что такое релевантность и как определить
Релевантность – это степень соответствия чего-либо при определенных условиях или в определенный момент времени. Это общее понятие, но что такое релевантность сайта при поисковом продвижении сайта?
Основная задача поисковых систем – дать релевантный ответ на запрос пользователя, чтобы он остался удовлетворенным и не полез искать информацию в других сервисах. Таким образом, степень соответствия запроса странице сайта (документу) является поисковая релевантность. Определяется она благодаря алгоритмам поисковых систем, которые очень сложные, постоянно самообучаются (matrixnet) и допиливаются.
Говоря о MatrixNet: благодаря данной технологии – Яндекс может выстраивать топы в разных нишах по-разному, таким образом значительно усложняя жизнь SEO-оптимизаторам. Асессоры ежедневно посещают огромное множество документов и оценивают их соответствие поисковому запросу, а полученные данные учитывают для усовершенствования алгоритма матрикснета.
В итоге, мы получаем ситуацию, в которой побеждает тот сайт, у которого выше релевантность по определенному запросу. Детально изучив и проанализировав ТОП, можно выявить закономерности и создать документ с лучшим ответом на запрос пользователя. Главное – не перестараться.
Как определить релевантность сайта?
При определении релевантности документа – учитываются различные факторы. При этом, есть сложные запросы, где невозможно определить, что хочет пользователь. К примеру, знакомый многим запрос “создание сайта”:
- Пользователь хочет заказать создание сайта?
- Пользователь хочет научиться сам создавать сайты?
- Пользователь хочет найти конструктор сайтов, где сможет бесплатно и быстро разместить свой сайт?
- и т.
 д.
д.
 д.
д.При таком запросе – выдача поисковой системы должна содержать как коммерческие сайты, так и информационные. При этом, один тип сайтов попадают в выдачу благодаря соответствию документа определенным факторам, а другой тип сайтов – по совсем иным правилам.
Например, бизнес-сайтам важно соответствовать по коммерческим факторам ранжирования для получения целевого трафика с поисковых систем. Но только КФ недостаточно, необходимо еще поработать над оптимизацией ресурса в целом.
Что нам поможет повысить релевантность? На самом деле – это и есть основная задача SEO-специалиста, без решения которой просто невозможно получить хороших позиций. Что повысит релевантность?
- Релевантность заголовков контенту сайта. Если указали в заголовках слово “Цена” – будьте добры дать пользователю информацию про цены на странице!
- Вхождение ключевого слова в URL – положительно скажется на соответствии сайта запросу
- Вхождение ключевого слова в доменное имя. В меру, чтобы не создавать длинные непривлекательные названия сайта
- Тематическая релевантность – видимость проекта в целом по всем запросам в нише
- Соответствие и качество ссылочного окружения проекта
 В меру, чтобы не создавать длинные непривлекательные названия сайта
В меру, чтобы не создавать длинные непривлекательные названия сайтаСервисы, которые позволяют определить релевантность запроса документу на странице – не существуют. Но попытки есть: кластеризаторы, анализаторы топа и т.д. Главное правило: если поисковая система считает, что топ необходимо выстраивать по определенным правилам, вы сможете лишь подстраиваться под них. При хорошем анализе топа, логическом мышлении и создании качественного ресурса: рано или поздно вы будете на первом месте.
Как определить релевантную страницу для продвижения сайта? Составляем карту релевантности
Что такое релевантная страница?
Чтобы полноценно ответить на этот вопрос, необходимо сначала разъяснить значение данного термина. Релевантность — это
мера, которая выражает соответствие чего-либо желаемого полученному. В сфере продвижения сайтов это означает
соответствие страницы в поисковой выдаче тому запросу, который был введен пользователем в поисковую строку. То есть,
если контент на странице может удовлетворить потребности посетителя по его запросу, то ее можно назвать релевантной.
В сфере продвижения сайтов это означает
соответствие страницы в поисковой выдаче тому запросу, который был введен пользователем в поисковую строку. То есть,
если контент на странице может удовлетворить потребности посетителя по его запросу, то ее можно назвать релевантной.
Вот что на этот счет говорится в статье «Принципы ранжирования поиска Яндекса»:
И наглядный пример определения релевантности от Google. Речь здесь идет о контекстной рекламе, но такой подход будет применим и в SEO:
Почитать об этом более подробно можно в статье Google «Как убедиться, что ваши объявления релевантны»
Насколько релевантность важна при продвижении сайта?
Релевантность является одним из важнейших принципов ранжирования сайтов любой тематики и направленности. Как сказано
в выдержке из статьи Яндекса, расположенной выше, ранжирование — это процесс упорядочивания найденных результатов по
их релевантности запросу. То есть, чем более полный ответ на запрос пользователя сможет дать web-ресурс, тем более
высокое положение он будет занимать в поисковой выдаче.
Как сделать страницу релевантной?
1. Первый и самый главный пункт. Задайте себе вопрос, полностью ли удовлетворит содержимое страницы посетителя? Найдет ли он ответ на свой вопрос? Действительно ли он получил то, что хотел увидеть? Поставьте себя на место пользователя, изучите конкурентов. Если не можете утвердительно ответить на эти вопросы, страницу нужно доработать.
2. Оптимизируйте страницу под ключевой запрос:
- пропишите МЕТА-теги;
- сделайте вхождения ключевых слов в тексте страницы;
- разместите изображения, например, фотографии товаров, которые вы продаете;
- если запрос коммерческий, необходимо добавить коммерческие факторы;
- улучшайте поведенческие характеристики страницы — вы можете добавить видео или интересную анимацию;
- разместите конверсионные элементы: формы обратной связи, кнопки для заказа товаров и т. д.
 д.
д.3. Обратите внимание на уровень вложенности страницы. Есть запросы, которые можно продвинуть только на главной странице сайта, а есть такие, которые эффективнее продвигать на втором уровне вложенности. Ориентируйтесь в этом вопросе на конкурентов из ТОП-10.
4. Работайте над юзабилити — сайт должен быть понятным и удобным в использовании.
Как правильно выбрать релевантную запросу посадочную страницу?
Чтобы успешно продвигать ключевые запросы, необходимо очень серьезно отнестись к выбору посадочной страницы. Стоит
обратить особое внимание на глубину расположения страницы — как правило, самые высокочастотные запросы находятся на
1-ом уровне вложенности, на 2-ом и 3-ем — среднечастотные и низкочастотные. Определиться с выбором, сузив область
поиска до одной или нескольких страниц, вам поможет сервис Labrika. При запуске SEO-аудита все продвигаемые ключевые
фразы будут проанализированы, и в специальном отчете вы сможете посмотреть рекомендуемые для них посадочные
страницы.
Найти этот отчет вы сможете в подразделе «Релевантные страницы» раздела «SEO-аудит», который расположен в левом боковом меню:
На странице отчета имеются следующие данные и возможности:
- Кнопка, при нажатии которой вы сможете обновить SEO-аудит и получить самые актуальные данные, в том числе, по релевантным страницам.
- Вкладки для выбора нужной поисковой системы — переключаясь между ними, вы сможете отобрать релевантные страницы по ключевым фразам отдельно для Яндекс и для Google.
- Продвигаемое ключевое слово.
- Список рекомендуемых посадочных страниц, которые будут релевантными для этого слова. Напротив каждой страницы в скобках написана глубина ее расположения. Рекомендуемая глубина страницы рассчитывается на основе анализа конкурентов из ТОП-10.
Релевантность — что это такое
Обновлено 22 июля 2021- Релевантность — что это
- Виды релевантности
- Внутренние факторы
- Внешние факторы релевантности
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo. ru. При общении друг с другом SEO-специалисты любят оперировать сложными словами и фразами, которые новичкам кажутся непонятными.
ru. При общении друг с другом SEO-специалисты любят оперировать сложными словами и фразами, которые новичкам кажутся непонятными.
Но если копнуть глубже, значение большинства из них оказывается довольно простым.
Сегодня я расскажу вам о таком термине, как релевантность, что это простыми словами и на что влияет.
Релевантность — что это
Термин пришел из английского языка. В переводе на русский relevant — «важный» или «относящийся к делу».
Релевантность — это соответствие результатов поиска ожиданиям пользователя. Говоря простыми словами, релевантность показывает, насколько точный и развернутый ответ получит человек, введя запрос в поисковую строку.
Объясню на примере, как это работает. Вы хотите узнать в Яндексе или Гугле по фразе «компьютеры» цену игровых ноутбуков, но вместо этого поисковая система выдает информацию о том, что такое компьютер, когда был изобретен, где использовалась первая ЭВМ.
Релевантен ли результат поиска запросу? Нет, так как вы не нашли того, что нужно. Поэтому вы продолжите искать дальше и будете использовать более конкретную фразу типа «купить ноутбуки в Москве». В таком случае поиск Yandex и Google выдаст ответы, которые лучше соответствуют вашим ожиданиям.
Поэтому вы продолжите искать дальше и будете использовать более конкретную фразу типа «купить ноутбуки в Москве». В таком случае поиск Yandex и Google выдаст ответы, которые лучше соответствуют вашим ожиданиям.
В результатах поиска наиболее релевантные страницы всегда располагаются на первых строчках выдачи.
Поэтому начинающим SEO-специалистам нужно заботиться не только об оптимизации контента, но также уделить внимание его информативности и адекватности.
Виды релевантности
Существует несколько видов релевантности сайтов:
- Формальная. На этом виде релевантности основано ранжирование поисковых систем. Принцип таков: содержимое запросов пользователей путем алгоритмов сравнивается с образом документа в индексе.
Релевантность здесь рассчитывается по определенной формуле на основе данных, которые собирает поисковый робот. Человеческий фактор здесь роли не играет.
- Содержательная. Определяется неформальным путем и применяется поисковыми системами для оценки качества поиска.
Специальные люди, именуемые асессорами и работающие в компаниях Google (читайте про асессоров Гугла) и Yandex (читайте про асессоров Яндекса), вручную оценивают результаты поиска, руководствуясь личными предположениями насчет соответствия ресурса введенному запросу.
- Пертинентность. Этот вид релевантности сайтов нужен для полного удовлетворения потребностей пользователя. Благодаря этому пертинентность стала эталоном для всех существующих поисковых систем.

Внутренние факторы релевантности
Вы уже знаете, что такое релевантность и каковы ее виды. Теперь я хотел бы рассказать о ее внутренних и внешних факторах.
Релевантность показывает, насколько эффективно работает поисковая система, что определяется по специальному алгоритму.
Учитываются количество, грамотность распределения и качество использованных ключевых фраз, их соотношение с общим объемом текста, информативность контента, тематика и посещаемость ресурса.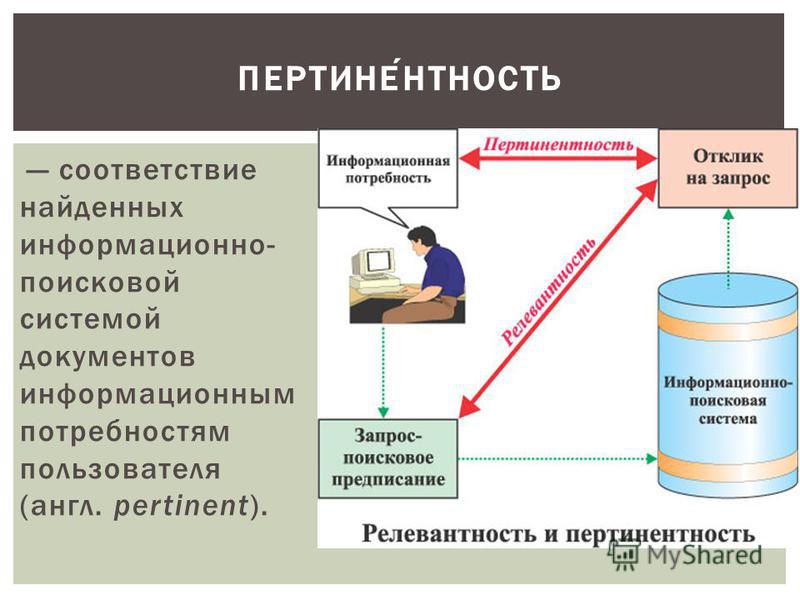
Улучшить поведенческие показатели сайта и заинтересовать пользователя остаться на сайте поможет интересный контент.
Если пользователь долго изучает содержимое страницы, на которую перешел из поиска, то, по мнению Яндекса и Гугла, контент на ней соответствует ожиданиям пользователя и дает ответ на его вопросы.
Поэтому в каждой статье важно полностью раскрывать тему, дополнять текст информативными уникальными изображениями и видео.
Что учитывать при добавлении ключевых слов
- Плотность. Слишком много ключевых фраз использовать не нужно, они должны распределяться по тексту равномерно и естественно. В случае их избытка поисковые системы могут посчитать контент спамным и пессимизировать сайт в выдаче.
Алгоритмы Яндекса и Гугла поощряют полноценные и развернутые ответы на вопросы, поэтому, если на статью в 10 тысяч символов присутствует только 1-2 ключевых слова, попасть на первую страницу поисковой выдачи все равно реально.
- Расположение. Ключевые слова рекомендуется использовать в тексте, тегах title и description, keywords, заголовке h2, подзаголовках h3-H6, а также в теге alt изображений.
Это следует делать не в ущерб читаемости и логичности, так как в противном случае получится обратный эффект.

Какие еще внутренние факторы влияют на ранжирование
- Технические показатели:
- скорость загрузки сайта;
- наличие файлов robots.txt и sitemap.xml;
- правильная настройка редиректов;
- грамотный кодинг;
- отсутствие дублей, битых ссылок и критических ошибок на сайте;
- Оптимизация сайта под просмотр на мобильных устройствах.
- Обновления. Контент должен обновляться с определенной периодичностью: чем чаще, тем лучше. Это способствует тому, что поисковый бот регулярно заходит на сайт и впоследствии проникается доверием к нему.
- Удобство навигации. Этот фактор напрямую влияет на поведенческие факторы: процент отказов, проведенное на ресурсе время, глубина просмотров и конверсии.
Ресурс должен иметь приятный дизайн, а текстовый контент — быть разбит на подзаголовки, небольшие абзацы, иметь нумерованные или маркированные списки.

Внешние факторы релевантности
Основной внешний фактор релевантности сайта — это его популярность, то есть количество ссылающихся на него ресурсов.
Но нельзя забывать о качестве: ссылки рекомендуются с авторитетных и заслуживающих доверия, по мнению поисковой системы, сайтов. Также желательно, чтобы тематика ресурсов-доноров была схожей с направленностью сайта-акцептора.
Для оценки качества входящих ссылок поисковыми системами были разработаны собственные критерии. У Яндекса — это ИКС (бывший тИЦ — тематический индекс цитирования), у Google — Page Rank (назван в честь основателя компании Ларри Пейджа).
Популярным сайтам многое прощается, но есть еще десятки (если не сотни) внешних факторов, влияющих на ранжирование и входящих в формулу ее расчета.
На вскидку:
- Удачное представление сайта в поисковой выдаче (сниппет, заголовок, дополнительная информация).
- Трафик (переходы) на сайт с других (не поисковых) источников (соцсетей, закладок браузера, других сайтов).
- Удачный вирусный маркетинг
- Рекламные кампании (для коммерческих сайтов)

Вот и все, дорогие друзья. Я постарался простым языком рассказать о понятии релевантность, что такое и какие факторы существуют. Надеюсь, что после прочтения статьи у вас не останется вопросов.
В любом случае приглашаю обсудить тему в комментариях, где вы сможете поделиться своими соображениями с другими читателями блога KtoNaNovenkogo.ru.
А в завершение предлагаю посмотреть видео о том, что такое релевантность:
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Эта статья относится к рубрикам:
-
- Чтение занимает 19 мин
В этой статье
ПРИМЕНИМО К: 2013 2016 2019 SharePoint Online в Microsoft 365
Повышение релевантности поиска путем настройки моделей ранжирования для точного вычисления ранга (степени релевантности) с помощью компонентов ранжирования в SharePoint.
Вы можете сортировать результаты поиска в SharePoint четырьмя способами, один из которых — по рангу. При сортировке результатов поиска по рангу SharePoint помещает наиболее релевантные результаты в начале набора результатов.
Результат поиска является релевантным, если он получает высокий ранг специальный числовой показатель, вычисляемый поисковой системой с помощью модели ранжирования. Модель ранжирования это список этапов, содержащих наборы компонентов ранжирования. Модель ранжирования задает, как поисковая система вычисляет ранг релевантности, с помощью различных факторов, которые представлены в модели как компоненты ранжирования.
- Наличие терминов запросов в полнотекстовом индексе, в частности таких сведений, как заголовок и основной текст документа.
- Метаданные, связанные с определенным элементом, например тип файла документа или длина URL-адреса.
- Текст привязки, связанный с URL-ссылками, указывающими на определенный элемент.
- Сведения о нажатиях элементов пользователями.
- Расположение терминов запросов в основном тексте или заголовке документа.
Чтобы упростить настройку, для начала используйте одну из стандартных моделей ранжирования SharePoint в качестве шаблона. Затем измените эту модель ранжирования в соответствии со своим набором данных.
По умолчанию SharePoint предоставляет 14 моделей ранжирования. В разделе Что такое «модель ранжирования»? (на сайте TechNet) представлены подробные сведения об этих моделях ранжирования и их назначении.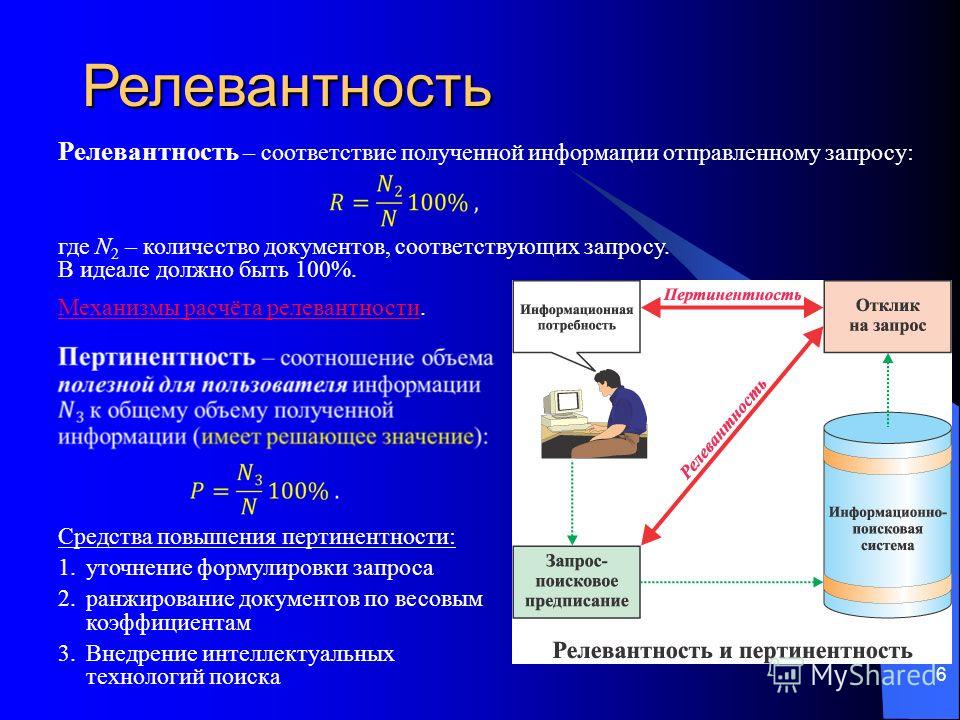
Важно!
Если установлен накопительный пакет обновления SharePoint за август 2013 г., рекомендуем использовать Модель ранжирования поиска с двумя линейными этапами в качестве основы для пользовательской модели ранжирования. Модель ранжирования поиска с двумя линейными этапами — это копия стандартной модели поиска с линейным вторым этапом вместо нейронной сети.
Для настройки моделей ранжирования используются следующие командлеты Windows PowerShell:
Получение списка всех доступных моделей ранжирования
- Откройте Командная консоль SharePoint от имени администратора.
- Запустите следующую последовательность командлетов Windows PowerShell.
$ssa = Get-SPEnterpriseSearchServiceApplication -Identity "Search Service Application"
$owner = Get-SPenterpriseSearchOwner -Level ssa
Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner
Получение стандартной модели ранжирования в качестве шаблона
- Откройте Командная консоль SharePoint от имени администратора.
- Запустите следующую последовательность командлетов Windows PowerShell. filename.xml это имя файла, в котором нужно сохранить модель ранжирования.

$ssa = Get-SPEnterpriseSearchServiceApplication
$owner = Get-SPenterpriseSearchOwner -Level ssa
$defaultRankingModel = Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner | Where-Object { $_.IsDefault -eq $True }
$defaultRankingModel.RankingModelXML > filename.xml
Если установлено накопительное обновление SharePoint за август 2013 г., вы можете выполнить указанные ниже действия, чтобы получить модель ранжирования поиска с двумя линейными этапами для использования в качестве шаблона пользовательской модели.
Получение модели ранжирования поиска с двумя линейными этапами в качестве шаблона
- Откройте Командная консоль SharePoint от имени администратора.
- Запустите следующую последовательность командлетов Windows PowerShell. filename. xml это имя файла, в котором нужно сохранить модель ранжирования.
 xml это имя файла, в котором нужно сохранить модель ранжирования.
xml это имя файла, в котором нужно сохранить модель ранжирования.$ssa = Get-SPEnterpriseSearchServiceApplication
$owner = Get-SPenterpriseSearchOwner -Level ssa
$twoLinearStagesRankingModel = Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner -Identity 5E9EE87D-4A68-420A-9D58-8913BEEAA6F2
$twoLinearStagesRankingModel.RankingModelXML > filename.xml
Развертывание пользовательской модели ранжирования
Скопируйте GUID нужной модели из списка доступных моделей ранжирования. Нужная последовательность командлетов Windows PowerShell описана в разделе Получение списка всех доступных моделей ранжирования.
Запустите следующую последовательность командлетов Windows PowerShell, используя GUID, скопированный на этапе 1, в качестве значения параметра .
$ssa = Get-SPEnterpriseSearchServiceApplication $owner = Get-SPenterpriseSearchOwner -Level ssa $rm = Get-SPEnterpriseSearchRankingModel -Identity <GUID> -SearchApplication $ssa -Owner $owner $rm.RankingModelXML > myrm.xmlОтредактируйте файл
myrm.xmlв редакторе XML. В качестве атрибутов id в элементе RankModel2Stage и всех элементах RankingModel2NN необходимо использовать новые значения GUID. Чтобы получить новое значение GUID, вы можете использовать следующую команду Windows PowerShell:[guid]::NewGuid()Создайте новую модель ранжирования с помощью командлета New-SPEnterpriseSearchRankingModel, выполнив следующие команды.
$myRankingModel = Get-Content .\\myrm.xml $myRankingModel = [String]$myRankingModel $ssa = Get-SPEnterpriseSearchServiceApplication $owner = Get-SPenterpriseSearchOwner -Level ssa $newrm = New-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner -RankingModelXML $myRankingModel
Сведения о ранге
Важно!
Мы предоставляем сведения о ранге и соответствующую страницу ExplainRank для вашего удобства и только с целью помочь вам в настройке и отладке ваших пользовательских моделей ранжирования. На содержимое сведений о ранге и соответствующую страницу ExplainRank не распространяется поддержка, и они могут меняться без уведомления с выходом будущих исправлений и обновлений программного обеспечения.
Сведения о ранге это XML-документ, содержащий сведения о вычислении ранга для отдельного элемента, который соответствует определенному запросу пользователя. Сведения о ранге хранятся в специальном управляемом свойстве под названием rankdetail.
У каждого компонента ранжирования в модели есть отдельный узел XML в сведениях о ранге, где описывается вычисление ранга. Подробные сведения о ранге предоставляются только для запросов, результаты поиска по которым содержат не более 100 элементов.
Концептуально общий формат сведений о ранге имеет следующий вид.
<rank_log version='15.0.0000.1000' >
<query tree='[representation of user query used for ranking]'/>
<stage type='linear'>
[Details of rank calculation of the first ranking stage. One XML node for each rank feature.]
<stage_model>
[Definition of the first stage of the ranking model]
</stage_model>
</stage>
<stage type='neural_net' >
[Details of rank calculation of the second ranking stage. One XML node for each rank feature.]
<stage_model>
[Definition of the second stage of the ranking model]
</stage_model>
</stage>
</rank_log>
Чтобы получить сведения о ранге, необходимо быть администратором приложения-службы поиска (SSA).
Получение сведений о ранге
- Откройте командную консоль SharePoint от имени администратора.
- Запустите следующую последовательность командлетов Windows PowerShell, заменив параметры <query_text> и фактическими значениями.
$app = Get-SPEnterpriseSearchServiceApplication
$searchAppProxy = Get-spenterprisesearchserviceapplicationproxy | Where-Object { ($_.ServiceEndpointUri.PathAndQuery -like $app.Uri.PathAndQuery)}
$request = New-Object Microsoft.Office.Server.Search.Query.KeywordQuery($searchAppProxy)
$request.ResultTypes = [Microsoft.Office.Server.Search.Query.ResultType]::RelevantResults
$request.QueryText = "<query_text> AND path:""<url>"""
$request.SelectProperties.Add("rankdetail")
$searchexecutor = new-Object Microsoft.Office.Server.Search.Query.SearchExecutor
$resultTables = $searchexecutor.ExecuteQuery($request)
$resultTables[([Microsoft.Office.Server.Search.Query.ResultType]::RelevantResults)].Table
Общие сведения о вычислении ранга на странице ExplainRank
SharePoint предоставляет страницу ExplainRank, расположенную в папке макетов (<searchCenter>/_layouts/15/). На этой странице представлены подробные сведения о ранге для каждого компонента ранжирования в соответствии с поисковым запросом, ИД документа и необязательным ИД модели ранжирования. Эти сведения получаются и анализируются из сведений о ранге.
Вы можете перейти на страницу ExplainRank по следующему URL-адресу: http:///_layouts/15/ExplainRank.aspx?q={x}&d={y}&rm={z}
Где:
- x — это поисковый запрос.
- y — это идентификатор документа.
- z — это необязательный идентификатор модели ранжирования. Если он не указан, используется модель ранжирования по умолчанию.
Как и со сведениями о ранге, для просмотра страницы ExplainRank необходимо быть администратором приложения-службы поиска (SSA).
Настройка модели с помощью компонентов ранжирования
Компоненты ранжирования подобны ручкам управления моделью ранжирования. В следующих разделах описываются компоненты ранжирования, доступные в стандартной модели ранжирования SharePoint, и то, как они участвуют в вычислении степени релевантности.
BM25
Компонент ранжирования BM25 оценивает элементы по внешнему виду терминов запросов в полнотекстовом индексе. Входными данными компонента BM25 могут быть любые управляемые свойства полнотекстового индекса.
Примечание
В этом контексте используется версия компонента ранжирования BM25 с полями, BM25F.
Компонент ранжирования BM25 вычисляет степень релевантности по приведенной ниже формуле.
Где:
- D это документ, представленный в виде списка текстовых полей, например заголовка или основного текста.
- Q запрос пользователя, представленный в виде списка терминов запроса, t.
- S задает список полей, которые участвуют в ранжировании релевантности. Этот список задается в модели ранжирования.
- _w_f — это числовое значение, которое задает относительный вес поля f ??? S. Это значение задается моделью ранжирования.
- _b_f это числовое значение, которое задает нормализацию длины документа для каждого поля f ??? S.
- _TF_f (t,D) — это число вхождений термина запроса t в поле f документа D.
- _DL_f (D) это общее количество слов в поле f документа D.
- N это общее количество документов в индексе.
- _n_t это количество документов, содержащих термин t хотя бы в одном из свойств.
- _AVDL_f это среднее значение _DL_f (D) во всех проиндексированных документах.
- _k_1 это скалярный параметр. Его значение задается моделью ранжирования.
Управляемые свойства, используемые компонентом ранжирования BM25, необходимо сопоставить со стандартным полнотекстовым индексом в интерфейсе Выбор дополнительных параметров поиска.
В поисковом запросе из вычислений ранга релевантности исключаются термины, являющиеся частью следующих операторов: NOT(???) в FQL, NOT(???) в KQL и FILTER(???) в FQL.
Кроме того, из вычислений исключаются термины, входящие в область, например title:apple AND body:orange.
Пример определения компонента ранжирования BM25
<BM25Main name="ContentRank" k1="1">
<Layer1Weights>
<Weight>0.26236235707678</Weight>
</Layer1Weights>
<Properties>
<Property name="body" w="0.019391078235467" b="0.44402228898786156" propertyName="body" />
<Property name="Title" w="0.36096989709360422" b="0.38179554361297785" propertyName="Title" />
<Property name="Author" w="0.15808522836934547" b="0.13896219383271818" propertyName="Author" />
<Property name="Filename" w="0.15115036355698144" b="0.96245017871125826" propertyName="Filename" />
<Property name="QLogClickedText" w="0.3092664171701901" b="0.056446823262849853" propertyName="QLogClickedText" />
<Property name="AnchorText" w="0.021768362296187508" b="0.74173561196103566" propertyName="AnchorText" />
<Property name="SocialTag" w="0.10217215754116529" b="0.55968554315932328" propertyName="SocialTag" />
</Properties>
</BM25Main>
Пример сведений о ранге для компонента ранжирования BM25
<bm25 name='ContentRank'>
<schema pid_mapping='[1:content::7:%default] [2:content::1:%default] [3:content::5:%default] [56:content::2:%default] [100:content::3:link] [10:content::6:link] [264:content::14:link] ' pids_not_mapped=''/>
<query_term term='WORDS(content:integration, content:integrations, content:integrations)'>
<index name='content' N='10035' n='8'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group
ext_doc_id='55' int_doc_id='16' precalc='0' tf_prime='0.500486' weight='1'
tf='0 1 1 0 0 0 0 11 0 0 0 0 0 0 0 0 '
dl='0 4 9 0 0 2 0 1291 0 0 0 0 0 0 0 0 '/>
<group/>
</index>
<rank score='2.37967' score_acc='2.37967' term_weight='7.13439'/>
</query_term>
<query_term term='WORDS(content:effort, content:efforts, content:efforts)'>
<index name='content' N='10035' n='9'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group/>
<group/>
</index>
<rank score='0' score_acc='2.37967' term_weight='7.01661'/>
</query_term>
<query_term term='PHRASE(content:fastserver, content:plugin)'>
<index name='content' N='10035' n='3'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group
ext_doc_id='55' int_doc_id='16' precalc='0' tf_prime='0.0399696' weight='1'
tf='0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 '
dl='0 4 9 0 0 2 0 1291 0 0 0 0 0 0 0 0 '/>
<group/>
</index>
<rank score='0.311896' score_acc='2.69157' term_weight='8.11522'/>
</query_term>
<final score='2.69157' transformed='2.69157' normalized='2.69157' hidden_nodes_adds='0.706166 '/>
</bm25>
Группы веса
In a custom ranking model, you can have two or more managed properties that are mapped to the same weight group in the search schema. In such cases, content of these managed properties is combined in the full-text index and can’t be ranked separately in BM25 calculation. This effect is the same as setting equal values for the _w_f and _b_f parameters within each group of managed properties, mapped to the same weight group in the search schema. To prevent this, map managed properties to one of the 16 different weight groups available in the search schema.
Группы веса также называют контекстом. Дополнительные сведения об отношениях между управляемым свойством и его контекстом см. в разделе Влияние на ранжирование результатов поиска с помощью схемы поиска (на сайте TechNet).
Статическое
Статический компонент ранжирования оценивает элементы по числовым управляемым свойствам, которые хранятся в индексе поиска. Числовые управляемые свойства, используемые для вычисления ранга релевантности в статических компонентах ранжирования, должны иметь тип Integer и атрибут Refinable или Sortable в схеме поиска. Многозначные управляемые свойства невозможно использовать в сочетании со статическим компонентом ранжирования.
Прежде чем объединить статический компонент ранжирования с остальными компонентами ранжирования, необходима предварительная обработка каждого статического компонента путем простого преобразования. В таблице 1 перечислены все поддерживаемые функции преобразования.
Таблица 1. Поддерживаемые функции преобразования для компонентов ранжирования с учетом расположения и статических компонентов ранжирования
Пример определения статического компонента ранжирования
<Static name="clickdistance" default="5" propertyName="clickdistance">
<Transform type="InvRational" k="0.27618729159042193" />
<Layer1Weights>
<Weight>0.616326852981262</Weight>
</Layer1Weights>
</Static>
Пример сведения о ранге для статического компонента ранжирования
<static_feature name='clickdistance' property_name='clickdistance'
used_default='1' raw_value='5' raw_value_transformed='5'
transformed='0.420003' normalized='0.420003'
hidden_nodes_adds='0.258859 '/>
Сегментированный статический компонент
Сегментированный статический компонент ранжирования оценивает документы по типу файла и языку. Определение сегментированного статического компонента в модели ранжирования зависит от того, является ли компонент ранжирования частью линейной модели или нейронной сети. Приведенные ниже примеры относятся только к линейным моделям. Для нейронных сетей количество атрибутов <Add> для каждого сегмента должно совпадать с количеством скрытых узлов нейронной сети.
Управляемые свойства, используемые для вычисления ранга релевантности в сегментированных статических компонентах ранжирования, должны иметь тип Integer и атрибут Refinable или Sortable в схеме поиска. Многозначные управляемые свойства невозможно использовать в сочетании с сегментированным статическим компонентом ранжирования.
Пример определения сегментированного статического компонента ранжирования для типа файла
С каждым документом связан тип файла, который компонент обработки содержимого определяет и сохраняет в индексе поиска как целое число от нуля. При использовании сегментированного статического компонента ранжирования для оценки документов по типу файла каждому типу документа назначается определенный показатель ранга релевантности. Например, в приведенном ниже определении сегмент 2 соответствует PPT-документу, а узел <Add>0.680984743282165</Add> задает дополнительные баллы ранга, которые добавляются к рангу релевантности всех PPT-документов.
<BucketedStatic name="InternalFileType" default="0" propertyName="InternalFileType">
<Bucket name="Html" value="0">
<HiddenNodesAdds>
<Add>0.464062832328107</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Doc" value="1">
<HiddenNodesAdds>
<Add>0.551558196047853</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Ppt" value="2">
<HiddenNodesAdds>
<Add>0.680984743282165</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Xls" value="3">
<HiddenNodesAdds>
<Add>-0.143152682829863</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Xml" value="4">
<HiddenNodesAdds>
<Add>-1.29219869408375</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Txt" value="5">
<HiddenNodesAdds>
<Add>-0.456669562992298</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="ListItems" value="6">
<HiddenNodesAdds>
<Add>0.170944938307345</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Message" value="7">
<HiddenNodesAdds>
<Add>-0.0666769377412764</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Image" value="8">
<HiddenNodesAdds>
<Add>0.106988843357609</Add>
</HiddenNodesAdds>
</Bucket>
</BucketedStatic>
Пример определения сегментированного статического компонента ранжирования по языку документа
Компонент обработки содержимого определяет язык каждого документа автоматически, прежде чем добавлять его в индекс поиска. Используя сегментированный статический компонент ранжирования для оценки документов по языку, вы можете задать способ вычисления показателя ранга в зависимости от того, совпадает ли автоматически определенный язык документа с языком запроса.
Во время запроса сведения о языке пользователя записываются в поисковую систему в виде свойства запроса.
Компонент ранжирования с учетом расположения
Компонент ранжирования с учетом расположения ранжирует элементы в соответствии с расстоянием между терминами запроса в полнотекстовом индексе. Ранг повышается, если два термина запроса встречаются в одних и тех же управляемых свойствах в полнотекстовом индексе. Вычисления с учетом расположения оказывают большую нагрузку на диск и ЦП, поэтому бонус за расстояние вычисляется только на втором этапе стандартной модели ранжирования (если он доступен).
Вы можете оценить компонент ранжирования с учетом расположения с помощью различных параметров, контролируемых атрибутами, которые описываются в таблице 2.
Таблица 2. Атрибуты, которые управляют оценкой компонентов ранжирования с учетом расположения
| Атрибуты | Описание |
|---|---|
isExact=0 | В этом режиме алгоритм пытается определить минимальный размер подмножества терминов запросов в документе. Алгоритм учитывает фрагменты с терминами запросов в том же порядке, в котором они встречаются в запросе пользователя. Если фрагмент для всех терминов запросов отсутствует, алгоритм ищет фрагменты, содержащие все термины, кроме одного. Этот процесс повторяется с уменьшением количества терминов, пока длина фрагмента не превысит значение maxMinSpan.maxMinSpan это атрибут компонента ранжирования с учетом расположения, который задает порог установки максимальной длины фрагмента. Идеальный фрагмент должен содержать все термины запросов и иметь длину меньше maxMinSpan. |
isExact=1 | В этом режиме алгоритм пытается найти цельный отрывок документа, содержащий все термины (или фразу) запроса. |
isDiscounted | Этот атрибут применим как к isExact=1, так и к isExact=0. Если атрибут isDiscounted включен, значение расположения умножается на (количество вхождений лучшего фрагмента или точных совпадений), разделенное на (количество вхождений самого редкого термина запроса в данном контексте). |
proximity="complete" | В этом режиме компонент повышает ранг только тех документов, где текст запроса встречается только в определенном управляемом свойстве. |
proximity="perfect" | Этот режим подобен режиму complete. но применяется к коротким полям, например title. Компонент ранжирования с учетом расположения повышает ранг только тех документов, где текст запроса полностью совпадает со значением title в определенном управляемом свойстве. Если значение title содержит термины, не входящие в запрос, алгоритм не учитывает элемент. |
default | Этот атрибут применяется только к запросам, состоящим из одного термина. Для элементов, содержащих термин запроса, значение default используется в качестве выходного показателя ранга для компонента ранжирования с учетом расположения.Результат perfect является исключением из этого правила. В случае получения результата perfect значение по умолчанию не используется. Вместо этого запросы, состоящие из одного термина, обрабатываются так же, как и остальные запросы. |
Пример определения компонента ранжирования с учетом расположения
Приведенный ниже пример представляет собой фрагмент стандартной модели ранжирования SharePoint. В этой модели компонент ранжирования с учетом расположения — лишь часть второго этапа вычислений, включающего нейронную сеть. Следовательно, пример содержит несколько элементов веса, <LayerWeights>, соответствующих числу нейронов на скрытом уровне нейронной сети.
<MinSpan name="Title_MinSpanExactDiscounted" default="0.43654446989518952" maxMinSpan="1" isExact="1" isDiscounted="1" propertyName="Title">
<Normalize SDev="0.20833333333333334" Mean="0.375" />
<Transform type="Linear" a="1" b="0" maxx="10000" />
<Layer1Weights>
<Weight>0.0399835450090479</Weight>
<Weight>-0.00693681478614802</Weight>
<Weight>0.0286196612755843</Weight>
<Weight>0.11775902923563</Weight>
<Weight>0.0885860088190342</Weight>
<Weight>0.102859503886488</Weight>
</Layer1Weights>
</MinSpan>
Управляемые свойства, используемые в компонентах ранжирования с учетом расположения, необходимо сопоставить со стандартным полнотекстовым индексом в схеме поиска.
Пример сведений о ранге для компонента ранжирования с учетом расположения
<proximity_feature name='Title_MinSpanExactDiscounted' pid='2'
proximity_type='exact_discounted'
used_default='0' raw_value='0' transformed='0'
normalized='-1.8'
hidden_nodes_adds='-0.0719704 0.0124863 -0.0515154 -0.211966 -0.159455 -0.185147 ' />
Динамическая группа
Динамический компонент ранжирования оценивает элемент в зависимости от того, совпадает ли свойство запроса с определенным управляемым свойством. Если обнаружено совпадение, показатель ранга элемента умножается на определенное значение, чтобы выделить этот элемент. Атрибут веса используется для управления влиянием компонента на общий показатель ранга.
Примечание
Компонент динамического ранжирования не поддерживает настройку. Он предназначен только для внутреннего использования. Тем не менее, если установлено накопительное обновление SharePoint за август 2013 г., компонент ранжирования AnchortextComplete является настраиваемым динамическим компонентом, входящим в стандартную модель ранжирования.
Пример определения динамического компонента ранжирования
<Dynamic name="AnchortextComplete" pid="501" default="0" property="AnchortextCompleteQueryProperty">
<Transform type="Rational" k="0.91495552365614574" />
<Layer1Weights>
<Weight>0.715419978898093</Weight>
</Layer1Weights>
</Dynamic>
Компонент ранжирования по актуальности
Стандартная модель ранжирования SharePoint не повышает ранг результатов поиска по их актуальности. Вы можете добавить эту возможность, создав новый статический компонент ранжирования, которые объединяет сведения из управляемого свойства LastModifiedTime со свойством запроса DateTimeUtcNow, используя функцию преобразования актуальности. Функция преобразования актуальности это единственная функция преобразования, которую можно использовать для этого компонента ранжирования, так как она преобразует возраст элемента из внутреннего представления в дни.
Преобразование актуальности выполняется по следующей формуле:
Где:
- c и _y_future определяются в модели ранжирования.
- x это возраст элемента в днях.
- Значение параметра _y_future задает бонус за актуальность для элементов, у которых значение свойства LastModifiedTime выше текущих даты и времени.
Пример определения компонента ранжирования по актуальности
<Static name='freshboost' propertyName='LastModifiedTime' default='-1' convertPropertyToDatetime='1' rawValueTransform='compare' property='DateTimeUtcNow'>
<Transform type="Freshness" constant="0.0333" futureValue="2" />
<Layer1Weights>
<Weight>1.0</Weight>
</Layer1Weights>
</Static>
Пример сведений о ранге для компонента ранжирования по актуальности (возраст около 580 дней)
<static_feature name='freshboost' property_name='LastModifiedTime' raw_value_transform='compare' used_default='0' property_value_found='1' property_value='9807115930137649186' raw_value='9.80661e+018' raw_value_transformed='-5.03135e+014' transformed='0.0490396' normalized='0.0490396' hidden_nodes_adds='0.0490396 '/>
Пример сведений о ранге для компонента ранжирования по актуальности с использованием нового документ (возраст <1 дня)
<static_feature name='freshboost' property_name='LastModifiedTime' raw_value_transform='compare' used_default='0' property_value_found='1' property_value='9807115934928966979' raw_value='9.80712e+018' raw_value_transformed='-2.55529e+011' transformed='0.990248' normalized='0.990248'hidden_nodes_adds='0.990248 '/>
Объединение компонентов ранжирования
Модель ранжирования состоит из различных компонентов ранжирования, которые учитываются при вычислении ранга.
Двухуровневые модели ранжирования
Модель ранжирования может состоять из двух уровней. На первом уровне модель ранжирования применяет относительно простые компоненты, чтобы получить примерные ранги результатов. На втором уровне модель применяет дополнительные, более затратные компоненты к элементам с самыми высокими показателями ранга.
Стандартная модель ранжирования SharePoint — пример двухэтапной модели ранжирования. Ее второй уровень работает с первыми 1000 элементами, которые получили самые высокие показатели ранга на первом уровне.
По завершении процесса ранжирования на первом уровне поисковая система повторно сортирует все элементы, включая те, которые были исключены из второго уровня. Как правило, в результате этого элементы из второго уровня имеют более низкий ранг, чем элементы на первом уровне.
Тем не менее, чтобы обеспечить точную сортировку элементов, элементы из второго уровня должны иметь более высокий ранг, чем элементы первого уровня. Для этого повышаются показатели ранга на втором уровне. Поисковая система автоматически выполняет эти вычисления с помощью сочетания компонентов ранжирования.
Примечание
Если установлен накопительный пакет обновления SharePoint за август 2013 г., по умолчанию модель ранжирования предусматривает два этапа (сначала выполняется линейный анализ, а затем применяется нейронная сеть). Модель ранжирования поиска с двумя этапами линейного анализа — это копия стандартной модели поиска с двумя этапами линейного анализа. Рекомендуем использовать эту модель в качестве основы для пользовательской модели ранжирования, так как линейную модель легче настраивать, чем модель с нейронной сетью.
Линейная модель
Линейная модель задает линейное сочетание показателей ранга из компонентов ранжирования.
Показатель ранга, предоставляемый линейными моделями, вычисляется по следующей формуле:
Где:
- score это результат, возвращаемый линейной моделью.
- M это количество компонентов ранжирования без учета сегментированных статических компонентов.
- K это количество сегментированных статических компонентов ранжирования.
- _f_j — это значение компонента _j_th после преобразования.
- _w_j — это значимый вес компонента _j_th для линейного сочетания.
Нейронная сеть
Нейронная сеть задает нелинейное сочетание показателей ранга из компонентов ранжирования. В настоящее время SharePoint поддерживает нейронные сети только с одним скрытым уровнем, содержащим до восьми нейронов.
Показатель ранга, возвращаемый нейронной сетью, вычисляется по следующей формуле:
Где:
- score это показатель ранга, возвращаемый нейронной сетью.
- N это количество нейронов в скрытом слое нейронной сети.
- M это количество компонентов ранжирования без учета сегментированных статических компонентов.
- K это количество сегментированных статических компонентов ранжирования.
- _W_i — это значимый вес скрытого нейрона _i_th.
- _t_i — это пороговое значение скрытого нейрона _i_th.
- _W_i,j — это значимый вес компонента _j_th для скрытого нейрона _i_th.
- _b_i,k — это добавление сегментированного статического компонента _k_th в скрытый нейрон _i_th.
Общая схема вычисления показателя ранга в двухслойной нейронной сети представлена на следующей диаграмме. В ней не учитывается сегментированный статический компонент ранжирования, который добавляет пользовательские значения непосредственно в скрытые узлы нейронных сетей без преобразования и нормализации.
Рисунок 1. Общая схема вычисления показателя ранга в двухслойной нейронной сети
Предварительное вычисление в BM25 и статических компонентах ранжирования
В модели ранжирования BM25 и статические компоненты ранжирования могут сократить задержку запросов для терминов, которые часто встречаются в запросах, с помощью предварительных вычислений. Это достигается за счет дополнительного индексирования, как в отношении дискового пространства, используемого индексом поиска, так и в отношении потребления ресурсов ЦП.
Предварительные вычисления следует использовать только на первом уровне модели ранжирования. Если включить предварительные вычисления, сведения о ранге для первого уровня будут неполными.
Чтобы включить предварительные вычисления, задайте для атрибута precalcEnabled значение 1 в определении уровня ранжирования. В модели ранжирования можно использовать предварительные вычисления только один раз.
Свойства запросов
Свойства запросов это механизм ранжирования, который заполняет дополнительные сведения, полезные для вычисления ранга. Например, свойствами запросов могут быть время и дата выполнения запроса, необходимые компоненту ранжирования по актуальности. В таблице 3 перечислены свойства запросов, доступные для ранжирования. Настраивать свойства запросов невозможно.
Таблица 3. Свойства запросов для ранжирования
| Свойство запроса | Описание |
|---|---|
| AnchortextCompleteQueryProperty | Задает полный текст привязки. |
| DateTimeUtcNow | Текущие дата и время. Это свойство запроса может использовать компонент ранжирования по актуальности. |
| DetectedLanguageRanking | Идентификатор языка запроса. Это свойство запроса используется компонентом ранжирования DetectedLanguageRanking. |
| PersonalizationData | Оценивает персонализированные данные. |
| RecommendedforQueryProperty | Оценивает рекомендации. |
Пример 1. Базовая модель ранжирования с одним линейным этапом, содержащим один статический компонент ранжирования
Эта модель предполагает, что клиент создал управляемое свойство под названием CustomRating. Статический компонент ранжирования требует, чтобы параметр CustomRating имел тип Integer и атрибут Sortable или Refinable в схеме поиска. Для каждого документа в наборе результатов показатель ранга, возвращаемый моделью ранжирования, равен значению параметра CustomRating для этого документа. Результат работы этой модель подобен сортировке всех результатов поиска по убыванию с помощью управляемого свойства CustomRating.
<?xml version="1.0"?>
<RankingModel2Stage name="RankModel1"
description="Rank model -- example 1"
xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN precalcEnabled="0" >
<HiddenNodes count="1">
<Thresholds>
<Threshold>0</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<Static name="CustomRating" propertyName="CustomRating" default="0.0">
<Transform type="Linear" a="1" b="0" maxx="1000"/>
<Layer1Weights>
<Weight>1.0</Weight>
</Layer1Weights>
</Static>
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
Пример 2. Более сложная модель ранжирования с одним линейным уровнем и четырьмя компонентами ранжирования
Эта модель ранжирования с одним линейным уровнем содержит четыре компоненты ранжирования:
BM25Этот компонент ранжирования основан на управляемых свойствах Title и body. Атрибутwдля title задан так, чтобы совпадения терминов запросов в Title были вдвое важнее, чем совпадения терминов в body.UrlDepthЭтот компонент ранжирования основан на управляемом свойстве UrlDepth, доступном по умолчанию в установках SharePoint. В URL-адресе документа UrlDepth содержит несколько обратных косых черт (\). Обратное рациональное (InvRational) преобразование обеспечивает более высокие показатели ранга для документов с короткими URL-адресами.TitleProximityЭтот компонент ранжирования повышает ранг документов, если некоторые из терминов запроса встречаются рядом друг с другом в свойстве title этих документов.InternalFileTypeЭтот компонент ранжирования повышает ранг документов типов HTML, DOC, XLS и PPT. имена сегментов в определении модели ранжирования приводятся только для удобочитаемости.Примечание
В управляемом свойстве
InternalFileType, доступном по умолчанию, нулевое значение (0) используется для кодирования документов HTML, значение1— для DOC-файлов, значение2— для XLS-файлов и т. д. В определении стандартной модели ранжирования SharePoint представлен список всех типов файлов, используемых для управляемого свойства FileType.
<?xml version="1.0"?>
<RankingModel2Stage name=" RankModel2"
description="Rank model -- example 2"
xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN precalcEnabled="0">
<HiddenNodes count="1">
<Thresholds>
<Threshold>0</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<BM25Main name="BM25" k1="1">
<Layer1Weights>
<Weight>1</Weight>
</Layer1Weights>
<Properties>
<Property name="Title" propertyName="Title" w="2" b="0.5" />
<Property name="body" propertyName="body" w="1" b="0.5" />
</Properties>
</BM25Main>
<Static name="UrlDepth" propertyName="UrlDepth" default="1">
<Transform type="InvRational" k="1.5"/>
<Layer1Weights>
<Weight>0.5</Weight>
</Layer1Weights>
</Static>
<MinSpan name="TitleProximity" propertyName="Title" default="0" maxMinSpan="1" isExact="0" isDiscounted="0">
<Normalize SDev="1" Mean="0"/>
<Transform type="Linear" a="1" b="-0.5" maxx="2"/>
<Layer1Weights>
<Weight>1.2</Weight>
</Layer1Weights>
</MinSpan>
<BucketedStatic name="InternalFileType" propertyName="InternalFileType" default="0">
<Bucket name="http" value="0">
<HiddenNodesAdds>
<Add>1.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="doc" value="1">
<HiddenNodesAdds>
<Add>2.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="ppt" value="2">
<HiddenNodesAdds>
<Add>0.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="xls" value="3">
<HiddenNodesAdds>
<Add>-3.5</Add>
</HiddenNodesAdds>
</Bucket>
</BucketedStatic>
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
См. также
Релевантность судебной практики
Не секрет, что наше право мало-помалу становится все более и более прецедентным, судебная практика стала фактически официальным источником права, а ссылки на нее — не только приемлемыми, но и одобряемыми в процессуальных документах сторон.
Но с материалами судебной практики тоже нужно уметь обращаться. За неимением в нашей стране исторической традиции работы с прецедентами нужно разрабатывать какие-то правила использования материалов практики.
В связи с этим хотелось бы обсудить вопрос релевантности судебной практики, т.е. ее относимости к делу и убедительности для суда.
Прежде всего, полагаю, что следует различать релевантность содержательную и формальную.
Содержательная релевантность — это рассмотрение в используемых материалах практики тех самых вопросов, которые предстоит рассмотреть в том деле, в которое эти материалы представляются. Или же хотя бы близкие аналогии, позволяющие распространять выводы по одним вопросам на решение иных вопросов. Содержательную релевантность я бы не стал сейчас обсуждать, поскольку, в принципе, тут вполне можно ссылаться на те правила применения аналогии права или толкования норм, которые разработаны в отношении любых правовых норм.
Более специфичным представляется вопрос о релевантности формальной, т.е. убедительности представляемых материалов практики для судьи по делу, исходя из места суда, чья практика используется, в судебной системе.
Так, например, опишу свой алгоритм отбора арбитражной практики:
1) в первую очередь ищу ответы на свои вопросы в постановлениях Пленума и информационных письмах Президиума ВАС,
2) затем — в постановлениях Президиума ВАС по конкретным делам,
3) затем — в определениях «троек» ВАС (один раз использовал определение о передаче в Президиум — просто потому, что постановления Президиума еще не было, но чаще, конечно же, отказные определения, несмотря на то, что есть устойчивое и достаточно обоснованное сомнение в практикообразуемости отказных определений),
4) затем — в обзорах практики «своего» ФАСа (т.е. того, до которого рассматриваемое дело может дойти),
5) постановления «своего» ФАСа по конкретным делам,
6 — n) далее устал расписывать, но аналогично — в отношении «своих» апелляционного суда и суда первой инстанции,
n+1) и только если содержательно релевантной практики на всех этих уровнях не нашлось — в том же порядке обращаюсь к «чужой» практике.
Отдельные вопросы:
1) релевантность практики иной судебной системы (практики СОЮ для АСов и, что более важно из-за бедности практики СОЮ, АСов — для СОЮ),
2) «вес» «чужой» практики (например, сказать, что Постановления ФАС МО более убедительны, чем ФАС СКО, при том, что я нахожусь в подсудности ФАС УО и «своей» или ВАСовской релевантной практики не нашел),
3) соотношение постановлений Пленума, обзоров практики и актов по отдельным делам. Формально первые, вроде как, значимее, но реально в случае их протворечия я бы стал, скорее, ориентироваться по времени: чем новее, тем убедительнее, в крайнем случае всегда можно сказать, что практика со времен издания постановления Пленума изменилась,
4) ну и, наконец, самый главный вопрос: что делать в случае противоречия практик? Речь, понятное дело, идет не о противоречии между практикой «своей» и «чужой» (тут «своя» однозначно в фаворе) и не о практике, значительно отличающейся по времени (тут, думаю, правило jurisprudentio posterior derogat jurisprudentione priori вполне применимо). Также вполне очевидно, как я буду решать вопрос, если есть равнозначная практика, при походе в суд: та, что в нашу пользу, будет использована, а та, что не в нашу — нет. Но глобально — как правильно выбрать? Да и не всегда есть «своя» и «чужая» позиция: зачатую есть необходимость дать объективную оценку.
А как вы отбираете практику?
Релевантный трафик: как найти компромисс?
Релевантность – это один из ключевых факторов, актуальность которого не подвергается сомнению. Привлечение пользователей, которые никогда не заинтересуются вашими товарами или услугами, по своей сути, является ошибочной тактикой. За исключением случаев, когда это правило может нарушаться.
А нарушаться это правило может довольно часто. На самом деле даже нерелевантный трафик нередко приносит большую пользу и дает конкурентные преимущества. В связи с этим, доля релевантного трафика – это своего рода компромисс, о котором стоит поговорить подробнее.
Преимущества трафика с низкой релевантностью Не смотря на то, что трафик с низкой релевантностью приносит небольшое количество продаж, он имеет массу преимуществ. В частности, помогает увеличить продажи косвенно. При этом стоит отметить, что трафик с низкой релевантностью получить значительно проще и для этого не потребуется слишком больших вложений.
Большое количество пусть даже нерелевантного трафика позволяет быстро наращивать ссылочную массу, ведь очевидно, что чем больше посетителей, тем больше и ссылок. Более того, ссылки лучше генерирует именно нерелевантный трафик, когда цель посетителей не приобрести что-либо, а получить полезную или развлекательную информацию. В свою очередь, ссылки положительно сказываются на SEO, что приводит к привлечению еще большего количества посетителей.
Хороший трафик повышает шансы, что о вашем проекте узнают люди, которые никогда бы о нем не узнали, если бы не те посетители, которые считаются нецелевыми. Сарафанное радио, например, вполне действенная стратегия, которую успешно используют многие крупные компании.
Значительный объем трафика позволяет лучше, точнее и главное – быстрее проводить A/B тестирование. Можно в сжатые сроки существенно улучшить сайт и повысить процент конверсий.
В конечном счете, увеличение нерелевантного трафика будет означать увеличение релевантных посещений с конверсией. Часто это происходит непредсказуемым образом, поскольку путей «добраться» до потенциальных покупателей и клиентов существует очень много.
Недостатки нерелевантного трафика Конечно, все не может быть так просто. Наряду с очевидными преимуществами, нерелевантный трафик имеет и не менее очевидные недостатки.
Ключевые слова, которые приносят пусть даже нецелевой трафик, но зато в большом количестве – вполне справедливо считаются конкурентными. Самые легкие в продвижении ключевые слова и фразы – те, которые не имеют потенциала и привлекают крайне мало посетителей. Конечно, такие ключевые слова значительно проще продвигать, чем коммерческие запросы, но даже здесь придется приложить определенные усилия.
Процент конверсий у нецелевого трафика невысокий. Это объективно ограничивает финансовые возможности данной стратегии. Конечно, можно некоторое время вкладывать средства для привлечения посетителей на сайт, но эти средства не будут окупаться напрямую.
Охват слишком большого количества тем, в том числе развлекательных, образовательных, информационных и мало связанных с деятельностью вашего проекта, может выглядеть безосновательным в глазах опытных пользователей, которые догадываются, какие мотивы за этим стоят.
Преимущества релевантного трафика Сегодня популярна точка зрения, согласно которой главное не количество трафика, а его качество. Под качеством здесь понимается процент целевых посещений и продаж.
Основное преимущество релевантного трафика очевидно – это высокий процент конверсий. Привлекаются посетители, которые заведомо готовы приобрести товар или заказать услугу.
Проект, который ориентирован на целевой трафик, может оказывать на потенциальных покупателей и заказчиков точечное психологическое воздействие. Если заранее известно, что сайт посещают люди, которые готовы что-либо приобрести прямо сейчас, нет необходимости распыляться.
Для привлечения целевого трафика SEO может сосредоточиться на построении определенной ссылочной массы, с заранее известными ключевыми словами и фразами, которых не так уж много. Определенность и ограниченный список ключевых слов делают работу в чем-то проще.
Недостатки релевантного трафика Как это ни странно, но релевантный трафик имеет ряд недостатков, которые обязательно нужно рассмотреть и учесть.
Релевантные целевые ключевые слова и фразы могут быть по-настоящему конкурентными. Что и не удивительно, учитывая высокие коэффициенты конверсии. Чтобы продвигать такие целевые, коммерческие ключевые слова, потребуется вложить немало сил, средств и времени.
Очень часто, сузив аудиторию до строго целевой, бизнес теряет возможность гибко масштабироваться. Чтобы расширить аудиторию и, как следствие – свой бизнес, нужно экспериментировать и ни в коем случае не ограничивать себя кратким перечнем ключевых слов, которые раз и навсегда были определены как «единственно-целевые».
В конце концов, слишком сильный акцент на ограниченном наборе ключевых слов делает бизнес безликим. Посетителям нравится, когда компания имеет индивидуальность. А для этого нужен информационный, развлекательный и обучающий контент, который имеет низкую релевантность, то есть не обязательно ведет к продажам.
Выводы Каждая компания и каждый проект уникален, имеет свои особенности, которые делают его до некоторой степени специфичным. В связи с этим невозможно раз и навсегда ответить на вопрос о компромиссе между релевантным и нерелевантным трафиком. Скорее всего, в большинстве случаев следует стремиться к балансу. Но каким будет этот баланс, приходится решать в каждом конкретном случае отдельно.
Релевантность – приемлемость, соответствие чему-либо
Релевантный (relevant) – уместный, значимый, соответствующий, имеющий отношение к чему-либо.
В поисковой оптимизации сайтов (SEO) понятие «релевантность» имеет особое значение по отношению к контенту веб-страниц и сайта в целом. Чтобы страницы сайта высоко ранжировались в поисковых системах, их контент должен быть максимально релевантен а) тематике страниц и б) поисковым запросам пользователей.
Релевантность контента тематике страниц означает, что контент – тексты, изображения, видео и проч. – должен описывать только то, чему посвящена страница сайта. Если это, например, статья, под названием «Как построить баню своими руками», – в ней должна быть представлена только эта тема. Если страница коммерческого сайта, например интернет-магазина одежды, посвящена теме «мужские куртки», на странице должны быть представлены только мужские куртки – а не женские, обувь, свитера и проч.
Релевантность контента поисковым запросам пользователей означает, что в контенте страницы должны быть слова и фразы, соответствующие тому, как их задают пользователи в поиске по соответствующей теме. Есть рассматривать бизнес-сайт, то речь о том, как представляют себе данный бизнес реальные люди и как ищут по нему информацию – например, определённые товары.
Часто бывает, что предприниматель описывает на сайте свой бизнес – продукцию и услуги – своими словами, не попадая при этом в лексику (поисковые запросы) своей целевой аудитории. А надо, чтобы попадал – максимально. Для этого необходимо собрать по своей тематике поисковые запросы и заложить их в виде ключевых слов и фраз (ключей) в контент своего сайта. Отдельно сформированный набор ключей сайта будет являться его семантическим ядром (СЯ), которое должно быть а) максимально полным и б) структурированным.
Полнота СЯ означает максимальный охват поисковых запросов по данной теме. Это, соответственно, увеличивает охват целевой аудитории, приходящей на сайт из поиска, что имеет критическое значение для коммерческих сайтов. Для интернет-магазинов с широким ассортиментом объём СЯ может достигать десятков тысяч ключей.
Структурированность (кластеризация) означает, что ключи в СЯ должны быть разбиты на группы и подгруппы (кластеры), соответствующие, например, товарным группам и отдельным товарам, которые, в свою очередь, представлены на отдельных страницах сайта. Это и позволяет сделать каждую веб-страницу максимально релевантной её тематике и конкретному интересу (интенту) целевой аудитории. Если пользователи ищут мужские куртки, им должна быть показана страница сайта, на которой представлены только мужские куртки. А это значит, что на данной странице не должно быть других – нерелевантных ключей и в целом нерелевантной информации.
При этом – и для расширения полноты СЯ, и во избежание переспама по отдельным ключам – в текстовом контенте веб-страницы стоит использовать не только прямые соответствия (прямые вхождения) ключей наиболее популярным поисковым запросам (высоко-, среднечастотным), но и непрямые соответствие (непрямые вхождения) – например словоформы, разбавления ключевых фраз дополнительными словами, перестановки слов, – а также синонимичные вхождения. Всё это позволяет сделать контент максимально естественным (не спамным) и при этом высоко релевантным как тематике конкретной страницы сайта, так и соответствующим поисковым запросам пользователей (интенту).
При ранжировании страниц сайтов алгоритмы поисковых систем учитывают и релевантность их контента специфичным поисковым запросам, и релевантность контента тематике отдельной страницы.
Например, если на странице будет хорошее соответствие контента определённым запросам («где купить мужскую куртку» и т.п.), но при этом будет информация, не имеющая отношения к данной теме (нерелевантная), поисковики сочтут эту страницу низкорелевантной и не дадут ей хороших позиций в своей выдаче – даже по целевым запросам (о мужских куртках).
С другой стороны, если контент страницы будет высоко релевантным данной теме (представлены только мужские куртки и ничего более), но в нём будет слишком мало ключей по ней – например, не будет коммерческих вхождений, таких как «цена мужской куртки», «заказать мужскую куртку», «купить мужскую куртку онлайн» и т.д. – это тоже негативно скажется на SEO страницы, т.к. в поиске она будет показываться меньшему числу людей (часть аудитории по неохваченным запросам будет выпадать).
Таким образом, при поисковой оптимизации сайта и отдельных веб-страниц следует одновременно ориентироваться и на релевантность контента заявленной тематике сайта (страницы), и на релевантность контента интенту пользователей, т.е. поисковым запросам, соответствующим данной тематике.
Дополнительно смежные вопросы рассматриваются в статьях Ключевые слова/фразы, Семантическое ядро, Поисковый запрос, Вхождение, Переспам, Интент.
В целом, оптимизация контента – прежде всего, текстов сайтов – является базовой составляющей SEO и требует хороших компетенций. Мы рекомендуем Вам обращаться в нашу компанию. Наши профессионалы не только проконсультируют Вас по всем SEO-вопросам, включая текстовую оптимизацию сайтов, но и возьмут на себя полное продвижение Вашего веб-ресурса.
Заказать поисковое продвижение
Cloudflare
| Для бесплатной пробной версии требуется действующая кредитная карта | ||||||
Basic Plus | Исследования | проспект | Премиум | Премиум Плюс | ||
| Ежемесячные планы подписки | $ 14 | $ 49 | $ 79 | $ 99 | $ 169 | |
| Годовые планы подписки | $ 99 | $ 399 | $ 699 | $ 899 | $ 1499 | |
| Подпишитесь на годовые планы и сэкономьте | 41% | 32% | 26% | 24% | 26% | |
| Исследования компании | ||||||
| Доступ к 17+ миллионам профилей компаний | ||||||
| Доступ к 18000+ отраслей | ||||||
| Создание и сохранение основных списков компаний | ||||||
| Доступ к основным фильтрам и форматам поиска | ||||||
| Создать и сохранить доп.Списки компаний и критерии поиска | ||||||
| Расширенный поиск (фильтрация по десяткам критериев, включая доход, сотрудников, деловую активность, географию, расстояние, отрасль, возраст, телефон и демографические данные) | ||||||
| Ограничения на экспорт информации о компании | 250 / месяц | 500 / месяц | 750 / месяц | 1000 / мес | ||
| Место исследования | ||||||
| Список арендаторов @ 6+ миллионов зданий | ||||||
| Поиск здания и арендатора по адресу или названию улицы | ||||||
| Создание, сохранение и публикация списков мест и критериев поиска | ||||||
| Связаться с отделом исследований | ||||||
| Доступ к информации о более чем 40 миллионах контактов (без электронной почты) | ||||||
| Расширенный поиск контактов | ||||||
| Создание, сохранение и обмен списками контактов и критериями поиска | ||||||
| Ограничения на экспорт контактной информации (без адресов электронной почты) | 500 / месяц | 750 / Месяц | 1,000 / Месяц | |||
| Ежемесячная подписка — Ограничения на контактный адрес электронной почты | 100 / Месяц | 200 / месяц | ||||
| Годовая подписка — Ограничения на контактный адрес электронной почты | 1,200 / год | 2,400 / год | ||||
| Лимиты использования контента (страниц в день) | 200 | 700 | 1 000 | 1,500 | 2 000 | |
| Нажмите здесь, чтобы начать бесплатную пробную версию 212-913-9151 доб.306 | ||||||
| Примечание. Бесплатная пробная версия требует регистрации и действующей кредитной карты. Каждый пользователь ограничен одной бесплатной пробной версией. [электронная почта защищена] | ||||||
Как регулирующие органы могут оставаться актуальными? Все начинается с прослушивания.
Регуляторы могут слишком легко застрять на своем пути. Слишком часто регулирующие органы не думают о более широкой картине и склонны придерживаться процессов, потому что « мы всегда так поступали » — используя те же методы работы, которые они определили много лет назад, не задумываясь о том, по-прежнему лучший вариант.
Но регулируемые отрасли меняются. Технологии предлагают больше возможностей для онлайн-взаимодействия и обработки, в то же время повышая риск кибермошенничества. Потребители становятся все более сообразительными и информированными, с более высокими требованиями и ожиданиями. Социальная этика со временем видоизменяется с ростом стремления к индивидуальным свободам, порождая потребность в смягчении связанных с ними угроз. Растет разнообразие регулируемых отраслей и увеличивается количество инноваций.
Если регулирующие органы не захотят меняться, это может дорого обойтись отрасли, которую они регулируют: в нашем недавнем исследовании мы обнаружили, что почти каждый бизнес, с которым мы разговаривали (95 процентов), ожидает потерять часть деловой активности или доходов из-за новых и подрывных конкурентов. в ближайшие пять лет.Если регулирующие органы не успеют, они рискуют оказаться неэффективными и неактуальными.
Что могут сделать регулирующие органы, если их процессы не работают или мышление устарело? Мы считаем, что слушать, учиться и отвечать — лучшее противоядие. Вот три способа добиться этого.
1. Слушайте людей, которых вы регулируете, и потребителей, которых они обслуживают
Когда Управление пенсионного обеспечения поговорило с представителями своей отрасли, они были удивлены результатами: организации сказали им, что они должны быть более четкими и жесткими в том, как они регулируют.Отзывы были ценными, потому что в процессе участвовало более 100 человек. В результате Орган пенсионного регулирования полностью изменил свою работу и подходы, коренным образом переосмыслив то, как они действуют.
Многие регулирующие органы имеют потребительские панели или отраслевые группы. Хорошее начало, но этого недостаточно. Не все взаимодействия одинаковы, и приглашение одних и тех же 100 человек на встречу один раз в год, вероятно, не принесет много полезной обратной связи. Регулирующие органы могли бы быть гораздо более активными: разговаривать с более широким кругом людей, задавать более сложные вопросы и сосредотачиваться на будущем.
2. Учитесь у людей, которые поступают иначе
Если когда-либо было время мыслить творчески, то это оно. Так что не смотрите просто на то, что делают другие люди в вашем секторе: смотрите на другие юрисдикции, смотрите на другие сектора. Многие регуляторы склонны считать свою отрасль уникальной. Конечно, некоторые элементы зависят от отрасли, но в основе своей работы регулирующих органов во многом пересекаются.
Регулирующие органы, как правило, не имеют отделов по идеям или инновациям, но многим была бы полезна такая команда, которая проанализировала бы проблемы в организациях и способы их решения.Это также может помочь регулирующим органам найти общие черты в выполняемой ими работе, а не работать разрозненно. Например, многие регулирующие органы собирают огромные объемы данных и ничего с ними не делают. Обучение у организаций, которые эффективно обрабатывают данные, может снизить нормативную нагрузку на бизнес и освободить время и пространство для регулирующих органов, чтобы они могли стимулировать инновации.
3. Действуйте в соответствии с тем, что вы узнали
Одно дело спрашивать людей, что они думают, другое — что-то делать с результатами.Ищите честную обратную связь и будьте готовы действовать в соответствии с ней. Это может означать переосмысление ключевых показателей эффективности, измерение воздействия, а не только активности. А это может означать переосмысление внутренних процессов или изменение культуры. Заманчиво оставить все как есть, но это ненадежно. Изменения — это непросто, но когда они основаны на четких свидетельствах людей, которым вы служите, они помогают создать аргументы в пользу новых способов работы. А это должно означать лучшее регулирование для всех.
Исторический, функциональный и актуальный — IT Jungle
12 июля 2021 г. Тимоти Прикетт Морган
Цель The Four Hundred , который на этой неделе вошел в свой 33 -й год публикации, состоит в том, чтобы поддержать сообщество компаний и их ИТ-персонал — и, в конечном итоге, конечных пользователей и успех этих компаний — которые развернули их критически важные приложения на платформах System / 38, System / 36, AS / 400, AS / 400e, iSeries, System i, а теперь и на платформах IBM i на десять лет дольше, чем мы.Мой наставник, Хеш Винер, и различные коллеги, работавшие в других публикациях, посвященных Системе / 38 и Системе / 36 со времен до моего появления на сцене в июле 1989 года, все верили в это.
Замечательная вещь.
За это время я наблюдал большое количество реорганизаций в IBM, и еще одна произошла 2 июля, когда большинство из нас не обращали на это внимания. Арвинд Кришна, главный исполнительный директор и председатель IBM, сделал объявление в IBM Newsroom, и, насколько мне известно, до или после объявления не было никакой связи с прессой или аналитическим сообществом.Учитывая существенные проблемы, с которыми сталкивается IBM при переносе Lotus Domino / Notes, размещенного на HCl Technologies, которая несколько лет назад купила пакет Lotus, на машины, размещенные на IBM, и похоже, что к этому миксу был добавлен некоторый сервер Microsoft Exchange Server, которые подробно описаны в The Register , возможно, мы не получили записку по этой причине. Независимо от того.
Сразу же вступает в силу 2 июля, президент IBM и бывший генеральный директор Red Hat Джим Уайтхерст, который должен был стать следующим генеральным директором IBM, «решил уйти в отставку», по словам Кришны.Уайтхерст остается старшим советником Кришны, которому 59 лет, и который останется генеральным директором в обозримом будущем и, как мы подозреваем, значительно превзойдет ранее обязательный, а затем традиционный пенсионный возраст генерального директора в 60 лет, который у IBM был столько же, сколько и у всех остальных. могу вспомнить. (Поскольку Томас Уотсон-младший сменил своего однофамильского отца в 1952 году и сам создал этот прецедент, когда вышел на пенсию в 1971 году) Я подробно писал о том, как Уайтхерст оставил IBM на моей другой работе в The Next Platform на прошлой неделе, а я Я не буду перебирать все это основание.Достаточно сказать, что я считаю очень подозрительным, что Уайтхерст был назначен президентом в апреле 2020 года, а это значит, что он собирался стать следующим генеральным директором, а затем покинул IBM, потому что хотел стать генеральным директором, пока не стал слишком старым. (Уайтхерсту 54 года). Джинни Рометти было почти 63 года, когда она передала пост генерального директора Кришне и роль президента Уайтхерсту, и ожидалось, что Кришна будет возглавлен, а Уайтхерст возглавит пост генерального директора и, в конечном итоге, через несколько лет , назначил своего преемника на пост президента, как это было сделано с тех пор, как Томас Уотсон-старший был назначен президентом Computing-Tabulating-Recording Company в 1915 году, через год после присоединения к компании, которая впоследствии стала International Business Machines Corporation.
Причина, по которой я заботился о том, чтобы Уайтхерст возглавил IBM, заключается в том, что я хочу, чтобы IBM стала лучше системной компанией — лучшей платформой — чем она есть сейчас. Я надеялся, что Red Hat окажет положительное влияние на Big Blue и что IBM будет помнить, что это производитель интегрированной платформы, и, честно говоря, что она будет помнить, что она всегда создавала и следующую платформу , справа. время, а не пытаться сохранить старые слишком далеко за пределами их прежнего состояния.IBM очень хорошо умеет создавать что-то новое и поддерживать что-то старое, и нам нужен конвергентный преемник AS / 400 и мэйнфрейм, который может снизить затраты IBM и, что наиболее важно, привлечь новых клиентов Big Blue так, как System / 360 подходит для крупных предприятий, а AS / 400 — для предприятий среднего уровня. Amazon Web Services, безусловно, пытается это сделать и, похоже, справляется лучше. То, что я указал девять лет назад, и с тех пор AWS построила только еще более интегрированный стек, с ИИ и базами данных повсюду и с бессерверными оверлеями.
Подробнее об этом через минуту, поскольку я твердо верю в конструктивную критику. Давайте сначала закончим с исполнительными изменениями.
Том Розамилия, который в свое время руководил бизнесом промежуточного программного обеспечения IBM WebSphere в старой группе программного обеспечения, а затем принял на себя мэйнфреймы System z, затем Power Systems, затем группу систем и который специально работал над объединением дочерних компаний IBM Microelectronics в Global Foundries и подразделения System x компании Lenovo в настоящее время является старшим вице-президентом группы облачного и когнитивного программного обеспечения, которая является ближайшим аналогом Software Group в текущей версии IBM.
Интересно, что IBM привлекла Рика Льюиса, который в 2012 году возглавил подразделение Business Critical Systems Hewlett Packard Enterprise, чтобы он возглавил группу Systems в IBM. Так что аутсайдера у нас все-таки получилось. BCS теперь известен как высокопроизводительные вычисления и критически важные системы (HPC & MCS) и является частью HPE, которая конкурирует с подразделением Power Systems, теперь подразделением Cognitive Systems, но никто не называет это так. Между прочим, в марте группа HPC & MCS в HPE провела собственную реструктуризацию.Кажется, эта штука крутится. Льюис руководил множеством различных бизнесов в HPE, в том числе управлял бизнесом кластеров баз данных Tandem NonStop после того, как Compaq был приобретен HPE в 2001 году, и управлял объединенным бизнесом HPE по аппаратным системам и технологиям, прежде чем взять на себя линию BCS, а затем взять на себя более широкое Enterprise Server Business, который добавлен в системы HP-UX, OpenVMS и NonStop, а также в блейд-серверы BladeSystem. Вплоть до февраля прошлого года, когда Льюис покинул HPE, он руководил ее Software Defined and Cloud Group, в которую входили его гиперконвергентные гибридные системы сервер / хранилище, а также компонуемые системы Synergy — продвинутый функционал.
Возможно, у IBM пока есть надежда.
По-видимому, теперь это будет зависеть от того, что Кришна думает о будущем IBM и как он может или не может пожелать или не сможет инвестировать в него.
Что подводит меня к моей точке зрения. У компании может быть глубокая история, как у IBM. И он даже может быть функциональным, достаточно хорошо обслуживая небольшое количество клиентов, поддерживая или расширяя их унаследованные платформы. И это прекрасно, и Льюис знает, как это сделать, не хуже всех в IBM.Но вы можете делать все это и при этом не иметь никакого отношения к ИТ-рынку в целом. Это то, что IBM забыла. Томас Уотсон-старший превратил CTR в гиганта табулирования, перфокарт IBM, а Томас Уотсон-младший с большим трудом и некоторым смущением создал System / 360 и положил начало современной компьютерной эре, какой мы ее знаем. Луи Герстнер сохранил все, что мог, от сбитого с толку Big Blue, превратив программное обеспечение и услуги в потоки доходов и открыв свои системы как нейтральные платформы.Какое-то время это работало, но, как мы видим, реальной проблемы не решило.
Если IBM хочет больше, чем просто функционировать, если она хочет быть актуальной для миллионов компаний и когда-либо снова получить доход от продаж выше 100 миллиардов долларов, а не жить только в учебниках истории, то ей необходимо создать новую платформу. Лучшие умы, на которые он способен, и больше денег, чем он думает, он может себе позволить. И если Apple сможет воскреснуть из пепла — дважды — IBM тоже сможет это сделать. Я надеялся, что это сделает Уайтхерст.
О том, как это можно сделать, поговорим на следующей неделе. Будьте на связи.
РОДСТВЕННЫЕ ИСТОРИИ
IBM: старейший государственный деятель полупроводников
Разговор с начальником энергосистем Стивеном Леонардом
IBM растет, Power Systems замедляется
IBM i Может ли преуспеть при новом генеральном директоре Арвинде Кришне?
Сообщество IBM i адаптируется к новым нормам
Коронавирус влияет на средний уровень
Любовь — и бизнес — во время коронавируса
Что означает новая верхняя латунь в Big Blue для IBM i
План IBM по травлению микросхем Power10 и более поздних версий
Немного понимания IBM i On Power Systems Base
Эра Power8 подходит к концу
Дорога к мощности вымощена с пропускной способностью
Наконец-то IBM i наконец-то получил Power9
Уроки AS / 400 возвращаются с Power9 Systems
Power Systems — теперь когнитивные системы
IBM делает ставку на будущие чипы питания
Что будет делать IBM i с процессором Power10?
Реорганизация IBM для создания новой бизнес-машины
IBM снова разделяет глобальные услуги, поскольку Майк Дэниэлс уходит с должности GM
Рометти начинает 2012 год со сменой руководства
Палмизано передает IBM поводья Рометти
Реорганизация IBM убирает системы под программное обеспечение
Обнаружение резервных данных не только актуально, но и пропорционально: eDiscovery Best Practices
Моя последняя запись в блоге IPRO посвящена тому, как данные из приложения для совместной работы Slack стали обычным источником ESI в судебных процессах, расследованиях и других случаях использования, связанных с eDiscovery, как обнаружение данных Slack стало обычным делом и как оно стало стать соразмерным в открытии судебных исков.
Если организация использует Slack и обязана сохранять потенциально отзывчивый ESI в судебных процессах, обнаружение данных Slack (или любого приложения для совместной работы, используемого в организации) должно рассматриваться как один из этих источников потенциально отзывчивого ESI. Но многие юристы до сих пор обычно не рассматривают данные из Slack и других приложений для совместной работы (или даже мобильных устройств в этом отношении).
В отчете о состоянии отрасли за 2021 год, выпущенном eDiscovery Today (и спонсируемом EDRM), только 26.8% респондентов заявили, что у них всегда или обычно есть мобильные устройства или данные для совместной работы, в то время как 20,2% сказали, что они редко или никогда не имеют их.
Итак, почему юристы должны регулярно рассматривать возможность обнаружения данных Slack в своих делах? И этот недавний случай иллюстрирует, что суды говорят о пропорциональности открытия Slack (подсказка: я освещал это в прошлом месяце!). Вы можете узнать об этом в блоге Ipro здесь. 😉 Еще один клик!
Итак, что вы думаете? Вы регулярно рассматриваете возможность обнаружения данных Slack в рабочих процессах eDiscovery? Если нет, то почему? Пожалуйста, поделитесь любыми комментариями, которые у вас могут быть, или если вы хотите узнать больше по определенной теме.
Раскрытие информации: Ipro является образовательным партнером и спонсором eDiscovery Today
Отказ от ответственности: Взгляды, представленные здесь, являются исключительно взглядами автора и не обязательно отражают взгляды моего работодателя, моих партнеров или моих клиентов. eDiscovery Today предоставляется исключительно в образовательных целях для предоставления общей информации об общих принципах обнаружения электронных данных, а не для предоставления конкретных юридических рекомендаций, применимых к каким-либо конкретным обстоятельствам.eDiscovery Today не следует использовать в качестве замены компетентной юридической консультации от нанятого вами юриста, который согласился представлять вас.
Как это:
Нравится Загрузка …
Эпизод «Черное зеркало» с Брайс Даллас Ховард настолько актуален, что это страшно
Черное зеркало — сериал, созданный еще в 2011 году, но он не стал таким популярным, как сегодня, до конца 2016 года, когда Netflix приобрела права на сериал и заказала третий и четвертый сезоны.«Носик» — первая серия третьего сезона, в которой играет Брайс Даллас Ховард. В частности, темы, представленные в этом эпизоде, имеют наибольшее отношение к жизни в 2021 году, а технологии, представленные в эпизоде, не слишком далеко опережают нынешнее состояние общества, что делает этот эпизод одним из самых страшных в сериале.
«Nosedive» использует слегка комедийный подход к рассказу о чем-то, что на самом деле довольно ужасающе. В наши дни обществом управляют социальные сети, и наличие большого числа подписчиков и лайков / комментариев имеет решающее значение в том, как люди воспринимают кого-то.Без популярности в социальных сетях многие люди и их идеи отвергаются или смотрят свысока. Этот эпизод явно сатира, но он проливает свет на будущее. Этот эпизод был довольно близок к домашнему в 2016 году, когда он был выпущен, но теперь, пять лет спустя, он стал более распространенным, чем когда-либо. И это не отрадная мысль.
СВЯЗАННЫЙ: поворот этого эпизода «Черное зеркало» делает его самой страшной историей в серии
Эпизод следует за Лейси Паунд (Брайс Даллас Ховард) и показывает общество, в котором каждому хирургически имплантированы специальные контактные линзы, которые позволяют им постоянно просматривать платформу социальных сетей.Это также позволяет им сразу увидеть, насколько человек «нравится», чтобы определить, как им следует с ним взаимодействовать. Людей оценивают по шкале от одного до пяти, но не определено, в каком возрасте люди добавляются в систему, поскольку в эпизоде нет детей. У Лейси 4,2 балла, но она мечтает о 4,5 балла или выше, чтобы жить лучше.
Когда лучшая подруга детства Лейси обращается к ней, чтобы стать подружкой невесты на ее свадьбе, она ухватывается за шанс быть замеченной с популярной девушкой, чтобы поднять свой счет и восстановить связь со своей давно потерянной подругой.Но, конечно, все идет не так, и она не успевает на свадьбу. К тому времени, когда Лейси действительно попадает на свадьбу, ее оценка снижается до менее 3. Некоторые из людей, которым «не нравилась» Лейси, сделали это, потому что она была не идеальна и выказывала искреннее разочарование. Другие люди «не любили» ее просто потому, что у нее был низкий балл.
Это происходит сегодня в социальных сетях. Если кто-то подвергается негативной или позитивной атаке в социальных сетях, большинство людей будут делать то же, что и все остальные, и им нравиться или не нравиться.Обычно это происходит из-за страха подвергнуться негативному вниманию из-за того, что «встанет на сторону» того, на кого в настоящее время нацелены. В начале эпизода есть еще один персонаж, который оказывается целью после разрыва отношений. У любого, кто взаимодействует с этим персонажем, также снижается собственный счет.
Как выясняется позже в эпизоде, подруга Лейси Наоми (у которой 4,8 балла) пригласила Лейси на свадьбу только потому, что у нее было 4 балла, и Наоми думала, что будет лучше, если у нее будет сочувствующий «лучший друг детства». на своей свадьбе, которого она до сих пор признает, хотя и не принадлежала к элите.Лейси полностью истощена, и ей нужно удалить контактные линзы. После удаления мир больше не представляет собой пастельно-розовый поддельный фильтр, где все и все идеально. Лейси видит пыль, летящую по комнате, когда солнце светит через окно. И для нее это прекрасное чувство — освободиться от цепочки популярности в социальных сетях.
Этот эпизод сделан очень хорошо. Звук того, как кто-то «не любит» другого человека, понижает его счет, звучит так, что вызывает у публики чувство отчаяния из-за Лейси, когда они становятся свидетелями ее борьбы за удержание головы над водой.Этот звук в конечном итоге становится частью саундтрека, поскольку мы наблюдаем, как Лейси получает столько отрицательных голосов, что на данный момент это даже не стоит подсчитывать. Сценаристами эпизода были Рашида Джонс и Майкл Шур (оба имеют известность Parks and Recreation ), поэтому от этих мастеров комедии следует ожидать комедийного оттенка. Этот эпизод был снят в Южной Африке и, как говорят, рассматривался как короткометражный фильм, учитывая большое увеличение бюджета по сравнению с эпизодами предыдущих двух сезонов.
Есть несколько тонких тем, касающихся того, как конкретно относятся к женщинам в социальных сетях. Фамилия Лейси Паунд, и видно, что она пытается тренироваться не для здоровья, а для того, чтобы быть более привлекательной и любимой. Наоми предполагает, что у нее размер 4, когда дает ей платье подружки невесты, в которое она не может поместиться. А фамилия Паунд — это комментарий к тому, как женщин всегда оценивают по их весу, и поэтому они постоянно думают о своем весе.Лейси идеализирует Наоми и хочет быть ею. В конце серии она заявляет о своей любви к Наоми. Но это не настоящая любовь, это навязчивая идея, созданная постоянным просмотром Наоми в социальных сетях, чтобы быть похожей на нее.
Black Mirror Эпизод «Носедание» пугает, потому что он представляет мир, в который мы идем без всяких тормозов. Это язвительный взгляд на то, как «социальный капитал» иногда определяется не чем иным, как тем, что люди публикуют о себе в Интернете.К концу истории Лейси оказывается в тюрьме, но, наконец, она достаточно свободна, чтобы раскрыть свои сокровенные чувства.
БОЛЬШЕ: Это причина, по которой вам не понравились фильмы о хоббите
В видеороликах о Fortnite и Peppa Pig на YouTube появилась игра Momo Suicide [ОБНОВЛЕНИЕ]Родители и дети находят на YouTube видеоролики с участием персонажей Fortnite и Свинки Пеппы, которые соединены с изображениями и видеороликами монстра Momo Suicide Game.
Читать дальше
Об авторе Мелисса С (135 опубликованных статей) Более От Мелиссы CТри способа оставаться актуальными в ИТ-индустрии
Одна из немногих постоянных в ИТ-индустрии — это изменения.Технологии развиваются шокирующе быстрыми темпами, часто намного быстрее, чем в других секторах, поэтому крайне важно поддерживать ваши навыки и знания в актуальном состоянии. Это включает больше, чем просто овладение определенным навыком, так как то, что вы знаете сейчас, может устареть быстрее, чем вы можете себе представить.
Сохранять актуальность необходимо, если вы хотите продолжить карьеру в ИТ. Имея это в виду, вот несколько советов, которые помогут вам сделать это более эффективно.
Будьте в курсе новостей и тенденций
Если вы надеетесь опережать других в своей отрасли, будьте в курсе последних новостей и тенденций — отличный способ начать.Это может помочь вам определить новые области, представляющие интерес в технологическом секторе, и даст вам возможность определить навыки, которые могут вскоре оказаться востребованными.
Быть в курсе последних новостей — довольно простой процесс. Вы можете подписаться на информационные бюллетени из ведущих источников информации, следить за определенными организациями или отдельными лицами в социальных сетях или участвовать в отраслевых форумах. Затем регулярно просматривайте информацию и углубляйтесь в темы, которые кажутся наиболее актуальными в вашей области.
Посещайте занятия и конференции
ИТ-индустрия предлагает одно из самых обширных сообществ в деловом мире. Практически в любой уик-энд можно найти что-то вроде конференции или занятия. Посещая эти мероприятия, вы можете получить новые навыки в общении с другими профессионалами. И, в некоторых случаях, ваша посещаемость может быть добавлена в ваше резюме в качестве основного момента.
Для некоторых мероприятий требуется, чтобы вы принадлежали к определенной отраслевой организации, что является еще одним отличным источником информации.Тем не менее, многие могут принять участие любой желающий, поэтому не бойтесь взглянуть и увидеть, что доступно в вашем районе, если поездка является непомерно высокой, или даже по стране.
Получить новые сертификаты
Сертификатымогут помочь вам быть более востребованными и актуальными в своей области. Эти ускорители резюме доказывают, что у вас есть определенный набор навыков, открывая путь к более высоким зарплатам и более желанным должностям. Если вы потратите время на то, чтобы выяснить, какие сертификаты наиболее востребованы и даже трудно найти в текущем пуле кандидатов, вы сможете выделиться среди других соискателей.Кроме того, это отличный способ улучшить свои навыки.
Как правило, получение сертификата требует финансовых и временных затрат, хотя суммы в каждой области могут сильно различаться. Некоторые также делают обязательным посещение занятий перед экзаменом, так что имейте это в виду при рассмотрении возможных вариантов.
Время, потраченное на улучшение своих навыков и изучение новых тенденций, как правило, потрачено не зря, когда дело касается ИТ-индустрии, особенно если вы хотите оставаться актуальным в долгосрочной перспективе.Приведенные выше советы могут послужить хорошей отправной точкой, помогая вам опережать конкурентов и быть в курсе последних событий в своей области.
Если вы ищете новую техническую должность, профессионалы The Squires Group могут связать вас с ведущими работодателями. Свяжитесь с нами сегодня, чтобы узнать, чем могут помочь наши услуги.
СвязанныеДело не в релевантности. Это примерно …
Дело не в релевантности.Речь идет о…
На Национальном собрании в марте группе пионеров было задано несколько вопросов, которые не были заданы лично. Поэтому мы продолжаем предлагать сообщения в блогах, чтобы отвечать на ваши вопросы и проблемы.
«Когда актуальность становится кумиром?»Когда что-нибудь становится идолом? Когда он заменяет законное место Бога в центре. Что-то становится идолом, когда мы начинаем поклоняться ему, позволяя ему управлять нашей жизнью и забирать нашу энергию.
Так что… да, актуальность может быть кумиром.
In Fresh Expressions мы приглашаем вас быть внимательными к тому, как сделать Евангелие связным .
Как мы можем помочь Евангелию ожить для группы людей? Как люди могут получить представление о том, как выглядит Царство Божье? Дело не столько в том, чтобы стать «инновационной» или «актуальной» церковью. Скорее, речь идет о том, чтобы указывать людям на Иисуса так, как они могут встретиться, связать отношения и ответить.
Оживите богатство любви Бога
Иногда то, что оживляет богатство Божьей любви к людям, — это то, что мы, церковные люди, считаем очень древними литургическими выражениями молитвы и поклонения.
Подумайте, сколько людей вне церковного контекста проводят общинные молитвенные бдения как выражение горя и боли.
Молитва при свечах — очень древний способ погрузиться в горе и жаждать справедливости или утешения. На этот раз вместе как сообщество также создает ощущение связи с божественным и с другими.Дело не в актуальности, а в выражении эмоций и приглашении на встречу с Богом, когда сообщество собирается вместе.
В других случаях богатство Божьей любви к ним оживает благодаря тому, что мы считаем весьма нелитургическими, нетрадиционными выражениями молитвы и поклонения.
Рассмотрим новое выражение церкви, которая предлагает людям подняться на горнолыжном подъемнике на вершину горы с другим участником группы.
На пути к вершине они разговаривают о том, где они видят Бога в своей жизни или в мире.Группа свежих самовыражений собирается на вершине горы, приветствует все великие дела, которые Бог задумал в мире, слышит чтение из Мира Бога и просит Духа дать им силы увидеть мир новыми глазами и оказать влияние мир с любовью Бога.
Затем они спускаются на лыжах с горы, чувствуя ветер на лице как знак того, что Дух Божий действует в них и через них.
В любом случае дело не в том, насколько «актуальным» может быть новое выражение. Речь идет о том, какие ритмы и практики могут духовно вовлечь людей, с которыми Бог приглашает вас к общению.
Если стиль участия в служении не состоит в том, чтобы слушать, любить и служить, вы, вероятно, вступаете на территорию идолопоклонства.
На что обращать внимание, чтобы избежать идолопоклонства.
Вот несколько предупреждающих знаков, которые вы можете склонить в зону идолопоклонства: если вы обнаружите, что сосредоточены на соответствующих программах, событиях или атмосфере, которые вы пытаетесь создать, и менее сосредоточены на приглашении людей к яркой и значимой встрече с Богом, вы можете находиться на территории идолопоклонства.