Поисковая система — Википедия. Что такое Поисковая система
Поиск информации во Всемирной паутине был трудной и не самой приятной задачей, но с прорывом в технологии поисковых систем в конце 1990-х годов осуществлять поиск стало намного удобнейПоиско́вая систе́ма (англ. search engine) — это компьютерная система, предназначенная для поиска информации. Одно из наиболее известных применений поисковых систем — веб-сервисы для поиска текстовой или графической информации во Всемирной паутине. Существуют также системы, способные искать файлы на FTP-серверах, товары в интернет-магазинах, информацию в группах новостей Usenet.
Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос[1]. Работа поисковой системы заключается в том, чтобы по запросу пользователя найти документы, содержащие либо указанные ключевые слова, либо слова, как-либо связанные с ключевыми словами[2]. При этом поисковая система генерирует страницу результатов поиска. Такая поисковая выдача может содержать различные типы результатов, например: веб-страницы, изображения, аудиофайлы. Некоторые поисковые системы также извлекают информацию из подходящих баз данных и каталогов ресурсов в Интернете.
Поисковая система тем лучше, чем больше документов, релевантных запросу пользователя, она будет возвращать. Результаты поиска могут становиться менее релевантными из-за особенностей алгоритмов (см. «Пузырь фильтров»[⇨]) или вследствие человеческого фактора[⇨]. По состоянию на 2015 год самой популярной поисковой системой в мире является Google, однако есть страны, где пользователи отдали предпочтение другим поисковикам. Так, например, в России «Яндекс» обгоняет Google больше, чем на 10 %[⇨].
- поисковый робот, собирающий информацию с сайтов сети Интернет или из других документов,
- индексатор, обеспечивающий быстрый поиск по накопленной информации, и
- поисковик — графический интерфейс для работы пользователя[⇨].
История
На раннем этапе развития сети Интернет Тим Бернерс-Ли поддерживал список веб-серверов, размещённый на сайте ЦЕРН[3]. Сайтов становилось всё больше, и поддерживать вручную такой список становилось всё сложнее. На сайте NCSA был специальный раздел «Что нового!» (англ. What’s New!)
Первой компьютерной программой для поиска в Интернете была программа Арчи[en] (англ. archie — архив без буквы «в»). Она была создана в 1990 году Аланом Эмтэджем (Alan Emtage), Биллом Хиланом (Bill Heelan) и Дж. Питером Дойчем (J. Peter Deutsch), студентами, изучающими информатику в университете Макгилла в Монреале. Программа скачивала списки всех файлов со всех доступных анонимных FTP-серверов и строила базу данных, в которой можно было выполнять поиск по именам файлов. Однако, программа Арчи не индексировала содержимое этих файлов, так как объём данных был настолько мал, что всё можно было легко найти вручную.
Развитие и распространение сетевого протокола Gopher, придуманного в 1991 году Марком Маккэхилом (Mark McCahill) в университете Миннесоты, привело к созданию двух новых поисковых программ, Veronica[en] и Jughead[en]. Как и Арчи, они искали имена файлов и заголовки, сохранённые в индексных системах Gopher. Veronica (англ. Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) позволяла выполнять поиск по ключевым словам большинства заголовков меню Gopher во всех списках Gopher. Программа Jughead (англ. Jonzy’s Universal Gopher Hierarchy Excavation And Display) извлекала информацию о меню от определённых Gopher-серверов. Хотя название поисковика Арчи не имело отношения к циклу комиксов «Арчи»
К лету 1993 года ещё не было ни одной системы для поиска в вебе, хотя вручную поддерживались многочисленные специализированные каталоги. Оскар Нирштрасс (Oscar Nierstrasz) в Женевском университете написал ряд сценариев на Perl, которые периодически копировали эти страницы и переписывали их в стандартный формат. Это стало основой для W3Catalog, первой примитивной поисковой системы сети, запущенной 2 сентября 1993 года[5].
Вероятно, первым поисковым роботом, написанным на языке Perl, был «World Wide Web Wanderer» — бот Мэтью Грэя (Matthew Gray) из Массачусетского технологического института в июне 1993 года. Этот робот создавал поисковый индекс «Wandex». Цель робота Wanderer состояла в том, чтобы измерить размер всемирной паутины и найти все веб-страницы, содержащие слова из запроса. В 1993 году появилась и вторая поисковая система «Aliweb». Aliweb не использовала поискового робота, но вместо этого ожидала уведомлений от администраторов веб-сайтов о наличии на их сайтах индексного файла в определённом формате.
JumpStation[en], [6] созданный в декабре 1993 года Джонатаном Флетчером, искал веб-страницы и строил их индексы с помощью поискового робота, и использовал веб-форму в качестве интерфейса для формулирования поисковых запросов. Это был первый инструмент поиска в Интернете, который сочетал три важнейших функции поисковой системы (проверка, индексация и собственно поиск). Из-за ограниченности ресурсов компьютеров того времени индексация и, следовательно, поиск были ограничены только названиями и заголовками веб-страниц, найденных поисковым роботом.
Первой полнотекстовой индексирующей ресурсы при помощи робота («craweler-based») поисковой системой, стала система «WebCrawler»[en], запущенная в 1994 году. В отличие от своих предшественниц, она позволяла пользователям искать по любым словам, расположенным на любой веб-странице — с тех пор это стало стандартом для большинства поисковых систем. Кроме того, это был первый поисковик, получивший широкое распространение. В 1994 году была запущена система «Lycos», разработанная в Университете Карнеги-Меллон и ставшая серьёзным коммерческим предприятием.
Вскоре появилось множество других конкурирующих поисковых машин, таких как: «Magellan»[en], «Excite», «Infoseek»[en], «Inktomi»[en], «Northern Light»[en] и «AltaVista». В некотором смысле они конкурировали с популярными интернет-каталогами, такими как «Yahoo!». Но поисковые возможности каталогов ограничивались поиском по самим каталогам, а не по текстам веб-страниц. Позже каталоги объединялись или снабжались поисковыми роботами с целью улучшения поиска.
В 1996 году компания Netscape хотела заключить эксклюзивную сделку с одной из поисковых систем, сделав её поисковой системой по умолчанию на веб-браузере Netscape. Это вызвало настолько большой интерес, что Netscape заключила контракт сразу с пятью крупнейшими поисковыми системами (Yahoo!, Magellan, Lycos, Infoseek и Excite). За 5 млн долларов США в год они предлагались по очереди на поисковой странице Netscape[7][8].
Поисковые системы участвовали в «Пузыре доткомов» конца 1990-х[9]. Несколько компаний эффектно вышли на рынок, получив рекордную прибыль во время их первичного публичного предложения. Некоторые отказались от рынка общедоступных поисковых движков и стали работать только с корпоративным сектором, например, Northern Light
Google взял на вооружение идею продажи ключевых слов в 1998 году, тогда это была маленькая компания, обеспечивавшая работу поисковой системы по адресу goto.com[en]. Этот шаг ознаменовал для поисковых систем переход от соревнований друг с другом к одному из самых выгодных коммерческих предприятий в Интернете[10]. Поисковые системы стали продавать первые места в результатах поиска отдельным компаниям.
Поисковая система Google занимает видное положение с начала 2000-х[11]. Компания добилась высокого положения благодаря хорошим результатам поиска с помощью алгоритма PageRank. Алгоритм был представлен общественности в статье «The Anatomy of Search Engine», написанной Сергеем Брином и Ларри Пейджем, основателями Google
К 2000 году Yahoo! осуществлял поиск на основе системы Inktomi. Yahoo! в 2002 году купил Inktomi, а в 2003 году купил Overture, которому принадлежали AlltheWeb
Фирма Microsoft впервые запустила поисковую систему Microsoft Network Search (MSN Search) осенью 1998 года, используя результаты поиска от Inktomi. Совсем скоро в начале 1999 года сайт начал отображать выдачу Looksmart[en], смешанную с результатами Inktomi. Недолго (в 1999 году) MSN search использовал результаты поиска от AltaVista. В 2004 году фирма Microsoft начала переход к собственной поисковой технологии с использованием собственного поискового робота — msnbot
Поиск информации на русском языке
В 1996 году был реализован поиск с учётом русской морфологии на поисковой машине Altavista и запущены оригинальные российские поисковые машины Рамблер и Апорт. 23 сентября 1997 года была открыта поисковая машина Яндекс. 22 мая 2014 года компанией Ростелеком была открыта национальная поисковая машина Спутник, которая на момент 2015 года находится в стадии бета-тестировании. 22 апреля 2015 года был открыт новый сервис Спутник. Дети специально для детей с повышенной безопасностью.
Большую популярность получили методы кластерного анализа и поиска по метаданным. Из международных машин такого плана наибольшую известность получила «Clusty»[en] компании Vivisimo[en]. В 2005 году в России при поддержке МГУ запущен поисковик «Нигма», поддерживающий автоматическую кластеризацию. В 2006 году открылась российская метамашина Quintura, предлагающая визуальную кластеризацию в виде облака тегов. «Нигма» тоже экспериментировала[13] с визуальной кластеризацией.
Как работает поисковая система
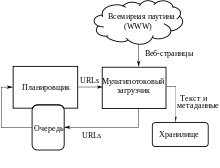 Высокоуровневая архитектура стандартного краулера
Высокоуровневая архитектура стандартного краулераОсновные составляющие поисковой системы: поисковый робот, индексатор, поисковик[14].
Как правило, системы работают поэтапно. Сначала поисковый робот получает контент, затем индексатор генерирует доступный для поиска индекс, и наконец, поисковик обеспечивает функциональность для поиска индексируемых данных. Чтобы обновить поисковую систему, этот цикл индексации выполняется повторно[14].
Поисковые системы работают, храня информацию о многих веб-страницах, которые они получают из HTML-страниц. Поисковый робот или «краулер» (англ. Crawler) — программа, которая автоматически проходит по всем ссылкам, найденным на странице, и выделяет их. Краулер, основываясь на ссылках или исходя из заранее заданного списка адресов, осуществляет поиск новых документов, ещё не известных поисковой системе. Владелец сайта может исключить определённые страницы при помощи robots.txt, используя который можно запретить индексацию файлов, страниц или каталогов сайта.
Поисковая система анализирует содержание каждой страницы для дальнейшего индексирования. Слова могут быть извлечены из заголовков, текста страницы или специальных полей — метатегов. Индексатор — это модуль, который анализирует страницу, предварительно разбив её на части, применяя собственные лексические и морфологические алгоритмы. Все элементы веб-страницы вычленяются и анализируются отдельно. Данные о веб-страницах хранятся в индексной базе данных для использования в последующих запросах. Индекс позволяет быстро находить информацию по запросу пользователя[15].
Ряд поисковых систем, подобных Google, хранят исходную страницу целиком или её часть, так называемый кэш, а также различную информацию о веб-странице. Другие системы, подобные системе AltaVista, хранят каждое слово каждой найденной страницы. Использование кэша помогает ускорить извлечение информации с уже посещённых страниц[15]. Кэшированные страницы всегда содержат тот текст, который пользователь задал в поисковом запросе. Это может быть полезно в том случае, когда веб-страница обновилась, то есть уже не содержит текст запроса пользователя, а страница в кэше ещё старая[15]. Эта ситуация связана с потерей ссылок (англ. linkrot[en]) и дружественным по отношению к пользователю (юзабилити) подходом Google. Это предполагает выдачу из кэша коротких фрагментов текста, содержащих текст запроса. Действует принцип наименьшего удивления, пользователь обычно ожидает увидеть искомые слова в текстах полученных страниц (User expectations[en]). Кроме того, что использование кэшированных страниц ускоряет поиск, страницы в кэше могут содержать такую информацию, которая уже нигде более не доступна.
Поисковик работает с выходными файлами, полученными от индексатора. Поисковик принимает пользовательские запросы, обрабатывает их при помощи индекса и возвращает результаты поиска[14].
Когда пользователь вводит запрос в поисковую систему (обычно при помощи ключевых слов), система проверяет свой индекс и выдаёт список наиболее подходящих веб-страниц (отсортированный по какому-либо критерию), обычно с краткой аннотацией, содержащей заголовок документа и иногда части текста[15]. Поисковый индекс строится по специальной методике на основе информации, извлечённой из веб-страниц[11]. С 2007 года поисковик Google позволяет искать с учётом времени, создания искомых документов (вызов меню «Инструменты поиска» и указание временного диапазона).
Большинство поисковых систем поддерживает использование в запросах булевых операторов И, ИЛИ, НЕ, что позволяет уточнить или расширить список искомых ключевых слов. При этом система будет искать слова или фразы точно так, как было введено. В некоторых поисковых системах есть возможность приближённого поиска[en], в этом случае пользователи расширяют область поиска, указывая расстояние до ключевых слов[15]. Есть также концептуальный поиск[en], при котором используется статистический анализ употребления искомых слов и фраз в текстах веб-страниц. Эти системы позволяют составлять запросы на естественном языке. Примером такой поисковой системы является сайт ask com.
Полезность поисковой системы зависит от релевантности найденных ею страниц. Хоть миллионы веб-страниц и могут включать некое слово или фразу, но одни из них могут быть более релевантны, популярны или авторитетны, чем другие. Большинство поисковых систем использует методы ранжирования, чтобы вывести в начало списка «лучшие» результаты. Поисковые системы решают, какие страницы более релевантны, и в каком порядке должны быть показаны результаты, по-разному[15]. Методы поиска, как и сам Интернет со временем меняются. Так появились два основных типа поисковых систем: системы предопределённых и иерархически упорядоченных ключевых слов и системы, в которых генерируется инвертированный индекс на основе анализа текста.
Большинство поисковых систем являются коммерческими предприятиями, которые получают прибыль за счёт рекламы, в некоторых поисковиках можно купить за отдельную плату первые места в выдаче для заданных ключевых слов. Те поисковые системы, которые не берут денег за порядок выдачи результатов, зарабатывают на контекстной рекламе, при этом рекламные сообщения соответствуют запросу пользователя. Такая реклама выводится на странице со списком результатов поиска, и поисковики зарабатывают при каждом клике пользователя на рекламные сообщения.
Типы поисковых систем
Существует четыре типа поисковых систем: с поисковыми роботами, управляемые человеком, гибридные и мета-системы[16].
- системы, использующие поисковые роботы
- Состоят из трёх частей: краулер («бот», «робот» или «паук»), индекс и программное обеспечение поисковой системы. Краулер нужен для обхода сети и создания списков веб-страниц. Индекс — большой архив копий веб-страниц. Цель программного обеспечения — оценивать результаты поиска. Благодаря тому, что поисковый робот в этом механизме постоянно исследует сеть, информация в большей степени актуальна. Большинство современных поисковых систем являются системами данного типа.
- Эти поисковые системы получают списки веб-страниц. Каталог содержит адрес, заголовок и краткое описание сайта. Каталог ресурсов ищет результаты только из описаний страницы, представленных ему веб-мастерами. Достоинство каталогов в том, что все ресурсы проверяются вручную, следовательно, и качество контента будет лучше по сравнению с результатами, полученными системой первого типа автоматически. Но есть и недостаток — обновление данных каталогов выполняется вручную и может существенно отставать от реального положения дел. Ранжирование страниц не может мгновенно меняться. В качестве примеров таких систем можно привести каталог Yahoo[en], dmoz и Galaxy.
- гибридные системы
- Такие поисковые системы, как Yahoo, Google, MSN, сочетают в себе функции систем, использующие поисковых роботов, и систем, управляемых человеком.
- Метапоисковые системы объединяют и ранжируют результаты сразу нескольких поисковиков. Эти поисковые системы были полезны, когда у каждой поисковой системы был уникальный индекс, и поисковые системы были менее «умными». Поскольку сейчас поиск намного улучшился, потребность в них уменьшилась. Примеры: MetaCrawler[en] и MSN Search.
Рынок поисковых систем
Google — самая популярная поисковая система в мире с долей на рынке 68,69 %. Bing занимает вторую позицию, его доля 12,26 %[17].
Самые популярные поисковые системы в мире[18]:
| Поисковая система | Доля рынка в июле 2014 | Доля рынка в октябре 2014 | Доля рынка в сентябре 2017 |
|---|---|---|---|
| 68,69 % | 58,01 % | 69,24 % | |
| Bing | 17,17 % | 29,06 % | 12,26 % |
| Baidu | 6,22 % | 8,01 % | 6,48 % |
| Yahoo! | 6,74 % | 4,01 % | 5,19 % |
| AOL | 0,13 % | 0,21 % | 1,11 % |
| Excite | 0,22 % | 0,00 % | 0,00 % |
| Ask | 0,13 % | 0,10 % | 0,24 % |
Азия
В восточноазиатских странах и в России Google — не самая популярная поисковая система. В Китае, например, более популярна поисковая система Soso[en].
В Южной Корее поисковым порталом собственной разработки Naver пользуется около 70 % жителей[19]Yahoo! Japan и Yahoo! Taiwan — самые популярные системы для поиска в Японии и Тайване соответственно[20].
Россия и русскоязычные поисковые системы
Яндексом пользуются 53,3 % пользователей в России (Google — 42,9 %)[21].
Согласно данным LiveInternet в декабре 2017 года об охвате русскоязычных поисковых запросов[22]:
- Всеязычные:
- Англоязычные и международные:
- Русскоязычные — большинство «русскоязычных» поисковых систем индексируют и ищут тексты на многих языках — украинском, белорусском, английском, татарском и других. Отличаются же они от «всеязычных» систем, индексирующих все документы подряд, тем, что, в основном, индексируют ресурсы, расположенные в доменных зонах, где доминирует русский язык, или другими способами ограничивают своих роботов русскоязычными сайтами.
Некоторые из поисковых систем используют внешние алгоритмы поиска.
Количественные данные поисковой системы Google
Число пользователей Интернета и поисковых систем и требований пользователей к этим системам постоянно растёт. Для увеличений скорости поиска нужной информации крупные поисковые системы содержат большое количество серверов. Сервера обычно группируют в серверные центры (дата-центры). У популярных поисковых систем серверные центры разбросаны по всему миру[23].
В октябре 2012 года Google запустила проект «Где живёт Интернет», где пользователям предоставляется возможность познакомиться с центрами обработки данных этой компании[24].
О работе дата-центров поисковой системе Google известно следующее[23]:
- Суммарная мощность всех дата-центров Google, по состоянию на 2011 год, оценивалась в 220 МВт.
- Когда в 2008 году Google планировала открыть в Орегоне новый комплекс, состоящий из трёх зданий общей площадью 6,5 млн м², в журнале Harper’s Magazine подсчитали, что такой большой комплекс потребляет свыше 100 МВт электроэнергии, что сравнимо с потреблением энергии города с населением 300 000 человек.
- Ориентировочное число серверов Google в 2012 году — 1 000 000.
- Расходы Google на дата-центры составили в 2006 году — $1,9 млрд, а в 2007 году — $2,4 млрд.
Размер всемирной паутины, проиндексированной Google на декабрь 2014 года, составляет примерно 4,36 миллиарда страниц[25].
Поисковые системы, учитывающие религиозные запреты
Глобальное распространение Интернета и увеличение популярности электронных устройств в арабском и мусульманском мире, в частности, в странах Ближнего Востока и Индийского субконтинента, способствовало развитию локальных поисковых систем, учитывающих исламские традиции. Такие поисковые системы содержат специальные фильтры, которые помогают пользователям не попадать на запрещённые сайты, например, сайты с порнографией, и позволяют им пользоваться только теми сайтами, содержимое которых не противоречит исламской вере.
Незадолго до мусульманского месяца Рамадан, в июле 2013 года, миру был представлен Halalgoogling[en] — система, выдающая пользователям только халяльные «правильные» ссылки[26], фильтруя результаты поиска, полученные от других поисковых систем, таких как Google и Bing. Двумя годами ранее, в сентябре 2011 года, был запущен поисковый движок I’mHalal, предназначенный для обслуживания пользователей Ближнего Востока. Однако этот поисковый сервис пришлось вскоре закрыть, по сообщению владельца, из-за отсутствия финансирования[27].
Отсутствие инвестиций и медленный темп распространения технологий в мусульманском мире препятствовали прогрессу и мешали успеху серьёзного исламского поисковика. Очевиден провал огромных инвестиций в веб-проекты мусульманского образа жизни, одним из которых был Muxlim[en]. Он получил миллионы долларов от инвесторов, таких как Rite Internet Ventures, и теперь — в соответствии с последним сообщением от I’mHalal перед его закрытием — выступает с сомнительной идеей о том, что «следующий Facebook или Google могут появиться только в странах Ближнего Востока, если вы поддержите нашу блестящую молодёжь»[28].
Тем не менее исламские эксперты в области Интернета в течение многих лет занимаются определением того, что соответствует или не соответствует шариату, и классифицируют веб-сайты как «халяль» или «харам». Все бывшие и настоящие исламские поисковые системы представляют собой просто специальным образом проиндексированный набор данных либо это главные поисковые системы, такие как Google, Yahoo и Bing, с определённой системой фильтрации, использующейся для того, чтобы пользователи не могли получить доступ к харам-сайтам, таким как сайты о наготе, ЛГБТ, азартных играх и каким-либо другим, тематика которых считается антиисламской[28].
Среди других религиозно-ориентированных поисковых систем распространёнными являются Jewogle — еврейская версия Google и SeekFind.org — христианский сайт, включающий в себя фильтры, оберегающие пользователей от контента, который может подорвать или ослабить их веру[29].
Персональные результаты и пузыри фильтров
Многие поисковые системы, такие как Google и Bing, используют алгоритмы выборочного угадывания того, какую информацию пользователь хотел бы увидеть, основываясь на его прошлых действиях в системе. В результате, веб-сайты показывают только ту информацию, которая согласуется с прошлыми интересами пользователя. Этот эффект получил название «пузырь фильтров»[30].
Всё это ведёт к тому, что пользователи получают намного меньше противоречащей своей точке зрения информации и становятся интеллектуально изолированными в своём собственном «информационном пузыре». Таким образом, «эффект пузыря» может иметь негативные последствия для формирования гражданского мнения[31].
Предвзятость поисковых систем
Несмотря на то, что поисковые системы запрограммированы, чтобы оценивать веб-сайты на основе некоторой комбинации их популярности и релевантности, в реальности экспериментальные исследования указывают на то, что различные политические, экономические и социальные факторы оказывают влияние на поисковую выдачу[32][33].
Такая предвзятость может быть прямым результатом экономических и коммерческих процессов: компании, которые рекламируются в поисковой системе, могут стать более популярными в результатах обычного поиска в ней. Удаление результатов поиска, не соответствующих местным законам, является примером влияния политических процессов. Например, Google не будет отображать некоторые неонацистские веб-сайты во Франции и Германии, где отрицание Холокоста незаконно[34].
Предвзятость может также быть следствием социальных процессов, поскольку алгоритмы поисковых систем часто разрабатываются, чтобы исключить неформатные точки зрения в пользу более «популярных» результатов[35]. Алгоритмы индексации главных поисковых систем отдают приоритет американским сайтам[33].
Поисковая бомба — один из примеров попытки управления результатами поиска по политическим, социальным или коммерческим причинам.
См. также
Примечания
- ↑ Chu & Rosenthal, 1996, p. 129.
- ↑ Tarakeswar & Kavitha, 2011, p. 29.
- ↑ World-Wide Web Servers.
- ↑ What’s New.
- ↑ Oscar Nierstrasz.
- ↑ Archive of NCSA.
- ↑ Yahoo! And Netscape.
- ↑ Netscape, 1996.
- ↑ The dynamics of competition, 2001.
- ↑ Intro to Computer Science.
- ↑ 1 2 Google`s history.
- ↑ Брин и Пейдж, p. 3.
- ↑ Nigma.
- ↑ 1 2 3 Risvik & Michelsen, 2002, p. 290.
- ↑ 1 2 3 4 5 6 Knowledge Management, 2011.
- ↑ Tarakeswar & Kavitha, 2011, p. 29.
- ↑ NMS.
- ↑ Статистика.
- ↑ Naver.
- ↑ Age of Internet Empires.
- ↑ LiveInternet.
- ↑ Liveinternet
- ↑ 1 2 Antula.
- ↑ Where the Internet lives.
- ↑ World wide web size.
- ↑ Islam.
- ↑ I’mHalal
- ↑ 1 2 Halalblog
- ↑ ChristianNews.
- ↑ Pariser, 2011.
- ↑ Auralist, 2012, p. 13.
- ↑ Segev, 2010.
- ↑ 1 2 Search engine coverage bias, 2004.
- ↑ Replacement of Google.
- ↑ Shaping the Web, 2000.
Литература
- Gandal, Neil. The dynamics of competition in the internet search engine market. — 2001. — Vol. 19. — P. 1103–1117. — DOI:10.1016/S0167-7187(01)00065-0.
- Tarakeswar M. K., Kavitha M. D. Search Engines:A Study (англ.) // Journal of Computer Applications (JCA) : journal. — 2011. — Vol. 4, no. 1. — P. 29—33. — ISSN 0974-1925.
- Vaughan L., Thelwall M. Search engine coverage bias: evidence and possible causes (англ.) // Information Processing & Management : journal. — 2004. — Vol. 40. — P. 693–707. — DOI:10.1016/S0306-4573(03)00063-3.
Ссылки
- FAQ. NetMarketShare. Проверено 23 ноября 2014.
wiki.sc
Поисковые системы — это… Что такое Поисковые системы?
Оптимизация под поисковые системы — методы усовершенствования веб страниц для повышения рейтинга сайта. Легальными методами оптимизации являются: методы создания веб страниц с оптимальной структурой и информационным наполнением; наилучший выбор ключевых слов; эффективное описание и … Финансовый словарь
информационно-поисковые системы — — [Е.С.Алексеев, А.А.Мячев. Англо русский толковый словарь по системотехнике ЭВМ. Москва 1993] Тематики информационные технологии в целом EN information storage and retrieval systemsINSTARS … Справочник технического переводчика
ИНФОРМАЦИОННО-ПОИСКОВЫЕ СИСТЕМЫ — 29. Информационно поисковая система ИПС D. Informationsrecherchesystem E. Information retrieval system F. Systeme documentaire Предназначенная для информационного поиска совокупность информационно поискового массива, информационно… … Словарь-справочник терминов нормативно-технической документации
ИНФОРМАЦИОННО-ПОИСКОВЫЕ СИСТЕМЫ (ИПС) — в химии, совокупность лингвистич., программно информац., технол. и техн. ср в для ввода, хранения, накопления, обработки, поиска и выдачи необходимой специалистам информации (документов или фактов). Данная статья посвящена автоматизир. ИПС, к рые … Химическая энциклопедия
Поисковые машины — Поисковая система веб сайт, предоставляющий возможность поиска информации в Интернете. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp серверах, товары в… … Википедия
Системы обработки данных — комплекс взаимоувязанных методов и средств сбора и обработки данных, необходимых для организации управления объектами. С. о. д. основываются на применении ЭВМ и других современных средств информационной техники, поэтому их также называют… … Большая советская энциклопедия
Информационные системы — Информационная система (ИС) это система, реализующая информационную модель предметной области, чаще всего какой либо области человеческой деятельности. ИС должна обеспечивать: получение (ввод или сбор), хранение, поиск, передачу и обработку… … Википедия
Вопросно-ответные системы — Вопросно ответная система (англ. Question answering system) это особый тип информационных систем, являющиеся гибридом поисковых, справочных и интеллектуальных систем (часто они рассматриваются как интеллектуальные поисковые системы). QA система… … Википедия
Робот поисковой системы — компонента поисковой системы; программа, которая посещает веб страницы, считывает (индексирует) полностью или частично их содержимое и далее следует по ссылкам, найденным на данной странице. Робот возвращается через определенные периоды времени и … Финансовый словарь
Индекс поисковой системы — в Интернет компонента поисковой системы; информационный массив, в котором хранятся специальным образом преобразованные текстовые составляющие всех посещенных и проиндексированных роботом веб страниц и текстовых файлов. По английски: Index См.… … Финансовый словарь
dic.academic.ru
Поисковая система — Википедия
Поиск информации во Всемирной паутине был трудной и не самой приятной задачей, но с прорывом в технологии поисковых систем в конце 1990-х годов осуществлять поиск стало намного удобнейПоиско́вая систе́ма (англ. search engine) — это компьютерная система, предназначенная для поиска информации. Одно из наиболее известных применений поисковых систем — веб-сервисы для поиска текстовой или графической информации во Всемирной паутине. Существуют также системы, способные искать файлы на FTP-серверах, товары в интернет-магазинах, информацию в группах новостей Usenet.
Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос[1]. Работа поисковой системы заключается в том, чтобы по запросу пользователя найти документы, содержащие либо указанные ключевые слова, либо слова, как-либо связанные с ключевыми словами[2]. При этом поисковая система генерирует страницу результатов поиска. Такая поисковая выдача может содержать различные типы результатов, например: веб-страницы, изображения, аудиофайлы. Некоторые поисковые системы также извлекают информацию из подходящих баз данных и каталогов ресурсов в Интернете.
Поисковая система тем лучше, чем больше документов, релевантных запросу пользователя, она будет возвращать. Результаты поиска могут становиться менее релевантными из-за особенностей алгоритмов (см. «Пузырь фильтров»[⇨]) или вследствие человеческого фактора[⇨]. По состоянию на 2015 год самой популярной поисковой системой в мире является Google, однако есть страны, где пользователи отдали предпочтение другим поисковикам. Так, например, в России «Яндекс» обгоняет Google больше, чем на 10 %[⇨].
По методам поиска и обслуживания разделяют четыре типа поисковых систем: системы, использующие поисковых роботов, системы, управляемые человеком, гибридные системы и мета-системы[⇨]. В архитектуру поисковой системы обычно входят:
- поисковый робот, собирающий информацию с сайтов сети Интернет или из других документов,
- индексатор, обеспечивающий быстрый поиск по накопленной информации, и
- поисковик — графический интерфейс для работы пользователя[⇨].
История
На раннем этапе развития сети Интернет Тим Бернерс-Ли поддерживал список веб-серверов, размещённый на сайте ЦЕРН[3]. Сайтов становилось всё больше, и поддерживать вручную такой список становилось всё сложнее. На сайте NCSA был специальный раздел «Что нового!» (англ. What’s New!)[4], где публиковали ссылки на новые сайты.
Первой компьютерной программой для поиска в Интернете была программа Арчи[en] (англ. archie — архив без буквы «в»). Она была создана в 1990 году Аланом Эмтэджем (Alan Emtage), Биллом Хиланом (Bill Heelan) и Дж. Питером Дойчем (J. Peter Deutsch), студентами, изучающими информатику в университете Макгилла в Монреале. Программа скачивала списки всех файлов со всех доступных анонимных FTP-серверов и строила базу данных, в которой можно было выполнять поиск по именам файлов. Однако, программа Арчи не индексировала содержимое этих файлов, так как объём данных был настолько мал, что всё можно было легко найти вручную.
Развитие и распространение сетевого протокола Gopher, придуманного в 1991 году Марком Маккэхилом (Mark McCahill) в университете Миннесоты, привело к созданию двух новых поисковых программ, Veronica[en] и Jughead[en]. Как и Арчи, они искали имена файлов и заголовки, сохранённые в индексных системах Gopher. Veronica (англ. Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) позволяла выполнять поиск по ключевым словам большинства заголовков меню Gopher во всех списках Gopher. Программа Jughead (англ. Jonzy’s Universal Gopher Hierarchy Excavation And Display) извлекала информацию о меню от определённых Gopher-серверов. Хотя название поисковика Арчи не имело отношения к циклу комиксов «Арчи»[en], тем не менее Veronica и Jughead — персонажи этих комиксов.
К лету 1993 года ещё не было ни одной системы для поиска в вебе, хотя вручную поддерживались многочисленные специализированные каталоги. Оскар Нирштрасс (Oscar Nierstrasz) в Женевском университете написал ряд сценариев на Perl, которые периодически копировали эти страницы и переписывали их в стандартный формат. Это стало основой для W3Catalog, первой примитивной поисковой системы сети, запущенной 2 сентября 1993 года[5].
Вероятно, первым поисковым роботом, написанным на языке Perl, был «World Wide Web Wanderer» — бот Мэтью Грэя (Matthew Gray) из Массачусетского технологического института в июне 1993 года. Этот робот создавал поисковый индекс «Wandex». Цель робота Wanderer состояла в том, чтобы измерить размер всемирной паутины и найти все веб-страницы, содержащие слова из запроса. В 1993 году появилась и вторая поисковая система «Aliweb». Aliweb не использовала поискового робота, но вместо этого ожидала уведомлений от администраторов веб-сайтов о наличии на их сайтах индексного файла в определённом формате.
JumpStation[en], [6] созданный в декабре 1993 года Джонатаном Флетчером, искал веб-страницы и строил их индексы с помощью поискового робота, и использовал веб-форму в качестве интерфейса для формулирования поисковых запросов. Это был первый инструмент поиска в Интернете, который сочетал три важнейших функции поисковой системы (проверка, индексация и собственно поиск). Из-за ограниченности ресурсов компьютеров того времени индексация и, следовательно, поиск были ограничены только названиями и заголовками веб-страниц, найденных поисковым роботом.
Первой полнотекстовой индексирующей ресурсы при помощи робота («craweler-based») поисковой системой, стала система «WebCrawler»[en], запущенная в 1994 году. В отличие от своих предшественниц, она позволяла пользователям искать по любым словам, расположенным на любой веб-странице — с тех пор это стало стандартом для большинства поисковых систем. Кроме того, это был первый поисковик, получивший широкое распространение. В 1994 году была запущена система «Lycos», разработанная в Университете Карнеги-Меллон и ставшая серьёзным коммерческим предприятием.
Вскоре появилось множество других конкурирующих поисковых машин, таких как: «Magellan»[en], «Excite», «Infoseek»[en], «Inktomi»[en], «Northern Light»[en] и «AltaVista». В некотором смысле они конкурировали с популярными интернет-каталогами, такими как «Yahoo!». Но поисковые возможности каталогов ограничивались поиском по самим каталогам, а не по текстам веб-страниц. Позже каталоги объединялись или снабжались поисковыми роботами с целью улучшения поиска.
В 1996 году компания Netscape хотела заключить эксклюзивную сделку с одной из поисковых систем, сделав её поисковой системой по умолчанию на веб-браузере Netscape. Это вызвало настолько большой интерес, что Netscape заключила контракт сразу с пятью крупнейшими поисковыми системами (Yahoo!, Magellan, Lycos, Infoseek и Excite). За 5 млн долларов США в год они предлагались по очереди на поисковой странице Netscape[7][8].
Поисковые системы участвовали в «Пузыре доткомов» конца 1990-х[9]. Несколько компаний эффектно вышли на рынок, получив рекордную прибыль во время их первичного публичного предложения. Некоторые отказались от рынка общедоступных поисковых движков и стали работать только с корпоративным сектором, например, Northern Light[en].
Google взял на вооружение идею продажи ключевых слов в 1998 году, тогда это была маленькая компания, обеспечивавшая работу поисковой системы по адресу goto.com[en]. Этот шаг ознаменовал для поисковых систем переход от соревнований друг с другом к одному из самых выгодных коммерческих предприятий в Интернете[10]. Поисковые системы стали продавать первые места в результатах поиска отдельным компаниям.
Поисковая система Google занимает видное положение с начала 2000-х[11]. Компания добилась высокого положения благодаря хорошим результатам поиска с помощью алгоритма PageRank. Алгоритм был представлен общественности в статье «The Anatomy of Search Engine», написанной Сергеем Брином и Ларри Пейджем, основателями Google[12]. Этот итеративный алгоритм ранжирует веб-страницы, основываясь на оценке количества гиперссылок на веб-страницу в предположении, что на «хорошие» и «важные» страницы ссылаются больше, чем на другие. Интерфейс Google выдержан в спартанском стиле, где нет ничего лишнего, в отличие от многих своих конкурентов, которые встраивали поисковую систему в веб-портал. Поисковая система Google стала настолько популярной, что появились подражающие ей системы, например, Mystery Seeker[en](тайный поисковик).
К 2000 году Yahoo! осуществлял поиск на основе системы Inktomi. Yahoo! в 2002 году купил Inktomi, а в 2003 году купил Overture, которому принадлежали AlltheWeb[en] и AltaVista. Затем Yahoo! работал на основе поисковой системы Google вплоть до 2004 года, пока не запустил, наконец, свой собственный поисковик на основе всех купленных ранее технологий.
Фирма Microsoft впервые запустила поисковую систему Microsoft Network Search (MSN Search) осенью 1998 года, используя результаты поиска от Inktomi. Совсем скоро в начале 1999 года сайт начал отображать выдачу Looksmart[en], смешанную с результатами Inktomi. Недолго (в 1999 году) MSN search использовал результаты поиска от AltaVista. В 2004 году фирма Microsoft начала переход к собственной поисковой технологии с использованием собственного поискового робота — msnbot[en]. После проведения ребрендинга компанией Microsoft 1 июня 2009 года была запущена поисковая система Bing. 29 июля 2009 Yahoo! и Microsoft подписали соглашение, согласно которому Yahoo! Search[en] работал на основе технологии Microsoft Bing. На момент 2015 года союз Bing и Yahoo! дал первые настоящие плоды. Теперь Bing занимает 20,1 % рынка, а Yahoo! 12,7 %, что в общем занимает 32,60 % от общего рынка поисковых систем в США по данным из разных источников.
Поиск информации на русском языке
В 1996 году был реализован поиск с учётом русской морфологии на поисковой машине Altavista и запущены оригинальные российские поисковые машины Рамблер и Апорт. 23 сентября 1997 года была открыта поисковая машина Яндекс. 22 мая 2014 года компанией Ростелеком была открыта национальная поисковая машина Спутник, которая на момент 2015 года находится в стадии бета-тестировании. 22 апреля 2015 года был открыт новый сервис Спутник. Дети специально для детей с повышенной безопасностью.
Большую популярность получили методы кластерного анализа и поиска по метаданным. Из международных машин такого плана наибольшую известность получила «Clusty»[en] компании Vivisimo[en]. В 2005 году в России при поддержке МГУ запущен поисковик «Нигма», поддерживающий автоматическую кластеризацию. В 2006 году открылась российская метамашина Quintura, предлагающая визуальную кластеризацию в виде облака тегов. «Нигма» тоже экспериментировала[13] с визуальной кластеризацией.
Как работает поисковая система
Высокоуровневая архитектура стандартного краулераОсновные составляющие поисковой системы: поисковый робот, индексатор, поисковик[14].
Как правило, системы работают поэтапно. Сначала поисковый робот получает контент, затем индексатор генерирует доступный для поиска индекс, и наконец, поисковик обеспечивает функциональность для поиска индексируемых данных. Чтобы обновить поисковую систему, этот цикл индексации выполняется повторно[14].
Поисковые системы работают, храня информацию о многих веб-страницах, которые они получают из HTML-страниц. Поисковый робот или «краулер» (англ. Crawler) — программа, которая автоматически проходит по всем ссылкам, найденным на странице, и выделяет их. Краулер, основываясь на ссылках или исходя из заранее заданного списка адресов, осуществляет поиск новых документов, ещё не известных поисковой системе. Владелец сайта может исключить определённые страницы при помощи robots.txt, используя который можно запретить индексацию файлов, страниц или каталогов сайта.
Поисковая система анализирует содержание каждой страницы для дальнейшего индексирования. Слова могут быть извлечены из заголовков, текста страницы или специальных полей — метатегов. Индексатор — это модуль, который анализирует страницу, предварительно разбив её на части, применяя собственные лексические и морфологические алгоритмы. Все элементы веб-страницы вычленяются и анализируются отдельно. Данные о веб-страницах хранятся в индексной базе данных для использования в последующих запросах. Индекс позволяет быстро находить информацию по запросу пользователя[15].
Ряд поисковых систем, подобных Google, хранят исходную страницу целиком или её часть, так называемый кэш, а также различную информацию о веб-странице. Другие системы, подобные системе AltaVista, хранят каждое слово каждой найденной страницы. Использование кэша помогает ускорить извлечение информации с уже посещённых страниц[15]. Кэшированные страницы всегда содержат тот текст, который пользователь задал в поисковом запросе. Это может быть полезно в том случае, когда веб-страница обновилась, то есть уже не содержит текст запроса пользователя, а страница в кэше ещё старая[15]. Эта ситуация связана с потерей ссылок (англ. linkrot[en]) и дружественным по отношению к пользователю (юзабилити) подходом Google. Это предполагает выдачу из кэша коротких фрагментов текста, содержащих текст запроса. Действует принцип наименьшего удивления, пользователь обычно ожидает увидеть искомые слова в текстах полученных страниц (User expectations[en]). Кроме того, что использование кэшированных страниц ускоряет поиск, страницы в кэше могут содержать такую информацию, которая уже нигде более не доступна.
Поисковик работает с выходными файлами, полученными от индексатора. Поисковик принимает пользовательские запросы, обрабатывает их при помощи индекса и возвращает результаты поиска[14].
Когда пользователь вводит запрос в поисковую систему (обычно при помощи ключевых слов), система проверяет свой индекс и выдаёт список наиболее подходящих веб-страниц (отсортированный по какому-либо критерию), обычно с краткой аннотацией, содержащей заголовок документа и иногда части текста[15]. Поисковый индекс строится по специальной методике на основе информации, извлечённой из веб-страниц[11]. С 2007 года поисковик Google позволяет искать с учётом времени, создания искомых документов (вызов меню «Инструменты поиска» и указание временного диапазона).
Большинство поисковых систем поддерживает использование в запросах булевых операторов И, ИЛИ, НЕ, что позволяет уточнить или расширить список искомых ключевых слов. При этом система будет искать слова или фразы точно так, как было введено. В некоторых поисковых системах есть возможность приближённого поиска[en], в этом случае пользователи расширяют область поиска, указывая расстояние до ключевых слов[15]. Есть также концептуальный поиск[en], при котором используется статистический анализ употребления искомых слов и фраз в текстах веб-страниц. Эти системы позволяют составлять запросы на естественном языке. Примером такой поисковой системы является сайт ask com.
Полезность поисковой системы зависит от релевантности найденных ею страниц. Хоть миллионы веб-страниц и могут включать некое слово или фразу, но одни из них могут быть более релевантны, популярны или авторитетны, чем другие. Большинство поисковых систем использует методы ранжирования, чтобы вывести в начало списка «лучшие» результаты. Поисковые системы решают, какие страницы более релевантны, и в каком порядке должны быть показаны результаты, по-разному[15]. Методы поиска, как и сам Интернет со временем меняются. Так появились два основных типа поисковых систем: системы предопределённых и иерархически упорядоченных ключевых слов и системы, в которых генерируется инвертированный индекс на основе анализа текста.
Большинство поисковых систем являются коммерческими предприятиями, которые получают прибыль за счёт рекламы, в некоторых поисковиках можно купить за отдельную плату первые места в выдаче для заданных ключевых слов. Те поисковые системы, которые не берут денег за порядок выдачи результатов, зарабатывают на контекстной рекламе, при этом рекламные сообщения соответствуют запросу пользователя. Такая реклама выводится на странице со списком результатов поиска, и поисковики зарабатывают при каждом клике пользователя на рекламные сообщения.
Типы поисковых систем
Существует четыре типа поисковых систем: с поисковыми роботами, управляемые человеком, гибридные и мета-системы[16].
- системы, использующие поисковые роботы
- Состоят из трёх частей: краулер («бот», «робот» или «паук»), индекс и программное обеспечение поисковой системы. Краулер нужен для обхода сети и создания списков веб-страниц. Индекс — большой архив копий веб-страниц. Цель программного обеспечения — оценивать результаты поиска. Благодаря тому, что поисковый робот в этом механизме постоянно исследует сеть, информация в большей степени актуальна. Большинство современных поисковых систем являются системами данного типа.
- Эти поисковые системы получают списки веб-страниц. Каталог содержит адрес, заголовок и краткое описание сайта. Каталог ресурсов ищет результаты только из описаний страницы, представленных ему веб-мастерами. Достоинство каталогов в том, что все ресурсы проверяются вручную, следовательно, и качество контента будет лучше по сравнению с результатами, полученными системой первого типа автоматически. Но есть и недостаток — обновление данных каталогов выполняется вручную и может существенно отставать от реального положения дел. Ранжирование страниц не может мгновенно меняться. В качестве примеров таких систем можно привести каталог Yahoo[en], dmoz и Galaxy.
- гибридные системы
- Такие поисковые системы, как Yahoo, Google, MSN, сочетают в себе функции систем, использующие поисковых роботов, и систем, управляемых человеком.
- Метапоисковые системы объединяют и ранжируют результаты сразу нескольких поисковиков. Эти поисковые системы были полезны, когда у каждой поисковой системы был уникальный индекс, и поисковые системы были менее «умными». Поскольку сейчас поиск намного улучшился, потребность в них уменьшилась. Примеры: MetaCrawler[en] и MSN Search.
Рынок поисковых систем
Google — самая популярная поисковая система в мире с долей на рынке 68,69 %. Bing занимает вторую позицию, его доля 12,26 %[17].
Самые популярные поисковые системы в мире[18]:
| Поисковая система | Доля рынка в июле 2014 | Доля рынка в октябре 2014 | Доля рынка в сентябре 2017 |
|---|---|---|---|
| 68,69 % | 58,01 % | 69,24 % | |
| Bing | 17,17 % | 29,06 % | 12,26 % |
| Baidu | 6,22 % | 8,01 % | 6,48 % |
| Yahoo! | 6,74 % | 4,01 % | 5,19 % |
| AOL | 0,13 % | 0,21 % | 1,11 % |
| Excite | 0,22 % | 0,00 % | 0,00 % |
| Ask | 0,13 % | 0,10 % | 0,24 % |
Азия
В восточноазиатских странах и в России Google — не самая популярная поисковая система. В Китае, например, более популярна поисковая система Soso[en].
В Южной Корее поисковым порталом собственной разработки Naver пользуется около 70 % жителей[19]Yahoo! Japan и Yahoo! Taiwan — самые популярные системы для поиска в Японии и Тайване соответственно[20].
Россия и русскоязычные поисковые системы
Яндексом пользуются 53,3 % пользователей в России (Google — 42,9 %)[21].
Согласно данным LiveInternet в декабре 2017 года об охвате русскоязычных поисковых запросов[22]:
- Всеязычные:
- Англоязычные и международные:
- Русскоязычные — большинство «русскоязычных» поисковых систем индексируют и ищут тексты на многих языках — украинском, белорусском, английском, татарском и других. Отличаются же они от «всеязычных» систем, индексирующих все документы подряд, тем, что, в основном, индексируют ресурсы, расположенные в доменных зонах, где доминирует русский язык, или другими способами ограничивают своих роботов русскоязычными сайтами.
Некоторые из поисковых систем используют внешние алгоритмы поиска.
Количественные данные поисковой системы Google
Число пользователей Интернета и поисковых систем и требований пользователей к этим системам постоянно растёт. Для увеличений скорости поиска нужной информации крупные поисковые системы содержат большое количество серверов. Сервера обычно группируют в серверные центры (дата-центры). У популярных поисковых систем серверные центры разбросаны по всему миру[23].
В октябре 2012 года Google запустила проект «Где живёт Интернет», где пользователям предоставляется возможность познакомиться с центрами обработки данных этой компании[24].
О работе дата-центров поисковой системе Google известно следующее[23]:
- Суммарная мощность всех дата-центров Google, по состоянию на 2011 год, оценивалась в 220 МВт.
- Когда в 2008 году Google планировала открыть в Орегоне новый комплекс, состоящий из трёх зданий общей площадью 6,5 млн м², в журнале Harper’s Magazine подсчитали, что такой большой комплекс потребляет свыше 100 МВт электроэнергии, что сравнимо с потреблением энергии города с населением 300 000 человек.
- Ориентировочное число серверов Google в 2012 году — 1 000 000.
- Расходы Google на дата-центры составили в 2006 году — $1,9 млрд, а в 2007 году — $2,4 млрд.
Размер всемирной паутины, проиндексированной Google на декабрь 2014 года, составляет примерно 4,36 миллиарда страниц[25].
Поисковые системы, учитывающие религиозные запреты
Глобальное распространение Интернета и увеличение популярности электронных устройств в арабском и мусульманском мире, в частности, в странах Ближнего Востока и Индийского субконтинента, способствовало развитию локальных поисковых систем, учитывающих исламские традиции. Такие поисковые системы содержат специальные фильтры, которые помогают пользователям не попадать на запрещённые сайты, например, сайты с порнографией, и позволяют им пользоваться только теми сайтами, содержимое которых не противоречит исламской вере.
Незадолго до мусульманского месяца Рамадан, в июле 2013 года, миру был представлен Halalgoogling[en] — система, выдающая пользователям только халяльные «правильные» ссылки[26], фильтруя результаты поиска, полученные от других поисковых систем, таких как Google и Bing. Двумя годами ранее, в сентябре 2011 года, был запущен поисковый движок I’mHalal, предназначенный для обслуживания пользователей Ближнего Востока. Однако этот поисковый сервис пришлось вскоре закрыть, по сообщению владельца, из-за отсутствия финансирования[27].
Отсутствие инвестиций и медленный темп распространения технологий в мусульманском мире препятствовали прогрессу и мешали успеху серьёзного исламского поисковика. Очевиден провал огромных инвестиций в веб-проекты мусульманского образа жизни, одним из которых был Muxlim[en]. Он получил миллионы долларов от инвесторов, таких как Rite Internet Ventures, и теперь — в соответствии с последним сообщением от I’mHalal перед его закрытием — выступает с сомнительной идеей о том, что «следующий Facebook или Google могут появиться только в странах Ближнего Востока, если вы поддержите нашу блестящую молодёжь»[28].
Тем не менее исламские эксперты в области Интернета в течение многих лет занимаются определением того, что соответствует или не соответствует шариату, и классифицируют веб-сайты как «халяль» или «харам». Все бывшие и настоящие исламские поисковые системы представляют собой просто специальным образом проиндексированный набор данных либо это главные поисковые системы, такие как Google, Yahoo и Bing, с определённой системой фильтрации, использующейся для того, чтобы пользователи не могли получить доступ к харам-сайтам, таким как сайты о наготе, ЛГБТ, азартных играх и каким-либо другим, тематика которых считается антиисламской[28].
Среди других религиозно-ориентированных поисковых систем распространёнными являются Jewogle — еврейская версия Google и SeekFind.org — христианский сайт, включающий в себя фильтры, оберегающие пользователей от контента, который может подорвать или ослабить их веру[29].
Персональные результаты и пузыри фильтров
Многие поисковые системы, такие как Google и Bing, используют алгоритмы выборочного угадывания того, какую информацию пользователь хотел бы увидеть, основываясь на его прошлых действиях в системе. В результате, веб-сайты показывают только ту информацию, которая согласуется с прошлыми интересами пользователя. Этот эффект получил название «пузырь фильтров»[30].
Всё это ведёт к тому, что пользователи получают намного меньше противоречащей своей точке зрения информации и становятся интеллектуально изолированными в своём собственном «информационном пузыре». Таким образом, «эффект пузыря» может иметь негативные последствия для формирования гражданского мнения[31].
Предвзятость поисковых систем
Несмотря на то, что поисковые системы запрограммированы, чтобы оценивать веб-сайты на основе некоторой комбинации их популярности и релевантности, в реальности экспериментальные исследования указывают на то, что различные политические, экономические и социальные факторы оказывают влияние на поисковую выдачу[32][33].
Такая предвзятость может быть прямым результатом экономических и коммерческих процессов: компании, которые рекламируются в поисковой системе, могут стать более популярными в результатах обычного поиска в ней. Удаление результатов поиска, не соответствующих местным законам, является примером влияния политических процессов. Например, Google не будет отображать некоторые неонацистские веб-сайты во Франции и Германии, где отрицание Холокоста незаконно[34].
Предвзятость может также быть следствием социальных процессов, поскольку алгоритмы поисковых систем часто разрабатываются, чтобы исключить неформатные точки зрения в пользу более «популярных» результатов[35]. Алгоритмы индексации главных поисковых систем отдают приоритет американским сайтам[33].
Поисковая бомба — один из примеров попытки управления результатами поиска по политическим, социальным или коммерческим причинам.
См. также
Примечания
- ↑ Chu & Rosenthal, 1996, p. 129.
- ↑ Tarakeswar & Kavitha, 2011, p. 29.
- ↑ World-Wide Web Servers.
- ↑ What’s New.
- ↑ Oscar Nierstrasz.
- ↑ Archive of NCSA.
- ↑ Yahoo! And Netscape.
- ↑ Netscape, 1996.
- ↑ The dynamics of competition, 2001.
- ↑ Intro to Computer Science.
- ↑ 1 2 Google`s history.
- ↑ Брин и Пейдж, p. 3.
- ↑ Nigma.
- ↑ 1 2 3 Risvik & Michelsen, 2002, p. 290.
- ↑ 1 2 3 4 5 6 Knowledge Management, 2011.
- ↑ Tarakeswar & Kavitha, 2011, p. 29.
- ↑ NMS.
- ↑ Статистика.
- ↑ Naver.
- ↑ Age of Internet Empires.
- ↑ LiveInternet.
- ↑ Liveinternet
- ↑ 1 2 Antula.
- ↑ Where the Internet lives.
- ↑ World wide web size.
- ↑ Islam.
- ↑ I’mHalal
- ↑ 1 2 Halalblog
- ↑ ChristianNews.
- ↑ Pariser, 2011.
- ↑ Auralist, 2012, p. 13.
- ↑ Segev, 2010.
- ↑ 1 2 Search engine coverage bias, 2004.
- ↑ Replacement of Google.
- ↑ Shaping the Web, 2000.
Литература
- Gandal, Neil. The dynamics of competition in the internet search engine market. — 2001. — Vol. 19. — P. 1103–1117. — DOI:10.1016/S0167-7187(01)00065-0.
- Tarakeswar M. K., Kavitha M. D. Search Engines:A Study (англ.) // Journal of Computer Applications (JCA) : journal. — 2011. — Vol. 4, no. 1. — P. 29—33. — ISSN 0974-1925.
- Vaughan L., Thelwall M. Search engine coverage bias: evidence and possible causes (англ.) // Information Processing & Management : journal. — 2004. — Vol. 40. — P. 693–707. — DOI:10.1016/S0306-4573(03)00063-3.
Ссылки
- FAQ. NetMarketShare. Проверено 23 ноября 2014.
wikipedia.green
Как работает поисковая система и какие бывают поисковики? | Интернет
 Интернет необходим многим пользователям для того, чтобы получать ответы на запросы (вопросы), которые они вводят.
Интернет необходим многим пользователям для того, чтобы получать ответы на запросы (вопросы), которые они вводят.
Если бы не было поисковых систем, пользователям пришлось бы самостоятельно искать нужные сайты, запоминать их, записывать. Во многих случаях найти «вручную» что-то подходящее было бы весьма сложно, а часто и просто невозможно.
За нас всю эту рутинную работу по поиску, хранению и сортировке информации на сайтах делают поисковики.
Содержание статьи:
1. Поисковые системы в Интернете на русском языке
2. Цель поисковиков
3. Работа поисковика и действия вебмастеров
4. Как работает поисковая система?
5. Сканирование
6. Индексирование
7. Ранжирование
Начнем с известных поисковиков Рунета.
Поисковые системы в Интернете на русском
1) Начнем с отечественной поисковой системы. Яндекс работает не только в России, но также работает в Белоруссии и Казахстане, в Украине, в Турции. Также есть Яндекс на английском языке.
Яндекс https://www.yandex.ru/
2) Поисковик Google пришел к нам из Америки, имеет русскоязычную локализацию:
Google https://www.google.ru/
3)Отечественный поисковик Майл ру, который одновременно представляет социальную сеть ВКонтакте, Одноклассники, также Мой мир, известные Ответы Mail.ru и другие проекты.
Майл ру https://mail.ru/
4) Интеллектуальная поисковая система
Nigma (Нигма) http://www.nigma.ru/
С 19 сентября 2017 года “интеллектуалка” nigma не работает. Она перестала для её создателей представлять финансовый интерес, они переключились на другой поисковик под названием CocCoc.
5) Известная компания Ростелеком создала поисковую систему Спутник.
Спутник http://www.sputnik.ru/
Есть поисковик Спутник, разработанный специально для детей, про который я писала ТУТ.
6) Рамблер был одним из первых отечественных поисковиков:
Рамблер http://www.rambler.ru/
В мире есть другие известные поисковики:
подробнее о них ЗДЕСЬ.
Попробуем разобраться, как же работает поисковая система, а именно, как происходит индексация сайтов, анализ результатов индексации и формирование поисковой выдачи. Принципы работы поисковых систем примерно одинаковые: поиск информации в Интернете, ее хранение и сортировка для выдачи в ответ на запросы пользователей. А вот алгоритмы, по которым работают поисковики, могут сильно отличаться. Эти алгоритмы держатся в тайне и запрещено ее разглашение.
Введя один и тот же запрос в поисковые строки разных поисковиков, можно получить разные ответы. Причина в том, что все поисковики используют собственные алгоритмы.
Цель поисковиков
В первую очередь нужно знать о том, что поисковики – это коммерческие организации. Их цель – получение прибыли. Прибыль можно получать с контекстной рекламы, других видов рекламы, с продвижения нужных сайтов на верхние строчки выдачи. В общем, способов много.
Прибыль поисковика зависит от того, какой размер аудитории у него, то есть, сколько человек пользуется данной поисковой системой. Чем больше аудитория, тем большему числу людей будет показываться реклама. Соответственно, стоить эта реклама будет больше. Увеличить аудиторию поисковики могут за счет собственной рекламы, а также привлекая пользователей за счет улучшения качества своих сервисов, алгоритма и удобства поиска.
Самое главное и сложное здесь – это разработка полноценного функционирующего алгоритма поиска, который бы предоставлял релевантные результаты на большинство пользовательских запросов.
Работа поисковика и действия вебмастеров
Каждый поисковик обладает своим собственным алгоритмом, который должен учитывать огромное количество разных факторов при анализе информации и составлении выдачи в ответ на запрос пользователя:
- возраст того или иного сайта,
- характеристики домена сайта,
- качество контента на сайте и его виды,
- особенности навигации и структуры сайта,
- юзабилити (удобство для пользователей),
- поведенческие факторы (поисковик может определить, нашел ли пользователь то, что он искал на сайте или пользователь вернулся снова в поисковик и там опять ищет ответ на тот же запрос)
- и т.д.
Все это нужно именно для того, чтобы выдача по запросу пользователя была максимально релевантной, удовлетворяющей запросы пользователя. При этом алгоритмы поисковиков постоянно меняются, дорабатываются. Как говорится, нет предела совершенству.
С другой стороны, вебмастера и оптимизаторы постоянно изобретают новые способы продвижения своих сайтов, которые далеко не всегда являются честными. Задача разработчиков алгоритма поисковых машин – вносить в него изменения, которые бы не позволяли «плохим» сайтам нечестных оптимизаторов оказываться в ТОПе.
Как работает поисковая система?
Теперь о том, как происходит непосредственная работа поисковой системы. Она состоит как минимум из трех этапов:
- сканирование,
- индексирование,
- ранжирование.
Число сайтов в интернете достигает просто астрономической величины. И каждый сайт – это информация, информационный контент, который создается для читателей (живых людей).
Сканирование
Это блуждание поисковика по Интернету для сбора новой информации, для анализа ссылок и поиска нового контента, который можно использовать для выдачи пользователю в ответ на его запросы. Для сканирования у поисковиков есть специальные роботы, которых называют поисковыми роботами или пауками.
Поисковые роботы – это программы, которые в автоматическом режиме посещают сайты и собирают с них информацию. Сканирование может быть первичным (робот заходит на новый сайт в первый раз). После первичного сбора информации с сайта и занесения его в базу данных поисковика, робот начинает с определенной регулярностью заходить на его страницы. Если произошли какие-то изменения (добавился новый контент, удалился старый), то все эти изменения будут поисковиком зафиксированы.
Главная задача поискового паука – найти новую информацию и отдать ее поисковику на следующий этап обработки, то есть, на индексирование.
Индексирование
Поисковик может искать информацию лишь среди тех сайтов, которые уже занесены в его базу данных (проиндексированы им). Если сканирование – это процесс поиска и сбора информации, которая имеется на том или ином сайте, то индексация – процесс занесения этой информации в базу данных поисковика. На этом этапе поисковик автоматически принимает решение, стоит ли заносить ту или иную информацию в свою базу данных и куда ее заносить, в какой раздел базы данных. Например, Google индексирует практически всю информацию, найденную его роботами в Интернете, а Яндекс более привередлив и индексирует далеко не все.
Для новых сайтов этап индексирования может быть долгим, поэтому посетителей из поисковых систем новые сайты могут ждать долго. А новая информация, которая появляется на старых, раскрученных сайтах, может индексироваться почти мгновенно и практически сразу попадать в «индекс», то есть, в базу данных поисковиков.
Ранжирование
Ранжирование – это выстраивание информации, которая была ранее проиндексирована и занесена в базу того или иного поисковика, по рангу, то есть, какую информацию поисковик будет показывать своим пользователям в первую очередь, а какую информацию помещать «рангом» ниже. Ранжирование можно отнести к этапу обслуживания поисковиком своего клиента – пользователя.
На серверах поисковой системы происходит обработка полученной информации и формирование выдачи по огромному спектру всевозможных запросов. Здесь уже вступают в работу алгоритмы поисковика. Все занесенные в базу сайты классифицируются по тематикам, тематики делятся на группы запросов. По каждой из групп запросов может составляться предварительная выдача, которая впоследствии будет корректироваться.
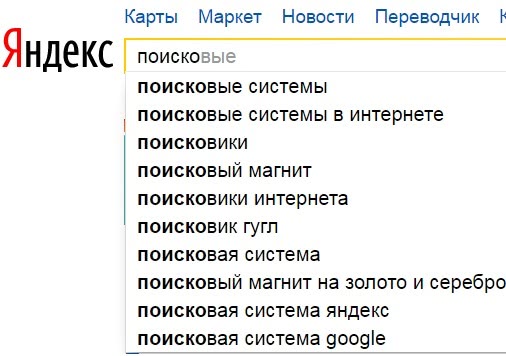 Рис. 1 Упреждающий поиск – выдаются подсказки при вводе первых букв в строку поиска
Рис. 1 Упреждающий поиск – выдаются подсказки при вводе первых букв в строку поискаПредварительная выдача называется еще «упреждающим поиском» – это когда пользователь только начинает вводить свой запрос, а ему уже предлагаются различные варианты ответов.
В каждой поисковой системе есть модераторы – люди, отвечающие за оценку сайтов и результаты выдачи по определенным группам запросов. Модераторы нужны для того, что контролировать работу поисковика, а также замещать алгоритм там, где он работает недостаточно хорошо (корректировать его работу). Модераторы могут вручную менять позиции тех или иных сайтов, если видят, что алгоритм поисковика в каких-то случаях сработал некорректно.
Голосование
Спасибо за Ваш голос!
 Загрузка …
Загрузка …P.S. К статье отлично подходит:
1. Что полезно знать о запросах в поисковых системах Google и Яндексе
2. Основная миссия и задачи поисковика Google
3. Поиск информации ВКонтакте
4. Семь необычных поисковых систем
www.inetgramotnost.ru
Поисковая система — это… Что такое Поисковая система?
- Поисковая система
- Поисковая система
- Поисковая система — в Интернет — специальный веб-сайт, на котором пользователь по заданному запросу может получить ссылки на сайты, соответствующие этому запросу.
Поисковая система состоит из трех компонент:
-1- поискового робота;
-2- индекса системы; и
-3- программы, которая (а) обрабатывает запрос пользователя, (б) находит в индексе документы, отвечающие критериям запроса, и (в) выводит список найденных документов в порядке убывания релевантности.По-английски: Search engine
Синонимы: Поисковая машина
См. также: Поисковые системы в Интернет Веб-серверы Информационно-поисковые системы Веб-страницы
Финансовый словарь Финам.
.
- Поисковая метамашина
- Поисковое предписание
Смотреть что такое «Поисковая система» в других словарях:
поисковая система — сущ., кол во синонимов: 3 • искалка (9) • ищейка (16) • поисковик (13) Словарь синонимов AS … Словарь синонимов
поисковая система — поисковик Сайт, при помощи которого ищутся другие сайты. Поиск осуществляется путём ввода ключевых слов в окошко поиска. В отличии от каталогов, даже, если сайт не был предварительно зарегистрирован, его можно найти при помощи поисковика.… … Справочник технического переводчика
Поисковая система — Эта статья должна быть полностью переписана. На странице обсуждения могут быть пояснения. Поисковая система программно аппаратный комплекс с веб интерфейсом, предоставляющий возможност … Википедия
поисковая система — ieškos sistema statusas T sritis automatika atitikmenys: angl. searching system vok. Suchsystem, n rus. поисковая система, f pranc. système de recherche, m … Automatikos terminų žodynas
Поисковая система — – (англ. search engine, синонимы: искалка, поисковый сервер, поисковая машина) – Инструмент для поиска информации в Интернете. Как правило, работа поисковой машины состоит из двух этапов. Специальная программа (поисковый робот, автомат, агент,… … Энциклопедический словарь СМИ
Поисковая система — управления, система автоматического управления (См. Автоматическое управление), в которой управляющие воздействия методом поиска автоматически изменяются т. о., чтобы осуществлялось наилучшее (в каком то смысле) управление объектом; при… … Большая советская энциклопедия
ПОИСКОВАЯ СИСТЕМА — управлення система автоматического управления, в к рой управляющие воздействия методом поиска автоматического изменяются т. о., чтобы осуществлять наилучшее управление объектом; при этом изменения хар к объекта или воздействий внеш. среды заранее … Большой энциклопедический политехнический словарь
Поисковая система на основе радиолокационных ответчиков — СМП 1 редназначена для поиска спасателей, попавших в критические условия, связанные с угрозой для жизни, а также поиска десантированных грузов и различных объектов в условиях плохой видимости. В ее состав входят: радиоблок поиска активных… … Словарь черезвычайных ситуаций
автоматизированная информационно-поисковая система — 3.2.5 автоматизированная информационно поисковая система: ИПС, реализованная на базе электронно вычислительной техники Источник … Словарь-справочник терминов нормативно-технической документации
Апорт (поисковая система) — У этого термина существуют и другие значения, см. Апорт. Апорт … Википедия
dic.academic.ru
Как работает поисковая система? Что такое поисковая система? Поисковая система Google
В архитектуру поисковой системы обычно входят:
Энциклопедичный YouTube
1 / 5
✪ Урок 3: Как работает поисковая система. Введение в SEO
✪ Поисковая система изнутри
✪ Shodan — черный Google
✪ Поисковая система ЧЕБУРАШКА заменит Google и Яндекс в России
✪ Урок 1 — Как устроена поисковая система
Субтитры
История
| Год | Система | Событие |
|---|---|---|
| 1993 | W3Catalog ?! | Запуск |
| Aliweb | Запуск | |
| JumpStation | Запуск | |
| 1994 | WebCrawler | Запуск |
| Infoseek | Запуск | |
| Lycos | Запуск | |
| 1995 | AltaVista | Запуск |
| Daum | Основание | |
| Open Text Web Index | Запуск | |
| Magellan | Запуск | |
| Excite | Запуск | |
| SAPO | Запуск | |
| Yahoo! | Запуск | |
| 1996 | Dogpile | Запуск |
| Inktomi | Основание | |
| Рамблер | Основание | |
| HotBot | Основание | |
| Ask Jeeves | Основание | |
| 1997 | Northern Light | Запуск |
| Яндекс | Запуск | |
| 1998 | Запуск | |
| 1999 | AlltheWeb | Запуск |
| GenieKnows | Основание | |
| Naver | Запуск | |
| Teoma | Основание | |
| Vivisimo | Основание | |
| 2000 | Baidu | Основание |
| Exalead | Основание | |
| 2003 | Info.com | Запуск |
| 2004 | Yahoo! Search | Окончательный запуск |
| A9.com | Запуск | |
| Sogou | Запуск | |
| 2005 | MSN Search | Окончательный запуск |
| Ask.com | Запуск | |
| Нигма | Запуск | |
| GoodSearch | Запуск | |
| SearchMe | Основание | |
| 2006 | wikiseek | Основание |
| Quaero | Основание | |
| Live Search | Запуск | |
| ChaCha | Запуск (бета) | |
| Guruji.com | Запуск (бета) | |
| 2007 | wikiseek | Запуск |
| Sproose | Запуск | |
| Wikia Search | Запуск | |
| Blackle.com | Запуск | |
| 2008 | DuckDuckGo | Запуск |
| Tooby | Запуск | |
| Picollator | Запуск | |
| Viewzi | Запуск | |
| Cuil | Запуск | |
| Boogami | Запуск | |
| LeapFish | Запуск (бета) | |
| Forestle | Запуск | |
| VADLO | Запуск | |
| Powerset | Запуск | |
| 2009 | Bing | Запуск |
| KAZ.KZ | Запуск | |
| Yebol | Запуск (бета) | |
| Mugurdy | Закрытие | |
| Scout | Запуск | |
| 2010 | Cuil | Закрытие |
| Blekko | Запуск (бета) | |
| Viewzi | Закрытие | |
| 2012 | WAZZUB | Запуск |
| 2014 | Спутник | Запуск (бета) |
На раннем этапе развития сети Интернет Тим Бернерс-Ли поддерживал список веб-серверов, размещённый на сайте ЦЕРН . Сайтов становилось всё больше, и поддерживать вручную такой список становилось всё сложнее. На сайте NCSA был специальный раздел «Что нового!» (англ. What»s New! ) , где публиковали ссылки на новые сайты.
Первой компьютерной программой для поиска в Интернете , была программа Арчи (англ. archie — архив без буквы «в»). Она была создана в 1990 году Аланом Эмтэджем (Alan Emtage), Биллом Хиланом (Bill Heelan) и Дж. Питером Дойчем (J. Peter Deutsch), студентами, изучающими информатику в университете Макгилла в Монреале . Программа скачивала списки всех файлов со всех доступных анонимных FTP -серверов и строила базу данных, в которой можно было выполнять поиск по именам файлов. Однако, программа Арчи не индексировала содержание этих файлов, так как объём данных был настолько мал, что всё можно было легко найти вручную.
Развитие и распространение сетевого протокола Gopher , придуманного в 1991 году Марком Маккэхилом (Mark McCahill) в университете Миннесоты , привело к созданию двух новых поисковых программ, Veronica и Jughead . Как и Арчи, они искали имена файлов и заголовки, сохранённые в индексных системах Gopher. Veronica (англ. Very Easy Rodent-Oriented Net-wide Index to Computerized Archives ) позволяла выполнять поиск по ключевым словам большинства заголовков меню Gopher во всех списках Gopher. Программа Jughead (англ. Jonzy»s Universal Gopher Hierarchy Excavation And Display ) извлекала информацию о меню от определённых Gopher-серверов. Хотя название поисковика Арчи не имело отношения к циклу комиксов «Арчи» , тем не менее Veronica и Jughead — персонажи этих комиксов.
К лету 1993 года ещё не было ни одной системы для поиска в вебе, хотя вручную поддерживались многочисленные специализированные каталоги. Оскар Нирштрасс (Oscar Nierstrasz) в Женевском университете написал ряд сценариев на Perl , которые периодически копировали эти страницы и переписывали их в стандартный формат. Это стало основой для W3Catalog ?! , первой примитивной поисковой системы сети, запущенной 2 сентября 1993 года .
Вероятно, первым поисковым роботом, написанным на языке Perl, был «World Wide Web Wanderer» — бот Мэтью Грэя (Matthew Gray) из в июне 1993 года. Этот робот создавал поисковый индекс «Wandex ». Цель робота Wanderer состояла в том, чтобы измерить размер всемирной паутины и найти все веб-страницы, содержащие слова из запроса. В 1993 году появилась и вторая поисковая система «Aliweb ». Aliweb не использовала поискового робота , но вместо этого ожидала уведомлений от администраторов веб-сайтов о наличии на их сайтах индексного файла в определённом формате.
JumpStation , созданный в декабре 1993 года Джонатаном Флетчером, искал веб-страницы и строил их индексы с помощью поискового робота, и использовал веб-форму в качестве интерфейса для формулирования поисковых запросов. Это был первый инструмент поиска в Интернете, который сочетал три важнейших функции поисковой системы (проверка, индексация и собственно поиск). Из-за ограниченности ресурсов компьютеров того времени индексация и, следовательно, поиск были ограничены только названиями и заголовками веб-страниц, найденных поисковым роботом.
Поисковые системы участвовали в «Пузыре доткомов» конца 1990-х . Несколько компаний эффектно вышли на рынок, получив рекордную прибыль во время их первичного публичного предложения . Некоторые отказались от рынка общедоступных поисковых движков и стали работать только с корпоративным сектором, например, Northern Light .
Google взял на вооружение идею продажи ключевых слов в 1998 году, тогда это была маленькая компания, обеспечивающая работу поисковой системы по адресу goto.com . Этот шаг ознаменовал для поисковых систем переход от соревнований друг с другом к одному из самых выгодных коммерческих предприятий в Интернете . Поисковые системы стали продавать первые места в результатах поиска отдельным компаниям.
Поисковая система Google занимает видное положение с начала 2000-х . Компания добилась высокого положения благодаря хорошим результатам поиска с помощью алгоритма PageRank . Алгоритм был представлен общественности в статье «The Anatomy of Search Engine», написанной Сергеем Брином и Ларри Пейджем, основателями Google . Этот итеративный алгоритм ранжирует веб-страницы, основываясь на оценке количества гиперссылок на веб-страницу в предположении, что на «хорошие» и «важные» страницы ссылаются больше, чем на другие. Интерфейс Google выдержан в спартанском стиле, где нет ничего лишнего, в отличие от многих своих конкурентов, которые встраивали поисковую систему в веб-портал. Поисковая система Google стала настолько популярной, что появились подражающие ей системы, например, Mystery Seeker (тайный поисковик).
Поиск информации на русском языке
В 1996 году был реализован поиск с учётом русской морфологии на поисковой машине Altavista и запущены оригинальные российские поисковые машины Рамблер и Апорт . 23 сентября 1997 года была открыта поисковая машина Яндекс . 22 мая 2014 года компанией Ростелеком была открыта национальная поисковая машина Спутник , которая на момент 2015 года находится в ст
geekpad.ru
Поисковая система — это… Что такое Поисковая система?
- Поисковая система
- – (англ. search engine, синонимы: искалка, поисковый сервер, поисковая машина) – Инструмент для поиска информации в Интернете. Как правило, работа поисковой машины состоит из двух этапов. Специальная программа (поисковый робот, автомат, агент, паук, червяк, crawler) постоянно обходит сеть и собирает информацию с зарегистрированных в данной системе веб-страниц (индексирует их). Когда пользователь задает запрос, поиск идет по предварительно построенному индексу. Результатом поиска является так называемая поисковая выдача – список ссылок на документы (веб-страницы), соответствующие запросу. Поисковые машины различаются по области действия на локальные (ограничивающиеся национальным доменом, определенным языком) и глобальные. Обычно глобальные системы хорошо покрывают американский интернет (который действительно является значительной частью мирового) и несколько хуже «знают» остальную часть. Поэтому, если ваш поиск заведомо ограничен страной или языком, лучше пользоваться локальной системой. Интернет – живая динамическая система, которая меняется быстрее, чем об этом успевает узнать робот поисковой машины. Поэтому иногда найденные документы могут оказаться измененными или вообще не существовать. Некоторые поисковые машины при индексации сохраняют у себя образ индексируемого документа и могут показать его пользователю даже после того, как оригинал перестал соответствовать образу. Скорость обновления индекса и полнота покрытия (размер поисковой базы) являются важной характеристикой поисковой машины. Ссылки на документы в результатах поиска сортируются по степени соответствия запросу. Этот критерий называется «релевантность». Способ вычисления релевантности является собственным know-how каждой поисковой машины, поэтому выдача по одному и тому же запросу в разных системах может заметно отличаться. Поисковые машины обычно имеют специальный язык запросов, с помощью которого можно точнее объяснить машине, что именно надо искать. Однако большинство систем не требуют от пользователя знания этого языка, как правило, достаточно просто написать в строке запроса несколько ключевых слов, определяющих область вашего интереса. Самым современным системам можно задавать запросы просто на естественном, «человеческом» языке. Система сама разберется, какие слова и словосочетания являются ключевыми. Основной объект индексации поисковой машины – тексты. Однако существуют системы, позволяющие осуществлять поиск по картинкам, по mp3, по архивам программ, по новостям и т.д. Все поисковые машины сталкиваются с проблемой так называемого поискового «спама». С большинством сайтов-спамеров удается бороться с помощью специальных алгоритмов, и меры, применяемые к спамерам, могут быть довольно суровыми – вплоть до полного исключения сайта из поисковой базы.
Князев А.А. Энциклопедический словарь СМИ. — Бишкек: Издательство КРСУ. А. А. Князев. 2002.
- Подводка
- Полилог
Смотреть что такое «Поисковая система» в других словарях:
Поисковая система — в Интернет специальный веб сайт, на котором пользователь по заданному запросу может получить ссылки на сайты, соответствующие этому запросу. Поисковая система состоит из трех компонент: 1 поискового робота; 2 индекса системы; и 3 программы,… … Финансовый словарь
поисковая система — сущ., кол во синонимов: 3 • искалка (9) • ищейка (16) • поисковик (13) Словарь синонимов AS … Словарь синонимов
поисковая система — поисковик Сайт, при помощи которого ищутся другие сайты. Поиск осуществляется путём ввода ключевых слов в окошко поиска. В отличии от каталогов, даже, если сайт не был предварительно зарегистрирован, его можно найти при помощи поисковика.… … Справочник технического переводчика
Поисковая система — Эта статья должна быть полностью переписана. На странице обсуждения могут быть пояснения. Поисковая система программно аппаратный комплекс с веб интерфейсом, предоставляющий возможност … Википедия
поисковая система — ieškos sistema statusas T sritis automatika atitikmenys: angl. searching system vok. Suchsystem, n rus. поисковая система, f pranc. système de recherche, m … Automatikos terminų žodynas
Поисковая система — управления, система автоматического управления (См. Автоматическое управление), в которой управляющие воздействия методом поиска автоматически изменяются т. о., чтобы осуществлялось наилучшее (в каком то смысле) управление объектом; при… … Большая советская энциклопедия
ПОИСКОВАЯ СИСТЕМА — управлення система автоматического управления, в к рой управляющие воздействия методом поиска автоматического изменяются т. о., чтобы осуществлять наилучшее управление объектом; при этом изменения хар к объекта или воздействий внеш. среды заранее … Большой энциклопедический политехнический словарь
Поисковая система на основе радиолокационных ответчиков — СМП 1 редназначена для поиска спасателей, попавших в критические условия, связанные с угрозой для жизни, а также поиска десантированных грузов и различных объектов в условиях плохой видимости. В ее состав входят: радиоблок поиска активных… … Словарь черезвычайных ситуаций
автоматизированная информационно-поисковая система — 3.2.5 автоматизированная информационно поисковая система: ИПС, реализованная на базе электронно вычислительной техники Источник … Словарь-справочник терминов нормативно-технической документации
Апорт (поисковая система) — У этого термина существуют и другие значения, см. Апорт. Апорт … Википедия
smi.academic.ru