Как сделать URL ссылку
Для того чтобы сайт не затерялся среди тысяч ему подобных, важно не только сделать его удобным в пользовании, но и привлечь к нему внимание поисковых систем. Грамотно подобранный синтаксис URL и правильно прописанные ссылки придают ресурсу более значимые позиции в сети интернет и, как правило, увеличивают количество целевых посетителей.
Uniform Resource Locator (URL) – это уникальный адрес web-ресурса или web-документа в глобальной сети. Другими словами, это набор знаков, который выведет посетителя на искомую страницу, если набрать их в адресной строке браузера.
URL пишется по определенной схеме, что делает его понятным для разных браузеров и поисковых систем. Вначале указывается метод доступа к ресурсу (так называемый протокол). Чаще всего это – HTTP или FTP. Далее пишется доменное имя сайта, и наконец, путь к данному файлу на сервере.
http://code-pattern.ru/html/div.php
Продвинутые seo-специалисты, знают, что URL играет не последнюю роль для роботов поисковых систем. Поэтому схему их работы нужно обязательно учитывать, прописывая уникальный адрес сайта.
Например, поисковые системы скорее увидят страницы, которые находятся ближе всего к главной странице ресурса. Чем короче этот путь, тем больше шансов, что вашу страницу заметят! А если еще научиться грамотно, преобразовывать URL при помощи модуля Apache ModRewrite, задача облегчится в несколько раз.
Еще одно мощное «оружие» – ключевые слова. Их можно и нужно использовать не только в текстовом наполнении сайта, но и в
Раздел фотоаппараты – «photo-apparatus».
Если ключевых слов несколько, и их нужно поместить в URL, то для этого пользуются дефисом. Именно эти знаки робот воспримет, как разделитель между словами. Пример:
где ключевые слова – total, module, correct и url.
Поисковому роботу будет более понятен правильный», а если набрать «pravelny» ссылка, конечно, будет работать, но для робота это будет просто набор букв.
Если URL набрать с нижним подчёркиванием то слова в переводе с иностранного языка получатся слитными, так как они не разделяют слова и анализируются, как символы.
correct_url – воспринимается поисковиком как целое слово состоящее из бессмысленного набора символов, а значит, так делать не следует.
Помните не только о поисковых роботах, но и о живых пользователях. Как показывают исследования, люди скорее заглянут на сайт с коротким
Удобство в пользовании ресурсом зависит и от того, насколько хорошо в нем прописаны ссылки на те, или иные его разделы. Или ссылки на сам ресурс.
Для того чтобы создать ссылки, необходимо сказать браузеру, что является ссылкой, и каков адрес документа, на который следует сделать ссылку. Делается это с помощью html-тегов. Одним из таких элементов является тег <a>, собственно который и предназначен для создания ссылок. Тег <a href="URL"> открывает ссылку, а тег </a>, ее закрывает. Между этими тегами прописывается текст, ссылки который ещё называют «URL-адрес. Для обозначения URL используют атрибут href.
Синтаксис ссылки выглядит следующим образом:
<a href="URL">анкор</a>
Чтобы при нажатии на ссылку открылось новое окно, когда это требуется, синтаксис записывается следующим образом:
<a href="URL" target="_blank">анкор</a>
Для перехода по ссылке внутри документа, используются так называемые «якоря».
Якорем называется ссылка, в состав которой входит атрибута «href» и именем якоря с символом решётки перед ним, создаёт условие для перехода.
<body>
<p><a name="top">Текст, на который переходят</a></p>
<p>...</p>
<p><a href="#top">Наверх к якорю</a></p>
</body>
Различаются два типа адресов ссылок – абсолютные и относительные. Первые дают полный адрес ресурса и указывают весь путь к нужной странице:
<a href="http://pagemodern.ru/total-module/">анкор</a>
Вторые дают возможность зайти на страницу только с текущего ресурса – их еще называют внутренними ссылками:
<a href="/total-module/">анкор</a>
Пользуясь этими нехитрыми правилами, вы значительно облегчите работу и пользователям, и роботам поисковых систем. И они обязательно ответят вам взаимностью.
code-pattern.ru
URI — сложно о простом (Часть 1) / Habr
Привет хабр!
Появилось таки некоторое количество времени, и я решил написать сий пост, идея которого возникла уже давно.
«Пфф, ссылки они и в Африке ссылки, чего тут разбираться?» — скажете вы, тогда я задам вопрос:
Что есть что и куда нас приведет?
http://example.comwww.example.com//www.example.commailto:[email protected]
Если вы не знаете однозначного ответа или вам просто интересно
Перед тем как начать хотел бы обозначить, что есть пост на схожую тему, в котором все обозначено проще и немного понятнее. Целью же этого поста, я ставлю более глубокое изучение вопроса и сбор информации об URI в одном месте, дабы «не потерять». Ну, почти в одном месте, статья будет разделена на две части
ОГЛАВЛЕНИЕ
- URI
1.1. Синтаксис
1.2. Компоненты URI - URL
2.1. Структура - URN
3.1. Структура
Ознакомление
1. URI
Унифицированный Идентификатор Ресурса
Самое свежее описание того, чем же все-таки являются эти пресловутые URI датируется январем аж 2005-го, а именно RFC3986, написанный самим Тимом Бёнесом-Ли, родоначальника всеми нами любимого тырнета.
Резюмируя п.1.1 можно сформулировать определение:
URI — последовательность символов, идентифицирующая физический или абстрактный ресурс, который не обязательно должен быть доступен через сеть Интернет, причем, тип ресурса, к которому будет получен доступ, определяется контекстом и/или механизмом.
Например:
- перейдя по
http://example.com— мы попадем на http-сервер ресурса идентифицируемого какexample.com ftp://example.com— приведет наc на ftp-сервер того же самого ресурса- или например
http://localhost/— URI идентифицирующий саму машину откуда производится доступ
В современном интернете, чаще всего используется две разновидности
URI — URL и URN.Основное различие между ними — в задачах:
- URL — Uniform Resource Locator, помогает найти какой либо ресурс
- URN — Uniform Resource Name, помогает этот ресурс идентифицировать
Упрощая:
URL — отвечает на вопрос: «Где и как найти что-то?», URN — отвечает на вопрос: «Как это что-то идентифицировать».Дело в том, что URL увидел свет и был документирован в 1990 году, в то время как URI был документирован лишь в 1994 году. И вплоть до 2002 года, до выхода RFC3305, уместными были оба варианта именования, что, порой вносило путаницу.
В п.2 RFC3305 сообщается об устаревании такого термина как URL, применимо к ссылкам, и что отныне верным будет именование URI, с того момента, во всех документах W3C использует термин URI. Исходя из этого, применяя термин URL к соответствующим ссылкам, вы не делаете смысловой ошибки, но делаете ее с точки зрения правильного именования.
Обобщая всевозможные варианты, URI имеет следующий вид:
Забегая вперед, стоит отметить, что не все три компоненты являются строго обязательными. Для того чтобы ссылка считалась URI необходимо наличие:
- либо
scheme+authority+path, - либо
sheme+path, - либо только
path.
1.1. Синтаксис
Согласно п.2 RFC3986:
URI составлен из ограниченного набора символов, состоящих из цифр, букв и нескольких графических символов, все эти символы вписываются в кодировку US-ASCII (ASCII). Зарезервированное подмножество символов может использоваться, чтобы разграничить компоненты синтаксиса в URI, в то время как остающиеся символы: не зарезервированный набор и включая те зарезервированные символы, которые не действуют как разделители в данной компоненте URI, определяют данные идентификации каждого компонента.
Зарезервированные символы
Зарезервированные символы делятся на два типа:- gen-delims, они же «главные разделители», т.е. символы, разделяющие URI на крупные компоненты.
":", "/", "?", "#", "[", "]", "@" - sub-delims, они же «под разделители» — символы, которые разделяют текущую крупную компоненту, на более мелкие составляющие, для каждой компоненты они свои, вот список самых распространенных:
"!", "$", "&", "'", "(", ")", "*", "+", ",", ";", "="
Не зарезервированные символы
Исходя из предыдущего пункта, не зарезервированные символы — символы, не входящие вgen-delims, а так же не значимые для данной компоненты sub-delims. Но в общем случае это:Для данного случая, согласно ABNF:ALPHA, DIGIT, "-", ".", "_", "~"ALPHA— любая буква верхнего и нижнего регистров кодировки ASCII (в regExp [A-Za-z])DIGIT— любая цифра (в regExp [0-9])HEXDIG— шестнадцатиричная цифра (в regExp [0-9A-F])
Процентное кодирование
В случае, если используются символы выходящие за пределы кодировки ASCII используется механизм т.н. «Процентного кодирования«. Так же он применяется для передачи зарезервированных символов в составе данных. Зарезервированные символы, по правилам, не участвуют в процентном кодировании.Процентно-кодированный символ представляет из себя символьный триплет, состоящий из знака «%» и следующих за ним двух шестнадцатиричных чисел:
Т.о., %20, например, означает пробел.pct-encoded = "%" HEXDIG HEXDIG
1.2. Компоненты URI
Следующий список содержит описания крупных компонент, составляющих URI:
- Scheme (схема)
Каждый URI начинается с имени схемы, которое относится к спецификации для присвоения идентификаторов в этой схеме. Также, синтаксис URI — объединенная и расширяемая система именования, причем, спецификация каждой схемы может далее ограничить синтаксис и семантику идентификаторов, использующих эту схему.
Название схемы обязательно начинается с буквы и далее может быть продолжено любым количеством разрешенных символов.
Разрешенные символы для схемы:ALPHA, DIGIT, "+", "-", "." - Authority (честно говоря, не знаю как перевести слово на русский, без потери смысла)
Компонента authority начинается с двойного слеша(//) и заканчивается следующим слешем(/), знаком вопроса(?) или октоторпом(#)(да-да, «решеточка» зовется именно так=)) или концом URI
Authority состоит из:
Каждую из подкомпонент, отдельно, мы рассмотрим чуть позже, в разделе посвященном URL.
где в квадратных скобках опциональные компоненты[ userinfo "@" ] host [ ":" port ] - Path (Путь)
Компонента пути содержит данные, обычно, организованные в иерархической форме, которые, вместе с данными в неиерархическом компоненте запроса (Query), служит, чтобы идентифицировать ресурс в рамках схемы URI и authority (если таковая компонента указана).
Путь начинается со слеша(/) и заканчивается знаком вопроса(?), октоторпом(#) или концом URI
Разрешенные символы для пути:Не зарезервированные, процентно-кодированные, sub-delims, ":", "@" - Query (Запрос)
Компонента запроса содержит данные, организованные в неиерархической форме, которые, вместе с данными в иерархическом компоненте пути (Path), служит, чтобы идентифицировать ресурс в рамках схемы URI и authority (если таковая компонента указана).
Запрос начинается с первого знака вопроса(?) и заканчивается октоторпом(#) или концом URI
Разрешенные символы для запроса:
В запросе чаще всего передаются данные в формате key=value (ключ=значение), значение рекомендуется передавать в процентно-кодированном виде, обусловлено это тем, что в значении может встретиться символ «&», который используется для разделения пар ключ-значение, в результате появления такого артефакта дальнейшая последовательность пар ключ-значение может быть нарушена.Не зарезервированные, процентно-кодированные, sub-delims, ":", "@", "/", "?" - Fragment (Фрагмент)
Компонента фрагмент позволяет осуществить косвенную идентификацию вторичного ресурса по отношению к первому.
Семантика фрагмента никак не ограничена, фрагмент начинается октоторпом(#) и заканчивается концом URI, при этом может состоять из абсолютно любого набора символов.
Примером применения фрагментов является оглавление данной статьи. Оно состоит из относительных ссылок
а по статье, в определенных местах, раскиданы т.н. «якоря» — теги<a href="#someanchor"></a><anchor>someanchor</anchor>Переходя по указанной в оглавлении ссылке, браузер производит переход ко вторичному ресурсу относительно данной страницы, т.е. скроллит вниз, до появления нужного
на экране.<anchor>
На этом, пожалуй, знакомство с URI можно закончить и начать углубляться в отдельные подвиды URI, а именно
2. URL
Стандарт URL документирован в RFC1738.
Из п.2:
URL используются, чтобы определить местоположение ресурсов, обеспечивая абстрактную идентификацию расположения ресурса. Определив местоположение ресурса, система может выполнить множество операций на ресурсе, которые могут быть характеризованы такими словами как ‘доступ’, ‘обновление’, ‘замена’, ‘поиск атрибутов’. В целом только метод доступа должен быть определен для любой схемы URL.Т. о.: URL призван решить широкий ряд задач, начиная с получения и заканчивая изменением данных на ресурсе, а обязательным параметром для получения доступа — является метод, т. е. любой полноценный (абсолютный) URL можно свести к виду:
<scheme>:<часть свойственная этой схеме>
2.1. Структура
В целом, URL имеет схожую структуру, для всех схем, хотя для каждой отдельно взятой схемы, структура может отличаться от общего шаблона.
Графически ее можно выразить в следующем виде:
И вот, примерно на этом моменте, можно рассмотреть различия между абсолютными (absolute) и относительными (relative) URL, данные определения распространяются не только на URL, но и на URI в целом.
- Относительная ссылка использует иерархический синтаксис, чтобы выразить ссылку URI относительно пространства имен другого иерархического URI.
Относительные ссылки так же делятся на несколько подвидов:- Ссылка сетевого пути
Имеет вид:
Такой тип ссылок применяется не часто, смысл заключается в переходе по указанной ссылке с применением текущей схемы.//<authority> <path> [<query>] [<fragment>]
Т. е.: находясь, например наhttp://example.comи перейдя по ссылке//domain.com— мы попадем наhttp://domain.com
А в случае если перейдем по той же ссылке сftp://example.com, то попадем наftp://domain.com - Ссылка абсолютного пути
Имеет вид:
На этот раз мы останемся в пределах текущего хоста, но попадем по пути path в любом случае, по какому бы пути мы сейчас не находились./<path> [<query>] [<fragment>]
Т. е.: даже находясь наhttp://example.com/just/some/long/pathи перейдя по ссылке/path, мы попадем наhttp://example.com/path - Ссылка относительного пути
Имеет вид:
Теперь же, мы будем перемещаться в пределах текущего положения.<path> [<query>] [<fragment>]
Т. е.: находясь наhttp://example.com/just/some/long/pathи перейдя по ссылкеpath, мы попадем наhttp://example.com/just/some/long/path/path - Ссылка того же документа
Фактически это ссылки, состоящие только из фрагментарной части URI, либо же ссылки, у которых все компоненты за исключением фрагментарной совпадают с исходной.
Т.е.#fragmentиhttp://habrahabr.ru/topic/232385/#fragmentявляются ссылками того же документа.
- Ссылка сетевого пути
- Абсолютная ссылка — ссылка вида
Применяя абсолютные ссылки, мы будем попадать на нужный нам ресурс вне зависимости от того, откуда мы переходим.<scheme> <authority> [<path>] [<query>] [<fragment>]
Т. е.: находись мы наhttp://example.com/just/some/long/pathили же наftp://example.com, перейдя поhttp://domain.com/path, мы в любом случае попадем наhttp://domain.com/path
После того, как мы разобрались с тем, что же такое относительные и абсолютные пути — можно отвечать на вопрос заданный в начале поста:
- http://example.com — откроет
http://example.com - www.example.com — по-идее должен открыть
http://habrahabr.ru/topic/232385/www.example.com, но хабр сам исправляет ссылку, хотя по стандартамwww.example.com— ссылка относительного пути - //www.example.com — откроет
www.example.comсо схемой с которой вы просматриваете текущую страницу, т.е. скорее всего будет открытhttp://example.com - mailto:[email protected] — здесь уже вступают в силу настройки браузера, он предложит вам открыть эту ссылку при помощи почтовой программы и отправить электронное письмо адресату
[email protected], а так, это абсолютный URL со схемойmailto
Мы уже рассмотрели крупные компоненты, а теперь давайте углубимся в детали построения URL.
- Scheme — как говорилось ранее: схема определяет метод доступа к ресурсу. Список актуальных схем можно посмотреть тут.
- Userinfo — под-компонент authority, использующийся для авторизации пользователя на ресурсе. Состоит из username и необязательного password, от остальной части authority отделяется символом «
@«. Не смотря на то, что параметр password указан в спецификации, его использование крайне не рекомендуется, т. к. фактически производится передача пароля к учетной записи username, в незашифрованном виде.
Разрешенные символы:Не зарезервированные, процентно-кодированные, sub-delims, ":"
Пример можно привести следующий:
На локалке есть папка test, на которую стоит доступ по паре логин-пароль. То есть, перейдя поhttp://localhost/test/, я увижу следующее:
А если я перейду по ссылкеhttp://admin:admin@localhost/test/, то процедура авторизации произойдет автоматически, с данными указанными в блоке userinfo: - Host — компонент authority, использующийся для определения целевого узла (или ресурса, если угодно, но понятие «узел» будет более точным), который может находиться как в сети интернет, так и вне её, в зависимости от указанной схемы. Данная компонента не чувствительна к регистру.
Хост может представлять из себя либо IP-адрес, либо регистрационное имя (reg-name) и, опционально, следующий за ними порт(port).
Предусматривается как поддержка существующих форматов IP-адресов (IPv4, IPv6), так и всевозможных будущих, которые будут описаны впоследствии.
Регистрационное имя — привычные нам, т. н. доменные имена — последовательность символов, обычно предназначенных для поиска в локально определенном узле или реестре имени службы, хотя специфичная для схемы семантика URI может потребовать, чтобы вместо этого использовался определенный реестр (или фиксированная таблица имен).
Наиболее распространенный механизм реестра имен — Система Доменных Имен (DNS).
Доменное имя, используемое для поиска в DNS, состоит из доменных меток, разделенных при помощи «.», каждая доменная метка может содержать следующие символы:
Синтаксис регистрационного имени позволяет использование процентно-кодированных символов, для представления не-ASCII символов, в едином порядке, не зависящем от технологии разрешения имен. Символы, не входящие в ASCII, должны быть сначала закодированы в UTF-8, а затем каждый октет UTF-8 последовательности должен быть процентно закодирован.Не зарезервированные, процентно-кодированные, sub-delims
В случае, если регистрационное имя с не-ASCII символами представляет собой многоязычное доменное имя, разрешаемое через DNS, оно должно быть преобразовано в кодировку IDNA (RFC3490) до поиска имени и, как следствие, регистраторами доменных имен такие регистрационные имена должны предоставляться в кодировке IDNA.
Port (Порт) — десятичный номер порта, отделяется от hostname одним двоеточием «:», может состоять только из цифр. Схема может определять порт по-умолчанию, который будет использоваться в случае если порт не указан. Например, для схемы HTTP порт по-умолчанию — 80, что соответствует зарезервированному под неё порту 80/TCP. Тип порта, так же как и назначенный номер порта, определяется схемой. - Компоненты Запрос и Фрагмент полностью описаны ранее.
3. URN
Стандарт URN документирован в RFC2141.
Из п.1:
Унифицированные имена ресурсов (URN) предназначены, чтобы служить постоянными, независимыми от расположения, идентификаторами ресурсов и разработаны для упрощения отображения других пространств имен (которые совместно используют свойства URN) в URN-пространство. Таким образом, синтаксис URN обеспечивает средство закодировать символьные данные в форме, которая может быть отправлена посредством существующих протоколов, записана при помощи большинства клавиатур, и т.д.Т. е., в отличие от URL, который ссылается на како-то место, где хранится документ, URN ссылается на сам документ, и при перемещении документа в другое место ссылка не изменится.
В силу того, что URN концептуально отличается от URL, то и система разрешения имен у него другая — DDDS, которая преобразует URN в URL, по которым можно найти ресурс/объект или что бы то ни было, на что ссылается URN.
3.1. Структура
URN имеет следующий вид:
"urn:" <NID> ":" <NSS>
- «urn:» — обязательная, регистронезависимая часть URN
- NID — Namespace Identifier, данная компонента определяет синтаксическую интерпретацию компоненты NSS.
Минимальная длина — 2 символа, максимальная — 32, разрешенные символы:
NID должен начинаться только с буквы или цифры.латинские буквы, цифры, "-"
Так же, слово «urn» для NID является зарезервированным, дабы избежать неоднозначности при определении URN в целом.
Список официально зарегистрированных NID можно посмотреть тут - NSS — Namespace Specific String, эта компонента служит непосредственно для передачи каких-либо данных.
Разрешенные символы:
Зарезервированные символы:латинские буквы, цифры, процентно-кодированные, "(", ")", "+", ",", "-", ".", ":", "=", "@", ";", "$", "_", "!", "*", "'"
Запрещенные символы должны быть процентно-кодированы. Если указанный символ встретится в явном виде, его позиция будет считаться концом URN:"%", "/", "?", "#"октеты 0-32 (0-20 hex), "\", """, "&", "<", ">", "[", "]", "^", "`", "{", "|", "}", "~", октеты 127-255 (7F-FF hex)
Самоидентифицирующийся URN
Такие URN содержат в NID название хэш-функции, а в NSS значение хэша, вычисленного для идентифицируемого объекта. Такие ссылки используются в magnet-ссылках и заголовках p2p-сети Gnutela2.Например, URN из magnet-ссылки с одного торрент-трекера:
magnet:?xt=urn:btih:c68abc1ba9b8c7c4bc373862cad1a8c01d69e53d...С теорией все, во второй части рассмотрим, что можно и что нужно делать с URI, если мы их обрабатываем, а именно — нормализация, разбор и т.д.
За сим откланяюсь, спасибо что читали, надеюсь не было скучно, удачи!
habr.com
URL адрес что это такое
Практически каждый работающий в Интернете пользователь встречает в сети упоминания о URL, URL-адресах, приглашениях перейти на какой-либо линк и воспользоваться ссылкой. Для тех, кто не знаком или плохо знаком с данными понятиями, я решил написать материал, в котором расскажу, что это такое URL адрес, как использовать URL, на какие части делится УРЛ, а я также поясню, как найти нужную ссылку в сети.

Поиск URL адреса
Что это такое URL
URL — это адрес, указывающий путь к интернет ресурсу, на котором размещены различные виды файлов (документы, картинки, видео, аудио и др.). Аббревиатура URL расшифровывается как «Uniform Resource Locator» (Единый Указатель Ресурсов), по-русски она обычно произносится как «урл», «ю-ар-эл», «у-эр-эл», часто используется просто слово «ссылка».
Помню, искал некоторое время назад что это такое URL адрес, для того чтобы грамотно рассказать братику все тонкости понятия. И самому стало интересно, когда появился данный термин.
Автором понятия URL считается британец Тим Бернес-Ли, а само изобретение (1990г.) ознаменовало качественный скачок в развитии интернет технологий. Сейчас URL является идентификатором адресов практически всех ресурсов в сети, при этом сам термин URL постепенно заменяется более обширным термином URI (Uniform Resource Identifier – Единый Идентификатор Ресурсов).
URL постов в социальных сетях
- Чтобы получить URL заметки Вконтакте нажмите на дату публикации заметки, а потом скопируйте ссылку с адресной строки вашего браузера (кликаем правой клавишей мыши на адрес в адресной строке браузера, а затем нажимаем «Копировать»).

URL-ссылка поста в ВК
- В Одноклассники то же самое, нужно нажать на пост, а затем скопировать адрес с адресной строки.
- На Фейсбуке URL поста вы получите, кликнув на дату поста или его время, а затем скопировав адрес с адресной строки, как в случае с «Вконтакте».
URL-ссылка поста в Фейсбуке
- В Твиттере нужно нажать на пост, а затем нажать на три точки внизу поста, где выбрать «Скопировать ссылку на твит». Система вам предоставит полный URL конкретного твита и вы сможете его скопировать. Нажав правую клавишу мыши, затем выбрать «копировать», а потом вставить ссылку, куда вам нужно с помощью функции «Вставить» (Ctrl+V)
- D Google+ нажимаем на стрелочку справа сверху заметки, и выбираем «Получить ссылку».

На какие части делится URL-адрес
Классический пример URL-адреса выглядит примерно так:
http://адрес_сайта/папка/страница.html
Как видим, адрес URL делится на несколько частей:
Первая часть (http://) определяет используемый протокол. Проще говоря, она говорит о методе, который будет использоваться для получения доступа к нужному ресурсу.
Используемый в данном URL протокол «HTTP» расшифровывается как «HyperText Transfer Protocol», и применяется он в абсолютном большинстве случаев. Но можно найти URL c использованием другие протоколов, к примеру, FTP (File Transfer Protocol – протокол для передачи файлов), HTTPS (HyperText Transfer Protocol Secure – безопасная, зашифрованная версия HTTP), mailto (адрес электронной почты) и другие.
Всего же видов протоколов URL насчитывается несколько десятков ftp, http, rtmp, rtsp, https, gopher, mailto, news, nntp, smb, prospero, telnet, wais, xmpp, file, data и др, но используются обычно несколько основных, перечисленных мной чуть выше.
Расшифровка URL адреса
Вторая часть (адрес_сайта) – это имя домена. Технически это просто линия символов, букв или комбинация слов, позволяющая людям легко запоминать адрес любимой страницы. В ином случае ссылки на ресурсы выглядели бы как http://192.168.384.656, запомнить такое сочетание цифр было бы на порядок труднее, нежели имя http://droidov.com.
Третья часть (папка/страница.html) обычно указывает на какую-либо страницу ресурса, к которой пользователь хочет получить доступ. Она может быть просто в виде названия, или в виде пути к определённому файлу через набор папок, последние обычно разделяются слешом (/). Расширение интернет страниц может быть разным – php, htm, html, shtml, asp и ряд других.
Визуально данные пояснения можно посмотреть на видео:
Используемая перед названием домена аббревиатуры www (World Wide Web – всемирная паутина) не является обязательной, вы можете использовать адрес сайта и без неё, сайт обязательно откроется.
Особенности использования URL адреса
Поисковые системы рекомендуют разработчикам создавать информативные адреса страниц, чтобы название страницы говорило пользователю и поисковому роботу о сути материала, расположенного на странице.
Если указанный пользователем URL не верен, то система покажем нам ошибку 404 с примечанием «Страница не найдена!». Значит, пользователь набрал или не правильный, или устаревший адрес страницы, потому при наборе адреса необходимы точность, аккуратность и внимание. Я бы рекомендовал при наборе URL использовать буфер обмена, скопировав адрес страницы через функции «копировать/вставить». Можно также попробовать набрать урезанный URL адрес в виде только основного имени сайта (без папок и страниц), а уже на главной странице сайта поискать переход на нужную нам страницу.

Значок URL ссылки используемый в Интернете
Недостатки URL
После описания, что это URL ссылка давайте разберём все недостатки УРЛ. Наряду с преимуществами, позволяющими легко вести навигацию в интернете, у URL есть свои недостатки. Это работа только цифрами, латинскими буквами и некоторыми символами, кириллица же обычно должна быть перекодирована (URL Encoding) в два этапа, на первом из которых каждый кириллический символ преобразовывается в два байта, а потом каждый из байтов переписывается с использованием шестнадцатеричной системы.
Кроме того, в адресе рекомендуется использовать преимущественно маленькие буквы (некоторые Unix-системы их заглавные варианты будут воспринимать как разные символы, что может привести к ошибке открытия страницы), также в адресах URL запрещается использовать пробелы.
Как найти URL адрес. Закладки.
Для поиска требуемого URL адреса можно воспользоваться поисковыми системами, в которых необходимо прописать ключевые слова вашего поиска. К примеру, если нужен какой-либо фильм – тогда ввести его название, или имена актёров, если музыка – имена исполнителей и название композиции. Нажав «Поиск» вы получите множество сайтов с URL адресами, кликнув на которые вы можете найти нужный результат.
URL страницы, на которой вы находитесь в данный момент, размещается в адресной строке вашего браузера, расположенной вверху.
Для запоминания URL адреса нужной страницы используйте панель закладок вашего браузера. К примеру, в популярном браузере Mozilla Firefox иконка закладок в виде звёздочки расположена справа сверху на уровне адресной строки. Кликнув на неё, вы получите возможность набрать имя для вашей закладки, а также папку, куда складывать закладки (обычно я использую специальную панель закладок, позволяющая по одному клику получать доступ к любой из них).
Заключение
Использование URL здорово облегчило работу в сети Интернет, позволив множеству пользователей легко и быстро получать доступ к нужным сайтам. Если у вас остались вопросы после прочтений статьи “URL адрес что это такое” пишите их в комментариях к статье.
Всё, что сегодня нужно – это вбить название сайта и его расширение в адресной строке, после чего пользователь получает практически мгновенный доступ к ресурсу. И всё это без необходимости запоминать достаточно сложный ряд трёхзначных цифр, всё делается легко, быстро, эффективно – в общем, то, что нужно, не правда ли.
droidov.com
какие адреса ссылок важны для SEO
Как оптимизировать URL, чтобы адреса ссылок нравились поисковикам и были удобны пользователям.
Для SEO важны URL-адреса: они влияют на восприятие страницы поисковиками и на отношение пользователей. Зарубежный эксперт по SEO Брайан Дин из «Backlinko» составил руководство по дружественным к SEO URL — «SEO Friendly URLs», в котором собрал рекомендации, основанные на своем опыте. Мы перевели, адаптировали и дополнили руководство.
Почему URL влияют на SEO
URL страницы отображается в результатах поиска в Google под заголовком. Поисковые системы наряду с заголовками, анкорами и самим текстом используют URL-адреса страниц, чтобы понять, о чем ваш контент. Информацию о содержании страницы поисковикам и пользователям лучше передают простые URL.
Создание описательных категорий и имен файлов для документов поможет удобнее организовать контент на сайте. К тому же это позволит создавать удобные URL-адреса для тех, кто хочет ссылаться на ваш контент. Длинные ссылки с непонятными символами могут отпугнуть пользователей, кликабельность у сниппета с такой ссылкой будет ниже.
К примеру, URL-адрес « http://en.wikipedia.org/wiki/Aviation» к статье об авиации выглядит привлекательнее, чем «http://www.example.com/index.php?id_sezione=360&si….».
Google хорошо умеет сканировать даже сложные структуры URL, но лучше потратить немного времени и сделать URL максимально простыми, как советует поисковик в рекомендациях для веб-мастеров.
Как поисковик воспринимает URL
Адрес ссылки делится на несколько отдельных разделов: «protocol://hostname/path/filename?querystring#fragment». Например, « https://www.example.com/RunningShoes/Womens. htm?size=8#info».
Google рекомендует, чтобы все сайты использовали «https: //», когда это возможно. Имя хоста — это то место, где размещается ваш сайт, обычно используют то же доменное имя, как и для электронной почты.
Разные версии URL
Google различает версии « www.example.com» и просто «example.com». При добавлении сайта в консоль поисковик рекомендует добавлять версии «http: //» и «https: //», а также версии «www» и «non-www».
Регистр в URL
В имени хоста и протоколе регистр не играет никакой роли. К регистру чувствительны путь, имя файла и строка запроса, которые определяют доступ к серверу. «FILE» в URL будет отличаться от «file».
Косой слэш «/» в URL
При обращении к домашней странице косая черта после имени хоста роли не играет: «https:// example.com/» совпадает с «https:// example.com», контент одинаковый. Но для пути и имени файла косая черта выглядит как другой URL: например, « https://example.com/fish» сигнализирует о файле, а «https: // example.com/fish/» о каталоге.
Информация о записи и различиях в URL есть в руководстве для начинающих Google SEO в разделе «Understand how search engines use URLs».
Оптимизированные URL: что важно для SEO
Как составить оптимизированные URL, которые понравятся пользователям и поисковикам.
Употребите ключевое слово
URL должен содержать целевое
ключевое слово, по которому вы хотите, чтобы страница ранжировалась. Когда вы включаете ключевое слово в свой URL, этот ключ сигнализирует Google, о чем страница.

Google утверждает: «URL-адреса со словами, которые имеют отношение к содержанию и структуре вашего сайта, удобнее для посетителей ресурса».
К примеру, пост из блога Брайана Дина, в котором перечислены более 150 инструментов SEO:
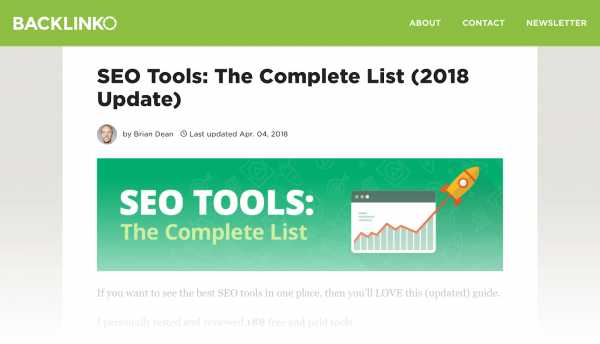
Целевая ключевая фраза для этой страницы — «Инструменты SEO», ее и содержит URL — « https://backlinko.com/seo-tools».
Не используйте хэши
Представитель поисковика Джон Мюллер предостерегает от использования хэшей в адресе. Если контент появляется, когда в URL-адресе есть хэш, например «http://www.example.com/office.html#mycontent», Google его не проиндексирует.
Поисковые системы также игнорируют якорные фрагменты, которые прокручивают браузер к нужному месту на странице, поскольку сам контент страницы одинаковый.
 Якорь в ссылке на странице статьи
Якорь в ссылке на странице статьиРазделяйте дефисами
Google заявляет, что лучше избегать подчеркивания или пробелов в своих URL, а использовать дефис для разделения слов.
К примеру, в ссылке «
https://backlinko.com/seo-site-audit» дефис говорит поисковым системам, что «SEO», «сайт» и «аудит» — это три отдельных слова.
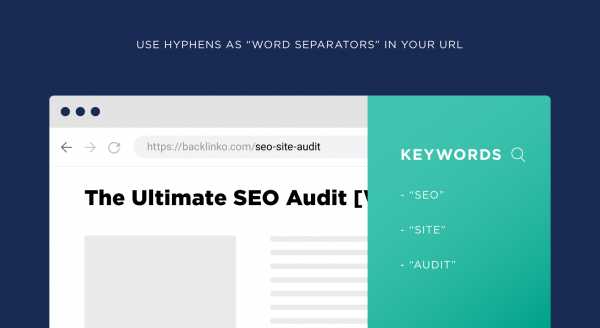
URL «backlinko.com/seositeaudit» у этой же статьи сложнее бы воспринимался поисковыми системами и был бы неудобен для понимания и чтения.
Формулируйте короче
Брайан Дин считает, что длинные URL-адреса сбивают с толку Google и другие поисковые системы, поэтому они должны быть короткими.
Например, этот URL содержит много лишнего:
Для Google эта страница о бейсболе, но по ключевым словам получается, что и по умолчанию о редиректах:
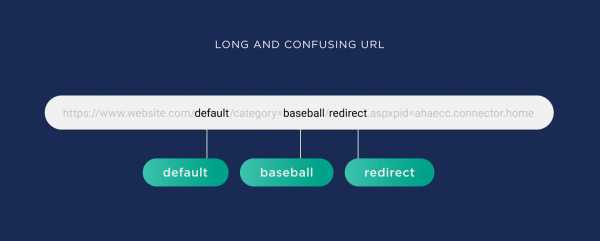
Короткая версия выглядит лучше, Google легко может определить тему этой страницы:
Исследование факторов рейтинга 2016 года от Backlinko выявило сильную корреляцию между короткими адресами ссылок и высокими позициями в Google:
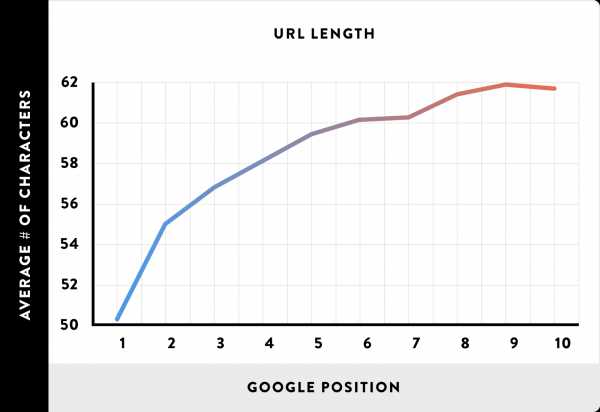 График корреляции длины URL и рейтинга
График корреляции длины URL и рейтингаВ исследовании участвовал миллион страниц из выдачи Google.
С другой стороны, представитель Google Джон Мюллер говорил, что алгоритм не отдает приоритет коротким URL при ранжировании. Поисковик советует короткие адреса, потому что так удобнее пользователям.
В руководстве Google написано, что слишком сложные URL-адреса затруднят краулеру сканирование. Динамическая генерация документов, фильтрация позиций, сортировка, реферальные ссылки приводят к тому, что появляется слишком много ссылок для обработки одного и того же контента.
К примеру, фильтр отелей по стоимости:
http://www.example.com/ hotel-search-results.jsp? Ne=292&N=461
плюс фильтр отелей на пляже:
http://www.example.com/ hotel-search-results.jsp? Ne=292&N=461+4294967240
плюс фильтр отелей с фитнес-центром:
http://www.example.com/ hotel-search-results.jsp? Ne=292&N=461+4294967240+4294967270
Закройте краулерам доступ к проблемным URL-адресам в файле robots.txt.
Используйте кликабельные URL
Внешний вид URL влияет на то, решит ли кто-нибудь нажать на сайт в результатах поиска, поэтому кликабельность важна для ранжирования.
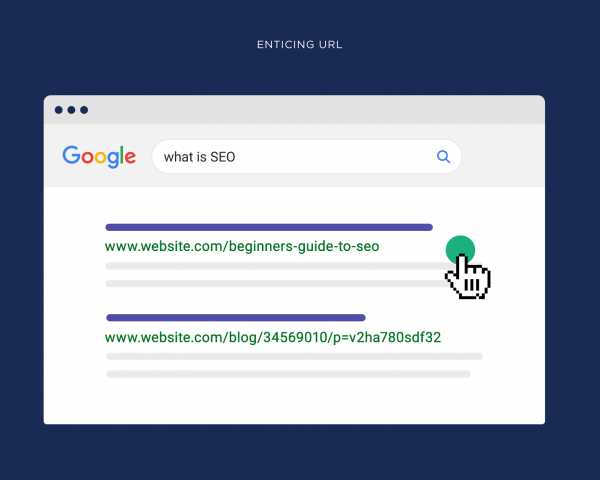
Часть пользователей смотрит на внешний вид URL, чтобы выяснить, куда их приведет ссылка. Если URL выглядит так, то они не будут знать, на какой странице окажутся, поэтому будут кликать реже:
Это касается не только результатов поиска Google. На «некрасивые» URL реже кликают в социальных сетях и онлайн-сообществах, реже делают репосты.
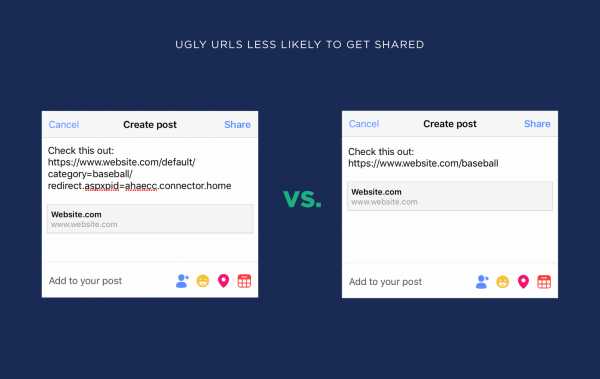
Следуйте рекомендациям к сниппетам и URL-адресам, тогда у вас получится сниппет, по которому пользователи захотят перейти.
Используйте строчные буквы
Большинство современных серверов одинаково воспринимают прописные и строчные буквы в URL, но для некоторых эти URL будут разными:

Поэтому на всякий случай используйте только строчные буквы в URL.
Избегайте использования дат
Некоторые CMS автоматически включают даты в URL. К примеру, раньше так делал WordPress:
В 2019 году это не так распространено, но многие веб-мастера еще используют такие ссылки. Даты в ссылках не очень хороши по двум причинам:
- Даты делают URL длиннее.
- Даты затрудняют обновление контента.
Например, этот URL содержит ключевое слово из четырех слов и дату, всего 43 символа:
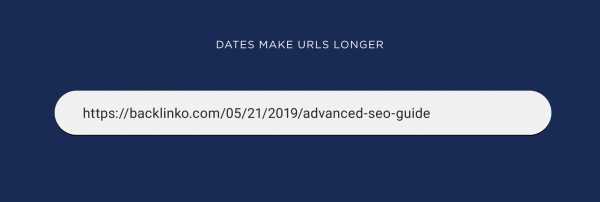 URL с датой
URL с датойБез даты длина URL уменьшается до 32 символов:
 URL без даты
URL без даты
Допустим, вы опубликовали список лучших приложений для iPhone на 2019 год:
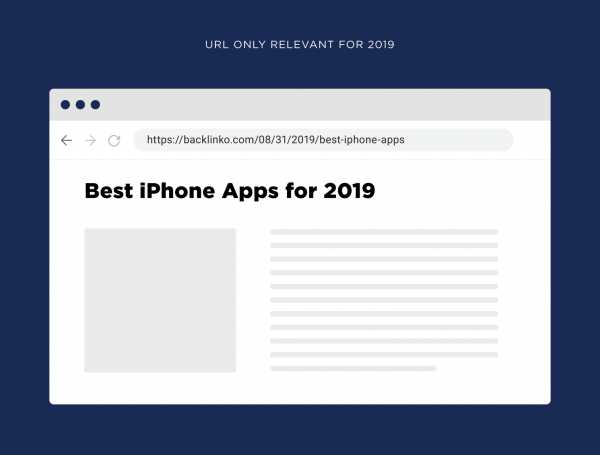 Подборка, привязанная к дате
Подборка, привязанная к дате
В январе 2020 года захотите обновить эту страницу, но в URL будет «2019»:
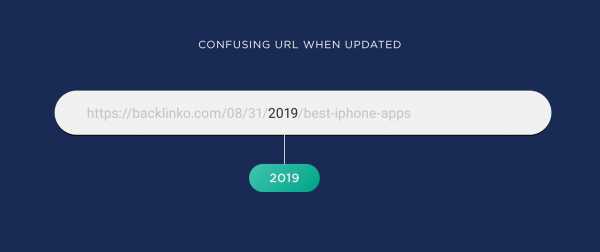 Год в URL
Год в URLЕсли вы дополните статью приложениями для iPhone 2020 года, то придется менять URL-адрес. Можно оставить его со старой датой, но это запутает пользователей, можно сделать 301 редирект, но это непросто делать каждый раз при обновлении контента. Проще сразу не включать дату в адрес ссылки.
Организуйте навигацию
Google заявляет: навигация по сайту важна для того, чтобы посетители могли быстро найти нужный контент, а также она может помочь поисковым системам понять, какой контент веб-мастер считает важным. С помощью страниц для навигации можно управлять ссылочным весом страницы.
Для объединения статей на одну тему подойдет страница-хаб. В своем блоге Брайан опубликовал «YouTube Marketing Hub»:
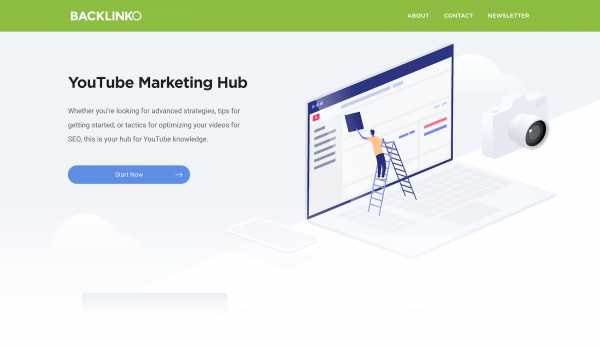 Страница-хаб
Страница-хабХаб содержит 32 статьи о продвижении на YouTube, распределенных по пяти категориям. Для удобства пользователей и для бота Google страницы имеют организованную структуру URL.
Любой URL с «/hub» сигнализирует о том, что на сайте есть страница-хаб — « https://backlinko.com/hub/youtube», слово или фраза после «/ hub» сообщают, что пользователь находится на странице внутри хаба — «https://backlinko.com/hub/youtube/create-channel».
В структурировании важно не перестараться: множество папок усложняет навигацию и может увеличивать количество кликов с главной до страницы. Чем дальше от главной находится страница по количеству кликов, тем меньше ее значимость для бота-краулера.
Интернет-магазин «PetSmart» использует разумный подход к URL-адресам и навигации по сайту:
 Главная интернет-магазина «PetSmart»
Главная интернет-магазина «PetSmart»«PetSmart» использует навигацию «Домашнее животное» → «Категория» → «Подкатегория» → «Продукт», чтобы структурировать 85 тысяч страниц и настроить передачу ссылочного веса.
Пример ссылки:
https://www.petsmart.com/dog/food/dry-food/blue-life-protection-formula-adult- dog-food-chicken-and-brown-rice-41846.html
Перейдите на HTTPS
HTTPS больше связан с безопасностью, чем с URL и оптимизацией, но HTTPS входит в сигналы ранжирования, его уже можно назвать стандартом для сайтов. По словам Джона Мюллера, при прочих равных поисковик отдаст предпочтение странице с безопасным сертификатом.
Почитать по теме: Как перейти на HTTPS
Не используйте заголовки постов
Брайан не советует использовать заголовки страниц в качестве текста в URL. Для одной статьи он настроил WordPress, чтобы заголовки страниц блога шли в URL:

Как и в случае с датами, это приводит к созданию более длинных URL-адресов. Если будете тестировать разные заголовки, изменять контент станет сложнее.
К примеру, если отредактировать статью с предыдущего скриншота и оформить ее как тематическое исследование или подборку, то URL устареет. Лучше использовать в URL целевой ключ с дополнительными словами.
Исключите динамические параметры
Ссылки с динамическими параметрами, к примеру, с метками UTM, могут вызвать проблемы с точки зрения оптимизации:
- динамические параметры удлиняют URL;
https://backlinko.com/?utm_source=facebook&utm_med… - динамические URL странно выглядят для пользователей, это может повредить органическому CTR;
- если поисковик проиндексировал разные версии этого URL, могут быть проблемы с дублированием контента в Google;
- динамические URL-адреса обычно такие длинные, что не умещаются в результатах поиска.
Организуйте подпапки, а не поддомены
Для оптимизации подпапки подходят гораздо лучше, чем поддомены. Google может рассматривать поддомен как отдельный сайт:

Но когда вы перемещаете этот раздел в подпапку, Google знает, что это часть вашего основного сайта:

Google утверждает, что относится к подкаталогам и поддоменам одинаково, но опыт веб-мастеров говорит, что для SEO лучше использовать подпапки. Веб-мастер переместил раздел сайта из субдомена в подпапку, и сразу после этого органический трафик вырос:
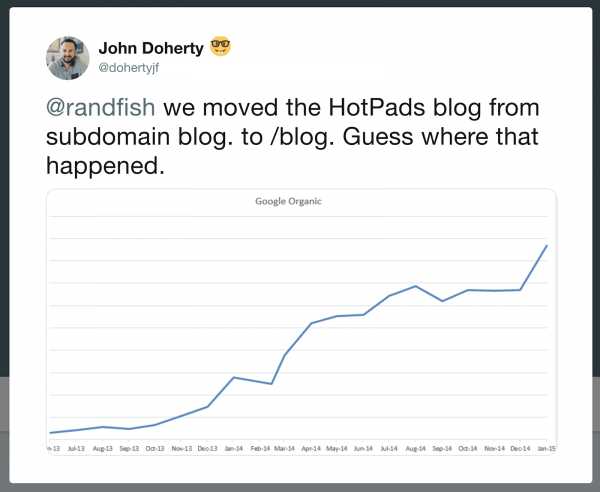 Изменение трафика после переноса раздела сайта
Изменение трафика после переноса раздела сайтаGoogle рекомендует сохранять простую структуру URL и сам в своих проектах следует этим советам.
Резюмируя, какие принципы лучше использовать в оптимизации URL:
- Употребите ключевое слово
- Не используйте хэши
- Формулируйте короче
- Используйте кликабельные URL
- Используйте строчные буквы
- Организуйте навигацию
- Перейдите на HTTPS
- Не используйте заголовки постов
- Исключите динамические параметры
- Организуйте подпапки, а не поддомены
На основе статьи Брайана Дина «SEO Friendly URLs»
pr-cy.ru
Ссылки | htmlbook.ru
Ссылки являются основой гипертекстовых документов и позволяют переходить с одной веб-страницы на другую. Особенность их состоит в том, что сама ссылка может вести не только на HTML-файлы, но и на файл любого типа, причем этот файл может размещаться совсем на другом сайте. Главное, чтобы к документу, на который делается ссылка, был доступ. Иными словами, если путь к файлу можно указать в адресной строке браузера, и файл при этом будет открыт, то на него можно сделать ссылку.
Для создания ссылки необходимо сообщить браузеру, что является ссылкой, а также указать адрес документа, на который следует сделать ссылку. Оба действия выполняются с помощью тега <a>. Общий синтаксис создания ссылок следующий.
<a href="URL">текст ссылки</a>Атрибут href определяет URL (Universal Resource Locator, универсальный указатель ресурса), иными словами, адрес документа, на который следует перейти, а содержимое контейнера <a> является ссылкой. Текст, расположенный между тегами <a> и </a>, по умолчанию становится синего цвета и подчеркивается. В примере 8.1 показано создание нескольких ссылок на разные веб-страницы.
Пример 8.1. Добавление ссылок
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>Ссылки на странице</title>
</head>
<body>
<p><a href="dog.html">Собаки</a></p>
<p><a href="cat.html">Кошки</a></p>
</body>
</html>В данном примере создаются две ссылки с разными текстами. При щелчке по тексту «Собаки» в окне браузера откроется документ dog.html, а при щелчке на «Кошки» — файл cat.html.
Результат примера показан на рис. 8.1. Обратите внимание, что при наведении курсора мыши на ссылку, в строке состояния браузера отображается полный путь к ссылаемому файлу.
Рис. 8.1. Вид ссылок на странице
Если указана ссылка на файл, которого не существует, например, его имя в атрибуте href набрано с ошибкой, то такая ссылка называется битая. Битых ссылок следует категорически избегать, поскольку они вводят посетителей сайта в заблуждение. Так, при щелчке по ссылке из примера 8.1 в браузере Safari откроется не сам документ, а окно с предупреждением (рис. 8.2).
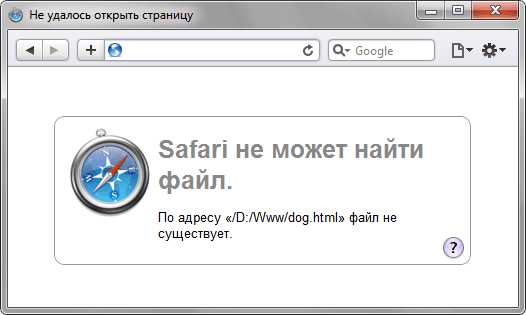
Рис. 8.2. Результат при открытии битой ссылки
Естественно, подобное сообщение будет различаться в браузерах, но смысл остается один — документ, на который ведет ссылка, не может быть открыт. Чтобы не возникало подобных ошибок, тестируйте все ссылки на их работоспособность и сразу же устраняйте имеющиеся погрешности.
Файл по ссылке открывается в окне браузера только в тех случаях, когда браузер знает тип документа. Но поскольку ссылку можно сделать на файл любого типа, то браузер не всегда может отобразить документ. При этом выводится сообщение, как следует обработать файл — открыть его или сохранить в указанную папку. Например, в браузере Firefox выводится следующее окно (рис. 8.3).
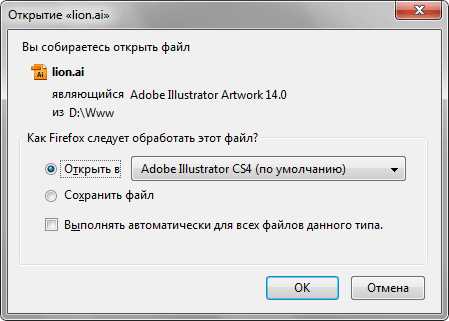
Рис. 8.3. Окно для выбора действия с файлом в Firefox
htmlbook.ru
путь, фрагмент, запрос и авторизация / Habr
URL’ы не должны были стать тем, чем стали: мудрёным способом идентифицировать сайт в интернете для пользователя. К сожалению, мы не смогли стандартизировать URN, который мог бы стать более полезной системой наименования. Считать, что современная система URL достаточно хороша — это как боготворить командную строку DOS и говорить, что все люди просто должны научиться пользоваться командной строкой. Оконные интерфейсы были придуманы, чтобы пользоваться компьютерами стало проще, и чтобы сделать их популярнее. Такие же мысли должны привести нас к более хорошему методу определения сайтов в Вебе.— Дейл Догэрти,
1996
Есть несколько вариантов определения слова «интернет». Один из них — это система компьютеров, соединенных через компьютерную сеть. Такая версия интернета появилась в 1969 году с созданием ARPANET. Почта, файлы и чат работали в этой сети еще до создания HTTP, HTML и веб-браузера.
В 1992 году Тим Бернерс-Ли создал три штуки, благодаря которым родилось то, что мы считаем интернетом: протокол HTTP, HTML и URL. Его целью было воплотить понятие гипертекста в реальности. Гипертекст, в двух словах — это возможность создавать документы, которые ссылаются друг на друга. В те годы идея гипертекста считалась панацеей из научной фантастики, заодно с гипермедиа, и любыми другими словами с приставкой «гипер».
Ключевым требованием гипертекста была возможность ссылаться из одного документа на другой. В то время для хранения документов использовалась куча форматов, а доступ осуществлялся по протоколу вроде Gopher или FTP. Тиму нужен был надежный способ ссылаться на файл, так, чтобы в ссылке был закодирован протокол, хост в интернете и местонахождение на этом хосте. Этим способом стал URL, впервые официально задокументированный в RFC в 1994 году.
В начальной презентации World-Wide Web в марте 1992 Тим Бернерс-Ли описал его как «универсальный идентификатор документов» (Universal Document Identifier или UDI). Множество других форматов также рассматривались в качестве такого идентификатора:
protocol: aftp host: xxx.yyy.edu path: /pub/doc/README
PR=aftp; H=xx.yy.edu; PA=/pub/doc/README;
PR:aftp/xx.yy.edu/pub/doc/README
/aftp/xx.yy.edu/pub/doc/README)
Этот документ также объясняет, почему пробелы должны кодироваться в URL (%20):
В UDI избегают использование пробелов: пробелы — это запрещенные символы. Это сделано потому, что часто появляются лишние пробелы когда строки оборачиваются системами вроде mail, или из-за обычной необходимости выровнять ширину колонки, а так же из-за преобразования различных видов пробелов во время конвертации кодов символов и при передаче текста от приложения к приложению.
Важно понимать, что URL был просто сокращенным способом обратиться к комбинации схемы, домена, порта, учетных данных и пути, которые ранее нужно было определять из контекста для каждой из систем коммуникации.
scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
Эта позволило обращаться к разным системам из гипертекста, но сегодня, возможно, такая форма уже избыточна, так как практически все передается через HTTP. В 1996 браузеры уже добавляли http:// и www. за пользователей автоматически (что делает рекламу с этими кусками URL по-настоящему бессмысленной).
Я не считаю, что вопрос «могут ли люди понять значение URL» имеет смысл. Я просто думаю, что морально неприемлемо заставлять бабушку или дедушку вникать в то, что в конечном итоге является нормами файловой системы UNIX.— Исраэль дель Рио,
1996
Слэш, отделяющий путь в URL, знаком любому, кто использовал компьютер за последние пятьдесят лет. Сама иерархическая файловая система была представлена в системе MULTICS. Ее создатель в свою очередь ссылается на двухчасовую беседу с Альбертом Эйнштейном, которая состоялась в 1952 году.
В MULTICS использовался символ «больше» (>) для разделения компонентов файлового пути. Например:
>usr>bin>local>awk
Это совершенно логично, но, к сожалению, ребята из Unix решили использовать > для обозначения перенаправления, а для разделения пути взяли слэш (/).
Неправильно. Теперь я четко вижу, что мы не согласны друг с другом. Вы и я.…
Как человек, я хочу сохранить за собой право использовать разные критерии для разных целей. Я хочу иметь возможность давать имена самим работам, и конкретным переводам и конкретным версиям. Я хочу более богатого мира чем тот, что вы предлагаете. Я не хочу ограничивать себя вашей двухуровневой системой «документов» и «вариантов».
— Тим Бернерс-Ли,
1993
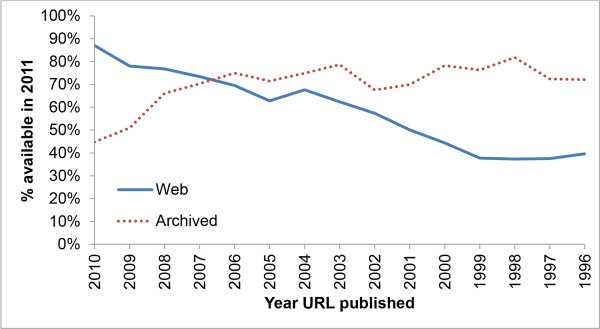
Половины URL-адресов, на которые ссылается Верховный Суд США, уже не существует. Если вы читаете академическую работу в 2011 году, и написана она была в 2001 году, то с большой вероятностью любой URL там будет нерабочим.
В 1993 году многие страстно верили, что URL отомрет, и на замену ему придет URN. Uniform Resource Name — это постоянная ссылка на любой фрагмент, который, в отличие от URL, никогда не изменится и не сломается. Тим Бернерс-Ли описал его как «срочную необходимость» еще в 1991.
Простейший способ создать URN — это использовать криптографический хэш содержания страницы, например:urn:791f0de3cfffc6ec7a0aacda2b147839. Однако, этот метод не удовлетворяет критериям веб-сообщества, так как невозможно выяснить, кто и как будет конвертировать этот хэш обратно в реальный контент. Такой способ также не учитывает изменений формата, которые часто происходят в файле (например, сжатие файла), которые не влияют на содержание.
В 1996 Киф Шэйфер и несколько других специалистов предложили решение проблемы поломанных URL. Ссылка на это решение сейчас не работает. Рой Филдинг опубликовал предложение реализации в июле 1995 года. Ссылка тоже поломана.
Я смог найти эти страницы через Google, который по сути сделал заголовки страниц современным аналогом URN. Формат URN был окончательно оформлен в 1997 году, и практически не использовался с тех пор. У него интересная реализация. Каждый URN состоит из двух частей: authority, который может преобразовать определенный тип URN, и конкретный идентификатор документа в понятном для authority формате. Например, urn:isbn:0131103628 будет обозначать книгу, формируя постоянную ссылку, которая (надеюсь) будет конвертирована в набор URL’ов вашим локальным преобразователем isbn .
Учитывая мощность поисковых движков, возможно, что лучшим на сегодня форматом URN могла бы стать простая возможность файлов ссылаться на свой прошлый URL. Мы можем позволить поисковым движкам индексировать эту информацию, и ссылаться на наши страницы корректно:
<!-- On http://zack.is/history -->
<link rel="past-url" href="http://zackbloom.com/history.html">
<link rel="past-url" href="http://zack.is/history.html">Формат application/x-www-form-urlencoded — это аномальный монстр во многих отношениях, результат многих лет случайностей реализаций и компромиссов, которые привели к необходимому для интероперабельности набору требований. Но это точно не образец хорошей архитектуры.— WhatWG URL Spec
Если вы использовали веб какое-то время, то вам знакомы параметры запросов. Они находятся после пути и нужны для кодирования параметров вроде ?name=zack&state=mi. Может показаться странным, что запросы используют символ амперсанда (&), который в HTML используется для кодирования специальных символов. Если вы писали на HTML, то скорее всего столкнулись с необходимостью кодировать амперсанды в URL, превращая http://host/?x=1&y=2 в http://host/?x=1&y=2 или http://host?x=1&y=2 (конкретно эта путаница существовала всегда).
Возможно, вы также замечали, что куки (cookies) используют похожий, но все же иной формат: x=1;y=2, и он никак не конфликтует с символами HTML. W3C не забыл про эту идею и рекомендовал всем поддерживать как ;, так и & в параметрах запросов еще в 1995 году.
Изначально эта часть URL использовалась исключительно для поиска индексов. Веб изначально был создан (и его финансирование было основано на этом) как метод совместной работы физиков, занимающихся элементарными частицами. Это не означает, что Тим Бернерс-Ли не знал, что он создает систему коммуникации с по-настоящему широким применением. Он не добавлял поддержку таблиц несколько лет, не смотря на то, что таблицы, наверное, пригодились бы физикам.
Так или иначе, физикам нужен был способ кодирования и связывания информации, и способ поиска этой информации. Для этого Тим Бернерс-Ли создал тег <ISINDEX>. Если <ISINDEX> присутствовал на странице, то браузер знал, что по этой странице можно делать поиск. Браузер показывал поисковую строку и позволял пользователю делать запрос на сервер.
Запрос представлял собой набор ключевых слов, отделенных друг от друга плюсами (+):
http://cernvm/FIND/?sgml+cmsКак это обычно случается в интернете, тег стали использовать для всего подряд, в том числе как поле ввода числа для вычисления квадратного корня. Вскоре предложили принять тот факт, что такое поле слишком специфично, и нужен тег общего характера <input>.
В том предложении использовался символ плюса для отделения компонентов запроса, но в остальном все напоминает современный GET-запрос:
http://somehost.somewhere/some/path?x=xxxx+y=yyyy+z=zzzzДалеко не все одобрили это. Некоторые считали, что нужен способ указать поддержку поиска по ту сторону ссылки:
<a HREF="wais://quake.think.com/INFO" INDEX=1>search</a>
Тим Бернерс-Ли думал, что нужен способ определения строго типизированных запросов:
<ISINDEX TYPE="iana:/www/classes/query/personalinfo">
Изучая прошлое, готов с определенной долей уверенности сказать: я рад, что победило более общее решение.
Работа над тегом <INPUT> началась в январе 1993 года, она основывалась на более старом типе SGML. Было решено (пожалуй, к сожалению), что тегу <SELECT> нужна своя, более широкая структура:
<select name=FIELDNAME type=CHOICETYPE [value=VALUE] [help=HELPUDI]>
<choice>item 1
<choice>item 2
<choice>item 3
</select>Если вам любопытно, то да, была идея повторно использовать элемент <li> вместо создания нового <option>. Однако, были и другие предложения. В одном из них происходила замена переменных, что напоминает современный Angular:
<ENTRYBLANK TYPE=int LENGTH=length DEFAULT=default VAR=lval>
Prompt </ENTRYBLANK>
<QUESTION TYPE=float DEFAULT=default VAR=lval> Prompt </QUESTION>
<CHOICE DEFAULT=default VAR=lval>
<ALTERNATIVE VAL=value1> Prompt1
...
<ALTERNATIVE VAL=valuen> Promptn
</CHOICE>В этом примере проверяется тип input’ов на основе указания type, а значения VAR доступны на странице для замены строк в URL, примерно так:
http://eager.io/apps/$appIdДополнительные предложения использовали @ вместо = для разделения компонентов запроса:
name@value+name@(value&value)Марк Андриссен предложил метод, основанный на том, что он уже реализовал в Mosaic:
name=value&name=value&name=value
Всего два месяца спустя Mosaic добавил поддержку method=POST в формы, и так родились современные HTML-формы.
Конечно, компания Netscape Марка Андриссена создала еще и формат куки (с другим разделителем). Их предложение было болезненно недальновидным, оно привело к попытке создания заголовка Set-Cookie2, и создало фундаментальные структурные проблемы, с которыми нам все еще приходится иметь дело в продукте Eager.
Часть URL после символа ‘#’ известна как «фрагмент» (fragment). Фрагменты были частью URL со времен первой спецификации, они использовались для создания ссылки на конкретное место на загруженной странице. Например, если у меня есть якорь на сайте:
<a name="bio"></a>
Я могу сделать на него ссылку:
http://zack.is/#bio
Эта концепция постепенно была расширена до всех элементов (а не только якорей), и перешла на атрибут id вместо name:
<h2>Bio</h2>
Тим Бернерс-Ли решил использовать этот символ, основываясь на связи с форматом почтовых адресов в США (не смотря на то, что сам Тим — британец). По его словам:
Как минимум в США в почтовых адресах часто используют знак номера для указания номера квартиры или комнаты в здании. 12 Acacia Av #12 означает «Здание 12 на Акация Авеню, и в этом здании квартира 12». Этот символ казался естественным для такой цели. Сегодня http://www.example.com/foo#bar означает «На ресурсе http://www.example.com/foo конкретный вид, известный как bar”.
Оказывается, первичная система гипертекста, созданная Дугласом Энгельбартом, также использовала «#» для таких целей. Это может быть совпадением или случайным «заимствованием идеи».
Фрагменты специально не включаются в HTTP-запросы, то есть они живут исключительно в браузере. Такая концепция оказалась ценной, когда пришло время реализовывать клиентскую навигацию (до изобретения pushState). Фрагменты также были очень полезными, когда пришло время задуматься о сохранении состояния в URL без отправки на сервер. Что это значит? Давайте разберемся:
Кротовые холмики и горы
Есть целый стандарт, такой же мерзкий как SGML, созданный для передачи электронных данных, другими словами — для форм и отправки форм. Единственное, что мне известно: он выглядит как фортран задом наперед без пробелов.— Тим Бернерс-Ли,
1993
Есть ощущение, разделяемое многими, что организации, отвечающие за стандарты интернета ничего особо не делали с момента окончательного принятия HTTP 1.1. и HTML 4.01 в 2002 до тех пор, пока HTML 5 не стал по-настоящему популярным. Этот период также известен (только для меня) как Темный Век XHTML. В реальности люди, занимающиеся стандартами, были безумно заняты. Просто они занимались тем, что в итоге оказалось не слишком ценным.
Одним из направлений было создание Семантического Веба. Была мечта: создать Фреймворк Описания Ресурсов (Resource Description Framework). (прим. ред.: бегите от любой команды, которая хочет сделать фреймворк). Такой фреймворк позволял бы универсально описывать мета-информацию о содержании. Например, вместо того, чтобы делать красивую веб-страницу про мой Корвет Стингрэй, я бы сделал RDF-документ с описанием размеров, цвета и количества штрафов за превышение скорости, которые мне выписали за все время езды.
Это, конечно, совсем не плохая идея. Но формат был основан на XML, и это большая проблема курицы и яйца: нужно задокументировать весь мир, и нужны браузеры, которые умеют делать полезные штуки с этой документацией.
Но эта идея хотя бы родила условия для философских споров. Один из лучших подобных споров длился как минимум десять лет, он известен под искусным кодовым именем ‘httpRange-14’.
Целью httpRange-14 было ответить на фундаментальный вопрос «чем является URL?». Всегда ли URL ссылается на документ или он может ссылаться на все, что угодно? Может ли URL ссылаться на мою машину?
Они не пытались ответить на этот вопрос хоть сколько-нибудь удовлетворительно. Вместо этого они фокусировались на том, как и когда можно использовать редирект 303 чтобы сообщить пользователю, что по ссылке нет документа, и перенаправить его туда, где документ есть. И на том, когда можно использовать фрагменты (часть после ‘#’), чтобы направлять пользователей на связанные данные.
Прагматичному современному человеку эти вопросы могут показаться смешными. Многие из нас привыкли, что если URL получается использовать для чего-то, то значит его можно использовать для этого. И люди или будут использовать ваш продукт, или нет.
Но Семантический Веб заботился только о семантике.
Эта конкретная тема обсуждалась 1 июля 2002 года, 15 июля 2002 года, 22 июля 2002 года, 29 июля 2002 года, 16 сентября 2002 года, и как минимум еще 20 раз в течение 2005 года. Обсуждение закончилось благодаря тому самому ‘решению httpRange-14’ в 2005 году, и к нему вернулись снова из-за жалоб в 2007 и 2011, а запрос новых решений был открыт в 2012. Вопрос долго обсуждался группой pedantic web, у которой очень подходящее название. Единственное, чего так и не произошло — никакие из этих семантических данных так и не были добавлены в веб в какой-либо URL.
Авторизация
Как вы знаете, в URL можно включить логин и пароль:
http://zack:[email protected]
Браузер кодирует эти данные в формат Base64 и посылает в виде заголовка:
Authentication: Basic emFjazpzaGhoaGho
Base64 используется только для того, чтобы можно было передавать запрещенные в заголовках символы. Он никак не скрывает логин и пароль.
Это было проблемой, особенно до распространения SSL. Любой человек, который следит за вашим соединением, мог с легкостью увидеть пароль. Предлагали много альтернатив, в том числе Kerberos, который был и остается популярным протоколом безопасности.
Как и с другими примерами нашей истории, простую базовую авторизацию было проще всего реализовать разработчикам браузеров (Mosaic). Так базовая авторизация стала первым и единственным решением до тех пор, пока разработчики не получили инструменты для создания собственных систем аутентификации.
Веб-приложение
В мире веб-приложений странно представить, что основой веба является гиперссылка. Это метод соединения одного документа с другим, который со временем оброс стилями, возможностью запуска кода, сессиями, аутентификацией и в конечном итоге стал общей социальной компьютерной системой, которую пытались (безуспешно) создать так много исследователей 70-х годов.
Вывод такой же, как и у любого современного проекта или стартапа: только распространение имеет смысл. Если вы сделали что-то, что люди используют, даже если это некачественный продукт, то они помогут вам превратить его в то, чего хотят сами. И с другой стороны, конечно, если никто не пользуется продуктом, то его техническое совершенство не имеет значения. Существует бесчисленное количество инструментов, на которые ушли миллионы часов работы, но ими пользуется ровно ноль человек.
habr.com
Ссылки | WebReference
Ссылки являются основой гипертекстовых документов и позволяют переходить с одной веб-страницы на другую. Особенность ссылки состоит в том, что она может указывать не только на html-документ, но и на файл любого типа, причём этот файл может размешаться совсем на другом сайте. Главное, чтобы к файлу, на который делается ссылка, был доступ.
Создание ссылок
Для создания ссылки необходимо сообщить браузеру, какой текст или изображение является ссылкой, а также указать адрес документа, на который следует сделать ссылку. Оба действия выполняются с помощью элемента <a>, адрес задаётся с помощью атрибута href (пример 1). Поскольку в качестве адреса ссылки может использоваться документ любого типа, то результат перехода по ссылке зависит от конечного файла. Так, архивы (файлы с расширениями zip) будут сохраняться на локальный диск, сайты открываться в браузере.
Пример 1. Создание ссылки
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Ссылки</title>
</head>
<body>
<p><a href="link.html">Ссылка на страницу link.html</a></p>
<p><a href="file.zip">Ссылка на файл file.zip</a></p>
<p><a href="http://webref.ru">Ссылка на сайт webref.ru</а></p>
</body>
</html>В качестве значения атрибута href используется адрес документа (URL, Universal Resource Locator, универсальный указатель ресурсов), на который происходит переход. Адрес может быть абсолютным и относительным. К абсолютному адресу относится полный путь к документу, включая протокол и наименование сайта, например http://mysite.ru/about/. Эта форма обращения работает везде и всюду, независимо от имени сайта или веб-страницы, где прописана ссылка. Как правило, абсолютные адреса применяются для перехода на другой ресурс, а внутри текущего сайта применяются относительные ссылки. Подобные ссылки, как следует из их названия, построены относительно текущего документа или корня сайта. Когда путь ведётся от корня сайта, в начале пути добавляют слэш (/), например /source/adm.html. В этом случае сервер понимает, что ему следует загрузить документ по адресу http://mysite.ru/source/adm.html. Учтите, что ссылки относительно корня сайта не работают на локальном компьютере, а только под управлением веб-сервера. Вот некоторые примеры адресов.
//mysite.ru
Обращение к сайту без указания протокола.
/
/demo/
Эти две ссылки называются неполными и указывают веб-серверу загружать файл index.html (или index.php), который находится в корне сайта или папке demo. Если файл index.html отсутствует, браузер, как правило, показывает список файлов или блокирует доступ к сайту из соображений безопасности.
/images/pic.html
Слэш перед адресом говорит о том, что адресация начинается от корня сайта. Ссылка ведёт на документ pic.html, который находится в папке images. А она, в свою очередь, размещена в корне сайта.
../help/me.html
Две точки перед именем указывают браузеру перейти на уровень выше в списке папок сайта.
manual/info.html
Если перед именем папки нет никаких дополнительных символов, вроде двух точек, то она размещена внутри текущей папки.
Открытие ссылки в новом окне
По умолчанию новый документ загружается в текущее окно браузера, однако это свойство можно изменить с помощью атрибута target. В качестве значения используется зарезервированное слово _blank, тогда страница откроется в новом окне браузера (пример 2). Открывать в новой вкладке или новом окне — задавать через HTML мы не можем, это определяется настройками браузера и пользователя.
Пример 2. Создание различных ссылок
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Ссылки</title>
</head>
<body>
<p><a href="1.html">Ссылка откроется в текущем окне</a></p>
<p><a href="2.html" target="_blank">Ссылка откроется в новом окне</а></p>
</body>
</html>Загрузка файлов
Что делать с тем или иным типом документа определяет веб-сервер. Как правило, если ссылка ведёт на файл в понятном браузеру формате, то он будет открыт. html-документ, изображения в JPEG, PNG, обычные текстовые документы, видео и аудио-файлы — всё это современным браузерам знакомо и они вполне могут это показать. Что касается архивов и других форматов, которые браузеры пока не распознают, то при щелчке по ссылке браузер предложит сохранить файл на локальный диск.
В некоторых случаях требуется не открыть файл, как, например, рисунок, а сохранить его. Для этого просто добавьте атрибут download к элементу <a>, как показано в примере 3.
Пример 3. Использование download
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>download</title>
</head>
<body>
<p><a href="images/xxx.jpg">Открыть файл в браузере</a></p>
<p><a href="images/xxx.jpg" download>Скачать файл</a></p>
</body>
</html>В данном примере первая ссылка откроется в браузере, а вторая сохранит файл. Браузер Internet Explorer не поддерживает атрибут download, поэтому в нём поведение для двух ссылок будет одинаковым.
Автор и редакторы
Автор: Влад Мержевич
Последнее изменение: 11.11.2015
Редакторы: Влад Мержевич
webref.ru