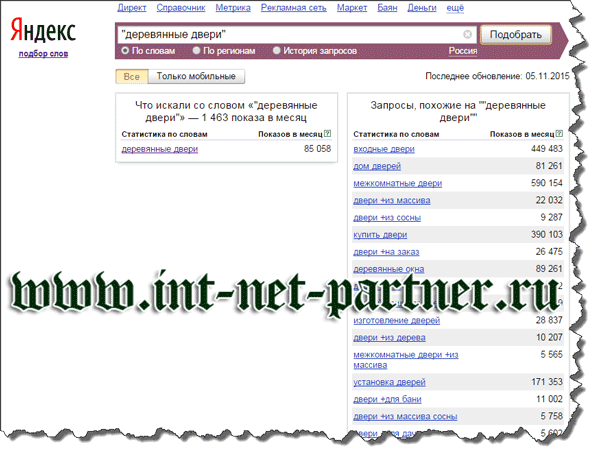
Конкретные цифры могут сильно отличаться в зависимости от популярности темы или региона, в котором делают запрос. Кроме того, существенное влияние на спрос оказывает сезон, особенно с ярко выраженными сезонными товарами: шины, одежда, обувь, путешествия. Для ВЧ-запросов обычно это тысячи или десятки тысяч запросов в месяц:
ВЧ поисковые запросы
Высокочастотные запросы обычно состоят из 1-2 слов, при этом часто запрашиваемых и имеющих информационную направленность, т.е. посетитель хочет получить общую информацию по направлению.
Например: «учет тепла» (количество запросов в месяц превышает 5 000) или «противотуманные фары» (172+ тыс. запросов).
Запрос носит общий характер, и без уточнений нет ясности: ищут реферат на эту тему, хотят найти алгоритм расчета, ищут приборы учета тепла или же ищут счетчики учета тепла, а так же компанию, которая сможет их установить и обслуживать.
Поэтому запрос, приведенный в примере можно смело называть «информационным» поскольку скорее всего ищут общую информацию по данной теме, а посетители поисковых систем, делающие подобные запросы, скорей всего только начинают собирать информацию об услуге или товаре.
ВЧ-запросы необходимо использовать для повышения известности компании, закрепления бренда на рынке или при выведении новой услуги/товара.
Обычно,
СЧ поисковые запросы
Среднечастотные запросы с суммарным количеством обращений к поисковой системе от нескольких сотен в месяц. Для примера можно взять СЧ-запрос «приборы учета тепла» (количество запросов около 2000 в месяц).
Относительно его ВЧ собрата в запросе появилось уточнение: посетитель ищет сами приборы учета тепла.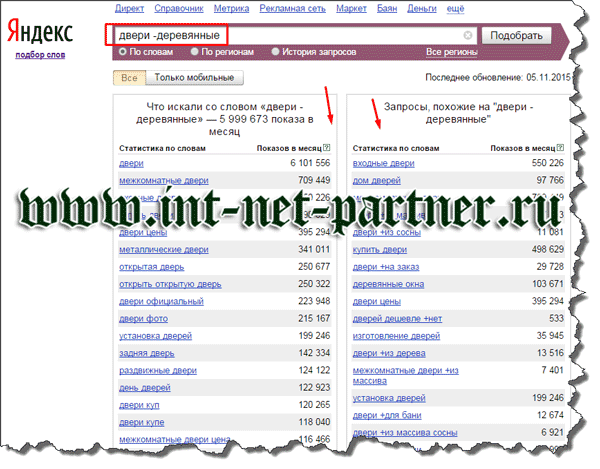
Ясности стало больше, но вопросы еще остаются: он хочет изучить их устройство или он хочет купить такой прибор или он хочет заказать установку прибора учета тепла?
Посетители, делающие среднечастотные поисковые запросы находятся в промежуточной стадии сбора информации, которая предшествует принятию решения о совершении покупки/заказа.
НЧ поисковые запросы
Низкочастотные запросы считаются «товарными» или «продуктовыми», поскольку они максимально конкретизированы и состоят обычно из большого числа слов, вплоть до 5-8 слов.
Продолжить начатый выше пример можно следующим НЧ-запросом: «стоимость установки приборов учета тепла» (количество запросов в месяц — около 20).
Дальнейшие уточнения уже могут идти только в сторону указания в запросе города или модели прибора, что еще уменьшит количество запросов в месяц, но позволит привлекать на сайт посетителей максимально готовых к покупке.
Таким образом низкочастотные запросы обычно вводят посетители поисковых систем, которые уже определились с выбором и в настоящий момент ищут конкретного продавца/поставщика.
Низкочастотные запросы запрашиваются реже всего, при этом за счет точности формулировки они имеют высокую конверсию, и при этом низкую конкуренцию, а значит и стоимость продвижения.
Правила подбора поисковых запросов
В зависимости от целей и задач продвижения сайта или ведения кампании в контекстной рекламе правила могут корректироваться в сторону преобладания тех или иных запросов.
Мы рекомендуем компоновать поисковые запросы так:
- ВЧ-запросы: 10-15% от общего числа поисковых запросов, по которым продвигается сайт,
- СЧ-запросы: 20-40% от общего числа запросов,
- НЧ-запросы: 45-70% от общего числа запросов.
Подобное разделение частотности запросов при продвижении сайта позволяет охватывать общий спрос по направлению (за счет ВЧ-запросов), привлекать посетителей, ищущих одно или несколько более конкретных направлений вашей деятельности (за счет СЧ-запросов), а так же приводить целевую аудиторию, уже готовую к покупке именно ваших товаров/услуг (за счет НЧ-запросов).
какая бывает и в чем отличия?
Частотность запроса — показатель популярности поиского запроса или фразы в той или иной поисковой системе.
Запросы, в зависимости от их частотности бывают:
- ВЧ (высокочастотный) — обычно это общий информационный запрос, состоящий из одного–двух слов.
Используется обычно как имиджевая реклама (для роста узнаваемости бренда) или как источник трафика.
По ВЧ-запросам невозможно продвижение молодых сайтов, а в случае сайтов с возрастом от 1 года продвижение по высокочастотным запросам рекомендуется только после продвижения по СЧ- и НЧ-запросам.
Обычно, минимальная частотность ВЧ-запроса – от 1 000 запросов в месяц для региональных сайтов, и от 10 000 запросов в месяц для федеральных проектов Масштабные или крупные проекты, например, информационные порталы или интернет-магазины федерального уровня. .ВЧ-запросы обычно задают посетители, находящиеся на начальной стадии изучения предметной области, или только формирующие свою потребность в каком-либо товаре или услуге.
Высокочастотные запросы — самые конкурентные, а значит и самые дорогие в продвижении, при этом, как это ни парадоксально, они обладают самой низкой конверсией.
- СЧ (среднечастотный) — уточненный ВЧ-запрос, обычно 2–3 слова.
Используется такая частотность запросов при сео продвижении интернет-магазинов и других сайтов. Подходит для оптимизации сайтов любого возраста. Как и НЧ-запрос является фундаментом для продвижения по ВЧ-запросам.
Обычно, минимальная частотность СЧ-запроса – от 100 запросов в месяц.
СЧ-запросы обычно задают посетители, уже знакомые с предметной областью, или понявшие как им необходимо уточнить свой исходный общий ВЧ-запрос. - НЧ (низкочастотный) — самый точный запрос от посетителя поисковой системы, обычно состоящий из 3–6 слов. Его задают посетители, точно знающие какой товар и в какой комплектации они хотят приобрести.
Обычно минимальная частотность низкочастотного запроса – от 1 запроса в месяц.
Цель НЧ-запроса поисковику — узнать где есть конкретная модель товара или поиск данного товара/услуги по минимальной цене.НЧ-запросы — самые конверсионные и потому интересные для продаж любых сайтов. При этом, небольшой спрос по данным запросам делает их менее конкурентными (а значит более дешевыми) при seo-продвижении. Опытные оптимизаторы легко могут заменить ВЧ-запрос на множество уточняющих НЧ-запросов, сохранив суммарную частотность и получив при этом низкую стоимость продвижения и гораздо более высокую конверсию.

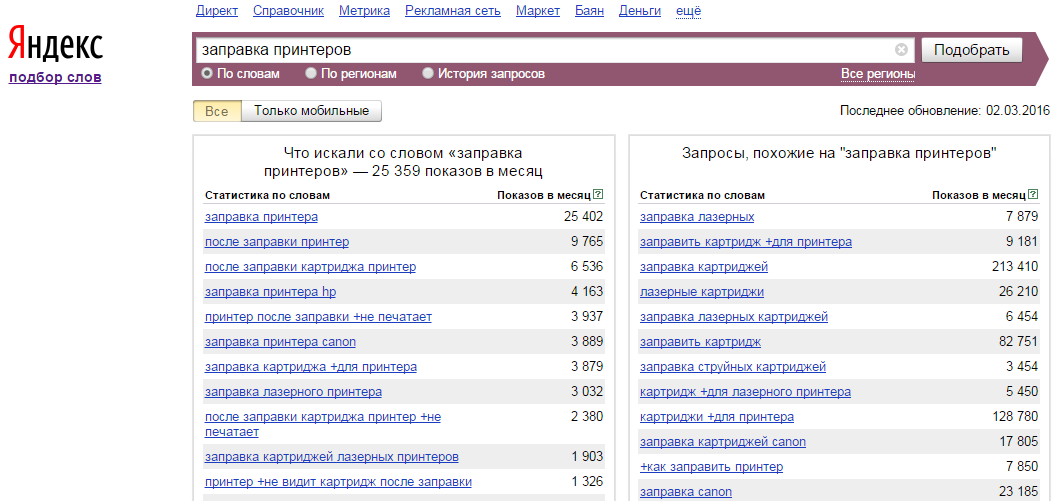

Примеры запросов разной частотности
Пример ВЧ-запроса для популярной тематики:
Пример СЧ-запроса для популярной тематики:
Пример НЧ-запроса:
В каждой тематике, в зависимости от ее популярности и суммарного спроса ВЧ-, СЧ- и НЧ-запросы могут иметь различное количество показов.
Общая и точная частотность запроса
Частотность поисковых запросов подразделяют на Общую, Точную и Уточненную. Для работы с запросами можно использовать специальный язык запросов.
- Базовая или общая частотность — количество запросов поискового слова по данным сервисов определение частотности запросов в общем случае. Рассчитать её очень легко, достаточно ввести в Вордстат запрос без использования каких-либо символов. Полученные данные не будут точными по причине, что будут включать в себя все остальные запросы, в которых есть те же слова.

например:
- Точная частотность — количество запросов в точном соответствии с регистром, последовательностью и составом фразы. Для расчёта необходимо взять запрос в специальные кавычки – » «. Полученная информация покажет количество ввода конкретного запроса, а также всех его склонений.
например:
- Уточненная частотность — для расчёта необходимо использовать запрос в кавычках » » и с восклицательным знаком перед каждым словом в запросе – !. Отражает данные исключительно по введённому запросу, игнорируя иные его формы (падежи, числа и т. д.). При составлении семантического ядра рекомендуется использовать именно этот вид частотности, потому что именно она отражает его популярность у аудитории.
например:
Кроме этого у любого запроса есть показатель эффективности данного запроса, называемый «полнота запроса», на основе которого имеет смысл принимать решение о применении или нет конкретного запроса при продвижении сайта.
Услуги, связанные с термином:
Что такое ВЧ | Высокочастотный запрос
ВЧ (высокочастотный запрос) – наиболее популярные пользовательские запросы на определенную тематику в поисковых системах. Представляют собой, как правило, отдельные слова и словосочетания, объединяющие в себе массив более конкретных запросов.
Синонимы: Высокочастотник
Использование
Для эффективного продвижения сайта и выбора оптимальной стратегии привлечения пользователей, вебмастеру необходимо знать, что такое ВЧ, СЧ и НЧ запросы, которые являются более или менее конкурентными и привлекают на сайт широкий или узкий круг посетителей. Работая с запросами различной частотности, можно охватить как общий спрос по основному направлению деятельности организации, так и спрос на конкретные товары/услуги, формируя таким образом стабильный поток посетителей сайта.
Классификация запросов по частотности:
- ВЧ или высокочастотные, например, «строительство», которые также называются информационными (пользователь находится на начальной стадии сбора информации).
- СЧ или среднечастотные, например, «строительство загородного дома», также известны как уточняющие (пользователь находится на промежуточной стадии сбора информации, за которой следует стадия принятия решения).
- НЧ или низкочастотные, например, «строительство загородного дома из клееного бруса» – это уже наиболее конкретные товарные/продуктовые запросы (пользователь принял решение и переходит к выбору конкретного продавца/поставщика).
Достоинства и недостатки ВЧ запросов
Высокочастотные запросы являются наиболее конкурентными, что предполагает наибольшую стоимость и трудоемкость продвижения сайта в топ, и является наименее эффективным, так как привлекает наиболее широкий круг пользователей, но лишь немногие из них становятся постоянными читателями. Как правило, эффективно продвигаются в поле высокочастотных запросов только крупные фирмы, продающие товары или услуги. При этом низкочастотные запросы являются наименее конкурентными, требуют значительно меньших затрат, однако способны привлечь целевого потребителя услуг сайта и сформировать его постоянную аудиторию. Таким образом, ВЧ запросы формируют количество, а НЧ запросы – качество привлеченной аудитории сайта.
Таким образом, ВЧ запросы формируют количество, а НЧ запросы – качество привлеченной аудитории сайта.
Как эффективно применять ВЧ запросы
Наиболее популярной является оптимизация главной страницы сайта под высокочастотные запросы. При этом остальные страницы направлены на работу с низко- и среднечастотными. Исходя из сложившейся практики, больший приток посетителей принесут несколько страниц, направленных на низкочастотные запросы, чем одна, ориентированная на высокочастотные. Рекомендуемое процентное соотношение для продвигаемого сайта: ВЧ/СЧ/НЧ = 10-15%/20-40%/45-70%.
Поисковые запросы (ВЧ, СЧ, НЧ)
Термином поисковый запрос называют слово или набор символов, вводимые в поисковик. Отыскать нужные сведения в Интернете можно именно с его помощью.
Что это такое?
Поскольку по одному-единственному слову найти желаемые сведения бывает нелегко, то зачастую в запросы входят несколько слов. Например, Яндекс и Google применяют алгоритмы, определяющие запросы, состоящие из нескольких фраз, повышая качество поиска. Поисковики также способны интерпретировать эти запросы. Благодаря этому в результатах поиска появляются самые релевантные страницы.
Например, Яндекс и Google применяют алгоритмы, определяющие запросы, состоящие из нескольких фраз, повышая качество поиска. Поисковики также способны интерпретировать эти запросы. Благодаря этому в результатах поиска появляются самые релевантные страницы.
Следует также отметить, что почти все поисковики имеют инструменты, расширяющие возможности поиска. Например, Яндекс способен расширять запросы посредством сочетания символов и слов.
Восклицательный знак — оператор уточнения в Яндексе
Если ввести обычный запрос, то в результатах будут выводиться сайты, содержащие искомые слова не только в верхнем, но также и нижнем регистре. Этот можно избежать, введя перед запросом восклицательный знак.
Например, чтобы найти только страницы, содержащие данный запрос, написанный в любом регистре, надо ввести запрос в виде «!фраза».
А чтобы найти только страницы, содержащие данный запрос, написанный с большой буквы, надо ввести запрос в виде «!Фраза».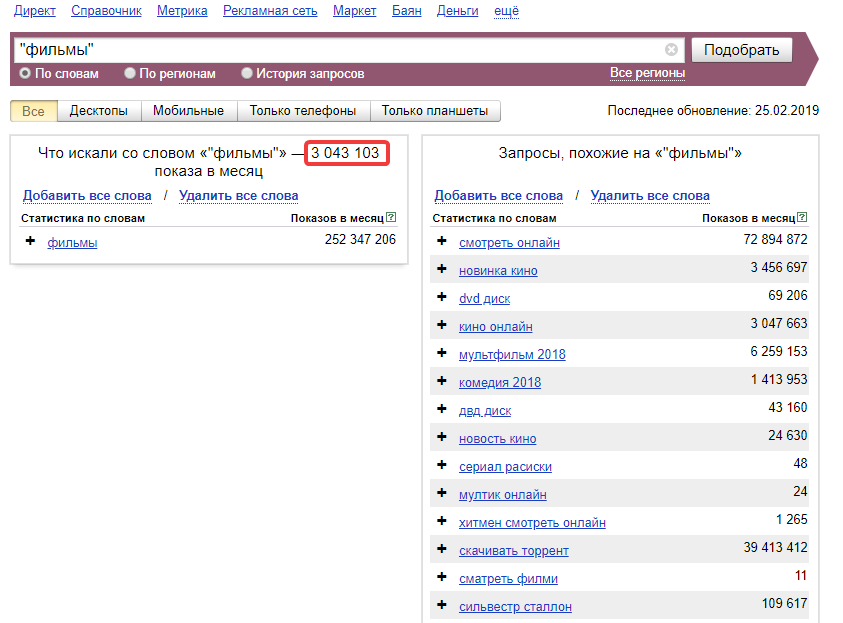
Оператор «+»
Поскольку поисковиками не учитываются так называемые стоп-слова, то на странице поиска могут появиться ошибочные результаты. Однако если поставить перед запросом знак «+», то будут выданы страницы, в которых слова стоят только в том порядке, в котором они записаны в запросе. Того же самого можно добиться, если заключить запрос в кавычки.
Оператор «~»
Яндекс иногда выдает сайты, содержащие информацию о предоставлении услуг или продаже товаров. Зачастую такие сайты не имеют информационной полезности. Этого можно избежать, введя перед запросом знак «~», который исключает из результатов поиска сайты рекламной направленности.
Очень многие поисковики умеют учитывать морфологию запросов и искать по любым вариантам, независимо от задействованной словоформы.
Частота и цели запросов
По целевому назначению запросы подразделяются на несколько категорий.
- Информационные запросы, выражающие потребность получения требуемых сведений.
- Навигационные запросы, отправляемые, чтобы узнать адрес конкретного интернет-сайта.
- Транзакционные запросы, выражающие потребность в приобретении товаров, заказе услуги, иных действиях, приносящих прибыль.
По частотности употребления за месяц запросы также подразделяются на три группы.
- Высокочастотные запросы — свыше 100 переходов из поисковиков.
- Среднечастотные запросы — от нескольких десятков до 100 переходов.
- Низкочастотные запросы — от 1 до нескольких десятков переходов.
Статистика употребления запросов
Сведения о частотности употребления и видах поисковых запросов открывают рекламодателям и SEO-оптимизаторам большие возможности продвижения сайтов и влияния на целевых посетителей. Для лингвистов статистика запросов зачастую представляет собой целое собрание слов современного языка. Запросы пользователей также имеют немалое значение и для государственных структур. В Америке, например, согласно местным законам, поисковики обязаны предоставлять госорганам детальную статистику запросов. Согласно заявлениям властей, делается это для контроля над распространением порнографических материалов в Интернете.
Запросы пользователей также имеют немалое значение и для государственных структур. В Америке, например, согласно местным законам, поисковики обязаны предоставлять госорганам детальную статистику запросов. Согласно заявлениям властей, делается это для контроля над распространением порнографических материалов в Интернете.
Сервисы доступа к статистике запросов
Яндекс располагает сервисом WordStat, который открывает полный доступ к статистическим данным. Помимо стандартных сведений о помесячной частотности запросов, с помощью WordStat также можно фильтровать статистику по датам, регионам, городам.
Корпорация Google дает больше подробностей. Предоставляемая ей статистическая информация выводится в графическом виде. На этих графиках видна конкуренция рекламодателей по конкретным запросам. Можно также посмотреть историю по ключевым словам и подробности об их стоимости, если они участвуют в системах контекстного рекламирования.
Наипопулярнейшие запросы
В Яндексе ими стали слова, имеющие отношение к соцсетям. Чуть менее популярными стали запросы, содержащие слово «порно».
Чуть менее популярными стали запросы, содержащие слово «порно».
Невзирая на общее сокращение количества ошибок и опечаток, допущенных интернет-пользователями за прошедшее время, по-прежнему пишутся безграмотно примерно 12 процентов всех запросов. Например, встречаются такие варианты, как «Одноклассники» с одной буквой «с» в-середине и «Русификатор» с двумя, «Агентство» без буквы «т», а также «шпаргалка» вместо «шпаргалка».
Возврат к списку
Типы поисковых запросов и их особенности
Как давно вы что-то искали в интернете? Я уверена, что большинство людей ищут нужную информацию в поисковиках каждый день. В данной статье мы рассмотрим основные типы поисковых запросов.
Как давно вы что-то искали в интернете? Я уверена, что большинство людей ищут нужную информацию в поисковиках каждый день. Так, например, в 2017 году Гугл раскрыл примерное количество обрабатываемых запросов: их не менее 2 триллионов в год или около 63 тыс. запросов в секунду, из них примерно 15% — это ранее неизвестные запросы.
запросов в секунду, из них примерно 15% — это ранее неизвестные запросы.
Итак, мы уже определились, что запросов очень много и их количество растет ежесекундно. Но зачем и кому нужна эта информация? Данная статья будет полезна для начинающих SEO-оптимизаторов и владельцев бизнеса. Первым она поможет при составлении семантического ядра сайта и распределения запросов по страницам, вторым — для базового понимания того, по каким запросам их сайт может появляться в поисковой выдаче и для контроля своего подрядчика по продвижению.
Интент запросаДля начала следует пояснить, что каждый запрос соответствует определенному интенту. Что это такое? Интент — это потребность пользователя. Есть запросы с точной потребностью, например, “такси минск”. Здесь понятно, что человеку необходимо вызвать такси и доехать из точки “А” в точку “Б”. Но если он введет в поисковик просто “такси”, то возможно он, вместо заказа услуги, хотел посмотреть фильм “Такси”.
Всегда задумывайтесь, какую информацию хотел бы увидеть человек на вашем сайте по определенному запросу. Не нужно бездумно “пихать” ключевые слова на страницу сайта, в надежде, что она выйдет на первые позиции Гугла и Яндекса. В эпоху умного поиска и персонализации выдачи нужно задумываться в первую очередь о том, для кого вы это все делаете.Классификация поисковых запросов
По частотности:
Высокочастотные (ВЧ) запросы обычно являются ключевыми в нише и состоят из 1-2 слов. Как правило, их достаточно сложно вывести в ТОП из-за высокой конкуренции, особенно в крупных городах. Чтобы продвинуться на первые позиции по таким ключам, необходимо развивать сайт по всем фронтам: тут и техническая часть, и отличное юзабилити, и качественный ссылочный профиль — во всем нужно быть лучше конкурентов. Еще один недостаток оптимизации только под такие запросы — это размытый интент. Например, по запросу “пластиковые окна” непонятно, хочет человек купить или просто почитать статью о видах окон.
Среднечастотные (СЧ) запросы дают меньшую посещаемость, но и являются более целевыми. Обычно они включают в себя до 4-5 слов и ведут на страницы разделов и подразделов сайта. Имеют более высокую конверсию по сравнению с ВЧ запросами.
Низкочастотные (НЧ) запросы — самые редко запрашиваемые фразы, состоящие обычно из 4-5 слов. Их легче и дешевле всего продвигать в органическом и платном поиске. Многие оптимизаторы отказываются от таких запросов из-за того, что они не приведут много трафика на сайт. Но всегда следует помнить о том, что они являются самыми конверсионными.
1 — ВЧ запрос, 2 — СЧ запрос, 3 — НЧ запрос
По конкурентности запроса:
Высококонкурентные (ВК) запросы
Среднеконкурентные (СК) запросы
Низкоконкурентные (НК) запросы
Конкурентность запроса показывает насколько тяжело будет продвинуть страницу в ТОП выдачи. Для этого показателя нет конкретной формулы, каждый SEO специалист выбирает для себя наиболее подходящий способ расчета (KEI, сторонние сервисы).
По геозависимости запроса:
- Геозависимые запросы — запросы, которые не имеют гео привязки внутри самого запроса и выдача формируется на основании местоположения пользователя, Банальный пример — “вылечить зуб недорого”. Для пользователя из Москвы будет показана выдача с московскими стоматологиями, для человека из Витебска — с витебскими клиниками.
Геозависимые запросы особенно важны для коммерческих организаций. Обязательно необходимо привязывать сайт к нужному региону в вебмастерах, добавлять его на карты Гугла и Яндекса, указывать адреса в справочниках — это все поможет поисковикам точно определить региональность.
Геонезависимые запросы — запросы без привязки к региону (т.к. это регион уже прописан в запросе), результаты поиска не будут зависеть от местонахождения пользователя. Примеры запросов: “как починить холодильник”, “как приготовить наполеон” и коммерческие вроде “вылечить зуб в Минске” В данном случае выдача для человека, где бы он ни находился, будет примерно одинаковой.
По степени ценности для бизнеса:
Коммерческие запросы — самые любимые запросы при SEO-продвижении сайтов товаров и услуг. Примеры: “iphone8 цена”, “заказать контекстную рекламу” и аналогичные. Это самые “горячие” запросы с высокой конверсией, человек их вводит в поиск, когда уже умеет намерение что-то приобрести.
Как понять, что перед вами — коммерческий запрос?
— Присутствуют слова-маркеры, например, “купить”, “цена”, “заказать”;
— Есть связка товар/услуга + топоним, например, “цветы минск”, «мойка машины в Москве»;
— При анализе выдачи в поисковике почти весь ТОП будут занимать коммерческие сайты;
Информационные запросы (или некоммерческие) — запросы, которые вводят без желания что-то купить/приобрести. Примеры: “iphone 8 плюсы и минусы”, “как настроить контекстную рекламу”.
Считается, что для бизнеса они несут меньшую ценность, что в корне неверно. Такие запросы принесут дополнительный трафик на сайт, и часть посетителей могут стать потенциальными покупателями в будущем. К тому же, через информационные статьи можно показать свою экспертность и заочно завоевать доверие.
Внимание! Коммерческие и некоммерческие запросы нельзя вести на одну страницу сайта, группируйте их и размещайте на разные посадочные страницы.
По сезонности:
- Сезонные запросы — запросы, частотность которых зависит от времени/сезона. Примеры: “подарки на новый год”, “тур на майские праздники”. Отследить сезонность позволяют сервисы Google Trends и Яндекс Вордстат.
На графике хорошо видна сезонность по запросу «Новогодние туры» - Несезонные запросы — запросы на товары/услуги, спрос на которые держится на одном уровне. Примеры: “купить часы”, “купить жесткий диск”.
Иные виды запросов:
Общие запросы — это высокочастотные односложные запросы, например, “кофе”, “книга”, “ноутбук”. По ним непонятно, что хотел бы узнать пользователь: стоимость ноутбука в интернет-магазине или статью о том, как его выбрать. По таким общим фразам целенаправленно не продвигаются ни в SEO, ни в контекстной рекламе, т.к по сумме это выйдет очень затратно, а конверсия будет очень низкая.
На скриншоте видно, что по запросу «Кофе» смешанная выдача: есть как информационные страницы, так и коммерческие.
- Транзакционные запросы — это запросы, вводя которые пользователь хочет совершить определенное действие. Примеры “купить елку”, “скачать альбом Muse”. Очень часто транзакционные и коммерческие запросы пересекаются.
- Навигационные запросы — запросы, которые вводят, когда хотят попасть на определенный сайт. Примеры: “магазин 5 элемент как проехать”, “БГМУ адрес”.
Витальные запросы можно отнести к разновидности навигационных запросов. Они состоят только из одного слова — названия бренда, без дополнительных поясняющих слов. Цель — привести на официальный сайт компании.
- Мультимедийные запросы — запросы с целью найти мультимедийный контент. Обычно эти фразы содержат слова “фото”, “видео”, “клип” и другие маркеры.
Классификация поисковых запросов на различные типы удобна не только SEO-специалистам, но и поисковым системам, так как позволяет сделать выдачу более релевантной и сформировать максимально точный ответ на запрос.
Юлия Клыковская
Практикующий SEO-специалист MAXI.BY media.
частотность и конкуренция в продвижении сайта
Поисковые запросы в интернете подразделяются на 4 вида:
- Высокочастотные — имеют более 1500 запросов в месяц.
- Среднечастотные — с показателем от 500 до 1500 запросов.
- Низкочастотные — от 100 до 500 запросов в месяц.
- Микро-низкочастотные — менее чем 100 запросов в месяц.
Данный показатель не является точным и может периодически меняться. Все изменения, как анализ популярных запросов, обычно отслеживаются при помощи специальных сервисов — Wordstat Yandex и Google Ads. Для возможности отслеживания необходимо пройти простую процедуру регистрации и после использовать встроенный инструмент «планировщик ключевых слов».
Высокочастотные запросы (ВЧ)
Высокочастотные запросы состоят из нескольких простых слов, и именно их пользователи интернета применяют чаще всего. Например: купить машину, свежие новости, фильм.
Новым проектам не подойдет продвижение по высокочастотным запросам, так как поисковики не особо доверяют им, и вероятность попадания в ТОП крайне мала. Чтобы раскрутка новостного сайта получилась данным образом понадобится несколько месяцев, а то и больше. Кроме того, ВЧ запросы считаются самыми конкурентными, так как ключевые слова очень схожи.
С целью получить успешное продвижение по высокочастотным запросам необходимо грамотно подойти к составлению листа с анкорами, для того чтобы иметь возможность продвигать сайт анкорным и безанкорным методом. Внимательно изучите и проведите анализ контента на площадках, с помощью которых планируете продвигать свой сайт и откуда будете привлекать целевой трафик. Обратите внимание на возраст ресурса, оригинальность контента и обязательно — на количество уникальных посетителей в сутки. Эти данные помогут вам подобрать наиболее подходящие площадки для продвижения ресурса.
Среднечастотные запросы (СЧ)
Этот вид запросов является самодостаточным и состоит из нескольких слов. Данная методика продвижения сайта используется вебмастерами чаще всего, ведь у него идеальное сочетание цена-качество. Вложенные средства достаточно быстро оправдывают себя, и результат не заставляет ждать.
Кроме этого, конкуренция в СЧ запросах значительно ниже ВЧ запросов, так как данный метод по своей сути является производным от высокочастотных. Например, к запросу купить машину добавляется конкретный регион или город. Или пользователь не просто хочет купить рекламное место, а на определенной площадке и так далее. Еще к среднечастотным запросам относятся сезонные ключевые фразы. Несмотря на то, что под Новый год количество запросов по фразе «купить елочку» возрастает до 20 тысяч и более, он будет относиться к разряду СЧ.
Продвижения сайта по СЧ запросам также не подходит для молодых проектов, по той же причине, что и продвижение по ВЧ запросам. Лучше всего начинать с низкочастотных и постепенно переходить к среднечастотным. Так вы сможете грамотно вложить деньги и не потратить лишнее.
Низкочастотные запросы (НЧ)
Это запросы, которые в месяц используют менее 500 человек. В этом случае также учитывается сезонность и актуальность запросов, например, запросы про установку каркасных бассейнов зимой.
Данный вид запросов по праву недооценён, многие предпочитают начинать раскрутку сайта при помощи среднечастотных запросов, тем самым совершая ошибку. НЧ запросы отлично подходят для начальных проектов, еще при их помощи можно раскрутить сайт по узконаправленным ключевым фразам, которые максимально точно соответствуют запросу пользователя.
От остальных видов продвижение сайта по низкочастотным запросам отличает обилие слов в фразе. Так, к запросу «купить телевизор» добавляется «в интернете дешево», а потом еще в определенном городе, а затем — «с доставкой» и так далее. Основной поток трафика формируется благодаря низкочастотным запросам и ключевым фразам, сформированным таким образом.
Продвижение низкочастотными запросами принято считать наиболее эффективным по определенным причинам:
- Высокая конверсия посетителей сайта благодаря привлечению целевой аудитории.
- Низкий уровень конкуренции.
- Первые результаты можно получить уже через 30-40 дней.
- Используются исключительно белые способы продвижения.
Но кроме плюсов есть, конечно же, и минусы, к которым относятся:
- Низкочастотные запросы приходится использовать сразу комплексом, так как по отдельности они не дадут должного эффекта.
- Все запросы необходимо контролировать.
- Сложно охватить большую аудиторию.
Специалисты компании AdButton рекомендуют делать оптимизацию всех страничек сайта для достижения более высокого эффекта от низкочастотного продвижения. Да, на это может понадобиться немало времени, но зато результат оправдает приложенные усилия.
Все сайты, которые сегодня занимают топовые позиции в поисковиках, когда-то начинали с низкочастотных запросов.
Микро-низкочастотные запросы запросы
При использовании МНЧ запросов возникает сомнение, а стоят ли они того? Ведь это примерно 10-20 пользователей в месяц, и то в лучшем случае.
Однако на них стоит обращать внимание по некоторым причинам:
- Статистические инструменты продвижения в интернете не могут дать точные данные.
- Новые виды запросов появляются ежедневно.
- По статистике поисковых систем, примерно 15% новых запросов не вводились никогда ранее.
Этот вид запросов чаще всего относится к сезонным и граничит с низкочастотными. Например, запрос «заказать деда мороза на корпоратив». В сентябре или октябре этот запрос будет МНЧ, а в ноябре или декабре может перейти в НЧ или даже в СЧ запросы. Данный вид запроса показывает реальные потребности посетителей сайта, и на них обязательно стоит обращать внимание.
Заключение
Не стоит гнаться сразу за высокочастотными запросами и стремиться молниеносно попасть в топ поисковых систем. Таким образом вы лишь потратите много денег, а в итоге не получите должного результата. Необходимо начинать свой путь по продвижению в лидеры с малого, с низкочастотных запросов, не забывая и о микронизкочастотных, так как именно благодаря им вы сможете выявить реальные потребности пользователей и привлечь на сайт максимальное количество уникальных пользователей.
Ирина Леонова
Ирина является автором множества статей и публикаций на тему интернет-рекламы, маркетинга, монетизации и продвижения сайтов с более чем 10-летним опытом. Благодаря консультациям, разговорам, публикациям, обучению и наставничеству, она пишет качественные статьи и публикации.
Похожие статьи
0 Комментариев
Оставить комментарий
Добавить комментарий
Какая частота запросов и как ее определить?
Частота запросов — SEO WIKI
Частота запросов — это количество раз, когда пользователь нажимает определенное слово или фразу для поисковой системы за месяц. Различают три основных типа: высокочастотный (HF), низкочастотный (LF) и среднечастотный (MF). Однако самих видов больше:
Superfrequency — самые популярные слова или фразы, т.е. они наиболее часто запрашиваются в определенной теме.Обычно микроволновые запросы состоят из одного слова, например «смартфон» или «одежда». Они наиболее конкурентоспособны, потому что их продвигают многие компании в определенных сферах. Частота показов — от 100 000 в месяц и выше. Продвижение на них подходит далеко не каждому бизнесу, поскольку из-за отсутствия в запросе уточняющих фраз релевантность страниц, выбранных поисковой системой, может быть размыта. Обычно при таких запросах поисковая система пытается показать как можно больше информации с искомым словом, например, при поиске слова «замок» Яндекс покажет и здания, и механические устройства для запирания дверей.
Высокая частота. Они отличаются от сверхчастотных тем, что могут указывать дополнительное слово, но это не делает запрос менее частым. Например, запрос «Московская квартира» (620 000 показов по московскому времени) остается частым, несмотря на то, что в нем есть уточняющее слово. Это не так уж и часто по сравнению с запросом «квартира» (5 250 000 показов MSC). Частота таких запросов от 10 000. На профессиональном жаргоне высокочастотные запросы называются «жирным».Их грамотное продвижение помогает привлечь на сайт максимальное количество пользователей. Но многие сайты продвигаются по высокочастотным запросам, что создает большую конкуренцию. Поэтому продвижение высокочастотных запросов обходится довольно дорого в финансовых и временных планах.
Midrange — как правило, состоят из нескольких слов со средней частотой показов от 500 до 5000-10000. Запросы среднего уровня задают пользователи, которые знакомы с их областью интересов или знают, как им нужно уточнить исходный общий высокочастотный запрос.
Низкочастотные — наиболее специфичный тип запросов, они имеют узкую направленность. Пример: «купите телевизор Samsung в Санкт-Петербурге». Частота показов — от 50-100 до 500 в месяц.
Microfrequency — может иметь частоту от 1 до 50. Запросы на MF считаются самыми неконкурентными, так как содержат длинный квалифицирующий «хвост» в запросе. Пример: «как внести деньги на банковский счет ООО».
Важно отметить, что частота одного и того же запроса сильно различается в разных поисковых системах.
Яндекс сознательно тормозит продвижение веб-ресурсов на высококонкурентные позиции, комментируя то, что сайт должен сначала прославиться, заработать репутацию и быть стабильным в развитии. И только после того, как он зарекомендовал себя, поисковая система даст ему возможность составить конкуренцию ведущим конкурентам.
запросов MF и LF, хотя и не требуют больших финансовых вложений, также способны обеспечить постоянный рост трафика на сайт и охватить большое количество пользователей.
На основе анализа запрошенных фраз SEO-оптимизатор составляет подборку наиболее популярных запросов и продвигает проект по ним.
Если вам нужно проверить частоту запросов, вы можете воспользоваться специальными услугами:
Яндекс.Wordstat — инструмент, помогающий определять частоту необходимых запросов в поисковой системе Яндекса. Недостатком сервиса является то, что вам нужно проверять запросы вручную и по одному.
Google Adwords — это служба статистики поиска Google.Предоставляет всю необходимую информацию по запросу, есть возможность установить язык и регион, предоставляются синонимы. Внимание, если в вашем аккаунте Adwords нет активных рекламных кампаний, то показания в сервисе могут быть очень приблизительными и неточными.
5 оптимизаций индекса SQL и запросов, о которых вы не знали | Уддешья Сингх | Geek Culture
Обратите внимание: вы можете определить способ сортировки индекса, метод по умолчанию — По возрастанию, поэтому в этом случае оба запроса будут работать одинаково!
В запросе, который мы обсуждали выше, мы создали составной индекс, т.е.е., создание индексов для комбинации двух столбцов, потому что мы будем именно этой комбинацией, чтобы идентифицировать конкретную строку и обновлять ее. Но здесь возникает вопрос:
Uddeshya, мы могли бы использовать индекс как для postId, так и для userId, верно?
Ответ на этот вопрос очень субъективен, и прежде чем я отвечу, что здесь, я рекомендую вам пройти этот отличный ответ о переполнении стека здесь от evilhomer [3], который охватывает этот вопрос аналогичным примером в контексте mysql ( не могу быть слишком уверен во всех поставщиках SQL).Но для базового охвата:
В нашем случае индекс nsfwModel_idx1 представляет собой составной индекс с несколькими столбцами, построенный на (postId, userId) , что означает, что мы ожидаем, что этот индекс будет полезен для запроса, когда мы запрашиваем:
- ✔️ И postId, и userId
- ✔️ Только postId
- Строка в таблице однозначно определяется комбинацией (postId, userId).
Но не при использовании только userId, потому что сервер SQL не сочтет это полезным (столбцы индексации, кстати, обрабатываются слева направо).
Возвращаясь к нашему вопросу, если бы мы должны были создать 2 отдельных индекса, то да, механизм оптимизатора запросов SQL будет искать оба индекса один за другим и уменьшать скорость запросов. НО:
- ❌ Это займет больше места на диске.
- ❌ Это еще больше снизит скорость вставки и обновления движка, потому что помните, больше индексов == большая задержка во вставках. Статья о специальной функции SQL
- ✔️ Но это будет потрясающе, если ваша система использует оба столбцы индивидуально в отдельных запросах.
В конце концов, это будет просто ваше дизайнерское решение и то, насколько умно вы используете существующие индексы для оптимизации ваших будущих запросов.
На самом деле это было ново для нас, но что-то настолько распространенное, я уверен, что вы тоже сделали что-то настолько глупое.
Этот короткий симпатичный запрос ничего не делает, но получает общее количество подписчиков для follwerIds как общее количество подписчиков из таблицы подписчиков User с некоторым типом данных перечисления в виде столбца, статуса и столбца с понятной датой.Честно говоря, в этом запросе нет ничего неправильного, не так ли?
Прежде чем я дам вам ответ, позвольте мне объяснить, как выглядят индексы в этой таблице. Столбец
- followerId является первичным ключом, следовательно, индексирован.
- статус — это перечисление, следовательно, тоже проиндексировано. Столбец даты
- также проиндексирован!
Итак, теоретически наш оператор SELECT должен использовать все три этих индивидуальных индекса, верно?
Неправильно.
Причина в том, что эта простая и приятная на вид функция SQL DATE () ссылается на эту точную проблему здесь, в статье о специальных функциях SQL [4]
… когда те же самые функции используются в предложении WHERE, это заставляет SQL Server выполнять сканирование таблицы или сканирование индекса для получения правильных результатов вместо поиска по индексу, если есть индекс, который можно использовать. Причина в том, что значение функции должно оцениваться для каждой строки данных, чтобы определить, соответствует ли она вашим критериям.
Итак, чтобы избежать полной оценки индексов, мы просто использовали тот факт, что нашему запросу требуется самая последняя дата, и, следовательно, применили функцию DATE () в правой части запроса и вуаля, среда выполнения запроса падение со средних 56 секунд до 5 секунд!
Любопытный случай неудачного ЗАКАЗА от
Много раз для выполнения простых и тривиальных задач, например, вы хотите найти 10 недавних уведомлений, которые находятся, скажем, в некоторой категории с идентификатором 19.
Но сложность в том, что наша дорогая таблица индексируется в возрастающем порядке по categoryId и createdAt time, и из-за этого мы выполняем дополнительную операцию ORDER BY, которая тоже в обратном направлении, чем та. который должен был быть взят. Умное использование индексов может облегчить вашу жизнь, безответственные индексы, ну, они могут сделать вашу жизнь 15-минутной (Я НЕ ДЕТЯМ, БУКВАЛЬНО 15 МИНУТ РАБОТЫ) runtime ад. Твой выбор.
Запрос, с которым мы столкнулись, был следующим:
Оптимизация SQL-запросов в SQL Server
Каковы передовые методы оптимизации запросов в SQL Server?Хорошо продуманные запросы критически важны для производительности базы данных SQL Server.Неэффективные запросы могут создавать слишком сложные алгоритмы, которые используют чрезмерные ресурсы и снижают производительность в целом. Оптимизация запросов может иметь огромное влияние на скорость обработки, использование ресурсов и многое другое. Рекомендации по настройке запросов SQL Server относительно просты и в основном основаны на использовании правильного синтаксиса:
● Используйте SELECT вместо списка столбцов SELECT *
● Используйте EXISTS вместо COUNT ()
● По возможности избегайте SQL DISTINCT
● Избегайте Пункт IN-operator
● Правильно используйте подстановочные знаки
● И многое другое.
SQL Diagnostic Manager дает администраторам баз данных видимость общей эффективности запросов, гарантируя, что планы выполнения запросов соответствуют передовым практикам, и дает администраторам баз данных возможность быстро решить проблему, если нет.
Как найти медленный запрос в SQL Server?С помощью Query Monitor администраторы баз данных могут устанавливать критерии для запросов и подзапросов, которые они хотят перехватывать, а затем фильтровать эти результаты по метрикам для анализа запросов в данной категории.Это позволяет администраторам баз данных быстро и легко определять и обрабатывать медленно выполняющиеся запросы в рамках своего обычного процесса настройки производительности.
Как вы анализируете производительность SQL-запросов?Мониторинг и анализ производительности SQL-запросов позволяет администраторам баз данных устранять потенциальные проблемы с производительностью задолго до того, как они вызовут серьезные проблемы. С помощью диспетчера диагностики SQL администраторы баз данных могут анализировать производительность SQL-запросов несколькими способами:
● Просмотр режима подписи, который отображает общую информацию о производительности для отдельных операторов SQL или сигнатур запросов
● Просмотр режима операторов, который показывает конкретную информацию о производительности для отдельных операторов SQL или сигнатуры запросов
● Просмотр истории запросов, который показывает ежедневное историческое влияние запроса на производительность.
● Просмотр ожидания запроса, который отображает ожидания во времени и по продолжительности для выявления основных узких мест
Когда были обнаружены медленно выполняющиеся или иным образом неэффективные запросы, Администраторы баз данных могут применять проверенные методы оптимизации для повышения общей производительности базы данных.Вообще говоря, большое количество медленно выполняющихся запросов указывает на низкую производительность, которую необходимо решить.
База данных MYSQL Сопоставление операторов высокочастотного запроса
запрос числовых данных:
SELECT * from Tb_name WHERE sum>;
предикат запроса:>, =, <, <>,! = ,!>,! <, =>, = <
Две строки запроса
SELECT * из tb_stu WHERE sname = ‘Xiao Liu’
SELECT * из Tb_stu WHERE sname like ‘Liu’
SELECT * from Tb_stu WHERE sname like ‘% Programmer’
_ SELECT * from Tb_stu WHERE sname like ‘% php%’
три запроса данных типа даты
SELECT * from tb_stu WHERE date = ‘2011-04-08’
Примечание: разные базы данных имеют различия в данных типа даты:
(1) mysql: select * from tb_name WHERE birthday = ‘2011-04-08’
(2) SQL Server: select * from tb_name WHERE birthday = ‘2011-04-08’
(3) Доступ: выберите * из tb_name WHERE birthday = # 2011-04-08 #
четыре запроса данных логического типа
SELECT * from tb_name WHERE type = ‘T’
SELECT * from tb_name WHERE type = ‘F’
логические операторы: и OR не
пять запросов непустых данных
SELECT * from Tb_name WHERE address <> «ORDER BY addtime Desc
Примечание: <> эквивалентно! = в PHP
Шесть переменных используют для запроса числовых данных
SELECT * from tb_name WHERE id = ‘$ _post [text]’
Примечание. При запросе данных с переменных, переменные, передаваемые в SQL, не должны быть заключены в кавычки, потому что, когда строка в PHP соединяется с числовыми данными, программа автоматически преобразует числовые данные в строку, а затем подключается к строке для конкатенации
Семь запросов строковых данных с переменными
SELECT * from Tb_name WHERE name like ‘% $ _ post [name]%’
Метод точного совпадения «процент» означает, что он может появляться в любой позиции
восемь предварительных запросов N записей
SELECT * from Tb_name LIM IT 0, $ N;
Оператор предела используется вместе с другими операторами, такими как порядок по, и использует различные операторы SQL, чтобы сделать программу очень гибкой
Девять запросов после N записей
SELECT * из Tb_stu ORDER по ID ASC LIMIT $ n
10 запросов N записей, начиная с указанного местоположения
SELECT * from Tb_stu ORDER by ID ASC LIMIT $ _post [начало], $ n
ПРИМЕЧАНИЕ. Идентификатор данных начинается с 0
11 Запросить первые N записей в результатах статистики
SELECT * , (Yw + sx + wy) как общее из Tb_score ORDER по (yw + sx + wy) DESC LIMIT 0, $ num
12 запрос данных для указанный период времени
SELECT Поле для поиска по имени таблицы WHERE имя поля между начальным значением и конечным значением
SELECT * from Tb_stu WHERE age от 0 до
13 статистика запросов по месяцам
SELECT * from Tb_stu WHERE month (date) = ‘$ _post [date]’ ORDER by date;
Примечание. В языке SQL доступны следующие функции, которые упрощают поиск по году, месяцу и дню
год (данные): возвращает значение, соответствующее A.D. в выражении данных
Месяц (данные): возвращает значение месяца в выражении данных
День (данные): возвращает числовое значение даты в выражении данных
14 запрос записей, размер которых превышает указанные критерии
SELECT * from Tb_stu WHERE age> $ _ post [age] ORDER by age;
15 В результатах запроса не отображаются повторяющиеся записи
SELECT DISTINCT имя поля из имени таблицы WHERE условие запроса
Примечание. Отдельные элементы в операторе SQL должны использоваться вместе с предложением WHERE, иначе выходная информация не изменится, и поле нельзя будет заменить *
16 запросов, которые не объединяют условия с предикатами
(1) Не между ними… И … Запрос строк между начальным и конечным значениями можно изменить на <начальное значение и> Конечное значение
(2) не равно NULL для запроса ненулевых значений
(3 ) является запросом NULL для значений NULL
(4) Не в этом стиле, в зависимости от того, включено ли используемое ключевое слово в список или исключено из него, выражение поиска может быть константой или именем столбца, а имя столбца может быть набором констант, но скорее подзапросом
17 отображение повторяющихся записей и полос записей в таблице данных
SELECT Имя, возраст, количество (*), возраст from tb_stu WHERE age = ‘+’ GROUP по дате
18 Нисходящий / восходящий запрос данных
ВЫБРАТЬ имя поля из Tb_stu WHERE condition order BY field desc по убыванию 900 07 ВЫБРАТЬ имя поля из Tb_stu ГДЕ условие ПОРЯДОК по полю ASC по возрастанию
Примечание: при сортировке поля без указания порядка сортировки по умолчанию используется ASC по возрастанию
19 Запрос данные в нескольких условиях
ВЫБРАТЬ имя поля из Tb_stu WHERE condition ORDER по полю 1 ASC Поле 2 DESC…
Примечание. Информация запроса упорядочена для совместного ограничения вывода записи, как правило, поскольку это не единственное ограничение условия, поэтому есть некоторые различия в эффекте вывода.
20 Сортировка результатов статистики
Функция sum ([All] field name) или sum ([DISTINCT] field name) может использоваться для суммирования полей , просуммируйте все записи для всех полей в функции и просуммируйте поля для всех полей, которые не являются повторяющимися записями для DISTINCT.
например: SELECT name, sum (Price) as Sumprice from Tb_price GROUP by name
SELECT * from Tb_name ORDER by Mount Desc, price ASC
21 статистика группировки данных в одну строку
ВЫБРАТЬ id, имя, сумму (цену) как заголовок, дату из Tb_price ГРУППА по PID ORDER по заголовку DESC
Примечание. order by присутствует в операторе SQL, оператор группировки записывается перед оператором сортировки, в противном случае возникает ошибка
22 статистика группировки данных по нескольким столбцам
статистика группировки данных по нескольким столбцам статистика группировки данных в одну строку аналогична
select *, sum (поле 1 * поле 2) AS (новое поле 1) FROM table nam e группировать по полю ORDER BY новое поле 1 desc
select id, name, sum (price * num) AS sumprice FROM tb_price Группировать по pid order by sumprice desc
ПРИМЕЧАНИЕ. За оператором Group by обычно следует ряд, который не агрегатная функция, которая не является столбцом для группировки
23 Статистика группировки нескольких таблиц
выберите a.name, avg (A.price), B.name, avg (B.price) из tb_demo058 как a, tb_demo058_1 как b, где a.id = b.id сгруппировать по типу b;
База данных MYSQL Сопоставление операторов высокочастотного запроса
NVivo 11 для Windows Справка
Вы можете использовать запросы Word Frequency, чтобы перечислить наиболее часто встречающиеся слова или понятия в ваших источниках.
В этой теме
Понять Слово Частота запросов
Используйте запросы Word Frequency, чтобы перечислить наиболее часто встречающиеся слова или понятия, встречающиеся в ваших источниках.
Вы можете использовать запрос Word Frequency для:
Определите возможные темы, особенно на ранних стадиях проекта
Анализируйте наиболее часто употреблял слова в определенной демографической группе. Например, проанализировать наиболее общие слова, используемые фермерами. Вы можете выполнить запрос кодирования, чтобы собрать весь контент закодирован в узлах case с атрибутом farmer — тогда выберите узел результата в качестве критерия для запроса Word Frequency.
Если вы используете NVivo Pro или NVivo Plus, вы можете также используйте запрос Word Frequency для:
Ищите точные слова, или расширьте область поиска, чтобы найти наиболее часто встречающиеся концепции. Например, если вы ищете наиболее часто встречающиеся слова в наборе данных опрос, вы можете обнаружить, что вода, здоровье, и вредные являются наиболее часто встречающиеся слова. Однако, если вы сгруппируете похожие слова вместе, вы может обнаружить, что концепция загрязнения (включая загрязняющие вещества, загрязнение, загрязненные, и загрязняет) встречается наиболее часто.
Перед запуском запроса Word Frequency убедитесь, что язык текстового контента установлен на язык ваших исходных материалов — см. установить язык текстового контента и стоп-слова для получения дополнительной информации.
Если вы запускаете запрос Word Frequency, созданный в другом версии NVivo, он может искать источники, которые не поддерживаются в вашем версия. Вы увидите точные результаты, но не сможете открыть или просмотреть некоторые ссылки.Обратитесь к О запросы (Работа с запросами по выпускам) для получения дополнительной информации.
Верх из страницы
Создайте запрос частоты слов с помощью мастера
по запросу на вкладке в группе Создать щелкните Мастер запросов.
| Шаг мастера | Описание |
Выбрать запрос, который вы хотите выполнить. | Нажмите Определите часто встречающиеся термины в содержании. |
Укажите термины, которые вы хотите найти. | В в поле Отображать слова укажите количество слов, отображаемых в результатах — например, показать только 20 лучших слов. В минимальном слове поле длины введите количество символов наименьшего слово, которое вы хотите включить. Например, длина слова 4 будет исключить из результатов короткие слова. Выберите группу
вариант. Выберите поиск точных совпадений или сгруппируйте слова с одинаковыми
вместе — например, вы можете искать спорт
и найти спорт. |
Выбрать где вы хотите считать слова. | Выбрать хотите ли вы подсчитывать слова во всех ваших источниках или ограничить счетчик слов в выбранных элементах или папках. |
Выберите, нужно ли чтобы добавить запрос в свой проект. | Ты можешь бежать запрос один раз или добавьте его в свой проект (и запустите). Если вы решите добавить его в свой проект, вы необходимо ввести имя.При желании вы можете ввести описание. |
Нажмите Бег.
ПРИМЕЧАНИЕ Если вы хотите использовать функции запроса Word Frequency, которые недоступны через Мастер — например, считает только слова в источниках, созданных конкретными пользователями — вы можете добавить запрос в свой проект и обновить его позже. Если вы знакомы с запросами NVivo вы можете предпочесть создавать запрос вне мастера.
Верх из страницы
Создание запроса частоты слов вне мастера
Если вы не знакомы с запросами NVivo, вы можете хотите создать свой запрос Word Frequency с помощью мастера — мастер помогает через процесс установки критериев запроса.Тем не менее, не все функции запроса доступны в мастере, поэтому иногда может потребоваться для создания запросов Word Frequency вне мастера.
по запросу на вкладке в группе «Создать» щелкните «Частота слов».
Выбери где хочешь для поиска совпадающего текста:
- Все источники — поиск для контента во всех источниках вашего проекта, включая внешние и служебные записки
- Выбранные элементы — ограничить ваш поиск по выбранным элементам (например, набор, содержащий интервью стенограммы)
- Выбранные папки — ограничить поиск по содержимому выбранных папок (например, папка стенограмм интервью)
Укажите, сколько слов вы хотите отобразить:
- <номер> наиболее частые — включают определенное количество слов.Например, вы можете отобразить 100 наиболее часто встречающихся слов.
- Все — включить все слова, найденные в выбранных элементах проекта.
(необязательно) Введите минимальная длина слова, чтобы исключить короткие слова из результатов, например, введите 5, чтобы отображать только слова, состоящие из пяти или более букв.
Выберите группу вариант. Выберите поиск точных совпадений или сгруппируйте слова с одинаковыми вместе — например, поиск спорта и найти спорт.Если у вас есть NVivo Pro или NVivo Plus можно регулировать ползунком чтобы расширить область поиска, чтобы найти похожие концепции. Например, найдите спорт, игра и отдых. Обратитесь к пониманию настройки соответствия текста для получения дополнительной информации.
Выберите, будете ли вы хотите искать закодированный контент во всех ваших источниках или ограничить поиск в выбранных элементах или папках — нажмите кнопку Выбрать кнопка для выбора конкретных элементов проекта.
Нажмите «Выполнить» Кнопка запроса вверху детального просмотра.
ПРИМЕЧАНИЕ Для сохранения Word Запрос частоты, нажмите Добавить в проект кнопку и введите имя и описание (необязательно) в поле Общие таб.
Верх из страницы
Понять результаты
Когда вы запускаете запрос Word Frequency, результаты отображается в подробном представлении. В зависимости от вашей версии может быть до четырех вкладки, отображаемые справа — Сводка, Word Облако, древовидная карта и кластер Вкладки анализа.Вы можете изменить вкладку, отображаемую по умолчанию — см. к параметрам отображения в Set параметры приложения для получения дополнительной информации.
Вкладка «Сводка»
1 Самый часто встречающиеся слова, исключая любую остановку слова. Если вы отрегулировали ползунок так, чтобы он возвращал похожие слова, наиболее в этом столбце отображается часто встречающееся слово из группы.
2 Длина — длина количество букв или символов в слове.
3 Счетчик — количество раз, когда это слово встречается в найденных элементах проекта.Если вы настроили ползунок, чтобы включить похожие слова, это количество итого для всех похожих слов.
4 Взвешенный Процент — частота слова по отношению к общему количеству подсчитанных слов. Если вы настроили ползунок, чтобы включить похожие слова, слово может быть частью более чем одной группы похожих слов. Взвешенный процент присваивает часть частоты слова для каждой группы, чтобы общая сумма не превышает 100%.
5 Похожий Слова — другие слова, которые были включены в результате включения сокращенных или похожие слова — например, если вы включаете слова с той же основой, затем загрязняющие вещества, загрязнения и загрязненные будут сгруппированы вместе.Этот столбец недоступен, если вы используете «Точный только совпадение ‘.
Вкладка «Облако слов»
На этой вкладке отображается до 100 слов с различным шрифтом. размеры, где часто встречающиеся слова выделены более крупным шрифтом.
Когда вы просматриваете результаты в виде облака слов, вы можно изменить стиль — в облаке слов вкладка (лента), выберите из галереи стилей.
Вкладка «Древовидная карта»
Эта функция доступна в NVivo Pro. и NVivo Plus.
Вкладка «Древовидная карта» отображает до 100 слов в виде серии прямоугольников, где часто встречаются слова в больших прямоугольниках.
Вкладка «Кластерный анализ»
Эта функция доступна в NVivo Pro. и NVivo Plus.
Кластерный анализ вкладка отображает до 100 слов в виде горизонтальной дендрограммы, где слова, сосуществуют вместе.
Если щелкнуть диаграмму кластерного анализа, становится доступной вкладка Cluster Analysis (на ленте), вы можете использовать команды на этой вкладке ленты:
Измените тип диаграммы — вы может отображать данные в виде горизонтальной или вертикальной дендрограммы, круга график, либо 2D- или 3D-карта кластера
На картах кластеров 2D или 3D, установите флажок Word Frequency если вы хотите использовать частоту слов для определения размера пузырей на карте кластера.
Для получения дополнительной информации см. Изменить внешний вид или содержание диаграммы кластерного анализа.
Верх из страницы
См. все ссылки для выбранного слова
Когда вы запускаете запрос Word Frequency, узел предварительного просмотра создается для каждого слова — это позволяет увидеть все ссылки на слово. Чтобы открыть узел предварительного просмотра, дважды щелкните слово, которое хотите изучить.
В узле предварительного просмотра вы видите каждое вхождение выбранное ключевое слово в контексте:
Отображается контекст (текст вокруг слова) серым цветом — по умолчанию это «узкий» контекст.Чтобы расширить контекст для выбранная ссылка на вкладке «Узел» в группе Просмотр щелкните Coding Context и выберите контекст кодирования.
ПРИМЕЧАНИЕ Для других типы узлов, название вкладки ленты другое. Например, если вы в настоящее время работаете в узле case, вы получите доступ к вышеуказанному команды на вкладке Дело.
Верх из страницы
При определении частоты слов NVivo применяет следующие правила:
слов, содержащих знаки препинания (например, дефисы, точки и другие символы) разделены на отдельные слова.Например, неполный рабочий день будет засчитываться как часть и время.
слов, содержащих апострофы (например, o’clock и d’accord) обрабатываются как одно слово, но если за апострофом следует тогда s не включается (Том будет считаться Томом).
В аудио и видео стенограммах, только слова в поле Content (столбец) подсчитываются — любые слова в настраиваемых полях расшифровки игнорируются.
В наборах данных только слова в кодируемых полях (столбцах) подсчитываются — любые слова в классифицирующих полях игнорируются.
При поиске текста в выбранные узлы, если слово закодировано для нескольких узлов, оно засчитывается один раз для каждого узла. Точно так же, если слово было закодировано несколькими пользователей к одному узлу, он учитывается один раз для каждого пользователя.
Word Frequency запросов не включайте «стоп-слова» — см. «Исключить» определенные слова при выполнении запросов Word Frequency для получения дополнительной информации Информация.
Запрос частоты слов не выполняет поиск текста в сводках каркасной матрицы
Word Frequency запросов не ищите текст в изображениях. PDF-файлы, созданные путем сканирования бумажных документов может содержать только изображения — каждая страница представляет собой отдельное изображение. Если хотите используйте запросы Word Frequency, чтобы исследовать текст в этих PDF-файлах, затем вам следует подумать об использовании оптического распознавания символов (OCR) для преобразования отсканированные изображения в текст (перед импортом файлов PDF в NVivo).
Если язык текстового содержимого является японским, «базовая форма» указана в результатах запроса, но count включает любые альтернативные формы слова — см. Рабочий с японским текстом в запросах для получения дополнительной информации.
Верх из страницы
Исключить конкретные слова при выполнении запросов Word Frequency
запросов Word Frequency не включают «стоп-слова» — по по умолчанию это менее значимые слова, такие как союзы или предлоги, это может не иметь значения для вашего анализа.Вы можете просматривать и редактировать список стоп-слов, см. Установить язык текстового контента и стоп-слова для получения дополнительной информации.
Вы можете добавить слово, отображаемое в результатах вашего запроса в список стоп-слов — выберите слово, которое хотите исключить из запроса результатов, затем нажмите Добавить в список стоп-слов, в группе Действия в Запросе таб. Слова, которые вы добавляете в список стоп-слов, будут исключены в следующий при выполнении запроса «Частота слов» или «Текстовый поиск».
ПРИМЕЧАНИЕ На сервере проектов, только владельцы проектов могут добавлять слова в список стоп-слов — см. сотрудничать в серверном проекте для получения дополнительной информации.
Верх из страницы
Вы можете создать узел, включающий все ссылки к слову, которое вы выбрали в результатах запроса Word Frequency.
В результатах запроса выберите слово, которое хотите использовать для создания узла.
Создание на вкладке в группе Элементы щелкните Создать как узел.
Выберите место и назовите узел.
Щелкните OK.
ПРИМЕЧАНИЕ Если текст язык содержимого — японский, узел будет содержать ссылки на основная форма или любые альтернативные формы слова — см. Рабочие с японским текстом в запросах для получения дополнительной информации.
Верх из страницы
Вы можете запустить текстовый поисковый запрос для выбранного слова в результатах запроса Word Frequency.
по запросу на вкладке в группе Действия щелкните Другие действия, а затем щелкните Запустить запрос текстового поиска.
(необязательно) Измените Критерии текстового поиска или запрос Параметры. Обратитесь к Выполнить запрос текстового поиска для получения дополнительной информации.
Щелкните «Выполнить».
ПРИМЕЧАНИЕ Если текст язык контента — японский, запрос текстового поиска найдет все вхождения базовой формы или любых альтернативных форм слова — см. Рабочую с японским текстом в запросах для получения дополнительной информации.
Верх из страницы
Связанные темы
непрерывных запросов | Архив документации InfluxData
При записи больших объемов данных в InfluxDB вы часто можете захотеть понизить выборку необработанных данных, то есть использовать GROUP BY time () с функцией InfluxQL, чтобы преобразовать высокочастотные данные в более низкочастотные. Многократное выполнение одних и тех же запросов вручную может быть утомительным. Непрерывные запросы InfluxDB (CQ) упрощают процесс понижающей дискретизации; CQ запускаются автоматически и записывают результаты запроса в другое измерение.
Определение CQ
CQ — это запрос InfluxQL, который система автоматически и периодически выполняет в базе данных. InfluxDB сохраняет результаты CQ в указанном измерении. Для CQ требуется функция в предложении SELECT и должно включать предложение GROUP BY time () .
CQ не поддерживают никакого состояния. Каждое выполнение CQ — это отдельный запрос, который повторно выбирает все точки в базе данных, соответствующие условиям запроса.
Временные диапазоны результатов CQ имеют границы округления, которые устанавливаются внутри базы данных.В настоящее время у пользователей нет возможности изменить время начала или окончания интервалов.
Только администраторы могут работать с непрерывными запросами. Подробнее о правах пользователя см. Аутентификация и авторизация.
Примечание: CQ выполняются только для данных, полученных после создания CQ. Если вы хотите выполнить субдискретизацию данных, записанных в InfluxDB до создания CQ, см. Примеры в разделе «Исследование данных».
InfluxQL для создания CQ
Оператор
CREATE CONTINUOUS QUERY CREATE CONTINUOUS QUERY ON [RESAMPLE [EVERY ] [FOR ]] BEGIN () [, ()] INTO FROM [WHERE ] GROUP BY time () [, ] END CREATE CONTINUOUS QUERY , по сути, является запросом InfluxQL, окруженным CREATE CONTINUOUS QUERY [...] НАЧАЛО и КОНЕЦ .
Следующее обсуждение разбивает оператор CQ на его мета-часть (все между CREATE и BEGIN ) и часть запроса (все между BEGIN и END ).
Мета-синтаксис:
СОЗДАТЬ НЕПРЕРЫВНЫЙ ЗАПРОС НА <имя_базы_данных> [ПЕРЕЗАГРУЗКА [КАЖДЫЙ <интервал>] [ДЛЯ <интервал>]]
CQ принадлежит базе данных.
Укажите базу данных, в которой вы хотите разместить CQ с ON .
Примечание: Если два непрерывных запроса в разных базах данных имеют одинаковое имя, будет запущен только один из непрерывных запросов. Этой проблемы нет в InfluxDB версии 0.11 (исправлено в PR # 5814).
Необязательное предложение RESAMPLE определяет, как часто InfluxDB запускает CQ ( EVERY <интервал> ) и временной диапазон, в течение которого InfluxDB выполняет CQ ( FOR ).
Если включено, предложение RESAMPLE должно указывать либо EVERY , либо FOR , либо и то, и другое.Без предложения RESAMPLE InfluxDB запускает CQ с тем же интервалом, что и интервал GROUP BY time () , и вычисляет запрос для самого последнего интервала GROUP BY time () (то есть, где время находится между сейчас () и сейчас () минус GROUP BY time () интервал).
Синтаксис запроса:
BEGIN SELECT <функция> () [, ()] INTO FROM [WHERE ] GROUP BY time ( ) [, <материал>] КОНЕЦ
Запрос в этой инструкции отличается от обычного SELECT [...] Оператор GROUP BY (время) двумя способами:
Предложение
INTO: Здесь вы указываете целевое измерение для результатов запроса.Необязательный пункт
WHERE: Поскольку CQ выполняются через регулярно увеличивающиеся интервалы времени, вам не нужно (и не следует!) Указывать временной диапазон в предложенииWHERE. При включении предложение CQWHEREдолжно фильтровать информацию о тегах.
Примечание: Если вы включаете тег в предложение CQ
SELECT, InfluxDB изменяет тег вна поле в.Чтобы сохранить тег в, включите только ключ тега в предложение CQGROUP BY.Если вы укажете тег в предложении
SELECTCQ и в предложенииGROUP BYCQ, вы не сможете запрашивать данные в. См. GitHub Issue # 4630 для получения дополнительной информации.
Примеры CQ:
Создать CQ с одной функцией:
> СОЗДАТЬ НЕПРЕРЫВНЫЙ ЗАПРОС minnie ON world НАЧАТЬ ВЫБРАТЬ min (мышь) INTO min_mouse FROM zoo GROUP BY time (30m) ENDПосле выполнения, InfluxDB автоматически вычисляет 30-минутный минимум поля
mouseв измеренииzooи записывает результаты в измерениеmin_mouse.Обратите внимание, что CQminnieсуществует только в базе данныхworld.Создайте CQ с одной функцией и запишите результаты в другую политику хранения:
> СОЗДАТЬ НЕПРЕРЫВНЫЙ ЗАПРОС minnie_jr В мире НАЧАТЬ ВЫБРАТЬ min (mouse) INTO world. "7days" .min_mouse FROM world. "1day". zoo GROUP BY time (30m) ENDCQ
minnie_jrдействует так же, как CQminnie, однако InfluxDB вычисляет 30-минутный минимум поляmouseв измеренииzooи ниже политика хранения1 день, и она автоматически записывает результаты запроса в измерениеmin_mouseв соответствии с политикой хранения7 дней.Объединение CQ и политик хранения обеспечивает полезный способ автоматического субдискретизации данных и удаления ненужных необработанных данных. Для полного обсуждения этой темы см. Понижение частоты дискретизации и сохранение данных.
Создание CQ с двумя функциями:
> СОЗДАТЬ НЕПРЕРЫВНЫЙ ЗАПРОС minnie_maximus В мире НАЧАТЬ ВЫБРАТЬ min (мышь), max (imus) INTO min_max_mouse FROM zoo GROUP BY time (30m) ENDThe C_max автоматически вычисляет 30-минутный минимум поля
mouseи 30-минутный максимум поляimus(оба поля находятся в измеренииzoo) и записывает результаты в измерениеmin_max_mouse.Создайте CQ с двумя функциями и персонализируйте ключи полей в результатах:
> СОЗДАТЬ НЕПРЕРЫВНЫЙ ЗАПРОС minnie_maximus_1 В мире НАЧАТЬ ВЫБРАТЬ min (мышь) AS minuscule, max (imus) AS чудовищно INTO min_max_mouse FROM zoo time (30m) ENDCQ
minnie_maximus_1действует так же, какminnie_maximus, однако InfluxDB называет полевые ключиminisculeиmonstrousв измерении назначения вместоminиmax.Для получения дополнительной информации оASсм. Функции.Создайте CQ с 30-минутным интервалом
GROUP BY time (), который запускается каждые 15 минут:> СОЗДАЙТЕ НЕПРЕРЫВНЫЙ ЗАПРОС вампиров в Трансильвании ИСПОЛЬЗУЙТЕ КАЖДЫЕ 15 м НАЧАЛО ВЫБРАТЬ количество (дракула) В vampire_populations FROM raw_vampires GROUP BY time (30m) ENDБез
RESAMPLE EVERY 15m,вампирыбудут запускаться каждые 30 минут — тот же интервал, что и интервалGROUP BY time ().Создайте CQ с 30-минутным интервалом
GROUP BY time (), который выполняется каждые 30 минут и вычисляет запрос для всехGROUP BY time () интерваловза последний час:> СОЗДАТЬ НЕПРЕРЫВНЫЙ ЗАПРОС vampires_1 В Трансильвании ПРЕОБРАЗОВАТЕЛЬ НА 60 м НАЧАТЬ СЧЕТ ВЫБОРА (dracula) INTO vampire_populations_1 FROM raw_vampires ГРУППА ПО времени (30 мин) КОНЕЦInfluxDB запускает
vampires_1каждые 30 минут (тот же интервал, что и интервалGROUP BY time ()интервал) и он вычисляет два запроса за запуск: один, где время находится междусейчас ()исейчас () - 30м, а второй, где время находится междусейчас () - 30мисейчас () - 60м.Без предложенияRESAMPLEInfluxDB будет вычислять запрос только для одного 30-минутного интервала, то есть, когда время находится междуnow ()иnow () - 30m.Создайте CQ с 30-минутным интервалом
GROUP BY time (), который выполняется каждые 15 минут и вычисляет запрос для всехGROUP BY time () интерваловза последний час:> СОЗДАТЬ НЕПРЕРЫВНЫЙ ЗАПРОС vampires_2 В Трансильвании ИСПОЛЬЗУЙТЕ КАЖДЫЕ 15 м. НА 60 м. НАЧАЛО ВЫБРАТЬ count (dracula) INTO vampire_populations_2 FROM raw_vampires ГРУППА ПО ВРЕМЕНИ (30 мин) КОНЕЦvampires_2запускается каждые 15 минут и вычисляет два запроса за запуск: один, где время находится междусейчас ()исейчас () - 30 мин., а второй, где время находится междусейчас () - 30 минисейчас () - 60 мин
CQ с обратными ссылками
Использовать : MEASUREMENT в операторе INTO для обратной ссылки на имена измерений:
CREATE CONTINUOUS QUERY ON BEGIN SELECT () [, ()] INTO < имя_базы_данных>..: MEASUREMENT FROM [WHERE ] GROUP BY time () [, ] END Пример обратной ссылки CQ:
> CREATE НЕПРЕРЫВНЫЙ ЗАПРОС в другом месте В фантазии НАЧАТЬ ВЫБРАТЬ среднее (значение) В реальность. "По умолчанию".: ИЗМЕРЕНИЕ ИЗ / elf / ГРУППА ПО времени (10 мин) КОНЕЦ CQ в другом месте автоматически вычисляет 10-минутное среднее значение поля в каждом измерении elf в базе данных fantasy .Он записывает результаты в уже существующую базу данных reality , сохраняя все названия измерений в fantasy .
Образец данных в fantasy :
> ПОКАЗАТЬ ИЗМЕРЕНИЯ
имя: измерения
------------------
имя
elf1
elf2
волшебник
>
> ВЫБРАТЬ * ИЗ elf1
имя: cpu_usage_idle
--------------------
временная стоимость
2015-12-19T01: 15: 30Z 97.76333874796951
2015-12-19T01: 15: 40Z 98.3129217695576
[...]
2015-12-19T01: 36: 00Z 94.71778221778222
2015-12-19T01: 35: 50Z 87,8 Образец данных в реальности после в другом месте запускается немного:
> ПОКАЗАТЬ ИЗМЕРЕНИЯ
имя: измерения
------------------
имя
elf1
elf2
>
> ВЫБРАТЬ * ИЗ elf1
имя: elf1
--------------------
среднее время
2015-12-19T01: 10: 00Z 97.11668879244841
2015-12-19T01: 20: 00Z 94.50035091670394
2015-12-19T01: 30: 00Z 95.997389172 Список CQ с
SHOW Список всех CQ по базе данных с:
Пример:
> ПОКАЗАТЬ НЕПРЕРЫВНЫЕ ЗАПРОСЫ
имя: реальность
-------------
запрос имени
имя: фэнтези
-------------
запрос имени
в другом месте СОЗДАЙТЕ НЕПРЕРЫВНЫЙ ЗАПРОС в другом месте НАЧАТЬ ВЫБРАТЬ среднее (значение) В реальность."default".: ИЗМЕРЕНИЕ ИЗ фантазии. "default" ./ cpu / WHERE cpu = 'cpu-total' GROUP BY time (10m) END Выходные данные показывают, что база данных , реальность не имеет CQ, а база данных У fantasy есть один CQ под названием в другом месте .
Удалить CQ с помощью
DROP Удалить CQ из конкретной базы данных с помощью:
DROP CONTINUOUS QUERY ON Пример:
U ONOUSO CONTINUE
> Успешный DROP CONTINUOUS QUERY возвращает пустой ответ.
Backfilling
CQ не заполняют данные, то есть они не вычисляют результаты для данных, записанных в базу данных до того, как CQ существовал. Вместо этого пользователи могут заполнять данные с помощью предложения INTO . В отличие от CQ, запросы обратной засыпки требуют предложения WHERE с ограничением времени .
Примеры
Вот базовый пример обратной засыпки:
> SELECT min (temp) as min_temp, max (temp) as max_temp INTO "reading.minmax.5m" FROM чтения
ГДЕ время> = '2015-12-14 00:05:20' И время <'2015-12-15 00:05:20'
GROUP BY time (5m) Теги ( sensor_id в приведенном ниже примере) могут использоваться дополнительно таким же образом, как и в CQ:
> SELECT min (temp) как min_temp, max (temp) как max_temp INTO "чтение.minmax.5m "ОТ чтения
ГДЕ время> = '2015-12-14 00:05:20' И время <'2015-12-15 00:05:20'
GROUP BY time (5m), sensor_id Чтобы предотвратить создание при обратной засыпке огромного количества «пустых» точек, содержащих только нулевых значений , в конце запроса можно использовать функцию fill ():
> SELECT min (temp) как min_temp, max (temp) как max_temp INTO "чтение.minmax.5m" ОТ чтения
ГДЕ время> = '2015-12-14 00:05:20' И время <'2015-12-15 00:05:20'
GROUP BY time (5m), fill (none) Если вы хотите дополнительно разбить запросы и выполнять их с еще большим контролем, вы можете добавить дополнительные предложения WHERE :
> SELECT min (temp) как min_temp, max (temp) как max_temp INTO "чтение.minmax.5m "ОТ чтения
ГДЕ sensor_id = "EG-21442" И время> = '2015-12-14 00:05:20' И время <'2015-12-15 00:05:20'
GROUP BY time (5 мин) Дальнейшее чтение
Теперь, когда вы знаете, как создавать CQ с InfluxDB, ознакомьтесь с Downsampling and Data Retention, чтобы узнать, как комбинировать CQ с политиками хранения для автоматического понижения выборки данных и удаления ненужных данных.
Amazon RDS Performance Insights с поддержкой метрик уровня SQL в Amazon RDS для MySQL
Amazon RDS Performance Insights поддерживает метрики на уровне SQL в Amazon RDS для баз данных MySQL, поэтому вы можете определять высокочастотные, длительные и зависшие запросы SQL за секунды.
Ранее сбор данных о производительности в базе данных требовал настройки и обслуживания приложений мониторинга и связанных ресурсов. Корреляция данных о производительности заняла часы без специальных знаний. Чтобы найти интересующий запрос, например зависший или долго выполняющийся SQL-запрос, нужно было исследовать каждый запрос по отдельности.
RDS Performance Insights позволяет неспециалистам определять основные нагрузки SQL и их источник на визуальной панели за считанные секунды.Теперь RDS Performance Insights также собирает метрики уровня SQL, такие как средняя задержка, количество вызовов в секунду и количество строк, возвращаемых за вызов. Вы можете определить, занимает ли SQL-запрос слишком много времени для выполнения или конкретный SQL-запрос вызывается с другой скоростью, чем вы ожидаете, а затем внести улучшения в свое приложение, такие как оптимизация медленного SQL-запроса, добавление индекса в вашу базу данных и масштабирование вашей базы данных.
Amazon RDS Performance Insights - это функция настройки и мониторинга производительности базы данных RDS, которая позволяет визуально оценить нагрузку на вашу базу данных и определить, когда и где предпринять действия.Одним щелчком мыши в консоли управления Amazon RDS вы можете добавить полностью управляемое решение для мониторинга производительности в свою базу данных Amazon RDS. RDS Performance Insights входит в состав поддерживаемых кластеров Amazon Aurora и инстансов Amazon RDS и сохраняет семидневную историю производительности в скользящем окне без дополнительных затрат. Если вам нужно долгосрочное хранение, вы можете оплатить хранение истории эффективности до двух лет.