Что такое релевантные страницы?
Продолжаем рубрику «Азбука SEO» и сегодня говорим об одном из ключевых понятий поискового продвижения.
Релевантность — это соответствие того, что вы искали тому, что нашли.
Если речь идет о страницах (сайтах), подразумевается соответствие контента запросу. Чем точнее страница отвечает на запрос, раскрывает нужную тему, решает задачу пользователя, тем (при прочих равных) выше ее позиция в поисковой выдаче.
Релевантность выглядит по-разному
Допустим, мы хотим купить iphone 11 pro max 256gb gold. В топе поисковой выдачи находятся интернет-магазины электроники. Перейдя по любой из ссылок первой страницы поиска, увидим нужный телефон.
Бывают более неоднозначные запросы, и поисковой системе приходится предугадывать, какой из результатов окажется полезнее пользователю. Выдача при таких запросах выглядит уже не столь однородно. Например, по запросу «бухгалтер» Google миксует в выдаче сайты поиска работы, Википедию и профессиональные сайты.
Еще один пример смешанного запроса:
Существуют довольно неожиданные результаты поисковой выдачи. Правда, неожиданными они будут не для всех.
Из года в год поисковые системы совершенствуют алгоритмы поиска и вероятность того, что на первых страницах поисковой выдачи будут нерелевантные результаты стремится к нулю.
Как поисковые системы оценивают релевантность
В интернете огромное количество страниц соответствует тому или иному запросу. Поисковые системы создают алгоритмы ранжирования, чтобы релевантные результаты занимали верхние позиции в выдаче.
Именно от ранжирования зависит качество поиска — то, насколько поисковая система умеет показать пользователю нужный и ожидаемый результат. Формулы ранжирования строятся также автоматически — с помощью машинного обучения — и постоянно совершенствуются.
Яндекс — принципы ранжирования поиска
Одного лишь релевантного контента будет недостаточно, чтобы занять высокое место в выдаче. Важно, чтобы он решал задачу пользователя, помогал находить пути выхода из проблемной ситуации — приносил пользу. При этом робот поисковой системы должен получить доступ к странице и понять контент.
Важно, чтобы он решал задачу пользователя, помогал находить пути выхода из проблемной ситуации — приносил пользу. При этом робот поисковой системы должен получить доступ к странице и понять контент.
Алгоритмы поисковых систем оценивают сотни самых разных факторов: от наличия ключевых слов до скорости загрузки сайта:
Поскольку алгоритм Google постоянно улучшается, не стоит пытаться разгадать его и соответствующим образом изменить свой сайт. Вместо этого создавайте хороший оригинальный контент, который понравится пользователям, и следуйте при этом нашим рекомендациям.
Google справка
SEO-специалисты предполагают, что таких факторов ранжирования более 200, а их вес зависит от тематики.
Методы оценки релевантности
Объективно оценить релевантность определенной страницы или сайта скорее невозможно, чем наоборот. С каждым днем результаты поиска становятся все более персонализированными. Они зависят от местоположения пользователя, истории поиска, устройства, с которого этот поиск совершают и множества других факторов. То есть, позиция сайта в поисковой выдаче меняется не только изо дня в день, но и от пользователя к пользователю.
Целесообразно проверять релевантна ли страница определенному запросу и какое место в поисковой выдаче она занимает. Это можно сделать вручную или с помощью специальных инструментов:
- Вручную.
Чтобы проверить ранжируется ли ваш сайт по ключевому запросу, можно воспользоваться поиском в Google, Яндекс или другой поисковой системе. Рекомендую делать это в режиме «Инкогнито», чтобы ваша история поиска не повлияла на результаты.
В моём случае, по ключевому запросу «купить nissan», сайт OLX.ua занимает пятую позицию в поиске.
- Вручную с использованием оператора сайта site:domen.com.
Чтобы определить наиболее релевантную ключевому запросу страницу на сайте, можно воспользоваться оператором поиска site:domen.com.
То есть первую в выдаче страницу Google определяет как наиболее релевантную ключевому запросу «купить машину» на сайте OLX.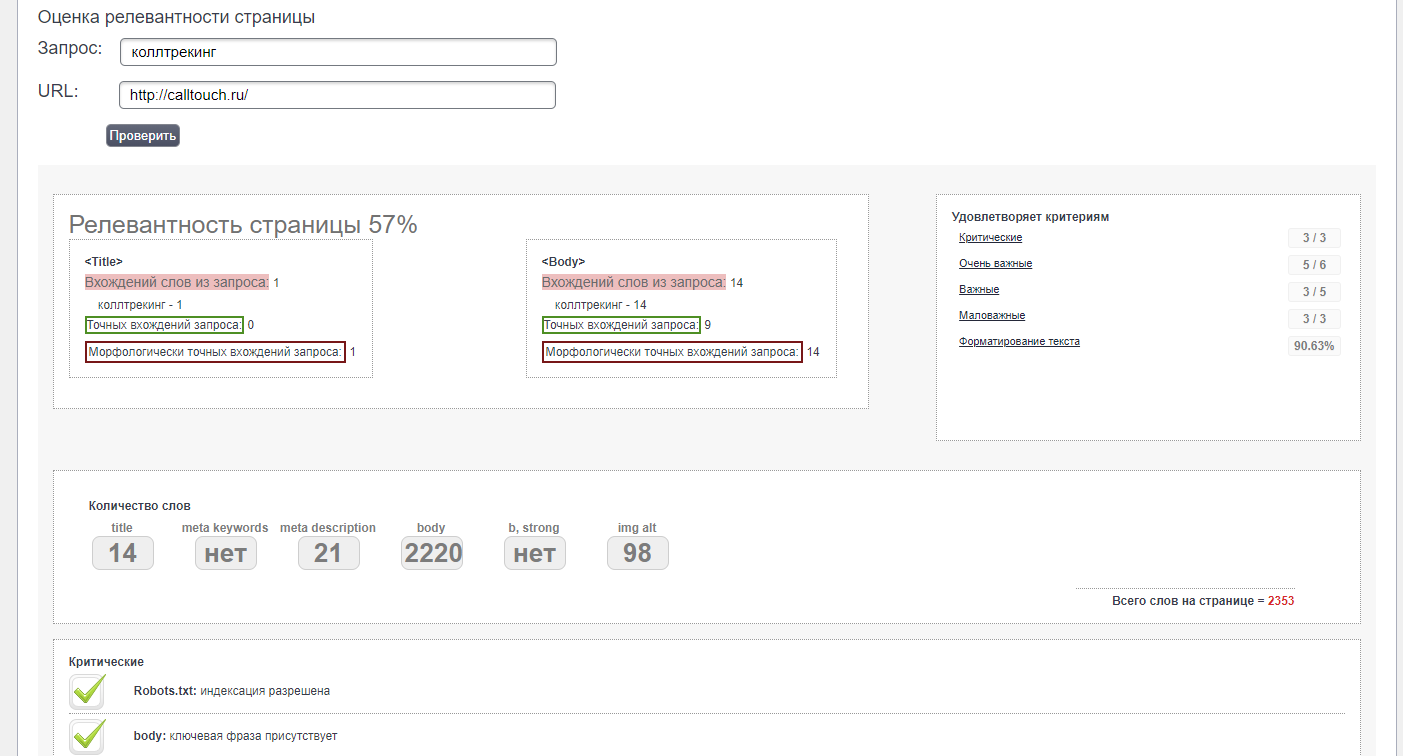 ua.
ua.
Поиск с оператором site:domen.com актуален и для Яндекса:
Без оператора поиска на первой позиции совсем другая страница:
- Netpeak Checker
Для проверки большого количества ключевых слов можно воспользоваться парсингом поисковой выдачи от Netpeak Checker.
В окно с левой стороны вписываем ключевые запросы:
Переходим во вкладку «Настройки»:
Выбираем выдачу поисковой системы, которую спарсим, далее определяем необходимое количество результатов. В дополнительных настройках выбираем пункт «Поисковые системы». Выбираем геолокацию и язык.
Результаты получаем в таком виде:
- Majento
Инструмент позволяет провести подробный анализ контента страницы на релевантность продвигаемых поисковых запросов.
В соответствующие окна вводим адрес страницы и ключевое слово, которое нас интересует.
- Istio
Бесплатный онлайн сервис, который анализирует такие параметры как длина текста, количество слов, их релевантность и плотность.
Как повысить релевантность страницы/сайта
Сбор семантического ядра и группировка по схожим запросам.
Необходимо понять, как ваш сайт ищет пользователь. На этом этапе собираем ключевые слова с помощью таких сервисов как Serpstat, Планировщик ключевых слов от Google ads или Яндекс Wordstat. Важно именно собирать семантическое ядро, а не генерировать его: вы удивитесь какие формулировки люди вбивают в строку поиска.
Оптимизация мета-тегов и заголовков h2-h6.
Далее, с помощью уже собранного ядра составляем мета-теги и заголовки для страницы. Размещайте ключевые слова ближе к началу title и description.
- Написание контента для страницы.
Опираясь на ключевые слова, составляйте полезный, уникальный контент для страницы. Помните, что тексты следует писать для пользователей, а не машин, не пытайтесь угодить поисковым роботам, иначе вас ждёт обратный эффект. После того, как текст написан проверьте его на текстовую релевантность ( уникальность, наличие ключевых и LSI слов).
После того, как текст написан проверьте его на текстовую релевантность ( уникальность, наличие ключевых и LSI слов).
- Технические характеристики сайта.
Не забывайте о юзабилити сайта и скорости загрузки страниц, при плохих показателях ваш контент рискует остаться непрочитанным.
- Ссылки
Наличие ссылок с тематических сайтов с релевантными анкорами помогут занять позиции в ТОПе.
- Правильная структура сайта
У SEO специалистов есть правило: «Одно ключевое слово — одна страница».
Каждую страницу сайта стоит оптимизировать под одно ключевое слово (+ хвост запросов). Для каждого ключевого запроса создаем отдельную посадочную страницу, за исключением синонимов.
Например, если страница по продаже автомобилей содержит авто марки BMW и Audi, по запросу пользователя «купить бмв» странице будет сложно занять ТОП в выдаче.
Выводы
Релевантные страницы — страницы, которые наиболее полно отвечают запросу пользователя. Поисковые системы заинтересованы размещать релевантные страницы как можно выше в результатах поиска, чтобы быть максимально полезными для пользователей.
Существуют специальные алгоритмы ранжирования, которые учитывают сотню разных факторов от наличия уникального контента до скорости загрузки сайта.
Для того, чтобы попасть в топ поисковой выдачи по ключевому запросу, нужно правильно оптимизировать страницу под этот запрос:
- собрать семантическое ядро;
- оптимизировать мета-теги страницы;
- подготовить полезный для пользователя контент;
- правильно составить структуру сайта;
- поработать с ссылочной массой и техническими характеристиками сайта.
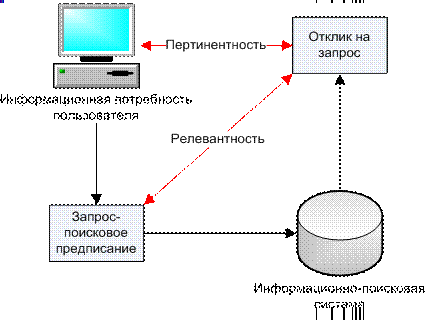
Релевантность — глоссарий КСК ГРУПП
Степень совпадения ожиданий пользователя при вводе поискового запроса и результатов, выданных программой, называется релевантностью. Эффективность поисковой системы определяется этим параметром. Алгоритм, которому следует робот при обработке запроса, ищет соответствующие требованиям слова на различных ресурсах. Релевантность какой-либо страницы сайта определяется числом фраз, совпадающих с использованными в поисковом запросе предложениями.
Алгоритм, которому следует робот при обработке запроса, ищет соответствующие требованиям слова на различных ресурсах. Релевантность какой-либо страницы сайта определяется числом фраз, совпадающих с использованными в поисковом запросе предложениями.
Как определяется релевантность?
Различные поисковые системы имеют разные пороги количества слов-ключей при определении релевантности. Для того чтобы страница была признана соответствующей запросу, уровень совпадающих слов должен быть больше пяти процентов. Если доля востребованных слов на сайте меньше пятипроцентного барьера, то такой ресурс признается недостаточно релевантным и просто игнорируется. Однако в том случае, когда площадка содержит намного большее количество искомых фраз, чем нужно для определения соответствия, то ее блокирует спам-фильтр. Поисковые системы открывают пользователям путь во Всемирную сеть. Развитие Интернета отдало главную роль этим программам.
Развитие алгоритма
После создания система поиска информации работала отлично до тех пор, пока не наступил очередной этап развития Интернета. В ответ на запрос пользователя выдавалась не пара тематических сайтов, а тысячи. Быстро определить, что из предоставленного имеет ценность, было невозможно. Среди выдаваемого списка сайтов присутствовали как высококачественные ресурсы, так и бесполезные. Для отсева нужного от ненужного и был разработан алгоритм определения релевантности. За счет него люди вновь могли получить желаемую информацию быстро, не разбирая груду лишних документов.
Сразу после создания программа-поисковик в определении релевантности руководствовалась исключительно внутренними параметрами рассматриваемого сайта. Такими критериями были:
- плотность слов-ключей на странице;
- частота нужных фраз в метатегах;
- искомые выражения в заголовках;
- совпадение с терминами в оформлении статьи.


Изобретение и распространение дорвеев (doorway) изменило всё. Эти специальные страницы содержали только слова из популярных запросов. Их цель — поднять рейтинг сайта в таблице выдачи бота. При переходе на такую страницу-наживку пользователь перенаправлялся на другой сайт или страницу. Для борьбы с данным жульничеством потребовалось создать систему оценки внешних критериев портала. Упрощенно данный алгоритм можно описать следующей формулой:
где:
- Р — общая релевантность сайта;
- Н — репутация сайта, оценка его наружных параметров независимо от запроса человека;
- В — соответствие наполнения сайта искомой фразе;
- С — степень совпадения текста ссылок на страницу и введенной пользователем фразы, ссылочное ранжирование.
Обдумав данное математическое выражение, можно понять принцип оценки релевантности современными поисковыми роботами. Реальная работа алгоритма гораздо сложнее, и ее смысл не уместится в формулу, которая лишь дает сведения о главных учитываемых параметрах.
Внутренняя релевантность сайта
Поисковая система оценивает внутреннюю релевантность портала путем подсчета количества искомых фраз на статью. Так, наиболее часто повторяемое слово программа сочтет ключевым.
При совпадении введенной человеком фразы с самой повторяемой последовательностью слов на сайте этот ресурс будет сочтен релевантным. Такое наиболее повторяемое предложение или слово вычисляется поисковиком для каждого портала.
Большое значение имеет не только наличие на странице сайта всех слов, введенных пользователем, но и их последовательность. Кроме того, учитывается расположение фраз в иерархии текста. Наибольшее значение придается словам в названиях. Если статья озаглавлена в той же формулировке, что и запрос посетителя, то релевантность портала для данного запроса будет высокой.
- Количество синонимов искомого слова.
- Положение относительно начала текста. Значимость ключа увеличивается в зависимости от того, насколько близок он к первой строке.
- Расстояние между словами, составляющими запрошенную фразу. Чем точнее предложение будет повторяться на сайте, тем этот ресурс предпочтительнее.
- Включение соответствующих слов в теги, метатеги, заголовки, названия страниц.
А также поисковый робот отмечает тематику ресурса и, если она полностью совпадает с запросом, выдает этот сайт как результат.
Внешняя релевантность сайта
Для оценки этого вида соответствия сайта используется термин ссылочной популярности. Величина этого критерия зависит от цитируемости обследуемого ресурса другими порталами. Авторитетность сайта зависит в данном случае от количества ссылок на него, размещенных на сторонних площадках. Таким образом, популярность в сети напрямую влияет на оценку качества контента. Алгоритм оценки внешней релевантности сохранил суть со времени своего изобретения основателями компании Google. С того момента он подвергся многим доработкам и работает до сих пор. Руководствуясь количеством найденных ссылок на сайт, поисковая система составляет PageRank — коэффициент, отражающий внешнюю релевантность ресурса.
Яндекс обзавелся своим клоном PR. Для составления критерия авторитетности сайта в 2001 году был разработан ВИЦ. Аббревиатура дословно расшифровывается как взвешенный индекс цитирования. Эта величина была ранее доступна, но в 2002 году ее скрыли от глаз пользователей из-за попыток ее накрутки. Сейчас есть возможность ознакомления лишь с критерием ТИЦ, который задействован для упорядочения сайтов в реестре Яндекса.
ИЦ используется и Рамблером тоже. Но данный индекс используется совместно с рейтингом посещений сайта пользователями. Система Рамблер улучшена этой технологией с 2002 года.
Система Рамблер улучшена этой технологией с 2002 года.
Первой программой, включившей в свой алгоритм ИЦ, была система «Апорт». Переменная была введена в 1999 году. В этом поисковике индекс составлялся лишь на основании самой значимой ссылки, полученной с наиболее популярного сайта.
Как повысить релевантность веб страниц
Если представитель целевой аудитории не может найти на страницах сайта необходимый ему контент (текст, аудиозапись, видеофайл, изображение), он приступает к поиску альтернативного источника для получения информации. Иными словами, посетитель уходит с сайта к одному из конкурентов, умеющему размещать качественный и актуальный контент.
Причины падения уровня релевантности
Формально исследование релевантности в области информационного поиска началось в середине прошлого века. Новая отрасль изучения позже получила называние библиометрики. Особое внимание в ходе ранних исследований уделялось поиску актуальных и точных текстов, отвечающих на конкретный вопрос.
С развитием и глобализацией Интернета информационный поток значительно увеличился. Появилось огромное количество нерелевантных веб-страниц, которые заточены исключительно под индексацию в поисковых системах. В результате появилось понятие технической релевантности. Во многом именно желание подстроиться под современные требования Яндекса и Google привело к значительному увеличению количества нерелевантных сайтов.
Причины падения релевантности веб-страниц
- Использование неуникального контента плохого качества.
- Несоответствие представленной информации заданным для ее поиска ключевым запросам.
- Размещение устаревшей, неактуальной или ложной информации.
- Проблемы с оптимизацией сайта, в том числе ссылочной массой и внутренней перелинковкой.
- Превышение оптимального уровня частности слов и прочие проблемы с семантическим ядром.
- Недостаточное или неправильное использование инструментов для раскрутки сайта.

В некоторых случаях запрос может иметь неоднозначную интерпретацию или различные правильные ответы, поэтому при оценке полезности веб-страниц учитывается разнообразие результатов. Наиболее релевантные веб-страницы необязательно являются самыми полезными для пользователя. Отображение сайта на первой странице в результатах поиска также не стоит приравнивать к высокому качеству общей релевантности. Временные передовые позиции в поисковой выдаче часто занимают сайты, хорошо оптимизированные с технической стороны.
Релевантность по ключевому запросу с точки зрения обычной поисковой системы — полученное после анализа соотношение количества запросов и остальных слов/словосочетаний в тексте. Качество самого контента при этом не оценивается. Для преодоления подобного недостатка была предложена специальная мера, называемая «максимальной предельной релевантностью» (MMR). В ее рамках рассчитывается актуальность каждого документа только с точки зрения того, сколько новой информации он приносит на фоне и с учетом предыдущих результатов.
Способы повышения релевантности веб-страниц
Релевантность контента влияет на процесс индексации и ранжирования сайта. Проблемы с оптимизацией информации приводят к сокращению уровня конверсии. Даже если страницы оптимизированы под требования поисковика, низкое качество контента со временем приведет к оттоку посетителей. Специалисты в области поискового продвижения предоставляют несколько полезных советов, связанных с повышением уровня релевантности.
Представитель целевой аудитории покинет сайт, на котором предоставлена хоть и хорошо технически оптимизированная, но устаревшая информация. Современные алгоритмы работы роботов поисковых систем учитывают поведенческие факторы, поэтому со временем веб-страница потеряет и свою техническую релевантность (позиции в топе выдачи снизятся).
Современные алгоритмы работы роботов поисковых систем учитывают поведенческие факторы, поэтому со временем веб-страница потеряет и свою техническую релевантность (позиции в топе выдачи снизятся).
Методы повышения релевантности сайта
- Привлечение профессиональных веб-дизайнеров, которые займутся разработкой сайта. Качественное юзабилити, приятный дизайн и продуманные параметры структуры сделают сайт приятным для аудитории.
- Использование ключевых слов в метатегах (title и descriprion), URL и заголовке h Внимание следует уделить описанию (descriprion), поскольку именно оно отображается в списке поисковой выдачи.
- Оптимизация изображений на сайте путем использования тегов alt и title. В современном SEO картинки влияют на процесс продвижения веб-страниц. Этот тип контента обязан соответствовать тематике сайта.
- Оптимизация частотности ключевых запросов в тексте. Показатель тошноты по слову не должен превышать 3,5%. Ключевые запросы рекомендуется размещать в первых и последних 100 словах текста.
- Повышение общего качества контента. Структурированный, уникальный, осмысленный и хорошо написанный текст высоко ценится аудиторией. Допускаются разбивка и изменение по падежам дополнительных ключевых слов. Использовать можно многоступенчатую систему подзаголовков (h3—h9).
- Продуманная внутренняя перелинковка и правильный обмен внешними ссылками. Наращивать ссылочную массу рекомендуется постепенно. Внутренние гиперссылки следует проверять на смысловое соответствие. Для обмена ссылками рекомендуется привлекать надежных партнеров, сайты которых считаются авторитетными источниками для получения тематической информации.
- Улучшение социальных сигналов с помощью размещения контекстной рекламы, различных маркетинговых объявлений и обзоров на тематических сайтах (виртуальные каталоги, блоги, площадки для размещения отзывов и рецензий). Сюда следует также отнести продвижение в социальных сетях (SMM).

Принцип релевантности предполагает использование на веб-страницах уникальных, полезных, актуальных и интересных текстов, разбавленных тематическим визуальным контентом (изображения, анимация и видеоролики). Поисковик — это роботизированная система, работающая по заранее прописанным алгоритмам. Во время индексации поисковая машина не в состоянии проверить красоту написания или актуальность текста. Реальную оценку релевантности сайта можно получить лишь в процессе личного изучения веб-станиц.
Владельцу сайта рекомендуется проследить за реакцией посетителей. Если речь заходит о площадке, нацеленной на диалог с представителями целевой аудитории, можно запустить опрос, в котором посетители отметят факторы, по их мнению, снижающие уровень релевантности веб-страниц.
Эффективные способы повысить релевантность страницы позволят удержать сайт на лидирующих местах в поисковой выдаче. Оптимизируя площадку под поисковое продвижение, следует также не забывать о прочих инструментах SEO. Только комплексный подход к раскрутке сайта позволит повысить уровень конверсии.
Возврат к списку
Релевантность страниц — оценка и анализ сайта, поиск, подбор и определение релевантных запросов
Для оценки используются факторы, которые составляют релевантность страниц. В определение закладывается принцип: чем точнее содержание сайта отвечает интересам пользователя, тем выше будут его позиции в выдаче. Адекватность информации и ее соответствие запросам – это главная цель, к которой должен стремиться каждый вебмастер или SEO-оптимизатор. Релевантный контент не гарантирует моментального попадания в топ, но это весомый параметр, влияющий на ранжирование.
Факторы релевантности
Как поисковые системы понимают, что страница содержит нужную для человека информацию? Чтобы избежать накруток, они не раскрывают все критерии ранжирования. В первое время это были только ключевые слова, но этот способ изжил себя, поскольку оптимизаторы стали создавать бессмысленные сайты с набором фраз. Для более точной выдачи алгоритмы постоянно дорабатываются и усложняются.
Для более точной выдачи алгоритмы постоянно дорабатываются и усложняются.
Сейчас определение релевантных страниц включает три фактора:
- содержание и организация статей: недостаточно добавить поисковые фразы – необходимо равномерно распределить их по тексту;
- внутренняя перелинковка и внешние ссылки;
- поведение пользователей.
Поисковые системы учитывают наличие ключевых слов и их плотность. Если материал перенасыщен повторяющимися запросами, он может получить негативную оценку за спам. Перелинковка важна для повышения активности пользователей, а внешние ссылки отражают популярность сайта. Последний показатель становится все менее значимым: Яндекс отказался от учета ИЦ (индекса цитируемости), а Google – от PageRank. Однако если на ресурс ссылаются источники той же тематики, которым доверяют поисковики – это может повлиять на ранжирование.
Принципы наполнения текстов ключевиками
Несмотря на добавление новых критериев оценки, определить, насколько материал релевантный помогают ключевые слова. Строгих требований к текстам нет, поэтому главная рекомендация – изучить первые страницы в выдаче в вашей сфере. Проведите конкурентный анализ с детальным разбором статей. Смотрите на то, как соотносится запрос с темой, как структурирована информация, какие методики применяются.
Для подготовки релевантных текстов изучите потребности целевой аудитории. Поставьте себя на место пользователя. Например, если он вводит в поиске «как настроить рекламную кампанию в Facebook», то не стоит предлагать ему инструкцию для других социальных сетей. Если же запрос не такой конкретный (например «пластиковые окна»), то выигрышной окажется общая статья с обзором или подборкой.
Что ещё стоит учитывать при подготовке материалов
-
Объем: необходимо выбрать оптимальный размер, чтобы его читали, а не пролистывали.
Это влияет на поведенческие факторы.
-
Заголовки и подзаголовки: используйте в них ключевые слова.
-
Частота и соотношение: избегайте повторений и распределяйте поисковые фразы равномерно.
-
Первый абзац: роботы сканируют текст с начала, поэтому употреблять ключи стоит в верхних строчках.
-
Синонимы: меняйте формулировки, чтобы охватить как можно больше похожих словосочетаний. Пользователи по-разному выражают свои запросы, ваша задача – учитывать варианты.
 Это влияет на поведенческие факторы.
Это влияет на поведенческие факторы.
Не забывайте о юзабилити текстов. Они должны быть читабельными и логичными. Стоит выделять определения, важные тезисы и списки.
Как проверить
Точная оценка релевантности страницы невозможна, поскольку это динамический показатель, который зависит от региона, языка, геолокации аудитории, браузера и постоянно меняющегося поведения пользователей. Для примерного определения позиций в выдаче можно выставить интересующий вас регион в поиске и произвести настройки браузера, а затем вручную протестировать каждый поисковой запрос.
Проверить показатели можно с помощью продвинутых сервисов веб-аналитики:
PR-CY
Одна из наиболее удобных платформ, которая поможет провести анализ релевантности. Здесь вы найдете информацию обо всех известных критериях, по которым поисковые системы проверяют ресурсы. Наглядные диаграммы и списки показывают, какие параметры соответствуют правилам и требованиям, а что нужно улучшить для роста позиций в выдаче. Для оценки текстового наполнения вы можете использовать инструмент аналитики ключевых слов.
Majento
Используйте этот сервис для определения релевантности размещенных на страницах материалов. Его данные субъективны, поскольку он ссылается на собственные критерии, однако их можно использовать для улучшения контента.
Seolib
Чтобы проверить количество вхождений ключей, плотность запросов в текстах, число страниц в топе выдачи и другие важные для релевантности показатели, вы можете использовать этот сервис. Вам останется только провести анализ этих метрик и составить стратегию по улучшению статистики.
Megaindex
Функционал этой платформы позволяет проверить все параметры, определяющие качество сайта. Помимо данных для анализа, сервис выдает рекомендации, которые помогут сделать контент релевантным.
Влияние поведенческих факторов на релевантность
Поисковые системы выявляют релевантные страницы с помощью поведения пользователей. Ключи – это первый этап оценки. После этого Яндекс и Google рассматривают, как посетители ведут себя на странице. Сколько времени длится сеанс, дочитывают ли они текст, переходят ли на другие разделы – всё это показывает, насколько контент интересен людям.
Хотя поведенческие факторы не являются составляющими релевантности, эти параметры влияют на ранжирование. Чтобы повысить позиции в выдаче, необходимо работать именно над этими показателями, поскольку они являются индикаторами качества сайта. Используя инструменты Google Analytics, вы можете проверить, как ведут себя посетители, попавшие на ресурс по конкретным запросам. Это позволяет понять, релевантный ли контент размещен на странице.
Определение ПФ помогает разработать стратегию по улучшению сайта. Позитивные изменения метрик покажут, что вы двигаетесь в правильном направлении.
Как улучшить
Первое направление работы по улучшению ресурса – это проработка контента. Однако каким бы полезным он ни был, если пользователь сталкивается с неудобным интерфейсом, все усилия по написанию статей окажутся бессмысленными. Поэтому помимо наполнения важно проверять юзабилити всех элементов. Оцените, легко ли найти нужную информацию на ресурсе, комфортны ли для зрения цвета и размер шрифтов, не мешают ли картинки восприятию. Подробнее о роли текстов для вовлечения мы рассказывали в материале из серии “UX-мифы”.
Подробнее о роли текстов для вовлечения мы рассказывали в материале из серии “UX-мифы”.
Для стабильного продвижения необходимо не только разово привлечь трафик, но и удерживать посетителей, стимулируя повторные заходы. Работая над релевантностью, в первую очередь думайте о своих пользователях, а затем уже о технических параметрах.
Закажи юзабилити-тестирование прямо сейчас
Заказать
Релевантность – что же это? – Блог ITC MEDIA
В Интернете на данный момент содержится огромное количество информации о разных сферах деятельности. И любой человек нуждается в какой-либо определенной информации по интересующим его вопросам. Самым же распространенным способом получения нужной информации в нашем современном мире является поисковой запрос в Интернете. Существует множество различных поисковых систем, работа которых заключается в том, чтобы на запрос пользователя выдать наиболее точные и полные ответы. Это и есть релевантность. Т. е. это определенная степень соответствия найденной информации (документа или страницы Интернета) сформированному запросу пользователя. Оценивая релевантность выданной на запрос страницы, проверяется, насколько полно была представлена нужная информация, и не присутствует ли чего-нибудь ненужного, не соответствующего запросу пользователя.
Релевантность бывает формальная и содержательная. Формальная релевантность — это именно то, насколько найденный документ или страница Интернета соответствует по смыслу запрашиваемой информации, введенной в поисковик.
Содержательная релевантность также называется пертинентность — это понятие отражает, насколько полезна пользователю найденная поисковой машиной информация.
Эти 2 понятия (пертинентности и релевантности) являются очень важными при создании сайтов. Ведь от того, как правильно и точно будет оцениваться ваш сайт поисковыми системами, зависит посещаемость сайта и его рейтинг в поиске. Поэтому если вы создали свой сайт и хотите, чтобы он был популярен среди пользователей мировой сети, чтобы его посещали множество людей, то вы должны позаботиться о том, чтобы информация на вашем сайте соответствовала тому, что вы рекламируете. Если вы правильно составите контент сайта и оцените его релевантность запросам пользователя по данной проблеме, то ваш сайт всегда будет находиться на самых первых местах в различных поисковых системах. А это в свою очередь, обеспечит вам должную популярность и посещаемость вашего сайта потенциальными покупателями рекламируемой на сайте продукции.
Ведь от того, как правильно и точно будет оцениваться ваш сайт поисковыми системами, зависит посещаемость сайта и его рейтинг в поиске. Поэтому если вы создали свой сайт и хотите, чтобы он был популярен среди пользователей мировой сети, чтобы его посещали множество людей, то вы должны позаботиться о том, чтобы информация на вашем сайте соответствовала тому, что вы рекламируете. Если вы правильно составите контент сайта и оцените его релевантность запросам пользователя по данной проблеме, то ваш сайт всегда будет находиться на самых первых местах в различных поисковых системах. А это в свою очередь, обеспечит вам должную популярность и посещаемость вашего сайта потенциальными покупателями рекламируемой на сайте продукции.
Правильно оценить сайт и его релевантность может только специалист, который долго занимается разработкой, раскруткой и продвижением различных сайтов. Но если вы не можете пока что себе позволить нанять специалиста, то исправить и сделать более релевантным контент вашего сайта вы можете и сами с помощью нехитрых правил.
Для начала попробуйте представить себя на месте вашего потенциального клиента. Т. е. представьте какой бы он мог задать запрос в поисковую систему, и в соответствии с этим скорректируйте содержание вашего сайта. Сущность коррекции релевантности сайта состоит в том, чтобы правильно подобрать ключевые слова и фразы, которые может использовать потенциальный посетитель вашего сайта при поиске нужной ему информации.
Релеваностность запросов. Что такое релевантный запрос?
Если опираться на толковый словарь, то релевантность — это соответствие чему-либо.
В случае с оптимизацией релевантность — это соответствие имеющейся на страницах информации поисковым запросам пользователей.
Грубо говоря, если пользователь вводит в строку поиска «Мультяшные кошечки», то ему на сайте должны показать именно мультипликационных героев породы «кошка», а не всякие разности. Релевантность отделяет полезные для пользователей проекты, на которых они могут найти нужную им информацию, от ресурсов, которые лишь оптимизированы под эти запросы, но никакой практической пользы посетителям проекта не несут.
Релевантность отделяет полезные для пользователей проекты, на которых они могут найти нужную им информацию, от ресурсов, которые лишь оптимизированы под эти запросы, но никакой практической пользы посетителям проекта не несут.
Контент сайта должен отвечать запросам целевой аудитории, лишь тогда он будет приносить прибыль.
Стоит понимать, что подбор ключевых слов — это важная задача. Грамотно выполненная, она позволяет сократить рекламный бюджет, увеличить конверсию и посещаемость сайта.
Релевантность запросов — основа правильной оптимизации.
Расчет релевантности поисковых запросов
Что влияет на релевантность?
- Частота ключевых слов в контенте.
- Расположение их в тексте.
- Соответствие ключевых слов тематике сайта.
- Количество страниц на сайте.
- Периодичность обновления ресурса.
- Наличие ключевых слов в заголовках и метатегах.
- Внутренняя оптимизация.
Сайт, отображающийся в поисковой выдаче на релевантный запрос, получает тематический трафик. Чем больше соответствие перечисленных факторов методам ранжирования, тем большее количество уникальных посетителей получит продвигаемый ресурс.
На релевантность влияет так же возраст домена, тематический индекс цитирования и посещаемость ресурса. Такая вот взаимосвязь.
Если вам нужна консультация по вопросам релевантности, если вы хотите увеличить посещаемость своего сайта, улучшить его оптимизацию и провести работу по продвижению, то просто напишите нам или позвоните.
Релевантность в контекстной рекламе — ppc.world
Релевантность в широком смысле — это мера соответствия желаемого результата полученному. Когда говорят о релевантности в контекстной рекламе, имеют в виду соответствие объявления, ключевых фраз и посадочной страницы пользовательскому запросу.
Например, пользователь хочет экскурсию в Санкт-Петербурге и ищет организаторов онлайн. Релевантное объявление с точки зрения рекламной системы будет содержать запрос, а также вести на подходящую посадочную страницу.
Релевантное объявление с точки зрения рекламной системы будет содержать запрос, а также вести на подходящую посадочную страницу.
Яндекс.Директ и Google AdWords учитывают релевантность при ранжировании объявлений и определении стоимости клика. Релевантные объявления, целевые страницы и ключевые слова, как правило, получают более высокую позицию в блоке по меньшей цене.
Как это работает в Google AdWords
В AdWords релевантность — это один из показателей, которые система анализирует при расчете показателя качества. Он отражает полезность объявлений, ключевых слов и посадочных страниц для пользователя.
Показатель качества зависит от трех факторов:
- Ожидаемое значение CTR — прогноз CTR для ключевого слова. Высокий показатель присваивается рекламе, где ключ совпадает с поисковым запросом.
- Релевантность объявления.
- Качество целевой страницы — оценка качества лендинга и ее релевантности ключевым словам.
Эти показатели доступны в AdWords в разделе «Ключевые слова» на уровне выбранной кампании, и их можно использовать, чтобы повышать эффективность рекламы. Нужно навести курсор на статус ключевой фразы, чтобы открылось всплывающее окно:
При этом в аукционе сам показатель качества — оценка от 1 до 10 — не участвует и не используется для определения рейтинга объявления, который как раз влияет на стоимость клика. Рейтинг объявления рассчитывается всегда в реальном времени в том числе с учетом тех же метрик, что и показатель качества, но нет только (полный список Google не раскрывает). Разница в том, что рейтинг всегда учитывает обстоятельства и индивидуальные условия аукциона, а показатель качества — сводная оценка эффективности объявлений.
Как в Яндекс.Директе
Директ учитывает релевантность, когда рассчитывает коэффициента качества объявления, аналогичный показателю качества в AdWords. Эта метрика наряду со ставкой за прогнозируемый объем трафика и прогнозом CTR влияет на ранжирование объявлений в выдаче.
Это означает, что даже если ставка одного рекламодателя ниже, чем у остальных участников, он сможет размещаться выше, если качество его объявлений выше. Таким образом, чем менее привлекательно объявление для пользователя, тем дороже рекламодатель будет платить за трафик.
При расчете коэффициента качества Яндекс учитывает релевантность объявления запросу и посадочной странице. Коэффициент качества определяется в режиме реального времени, его значение нельзя посмотреть в интерфейсе.
Как повысить релевантность
Чтобы создать релевантную рекламу, необходимо изучить целевую аудиторию, знать ее потребности, в том числе работать с семантикой. Рабочая связка из привлекательного объявления, полезной посадочной страницы и тщательно подобранных ключевых слов увеличивает конверсию.
Релевантное объявление:
- содержит ключевые слова в заголовке и тексте объявления;
- включает ссылку на работающую и качественную посадочную страницу;
- адаптировано для показа на мобильных устройствах.
Релевантная посадочная страница:
- посвящена товару или услуге, которые рекламируются в объявлении;
- подробно рассказывает о предложении;
- позволяет быстро позвонить в офис или сделать заказ онлайн;
- технически оптимизирована для продвижения.
А как повысить релевантность в контексте? Четыре совета для объявлений
- Добавьте ключевые фразы в заголовок и текст объявления. Это можно сделать вручную или с помощью динамической вставки ключевых фраз в AdWords и шаблонов в Директе.
- В группы объявлений добавляйте похожие и близкие ключевые фразы. Так будет проще написать релевантные объявления. Например, для ключевых фраз, связанных с курсами английского и немецкого языка, сложно составить одно релевантное объявление с ключевыми фразами в заголовке.
- Прорабатывайте семантику. С помощью минус-слов вы можете исключить показы по неподходящим запросам.
- Создавайте понятные и привлекающие внимание объявления:
- используйте расширения, дополнения и быстрые ссылки;
- расскажите о преимуществах предложения;
- добавьте призыв к действию;
- добавьте информацию о скидках, акциях или распродаже.
 С помощью минус-слов вы можете исключить показы по неподходящим запросам.
С помощью минус-слов вы можете исключить показы по неподходящим запросам.И пять — для посадочных страниц
- Подбирайте подходящие посадочные страницы. Вместо главной страницы сайта укажите страницу, посвященную рекламируемому товару или услуге. Следите также за тем, чтобы страницы соответствовали типу запроса: если пользователь вводит информационный запрос о решении проблемы, ведите его на страницу, где рассказываете, как решить проблему, а не как купить у вас товар, и наоборот.
- Публикуйте вовлекающий и полезный контент на посадочной странице, чтобы задержать пользователя на сайте. При этом не обязательно наполнять страницу ключевыми фразами.
- Следите за актуальностью информации: если в объявлении вы обещали скидку и акцию, то пользователь должен найти их на сайте.
- Если для рекламы используется одностраничный сайт, то для каждого предложения лучше создать отдельный одностраничник и адаптировать под него объявления и ключевые фразы.
- Убедитесь, что страница быстро загружается на всех типах устройств и правильно отображается на дисплеях с популярными разрешениями и в браузерах. Как это сделать, читайте в материале о подготовке сайта к мобильному трафику из контекста. Если есть проблемы с отображением на мобильных, их надо устранить, как вариант — с помощью турбо-страниц и AMP для мобильного трафика.
Принцип релевантности лежит в основе контекстной рекламы: пользователи хотят приобрести товар или услугу и «спрашивают» у поисковика, где это можно сделать и как. В ответ они получают предложения купить или заказать его. Поисковые системы стараются защитить пользователей от некачественной рекламы и ставят на более высокие места подходящие объявления.
Релевантное предложение не содержит лишней информации, оно показывает решение проблемы или ответ на вопрос. Работа над релевантностью рекламы повышает эффективность продвижения и помогает увеличить число конверсий.
Подпишитесь, чтобы получать полезные материалы о платном трафике
Релевантность текста запросам
Что такое релевантность страниц сайта? Существует два самых важных параметра, по которым роботы ПС определяют, релевантна ли (то есть, соответствует или нет) страница сайта запросам пользователей:
1. Наличие слов из запрашиваемой в поиске фразы и их плотность в документе.
Если вы введете в поисковую строку запрос «купить телефон», то в выдаче не увидите текста, в котором нет такого словосочетания. Как, впрочем, не увидите и сайта, в материалах которого слова из запроса встречаются слишком редко. По крайней мере, такой web-сайт не будет ранжироваться высоко.
Важно соблюдать оптимальную плотность слов в тексте. Вхождений запроса должно быть достаточно для того, чтобы страница была определена поисковиком как релевантная, и не слишком много, чтобы роботы не восприняли её как поисковый спам и не отправили сайт под фильтр. Считается, что частота использования ключевого слова должна составлять минимум 3% и максимум 5% от общего количества слов в тексте. Как определить золотую середину? Писать «для людей» – в первую очередь. Если текст понравится людям, он понравится и машинам.
Чтобы текст был релевантен запросу, вписывайте ключевое слово в заголовок статьи и обязательно – в тайтл и дескрипшин (см. урок «Title и мета-данные»), употребляйте запрос в различных формах, используйте синонимы.
2. Поведение пользователей, которые переходят из поиска на сайт.
Если они сразу же возвращаются в поисковик и продолжают искать нужную информацию, значит, «отвергнутый» ими ресурс не содержит полезных данных. В соответствии с заданными алгоритмами ранжирования, робот-поисковик решит, что веб-страница не релевантна запросу, и её позиции в списке результатов поиска нужно понизить.
SEO-тексты – это не только оптимизация под запросы
Опытный SEO-копирайтер умеет не только виртуозно вписывать сложные «ключи» в свои статьи. Он способен создавать действительно релевантные поисковым запросам тексты – интересные, информативные, в которых всё – «строго по теме». Тексты, которые будут отвечать на вопросы потенциальных покупателей, и приносить хорошую прибыль владельцу сайта. Качественные продающие seo-статьи стоят дорого именно потому, что они способны зарабатывать!
Вы встречали когда-нибудь в Сети сайт (не новостной портал, а коммерческий ресурс), на котором один раздел посвящен, например, установке пластиковых окон, второй – продаже бытовой техники, а третий, допустим, – недвижимости? Конечно, нет! Даже если и существует такое веб-чудо, оно почивает на задворках поисковой выдачи, потому что тематику подобного сайта поисковикам определить очень нелегко.
Такой же принцип применим и к статьям. Если в тексте о покупке телефонов много не относящейся к теме информации, ему будет не суждено попасть на высокие позиции в выдаче поиска. Поэтому берите в работу только те заказы, в тематике которых разбираетесь, а при написании текстов избегайте отклонений от темы. Поставьте себя на место потенциального читателя: что он может искать, введя тот или иной запрос? Если вам удастся понять, что его интересует, вы сможете написать действительно полезную и релевантную статью.
Как сделать текст релевантным запросу? Резюме
- Используйте ключевые слова в title, description и в заголовках.
- Соблюдайте оптимальную плотность заданных «ключей».
- Строго придерживайтесь темы, которая определена ключевыми фразами.
- Пишите интересные и полезные для потенциальных читателей тексты.
Подробнее о плотности ключевых слов и о том, почему важно создавать полезные людям тексты, вы узнаете из других уроков курса.
Что такое релевантность поиска? | Блог Algolia
Релевантность поиска — это мера точности взаимосвязи между поисковым запросом и результатами поиска.
Сегодняшние пользователи Интернета возлагают большие надежды. Благодаря высокой планке, установленной такими сайтами, как Google, Amazon и Netflix, они ожидают точных, актуальных и быстрых результатов. Однако в действительности на многих сайтах нет оптимизированных страниц результатов, которые понимают намерения пользователя и с легкостью удовлетворяют их потребности.
Если вы когда-либо выполняли поиск на веб-сайте только для того, чтобы увидеть кучу бесполезных, несвязанных результатов, то вы знаете, что могут чувствовать ваши пользователи: разочарование и желание перейти на сайт конкурента, чтобы найти результаты. Релевантность поиска является неотъемлемой частью пользовательского опыта.
Владельцы веб-сайтов могут точно настроить свою поисковую релевантность, чтобы упорядочить результаты поиска наиболее удобным для пользователей способом. Это может быть основано на ряде факторов, таких как цель поиска, бизнес-приоритеты, релевантность текста, точность написания, геолокация пользователя или близость ключевых слов в искомом контенте.
Точная настройка релевантности поиска для повышения точности
Релевантность может быть труднодостижимой, поскольку она сильно зависит от контекста и количества изменяющихся переменных. Например, тип сайта имеет значение: способ ранжирования товаров на веб-сайте электронной коммерции по сравнению с академическим сайтом не будет одинаковым. Тип искателя также имеет значение. Результат, релевантный для клиента, может не иметь отношения к бизнесу, владеющему поисковой системой, и наоборот. Кроме того, у разных людей будут разные способы выразить то, что они ищут, и даже для одного и того же запроса разные пользователи будут ожидать разных результатов.Формула ранжирования результатов должна учитывать эти нюансы.
Почему важна релевантность поиска?
Оптимизация поисковой релевантности — чрезвычайно важный, но часто упускаемый из виду аспект дизайна пользовательского опыта. Исследования показывают, что 43% посетителей веб-сайта сразу переходят на панель поиска, и вероятность конверсии у этих искателей примерно в 2-3 раза выше. Когда пользователи получают результаты, соответствующие их запросу и интересам, они будут более удовлетворены, более вовлечены и даже с большей вероятностью совершат конверсию.
Кроме того, современные онлайн-пользователи возлагают большие надежды на удобство использования веб-сайта, поэтому простота использования и простота дизайна являются важными факторами в том, как клиенты воспринимают бренд.
Краткая история поисковой релевантности
История поисковой релевантности восходит к ранним дням Интернета, когда исследователи пытались выяснить методы поиска информации, а также способы исследования всего нового создаваемого контента.Это быстро привело к изобретению поисковой машины.
Поисковые системы
Ранние поисковые системы и протоколы, такие как Archie, созданный в 1990 году аспирантом Университета Макгилла, и Gopher, созданный в 1991 году исследователями из Университета Миннесоты, были важными вехами в развитии современных систем релевантности поиска. Они позволили исследователям использовать поисковые запросы для поиска в файловых системах других учреждений, к которым они были подключены через Интернет.
Тем не менее, это были очень технические системы, требующие от пользователей глубоких знаний о компьютерах и низкоуровневых концепциях Интернета. Однако всего через пару лет, в 1993 году, всемирная паутина начала процветать, когда сотни веб-сайтов стали выходить в Интернет, положив начало совершенно новой волне поисковых систем.
Ранние поисковые системы
Вскоре было изобретено сканирование веб-страниц для автоматической загрузки и обновления веб-страниц в индексы поисковых систем, что позволило выполнять поиск гораздо большего количества контента.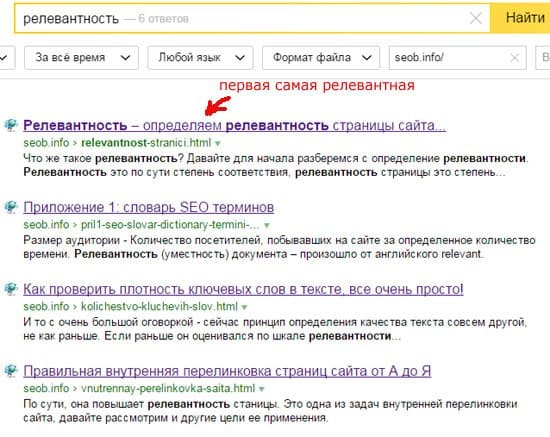
, такие как Excite в 1993 г. и Yahoo в 1994 г., быстро завоевали популярность благодаря простоте использования. Они даже включили некоторые базовые статистические модели, направленные на понимание пользовательских запросов и их отношения к контенту.
Эти новые ранние системы использовали работоспособный, но ограниченный метод упорядочивания наиболее релевантных результатов поиска для пользователей. То есть, ранжирование релевантности во многом основывалось на том, сколько раз ключевые слова появлялись на веб-страницах, и не учитывало никаких других критериев для оценки качества веб-страниц.
Затем на сцену вышел Google. Компания Google, основанная 4 сентября 1998 года в Менло-Парке, Калифорния, значительно улучшила релевантность поиска и окно поиска, создав передовые технологии поисковых систем.
Например, на протяжении 2000-х годов поисковые системы начали создавать больше статистических систем для интерпретации семантики запросов, прогнозирования взаимосвязей между различными ключевыми словами и использования данных перехода по ссылкам для динамической корректировки результатов. По мере того как профессионалы поисковой оптимизации (SEO) начали изучать, как работают эти алгоритмы, поисковым системам также приходилось не отставать и защищаться от более изощренных попыток «игры» с системой, чтобы результаты оставались как можно более справедливыми.
Создание релевантного поиска документов
С увеличением количества сайтов возрастала и потребность в поиске релевантных документов на определенных сайтах и в базах данных. Поиск по документам был важным предшественником того, как мы ищем на сайтах сегодня.
Традиционные системы ранжирования часто смотрят на частоту ключевых слов в документах, чтобы предсказать их релевантность. Например, классический алгоритм, известный как TF-IDF, будет проверять, сколько раз ключевые слова появлялись в соответствующих документах (Term Frequency) и сколько раз ключевые слова появлялись во всех других документах в репозитории (Inverse Document Frequency).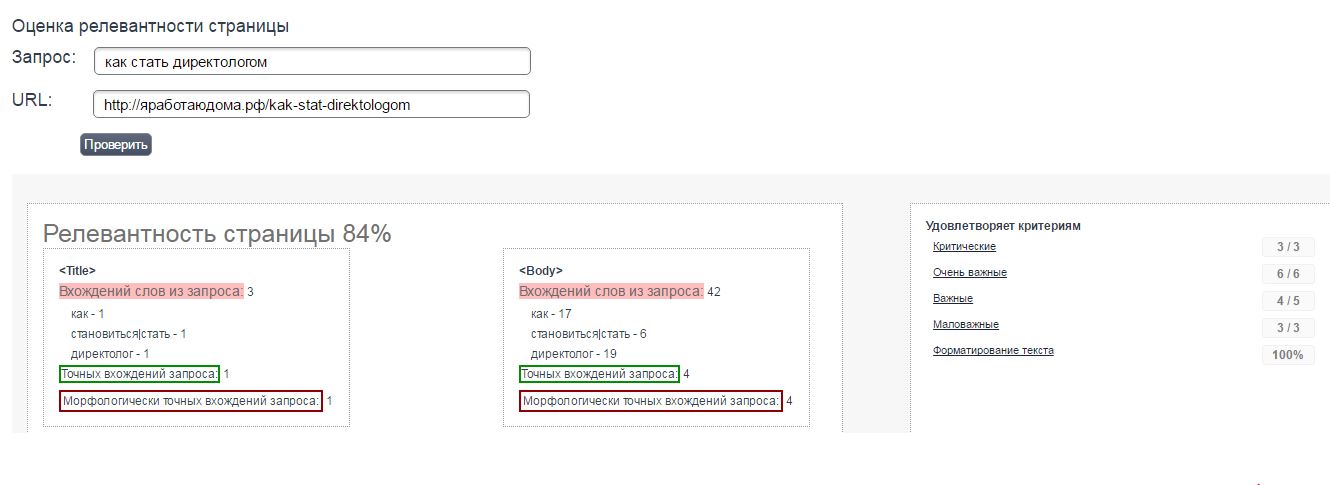 Последний анализ помогает отфильтровать общие слова, которые обычно являются шумом, например предлоги.
Последний анализ помогает отфильтровать общие слова, которые обычно являются шумом, например предлоги.
Хотя эти ранние подходы к релевантности, такие как TF-IDF, были хороши для поиска документов общего назначения, они не смогли воспользоваться преимуществами дополнительной структуры и метаданных, которые доступны на большинстве веб-сайтов. У современного контента есть заголовки, описания, категории, теги и многое другое, которые можно использовать для интерпретации контента сайта и повышения релевантности поиска.
Текущая поисковая релевантность
Сегодня, когда веб-сайты расширили свой контент и ассортимент продуктов, оптимизация поисковой релевантности является одним из основных соображений для отдельных поисковых систем.Компании, использующие собственные системы релевантности, должны учитывать свои специфические бизнес-потребности, чтобы поиск был полезным.
Например, у бренда электронной коммерции могут быть тысячи разнообразных продуктов и клиентов самых разных демографических групп. Таким образом, когда покупатель ищет продукт, внутренняя поисковая система должна иметь возможность предоставлять результаты, которые не только связаны с запросом, но и контекстуально релевантны конкретному пользователю.
Кроме того, маркетологи могут захотеть продвигать сезонные товары, аналогичные их усилиям по маркетингу в магазинах, или бизнес-операторы могут захотеть продвигать товары с более высокой маржой.Следовательно, релевантная поисковая система также должна уметь учитывать эти факторы и обеспечивать индивидуальное ранжирование, которое со временем может быть скорректировано для удовлетворения этих потребностей.
Однако многие из этих алгоритмов все еще неуклюжи. Однако некоторые алгоритмы, такие как алгоритм Algolia, принимают во внимание такие факторы, как важность атрибута соответствия и близость ключевых слов. Таким образом, результаты поиска с большей вероятностью будут релевантны пользователям, чем поисковые алгоритмы общего назначения.
Совсем недавно, чтобы повысить релевантность, дизайнеры поиска работали над расширением персонализации и контекстуализации. Это включает в себя такие вещи, как машинное обучение и обработка естественного языка для обеспечения более диалогового поиска, отслеживание пользовательского поиска и истории просмотров, чтобы обеспечить индивидуальную интерпретацию запросов, а также автоматическую пометку и категоризацию веб-страниц для понимания контента на более высоком уровне, чем просто что текстовых ключевых слов.
Оптимизируйте релевантность поиска с помощью Algolia
Оптимизация поисковой релевантности веб-сайта — сложный и непрерывный процесс.Это требует не только предоставления результатов, соответствующих запросам пользователей, но также предоставления персонализированных результатов и удовлетворения конкретных бизнес-потребностей. Кроме того, по мере того, как пользователи все больше переходят на устройства с поддержкой голоса и цифровых помощников, компаниям придется придумать, как предоставить новый тип интерфейса, который может естественно разговаривать с пользователями.
Чтобы предоставить все эти функции своим клиентам, вам понадобится поиск в качестве сервисного партнера, который предлагает все передовые отраслевые практики прямо из коробки.Узнайте, как Algolia может помочь обеспечить персонализированный и релевантный поиск для ваших пользователей.
Определение релевантности: как оценивается сходство
Сегодняшние поисковые системы имеют изощренные способы измерения того, связана ли веб-страница с заданным запросом, на основе десятилетий исследований в области информационного поиска. Присоединяйтесь ко мне, я исследую внутреннюю работу механизма релевантности поисковой системы и объясню, что это значит для оптимизаторов поисковых систем.Определение релевантности
Когда пользователь отправляет запрос в поисковую систему, первое, что он должен сделать, это определить, какие страницы в индексе связаны с запросом, а какие нет. В этом посте я буду называть это проблемой «актуальности». Более формально мы можем сформулировать это следующим образом:
В этом посте я буду называть это проблемой «актуальности». Более формально мы можем сформулировать это следующим образом:
Учитывая поисковый запрос и документ, вычислите оценку релевантности, которая измеряет сходство между запросом и документом.
«Документ» в этом контексте может также относиться к таким вещам, как тег заголовка, мета-описание, входящий текст привязки или что-то еще, что, по нашему мнению, может помочь определить, связан ли запрос со страницей. На практике поисковая система вычисляет несколько оценок релевантности, используя разные элементы страницы, и взвешивает их все, чтобы получить одну окончательную оценку.
Проблема актуальности чрезвычайно хорошо изучена в научном сообществе. Первые статьи появились несколько десятилетий назад, и это все еще активная область исследований. В этом посте я остановлюсь на наиболее влиятельных подходах, которые выдержали испытание временем.
Релевантность и ранжирование
Концептуально мы можем отделить определение релевантности от ранжирования релевантных документов, даже если они реализованы как один шаг внутри поисковой системы. В этой ментальной структуре шаг релевантности сначала принимает двоичное (Истинно / Ложно) решение для каждой страницы, затем шаг ранжирования приказывает документам вернуться к пользователю.Позже в этом посте я представлю некоторые данные, которые наглядно иллюстрируют это разделение и его связь с различными сигналами ранжирования.
Модели запросов и документов
Преобразование запроса и документа из необработанных строк во что-то, что мы можем использовать для вычислений, является первым препятствием при вычислении оценки сходства. Для этого мы используем «модели запросов» и «модели документов». «Модели» здесь — это просто причудливый способ сказать, что строки представлены каким-то другим способом, который делает возможными вычисления.
На изображении выше показан этот процесс для запроса «philadelphia phillies» и страницы в Википедии о семье Phillies.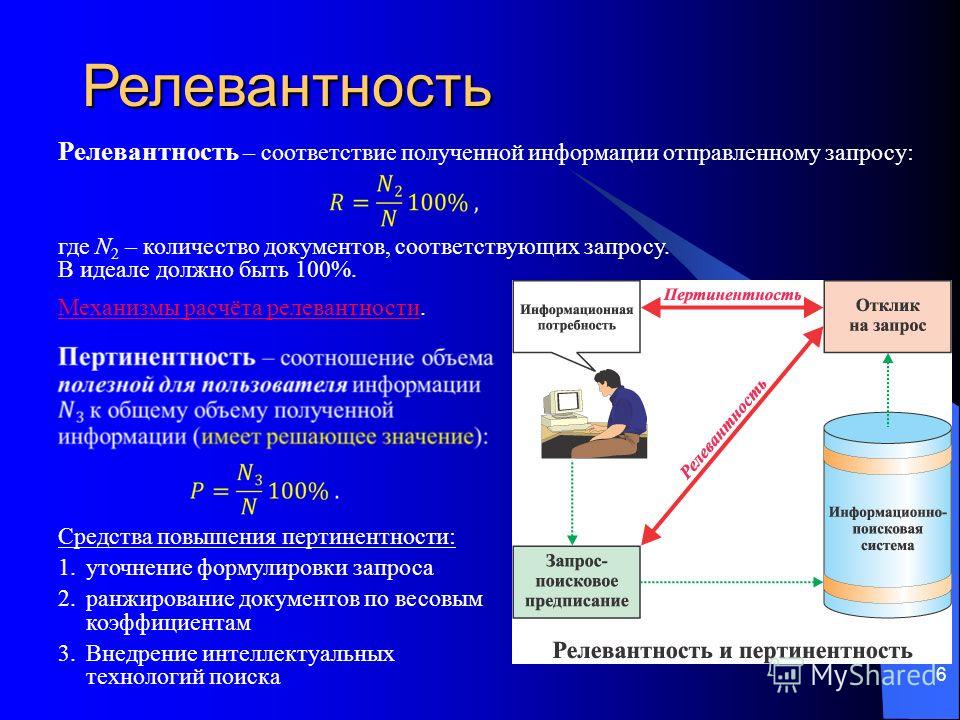 На последнем этапе вычисления оценки сходства запросы и представления документов выполняются с помощью функции оценки.
На последнем этапе вычисления оценки сходства запросы и представления документов выполняются с помощью функции оценки.
Модели запросов
На следующем изображении показаны несколько различных типов моделей запросов:
Строительные блоки внизу включают такие вещи, как токенизация (разделение строки на слова), нормализация слов (например, выделение корней, когда общие окончания слов удаляются) , и исправление орфографии (если запрос содержит слово с ошибкой, поисковая система исправляет его и возвращает результаты для исправленного слова).
На основе этих стандартных блоков построены такие вещи, как классификация запросов и намерение. Если поисковая система определяет, что конкретный запрос чувствителен ко времени, она вернет результаты новостей, или, если она считает, что намерение запроса является транзакционным, она отобразит результаты покупок.
Наконец, на вершине пирамиды находятся более абстрактные представления запроса, такие как извлечение сущностей или представления скрытых тем (LDA). Действительно, Google знает, что «филадельфия филлис» — это бейсбольная команда высшей лиги, и, поскольку сейчас бейсбольный сезон, возвращает счет прошлой ночи вверху результатов поиска (в дополнение к диаграмме знаний справа).
Модели документов
Как и модели запросов, существует несколько различных типов моделей документов, обычно используемых в поиске.
TF-IDF — один из старейших и наиболее известных подходов, который представляет каждый запрос и документ в виде вектора и использует некоторый вариант косинусного подобия в качестве функции оценки. Языковая модель кодирует некоторую информацию о статистике языка и включает в себя такие знания, как фраза «поисковая оптимизация» гораздо более распространена, чем «поисковая машина».«Языковые модели широко используются в машинном переводе и распознавании речи, среди других приложений. Они также чрезвычайно полезны при поиске информации. Еще один класс моделей использует принцип вероятностного ранжирования, который непосредственно моделирует вероятность релевантности для данного запроса и документа. Из них Okapi BM25 оказался особенно эффективным.
Из них Okapi BM25 оказался особенно эффективным.
Исследование корреляции
К настоящему времени вы, вероятно, задаетесь вопросом, действительно ли поисковые системы используют что-либо из этих вещей, и если да, то какие из них являются наиболее важными.Чтобы изучить это, мы разработали исследование корреляции, аналогичное тем, которые мы проводили в прошлом (см. Это для некоторой предыстории общего подхода). В данном случае мы собрали 50 лучших результатов из Google-US примерно по 14 000 ключевых слов. В результате получилось около 600 000 страниц, которые мы затем просканировали и использовали для вычисления ряда различных оценок сходства.
Как видите, подход языковой модели показал наилучшие результаты при средней корреляции Спирмена 0,10, что согласуется с результатами, опубликованными в исследовательской литературе.
Если мы сначала произведем некоторую корректировку как запроса, так и документа, а затем пересчитаем, корреляции немного увеличатся по всем направлениям:
Это говорит о том, что Google действительно выполняет какой-то тип нормализации слов или корреляции при вычислении их релевантности.
Релевантность и ранжирование повторно настолько полезны, почему корреляции не выше? Ответ кроется в концептуальной релевантности и разбиении ранжирования, о котором я говорил ранее.
Чтобы убедить себя, я построил эксперимент, как показано ниже:
Для проведения эксперимента я сначала взял 450 случайных страниц из нашего набора данных, разделенных на 50 лучших результатов (так что они включают девять страниц с рейтингом №1, девять страниц с рейтингом №2. ранжированные страницы и т. д.). Затем я добавил 450 случайных страниц к первым 50 страницам каждого результата поиска, чтобы получить одну группу из 500 страниц для каждого ключевого слова. Поскольку 50 из этих страниц находятся в результатах поиска, а 450 — нет, 10% из них релевантны ключевому слову, а 90% — нет (здесь предполагается, что если страница появляется в поиске Google, значит, она релевантна). Затем для каждого ключевого слова я собрал оценку сходства авторитета страницы и языковой модели и отсортировал по каждому из них (таблицы посередине).
Затем для каждого ключевого слова я собрал оценку сходства авторитета страницы и языковой модели и отсортировал по каждому из них (таблицы посередине).
Наконец, я вычислил точность 50, которая представляет собой процент из 50 лучших результатов, отсортированных по оценке PA / языковой модели, которые фактически присутствуют в результатах поиска. Это напрямую измеряет степень, в которой PA или языковая модель могут отделить релевантные страницы от нерелевантных. Поскольку 10% из 500 документов находятся в результатах поиска, мы можем добиться 10% точности, отсортировав их случайным образом.Эта 10% точность и является нашей базовой линией (нижние серые полосы на изображении).
Результаты поразительны. Точность PA очень близка к базовой, что говорит о том, что это не лучше случайного числа при определении релевантности, даже если оно действительно хорошо помогает при ранжировании 50 лучших, если известно, что они релевантны. С другой стороны, точность языковой модели близка к 100%. Другими словами, языковая модель почти идеально подходит для определения того, какая из 500 страниц находится в результатах поиска, но плохо справляется с фактическим ранжированием этих релевантных документов.
Выводы
Этот тип оценки сходства запросов и документов хорошо известен в исследовательской литературе и лежит в основе каждой современной системы поиска информации. Таким образом, он имеет фундаментальное значение для поиска и невосприимчив к изменению алгоритма.
Поскольку поисковые системы используют сложные модели запросов и документов, нет необходимости отдельно выполнять оптимизацию для похожих ключевых слов. Например, любая страница с таргетингом на «обзоры фильмов» также будет нацелена на «обзор фильмов».
Наконец, вы можете использовать концептуальное разделение между релевантностью и ранжированием в своем рабочем процессе.Создавая или изменяя существующий контент, сначала сконцентрируйтесь на том, чтобы сделать страницу релевантной для широкого набора связанных ключевых слов. Затем сконцентрируйтесь на увеличении поисковой позиции.
Затем сконцентрируйтесь на увеличении поисковой позиции.
Скоро появятся результаты с дополнительными факторами ранжирования
Это первые результаты, которые мы опубликовали в рамках проекта «Факторы ранжирования» за 2013 год. Как и в прошлые годы, проект включает в себя отраслевое обследование и крупное корреляционное исследование. Я представлю результаты на MozCon в этом году (так что покупайте билеты, если вы еще этого не сделали!), И мы подготовим полный отчет позже этим летом.
Чтобы копнуть глубже
Вот все слайды из моего выступления по SMX Advanced:
Я настоятельно рекомендую книгу « Введение в поиск информации » Маннинга и др. Он доступен для бесплатного онлайн-чтения с их сайта и предоставляет исчерпывающее описание всего, что обсуждается в этом посте (и многое, многое другое). В частности, см. Главы 2, 6, 11 и 12.
Спасибо за чтение. С нетерпением жду продолжения обсуждения в комментариях ниже!
Повышение релевантности поиска с помощью оптимизации запросов на основе данных
При создании полнотекстового поиска, такого как поиск по часто задаваемым вопросам или поиск вики, есть несколько способов решить эту проблему с помощью Elasticsearch Query DSL.Для полнотекстового поиска существует относительно длинный список возможных типов запросов, начиная от простейшего запроса на соответствие и заканчивая мощным запросом интервалов .
Независимо от типа запроса, который вы выберете, вам также придется понимать и настраивать список параметров. Хотя Elasticsearch использует хорошие значения по умолчанию для параметров запроса, их можно улучшить на основе документов в базовом индексе (корпусе) и конкретных типов строк запроса, по которым пользователи будут искать.3 «,» сообщение «] } } }
Здесь мы используем параметр повышения поля, чтобы указать, что оценки с совпадениями в поле темы должны быть , увеличены на и умножены на три. Мы делаем это в попытке улучшить общую релевантность запроса — документы, которые являются наиболее значимыми по отношению к запросу, должны быть как можно ближе к началу результатов. Но как выбрать подходящее значение для повышения? Как мы можем установить параметр ускорения не только для двух полей, но и для десятка полей?
Мы делаем это в попытке улучшить общую релевантность запроса — документы, которые являются наиболее значимыми по отношению к запросу, должны быть как можно ближе к началу результатов. Но как выбрать подходящее значение для повышения? Как мы можем установить параметр ускорения не только для двух полей, но и для десятка полей?
Процесс настройки релевантности заключается в понимании влияния этих различных параметров.Из всех параметров, которые вы могли настроить и настроить, какие из них вам следует попробовать, с какими значениями и в каком порядке? Нельзя игнорировать глубокое понимание оценки и настройки релевантности, но как мы можем применить более принципиальный подход к оптимизации наших запросов? Можем ли мы использовать данные о кликах пользователей или явную обратную связь (например, поднятие или опускание большого пальца к результату) для настройки параметров запроса с целью повышения релевантности поиска? Мы можем, так что давайте приступим!
В дополнение к этому сообщению в блоге мы собрали несколько примеров кода и записных книжек Jupyter, которые проведут вас по этапам оптимизации запроса с помощью описанных ниже методов.Сначала прочтите этот пост, затем перейдите к коду и посмотрите, как все работает. На момент написания этого сообщения мы использовали Elasticsearch 7.10, и все должно работать с любой из лицензий Elasticsearch.
Знакомство с MS MARCO
Чтобы лучше объяснить принципы и эффекты настройки параметров запроса, мы собираемся использовать общедоступный набор данных под названием MS MARCO. Набор данных MS MARCO — это большой набор данных, созданный Microsoft Research, содержащий 3,2 миллиона документов, извлеченных с веб-страниц, и более 350 000 запросов, полученных из реальных поисковых запросов Bing.В MS MARCO есть несколько поднаборов данных и связанные с ними проблемы, поэтому в этом посте мы сосредоточимся конкретно на задаче с рейтингом , поскольку она наиболее точно соответствует традиционному поиску.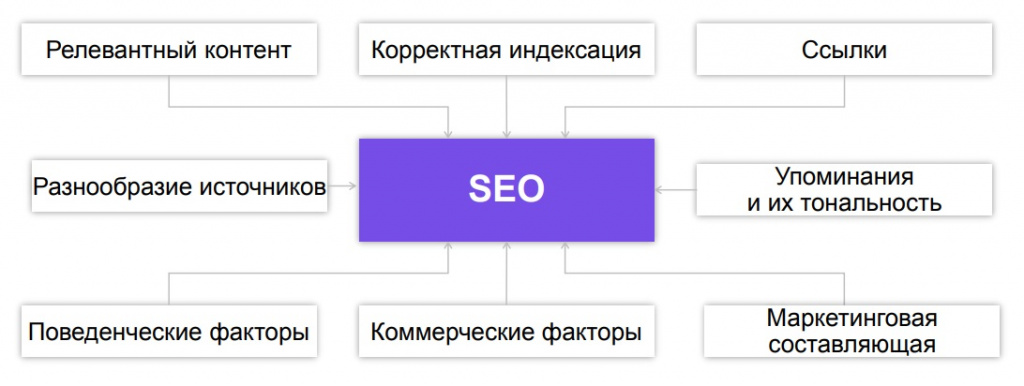 Задача состоит в том, чтобы эффективно обеспечить наилучшее ранжирование релевантности для набора выбранных запросов из набора данных MS MARCO. Задача открыта для общественности, и любой исследователь или практик может принять в ней участие, представив свои собственные попытки составить максимально возможный рейтинг релевантности для набора запросов.Позже в этом посте вы увидите, насколько мы добились успеха, применив описанные здесь методы. Текущий рейтинг представленных работ вы можете найти в официальной таблице лидеров.
Задача состоит в том, чтобы эффективно обеспечить наилучшее ранжирование релевантности для набора выбранных запросов из набора данных MS MARCO. Задача открыта для общественности, и любой исследователь или практик может принять в ней участие, представив свои собственные попытки составить максимально возможный рейтинг релевантности для набора запросов.Позже в этом посте вы увидите, насколько мы добились успеха, применив описанные здесь методы. Текущий рейтинг представленных работ вы можете найти в официальной таблице лидеров.
Наборы данных и инструменты
Теперь, когда у нас есть приблизительная цель повышения релевантности за счет настройки параметров запроса, давайте взглянем на инструменты и наборы данных, которые мы собираемся использовать. Сначала дадим более формальное описание того, чего мы хотим достичь, и данных, которые нам понадобятся.
- Дано:
- Корпус (документы в индексе)
- Поисковый запрос с параметрами
- Размеченный набор данных релевантности
- Метрика для измерения релевантности
- Поиск: значения параметров запроса, которые максимизируют выбранный показатель
Размеченный набор данных релевантности около
Справа теперь вы можете подумать: «Подождите, подождите, подождите, что же такое набор данных релевантности , помеченный как , и где его взять ?!» Короче говоря, помеченный набор данных релевантности — это набор запросов с результатами, которые были , помечены как с рейтингом релевантности.Вот пример очень маленького набора данных с одним запросом:
{
"id": "query1",
"value": "настройка Elasticsearch для релевантности",
"полученные результаты": [
{"rank": 1, "id": "doc2", "label_id": 2, "label": "релевантный"},
{"rank": 2, "id": "doc1", "label_id": 3, "label": "очень актуально"},
{"rank": 3, "id": "doc8", "label_id": 0, "label": "нерелевантно"},
{"rank": 4, "id": "doc7", "label_id": 1, "label": "related"},
{"rank": 5, "id": "doc3", "label_id": 3, "label": "очень актуально"}
]
}
В этом примере мы использовали ярлыки релевантности: ( 3 ) очень релевантно, ( 2 ) релевантно, ( 1 ) связано и ( 0 ) нерелевантно. Эти метки произвольны, и вы можете выбрать другой масштаб, но четыре метки выше довольно распространены. Один из способов получить эти ярлыки — получить их от судей-людей. Группа людей может просматривать журналы ваших поисковых запросов и для каждого результата поставить метку. Это может занять довольно много времени, поэтому многие люди предпочитают собирать эти данные напрямую от своих пользователей. Они регистрируют кликов пользователя и используют модель кликов для преобразования активности кликов в метки релевантности.
Эти метки произвольны, и вы можете выбрать другой масштаб, но четыре метки выше довольно распространены. Один из способов получить эти ярлыки — получить их от судей-людей. Группа людей может просматривать журналы ваших поисковых запросов и для каждого результата поставить метку. Это может занять довольно много времени, поэтому многие люди предпочитают собирать эти данные напрямую от своих пользователей. Они регистрируют кликов пользователя и используют модель кликов для преобразования активности кликов в метки релевантности.
Подробности этого процесса выходят за рамки этого сообщения в блоге, но вы можете найти презентации и исследования по моделям кликов 123 .Хорошее место для начала — сбор событий кликов для аналитических целей, а затем просмотр моделей кликов, когда у вас будет достаточно поведенческих данных от пользователей. Ознакомьтесь с недавним сообщением в блоге «Анализ показателей релевантности онлайн-поиска с помощью Elasticsearch и Elastic Stack», чтобы узнать больше.
Набор данных документа MS MARCO
Как обсуждалось во введении, в целях демонстрации мы собираемся использовать задачу ранжирования документов MS MARCO и связанный с ним набор данных, в котором есть все, что нам нужно: корпус и помеченный набор данных релевантности.
MS MARCO была впервые создана для тестирования систем вопросов и ответов (Q&A), и все запросы в наборе данных на самом деле являются вопросами той или иной формы. Например, вы не найдете запросов, которые выглядят как типичные запросы с ключевыми словами, такие как «Лига чемпионов по правилам». Вместо этого вы увидите такие строки запроса, как «Каковы правила футбола в Лиге чемпионов УЕФА?». Поскольку это набор данных с ответами на вопросы, помеченный набор данных релевантности также выглядит немного иначе.Поскольку на вопросы обычно есть только один лучший ответ, у результатов есть только один «релевантный» ярлык ( 1 ) и ничего больше. Документы довольно простые и состоят всего из трех полей: url , title , body . Вот пример (фрагмент) документа:
Вот пример (фрагмент) документа:
- ID: D2286643
- URL: http: //www.answers.com/Q/Why_is_the_Manhattan_Proj …
- Название: Почему Манхэттенский проект важен?
- Тело: ответов.com ® Wiki Answers ® Категории История, Политика и общество История Война и военная история Вторая мировая война
Это был второй самый секретный проект войны (криптографические работы были первым). Это был самый приоритетный проект войны, ему было присвоено кодовое слово «серебряная пластина», и он превосходил все другие приоритеты военного времени. Это стоило 2000000000 долларов. <снип> Редактировать Mike M Ответ на 656 вкладов в США во время Второй мировой войны Почему Манхэттенский проект был назван Манхэттенским проектом? Первые части проекта «Манхэттен» приняли участие в цокольном этаже здания, расположенного на Манхэттене.Редактировать Пэт Ши Ответы на 3 370 статей, посвященных войне и военной истории Что такое секретный проект Манхэттенского проекта? Манхэттенский проект был кодовым названием проекта Второй мировой войны по созданию первого ядерного оружия — атомной бомбы. Редактировать
Как видите, документы были очищены и разметка HTML удалена, однако иногда они могут содержать всевозможные метаданные. Это особенно верно для пользовательского контента, как мы видим выше.
Измерение релевантности поиска
Наша цель в этом сообщении в блоге — установить систематический способ настройки параметров запроса для повышения релевантности результатов поиска.Чтобы измерить, насколько хорошо мы справляемся с этой целью, нам нужно определить метрику, которая фиксирует, насколько хорошо результаты данного поискового запроса удовлетворяют потребности пользователя. Другими словами, нам нужен способ измерения релевантности. К счастью, у нас уже есть инструмент для этого в Elasticsearch, который называется Rank Evaluation API. Этот API позволяет нам брать наборы данных, описанные выше, и вычислять одну из многих метрик релевантности поиска.
Для этого API выполняет все запросы из помеченного набора данных релевантности и сравнивает результаты каждого запроса с результатами , помеченными как , для вычисления метрики релевантности, такой как точность , , отзыв, или средний взаимный ранг (MRR) .В нашем случае задача ранжирования документов MS MARCO уже выбрала средний взаимный ранг (MRR) в результатах top 100 (MRR @ 100) в качестве показателя релевантности. Это имеет смысл для набора данных вопросов и ответов, поскольку MRR заботится только о первом релевантном документе в наборе результатов. Он берет взаимный ранг ( 1 / ранг ) первого релевантного документа и усредняет их по всем запросам.
Для тех, кто склонен к зрительному восприятию, вот пример расчета MRR для небольшого набора запросов:
Рисунок 2: пример расчета MRRШаблоны поиска
Теперь, когда мы определились, как мы хотим измерять релевантность с помощью Rank Evaluation API, нам нужно посмотреть, как раскрыть параметры запроса, чтобы мы могли пробовать разные значения.3 «,» сообщение «] } } }
Когда мы используем API оценки рейтинга, мы указываем метрику, помеченный набор данных релевантности и, при необходимости, шаблоны поиска, которые будут использоваться для каждого запроса. Метод, который мы опишем ниже, на самом деле довольно эффективен, поскольку мы можем полагаться на шаблоны поиска. Фактически, мы можем превратить все, что мы можем параметризовать в шаблоне поиска, в параметр, который мы можем оптимизировать. Вот еще один запрос multi_match , но использующий реальные поля из набора данных документа MS MARCO и предоставляющий параметр повышения для каждого.{{body_boost}} »
]
}
}
}
query_string будет заменен, когда мы запустим Rank Evaluation API, но эти другие параметры boost будут устанавливаться каждый раз, когда мы хотим проверить новые значения параметров. Если вы используете запросы с разными параметрами, например,
Если вы используете запросы с разными параметрами, например, tie_breaker , вы можете использовать тот же шаблон для предоставления параметра. Дополнительную информацию см. В документации по шаблонам поиска.
Оптимизация параметров: Собираем все вместе
Хорошо, оставайся здесь! Наконец-то пришло время собрать все воедино.Мы увидели все необходимые компоненты:
- Corpus
- Размеченный набор данных релевантности
- Метрика для измерения релевантности
- Шаблон поиска с параметрами
В этом примере мы собираемся объединить все это вместе, используя скрипт Python для отправки запросов в API оценки рейтинга и организовать рабочий процесс. Рабочий процесс довольно прост: отправьте вызов API оценки ранга с некоторыми значениями параметров, чтобы попробовать, получите оценку метрики (MRR @ 100), запишите значения параметров, которые привели к этой оценке метрики, и повторите, выбирая новые значения параметров, чтобы попробовать.В конце мы возвращаем значения параметров, которые дали лучший результат в метрике. Этот рабочий процесс представляет собой процедуру оптимизации параметров , в которой мы максимизируем показатель показателя.
Рисунок 3: Рабочий процесс оптимизации параметровВ рабочем процессе на рисунке 3 мы можем видеть, где используются все наши наборы данных и инструменты, при этом API оценки ранга занимает центральное место для выполнения запросов и измерения релевантности по предоставленной метрике. Единственное, чего мы еще не коснулись, — это то, как выбирать значения параметров для каждой итерации.В следующих разделах мы обсудим два разных метода выбора значений параметров: поиск по сетке и байесовская оптимизация. Прежде чем мы поговорим о методах, нам нужно представить концепцию пространства параметров .
Пространства параметров
Когда мы говорим о параметрах, таких как url_boost , title_boost или body_boost из нашего примера выше, и возможных значениях, которые они могут принимать, мы используем термин пространство параметров . Пространство параметров — это мир возможных значений всех параметров вместе взятых. В контексте оптимизации параметров (выбор значений параметров, которые максимизируют какую-либо метрику или оценку), у нас есть параметры плюс оценка метрики. Давайте рассмотрим простой пример пространства параметров размера два или двумерного пространства параметров с параметрами x и y. Поскольку у нас всего два измерения, мы можем легко изобразить это пространство параметров на трехмерном графике. В этом случае мы используем контурный график, где третье измерение, цветовой градиент, представляет собой метрическую оценку.Цветовой градиент меняется от синего к самому низкому баллу метрики, к желтому — к наивысшему (чем выше, тем лучше).
Пространство параметров — это мир возможных значений всех параметров вместе взятых. В контексте оптимизации параметров (выбор значений параметров, которые максимизируют какую-либо метрику или оценку), у нас есть параметры плюс оценка метрики. Давайте рассмотрим простой пример пространства параметров размера два или двумерного пространства параметров с параметрами x и y. Поскольку у нас всего два измерения, мы можем легко изобразить это пространство параметров на трехмерном графике. В этом случае мы используем контурный график, где третье измерение, цветовой градиент, представляет собой метрическую оценку.Цветовой градиент меняется от синего к самому низкому баллу метрики, к желтому — к наивысшему (чем выше, тем лучше).
Поиск по сетке
Чтобы построить график, подобный тому, что мы видели выше, мы вызываем API оценки ранга со всеми возможными перестановками двух параметров и каждый раз сохраняем возвращаемый результат метрики. В псевдокоде это может выглядеть примерно так:
для x в [1, 2, 3, 4, 5]:
для y в [1, 2, 3, 4, 5]:
params = {‘x’: x, ‘y’: y}
оценка = rank_eval (шаблон_поиска, релевантные_данные,
метрика, параметры)
В этом двойном цикле будет получена таблица показателей:
1 2 3 4 5 5: 0 5 7 3 0 4: 5 7 9 7 5 3: 0 7 9 10 4 2: 0 5 7 9 0 1: 0 2 6 5 2
Пространство параметров, показанное на рисунке 4, где x и y — это диапазон размера 5, означает, что мы вызываем API оценки ранга 25 ( 5 * 5 ) раз.Если мы удвоим размер каждого диапазона параметров до 10, мы получим пространство параметров размером 100 ( 10 * 10 ). Если мы добавим к количеству параметров, скажем, размерность z, но оставим диапазон неизменным, мы получим еще большее количество выполнений API оценки ранга — 125 ( 5 * 5 * 5 ).
Когда пространство параметров невелико, поиск по сетке — хороший вариант, потому что он исчерпывающий — он проверяет все возможные комбинации. Однако из-за быстрого, а иногда и экспоненциального роста количества вызовов API оценки ранга с большим пространством параметров поиск по сетке становится непрактичным, поскольку он может увеличить время, необходимое для оптимизации запроса, до часов или даже дней.Помните, что при вызове API оценки ранга он выполняет все запросы в нашем наборе данных. Это могут быть сотни или тысячи запросов, которые необходимо выполнять при каждом вызове и для больших корпусов или сложных поисковых запросов, что может занять очень много времени даже в большом кластере Elasticsearch.
Однако из-за быстрого, а иногда и экспоненциального роста количества вызовов API оценки ранга с большим пространством параметров поиск по сетке становится непрактичным, поскольку он может увеличить время, необходимое для оптимизации запроса, до часов или даже дней.Помните, что при вызове API оценки ранга он выполняет все запросы в нашем наборе данных. Это могут быть сотни или тысячи запросов, которые необходимо выполнять при каждом вызове и для больших корпусов или сложных поисковых запросов, что может занять очень много времени даже в большом кластере Elasticsearch.
Байесовская оптимизация
Более эффективным с вычислительной точки зрения подходом к оптимизации параметров является Байесовская оптимизация . Вместо того, чтобы пробовать все возможные комбинации значений параметров, как при поиске по сетке, байесовская оптимизация принимает решения о том, какие значения параметров пробовать следующим образом, на основе предыдущих оценок показателей.Байесовская оптимизация будет искать области пространства параметров, которые она еще не видела, но похоже, что они могут содержать лучшие метрические оценки. В качестве примера возьмем следующее пространство параметров.
Рисунок 5: Контурный график пространства параметров с отметками измеренных параметров На рисунке 5 мы случайным образом разместили десять черных отметок размером X . Красный цвет X отмечает точку в пространстве параметров с максимальной метрической оценкой. Основываясь на случайных черных отметках X , мы уже можем немного узнать о пространстве параметров.Метки X в нижнем левом и нижнем правом углах не выглядят очень многообещающими областями, и, вероятно, не стоит тестировать дополнительные значения параметров в этой области. Если мы посмотрим в верхнюю часть пространства параметров, мы увидим несколько точек с гораздо более высокими показателями метрики. Мы видим особенно высокие значения в четырех отметках X посередине, и это выглядит как гораздо более многообещающая область, в которой можно найти максимальную метрическую оценку. Байесовская оптимизация будет использовать эти начальные случайные точки плюс любые последующие точки, которые она пробует, и применяет некоторую статистику, чтобы выбрать следующие значения параметров для проверки.Статистика работает на нас — спасибо за это Байесу!
Байесовская оптимизация будет использовать эти начальные случайные точки плюс любые последующие точки, которые она пробует, и применяет некоторую статистику, чтобы выбрать следующие значения параметров для проверки.Статистика работает на нас — спасибо за это Байесу!
Результаты
Используя описанные здесь методы и основанные на серии оценок с различными анализаторами, типами запросов и оптимизациями, мы внесли некоторые улучшения по сравнению с базовыми, неоптимизированными запросами в документе MS MARCO, ранжирующем задачу 4 . Все эксперименты с полными подробностями и объяснениями можно найти в упомянутой записной книжке Jupyter, но ниже вы можете увидеть сводку 5 наших результатов.Мы видим прогресс от простых и неоптимизированных запросов и от оптимизации параметров к запросам с более высокими оценками MRR @ 100 (чем выше, тем лучше, лучшие результаты из каждой записной книжки выделены красным). Это показывает нам, что мы действительно можем использовать данные и принципиальный подход для повышения релевантности поиска за счет оптимизации параметров запроса!
| Справочная тетрадь | Эксперимент | MRR @ 100 |
0 - Анализаторы | Анализаторы по умолчанию, объединенные по полю соответствие es | 0.2403 |
Пользовательские анализаторы, комбинированные по полю соответствие es | 0,2504 | |
Анализаторы по умолчанию, multi_match cross_fields (параметры по умолчанию) | 0,2475 | |
Пользовательские анализаторы, multi_match cross_fields (параметры по умолчанию) | 0,2683 | |
Анализаторы по умолчанию, multi_match best_fields (параметры по умолчанию) | 0.2714 | |
Пользовательские анализаторы, multi_match best_fields (параметры по умолчанию) | 0,2873 | |
1 - Настройка запроса | multi_match cross_fields baseline: параметры по умолчанию | 0,2683 |
multi_match cross_fields настроено (пошагово): tie_breaker , minimum_should_match | 0. 2841 2841 | |
multi_match cross_fields настроено (пошагово): все параметры | 0,3007 | |
multi_match cross_fields tuned (all-in-one v1): все параметры | 0,2945 | |
multi_match cross_fields настроено (все-в-одном v2, уточненное пространство параметров): все параметры | 0,2993 | |
multi_match cross_fields tuned (all-in-one v3, random): все параметры | 0.2966 | |
2 - Настройка запроса - best_fields | multi_match best_fields baseline: параметры по умолчанию | 0,2873 |
multi_match best_fields tuned (all-in-one): все параметры | 0,3079 |
| Обновление (25 ноября 2020 г.): Мы отправили официальную заявку и получили оценку по набору оценочных запросов (используется только для рейтинга лидеров) MRR @ 100 0.268 . Это дает нам лучший результат для не-нейронного (не использующего глубокое обучение) ранжатора в таблице лидеров! Следите за обновлениями. Обновление (20 января 2021 г.): Мы улучшили нашу первую отправку, добавив метод под названием doc2query (T5), а также некоторые другие более мелкие исправления и улучшения. С новой отправкой мы достигли оценки по набору оценочных запросов MRR @ 100 0,300. Это на +0,032 больше, чем в нашей предыдущей заявке! Более подробную информацию можно найти в проекте README и в прилагаемых к нему записных книжках Jupyter. |
Руководство к успеху
Теперь мы увидели два подхода к оптимизации запросов и то, каких результатов мы можем достичь с помощью задачи ранжирования документов MS MARCO.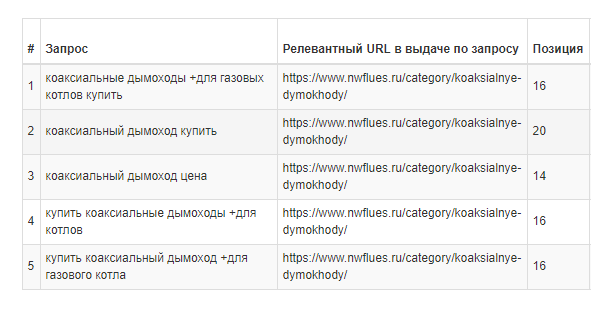 Вот несколько советов и общих рекомендаций, которые следует учитывать, чтобы помочь вам добиться успеха в оптимизации собственных запросов.
Вот несколько советов и общих рекомендаций, которые следует учитывать, чтобы помочь вам добиться успеха в оптимизации собственных запросов.
- Поскольку эти подходы основаны на данных, очень важно, чтобы у вас было достаточно качественных данных. Эти подходы хороши ровно настолько, насколько хороши ваши данные.«Достаточно» обычно означает не менее сотни запросов с помеченными результатами. «Качество» означает, что данные должны быть точными и репрезентативными для запросов, которые вы пытаетесь улучшить и оптимизировать.
- Это не полная замена ручной настройки релевантности: отладка оценок, создание хороших анализаторов, понимание ваших пользователей и их информационных потребностей и т. Д.
- Байесовская оптимизация чувствительна к собственным параметрам. Обратите внимание, сколько общих итераций вам нужно, и сколько случайных инициализаций использовать для заполнения процесса.Если у вас большое пространство параметров, вам следует подумать о поэтапном подходе, чтобы разбить его.
- Остерегайтесь переобучения с большими пространствами параметров. Подумайте о перекрестной проверке, чтобы исправить это, но имейте в виду, что вам нужно будет сделать это самостоятельно в Python.
- Параметры будут настроены для определенного корпуса и набора запросов. Скорее всего, они не будут перенесены, если общая статистика другого корпуса и набора запросов не будет достаточно похожей. Это также может означать, что вам необходимо регулярно перенастраивать, чтобы поддерживать оптимальные параметры.
Заключение
В этом сообщении в блоге много всего, и мы надеемся, что вам удавалось следовать вместе с нами до сих пор! Примеры кода и записные книжки Jupyter очень конкретно показывают, как выполнить и настроить запрос. Принципы не ограничиваются параметрами запроса, поэтому есть также пример записной книжки, показывающий, как настроить параметры BM25. Мы надеемся, что у вас будет возможность ознакомиться с этими примерами и поэкспериментировать самостоятельно. Мы добились наибольшего успеха, используя изолированные крупномасштабные кластеры Elastic Cloud, которые мы запускаем и выключаем, когда они нам нужны.Теперь идите вперед и используйте свои собственные данные для оптимизации ваших запросов! Не забудьте задать свои вопросы или истории успеха на наших дискуссионных форумах.
Мы добились наибольшего успеха, используя изолированные крупномасштабные кластеры Elastic Cloud, которые мы запускаем и выключаем, когда они нам нужны.Теперь идите вперед и используйте свои собственные данные для оптимизации ваших запросов! Не забудьте задать свои вопросы или истории успеха на наших дискуссионных форумах.
Источники
1 Модели кликов для веб-поиска Александра Чуклина, Ильи Маркова и Мартена де Рийке
2 Модели преобразования: построение обучения для ранжирования данных обучения Дуг Тернбулл
3 Модель кликов динамической байесовской сети для ранжирования в веб-поиске Оливье Шапель
4 Мы ранжируем все документа на одном этапе ранжирования, а затем берем 100 лучших для MRR.Это считается подходом «полного ранжирования», в отличие от «повторного ранжирования», который пытается повторно ранжировать только 1000 лучших документов-кандидатов из заранее заданного списка результатов.
5 Эти результаты актуальны на дату публикации этого поста, но проект README будет содержать актуальные результаты, если мы продолжим экспериментировать с новыми методами.
Как поисковая система может определить релевантность поисковой системы по связанным запросам
Совместное использование — это забота!
Интересно посмотреть, как поисковая система может попытаться вычислить релевантность результатов поиска и найти связанные запросы.
Недавно выданный патент Yahoo исследует подход, который может помочь определить, насколько на самом деле могут быть релевантны результаты, которые он отображает для поисковиков. , и насколько вероятно, что эти результаты покажут различные результаты, когда искатель использует термин запроса, который может охватывать диапазон тем.
Перед тем, как представить автоматизированный подход к проверке релевантности и разнообразия, патент сообщает нам о некоторых ограничениях, которые он видит при использовании ручных обзоров или данных о кликах для определения того, насколько релевантными могут быть результаты.
Human Reviewers
Один из вариантов проверки релевантности результатов поиска — вручную просмотреть результаты для каждого запроса. Это может занять довольно много времени, влечет за собой возможность человеческой ошибки и не похоже, чтобы он даже начал охватывать все запросы, которые выполняются в Интернете.
Несколько недель назад в списке Крейга я видел объявление компании Lionbridge Technologies, Inc., в котором предлагалось работникам, работающим неполный рабочий день, выступать в качестве Интернет-судей. Небольшое исследование в Интернете показало, что Google, возможно, использовал Lionbridge в прошлом, чтобы нанимать людей для ранжирования релевантности результатов поиска, хотя публикация Craig’s List не определяла конечного работодателя. Из описания вакансии из объявления:
Описание должности
Измерение релевантности — это основа всех поисковых систем, без него никто не может сказать, сделало ли изменение систему лучше или хуже.Как интернет-судья вы будете ключевым участником в определении релевантности поисковых систем. Мы ищем интернет-судей, которые будут работать из дома; просматривайте и оценивайте веб-сайты на основе набора объективных рекомендаций. Кандидаты должны быть заядлыми энтузиастами Интернета. Если вы любите просматривать веб-страницы и можете следовать определенному набору правил для оценки веб-сайтов, мы хотим услышать ваше мнение.
Поисковые системы используют рецензентов вручную. Как и бейсбол. Они никогда не ошибаются, не так ли?
Отслеживание кликов
В недавнем посте я описал патентную заявку Yahoo, в которой они представили метод ранжирования изображений, основанный на методе прогнозирования переходов по ссылкам на изображения на различных позициях в результатах поиска.
Предположение, лежащее в основе этого подхода, заключалось в том, что на изображения, которые кажутся релевантными для запроса, будут нажиматься, и что скорость прогноза для изображений в определенных позициях в результатах поиска может использоваться для определения изображений, которые имеют более высокую производительность, в зависимости от того, где они появляются. в результатах и переместите их вверх, а также найдите изображения, которые неэффективны в зависимости от их положения, и переместите их вниз в результатах. Если в результатах поиска изображений отображается миниатюра изображения, это может хорошо работать с изображениями.
в результатах и переместите их вверх, а также найдите изображения, которые неэффективны в зависимости от их положения, и переместите их вниз в результатах. Если в результатах поиска изображений отображается миниатюра изображения, это может хорошо работать с изображениями.
Будет ли отслеживание количества нажатий на результаты веб-поиска, когда они появляются в результатах поиска, показывать, что эти результаты соответствуют условиям запроса, по которым они ранжируются? Что это могут быть связанные запросы?
Проблема с этим подходом заключается в том, что поисковики видят только заголовок страницы, аннотацию (или фрагмент) и URL-адрес веб-страниц, и они могут неточно отражать контент, который появляется на страницах, которые они представляют. Это ограничение означает, что клики по результатам поиска для веб-страниц не могут быть хорошим показателем того, насколько эти результаты актуальны для конкретного запроса.
Изображение вверху взято из патента на автоматизированную систему судейства бейсбола. Хотя он, возможно, может хорошо справляться с вызовом мячей и ударов, он, вероятно, не будет полезен для других задач, таких как определение того, был ли нападающий попал в поле, или находится ли бегун в безопасности или находится на закрытии. играть на тарелке.
Алгоритм определения релевантности и разнообразия результатов поиска
Запатентованный процесс Yahoo использует информацию из недавних поисков, чтобы увидеть, совпадают ли результаты поиска с поисками, выполняемыми людьми в поисковой системе.
Автоматическая проверка релевантности и разнообразия для веб-сайтов и вертикальных поисковых систем
Изобретено Джигнашу Г. Парих
Назначено Yahoo
Патент США 7,558,787
Выдан 7 июля 2009 г.
Подан 5 июля 2006 г.
Реферат
Методы автоматической проверки обеспечивается релевантность и разнообразие результатов поиска.
Запрос отправляется в поисковую систему, которая использует алгоритм поиска для получения результатов поиска на основе запроса.
В противном случае релевантность результатов поиска вычисляется путем сравнения доли результатов, содержащих термин, с относительной частотой использования термина для термина. Этот процесс повторяется для всех терминов в наборе связанных терминов, чтобы получить полное разнообразие и актуальность для результатов.
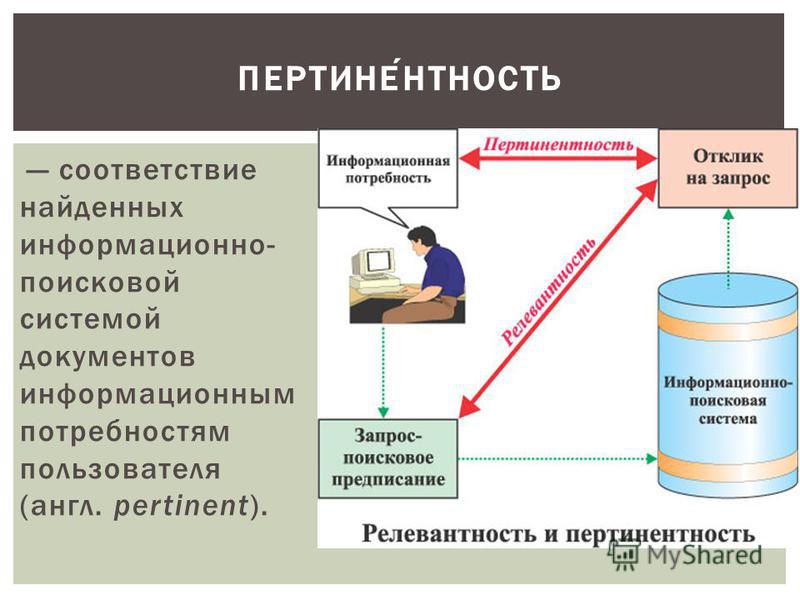 Идентифицируется набор из n первых связанных терминов для запроса.Для каждого связанного термина в наборе терминов определяется его относительная частота по отношению ко всем терминам в наборе терминов. Если термин не встречается ни в одном из результатов, то произошла потеря разнообразия, пропорциональная относительной частоте термина для термина.
Идентифицируется набор из n первых связанных терминов для запроса.Для каждого связанного термина в наборе терминов определяется его относительная частота по отношению ко всем терминам в наборе терминов. Если термин не встречается ни в одном из результатов, то произошла потеря разнообразия, пропорциональная относительной частоте термина для термина.Когда кто-то выполняет поиск в поисковой системе, он вводит термин запроса в поле поиска и нажимает Enter.
Набор результатов возвращается поисковой системой, которая ранжирует эти результаты в соответствии с алгоритмами поиска. Фактические алгоритмы, используемые для ранжирования этих результатов, обычно включают элементы, которые измеряют как релевантность, так и важность страниц, соответствующих искомому запросу.
В этой патентной заявке описан интерфейс тестирования, который разработчики поисковых алгоритмов и поисковых систем могут использовать для тестирования связанных запросов.
Как я отмечал в начале этого поста, интересно посмотреть, как поисковая система может попытаться определить, насколько релевантными могут быть результаты поиска.
Использование связанных терминов
Этот процесс определения релевантности и разнообразия результатов поиска начинается с определения терминов, которые могут быть в связанных запросах.
Кто-то ищет [Amazon], и поисковая система находит результаты, связанные с запросом, и отображает результаты поисковику.
Отображаемые результаты могут иметь отношение к интернет-магазину «Amazon.com »или к« реке Амазонка ».
Невозможно определить автоматически, хочет ли искатель информацию об одном или другом, или о чем-то даже другом.
Но поисковая машина может просматривать журналы запросов, данные поиска на основе сеанса и другие наборы данных, чтобы определить подконцепции запроса.
Эти подконцепции могут быть из тех, которые вы видите в предложениях запроса поисковой системой. См. Мой предыдущий пост «Как поисковые системы могут принимать решения и оптимизировать предложения запроса», чтобы получить некоторые идеи о том, как поисковая система может определять и оптимизировать предложения по конкретному запросу.
Те же самые данные, которые Yahoo может использовать для предложения запросов типа «Также попробуйте» или предложений прогнозирующего поиска Yahoo, также могут использоваться для определения наборов связанных терминов для запроса пользователя.
Поисковая система также отслеживает время, когда запросы отправляются в поисковую систему, что может быть полезно при идентификации запросов, чувствительных ко времени.
Связанные термины могут быть собраны из данных журнала запросов поисковой системы за последнюю неделю, а не за последний год, чтобы гарантировать своевременность информации.
Итак, если землетрясение произошло пару месяцев назад, журналы запросов примерно в то время могли включать множество поисков по запросу [Amazon earthquake]
Через месяц или около того поисков по этому термину могло бы быть намного меньше, и [землетрясение в амазонке] нельзя считать связанным запросом, как это было бы недавно после события.
Поиск в журналах последних запросов может показать, сколько раз в этих данных появлялись запросы, включенные или совпавшие с «Amazon».Таким образом, связанные запросы, такие как «книги амазонки», «река амазонки» и «тропический лес амазонки», могут быть определены как связанные запросы, если они достаточно часто появляются в проверяемых журналах запросов.
Поисковая система может также просматривать поисковые сеансы от пользователей в журналах запросов, чтобы увидеть, как часто другие запросы появляются в тех же поисковых сеансах, что и запросы, или содержащие слово «Amazon».
Сеанс поиска может быть определен как несколько поисков от искателя в течение определенного периода времени, например часа или дня.
Относительная частота терминов и проверка на релевантность
После того, как поисковая система предложит набор связанных терминов для запроса, она может вычислить относительную частоту каждого из этих связанных терминов по сравнению с исходным запросом поисковика в журналы запросов, которые были изучены, для выявления связанных запросов. Вот пример того, как этот расчет может работать из заявки на патент.
Например, ссылаясь на таблицу 216, термин F термина «книги» равен 25, что означает, что «книги» совпадают с «Amazon» 25 раз в выбранной части журнала запросов 210, представленного по таблице 212.Кроме того, Ftotal составляет 50, что соответствует общему количеству одновременных вхождений для всех терминов в наборе таблицы 216.
Таким образом, можно определить, что F относительно термина « книги »составляет 25/50 или 50%. Таблица 216 дополнительно содержит относительную частоту всех других терминов в наборе связанных терминов. В частности, частота встречаемости термина «тропический лес» составляет 12/50, или 24%, «частота реки» — 8/50, или 16%; а «рыбы» — 5/50, или 10%.
Относительная частота каждого связанного термина в наборе используется для определения как релевантности, так и разнообразия результатов поиска для первичного запроса, как дополнительно описано в данном документе.
Эти отношения могут использоваться при просмотре результатов поиска по исходному поисковому запросу.
Если вы посмотрите на заголовки и отрывки (или фактическое содержание) десяти лучших результатов поиска по запросу [amazon], будет ли половина этих результатов содержать слово «книги», как в проверенных журналах запросов? Четверть из них содержит слово тропический лес? Есть ли упоминание слова «река» в одном или двух из них? Есть ли хоть один, в котором есть слово «рыба»?
Если соотношения между журналами запросов и результатами поиска совпадают, это может указывать на то, что релевантность этих результатов довольно хорошая.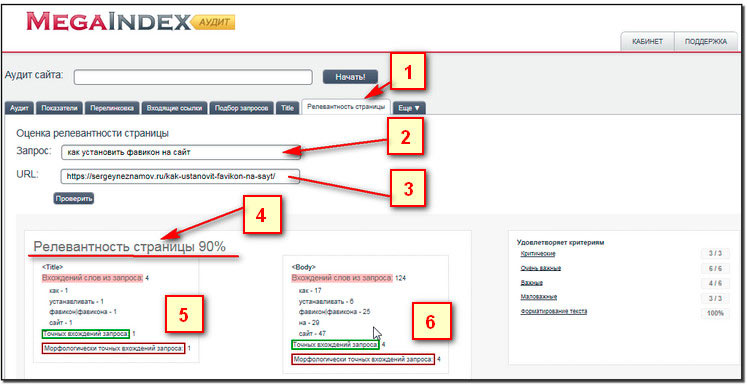 Это также может указывать на то, что разнообразие результатов тоже хорошее.
Это также может указывать на то, что разнообразие результатов тоже хорошее.
Патент предупреждает, что некоторые результаты поиска могут быть очень релевантными, но могут также полностью отсутствовать разнообразие, если поисковый запрос не содержит подтем или связанных терминов, относящихся к разным темам.
Заключение
Мне показалось интересным, что этот патент описывает способ поиска связанных запросов, который очень похож на метод, описанный в заявке на патент Microsoft в моем последнем посте.
Идея о том, что частота появления слов из связанных запросов может быть использована для оценки релевантности и разнообразия результатов для поискового запроса, также заслуживает внимания.
Если половина людей, использующих [amazon] в своих поисках, включают слово «книги» в этих поисках, должна ли половина результатов поиска в поиске [amazon] содержать слово «книги?» Если 20 процентов пользователей, ищущих [amazon], включают слово «тропический лес» в эти поисковые запросы, должны ли два из десяти лучших результатов поиска относиться к тропическим лесам Амазонки?
В настоящее время в первой десятке результатов поиска Yahoo для [amazon] есть два результата для домена.com версии книжного магазина, за которыми следуют два результата для версии книжного магазина .ca, затем страница википедии для amazon.com, запись о реке Амазонка, пара страниц о веб-сервисах Amazon, результат для co. uk Amazon store, и конечный результат для сервисов продавцов Amazon, которые позволяют людям продавать свои товары через Amazon.
Отражают ли эти результаты недавние поисковые запросы, содержащиеся в журналах запросов Yahoo и содержащие слово «Amazon», или обнаруженные в тех же поисковых сеансах, что и поиск [amazon]?
Должна ли релевантность результатов поиска основываться на частоте связанных терминов в последних журналах запросов? Это хороший показатель того, насколько актуальными могут быть эти результаты?
Я уже писал об этом патенте раньше, когда он был опубликован в виде заявки на патент в январе 2008 года. Я не осознавал этого, пока не закончил большую часть пути с этим постом, но я думаю, что эти два поста фактически дополняют друг друга, поэтому я решил пойти дальше и опубликовать этот пост.
Я не осознавал этого, пока не закончил большую часть пути с этим постом, но я думаю, что эти два поста фактически дополняют друг друга, поэтому я решил пойти дальше и опубликовать этот пост.
Я думаю, что эти два сообщения хорошо подчеркивают важность попытки понять, что поисковая система может рассматривать как «связанные запросы» для конкретного запроса, и как они могут не только влиять на то, какие поисковые предложения могут отображаться в набор результатов поиска, но также и то, насколько релевантными поисковая система может считать, что эти результаты поиска основаны на этих связанных запросах.
Обмен — это забота!
Три типа поисковых запросов и способы их таргетинга
Поисковые запросы — слова и фразы, которые люди вводят в поле поиска, чтобы вывести список результатов, — бывают разных видов. Принято считать, что существует три различных типа поисковых запросов:
- Навигационные поисковые запросы
- Информационно-поисковые запросы
- Транзакционные поисковые запросы
В мире поискового маркетинга мы склонны больше говорить о ключевых словах, чем о поисковых запросах (вспышка новостей: это не совсем одно и то же).Но сегодня мы говорим о поисковых запросах. Давайте подробнее рассмотрим, что это за три типа поисковых запросов и как вы можете настроить таргетинг на них с помощью содержания вашего сайта.
Навигационные поисковые запросы
Что такое навигационный поисковый запрос?
Навигационный запрос — это поисковый запрос, введенный с целью поиска определенного веб-сайта или веб-страницы. Например, пользователь может ввести «youtube» в строку поиска Google, чтобы найти сайт YouTube, вместо того, чтобы вводить URL-адрес в панель навигации браузера или использовать закладку.Фактически, «facebook» и «youtube» — это два самых популярных запроса в Google, и оба они являются навигационными запросами.
Как настроить таргетинг на навигационные поисковые запросы?
Дело в том, что у вас мало шансов настроить таргетинг на навигационный запрос, если только вы не являетесь владельцем сайта, который ищет человек. Истинные навигационные запросы имеют очень четкое намерение — пользователь имеет в виду конкретный сайт, и если вы не тот сайт, вы не отвечаете его потребностям. Google, который классифицирует этот тип запроса как «поисковый запрос» согласно некоторым отчетам, даже предпринял шаги по сокращению общего количества результатов на первой странице до 7 для навигационных запросов по брендам, что привело к 5.Снижение на 5% общего количества органических размещений на первой странице. Однако некоторые запросы, которые кажутся навигационными по своей природе, могут не быть . Например, тот, кто набирает в Google «facebook», может на самом деле искать новости или информацию о компании.
Истинные навигационные запросы имеют очень четкое намерение — пользователь имеет в виду конкретный сайт, и если вы не тот сайт, вы не отвечаете его потребностям. Google, который классифицирует этот тип запроса как «поисковый запрос» согласно некоторым отчетам, даже предпринял шаги по сокращению общего количества результатов на первой странице до 7 для навигационных запросов по брендам, что привело к 5.Снижение на 5% общего количества органических размещений на первой странице. Однако некоторые запросы, которые кажутся навигационными по своей природе, могут не быть . Например, тот, кто набирает в Google «facebook», может на самом деле искать новости или информацию о компании.
Совет: Убедитесь, что у вас есть навигационный запрос вашего бренда. В идеале ваш сайт будет отображаться как в верхней органической позиции, так и в списке лучших спонсируемых результатов при поиске по вашему бренду или названию компании. Как заметил Брэд Геддес, «во многих случаях стоит покупать ключевые слова, даже если вы занимаетесь по ним органически», потому что ваша общая прибыль в конечном итоге будет выше.Брендированные ключевые слова, как правило, стимулируют как клики, так и конверсии.
Информационные поисковые запросы
Что такое информационный поисковый запрос?
Википедия определяет информационных поисковых запросов как «запросы, которые охватывают широкую тему (например, колорадо или грузовик ), для которых могут быть тысячи релевантных результатов». Когда кто-то вводит информационный поисковый запрос в Google или другую поисковую систему, он ищет информацию — отсюда и название.Вероятно, они не ищут конкретный сайт, как в навигационном запросе, и не хотят совершать коммерческую транзакцию. Они просто хотят ответить на вопрос или научиться что-то делать.
Запустите наш бесплатный инструмент оценки эффективности Google Рекламы сегодня, и вы узнаете, какие ключевые слова сжигают ваш бюджет!
Как следует настраивать таргетинг на информационные поисковые запросы?
Информационные запросы сложно монетизировать. Google это знает, поэтому он продвигает Сеть знаний для решения таких типов запросов.Лучший способ нацелить информационный поиск — это использовать высококачественный SEO-контент, который действительно предоставляет полезную информацию, относящуюся к запросу. Википедия, несмотря на все ее недостатки, довольно хороша в предоставлении базовой, достаточно надежной информации по чрезвычайно широкому кругу тем, поэтому они занимают первую страницу примерно в половине всех поисковых запросов (ну, и их чрезвычайно мощная ссылка профиль).
Google это знает, поэтому он продвигает Сеть знаний для решения таких типов запросов.Лучший способ нацелить информационный поиск — это использовать высококачественный SEO-контент, который действительно предоставляет полезную информацию, относящуюся к запросу. Википедия, несмотря на все ее недостатки, довольно хороша в предоставлении базовой, достаточно надежной информации по чрезвычайно широкому кругу тем, поэтому они занимают первую страницу примерно в половине всех поисковых запросов (ну, и их чрезвычайно мощная ссылка профиль).
Однако Википедия оставляет желать лучшего для большого количества информационных запросов. Вот где вы входите! Вот несколько способов, с помощью которых вы можете настроить таргетинг на информационные запросы, чтобы привлечь трафик и привести на ваш сайт через обычный поиск:
- Напишите сообщение в блоге, полное советов , которые будут полезны вашим потенциальным клиентам — например, если вы консультант по связям с общественностью, вы можете написать в блоге сообщение о том, как создать пресс-релиз.
- Создайте обучающее видео , имеющее отношение к вашему бизнесу (например, этот чувак, занимающийся ремонтом дома, который снял видео о том, как построить дом на дереве).
- Напишите подробное пошаговое руководство , которое разъясняет процесс, имеющий отношение к вашему бизнесу (например, возьмите отличное руководство SEOmoz для новичков по SEO).
- Создайте инфографику , иллюстрирующую концепцию (например, нашу инфографику о том, как работает аукцион AdWords).
Есть много способов приблизиться к информационному содержанию.Проявите творческий подход. Цель состоит в том, чтобы позиционировать себя как надежный и авторитетный источник информации , , а не , чтобы попытаться запихнуть ваши продукты в глотку поисковикам. Пришло время повысить узнаваемость вашего бренда. Если вы ответите на вопрос пользователя, он с большей вероятностью будет относиться к вам положительно в будущем, если ему понадобится то, что вы предлагаете.
Если вы ищете больше направлений, когда дело доходит до контент-маркетинга, ознакомьтесь со следующими публикациями по теме:
Транзакционные поисковые запросы
Что такое транзакционный поисковый запрос?
Транзакционный поисковый запрос — это запрос, который указывает намерение завершить транзакцию, например совершить покупку.Транзакционные поисковые запросы могут включать в себя точные названия брендов и продуктов (например, «samsung galaxy s3»), быть общими (например, «кофеварка со льдом») или фактически включать такие термины, как «покупка», «покупка» или «заказ». Во всех этих примерах вы можете сделать вывод, что пользователь рассматривает возможность совершения покупки в ближайшем будущем, если он еще не вынул свою кредитную карту. Другими словами, они находятся на бизнес-конце воронки конверсии . Многие местные запросы (например, «Винный магазин Денвера») также являются транзакционными.
Вертикальный поиск — это подмножество транзакционных поисковых запросов, и они представляют людей, желающих совершить транзакцию в определенной отрасли. Сюда входят местные поиски, поиск ресторанов, поиск отелей, поиск рейсов и т. Д. Действия Google в последние годы по прямому нацеливанию на вертикальный поиск привели к обвинениям в нарушении антимонопольного законодательства.
Как настроить таргетинг на транзакционные поисковые запросы?
Мы рекомендуем здесь двусторонний подход.Нет причин, по которым или нацелены на транзакционные запросы с органическим контентом, такие как оптимизированные страницы продуктов и локальные стратегии SEO, но вам следует рассмотреть возможность использования PPC для нацеливания на эти поисковые запросы. Вот почему:
- Это именно те запросы, которые, скорее всего, принесут рентабельность инвестиций в платный поиск. Если люди ищут продукт определенного типа для покупки, спонсируемая реклама с такой же вероятностью, как и органический результат, доставит то, что им нужно.
- Рекламные результаты занимают много места в поисковой выдаче для коммерческих / транзакционных запросов. Если вы хотите, чтобы ключевые слова транзакций были видны в верхней части страницы, вам следует подумать о PPC.
- Google предлагает множество наворотов для спонсируемой рекламы и списков продуктов. Например, вы можете добавить изображение вашего продукта. Ваши варианты органических результатов более ограничены и менее контролируемы.
- В одном исследовании мы обнаружили, что люди нажимают на платные результаты вместо обычных результатов 2 к 1 для запросов с высоким коммерческим намерением. Вероятно, это связано с тем, что спонсируемые результаты занимают так много места в верхней части страницы при этих типах поиска, потому что новые форматы рекламы настолько привлекательны для кликов и потому что многие пользователи поисковых систем не могут сказать разница между рекламой и не-рекламой. (Примечание: коммерческие поисковые запросы составляют лишь небольшой процент от общего объема поисковых запросов, поэтому обычные результаты по-прежнему составляют львиную долю от общего числа кликов. Подробнее об этом читайте здесь.)
Вот некоторые из причин, по которым мы рекомендуем использовать AdWords для транзакционных поисковых запросов.Это масштабируемый и экономичный способ привлечения потенциальных клиентов и продаж. Однако знайте, что если вы хотите привлечь больше общего трафика, лучше всего также создать свой SEO-контент, поскольку информационных запросов больше, чем транзакционных.
Есть вопросы об этих типах поисковых запросов и их значении для маркетологов? Дайте нам знать об этом в комментариях!
mysql — оптимизация SQL-запросов для поиска на основе релевантности
Этот запрос возвращает строки, упорядоченные по релевантности при поиске названия вида.Я использую его для списка предложений автозаполнения, и расчет релевантности работает нормально, но запрос немного медленный для большой таблицы, и я благодарен за любые советы по его оптимизации (MySQL). Мой главный вопрос:
Мой главный вопрос:
РЕДАКТИРОВАТЬ: Я использую InnoDB как тип таблицы, поэтому, к сожалению, я не могу использовать полнотекстовую индексацию в этом случае (работает только с таблицами MyIsam).
SQL-скрипт здесь: http://sqlfiddle.com/#!2/f03c4c/5
ВЫБРАТЬ ЗАПРОС:
НАБОР @search = 'Подберезовик а';
ВЫБЕРИТЕ идентификатор, род, вид, полное имя,
(CASE WHEN (CONCAT (род, '', разновидность) = @ search) THEN 1 ELSE 0 END) # ТОЧНОЕ СООТВЕТСТВИЕ ЦЕЛОМ ИМЕНИ
+ (CASE WHEN (CONCAT (род, '', разновидность) LIKE CONCAT (@search, '%')) THEN 1 ELSE 0 END) # НАЧАЛО ПОИСКА ПО ЦЕЛОМ ИМЕНИ
+ (CASE WHEN (CONCAT (род, '', разновидность) LIKE CONCAT ('%', @ search, '%')) THEN 1 ELSE 0 END) # LIKE MATCH OF ALL NAME
+ (CASE WHEN (genus = @ search) THEN 1 ELSE 0 END) # Точное совпадение рода
+ (CASE WHEN (разновидности = @ search) THEN 1 ELSE 0 END) # ТОЧНОЕ СООТВЕТСТВИЕ разновидностей
+ (CASE WHEN (род LIKE CONCAT (@search, '%')) THEN 1 ELSE 0 END) # НАЧАЛО ПОИСКА РОДА
+ (CASE WHEN (разновидности LIKE CONCAT (@search, '%')) THEN 1 ELSE 0 END) # НАЧАЛО МАТЧА видов
Как релевантные
ОТ видов
ГДЕ `полное имя` LIKE CONCAT ('%', @ search, '%')
ЗАКАЗАТЬ по значению DESC, роду, виду
LIMIT 50;
Предыстория: название вида состоит как минимум из двух частей: рода и эпитета (в моей таблице столбец эпитетов назван «виды»).У меня в таблице три столбца: род, вид и полное имя. Столбец «fullname» может также содержать названия низших таксонов (разновидностей и форм, как в примере sqlfiddle). Я открыт для любых предложений, как сделать поиск более эффективным. Может быть, регулярное выражение в строке поиска и таргетинг только на столбец «полное имя» вместо объединения двух столбцов?
ПРИМЕР СХЕМЫ БАЗЫ ДАННЫХ:
СОЗДАТЬ ТАБЛИЦУ виды
(`id` int,` genus` varchar (50), `разновидности` varchar (50),` fullname` varchar (100))
;
ВСТАВИТЬ виды
(id, род, виды, полное имя)
ЗНАЧЕНИЯ
(360052, 'Afroboletus', 'azureotinctus', 'Afroboletus azureotinctus'),
(360053, 'Afroboletus', 'costatisporus', 'Afroboletus costatisporus'),
(464267, 'Afroboletus', 'elegans', 'Afroboletus elegans'),
(360054, 'Afroboletus', 'lepidellus', 'Afroboletus lepidellus'),
(112100, 'Afroboletus', 'luteolus', 'Afroboletus luteolus'),
(464266, 'Afroboletus', 'multijugus', 'Afroboletus multijugus'),
(112101, 'Afroboletus', 'pterosporus', 'Afroboletus pterosporus'),
(326826, Aureoboletus, auriporus, Aureoboletus auriporus),
(326828, Aureoboletus, gentilis, Aureoboletus gentilis),
(309389, Aureoboletus, novoguineensis, Aureoboletus novoguineensis),
(326829, Aureoboletus, subacidus, Aureoboletus subacidus),
(113146, Aureoboletus, thibetanus, Aureoboletus thibetanus),
(118425, 'Austroboletus', 'cookei', 'Austroboletus cookei'),
(118427, 'Austroboletus', 'dictyotus', 'Austroboletus dictyotus'),
(412550, 'Austroboletus', 'lacunosus', 'Austroboletus lacunosus'),
(159051, 'Boletus', 'aereus', 'Boletus aereus'),
(171640, 'Boletus', 'appendiculatus', 'Boletus appendiculatus'),
(161237, 'Подберезовик', 'armeniacus', 'Boletus armeniacus'),
(563944, 'Boletus', 'australiensis', 'Boletus australiensis'),
(444094, 'Boletus', 'badius', 'Boletus badius'),
(215376, 'Boletus', 'brunneus', 'Boletus brunneus'),
(129701, 'Boletus', 'bubalinus', 'Boletus bubalinus'),
(203954, 'Boletus', 'byssinus', 'Boletus byssinus'),
(162779, 'Boletus', 'calopus', 'Boletus calopus'),
(129469, 'Boletus', 'caucasicus', 'Boletus caucasicus'),
(208740, Подберезовик, chrysenteron, Boletus chrysenteron),
(486540, 'Boletus', 'cisalpinus', 'Boletus cisalpinus'),
(368037, 'Boletus', 'declivitatum', 'Boletus declivitatum'),
(104061, 'Boletus', 'depilatus', 'Boletus depilatus'),
(356530, 'Подосиновик', 'edulis', 'Boletus edulis'),
(356278, 'Boletus', 'erythropus', 'Boletus erythropus var. immutatus '),
(417068, 'Boletus', 'erythropus', 'Boletus erythropus var. Erythropus'),
(563943, 'Boletus', 'eximius', 'Boletus eximius'),
(264716, 'Подберезовик', 'fechtneri', 'Boletus fechtneri'),
(372473, 'Boletus', 'ferrugineus', 'Boletus ferrugineus'),
(141943, 'Boletus', 'flavus', 'Boletus flavus'),
(247434, 'Подосиновики', 'Fragrans', 'Boletus Fragrans'),
(302971, 'Boletus', 'fuligineus', 'Boletus fuligineus'),
(218213, 'Boletus', 'impolitus', 'Boletus impolitus'),
(327048, 'Boletus', 'legaliae', 'Boletus legaliae'),
(327051, 'Подберезовик', 'leptospermi', 'Boletus leptospermi'),
(235486, 'Подберезовик', 'lignatilis', 'Boletus lignatilis'),
(354822, 'Boletus', 'luridiformis', 'Boletus luridiformis var.junquilleus '),
(354845, 'Boletus', 'luridiformis', 'Boletus luridiformis var. Обесцвечивание'),
(430254, 'Подберезовик', 'luridiformis', 'Boletus luridiformis var. Luridiformis'),
(132915, 'Boletus', 'luridus', 'Boletus luridus var. Rubriceps'),
(417113, 'Boletus', 'luridus', 'Boletus luridus var. Luridus'),
(241417, 'Boletus', 'megalosporus', 'Boletus megalosporus'),
(282394, 'Boletus', 'moravicus', 'Boletus moravicus'),
(196024, 'Подберезовик', 'Подберезовик', 'Подберезовик')
;
 immutatus '),
(417068, 'Boletus', 'erythropus', 'Boletus erythropus var. Erythropus'),
(563943, 'Boletus', 'eximius', 'Boletus eximius'),
(264716, 'Подберезовик', 'fechtneri', 'Boletus fechtneri'),
(372473, 'Boletus', 'ferrugineus', 'Boletus ferrugineus'),
(141943, 'Boletus', 'flavus', 'Boletus flavus'),
(247434, 'Подосиновики', 'Fragrans', 'Boletus Fragrans'),
(302971, 'Boletus', 'fuligineus', 'Boletus fuligineus'),
(218213, 'Boletus', 'impolitus', 'Boletus impolitus'),
(327048, 'Boletus', 'legaliae', 'Boletus legaliae'),
(327051, 'Подберезовик', 'leptospermi', 'Boletus leptospermi'),
(235486, 'Подберезовик', 'lignatilis', 'Boletus lignatilis'),
(354822, 'Boletus', 'luridiformis', 'Boletus luridiformis var.junquilleus '),
(354845, 'Boletus', 'luridiformis', 'Boletus luridiformis var. Обесцвечивание'),
(430254, 'Подберезовик', 'luridiformis', 'Boletus luridiformis var. Luridiformis'),
(132915, 'Boletus', 'luridus', 'Boletus luridus var. Rubriceps'),
(417113, 'Boletus', 'luridus', 'Boletus luridus var. Luridus'),
(241417, 'Boletus', 'megalosporus', 'Boletus megalosporus'),
(282394, 'Boletus', 'moravicus', 'Boletus moravicus'),
(196024, 'Подберезовик', 'Подберезовик', 'Подберезовик')
;
immutatus '),
(417068, 'Boletus', 'erythropus', 'Boletus erythropus var. Erythropus'),
(563943, 'Boletus', 'eximius', 'Boletus eximius'),
(264716, 'Подберезовик', 'fechtneri', 'Boletus fechtneri'),
(372473, 'Boletus', 'ferrugineus', 'Boletus ferrugineus'),
(141943, 'Boletus', 'flavus', 'Boletus flavus'),
(247434, 'Подосиновики', 'Fragrans', 'Boletus Fragrans'),
(302971, 'Boletus', 'fuligineus', 'Boletus fuligineus'),
(218213, 'Boletus', 'impolitus', 'Boletus impolitus'),
(327048, 'Boletus', 'legaliae', 'Boletus legaliae'),
(327051, 'Подберезовик', 'leptospermi', 'Boletus leptospermi'),
(235486, 'Подберезовик', 'lignatilis', 'Boletus lignatilis'),
(354822, 'Boletus', 'luridiformis', 'Boletus luridiformis var.junquilleus '),
(354845, 'Boletus', 'luridiformis', 'Boletus luridiformis var. Обесцвечивание'),
(430254, 'Подберезовик', 'luridiformis', 'Boletus luridiformis var. Luridiformis'),
(132915, 'Boletus', 'luridus', 'Boletus luridus var. Rubriceps'),
(417113, 'Boletus', 'luridus', 'Boletus luridus var. Luridus'),
(241417, 'Boletus', 'megalosporus', 'Boletus megalosporus'),
(282394, 'Boletus', 'moravicus', 'Boletus moravicus'),
(196024, 'Подберезовик', 'Подберезовик', 'Подберезовик')
;
запросов — Amazon Kendra
Чтобы получить ответы, пользователи запрашивают индекс.Пользователи могут использовать естественные язык в своих запросах. Ответ содержит информация, такая как заголовок, отрывок текста и расположение документы в указателе, которые предоставляют лучшие отвечать.
Amazon Kendra использует всю информацию
который
вы сообщаете о своих документах, а не только о содержании
документы, чтобы определить,
документ
имеет отношение к запросу.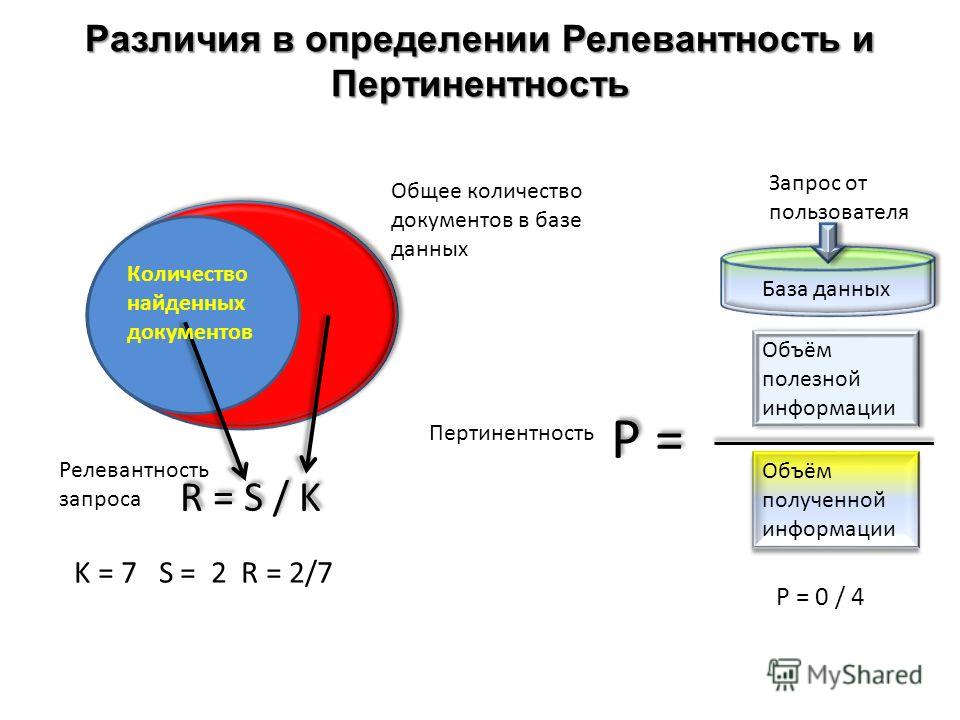 За
Например, если ваш индекс содержит информацию о том, когда документы
были обновлены в последний раз, вы можете указать Amazon Kendra назначить более высокий
актуальность для документов, которые были обновлены совсем недавно.
За
Например, если ваш индекс содержит информацию о том, когда документы
были обновлены в последний раз, вы можете указать Amazon Kendra назначить более высокий
актуальность для документов, которые были обновлены совсем недавно.
Запрос может также содержать критерии фильтрации ответа. так что Amazon Kendra возвращает только те документы, которые удовлетворяют фильтру критерии.Например, если вы создали индексное поле с именем отдел , можно фильтровать ответ так, чтобы только документы с полем отдела, установленным на Возвращено законных . Для большего информацию см. в разделе Фильтрация запросов.
Вы можете повлиять на результаты запроса, настроив релевантность отдельных полей в индексе.Тюнинг меняет важность поле результатов. Например, если вы повысите важность документы с типом файла pdf , Файлы PDF с большей вероятностью будут включены в ответ. Для большего информацию см. в разделе Настройка индекса вручную.
Для получения дополнительной информации об использовании запросов см. Поиск в индексах.
.