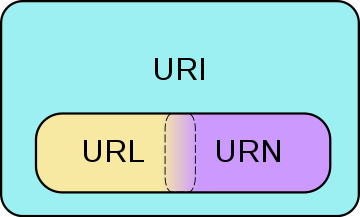
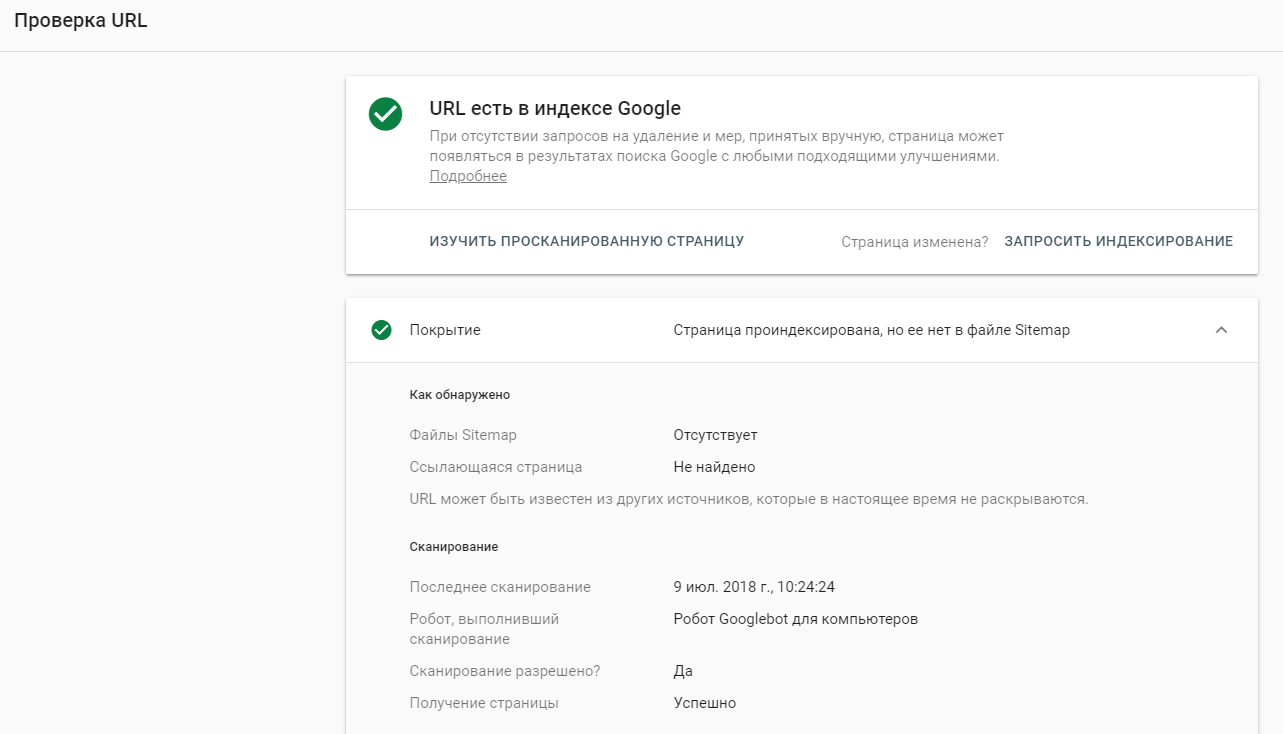
URI, URL, URN. Что это, чем отличаются
Сегодня обсудим еще три определения – это URI, URL, URN, что каждое из них обозначает и чем они отличаются друг от друга.
Давайте вспомним, в одном из прошлых уроков мы узнали, что на сервере могут храниться различные ресурсы. Это могут быть статичные файлы в файловой системе, также это может быть динамически создаваемый контент, который потом отдается клиенту. Сейчас важно понять, что на сервере в сети Интернет хранятся разнородные данные, и каждый элемент этих данных можно назвать отдельным ресурсом, будь то изображение PNG, либо данные курсов валют.
Ресурсы на сервере
URI
Итак, давайте начнем с первого термина URI и дадим ему такое определение:
URI (Uniform Resource Identifier) – это строка символов, которая используется для идентификации какого-либо ресурса по его адресу или по его имени, либо по тому и тому вместе.
Чтобы стало понятнее проведем аналогию с реальным миром на примере какого-нибудь человека.
URI
Возвращаясь обратно к терминологии, вместо человека выступает какой-нибудь ресурс на сервере, и при помощи URI мы можем идентифицировать ресурс на сервере по его адресу или по его названию, либо по тому и тому вместе.
URL
Следующий термин – это URL. Дадим такое определение:
URL (Uniform Resource Locator) – это строка символов, которая используется для идентификации какого-либо ресурса, но только по его адресу, по его местоположению.
URL
В примере с человеком это выглядит примерно так. К слову сказать, в вебе, в сети Интернет именно URL чаще всего используется для обнаружения ресурсов на сервере. Наверняка вы не раз встречали эту аббревиатуру.
URN
И последний термин – это URN. Дадим такое определение:
Дадим такое определение:
URN (Uniform Resource Name) – это строка символов, которая используется для идентификации какого-либо ресурса, но только по его имени.
URN
В нашем примере это выглядит так. Мы знаем этого человека, знаем, что его зовут Боб. Но мы не знаем, где он живет. Нам придется искать его только по имени.
Важно запомнить такой момент. Все эти три термина находятся в такой условной зависимости (или иерархии), как на картинке ниже. Потому что URI может использовать и адрес, и имя при идентификации ресурса. В то время как URL и URN только адрес и только имя соответственно.
Каждый URL является URI. Каждый URN является URI. Но не каждый URI, к примеру, является URL (он может быть URN).
Теперь давайте более подробно разберем каждое из этих понятий.
URL чаще всего используется в Интернете для поиска ресурсов на сервере. URL буквально точно показывает нам, как определить ресурс, именно по его адресу. Если ввести подобный URL в строке поиска браузера, то будет осуществлен поиск соответствующего ресурса.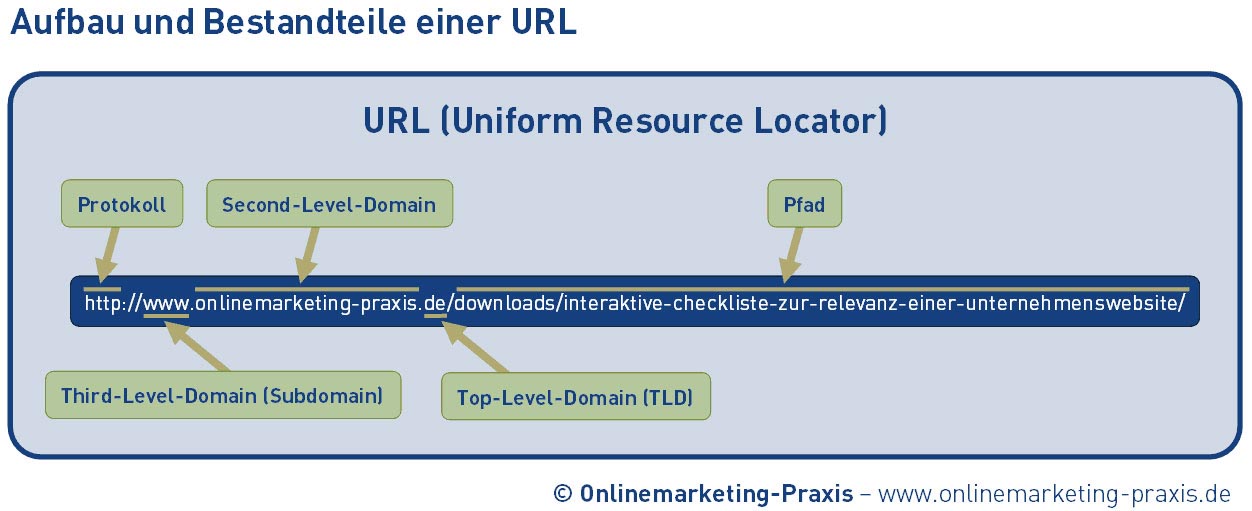
Любой URL состоит из нескольких компонентов. Протокол и хост являются обязательными, все остальные — нет.
Любой URL состоит из нескольких компонентов. Протокол и хост являются обязательными, все остальные — нет.
Подопытный URL выше можно прочитать как: используя протокол https обратиться к домену www.mysite.com по стандартному порту 80, в каталоге найти товар желтого цвета с идентификатором 15, в браузере пользователя сразу же переместиться в область где указана цена.
URN служит для обозначения уникального имени ресурса, неважно, где этот ресурс располагается в данный момент времени или вообще. Такая природа URN (независимость от адреса) позволяет ресурсам перемещаться с одного места на другое. URN позволяет получить доступ к ресурсу по различным сетевым протоколам, обращаясь к одному и тому же имени.
. URN позволяет получить доступ к ресурсу по различным сетевым протоколам, обращаясь к одному и тому же имени
На текущий день URN все еще считается экспериментальным и не так сильно распространен, как URL, так как для полной поддержки URN требуется поддерживающая его развитая сетевая инфраструктура.
Выводы
Подводя итог можно сказать, что если мы говорим про сеть Интернет, то чаще всего используем термин URL, так как находим определенный ресурс в сети именно по его адресу на каком-то сервере. Также часто можно встретить аббревиатуру URI, подразумевающую именно URL. Хотя по факту это не совсем так, потому что URL является часть URI. В то же время в контексте веба URN практически не используется.
путь, фрагмент, запрос и авторизация / Хабр
URL’ы не должны были стать тем, чем стали: мудрёным способом идентифицировать сайт в интернете для пользователя. К сожалению, мы не смогли стандартизировать URN, который мог бы стать более полезной системой наименования. Считать, что современная система URL достаточно хороша — это как боготворить командную строку DOS и говорить, что все люди просто должны научиться пользоваться командной строкой. Оконные интерфейсы были придуманы, чтобы пользоваться компьютерами стало проще, и чтобы сделать их популярнее.Такие же мысли должны привести нас к более хорошему методу определения сайтов в Вебе. — Дейл Догэрти,
1996
Есть несколько вариантов определения слова «интернет». Один из них — это система компьютеров, соединенных через компьютерную сеть. Такая версия интернета появилась в 1969 году с созданием ARPANET. Почта, файлы и чат работали в этой сети еще до создания HTTP, HTML и веб-браузера.
В 1992 году Тим Бернерс-Ли создал три штуки, благодаря которым родилось то, что мы считаем интернетом: протокол HTTP, HTML и URL. Его целью было воплотить понятие гипертекста в реальности. Гипертекст, в двух словах — это возможность создавать документы, которые ссылаются друг на друга. В те годы идея гипертекста считалась панацеей из научной фантастики, заодно с гипермедиа, и любыми другими словами с приставкой «гипер».
Ключевым требованием гипертекста была возможность ссылаться из одного документа на другой. В то время для хранения документов использовалась куча форматов, а доступ осуществлялся по протоколу вроде Gopher или FTP.
В начальной презентации World-Wide Web в марте 1992 Тим Бернерс-Ли описал его как «универсальный идентификатор документов» (Universal Document Identifier или UDI). Множество других форматов также рассматривались в качестве такого идентификатора:
protocol: aftp host: xxx.yyy.edu path: /pub/doc/README
PR=aftp; H=xx.yy.edu; PA=/pub/doc/README;
PR:aftp/xx.yy.edu/pub/doc/README
/aftp/xx.yy.edu/pub/doc/README)
Этот документ также объясняет, почему пробелы должны кодироваться в URL (%20):
В UDI избегают использование пробелов: пробелы — это запрещенные символы. Это сделано потому, что часто появляются лишние пробелы когда строки оборачиваются системами вроде mail, или из-за обычной необходимости выровнять ширину колонки, а так же из-за преобразования различных видов пробелов во время конвертации кодов символов и при передаче текста от приложения к приложению.

Важно понимать, что URL был просто сокращенным способом обратиться к комбинации схемы, домена, порта, учетных данных и пути, которые ранее нужно было определять из контекста для каждой из систем коммуникации.
scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
Эта позволило обращаться к разным системам из гипертекста, но сегодня, возможно, такая форма уже избыточна, так как практически все передается через HTTP. В 1996 браузеры уже добавляли http:// и www. за пользователей автоматически (что делает рекламу с этими кусками URL по-настоящему бессмысленной).
Я не считаю, что вопрос «могут ли люди понять значение URL» имеет смысл. Я просто думаю, что морально неприемлемо заставлять бабушку или дедушку вникать в то, что в конечном итоге является нормами файловой системы UNIX.— Исраэль дель Рио,
1996
Слэш, отделяющий путь в URL, знаком любому, кто использовал компьютер за последние пятьдесят лет. Сама иерархическая файловая система была представлена в системе MULTICS. Ее создатель в свою очередь ссылается на двухчасовую беседу с Альбертом Эйнштейном, которая состоялась в 1952 году.
Сама иерархическая файловая система была представлена в системе MULTICS. Ее создатель в свою очередь ссылается на двухчасовую беседу с Альбертом Эйнштейном, которая состоялась в 1952 году.
В MULTICS использовался символ «больше» (>) для разделения компонентов файлового пути. Например:
>usr>bin>local>awk
Это совершенно логично, но, к сожалению, ребята из Unix решили использовать > для обозначения перенаправления, а для разделения пути взяли слэш (/).
Неправильно. Теперь я четко вижу, что мы не согласны друг с другом. Вы и я.…
Как человек, я хочу сохранить за собой право использовать разные критерии для разных целей. Я хочу иметь возможность давать имена самим работам, и конкретным переводам и конкретным версиям. Я хочу более богатого мира чем тот, что вы предлагаете. Я не хочу ограничивать себя вашей двухуровневой системой «документов» и «вариантов».
— Тим Бернерс-Ли,
1993

Половины URL-адресов, на которые ссылается Верховный Суд США, уже не существует. Если вы читаете академическую работу в 2011 году, и написана она была в 2001 году, то с большой вероятностью любой URL там будет нерабочим.
В 1993 году многие страстно верили, что URL отомрет, и на замену ему придет URN. Uniform Resource Name — это постоянная ссылка на любой фрагмент, который, в отличие от URL, никогда не изменится и не сломается. Тим Бернерс-Ли описал его как «срочную необходимость» еще в 1991.
Простейший способ создать URN — это использовать криптографический хэш содержания страницы, например:urn:791f0de3cfffc6ec7a0aacda2b147839. Однако, этот метод не удовлетворяет критериям веб-сообщества, так как невозможно выяснить, кто и как будет конвертировать этот хэш обратно в реальный контент. Такой способ также не учитывает изменений формата, которые часто происходят в файле (например, сжатие файла), которые не влияют на содержание.
В 1996 Киф Шэйфер и несколько других специалистов предложили решение проблемы поломанных URL. Ссылка на это решение сейчас не работает. Рой Филдинг опубликовал предложение реализации в июле 1995 года. Ссылка тоже поломана.
Я смог найти эти страницы через Google, который по сути сделал заголовки страниц современным аналогом URN. Формат URN был окончательно оформлен в 1997 году, и практически не использовался с тех пор. У него интересная реализация. Каждый URN состоит из двух частей: authority, который может преобразовать определенный тип URN, и конкретный идентификатор документа в понятном для authority формате. Например, urn:isbn:0131103628 будет обозначать книгу, формируя постоянную ссылку, которая (надеюсь) будет конвертирована в набор URL’ов вашим локальным преобразователем isbn .
Учитывая мощность поисковых движков, возможно, что лучшим на сегодня форматом URN могла бы стать простая возможность файлов ссылаться на свой прошлый URL. Мы можем позволить поисковым движкам индексировать эту информацию, и ссылаться на наши страницы корректно:
Мы можем позволить поисковым движкам индексировать эту информацию, и ссылаться на наши страницы корректно:
<!-- On http://zack.is/history -->
<link rel="past-url" href="http://zackbloom.com/history.html">
<link rel="past-url" href="http://zack.is/history.html">Формат application/x-www-form-urlencoded — это аномальный монстр во многих отношениях, результат многих лет случайностей реализаций и компромиссов, которые привели к необходимому для интероперабельности набору требований. Но это точно не образец хорошей архитектуры.— WhatWG URL Spec
Если вы использовали веб какое-то время, то вам знакомы параметры запросов. Они находятся после пути и нужны для кодирования параметров вроде ?name=zack&state=mi. Может показаться странным, что запросы используют символ амперсанда (&), который в HTML используется для кодирования специальных символов. Если вы писали на HTML, то скорее всего столкнулись с необходимостью кодировать амперсанды в URL, превращая http://host/?x=1&y=2 в http://host/?x=1&y=2 или http://host?x=1&y=2 (конкретно эта путаница существовала всегда).
Возможно, вы также замечали, что куки (cookies) используют похожий, но все же иной формат: x=1;y=2, и он никак не конфликтует с символами HTML. W3C не забыл про эту идею и рекомендовал всем поддерживать как ;, так и & в параметрах запросов еще в 1995 году.
Изначально эта часть URL использовалась исключительно для поиска индексов. Веб изначально был создан (и его финансирование было основано на этом) как метод совместной работы физиков, занимающихся элементарными частицами. Это не означает, что Тим Бернерс-Ли не знал, что он создает систему коммуникации с по-настоящему широким применением. Он не добавлял поддержку таблиц несколько лет, не смотря на то, что таблицы, наверное, пригодились бы физикам.
Так или иначе, физикам нужен был способ кодирования и связывания информации, и способ поиска этой информации. Для этого Тим Бернерс-Ли создал тег <ISINDEX>. Если <ISINDEX> присутствовал на странице, то браузер знал, что по этой странице можно делать поиск. Браузер показывал поисковую строку и позволял пользователю делать запрос на сервер.
Браузер показывал поисковую строку и позволял пользователю делать запрос на сервер.
Запрос представлял собой набор ключевых слов, отделенных друг от друга плюсами (+):
http://cernvm/FIND/?sgml+cmsКак это обычно случается в интернете, тег стали использовать для всего подряд, в том числе как поле ввода числа для вычисления квадратного корня. Вскоре предложили принять тот факт, что такое поле слишком специфично, и нужен тег общего характера <input>.
В том предложении использовался символ плюса для отделения компонентов запроса, но в остальном все напоминает современный GET-запрос:
http://somehost.somewhere/some/path?x=xxxx+y=yyyy+z=zzzzДалеко не все одобрили это. Некоторые считали, что нужен способ указать поддержку поиска по ту сторону ссылки:
<a HREF="wais://quake.think.com/INFO" INDEX=1>search</a>
Тим Бернерс-Ли думал, что нужен способ определения строго типизированных запросов:
<ISINDEX TYPE="iana:/www/classes/query/personalinfo">
Изучая прошлое, готов с определенной долей уверенности сказать: я рад, что победило более общее решение.
Работа над тегом <INPUT> началась в январе 1993 года, она основывалась на более старом типе SGML. Было решено (пожалуй, к сожалению), что тегу <SELECT> нужна своя, более широкая структура:
<select name=FIELDNAME type=CHOICETYPE [value=VALUE] [help=HELPUDI]>
<choice>item 1
<choice>item 2
<choice>item 3
</select>Если вам любопытно, то да, была идея повторно использовать элемент <li> вместо создания нового <option>. Однако, были и другие предложения. В одном из них происходила замена переменных, что напоминает современный Angular:
<ENTRYBLANK TYPE=int LENGTH=length DEFAULT=default VAR=lval>
Prompt </ENTRYBLANK>
<QUESTION TYPE=float DEFAULT=default VAR=lval> Prompt </QUESTION>
<CHOICE DEFAULT=default VAR=lval>
<ALTERNATIVE VAL=value1> Prompt1
...
<ALTERNATIVE VAL=valuen> Promptn
</CHOICE>В этом примере проверяется тип input’ов на основе указания type, а значения VAR доступны на странице для замены строк в URL, примерно так:
http://eager. io/apps/$appId
io/apps/$appId io/apps/$appId
io/apps/$appIdДополнительные предложения использовали @ вместо = для разделения компонентов запроса:
name@value+name@(value&value)Марк Андриссен предложил метод, основанный на том, что он уже реализовал в Mosaic:
name=value&name=value&name=value
Всего два месяца спустя Mosaic добавил поддержку method=POST в формы, и так родились современные HTML-формы.
Конечно, компания Netscape Марка Андриссена создала еще и формат куки (с другим разделителем). Их предложение было болезненно недальновидным, оно привело к попытке создания заголовка Set-Cookie2, и создало фундаментальные структурные проблемы, с которыми нам все еще приходится иметь дело в продукте Eager.
Часть URL после символа ‘#’ известна как «фрагмент» (fragment). Фрагменты были частью URL со времен первой спецификации, они использовались для создания ссылки на конкретное место на загруженной странице. Например, если у меня есть якорь на сайте:
Например, если у меня есть якорь на сайте:
<a name="bio"></a>
Я могу сделать на него ссылку:
http://zack.is/#bio
Эта концепция постепенно была расширена до всех элементов (а не только якорей), и перешла на атрибут id вместо name:
<h2>Bio</h2>
Тим Бернерс-Ли решил использовать этот символ, основываясь на связи с форматом почтовых адресов в США (не смотря на то, что сам Тим — британец). По его словам:
Как минимум в США в почтовых адресах часто используют знак номера для указания номера квартиры или комнаты в здании. 12 Acacia Av #12 означает «Здание 12 на Акация Авеню, и в этом здании квартира 12». Этот символ казался естественным для такой цели. Сегодня http://www.example.com/foo#bar означает «На ресурсе http://www.example.com/foo конкретный вид, известный как bar”.
Оказывается, первичная система гипертекста, созданная Дугласом Энгельбартом, также использовала «#» для таких целей. Это может быть совпадением или случайным «заимствованием идеи».
Это может быть совпадением или случайным «заимствованием идеи».
Фрагменты специально не включаются в HTTP-запросы, то есть они живут исключительно в браузере. Такая концепция оказалась ценной, когда пришло время реализовывать клиентскую навигацию (до изобретения pushState). Фрагменты также были очень полезными, когда пришло время задуматься о сохранении состояния в URL без отправки на сервер. Что это значит? Давайте разберемся:
Кротовые холмики и горы
Есть целый стандарт, такой же мерзкий как SGML, созданный для передачи электронных данных, другими словами — для форм и отправки форм. Единственное, что мне известно: он выглядит как фортран задом наперед без пробелов.— Тим Бернерс-Ли,
1993
Есть ощущение, разделяемое многими, что организации, отвечающие за стандарты интернета ничего особо не делали с момента окончательного принятия HTTP 1.1. и HTML 4.01 в 2002 до тех пор, пока HTML 5 не стал по-настоящему популярным. Этот период также известен (только для меня) как Темный Век XHTML. В реальности люди, занимающиеся стандартами, были безумно заняты. Просто они занимались тем, что в итоге оказалось не слишком ценным.
Этот период также известен (только для меня) как Темный Век XHTML. В реальности люди, занимающиеся стандартами, были безумно заняты. Просто они занимались тем, что в итоге оказалось не слишком ценным.
Одним из направлений было создание Семантического Веба. Была мечта: создать Фреймворк Описания Ресурсов (Resource Description Framework). (прим. ред.: бегите от любой команды, которая хочет сделать фреймворк). Такой фреймворк позволял бы универсально описывать мета-информацию о содержании. Например, вместо того, чтобы делать красивую веб-страницу про мой Корвет Стингрэй, я бы сделал RDF-документ с описанием размеров, цвета и количества штрафов за превышение скорости, которые мне выписали за все время езды.
Это, конечно, совсем не плохая идея. Но формат был основан на XML, и это большая проблема курицы и яйца: нужно задокументировать весь мир, и нужны браузеры, которые умеют делать полезные штуки с этой документацией.
Но эта идея хотя бы родила условия для философских споров.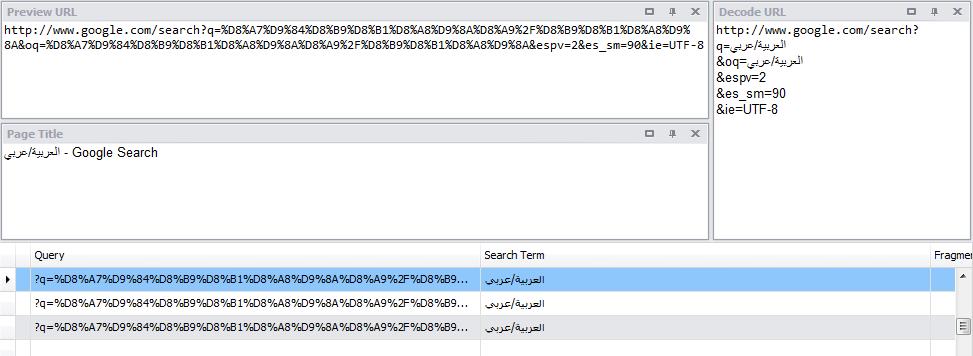 Один из лучших подобных споров длился как минимум десять лет, он известен под искусным кодовым именем ‘httpRange-14’.
Один из лучших подобных споров длился как минимум десять лет, он известен под искусным кодовым именем ‘httpRange-14’.
Целью httpRange-14 было ответить на фундаментальный вопрос «чем является URL?». Всегда ли URL ссылается на документ или он может ссылаться на все, что угодно? Может ли URL ссылаться на мою машину?
Они не пытались ответить на этот вопрос хоть сколько-нибудь удовлетворительно. Вместо этого они фокусировались на том, как и когда можно использовать редирект 303 чтобы сообщить пользователю, что по ссылке нет документа, и перенаправить его туда, где документ есть. И на том, когда можно использовать фрагменты (часть после ‘#’), чтобы направлять пользователей на связанные данные.
Прагматичному современному человеку эти вопросы могут показаться смешными. Многие из нас привыкли, что если URL получается использовать для чего-то, то значит его можно использовать для этого. И люди или будут использовать ваш продукт, или нет.
Но Семантический Веб заботился только о семантике.
Эта конкретная тема обсуждалась 1 июля 2002 года, 15 июля 2002 года, 22 июля 2002 года, 29 июля 2002 года, 16 сентября 2002 года, и как минимум еще 20 раз в течение 2005 года. Обсуждение закончилось благодаря тому самому ‘решению httpRange-14’ в 2005 году, и к нему вернулись снова из-за жалоб в 2007 и 2011, а запрос новых решений был открыт в 2012. Вопрос долго обсуждался группой pedantic web, у которой очень подходящее название. Единственное, чего так и не произошло — никакие из этих семантических данных так и не были добавлены в веб в какой-либо URL.
Авторизация
Как вы знаете, в URL можно включить логин и пароль:
http://zack:[email protected]
Браузер кодирует эти данные в формат Base64 и посылает в виде заголовка:
Authentication: Basic emFjazpzaGhoaGho
Base64 используется только для того, чтобы можно было передавать запрещенные в заголовках символы. Он никак не скрывает логин и пароль.
Это было проблемой, особенно до распространения SSL. Любой человек, который следит за вашим соединением, мог с легкостью увидеть пароль. Предлагали много альтернатив, в том числе Kerberos, который был и остается популярным протоколом безопасности.
Любой человек, который следит за вашим соединением, мог с легкостью увидеть пароль. Предлагали много альтернатив, в том числе Kerberos, который был и остается популярным протоколом безопасности.
Как и с другими примерами нашей истории, простую базовую авторизацию было проще всего реализовать разработчикам браузеров (Mosaic). Так базовая авторизация стала первым и единственным решением до тех пор, пока разработчики не получили инструменты для создания собственных систем аутентификации.
Веб-приложение
В мире веб-приложений странно представить, что основой веба является гиперссылка. Это метод соединения одного документа с другим, который со временем оброс стилями, возможностью запуска кода, сессиями, аутентификацией и в конечном итоге стал общей социальной компьютерной системой, которую пытались (безуспешно) создать так много исследователей 70-х годов.
Вывод такой же, как и у любого современного проекта или стартапа: только распространение имеет смысл. Если вы сделали что-то, что люди используют, даже если это некачественный продукт, то они помогут вам превратить его в то, чего хотят сами. И с другой стороны, конечно, если никто не пользуется продуктом, то его техническое совершенство не имеет значения. Существует бесчисленное количество инструментов, на которые ушли миллионы часов работы, но ими пользуется ровно ноль человек.
И с другой стороны, конечно, если никто не пользуется продуктом, то его техническое совершенство не имеет значения. Существует бесчисленное количество инструментов, на которые ушли миллионы часов работы, но ими пользуется ровно ноль человек.
Протокол HTTP, URI и URL, заголовок сообщения
1. Концепция URI
URI — это идентификатор местоположения ресурса, представленный определенной схемой протокола.Схема протокола относится к имени типа протокола, используемого для доступа к ресурсу.
При использовании протокола HTTP используется схема протокола http. Кроме того, есть ftp, mailto, telnet, file и т. Д. Существует около 30 стандартных протоколов URI.
2. Разница и связь между URI и URL
URI использует строку для идентификации определенного Интернет-ресурса, а URL-адрес представляет местоположение ресурса, то есть местоположение в Интернете. Следовательно, URL — это подмножество URI.
3. Формат URI
Указывает указанный URI. Используйте абсолютный URI, абсолютный URL и относительный URL, которые содержат всю необходимую информацию. Относительный URL-адрес относится к URL-адресу, указанному в базовом URI в браузере.
Относительный URL-адрес относится к URL-адресу, указанному в базовом URI в браузере.
Давайте посмотрим на абсолютный формат URI.
При использовании имен схем протокола, таких как http: или https: для получения доступа к ресурсам, вы должны указать тип протокола, не различая размер букв, с двоеточием в конце.
Вы также можете использовать data: или javascript: для указания имени программы для данных или программы-скрипта.
Введение в поле
(1) Информация для входа (аутентификация)
Указывать имя пользователя или пароль в качестве информации для входа, необходимой для получения ресурсов с сервера, необязательно.
(2) Адрес сервера
Чтобы использовать абсолютный URI, должен быть адрес сервера, к которому необходимо получить доступ. Адрес может быть разрешен, в десятичной системе счисления с точками (IPV4) или имя адреса IPV6 заключено в квадратные скобки.
(3) Номер порта сервера
Укажите номер сетевого порта, к которому подключен сервер. Это необязательно. Если пользователь опускает его, автоматически будет использоваться номер порта по умолчанию.
Это необязательно. Если пользователь опускает его, автоматически будет использоваться номер порта по умолчанию.
(4) Путь к файлу с иерархией
Укажите путь к файлу на сервере, чтобы найти указанный ресурс.
(5) Строка запроса
Для ресурсов в указанном пути к файлу вы можете использовать строку запроса для передачи любых параметров, этот параметр является необязательным.
(6) Идентификатор фрагмента
Вы можете отметить подресурсы в приобретенном ресурсе. Необязательно.
Приведи простой пример.
1. Запрос
POST /index.html HTTP/1.1
HOST: www.XXX.com
User-Agent:Mozilla/5.0(Windows NT 6.1
Username=admin&password=admin
POST в начале первой строки указывает тип запроса на доступ к серверу, который называется методом. Последующий /index.html указывает объект ресурса, к которому запрашивается доступ, также называемый URI запроса. Последний HTTP / 1.1 — это номер версии HTTP, который используется, чтобы предложить клиенту использовать функцию протокола HTTP.
Содержание этого запроса означает: запрос на доступ к ресурсу страницы /index.html на определенном HTTP-сервере.
Сообщение запроса состоит из метода запроса, URL-адреса запроса, версии протокола, необязательного поля заголовка запроса и объекта содержимого.
2. Ответ
HTTP/1.1 200 OK
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Document</title>
</head>
<body>
<p>this is http response</p>
</body>
</html>
HTTP / 1.1 в начале начальной строки указывает версию HTTP, соответствующую серверу. 200 OK указывает код состояния и фразу причины результата обработки запроса. Ответное сообщение отделяется пустой строкой, а содержимое после него является основным телом объекта ресурса.
Ответное сообщение в основном состоит из протокола версии, кода состояния, фразы причины, используемой для объяснения кода состояния, дополнительных полей заголовка ответа и темы объекта.
HTTP-метод для информирования сервера о намерениях
| метод | эффект |
|---|---|
| GET | Доступ к ресурсам |
| POST | Передающий объект |
| PUT | Перенести файлы |
| HEAD | Получить заголовок файла |
| DELETE | Удалить файлы |
| OPTIONS | Как обратиться за поддержкой |
| TRACE | Трассировка пути |
| CONNECT | Требовать протокол туннелирования для подключения к агенту |
Код ответа HTTP
| категория | Причина фраза |
|---|---|
| 1XX | Информационная (код состояния информации) |
| 2XX | Успех (код состояния успеха) |
| 3XX | Перенаправление (код состояния перенаправления) |
| 4XX | Ошибка клиента (код состояния ошибки клиента) |
| 5XX | Ошибка сервера (код состояния ошибки сервера) |
Сообщение HTTP-запроса
HTTP-ответное сообщение
1.
 Информация заголовка HTTP
Информация заголовка HTTPПоле заголовка HTTP включает информацию, требуемую клиентом и сервером для обработки запроса и предоставления ответа, включая размер тела сообщения, используемый язык и информацию аутентификации. Пользователям-клиентам не требуется просматривать большую часть этой информации лично.
2. Структура поля заголовка HTTP.
Поле заголовка HTTP состоит из имен полей заголовка и значений полей.
Имя первого поля: значение поля3. Тип поля заголовка HTTP.
Поле заголовка HTTP делится на 4 типа.
Общее поле заголовка
Заголовок, используемый как сообщениями запроса, так и сообщениями ответа.
Поле заголовка запроса
Заголовок, используемый при отправке сообщения запроса от клиента на сервер. Дополняет запрошенный дополнительный контент, информацию о клиенте, контент ответа и соответствующую информацию о приоритете.
Поле заголовка ответа
Заголовок, используемый в ответном сообщении, возвращается с сервера клиенту. Добавление дополнительного содержимого ответа также потребует от клиента прикрепления дополнительной информации содержимого.
Добавление дополнительного содержимого ответа также потребует от клиента прикрепления дополнительной информации содержимого.
Поле заголовка объекта
Заголовок, используемый для физической части сообщения запроса и сообщения ответа. Добавлена информация о сущности, такая как время обновления содержимого ресурса.
Спецификация HTTP / 1.1 определяет 47 полей заголовка.
Вот несколькоОбщие поля заголовка。
| Имя поля заголовка | Описание |
|---|---|
| Content-Type | Медиа-тип субъекта |
| Content-Length | Размер тела объекта (единица: байт) |
| Host | Сервер, на котором находится запрашиваемый ресурс |
| User-Agent | Информация о клиентской программе HTTP |
| Referer | Первоначальный эквайер URI запроса |
| Location | Перенаправить клиента на указанный URI |
Cookie (не HTTP / 1. 1) 1) | Используется для хранения небольшого количества информации о клиенте. |
Короткая ссылка HTTP:
Один запрос, один ответ, и обе стороны отвечают туда и обратно. Обычно сервер закрывает ответ. Например: рация.
Длинная ссылка HTTP:
Установите соединение один раз, а затем общайтесь. Пример: процесс звонка.
Что такое HTTP?
HTTP (HyperText Transfer Protocol) — это набор правил, которым сервер должен следовать, когда дело доходит до передачи файлов (изображений, видео, аудио и других форм файлов) через Всемирную паутину (WWW). Когда пользователь открывает браузер, он уже использует HTTP. По сути, это протокол приложения, который проходит через верхнюю часть набора протоколов TCP/IP.
Функциональность
Механизм и концепция HTTP включает в себя то, что файлы связаны с другими файлами через ряд ссылок. Этот выбор вызовет дополнительные запросы на передачу. Любое устройство веб-сервера на самом деле содержит программу, которая называется HTTP-демоном, которая предназначена для прогнозирования HTTP-запросов и обработки их по их получении. Типичный веб-браузер — это HTTP-клиент, который постоянно посылает запросы на серверные устройства. Пользователь вводит запросы в файл, проходя через веб-файл, который в данном случае обычно является URL-адресом, или нажимает на ссылку; браузер формирует HTTP-запрос, а затем отправляет его на IP-адрес, указанный через URL.
Типичный веб-браузер — это HTTP-клиент, который постоянно посылает запросы на серверные устройства. Пользователь вводит запросы в файл, проходя через веб-файл, который в данном случае обычно является URL-адресом, или нажимает на ссылку; браузер формирует HTTP-запрос, а затем отправляет его на IP-адрес, указанный через URL.
HTTP следует заданному циклу всякий раз, когда посылает запрос:
- Браузер запросит HTML-страницу. Затем сервер возвращает HTML-файл с хоста.1
- Браузер запросит таблицу стилей. Затем сервер возвращает файл CSS.
- Браузер запрашивает изображение в формате JPG. Сервер возвращает файл JPG.
- Браузер запросит код JavaScript (язык программирования). После этого сервер возвращает JS-файл.
- Браузер запрашивает различные формы данных. Сервер возвращает данные в виде XML или JSON файлов.
Различие между HTTP и HTTPS
Большинство людей не знают о различиях между http:// и https://, поскольку оба они почти визуально схожи. Знание различий между ними имеет первостепенное значение для поддержания безопасного и эффективного сайта, способного защитить информацию и данные. Браузеры были разработаны таким образом, что строка URL-адреса будет выделять буквы S в HTTPS другим цветом, чтобы пользователи могли их заметить.
Знание различий между ними имеет первостепенное значение для поддержания безопасного и эффективного сайта, способного защитить информацию и данные. Браузеры были разработаны таким образом, что строка URL-адреса будет выделять буквы S в HTTPS другим цветом, чтобы пользователи могли их заметить.
Вот некоторые очевидные различия между ними:
- HTTP — В настоящее время шифрование данных не осуществляется.
- Каждая URL-ссылка использует HTTP в качестве основного типа протокола передачи гипертекста. Учитывая это, HTTP уподобляется системе, которая не принадлежит ни одному государству. Это позволяет включить любое соединение по требованию.
- По сути, этот протокол является протоколом прикладного уровня. Это означает, что он больше фокусируется на информации, которая предоставляется пользователю, но не на том, как эти данные передаются от узла-источника к получателю. Это может нанести ущерб, так как это средство доставки может быть легко перехвачено и отслежено злоумышленниками сторонних пользователей (обычно известными как хакеры).
- HTTPS — Данные зашифрованы.
- По сравнению с HTTP, информация о пользователе, такая как номера кредитных карт и другие формы важной личной информации, зашифрована. Это предотвращает доступ вредоносных пользователей третьих сторон к этим формам конфиденциальных данных в любой форме.
- При более безопасной сети пользователи будут иметь более высокий уровень доверия при использовании сайта, поскольку их данные зашифрованы, а пользователям со злым умыслом будет трудно взломать свои данные.
- Статистика показывает, что 84% покупателей покидают веб-сайты после того, как узнают, что веб-сайт передает данные по незащищенному каналу.
- 29% пользователей осознают разницу между HTTP и HTTPS и активно ищут эту разницу в адресной строке.
- Являясь новой формой технологии, HTTPS все еще имеет несколько особенностей, которые до сих пор считаются экспериментальными. В связи с этим более старые типы браузеров будут испытывать трудности с адаптацией к этим веб-сайтам.
- По сравнению с простой настройкой сайта с HTTP, переход на HTTPS требует от пользователя прохождения нескольких юридических процедур для получения SSL-сертификата. Это означает, что владельцы страниц и сайтов вынуждены тратить деньги. Получение SSL-сертификатов является платной услугой от центра сертификации.
- Благодаря процессу кодирования сервер направляет энергию и время обработки на кодирование информации до того, как она будет передана.
- Являясь новой формой технологии, HTTPS все еще имеет несколько особенностей, которые до сих пор считаются экспериментальными. В связи с этим более старые типы браузеров будут испытывать трудности с адаптацией к этим веб-сайтам.

Резюме технических различий между HTTP и HTTPS:
- HTTP небезопасен, в то время как HTTPS является безопасным протоколом.
- HTTP использует TCP порт 80, в то время как HTTPS использует TCP порт 4433.
- HTTP работает на прикладном уровне, в то время как HTTPS работает на транспортном уровне безопасности (TLS).
- Для HTTP не требуется сертификат SSL, но HTTPS требует, чтобы сертификат SSL был подписан и внедрен центром сертификации (ЦС).
- HTTP не обязательно требует подтверждения домена, в то время как HTTPS в обязательном порядке требует подтверждения домена и определенных сертификатов, которые требуют юридического оформления.
- Во время зашифровки данных непосредственно перед их передачей для протокола HTTPS шифрование данных в HTTP не выполняется.
- HTTPS является расширением протокола HTTP. В этом случае он работает совместно с другим протоколом, а именно Secure Sockets Layer (SSL) для безопасной передачи данных.
- Как HTTP, так и HTTPS не обращаются к данным, которые будут передаваться по назначению. И наоборот, SSL не имеет никакого отношения к тому, как будут выглядеть данные.
Пользователи часто ошибочно полагают, что HTTPS и SSL являются одними и теми же протоколами. HTTPS безопасен, так как использует SSL для передачи данных. В настоящее время TSL медленно сворачивает использование SSL, поскольку это еще более безопасный способ шифрования данных, который будет отправляться.
Протокол HTTP для чайников: обзор простым языком
Каждый раз, когда вы посещаете страницу в интернете, ваш компьютер использует протокол передачи гипертекста (HTTP) для загрузки этой страницы. HTTP — это набор правил для передачи файлов: текста, изображений, звука, видео и других мультимедиа. HTTP работает поверх набора протоколов TCP/IP, которые составляют основу интернета.
HTTP — это набор правил для передачи файлов: текста, изображений, звука, видео и других мультимедиа. HTTP работает поверх набора протоколов TCP/IP, которые составляют основу интернета.
Содержание:
1. Составляющие HTTP
2. Клиент
3. Веб-сервер
4. Прокси
5. Как работает HTTP-протокол
6. Основные характеристики HTTP-протокола
7. HTTP-протокол — простой, но многофункциональный
Составляющие HTTP
В HTTP-протоколе есть две разные роли: сервер и клиент. Запрос всегда инициирует клиент, а сервер на него отвечает. Клиентом может быть как браузер, так и, к примеру, поисковый робот, который просматривает страницы в интернете и индексирует их согласно релевантности ключевого запроса. HTTP основан на тексте — сообщения между клиентом и сервером по сути представляют собой фрагменты текста, хотя в теле сообщения могут быть другие элементы: видео, фото, аудио и т.д.
Каждый отдельный запрос отправляется на сервер, который обрабатывает его и предоставляет ответ. Между клиентом и сервером существует множество объектов, которые называются прокси-серверами. Они обеспечивают различные уровни функциональности, безопасности и конфиденциальности в зависимости от ваших потребностей или политики компании.
Между клиентом и сервером существует множество объектов, которые называются прокси-серверами. Они обеспечивают различные уровни функциональности, безопасности и конфиденциальности в зависимости от ваших потребностей или политики компании.
Схематичное изображение работы HTTP-протокола
Итак, мы выяснили, что HTTP содержит три основных элемента:
- Клиент
- Сервер
- Прокси-сервер
Рассмотрим подробнее, что это такое и как они работают.
Клиент
Клиент — это любой инструмент, который действует от имени пользователя. В основном эту роль выполняет веб-браузер, но помимо браузера это быть программы, используемые инженерами или веб-разработчиками для отладки своих приложений. Клиент всегда инициирует запрос, это никогда не делает сервер.
Веб-сервер
На другой стороне канала связи находится сервер, который обслуживает документ по запросу клиента. Хотя для пользователя сервер выглядит как одна виртуальная машина, на самом деле это может быть набор серверов, разделяющих нагрузку. С другой стороны, несколько серверов могут быть расположены на одной и той же машине. При HTTP/1.1 и заголовке Host они могут даже использовать один и тот же IP-адрес.
Хотя для пользователя сервер выглядит как одна виртуальная машина, на самом деле это может быть набор серверов, разделяющих нагрузку. С другой стороны, несколько серверов могут быть расположены на одной и той же машине. При HTTP/1.1 и заголовке Host они могут даже использовать один и тот же IP-адрес.
Прокси
Прокси-серверы — это серверы, компьютеры или другие машины уровня приложений, которые находятся между клиентским устройством и непосредственно сервером. Они ретранслируют HTTP-запросы и ответы. Обычно для каждого взаимодействия клиент-сервер используется один или несколько прокси.
Веб-разработчики могут использовать прокси для следующих целей:
- Кэширование. Кэш-серверы сохраняют веб-страницы или другой контент локально, для более быстрого поиска информации и снижения требований к пропускной способности сайта.
- Аутентификация. Для контроля прав доступа к приложениям и онлайн-информации.
- Логирование. Нужен для хранения данных, таких как IP-адреса клиентов, отправивших запросы на сервер.
- Веб-фильтрация. Контролирует доступ к веб-страницам, которые могут быть небезопасными или содержать неприемлемый контент.
- Балансировка нагрузки. Позволяет обрабатывать клиентские запросы не одному серверу, а сразу нескольким.
Как работает HTTP-протокол
Шаг первый: направляем URL в браузер.
Когда мы хотим посмотреть веб-страницу, мы можем использовать разные типы девайсов: ноутбук, стационарный компьютер или телефон. Главное, чтобы на устройстве было приложение браузера. Пользователь либо вводит унифицированный указатель ресурса (URL) в поисковую строку браузера, либо переходит по ссылке с уже открытой страницы:
URL-адрес начинается с HTTP. Это сигнал браузеру, что ему необходимо использовать HTTP-протокол для получения документа по этому адресу.
Шаг второй: браузер ищет нужный IP-адрес.
Обычно IP-адреса содержат удобные и читабельные для человека названия доменов, например «highload.today» или «wikipedia.org». Браузер использует преобразователь DNS для сопоставления домена с IP-адресом.
Шаг третий: браузер посылает HTTP-запрос.
Как только браузер определяет IP-адрес компьютера, на котором размещен запрошенный URL, он отправляет HTTP-запрос.
HTTP-запрос может состоять всего из двух строк текста:
GET/index.html HTTP/1.1 Host: www.example.com
Первое слово — это GET. С его помощью мы показываем, что хотим получить информацию. Следующая часть указывает путь: /index.html. Главный компьютер хранит содержимое всего веб-сайта, поэтому необходимо прописать, какую именно страницу нужно загрузить. Последняя часть первой строки указывает протокол и версию протокола: «HTTP/ 1. 1». Во второй строке указывается домен запрошенного URL.
1». Во второй строке указывается домен запрошенного URL.
Кроме GET в HTTP-протоколе существует еще два вида запросов. Разберем их отличия:
GET. Сообщения, отправленные на сервер, содержат только URL-адрес. В конец URL-адреса можно добавить несколько дополнительных параметров данных. Сервер обрабатывает необязательную часть данных URL-адреса, если она есть, и возвращает результат (веб-страницу или элемент веб-страницы) в браузер.POST. Сообщения помещают любые необязательные параметры данных в тело сообщения запроса, а не добавляют их в конец URL-адреса.HEAD. Запросы работают так же, как и в случаеGET. Но вместо ответа с полным содержимым URL-адреса сервер отправляет обратно только информацию заголовка, которая находится в разделе HTML.
Шаг четвертый: сервер отправляет HTTP-ответ.
Как только хост-компьютер получает HTTP-запрос, он отправляет клиенту ответ с содержанием и метаданными.
HTTP-ответ начинается аналогично запросу:
HTTP/1.1 200 ОК
Ответ начинается с указания версии HTTP-протокола — 1.1. Следующее число — это код статуса HTTP, в примере это число 200. Этот код значит, что запрашиваемый документ был успешно извлечен.
Следующая часть ответа HTTP — это заголовки. Они предоставляют браузеру дополнительные сведения и помогают ему отображать контент. Эти два заголовка являются общими для большинства запросов:
Content-Type: text/html; charset=UTF-8 Content-Length: 208
Content-type сообщает браузеру, какой тип документа он отправляет обратно. Самый распространенный тип документа в интернете — это text/html, потому что все веб-страницы представляют собой текстовые файлы HTML. Но есть и другие типы, например, изображения, видео, скрипты и все остальное, что можно загрузить в браузер.
Content-length показывает длину документа в байтах, что помогает браузеру узнать, сколько времени потребуется для загрузки файла.
Кроме кода 200, в случае если загрузка страницы прошла успешно, есть еще несколько статусов:
- 201 Created. Это означает, что запрос был успешным и ресурс был создан. Код используется для подтверждения успеха запроса
PUTилиPOST. - 300 Moved Permanently. Этот код ответа означает, что URL-адрес запрошенного ресурса был изменен навсегда.
- 400 Bad Request. Запрос был сформирован неверно. Это происходит с запросами
POSTиPUT, когда данные не проходят проверку или имеют неправильный формат. - 401 Unauthorized. Эта ошибка указывает на то, что вам необходимо выполнить аутентификацию перед доступом к ресурсу.
- 404 Not Found. Этот код показывает, что не удалось найти требуемый ресурс. 404 означает, что URL-адрес не распознается или запрашиваемого ресурса нет в указанном месте.
- 405 Forbidden. Используемый метод HTTP не поддерживается для этого ресурса.
- 409 Conflict. Код указывает на произошедший конфликт. Например, вы используете запрос
PUTдля создания одного и того же ресурса дважды. - 500 Internal Server Error. Как правило, ответ 500 используется, когда обработка запроса завершается неудачно из-за непредвиденных обстоятельств на стороне сервера.
Шаг пятый: отображается нужная веб-страница. После выполнения всех шагов, браузер получает всю необходимую информацию, для отображения запрошенного документа.
Основные характеристики HTTP-протокола
Есть три основные особенности, которые делают HTTP простым, но мощным протоколом.
- HTTP-клиент, то есть браузер, инициирует HTTP-запрос и после этого ожидает ответ. Сервер обрабатывает запрос и отправляет ответ, после чего соединение прерывается. Получается, что клиент и сервер знают друг о друге только во время текущей сессии. Дальнейшие запросы выполняются уже при новом подключении, а клиент и сервер будут новыми друг для друга.
- HTTP не зависит от носителя. Любой тип данных может быть отправлен по HTTP, если и клиент и сервер знают, как обрабатывать его содержимое. От клиента и сервера требуется только указать тип контента, используя соответствующий MIME-тип.
- HTTP не имеет состояния (stateless). Как уже говорилось выше, HTTP не поддерживает постоянное соединение и поэтому HTTP является протоколом без состояния. Сервер и клиент знают друг друга только во время текущего запроса. Из-за такого характера протокола ни клиент, ни браузер не могут сохранять информацию между различными запросами.
HTTP-протокол — простой, но многофункциональный
HTTP — это основа всего интернета. Он быстрый, легкий и многофункциональный. Подводя итоги, рассмотрим преимущества и особенности HTTP-протокола.
- Скорость передачи. Веб-страница содержит разные элементы, такие как текст и изображения. Для каждого элемента требуется разное количество ресурсов для хранения и загрузки. HTTP позволяет нескольким соединениям загружать отдельные элементы одновременно, тем самым ускоряя передачу данных.
- Гибкость протокола. Клиент всегда знает, какой тип файла нужно будет загрузить. Благодаря этому приложение на стороне клиента может быстро загрузить расширения или модули, если для отображения данных необходимы дополнительные ресурсы. Так, например, это могут быть Flash-плееры или программы чтения PDF-документов.
- Безопасность соединения. HTTP 1.0 загружает каждый файл через независимое соединение, а затем закрывает его. Это снижает риск перехвата данных во время передачи..
- Легкость программирования. HTTP закодирован в виде обычного текста, поэтому его легче реализовать, чем протоколы, которые используют код. Данные форматируются в виде текста, а не строк переменных или полей.
- Возможности поиска. Хотя HTTP — простой протокол обмена сообщениями, он позволяет искать информацию в базе данных с помощью одного запроса.Можно использовать протокол для выполнения SQL-поиска и возврата результатов, отформатированных в HTML-документе.
Для закрепления материала можно посмотреть эти два образовательные видео:
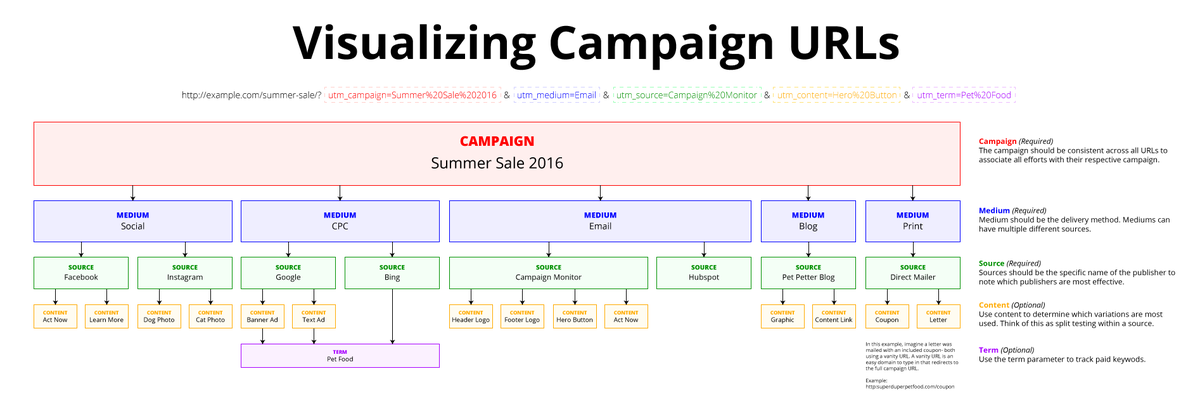
URL Encode Decode — процентное кодирование и декодирование URL.
Используйте онлайн-инструмент, указанный выше, для кодирования или декодирования строки текста. Для всемирной совместимости URI должны кодироваться единообразно. Чтобы сопоставить широкий диапазон символов, используемых во всем мире, с 60 или около того разрешенными символами в URI, используется двухэтапный процесс:
- Преобразование строки символов в последовательность байтов с использованием кодировки UTF-8
- Преобразует каждый байт, не являющийся буквой или цифрой ASCII, в% HH, где HH — шестнадцатеричное значение байта
Например, строка: François, будет закодирована как: Fran% C3% A7ois
(«ç» кодируется в UTF-8 как два байта C3 (шестнадцатеричный) и A7 (шестнадцатеричный), которые затем записываются как три символа «% c3» и «% a7» соответственно.) Это может сделать URI довольно длинным (до 9 символов ASCII для одного символа Unicode), но намерение состоит в том, что браузерам требуется только для отображения декодированной формы, и многие протоколы могут отправлять UTF-8 без экранирования% HH.
Что такое кодировка URL?
Кодировка URL-адреса означает кодирование определенных символов в URL-адресе путем их замены одним или несколькими тройками символов, которые состоят из символ процента «% «, за которым следуют две шестнадцатеричные цифры.Две шестнадцатеричные цифры тройки (ей) представляют числовое значение заменяемого символа.
Термин Кодирование URL немного неточен, поскольку процедура кодирования не ограничивается URL-адреса (унифицированные указатели ресурсов), но также могут применяться к любым другие URI (унифицированные идентификаторы ресурсов) такие как URN (унифицированные имена ресурсов). Следовательно, следует предпочесть термин процентное кодирование.
Допустимые символы в URI: зарезервировано или незарезервировано (или символ процента как часть процентного кодирования). Зарезервировано символов — это те символы, которые иногда имеют особое значение, в то время как незарезервированных символов не имеют такого значения. имея в виду. Используя процентное кодирование, символы, которые в противном случае не были бы разрешены, представляются с помощью разрешенных символов. Наборы зарезервированных и незарезервированных символов и обстоятельства, при которых определенные зарезервированные символы имеют особое значение незначительно менялись с каждым пересмотром спецификаций, управляющих URI и схемами URI.
Согласно RFC 3986, символы в URL-адресе должны быть взятым из определенного набора незарезервированных и зарезервированных символов ASCII. В URL нельзя использовать любые другие символы.
Незарезервированные символы могут кодироваться, но не должны кодироваться. Незарезервированные символы:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЫЭЮЯ
0 1 2 3 4 5 6 7 8 9 - _. ~
Зарезервированные символы необходимо кодировать только при определенных обстоятельствах.Зарезервированные символы:
! * '(); : @ & = + $, /? % # []
RFC 3986 не определяет, в соответствии с каким символом таблица кодирования не-ASCII-символов (например, умляуты ä, ö, ü) должны быть закодированным. Поскольку кодирование URL включает пару шестнадцатеричных цифр, а поскольку пара шестнадцатеричных цифр эквивалентна 8 битам, это будет теоретически можно использовать одну из 8-битных кодовых страниц для символов, отличных от ASCII (например,грамм. ISO-8859-1 для умляутов).
С другой стороны, поскольку многие языки имеют свою собственную 8-битную кодовую страницу, обработка всех этих различных 8-битных кодовых страниц была бы довольно сложной задачей. громоздкое дело. Некоторые языки даже не помещаются в 8-битную кодовую страницу (например, китайский). Следовательно, RFC 3629 предлагает использовать Таблица кодировки символов UTF-8 для символов, отличных от ASCII. Следующий инструмент учитывает это и предлагает выбрать между таблицей кодировки символов ASCII и символом UTF-8. таблица кодирования.Если вы выберете таблицу кодировки символов ASCII, появится предупреждающее сообщение, если URL-адрес закодирован / декодирован текст содержит символы, отличные от ASCII.
При отправке данных, которые были введены в формы HTML, имена и значения полей формы кодируются и отправляются на сервер в Сообщение HTTP-запроса с использованием метода GET или POST, или, исторически, по электронной почте. Кодировка, используемая по умолчанию, основана на очень ранней версии общих правил процентного кодирования URI с рядом модификаций, таких как нормализация новой строки и замена пробелов с « + » вместо «% 20 ».Тип данных MIME, закодированных таким образом, — application / x-www-form-urlencoded , и в настоящее время он определен (все еще очень устаревшим) в спецификациях HTML и XForms. В дополнение Спецификация CGI содержит правила того, как веб-серверы декодируют данные этого типа и делают их доступными для приложений.
При отправке в HTTP-запросе GET данные application / x-www-form-urlencoded включаются в компонент запроса URI запроса. При отправке в запросе HTTP POST или по электронной почте данные помещаются в тело сообщения, а имя типа мультимедиа включается в заголовок Content-Type сообщения.
Сетевая рабочая группа Т. Бернерс-Ли Запрос комментариев: 1738 ЦЕРН Категория: Стандарты Track L. Masinter Xerox Corporation М. МакКахилл Университет Миннесоты Редакторы Декабрь 1994 Унифицированные указатели ресурсов (URL) Статус этого меморандума Этот документ определяет протокол отслеживания стандартов Интернета для Интернет-сообщество и просит обсуждения и предложения по улучшения.Пожалуйста, обратитесь к текущему выпуску «Интернет Официальные стандарты протокола »(STD 1) для состояния стандартизации и статус этого протокола. Распространение этой памятки не ограничено. Абстрактный Этот документ определяет унифицированный указатель ресурса (URL), синтаксис и семантика формализованной информации о местонахождении и доступе ресурсы через Интернет. 1. Введение В этом документе описывается синтаксис и семантика компактной строки. представление ресурса, доступного в сети Интернет.Эти строки называются «унифицированными указателями ресурсов» (URL). Спецификация основана на концепциях, введенных World- Глобальная информационная инициатива Wide Web, чье использование таких объектов датируется 1990 годом и описывается в «Универсальных идентификаторах ресурсов» в WWW », RFC 1630. Спецификация URL-адресов разработана с учетом требования изложены в «Функциональных требованиях к Интернету. Локаторы ресурсов »[12]. Этот документ был написан рабочей группой URI в Интернете. Инженерная рабочая группа.Комментарии могут быть адресованы редакции, или в URI-WG. Обсуждения группы архивируются в Бернерс-Ли, Масинтер и МакКахилл [Страница 1] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. 2. Общий синтаксис URL Так же, как существует множество различных методов доступа к ресурсам, существует несколько схем описания расположения таких Ресурсы. Общий синтаксис для URL-адресов обеспечивает основу для новых схем устанавливаться с использованием протоколов, отличных от тех, которые определены в данном документ.URL-адреса используются для «поиска» ресурсов путем предоставления абстрактных идентификация местонахождения ресурса. Найдя ресурс, система может выполнять множество операций с ресурсом, например можно охарактеризовать такими словами, как «доступ», «обновление», `заменить ‘,` найти атрибуты’. В общем, только метод «доступа» необходимо указать для любой схемы URL. 2.1. Основные части URL-адресов Полное описание BNF синтаксиса URL приведено в Разделе 5. Обычно URL-адреса записываются следующим образом: : URL-адрес содержит имя используемой схемы (), за которым следует двоеточием, а затем строкой (), чья интерпретация зависит от схемы.Имена схем состоят из последовательности символов. Нижний регистр буквы «a» — «z», цифры и символы плюс («+»), точка («.») и дефис («-«) разрешены. Для обеспечения отказоустойчивости программы интерпретация URL-адресов должна рассматривать заглавные буквы как эквивалент строчные буквы в именах схем (например, разрешить «HTTP», а также «http»). 2.2. Проблемы с кодировкой символов URL URL-адреса представляют собой последовательности символов, т. Е. Букв, цифр и специальных символы. URL-адреса могут быть представлены различными способами: e.г., тушь на бумаге или последовательность октетов в кодированном наборе символов. В интерпретация URL зависит только от идентичности использованные символы. В большинстве схем URL-адресов последовательности символов в разных частях URL-адреса используются для представления последовательностей октетов, используемых в Интернете. протоколы. Например, в схеме ftp имя хоста, каталог имя и имена файлов — это такие последовательности октетов, представленные части URL-адреса. В этих частях октет может быть представлен Бернерс-Ли, Масинтер и МакКахилл [Страница 2] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. символ, который имеет этот октет в качестве своего кода в US-ASCII [20] кодовый набор символов.Кроме того, октеты могут быть закодированы тройкой символов, состоящей из символа «%», за которым следуют две шестнадцатеричные цифры (от «0123456789ABCDEF»), который формирует шестнадцатеричное значение октета. (Символы «abcdef» также могут использоваться в шестнадцатеричной кодировке.) Октеты необходимо закодировать, если они не имеют соответствующей графики. символ в кодировке US-ASCII, если используется соответствующий символ небезопасен, или если соответствующий символ зарезервировано для другой интерпретации в конкретном URL схема.Нет соответствующей графики US-ASCII: URL-адреса пишутся только графическими печатными символами Набор символов в кодировке US-ASCII. Шестнадцатеричные октеты 80-FF не являются используется в US-ASCII, а шестнадцатеричные октеты 00-1F и 7F представляют управляющие символы; они должны быть закодированы. Небезопасно: Персонажи могут быть небезопасными по ряду причин. Космос символ небезопасен, поскольку значимые пробелы могут исчезнуть и незначительные пробелы могут быть введены при расшифровке URL-адресов или набранные или подвергнутые обработке текстовыми программами.Символы «» небезопасны, потому что они используются в качестве разделители вокруг URL в произвольном тексте; кавычка («» «) используется для разграничивать URL-адреса в некоторых системах. Символ «#» небезопасен и должен всегда кодироваться, потому что он используется во всемирной паутине и других системы для отделения URL-адреса от идентификатора фрагмента / привязки, который может следуй за ним. Символ «%» небезопасен, потому что он используется для кодировки других символов. Другие персонажи небезопасны, потому что известно, что шлюзы и другие транспортные агенты иногда изменяют такие персонажи.»,» ~ «, «[», «]» и «` ». Все небезопасные символы всегда должны кодироваться в URL-адресе. Для Например, символ «#» должен быть закодирован в URL-адресах даже в системы, которые обычно не работают с фрагментом или якорем идентификаторы, так что если URL-адрес копируется в другую систему, использует их, нет необходимости изменять кодировку URL. Бернерс-Ли, Масинтер и МакКахилл [Страница 3] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. Зарезервированный: Многие схемы URL резервируют определенные символы для особого значения: их появление в части URL-адреса, относящейся к схеме, имеет обозначенная семантика.Если символ, соответствующий октету, равен зарезервировано в схеме, октет должен быть закодирован. Персонажи «;», «/», «?», «:», «@», «=» и «&» — символы, которые могут быть зарезервировано для особого значения в схеме. Никакие другие персонажи не могут быть зарезервированным в схеме. Обычно URL-адрес имеет ту же интерпретацию, когда октет представлен символом и когда он закодирован. Однако это не истина для зарезервированных символов: кодирование символа, зарезервированного для конкретная схема может изменить семантику URL-адреса.Таким образом, только буквенно-цифровые символы, специальные символы «$ -_. +! * ‘(),» И могут использоваться зарезервированные символы, используемые для их зарезервированных целей не закодировано в URL. С другой стороны, символы, которые не требуется кодировать (включая буквенно-цифровые) могут быть закодированы в рамках конкретной схемы часть URL-адреса, если они не используются для зарезервированного цель. 2.3 Иерархические схемы и относительные ссылки В некоторых случаях URL-адреса используются для поиска ресурсов, содержащих указатели на другие ресурсы.В некоторых случаях эти указатели представлены как относительные ссылки, где выражение местоположения второй ресурс находится в том же месте, что и этот кроме следующего относительного пути «. Относительные ссылки не описано в этом документе. Однако использование относительных ссылок зависит от исходного URL-адреса, содержащего иерархическую структуру на котором основана относительная связь. Некоторые схемы URL (например, ftp, http и файловые схемы) содержат имена, которые можно считать иерархическими; компоненты иерархия разделены «/».Бернерс-Ли, Масинтер и МакКахилл [Страница 4] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. 3. Конкретные схемы Отображение некоторых существующих стандартных и экспериментальных протоколов изложены в определении синтаксиса BNF. Примечания к конкретным протоколам следить. Охватываемые схемы: ftp протокол передачи файлов HTTP протокол передачи гипертекста суслик Протокол суслика mailto Адрес электронной почты новости новости USENET nntp новости USENET с использованием доступа NNTP telnet Ссылка на интерактивные сеансы Серверы глобальной информации wais файл Имена файлов, зависящие от хоста Просперо Служба каталогов Просперо Другие схемы могут быть указаны в будущих спецификациях.Раздел 4 в этом документе описывается, как могут быть зарегистрированы новые схемы, и перечислены некоторые названия схем, которые находятся в стадии разработки. 3.1. Общий синтаксис интернет-схемы Хотя синтаксис остальной части URL-адреса может отличаться в зависимости от выбранная конкретная схема, схемы URL, предполагающие прямое использование протокола на основе IP к указанному узлу в Интернете использовать общий синтаксис для данных, специфичных для схемы: //: @: / Некоторые или все части «: @», «:», «:» и «/» можно исключить.Специфическая схема данные начинаются с двойной косой черты «//», чтобы указать, что они соответствуют общий синтаксис схемы Интернета. Различные компоненты подчиняются следующие правила: Пользователь Необязательное имя пользователя. Некоторые схемы (например, ftp) позволяют указание имени пользователя. пароль Необязательный пароль. Если присутствует, он следует за пользователем имя, отделенное от него двоеточием. После имени пользователя (и пароля), если он присутствует, следует рекламный знак «@».В поле пользователя и пароля любое «:», «@» или «/» должны быть закодированы. Бернерс-Ли, Масинтер и МакКахилл [Страница 5] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. Обратите внимание, что пустое имя пользователя или пароль отличается от отсутствия пользователя. имя или пароль; нет возможности указать пароль без указание имени пользователя. Например, имеет пустой имя пользователя и пароль, не имеет имени пользователя, в то время как имеет имя пользователя «foo» и пустой пароль.хозяин Полное доменное имя сетевого хоста или его IP-адрес. адрес как набор из четырех групп десятичных цифр, разделенных «.». Полные доменные имена принимают форму, как описано в Раздел 3.5 RFC 1034 [13] и Раздел 2.1 RFC 1123 [5]: последовательность меток доменов, разделенных «.», Каждый домен метка, начинающаяся и заканчивающаяся буквенно-цифровым символом и возможно также содержащие символы «-». Самый правый домен ярлык никогда не будет начинаться с цифры, которая синтаксически отличает все доменные имена от IP адреса.порт Номер порта для подключения. Большинство схем обозначают протоколы, у которых есть номер порта по умолчанию. Другой номер порта опционально может быть указано в десятичном виде, отделенном от host через двоеточие. Если порт опущен, также используется двоеточие. url-путь Остальная часть локатора состоит из данных, специфичных для схема и известна как «url-путь». Он поставляет подробности о том, как можно получить доступ к указанному ресурсу. Примечание что «/» между хостом (или портом) и URL-путем НЕ является частью url-пути.Синтаксис url-path зависит от используемой схемы, как и способ его толкования. 3.2. FTP Схема URL FTP используется для обозначения файлов и каталогов на Интернет-хосты, доступные по протоколу FTP (RFC959). URL-адрес FTP соответствует синтаксису, описанному в разделе 3.1. Если есть опущено, порт по умолчанию 21. Бернерс-Ли, Масинтер и МакКахилл [Страница 6] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. 3.2.1. Имя и пароль FTP Могут быть предоставлены имя пользователя и пароль; они используются в ftp Команды «USER» и «PASS» после первого подключения к FTP-сервер. Если имя пользователя или пароль не указаны, а один запрашивается FTP-сервером, соглашения для «анонимного» FTP будут использоваться следующим образом: Предоставляется имя пользователя «анонимный». Пароль предоставляется как адрес электронной почты в Интернете. конечного пользователя, обращающегося к ресурсу. Если URL-адрес содержит имя пользователя, но не пароль, а удаленный сервер запрашивает пароль, программа интерпретирует URL-адрес FTP следует запросить его у пользователя.3.2.2. URL-адрес FTP Путь URL-адреса FTP имеет следующий синтаксис: //…//;type= Где сквозные и (возможно, закодированные) строки и является одним из символов «a», «i» или «d». Часть «; type =» можно опустить. Части и могут быть пустой. Весь URL-путь может быть опущен, включая «/» отделяя его от префикса, содержащего пользователя, пароль, хост и порт. URL-путь интерпретируется как последовательность команд FTP следующим образом: Каждый из элементов должен поставляться последовательно, как аргумент команды CWD (изменить рабочий каталог).Если код типа «d», выполните команду NLST (список имен) с в качестве аргумента и интерпретируйте результаты как файл список каталогов. В противном случае выполните команду TYPE с аргументом, а затем получить доступ к файлу с именем (например, используя команду RETR.) Внутри имени или компонента CWD символы «/» и «;» находятся зарезервировано и должно быть закодировано. Компоненты декодируются до их использование в протоколе FTP. В частности, если соответствующий FTP последовательность для доступа к определенному файлу требует предоставления строки содержащий «/» в качестве аргумента команды CWD или RETR, это Бернерс-Ли, Масинтер и МакКахилл [Страница 7] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. необходимо закодировать каждый «/».Например, URL-адрес интерпретируется FTP как «host.dom», при входе в систему как «myname» (запрос пароля, если он запрашивается), а затем выполнение «CWD / etc», а затем «RETR motd». Это имеет другое значение, чем который будет «CWD etc», а затем «РЭТР мотд»; начальный «CWD» может быть выполнен относительно каталог по умолчанию для «myname». С другой стороны, , будет «CWD» с нулем аргумент, затем «CWD etc», а затем «RETR motd». URL-адреса FTP также могут использоваться для других операций; например, это возможно обновить файл на удаленном файловом сервере или сделать вывод информация об этом из списков каталогов.Механизм для здесь не говорится об этом. 3.2.3. FTP Typecode не является обязательным Целая; type = часть URL-адреса FTP не является обязательной. Если это опущено, клиентская программа, интерпретирующая URL, должна угадать подходящий режим для использования. Как правило, тип содержимого данных файла можно догадаться только по имени, например, по суффиксу имени; соответствующий код типа, который будет использоваться для передачи файла, может затем можно вывести из содержимого файла. 3.2.4 Иерархия В некоторых файловых системах знак «/» используется для обозначения иерархической структура URL-адреса соответствует разделителю, используемому для создания иерархия имен файлов, и, таким образом, имя файла будет похоже на URL-путь.Это НЕ означает, что URL-адрес является именем файла Unix. 3.2.5. Оптимизация Клиенты, получающие доступ к ресурсам через FTP, могут использовать дополнительную эвристику. для оптимизации взаимодействия. Например, для некоторых FTP-серверов это может быть разумным держать контрольное соединение открытым при доступе несколько URL-адресов с одного сервера. Однако общего иерархическая модель для протокола FTP, поэтому при изменении каталога была дана команда, в общем, невозможно вывести, что последовательность должна быть дана для перехода к другому каталогу для второй поиск, если пути разные.Единственный надежный алгоритм заключается в отключении и восстановлении контрольного соединения. Бернерс-Ли, Масинтер и МакКахилл [Страница 8] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. 3.3. HTTP Схема URL HTTP используется для обозначения интернет-ресурсов. доступный по протоколу HTTP (протокол передачи гипертекста). Протокол HTTP указан в другом месте. Только эта спецификация описывает синтаксис URL-адресов HTTP. URL-адрес HTTP принимает форму: http: //: /? где и такие, как описано в разделе 3.1. Если: не указан, по умолчанию используется порт 80. Имя пользователя или пароль не указаны. разрешается. это HTTP-селектор, и это запрос нить. Необязательно, как и его предшествующий «?». Если ни ни присутствует, то «/» также может быть опущено. Внутри компонентов и «/», «;», «?» находятся зарезервированный. Символ «/» может использоваться в HTTP для обозначения иерархическая структура. 3.4. Гофер Схема URL Gopher используется для обозначения интернет-ресурсов. доступный по протоколу Gopher.Базовый протокол Gopher описан в RFC 1436 и поддерживает элементы и коллекции предметов (каталоги). Протокол Gopher + — это набор расширений с восходящей совместимостью к базовому протоколу Gopher и описан в [2]. Gopher + поддерживает связывание произвольных наборов атрибуты и альтернативные представления данных с элементами Gopher. URL-адреса Gopher содержат элементы и элементы Gopher и Gopher + атрибуты. 3.4.1. Синтаксис URL-адреса Gopher URL-адрес Gopher принимает форму: суслик: //: / где один из % 09% 09% 09 Бернерс-Ли, Масинтер и МакКахилл [Страница 9] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. Если: опущено, по умолчанию используется порт 70.это односимвольное поле для обозначения типа Gopher ресурса для на который ссылается URL. Все также может быть пустым, в в этом случае разделитель «/» также является необязательным, а по умолчанию «1». — строка выбора Gopher. В протоколе Gopher Строки селектора Gopher — это последовательность октетов, которые могут содержать любые октеты, кроме шестнадцатеричного 09 (US-ASCII HT или табуляция) 0A шестнадцатеричного (Символ US-ASCII LF) и 0D (символ US-ASCII CR). Клиенты Gopher указывают, какой элемент извлекать, отправляя Gopher строку селектора на сервер Gopher.Внутри символы не зарезервированы. Обратите внимание, что некоторые струны Gopher начинаются с копии символ, и в этом случае этот символ встречается дважды последовательно. Строка селектора Gopher может быть пустой строкой; так клиенты Gopher относятся к каталогу верхнего уровня на Сервер Gopher. 3.4.2 Указание URL-адресов для поисковых систем Gopher Если URL-адрес относится к поиску, который будет отправлен в поиск Gopher Engine, за селектором следует закодированная вкладка (% 09) и строка поиска.Чтобы отправить поиск в поисковую систему Gopher, Клиент Gopher отправляет строку (после декодирования), табуляцию, и строку поиска на сервер Gopher. 3.4.3 Синтаксис URL для элементов Gopher + URL-адреса для элементов Gopher + имеют вторую закодированную вкладку (% 09) и Gopher + нить. Обратите внимание, что в этом случае строка% 09 должна быть предоставляется, хотя элемент может быть пустой строкой. Используется для представления информации, необходимой для поиск предмета Gopher +. Предметы Gopher + могут иметь альтернативные представления, произвольные наборы атрибутов и могут иметь электронные формы связанные с ними.Чтобы получить данные, связанные с URL-адресом Gopher +, клиент подключитесь к серверу и отправьте селектор Gopher, а затем вкладку и строку поиска (которая может быть пустой), за которой следует табуляция и Gopher + команды. Бернерс-Ли, Масинтер и МакКахилл [Страница 10] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. 3.4.4 Представление данных Gopher + по умолчанию Когда сервер Gopher возвращает клиенту список каталогов, Предметы Gopher + помечены знаком «+» (обозначающие предметы Gopher +). или «?» (обозначает элементы Gopher +, с которыми связана форма + ASK с ними).URL-адрес Gopher со строкой Gopher +, состоящей только из «+» относится к виду по умолчанию (представление данных) элемента. в то время как строка Gopher + содержит только «?» ссылаться на элемент с С ним связана электронная форма Gopher. 3.4.5 Предметы Gopher + с электронными формами Gopher + предметы, с которыми связан + ASK (например, Gopher + элементы, помеченные знаком «?») требуют, чтобы клиент получил + ASK элемента атрибут, чтобы получить определение формы, а затем попросите пользователя заполнить из формы и вернуть ответы пользователя вместе с селектором строка для получения элемента.Клиенты Gopher + знают, как это сделать, но зависит от символа «?» в описании предмета Gopher +, чтобы знать, когда справиться с этим делом. Знак «?» используется в строке Gopher +, чтобы быть в соответствии с использованием этого символа в протоколе Gopher +. 3.4.6 Коллекции атрибутов предметов Gopher + Чтобы обратиться к атрибутам Gopher + элемента, URL-адрес Gopher Gopher + строка состоит из «!» или «$». «!» относится ко всему Атрибуты Gopher + предмета. «$» относится ко всем атрибутам элемента для все элементы в каталоге Gopher.3.4.7 Обращение к определенным атрибутам Gopher + Для обозначения определенных атрибутов используется gopher + _string в URL-адресе. «!» или «$». Например, чтобы сослаться на атрибут, содержащий аннотацию элемента, gopher + _string будет «! + АБСТРАКТ». Для обозначения нескольких атрибутов gopher + _string состоит из имена атрибутов разделены кодированными пробелами. Например, «! + ABSTRACT% 20 + SMELL» относится к атрибутам + ABSTRACT и + SMELL. элемента. 3.4.8 Синтаксис URL для альтернативных представлений Gopher + Gopher + допускает необязательные альтернативные представления данных (альтернативный просмотров) элементов.Чтобы получить альтернативный вид Gopher +, Gopher + клиент отправляет соответствующий идентификатор представления и языка (находится в атрибут + VIEW элемента). Для обозначения конкретного Gopher + альтернативный view, строка Gopher + URL-адреса будет иметь следующий вид: Бернерс-Ли, Масинтер и МакКахилл [Страница 11] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. +% 20 Например, Gopher + строка «+ application / postscript% 20Es_ES» относится к приписку на испанском языке, альтернативному изображению суслика. элемент.3.4.9 Синтаксис URL для электронных форм Gopher + Gopher + _string для URL, который ссылается на элемент, на который ссылается Электронная форма Gopher + (блок ASK), заполненная конкретными values - это закодированная версия того, что клиент отправляет на сервер. Gopher + _string имеет вид: +% 091% 0D% 0A + -1% 0D% 0A% 0D% 0A% 0D% 0A.% 0D% 0A Чтобы получить этот элемент, клиент Gopher отправляет: +1 + -1 . на сервер Gopher. 3.5. ПОЧТА Схема URL mailto используется для обозначения интернет-рассылки. адрес физического лица или службы.Нет дополнительной информации другое чем присутствует или подразумевается почтовый адрес в Интернете. URL-адрес mailto принимает форму: mailto: где (кодировка) addr-spec, как указано в RFC 822 [6]. В адресах mailto нет зарезервированных символы. Обратите внимание, что знак процента («%») обычно используется в RFC 822. адреса и должны быть закодированы. В отличие от многих URL-адресов, схема mailto не представляет собой объект данных. для прямого доступа; нет смысла, в котором он обозначает объект.Его использование отличается от типа message / external-body в MIME. Бернерс-Ли, Масинтер и МакКахилл [Страница 12] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. 3.6. НОВОСТИ Схема URL новостей используется для ссылки либо на группы новостей, либо на отдельные статьи новостей USENET, как указано в RFC 1036. URL-адрес новости может иметь одну из двух форм: Новости: Новости: A — это иерархическое имя, разделенное точками, например «комп.инфосистемы.www.misc «. A соответствует Идентификатор сообщения из раздела 2.1.5 RFC 1036 без заключительного «»; он принимает вид @. Сообщение идентификатор можно отличить от названия группы новостей по наличие рекламы у символа «@». Никаких дополнительных символов зарезервированы в компонентах URL-адреса новостей. Если это «*» (как в), оно используется для обозначения во «все доступные группы новостей». URL-адреса новостей необычны тем, что сами по себе не содержат достаточно информации, чтобы найти единственный ресурс, но, скорее, не зависит от местоположения.3.7. NNTP Схема URL nntp — альтернативный метод ссылки на новости. статьи, полезные для указания новостных статей с серверов NNTP (RFC 977). URL-адрес nntp имеет вид: nntp: //: // где и соответствуют описанию в разделе 3.1. Если : опущен, по умолчанию используется порт 119. Это имя группы, а числовой идентификатор статьи в этой группе новостей. Обратите внимание, что в то время как URL-адреса nntp: указывают уникальное расположение статьи ресурс, большинство серверов NNTP в настоящее время в Интернете настроен только для разрешения доступа с локальных клиентов, и, следовательно, nntp URL-адреса не обозначают глобально доступные ресурсы.Итак, новость: Форма URL предпочтительна как способ идентификации новостных статей. Бернерс-Ли, Масинтер и МакКахилл [Страница 13] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. 3.8. ТЕЛНЕТ Схема URL-адресов Telnet используется для обозначения интерактивных служб, которые могут быть доступны по протоколу Telnet. URL-адрес telnet имеет вид: telnet: //: @: / как указано в разделе 3.1. Последний символ «/» можно опустить. Если: опущено, по умолчанию используется порт 23.Банка опускается, а также целиком: часть. Этот URL-адрес не обозначает объект данных, а скорее интерактивный услуга. Удаленные интерактивные службы широко различаются по средствам: которые они разрешают удаленный вход; на практике, и предоставлены только для справки: клиенты обращаются к URL-адресу telnet просто сообщите пользователю предлагаемые имя пользователя и пароль. 3.9. WAIS Схема URL WAIS используется для обозначения баз данных WAIS, поиска или отдельные документы доступны из базы данных WAIS.WAIS — это описан в [7]. Протокол WAIS описан в RFC 1625 [17]; Хотя протокол WAIS основан на Z39.50-1988, URL-адрес WAIS Схема не предназначена для использования с произвольными сервисами Z39.50. URL-адрес WAIS принимает одну из следующих форм: wais: //: / wais: //: /? wais: //: /// где и соответствуют описанию в разделе 3.1. Если : опущен, порт по умолчанию — 210. Первая форма обозначает База данных WAIS, доступная для поиска. Вторая форма обозначает конкретный поиск.это название WAIS запрашиваемая база данных. Третья форма обозначает конкретный документ в WAIS. база данных для извлечения. В таком виде WAIS обозначение типа объекта. Многие реализации WAIS требовать, чтобы клиент знал «тип» объекта до извлечение, тип, возвращаемый вместе с внутренним объектом идентификатор в поисковом ответе. Включено в URL-адрес, чтобы клиент мог адекватно интерпретировать URL-адрес информация для фактического извлечения документа.Бернерс-Ли, Масинтер и МакКахилл [Страница 14] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. URL-адрес WAIS состоит из идентификатора документа WAIS, закодированного при необходимости, используя метод, описанный в разделе 2.2. WAIS идентификатор документа следует обрабатывать непрозрачно; это может быть разложено только сервер, который его выпустил. 3.10 ФАЙЛЫ Схема URL-адресов файлов используется для обозначения файлов, доступных на конкретный хост-компьютер. Эта схема, в отличие от большинства других схем URL, не обозначает ресурс, который доступен повсеместно через Интернет.URL-адрес файла имеет вид: файл:/// где — полное доменное имя системы на который доступен и является иерархическим путь к каталогу формы //…/. Например, файл VMS ПОЛЬЗОВАТЕЛЬ DISK $: [MY.NOTES] NOTE123456.TXT может стать В особом случае это может быть строка localhost или пустой нить; это интерпретируется как `машина, с которой интерпретируется ». Схема URL файла необычна тем, что не указывает Интернет-протокол или метод доступа к таким файлам; как таковой, его Утилита в сетевых протоколах между хостами ограничена.3.11 ПРОСПЕРО Схема URL Prospero используется для обозначения ресурсов, которые доступ через Службу каталогов Просперо. Протокол Просперо описано в [14]. URL-адреса prospero имеют вид: prospero: //: /; = где и соответствуют описанию в разделе 3.1. Если : не указан, по умолчанию используется порт 1525. Имя пользователя или пароль не указаны. Бернерс-Ли, Масинтер и МакКахилл [Страница 15] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. разрешается.- это имя объекта, зависящее от хоста, в Prospero. протокол, закодированный соответствующим образом. Это имя непрозрачно и интерпретируется сервер Просперо. Точка с запятой «;» зарезервировано и не может появляются без кавычек в. URL-адреса Prospero интерпретируются путем обращения в каталог Prospero. сервер на указанном хосте и порту для определения подходящего доступа методы для ресурса, которые сами могут быть представлены как разные URL. Внешние ссылки на Просперо представлены как URL-адреса базовый метод доступа и не представлены как Просперо URL-адреса.Обратите внимание, что косая черта «/» может стоять без кавычек и приложение не может иметь никакого значения. Хотя косые черты может указывать на иерархическую структуру на сервере, такая структура не гарантировано. Обратите внимание, что многие s начинаются с косой черты, в в этом случае за хостом или портом будет стоять двойная косая черта: косая черта от синтаксиса URL, за которой следует начальная косая черта от . (Например, обозначает из «/ pro / name».) Кроме того, после необязательных полей и значений связанный со ссылкой Просперо, может быть указан как часть URL-адреса.Если присутствует, каждая пара поле / значение отделена друг от друга и от остальной части URL-адреса на «;» (точка с запятой). Название поля и его значение разделяются знаком «=» (знак равенства). Если есть, эти Поля служат для определения цели URL. Например, Поле OBJECT-VERSION может быть указано для идентификации конкретной версии объекта. 4. РЕГИСТРАЦИЯ НОВЫХ СХЕМ Новая схема может быть введена путем определения отображения на соответствующий синтаксис URL с использованием нового префикса.URL для экспериментальных схемы могут использоваться по взаимному соглашению сторон. Имена схем начинающиеся с символов «x-» зарезервированы для экспериментальных целей. Управление по распределению номеров в Интернете (IANA) будет поддерживать реестр схем URL. Любая отправка новой схемы URL-адресов должна включить определение алгоритма доступа к ресурсам внутри этой схемы и синтаксис для представления такой схемы. Схемы URL должны демонстрировать очевидную полезность и работоспособность.В одну сторону для обеспечения такой демонстрации через шлюз, который обеспечивает объекты в новой схеме для клиентов, использующих существующий протокол. Если Бернерс-Ли, Масинтер и МакКахилл [Страница 16] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. новая схема не находит ресурсы, которые являются объектами данных, свойства имен в новом пространстве должны быть четко определены. Новые схемы должны стараться следовать тем же синтаксическим соглашениям, что и существующие схемы, где это уместно.Также рекомендуется что, если протокол позволяет получать по URL-адресу, клиент программное обеспечение может быть настроено для использования определенного шлюза локаторы для косвенного доступа через новые схемы именования. Следующая схема предлагалась в разное время, но это документ не определяет их синтаксис или использование в настоящее время. это предложили IANA зарезервировать свои названия схем для будущего определения: afs — глобальные имена файлов файловой системы Andrew File System.mid Идентификаторы сообщений для электронной почты. cid Идентификаторы содержимого для частей тела MIME. nfs Имена файлов сетевой файловой системы (NFS). tn3270 Интерактивные сеансы эмуляции 3270. почтовый сервер Доступ к данным, доступным с почтовых серверов. z39.50 Доступ к службам ANSI Z39.50. 5. BNF для определенных схем URL. Это похожее на BNF описание Uniform Resource Locator. синтаксис с использованием соглашений RFC822, за исключением «|» используется, чтобы обозначают альтернативы, а скобки [] используются вокруг необязательных или повторяющиеся элементы.Вкратце, литералы заключаются в кавычки «», необязательно элементы заключаются в [квадратные скобки], и перед элементами могут стоять с * для обозначения n или более повторений следующего элемент; n по умолчанию 0. ; Общая форма URL-адреса: genericurl = scheme «:» schemepart ; Здесь определены конкретные предопределенные схемы; новые схемы ; может быть зарегистрирован в IANA url = httpurl | ftpurl | newsurl | nntpurl | telneturl | gopherurl | waisurl | mailtourl | fileurl | prosperourl | другой URL ; новые схемы следуют общему синтаксису otherurl = genericurl ; схема строчная; интерпретаторы должны использовать игнорирование регистра схема = 1 * [lowalpha | цифра | «+» | «-» | «.»] Бернерс-Ли, Масинтер и МакКахилл [Страница 17] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. schemepart = * xchar | ip-schemepart ; Части схемы URL для протоколов на основе IP: ip-schemepart = «//» логин [«/» urlpath] логин = [пользователь [«:» пароль] «@»] хост-порт hostport = host [«:» порт] host = hostname | hostnumber hostname = * [domainlabel «.» ] toplabel domainlabel = alphadigit | alphadigit * [alphadigit | «-«] альфа-цифра toplabel = alpha | альфа * [альфацифра | «-«] альфа-цифра alphadigit = alpha | цифра hostnumber = цифры «.»цифры». «цифры». «цифры порт = цифры user = * [uchar | «;» | «?» | «&» | знак равно пароль = * [учар | «;» | «?» | «&» | знак равно urlpath = * xchar; зависит от протокола см. раздел 3.1 ; Предустановленные схемы: ; FTP (см. Также RFC959) ftpurl = «ftp: //» логин [«/» fpath [«; type =» ftptype]] fpath = fsegment * [«/» fsegment] fsegment = * [uchar | «?» | «:» | «@» | «&» | знак равно ftptype = «A» | «Я» | «Д» | «а» | «я» | «д» ; ФАЙЛ fileurl = «file: //» [хост | «localhost»] «/» путь к файлу » ; HTTP httpurl = «http: //» hostport [«/» hpath [«?» поиск ]] hpath = hsegment * [«/» hsegment] hsegment = * [uchar | «;» | «:» | «@» | «&» | знак равно поиск = * [учар | «;» | «:» | «@» | «&» | знак равно ; GOPHER (см. Также RFC1436) gopherurl = «gopher: //» hostport [/ [gtype [селектор [«% 09» поиск [«% 09» gopher + _string]]]]] gtype = xchar селектор = * xchar суслик + _string = * xchar Бернерс-Ли, Масинтер и МакКахилл [Страница 18] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. ; MAILTO (см. Также RFC822) mailtourl = «mailto:» encoded822addr encoded822addr = 1 * xchar; дополнительно определено в RFC822 ; НОВОСТИ (см. Также RFC1036) newsurl = «news:» grouppart grouppart = «*» | группа | статья группа = альфа * [альфа | цифра | «-» | «.»|» + «|» _ «] article = 1 * [учар | «;» | «/» | «?» | «:» | «&» | «=»] «@» хост ; NNTP (см. Также RFC977) nntpurl = «nntp: //» hostport «/» группа [«/» цифры] ; ТЕЛНЕТ telneturl = «telnet: //» логин [«/»] ; WAIS (см. Также RFC1625) waisurl = waisdatabase | waisindex | Waisdoc waisdatabase = «wais: //» hostport «/» база данных waisindex = «wais: //» hostport «/» database «?» поиск waisdoc = «wais: //» hostport «/» database «/» wtype «/» wpath база данных = * учар wtype = * uchar wpath = * uchar ; Просперо prosperourl = «prospero: //» hostport «/» ppath * [fieldpec] ppath = psegment * [«/» psegment] psegment = * [uchar | «?» | «:» | «@» | «&» | знак равно fieldspec = «;» fieldname «=» fieldvalue fieldname = * [uchar | «?» | «:» | «@» | «&»] fieldvalue = * [uchar | «?» | «:» | «@» | «&»] ; Разные определения lowalpha = «а» | «б» | «с» | «д» | «е» | «е» | «г» | «h» | «я» | «j» | «к» | «л» | «м» | «п» | «о» | «р» | «q» | «г» | «s» | «т» | «u» | «v» | «ш» | «х» | «у» | «z» hialpha = «A» | «Б» | «C» | «Д» | «E» | «F» | «G» | «H» | «Я» | «J» | «К» | «L» | «М» | «N» | «О» | «П» | «Q» | «Р» | «S» | «Т» | «U» | «V» | «W» | «Х» | «Y» | «Z» Бернерс-Ли, Масинтер и МакКахилл [Страница 19] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. альфа = низкая альфа | хиальфа цифра = «0» | «1» | «2» | «3» | «4» | «5» | «6» | «7» | «8» | «9» safe = «$» | «-» | «_» | «.»|» ~ «|» [«|»] «|» `» пунктуация = «» | «#» | «%» | зарезервировано = «;» | «/» | «?» | «:» | «@» | «&» | «=» шестнадцатеричный = цифра | «А» | «Б» | «C» | «Д» | «E» | «F» | «а» | «б» | «с» | «д» | «е» | «е» escape = «%» шестнадцатеричный шестнадцатеричный unreserved = альфа | цифра | сейф | дополнительный учар = без резервирования | побег xchar = без резервирования | зарезервировано | побег цифры = 1 * цифра 6. Соображения безопасности Схема URL-адресов сама по себе не представляет угрозы для безопасности.Пользователи следует помнить, что нет общей гарантии, что URL-адрес один раз указывает на данный объект продолжает делать это, и не даже в какой-то более поздний момент времени на другой объект из-за перемещение объектов по серверам. Угроза безопасности, связанная с URL-адресами, заключается в том, что иногда можно создать URL так, чтобы попытка выполнить безобидный идемпотент такая операция, как извлечение объекта, на самом деле вызовет возможно повреждение удаленного управления.Небезопасный URL обычно создается путем указания номера порта, отличного от этого зарезервировано для рассматриваемого сетевого протокола. Клиент невольно связывается с сервером, на котором фактически работает другой протокол. Содержимое URL-адреса содержит инструкции, которые при интерпретируется в соответствии с этим другим протоколом, вызывает неожиданное операция. Примером может служить использование URL-адресов суслика, чтобы вызвать грубый сообщение для отправки через SMTP-сервер. Следует соблюдать осторожность при используя любой URL-адрес, который указывает номер порта, отличный от значения по умолчанию для протокола, особенно если это число в пределах зарезервированного Космос.Следует проявлять осторожность, если URL-адреса содержат встроенные закодированные разделители. для данного протокола (например, символы CR и LF для telnet протоколы), чтобы они не были незакодированы перед передачей. Этот нарушит протокол, но может использоваться для имитации лишнего операция или параметр, снова вызывая неожиданное и возможное выполнение вредных удаленных операций. Бернерс-Ли, Масинтер и МакКахилл [Страница 20] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. Использование URL-адресов, содержащих пароли, которые должны быть секретными, явно неразумно.7. Благодарности Этот документ основан на основном дизайне WWW (RFC 1630) и многих обсуждение этих вопросов многими людьми в сети. В обсуждение было особенно стимулировано статьями Клиффорда Линча, Брюстер Кале [10] и Венгик Ён [18]. Вклад Джона Курран, Клиффорд Нойман, Эд Вильметти, а затем IETF URL BOF и Была создана рабочая группа URI. Совсем недавно внимательные чтения и комментарии Дэна Коннолли, Неда Фрид, Рой Филдинг, Гвидо ван Россум, Майкл Долан, Берт Бос, Джон Кунце, Олле Ярнефорс, Петер Сванберг и многие другие помогли доработать этот RFC.Бернерс-Ли, Масинтер и МакКахилл [Страница 21] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. ПРИЛОЖЕНИЕ: Рекомендации для URL-адресов в контексте URI, включая URL-адреса, предназначены для передачи через протоколы, которые предоставляют контекст для их интерпретации. В некоторых случаях необходимо будет отличать URL-адреса от других возможные структуры данных в синтаксической структуре. В этом случае рекомендуется ставить перед URL-адресами префикс, состоящий из символы «URL:».Например, этот префикс можно использовать для отличать URL-адреса от других типов URI. Кроме того, во многих случаях URL-адреса включаются в другие виды текста; примеры включают электронную почту, новости USENET сообщения или распечатанные на бумаге. В таких случаях удобно иметь отдельную синтаксическую оболочку, которая ограничивает URL и разделяет это от остального текста, и в частности от знаков препинания знаки, которые могут быть ошибочно приняты за часть URL-адреса. Для этого рекомендуется использовать угловые скобки («») вместе с префикс «URL:», используется для ограничения границ URL.Этот оболочка не является частью URL-адреса и не должна использоваться в контексты, в которых уже указаны разделители. В случае, когда идентификатор фрагмента / привязки связан с URL (после «#») идентификатор будет помещен в скобки. В некоторых случаях лишние пробелы (пробелы, разрывы строк, табуляции и т. Д.) Могут необходимо добавить, чтобы разбить длинные URL-адреса на строки. Пробел следует игнорировать при извлечении URL-адреса. После символа дефиса («-«) не должно быть пробелов.Поскольку некоторые наборщики и принтеры могут (ошибочно) вводить дефис в конце строки при разрыве строки, интерпретатор URL-адрес, содержащий разрыв строки сразу после дефиса, должен игнорироваться все незакодированные пробелы вокруг разрыва строки, и следует помнить что дефис может быть, а может и не быть частью URL-адреса. Примеры: Да, Джим, я нашел это внизу, но ты, наверное, сможешь его забрать. Обратите внимание на предупреждение в. Бернерс-Ли, Масинтер и МакКахилл [Страница 22] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. использованная литература [1] Анклесария, Ф., МакКахилл, М., Линднер, П., Джонсон, Д., Д. Торри и Б. Альберти, «Протокол Интернет-суслика» (протокол распределенного поиска и извлечения документов) «, RFC 1436, Университет Миннесоты, март 1993 г. [2] Анклесария, Ф., Линднер, П., МакКахилл, М., Торри, Д., Джонсон Д. и Б. Альберти, «Gopher +: восходящая совместимость. усовершенствования протокола Internet Gopher «, Университет Миннесоты, июль 1993 г. [3] Бернерс-Ли, Т. «Универсальные идентификаторы ресурсов в WWW: A Унифицирующий синтаксис для выражения имен и адресов Объекты в сети, используемые во всемирной паутине », RFC 1630, ЦЕРН, июнь 1994 г.[4] Бернерс-Ли, Т., «Протокол передачи гипертекста (HTTP)», ЦЕРН, ноябрь 1993 г. [5] Брейден Р., редактор, «Требования к хостам Интернета — Применение и поддержка », STD 3, RFC 1123, IETF, октябрь 1989 г. [6] Крокер, Д. «Стандарт формата Интернет-текста ARPA. Сообщения », STD 11, RFC 822, UDEL, апрель 1982 г. [7] Дэвис, Ф., Кале, Б., Моррис, Х., Салем, Дж., Шен, Т., Ван, Р., Суй, Дж. И М. Гринбаум, «Прототип протокола интерфейса WAIS. Функциональная спецификация », (v1.5), мыслящие машины Корпорация, апрель 1990 г. [8] Хортон, М. и Р. Адамс, «Стандарт обмена USENET Сообщения », RFC 1036, AT&T Bell Laboratories, Центр сейсмики Исследования, декабрь 1987 г. [9] Huitema, C., «Нейминг: стратегии и методы», Компьютер. Сети и системы ISDN 23 (1991) 107-110. Бернерс-Ли, Масинтер и МакКахилл [Страница 23] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. [10] Кале, Б., «Идентификаторы документов или Международный стандарт Книжные номера для электронной эры », 1991. [11] Кантор, Б. и П. Лэпсли, «Протокол передачи сетевых новостей: Предлагаемый стандарт потоковой передачи новостей «, RFC 977, Калифорнийский университет в Сан-Диего и Калифорнийский университет в Беркли, февраль 1986 г. [12] Кунце, Дж., «Функциональные требования к Интернет-ресурсам. Локаторы », Работа в процессе, декабрь 1994 г. [13] Мокапетрис, П., «Доменные имена — концепции и возможности», STD 13, RFC 1034, USC / Институт информационных наук, Ноябрь 1987 г.[14] Нойман, Б. и С. Огарт, «Протокол Просперо», USC / Институт информационных наук, июнь 1993 г. [15] Постел, Дж. И Дж. Рейнольдс, «Протокол передачи файлов (FTP)», STD 9, RFC 959, USC / Институт информационных наук, Октябрь 1985 г. [16] Sollins, K. and L. Masinter, «Функциональные требования к Унифицированные имена ресурсов », RFC 1737, MIT / LCS, Xerox Corporation, Декабрь 1994 г. [17] Сен-Пьер, М., Фултон, Дж., Гамиэль, К., Гольдман, Дж., Кале, Б., Кунце, Дж., Моррис, Х. и Ф. Шьеттекатт, «WAIS over Z39.50-1988 «, RFC 1625, WAIS, Inc., CNIDR, Thinking Machines Corp., Калифорнийский университет в Беркли, FS Consulting, июнь 1994 г. [18] Йонг, В. «На пути к сетевому поиску информации», Технические отчет 91-06-25-01, Performance Systems International, Inc. , Июнь 1991 г. [19] Йонг, В., «Представление публичных архивов в справочнике», Работа в процессе, ноябрь 1991 г. Бернерс-Ли, Масинтер и МакКахилл [Страница 24] RFC 1738 Uniform Resource Locators (URL), декабрь 1994 г. [20] «Набор кодированных символов — 7-битный американский стандартный код для Обмен информацией », ANSI X3.4-1986. Адреса редакторов Тим Бернерс-Ли Проект во всемирной паутине ЦЕРН, 1211 Женева 23, Швейцария Телефон: +41 (22) 767 3755 Факс: +41 (22) 767 7155 Электронная почта: [email protected] Ларри Масинтер Xerox PARC 3333 Coyote Hill Road Пало-Альто, Калифорния 94034 Телефон: (415) 812-4365 Факс: (415) 812-4333 Электронная почта: [email protected] Марк МакКахилл Компьютерные и информационные услуги, Университет Миннесоты Комната 152 Shepherd Labs 100 Union Street SE Миннеаполис, Миннесота 55455 Телефон: (612) 625 1300 Электронная почта: mpm @ boombox.micro.umn.edu Бернерс-Ли, Масинтер и МакКахилл [Страница 25]
HTML Кодировка URL-адреса
URL — это другое слово для обозначения веб-адреса.
URL-адрес может состоять из слов (например, w3schools.com) или IP-адреса (например, 192.68.20.50).
Большинство людей вводят имя во время серфинга, потому что имена легче запомнить, чем числа.
URL — унифицированный указатель ресурсов
Веб-браузеры запрашивают страницы с веб-серверов, используя URL-адрес.
Унифицированный указатель ресурса (URL) используется для адресации документа (или других данных) в сети.
Веб-адрес, например https://www.w3schools.com/html/default.asp следует этим правилам синтаксиса:
схема: //префикс. домен: порт / путь / имя файла
Пояснение:
- схема — определяет тип интернет-сервиса (наиболее распространенный — http или https )
- префикс — определяет префикс домена (по умолчанию для http www )
- domain — определяет интернет-домен , имя (например, w3schools.com)
- порт — определяет номер порта на хосте (по умолчанию для http: 80 )
- путь — определяет путь на сервере (если не указано: корневой каталог сайта)
- filename — определяет имя документа или ресурса
Общие схемы URL
В таблице ниже перечислены некоторые общие схемы:
| Схема | Сокращение для | Используется для |
|---|---|---|
| http | Протокол передачи гипертекста | Общие веб-страницы.Незашифрованный |
| https | Безопасный протокол передачи гипертекста | Защищенные веб-страницы. Зашифрованный |
| ftp | Протокол передачи файлов | Скачивание или выгрузка файлов |
| файл | Файл на вашем компьютере |
Кодировка URL
URL-адресов можно отправить только через Интернет с помощью Набор символов ASCII. Если URL-адрес содержит символы вне набора ASCII, URL-адрес должен быть преобразован.
КодировкаURL преобразует символы, отличные от ASCII, в формат, который можно передавать через Интернет.
КодировкаURL заменяет символы, отличные от ASCII, на «%», за которым следуют шестнадцатеричные цифры.
URL-адреса не могут содержать пробелов. Кодировка URL-адреса обычно заменяет пробел знаком плюса (+) или% 20.
Попробуйте сами
Если вы нажмете «Отправить», браузер закодирует ввод по URL перед его отправкой на сервер.
Страница на сервере отобразит полученный ввод.
Попробуйте ввести другие данные и снова нажмите «Отправить».
Примеры кодирования ASCII
Ваш браузер закодирует ввод в соответствии с набором символов, используемым на вашей странице.
Набор символов по умолчанию в HTML5 — UTF-8.
| Персонаж | из Windows-1252 | из UTF-8 |
|---|---|---|
| € | % 80 | % E2% 82% AC |
| £ | % A3 | % C2% A3 |
| © | % A9 | % C2% A9 |
| ® | % AE | % C2% AE |
| À | % C0 | % C3% 80 |
| Á | % C1 | % C3% 81 |
| Â | % C2 | % C3% 82 |
| Ã | % C3 | % C3% 83 |
| Ä | % C4 | % C3% 84 |
| Å | % C5 | % C3% 85 |
Для получения полной информации обо всех кодировках URL посетите наш Справочник по кодировке URL.
В чем разница между HTTP и HTTPS?
Подождите, а их действительно два? Обычные пользователи редко их замечают, но HTTP (или http: //) и HTTPS (https: //) — оба варианта для начала URL-адреса, демонстрируя важную разницу во всех тех веб-страницах, которые вы посещаете ежедневно. Даже если вы не очень хотите разбираться в принципах работы, мы держим пари, что это расширит ваши горизонты. Считайте это своим первым уроком, если хотите узнать больше о безопасности в Интернете.
В этом разница между HTTP и HTTPS, как объясняется в этой удивительной инфографике, созданной FirstSiteGuide. Ниже я объясню наиболее важные моменты.
HTTP: шифрование данных не реализовано
Каждая ссылка URL, начинающаяся с HTTP, использует базовый тип «протокола передачи гипертекста». Созданный Тимом Бернерсом-Ли еще в начале 1990-х, когда Интернет еще только зарождался, этот стандарт сетевого протокола — это то, что позволяет веб-браузерам и серверам обмениваться данными.
HTTP также называют «системой без сохранения состояния», что означает, что он разрешает соединение по запросу. Вы нажимаете ссылку, запрашивая соединение, и ваш веб-браузер отправляет этот запрос на сервер, который отвечает, открывая страницу. Чем быстрее будет соединение, тем быстрее вам будут представлены данные.
Как «протокол прикладного уровня» HTTP по-прежнему сосредоточен на представлении информации, но меньше заботится о том, как эта информация перемещается из одного места в другое. К сожалению, это означает, что HTTP может быть перехвачен и потенциально изменен, что делает уязвимыми как информацию, так и получателя информации (то есть вас).
HTTPS: зашифрованные соединения
HTTPS — это не противоположность HTTP, а его младший родственник. По сути, они одинаковы, поскольку оба относятся к одному и тому же «протоколу передачи гипертекста», который позволяет отображать запрошенные веб-данные на вашем экране. Но HTTPS все же немного другой, более продвинутый и гораздо более безопасный.
Проще говоря, протокол HTTPS является расширением HTTP. Буква «S» в аббревиатуре происходит от слова Secure, и она основана на Transport Layer Security (TLS) [преемнике Secure Sockets Layer (SSL)], стандартной технологии безопасности, которая устанавливает зашифрованное соединение между веб-сервером и браузер.
Без HTTPS любые данные, которые вы вводите на сайт (например, ваше имя пользователя / пароль, данные кредитной карты или банковские реквизиты, любые другие данные для отправки формы и т. Д.), Будут отправлены в виде открытого текста и, следовательно, станут уязвимыми для перехвата или подслушивания. По этой причине вы всегда должны проверять, использует ли сайт HTTPS, прежде чем вводить какую-либо информацию.
Помимо шифрования данных, передаваемых между сервером и вашим браузером, TLS также аутентифицирует сервер, к которому вы подключаетесь, и защищает передаваемые данные от несанкционированного доступа.
Это помогает мне думать об этом так: HTTP в HTTPS — это эквивалент пункта назначения, а SSL — это эквивалент путешествия. Первый отвечает за вывод данных на ваш экран, а второй управляет тем, как они туда попадают. Совместными усилиями они безопасно перемещают данные.
Преимущества и недостатки HTTPS
Как обсуждалось выше, HTTPS помогает обеспечить кибербезопасность. Это, без сомнения, лучшее решение для сетевого протокола, чем его старший родственник HTTP.
Но разве HTTPS — это все о преимуществах? Может быть, во всем этом есть недостаток? Давайте разберемся.
Преимущества использования HTTPS
Упомянутые выше преимущества безопасности — аутентификация сервера, шифрование передачи данных и защита обменов от несанкционированного доступа — очевидные основные преимущества использования HTTPS. Операторы сайтов хотят и должны защищать данные своих посетителей (HTTPS фактически является требованием для любых сайтов, собирающих платежную информацию в соответствии со стандартом безопасности данных PCI), а посетители сайта хотят знать, что их данные передаются безопасно.
Растущий спрос на конфиденциальность и безопасность данных со стороны широкой общественности — еще одно преимущество использования HTTPS. Фактически, согласно данным We Make Websites, 13% всех отказов от корзины связано с проблемами безопасности платежей. Посетители сайта хотят знать, что они могут доверять вашему сайту, особенно если они вводят финансовые данные, и использование HTTPS — один из способов сделать это (т. Е. Один из способов показать вашим посетителям, что любая вводимая ими информация будет зашифрована).
HTTPS также может помочь с вашим SEO.Еще в 2014 году Google объявил HTTPS как сигнал ранжирования. С тех пор некоторые исследования и анекдотический опыт компаний, внедривших HTTPS, указывают на корреляцию с более высоким рейтингом и видимостью страниц.
Браузеры также прилагают усилия для увеличения использования HTTPS путем внесения изменений пользовательского интерфейса, которые негативно повлияют на сайты, не использующие HTTPS. Например, ранее в этом году Google объявил, что к июлю (всего через несколько месяцев!) Chrome пометит всех HTTP-сайтов как незащищенные.
Запланированные изменения пользовательского интерфейса Chrome по сравнению с первоначальным объявлением Google в феврале 2018 г. ( источник )
Даже если вы посмотрите сейчас сайт HTTP (в Chrome 66), вы увидите, что они добавили уведомление, предупреждающее посетителей о том, что их соединение небезопасно, если вы нажмете значок «Дополнительная информация» в адресной строке.
Пример предупреждения HTTP-сайта в Chrome 66 (спасибо badssl.com за пример HTTP-сайта)
Firefox также объявил о планах отмечать HTTP-сайты.Представьте, как это повлияет на создание вашего бренда и маркетинг, привлечение клиентов и продажи. Единственный способ противостоять входящим изменениям — это принять их — установите HTTPS на свой сайт!
На что следует обратить внимание перед переходом на HTTPS
Несмотря на то, что процесс переключения с HTTP на HTTPS является улицей с односторонним движением, есть еще много людей, которые сбиваются с пути, вероятно, из-за большого количества возможностей, которые им возложены.
Короче говоря, вышеупомянутый процесс состоит из следующих четырех шагов:
- Получение SSL-сертификата от доверенного центра сертификации
- Установка на хостинг-аккаунт вашего сайта
- Настройка 301 редиректа путем редактирования.htaccess в корневой папке, добавив:
- RewriteEngine на
- RewriteCond% {HTTPS} со скидкой
- RewriteRule (. *) Https: //% {HTTP_HOST}% {REQUEST_URI} [R = 301, L]
- Уведомление поисковых систем об изменении адресов вашего сайта и о том, что кто-либо посещает ваш сайт после этого, автоматически перенаправляется на HTTPS-адрес.
Если это все еще кажется вам сложным, не волнуйтесь. Ваши возможности не исчерпаны!
Многие хостинговые компании в настоящее время предлагают сертификаты SSL как часть своих услуг, выполняя большую часть работы самостоятельно (первые три из четырех шагов, упомянутых выше).Вам нужно только указать своим посетителям на новые адреса. Но будьте осторожны! Это может стоить вам дополнительных долларов.
Будущее
Как бы то ни было, в Интернете сейчас более 4 миллиардов пользователей, потребителей контента, покупателей и т.п. Комбинация требований пользователей (посетители сайта более осведомлены о безопасности данных, чем когда-либо прежде), нормативных требований (например, PCI DSS) и поддержки со стороны браузеров (например, планы пометить сайты HTTP как небезопасные), дает понять, что полный переход с HTTP на HTTPS в ближайшее время.
Примечание : Эта статья в блоге была написана приглашенным участником с целью предложить нашим читателям более широкий спектр контента. Мнения, выраженные в этой статье приглашенного автора, принадлежат исключительно автору и не обязательно отражают точку зрения GlobalSign.
Источник журналов и показателей HTTP
Источник журналов и показателей HTTP — это конечная точка для получения данных журнала и показателей, загруженных на уникальный URL-адрес, созданный для источника.URL-адрес надежно кодирует информацию о сборщике и источнике. Вы можете добавить столько HTTP-журналов и источников показателей, сколько захотите, в один размещенный сборщик.
С помощью источника журналов и метрик HTTP вы можете выгружать журналы и метрики из источников данных, из которых нельзя установить сборщик. Например, вы можете экспортировать данные с платформы как услуги (PaaS) или из инфраструктуры как поставщика услуги (IaaS), что позволит вам получить доступ, например, к поставщику услуг вашей биллинговой системы, используя те же инструменты Sumo, что и ваша организация. уже использует.Обратитесь к своим поставщикам IaaS или PaaS за информацией об использовании их API-интерфейсов для пересылки данных журнала или показателей в конечную точку HTTP Sumo Logic.
При настройке источника журналов и показателей HTTP этому источнику назначается уникальный URL-адрес. Сгенерированный URL-адрес представляет собой длинную строку букв и цифр. Вы можете сгенерировать новый URL-адрес в любое время. Для получения дополнительной информации см. Создание нового URL-адреса.
Рекомендации по полезной нагрузке данных
Мы рекомендуем, чтобы полезные данные запроса POST имели размер до сжатия от 100 КБ до 1 МБ.
Sumo Logic рекомендует группировать данные в каждый запрос POST, чтобы уменьшить количество запросов, отправляемых по сети. Пакетирование данных в один запрос сводит к минимуму количество запросов, необходимых для перемещения заданного объема данных, и снижает использование ресурсов на отправляющей машине. Вы можете отправлять пакетные запросы размером не более 1 МБ несжатых данных. Однако оптимальный пакет для данного варианта использования зависит от скорости и частоты появления журналов или показателей в вашей системе.
Настройка источника журналов и показателей HTTP
Для настройки источника журналов и показателей HTTP:
- В веб-приложении Sumo Logic выберите Управление данными> Коллекция> Коллекция .
- На странице сборщиков щелкните Добавить источник рядом с размещенным сборщиком .
- Выберите Журналы и показатели HTTP .
- Введите Имя , которое будет отображаться для источника в веб-приложении Sumo.Описание не является обязательным.
- (Необязательно) Для хоста источника и категории источника введите любую строку, чтобы пометить выходные данные, собранные из источника. (Метаданные категории хранятся в доступном для поиска поле _sourceCategory.)
- Поля . Щелкните ссылку + Добавить поле , чтобы добавить настраиваемые поля метаданных журнала. Определите поля, которые вы хотите связать, каждое поле должно иметь имя (ключ) и значение.
- Зеленый кружок с галочкой отображается, когда поле существует и включено в схеме таблицы полей.
- Оранжевый треугольник с восклицательным знаком отображается, когда поле не существует или отключено в схеме таблицы полей. В этом случае появится опция Автоматически активировать все поля при сохранении .
- Проверка Автоматически активировать все поля при сохранении дает следующий результат:
- Поле будет сохранено в вашей схеме полей.
- Поле будет применяться к журналам, собранным сборщиком или источником.
- Если вы добавляете поле в источник HTTP или в коллектор, у которого есть источник HTTP, поле будет применено к метрикам, собранным источником.
- Если вы не выбрали Автоматически активировать все поля при сохранении :
- Поле не будет сохранено в вашей схеме полей
- Поле будет применено к собранным или исходным журналам, но поскольку поле не будет добавлено в вашу схему полей, оно будет удалено Sumo Logic при загрузке журналов с этим полем.
- Поле будет применяться к метрикам, собранным источником.
- Проверка Автоматически активировать все поля при сохранении дает следующий результат:
- Установите любой из следующих параметров в Advanced. Дополнительные параметры , а не , применяются к загруженным показателям.
Включить синтаксический анализ метки времени. Этот параметр выбран по умолчанию. Если он не выбран, информация о временных метках не анализируется.
- Часовой пояс. Есть два варианта Часовой пояс. Вы можете использовать часовой пояс, представленный в ваших файлах журнала, а затем выбрать вариант, если информация о часовом поясе отсутствует в сообщении журнала. Или вы можете заставить Sumo полностью игнорировать любую информацию о часовом поясе, представленную в журналах, установив часовой пояс. Какой бы вариант вы ни выбрали, важно установить правильный часовой пояс. Если часовой пояс журналов не может быть определен, Sumo назначает журналам UTC; если остальные журналы относятся к другому часовому поясу, это повлияет на результаты поиска.
- Формат отметки времени. По умолчанию Sumo автоматически определяет формат метки времени в ваших журналах. Однако вы можете вручную указать формат метки времени для источника. См. «Метки времени», «Часовые пояса», «Временные диапазоны» и «Форматы даты» для получения дополнительной информации.
Включить многострочную обработку. См. Сбор многострочных журналов для получения подробной информации о многострочной обработке и ее параметрах. Используйте эту опцию, если вы работаете с многострочными сообщениями (например, сообщениями log4J или трассировкой стека исключений).Снимите этот флажок, если вы хотите избежать ненужной обработки при сборе файлов с одним сообщением в строке (например, Linux system.log).
- Выведенные границы. Включите, если вы хотите, чтобы Sumo автоматически определяла, какие строки принадлежат одному и тому же сообщению.
Если вы отмените выбор параметра Infer Boundaries, введите регулярное выражение в поле Boundary Regex , чтобы использовать его для определения всей первой строки многострочных сообщений. - Граничное регулярное выражение. Вы можете указать границу между сообщениями, используя регулярное выражение. Введите регулярное выражение для полной первой строки каждого многострочного сообщения в файлах журнала.
- Разрешить одно сообщение на запрос. Выберите этот вариант, если вы будете отправлять одно сообщение с каждым HTTP-запросом. Дополнительные сведения см. В разделе Параметры многострочного режима в источниках HTTP.
- Правила обработки журналов. Сконфигурируйте требуемые фильтры, такие как включить, исключить, хэш или маску, как описано в разделе «Создание правила обработки».Правила обработки применяются к данным журнала, но не к данным показателей. Обратите внимание, что пока служба Sumo будет получать ваши данные, прием данных будет выполняться в соответствии с регулярными выражениями, которые вы указываете в правилах обработки.
- Когда вы закончите настройку источника, нажмите Сохранить .
- Когда отображается URL-адрес, связанный с источником, скопируйте URL-адрес, чтобы его можно было использовать для загрузки данных.
Загрузить данные в источник журналов и показателей HTTP
Вы можете загружать журналы и поддерживаемые типы показателей в источник HTTP.Существуют разные требования в зависимости от того, загружаете ли вы журналы или показатели в источник.
Контроль доступа HTTP (CORS)
Источники HTTPSumo Logic поддерживают клиентов, связанных механизмом CORS.
Чтобы убедиться, что установлены соответствующие заголовки ответа Access-Control- *, убедитесь, что заголовок Origin заполнен в исходной проверке OPTIONS и во всех последующих запросах.
Сжатые данные
Вы можете отправить Sumo простые несжатые данные (например, простой текст) или вы можете отправить данные, сжатые с помощью метода deflate или gzip.Сжатые данные можно отправить только методом POST. Вы можете сжать данные журнала или метрики перед загрузкой.
Чтобы отправить сжатую полезную нагрузку, укажите значение gzip (для сжатия gzip) или deflate (для сжатия zlib) в заголовке Content-Encoding вашего запроса и включите сжатые данные в качестве тела запроса.
Сжатые файлы распаковываются перед загрузкой, поэтому они загружаются со скоростью распакованного файла.
Доступ к URL-адресу источника
Если вам нужно снова получить доступ к URL-адресу источника, щелкните Показать URL-адрес .
URL-адрес источника можно просмотреть, отправив запрос GET в API управления сборщиками для конфигурации JSON источника.
Многострочные параметры в источниках HTTP
Источник журналов и показателей HTTP не предназначен для поддержки большого количества подключений к источнику. Если возможно, вы должны пакетировать сообщения журнала локально и отправлять пакеты в одном потоке.
Чтобы увеличить пропускную способность, отправьте несколько сообщений журнала в один запрос к источнику.Если какой-либо из этих журналов может содержать многострочные сообщения, такие как трассировки стека, активируйте Включить многострочную обработку .
Для базовой многострочной обработки выберите Вывести границы ; если это приводит к искажению сообщений, вместо этого можно указать регулярное выражение для определения многострочной границы.
Кроме того, в конфигурации источника HTTP убедитесь, что флажок Разрешить одно сообщение на запрос — деактивирован .Этот параметр позволяет указать, что все данные, отправленные в отдельном HTTP-запросе к конечной точке HTTP-источника, должны рассматриваться как одно сообщение журнала.
Sumo ожидает, что все содержимое отдельного сообщения журнала будет отправлено Sumo в рамках одного и того же HTTP-запроса. Правила многострочной обработки применяются только в пределах данных, отправленных в рамках одного HTTP-запроса. Это означает, что многострочный журнал, отправляемый Sumo по нескольким HTTP-запросам, не будет обнаружен как одно сообщение.Он будет разбит на отдельные сообщения журнала. Sumo в настоящее время не имеет возможности обнаруживать и объединять отдельные сообщения журнала, отправленные через несколько HTTP-запросов.
Инструменты для пакетной обработки сообщений см. На https://github.com/SumoLogic/sumologic-net-appenders.
Подробнее о том, как Collector обрабатывает многострочные журналы, см. Сбор многострочных журналов.
16,393,865 | 16.07.2012 | |||
http: // ураганы.gov / nhc_storms.shtml | 11,859,701 | 6/09/2011 | ||
http: //www.hpc.ncep.noaa.gov/discussions/hpcdiscussions.php? disc = … | 4279174 | 12.01.2012 | ||
http: //preview.weather.gov/edd/? Lat = 40.329452873812926 & lon = -75.73 … EDD: NOAA / NWS — дисплей с расширенными данными картографический веб-интерфейс для доступа к наблюдаемым и прогнозируемым погодным данным в реальном времени. примечания за исключением | 3,913,016 | 4.01.2014 | ||
3,361,555 | 7/11/2017 | |||
| 4/9011 | ||||
| 48 | 3https://afvec.langley.af.mil/afvec/Home.aspx | 2,943,886 | 12.06.2015 | |
2,898,886 | 6 | |||
2,749,226 | 13.03.2020 | |||
http: // www.spc.noaa.gov/products/outlook/day1otlk.html Суровая погода, торнадо, гроза, пожарная погода, отчет о шторме, часы с торнадо, часы с сильной грозой, мезомасштабная дискуссия, конвективные прогнозы продуктов от Storm Центр прогнозов. | 2,331,532 | 10.05.2012 | ||
http://www.spc.noaa.gov/products/exper/enhtstm/ | 1,740911 | 10/05 | ||
1,634,883 | 11.07.2017 | |||
http: // www.spc.noaa.gov/products/outlook/day1otlk.html Суровая погода, торнадо, гроза, пожарная погода, отчет о шторме, часы с торнадо, часы с сильной грозой, мезомасштабная дискуссия, конвективные прогнозы продуктов от Storm Центр прогнозов. | 1,547,332 | 17.01.2012 | ||
1,363,367 | 9 февраля 2018 г. | 1,314,457 | 27.04.2020 | |
1,182,237 | 9/25/2017 | |||
1,154,05943 | 52 1,154,059435127.01.2016 | |||
1,116,189 | 4 июля 2016 г. | 4.07.2020 | ||
950462 | 23.03.2020 | |||
http: // www.spc.noaa.gov/products/outlook/day2otlk.html Суровая погода, торнадо, гроза, пожарная погода, отчет о шторме, часы с торнадо, часы с сильной грозой, мезомасштабная дискуссия, конвективные прогнозы продуктов от Storm Центр прогнозов. | 913,765 | 10.05.2012 | ||
909,377 | 7/10/2015 |
Источники модулей — Terraform от HashiCorp
Исходный аргумент в блоке модуля сообщает Terraform, где найти исходный код желаемого дочернего модуля.
Terraform использует это на этапе установки модуля terraform init чтобы загрузить исходный код в каталог на локальном диске, чтобы его можно было
используется другими командами Terraform.
Установщик модуля поддерживает установку из различных источников. типы, как указано ниже.
Каждый из них описан в следующих разделах. Адреса источников модулей использовать URL-подобный синтаксис , но с расширениями для поддержки однозначного выбора источников и дополнительных возможностей.
Мы рекомендуем использовать локальные пути к файлам для тесно связанных модулей, используемых в основном с целью выделения повторяющихся элементов кода и использования собственного Реестр модулей Terraform для модулей, предназначенных для совместного использования несколькими вызовами конфигурации. Мы поддерживаем другие источники, чтобы вы могли распространять Модули Terraform внутри с существующей инфраструктурой.
Многие типы источников будут использовать «внешние» учетные данные. при запуске Terraform, например, из переменных среды или файлов учетных данных в вашем домашнем каталоге.Это рассматривается более подробно в каждом из следующих разделы.
Мы рекомендуем помещать каждый модуль, предназначенный для повторного использования, в корневой каталог. собственного репозитория или архивного файла, но также возможно ссылочные модули из подкаталогов.
» Локальные пути
Ссылки локального пути позволяют выносить части конфигурации в едином исходном репозитории.
модуль "консул" {
source = "./consul"
}
Локальный путь должен начинаться с ./ или ../ , чтобы указать, что местный
путь предназначен для отличия от
адрес реестра модуля.
Локальные пути отличаются тем, что они не «устанавливаются» в том же смысле. другими источниками являются: файлы уже присутствуют на локальном диске (возможно, в результате установки родительского модуля), поэтому его можно использовать напрямую. Их исходный код обновляется автоматически при обновлении родительского модуля.
» Реестр Terraform
Реестр модулей — это собственный способ распространения модулей Terraform для использования в нескольких конфигурациях, используя протокол, специфичный для Terraform, который имеет полную поддержку управления версиями модулей.
Terraform Registry — это указатель модулей опубликовано публично с использованием этого протокола. Этот публичный реестр — самый простой способ чтобы начать работу с Terraform и найти модули, созданные другими в сообщество.
Вы также можете использовать частный реестр, либо через встроенную функцию из Terraform Cloud или запустив настраиваемый сервис, который реализует протокол реестра модуля.
На модулей в общедоступном реестре Terraform можно ссылаться с помощью реестра.
исходный адрес формы , с каждым
информационная страница модуля на сайте реестра с точным адресом
использовать.
модуль "консул" {
источник = "hashicorp / consul / aws"
версия = "0.1.0"
}
В приведенном выше примере будет использоваться Модуль Consul для AWS из публичного реестра.
Для модулей, размещенных в других реестрах, укажите перед адресом источника префикс
дополнительная часть , дающая имя хоста частного реестра:
модуль "консул" {
source = "app.terraform.io/example-corp/k8s-cluster/azurerm"
версия = "1.1.0"
}
Если вы используете SaaS-версию Terraform Cloud, ее частный
имя хоста реестра — app.terraform.io . Если вы используете автономный Terraform
Экземпляр предприятия, его частное имя хоста реестра совпадает с именем хоста
где вы получите доступ к веб-интерфейсу и хосту, который вы будете использовать при настройке
удаленный бэкэнд .
поддерживают управление версиями. Вы можете предоставить конкретную версию, как показано в приведенных выше примерах или используйте гибкий ограничения версии.
Подробнее о реестре можно узнать на Документация Terraform Registry.
Для доступа к модулям из частного реестра вам может потребоваться настроить доступ токен в конфигурации CLI.Использовать то же имя хоста, что и в исходной строке модуля. Для частного реестра в Terraform Cloud используйте тот же токен аутентификации, что и вы использовать с Enterprise API или клиентами командной строки.
» GitHub
Terraform распознает URL-адреса github.com без префикса и интерпретирует их
автоматически как источники репозитория Git.
модуль "консул" {
источник = "github.com/hashicorp/example"
}
Приведенная выше адресная схема будет клонирована через HTTPS.Чтобы клонировать через SSH, используйте следующая форма:
модуль "консул" {
source = "[email protected]: hashicorp / example.git"
}
Эти схемы GitHub рассматриваются как удобные псевдонимы для
общая схема адресов репозитория Git, и так
они получают учетные данные таким же образом и поддерживают аргумент ref для
выбор конкретной ревизии. Вам нужно будет настроить учетные данные в
особенно для доступа к частным репозиториям.
» Bitbucket
Terraform распознает битбакет без префикса.org URL и интерпретировать их
автоматически как репозитории BitBucket:
модуль "консул" {
source = "bitbucket.org/hashicorp/terraform-consul-aws"
}
Это сокращение работает только для общедоступных репозиториев, потому что Terraform должен получить доступ к API BitBucket, чтобы узнать, использует ли данный репозиторий Git или Mercurial.
Terraform обрабатывает результат либо как источник Git или источник Mercurial в зависимости от тип репозитория. Для получения информации см. Разделы о каждом типе управления версиями. о том, как настроить учетные данные для частных репозиториев и как указать конкретная версия для установки.
» Общий репозиторий Git
Можно использовать произвольные репозитории Git, добавив к адресу префикс
специальный префикс git :: . После этого префикса любой допустимый
Git URL
можно указать, чтобы выбрать один из протоколов, поддерживаемых Git.
Например, для использования HTTPS или SSH:
модуль "vpc" {
source = "git :: https: //example.com/vpc.git"
}
модуль "хранилище" {
source = "git :: ssh: //[email protected]/storage.git"
}
Terraform устанавливает модули из репозиториев Git, запустив git clone и
поэтому он будет уважать любую локальную конфигурацию Git, установленную в вашей системе, включая
реквизиты для входа.Чтобы получить доступ к закрытому репозиторию Git, настройте Git с
подходящие учетные данные для этого репозитория.
Если вы используете протокол SSH, будут использоваться любые настроенные ключи SSH. автоматически. Это наиболее распространенный способ доступа к закрытому Git. репозиториев из автоматизированных систем, потому что это позволяет получить доступ к частным репозитории без интерактивных подсказок.
При использовании протокола HTTP / HTTPS или любого другого протокола, использующего учетные данные имени пользователя / пароля, настроить Хранилище учетных данных Git чтобы выбрать подходящий источник учетных данных для вашей среды.
Если ваша конфигурация Terraform будет использоваться в Terraform Cloud, поддерживается только аутентификация по ключу SSH, и ключи можно настроить для каждой рабочей области.
» Выбор редакции
По умолчанию Terraform будет клонировать и использовать ветку по умолчанию (на которую указывает HEAD ) в выбранном репозитории. Вы можете переопределить это, используя ref аргумент:
модуль "vpc" {
source = "git :: https: //example.com/vpc.git? ref = v1.2,0 "
}
Значением аргумента ref может быть любая ссылка, которая будет принята
командой git checkout , включая имена веток и тегов.
» «scp-подобный» синтаксис адреса
При использовании Git через SSH мы рекомендуем использовать форму URL с префиксом ssh: // .
для согласованности со всеми другими URL-подобными формами адресов git.
Вместо этого вы можете использовать альтернативный «scp-подобный» синтаксис, и в этом случае вы
должен опускать часть схемы ssh: // и включать только часть git :: .Например:
модуль "Хранилище" {
source = "git :: [email protected]: storage.git"
}
Если вы используете схему URL ssh: // , то Terraform будет считать, что двоеточие
отмечает начало номера порта, а не начало пути.
Это соответствует тому, как сам Git интерпретирует эти разные формы, помимо
префикс селектора git :: , специфичный для Terraform.
» Универсальный Mercurial Repository
Вы можете использовать произвольные репозитории Mercurial, добавив к адресу префикс
специальный префикс hg :: .После этого префикса любой допустимый
Mercurial URL
можно указать, чтобы выбрать один из протоколов, поддерживаемых Mercurial.
модуль "vpc" {
source = "hg :: http: //example.com/vpc.hg"
}
Terraform устанавливает модули из репозиториев Mercurial, запустив hg clone и
поэтому он будет уважать любую локальную конфигурацию Mercurial, установленную в вашей системе,
включая учетные данные. Чтобы получить доступ к непубличному репозиторию, настройте Mercurial
с подходящими учетными данными для этого репозитория.
Если вы используете протокол SSH, будут использоваться любые настроенные ключи SSH. автоматически. Это наиболее распространенный способ доступа к закрытому Mercurial. репозиториев из автоматизированных систем, потому что это позволяет получить доступ к частным репозитории без интерактивных подсказок.
Если ваша конфигурация Terraform будет использоваться в Terraform Cloud, поддерживается только аутентификация по ключу SSH, и ключи можно настроить для каждой рабочей области.
» Выбор редакции
Вы можете выбрать ветвь или тег не по умолчанию, используя необязательный аргумент ref :
модуль "vpc" {
source = "hg :: http: // пример.com / vpc.hg? ref = v1.2.0 "
}
» URL-адреса HTTP
Когда вы используете URL-адрес HTTP или HTTPS, Terraform отправит запрос GET к
данный URL, который может вернуть еще один адрес источника. Это косвенное обращение
позволяет использовать URL-адреса HTTP как своего рода «тщеславное перенаправление» для более сложных
адрес источника модуля.
Terraform добавит дополнительный аргумент строки запроса terraform-get = 1 к
данный URL-адрес перед отправкой запроса GET , позволяя серверу
необязательно возвращать другой результат, когда Terraform запрашивает его.
Если ответ успешен (код состояния 200 ), Terraform просматривает
следующие места для доступа по следующему адресу:
Значение поля заголовка ответа с именем
X-Terraform-Get.Если ответ представляет собой HTML-страницу, мета-элемент
terraform-get:
В любом случае результат интерпретируется как адрес источника другого модуля. используя одну из форм, задокументированных в другом месте на этой странице.
Если URL-адрес HTTP / HTTPS требует учетных данных для аутентификации, используйте .netrc файл в вашем домашнем каталоге, чтобы настроить их. Для получения информации об этом формате,
см. документацию по его использованию в curl .
» Получение архивов через HTTP
В качестве особого случая, если Terraform обнаруживает, что URL-адрес имеет общий файл
расширение, связанное с форматом файла архива, тогда оно будет обходить
специальное перенаправление terraform-get = 1 , описанное выше, и вместо этого просто используйте
содержимое указанного архива в качестве исходного кода модуля:
модуль "vpc" {
source = "https: // пример.com / vpc-module.zip "
}
Расширения, которые Terraform распознает для этого особого поведения:
Если ваш URL не имеет одного из этих расширений , но ссылается на архив
в любом случае, используйте аргумент архива , чтобы заставить эту интерпретацию:
модуль "vpc" {
источник = "https://example.com/vpc-module?archive=zip"
}
Примечание: Если содержимым файла архива является каталог, вам необходимо включить этот каталог в исходный код модуля.Прочтите раздел о Модули в подкаталогах пакетов для получения дополнительной информации Информация.
» Ковш S3
Вы можете использовать архивы, хранящиеся в S3, как источники модулей, используя специальный s3 :: префикс, за которым следует
URL-адрес объекта корзины S3.
модуль "консул" {
source = "s3 :: https: //s3-eu-west-1.amazonaws.com/examplecorp-terraform-modules/vpc.zip"
}
Примечание. Для сегментов в регионе AWS us-east-1 необходимо использовать имя хоста s3.amazonaws.com (вместо s3-us-east-1.amazonaws.com ).
Префикс s3 :: заставляет Terraform использовать аутентификацию в стиле AWS, когда
доступ к заданному URL-адресу. В результате эта схема может работать и для других
сервисы, имитирующие S3 API, при условии, что они обрабатывают аутентификацию в
так же, как AWS.
Результирующий объект должен быть архивом с одним и тем же файлом. расширения как для архивов через стандартный HTTP. Terraform распакует архив, чтобы получить дерево исходных текстов модуля.
Установщик модуля ищет учетные данные AWS в следующих местах: предпочитая те, что указаны ранее в списке, когда доступно несколько:
- Переменные среды
AWS_ACCESS_KEY_IDиAWS_SECRET_ACCESS_KEY. - Профиль по умолчанию в файле
.aws / credentialsв вашем домашнем каталоге. - При работе на экземпляре EC2 временные учетные данные, связанные с профиль экземпляра IAM экземпляра.
» Сегмент GCS
Вы можете использовать архивы, хранящиеся в Google Cloud Storage, в качестве источников модулей, используя специальный gcs :: префикс, за которым следует
URL-адрес объекта корзины GCS.
Например,
модуль "консул" {
source = "gcs :: https: //www.googleapis.com/storage/v1/modules/foomodule.zip"
}
Установщик модуля использует Google Cloud SDK для аутентификации с помощью GCS. Чтобы установить учетные данные, вы можете:
- Введите путь к файлу ключа учетной записи службы в переменной среды GOOGLE_APPLICATION_CREDENTIALS, или;
- Если вы запускаете Terraform из экземпляра GCE, учетные данные по умолчанию доступны автоматически.Дополнительные сведения см. В разделе «Создание и включение учетных записей служб для экземпляров».
- На своем компьютере вы можете сделать свою учетную запись Google доступной, запустив
gcloud auth application-default login.
» Модули в подкаталогах пакетов
Когда источником модуля является репозиторий системы контроля версий или архивный файл (обычно «пакет»), сам модуль может находиться в относительном подкаталоге в корень пакета.
Terraform интерпретирует специальный синтаксис с двойной косой чертой, чтобы указать, что оставшийся после этой точки путь — это подкаталог внутри пакета.Например:
Если исходный адрес имеет аргументы, такие как ref аргумент, поддерживаемый для
источники управления версиями, часть подкаталога должна быть до , которые
аргументы:
Terraform все равно распакует весь пакет на локальный диск, но будет читать модуль из подкаталога. В результате это безопасно для модуля в подкаталог пакета, чтобы использовать локальный путь к другому модуль, если он находится в той же упаковке и .
.