База данных master — SQL Server
- Чтение занимает 3 мин
В этой статье
Применимо к: SQL Server (все поддерживаемые версии) База данных SQL Azure
База данных master содержит всю системную информацию о SQL Server . в том числе общие для всего экземпляра метаданные, такие как сведения об учетных записях входа, конечных точках и связанных серверах, а также параметры конфигурации системы. В SQL Serverсистемные объекты больше не хранятся в базе данных master ; они хранятся в базе данных ресурсов. Кроме этого, в базе данных master регистрируются все остальные базы данных и хранится информация о расположении их файлов.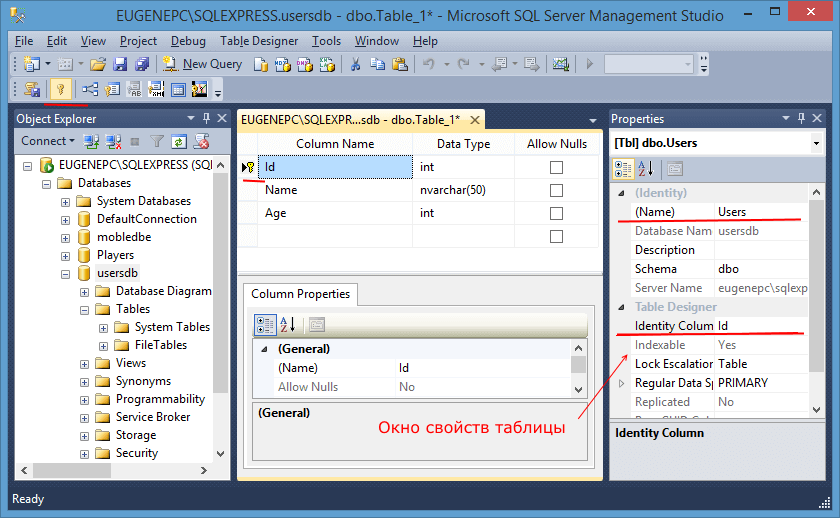
Физические свойства базы данных master
Исходные конфигурационные значения файлов данных и файлов журнала базы данных master для SQL Server и Управляемого экземпляра SQL Azure приведены в следующей таблице. Размеры этих файлов могут немного изменяться в зависимости от выпуска SQL Server.
| Файл | Логическое имя | Физическое имя | Увеличение размера файлов |
|---|---|---|---|
| Первичные данные | master | master.mdf | Автоувеличение на 10 % до заполнения диска. |
| Журнал | mastlog | mastlog.ldf | Автоувеличение на 10 % до максимального размера в 2 ТБ. |
Сведения о перемещении файлов данных и журнала базы данных master см. в разделе Перемещение системных баз данных.
Важно!
При работе с сервером Базы данных SQL Azure пользователь не может управлять размером базы данных master.
Параметры базы данных
Значения по умолчанию для всех параметров базы данных master для SQL Server и Управляемого экземпляра SQL Azure и сведения о том, можно ли их изменять, приведены в следующей таблице. Чтобы просмотреть текущие настройки этих параметров, используйте представление каталога sys.databases .
Важно!
При работе с отдельными базами данных и эластичными пулами Базы данных SQL Azure пользователь не может управлять этими параметрами базы данных.
| Параметр базы данных | Значение по умолчанию | Можно ли изменить |
|---|---|---|
| ALLOW_SNAPSHOT_ISOLATION | ON | нет |
| ANSI_NULL_DEFAULT | OFF | Да |
| ANSI_NULLS | OFF | Да |
| ANSI_PADDING | OFF | Да |
| ANSI_WARNINGS | OFF | Да |
| ARITHABORT | OFF | Да |
| AUTO_CLOSE | OFF | нет |
| AUTO_CREATE_STATISTICS | ON | Да |
| AUTO_SHRINK | OFF | нет |
| AUTO_UPDATE_STATISTICS | ON | Да |
| AUTO_UPDATE_STATISTICS_ASYNC | OFF | Да |
| CHANGE_TRACKING | OFF | нет |
| CONCAT_NULL_YIELDS_NULL | OFF | Да |
| CURSOR_CLOSE_ON_COMMIT | OFF | Да |
| CURSOR_DEFAULT | GLOBAL | Да |
| Параметры доступности базы данных | ONLINE MULTI_USER READ_WRITE | нет Нет нет |
| DATE_CORRELATION_OPTIMIZATION | OFF | Да |
| DB_CHAINING | ON | нет |
| ENCRYPTION | OFF | нет |
| MIXED_PAGE_ALLOCATION | ON | нет |
| NUMERIC_ROUNDABORT | OFF | Да |
| PAGE_VERIFY | CHECKSUM | Да |
| PARAMETERIZATION | ПРОСТОЙ | Да |
| QUOTED_IDENTIFIER | OFF | Да |
| READ_COMMITTED_SNAPSHOT | OFF | нет |
| RECOVERY | ПРОСТОЙ | Да |
| RECURSIVE_TRIGGERS | OFF | Да |
| Параметры компонента Service Broker | DISABLE_BROKER | нет |
| TRUSTWORTHY | OFF | Да |
Описание этих параметров баз данных см. в разделе ALTER DATABASE (Transact-SQL).
в разделе ALTER DATABASE (Transact-SQL).
Ограничения
База данных master не поддерживает следующие операции:
- добавление файлов или файловых групп;
- Резервное копирование, для базы данных master может быть выполнено только полное резервное копирование.
- Изменение параметров сортировки. Параметрами сортировки по умолчанию являются параметры сортировки сервера.
- Изменение владельца базы данных. Владельцем master является sa.
- создание полнотекстового каталога или полнотекстового индекса;
- создание триггеров для системных таблиц базы данных;
- Удаление базы данных.
- Удаление пользователя guest из базы данных.
- Включение системы отслеживания измененных данных.
- Участие в зеркальном отображении базы данных.
- Удаление первичной файловой группы, первичного файла данных или файла журнала.
- Переименование базы данных или первичной файловой группы.

- Перевод базы данных в режим «вне сети» (OFFLINE).
- Перевод базы данных или первичной файловой группы в режим READ_ONLY.

Рекомендации
При работе с базой данных master учитывайте следующие рекомендации:
всегда имейте в наличии актуальную резервную копию базы данных master ;
после выполнения следующих операций как можно быстрее создавайте резервную копию базы данных master :
- создание, изменение или удаление базы данных;
- изменение значений параметров конфигурации сервера или базы данных;
- изменение или удаление учетных записей входа;
не создавайте в базе данных master пользовательские объекты. Если сделать это, придется чаще создавать резервные копии базы данных master .
не устанавливайте в базе данных master параметр TRUSTWORTHY в значение ON.
Что делать, если база данных master становится непригодна к использованию
Если база данных master непригодна к использованию, ее можно вернуть в нормальное состояние следующими способами.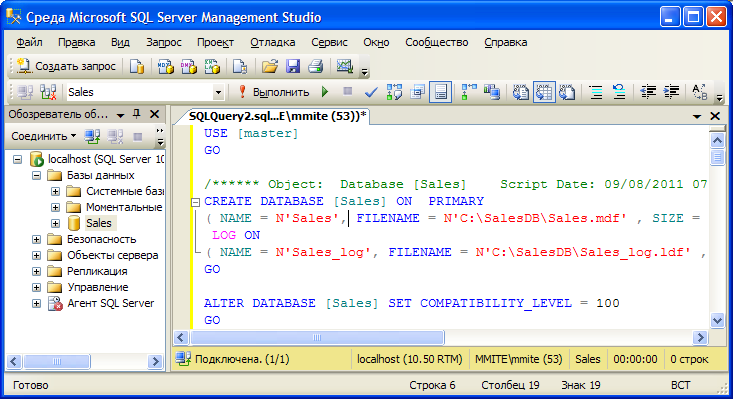
Восстановить базу данных master на основе актуальной резервной копии.
Если экземпляр сервера удалось запустить, базу данных master можно восстановить из полной резервной копии. Дополнительные сведения см. в разделе Восстановление базы данных master (Transact-SQL).
Перестроить базу данных master с нуля.
Если серьезное повреждение базы данных master не позволяет запустить экземпляр SQL Server, базу данных master нужно перестроить. Дополнительные сведения см. в разделе Перестроение системных баз данных.
Важно!
При перестроении базы данных master все системные базы данных также перестраиваются.
См. также
Что такое SQL и как он работает | GeekBrains
https://d2xzmw6cctk25h.cloudfront.net/post/2491/og_image/9d0f392ec052f922f41e5792374d7fcd.png
Википедия гласит, что SQL — это декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных. Не самое удобоваримое определение. Чтобы понять, о чём вообще речь, разберём его.
Не самое удобоваримое определение. Чтобы понять, о чём вообще речь, разберём его.
Декларативный язык программирования говорит, что должно быть сделано, а не как это необходимо сделать. Ещё один пример декларативного языка — HTML. Рассмотрим такой код:
<div class=”className”>
<input type=”button” value=”Ясно. Понятно.”></input>
</div>С его помощью мы заявляем (declaration — заявление) браузеру, что хотим увидеть блок с классом className и кнопкой с текстом «Ясно. Понятно.» внутри. Для этого мы не создаём каких-либо переменных, циклов, условий. Мы знаем, что браузер нас понял, сам разберёт команду и вернёт результат или ошибку.
Здесь смысл довольно прост: мы даём команду и получаем результат. Мы не описываем, как эту команду выполнять. Чтобы понять, что такое реляционная база данных, разберём, что такое база данных в принципе. Декомпозируем это понятие на «база» и «данные».
Данные
В контексте баз данных под данными понимают набор значений, который собирается в строки и столбцы, тем самым представляя таблицу.
- название производителя;
- название модели;
- высота;
- длина;
- цвет;
- количество дверей.
Составим таблицу и вобьём в неё выдуманные данные.
У нас есть таблица с данными. Столбцами мы показываем, как они будут храниться. В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
Добавляя в таблицу строки, я вводил в неё данные, ориентируясь на структуру, заданную в столбцах. Чем больше строк, тем больше данных. Чем больше столбцов, тем подробнее будут эти данные.
Ещё есть такое понятие, как «значение» — это пересечение столбца и строки. Например, у последней строки в столбце «Цвет» написано «хаки». Здесь «хаки» — значение. Если мы начнём группировать таблицы и добавим возможность манипулирования ими, то получим базу данных.
Здесь «хаки» — значение. Если мы начнём группировать таблицы и добавим возможность манипулирования ими, то получим базу данных.
Теперь про базы
Получается, что БД — это совокупность данных, представленных определённым образом (в нашем случае — таблицей), и набор инструментов для манипулирования ими.
Данные могут быть сгруппированы не только в таблицы, но и в коллекции. У каждой базы есть свой инструмент для создания таблиц/коллекций, добавления, удаления или изменения данных, а также для составления выборки. В статье мы рассмотрим базы, которые состоят из таблиц, а инструментом манипулирования данными будет язык SQL.
Таблицы между собой могут объединяться в схемы — в одной базе данных их может быть несколько, а может и не быть деления на схемы вообще. Это зависит от БД.
Вернёмся к определению из Википедии и вспомним про слово «реляционные». Реляционные (от англ. relation — отношения) — это базы данных, таблицы которых могут выстраиваться в различных отношениях. Возьмём предыдущий пример и добавим в него тех самых «отношений». Создадим таблицу «Производитель», а ту, что в примере, обозначим как «Каталог».
Возьмём предыдущий пример и добавим в него тех самых «отношений». Создадим таблицу «Производитель», а ту, что в примере, обозначим как «Каталог».
Таблица «Производитель»:
Теперь таблицу «Каталог» можно оформить в другом виде:
Получилось так, что у таблиц «Каталог» и «Прозводитель» появились отношения. Значения из столбца «Каталог» ссылаются на строки из таблицы «Производитель». Добавлением отношения мы решили нескольких проблем:
- Избавились от избыточных данных. Каталог стал занимать меньше места. Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель».
- Снизили вероятность ошибиться. При смене названия производителя нам достаточно отредактировать строку в таблице «Производитель», «Каталог» останется без изменений.
Это не все проблемы, которые мы решили добавлением отношений. Для понимания других проблем необходимо углубиться в тему баз данных. Разделение данных на таблицы с отношениями — это процесс нормализации. Так можно достигать различных нормализованных форм данных. При достижении каждой из нормализованных форм мы избавляем данные от дополнительных проблем.
Так можно достигать различных нормализованных форм данных. При достижении каждой из нормализованных форм мы избавляем данные от дополнительных проблем.
Вернёмся к SQL
Если читателю показалось, что мы ушли в сторону от SQL, так оно и есть. Но очень трудно понять, что такое SQL, не зная, с чем он работает.
Выходит, что SQL — это язык программирования, необходимый для написания команд к БД, после выполнения которых она вернёт результат. Результат будет зависеть от команды, написанной на SQL. Как в любом другом языке программирования, в SQL есть операторы для работы с данными, из которых складываются команды. Операторы распределены по четырём языкам:
- DDL — Data Definition Language;
- DML — Data Manipulation Language;
- DCL — Data Control Language;
- TCL — Transaction Control Language.
DDL
DDL (Data Definition Language, язык описания данных) — язык, включающий операторы для работы со структурой данных. Операторы DDL нужны для реализации этих возможностей:
Операторы DDL нужны для реализации этих возможностей:
- Создание объектов базы данных (таблиц, схем). Оператор: CREATE.
- Удаление объектов базы данных. Оператор: DROP.
- Изменение объектов базы данных. Оператор: ALTER.
DDL используется, когда нужно создать структуру для хранения данных. Он не отвечает за сами данные — только за то, как они будут разделены по таблицам и схемам.
DML
DML (Data Manipulation Language, язык манипуляции данными) — язык, который нужен для добавления, удаления, изменения данных и для выборки их из базы. Иными словами, для манипулирования данными. Пройдёмся по операторам:
- Оператор SELECT позволяет выбрать данные.
- Оператор INSERT — добавить новые.
- Оператор UPDATE — изменить существующие.
- Оператор DELETE — удалить.
DCL
DCL (Data Control Language, язык управления доступом к данным) — набор операторов, необходимых для предоставления доступа к данным. Кроме данных, в БД есть такие сущности, как пользователи. Нужно обязательно иметь возможность ограничить пользователям доступ к данным. Например, мы не хотим, чтобы менеджер проекта мог редактировать данные или их структуру. Для этого есть три группы операторов.
Кроме данных, в БД есть такие сущности, как пользователи. Нужно обязательно иметь возможность ограничить пользователям доступ к данным. Например, мы не хотим, чтобы менеджер проекта мог редактировать данные или их структуру. Для этого есть три группы операторов.
- GRANT — оператор предоставления пользователю или группе набор каких-либо разрешений;
- REVOKE — оператор отзыва разрешений;
- DENY — задаёт запрет. Приоритет оператора DENY выше, чем у разрешения, выданного оператором GRANT.
TCL
Есть такое понятие, как транзакции. Это набор команд (там может быть и всего одна), который завершается успешно тогда, когда правильно выполнены все команды из него. В случае неудачного завершения одной команды из транзакции, она вся откатывается (отменяются результаты выполнения предыдущих команд), реализуя принцип атомарности. Обычно в транзакцию включаются DML-команды.
Для управления транзакциями существует TCL (Transaction Control Language — язык управления транзакциями). Операторы здесь следующие:
Операторы здесь следующие:
- BEGIN TRANSACTION — необходим для обозначения начала транзакции;
- COMMIT TRANSACTION — применяет изменения команд внутри транзакции;
- ROLLBACK TRANSACTION — откатывает транзакцию;
- SAVE TRANSACTION — указывает промежуточную точку сохранения внутри транзакции.
TCL есть только в тех БД, которые поддерживают транзакции. Самое время поговорить о видах БД.
Виды СУБД
Познакомимся с новым понятием — СУБД, системой управления базой данных.
Сергей Кузнецов в книге «Основы баз данных» описал СУБД как комплекс программ, позволяющих создать базу данных (БД) и манипулировать данными (вставлять, обновлять, удалять и выбирать). Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД.
Получается что, СУБД — это SQL плюс комплекс программного обеспечения. Очень часто базы данных путают с системой управления базой данных.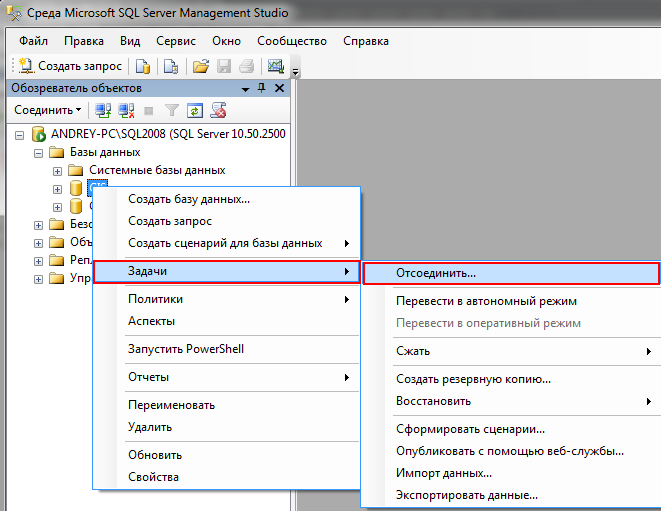 Это нормально: понятия неразрывны, сама по себе БД без системы управления мало чем отличается от текстового файла со строчками. Важно не только хранить данные, но и управлять ими. СУБД применяются везде, где нужно структурировано хранить данные — от простого блога до проектов Data Science.
Это нормально: понятия неразрывны, сама по себе БД без системы управления мало чем отличается от текстового файла со строчками. Важно не только хранить данные, но и управлять ими. СУБД применяются везде, где нужно структурировано хранить данные — от простого блога до проектов Data Science.
Есть много популярных СУБД, рассмотрим несколько из них.
MySQL
MySQL — свободная реляционная СУБД. Разрабатывалась как легковесная замена тяжёлым СУБД, которую можно было установить на маломощный сервер, без сильных потерь в возможностях. MySQL трудится под капотом таких гигантов, как YouTube, Facebook, Twitter, GitHub.
СУБД написана на C и C++. MySQL породил множество ответвлений, которые сейчас стали самостоятельными СУБД, например Percona и MariaDB.
Oracle Database
История Oracle Database начинается с 1977 года. Это объектно-реляционная система управления данными. Это довольно тяжёлая СУБД, поддерживает системы любой сложности, например, в банковской или финансовой сферах.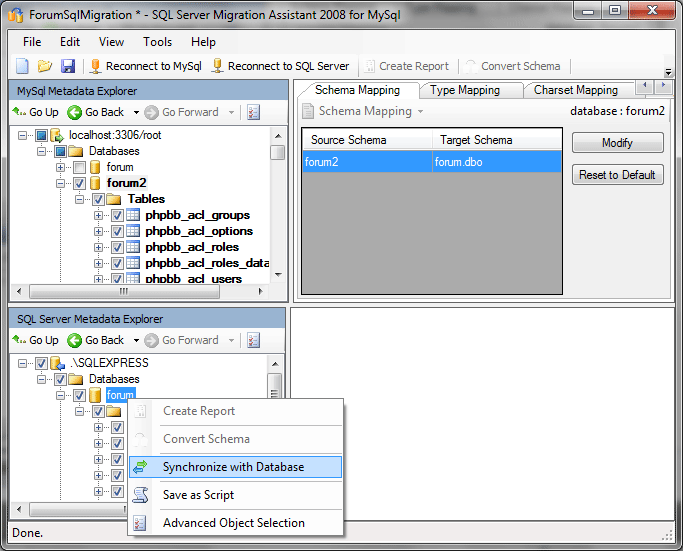 У неё нет бесплатной лицензии. Процедурный SQL — PL/SQL. Языки написания СУБД — Java/C/С++
У неё нет бесплатной лицензии. Процедурный SQL — PL/SQL. Языки написания СУБД — Java/C/С++
Microsoft SQL Server
Microsoft SQL Server — система управления реляционными базами данных, разработанная Microsoft. Первая версия SQL Server появилась 29 апреля 1989 года. Это конкурент Oracle Database. Есть бесплатная лицензия для разработчиков, но не для коммерческого использования. Процедурный SQL — Transact-SQL. СУБД написана на C/C++/C#.
PostgreSQL
PostgreSQL — свободная объектно-реляционная система управления базами данных. Эта СУБД увидела свет 8 июля 1996 года. Конкурент MySQL в веб-разработке проектов любой сложности, также соперничает с базами от Oracle и Microsoft в промышленной разработке. У неё прекрасная русскоязычная документация. Как и MySQL, имеет бесплатную лицензию для коммерческой разработки, за что так же, как и MySQL, горячо любима. Процедурный SQL — PL/pgSQL. Разработана на языке С.
Каждая из приведённых СУБД работает на своём расширении SQL. У каждой — своя ниша применения, плюсы и минусы.
У каждой — своя ниша применения, плюсы и минусы.
Что после знакомства?
Если вы не знаете, какая конкретно СУБД вам нужна, выбирайте MySQL. Она лишена изысканных возможностей, которые будут только сбивать начинающего разработчика. Большое комьюнити не оставит в беде и уже решило 95% проблем. Разнообразие графических клиентов для всех операционных систем хорошо помогает на ранних этапах. MySQL позволит набраться опыта и понять, чем она хуже или лучше других СУБД. Когда вы поймёте принципы работы MySQL, для вас не составит труда переключиться на работу с PostgreSQL или другой СУБД. Цель работы у всех СУБД одна — рациональное и надёжное хранение данных и быстрое их извлечение или изменение.
После того как вы определитесь с выбором, хорошо будет посмотреть практики других разработчиков на YouTube-каналах «Технострим Mail.ru Group» или HighLoad Channel, почитать замечательный портал ruhighload.com, где, кроме статей про базы данных, рассматриваются проблемы больших нагрузок. А для тех, кто любит почитать больше, подойдёт книга «MySQL по максимуму. 3-е издание» Бэрона Шварца, Петра Зайцева и Вадима Ткаченко. Узнать больше вы, конечно, можете и в GeekBrains — приходите ко мне или моим коллегам на курс «Основы баз данных».
А для тех, кто любит почитать больше, подойдёт книга «MySQL по максимуму. 3-е издание» Бэрона Шварца, Петра Зайцева и Вадима Ткаченко. Узнать больше вы, конечно, можете и в GeekBrains — приходите ко мне или моим коллегам на курс «Основы баз данных».
Что такое база данных и SQL. Как работают с базами и что в них хранят
Если сказать упрощённо, то база данных — это среда, в которой существуют таблицы с данными. Если вы когда-нибудь работали в офисной программе «Excel», в которой можно делать таблицы, то считайте что работали с базой данных.В базах данных сайтов могут содержаться таблицы, в которых может быть записано всё что угодно:
- данные новостей, которые опубликованы на сайте
- данные пользователей, которые зарегистрированы на сайте
+--------------------+ | Пользователи | +--------------------+ | Имя | Любимая еда | +------+-------------+ | Мышь | Сыр | +------+-------------+ | Кот | Молоко | +------+-------------+Как можно заметить, это обычная таблица.
 Но в таком виде на сайте её увидеть нельзя. Сайт делает запрос к ней с помощью специального языка, который называется SQL (Structured Query Language — «язык структурированных запросов»). Эти запросы возвращают массив строк, которые подходят под параметр запроса. Разберём далее логику запросов.
Но в таком виде на сайте её увидеть нельзя. Сайт делает запрос к ней с помощью специального языка, который называется SQL (Structured Query Language — «язык структурированных запросов»). Эти запросы возвращают массив строк, которые подходят под параметр запроса. Разберём далее логику запросов.Представьте, что необходимо получить из примера выше все данные таблицы и вывести их на экран. Тогда нужно сделать запрос к базе данных на языке SQL:
SELECT 'Имя пользователя', 'Любимая еда' FROM 'Пользователи';
Последняя часть запроса содержит слово FROM, которое дословно переводится как «из». После этого слова стоит таблица ИЗ которой надо получить данные. Если не указать из какой таблицы нужны данные, то база данных выдаст ошибку.
Пример SQL запроса, который приведён выше, сильно утрирован для большей наглядности и простоты. Потому что в базах данных крайне нежелательно создавать таблицы с кириллическими названиями таблиц и столбцов. А ещё названия столбцов и самой таблицы нужно заключать не в одинарную кавычку ‘ , а в наколнную `
Перейдём к обработке результатов выполнения запроса. Если утрировать, то после выполнения запроса из примера выше база данных вернёт такой массив:Array
(
[0] => Array
(
[Имя] => Мышь
[Любимая еда] => Сыр
)
[1] => Array
(
[Имя] => Кот
[Любимая еда] => Молоко
)
)После получения этого массива необходимо сделать цикл аналогичный foreach( ) по всем элементам полученного массива. Внутри цикла можно обернуть полученные значения в различные HTML теги, чтобы вывод был красивым, чтобы у страницы сайта был дизайн. Так и происходит взаимодействие сайтов с базами данных. Базы данных — это не лучшее хранилище информации. Конёк баз данных — это быстрый поиск информации и вывод с сортировкой. Поэтому базы данных целесообразно использовать далеко не везде. Если же нужно обрабатывать терабайты статичной информации без необходимости поиска и сортировки, то выгоднее использовать использовать простые файлы для хранения информации.
Внутри цикла можно обернуть полученные значения в различные HTML теги, чтобы вывод был красивым, чтобы у страницы сайта был дизайн. Так и происходит взаимодействие сайтов с базами данных. Базы данных — это не лучшее хранилище информации. Конёк баз данных — это быстрый поиск информации и вывод с сортировкой. Поэтому базы данных целесообразно использовать далеко не везде. Если же нужно обрабатывать терабайты статичной информации без необходимости поиска и сортировки, то выгоднее использовать использовать простые файлы для хранения информации.Базы данных используются для сайтов в основном потому, что с их помощью можно организовать уровни доступа к информации. И базы данных большинства сайтов в интернете очень редко когда превышают 10 Гигабайт (считая размеры всех таблиц в базе).
В следующих статьях мы разберём более сложные примеры обращения с базой данных: научимся создавать и удалять таблицы, объединять результаты выборки из нескольких разных таблиц и обновлять данные в таблицах.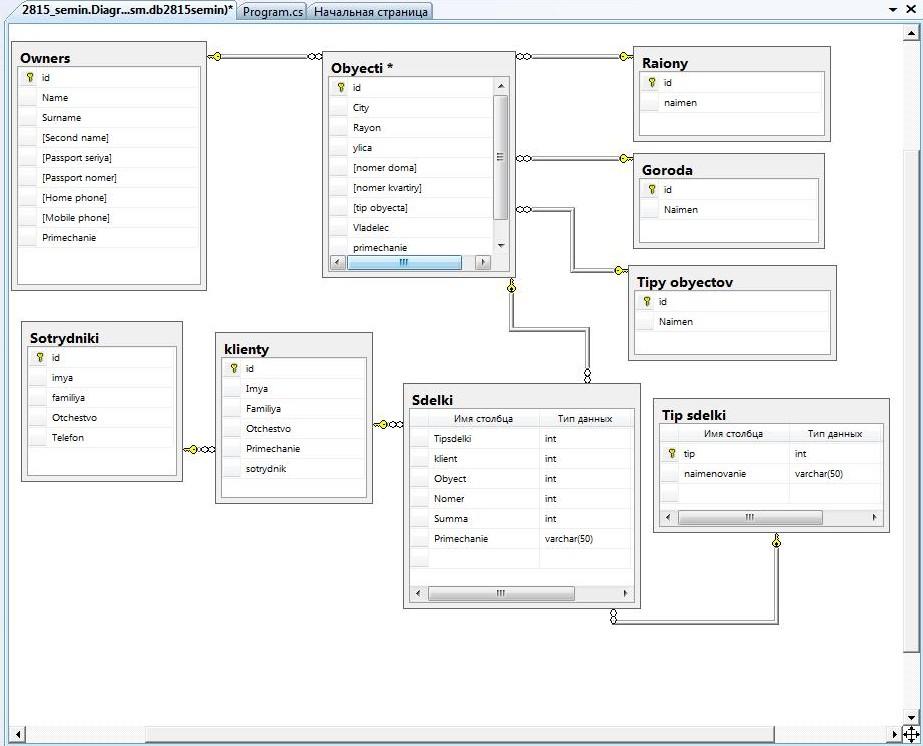 Если вам не терпится приступить к программированию, то рекомендуем ознакомиться со статьёй «Как сделать запрос из PHP к базе данных».
Если вам не терпится приступить к программированию, то рекомендуем ознакомиться со статьёй «Как сделать запрос из PHP к базе данных».Создание базы данных в Microsoft SQL Server – инструкция для новичков | Info-Comp.ru
Приветствую всех на сайте Info-Comp.ru! В этой статье я подробно, специально для начинающих программистов, расскажу о том, как создать базу данных в Microsoft SQL Server, а также о том, что Вы должны знать, перед тем как создавать базу данных.
Сегодняшний материал, как я уже сказал, ориентирован на начинающих программистов, которые хотят научиться работать с Microsoft SQL Server. Поэтому я и буду исходить из того, что Вам нужно создать базу данных для обучения, т.е. основной посыл этой статьи направлен на то, чтобы тот, кто хочет создать базу данных в Microsoft SQL Server, после прочтения статьи четко знал, что ему для этого нужно сделать.
Заметка! Профессиональный онлайн-курс по T-SQL для начинающих.
Что нужно, для того чтобы создать базу данных в Microsoft SQL Server?
В данном разделе я представлю своего рода этапы создания базы данных в Microsoft SQL Server, т.е. это как раз то, что Вы должны знать и что у Вас должно быть, для того чтобы создать базу данных:
- У Вас должна быть установлена СУБД Microsoft SQL Server. Для обучения идеально подходит бесплатная редакция Microsoft SQL Server Express. Если Вы еще не установили SQL сервер, то вот подробная видео-инструкция, там я показываю, как установить Microsoft SQL Server 2017 в редакции Express;
- У Вас должна быть установлена среда SQL Server Management Studio (SSMS). SSMS – это основной инструмент, с помощью которого осуществляется разработка баз данных в Microsoft SQL Server. Эта среда бесплатная, если ее у Вас нет, то в вышеупомянутой видео-инструкции я также показываю и установку этой среды;
- Спроектировать базу данных. Перед тем как переходить к созданию базы данных, Вы должны ее спроектировать, т. е. определить все сущности, которые Вы будете хранить, определить характеристики, которыми они будут обладать, а также определить все правила и ограничения, применяемые к данным, в процессе их добавления, хранения и изменения. Иными словами, Вы должны определиться со структурой БД, какие таблицы она будет содержать, какие отношения будут между таблицами, какие столбцы будет содержать каждая из таблиц. В нашем случае, т.е. при обучении, этот этап будет скорей формальным, так как правильно спроектировать БД начинающий не сможет. Но начинающий должен знать, что переходить к созданию базы данных без предварительного проектирования нельзя, так как реализовать БД, не имея четкого представления, как эта БД должна выглядеть в конечном итоге, скорей всего не получится;
- Создать пустую базу данных. В среде SQL Server Management Studio создать базу данных можно двумя способами: первый — с помощью графического интерфейса, второй — с помощью языка T-SQL;
- Создать таблицы в базе данных. К этому этапу у Вас уже будет база данных, но она будет пустая, так как в ней еще нет никаких таблиц. На этом этапе Вам нужно будет создать таблицы и соответствующие ограничения;
- Наполнить БД данными. В базе данных уже есть таблицы, но они пусты, поэтому сейчас уже можно переходить к добавлению данных в таблицы;
- Создать другие объекты базы данных. У Вас уже есть и база данных, и таблицы, и данные, поэтому можно разрабатывать другие объекты БД, такие как: представления, функции, процедуры, триггеры, с помощью которых реализуется бизнес-правила и логика приложения.
 е. определить все сущности, которые Вы будете хранить, определить характеристики, которыми они будут обладать, а также определить все правила и ограничения, применяемые к данным, в процессе их добавления, хранения и изменения. Иными словами, Вы должны определиться со структурой БД, какие таблицы она будет содержать, какие отношения будут между таблицами, какие столбцы будет содержать каждая из таблиц. В нашем случае, т.е. при обучении, этот этап будет скорей формальным, так как правильно спроектировать БД начинающий не сможет. Но начинающий должен знать, что переходить к созданию базы данных без предварительного проектирования нельзя, так как реализовать БД, не имея четкого представления, как эта БД должна выглядеть в конечном итоге, скорей всего не получится;
е. определить все сущности, которые Вы будете хранить, определить характеристики, которыми они будут обладать, а также определить все правила и ограничения, применяемые к данным, в процессе их добавления, хранения и изменения. Иными словами, Вы должны определиться со структурой БД, какие таблицы она будет содержать, какие отношения будут между таблицами, какие столбцы будет содержать каждая из таблиц. В нашем случае, т.е. при обучении, этот этап будет скорей формальным, так как правильно спроектировать БД начинающий не сможет. Но начинающий должен знать, что переходить к созданию базы данных без предварительного проектирования нельзя, так как реализовать БД, не имея четкого представления, как эта БД должна выглядеть в конечном итоге, скорей всего не получится; К этому этапу у Вас уже будет база данных, но она будет пустая, так как в ней еще нет никаких таблиц. На этом этапе Вам нужно будет создать таблицы и соответствующие ограничения;
К этому этапу у Вас уже будет база данных, но она будет пустая, так как в ней еще нет никаких таблиц. На этом этапе Вам нужно будет создать таблицы и соответствующие ограничения;Вот это общий план создания базы данных, который Вы должны знать, перед тем как начинать свое знакомство с Microsoft SQL Server и языком T-SQL.
В этой статье мы рассмотрим этап 4, это создание пустой базы данных, будут рассмотрены оба способа создания базы данных: и с помощью графического интерфейса, и с помощью языка T-SQL. Первые три этапа Вы должны уже сделать, т.е. у Вас уже есть установленный SQL Server и среда Management Studio, и примерная структура базы данных, которую Вы хотите реализовать, как я уже сказал, на этапе обучения этот пункт можно пропустить, а в следующих материалах я покажу, как создавать таблицы в Microsoft SQL Server пусть с простой, но с более-менее реальной структурой.
Создание базы данных в SQL Server Management Studio
Первое, что Вам нужно сделать, это запустить среду SQL Server Management Studio и подключиться к SQL серверу.
Затем в обозревателе объектов щелкнуть по контейнеру «Базы данных» правой кнопкой мыши и выбрать пункт «Создать базу данных».
В результате откроется окно «Создание базы данных». Здесь обязательно нужно заполнить только поле «Имя базы данных», остальные параметры настраиваются по необходимости. После того, как Вы ввели имя БД, нажимайте «ОК».
Если БД с таким именем на сервере еще нет, то она будет создана, в обозревателе объектов она сразу отобразится.
Как видите, база данных создана, и в этом нет ничего сложного.
Создание базы данных на T-SQL (CREATE DATABASE)
Процесс создания базы данных на языке T-SQL, наверное, еще проще, так как для того чтобы создать БД с настройками по умолчанию (как мы это сделали чуть выше), необходимо написать всего три слова в редакторе SQL запросов – инструкцию CREATE DATABASE и название БД.
Сначала открываем редактор SQL запросов, для этого щелкаем на кнопку «Создать запрос» на панели инструментов.
Затем вводим следующую инструкцию, и запускаем ее на выполнение, кнопка «Выполнить».
CREATE DATABASE TestDB;
Где CREATE – это команда языка T-SQL для создания объектов на SQL сервере, командой DATABASE мы указываем, что хотим создать базу данных, а TestDB — это имя новой базы данных.
Конечно же, на данном этапе многие не знают ни Microsoft SQL Server, ни языка T-SQL, многие, наверное, как раз и создают базу данных для того, чтобы начать знакомиться с этой СУБД и начать изучать язык SQL. Поэтому чтобы Вам легче было это делать, советую почитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
С помощью инструкции CREATE DATABASE можно задать абсолютно все параметры, которые отображались у нас в графическом интерфейсе SSMS. Например, если бы мы заменили вышеуказанную инструкцию следующей, то у нас база данных создалась бы в каталоге DataBases на диске D.
Например, если бы мы заменили вышеуказанную инструкцию следующей, то у нас база данных создалась бы в каталоге DataBases на диске D.
--Создание БД TestDB
CREATE DATABASE TestDB
ON PRIMARY --Первичный файл
(
NAME = N'TestDB', --Логическое имя файла БД
FILENAME = N'D:\DataBases\TestDB.mdf' --Имя и местоположение файла БД
)
LOG ON --Явно указываем файлы журналов
(
NAME = N'TestDB_log', --Логическое имя файла журнала
FILENAME = N'D:\DataBases\TestDB_log.ldf' --Имя и местоположение файла журнала
)
GO
Удаление базы данных в Microsoft SQL Server
В случае необходимости можно удалить базу данных. В реальности, конечно же, такое редко будет требоваться, но в процессе обучения, может быть, и часто. Это можно сделать также, как с помощью графического интерфейса, так и с помощью языка T-SQL.
В случае с графическим интерфейсом необходимо в обозревателе объектов щелкнуть правой кнопкой мыши по нужной базе данных и выбрать пункт «Удалить».
Примечание! Удалить базу данных возможно, только если к ней нет никаких подключений, т.е. в ней никто не работает, даже Ваш собственный контекст подключения в SSMS должен быть настроен на другую БД (например, с помощью команды USE). Поэтому предварительно перед удалением необходимо попросить всех завершить сеансы работы с БД, или в случае с тестовыми базами данных принудительно закрыть все соединения.
В окне «Удаление объекта» нажимаем «ОК». Для принудительного закрытия существующих подключений к БД можете поставить галочку «Закрыть существующие соединения».
В случае с T-SQL, для удаления базы данных достаточно написать следующую инструкцию (в БД также никто не должен работать).
DROP DATABASE TestDB;
Где DROP DATABASE — это инструкция для удаления базы данных, TestDB – имя базы данных. Иными словами, командой DROP объекты на SQL сервере удаляются.
Заметка! Для комплексного изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL.
Видео-урок по созданию базы данных в Microsoft SQL Server
На этом наш сегодняшний урок закончен, надеюсь, материал был Вам интересен и полезен, в следующем материале я расскажу про то, как создавать таблицы в Microsoft SQL Server, удачи Вам, пока!
Нравится52Не нравится6Развернуть базу данных MS SQL
Для работы с базой данных на сервере БД требуется установить Microsoft SQL Server Management Studio. Ознакомиться с описанием программы и скачать установочные файлы можно в документации Microsoft.
На заметку. Развертывание Creatio с отказоустойчивостью на MS SQL успешно тестировалось. Для развертывания системы с высокой доступностью рекомендуется использовать группы доступности MS SQL Always On. Подробнее о технологии MS SQL Always On читайте в документации Microsoft.
Подробнее о технологии MS SQL Always On читайте в документации Microsoft.
После установки Microsoft SQL Server Management Studio вам необходимо создать пользователей базы данных.
Пользователь с ролью ”sysadmin” и неограниченными полномочиями на уровне сервера базы данных — нужен для восстановления базы данных и настройки доступа к ней.
Пользователь с ролью ”public” и ограниченными полномочиями — используется для настройки безопасного подключения Creatio к базе данных через аутентификацию средствами MS SQL Server.
Подробно о создании пользователей и настройке прав читайте в документации Microsoft.
Для восстановления базы данных:
Авторизируйтесь в Microsoft SQL Server Management Studio как пользователь с ролью ”sysadmin”.
Нажмите правой клавишей мыши по каталогу Databases и в контекстном меню выберите команду Restore Database (Рис.
1).В окне Restore Database:
В поле Database введите название базы данных;
Выберите переключатель Device и укажите путь к файлу резервной копии базы данных. По умолчанию данный файл находится в директории ~\db с исполняемыми файлами Creatio (Рис. 2).
Укажите папку на сервере, в которой будет храниться развернутая база данных. Необходимо заранее создать папку, которая будет указываться для восстановления файлов базы данных, т.к. SQL сервер не имеет прав на создание директорий.
Перейдите на вкладку Files.
В области Restore the database files as установите признак Relocate all files and folders.
Укажите пути к папкам, в которые будут сохранены файлы базы данных TS_Data.mdf и TS_Log.ldf (Рис. 3).
Нажмите на кнопку OK и дождитесь завершения процесса восстановления базы данных.
Настройте для восстановленной базы возможность подключения пользователя MS SQL с ролью ”public”, от имени которого приложение Creatio будет подключаться к базе данных:
В MS SQL Server Managment Studio найдите восстановленную базу данных Creatio.
Откройте вкладку Security выбранной базы данных.
В списке пользователей Users добавьте созданного ранее пользователя.
На вкладке Membership укажите роль ”db_owner” — таким образом пользователю будет предоставлен неограниченный доступ к восстановленной базе.
 1).
1).
Пример базы данных SQL Server для обучения SQL
1- Введение
LearningSQL это маленькая база данных, использующаяся для примера в инструкциях по изучению SQL имеющиеся на вебсайте o7planning, существует 3 версии на Database:
- Oracle
- MySQL
- SQLServer.

В данной статье я покажу вам как создать данную базу данных на SQLServer.
Эта база данных предоставлена как модельная база данных для изучения SQL Server по ссылке:
- Руководство SQL для начинающих с SQL Server
2- Download Script
Скачать script по ссылке:
| Direct | Mediafire |
| Download | Download |
С SQLServer вам нужно обратить внимание только на файл:
- LearningSQL-SQLServer-Script.sql
3- Запуск Script
3.1- Создать LearningSQL SCHEMA на SQLServer Management Studio
Создайть новый Database
- Database Name: learingsql
Скопировать содержание файла LearningSQL-SQLServer-Script. sql в окоSQL и выполнить
sql в окоSQL и выполнить
4- Обзор LearningSQL
LearningSQL это маленькая база данных симулирующая данные банка:
| НАЗВАНИЕ ТАБЛИЦЫ | ЗНАЧЕНИЕ |
| ACCOUNT | Таблица хранящая банковский счет. Каждый клиет может зарегистрировать несколько счетов, каждый счет соответствует услуге предоставленной банком. (Смотрите так же PRODUCT) |
| ACC_TRANSACTION | Таблица хранящая информацию транзакции с банком определенного счета. |
| BRANCH | Филиал банка |
| BUSSINESS | |
| CUSTOMER | Таблица клиентов |
| DEPARTMENT | Таблица департаментов банка. |
| EMPLOYEE | Таблица работников банка. |
| OFFICER | |
| PRODUCT | Продукты услуг банка, например:
|
| PRODUCT_TYPE | Продукты услуг банка, например:
|
 ….
….5- Структура таблиц
5.1- ACCOUNT
5.2- ACC_TRANSACTION
5.3- BRANCH
5.4- BUSINESS
5.5- CUSTOMER
5.6- DEPARTMENT
5.7- EMPLOYEE
5.8- INDIVIDUAL
5.9- OFFICER
5.10- PRODUCT
5.11- PRODUCT_TYPE
База данных SQl или NoSQL: какую выбрать для проекта?
Масштабируемость. Вертикальная, то есть при росте нагрузки растет производительность сервера. Если в базу поступает большой объем данных, рано или поздно наступит порог вертикального масштабирования — сервер не сможет далее увеличивать производительность. Тогда понадобится горизонтальное масштабирование — параллельная обработка данных в кластере серверов.
В больших распределенных системах это может привести к тому, что общая производительность системы упадет, так как нужно поддерживать согласованность данных в нескольких узлах. Это не значит, что СУБД на SQL не подходят для больших проектов — они поддерживают кластеризацию, просто нужно приложить усилия, чтобы настроить систему. Либо использовать базы данных в облаке — там можно получить уже настроенные и надежно работающие кластеры в несколько кликов.
Самые известные SQL-базы данных
MySQL — одна из самых популярных open source реляционных баз данных. Подходит небольшим и средним проектам, которым нужен недорогой и надежный инструмент работы с данными. Поддерживает множество типов таблиц, есть огромное количество плагинов и расширений, облегчающих работу с системой.
Отличается простой установкой, может быть интегрирована с другими СУБД, также интеграция с MySQL есть в любой CMS, фреймворке, языке программирования. Среди минусов — не все задачи выполняет автоматически, если что-то нужное не включено в функционал, придется потратить время на доработку, нет встроенной поддержки OLAP.
PostgreSQL — вторая по популярности open source SQL СУБД. У нее много встроенных функций и дополнений, в том числе для масштабирования в кластер и шардинга таблиц. Подходит, если важна сохранность данных, предполагается их сложная структура. Позволяет работать со структурированными данными, но поддерживает JSON/BSON, что дает некоторую гибкость в схеме данных.
Отличается стабильностью, ее практически невозможно вывести из строя или что-то сломать в таблицах.
Из минусов — сложность конфигурации требует от пользователей некоторого опыта. Также скорость работы может падать во время проведения пакетных операций или при запросах на чтение.
PostgreSQL также можно развернуть в облаке — в отличие от MySQL, она подходит для крупных и масштабных проектов. Кроме того, ее стоит выбрать, если недопустимы ошибки в данных или есть особые требования к базе данных, например поддержка геоданных. Различные расширения PostgreSQL позволяют реализовать многие специализированные запросы.
Кроме того, ее стоит выбрать, если недопустимы ошибки в данных или есть особые требования к базе данных, например поддержка геоданных. Различные расширения PostgreSQL позволяют реализовать многие специализированные запросы.
Введение в SQL
SQL — это стандартный язык для доступа к базам данных и управления ими.
Что такое SQL?
- SQL — это аббревиатура от языка структурированных запросов .
- SQL позволяет получать доступ к базам данных и управлять ими
- SQL стал стандартом Американского национального института стандартов (ANSI) в 1986 г. и Международной организации по стандартизации (ISO) в 1987
Что умеет SQL?
- SQL может выполнять запросы к базе данных
- SQL может извлекать данные из базы данных
- SQL может вставлять записи в базу данных
- SQL может обновлять записи в базе данных
- SQL может удалять записи из базы данных
- SQL может создавать новые базы данных
- SQL может создавать новые таблицы в базе данных
- SQL может создавать хранимые процедуры в базе данных
- SQL может создавать представления в базе данных
- SQL может устанавливать разрешения для таблиц, процедур и представлений
SQL — это Стандарт — НО.
 …
…Хотя SQL является стандартом ANSI / ISO, существуют разные версии языка SQL.
Однако, чтобы соответствовать стандарту ANSI, все они поддерживают, по крайней мере, основные команды (например, ВЫБЕРИТЕ , ОБНОВЛЕНИЕ , УДАЛИТЬ , ВСТАВИТЬ , WHERE ) аналогичным образом.
Примечание: Большинство программ баз данных SQL также имеют собственные проприетарные расширения в дополнение к стандарту SQL!
Использование SQL на вашем веб-сайте
Для создания веб-сайта, отображающего данные из базы данных, вам потребуется:
- Программа базы данных СУБД (т.е. MS Access, SQL Server, MySQL)
- Для использования языка сценариев на стороне сервера, такого как PHP или ASP
- Использование SQL для получения нужных данных
- Использование HTML / CSS для стилизации страницы
РСУБД
RDBMS — это система управления реляционными базами данных.
является основой для SQL и для всех современных систем баз данных, таких как MS SQL Server, IBM DB2, Oracle, MySQL и Microsoft Access.
Данные в СУБД хранятся в объектах базы данных, называемых таблицами.Таблица — это набор связанных записей данных, состоящий из столбцов и строк.
Посмотрите в таблице «Клиенты»:
Каждая таблица разбита на более мелкие объекты, называемые полями. Поля в таблица клиентов состоит из идентификатора клиента, имени клиента, имени контакта, адреса, Город, почтовый индекс и страна. Поле — это столбец в таблице, предназначенный для поддержки конкретная информация о каждой записи в таблице.
Запись, также называемая строкой, — это каждая отдельная запись, существующая в таблице.Например, в приведенной выше таблице «Клиенты» 91 запись. Рекорд — это горизонтальный объект в таблице.
Столбец — это вертикальный объект в таблице, который содержит всю информацию.
связанный с определенным полем в таблице.
Что такое база данных SQL?
Базы данных SQL использовались десятилетиями — и используются до сих пор. В этом блоге мы даем базовый обзор того, что такое база данных SQL, и приводим примеры.
Что такое база данных SQL?
SQL означает язык структурированных запросов.Используется для реляционных баз данных . База данных SQL — это набор таблиц, в которых хранится определенный набор структурированных данных.
База данных SQL долгое время была проверенной и верной рабочей лошадкой серверного предприятия и лежала в основе всего, что мы делаем в этот электронный век. SQL был создан в начале 1970-х в IBM как метод доступа к системе баз данных IBM System R.
История баз данных SQL
Полезность возможности доступа к нескольким записям с помощью одной команды, не требующей указания способа достижения данной записи, была немедленно признана компьютерным миром. Он был быстро принят в качестве основного языка запросов для других систем управления базами данных или СУБД, таких как IBM DB2, а в 1979 году — сервера базы данных Oracle V2 от Relational Software Inc. (теперь известного как Oracle Software) для систем Vax. В конце концов, в 1986 году SQL был принят организациями по стандартизации ANSI и ISO, проложив путь для Microsoft SQL Server и различных баз данных с открытым исходным кодом, имеющихся сегодня на рынке.
Он был быстро принят в качестве основного языка запросов для других систем управления базами данных или СУБД, таких как IBM DB2, а в 1979 году — сервера базы данных Oracle V2 от Relational Software Inc. (теперь известного как Oracle Software) для систем Vax. В конце концов, в 1986 году SQL был принят организациями по стандартизации ANSI и ISO, проложив путь для Microsoft SQL Server и различных баз данных с открытым исходным кодом, имеющихся сегодня на рынке.
СУБД, которую мы использовали сегодня, полагается на SQL как на механизм, который позволяет нам выполнять все операции, необходимые для создания, извлечения, обновления и удаления данных по мере необходимости.С точки зрения открытого исходного кода, эти СУБД включают MySQL, MariaDB и PostgreSQL как наиболее часто используемые СУБД с открытым исходным кодом в настоящее время. Многие компании из списка Fortune 100 в нескольких различных секторах бизнеса, включая финансовую, розничную торговлю, здравоохранение и другие, обратились к этим альтернативам с открытым исходным кодом, чтобы значительно снизить общую стоимость владения по сравнению с предложениями с оплатой за игру, такими как сервер Oracle Database и Microsoft. SQL Server.
SQL Server.
Какая база данных вам подходит?
Получите полное руководство для лиц, принимающих решения по выбору баз данных с открытым исходным кодом, включая разновидности SQL.
📘 ПОЛУЧИТЬ РУКОВОДСТВО
Примеры баз данных SQL
MariaDB и MySQL
MariaDB и MySQL — это бинарно-совместимые серверы баз данных SQL с открытым исходным кодом, которые изначально начинались как просто MySQL. Однако из-за опасений по поводу будущего MySQL после того, как она была приобретена Oracle Software, MariaDB была выделена из проекта как отдельная сущность, но сохраняет свою совместимость с клиентскими API и протоколами MySQL в дополнение к файлам данных и определений таблиц.
Это означает, что в большинстве случаев сторонние инструменты будут работать с обеими версиями и, как правило, их можно рассматривать как замену любой версии.С приобретением MySQL Oracle стала довольно доброжелательным руководителем проекта с открытым исходным кодом, и большинство опасений, которые сообщество испытывало в первые дни приобретения, не сбылось, однако некоторые пуристы с открытым исходным кодом все еще могут предпочесть MariaDB MySQL. .
.
PostgreSQL
PostgreSQL — это объектно-реляционная система управления базами данных (ORDBMS), а не чисто СУБД, такая как MySQL и MariaDB. Это означает, что модели данных PostgreSQL могут быть основаны на моделях реляционных баз данных, но также могут быть объектно-ориентированными.На практике это означает, что мы видим, что PostgreSQL используется в более сложных и разнообразных моделях данных, а MariaDB и MySQL используются для более легких моделей данных.
Развиваясь из проекта Ingres в Калифорнийском университете в Беркли в 1982 году, PostgreSQL был создан с целью добавления минимального количества функций, необходимых для поддержки всех основных типов данных. Этот менталитет «большой отдачи» продолжает стимулировать развитие PostgreSQL и по сей день. Для пуриста с открытым исходным кодом, как правило, выбирают эту базу данных, поскольку это настоящий проект с открытым исходным кодом, который видят в PostgreSQL Global Development Group, некоммерческой организации, которую нелегко продать из-за ее образования.
Какое будущее у баз данных SQL?
В последние годы появились новые технологии, отвечающие потребностям серверов баз данных, которые могут обрабатывать чрезвычайно большие наборы данных с чрезвычайно высокой общей скоростью без ущерба для стабильности или доступности. Базы данных NoSQL (не только SQL или не-SQL) становятся все более популярными для удовлетворения этих требований. Базы данных NoSQL хранят свои данные иначе, чем реляционные базы данных, используя базы данных на основе JSON или базы данных «ключ-значение», чтобы назвать несколько распространенных типов хранилищ.PostgreSQL с JSON и его методология, основанная на OORDMS, является свидетельством долговечности этих баз данных NoSQL.
Тем не менее, до традиционной базы данных SQL еще долго не зайдет солнце. Степень того, что базы данных SQL вошли в нашу повседневную жизнь, означает, что эти высокофункциональные и надежные СУБД будут опорой предприятия на десятилетия вперед.
Дальнейшие действия
Если вам нужна дополнительная информация о переходе с дорогостоящего предложения РСУБД с оплатой за игру на более экономически целесообразную альтернативу, свяжитесь с командой OpenLogic от Perforce. OpenLogic помог многим организациям во многих масштабах отказаться от дорогостоящего мира серверов баз данных с закрытым исходным кодом и добиться значительной экономии, переключившись на мир с открытым исходным кодом. Узнайте, как мы можем помочь вам с поддержкой баз данных, например с поддержкой PostgreSQL и т. Д.
OpenLogic помог многим организациям во многих масштабах отказаться от дорогостоящего мира серверов баз данных с закрытым исходным кодом и добиться значительной экономии, переключившись на мир с открытым исходным кодом. Узнайте, как мы можем помочь вам с поддержкой баз данных, например с поддержкой PostgreSQL и т. Д.
СВЯЗАТЬСЯ С ЭКСПЕРТОМ
Базы данных SQL и NoSQL: в чем разница?
В мире технологий баз данных существует два основных типа баз данных: SQL и NoSQL — или реляционные базы данных и нереляционные базы данных.Разница говорит о том, как они устроены, о типе информации, которую они хранят, и о том, как они ее хранят. Реляционные базы данных структурированы, как телефонные книги, в которых хранятся номера телефонов и адреса. Нереляционные базы данных ориентированы на документы и распределены, как папки с файлами, в которых хранится все, от адреса и номера телефона человека до его лайков в Facebook и предпочтений в онлайн-покупках.
Мы называем их SQL и NoSQL, имея в виду, написаны ли они исключительно на языке структурированных запросов (SQL).В этой статье мы рассмотрим, что такое SQL, как он отличает эти базы данных и как каждый тип структурирует данные, которые он хранит, чтобы вы могли легко определить, какой тип подходит именно вам.
SQL: реляционные базы данных
Во-первых, давайте взглянем на одну из основных особенностей, разделяющих эти две системы: способ, которым они структурируют данные. Реляционная база данных — или база данных SQL, названная в честь языка, на котором она написана, язык структурированных запросов (SQL) — является более жестким и структурированным способом хранения данных, как телефонная книга.Разработанная IBM в 1970-х годах реляционная база данных состоит из двух или более таблиц со столбцами и строками. Каждая строка представляет собой запись, а в каждом столбце сортируется очень определенный тип информации, такой как имя, адрес и номер телефона. Связь между таблицами и типами полей называется схемой . В реляционной базе данных схема должна быть четко определена, прежде чем можно будет добавить какую-либо информацию.
Связь между таблицами и типами полей называется схемой . В реляционной базе данных схема должна быть четко определена, прежде чем можно будет добавить какую-либо информацию.
Чтобы реляционная база данных была эффективной, данные, которые вы храните в ней, должны быть очень организованы.Хорошо спроектированная схема сводит к минимуму избыточность данных и предотвращает рассинхронизацию таблиц, что является важной функцией для многих предприятий, особенно тех, которые регистрируют финансовые транзакции. Плохо спроектированная схема может вызвать головную боль организации из-за ее жесткости. Например, в столбце, предназначенном для хранения телефонных номеров США, может потребоваться 10 цифр, поскольку это стандарт для телефонных номеров в США. Преимущество этого метода заключается в отклонении любых недопустимых значений (например, если в номере отсутствует код города).Однако, если вам нужно изменить схему (например, если вам нужно включить международный телефонный номер, содержащий более 10 цифр), то необходимо отредактировать всю базу данных. Ключевой вывод: отличная организация приводит к компромиссу в гибкости с реляционной базой данных.
Ключевой вывод: отличная организация приводит к компромиссу в гибкости с реляционной базой данных.
Язык структурированных запросов (SQL) — это язык программирования, используемый разработчиками баз данных для проектирования реляционных баз данных. В базе данных SQL, такой как MySQL, Sybase, Oracle или IBM DM2, SQL выполняет запросы, извлекает данные и редактирует данные, обновляя, удаляя или создавая новые записи.SQL — это легкий декларативный язык, который выполняет большую часть тяжелой работы для реляционной базы данных, действуя как версия серверного сценария для базы данных. Одним из особых преимуществ SQL является его простое, но мощное предложение JOIN, которое позволяет разработчикам извлекать связанные данные, хранящиеся в нескольких таблицах, с помощью одной команды.
Еще одна причина, по которой базы данных SQL остаются популярными, заключается в том, что они естественным образом вписываются во многие известные стеки программного обеспечения, включая LAMP и стеки на основе Ruby. Эти базы данных хорошо изучены и широко поддерживаются, что может стать большим преимуществом, если у вас возникнут проблемы.
Эти базы данных хорошо изучены и широко поддерживаются, что может стать большим преимуществом, если у вас возникнут проблемы.
Популярные базы данных SQL и СУБД
- MySQL — самая популярная база данных с открытым исходным кодом, отлично подходящая для сайтов CMS и блогов.
- Oracle — объектно-реляционная СУБД, написанная на языке C ++. Если у вас есть бюджет, это вариант с полным спектром услуг с отличным обслуживанием клиентов и надежностью. Oracle также выпустила базу данных Oracle NoSQL.
- IMB DB2 — семейство продуктов серверов баз данных от IBM, предназначенных для обработки расширенной аналитики «больших данных».
- Sybase — серверный продукт реляционной модели базы данных для предприятий, в основном используемый на ОС Unix, которая была первой СУБД корпоративного уровня для Linux.
- MS SQL Server — РСУБД, разработанная Microsoft для баз данных корпоративного уровня, которая поддерживает архитектуры как SQL, так и NoSQL.
- Microsoft Azure — платформа облачных вычислений, которая поддерживает любую операционную систему и позволяет хранить, вычислять и масштабировать данные в одном месте. Недавний опрос даже поставил его перед Amazon Web Services и Google Cloud Storage для корпоративного хранения данных.
- MariaDB — расширенная версия MySQL.
- PostgreSQL — объектно-реляционная СУБД корпоративного уровня, в которой помимо кода уровня SQL используются процедурные языки, такие как Perl и Python.

Базы данных NoSQL: нереляционные и распределенные данные
Если ваши требования к данным не ясны с самого начала или если вы имеете дело с огромными объемами неструктурированных данных, у вас может не быть роскоши разработки реляционной базы данных с четко определенная схема.Откройте для себя нереляционные базы данных, которые предлагают гораздо большую гибкость, чем их традиционные аналоги.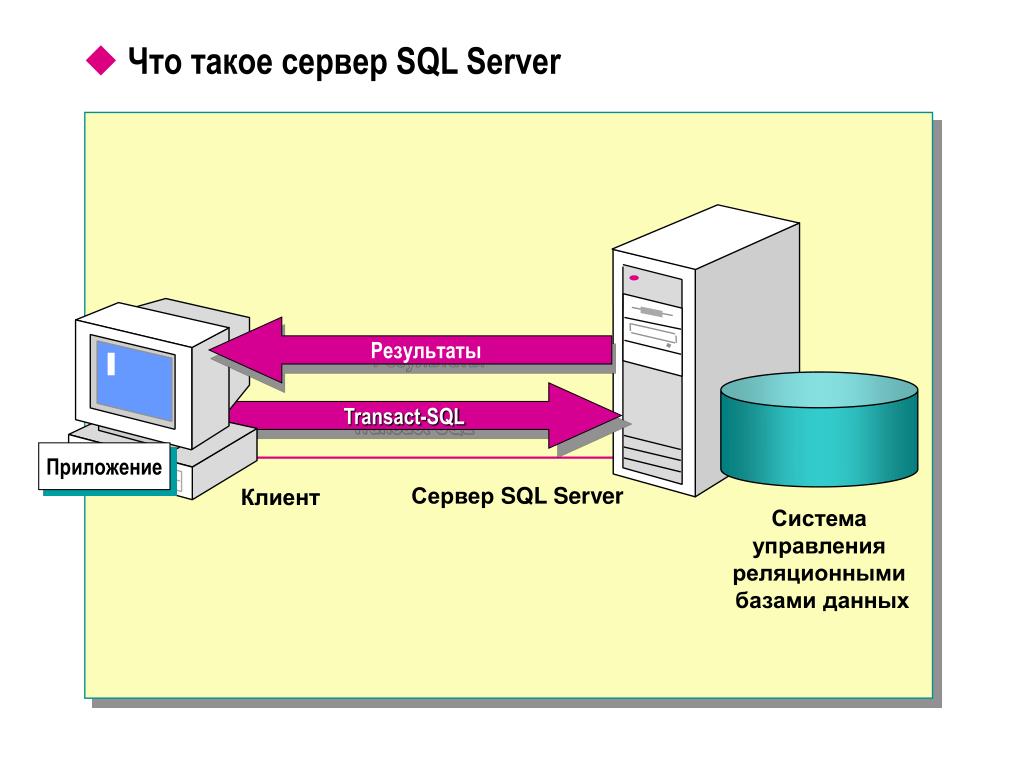 Думайте о нереляционных базах данных больше как о папках с файлами, где собрана связанная информация всех типов. Если бы блог WordPress использовал базу данных NoSQL, каждый файл мог бы хранить данные для сообщения блога: лайки в социальных сетях, фотографии, текст, показатели, ссылки и многое другое.
Думайте о нереляционных базах данных больше как о папках с файлами, где собрана связанная информация всех типов. Если бы блог WordPress использовал базу данных NoSQL, каждый файл мог бы хранить данные для сообщения блога: лайки в социальных сетях, фотографии, текст, показатели, ссылки и многое другое.
Неструктурированные данные из Интернета могут включать данные датчиков, совместное использование в социальных сетях, личные настройки, фотографии, информацию о местоположении, онлайн-активность, показатели использования и многое другое.Попытки хранить, обрабатывать и анализировать все эти неструктурированные данные привели к разработке бессхемных альтернатив SQL. Взятые вместе, эти альтернативы называются NoSQL, что означает «Не только SQL». Хотя термин NoSQL охватывает широкий спектр альтернатив реляционным базам данных, их объединяет то, что они позволяют более гибко обрабатывать данные.
Как работают базы данных NoSQL? Вместо таблиц базы данных NoSQL ориентированы на документы . Таким образом, неструктурированные данные (такие как статьи, фотографии, данные из социальных сетей, видео или контент в сообщении блога) могут храниться в одном документе, который можно легко найти, но не обязательно разделен на поля, такие как реляционные база данных делает.Это более интуитивно понятно, но учтите, что такое массовое хранение данных требует дополнительных усилий по обработке и большего объема памяти, чем высокоорганизованные данные SQL. Вот почему Hadoop, платформа для вычислений и анализа данных с открытым исходным кодом, способная обрабатывать огромные объемы данных в облаке, так популярна в сочетании со стеками баз данных NoSQL.
Базы данных NoSQL предлагают еще одно важное преимущество, особенно для разработчиков приложений: простоту доступа. Реляционные базы данных тесно связаны с приложениями, написанными на объектно-ориентированных языках программирования, таких как Java, PHP и Python.Базы данных NoSQL часто могут обойти эту проблему с помощью API-интерфейсов, которые позволяют разработчикам выполнять запросы без необходимости изучать SQL или понимать базовую архитектуру своей системы баз данных.
Общие типы баз данных NoSQL
- Модель «ключ-значение» — наименее сложный вариант NoSQL, который хранит данные без схемы, состоящей из индексированных ключей и значений. Примеры: Cassandra, Azure, LevelDB и Riak.
- Хранилище столбцов — или хранилище с широкими столбцами, в котором таблицы данных хранятся в виде столбцов, а не строк.Это больше, чем просто перевернутая таблица — разделение столбцов на разделы обеспечивает отличную масштабируемость и высокую производительность. Примеры: HBase, BigTable, HyperTable.
- База данных документов — принимая концепцию «ключ-значение» и усложняя, каждый документ в этом типе базы данных имеет свои собственные данные и свой собственный уникальный ключ, который используется для их извлечения. Это отличный вариант для хранения, извлечения и управления данными, ориентированными на документы, но все же в некоторой степени структурированными. Примеры: MongoDB, CouchDB.
- База данных графиков — есть данные, которые взаимосвязаны и лучше всего представлены в виде графика? Этот метод может быть очень сложным. Примеры: Полиглот, Neo4J.
Популярные базы данных NoSQL
- MongoDB — самая популярная система NoSQL, особенно среди стартапов. Документно-ориентированная база данных с JSON-подобными документами в динамических схемах вместо реляционных таблиц, которые используются на бэкенде таких сайтов, как Craigslist, eBay, Foursquare.Это открытый исходный код, поэтому он бесплатный, с хорошим обслуживанием клиентов.
- Apache CouchDB — настоящая БД для Интернета, она использует формат обмена данными JSON для хранения своих документов; JavaScript для индексации, объединения и преобразования документов; и HTTP для своего API.
- HBase — еще один проект Apache, разработанный как часть Hadoop, эта нереляционная база данных NoSQL с открытым исходным кодом «хранилище столбцов» написана на Java и предоставляет возможности, подобные BigTable.
- Oracle NoSQL — Вхождение Oracle в категорию NoSQL.
- Apache Cassandra DB — созданная в Facebook, Cassandra представляет собой распределенную базу данных, которая отлично подходит для обработки больших объемов структурированных данных. Ожидаете роста приложения? Кассандра отлично умеет увеличивать масштаб. Примеры: Instagram, Comcast, Apple и Spotify.
- Riak — база данных хранилища ключей и значений с открытым исходным кодом, написанная на Erlang. Он имеет встроенную отказоустойчивую репликацию и автоматическое распределение данных для обеспечения отличной производительности.
Какое решение для баз данных вам подходит?
Причины использования базы данных SQL
Когда дело доходит до технологии баз данных, универсального решения не существует.Вот почему многие компании используют как реляционные, так и нереляционные базы данных для решения различных задач. Несмотря на то, что базы данных NoSQL набирают популярность благодаря своей скорости и масштабируемости, все еще существуют ситуации, когда база данных SQL с высокой структурой может быть предпочтительнее. Вот несколько причин, по которым вы можете выбрать базу данных SQL:
- Вам необходимо обеспечить соответствие ACID (атомарность, согласованность, изоляция, надежность). Соответствие ACID сокращает количество аномалий и защищает целостность вашей базы данных, точно предписывая, как транзакции взаимодействуют с базой данных.Как правило, базы данных NoSQL жертвуют совместимостью с ACID ради гибкости и скорости обработки, но для многих приложений электронной коммерции и финансовых приложений предпочтительным вариантом остается ACID-совместимая база данных.
- Ваши данные структурированы и неизменны. Если ваш бизнес не демонстрирует значительного роста, для которого потребовалось бы больше серверов, и вы работаете только с согласованными данными, то, возможно, нет причин использовать систему, предназначенную для поддержки различных типов данных и большого объема трафика.
Причины использования базы данных NoSQL
Когда все остальные компоненты серверного приложения разработаны так, чтобы работать быстро и без проблем, базы данных NoSQL не позволяют данным быть узким местом. Настоящим мотиватором NoSQL здесь являются большие данные, которые делают то, чего не могут делать традиционные реляционные базы данных. Это способствует росту популярности баз данных NoSQL, таких как MongoDB, CouchDB, Cassandra и HBase.
- Хранение больших объемов данных, которые часто практически не имеют структуры. База данных NoSQL не устанавливает ограничений на типы данных, которые вы можете хранить вместе, и позволяет вам добавлять различные новые типы по мере изменения ваших потребностей. С базами данных на основе документов вы можете хранить данные в одном месте, не определяя заранее, какие «типы» это данные.
- Максимально эффективное использование облачных вычислений и хранения. Облачное хранилище — отличное экономичное решение, но требует, чтобы данные легко распределялись по нескольким серверам для масштабирования. Использование стандартного (доступного, меньшего по размеру) оборудования на месте или в облаке избавляет вас от лишних хлопот, связанных с дополнительным программным обеспечением, а базы данных NoSQL, такие как Cassandra, спроектированы для масштабирования в нескольких центрах обработки данных без особых проблем.
- Быстрое развитие. Если вы разрабатываете в рамках двухнедельных Agile-спринтов, выполняете быстрые итерации или вам нужно часто обновлять структуру данных без больших простоев между версиями, реляционная база данных замедлит вас. Данные NoSQL не нужно подготавливать заранее.
Теперь, когда у вас есть обзор SQL и NoSQL, кто вам нужен, чтобы помочь вам создавать и поддерживать свои системы баз данных? Системы управления реляционными и нереляционными базами данных могут стать чрезвычайно сложными и определенно потребовать обслуживания, особенно если учесть переход в облако.Хотя в такой программе, как Microsoft Access, легко управлять базовой однофайловой базой данных, вам нужно нанять способного архитектора баз данных для управления вашей системой управления реляционными базами данных (RDBMS) или управлением базами данных NoSQL. Изучите администраторов баз данных на Upwork.
Введение в базы данных и SQL — управление данными с помощью SQL для экологов
Обзор
Обучение: 60 мин.
Цели
Упражнения: 5 мин.
Опишите, почему реляционные базы данных полезны.
Создайте и заполните базу данных из текстового файла.
Определите типы данных SQLite.
Выбирать, группировать, добавлять и анализировать подмножества данных.
Объедините данные из нескольких таблиц.
Настройка
Примечание: это должны были сделать участники до начала семинара.
Мы используем Браузер БД для SQLite и Набор данных проекта портала на протяжении всего урока.См. Раздел «Настройка» для инструкции по загрузке данных, а также по установке браузера БД для SQLite.
Для начала давайте сориентируемся в рабочем процессе нашего проекта. Ранее, мы использовали Excel и OpenRefine, чтобы избавиться от беспорядочных, созданных людьми данных к очищенным, машиночитаемым данным. Теперь перейдем к следующему фрагменту. рабочего процесса данных, используя компьютер для чтения наших данных, а затем использовать его для анализа и визуализации.
Что такое SQL?
SQL означает язык структурированных запросов.SQL позволяет нам взаимодействовать с реляционными базами данных через запросы. Эти запросы могут позволить вам выполнять ряд действий, таких как: вставка, выбор, обновление и удаление информации в базе данных.
Описание набора данных
Данные, которые мы будем использовать, представляют собой временные ряды для сообщества мелких млекопитающих в южная Аризона. Это часть проекта по изучению воздействия грызунов и муравьи в растительном сообществе, которое существует уже почти 40 лет. В грызунов отбирают на сериях из 24 делянок с разными экспериментальными манипуляции, контролирующие, каким грызунам разрешен доступ к каким участкам.
Это реальный набор данных, который использовался в более чем 100 публикациях. Мы упростил его для семинара, но вы можете скачать полный набор данных и работать с ним, используя точно такие же инструменты, о которых мы узнаем сегодня.
вопросов
Сначала загрузим и посмотрим на некоторые очищенные таблицы. от Набор данных проекта портала. Нам понадобятся следующие три файла:
-
Survey.csv -
разновидностей.csv -
земельных участков.csv
Вызов
Откройте каждый из этих CSV-файлов и исследуйте их. Какая информация содержится в каждом файле? В частности, если бы у меня было следующие вопросы исследования:
- Как изменились со временем длина и вес задней части стопы у видов Dipodomys ?
- Каков средний вес каждого вида в год?
- Какую информацию я могу узнать о видах Dipodomys в 2000-е годы с течением времени?
Что мне нужно, чтобы ответить на эти вопросы? В каких файлах есть нужные мне данные? Какие какие операции мне нужно было бы выполнить, если бы я делал эти анализы вручную?
Голы
Чтобы ответить на вопросы, описанные выше, нам нужно будет выполнить следующие основные операции с данными:
- выбрать подмножества данных (строки и столбцы)
- группировать подмножества данных
- выполнять математические и другие вычисления
- объединить данные в таблицах
Кроме того, мы не хотим делать это вручную! Вместо поиска сами нужные фрагменты данных или щелкая мышью между таблицами, или вручную сортируя столбцы, мы хотим, чтобы компьютер выполнял всю работу.
В частности, мы хотим использовать инструмент, позволяющий легко повторить наш анализ. в случае изменения наших данных. Мы также хотим проделать весь этот поиск без фактически изменяя наши исходные данные.
Помещение наших данных в реляционную базу данных и использование SQL поможет нам достичь этих целей.
Определение:
Реляционная база данныхРеляционная база данных хранит данные в отношениях , состоящих из записей с полями .Отношения обычно представлены в виде таблиц ; каждая запись обычно отображается в виде строки, а поля — в виде столбцов. В большинстве случаев каждая запись будет иметь уникальный идентификатор, называемый ключом , который хранится как одно из его полей. Записи также могут содержать ключи, которые относятся к записям в других таблицах, что позволяет нам объединять информацию из двух или более источников.
Зачем нужны реляционные базы данных
Использование реляционной базы данных служит нескольким целям.
- Он хранит ваши данные отдельно от анализа.
- Это означает, что нет риска случайного изменения данных при их анализе.
- Если мы получим новые данные, мы можем повторно запустить запрос.
- Это быстро даже для больших объемов данных.
- Улучшает контроль качества ввода данных (ограничения типов и использование форм в MS Access, Filemaker, Oracle Application Express и т. Д.).
- Концепции запросов к реляционной базе данных являются ключевыми для понимания того, как делать аналогичные вещи с использованием таких языков программирования, как R или Python.
Системы управления базами данных
Существуют различные системы управления базами данных для работы с реляционными базами данных. такие как SQLite, MySQL, Potsgresql, MSSQL Server и многие другие. Каждый из них отличается в основном на основе их масштабируемости, но все они разделяют одни и те же основные принципы реляционные базы данных. В этом уроке мы используем SQLite, чтобы познакомить вас с SQL и получение данных из реляционной базы данных.
Реляционные базы данных
Давайте посмотрим на уже существующую базу данных portal_mammals.sqlite файл из набора данных проекта портала, который мы загрузили во время
Настраивать. Нажмите кнопку «Открыть базу данных», выберите файл portal_mammals.sqlite и нажмите «Открыть», чтобы открыть базу данных.
Вы можете увидеть таблицы в базе данных, посмотрев на левую часть
на вкладке «Структура базы данных». Здесь вы увидите список в разделе «Таблицы». Каждый элемент, указанный здесь, соответствует одному из файлов csv мы исследовали ранее. Чтобы увидеть содержимое любой таблицы, щелкните по ней и
затем щелкните вкладку «Обзор данных» рядом с вкладкой «Структура базы данных».Это будет
дайте нам представление, к которому мы привыкли — копию таблицы. Надеюсь, это
помогает показать, что база данных в некотором смысле представляет собой просто набор таблиц,
где в таблицах есть какое-то значение, которое позволяет связать их с каждым
прочее («связанная» часть «реляционной базы данных»).
Вкладка «Структура базы данных» также предоставляет некоторые метаданные о каждой таблице. Если вы щелкните стрелку вниз рядом с именем таблицы, вы увидите информацию о столбцах, которые в базах данных называются «полями», и назначенных им типах данных.(Строки таблицы базы данных
называются записей .) Каждое поле содержит
одна разновидность или тип данных, часто числа или текст. Вы можете увидеть в просматривает таблицу , в которой большинство полей содержат числа (BIGINT, или большие целые числа, и FLOAT, или числа с плавающей запятой / десятичные дроби), в то время как разновидностей таблица полностью состоит из текстовых полей.
Вкладка «Выполнить SQL» теперь пуста — здесь мы будем вводить наши запросы. для получения информации из таблиц базы данных.
Суммируем:
- Реляционные базы данных хранят данные в таблицах с полями (столбцами) и записями (ряды)
- Данные в таблицах имеют типы, и все значения в поле имеют однотипный (список типов данных)
- Запросы позволяют нам искать данные или производить вычисления на основе столбцов
Дизайн базы данных
- Каждая комбинация строка-столбец содержит одно атомарное значение , т. Е. Не содержащие части, с которыми мы, возможно, захотим поработать отдельно.
- Одно поле для каждого типа информации
- Нет избыточной информации
- Разделить на отдельные таблицы по одной таблице на класс информации
- Требуется общий идентификатор между таблицами — общий столбец — для переподключиться (известный как внешний ключ ).
Импорт
Прежде чем приступить к написанию собственных запросов, мы создадим собственные
база данных. Мы будем создавать эту базу данных из трех файлов csv мы скачали раньше.Закройте текущую открытую базу данных ( File> Close Database ), а затем
следуйте этим инструкциям:
- Создать новую базу данных
- Нажмите кнопку Новая база данных
- Дайте имя и нажмите Сохранить, чтобы создать базу данных в открытой папке
- В появившемся окне «Редактировать определение таблицы» нажмите «Отмена», так как мы будем импортировать таблицы, а не создавать их с нуля.
- Выберите Файл »Импорт» Таблица из файла CSV…
- Выберите
опросов.csvиз папки данных, которую мы скачали, и нажмите Открыть . - Присвойте таблице имя, которое соответствует имени файла (опросы
,), или используйте значение по умолчанию - Если в первой строке есть заголовки столбцов, обязательно установите флажок «Имена столбцов в первой строке».
- Убедитесь, что параметры разделителя полей и цитаты указаны правильно. Если вы не уверены, какие параметры верны, проверьте некоторые из них, пока предварительный просмотр в нижней части окна не будет выглядеть правильно.
- Нажмите OK , вы должны впоследствии получить сообщение о том, что таблица была импортирована.
- Вернувшись на вкладку «Структура базы данных», вы должны увидеть перечисленную таблицу. Щелкните правой кнопкой мыши имя таблицы и выберите Изменить таблицу или нажмите кнопку Изменить таблицу прямо под вкладками и над списком таблиц.
- Нажмите Сохранить , если будет предложено сохранить все ожидающие изменения.
- На центральной панели появившегося окна задайте типы данных для каждого поля, используя предложения в таблице ниже (сюда входят поля из графиков
,итакже таблиц видов):
| Поле | Тип данных | Мотивация | Таблица (-и) |
|---|---|---|---|
| день | ЦЕЛОЕ | Использование числовых данных позволяет проводить осмысленные арифметические операции и сравнения | опросов |
| род | ТЕКСТ | Поле содержит текстовые данные | видов |
| hindfoot_length | НАСТОЯЩИЙ | Поле содержит измеренные числовые данные | опросов |
| месяц | ЦЕЛОЕ | Использование числовых данных позволяет проводить осмысленные арифметические операции и сравнения | опросов |
| plot_id | ЦЕЛОЕ | Поле содержит числовые данные | участков, обследований |
| тип участка | ТЕКСТ | Поле содержит текстовые данные | участков |
| record_id | ЦЕЛОЕ | Поле содержит числовые данные | опросов |
| пол | ТЕКСТ | Поле содержит текстовые данные | опросов |
| разновидностей_id | ТЕКСТ | Поле содержит текстовые данные | видов, обзоров |
| видов | ТЕКСТ | Поле содержит текстовые данные | видов |
| таксонов | ТЕКСТ | Поле содержит текстовые данные | видов |
| вес | НАСТОЯЩИЙ | Поле содержит измеренные числовые данные | опросов |
| год | ЦЕЛОЕ | Позволяет выполнять осмысленную арифметику и сравнения | опросов |
- Наконец, нажмите OK еще раз, чтобы подтвердить операцию.Затем нажмите кнопку Записать изменения , чтобы сохранить базу данных.
Вызов
- Импортировать
участковивидовтаблиц
Вы также можете использовать этот же подход для добавления новых полей в существующую таблицу.
Добавление полей в существующие таблицы
- Перейдите на вкладку «Структура базы данных», щелкните правой кнопкой мыши таблицу, в которую хотите добавить данные, и выберите Изменить таблицу или нажмите Изменить таблицу прямо под вкладками и над таблицей.
- Нажмите кнопку Добавить поле , чтобы добавить новое поле и назначить ему тип данных.
Типы данных
| Тип данных | Описание |
|---|---|
| СИМВОЛ (n) | Строка символов. Фиксированная длина n |
| VARCHAR (n) или CHARACTER VARYING (n) | Строка символов. Переменная длина. Максимальная длина n |
| ДВОИЧНЫЙ (n) | Двоичная строка.Фиксированная длина n |
| BOOLEAN | Сохраняет значения ИСТИНА или ЛОЖЬ |
| VARBINARY (n) или BINARY VARYING (n) | Двоичная строка. Переменная длина. Максимальная длина n |
| ЦЕЛОЕ (p) | Целое число (без десятичного числа). |
| МАЛЕНЬКИЙ | Целое число (без десятичного числа). |
| ЦЕЛОЕ | Целое число (без десятичного числа). |
| BIGINT | Целое число (без десятичного числа). |
| ДЕСЯТИЧНЫЙ (п, с) | Точное числовое, точность p, шкала s. |
| ЧИСЛ (p, s) | Точное числовое, точность p, шкала s. (То же, что и DECIMAL) |
| ПОПЛАВОК (p) | Приблизительное числовое значение с точностью до мантиссы стр. Число с плавающей запятой в экспоненциальной системе счисления с основанием 10. |
| НАСТОЯЩИЙ | Числовое приблизительное |
| ПОПЛАВОК | Числовое приблизительное |
| ДВОЙНАЯ ТОЧНОСТЬ | Числовое приблизительное |
| ДАТА | Сохраняет значения года, месяца и дня |
| ВРЕМЯ | Сохраняет значения часов, минут и секунд |
| TIMESTAMP | Сохраняет значения года, месяца, дня, часа, минуты и секунды |
| ИНТЕРВАЛ | Состоит из ряда целочисленных полей, представляющих период времени, в зависимости от типа интервала |
| МАССИВ | Заданная длина и упорядоченный набор элементов |
| MULTISET | Неупорядоченный набор элементов переменной длины |
| XML | Хранит данные XML |
Краткий справочник по типу данных SQL
Различные базы данных предлагают разные варианты определения типа данных.
В следующей таблице показаны некоторые общие имена типов данных между различными платформами баз данных:
| Тип данных | Доступ | SQLServer | Оракул | MySQL | PostgreSQL |
|---|---|---|---|---|---|
| логический | Да / Нет | Бит | Байт | НЕТ | логический |
| целое | Число (целое) | Внутр. | Число | Целое / Целое | Целое / Целое |
| поплавок | Номер (одиночный) | Float / Real | Число | Поплавок | Числовой |
| валюта | Валюта | Деньги | НЕТ | НЕТ | Деньги |
| струна (фиксированная) | НЕТ | Char | Char | Char | Char |
| строка (переменная) | Текст (<256) / Заметка (65k +) | Варчар | Варчар2 | Варчар | Варчар |
| двоичный объект OLE Object Memo Binary (фиксированный до 8K) | Varbinary (<8K) | Изображение (<2 ГБ) Длинное | Необработанная капля | Двоичный текст | Варбинарный |
Ключевые моменты
SQL позволяет нам выбирать и группировать подмножества данных, выполнять математические и другие вычисления и комбинировать данные.
Реляционная база данных состоит из таблиц, связанных друг с другом общими ключами.
В разных системах управления базами данных (СУБД) используются несколько различающиеся термины, но все они основаны на одних и тех же идеях.
самых популярных баз данных в 2020 году
Какое решение для баз данных в настоящее время наиболее популярно? Какой диалект SQL вам следует изучить? В этой статье я поделюсь результатами своего исследования и своим личным опытом.Вот базы данных, которые стоит изучить с помощью SQL.
Во-первых, давайте ответим на несколько простых вопросов: полезен ли SQL по-прежнему? Стоит ли учиться? Если вы пройдете онлайн-курс SQL, упростит ли это вашу работу? Ответ ДА!
Почему? Взгляните на результаты опроса разработчиков StackOverflow 2020 года. StackOverflow — это гигантский веб-сайт с более чем 50 миллионами пользователей. Обзор обобщает последние тенденции в сфере ИТ. StackOverflow задавал программистам вопросы о том, как они учатся, какие инструменты используют и как они хотят развиваться дальше.Участвовали 65 000 разработчиков.
Один вопрос опроса касался самых популярных технологий. Что ответили профессиональные разработчики?
Неудивительно, что первые два места в рейтинге заняли JavaScript и HTML, популярные языки веб-разработки. SQL занял третье место в списке, набрав 54,7% голосов для всех пользователей и 57% для профессионалов. Это не совпадение. Использование и обработка данных были важной задачей ИТ в течение многих лет.Каждый день генерируются тысячи терабайт данных. Вопрос не в том, почему вы должны изучать SQL, а в том, почему вы его не изучаете?
Самые популярные базы данных в 2020 году
А теперь конкретика. Какие решения для баз данных в настоящее время наиболее популярны? Какие набирают пользователей?
Как и в прошлом году, подиум принадлежит большой тройке: MySQL, PostgreSQL и MS SQL Server. Нет никаких признаков того, что в ближайшее время для этих троих что-то изменится. MySQL и PostgreSQL бесплатны и работают под лицензиями с открытым исходным кодом.Кроме того, у них есть огромные сообщества пользователей, которые продолжают их развивать и добавлять новые плагины и улучшения.
Давайте кратко рассмотрим пятерку лучших баз данных в этом рейтинге:
1. MySQL
MySQL находится на вершине рейтинга популярности в течение нескольких лет. Почему? Он бесплатный, работает с большинством приложений и работает на большинстве популярных платформ, включая Linux, Windows и macOS.
Недавно мы отметили 25-летие MySQL; он был запущен в 1994 году шведскими программистами Дэвидом Аксмарком и Майклом Видениусом.В 2008 году MySQL была приобретена ИТ-гигантом Sun Microsystems; в 2010 году Sun (и, следовательно, MySQL) была приобретена Oracle. Здесь некоторые пользователи замечают противоречие: хотя представители Oracle поклялись, что одна версия MySQL останется с открытым исходным кодом, многие люди опасаются, что она перейдет на проприетарную (лицензионную) версию. (Примечание. Доступны версии с открытым исходным кодом и проприетарные версии.) Поэтому они предпочитают решения, не связанные с лидерами ИТ, например, PostgreSQL, следующую в рейтинге.
2.PostgreSQL
PostgreSQL является бесплатным, с открытым исходным кодом и будет работать во всех возможных ситуациях и на всех платформах. У него очень динамичное сообщество пользователей, которые помогают разрабатывать проект и писать свои собственные плагины и расширения.
PostgreSQL (сокращенно Postgres) — мой личный фаворит. Я недавно писал об этом в книге «Какие крупные компании используют PostgreSQL?» Для чего они его используют ?. Это система баз данных, используемая Instagram, Twitch и Skype. Этого должно быть достаточно.К тому же исследования StackOverflow подтверждают это: PostgreSQL с каждым годом набирает пользователей.
Вы еще не знаете Postgres? Начни изучать это сегодня; это действительно хороший ход для карьерного роста. Я рекомендую отслеживать SQL от А до Я в PostgreSQL. Вы найдете все необходимое, чтобы стать профессиональным пользователем Postgres. Не бойтесь, если у вас нет опыта работы с ИТ или базами данных — наши курсы SQL разработаны таким образом, чтобы вы постепенно накапливали знания и осваивали новые навыки с практикой.
3.Microsoft SQL Server
Это продукт Microsoft, созданный в 1989 году и с тех пор постоянно развивающийся.
Это продукт Microsoft, созданный в 1989 году и с тех пор постоянно развивающийся.
Многие компании доверяют Microsoft, используют другие решения этой компании и не хотят включать что-либо еще в свою ИТ-экосистему. Таким образом, вы найдете MS Server во многих компаниях, особенно в крупных корпорациях.
Несмотря на доминирование на рынке решений с открытым исходным кодом, MS Server преуспевает.Не бойтесь, что однажды выучив его, вы никогда не воспользуетесь им. Каждый доллар, потраченный на изучение MS SQL Server, окупится.
Также полезно знать, что, хотя обычно используется платная коммерческая версия, есть и бесплатные версии. У них очень ограниченные возможности и возможности. Например, в экспресс-версии можно использовать только один процессор, 1 ГБ памяти и файлы базы данных 10 ГБ. Эта версия идеально подходит для изучения SQL, если не для использования в бизнесе.
Помимо SQL Server, Microsoft также предлагает отличную облачную платформу Azure.Это означает, что вы можете не устанавливать MS Server на физический компьютер, а вместо этого размещать его в облаке. Это облегчает работу с базой данных для нескольких пользователей, а также обеспечивает большую безопасность по сравнению с одной установкой на месте.
SQL Azure, как и MS SQL Server, использует язык реляционных запросов T-SQL. Вы хотите этому научиться? LearnSQL.com предлагает несколько отличных курсов. Если вы начинаете свое приключение с SQL, я рекомендую курс «Основы SQL в MS SQL Server». Если вы уже являетесь пользователем SQL, попробуйте курс «Рекурсивные запросы в MS SQL Server».Это улучшит ваши навыки работы с SQL.
Если вы хотите узнать больше о MS SQL Server, мой коллега Роман очень хорошо описал его в своей статье Microsoft SQL Server: плюсы и минусы. Проверить это.
4. SQLite
Это отличное решение набирает популярность. Его можно использовать бесплатно и по лицензии с открытым исходным кодом. Даже исходный код SQLite находится в открытом доступе.
SQLite чаще всего выбирают разработчики мобильных приложений. Содержимое базы данных хранится в одном файле (до 140 ТБ).Библиотека реализует механизм SQL, что позволяет использовать базу данных без запуска отдельного процесса СУБД. Для приложений это часто бывает очень практично.
SQLite основан на стандарте SQL-92. Это означает, что вы сможете работать с ним после того, как закончите наш SQL от А до Я.
Проект SQLite находится в разработке с 2000 года и получает постоянную поддержку. В 2018 году только 19,7% профессиональных разработчиков указали, что использовали эту базу данных; в этом году — более 30 процентов.И это не случайно. Это отличное решение для конкретных приложений.
5. MongoDB
MongoDB — единственное решение в пятерке лидеров, не основанное на реляционной базе данных. В этом предложении с открытым исходным кодом данные хранятся в файлах JSON или BSON (двоичный JSON).
Если вы работали с классическими реляционными базами данных, MongoDB может показаться немного странным. Но он может легко справиться с конкретными приложениями, например в качестве хранилища данных веб-сайта или агрегатора журналов. В традиционной базе данных обработка файлов такого типа может быть обременительной.
Признаюсь, я не фанат движения NoSQL. Я считаю, что SQL настолько совершенен, что вам больше ничего не нужно в базах данных. Ясно, что не все согласны с этим мнением: 26% опрошенных StackOverflow указали, что предпочитают MongoDB. И технологические гиганты, такие как eBay, Adobe и Google, используют его.
Хотя рыночные тенденции показывают, что, хотя NoSQL используется, SQL и его диалекты еще долгое время останутся отраслевым стандартом.
А теперь перейдем к другому вопросу: нужно ли вам формальное образование в области информатики, чтобы стать программистом?
Насколько важно формальное образование для программистов?
Не волнуйтесь, вам не нужна степень, чтобы стать программистом и писать код.Большинство опрошенных профессиональных программистов считают, что формальное образование важно, но не обязательно. Так что работать в этом бизнесе не обязательно. Более того, 15% считают, что формальное образование вообще не важно.
Что делать, если вы хотите заниматься программированием без ученой степени? Лучше всего сосредоточиться на конкретных навыках и получить знания с помощью профессиональных онлайн-курсов, например, предлагаемых на LearnSQL.com. Вы найдете что-то для полных новичков (курс «Основы SQL») и пользователей среднего / продвинутого уровня (оконные функции или анализ тенденций доходов в SQL).Все курсы интерактивны и требуют только подключения к Интернету, браузера и немного мотивации.
Дайте себе шанс стать профессиональным разработчиком SQL, аналитиком SQL или инженером по данным. Узнайте, какие варианты доступны в статье Типы заданий для баз данных: выберите одно из них и начните быть крутым.
SQL: что это такое?
Язык структурированных запросов, широко известный как SQL, является стандартным языком программирования для реляционных баз данных. Несмотря на то, что он старше многих других типов кода, это наиболее широко используемый язык баз данных.
Поскольку SQL настолько распространен, знание его важно для всех, кто занимается компьютерным программированием или использует базы данных для сбора и организации информации. Узнайте больше о том, что такое SQL, и о возможностях карьерного роста в этой области.
Что такое SQL?
SQL можно использовать для совместного использования и управления данными, особенно данными, которые находятся в системах управления реляционными базами данных, которые включают данные, организованные в таблицы. Несколько файлов, каждый из которых содержит таблицы данных, также могут быть связаны общим полем.Используя SQL, вы можете запрашивать, обновлять и реорганизовывать данные, а также создавать и изменять схему (структуру) системы баз данных и контролировать доступ к ее данным.
В электронную таблицу, такую как Microsoft Excel, можно скомпилировать много информации, но SQL предназначен для компиляции и управления данными в гораздо больших объемах. В то время как электронные таблицы могут стать громоздкими из-за слишком большого количества информации, базы данных SQL могут обрабатывать миллионы или даже миллиарды ячеек данных.
Используя SQL, вы можете хранить данные о каждом клиенте, с которым когда-либо работал ваш бизнес, от основных контактов до сведений о продажах.Так, например, если вы хотите найти каждого клиента, который потратил не менее 5000 долларов на ваш бизнес за последнее десятилетие, база данных SQL могла бы получить эту информацию для вас мгновенно.
Как работает изучение SQL
Язык структурированных запросов более простой, чем другие более сложные языки программирования. Как правило, новичкам легче изучить SQL, чем им освоить такие языки, как Java, C ++, PHP или C #.
Некоторые онлайн-ресурсы, включая бесплатные учебные пособия и платные курсы дистанционного обучения, доступны для тех, у кого мало опыта программирования, но которые хотят изучить SQL.Официальные курсы университета или колледжа также обеспечат более глубокое понимание языка.
История SQL
История SQL насчитывает более полувека. В 1969 году исследователь IBM Эдгар Ф. Кодд определил модель реляционной базы данных, которая стала основой для разработки языка SQL. Эта модель построена на общих порциях информации (или «ключах»), связанных с различными данными. Например, имя пользователя может быть связано с фактическим именем и номером телефона.
Несколько лет спустя IBM начала работу над новым языком для систем управления реляционными базами данных на основе результатов исследований Кодда. Первоначально этот язык назывался SEQUEL, или язык структурированных английских запросов. Названный System R, проект претерпел несколько реализаций и изменений, и название языка менялось несколько раз, прежде чем окончательно перейти на SQL.
После начала тестирования в 1978 году IBM приступила к разработке коммерческих продуктов, включая SQL / DS (1981) и DB2 (1983).Другие производители последовали их примеру, объявив о своих собственных коммерческих предложениях на основе SQL. К ним относятся Oracle, выпустившая свой первый продукт в 1979 году, а также Sybase и Ingres.
SQL в действии: MySQL
Обычное программное обеспечение, используемое для серверов SQL, включает MySQL Oracle, возможно, самую популярную программу для управления базами данных SQL. MySQL — это программное обеспечение с открытым исходным кодом, что означает, что его можно использовать бесплатно и важно для веб-разработчиков, потому что большая часть Интернета и очень много приложений построены на базах данных.
Рассмотрим музыкальную программу, такую как iTunes, которая хранит музыку по исполнителям, песням, альбомам, спискам воспроизведения и т. Д. Как пользователь, вы можете искать музыку по любому из этих и других параметров, чтобы найти то, что ищете. Чтобы создать подобное приложение, вам понадобится программное обеспечение для управления вашей базой данных SQL, и это то, что делает MySQL.
Требуемые навыки SQL
Большинству организаций нужен кто-то со знанием SQL. Заработная плата на должностях, основанных на SQL, варьируется в зависимости от типа работы и опыта, но, как правило, выше среднего.
Некоторые должности, требующие навыков SQL, включают:
- Администратор базы данных (DBA ): это тот, кто специализируется на обеспечении правильного и эффективного хранения и управления данными. Базы данных наиболее ценны, когда они позволяют пользователям быстро и легко извлекать желаемые комбинации данных.
- Инженер по миграции баз данных : Этот человек специализируется на перемещении данных из различных баз данных на сервер SQL.
- Специалист по анализу данных : Эта должность очень похожа на должность аналитика данных, но специалистам по данным обычно поручено обрабатывать данные в гораздо больших объемах и накапливать их с гораздо большей скоростью.
- Архитектор больших данных : Кто-то в этой роли создает продукты для обработки больших объемов данных.
Ключевые выводы
- Язык структурированных запросов (SQL) — это стандартный и наиболее широко используемый язык программирования для реляционных баз данных.
- Он используется для управления и организации данных во всех видах систем, в которых существуют различные отношения данных.
- SQL — ценный язык программирования с хорошими карьерными перспективами.
Основы проектирования баз данных SQL с примерами
Это общепринятая практика, когда архитектор БД должен проектировать реляционную базу данных, адаптированную к конкретному решению.
Однажды вечером в пятницу я возвращался с работы в электричке и думал о создании своего рода службы найма. Насколько мне известно, ни один из существующих сервисов не позволяет быстро оценить кандидата, создать сложные фильтры по определенным навыкам, проектам или должностям или исключить определенные навыки, должности или проекты.Максимальный диапазон использования — фильтрация по компаниям и частично по навыкам.
В этой серии статей я немного побалую себя некоторыми нетехническими примерами из своей жизни, чтобы попытаться нарушить строгий технический стиль.
В этой части я напишу об основах проектирования реляционных баз данных и проиллюстрирую дизайн базы данных MS SQL Server для службы набора персонала.
Теперь, что касается следующих статей, я покажу вам, как заполнить базу данных данными с помощью генератора данных для SQL Server и выполнить поиск данных и объектов базы данных с помощью бесплатного инструмента поиска dbForge.Я буду использовать dbForge Studio для SQL Server для реализации диаграмм для своих примеров и dbForge Data Pump для импорта и экспорта данных.
Основы проектирования БД
Для разработки схем базы данных давайте вспомним 7 нормальных форм и сами концепции нормализации и денормализации. Они лежат в основе всех правил проектирования.
Приведу подробное описание 7 нормальных форм:
1. Индивидуальные отношения:
1.1 Обязательное отношение:
Примером может быть гражданин с паспортом (у каждого гражданина должен быть паспорт, и паспорт один на каждого гражданина)
Это отношение реализуется двумя способами:
1.1.1 В одном предприятии (таблица):
Изображение 1. Субъект «Гражданин»
Здесь таблица Citizen представляет сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (НЕ NULL)
1.1.2. В двух разных объектах (таблицах):
Изображение 2. Связь между сущностями Citizen и PassportData
Таблица Citizen представляет сущность гражданина, а таблица PassportData представляет сущность паспортных данных гражданина.Сущность гражданина содержит атрибут (поле) PassportID , который относится к первичному ключу таблицы PassportData . Принимая во внимание, что объект паспортных данных имеет атрибут (поле) CitizenID , который относится к первичному ключу CitizenID таблицы Citizen .
Также важно гарантировать целостность поля CitizenID и таблицы PassportData , чтобы обеспечить взаимно-однозначную связь.То есть поле PassportID в таблице Citizen и поле CitizenID в таблице PassportData должно ссылаться на одну и ту же запись, как если бы это была одна сущность (таблица), которая была проиллюстрирована в параграфе 1.1.1.
1,2 Необязательное отношение:
An Примером может быть человек, который может иметь паспортные данные и не может иметь указанную страну. Итак, в первом случае он гражданин данной стране, а во втором случае его нет.
Эта связь реализуется двумя способами:
1.2.1 В одном лице (таблица):
Изображение 3. Личность
Здесь таблица Person представляет физическое лицо, а атрибут (поле) PassportData содержит все паспортные данные человека и может быть пустым (NULL)
1.2.2 В двух объектах (таблицы):
Изображение 4. Связь между Person и PassportData
Здесь таблица Person представляет физическое лицо, а таблица PassportData представляет сущность паспортных данных человека (то есть сам паспорт).Физическое лицо содержит атрибут (поле) PassportID , который относится к первичному ключу таблицы PassportData . Принимая во внимание, что объект паспортных данных имеет атрибут (поле) PersonID в таблице Person . Поле PassportID таблицы Person может быть пустым (NULL).
Также важно гарантировать целостность поля PersonID и таблицы PassportData , чтобы обеспечить взаимно-однозначную связь.То есть поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи, как если бы это была одна сущность (таблица), показанная в параграфе 1.2.1, или эти поля должны быть неуказанными, то есть содержать NULL.
2. Отношение «один ко многим»
2.1 Обязательные отношения:
Иллюстрацией этого могут быть родители и их дети. У каждого родителя есть хотя бы один ребенок.
Эту связь можно реализовать двумя способами:
2.1.1 В одном лице (таблица):
Изображение 5. Материнская компания
Здесь таблица Parent представляет родительский объект, а атрибут (поле) ChildList содержит информацию о дочерних элементах, то есть самих дочерних элементах. Это поле не может быть пустым (НЕ NULL). Тип поля ChildList обычно представляет собой полуструктурированные данные (NoSQL), такие как XML, JSON и т. Д.
2.1.2 В двух объектах (таблицы):
Изображение 6. Связь между родительским и дочерним объектами
Здесь таблица Parent представляет родительский объект, а таблица Child представляет дочерний объект. Таблица Child имеет поле ParentID , которое ссылается на основной ключ ParentID таблицы Parent . Поле ParentID таблицы Child не может быть пустым (НЕ NULL).
2.2) необязательный отношения:
Примером может быть человек, который может иметь детей или может не иметь детей.
Это отношение реализуется двумя способами:
2.2.1 В одном лице (таблица):
Изображение 7. Личность
Здесь таблица Parent представляет родительский объект, а атрибут (поле) ChildList содержит информацию о дочерних элементах, то есть самих дочерних элементах.Это поле может быть пустым (NULL). Обычный тип поля ChildList — это полуструктурированные данные (NoSQL), такие как XML, JSON и другие.
2.2.2 В двух объектах (таблицы):
Изображение 8. Связь между сущностями «Лицо» и «Дочерний»
Здесь таблица Parent представляет родительский объект, а таблица Child представляет дочерний объект. Таблица Child имеет поле ParentID , которое ссылается на основной ключ ParentID таблицы Parent .Поле ParentID таблицы Child может быть пустым (NULL).
Также существует третий способ реализации одной сущности, который ссылается на себя, при условии, что дочерняя и родительская сущности (таблицы) имеют одинаковый набор атрибутов (полей) без ссылки на родительский:
Изображение 9. Сущность Person с самооценкой
Здесь сущность Person (таблица) содержит атрибут (поле) ParentID , который относится к первичному ключу PersonID той же таблицы Person и может иметь пустое значение (NULL).
Это реализация отношения «многие к одному» с необязательным характером.
3. Отношения «многие-к-одному»
Это отношение отражает проиллюстрированное выше отношения один-ко-многим. Это отношения между ребенком сущность и родительская сущность, где обязательными отношениями являются возможно, если у ребенка есть хотя бы один родитель, и если мы возьмем все дети, в том числе в детских домах, то такие отношения имеет необязательный характер.
Отношения «один ко многим» и «многие к одному» также могут быть реализованы через более чем 2 объекта, путем добавления необходимых атрибутов, которые относятся к первичным ключам соответствующих объектов. Эта реализация аналогична примерам, приведенным выше в параграфах 1.1.2 и 1.2.2.
4. Отношение «многие ко многим»
В этом случае примером может быть недвижимость, которая может принадлежать одному человеку или несколько человек. При этом человек может владеть несколькими домами или имеют долю собственности на многие дома.
Вы можете реализовать эту взаимосвязь с NoSQL способами, описанными выше для предыдущих взаимосвязей. Однако в реляционной модели эта связь обычно реализуется через 3 объекта (таблицы):
Изображение 10. Отношения между Лицом и объектами RealEstate
Здесь таблицы Person и RealEstate представляют объекты человека и недвижимости соответственно. Эти сущности (таблицы) связаны посредством сущности PersonRealEstate (таблицы) через атрибуты (поля) PersonID и RealEstateID , которые относятся к первичным ключам PersonID таблицы Person и RealEstateID . таблицы RealEstate соответственно.Обратите внимание, что пара ( PersonID ; RealEstateID ) всегда уникальна для таблицы PersonRealEstate , поэтому она может быть первичным ключом для самого PersonRealEstate связывающего объекта (таблицы).
Это отношение может быть реализовано более чем через 3 объекта путем добавления необходимые атрибуты, которые относятся к первичным ключам соответствующие лица. Такая реализация похожа на примеры описаны в пунктах 1.1.2 и 1.2.2.
Так где же 7 нормальных форм, спросите вы?
Ну вот они:
- Par.1 (par.1.1 и par.1.2) является первое и второе формальное правило.
- Par.2 (par.2.1 и par.2.2) является третье и четвертое формальные правила.
- Par.3 (аналогично пункту 2) — это пятое и шестое формальные правила.
- Пункт 4 — седьмое формальное правило.
Это просто эти 7 нормальных форм сгруппированы в 4 функциональных блока в тексте выше.
Нормализация устраняет избыточность данных и, следовательно, снижает риски данных аномалии. Однако нормализация при декомпозиции сущностей (таблиц) приводит к более сложному построению запроса для манипулирования данными (вставка, обновление, выбор и удаление).
Противоположный процесс — денормализация. Он упрощает обработку запросов на доступ к данным за счет добавления избыточных данных (например, как было упомянуто выше в пп. 2.1.1 и 2.2.1 с помощью полуструктурированных данных (NoSQL)).
Вы уверены, что поняли 7 нормальных форм? Что вы действительно это поняли, а не просто ознакомились с этим. Спросите себя, удастся ли вам за пару часов спроектировать модель базы данных, даже с избыточным количеством сущностей, для любой области данных или любой информационной системы. Позже вы сможете уточнить сложности и детали, обратившись к аналитикам и представителям клиентов.
Если этот вопрос застал вас врасплох и вы думаете, что это маловероятно, то вы знаете 7 нормальных форм, но не понимаете их.
Почему-то в источниках не говорится, что эти отношения между сущностями были не просто придуманы, но обнаружены. То есть с самого начала они действительно существовали в реальном мире между субъектами и объектами.
В дополнение к что эти отношения могут меняться, переходя от одного к одному к один-ко-многим, или многие-к-одному, или многие-ко-многим, изменяя их обязательный характер или его сохранение.
Я думаю, вам следует попробовать наблюдать за людьми и обнаруживать существующие отношения как между субъектами, так и между субъектами и объектами (в приведенном выше примере показан гражданин и паспорт как взаимно однозначные отношения с обязательным характером, а человек и паспорт — как взаимно однозначное отношение, которое не является обязательным).
Когда вы познакомитесь с 7 обычными формами, вы сможете легко спроектировать модель базы данных любой сложности для любой информационной системы.
Кроме того, вы узнаете, что вы можете реализовать отношения разными способами, и сами отношения могут меняться. Таким образом, модель (схема) базы данных — это моментальный снимок отношений между сущностями в определенный момент времени. Следовательно, важно указать как сущности, которые являются изображениями объектов реального мира или предметной области, так и отношения между ними с учетом будущих изменений.
Хорошо продуманный модель базы данных, с учетом изменения отношений в реальности и в предметной области, не требует длительных изменений время. Это особенно важно для хранения данных, где изменения включают повторное сохранение больших объемов данных, от нескольких гигабайт до многих терабайты.
Примечание: в модели реляционной базы данных это связь между сущностями, а строки (кортежи) являются примерами этих отношений. Но для простоты мы часто подразумеваем сущности по таблицам, экземпляры сущностей по строкам, а их отношения — по отношениям внешних ключей.
Проектирование схемы базы данных для набора персонала
После в первой части статьи мы рассказали об основах проектирования БД, давайте теперь создадим схему базы данных для набора.
Прежде всего, нам нужно определить, какая информация важна для сотрудников компании, ищущих соискателей:
- Для HR-менеджера:
- Компании, в которых раньше работал соискатель.
- Должности, которые кандидат занимал в этих компаниях.
- Навыки, которые кандидат использовал на работе, стаж работы в каждой из компаний и на каждой должности, продолжительность использования каждого навыка.
- Для технического специалиста:
- Должности, которые соискатель занимал на прежних местах работы.
- Навыки, которые соискатель использовал на работе.
- Проекты, в которых принимал участие кандидат. Кроме того, важно знать стаж работы кандидата на каждой должности и в каждом проекте, а также продолжительность использования каждого навыка.
Давайте сначала определим необходимые сущностей:
- Сотрудник
- Компания
- Позиция
- пр.
- Навык
Компания и сотрудник связаны отношениями «многие ко многим», поскольку сотрудник может работать в разных компаниях, а в компаниях много сотрудников.
То же самое работает для должности и сотрудника, потому что многие сотрудники могут работать на одной должности в одной компании, а также в разных компаниях.При этом сотрудник мог работать на разных должностях как в одной компании, так и в разных. В результате отношения между должностью и компанией также являются отношениями «многие ко многим».
Сущность «проект» следует той же логике: проект относится ко всем другим вышеупомянутым сущностям как «многие ко многим».
Для простоты скажем, что сотрудник использует один набор навыков в проекте. Тогда отношения Между проектом и навыком также много ко многим.
Учитывая важность указания стажа работы сотрудника в той или иной компании, на определенной должности и в определенном проекте, наша схема базы данных может иметь следующую диаграмму ER:
Изображение.11. Схема базы данных кадровой службы
Здесь таблица JobHistory представляет сущность истории работы каждого сотрудника, то есть само резюме который реализует отношения «многие ко многим» между сотрудниками, компания, должности и проект.
Проект и умение соотносятся как многие-ко-многим, таким образом, они связаны с помощью ProjectSkill юридическое лицо.
Если вы понимаете отношения между субъектами и субъектами и объектами, что означает дизайн базы данных норм, вы можете создать аналогичную схему на листе бумаги в под час.
Здесь мы могли бы упростить схему и добавление данных, если мы вложим умение в сущность проекта через полуструктурированные данные (NoSQL) в форме XML, JSON или просто списка названия навыков через точку с запятой. Но это сделало бы это сложно выбрать группировку по навыкам и фильтрацию по определенным навыкам.
Заключение
Как видите, проектирование систем — это просто превращение объектов и субъектов из реальности в сущности базы данных, где связь между этими сущностями фиксируется в определенный момент времени с учетом будущих изменений.Что именно мы берем из реальности и реализуем как объект схемы, и какие отношения мы строим в модели, зависит от того, чего мы хотим от информационной системы в целом, сейчас и в будущем. То есть, какие данные мы хотим получить на настоящий момент и в какое-то время в будущем. Следующая часть будет посвящена заполнению полученной базы данных данными. Чтобы заполнить нашу базу данных данными, мы собираемся использовать dbForge для SQL Server.
Евгений Грибков
Евгений — аналитик, разработчик и администратор баз данных MS SQL Server.Он участвует в разработке и тестировании инструментов управления базами данных SQL Server. Евгений также пишет статьи, связанные с SQL Server.
Последние сообщения Евгения Грибкова (посмотреть все)
дизайн базы данных, схема базы данных, sql server, студия для sql server
.