Что такое robots.txt и зачем он вообще нужен
Каждый блог дает свой ответ на этот счет. Поэтому новички в поисковом продвижении часто путаются, вот так:
Что за роботс ти экс ти?
Файл robots.txt или индексный файл — обычный текстовый документ в кодировке UTF-8, действует для протоколов http, https, а также FTP. Файл дает поисковым роботам рекомендации: какие страницы/файлы стоит сканировать. Если файл будет содержать символы не в UTF-8, а в другой кодировке, поисковые роботы могут неправильно их обработать. Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, протокола и номера порта, где размещен файл.
Файл должен располагаться в корневом каталоге в виде обычного текстового документа и быть доступен по адресу: https://site.com.ua/robots.txt.
В других файлах принято ставить отметку ВОМ (Byte Order Mark). Это Юникод-символ, который используется для определения последовательности в байтах при считывании информации. Его кодовый символ — U+FEFF. В начале файла robots.txt отметка последовательности байтов игнорируется.
Его кодовый символ — U+FEFF. В начале файла robots.txt отметка последовательности байтов игнорируется.
Google установил ограничение по размеру файла robots.txt — он не должен весить больше 500 Кб.
Ладно, если вам интересны сугубо технические подробности, файл robots.txt представляет собой описание в форме Бэкуса-Наура (BNF). При этом используются правила RFC 822.
При обработке правил в файле robots.txt поисковые роботы получают одну из трех инструкций:
- частичный доступ: доступно сканирование отдельных элементов сайта;
- полный доступ: сканировать можно все;
- полный запрет: робот ничего не может сканировать.
При сканировании файла robots.txt роботы получают такие ответы:
- 2xx — сканирование прошло удачно;
- 3xx — поисковый робот следует по переадресации до тех пор, пока не получит другой ответ. Чаще всего есть пять попыток, чтобы робот получил ответ, отличный от ответа 3xx, затем регистрируется ошибка 404;
- 4xx — поисковый робот считает, что можно сканировать все содержимое сайта;
- 5xx — оцениваются как временные ошибки сервера, сканирование полностью запрещается.
 Робот будет обращаться к файлу до тех пор, пока не получит другой ответ.Поисковый робот Google может определить, корректно или некорректно настроена отдача ответов отсутствующих страниц сайта, то есть, если вместо 404 ошибки страница отдает ответ 5xx, в этом случае страница будет обрабатываться с кодом ответа 404.
Робот будет обращаться к файлу до тех пор, пока не получит другой ответ.Поисковый робот Google может определить, корректно или некорректно настроена отдача ответов отсутствующих страниц сайта, то есть, если вместо 404 ошибки страница отдает ответ 5xx, в этом случае страница будет обрабатываться с кодом ответа 404.
 Робот будет обращаться к файлу до тех пор, пока не получит другой ответ.Поисковый робот Google может определить, корректно или некорректно настроена отдача ответов отсутствующих страниц сайта, то есть, если вместо 404 ошибки страница отдает ответ 5xx, в этом случае страница будет обрабатываться с кодом ответа 404.
Робот будет обращаться к файлу до тех пор, пока не получит другой ответ.Поисковый робот Google может определить, корректно или некорректно настроена отдача ответов отсутствующих страниц сайта, то есть, если вместо 404 ошибки страница отдает ответ 5xx, в этом случае страница будет обрабатываться с кодом ответа 404.Пока что неизвестно, как обрабатывается файл robots.txt, который недоступен из-за проблем сервера с выходом в интернет.
Зачем нужен файл robots.txt
Например, иногда роботам не стоит посещать:
- страницы с личной информацией пользователей на сайте;
- страницы с разнообразными формами отправки информации;
- сайты-зеркала;
- страницы с результатами поиска.
Важно: даже если страница находится в файле robots.txt, существует вероятность, что она появится в выдаче, если на неё была найдена ссылка внутри сайта или где-то на внешнем ресурсе.
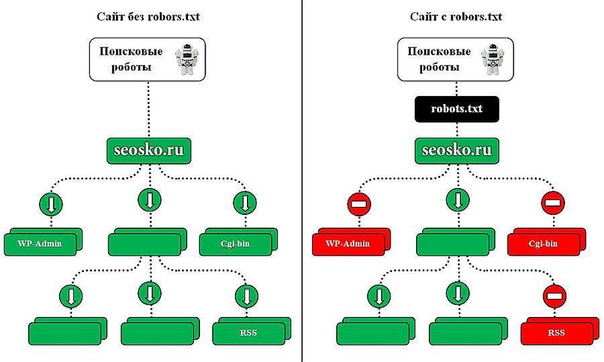
Так роботы поисковых систем видят сайт с файлом robots.txt и без него:
Без robots. txt та информация, которая должна быть скрыта от посторонних глаз, может попасть в выдачу, а из-за этого пострадаете и вы, и сайт.
txt та информация, которая должна быть скрыта от посторонних глаз, может попасть в выдачу, а из-за этого пострадаете и вы, и сайт.
Так робот поисковых систем видит файл robots.txt:
Google обнаружил файл robots.txt на сайте и нашел правила, по которым следует сканировать страницы сайта
Как создать файл robots.txt
С помощью блокнота, Notepad, Sublime, либо любого другого текстового редактора.
В содержании файла должны быть прописаны инструкция User-agent и правило Disallow, к тому же есть еще несколько второстепенных правил.
User-agent — визитка для роботов
User-agent — правило о том, каким роботам необходимо просмотреть инструкции, описанные в файле robots.txt. На данный момент известно 302 поисковых робота. Чтобы не прописывать всех по отдельности, стоит использовать запись:
Она говорит о том, что мы указываем правила в robots.txt для всех поисковых роботов.
Для Google главным роботом является Googlebot. Если мы хотим учесть только его, запись в файле будет такой:
Если мы хотим учесть только его, запись в файле будет такой:
В этом случае все остальные роботы будут сканировать контент на основании своих директив по обработке пустого файла robots.txt.
Для Yandex главным роботом является… Yandex:
Другие специальные роботы:
- Mediapartners-Google — для сервиса AdSense;
- AdsBot-Google — для проверки качества целевой страницы;
- YandexImages — индексатор Яндекс.Картинок;
- Googlebot-Image — для картинок;
- YandexMetrika — робот Яндекс.Метрики;
- YandexMedia — робот, индексирующий мультимедийные данные;
- YaDirectFetcher — робот Яндекс.Директа;
- Googlebot-Video — для видео;
- Googlebot-Mobile — для мобильной версии;
- YandexDirectDyn — робот генерации динамических баннеров;
- YandexBlogs — робот поиск по блогам, индексирующий посты и комментарии;
- YandexMarket— робот Яндекс. Маркета;
- YandexNews — робот Яндекс.Новостей;
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы;
- YandexPagechecker — валидатор микроразметки;
- YandexCalendar — робот Яндекс.Календаря.
 Маркета;
Маркета;Disallow — расставляем «кирпичи»
Disallow дает рекомендацию, какую именно информацию не стоит сканировать.
Такая запись открывает для сканирования весь сайт:
А эта запись говорит о том, что абсолютно весь контент на сайте запрещен для сканирования:
Ее стоит использовать, если сайт находится в процессе доработок, и вы не хотите, чтобы он в нынешнем состоянии засветился в выдаче.
Важно снять это правило, как только сайт будет готов к тому, чтобы его увидели пользователи. К сожалению, об этом забывают многие вебмастера.
Пример. Как прописать правило Disallow, чтобы дать рекомендации роботам не просматривать содержимое папки /papka/:
Чтобы роботы не сканировали конкретный URL:
Чтобы роботы не сканировали конкретный файл:
Чтобы роботы не сканировали все файлы определенного разрешения на сайте:
Данная строка запрещает индексировать все файлы с расширением . gif
gif
Allow — направляем роботов
Allow разрешает сканировать какой-либо файл/директиву/страницу. Допустим, необходимо, чтобы роботы могли посмотреть только страницы, которые начинались бы с /catalog, а весь остальной контент закрыть. В этом случае прописывается следующая комбинация:
Правила Allow и Disallow сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для страницы подходит несколько правил, робот выбирает последнее правило в отсортированном списке.
Host — выбираем зеркало сайта
Host — одно из обязательных для robots.txt правил, оно сообщает роботу Яндекса, какое из зеркал сайта стоит учитывать для индексации.
Зеркало сайта — точная или почти точная копия сайта, доступная по разным адресам.
Робот не будет путаться при нахождении зеркал сайта и поймет, что главное зеркало указано в файле robots.txt. Адрес сайта указывается без приставки «http://», но если сайт работает на HTTPS, приставку «https://» указать нужно.
Как необходимо прописать это правило:
Пример файла robots.txt, если сайт работает на протоколе HTTPS:
Sitemap — медицинская карта сайта
Sitemap сообщает роботам, что все URL сайта, обязательные для индексации, находятся по адресу http://site.ua/sitemap.xml. При каждом обходе робот будет смотреть, какие изменения вносились в этот файл, и быстро освежать информацию о сайте в базах данных поисковой системы.
Инструкция должна быть грамотно вписана в файл:
Crawl-delay — секундомер для слабых серверов
Crawl-delay — параметр, с помощью которого можно задать период, через который будут загружаться страницы сайта. Данное правило актуально, если у вас слабый сервер. В таком случае возможны большие задержки при обращении поисковых роботов к страницам сайта. Этот параметр измеряется в секундах.
Clean-param — охотник за дублирующимся контентом
Clean-param помогает бороться с get-параметрами для избежания дублирования контента, который может быть доступен по разным динамическим адресам (со знаками вопроса). Такие адреса появляются, если на сайте есть различные сортировки, id сессии и так далее.
Такие адреса появляются, если на сайте есть различные сортировки, id сессии и так далее.
Допустим, страница доступна по адресам:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
В таком случае файл robots.txt будет выглядеть так:
Здесь ref указывает, откуда идет ссылка, поэтому она записывается в самом начале, а уже потом указывается остальная часть адреса.
Но прежде чем перейти к эталонному файлу, необходимо еще узнать о некоторых знаках, которые применяются при написании файла robots.txt.
Символы в robots.txt
Основные символы файла — «/, *, $, #».
С помощью слэша «/» мы показываем, что хотим закрыть от обнаружения роботами. Например, если стоит один слеш в правиле Disallow, мы запрещаем сканировать весь сайт. С помощью двух знаков слэш можно запретить сканирование какой-либо отдельной директории, например: /catalog/.
Такая запись говорит, что мы запрещаем сканировать все содержимое папки catalog, но если мы напишем /catalog, запретим все ссылки на сайте, которые будут начинаться на /catalog.
Звездочка «*» означает любую последовательность символов в файле. Она ставится после каждого правила.
Эта запись говорит, что все роботы не должны индексировать любые файлы с расширением .gif в папке /catalog/
Знак доллара «$» ограничивает действия знака звездочки. Если необходимо запретить все содержимое папки catalog, но при этом нельзя запретить урлы, которые содержат /catalog, запись в индексном файле будет такой:
Решетка «#» используется для комментариев, которые вебмастер оставляет для себя или других вебмастеров. Робот не будет их учитывать при сканировании сайта.
Например:
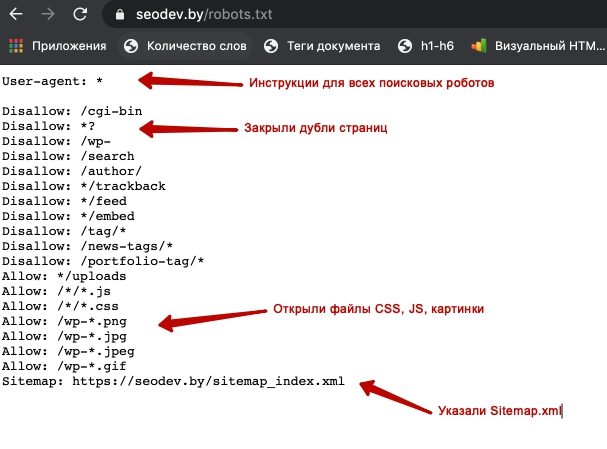
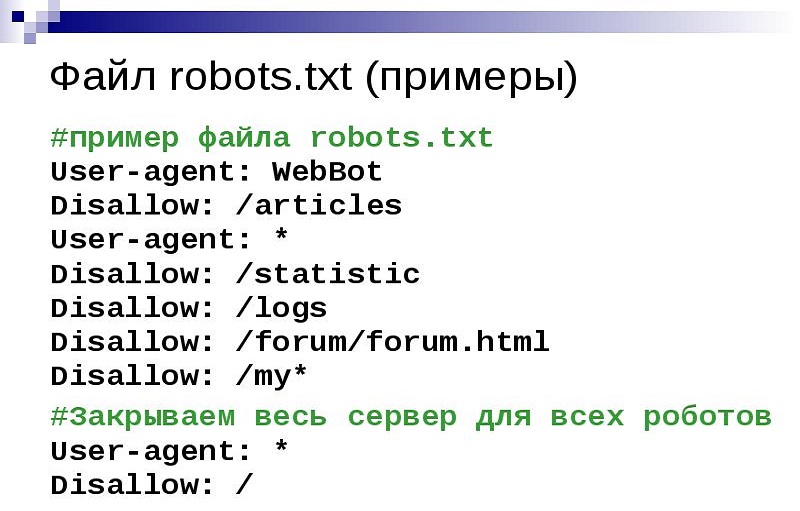
Как выглядит идеальный robots.txt
Такой файл robots.txt можно разместить почти на любом сайте:
Файл открывает содержимое сайта для индексирования, прописан хост и указана карта сайта, которая позволит поисковым системам всегда видеть адреса, которые должны быть проиндексированы. Отдельно прописаны правила для Яндекса, так как не все роботы понимают инструкцию Host.
Отдельно прописаны правила для Яндекса, так как не все роботы понимают инструкцию Host.
Но не спешите копировать содержимое файл к себе — для каждого сайта должны быть прописаны уникальные правила, которые зависит от типа сайта и CMS. поэтому тут стоит вспомнить все правила при заполнении файла robots.txt.
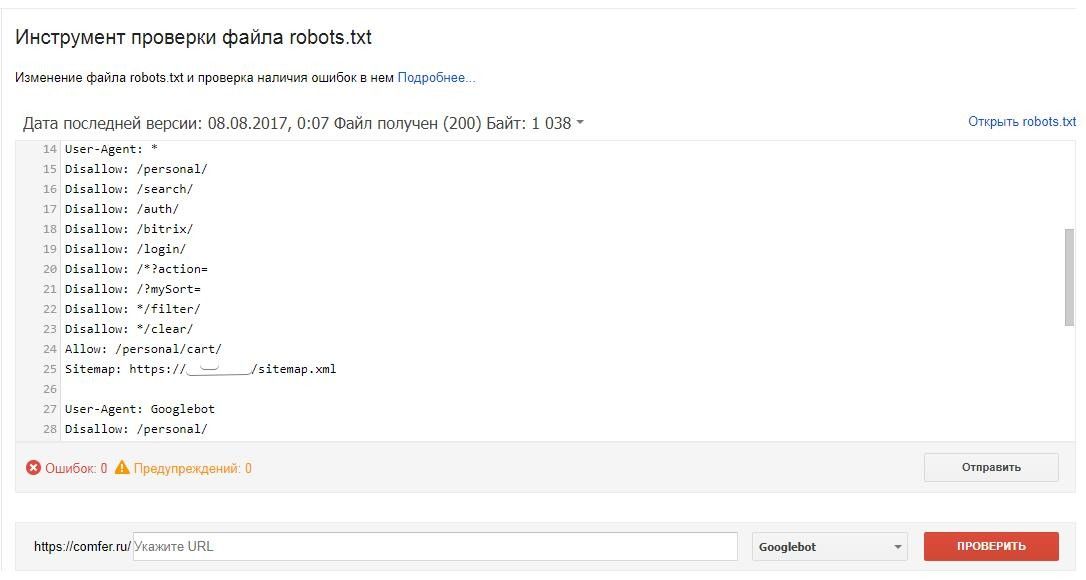
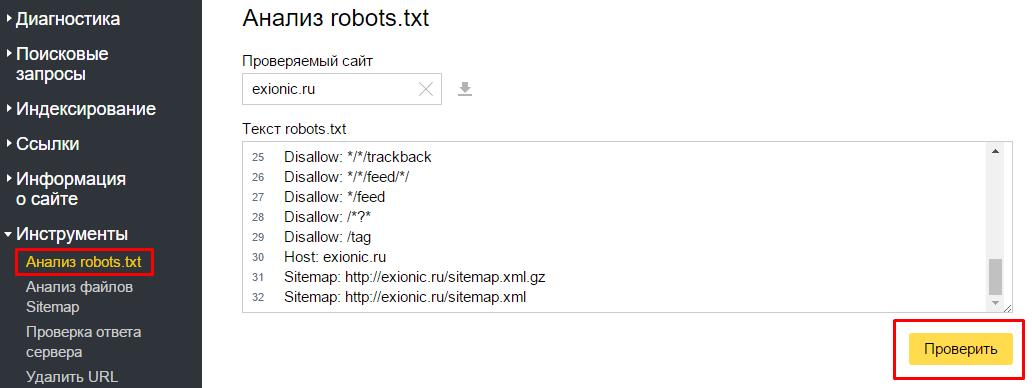
Как проверить файл robots.txt
Если хотите узнать, правильно ли заполнили файл robots.txt, проверьте его в инструментах вебмастеров Google и Яндекс. Просто введите исходный код файла robots.txt в форму по ссылке и укажите проверяемый сайт.
Как не нужно заполнять файл robots.txt
Часто при заполнении индексного файла допускаются досадные ошибки, причем они связаны с обычной невнимательностью или спешкой. Чуть ниже — чарт ошибок, которые я встречала на практике.
1. Перепутанные инструкции:
Правильный вариант:
2. Запись нескольких папок/директорий в одной инструкции Disallow:
Такая запись может запутать поисковых роботов, они могут не понять, что именно им не следует индексировать: то ли первую папку, то ли последнюю, — поэтому нужно писать каждое правило отдельно.
3. Сам файл должен называться только robots.txt, а не Robots.txt, ROBOTS.TXT или как-то иначе.
4. Нельзя оставлять пустым правило User-agent — нужно сказать, какой робот должен учитывать прописанные в файле правила.
5. Лишние знаки в файле (слэши, звездочки).
6. Добавление в файл страниц, которых не должно быть в индексе.
Нестандартное применение robots.txt
Кроме прямых функций индексный файл может стать площадкой для творчества и способом найти новых сотрудников.
Вот сайт, в котором robots.txt сам является маленьким сайтом с рабочими элементами и даже рекламным блоком.
Хотите что-то поинтереснее? Ловите ссылку на robots.txt со встроенной игрой и музыкальным сопровождением.
Многие бренды используют robots.txt, чтобы еще раз заявить о себе:
В качестве площадки для поиска специалистов файл используют в основном SEO-агентства. А кто же еще может узнать о его существовании? 🙂
А у Google есть специальный файл humans. txt, чтобы вы не допускали мысли о дискриминации специалистов из кожи и мяса.
txt, чтобы вы не допускали мысли о дискриминации специалистов из кожи и мяса.
Когда у вебмастера появляется достаточно свободного времени, он часто тратит его на модернизацию robots.txt:
Хотите, чтобы все страницы вашего сайта заходили в индекс быстро? Мы выберем для вас оптимальную стратегию SEO-продвижения:
{«0»:{«lid»:»1531306243545″,»ls»:»10″,»loff»:»»,»li_type»:»nm»,»li_name»:»name»,»li_ph»:»Имя»,»li_req»:»y»,»li_nm»:»name»},»1″:{«lid»:»1573230091466″,»ls»:»20″,»loff»:»»,»li_type»:»ph»,»li_name»:»phone»,»li_req»:»y»,»li_masktype»:»a»,»li_nm»:»phone»},»2″:{«lid»:»1573567927671″,»ls»:»30″,»loff»:»y»,»li_type»:»in»,»li_name»:»surname»,»li_ph»:»Фамилия»,»li_req»:»y»,»li_nm»:»surname»},»3″:{«lid»:»1531306540094″,»ls»:»40″,»loff»:»»,»li_type»:»in»,»li_name»:»domains»,»li_ph»:»Адрес сайта»,»li_rule»:»url»,»li_req»:»y»,»li_nm»:»domains»},»4″:{«lid»:»1573230077755″,»ls»:»50″,»loff»:»»,»li_type»:»em»,»li_name»:»email»,»li_ph»:»Email»,»li_req»:»y»,»li_nm»:»email»},»5″:{«lid»:»1575903646714″,»ls»:»60″,»loff»:»»,»li_type»:»hd»,»li_name»:»comment»,»li_value»:»Автоматический коммент: заявка из блога, без пользовательского комментария»,»li_nm»:»comment»},»6″:{«lid»:»1575903664523″,»ls»:»70″,»loff»:»»,»li_type»:»hd»,»li_name»:»lead_channel_id»,»li_value»:»24″,»li_nm»:»lead_channel_id»},»7″:{«lid»:»1584374224865″,»ls»:»80″,»loff»:»»,»li_type»:»hd»,»li_name»:»ip»,»li_nm»:»ip»},»8″:{«lid»:»1609939359940″,»ls»:»90″,»loff»:»»,»li_type»:»hd»,»li_name»:»post_id»,»li_nm»:»post_id»}}
Поможем обогнать конкурентов
Выводы
С помощью Robots. txt вы сможете задавать инструкции поисковым роботам, рекламировать себя, свой бренд, искать специалистов. Это большое поле для экспериментов. Главное, помните о грамотном заполнении файла и типичных ошибках.
txt вы сможете задавать инструкции поисковым роботам, рекламировать себя, свой бренд, искать специалистов. Это большое поле для экспериментов. Главное, помните о грамотном заполнении файла и типичных ошибках.
Правила, они же директивы, они же инструкции файла robots.txt:
- User-agent — правило о том, каким роботам необходимо просмотреть инструкции, описанные в robots.txt.
- Disallow дает рекомендацию, какую именно информацию не стоит сканировать.
- Sitemap сообщает роботам, что все URL сайта, обязательные для индексации, находятся по адресу http://site.ua/sitemap.xml.
- Crawl-delay — параметр, с помощью которого можно задать период, через который будут загружаться страницы сайта.
- Host сообщает роботу Яндекса, какое из зеркал сайта стоит учитывать для индексации.
- Allow разрешает сканировать какой-либо файл/директиву/страницу.
- Clean-param помогает бороться с get-параметрами для избежания дублирования контента.
Знаки при составлении robots.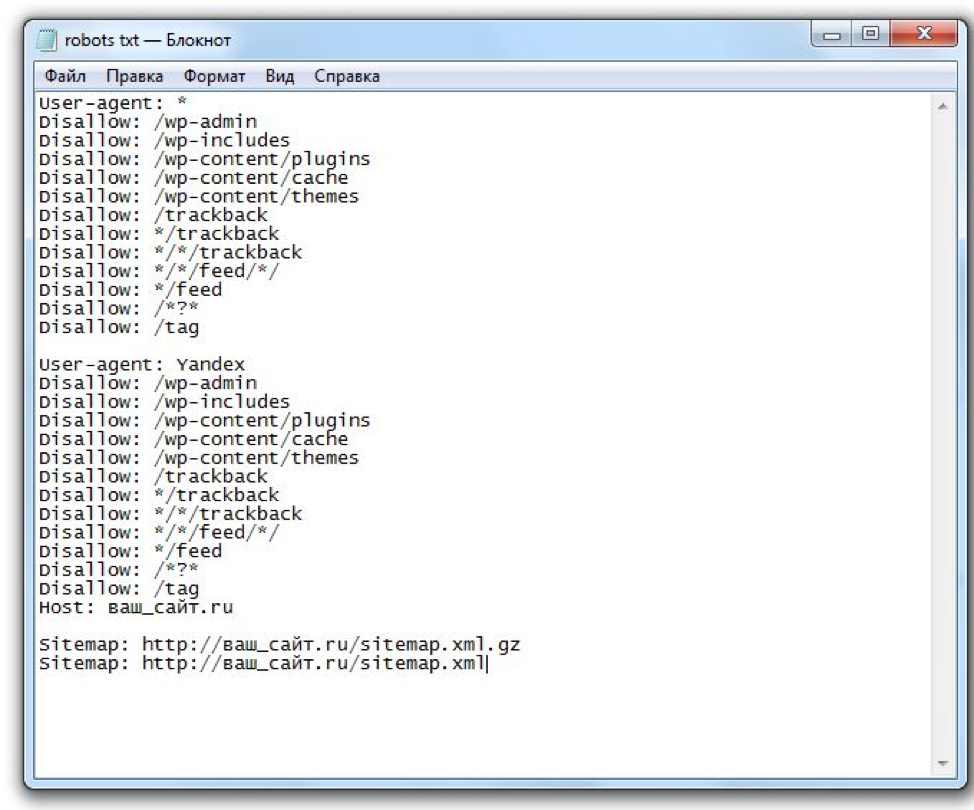 txt:
txt:
- Знак доллара «$» ограничивает действия знака звездочки.
- С помощью слэша «/» мы показываем, что хотим закрыть от обнаружения роботами.
- Звездочка «*» означает любую последовательность символов в файле. Она ставится после каждого правила.
- Решетка «#» используется, чтобы обозначить комментарии, которые пишет вебмастер для себя или других вебмастеров.
Используйте индексный файл с умом — и сайт всегда будет в выдаче.
Как закрыть сайт от индексации в robots.txt
Если закрывать сайт полностью не требуется, запрещайте индексацию отдельных страниц. Пользователям не следует видеть в поиске служебные разделы сайта, личные кабинеты, устаревшую информацию из раздела акций или календаря.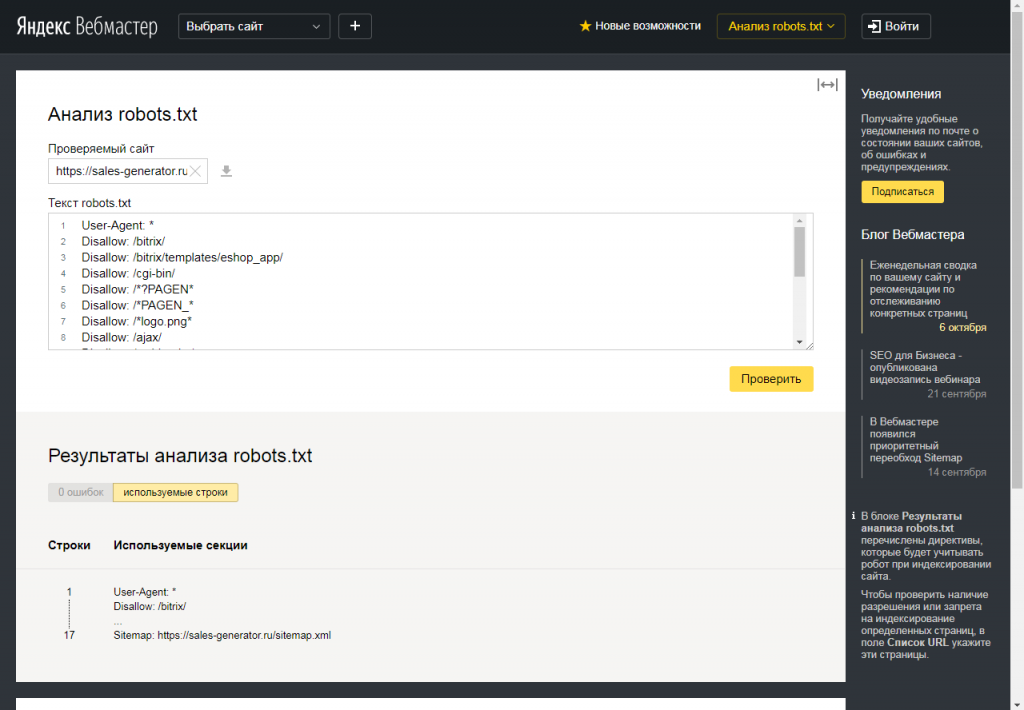 Дополнительно нужно закрыть от индексации скрипты, всплывающие окна и баннеры, тяжелые файлы. Это поможет уменьшить время индексации и снизит нагрузку на сервер.
Дополнительно нужно закрыть от индексации скрипты, всплывающие окна и баннеры, тяжелые файлы. Это поможет уменьшить время индексации и снизит нагрузку на сервер.
Как закрыть сайт полностью
Запретить индексацию сайта можно для всех поисковиков, для отдельного робота или запретить для всех, кроме одного.
| Запрет для всех |
User-agent: * Disallow: / |
| Запрет для отдельного робота |
User-agent: YandexImages Disallow: / |
|
User-agent: * Disallow: / User-agent: Yandex Allow: / |
Как закрыть отдельные страницы
Маленькие сайты-визитки обычно не требуют сокрытия отдельных страниц. Для ресурсов с большим количеством служебной информации закрывайте страницы и целые разделы:
Для ресурсов с большим количеством служебной информации закрывайте страницы и целые разделы:
- административная панель;
- служебные каталоги;
- личный кабинет;
- формы регистрации;
- формы заказа;
- сравнение товаров;
- избранное;
- корзина;
- каптча;
- всплывающие окна и баннеры;
- поиск на сайте;
- идентификаторы сессий.
Желательно запрещать индексацию т.н. мусорных страниц. Это старые новости, акции и спецпредложения, события и мероприятия в календаре. На информационных сайтах закрывайте статьи с устаревшей информацией. Иначе ресурс будет восприниматься неактуальным. Чтобы не закрывать статьи и материалы, регулярно обновляйте данные в них.
Запрет индексации
| Отдельной страницы |
User-agent: * Disallow: /contact. 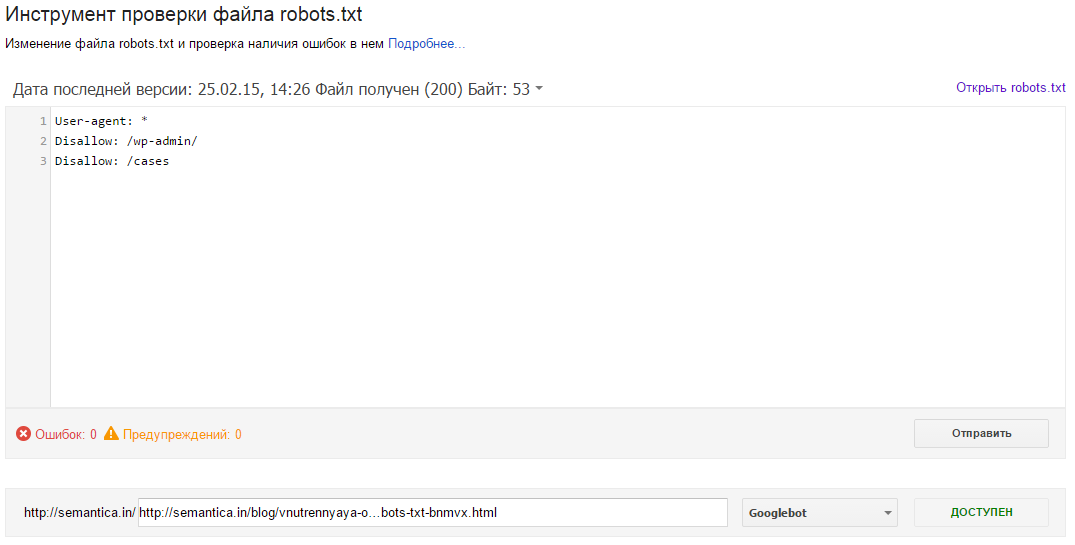 html html
|
| Раздела |
User-agent: * Disallow: /catalog/ |
| Всего сайта, кроме одного раздела |
User-agent: * Allow: /catalog |
| Всего раздела, кроме одного подраздела |
User-agent: * Disallow: /product Allow: /product/auto |
| Поиска на сайте |
User-agent: * Disallow: /search |
| Административной панели |
User-agent: * Disallow: /admin |
Как закрыть другую информацию
 txt позволяет закрывать папки на сайте, файлы, скрипты, utm-метки. Их можно скрыть полностью или выборочно. Указывайте запрет для индексации всем роботам или отдельным.
txt позволяет закрывать папки на сайте, файлы, скрипты, utm-метки. Их можно скрыть полностью или выборочно. Указывайте запрет для индексации всем роботам или отдельным.
Запрет индексации
| Типа файлов |
User-agent: * Disallow: /*.jpg |
| Папки |
User-agent: * Disallow: /images/ |
| Папку, кроме одного файла |
User-agent: * Disallow: /images/ Allow: file.jpg |
| Скриптов |
User-agent: * Disallow: /plugins/*.js |
| utm-меток |
User-agent: * Disallow: *utm= |
| utm-меток для Яндекса | Clean-Param: utm_source&utm_medium&utm_campaign |
Как закрыть сайт через мета-теги
Альтернативой файлу robots. txt является мета-тег robots. Прописывайте его в исходный код сайта в файле index.html. Размещайте в контейнере <head>. Указывайте, для каких краулеров сайт закрыт от индексации. Если для всех, напишите robots. Если для одного робота, укажите его название. Для Google — Googlebot, для Яндекса — Yandex. Существуют два варианта записи мета-тега.
txt является мета-тег robots. Прописывайте его в исходный код сайта в файле index.html. Размещайте в контейнере <head>. Указывайте, для каких краулеров сайт закрыт от индексации. Если для всех, напишите robots. Если для одного робота, укажите его название. Для Google — Googlebot, для Яндекса — Yandex. Существуют два варианта записи мета-тега.
Вариант 2.
<meta name=”robots” content=”none”/>
Атрибут “content” имеет следующие значения:
- none — индексация запрещена, включая noindex и nofollow;
- noindex — запрещена индексация содержимого;
- nofollow — запрещена индексация ссылок;
- follow — разрешена индексация ссылок;
- index — разрешена индексация;
- all — разрешена индексация содержимого и ссылок.
 На такой странице ссылки будут индексироваться, а текст — нет. Используйте для разных случаев сочетания значений.
На такой странице ссылки будут индексироваться, а текст — нет. Используйте для разных случаев сочетания значений. Если закрыть сайт от индексации через мета-теги, создавать robots.txt отдельно не нужно.
Какие встречаются ошибки
Логические — когда правила противоречат друг другу. Выявляйте логические ошибки через проверку файла robots.txt в инструментах Яндекс.Вебмастере и Google Robots Testing Tool.
Синтаксические — когда неправильно записаны правила в файле.
К наиболее часто встречаемым относятся:
- запись без учета регистра;
- запись заглавными буквами;
- перечисление всех правил в одной строке;
- отсутствие пустой строки между правилами;
- указание краулера в директиве;
- перечисление множества вместо закрытия целого раздела или папки;
- отсутствие обязательной директивы disallow.

Шпаргалка
-
Для запрета на индексацию сайта используйте два варианта. Создайте файл robots.txt и укажите запрет через директиву disallow для всех краулеров. Другой вариант — пропишите запрет через мета-тег robots в файле index.html внутри тега .
-
Закрывайте служебные информацию, устаревающие данные, скрипты, сессии и utm-метки. Для каждого запрета создавайте отдельное правило. Запрещайте всем поисковым роботам через * или указывайте название конкретного краулера. Если вы хотите разрешить только одному роботу, прописывайте правило через disallow.
-
При создании файла robots.txt избегайте логических и синтаксических ошибок. Проверяйте файл через инструменты Яндекс.
Вебмастер и Google Robots Testing Tool.
 Вебмастер и Google Robots Testing Tool.
Вебмастер и Google Robots Testing Tool.
Материал подготовила Светлана Сирвида-Льорентэ.
Что такое robots.txt [Основы для новичков]
Успешная индексация нового сайта зависит от многих слагаемых. Один из них — файл robots.txt, с правильным заполнением которого должен быть знаком любой начинающий веб-мастер. Обновили материал для новичков.
Подробно о правилах составления файла в полном руководстве «Как составить robots.txt самостоятельно».
А в этом материале основы для начинающих, которые хотят быть в курсе профессиональных терминов.
Что такое robots.txt
Файл robots.txt — это документ в формате .txt, содержащий инструкции по индексации конкретного сайта для поисковых ботов. Он указывает поисковикам, какие страницы веб-ресурса стоит проиндексировать, а какие не нужно допустить к индексации.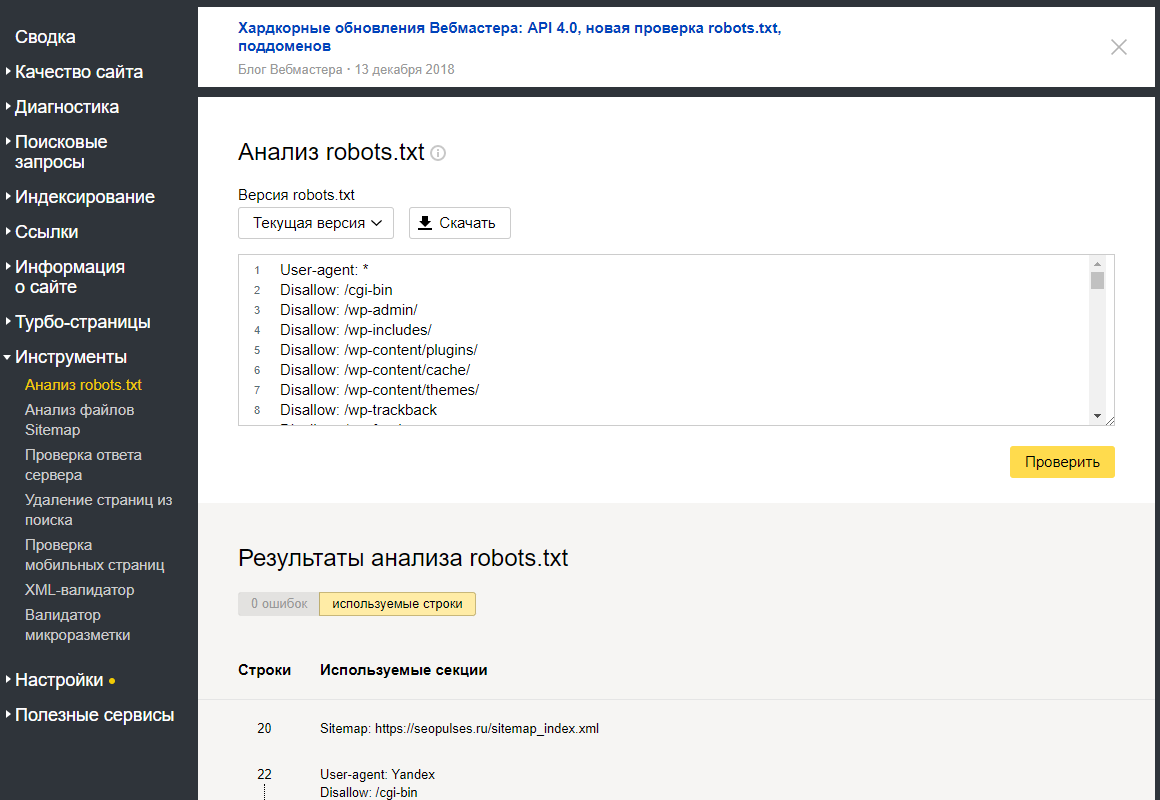
Поисковый робот, придя к вам на сайт, первым делом пытается отыскать robots.txt. Если робот не нашел файл или он составлен неправильно, бот будет изучать сайт по своему собственному усмотрению. Далеко не факт, что он начнет с тех страниц, которые нужно вводить в поиск в первую очередь (новые статьи, обзоры, фотоотчеты и так далее). Индексация нового сайта может затянуться. Поэтому веб-мастеру нужно вовремя позаботиться о создании правильного файла robots.txt.
На некоторых конструкторах сайтов файл формируется сам. Например, Wix автоматически создает robots.txt. Чтобы посмотреть файл, добавьте к домену «/robots.txt». Если вы увидите там странные элементы типа «noflashhtml» и «backhtml», не пугайтесь: они относятся к структуре сайтов на платформе и не влияют на отношение поисковых систем.
Зачем нужен robots.txt
Казалось бы, зачем запрещать индексировать какое-то содержимое сайта? Далеко не весь контент, из которого состоит сайт, нужен поисковым роботам. Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. Есть одно но:
Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. Есть одно но:
Содержимое файла robots.txt — это рекомендации для ботов, а не жесткие правила. Рекомендации боты могут проигнорировать.
Google предупреждает, что через robots.txt нельзя заблокировать страницы для показа в Google. Даже если вы закроете доступ к странице в robots.txt, если на какой-то другой странице будет ссылка на эту, она может попасть в индекс. Лучше использовать и ограничения в robots, и другие методы запрета:
Запрет индексирования сайта, Яндекс
Блокировка индексирования, Google
Тем не менее, без robots.txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
User-agent: Yandex Disallow: /
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
User-agent: Yandex Disallow: /wp-admin
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots. txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
User-agent: * Allow: /catalog Disallow: /
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
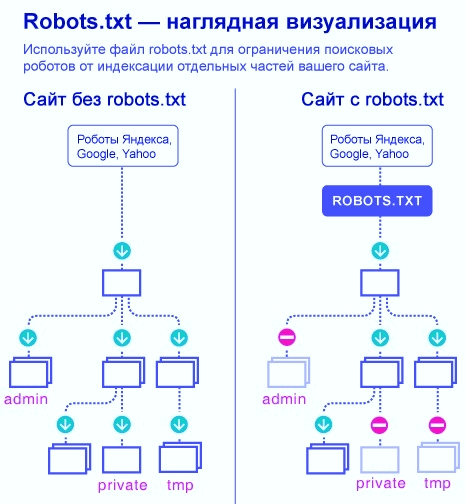
Директива «Sitemap:» — указание на карту сайта
«Sitemap:» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap.xml и sitemap.xml.gz в случае с CMS WordPress.
User-agent: * Sitemap: http://pr-cy.
 ru/sitemap.xml
Sitemap: http://pr-cy.ru/sitemap.xml.gz
ru/sitemap.xml
Sitemap: http://pr-cy.ru/sitemap.xml.gz
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
Файл robots.txt готов — что дальше
Итак, вы создали текстовый документ robots.txt с учетом особенностей вашего сайта. Его можно сделать автоматически, к примеру, с помощью нашего инструмента.
Что делать дальше:
- проверить корректность созданного документа, например, посредством сервиса Яндекса;
- при помощи FTP-клиента закачать готовый файл в корневую папку своего сайта. В ситуации с WordPress речь обычно идет о системной папке Public_html.
Дальше остается только ждать, когда появятся поисковые роботы, изучат ваш robots.txt, а после возьмутся за индексацию вашего сайта.
Как посмотреть robots.txt чужого сайта
Если вам интересно сперва посмотреть на готовые примеры файла robots.txt в исполнении других, то нет ничего проще. Для этого в адресной строке браузера достаточно ввести site.ru/robots.txt. Вместо «site.ru» — название интересующего вас ресурса.
Все о файле «robots.txt» по-русски — как составить robots.txt
Файл robots.txt
Все поисковые роботы при заходе на сайт в первую очередь ищут файл robots.txt. Если вы – вебмастер, вы должны знать назначение и синтаксис robots.txt.
Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации некоторые разделы или страницы на сайте, указывать на правильное «зеркалирование» домена, рекомендовать поисковому роботу соблюдать определенный временной интервал между скачиванием документов с сервера и т.д.
Создание robots.txt
Файл с указанным расширением – простой текстовый документ. Он создается с помощью обычного блокнота, программ Notepad или Sublime, а также любого другого редактора текстов. Важно, что в его названии должен быть нижний регистр букв – robots.txt.
Важно, что в его названии должен быть нижний регистр букв – robots.txt.
Также существует ограничение по количеству символов и, соответственно, размеру. Например, в Google максимальный вес установлен как 500 кб, а у Yandex – 32 кб. В случае их превышения корректность работы может быть нарушена.
Создается документ в кодировке UTF-8, и его действие распространяется на протоколы HTTP, HTTPS, FTP.
При написании содержимого файла запрещается использование кириллицы. Если есть необходимость применения кириллических доменов, необходимо прибегать к помощи Punycode. Кодировка адресов отдельных страниц должна происходить в соответствии с кодировкой структуры сайта, которая была применена.
После того как файл создан, его следует запустить в корневой каталог. При этом используется FTP-клиент, проверяется возможность доступа по ссылке https://site.com./robots.txt и полнота отображения данных.
Важно помнить, что для каждого поддомена сайта оформляется свой файл с ограничениями.
Описание robots.txt
Чтобы правильно написать robots.txt, предлагаем вам изучить разделы этого сайта. Здесь собрана самая полезная информация о синтаксисе robots.txt, о формате robots.txt, примеры использования, а также описание основных поисковых роботов Рунета.
- Как работать с robots.txt — узнайте, что вы можете сделать, чтобы управлять роботами, которые посещают ваш веб-сайт.
- Роботы Рунета — разделы по роботам поисковых систем, популярных на просторах Рунета.
- Частые ошибки в robots.txt — список наиболее частых ошибок, допускаемых при написании файла robots.txt.
- ЧаВо по веб-роботам — часто задаваемые вопросы о роботах от пользователей, авторов и разработчиков.
- Ссылки по теме — аналог оригинального раздела «WWW Robots Related Sites», но дополненый и расширенный, в основном по русскоязычной тематике.
Где размещать файл robots.
 txt
txtРобот просто запрашивает на вашем сайте URL «/robots.txt», сайт в данном случае – это определенный хост на определенном порту.
На сайте может быть только один файл «/robots.txt». Например, не следует помещать файл robots.txt в пользовательские поддиректории – все равно роботы не будут их там искать. Если вы хотите иметь возможность создавать файлы robots.txt в поддиректориях, то вам нужен способ программно собирать их в один файл robots.txt, расположенный в корне сайта. Вместо этого можно использовать Мета-тег Robots.
Не забывайте, что URL-ы чувствительны к регистру, и название файла «/robots.txt» должно быть написано полностью в нижнем регистре.
Как видите, файл robots.txt нужно класть исключительно в корень сайта.
Что писать в файл robots.txt
В файл robots.txt обычно пишут нечто вроде:
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
В этом примере запрещена индексация трех директорий.
Затметьте, что каждая директория указана на отдельной строке – нельзя написать «Disallow: /cgi-bin/ /tmp/». Нельзя также разбивать одну инструкцию Disallow или User-agent на несколько строк, т.к. перенос строки используется для отделения инструкций друг от друга.
Регулярные выражения и символы подстановки так же нельзя использовать. «Звездочка» (*) в инструкции User-agent означает «любой робот». Инструкции вида «Disallow: *.gif» или «User-agent: Ya*» не поддерживаются.
Конкретные инструкции в robots.txt зависят от вашего сайта и того, что вы захотите закрыть от индексации. Вот несколько примеров:
Запретить весь сайт для индексации всеми роботами
User-agent: *
Disallow: /
Разрешить всем роботам индексировать весь сайт
User-agent: *
Disallow:
Или можете просто создать пустой файл «/robots.txt».
Закрыть от индексации только несколько каталогов
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /private/
Запретить индексацию сайта только для одного робота
User-agent: BadBot
Disallow: /
Разрешить индексацию сайта одному роботу и запретить всем остальным
User-agent: Yandex
Disallow:
User-agent: *
Disallow: /
Запретить к индексации все файлы кроме одного
Это довольно непросто, т. к. не существует инструкции “Allow”. Вместо этого можно переместить все файлы кроме того, который вы хотите разрешить к индексации в поддиректорию и запретить ее индексацию:
к. не существует инструкции “Allow”. Вместо этого можно переместить все файлы кроме того, который вы хотите разрешить к индексации в поддиректорию и запретить ее индексацию:
User-agent: *
Disallow: /docs/
Либо вы можете запретить все запрещенные к индексации файлы:
User-agent: *
Disallow: /private.html
Disallow: /foo.html
Disallow: /bar.html
Инфографика
Проверка
Оценить правильность созданного документа robots.txt можно с помощью специальных проверочных ресурсов:
- Анализ robots.txt. – при работе с Yandex.
- robots.txt Tester – для Google.
Важно помнить, что неправильно созданный или прописанный документ может являться угрозой для посещаемости и ранжирования сайта.
О сайте
Этот сайт — некоммерческий проект. Значительная часть материалов — это переводы www.robotstxt.org, другая часть — оригинальные статьи. Мы не хотим ограничиваться только robots.txt, поэтому в некоторых статьях описаны альтернативные методы «ограничения» роботов.
Мы не хотим ограничиваться только robots.txt, поэтому в некоторых статьях описаны альтернативные методы «ограничения» роботов.
robots txt: что это такое за файл и как использовать его
1. Введение
Технические аспекты созданного сайта играют не менее важную роль для продвижения сайта в поисковых системах, чем его наполнение. Одним из наиболее важных технических аспектов является индексирование сайта, т. е. определение областей сайта (файлов и директорий), которые могут или не могут быть проиндексированы роботами поисковых систем. Для этих целей используется robots.txt – это специальный файл, который содержит команды для роботов поисковиков. Правильный файл robots.txt для Яндекса и Google поможет избежать многих неприятных последствий, связанных с индексацией сайта.
2. Понятие файла robots.txt и требования, предъявляемые к нему
Файл /robots.txt предназначен для указания всем поисковым роботам (spiders) индексировать информационные сервера так, как определено в этом файле, т. е. только те директории и файлы сервера, которые не описаны в /robots.txt. Этот файл должен содержать 0 или более записей, которые связаны с тем или иным роботом (что определяется значением поля agent_id) и указывают для каждого робота или для всех сразу, что именно им не надо индексировать.
е. только те директории и файлы сервера, которые не описаны в /robots.txt. Этот файл должен содержать 0 или более записей, которые связаны с тем или иным роботом (что определяется значением поля agent_id) и указывают для каждого робота или для всех сразу, что именно им не надо индексировать.
Синтаксис файла позволяет задавать запретные области индексирования, как для всех, так и для определенных, роботов.
К файлу robots.txt предъявляются специальные требования, не выполнение которых может привести к неправильному считыванию роботом поисковой системы или вообще к недееспособности данного файла.
Основные требования:
- все буквы в названии файла должны быть прописными, т. е. должны иметь нижний регистр:
- robots.txt – правильно,
- Robots.txt или ROBOTS.TXT – неправильно;
- файл robots.txt должен создаваться в текстовом формате Unix. При копировании данного файла на сайт ftp-клиент должен быть настроен на текстовый режим обмена файлами;
- файл robots. txt должен быть размещен в корневом каталоге сайта.
 txt должен быть размещен в корневом каталоге сайта.
txt должен быть размещен в корневом каталоге сайта.3. Содержимое файла robots.txt
Файл robots.txt включает в себя две записи: «User-agent» и «Disallow». Названия данных записей не чувствительны к регистру букв.
Некоторые поисковые системы поддерживают еще и дополнительные записи. Так, например, поисковая система «Yandex» использует запись «Host» для определения основного зеркала сайта (основное зеркало сайта – это сайт, находящийся в индексе поисковых систем).
Каждая запись имеет свое предназначение и может встречаться несколько раз, в зависимости от количества закрываемых от индексации страниц или (и) директорий и количества роботов, к которым Вы обращаетесь.
Предполагается следующий формат строк файла robots.txt:
имя_записи[необязательные
пробелы]:[необязательные
пробелы]значение[необязательные пробелы]
Чтобы файл robots.txt считался верным, необходимо, чтобы, как минимум, одна директива «Disallow» присутствовала после каждой записи «User-agent».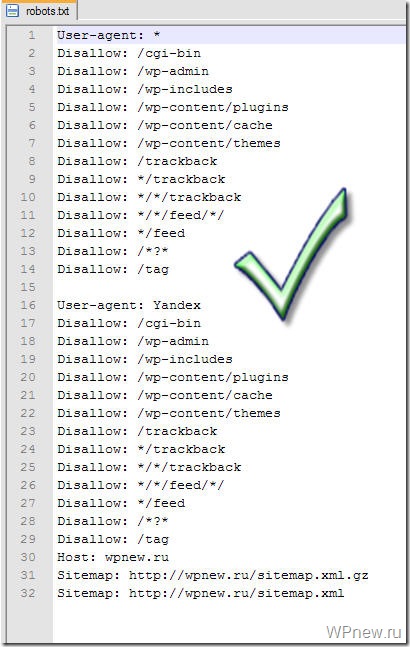
Полностью пустой файл robots.txt эквивалентен его отсутствию, что предполагает разрешение на индексирование всего сайта.
Запись «User-agent»
Запись «User-agent» должна содержать название поискового робота. В данной записи можно указать каждому конкретному роботу, какие страницы сайта индексировать, а какие нет.
Пример записи «User-agent», где обращение происходит ко всем поисковым системам без исключений и используется символ «*»:
User-agent: *
Пример записи «User-agent», где обращение происходит только к роботу поисковой системы Rambler:
User-agent: StackRambler
Робот каждой поисковой системы имеет свое название. Существует два основных способа узнать его (название):
на сайтах многих поисковых систем присутствует специализированный§ раздел «помощь веб-мастеру», в котором часто указывается название поискового робота;
при просмотре логов веб-сервера, а именно при просмотре обращений к§ файлу robots.txt, можно увидеть множество имен, в которых присутствуют названия поисковых систем или их часть. Поэтому Вам остается лишь выбрать нужное имя и вписать его в файл robots.txt.
Поэтому Вам остается лишь выбрать нужное имя и вписать его в файл robots.txt.
Запись «Disallow»
Запись «Disallow» должна содержать предписания, которые указывают поисковому роботу из записи «User-agent», какие файлы или (и) каталоги индексировать запрещено.
Рассмотрим различные примеры записи «Disallow».
Пример записи в robots.txt (разрешить все для индексации):
Disallow:
Пример (сайт полностью запрещен к индексации. Для этого используется символ «/»):Disallow: /
Пример (для индексирования запрещен файл «page.htm», находящийся в корневом каталоге и файл «page2.htm», располагающийся в директории «dir»):
Disallow: /page.htm
Disallow: /dir/page2.htm
Пример (для индексирования запрещены директории «cgi-bin» и «forum» и, следовательно, все содержимое данной директории):
Disallow: /cgi-bin/
Disallow: /forum/
Возможно закрытие от индексирования ряда документов и (или) директорий, начинающихся с одних и тех же символов, используя только одну запись «Disallow». Для этого необходимо прописать начальные одинаковые символы без закрывающей наклонной черты.
Для этого необходимо прописать начальные одинаковые символы без закрывающей наклонной черты.
Пример (для индексирования запрещены директория «dir», а так же все файлы и директории, начинающиеся буквами «dir», т. е. файлы: «dir.htm», «direct.htm», директории: «dir», «directory1», «directory2» и т. д.):
Запись «Allow»
Опция «Allow» используется для обозначения исключений из неиндексируемых директорий и страниц, которые заданы записью «Disallow».
Например, есть запись следующего вида:
Disallow: /forum/
Но при этом нужно, чтобы в директории /forum/ индексировалась страница page1. Тогда в файле robots.txt потребуются следующие строки:
Disallow: /forum/
Allow: /forum/page1
Запись «Sitemap»
Эта запись указывает на расположение карты сайта в формате xml, которая используется поисковыми роботами. Эта запись указывает путь к данному файлу.
Пример:
Sitemap: http://site.ru/sitemap.xml
Запись «Host»
Запись «host» используется поисковой системой «Yandex». Она необходима для определения основного зеркала сайта, т. е. если сайт имеет зеркала (зеркало – это частичная или полная копия сайта. Наличие дубликатов ресурса бывает необходимо владельцам высокопосещаемых сайтов для повышения надежности и доступности их сервиса), то с помощью директивы «Host» можно выбрать то имя, под которым Вы хотите быть проиндексированы. В противном случае «Yandex» выберет главное зеркало самостоятельно, а остальные имена будут запрещены к индексации.
Она необходима для определения основного зеркала сайта, т. е. если сайт имеет зеркала (зеркало – это частичная или полная копия сайта. Наличие дубликатов ресурса бывает необходимо владельцам высокопосещаемых сайтов для повышения надежности и доступности их сервиса), то с помощью директивы «Host» можно выбрать то имя, под которым Вы хотите быть проиндексированы. В противном случае «Yandex» выберет главное зеркало самостоятельно, а остальные имена будут запрещены к индексации.
В целях совместимости с поисковыми роботами, которые при обработке файла robots.txt не воспринимают директиву Host, необходимо добавлять запись «Host» непосредственно после записей Disallow.
Пример: www.site.ru – основное зеркало:
Host: www.site.ru
Запись «Crawl-delay»
Эту запись воспринимает Яндекс. Она является командой для робота делать промежутки заданного времени (в секундах) между индексацией страниц. Иногда это бывает нужно для защиты сайта от перегрузок.
Так, запись следующего вида обозначает, что роботу Яндекса нужно переходить с одной страницы на другую не раньше чем через 3 секунды:
Crawl-delay: 3
Комментарии
Любая строка в robots. txt, начинающаяся с символа «#», считается комментарием. Разрешено использовать комментарии в конце строк с директивами, но некоторые роботы могут неправильно распознать данную строку.
Пример (комментарий находится на одной строке вместе с директивой):
Disallow: /cgi-bin/ #комментарий
Желательно размещать комментарий на отдельной строке. Пробел в начале строки разрешается, но не рекомендуется.
4. Примеры файлов robots.txt
Пример (комментарий находится на отдельной строке):
Disallow: /cgi-bin/#комментарий
Пример файла robots.txt, разрешающего всем роботам индексирование всего сайта:
User-agent: *
Disallow:
Host: www.site.ru
Пример файла robots.txt, запрещающего всем роботам индексирование сайта:
User-agent: *
Disallow: /
Host: www.site.ru
Пример файла robots.txt, запрещающего всем роботам индексирование директории «abc», а так же всех директорий и файлов, начинающихся с символов «abc».
User-agent: *
Disallow: /abc
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование страницы «page.htm», находящейся в корневом каталоге сайта, поисковым роботом «googlebot»:
User-agent: googlebot
Disallow: /page.htm
Host: www.site.ru
Пример файла robots.txt, запрещающего индексирование:
– роботу «googlebot» – страницы «page1.htm», находящейся в директории «directory»;
– роботу «Yandex» – все директории и страницы, начинающиеся символами «dir» (/dir/, /direct/, dir.htm, direction.htm, и т. д.) и находящиеся в корневом каталоге сайта.
User-agent: googlebot
Disallow: /directory/page1.htm
User-agent: Yandex
Disallow: /dir
Host: www.site.ru
5. Ошибки, связанные с файлом robots.txt
Одна из самых распространенных ошибок – перевернутый синтаксис.
Неправильно:
User-agent: /
Disallow: Yandex
Правильно:
User-agent: Yandex
Disallow: /
Неправильно:
User-agent: *
Disallow: /dir/ /cgi-bin/ /forum/
Правильно:
User-agent: *
Disallow: /dir/
Disallow: /cgi-bin/
Disallow: /forum/
Если при обработке ошибки 404 (документ не найден), веб-сервер выдает специальную страницу, и при этом файл robots. txt отсутствует, то возможна ситуация, когда поисковому роботу при запросе файла robots.txt выдается та самая специальная страница, никак не являющаяся файлом управления индексирования.
txt отсутствует, то возможна ситуация, когда поисковому роботу при запросе файла robots.txt выдается та самая специальная страница, никак не являющаяся файлом управления индексирования.
Ошибка, связанная с неправильным использованием регистра в файле robots.txt. Например, если необходимо закрыть директорию «cgi-bin», то в записе «Disallow» нельзя писать название директории в верхнем регистре «cgi-bin».
Неправильно:
User-agent: *
Disallow: /CGI-BIN/
Правильно:
User-agent: *
Disallow: /cgi-bin/
Ошибка, связанная с отсутствием открывающей наклонной черты при закрытии директории от индексирования.
Неправильно:
User-agent: *
Disallow: dir
User-agent: *
Disallow: page.HTML
Правильно:
User-agent: *
Disallow: /dir
User-agent: *
Disallow: /page.HTML
Чтобы избежать наиболее распространенных ошибок, файл robots.txt можно проверить средствами Яндекс.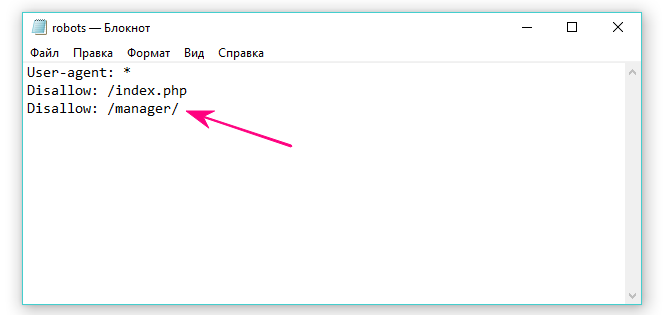 Вебмастера или Инструментами для вебмастеров Google. Проверка осуществляется после загрузки файла.
Вебмастера или Инструментами для вебмастеров Google. Проверка осуществляется после загрузки файла.
6. Заключение
Таким образом, наличие файла robots.txt, а так же его составление, может повлиять на продвижение сайта в поисковых системах. Не зная синтаксиса файла robots.txt, можно запретить к индексированию возможные продвигаемые страницы, а так же весь сайт. И, наоборот, грамотное составление данного файла может очень помочь в продвижении ресурса, например, можно закрыть от индексирования документы, которые мешают продвижению нужных страниц.
Robots.txt — инструкция для SEO
Файл robots.txt предоставляет важную информацию для поисковых роботов, которые сканируют интернет. Перед тем как пройтись по страницам вашего сайта, поисковые роботы проверяют данный файл.
Это позволят им с большей эффективностью сканировать сайт, так как вы помогаете роботам сразу приступать к индексации действительно важной информации на вашем сайте (это при условии, что вы правильно настроили robots. txt).
txt).
Но, как директивы в robots.txt, так и инструкция noindex в мета-теге robots являются лишь рекомендацией для роботов, поэтому они не гарантируют что закрытые страницы не будут проиндексированы и не будут добавлены в индекс.
Если вам нужно действительно закрыть часть сайта от индексации, то, например, можно дополнительно воспользоваться закрытие директорий паролем.
Основной синтаксисUser-Agent: робот для которого будут применяться следующие правила (например, «Googlebot»)
Disallow: страницы, к которым вы хотите закрыть доступ (можно указать большой список таких директив с каждой новой строки)
Каждая группа User-Agent / Disallow должны быть разделены пустой строкой. Но, не пустые строки не должны существовать в рамках группы (между User-Agent и последней директивой Disallow).
Символ хэш (#) может быть использован для комментариев в файле robots. txt: для текущей строки всё что после # будет игнорироваться. Данные комментарий может быть использован как для всей строки, так в конце строки после директив.
txt: для текущей строки всё что после # будет игнорироваться. Данные комментарий может быть использован как для всей строки, так в конце строки после директив.
Каталоги и имена файлов чувствительны к регистру: «catalog», «Catalog» и «CATALOG» – это всё разные директории для поисковых систем.
Host: применяется для указание Яндексу основного зеркала сайта. Поэтому, если вы хотите склеить 2 сайта и делаете постраничный 301 редирект, то для файла robots.txt (на дублирующем сайте) НЕ надо делать редирект, чтобы Яндекс мог видеть данную директиву именно на сайте, который необходимо склеить.
Crawl-delay: можно ограничить скорость обхода вашего сайта, так как если у вашего сайта очень большая посещаемость, то, нагрузка на сервер от различных поисковых роботов может приводить к дополнительным проблемам.
Регулярные выражения: для более гибкой настройки своих директив вы можете использовать 2 символа
- * (звездочка) – означает любую последовательность символов
- $ (знак доллара) – обозначает конец строки
 txt
txtЗапрет на индексацию всего сайта
User-agent: *
Disallow: /
Эту инструкцию важно использовать, когда вы разрабатываете новый сайт и выкладываете доступ к нему, например, через поддомен.
Очень часто разработчики забывают таким образом закрыть от индексации сайт и получаем сразу полную копию сайта в индексе поисковых систем. Если это всё-таки произошло, то надо сделать постраничный 301 редирект на ваш основной домен.
А такая конструкция ПОЗВОЛЯЕТ индексировать весь сайт:
User-agent: *
Disallow:
Запрет на индексацию определённой папки
User-agent: Googlebot
Disallow: /no-index/
Запрет на посещение страницы для определенного робота
User-agent: Googlebot
Disallow: /no-index/this-page.html
Запрет на индексацию файлов определенного типа
User-agent: *
Disallow: /*.pdf$
Разрешить определенному поисковому роботу посещать определенную страницу
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page. html
html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.html
Ссылка на Sitemap
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Нюансы с использованием данной директивы: если у вас на сайте постоянно добавляется уникальный контент, то
- лучше НЕ добавлять в robots.txt ссылку на вашу карту сайта,
- саму карту сайта сделать с НЕСТАНДАРТНЫМ названием sitemap.xml (например, my-new-sitemap.xml и после этого добавить эту ссылку через «вебмастерсы» поисковых систем),
так как, очень много недобросовестных вебмастеров парсят с чужих сайтов контент и используют для своих проектов.
Что лучше использовать robots.txt или noindex?Статья в тему: Создаем sitemap для Google и Яндекс
Если вы хотите, чтобы страница не попала в индекс, то лучше использовать noindex в мета-теге robots. Для этого на странице в секции <head> необходимо добавить следующий метатег:
<meta name=”robots” content=”noindex, follow”>.
Это позволит вам
- убрать из индекса страницу при следующем посещение поискового робота (и не надо будет делать в ручном режиме удаление данной страницы, через вебмастерс)
- позволит вам передать ссылочный вес страницы
Через robots.txt лучше всего закрывать от индексации:
- админку сайта
- результаты поиска по сайту
- страницы регистрации/авторизации/восстановление пароля
После того, как вы окончательно сформировали файл robots.txt необходимо проверить его на ошибки. Для этого можно воспользоваться инструментами проверки от поисковых систем:
Google Вебмастерс: войти в аккаунт с подтверждённым в нём текущим сайтом, перейти на Сканирование -> Инструмент проверки файла robots.txt.
В данном инструменте вы можете:
- сразу увидеть все свои ошибки и возможные проблемы,
- прямо в этом инструменте провести все правки и сразу проверить на ошибки, чтобы потом уже перенести готовый файл себе на сайт,
- проверить правильно ли вы закрыли все не нужные для индексации страницы и открыты ли все нужные страницы.

Яндекс Вебмастер: чтобы воспользоваться данным инструментом просто перейдите по этой ссылке http://webmaster.yandex.ru/robots.xml.
Этот инструмент почти аналогичный предыдущему с тем небольшим отличием, что:
- тут можно не авторизоваться и нет необходимости в подтверждении прав на сайт, а поэтому, можно сразу приступать к проверке вашего файла robots.txt,
- для проверки сразу можно задать список страниц, а не вбивать их по одному,
- точно убедиться, что Яндекс правильно понял ваши инструкции.
Создание и настройка robots.txt является в списке первых пунктов по внутренней оптимизации сайта и началом поискового продвижения.
Важно его настроить грамотно, чтобы нужные страницы и разделы были доступны к индексации поисковых систем. А не нужные были закрыты.
Но главное помнить, что robots.txt не гарантирует того, что страницы не будут проиндексированы. Как когда-то сказала наша коллега Анастасия Пареха:
Robots.
 txt — как презерватив, вроде защищает, но вероятность всегда есть)
txt — как презерватив, вроде защищает, но вероятность всегда есть)Хорошие статьи в продолжение:
— 301 редирект – самое полное руководство
— Пагинация для SEO – пошаговое руководство
— Ответы сервера – практичная методичка
А что вы думаете про настройку robots.txt на сайте?
Оцените статью
Загрузка…Управление robots.txt
Общие правила
Данная вкладка служит для указания общих правил для индексирования сайта поисковыми системами. В поле отображается текущий набор инструкций. Любая из инструкций (кроме User-Agent: *) может быть удалена, если навести на нее курсор мыши и нажать на «крестик». Для генерации инструкций необходимо воспользоваться кнопками, расположенными рядом с полем.
| Кнопка | Описание |
|---|---|
| Стартовый набор | Позволяет задать набор стандартных правил и ограничений (закрываются от индексации административные страницы, личные данные пользователя, отладочная информация).
Если часть стандартного набора уже задана, то будут добавлены только необходимые отсутствующие инструкции. |
| Запретить файл/папку (Disallow) | Позволяет составить инструкции, запрещающие индексировать файлы и папки по маске пути.
При нажатии на кнопку открывается форма со списком уже имеющихся инструкций запрета индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые индексировать не нужно. |
| Разрешить файл/папку (Allow) | Позволяет указать файлы и папки, разрешенные для индексации.
При нажатии на кнопку открывается форма со списком путей к файлам и папкам, разрешенных для индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы. |
| Главное зеркало (Host) | Позволяет задать адрес главного зеркала сайта. Главное зеркало необходимо обязательно указывать, если сайт обладает несколькими зеркалами. |
| Интервал между запросами (Crawl-delay) | Служит для указания минимального временного интервала (в сек.) между запросами поискового робота. |
| Карта сайта | Позволяет задать ссылку к файлу карты сайта sitemap.xml. |
Яндекс
Настройка правил и ограничений для роботов Яндекса. Настройку можно выполнить как сразу для всех роботов Яндекса (вкладка «Yandex»), так и каждого в отдельности (на вкладке с соответствующим названием робота). Внешний вид вкладок одинаков и содержит следующий набор кнопок для генерации инструкций:
| Кнопка | Описание |
|---|---|
| Запретить файл/папку (Disallow) | Позволяет составить инструкции, запрещающие индексировать файлы и папки по маске пути.
При нажатии на кнопку открывается форма со списком уже имеющихся инструкций запрета индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые индексировать не нужно.  |
| Разрешить файл/папку (Allow) | Позволяет указать файлы и папки, разрешенные для индексации.
При нажатии на кнопку открывается форма со списком путей к файлам и папкам, разрешенных для индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы. |
| Главное зеркало (Host) | Позволяет задать адрес главного зеркала сайта. Главное зеркало необходимо обязательно указывать, если сайт обладает несколькими зеркалами.
Важно! Для каждого файла robots.txt обрабатывается только одна директива Host. |
| Интервал между запросами (Crawl-delay) | Служит для указания минимального временного интервала (в сек.) между запросами поискового робота. |
Настройка правил и ограничений для роботов Google. Настройка выполняется для каждого робота в отдельности (на вкладке с соответствующим названием робота). Внешний вид вкладок одинаков и содержит следующий набор кнопок для генерации инструкций:
Внешний вид вкладок одинаков и содержит следующий набор кнопок для генерации инструкций:
| Кнопка | Описание |
|---|---|
| Запретить файл/папку (Disallow) | Позволяет составить инструкции, запрещающие индексировать файлы и папки по маске пути.
При нажатии на кнопку открывается форма со списком уже имеющихся инструкций запрета индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые индексировать не нужно. |
| Разрешить файл/папку (Allow) | Позволяет указать файлы и папки, разрешенные для индексации.
При нажатии на кнопку открывается форма со списком путей к файлам и папкам, разрешенных для индексации. В открывшейся форме кнопка […] позволяет выбрать файлы или папки, которые должны быть проиндексированы. |
| Главное зеркало (Host) | Позволяет задать адрес главного зеркала сайта. Главное зеркало необходимо обязательно указывать, если сайт обладает несколькими зеркалами.
Важно! Для каждого файла robots.txt обрабатывается только одна директива Host. |
Редактировать
На данной вкладке представлено текстовое поле, в котором можно вручную отредактировать содержимое файла robots.txt.
Смотрите также
© «Битрикс», 2001-2021, «1С-Битрикс», 2021
Наверх
Robots.txt Введение и руководство | Центр поиска Google
Что такое файл robots.txt?
Файл robots.txt сообщает сканерам поисковых систем, какие страницы или файлы он может или
не могу запросить с вашего сайта. Это используется в основном для того, чтобы избежать перегрузки вашего сайта
Запросы; , это не механизм для защиты веб-страницы от Google.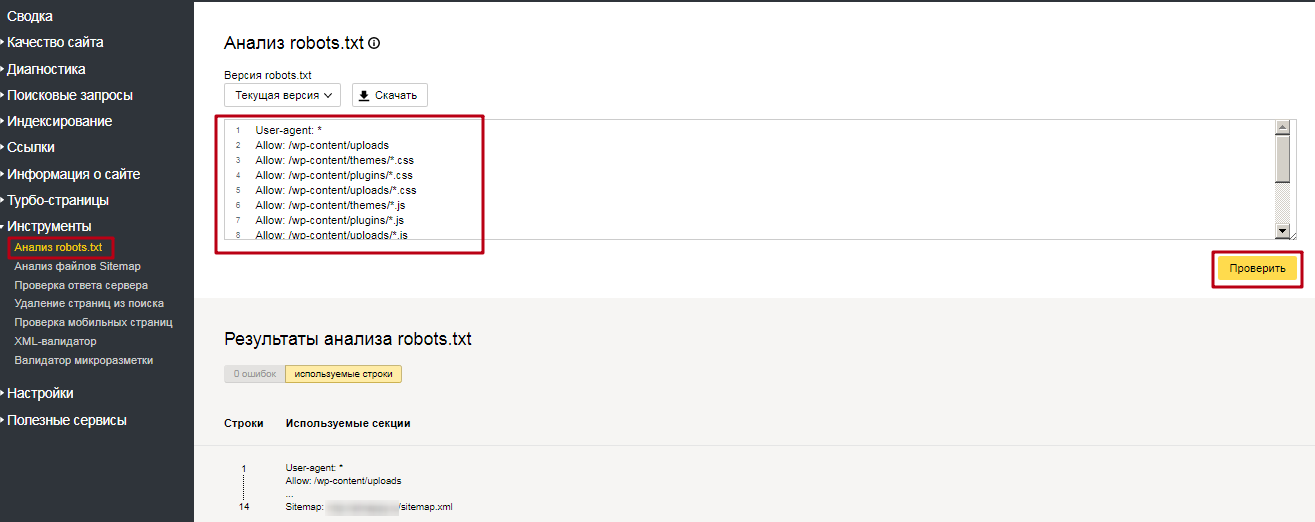 Чтобы веб-страница не попала в Google, вы должны использовать
Чтобы веб-страница не попала в Google, вы должны использовать директив noindex ,
или защитите свою страницу паролем.
Для чего используется robots.txt?
Файлrobots.txt используется в основном для управления трафиком сканера на ваш сайт, а обычно для защиты страницы от Google, в зависимости от типа файла:
| Тип страницы | Управление движением | Скрыть от Google | Описание |
|---|---|---|---|
| Интернет-страница | Для веб-страниц (HTML, PDF или другие немедийные форматы, которые может читать Google), robots.txt можно использовать для управления обходным трафиком, если вы считаете, что ваш сервер будет перегружен запросами от поискового робота Google, или чтобы избежать сканирования неважных или похожих страниц на вашем сайте. Вы не должны использовать robots.txt как средство, чтобы скрыть свои веб-страницы от результатов поиска Google. Это связано с тем, что, если другие страницы указывают на вашу страницу с описательным текстом, ваша страница все равно может быть проиндексирована без посещения страницы. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или директиву Если ваша веб-страница заблокирована файлом robots.txt , она все равно может отображаться в результатах поиска, но результат поиска не будет иметь описания и будет выглядеть примерно так. Файлы изображений, видеофайлы, PDF-файлы и другие файлы, отличные от HTML, будут исключены. Если вы видите этот результат поиска для своей страницы и хотите его исправить, удалите запись robots.txt, блокирующую страницу. Если вы хотите полностью скрыть страницу от поиска, воспользуйтесь другим методом. | ||
| Медиа-файл | Используйте роботов.txt для управления трафиком сканирования, а также для предотвращения появления изображений, видео и аудио файлов в результатах поиска Google. (Обратите внимание, что это не помешает другим страницам или пользователям ссылаться на ваш файл изображения / видео / аудио.) | ||
| Файл ресурсов | Вы можете использовать robots.txt для блокировки файлов ресурсов, таких как неважные изображения, скрипты или файлы стилей, , если вы считаете, что страницы, загруженные без этих ресурсов, не пострадают от потери .Однако, если отсутствие этих ресурсов затрудняет понимание страницы поисковым роботом Google, вы не должны блокировать их, иначе Google не сможет хорошо проанализировать страницы, которые зависят от этих ресурсов. |

Пользуюсь услугами хостинга сайтов
Если вы используете службу хостинга веб-сайтов, такую как Wix, Drupal или Blogger, вам может не потребоваться (или у вас будет возможность) напрямую редактировать файл robots. txt. Вместо этого ваш провайдер может открыть страницу настроек поиска или какой-либо другой механизм, чтобы сообщить поисковым системам, сканировать ли вашу страницу или нет.
txt. Вместо этого ваш провайдер может открыть страницу настроек поиска или какой-либо другой механизм, чтобы сообщить поисковым системам, сканировать ли вашу страницу или нет.
Чтобы узнать, просканировала ли ваша страница Google, найдите URL-адрес страницы в Google.
Если вы хотите скрыть (или показать) свою страницу от поисковых систем, добавьте (или удалите) любые требования для входа на страницу, которые могут существовать, и выполните поиск инструкций по изменению видимости вашей страницы в поисковых системах на вашем хостинге, например: wix скрыть страницу от поисковых систем
Узнайте об ограничениях robots.txt
Прежде чем создавать или редактировать robots.txt, вы должны знать ограничения этого метода блокировки URL.Иногда вам может потребоваться рассмотреть другие механизмы, чтобы гарантировать, что ваши URL-адреса не будут найдены в Интернете.
- Директивы Robots.txt могут поддерживаться не всеми поисковыми системами.
Инструкции в файлахrobots.txtне могут принудить сканер к вашему сайту, он должен им подчиняться. В то время как робот Googlebot и другие уважаемые веб-сканеры подчиняются инструкциям из файлаrobots.txt, другие сканеры могут этого не делать. Поэтому, если вы хотите защитить информацию от веб-сканеров, лучше использовать другие методы блокировки, такие как защита паролем личных файлов на вашем сервере. - Разные сканеры по-разному интерпретируют синтаксис
Хотя уважаемые веб-сканеры следуют директивам в файле robots.txt, каждый сканер может интерпретировать директивы по-разному. Вы должны знать правильный синтаксис для обращения к различным поисковым роботам, поскольку некоторые из них могут не понимать определенные инструкции. - Роботизированная страница все еще может быть проиндексирована, если на нее есть ссылки с других сайтов
В то время как Google не будет сканировать и индексировать контент, заблокированныйrobots., мы все равно можем найти и проиндексировать запрещенный URL, если на него есть ссылки из других мест в Интернете. В результате URL-адрес и, возможно, другая общедоступная информация, такая как текст привязки в ссылках на страницу, может по-прежнему отображаться в результатах поиска Google. Чтобы правильно предотвратить появление вашего URL в результатах поиска Google, вы должны защитить паролем файлы на своем сервере или использовать метатег noindex или заголовок ответа (или полностью удалить страницу). txt

 txt
txt Тестирование страницы на наличие роботов.txt блоки
Вы можете проверить, заблокирована ли страница или ресурс правилом robots.txt.
Для проверки директив noindex используйте инструмент проверки URL.
Создайте файл robots.txt | Центр поиска Google | Разработчики Google
Если вы пользуетесь услугами хостинга сайтов, например Wix или Blogger, вам может не понадобиться создавать или редактировать файл robots. txt.
txt.Начало работы
Файл robots.txt находится в корне вашего сайта. Итак, для сайта www.example.com, файл robots.txt находится по адресу www.example.com/robots.txt. robots.txt - это простой текстовый файл, соответствующий Стандарту исключения для роботов. Файл robots.txt состоит из одного или нескольких правил. Каждое правило блокирует (или разрешает) доступ для данного сканера к указанному пути к файлу на этом веб-сайте.
Вот простой файл robots.txt с двумя правилами, описанными ниже:
# Группа 1 Пользовательский агент: Googlebot Запретить: / nogooglebot / # Группа 2 Пользовательский агент: * Позволять: / Карта сайта: http: //www.example.ru / sitemap.xml
Пояснение:
- Пользовательский агент с именем "робот Googlebot" не должен сканировать папку
http://example.com/nogooglebot/или любые ее подкаталоги. - Все остальные пользовательские агенты могут получить доступ ко всему сайту. (Его можно было бы опустить, и результат был бы таким же, поскольку предполагается полный доступ.)
- Файл Sitemap сайта находится по адресу http://www.example.com/sitemap.xml
 (Его можно было бы опустить, и результат был бы таким же, поскольку предполагается полный доступ.)
(Его можно было бы опустить, и результат был бы таким же, поскольку предполагается полный доступ.)Мы предоставим более подробный пример позже.
Основные правила robots.txt
Вот несколько основных рекомендаций для файлов robots.txt. Мы рекомендуем вам прочитать полный синтаксис файлов robots.txt, потому что синтаксис robots.txt имеет некоторые тонкие особенности, которые вы должны понять.
Формат и расположение
Для создания файла robots.txt можно использовать практически любой текстовый редактор. Текстовый редактор должен уметь создавать стандартные текстовые файлы UTF-8. Не используйте текстовый процессор; текстовые процессоры часто сохраняют файлы в проприетарном формате и могут добавлять неожиданные символы, такие как фигурные кавычки, что может вызвать проблемы для поисковых роботов.
Правила формата и расположения:
- Файл должен называться robots.txt
- На вашем сайте может быть только один файл robots.txt.
- Файл robots.txt должен находиться в корне хоста веб-сайта, к которому он применяется. Например, для управления сканированием всех URL ниже
http: // www.example.com/, файл robots.txt должен находиться по адресуhttp://www.example.com/robots.txt. Это не может быть помещенным в подкаталог (например,http://example.com/pages/robots.txt). Если вы не знаете, как получить доступ к корню вашего веб-сайта или вам нужны разрешения для этого, обратитесь к поставщику услуг веб-хостинга. Если вы не можете получить доступ к корню своего веб-сайта, используйте альтернативный метод блокировки, например метатеги. - Файл robots.txt может применяться к поддоменам (например,
http: // , веб-сайт .example.com/robots.txt) или на нестандартных портах (например,http://example.com: 8181 /robots.txt). - Комментарии - это любое содержимое после знака #.
 Если вы не можете получить доступ к корню своего веб-сайта, используйте альтернативный метод блокировки, например метатеги.
Если вы не можете получить доступ к корню своего веб-сайта, используйте альтернативный метод блокировки, например метатеги.Синтаксис
- robots.txt должен быть текстовым файлом в кодировке UTF-8 (включая ASCII). Использование других наборов символов невозможно.
- Файл robots.txt состоит из одной или нескольких группы .
- Каждая группа состоит из нескольких правил или директив (инструкций), по одной директиве на строку.
- Группа предоставляет следующую информацию:
- Кому относится группа (пользовательский агент )
- К каким каталогам или файлам может обращаться агент и / или
- Какие каталоги или файлы не может получить агент .
- Группы обрабатываются сверху вниз, и пользовательский агент может соответствовать только одному набору правил, который является первым, наиболее конкретным правилом, которое соответствует данному пользовательскому агенту.
- Предположение по умолчанию состоит в том, что пользовательский агент может сканировать любую страницу или каталог, не заблокированные правилом
Disallow:. - Правила чувствительны к регистру . Например,
Disallow: /file.aspприменяется кhttp://www.example.com/file.asp, но неhttp://www.example.com/FILE.asp.
В файлах robots.txt используются следующие директивы:
-
Агент пользователя:[ Обязательно, один или несколько на группу ] Имя поисковой системы , робот (программное обеспечение веб-краулера), к которому применяется правило. Это первая строка любого правила. Большинство имен пользовательских агентов Google перечислены в базе данных веб-роботов или в списке пользовательских агентов Google. Поддерживает подстановочный знак *для префикса пути, суффикса или всей строки. Использование звездочки (*), как в примере ниже, будет соответствовать всем поисковым роботам , кроме различных поисковых роботов AdsBot , которые должны иметь явное имя. (См. Список имен сканеров Google.) Примеры:# Пример 1. Блокировать только Googlebot Пользовательский агент: Googlebot Запретить: / # Пример 2. Блокировка роботов Google и Adsbot Пользовательский агент: Googlebot Пользовательский агент: AdsBot-Google Запретить: / # Пример 3. Блокировка всех сканеров, кроме AdsBot Пользовательский агент: * Disallow: /
-
Disallow:[ По крайней мере один или несколькоDisallowилиAllowзаписей на правило ] Каталог или страница относительно корневого домена, которые не должны сканироваться пользовательским агентом. Если страница, это должно быть полное имя страницы, как показано в браузере; если каталог, он должен заканчиваться отметкой /. Поддерживает подстановочный знак*для префикса пути, суффикса или всей строки. -
Разрешить:[ По крайней мере один или несколькоЗапретитьилиРазрешитьзаписей на правило ] Каталог или страница относительно корневого домена, которые должен сканировать только что упомянутый пользовательский агент. Это используется для переопределения директивыDisallow, чтобы разрешить сканирование подкаталога или страницы в запрещенном каталоге.Если страница, это должно быть полное имя страницы, как показано в браузере; если каталог, он должен заканчиваться отметкой/. Поддерживает подстановочный знак *для префикса пути, суффикса или всей строки. -
Sitemap:[ Необязательно, ноль или более на файл ] Местоположение карты сайта для этого веб-сайта. Должен быть полностью определенный URL; Google не предполагает и не проверяет альтернативы http / https / www.non-www. Файлы Sitemap - хороший способ указать, какой контент Google должен сканировать , а не какой контент может сканировать или не может сканировать .Узнайте больше о файлах Sitemap. Пример:Карта сайта: https://example.com/sitemap.xml Карта сайта: http://www.example.com/sitemap.xml
 Это первая строка любого правила. Большинство имен пользовательских агентов Google перечислены в базе данных веб-роботов или в списке пользовательских агентов Google. Поддерживает подстановочный знак
Это первая строка любого правила. Большинство имен пользовательских агентов Google перечислены в базе данных веб-роботов или в списке пользовательских агентов Google. Поддерживает подстановочный знак  Если страница, это должно быть полное имя страницы, как показано в браузере; если каталог, он должен заканчиваться отметкой
Если страница, это должно быть полное имя страницы, как показано в браузере; если каталог, он должен заканчиваться отметкой  Поддерживает подстановочный знак
Поддерживает подстановочный знак Остальные правила игнорируются.
Другой пример файла
Файл robots.txt состоит из одной или нескольких групп, каждая из которых начинается со строки User-agent , в которой указывается цель групп. Вот файл с двумя группами; встроенные комментарии объясняют каждую группу:
Вот файл с двумя группами; встроенные комментарии объясняют каждую группу:
# Заблокируйте googlebot из примера.com / directory1 / ... и example.com/directory2 / ... # но разрешить доступ к directory2 / subdirectory1 / ... # Все остальные каталоги на сайте разрешены по умолчанию. Пользовательский агент: googlebot Запретить: / directory1 / Запретить: / каталог2 / Разрешить: / directory2 / subdirectory1 / # Блокировать весь сайт от другого сканера. Пользовательский агент: anothercrawler Запретить: /
Полный синтаксис robots.txt
Полный синтаксис robots.txt можно найти здесь. Пожалуйста, прочтите полную документацию, так как синтаксис robots.txt имеет несколько сложных частей, которые важно изучить.
Полезные правила robots.txt
Вот несколько общих полезных правил robots.txt:
| Правило | Образец |
|---|---|
Запретить сканирование всего веб-сайта. Имейте в виду, что в некоторых ситуациях URL-адреса с веб-сайта все еще могут индексироваться, даже если они не сканировались. Примечание. Это не относится к различным сканерам AdsBot, которые должны иметь явное имя. Имейте в виду, что в некоторых ситуациях URL-адреса с веб-сайта все еще могут индексироваться, даже если они не сканировались. Примечание. Это не относится к различным сканерам AdsBot, которые должны иметь явное имя. | Пользовательский агент: * Запретить: / |
| Запретить сканирование каталога и его содержимого , поставив после имени каталога косую черту.Помните, что вам не следует использовать robots.txt для блокировки доступа к личному контенту: вместо этого используйте правильную аутентификацию. URL-адреса, запрещенные файлом robots.txt, могут по-прежнему индексироваться без сканирования, а файл robots.txt может быть просмотрен кем угодно, потенциально раскрывая местонахождение вашего личного содержания. | Пользовательский агент: * Запретить: / календарь / Запретить: / junk / |
| Разрешить доступ одному сканеру | User-agent: Googlebot-news Позволять: / Пользовательский агент: * Запретить: / |
| Разрешить доступ всем, кроме одного поискового робота | User-agent: Ненужный бот Запретить: / Пользовательский агент: * Позволять: / |
Запретить сканирование отдельной веб-страницы , указав страницу после косой черты: | Пользовательский агент: * Запретить: / частный_файл. |
Заблокировать определенное изображение из Картинок Google: | Пользовательский агент: Googlebot-Image Запретить: /images/dogs.jpg |
Заблокировать все изображения на вашем сайте из Картинок Google: | Пользовательский агент: Googlebot-Image Disallow: / |
Запретить сканирование файлов определенного типа (например, | Пользовательский агент: Googlebot Disallow: /*.gif$ |
Запретить сканирование всего сайта, но показать рекламу AdSense на этих страницах , запретить все веб-сканеры, кроме | Пользовательский агент: * Запретить: / Пользовательский агент: Mediapartners-Google Разрешить: / |
Соответствие URL-адресам, которые заканчиваются определенной строкой , используйте $ .Например, пример кода блокирует любые URL-адреса, заканчивающиеся на .xls : | .Пользовательский агент: Googlebot Запрещено: /*.xls$ |
 HTML
HTML 
Файл robots.txt [примеры 2021] - Moz
Что такое файл robots.txt?
Robots.txt - это текстовый файл, который веб-мастера создают, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем), как сканировать страницы на своем веб-сайте. Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя такие директивы, как мета-роботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «следовать» или «nofollow»).
REP также включает в себя такие директивы, как мета-роботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «следовать» или «nofollow»).
На практике файлы robots.txt показывают, могут ли определенные пользовательские агенты (программное обеспечение для веб-сканирования) сканировать части веб-сайта. Эти инструкции сканирования определяются как «запрещающие» или «разрешающие» поведение определенных (или всех) пользовательских агентов.
Базовый формат:User-agent: [имя user-agent] Disallow: [URL-строка, которую нельзя сканировать]
Вместе эти две строки считаются полными robots.txt - хотя один файл robots может содержать несколько строк пользовательских агентов и директив (например, запрещает, разрешает, задержки сканирования и т. д.).
В файле robots.txt каждый набор директив пользовательского агента отображается как дискретный набор , разделенных разрывом строки:
В файле robots.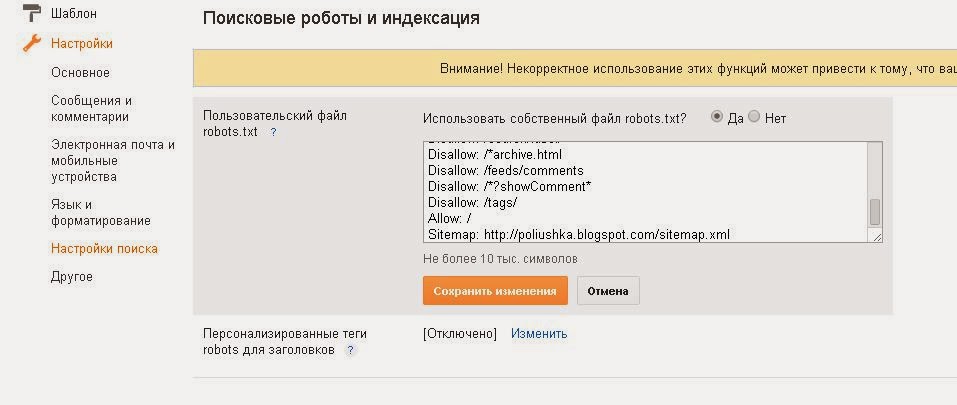 txt с несколькими директивами пользовательского агента, каждая из которых запрещает или разрешает правило только применяется к агентам-пользователям, указанным в этом конкретном наборе, разделенном разрывом строки. Если файл содержит правило, которое применяется более чем к одному пользовательскому агенту, поисковый робот только обратит внимание на (и будет следовать директивам в) наиболее конкретной группе инструкций .
txt с несколькими директивами пользовательского агента, каждая из которых запрещает или разрешает правило только применяется к агентам-пользователям, указанным в этом конкретном наборе, разделенном разрывом строки. Если файл содержит правило, которое применяется более чем к одному пользовательскому агенту, поисковый робот только обратит внимание на (и будет следовать директивам в) наиболее конкретной группе инструкций .
Вот пример:
Msnbot, discobot и Slurp все вызываются специально, поэтому только пользовательские агенты будут обращать внимание на директивы в своих разделах файла robots.txt. Все остальные пользовательские агенты будут следовать директивам в группе user-agent: *.
Пример robots.txt:
Вот несколько примеров использования robots.txt для сайта www.example.com:
URL файла Robots.txt: www.example.com/robots.txt Блокирование всех веб-сканеров для доступа ко всему содержимомуUser-agent: * Disallow: /
Использование этого синтаксиса в файле robots.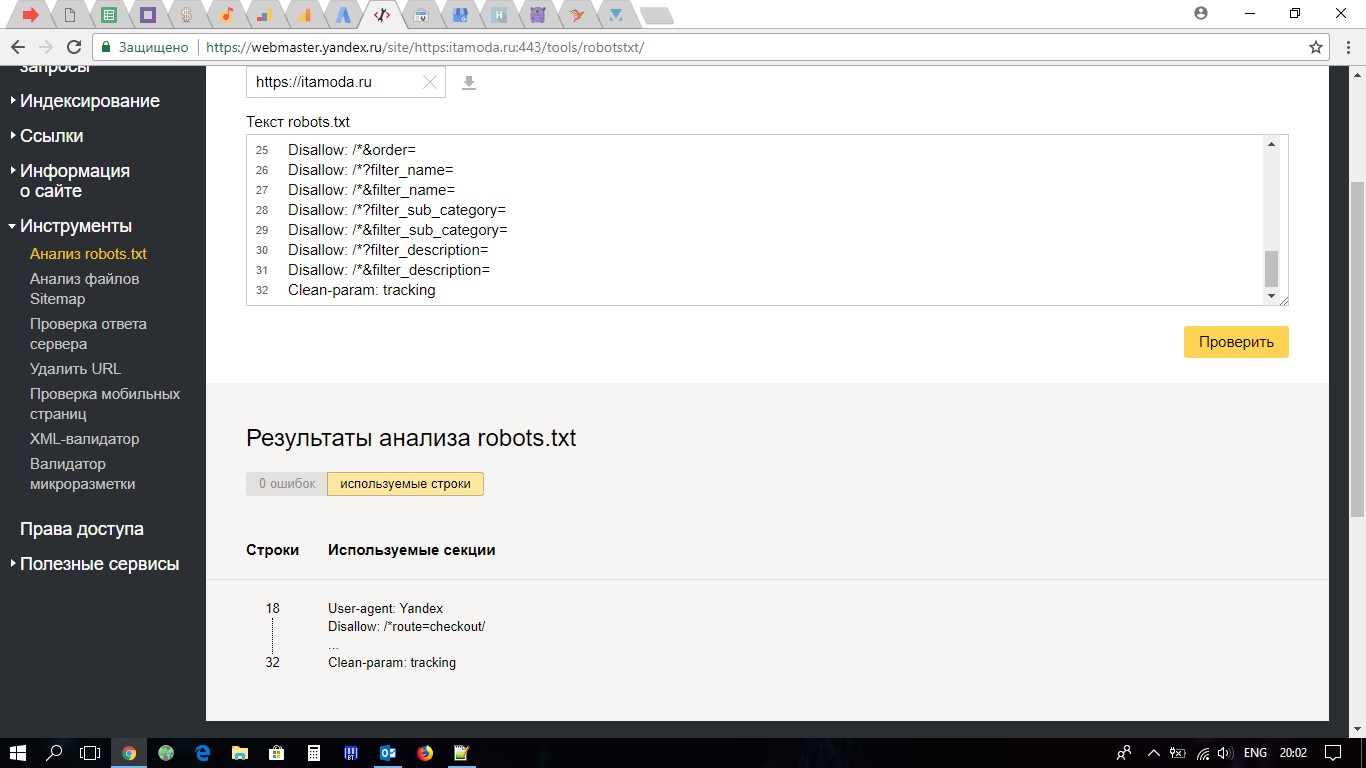 txt укажет всем веб-сканерам не сканировать страницы www.example .com, включая домашнюю страницу.
txt укажет всем веб-сканерам не сканировать страницы www.example .com, включая домашнюю страницу.
User-agent: * Disallow:
Использование этого синтаксиса в файле robots.txt указывает поисковым роботам сканировать все страницы на www.example.com, включая домашнюю страницу.
Блокировка определенного поискового робота из определенной папкиUser-agent: Googlebot Disallow: / example-subfolder /
Этот синтаксис сообщает только поисковому роботу Google (имя агента пользователя Googlebot) не сканировать страницы, которые содержат строку URL www.example.com/example-subfolder/.
Блокирование определенного веб-сканера с определенной веб-страницыПользовательский агент: Bingbot Disallow: /example-subfolder/blocked-page.html
Этот синтаксис сообщает только поисковому роботу Bing (имя пользовательского агента Bing) избегать сканирование конкретной страницы www. example.com/example-subfolder/blocked-page.html.
example.com/example-subfolder/blocked-page.html.
Как работает robots.txt?
У поисковых систем есть две основные задачи:
- Сканирование Интернета для обнаружения контента;
- Индексирование этого контента, чтобы его могли обслуживать искатели, ищущие информацию.
Чтобы сканировать сайты, поисковые системы переходят по ссылкам с одного сайта на другой - в конечном итоге обходя многие миллиарды ссылок и веб-сайтов. Такое ползание иногда называют «пауками».”
После перехода на веб-сайт, но перед его сканированием поисковый робот будет искать файл robots.txt. Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы. Поскольку файл robots.txt содержит информацию о , как должна сканировать поисковая система, найденная там информация будет указывать дальнейшие действия поискового робота на этом конкретном сайте. Если файл robots.txt содержит , а не директивы, запрещающие действия пользовательского агента (или если на сайте нет файла robots. txt), он перейдет к сканированию другой информации на сайте.
txt), он перейдет к сканированию другой информации на сайте.
Другой быстрый файл robots.txt, который необходимо знать:
(более подробно обсуждается ниже)
Чтобы его можно было найти, файл robots.txt должен быть помещен в каталог верхнего уровня веб-сайта.
Robots.txt чувствителен к регистру: файл должен называться «robots.txt» (не Robots.txt, robots.TXT и т. Д.).
Некоторые пользовательские агенты (роботы) могут игнорировать ваш robots.txt файл. Это особенно характерно для более гнусных поисковых роботов, таких как вредоносные роботы или парсеры адресов электронной почты.
Файл /robots.txt является общедоступным: просто добавьте /robots.txt в конец любого корневого домена, чтобы увидеть директивы этого веб-сайта (если на этом сайте есть файл robots.txt!). Это означает, что любой может видеть, какие страницы вы просматриваете или не хотите сканировать, поэтому не используйте их для сокрытия личной информации пользователя.
Каждый субдомен в корневом домене использует отдельных роботов.txt файлы. Это означает, что и blog.example.com, и example.com должны иметь свои собственные файлы robots.txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).
Обычно рекомендуется указывать расположение любых карт сайта, связанных с этим доменом, в нижней части файла robots.txt. Вот пример:
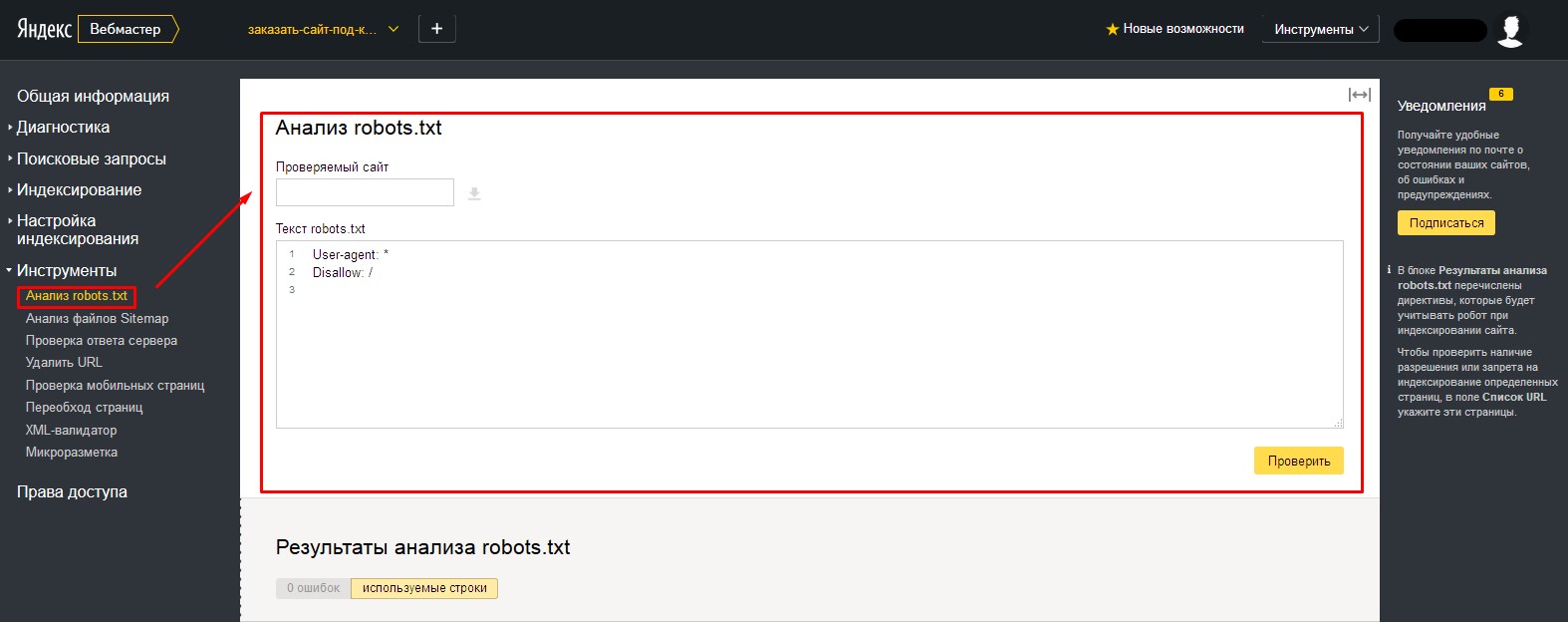
Технический синтаксис robots.txt
Синтаксис Robots.txt можно рассматривать как «язык» файлов robots.txt. Есть пять общих терминов, которые вы, вероятно, встретите в файле robots.К ним относятся:
User-agent: Конкретный веб-сканер, которому вы даете инструкции для сканирования (обычно это поисковая система). Список большинства пользовательских агентов можно найти здесь.
Disallow: Команда, используемая для указания агенту пользователя не сканировать определенный URL. Для каждого URL разрешена только одна строка «Disallow:».
Разрешить (применимо только для робота Googlebot): команда, сообщающая роботу Googlebot, что он может получить доступ к странице или подпапке, даже если его родительская страница или подпапка могут быть запрещены.
Crawl-delay: Сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что робот Googlebot не принимает эту команду, но скорость сканирования можно установить в консоли поиска Google.
Карта сайта: Используется для вызова местоположения любых XML-файлов Sitemap, связанных с этим URL. Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.

Сопоставление с шаблоном
Когда дело доходит до фактических URL-адресов, которые нужно заблокировать или разрешить, robots.txt могут быть довольно сложными, поскольку они позволяют использовать сопоставление с шаблоном для охвата диапазона возможных вариантов URL. И Google, и Bing соблюдают два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые SEO хочет исключить. Эти два символа - звездочка (*) и знак доллара ($).
И Google, и Bing соблюдают два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые SEO хочет исключить. Эти два символа - звездочка (*) и знак доллара ($).
- * - это подстановочный знак, который представляет любую последовательность символов.
- $ соответствует концу URL-адреса
Google предлагает здесь большой список возможных синтаксисов и примеров сопоставления с образцом.
Где находится файл robots.txt на сайте?
Когда бы они ни заходили на сайт, поисковые системы и другие роботы, сканирующие Интернет (например, сканер Facebook Facebot), знают, что нужно искать файл robots.txt. Но они будут искать этот файл в только в одном конкретном месте : в основном каталоге (обычно в корневом домене или на домашней странице). Если пользовательский агент посещает www.example.com/robots.txt и не находит там файла роботов, он будет считать, что на сайте его нет, и продолжит сканирование всего на странице (и, возможно, даже на всем сайте. ).Даже если страница robots.txt и существует ли , скажем, по адресу example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами и, следовательно, сайт будет обрабатываться так, как если бы он вообще не имел файла robots.
).Даже если страница robots.txt и существует ли , скажем, по адресу example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами и, следовательно, сайт будет обрабатываться так, как если бы он вообще не имел файла robots.
Чтобы гарантировать, что ваш файл robots.txt найден, всегда включайте его в свой основной каталог или корневой домен.
Зачем нужен robots.txt?
Файлы Robots.txt управляют доступом поискового робота к определенным областям вашего сайта.Хотя это может быть очень опасным, если вы случайно запретите роботу Googlebot сканировать весь ваш сайт (!!), в некоторых ситуациях файл robots.txt может оказаться очень полезным.
Вот некоторые распространенные варианты использования:
- Предотвращение появления дублированного контента в результатах поиска (обратите внимание, что мета-роботы часто являются лучшим выбором для этого)
- Сохранение конфиденциальности целых разделов веб-сайта (например, промежуточного сайта вашей группы инженеров)
- Предотвращение показа страниц результатов внутреннего поиска в общедоступной поисковой выдаче
- Указание местоположения карты (карт) сайта
- Запрет поисковым системам индексировать определенные файлы на вашем веб-сайте (изображения, PDF-файлы и т. Д.))
- Указание задержки сканирования для предотвращения перегрузки ваших серверов, когда сканеры загружают сразу несколько частей контента
 Д.))
Д.)) Если на вашем сайте нет областей, к которым вы хотите контролировать доступ агента пользователя, вы не можете вообще нужен файл robots.txt.
Проверка наличия файла robots.txt
Не уверены, есть ли у вас файл robots.txt? Просто введите свой корневой домен и добавьте /robots.txt в конец URL-адреса. Например, файл роботов Moz находится по адресу moz.ru / robots.txt.
Если страница .txt не отображается, значит, у вас нет (активной) страницы robots.txt.
Как создать файл robots.txt
Если вы обнаружили, что у вас нет файла robots.txt или вы хотите изменить свой, создание файла - простой процесс. В этой статье от Google рассматривается процесс создания файла robots.txt, и этот инструмент позволяет вам проверить, правильно ли настроен ваш файл.
Хотите попрактиковаться в создании файлов роботов? В этом сообщении блога рассматриваются некоторые интерактивные примеры.
Лучшие практики SEO
Убедитесь, что вы не блокируете какой-либо контент или разделы своего веб-сайта, которые нужно просканировать.
Ссылки на страницах, заблокированных файлом robots.txt, переходить не будут. Это означает 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т. Е. Страницы, не заблокированные через robots.txt, мета-роботы или иным образом), связанные ресурсы не будут сканироваться и индексироваться. 2.) Никакой ссылочный капитал не может быть передан с заблокированной страницы на место назначения ссылки.Если у вас есть страницы, на которые вы хотите передать средства, используйте другой механизм блокировки, отличный от robots.txt.
Не используйте robots.txt для предотвращения появления конфиденциальных данных (например, личной информации пользователя) в результатах поисковой выдачи. Поскольку другие страницы могут напрямую ссылаться на страницу, содержащую личную информацию (таким образом, в обход директив robots.
txt в вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или метадирективу noindex.Некоторые поисковые системы имеют несколько пользовательских агентов. Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но возможность делать это позволяет вам точно настроить способ сканирования содержания вашего сайта.
Поисковая система кэширует содержимое robots.txt, но обычно обновляет кэшированное содержимое не реже одного раза в день.Если вы изменили файл и хотите обновить его быстрее, чем это происходит, вы можете отправить свой URL-адрес robots.txt в Google.
 txt в вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или метадирективу noindex.
txt в вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или метадирективу noindex.
Robots.txt против мета-роботов против x-роботов
Так много роботов! В чем разница между этими тремя типами инструкций для роботов? Во-первых, robots.txt - это фактический текстовый файл, тогда как мета и x-роботы - это метадирективы. Помимо того, чем они являются на самом деле, все три выполняют разные функции. Файл robots.txt определяет поведение сканирования сайта или всего каталога, тогда как мета и x-роботы могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).
Продолжайте учиться
Используйте свои навыки на практике
Moz Pro может определить, блокирует ли ваш файл robots.txt доступ к вашему сайту. Попробовать >>
Как создать идеальный файл Robots.txt для SEO
Все любят «хаки».
Я не исключение - мне нравится находить способы сделать свою жизнь лучше и проще.
Вот почему техника, о которой я расскажу вам сегодня, - одна из моих самых любимых. Это законный SEO-прием, которым вы можете сразу начать пользоваться.
Это законный SEO-прием, которым вы можете сразу начать пользоваться.
Это способ повысить эффективность SEO за счет использования естественной части каждого веб-сайта, о которой редко говорят. Реализовать тоже несложно.
Это файл robots.txt (также называемый протоколом исключения роботов или стандартом).
Этот крошечный текстовый файл является частью каждого веб-сайта в Интернете, но большинство людей даже не знают о нем.
Он разработан для работы с поисковыми системами, но, что удивительно, это источник сока SEO, который только и ждет, чтобы его разблокировали.
Я видел, как клиент за клиентом отклонялись назад, пытаясь улучшить свое SEO. Когда я говорю им, что они могут редактировать небольшой текстовый файл, они мне почти не верят.
Однако существует множество несложных или трудоемких методов улучшения SEO, и это один из них.
Для использования всех возможностей robots.txt не требуется никакого технического опыта. Если вы можете найти исходный код для своего веб-сайта, вы можете использовать его.
Итак, когда вы будете готовы, следуйте за мной, и я покажу вам, как именно изменить ваших роботов.txt, чтобы поисковые системы полюбили его.
Почему важен файл robots.txtВо-первых, давайте посмотрим, почему файл robots.txt вообще важен.
Файл robots.txt, также известный как протокол или стандарт исключения роботов, представляет собой текстовый файл, который сообщает веб-роботам (чаще всего поисковым системам), какие страницы вашего сайта сканировать.
Он также сообщает веб-роботам, какие страницы , а не сканировать.
Допустим, поисковая система собирается посетить сайт.Перед посещением целевой страницы он проверяет robots.txt на наличие инструкций.
Существуют разные типы файлов robots.txt, поэтому давайте рассмотрим несколько различных примеров того, как они выглядят.
Допустим, поисковая система находит этот пример файла robots.txt:
Это базовый скелет файла robots. txt.
Звездочка после «user-agent» означает, что файл robots.txt применяется ко всем веб-роботам, которые посещают сайт.
Косая черта после «Запретить» указывает роботу не посещать никакие страницы на сайте.
Вы можете спросить, зачем кому-то мешать веб-роботам посещать свой сайт.
В конце концов, одна из основных целей SEO - заставить поисковые системы легко сканировать ваш сайт, чтобы повысить ваш рейтинг.
Вот где кроется секрет этого SEO-взлома.
У вас наверняка много страниц на сайте? Даже если вы так не думаете, пойдите и проверьте. Вы можете быть удивлены.
Если поисковая система просканирует ваш сайт, она просканирует каждую из ваших страниц.
А если у вас много страниц, боту поисковой системы потребуется время, чтобы их просканировать, что может отрицательно повлиять на ваш рейтинг.
Это потому, что у Googlebot (робота поисковой системы Google) есть «краулинговый бюджет».
Это делится на две части. Первый - это ограничение скорости сканирования. Вот как Google объясняет это:
Первый - это ограничение скорости сканирования. Вот как Google объясняет это:
Вторая часть - требование сканирования:
По сути, краулинговый бюджет - это «количество URL-адресов, которые робот Googlebot может и хочет просканировать.”
Вы хотите помочь роботу Googlebot оптимально расходовать бюджет сканирования для вашего сайта. Другими словами, он должен сканировать ваши самые ценные страницы.
Есть определенные факторы, которые, по мнению Google, «негативно повлияют на сканирование и индексирование сайта».
Вот эти факторы:
Итак, вернемся к robots.txt.
Если вы создадите правильную страницу robots.txt, вы сможете указать роботам поисковых систем (и особенно роботу Googlebot) избегать определенных страниц.
Подумайте о последствиях. Если вы укажете роботам поисковых систем сканировать только ваш самый полезный контент, они будут сканировать и индексировать ваш сайт только на основе этого контента.
По словам Google:
«Вы не хотите, чтобы ваш сервер был перегружен поисковым роботом Google или тратил краулинговый бюджет на сканирование неважных или похожих страниц вашего сайта».
Правильно используя robots.txt, вы можете указать роботам поисковых систем разумно расходовать свой краулинговый бюджет.Именно это делает файл robots.txt таким полезным в контексте SEO.
Заинтригованы силой robots.txt?
Так и должно быть! Поговорим о том, как его найти и использовать.
Поиск файла robots.txtЕсли вы просто хотите быстро просмотреть свой файл robots.txt, существует очень простой способ просмотреть его.
На самом деле этот метод будет работать для любого сайта . Так вы можете заглянуть в файлы других сайтов и увидеть, что они делают.
Все, что вам нужно сделать, это ввести основной URL-адрес сайта в строку поиска вашего браузера (например,g., neilpatel.com, quicksprout. com и т. д.). Затем добавьте в конец /robots.txt.
com и т. д.). Затем добавьте в конец /robots.txt.
Произойдет одна из трех ситуаций:
1) Вы найдете файл robots.txt.
2) Вы найдете пустой файл.
Например, у Disney не хватает файла robots.txt:
3) Вы получите 404.
Метод возвращает 404 для robots.txt:
Найдите секунду и просмотрите файл robots.txt своего сайта.
Если вы найдете пустой файл или ошибку 404, вы захотите это исправить.
Если вы все же найдете действительный файл, вероятно, для него установлены настройки по умолчанию, которые были созданы при создании вашего сайта.
Мне особенно нравится этот метод просмотра файлов robots.txt других сайтов. После того, как вы изучите все тонкости robots.txt, это может стать полезным упражнением.
А теперь давайте посмотрим, как на самом деле изменить файл robots.txt.
Поиск файла robots.txt Все ваши следующие шаги будут зависеть от того, есть ли у вас robots.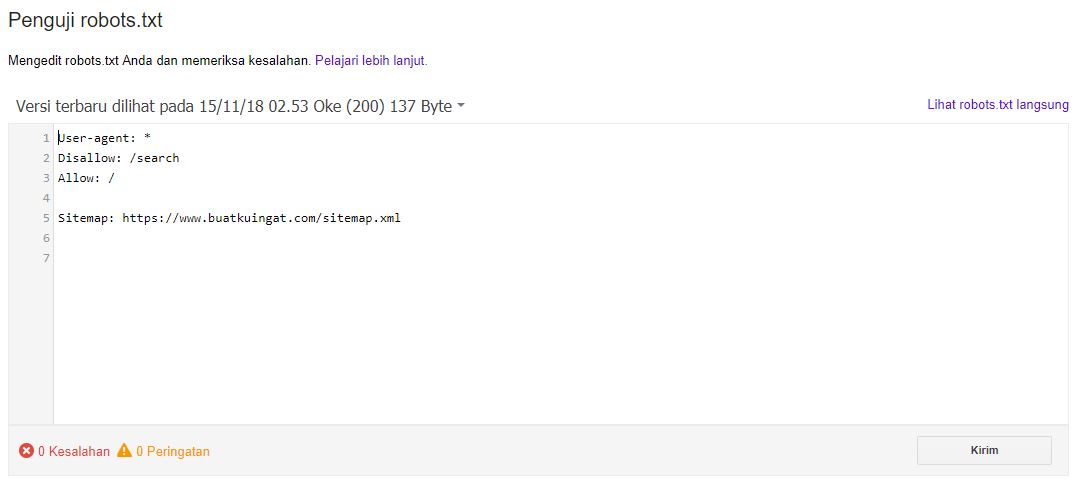 txt файл. (Проверьте, делаете ли вы это, используя метод, описанный выше.)
txt файл. (Проверьте, делаете ли вы это, используя метод, описанный выше.)
Если у вас нет файла robots.txt, вам нужно создать его с нуля. Откройте текстовый редактор, например Блокнот (Windows) или TextEdit (Mac).
Используйте для этого только текстовый редактор . Если вы используете такие программы, как Microsoft Word, программа может вставлять дополнительный код в текст.
Editpad.org - отличный бесплатный вариант, и вы увидите, что я использую в этой статье.
Вернуться к роботам.текст. Если у вас есть файл robots.txt, вам необходимо найти его в корневом каталоге вашего сайта.
Если вы не привыкли копаться в исходном коде, то найти редактируемую версию вашего файла robots.txt может быть немного сложно.
Обычно вы можете найти свой корневой каталог, перейдя на сайт своей учетной записи хостинга, войдя в систему и перейдя в раздел управления файлами или FTP вашего сайта.
Вы должны увидеть что-то вроде этого:
Найдите своих роботов.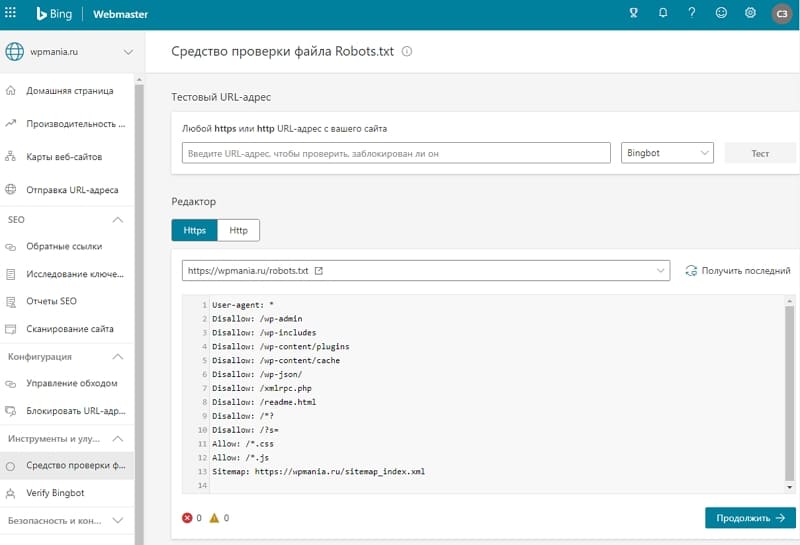 txt и откройте его для редактирования. Удалите весь текст, но сохраните файл.
txt и откройте его для редактирования. Удалите весь текст, но сохраните файл.
Примечание. Если вы используете WordPress, вы можете увидеть файл robots.txt при переходе на yoursite.com/robots.txt, но вы не сможете найти его в своих файлах.
Это связано с тем, что WordPress создает виртуальный файл robots.txt, если в корневом каталоге нет файла robots.txt.
Если это произойдет с вами, вам потребуется создать новый файл robots.txt.
Создание файла robots.txtВы можете создать новый robots.txt с помощью любого текстового редактора. (Помните, используйте только текстовый редактор.)
Если у вас уже есть файл robots.txt, убедитесь, что вы удалили текст (но не файл).
Во-первых, вам нужно познакомиться с некоторым синтаксисом, используемым в файле robots.txt.
У Google есть хорошее объяснение некоторых основных терминов robots.txt:
Я собираюсь показать вам, как настроить простой файл robot. txt, а затем мы рассмотрим, как настроить его для SEO.
txt, а затем мы рассмотрим, как настроить его для SEO.
Начните с установки термина пользовательского агента. Мы собираемся настроить его так, чтобы он применялся ко всем веб-роботам.
Сделайте это, поставив звездочку после термина пользовательского агента, например:
Затем введите «Disallow:», но после этого ничего не вводите.
Поскольку после запрета нет ничего, веб-роботы будут направлены на сканирование всего вашего сайта. Прямо сейчас все на вашем сайте честно.
На данный момент ваш файл robots.txt должен выглядеть так:
Я знаю, что это выглядит очень просто, но эти две строчки уже многое делают.
Вы также можете добавить ссылку на свою карту сайта XML, но это не обязательно. Если хотите, вот что нужно набрать:
Вы не поверите, но именно так выглядит базовый файл robots.txt.
Теперь давайте перейдем на новый уровень и превратим этот небольшой файл в средство повышения SEO.
Оптимизация robots.txt для SEO
Как вы оптимизируете robots.txt, все зависит от содержания вашего сайта. Есть много способов использовать robots.txt в ваших интересах.
Я рассмотрю некоторые из наиболее распространенных способов его использования.
(Имейте в виду, что вам следует , а не , использовать robots.txt для блокировки страниц от поисковых систем . Это большой запрет)
Одно из лучших применений файла robots.txt - увеличить бюджеты сканирования поисковых систем, запретив им сканировать те части вашего сайта, которые не отображаются для публики.
Например, если вы посетите файл robots.txt для этого сайта (neilpatel.com), вы увидите, что страница входа запрещена (wp-admin).
Поскольку эта страница используется только для входа в серверную часть сайта, роботам поисковых систем не имеет смысла тратить свое время на ее сканирование.
(Если у вас WordPress, вы можете использовать ту же самую запрещающую строку. )
)
Вы можете использовать аналогичную директиву (или команду), чтобы запретить ботам сканировать определенные страницы. После запрета введите часть URL-адреса после .com. Поместите это между двумя косыми чертами.
Итак, если вы хотите запретить боту сканировать вашу страницу http://yoursite.com/page/, введите это:
Возможно, вам интересно, какие типы страниц исключить из индексации. Вот несколько распространенных сценариев, когда это может произойти:
Умышленное дублирование контента. Хотя дублированный контент - это в большинстве случаев плохо, в некоторых случаях это необходимо и приемлемо.
Например, если у вас есть версия страницы для печати, технически у вас дублированное содержимое.В этом случае вы можете сказать ботам, чтобы они не сканировали одну из этих версий (обычно версию для печати).
Это также удобно, если вы тестируете страницы с одинаковым содержанием, но с разным дизайном.
Страницы с благодарностью. Страница с благодарностью - одна из любимых страниц маркетологов, потому что она означает нового лида.
Страница с благодарностью - одна из любимых страниц маркетологов, потому что она означает нового лида.
… Верно?
Как оказалось, некоторые страницы благодарности доступны через Google . Это означает, что люди могут получить доступ к этим страницам, не проходя процесс захвата лидов, и это плохие новости.
Блокируя страницы с благодарностью, вы можете быть уверены, что их видят только квалифицированные клиенты.
Допустим, ваша страница с благодарностью находится по адресу https://yoursite.com/thank-you/. В вашем файле robots.txt блокировка этой страницы будет выглядеть так:
Так как не существует универсальных правил для запрещенных страниц, ваш файл robots.txt будет уникальным для вашего сайта. Используйте здесь свое суждение.
Вам следует знать еще две директивы: noindex и nofollow .
Вы знаете эту директиву запрета, которую мы использовали? На самом деле это не препятствует индексации страницы.
Итак, теоретически вы можете запретить страницу, но она все равно может оказаться в индексе.
Как правило, вы этого не хотите.
Вот почему вам нужна директива noindex. Он работает с директивой disallow, чтобы роботы не посещали или , индексируя определенные страницы.
Если у вас есть страницы, которые вы не хотите индексировать (например, эти драгоценные страницы с благодарностью), вы можете использовать директиву disallow и noindex:
Теперь эта страница не будет отображаться в поисковой выдаче.
Наконец, есть директива nofollow. Фактически это то же самое, что и ссылка nofollow. Короче говоря, он сообщает веб-роботам, чтобы они не сканировали ссылки на странице.
Но директива nofollow будет реализована несколько иначе, потому что на самом деле она не является частью файла robots.txt.
Однако директива nofollow по-прежнему инструктирует веб-роботов, так что это та же концепция. Единственная разница в том, где это происходит.
Найдите исходный код страницы, которую вы хотите изменить, и убедитесь, что вы находитесь между тегами .
Затем вставьте эту строку:
Вот так должно получиться:
Убедитесь, что вы не помещаете эту строку между другими тегами - только тегами
.Это еще один хороший вариант для страниц с благодарностью, поскольку веб-роботы не будут сканировать ссылки на какие-либо лид-магниты или другой эксклюзивный контент.
Если вы хотите добавить директивы noindex и nofollow, используйте эту строку кода:
Это даст веб-роботам сразу обе директивы.
Проверяем всеНаконец, проверьте файл robots.txt, чтобы убедиться, что все в порядке и работает правильно.
Google предоставляет бесплатный тестер robots. txt как часть инструментов для веб-мастеров.
txt как часть инструментов для веб-мастеров.
Сначала войдите в свою учетную запись для веб-мастеров, нажав «Войти» в правом верхнем углу.
Выберите свой ресурс (например, веб-сайт) и нажмите «Сканировать» на левой боковой панели.
Вы увидите «robots.txt Tester. " Щелкните по нему.
Если в поле уже есть какой-либо код, удалите его и замените новым файлом robots.txt.
Щелкните «Тест» в правой нижней части экрана.
Если текст «Тест» изменится на «Разрешено», это означает, что ваш robots.txt действителен.
Вот еще немного информации об инструменте, чтобы вы могли подробно узнать, что все означает.
Наконец, загрузите файл robots.txt в корневой каталог (или сохраните его там, если он у вас уже есть).Теперь у вас есть мощный файл, и ваша видимость в результатах поиска должна повыситься.
Заключение Мне всегда нравится делиться малоизвестными «хитростями» SEO, которые могут дать вам реальное преимущество во многих отношениях.
Правильно настроив файл robots.txt, вы не просто улучшите свое собственное SEO. Вы также помогаете своим посетителям.
Если роботы поисковых систем могут разумно расходовать свои бюджеты сканирования, они будут организовывать и отображать ваш контент в поисковой выдаче наилучшим образом, что означает, что вы будете более заметны.
Также не требуется много усилий для настройки файла robots.txt. В основном это однократная настройка, и при необходимости вы можете вносить небольшие изменения.
Независимо от того, запускаете ли вы свой первый или пятый сайт, использование robots.txt может иметь большое значение. Я рекомендую попробовать, если вы не делали этого раньше.
Каков ваш опыт создания файлов robots.txt?
Узнайте, как мое агентство может привлечь огромное количество трафика на ваш веб-сайт
- SEO - разблокируйте огромное количество SEO-трафика.Смотрите реальные результаты.
- Контент-маркетинг - наша команда создает эпический контент, которым будут делиться, получать ссылки и привлекать трафик.
- Paid Media - эффективные платные стратегии с четким ROI.

Заказать звонок
Robots.txt и SEO: полное руководство
Что такое Robots.txt?
Robots.txt - это файл, который сообщает паукам поисковых систем не сканировать определенные страницы или разделы веб-сайта. Большинство основных поисковых систем (включая Google, Bing и Yahoo) признают и уважают роботов.txt запросы.
Почему важен файл robots.txt?
Большинству веб-сайтов файл robots.txt не нужен.
Это потому, что Google обычно может найти и проиндексировать все важные страницы вашего сайта.
И они автоматически НЕ будут индексировать несущественные страницы или дублировать версии других страниц.
Тем не менее, есть 3 основные причины, по которым вы хотите использовать файл robots.txt.
Блокировать закрытые страницы. Иногда на вашем сайте есть страницы, которые вы не хотите индексировать.Например, у вас может быть промежуточная версия страницы. Или страницу входа в систему. Эти страницы должны существовать. Но вы же не хотите, чтобы на них садились случайные люди. Это случай, когда вы использовали robots.txt, чтобы заблокировать эти страницы от роботов и роботов поисковых систем.
Или страницу входа в систему. Эти страницы должны существовать. Но вы же не хотите, чтобы на них садились случайные люди. Это случай, когда вы использовали robots.txt, чтобы заблокировать эти страницы от роботов и роботов поисковых систем.
Максимальное увеличение бюджета сканирования. Если вам сложно проиндексировать все страницы, возможно, у вас проблемы с бюджетом сканирования. Блокируя неважные страницы с помощью robots.txt, робот Googlebot может тратить большую часть вашего бюджета сканирования на действительно важные страницы.
Предотвращение индексации ресурсов: использование метадиректив может работать так же, как Robots.txt для предотвращения индексации страниц. Однако метадирективы плохо работают с мультимедийными ресурсами, такими как файлы PDF и изображения. Вот тут-то и пригодится robots.txt.
В нижней строке? Robots.txt сообщает паукам поисковых систем не сканировать определенные страницы вашего сайта.
Вы можете проверить, сколько страниц вы проиндексировали, в Google Search Console.
Если число совпадает с количеством страниц, которые вы хотите проиндексировать, вам не нужно возиться с роботами.txt файл.
Но если это число больше, чем вы ожидали (и вы заметили проиндексированные URL-адреса, которые не следует индексировать), то пора создать файл robots.txt для вашего веб-сайта.
Лучшие Лрактики
Создание файла Robots.txt
Ваш первый шаг - это собственно создание файла robots.txt.
Будучи текстовым файлом, вы можете создать его с помощью блокнота Windows.
И независимо от того, как вы в конечном итоге создаете свой файл robots.txt, формат точно такой же:
Пользовательский агент: X
Запрещено: Y
User-agent - это конкретный бот, с которым вы разговариваете.
И все, что идет после «запретить», - это страницы или разделы, которые вы хотите заблокировать.
Вот пример:
User-agent: googlebot
Disallow: / images
Это правило указывает роботу Googlebot не индексировать папку изображений на вашем веб-сайте.
Вы также можете использовать звездочку (*), чтобы общаться со всеми ботами, которые останавливаются на вашем сайте.
Вот пример:
User-agent: *
Disallow: / images
Знак «*» сообщает всем паукам НЕ сканировать папку с изображениями.
Это лишь один из многих способов использования файла robots.txt. Это полезное руководство от Google содержит дополнительную информацию о различных правилах, которые вы можете использовать, чтобы блокировать или разрешать ботам сканировать разные страницы вашего сайта.
Сделайте ваш файл Robots.txt удобным для поиска
Когда у вас есть файл robots.txt, самое время запустить его.
Технически вы можете разместить файл robots.txt в любом основном каталоге вашего сайта.
Но чтобы увеличить вероятность того, что ваш файл robots.txt будет найден, я рекомендую разместить его по адресу:
https: // пример.com / robots.txt
(обратите внимание, что ваш файл robots. txt чувствителен к регистру. Поэтому обязательно используйте строчную букву «r» в имени файла)
txt чувствителен к регистру. Поэтому обязательно используйте строчную букву «r» в имени файла)
Проверка ошибок и ошибок
ДЕЙСТВИТЕЛЬНО важно, чтобы ваш файл robots.txt был настроен правильно. Одна ошибка - и весь ваш сайт может быть деиндексирован.
К счастью, вам не нужно надеяться, что ваш код настроен правильно. У Google есть отличный инструмент для тестирования роботов, который вы можете использовать:
Он показывает ваш файл robots.txt… и все обнаруженные ошибки и предупреждения:
Как видите, мы блокируем сканирование нашей страницы администратора WP.
Мы также используем robots.txt, чтобы блокировать сканирование страниц с автоматически созданными тегами WordPress (для ограничения дублирования контента).
Robots.txt и мета-директивы
Зачем вам использовать robots.txt, если вы можете блокировать страницы на уровне страницы с помощью метатега noindex?
Как я упоминал ранее, тег noindex сложно реализовать в мультимедийных ресурсах, таких как видео и PDF-файлы.
Кроме того, если у вас есть тысячи страниц, которые вы хотите заблокировать, иногда проще заблокировать весь раздел этого сайта с помощью robots.txt вместо того, чтобы вручную добавлять тег noindex на каждую страницу.
Также есть крайние случаи, когда вы не хотите тратить бюджет сканирования на целевые страницы Google с тегом noindex.
Тем не менее:
Помимо этих трех крайних случаев, я рекомендую использовать метадирективы вместо robots.txt. Их проще реализовать. И меньше шансов на катастрофу (например, блокировку всего вашего сайта).
Узнать больше
Узнайте о роботах.txt: полезное руководство по использованию и интерпретации файла robots.txt.
Что такое файл Robots.txt? (Обзор SEO + Key Insight): подробное видео о различных вариантах использования robots.txt.
Файлы Robots.txt
Файл /robots.txt - это текстовый файл, который инструктирует автоматизированных веб-ботов о том, как сканировать и / или индексировать веб-сайт. Веб-группы используют их, чтобы предоставить информацию о том, какие каталоги сайта следует сканировать, а какие нет, как быстро следует получать доступ к контенту и какие боты приветствуются на сайте.
Веб-группы используют их, чтобы предоставить информацию о том, какие каталоги сайта следует сканировать, а какие нет, как быстро следует получать доступ к контенту и какие боты приветствуются на сайте.
Как должен выглядеть мой файл robots.txt?
Пожалуйста, обратитесь к протоколу robots.txt (Внешняя ссылка) для получения подробной информации о том, как и где создать свой robots.txt. Ключевые моменты, о которых следует помнить:
- Файл должен быть расположен в корне домена, и каждому поддомену нужен свой собственный файл.
- Протокол robots.txt чувствителен к регистру.
- Легко случайно заблокировать сканирование всего
-
Disallow: /означает запретить все -
Disallow:означает ничего не запрещать, тем самым разрешая все -
Разрешить: /означает разрешить все -
Разрешить:означает ничего не разрешить, что запрещает все
-
- Инструкции в robots. txt - это руководство для ботов, а не обязательные требования.
 txt - это руководство для ботов, а не обязательные требования.
txt - это руководство для ботов, а не обязательные требования.Как я могу оптимизировать свой robots.txt для Search.gov?
Задержка сканирования
Файл robots.txt может указывать директиву «задержки сканирования» для одного или нескольких пользовательских агентов, которая сообщает боту, как быстро он может запрашивать страницы с веб-сайта. Например, задержка сканирования, равная 10, означает, что поисковый робот не должен запрашивать новую страницу чаще, чем каждые 10 секунд.
500 000 URL
x 10 секунд между запросами
5 000 000 секунд на все запросы
5 000 000 секунд = 58 дней на однократное индексирование сайта. Мы рекомендуем задержку сканирования в 2 секунды для нашего пользовательского агента usasearch и установить более высокую задержку сканирования для всех остальных ботов. Чем меньше задержка сканирования, тем быстрее Search.gov сможет проиндексировать ваш сайт. В файле robots.txt это будет выглядеть так:
Пользовательский агент: usasearch
Задержка сканирования: 2
Пользовательский агент: *
Задержка сканирования: 10
XML-файлы Sitemap
В вашем файле robots. txt также должна быть указана одна или несколько ваших XML-карт сайта.Например:
txt также должна быть указана одна или несколько ваших XML-карт сайта.Например:
Карта сайта: https://www.exampleagency.gov/sitemap.xml
Карта сайта: https://www.exampleagency.gov/independent-subsection-sitemap.xml
- Отображает только карты сайта для домена, в котором находится файл robots.txt. Карта сайта другого субдомена должна быть указана в файле robots.txt этого субдомена.
Разрешить только тот контент, который должен быть доступен для поиска
Мы рекомендуем запретить использование любых каталогов или файлов, которые не должны быть доступны для поиска.Например:
Запретить: / archive /
Disallow: / новости-1997 /
Запретить: /reports/duplicative-page.html
- Обратите внимание: если вы запретите использование каталога после того, как он проиндексирован поисковой системой, это может не привести к удалению этого содержания из индекса. Чтобы запросить удаление, вам нужно будет открыть инструменты для веб-мастеров поисковой системы.
- Также обратите внимание, что поисковые системы могут индексировать отдельные страницы в запрещенной папке, если поисковая система узнает об URL-адресе из метода без сканирования, например ссылки с другого сайта или вашей карты сайта.Чтобы гарантировать, что данная страница недоступна для поиска, установите на этой странице метатег robots.
Настройка параметров для разных ботов
Вы можете установить разные разрешения для разных ботов. Например, если вы хотите, чтобы мы проиндексировали ваш заархивированный контент, но не хотите, чтобы Google или Bing индексировали его, вы можете указать это:
Пользовательский агент: usasearch
Задержка сканирования: 2
Разрешить: / archive /
Пользовательский агент: *
Задержка сканирования: 10
Запретить: / архив /
Контрольный список Robots.txt
1.В корневом каталоге сайта был создан файл robots.txt ( https://exampleagency.gov/robots.txt )
2. Файл robots.txt запрещает любые каталоги и файлы, которые автоматические боты не должны сканировать.
3. В файле robots.txt перечислены одна или несколько карт сайта XML
4. Формат файла robots.txt подтвержден (Внешняя ссылка)
Дополнительные ресурсы
Полное руководство по роботам Yoast SEO.txt (Внешняя ссылка)
Google «Узнайте о файлах robots.txt» (Внешняя ссылка)
Robots.txt - Все, что нужно знать оптимизаторам поисковых систем
В этом разделе нашего руководства по директивам для роботов мы более подробно рассмотрим текстовый файл robots.txt и то, как его можно использовать для инструктирования поисковой системе в Интернете. краулеры. Этот файл особенно полезен для , управляющего бюджетом сканирования и проверки того, что поисковые системы проводят время на вашем сайте эффективно и сканируют только важные страницы.
Для чего используется txt-файл robots?
Файл robots. txt предназначен для того, чтобы сообщить сканерам и роботам, какие URL-адреса им не следует посещать на вашем веб-сайте. Это важно, чтобы помочь им избежать сканирования страниц низкого качества или застревания в ловушках сканирования, где потенциально может быть создано бесконечное количество URL-адресов, например, раздел календаря, который создает новый URL-адрес для каждого дня.
txt предназначен для того, чтобы сообщить сканерам и роботам, какие URL-адреса им не следует посещать на вашем веб-сайте. Это важно, чтобы помочь им избежать сканирования страниц низкого качества или застревания в ловушках сканирования, где потенциально может быть создано бесконечное количество URL-адресов, например, раздел календаря, который создает новый URL-адрес для каждого дня.
Как объясняет Google в своем руководстве по спецификациям robots.txt , формат файла должен быть простым текстом в кодировке UTF-8.Записи (или строки) файла должны быть разделены CR, CR / LF или LF.
Следует помнить о размере файла robots.txt, поскольку поисковые системы имеют свои собственные ограничения на максимальный размер файла. Максимальный размер для Google - 500 КБ.
Где должен существовать файл robots.txt?
Файл robots.txt всегда должен существовать в корне домена, например:
Этот файл относится к протоколу и полному домену, поэтому robots. txt на https: // www.example.com не влияет на сканирование http://www.example.com или https://subdomain.example.com ; у них должны быть собственные файлы robots.txt.
txt на https: // www.example.com не влияет на сканирование http://www.example.com или https://subdomain.example.com ; у них должны быть собственные файлы robots.txt.
Когда следует использовать правила robots.txt?
В общем, веб-сайты должны стараться как можно реже использовать robots.txt для контроля сканирования. Лучшее решение - улучшить архитектуру вашего веб-сайта и сделать его чистым и доступным для поисковых роботов. Однако с помощью robots.txt, если это необходимо для предотвращения доступа сканеров к некачественным разделам сайта, рекомендуется, если эти проблемы не могут быть устранены в краткосрочной перспективе.
Google рекомендует использовать файл robots.txt только при возникновении проблем с сервером или при проблемах с эффективностью сканирования, например, когда робот Google тратит много времени на сканирование неиндексируемого раздела сайта.
Вот несколько примеров страниц, сканирование которых может быть нежелательно:
- Страницы категорий с нестандартной сортировкой , так как это обычно создает дублирование со страницей основной категории
- Пользовательский контент , который нельзя модерировать
- Страницы с конфиденциальной информацией
- Внутренние поисковые страницы , так как таких страниц результатов может быть бесконечное количество, что создает неудобства для пользователей и расходует бюджет сканирования
Когда нельзя использовать robots.
 текст?
текст?Файл robots.txt - полезный инструмент при правильном использовании, однако в некоторых случаях это не лучшее решение. Вот несколько примеров того, когда не следует использовать robots.txt для управления сканированием:
1. Блокировка Javascript / CSS
Поисковые системы должны иметь доступ ко всем ресурсам на вашем сайте, чтобы правильно отображать страницы, что является необходимой частью поддержания хорошего рейтинга. Файлы JavaScript, которые кардинально меняют взаимодействие с пользователем, но которым запрещено сканирование поисковыми системами, могут привести к ручным или алгоритмическим штрафам.
Например, если вы показываете рекламное межстраничное объявление или перенаправляете пользователей с помощью JavaScript, к которому поисковая система не имеет доступа, это может рассматриваться как маскировка, и рейтинг вашего контента может быть соответствующим образом скорректирован.
2. Параметры блокировки URL
Вы можете использовать robots. txt для блокировки URL-адресов, содержащих определенные параметры, но это не всегда лучший способ действий. Лучше обрабатывать их в консоли поиска Google, поскольку там есть больше параметров для конкретных параметров, чтобы сообщить Google о предпочтительных методах сканирования.
txt для блокировки URL-адресов, содержащих определенные параметры, но это не всегда лучший способ действий. Лучше обрабатывать их в консоли поиска Google, поскольку там есть больше параметров для конкретных параметров, чтобы сообщить Google о предпочтительных методах сканирования.
Вы также можете разместить информацию во фрагменте URL ( / page # sort = price ), поскольку поисковые системы не сканируют его. Кроме того, если необходимо использовать параметр URL, ссылки на него могут содержать атрибут rel = nofollow, чтобы предотвратить попытки поисковых роботов получить к нему доступ.
3. Блокировка URL с обратными ссылками
Запрет URL-адресов в файле robots.txt предотвращает передачу ссылочного веса на веб-сайт. Это означает, что если поисковые системы не могут переходить по ссылкам с других веб-сайтов, поскольку целевой URL-адрес запрещен, ваш веб-сайт не получит авторитет, который передаются по этим ссылкам, и, как следствие, вы не сможете получить такой высокий рейтинг в целом.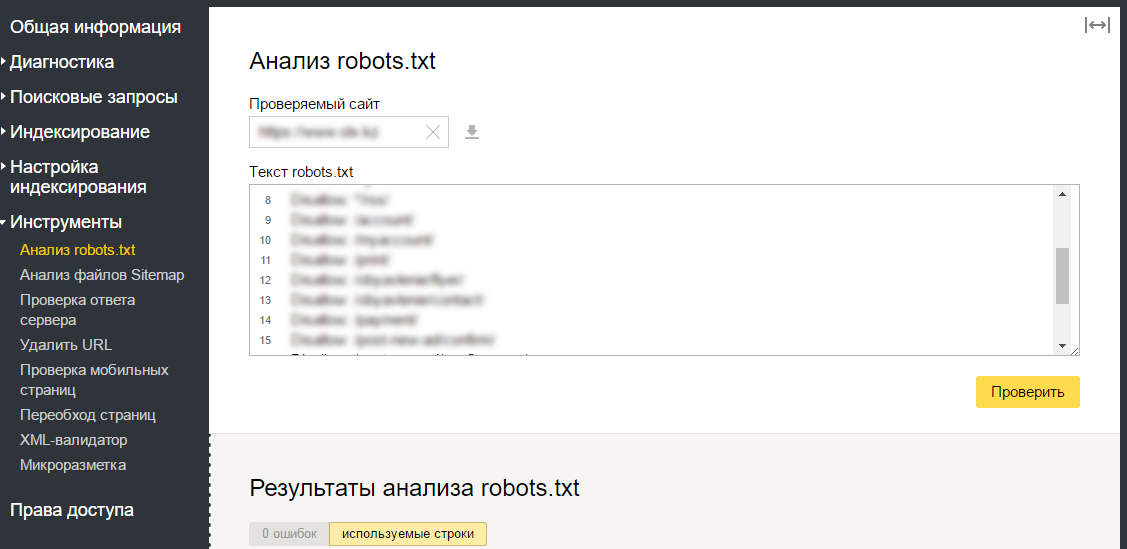
4. Получение деиндексированных проиндексированных страниц
Использование Disallow не приводит к деиндексированию страниц, и даже если URL-адрес заблокирован и поисковые системы никогда не сканировали страницу, запрещенные страницы все равно могут быть проиндексированы. Это связано с тем, что процессы сканирования и индексирования в значительной степени разделены.
5. Установка правил, игнорирующих поисковые роботы социальных сетей
Даже если вы не хотите, чтобы поисковые системы сканировали и индексировали страницы, вы можете захотеть, чтобы социальные сети имели доступ к этим страницам, чтобы можно было создать фрагмент страницы.Например, Facebook попытается посетить каждую страницу, размещенную в сети, чтобы они могли предоставить соответствующий фрагмент. Помните об этом при настройке правил robots.txt.
6. Блокировка доступа с тестовых сайтов или сайтов разработчиков
Использование robots.txt для блокировки всего промежуточного сайта - не лучшая практика.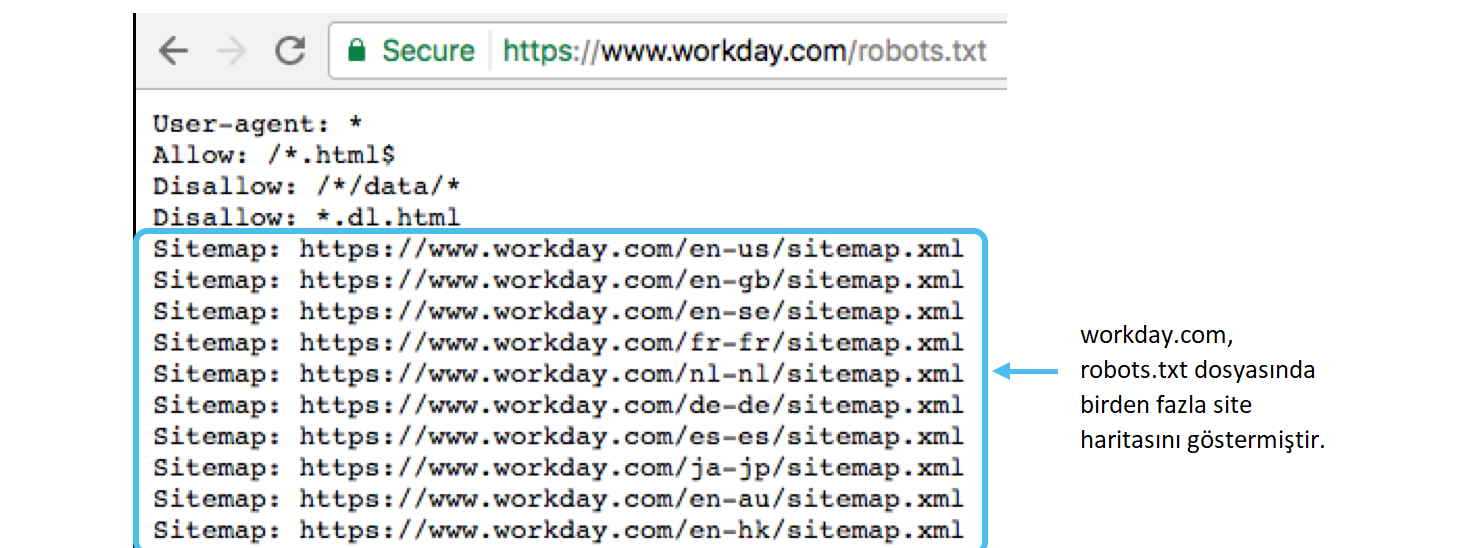 Google рекомендует не индексировать страницы, но разрешить их сканирование, но в целом лучше сделать сайт недоступным для внешнего мира.
Google рекомендует не индексировать страницы, но разрешить их сканирование, но в целом лучше сделать сайт недоступным для внешнего мира.
7. Когда нечего блокировать
Некоторым веб-сайтам с очень чистой архитектурой не нужно блокировать поисковые роботы с каких-либо страниц.В этой ситуации вполне приемлемо не иметь файла robots.txt и возвращать статус 404 по запросу.
Синтаксис и форматирование файла Robots.txt
Теперь, когда мы узнали, что такое robots.txt и когда его следует и не следует использовать, давайте взглянем на стандартизованный синтаксис и правила форматирования, которых следует придерживаться при написании файла robots.txt.
Комментарии
Комментарии - это строки, которые полностью игнорируются поисковыми системами и начинаются с # .Они существуют, чтобы вы могли писать заметки о том, что делает каждая строка вашего robots.txt, почему она существует и когда была добавлена. В общем, рекомендуется задокументировать назначение каждой строки файла robots. txt, чтобы ее можно было удалить, когда она больше не нужна, и не изменять, пока она еще необходима.
txt, чтобы ее можно было удалить, когда она больше не нужна, и не изменять, пока она еще необходима.
Указание агента пользователя
Блок правил может быть применен к определенным пользовательским агентам с помощью директивы « User-agent ». Например, если вы хотите, чтобы определенные правила применялись к Google, Bing и Яндекс. но не Facebook и рекламные сети, этого можно достичь, указав токен пользовательского агента, к которому применяется набор правил.
У каждого искателя есть собственный токен агента пользователя, который используется для выбора совпадающих блоков.
Поисковые роботыбудут следовать наиболее конкретным правилам пользовательского агента, установленным для них с именами, разделенными дефисами, а затем будут использовать более общие правила, если точное совпадение не найдено. Например, Googlebot News будет искать соответствие " googlebot-news ", затем " googlebot ", затем " * ".
Вот некоторые из наиболее распространенных токенов пользовательских агентов, с которыми вы можете столкнуться:
- * - Правила применяются к каждому боту, если нет более конкретного набора правил
- Googlebot - Все сканеры Google
- Googlebot-News - Поисковый робот для новостей Google
- Googlebot-Image - сканер изображений Google
- Mediapartners-Google - сканер Google AdSense
- Bingbot - сканер Bing
- Яндекс - сканер Яндекса
- Baiduspider - гусеничный робот Baidu
- Facebot - поисковый робот Facebook
- Twitterbot - поисковый робот Twitter
Этот список токенов пользовательских агентов ни в коем случае не является исчерпывающим, поэтому, чтобы узнать больше о некоторых сканерах, взгляните на документацию, опубликованную Google , Bing , Yandex , Baidu , Facebook и Twitter .
При сопоставлении токена пользовательского агента с блоком robots.txt регистр не учитывается. Например. «Googlebot» будет соответствовать токену пользовательского агента Google «Googlebot».
URL с сопоставлением с шаблоном
У вас может быть определенная строка URL-адреса, которую вы хотите заблокировать от сканирования, поскольку это намного эффективнее, чем включение полного списка полных URL-адресов, которые следует исключить в вашем файле robots.txt.
Чтобы помочь вам уточнить пути URL, вы можете использовать символы * и $. Вот как они работают:
- * - Это подстановочный знак, представляющий любое количество любого символа.Он может быть в начале или в середине пути URL, но не обязателен в конце. В строке URL-адреса можно использовать несколько подстановочных знаков, например, « Disallow: * / products? * Sort = ». Правила с полными путями не должны начинаться с подстановочного знака.
- $ - этот символ обозначает конец строки URL-адреса, поэтому « Disallow: * / dress $ » будет соответствовать только URL-адресам, заканчивающимся на « / dress », но не « / dress? Parameter ».

Стоит отметить, что robots.txt чувствительны к регистру, что означает, что если вы запретите URL-адреса с параметром « search » (например, « Disallow: *? search = »), роботы все равно могут сканировать URL-адреса с разными заглавными буквами, например «? Search = ничего ».
Правила директивы сопоставляются только с путями URL и не могут включать протокол или имя хоста. Косая черта в начале директивы совпадает с началом пути URL. Например. « Disallow: / start » будет соответствовать www.example.com/starts .
Если вы не добавите начало директивы, совпадающей с / или * , она ни с чем не будет соответствовать. Например. « Disallow: start » никогда ни с чем не будет соответствовать.
Чтобы помочь наглядно представить, как работают разные правила для URL, мы собрали для вас несколько примеров:
Robots.txt Ссылка на карту сайта
Директива карты сайта в файле robots. txt сообщает поисковым системам, где найти XML-карту сайта, которая помогает им обнаруживать все URL-адреса на веб-сайте.Чтобы узнать больше о файлах Sitemap, ознакомьтесь с нашим руководством по аудиту карт сайта и расширенной настройке .
txt сообщает поисковым системам, где найти XML-карту сайта, которая помогает им обнаруживать все URL-адреса на веб-сайте.Чтобы узнать больше о файлах Sitemap, ознакомьтесь с нашим руководством по аудиту карт сайта и расширенной настройке .
При включении карт сайта в файл robots.txt следует использовать абсолютные URL-адреса (например, https://www.example.com/sitemap.xml ) вместо относительных URL (например, /sitemap.xml ). Это также Стоит отметить, что карты сайта не обязательно должны размещаться в одном корневом домене, они также могут размещаться во внешнем домене.
Поисковые системы обнаружат и могут сканировать карты сайта, перечисленные в вашем файле robots.txt, однако эти карты сайта не будут отображаться в Google Search Console или Bing Webmaster Tools без отправки вручную.
Robots.txt Блокирует
Правило «запрета» в файле robots.txt может использоваться разными способами для различных пользовательских агентов. В этом разделе мы рассмотрим некоторые из различных способов форматирования комбинаций блоков.
В этом разделе мы рассмотрим некоторые из различных способов форматирования комбинаций блоков.
Важно помнить, что директивы в файле robots.txt - это всего лишь инструкции. Вредоносные сканеры проигнорируют ваших роботов.txt и сканировать любую часть вашего сайта, которая является общедоступной, поэтому запрет не следует использовать вместо надежных мер безопасности.
Несколько блоков пользовательского агента
Вы можете сопоставить блок правил с несколькими пользовательскими агентами, указав их перед набором правил, например, следующие запрещающие правила будут применяться как к Googlebot, так и к Bing в следующем блоке правил:
Пользовательский агент: googlebot
Пользовательский агент: bing
Запрещено: / a
Расстояние между блоками директив
Google игнорирует пробелы между директивами и блоками.В этом первом примере будет выбрано второе правило, даже если есть пробел, разделяющий две части правила:
[код]
User-agent: *
Disallow: / disallowed /Запретить: / test1 / robots_excluded_blank_line
[/ code]
Во втором примере робот Googlebot-mobile наследует те же правила, что и Bingbot:
[код]
Пользовательский агент: googlebot-mobileUser-agent: bing
Disallow: / test1 / deepcrawl_excluded
[/ code]
Блоки раздельные комбинированные
Объединяются несколько блоков с одним и тем же пользовательским агентом. Таким образом, в приведенном ниже примере верхний и нижний блоки будут объединены, и роботу Googlebot будет запрещено сканировать « / b » и « / a ».
Таким образом, в приведенном ниже примере верхний и нижний блоки будут объединены, и роботу Googlebot будет запрещено сканировать « / b » и « / a ».
User-agent: googlebot
Disallow: / bUser-agent: bing
Disallow: / aUser-agent: googlebot
Disallow: / a
Robots.txt Разрешить
«Разрешающее» правило robots.txt явно дает разрешение на сканирование определенных URL. Хотя это значение по умолчанию для всех URL-адресов, это правило можно использовать для перезаписи запрещающего правила.Например, если « / location » не разрешено, вы можете разрешить сканирование « / locations / london » с помощью специального правила « Allow: / locations / london ».
Robots.txt Приоритизация
Когда к URL-адресу применяется несколько разрешающих и запрещающих правил, применяется самое длинное правило соответствия. Давайте посмотрим, что произойдет с URL « / home / search / shirts » при следующих правилах:
Disallow: / home
Allow: * search / *
Disallow: * рубашки
В этом случае сканирование URL разрешено, потому что правило разрешения состоит из 9 символов, а правило запрета - только из 7.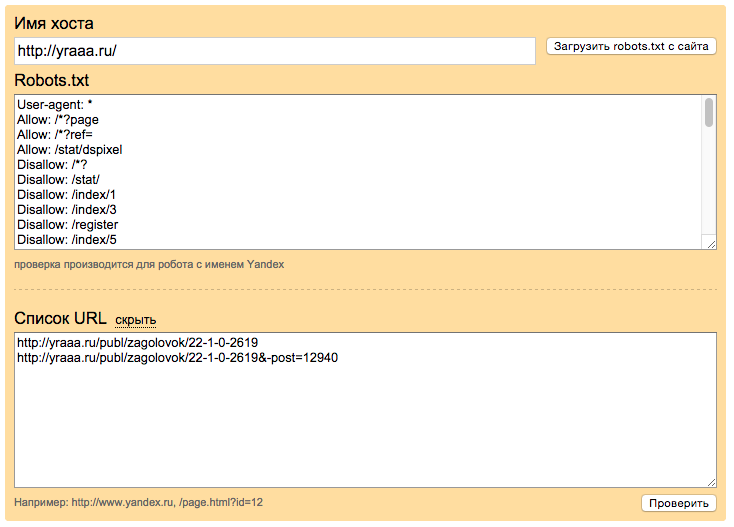 Если вам нужно разрешить или запретить конкретный URL-путь, вы можете использовать *, чтобы сделать строку длиннее. Например:
Если вам нужно разрешить или запретить конкретный URL-путь, вы можете использовать *, чтобы сделать строку длиннее. Например:
Disallow: ******************* / рубашки
Если URL-адрес соответствует как разрешающему правилу, так и запрещающему правилу, но правила имеют одинаковую длину, будет выполняться запрет. Например, URL « / search / shirts » будет запрещен в следующем сценарии:
Disallow: / search
Allow: * рубашки
Роботы.txt Директивы
Директивы уровня страницы (которые мы рассмотрим позже в этом руководстве) - отличные инструменты, но проблема с ними заключается в том, что поисковые системы должны сканировать страницу, прежде чем смогут прочитать эти инструкции, что может потреблять бюджет сканирования.
Директивы Robots.txt могут помочь снизить нагрузку на бюджет сканирования, поскольку вы можете добавлять директивы непосредственно в файл robots.txt, а не ждать, пока поисковые системы просканируют страницы, прежде чем принимать меры.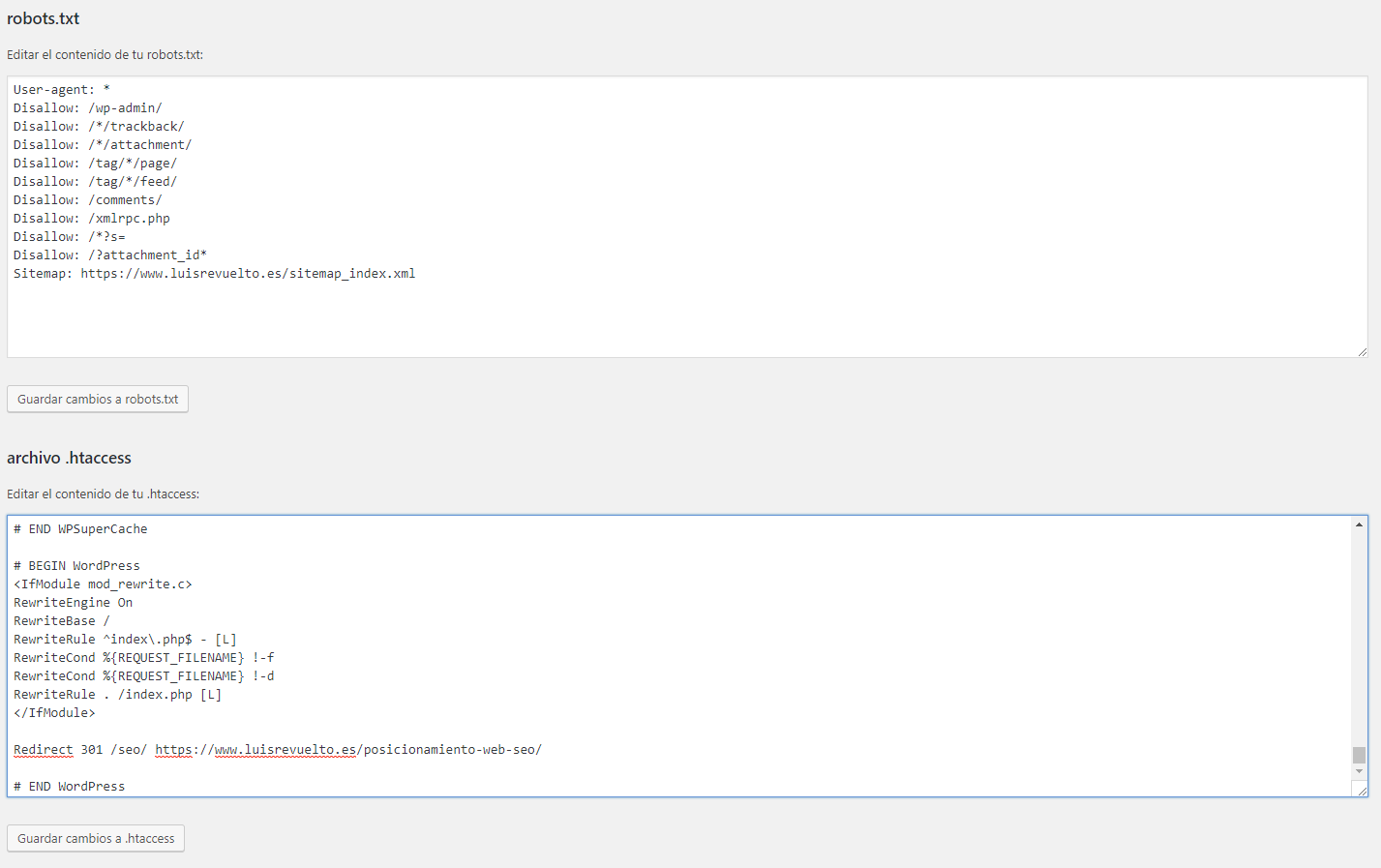 Это решение намного быстрее и проще в использовании.
Это решение намного быстрее и проще в использовании.
Следующие директивы robots.txt работают так же, как директивы allow и disallow, в том, что вы можете указать подстановочные знаки ( * ) и использовать символ $ для обозначения конца строки URL.
Robots.txt NoIndex
Robots.txt noindex - полезный инструмент для управления индексированием поисковой системы без использования бюджета сканирования. Запрещение страницы в robots.txt не означает, что она удаляется из индекса, поэтому для этой цели гораздо эффективнее использовать директиву noindex.
Google официально не поддерживает noindex в robots.txt, и вам не следует полагаться на него, потому что, хотя он работает сегодня, он может не работать завтра. Этот инструмент может быть полезен и должен использоваться в качестве краткосрочного исправления в сочетании с другими долгосрочными элементами управления индексами, но не в качестве критически важной директивы. Взгляните на тесты, проведенные ohgm и Stone Temple , которые доказывают, что эта функция работает эффективно.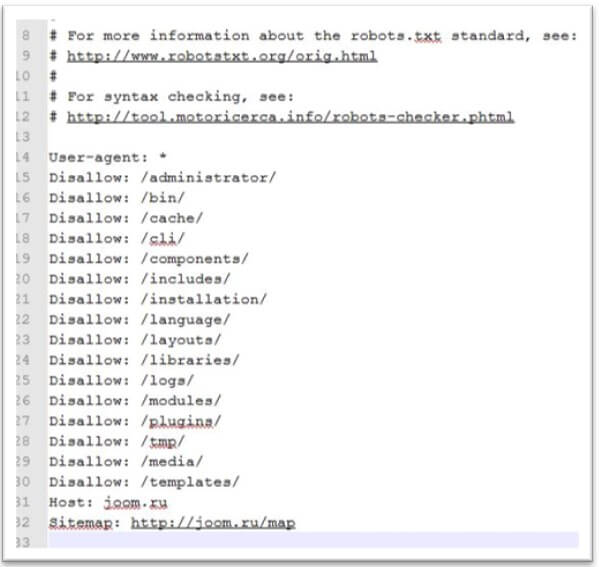
Вот пример использования robots.txt noindex:
[код]
User-agent: *
NoIndex: / directory
NoIndex: / *? * Sort =
[/ code]
Помимо noindex, Google в настоящее время неофициально подчиняется нескольким другим директивам индексирования, когда они помещаются в robots.txt. Важно отметить, что не все поисковые системы и сканеры поддерживают эти директивы, а те, которые поддерживают, могут перестать поддерживать их в любой момент - не следует полагаться на их постоянную работу.
Обычные роботы.txt, проблемы
Есть несколько ключевых проблем и соображений, касающихся файла robots.txt и его влияния на производительность сайта. Мы нашли время, чтобы перечислить некоторые ключевые моменты, которые следует учитывать при использовании robots.txt, а также некоторые из наиболее распространенных проблем, которых вы, надеюсь, можете избежать.
- Иметь запасной блок правил для всех ботов - Использование блоков правил для определенных строк пользовательского агента без резервного блока правил для каждого другого бота означает, что ваш сайт в конечном итоге встретит бота, у которого нет никаких наборов правил следить.
- I t Важно, чтобы файл robots.txt поддерживался в актуальном состоянии. - Относительно частая проблема возникает, когда файл robots.txt устанавливается на начальной стадии разработки веб-сайта, но не обновляется по мере роста веб-сайта, что означает, что потенциально полезные страницы запрещены.
- Помните о перенаправлении поисковых систем через запрещенные URL-адреса - Например, / продукт > / запрещенный > / категория
- Чувствительность к регистру может вызвать множество проблем - Веб-мастера могут ожидать, что какой-то раздел веб-сайта не будет сканироваться, но эти страницы могут сканироваться из-за альтернативного регистра i.е. «Disallow: / admin» существует, но поисковые системы сканируют « / ADMIN ».
- Не запрещать URL-адреса с обратными ссылками - Это предотвращает переход PageRank на ваш сайт от других пользователей, которые ссылаются на вас.
- Задержка сканирования может вызвать проблемы с поиском - Директива « crawl-delay » заставляет сканеры посещать ваш веб-сайт медленнее, чем им хотелось бы, а это означает, что ваши важные страницы могут сканироваться реже, чем это необходимо. Эта директива не соблюдается Google или Baidu, но поддерживается Bing и Яндексом.
- Убедитесь, что robots.txt возвращает код состояния 5xx только в том случае, если весь сайт не работает. - Возвращение кода состояния 5xx для /robots.txt указывает поисковым системам, что веб-сайт недоступен для обслуживания. Обычно это означает, что они снова попытаются сканировать веб-сайт позже.
- Disallow Robots.txt переопределяет инструмент удаления параметров. - Помните, что ваши правила robots.txt могут переопределять обработку параметров и любые другие подсказки по индексации, которые вы могли дать поисковым системам.
- Разметка окна поиска дополнительных ссылок будет работать с заблокированными страницами внутреннего поиска - Страницы внутреннего поиска на сайте не должны сканироваться, чтобы разметка окна поиска дополнительных ссылок работала.
- Запрещение перенесенного домена повлияет на успех миграции - Если вы запретите перенесенный домен, поисковые системы не смогут отслеживать перенаправления со старого сайта на новый, поэтому миграция маловероятна быть успешным.


Роботы для тестирования и аудита.txt
Учитывая, насколько опасным может быть файл robots.txt, если содержащиеся в нем директивы не обрабатываются должным образом, есть несколько различных способов проверить его, чтобы убедиться, что он настроен правильно. Взгляните на это руководство о том, как проверять URL-адреса, заблокированные файлом robots.txt , а также на эти примеры:
- Используйте DeepCrawl - Запрещенные страницы и Запрещенные URL (не просканированные) Отчеты могут показать вам, какие страницы блокируются поисковыми системами вашими роботами.txt файл.
- Используйте Google Search Console - с помощью инструмента GSC robots. txt тестера вы можете увидеть последнюю кэшированную версию страницы, а также с помощью инструмента Fetch and Render просмотреть рендеры от пользовательского агента Googlebot, а также пользовательский агент браузера. На заметку: GSC работает только с пользовательскими агентами Google, и можно тестировать только отдельные URL.
- Попробуйте объединить идеи обоих инструментов, выбрав выборочную проверку запрещенных URL-адресов, которые DeepCrawl пометил в роботах GSC.txt, чтобы уточнить конкретные правила, которые приводят к запрету.
Monitoring Robots.txt Changes
Когда над сайтом работает много людей, и возникают проблемы, которые могут возникнуть, если хотя бы один символ неуместен в файле robots.txt, постоянный мониторинг вашего robots.txt имеет решающее значение. Вот несколько способов проверить наличие проблем:
- Проверьте Google Search Console, чтобы увидеть текущий файл robots.txt, который использует Google.
