Что такое SQL и как он работает | GeekBrains
https://d2xzmw6cctk25h.cloudfront.net/post/2491/og_image/9d0f392ec052f922f41e5792374d7fcd.png
Википедия гласит, что SQL — это декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных. Не самое удобоваримое определение. Чтобы понять, о чём вообще речь, разберём его.
Декларативный язык программирования говорит, что должно быть сделано, а не как это необходимо сделать. Ещё один пример декларативного языка — HTML. Рассмотрим такой код:
<div class=”className”>
<input type=”button” value=”Ясно. Понятно.”></input>
</div>С его помощью мы заявляем (declaration — заявление) браузеру, что хотим увидеть блок с классом className и кнопкой с текстом «Ясно. Понятно.» внутри. Для этого мы не создаём каких-либо переменных, циклов, условий.
Здесь смысл довольно прост: мы даём команду и получаем результат. Мы не описываем, как эту команду выполнять. Чтобы понять, что такое реляционная база данных, разберём, что такое база данных в принципе. Декомпозируем это понятие на «база» и «данные».
Данные
В контексте баз данных под данными понимают набор значений, который собирается в строки и столбцы, тем самым представляя таблицу. Представим, что у нас есть каталог мебельного магазина. Нам нужно сохранить все данные из раздела «Шкафы» этого каталога в таблицу. Мы решили, что все шкафы отличаются друг от друга характеристиками:
- название производителя;
- название модели;
- высота;
- длина;
- цвет;
- количество дверей.
Составим таблицу и вобьём в неё выдуманные данные.
У нас есть таблица с данными. Столбцами мы показываем, как они будут храниться. В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
Добавляя в таблицу строки, я вводил в неё данные, ориентируясь на структуру, заданную в столбцах. Чем больше строк, тем больше данных. Чем больше столбцов, тем подробнее будут эти данные.
Ещё есть такое понятие, как «значение» — это пересечение столбца и строки. Например, у последней строки в столбце «Цвет» написано «хаки». Здесь «хаки» — значение. Если мы начнём группировать таблицы и добавим возможность манипулирования ими, то получим базу данных.
Теперь про базы
Получается, что БД — это совокупность данных, представленных определённым образом (в нашем случае — таблицей), и набор инструментов для манипулирования ими.
Данные могут быть сгруппированы не только в таблицы, но и в коллекции. У каждой базы есть свой инструмент для создания таблиц/коллекций, добавления, удаления или изменения данных, а также для составления выборки.
Таблицы между собой могут объединяться в схемы — в одной базе данных их может быть несколько, а может и не быть деления на схемы вообще. Это зависит от БД.
Вернёмся к определению из Википедии и вспомним про слово «реляционные». Реляционные (от англ. relation — отношения) — это базы данных, таблицы которых могут выстраиваться в различных отношениях. Возьмём предыдущий пример и добавим в него тех самых «отношений». Создадим таблицу «Производитель», а ту, что в примере, обозначим как «Каталог».
Таблица «Производитель»:
Теперь таблицу «Каталог» можно оформить в другом виде:
Получилось так, что у таблиц «Каталог» и «Прозводитель» появились отношения. Значения из столбца «Каталог» ссылаются на строки из таблицы «Производитель». Добавлением отношения мы решили нескольких проблем:
- Избавились от избыточных данных. Каталог стал занимать меньше места.
 Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель».
Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель». - Снизили вероятность ошибиться. При смене названия производителя нам достаточно отредактировать строку в таблице «Производитель», «Каталог» останется без изменений.
 Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель».
Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель». Это не все проблемы, которые мы решили добавлением отношений. Для понимания других проблем необходимо углубиться в тему баз данных. Разделение данных на таблицы с отношениями — это процесс нормализации. Так можно достигать различных нормализованных форм данных. При достижении каждой из нормализованных форм мы избавляем данные от дополнительных проблем.
Вернёмся к SQL
Если читателю показалось, что мы ушли в сторону от SQL, так оно и есть. Но очень трудно понять, что такое SQL, не зная, с чем он работает.
Выходит, что SQL — это язык программирования, необходимый для написания команд к БД, после выполнения которых она вернёт результат. Результат будет зависеть от команды, написанной на SQL.
- DDL — Data Definition Language;
- DML — Data Manipulation Language;
- DCL — Data Control Language;
- TCL — Transaction Control Language.
DDL
DDL (Data Definition Language, язык описания данных) — язык, включающий операторы для работы со структурой данных. Операторы DDL нужны для реализации этих возможностей:
- Создание объектов базы данных (таблиц, схем). Оператор: CREATE.
- Удаление объектов базы данных. Оператор: DROP.
- Изменение объектов базы данных. Оператор: ALTER.
DDL используется, когда нужно создать структуру для хранения данных. Он не отвечает за сами данные — только за то, как они будут разделены по таблицам и схемам.
DML
DML (Data Manipulation Language, язык манипуляции данными) — язык, который нужен для добавления, удаления, изменения данных и для выборки их из базы. Иными словами, для манипулирования данными. Пройдёмся по операторам:
Иными словами, для манипулирования данными. Пройдёмся по операторам:
- Оператор SELECT позволяет выбрать данные.
- Оператор INSERT — добавить новые.
- Оператор UPDATE — изменить существующие.
- Оператор DELETE — удалить.
DCL
DCL (Data Control Language, язык управления доступом к данным) — набор операторов, необходимых для предоставления доступа к данным. Кроме данных, в БД есть такие сущности, как пользователи. Нужно обязательно иметь возможность ограничить пользователям доступ к данным. Например, мы не хотим, чтобы менеджер проекта мог редактировать данные или их структуру. Для этого есть три группы операторов.
- GRANT — оператор предоставления пользователю или группе набор каких-либо разрешений;
- REVOKE — оператор отзыва разрешений;
- DENY — задаёт запрет. Приоритет оператора DENY выше, чем у разрешения, выданного оператором GRANT.
TCL
Есть такое понятие, как транзакции. Это набор команд (там может быть и всего одна), который завершается успешно тогда, когда правильно выполнены все команды из него. В случае неудачного завершения одной команды из транзакции, она вся откатывается (отменяются результаты выполнения предыдущих команд), реализуя принцип атомарности. Обычно в транзакцию включаются DML-команды.
Это набор команд (там может быть и всего одна), который завершается успешно тогда, когда правильно выполнены все команды из него. В случае неудачного завершения одной команды из транзакции, она вся откатывается (отменяются результаты выполнения предыдущих команд), реализуя принцип атомарности. Обычно в транзакцию включаются DML-команды.
Для управления транзакциями существует TCL (Transaction Control Language — язык управления транзакциями). Операторы здесь следующие:
- BEGIN TRANSACTION — необходим для обозначения начала транзакции;
- COMMIT TRANSACTION — применяет изменения команд внутри транзакции;
- ROLLBACK TRANSACTION — откатывает транзакцию;
- SAVE TRANSACTION — указывает промежуточную точку сохранения внутри транзакции.
TCL есть только в тех БД, которые поддерживают транзакции. Самое время поговорить о видах БД.
Виды СУБД
Познакомимся с новым понятием — СУБД, системой управления базой данных.
Сергей Кузнецов в книге «Основы баз данных» описал СУБД как комплекс программ, позволяющих создать базу данных (БД) и манипулировать данными (вставлять, обновлять, удалять и выбирать). Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД.
Получается что, СУБД — это SQL плюс комплекс программного обеспечения. Очень часто базы данных путают с системой управления базой данных. Это нормально: понятия неразрывны, сама по себе БД без системы управления мало чем отличается от текстового файла со строчками. Важно не только хранить данные, но и управлять ими. СУБД применяются везде, где нужно структурировано хранить данные — от простого блога до проектов Data Science.
Есть много популярных СУБД, рассмотрим несколько из них.
MySQL
MySQL — свободная реляционная СУБД. Разрабатывалась как легковесная замена тяжёлым СУБД, которую можно было установить на маломощный сервер, без сильных потерь в возможностях. MySQL трудится под капотом таких гигантов, как YouTube, Facebook, Twitter, GitHub.
MySQL трудится под капотом таких гигантов, как YouTube, Facebook, Twitter, GitHub.
СУБД написана на C и C++. MySQL породил множество ответвлений, которые сейчас стали самостоятельными СУБД, например Percona и MariaDB.
Oracle Database
История Oracle Database начинается с 1977 года. Это объектно-реляционная система управления данными. Это довольно тяжёлая СУБД, поддерживает системы любой сложности, например, в банковской или финансовой сферах. У неё нет бесплатной лицензии. Процедурный SQL — PL/SQL. Языки написания СУБД — Java/C/С++
Microsoft SQL Server
Microsoft SQL Server — система управления реляционными базами данных, разработанная Microsoft. Первая версия SQL Server появилась 29 апреля 1989 года. Это конкурент Oracle Database. Есть бесплатная лицензия для разработчиков, но не для коммерческого использования. Процедурный SQL — Transact-SQL. СУБД написана на C/C++/C#.
PostgreSQL
PostgreSQL — свободная объектно-реляционная система управления базами данных. Эта СУБД увидела свет 8 июля 1996 года. Конкурент MySQL в веб-разработке проектов любой сложности, также соперничает с базами от Oracle и Microsoft в промышленной разработке. У неё прекрасная русскоязычная документация. Как и MySQL, имеет бесплатную лицензию для коммерческой разработки, за что так же, как и MySQL, горячо любима. Процедурный SQL — PL/pgSQL. Разработана на языке С.
Эта СУБД увидела свет 8 июля 1996 года. Конкурент MySQL в веб-разработке проектов любой сложности, также соперничает с базами от Oracle и Microsoft в промышленной разработке. У неё прекрасная русскоязычная документация. Как и MySQL, имеет бесплатную лицензию для коммерческой разработки, за что так же, как и MySQL, горячо любима. Процедурный SQL — PL/pgSQL. Разработана на языке С.
Каждая из приведённых СУБД работает на своём расширении SQL. У каждой — своя ниша применения, плюсы и минусы.
Что после знакомства?
Если вы не знаете, какая конкретно СУБД вам нужна, выбирайте MySQL. Она лишена изысканных возможностей, которые будут только сбивать начинающего разработчика. Большое комьюнити не оставит в беде и уже решило 95% проблем. Разнообразие графических клиентов для всех операционных систем хорошо помогает на ранних этапах. MySQL позволит набраться опыта и понять, чем она хуже или лучше других СУБД. Когда вы поймёте принципы работы MySQL, для вас не составит труда переключиться на работу с PostgreSQL или другой СУБД. Цель работы у всех СУБД одна — рациональное и надёжное хранение данных и быстрое их извлечение или изменение.
Цель работы у всех СУБД одна — рациональное и надёжное хранение данных и быстрое их извлечение или изменение.
После того как вы определитесь с выбором, хорошо будет посмотреть практики других разработчиков на YouTube-каналах «Технострим Mail.ru Group» или HighLoad Channel, почитать замечательный портал ruhighload.com, где, кроме статей про базы данных, рассматриваются проблемы больших нагрузок. А для тех, кто любит почитать больше, подойдёт книга «MySQL по максимуму. 3-е издание» Бэрона Шварца, Петра Зайцева и Вадима Ткаченко. Узнать больше вы, конечно, можете и в GeekBrains — приходите ко мне или моим коллегам на курс «Основы баз данных».
Пример базы данных SQL Server для обучения SQL
1- Введение
LearningSQL это маленькая база данных, использующаяся для примера в инструкциях по изучению SQL имеющиеся на вебсайте o7planning, существует 3 версии на Database:
- Oracle
- MySQL
- SQLServer.
В данной статье я покажу вам как создать данную базу данных на SQLServer.
Эта база данных предоставлена как модельная база данных для изучения SQL Server по ссылке:
- Руководство SQL для начинающих с SQL Server
2- Download Script
Скачать script по ссылке:
| Direct | Mediafire |
| Download | Download |
С SQLServer вам нужно обратить внимание только на файл:
- LearningSQL-SQLServer-Script.sql
3- Запуск Script
3.1- Создать LearningSQL SCHEMA на SQLServer Management Studio
Создайть новый Database
- Database Name: learingsql
Скопировать содержание файла LearningSQL-SQLServer-Script. sql в окоSQL и выполнить
sql в окоSQL и выполнить
4- Обзор LearningSQL
LearningSQL это маленькая база данных симулирующая данные банка:
| НАЗВАНИЕ ТАБЛИЦЫ | ЗНАЧЕНИЕ |
| ACCOUNT | Таблица хранящая банковский счет. Каждый клиет может зарегистрировать несколько счетов, каждый счет соответствует услуге предоставленной банком. (Смотрите так же PRODUCT) |
| ACC_TRANSACTION | Таблица хранящая информацию транзакции с банком определенного счета. |
| BRANCH | Филиал банка |
| BUSSINESS | |
| CUSTOMER | Таблица клиентов |
| DEPARTMENT | Таблица департаментов банка. |
| EMPLOYEE | Таблица работников банка. |
| OFFICER | |
| PRODUCT | Продукты услуг банка, например:
|
| PRODUCT_TYPE | Продукты услуг банка, например:
|
 ….
….5- Структура таблиц
5.1- ACCOUNT
5.2- ACC_TRANSACTION
5.3- BRANCH
5.4- BUSINESS
5.5- CUSTOMER
5.6- DEPARTMENT
5.7- EMPLOYEE
5.8- INDIVIDUAL
5.9- OFFICER
5.10- PRODUCT
5.11- PRODUCT_TYPE
Функции службы Базы данных SQL Azure — Azure SQL Database
- Чтение занимает 19 мин
В этой статье
ОБЛАСТЬ ПРИМЕНЕНИЯ: База данных SQL Azure
База данных SQL Azure — это полностью управляемое ядро СУБД, предоставляемое по модели «платформа как услуга» (PaaS), которое автоматизирует большинство функций управления базами данных, таких как обновление, исправление, резервное копирование и мониторинг. База данных SQL Azure всегда работает на последней стабильной версии ядра СУБД SQL Server и исправленной ОС с 99,99 % доступности. Возможности PaaS, встроенные в Базу данных SQL Azure, позволяют сосредоточиться на важных для бизнеса задачах администрирования и оптимизации баз данных для конкретных областей.
База данных SQL Azure всегда работает на последней стабильной версии ядра СУБД SQL Server и исправленной ОС с 99,99 % доступности. Возможности PaaS, встроенные в Базу данных SQL Azure, позволяют сосредоточиться на важных для бизнеса задачах администрирования и оптимизации баз данных для конкретных областей.
С помощью Базы данных SQL Azure можно создать высокодоступный и высокопроизводительный уровень хранения данных для приложений и решений в Azure. База данных SQL может оказаться верным выбором для множества современных облачных приложений, поскольку она позволяет обрабатывать реляционные данные и нереляционные структуры, например графы, JSON, пространственные данные и XML.
База данных SQL Azure основана на последней стабильной версии ядра СУБД Microsoft SQL Server. Вы можете использовать расширенные функции обработки запросов, например технологии высокопроизводительных вычислений в памяти и интеллектуальную обработку запросов. На самом деле, новые возможности SQL Server выпускаются сначала для базы данных SQL и только потом для SQL Server. Вы получаете новейшие возможности SQL Server без дополнительных издержек на исправление или обновление, после тестирования на миллионах баз данных.
Вы получаете новейшие возможности SQL Server без дополнительных издержек на исправление или обновление, после тестирования на миллионах баз данных.
База данных SQL позволяет с легкостью определить и масштабировать производительность в двух разных моделях приобретения: на основе виртуальных ядер и единиц DTU. База данных SQL — это полностью управляемая служба со встроенными возможностями высокого уровня доступности, резервного копирования и других общих операций обслуживания. Корпорация Майкрософт обрабатывает все исправления и обновления кода SQL и операционной системы, так что вам не придется управлять базовой инфраструктурой самостоятельно.
Если вы не работали с Базой данных Azure SQL, просмотрите это обзорное видео из серии видео, посвященных SQL Azure:
Модели развертывания
База данных SQL Azure предоставляет следующие возможности развертывания для базы данных:
База данных SQL обеспечивает прогнозируемую производительность с использованием нескольких типов ресурсов, уровней служб и объемов вычислительных ресурсов. Она предоставляет динамическую масштабируемость без простоя, встроенную интеллектуальную оптимизацию, глобальную масштабируемость и доступность, а также дополнительные параметры безопасности. Эти возможности позволяют вам сосредоточиться не на управлении виртуальными машинами и инфраструктурой, а на быстрой разработке приложений и ускорении их выхода на рынок. База данных SQL сейчас размещается в 38 центрах обработки данных по всему миру, благодаря чему вы можете выполнять ее в ближайшем к вам центре.
Она предоставляет динамическую масштабируемость без простоя, встроенную интеллектуальную оптимизацию, глобальную масштабируемость и доступность, а также дополнительные параметры безопасности. Эти возможности позволяют вам сосредоточиться не на управлении виртуальными машинами и инфраструктурой, а на быстрой разработке приложений и ускорении их выхода на рынок. База данных SQL сейчас размещается в 38 центрах обработки данных по всему миру, благодаря чему вы можете выполнять ее в ближайшем к вам центре.
Масштабируемая производительность и пулы
Вы можете самостоятельно определить объем назначаемых ресурсов.
- При использовании отдельных баз данных каждая из них изолирована от остальных и является переносимой. Каждая из них имеет свой гарантированный объем вычислительных ресурсов, а также ресурсов памяти и хранилища. Объем ресурсов, назначенных базе данных, выделяется для этой конкретной базы данных и не используется совместно с другими базами данных в Azure. Количество ресурсов отдельной базы данных можно динамически увеличивать и уменьшать. Вариант с отдельной базой данных предоставляет различные вычислительные ресурсы, а также ресурсы памяти и хранилища для различных нужд. Например, можно получить от 1 до 80 виртуальных ядер или от 32 ГБ до 4 ТБ. Уровень служб «Гипермасштабирование» для отдельной базы данных позволяет увеличить масштаб до 100 ТБ с возможностью быстрого резервирования и восстановления.
- С помощью эластичных пулов можно назначать ресурсы, совместно используемые всеми базами данных в пуле. Чтобы максимально эффективно использовать ресурсы и сэкономить средства, можно создать новую базу данных в пуле ресурсов или переместить в него имеющиеся отдельные базы данных. Этот вариант также обеспечивает возможность динамического увеличения и уменьшения количества ресурсов в эластичном пуле.
 Вариант с отдельной базой данных предоставляет различные вычислительные ресурсы, а также ресурсы памяти и хранилища для различных нужд. Например, можно получить от 1 до 80 виртуальных ядер или от 32 ГБ до 4 ТБ. Уровень служб «Гипермасштабирование» для отдельной базы данных позволяет увеличить масштаб до 100 ТБ с возможностью быстрого резервирования и восстановления.
Вариант с отдельной базой данных предоставляет различные вычислительные ресурсы, а также ресурсы памяти и хранилища для различных нужд. Например, можно получить от 1 до 80 виртуальных ядер или от 32 ГБ до 4 ТБ. Уровень служб «Гипермасштабирование» для отдельной базы данных позволяет увеличить масштаб до 100 ТБ с возможностью быстрого резервирования и восстановления.Вы можете создать свое первое приложение в небольшой отдельной базе данных на уровне служб общего назначения с низкой месячной платой. Уровень служб можно в любое время изменить на критически важный для бизнеса в соответствии с потребностями вашего решения.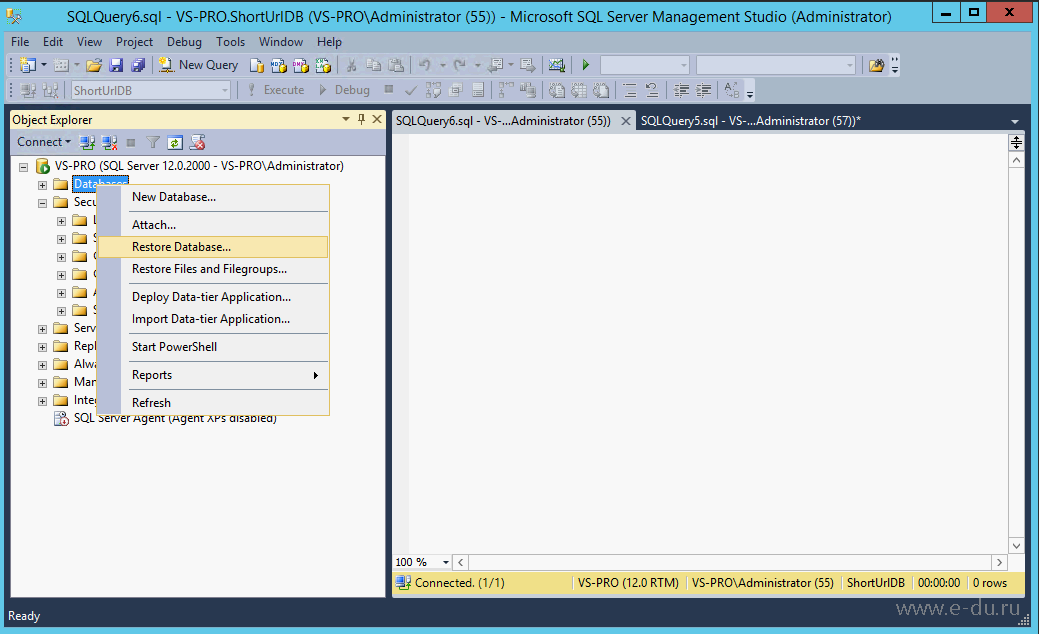 Сделать это можно вручную или программно. Вы можете настроить производительность без простоя для приложения и работы клиентов. Благодаря динамической масштабируемости база данных может прозрачно реагировать на быстро меняющиеся требования к ресурсам. Вы платите только за необходимые ресурсы и только тогда, когда они вам нужны.
Сделать это можно вручную или программно. Вы можете настроить производительность без простоя для приложения и работы клиентов. Благодаря динамической масштабируемости база данных может прозрачно реагировать на быстро меняющиеся требования к ресурсам. Вы платите только за необходимые ресурсы и только тогда, когда они вам нужны.
Динамическое масштабирование отличается от автомасштабирования. Автомасштабирование — процесс, когда масштабирование службы проходит автоматически (в зависимости от критериев). В то время как динамическая масштабируемость дает возможность для ручного масштабирования без простоев. В варианте с отдельной базой данных поддерживается только динамическое масштабирование вручную, а автомасштабирование невозможно. Чтобы изучить автомасштабирование более детально, необходимо рассмотреть возможность использования эластичных пулов, которые позволяют базам данных обмениваться ресурсами в пуле, исходя из потребностей конкретной базы данных. Другой вариант — использовать скрипты, с помощью которых можно автоматизировать масштабирование отдельной базы данных. С ними можно ознакомиться в статье Мониторинг и масштабирование отдельной базы данных SQL с помощью PowerShell.
С ними можно ознакомиться в статье Мониторинг и масштабирование отдельной базы данных SQL с помощью PowerShell.
Модели приобретения
Для Базы данных SQL предлагаются следующие модели приобретения.
- Модель приобретения на основе виртуальных ядер позволяет выбрать число виртуальных ядер, объем памяти, а также объем и скорость хранилища. Модель приобретения на основе виртуальных ядер также позволяет применять Преимущество гибридного использования Azure для SQL Server, чтобы добиться снижения затрат. Дополнительные сведения о Преимуществе гибридного использования Azure см. в разделе часто задаваемых вопросов далее в этой статье.
- В модели приобретения на основе единиц DTU набор вычислительных операций, памяти и ресурсов ввода-вывода предоставляется на трех уровнях обслуживания (каждый из которых предусматривает поддержку различных рабочих нагрузок баз данных). Для каждого объема вычислительных ресурсов на всех уровнях обслуживания предусмотрено отдельное сочетание этих ресурсов, к которым можно добавить ресурсы хранилища.
- В бессерверной модели вычислительные ресурсы автоматически масштабируются в соответствии с потребностями в рабочей нагрузке, а счета выставляются за количество использованных вычислительных ресурсов в секунду. Уровень бессерверных вычислений также автоматически приостанавливает базы данных в периоды отсутствия активности, когда оплачивается только хранилище, и автоматически возобновляет работу баз данных, когда активность восстанавливается.
Уровни службы
Для Базы данных SQL Azure предлагается три уровня служб, предназначенные для различных типов приложений.
- Уровень служб «Общего назначения» и «Стандартный», предназначенный для распространенных рабочих нагрузок. На нем предлагаются бюджетные сбалансированные варианты вычислительных ресурсов и ресурсов хранилища.
- Уровень служб «Критически важный для бизнеса» и «Премиум», предназначенный для приложений OLTP с высокой частотой транзакций и минимальными задержками ввода-вывода. Обеспечивает самую высокую отказоустойчивость благодаря использованию нескольких изолированных реплик.
- Уровень служб Гипермасштабирование, предназначенный для очень большой базы данных OLTP и обеспечивающий возможность плавного автомасштабирования хранилища и масштабирования вычислительных ресурсов.

Эластичные пулы для максимального использования ресурсов
Для многих организаций и приложений достаточно иметь возможность создавать отдельные базы данных и уменьшать или увеличивать их производительность по запросу, особенно если закономерности использования базы данных предсказуемы. Непредсказуемые изменения в закономерностях использования могут усложнить управление расходами и бизнес-моделью. Эластичные пулы предназначены для решения этой проблемы. Предназначенные для обеспечения производительности ресурсы выделяются не отдельной базе данных, а пулу. Вы платите за общую производительность пула, а не производительность отдельной базы данных.
Благодаря использованию эластичных пулов нет необходимости тщательно отслеживать колебания потребностей в ресурсах для повышения или понижения производительности базы данных. Базы данных в пуле потребляют ресурсы производительности пула эластичных баз данных по мере необходимости. Базы данных в пуле используют его ресурсы, но не превышают ограничений пула, поэтому ваши расходы остаются прогнозируемыми, даже если производительность отдельной базы данных прогнозировать сложно.
Базы данных в пуле потребляют ресурсы производительности пула эластичных баз данных по мере необходимости. Базы данных в пуле используют его ресурсы, но не превышают ограничений пула, поэтому ваши расходы остаются прогнозируемыми, даже если производительность отдельной базы данных прогнозировать сложно.
При этом вы можете добавлять базы данных в пул и удалять их из него, масштабируя приложение так, чтобы количество используемых баз данных составляло от нескольких экземпляров до многих тысяч, не выходя за рамки бюджета. Вы также можете управлять минимальным и максимальным объемом ресурсов, доступных для баз данных в пуле. Таким образом ни одна база данных в пуле не будет потреблять все ресурсы пула и в каждой из этих баз данных будет гарантированный минимальный объем ресурсов. Дополнительные сведения о конструктивных шаблонах для предоставляемых в виде услуги приложений SaaS, использующих эластичные пулы, см. в статье Конструктивные шаблоны для приложений SaaS на нескольких клиентах с Базой данных SQL Azure.
Сценарии могут быть полезны для использования в мониторинге и масштабировании эластичных пулов. Примеры приведены в статье Отслеживание и масштабирование эластичного пула в Базе данных SQL Azure с помощью PowerShell.
Совмещение отдельных баз данных и баз данных в пуле
Вы можете смешивать отдельные базы данных с эластичными пулами и изменять уровни служб отдельных баз данных и эластичных пулов, что позволяет адаптировать их под конкретные задачи. Вы сможете сочетать службы Azure с Базой данных SQL, чтобы восполнить уникальные потребности архитектуры приложений, повысить эффективность использования ресурсов и снизить расходы, а также узнать о новых возможностях для развития бизнеса.
Возможности комплексного мониторинга и оповещения
База данных SQL Azure предоставляет расширенные возможности мониторинга и устранения неполадок, которые позволяют получить более подробные сведения о характеристиках рабочей нагрузки. К числу этих возможностей и средств относятся следующие.
- Встроенные возможности мониторинга, предоставляемые последней версией ядра СУБД SQL Server. Они позволяют получать полезные сведения о производительности в режиме реального времени.
- Предоставляемые Azure возможности мониторинга PaaS, которые позволяют следить за большим количеством экземпляров базы данных и устранять в них неполадки.
Хранилище запросов — это встроенная функция мониторинга SQL Server, которая записывает производительность при обработке запросов в режиме реального времени и позволяет выявить потенциальные проблемы с производительностью и основные потребители ресурсов. Автоматическая настройка и рекомендации предоставляют полезные сведения о запросах с пониженной производительностью, а также об отсутствующих или повторяющихся индексах. Автоматическая настройка в Базе данных SQL позволяет либо применить скрипты для устранения проблем вручную, либо воспользоваться автоматическим исправлением. База данных SQL может также протестировать исправление и убедиться в его результативности, а также сохранить или отменить изменения в зависимости от результата. Помимо возможностей хранилища запросов и автоматической настройки, для мониторинга производительности рабочей нагрузки можно использовать стандартные динамические административные представления и XEvent.
Помимо возможностей хранилища запросов и автоматической настройки, для мониторинга производительности рабочей нагрузки можно использовать стандартные динамические административные представления и XEvent.
Azure предоставляет встроенные средства мониторинга производительности и оповещения в сочетании с рейтингами производительности, которые позволяют отслеживать состояние тысяч баз данных. Используя эти средства, вы сможете быстро оценить эффект от увеличения и уменьшения масштаба, исходя из текущей или планируемой загрузки. Кроме того, База данных SQL может выдавать значения метрик и журналы ресурсов для упрощения мониторинга. Вы можете настроить Базу данных SQL для хранения сведений об использовании ресурсов, о рабочих ролях и сеансах, а также настроить подключение к одному из этих ресурсов Azure:
- Служба хранилища Azure: для архивации больших объемов телеметрии по оптимальной стоимости.
- Центры событий Azure. Для интеграции телеметрии Базы данных SQL с настраиваемым решением для мониторинга или горячими конвейерами.
- Журналы Azure Monitor. Для встроенного решения для мониторинга с возможностями предоставления отчетов, предупреждений и выполнения исправлений.

Возможности доступности
База данных SQL Azure позволяет продолжать выполнение бизнес-операций во время прерываний в работе. В традиционной среде SQL Server обычно настроены по крайней мере два локальных компьютера. На этих компьютерах хранятся точные синхронно обслуживаемые копии данных для защиты от сбоя одного компьютера или компонента. Эта среда обеспечивает высокий уровень доступности, но не защищает ваш центр обработки данных от уничтожения вследствие стихийного бедствия.
Аварийное восстановление предполагает, что катастрофическое событие локализовано в определенной географической зоне, поэтому другой компьютер или набор компьютеров с копией данных располагаются на достаточном удалении. Чтобы получить эту возможность в SQL Server, можно воспользоваться группами доступности Always On, работающими в асинхронном режиме. Пользователи часто не хотят дожидаться окончания репликации в удаленное расположение перед фиксацией транзакции, поэтому при внеплановой отработке отказа возможна потеря данных.
Пользователи часто не хотят дожидаться окончания репликации в удаленное расположение перед фиксацией транзакции, поэтому при внеплановой отработке отказа возможна потеря данных.
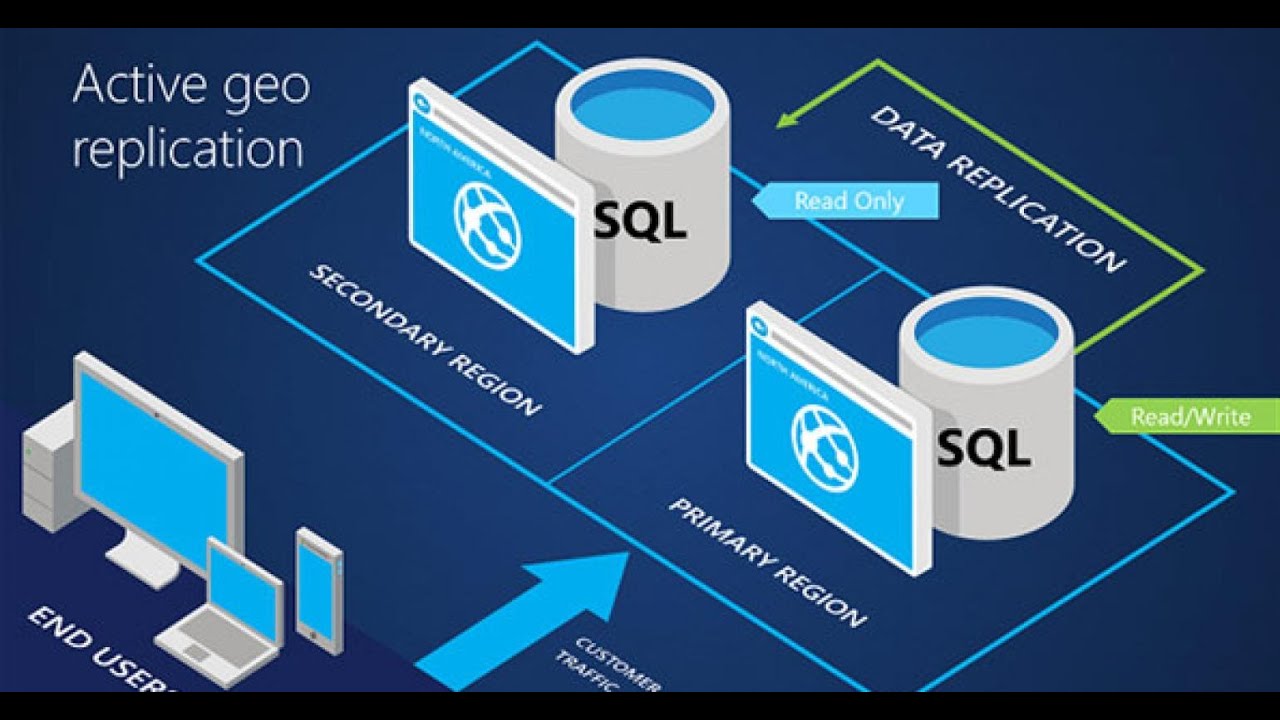
В базах данных на уровнях служб «Премиум» и «Критически важный для бизнеса» уже реализован механизм, сходный с синхронизацией группы доступности. Базы данных на более низких уровнях служб обеспечивают избыточность через хранилище, используя несколько иной, но по сути эквивалентный механизм. Защититься от сбоев одного компьютера помогает встроенная логика. Функция активной георепликации дает возможность защититься от аварии, при которой уничтожается весь регион.
Зоны доступности Azure используются для защиты от сбоя одного здания центра обработки данных в одном регионе. Эта возможность помогает защититься от потери питания или сбоя сети в здании. В Базе данных SQL разные реплики помещаются в разные зоны доступности (по сути в разные здания).
Фактически Соглашение об уровне обслуживания (SLA) в Azure предусматривает использование глобальной сети центров обработки данных под управлением корпорации Майкрософт для обеспечения непрерывной работы приложения — 24 часа в сутки и 7 дней в неделю. Платформа Azure полностью управляет каждой базой данных и гарантирует высокий процент доступности данных без их потери. Azure автоматически обрабатывает исправления, резервное копирование, репликацию, выявление сбоев, потенциальные сбои основного оборудования, программного обеспечения или сети, исправления ошибок при развертывании, отработку отказа, обновления баз данных и другие задачи обслуживания. На уровне «Стандартный» доступность достигается за счет разделения уровня вычислений и уровня хранения. На уровне «Премиум» доступность достигается за счет интеграции вычислительных систем и хранилища на одном узле для повышения производительности, а также за счет реализации технологии, схожей с группами доступности Always On. Полное описание возможностей для обеспечения высокого уровня доступности, предоставляемых в Базе данных SQL Azure, см. в статье Высокая доступность и база данных SQL Azure.
Платформа Azure полностью управляет каждой базой данных и гарантирует высокий процент доступности данных без их потери. Azure автоматически обрабатывает исправления, резервное копирование, репликацию, выявление сбоев, потенциальные сбои основного оборудования, программного обеспечения или сети, исправления ошибок при развертывании, отработку отказа, обновления баз данных и другие задачи обслуживания. На уровне «Стандартный» доступность достигается за счет разделения уровня вычислений и уровня хранения. На уровне «Премиум» доступность достигается за счет интеграции вычислительных систем и хранилища на одном узле для повышения производительности, а также за счет реализации технологии, схожей с группами доступности Always On. Полное описание возможностей для обеспечения высокого уровня доступности, предоставляемых в Базе данных SQL Azure, см. в статье Высокая доступность и база данных SQL Azure.
Кроме того, База данных SQL обеспечивает встроенные функции непрерывности бизнес-процессов и глобальной масштабируемости. К ним относятся следующие объекты.
К ним относятся следующие объекты.
Автоматическое резервное копирование
База данных SQL автоматически создает полные, разностные резервные копии и резервные копии журналов транзакций баз данных, обеспечивая восстановление до любой точки во времени. Для отдельных баз данных и баз данных в пуле можно настроить Базу данных SQL для сохранения полных резервных копий в службе хранилища Azure для долгосрочного хранения резервной копии. Для управляемых экземпляров также можно создать резервную копию только для копирования для долгосрочного хранения.
Восстановление на определенный момент времени
Все варианты развертывания Базы данных SQL поддерживают восстановление до любой точки во времени в пределах автоматического периода хранения резервной копии для любой базы данных.
Активная георепликация.
Варианты с отдельной базой данных и базой данных в пуле позволяют настроить до четырех доступных для чтения баз данных-получателей в одном центре обработки данных или в глобально распределенных центрах обработки данных Azure.
Например, при наличии приложения SaaS с базой данных каталога, содержащей большой объем параллельных транзакций, доступных только для чтения, необходимо использовать активную георепликацию, чтобы включить глобальное масштабирование для чтения. Это устраняет узкие места в основной системе, вызванные рабочими нагрузками чтения. Используйте группы автоматической отработки отказа для управляемых экземпляров.Группы автоматической отработки отказа.
Все варианты развертывания Базы данных SQL позволяют использовать группы отработки отказа для обеспечения высокого уровня доступности и балансировки нагрузки в глобальном масштабе. В частности, они обеспечивают прозрачную георепликацию и отработку отказа больших наборов баз данных, эластичные пулы и управляемые экземпляры. Группы отработки отказа позволяют создавать глобально распределенные приложения SaaS с минимальными затратами на администрирование. При этом все сложные процессы оркестрации мониторинга, маршрутизации и отработки отказа выполняются в Базе данных SQL.
Избыточные между зонами базы данных
База данных SQL позволяет подготовить базы данных и эластичные пулы уровня «Премиум» или «Критически важный для бизнеса» в нескольких зонах доступности. Так как эти базы данных или эластичные пулы имеют несколько избыточных реплик для обеспечения высокого уровня доступности, размещение этих реплик в нескольких зонах доступности гарантирует более высокую устойчивость. Это, в частности, обеспечивает возможность автоматического восстановления без потери данных после масштабных сбоев центра обработки данных.
 Например, при наличии приложения SaaS с базой данных каталога, содержащей большой объем параллельных транзакций, доступных только для чтения, необходимо использовать активную георепликацию, чтобы включить глобальное масштабирование для чтения. Это устраняет узкие места в основной системе, вызванные рабочими нагрузками чтения. Используйте группы автоматической отработки отказа для управляемых экземпляров.
Например, при наличии приложения SaaS с базой данных каталога, содержащей большой объем параллельных транзакций, доступных только для чтения, необходимо использовать активную георепликацию, чтобы включить глобальное масштабирование для чтения. Это устраняет узкие места в основной системе, вызванные рабочими нагрузками чтения. Используйте группы автоматической отработки отказа для управляемых экземпляров.
Встроенная система аналитики
С Базой данных SQL вы получаете встроенную систему аналитики, которая позволяет значительно сократить расходы на выполнение и обслуживание баз данных, а также повышает производительность и безопасность приложения. Круглосуточно выполняя миллионы пользовательских рабочих нагрузок, База данных SQL собирает и обрабатывает большие объемы данных телеметрии при обеспечении полной конфиденциальности пользователей. Различные алгоритмы постоянно оценивают данные телеметрии, чтобы служба могла согласовать работу с приложением.
Различные алгоритмы постоянно оценивают данные телеметрии, чтобы служба могла согласовать работу с приложением.
Автоматический мониторинг и настройка производительности
База данных SQL обеспечивает точное представление о запросах, которые необходимо отслеживать. База данных SQL дает возможность адаптировать схемы базы данных к рабочей нагрузке на основе шаблонов базы данных. База данных SQL предоставляет рекомендации по настройке производительности. Вы можете просмотреть действия по настройке и применить их.
При этом постоянный мониторинг базы данных — это сложная и трудоемкая задача, особенно при работе с несколькими базами данных. Средство Intelligent Insights делает это автоматически, отслеживая производительность Базы данных SQL в нужном масштабе. Оно информирует вас об ухудшении производительности, определяет причину каждой проблемы и по возможности предоставляет рекомендации по повышению производительности.
Эффективное управление огромным числом баз данных невозможно даже с учетом всех доступных средств и отчетов, предоставленных Базой данных SQL и Azure. Вместо того чтобы вручную выполнять мониторинг и настройку базы данных, мы рекомендуем делегировать некоторые действия по настройке и мониторингу Базе данных SQL с помощью автоматической настройки. База данных SQL автоматически применяет рекомендации, тестирует и проверяет все действия по настройке, чтобы гарантировать оптимальную производительность. В этом случае База данных SQL автоматически безопасно адаптируется к рабочей нагрузке. Автоматическая настройка означает, что производительность базы данных тщательно отслеживается и сравнивается перед выполнением действия настройки и после него. Если производительность не улучшается, действие настройки отменяется.
Вместо того чтобы вручную выполнять мониторинг и настройку базы данных, мы рекомендуем делегировать некоторые действия по настройке и мониторингу Базе данных SQL с помощью автоматической настройки. База данных SQL автоматически применяет рекомендации, тестирует и проверяет все действия по настройке, чтобы гарантировать оптимальную производительность. В этом случае База данных SQL автоматически безопасно адаптируется к рабочей нагрузке. Автоматическая настройка означает, что производительность базы данных тщательно отслеживается и сравнивается перед выполнением действия настройки и после него. Если производительность не улучшается, действие настройки отменяется.
Многие наши партнеры, выполняющие приложения SaaS на нескольких клиентах на основе Базы данных SQL, используют автоматическую настройку производительности для обеспечения стабильности и предсказуемой производительности приложений. Они уверены, что эта функция значительно уменьшает риск снижения производительности ночью. Кроме того, так как часть клиентской базы также использует SQL Server, они применяют те же рекомендации по индексации, предоставленные Базой данных SQL, для поддержки клиентов SQL Server.
В Базе данных SQL есть две функции автоматической настройки.
- Автоматическое управление индексами: определяет индексы, которые необходимо добавить в базу данных или удалить.
- Автоматическое изменение плана. Определяет проблемные планы и исправляет проблемы с производительностью плана SQL.
Адаптивная обработка запросов
Вы можете использовать адаптивную обработку запросов, включая чередующееся выполнение для функций с табличными значениями и несколькими инструкциями, обратную связь с выделением памяти в пакетном режиме и адаптивные соединения в пакетном режиме. Каждая из этих функций адаптивной обработки запросов применяет сходные методы «обучения и адаптации», чтобы устранить в дальнейшем проблемы производительности, связанные с традиционно трудноразрешимыми проблемами оптимизации запросов.
Расширенный уровень безопасности и соответствие требованиям
База данных SQL обеспечивает ряд встроенных функций безопасности и соответствия, чтобы выполнить различные требования по защите вашего приложения.
Важно!
Корпорация Майкрософт сертифицировала Базу данных SQL Azure (все варианты развертывания) по ряду стандартов соответствия. Дополнительные сведения см. в центре управления безопасностью Microsoft Azure, где представлен актуальный список сертификатов соответствия Базы данных SQL.
Расширенная защита от угроз
Azure Defender для SQL — это унифицированный пакет расширенных функций защиты SQL, включая управление уязвимостями базы данных и выявление аномальных действий, которые могут указывать на угрозу для базы данных. Эта служба предоставляет единый центр для включения этих возможностей и управления ими.
Оценка уязвимости.
Эта служба может обнаруживать, отслеживать потенциальные уязвимости базы данных и помогает устранять их. Эта служба обеспечивает представление о состоянии безопасности и предлагает практические действия для устранения проблем безопасности и усиления защиты базы данных.
Обнаружение угроз.
Эта функция обнаружения угроз выявляет аномальные операции, указывающие на нестандартные и потенциально вредоносные попытки получить доступ к базам данных или воспользоваться ими.
Она непрерывно отслеживает базу данных для выявления подозрительных действий и немедленно выдает оповещения системы безопасности о потенциальных уязвимостях, атаках путем внедрения кода SQL и аномальных шаблонах доступа к базам данных. Оповещения защиты от угроз содержат сведения о подозрительных операциях и рекомендации для исследования причины угрозы и ее устранения.
 Она непрерывно отслеживает базу данных для выявления подозрительных действий и немедленно выдает оповещения системы безопасности о потенциальных уязвимостях, атаках путем внедрения кода SQL и аномальных шаблонах доступа к базам данных. Оповещения защиты от угроз содержат сведения о подозрительных операциях и рекомендации для исследования причины угрозы и ее устранения.
Она непрерывно отслеживает базу данных для выявления подозрительных действий и немедленно выдает оповещения системы безопасности о потенциальных уязвимостях, атаках путем внедрения кода SQL и аномальных шаблонах доступа к базам данных. Оповещения защиты от угроз содержат сведения о подозрительных операциях и рекомендации для исследования причины угрозы и ее устранения.Аудит для обеспечения безопасности и соответствия
Аудит позволяет отслеживать события базы данных и записывать их в журнал аудита в учетной записи хранения Azure. Аудит может помочь вам соблюсти стандарты, проанализировать работу с базой данных и получить аналитические сведения о расхождениях и аномалиях, которые могут указывать на бизнес-проблемы или предполагаемые нарушения безопасности.
Шифрование данных
База данных SQL помогает защитить ваши данные с помощью шифрования. Для передаваемых данных в ней используется протокол TLS, для неактивных данных — прозрачное шифрование данных, а для используемых данных — шифрование Always Encrypted.
Обнаружение и классификация данных
Функции обнаружения и классификации данных в Базе данных SQL Azure предоставляют встроенные возможности для обнаружения, классификации, маркировки и защиты конфиденциальных данных в базах данных. Она обеспечивает возможность просмотра состояния классификации базы данных, а также отслеживания доступа к конфиденциальным данным в базе данных и за ее пределами.
Интеграция Azure Active Directory и Многофакторная идентификация
База данных SQL позволяет централизованно управлять удостоверениями пользователя базы данных и другими службами Майкрософт с помощью интеграции Azure Active Directory. Эта возможность упрощает управление разрешениями и повышает уровень безопасности. Azure Active Directory поддерживает многофакторную проверку подлинности для повышения безопасности данных и приложений, поддерживая процесс единого входа.
База данных SQL делает создание и обслуживание приложений более удобным и эффективным. Она позволяет сконцентрироваться на том, что у вас получается лучше всего, — на создании отличных приложений. В Базе данных SQL вы можете разрабатывать и обслуживать базы данных, используя имеющиеся средства и навыки.
В Базе данных SQL вы можете разрабатывать и обслуживать базы данных, используя имеющиеся средства и навыки.
| Средство | Описание |
|---|---|
| Портал Azure | Веб-приложение для управления всеми службами Azure. |
| Azure Data Studio | Кросс-платформенное средство для работы с базами данных для Windows, macOS и Linux. |
| Среда SQL Server Management Studio | Бесплатное, доступное для скачивания клиентское приложение для управления любой инфраструктурой SQL, от SQL Server до Базы данных SQL. |
| SQL Server Data Tools в Visual Studio | Бесплатное и доступное для скачивания клиентское приложение для разработки реляционных баз данных SQL Server, баз данных в Базе данных SQL Azure, пакетов Integration Services, моделей данных Analysis Services и отчетов Reporting Services. |
| Visual Studio Code | Бесплатный скачиваемый редактор кода с открытым кодом для Windows, macOS и Linux. Он поддерживает расширения, включая расширение mssql, для выполнения запросов к Microsoft SQL Server, Базе данных SQL Azure и Azure Synapse Analytics. Он поддерживает расширения, включая расширение mssql, для выполнения запросов к Microsoft SQL Server, Базе данных SQL Azure и Azure Synapse Analytics. |
База данных SQL поддерживает создание приложений на языках Python, Java, Node.js, PHP, Ruby и .NET для операционных систем macOS, Windows и Linux. База данных SQL поддерживает те же библиотеки подключений, что и SQL Server.
Создание ресурсов SQL Azure и управление ими с помощью портала Azure
Портал Azure предоставляет отдельную страницу, на которой вы можете управлять всеми ресурсами SQL Azure, а также виртуальными машинами SQL.
Чтобы получить доступ к странице SQL Azure в меню на портале Azure, выберите SQL Azure или найдите и выберите SQL Azure на любой странице.
Примечание
Azure SQL — это быстрый и простой способ получения доступа ко всем ресурсам SQL на портале Azure, включая отдельную базу данных и базу данных в пуле в Базе данных SQL Azure, а также логические экземпляры SQL Server, на которых размещены эти ресурсы, Управляемые экземпляры SQL и виртуальные машины SQL.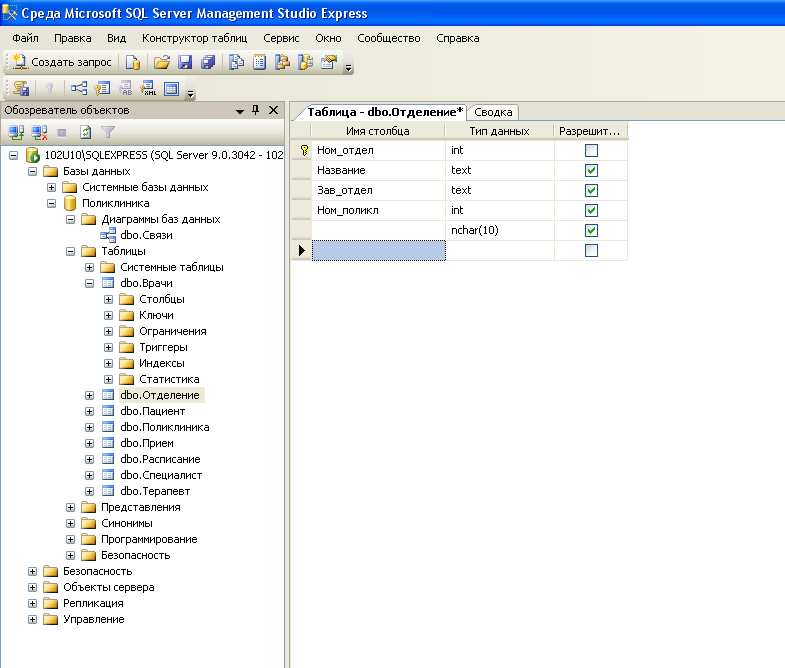 SQL Azure — это не служба или ресурс, а семейство служб, связанных с SQL.
SQL Azure — это не служба или ресурс, а семейство служб, связанных с SQL.
Чтобы управлять существующими ресурсами, выберите нужный элемент в списке. Чтобы создать ресурсы SQL Azure, выберите + Добавить.
После выбора параметра + Добавить, просмотрите дополнительные сведения о различных параметрах, щелкнув Показать сведения для любой плитки.
Подробная информация доступна в следующих статьях:
База данных SQL
Могу ли я контролировать простой в связи с установкой исправлений?
Нет. Влияние исправления в основном незаметно, если в вашем приложении применяется логика повторных попыток. Дополнительные сведения см. в статье Планирование событий обслуживания Azure в Базе данных SQL Azure.
Связаться с командой разработчиков SQL Server
Дальнейшие действия
Сравнение цен и калькуляторы для отдельных баз данных и эластичных пулов см. на странице расценок.
См.
эти краткие руководства по быстрому запуску:Примеры использования Azure CLI и PowerShell:
Дополнительные сведения о новых возможностях см. в стратегии развития Azure для Базы данных SQL.
Читайте блог о Базе данных SQL Azure, в котором участники команды по разработке продукта SQL Server публикуют новые сведения о возможностях и новостях, касающихся Базы данных SQL.
 эти краткие руководства по быстрому запуску:
эти краткие руководства по быстрому запуску:Присоединение и отсоединение базы данных (SQL Server) — SQL Server
- Чтение занимает 6 мин
В этой статье
Применимо к: SQL Server (все поддерживаемые версии)
Файлы данных и журналов транзакций базы данных можно отсоединить, а затем снова присоединить к тому же или другому экземпляру SQL Server. Отсоединение и присоединение базы данных полезно, если необходимо переместить базу данных на другой экземпляр SQL Server на том же компьютере либо перенести базу данных.
Отсоединение и присоединение базы данных полезно, если необходимо переместить базу данных на другой экземпляр SQL Server на том же компьютере либо перенести базу данных.
безопасность
Разрешения на доступ к файлам устанавливаются во время выполнения определенных операций с базами данных, включая отсоединение и присоединение баз данных.
Важно!
Не рекомендуется подключать или восстанавливать базы данных, полученные из неизвестных или ненадежных источников. В этих базах данных может содержаться вредоносный код, вызывающий выполнение непредусмотренных инструкций Transact-SQL или появление ошибок из-за изменения схемы или физической структуры базы данных.
Перед тем как использовать базу данных, полученную из неизвестного или ненадежного источника, выполните на тестовом сервере инструкцию DBCC CHECKDB для этой базы данных, а также изучите исходный код в базе данных, например хранимые процедуры и другой пользовательский код.
Отсоединение базы данных
Отсоединение базы данных означает удаление ее с экземпляра SQL Server , но сама база данных остается неповрежденной со всеми своими файлами данных и журналов транзакций. Эти файлы затем можно использовать для присоединения базы данных к любому экземпляру SQL Server, включая сервер, от которого она была отсоединена.
Базу данных невозможно отсоединить в следующих случаях.
База данных реплицируется и публикуется. При репликации база данных должна быть снята с публикации. Перед тем как отсоединить базу данных, необходимо отключить публикацию, выполнив процедуру sp_replicationdboption.
Примечание
Если невозможно использовать процедуру sp_replicationdboption, можно удалить репликацию, выполнив процедуру sp_removedbreplication.
Имеется моментальный снимок базы данных.
Перед отсоединением базы данных необходимо удалить все моментальные снимки. Дополнительные сведения см. в разделе Удаление моментального снимка базы данных (Transact-SQL).
Примечание
Невозможно отсоединить или присоединить моментальный снимок базы данных.
Эта база данных является частью группы доступности AlwaysOn.
База данных не может быть отсоединена, пока она не будет удалена из группы доступности. Дополнительные сведения см. в разделе Удаление базы данных — источника из группы доступности Always On.
База данных находится в сеансе зеркального копирования.
Отключить базу данных невозможно, пока этот сеанс не завершится. Дополнительные сведения см. в разделе Удаление зеркального отображения базы данных (SQL Server).
База данных помечена как подозрительная. Подозрительную базу данных невозможно отсоединить. Для отсоединения ее необходимо перевести в аварийный режим. Дополнительные сведения о переводе базы данных в аварийный режим см. в разделе ALTER DATABASE (Transact-SQL).
База данных является системной базой данных.
Резервное копирование, восстановление и отсоединение
Для разностных резервных копий отсоединение базы данных, доступной только для чтения, приводит к потере сведений о базовой копии для разностного копирования. Дополнительные сведения см. в разделе Разностные резервные копии (SQL Server).
Реакция на ошибки отсоединения
Ошибки, возникшие во время отсоединения базы данных, могут воспрепятствовать чистому закрытию базы данных и перестроению журнала транзакций. При получении сообщения об ошибке выполните следующие действие по исправлению.
Заново присоедините все файлы, связанные с базой данных, а не только первичный файл.
Исправьте неполадку, ставшую причиной сообщения об ошибке.
Отсоедините базу данных повторно.
Присоединение базы данных
Можно присоединить скопированную или отсоединенную базу данных SQL Server . Когда базу данных SQL Server 2005 (9.x) с файлами полнотекстовых каталогов присоединяют к экземпляру сервера SQL Server , то присоединение файлов каталогов выполняется из их предыдущего расположения вместе с другими файлами баз данных, как и в SQL Server 2005 (9.x). Дополнительные сведения см. в разделе Обновление полнотекстового поиска.
При присоединении базы данных должны быть доступны все файлы данных (файлы MDF и NDF). Если у какого-либо файла данных путь отличается от того, каким он был при первом создании или последнем присоединении, необходимо указать текущий путь к файлу.
Примечание
Если присоединяемый первичный файл данных доступен только для чтения, компонент Компонент Database Engine предполагает, что и база данных доступна только для чтения.
Когда зашифрованная база данных впервые присоединяется к экземпляру SQL Server, владелец базы данных должен открыть главный ключ базы данных, выполнив следующую инструкцию: OPEN MASTER KEY DECRYPTION BY PASSWORD = 'password'. Рекомендуется включить автоматическую расшифровку главного ключа, выполнив следующую инструкцию: ALTER MASTER KEY ADD ENCRYPTION BY SERVICE MASTER KEY. Дополнительные сведения см. в разделах CREATE MASTER KEY (Transact-SQL) и ALTER MASTER KEY (Transact-SQL).
Требования для присоединения файлов журналов частично зависят от того, доступна база данных для записи и чтения или только для чтения.
Для базы данных, доступной для записи и чтения, обычно можно присоединить файл журнала в новом расположении. Однако в некоторых случаях для повторного соединения базы данных требуются файлы ее существующих журналов. Поэтому всегда храните все отсоединенные файлы журналов, пока база данных не будет успешно присоединена без них.
Если у базы данных, доступной для записи и чтения, только один файл журнала и для него не указано новое расположение, операция присоединения использует старое расположение файла. Если он найден, применяется старый файл журнала независимо от того, была ли база данных выключена чисто. Однако если старый файл журнала не найден и база данных была выключена чисто и не имеет активной цепочки журналов, то операция присоединения пытается построить новый файл журнала для базы данных.
Если присоединяемый первичный файл данных доступен только для чтения, компонент Компонент Database Engine предполагает, что и база данных доступна только для чтения. Для базы данных, доступной только для чтения, файл или файлы журнала должны быть доступны в расположении, указанном в первичном файле базы данных. Новый файл журнала построить невозможно, так как SQL Server не может обновить расположение журнала, указанное в первичном файле.
Изменение метаданных при присоединении базы данных
Если база данных, доступная только для чтения, отсоединяется, а затем снова присоединяется, то данные о текущей базовой копии для разностного копирования будут утеряны. Базовая копия для разностного копирования — это последняя из полных резервных копий всех данных из базы данных или из подмножества файлов и файловых групп, содержащихся в базе данных. Без сведений о базовой резервной копии база данных master утрачивает синхронизацию с базой данных, доступной только для чтения, и дальнейшее создание разностных резервных копий может привести к непредвиденным результатам. Таким образом, если с базой данных, доступной только для чтения, используются разностные резервные копии, то после повторного присоединения базы данных необходимо установить новую базовую копию для разностного копирования, создав полную резервную копию. Сведения о разностных резервных копиях см. в разделе Разностные резервные копии (SQL Server).
После присоединения происходит запуск базы данных. Обычно присоединение базы данных переводит ее в то же состояние, в котором она находилась на момент отсоединения или копирования. Однако операции присоединения и отсоединения отключают создание межбазовых цепочек владения для этой базы данных. Сведения о том, как включить цепочки владения, см. в разделе Параметр конфигурации сервера «cross db ownership chaining».
Резервное копирование, восстановление и присоединение
Подобно любой базе данных, которая полностью или частично вне сети, база данных с восстановлением файлов не может быть присоединена. Базу данных можно присоединить после остановки последовательности восстановления. Затем можно снова запустить последовательность восстановления.
Присоединение базы данных к другому экземпляру сервера
При присоединении базы данных к другому экземпляру сервера для обеспечения ее согласованного функционирования для пользователей и приложений может понадобиться повторное создание некоторых или всех метаданных базы данных, например имен входа и задания, на другом экземпляре сервера. Дополнительные сведения см. в статье Управление метаданными при обеспечении доступности базы данных на другом экземпляре сервера (SQL Server).
Отсоединение базы данных
Присоединение базы данных
Обновление базы данных при помощи операций отсоединения и присоединения
Перемещение базы данных при помощи операций отсоединения и присоединения
Удаление моментального снимка базы данных
См. также:
Файлы и файловые группы базы данных
Развернуть базу данных MS SQL
Для работы с базой данных на сервере БД требуется установить Microsoft SQL Server Management Studio. Ознакомиться с описанием программы и скачать установочные файлы можно в документации Microsoft.
На заметку. Развертывание Creatio с отказоустойчивостью на MS SQL успешно тестировалось. Для развертывания системы с высокой доступностью рекомендуется использовать группы доступности MS SQL Always On. Подробнее о технологии MS SQL Always On читайте в документации Microsoft.
После установки Microsoft SQL Server Management Studio вам необходимо создать пользователей базы данных.
Пользователь с ролью ”sysadmin” и неограниченными полномочиями на уровне сервера базы данных — нужен для восстановления базы данных и настройки доступа к ней.
Пользователь с ролью ”public” и ограниченными полномочиями — используется для настройки безопасного подключения Creatio к базе данных через аутентификацию средствами MS SQL Server.
Подробно о создании пользователей и настройке прав читайте в документации Microsoft.
Для восстановления базы данных:
Авторизируйтесь в Microsoft SQL Server Management Studio как пользователь с ролью ”sysadmin”.
Нажмите правой клавишей мыши по каталогу Databases и в контекстном меню выберите команду Restore Database (Рис. 1).
В окне Restore Database:
В поле Database введите название базы данных;
Выберите переключатель Device и укажите путь к файлу резервной копии базы данных. По умолчанию данный файл находится в директории ~\db с исполняемыми файлами Creatio (Рис. 2).
Укажите папку на сервере, в которой будет храниться развернутая база данных. Необходимо заранее создать папку, которая будет указываться для восстановления файлов базы данных, т.к. SQL сервер не имеет прав на создание директорий.
Перейдите на вкладку Files.
В области Restore the database files as установите признак Relocate all files and folders.
Укажите пути к папкам, в которые будут сохранены файлы базы данных TS_Data.mdf и TS_Log.ldf (Рис. 3).
Нажмите на кнопку OK и дождитесь завершения процесса восстановления базы данных.
Настройте для восстановленной базы возможность подключения пользователя MS SQL с ролью ”public”, от имени которого приложение Creatio будет подключаться к базе данных:
В MS SQL Server Managment Studio найдите восстановленную базу данных Creatio.
Откройте вкладку Security выбранной базы данных.
В списке пользователей Users добавьте созданного ранее пользователя.
На вкладке Membership укажите роль ”db_owner” — таким образом пользователю будет предоставлен неограниченный доступ к восстановленной базе.
Что такое база данных и SQL. Как работают с базами и что в них хранят
Если сказать упрощённо, то база данных — это среда, в которой существуют таблицы с данными. Если вы когда-нибудь работали в офисной программе «Excel», в которой можно делать таблицы, то считайте что работали с базой данных.В базах данных сайтов могут содержаться таблицы, в которых может быть записано всё что угодно:
- данные новостей, которые опубликованы на сайте
- данные пользователей, которые зарегистрированы на сайте
+--------------------+ | Пользователи | +--------------------+ | Имя | Любимая еда | +------+-------------+ | Мышь | Сыр | +------+-------------+ | Кот | Молоко | +------+-------------+Как можно заметить, это обычная таблица. Но в таком виде на сайте её увидеть нельзя. Сайт делает запрос к ней с помощью специального языка, который называется SQL (Structured Query Language — «язык структурированных запросов»). Эти запросы возвращают массив строк, которые подходят под параметр запроса. Разберём далее логику запросов.
Представьте, что необходимо получить из примера выше все данные таблицы и вывести их на экран. Тогда нужно сделать запрос к базе данных на языке SQL:
SELECT 'Имя пользователя', 'Любимая еда' FROM 'Пользователи';Последняя часть запроса содержит слово FROM, которое дословно переводится как «из». После этого слова стоит таблица ИЗ которой надо получить данные. Если не указать из какой таблицы нужны данные, то база данных выдаст ошибку.
Пример SQL запроса, который приведён выше, сильно утрирован для большей наглядности и простоты. Потому что в базах данных крайне нежелательно создавать таблицы с кириллическими названиями таблиц и столбцов. А ещё названия столбцов и самой таблицы нужно заключать не в одинарную кавычку ‘ , а в наколнную `
Перейдём к обработке результатов выполнения запроса. Если утрировать, то после выполнения запроса из примера выше база данных вернёт такой массив:Array
(
[0] => Array
(
[Имя] => Мышь
[Любимая еда] => Сыр
)
[1] => Array
(
[Имя] => Кот
[Любимая еда] => Молоко
)
)После получения этого массива необходимо сделать цикл аналогичный foreach( ) по всем элементам полученного массива. Внутри цикла можно обернуть полученные значения в различные HTML теги, чтобы вывод был красивым, чтобы у страницы сайта был дизайн. Так и происходит взаимодействие сайтов с базами данных. Базы данных — это не лучшее хранилище информации. Конёк баз данных — это быстрый поиск информации и вывод с сортировкой. Поэтому базы данных целесообразно использовать далеко не везде. Если же нужно обрабатывать терабайты статичной информации без необходимости поиска и сортировки, то выгоднее использовать использовать простые файлы для хранения информации.Базы данных используются для сайтов в основном потому, что с их помощью можно организовать уровни доступа к информации. И базы данных большинства сайтов в интернете очень редко когда превышают 10 Гигабайт (считая размеры всех таблиц в базе).
В следующих статьях мы разберём более сложные примеры обращения с базой данных: научимся создавать и удалять таблицы, объединять результаты выборки из нескольких разных таблиц и обновлять данные в таблицах. Если вам не терпится приступить к программированию, то рекомендуем ознакомиться со статьёй «Как сделать запрос из PHP к базе данных».Создание базы данных Microsoft SQL Server – AWS
Сеть и безопасность
- Virtual Private Cloud (VPC): выберите Default VPC (VPC по умолчанию). Дополнительную информацию о VPC см. в разделе Amazon RDS и Amazon Virtual Private Cloud (VPC).
- Subnet Group (Группа подсетей): выберите группу подсетей default (По умолчанию). Дополнительную информацию о группах подсетей см. в разделе Работа с группами подсетей БД.
- Public accessibility (Общий доступ): выберите Yes (Да). Инстансу базы данных будет присвоен IP-адрес, что позволит подключаться к базе данных непосредственно с пользовательского устройства.
- Availability Zone (Зона доступности): выберите значение No Preference (Нет предпочтений). Для получения дополнительной информации см. раздел Регионы и зоны доступности.
- VPC security groups (Группы безопасности VPC): выберите Create new VPC security group (Создать новую группу безопасности VPC). Будет создана группа безопасности, поддерживающая соединение между IP-адресом используемого устройства и созданной базой данных.
Аутентификация Microsoft SQL Server для Windows
- Directory (Каталог): выберите значение по умолчанию None (Нет).
Настройки базы данных
- Port (Порт): сохраните значение по умолчанию – 1433.
- Option group (Группа настроек): выберите значение по умолчанию default.sqlserver-ex-14.00. С помощью групп настроек в Amazon RDS активируются и настраиваются дополнительные возможности. Дополнительную информацию см. в разделе Работа с группами настроек.
Шифрование
Эта настройка недоступна на уровне бесплатного пользования. Дополнительную информацию см. в разделе Шифрование ресурсов Amazon RDS.
Резервное копирование
- Backup Retention Period (Срок хранения резервных копий): в этом поле можно выбрать количество дней, в течение которого сохраняются резервные данные. В данном случае выберите значение 1 day (1 день).
- Backup Window (Окно резервного копирования): задайте значение по умолчанию – No Preference (Нет предпочтений).
Мониторинг
- Enable Enhanced Monitoring (Включить расширенный мониторинг): задайте значение по умолчанию – Enable Enhanced Monitoring (Включить расширенный мониторинг). В случае активации расширенного мониторинга в режиме реального времени становятся доступны метрики для операционной системы (ОС), на которой работает инстанс БД. Дополнительную информацию см. в разделе Просмотр метрик инстанса БД.
Performance Insights
Для выполнения заданий этого учебного пособия выберите Disable Performance Insights (Отключить Performance Insights).
Обслуживание
- Auto minor version upgrade (Автоматическое промежуточное обновление версии): выберите Enable auto minor version upgrade (Включить автоматическое промежуточное обновление версии), чтобы получать автоматические обновления, как только они станут доступны.
- Maintenance Window (Окно обслуживания): выберите No preference (Нет предпочтений).
Защита от удаления
Отключите параметр Enable deletion protection (Включить защиту от удаления) для выполнения заданий этого учебного пособия. Если этот параметр включен, базу данных невозможно удалить.
Что такое база данных SQL?
Базы данных SQL использовались десятилетиями — и используются до сих пор. В этом блоге мы даем базовый обзор того, что такое база данных SQL, и приводим примеры.
Что такое база данных SQL?
SQL означает язык структурированных запросов. Используется для реляционных баз данных . База данных SQL — это набор таблиц, в которых хранится определенный набор структурированных данных.
База данных SQL долгое время была проверенной и верной рабочей лошадкой серверного предприятия и лежала в основе всего, что мы делаем в этот электронный век.SQL был создан в начале 1970-х в IBM как метод доступа к системе баз данных IBM System R.
История баз данных SQL
Полезность возможности доступа к нескольким записям с помощью одной команды, которая не требует указания способа достижения данной записи, была немедленно признана компьютерным миром. Он был быстро принят в качестве основного языка запросов для других систем управления базами данных или СУБД, таких как IBM DB2, а в 1979 году — сервера базы данных Oracle V2 от Relational Software Inc. (теперь известного как Oracle Software) для систем Vax.В конце концов, в 1986 году SQL был принят организациями по стандартизации ANSI и ISO, проложив путь для Microsoft SQL Server и различных баз данных с открытым исходным кодом, имеющихся сегодня на рынке.
СУБД, которую мы использовали сегодня, полагается на SQL как на механизм, который позволяет нам выполнять все операции, необходимые для создания, извлечения, обновления и удаления данных по мере необходимости. С точки зрения открытого исходного кода, эти СУБД включают MySQL, MariaDB и PostgreSQL как наиболее часто используемые СУБД с открытым исходным кодом в настоящее время.Многие компании из списка Fortune 100 в нескольких различных секторах бизнеса, включая финансовую, розничную торговлю, здравоохранение и другие, обратились к этим альтернативам с открытым исходным кодом, чтобы значительно снизить общую стоимость владения по сравнению с предложениями с оплатой за игру, такими как сервер Oracle Database и Microsoft. SQL Server.
[Узнайте о плюсах и минусах баз данных с открытым исходным кодом здесь]
Примеры баз данных SQL
MariaDB и MySQL
MariaDB и MySQL — это бинарно-совместимые серверы баз данных SQL с открытым исходным кодом, которые изначально начинались как просто MySQL.Однако из-за опасений по поводу будущего MySQL после того, как она была приобретена Oracle Software, MariaDB была выделена из проекта как отдельная сущность, но сохраняет свою совместимость с клиентскими API и протоколами MySQL в дополнение к файлам данных и определений таблиц.
Это означает, что в большинстве случаев сторонние инструменты будут работать с обеими версиями и, как правило, их можно рассматривать как замену любой версии. С приобретением MySQL Oracle стала довольно доброжелательно относиться к проекту с открытым исходным кодом, и большинство опасений, которые сообщество испытывало в первые дни приобретения, не сбылось, однако некоторые пуристы с открытым исходным кодом все еще могут предпочесть MariaDB MySQL. .
PostgreSQL
PostgreSQL — это объектно-реляционная система управления базами данных (ORDBMS), а не чисто СУБД, такая как MySQL и MariaDB. Это означает, что модели данных PostgreSQL могут быть основаны на моделях реляционных баз данных, но также могут быть объектно-ориентированными. На практике это означает, что мы видим, что PostgreSQL используется в более сложных и разнообразных моделях данных, а MariaDB и MySQL используются для более легких моделей данных.
Развиваясь из проекта Ingres в Калифорнийском университете в Беркли в 1982 году, PostgreSQL был создан с целью добавления минимального количества функций, необходимых для поддержки всех основных типов данных.Этот менталитет «большой отдачи» продолжает стимулировать развитие PostgreSQL и по сей день. Для сторонников открытого исходного кода это, как правило, предпочтительная база данных, так как это настоящий проект с открытым исходным кодом, который видела некоммерческая организация PostgreSQL Global Development Group, которую нелегко продать из-за ее образования.
Какое будущее у баз данных SQL?
В последние годы появились новые технологии для удовлетворения потребностей серверов баз данных, которые могут обрабатывать чрезвычайно большие наборы данных с чрезвычайно высокой общей скоростью без ущерба для стабильности или доступности.Базы данных NoSQL (не только SQL или не-SQL) становятся все более популярными для удовлетворения этих требований. Базы данных NoSQL хранят свои данные иначе, чем реляционные базы данных, используя базы данных на основе JSON или базы данных «ключ-значение», чтобы назвать несколько распространенных типов хранилищ. PostgreSQL с JSON и его методология, основанная на OORDMS, является свидетельством долговечности этих баз данных NoSQL.
Тем не менее, до традиционной базы данных SQL еще долго не зайдет солнце. Степень того, что базы данных SQL вошли в нашу повседневную жизнь, означает, что эти высокофункциональные и надежные СУБД будут опорой предприятия на десятилетия вперед.
Дальнейшие действия
Если вам нужна дополнительная информация о переходе с дорогостоящей реляционной СУБД с оплатой за игру на более экономически целесообразную альтернативу, свяжитесь с командой OpenLogic от Perforce. OpenLogic помог многим организациям во многих масштабах отказаться от дорогостоящего мира серверов баз данных с закрытым исходным кодом и добиться значительной экономии, переключившись на мир с открытым исходным кодом.
СВЯЗАТЬСЯ С ЭКСПЕРТОМ
Базы данных SQL и NoSQL: в чем разница?
В мире технологий баз данных существует два основных типа баз данных: SQL и NoSQL — или реляционные базы данных и нереляционные базы данных.Разница говорит о том, как они устроены, о типе информации, которую они хранят, и о том, как они ее хранят. Реляционные базы данных структурированы, как телефонные книги, в которых хранятся номера телефонов и адреса. Нереляционные базы данных ориентированы на документы и распределены, как папки с файлами, в которых хранится все, от адреса и номера телефона человека до его лайков в Facebook и предпочтений при совершении покупок в Интернете.
Мы называем их SQL и NoSQL, имея в виду, написаны ли они исключительно на языке структурированных запросов (SQL).В этой статье мы рассмотрим, что такое SQL, как он отличает эти базы данных и как каждый тип структурирует данные, которые он хранит, чтобы вы могли легко определить, какой тип подходит именно вам.
SQL: реляционные базы данных
Во-первых, давайте взглянем на одну из основных особенностей, разделяющих эти две системы: способ, которым они структурируют данные. Реляционная база данных — или база данных SQL, названная в честь языка, на котором она написана, язык структурированных запросов (SQL) — является более жестким и структурированным способом хранения данных, например в телефонной книге.Разработанная IBM в 1970-х годах реляционная база данных состоит из двух или более таблиц со столбцами и строками. Каждая строка представляет собой запись, а в каждом столбце сортируется очень определенный тип информации, такой как имя, адрес и номер телефона. Связь между таблицами и типами полей называется схемой . В реляционной базе данных схема должна быть четко определена, прежде чем можно будет добавить какую-либо информацию.
Чтобы реляционная база данных была эффективной, данные, которые вы храните в ней, должны быть очень организованы.Хорошо спроектированная схема сводит к минимуму избыточность данных и предотвращает рассинхронизацию таблиц, что является важной функцией для многих предприятий, особенно тех, которые регистрируют финансовые транзакции. Плохо спроектированная схема может вызвать головную боль организации из-за ее жесткости. Например, в столбце, предназначенном для хранения телефонных номеров США, может потребоваться 10 цифр, поскольку это стандарт для телефонных номеров в США. Преимущество этого метода заключается в отклонении любых недопустимых значений (например, если в номере отсутствует код города).Однако, если вам нужно изменить схему (например, если вам нужно включить международный телефонный номер, содержащий более 10 цифр), то необходимо отредактировать всю базу данных. Ключевой вывод: отличная организация приводит к компромиссу в гибкости с реляционной базой данных.
Язык структурированных запросов (SQL) — это язык программирования, используемый разработчиками баз данных для проектирования реляционных баз данных. В базе данных SQL, такой как MySQL, Sybase, Oracle или IBM DM2, SQL выполняет запросы, извлекает данные и редактирует данные, обновляя, удаляя или создавая новые записи.SQL — это легкий декларативный язык, который выполняет большую часть тяжелой работы для реляционной базы данных, действуя как версия серверного сценария для базы данных. Одним из особых преимуществ SQL является его простое, но мощное предложение JOIN, которое позволяет разработчикам извлекать связанные данные, хранящиеся в нескольких таблицах, с помощью одной команды.
Еще одна причина, по которой базы данных SQL остаются популярными, заключается в том, что они естественным образом вписываются во многие известные программные стеки, включая LAMP и стеки на основе Ruby. Эти базы данных хорошо изучены и широко поддерживаются, что может стать большим преимуществом, если у вас возникнут проблемы.
Популярные базы данных SQL и СУБД
- MySQL — самая популярная база данных с открытым исходным кодом, отлично подходящая для сайтов CMS и блогов.
- Oracle — объектно-реляционная СУБД, написанная на языке C ++. Если у вас есть бюджет, это вариант с полным спектром услуг с отличным обслуживанием клиентов и надежностью. Oracle также выпустила базу данных Oracle NoSQL.
- IMB DB2 — семейство продуктов серверов баз данных от IBM, предназначенных для обработки расширенной аналитики «больших данных».
- Sybase — серверный продукт реляционной модели базы данных для предприятий, в основном используемый на ОС Unix, которая была первой СУБД корпоративного уровня для Linux.
- MS SQL Server — РСУБД, разработанная Microsoft для баз данных корпоративного уровня, которая поддерживает архитектуры SQL и NoSQL.
- Microsoft Azure — платформа облачных вычислений, которая поддерживает любую операционную систему и позволяет хранить, вычислять и масштабировать данные в одном месте. Недавний опрос даже опередил Amazon Web Services и Google Cloud Storage для корпоративного хранения данных.
- MariaDB — расширенная версия MySQL.
- PostgreSQL — объектно-реляционная СУБД корпоративного уровня, в которой помимо кода уровня SQL используются процедурные языки, такие как Perl и Python.
Базы данных NoSQL: нереляционные и распределенные данные
Если ваши требования к данным не ясны с самого начала или если вы имеете дело с огромными объемами неструктурированных данных, у вас может не быть роскоши разработки реляционной базы данных с четко определенная схема.Откройте для себя нереляционные базы данных, которые предлагают гораздо большую гибкость, чем их традиционные аналоги. Думайте о нереляционных базах данных больше как о папках с файлами, где собрана связанная информация всех типов. Если бы блог WordPress использовал базу данных NoSQL, каждый файл мог бы хранить данные для сообщения блога: лайки в социальных сетях, фотографии, текст, показатели, ссылки и многое другое.
Неструктурированные данные из Интернета могут включать данные датчиков, совместное использование в социальных сетях, личные настройки, фотографии, информацию о местоположении, онлайн-активность, показатели использования и многое другое.Попытки хранить, обрабатывать и анализировать все эти неструктурированные данные привели к разработке бессхемных альтернатив SQL. Взятые вместе, эти альтернативы называются NoSQL, что означает «Не только SQL». Хотя термин NoSQL охватывает широкий спектр альтернатив реляционным базам данных, их объединяет то, что они позволяют более гибко обрабатывать данные.
Как работают базы данных NoSQL? Вместо таблиц базы данных NoSQL ориентированы на документы . Таким образом, неструктурированные данные (например, статьи, фотографии, данные из социальных сетей, видео или контент в сообщении блога) могут храниться в одном документе, который можно легко найти, но не обязательно категоризировать по полям, таким как реляционный база данных делает.Это более интуитивно понятно, но учтите, что такое массовое хранение данных требует дополнительных усилий по обработке и большего объема памяти, чем высокоорганизованные данные SQL. Вот почему Hadoop, платформа для вычислений и анализа данных с открытым исходным кодом, способная обрабатывать огромные объемы данных в облаке, так популярна в сочетании со стеками баз данных NoSQL.
Базы данных NoSQL предлагают еще одно важное преимущество, особенно для разработчиков приложений: простоту доступа. Реляционные базы данных тесно связаны с приложениями, написанными на объектно-ориентированных языках программирования, таких как Java, PHP и Python.Базы данных NoSQL часто могут обойти эту проблему с помощью API-интерфейсов, которые позволяют разработчикам выполнять запросы без необходимости изучать SQL или понимать базовую архитектуру своей системы баз данных.
Общие типы баз данных NoSQL
- Модель «ключ-значение» — наименее сложный вариант NoSQL, который хранит данные без схемы, состоящей из индексированных ключей и значений. Примеры: Cassandra, Azure, LevelDB и Riak.
- Хранилище столбцов — или хранилище с широкими столбцами, в котором таблицы данных хранятся в виде столбцов, а не строк.Это больше, чем просто перевернутая таблица — разделение столбцов на разделы обеспечивает отличную масштабируемость и высокую производительность. Примеры: HBase, BigTable, HyperTable.
- База данных документов — принимая концепцию «ключ-значение» и усложняя, каждый документ в этом типе базы данных имеет свои собственные данные и свой собственный уникальный ключ, который используется для их извлечения. Это отличный вариант для хранения, извлечения и управления данными, ориентированными на документы, но все же в некоторой степени структурированными. Примеры: MongoDB, CouchDB.
- База данных графиков — есть данные, которые взаимосвязаны и лучше всего представлены в виде графика? Этот метод может быть очень сложным. Примеры: Полиглот, Neo4J.
Популярные базы данных NoSQL
- MongoDB — самая популярная система NoSQL, особенно среди стартапов. Документно-ориентированная база данных с JSON-подобными документами в динамических схемах вместо реляционных таблиц, которые используются на бэкенде таких сайтов, как Craigslist, eBay, Foursquare.Это открытый исходный код, поэтому он бесплатный, с хорошим обслуживанием клиентов.
- Apache CouchDB — настоящая БД для Интернета, она использует формат обмена данными JSON для хранения своих документов; JavaScript для индексации, объединения и преобразования документов; и HTTP для своего API.
- HBase — еще один проект Apache, разработанный как часть Hadoop, эта нереляционная база данных NoSQL с открытым исходным кодом, написанная на Java, и предоставляет возможности, подобные BigTable.
- Oracle NoSQL — вход Oracle в категорию NoSQL.
- Apache Cassandra DB — созданная в Facebook, Cassandra представляет собой распределенную базу данных, которая отлично подходит для обработки больших объемов структурированных данных. Ожидаете роста приложения? Кассандра отлично умеет увеличивать масштаб. Примеры: Instagram, Comcast, Apple и Spotify.
- Riak — база данных хранилища ключей и значений с открытым исходным кодом, написанная на Erlang. Он имеет встроенную отказоустойчивую репликацию и автоматическое распределение данных для обеспечения отличной производительности.
Какое решение для баз данных вам подходит?
Причины использования базы данных SQL
Когда дело доходит до технологии баз данных, не существует универсального решения.Вот почему многие компании используют как реляционные, так и нереляционные базы данных для решения различных задач. Несмотря на то, что базы данных NoSQL набирают популярность благодаря своей скорости и масштабируемости, все еще существуют ситуации, когда база данных SQL с высокой структурой может быть предпочтительнее. Вот несколько причин, по которым вы можете выбрать базу данных SQL:
- Вам необходимо обеспечить соответствие ACID (атомарность, согласованность, изоляция, надежность). Соответствие ACID сокращает количество аномалий и защищает целостность вашей базы данных, точно предписывая, как транзакции взаимодействуют с базой данных.Как правило, базы данных NoSQL жертвуют совместимостью с ACID ради гибкости и скорости обработки, но для многих приложений электронной коммерции и финансовых приложений предпочтительным вариантом остается ACID-совместимая база данных.
- Ваши данные структурированы и неизменны. Если ваш бизнес не демонстрирует значительного роста, для которого потребовалось бы больше серверов, и вы работаете только с согласованными данными, то, возможно, нет причин использовать систему, предназначенную для поддержки различных типов данных и большого объема трафика.
Причины использования базы данных NoSQL
Когда все другие компоненты серверного приложения разработаны так, чтобы работать быстро и без проблем, базы данных NoSQL не позволяют данным быть узким местом. Настоящим мотиватором NoSQL здесь являются большие данные, которые делают то, чего не могут делать традиционные реляционные базы данных. Это способствует росту популярности баз данных NoSQL, таких как MongoDB, CouchDB, Cassandra и HBase.
- Хранение больших объемов данных, которые часто практически не имеют структуры. База данных NoSQL не устанавливает ограничений на типы данных, которые вы можете хранить вместе, и позволяет вам добавлять различные новые типы по мере изменения ваших потребностей. С базами данных на основе документов вы можете хранить данные в одном месте, не определяя заранее, какие «типы» это данные.
- Максимально эффективное использование облачных вычислений и хранения. Облачное хранилище — отличное экономичное решение, но требует, чтобы данные легко распределялись по нескольким серверам для масштабирования. Использование стандартного (доступного, меньшего по размеру) оборудования на месте или в облаке избавляет вас от лишних хлопот, связанных с дополнительным программным обеспечением, а базы данных NoSQL, такие как Cassandra, спроектированы для масштабирования в нескольких центрах обработки данных без особых проблем.
- Быстрое развитие. Если вы разрабатываете в рамках двухнедельных Agile-спринтов, выполняете быстрые итерации или вам нужно часто обновлять структуру данных без больших простоев между версиями, реляционная база данных замедлит вас. Данные NoSQL не нужно подготавливать заранее.
Теперь, когда у вас есть обзор SQL и NoSQL, кто вам нужен, чтобы помочь вам создавать и поддерживать свои системы баз данных? Системы управления реляционными и нереляционными базами данных могут стать чрезвычайно сложными и определенно потребовать обслуживания, особенно если принять во внимание переход в облако.Хотя в такой программе, как Microsoft Access, легко управлять базовой однофайловой базой данных, вам нужно нанять способного архитектора баз данных для управления вашей системой управления реляционными базами данных (RDBMS) или управлением базами данных NoSQL. Изучите администраторов баз данных на Upwork.
После трех десятилетий вы, наконец, можете получить распределенную базу данных SQL
Без хороших технологий весь мировой маркетинг не поможет компании сдвинуться с мертвой точки и удержать ее в воздухе, и, наоборот, без хорошего маркетинга и продаж все технологии в мире тоже этого не сделают. .За многие десятилетия наблюдения за ИТ-сектором здесь, в The Next Platform , у нас всегда было это бинокулярное видение, наблюдая за технологиями и рынками, которые они преследуют. Мы всегда говорили с обоими лагерями: технологиями и маркетингом.
В последние годы мы провели кучу времени с техниками из Cockroach Labs, особенно со Спенсером Кимбаллом, соучредителем и главным исполнительным директором компании, особенно когда ее распределенная реляционная база данных SQL, вдохновленная гаечным ключом Google, вышла из строя. stealth в феврале 2017 года и снова в последнее время, когда Кимбалл говорил о том, как CockroachDB может противостоять действующим реляционным базам данных, особенно Oracle, в июле 2019 года.
Поскольку рынок баз данных неплохо работает даже во время пандемии, по причинам, которые станут очевидны через несколько минут, мы полагаем, что пришло время обратиться к маркетинговой стороне Cockroach Labs, которым является не кто иной, как главный директор по маркетингу Питер Гуагенти. , пришедший в компанию в прошлом году.
Гуагенти — необычный менеджер по маркетингу в том смысле, что он был по обе стороны стола переговоров. Гуагенти был веб-мастером журнала People , поскольку он начал свою карьеру еще в первые дни бума доткомов, когда коммерческая всемирная паутина была блестящей и новой, и в итоге попал в несколько рекламных агентств, которые были приобретены такими крупными людьми, как Razorfish и Omnicom.Затем он перешел в Accenture и Cap Gemini, чтобы разрабатывать продукты и маркетинговую стратегию после краха dot-come, вернулся в Razorfish на несколько лет, чтобы управлять рекламными технологиями с книгой о бизнесе на 120 миллионов долларов, а затем перешел на программное обеспечение. управление продуктами и маркетинг в Acquia (ранний поставщик PaaS), Nginx (сервер веб-приложений), Mesosphere (платформа, проигравшая Kubernetes) и MemSQL (один из первых поставщиков распределенных баз данных SQL, а теперь и его конкурент).
Поскольку в этом месяце Cockroach Labs собрали еще 160 миллионов долларов в рамках своего раунда финансирования серии E, это хорошее время, чтобы проверить, каков план на ближайшие годы, и проверить пульс новой базы данных.
Тимоти Прикетт Морган: Что насчет баз данных делает их идеальным местом для работы прямо сейчас? Я тоже это чувствую, и поэтому прошлым летом мы провели мероприятие The Next Database Platform , но я хочу услышать ваш ответ.
Питер Гуагенти: Последние десять лет я занимался стартапами в области программного обеспечения. Я был в разработке с самого начала, и когда я перешел на Nginx, меня взволновали данные. Если вы действительно думаете об эволюции приложений, когда мы впервые начали оптимизировать бизнес-процессы и превратить их в программное обеспечение, все дело в данных.А затем в конце 1990-х — начале 2000-х годов занял место Интернет, и на самом деле речь шла не о данных. Может быть, дело было в содержании и других вещах. Но по большей части это не были приложения, интенсивно использующие данные. Это были переживания.
TPM: Это были приложения, интенсивно использующие пользовательский интерфейс. Многие люди сталкиваются с простыми вещами. Это было достаточно сложно и потребовало гипермасштабирования, которого мы никогда не видели.
Питер Гуагенти: Интенсивный пользователь — это отличный способ описать это.Затем мы перешли от интенсивного использования пользователем к интенсивному использованию данных с помощью Web 2.0, и все действительно начало разворачиваться в сторону данных. Мы видели рост Facebook, Google и других, которые научились использовать данные — много данных — для получения конкурентного преимущества. Некоторые будут возражать против использования данных в качестве оружия. Поэтому, когда я искал путь для себя там, где я хотел быть, я сосредоточился на данных, потому что чувствовал, что именно здесь будут происходить самые интересные вещи.
Если вы посмотрите на данные о расходах на ИТ от Gartner, данные в самом широком смысле являются самой большой категорией.Они оценивают рынок примерно в 70 миллиардов долларов в ближайшие несколько лет. Примерно две трети этой суммы составляют транзакционные данные.
TPM: Какие еще данные, если они не транзакционные? Аналитический?
Питер Гуагенти: Типа. Я думаю, что Gartner смотрит на это как на исторические и аналитические вместе, а также как на операционные и транзакционные вместе, как на два общих класса данных, которые появляются сейчас.
TPM: Я думал, что транзакции — это гораздо меньшая часть пирога.
Питер Гуагенти: Интересно, что это не так. С данными IoT есть много рабочих данных — только аналитические датчики и тому подобное. А о большинстве транзакционных вещей мы просто не задумываемся, потому что это просто происходит. Все банковские системы, все системы CRM, все коммерческие и розничные приложения. Мы ожидаем, что это будет просто работать.
TPM: Я начал с мэйнфреймов IBM и миникомпьютеров IBM AS / 400, систем записи, хранящих транзакционные данные, а затем на протяжении десятилетий наблюдал, как этот транзакционный мир стал аналитическим.Это стало хранилищем данных или обслуживанием OLAP, что было признанием того, что в мире недостаточно денег для выполнения этой работы на мэйнфрейме или мини-компьютере. У меня создалось впечатление, что разрыв между транзакционными и аналитическими данными становился все больше и больше, и что транзакционный материал был супертонким и очень дорогим слоем.
Питер Гуагенти: На самом деле все идет по другому пути. Дело обстоит совсем иначе.
TPM: Я не могу быть единственным, кто придерживается этого заблуждения, поэтому я рад, что мы ведем этот разговор.
Питер Гуагенти: Вы определенно не один такой. Я думаю, что это одна из тех вещей, когда мы все думаем о данных как о монолитной части ИТ-организации. Но мы не задумываемся о нюансах, связанных с данными, или не думаем о их важности. Если, например, ваш доступ к средству развертывания прерывается, вам придется делать что-то вручную, но это еще не конец света, верно? Если ваша база данных выйдет из строя, это конец вашего мира .Это. совсем проблема.
Мы находимся при этом интересном стечении обстоятельств. Все переходит в облако, и поэтому каждая организация в мире переосмысливает весь свой стек. Цифровая трансформация резко ускорилась благодаря пандемии коронавируса — то, что мы видели за последние девять месяцев, является таким же большим изменением в цифровой сфере, как и последние девять лет трансформации. Сейчас данные — это сердце каждого бизнеса и приложения. У нас всегда были транзакционные и аналитические данные внутри организаций.У нас также был рост Интернета, просто данные приложений — подумайте о вещах, которые будут жить в базе данных NoSQL. Это действительно как раз про то приложение, интенсивно использующее пользователя, о котором мы говорили выше.
С появлением облака мы поняли, что облако всегда было для ИТ-директора расчетом соотношения риска и вознаграждения. Если они собираются сэкономить средства и ускорить выход на рынок, они посмотрят на все, что у них запущено, и скажут , если , , если , и , как мне перейти в облако.
TPM: Я не уверен, что они сэкономят деньги в долгосрочной перспективе. Они платят больше за единицу вычислительного времени и больше за единицу хранилища. Но им также не нужно чрезмерно выделять ресурсы, и если бюджеты останутся прежними после того, как вы все это сложите, локально или облачно, и они получают гибкость в сделке, то они это делают. И если вам придется заплатить немного больше, вы все равно это сделаете.
Питер Гуагенти: Если вы один из крупнейших банков мира — выберите тот, который управляет центрами обработки данных на всех континентах, и вы действительно хороши в этом, облака — не место.Это возможность. Значит, некоторые из них — это серверы других людей, а некоторые — ваши собственные. Однако я думаю, что большинство людей смотрят на это и хотят гибкости облака. Это действительно то, что они ищут.
TPM: Или так в некоторых случаях, и я сам делал это вокруг своей собственной инфраструктуры, потому что после десяти лет эксплуатации они приходят к одному дню и думают: «Я не хочу этого делать любой подробнее ». Я не этим занимаюсь. В этот момент, даже при более высоких затратах, возникает вопрос: опаснее ли управлять своим собственным центром обработки данных, чем использовать их? Мне было нетрудно догадаться, что это так, и когда затраты выровнялись, я вообще не принимал решения.Решение принял я.
Питер Гуагенти: Это отличный момент. Если вы один из крупных банков, на самом деле центры обработки данных являются частью вашего конкурентного преимущества. Вы думаете об алгоритмических торговых системах и тому подобном. У них есть компьютерные ученые и инженеры, которые конкурируют с волшебниками, которые есть у Google, и они, вероятно, зарабатывают больше, чем платит Google. В этом случае центр обработки данных является частью вашей основной бизнес-модели. Но если вы крупный производитель, производитель или продавец среднего размера, по сравнению с ним у вас уже плохо получается, так зачем вам продолжать?
Итак, в мире данных данные приложений сначала отправлялись в облако в начале 2000-х годов, и это были приложения на AWS, прикрепляемые к корзинам S3.Вторая волна представляла собой аналитические данные, потому что у них было ограниченное количество пользователей, ограниченный объем параллелизма, и было очень дорого поддерживать локально из-за размера данных. Итак, мы увидели, как взорвался Redshift, мы увидели взрыв BigQuery. И затем вы в конечном итоге видите Snowflake, который является своего рода образцом перемещения аналитических данных в облако, потому что он работает в потоковом режиме, он работает со всем, что вас действительно волнует. И если вы являетесь ИТ-директором и у вас есть все эти устаревшие системы, такие как Teradata или Netezza, у которых закончился срок службы, переходить на эти службы обработки данных было несложно из-за ограниченного числа пользователей.И как только выйдет Snowflake, у них может быть мультиоблако, и их не будут приковывать наручниками к поставщику, как к Oracle. Они могли натравить каждое из этих облаков друг на друга.
Транзакционные данные — это единственное, что не изменилось. И почему это так — важный вопрос. Подумайте обо всех известных вам системах. Многие вещи по-прежнему живут на мэйнфрейме, потому что мэйнфреймы быстрые и работают. Но когда вы разговариваете с некоторыми крупными банками — и я призываю вас к этому, — они сталкиваются с ограниченным количеством мэйнфреймов.Им буквально не хватает места для хранения данных, а приложения все еще работают. В ближайшие пять-десять лет произойдёт интересная вещь: крупнейшие сторонники мэйнфреймов сейчас смотрят на них и говорят, что эти вещи не будут работать долго.
TPM: Да ладно, они могут просто использовать Parallel Sysplex целую кучу из них вместе, и все это будет просто гигантской кластерной базой данных. [Смех] Я посчитал это.Вы могли бы … о, подождите. Неважно, это будет 100 миллионов долларов, а может быть, 250 миллионов долларов. Вы понимаете, что я шучу. Если бы это было правдой, Google работал бы на IBM Parallel Googleplex.
Peter Guagenti: Если вы крупный розничный банк с бизнесом на четырех континентах, это не сработает. В какой-то момент вы выжали все, что могли, из этих инвестиций в мэйнфрейм. Розничная торговля и торговля стремительно растут, а объем данных о транзакциях стремительно растет, потому что вместо группы дистрибьюторов они продают напрямую потребителю.И при этом ожидается нулевая задержка.
TPM: Ну, 200 миллисекунд, а не ноль, это точная продолжительность концентрации внимания и терпения человека в наши дни.
Питер Гуагенти: Я думаю, вы проявите щедрость на 200 миллисекунд [Смех]. Возможно, количество времени, которое нам нужно, чтобы моргнуть.
TPM: Итак, позвольте мне задать следующий вопрос. В Oracle, DB2, SQL Server и т. Д. Очень много транзакционных данных.Это твоя цель? Как вы думаете, сможете ли вы перемещать эти данные внутри компании или в облаке? Как вы собираетесь, как вы собираетесь победить этих ребят и получить их деньги?
Питер Гуагенти: Это наша цель? Я бы сказал да и нет. И это не наша цель, это фокус наших клиентов. Позволь мне объяснить.
На самом деле существует три типа облачных приложений. Это полностью с нуля, и на самом деле, вероятно, все еще происходит большая часть того, что происходит.За последние 20 лет мы претерпели больше изменений, чем, вероятно, произошло с начала промышленной революции. И мы должны быть честны с собой в том, насколько общество изменило бизнес. Сейчас мы, по крайней мере, так же изменяем, как изобретение паровой машины.
Я не разговариваю ни с одной компанией из списка Fortune 50, у которой в повестке дня нет 30 новых стратегических инициатив, и все они собираются включать новые приложения. Это наша рулевая рубка. Но эти новые приложения имеют те же требования и требования, что и другие критически важные системы, которые уже работают в бизнесе, потому что они обычно гиперподключены.Возможно, мы разрушим все эти монолиты, перейдем к большему количеству микросервисов или даже — не дай бог, мы больше не будем называть это так — архитектурой, ориентированной на сервисы. Таким образом, для этих приложений они ищут что-то, что является облачным и современным, но им нужно что-то, что будет иметь такую же согласованность, надежность и долговечность, которые они получают от традиционных систем, с которыми они работали на протяжении десятилетий.
Второе, что происходит — это модернизация.Многое из того, что работает на сервере Oracle, DB2 или SQL — давайте будем честными — было написано примерно во времена Web 1.0 или Web 2.0.
TPM: Некоторые из них были написаны, когда я был младенцем. Я помню, как SQL Server 200 был сервером OLAP, который выбирали многие предприятия, в том числе те, которые были полностью и полностью посвящены IBM AS / 400 или мэйнфреймам для своих критически важных приложений. Это стоит намного меньше денег, чтобы сбросить это на Windows Server, SQL Server и дешевом сервере X86, и кого волнует, если он время от времени выйдет из строя.Его приобретение и эксплуатация обходились в пятую часть дешевле.
Питер Гуагенти: Реальность такова, что даже на этих устаревших платформах этот материал постоянно меняется из-за его важности для бизнеса. Он всегда модифицируется. Так что сейчас мы часто видим не только новые разработки, но и модернизацию приложений. Возьмем крупного производителя, продающего напрямую потребителю, а не только через дистрибьюторов, я должен предъявить требования к этой серверной системе, но эти системы не будут работать так, как я хочу.Мне нужно будет модернизировать это приложение, а затем добавить в него кое-что новое. И тогда они начинают пристально смотреть на такие вещи, как Oracle и DB2, и спрашивают: ну, а зачем мне продолжать строить на этой штуке? Почему бы мне не начать сокращать его, когда я начинаю сокращать рабочие нагрузки, которые ему противостоят, а не менять систему управления запасами, которая сегодня прекрасно работает на складе. Из-за чего пойти и возиться с этим. ИТ-директора отлично справляются с управлением портфелем. Куда я вкладываю, куда я деинвестирую, где я сохраняю стабильность? Они смотрят и говорят, что многое из того, что происходит в базе данных, я собираюсь сохранить в стабильном состоянии.Все нормально, не сломано. Мы оставим это в покое. Но эти новые требования потребуют новых систем, потому что они не будут работать должным образом.
И именно здесь, я думаю, мы наблюдаем это изменение в этой третьей волне технологий баз данных, а именно в этих распределенных реляционных базах данных SQL, родных для облака. Это не только CockroachDB. Это Google Spanner. Это Microsoft CosmosDB и другие.
Сейчас в этой сфере происходит много инноваций, потому что нам нравятся эти транзакционные системы, но они были только расширены.Масштабирование было кошмаром. Все мы увлекаемся NoSQL, NoSQL отлично работает с данными наших приложений. Почему бы нам не попробовать что-то еще? Когда мы поняли, что это абсолютно не подходит, это не работает. Вся компания, которая говорит на английском (SQL), и теперь мы ожидаем, что все выучат эсперанто (NoSQL) только потому, что кто-то решил, что это действительно так. Итак, круг замкнулся. Нам по-прежнему нужен реляционный, нам по-прежнему нужен SQL, но мы хотим масштабирование, а не масштабирование, и нам нужна отказоустойчивость.
TPM: Точно так же, как нам пришлось пройти виртуализацию сервера, чтобы добраться до контейнеров, может быть, нам нужно было пройти через NoSQL, чтобы добраться до распределенного SQL? Мы не знали, как это сделать.Было много людей, которые пытались, но всегда приходилось идти на компромиссы с NoSQL. Я не верю, что в долгосрочной перспективе для NoSQL найдется место.
Питер Гуагенти: Я бы поспорил с этим для случаев использования легких приложений, когда вы просто работаете с объектами. На самом деле NoSQL работает очень хорошо. Но есть также аргумент, чтобы использовать простое хранилище, а не хранилище данных. С кем-то, кто пришел из опыта, с этим намного легче работать, потому что это ведро, верно? Я имею в виду, что я думаю об этом как о сортировке вещей на полу.
TPM: Я бы сказал, что MongoDB идеально подходит для этого?
Питер Гуагенти: Согласен.
TPM: MongoDB считает, что большая часть данных, которые генерируются в мире, могут быть сохранены в документе и по праву должны быть и будут, а все остальное будет храниться в чем-то вроде CockroachDB. Они не заявляют, что хотят захватить весь мир.
Питер Гуагенти: Да, вообще-то, но я думаю, что они могут пожалеть о своем решении.Если вы помните, они приводили тот же аргумент при первом запуске. Специалисты по связям с разработчиками MongoDB между 2010 и 2012 годами были известны тем, что говорили обо всем, что можно заменить. А потом люди пытаются, потому что они были защитниками и евангелистами, а данные были противоречивыми, и они что-то теряли. И вот они отступили.
TPM: Теперь, когда распределенные системы SQL доступны, масштабируемы и относительно доступны, готовы ли мы?
Питер Гуагенти: Трудно сказать, потому что вы не знаете того, чего не знаете.Но я думаю, что мы идем по этому пути уже 25 лет. Эту концепцию строили очень давно. Я думаю, что мы наконец достигли такого уровня зрелости компьютерных наук и оборудования, что мы действительно можем сделать это реальностью. Так что, я думаю, мы собираемся, я думаю, мы начнем видеть некоторые урегулирования вокруг этого, потому что это то, для чего текущее состояние оборудования, с которым мы работаем, действительно оптимизировано.
TPM: Как обстоят дела с учетом всех этих изменений в Cockroach Labs?
Питер Гуагенти: Наш бизнес стремительно развивается благодаря этим макроэкономическим тенденциям и модернизации приложений, вызванной COVID-19.Возьмите розничных продавцов товаров для дома, которые стали для нас большой победой. То, что раньше выглядело как лучший день в году для их заказов с доставкой на дом, стало их бизнесом каждый день . И единственное, что не удалось для всех, — это их инфраструктура данных, потому что по мере роста всей этой нагрузки на транзакционные системы и масштабирования сегментирование базы данных перестало работать.
Я присоединился к Cockroach Labs на третьей неделе марта 2020 года из MemSQL. Так что я стал первым сотрудником компании, подключившимся удаленно.И я помню, как мы, как команда руководителей, остановились и сказали: «Мы не знаем, что будет дальше». Мы просто не знаем. Вам нужно просто набраться терпения, продолжать поддерживать наших клиентов и продолжать делать все возможное, чтобы помочь им. Перенесемся на десять месяцев вперед, и мы увидим взрывной рост.
Мы — частная компания, и мы не раскрываем цифры по многим вещам, но наша клиентская база увеличилась более чем вдвое. А за последний год мы удвоили доход и в четыре раза увеличили использование облачных технологий.Более половины нашей клиентской базы сейчас работает в облаке Cockroach Cloud. Мы наблюдаем двукратное увеличение количества обновлений в рамках нашего существующего клиента.
TPM: Это те кривые, которые использовались Nutanix и Pure Storage десять лет назад. Но можешь ли ты сделать мне одолжение? Сможете ли вы заработать деньги до того, как доживете до десяти лет? [Смех]
Питер Гуагенти: Ну, это всегда игра. И поэтому мы пока собрали 355,1 миллиона долларов. Оценка более чем в 2 миллиарда долларов — это довольно впечатляюще для компании нашего размера.Но на самом деле нет, мы не будем прибыльными, потому что посмотрите, против кого мы идем и что заменяем. В одном из отчетов, которые я прочитал, было подсчитано, что треть всех ИТ-расходов ушла на данные и системы данных. Третий . Так что мы собираемся продолжать собирать деньги и удваивать объем НИОКР, потому что это размер рынка, за которым мы гоняемся.
Самое приятное в бизнесе баз данных — и вы это хорошо знаете — это то, что мы могли бы оказаться на 100-м месте и по-прежнему оставаться компанией с доходом в 1 миллиард долларов.Но мы не хотим быть на сотом месте. Мы хотим быть одним из брендов, который используется по умолчанию, если вы разработчик, специализирующийся на транзакционных данных. И чтобы заслужить такой уровень доверия и уважения, требуются большие инвестиции в исследования и разработки. Это то, на чем мы сосредоточены.
Что такое распределенный SQL? Эволюция базы данных
По мере того, как организации переходят на облако, они в конечном итоге обнаруживают, что устаревшие реляционные базы данных, которые стоят за некоторыми из их наиболее важных приложений, просто не используют преимущества облака и их трудно масштабировать.Именно база данных ограничивает скорость и эффективность этого перехода. Чтобы решить эту проблему, организациям нужна надежность проверенных реляционных хранилищ данных, таких как Oracle, SQL Server, Postgres и MySQL, но с преимуществами масштаба и глобального охвата, которые дает облако.
Некоторые обратились к хранилищам NoSQL, чтобы попытаться удовлетворить эти требования. Эти альтернативы обычно могут соответствовать требованиям к масштабированию, но затем не подходят для транзакционной базы данных, потому что они не были разработаны с нуля для обеспечения истинной согласованности.В последнее время некоторые решения NoSQL предлагают «транзакции ACID», но они полны предостережений и не могут обеспечить уровни изоляции, необходимые для критически важных рабочих нагрузок, таких как финансовая книга, управление запасами и управление идентификацией.
Распределенный SQL — это новое поколение баз данных
Некоторые из наиболее успешных компаний, работающих в глобальном масштабе, фактически решили эту проблему и создали специальные базы данных для ее решения. Самый публичный пример — Google Cloud Spanner.В 2012 году Google опубликовал статью о Spanner, в которой продемонстрировал новый взгляд на базы данных, основанный на распределенных системах и глобальном масштабе.
«Spanner — это масштабируемая, многоверсионная, глобально распределенная и синхронно реплицируемая база данных Google. Это первая система, которая распределяет данные в глобальном масштабе и поддерживает внешне согласованные распределенные транзакции ».
— Spanner: Глобально-распределенная база данных Google
В описании содержится много всего, а также 14-страничный документ, в котором подробно рассказывается о том, как им удалось создать согласованную и масштабируемую базу данных.Эта гениальная статья описывает основу следующей эволюции базы данных: распределенный SQL.
Распределенный SQL — это единая логическая база данных, развернутая на нескольких физических узлах в одном центре обработки данных или во многих центрах обработки данных, если это необходимо; все это позволяет ему обеспечивать эластичную накипь и пуленепробиваемую устойчивость.
Что представляет собой распределенная база данных SQL?
Было предпринято несколько попыток предоставить действительно масштабируемый SQL в распределенной среде.Некоторые пытались модернизировать существующие базы данных в соответствии со своими потребностями, но в конечном итоге это не соответствует обещаниям истинно распределенной базы данных SQL. Итак, что составляет базу данных распределенного SQL? Требования можно суммировать в пяти основных условиях:
1. Масштабирование
Распределенная база данных SQL должна легко масштабироваться, чтобы отражать возможности облачных сред, не усложняя работу. Точно так же, как мы можем масштабировать вычисления без тяжелой работы, база данных также должна иметь возможность масштабирования.Это включает в себя возможность равномерного распределения данных между несколькими распределенными участниками в базе данных.
2. Согласованность
Распределенная база данных SQL должна обеспечивать высокий уровень изоляции в распределенной среде. В облачном мире с распределенными системами и микросервисами являются архитектурами по умолчанию, согласованность транзакций становится сложной, поскольку несколько операторов могут пытаться работать с одними и теми же данными. База данных должна выступать посредником в конфликтах и обеспечивать тот же уровень изоляции транзакций, который мы ожидаем от единой базы данных.
3. Отказоустойчивость
Распределенная база данных SQL, естественно, должна обеспечивать высочайший уровень отказоустойчивости без каких-либо внешних инструментов для достижения этой цели. Облако представляет собой постоянную среду для наших рабочих нагрузок, и база данных должна иметь те же свойства. С помощью распределенной базы данных мы можем сократить время, необходимое для восстановления после сбоя, почти до нуля и реплицировать данные естественным образом без какой-либо внешней конфигурации.
4. Георепликация
Распределенная база данных SQL должна обеспечивать возможность распределения данных в сложной, широко рассредоточенной географической среде.Облако дает возможность достичь любого уголка земного шара с приемлемым качеством обслуживания, и база данных не должна ограничивать ваши приложения в этом. Он должен соответствовать вашим ожиданиям.
5. SQL
И хотя эти четыре технических требования имеют первостепенное значение, прежде всего существует одно ключевое предварительное условие. База данных должна говорить на языке SQL. Это язык данных, используемый по умолчанию для всей логики приложения. Нам не нужно переучивать разработчиков пользоваться базой данных.Они должны уметь использовать диалект SQL, с которым они уже знакомы.
Есть несколько баз данных, отвечающих этим требованиям. В список, конечно же, входит Spanner, но вы также можете рассматривать Amazon Aurora, Yugabyte, FaunaDB и CockroachDB в качестве членов этой новой категории. Все эти участники в той или иной форме удовлетворяют требованиям, некоторые лучше, чем другие. В этом списке заметно отсутствуют Oracle, Postgres, MySQL и все варианты NoSQL. Хотя каждый из них может соответствовать некоторым требованиям, ни один из них не отвечает всем требованиям и не может рассматриваться как альтернатива.
Дьявола шесть: Локальность данных
Когда вы живете в распределенном мире, становится очевидным, что сама база данных может позаботиться о размещении данных. С участниками, расположенными в разных регионах или центрах обработки данных, становится возможным понять местоположение каждого из них, а затем привязать данные, которые он хранит, к местоположению. Некоторые архитекторы приложений реализовали это как часть приложения, но этот подход подвержен ошибкам и ненадежен. Использование базы данных для географического разделения данных на основе некоторого поля в таблице является новым требованием для распределенного SQL.Это позволяет использовать базу данных для решения проблем суверенитета данных. Его также можно использовать, чтобы данные следовали за пользователем, чтобы вы могли обеспечить доступ к его информации с малой задержкой, или привязать данные к явному облаку, чтобы минимизировать исходящие расходы.
И бог семь: мультиоблако
Уникальная черта базы данных с распределенным SQL состоит в том, что в ней есть полуавтономные единицы, которые все участвуют в более крупной системе. Каждый модуль должен быть развернут сам по себе, а затем присоединиться к более крупной системе, кластеру CockroachDB.Это неотъемлемая черта, которая поддерживает первые пять перечисленных выше требований. Однако это также можно использовать для расширения базы данных, чтобы она стала действительно многооблачной. База данных не должна полагаться на одну сеть для выполнения распределения. Его следует отделить от этих ограничений, чтобы участник мог находиться где угодно, из любого общедоступного облака, частного облака и даже одного локального экземпляра. Это требование важно для вычислений в будущем, когда мы живем в мире распределенных гибридных и многооблачных сред.
Основополагающие требования для распределенного SQL
Хотя вышеупомянутые семь требований уникальны для распределенного SQL (ну, все они, кроме самого SQL), важно отметить, что это все еще база данных и, конечно, требуется для выполнить базовые требования к базе данных. Существует ряд ожиданий в отношении следующего:
- Администрирование: У вас должна быть возможность легко установить и настроить базу данных с помощью набора командной строки и графических инструментов.Сюда входят возможности управления средой и жизненным циклом данных для резервного копирования / восстановления. А также возможность создавать таблицы, определять и реализовывать схемы, устанавливать индексы / разделы и воссоздавать DDL.
- Оптимизация: База данных должна позволять администраторам баз данных получать представление о производительности запросов и возможности оптимизировать их выполнение. Сюда входят такие расширенные функции, как оптимизатор на основе затрат, который в распределенном мире становится сложной и новой концепцией.
- Безопасность: Как и в любом корпоративном программном пакете, безопасность имеет решающее значение, и база данных должна обеспечивать ключевые возможности AAA для аутентификации, авторизации и подотчетности. Он не должен стоять сам по себе и должен интегрироваться с центральным источником истины для управления идентификацией и управления, чтобы можно было установить согласованную политику для данных (на уровне таблицы, строки и столбца), которые он содержит.
- Интеграция: База данных не работает сама по себе и должна интегрироваться с вашими существующими приложениями с использованием хорошо протестированных или известных драйверов.Он должен хорошо интегрироваться с существующими ORM, а также обеспечивать возможность массового приема или экспорта. Он также должен предоставлять ключевые возможности, позволяющие ему работать с инструментами ETL и изменять возможности сбора данных для интеграции с более продвинутыми сервисами, такими как потоковая аналитика или облачное хранилище.
Эти «основополагающие» требования являются критическими и сигнализируют о более зрелой, готовой к работе в масштабе предприятия базе данных. Они могут быть не самыми захватывающими функциями, но имеют решающее значение для принятия и успеха в любом проекте.
Как оценить распределенные базы данных SQL
CockroachDB — прекрасный вариант для вашей облачной распределенной базы данных SQL. Это помогло сотням организаций перевести в облако как самые рутинные, так и некоторые из наиболее критически важных рабочих нагрузок. Это было основой стратегии облачных вычислений в более продвинутых оркестрированных средах. Мы очень гордимся тем, что построили.
Мы также сторонники этой развивающейся категории и считаем, что распределенный SQL — это правильное развитие базы данных и будущее способов управления данными в облаке.С этой целью мы твердо уверены, что к нашему решению и к любому другому следует относиться с высочайшим вниманием, когда речь идет о следующих основных требованиях:
- Масштаб
- Согласованность
- Устойчивость
- Георепликация
- SQL
- Локальность
- Мультиоблако
- Администрирование
- Оптимизация
- Безопасность
- Интеграция
База данных, отвечающая всем этим требованиям, стала надежной для критически важных (и не очень критически важных) приложений в облаке.И некоторые из этих требований непростые. Это сложные темы, требующие времени, чтобы разобраться в них. Когда вы обсуждаете эти вопросы со своим поставщиком, мы рекомендуем вам углубиться в такие понятия, как согласованность и локальность. Хотя все читали одни и те же документы, в конечном итоге все сводится к реализации и, что более важно, к использованию в производственной среде. Как и в случае с любой новой категорией, это становится первостепенной проблемой, поскольку только в производственной среде можно выявить и исправить сложные угловые случаи и проблемы. Итак, я предполагаю, что последнее (и 12-е) требование — , срок погашения .
Основы проектирования баз данных SQL с примерами
Это общепринятая практика, когда архитектор БД должен проектировать реляционную базу данных, адаптированную к конкретному решению.
Однажды вечером в пятницу я возвращался с работы в электричке и думал о создании своего рода службы найма. Насколько мне известно, ни одна из существующих услуг не позволяет быстро оценить кандидата, создать сложные фильтры по определенным навыкам, проектам или должностям или исключить определенные навыки, должности или проекты.Максимальный диапазон использования — фильтрация по компаниям и частично по навыкам.
В этой серии статей я немного побалую себя некоторыми нетехническими примерами из моей жизни, чтобы попытаться нарушить строгий технический стиль.
В этой части я напишу об основах проектирования реляционных баз данных и проиллюстрирую дизайн базы данных MS SQL Server для службы найма.
Теперь, что касается следующих статей, я покажу вам, как заполнить базу данных данными с помощью генератора данных для SQL Server и искать данные и объекты базы данных с помощью бесплатного инструмента поиска dbForge.Я буду использовать dbForge Studio для SQL Server для реализации диаграмм для моих примеров и dbForge Data Pump для импорта и экспорта данных.
Основы проектирования БД
Для разработки схем базы данных давайте вспомним 7 нормальных форм и сами концепции нормализации и денормализации. Они лежат в основе всех правил проектирования.
Приведу подробное описание 7 нормальных форм:
1. Индивидуальные отношения:
1.1 Обязательное отношение:
Примером может быть гражданин с паспортом (у каждого гражданина должен быть паспорт, и паспорт один на каждого гражданина)
Это отношение реализуется двумя способами:
1.1.1 В одном предприятии (таблица):
Изображение 1. Субъект «Гражданин»
Здесь таблица Citizen представляет сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (НЕ NULL)
1.1.2. В двух разных объектах (таблицах):
Изображение 2. Связь между сущностями Citizen и PassportData
Таблица Citizen представляет сущность гражданина, а таблица PassportData представляет сущность паспортных данных гражданина.Сущность гражданина содержит атрибут (поле) PassportID , который относится к первичному ключу таблицы PassportData . Принимая во внимание, что объект паспортных данных имеет атрибут (поле) CitizenID , который относится к первичному ключу CitizenID таблицы Citizen .
Также важно гарантировать целостность поля CitizenID и таблицы PassportData , чтобы обеспечить взаимно-однозначную связь.То есть поле PassportID в таблице Citizen и поле CitizenID в таблице PassportData должно ссылаться на одну и ту же запись, как если бы это была одна сущность (таблица), которая была проиллюстрирована в параграфе 1.1.1.
1.2 Необязательное отношение:
An Примером может быть человек, который может иметь паспортные данные и не может иметь указанную страну. Итак, в первом случае он гражданин данной стране, а во втором случае его нет.
Эта связь реализуется двумя способами:
1.2.1 В одном лице (таблица):
Изображение 3. Личность
Здесь таблица Person представляет физическое лицо, а атрибут (поле) PassportData содержит все паспортные данные человека и может быть пустым (NULL)
1.2.2 В двух объектах (таблицы):
Изображение 4. Связь между Person и PassportData
Здесь таблица Person представляет физическое лицо, а таблица PassportData представляет объект паспортных данных человека (то есть сам паспорт).Физическая сущность содержит атрибут (поле) PassportID , который относится к первичному ключу таблицы PassportData . Принимая во внимание, что объект паспортных данных имеет атрибут (поле) PersonID в таблице Person . Поле PassportID таблицы Person может быть пустым (NULL).
Также важно гарантировать целостность поля PersonID и таблицы PassportData , чтобы обеспечить взаимно-однозначную связь.То есть поле PassportID таблицы Person и поле PersonID таблицы PassportData должны относиться к одним и тем же записям, как если бы это была одна сущность (таблица), показанная в параграфе 1.2.1, или эти поля должны быть неуказанными, то есть содержать NULL.
2. Отношение «один ко многим»
2.1 Обязательные отношения:
Иллюстрацией этого могут быть родители и их дети. У каждого родителя есть хотя бы один ребенок.
Эту связь можно реализовать двумя способами:
2.1.1 В одном лице (таблица):
Изображение 5. Материнская компания
Здесь таблица Parent представляет родительский объект, а атрибут (поле) ChildList содержит информацию о дочерних элементах, то есть самих дочерних элементах. Это поле не может быть пустым (НЕ NULL). Тип поля ChildList обычно представляет собой полуструктурированные данные (NoSQL), такие как XML, JSON и т. Д.
2.1.2 В двух объектах (таблицы):
Изображение 6. Связь между родительским и дочерним объектами
Здесь таблица Parent представляет родительский объект, а таблица Child представляет дочерний объект. Таблица Child имеет поле ParentID , которое относится к первичному ключу ParentID таблицы Parent . Поле ParentID таблицы Child не может быть пустым (НЕ NULL).
2.2) необязательный отношения:
Примером может быть человек, который может иметь детей или может не иметь детей.
Это отношение реализуется двумя способами:
2.2.1 В одном лице (таблица):
Изображение 7. Личность
Здесь таблица Parent представляет родительский объект, а атрибут (поле) ChildList содержит информацию о дочерних элементах, то есть самих дочерних элементах.Это поле может быть пустым (NULL). Обычный тип поля ChildList — это полуструктурированные данные (NoSQL), такие как XML, JSON и другие.
2.2.2 В двух объектах (таблицы):
Изображение 8. Связь между объектами «Лицо» и «Дочерний»
Здесь таблица Parent представляет родительский объект, а таблица Child представляет дочерний объект. Таблица Child имеет поле ParentID , которое относится к первичному ключу ParentID таблицы Parent .Поле ParentID таблицы Child может быть пустым (NULL).
Также существует третий способ реализации одной сущности, который ссылается на себя, при условии, что дочерняя и родительская сущности (таблицы) имеют одинаковый набор атрибутов (полей) без ссылки на родительский:
Изображение 9. Сущность Person с самооценкой
Здесь объект Person (таблица) содержит атрибут (поле) ParentID , который относится к первичному ключу PersonID той же таблицы Person и может иметь пустое значение (NULL).
Это реализация отношения «многие к одному» с необязательным характером.
3. Отношения «многие-к-одному»
Это отношение отражает проиллюстрированное выше отношения один-ко-многим. Это отношения между ребенком сущность и родительская сущность, где обязательными отношениями являются возможно, если у ребенка есть хотя бы один родитель, и если мы возьмем все дети, в том числе в детских домах, то такие отношения имеет необязательный характер.
Отношения «один ко многим» и «многие к одному» также могут быть реализованы с помощью более чем двух объектов, путем добавления необходимых атрибутов, которые относятся к первичным ключам соответствующих объектов. Эта реализация аналогична примерам, приведенным выше в параграфах 1.1.2 и 1.2.2.
4. Отношение «многие ко многим»
В этом случае примером может быть недвижимость, которая может принадлежать одному человеку или несколько человек. При этом человек может владеть несколькими домами или имеют долю собственности на многие дома.
Вы можете реализовать эту связь с NoSQL способами, описанными выше для предыдущих отношений. Однако в реляционной модели эта связь обычно реализуется через 3 объекта (таблицы):
Изображение 10. Отношения между Лицом и объектами RealEstate
Здесь таблицы Person и RealEstate представляют объекты физического лица и недвижимости соответственно. Эти сущности (таблицы) связаны посредством сущности PersonRealEstate (таблицы) через атрибуты (поля) PersonID и RealEstateID , которые относятся к первичным ключам PersonID таблицы Person и RealEstateID . таблицы RealEstate соответственно.Обратите внимание, что пара ( PersonID ; RealEstateID ) всегда уникальна для таблицы PersonRealEstate , поэтому она может быть первичным ключом для самого PersonRealEstate связывающего объекта (таблица).
Это отношение может быть реализовано более чем через 3 объекта путем добавления необходимые атрибуты, которые относятся к первичным ключам соответствующие лица. Такая реализация похожа на примеры описаны в пунктах 1.1.2 и 1.2.2.
Так где же 7 нормальных форм, спросите вы?
Ну вот они:
- Par.1 (par.1.1 и par.1.2) является первое и второе формальное правило.
- Par.2 (par.2.1 и par.2.2) является третье и четвертое формальные правила.
- Par.3 (аналогично пункту 2) — это пятое и шестое формальные правила.
- Пункт 4 — седьмое формальное правило.
Это просто эти 7 нормальных форм сгруппированы в 4 функциональных блока в тексте выше.
Нормализация устраняет избыточность данных и, следовательно, снижает риски данных аномалии. Однако нормализация при декомпозиции сущностей (таблиц) приводит к более сложному построению запроса для обработки данных (вставка, обновление, выбор и удаление).
Противоположный процесс — денормализация. Он упрощает обработку запросов для доступа к данным за счет добавления избыточных данных (например, как было упомянуто выше в пп. 2.1.1 и 2.2.1 с помощью полуструктурированных данных (NoSQL)).
Вы уверены, что поняли смысл 7 нормальных форм? Что вы действительно это поняли, а не просто ознакомились с этим. Спросите себя, удастся ли вам за пару часов спроектировать модель базы данных, даже с избыточным количеством сущностей, для любой области данных или любой информационной системы. Позже вы сможете уточнить сложности и детали, обратившись к аналитикам и представителям клиентов.
Если этот вопрос застал вас врасплох и вы думаете, что это маловероятно, то вы знаете 7 нормальных форм, но не понимаете их.
Почему-то в источниках не говорится, что эти отношения между сущностями были не просто придуманы, но обнаружены. То есть с самого начала они действительно существовали в реальном мире между субъектами и объектами.
В дополнение к что эти отношения могут меняться, переходя от одного к одному к один-ко-многим, или многие-к-одному, или многие-ко-многим, изменяя их обязательный характер или его сохранение.
Я думаю, вам следует попробовать наблюдать за людьми и определять существующие отношения как между субъектами, так и между субъектами и объектами (в приведенном выше примере показан гражданин и паспорт как взаимно однозначные отношения с обязательным характером, а человек и паспорт — как взаимно однозначное отношение, которое не является обязательным).
Когда вы изучите 7 нормальных форм, вы сможете легко разработать модель базы данных любой сложности для любой информационной системы.
Кроме того, вы узнаете, что вы можете реализовать отношения разными способами, и сами отношения могут меняться. Таким образом, модель (схема) базы данных — это моментальный снимок отношений между сущностями в определенный момент времени. Следовательно, важно указать как сущности, которые являются изображениями объектов реального мира или предметной области, так и отношения между ними с учетом будущих изменений.
Хорошо продуманный модель базы данных, с учетом изменения отношений в реальности и в предметной области, не требует длительных изменений время. Это особенно важно для хранения данных, где изменения включают повторное сохранение больших объемов данных, от нескольких гигабайт до многих терабайты.
Примечание: в модели реляционной базы данных это связь между сущностями, а строки (кортежи) являются примерами этих отношений. Но для упрощения мы часто подразумеваем сущности по таблицам, экземпляры сущностей по строкам, а их отношения — по отношениям внешних ключей.
Разработка схемы базы данных для набора персонала
После в первой части статьи мы рассказали об основах проектирования БД, давайте теперь создадим схему базы данных для набора.
Прежде всего, нам нужно определить, какая информация важна для сотрудников компании, которые ищут соискателей:
- Для HR-менеджера:
- Компании, в которых работал соискатель.
- Должности, которые кандидат занимал в этих компаниях.
- Навыки, которые кандидат использовал на работе, стаж работы в каждой из компаний и на каждой должности, продолжительность использования каждого навыка.
- Техническому специалисту:
- Должности, которые соискатель занимал на прежних местах работы.
- Навыки, которые соискатель использовал на работе.
- Проекты, в которых принимал участие соискатель. Кроме того, важно знать стаж работы соискателя на каждой должности и в каждом проекте, а также продолжительность использования каждого навыка.
Давайте сначала определим необходимые сущностей:
- Сотрудник
- Компания
- Позиция
- Проект
- Навык
Компания и сотрудник связаны отношениями «многие ко многим», поскольку сотрудник может работать в разных компаниях, а в компаниях много сотрудников.
То же самое работает для должности и сотрудника, потому что многие сотрудники могут работать на одной должности в одной компании, а также в разных компаниях.При этом сотрудник мог работать на разных должностях как внутри одной компании, так и в разных. В результате отношения между должностью и компанией также являются отношениями «многие ко многим».
Сущность «проект» следует той же логике: проект относится ко всем другим вышеупомянутым сущностям как «многие ко многим».
Для простоты скажем, что сотрудник использует один набор навыков в проекте. Тогда отношения Между проектом и навыком также много ко многим.
Учитывая важность указания стажа работы сотрудника в той или иной компании, на определенной должности и в определенном проекте, наша схема базы данных может иметь следующую диаграмму ER:
Изображение.11. Схема базы данных кадровой службы
Здесь таблица JobHistory представляет сущность истории работы каждого сотрудника, то есть само резюме который реализует отношения «многие ко многим» между сотрудниками, компания, должности и проект.
Проект и умение соотносятся как многие-ко-многим, таким образом, они связаны с помощью ProjectSkill юридическое лицо.
Если вы понимаете отношения между субъектами и субъектами и объектами, что означает дизайн базы данных норм, вы можете создать аналогичную схему на листе бумаги в под час.
Здесь мы могли бы упростить схему и добавление данных, если мы вложим умение в сущность проекта через полуструктурированные данные (NoSQL) в форме XML, JSON или просто списка названия навыков через точку с запятой. Но это сделало бы это сложно выбрать группировку по навыкам и фильтрацию по определенным навыкам.
Заключение
Как видите, проектирование систем просто превращает объекты и субъекты из реальности в сущности базы данных, где связь между этими сущностями фиксируется в определенный момент времени с учетом будущих изменений.Что именно мы берем из реальности и реализуем как объект схемы, и какие отношения мы строим в модели, зависит от того, чего мы хотим от информационной системы в целом, сейчас и в будущем. То есть, какие данные мы хотим получить на настоящий момент и в какое-то время в будущем. Следующая часть будет посвящена заполнению полученной базы данных данными. Чтобы заполнить нашу базу данных данными, мы собираемся использовать dbForge для SQL Server.
Евгений Грибков
Евгений — аналитик, разработчик и администратор баз данных MS SQL Server.Он участвует в разработке и тестировании инструментов управления базами данных SQL Server. Евгений также пишет статьи, связанные с SQL Server.
Последние сообщения Евгения Грибкова (посмотреть все)
дизайн базы данных, схема базы данных, sql server, студия для sql server
SQL: что это такое?
Язык структурированных запросов, широко известный как SQL, является стандартным языком программирования для реляционных баз данных. Несмотря на то, что он старше многих других типов кода, это наиболее широко используемый язык баз данных.
Поскольку SQL настолько распространен, знание его важно для всех, кто занимается компьютерным программированием или использует базы данных для сбора и организации информации. Узнайте больше о том, что такое SQL, и о возможностях карьерного роста в этой области.
Что такое SQL?
SQL можно использовать для совместного использования и управления данными, особенно данными, которые находятся в системах управления реляционными базами данных, которые включают данные, организованные в таблицы. Несколько файлов, каждый из которых содержит таблицы данных, также могут быть связаны общим полем.Используя SQL, вы можете запрашивать, обновлять и реорганизовывать данные, а также создавать и изменять схему (структуру) системы баз данных и контролировать доступ к ее данным.
В электронную таблицу, такую как Microsoft Excel, можно скомпилировать много информации, но SQL предназначен для компиляции и управления данными в гораздо больших объемах. В то время как электронные таблицы могут стать громоздкими из-за слишком большого количества информации, базы данных SQL могут обрабатывать миллионы или даже миллиарды ячеек данных.
Используя SQL, вы можете хранить данные о каждом клиенте, с которым когда-либо работал ваш бизнес, от основных контактов до сведений о продажах.Так, например, если вы хотите найти каждого клиента, который потратил не менее 5000 долларов на ваш бизнес за последнее десятилетие, база данных SQL могла бы получить эту информацию для вас мгновенно.
Как работает изучение SQL
Язык структурированных запросов более простой, чем другие более сложные языки программирования. Как правило, новичкам легче изучить SQL, чем им освоить такие языки, как Java, C ++, PHP или C #.
Некоторые онлайн-ресурсы, включая бесплатные учебные пособия и платные курсы дистанционного обучения, доступны для тех, у кого мало опыта программирования, но которые хотят изучить SQL.Официальные курсы университета или колледжа также обеспечат более глубокое понимание языка.
История SQL
История SQL насчитывает более полувека. В 1969 году исследователь IBM Эдгар Ф. Кодд определил модель реляционной базы данных, которая стала основой для разработки языка SQL. Эта модель построена на общих порциях информации (или «ключах»), связанных с различными данными. Например, имя пользователя может быть связано с фактическим именем и номером телефона.
Несколько лет спустя IBM начала работу над новым языком для систем управления реляционными базами данных, основанным на выводах Кодда. Первоначально этот язык назывался SEQUEL, или язык структурированных английских запросов. Названный System R, проект претерпел несколько реализаций и изменений, и название языка менялось несколько раз, прежде чем окончательно перейти на SQL.
После начала тестирования в 1978 году IBM приступила к разработке коммерческих продуктов, включая SQL / DS (1981) и DB2 (1983).Другие производители последовали их примеру, объявив о своих собственных коммерческих предложениях на основе SQL. К ним относятся Oracle, выпустившая свой первый продукт в 1979 году, а также Sybase и Ingres.
SQL в действии: MySQL
Обычное программное обеспечение, используемое для серверов SQL, включает MySQL Oracle, возможно, самую популярную программу для управления базами данных SQL. MySQL — это программное обеспечение с открытым исходным кодом, что означает, что его можно использовать бесплатно и важно для веб-разработчиков, потому что большая часть Интернета и очень много приложений построены на базах данных.
Рассмотрим музыкальную программу, такую как iTunes, которая хранит музыку по исполнителям, песням, альбомам, спискам воспроизведения и т. Д. Как пользователь, вы можете искать музыку по любому из этих и других параметров, чтобы найти то, что ищете. Чтобы создать подобное приложение, вам понадобится программное обеспечение для управления вашей базой данных SQL, и это то, что делает MySQL.
Требуемые навыки SQL
Большинству организаций нужен кто-то со знанием SQL. Заработная плата на должностях, основанных на SQL, варьируется в зависимости от типа работы и опыта, но, как правило, выше среднего.
Некоторые должности, требующие навыков SQL, включают:
- Администратор базы данных (DBA ): это тот, кто специализируется на обеспечении правильного и эффективного хранения и управления данными. Базы данных наиболее ценны, когда они позволяют пользователям быстро и легко извлекать желаемые комбинации данных.
- Инженер по миграции баз данных : Этот человек специализируется на перемещении данных из различных баз данных на сервер SQL.
- Специалист по данным : Эта должность очень похожа на должность аналитика данных, но перед специалистами по обработке данных обычно стоит задача обрабатывать данные в гораздо больших объемах и накапливать их с гораздо большей скоростью.
- Архитектор больших данных : Кто-то в этой роли создает продукты для обработки больших объемов данных.
Ключевые выводы
- Язык структурированных запросов (SQL) — стандартный и наиболее широко используемый язык программирования для реляционных баз данных.
- Он используется для управления и организации данных во всех видах систем, в которых существуют различные отношения данных.
- SQL — ценный язык программирования с хорошими карьерными перспективами.
Введение в базы данных и SQL — Управление данными с помощью SQL для экологов
Обзор
Обучение: 60 мин.
Цели
Упражнения: 5 мин.
Опишите, почему реляционные базы данных полезны.
Создайте и заполните базу данных из текстового файла.
Определите типы данных SQLite.
Выбирать, группировать, добавлять и анализировать подмножества данных.
Объедините данные из нескольких таблиц.
Настройка
Примечание: это должны были сделать участники до начала семинара.
Мы используем Браузер БД для SQLite и Набор данных проекта портала на протяжении всего урока. См. Раздел «Настройка» для инструкции по загрузке данных, а также по установке браузера БД для SQLite.
Для начала давайте сориентируемся в рабочем процессе нашего проекта. Ранее, мы использовали Excel и OpenRefine, чтобы избавиться от беспорядочных, созданных людьми данных к очищенным, машиночитаемым данным. Теперь перейдем к следующему фрагменту. рабочего процесса данных, используя компьютер для чтения наших данных, а затем используйте его для анализа и визуализации.
Что такое SQL?
SQL означает язык структурированных запросов. SQL позволяет нам взаимодействовать с реляционными базами данных через запросы. Эти запросы могут позволить вам выполнять ряд действий, таких как: вставка, выбор, обновление и удаление информации в базе данных.
Описание набора данных
Данные, которые мы будем использовать, представляют собой временные ряды для сообщества мелких млекопитающих в южная Аризона. Это часть проекта по изучению воздействия грызунов и муравьи в растительном сообществе, которое существует уже почти 40 лет. В грызунов отбирают на сериях из 24 делянок с разными экспериментальными манипуляции, контролирующие, каким грызунам разрешен доступ к каким участкам.
Это реальный набор данных, который использовался в более чем 100 публикациях.Мы упростил его для семинара, но вы можете скачать полный набор данных и работать с ним, используя точно такие же инструменты, о которых мы узнаем сегодня.
вопросов
Сначала загрузим и посмотрим на некоторые очищенные таблицы. от Набор данных проекта портала. Нам понадобятся следующие три файла:
-
Survey.csv -
разновидностей.csv -
plots.csv
Вызов
Откройте каждый из этих CSV-файлов и исследуйте их.Какая информация содержится в каждом файле? В частности, если бы у меня было следующие вопросы исследования:
- Как изменились со временем длина и вес задней части стопы у видов Dipodomys ?
- Каков средний вес каждого вида в год?
- Какую информацию я могу узнать о видах Dipodomys в 2000-х годах с течением времени?
Что мне нужно, чтобы ответить на эти вопросы? В каких файлах есть нужные мне данные? Какие какие операции мне нужно было бы выполнить, если бы я делал эти анализы вручную?
Голы
Чтобы ответить на вопросы, описанные выше, нам нужно будет выполнить следующие основные операции с данными:
- выбрать подмножества данных (строки и столбцы)
- группировать подмножества данных
- выполнять математические и другие вычисления
- объединить данные в таблицах
Кроме того, мы не хотим делать это вручную! Вместо поиска сами нужные фрагменты данных или щелкая мышью между таблицами, или вручную сортируя столбцы, мы хотим, чтобы компьютер выполнял всю работу.
В частности, мы хотим использовать инструмент, позволяющий легко повторить наш анализ. в случае изменения наших данных. Мы также хотим проделать весь этот поиск без фактически изменяя наши исходные данные.
Помещение наших данных в реляционную базу данных и использование SQL поможет нам достичь этих целей.
Определение:
Реляционная база данныхРеляционная база данных хранит данные в отношениях , состоящих из записей с полями .Отношения обычно представлены в виде таблиц ; каждая запись обычно отображается в виде строки, а поля — в виде столбцов. В большинстве случаев каждая запись будет иметь уникальный идентификатор, называемый ключом , который хранится как одно из его полей. Записи также могут содержать ключи, которые относятся к записям в других таблицах, что позволяет нам объединять информацию из двух или более источников.
Зачем нужны реляционные базы данных
Использование реляционной базы данных служит нескольким целям.
- Он хранит ваши данные отдельно от анализа.
- Это означает, что нет риска случайного изменения данных при их анализе.
- Если мы получим новые данные, мы можем повторно запустить запрос.
- Это быстро даже для больших объемов данных.
- Улучшает контроль качества ввода данных (ограничения типов и использование форм в MS Access, Filemaker, Oracle Application Express и т. Д.).
- Концепции запросов к реляционной базе данных являются ключевыми для понимания того, как делать подобные вещи с использованием таких языков программирования, как R или Python.
Системы управления базами данных
Существуют различные системы управления базами данных для работы с реляционными базами данных. такие как SQLite, MySQL, Potsgresql, MSSQL Server и многие другие. Каждый из них отличается в основном на основе их масштабируемости, но все они разделяют одни и те же основные принципы реляционные базы данных. В этом уроке мы используем SQLite, чтобы познакомить вас с SQL и получение данных из реляционной базы данных.
Реляционные базы данных
Давайте посмотрим на уже существующую базу данных portal_mammals.sqlite файл из набора данных проекта портала, который мы загрузили во время
Настраивать. Нажмите кнопку «Открыть базу данных», выберите файл portal_mammals.sqlite и нажмите «Открыть», чтобы открыть базу данных.
Вы можете увидеть таблицы в базе данных, посмотрев на левую часть
на вкладке «Структура базы данных». Здесь вы увидите список в разделе «Таблицы». Каждый элемент, указанный здесь, соответствует одному из файлов csv мы исследовали ранее. Чтобы увидеть содержимое любой таблицы, щелкните по ней и
затем щелкните вкладку «Обзор данных» рядом с вкладкой «Структура базы данных».Это будет
дайте нам представление, к которому мы привыкли — копию таблицы. Надеюсь, это
помогает показать, что база данных в некотором смысле представляет собой просто набор таблиц,
где в таблицах есть какое-то значение, которое позволяет связать их с каждым
прочее («связанная» часть «реляционной базы данных»).
Вкладка «Структура базы данных» также предоставляет некоторые метаданные о каждой таблице. Если вы щелкните стрелку вниз рядом с именем таблицы, вы увидите информацию о столбцах, которые в базах данных называются «полями», и назначенных им типах данных.(Строки таблицы базы данных
называются записей .) Каждое поле содержит
одна разновидность или тип данных, часто числа или текст. Вы можете увидеть в опрашивает таблицу , в которой большинство полей содержат числа (BIGINT, или большое целое, и FLOAT, или числа с плавающей запятой / десятичные дроби), в то время как видов таблица полностью состоит из текстовых полей.
Вкладка «Выполнить SQL» теперь пуста — здесь мы будем вводить наши запросы. для получения информации из таблиц базы данных.
Суммируем:
- Реляционные базы данных хранят данные в таблицах с полями (столбцами) и записями (ряды)
- Данные в таблицах имеют типы, и все значения в поле имеют однотипный (список типов данных)
- Запросы позволяют нам искать данные или производить вычисления на основе столбцов
Дизайн базы данных
- Каждая комбинация строка-столбец содержит одно атомарное значение , т. Е. Не содержащие части, с которыми мы, возможно, захотим поработать отдельно.
- Одно поле для каждого типа информации
- Нет избыточной информации
- Разделить на отдельные таблицы по одной таблице на класс информации
- Требуется общий идентификатор между таблицами — общий столбец — для переподключиться (известный как внешний ключ ).
Импорт
Прежде чем приступить к написанию собственных запросов, мы создадим собственные
база данных. Мы будем создавать эту базу данных из трех файлов csv мы скачали раньше.Закройте текущую открытую базу данных ( File> Close Database ), а затем
следуйте этим инструкциям:
- Создать новую базу данных
- Нажмите кнопку Новая база данных
- Дайте имя и нажмите Сохранить, чтобы создать базу данных в открытой папке
- В появившемся окне «Редактировать определение таблицы» нажмите «Отмена», так как мы будем импортировать таблицы, а не создавать их с нуля.
- Выберите Файл »Импорт» Таблица из файла CSV…
- Выберите
опросов.csvиз папки данных, которую мы скачали, и нажмите Открыть . - Присвойте таблице имя, которое соответствует имени файла (
опросов,), или используйте значение по умолчанию - Если в первой строке есть заголовки столбцов, обязательно установите флажок «Имена столбцов в первой строке».
- Убедитесь, что параметры разделителя полей и цитаты указаны правильно. Если вы не уверены, какие параметры верны, проверьте некоторые из них, пока предварительный просмотр в нижней части окна не будет выглядеть правильно.
- Нажмите ОК , вы должны впоследствии получить сообщение о том, что таблица была импортирована.
- Вернувшись на вкладку «Структура базы данных», вы должны увидеть перечисленную таблицу. Щелкните правой кнопкой мыши имя таблицы и выберите Изменить таблицу или нажмите кнопку Изменить таблицу прямо под вкладками и над списком таблиц.
- Нажмите Сохранить , если будет предложено сохранить все ожидающие изменения.
- На центральной панели появившегося окна установите типы данных для каждого поля, используя предложения в таблице ниже (сюда входят поля из
графиковитаблиц видов):
| Поле | Тип данных | Мотивация | Таблица (-и) |
|---|---|---|---|
| день | ЦЕЛОЕ | Использование числовых данных позволяет проводить осмысленные арифметические операции и сравнения | опросов |
| род | ТЕКСТ | Поле содержит текстовые данные | видов |
| hindfoot_length | НАСТОЯЩИЙ | Поле содержит измеренные числовые данные | опросов |
| мес | ЦЕЛОЕ | Использование числовых данных позволяет проводить осмысленные арифметические операции и сравнения | опросов |
| plot_id | ЦЕЛОЕ | Поле содержит числовые данные | участков, обследований |
| тип участка | ТЕКСТ | Поле содержит текстовые данные | участков |
| record_id | ЦЕЛОЕ | Поле содержит числовые данные | опросов |
| пол | ТЕКСТ | Поле содержит текстовые данные | опросов |
| разновидностей_id | ТЕКСТ | Поле содержит текстовые данные | видов, обзоров |
| видов | ТЕКСТ | Поле содержит текстовые данные | видов |
| таксонов | ТЕКСТ | Поле содержит текстовые данные | видов |
| вес | НАСТОЯЩИЙ | Поле содержит измеренные числовые данные | опросов |
| год | ЦЕЛОЕ | Позволяет выполнять осмысленную арифметику и сравнения | опросов |
- Наконец, нажмите OK еще раз, чтобы подтвердить операцию.Затем нажмите кнопку Записать изменения , чтобы сохранить базу данных.
Вызов
- Импортировать
участковивидовтаблиц
Вы также можете использовать этот же подход для добавления новых полей в существующую таблицу.
Добавление полей в существующие таблицы
- Перейдите на вкладку «Структура базы данных», щелкните правой кнопкой мыши таблицу, в которую вы хотите добавить данные, и выберите Изменить таблицу или щелкните Изменить таблицу прямо под вкладками и над таблицей.
- Нажмите кнопку Добавить поле , чтобы добавить новое поле и назначить ему тип данных.
Типы данных
| Тип данных | Описание |
|---|---|
| СИМВОЛ (n) | Символьная строка. Фиксированная длина n |
| VARCHAR (n) или CHARACTER VARYING (n) | Строка символов. Переменная длина. Максимальная длина n |
| ДВОИЧНЫЙ (n) | Двоичная строка.Фиксированная длина n |
| BOOLEAN | Сохраняет значения ИСТИНА или ЛОЖЬ |
| VARBINARY (n) или BINARY VARYING (n) | Двоичная строка. Переменная длина. Максимальная длина n |
| ЦЕЛОЕ (p) | Целое число (без десятичного числа). |
| МАЛЕНЬКИЙ | Целое число (без десятичного числа). |
| ЦЕЛОЕ | Целое число (без десятичного). |
| BIGINT | Целое число (без десятичного). |
| ДЕСЯТИЧНЫЙ (п, с) | Точное числовое, точность p, шкала s. |
| ЧИСЛО (п, с) | Точное числовое, точность p, шкала s. (То же, что и DECIMAL) |
| ПОПЛАВОК (p) | Приблизительное числовое значение с точностью до мантиссы стр. Число с плавающей запятой в экспоненциальной системе счисления с основанием 10. |
| НАСТОЯЩИЙ | Числовой ориентировочно |
| ПОПЛАВОК | Числовой ориентировочно |
| ДВОЙНАЯ ТОЧНОСТЬ | Числовой ориентировочно |
| ДАТА | Сохраняет значения года, месяца и дня |
| ВРЕМЯ | Сохраняет значения часов, минут и секунд |
| TIMESTAMP | Сохраняет значения года, месяца, дня, часа, минуты и секунды |
| ИНТЕРВАЛ | Состоит из ряда целочисленных полей, представляющих период времени, в зависимости от типа интервала |
| МАССИВ | Заданная длина и упорядоченный набор элементов |
| MULTISET | Неупорядоченный набор элементов переменной длины |
| XML | Хранит данные XML |
Краткий справочник по типам данных SQL
Различные базы данных предлагают разные варианты определения типа данных.
В следующей таблице показаны некоторые общие имена типов данных между различными платформами баз данных:
| Тип данных | Доступ | SQLServer | Оракул | MySQL | PostgreSQL |
|---|---|---|---|---|---|
| логический | Да / Нет | Бит | Байт | НЕТ | логический |
| целое | Число (целое) | Инт | Число | Целое / Целое | Целое / Целое |
| поплавок | Номер (разовый) | с плавающей точкой / реальное значение | Число | Поплавок | Числовой |
| валюта | Валюта | Деньги | НЕТ | НЕТ | Деньги |
| строка (фиксированная) | НЕТ | Char | Char | Char | Char |
| строка (переменная) | Текст (<256) / Заметка (65k +) | Варчар | Варчар2 | Варчар | Варчар |
| двоичный объект OLE Object Memo Binary (фиксированный до 8K) | Варбинарный (<8K) | Изображение (<2 ГБ) Длинное | Сырая капля | Двоичный текст | Варбинар |
Ключевые моменты
SQL позволяет нам выбирать и группировать подмножества данных, выполнять математические и другие вычисления и комбинировать данные.