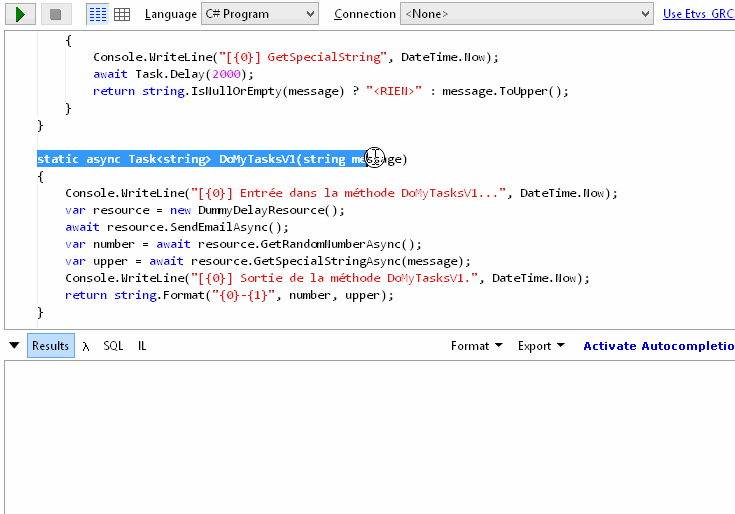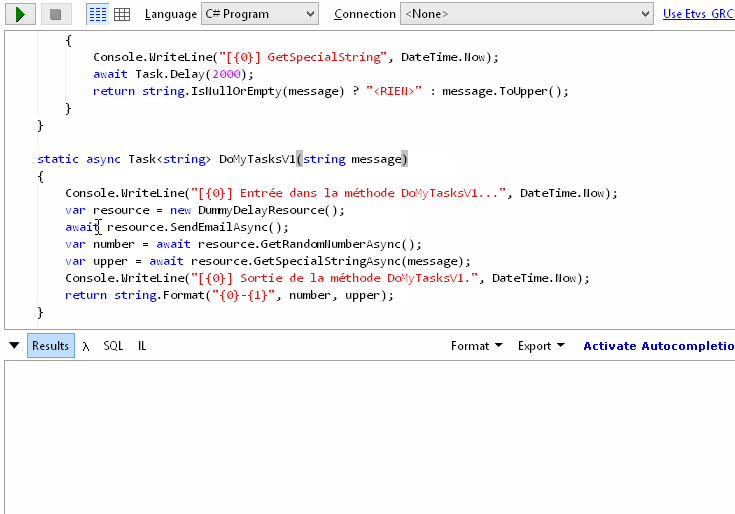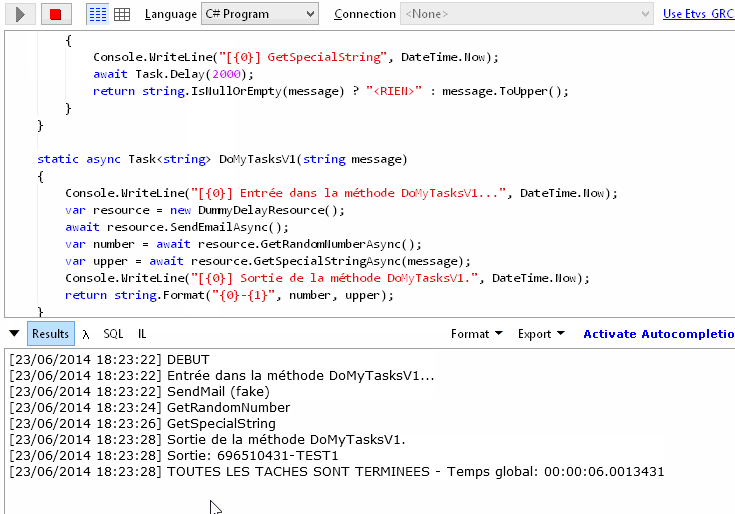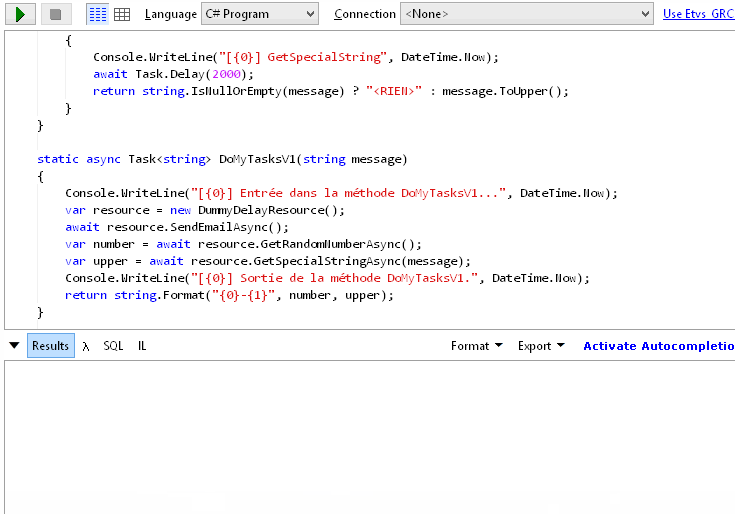
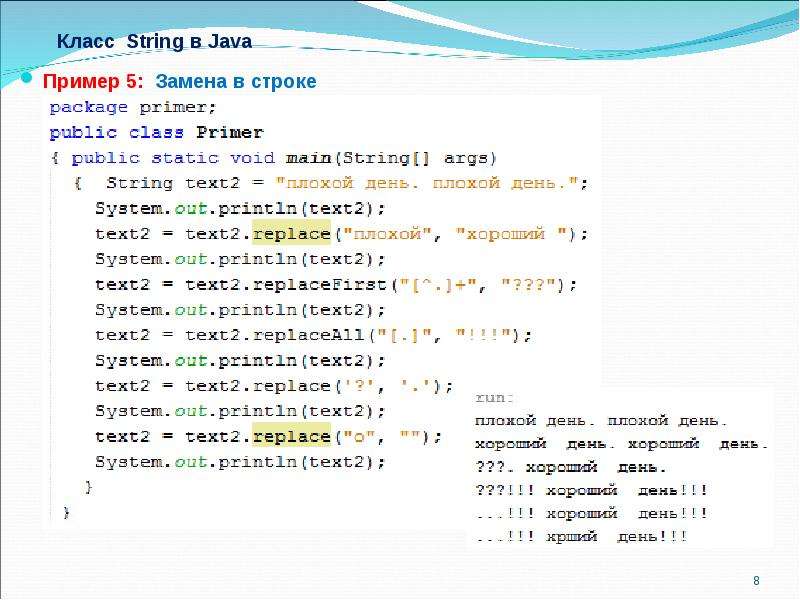
методы для форматирования и преобразование в строку
Строками в языках программирования принято называть упорядоченные последовательности символов, которые используются для представления любой текстовой информации. В Python они являются самостоятельным типом данных, а значит при помощи встроенных функций языка над ними можно производить различные операции и форматировать их для вывода.
Создание
Получить новую строку можно несколькими способами: при помощи соответствующего литерала либо же вызвав готовую функцию. Для начала рассмотрим первый метод, который продемонстрирован ниже. Здесь переменная string получает значение some text, благодаря оператору присваивания. Вывести на экран созданную строку помогает функция print.
string = 'some text' print(string) some text
Как видно из предыдущего примера, строковый литерал обрамляется в одиночные кавычки. Если необходимо, чтобы данный символ был частью строки, следует применять двойные кавычки, как это показано в следующем фрагменте кода.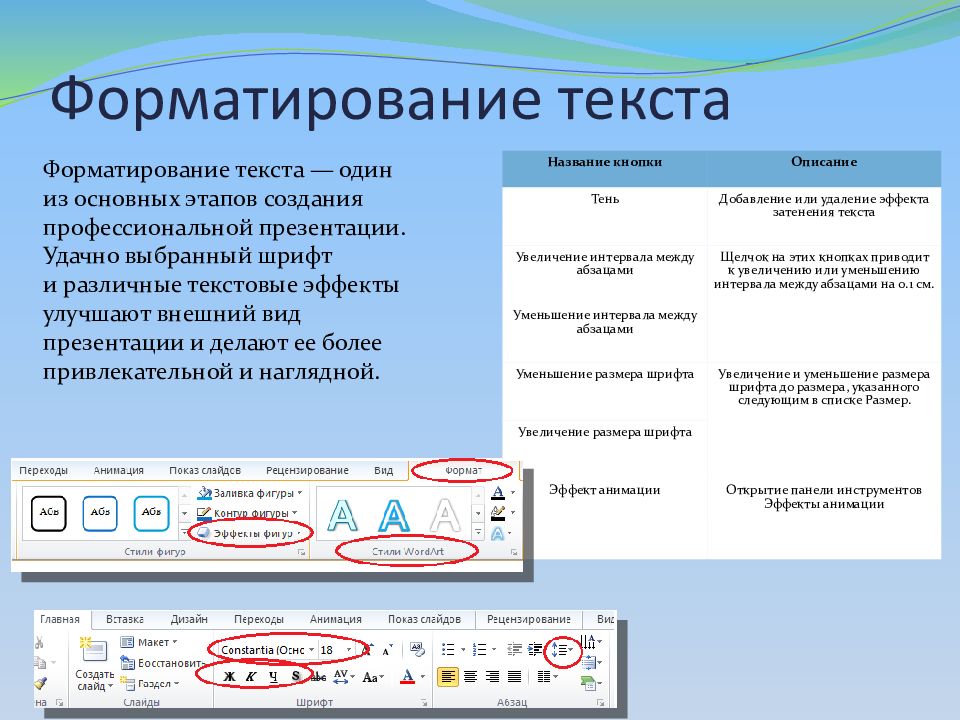
string = "some 'new' text" print(string) some 'new' text
Иногда возникает потребность в создании объектов, включающих в себя сразу несколько строк с сохранением форматирования. Эту задачу поможет решить троекратное применение символа двойных кавычек для выделения литерала. Объявив строку таким образом, можно передать ей текст с неограниченным количеством абзацев, что показано в данном коде.
string = """some 'new' text with new line here""" print(string) some 'new' text with new line here
Специальные символы
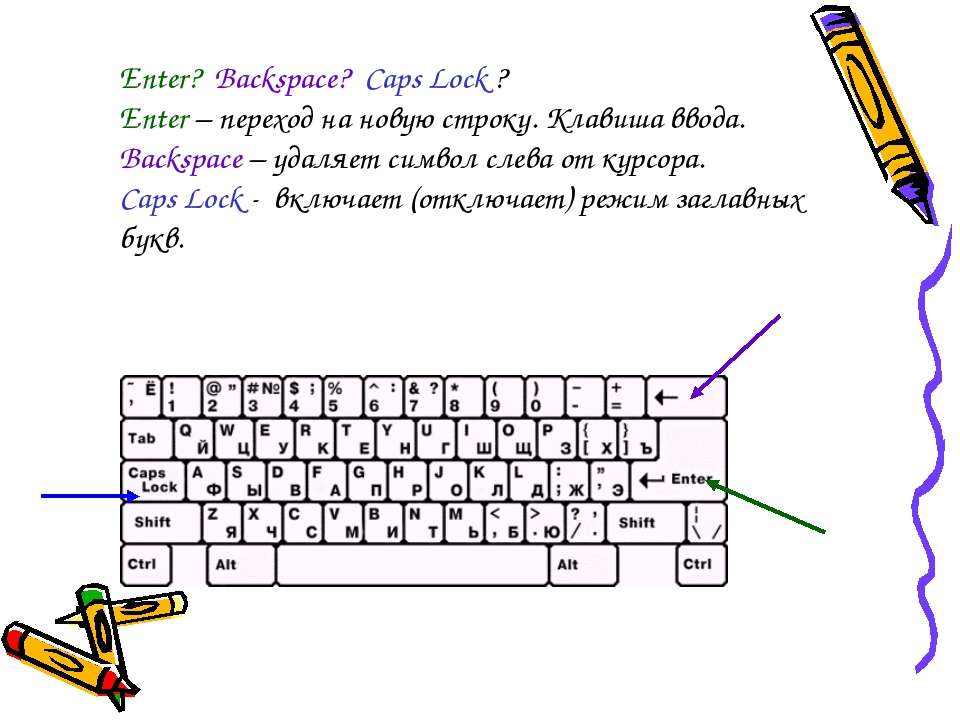
Пользоваться тройными кавычками для форматирования строк не всегда удобно, так как это порой занимает слишком много места в коде. Чтобы задать собственное форматирование текста, достаточно применять специальные управляющие символы с обратным слэшем, как это показано в следующем примере.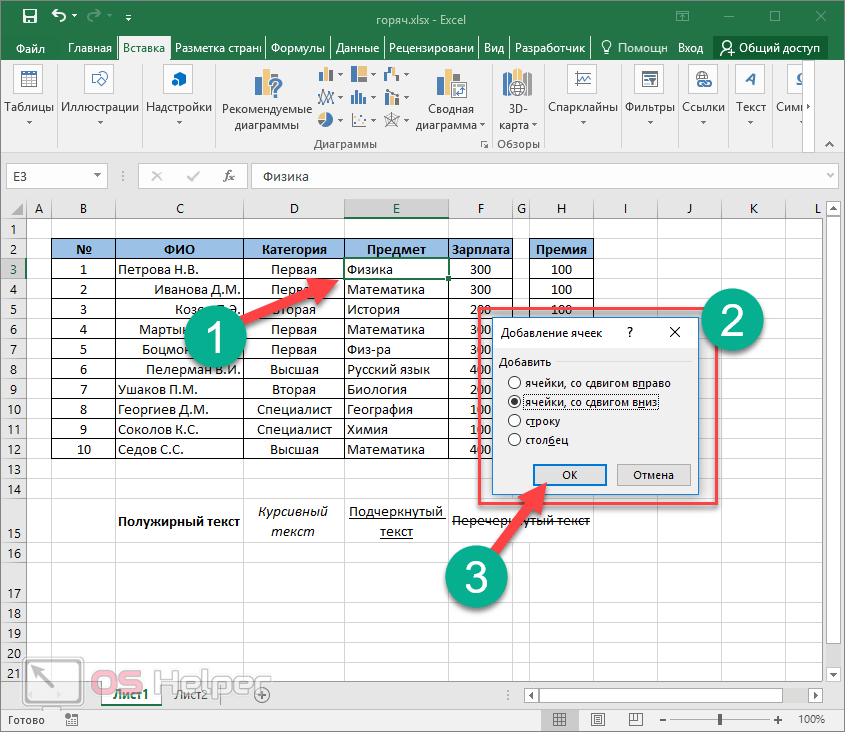 Здесь используется символ табуляции \t, а также знак перехода на новую строку \n. Метод print демонстрирует вывод нового объекта на экран.
Здесь используется символ табуляции \t, а также знак перехода на новую строку \n. Метод print демонстрирует вывод нового объекта на экран.
string = "some\ttext\nnew line here" print(string) some text new line here
Служебные символы для форматирования строк выполняют свои функции автоматически, но иногда это мешает, к примеру, когда требуется сохранить путь к файлу на диске. Чтобы их отключить, необходимо применить специальный префикс r перед первой кавычкой литерала. Таким образом, обратные слэши будут игнорироваться программой во время ее запуска.
string = r"D:\dir\new"
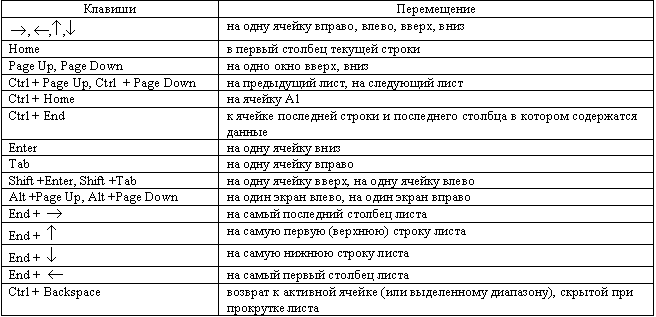
Следующая таблица демонстрирует перечень всех используемых в языке Python служебных символов для форматирования строк. Как правило, большинство из них позволяют менять положение каретки для выполнения перевода строки, табуляции или возврата каретки.
| Символ | Назначение |
| \n | Перевод каретки на новую строку |
| \b | Возврат каретки на один символ назад |
| \f | Перевод каретки на новую страницу |
| \r | Возврат каретки на начало строки |
| \t | Горизонтальная табуляция |
| \v | Вертикальная табуляция |
| \a | Подача звукового сигнала |
| \N | Идентификатор базы данных |
| \u, \U | 16-битовый и 32-битовый символ Unicode |
| \x | Символ в 16-ричной системе исчисления |
| \o | Символ в 8-ричной системе исчисления |
| \0 | Символ Null |
Очень часто испльзуется \n.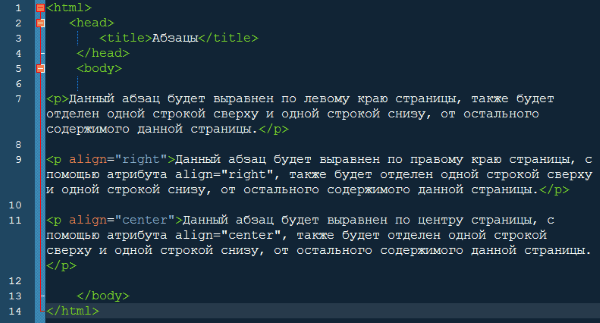 С помощью него осуществляется в Python перенос строки. Рассмотрим пример:
С помощью него осуществляется в Python перенос строки. Рассмотрим пример:
print('first\nsecond')
first
secondФорматирование
Выполнить форматирование отдельных частей строки, задав в качестве ее компонентов некие объекты программы позволяет символ %, указанный после литерала. В следующем примере показано, как строковый литерал включает в себя не только текст, но также строку и целое число. Стоит заметить, что каждой переменной в круглых скобках должен соответствовать специальный символ в самом литерале, обладающий префиксом % и подходящим значением.
string = "text" number = 10 newString = "this is %s and digit %d" % (string, number) print(newString) this is text and digit 10
В приведенном ниже фрагменте кода демонстрируется использование форматирования для вывода строки с выравниванием по правому краю (общая длина символов указана как 10).
string = "text" newString = "%+10s" % string print(newString) text
Данная таблица содержит в себе все управляющие символы для форматирования строк в Python, каждый из которых обозначает определенный объект: числовой либо же символьный.
| Символ | Назначение |
| %d, %i, %u | Число в 10-ричной системе исчисления |
| %x, %X | Число в 16-ричной системе исчисления с буквами в нижнем и верхнем регистре |
| %o | Число в 8-ричной системе исчисления |
| %f, %F | Число с плавающей точкой |
| %e, %E | Число с плавающей точкой и экспонентой в нижнем и верхнем регистре |
| %c | Одиночный символ |
| %s, %r | Строка из литерала и обычная |
| %% | Символ процента |
Более удобное форматирование выполняется с помощью функции format. Ей необходимо передать в качестве аргументов объекты, которые должны быть включены в строку, а также указать места их расположения с помощью числовых индексов, начиная с нулевого.
string = "text"
number = 10
newString = "this is {0} and digit {1}". ’
Выравнивание строки по центру с символами-заполнителями с обеих сторон
‘+’
Применение знака для любых чисел
‘-‘
Применение знака для отрицательных чисел и ничего для положительных
‘ ‘
Применение знака для отрицательных чисел и пробела для положительных
’
Выравнивание строки по центру с символами-заполнителями с обеих сторон
‘+’
Применение знака для любых чисел
‘-‘
Применение знака для отрицательных чисел и ничего для положительных
‘ ‘
Применение знака для отрицательных чисел и пробела для положительных
Операции над строками
Прежде чем перейти к функциям для работы со строками, следует рассмотреть основные операции с ними, которые позволяют быстро преобразовывать любые последовательности символов. При помощи знака плюс можно производить конкатенацию строк, соединяя их вместе. В следующем примере продемонстрировано объединение this is new и text.
string = "text"
newString = "this is new " + string
print(newString)
this is new text
Пользуясь символом умножения, программист получает возможность дублировать строку любое количество раз. В данном коде слово text записывается в новую строку трижды.
string = "text "
newString = string * 3
print(newString)
text text text
Как и в случае с числами, со строками можно использовать операторы сравнения, например двойное равно. Очевидно, что литералы some text и some new text разные, поэтому вызов метода print выводит на экран булево значение False для строк string и newString.
string = "some text"
newString = "some new text"
print(string == newString)
False
Операции над строками позволяют получать из них подстроки, делая срезы, как с обычными элементами последовательностей. В следующем примере, необходимо лишь указать нужный интервал индексов в квадратных скобках, помня, что нумерация осуществляется с нуля.
string = "some text"
newString = string[2:4]
print(newString)
me
Отрицательный индекс позволяет обращаться к отдельным символами строки не с начала, а с конца. Таким образом, элемент под номером -2 в строке some text является буквой x.
string = "some text"
print(string[-2])
x
Методы и функции
Очень часто используется для приведения типов к строковому виду функция str. С ее помощью можно создать новую строку из литерала, который передается в качестве аргумента. Данный пример демонстрирует инициализацию переменной string новым значением some text.
string = str("some text")
print(string)
some textАргументом этой функции могут быть переменные разных типов, например числа или списки. Эта функция позволяет в Python преобразовать в строку разные типы данных. Если вы создаете свой класс, то желательно определить для него метод __str__. Этот метод должен возвращать строку, которая будет возвращена в случае, когда в качестве аргумента str будет использован объект вашего класса.
В Python получения длины строки в символах используется функция len. Как видно из следующего фрагмента кода, длина объекта some text равняется 9 (пробелы тоже считаются).
string = "some text"
print(len(string))
9
Метод find позволяет осуществлять поиск в строке. При помощи него в Python можно найти одиночный символ или целую подстроку в любой другой последовательности символов. В качестве результата своего выполнения он возвращает индекс первой буквы искомого объекта, при этом нумерация осуществляется с нуля.
string = "some text"
print(string.find("text"))
5Метод replace служит для замены определенных символов или подстрок на введенную программистом последовательность символов. Для этого необходимо передать функции соответствующие аргументы, как в следующем примере, где пробелы заменяются на символ ‘-‘.
string = "some text"
print(string.replace(" ", "-"))
some-textДля того чтобы разделить строку на несколько подстрок при помощи указанного разделителя, следует вызвать метод split. По умолчанию его разделителем является пробел. Как показано в приведенном ниже примере, some new text трансформируется в список строк strings.
string = "some new text"
strings = string.split()
print(strings)
['some', 'new', 'text']
Выполнить обратное преобразование, превратив список строк в одну можно при помощи метода join. В следующем примере в качестве разделителя для новой строки был указан пробел, а аргументом выступил массив strings, включающий some, new и text.
strings = ["some", "new", "text"]
string = " ".join(strings)
print(string)
some new text
Наконец, метод strip используется для автоматического удаления пробелов с обеих сторон строки, как это показано в следующем фрагменте кода для значения объекта string.
string = " some new text "
newString = string.strip()
print(newString)
some new text
Ознакомиться с функциями и методами, используемыми в Python 3 для работы со строками можно из данной таблицы. В ней также приведены методы, позволяющие взаимодействовать с регистром символов.
 ’
Выравнивание строки по центру с символами-заполнителями с обеих сторон
‘+’
Применение знака для любых чисел
‘-‘
Применение знака для отрицательных чисел и ничего для положительных
‘ ‘
Применение знака для отрицательных чисел и пробела для положительных
’
Выравнивание строки по центру с символами-заполнителями с обеих сторон
‘+’
Применение знака для любых чисел
‘-‘
Применение знака для отрицательных чисел и ничего для положительных
‘ ‘
Применение знака для отрицательных чисел и пробела для положительных

| Метод | Назначение |
| str(obj) | Преобразует объект к строковому виду |
| len(s) | Возвращает длину строки |
| find(s, start, end), rfind(s, start, end) | Возвращает индекс первого и последнего вхождения подстроки в s или -1, при этом поиск идет в границах от start до end |
| replace(s, ns) | Меняет выбранную последовательность символов в s на новую подстроку ns |
| split(c) | Разбивает на подстроки при помощи выбранного разделителя c |
| join(c) | Объединяет список строк в одну при помощи выбранного разделителя c |
| strip(s), lstrip(s), rstrip(s) | Убирает пробелы с обоих сторон s, только слева или только справа |
| center(num, c), ljust(num, c), rjust(num, c) | Возвращает отцентрированную строку, выравненную по левому и по правому краю с длиной num и символом c по краям |
| lower(), upper() | Перевод всех символов в нижний и верхний регистр |
| startwith(ns), endwith(ns) | Проверяет, начинается ли или заканчивается строка подстрокой ns |
| islower(), isupper() | Проверяет, состоит ли строка только из символов в нижнем и верхнем регистре |
| swapcase() | Меняет регистр всех символов на противоположный |
| title() | Переводит первую букву каждого слова в верхний регистр, а все остальные в нижний |
| capitalize() | Переводит первую букву в верхний регистр, а все остальные в нижний |
| isalpha() | Проверяет, состоит ли только из букв |
| isdigit() | Проверяет, состоит ли только из цифр |
| isnumeric() | Проверяет, является ли строка числом |
Кодировка
Чтобы задать необходимую кодировку для используемых в строках символов в Python достаточно поместить соответствующую инструкцию в начало файла с кодом, как это было сделано в следующем примере, где используется utf-8. С помощью префикса u, который стоит перед литералом, можно помечать его соответствующей кодировкой. В то же время префикс b применяется для литералов строк с элементами величиной в один байт.
С помощью префикса u, который стоит перед литералом, можно помечать его соответствующей кодировкой. В то же время префикс b применяется для литералов строк с элементами величиной в один байт.
# coding: utf-8 string = u'some text' newString = b'text'
Производить кодирование и декодирование отдельных строк с заданной кодировкой позволяют встроенные методы decode и encode. Аргументом для них является название кодировки, как в следующем примере кода, где применяется наименование utf-8.
string = string.decode('utf8')
newString = newString.encode('utf8')Особенности работы со строками. Урок 14 курса "Основы языка C"
Неформатированные ввод из стандартного потока и вывод в стандартный поток
С помощью функции printf() можно легко вывести на экран строку, содержащую пробелы:
printf("%s", "Hello world");С другой стороны, ввести строку произвольной длины, содержащую пробелы в неизвестных местах, исключительно с помощью функции scanf() невозможно. Для
Для scanf() любой символ пустого пространства является сигналом завершения ввода очередных данных, если только не производится считывание символа.
На помощь может прийти функция getchar(), осуществляющая посимвольный ввод данных:
int i;
char str[20];
for (i=0; (str[i]=getchar())!='\n'; i++);
str[i] = '\0';
printf("\n%s\n", str);В заголовке цикла getchar() возвращает символ, далее записываемый в очередную ячейку массива. После этого элемент массива сравнивается с символом '\n'. Если они равны, то цикл завершается. После цикла символ '\n' в массиве "затирается" символом '\0'. В условии цикла должна быть также предусмотрена проверка на выход за пределы массива; чтобы не усложнять пример, опущена.
Однако в языке программирования C работать со строками можно проще. С помощью функций стандартной библиотеки gets() и puts() получают строку из стандартного потока и выводят в стандартный поток. Буква s в конце слов gets и puts является сокращением от слова string (строка).
Буква s в конце слов gets и puts является сокращением от слова string (строка).
В качестве параметров обе функции принимают указатель на массив символов (либо имя массива, либо указатель).
Функция gets() помещает полученные с ввода символы в указанный в качестве аргумента массив. При этом символ перехода на новую строку, который завершает ее работу, игнорируется.
Функция puts() выводит строку на экран и при этом сама добавляет символ перехода на новую строку. Простейший пример использования этих функций выглядит так:
char str[20]; gets(str); puts(str);
Итак, если вы работаете со строками, а не другими типами данных, при этом нет необходимости выполнять их посимвольную обработку, то удобнее пользоваться функциями puts() и gets(). (Однако функция gets() считается опасной и была выпилена из версии языка C11.)
Массив символов и указатель на строку
Как мы знаем, строка представляет собой массив символов, последний элемент которого является нулевым символом по таблице ASCII, обозначаемым '\0'. При работе со строками также как с численными массивами можно использовать указатели. Мы можем объявить в программе массив символов, записать туда строку, потом присвоить указателю адрес на первый или любой другой элемент этого массива и работать со строкой через указатель:
При работе со строками также как с численными массивами можно использовать указатели. Мы можем объявить в программе массив символов, записать туда строку, потом присвоить указателю адрес на первый или любой другой элемент этого массива и работать со строкой через указатель:
char name[30];
char *nP;
printf("Введите имя и фамилию: ");
gets(name);
printf("Имя: ");
for(nP = name; *nP != ' '; nP++)
putchar(*nP);
printf("\nФамилия: ");
puts(nP+1);В заголовке цикла указателю сначала присваивается адрес первого элемента массива, его значение увеличивается до тех пор, пока не встретится пробел. В итоге указатель указывает на пробел и мы можем получить с его помощью вторую часть строки.
Иногда в программах можно видеть такое объявление и определение переменной-указателя:
char *strP = "Hello World!";
Строку, которая была присвоена не массиву, а указателю, также можно получить, обратившись по указателю:
puts(strP);
Но давайте посмотрим, что же все-таки происходит, и чем такая строка, присвоенная указателю, отличается от строки, присвоенной массиву.
Когда в программе определяются данные и объявляются переменные, то под них отводится память. При этом данные, которые не были присвоены переменным, поменять в процессе выполнения программы уже нельзя.
Что происходит в примере? В программе вводится строковый объект, который по сути является строковой константой (литералом). Ссылка на первый элемент этой строки присваивается указателю. Мы можем менять значение указателя сколько угодно, переходить к любому из элементов константного массива символов или даже начать ссылаться на совершенно другую строку. Но вот поменять значение элементов строки не можем. Это можно доказать таким кодом:
char *strP;
// работает, но строку нельзя изменить
strP = "This is a literal";
puts(strP);
printf("%c\n",strP[3]);
strP[3] = 'z'; // не получитсяВ последней строке кода возникнет ошибка, т.к. совершается попытка изменить строку-константу.
Тем более нельзя делать так:
char *strP;
// ошибка сегментирования
scanf("%s",strP); В данном случае память не была выделена под массив символов, который мы пытаемся считать функцией scanf(); память была выделена только под указатель. Поэтому записать строку просто некуда. Другое дело, если память была выделена с помощью объявления массива, после чего указателю был присвоен адрес на этот массив:
Поэтому записать строку просто некуда. Другое дело, если память была выделена с помощью объявления массива, после чего указателю был присвоен адрес на этот массив:
char str[12]; char *strP; strP = str; // память резервируется под массив ранее gets(strP); puts(strP);
Поэтому если вам требуется в программе неизменяемый массив символов, то можете определить его через указатель.
Передача строки в функцию
Передача строки в функцию ничем не отличается от передачи туда массива чисел:
void change (char *s) {
for (;*s != '\0'; s++)
(*s)++;
}В этом примере функция change() принимает в качестве параметра указатель на символ. В теле функции значение указателя инкрементируется, указывая на следующий символ массива. В теле цикла инкрементируется значение, которое находится по адресу, который содержит указатель.
Объявите в программе три массива символов. Данные для двух из них получите с помощью вызовов функции gets(). Третий массив должен содержать результат конкатенации (соединения) двух введенных строк. Напишите функцию, которая выполняет конкатенацию строк.
Третий массив должен содержать результат конкатенации (соединения) двух введенных строк. Напишите функцию, которая выполняет конкатенацию строк.
Массив строк и массив указателей
Рассмотрим более сложный пример. Допустим, у нас есть набор строк. Требуется выполнить сортировку строк по возрастанию по признаку длины: сначала вывести самые короткие строки, затем более длинные.
Набор строк можно представить как двумерный массив, т.е. массив, состоящий из одномерных массивов, где каждый одномерный массив — это строка символов:
char str[][10] = {"Hello", "World",
"!!!", "&&&"};Представьте себе, что значит выполнить сортировку строк. Это значит, надо поменять местами содержимое множества ячеек памяти. Это достаточно трудоемкая для компьютера работа, особенно если строк очень много. Однако можно поступить по-иному. Достаточно создать массив указателей, каждый элемент которого будет указывать на соответствующую ему строку первого массива.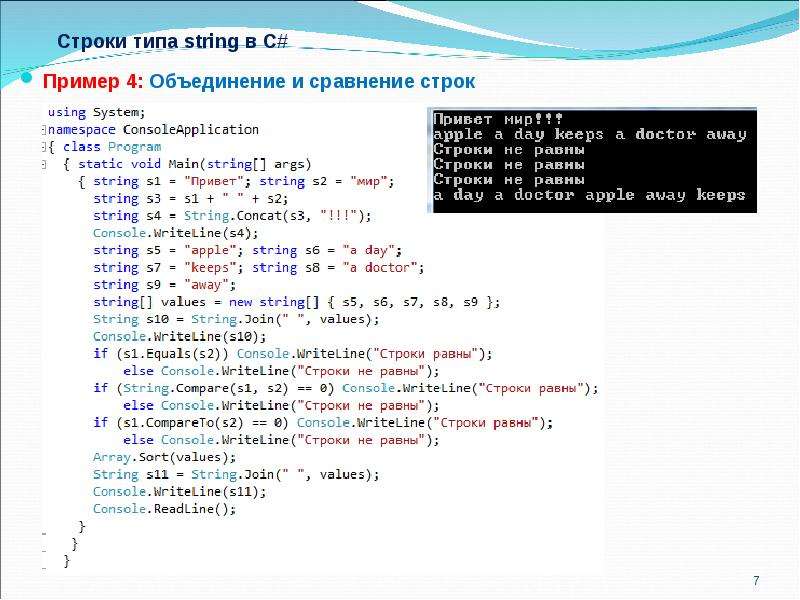 Далее выполнить сортировку указателей, что несомненно быстрее. Конечно, сам массив строк отсортирован не будет, однако благодаря указателям у нас будет хранится отсортированный "срез" массива:
Далее выполнить сортировку указателей, что несомненно быстрее. Конечно, сам массив строк отсортирован не будет, однако благодаря указателям у нас будет хранится отсортированный "срез" массива:
#include <stdio.h>
#include <string.h>
#define N 6
void sortlen(char *s[]);
int main() {
char strings[N][30];
char *strP[N];
int i;
for(i=0; i<N; i++) {
gets(strings[i]);
strP[i] = &strings[i][0];
}
printf("\n");
sortlen(strP);
for(i=0; i<N; i++) {
printf("%s\n",strP[i]);
}
}
// **s == *s[] - массив указателей
void sortlen(char **s) {
int i, j;
char *str;
for (i=0; i<N-1; i++)
for (j=0; j < N-i-1; j++)
if (strlen(s[j])>strlen(s[j+1])){
str = s[j];
s[j] = s[j+1];
s[j+1] = str;
}
}Примечания к программе:
- На самом деле параметром функции
sortlen()является указатель на указатель. Хотя для понимания проще сказать, что параметром является массив указателей на символы. Мы передаем в функцию указатель на первый элемент массива strP, который сам является указателем. Если бы в функции мы инкрементировали переменную s, то переходили бы к следующему элементу-указателю массива strP. - Сортировка выполняется методом пузырька: если длина строки, на которую ссылается следующий указатель массива strP, меньше длины строки под текущим указателем, то значения указателей меняются.
- Выражение strP[i] = &strings[i][0] означает, что элементу массива указателей присваивается ссылка на первый символ каждой строки.
 Хотя для понимания проще сказать, что параметром является массив указателей на символы. Мы передаем в функцию указатель на первый элемент массива strP, который сам является указателем. Если бы в функции мы инкрементировали переменную s, то переходили бы к следующему элементу-указателю массива strP.
Хотя для понимания проще сказать, что параметром является массив указателей на символы. Мы передаем в функцию указатель на первый элемент массива strP, который сам является указателем. Если бы в функции мы инкрементировали переменную s, то переходили бы к следующему элементу-указателю массива strP.Напишите программу, которая сортирует строки по алфавиту. Для упрощения задачи пусть сортировка выполняется только по первым буквам строк (если первые буквы слов одинаковы, то вторые и последующие символы проверять не надо).
Курс с решением части задач:
android-приложение, pdf-версия
Строки в языке C++ (класс string)
Строки в языке C++ (класс string)В языке C++ для удобной работы со строками есть класс string, для использования которого необходимо подключить заголовочный файл string.
Строки можно объявлять и одновременно присваивать им значения:
Строка S1 будет пустой, строка S2 будет состоять из 5 символов.
К отдельным символам строки можно обращаться по индексу, как к элементам массива или C-строк. Например S[0] - это первый символ строки.
Для того, чтобы узнать длину строки можно использовать метод size() строки. Например, последний символ строки S это S[S.size() - 1].
Строки в языке C++ могут
Конструкторы строк
Строки можно создавать с использованием следующих конструкторов:string() - конструктор по умолчанию (без параметров) создает пустую строку.string(string & S) - копия строки Sstring(size_t n, char c)c заданное число n раз.string(size_t c) - строка из одного символа c.string(string & S, size_t start, size_t len)len символов данной строки S, начиная с символа номер start.
Конструкторы можно вызывать явно, например, так:
В этом примере явно вызывается конструктор string для создания строки, состоящей из 10 символов 'z'.
Неявно конструктор вызывается при объявлении строки с указанием дополнительных параметров. Например, так:
Подробней о конструкторах для строк читайте здесь.
Ввод-вывод строк
Строка выводится точно так же, как и числовые значения:
Для считывания строки можно использовать операцию ">>" для объекта cin:
В этом случае считывается строка из непробельных символов, пропуская пробелы и концы строк. Это удобно для того, чтобы разбивать текст на слова, или чтобы читать данные до конца файла при помощи while (cin >> S).
Можно считывать строки до появления символа конца строки при помощи функции getline. Сам символ конца строки считывается из входного потока, но к строке не добавляется:
Арифметические операторы
Со строками можно выполнять следующие арифметические операции:= - присваивание значения.
+= - добавление в конец строки другой строки или символа.+ - конкатенация двух строк, конкатенация строки и символа.==, != - посимвольное сравнение.<, >, <=, >= - лексикографическое сравнение.
То есть можно скопировать содержимое одной строки в другую при помощи операции S1 = S2, сравнить две строки на равенство при помощи S1 == S2, сравнить строки в лексикографическом порядке при помощи S1 < S2, или сделать сложение (конкатенацию) двух строк в виде S = S1 + S2.
Подробней об операторах для строк читайте здесь.
Методы строк
У строк есть разные методы, многие из них можно использовать несколькими разными способами (с разным набором параметров).
Рассмотрим эти методы подробней.
size
Метод size() возращает длину длину строки. Возвращаемое значение является беззнаковым типом (как и во всех случаях, когда функция возращает значение, равное длине строке или индексу элемента - эти значения беззнаковые).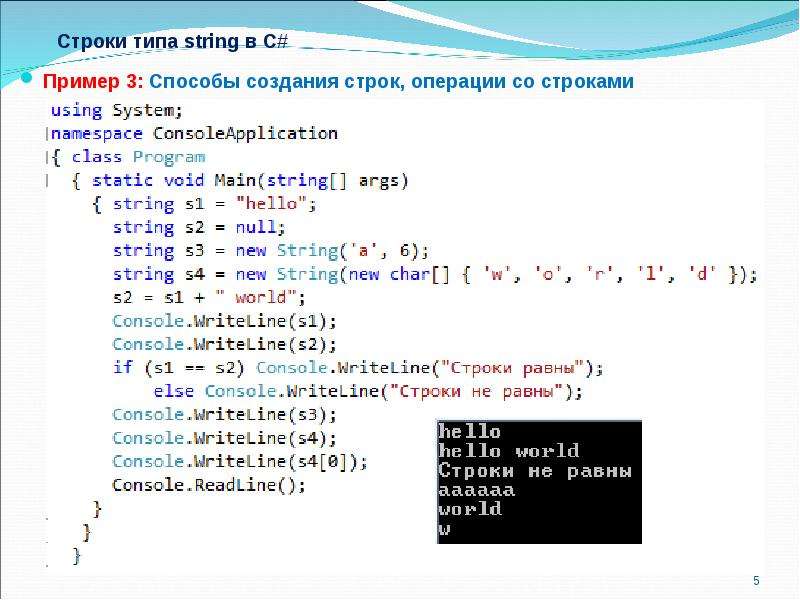 Поэтому нужно аккуратно выполнять операцию вычитания из значения, которое возвращает size(). Например, ошибочным будет запись цикла, перебирающего все символы строки, кроме последнего, в виде for (int i = 0; i < S.size() - 1; ++i).
Поэтому нужно аккуратно выполнять операцию вычитания из значения, которое возвращает size(). Например, ошибочным будет запись цикла, перебирающего все символы строки, кроме последнего, в виде for (int i = 0; i < S.size() - 1; ++i).
Кроме того, у строк есть метод length(), который также возвращает длину строки.
Подробней о методе size.
resize
S.resize(n) - Изменяет длину строки, новая длина строки становится равна n. При этом строка может как уменьшится, так и увеличиться. Если вызвать в виде S.resize(n, c), где c - символ, то при увеличении длины строки добавляемые символы будут равны c.
Подробней о методе resize.
clear
S.clear() - очищает строчку, строка становится пустой.
Подробней о методе clear.
empty
S.empty() - возвращает true, если строка пуста, false - если непуста.
Подробней о методе empty.
push_back
S.push_back(c) - добавляет в конец строки символ c, вызывается с одним параметром типа char.
Подробней о методе push_back.
append
Добавляет в конец строки несколько символов, другую строку или фрагмент другой строки. Имеет много способов вызова.
S.append(n, c) - добавляет в конец строки n одинаковых символов, равных с. n имеет целочисленный тип, c - char.
S.append(T) - добавляет в конец строки S содержимое строки T. T может быть объектом класса string или C-строкой.
S.append(T, pos, count) - добавляет в конец строки S символы строки T начиная с символа с индексом pos количеством count.
Подробней о методе append.
erase
S.erase(pos) - удаляет из строки S с символа с индексом pos и до конца строки.
S.erase(pos, count) - удаляет из строки S с символа с индексом pos количеством count или до конца строки, если pos + count > S.size().
Подробней о методе erase.
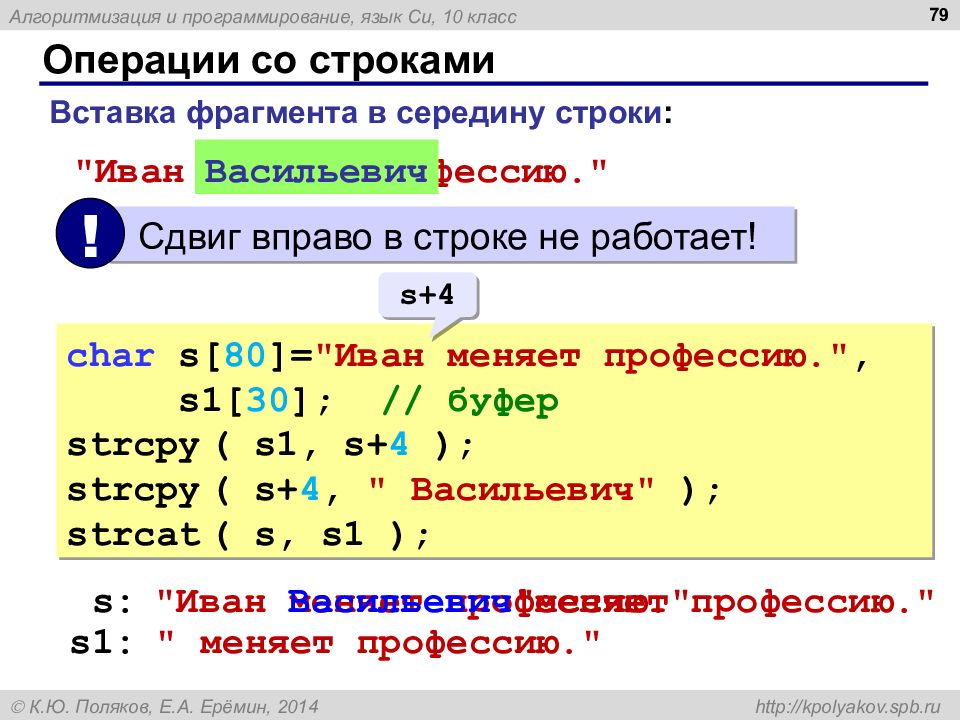
insert
Вставляет в середину строки несколько символов, другую строку или фрагмент другой строки. Способы вызова аналогичны способам вызова метода append, только первым параметром является значение i - позиция, в которую вставляются символы. Первый вставленный символ будет иметь индекс i, а все символы, которые ранее имели индекс i и более сдвигаются вправо.
Первый вставленный символ будет иметь индекс i, а все символы, которые ранее имели индекс i и более сдвигаются вправо.
S.insert(i, n, c) - вставить n одинаковых символов, равных с. n имеет целочисленный тип, c - char.
S.insert(i, T) - вставить содержимое строки T. T может быть объектом класса string или C-строкой.
S.insert(i, T, pos, count) - вставить символы строки T начиная с символа с индексом pos количеством count.
Подробней о методе insert.
substr
S.substr(pos) - возвращает подстроку данной строки начиная с символа с индексом pos и до конца строки.
S.substr(pos, count) - возвращает подстроку данной строки начиная с символа с индексом pos количеством count или до конца строки, если pos + count > S.size().
Подробней о методе substr.
replace
Заменяет фрагмент строки на несколько равных символов, другую строку или фрагмент другой строки. Способы вызова аналогичны способам вызова метода append, только первыми двумя параметрами являются два числа: pos и count. Из данной строки удаляется count символов, начиная с символа pos, и на их место вставляются новые символы.
Из данной строки удаляется count символов, начиная с символа pos, и на их место вставляются новые символы.
S.replace(pos, count, n, c) - вставить n одинаковых символов, равных с. n имеет целочисленный тип, c - char.
S.replace(pos, count, T) - вставить содержимое строки T. T может быть объектом класса string или C-строкой.
S.replace(pos, count, T, pos2, count2) - вставить символы строки T начиная с символа с индексом pos количеством count.
Подробней о методе replace.
find
Ищет в данной строке первое вхождение другой строки str. Возвращается номер первого символа, начиная с которого далее идет подстрока, равная строке str. Если эта строка не найдена, то возвращается константа string::npos (которая равна -1, но при этом является беззнаковой, то есть на самом деле является большим безннаковым положительным числом).
Если задано значение pos, то поиск начинается с позиции pos, то есть возращаемое значение будет не меньше, чем pos. Если значение pos не указано, то считается, что оно равно 0 - поиск осуществляется с начала строки.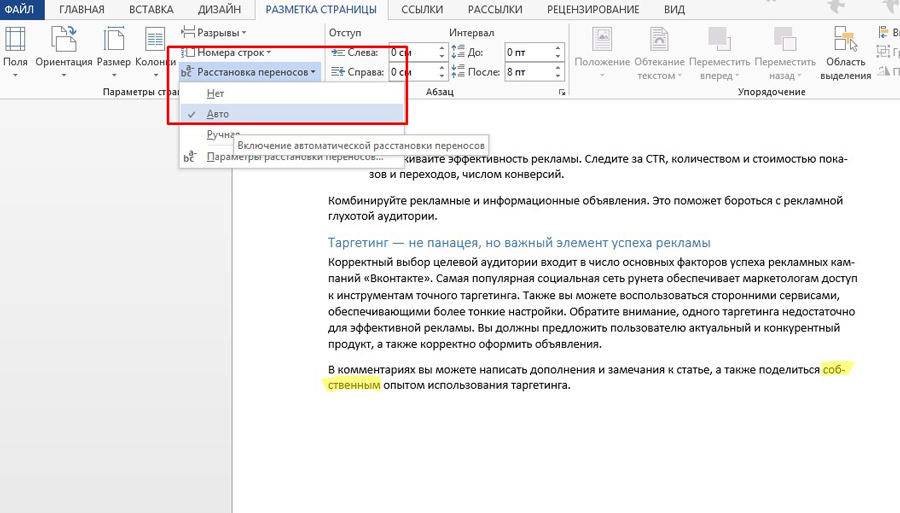
S.find(str, pos = 0) - искать первое входение строки str начиная с позиции pos. Если pos не задано - то начиная с начала строки S.
S.find(str, pos, n) - искать в данной строке подстроку, равную первым n символам строки str. Значение pos должно быть задано.
Подробней о методе find.
rfind
Ищет последнее вхождение подстроки ("правый" поиск). Способы вызова аналогичны способам вызова метода find.
Подробней о методе rfind.
find_first_of
Ищет в данной строке первое появление любого из символов данной строки str. Возвращается номер этого символа или значение string::npos.
Если задано значение pos, то поиск начинается с позиции pos, то есть возращаемое значение будет не меньше, чем pos. Если значение pos не указано, то считается, что оно равно 0 - поиск осуществляется с начала строки.
S.find_first_of(str, pos = 0) - искать первое входение любого символа строки str начиная с позиции pos. Если pos не задано - то начиная с начала строки S.
Подробней о методе find_first_of.
find_last_of
Ищет в данной строке последнее появление любого из символов данной строки str. Способы вызова и возвращаемое значение аналогичны методу find_first_of.
Подробней о методе find_last_of.
find_first_not_of
Ищет в данной строке первое появление символа, отличного от символов строки str. Способы вызова и возвращаемое значение аналогичны методу find_first_of.
Подробней о методе find_first_not_of.
find_last_not_of
Ищет в данной строке последнее появление символа, отличного от символов строки str. Способы вызова и возвращаемое значение аналогичны методу find_first_of.
Подробней о методе find_last_not_of.
c_str
Возвращает указать на область памяти, в которой хранятся символы строки, возвращает значение типа char*. Возвращаемое значение можно рассматривать как C-строку и использовать в функциях, которые должны получать на вход C-строку.
Подробней о методе c_str.
c textbox переход на новую строку
На чтение 4 мин. Просмотров 100 Опубликовано
Просмотров 100 Опубликовано
На Grid -е у меня есть TextBox :
При вводе строки, длина которой превышает ширину текстового поля, она переводится на новую строку. С этим все нормально. Однако я не могу сделать так, что бы каретка переводилась на новую строку при нажатии определенных кнопок.
Я пытался сделать это так:
Только это работает не так как нужно — переводит каретку в самое начало текстового поля.
Я делаю чат-клиент, и в настоящее время у меня есть кнопка, которая будет отображать данные в многострочное текстовое поле при нажатии. Это единственный способ добавить данные в многострочное текстовое поле? Я чувствую, что это крайне неэффективно, потому что, если разговор становится очень длинным, строка тоже будет очень длинной.
5 ответов
если вы используете WinForms:
использовать AppendText(myTxt) метод TextBox вместо этого (. net 3.5+):
net 3.5+):
текст сам по себе обычно имеет низкий объем памяти (вы можете сказать много в f.бывший. 10кб, которая «ничего»). Текстовое поле не отображается весь текст, который находится в буфере, только видимую часть, поэтому вам не нужно слишком беспокоиться о отставание. Замедление операций вставки текста. Добавление текста происходит относительно быстро.
Если вам нужно более сложное обработка содержимого, которое вы можете использовать StringBuilder в сочетании с текстовым полем. Это даст вам очень эффективный способ обработки текста.
из кода (как вы упомянули) ->
нажмите клавишу Enter в текстовом поле, и будет создана новая строка
b) текстовое поле Winform
потому что вы не указали, какой интерфейс (технология GUI) вы используете, было бы трудно сделать конкретную рекомендацию. В WPF вы можете создать listbox и для каждой новой строки чата добавить новый listboxitem в конец коллекции. Это ссылке предоставляет некоторые предложения о том, как вы можете достичь того же результата в среде приложения WinForms.
Я считаю, что этот метод экономит много ввода и предотвращает много опечаток.
txtOutput.Text = «первая строка» + nl + «вторая строка» + nl + «Третья строка»;
C# — serialData является ReceivedEventHandler на TextBox .
теперь Visual Studio удаляет мои строки. TextBox, конечно,имел все правильные параметры.
Уроки программирования, алгоритмы, статьи, исходники, примеры программ и полезные советы
ОСТОРОЖНО МОШЕННИКИ! В последнее время в социальных сетях участились случаи предложения помощи в написании программ от лиц, прикрывающихся сайтом vscode.ru. Мы никогда не пишем первыми и не размещаем никакие материалы в посторонних группах ВК. Для связи с нами используйте исключительно эти контакты: vscoderu@yandex.ru, https://vk.com/vscode
Перенос строки в TextBox с Multiline
Покажем, как выполнить перенос строки в TextBox с атрибутом Multiline (когда текстовое поле занимает несколько строк). Сделаем это на примере программы в Windows Forms и языка C#.
Создание интерфейса программы для демонстрации переноса строки в TextBox
Создадим проект Windows Forms. На окне формы расположим два элемента управления: кнопку (Button) и текстовое поле (TextBox). В кнопке параметру Text зададим значение “Прочитать файл”, поскольку текст в TextBox будем считывать из файла.
Далее займёмся настройкой TextBox. Нажмите правой кнопкой на данном элементе управления и перейдите к Свойствам.
Значение атрибута Multiline установим, как True. Это позволит выводить в TextBox текст в несколько строк, а не в одну.
Далее активируем полосы прокрутки у TextBox. Это позволит удобнее просматривать и работать с многострочным текстом. Для активации параметр ScrollBars переведём в положение Both – полосы будут по обоим измерениям: по горизонтали и по вертикали.
Растянем TextBox по горизонтали до низа формы и получим нечто подобное:
Интерфейс программы готов.
Создание кода программы для показа возможности перехода на новую строку в TextBox
В Visual Studio два раза щёлкнем на кнопку (Button). Откроется редактор кода обработки нажатия на кнопку. Добавим следующие строки:
Откроется редактор кода обработки нажатия на кнопку. Добавим следующие строки:
Как пользоваться vim
David Rayner (zzapper) 15 Years of Vi + 7 years of Vim and still learning © ← O_OВыбрать синтаксис редактируемого файла
:set ft=rubyСпособы перейти в режим вставки
- i - вставить текст слева от текущего
- I - вставить текст в начало строки
- a - вставить текст справа от текущего символа
- A - вставить текст в конец текущей строки
- o - создать новую строку под текущей
- O - создать новую строку над текущей
- C - заменить всё до конца строки
- r - заменить 1 символ
- 3s - удалить 3 символа и перейти в режим вставки
- ciW - заменить большое слово под курсором
- ci" - заменить текст между кавычками
- ci( - заменить текст между круглыми скобками
- gi - перейти к последнему месту, где производилось редактирование
Передвижение по тексту
- fx - Передвинуть курсор вперед к
следующему вхождению символа х в текущей строке
- tx - Передвинуть курсор вперед
к следующему вхождению символа х в текущей строке и установить курсор перед символом x
- Fx - Передвинуть курсор назад к предыдущему вхождению символа х в текущей строке
- w - Передвинуть курсор вперед на одно слово
- b - Передвинуть курсор назад на одно слово
- 0 - Передвинуть курсор на начало текущей строки
- ^ - Передвинуть курсор на первый символ в текущей строке
- $ - Передвинуть курсор на конец текущей строки
- * - начать поиск по слову под курсором
- # - начать поиск по слову под курсором в обратном порядке
- w - перейти к следующему слову
- W - перейти к следующему большому слову (тому, что разделено пробелом)
- b/e - перейти к началу/концу текущего слова
- B/E - перейти к началу/концу текущего большого слова
- gg/G - перейти в начало/конец файла
- % - перейти к парной скобке
- {/} - перейти к следующему/предыдущему параграфу
- '. - перейти к последнему месту, где производилось редактирование
 - перейти к последнему месту, где производилось редактирование
- перейти к последнему месту, где производилось редактированиеУдаление данных
- 4dd - удалить 4 строки
- 3x - удалить 3 символа
- D - удалить от текущей позиции до конца строки
Способы сложного выделения текста
- v% - когда курсор установлен на одной из скобок - выделит всё до её пары.
- vib - выделить всё между двумя ближайшими к курсору круглыми скобками
- viB - выделить всё между двумя ближайшими к курсору фигурными скобками
- vi" - выделить всё между двумя ближайшими двойными кавычками
- vi' - выделить всё между двумя ближайшими одинарными кавычками
- ggVG - выделить весь файл
- Ctrl+v - выделять прямоугольником
Заменить все вхождения 'old' на 'new'
:%s/old/new/gЗаменить все вхождения 'old' на 'new' с запросом подтверждения
:%s/old/new/gwУдалить все строки, не содержащие 'string'
:v/string/dУдаление всех пустых строк в VIM
:g/^$/dСокращения для быстрого создания закомментированных участков кода
:ab #b /*************************************************
:ab #e *************************************************/
Заставить вим не раскрывать табы при редактировании makefile
# vim: set tabstop=4 shiftwidth=4 noexpandtab:Открыть файл, но предопределить синтаксис редактора
$ vim "+set filetype=lisp" file. /-1j
 /-1j
/-1j
Во всех строках содержащих "foo", заменить "bar" на "zzz"
:%g/foo/s/bar/zzz/g
Между метками 'a' и 'b', объединить строки, что содержат 'foo' с теми что идут после них.
:'a,'bg/foo/j
Вставка содержимого из другого места
- :r file.txt
- прочитать и вставить содержимое файла 'file.txt' в место под курсором
- :0r file.txt
- вставить файл в начало документа
- :$r file.txt
- вставить файл в конец документа
- :r !uptime
- вставить вывод команды в место под курсором
Дописать содержимое буфера в конец другого файла
:w >>~/file.txt
Отсортировать весь файл с помощью sort
:%!sort
увеличить/уменьшить число под курсором на 1
Ctrl+a
Ctrl+x Изменить регистр символа под курсором на противоположный
~Объединить текущую строку со следующей
JВ режиме вставки, комбинация Ctrl+R позволяет вставлять некоторые полезные вещи:
- " - последний удалённый/скопированный текст
- % - текущее имя файла
- * - содержимое буфера обмена (X11: primary selection)
- + - содержимое буфера обмена
- / - последний запрос поиска
- : - последняя команда
- . - последний вставленный текст
- - - последний маленький удалённый текст (меньше строки)
- =5*5 - вставит 25. Мини калькулятор
 - последний вставленный текст
- последний вставленный текстДополнить слово в режиме вставки
Ctrl+p
Ctrl+n Путешествие по результатам поиска.
Переход будет осуществляться по местам, которые были указаны явно:
- поиск с помощью / - переход gg, G, [\d]G Так же будут открываться другие файлы, где осуществлялись подобные действия.
Ctrl+o
Ctrl+i Работа с сессиями
Сохраняем
:mks sessionname
" или принудительно:
:mks! sessionname
Загружаем
$ vim -S sessionnameРабота со встроенным файловым менеджером.
Вызвать его можно командой :Explore или попытавшись открыть на
редактирование каталог :sp . /
/
- - - перейти на каталог выше
- mf - пометить файл
- D - удалить помеченые файлы. Удалит файл под курсором, если помеченых нет
- R - переименовать файл под курсором
- d - создать новый каталог
- % - создать новый файл
отправить текущий файл на исполнение питоном
:!python %
работа с несколькими окнами
- Ctrl+wv - разбить окно по вертикали
- Ctrl+ws - разбить окно по горизонтали
- Ctrl+ww - переключиться между окнами
- Ctrl+w{h,j,k,l} - перейти к окну левее, ниже, выше, правее
- Ctrl+w{,+,-} - изменить размеры текущего окна
- Ctrl+wq - закрыть окно
Проставить отступы для всего документа
gg=GДля того чтобы это работало - надо добавить в . vimrc следующую строку:
filetype plugin indent on
 vimrc следующую строку:
vimrc следующую строку:Копируем содержимое строк выше/ниже курсора, не покидая режима вставки
- Ctrl+y - вставить символ над курсором
- Ctrl+e - вставить символ под курсором
Отбросить правки до последнего сохранённого состояния
:e!
- Q - войти в ex-режим
- :vi - выйти из ex-режима
Удалить все строки что не содержат слова "git"
:v/git/d
:g!/git/d
Для всех строк, что содержат слово git добавить в начало '>>'
и в конец ':g/git/norm I>>ctrl+vescA<<
-----------
-----------
Ссылки по теме:
Новосибирский государственный архитектурно-строительный университет - Сибстрин
Море, горы, аэропорт: производственная практика студентов-строителей НГАСУ (Сибстрин) на крупнейшей стройке юга России Благодаря стратегическому партнеру университета – ЗАО «ЛОММЕТА» – студенты работают не на обычном объекте, а на крупнейшей стройке России – возведении нового терминала аэропорта «Геленджик» в Краснодарском крае. Современный аэровокзальный комплекс, строительство которого будет завершено в декабре этого года, значительно улучшит транспортную инфраструктуру курортной зоны юга страны.
В Геленджик приехали 23 студента 3-5 курсов бакалавриата по профилю «Промышленное и гражданское строительство» и специалитета «Строительство уникальных зданий и сооружений». ЗАО «ЛОММЕТА» оплатило студентам стоимость проезда в Геленджик и обратно, проживание и питание, а также выплачивает заработную плату. Непосредственно производственная практика проходит с 24 июня по 28 июля, однако у желающих есть возможность остаться работать на объекте и после ее окончания. Современный аэровокзальный комплекс, строительство которого будет завершено в декабре этого года, значительно улучшит транспортную инфраструктуру курортной зоны юга страны.
В Геленджик приехали 23 студента 3-5 курсов бакалавриата по профилю «Промышленное и гражданское строительство» и специалитета «Строительство уникальных зданий и сооружений». ЗАО «ЛОММЕТА» оплатило студентам стоимость проезда в Геленджик и обратно, проживание и питание, а также выплачивает заработную плату. Непосредственно производственная практика проходит с 24 июня по 28 июля, однако у желающих есть возможность остаться работать на объекте и после ее окончания. |
Профессия дорожник всегда будет востребована! Строительная специальность НГАСУ (Сибстрин) «Автомобильные дороги» Старейший вуз города – Новосибирский государственный архитектурно-строительный университет (Сибстрин) – вот уже более 90 лет занимает лидирующие позиции в обучении студентов по направлению «Строительство». С 2017 года в нашем вузе началась подготовка специалистов по профилю «Автомобильные дороги»
На сегодняшний день это одно из самых актуальных направлений строительства. Национальный проект «Безопасные и качественные автомобильные дороги» предполагает приоритетное развитие транспортной инфраструктуры страны за счет средств федерального бюджета. Поэтому специалисты – строители автомобильных дорог – будут востребованы во всех регионах страны.
Объектами профессиональной деятельности выпускника являются: изыскания, проектирование, строительство и эксплуатация автомобильных дорог, включая земляное полотно, дорожные одежды, водопропускные сооружения, инженерные транспортные сооружения.
С 2017 года в нашем вузе началась подготовка специалистов по профилю «Автомобильные дороги»
На сегодняшний день это одно из самых актуальных направлений строительства. Национальный проект «Безопасные и качественные автомобильные дороги» предполагает приоритетное развитие транспортной инфраструктуры страны за счет средств федерального бюджета. Поэтому специалисты – строители автомобильных дорог – будут востребованы во всех регионах страны.
Объектами профессиональной деятельности выпускника являются: изыскания, проектирование, строительство и эксплуатация автомобильных дорог, включая земляное полотно, дорожные одежды, водопропускные сооружения, инженерные транспортные сооружения. |
Важное направление подготовки «Природообустройство и водопользование»: много бюджетных мест Новосибирский государственный архитектурно-строительный университет (Сибстрин) ждет абитуриентов на направление подготовки «Природообустройство и водопользование», профиль «Комплексное использование и охрана водных ресурсов». В 2021 году на данное направление выделено 30 бюджетных мест.
Деятельность выпускников НГАСУ (Сибстрин) по данному профилю направлена на повышение эффективности использования водных и земельных ресурсов, устойчивости и экологической безопасности, а именно:
создание водохозяйственных систем комплексного назначение, охрана и восстановление водных объектов;
охрана земель различного назначения, рекультивация земель, нарушенных или загрязненных в процессе природопользования;
природоохранное обустройство территорий с целью защиты от воздействия природных стихий;
водоснабжение сельских поселений, отвод и очистка сточных вод, обводнение территорий. В 2021 году на данное направление выделено 30 бюджетных мест.
Деятельность выпускников НГАСУ (Сибстрин) по данному профилю направлена на повышение эффективности использования водных и земельных ресурсов, устойчивости и экологической безопасности, а именно:
создание водохозяйственных систем комплексного назначение, охрана и восстановление водных объектов;
охрана земель различного назначения, рекультивация земель, нарушенных или загрязненных в процессе природопользования;
природоохранное обустройство территорий с целью защиты от воздействия природных стихий;
водоснабжение сельских поселений, отвод и очистка сточных вод, обводнение территорий. |
Обучение в НГАСУ (Сибстрин) по актуальному направлению «Жилищное хозяйство и коммунальная инфраструктура»! В 2020 года НГАСУ (Сибстрин) прошел государственную аккредитационную экспертизу и получил аккредитацию (а значит, и право выдавать дипломы государственного образца) по направлениям: 38. 03.10 Жилищное хозяйство и коммунальная инфраструктура (бакалавриат), профиль «Управление жилищным фондом и многоквартирными домами».
38.04.10 Жилищное хозяйство и коммунальная инфраструктура (магистратура), профиль «Управление жилищным фондом и многоквартирными домами».
Подготовка кадров для сферы ЖКХ чрезвычайно актуальна. Особое внимание уделяется подготовке управленческих кадров, компетентных не только в технических вопросах, связанных с функционированием объектов отрасли, но и обладающими управленческими компетенциями: приёмами и методами принятия управленческих решений, способностью к формированию эффективной структуры управления, коммуникативными навыками и организаторскими способностями, проектным мышлением.
После окончан 03.10 Жилищное хозяйство и коммунальная инфраструктура (бакалавриат), профиль «Управление жилищным фондом и многоквартирными домами».
38.04.10 Жилищное хозяйство и коммунальная инфраструктура (магистратура), профиль «Управление жилищным фондом и многоквартирными домами».
Подготовка кадров для сферы ЖКХ чрезвычайно актуальна. Особое внимание уделяется подготовке управленческих кадров, компетентных не только в технических вопросах, связанных с функционированием объектов отрасли, но и обладающими управленческими компетенциями: приёмами и методами принятия управленческих решений, способностью к формированию эффективной структуры управления, коммуникативными навыками и организаторскими способностями, проектным мышлением.
После окончан |
Как осуществить с помощью flexbox перенос на новую строку: позиционирование элементов
От автора: вот проблема: если вы хотите создать макет с несколькими строками элементов, как вы можете контролировать во flexbox перенос элементов на новую строку?
Предположим, вы хотите создать макет, который выглядит примерно так, с чередующимися строками из трех элементов и одним элементом на всю ширину:
Распространенным способом управления позиционированием и размером flex-элементов является использование width или flex-basic; если мы установим для четвертого элемента width 100%, он будет расположен в отдельной строке. Но что, если мы не хотим или не можем установить ширину отдельных элементов? Или есть ли способ просто указать flexbox разрыв строки в определенных точках?
Но что, если мы не хотим или не можем установить ширину отдельных элементов? Или есть ли способ просто указать flexbox разрыв строки в определенных точках?
Нет никакого свойства, которое мы могли бы установить для flex, чтобы оно переносило элементы на новую строку, но мы можем вставить перенос строки (вы можете представить это, как br) между двумя flex-элементами для достижения чего-то похожего:
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее/* Вставка разрыва строки между двумя flex-элементами заставит * flex-элемент, который расположен после него переноситься на новую строку */ .break { flex-basis: 100%; height: 0; }
/* Вставка разрыва строки между двумя flex-элементами заставит * flex-элемент, который расположен после него переноситься на новую строку */ . flex-basis: 100%; height: 0; } |
 break {
break {<div> <div></div> <div></div> <!-- break --> <div></div> </div>
<div> <div></div> <div></div> <!-- break --> <div></div> </div> |
Давайте рассмотрим некоторые сценарии, когда вы, возможно, захотите использовать это, а также некоторые интересные методы компоновки, которые позволяет нам это использовать.
Обратите внимание , что все примеры кода ниже, требуют и предполагают, что у вас есть контейнер с display: flex и flex-wrap: wrap и flex-элементы добавляются в этот контейнер:
.container { display: flex; flex-wrap: wrap; }
.container { display: flex; flex-wrap: wrap; } |
<div>
<div></div>
<div></div>
<div></div>
. ..
</div>
..
</div>
<div> <div></div> <div></div> <div></div> ... </div> |
Вставка элемента разрыва
Использование элемента для перехода к новой строке flexbox дает интересный эффект: мы можем пропустить указание ширины любого элемента в макете и полностью полагаться на разрывы строк для определения потока сетки.
Давайте начнем с простого примера. Скажем, у нас есть два элемента, отображаемые рядом (они будут растягиваться с помощью flex-grow: 1, и для них не определены ни width, ни flex-basis):
Мы можем вставить элемент разрыва строки между элементами, чтобы они оба заняли 100% доступного пространства:
<div>...</div> <div></div> <!-- перенос на новую строку --> <div>...</div>
<div>. <div></div> <!-- перенос на новую строку --> <div>...</div> |
 ..</div>
..</div>Это создает макет с двумя вертикальными элементами полной ширины (я добавил границу к элементу .break, чтобы проиллюстрировать его положение и поведение):
Как это работает? Так как мы указали, что .break должен занимать 100% ширины контейнера (потому что мы установили flex-basis: 100%), flex-элемент переноса должен размещаться в собственном ряду, чтобы достигнуть этого. Он не может размещаться в одном ряду с первым элементом, поэтому перейдет к новой строке, в результате чего первый элемент останется один в одной строке. Первый элемент будет растягиваться, чтобы заполнить оставшееся пространство (так как мы установили flex-grow: 1). Та же логика применима ко второму элементу.
Мы можем использовать эту технику для компоновки макета, описанного в начале статьи, разбивая последовательность до и после каждого четвертого элемента:
<div>. ..</div>
<div>...</div>
<div>...</div>
<div></div> <!-- разрыв -->
<div>...</div>
<div></div> <!-- разрыв -->
<div>...</div>
<div>...</div>
<div>...</div>
<div>...</div> <div>...</div> <div>...</div> <div></div> <!-- разрыв --> <div>...</div> <div></div> <!-- разрыв --> <div>...</div> <div>...</div> <div>...</div> |
Это создаст нужный макет. По сути, элемент не будет переноситься на новую строку, если мы не вставим элемент разрыва строки:
Опять же, нам не нужно было указывать ширину ни для одного из этих элементов. Тот же самый метод будет работать для столбцов, если у нас есть гибкий контейнер с flex-direction: column, и установлено значение width 0 (вместо height) для элемента разрыва строки:
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее /* Используем столбец разрыва для переноса в новый столбец */
. break-column {
flex-basis: 100%;
width: 0;
}
break-column {
flex-basis: 100%;
width: 0;
}
/* Используем столбец разрыва для переноса в новый столбец */ .break-column { flex-basis: 100%; width: 0; } |
Такой подход с использованием элементов разрыва для определения макета добавляет некоторое раздутие и шум в HTML, но он может быть мощным инструментом при правильном использовании. Мы можем, например, использовать его для верстки макета кладки с помощью чистого CSS и динамически размещать разрывы с помощью свойства order. Мы также можем перейти к новой строке, не изменяя ширину какого-либо элемента содержимого, и мы можем полагаться исключительно на распределение пространства в макете сетки с помощью flex-grow.
Предположим, что мы хотим создать этот макет:
И предположим, что мы хотим сделать это, задав разные значения flex-grow для распределения пространства (вместо использования flex-basis или width, которые вам придется пересчитывать, когда вы добавляете или удаляете элементы):
. item { flex-grow: 1; }
.item-wide { flex-grow: 3; }
item { flex-grow: 1; }
.item-wide { flex-grow: 3; }
.item { flex-grow: 1; } .item-wide { flex-grow: 3; } |
<div></div> <div></div> <div></div>
<div></div> <div></div> <div></div> |
Если затем мы хотим добавить еще одну строку элементов ниже этой:
Мы не сможем сделать это, не устанавливая flex-basis или width, по крайней мере, для некоторых элементов (или не создавая вложенный макет flexbox с одним flex-элементом для каждой строки). Если все элементы имеют разные значения flex-grow, и ничто не заставляет их переноситься на новую строку, они все просто втиснутся в одну строку:
Неплохо. Однако, если мы вставим элемент разрыва строки, мы можем построить этот макет, распределяя все пространство с помощью flex-grow:
. item { flex-grow: 1; }
.item-wide { flex-grow: 3; }
item { flex-grow: 1; }
.item-wide { flex-grow: 3; }
.item { flex-grow: 1; } .item-wide { flex-grow: 3; } |
<div></div> <div></div> <div></div> <div></div> <!-- разрыв --> <div></div> <div></div>
<div></div> <div></div> <div></div> <div></div> <!-- разрыв --> <div></div> <div></div> |
Это задает нужный макет, со всеми размерами, определенными пропорционально через flex-grow:
И если будет сценарий, когда нам нужно пять элементов в первой строке, нам не нужно менять какой-либо CSS-код, чтобы это заработало, мы можем просто добавить эти элементы до разрыва строки:
<div></div> <div></div> <div></div> <div></div> <div></div> <div></div> <!-- разрыв --> <div></div> <div></div>
<div></div> <div></div> <div></div> <div></div> <div></div> <div></div> <!-- разрыв --> <div></div> <div></div> |
Все, что вам нужно добавить в CSS, чтобы использовать элементы разрыва строки — это эти два класса (единственное различие между этими двумя классами состоит в том, что для width (а не для height) необходимо установить 0, чтобы элемент разрывал столбец при использовании в макете столбцов):
/* Использование разрыва строки между двумя flex-элементами заставит * flex-элемент, который расположен после него, перенестись в новую строку */ .break { flex-basis: 100%; height: 0; } /* Используем разрыв столбца, чтобы перенести элемент в новый столбец */ .break-column { flex-basis: 100%; width: 0; }
/* Использование разрыва строки между двумя flex-элементами заставит * flex-элемент, который расположен после него, перенестись в новую строку */ .break { flex-basis: 100%; height: 0; }
/* Используем разрыв столбца, чтобы перенести элемент в новый столбец */ .break-column { flex-basis: 100%; width: 0; } |
Вы, безусловно, может достичь того же или подобного эффекта с помощью вложенных flexbox, когда для каждого ряда будет задан отдельный flexbox, но во многих случаях простое использование flex-basis, width или контента в пределах flex-элементов, вероятно, будет предпочтительным способ управления потоком элементов в макете flexbox. Вставка элементов разрыва является доступной и простой в использовании, она работает, и данная техника обладает некоторыми уникальными характеристиками, которые могут вам пригодиться.
Автор: Tobias Bjerrome Ahlin
Источник: //tobiasahlin.com
Редакция: Команда webformyself.
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееPSD to HTML
Практика верстки сайта на CSS Grid с нуля
Смотреть Стиль кодирования- должны ли фигурные скобки появляться на отдельной строке?
В течение долгого времени я утверждал, что они имеют одинаковую ценность, или около очень близко к , что возможный выигрыш от правильного выбора был намного ниже стоимости споров по этому поводу.
Тем не менее, соответствие важно . Итак, я сказал: давайте подбросим монетку и приступим к написанию кода.
Я видел, как программисты сопротивлялись подобным изменениям раньше. Преодолей это! Я много раз менял свою карьеру.Я даже использую разные стили в моем C #, чем в моем PowerShell.
Несколько лет назад я работал в команде (около 20 разработчиков), которая решила запросить ввод, а затем принять решение, а затем обеспечить его соблюдение во всей кодовой базе. У нас будет 1 неделя, чтобы решить.
Стонет и закатывает глаза. Много слов «Мне нравится мой путь, потому что он лучше», но без содержания.
Когда мы изучали тонкости вопроса, кто-то спросил, как решить эту проблему в стиле скобок на той же линии:
void MyFunction (
int параметрOne,
int parameterTwo) {
int localOne,
int localTwo
}
Обратите внимание, что не сразу видно, где заканчивается список параметров и начинается тело.Сравните с:
void MyFunction (
int параметрOne,
int параметрTwo)
{
int localOne,
int localTwo
}
Мы прочитали, как люди во всем мире решили эту проблему, и нашли образец добавления пустой строки после открытой фигурной скобки:
void MyFunction (
int параметрOne,
int parameterTwo) {
int localOne,
int localTwo
}
Если вы собираетесь сделать визуальный перерыв, вы можете сделать это с помощью бандажа.Тогда ваши визуальные перерывы тоже станут последовательными.
Edit : две альтернативы решению «лишняя пустая строка» при использовании K&R:
1 / Отступ аргументов функции отличается от отступа тела функции
2 / Поместите первый аргумент в ту же строку, что и имя функции, и выровняйте следующие аргументы в новых строках с этим первым аргументом
Примеры:
1/
void MyFunction (
int параметрOne,
int parameterTwo) {
int localOne,
int localTwo
}
2/
void MyFunction (int parameterOne,
int parameterTwo) {
int localOne,
int localTwo
}
/ Редактировать
Я по-прежнему утверждаю, что согласованность важнее других соображений, но если у нас нет установленного прецедента , то можно использовать скобки на следующей строке.
pdb - Отладчик Python - документация Python 3.9.6
Исходный код: Lib / pdb.py
Модуль pdb определяет интерактивный отладчик исходного кода для Python
программы. Он поддерживает установку (условных) точек останова и пошаговое выполнение
уровень исходной строки, проверка кадров стека, листинг исходного кода и
оценка произвольного кода Python в контексте любого кадра стека. Это также
поддерживает посмертную отладку и может вызываться под управлением программы.
Отладчик расширяемый - он фактически определен как класс Pdb .
В настоящее время это недокументировано, но легко понять, прочитав источник. В
Интерфейс расширения использует модули bdb и cmd .
Приглашение отладчика - (Pdb) . Типичное использование для запуска программы под контролем
отладчика:
>>> импорт pdb
>>> import mymodule
>>> pdb.run ('mymodule.test ()')
> <строка> (0)? ()
(Pdb) продолжить
> <строка> (1)? ()
(Pdb) продолжить
NameError: 'спам'
> <строка> (1)? ()
(PDB)
Изменено в версии 3.3: Завершение табуляции через модуль чтения доступно для команд и
аргументы команды, например текущие глобальные и локальные имена предлагаются как
аргументы команды p .
pdb.py также можно вызывать как сценарий для отладки других сценариев. Для
пример:
python3 -m pdb myscript.py
При запуске в качестве сценария pdb автоматически переходит в режим посмертной отладки, если отлаживаемая программа завершает работу ненормально. После посмертной отладки (или после нормального выхода из программы) pdb перезапустит программу.Автоматический перезапуск сохраняет состояние PDB (например, точки останова), и в большинстве случаев полезно, чем выход из отладчика при выходе из программы.
Новое в версии 3.2: pdb.py теперь принимает параметр -c , который выполняет команды, как если бы они были заданы
в файле .pdbrc см. Команды отладчика.
Новое в версии 3.7: pdb.py теперь принимает параметр -m , который выполняет модули аналогично python3 -m делает. Как и в случае со сценарием, отладчик просто приостанавливает выполнение.
перед первой строкой модуля.
Типичное использование для взлома отладчика из работающей программы: вставка
import pdb; pdb.set_trace ()
в том месте, которое вы хотите взломать отладчик. Затем вы можете пройти через
код, следующий за этим оператором, и продолжить работу без отладчика
используя команду continue .
Новое в версии 3.7: можно использовать встроенную точку останова () при вызове со значениями по умолчанию.
вместо import pdb; pdb.set_trace () .
Типичное использование для проверки сбойной программы:
>>> импорт pdb >>> import mymodule >>> mymodule.test () Отслеживание (последний вызов последний): Файл "", строка 1, в Файл "./mymodule.py", строка 4, в тесте test2 () Файл "./mymodule.py", строка 3, в test2 печать (спам) NameError: спам >>> pdb.pm () > ./mymodule.py (3) test2 () -> печать (спам) (PDB)
Модуль определяет следующие функции; каждый входит в отладчик в немного иначе:
-
pdb.run( statement , globals = None , locals = None ) Выполнить инструкцию (заданную как строку или объект кода) в отладчике контроль. Приглашение отладчика появляется перед выполнением любого кода; ты можешь установите точки останова и введите
продолжить, или вы можете пройти через оператор, используяшагилиследующий(все эти команды объяснено ниже). Необязательные аргументы globals и locals указывают среда, в которой выполняется код; по умолчанию словарь модуль__main__используется.(См. Объяснение встроенногоexec ()илиeval ()функций.)
-
pdb.runeval( выражение , globals = None , locals = None ) Оценить выражение (заданное как строка или объект кода) в отладчике контроль. Когда
runeval ()возвращается, он возвращает значение выражение. В остальном эта функция аналогичнаrun ().
-
pdb.runcall( функция , * args , ** kwds ) Вызовите функцию (объект функции или метода, а не строку) с приводятся аргументы. Когда
runcall ()возвращается, он возвращает все, что вызов функции возвращен. Запрос отладчика появляется, как только функция введен.
-
pdb.set_trace( * , заголовок = Нет ) Войдите в отладчик в вызывающем кадре стека.Это полезно для жесткого кодирования точка останова в данной точке программы, даже если код не в противном случае выполняется отладка (например, когда утверждение не выполняется). Если дано, Заголовок выводится на консоль непосредственно перед началом отладки.
Изменено в версии 3.7: аргумент , содержащий только ключевое слово, заголовок .
-
pdb.post_mortem( traceback = Нет ) Войти в посмертную отладку данного объекта трассировки .Если нет traceback , он использует одно из исключений, которое в настоящее время обрабатывается (исключение должно обрабатываться, если значение по умолчанию использовал).
-
pdb.вечера() Введите посмертную отладку трассировки, найденной в
sys.last_traceback.
Функции запуска * и set_trace () являются псевдонимами для создания экземпляра Pdb class и вызов одноименного метода.Если хотите
доступ к дополнительным функциям, вы должны сделать это самостоятельно:
- класс
pdb.Pdb( completekey = 'tab' , stdin = None , stdout = None , skip = None , nosigint = False , readrc = True ) Pdb- класс отладчика.Аргументы completekey , stdin и stdout передаются в лежащий в основе
cmd.Cmdкласс; см. описание там.Аргумент skip , если он задан, должен быть повторением имени модуля в стиле глобуса. узоры. Отладчик не будет переходить к кадрам, исходящим из модуля. что соответствует одному из этих шаблонов.
По умолчанию Pdb устанавливает обработчик для сигнала SIGINT (который отправляется, когда пользователь нажимает Ctrl-C на консоли), когда вы даете команду
продолжить. Это позволяет вам снова войти в отладчик, нажав Ctrl-C .если ты хотите, чтобы Pdb не касался обработчика SIGINT, установите для nosigint значение true.Аргумент readrc по умолчанию имеет значение true и определяет, будет ли Pdb загружаться. .pdbrc файлы из файловой системы.
Пример вызова для включения трассировки с пропуском :
import pdb; pdb.Pdb (skip = ['django. *']). set_trace ()
Вызывает событие аудита
pdb.Pdbбез аргументов.Новое в версии 3.1: аргумент пропустить аргумент .
Новое в версии 3.2: аргумент nosigint . Ранее обработчик SIGINT никогда не устанавливался Pdb.
Изменено в версии 3.6: аргумент readrc .
-
запустить( инструкция , глобальные = нет , локальные = нет ) -
runeval( выражение , globals = None , locals = None ) -
runcall( функция , * args , ** kwds ) -
set_trace() См. Документацию по функциям, описанным выше.
-
Команды отладчика
Команды, распознаваемые отладчиком, перечислены ниже. Большинство команд можно
сокращенно до одной или двух букв, как указано; например ч (эл.) означает, что
для ввода команды справки можно использовать h или help (но не he или hel , или H или Help или HELP ). Аргументы команд должны быть
разделены пробелами (пробелами или табуляциями).Необязательные аргументы заключены в
квадратные скобки ( [] ) в синтаксисе команды; квадратные скобки не должны быть
набрал. Альтернативы в синтаксисе команд разделены вертикальной чертой
( | ).
При вводе пустой строки повторяется последняя введенная команда. Исключение: если последний
команда была командой list , перечислены следующие 11 строк.
Команды, которые отладчик не распознает, считаются операторами Python.
и выполняются в контексте отлаживаемой программы.Python
операторы также могут иметь префикс восклицательного знака (! ). Это
мощный способ проверки отлаживаемой программы; это даже возможно
изменить переменную или вызвать функцию. Когда возникает исключение в таком
оператор, имя исключения печатается, но состояние отладчика не
измененный.
Отладчик поддерживает псевдонимы. Псевдонимы могут иметь параметры, которые обеспечивают определенный уровень адаптации к контексту в экспертиза.
В одной строке можно ввести несколько команд, разделенных ;; .(А
одиночный ; не используется, так как это разделитель для нескольких команд в строке
который передается синтаксическому анализатору Python.) Никакой интеллект не применяется к разделению
команды; вход разделен на первые ;; , даже если он находится в
середина строки в кавычках.
Если файл .pdbrc существует в домашнем каталоге пользователя или в текущем
каталог, он читается и выполняется, как если бы он был набран в отладчике
Подсказка. Это особенно полезно для псевдонимов.Если существуют оба файла, один
в домашнем каталоге сначала читается, и псевдонимы, определенные там, могут быть переопределены
локальным файлом.
Изменено в версии 3.2: .pdbrc теперь может содержать команды, продолжающие отладку, например продолжить или следующий . Ранее в этих командах не было
эффект.
-
h (elp)[команда] Без аргумента распечатать список доступных команд. С командой как аргумент, выведите справку по этой команде.
help pdbотображает полную документация (строка документации модуляpdb). Начиная с команды аргумент должен быть идентификатором,help execдолжен быть введен для получения справки по!команда.
-
w (здесь) Распечатайте трассировку стека с самым последним кадром внизу. Стрелка указывает текущий кадр, который определяет контекст большинства команд.
-
д (собственный)[кол-во] Переместить текущий кадр count (по умолчанию) уровней вниз в трассировке стека (к более новой раме).
-
u (p)[кол-во] Переместить текущий кадр счетчик (по умолчанию) уровней вверх в трассировке стека (чтобы старый кадр).
-
b (reak)[([имя файла:] белье | функция) [, условие]] С аргументом cabin установите разрыв в текущем файле. С функция аргумент, установите перерыв в первом исполняемом операторе в пределах эта функция.Номер строки может начинаться с имени файла и двоеточия, чтобы указать точку останова в другом файле (возможно, тот, который не был загружен все же). Файл ищется по
sys.path. Обратите внимание, что каждая точка останова присваивается номер, на который ссылаются все остальные команды точки останова.Если присутствует второй аргумент, это выражение, которое должно оцениваться как истина до того, как будет соблюдена точка останова.
Без аргумента перечислить все перерывы, включая для каждой точки останова номер раз, когда эта точка останова была достигнута, текущий счетчик игнорирования и связанное условие, если таковое имеется.
-
tbreak[([имя файла:] белье | функция) [, условие]] Временная точка останова, которая автоматически удаляется при первом достижении. Аргументы те же, что и для
break.
-
cl (ухо)[имя файла: белье | bpnumber ...] С аргументом имя_файла: белье очистите все точки останова в этой строке. С помощью списка номеров точек останова, разделенных пробелами, удалите эти точки останова.Без аргументов удалите все перерывы (но сначала спросите подтверждение).
-
отключить[bpnumber ...] Отключить точки останова, указанные как список точек останова, разделенных пробелами числа. Отключение точки останова означает, что она не может привести к остановке программы. выполнения, но в отличие от очистки точки останова, он остается в списке точки останова и могут быть (повторно) включены.
-
включить[bpnumber...] Включить указанные точки останова.
-
игнорироватьbpnumber [количество] Установить счетчик игнорирования для заданного номера точки останова. Если счетчик опущен, счетчик игнорирования установлен на 0. Точка останова становится активной, когда игнорируется счетчик равен нулю. Если не равен нулю, счет уменьшается каждый раз, когда точка останова достигнута, и точка останова не отключена, и все связанные условие оценивается как истинное.
-
условиеномер bp [условие] Установить новое условие для точки останова, выражение, которое должно вычисляться значение true до того, как будет соблюдена точка останова.Если условие отсутствует, любое существующее состояние удалено; т.е. точка останова делается безусловной.
-
команды[bpnumber] Укажите список команд для точки останова с номером bpnumber . Команды сами появляются в следующих строках. Введите строку, содержащую только
конец, чтобы завершить команды. Пример:(Pdb) команды 1 (com) p some_variable (com) конец (PDB)
Чтобы удалить все команды из точки останова, введите
командуи следуйте ей. сразу сконец; то есть не отдавать команд.Без аргумента bpnumber команда
Вы можете использовать команды точки останова, чтобы снова запустить вашу программу. Просто используйте
продолжить командуилишаг, или любая другая команда, возобновляющая выполнение.Указание возобновления выполнения любой команды (в настоящее время
продолжить,шаг,следующий,вернуть,перейти,выйтии их сокращения) завершает список команд (как если бы за этой командой сразу же следовало end).Это потому, что каждый раз, когда ты возобновить выполнение (даже с простым next или step), вы можете столкнуться с другим точка останова - у которого может быть собственный список команд, что приводит к двусмысленности какой список выполнить.Если вы используете команду «без звука» в списке команд, обычное сообщение о остановка в точке останова не печатается. Это может быть желательно для точек останова которые должны напечатать конкретное сообщение, а затем продолжить. Если никто другой команды печатают что угодно, вы не видите никаких признаков того, что точка останова была достигнута.
-
с (теп) Выполнить текущую строку, остановить при первой возможности (либо в вызываемой функции или в следующей строке текущей функции).
-
n (доб) Продолжать выполнение, пока не будет достигнута следующая строка в текущей функции или он возвращается. (Разница между
следующимишагомсоставляет чтошагостанавливается внутри вызываемой функции, аследующийвыполняет вызываемые функции на (почти) полной скорости, останавливаясь только на следующем строка в текущей функции.)
-
Unt (il)[белье] Без аргумента, продолжить выполнение до строки с номером больше чем достигается текущий.
С номером строки продолжить выполнение до тех пор, пока не появится строка с номером больше или равный этому достигается. В обоих случаях также остановитесь, когда текущий кадр возвращается.
Изменено в версии 3.2: Разрешить явный номер строки.
-
r (этурн) Продолжить выполнение, пока не вернется текущая функция.
-
c (ont (inue)) Продолжить выполнение, останавливаться только при обнаружении точки останова.
-
j (ump)полотно Установить следующую строку, которая будет выполняться. Доступно только в самом нижнем Рамка. Это позволяет вам вернуться назад и снова выполнить код или перейти вперед к пропустить код, который вы не хотите запускать.
Следует отметить, что не все прыжки разрешены - например, это не можно прыгнуть в середину петли
наили выйти изнаконецпункт.
-
л (ист)[первая [, последняя]] Вывести исходный код текущего файла. Без аргументов перечислить 11 строк вокруг текущей строки или продолжить предыдущее перечисление. С
.как аргумент, перечислите 11 строк вокруг текущей строки. С одним аргументом, перечислите 11 строк вокруг этой строки. С двумя аргументами перечислите данный диапазон; если второй аргумент меньше первого, он интерпретируется как счетчик.Текущая строка в текущем кадре обозначается как
->.Если исключение отлаживается, строка, в которой изначально было исключение поднятый или размноженный обозначается>>, если он отличается от текущего линия.Новое в версии 3.2: Маркер
>>.
-
ll| длинный список Вывести весь исходный код для текущей функции или кадра. Интересные строчки помечены как для списка
-
а (ргс) Распечатать список аргументов текущей функции.
-
pвыражение Вычислить выражение в текущем контексте и распечатать его значение.
Примечание
print ()также можно использовать, но это не команда отладчика - она выполняет Функция Pythonprint ().
-
ppвыражение Аналогично команде
p, за исключением того, что значение выражения равно красиво напечатано с использованием модуляpprint.
-
whatisвыражение Выведите тип выражения .
-
источниквыражение Попробуйте получить исходный код для данного объекта и отобразить его.
-
дисплей[выражение] Отображать значение выражения, если оно изменилось, каждый раз, когда выполнение останавливается в текущем кадре.
Без выражения, перечислить все отображаемые выражения для текущего кадра.
-
не отображать[выражение] Больше не отображать выражение в текущем кадре. Без выражение, очистить все отображаемые выражения для текущего кадра.
-
взаимодействовать Запустить интерактивный интерпретатор (используя модуль
code), глобальный пространство имен содержит все (глобальные и локальные) имена, найденные в текущем объем.
-
псевдоним[имя [команда]] Создайте псевдоним с именем name , который выполняет команду . Команда должна , а не следует заключать в кавычки. Заменяемые параметры могут быть обозначены
% 1,% 2и так далее, при этом% *заменяются всеми параметрами. Если команда не задана, отображается текущий псевдоним для имя . Если нет приведены аргументы, перечислены все псевдонимы.Псевдонимы могут быть вложенными и содержать все, что можно ввести на законных основаниях. приглашение pdb. Обратите внимание, что внутренние команды pdb могут быть отменены с помощью команды . псевдонимы. Затем такая команда скрывается до тех пор, пока псевдоним не будет удален. Сглаживание рекурсивно применяется к первому слову командной строки; все остальные слова в очереди остались одни.
В качестве примера, вот два полезных псевдонима (особенно при размещении в
.pdbrcфайл):# Печатать переменные экземпляра (использование "pi classInst") псевдоним pi для k в% 1.__dict __. keys (): print ("% 1.", k, "=",% 1 .__ dict __ [k]) # Печатать переменные экземпляра в себе псевдоним ps pi self
-
unaliasимя Удалить указанный псевдоним.
-
!ведомость Выполнить (однострочный) оператор в контексте текущего кадра стека. Восклицательный знак можно опустить, если только первое слово утверждения напоминает команду отладчика.Чтобы установить глобальную переменную, вы можете префикс команда присвоения с глобальным оператором
(Pdb) global list_options; list_options = ['-l'] (PDB)
-
прогон[аргументы ...] -
перезапуск[аргументы ...] Перезапустите отлаженную программу Python. Если указан аргумент, он разбивается с
shlex, и результат используется как новыйsys.argv. История, точки останова, действия и параметры отладчика сохраняются.restart- это псевдоним дляrun.
-
кв (уит) Закройте отладчик. Выполняемая программа прерывается.
-
отладкакод Введите рекурсивный отладчик, который выполняет код аргумент (который является произвольным выражением или утверждением, выполняется в текущей среде).
-
возврат Распечатать возвращаемое значение для последнего возврата функции.
Сноски
vim - vimdiff: перейти к следующему отличию внутри строки?
vim - vimdiff: перейти к следующему отличию внутри строки? - СуперпользовательСеть обмена стеков
Сеть Stack Exchange состоит из 178 сообществ вопросов и ответов, включая Stack Overflow, крупнейшее и пользующееся наибольшим доверием онлайн-сообщество, где разработчики могут учиться, делиться своими знаниями и строить свою карьеру.
Посетить Stack Exchange- 0
- +0
- Авторизоваться Зарегистрироваться
Super User - это сайт вопросов и ответов для компьютерных энтузиастов и опытных пользователей.Регистрация займет всего минуту.
Зарегистрируйтесь, чтобы присоединиться к этому сообществуКто угодно может задать вопрос
Кто угодно может ответить
Лучшие ответы голосуются и поднимаются наверх
Спросил
Просмотрено 29к раз
vimdiff очень удобен для сравнения файлов.Однако я часто использую его для файлов с длинными строками и относительно небольшим количеством различий внутри строк.
vimdiff будет правильно выделять различия внутри строки (вся строка - розовым, разные символы - красным). В этих случаях было бы неплохо иметь возможность перейти к следующей разности внутри строки .
Вы можете перейти к «следующей разнице» (] c ), но это перейдет к следующей строке с разницей.
Есть ли способ перейти к следующему другому символу в текущей строке?
Flimm8,05055 золотых знаков2626 серебряных знаков3535 бронзовых знаков
задан 27 мая '10 в 16: 162010-05-27 16:16
Sleskesleske21.2k99 золотых знаков5959 серебряных знаков9090 бронзовых знаков
Я вижу два решения:
- вам нужно будет проверить текущую подсветку синтаксиса, чтобы перейти к красной части строки.
- вам нужно будет извлечь текущую строку в обоих буферах и найти первый символ, который отличается, чтобы правильно расположить курсор
Оба решения должны выполняться после] c и требуют написания сценария vim.
РЕДАКТИРОВАТЬ: Вот первый набросок, который, кажется, работает:
nnoremap (& diff? "] C: call \ NextDiff () \ ": ": cn \ ")
функция! s: GotoWinline (w_l)
нормальный! ЧАС
в то время как winline () GotoWinline (w_l) | let lines [winnr ()] = {'текст': getline ('.'), 'число': строка ('.')} | endif
Ну наконец то
let & foldenable = складной
Endtry
"echomsg строка (строки)
если len (строк) <2 | возврат | endif
пусть индексы = повторение ([0], len (строки))
пусть tLines = значения (строки)
пусть найдено = 0
«бесконечный цикл по двум пустым текстам ...
пока ! найденный
пусть c = ''
пусть next_idx = []
пусть я = 0
в то время как i! = len (индексы)
пусть crt_line = tLines [i].текст
пусть n = индексы [i]
если len (crt_line) == n
пусть найдено = 1
сломать
endif
пусть c2 = (len (crt_line) == n)? 'EOL': crt_line [n]
если пусто (c)
пусть c = c2
endif
"проверяет соответствие
пусть n + = 1
если c = ~ '\ s'
если (c2! = c) && (ignore_blanks && c2! ~ '\ s')
пусть найдено = 1
сломать
иначе "продвижение
в то время как ignore_blanks && (n == len (crt_line) || crt_line [n] = ~ '\ s')
пусть n + = 1
в конце концов
endif
еще
если c2! = c
пусть найдено = 1
сломать
endif
endif
пусть next_idx + = [n]
пусть я + = 1
в конце концов
если найден | перерыв | endif
пусть индексы = next_idx
в конце концов
"теперь перейдите в правый столбец
пусть окна = ключи (строки)
"Утвердить len (windows) == len (индексы)
пусть w = 0
а w! = len (окна)
"echomsg 'W #'.windows [w]. ' ->: '(tLines [w] .number).' нормально! '. (индексы [w] +1).' | '
exe windows [w]. 'wincmd w'
тихий! exe (tLines [w] .number). 'нормально! 0 '. (Индексы [w]).' L '
пусть w + = 1
в конце концов
"echomsg строка (индексы)
конечная функция