Как осуществлять поиск в сети интернет
В настоящее время глобальная сеть интернет пестрит свои многообразием и количеством информации, что порой для пользователей является сложной задачей поиск необходимого для них контента. С большим количеством трудностей, как правило, сталкиваются новички, которые еще не знакомы с главными правилами поиска в сети интернет.
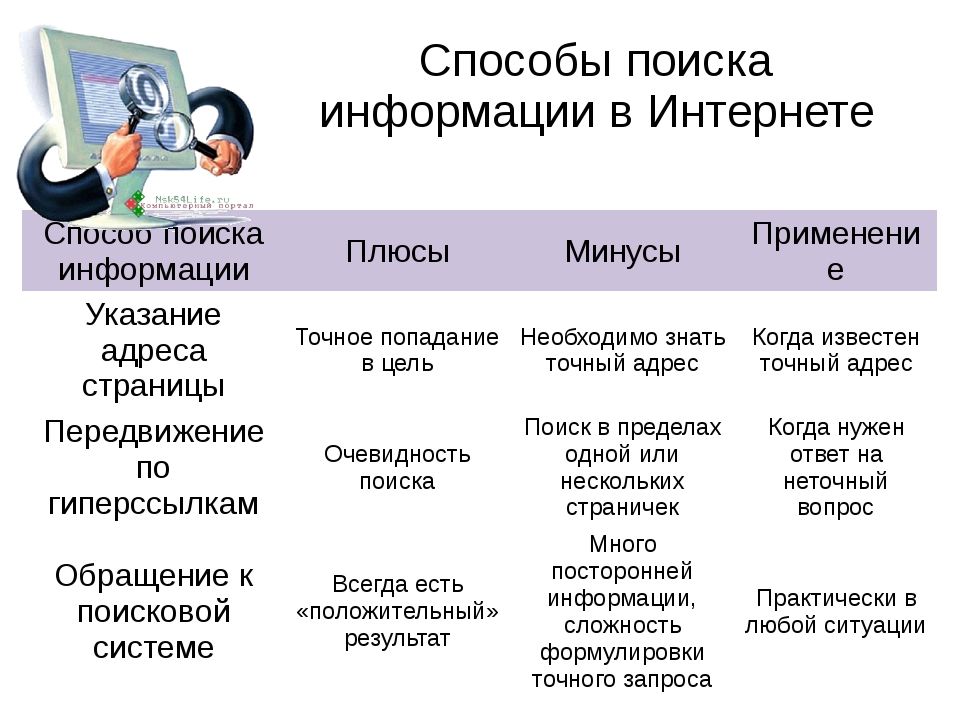
Не редко пользователи сталкиваются с такой ситуацией, когда не удается отыскать необходимые сведения в сети интернет. Также имеется большое количество случаев, когда пользователи забывают или теряют ссылки на любимые интернет странички, но у них отложены в памяти примерные фразы из нужных статей. Иногда на поиск нужно информации стандартными методами может уйти большое количество времени. С данными трудностями поможет справиться метод правильного составления поискового запроса и использование расширенного поиска, который предлагает каждый оператор.
расширенный поиск в сети интернет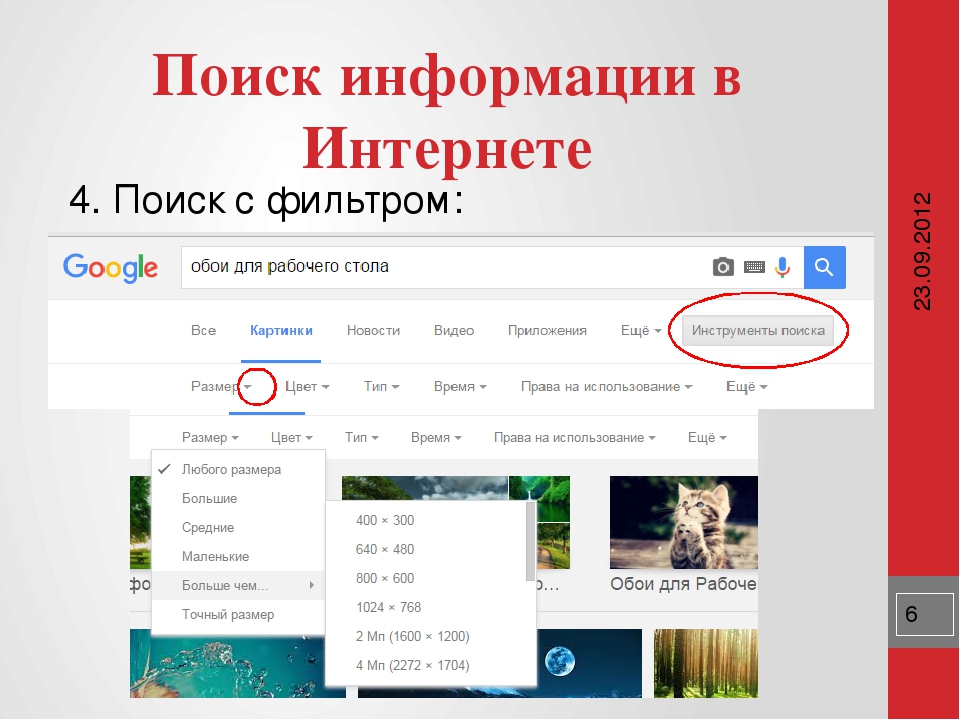 Для этой цели можно воспользоваться Википедией, где собрано большое количество информации на любые темы. Также имеется возможность использования поисковиков. Данные методы обладают собственными отрицательными и положительными качествами. В данной статье речь более подробно пойдет об использовании поисковиков.
Для этой цели можно воспользоваться Википедией, где собрано большое количество информации на любые темы. Также имеется возможность использования поисковиков. Данные методы обладают собственными отрицательными и положительными качествами. В данной статье речь более подробно пойдет об использовании поисковиков.
Что представляет собой поисковик
Со временем появляется большое количество сайтов на современных интернет просторах. И постепенно перед пользователям встает вопрос о том, как же именно среди всего многообразия контента найти для себя наиболее оптимальный вариант. Время от времени появляются новые интернет ресурсы, а старые куда-то пропадают. В данной ситуации без качественного проводника в мире сети интернет практически невозможно представить себе виртуальный мир. Именно его роль выполняют в сегодня имеющиеся поисковые системы.
У всех у них имеется свой собственный интернет ресурс, где в строке для поиска определенной информации есть возможность вводить определенные фразы для получения доступа к необходимым сведениям. Следует отметить, что та часть поисковика, которая является видимой для пользователей. Также имеется и скрытая часть, которая представлена специальными программами, имеющими название пауки. Они заходят на страницы сайтов и посещают различные ссылки и скачивают определенную информацию.
Следует отметить, что та часть поисковика, которая является видимой для пользователей. Также имеется и скрытая часть, которая представлена специальными программами, имеющими название пауки. Они заходят на страницы сайтов и посещают различные ссылки и скачивают определенную информацию.
Затем все содержимое страницы интернет ресурсов проходит процедуру индексации и вводится в хранилище данных поисковика. После этого вступаю в действие конкретные алгоритмы, по которым определяется вес информации и к какому поисковому вопросу она может относиться.
Именно поэтому после ввода определенных слов в поисковую строку, пользователь имеет возможность получать результаты поиска, состоящие из большого количества интернет страниц. Программа поисковика находит в своей базе наиболее релевантные интернет страницы, которые подходят под конкретный запрос. Следует отметить тот факт, что все поисковики не работают в режиме реального времени. Они не ищут информацию в сети интернет в данный момент.
Для того чтобы показывать только актуальные интернет ресурсы утилиты поисковиков тщательно проверяют проиндексированные сайты в своем хранилище. Они определяют были ли там какие либо изменения, или нет.
У каждой поисковой системы существуют определенные алгоритмы проведения индексации страниц в интернете, частота посещения интернет ресурсов и многое другое. Именно по этой причине итоги поиска в разных поисковиках на абсолютно одинаковые запросы на получение информации могут иметь различия.
На сегодняшний день в мире представлено большое количество поисковых систем. Среди них все время появляются новые, многие из них объединяются или удаляются. Имеются поисковики, которые используются для описка информации по самой разной тематике:
- yandex,
- Google,
- Mail.ru,
- Yahoo!,
- Bing.
Также сегодня представлены и прочие виды поисковиков, отличные от этих.
Кроме этих поисковых систем обширного назначенния имеется еще и ряд поисковиков, которые пользуются их базами данных, но предоставляют результаты по определенной тематике. Иногда в них поиск информации становится более комфортным для пользователей.
В настоящее время в сети интернет имеется сразу две самые распространенные поисковые системы, которые предназначены для поиска информации самого разного вида тематики. Они представлены Google и Яндекс. Последний поисковик является отечественным. Google же относится к разряду локализованных программ мировой поисковой системы.
У них имеется отличие в том, что в Google новые интернет ресурсы появляются гораздо быстрее, чем в Яндексе. Однако для русскоязычных пользователей гораздо проще пользоваться Яндексом, потому что он изначально создан для поиска информации на русском языке.
Для пользователей, которые ищут информацию на зарубежных интернет ресурсах, более полезным может стать браузер Google. Данные отличия относятся к практически любому поисковику, имеющемуся в современном мире.
Данные отличия относятся к практически любому поисковику, имеющемуся в современном мире.
Как правильно осуществлять поиск нужных сведений в сети интернет
От качественно сформулированной поисковой фразы иногда зависит качество выдаваемых интернет ресурсов в поисковике. Одним из самых основных правил для всех, кто пользуется различными поисковыми системами, является составление максимально коротких поисковых запросов. Здесь требуется определенный опыт использования поисковиков. Ведь, если использовать слишком общие поисковые фразы, то может появиться огромное количество сайтов, которые не всегда предлагают необходимый контент. При этом есть риск, что ничего необходимого и не окажется.
Следует привести пример того, как нужно и не нужно составлять поисковые запросы. Например, если пользователь ищет информацию об отдыхе в Италии на Адриатическом море, то нельзя искать данные сведения только по фразе «отдых в Италии». Необходимо составить запрос правильно, но без всяческих усложнений.
Современные поисковики сегодня стали более продвинутыми. Во время ввода фразы для поиска по ней информации в интернете они выдают несколько похожих запросов, которые наиболее часто встречаются у пользователей. Среди них можно выбрать что-то для себя. Данная опция в некоторых случаях отлично может пригодиться. Особенно это полезно, когда у самого пользователя не получается правильным образом обозначить поисковую фразу.
Поисковик обычно не является чувствительным к введенным фразам. Он самостоятельно удаляет знаки препинания и наиболее часто повторяющиеся слова.
Данные методы являются одним из самых универсальных для новичков, которые только познают мир сети интернет. Следует отметить, что лучше на этом не ограничиваться, потому что современные поисковики обладают расширенными возможностями, которые подразумевают облегчение процесса поиска необходимых сведений для пользователей.
При вводе определенного набора слов в поисковике его программы начинают активизироваться и искать на страницах имеющихся в хранилище сайтов определенные фразы. Слова могут располагаться в любой форме и в последовательности. Иными словами это можно объяснить тем, что слова из поискового запроса в найденном документе могут находиться в различных частях той или иной страницы. Они даже встречаются в разбавленном виде. Помимо этого на некоторых страницах они могут вообще отсутствовать. Однако там могут быть расположены фразы, которые подразумевают их значение.
Для решения этой проблемы необходимо поставить во фразе кавычки. С их помощью программы в поисковике будут искать именно странички с данными фразами.
Если необходимо отыскать точную фразу, то ее нужно обозначить кавычками. Если точной фразы пользователь не имеет возможности запомнить, то между запомненными словами можно поставить звездочку.
Иногда бывают такие ситуации, что для поиска определенного контента на различных интернет ресурсах необходимо для начала зарегистрироваться. Для облегчения своей задачи необходимо ввести в строке поискового запроса конструкцию кластер site: название интернет ресурса. В этом случае кластер обозначает фразу, которую необходимо отыскать на необходимом сайте. В этой ситуации следует учесть тот факт, что определенная страница может быть еще не анализирована программами поисковика. Поэтому может оказаться и отсутствие итогов по запросу.
Для облегчения своей задачи необходимо ввести в строке поискового запроса конструкцию кластер site: название интернет ресурса. В этом случае кластер обозначает фразу, которую необходимо отыскать на необходимом сайте. В этой ситуации следует учесть тот факт, что определенная страница может быть еще не анализирована программами поисковика. Поэтому может оказаться и отсутствие итогов по запросу.
Самым не сложным вариантом поиска является использование кавычек. Однако имеется еще множество методов, которые позволяют расширить возможности поиска необходимой информации в сети интернет. Для различных поисковиков они свои собственные и их рекомендуется рассматривать отдельно друг от друга.
Как осуществлять поиск в Яндексе
В некоторых случаях появляются ситуации, когда необходимо удалить из поискового запроса слов, которое не должно содержаться в документах, выдаваемых в результате поиска. Для этого необходимо поставить перед данным словом две тильды.
В противоположном случае есть необходимость в том, чтобы слово из поисковой фразы обязательно имелось в документах. Тогда перед ним необходимо поставить знак плюсика.
Ранее отмечалось, что для поискового запроса не важно, каким способом написана та или иная фраза. Однако для того чтобы слово было найдено именно таким образом, каким его написал пользователь, необходимо отметить его знаком важности. Перед словом необходимо указать восклицательный знак. Если слово написано с большой буквы, то именно так оно и будет встречаться в искомых документах.
Для поиска страниц, в которых поисковая фраза встречается в качестве единого целого, но не в разбавленном виде, то необходимо разделить все слова фразы ипендансом.
В обратном случае для разделения слов, чтобы они встречались не в одном предложении необходимо поставить перед ними тильду.
Если необходимо отыскать сразу несколько вариантов, то необходимо слова из поискового запроса разделить вертикальной чертой.
Бывают ситуации, когда требуется отыскать информацию только на конкретном языке. В этом случае необходимо использовать конструкцию: поисковая фраза или слово Lang:en. В такой ситуации будут показаны сайты по запросу на английском языке.
Таким же образом можно искать информацию только на определенных доменах. Тогда следует воспользоваться конструкцией: поисковая фраза или слов domain: РФ.
Данные методы расширения возможностей поисковика являются наиболее популярными. Их есть возможность сочетать между собой. Для того чтобы искать сложные фразы их можно определять в скобки.
Для тех пользователей, которым кажется невозможным запоминание всех данных методов упрощения поиска можно воспользоваться графическим расширенным поиском Yandex. Именно в данном разделе применены самые популярные поисковые запросы пользователей. Благодаря этому есть возможность правильно создать поисковую фразу. Помимо этого имеется возможность уменьшать количество результатов поиска, постепенно нажимая на раздел «в найденном».
Как осуществлять поиск информации в Google
В поисковике Google синтаксические особенности поисковых запросов очень часто имеют некоторые отличия от тех, которые применяются в Яндексе. Одним из примеров отличия является то, что вместо тильды для удаления слова использует знак минуса.
Тильда перед словами поискового запроса применяется для того, что в результатах поиска были выданы страницы с сайтами, содержащими синонимы необходимого слова или фразы.
Для поиска любого слова из определенной фразы в поисковой системе Google используется английский союз OR. Благодаря этому в результате будут найдены те страницы, которые содержат хотя бы одно из тех слов, которые необходимы пользователю.
В поисковике Google помимо всего прочего пользователям предлагается возможность использовать графический расширенный поиск. Это необходимо для пользователей, которые не могут запомнить необходимые для поиска наборы команд. В данной поисковой системе предоставляется возможность использования голосового поиска.
В данной поисковой системе предоставляется возможность использования голосового поиска.
Также современнее поисковики предлагают искать сведения в определенных разделах поиска. Для поиска фотографий и других изображений необходимо перейти в картинки. В результате поиска появятся только фото, которые релевантны поисковому запросу. Также таким образом есть возможность искать новости, блоги и многие другие категории для поиска. Они доступны для каждого поисковика в определенном списке.
Эти способы поиска в сети интернет являются одними из самых эффективных на сегодняшний день для облегчения процесса поиска нужной информации. Следует отметить, что разобраться с тем, как правильно составлять поисковый запрос является трудно выполнимой задачей. По данной теме написано большое количество книг. Однако заметно упростить себе жизнь есть возможность и с помощью данных способов.
Видео: Как искать в интернете?
 youtube.com/embed/ni6zx1h-1t8″ frameborder=»0″ allowfullscreen=»»/>
youtube.com/embed/ni6zx1h-1t8″ frameborder=»0″ allowfullscreen=»»/>
Твитнуть
Поделиться
Плюсануть
Поделиться
Класснуть
Сегодня имеется большое количество пользователей,которые ежедневно посещают огромное множество интернет ресурсов с самым разным контентом, но не всем известно, каким образом работает система описка информации в сети. Сеть 4.81 14 Идёт загрузка…|
Урок 7.
7.2. Поиск по ключевым словамНаиболее простым и результативным поиском является поиск по ключевым словам. Давайте подключимся к Internet, откроем программу Internet Explorer и введем в адресную строку адрес поисковой системы: http://www.yandex.ru. Мы подробно разберемся с правилами поиска по ключевым словам в поисковой системе Яндекс. В других системах эти правила могут отличаться, но основные положения будут идентичны. Мы
выбрали Яндекс, поскольку Яндекс – это весьма крупная и популярная
поисковая система. В течение дня Яндекс посещают, в среднем, не менее 75%
пользователей русскоязычной зоны Internet. Рис. 6.1. Заглавная страница поисковой системы Яндекс. Основной алгоритм поиска следующий:
После нажатия кнопки Найти, Яндекс выведет список ссылок на документы, наиболее точно соответствующие запросу, и Вы увидите следующее: Рис. 6.2. Результат выполнения запроса. Давайте
разберемся, какая информация содержится на данной странице. Здесь имеются
некоторые специальные обозначения и ссылки, предназначенные для облегчения
просмотра и сортировки найденных страниц.
Поскольку в системе Яндекс очень много различной информации, то результат поиска по фразе «расписание поездов» очень обширен, для облегчения нахождения нужной информации его следует уточнить, для этого давайте рассмотрим, что для этого предусмотрено в поисковой форме. Рис. 6.3. Поисковая форма системы Яндекс. Два
основных элемента в поисковой форме мы уже знаем, это поисковое поле и
кнопка Найти. Флажок «в найденном» позволяет искать в результатах
предыдущего запроса. Например, по запросу расписание поездов
система выдала 300 тыс. страниц, мы вводим следующий запрос дальнего
следования и устанавливаем флажок «в найденном» – теперь
поиск будет вестись среди этих 300 тыс. Ограничить область поиска можно, щелкнув по ссылкам Каталог, Новости, Маркет, Энциклопедии, Картинки. Щелчок по нужной ссылке заменяет нажатие кнопки Найти. Удобно сужать область поиска для нахождения картинок, например, введите в поисковое поле Путин и щелкните по ссылке Картинки. Для поиска картинки можно также указать желаемый размер картинки от значения «Мелочь» до «Огромные». Ограничивая область поиска, мы тем самым отсекаем часть заведомо ненужной нам информации. Но часто бывает необходимость вести поиск во всей базе, но для отсечения ненужной информации приходится вводить различные дополнительные сведения. Для этого служит Расширенный поиск. Он включается щелчком по ссылке «расширенный поиск», либо по значку «+». Рис. 6.4. Страница ввода условий расширенного поиска. Эта
страница позволяет Вам более тонко указать условия поиска.
В нижней желтой панели «Итого:» будет полностью сформулирован Ваш запрос. Поскольку мы ищем «свежее» расписание движения поездов, то можно воспользоваться условием Дата страницы. |

 Ежедневная аудитория Яндекса
составляет более 1 миллиона человек, а ежемесячная – около 8 миллионов.
Объем проиндексированной информации и включенной и поисковый индекс
составляет 5610 Гб – это 180 миллионов уникальных документов, расположенных
более чем на миллионе серверов, и, конечно, эти цифры постоянно растут.
Ежедневная аудитория Яндекса
составляет более 1 миллиона человек, а ежемесячная – около 8 миллионов.
Объем проиндексированной информации и включенной и поисковый индекс
составляет 5610 Гб – это 180 миллионов уникальных документов, расположенных
более чем на миллионе серверов, и, конечно, эти цифры постоянно растут.
 Сортировка по убыванию дат (первоначально список
сортируется по ревалентности, то есть по степени соответствия
результата запросу).
Сортировка по убыванию дат (первоначально список
сортируется по ревалентности, то есть по степени соответствия
результата запросу).
 страниц.
страниц. Важно то, что
найденные в результате документы будут соответствовать сразу всем
условиям, поставленным Вами. Давайте разберемся с особенностями ввода
условий расширенного поиска.
Важно то, что
найденные в результате документы будут соответствовать сразу всем
условиям, поставленным Вами. Давайте разберемся с особенностями ввода
условий расширенного поиска.
Поиск информации в Интернете. Windows Vista
Читайте также
Поиск информации в Интернете
Поиск информации в Интернете
Посещая Интернет, вы будете регулярно обращаться к функции поиска, чтобы найти сайты интересующей вас тематики. В Internet Explorer 7 эта процедура значительно упрощена по сравнению с предыдущими версиями благодаря встроенной строке поиска.
Глава 5 Поиск в Интернете
Глава 5 Поиск в Интернете • Поисковые серверы. Некоторые правила поиска• Поисковые запросы: подробно• Поиск рисунков• Поиск музыки и видео• Поиск по FTP-серверам• Альтернативные средства поиска• «Википедия» – живая энциклопедия и ее альтернативыПроблема поиска во
5.3. Поиск в Интернете
5.3. Поиск в Интернете Поиск информации в Интернете считается наиболее сложным типом поиска. Особенно сильно это чувствуется, если нужно найти что-то конкретное. Причина сложности заключается даже не в том, что в Интернете существуют миллиарды страниц, а вам нужно найти
Особенности распространения информации в Интернете
Особенности распространения информации в Интернете Информация в Интернете распространяется очень быстро
Любой компьютер, подключенный к Сети, в принципе может получить доступ на сайт, расположенный физически сколь угодно далеко. С точки зрения скорости работы, нет
С точки зрения скорости работы, нет
1.6. Поиск информации
1.6. Поиск информации Не вызывает сомнений необходимость автоматизации поиска заданных текстовых фрагментов в текстах на естественном языке.Однако часто даже при поиске информации другого рода (например, аудио- и видео-) работа на самом деле ведется с описаниями на
Глава 10 Поиск информации в Интернете
Глава 10 Поиск информации в Интернете • Поиск в Интернете: общие понятия• Виртуальные библиотеки• Форматы электронных книг• Поиск рефератов• Поиск в библиотекахДля многих людей на сегодняшний день Интернет стал обязательным источником информации. Если раньше при
Глава 3 Поиск в Интернете
Глава 3
Поиск в Интернете
Поисковые серверы. Некоторые правила поискаПоисковые запросы: подробноАльтернативные средства поискаПоиск рисунков в ИнтернетеПоиск музыки и видеоПоиск по FTP-серверамПроблема поиска во Всемирной паутине не в том, что информации мало, а в том,
Некоторые правила поискаПоисковые запросы: подробноАльтернативные средства поискаПоиск рисунков в ИнтернетеПоиск музыки и видеоПоиск по FTP-серверамПроблема поиска во Всемирной паутине не в том, что информации мало, а в том,
Поиск рисунков в Интернете
Поиск рисунков в Интернете Миллиарды картинок, хранящихся в Сети, могут быть использованы с самыми разными целями: в качестве рисунка Рабочего стола, как иллюстрация к научной или другой работе, для создания собственных открыток или презентаций и т. д. Искать рисунки
Эффективный поиск в Интернете
Эффективный поиск в Интернете
Еще несколько лет назад, выбирая поисковик, большинство из нас смотрело на то, сколько сайтов в его базе. Считалось, что чем больше страниц проиндексировано, тем выше шанс что-нибудь найти в Интернете. Сегодня все изменилось. Всемирная сеть
Сегодня все изменилось. Всемирная сеть
Глава 9 Поиск информации в Интернете
Глава 9 Поиск информации в Интернете Для очень многих людей Интернет стал на сегодняшний день обязательным источником информации. Если раньше при написании работы, да и просто при необходимости что-то узнать, пользовались справочниками, каталогами, книгами и журналами,
Поиск сотрудников в Интернете
Поиск сотрудников в Интернете Как отмечалось выше, многие кадровые агентства, не мудрствуя лукаво, выискивают своим клиентам сотрудников в Интернете – на сайтах по трудоустройству, досках бесплатных объявлений, и т. д. При этом за свои услуги такие агентства берут
Глава 2 Поиск информации в Интернете
Глава 2
Поиск информации в Интернете
Любая область человеческой деятельности в том или ином виде нашла свое отражение в Интернете. Важнейшая задача — уметь быстро найти то, что интересует именно вас. Сейчас проводятся международные соревнования по поиску информации.
Важнейшая задача — уметь быстро найти то, что интересует именно вас. Сейчас проводятся международные соревнования по поиску информации.
10.2. Поиск информации в Интернете
10.2. Поиск информации в Интернете 10.2.1. Поисковые машины Интернет содержит огромное количество информации. Ведь в Интернете создать сайт может любой желающий, поэтому количество новых сайтов растет с каждым днем. Для поиска в Интернете используются поисковые
6.2. Адреса сайтов, поиск информации в Интернете
6.2. Адреса сайтов, поиск информации в Интернете
Каждая страница в Сети имеет свой адрес, который обычно указывается в адресной строке браузера. Также имеет адрес и каждый сайт. Возьмем для примера адрес моего старого сайта — http://www. egorov.tvernet.ru. Данный адрес состоит из
egorov.tvernet.ru. Данный адрес состоит из
Поиск в Интернете
Поиск в Интернете Для поиска информации в Интернете используются специальные поисковые серверы: www.google.com, www.yandex.ru и многие другие. В Internet Explorer 7 имеется встроенная строка поиска, с помощью которой можно отсылать поисковые запросы на любой сервер и сразу же получать
Поиск в Интернете
Поиск в Интернете Итак, мои самые обаятельные и любознательные, Интернет – это просто золотое дно для нас. Здесь можно найти все, что угодно. Нет, конечно, ту чертову сережку, которая куда-то запропастилась еще в прошлом году, мы вряд ли там найдем. А вот информацию о чем
Свободное API для поиска в интернете / Хабр
Во время разработки некоторых проектов может понадобиться удобное API для поиска в интернете.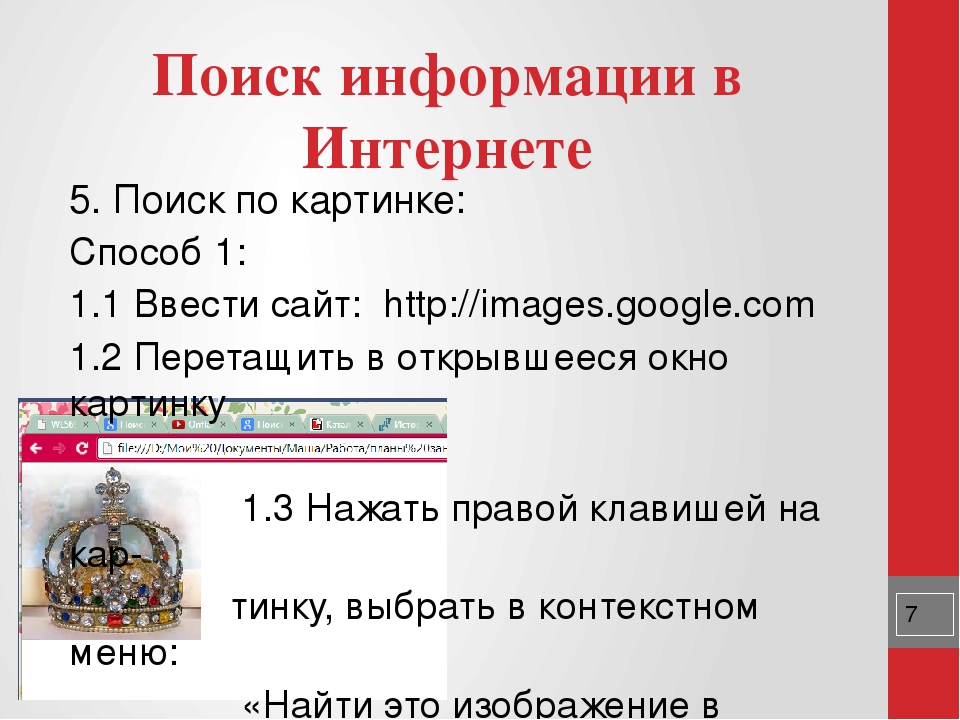 К сожалению, популярные поисковики, такие как Google и Яндекс, не дают свободного доступа к своей поисковой выдаче.
К сожалению, популярные поисковики, такие как Google и Яндекс, не дают свободного доступа к своей поисковой выдаче.
На замену закрытым API приходит Searx.
Searx — это свободная поисковая система, объединяющая результаты других поисковых систем, но не хранящая информацию о своих пользователях.
Создать свой инстанс Searx может каждый. Полный их список есть на сайте searx.space. Для своих целей мы будем использовать Roughs Searx, так как он никак не ограничивает число запросов и позволяет получать поисковую выдачу даже с помощью автоматизированных скриптов.
Адрес API-сервиса: https://searx.roughs.ru/search
Поддерживаются как GET, так и POST запросы.
Параметры запроса
q — (обязательно) Текст запроса, результаты которого нужно получить.
format — (обязательно) Формат вывода результатов. Доступные форматы: json, csv, rss.
categories — Список категорий поиска, разделенных запятыми.

safesearch — Фильтр безопасного поиска. 0 — выключен, 1 — включен.

С полным списком параметров можно ознакомиться на этой странице.
Примеры запросов
Найти новость по запросу «Технологии» и вывести результат в формате RSS:
https://searx.roughs.ru/search?q=Технологии&format=rss&categories=news
Выполнить поиск картинок по запросу «Горы» с фильтром безопасного поиска и вывести результаты в формате json:
https://searx.roughs.ru/search?q=Горы&format=json&categories=images&safesearch=1
Найти решение для «2+2*2» с помощью WolframAlpha и получить ответ в формате таблицы CSV:
https://searx.roughs.ru/search?q=2+2*2&engines=wolframalpha&format=csv
Бюро переводов: Статья — Лингвистический поиск в Интернет.
 youtube.com/embed/4D4u-auXNcI» frameborder=»0″ allowfullscreen=»»>
youtube.com/embed/4D4u-auXNcI» frameborder=»0″ allowfullscreen=»»>
При всем многообразии словарей и энциклопедий ценность Интернета для переводчика далеко не исчерпывается справочными ресурсами. Фактически вся совокупность размещенных в Сети страниц представляет собой колоссальный корпус текстов, охватывающий собой все мыслимые темы. Современные поисковые системы позволяют весьма эффективно использовать его для лингвистических изысканий.
Здесь имеет смысл сказать несколько слов о принципах работы поисковых систем. Каждая такая система представляет собой обширную базу данных, в которой хранятся копии вэб-страниц, размещенных на миллионах сайтов по всей Сети. Программа-робот (web crawler) постоянно пополняет эту базу, путешествуя по Всемирной паутине и переходя от страницы к странице, от сайта к сайту по гипертекстовым ссылкам. Все найденные страницы автоматически индексируются, что и позволяет в дальнейшем мгновенно находить нужную информацию: при получении запроса пользователя программа уже не просматривает сотни миллионов страниц, а находит ключевые слова в алфавитном индексе и выдает ссылки на страницы, где эти слова присутствуют.
Использование поисковых сайтов позволяет очень быстро, порой всего за несколько минут, найти ответы на самые разнообразные вопросы и справиться с многочисленными переводческими проблемами, которые раньше были неразрешимы без обращения к носителю языка или к специалисту в той или иной предметной области. Все это позволяет радикально повысить качество перевода, особенно при переводе текстов с родного на иностранный язык — что в России, особенно в сфере делового перевода, происходит едва ли не чаще, чем перевод с иностранного на родной, — а также в тех областях, где идет постоянное обновление терминологии: компьютеры и телекоммуникации, бизнес и финансы, СМИ, международные отношения, фармацевтика и многих других. Кроме того, даже самый опытный переводчик, делающий переводы только на родной язык и только в той области, в которой он специализируется уже 20 лет, с неизбежностью и регулярно встречает неизвестные ему термины из смежных областей, загадочные сокращения, неологизмы, профессиональный сленг и т. д. — то, чего днем с огнем не найти даже в самых современных словарях.
д. — то, чего днем с огнем не найти даже в самых современных словарях.
В этой ситуации Интернет — настоящий подарок для переводчика. Ему больше не нужно изобретать велосипед или судорожно вспоминать, есть ли среди его знакомых специалист по вентиляторам и системам кондиционирования. Ему достаточно войти в Сеть и набрать несколько ключевых слов в поисковой системе — и вся терминология у него перед глазами. Главное, что для этого необходимо — владение эффективными технологиями поиска.
В заключение следует сказать, что переводчик тоже в каком-то смысле необходим интернету. Как часто нам для сайтов нужен уникальный текст — и тут на помощь приходят иностранные сайты. Достаточно выполнить их перевод на русский язык — и вам не понадобится копирайтер. Ведь переводной контент — он по определению считается поисковыми системами уникальным. Ведь поисковики еще не научились понимать смысл текста (да и вряд ли вообще научатся), а тем более на разных языках. Так что переводите — и наполняйте свои сайты!
Специалист рассказал, какие слова лучше не искать в интернете
МОСКВА, 7 мар – ПРАЙМ. Все мы пользуемся поисковыми сервисами для работы или чтобы скоротать время. Большинство запросов находятся в правовом поле и не несут за собой никаких рисков, но существуют и запретные темы, которые порой выглядят неочевидно, рассказывает агентству «Прайм» партнер и директор компании «Интеллектуальный Резерв» Павел Мясоедов.
Все мы пользуемся поисковыми сервисами для работы или чтобы скоротать время. Большинство запросов находятся в правовом поле и не несут за собой никаких рисков, но существуют и запретные темы, которые порой выглядят неочевидно, рассказывает агентству «Прайм» партнер и директор компании «Интеллектуальный Резерв» Павел Мясоедов.
Эксперт объяснил, почему не стоит писать свои имя и фамилию в интернете
Большинство таких запретов известны всем: поиск в интернете наркотических средств, детской порнографии, запросы по террористической и преступной деятельности. Любые слова, которые связаны с этим, должны вызвать настороженность.
«Конечно, сам по себе поиск даже по запретным темам не является преступлением, но последующее скачивание информации и её использование вполне может подпадать под Уголовный кодекс. Вопрос будет лежать в плоскости намерений пользователя и трактования закона», — отмечает эксперт.
Более того, в целях профилактики преступлений активность пользователей в интернете периодически мониторится правоохранительными органами.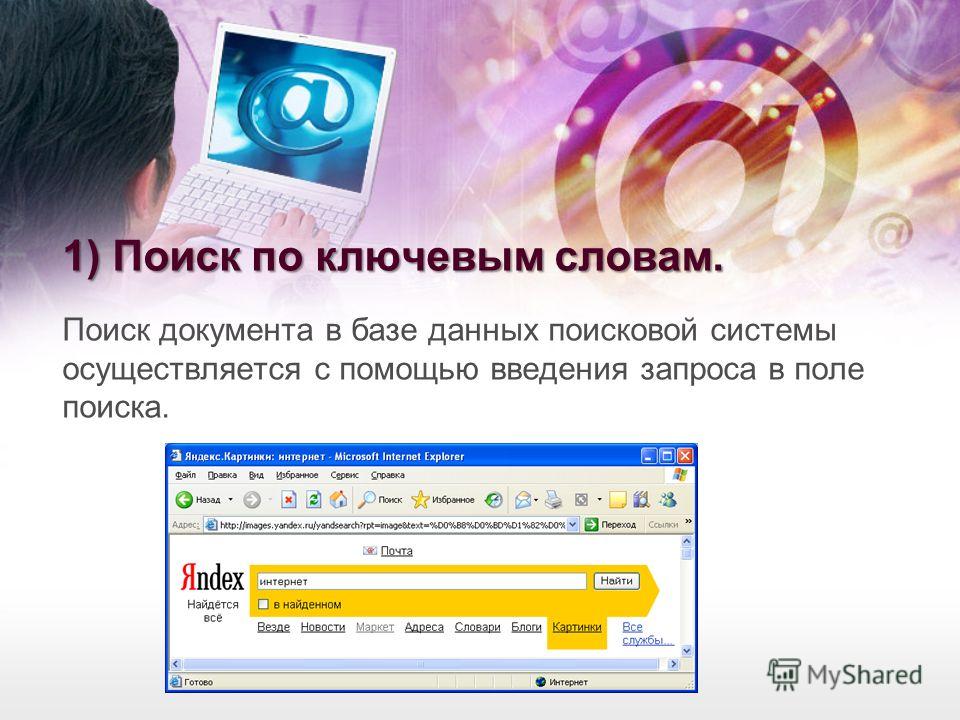 История поисковых запросов в данной ситуации может быть признаком преступных намерений человека.
История поисковых запросов в данной ситуации может быть признаком преступных намерений человека.
По словам специалиста, известны случаи, когда действия на финансовых рынках в виде покупки ценных бумаг признавались инсайдерской торговлей, которая нелегальна, на основании истории поиска на компьютере финансиста.
Поиск ссылки на скачивание пиратского фильма формально тоже указывает на нарушение закона. Но количество таких запросов, степень общественного вреда и вероятность последующего правонарушения могут отличаться от случая к случаю.
Специалист предупредил, какие сообщения в телефоне нужно срочно удалять
«Важно сохранять здравый смысл. В исследовательских целях, для написания научной работы по химии, например, студент вынужденно может касаться подозрительных тем в интернете, но в контексте его личности и профессии у этого есть оправдание. А вот целенаправленный поиск нелегального контента обычным человеком уже вызовет вопросы, поэтому острых и нелегальных тем, даже в рамках обычного любопытства, в интернете лучше избегать», — заключил эксперт.
Поиск в Интернет. Русскоязычные системы поиска :: Федеральный образовательный портал
Опубликовано на портале: 28-05-2004
Ольга Владиславовна Леонова Университетское управление. 1997. № 3(3). С. 41-52.Тематический раздел:
Сегодня в России уже несколько десятков тысяч серверов, а число пользователей, работающих в режиме онлайн, превысило стотысячный рубеж.
Интернет предоставляет информационный сервис, которым могут воспользоваться как компании, так и отдельные граждане, как для работы, так и для повседневной жизни (например, поисковые системы и базы данных или электронные формы для заказа товаров). Основной вопрос, который сегодня стоит перед пользователями Интернет: как найти и получить необходимую информацию? В статье объясняется устройство и возможные варианты поиска нужной информации в Интернете.
О.В. Леонова
ведущий математик ЦКТ
Уральского государственного университета.
ПОИСК В ИНТЕРНЕТ.
РУССКОЯЗЫЧНЫЕ СИСТЕМЫ ПОИСКА.
Сегодня в России уже несколько десятков тысяч серверов, а число пользователей, работающих в режиме on-line, превысило стотысячный рубеж.
Все эти компьютеры предоставляют информационный сервис, который компании или отдельные граждане могут использовать в работе и повседневной жизни, например, поисковые системы и базы данных или электронные формы для заказа товаров. Основной вопрос, который сегодня стоит перед пользователями Интернет, — как найти и получить необходимую информацию.
За годы развития Интернет были разработаны различные средства доступа к информации. Это такие виды сетевого взаимодействия как
- FTP, Gopher — системы передачи информации
- Archie, WAIS, Veronica — системы поиска информации в сети
- Telnet, E-mail, UseNet, IRC — коммуникационные сервисы
- WWW (World Wide Web) — мультимедиа система
World Wide Web («Всемирная паутина») возникла в 1994 году в CERN (Европейская
лаборатория физики элементарных частиц). Ее появление было вызвано необходимостью
единообразного способа доступа к различным видам информации (текстам, графическим
изображениям, звуковым фрагментам), не требуя при этом выполнения большого количества
действий и специальной подготовки со стороны пользователя.
Ее появление было вызвано необходимостью
единообразного способа доступа к различным видам информации (текстам, графическим
изображениям, звуковым фрагментам), не требуя при этом выполнения большого количества
действий и специальной подготовки со стороны пользователя.
Для работы с системой WWW вам необходимо установить на своем компьютере WWW-browser
(WWW-браузер) — специальную программу просмотра. Браузер — это программа
— клиент, которая взаимодействует с системой WWW, получает затребованные вами документы
и отображает их на экране. Документы, используемые системой WWW, называются гипертекстовыми
документами. Гипертекст — это текст, который внутри себя содержит ссылки на другие документы. При подготовке документов для WWW используется специальный
язык HTML (HyperText Markup Language — язык разметки гипертекста). HTML — стандарт,
который представляет собой набор команд, описывающих структуру документа. Конкретный
вид документа определяет программа-браузер, которая интерпретирует HTML-документ
и отображает его на экране в отформатированном виде. Команды HTML вставляются в текст
и определяют, наряду с внешним видом документа, логический статус отдельных фрагментов
текста. Например, среди команд HTML есть команда для выделения названия документа
(<TITLE>), есть команды для выделения заголовков различных уровней внутри документа
(<h2>, <h3>, <h4>, ), есть команды, позволяющие вставить в документ
другие объекты (изображения, звуки, анимацию), команды, с помощью которых устанавливаются
гипертекстовые связи с другими документами — ссылки (<A>) и т.д.
Команды HTML вставляются в текст
и определяют, наряду с внешним видом документа, логический статус отдельных фрагментов
текста. Например, среди команд HTML есть команда для выделения названия документа
(<TITLE>), есть команды для выделения заголовков различных уровней внутри документа
(<h2>, <h3>, <h4>, ), есть команды, позволяющие вставить в документ
другие объекты (изображения, звуки, анимацию), команды, с помощью которых устанавливаются
гипертекстовые связи с другими документами — ссылки (<A>) и т.д.
С помощью WWW-браузера возможно пользоваться также другими сервисами Интернет. Например, два наиболее популярных сейчас браузера Netscape Navigator и Microsoft Internet Explorer позволяют обращаться к анонимным Gopher-, Wais-, FTP-серверам, серверам телеконференций UseNet, пользоваться электронной почтой (E-mail), а также дают возможность доступа к удаленному компьютеру по протоколу Telnet.
По мере развития Интернет увеличивается объем информации в ней содержащейся и
вместе с этим возникает проблема поиска нужной информации. Таким образом, вероятность
существования необходимой информации возрастает, а возможность ее нахождения уменьшается.
Теоретически гипертекстовая природа WWW обеспечивает нахождение любой информации
в процессе целенаправленного продвижения по ссылкам. Однако, среди более 60 млн.
документов (а именно столько документов, по некоторым оценкам, существует сегодня
в Интернет), найти нужный документ, продвигаясь от ссылки к ссылке, практически невозможно.
Таким образом, вероятность
существования необходимой информации возрастает, а возможность ее нахождения уменьшается.
Теоретически гипертекстовая природа WWW обеспечивает нахождение любой информации
в процессе целенаправленного продвижения по ссылкам. Однако, среди более 60 млн.
документов (а именно столько документов, по некоторым оценкам, существует сегодня
в Интернет), найти нужный документ, продвигаясь от ссылки к ссылке, практически невозможно.
Перед тем как перейти к вопросу о том, как правильно искать в Интернет нужный вам документ, необходимо разобраться в том, где искать. Прежде всего, необходимо классифицировать информационные ресурсы Интернет.По способу представления информации все информационные ресурсы можно разделить следующим образом:
- Web-ресурсы
- Базы данных
- Файловые серверы
- Телеконференции (UseNet)
- Gopher-серверы
Все чаще WWW интерфейс используется как стандартный метод доступа к остальным
ресурсам. Методы поиска информации могут быть различны. Как уже отмечалось, есть
возможность искать необходимую вам информацию переходя от ссылки к ссылке, т.е. вручную.
Однако, учитывая размеры Интернет, можно предположить, что вероятность найти нужный
документ очень низкая. Лучший вариант — воспользоваться специально предназначенным
для этого сервером Интернет. Сервер — это компьютер, программа, а также набор
данных. Сервер (или сайт) обеспечивает определенный сервис в Интернет. Здесь можно
провести аналогию с поиском книги в библиотеке. Для того, чтобы книгу или статью
легко было найти, ей присваивается уникальный идентификатор, состоящий из букв и
цифр. Таким образом, зная название книги, библиотекарь легко найдет ее среди бесчисленного
множества других. Поисковый сервер занимается тем, что собирает данные в Интернет,
а затем позволяет этими данными воспользоваться. Сегодня поисковых серверов насчитывается
свыше 120. Наиболее полный их список есть по адресу http://ugweb.
Методы поиска информации могут быть различны. Как уже отмечалось, есть
возможность искать необходимую вам информацию переходя от ссылки к ссылке, т.е. вручную.
Однако, учитывая размеры Интернет, можно предположить, что вероятность найти нужный
документ очень низкая. Лучший вариант — воспользоваться специально предназначенным
для этого сервером Интернет. Сервер — это компьютер, программа, а также набор
данных. Сервер (или сайт) обеспечивает определенный сервис в Интернет. Здесь можно
провести аналогию с поиском книги в библиотеке. Для того, чтобы книгу или статью
легко было найти, ей присваивается уникальный идентификатор, состоящий из букв и
цифр. Таким образом, зная название книги, библиотекарь легко найдет ее среди бесчисленного
множества других. Поисковый сервер занимается тем, что собирает данные в Интернет,
а затем позволяет этими данными воспользоваться. Сегодня поисковых серверов насчитывается
свыше 120. Наиболее полный их список есть по адресу http://ugweb. cs.ualberta.ca/~mentor02/search/search-all.html.
Остается только выбрать, какому из них отдать предпочтение.
cs.ualberta.ca/~mentor02/search/search-all.html.
Остается только выбрать, какому из них отдать предпочтение.
Чтобы определить, на каком поисковом сервере остановить свой выбор, необходимо знать, как организован сбор информации для этих серверов. Для того, чтобы поисковая система отвечала своему назначению, информация должна быть предварительно накоплена и просмотрена. Есть два основных способа сбора информации для систем поиска и связанных с ними способа организации собранной информации.
- Первый способ — ручной сбор информации — означает, что все документы последовательно
просматриваются группой специалистов.
Такой подход предполагает организацию поисковой системы как предметно-ориентированной, где информация по определенным темам собрана в соответствующих каталогах. Примерами таких каталогов являются: Yahoo! (http://www.yahoo.com/), Magellan (http://www.mckinley.com/) — среди зарубежных каталогов; Созвездие Интернет (http://www.stars.ru/), Russia on the Net (http://www.ru/), «Ау!» (http://www.rocit.ru/) — среди российских каталогов. - Сбор информации с помощью роботов (search robots). В этом случае поисковая система представляет собой Search Engine (SE) — машину поиска. Вся предварительная работа по просмотру документов выполняется поисковым роботом. Робот — это программа, которая автоматически просматривает структуру всех гипертекстовых ссылок и индексирует содержимое всех обнаруженных по ссылкам документов. При индексации фиксируются положения всех более или менее значащих слов, которые называются ключевыми (к «неключевым» словам относятся союзы, предлоги, местоимения и т.д.). После разбора документа робот включает его в свою базу данных. В данном случае пользователь будет иметь дело с SE, обращаться к базе данных которой можно только посредством специального интерфейса.
Этот подход требует очень большой доли труда квалифицированных специалистов. Однако документы, просмотренные и разобранные таким образом, более адекватны теме.
Информация, собранная роботом, имеет больший объем, чем при ручном сборе, поскольку количество документов, которые просматривает робот, может быть любым. Однако в этом случае формальным критерием оценки документов служат отдельные слова, а также то, как часто они встречаются в документе, в какой части документа они находятся и т.д. в зависимости от алгоритма, а не общий смысл документа. Поэтому, разные по смыслу документы могут быть объединены по формальным признакам. По этой причине среди найденных документов может быть много совершенно не относящихся к теме поиска. В этом отличие SE от ручного сбора информации.
Общее количество известных программ-роботов уже превышает 150. Каждый робот использует свой алгоритм просмотра и индексации документов, поэтому информация, накопленная двумя разными роботами, может быть различна. Это означает, что использование одних и тех же ключевых слов в различных SE приведет к разным результатам. Важно знать также, что с помощью SE возможен поиск как среди HTML-документов на WWW-серверах, так и среди других типов документов и на других типах серверов.
Рассмотрим самые популярные машины поиска. Качество, а значит, и популярность поисковой машины определяются несколькими параметрами:
- размером базы данных SE (т.е. пространством проиндексированных документов)
- процедурой создания запросов к данной SE
- характером выдаваемой информации (ранжирование, фрагменты текста, краткое содержание и т.п.)
- скоростью обработки запроса
- обратной связью (возможность уточнения результатов поиска)
Российские системы поиска.
Для поиска документа на русском языке лучше воспользоваться русской поисковой системой. Если известна тематика искомого документа или можно оценить, на каком сервере он может находиться, но неизвестен адрес этого сервера, тогда лучше будет использовать какой-нибудь тематический каталог (или, рубрикатор). Пользоваться таким предметным каталогом несложно. Рассмотрим один из каталогов в русской части Интернет.
«Созвездие Интернет»
(http://www.stars.ru/).
Слева на экране находятся темы, по которым рассортированы все ресурсы, зарегистрированные в каталоге: поисковые сервисы и каталоги, компьютеры и технологии, экономика и бизнес, политика и право, культура и искусство, образование и наука, средства массовой информации, техника и транспорт, медицина и здоровье, отдых и развлечения, разное. Кроме того, вы можете воспользоваться быстрым поиском. Дело в том, что при регистрации ресурса в этом каталоге для каждого ресурса вводятся слова с его описанием. На первой же странице каталога появляется строка для ввода с предложением ввести слово в описании ресурса. Наберите, например, в поле для ввода слово управление, и нажмите кнопку ПОИСК. На экране появится сообщение о том, сколько ресурсов, содержащих в описании слово управление имеется в данном каталоге. Ниже будет выведена таблица (по 10 ресурсов на страницу), в левой части которой название сервера и ссылки на первую страницу данного сервера, или несколько первых страниц для различных кодировок: Win (windows-1251), KOI (koi8-r — кодировки русского языка, Eng (english) — английского языка.
Теперь рассмотрим, как пользоваться поисковой машиной (SE). Для того чтобы эффективно пользоваться SE, необходимо помнить, что на каждой поисковой машине существует свой язык запросов к накопленной ею базе данных. Поэтому, зайдя на поисковый сервер, прежде чем формировать запрос, надо посмотреть ссылку «Помощь» (или «Help») с описанием порядка формирования запросов. В этой статье приводится описание языка запросов для нескольких поисковых машин. Отличием русских поисковых машин является то, что с их помощью, в отличие от иностранных SE, можно искать документы, набирая русские ключевые слова в поле запроса. Особенности морфологии русского языка накладывают определенные требования на SE, которые используются для индексации русской части Интернет. Если в английском языке достаточно поменять окончание, чтобы найти различные варианты одного и того же слова, то в русском языке может изменяться все слово целиком. С этим связаны трудности индексации и поиска русских документов в Интернет.
Машина поиска Rambler
(http://www.rambler.ru).
Данная система служит для поиска документов на серверах России и стран СНГ. В ее базе данных содержится более 2,000,000 документов (адресов URL1) с более чем 15,000 хостов (имен DNS2). Имеет развитый язык запросов и гибкую форму вывода результатов. Однако морфологический разбор слова не производится.
ПРОСТОЙ ЗАПРОС
В простом запросе вы можете использовать одно или несколько слов, разделенных пробелами. Могут быть использованы как русские, так и английские словосочетания. По умолчанию, если вы не используете расширенный поиск и не отметили в нем, что должно встретиться любое слово, считается, что в найденных документах должны содержаться все слова. После того, как вы ввели ключевые слова, нажмите правой кнопкой мыши на надписи «Поиск», которая расположена справа. Кроме простого ввода слов, вы можете использовать язык запросов, принятый для поиска документов на «Rambler». В этой таблице коротко описаны элементы этого языка.
| Элементы | Пояснение | Примеры |
| Логические связки: And, Or, Not. | Поисковые термины могут быть объеденены логическими операциями посредством служебных слов And, Or и Not. Символы ‘&’, ‘|’ и ‘!’ могут использоваться в сочетании со служебными словами или вместо них. | Управление and законодательство not бюджет Во всех найденных документах будут присутствовать слова управление и законодательство и отсутствовать слово бюджет. |
| Регистр букв. | Любой поисковый термин может содержать в себе как заглавные, так и прописные символы. Индекс базы данных строится с приведением слов к прописным символам. | Федеральный бюджет или федеральный Бюджет Будут найдены одни и те же документы. |
| Усечение слов. * и ? | Возможно использование метасимволов ‘*’ и ‘?’ для обозначения произвольной части слова и произвольного символа слова. По умолчанию система ищет документы с теми ключевыми словами, которые вы ввели. | орган?зация and управлен* and ВУЗ Знак ? используется, если нет уверенности в написании слова. Знак * заменяет несколько букв слова. |
| Весовые коэффициенты. + и — | Вы можете использовать ‘+’ и ‘-‘ для увеличения/уменьшения весового значения любого слова. Возможно многократное использование данных символов. | —система and ++управлен* Слово система будет иметь меньший вес, поэтому документы с этим словом будут расположены после слов, начинающихся на управлен |
| Поиск в части документа. $спец.слово | Для этого вы можете использовать специальные слова: $All (используется по умолчанию), $URL, $Title, $Header, $Essence, $Address. Специальные слова начинаются с символа ‘$’. | $TITLE: управление and $URL: virlib.eunnet.net Будут найдены документы, у которых в поле заголовка есть слово управление и они содержат ссылку на сервер с адресом http://virlib.eunnet.net/ |
| Логические группы. ( ) | Термины могут быть сгруппированы посредством использования символов ‘(‘ и ‘)’. Возможна многократная вложенность скобок в сочетании с логическими операторами. | управленческие and(функции or полномочия) |
Вывод результатов поиска.
На одну страницу будет выведено15 первых из всех найденных документов, а внизу страницы (если общее число найденных документов больше 15) появится стока со ссылками на страницы с остальными найденными документами: по 15 документов на страницу. «Rambler»производит ранжирование найденных документов в зависимости от частоты употребления и местоположения искомых слов. В начале списка будут выведены документы, наиболее полно удовлетворяющие запросу. После заголовка документа, который одновременно является ссылкой на данный документ, в скобках будет стоять число — 1,0000, что означает максимальное соответствие запросу, и ниже. Далее следует несколько первых строк документа, его адрес в явной форме, дата его создания или модификации, объем файла, в скобках вид кодировки. Если адресов у документа несколько, это означает что, либо найдены полностью идентичные документы, либо это один и тот же документ, но в разных кодировках.
ДЕТАЛЬНЫЙ ЗАПРОС
Механизм составления детального запроса реализован через меню.
Ключевые слова набираются в поле запроса через пробел. Под строкой для ввода ключевых слов можно выбрать позиции для поиска.
- Поиск в: Российский Web, Российский Usenet, имена URL (адреса), название документов, заголовках документов, начале документов, поле адресов. Выбрав одно из полей, можно ограничить область поиска документа: www серверами; телеконференциями Usenet; адресами серверов Интернет; именами файлов; полями <TITLE> в гипертекстовых документах; первыми абзацами документов.
- Кол-во: 15, 30, 50. Количество результатов, которые будут выводиться на одну страницу.
- Слова. Логические операции над ключевыми словами. Опция «Все» означает, что в каждом найденном документе будут все ключевые слова (аналог and и &). «Любое» означает, что в каждом найденном документе будет присутствовать хотя бы одно из ключевых слов (аналог or и |).
- Форма вывода результатов. Нормальная форма (используется по умолчанию при простом запросе): заголовок, показатель соответствия запросу (числовой и в виде точек), первые строки документа, URL документа, дата создания, объем, кодировка. Краткая форма: заголовок, степень соответствия запросу. Детальная форма: более подробная информация о документе, например, перечислены все заголовки, а также когда документ последний раз проверялся роботом.
- Расширить слова. Опция «нет» означает, что искать надо строго по введенным ключевым словам, не добавляя окончаний. «Да» — добавить к введенным ключевым словам все возможные окончания (аналог *).
- От даты: До даты: Например, От даты: 21/Mar/96 До даты: 1/Jan/98. Будут найдены документы, созданные или модифицированные в период с 21 марта 1996 г. до 1 января 1998 г.
- Исключить документы, содержащие следующие слова. Слова, которые будут введены в этом поле, будут отсутствовать в найденных документах.
- Сайт или часть URL, в которых произвести поиск. Можно ограничить поиск только одним сервером (сайтом), набрав в этом поле его URL или несколькими сайтами, введя только часть URL, а не искать во всей базе данных поисковой машины. Например, www.stack.net, gopher://gopher.dux.ru/, ua.
Главный недостаток «Rambler» — невозможность осуществлять поиск по целой фразе или хотя бы указывать в запросах предельное расстояние между искомыми терминами. Случайное сочетание совершенно не связанных слов, например, в начале и конце текста, приводит к выдаче ссылок на документы, совершенно не релевантные запросу. Несовершенный метод ранжирования результатов по степени соответствия запросу приводит к тому, что искомые документы часто оказываются не в начале списка.
«Апорт!»
(http://www.aport.ru/).
Поиск ведется по 1 327 132 документам (2 759 935 URL, 10 971 сервер). Это данные на 1998-02-28. Вы можете набрать интересующие вас ключевые слова через пробел. Машина найдет все документы, в каждом из которых содержатся все введенные слова. Важное достоинство «Апорт» — поиск с учетом морфологии русского языка. Вы можете вводить слова в любой грамматической форме. Например, запрос университетское управление будет полностью эквивалентен запросу университетским управлением. Кроме того, английские слова могут указываться в запросе наравне с русскими.
В таблице — краткое описание языка запросов поисковой машины «Апорт».
| Логические операторы: и, или | Оператор и подразумевается (т.е. действует по умолчанию), его можно опускать: запрос университетское управление полностью эквивалентен университетское и управление. По любому из этих запросов будут найдены документы, содержащие оба слова. По запросу университетское или управление будут найдены документы, содержащие хотя бы одно из указанных слов. |
| Двойные кавычки » » | Двойные кавычки следует использовать, если вы хотите искать словосочетание. По запросу «университетское управление» будут выданы только документы, содержащие указанное словосочетание (возможно, в разных грамматических формах), тогда как по запросу университетское управление будут выданы и те документы, где заданные слова стоят далеко друг от друга и, может быть, даже в обратном порядке. |
| Круглые скобки ( ) | Круглые скобки задают порядок действия логических операторов. По запросу быстрый или качественный поиск будут выданы документы, содержащие либо слово «быстрый«, либо одновременно слова «качественный» и «поиск» (оператор и действует первым). По запросу (быстрый или качественный) поиск будут выданы документы, где встречаются одновременно слова «быстрый» и «поиск«, либо «качественный» и «поиск«. |
| Фигурные скобки { } | Фигурные скобки ограничивают расстояние между словами, задавая его числом предложений. Запросу {3, управленческие функции} будут соответствовать документы, где слова « управленческие» и «функции» встречаются в пределах трех соседних предложений. Цифра (вместе с запятой) может опускаться, тогда подразумевается 1, то есть слова должны встречаться в одном предложении: {управленческие функции. |
| Квадратные скобки [ ] | Квадратные скобки аналогичны фигурным с той лишь разницей, что расстояние между словами измеряется не в предложениях, а в словах. По запросу [4, уголовные преступления] будут найдены документы, где между словами стоит не более двух посторонних слов. |
Для поиска по URL используйте оператор URL (в форме URL: или URL=). Если надо найти упоминания адреса сервера в текстах документов, рекомендуется использовать поиск в пределах предложения с заменой ‘/’ на пробелы.
Например, {UniMgmt.EUNnet.net unimng}.
Не используйте в запросе так называемые «стоп-слова». К «стоп-словам» относятся предлоги, союзы, междометия и т.д. Если вы укажете в запросе слово пожалуйста, то «Апорт» не найдет никаких документов.
Дополнительные возможности.
- Исправлять ошибки в запросе. Если вы не уверены в правильности написания ключевых слов, вы можете выбрать эту опцию. Машина автоматически исправит ошибки.
- Очистить историю запросов. Все предыдущие запросы сохраняются.
- Форма результата. Предлагается возможность гибкого указания формы выдачи результатов поиска.
- Перевод запроса. Автоматического перевода запроса с русского на английский и наоборот. В поисковую строку можно ввести термины на любом из двух языков и выбрать из меню условие: искать только на английском, на английском и русском, только на русском.
- Перевод результата. Возможно указать необходимость перевода результатов на английский, русский, либо не переводить.
Результат поиска.
По 10 на страницу. Название документа, дата создания, ссылка на документ в явном виде (URL документа), кодировка, степень соответствия запроса (в процентах), количество предложений, соответствующих запросу. Есть возможность посмотреть на реконструкцию текста (т.е. не весь текст, а только его реконструкция). «Апорт!» показывает фрагмент текста, который удовлетворяет искомому запросу.
Недостатком «Апорт!» является невозможность управлять ранжированием результатов.
Яndex
(http://yandex.ru/).
Проанализировано 12043 серверов. Накоплена информация о 2 402 168 ссылок (URL). Область поиска этой SE — «русская Интернет», т.е. домены верхнего уровня ‘su’ и ‘ru’, домены бывшего СССР (например, ‘ua’, ‘kz’) и Web-сайты в других доменах, содержащие русские тексты. «Яndex» «понимает» русскую морфологию и различные русские кодовые таблицы. Учитывает при разборе ключевых слов морфологию русского языка. В русском языке возможно изменение слова в целом, а не только его окончание.
ПРОСТОЙ ПОИСК.
При заходе на сервер этой SE в окне браузера появляется окошко для ввода запроса.
Естественный язык запросов.
Поскольку использование специального языка запросов требует некоторого навыка работы с SE, очень важно, что «Яndex» предоставляет возможность свободного запроса, то есть вы можете набрать запрос на естественном языке. В этом случае вы тоже получите документы в той или иной степени удовлетворяющие запросу.
Специальный язык запросов.
В том случае, если удовлетворяющие вас документы не найдены по запросу на естественном языке, вы можете воспользоваться специальными символами для формирования запроса. Внизу поля для ввода запроса имеется надпись: «строгий поиск (с языком запросов)». Если вы поставите флажок напротив этой надписи, то все символы этого языка запросов могут быть использованы.
Независимо от того, в какой форме вы употребили слово в запросе, поиск учитывает все его формы по правилам русского языка. Например, если задан запрос идти, то в результате поиска будут найдены ссылки на документы, содержащие слова идти, идет, шел, шла и т.д. На запрос окно будет выдана информация, содержащая и слово окон, а на запрос отзывали — документы, содержащие слово отозвали.
Кроме того, возможен поиск с указанием желаемого расстояния между словами. Если все слова в тексте перенумеровать по порядку их следования, то расстояние между словами a и b — это разница между номерами слов a и b. Таким образом, расстояние между соседними словами равно 1 (а не 0), а расстояние между соседними словами, стоящими «не в том порядке», равно -1. То же самое относится и к абзацам. В таблице приведен язык запросов к поисковой машине «Яndex».
| Элементы | Пояснение | Примеры |
| Заглавные буквы | Если в запросе набрано слово с большой буквы, будут найдены только слова с большой буквы, в противном случае будут найдены как слова с большой, так и с маленькой буквы. | Например, запрос вуз (также как и ВУЗ) найдет любое упоминание этого слова. Запрос Вуз — только те случаи, когда слово написано с большой буквы. |
| Точная словоформа ‘!’. | По умолчанию поиск учитывает все формы заданного слова согласно правилам русского языка. Однако существует возможность поиска по точной словоформе, для этого перед словом надо поставить восклицательный знак ‘!’. | Так по запросу ‘!управленческих‘ будут найдены все документы, содержащие словоформу управленческих, а по запросу ‘управленческие ~~ ! управленческих‘ — документы, в которых есть слово управленческие, кроме тех, которые были найдены по первому запросу. |
| Логическое сложение & | Несколько набранных в запросе слов, разделенных пробелами, означают, что каждое из них должно входить в один абзац искомого документа. Тот же самый эффект произведет употребление символа ‘&’. | Например, при запросе ‘документооборот управление‘ (или ‘документооборот & управление‘), результатом поиска будет список документов, в которых в одном абзаце содержатся и слово ‘документооборот‘, и слово ‘управление‘. |
| && | Двойной оператор && ищет также как и &, но во всем документе. | По запросу ‘документооборот && управление’ будут найдены документы, содержащие где бы то ни было оба эти слова |
| Логическое вычитание | или , | Между словами можно поставить знак ‘|’ (или запятую ‘,’), чтобы найти документы, содержащие любое из этих слов. | Запрос вида ‘функции | полномочия‘ или ‘функции, полномочия ‘ задает поиск документов, содержащих в одном абзаце хотя бы одно из слов функции или полномочия. |
| Логическое отрицание ~ | Этот знак, тильда ~, позволит найти документы с абзацем, содержащим первое слово, но не содержащим второе. | По запросу ‘централизация ~ децентрализация‘ будут найдены все документы, содержащие слово ‘ централизация ‘, рядом с которым (в пределах абзаца) нет слова ‘децентрализация‘. |
| ~~ | Двойной оператор ~~ ищет в пределах документа. | Запрос ‘централизация ~~ децентрализация‘ выдаст все документы со словом ‘централизация‘, но без слова ‘децентрализация‘ |
| /n | Если между двумя словами поставлен знак ‘/’, за которым сразу напечатано число, значит, требуется, чтобы расстояние между ними не превышало этого числа слов. | Например, задав фразу ‘система /2 управления‘, Вы требуете найти документы, в которых содержатся и слово ‘холодный’ и слово ‘вода’, причем расстояние между ними должно быть не более двух слов и они должны находиться в одном абзаце. |
| /+n | Если порядок слов и расстояние точно известны, можно воспользоваться пунктуацией /+n. Так, например, задается поиск слов, стоящих подряд. | Запрос ‘система /+1 управления‘ означает, что слово ‘вода’ должно следовать непосредственно за словом ‘холодный’. (Кстати. к тому же результату приведет запрос «холодная вода») |
| Ограничение по расстоянию /(n m) | В общем виде ограничение по расстоянию задается при помощи пунктуации вида ‘/(n m)’, где ‘n’ минимальное, а ‘m’ максимально допустимое расстояние. Отсюда следует, что запись ‘/n’ эквивалентна ‘/(-n +n)’, а запись ‘/+n’ эквивалентна ‘/(+n +n)’. | Запрос ‘система /(-2 4) управления‘ означает, что ‘управления‘ должна находиться от ‘система‘ в интервале расстояний от 2 слов слева до 4 слов справа. |
| Практически все знаки можно комбинировать с ограничением расстояния. | Например, результатом поиска по запросу система ~ /+1 управления будут документы, содержащие слово ‘система‘, причем в этих документах слово ‘управления‘ не следует непосредственно за словом ‘система‘. | |
| Когда знаки ограничения по расстоянию стоят после двойных операторов, то употребленные там числа — это расстояние не в словах, а в абзацах. Расстояние в абзацах определяется аналогично расстоянию в словах. | Запрос ‘ система && /1 управления‘ означает, что слово ‘вода’ должно находиться в том же самом, либо в соседнем со словом ‘холодный’ абзаце. | |
| Круглые скобки ( ) | Вместо одного слова в запросе можно подставить целое выражение. Для этого его надо взять в скобки. | Например, запрос ‘(организация,система) /+1 (управления|менеджмента)’ задает поиск документов, которые содержат любую из фраз ‘организация управления‘, ‘организация менеджмента‘, ‘система управления‘, ‘система менеджмента‘. |
| $Title: | Можно искать информацию в заголовках (имя «зоны»: Title) и ссылках (имя «зоны»: A). Cинтаксис: $имя_зоны логический_множитель | Запрос ‘$Title КомпТек’ ищет в заголовках документов слово ‘КомпТек’. |
| $A: | Можно искать информацию в ссылках. | |
| $А логическое выражение или $Title логическое выражение | Можно использовать логические операторы после $A или $Title | Запрос ‘ $A (КомпТек | Dialogic)’ находит документы, в cсылках внутри которых есть одно из слов ‘КомпТек’ или ‘Dialogic’. |
Ранжирование результатов поиска.
При поиске для каждого найденного документа «Яндекс» вычисляет величину релевантности (соответствия) содержания этого документа поисковому запросу. Список найденных документов перед выдачей пользователю сортируется по этой величине в порядке убывания. Релевантность документа зависит от ряда факторов, в том числе от частотных характеристик искомых слов, веса слова или выражения, близости искомых слов в тексте документа друг к другу и т.д.
Пользователь может повлиять на порядок сортировки, используя операторы веса и уточнения запроса. Задание веса слова или выражения применяется для того, чтобы увеличить релевантность документов, cодержащих «взвешенное» выражение.
Синтаксис:
слово:число
или
(поисковое_выражение):число
Например, по запросу ‘поисковые механизмы:5’ будут найдены те же документы, что и по запросу ‘поисковые механизмы’. Разница состоит в том, что наверху списка найденного окажутся документы, где чаще встречается именно слово ‘механизмы’. Запрос ‘поисковые (механизмы|машины|аппараты):5 ‘ равнозначен запросу ‘поисковые (механизмы:5|машины:5|аппараты:5) ‘.
Задание уточняющего слова или выражения применяется для того, чтобы увеличить релеватность документов, cодержащих уточняющее выражение.
Синтаксис:
<- слово
или
<- (уточняющее_выражение)
Например, по запросу ‘компьютер <- телефон ‘ будут найдены все документы, содержащие слово ‘компьютер’, при этом первыми будут выданы документы, содержащие слово ‘телефон’. Если ни в одном документе со словом ‘компьютер’ нет слова ‘телефон’, результат запроса будет эквивалентен запросу ‘компьютер’.
Результаты поиска.
Результаты поиска появляются на экране по 10 на страницу по мере убывания степени соответствия запросу (максимальная степень соответствия — [1.000000]). Внизу каждой страницы находятся ссылки (по номерам) на другие страницы с найденными по запросу документами. Для каждого документа в списке найденного указан его заголовок, ссылающийся на размеченный документ, начало текста документа, кодировка, размер в байтах, дата и URL документа, ссылающийся на оригинальный документ. Если вы не хотите , чтобы результаты запроса пропадали с экрана, вы можете нажать на маленькие окошечки слева от явной ссылки на оригинальный документ. При этом документ загружается в новое окно браузера. При нажатии на явную ссылку оригинальный документ загрузится в текущее окно браузера.
Что означает разметка документа? Если в списке найденного нажать на заголовок документа, Вы увидите так называемую «подсветку». «Яndex» при индексации запоминает положение слова в документе, что дает возможность выделить (подсветить) слова, найденные в тексте. И не просто подсветить, а переходить с одного слова на другое. При этом подсвечиваются не все слова, входящие в запрос, а только те, которые удовлетворяют поисковому выражению.
Слова выделены угловыми стрелочками. Каждая стрелочка ссылается на следующее или предыдущее «найденное» слово. Чтобы увидеть первое найденное слово, нажмите на стрелочку влево , чтобы увидеть последнее — на стрелочку вправо . Переход на следующее слово — стрелочка > справа от слова, переход на предыдущее — слева <. Первое и последнее слова указывают на верхнюю и нижнюю таблицу соответственно. В начале размеченного документа помещается табличка с ссылками на первое и последнее найденное слово и на оригинальный документ. В конце документа — аналогичная табличка, где приводится статистика, то есть — сколько слов найдено (подсвечено) в данном документе. Если файлы были изменены, а индекс по ним не обновлен, об этом выдается соответствующее предупреждение.
Можно ограничить область поиска, отметив «искать в найденном» на странице результата.
Если же удовлетворяющий вас документ не найден, есть еще возможность воспользоваться поиском документов по образцу. Для этого нажмите на надпись «Найти похожие документы», которая находится под наиболее удовлетворяющим вас документом. При этом будет сформирован новый запрос к поисковой машине «Яndex» и найденные документы будут походить на исходный. Однако этой опцией надо пользоваться аккуратно, поскольку количество документов, найденных в результате может превысить разумный предел и, следовательно, не приведет ни к чему.
АКАДЕМИЧЕСКИЙ ПОИСК.
Нажав левой клавишей мыши на надпись «Advanced», расположенную в правой части экрана вместе с другими пунктами меню, на экране вы получите поле для ввода запроса и меню:
- Уточнение запроса. Если вы введете слова в этом поле, то первыми документами в списке результатов будут документы, содержащие эти слова.
- Выдача результатов.
Здесь можно выбрать краткую (заголовок и степень соответствия запросу) либо стандартную (которая была описана выше) форму выдачи результатов, а также количество документов, выводимых на страницу (10, 20 или 50). - Зона поиска. Искать во всем документе, только в заголовках, только в ссылках.
В остальном этот раздел ничем не отличается от простого поиска с «Яndex», т.е. в поле запроса можно использовать как естественный язык, так и специальный язык запросов, пометив пункт «строгий поиск (с языком запросов)».
Кроме прямого использования «Яndex», есть возможность сформировать с ее помощью запрос и отправить его на поисковые машины «AltaVista» или «Rambler». Для каждой из этих SE у «Яndex» есть специальный интерфейс, где пользователь набирает ключевые слова, отмечает необходимые для поиска опции. Нажав на кнопку «Обработка запроса», вы передаете свой запрос на «Яndex», которая обрабатывает его с учетом морфологии русского языка и отправляет на «AltaVista» или «Rambler» (в зависимости от выбранного вами интерфейса). Интерфейсы написаны для двух кодировок русского языка: Windows-1251 или KOI8-R
Интерфейс «Яndex» для «Rambler»
(http://www.comptek.ru/ramb.html).
- Учет словосочетаний. Если поле не помечено каждое слово заменяется на все свои формы, т.е. реализуется морфологический режим обработки запроса. Если поле помечено, по возможности учитываются синтаксические связи между словами в запросе, т.е. реализуется морфосинтаксический режим обработки запроса..
- Режим. Режим «Поиск» — запрос посылается на «Rambler». Если выбран режим «разбор запроса», то при нажатии на кнопку «ПОИСК!» на экран выдаётся протокол морфологического анализа всех слов запроса (из поля «Запрос»). Для каждого слова приводятся все варианты его морфологического разбора. Для каждого варианта разбора указаны все его грамматические характеристики. Если слово отсутствует в словарях системы, то она генерирует гипотетическую модель словоизменения этого слова. В конце протокола приводится расширенный запрос, сгенерированный словарным сервером.
- Поиск в WWW, UseNet, именах URLs (указывает на область поиска)
- Операции со словами. Все — означает логическую операцию И. Или — логическая операция ИЛИ.
- Количество результатов на страницу (10, 20 и т.д.)
- Форма вывода (нормальная, краткая, детальная)
Следующие поля не являются обязательными и применяются только для поиска в WWW (использование этих полей может замедлить поиск). (Вы не можете использовать мета-символы ‘*’ и ‘?’ в следующих полях)
- От даты: До даты: формат 21/Mar/96. Дата последнего изменения искомых документов.
- Исключить документы, содержащие следующие слова.
- Сайт или часть URLs, в которых произвести поиск. Примеры: ‘www.stack.net’ ‘gopher://gopher.dux.ru/’ ‘ua’
Запрос задается в формате детального запроса Rambler .
Морфологический режим обработки запроса.
В этом режиме каждое слово из запроса заменяется на все свои формы — с учётом родов, чисел, склонений, спряжений. Учитывается также омонимия (напр. по слову «раздел» будут даны все формы глагола «раздевать» и существительного «раздел»). Если Вы хотите искать слово только в той форме, в которой Вы его задали, поставьте его в кавычки. Слова, заключённые в квадратные скобки, трактуются как словосочетание, то есть часть запроса (их может быть несколько), взятая в квадратные скобки, обрабатывается в морфосинтаксическом режиме (как запрос при помеченном поле «Учет словосочетаний»). Вложенность квадратных скобок не допускается.
Морфосинтаксический режим обработки запроса.
Реализуется при помеченном поле «Учет словосочетаний» для всего запроса, или для частей запроса, взятых в квадратные скобки, когда это поле не отмечено. В этом режиме поисковый запрос трактуется как фраза на естественном языке. При этом поиск становится более релевантным, поскольку находится гораздо меньше «мусора», так как учитываются синтаксические связи между словами запроса. Также происходит частичное снятие омонимии: например, в случае задания поисковой фразы после проверки предлог после не будет считаться формой слова посол и последнее не будет дано для поиска во всех формах.
Запрос обрабатывается следующим образом.
- Все слова из запроса должны находиться в искомых документах, поэтому при генерации расширенного запроса применяется оператор and (&).
- Если слова в запросе синтаксически связаны, то расширенный запрос строится с учетом синтаксических связей.
- Знаки препинания игнорируются.
- Слова, набранные латиницей, в том числе and,or,near,not, считаются составной частью фразы (а не операторами языка запроса).
В данный момент учитываются два вида синтаксической связи:
1) Cогласование существительного с прилагательным или причастием в роде, числе и падеже.
Например, если задан запрос
информационные технологии, то расширенный запрос будет выглядеть следующим образом: ((информационная & технология) | (информационной & технологии) | (информационную & технологию) | ((информационной | информационною) & (технологией | технологиею)) | (информационные & технологии) | (информационных & (технологий | технологиях)) | (информационным & технологиям) | (информационными & технологиями)) , т.е. существительное и прилагательное согласованы в роде, числе и падеже.
«Морфологическое» расширение этого запроса выглядело бы так: (информационная or информационной or … /*далее по всем падежам и числам*/ ) & (технология or технологии or … /*по всем падежам и числам*/).
2) Управление предлога существительным или именной группой.
Например, запрос документооборот в управлении приводит к генерации расширенного запроса (документооборот or документооборота or … /*по всем падежам и числам*/) near в near (управлении or управлениях)
Интерфейс Яndex» для «AltaVista»
(http://www.comptek.ru/alta.html).
Используя этот интерфейс, «Яndex» посылает ваш запрос на поисковую систему «AltaVista», предварительно его обработав. «AltaVista» имеет русский интерфейс, но поиск с помощью этого интерфейса не учитывает морфологии русского языка. Однако эта SE обладает огромной базой данных проиндексированных документов, поэтому использование «Яndex» для формирования запроса в сочетании с большим количеством документов может дать хороший результат.
- Учет словосочетаний аналогичен такому же пункту для «Rambler».
- Область поиска: WWW, UseNet, Россия (домены ‘su’ и ‘ru’), Россия и США (домены ‘su’, ‘ru’, ‘com’, ‘edu’, ‘org’).
- Вывод результата. Стандартная, компактная, детализация, счетчик (будет указано только количество релевантных документов).
- Запрос:
- Наиболее значимые слова. Слова в этом поле будут восприняты как дополнительные ключевые, кроме того документы, в которых они встречаются, будут располагаться в начале списка результатов.
- Нач. дата: Конеч. дата: (напр.: 12/Янв/96)
- Режим («поиск» или «разбор запроса») аналогичен такому же пункту для «Rambler».
- Кодировка (Windows-1251 или KOI8-R)
В таблице приведен пример использования рассмотренных выше SE для поиска информации об университетском управлении.
| Машина поиска | Запрос | Результат |
| Яndex | университетский (менеджмент,управление) | Найдено 111 уникальных документов. |
| университетский &/2 (менеджмент,управление) | Найдено 14 уникальных документов | |
| Rambler | университетск* and (менеджмент or управление) | Найдено: 926 [676 уникальных] |
| университетский and (менеджмент or управление) | Найдено: 130 [106 уникальных] | |
| университетское & управление | Найдено: 36 [26 уникальных] | |
| университетское & управление or университетский & менеджмент | Найдено: 53 [43 уникальных] | |
| Апорт! | университетское (управление или менеджмент) | Найдено 989 документов |
| {2,университетское управление} или {2,университетский менеджмент) | Найдено 233 документа | |
| {1,университетское управление} или {1,университетский менеджмент} | Найдено 192 документа |
«Яndex»
Искомые документы находятся в начале списка. Кроме того, при большом количестве документов
возможно уточнение результатов («искать в найденном»).
«Rambler»
Необходимо отметить, что наличие * в конце слова позволяет «выловить» даже те документы,
в которых окончания этого слова были набраны ошибочно. В начале списка много документов,
мало относящихся к предмету поиска. Уточнение поиска невозможно.
«Апорт»
Находит слишком много документов, дальнейшее уточнение поиска не предусмотрено. Однако
среди первых документов есть документы, относящиеся к теме поиска.
Конечно, с другими ключевыми словами результаты поиска будут отличаться от результатов приведенных здесь.
1Uniform Resource Locator (универсальный указатель ресурса) — адрес документа в Интернет, включающий в себя имя протокола, имя компьютера, а также путь до документа. Например, http://www.usu.ru/eb-engl.htm . Здесь http — имя протокола передачи гипертекста, www.usu.ru — имя www-сервера Уральского государственного университета, eb-engl.htm — имя файла (документа). 2Domain Name System (доменная система имен) — устанавливает соответствие между компьютером в Интернет и его именем. Система служит для облегчения запоминания имен компьютеров в Интернет.
Использование поисковых систем для интернет-исследований
Использование Поисковые системы для интернет-исследованийизм. 11/01
Поиск поисковые системы позволяют проводить исследования в Интернете, и они могут быть эффективными инструментами. Однако чтобы использовать их эффективно для исследования вам необходимо знать их сильные стороны и слабые стороны, а также как и когда их использовать.
Что
поисковая машина — нет.
Поисковые системы не являются авторитетным ресурсом для всех
информация в Интернете. По оценкам экспертов, возможно
одна треть Интернета проиндексирована в поисковых системах. Поиск
поисковые системы не ищут документы в специальных форматах, таких как
как онлайн-базы данных.Просто потому, что ты чего-то не нашел
через поисковую систему, это не значит, что он не существует на
интернет. Кроме того, есть много ценной информации.
который вообще не попал в Интернет или был опубликован ранее
до середины 1990-х годов, когда Интернет стал популярен. Быть
наиболее эффективно используйте поисковые системы вместе
с другими методами исследования — специализированными веб-сайтами, книгами,
журналы, публичная библиотека, люди, телефон, электронная почта и т. д.
Когда
использовать поисковую систему.
Поисковые системы наиболее полезны для поиска информации, когда
у вас есть четкое представление о том, что вы ищете, но нет
идея с чего начать искать. Если у вас есть хорошая идея, где
информация будет, например, государственным учреждением
или газету, перейдите на сайт, на котором организована организация такого типа,
не поисковая система (Yahoo подходит для этого).
Как
использовать поисковую систему.
Чем точнее вы укажете условия поиска, тем больше
продуктивным будет ваше исследование. Это того стоит
чтобы узнать и использовать специальные методы поиска, которые ищут
поисковые системы помогают сфокусировать поиск, чтобы в итоге вы
с более актуальным материалом.Методы включают: в том числе
или исключая условия поиска, точный поиск по фразе (с использованием
кавычки), поиск близости и другие инструменты.
Каждая поисковая система работает по-своему, поэтому обязательно
чтобы ознакомиться с их советами по поиску, справкой или расширенным поиском
варианты, чтобы вы знали, как они настроены.
Выбрано Поисковые системы.
Google http://www.google.com
Google пытается найти «авторитетный» источник
подсчитав количество ссылок на этот сайт.
Северный
Фонарь http://www.nintagelight.com
Имеет папки, которые пытаются организовать ваши обращения.
Обычный
окончания:
com для рекламы, edu для образовательных, org для других организаций, gov для U.С. федеральный
правительство, мил для вооруженных сил США, нетто для интернет-провайдеров и сетей.
Google, демократия и правда об интернет-поиске | Интернет
Вот то, чем вы не хотите заниматься поздно вечером в воскресенье. Вы же не хотите вводить семь букв в Google. Это все, что я сделал. Я набрал: «а-р-е». А потом «j-e-w-s».С 2008 года Google пытается предсказать, какой вопрос вы задаете, и предлагает вам выбор. И вот что он сделал. Он предложил мне выбор потенциальных вопросов, которые, как мне показалось, я мог бы захотеть задать: «евреи — это раса?», «Евреи белые?», «Евреи-христиане?» И, наконец, «евреи злы?»
Злые ли евреи? Я никогда не задумывался об этом. Я не искал его. Но так оно и было. Жму ввод. Появится страница результатов. Это был вопрос Google. И это был ответ Google: евреев — это зло.Потому что на моем экране было доказательство: целая страница результатов, девять из 10 из которых «подтверждают» это. Главный результат, полученный с сайта Listovative, имеет заголовок: «10 основных причин, по которым люди ненавидят евреев». Я нажимаю на нее: «Евреи сегодня взяли на себя маркетинговые, милицейские, медицинские, технологические, медиа, промышленные, кинематографические проблемы и т. Д. И продолжают сталкиваться с мировой [sic] завистью через необъяснимые истории успеха, учитывая их бесславное прошлое и паразиты, подобные репрессиям повсюду. Европа.”
Google — это поиск . Для Google это глагол. Это то, что мы все делаем постоянно, когда хотим что-то узнать. Мы это делаем в Google. Сайт обрабатывает не менее 63 000 запросов в секунду, 5,5 млрд запросов в день. Ее миссия как компании, однострочный обзор, который информировал компанию с момента ее основания и до сих пор остается заголовком на ее корпоративном веб-сайте, заключается в том, чтобы «упорядочить мировую информацию и сделать ее общедоступной и полезной». Он стремится дать вам наилучшие и наиболее релевантные результаты.И в этом случае третьим по значимости и наиболее релевантным результатом для поискового запроса «являются евреями…» является ссылка на статью с неонацистского веб-сайта stormfront.org. Пятый — это видео на YouTube: «Почему евреи злые. Почему мы против них ».
Шестое из ответов Yahoo: «Почему евреи такие злые?» Седьмой результат: «Евреи — демонические души из другого мира». А 10-е — с сайта jesus-is-saviour.com: «Иудаизм — сатанинский!»
Один результат из 10 предлагает другую точку зрения.Это ссылка на довольно объемный научный обзор книги еврейского журнала thetabletmag.com с, к сожалению, вводящим в заблуждение заголовком: «Почему буквально все в мире ненавидят евреев».
Мне кажется, что я упал в червоточину, попал в какую-то параллельную вселенную, где черное есть белое, а хорошее — плохое. Хотя позже я думаю, что, возможно, на самом деле я соскреб верхний слой почвы с поверхности 2016 года и нашел один из подземных источников, который тихо питал его. Конечно, он был там все время.Всего несколько нажатий клавиш … на наших ноутбуках, планшетах, телефонах. Это не секретная нацистская ячейка, скрывающаяся в тени. Он прячется на виду.
Женщины… Результаты поиска Google.Истории о фейковых новостях в Facebook доминировали в определенных разделах прессы в течение нескольких недель после президентских выборов в США, но, возможно, они еще более сильны и коварны. Фрэнк Паскуале, профессор права в Университете Мэриленда и один из ведущих научных деятелей, призывающий технологические компании быть более открытыми и прозрачными, называет результаты «очень глубокими и очень тревожными».
Он натолкнулся на похожий случай в 2006 году, когда: «Если вы наберете« еврей »в Google, первым результатом будет jewwatch.org. Это было «берегитесь этих ужасных евреев, которые разрушают вашу жизнь». И Антидиффамационная лига пошла за ними, и поэтому они поставили рядом с ней звездочку, которая гласила: «Эти результаты поиска могут вызывать беспокойство, но это автоматизированный процесс». Но то, что вы показываете — и я очень рад, что вы документируют это и делают снимки экрана — это то, что, несмотря на то, что они тщательно исследовали эту проблему, она стала намного хуже.
И порядок результатов поиска действительно влияет на людей, — говорит Мартин Мур, директор Центра изучения средств массовой информации, коммуникации и власти при Королевском колледже в Лондоне, который подробно писал о влиянии крупных технологических компаний на нашу гражданская и политическая сферы. «Существует крупномасштабное статистически значимое исследование влияния результатов поиска на политические взгляды. И то, как вы видите результаты, и типы результатов, которые вы видите на странице, обязательно влияет на вашу точку зрения.По его словам, фейковые новости просто «выявили гораздо более серьезную проблему. Эти компании настолько могущественны и стремятся к подрыву. Они думали, что подрывают политику, но в положительном смысле. Они не думали о минусах. Эти инструменты предлагают замечательные возможности, но у них есть и темная сторона. Это позволяет людям делать очень циничные, разрушительные поступки ».
Google — это знание. Это то место, куда вы идете, чтобы все выяснить. И злые евреи — это только начало. Есть и злые женщины.Я их тоже не искал. Вот что я набираю: «а-р-е-ш-о-м-е-н». И Google предлагает мне всего два варианта ответа, первый из которых: «Являются ли женщины злом?» Жму возврат. Да, они. Каждый из 10 результатов «подтверждает», что они, включая самый верхний, получены с сайта sheddingoftheego.com, который выделен рамкой и выделен: «В каждой женщине есть какая-то проститутка. В каждой женщине есть немного зла … Женщины не любят мужчин, им нравится то, что они могут для них сделать. Есть основания сказать, что женщины чувствуют влечение, но они не могут любить мужчин.
Затем я набираю: «а-р-е м-у-с-л-и-м-с». И Google предлагает мне спросить: «Мусульмане плохие?» И вот что я узнал: да, они есть. Об этом говорит главный результат и шесть других. Не вводя больше ничего, просто помещая курсор в поле поиска, Google предлагает мне два новых запроса, и я выбираю первый: «Ислам вреден для общества». В следующем списке предложений мне предлагается: «Ислам должен быть уничтожен».
Это то же самое, что пойти в библиотеку и спросить библиотекаря об иудаизме и получить 10 книг ненавистиДэнни Салливан
Евреи — зло.Необходимо искоренить мусульман. А Гитлер? Вы хотите знать о Гитлере? Давай погуглим. «Был ли Гитлер плохим?» Я печатаю. И вот главный результат Google: «10 причин, по которым Гитлер был одним из хороших парней». Я нажимаю на ссылку: «Он никогда не хотел убивать евреев»; «Он заботился об условиях для евреев в трудовых лагерях»; «Он провел социальную и культурную реформу». Восемь из остальных 10 результатов поиска согласны: Гитлер действительно был не так уж и плох.
Несколько дней спустя я разговариваю с Дэнни Салливаном, редактором-основателем SearchEngineLand.com. Несколько ученых рекомендовали мне его как одного из самых знающих экспертов в области поиска. Я спрашиваю его, я просто наивен? Должен ли я знать, что это было где-то там? «Нет, ты не наивен», — говорит он. «Это ужасно. Это ужасно. Это все равно, что пойти в библиотеку и спросить библиотекаря об иудаизме, и ему вручат 10 книг ненависти. Google делает ужасную, ужасную работу по предоставлению ответов здесь. Он может и должен работать лучше ».
Он тоже удивлен. «Я думал, что в 2011 году они перестали предлагать автозаполнение для религий.А затем он набирает «женщины» в свой компьютер. «О Боже! Этот ответ вверху. Это замечательный результат. Это называется «прямой ответ». Это должно быть бесспорным. Это высшая оценка Google «. Что в каждой женщине есть какая-то проститутка? «Да. Это ужасно неверный алгоритм Google ».
Я связался с Google по поводу предположительно неисправных предложений автозаполнения и получил следующий ответ: «Наши результаты поиска отражают контент в Интернете.Это означает, что иногда неприятное изображение деликатной темы в Интернете может повлиять на то, какие результаты поиска появляются по заданному запросу. Эти результаты не отражают собственное мнение или убеждения Google — как компания мы высоко ценим разнообразие точек зрения, идей и культур ».
Google — это, конечно, не просто поисковая система. Поиск был основой компании, но это было только начало. Alphabet, материнская компания Google, сегодня имеет самую большую в мире концентрацию экспертов по искусственному интеллекту.Он расширяется в сфере здравоохранения, транспорта и энергетики. Он может привлечь ведущих компьютерных ученых, физиков и инженеров мира. Были куплены сотни стартапов, в том числе Calico, чья заявленная миссия — «лечить смерть», и DeepMind, цель которого — «раскрыть разведку».
Соучредители Google Ларри Пейдж и Сергей Брин в 2002 году. Фотография: Майкл Греко / Getty ImagesА 20 лет назад его даже не существовало. Когда Тони Блэр стал премьер-министром, гуглить его было невозможно: поисковую систему еще не изобрели.Компания была основана только в 1998 году, а Facebook не появлялся до 2004 года. Основателям Google Сергею Брину и Ларри Пейджу все еще всего 43 года. Марку Цукербергу из Facebook 32 года. Все, что они сделали, мир, который они переделали, было сделано в мгновение ока.
Но кажется, что значение силы и охвата этих компаний только сейчас просачивается в общественное сознание. Я спрашиваю Ребекку Маккиннон, директора проекта «Рейтинг цифровых прав» в New America Foundation, был ли недавний фурор из-за фейковых новостей, который разбудил людей об опасности уступки наших прав как граждан корпорациям.«Сейчас это немного странно, — говорит она, — потому что люди наконец говорят:« Ну и дела, у Facebook и Google действительно много власти », как будто это большое откровение. И это похоже на «Да».
Маккиннон обладает особым опытом в том, как авторитарные правительства приспосабливаются к Интернету и подчиняют его своим целям. «Китай и Россия — поучительная история для нас. Я думаю, что происходит то, что он движется вперед и назад. Так что во время арабской весны казалось, что хорошие парни далеко впереди. А теперь похоже, что плохие парни такие.Активисты, выступающие за демократию, используют Интернет больше, чем когда-либо, но в то же время противник стал намного более опытным ».
На прошлой неделе Джонатан Олбрайт, доцент кафедры коммуникаций Университета Илона в Северной Каролине, опубликовал первое подробное исследование того, как правые веб-сайты распространяли свое послание. «Я взял список этих распространявшихся фальшивых новостных сайтов, у меня был первоначальный список из 306 из них, и я использовал инструмент — наподобие того, что использует Google — для поиска с них ссылок, а затем сопоставил их.Так что я посмотрел, куда идут ссылки — на YouTube и Facebook, и между собой, миллионы их… и я просто не мог поверить в то, что видел.
«Они создали сеть, которая просачивается в нашу сеть. Это не заговор. Нет ни одного человека, создавшего это. Это обширная система, состоящая из сотен различных сайтов, использующих все те же приемы, что и все веб-сайты. Они рассылают тысячи ссылок на другие сайты, и вместе это создало обширную спутниковую систему правых новостей и пропаганды, которая полностью окружила систему основных СМИ.
Он нашел 23 000 страниц и 1,3 млн гиперссылок. «А Facebook — всего лишь усилитель. Когда вы смотрите на это в 3D, это действительно похоже на вирус. А Facebook был лишь одним из носителей вируса, который помогает ему быстрее распространяться. Вы можете увидеть там New York Times и Washington Post , а затем вы увидите, что их окружает обширная обширная сеть. Лучше всего это описать как экосистему. Это действительно выходит за рамки отдельных сайтов или отдельных историй.На этой карте изображена сеть распространения, и вы можете видеть, что она окружает и фактически подавляет экосистему основных новостей ».
Как рак? «Как организм, который все время растет и становится сильнее».
Чарли Беккет, профессор школы средств массовой информации и коммуникаций Лондонской школы экономики, говорит мне: «Мы уже некоторое время спорим о том, что множественность средств массовой информации — это хорошо. Разнообразие — это хорошо. Критиковать основные СМИ — это хорошо. Но теперь … все вышло из-под контроля.Исследование Джонатана Олбрайта показало, что это не побочный продукт Интернета. И это даже не делается по коммерческим причинам. Это продиктовано идеологией, людьми, которые сознательно пытаются дестабилизировать Интернет ».
Пространственная карта правой экосистемы фейковых новостей. Джонатан Олбрайт, доцент кафедры коммуникаций Университета Илона, Северная Каролина, «соскреб» 300 сайтов с фальшивыми новостями (темные фигуры на этой карте), чтобы выявить 1,3 миллиона гиперссылок, которые соединяют их вместе и связывают в основную новостную экосистему.Здесь Олбрайт показывает, что это «обширная спутниковая система правых новостей и пропаганды, которая полностью окружила господствующую систему СМИ». Фотография: Джонатан ОлбрайтКарта Олбрайта также дает ключ к пониманию результатов поиска Google, которые я нашел. Он объясняет, что эти правые новостные сайты сделали то, что пытаются делать большинство коммерческих сайтов. Они пытаются найти уловки, которые помогут им подняться в системе PageRank Google. Они пытаются «обыгрывать» алгоритм. И его карта показывает, насколько хорошо они это делают.
Это то, что тоже показывают мои поисковые запросы. Правые колонизировали цифровое пространство вокруг этих предметов — мусульман, женщин, евреев, Холокост, чернокожие — гораздо более эффективно, чем левые либералы.
«Это информационная война», — говорит Олбрайт. «Это то, к чему я постоянно возвращаюсь».
Но вот что действительно пугает. Я спрашиваю его, как это можно остановить. «Я не знаю. Я не уверен, что это возможно. Это сеть. Он намного сильнее любого актера.
Значит, у него почти своя жизнь? «Да, и это обучение. С каждым днем он становится сильнее ».
Чем больше людей ищут информацию о евреях, тем больше людей увидят ссылки на сайты ненависти, и чем больше они будут переходить по этим ссылкам (очень немногие люди переходят на вторую страницу результатов), тем больше трафика получат сайты. , чем больше ссылок они получат и тем более авторитетными они будут. Это полностью замкнутая экономика знаний, которая имеет только один результат: усиление сообщения.Евреи злые. Женщины злы. Ислам должен быть уничтожен. Гитлер был одним из хороших парней.
А созвездие веб-сайтов, которые нашла Олбрайт, — своего рода теневой Интернет — выполняет еще одну функцию. Они не просто распространяют правую идеологию, они используются для отслеживания, контроля и влияния на всех, кто сталкивается с их контентом. «Я поскреб трекеры на этих сайтах и был совершенно ошарашен. Каждый раз, когда кому-то нравится одна из этих публикаций на Facebook или посещается один из этих веб-сайтов, сценарии следят за вами по всей сети.И это позволяет компаниям, занимающимся анализом данных и влияющим на них, таким как Cambridge Analytica, точно нацеливать людей, следить за ними в сети и отправлять им в высшей степени персонализированные политические сообщения. Это пропагандистская машина. Он нацелен на людей индивидуально, чтобы привлечь их к идее. Я никогда раньше не видел такого уровня социальной инженерии. Они захватывают людей, а затем держат их на эмоциональном поводке и никогда не отпускают ».
Cambridge Analytica, американская компания, базирующаяся в Лондоне, участвовала как в кампании «Голосование за отказ», так и в кампании Трампа.Доминик Каммингс, директор кампании Vote Leave, сделал несколько публичных заявлений после референдума о Брексите, но он сказал следующее: «Если вы хотите значительно улучшить коммуникацию, мой совет — нанимайте физиков».
Стив Бэннон, основатель Breitbart News и недавно назначенный главным стратегом Трампа, входит в совет директоров Cambridge Analytica, и выяснилось, что компания ведет переговоры о проведении политической работы для администрации Трампа. Он утверждает, что построил психологические профили с использованием 5000 отдельных данных о 220 миллионах американских избирателей.Он знает их причуды, нюансы и повседневные привычки и может ориентироваться на них индивидуально.
«Они использовали 40-50 000 различных вариантов рекламы каждый день, которые непрерывно измеряли отклики, а затем адаптировались и развивались на основе этого отклика», — говорит Мартин Мур из Kings College. Поскольку у них так много данных о физических лицах и они используют такие феноменально мощные сети распространения, они позволяют кампаниям обходить множество существующих законов.
«Все сделано совершенно непрозрачно, и они могут потратить столько денег, сколько захотят, в определенных местах, потому что вы можете сосредоточиться на радиусе пяти миль или даже на одной демографической группе.Фальшивые новости важны, но это только одна часть. Эти компании нашли способ нарушить 150-летнее законодательство, которое мы разработали, чтобы сделать выборы справедливыми и открытыми ».
Повлияла ли такая микротаргетированная пропаганда — в настоящее время законная — на голосование за Брексит? У нас нет возможности узнать. Помогли ли Трампу одержать победу те же методы, которые использовала Cambridge Analytica? Опять же, у нас нет возможности узнать. Все это происходит в полной темноте. У нас нет возможности узнать, как наши личные данные собираются и используются для влияния на нас.Мы не осознаем, что просматриваемая страница Facebook, страница Google, реклама, которую мы видим, результаты поиска, которые мы используем, персонализируются для нас. Мы этого не видим, потому что нам не с чем сравнивать. И это не отслеживается и не записывается. Это не регулируется. Мы находимся внутри машины, и у нас просто нет возможности увидеть элементы управления. В большинстве случаев мы даже не осознаем, что есть средства контроля.
Ребекка Маккиннон говорит, что большинство из нас считает Интернет похожим на «воздух, которым мы дышим, и воду, которую мы пьем».Он нас окружает. Мы этим пользуемся. И мы в этом не сомневаемся. «Но это не природный ландшафт. Программисты, руководители, редакторы и дизайнеры создают этот ландшафт. Они люди, и все они делают выбор ».
Но мы не знаем, какой выбор они делают. Ни Google, ни Facebook не публикуют свои алгоритмы. Почему мой поиск в Google дал девять из 10 результатов поиска, в которых утверждается, что евреи — зло? Мы не знаем и не можем знать. Их системы — это то, что Фрэнк Паскуале называет «черными ящиками».Он называет Google и Facebook «ужасающей властью» и возглавляет растущее движение ученых, призывающих к «алгоритмической ответственности». «Нам необходимо проводить регулярные аудиты этих систем», — говорит он. «Нам нужно, чтобы люди в этих компаниях несли ответственность. В США в соответствии с Законом об авторском праве в цифровую эпоху у каждой компании должен быть представитель, с которым можно связаться. И вот что должно произойти. Им нужно отвечать на жалобы на разжигание ненависти и предвзятость ».
Встроено ли в систему смещение? Влияет ли это на результаты, которые я видел? «Существует множество предубеждений в отношении того, что считается законным источником информации и как это оценивается.Существует огромная коммерческая предвзятость. И если вы посмотрите на персонал, то увидите, что они молодые, белые и, возможно, азиатские, но не черные или латиноамериканцы, а в подавляющем большинстве — мужчины. Все эти суждения основываются на мировоззрении молодых богатых белых мужчин ».
Позже я разговариваю с Робертом Эпштейном, психологом-исследователем из Американского института поведенческих исследований и технологий и автором исследования, о котором мне рассказал Мартин Мур (и которое Google публично критиковал), показывающего, как результаты поиска влияют на модели голосования.На другом конце телефона он повторяет один из моих поисков. Он набирает в Google «делать черных…».
«Посмотрите на это. Я даже не нажимал кнопку, и страница автоматически заполнялась ответами на вопрос: «Совершают ли черные больше преступлений?» И послушайте, я мог бы задавать самые разные вопросы. «У черных преуспевают в спорте?» Или что-то в этом роде. И у меня есть только два варианта, и это не просто поисковые запросы или термины, которые сейчас чаще всего ищут. Раньше Google использовал это, но теперь они используют алгоритм, который смотрит на другие вещи.Теперь позвольте мне взглянуть на Bing и Yahoo. Я использую Yahoo, и у меня есть 10 предложений, среди которых нет ни одного: «Совершают ли черные люди больше преступлений?»
«И люди в этом не сомневаются. Google не просто предлагает предложение. Это отрицательное предложение, и мы знаем, что отрицательные предложения, в зависимости от множества факторов, могут привлечь от пяти до 15 дополнительных кликов. И все это запрограммировано. И это можно было запрограммировать по-другому ».
Работа Эпштейна показала, что содержание страницы с результатами поиска может влиять на взгляды и мнения людей.В двойных слепых испытаниях было показано, что тип и порядок ранжирования при поиске влияют на избирателей в Индии. Были аналогичные результаты, относящиеся к предложенным вам поисковым предложениям.
«Широкая общественность полностью в неведении относительно фундаментальных вопросов, касающихся онлайн-поиска и влияния. Мы говорим о самой мощной машине управления разумом, когда-либо изобретенной в истории человечества. А люди этого даже не замечают ».
Дэмиен Тамбини, адъюнкт-профессор Лондонской школы экономики, специализирующийся на регулировании СМИ, говорит, что у нас нет какой-либо основы для борьбы с потенциальным влиянием этих компаний на демократический процесс.«У нас есть структуры, которые работают с мощными медиакорпорациями. У нас есть законы о конкуренции. Но эти компании не несут ответственности. Нет полномочий заставить Google или Facebook что-либо раскрывать. У Google и Facebook есть редакционная функция, но она выполняется с помощью сложных алгоритмов. Говорят, это машины, а не редакторы. Но это просто механизированная редакционная функция «.
А компании, как говорит Джон Нотон, обозреватель Observer и старший научный сотрудник Кембриджского университета, боятся брать на себя ненужные им редакционные обязанности.«Хотя они могут и регулярно корректируют результаты самыми разными способами».
Конечно, результаты о Google в Google не кажутся полностью нейтральными. Google «Является ли Google расистским?» и представленный результат — ответ Google в рамке вверху страницы — совершенно ясен: нет. Нет.
Google и Facebook думают о долгосрочной перспективе. У них есть ресурсы, деньги и амбиции, чтобы делать все, что они хотят. что «у нас даже нет психического аппарата, чтобы даже знать, в чем заключаются проблемы».И особенно это касается будущего. Google и Facebook находятся в авангарде ИИ. Они собираются владеть будущим. А остальные из нас едва ли могут сформулировать те вопросы, которые нам следует задавать. «Политики не думают о долгосрочной перспективе. А корпорации не думают о долгосрочной перспективе, потому что они сосредоточены на результатах следующего квартала, и это то, что делает Google и Facebook интересными и разными. Они абсолютно думают о долгосрочной перспективе. У них есть ресурсы, деньги и стремление делать все, что они хотят.
«Они хотят оцифровать каждую книгу в мире: они это делают. Они хотят построить беспилотный автомобиль: они это делают. Тот факт, что люди читают эти фальшивые новости и понимают, что это может повлиять на политику и выборы, напоминает: «На какой планете вы живете?» Ради всего святого, это очевидно ».
«Интернет — одна из немногих вещей, созданных людьми, которых они не понимают». Это «крупнейший эксперимент с анархией в истории.Сотни миллионов людей каждую минуту создают и потребляют неисчислимое количество цифрового контента в онлайн-мире, который на самом деле не связан земными законами ». Интернет как беззаконное анархическое государство? Масштабный человеческий эксперимент без сдержек и противовесов и неописуемых потенциальных последствий? Что за «цифровой дум-монгер» сказал бы такое? Шаг вперед, Эрик Шмидт — председатель Google. Это первые строки книги The New Digital Age , которую он написал вместе с Джаредом Коэном.
Мы этого не понимаем. Он не связан земными законами. И он находится в руках двух огромных, всемогущих корпораций. Это их эксперимент, а не наш. Технология, которая должна была освободить нас, вполне могла помочь Трампу прийти к власти или тайно помогла поднять голоса за Брексит. Он создал обширную сеть пропаганды, которая, как рак, распространилась по всему Интернету. Это технология, которая позволила компаниям, подобным Cambridge Analytica, создавать политические сообщения, специально предназначенные для вас.Они понимают ваши эмоциональные реакции и то, как их вызвать. Они знают, что вам нравится, а что не нравится, где вы живете, что едите, что заставляет вас смеяться, что заставляет плакать.
А что дальше? Исследование Ребекки Маккиннон показало, как авторитарные режимы переделывают Интернет в своих собственных целях. Это то, что произойдет с Кремниевой долиной и Трампом? Как указывает Мартин Мур, избранный президент заявил, что глава Apple Тим Кук позвонил ему, чтобы поздравить его вскоре после победы на выборах.«И, несомненно, они будут вынуждены сотрудничать», — говорит Мур.
Журналистика терпит поражение перед лицом таких изменений и будет терпеть неудачу только дальше. Новые платформы заложили бомбу в финансовую модель — рекламу — ресурсы сокращаются, трафик все больше зависит от них, а издатели не имеют доступа и вообще не имеют представления о том, что эти платформы делают в своих штаб-квартирах, в своих лабораториях. И теперь они переходят из цифрового мира в физический.Следующие рубежи — здравоохранение, транспорт, энергетика. И точно так же, как Google является почти монополистом в области поиска, его стремление владеть и контролировать физическую инфраструктуру нашей жизни — вот что нас ждет дальше. Он уже владеет нашими данными, а вместе с ними и нашей идентичностью. Что это будет означать, когда перейдет во все другие сферы нашей жизни?
Основатель Facebook Марк Цукерберг: ему всего 32 года. Фотография: Мариана Базо / Reuters«В настоящий момент существует определенная дистанция, когда вы гуглите« евреи есть »и получаете« евреи — это зло », — говорит Джулия Паулз, исследователь из Кембриджа в области технологий и права.«Но когда вы переходите в физическую сферу, и эти концепции становятся частью инструментов, используемых, когда вы перемещаетесь по своему городу или влияете на то, как люди работают, я думаю, это имеет действительно пагубные последствия».
Паулз вскоре опубликует документ, посвященный отношениям DeepMind с NHS. «Год назад DeepMind передали 2 миллиона медицинских карт лондонцев. И было полное молчание со стороны политиков, регулирующих органов, всех, кто наделен властью.Это компания без какого-либо опыта в сфере здравоохранения, получившая беспрецедентный доступ к NHS, и потребовалось семь месяцев, чтобы даже узнать, что у них есть данные. И чтобы это выяснить, потребовались журналистские расследования ».
Заголовок гласил, что DeepMind собирается работать с NHS над разработкой приложения, которое обеспечит раннее предупреждение для людей, страдающих заболеванием почек. И это так, но амбиции DeepMind — «решить разведку» — выходят далеко за рамки этого. Для исследователей искусственного интеллекта вся история двух миллионов пациентов NHS — настоящая сокровищница.И их вступление в NHS — предоставление полезных услуг в обмен на наши личные данные — это еще один важный шаг в их влиянии и влиянии во всех сферах нашей жизни.
Потому что этап, выходящий за рамки поиска, — это прогнозирование. Google хочет знать, чего вы хотите, прежде чем вы узнаете себя. «Это следующий этап», — говорит Мартин Мур. «Мы говорим о всеведении этих технологических гигантов, но это всеведение снова делает огромный шаг вперед, если они способны предсказывать. И вот куда они хотят попасть.Прогнозировать болезни в здоровье. Это действительно очень проблематично ».
За почти 20 лет существования Google на наше мнение о компании повлияла молодежь и либеральные взгляды ее основателей. Точно так же Facebook, чья миссия, по словам Цукберга, не заключалась в том, чтобы быть «компанией». Он был построен для выполнения социальной миссии — сделать мир более открытым и взаимосвязанным ».
Чем больше мы с ними спорим, тем больше они о нас знают. Все это входит в круговую систему.Джонатан ОлбрайтБыло бы интересно узнать, как он думает, что это работает.Дональд Трамп подключается через те же технологические платформы, которые якобы помогли разжечь «арабскую весну»; связь с расистами и ксенофобами. Facebook и Google усиливают и распространяют это сообщение. И мы тоже — основные СМИ. Наше возмущение — всего лишь еще один узел на карте данных Джонатана Олбрайта.
«Чем больше мы с ними спорим, тем больше они знают о нас», — говорит он. «Все это входит в круговую систему. Мы наблюдаем новую эру сетевой пропаганды.
Мы все точки на этой карте. И наше соучастие, наша доверчивость, будучи потребителями, а не гражданами, являются важной частью этого процесса. А что будет дальше, зависит от нас. «Я бы сказала, что все были действительно наивны, и нам нужно вернуться в гораздо более циничное место и действовать исходя из этого», — советует Ребекка Маккиннон. «Несомненно, то место, где мы сейчас находимся, очень плохое. Но это мы как общество совместно создали эту проблему. И если мы хотим стать лучше, когда дело касается информационной экосистемы, которая служит правам человека и демократии, а не разрушает ее, мы должны разделить ответственность за это.
Злые ли евреи? Как вы хотите получить ответ на этот вопрос? Это наш интернет. Не Google. Не Facebook. Не правые пропагандисты. И только мы можем его вернуть.
Эта статья содержит партнерские ссылки, что означает, что мы можем заработать небольшую комиссию, если читатель перейдет по ссылке и совершает покупку. Вся наша журналистика независима и никоим образом не зависит от рекламодателей или коммерческих инициатив. Нажимая на партнерскую ссылку, вы соглашаетесь с установкой сторонних файлов cookie.Больше информации.
Как сделать ваш поиск в Интернете более безопасным и конфиденциальным
Когда дело доходит до поиска чего-либо в Интернете, большинство из нас по умолчанию использует поиск в Google — поисковая система стала настолько доминирующей, что теперь это глагол, точно так же, как Фотошоп есть. Но использование Google для поиска требует компромисса с конфиденциальностью.
Бизнес Google, конечно же, основан на рекламе, и каждый выполняемый вами поиск попадает в ваш профиль, который используется для таргетинга рекламы, которую вы видите в Интернете.Хотя Google не сообщает маркетинговым фирмам, какие поисковые запросы вы выполняете, он использует эти запросы, чтобы создать ваше представление о вас, против которого можно продавать рекламу.
Хотя Google предпринял шаги по ограничению этого сбора данных — например, ввел инструменты для автоматического удаления истории веб-поиска по истечении определенного периода времени — вы можете захотеть переключиться на другую поисковую систему, которая не регистрирует ваши запросы. И если вы хотите придерживаться Google, есть способы ограничить объем записываемых данных.
Brave Search
Brave не будет отслеживать то, что вы ищете.
Снимок экрана: Дэвид Нильд через Brave. Ранее Brave был известен своим браузером, ориентированным на конфиденциальность, а теперь запустил свою собственную поисковую систему, хотя и помеченную как бета-продукт, поэтому ожидайте появления случайных ошибок и технических проблем. Даже на этом раннем этапе он впечатляюще всеобъемлющ, и, конечно же, вы пытаетесь его защитить как с точки зрения безопасности, так и с точки зрения получаемых результатов.
Проще говоря, поисковая система не ведет журналы ваших запросов. Хотя это может сделать несколько менее удобный пользовательский интерфейс — Google может автоматически узнать, что вас больше интересуют дельфины Майами, чем, например, настоящие дельфины — это означает, что вы можете искать, не беспокоясь о том, что вы увидите какие-либо связанные Реклама.
«Для нас невозможно поделиться, продать или потерять ваши данные, потому что мы вообще не собираем их», — говорит Брейв. Хотя служба может в конечном итоге стать поддерживаемой рекламой, эта реклама ничего не будет знать о вас или о том, что вы искали в Интернете, что сильно отличает ее от предложения Google.
Зачем нужен словарь в эпоху поиска в Интернете?
Я не могу вспомнить, сколько мне было лет, когда я впервые выучил слова , обозначение (определение слова) и , значение (предположение слова). Но я помню, как меня немного обманула мысль о том, что существует целый пласт языка, который невозможно передать с помощью словаря. Как и большинству молодых людей, мне нравилось учиться, но я думал об этом как о чем-то, с чем я в конце концов закончу.Я предполагал, что в каком-то возрасте мне нужно будет знать все. Понимание нюансов языка казалось препятствием на пути к этой цели.
Это было только после того, как я окончил колледж и впоследствии понял, что не существует такой вещи, как всеобъемлющие знания, которые я мог бы читать для удовольствия. Мною руководило чувство любопытства, а не отчаянная завершенность. Я начал видеть словари, даже если они неточные, как практические справочники по языковой жизни. Поиск слов, встречающихся в природе, был не столько неудачей, сколько признанием того, что есть много вещей, которых я не знаю, и возможностью узнать, сколько именно.
Я высоко ценю свой экземпляр Второго издания Нового международного словаря Вебстера 1954 года, который я купил на улице недалеко от своей квартиры в Бруклине несколько лет назад. Его 3000 страниц (индийская бумага с мраморным передним краем) отмечены указателем большого пальца. Я держу его открытым, одиноким на столе, как словари в библиотеках. Я часто обращаюсь к нему во время вечерних игр в скрэббл или чтения дневных журналов. В основном я читаю романы по ночам, в постели, поэтому, когда я натыкаюсь на незнакомые слова, я наклоняю ухо к нижней части страницы, а затем ищу слова рывками.Когда я начинаю сталкиваться с этими словами, вновь появившимися в моем поиске закономерностей, в статьях, подкастах, других книгах и даже в случайных разговорах, языковая вселенная, кажется, сжимается до размеров небольшого городка. Словари обостряют мои чувства, почти как определенные вещества, изменяющие сознание: они направляют мое внимание вовне, на разговор с языком. Они заставляют меня задуматься, к чему еще я не обращаю внимания, потому что я еще не научился их замечать. Недавно обнаруженные образцы включают или , «механическую модель, обычно часовую, разработанную для представления движения Земли и Луны (а иногда и планет) вокруг Солнца.Оксфордский словарь английского языка также сообщает мне, что это слово происходит от четвертого графа Оррери, для которого была сделана копия первой машины около 1700 года. Полезно? Очевидно нет. Удовлетворяет? Глубоко.
Со словарями неизвестные слова становятся разрешимыми загадками. Зачем оставлять их наугад?
Википедия и Google отвечают на вопросы другими вопросами, открывая страницы с информацией, о которой вы никогда не просили. Но словарь основан на общих знаниях, используя простые слова для объяснения более сложных.Его использование похоже на то, как будто вы открываете устрицу, а не падаете в кроличью нору. Неизвестные слова становятся разгадываемыми загадками. Зачем оставлять их наугад? Почему бы не заглянуть в словарь и не ощутить мгновенное удовлетворение от сочетания контекста с определением? Словари вознаграждают вас за внимание как к тому, что вы потребляете, так и к собственному любопытству. Они — портал в своего рода иррациональное детское стремление всего знать вещи, которые у меня были до того, как научиться, стало обязанностью, а не игрой.Меня больше всего забавляют слова, которые совершенно не означают то, что, как я думал, они имели в виду. Как cygnet . Это не имеет ничего общего с кольцами или канцелярскими принадлежностями. (Это молодой лебедь.)
Есть, конечно, разные словари. То, как они размножались с течением времени, является напоминанием о том, насколько бесполезно подходить к языку как к чему-то, что можно полностью понять и сдержать. Словарь английского языка Сэмюэля Джонсона, опубликованный в 1755 году, дал определение мизерным 40 000 слов.Оригинальный O.E.D., предложенный Филологическим обществом Лондона в 1857 году и завершенный более 70 лет спустя, содержал более 400000 статей. Вселенная Мерриама-Вебстера является прямым потомком Американского словаря английского языка Ноя Вебстера, опубликованного в 1828 году. Составленный одним Вебстером в течение более 20 лет, он содержал 70 000 слов, почти пятая часть которых никогда не использовалась. определено ранее. Вебстер, который переписывался с такими отцами-основателями, как Бенджамин Франклин и Джон Адамс, рассматривал лексикографию как акт патриотизма.Он считал, что установление американских стандартов правописания и определения необходимо для упрочения культурной самобытности молодой нации, отдельной от английской.
Возможно, из-за энтузиазма Вебстера по отношению к правилам словари долгое время имели несправедливую репутацию арбитров языка, как инструменты, используемые для ограничения, а скорее, расширения диапазона вашего выражения. Но не словари создают язык, а люди. Возьмите дилетанта : Поверхностное значение этого слова — современное изобретение.Вышеупомянутый Американский словарь Ноя Вебстера определяет его как «того, кто любит продвигать науку или изящные искусства». O.E.D. ссылается на его связь с латинским глаголом delectare , что означает «радовать или радовать». Когда-то быть дилетантом означало, что любовь и любопытство пробуждают в вас интерес к определенной дисциплине. Для меня словари — это портал в такого рода неисчислимые поиски знаний. Они напоминают мне, что когда дело доходит до учебы, удовлетворение любопытства так же важно, как и внимание.В конце концов, разве любопытство не является еще одной формой внимания? Следить за своим любопытством вместо того, чтобы его отбрасывать, — это один из лучших способов почувствовать связь с чем-то большим, чем то, что находится прямо перед вами.
Рэйчел дель Валле — писатель-фрилансер, чьи работы публиковались в GQ и журнале Real Life.
Что люди использовали до Google для поиска в Интернете?
Иллюстрация: Анжелика Алсона / Gizmodo
Год 1997. Вы носите то, что люди носили тогда — что-то вроде джинсовой куртки, я полагаю, — и разговариваете со своим другом о вашем новом любимом фильме, недавно вышедшем Автомобиль Майка Майерса Остин Пауэрс .Вы цитируете фильм, и ваш друг думает, что это весело. Затем все принимает мрачный оборот. «Я думал, что Рэнди Куэйд великолепен», — говорит ваш друг. «Рэнди Куэйд?» — думаете вы, изо всех сил стараясь не пробить стену. «Рэнди Куэйд не был в« Остин Пауэрс ». «Вы пытаетесь объяснить это своему другу -« Я полагаю, — кратко говорите вы, — что вы думаете о Клинте Ховарде », — но ваш друг непреклонен. Чтобы разрешить этот спор и спасти то, что осталось от вашей дружбы, вы загружаете свою 90-фунтовую компьютерную башню.Сорок минут спустя вы попали в Интернет. Теперь вопрос: куда вы идете? Как до Google люди разрешали глупые споры и / или находили другую информацию? На этой неделе мы обратились за помощью к ряду экспертов, чтобы узнать об этом в Giz Asks.
Амелия АкерДоцент, информация, Техасский университет в Остине, чьи исследования связаны с появлением, стандартизацией и сохранением новых информационных объектов на мобильных платформах и платформах социальных сетей
«Первые поисковые машины были каталогами веб-сайтов, которые курировали люди.” Кристин Л. БоргманGoogle Search доминирует на более чем 90% рынка, который включает такие поисковые системы, как Yahoo, Bing и DuckDuckGo, ориентированные на конфиденциальность.Но до того, как персонализированный поисковый алгоритм Google, основанный на рекламе, завладел почти всем, что мы можем найти в Интернете, существовали каталоги веб-сайтов и индексированные поисковые системы, которые собирали веб-ресурсы по темам.
Первые поисковые машины были каталогами веб-сайтов, которые курировали люди. Эти веб-онтологи (Yahoo назвал их «серферами») читали все веб-страницы по определенным темам и затем оценивали их. В конце концов, эта управляемая человеком модель категоризации была заменена сканированием веб-сайтов с помощью ботов (иногда называемых пауками), а затем ранжированием веб-сайтов по их надежности и релевантности для различных типов поисковых запросов.В начале 1990-х на выбор было около двадцати различных поисковых систем, включая WebCrawler, Lycos, AltaVista и Яндекс. Подобно библиотечным каталогам, эти индексы поисковых систем были составлены и организованы по темам, содержанию, структуре и предметам. Ранние поисковые системы были разработаны таким образом, чтобы пользователи могли переходить к пакетам ресурсов с гиперссылками в различных категориях высокого уровня, таких как «Новости», «Путешествия», «Спорт» и «Бизнес». Столбцы широких категорий, заполненные синими гиперссылками, из которых пользователи могут выбирать, сделали домашние страницы ранних поисковых систем похожими на переполненный указатель в конце учебника.
Важно помнить, что поиск в Интернете в 1990-е годы преследовал разные цели и стимулы для людей, «просматривающих веб-страницы». В ранних онлайн-культурах поиск факта или продукта не всегда был целью поиска. Вместо этого поисковые системы помогали людям открывать и исследовать цифровые ресурсы и работать во всемирной паутине. Веб-поиск в 1990-х годах имел меньший таргетинг на рекламу и давал пользователям больше возможностей для изучения, даже если результаты были элементарными и не всегда надежно отфильтровывали порнографию. По сравнению с сегодняшним опытом поиска, ранний поиск в Интернете был скорее поиском.Под квестом я имею в виду активное участие в навигации и поиске контента способами, которые персонализированный, тщательно подобранный поиск с таких платформ, как Google и Facebook, в значительной степени узурпировал с помощью целевой рекламы. Позвольте мне привести пример авантюрной ранней поисковой экспедиции в Интернете. Было время, когда поиск текста песни для «Small Town Boy» мог привести вас к поиску первой немецкой фан-страницы Джимми Сомервилля. В наши дни, если вы ищете текст песни, Google будет извлекать текст с такого веб-сайта, как LyricFind.com. Когда вы переходите от поискового опыта к точному алгоритмическому опыту, поиск становится рутинным и относительно предписывающим. Вы можете получить именно то, что хотите, с помощью Google Search, но вы, скорее всего, потеряете множество случайных функций и доступ к странному, разнородному контенту, который сделал раннюю веб-версию настолько интересной и увлекательной для изучения.
Сегодня, когда мы говорим о «поиске», мы обычно не думаем о просмотре индексов или посещении веб-страниц. Вместо этого мы думаем о прокрутке и пролистывании информации из каналов и приложений, которые объединяют множество разного контента и профилей пользователей в один поток.Или, может быть, мы ожидаем, что точный ответ будет представлен в виде фрагмента информации, извлеченного из онлайн-ресурса. Большинство современных функций поиска, особенно поиск на таких платформах, как Facebook, Amazon или App Store, еще больше монетизировали этот процесс, собирая все больше и больше пользовательских данных до такой степени, что отслеживание поведения пользователей, таких как условия поиска и привычки просмотра, почти всегда требуется людям. чтобы воспользоваться этими услугами, которые становятся все более необходимыми. Когда мы спрашиваем себя, что мы потеряли, рассматривая эти ранние поисковые системы, мы должны попытаться представить себе все возможности, которые мы упустили, предоставив монополию на поиск в Интернете цифровой информации по всему миру одной фирме, такой как Google, а затем спросите себя: как еще я могу просматривать веб-страницы?
Заслуженный профессор-исследователь, Информационные исследования Калифорнийского университета в Лос-Анджелесе, и автор книги Большие данные, мало данных, нет данных: стипендия в сетевом мире
В ‘ 90-е, Yahoo и Altavista преуспели. Но компьютеризированный поиск информации — это очень старая область, восходящая, по крайней мере, к 1950-м годам. Первые коммерческие онлайн-системы удаленного доступа появились в начале 1970-х годов.
Google никоим образом не изобретал поиск информации — он основывался на очень старых методах документирования, таких как методы Пола Отлета, который изобрел универсальную десятичную классификацию в 1930-х годах и был одним из основоположников современной информатики.
История онлайн-поиска информации является предметной дисциплиной — очень глубокое индексирование специалистов в области медицины, металлургии, материаловедения, химии, инженерии, образования, социальных наук. К началу 1970-х у нас были очень хорошие онлайн-базы данных, которые были коммерчески доступны — вы платили за минуту подключения.
Некоторые из самых основных принципов Google основаны на td-idf, или «Частота текста, время обратная частота документа», — понятие, появившееся в Кембриджской докторской диссертации Карен Спарк Джонс в 1958 году.Ее метод заключался в поиске частоты употребления термина в произведении и делении ее на обратную частоту встречаемости документов. Она действительно новатор и позже будет консультировать Google вместе со многими другими известными специалистами в области информации. Пейдж и Брин определенно глубоко разбирались в этой истории.
Google возник в результате Инициативы по цифровым библиотекам, проекта, возглавляемого Национальным научным фондом и включающего 8 или 10 различных федеральных агентств. У меня было финансирование, и я вспоминаю собрание всех участников, на котором Брин и Пейдж представили плакат с предложением Google.Я помню, как подумал: это действительно круто, они заново изобрели библиометрию для Интернета.
Библиометрия — это средство для создания связей между документами и последующего отслеживания в сети. Этот метод особенно полезен при изучении тем, терминология которых со временем меняется. Например, если вы хотите узнать, что предшествовало современным дискуссиям об абортах, вы должны пойти на дискуссию Роу против Уэйда в середине 1970-х годов и найти все, что там цитировалось, и все, что это цитировало, так что вы можете пойти в обоих направлениях.
Индекс научного цитирования, также начатый в 1950-х годах, привнес старые принципы библиотечного дела в современные технологии. Библиометрия и индексирование цитирования — это идеи, которые можно проследить веками до таких разработок, как библейские аннотации.
G / O Media может получить комиссию
Новое поколение AirPods
«Google ни в коем случае не изобретал поиск информации — он основывался на очень старых методах документации, таких как методы Пола Отлета, который изобрел универсальную десятичную классификацию в 1930-х годах и был одним из основоположников современной информатики.” Safiya Umoja Noble
Более доступная альтернатива AirPods Pro со многими из тех же функций.Доцент информационных исследований и содиректор Центра критических запросов в Интернете Калифорнийского университета в Лос-Анджелесе, а также автор книги Алгоритмы угнетения: как поисковые системы усиливают расизм
«Первые поисковые машины были фактически виртуальными библиотеками, и многие люди понимали ценность библиотек как общественного блага. По мере роста автоматизации и замены библиотекарей и экспертов искусственным интеллектом мы многое потеряли. Общественное благо, которое могло быть реализовано, было заменено крупными рекламными платформами, такими как Yahoo! и Google ». Ян МиллиганОдин из Наиболее важным аспектом раннего обмена информацией в Интернете было то, что эксперты в предметной области, от библиотекарей до ученых и любителей, были задействованы для накопления и систематизации знаний. Это сделало людей, вовлеченных в эти практики, видимыми, даже когда были разработаны ИИ и инструменты поиска.Мы понимали, что сила людей — это то, что заставляет делиться информацией в Интернете, и мы стремились выяснить, что вызывает доверие, на основе наборов веб-сайтов, которыми управляют организации, особенно университеты и исследовательские организации.
Первые поисковые машины были фактически виртуальными библиотеками, и многие люди понимали ценность библиотек как общественного блага. По мере роста автоматизации и замены библиотекарей и экспертов искусственным интеллектом мы многое потеряли. Общественное благо, которое могло быть реализовано, было заменено крупными рекламными платформами, такими как Yahoo! и Google.
Теперь экспертиза передается на аутсорсинг и часто оптимизируется содержание, за что платит тот, кто предлагает самую высокую цену в AdWords. Это привело к большому разрыву между знаниями и рекламой в поисковых системах, особенно при попытке разобраться в сложных проблемах. В некотором смысле поиск подорвал наше доверие к опыту и критическому мышлению, подкрепленным изученными фактами и исследованиями, и сделал нас открытыми для манипуляций со стороны пропаганды. Поисковые системы могут отлично помочь нам найти банальную информацию, но они также уменьшили нашу чувствительность к ценности медленных, целенаправленных исследований — таких, которые делают демократию более информированной.
Адъюнкт-профессор истории Университета Ватерлоо и автор книги История в эпоху изобилия: как Интернет трансформирует исторические исследования
«Конечно, Google не был первой поисковой системой в Интернете. Еще в 1993 году был Wandex (или World Wide Web Wanderer), который измерял Интернет и приводил к поисковому индексу; в Lycos и Infoseek в 1994 году и в такие каталоги, как Yahoo! в 1995 году ». Итан ЦукерманGoogle, конечно, не был первая поисковая система в Интернете.Еще в 1993 году был Wandex (или World Wide Web Wanderer), который измерял Интернет и приводил к поисковому индексу; в Lycos и Infoseek в 1994 году и в такие каталоги, как Yahoo! в 1995 году.
Однако многие из этих ранних поисковых систем или каталогов были довольно неуклюжими. Если бы вы были создателем веб-сайта, вам во многих случаях пришлось бы заполнить форму для добавления в каталог или вставить довольно громоздкие метатеги в свой HTML. К середине 1990-х, когда все больше и больше людей начали создавать веб-сайты и размещать их на сторонних платформах, они не всегда регистрировали свои сайты.
Частично это связано с тем, что первые веб-сайты могли полагаться на гиперссылки — гораздо больше, чем мы сегодня, в наш век поиска — для привлечения посетителей на свои сайты.
WebRing — отличный тому пример. WebRing был разработан в 1995 году молодым разработчиком программного обеспечения по имени Сейдж Вейл. Веб-кольца представляли собой тематически объединенные группы веб-сайтов. Итак, люди, интересующиеся старыми автомобилями, присоединятся к автомобильному энтузиасту WebRing, любители кошек — к WebRing, ориентированному на кошек, и так далее. Внизу этих страниц будет интерфейс WebRing, побуждающий пользователей перейти на «следующий» сайт или «предыдущий» сайт, или даже в общий индекс всех, кто присоединился к кольцу.
Это был довольно демократичный и доступный способ поиска сайтов. Кто угодно мог создать веб-кольцо, любой мог присоединиться к нему, если бы администратор считал, что он вписывается в сообщество. Что особенно важно, они сформировали новый способ связи людей. Расцвет WebRings длился примерно до 2000 года, когда технология оказалась в руках Yahoo! и некоторые изменения в руководстве привели к отчуждению пользователей.
Я не хочу испытывать чрезмерную ностальгию: я бы не хотел возвращаться в мир, где мы открывали для себя контент в основном через гиперссылки, и я использую Google так же часто, как и все остальные.Но способ, которым Google работает, благодаря PageRank, заключается в том, что чем больше ссылок на сайт поступает из влиятельных источников, тем выше он поднимается на страницах результатов поиска. Это приводит к перенаправлению трафика к нескольким крупным победителям. Если я буду искать «кошек», я могу изучить первую дюжину или около того из почти четырех миллиардов результатов. Где-то на этих миллиардах страниц, несомненно, есть классные домашние страницы людей, которые просто действительно любят своих кошек. В 1998 году, щелкнув веб-ссылку, я мог по счастливой случайности обнаружить какой-нибудь увлекательный контент или почувствовать некое сообщество, найдя единомышленников.Это труднее найти с Google.
Адъюнкт-профессор практики медиаискусств и наук в MIT Media Lab, директор Центра гражданских медиа в Массачусетском технологическом институте и автор книги Digital Cosmopolitans: Почему мы думаем, что Интернет соединяет нас, почему Это не так, и как это исправить
«Yahoo! работал очень хорошо в течение первых нескольких лет Интернета, но он был громоздким и рухнул к 1997 году или около того… ”Что ж, в те темные времена мы использовали несколько разных поисковых систем, которые работали на двух разных философиях: TFIDF и человеческое курирование.
TF-IDF означает «Частота, обратная документальной частоте». Это означает, что поисковая машина взяла ваш запрос — «сила мула» — и искала документы, содержащие этот термин. Но он также учитывает, насколько распространен этот термин во всем корпусе в целом, чтобы избежать чрезмерного совпадения в очень общих терминах. Таким образом, при поиске слова «сила мула» движок TF-IDF, скорее всего, предпочтет документы, в которых упоминаются мулы, а не те, в которых упоминается сила, потому что «сила» является более распространенным словом, чем «мул».
TF-IDF уязвима для очень специфического взлома.Если я хочу продать вам мой новый веб-браузер на основе мулов (они были в моде в начале 1990-х …), я просто публикую веб-страницу, на которой много раз повторяется «власть мула». В Интернете нет документа, который бы лучше соответствовал вашему запросу, поэтому я каждый раз буду занимать первое место. Это слабость, которая побудила Ларри Пейджа и Сергея Брина работать над Page Rank. Идея заключалась в том, что на такие страницы, как моя страница со спамом, вряд ли будут ссылаться, в то время как полезные страницы будут иметь много входящих ссылок. Google по сути соединил TF-IDF с Page Rank, чтобы запустить свою первоначальную поисковую систему.(Люди придумали, как ранжировать страницу игры, создавая фермы веб-страниц, на которых все написано «сила мула» и связаны друг с другом. В ответ Google создал более сложные алгоритмы. Прогресс. Люди перестали использовать браузеры, работающие на мулах, и браузер Steam стал Буквально — вы можете очень сильно обжечься на одном, если не будете осторожны.)
Lycos, на который я некоторое время работал после того, как они купили Tripod, компанию, которую я помог запустить, работала на TF-IDF, как и раньше. Excite, HotWired и Altavista, которые я помню как лучшие из всех.
TFIDF никогда не работал особенно хорошо. Со временем умные поисковые системы обнаружили, что 30% -50% запросов могут быть решены с помощью вручную подобранных поисковых страниц. Например, если вы искали «результаты гонок на мулах», то обнаружив страницу, на которой явно упоминалась эта фраза, вероятно, не помогли — отправка вас на первую страницу AMF (Американской федерации мулеров) будет лучшим результатом. Когда я ушел в 1999 году, Lycos обслужил не менее 30% страниц результатов, созданных вручную.
Yahoo, напротив, изначально работала полностью под контролем человека.Это была не поисковая машина, а каталог. Когда вы вводите поисковый запрос «гонки на мулах», он покажет вам, какое место занимают гонки на мулах в различных иерархиях:
Спорт -> Спортивные лиги -> Гонки -> Гонки на мулах
, а затем ссылку на AMF, OOM (Only Ornery Mules) и ESPN (Сеть программ развлечений и животноводства)
Закон -> Жестокое обращение с животными -> Гонки на мулах
, а затем в PET’eM (Люди за этичное обращение с мулами)
Что было замечательно в этом, так это то, что он мог показать вам, как одна организация (AMF) вписалась в большой мир гонок на мулах.Это было особенно здорово, если вы исследуете компании, так как вы можете быстро найти потенциальных конкурентов или других поставщиков. Но создание этого было королевской головной болью, требующей от настоящих таксономистов-людей смотреть на сайты и выяснять, где они оказались в иерархии. И бог в помощь, когда кто-то изобрел что-то новое, например, гоночного мула на паровой тяге. Это связано с гонками на мулах или паровой тягой? Оба? Или новая категория, полностью подтверждающая появление новых спортивных лиг, таких как NASCAR (Национальные активные гонки на паровых скотах)?
Yahoo! работал очень хорошо в течение первых нескольких лет Интернета, но он был громоздким и рухнул к 1997 году или около того — они начали передавать свой поиск другим компаниям (сначала Excite… Бинг сейчас.) Я скучаю по этому, хотя бы потому, что было захватывающе видеть способы, выбранные людьми для организации всего человеческого знания. (Мелвил Дьюи отнес 200 к «религии», а затем посвятил 220–280 различным темам, связанным с Библией. 290-е годы относятся к «другим религиям» … включая буддизм, индуизм и т. Д.)
Трудно представить Yahoo возвращаться — это чертовски много работы. В каком-то смысле поисковые страницы, созданные людьми, вернулись. Большая часть страницы результатов Google — это не веб-поиск типа TF-IDF, а страница, созданная на основе различных запросов к базе данных — поиск погоды, а Google использует геолокацию, чтобы определить, где вы находитесь, и находит местные новости погоды из базы данных.Я на самом деле думаю, что страницы, курируемые людьми — например, библиотекари, работающие вместе в стиле Википедии, — могут быть отличным решением для решения быстро возникающих тем, которые, как правило, захватываются политическими экстремистами или торговцами дезинформацией.
Что касается того, что мне не хватает: я скучаю по мулам. Мой браузер Netscape с питанием от мула работал медленно, но я скучаю по этим нежным ритмам бега по сети.
У вас есть животрепещущий вопрос для Giz Asks? Напишите нам по адресу [email protected].
Первая поисковая система в Интернете была выпущена в 1990 году — Poynter
.Ранние онлайн-журналисты использовали инструмент поиска в Интернете под названием Archie,
, выпущенный 10 сентября 1990 года.Вот снимок экрана поисковой системы Archie в Интернете. А вот ссылка на архивную версию, опубликованную Варшавским университетом.
(archie.icm.edu.pl image)
«Первоначально Интернет был не чем иным, как сборником FTP-сайтов, которые пользователи могли просматривать в
попытках найти определенные общие файлы. По мере того, как список веб-серверов, присоединяющихся к Интернету
, увеличивался, Всемирная паутина стала предпочтительным интерфейсом для
доступа к информации в Интернете. Естественно, возникла потребность в поиске
и организации географически разнесенных файлов данных.В начале 1990-х поисковые машины
порождены потребностями пользователей и легко перемещаются по файлам на веб-серверах, составляющих
Интернет.Арчи стал первым индексом, который попытался организовать этот контент.
Gopher сделал базу данных доступной для поиска ».— «Где поиск?»
Search Engine Watch, 16 января 2014 г.«Первая поисковая система была разработана в качестве школьного проекта Аланом
Эмтадж, студентом Университета Макгилла в Монреале. Еще в 1990 году Алан
создал Archie, индекс (или архивы) компьютерных файлов, хранящихся на
анонимных FTP-сайтах в данной сети компьютеров (параметры длины имени соответствовали параметрам длины имени «Archie»
, а не «Archives» — таким образом, он стал
название первой поисковой системы).В 1991 году Марк МакКахилл, студент
Университета Миннесоты, эффективно использовал гипертекстовую парадигму для создания
Gopher, который также выполнял поиск текстовых ссылок в файлах.В доступной для поиска базе данных веб-сайтов Archie and Gopher не было
возможностей ключевых слов на естественном языке, используемых в современных поисковых системах.
Скорее, в 1993 году графический веб-браузер Mosaic был усовершенствован по сравнению с преимущественно текстовым интерфейсом
Gopher. Примерно в то же время Мэтью
Грей разработал Wandex, первую поисковую систему в том виде, в котором мы
знаем поисковые системы сегодня.Технология Wandex была первой, которая просканировала
веб-индексацию и поиск по каталогу проиндексированных страниц в сети
. Другое значительное развитие поисковых систем произошло в 1994 году
, когда поисковая система WebCrawler начала индексировать полный текст веб-сайтов
, а не только заголовки веб-страниц ».— «Краткая история ранних поисковых систем»
Видео: «Поиск в Интернете — FTP Anarchie | The Internet Revealed (1995) »
А вот снимок экрана раннего текстового поиска Арчи в Интернете.
(VozExpress Image)
Как искать ресурсы в Интернете для использования на уроке
.
У вас есть любимая поисковая система, которую мы здесь не перечислили? Пожалуйста дай нам знать.Ссылки проверены 31.07.2018
Стратегии поиска | Консультации по поиску | Кластеризация поисковых систем
- 43Marks — Эта новая мета-поисковая система представляет собой настраиваемую страницу хранения закладок — взгляните на настроенный образец
- Academic Reference and Research Index — десятки тысяч академических справочных и исследовательских сайтов
- AOL Search — это поисковая система на базе Excite и улучшенная Google.
- Arielis — корневая поисковая система, поэтому вы можете искать по корневому слову
- Задать — введите вопрос в обычном порядке
- Beaucoup — основной источник бесплатной информации
- Congress.gov — [заменяет Томаса] Законодательная информация в Интернете
- Dogpile выполняет поиск с помощью нескольких поисковых систем. Если вы использовали поисковую систему MetaFind, теперь вы автоматически перенаправляетесь на Dogpile.
- Весь Интернет — поисковая машина общего назначения
- FindSounds.com — это поисковая система для поиска звуковых эффектов в Интернете.
- Giga Blast новая мощная поисковая система, которая индексирует в реальном времени
- Google оценивает качество сайтов на основе качества сайтов, которые ссылаются на него.
- Система пользовательского поиска Google — Создайте свою собственную поисковую систему по определенным темам и ограничьте ее только веб-сайтами, которые вы хотите, чтобы учащиеся использовали.
- Карты Google — карты улиц или спутниковые карты, маршруты и поиск предприятий, они даже содержат информацию о пробках для некоторых городов
- Функции веб-поиска Google — из Справочного центра Google
- ixБыстрый метапоисковый механизм
- KartOO — метапоисковый движок с визуальным отображением интерфейсов
- MetaEureka — простой текстовый мета-поисковик
- Oscobo — поисковая система для людей, заботящихся о конфиденциальности в Интернете
- Partners in Rhyme предоставляет огромную базу данных звуков для поиска.
- Безопасный поиск Google Экраны SafeSearch для сайтов, которые содержат неприемлемую для учащихся информацию, и исключают их из результатов поиска
- Search.com размещен c | net и поддерживается Excite. Их тематический указатель представлен в виде раскрывающегося меню или списка тем, которые они называют специальными поисками.
- Просто Google — множество вариантов поиска, упорядоченных по столбцам
- Start — претендует на звание первой в мире системы ответов на вопросы в Интернете
- Визуальный тезаурус — действительно отличный способ найти синонимы.Это всего лишь пробная версия, но вы можете искать несколько слов за раз, не платя.
- Wayback Machine — Просмотрите 55 миллиардов веб-страниц, заархивированных с 1996 года по несколько месяцев назад.
- Список поисковых систем в Википедии
- Wotbox — небольшие поисковики с быстрым интерфейсом
- Yahoo имеет актуальный индекс, а также функцию поиска. Тематический указатель предоставляет предварительно определенные результаты поиска.
- Yippy — поисковая система кластеризации
- Zanran — поиск числовых данных, источник данных и статистики (графики, диаграммы и таблицы)
- Zapmeta — Мне действительно нравится их функция быстрого просмотра, попробуйте.Хотя эта мета-поисковая система действительно предоставляет небольшое управляемое количество ресурсов, первые перечисленные сайты являются коммерческими. Рекомендация: пропустите списки избранных спонсоров и сразу перейдите в раздел результатов веб-сайта.
Поисковые системы для кластеризации
- Carrot — Carrot систематизирует результаты поиска по темам, что дает мгновенный обзор того, что доступно
- Dot Hop — классная графика, кластеры по сети, изображения или видео
- Search Cube — Search-Cube — это визуальная поисковая машина, которая представляет результаты веб-поиска в уникальном трехмерном интерфейсе куба.Он показывает превью до девяноста шести веб-сайтов, видео и изображений.
- Поисковые системы с кластерной технологией — Более 40 поисковых систем с кластерной технологией генерируют различные группы по конкретным темам
- Yippy — Группирует результаты поиска, чтобы вы могли настроить таргетинг на определенную тему.
Поисковые системы Kid Safe
Я всегда рекомендовал учителям искать Интернет-ресурсы, которые они хотят, чтобы их ученики использовали, и разрабатывать уроки / проекты / блоки так, чтобы используемые Интернет-сайты были четко определены.Однако, если вы планируете отправить своих учеников на поиски, воспользуйтесь одной из поисковых систем Kid-Safe, указанных ниже:
Kids.Net — Поисковая система Только для детей и детей — Поиск безопасных и чистых сайтов.
KidRex — веселый и безопасный поиск для детей, созданный детьми [Не позволяйте T Rex вас напугать!] Поисковые системы Kid Safe — список сайтов из ресурсов для школьных библиотекарей Kidz Search — поиск в KidzSearch.com, он может возвращать только «строгие» результаты поиска Google. Стратегии поиска для поиска ресурсов для поддержки классной единицы
Взгляните на список, предоставленный Дебби Абилок, озаглавленный «Выберите лучший поиск для вашей информации». Например, у вас может быть «широкий академический предмет и вам нужны указатели на качественные сайты». Если это так, Дебби предлагает вам зайти в Индекс библиотекарей в Интернете или в Infomine. С другой стороны, если вам нужно увидеть взаимосвязь между идеями, она предлагает вам использовать KartOO или Web Brain.[Эта ссылка с истекшим сроком действия доступна в Интернет-архиве Wayback Machine.]
Это отличный сайт, проверьте его!
Рекомендуемая стратегия поиска: анализируйте свою тему и выполняйте поиск периферийным зрением — от Калифорнийского университета в Беркли [Эта ссылка с истекшим сроком действия доступна в Интернет-архиве Wayback Machine.]Студенческое руководство по Интернет-исследованиям — Это исследовательское руководство предназначено для помощи студентам в изучении тонкостей проведения эффективных исследований в Интернете.Руководство также помогает с правильным форматированием цитирования. Включены игры и викторины, которые можно распечатать.
Использование поисковых систем Deep Web для академических и научных исследований — узнайте все, что вам нужно знать о Deep Web, в том числе, что это значит, где он живет и как вы можете использовать его в своих интересах
Шаг 1. Выберите несколько поисковых систем и узнайте, как они работают
Найдите 3–4 поисковых системы, которые вам удобно использовать, и выполняйте с ними большую часть поиска.В этом руководстве будет использоваться Vivisimo, который отправляет поисковые запросы в несколько поисковых систем, а затем группирует результаты. Я обнаружил, что Vivisimo неизменно дает мне хорошие результаты. Если вы хотите использовать другую поисковую систему, посмотрите список вверху этой страницы. Выше также приведен список поисковых систем, безопасных для детей.Совет: не выполняйте поиск с помощью кнопки. Перейдите на главную страницу поисковой системы, а не туда, куда вас отправит браузер.
Шаг 2. Используйте поисковую систему кластеризации (Yippy)Yippy — Эта поисковая система группирует результаты по темам.Это лучший способ увидеть все содержимое поиска, но при этом не нужно прокручивать страницы и страницы с информацией.
Шаг 3. Поиск картинок
PicSearch — Если вы ищете изображение, вы, вероятно, найдете его здесь. Некоторые поисковые системы предлагают возможность поиска по графике. ( Предупреждение : страницы поиска изображений в поисковых системах блокируются многими фильтрами состояний.)
Internet4Classrooms содержит коллекцию графических ссылок с разделом по коллекциям изображений, найденным в Интернете.Шаг 4. Поиск звуков в Интернете
FindSounds.com — это поисковая система для поиска звуковых эффектов в Интернете. Поищите в Интернете звуковые эффекты и образцы звуков. Обратите внимание на типы звуков, которые вы можете найти. Это неполный список. Доступно еще много звуков. Вы также можете найти большое количество звуковых файлов всех типов на сайте Partners in Rhyme.
Шаг 5. Пусть цель вашего поиска определяет используемую поисковую систему.
Взгляните на список, предоставленный Дебби Абилок, озаглавленный «Выберите лучший поиск для вашей информации». Например, у вас может быть «широкий академический предмет и вам нужны указатели на качественные сайты». Если это так, Дебби предлагает вам зайти в Индекс библиотекарей в Интернете или в Infomine. С другой стороны, если вам нужно увидеть взаимосвязь между идеями, она предлагает вам использовать KartOO или Web Brain. Это отличный сайт, проверьте его!
Шаг 6. Если вы чувствуете себя комфортно как интернет-сыщик, переходите к изучению того, как оценивать веб-сайты.
Калифорнийский университет в Беркли проводит упражнение по оценке веб-сайтов. По сути, WebQuest по оценке сайтов, это задание используется, чтобы показать студентам Калифорнийского университета в Беркли, почему так важно оценивать источник информации в Интернете. Попробуйте сами. [Эта ссылка с истекшим сроком действия доступна в Интернет-архиве Wayback Machine.]
Шаг 7. Научитесь использовать логическую логику в поиске
«Логический поиск назван в честь Джорджа Буля, британского математика (1815-1864), который написал о логических способах формулирования точных запросов с использованием соединителей истинно-ложно или« операторов »между понятиями.Природа булевой логики, как обычно называют эту систему, делает ее совместимой с двоичной логикой, используемой в цифровых компьютерах. Он стал обычной основой для поиска в большинстве компьютеризированных систем ». Цитата из Джо Баркера ([email protected]) из« Лучшие материалы в Интернете »- Copyright 2002 The Teaching Library, University of California, Berkeley, CA. См. двухстраничный документ в формате .pdf об использовании основных операторов. [Эта ссылка с истекшим сроком действия доступна в Интернет-архиве Wayback Machine.]