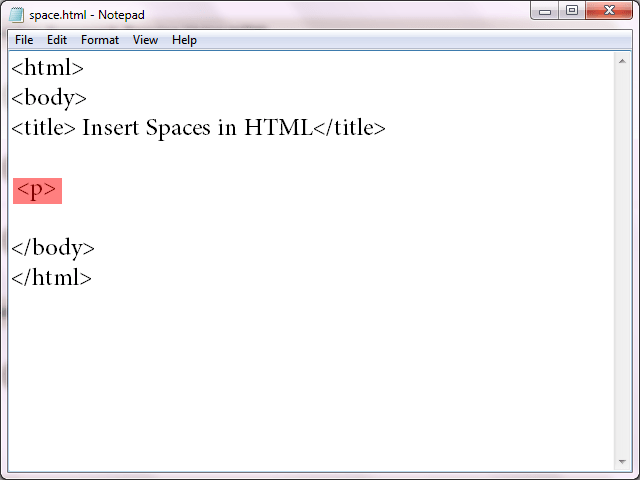
| Код | Символ | Описание символа |
|---|---|---|
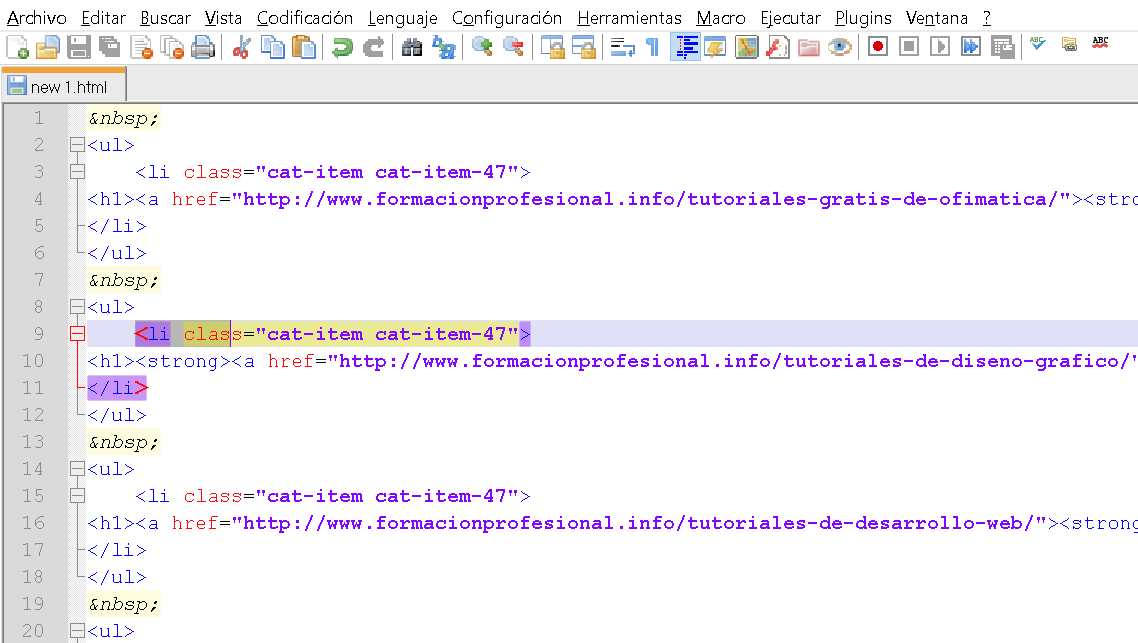
| Часто используемые | ||
| | неразрывный пробел | |
|   | короткий пробел | |
|   | длинный пробел | |
| ­ | мягкий перенос | |
| • | • | маленький кружок |
| · | · | точка на середине высоты строки |
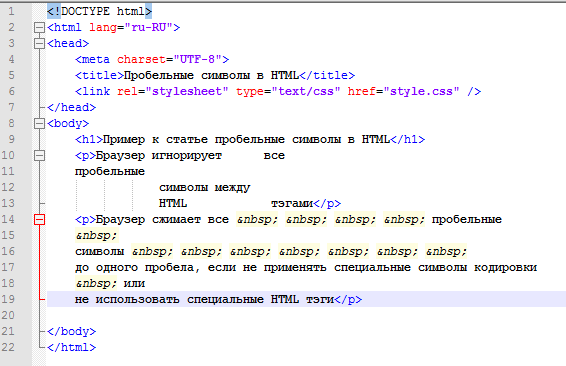
| — | — | длинное тире |
| – | – | короткое тире |
| … | … | многоточие |
| « | « | левая кавычка елочка |
| » | » | правая кавычка елочка |
| © | © | Копирайт |
| Математические | ||
| ± | ± | плюс/минус |
| × | × | умножить |
| ≠ | ≠ | не равно |
| ≈ | ≈ | почти равно (приблизительно) |
| ≡ | ≡ | тождественно |
| ≤ | ≤ | |
| ≥ | ≥ | >= |
| √ | √ | квадратный корень |
| ² | ² | квадрат, вторая степень |
| ³ | ³ | куб, третья степень |
| ¼ | ¼ | 1/4 |
| ½ | ½ | 1/2 |
| ¾ | ¾ | 3/4 |
| ∞ | ∞ | бесконечность |
| Стрелки | ||
| ← | ← | трелка влево |
| ↑ | ↑ | стрелка вверх |
| → | → | стрелка вправо |
| ↓ | ↓ | стрелка вниз |
| ↔ | ↔ | стрелка влево и вправо |
| ↕ | ↕ | стрелка вверх-вниз |
| ⇒ | ⇒ | стрелка двойная вправо |
| Прочие | ||
| & | & | & амперсанд |
| € | € | Евро |
| £ | £ | Фунт стерлингов |
| λ | λ | лямбда — теплопроводность |
| ρ | ρ | ро — плотность |
| Δ | Δ | дельта |
| &pi | π | пи |
| Ø | Ø | диаметр |
| º | º | градус (или °) |
| ƒ | ƒ | знак функции |
| ○ | ○ | круг |
| № | № | знак номера |
Все о пробелах
Пробелы это не только та большая клавиша, с помощью которой вы разделяете слова в тексте. В этой статье мы рассмотрим дополнительные символы пробелов, их назначение и возможности современного использования.
В этой статье мы рассмотрим дополнительные символы пробелов, их назначение и возможности современного использования.
Ниже вы видите два твита. В одном из них Пол Айриш уведомляется о моем ответе, а о другом — нет. В чем разница между твитами? Читайте!
Век обычной типографии
В типографии и издательском деле всегда приходилось прикладывать на удивление много физических усилий. Отдельные буквы выбирались и составлялись вместе, одна за другой, в слова, затем фразы, а затем колонки. Цвета были чернилами — их надо было смешать и подготовить. Отдельной индустрией была подготовка и нарезка бумаги.
Черная типографская краска. (увеличенная версия)
Деревянные блоки для задания высоты строки. (увеличенная версия)
Смешивание синей и белой краски. (увеличенная версия)
Это касалось и пробелов. Пробелы не были отсутствием атомов, это были атомы другого вида. При создании композиции страницы для печатного пресса, надо было не только положить блоки пробелов между предложениями, но и добавить в оставшееся пространство блоки свинца или дерева. Все что сейчас называется промежутком между буквами, высотой строк, внешними и внутренними отступами — все это было физическим.
Все что сейчас называется промежутком между буквами, высотой строк, внешними и внутренними отступами — все это было физическим.
Выравнивание текста влево требовало не меньше усилий, чем выравнивание по ширине, так как пробелы все равно требовалось располагать. Необходимо было учитывать каждую долю дюйма.
Цитата в середине верстки. Обратите внимание на все блоки пробелов вокруг цитаты, удерживающие ее на месте. (увеличенная версия)
Вы можете сказать: — “это так мило, что сегодня у нас есть position: absolute, отрицательные отступы и CSS трансформации для размеров больше, чем у дисплея.” И вы будете правы. Неуклонный марш закона Мура дал нам дисплеи с крошечными пикселями и миллионами цветов. И вы можете делать все, что хотите.
Но никто не делает. Когда мы работаем с текстом, мы обычно полагаемся на браузеры, ведь это гораздо удобнее. Многие остатки традиционной типографской техники доступны сегодня и некоторые из них действительно полезны. Это история о физических пробелах в цифровом мире.
Это история о физических пробелах в цифровом мире.
Знакомимся с пробелами
Видели ли вы когда-нибудь полную таблицу символов Unicode? Нет? Посмотрите, это завораживает. Это история нашей цивилизации, выраженная в типографике. Она может быть недостаточно упорядочена и не объяснена полностью, но в ней есть все: языки, культуры, концепции. Географические и транспортные обозначения находятся рядом с алхимическими. Эмодзи рядом со счетными палочками. Символы валют влекут к изучению мира финансов, а дополнительные технические символы — инженерии. Здесь есть неудачные эксперименты с алфавитом и такие странности как неполная неопределенность. На другой странице будут символы проигрывания со старых видеомагнитофонов и рисунок снеговика.
И, конечно, история типографского дела здесь также сполна представлена. Вы можете путешествовать назад во времени с печатными орнаментами, расшифровывать загадки буквенных символов и сравнивать дюжину разновидностей тире — у каждого из которых есть свое назначение.
Пробелы также играют свою роль. Есть один основной, связанный с самой большой клавишей на клавиатуре, но есть и другие: очень короткие Hairspace и Thinspace и очень широкие En space и Em space и еще несколько промежуточных.
- Hair space
- Six-per-em space
- Thin space
- Normal space
- Four-per-em space
- Mathematical space
- Punctuation space
- Three-per-em space
- En space
- Ideographic space
- Em space
Вы можете использовать их также как и обычный пробел. Просто скопируйте из списка. Но зачем?
Очевидно. Пробелы разных размеров можно использовать для тонкой настройки сочетания элементов. Например, medium использует hair space (самый тонкий пробел, равный по ширине самой узкой шпации) для обертывания длинных тире, чтобы они не касались соседних букв:
Длинные тире в окружении очень узких пробелов на сайте Medium. (увеличенная версия)
(увеличенная версия)
То же самое мы делаем в письмах, в которых используется среднее тире для указания диапазона. Без узких пробелов оно будет выглядеть зажатым (а с обычным пробелом слишком свободным).
Очень узкие пробелы используются при указании диапазона на Medium. (увеличенная версия)
Точно также, если элемент меню содержит слэш, мы обертываем его узкими пробелами для лучшего баланса:
Слэш и узкие пробелы в меню на Medium. (увеличенная версия)
И так далее. Многие пробелы названы исходя из их ширины (шириной в волос, узкий, Н и М пробелы), но у некоторых название основано на их назначении. Пунктуационный пробел призван занимать столько же места, сколько и знаки пунктуации, точно также названы идеографический и математический пробелы.
Вы можете сказать, что это не круто. В конце концов, того же эффекта можно достигнуть путем обертывания элементов в <span> и применения горизонтального пэддинга, или путем изменения свойства word-spacing и использования обычных пробелов.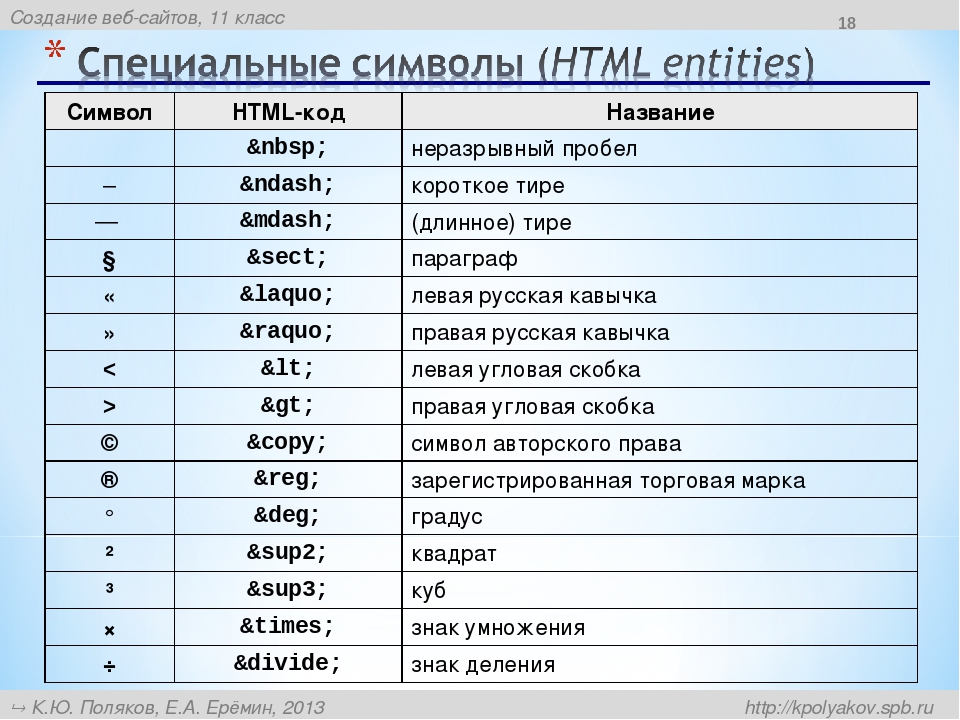
Проблема этих решений в том, что они являются более громоздкими. Использование разных пробелов Юникода работает везде, не только в HTML, но и в кнопках, лейблах, полях ввода текста и заголовках E-mail. Пробелы в Юникоде очень гибкие.
Пробелы, остающиеся на месте
Теперь мы перейдем к еще трем пробелам с магическими свойствами:
- Narrow no-break space
- No-break space
- Figure space
Все эти пробелы ведут себя так, как будто их приклеили к соседним символам. Это значит в первую очередь то, что при переносе на новую линию слова, скрепленные такими пробелами останутся вместе. Это полезно, если вы хотите предотвратить разделение слов или символов, которые могут смотреться нелепо оказавшись на разных строках, брошенные и без присмотра (в типографии их называют сиротами).
Вот еще один пример с Medium. Мы используем неразрывные пробелы внутри фразы “and 3 others”, в результате они всегда остаются рядом, а не разбиваются на половинки.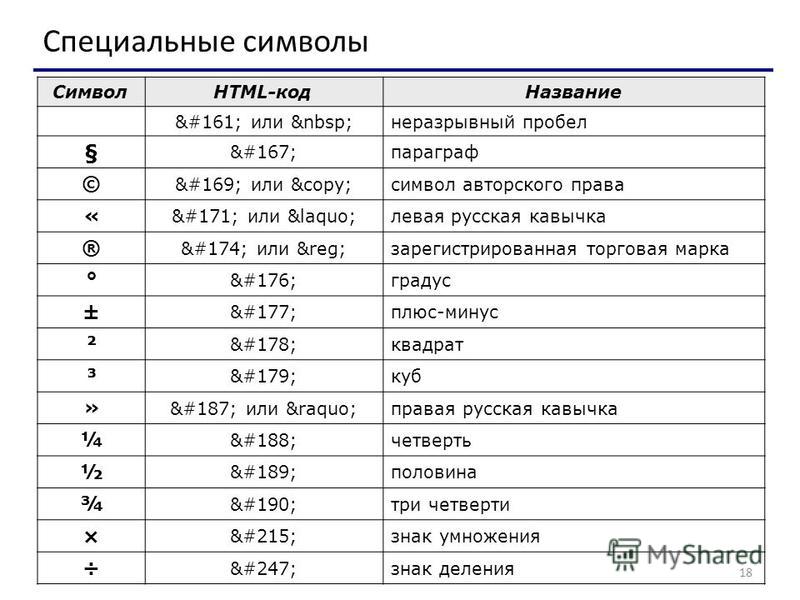
Текст с обычными и неразрывными пробелами. (увеличенная версия)
Точно также в французском языке принято отделять завершающий знак пунктуации в предложении узким пробелом. Этот пробел тоже должен быть неразрывным, чтобы знак вопроса или кавычка были привязаны к своим словам.
Текст с французской пунктуацией. (увеличенная версия)
Та же техника применима к длинным числам, разделенным на блоки по три цифры, телефонным номерам и прочим вещам, которые по смыслу должны находиться в одном месте.
Опять-таки, вы можете делать все это, оборачивая не разбиваемые сочетания древним тегом <nobr> или span с применением свойства white-space в CSS. Но также как и в предыдущем случае, использование нужного символа, соответствующего контексту будет решением более простым и работающим независимо от разметки.
Еще один момент: несмотря на невидимость, неразрывные пробелы сохраняют свои размеры — и ширину, и высоту. Иногда это помогает правильно задать размер их контейнеру. Некоторые из вас помнят темные времена табличной верстки, когда использование неразрывного пробела помогало обеспечить видимость ячеек таблицы. Это был хак, основанный на другом хаке. Сегодня у нас есть лучшие способы для верстки макетов. Но даже сейчас, пару месяцев назад, я использовал неразрывный пробел при разработке для IOS с той же целью — он был в поле пользовательского ввода и без него высота поля была недостаточной.
Иногда это помогает правильно задать размер их контейнеру. Некоторые из вас помнят темные времена табличной верстки, когда использование неразрывного пробела помогало обеспечить видимость ячеек таблицы. Это был хак, основанный на другом хаке. Сегодня у нас есть лучшие способы для верстки макетов. Но даже сейчас, пару месяцев назад, я использовал неразрывный пробел при разработке для IOS с той же целью — он был в поле пользовательского ввода и без него высота поля была недостаточной.
Не отбрасывайте вчерашние хаки и знания. Иногда они могут пригодиться и в современных условиях. 🙂
Невидимые, но не совсем
Теперь настало время перейти к самой любопытной разновидности пробелов — к тем, у которых нет размеров совсем.
Да, он где-то здесь. Скопируйте и вставьте фрагмент целиком и удалите символы вокруг него. Вы найдете невидимый пробел, если будете проводить по фрагменту стрелками на клавиатуре — вы заметите остановку, в месте нахождения невидимого пробела.
У него нет никакой ширины, это пробел для современной цифровой эры.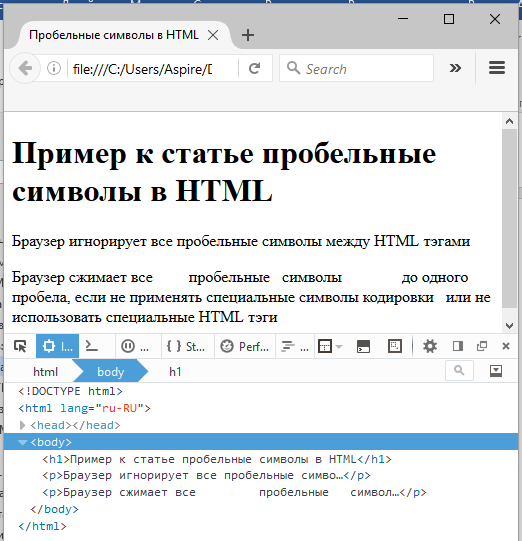 Но какое может быть у применение у пробела, которого нет? Целых два:
Но какое может быть у применение у пробела, которого нет? Целых два:
- Он позволяет разбивать слова.
- Он обманывает алгоритмы, осуществляющие поиск по строкам.
В первом случае пробел нулевой ширины работает как разбиватель слов (<wbr>) там, где HTML недоступен. В таком случае это абсолютный антагонист неразрывного пробела. Вот пример, где он позволяет разбивать слова, разделенные слэшем:
Пробел нулевой ширины помогает разбить слова, разделенные слэшем. (увеличенная версия)
Что касается другого применения… Помните пример в самом верху? Это был пробел нулевой ширины, который предотвратил создание ссылки в моем твите. Он расположен сразу после @ и это он помешал парсеру, ищущему цифры и буквы и прекращающему поиск, при обнаружении других символов.
Два твита с нулевым пробелом. (увеличенная версия)
Можно найти и другие применения:
- Предотвращение автоматической токенизации.
 Если вы хотите обсудить в Твиттере
Если вы хотите обсудить в Твиттере @importили@extendи не хотите при этом напрасно беспокоить пользователей с одноименными никами, то пробелы нулевой ширины придут на помощь. - Предотвращение автоматического создания ссылок. Некоторые алгоритмы плохо обрабатывают знаки пунктуации после ссылок, вставляя их в ссылку. Нулевой пробел решает эту проблему.
- Предотвращение автоматического конвертирования символов в эмотиконы. Это можно использовать в чате Google для сохранения олдскульных смайликов, без замены проверенной классики на многоцветную мерзость.
- Манипуляция с алгоритмами сортировки позволяет перемещать требуемые элементы вверх или вниз списка без добавления видимых символов.
- Оставление полей ввода пустыми, когда их
требуетсязаполнить.
 Если вы хотите обсудить в Твиттере
Если вы хотите обсудить в Твиттере Существуют как творческие, так и хитрые использования невидимого пробела и надо учитывать, что некоторые парсеры умнее других. Но при разумном использовании это просто еще один инструмент для управления парсерами, когда они делают не то, что нам нужно.
А теперь все вместе
Это список всех пробелов, которые были упомянуты в статье. Вы можете скопировать этот текст и все эти пробелы будут также работать в IOS и Android.
| Название пробела | HTML сущность | Код юникода |
|---|---|---|
| Hair space |   | \u200A |
| Six-per-em space |   | \u2006 |
| Thin space |   | \u2009 |
| Normal space |   | \u0020 |
| Four-per-em space |   | \u2005 |
| Mathematical space |   | \u205F |
| Punctuation space |   | \u2008 |
| Three-per-em space |   | \u2004 |
| En space |   | \u2002 |
| Ideographic space |   | \u3000 |
| Em space |   | \u2003 |
| Narrow no-break space |   | \u202F |
| No-break space |   | \u00A0 |
| Figure space |   | \u2007 |
| Zero-widthspace | ​ | \u200B |
Что нужно учитывать при работе с пробелами
При более активном использовании пробелов надо держать в уме следующие пункты:
- Все пробелы выглядят одинаково. Имеет смысл оставлять комментарий или другое напоминание о том, для чего оставлен конкретный вид пробела.
- Пользователи любят копипейст. В зависимости от обстоятельств, используемые вами пробелы могут проявится, а могут и не проявится после того, как пользователь скопирует их и куда-либо вставит. Если это важно для вас (например, вы используете пробелы для разделения чисел), проверьте все перед использованием.
- Поддержка в шрифтах. Пробелы это такие же глифы как и остальные и если их нет в выбранном шрифте, они не возникнут из воздуха. Поэтому не удивляйтесь, если вместо отсутствия пикселей вы увидите квадратик битого Юникода.
- И запомните — всегда убирайте блок с пробелами на место. Хотя нет, мы уже можем не парится над такими вещами.
 Имеет смысл оставлять комментарий или другое напоминание о том, для чего оставлен конкретный вид пробела.
Имеет смысл оставлять комментарий или другое напоминание о том, для чего оставлен конкретный вид пробела.Блок с 12-пунктным пробелом из Центра книги в Сан-франциско. Да, изменение размера шрифта, требует замены блока пробела. (увеличенная версия)
Тайны Юникода
Юникод полон других занятностей и странностей. Есть среди них и другие
Есть среди них и другие разновидности пробелов, включая “не объединяющий нулевой пробел”. Есть мягкий дефис, в котором дефис виден только при необходимости. Цифры верхнего индекса и зачеркнутые символы, которые могут быть использованы даже на тех платформах, которые не поддерживают такие фичи. Комбинирующие символы, использующие другие символы неоднократно, снова и снова. Просто взгляните. Оцените. Вникните.
Я действительно считаю, что стоит написать хороший гайд по Юникоду. Но это уже совершенно другая история.
Дефисы и тиреРасстановка дефисов в обезличенных местоимениях и междометиях (напр.: кто то → Dash.to_libo_nibud Расстановка дефисов между из-за, из-под. Расстановка дефисов перед -ка, -де, -кась. Тире заменять на длинное тире и привязывать его к предыдущему слову. Выделение прямой речи. Тире в конце строки (стихотворная форма):
Пунктуация и знаки препинанияРасстановка запятых перед а, но. Замена трех точек на знак многоточия. Замена сдвоенных знаков препинания на одинарные. Замена восклицательного и вопросительного знаков местами. Ставить в конце предложения !? не совсем верно, мы заменим на ?!. Многоточие для обозначения незаконченности высказывания с сохранением вопросительного и восклицательного знаков. Добавление точки в конце последнего предложения (по умолчанию выключено). Расстановка апострофа в английских и русских словах. Удаление повторяющихся знаков препинания (восклицательные и вопросительные обрезаются до трех, море точек — до многоточия). Расстановка точек в сокращениях «и т. Пробелы и табуляцииУдаление лишних пробельных символов и табуляций. Удаление лишних пробелов между дефисом в местоимениях и наречиях (напр.: кто- то, заменится на кто-то). Удаление пробелов перед и после знаков препинания. Расстановка пробела после знаков препинания. Расстановка пробела в словах после двоеточия. Удаление пробела перед символом процента. Удаление пробелов после открывающейся скобки и его расстановка перед и после блока скобок. Неразрывный пробел после «как то:» в случае перечисления. Текст и абзацыУдаление повторяющихся слов (по умолчанию выключено). Обрамление в <p></p> каждого абзаца. Проставлять <br /> для новой строки. Выделение ссылок из текста. Выделение эл. почты из текста. Специальные символыЗамена (r) на символ зарегистрированной торговой марки ®. Замена (c) на символ копирайта ©. Замена (tm) на символ торговой марки ™. Замена стрелок на символы ← и →. Расстановка дюйма после числа:
Сокращения и аббревиатурыФорматирование денежных сокращений (расстановка пробелов и привязка названия валюты к числу). Объединение сокращений: и т. д., и т. п., в т. ч. Расстановка пробелов перед сокращениями: см., им. Расстановка пробелов перед сокращениями: гл., стр., рис., илл., ст., п. Объединение сокращений и др. Расстановка пробелов в сокращениях: г., ул., пер., д. Расстановка пробелов перед сокращениями dpi и lpi. Объединение сокращений P. S. и P. P. S. Привязка аббревиатур форм собственности к названиям организаций. Привязка аббревиатуры ГОСТ к номеру. Установка пробельных символов в сокращении вольт. Привязка сокращений: до н. э., н. э. Замена символов и привязка сокращений в размерных величинах: м, см, м2, …. | КавычкиДля расстановки кавычек мы написали несколько функций. Это позволяет максимально точно определить где именно должна закрываться кавычка, а также не запутаться между знаком дюйма и очередной кавычкой.
Мы считаем, что двухуровневые кавычки делают текст красивее. Ничего настраивать не надо. Мильчин А. Э. Оптическое выравниваниеНекоторые еще это называют висящей пунктуацией, когда открывающаяся скобка, кавычка-ёлочка и запятая выходят за вертикальную линию основного текста.
Свешивать открывающуюся кавычку-ёлочку. Свешивать запятую и левую скобку. Использовать inline-стилиto_libo_nibud:
Использовать классыto_libo_nibud:
Неразрывные конструкцииПривязка союзов и предлогов к написанным после словам. Объединение в неразрывные конструкции слов с дефисом (по умолчанию выключено). Объединение в неразрывные конструкции номера телефонов. Объединение IP-адресов. Привязка инициалов к фамилиям. Объединение пятисимвольных слов разделенных дефисом (по умолчанию выключено). Привязка союзов и предлогов к предыдущим словам в случае конца предложения. Использовать nobr (по умолчанию) для неразрывных конструкций Использовать nowrap для неразрывных конструкций. Числа, дроби и математические знакиЗамена x на символ x в размерных единицах. Замена дробей 1/2, 1/4, 3/4 на соответствующие символы (по умолчанию выключено). Привязка символа параграфа к после идущему числу и слову. Замена символа номер с привязкой к после идущему числу. Объединение триад чисел полупробелом. Замена символа градус, плюс-минус. Даты и дниУстановка длинного тире и пробельных символов в периодах дат. Привязка даты к году. Расстановка тире и объединение периодов дней (по умолчанию выключено). Расстановка тире и объединение периодов месяцев (по умолчанию выключено). ВыдачаHTML-мнемоника (кодом). Unicode (символами). ПрочееДля неразрывных конструкций использовать nobr (по умолчанию). Для неразрывных конструкций использовать nowrap. Удаление nbsp в nobr/nowrap тега. Безопасный блок в тегах <notg></notg> (полностью отключает работу типографа). Игнорирование явного HTML-кода в: script, style, pre. Повторное типографирование текста. | ЗнанияПравила русского языка про «Кавычки». Книга «Справочник издателя и автора» Аркадия Мильчина и Людмилы Чельцовой. Третье издание, исправленное и дополненное. Эдиториум.ру, «О редактировании и редакторах». |


 Например:
Например: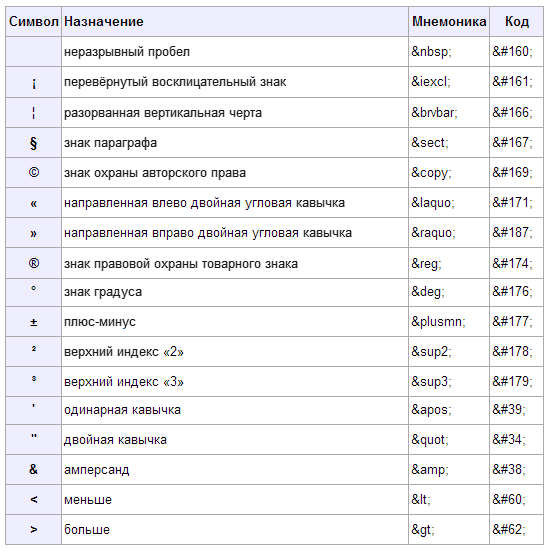
Skirtle’s Den
Автор: skirtle Впервые опубликовано: 28 мая 2020 г. Последнее обновление: 28 мая 2020 г.
Кодирование JavaScript JSON с экранированием Unicode
Как написать неразрывный пробел в JavaScript или JSON?
Потеряйте 10 очков, если вы сказали & nbsp; .
Проблема
Представим, что мы работаем на языке шаблонов HTML и у нас есть шаблон, который выглядит примерно так:
В настоящее время для текста установлено значение «Сохранить изменения» , но он продолжает переноситься в пространство,
нравится:
Сохранить  «/>
изменения
«/>
изменения
Эту проблему следует решать с помощью CSS, но для обсуждения попробуем заменить пробел в тексте с неразрывным пробелом.
У вас может возникнуть соблазн попробовать что-то вроде этого:
text = 'Сохранить & nbsp; изменения'
Предполагая, что шаблон обрабатывает экранирование правильно, мы, скорее всего, получим что-то вроде этого:
Сохранить изменения
О, Боже. Модель & nbsp; не превращается в неразрывное пространство, мы просто
выводить его буквально как текст.
На этом этапе вы можете использовать любой механизм, который язык шаблонов предоставляет для вставки содержимого HTML. вместо.Взяв в качестве примера Vue.js, вы можете сделать что-то вроде этого:
Если шаблон является частью стороннего компонента, то изменить его таким образом будет непрактично, но даже если вы
может изменить это, это все еще совершенно неправильный способ вставки неразрывного пробела.
Чтобы было ясно, нет ничего плохого в использовании & nbsp; в HTML. Если & nbsp; появился прямо в шаблоне, все было бы хорошо.Это не то, что у нас здесь.
Это строка JavaScript, представляющая обычный текст, и в ней не должно быть HTML.
Понимание & nbsp;
Последовательность & nbsp; — это не какое-то волшебное заклинание для вставки неразрывного
Космос. Это просто объект HTML, эквивалентный & # 160; или & # xa0; . Это все способы сообщить парсеру HTML, что вам нужен символ Unicode.
160, обычно записывается в виде U + 00A0.
Важно отметить, что это HTML-синтаксический анализатор, который интерпретирует сущность. Пока он не достигнет этого парсера, у нас нет неразрывный пробел, у нас есть 6 отдельных символов &, n, b, s, p и;.
Мы можем убедиться в этом, проверив длину строки в JavaScript:
'& nbsp;'. length // => 6
Нет необходимости представлять это таким образом.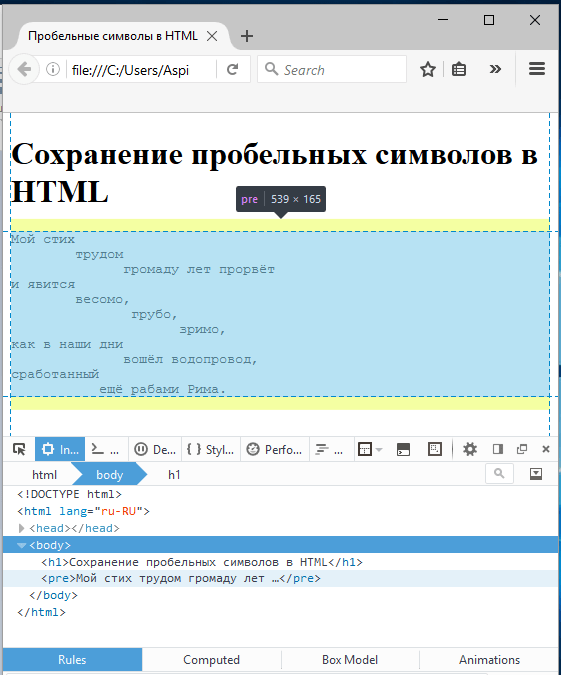 Строка JavaScript может содержать неразрывный пробел как одиночный
персонаж. Однако попытка включить этот символ непосредственно в исходный код создает 3 проблемы:
Строка JavaScript может содержать неразрывный пробел как одиночный
персонаж. Однако попытка включить этот символ непосредственно в исходный код создает 3 проблемы:
- Как набрать символ, которого нет на стандартной клавиатуре?
- Как любой, кто поддерживает код, сможет визуально отличить неразрывное пространство от нормального? Космос?
- Файлы содержат байты, а не символы, а неразрывный пробел находится за пределами диапазона ASCII.Собирались необходимо использовать определенную кодировку символов (например, UTF-8), а затем надеяться, что мы сможем убедить все соответствующие инструменты для использования этой кодировки.
На практике мы можем избежать всего этого, написав вместо этого с помощью escape-последовательности:
'\ u00a0'.length // => 1
Несмотря на то, что escape-последовательность включает 6 символов, результирующая строка содержит только один неразрывный
пробел. Важно понимать, что экранирование, используемое здесь, является частью синтаксиса строкового литерала.
для создания строки и фактически не является функцией результирующей строки.Это парсер JavaScript, который
оценивает эту escape-последовательность, и не имеет значения, проходит ли она впоследствии анализатор HTML.
Важно понимать, что экранирование, используемое здесь, является частью синтаксиса строкового литерала.
для создания строки и фактически не является функцией результирующей строки.Это парсер JavaScript, который
оценивает эту escape-последовательность, и не имеет значения, проходит ли она впоследствии анализатор HTML.
Чтобы усилить этот момент, мы можем использовать ту же технику для создания строк, содержащих другие, менее экзотические
символы. Рассмотрим заглавную букву A. Это символ Юникода U + 0041. Очевидно
обычно вы пишете это как 'A' , но это также можно записать как '\ u0041' . Полученные строки идентичны.
Если мы используем text = 'Save \ u00a0changes' в нашем предыдущем примере, тогда все будет работать нормально.
Неважно, применяет ли язык шаблонов кодировку HTML к тексту или нет, в любом случае мы закончим
с использованием правильного символа.
В JavaScript есть символьные строки, что позволяет мне игнорировать проблемы, связанные с байтовыми строками. я
также пишет по-английски, что позволяет мне игнорировать i18n и делать вид, что манипуляции со строками — это не кошмар.
я
также пишет по-английски, что позволяет мне игнорировать i18n и делать вид, что манипуляции со строками — это не кошмар.
Кроме того, поскольку мы используем фактический символ, все, что встречается с этой строкой, сможет это тоже правильно понимаю. Например:
- Проверка длины даст правильную длину.
- При поиске и фильтрации не нужно беспокоиться о сопоставлении сущностей HTML.
- Хотя во время усечения сущность HTML может быть разделена на две части, этого не может произойти с использованием фактического символа.
Пример в Vue
Предположим, мы хотим написать функцию форматирования, которая автоматически меняет нормальные пробелы на неразрывные. пробелы.Во Vue мы могли бы включить его в шаблон следующим образом:
Другие языки шаблонов обычно имеют эквивалентный синтаксис.
Как и следовало ожидать, попытка реализовать spaceToNbsp таким образом не сработает:
spaceToNbsp (str) {
return str. replace (/ / g, '& nbsp;')
}
 replace (/ / g, '& nbsp;')
}
replace (/ / g, '& nbsp;')
}
Как и в предыдущем примере, в итоге получится & nbsp; трактуется буквально.
Чтобы он заработал, это должно быть так:
spaceToNbsp (str) {
вернуть str.replace (/ / g, '\ u00a0')
}
Другие символы
Неразрывные пробелы — не единственные символы, которые излишне кодируются как объекты HTML. Если вы работаете с Строки JavaScript, и вы обнаружите соблазн включить любой объект HTML, который вам следует рассмотреть, используя фактический персонаж вместо этого. Например, с диакритическими знаками, такими как é:
text = 'caf & eacute;'
В зависимости от раскладки клавиатуры может быть сложно ввести é напрямую и, как и прежде, сохранить
все как ASCII может помочь избежать проблем с кодировкой символов.Но & eacute; У все те же проблемы, что и у & nbsp; . В этом случае
это символ Юникода U + 00E9, поэтому мы можем записать его как:
text = 'caf \ u00e9'
Конечно, именованный объект легче понять, но это спорный вопрос, потому что он создает неправильную строку.
JSON
То же самое относится и к JSON. Мое сердце всегда замирает, когда я вижу такие данные JSON:
[
{
"name": "Th & eacute; r & egrave; se"
},
...
]
Почему в данных скрываются объекты HTML? Скорее всего, это связано с проблемой кодировки символов. это было отправлено на рассмотрение с использованием сущностей HTML, а не исправлено должным образом. Где-то что-то нужно установив UTF-8, но вместо этого мы получаем эту пародию.
Ладно, похоже, я все-таки не смог избежать погружения в пучину манипуляций со строками i18n.
Такие неправильно закодированные данные очень усложняют реализацию поиска на стороне клиента.Некоторые серьезные прыжки в обруч
потребуется, чтобы гарантировать, что поисковые запросы «вырезать» или «рейв» не совпадают и
поиски Терезы делают.
Searching
достаточно сложно, как и с
Эквивалентность Unicode,
учет регистра, акценты и языковые стандарты, которые следует учитывать без необходимости обрабатывать бессмысленные объекты HTML. JSON поддерживает
та же экранирующая нотация \ uXXXX, что и в JavaScript:
JSON поддерживает
та же экранирующая нотация \ uXXXX, что и в JavaScript:
[
{
"name": "Th \ u00e9r \ u00e8se"
},
...
]
На практике вы, вероятно, используете стандартную библиотеку JSON, и она может не поддерживать экранирование этих символов.Это не имеет значения. Ожидается, что JSON будет передан в UTF-8, поэтому вам просто нужно получить все свои потоки, каналы и каналы настроены правильно и все будет хорошо.
——
Внешние ссылки
Обратная связь
Отправьте отзыв по электронной почте skirtle на Skirtle на сайте Skirtle.com
. Отзывы и конструктивная критика приветствуются, включая исправления мелких ошибок, таких как орфографические ошибки. Имена и адреса электронной почты тех, кто оставил отзыв, не будут опубликованы. без их разрешения.
Управляющий символ HTML & NPSP; указывает неразрывный пробел
1. Ссылка
Beautiful Soup and Unicode Problems
эксплицит
unicodedata.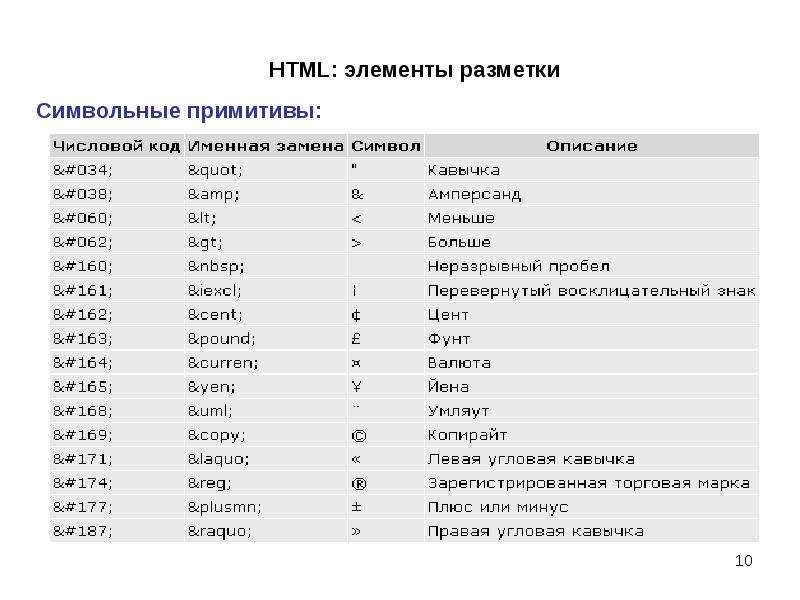 normalize (‘nfkd‘, string) фактическая функция ???
normalize (‘nfkd‘, string) фактическая функция ???
Scrapy: выберите тег с неразрывным пробелом с помощью xpath
>>> selector.xpath (u '' '
... // p [normalize-space ()]
... [не (содержит (normalize-space (), "\ u00a0"))] Нормализовать функцию space () ???
В [244]: сел.css (‘. content’)
Out [244]: [https://en.wikipedia.org/wiki/ Comparison_of_text_editors Элемент позиционирования отображается как & NPSP;
Исходный код веб-страницы представлен как & ා 160;
память = Ограничено доступной памятью Нет (64 КБ) = Некоторое ограничение меньше доступной памяти (укажите максимальный размер, если известен) Фактическая шестнадцатеричная передача:
Unicode-представление непрерывных пробелов —
u \ xa0 'При сохранении код UTF-8 —\ xc2 \ xa0‘В [211]: для tr в ответ.
…: print [u ”.join (i.xpath (‘.// text ()’). extract ()) для i в tr. xpath (‘./*’)]
…:[u’memory ’, u’ = Ограничено доступной памятью \ xa0 \ xa0 ′, u’No (64 \ xa0KB) ’, u’ = Некоторое ограничение меньше доступной памяти (укажите максимальный размер, если известен) ’]
In [212]: u’No (64 \ xa0KB) ’. Encode (‘ utf-8 ’)
Out [212]:‘ No (64 \ xc2 \ xa0KB) ’In [213]: u’No (64 \ xa0KB) ’. Encode (‘ utf-8 ’). Decode (‘ utf-8 ’)
Out [213]: u’No (64 \ xa0KB)’Если вы сохраните CSV и откроете его напрямую в Excel, будет искаженный код (ANSI GBK открыт по умолчанию) ??? , u ‘\ xa0’ выходит за пределы диапазона кодирования GBK. Использование Блокнота или Блокнота + + может автоматически открываться в UTF-8.
С помощью Блокнота откройте файл CSV, сохраните его как код ANSI, а затем откройте Excel в обычном режиме. Замените на «?», Если он выходит за пределы диапазона кодировки GBK
.3. Как с этим бороться
.extract_first (). Replace (u ’\ xa0 ′, u’ ‘) .strip (). Encode (‘ utf-8 ’,’ replace ’)
Это escape-символ HTML & NPSP; означает неразрывный пробел / xa0. Для получения дополнительной информации о escape-символах HTML, пожалуйста, обратите внимание на другие статьи в developeppaer!
 xpath (‘// table [8] / tr [2]’):
xpath (‘// table [8] / tr [2]’): 
Вспоминая неразрывную космическую сущность • TheOverAnalyzed
Неразрывная космическая сущность, ох как я забыл о тебе. Несколько дней назад, вдохновленный критикой дизайна моего сайта, я наконец исправил мой .content , который был слишком широким на iPhone с меньшим экраном, а также некоторые другие аспекты моего худшего макета для маленького экрана.
И, как и ожидалось, это привело меня в кроличью нору мастерить. Когда я просматривал сайт в режиме адаптивного дизайна Safari, мне напомнила одна из тех вещей, которые раздражали меня в течение многих месяцев, но я так и не нашел времени, чтобы исправить:
Это была та стрела.
Вы знаете, что символ стрелки → , который так часто обозначает связанный пост в блогах.
Время от времени я заходил на свой сайт и что-то проверял, но обнаруживал, что стрелка в заголовке связанного сообщения перенесена на новую строку сама по себе .
Тьфу.
Ужасно.
Я не был уверен, было ли это вызвано моим упущением, поэтому я проверил Marco.org, Liss is More и еще пару сайтов. Все они демонстрировали одинаковую склонность к наматыванию стрел.Я спросил каждого владельца сайта в Твиттере, и по крайней мере один из них не знал, как это исправить.
Я думал, что свойство CSS white-space от до nowrap , вот так:
белое пространство: nowrap
Хорошая идея, без сомнения, но это решило бы одну проблему, а создало бы другую. Стрелка → больше не будет оборачиваться, что может привести к выходу за пределы горизонтального контейнера. (Это даже хуже, чем моя проблема с переносом стрелок на строку сама по себе.)
(Это даже хуже, чем моя проблема с переносом стрелок на строку сама по себе.)
К счастью, я слежу за несколькими экспертами по CSS. И никто иной, как сам мистер CSS-Tricks — Крис Койер — нашел решение:
@ToniWonKanobi & nbsp; между стрелкой и последним словом
— Крис Койер (@chriscoyier) 5 октября 2015 г. Ааа. & nbsp; — объект HTML для «неразрывного пробела». Что именно? Это просто то, на что это похоже. Это пробел, за исключением обычных пробелов, которые HTML обрезает, & nbsp; символ не сломает .
Другими словами, если у вас есть строка текста, которая выглядела бы глупо сломанной, например, имена собственные, содержащие модификатор числа (например, Tweetbot 4 ), вы можете использовать & nbsp; , чтобы слово и число не попадали в отдельные строки.
Чтобы реализовать неразрывный пробел, я копался в файле ., который является шаблоном для моих сообщений ( html
html .postHeader.html ), и удалил буквальные пробелы и заменил их неразрывным пробелом, & nbsp; .
Итак,
{{Title}} & # 10142;
становится
{{Title}} & nbsp; & # 10142;
Вот и все.
Вот заголовок сообщения, в котором между заголовком и стрелкой (слева) есть обычный пробел, а в другом заголовке сообщения вместо него используется неразрывный пробел.Какой из них вам больше нравится? Да, я так и думал.
Вспомните, что Гэндальф сказал это Фродо:
Мой дорогой Фродо. Хоббиты действительно удивительные существа. Вы можете узнать все, что нужно знать об их путях, за месяц, и, тем не менее, через сто лет они все еще могут вас удивить.
HTML — мои «хоббиты» — просто когда я думаю, что у меня есть справка, что-то вроде неразрывного пробела всплывает и меня удивляет. Показывает то, что я знаю.
Показывает то, что я знаю.
Неразрывный промежуток и дополнительный разрыв без ширины
Пн
12
декабрь 2016
Перенос текста по границам слова вместо границ отдельных символов — отличное изобретение.Текст выглядит намного лучше при вставке в Word:
Чем при печати на старой консоли:
Но есть места, где мы не хотим, чтобы разрыв строки был возможен, несмотря на то, что мы вставляем пробел. Например, в Европе мы используем пробел в качестве разделителя тысяч (и запятую в качестве десятичного знака) при записи чисел.
В таких случаях очень помогает специальный символ, называемый «неразрывным пробелом». Вы можете вставить его в Word, щелкнув: «Вставить»> «Символ»> «Дополнительные символы»> «Специальные символы»> «Неразрывный пробел».Этот символ выглядит как пробел, но не вызывает разрыв строки.
Вы действительно можете увидеть этот «невидимый» символ, когда нажмете Ctrl + *. Это похоже на маленький кружок или знак градуса.
Это похоже на маленький кружок или знак градуса.
В HTML вы можете указать неразрывный пробел как: & nbsp; .
Совсем недавно я обнаружил, что существует также противоположный специальный символ, называемый «необязательный разрыв без ширины» или «пробел нулевой ширины». Это полезно в случаях, когда у вас есть длинная последовательность символов (например, путь к файлу) и вы хотите, чтобы она была разбита на строки, несмотря на то, что она не содержит пробелов.Это особенно важно при использовании выравнивания текста, потому что такой длинный текст, перемещенный на отдельную строку целиком, может вызвать неприятный эффект:
Вы можете вставить этот специальный символ в Word (например, после каждого обратного пробела в пути), щелкнув: Вставить> Символы> Дополнительные символы> Специальные символы> Необязательный разрыв без ширины. Он не занимает места, но сообщает текстовому процессору, что в этом месте строку можно разорвать. Теперь это выглядит намного лучше:
Когда вы нажимаете Ctrl + *, вы можете увидеть этот специальный символ в виде прямоугольника.
В HTML вы также можете использовать его, набрав: & # 8203; . Это символ Unicode «Пробел нулевой ширины».
Комментарии | #html Делиться
Пожалуйста, включите JavaScript, чтобы просматривать комментарии от Disqus.Пустое пространство HTML — Как создать и использовать код неразрывного пространства
& nbsp; & nbsp; & nbsp;
Нет, Белла больше не начала печатать на клавиатуре.
& nbsp; — это HTML-код : для — пробел или — неразрывный пробел .
Вы полностью запутались? Позвольте мне начать с самого начала.
HTML — это аббревиатура от Hypertext Markup Language , который представляет собой стандартизированную систему тегирования текстовых файлов для создания определенного шрифта, цвета, графики и создания эффектов гиперссылок на страницах World Wide Web.
Иногда при кодировании страницы необходимо поставить пустое место, чтобы все было правильно выстроено.Вот где & nbsp; становится очень удобным, потому что & nbsp; — это HTML-код, представляющий пустое пространство .
Вот как мог бы выглядеть код, если бы он использовался как двойной отступ перед абзацем:
& NBSP; & NBSP; Пункт приговор приговор приговор приговор приговор приговор приговор приговор приговор приговор приговор.
Вот как это будет выглядеть читателю сайта:
Пункт приговор приговор приговор приговор приговор приговор приговор приговор приговор приговор приговор.
Вы можете сказать, что перед словом «Абзац» есть пробел? Если нет, то это подтверждает мою точку зрения о том, почему не рекомендуется использовать пустой код & nbsp; как средство для отступа абзаца. Некоторые браузеры сжимают HTML-коды & nbsp; вместе, что разрушает всю цель их использования!
Я обнаружил, что одним из лучших способов использования неразрывного пробела является предотвращение разделения слов. Например, если я набираю «6 футов» или «1 милю», я определенно не хочу, чтобы «6» и «фут» или «1» и «ми» разделялись в разных строках абзаца. Если «6 футов» попадает в конец предложения, я не хочу, чтобы «футы» переходили на следующую строку. Чтобы этого не происходило, я набирал «6 футов», и он отображался для читателя как «6 футов», не отделяя символы друг от друга на двух разных строках, даже если он попадает в конец предложения.
Например, если я набираю «6 футов» или «1 милю», я определенно не хочу, чтобы «6» и «фут» или «1» и «ми» разделялись в разных строках абзаца. Если «6 футов» попадает в конец предложения, я не хочу, чтобы «футы» переходили на следующую строку. Чтобы этого не происходило, я набирал «6 футов», и он отображался для читателя как «6 футов», не отделяя символы друг от друга на двух разных строках, даже если он попадает в конец предложения.
Лично я считаю, что при использовании & nbsp; , чтобы хранить важные слова вместе как лучшее использование кода HTML.
Теперь вы знаете, что & nbsp; — это HTML-код для неразрывного пробела . Когда вы меньше всего этого ожидаете, вы, вероятно, найдете применение коду, и я уверен, что он всплывет в разговоре довольно случайно.
Например, когда вы сидите со своими друзьями, не ведущими блог, за обычным обедом, я не думаю, что вы скажете: «Я так взволнован, что узнал, что« & nbsp; »- это HTML-код для неразрывного пробела , и он поможет мне больше никогда не разделять слова в конце предложения!» Но когда вы сидите перед монитором компьютера и печатаете как злодей, однажды у вас будет пара слов, которые вы захотите скрепить. Тогда лампочка погаснет, и вы вспомните, что & nbsp; — это HTML-код для неразрывного пробела .
Тогда лампочка погаснет, и вы вспомните, что & nbsp; — это HTML-код для неразрывного пробела .
Я знаю … это был совершенно захватывающий пост! Честно говоря, & nbsp; — это один из первых HTML-кодов, которые я изучил, и я действительно очень взволнован, говоря об этом.
= whooooop =
= whooooop =
= whooooop =
Это было ваше предупреждение для ботаников.
Неразрывный пробел — графически
Лесные участки бывают разных видов.Пример графика леса с использованием GTL доступен на веб-сайте поддержки SAS. Простые графики леса также можно создать с помощью процедуры SGPLOT, используя оператор SCATTER с MARKERCHAR для отображения данных, выровненных с графиком по названиям исследований.
Одна из возникших проблем — необходимость отображать исследования по подгруппам. В этом случае значения исследований сгруппированы по категориям, а названия исследований имеют отступ, чтобы показать группировку, как показано в данных ниже.
Названия исследований для возрастных групп имеют отступ с использованием ведущих пробелов для обозначения группировки.Вот график этого с использованием процедуры SGPLOT. Нажмите на график, чтобы увидеть увеличенную версию.
Код SGPLOT:
proc sgplot data = forest noautolegend;
refline 1.0 / axis = x;
разброс y = подгруппа x = среднее / xerrorlower = низкое xerrorupper = высокое
markerattrs = (символ = закрашенный кружком);
разброс y = подгруппа x = pci_lbl / markerchar = pcigroup x2axis;
разброс y = подгруппа x = grp_lbl / markerchar = группа x2axis;
xaxis display = (nolabel noticks) offsetmin = 0.5 значений = (от 0 до 2 по 0,5)
valueattrs = (размер = 6);
x2axis display = (nolabel noticks) offsetmax = 0,7 valueattrs = (size = 6);
yaxis reverse display = (noticks nolabel) valueattrs = (size = 6);
запустить; |
На графике выше мы использовали переменную подгруппы в качестве роли оси Y.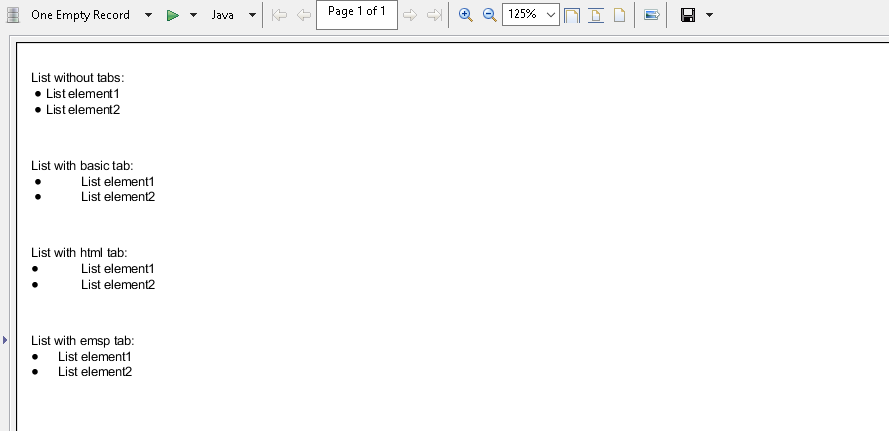 Как мы видим, на графике удаляются начальные и конечные пробелы для значений деления оси Y, а отступы теряются.
Как мы видим, на графике удаляются начальные и конечные пробелы для значений деления оси Y, а отступы теряются.
Вместо того, чтобы использовать ось Y для названий исследований, мы можем использовать опцию MarkerChar точечной диаграммы для отображения подгрупп, как мы это делаем для значений.Однако и здесь начальные и конечные пробелы удаляются, а оставшийся текст выравнивается по центру, поэтому отступы снова теряются.
Неразрывное пространство спешит на помощь. Известный в мире html как nbsp (xA0), неразрывный пробел похож на обычный пробел (пробел), за исключением того, что предложение не прерывается в таком месте на странице html. Для нас это означает, что начальные и конечные пробелы nbsp не удаляются, тем самым сохраняя отступ в исходном тексте.Кроме того, чтобы правильно выровнять текст, нам нужно будет использовать шрифт фиксированной ширины или непропорциональный шрифт для отображения этого текста.
Вот те же данные с использованием nbsp для пробелов в переменной Subgroup. Обратите внимание, что nbsp используются как для начальных, так и для конечных пробелов и сохраняются при выводе на печать процедуры.
Обратите внимание, что nbsp используются как для начальных, так и для конечных пробелов и сохраняются при выводе на печать процедуры.
Вот график с использованием процедуры SGPLOT:
Код SGPLOT:
proc sgplot data = forest_nbsp noautolegend;
refline idref / axis = y lineattrs = (толщина = 9 цвет = cxf0f0f0);
ссылка 1.0 / ось = х;
разброс y = id x = среднее / xerrorlower = низкий xerrorupper = высокий
markerattrs = (символ = закрашенный кружком);
разброс y = id x = sub_lbl / markerchar = подгруппа x2axis
markercharattrs = (семейство = & font weight = жирный);
разброс y = id x = pci_lbl / markerchar = pcigroup x2axis;
разброс y = id x = grp_lbl / markerchar = group x2axis;
xaxis display = (nolabel noticks) offsetmin = 0,6 значения = (от 0 до 2 на 0,5)
valueattrs = (размер = 7);
x2axis display = (nolabel noticks) offsetmax = 0,5 valueattrs = (size = 7);
yaxis reverse display = нет;
запустить; |
На графике выше мы использовали следующие функции:
- Переменная Subgroup содержит текст с nbsp для начальных и конечных пробелов.
- Символ «xA0» был скопирован из инструмента «Карта символов Windows».
- Параметр MarkerChar на точечной диаграмме используется для рисования значений подгруппы.
- Установлен шрифт с фиксированной шириной шрифта.
- Ось Y подавлена.
- Чередующиеся серые полосы используются для облегчения просмотра данных.

При использовании SGPLOT для создания этого графика все значения, отображаемые с помощью параметра MarkerChar, находятся с одной стороны, а график — с другой.Но этот пример предназначен для иллюстрации использования nbsp. Для диаграммы с лучшим форматированием вы также можете использовать GTL, как показано ниже.
Я работаю над этим примером для CTSPedia с использованием SAS 9.2 (TS2M3). После доработки я отправлю код.
Полный код SAS: NBSP_Code
Неразрывной пробел нулевой ширины | Newbedev
Непрерывный пробел очень похож на Word-Joiner, так же как он очень похож на пробел. Но у каждого из них очень разное использование. Все эти варианты существуют для обозначения разной ширины и функций символа пробела.
Но у каждого из них очень разное использование. Все эти варианты существуют для обозначения разной ширины и функций символа пробела.
- U + 00A0 Беспрерывное пространство
& nbsp;представлен аналогично пробелу, он предотвращает автоматический разрыв строки. - U + 2007 Фигурное пространство
& # 8199;пробел, несколько равный цифрам (0–9) знаков. - U + 202F Узкое непрерывное пространство
& # 8239;или& nnbsp;) используется для отделения суффикса от основы слова без указания границы слова.Примерно 1/3 репрезентативного пространства обычного пространства, хотя оно может варьироваться в зависимости от шрифта. - U + 2060 Word-Joiner
& # 8288;не имеет видимого символа, он запрещает разрыв строки в его позиции.
Прочие непревзойденные персонажи
- НЕПРЕРЫВНЫЙ ДЕФИС (U + 2011)
- ФИГУРКА ПРОСТРАНСТВО (U + 2007)
- УЗКОЕ ПРОСТРАНСТВО БЕЗ РАЗРЫВА (U + 202F)
- РАЗДЕЛИТЕЛЬ ТИБЕТСКОЙ МАРКИ TSHEG BSTAR (U + 0F0C)
W3C рекомендует использовать Word-Joiner всякий раз, когда вам нужно соединить два символа или слова, чтобы они не переносились. [1]
[1]
Чтобы получить ту же функциональность, которая ранее предоставлялась через NON-BAKING SPACE с ZERO-WIDTH NON-BAKING SPACE, авторы должны использовать WORD JOINER (U + 2060) вместо
Однако нигде в справочнике символов HTML4 не упоминается Word-Joiner . [2]
В дополнение к этим символам, МЯГКИЙ ДЕФИС (U + 00AD) может использоваться для предоставления подсказок о переносе строки в словах, которые UA могут не иметь в их собственных словарях расстановки переносов.
Единственные символы, которые явно не рекомендуются: ZERO WIDTH NON-JOINER (U + 200C) : предотвращает лигирование и скорописные соединения между символами, которые в противном случае были бы лигированы или соединены курсивом.
- СОЕДИНИТЕЛЬ НУЛЕВОЙ ШИРИНЫ (U + 200D) : поощряет лигирование и скорописные соединения.

Артикул:
- W3C Wiki: Использование символов HTML
- Ссылки на символьные сущности в HTML 4
Далее:
- Юникод.org Исправление значения свойства Word_Break для U + 00A0 NBSP
- Unicode v.3.2.0 Свойства разрыва строки
- Unicode? Предлагается? Разрыв линии
- Полные стандарты Unicode v7
- Юникод, объясненный Юккой Корпела
В HTML нет ссылки на сущность ZWNBSP (неразрывного пробела нулевой ширины), но она, как и любой символ Unicode, может быть выражена с помощью ссылки на символ: & # xfeff; (или, что то же самое, & # 65279; ).Однако это неэффективно для хранения изображений в одной строке. Изображения не являются символами, и браузеры не обязаны реализовывать семантику Unicode для ZWNBSP, даже если они используются между символами. То же самое относится к WORD JOINER, U + 2060.
Самый эффективный способ — обернуть теги img в элемент nobr : . Хотя этот метод не является частью какой-либо спецификации HTML и упоминается в черновиках HTML5 как «устаревший», он работает во всех браузерах.Если вы предпочитаете делать что-то более неуклюжим, что не работает при отключенном CSS, вы можете использовать элемент искусственной оболочки и установить на нем 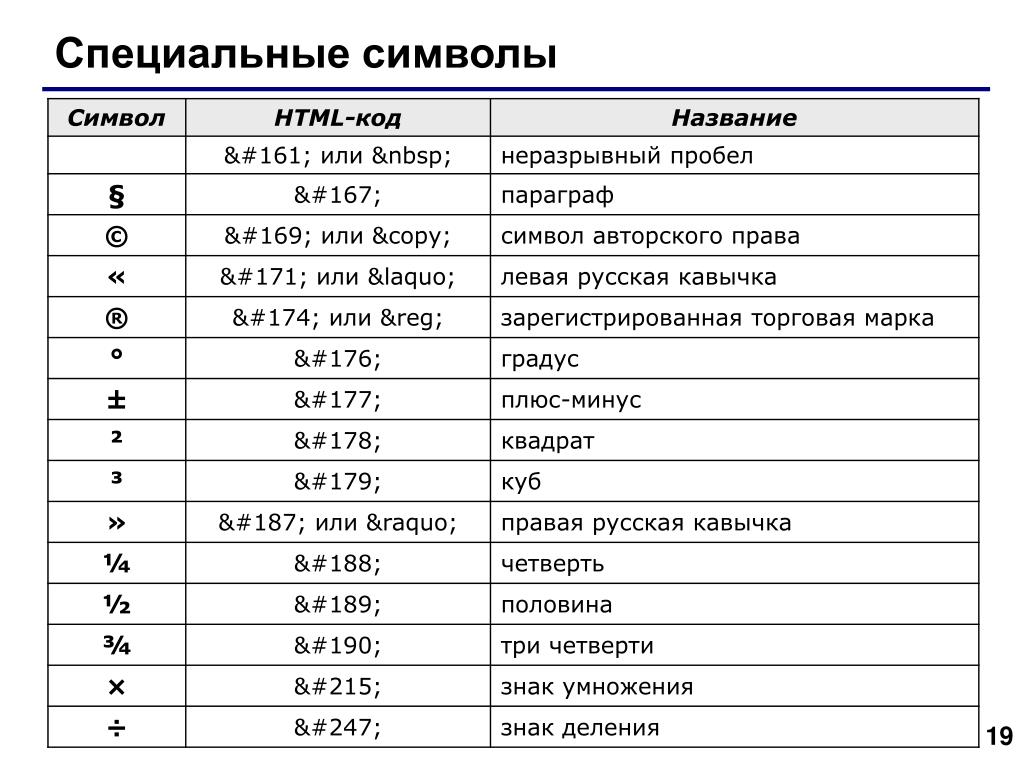 ..>
..>
white-space: nowrap .
Попробуйте обернуть изображения в диапазон со свойством css white-space: nowrap; :
![]()
![]()
.