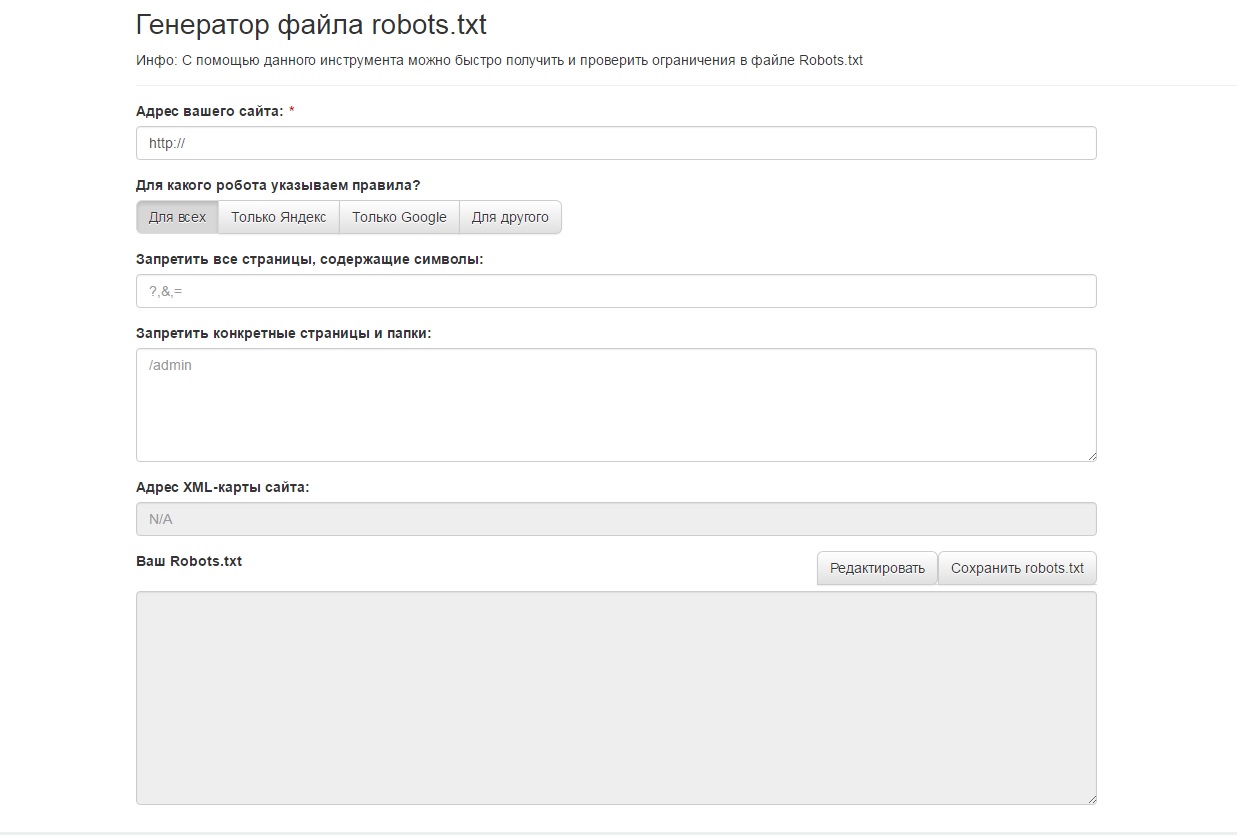
Запрет индексации сайта поисковыми системами. Самостоятельно проверяем и меняем файл robots.txt. Зачем закрывать сайт от индексации?
Зачем закрывать сайт от индексации? Проверяем и меняем файл robots.txt самостоятельно.
Ответ
Для закрытия всего сайта от индексации во всех поисковых системах необходимо в файле robots.txt прописать следующую директиву:
Disallow: /
Далее, подробнее разберемся в вопросе подробнее и ответим на другие вопросы:
- Процесс индексации что это?
- Зачем закрывать сайт от индексации?
- Инструкции по изменению файла robots.txt
- Проверка корректности закрытия сайта от индексации
- Альтернативные способы закрыть сайт от поисковых систем
Оглавление
Процесс индексации
Индексация сайта – это процесс добавления данных вашего ресурса в индексную базу поисковых систем.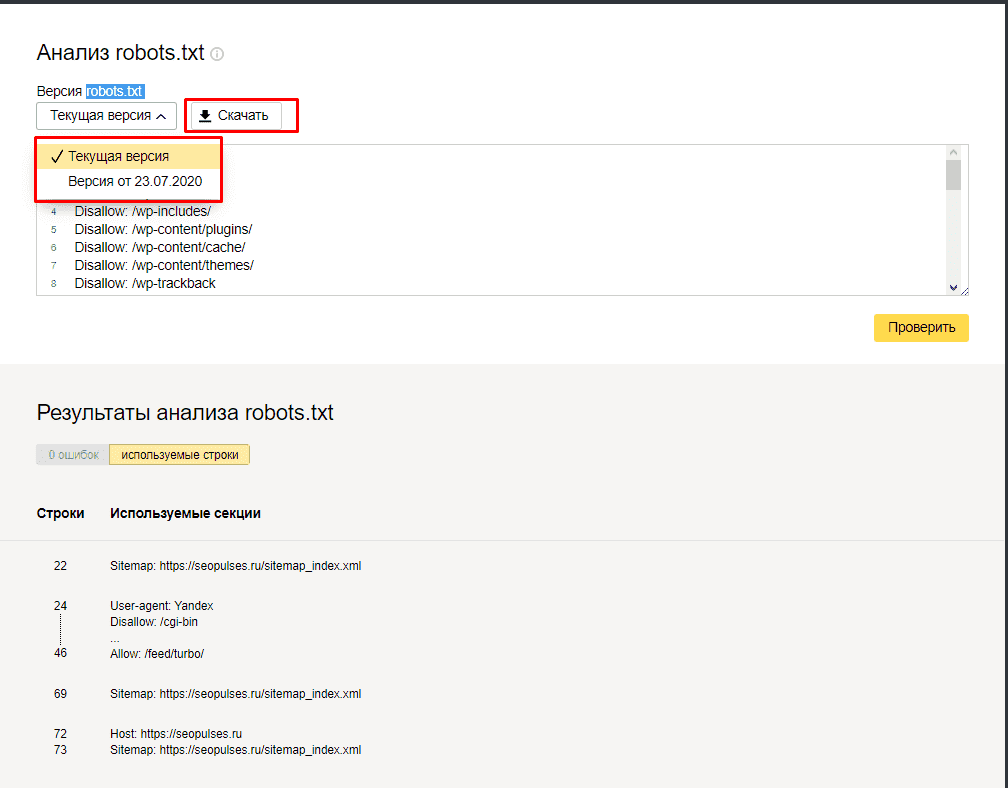 Ранее мы подробно разбирали вопрос индексации сайта в Яндекс и Google.
Ранее мы подробно разбирали вопрос индексации сайта в Яндекс и Google.
Именно в этой базе и происходит поиск информации в тот момент, когда вы вводите любой запрос в строку поиска:
Именно из индексной базы поисковая система в момент ввода запроса производит поиск информации.Если сайта нет в индексной базе поисковой системе = тогда сайте нет и в поисковой выдаче. Его невозможно будет найти по поисковым запросам.
В каких случаях может потребоваться исключать сайт из баз поисковых систем?
Зачем закрывать сайт от индексации
Причин, по которым необходимо скрыть сайт от поисковых систем может быть множество. Мы не можем знать личных мотивов всех вебмастеров. Давайте выделим самые основные объективные причины, когда закрытие сайта от индексации оправданно.
Сайт еще не готов
Ваш сайт пока не готов для просмотра целевой аудиторией. Вы
находитесь в стадии разработки (или доработки) ресурса. В таком случае его
лучше закрыть от индексации. Тогда сырой и недоработанный ресурс не попадет в
индексную базу и не испортит «карму» вашему сайту. Открывать сайт лучше после его полной
готовности и наполненности контентом.
В таком случае его
лучше закрыть от индексации. Тогда сырой и недоработанный ресурс не попадет в
индексную базу и не испортит «карму» вашему сайту. Открывать сайт лучше после его полной
готовности и наполненности контентом.
Сайт узкого содержания
Ресурс предназначен для личного пользования или для узкого круга посетителей. Он не должен быть проиндексирован поисковыми системами. Конечно, данные такого ресурса можно скрыть под паролем, но это не всегда необходимо. Часто, достаточно закрыть его от индексации и избавить от переходов из поисковых систем случайных пользователей.
Переезд сайта или аффилированный ресурс
Вы решили изменить главное зеркало сайта. Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.
Стратегия продвижения
Возможно, Ваша стратегия предусматривает продвижение ряда доменов, например, в разных регионах или поисковых системах.
Другие мотивы
Может быть целый ряд других личных причин закрытия сайта от индексации поисковыми системами. Можете написать в комментариях Вашу причину закрытия сайта от индексации.
Закрываем сайт от индексации в robots.txt
Обращение к Вашему сайту поисковой системой начинается с прочтения содержимого файла robots.txt. Это служебный файл со специальными правилами для поисковых роботов.
Подробнее о директивах robots.txt:
Самый простой и быстрый способ это при первом обращении к вашему ресурсу со стороны поисковых систем (к файлу robots.txt) сообщить поисковой системе о том, что этот сайт закрыт от индексации. В зависимости от задач, сайт можно закрыть в одной или нескольких поисковых системах. Вот так:
| Закрыть во всех системах | Закрыть только в Яндекс | Закрыть только в Google |
| User-agent: * Disallow: / | User-agent: Yandex Disallow: / | User-agent: Googlebot Disallow: / |
Инструкция по изменению файла robots.
 txt
txtМы не ставим целью дать подробную инструкцию по всем способам подключения к хостингу или серверу, укажем самый простой способ на наш взгляд.
Файл robots.txt всегда находится в корне Вашего сайта. Например, robots.txt сайта iqad.ru будет находится по адресу:
Для подключения к сайту, мы должны в административной панели нашего хостинг провайдера получить FTP (специальный протокол передачи файлов по сети) доступ: <ЛОГИН> И <ПАРОЛЬ>.
Авторизуемся в панели управления вашим хостингом и\или сервером, находим раздел FTP и создаем ( получаем ) уникальную пару логин \ пароль.В описании раздела или в разделе помощь, необходимо найти и сохранить необходимую информацию для подключения по FTP к серверу, на котором размещены файлы Вашего сайта. Данные отражают информацию, которую нужно указать в FTP-клиенте:
- Сервер (Hostname) – IP-адрес сервера, на котором размещен Ваш аккаунт
- Логин (Username) – логин от FTP-аккаунта
- Пароль (Password) – пароль от FTP-аккаунта
- Порт (Port) – числовое значение, обычно 21
Далее, нам потребуется любой FTP-клиент, можно
воспользоваться бесплатной программой filezilla (https://filezilla. ru/).
Вводим данные в соответствующие поля и нажимаем подключиться.
ru/).
Вводим данные в соответствующие поля и нажимаем подключиться.
После подключения прописываем необходимые директивы. См.
раздел:
Закрываем сайт от индексации в robots.txt
Проверка корректности закрытия сайта от индексации
После того, как вы внесли все необходимые коррективы в файл robots.txt необходимо убедится в том, что все сделано верно. Для этого открываем файл robots.txt на вашем сайте.
Инструменты iqadВ арсенале команды IQAD есть набор бесплатных инструментов для SEO-оптимизаторов. Вы можете воспользоваться бесплатным сервисом просмотра файла robots.txt:
Проверить индексацию
Открыть самостоятельно, файл находится корне Вашего сайта, по адресу:
www.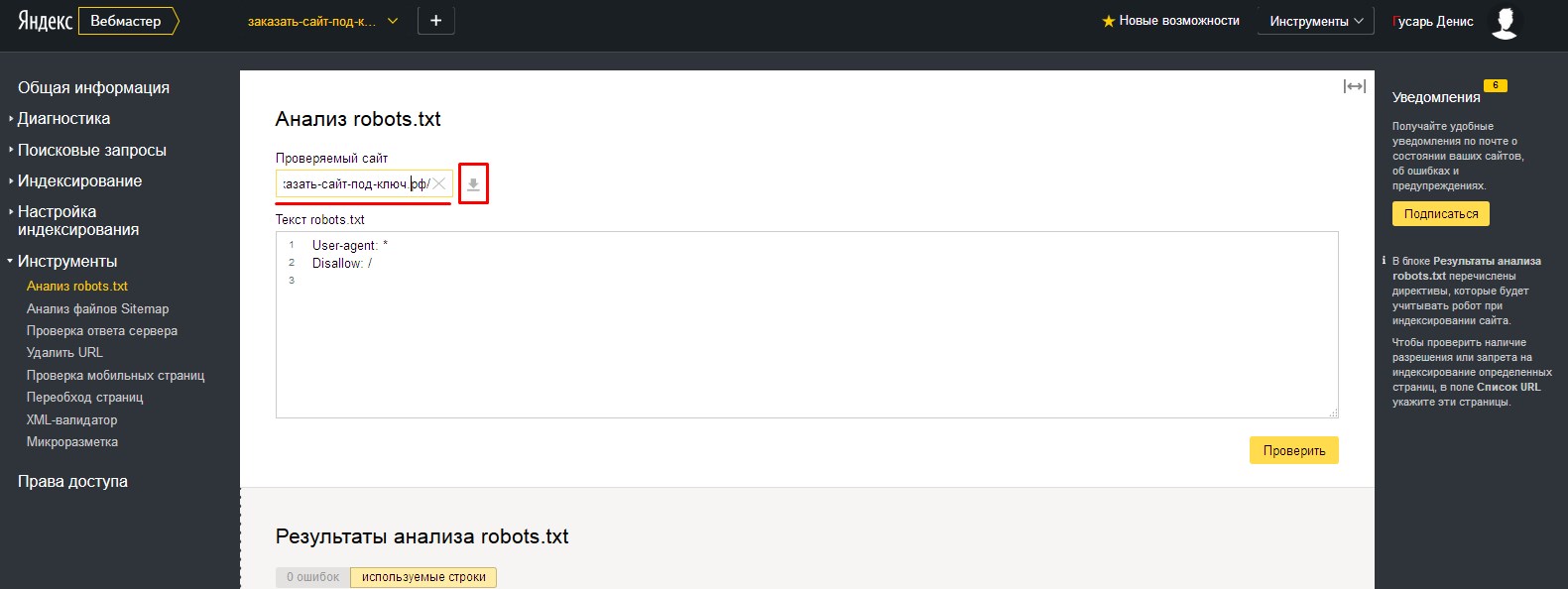 site.ru/robots.txt
site.ru/robots.txt
Где www.site.ru – адрес Вашего сайта.
Сервис Я.ВЕБМАСТЕРБесплатный сервис Я.ВЕБМАСТЕР – анализ robots.txt.
Бесплатный сервис ЯНДЕКС.ВЕБМАСТЕР проверит ваш robots.txt, покажет какими секциями Вашего файла пользуется поисковая система Яндекс:
Так же, в сервисе можно проверить запрещена ли та или иная страница вашего сайта к индексации:
Достаточно в специальное поле внести интересующие Вас страницы и ниже отобразится результат.Альтернативные способы закрыть сайт от поисковых систем
- Вы можете
отдавать поисковым роботам отличный от 200 код ответа сервера. Но это не
гарантирует 100% исключения сайта из индекса. Какое-то время робот может
хранить копию Ваших страниц и отдавать именно их.

- С помощью специального meta тега: <meta name=”robots”>

<meta name=”robots” content=”noindex, nofollow”>
Недостатком этого может быть несовершенство поисковых систем и проблемы с индексацией ресурса. Пока робот не переиндексирует весь сайт, а на это может потребоваться много времени, иногда несколько месяцев, часть страниц будет присутствовать в поиске.
- Использование
технологий, усложняющих индексацию Вашего сайта. Вы можете спрятать контент
Вашего сайта под AJAX или скриптами. Таким образом поисковая система не сможет
увидеть контент сайта. При этом по названию сайта или по открытой части в
индексе поисковиков может что-то хранится. Более того, уже завра новое
обновление поисковых роботов может научится индексировать такой контент.
- Скрыть все данные Вашего сайта за регистрационной формой. При этом стартовая страница в любом случае будет доступна поисковым роботам.

Заключение
Самым простым способом закрыть сайт от индексации, во всех поисковых системах, необходимо в файле robots.txt прописать следующую директиву:
Disallow: /
«robots.txt» это служебный файл со специальными правилами для поисковых роботов.
Файл robots.txt всегда находится в корне Вашего сайта. Для изменения директив файла Вам потребуется любой FTP-клиент.
Помимо классического способа с использованием файла robots.txt можно прибегнуть и к другим, не стандартным, подходам. Однако у них есть ряд недостатков. Для проверки текущих директив Вашего сайта предлагаем воспользоваться бесплатным сервисом просмотра файла robots.txt:
Проверить индексацию
Метатег robots | Закрыть страницу от индексации
Статья для тех, кому лень читать справку по GoogleWebmaster и ЯндексВебмастер
Закрывание ненужных страниц веб-ресурса от поисковой индексации очень важно для его SEO-оптимизации, особенно на начальном этапе становления сайта или блога «на ноги». Такое действие способствует продвижению в SERP (СЕРП) и рекомендовано к применению для служебных страниц. К служебным страницам относятся технические и сервисные страницы, предназначенные исключительно для удобства и обслуживания уже состоявшихся клиентов. Эти страницы с неудобоваримым или дублирующим контентом, который не представляет абсолютно никакой поисковой ценности. Сюда входят – пользовательская переписка, рассылка, статистика, объявления, комментарии, личные данные, пользовательские настройки и т.д. А, также – страницы для сортировки материала (пагинация), обратной связи, правила и инструкции и т.п. Такое действие способствует продвижению в SERP (СЕРП) и рекомендовано к применению для служебных страниц. К служебным страницам относятся технические и сервисные страницы, предназначенные исключительно для удобства и обслуживания уже состоявшихся клиентов. Эти страницы с неудобоваримым или дублирующим контентом, который не представляет абсолютно никакой поисковой ценности. Сюда входят – пользовательская переписка, рассылка, статистика, объявления, комментарии, личные данные, пользовательские настройки и т.д. А, также – страницы для сортировки материала (пагинация), обратной связи, правила и инструкции и т.п. |
- Метатег robots
- Почему метатег robots лучше файла robots.txt
Метатег robots
Для управления поведением поисковых роботов на веб-странице, в HTML существует метатег robots и его атрибут content. закрытия веб-страницы от поисковой индексации,
nofollow и noindex – самые загадочные персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.
nofollow (Яндекс & Google)
nofollow – валидное значение в HTML для атрибута rel тега «a» (rel=»nofollow») |
rel=»nofollow» – не переходить по ссылке
Оба главных русскоязычных поисковика (Google и Яндекс) – прекрасно знают атрибут rel=»nofollow» и, поэтому – превосходно управляются с ним. В этом, и Google, и Яндекс, наконец-то – едины. Ни один поисковый робот не пойдёт по ссылке, если у неё имеется атрибут rel=»nofollow»:
<a href=»http://example.ru» rel=»nofollow»>анкор (видимая часть ссылки)</a>
content=»nofollow» – не переходить по всем ссылкам на странице
Допускается указывать значение nofollow для атрибута content метатега <meta>.
В этом случае, от поисковой индексации будут закрыты все ссылки на веб-странице
<meta name=»robots» content=»nofollow»/>
Атрибут content является атрибутом тега <meta> (метатега). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса несколько разное:
- Увидев атрибут rel=»nofollow» у отдельно стоящей ссылки, поисковые роботы Google не переходят по такой ссылке и не индексируют её видимую часть (анкор). Увидев атрибут content=»nofollow» у метатега <meta> в заголовке страницы, поисковые роботы Google сразу «разворачивают оглобли» и катят к себе восвояси, даже не пытаясь заглянуть на такую страницу. Таким образом, чтобы раз и навсегда закрыть от роботов Google отдельно стоящую ссылку (тег <а>) достаточно добавить к ней атрибут rel=»nofollow»:
<a href=»http://example. ru» rel=»nofollow»>Анкор</a>
А, чтобы раз и навсегда закрыть от роботов Google всю веб-страницу,
достаточно добавить в её заголовок строку с метатегом:
<meta name=»robots» content=»nofollow»/> - Яндекс
- Для роботов Яндекса атрибут rel=»nofollow» имеет действие запрета только! на индексацию ссылки и переход по ней. Видимую текстовую часть ссылки (анкор) – роботы Яндекса всё равно проиндексируют.
Для роботов Яндекса атрибут метатега content=»nofollow» имеет действие запрета только! на индексацию ссылок на странице и переходов по них. Всю видимую текстовую часть веб-страницы – роботы Яндекса всё равно проиндексируют.
Для запрета индексации видимой текстовой части ссылки или страницы для роботов Яндекса – ещё потребуется добавить его любимый тег или значение noindex
 ru» rel=»nofollow»>Анкор</a>
ru» rel=»nofollow»>Анкор</a>noindex – не индексировать текст
(тег и значение только для Яндекса)
Тег <noindex> не входит в спецификацию HTML-языка.
Тег <noindex> – это изобретение Яндекса, который предложил в 2008 году использовать этот тег в качестве маркера текстовой части веб-страницы для её последующего удаления из поискового индекса. Поисковая машина Google это предложение проигнорировала и Яндекс остался со своим ненаглядным тегом, один на один. Поскольку Яндекс, как поисковая система – заслужил к себе достаточно сильное доверие и уважение, то придётся уделить его любимому тегу и его значению – должное внимание.
Тег <noindex> – не признанное изобретение Яндекса
Тег <noindex> используется поисковым алгоритмом Яндекса для исключения служебного текста веб-страницы поискового индекса. Тег <noindex> поддерживается всеми дочерними поисковыми системами Яндекса, вида Mail.ru, Rambler и иже с ними.
Тег noindex – парный тег, закрывающий тег – обязателен!
Учитывая не валидность своего бедного и непризнанного тега,
Яндекс соглашается на оба варианта для его написания:
Не валидный вариант – <noindex></noindex>,
и валидный вариант – <!— noindex —><!—/ noindex —>.
Хотя, во втором случае – лошади понятно, что для гипертекстовой разметки HTML, это уже никакой не тег, а так просто – html-комментарий на веб-странице.
Тег <noindex> – не индексировать кусок текста
Как утверждает справка по Яндекс-Вебмастер, тег <noindex> используется для запрета поискового индексирования служебных участков текста. Иными словами, часть текста на странице, заключённая в теги <noindex></noindex> удаляется поисковой машиной из поискового индекса Яндекса. Размеры и величина куска текста не лимитированы. Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части.
Поскольку Яндекс подходит раздельно к индексированию непосредственно самой ссылки и её видимого текста (анкора), то для полного исключения отдельно стоящей ссылки из индекса Яндекса потребуется наличие у неё сразу двух элементов – атрибута rel=»nofollow» и тега <noindex>. Такой избирательный подход Яндекса к индексированию ссылок даёт определённую гибкость при наложении запретов.
Такой избирательный подход Яндекса к индексированию ссылок даёт определённую гибкость при наложении запретов.
Так, например, можно создать четыре конструкции, где:
- Ссылка индексируется полностью
- <a href=»http://example.ru»>Анкор (видимая часть ссылки)</a>
- Индексируется только анкор (видимая часть) ссылки
- <a href=»http://example.ru» rel=»nofollow»>Анкор</a>
- Индексируется только ссылка, без своего анкора
- <a href=»http://example.ru»><noindex>Анкор</noindex></a>
- Ссылка абсолютно НЕ индексируется
- <a href=»http://example.ru» rel=»nofollow»><noindex>Анкор</noindex></a>
Для справки: теги <noindex></noindex>, особенно их валидный вариант <!— noindex —><!—/ noindex —> – абсолютно не чувствительны к вложенности. Их можно устанавливать в любом месте HTML-кода. Главное, не забывать про закрывающий тег, а то – весь текст, до самого конца страницы – вылетит из поиска Яндекса.
Метатег noindex – не индексировать текст всей страницы
Допускается применять noindex в качестве значения для атрибута метатега content –
в этом случае устанавливается запрет на индексацию Яндексом текста всей страницы.
Атрибут content является атрибутом тега <meta> (метатег). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Абсолютно достоверно, ясно и точно, что использование noindex в качестве значения атрибута content для метатега <meta> даёт очень хороший результат и уверенно «выбивает» такую страницу из поискового индекса Яндекса.
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом в заголовке –
Яндекс совершенно не индексирует, но при этом он –
проиндексирует все ссылки на ней.
Разница в действии тега и метатега noindex
Визуально, разница в действии тега и метатега noindex заключается в том, что запрет на поисковую индексацию тега noindex распространяется только на текст внутри тегов <noindex></noindex>, тогда как запрет метатега – сразу на текст всей страницы.
Пример: <noindex>Этот текст будет не проиндексирован</noindex>
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом – Яндекс полностью не индексирует
Принципиально, разница в действии тега и метатега проявляется в различиях алгоритма по их обработке поисковой машиной Яндекса. В случае с метатегом noindex, робот просто уходит со страницы, совершенно не интересуясь её содержимым (по крайней мере – так утверждает сам Яндекс). А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире.
Поэтому, кусок текста страницы, заключённого в теги <noindex></noindex> – могёт запросто попасть Яндексу «на зуб» для дальнейшей поисковой индексации. Как утверждает сам Яндекс – это временное неудобство будет сохраняться до следующего посещения робота. Чему я не очень охотно верю, потому как, некоторые мои тексты и страницы, с тегом и метатегом noindex – висели в Яндексе по нескольку месяцев.
Как утверждает сам Яндекс – это временное неудобство будет сохраняться до следующего посещения робота. Чему я не очень охотно верю, потому как, некоторые мои тексты и страницы, с тегом и метатегом noindex – висели в Яндексе по нескольку месяцев.
Особенности метатега noindex
Равно, как и в случае с тегом <noindex>, действие метатега noindex позволяет гибко накладывать запреты на всю страницу. Примеры метатегов для всей страницы сдерём из Яндекс-Вебмастера:
- не индексировать текст страницы
- <meta name=»robots» content=»noindex»/>
- не переходить по ссылкам на странице
- <meta name=»robots» content=»nofollow»/>
- не индексировать текст страницы и не переходить по ссылкам на странице
- <meta name=»robots» content=»noindex, nofollow»/>
- что, аналогично следующему:
- запрещено индексировать текст и переходить
по ссылкам на странице для роботов Яндекса - <meta name=»robots» content=»none»/>
Вот такой он, тег и значение noindex на Яндексе :):):).
Тег и метатег noindex для Google
Что-же касается поисковика Google, то он никак не реагирует на присутствие выражения noindex, ни в заголовке, ни в теле веб-страницы. Google остаётся верен своему валидному «nofollow», который он понимает и выполняет – и для отдельной ссылки, и для всей страницы сразу (в зависимости от того, как прописан запрет). После некоторого скрипения своими жерновами, Яндекс сдался и перестал продвижение своего тега и значения noindex, хотя – и не отказывается от него полностью. Если роботы Яндекса находят тег или значение noindex на странице – они исправно выполняют наложенные запреты.
Универсальный метатег (Яндекс & Google)
С учётом требований Яндекса, общий вид универсального метатега,
закрывающего полностью всю страницу от поисковой индексации,
выглядит так:
- <meta name=»robots» content=»noindex, nofollow»/>
- – запрещено индексировать текст и переходить по ссылкам на странице
для всех поисковых роботов Яндекса и Google
Почему метатег robots лучше файла robots.
 txt
txtСамый простой и популярный способ закрыть веб-страницу от индексации – это указать для неё соответствующую директиву в файле robots.txt. Для этого, собственно файл robots.txt и существует. Однако, закрывать через метатег robots – гораздо надёжнее.
И, вот почему.
Алгоритмы обработки роботами метатега robots и файла robots – совершенно различные. Работу этих алгоритмов можно сравнить с действием в известном анекдоте, где бьют не «по паспорту», а – «по морде». Пусть этот пример весьма груб и примитивен, но он, как нельзя лучше – отображает поведение поискового робота на странице:
- В случае использования метатега robots, поисковик просто и прямо заходит на веб-страницу и читает её заголовок («смотрит в её морду». Если робот там находит метатег robots – он разворачивается и уходит восвояси. Вуаля! Всё предельно просто. Робот увидел запись, что здесь ловить нечего, и сразу же – «свалил». Ему проблемы не нужны. Это есть работа по факту записи прямо в заголовке страницы («по морде»).
- В случае использования файла robots.txt, поисковик, перед заходом на страницу – сверяется с этим файлом (читает «паспорт»). Это есть работа по факту записи в постороннем файле («по паспорту»). Если в файле robots.txt («паспорте») прописана соответствующая директива – робот её выполняет. Если нет, то он – сканирует страницу в общем порядке, поскольку по-умолчанию – к сканированию разрешены все страницы.

Казалось-бы, какая разница.
Тем более, что сам Яндекс рассказывает следующее:
При сканировании сайта, на основании его файла robots.txt – составляется специальный список (пул), в котором ясно и чётко указываются и излагаются директории и страницы, разрешённые к поисковому индексированию сайта.
Ну, чего ещё проще – составил списочек,
прошёлся списочком по сайту,
и всё – можно «баиньки»…
Простота развеется, как майский дым, если мы вспомним, что роботов много, что все они разные, и самое главное – что все роботы ходят по ссылкам. А сей час, представим себе стандартную ситуацию, которая случается в интернете миллионы раз на дню – поисковый робот пришёл на страницу по ссылке из другого сайта. Вот он, трудяга Сети – уже стоит у ворот (у заголовка) странички. Ну, и где теперь файл robots.txt?
А сей час, представим себе стандартную ситуацию, которая случается в интернете миллионы раз на дню – поисковый робот пришёл на страницу по ссылке из другого сайта. Вот он, трудяга Сети – уже стоит у ворот (у заголовка) странички. Ну, и где теперь файл robots.txt?
У робота, пришедшего на сайт по внешней ссылке, выбор не большой. Робот может, либо лично «протопать» к файлу robots.txt и свериться с ним, либо просто скачать страницу себе в кэш и уже потом разбираться – индексировать её или нет.
Как поступит наш герой, мы не знает. Это коммерческая тайна каждой поисковой системы. Несомненно, одно. Если в заголовке страницы будет указан метатег robots – поисковик выполнит его немедля. И, если этот метатег запрещает индексирование страницы – робот уйдёт немедля и без раздумий.
Вот теперь, совершенно ясно, что прямой заход на страницу, к метатегу robots –
всегда короче и надёжнее, нежели долгий путь через закоулки файла robots.txt
Метатег robots | Закрыть страницу от индексации на tehnopost.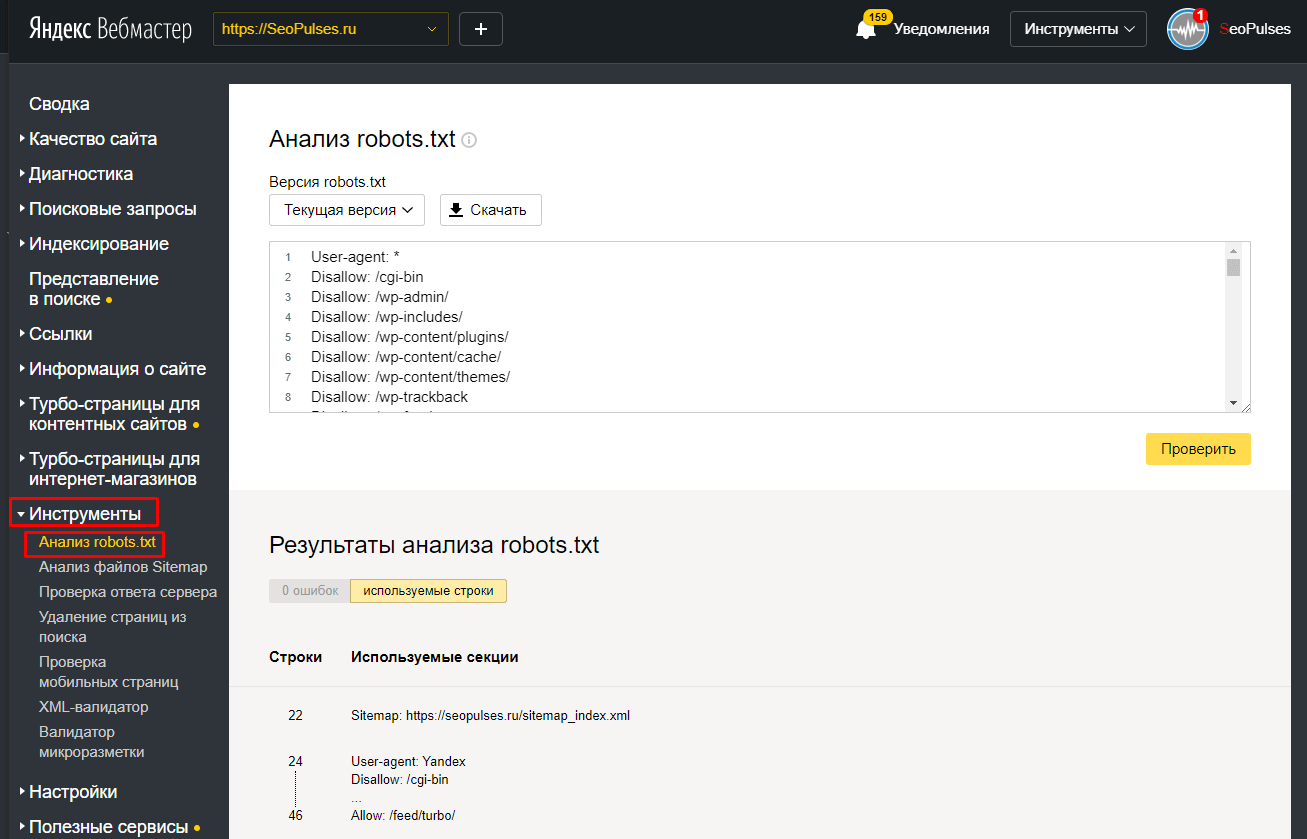 info
info
- Метатег robots
- Почему метатег robots лучше файла robots.txt
Внимание! У Вас нет прав для просмотра скрытого текста.
Как закрыть контент от индексации — пошаговое руководство
Иногда возникают такие ситуации, когда нужно Закрыть от индексации часть контента. Пример такой ситуации мы рассматривали здесь.
Также, иногда нужно:
- Скрыть от поиска техническую информацию
- Закрыть от индекса не уникальный контент
- Скрыть сквозной,повторяющийся внутри сайта, контент
- Закрыть мусорные страницы, которые нужны пользователям, но для робота выглядят как дубль
Постараемся в данной статье максимально подробно расписать инструменты при помощи которых можно закрывать контент от индексации.
Закрываем от индексации домен/поддомен:
Для того, чтобы закрыть от индексации домен, можно использовать:
1. Robots.txt
В котором прописываем такие строки.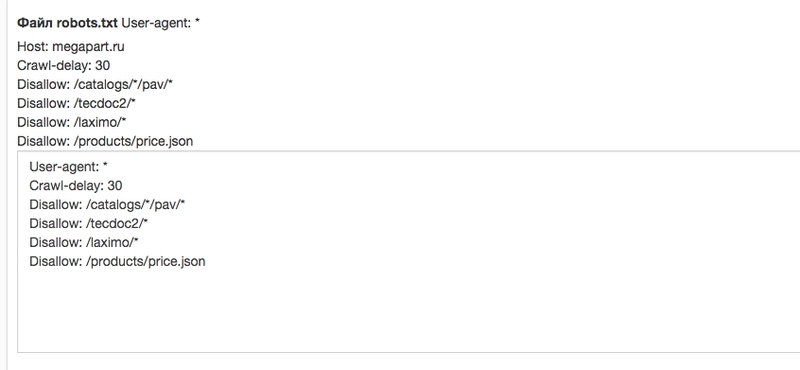
User-agent: *
Disallow: /
При помощи данной манипуляции мы закрываем сайт от индексации всеми поисковыми системами.
При необходимости Закрыть от индексации конкретной поисковой системой, можно добавить аналогичный код, но с указанием Юзерагента.
User-agent: yandex
Disallow: /
Иногда, же бывает нужно наоборот открыть для индексации только какой-то конкретной ПС. В таком случае нужно составить файл Robots.txt в таком виде:
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Таким образом мы позволяем индексировать сайт только однайо ПС. Однако минусом есть то, что при использовании такого метода, все-таки 100% гарантии не индексации нет. Однако, попадание закрытого таким образом сайта в индекс, носит скорее характер исключения.
Для того, чтобы проверить корректность вашего файла Robots.txt можно воспользоваться данным инструментом просто перейдите по этой ссылке http://webmaster.yandex.ru/robots. xml.
xml.
Статья в тему: Robots.txt — инструкция для SEO
2. Добавление Мета-тега Robots
Также можно закрыть домен от индексации при помощи Добавления к Код каждой страницы Тега:
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Куда писать META-тег “Robots”
Как и любой META-тег он должен быть помещен в область HEAD HTML страницы:
Данный метод работает лучше чем Предыдущий, темболее его легче использовать точечно нежели Вариант с Роботсом. Хотя применение его ко всему сайту также не составит особого труда.
3. Закрытие сайта при помощи .htaccess
Для Того, чтобы открыть доступ к сайту только по паролю, нужно добавить в файл .htaccess, добавляем такой код:
После этого доступ к сайту будет возможен только после ввода пароля.
Защита от Индексации при таком методе является стопроцентной, однако есть нюанс, со сложностью просканить сайт на наличие ошибок. Не все парсеры могут проходить через процедуру Логина.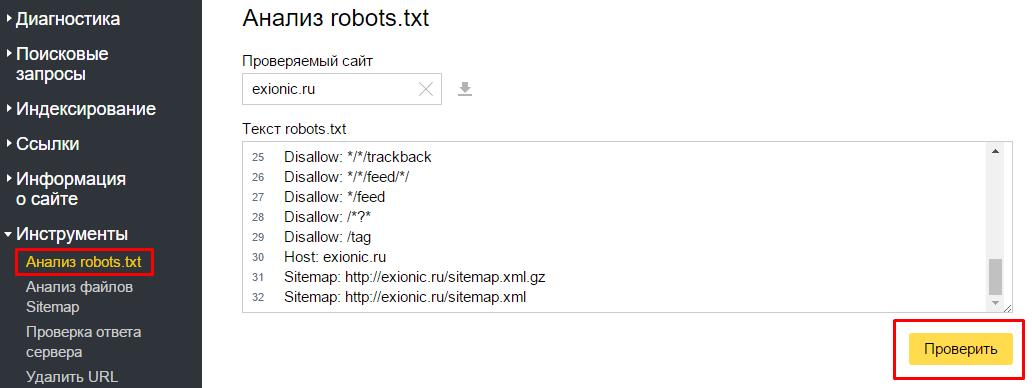
Закрываем от индексации часть текста
Очень часто случается такая ситуация, что необходимо закрыть от индексации Определенные части контента:
- меню
- текст
- часть кода.
- ссылку
Скажу сразу, что распространенный в свое время метод при помощи тега <noindex> не работает.
<noindex>Тут мог находится любой контент, который нужно было закрыть</noindex>
Однако существует альтернативный метод закрытия от индексации, который очень похож по своему принципу, а именно метод закрытия от индексации при помощи Javascript.
Закрытие контента от индексации при помощи Javacascript
При использовании данного метода текст, блок, код, ссылка или любой другой контент кодируется в Javascript, а далее Данный скрипт закрывается от индексации при помощи Robots.txt
Такой Метод можно использовать для того, чтобы скрыть например Меню от индексации, для лучшего контроля над распределением ссылочного веса. К примеру есть вот такое меню, в котором множество ссылок на разные категории. В данном примере это — порядка 700 ссылок, если не закрыть которые можно получить большую кашу при распределении веса.
К примеру есть вот такое меню, в котором множество ссылок на разные категории. В данном примере это — порядка 700 ссылок, если не закрыть которые можно получить большую кашу при распределении веса.
Данный метод гугл не очень то одобряет, так-как он всегда говорил, что нужно отдавать одинаковый контент роботам и пользователям. И даже рассылал письма в средине прошлого года о том, что нужно открыть для индексации CSS и JS файлы.
Подробнее об этом можно почитать тут.
Однако в данный момент это один из самых действенных методов по борьбе с индексацией нежелательного контента.
Точно также можно скрывать обычный текст, исходящие ссылки, картинки, видео материалы, счетчики, коды. И все то, что вы не хотите показывать Роботам, или что является не уникальным.
Как закрыть от индексации конкретную страницу:
Для того, чтобы закрыть от индекса конкретную страницу чаще всего используются такие методы:
- Роботс txt
- Мета robots noindex
В случае первого варианта закрытия страницы в данный файл нужно добавить такой текст:
User-agent: ag
Disallow: http://site. com/page
com/page
Таким образом данная страница не будет индексироваться с большой долей вероятности. Однако использование данного метода для точечной борьбы со страницами, которые мы не хотим отдавать на индексацию не есть оптимальным.
Так, для закрытия одной страницы от индекса лучше воспользоваться тегом
META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»
Для этого просто нужно добавить в область HEAD HTML страницы. Данный метод позволяет не перегружать файл robots.txt лишними строчками.
Ведь если Вам нужно будет закрыть от индекса не 1 страницу, а к примеру 100 или 200 , то нужно будет добавить 200 строк в этот файл. Но это в том случае, если все эти страницы не имеют общего параметра по которому их можно идентифицировать. Если же такой параметр есть, то их можно закрыть следующим образом.
Закрытие от индексации Раздела по параметру в URL
Для этого можно использовать 2 метода:
Рассмотрим 1 вариант
К примеру, у нас на сайте есть раздел, в котором находится неуникальная информация или Та информация, которую мы не хотим отдавать на индексацию и вся эта информация находится в 1 папке или 1 разделе сайта.
Тогда для закрытия данной ветки достаточно добавить в Robots.txt такие строки:
Если закрываем папку, то:
Disallow: /папка/
Если закрываем раздел, то:
Disallow: /Раздел/*
Также можно закрыть определенное расшерение файла:
User-agent: *
Disallow: /*.js
Данный метод достаточно прост в использовании, однако как всегда не гарантирует 100% неиндексации.
Потому лучше в добавок делать еще закрытие при помощи
META NAME=»ROBOTS» CONTENT=»NOINDEX”
Который должен быть добавлен в секцию Хед на каждой странице, которую нужно закрыть от индекса.
Точно также можно закрывать от индекса любые параметры Ваших УРЛ, например:
?sort
?price
?”любой повторяющийся параметр”
Однозначно самым простым вариантом является закрытие от индексации при помощи Роботс.тхт, однако, как показывает практика — это не всегда действенный метод.
Методы, с которыми нужно работать осторожно:
Также существует достаточно грубый метод Закрытия чего — либо от роботов, а именно запрет на уровне сервера на доступ робота к конкретному контенту.
1. Блокируем все запросы от нежелательных User Agents
Это правило позволяет заблокировать нежелательные User Agent, которые могут быть потенциально опасными или просто перегружать сервер ненужными запросами.
В данному случае плохим ботом можно указать Любую поисковую машину, парсер либо что либо еще.
Подобные техники используются например для скрытия от робота Ахрефса ссылки с сайта, который был создан/сломан, чтобы конкуренты сеошники не увидели истинных источников ссылочной массы сайта.
Однако это метод стоит использовать если вы точно знаете, что хотите сделать и здраво оцениваете последствия от этих действий.
Использование HTTP-заголовка X-Robots-Tag
Заголовок X-Robots-Tag, выступает в роли элемента HTTP-заголовка для определенного URL. Любая директива, которая может использоваться в метатеге robots, применима также и к X-Robots-Tag.
В X-Robots-Tag перед директивами можно указать название агента пользователя. Пример HTTP-заголовка X-Robots-Tag, который запрещает показ страницы в результатах поиска различных систем:
В заключение
Ситуации, когда необходимо закрыть контент от индексации случаются довольно часто, иногда нужно почистить индекс, иногда нужно скрыть какой-то нежелательный материал, иногда нужно взломать чужой сайт и в роботсе указать disalow all, чтобы выбросить сайт зеркало из индекса.
Основные и самые действенные методы мы рассмотрели, как же их применять — дело вашей фантазии и целей, которые вы преследуете.
Хорошие статьи в продолжение:
— Стоит ли открывать рубрики для индексации, если в разных рубриках выводятся одни и те же посты?
— Как открывать страницы поиска в интернет магазине — руководство
А что вы думаете по этому поводу? Давайте обсудим в комментариях!)
Оцените статью
Загрузка…Как правильно настроить robots.txt — Академия SEO (СЕО)
Содержание:
Правильный robots.txt и его важность
Хотите узнать как закрыть сайт от индексации поисковиками, когда Вы в этом не нуждаетесь?
Оказывается, это не так уж сложно. Потребуется лишь правильный robots.txt, размещенный в корневой папке Вашего веб-ресурса.
Ну а теперь по порядку.
robots.txt – текстовый файл, в котором предписываются рекомендации для действий роботов поисковиков. Именно его они первым делом ищут, едва «переступив порог» Вашего веб-ресурса. Если его нет или он присутствует, но не содержит в себе никакой информации, поисковые боты воспринимают это как разрешение «прогуляться» по всему сайту без каких-либо ограничений.
И наоборот, если в нем прописаны определенные инструкции по запрещению индексации, поисковые роботы будут стараться их придерживаться.
Принцип действия и настройка robots.txt
Правильный robots.txt содержит в своем теле записи, каждая из которых начинается со строки, в которой указывается клиентское приложение User-agent. В нем прописывается название робота, к которому относятся инструкции в следующей строке/строках.
В нем прописывается название робота, к которому относятся инструкции в следующей строке/строках.
Если же инструкция относится ко всем паукам-индексаторам, вместо имени используется символ «звездочка»:
Далее прописывается строка с директивой Disallow и несколько спец. символов, которые выбираются в зависимости от цели инструкции.
Закрыть сайт от индексации? Нет ничего проще!
Собственно говоря, основная функция robots – запретить индексацию. Чего именно? Тут уж Вам выбирать. Вариантов существует предостаточно:
- Полностью запретить индексацию сайта. Подразумевается возможность отказать пришедшему «в гости» роботу заходить на Ваш веб-ресурс и выполнять свою работу. Может быть полезно на ранних стадиях разработки сайта, когда публикация контента уже началась, но еще не доведена до нужного уровня. В этом случае индексация неоптимизированных страниц нежелательна, дабы «не подпортить» заранее репутацию сайта.
- Закрыть от индексации раздел/категорию. Используется в случае вполне действующего веб-ресурса, имеющем определенный рейтинг в глазах поисковиков, когда готовится новый раздел или категория, индексация которых пока что нежелательна.
- Запретить индексацию страницы. Удобно использовать в случае, если на сайте размещены документы, которые нужны, но не должны индексироваться и влиять на общий рейтинг веб-ресурса. Например, это может быть «Политика конфиденциальности», состоящая из неуникального текста.
Настройка robots.txt. 10 важных фишек
- Если в robots запретить индексацию, то она будет действовать по принципу старшинства. То есть запрет распространяется на все файлы, страницы и директории, которые подчинены указанному элементу.
- Правильный robots.txt всегда содержит минимум одну строку User-agent, чтобы его принимали к сведению.
- Возможна настройка robots.txt, при которой для одного бота может быть прописана запись, состоящая сразу из нескольких инструкций.
- Символ «*» перед названием поможет запретить индексацию всех объектов с указанным словом.
- Символ «/» используется как в начале, так и в конце названия директории. В противном случае robots может запретить индексацию всех страниц, в имени которых встречается «slovo».
- Пустая директива Disallow дает роботу разрешение индексировать все странички веб-ресурса.
- Желательно, чтобы правильный robots.txt указывал, где находится карта сайта. Это значительно ускорит индексацию страниц и исключит вероятность случайного пропуска роботом некоторых из них.
- Правильный robots.txt может содержать инструкции, прописанные только при использовании нижнего регистра.
- Любая Disallow может указывать только на один файл/раздел/страницу и должна прописываться с новой строки.
- Нельзя прописывать сначала Disallow, а потом User-agent. Подобная настройка robots.txt будет пустой тратой времени, поскольку боты не смогут понять таких инструкций.

И самое главное правило – перед тем, как залить правильный robots.txt в корень веб-сайта, нужно убедить в его правильности. Рекомендуется проверять его на ошибки несколько раз. А еще лучше – дать проверить кому-нибудь другому. Свежему взгляду проще будет увидеть опечатки и прочие неприятности в теле файла.
Только верная настройка robots.txt поможет запретить индексацию именно тех элементов Вашего сайта, которые Вы пока что решили скрыть от «зоркого взгляда» поисковиков.
Остались вопросы? Задавайте! Ждем Вас в комментариях!
Как закрыть сайт от индексации: краткое руководство
Как закрыть сайт от индексации в поиске
Как закрыть сайт от индексацииДля закрытия от индексации всего ресурса достаточно просто создать в корневой папке файл robots. txt с таким текстом:
txt с таким текстом:
Usеr-аgеnt: Yаndех
Dіsаllоw: /
Это позволит закрыть сайт от робота Яндекса. А сделать так, чтобы он не индексировался ни одним поисковиком, можно при помощи такой команды:
Usеr-аgеnt: *
Dіsаllоw: /
Ввод такого текста в «роботс» позволяет скрыть ресурс не только от Яндекса, но и от всех остальных поисковых систем. Можно также использовать файл .htассеss, но при этом устанавливается пароль, что приводит к некоторым сложностям в работе с сайтом.
Как
запретить индексацию папки?Можно отключить робота как полностью, так и частично. Чтобы поисковая система не видела определенную папку, указываем в robots.txt ее название. В результате будет установлен запрет на индексирование всех находящихся в ней объектов.
Шаблон:
Usеr-аgеnt: *
Dіsаllоw: /fоldеr/ (название папки)
Есть также возможность открыть отдельный файл. При такой необходимости дополнительно используется команда Allow. Прописываем разрешение на индексацию нужного объекта и запрет на доступ к папке:
Прописываем разрешение на индексацию нужного объекта и запрет на доступ к папке:
Usеr-аgеnt: *
Аllоw: /fоldеr/fіlе.рhр (местонахождение объекта – его название и папка)
Dіsаllоw: /fоldеr/
Как запретить Яндексу доступ к определенному файлу?
Тут нужно действовать по аналогии с предыдущим примером. Команда та же, но указывается адрес местонахождения файла и название поисковика.
Шаблон команд, блокирующих индексацию:
User-agent: Yandex
Disallow: /folder/file.php
Как определить, документ открыт для индексации или нет?
С этой целью можно использовать специализированные сервисы, в том числе бесплатные. Работают они довольно просто, например по такой схеме: вы вводите перечень адресов, которые нужно проверить, и запрашиваете информацию об их возрасте в поисковике. Для документа, который индексируется, будет указана дата его попадания в индекс, а если он недоступен для поисковых роботов, отобразится соответствующая надпись.
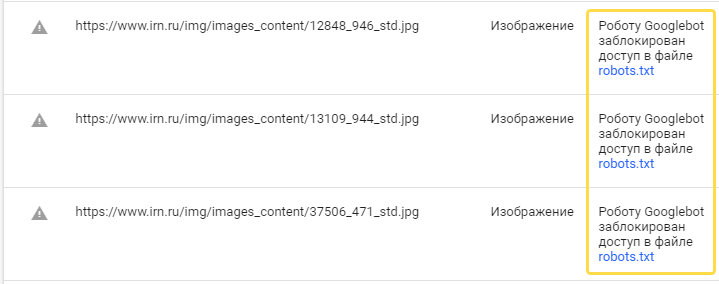
Как блокируется индексирование изображений?
Можно запретить поисковикам индексировать картинки таких распространенных форматов как gif, png и jpg. Для этого в robots.txt указывается расширение файлов.
В зависимости от того, какие изображения блокируются, команды имеют такой вид:
User-Agent: *
Disallow: *.gif (*.png или *.jpg)
Алгоритм действий в этом случае такой же, как при запрете индексации основного сайта. У каждого поддомена есть собственный robots.txt, чаще всего расположенный в его корневой папке. Если не удалось его обнаружить, нужно создать такой файл. Содержащиеся в нем данные корректируются с использованием команды Disallow путем упоминания разделов, которые закрываются.
Как запретить индексацию поддомена с CDN?
При использовании этой версии наличие дубля может превратиться в серьезную помеху для SEO-продвижения. Есть два способа этого избежать. Первый – провести предварительную настройку на домене тега <link> атрибута rel=»canonical», а второй – создать собственный robots. txt на поддомене. Лучше остановиться на первом варианте, поскольку так данные о поведенческих факторах удастся сохранить в полном объеме по каждому из адресов.
txt на поддомене. Лучше остановиться на первом варианте, поскольку так данные о поведенческих факторах удастся сохранить в полном объеме по каждому из адресов.
Как называть роботов разных поисковых систем?
В robots.txt содержатся обращения к индексаторам, и необходимо правильно указать их названия. У каждого поисковика собственный набор роботов.
- У Google главный индексатор – это Googlebot.
- У Яндекса – Yandex.
- У отечественной поисковой системы «Спутник» от компании «Ростелеком» – SputnikBot.
- У поисковика Bing от корпорации «Майкрософт» – робот-индекстор от MSN под названием MSNBot.
- Yahoo! – Slurp.
Как дополнительные команды можно прописать в robots.txt?
Яндексом, кроме рассмотренных выше директив, поддерживаются и такие.
- Sitemap: – показывает путь к карте сайта. Кроме Яндекса, на него реагирует Google и многие другие поисковые системы.
- Clean-param: – демонстрирует параметры GET, не влияющие на то, как на сайте отображается контент, например ref-ссылки или метки UTM.
- Crawl-delay: – устанавливает минимальный временной интервал для поочередного скачивания файлов. Работает в большинстве поисковиков.

Чтобы роботы не индексировали сайт или определенную страницу, можно воспользоваться командой name=»robots» #. Установка запрета на поиск при помощи этого метатега является удачным способом закрытия ресурса, поисковые роботы с большой вероятностью будут выполнять вашу команду. Допускается использование одного из двух равносильных вариантов кода:
1) <meta name=»robots» соntent=»none»/>,
2) <meta name=»robots» content=»nоіndex, nofollow»/>.
Метатег прописывается в зоне <head> </head>. Так блокируется доступ для всех роботов, но при желании можно обратиться к какому-то конкретному, заменив в коде «robots» на его название. Например, для Яндекса команда выглядит так:
<meta name=»yandex» content=»nоіndex, nofollow»/>
Теги
Вам также будет интересно
Файл robots.
 txt и мета-тег robots — настройка индексации сайта Яндексом и Гуглом, правильный роботс и его проверка Обновлено 24 января 2021 Просмотров: 28 420 Автор: Дмитрий Петров
txt и мета-тег robots — настройка индексации сайта Яндексом и Гуглом, правильный роботс и его проверка Обновлено 24 января 2021 Просмотров: 28 420 Автор: Дмитрий Петров- Почему так важно управлять индексацией сайта
- Как можно запретить индексацию отдельных частей сайта
- Robots.txt — директива user-agent и боты поисковых систем
- Примеры использования директив Disallow и Allow
- Директивы Sitemap и Host (для Яндекса уже не нужна)
- Проверка robots.txt в Яндексе и Гугле, примеры ошибок
- Мета-тег Robots — помогает закрыть дубли при индексации сайта
- Как создать правильный роботс.тхт?
При самостоятельном продвижении и раскрутке сайта важно не только создание уникального контента или подбор запросов в статистике Яндекса, но и так же следует уделять должное внимание такому показателю, как индексация ресурса поисковиками, ибо от этого тоже зависит весь дальнейший успех продвижения.
У нас с вами имеются в распоряжении два набора инструментов, с помощью которых мы можем управлять этим процессом как бы с двух сторон. Во-первых, существует такой важный инструмент как карта сайта (Sitemap xml). Она говорит поисковикам о том, какие страницы сайта подлежат индексации и как давно они обновлялись.
Во-первых, существует такой важный инструмент как карта сайта (Sitemap xml). Она говорит поисковикам о том, какие страницы сайта подлежат индексации и как давно они обновлялись.
А, во-вторых, это, конечно же, файл robots.txt и похожий на него по названию мета-тег роботс, которые помогают нам запретить индексирование на сайте того, что не содержит основного контента (исключить файлы движка, запретить индексацию дублей контента), и именно о них и пойдет речь в этой статье…
Индексация сайта
Упомянутые выше инструменты очень важны для успешного развития вашего проекта, и это вовсе не голословное утверждение. В статье про Sitemap xml (см. ссылку выше) я приводил в пример результаты очень важного исследования по наиболее частым техническим ошибкам начинающих вебмастеров, там на втором и третьем месте (после не уникального контента) находятся как раз отсутствие этих файлов роботс и сайтмап, либо их неправильное составление и использование.
Почему так важно управлять индексацией сайта
Надо очень четко понимать, что при использовании CMS (движка) не все содержимое сайта должно быть доступно роботам поисковых систем. Почему?
Почему?
- Ну, хотя бы потому, что, потратив время на индексацию файлов движка вашего сайта (а их может быть тысячи), робот поисковика до основного контента сможет добраться только спустя много времени. Дело в том, что он не будет сидеть на вашем ресурсе до тех пор, пока его полностью не занесет в индекс. Есть лимиты на число страниц и исчерпав их он уйдет на другой сайт. Адьес.
- Если не прописать определенные правила поведения в роботсе для этих ботов, то в индекс поисковиков попадет множество страниц, не имеющих отношения к значимому содержимому ресурса, а также может произойти многократное дублирование контента (по разным ссылкам будет доступен один и тот же, либо сильно пересекающийся контент), что поисковики не любят.
Хорошим решением будет запрет всего лишнего в robots.txt (все буквы в названии должны быть в нижнем регистре — без заглавных букв). С его помощью мы сможем влиять на процесс индексации сайта Яндексом и Google. Представляет он из себя обычный текстовый файл, который вы сможете создать и в дальнейшем редактировать в любом текстовом редакторе (например, Notepad++).
Поисковый бот будет искать этот файл в корневом каталоге вашего ресурса и если не найдет, то будет загонять в индекс все, до чего сможет дотянуться. Поэтому после написания требуемого роботса, его нужно сохранить в корневую папку, например, с помощью Ftp клиента Filezilla так, чтобы он был доступен к примеру по такому адресу:
https://ktonanovenkogo.ru/robots.txt
Кстати, если вы хотите узнать как выглядит этот файл у того или иного проекта в сети, то достаточно будет дописать к Урлу его главной страницы окончание вида /robots.txt. Это может быть полезно для понимания того, что в нем должно быть.
Однако, при этом надо учитывать, что для разных движков этот файл будет выглядеть по-разному (папки движка, которые нужно запрещать индексировать, будут называться по-разному в разных CMS). Поэтому, если вы хотите определиться с лучшим вариантом роботса, допустим для Вордпресса, то и изучать нужно только блоги, построенные на этом движке (и желательно имеющие приличный поисковый трафик).
Как можно запретить индексацию отдельных частей сайта и контента?
Прежде чем углубляться в детали написания правильного файла robots.txt для вашего сайта, забегу чуть вперед и скажу, что это лишь один из способов запрета индексации тех или иных страниц или разделов вебсайта. Вообще их три:
- Роботс.тхт — самый высокоуровневый способ, ибо позволяет задать правила индексации для всего сайта целиком (как его отдельный страниц, так и целых каталогов). Он является полностью валидным методом, поддерживаемым всеми поисковиками и другими ботами живущими в сети. Но его директивы вовсе не являются обязательными для исполнения. Например, Гугл не шибко смотрит на запреты в robots.tx — для него авторитетнее одноименный мета-тег рассмотренный ниже.
- Мета-тег robots — имеет влияние только на страницу, где он прописан. В нем можно запретить индексацию и переход робота по находящимся в этом документе ссылкам (подробнее смотрите ниже). Он тоже является полностью валидным и поисковики будут стараться учитывать указанные в нем значения. Для Гугла, как я уже упоминал, этот метод имеет больший вес, чем файлик роботса в корне сайта.
- Тег Noindex и атрибут rel=»nofollow» — самый низкоуровневый способ влияния на индексацию. Они позволяют закрыть от индексации отдельные фрагменты текста (noindex) и не учитывать вес передаваемый по ссылке. Они не валидны (их нет в стандартах). Как именно их учитывают поисковики и учитывают ли вообще — большой вопрос и предмет долгих споров (кто знает наверняка — тот молчит и пользуется).
 Он тоже является полностью валидным и поисковики будут стараться учитывать указанные в нем значения. Для Гугла, как я уже упоминал, этот метод имеет больший вес, чем файлик роботса в корне сайта.
Он тоже является полностью валидным и поисковики будут стараться учитывать указанные в нем значения. Для Гугла, как я уже упоминал, этот метод имеет больший вес, чем файлик роботса в корне сайта.Важно понимать, что даже «стандарт» (валидные директивы robots.txt и одноименного мета-тега) являются необязательным к исполнению. Если робот «вежливый», то он будет следовать заданным вами правилам. Но вряд ли вы сможете при помощи такого метода запретить доступ к части сайта роботам, ворующим у вас контент или сканирующим сайт по другим причинам.
Вообще, роботов (ботов, пауков, краулеров) существует множество. Какие-то из них индексируют контент (как например, боты поисковых систем или воришек). Есть боты проверяющие ссылки, обновления, зеркалирование, проверяющие микроразметку и т.д.
Какие-то из них индексируют контент (как например, боты поисковых систем или воришек). Есть боты проверяющие ссылки, обновления, зеркалирование, проверяющие микроразметку и т.д.
Большинство роботов хорошо спроектированы и не создают каких-либо проблем для владельцев сайтов. Но если бот написан дилетантом или «что-то пошло не так», то он может создавать существенную нагрузку на сайт, который он обходит. Кстати, пауки вовсе на заходят на сервер подобно вирусам — они просто запрашивают нужные им страницы удаленно (по сути это аналоги браузеров, но без функции просмотра страниц).
Robots.txt — директива user-agent и боты поисковых систем
Роботс.тхт имеет совсем не сложный синтаксис, который очень подробно описан, например, в хелпе яндекса и хелпе Гугла. Обычно в нем указывается, для какого поискового бота предназначены описанные ниже директивы: имя бота (‘User-agent‘), разрешающие (‘Allow‘) и запрещающие (‘Disallow‘), а также еще активно используется ‘Sitemap’ для указания поисковикам, где именно находится файл карты.
Стандарт создавался довольно давно и что-то было добавлено уже позже. Есть директивы и правила оформления, которые будут понятны только роботами определенных поисковых систем. В рунете интерес представляют в основном только Яндекс и Гугл, а значит именно с их хелпами по составлению robots.txt следует ознакомиться особо детально (ссылки я привел в предыдущем абзаце).
Например, раньше для поисковой системы Яндекс было полезным указать, какое из зеркал вашего вебпроекта является главным в специальной директиве ‘Host’, которую понимает только этот поисковик (ну, еще и Майл.ру, ибо у них поиск от Яндекса). Правда, в начале 2018 Яндекс все же отменил Host и теперь ее функции как и у других поисковиков выполняет 301-редирект.
Если даже у вашего ресурса нет зеркал, то полезно будет указать, какой из вариантов написания является главным — с www или без него.
Теперь поговорим немного о синтаксисе этого файла. Директивы в robots.txt имеют следующий вид:
<поле>:<пробел><значение><пробел> <поле>:<пробел><значение><пробел>
Правильный код должен содержать хотя бы одну директиву «Disallow» после каждой записи «User-agent».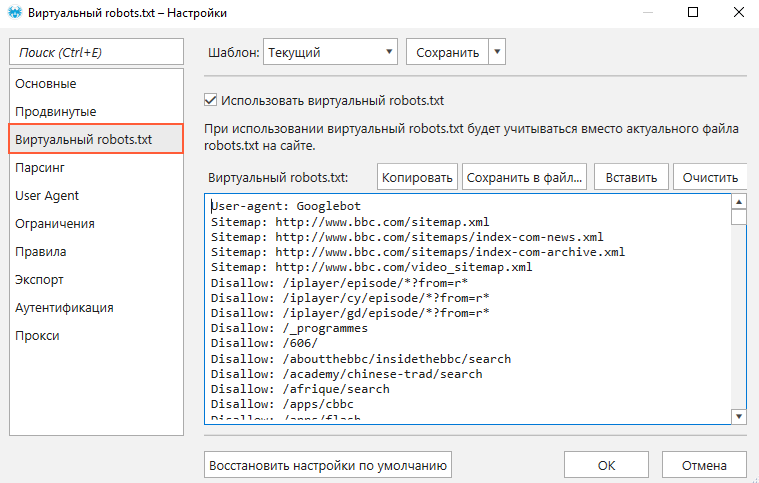 Пустой файл предполагает разрешение на индексирование всего сайта.
Пустой файл предполагает разрешение на индексирование всего сайта.
User-agent
Директива «User-agent» должна содержать название поискового бота. При помощи нее можно настроить правила поведения для каждого конкретного поисковика (например, создать запрет индексации отдельной папки только для Яндекса). Пример написания «User-agent», адресованной всем ботам зашедшим на ваш ресурс, выглядит так:
User-agent: *
Если вы хотите в «User-agent» задать определенные условия только для какого-то одного бота, например, Яндекса, то нужно написать так:
User-agent: Yandex
Название роботов поисковых систем и их роль в файле robots.txt
Бот каждой поисковой системы имеет своё название (например, для рамблера это StackRambler). Здесь я приведу список самых известных из них:
Google http://www.google.com Googlebot Яндекс http://www.ya.ru Yandex Бинг http://www.bing.com/ bingbot
У крупных поисковых систем иногда, кроме основных ботов, имеются также отдельные экземпляры для индексации блогов, новостей, изображений и т.![]() д. Много информации по разновидностям ботов вы можете почерпнуть тут (для Google).
д. Много информации по разновидностям ботов вы можете почерпнуть тут (для Google).
Как быть в этом случае? Если нужно написать правило запрета индексации, которое должны выполнить все типы роботов Гугла, то используйте название Googlebot и все остальные пауки этого поисковика тоже послушаются. Однако, можно запрет давать только, например, на индексацию картинок, указав в качестве User-agent бота Googlebot-Image. Сейчас это не очень понятно, но на примерах, я думаю, будет проще.
Примеры использования директив Disallow и Allow в роботс.тхт
Приведу несколько простых примеров использования директив с объяснением его действий.
- Приведенный ниже код разрешает всем ботам (на это указывает звездочка в User-agent) проводить индексацию всего содержимого без каких-либо исключений. Это задается пустой директивой Disallow.
User-agent: * Disallow:
- Следующий код, напротив, полностью запрещает всем поисковикам добавлять в индекс страницы этого ресурса. Устанавливает это
Disallowс «/» в поле значения.User-agent: * Disallow: /
- В этом случае будет запрещаться всем ботам просматривать содержимое каталога /image/ (http://mysite.ru/image/ — абсолютный путь к этому каталогу)
User-agent: * Disallow: /image/
- Чтобы заблокировать один файл, достаточно будет прописать его абсолютный путь до него (читайте про абсолютные и относительные пути по ссылке):
User-agent: * Disallow: /katalog1//katalog2/private_file.html
Забегая чуть вперед скажу, что проще использовать символ звездочки (*), чтобы не писать полный путь:
Disallow: /*private_file.html
- В приведенном ниже примере будут запрещены директория «image», а также все файлы и директории, начинающиеся с символов «image», т. е. файлы: «image.htm», «images.htm», каталоги: «image», «images1», «image34» и т. д.):
User-agent: * Disallow: /image
Дело в том, что по умолчанию в конце записи подразумевается звездочка, которая заменяет любые символы, в том числе и их отсутствие. Читайте об этом ниже. - С помощью директивы Allow мы разрешаем доступ. Хорошо дополняет Disallow. Например, таким вот условием поисковому роботу Яндекса мы запрещаем выкачивать (индексировать) все, кроме вебстраниц, адрес которых начинается с /cgi-bin:
User-agent: Yandex Allow: /cgi-bin Disallow: /
Ну, или такой вот очевидный пример использования связки Allow и Disallow:
User-agent: * Disallow: /catalog Allow: /catalog/auto
- При описании путей для директив
Allow-Disallowможно использовать символы ‘*’ и ‘$’, задавая, таким образом, определенные логические выражения.- Символ ‘*'(звездочка) означает любую (в том числе пустую) последовательность символов. Следующий пример запрещает всем поисковикам индексацию файлов с расширение «.php»:
User-agent: * Disallow: *.php$
- Зачем нужен на конце знак $ (доллара)? Дело в том, что по логике составления файла robots. txt, в конце каждой директивы как бы дописывается умолчательная звездочка (ее нет, но она как бы есть). Например мы пишем:
Disallow: /images
Подразумевая, что это то же самое, что:
Disallow: /images*
Т.е. это правило запрещает индексацию всех файлов (вебстраниц, картинок и других типов файлов) адрес которых начинается с /images, а дальше следует все что угодно (см. пример выше). Так вот, символ $ просто отменяет эту умолчательную (непроставляемую) звездочку на конце. Например:
Disallow: /images$
Запрещает только индексацию файла /images, но не /images.html или /images/primer.html. Ну, а в первом примере мы запретили индексацию только файлов оканчивающихся на .php (имеющих такое расширение), чтобы ничего лишнего не зацепить:
Disallow: *.php$
- Символ ‘*'(звездочка) означает любую (в том числе пустую) последовательность символов. Следующий пример запрещает всем поисковикам индексацию файлов с расширение «.php»:
- Во многих движках пользователи настраивают так называемые ЧПУ (человеко-понятные Урлы), в то время как Урлы, генерируемые системой, имеют знак вопроса ‘?’ в адресе. Этим можно воспользоваться и написать такое правило в robots.txt:
User-agent: * Disallow: /*?
Звездочка после вопросительного знака напрашивается, но она, как мы с вами выяснили чуть выше, уже подразумевается на конце. Таким образом мы запретим индексацию страниц поиска и прочих служебных страниц создаваемых движком, до которых может дотянуться поисковый робот. Лишним не будет, ибо знак вопроса чаще всего CMS используют как идентификатор сеанса, что может приводить к попаданию в индекс дублей страниц.
 Устанавливает это
Устанавливает это  Читайте об этом ниже.
Читайте об этом ниже. txt, в конце каждой директивы как бы дописывается умолчательная звездочка (ее нет, но она как бы есть). Например мы пишем:
txt, в конце каждой директивы как бы дописывается умолчательная звездочка (ее нет, но она как бы есть). Например мы пишем: Этим можно воспользоваться и написать такое правило в robots.txt:
Этим можно воспользоваться и написать такое правило в robots.txt:Директивы Sitemap и Host (для Яндекса) в Robots.txt
Во избежании возникновения неприятных проблем с зеркалами сайта, раньше рекомендовалось добавлять в robots.txt директиву Host, которая указывал боту Yandex на главное зеркало.
Однако, в начале 2018 год это было отменено и и теперь функции Host выполняет 301-редирект.
Директива Host — указывает главное зеркало сайта для Яндекса
Например, раньше, если вы еще не перешли на защищенный протокол, указывать в Host нужно было не полный Урл, а доменное имя (без http://, т. е. ktonanovenkogo.ru, а не https://ktonanovenkogo.ru). Если же уже перешли на https, то указывать нужно будет полный Урл (типа https://myhost.ru).
е. ktonanovenkogo.ru, а не https://ktonanovenkogo.ru). Если же уже перешли на https, то указывать нужно будет полный Урл (типа https://myhost.ru).
Сейчас переезд сайта после отказа от директивы Host очень сильно упростился, ибо теперь не нужно ждать пока произойдет склейка зеркал по директиве Host для Яндекса, а можно сразу после настройки Https на сайте делать постраничный редирект с Http на Https.
Напомню в качестве исторического экскурса, что по стандарту написания роботс.тхт за любой директивой User-agent должна сразу следовать хотя бы одна директива Disallow (пусть даже и пустая, ничего не запрещающая). Так же, наверное, имеется смысл прописывать Host для отдельного блока «User-agent: Yandex», а не для общего «User-agent: *», чтобы не сбивать с толку роботов других поисковиков, которые эту директиву не поддерживают:
User-agent: Yandex Disallow: Host: www.site.ru
либо
User-agent: Yandex Disallow: Host: site.
 ru
ru либо
User-agent: Yandex Disallow: Host: https://site.ru
либо
User-agent: Yandex Disallow: Host: https://www.site.ru
в зависимости от того, что для вас оптимальнее (с www или без), а так же в зависимости от протокола.
Указываем или скрываем путь до карты сайта sitemap.xml в файле robots
Директива Sitemap указывает на местоположение файла карты сайта (обычно он называется Sitemap.xml, но не всегда). В качестве параметра указывается путь к этому файлу, включая http:// (т.е. его Урл).Благодаря этому поисковый робот сможете без труда его найти. Например:
Sitemap: http://site.ru/sitemap.xml
Раньше файл карты сайта хранили в корне сайта, но сейчас многие его прячут внутри других директорий, чтобы ворам контента не давать удобный инструмент в руки. В этом случае путь до карты сайта лучше в роботс.тхт не указывать. Дело в том, что это можно с тем же успехом сделать через панели поисковых систем (Я.Вебмастер, Google.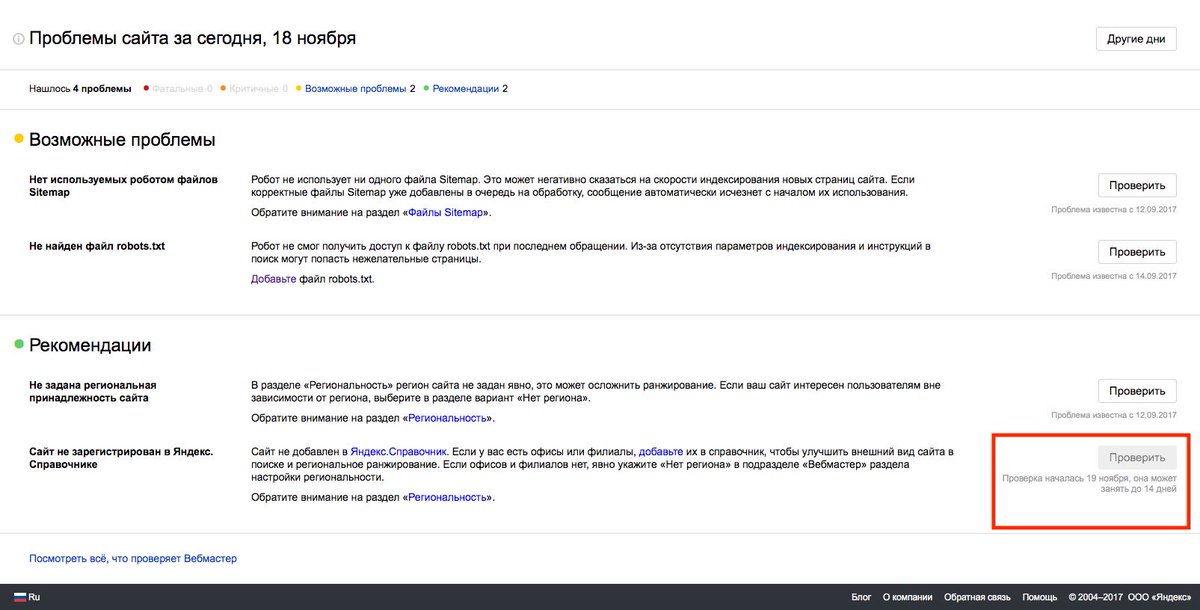 Вебмастер, панель Майл.ру), тем самым «не паля» его местонахождение.
Вебмастер, панель Майл.ру), тем самым «не паля» его местонахождение.
Местоположение директивы Sitemap в файле robots.txt не регламентируется, ибо она не обязана относиться к какому-то юзер-агенту. Обычно ее прописывают в самом конце, либо вообще не прописывают по приведенным выше причинам.
Проверка robots.txt в Яндекс и Гугл вебмастере
Как я уже упоминал, разные поисковые системы некоторые директивы могут интерпритировать по разному. Поэтому имеет смысл проверять написанный вами файл роботс.тхт в панелях для вебмастеров обоих систем. Как проверять?
- Зайти в инструменты проверки Яндекса и Гугла.
Убедиться, что в панель вебмастера загружена версия файла с внесенными вами изменениями. В Яндекс вебмастере загрузить измененный файл можно с помощью показанной на скриншоте иконки:
В Гугл Вебмастере нужно нажать кнопку «Отправить» (справа под списком директив роботса), а затем в открывшемся окне выбрать последний вариант нажатием опять же на кнопку «Отправить»:
- Набрать список адресов страниц своего сайта (по Урлу в строке), которые должны индексироваться, и вставить их скопом (в Яндексе) или по одному (в Гугле) в расположенную снизу форму. После чего нажать на кнопку «Проверить».
Если возникли нестыковки, то выяснить причины, внести изменения в robots.txt, загрузить обновленный файл в панель вебмастеров и повторить проверку. Все ОК?
Тогда составляйте список страниц, которые не должны индексироваться, и проводите их проверку. При необходимости вносите изменения и проверку повторяйте. Естественно, что проверять следует не все страницы сайта, а ярких представителей своего класса (страницы статей, рубрики, служебные страницы, файлы картинок, файлы шаблона, файлы движка и т.д.)
 После чего нажать на кнопку «Проверить».
После чего нажать на кнопку «Проверить».Причины ошибок выявляемых при проверке файла роботс.тхт
- Файл должен находиться в корне сайта, а не в какой-то папке (это не .htaccess, и его действия распространяются на весь сайт, а не на каталог, в котором его поместили), ибо поисковый робот его там искать не будет.
- Название и расширение файла robots.txt должно быть набрано в нижнем регистре (маленькими) латинскими буквами.
- В названии файла должна быть буква S на конце (не robot. txt, как многие пишут)
- Часто в User-agent вместо звездочки (означает, что этот блок robots.txt адресован всем ботам) оставляют пустое поле. Это не правильно и * в этом случае обязательна
User-agent: * Disallow: /
- В одной директиве Disallow или Allow можно прописывать только одно условие на запрет индексации директории или файла. Так нельзя:
Disallow: /feed/ /tag/ /trackback/
Для каждого условия нужно добавить свое Disallow:
Disallow: /feed/ Disallow: /tag/ Disallow: /trackback/
- Довольно часто путают значения для директив и пишут:
User-agent: / Disallow: Yandex
вместо
User-agent: Yandex Disallow: /
- Порядок следования Disallow (Allow) не важен — главное, чтобы была четкая логическая цепь
- Пустая директива Disallow означает то же, что «Allow: /»
- Нет смысла прописывать директиву sitemap под каждым User-agent, если будете указывать путь до карты сайта (читайте об этом ниже), то делайте это один раз, например, в самом конце.
- Директиву Host лучше писать под отдельным «User-agent: Yandex», чтобы не смущать ботов ее не поддерживающих
 txt, как многие пишут)
txt, как многие пишут)
Мета-тег Robots — помогает закрыть дубли контента при индексации сайта
Существует еще один способ настроить (разрешить или запретить) индексацию отдельных страниц вебсайта, как для Яндекса, так и для Гугл. Причем для Google этот метод гораздо приоритетнее описанного выше. Поэтому, если нужно наверняка закрыть страницу от индексации этой поисковой системой, то данный мета-тег нужно будет прописывать в обязательном порядке.
Для этого внутри тега «HEAD» нужной вебстраницы дописывается МЕТА-тег Robots с нужными параметрами, и так повторяется для всех документов, к которым нужно применить то или иное правило (запрет или разрешение). Выглядеть это может, например, так:
<html> <head> <meta name="robots" content="noindex,nofollow"> <meta name="description" content="Эта страница ...."> <title>...</title> </head> <body> .
 ..
..
В этом случае, боты всех поисковых систем должны будут забыть об индексации этой вебстраницы (об этом говорит присутствие noindex в данном мета-теге) и анализе размещенных на ней ссылок (об этом говорит присутствие nofollow — боту запрещается переходить по ссылкам, которые он найдет в этом документе).
Существуют только две пары параметров у метатега robots: [no]index и [no]follow:
- Index — указывают, может ли робот проводить индексацию данного документа
- Follow — может ли он следовать по ссылкам, найденным в этом документе
Значения по умолчанию (когда этот мета-тег для страницы вообще не прописан) – «index» и «follow». Есть также укороченный вариант написания с использованием «all» и «none», которые обозначают активность обоих параметров или, соответственно, наоборот: all=index,follow и none=noindex,nofollow.
Более подробные объяснения можно найти, например, в хелпе Яндекса:
Для блога на WordPress вы сможете настроить мета-тег Robots, например, с помощью плагина All in One SEO Pack. Если используете другие плагины или другие движки сайта, то гуглите на тему прописывания для нужных страниц meta name=»robots».
Если используете другие плагины или другие движки сайта, то гуглите на тему прописывания для нужных страниц meta name=»robots».
Как создать правильный роботс.тхт?
Ну все, с теорией покончено и пора переходить к практике, а именно к составлению оптимальных robots.txt. Как известно, у проектов, созданных на основе какого-либо движка (Joomla, WordPress и др), имеется множество вспомогательных объектов не несущих никакой информативной нагрузки.
Если не запретить индексацию всего этого мусора, то время, отведенное поисковиками на индексацию вашего сайта, будет тратиться на перебор файлов движка (на предмет поиска в них информационной составляющей, т.е. контента). Но фишка в том, что в большинстве CMS контент хранится не в файликах, а в базе данных, к которой поисковым ботам никак не добраться. Полазив по мусорным объектам движка, бот исчерпает отпущенное ему время и уйдет не солоно хлебавши.
Кроме того, следует стремиться к уникальности контента на своем проекте и не следует допускать полного или даже частичного дублирования контента (информационного содержимого). Дублирование может возникнуть в том случае, если один и тот же материал будет доступен по разным адресам (URL).
Дублирование может возникнуть в том случае, если один и тот же материал будет доступен по разным адресам (URL).
Яндекс и Гугл, проводя индексацию, обнаружат дубли и, возможно, примут меры к некоторой пессимизации вашего ресурса при их большом количестве (машинные ресурсы стоят дорого, а посему затраты нужно минимизировать). Да, есть еще такая штука, как мета-тэг Canonical.
Замечательный инструмент для борьбы с дублями контента — поисковик просто не будет индексировать страницу, если в Canonical прописан другой урл. Например, для такой страницы https://ktonanovenkogo.ru/page/2 моего блога (страницы с пагинацией) Canonical указывает на https://ktonanovenkogo.ru и никаких проблем с дублированием тайтлов возникнуть не должно.
<link rel="canonical" href="https://ktonanovenkogo.ru/" />
Но это я отвлекся…
Если ваш проект создан на основе какого-либо движка, то дублирование контента будет иметь место с высокой вероятностью, а значит нужно с ним бороться, в том числе и с помощью запрета в robots.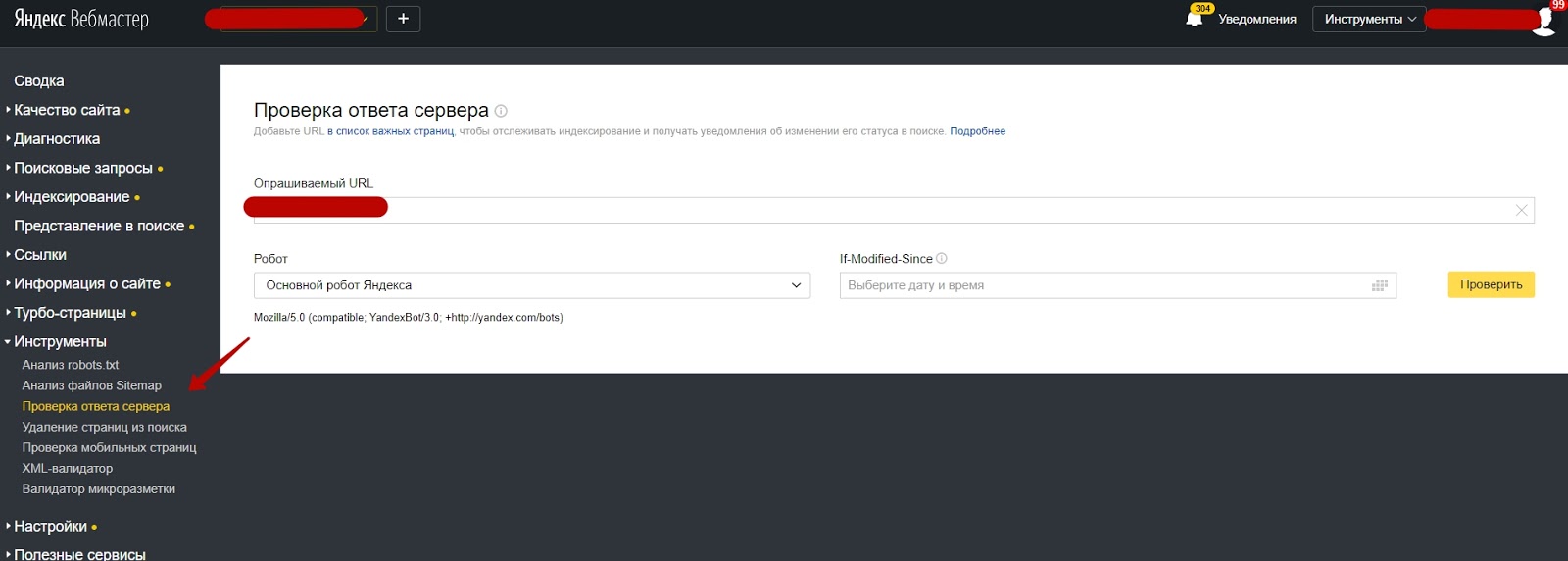 txt, а особенно в мета-теге, ибо в первом случае Google запрет может и проигнорировать, а вот на метатег наплевать он уже не сможет (так воспитан).
txt, а особенно в мета-теге, ибо в первом случае Google запрет может и проигнорировать, а вот на метатег наплевать он уже не сможет (так воспитан).
Например, в WordPress страницы с очень похожим содержимым могут попасть в индекс поисковиков, если разрешена индексация и содержимого рубрик, и содержимого архива тегов, и содержимого временных архивов. Но если с помощью описанного выше мета-тега Robots создать запрет для архива тегов и временного архива (можно теги оставить, а запретить индексацию содержимого рубрик), то дублирования контента не возникнет. Как это сделать описано по ссылке приведенной чуть выше (на плагин ОлИнСеоПак)
Подводя итог скажу, что файл Роботс предназначен для задания глобальных правил запрета доступа в целые директории сайта, либо в файлы и папки, в названии которых присутствуют заданные символы (по маске). Примеры задания таких запретов вы можете посмотреть чуть выше.
Теперь давайте рассмотрим конкретные примеры роботса, предназначенного для разных движков — Joomla, WordPress и SMF. Естественно, что все три варианта, созданные для разных CMS, будут существенно (если не сказать кардинально) отличаться друг от друга. Правда, у всех у них будет один общий момент, и момент этот связан с поисковой системой Яндекс.
Естественно, что все три варианта, созданные для разных CMS, будут существенно (если не сказать кардинально) отличаться друг от друга. Правда, у всех у них будет один общий момент, и момент этот связан с поисковой системой Яндекс.
Т.к. в рунете Яндекс имеет достаточно большой вес, то нужно учитывать все нюансы его работы, и тут нам поможет директива Host. Она в явной форме укажет этому поисковику главное зеркало вашего сайта.
Для нее советуют использовать отдельный блог User-agent, предназначенный только для Яндекса (User-agent: Yandex). Это связано с тем, что остальные поисковые системы могут не понимать Host и, соответственно, ее включение в запись User-agent, предназначенную для всех поисковиков (User-agent: *), может привести к негативным последствиям и неправильной индексации.
Как обстоит дело на самом деле — сказать трудно, ибо алгоритмы работы поиска — это вещь в себе, поэтому лучше сделать так, как советуют. Но в этом случае придется продублировать в директиве User-agent: Yandex все те правила, что мы задали User-agent: *. Если вы оставите User-agent: Yandex с пустым
Если вы оставите User-agent: Yandex с пустым Disallow:, то таким образом вы разрешите Яндексу заходить куда угодно и тащить все подряд в индекс.
Robots для WordPress
Не буду приводить пример файла, который рекомендуют разработчики. Вы и сами можете его посмотреть. Многие блогеры вообще не ограничивают ботов Яндекса и Гугла в их прогулках по содержимому движка WordPress. Чаще всего в блогах можно встретить роботс, автоматически заполненный плагином Google XML Sitemaps.
Но, по-моему, все-таки следует помочь поиску в нелегком деле отсеивания зерен от плевел. Во-первых, на индексацию этого мусора уйдет много времени у ботов Яндекса и Гугла, и может совсем не остаться времени для добавления в индекс вебстраниц с вашими новыми статьями. Во-вторых, боты, лазящие по мусорным файлам движка, будут создавать дополнительную нагрузку на сервер вашего хоста, что не есть хорошо.
Мой вариант этого файла вы можете сами посмотреть. Он старый, давно не менялся, но я стараюсь следовать принципу «не чини то, что не ломалось», а вам уже решать: использовать его, сделать свой или еще у кого-то подсмотреть. У меня там еще запрет индексации страниц с пагинацией был прописан до недавнего времени (Disallow: */page/), но недавно я его убрал, понадеясь на Canonical, о котором писал выше.
У меня там еще запрет индексации страниц с пагинацией был прописан до недавнего времени (Disallow: */page/), но недавно я его убрал, понадеясь на Canonical, о котором писал выше.
А вообще, единственно правильного файла для WordPress, наверное, не существует. Можно, кончено же, реализовать в нем любые предпосылки, но кто сказал, что они будут правильными. Вариантов идеальных robots.txt в сети много.
Приведу две крайности:
- Тут можно найти мегафайлище с подробными пояснениями (символом # отделяются комментарии, которые в реальном файле лучше будет удалить):
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*. gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site. ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команду Host понимает
# Яндекс и Mail.RU, Google не учитывает.
Host: www.site.ru
- А вот тут можно взять на вооружение пример минимализма:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Host: https://site.ru Sitemap: https://site.ru/sitemap.xml
 xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.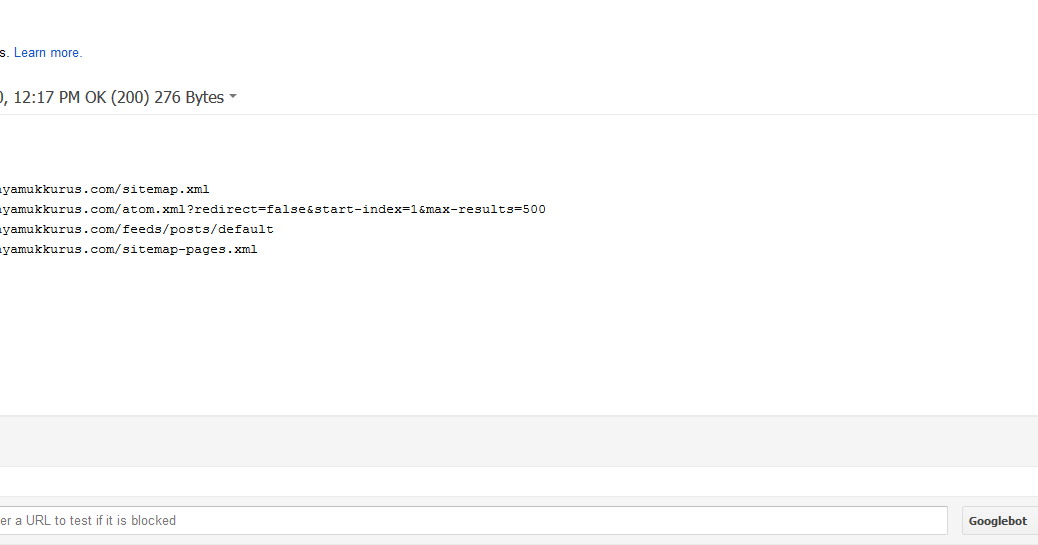 gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.
gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site. ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команду Host понимает
# Яндекс и Mail.RU, Google не учитывает.
Host: www.site.ru
ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команду Host понимает
# Яндекс и Mail.RU, Google не учитывает.
Host: www.site.ru
Истина, наверное, лежит где-то посредине. Еще не забудьте прописать мета-тег Robots для «лишних» страниц, например, с помощью чудесного плагина — All in One SEO Pack. Он же поможет и Canonical настроить.
Правильный robots.txt для Joomla
Рекомендованный файл для Джумлы 3 выглядит так (живет он в файле robots.txt.dist корневой папки движка):
User-agent: * Disallow: /administrator/ Disallow: /bin/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /layouts/ Disallow: /libraries/ Disallow: /logs/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/
В принципе, здесь практически все учтено и работает он хорошо.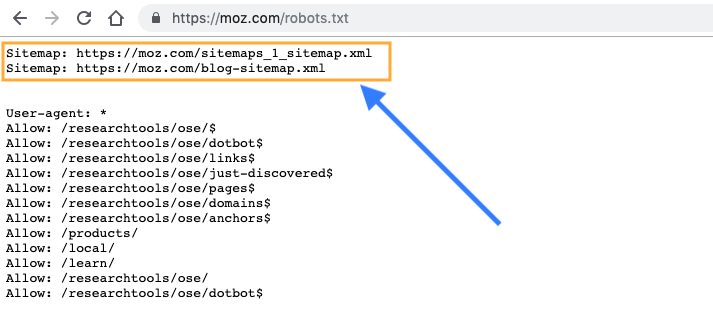 Единственное, в него следует добавить отдельное правило User-agent: Yandex для вставки директивы Host, определяющей главное зеркало для Яндекса, а так же указать путь к файлу Sitemap.
Единственное, в него следует добавить отдельное правило User-agent: Yandex для вставки директивы Host, определяющей главное зеркало для Яндекса, а так же указать путь к файлу Sitemap.
Поэтому в окончательном виде правильный robots для Joomla, по-моему мнению, должен выглядеть так:
User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/ Disallow: /layouts/ Disallow: /cli/ Disallow: /bin/ Disallow: /logs/ Disallow: /components/ Disallow: /component/ Disallow: /component/tags* Disallow: /*mailto/ Disallow: /*.pdf Disallow: /*% Disallow: /index.php Host: vash_sait.ru (или www.vash_sait.ru) User-agent: * Allow: /*.css?*$ Allow: /*.js?*$ Allow: /*.jpg?*$ Allow: /*.png?*$ Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/ Disallow: /layouts/ Disallow: /cli/ Disallow: /bin/ Disallow: /logs/ Disallow: /components/ Disallow: /component/ Disallow: /*mailto/ Disallow: /*.
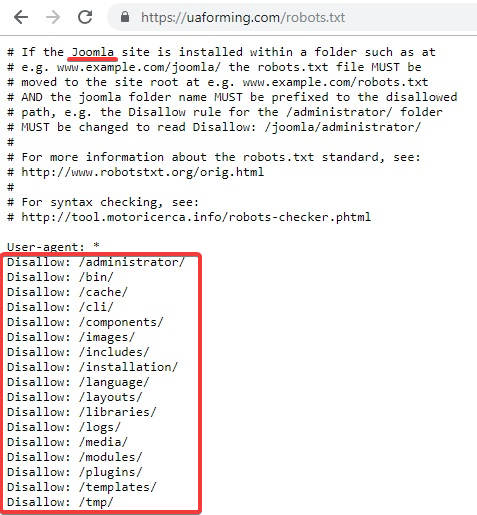 pdf
Disallow: /*%
Disallow: /index.php
Sitemap: http://путь к вашей карте XML формата
pdf
Disallow: /*%
Disallow: /index.php
Sitemap: http://путь к вашей карте XML формата
Да, еще обратите внимание, что во втором варианте есть директивы Allow, разрешающие индексацию стилей, скриптов и картинок. Написано это специально для Гугла, ибо его Googlebot иногда ругается, что в роботсе запрещена индексация этих файлов, например, из папки с используемой темой оформления. Даже грозится за это понижать в ранжировании.
Поэтому заранее все это дело разрешаем индексировать с помощью Allow. То же самое, кстати, и в примере файла для Вордпресс было.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Какие страницы закрывать от индексации и как
Любая страница на сайте может быть открыта или закрыта для индексации поисковыми системами. Если страница открыта, поисковая система добавляет ее в свой индекс, если закрыта, то робот не заходит на нее и не учитывает в поисковой выдаче.
При создании сайта важно на программном уровне закрыть от индексации все страницы, которые по каким-либо причинам не должны видеть пользователи и поисковики.
К таким страницам можно отнести административную часть сайта (админку), страницы с различной служебной информацией (например, с личными данными зарегистрированных пользователей), страницы с многоуровневыми формами (например, сложные формы регистрации), формы обратной связи и т.д.
Пример:
Профиль пользователя на форуме о поисковых системах Searchengines.
Обязательным также является закрытие от индексации страниц, содержимое которых уже используется на других страницах.Такие страницы называются дублирующими. Полные или частичные дубли сильно пессимизируют сайт, поскольку увеличивают количество неуникального контента на сайте.
Пример:
Типичный блог на CMSWordPress, который содержит дубли.http://reaktivist.ru/ — главная страница.
http://reaktivist.ru/category/liniya-zhizni — страница категории.
Как видим, контент на обеих страницах частично совпадает. Поэтому страницы категорий на WordPress-сайтах закрывают от индексации, либо выводят на них только название записей.
То же самое касается и страниц тэгов– такие страницы часто присутствуют в структуре блогов на WordPress. Облако тэгов облегчает навигацию по сайту и позволяет пользователям быстро находить интересующую информацию. Однако они являются частичными дублями других страниц, а значит – подлежат закрытию от индексации.
Еще один пример – магазин на CMS OpenCart.
Страница категории товаров http://www.masternet-instrument.ru/Lampy-energosberegajuschie-c-906_910_947.html.
Страница товаров, на которые распространяется скидка http://www.masternet-instrument.ru/specials.php.
Данные страницы имеют схожее содержание, так как на них размещено много одинаковых товаров.
Особенно критично к дублированию контента на различных страницах сайта относится Google. За большое количество дублей в Google можно заработать определенные санкции вплоть до временного исключения сайта из поисковой выдачи.
Мы рекомендуем закрывать страницу от индексации, если она содержит более 40 % контента с другой страницы. В идеале структуру сайта нужно создавать таким образом, чтобы дублирования контента не было вовсе.
В идеале структуру сайта нужно создавать таким образом, чтобы дублирования контента не было вовсе.
Примечание:
Для авторитетных сайтов с большим количеством страниц и хорошей посещаемостью (от 3000 человек в сутки) дублирование не столь существенно, как для новых сайтов.
Еще один случай, когда содержимое страниц не стоит «показывать» поисковику – страницы с неуникальным контентом. Типичный пример — инструкции к медицинским препаратам в интернет-аптеке. Контент на странице с описанием препарата http://www.piluli.ru/product271593/product_info.html неуникален и опубликован на сотнях других сайтов.
Сделать его уникальным практически невозможно, поскольку переписывание столь специфических текстов – дело неблагодарное и запрещенное. Наилучшим решением в этом случае будет закрытие страницы от индексации, либо написание письма в поисковые системы с просьбой лояльно отнестись к неуникальности контента, который сделать уникальным невозможно по тем или иным причинам.
Как закрывать страницы от индексации
Классическим инструментом для закрытия страниц от индексации является файл robots.txt. Он находится в корневом каталоге вашего сайта и создается специально для того, чтобы показать поисковым роботам, какие страницы им посещать нельзя. Это обычный текстовый файл, который вы в любой момент можете отредактировать. Если файла robots.txt у вас нет или если он пуст, поисковики по умолчанию будут индексировать все страницы, которые найдут.
Структура файла robots.txt довольно проста. Он может состоять из одного или нескольких блоков (инструкций). Каждая инструкция, в свою очередь, состоит из двух строк. Первая строка называется User-agent и определяет, какой поисковик должен следовать этой инструкции. Если вы хотите запретить индексацию для всех поисковиков, первая строка должна выглядеть так:
User-agent: *
Если вы хотите запретить индексацию страницы только для одной ПС, например, для Яндекса, первая строка выглядит так:
User-agent: Yandex
Вторая строчка инструкции называется Disallow (запретить). Для запрета всех страниц сайта напишите в этой строке следующее:
Для запрета всех страниц сайта напишите в этой строке следующее:
Disallow: /
Чтобы разрешить индексацию всех страниц вторая строка должна иметь вид:
Disallow:
В строке Disallow вы можете указывать конкретные папки и файлы, которые нужно закрыть от индексации.
Например, для запрета индексации папки images и всего ее содержимого пишем:
User-agent: *
Disallow: /images/
Чтобы «спрятать» от поисковиков конкретные файлы, перечисляем их:
User-agent: *
Disallow: /myfile1.htm
Disallow: /myfile2.htm
Disallow: /myfile3.htm
Это – основные принципы структуры файла robots.txt. Они помогут вам закрыть от индексации отдельные страницы и папки на вашем сайте.
Еще один, менее распространенный способ запрета индексации – мета-тэг Robots. Если вы хотите закрыть от индексации страницу или запретить поисковикам индексировать ссылки, размещенные на ней, в ее HTML-коде необходимо прописать этот тэг. Его надо размещать в области HEAD, перед тэгом <title>.
Мета-тег Robots состоит из двух параметров. INDEX – параметр, отвечающий за индексацию самой страницы, а FOLLOW – параметр, разрешающий или запрещающий индексацию ссылок, расположенных на этой странице.
Для запрета индексации вместо INDEX и FOLLOW следует писать NOINDEX и NOFOLLOW соответственно.
Таким образом, если вы хотите закрыть страницу от индексации и запретить поисковикам учитывать ссылки на ней, вам надо добавить в код такую строку:
<meta name=“robots” content=“noindex,nofollow”>
Если вы не хотите скрывать страницу от индексации, но вам необходимо «спрятать» ссылки на ней, мета-тег Robots будет выглядеть так:
<metaname=“robots” content=“index,nofollow”>
Если же вам наоборот, надо скрыть страницу от ПС, но при этом учитывать ссылки, данный тэг будет иметь такой вид:
<meta name=“robots” content=“noindex,follow”>
Большинство современных CMS дают возможность закрывать некоторые страницы от индексации прямо из админ.панели сайта. Это позволяет избежать необходимости разбираться в коде и настраивать данные параметры вручную. Однако перечисленные выше способы были и остаются универсальными и самыми надежными инструментами для запрета индексации.
Блокировать страницы или сообщения блога от индексации поисковыми системами
Есть несколько способов запретить поисковым системам индексировать определенные страницы вашего сайта. Рекомендуется тщательно изучить каждый из этих методов, прежде чем вносить какие-либо изменения, чтобы гарантировать, что только нужные страницы заблокированы для поисковых систем.Обратите внимание: : эти инструкции блокируют индексирование URL страницы для поиска. Узнайте, как настроить URL-адрес файла в инструменте файлов, чтобы заблокировать его от поисковых систем.
Файл Robots.txt
Ваш файл robots.txt — это файл на вашем веб-сайте, который сканеры поисковых систем читают, чтобы узнать, какие страницы они должны и не должны индексировать. Узнайте, как настроить файл robots.txt в HubSpot.
Google и другие поисковые системы не могут задним числом удалять страницы из результатов после реализации метода файла robots.txt. Хотя это говорит ботам не сканировать страницу, поисковые системы все равно могут индексировать ваш контент (например, если на вашу страницу есть входящие ссылки с других веб-сайтов).Если ваша страница уже проиндексирована и вы хотите удалить ее из поисковых систем задним числом, рекомендуется вместо этого использовать метод метатега «Без индекса».
Мета-тег «Без индекса»
Обратите внимание: : , если вы решите использовать метод метатега «Без индекса», имейте в виду, что его не следует комбинировать с методом файла robots.txt. Поисковым системам необходимо начать сканирование страницы, чтобы увидеть метатег «Без индекса», а файл robots.txt полностью предотвращает сканирование.
Мета-тег «без индекса» — это строка кода, введенная в раздел заголовка HTML-кода страницы, который сообщает поисковым системам не индексировать страницу.
- Щелкните имя определенной страницы или сообщения в блоге.
- В редакторе содержимого щелкните вкладку Настройки .
- Щелкните Дополнительные параметры .
- В разделе Head HTML скопируйте и вставьте следующий код:
Консоль поиска Google
Если у вас есть учетная запись Google Search Console , вы можете отправить URL-адрес для удаления из результатов поиска Google.Обратите внимание, что это будет применяться только к результатам поиска Google. Если вы хотите заблокировать файлы в файловом менеджере HubSpot (например, PDF-документ) от индексации поисковыми системами, вы должны выбрать подключенный субдомен для файла (ов) и использовать URL-адрес файла для блокировки веб-сканеров.
Как HubSpot обрабатывает запросы от пользовательского агента
Если вы устанавливаете строку пользовательского агента для проверки сканирования вашего веб-сайта и видите сообщение об отказе в доступе, это ожидаемое поведение. Google все еще сканирует и индексирует ваш сайт.
Причина, по которой вы видите это сообщение, заключается в том, что HubSpot разрешает запросы от пользовательского агента googlebot только с IP-адресов, принадлежащих Google. Чтобы защитить сайты, размещенные на HubSpot, от злоумышленников или спуферов, запросы с других IP-адресов будут отклонены. HubSpot делает то же самое для других сканеров поисковых систем, таких как BingBot, MSNBot и Baiduspider.
SEO Целевые страницы Блог Настройки аккаунта Страницы веб-сайта
Руководство для новичков по блокировке URL-адресов в роботах.txt файл | Ignite Visibility
Robots.txt, также известный как исключение роботов, является ключом к предотвращению сканирования роботами поисковых систем ограниченных областей вашего сайта.
В этой статье я расскажу об основах блокировки URL-адресов в robots.txt.
Что мы расскажем:
Что такое файл Robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы научить роботов сканировать страницы веб-сайтов и позволяет сканерам узнать, обращаться к файлу или нет.
Вы можете заблокировать URL-адреса в robots txt, чтобы Google не индексировал личные фотографии, просроченные специальные предложения или другие страницы, к которым вы не готовы для пользователей. Использование его для блокировки URL-адреса может помочь в SEO.
Он может решить проблемы с дублированным контентом (однако могут быть более эффективные способы сделать это, о чем мы поговорим позже). Когда робот начинает сканирование, он сначала проверяет наличие файла robots.txt, который не позволяет им просматривать определенные страницы.
Когда мне следует использовать файл Robots.txt?
Вам нужно будет использовать его, если вы не хотите, чтобы поисковые системы индексировали определенные страницы или контент. Если вы хотите, чтобы поисковые системы (например, Google, Bing и Yahoo) получали доступ и индексировали весь ваш сайт, вам не нужен файл robots.txt. Хотя стоит упомянуть, что в некоторых случаях люди все же используют его, чтобы направлять пользователей на карту сайта.
Однако, если другие сайты ссылаются на страницы вашего сайта, заблокированные, поисковые системы могут по-прежнему индексировать URL-адреса, и в результате они могут по-прежнему отображаться в результатах поиска.Чтобы этого не произошло, используйте метатег x-robots-tag , метатег noindex или относительный канонический к соответствующей странице.
Эти типы файлов помогают веб-сайтам в следующих случаях:
- Сохраняйте конфиденциальность частей сайта — например, страницы администратора или изолированную программную среду вашей команды разработчиков.
- Предотвратить появление дублирующегося контента в результатах поиска.
- Избегайте проблем с индексацией
- блокирует URL
- Запретить поисковым системам индексировать определенные файлы, такие как изображения или PDF-файлы
- Управляйте трафиком сканирования и предотвращайте появление медиафайлов в результатах поиска.
- Используйте его, если вы размещаете платные объявления или ссылки, требующие специальных инструкций для роботов.
Тем не менее, если у вас нет каких-либо областей на вашем сайте, которые вам не нужно контролировать, то она вам и не нужна. В рекомендациях Google также упоминается, что вам не следует использовать robots.txt для блокировки веб-страниц из результатов поиска.
Причина в том, что если другие страницы ссылаются на ваш сайт с описательным текстом, ваша страница все равно может быть проиндексирована благодаря отображению на этом стороннем канале.Здесь лучше использовать директивы Noindex или защищенные паролем страницы.
Начало работы с Robots.txt
Прежде чем вы начнете собирать файл, убедитесь, что у вас его еще нет. Чтобы найти его, просто добавьте «/robots.txt» в конец любого доменного имени — www.examplesite.com/robots.txt. Если он у вас есть, вы увидите файл со списком инструкций. В противном случае вы увидите пустую страницу.
Затем проверьте, не блокируются ли какие-либо важные файлы
Зайдите в консоль поиска Google, чтобы узнать, не блокирует ли ваш файл какие-либо важные файлы.Тестер robots.txt покажет, препятствует ли ваш файл поисковым роботам Google доступ к определенным частям вашего веб-сайта.
Также стоит отметить, что вам может вообще не понадобиться файл robots.txt. Если у вас относительно простой веб-сайт, и вам не нужно блокировать определенные страницы для тестирования или для защиты конфиденциальной информации, вам ничего не нужно. И на этом учебник заканчивается.
Настройка файла Robots.Txt
Эти файлы можно использовать по-разному.Однако их главное преимущество заключается в том, что маркетологи могут разрешать или запрещать использование нескольких страниц одновременно, не обращаясь к коду каждой страницы вручную.
Все файлы robots.txt приведут к одному из следующих результатов:
- Полное разрешение — все содержимое можно сканировать
- Полное запрещение — сканирование контента невозможно. Это означает, что вы полностью блокируете доступ поисковых роботов Google к любой части вашего веб-сайта.
- Условное разрешение — правила, описанные в файле, определяют, какой контент открыт для сканирования, а какой заблокирован.Если вам интересно, как запретить использование URL-адреса, не заблокировав для поисковых роботов доступ ко всему сайту, то вот оно.
Если вы хотите создать файл, процесс на самом деле довольно прост и включает два элемента: «пользовательский агент», который является роботом, к которому применяется следующий блок URL, и «запретить», который является URL-адресом. вы хотите заблокировать. Эти две строки рассматриваются как одна запись в файле, что означает, что вы можете иметь несколько записей в одном файле.
Как заблокировать URL-адреса в роботах txt:
Для строки пользовательского агента вы можете указать конкретного бота (например, Googlebot) или применить блок URL txt ко всем ботам, используя звездочку.Ниже приведен пример того, как пользовательский агент блокирует всех ботов.
Пользовательский агент: *
Во второй строке записи, disallow, перечислены конкретные страницы, которые вы хотите заблокировать. Чтобы заблокировать весь сайт, используйте косую черту. Для всех остальных записей сначала используйте косую черту, а затем укажите страницу, каталог, изображение или тип файла
Disallow: / блокирует весь сайт.
Disallow: / bad-directory / блокирует как каталог, так и все его содержимое.
Disallow: /secret.html блокирует страницу.
После создания пользовательского агента и запрета выбора одна из ваших записей может выглядеть так:
User-agent: *
Disallow: / bad-directory /
Посмотреть другие примеры записей из Google Search Console .
Как сохранить файл
- Сохраните файл, скопировав его в текстовый файл или блокнот и сохранив как «robots.текст».
- Обязательно сохраните файл в каталоге верхнего уровня вашего сайта и убедитесь, что он находится в корневом домене с именем, точно соответствующим «robots.txt».
- Добавьте файл в каталог верхнего уровня кода вашего веб-сайта для упрощения сканирования и индексации.
- Убедитесь, что ваш код имеет правильную структуру: User-agent → Disallow → Allow → Host → Sitemap. Это позволяет поисковым системам получать доступ к страницам в правильном порядке.
- Поместите все URL-адреса, для которых требуется «Разрешить:» или «Запретить:», в отдельной строке.Если несколько URL-адресов отображаются в одной строке, сканерам будет сложно разделить их, и у вас могут возникнуть проблемы.
- Всегда используйте строчные буквы для сохранения файла, так как имена файлов чувствительны к регистру и не содержат специальных символов.
- Создавать отдельные файлы для разных поддоменов. Например, «example.com» и «blog.example.com» имеют отдельные файлы со своим собственным набором директив.
- Если вы должны оставлять комментарии, начните с новой строки и поставьте перед комментарием символ #.Знак # позволяет сканерам знать, что эту информацию нельзя включать в свою директиву.
Как проверить свои результаты
Проверьте свои результаты в своей учетной записи Google Search Console, чтобы убедиться, что боты сканируют те части сайта, которые вам нужны, и блокируют URL-адреса, которые вы не хотите, чтобы поисковики видели.
- Сначала откройте инструмент тестера и просмотрите свой файл на предмет предупреждений или ошибок.
- Затем введите URL-адрес страницы вашего веб-сайта в поле внизу страницы.
- Затем выберите user-agent , который вы хотите смоделировать, из раскрывающегося меню.
- Щелкните ТЕСТ.
- Кнопка TEST должна читать либо ACCEPTED , либо BLOCKED, , что укажет, заблокирован файл сканерами или нет.
- При необходимости отредактируйте файл и повторите попытку.
- Помните, любые изменения, которые вы вносите в тестере GSC, не будут сохранены на вашем веб-сайте (это симуляция).
- Если вы хотите сохранить изменения, скопируйте новый код на свой веб-сайт.
Имейте в виду, что это будет проверять только Googlebot и другие пользовательские агенты, связанные с Google. Тем не менее, использование тестера имеет огромное значение, когда дело доходит до SEO. Видите ли, если вы все же решите использовать файл, вам обязательно нужно правильно его настроить. Если в вашем коде есть какие-либо ошибки, робот Google может не проиндексировать вашу страницу или вы можете случайно заблокировать важные страницы из результатов поиска.
Наконец, убедитесь, что вы не используете его вместо реальных мер безопасности. Когда дело доходит до защиты вашего сайта от хакеров, мошенников и посторонних глаз, лучше использовать пароли, брандмауэры и зашифрованные данные.
Завершение
Готовы начать работу с robots.txt? Большой!
Если у вас есть вопросы или вам нужна помощь в начале работы, дайте нам знать!
Все, что вам нужно знать
У вас больше контроля над поисковыми системами, чем вы думаете.
Это правда; вы можете управлять тем, кто сканирует и индексирует ваш сайт, вплоть до отдельных страниц. Чтобы контролировать это, вам нужно будет использовать файл robots.txt. Robots.txt — это простой текстовый файл, который находится в корневом каталоге вашего веб-сайта.Он сообщает роботам, которых отправляют поисковые системы, какие страницы сканировать, а какие игнорировать.
Хотя это не совсем универсальный инструмент, вы, вероятно, догадались, что это довольно мощный инструмент, который позволит вам представить свой веб-сайт в Google так, как вы хотите, чтобы они его увидели. Поисковые системы сурово разбираются в людях, поэтому очень важно произвести хорошее впечатление. При правильном использовании robots.txt может повысить частоту сканирования, что может повлиять на ваши усилия по поисковой оптимизации.
Итак, как его создать? Как Вы этим пользуетесь? Чего следует избегать? Прочтите этот пост, чтобы найти ответы на все эти вопросы.
Что такое файл Robots.txt?
Раньше, когда Интернет был всего лишь ребенком с детским лицом, способным творить великие дела, разработчики изобрели способ сканирования и индексации новых страниц в сети. Они назвали их «роботами» или «пауками».
Иногда эти маленькие ребята забредали на веб-сайты, которые не были предназначены для сканирования и индексации, например, на сайты, находящиеся на техническом обслуживании.Создатель первой в мире поисковой системы Aliweb порекомендовал решение — своего рода дорожную карту, которой должен следовать каждый робот.
Эта дорожная карта была доработана в июне 1994 года группой технически подкованных в Интернете технических специалистов под названием «Протокол исключения роботов».
Файл robots.txt является исполнением этого протокола. В протоколе изложены правила, которым должен следовать каждый настоящий робот, включая ботов Google. Некоторые незаконные роботы, такие как вредоносное ПО, шпионское ПО и т. П., По определению, действуют вне этих правил.
Вы можете заглянуть за занавес любого веб-сайта, введя любой URL-адрес и добавив в конце: /robots.txt.
Например, вот версия POD Digital:
Как видите, нет необходимости иметь файл, состоящий только из песен и танцев, поскольку наш веб-сайт относительно небольшой.
Где найти файл Robots.txt
Ваш файл robots.txt будет храниться в корневом каталоге вашего сайта. Чтобы найти его, откройте свою FTP cPanel, и вы сможете найти файл в каталоге вашего веб-сайта public_html.
В этих файлах нет ничего, чтобы они не были здоровенными — возможно, всего несколько сотен байт, если это так.
Как только вы откроете файл в текстовом редакторе, вас встретит что-то вроде этого:
Если вы не можете найти файл во внутренней работе вашего сайта, вам придется создать свой собственный.
Как собрать файл Robots.txt
Robots.txt — это очень простой текстовый файл, поэтому его действительно просто создать.Все, что вам понадобится, это простой текстовый редактор, например Блокнот. Откройте лист и сохраните пустую страницу как robots.txt.
Теперь войдите в свою cPanel и найдите папку public_html, чтобы получить доступ к корневому каталогу сайта. Как только он откроется, перетащите в него свой файл.
Наконец, вы должны убедиться, что вы установили правильные разрешения для файла. Как правило, вам, как владельцу, нужно будет писать, читать и редактировать файл, но никакие другие стороны не должны иметь права делать это.
Файл должен отображать код разрешения «0644».
Если нет, вам нужно будет изменить это, поэтому щелкните файл и выберите «Разрешение файла».
Вуаля! У вас есть файл Robots.txt.
Robots.txt Синтаксис
Файл robots.txt состоит из нескольких разделов «директив», каждый из которых начинается с указанного пользовательского агента. Пользовательский агент — это имя конкретного робота-обходчика, с которым обращается код.
Доступны два варианта:
- Вы можете использовать подстановочный знак для одновременного обращения ко всем поисковым системам.
- Вы можете обращаться к конкретным поисковым системам индивидуально.
Когда бот развернут для сканирования веб-сайта, он будет привлечен к блокам, которые обращаются к нему.
Вот пример:
Директива пользователя-агента
Первые несколько строк в каждом блоке — это «пользовательский агент», который определяет конкретного бота. Пользовательский агент будет соответствовать определенному имени бота, например:
Итак, если вы хотите сказать роботу Google, что делать, например, начните с:
Пользовательский агент: Googlebot
Поисковые системы всегда пытаются чтобы определить конкретные директивы, которые наиболее к ним относятся.
Так, например, если у вас есть две директивы, одна для Googlebot-Video и одна для Bingbot. Бот, который поставляется вместе с пользовательским агентом Bingbot, будет следовать инструкциям. Тогда как бот «Googlebot-Video» пропустит это и отправится на поиски более конкретной директивы.
В большинстве поисковых систем есть несколько разных ботов, вот список наиболее распространенных.
Директива хоста
Директива хоста в настоящее время поддерживается только Яндексом, хотя некоторые предположения говорят, что Google ее поддерживает.Эта директива позволяет пользователю решить, отображать ли www. перед URL, использующим этот блок:
Хост: poddigital.co.uk
Поскольку Яндекс является единственным подтвержденным сторонником директивы, полагаться на нее не рекомендуется. Вместо этого 301 перенаправляет имена хостов, которые вам не нужны, на те, которые вам нужны.
Disallow Directive
Мы рассмотрим это более конкретно чуть позже.
Вторая строка в блоке директив — Disallow. Вы можете использовать это, чтобы указать, какие разделы сайта не должны быть доступны ботам.Пустое запрещение означает, что это является бесплатным для всех, и боты могут угождать себе, где они делают, а где не ходят.
Директива карты сайта (XML-карты сайта)
Использование директивы карты сайта сообщает поисковым системам, где найти карту сайта в формате XML.
Однако, вероятно, наиболее полезным было бы отправить каждый из них в специальные инструменты для веб-мастеров поисковых систем. Это потому, что вы можете узнать много ценной информации от каждого о своем веб-сайте.
Однако, если у вас мало времени, директива карты сайта является жизнеспособной альтернативой.
Директива о задержке сканирования
Yahoo, Bing и Яндекс могут быть немного счастливы, когда дело доходит до сканирования, но они действительно реагируют на директиву задержки сканирования, которая удерживает их на некоторое время.
Применение этой строки к вашему блоку:
Crawl-delay: 10
означает, что вы можете заставить поисковые системы ждать десять секунд перед сканированием сайта или десять секунд, прежде чем они повторно получат доступ к сайту после сканирования — это, по сути, то же самое, но немного отличается в зависимости от поисковой системы.
Зачем использовать Robots.txt
Теперь, когда вы знаете об основах и о том, как использовать несколько директив, вы можете собрать свой файл. Однако следующий шаг будет зависеть от типа контента на вашем сайте.
Robots.txt не является важным элементом успешного веб-сайта; на самом деле, ваш сайт может нормально функционировать и хорошо ранжироваться и без него.
Тем не менее, есть несколько ключевых преимуществ, о которых вы должны знать, прежде чем отказаться от него:
Укажите ботам, удаленным от личных папок : запрет ботам проверять ваши личные папки значительно усложнит их поиск и индексирование.
Держите ресурсы под контролем : каждый раз, когда бот просматривает ваш сайт, он поглощает пропускную способность и другие ресурсы сервера. Для сайтов с тоннами контента и большим количеством страниц, например, на сайтах электронной коммерции могут быть тысячи страниц, и эти ресурсы могут быть истощены очень быстро. Вы можете использовать robots.txt, чтобы затруднить доступ ботам к отдельным скриптам и изображениям; это позволит сохранить ценные ресурсы для реальных посетителей.
Укажите местоположение вашей карты сайта : Это довольно важный момент, вы хотите, чтобы сканеры знали, где находится ваша карта сайта, чтобы они могли ее просканировать.
Держите дублированный контент подальше от результатов поиска : добавив правило к вашим роботам, вы можете запретить поисковым роботам индексировать страницы, содержащие дублированный контент.
Вы, естественно, захотите, чтобы поисковые системы находили путь к наиболее важным страницам вашего веб-сайта. Вежливо ограничивая определенные страницы, вы можете контролировать, какие страницы будут отображаться для поисковиков (однако убедитесь, что никогда не блокирует полностью поисковым системам для просмотра определенных страниц).
Например, если мы посмотрим на файл роботов POD Digital, мы увидим, что этот URL:
poddigital.co.uk/wp-admin был запрещен.
Поскольку эта страница предназначена только для того, чтобы мы могли войти в панель управления, нет смысла позволять ботам тратить свое время и энергию на ее сканирование.
Noindex
В июле 2019 года Google объявил о прекращении поддержки директивы noindex, а также многих ранее неподдерживаемых и неопубликованных правил, на которые многие из нас ранее полагались.
Многие из нас решили поискать альтернативные способы применения директивы noindex, и ниже вы можете увидеть несколько вариантов, которые вы можете выбрать вместо этого:
Тег Noindex / Заголовок ответа HTTP Noindex: Этот тег может быть реализовано двумя способами: сначала в виде заголовка HTTP-ответа с тегом X-Robots-Tag или создания тега, который необходимо будет реализовать в разделе
.
Ваш тег должен выглядеть так, как показано ниже:
СОВЕТ : помните, что если эта страница была заблокирована роботами.txt, сканер никогда не увидит ваш тег noindex, и все еще есть вероятность, что эта страница будет представлена в результатах поиска.
Защита паролем: Google заявляет, что в большинстве случаев, если вы скрываете страницу за логином, ее следует удалить из индекса Google. Единственное исключение предоставляется, если вы используете разметку схемы, которая указывает, что страница связана с подпиской или платным контентом.
Код состояния HTTP 404 и 410: Коды состояния 404 и 410 представляют страницы, которые больше не существуют.После того, как страница со статусом 404/410 просканирована и полностью обработана, она должна быть автоматически удалена из индекса Google.
Вам следует систематически сканировать свой веб-сайт, чтобы снизить риск появления страниц с ошибками 404 и 410, и при необходимости использовать переадресацию 301 для перенаправления трафика на существующую страницу.
Правило запрета в robots.txt: Добавив правило запрета для конкретной страницы в файл robots.txt, вы предотвратите сканирование страницы поисковыми системами.В большинстве случаев ваша страница и ее содержание не индексируются. Однако следует иметь в виду, что поисковые системы по-прежнему могут индексировать страницу на основе информации и ссылок с других страниц.
Инструмент удаления URL-адреса Search Console: Этот альтернативный корень не решает проблему индексации в полной мере, поскольку инструмент удаления URL-адреса Search Console удаляет страницу из результатов поиска на ограниченное время.
Однако это может дать вам достаточно времени, чтобы подготовить дальнейшие правила и теги для роботов, чтобы полностью удалить страницы из результатов поиска.
Инструмент удаления URL-адреса находится в левой части основной панели навигации в Google Search Console.
Noindex против Disallow
Многие из вас, вероятно, задаются вопросом, что лучше использовать тег noindex или правило запрета в вашем файле robots.txt. В предыдущей части мы уже рассмотрели, почему правило noindex больше не поддерживается в robots.txt и других альтернативах.
Если вы хотите убедиться, что одна из ваших страниц не проиндексируется поисковыми системами, вам обязательно стоит взглянуть на метатег noindex.Он позволяет ботам получить доступ к странице, но тег позволит роботам узнать, что эта страница не должна индексироваться и не должна отображаться в поисковой выдаче.
Правило запрета может быть не так эффективно, как тег noindex в целом. Конечно, добавляя его в robots.txt, вы блокируете сканирование вашей страницы ботами, но если упомянутая страница связана с другими страницами внутренними и внешними ссылками, боты все равно могут индексировать эту страницу на основе информации, предоставленной другими страницами. / сайты.
Вы должны помнить, что если вы запретите страницу и добавите тег noindex, то роботы никогда не увидят ваш тег noindex, что по-прежнему может вызывать появление страницы в поисковой выдаче.
Использование регулярных выражений и подстановочных знаков
Итак, теперь мы знаем, что такое файл robots.txt и как его использовать, но вы можете подумать: «У меня большой веб-сайт электронной коммерции, и я хотел бы запретить все страницы, которые содержат вопросительные знаки (?) в своих URL «.
Здесь мы хотели бы представить ваши подстановочные знаки, которые могут быть реализованы в файле robots.txt. В настоящее время у вас есть два типа подстановочных знаков на выбор.
* Подстановочные знаки — где * подстановочные знаки будут соответствовать любой последовательности символов по вашему желанию.Этот тип подстановочного знака будет отличным решением для ваших URL-адресов, которые следуют тому же шаблону. Например, вы можете запретить сканирование всех страниц с фильтрами, в URL-адресах которых стоит вопросительный знак (?).
$ Подстановочные знаки — где $ соответствует концу вашего URL. Например, если вы хотите убедиться, что ваш файл роботов запрещает ботам доступ ко всем файлам PDF, вы можете добавить правило, подобное приведенному ниже:
Давайте быстро разберем приведенный выше пример.Ваш файл robots.txt позволяет любым ботам User-agent сканировать ваш веб-сайт, но запрещает доступ ко всем страницам, содержащим конец .pdf.
Ошибок, которых следует избегать
Мы немного поговорили о том, что вы можете сделать, и о различных способах работы со своим robots.txt. Мы собираемся немного углубиться в каждый пункт этого раздела и объяснить, как каждый из них может обернуться катастрофой для SEO, если не используется должным образом.
Не блокировать хороший контент
Важно не блокировать любой хороший контент, который вы хотите представить роботам для всеобщего сведения.txt или тега noindex. В прошлом мы видели много подобных ошибок, которые отрицательно сказывались на результатах SEO. Вам следует тщательно проверять свои страницы на наличие тегов noindex и запрещающих правил.
Чрезмерное использование Crawl-Delay
Мы уже объяснили, что делает директива crawl-delay, но вам не следует использовать ее слишком часто, поскольку вы ограничиваете страницы, просматриваемые ботами. Это может быть идеальным для некоторых веб-сайтов, но если у вас большой веб-сайт, вы можете выстрелить себе в ногу и помешать хорошему ранжированию и устойчивому трафику.
Чувствительность к регистру
Файл Robots.txt чувствителен к регистру, поэтому вы должны не забыть создать файл robots правильно. Вы должны называть файл роботов «robots.txt», все в нижнем регистре. Иначе ничего не получится!
Использование Robots.txt для предотвращения индексации содержимого
Мы уже немного рассмотрели это. Запрет доступа к странице — лучший способ предотвратить ее прямое сканирование ботами.
Но это не сработает в следующих случаях:
Если на страницу есть ссылка из внешнего источника, боты все равно будут проходить и индексировать страницу.
Незаконные боты по-прежнему будут сканировать и индексировать контент.
Использование Robots.txt для защиты личного содержимого
Некоторое личное содержимое, такое как PDF-файлы или страницы с благодарностью, можно индексировать, даже если вы направите ботов в сторону от него. Один из лучших способов дополнить директиву disallow — разместить весь ваш личный контент за логином.
Конечно, это означает, что он добавляет дополнительный шаг для ваших посетителей, но ваш контент останется безопасным.
Использование Robots.txt для скрытия вредоносного дублированного содержимого
Дублированное содержимое иногда является неизбежным злом — например, страницы, удобные для печати.
Однако Google и другие поисковые системы достаточно умны, чтобы знать, когда вы пытаетесь что-то скрыть. Фактически, это может привлечь к нему больше внимания, и это потому, что Google распознает разницу между страницей, удобной для печати, и тем, кто пытается заткнуть себе глаза:
Есть еще шанс, что ее можно найти в любом случае.
Вот три способа справиться с этим типом контента:
Перепишите контент — Создание интересного и полезного контента побудит поисковые системы рассматривать ваш веб-сайт как надежный источник. Это предложение особенно актуально, если контент представляет собой задание копирования и вставки.
301 редирект — 301 редирект информирует поисковые системы о том, что страница переместилась в другое место. Добавьте 301 на страницу с дублированным контентом и перенаправьте посетителей на исходное содержание на сайте.
Rel = «canonical » — это тег, который информирует Google об исходном местонахождении дублированного контента; это особенно важно для веб-сайта электронной коммерции, где CMS часто генерирует повторяющиеся версии одного и того же URL-адреса.
Момент истины: проверка вашего файла Robots.txt
Пришло время протестировать ваш файл, чтобы убедиться, что все работает так, как вы хотите.
Инструменты Google для веб-мастеров содержат файл robots.txt, но в настоящее время он доступен только в старой версии Google Search Console. Вы больше не сможете получить доступ к тестеру robot.txt с помощью обновленной версии GSC (Google усердно работает над добавлением новых функций в GSC, поэтому, возможно, в будущем мы сможем увидеть тестер Robots.txt в основная навигация).
Итак, сначала вам нужно посетить страницу поддержки Google, на которой представлен обзор возможностей тестера Robots.txt.
Там вы также найдете роботов.txt Tester tool:
Выберите свойство, над которым вы собираетесь работать, например, веб-сайт вашей компании из раскрывающегося списка.
Удалите все, что находится в коробке, замените его новым файлом robots.txt и нажмите, протестируйте:
. Если «Тест» изменится на «Разрешено», значит, вы получили полностью работающий robots.txt.
Правильное создание файла robots.txt означает, что вы улучшаете SEO и удобство работы посетителей.
Позволяя ботам тратить свои дни на сканирование нужных вещей, они смогут систематизировать и показывать ваш контент так, как вы хотите, чтобы он отображался в поисковой выдаче.
Ресурсы для платформ CMS
Получите бесплатную 7-дневную пробную версию
Начните работать над своей видимостью в Интернете
Как запретить поисковым системам сканировать ваш веб-сайт — Центр поддержки хостинга InMotion
Чтобы ваш веб-сайт был найденные другими людьми, поисковые машины сканеры, также иногда называемые ботами или пауками, будут сканировать ваш веб-сайт в поисках обновленного текста и ссылок для обновления своих поисковых индексов.
Как управлять сканерами поисковых систем с помощью файла robots.txt
Владельцы веб-сайтов могут указать поисковым системам, как им следует сканировать веб-сайт, с помощью файла robots.txt .
Когда поисковая система просматривает веб-сайт, она сначала запрашивает файл robots.txt , а затем следует внутренним правилам.
Измените или создайте файл robots.txt
Файл robots.txt должен находиться в корне вашего сайта. Если ваш домен был например.com следует найти:
На вашем сайте :
https://example.com/robots.txt
На вашем сервере :
/home/userna5/public_html/robots.txt
Вы также можете создать новый файл и называть его robots.txt как обычный текстовый файл, если у вас его еще нет.
Поисковая машина Пользовательские агенты
Наиболее распространенное правило, которое вы используете в файле robots.txt , основано на User-agent сканера поисковой системы.
Сканеры поисковой системы используют User-agent для идентификации себя при сканировании, вот несколько распространенных примеров:
Топ-3 агентов пользователей поисковых систем США :
Googlebot Yahoo! Slurp bingbot
Обычная поисковая система Пользовательские агенты заблокированы :
AhrefsBot Байдуспайдер Ezooms MJ12bot YandexBot
Доступ сканера поисковой системы через файл robots.txt
Существует довольно много вариантов, когда дело доходит до управления сканированием вашего сайта роботами .txt файл.
Правило User-agent: определяет, к какому User-agent применяется правило, а * — это подстановочный знак, соответствующий любому User-agent.
Disallow: устанавливает файлы или папки, для которых запрещен для сканирования.
Установите задержку сканирования для всех поисковых систем. :
. Если бы на вашем веб-сайте было 1000 страниц, поисковая система могла бы проиндексировать весь ваш сайт за несколько минут.
Однако это может привести к высокому использованию системных ресурсов, поскольку все эти страницы загружаются за короткий период времени.
A Задержка сканирования: из 30 секунд позволит сканерам проиндексировать весь ваш 1000-страничный веб-сайт всего за 8,3 часа
A Задержка сканирования: из 500 секунд позволит сканерам проиндексировать ваш весь сайт из 1000 страниц за 5,8 дней
Вы можете установить Crawl-delay: для всех поисковых систем одновременно с:
User-agent: * Crawl-delay: 30
Разрешить всем поисковым системам сканировать веб-сайт :
По умолчанию поисковые системы должны иметь возможность сканировать ваш веб-сайт, но вы также можете указать, что им разрешено с:
Пользователь -агент: * Disallow:
Запретить всем поисковым системам сканировать веб-сайт :
Вы можете запретить любой поисковой системе сканировать ваш веб-сайт со следующими правилами:
User-agent: * Disallow: /
Запретить одной конкретной поисковой системе сканирование веб-сайта :
Вы можете запретить сканировать ваш веб-сайт только одной конкретной поисковой системе с помощью следующих правил:
User-agent: Baiduspider Disallow: /
Запретить все поисковые системы из определенных папок :
Если бы у нас было несколько каталогов, таких как / cgi-bin / , / private / и / tmp / , мы не хотели, чтобы боты сканировали, мы могли бы использовать это:
User-agent: * Disallow: / cgi-bin / Disallow: / частный / Disallow: / tmp /
Запретить всем поисковым системам доступ к определенным файлам :
Если бы у нас были такие файлы, как contactus.htm , index.htm и store.htm мы не хотели, чтобы боты сканировали, мы могли использовать это:
User-agent: * Disallow: /contactus.htm Disallow: /index.htm Disallow: /store.htm
Запретить все поисковые системы, кроме одной :
Если бы мы только хотели разрешить Googlebot доступ к нашему каталогу / private / и запретить всем остальным ботам, которые мы могли бы использовать :
Пользовательский агент: * Disallow: / частный / User-agent: Googlebot Disallow:
Когда Googlebot читает наши robots.txt , он увидит, что сканирование каталогов не запрещено.
Google прекращает поддержку Robots.txt Noindex: что это значит
[ОГРАНИЧЕННЫЕ МЕСТА] Хотите раскрыть свой истинный потенциал и достичь финансовой свободы? Мы приглашаем вас присоединиться к БЕСПЛАТНОМУ мастер-классу с удостоенным наград бизнес-лидером Эриком Сиу, где он делится своим 5-шаговым планом по запуску онлайн-бизнеса вашей мечты, который дает вам свободу и реализацию.
Нажмите здесь, чтобы зарезервировать место сейчас.
Начиная с 1 сентября 2019 г. , Google больше не будет поддерживать директиву robots.txt, связанную с индексированием. Это означает, что Google начнет индексировать ваши веб-страницы, если вы использовали только директиву noindex в robots.txt для удаления этих страниц из результатов поиска. У вас есть время до первого сентября, чтобы удалить его и использовать другой метод.
noindex robots.txt — это тег (обычно в HTML) в вашем файле robots.txt, который не позволяет поисковым системам включать эту страницу в результаты поиска.
Почему Google больше не поддерживает его? Потому что директива noindex robots.txt не является официальной директивой. И, как сообщает Google:
«В интересах поддержания здоровой экосистемы и подготовки к возможным будущим выпускам с открытым исходным кодом мы снимаем с использования весь код, который обрабатывает неподдерживаемые и неопубликованные правила (например, noindex) 1 сентября 2019 года. ”
Мы помогли компаниям из списка Fortune 500, стартапам с венчурным капиталом и таким компаниям, как ваша , быстрее увеличить выручку .Получите бесплатную консультациюПоследние обновления Google
В 2019 году Google был занят большим количеством обновлений. Напоминаем, что наиболее важными из них являются:
- Обновление ядра , июнь 2019 года. Google опубликовал официальное заявление, в котором говорится, что – Завтра мы выпускаем широкое обновление основного алгоритма, как мы делаем это несколько раз в год. Он называется Core Update за июнь 2019 года. Наши рекомендации по поводу таких обновлений остаются такими же, как и раньше ».
Завтра мы выпускаем широкое обновление основного алгоритма, как мы делаем это несколько раз в год.Он называется Core Update за июнь 2019 года. Наши рекомендации по поводу таких обновлений остаются такими же, как и раньше. Пожалуйста, просмотрите этот твит, чтобы узнать больше об этом: https: //t.co/tmfQkhdjPL
— Google SearchLiaison (@searchliaison) 2 июня 2019 г.
- Обновление разнообразия. Это небольшое июньское обновление больше всего влияет на транзакционный поиск. Согласно обновлению, Google теперь стремится возвращать результаты из уникальных доменов и больше не будет отображать более двух результатов из одного и того же домена.
- Обновление ядра за март 2019 г. Это еще одно широкое изменение его алгоритма. Google подтвердил это обновление, но не назвал его названия, поэтому оно называлось либо Florida 2 update , либо Google 3/12 wide core update . Для этого обновления не было дано никаких новых указаний.
Соответствующий контент:
Прощай, директива Google Robots.txt Noindex
Теперь, в июле 2019 года, Google попрощался с недокументированными и неподдерживаемыми правилами в robots.текст. Это то, что Google написал в Твиттере 2 июля 2019 года:
Сегодня мы прощаемся с недокументированными и неподдерживаемыми правилами в robots.txt?
Если вы полагались на эти правила, узнайте о своих возможностях в нашем блоге. Https://t.co/Go39kmFPLT
— Google Webmasters (@googlewmc) 2 июля 2019 г.
Если на вашем веб-сайте используется noindex в файле robots.txt, тогда вам нужно будет использовать другие параметры. Согласно заявлению, опубликованному в официальном блоге Google Webmaster Central:
«В интересах поддержания здоровой экосистемы и подготовки к возможным будущим выпускам с открытым исходным кодом мы удаляем весь код, который обрабатывает неподдерживаемые и неопубликованные правила (например, noindex ) 1 сентября 2019 г.»
Причина отмены поддержки noindex robots.txt также обсуждалась в блоге Google:
« В частности, мы сосредоточились на правилах, не поддерживаемых интернет-проектом, таких как задержка сканирования, nofollow и noindex. . Поскольку эти правила никогда не были задокументированы Google, естественно, их использование по отношению к Googlebot очень мало. Копнув дальше, мы увидели, что их использование противоречит другим правилам во всех файлах robots.txt в Интернете, кроме 0,001%. Эти ошибки наносят ущерб присутствию веб-сайтов в результатах поиска Google так, как мы не думаем, что веб-мастера предполагали.»
Robots.txt — Протокол исключения роботов (REP)Протокол исключения роботов (REP), более известный как Robots.txt, используется с 1994 года, но так и не стал официальным Интернет-стандартом. . Но без надлежащего стандарта и веб-мастера, и сканеры не понимали, что сканировать. Кроме того, REP никогда не обновлялся, чтобы охватить сегодняшние критические ситуации.
Согласно официальному блогу Google:
« REP никогда не превращался в официальный интернет-стандарт , что означает, что разработчики интерпретировали протокол несколько иначе на протяжении многих лет.И с момента своего создания REP не обновлялся, чтобы охватить сегодняшние критические ситуации. Это серьезная проблема для владельцев веб-сайтов, потому что неоднозначный стандарт де-факто затрудняет правильное написание правил ».
Чтобы положить конец этой путанице, Google задокументировал, как REP используется в Интернете, и представил его в IETF (Internet Engineering Task Force), которая является организацией открытых стандартов, чтобы улучшить работу Интернета.
В официальном заявлении Google говорится:
«Мы хотели помочь владельцам веб-сайтов и разработчикам создавать удивительные возможности в Интернете, вместо того, чтобы беспокоиться о том, как управлять поисковыми роботами.Вместе с первоначальным автором протокола, веб-мастерами и другими поисковыми системами мы задокументировали, как REP используется в современной сети, и отправили его в IETF ».
Что это значит для васЕсли вы используете noindex в своем файле robots.txt, Google больше не будет его соблюдать. Они уважают некоторые из этих реализаций, даже несмотря на то, что Джон Мюллер напоминает нам:
Что ж, мы говорили, что не стоит полагаться на это уже много лет :).
-? Джон ? (@JohnMu) 2 июля 2019 г.
Если вы продолжите использовать noindex в своих файлах robots.txt файлы.
Связанное содержание:
Альтернативы использованию директивы индексирования robots.txtЕсли ваш веб-сайт по-прежнему полагается на директиву noindex robots.txt, то ее необходимо изменить, потому что роботы Google не будут следовать этой директиве правила, начиная с 1 сентября 2019 года. Но что вы должны использовать вместо этого? Вот несколько альтернатив:
1) Блокировать поисковую индексацию с метатегом noindexЧтобы сканеры поисковой системы не индексировали страницу, вы можете использовать метатег noindex и добавить его в
раздел вашей страницы.
В качестве альтернативы вы можете использовать заголовки HTTP-ответа с тегом X-Robots-Tag, инструктирующим сканеры не индексировать страницу:
HTTP / 1.1 200 OK
(…)
X-Robots-Tag: noindex
2) Используйте коды состояния HTTP 404 и 410410 — это код состояния, который возвращается, когда целевой ресурс больше не является доступно на исходном сервере.
Как указано в статусе HTTP:
“ Ответ 410 в первую очередь предназначен для поддержки задачи обслуживания сети, уведомляя получателя о том, что ресурс намеренно недоступен и что владельцы серверов желают, чтобы удаленные ссылки на этот ресурс были удалены. . »
404 аналогичен коду состояния 410. По словам Джона Мюллера:
« С нашей точки зрения, в среднесрочной / долгосрочной перспективе, 404 — это то же самое, что 410 для нас.Поэтому в обоих случаях мы удаляем эти URL-адреса из нашего индекса.
Обычно мы немного сокращаем сканирование этих URL, чтобы не тратить слишком много времени на сканирование вещей, которых, как нам известно, не существует.
Небольшая разница в том, что 410 иногда выпадает немного быстрее, чем 404. Но обычно мы говорим примерно через пару дней.
Итак, если вы просто удаляете контент естественным образом, то вы можете использовать любой из них.Если вы уже давно удалили этот контент, значит, он еще не проиндексирован, поэтому для нас не имеет значения, используете ли вы 404 или 410 ».
3) Используйте защиту паролемВы можете скрыть страницу за логинами, потому что Google не индексирует страницы, которые скрыты за платным контентом или логинами.
4) Запретить роботам использование Robots.txtВы можете использовать директиву disallow в файле robots.txt, чтобы заставить поисковые системы запретить индексацию выбранных вами страниц, что просто означает, что вы говорите поисковым системам, что для сканирования определенной страницы.
По словам Google:
«Хотя поисковая система может также индексировать URL-адрес на основе ссылок с других страниц, не видя самого контента, мы стремимся сделать такие страницы менее заметными в будущем».
5) Используйте инструмент удаления URL-адреса Search ConsoleВы можете использовать инструмент удаления URL-адреса Search Console, чтобы временно удалить URL-адрес из результатов поиска. Этот блок продлится 90 дней. Если вы хотите сделать блокировку постоянным, вы можете использовать любой из четырех методов, предложенных выше.
Мы помогли компаниям из списка Fortune 500, стартапам с венчурным капиталом и таким компаниям, как ваша , быстрее увеличить выручку . Получите бесплатную консультациюLast Word
Если вы хотите узнать больше о том, как удалить свой контент из результатов поиска Google, перейдите в Справочный центр Google.
Robots.txt: как создать идеальный файл для SEO
В этой статье мы расскажем, что такое robot.txt в SEO, как он выглядит и как его правильно создать.Это файл, который отвечает за блокировку индексации страниц и даже всего сайта. Неправильная структура файла — обычная ситуация даже среди опытных SEO-оптимизаторов, поэтому остановимся на типичных ошибках при редактировании robot.txt.
Что такое Robots.txt?
Robots.txt — это текстовый файл, который сообщает поисковым роботам, какие файлы или страницы закрыты для сканирования и индексации. Документ размещается в корневом каталоге сайта.
Давайте посмотрим, как работает робот.txt работает. У поисковых систем две цели:
- Для сканирования сети для обнаружения содержимого;
- Индексировать найденный контент, чтобы показывать его пользователям по идентичным поисковым запросам.
Для индексации поисковый робот посещает URL-адреса с одного сайта на другой, просматривая миллиарды ссылок и веб-ресурсов. После открытия сайта система ищет файл robots.txt. Если сканер находит документ, он сначала сканирует его, а после получения от него инструкций продолжает сканирование страницы.
Если в файле нет директив или он не создается вовсе, робот продолжит сканирование и индексацию без учета данных о том, как система должна выполнять эти действия. Это может привести к индексации нежелательного содержания поисковой системой.
Но многие SEO-специалисты отмечают, что некоторые поисковые системы игнорируют инструкции в файле robot.txt. Например, парсеры электронной почты и вредоносные robots. Google также не воспринимает документ как строгую директиву, но рассматривает его как рекомендацию при сканировании страницы.
User-agent и основные директивы
Агент пользователя
У каждой поисковой системы есть свои собственные пользовательские агенты. Robots.txt прописывает правила для каждого. Вот список самых популярных поисковых ботов:
- Google: Googlebot
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
При создании правила для всех поисковых систем используйте этот символ: (*). Например, давайте создадим бан для всех роботов, кроме Bing. В документе это будет выглядеть так:
Пользовательский агент: *
Запрещено: /
Пользовательский агент: Bing
Разрешить: /
Роботы.txt может содержать различное количество правил для поисковых агентов. При этом каждый робот воспринимает только свои директивы. То есть, инструкции для Google, например, не актуальны для Yahoo или какой-либо другой поисковой системы. Исключение будет, если вы укажете один и тот же агент несколько раз. Тогда система выполнит все директивы.
Важно указать точные имена поисковых ботов; в противном случае роботы не будут следовать указанным правилам.
Директивы
Это инструкции по сканированию и индексации сайтов поисковыми роботами.
Поддерживаемые директивы
Это список директив, поддерживаемых Google:
1. Запретить
Позволяет закрыть доступ поисковых систем к контенту. Например, если вам нужно скрыть каталог и все его страницы от сканера для всех систем, то файл robots.txt будет иметь следующий вид:
Пользовательский агент: *
Запрещено: / catalog /
Если это для конкретного краулера, то это будет выглядеть так:
Пользовательский агент: Bingbot
Запрещено: / catalog /
Примечание: Укажите путь после директивы, иначе роботы его проигнорируют.
2. Разрешить
Это позволяет роботам сканировать определенную страницу, даже если она была ограничена. Например, вы можете разрешить поисковым системам сканировать только одно сообщение в блоге:
.Пользовательский агент: *
Запретить: / blog /
Разрешить: / blog / что такое SEO
Также можно указать robots.txt, чтобы разрешить весь контент:
Пользовательский агент: *
Разрешить: /
Примечание. Поисковые системы Google и Bing поддерживают эту директиву.Как и в случае с предыдущей директивой, всегда указывайте путь после , разрешите .
Если вы допустили ошибку в robots.txt, запретят и разрешат будут конфликтовать. Например, если вы упомянули:
Пользовательский агент: *
Disallow: / blog / что такое SEO
Разрешить: / blog / что такое SEO
Как видите, URL разрешен и запрещен для индексации одновременно. Поисковые системы Google и Bing будут отдавать приоритет директиве с большим количеством символов.В данном случае это , запретить . Если количество символов такое же, то будет использоваться директива allow , то есть ограничивающая директива.
Другие поисковые системы выберут первую директиву из списка. В нашем примере это , запретить .
3. Карта сайта
Карта сайта, указанная в robots.txt, позволяет поисковым роботам указывать адрес карты сайта. Вот пример такого файла robots.txt:
Карта сайта: https: // www.site.com/sitemap.xml
Пользовательский агент: *
Запретить: / blog /
Разрешить: / blog / что такое SEO
Если карта сайта указана в Google Search Console, то этой информации Google будет достаточно. Но другие поисковые системы, такие как Bing, ищут его в robots.txt.
Не нужно повторять директиву для разных роботов, она работает для всех. Рекомендуем записать его в начале файла.
Примечание : Вы можете указать любое количество карт сайта.
Вы также можете прочитать соответствующую статью XML-руководство по файлам Sitemap: лучшие приемы, советы и инструменты.
Неподдерживаемые директивы
1. Задержка сканирования
Ранее директива показывала задержку между сканированиями. Google в настоящее время не поддерживает его, но может быть указан для Bing. Для робота Googlebot скорость сканирования указывается в консоли поиска Google.
Например:
Пользовательский агент: Bingbot
Задержка сканирования: 10
2.Noindex
Для робота Googlebot в файле robots.txt noindex никогда не поддерживался. Мета-теги роботов используются для исключения страницы из поисковой системы.
3. Nofollow
Это не поддерживается Google с прошлого года. Вместо этого используется атрибут URL rel = «nofollow».
Примеры robots.txt
Рассмотрим пример стандартного файла robot.txt:
Карта сайта: https://www.site.com/sitemap.xml
Пользовательский агент: Googlebot
Запретить: / blog /
Разрешить: / blog / что такое SEO
Пользовательский агент: Bing
Запретить: / blog /
Разрешить: / blog / что такое SEO
Примечание: Вы можете указать любое количество пользовательских агентов и директив по своему усмотрению.Всегда пишите команды с новой строки.
Почему Robots.txt важен для SEO?
ФайлRobots txt для SEO играет важную роль, так как позволяет вам давать инструкции поисковым роботам, какие страницы вашего сайта следует сканировать, а какие нет. Кроме того, файл позволяет:
- Избегайте дублирования контента в результатах поиска;
- Блокировать закрытые страницы; например, если вы создали промежуточную версию;
- Запретить индексирование определенных файлов, например PDF-файлов или изображений; и
- Увеличьте бюджет сканирования Google.Это количество страниц, которые может сканировать робот Googlebot. Если на сайте их много, то поисковому роботу потребуется больше времени, чтобы просмотреть весь контент. Это может негативно повлиять на рейтинг сайта. Вы можете закрыть неприоритетные страницы со сканера, чтобы бот мог проиндексировать только те страницы, которые важны для продвижения.
Если на вашем сайте нет контента для управления доступом, возможно, вам не потребуется создавать файл robots.txt. Но мы все же рекомендуем создать его, чтобы лучше оптимизировать свой сайт.
Robots.txt и Мета-теги роботов
Мета-теги robots не являются директивами robots.txt; они являются фрагментами HTML-кода. Это команды для поисковых роботов, которые позволяют сканировать и индексировать контент сайта. Они добавляются в раздел страницы.
Мета-теги роботов состоят из двух частей:
- name = ”‘. Здесь нужно ввести название поискового агента, например, Bingbot.
- content = ». Вот инструкции, что должен делать бот.
Итак, как выглядят роботы? Взгляните на наш пример:
Существует два типа мета-тегов роботов:
- Тег Meta Robots: указывает поисковым системам, как сканировать определенные файлы, страницы и подпапки сайта.
- Тег X-robots: фактически выполняет ту же функцию, но в заголовках HTTP. Многие эксперты склоняются к мнению, что теги X-robots более функциональны, но требуют открытого доступа к файлам .php и .htaccess или к серверу. Поэтому использовать их не всегда возможно.
В таблице ниже приведены основные директивы для мета-тегов роботов с учетом поисковых систем.
Содержимое файла robots.txt должно соответствовать мета-тегам robots.Самая распространенная ошибка SEO-оптимизаторов: в robots.txt закрывают страницу от сканирования, а в данных мета-тегов роботов открывают.
Многие поисковые системы, включая Google, отдают приоритет содержанию robots.txt, чтобы важную страницу можно было скрыть от индексации. Вы можете исправить это несоответствие, изменив содержание в метатегах robots и в документе robots.txt.
Как найти Robots.txt?
Robots.txt можно найти во внешнем интерфейсе сайта.Этот способ подходит для любого сайта. Его также можно использовать для просмотра файла любого другого ресурса. Просто введите URL-адрес сайта в строку поиска своего браузера и добавьте в конце /robots.txt. Если файл найден, вы увидите:
Нил Патель
Или откроется пустой файл, как в примере ниже:
Нил Патель
Также вы можете увидеть сообщение об ошибке 404, например, здесь:
MOZ
Если при проверке robots.txt на своем сайте, вы обнаружили пустую страницу или ошибку 404, значит, для ресурса не был создан файл или в нем были ошибки.
Для сайтов, разработанных на базе CMS WordPress и Magento 2, есть альтернативные способы проверки файла:
- Вы можете найти robots.txt WordPress в разделе WP-admin. На боковой панели вы найдете один из плагинов Yoast SEO, Rank Math или All in One SEO, которые генерируют файл. Подробнее читайте в статьях Yoast против Rank Math SEO, Пошаговое руководство по установке плагина Rank Math, Настройка плагинов SEO, Yoast против All in One SEO Pack.
- В Magento 2 файл можно найти в разделе Content-Configuration на вкладке Design.
Для платформы Shopware сначала необходимо установить плагин, который позволит вам создавать и редактировать robots.txt в будущем.
Как создать Robots.txt
Для создания robots.txt вам понадобится любой текстовый редактор. Чаще всего специалисты выбирают Блокнот Windows. Если этот документ уже был создан на сайте, но вам нужно его отредактировать, удалите только его содержимое, а не весь документ.
Вне зависимости от ваших целей формат документа будет иметь вид стандартного образца robot.txt:
Карта сайта: URL – адрес (рекомендуем всегда указывать)
user – agent: * (или укажите имя определенного поискового бота)
Disallow: / (путь к контенту, который вы хотите скрыть)
Затем добавьте оставшиеся директивы в необходимом количестве.
Вы можете ознакомиться с полным руководством от Google по созданию правил для поисковых роботов здесь.Информация обновляется, если поисковая система вносит изменения в алгоритм создания документа.
Сохраните файл под именем robot.txt.
Для создания файла можно использовать генератор robots.txt.
Инструменты SEO Книга
Основным преимуществом этой услуги является то, что она помогает избежать синтаксических ошибок.
Где разместить Robots.txt?
Файл robots.txt по умолчанию находится в корневой папке сайта. Управлять сканером на сайте.com, документ должен находиться по адресу sitename.com/robots.txt.
Если вы хотите контролировать сканирование контента на субдоменах, например blog.sitename.com, то документ должен быть расположен по этому URL-адресу: blog.sitename.com/robots.txt.
Используйте любой FTP-клиент для подключения к корневому каталогу.
Лучшие практики оптимизации Robots.txt для SEO
- Маски (*) можно использовать для указания не только всех поисковых роботов, но и идентичных URL-адресов на сайте. Например, если вы хотите закрыть от индексации все категории продуктов или разделы блога с определенными параметрами, то вместо их перечисления вы можете сделать следующее:
пользовательский агент: *
Запретить: / blog / *?
Боты не будут сканировать все адреса в подпапке / blog / со знаком вопроса.
- Не используйте документ robots.txt для скрытия конфиденциальной информации в результатах поиска. Иногда другие страницы могут ссылаться на контент вашего сайта, и данные будут индексироваться в обход директив. Чтобы заблокировать страницу, используйте пароль или NoIndex.
- В некоторых поисковых системах есть несколько ботов. Например, у Google есть агент для общего поиска контента — Googlebot и Googlebot-Image, который сканирует изображения. Рекомендуем прописать директивы для каждого из них, чтобы лучше контролировать процесс сканирования на сайте.
- Используйте символ $ для обозначения конца URL-адресов. Например, если вам нужно отключить сканирование файлов PDF, директива будет выглядеть так: Disallow: / * .pdf $.
- Вы можете скрыть версию страницы для печати, так как это технически дублированный контент. Сообщите ботам, какой из них можно сканировать. Это полезно, если вам нужно протестировать страницы с одинаковым содержанием, но с разным дизайном.
- Обычно при внесении изменений содержимое robots.txt кэшируется через 24 часа. Можно ускорить этот процесс, отправив адрес файла в Google.
- При написании правил указывайте путь как можно точнее. Например, предположим, что вы тестируете французскую версию сайта, находящуюся в подпапке / fr /. Если вы напишете такую директиву: Disallow: / fr, вы закроете доступ к другому контенту, который начинается с / fr. Например: / французская парфюмерия /. Поэтому всегда добавляйте «/» в конце.
- Для каждого поддомена необходимо создать отдельный файл robots.txt.
- Вы можете оставлять в документе комментарии оптимизаторам или себе, если вы работаете над несколькими проектами.Чтобы ввести текст, начните строку с символа «#».
Как проверить файл robots.txt
Проверить корректность созданного документа можно в Google Search Console. Поисковая система предлагает бесплатный тестер robots.txt.
Чтобы начать процесс, откройте свой профиль для веб-мастеров.
Выберите нужный веб-сайт и нажмите кнопку «Сканировать» на левой боковой панели.
Нил Патель
Вы получите доступ к сервису роботов Google.txt тестер.
Нил Патель
Если адрес robots.txt уже был введен в поле, удалите его и введите свой собственный. Нажмите кнопку test в правом нижнем углу.
Нил Патель
Если текст изменится на «разрешено», значит ваш файл был создан правильно.
Вы также можете протестировать новые директивы прямо в инструменте, чтобы проверить, насколько они верны. Если ошибок нет, вы можете скопировать текст и добавить его в файл robots.txt документ. Подробные инструкции по использованию сервиса читайте здесь.
Распространенные ошибки в файлах Robots.txt
Ниже приводится список наиболее распространенных ошибок, которые допускают веб-мастера при работе с файлом robots.txt.
- Имя состоит из прописных букв. Файл называется просто robots.txt. Не используйте заглавные буквы.
- Он содержит неверный формат поискового агента. Например, некоторые специалисты пишут имя бота в директиве: Disallow: Googlebot.Всегда указывайте роботов после строки пользовательского агента.
- Каждый каталог, файл или страница следует записывать с новой строки. Если вы добавите их в один, боты проигнорируют данные.
- Правильно напишите директиву host, если она вам нужна в работе.
Неправильно:
Пользовательский агент: Bingbot
Disallow: / cgi-bin
Правильно:
Пользовательский агент: Bingbot
Disallow: / cgi-bin
Хост: www.sitename.com
5. Неверный заголовок HTTP.
Неправильно:
Content-Type: text / html
Правильно:
Content-Type: text / plain
Не забудьте проверить отчет об охвате в Google Search Console. Там будут отображаться ошибки в документе.
Рассмотрим самые распространенные.
1. Доступ к URL-адресу заблокирован:
Эта ошибка появляется, когда один из URL-адресов в карте сайта заблокирован роботами.текст. Вам необходимо найти эти страницы и внести в файл изменения, чтобы снять запрет на сканирование. Чтобы найти директиву, блокирующую URL, вы можете использовать тестер robots.txt от Google. Основная цель — исключить дальнейшие ошибки при блокировке приоритетного контента.
2. Запрещено в robots.txt:
Сайт содержит контент, заблокированный файлом robots.txt и не индексируемый поисковой системой. Если эти страницы необходимы, вам необходимо снять блокировку, предварительно убедившись, что страница не запрещена для индексации с помощью noindex.
Если вам нужно закрыть доступ к странице или файлу, чтобы исключить их из индекса поисковой системы, мы рекомендуем использовать метатег robots вместо директивы disallow. Это гарантирует положительный результат. Если не снять блокировку сканирования, то поисковая система не найдет noindex, и контент будет проиндексирован.
3. Контент индексируется без блокировки в документе robots.txt:
Некоторые страницы или файлы могут все еще присутствовать в индексе поисковой системы, несмотря на то, что они запрещены в robots.текст. Возможно, вы случайно заблокировали нужный контент. Чтобы исправить это, исправьте документ. В других случаях для вашей страницы следует использовать метатег robots = noindex. Подробнее читайте в статье Возможности ссылок Nofollow. Новая тактика SEO.
Как закрыть страницу из индексации в Robots.txt
Одна из основных задач robots.txt — скрыть определенные страницы, файлы и каталоги от индексации в поисковых системах. Вот несколько примеров того, какой контент чаще всего блокируется от ботов:
- Дублированный контент;
- страниц пагинации;
- Категории товаров и услуг;
- Контентных страниц для модераторов;
- Интернет-корзины для покупок;
- Чаты и формы обратной связи; и
- Страницы с благодарностью.
Чтобы предотвратить сканирование содержимого, следует использовать директиву disallow. Давайте рассмотрим примеры того, как можно заблокировать поисковым агентам доступ к различным типам страниц.
1. Если вам нужно закрыть определенную подпапку:
user – agent: (укажите имя бита и добавьте *, если правило должно применяться ко всем поисковым системам)
Disallow: / name – subfolder /
2. Если закрыть определенную страницу на сайте:
user – agent: (* или имя робота)
Disallow: / name –subfolder / page.HTML
Вот пример того, как интернет-магазин указывает запрещающие директивы:
Журнал поисковых систем
Оптимизаторы заблокировали весь контент и страницы, которые не являются приоритетными для продвижения в результатах поиска. Это увеличивает краулинговый бюджет некоторых поисковых роботов, например Googlebot. Это действие позволит улучшить рейтинг сайтов в будущем, конечно, с учетом других важных факторов.
Мы не рекомендуем скрывать конфиденциальную информацию с помощью директивы disallow, так как вредоносные системы могут обойти блокировку.Некоторые эксперты используют приманки для занесения IP-адресов в черный список. Для этого в файл добавляется директива с привлекательным для мошенников названием, например, Disallow: /logins/page.html. Таким образом, вы можете создать свой собственный черный список IP-адресов.
Robots.txt — простой, но важный документ для практики SEO. С его помощью поисковые роботы могут эффективно сканировать и индексировать ресурс, а также отображать только полезный и приоритетный контент для пользователей в поисковой выдаче. Результаты поиска будут формироваться более точно, что поможет привлечь больше целевых посетителей на ваш сайт и повысить CTR.
Обычно создание robots.txt — это одноразовая и кропотливая работа. Тогда вам останется только скорректировать содержание документа в зависимости от развития сайта. Большинство SEO-специалистов рекомендуют использовать robots.txt вне зависимости от типа ресурса.
Управление файлами Robots.txt и Sitemap
- 7 минут на чтение
Оцените свой опыт
да Нет
Любой дополнительный отзыв?
Отзыв будет отправлен в Microsoft: при нажатии кнопки отправки ваш отзыв будет использован для улучшения продуктов и услуг Microsoft.Политика конфиденциальности.
Представлять на рассмотрение
Спасибо.
В этой статье
Руслана Якушева
Набор инструментов поисковой оптимизации IIS включает в себя функцию исключения роботов , которую вы можете использовать для управления содержимым файла Robots.txt для своего веб-сайта, а также включает функцию Sitemaps и Sitemap Indexes , которую вы можете использовать для управления своими карты сайта.В этом пошаговом руководстве объясняется, как и зачем использовать эти функции.
Фон
Поисковые роботыбудут тратить на ваш веб-сайт ограниченное время и ресурсы. Поэтому очень важно сделать следующее:
- Запретить поисковым роботам индексировать контент, который не важен или который не должен отображаться на страницах результатов поиска.
- Направьте поисковые роботы на контент, который вы считаете наиболее важным для индексации.
Для решения этих задач обычно используются два протокола: протокол исключения роботов и протокол Sitemaps.
Протокол исключения роботов используется для того, чтобы сообщить сканерам поисковых систем, какие URL-адреса НЕ следует запрашивать при сканировании веб-сайта. Инструкции по исключению помещаются в текстовый файл с именем Robots.txt, который находится в корне веб-сайта. Большинство сканеров поисковых систем обычно ищут этот файл и следуют содержащимся в нем инструкциям.
Протокол Sitemaps используется для информирования сканеров поисковых систем об URL-адресах, доступных для сканирования на вашем веб-сайте. Кроме того, файлы Sitemap используются для предоставления некоторых дополнительных метаданных об URL-адресах сайта, таких как время последнего изменения, частота изменений, относительный приоритет и т. Д.Поисковые системы могут использовать эти метаданные при индексировании вашего веб-сайта.
Предварительные требования
1. Настройка веб-сайта или приложения
Для выполнения этого пошагового руководства вам понадобится размещенный веб-сайт IIS 7 или выше или веб-приложение, которым вы управляете. Если у вас его нет, вы можете установить его из галереи веб-приложений Microsoft. В этом пошаговом руководстве мы будем использовать популярное приложение для ведения блогов DasBlog.
2. Анализ веб-сайта
Если у вас есть веб-сайт или веб-приложение, вы можете проанализировать его, чтобы понять, как обычная поисковая система будет сканировать его содержимое.Для этого выполните действия, описанные в статьях «Использование анализа сайта для сканирования веб-сайта» и «Использование отчетов анализа сайта». Когда вы проведете свой анализ, вы, вероятно, заметите, что у вас есть определенные URL-адреса, которые доступны для сканирования поисковыми системами, но нет никакой реальной пользы от их сканирования или индексации. Например, страницы входа или страницы ресурсов не должны даже запрашиваться сканерами поисковых систем. Подобные URL-адреса следует скрыть от поисковых систем, добавив их в файл Robots.txt файл.
Управление файлом Robots.txt
Вы можете использовать функцию исключения роботов IIS SEO Toolkit для создания файла Robots.txt, который сообщает поисковым системам, какие части веб-сайта не должны сканироваться или индексироваться. Следующие шаги описывают, как использовать этот инструмент.
- Откройте консоль управления IIS, набрав INETMGR в меню «Пуск».
- Перейдите на свой веб-сайт, используя древовидное представление слева (например, веб-сайт по умолчанию).
- Щелкните значок Search Engine Optimization в разделе «Управление»:
- На главной странице SEO щелкните ссылку задачи « Добавить новое правило запрета » в разделе Исключение роботов .
Добавление запрещающих и разрешающих правил
Диалоговое окно «Добавить запрещающие правила» откроется автоматически:
Протокол исключения роботовиспользует директивы «Разрешить» и «Запрещать», чтобы информировать поисковые системы о путях URL, которые можно сканировать, и о тех, которые нельзя сканировать.Эти директивы могут быть указаны для всех поисковых систем или для определенных пользовательских агентов, идентифицированных HTTP-заголовком пользовательского агента. В диалоговом окне «Добавить запрещающие правила» вы можете указать, к какому искателю поисковой системы применяется директива, введя пользовательский агент искателя в поле «Робот (пользовательский агент)».
Древовидное представление пути URL-адреса используется для выбора запрещенных URL-адресов. Вы можете выбрать один из нескольких вариантов при выборе путей URL с помощью раскрывающегося списка «Структура URL»:
- Физическое расположение — вы можете выбрать пути из физической структуры файловой системы вашего веб-сайта.
- From Site Analysis (название анализа) — вы можете выбрать пути из виртуальной структуры URL-адресов, которая была обнаружена при анализе сайта с помощью инструмента IIS Site Analysis.
- <Запустить новый анализ сайта ...> — вы можете запустить новый анализ сайта, чтобы получить виртуальную структуру URL-адресов для вашего веб-сайта, а затем выбрать оттуда пути URL.
После выполнения шагов, описанных в разделе предварительных требований, вам будет доступен анализ сайта. Выберите анализ в раскрывающемся списке, а затем проверьте URL-адреса, которые необходимо скрыть от поисковых систем, установив флажки в дереве «Пути URL-адресов»:
После выбора всех каталогов и файлов, которые необходимо запретить, нажмите OK.Вы увидите новые запрещающие записи в главном окне функций:
Также будет обновлен файл Robots.txt для сайта (или создан, если он не существует). Его содержимое будет выглядеть примерно так:
Агент пользователя: *
Запретить: /EditConfig.aspx
Запретить: /EditService.asmx/
Запретить: / images /
Запретить: /Login.aspx
Запретить: / scripts /
Запретить: /SyndicationService.asmx/
Чтобы увидеть, как работает Robots.txt, вернитесь к функции анализа сайта и повторно запустите анализ сайта.На странице «Сводка отчетов» в категории Links выберите Links Blocked by Robots.txt . В этом отчете будут отображаться все ссылки, которые не были просканированы, поскольку они были запрещены только что созданным файлом Robots.txt.
Управление файлами карты сайта
Вы можете использовать функцию Sitemap и Sitemap Indexes IIS SEO Toolkit для создания карт сайта на своем веб-сайте, чтобы информировать поисковые системы о страницах, которые следует сканировать и проиндексировать.Для этого выполните следующие действия:
- Откройте диспетчер IIS, набрав INETMGR в меню Start .
- Перейдите на свой веб-сайт с помощью древовидной структуры слева.
- Щелкните значок Search Engine Optimization в разделе «Управление»:
- На главной странице SEO щелкните ссылку задачи « Создать новую карту сайта » в разделе «Карты сайта и индексы ».
- Диалоговое окно Добавить карту сайта откроется автоматически.
- Введите имя файла карты сайта и нажмите ОК . Откроется диалоговое окно Добавить URL-адреса .
Добавление URL в карту сайта
Диалоговое окно Добавить URL-адреса выглядит следующим образом:
Файл Sitemap в основном представляет собой простой XML-файл, в котором перечислены URL-адреса вместе с некоторыми метаданными, такими как частота изменений, дата последнего изменения и относительный приоритет. Используйте диалоговое окно Добавить URL-адреса для добавления новых записей URL-адресов в XML-файл Sitemap.Каждый URL-адрес в карте сайта должен иметь полный формат URI (т.е. он должен включать префикс протокола и имя домена). Итак, первое, что вам нужно указать, — это домен, который будет использоваться для URL-адресов, которые вы собираетесь добавить в карту сайта.
Древовидное представление пути URL-адреса используется для выбора URL-адресов, которые следует добавить в карту сайта для индексации. Вы можете выбрать один из нескольких вариантов, используя раскрывающийся список «Структура URL»:
- Физическое расположение — вы можете выбрать URL-адреса из физического макета файловой системы вашего веб-сайта.
- Из анализа сайта (название анализа) — вы можете выбрать URL-адреса из виртуальной структуры URL-адресов, которая была обнаружена при анализе сайта с помощью инструмента анализа сайта.
- <Запустить новый анализ сайта ...> — вы можете запустить новый анализ сайта, чтобы получить виртуальную структуру URL-адресов для вашего веб-сайта, а затем выбрать оттуда URL-пути, которые вы хотите добавить для индексации.
После того, как вы выполнили шаги в разделе предварительных требований, вам будет доступен анализ сайта.Выберите его из раскрывающегося списка, а затем проверьте URL-адреса, которые необходимо добавить в карту сайта.
При необходимости измените параметры Частота изменения , Дата последнего изменения и Приоритет , а затем нажмите ОК , чтобы добавить URL-адреса в карту сайта. Файл sitemap.xml будет обновлен (или создан, если он не существует), и его содержимое будет выглядеть следующим образом:
http: // myblog / 2009/03/11 / Поздравляем, вы установилиDasBlogWithWebDeploy.aspx
2009-06-03T16: 05: 02
еженедельно
0,5
http: //myblog/2009/06/02/ASPNETAndURLRewriting.aspx
2009-06-03T16: 05: 01
еженедельно
0,5
Добавление местоположения карты сайта в Robots.txt файл
Теперь, когда вы создали карту сайта, вам нужно сообщить поисковым системам, где она находится, чтобы они могли начать ее использовать. Самый простой способ сделать это — добавить URL-адрес карты сайта в файл Robots.txt.
В функции Sitemaps и Sitemap Indexes выберите карту сайта, которую вы только что создали, а затем щелкните Добавить в Robots.txt на панели Действия :
Ваш файл Robots.txt будет выглядеть примерно так:
Агент пользователя: *
Запретить: / EditService.asmx /
Запретить: / images /
Запретить: / scripts /
Запретить: /SyndicationService.asmx/
Запретить: /EditConfig.aspx
Запретить: /Login.aspx
Карта сайта: http: //myblog/sitemap.xml
Регистрация карты сайта в поисковых системах
Помимо добавления местоположения карты сайта в файл Robots.txt, рекомендуется отправить URL-адрес карты сайта в основные поисковые системы. Это позволит вам получать полезный статус и статистику о вашем веб-сайте с помощью инструментов веб-мастеров поисковой системы.