Лексический синтаксис — JavaScript | MDN
Этот раздел описывает синтаксис JavaScript. Исходный код ECMAScript скриптов сканируется слева направо и преобразуется в последовательность найденных элементов в токены, управляющие символы, окончания строк, комментарии или пробелы.
ECMAScript также определяет ключевые слова и литералы и имеет указания для автоматической вставки точек с запятой к концу инструкции.
Спецсимволы не имеют визуального представления, однако используются для управления интерпретацией текста.
| Code point | Name | Abbreviation | Description |
|---|---|---|---|
U+200C | Zero width non-joiner | <ZWNJ> | Размещается между символами во избежание их соединений в лигатуры для некоторых языков (Wikipedia) |
U+200D | Zero width joiner | <ZWJ> | Размещается между символами, которые не могли бы нормально объединиться для того, чтобы символы отрисовывались, используя их соединительную форму в некоторых языках (Wikipedia) |
U+FEFF | Byte order mark | <BOM> | Используется вначале скрипта для того, чтобы пометить Юникод и порядок байтов (Wikipedia) |
Пробельные символы улучшают читабельность исходного текста и разделяет токены друг от друга.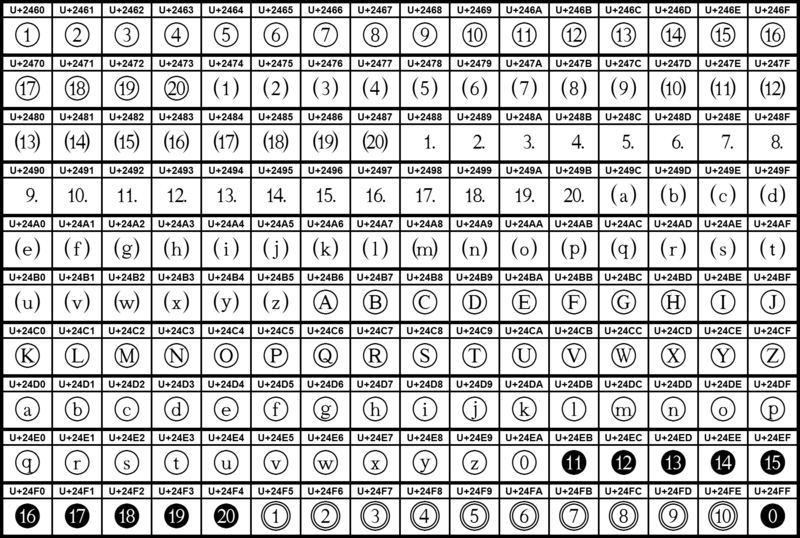 Пробельные символы обычно не обязательны для функционирования кода. Утилиты для уменьшения объёма кода часто удаляют пробельные символы, чтобы уменьшить объем кода.
Пробельные символы обычно не обязательны для функционирования кода. Утилиты для уменьшения объёма кода часто удаляют пробельные символы, чтобы уменьшить объем кода.
| Code point | Name | Abbreviation | Description | Escape sequence |
|---|---|---|---|---|
| U+0009 | Character tabulation | <HT> | Горизонтальная табуляция | \t |
| U+000B | Line tabulation | <VT> | Вертикальная табуляция | \v |
| U+000C | Form feed | <FF> | Символ контроля разрыва страницы (Wikipedia) | \f |
| U+0020 | Space | <SP> | Обычный пробел | |
| U+00A0 | No-break space | <NBSP> | Обычный пробел без точки, на которой может произойти разрыв страницы | |
| Others | Other Unicode space characters | <USP> | Другие символы в Юникоде на Википедии |
В дополнение к пробельным символам, символы окончания строк тоже используются для читабельности исходного кода. Однако, в некоторых случаях, символы окончания строк могут влиять на выполнение JavaScript-кода, т.к. есть некоторые места, где они запрещены.
Однако, в некоторых случаях, символы окончания строк могут влиять на выполнение JavaScript-кода, т.к. есть некоторые места, где они запрещены.
Окончания строк также затрагивают процесс автоматического проставления точки с запятой. Также окончания строк попадают под условия регулярных выражений при поиске \s класса.
В ECMAScript, в качестве окончания строк можно использовать только ниже перечисленные Юникод символы. Другие символы окончания строк будут интерпретированы, как пробельные символы (например, Next Line, NEL, U+0085 будут интерпретироваться, как пробельные символы).
| Code point | Name | Abbreviation | Description | Escape sequence |
|---|---|---|---|---|
| U+000A | Line Feed | <LF> | Новая строка в UNIX системах. | \n |
| U+000D | Carriage Return | <CR> | Новая строка в Commodore и ранних Mac systems. | \r |
| U+2028 | Line Separator | <LS> | Wikipedia | |
| U+2029 | Paragraph Separator | <PS> | Wikipedia |
Комментарии используются для добавления подсказок, заметок, предложений или предупреждений. Они могут упростить чтение и понимание кода. Также они могут быть использованы для предотвращения выполнения кода (этот приём практикуется при отладке кода).
В JavaScript есть несколько способов указать комментарии в коде.
Первый способ // комментарий; в этом случае весь текст в строке после двойного слеша будет комментарием, например:
function comment() {
console.log("Hello world!");
}
comment();
Второй способ — это /* */, такой способ более гибок, чем первый.
Например, вы можете использовать его в одной строке:
function comment() { console.log("Hello world!"); } comment();
 log("Hello world!");
}
comment();
log("Hello world!");
}
comment();Либо вы можете сделать многострочный комментарий, как показано здесь:
function comment() {
console.log("Hello world!");
}
comment(); Также, если пожелаете, то вы можете использовать такое комментирование посреди строки кода. Хотя это может ухудшить читабельность кода:
function comment(x) {
console.log("Hello " + x + " !");
}
comment("world");Чтобы отключить выполнение кода, просто оберните код в комментарий, как здесь:
function comment() {
}
comment();В этом случае console.log() никогда не выполнится, пока он внутри комментария. Таким способом можно отключить любое количество строк кода.
Третий специализированный синтаксис комментариев, шебанг комментарий, в процессе стандартизации в ECMAScript (смотреть Hashbang Grammar proposal).
Шебанг комментарий ведёт себя точно также как и однострочный (//) комментарий. Вместо этого, он начинается с
Вместо этого, он начинается с #! и действителен только в самом начале скрипта или модуля. Обратите внимание, что никакие пробелы не разрешены перед #!. Комментарий состоит из всех символов после #! до конца первой строки; только такой комментарий разрешён.
Шебанг комментарий определяет путь к JavaScript интерпретатору, скрипт которого вы хотите выполнить. Пример, как это работает:
console.log("Hello world");
Note: Hashbang comments in JavaScript mimic shebangs in Unix used to run files with proper interpreter.
Although BOM before hashbang comment will work in a browser it is not advised to use BOM in a script with hasbang. BOM will not work when you try to run the script in Unix/Linux. So use UTF-8 without BOM if you want to run scripts directly from shell.
Для определения JavaScript интерпретатора используйте только #! . В любых других случаях используйте 
Ключевые слова
Зарезервированные ключевые слова в ECMAScript 2015
Ключевые слова, зарезервированные на будущее
Следующие ключевые слова зарезервированы на будущее ECMAScript спецификацией. За ними сейчас не стоит никакой функциональности, но она может появиться в будущих версиях, поэтому эти ключевые слова не могут быть использованы, как идентификаторы. Эти ключевые слова не могут быть использованы даже в strict или non-strict режимах.
Следующие ключевые слова зарезервированы для кода, который выполняется в strict режиме:
implementspackageprotectedstaticinterfaceprivatepublic
Зарезервированные ключевые слова в более старых версиях
Перечисленные ниже ключевые слова зарезервированы для старых версий ECMAScript спецификаций (ECMAScript от 1 по 3).
abstractbooleanbytechardoublefinalfloatgotointlongnativeshortsynchronizedtransientvolatile
К тому же, литералы null, true, и false зарезервированы в ECMAScript для их обычной функциональности.
Использование зарезервированных слов
Зарезервированные слова действительно применяются только к идентификаторам (vs. IdentifierNames). Как описано в es5.github.com/#A.1, это все имена IdentifierNames, которые не исключают зарезервированных слов.
a.import
a["import"]
a = { import: "test" }.
С другой стороны, следующее выражение неправильно, т.к. Идентификатор IdentifierName не содержит зарезервированных слов. Идентификаторы используются для IdentifierNames используются для MemberExpression, CallExpression и т.п.
Литерал Null
Подробнее о nullnull
Литерал Boolean
Литералы чисел
Decimal (десятичные числа)
Имейте в виду, что литералы десятичных чисел могут начинаться с нуля (0), за которым следует другое десятичное число, но в случае, если число начинается с нуля и за ним идёт цифра меньше 8, то число будет распознано как восьмеричное. This won’t throw in JavaScript, see баг 957513. See also the page about
This won’t throw in JavaScript, see баг 957513. See also the page about parseInt()
Binary (двоичные числа)
Синтаксис двоичных чисел состоит из цифры ноль, за которой следует маленькая или большая латинская буква «B» (0b или 0B). Этот синтаксис новый и появился только в ECMAScript 2015, пожалуйста посмотрите таблицу совместимости с браузерами. Это может производить ошибку SyntaxError
var FLT_SIGNBIT = 0b10000000000000000000000000000000;
var FLT_EXPONENT = 0b01111111100000000000000000000000;
var FLT_MANTISSA = 0B00000000011111111111111111111111; Octal (восьмеричные числа)
Восьмеричный числовой синтаксис, который использует 0 с последующей, в нижнем или верхнем регистре, латинскую букву «О» (0o или 0O). Этот синтаксис появился в ECMAScript 2015, пожалуйста, посмотрите таблицу совместимости с браузерами. Это может производить ошибку
Это может производить ошибку SyntaxError: «Missing octal digits after 0o», если цифры не между 0 и 7.
var n = 0O755;
var m = 0o644;
0755
0644
Hexadecimal (шестнадцатеричные числа)
Шестнадцатеричный числовой синтаксис, который использует 0 с последующей, в нижнем или верхнем регистре, латинскую букву «X» (0x или 0X). Если числа после 0x вне диапазона (0123456789ABCDEF), то может последовать за этим SyntaxError: «Identifier starts immediately after numeric literal».
0xFFFFFFFFFFFFFFFFF
0x123456789ABCDEF
0XA
Литерал Object (Объект)
Смотрите также Object и Object initializer для получения более подробной информации.
var o = { a: "foo", b: "bar", c: 42 };
var a = "foo", b = "bar", c = 42;
var o = {a, b, c};
var o = { a: a, b: b, c: c };
Литерал Array (Массив)
Смотрите также Array для получения более подробной информации.
Литерал String (Строка)
Экранирование шестнадцатеричной последовательности
Экранирование Юникод символов
Для экранирования Юникод символов обязательно нужно указать по крайней мере 4 символа после \u.
Unicode code point escapes
Новое в ECMAScript 2015. With Unicode code point escapes, any character can be escaped using hexadecimal numbers so that it is possible to use Unicode code points up to 0x10FFFF. With simple Unicode escapes it is often necessary to write the surrogate halves separately to achieve the same.
See also String.fromCodePoint() or String.prototype.codePointAt().
'\u{2F804}'
'\uD87E\uDC04'Литерал Регулярного выражения
Смотрите также RegExp
Литерал Шаблона
Смотрите также template strings для получения более подробной информации.
`string text`
`string text line 1
string text line 2`
`string text ${expression} string text`
tag `string text ${expression} string text`Некоторые JavaScript условия должны быть завершены точкой с запятой и поэтому на них влияет автоматическая вставка точки с запятой (ASI):
- Пустое условие
let,const, переменныеimport,export, объявление модулей- Оператор-выражение
debuggercontinue,break,throwreturn
Спецификация ECMAScript напоминает о трёх правилах вставки точки с запятой.
1. Точка с запятой ставится до, когда ограничитель строки или «}» is encountered that is not allowed by the grammar.
2. Точка с запятой ставится в конце, когда обнаружен конец вводимой строки токенов и парсер is unable to parse the single input stream as a complete program.
Here ++ is not treated as a postfix operator (en-US) applying to variable b, because a line terminator occurs between b and ++.
3. Точка с запятой вставляется в конце, когда согласно инструкции с ограниченным производством в грамматике следует ограничитель строки. Эти утверждения с правилами «no LineTerminator here» здесь:
- PostfixExpressions (
++and--) continuebreakreturnyield,yield*module
return
a + b
return;
a + b;
BCD tables only load in the browser
- Prior to Firefox 5 (JavaScript 1. 8.6), future reserved keywords could be used when not in strict mode. This ECMAScript violation was fixed in Firefox 5.
 8.6), future reserved keywords could be used when not in strict mode. This ECMAScript violation was fixed in Firefox 5.
8.6), future reserved keywords could be used when not in strict mode. This ECMAScript violation was fixed in Firefox 5.Типографика — Принципы — Контур.Гайды
Интерфейсы во многом состоят из текста, и от того как набран этот текст, зависит общее восприятие дизайна и удобство работы с системой.
Разрядка
Текст ПРОПИСНЫМИ набирается вразрядку. Чем мельче текст, тем бо́льшая разрядка нужна. Большой объем текста набирать прописными нежелательно — читаемость хуже.
Текст строчными никогда не набирается вразрядку. Благодаря выносным элементам у строчных, человек узнает слово по форме. Большая разрядка наоборот превращает слово в набор отдельных букв, что сильно замедляет чтение.
Фредерик Гауди говорил: «Тот, кто набирает строчными вразрядку, способен красть овец».
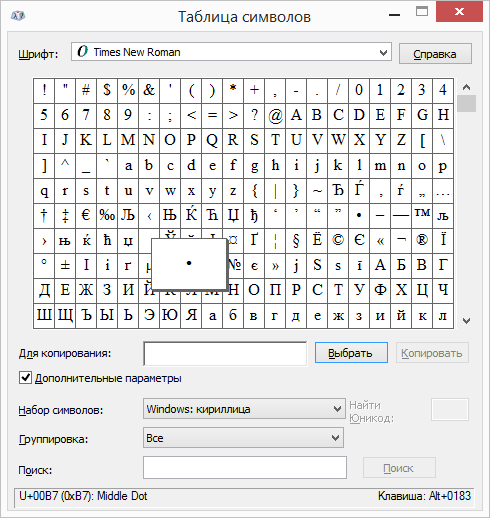
Тонкий пробел
Тонкий пробел или 1/8 круглой шпации используется для отделения порядков в числах, наборе инициалов и некоторых других случаях. В HTML тонкий пробел вставляется мнемонимом &thinsp. Чтобы вставить тонкий пробел в макет, включите в настройках Mac OS ввод юникод символов:
В HTML тонкий пробел вставляется мнемонимом &thinsp. Чтобы вставить тонкий пробел в макет, включите в настройках Mac OS ввод юникод символов:
Откройте System Preferences > Keyboard > Input Sources.
Нажмите кнопку + под списком источников ввода.
В самом низу списка выберите «Other», а в окне справа — «Unicode Hex Input» и добавьте его в список источников ввода.
Перед вводом юникод символов выберете источник ввода «Unicode Hex Input». Зажав клавишу Option наберите «2009» — с нажатием последней цифры введется тонкий пробел. Не забудьте написать отдельный комментарий для верстальщика, иначе тонкий пробел при переносе макета в верстку может превратится в обычный.
Когда тонкий пробел недоступен, нужно ставить обычный. За исключением знаков % и №, их в таком случае лучше набирать без отступов.
Знак рубля
Используйте знак рубля — ₽. За знаком рубля закреплен юникодовский символ U+20BD и он присутствует в актуальных версиях Lab Grotesque K и Helvetica Neue.
Телефонные номера
Телефонные номера вида (343) 123-45-67 Айфон понимает неправильно. Если открыть на Айфоне страницу с таким телефоном и тапнуть по номеру, то Айфон попытается набрать 343 123-45-67 — не догадается добавить в начало 8 или +7. Решить проблему можно: сверстать так, чтобы Айфон видел +7, а пользователь Айфона — не видел. Если хитрое решение по каким-то причинам невозможно, пишите бесхитростно: +7 343 123-45-67.
Исчерпывающее руководство по Юникоду и кодировке символов в Python
Работа с кодировкой символов на Python, да и на любом другом языке, временами выглядит довольно сложной. На Stack Overflow можно найти тысячи вопросов, посвящённых таким исключениям, как UnicodeDecodeError и UnicodeEncodeError. Данное руководство призвано прояснить сложные аспекты работы с этими исключениями и продемонстрировать, что работа с текстовыми и двоичными данными на Python 3 может быть приятной. В Python хорошо реализована поддержка Юникода, однако для работы с кодировкой всё же потребуется приложить усилия.
Вводная часть статьи даст общее понимание работы с Юникодом, не привязанное к какому-то определённому языку, однако практические примеры будут приведены именно на Python, а их описание будет довольно лаконичным.
Изучив эту статью, вы:
- Освоите концепции кодировки символов и системы нумерации;
- Поймёте, как кодировка работает с объектами
strиbytes; - Узнаете, как в Python поддерживается система нумерации посредством различных форм литералов
int; - Познакомитесь со встроенными функциями языка, относящимися к кодировке и системе нумерации.
Система нумерации и кодировка символов настолько тесно связаны, что их придётся раскрыть в одном руководстве, в противном случае материал будет неполным.
Прим. Статья ориентирована на Python 3, а все примеры кода созданы с помощью оболочки CPython 3.7.2. Большая часть более ранних версий Python 3 также будут корректно обрабатывать код. Если вы всё ещё используете Python 2 и различия в обработке текста и бинарных данных между 2 и 3 версиями языка вас отпугивают, это руководство может помочь вам преодолеть барьер.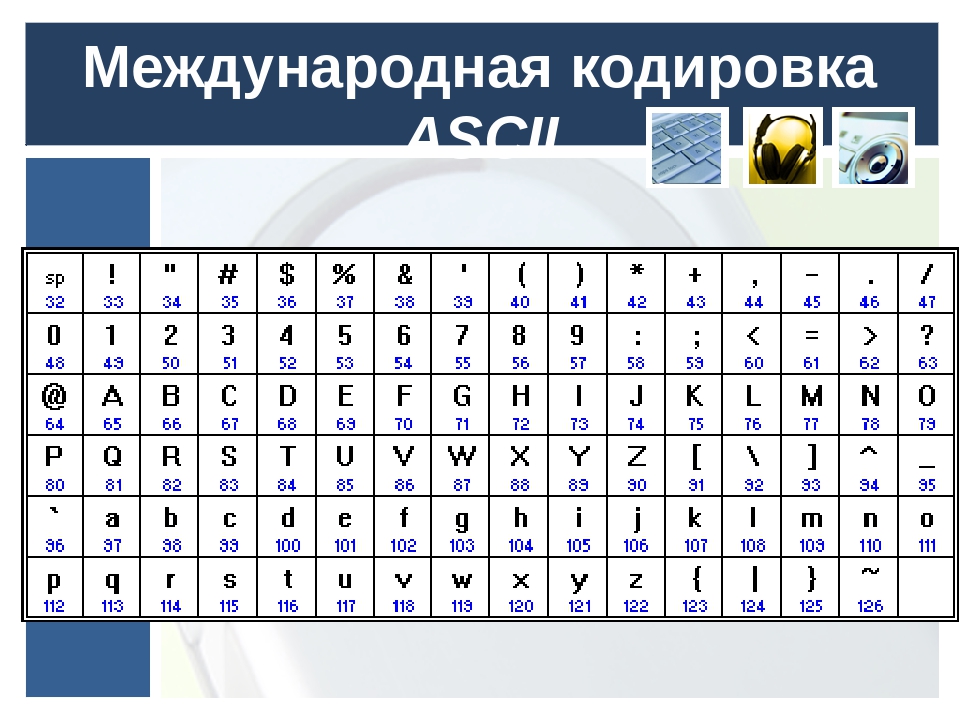
Что такое кодировка символов?
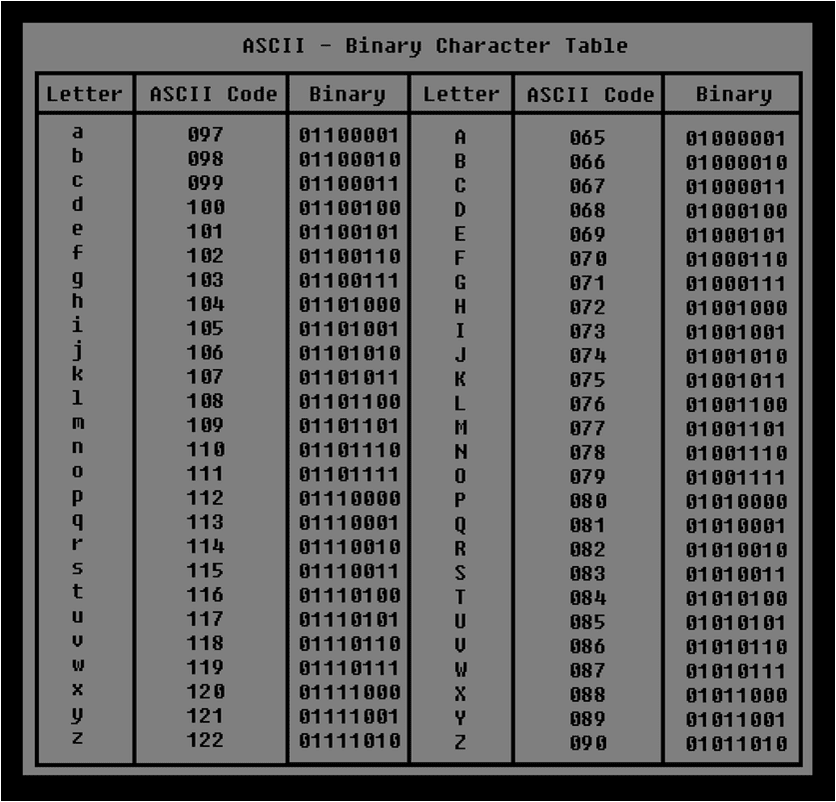
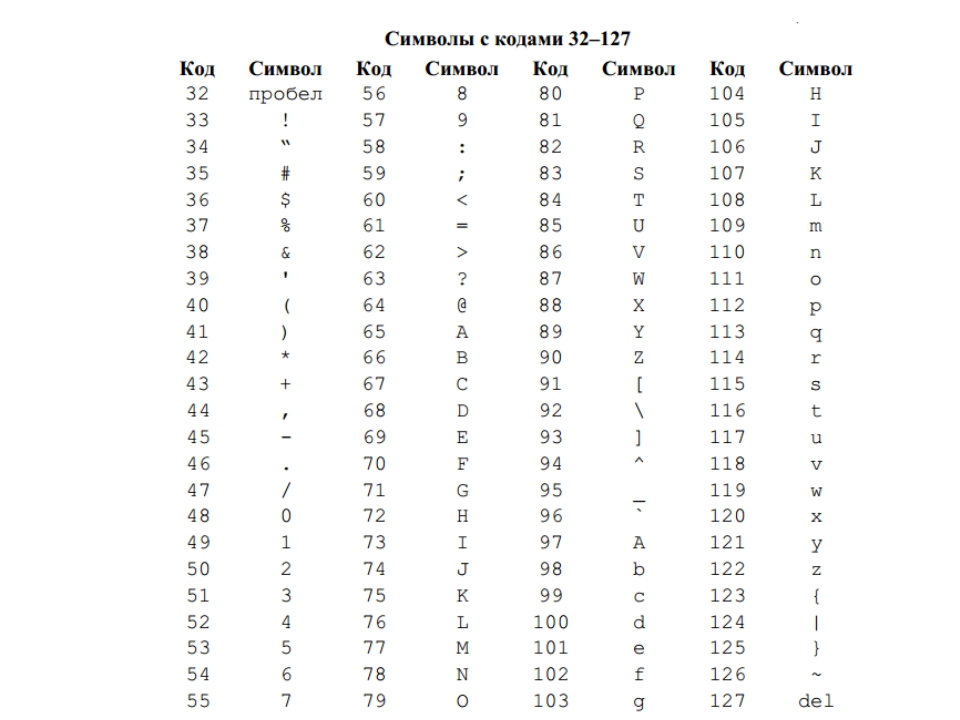
Существуют десятки, если не сотни, кодировок символов. Понять эту концепцию легче всего, разобрав одну из самых простых, ASCII.
Независимо от того, занимаетесь вы самообразованием или получили более формальное образование в сфере IT , наверняка пару раз вы уже видели таблицу ASCII. Эта таблица — хорошее начало для изучения принципов кодировки, так как она простая и маленькая (как вы увидите дальше, даже слишком маленькая).
Она охватывает следующее:
- Символы английского алфавита в нижнем регистре: от a до z;
- Символы английского алфавита в верхнем регистре: от A до Z;
- Некоторые знаки препинания и символы: например «$» или «!»;
- Символы, отображаемые как пустое место: пробел (« »), символ новой строки, возврата каретки, горизонтальной и вертикальной табуляции и несколько других;
- Некоторые непечатаемые символы: такие как бекспейс, «\b», которые просто невозможно отобразить, так, как к примеру, букву А.

Приведём формальное определение кодировки символов.
На самом высоком уровне — это способ перевода символов (таких как буквы, знаки пунктуации, служебные знаки, пробелы и контрольные символы) в целые числа и затем непосредственно в биты. Каждый символ может быть закодирован уникальным двоичным кодом. Если вы плохо знакомы с концепцией битов, не волнуйтесь, мы вскоре о ней поговорим.
Группы символов выделяют в отдельные категории. Каждому символу соответствует кодовая точка, которую можно рассматривать просто как целое число. В таблице ASCII символы сегментированы следующим образом:
| Диапазон кодовых точек | Класс |
|---|---|
| от 0 до 31 | Контрольные и неотображаемые символы |
| от 32 до 64 | Знаки пунктуации, символы, числа и пробел |
| от 65 до 90 | Буквы английского алфавита в верхнем регистре |
| от 91 до 96 | Дополнительные графемы, такие как [ и \ |
| от 97 до 122 | Буквы английского алфавита в нижнем регистре |
| от 123 до 126 | Дополнительные графемы, такие как { и | |
| 127 | Контрольный неотображаемый символ (DEL) |
Всего кодировка ASCII содержит 128 символов. В таблице ниже вы видите исчерпывающий набор знаков, которые позволяет отобразить эта кодировка. Если вы не видите какого-то символа, значит вы просто не сможете его вывести с помощью ASCII.
В таблице ниже вы видите исчерпывающий набор знаков, которые позволяет отобразить эта кодировка. Если вы не видите какого-то символа, значит вы просто не сможете его вывести с помощью ASCII.
| Кодовая точка | Символ (имя) | Кодовая точка | Символ (имя) |
|---|---|---|---|
| 0 | NUL (Null) | 64 | @ |
| 1 | SOH (Start of Heading) | 65 | A |
| 2 | STX (Start of Text) | 66 | B |
| 3 | ETX (End of Text) | 67 | C |
| 4 | EOT (End of Transmission) | 68 | D |
| 5 | ENQ (Enquiry) | 69 | E |
| 6 | ACK (Acknowledgment) | 70 | F |
| 7 | BEL (Bell) | 71 | G |
| 8 | BS (Backspace) | 72 | H |
| 9 | HT (Horizontal Tab) | 73 | I |
| 10 | LF (Line Feed) | 74 | J |
| 11 | VT (Vertical Tab) | 75 | K |
| 12 | FF (Form Feed) | 76 | L |
| 13 | CR (Carriage Return) | 77 | M |
| 14 | SO (Shift Out) | 78 | N |
| 15 | SI (Shift In) | 79 | O |
| 16 | DLE (Data Link Escape) | 80 | P |
| 17 | DC1 (Device Control 1) | 81 | Q |
| 18 | DC2 (Device Control 2) | 82 | R |
| 19 | DC3 (Device Control 3) | 83 | S |
| 20 | DC4 (Device Control 4) | 84 | T |
| 21 | NAK (Negative Acknowledgment) | 85 | U |
| 22 | SYN (Synchronous Idle) | 86 | V |
| 23 | ETB (End of Transmission Block) | 87 | W |
| 24 | CAN (Cancel) | 88 | X |
| 25 | EM (End of Medium) | 89 | Y |
| 26 | SUB (Substitute) | 90 | Z |
| 27 | ESC (Escape) | 91 | [ |
| 28 | FS (File Separator) | 92 | \ |
| 29 | GS (Group Separator) | 93 | ] |
| 30 | RS (Record Separator) | 94 | ^ |
| 31 | US (Unit Separator) | 95 | _ |
| 32 | SP (Space) | 96 | ` |
| 33 | ! | 97 | a |
| 34 | " | 98 | b |
| 35 | # | 99 | c |
| 36 | $ | 100 | d |
| 37 | % | 101 | e |
| 38 | & | 102 | f |
| 39 | ' | 103 | g |
| 40 | ( | 104 | h |
| 41 | ) | 105 | i |
| 42 | * | 106 | j |
| 43 | + | 107 | k |
| 44 | , | 108 | l |
| 45 | - | 109 | m |
| 46 | . | 110 | n |
| 47 | / | 111 | o |
| 48 | 0 | 112 | p |
| 49 | 1 | 113 | q |
| 50 | 2 | 114 | r |
| 51 | 3 | 115 | s |
| 52 | 4 | 116 | t |
| 53 | 5 | 117 | u |
| 54 | 6 | 118 | v |
| 55 | 7 | 119 | w |
| 56 | 8 | 120 | x |
| 57 | 9 | 121 | y |
| 58 | : | 122 | z |
| 59 | ; | 123 | { |
| 60 | < | 124 | | |
| 61 | = | 125 | } |
| 62 | > | 126 | ~ |
| 63 | ? | 127 | DEL (delete) |
Модуль string
Модуль string — простой и удобный инструмент, разграничивающий содержащиеся в ASCII символы по группам, разделяя их в строки-константы. _`{|}~»»»
printable = digits + ascii_letters + punctuation + whitespace
_`{|}~»»»
printable = digits + ascii_letters + punctuation + whitespace
Большинство этих констант исчерпывающе описаны их идентификаторами. Мы вкратце коснёмся констант hexdigits и octdigits.
Мы можем использовать определённые в модуле константы для рутинных операций:
>>> import string
>>> s = "What's wrong with ASCII?!?!?"
>>> s.rstrip(string.punctuation)
'What's wrong with ASCII'Прим. Обратите внимание, string.printable включает string.whitespace. Это несколько не соответствует тому, как печатаемые символы определяет метод str.isprintable(), который не рассматривает ни один из символов {'\v', '\n', '\r', '\f', '\t'} как печатаемый.
Это различие происходит из определения метода: str.isprintable() рассматривает что-либо печатаемым, если «все символы рассматриваются как печатаемые методом repr().
Что такое биты
Настало время вспомнить, что такое бит, базовая единица информации, которой оперируют вычислительные устройства.
Бит — это сигнал, который имеет два возможных состояния. Есть различные способы символического отображения этих состояний:
- 0 или 1;
- «да» или «нет»;
TrueилиFalse;- «включено» или «выключено».
Таблица ASCII из предыдущего раздела использует то, что обычно назвали бы числами (от 0 до 127), однако для наших целей важно понимать, что это десятичные числа (с основанием 10).
Каждое из этих десятичных чисел можно выразить последовательностью бит (числом с основанием 2). Вот таблица соотношения двоичных и десятичных чисел:
| Десятичное | Двоичное (кратко) | Двоичное (в байте) |
|---|---|---|
| 0 | 0 | 00000000 |
| 1 | 1 | 00000001 |
| 2 | 10 | 00000010 |
| 3 | 11 | 00000011 |
| 4 | 100 | 00000100 |
| 5 | 101 | 00000101 |
| 6 | 110 | 00000110 |
| 7 | 111 | 00000111 |
| 8 | 1000 | 00001000 |
| 9 | 1001 | 00001001 |
| 10 | 1010 | 00001010 |
Обратите внимание, что при увеличении десятичного числа n для его отображения (а следовательно и для отображения символа, относящегося к этому числу) требуется всё больше значимых бит.
Вот удобный метод представить строки ASCII как последовательность бит. Каждый символ из строки ASCII переводится в последовательность из 8 нолей и единиц с пробелами между этими последовательностями:
>>> def make_bitseq(s: str) -> str:
... if not s.isascii():
... raise ValueError("ASCII only allowed")
... return " ".join(f"{ord(i):08b}" for i in s)
>>> make_bitseq("bits")
'01100010 01101001 01110100 01110011'
>>> make_bitseq("CAPS")
'01000011 01000001 01010000 01010011'
>>> make_bitseq("$25.43")
'00100100 00110010 00110101 00101110 00110100 00110011'
>>> make_bitseq("~5")
'01111110 00110101'Прим. Обратите внимание, что метод .isascii() появился в Python 3.7.
Строковой литерал f-string f"{ord(i):08b}" использует мини-язык форматирования Format Specification Mini-Language, а именно его возможность замещения полей при форматировании строк.
- левая часть выражения,
ord(i), представляет объект, значение которого будет отформатировано и отображено при выводе.ord()возвращает кодовую точку одиночного символаstrв десятичном выражении; - Правая сторона выражения определяет форматирование объекта.
08означает ширина 8, заполнение нулями, аbработает как команда вывести число в двоичном (binary) эквиваленте.
На самом деле этот метод можно использовать разве что для развлечения. Он выдаст ошибку для любого символа, не представленного в ASCII-таблице. Позже мы рассмотрим, как эта проблема решается в других кодировках.
Нам нужно больше бит
Исходя из определения бита, можно вывести следующую закономерность: при определённом количестве бит n с их помощью можно выразить 2n разных значений.
def n_possible_values(nbits: int) -> int:
return 2 ** nbitsВот что это означает:
- 1 бит позволяет выразить 21 == 2 возможных значения;
- 8 бит позволяют выразить 28 == 256 возможных значений;
- 64 бита позволяют выразить 264 == 18 446 744 073 709 551 616 возможных значений.

В качестве естественного вывода из приведённой выше формулы мы можем установить следующее: для того, чтобы вычислить количество бит, необходимых для выражения определённого числа разных значений, нам нужно найти n в уравнении 2n=x, где переменная x известна.
Вот как можно это рассчитать:
>>> from math import ceil, log
>>> def n_bits_required(nvalues: int) -> int:
... return ceil(log(nvalues) / log(2))
>>> n_bits_required(256)
8Округление вверх в методе n_bits_required() требуется для расчёта значений, которые не являются чистой степенью двойки. К примеру, вам нужно сохранить набор из 110 различных символов. Для этого потребуется log(110) / log(2) == 6.781 бит, но поскольку бит для вычислительной техники является мельчайшей неделимой величиной, для отображения 110 различных значений нам понадобится 7 бит, при этом несколько значений останутся невостребованными.
>>> n_bits_required(110)
7Всё сказанное служит для обоснования одной идеи: ASCII, строго говоря, семибитная кодировка. Эта таблица содержит 128 кодовых точек, и, соответственно, символов, от 0 до 127 включительно. Это требует 7 бит:
>>> n_bits_required(128) # от 0 до 127
7
>>> n_possible_values(7)
128Проблема заключается в том, что современные компьютеры не используют для хранения чего-либо семибитные последовательности. Основной единицей хранения информации современных вычислительных устройств являются восьмибитные последовательности, байты.
Прим. В этой статье под байтом подразумевается группа из 8 бит, как повелось с 60-х годов прошлого века. Если вам не по душе это новомодное название, можете называть их октетами.
То, что ASCII-таблица использует 7 бит из доступных 8, означает, что память вычислительного устройства, занятого строками символов ASCII, наполовину пуста. Для того, чтобы лучше понять, почему это происходит, вернитесь к приведённой выше таблице соответствия двоичных и десятичных чисел. Вы можете выразить числа 0 и 1 с помощью 1 бита, или вы можете использовать 8 бит, чтобы выразить их как 00000000 и 00000001 соответственно.
Для того, чтобы лучше понять, почему это происходит, вернитесь к приведённой выше таблице соответствия двоичных и десятичных чисел. Вы можете выразить числа 0 и 1 с помощью 1 бита, или вы можете использовать 8 бит, чтобы выразить их как 00000000 и 00000001 соответственно.
Прим. перев. Если быть точным, то пустой остаётся только одна восьмая часть памяти. Однако с помощью именно этого незадействованного бита можно было бы создать вдвое больше кодовых точек.
Вы можете выразить числа от 0 до 3 всего двумя битами, от 00 до 11, или использовать 8 бит, чтобы выразить их как 00000000, 00000001, 00000010 и 00000011. Самая большая кодовая точка ASCII, 127, требует только 7 значимых бит.
С учётом этого взгляните, как метод make_bitseq() преобразует строки ASCII в строки, состоящие из байт, где каждый символ требует один байт:
>>> make_bitseq("bits")
'01100010 01101001 01110100 01110011'Неэффективное использование восьмибитной структуры памяти современных вычислительных устройств привело к появлению неструктурированного семейства конфликтующих кодировок, задействующих оставшуюся незанятой половину кодовых точек, доступных в одном байте.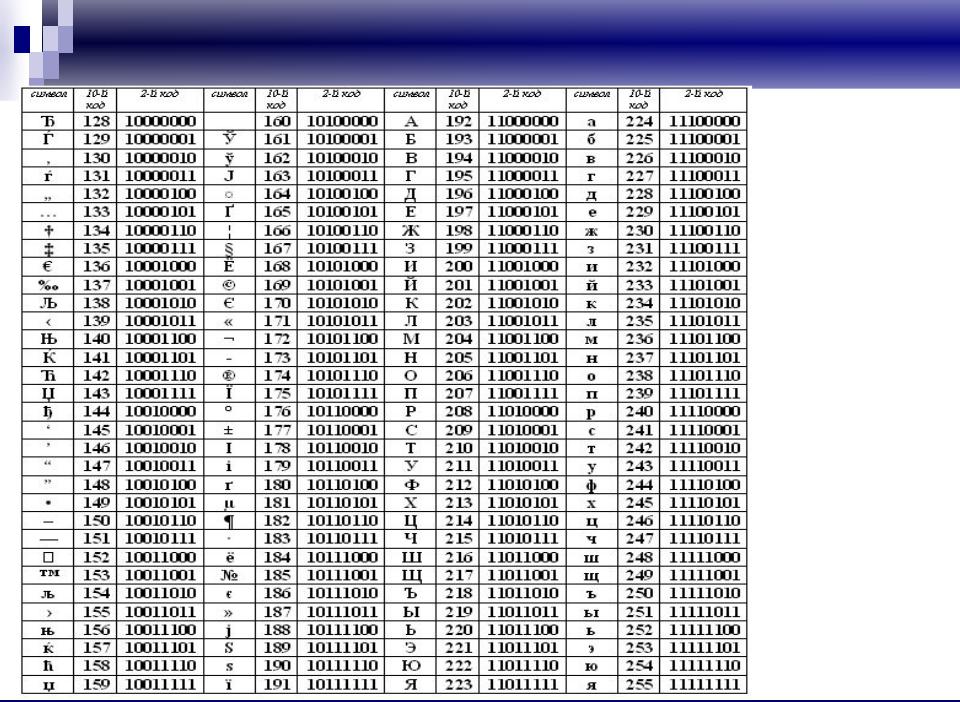
Несмотря на попытку задействовать дополнительный бит, эти конфликтующие кодировки не могли отобразить все возможные символы, используемые человечеством в письменности.
Со временем появилась одна большая схема кодировки, которая объединила их. Однако, прежде чем мы до этого доберёмся, поговорим немного о краеугольных камнях схем кодировки символов — системах счисления.
Изучаем основы: другие системы счисления
В ASCII-таблице, как мы увидели, каждый символ соответствует числу от 0 до 127.
Этот диапазон чисел выражен в десятичной системе счисления. Именно эту систему используют для счёта люди, просто потому что на руках у нас по 10 пальцев.
Однако существуют и другие системы счисления, которые, в частности, широко используются в исходном коде CPython. Следует понимать, что действительное число не изменяется, а системы счисления просто по-разному его выражают.
Вопрос, какое число записано в строке "11" покажется странным, ведь для большинства очевидно, что это одиннадцать.
Однако в строке может быть представлено и другое число, в зависимости от системы счисления. Помимо десятичной, используются такие общепринятые альтернативы:
- Двоичная: с основой 2;
- Восьмеричная: с основой 8;
- Шестнадцатеричная (hex): с основой 16.
Что же мы подразумеваем, говоря что определённая система счисления имеет основу N?
Один из способов объяснения разных систем счисления заключается в том, чтобы представить, что у вас N пальцев.
Если же вам требуется более подробное объяснение систем счисления, обратитесь к книге Чарльза Петцольда «Код». В этой книге детально объясняются основы работы вычислительной техники.
Конструктор int() — один из способов показать, как разные системы счисления преобразуют одну и ту же строку с помощью Python. Если вы передадите str в int(), Python по умолчанию будет считать, что строка содержит число в десятичной системе.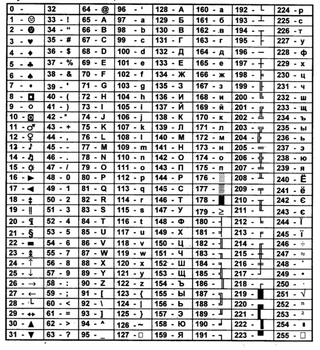 Однако вы можете дать другие указания:
Однако вы можете дать другие указания:
>>> int('11')
11
>>> int('11', base=10) # 10 установлено по умолчанию
11
>>> int('11', base=2) # Двоичная
3
>>> int('11', base=8) # Восьмеричная
9
>>> int('11', base=16) # Шестнадцатеричная
17Чаще в Python для обозначения того, что целое число представлено в системе счисления, отличной от десятичной, используют префиксы-литералы. Для каждой из трёх альтернативных систем существует свой литерал.
| Тип литерала | Префикс | Пример |
|---|---|---|
| Нет | Нет | 11 |
| Binary literal | 0b или 0B | 0b11 |
| Octal literal | 0o или 0O | 0o11 |
| Hex literal | 0x или 0X | 0x11 |
Всё это — разновидности целочисленных литералов. Результаты применения префиксов будут такими же, как и в случае использования
Результаты применения префиксов будут такими же, как и в случае использования int() с определением параметра base. Для Python всё это просто целые числа:
>>> 11
11
>>> 0b11 # Двоичный литерал
3
>>> 0o11 # Восьмеричный литерал
9
>>> 0x11 # Шестнадцатеричный литерал
17В таблице ниже отражено, как можно ввести десятичные числа от 0 до 20 в двоичном, восьмеричном и шестнадцатеричном эквиваленте. Любой из этих способов можно использовать как в оболочке интерпретатора Python, так и в исходном коде, и все эти числа будут рассматриваться как относящиеся к типу int.
| Десятичные | Двоичные | Восмеричные | Шестнадцатеричные |
|---|---|---|---|
0 | 0b0 | 0o0 | 0x0 |
1 | 0b1 | 0o1 | 0x1 |
2 | 0b10 | 0o2 | 0x2 |
3 | 0b11 | 0o3 | 0x3 |
4 | 0b100 | 0o4 | 0x4 |
5 | 0b101 | 0o5 | 0x5 |
6 | 0b110 | 0o6 | 0x6 |
7 | 0b111 | 0o7 | 0x7 |
8 | 0b1000 | 0o10 | 0x8 |
9 | 0b1001 | 0o11 | 0x9 |
10 | 0b1010 | 0o12 | 0xa |
11 | 0b1011 | 0o13 | 0xb |
12 | 0b1100 | 0o14 | 0xc |
13 | 0b1101 | 0o15 | 0xd |
14 | 0b1110 | 0o16 | 0xe |
15 | 0b1111 | 0o17 | 0xf |
16 | 0b10000 | 0o20 | 0x10 |
17 | 0b10001 | 0o21 | 0x11 |
18 | 0b10010 | 0o22 | 0x12 |
19 | 0b10011 | 0o23 | 0x13 |
20 | 0b10100 | 0o24 | 0x14 |
Кстати, вы можете сами убедиться, что подобные способы записи чисел очень часто используется в Стандартной Библиотеке Python. Найдите папку
Найдите папку lib/python3.7/ в своей системе, перейдите в неё и введите команду:
$ grep -nri --include "*\.py" -e "\b0x" lib/python3.7Команда сработает в любой Unix-системе с утилитой grep. С её помощью вы найдёте все шестнадцатеричные литералы. Для поиска двоичных используйте \b0b, а для восьмеричных — \b0o.
Для чего же нужны альтернативные литералы целых чисел? Если коротко, числа 2, 8 и 16, в отличие от 10, являются степенями двойки. Основанные на них системы счисления выражают численные значения способами, более удобными для обработки бинарными вычислительными устройствами. К примеру, 65536, или 216, в шестнадцатеричной системе просто 10000 или, используя литерал, 0x10000.
Введение в Юникод
Как видите, проблема ASCII в том, что этой таблицы недостаточно для отображения знаков, символов и глифов, использующихся во всех языках и диалектах мира. Её недостаточно даже для английского языка.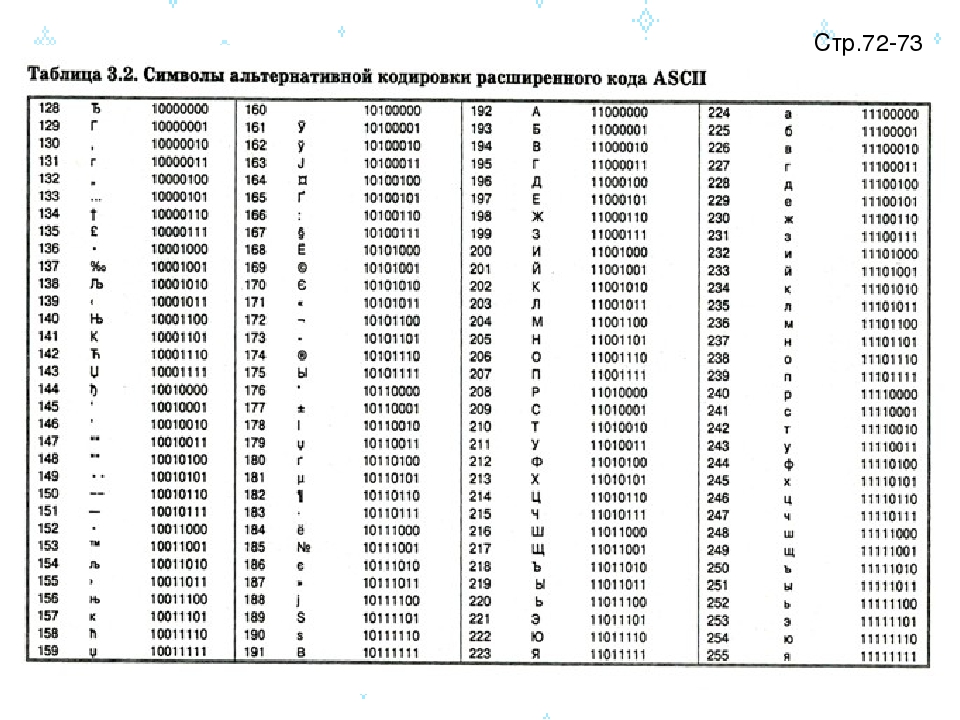
Юникод служит тем же целям, что и ASCII, но содержит намного больший набор кодовых точек. В период времени между появлением ASCII и принятием Юникода использовалось ещё несколько различных кодировок, но рассматривать их подробно нет смысла, так как Юникод и одна из его схем, UTF-8, в настоящее время стали использоваться практически повсеместно.
Вы можете представить Юникод как расширенную версию ASCII-таблицы — с 1 114 112 возможными кодовыми точками, от 0 до 1 114 111. Это 17*(216) или 0x10ffff в шестнадцатеричном представлении. Фактически, ASCII является частью Юникода, так как первые 128 символов этих кодировок полностью совпадают.
Чтобы соблюсти технические детали, сам по себе Юникод не является кодировкой. Он скорее реализуется в различных кодировках символов, как вы вскоре увидите. По структуре Юникод скорее ассоциативный массив (что-то вроде dict) или база данных, состоящая из таблицы с двумя колонками. В этой таблице разные символы (такие как "a", "¢", или даже "ቈ") соотносятся с различными целыми положительными числами. Кодировка же должна предоставлять несколько больше возможностей.
Кодировка же должна предоставлять несколько больше возможностей.
Юникод содержит практически любой символ, который только можно представить, включая дополнительные непечатаемые. Например, кодовая точка 8207 соответствует отметке RTL, которая используется для смены направления письма. Она полезна в текстах, где абзацы на одном из европейских языков соседствуют с абзацами на арабских языках.
Прим. Кстати, если уж мы хотим быть совсем точны в деталях, то надо отметить ещё один факт. Исторически сложилось, что в Юникоде доступны только 1 111 998 кодовых точек.
Юникод и UTF-8
Довольно скоро стало понятно, что все необходимые символы невозможно вместить в таблицу, используя только один байт. Современные, более ёмкие кодировки требовали использования больших объёмов.
Ранее мы упоминали, что Юникод сам по себе не является кодировкой. И вот почему.
Юникод не содержит указаний по извлечению из текста бит, он работает только с кодовыми точками. В нём нет стандарта конверсии текста в двоичные данные и обратно.
Юникод является абстрактным стандартом кодировки. Для практического его применения чаще всего используют схему UTF-8. Стандарт Юникод (таблица соответствий символов кодовыми точкам) определяет несколько различных кодировок на основе единого набора символов.
Как и менее распространённые UTF-16 и UTF-32, UTF-8 — формат кодировки для отображения символов Юникода в двоичном виде, используя один или несколько байт на один символ. UTF-16 и UTF-32 мы обсудим чуть позже, но пока нам интересен UTF-8 как самый популярный формат.
Сначала требуется разобрать термины «кодирование» и «декодирование».
Кодирование и декодирование в Python 3
Тип данных str в Python 3 рассчитан на представление текста в удобном для чтения формате и может содержать любые символы Юникода.
Тип bytes, напротив, представляет двоичные данные, последовательность байт, без указания на кодировку.
Кодирование и декодирование — это процесс перехода данных из одной формы в другую.
В методах .encode() и .decode() по умолчанию используется параметр "utf-8", однако для большей уверенности этот параметр можно определить самостоятельно:
>>> "résumé".encode("utf-8")
b'r\xc3\xa9sum\xc3\xa9'
>>> "El Niño".encode("utf-8")
b'El Ni\xc3\xb1o'
>>> b"r\xc3\xa9sum\xc3\xa9".decode("utf-8")
'résumé'
>>> b"El Ni\xc3\xb1o".decode("utf-8")
'El Niño'str.encode() возвращает объект типа bytes. И литералы этого типа объектов (такие как b"r\xc3\xa9sum\xc3\xa9"), и его отображение допускают только символы ASCII.
Вот почему при вызове "El Niño".encode("utf-8"), ASCII-совместимое "El" отображается как есть, а n с тильдой экранируется в "\xc3\xb1". Этой с виду неудобочитаемой последовательностью представлены два байта, 0xc3 и 0xb1 в шестнадцатеричной системе:
>>> " ". join(f"{i:08b}" for i in (0xc3, 0xb1))
'11000011 10110001' join(f"{i:08b}" for i in (0xc3, 0xb1))
'11000011 10110001'
join(f"{i:08b}" for i in (0xc3, 0xb1))
'11000011 10110001'Таким образом символ ñ требует два байта для бинарного представления с помощью UTF-8.
Прим. Если вы введёте help(str.encode), скорее всего, увидите параметр по умолчанию encoding='utf-8'. Однако имейте в виду, что настройки Windows для Python 3.6 могут отличаться, поэтому использовать методы кодирования и декодирования без указания необходимой кодировки (например "résumé".encode()) следует с осторожностью.
Python 3: всё на Юникоде
Python 3 полностью реализован на Юникоде, а точнее на UTF-8. Вот что это означает:
- По умолчанию предполагается, что исходный код Python 3 написан с помощью UTF-8. Это значит, что вам не нужно использовать определение
# -*- coding: UTF-8 -*-в начале файлов.pyв этой версии языка. - Все тексты (объекты формата
str) реализованы на Юникоде. Кодированный текст представлен двоичными данными (bytes). Тип strможет содержать любой символ-литерал из Юникода (например"Δv / Δt"), и все они хранятся в Юникоде. - Любой из символов Юникода приемлем в качестве идентификатора. Например, вы можете использовать выражение
résumé = "~/Documents/resume.pdf". - В модуле
reпо умолчанию установлен флагre.UNICODE, а неre.ASCII. Это означает, чтоr"\w"соответствует буквам из Юникода, а не просто символам ASCII. - По умолчанию
encodingвstr.encode()вbytes.decode()установлен в UTF-8.
 Тип
Тип Нужно отметить также нюанс, касающийся встроенного метода open(). Его параметр encoding зависит от платформы и определяется значением locale.getpreferredencoding():
>>> # Mac OS X High Sierra
>>> import locale
>>> locale.getpreferredencoding()
'UTF-8'
>>> # Windows Server 2012; другие сборки Windows могут использовать UTF-16
>>> import locale
>>> locale. getpreferredencoding()
'cp1252' getpreferredencoding()
'cp1252'
getpreferredencoding()
'cp1252'Мы делаем упор на эти моменты, чтобы вы вдруг не подумали, что кодировка UTF-8 является универсальной. Она действительно широко распространена, но вы вполне можете столкнуться и с другими вариантами. Не будет лишним предусмотреть это в коде.
Один байт, два байта, три байта, четыре…
Одна из важнейших особенностей UTF-8 состоит в том, что это кодировка с переменным размером.
Вспомните раздел, посвящённый ASCII. Любой символ в этой таблице требует максимум одного байта пространства. Это можно быстро проверить с помощью следующего генератора:
>>> all(len(chr(i).encode("ascii")) == 1 for i in range(128))
TrueС UTF-8 дела обстоят по-другому. Символы Юникода могут занимать от одного до четырёх байт. Вот пример четырёхбайтного символа:
>>> ibrow = "🤨"
>>> len(ibrow)
1
>>> ibrow.encode("utf-8")
b'\xf0\x9f\xa4\xa8'
>>> len(ibrow. encode("utf-8"))
4
>>> # Вызов list() с объектом типа bytes возвращает
>>> # значение каждого байта
>>> list(b'\xf0\x9f\xa4\xa8')
[240, 159, 164, 168]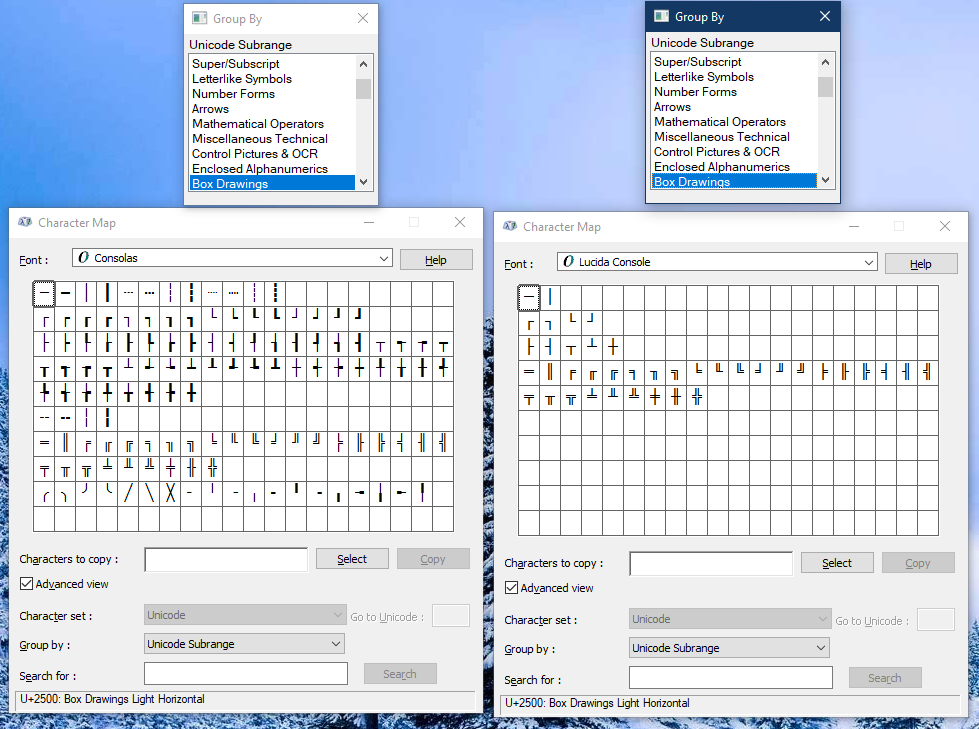 encode("utf-8"))
4
>>> # Вызов list() с объектом типа bytes возвращает
>>> # значение каждого байта
>>> list(b'\xf0\x9f\xa4\xa8')
[240, 159, 164, 168]
encode("utf-8"))
4
>>> # Вызов list() с объектом типа bytes возвращает
>>> # значение каждого байта
>>> list(b'\xf0\x9f\xa4\xa8')
[240, 159, 164, 168]Это небольшая, но важная особенность метода len():
- Размер единичного символа Юникода в объекте
strязыка Python всегда будет равен 1, вне зависимости от количества занимаемых байт. - Длина того же символа в объекте типа
bytesбудет варьироваться от 1 до 4.
Таблица ниже показывает, сколько байт занимают основные типы символов.
| Десятичный диапазон | Шестнадцатеричный диапазон | Включённые символы | Примеры |
|---|---|---|---|
| от 0 до 127 | от "\u0000" до "\u007F" | U.S. ASCII | "A", "\n", "7", "&" |
| от 128 до 2047 | от "\u0080" до "\u07FF" | Большая часть латинских алфавитов* | "ę", "±", "ƌ", "ñ" |
| от 2048 до 65535 | от "\u0800" до "\uFFFF" | Дополнительные части многоязыковых символов (BMP)** | "ത", "ᄇ", "ᮈ", "‰" |
| от 65536 до 1114111 | от "\U00010000" до "\U0010FFFF" | Другое*** | "𝕂", "𐀀", "😓", "🂲", |
*Такие как английский, арабский, греческий, ирландский.
**Масса языков и символов, в основном китайский, японский и корейский с разделением по томам (а также ASCII и латиница).
***Дополнительные символы китайского, японского, корейского и вьетнамского, а также другие символы и эмоджи.
Прим. У UTF-8 есть и другие технические особенности. Те, кто работает на Python, редко с ними сталкиваются, поэтому мы не будем раскрывать их в этой статье, но упомянем вкратце, чтобы сохранить полноту картины. Так, UTF-8 использует коды-префиксы, указывающие на количество байт в последовательности. Такой приём позволяет декодеру группировать байты в условиях кодировки с переменным размером. Количество байт в последовательности определяется первым её байтом. Другие технические подробности можно найти на странице Википедии, посвящённой UTF-8 или на официальном сайте.
Особенности UTF-16 и UTF-32
Рассмотрим альтернативные кодировки, UTF-16 и UTF-32. Различие между ними и UTF-8 в основном практическое. Продемонстрируем величину расхождения с помощью перевода туда и обратно:
>>> letters = "αβγδ"
>>> rawdata = letters. encode("utf-8")
>>> rawdata.decode("utf-8")
'αβγδ'
>>> rawdata.decode("utf-16") # 😧
'뇎닎돎듎'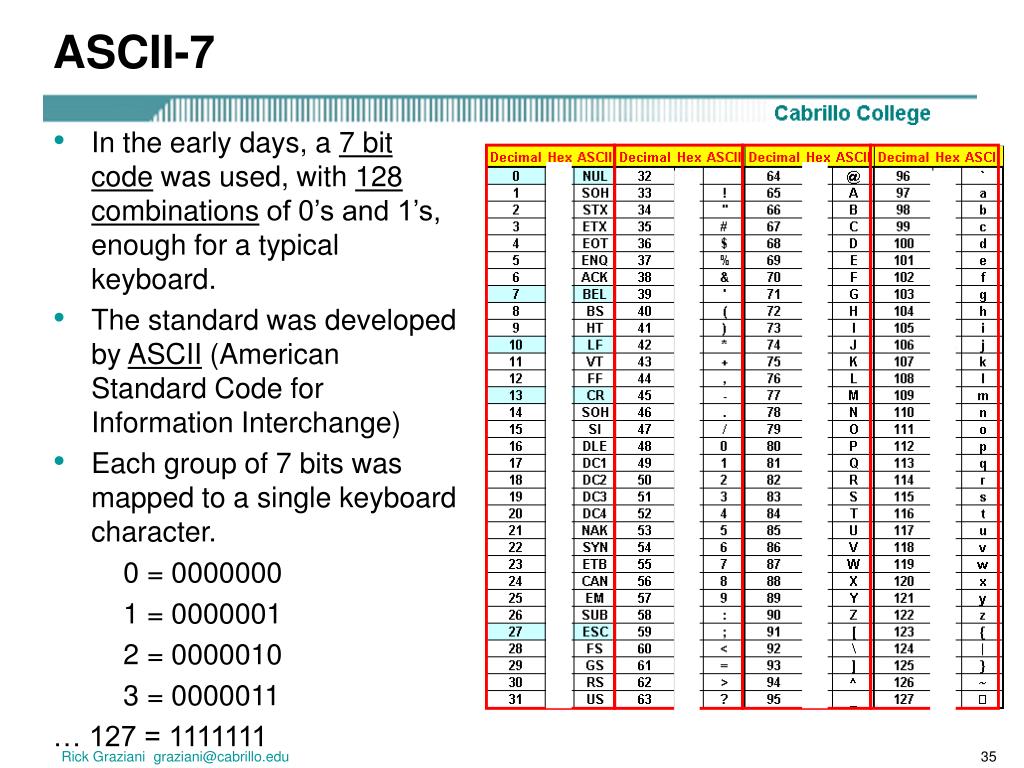 encode("utf-8")
>>> rawdata.decode("utf-8")
'αβγδ'
>>> rawdata.decode("utf-16") # 😧
'뇎닎돎듎'
encode("utf-8")
>>> rawdata.decode("utf-8")
'αβγδ'
>>> rawdata.decode("utf-16") # 😧
'뇎닎돎듎'В данном случае, когда мы кодируем четыре буквы греческого алфавита в двоичные данные с помощью UTF-8, а декодируем обратно в текст с использованием UTF-16, на выходе получается строка с совершенно другими символами (из корейского алфавита).
Так происходит, если для кодирования и декодирования применяют разные кодировки. Два варианта декодирования одного бинарного объекта могут вернуть текст даже на другом языке.
Таблица ниже демонстрирует количество байт, используемых в разных кодировках:
| Кодировка | Байт на символ (включительно) | Варьируемая длина |
|---|---|---|
| UTF-8 | От 1 до 4 | Да |
| UTF-16 | От 2 до 4 | Да |
| UTF-32 | 4 | Нет |
Любопытный аспект семейства UTF: UTF-8 не всегда занимает меньше памяти, чем UTF-16.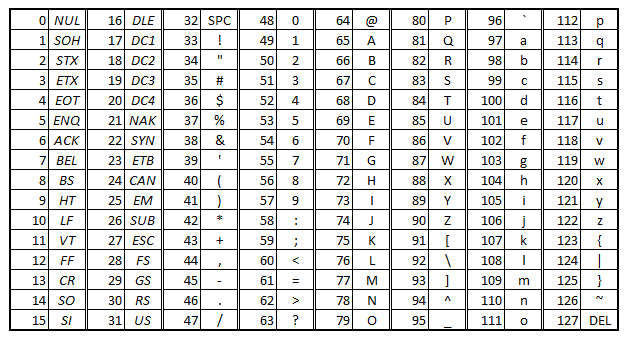 Хотя с точки зрения математики это выглядит маловероятным, однако это возможно:
Хотя с точки зрения математики это выглядит маловероятным, однако это возможно:
>>> text = "記者 鄭啟源 羅智堅"
>>> len(text.encode("utf-8"))
26
>>> len(text.encode("utf-16"))
22Так получается из-за того, что кодовые точки в диапазоне от U+0800 до U+FFFF (от 2048 до 65535 в десятичной системе) в кодировке UTF-8 занимают три байта, а в UTF-16 только два.
Это не означает, что нужно работать с UTF-16, независимо от того, насколько часто вы работаете с символами в этом диапазоне. Один из самых важных поводов придерживаться UTF-8 — в мире кодировок лучше держаться вместе с большинством.
Кроме того, в 2019 году компьютерная память стоит дёшево, и экономия четырёх байт за счёт использования нестандартной кодировки вряд ли стоит усилий.
Прим. перев. Есть и более весомые причины использовать UTF-8. Среди них её обратная совместимость с ASCII, а также то, что это самосинхронизирующаяся кодировка.
Python и встроенные функции
Вы освоили самую сложную часть статьи. Теперь посмотрим, как всё изученное реализуется на Python.
В Python есть несколько встроенных функций, каким-либо образом относящихся к системам счисления и кодировке:
Логически их можно сгруппировать по назначению.
ascii(),bin(),hex()иoct()предназначены для различного представления вводных данных. Все они возвращаютstr. Первая,ascii(), производит представление объекта в ASCII, экранируя не входящие в эту таблицу символы. Оставшиеся три дают соответственно двоичное, шестнадцатеричное и восьмеричное представление целого числа. Все эти функции меняют только представление объекта, не изменяя непосредственно вводные данные.bytes(),str()иint()— конструкторы классов соответствующих типов:bytes,str, иint. Все они предлагают способы подогнать данные под желаемый тип.ord()иchr()выполняют противоположные действия.ord()конвертирует символ в десятичную кодовую точку, аchr()принимает в качестве аргумента целое число, и возвращает символ, кодовой точкой которого это число является.
В таблице ниже эти функции разобраны более подробно:
| Функция | Форма | Тип аргументов | Тип возвращаемых данных | Назначение |
|---|---|---|---|---|
ascii() | ascii(obj) | Различный | str | Представление объекта символами ASCII. Не входящие в таблицу символы экранируются |
bin() | bin(number) | number: int | str | Бинарное представление целого чиста с префиксом "0b" |
bytes() | bytes(последовательность_целых_чисел)
| Различный | bytes | Приводит аргумент к двоичным данным, типу bytes |
chr() | chr(i) | i: int
| str | Преобразует кодовую точку (целочисленное значение) в символ Юникода |
hex() | hex(number) | number: int | str | Шестнадцатеричное представление целого числа с префиксом "0x" |
int() | int([x])
| Различный | int | Приводит аргумент к типу int |
oct() | oct(number) | number: int | str | Восьмеричное представление целого числа с префиксом "0o" |
ord() | ord(c) | c: str
| int | Возвращает значение кодовой точки символа Юникода |
str() | str(object=’‘)
| Различный | str | Приводит аргумент к текстовому представлению, типу str |
Дальше можно посмотреть полезные примеры использования этих функций.
ascii():
>>> ascii("abcdefg")
"'abcdefg'"
>>> ascii("jalepeño")
"'jalepe\\xf1o'"
>>> ascii((1, 2, 3))
'(1, 2, 3)'
>>> ascii(0xc0ffee) # Шестнадцатеричный литерал (int)
'12648430'bin():
>>> bin(0)
'0b0'
>>> bin(400)
'0b110010000'
>>> bin(0xc0ffee) # Шестнадцатеричный литерал (int)
'0b110000001111111111101110'
>>> [bin(i) for i in [1, 2, 4, 8, 16]] # `int` + обработка списка
['0b1', '0b10', '0b100', '0b1000', '0b10000']bytes():
>>> # Последовательность целых чисел
>>> bytes((104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100))
b'hello world'
>>> bytes(range(97, 123)) # Последовательность целых чисел
b'abcdefghijklmnopqrstuvwxyz'
>>> bytes("real 🐍", "utf-8") # Строка + кодировка
b'real \xf0\x9f\x90\x8d'
>>> bytes(10)
b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
>>> bytes. fromhex('c0 ff ee')
b'\xc0\xff\xee'
>>> bytes.fromhex("72 65 61 6c 70 79 74 68 6f 6e")
b'realpython' fromhex('c0 ff ee')
b'\xc0\xff\xee'
>>> bytes.fromhex("72 65 61 6c 70 79 74 68 6f 6e")
b'realpython'
fromhex('c0 ff ee')
b'\xc0\xff\xee'
>>> bytes.fromhex("72 65 61 6c 70 79 74 68 6f 6e")
b'realpython'chr():
>>> chr(97)
'a'
>>> chr(7048)
'ᮈ'
>>> chr(1114111)
'\U0010ffff'
>>> chr(0x10FFFF) # Шестнадцатеричный литерал (int)
'\U0010ffff'
>>> chr(0b01100100) # Двоичный литерал (int)
'd'hex():
>>> hex(100)
'0x64'
>>> [hex(i) for i in [1, 2, 4, 8, 16]]
['0x1', '0x2', '0x4', '0x8', '0x10']
>>> [hex(i) for i in range(16)]
['0x0', '0x1', '0x2', '0x3', '0x4', '0x5', '0x6', '0x7',
'0x8', '0x9', '0xa', '0xb', '0xc', '0xd', '0xe', '0xf']int():
>>> int(11.0)
11
>>> int('11')
11
>>> int('11', base=2)
3
>>> int('11', base=8)
9
>>> int('11', base=16)
17
>>> int(0xc0ffee - 1. 0)
12648429
>>> int.from_bytes(b"\x0f", "little")
15
>>> int.from_bytes(b'\xc0\xff\xee', "big")
12648430 0)
12648429
>>> int.from_bytes(b"\x0f", "little")
15
>>> int.from_bytes(b'\xc0\xff\xee', "big")
12648430
0)
12648429
>>> int.from_bytes(b"\x0f", "little")
15
>>> int.from_bytes(b'\xc0\xff\xee', "big")
12648430oct():
>>> ord("a")
97
>>> ord("ę")
281
>>> ord("ᮈ")
7048
>>> [ord(i) for i in "hello world"]
[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]str():
>>> str("str of string")
'str of string'
>>> str(5)
'5'
>>> str([1, 2, 3, 4]) # Like [1, 2, 3, 4].__str__(), but use str()
'[1, 2, 3, 4]'
>>> str(b"\xc2\xbc cup of flour", "utf-8")
'¼ cup of flour'
>>> str(0xc0ffee)
'12648430'Литералы для строк на Python
Вместо использования конструктора str(), объект этого типа чаще вводят напрямую:
>>> meal = "shrimp and grits"Выглядит достаточно просто. Но есть один аспект, о котором нужно помнить. Поскольку Python позволяет использовать все возможности Юникода, можно «напечатать» символы, которых вы никогда не найдёте на клавиатуре. Можно скопировать и вставить их прямо в оболочку интерпретатора:
Но есть один аспект, о котором нужно помнить. Поскольку Python позволяет использовать все возможности Юникода, можно «напечатать» символы, которых вы никогда не найдёте на клавиатуре. Можно скопировать и вставить их прямо в оболочку интерпретатора:
>>> alphabet = 'αβγδεζηθικλμνξοπρςστυφχψ'
>>> print(alphabet)
αβγδεζηθικλμνξοπρςστυφχψКроме ввода через консоль реальных, неэкранированых символов Юникода, существуют и другие способы ввода текстовых строк.
Самые насыщенные разделы документации Python посвящены лексическому анализу. В частности, раздел о строках и литералах. Возможно, для понимания данного аспекта языка этот раздел придётся неоднократно перечитать.
Кроме прочего, там говорится о шести возможных способах ввода одного символа Юникода.
Первый, и самый распространённый метод, как вы уже видели — прямой ввод. Проблема состоит в поиске необходимых сочетаний клавиш. Здесь и могут пригодиться другие способы получения и представления символов. Вот полный список:
Вот полный список:
| Экранирующая последовательность | Значение | Как отобразить "a" |
|---|---|---|
"\ooo" | Символ с восьмеричным значением ooo | "\141" |
"\xhh" | Символ с шестнадцатеричным значением hh | "\x61" |
"\N{name}" | Символ с именем name в базе данных Юникода | "\N{LATIN SMALL LETTER A}" |
"\uxxxx" | Символ с шестнадцатибитным (двухбайтным) шестнадцатеричным значением xxxx | "\u0061" |
"\Uxxxxxxxx" | Символ с тридцатидвухбитным (четырёхбайтным) шестнадцатеричным значением xxxxxxxx | "\U00000061" |
Это соответствие можно проверить на практике:
>>> (
. .. "a" ==
... "\x61" ==
... "\N{LATIN SMALL LETTER A}" ==
... "\u0061" ==
... "\U00000061"
... )
True .. "a" ==
... "\x61" ==
... "\N{LATIN SMALL LETTER A}" ==
... "\u0061" ==
... "\U00000061"
... )
True
.. "a" ==
... "\x61" ==
... "\N{LATIN SMALL LETTER A}" ==
... "\u0061" ==
... "\U00000061"
... )
TrueНужно однако упомянуть и два основных затруднения при использовании этих методов:
- Не каждый способ работает со всеми символами. Шестнадцатеричное представление числа 300 выглядит как
0x012c, а это значение просто не поместится в экранирующий код"\xhh", так как в нём допускаются всего две цифры. Самая большая кодовая точка, которую можно втиснуть в этот формат —"\xff"("ÿ"). Аналогичо"\ooo"можно использовать только до"\777"("ǿ"). - Для
\xhh,\uxxxx, и\Uxxxxxxxxтребуется вводить ровно столько цифр, сколько указано в примерах. Это может стать неприятным сюрпризом, поскольку обычно основанные на Юникоде таблицы содержат кодовые точки для символов с префиксомU+и варьирующимся количеством шестнадцатеричных символов. В этих таблицах кодовые точки отображают только значимые цифры.
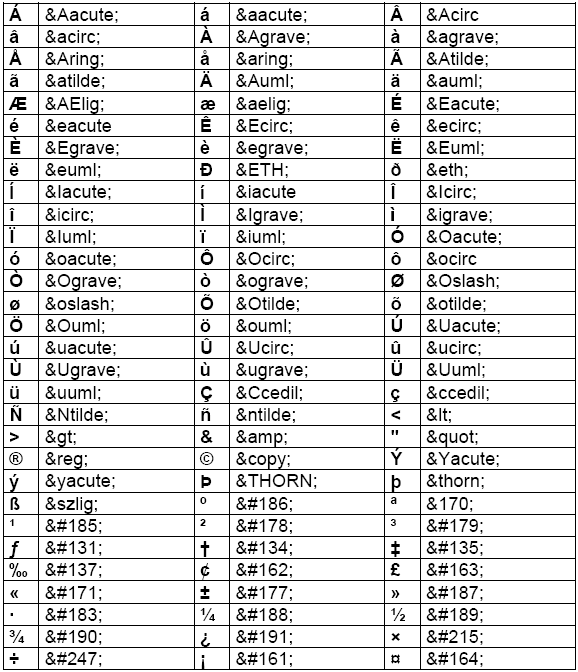 В этих таблицах кодовые точки отображают только значимые цифры.
В этих таблицах кодовые точки отображают только значимые цифры.Например, если вы обратитесь к сайту unicode-table.com с целью получить данные готического символа faihu (или fehu), "𐍆", его кодовая точка будет U+10346.
Как же можно разместить его в "\uxxxx" или "\Uxxxxxxxx"? В "\uxxxx" эту кодовую точку вместить невозможно, поскольку она соответствует четырёхбайтному символу. А чтобы представить его в "\Uxxxxxxxx", придётся выровнять последовательность с левой стороны:
>>> "\U00010346"
'𐍆'Это также значит, что экранирующая последовательность "\Uxxxxxxxx" — единственная последовательность, способная вместить любой символ Юникода.
Прим. Вот код небольшой, но удобной функции, переводящей записи типа "U+10346" в приемлемый для Python формат с помощью str.zfill():
>>> def make_uchr(code: str):
. .. return chr(int(code.lstrip("U+").zfill(8), 16))
>>> make_uchr("U+10346")
'𐍆'
>>> make_uchr("U+0026")
'&' .. return chr(int(code.lstrip("U+").zfill(8), 16))
>>> make_uchr("U+10346")
'𐍆'
>>> make_uchr("U+0026")
'&'
.. return chr(int(code.lstrip("U+").zfill(8), 16))
>>> make_uchr("U+10346")
'𐍆'
>>> make_uchr("U+0026")
'&'Другие поддерживаемые Python кодировки
Пока что мы рассказали про 4 разные кодировки символов:
- ASCII;
- UTF-8;
- UTF-16;
- UTF-32.
Однако существует большое количество и других вариантов кодировки.
Один из примеров — Latin-1 (другое название ISO-8859-1). Это базовая кодировка для Hypertext Transfer Protocol (HTTP) в спецификации RFC 2616. Для Windows существует собственный вариант Latin-1, который называется cp1252.
Прим. Кодировка ISO-8859-1 всё ещё широко используется. Библиотека requests неукоснительно придерживается спецификации RFC 2616, используя её по умолчанию для содержимого отзывов HTTP/HTTPS. Если в заголовке Content-Type находится слово «text» и не выбрана другая кодировка, requests использует ISO-8859-1.
Полный список допустимых кодировок можно найти в документации модуля codecs, входящего в набор стандартных библиотек Python.
Среди этих кодировок стоит упомянуть ещё одну, зачастую весьма полезную. Это "unicode-escape". Если вы декодировали str и хотите быстро получить представление содержащихся в ней экранированных литералов Юникода, можно определить эту кодировку в .encode:
>>> alef = chr(1575) # Или "\u0627"
>>> alef_hamza = chr(1571) # Или "\u0623"
>>> alef, alef_hamza
('ا', 'أ')
>>> alef.encode("unicode-escape")
b'\\u0627'
>>> alef_hamza.encode("unicode-escape")
b'\\u0623'Вы знаете, что говорят насчёт предположений…
Хотя Python по умолчанию предполагает, что файлы и код созданы на основе кодировки UTF-8, вам, как программисту, не следует делать аналогичное предположение относительно сторонних данных.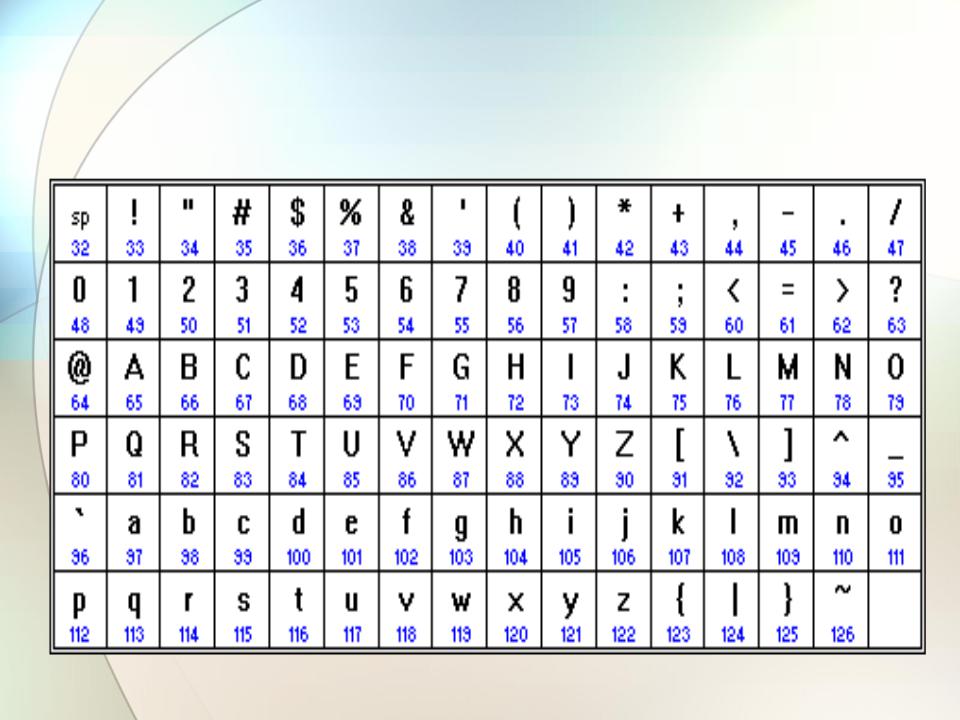
Когда вы получаете данные в двоичном коде из внешних источников, из файла или по сетевому соединению, стоит проверить, указана ли кодировка. Если нет — вы можете уточнить.
Все операции ввода-вывода осуществляют в байтах, наборе нулей и единиц, пока вы не сообщите системе кодировку для преобразования этих данных в текст.
Приведём пример того, что может пойти не так. Допустим, вы подписаны на API, который передаёт вам рецепт блюда дня. Вы получаете его в формате bytes и раньше всегда без проблем декодировали с использованием .decode("utf-8") . Но именно в этот день часть рецепта выглядела так:
>>> data = b"\xbc cup of flour"Похоже, нам потребуется мука, но сколько?
>>> data.decode("utf-8")
Traceback (most recent call last):
File "", line 1, in
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 0: invalid start byteА вот и та самая неприятная ошибка UnicodeDecodeError.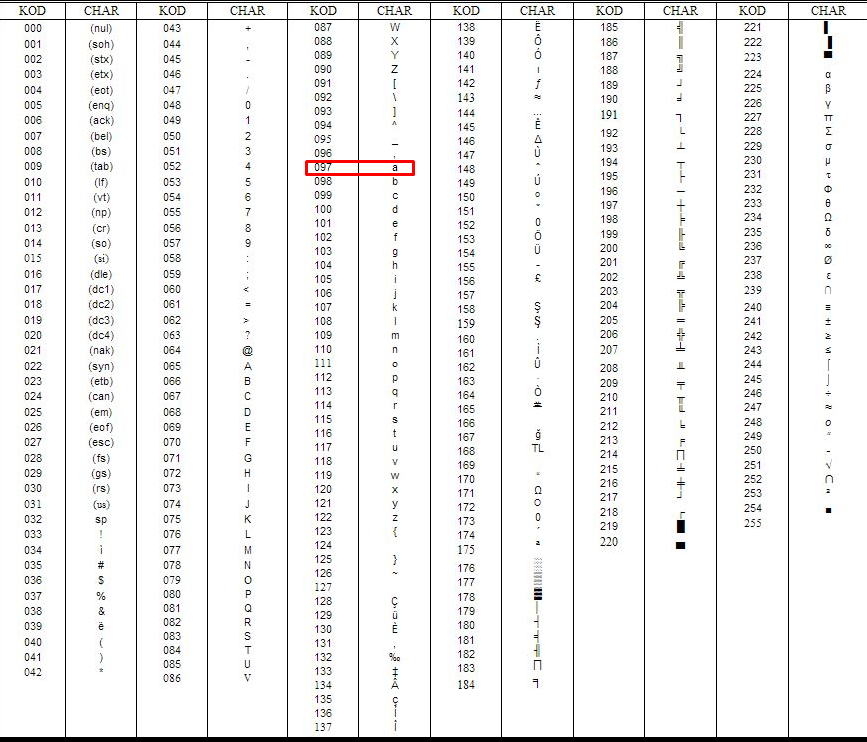 Подобное вполне может произойти, когда вы делаете предположение об используемой кодировке. Уточняем у разработчика ресурса, предоставляющего API. Выясняется, что полученный вами файл был закодирован с помощью Latin-1:
Подобное вполне может произойти, когда вы делаете предположение об используемой кодировке. Уточняем у разработчика ресурса, предоставляющего API. Выясняется, что полученный вами файл был закодирован с помощью Latin-1:
>>> data.decode("latin-1")
'¼ cup of flour'Именно в этом и крылась проблема. В Latin-1 каждый символ кодируется одним байтом, в вот в UTF-8 символ «¼» требует два байта ("\xc2\xbc").
Как видите, делать предположения относительно кодировки полученных данных довольно рискованно. Обычно это UTF-8, однако в тех случаях, когда это не так, у вас могут возникнуть проблемы.
Если уж у вас нет другого выхода и кодировку приходится угадывать, обратите внимание на библиотеку chardet. В ней используются разработанные в Mozilla методы, позволяющие сделать обоснованное предположение насчёт кодировки данных. Однако учтите, что такие инструменты должны быть вашим последним средством, не стоит прибегать к ним, если есть возможность решить вопрос другим способом.
Всякая всячина: unicodedata
Нельзя не упомянуть также модуль unicodedata. Он позволяет взаимодействовать с базой данных символов Юникода (Unicode Character Database, UCD).
>>> import unicodedata
>>> unicodedata.name("€")
'EURO SIGN'
>>> unicodedata.lookup("EURO SIGN")
'€'Подводим итоги
Итак, в этой статье вы познакомились со следующими концепциями кодировки символов в Python:
- Фундаментальные принципы кодировки символов и систем счисления;
- Целочисленные, двоичные, восьмеричные, шестнадцатеричные, строковые и байтовые литералы в Python;
- Встроенные функции языка, работающие с кодировкой и системами счисления;
- Особенности обработки текстовых и двоичных данных.
Дополнительные источники
Ещё больше информации можно получить из следующих материалов (на английском языке):
- UTF-8 Everywhere Manifesto.
- Joel Spolsky: Минимальный уровень знаний о Юникоде и наборах символов, требующийся каждому разработчику ПО (Без отговорок!).
- David Zentgraf: Что обязательно должен знать о кодировках и наборах символов каждый программист для работы с текстом.
- Mozilla: Комплексный подход к определению языков и кодировок.
- Wikipedia.
- John Skeet: Юникод и .NET.
- Network Working Group, RFC 3629: UTF-8, формат преобразования ISO 10646.
- Unicode Technical Standard #18: Регулярные выражения Юникода.
В документации языка нашему вопросу посвящены два раздела:
Перевод статьи Unicode & Character Encodings in Python: A Painless Guide
18История. Использование и типы пробелов | by dui
Саммари на статью – https://is.gd/QadtXI
Типы пробелов
Существует несколько типов пробелов:
⁃ Спусковые,
⁃ Абзацные,
⁃ Межстрочные,
⁃ Межсловные,
⁃ Межбуквенные.
Статья посвящена межсловным пробелам.
История пробела
Пробел начал активно использоваться в письменности в VII – IX вв. В кириллице используется с XVII века.
В кириллице используется с XVII века.
В ручном наборе текста, строки текста набирались с помощью литер. Литера – брусок на торце, которого располагается буква в зеркальном отражении. С помощью литер печатали строки текста.
Пробелы создавались с помощью похожих литер, но без буквенного оттиска. Пробельные литеры назывались – шпации. Шпации (пробелы) были различной ширины.
Типы шпаций.
⁃ Круглая
⁃ Полукруглая
⁃ Тонкая
Круглая шпация – шпация шириной в кегль.
Полукруглая шпация – равняется примерно половине ширины кегля.
Тонкая шпация – точного размера для тонкой шпации нет, но можно считать, что она равна 1/5 ширины кегля.
Веб-типографика и пробелы
В веб-типографике мы ограничены возможностями шрифтов. Не все шрифты содержат большинство пробельных Unicode символов.
Символы пробела в Unicode:
• Межсловный пробел, U+0020,   – ширина от 1⁄5 до 1⁄2 круглой в зависимости от шрифта.
• Неразрывный межсловный пробел, U+00A0,
• Круглая шпация, U+2003,  
• Полукруглая шпация, U+2002,   – половина круглой
• Третная шпация, U+2004,  
• Четвертная шпация, U+2005,  
• Одна шестая круглой, U+2006,  
• Тонкая шпация, U+2009,   ширина около 1/5 круглой.
• Волосяная шпация, U+200A,   – самая узкая шпация, шириной около 1⁄10 – 1⁄16 круглой.
Использование пробелов
Использование символов пробела оправданно только при наборе печатных изданий.
В обычной вёрстке для веба, для разделения слов достаточно пользоваться обычными, неразрывными межсловными пробелами и тонкой шпацией.
Неразрывным пробелом отбиваются:
• Сокращения «и т. д», «и т. п.» и другие. Отделяются неразрывными пробелами.
• Инициалы отбиваются друга от друга и фамилий неразрывным пробелом.
• Сокращённое слово отбиваются от имени собственного неразрывным пробелом.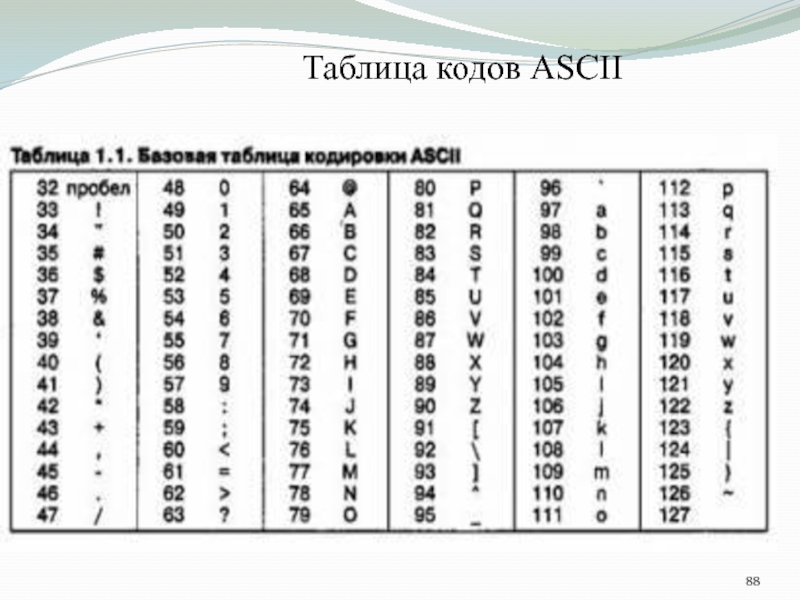
• Число и соответствующее ему счётное слово
Тонкой шпацией отбиваются:
• Число и соответствующая ему единица измерения (кроме знаков градуса, минуты и секунды)
• Знаки градуса, минуты и секунды от последующих цифр
Про другие правила использования типов пробела читайте в статье по ссылке – https://is.gd/QadtXI
ОГЭ по информатике 2020 — Задание 1 (Бомбим экзамен!)
Наконец-то выходит стартовый видеоурок по новой версии ОГЭ по информатике — 2020! Сегодня разберём, как решать первое задание из ОГЭ по информатике 2020.
Для начала необходимо выучить таблицу перевода различных единиц информации. Всего необходимо запомнить два числа 8 и 1024 — и таблица автоматически запоминается.
Самой маленькой единицей информации является 1 бит (и имеет самое маленькое название — три буквы). Приставка «Кило» обычно обозначает 1000, но у нас 1 Кбайт = 1024 байт.
Теперь давайте посмотрим на задание номер 1 в ОГЭ по информатике 2020!
Задача:
В кодировке КОИ-8 каждый символ кодируется 8 битами.
 Вася написал текст (в нём нет лишних пробелов):
Вася написал текст (в нём нет лишних пробелов):«Лена, Иртыш, Обь, Колыма, Днепр, Колыма – реки России.»
Ученик добавил в список название ещё одной реки – Волга. При этом он добавил в текст необходимую запятую и пробел. На сколько байт при этом увеличился размер нового предложения в данной кодировке? В ответе укажите только одно число – количество байт.
Решение:
В первой задаче ОГЭ по информатике 2020 обычно есть текст в кавычках, который написан учеником. И в этом тексте идёт некоторое перечисление. И в это перечисление добавил ученик слово «Волга», плюс запятую и пробел. Итого ученик добавил 7 символов.
Каждый символ кодируется 8-ю битами (т.е. 1 байтом).
Итого 7 сим * 1 байт = 7 байт добавил ученик. Значит и предложение увеличилось на 7 байт.
Ответ: 7
Разберём ещё один пример из первого номера из ОГЭ по информатике 2020.
Задача:
В одной из кодировок Unicode каждый символ кодируется 16 битами.
 Серьгуша написал текст (в нём нет лишних пробелов):
Серьгуша написал текст (в нём нет лишних пробелов):«Меркурий, Венера, Земля, Марс, Юпитер, Сатурн— планеты солнечной системы».
Ученик вычеркнул из списка название одной планеты. Заодно он вычеркнул ставшие лишними запятые и пробелы — два пробела не должны идти подряд. При этом размер нового предложения в данной кодировке оказался на 12 байт меньше, чем размер исходного предложения. Напишите в ответе вычеркнутое название планеты.
Решение:
Задача похоже на предыдущую, но теперь мы не добавляем слово в перечисление, а вычеркиваем. Заодно, как и в прошлый раз, нужно убрать лишнюю запятую и лишний пробел.
Каждый символ кодируется 16 битами т.е. 2 байтами. После вычёркивания, наше предложение стало меньше на 12 байт. Если мы разделим 12 байт на размер одного символа (2 байта), то мы найдём количество вычеркнутых символов. 12 байт : 2 байта = 6 символов — вычеркнул ученик. Но в эти символы входит и пробел, и запятая. Если их не учитывать, то на наше слово останется 4 символов. Если мы посмотрим на наше перечисление, то обнаружим, что 4 символа имеет слово только «Марс».
Если мы посмотрим на наше перечисление, то обнаружим, что 4 символа имеет слово только «Марс».
Ответ: Марс
Задача:
В кодировке UTF-32 каждый символ кодируется 32 битами. Даша написала текст (в нём нет лишних пробелов):
«комары, мухи, бабочки— насекомые».
Ученица вычеркнула из списка одно название насекомых. Заодно она вычеркнула ставшие лишними запятые и пробелы — два пробела не должны идти подряд.
При этом размер нового предложения в данной кодировке оказался на 32 байта меньше, чем размер исходного предложения. Напишите в ответе вычеркнутое название насекомых.
Решение:
Каждый символ кодируется 32 битами т.е. 4 байтами. После вычёркивания, наше предложение стало меньше на 32 байт. Если мы разделим 32 байт на размер одного байта (4 байта), то мы найдём количество вычеркнутых символов. 32 байт : 4 байта = 8 символов — вычеркнул ученик. Но в эти символы входит и пробел, и запятая. Если их не учитывать, то на наше слово останется 6 символа. Если мы посмотрим на наше перечисление, то обнаружим, что 6 символа имеет слово только «комары».
Если мы посмотрим на наше перечисление, то обнаружим, что 6 символа имеет слово только «комары».
Ответ: комары
На этом всё! Разбомбим ОГЭ по информатике 2020!
.Как исправить шрифт если вместо русских букв символы
В этой статье рассмотрено, почему вместо русских букв, возникают квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики в windows 7, vista, XP?
Что делать, чтобы избавиться от этих явлений? Универсального рецепта — нет. Много зависит от версии виндовс, да и самой сборки.
Первая причина, почему такое происходит – сбой кодировок. Нарушается целостность реестра, и происходят сбои. Только не всегда это основной источник.
Часто бывает, что даже на ново установленной операционной системе, после запуска некоторых программ вместо русских букв возникают квадратики, непонятные символы, крякозябры, вопросительные знаки, точки, каракули или кубики.
Если же проблема с цифрами, тогда она быстро устраняется применением изменений описанных здесь, а избавиться от знаков вопросов вместо нормальных букв поможет эта инструкция.
Особенно часто такое случается после установки русификаторов. Народные «умельцы», не учитывают все, а возможно и переводы делают только под одну операциоку.
Возможно и не это главное, если учесть, что все заключаться в кодировке. Может программа, просто не поддерживает определенные буквы.
Хотя это и удивительно, но по умолчанию операционная система windows 7 вместо русских букв в некоторых программа отображает квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики.
Я всегда после переустановки вношу изменения в реестр, даже если все работает нормально. В будущем проблем с непонятными символами не возникает.
Устранение проблемы через реестр
Сделать такую манипуляцию очень легко. Для этого скачиваем здесь архив и запускаем первый файл.
Подчеркиваю, только первый, второй — если после первого непонятные символы, иероглифы или кракозябры не пропадут и не появляться нормальные русские буквы.
Только не забудьте после внесения изменений в реестр системы компьютер перезагрузить, иначе изменений не ждите.
Есть еще несколько способов изменить кодировку, но лучше их не делать, поскольку это будет перекладывание ноши (груза) с больного места на нездоровое.
Программа что в данный момент отображает кракозябры, иероглифы и вообще непонятно что, может начать работать, а вот русские буквы в других нарушаться.
На всякий случай можете попробовать переименовать файлы «c_1252.nls….. c_1255.nls». добавьте к ним в самый конец «bak» Должно выглядеть так c_1252.nls.bak». Сделайте так с всеми четырьмя. Они находятся по такому пути: C:\Windows\System32.
Хочется сказать, что я переустановил не менее 100 виндовс 7. Правда, почти все были 32 (86) максимум. Были проблемы с отображением русских букв.
Особенно это касалось программ. В некоторых появлялись, возникают вопросы, квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики, но описанный самый первый способ помогал всегда.
Также квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики могут появиться в документах word или skyrim.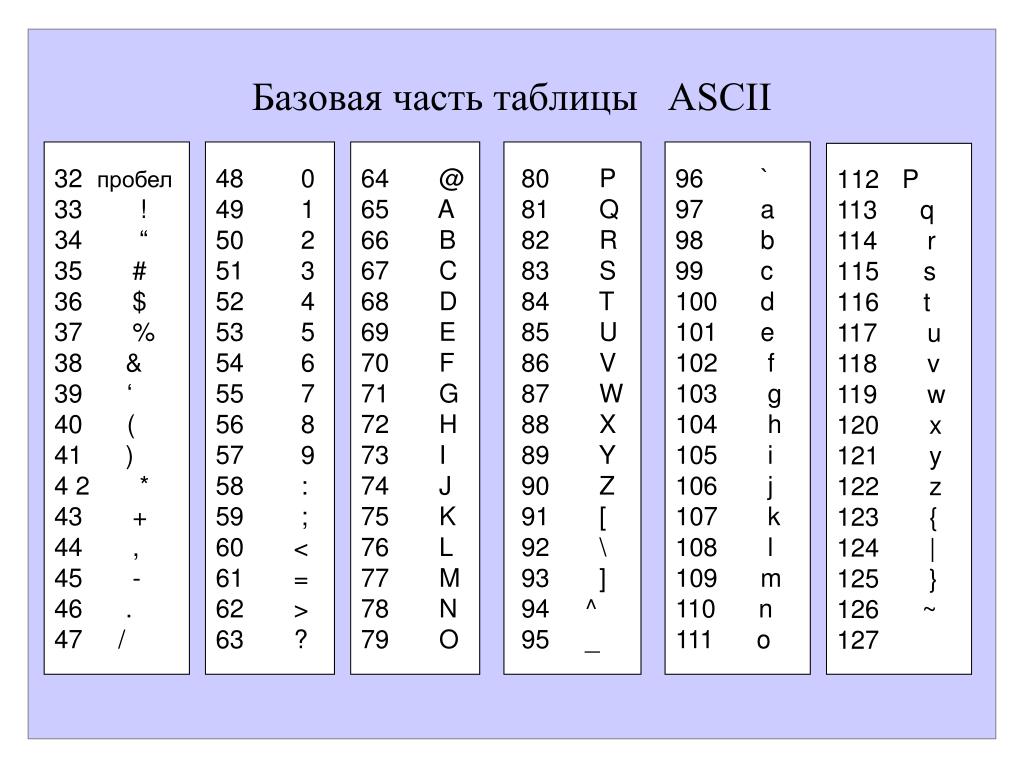
Такое получается, из-за несовпадения форматов (кодировок). Их можно устанавливать самостоятельно для каждого случая отдельно (в ручном режиме) Смотрите на рис:
В самом верху нажмите «файл», после чего подведите курсор к месту «кодировка» и нажав измените. Успехов.
| Кодовая точка Unicode | символ | UTF-8 кодировка (шестнадцатеричная) | Имя символа Unicode | Имя символа Unicode 1.0 (устарело) |
|---|---|---|---|---|
| U + | 20 | ПРОСТРАНСТВО | ||
| U + | c2 a0 | НЕТ- | НЕПРЕРЫВНЫЙ ПРОСТРАНСТВО | |
| U + | e1 9a 80 | OGHAM SPACE MARK | ||
| U + | e2 80 82 | EN ПРОСТРАНСТВО | ||
| U + | e2 80 83 | EM ПРОСТРАНСТВО | ||
| U + | e2 80 84 | ТРИ- | ||
| U + | e2 80 85 | ЧЕТЫРЕ- | ||
| U + | e2 80 86 | SIX- | ||
| U + | e2 80 87 | РИСУНОК ПРОСТРАНСТВО | ||
| U + | e2 80 88 | ПУНКТУАЦИЯ ПРОСТРАНСТВО | ||
| U + | e2 80 89 | ТОНКИЙ ПРОСТРАНСТВО | ||
| U + | e2 80 8a | ВОЛОС ПРОСТРАНСТВО | ||
| U + | e2 80 8b | НУЛЕВАЯ ШИРИНА ПРОСТРАНСТВО | ||
| U + | E2 80 AF | УЗКИЙ НОМЕР — | ||
| U + | e2 81 9f | СРЕДНИЙ МАТЕМАТИЧЕСКИЙ ПРОСТРАНСТВО | ||
| U + | ␠ | e2 90 a0 | СИМВОЛ ДЛЯ ПРОСТРАНСТВА | ГРАФИКА ДЛЯ ПРОСТРАНСТВА |
| U + | e3 80 80 | ИДЕОГРАФИЯ ПРОСТРАНСТВО | ||
| U + | 〿 | e3 80 bf | ИДЕОГРАФИЧЕСКАЯ ПОЛОВИНА ЗАПОЛНЕНИЯ ПРОСТРАНСТВО | |
| U + | ef bb bf | НУЛЕВАЯ ШИРИНА, НОМЕР — | БАЙТНАЯ МЕТКА ЗАКАЗА | |
| U + | 𝩿 | f0 9d a9 bf | — цена: + 0 руб. МЕСТО ДЛЯ НАПИСАНИЯ — | |
| U + | 𝪀 | f0 9d аа 80 | МЕСТО ДЛЯ НАПИСАНИЯ ПОДПИСЕЙ — | |
| U + | | f3 а0 80 а0 | ТЕГ ПРОСТРАНСТВО |

Пример 17 — Загрузка в табличное пространство Unicode из ввода EBCDIC — Документация по LOADPLUS для DB2 11.2
В этом примере показано выполнение LOAD REPLACE в сегментированном табличном пространстве, которое определено как Unicode. В табличном пространстве нет индексов.
Опция EBCDIC сообщает LOADPLUS, что схема кодирования входных данных — EBCDIC, а опция CCSID сообщает LOADPLUS, какие кодовые страницы использовались для кодирования данных. LOADPLUS переводит входные данные EBCDIC в данные Unicode во время процесса загрузки.
Сообщение 50041I указывает состояние обработки zIIP. В этом примере опция установки ZIIP ВКЛЮЧЕНА, но подсистема XBM не указана.LOADPLUS автоматически обнаружил доступную подсистему XBM для обеспечения обработки zIIP.
В команду LOAD не включена опция COPY, поэтому LOADPLUS принимает значение по умолчанию COPY NO и не делает копию. Поскольку для параметра установки COPYPEND задано значение YES, LOADPLUS переводит табличное пространство в состояние ожидания COPY, и задание завершается с кодом возврата 4.
На следующем рисунке показан DDL, используемый для создания табличного пространства Unicode:
CREATE DATABASE AMUEX17D
CCSID UNICODE
STOGROUP AMUQASTO
BUFFERPOOL BP0;
СОВЕРШИТЬ ;
СОЗДАЙТЕ ТАБЛИЧНОЕ ПРОСТРАНСТВО EX17TS В AMUEX17D
РАЗМЕР 64
CCSID UNICODE
ИСПОЛЬЗОВАНИЕ STOGROUP AMUQASTO
ЧАСТЬ 50
СЕКТОР 10
СТЕРЕТЬ НЕТ
BUFFERPOOL BP0;
СОВЕРШИТЬ ;
СОЗДАТЬ ПРИМЕР ТАБЛИЦЫ 17.TBL1
(SMINT_COL1 МАЛЕНЬКИЙ
, TIMESTAMP_COL2 TIMESTAMP
, DATE_COL3 DATE
, CHAR_COL4 CHAR (7)
ДЛЯ ДАННЫХ SBCS
) В AMUEX17D.EX17TS; На следующем рисунке показан JCL, например 17:
// EXAMPL17 EXEC PGM = AMUUMAIN,
// PARM = '& SSID, EXAMPL17, NEW / RESTART ,, MSGLEVEL (1), AMU $ OPTO'
// * SSID, UTILID, RSTART, NOTIFY, MSGLEVEL
// STEPLIB DD DISP = SHR, DSN = product.библиотеки
// DD DISP = SHR, DSN = DB2.DSNEXIT
// DD DISP = SHR, DSN = DB2.DSNLOAD
// SYSPRINT DD SYSOUT = *
// SYSOUT DD SYSOUT = *
// UTPRINT DD SYSOUT = *
// SYSUDUMP DD SYSOUT = *
// *
// SYSREC DD DISP = SHR, DSN = AMU.VQA.EXAMP17A.SYSREC
// SORTOUT DD DSN = AMU.EXAMP17.SORTOUT,
// UNIT = SYSDA, SPACE = (CYL, (1,1)), DISP = (MOD, CATLG, CATLG)
// SYSERR DD DSN = AMU.EXAMP17.SYSERR,
// UNIT = SYSDA, SPACE = (CYL, (1,1)), DISP = (MOD, CATLG, CATLG)
// SYSDISC DD DSN = AMU.EXAMP17.SYSDISC,
// UNIT = SYSDA, SPACE = (CYL, (1,1)), DISP = (NEW, CATLG, CATLG)
// *
// SYSIN DD *
ЗАМЕНА НАГРУЗКИ
ПРЕДВАРИТЕЛЬНАЯ ЗАГРУЗКА ПРОДОЛЖИТЬ
EBCDIC CCSID (37,65534,65534)
В ПРИМЕР ТАБЛИЦЫ 17.TBL1
(ПОЛОЖЕНИЕ SMINT_COL1 (1: 2) МАЛЕНЬКАЯ ИНФОРМАЦИЯ
, TIMESTAMP_COL2 POSITION (4:29) TIMESTAMP EXTERNAL (26)
, DATE_COL3 POSITION (31:40) DATE EXTERNAL (10)
, CHAR_COL4 POSITION (42:48) CHAR (7)
)
/ * SYSPRINT, например 17На следующем рисунке показан вывод SYSPRINT для примера 17:
1 ************* B M C L O A D P L U S F O R D B 2 V11R2.00 ************
(C) АВТОРСКИЕ ПРАВА 1990-2015 BMC SOFTWARE, INC.ТЕХНОЛОГИЯ LOADPLUS ЗАЩИЩЕНА НОМЕРАМИ ПАТЕНТА США 7,664,790 И 7,930,291.
-BMC50001I ВЫПОЛНЕНИЕ УТИЛИТЫ НАЧАЛО ВЫПОЛНЕНИЯ 3/09/2015 15:27:24 ...
BMC50002I UTILITY ID = 'EXAMPL17'. ИД ПОДСИСТЕМЫ DB2 = 'DEHJ'. ДОПОЛНИТЕЛЬНЫЙ МОДУЛЬ = 'AMU $ OPTO'.
BMC50471I z / OS 2.1.0, PID = HBB7790, DFSMS FOR Z / OS = 2.1.0, DB2 = 11.1.0
BMC50471I REGION = 0M, НИЖЕ 16M = 8836K, ВЫШЕ 16M = 1312604K, IEFUSI = NO, CPUS = 3
BMC50471I MEMLIMIT = 175040320M, ДОСТУПНО = 175 040312M, MEMLIMIT SET BY: REGION = 0
0
BMC50471I LOADPLUS ДЛЯ DB2 - V11.02.00
BMC50471I О ТЕХОБСЛУЖИВАНИИ НЕТ ОТЧЕТА
BMC50471I ОБЩИЙ КОД УТИЛИТ DB2 - V11.02.00
BMC50471I О ТЕХОБСЛУЖИВАНИИ НЕТ ОТЧЕТА
ОБЩИЙ КОД РЕШЕНИЯ BMC50471I - V11.01.00
BMC50471I ГЛАВНАЯ: BPJ0661 BPJ0667 BPJ0671 BPJ0674 BPJ0675 BPJ0676 BPJ0682 BPJ0686 BPJ0689 BPJ0697 BPJ0700 BPJ0702
BMC50471I BPJ0703 BPJ0706 BPJ0712 BPJ0715 BPJ0729 BPJ0773 BPJ0786 BPJ0794 BPJ0806 BPJ0830 BPJ0833 BPJ0839
BMC50471I BPJ0845 BPJ0866 BPJ0892 BPJ0913 BPJ0914 BPJ0916 BPJ0930 BPJ0944 BPJ0946
BMC50471I ДВИГАТЕЛЬ BMCSORT - V02.04.01
BMC50471I ОСНОВАНИЕ: BPJ0691 BPJ0718 BPJ0881 BPJ0922
BMC50471I BMC STATS API - V11.02.00
BMC50471I О ТЕХОБСЛУЖИВАНИИ НЕТ ОТЧЕТА
BMC50471I РАСШИРЕННЫЙ БУФЕРНЫЙ МЕНЕДЖЕР - V06.01.00
BMC50471I ОБСЛУЖИВАНИЕ: BPE0401 BPE0403 BPE0405 BPE0407 BPE0410 BPE0412 BPE0416 BPE0420 BPE0422 BPE0423 BPE0426 BPE0428
BMC50471I BPE0430 BPE0433 BPE0435 BPE0438 BPE0439
BMC50471I БЫСТРЫЙ ДВИГАТЕЛЬ - V11.02.00
BMC50471I О ТЕХОБСЛУЖИВАНИИ НЕТ ОТЧЕТА
0
BMC50471I APCOMMIT = 2500 FORCE_AT = (START, 3) RCVYDDN = (BMCRCY, BMCRCZ)
BMC50471I APDOPTS = FORCE_RPT = NO REDEFINE = YES
BMC50471I APMULTIROW = 100 FORCE = NONE RENMMAX = 30
BMC50471I APMXAGNT = 10 IBUFFS = 20 ПРАВИЛ = СТАНДАРТ
BMC50471I APRETLIM = COUNT IDCACHE = 1000 SDUMP = ДА
BMC50471I APRETVAL = 5 IDCDDN = SYSIDCIN SHORTMEMORY = ПРОДОЛЖИТЬ
BMC50471I AUTOENUMROWS = YES IDERROR = DISCARD SHRLEVEL = (NONE, NONE)
BMC50471I AVAILPAGEPCT = 0 INDDN = SYSREC SMAX = 16
BMC50471I CBUFFS = 30 INFORI = NO SMCORE = (0K, 0K)
BMC50471I CENTURY = (1950,2049) INLINECP = YES SORTDEVT = (, SYSALLDA)
BMC50471I CHEKPEND = YES KEEPDICTIONARY = NO SORTNUM = 32
BMC50471I COPYDDN = (BMCCPY, BMCCPZ) LBUFFS = 20 SQLDELAY = 3
BMC50471I COPYLVL = FULL LOADDN = SORTOUT SQLRETRY = 100
BMC50471I COPYPEND = ДА LOBAVGPCT = 50 STOP @ CMT = ДА
BMC50471I ПОДБОР КОПИРОВАНИЯ = NO LOCKROW = YES STOPDELAY = 1
BMC50471I DELFILES = (ДА, НЕТ) LONGNAMETRUNC = MIDDLE STOPRETRY = 300
BMC50471I DISCARDLIMRC = 8 MAPDDN = SYSMAP TAPEDISP = УДАЛИТЬ
BMC50471I DISCARDRC = 0 MAXP = 5 TOTALPAGEPCT = 30
BMC50471I DISCDDN = SYSDISC MAXSORTMEMORY = 0 TSSAMPLEPCT = 100
BMC50471I DRNDELAY = 1 MAXTAPE = 3 UPDMAXA_AUTHID = ПОЛЬЗОВАТЕЛЬ
BMC50471I DRNRETRY = 255 MGEXTENT = ПРОДОЛЖИТЬ UPDMAXA = НЕТ
BMC50471I DRNWAIT = NONE MINSORTMEMORY = 0 UXSTATE = SUP
BMC50471I DSNUEXIT = (НЕТ, ASM) MSGLEVEL = 1 WBUFFS = (20,10)
BMC50471I DSNUTILB = ДА OPNDB2ID = ДА WORKDDN = SYSUT1
BMC50471I ENFORCE = CHECK ORIGDISP = DELETE WORKUNIT = SYSALLDA
BMC50471I ERRDDN = SYSERR PAUSEDISCARDRC = 4 XBLKS = 3
BMC50471I EXCLDUMP = (X37, X22, X06) PLAN = AMUQA XMLAVGSIZE = 10240
BMC50471I FASTSWITCH = NO PREFORMAT = NO ZEROROWRC = 0
BMC50471I FILECHK = ПРЕДУПРЕЖДЕНИЕ ПРЕДВАРИТЕЛЬНАЯ ЗАГРУЗКА = ЗАГРУЗКА ZIIP = ВКЛЮЧЕНО
0
BMC50471I ПРИЛОЖЕНИЕ =
BMC50471I APOWNER =
0
BMC50470I DDTYPE = ЗАГРУЗИТЬ РАБОЧИЕ РАБОТЫ
BMC50470I АКТИВНЫЙ = ДА ДА НЕТ
BMC50470I IFALLOC = ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ
BMC50470I SMS = НЕТ НЕТ НЕТ
BMC50470I SMSUNIT = НЕТ НЕТ НЕТ
BMC50470I РАЗМЕРCT = (100,100) (100,100) (100,100)
BMC50470I UNIT = (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA)
BMC50470I UNITCNT = (0,0) (0,0) НЕТ
BMC50470I VOLCNT = (25,25) (25,25) Н / Д
BMC50470I AVGVOLSP = ((30000, TRK), (30000, TRK)) ((30000, TRK), (30000, TRK)) N / A
BMC50470I DSNTYPE = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I DATACLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I MGMTCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I STORCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I ПОРОГ = 0 0 0
BMC50470I MAXEXTSZ = ((0, K), (0, K)) ((0, K), (0, K)) Н / Д
BMC50470I EXPDT = НЕТ НЕТ НЕТ
BMC50470I RETPD = НЕТ НЕТ НЕТ
BMC50470I GDGLIMIT = НЕТ НЕТ НЕТ
BMC50470I GDGEMPTY = N / A N / A N / A
BMC50470I GDGSCRAT = НЕТ НЕТ НЕТ
0
BMC50470I DDTYPE = ОШИБКА ОТКАЗАТЬ LOCPFCPY
BMC50470I АКТИВНЫЙ = ДА ДА ДА
BMC50470I IFALLOC = ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ
BMC50470I SMS = НЕТ НЕТ НЕТ
BMC50470I SMSUNIT = НЕТ НЕТ НЕТ
BMC50470I РАЗМЕРCT = (100,100) (100,100) (100,100)
BMC50470I UNIT = (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA)
BMC50470I UNITCNT = (0,0) (0,0) (0,0)
BMC50470I VOLCNT = (25,25) (25,25) (25,25)
BMC50470I AVGVOLSP = ((30000, TRK), (30000, TRK)) ((30000, TRK), (30000, TRK)) ((30000, TRK), (30000, TRK))
BMC50470I DSNTYPE = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I DATACLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I MGMTCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I STORCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I ПОРОГ = 0 0 0
BMC50470I MAXEXTSZ = ((0, K), (0, K)) ((0, K), (0, K)) ((0, K), (0, K))
BMC50470I EXPDT =
BMC50470I RETPD =
BMC50470I GDGLIMIT = НЕТ НЕТ 5
BMC50470I GDGEMPTY = НЕТ НЕТ НЕТ
BMC50470I GDGSCRAT = НЕТ НЕТ НЕТ
0
BMC50470I DDTYPE = LOCBFCPY REMPFCPY REMBFCPY
BMC50470I АКТИВНЫЙ = НЕТ НЕТ НЕТ
BMC50470I IFALLOC = ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ
BMC50470I SMS = НЕТ НЕТ НЕТ
BMC50470I SMSUNIT = НЕТ НЕТ НЕТ
BMC50470I РАЗМЕРCT = (100,100) (100,100) (100,100)
BMC50470I UNIT = (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA)
BMC50470I UNITCNT = (0,0) (0,0) (0,0)
BMC50470I VOLCNT = (25,25) (25,25) (25,25)
BMC50470I AVGVOLSP = ((30000, TRK), (30000, TRK)) ((30000, TRK), (30000, TRK)) ((30000, TRK), (30000, TRK))
BMC50470I DSNTYPE = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I DATACLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I MGMTCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I STORCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I ПОРОГ = 0 0 0
BMC50470I MAXEXTSZ = ((0, K), (0, K)) ((0, K), (0, K)) ((0, K), (0, K))
BMC50470I EXPDT =
BMC50470I RETPD =
BMC50470I GDGLIMIT = 5 5 5
BMC50470I GDGEMPTY = НЕТ НЕТ НЕТ
BMC50470I GDGSCRAT = НЕТ НЕТ НЕТ
0
BMC50470I DDTYPE = SYSMAP LOCPLCPY LOCBLCPY
BMC50470I АКТИВНЫЙ = ДА ДА НЕТ
BMC50470I IFALLOC = ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ
BMC50470I SMS = НЕТ НЕТ НЕТ
BMC50470I SMSUNIT = НЕТ НЕТ НЕТ
BMC50470I РАЗМЕРCT = (100,100) (100,100) (100,100)
BMC50470I UNIT = (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA)
BMC50470I UNITCNT = (0,0) (0,0) (0,0)
BMC50470I VOLCNT = (25,25) (25,25) (25,25)
BMC50470I AVGVOLSP = ((30000, TRK), (30000, TRK)) ((30000, TRK), (30000, TRK)) ((30000, TRK), (30000, TRK))
BMC50470I DSNTYPE = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I DATACLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I MGMTCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I STORCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I ПОРОГ = 0 0 0
BMC50470I MAXEXTSZ = ((0, K), (0, K)) ((0, K), (0, K)) ((0, K), (0, K))
BMC50470I EXPDT = НЕТ
BMC50470I RETPD = НЕТ
BMC50470I GDGLIMIT = НЕТ 5 5
BMC50470I GDGEMPTY = НЕТ НЕТ НЕТ
BMC50470I GDGSCRAT = НЕТ НЕТ НЕТ
0
BMC50470I DDTYPE = REMPLCPY REMBLCPY LOCPXCPY
BMC50470I АКТИВНЫЙ = НЕТ НЕТ ДА
BMC50470I IFALLOC = ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ
BMC50470I SMS = НЕТ НЕТ НЕТ
BMC50470I SMSUNIT = НЕТ НЕТ НЕТ
BMC50470I РАЗМЕРCT = (100,100) (100,100) (100,100)
BMC50470I UNIT = (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA)
BMC50470I UNITCNT = (0,0) (0,0) (0,0)
BMC50470I VOLCNT = (25,25) (25,25) (25,25)
BMC50470I AVGVOLSP = ((30000, TRK), (30000, TRK)) ((30000, TRK), (30000, TRK)) ((30000, TRK), (30000, TRK))
BMC50470I DSNTYPE = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I DATACLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I MGMTCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I STORCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I ПОРОГ = 0 0 0
BMC50470I MAXEXTSZ = ((0, K), (0, K)) ((0, K), (0, K)) ((0, K), (0, K))
BMC50470I EXPDT =
BMC50470I RETPD =
BMC50470I GDGLIMIT = 5 5 5
BMC50470I GDGEMPTY = НЕТ НЕТ НЕТ
BMC50470I GDGSCRAT = НЕТ НЕТ НЕТ
0
BMC50470I DDTYPE = LOCBXCPY REMPXCPY REMBXCPY
BMC50470I АКТИВНЫЙ = НЕТ НЕТ НЕТ
BMC50470I IFALLOC = ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЕ
BMC50470I SMS = НЕТ НЕТ НЕТ
BMC50470I SMSUNIT = НЕТ НЕТ НЕТ
BMC50470I РАЗМЕРCT = (100,100) (100,100) (100,100)
BMC50470I UNIT = (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA) (SYSALLDA, SYSALLDA)
BMC50470I UNITCNT = (0,0) (0,0) (0,0)
BMC50470I VOLCNT = (25,25) (25,25) (25,25)
BMC50470I AVGVOLSP = ((30000, TRK), (30000, TRK)) ((30000, TRK), (30000, TRK)) ((30000, TRK), (30000, TRK))
BMC50470I DSNTYPE = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I DATACLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I MGMTCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I STORCLAS = (НЕТ, НЕТ) (НЕТ, НЕТ) (НЕТ, НЕТ)
BMC50470I ПОРОГ = 0 0 0
BMC50470I MAXEXTSZ = ((0, K), (0, K)) ((0, K), (0, K)) ((0, K), (0, K))
BMC50470I EXPDT =
BMC50470I RETPD =
BMC50470I GDGLIMIT = 5 5 5
BMC50470I GDGEMPTY = НЕТ НЕТ НЕТ
BMC50470I GDGSCRAT = НЕТ НЕТ НЕТ
0
BMC50483I ЗАГРУЗИТЬ DSNPAT = & UID..BMC. & TS. & DDNAME
BMC50483I РАБОТАЕТ DSNPAT = & UID..BMC. & TS. & DDNAME
BMC50483I SORTWORK DSNPAT = NONE
BMC50483I ОШИБКА DSNPAT = & UID..BMC. & TS. & DDNAME
BMC50483I ОТКАЗАТЬ DSNPAT = & UID..BMC. & TS. & DDNAME
BMC50483I SYSMAP DSNPAT = & UID..BMC. & TS. & DDNAME
0
BMC50483I LOCPFCPY DSNPAT = & UID. & DDNAME. & TS..F & PART..T & TIME
BMC50483I LOCBFCPY DSNPAT = & UID. & DDNAME. & TS..F & PART..T & TIME
BMC50483I REMPFCPY DSNPAT = & UID.& DDNAME. & TS..F & PART..T & TIME
BMC50483I REMBFCPY DSNPAT = & UID. & DDNAME. & TS..F & PART..T & TIME
0
BMC50483I LOCPLCPY DSNPAT = & UID. & DDNAME. & TS..T & TIME
BMC50483I LOCBLCPY DSNPAT = & UID. & DDNAME. & TS..T & TIME
BMC50483I REMPLCPY DSNPAT = & UID. & DDNAME. & TS..T & TIME
BMC50483I REMBLCPY DSNPAT = & UID. & DDNAME. & TS..T & TIME
0
BMC50483I LOCPXCPY DSNPAT = & UID. & DDNAME. & TS..F & PART..T & TIME
BMC50483I LOCBXCPY DSNPAT = & UID.& DDNAME. & TS..F & PART..T & TIME
BMC50483I REMPXCPY DSNPAT = & UID. & DDNAME. & TS..F & PART..T & TIME
BMC50483I REMBXCPY DSNPAT = & UID. & DDNAME. & TS..F & PART..T & TIME
0
BMC50471I НАСТРОЙКИ МОДУЛЯ DB2 DSNHDECP:
BMC50471I ВЕРСИЯ = 1110
BMC50471I ПО УМОЛЧАНИЮ ПОДСИСТЕМЫ = DEHJ
BMC50471I НАБОР СИМВОЛОВ = АЛФАНОВЫЙ
BMC50471I ФОРМАТ ДАТЫ = США
BMC50471I ФОРМАТ ВРЕМЕНИ = США
BMC50471I ДЛИНА МЕСТНОЙ ДАТЫ = 0
BMC50471I МЕСТНОЕ ВРЕМЯ ДЛИНА = 0
BMC50471I ДЕСЯТИЧНАЯ ТОЧКА = ПЕРИОД
BMC50471I ДЕСЯТИЧНАЯ АРИФМЕТИКА = 15
BMC50471I DELIMITER = ПО УМОЛЧАНИЮ
BMC50471I SQL DELIMITER = ПО УМОЛЧАНИЮ
BMC50471I СХЕМА КОДИРОВАНИЯ = EBCDIC
BMC50471I ПРИЛОЖЕНИЕ.СХЕМА КОДИРОВАНИЯ = EBCDIC
BMC50471I MIXED = НЕТ
BMC50471I EBCDIC CCSID = (37,65534,65534)
BMC50471I ASCII CCSID = (819,65534,65534)
BMC50471I UNICODE CCSID = (367,1208,1200)
BMC50471I НЕПРИЯТНЫЙ ЧАСОВОЙ ПОЯС = ТЕКУЩИЙ (-05: 00)
BMC50028I РЕЖИМ DB2 = NFM
BMC50471I BMC_BMCUTIL = 'BMCUTIL.CMN_BMCUTIL'
BMC50471I BMC_BMCSYNC = 'BMCUTIL.CMN_BMCSYNC'
BMC50471I BMC_BMCHIST = 'BMCUTIL.CMN_BMCHIST'
BMC50471I BMC_BMCDICT = 'BMCUTIL.CMN_BMCDICT '
0
0
BMC50102I НАГРУЗКА ЗАМЕНА
BMC50102I ПРЕДВАРИТЕЛЬНАЯ ЗАГРУЗКА ПРОДОЛЖИТЬ
BMC50102I EBCDIC CCSID (37,65534,65534)
BMC50102I В ПРИМЕР ТАБЛИЦЫ17.TBL1
BMC50102I (SMINT_COL1 ПОЛОЖЕНИЕ (1: 2) МАЛЕНЬКОЕ
BMC50102I, TIMESTAMP_COL2 POSITION (4:29) TIMESTAMP EXTERNAL (26)
BMC50102I, DATE_COL3 POSITION (31:40) DATE EXTERNAL (10)
BMC50102I, СИМВОЛ_COL4 ПОЛОЖЕНИЕ (42:48) СИМВОЛ (7)
BMC50102I)
BMC51424I ФАЗА АНАЛИЗА БУДЕТ ВЫПОЛНЕНА ИЗ-ЗА ДИНАМИЧЕСКОГО РАСПРЕДЕЛЕНИЯ РАБОЧИХ ФАЙЛОВ
BMC51561I РАСЧЕТНОЕ КОЛИЧЕСТВО ВХОДНЫХ ЗАПИСЕЙ = 26 С ИСПОЛЬЗОВАНИЕМ МАСШТАБИРУЮЩЕГО КОЭФФИЦИЕНТА 100%
BMC50004I UTILINIT ФАЗА ЗАВЕРШЕНА.ПРОШЕДШЕЕ ВРЕМЯ = 00:00:00
BMC50041I 0: ZIIP ВКЛЮЧЕН (0) ИСПОЛЬЗОВАНИЕ ПОДСИСТЕМЫ XBM XBMB
BMC50004I АНАЛИЗ ФАЗЫ ЗАВЕРШЕН. ПРОШЕДШЕЕ ВРЕМЯ = 00:00:00
BMC50041I 0: ZIIP НЕ ВКЛЮЧЕН (0) ИСПОЛЬЗОВАНИЕ ПОДСИСТЕМЫ XBM XBMB
BMC50425I & JOBNAME = AMUEX17 & STEPNAME = EXAMPL17 & DB = AMUEX17D & TS = EX17TS & UID = RDAMZL
BMC50425I & RESUME = N & REPLACE = Y & DATE = 030915 & TIME = 152724 & SSID = DEHJ
BMC50425I & UTIL = EXAMPL17 & UTILPFX = EXAMPL17 & UTILSFX = & DATE8 = 030 & GRPNM = DEHJ
BMC50425I & VCAT = DEHJCAT & TIME4 = 1527 & DATEJ = 2015068 & JDATE = 15068
BMC50445I LOAD PLUS ДИНАМИЧЕСКИЙ ОТЧЕТ О РАСПРЕДЕЛЕНИИ ФАЙЛОВ
BMC50041I 0: ZIIP ВКЛЮЧЕН (0) ИСПОЛЬЗОВАНИЕ ПОДСИСТЕМЫ XBM XBMB
BMC50474I НИЖЕ 16M = 8488K, ВЫШЕ 16M = 12K, CPUS = 3
BMC50479I ВСЕГО СТРАНИЦ: 3981642, РАЗРЕШЕНО: 11 ; ДОСТУПНЫЕ СТРАНИЦЫ: 583318, РАЗРЕШЕНО: 0
BMC51495I ОПТИМИЗАЦИЯ ПРЕДВАРИТЕЛЬНОЙ ЗАГРУЗКИ, RC = 0, #SORTS = 1, #READERS = 1, INDEX TASKS = 0, TIME = 29696
BMC51496I ПРЕДВАРИТЕЛЬНЫЙ АНАЛИЗ, #SORTS = 1, #READERS = 1, INDEX TASKS = 0
BMC50481I 1: ЗАДАЧА ПРОЧИТАТЬ ЗАВЕРШЕНА.ПРОШЕДШЕЕ ВРЕМЯ = 00:00:00
BMC51510I 1: ЗАДАЧА ЧТЕНИЯ, XBLK XFERS = 1, ПУСТЫЕ WAITS = 0, FULL WAITS = 0
BMC51478I СТАТИСТИКА ПРЕДВАРИТЕЛЬНОЙ ЗАГРУЗКИ: 20 ФИЗИЧЕСКИХ (20 ЛОГИЧЕСКИХ) ЗАПИСЕЙ, ПРОЧИТАННЫХ ИЗ SYSREC
BMC50481I 2: ЗАДАЧА ДАННЫХ ВЫПОЛНЕНА. ПРОШЕДШЕЕ ВРЕМЯ = 00:00:00
BMC51510I 2: ЗАДАЧА СОРТИРОВКИ, XBLK XFERS = 1, EMPTY WAITS = 0, FULL WAITS = 0
BMC50476I DDNAME = SYSREC, I / OS = 1, I / O WAITS = 1, RDB LOCK WAITS = 0
BMC50476I DDNAME = SORTOUT, I / OS = 2, I / O WAITS = 2, RDB LOCK WAITS = 0
BMC50476I DDNAME = SYSERR, I / OS = 1, I / O WAITS = 1, RDB LOCK WAITS = 0
BMC51507I XBLKS = 5, XFERS = 1, ПУСТЫЕ ОЖИДАНИЯ = 0, ПОЛНЫЕ ОЖИДАНИЯ = 0
BMC50476I DDNAME = SYSDISC, I / OS = 0, I / O WAITS = 0, RDB LOCK WAITS = 0
BMC51486I ЗАГРУЗКА НАБОРА ДАННЫХ DEHJCAT.DSNDBD.AMUEX17D.EX17TS.I0001.A001 'ТРЕБУЕТСЯ 3 СТРАНИЦЫ
BMC51472I СТАТИСТИКА ФАЗЫ ПРЕДВАРИТЕЛЬНОЙ ЗАГРУЗКИ: 20 СТРОК ВЫБРАНО ДЛЯ ПРОСТРАНСТВА 'AMUEX17D.EX17TS', 0 СТРОК ВЫБРАНО, НО ОТКЛЮЧЕНЫ ИЗ-ЗА ОШИБОК
BMC51479I ФАЗНАЯ СТАТИСТИКА ПРЕДВАРИТЕЛЬНОЙ ЗАГРУЗКИ: 0 ФИЗИЧЕСКИХ (0 ЛОГИЧЕСКИХ) ЗАПИСЕЙ ОТПРАВЛЕНО В SYSDISC
BMC50041I 0: ZIIP НЕ ВКЛЮЧЕН (0) ИСПОЛЬЗОВАНИЕ ПОДСИСТЕМЫ XBM XBMB
BMC50004I ФАЗА ПРЕДВАРИТЕЛЬНОЙ ЗАГРУЗКИ ЗАВЕРШЕНА. ПРОШЕДШЕЕ ВРЕМЯ = 00:00:00
BMC50041I 0: ZIIP ВКЛЮЧЕН (0) ИСПОЛЬЗОВАНИЕ ПОДСИСТЕМЫ XBM XBMB
BMC50474I НИЖЕ 16M = 8568K, ВЫШЕ 16M = 1306100K, CPUS = 3
BMC50479I ВСЕГО СТРАНИЦ: 3982361, РАЗРЕШЕНО: 11; ДОСТУПНЫЕ СТРАНИЦЫ: 583543, РАЗРЕШЕННЫЕ: 0
BMC51498I ОПТИМИЗАЦИЯ ЗАГРУЗКИ, RC = 0, # ЗАДАЧИ ЗАГРУЗКИ = 1, # ЗАДАЧИ КОПИРОВАНИЯ = 0, # ЗАДАЧИ ИНДЕКС = 0
BMC51508I МАКС.ЗАДАЧ ПО ДАННЫМ = 1, МАКС.ЧАСТЕЙ НА ЗАДАЧУ = 1, СОРТИРОВКИ НА ЗАДАЧУ = 0, МАКСИМАЛЬНОЕ ОТКРЫТЫЕ РАЗДЕЛЫ НА ЗАДАЧУ = 1
BMC51453I СУЩЕСТВУЮЩИЕ РЯДЫ В TABLESPACE 'AMUEX17D.EX17TS УДАЛЕНО
BMC50482I 0: ЗАГРУЗИТЬ ЗАВЕРШЕНА. ПРОШЕДШЕЕ ВРЕМЯ = 00:00:00 DSN = 'DEHJCAT.DSNDBD.AMUEX17D.EX17TS.I0001.A001'
BMC50477I 0: РАЗДЕЛ = 0, ROWS / KEYS = 20, I / O WAITS = 5, DDNAME = SYS00004
BMC50476I DDNAME = SORTOUT, I / OS = 1, I / O WAITS = 1, RDB LOCK WAITS = 0
BMC51475I НАГРУЗОЧНАЯ СТАТИСТИКА: 20 СТРОК, ЗАГРУЖЕННЫХ В ТАБЛИЧНОЕ ПРОСТРАНСТВО 'AMUEX17D.EX17TS'
BMC50318I НАБОР ДАННЫХ УСПЕШНО УДАЛЕН, DDNAME = 'SYSERR', DSNAME = 'AMU.EXAMP017.SYSERR'
BMC50318I НАБОР ДАННЫХ УСПЕШНО УДАЛЕН, DDNAME = 'SORTOUT', DSNAME = 'AMU.ПРИМЕР017.SORTOUT '
BMC50041I 0: ZIIP НЕ ВКЛЮЧЕН (0) ИСПОЛЬЗОВАНИЕ ПОДСИСТЕМЫ XBM XBMB
BMC50004I ФАЗА НАГРУЗКИ ЗАВЕРШЕНА. ПРОШЕДШЕЕ ВРЕМЯ = 00:00:01
BMC50501I СТАТИСТИКА ОБЪЕКТОВ DB2
0BMC50515I TABLESPACE AMUEX17D.EX17TS PARTS = 0 TABLES = 1 SEGSIZE = 64 DSSIZE = 0G PAGESIZE = 4K
BMC50516I ЧАСТЬ НАПРЯЖЕННАЯ КАРТА РАСШИРЕНИЯ DBCARD PCOMP KSAVED PSAVED
BMC50517I 0 3 20 1 0 0 0 0
BMC50518I ТАБЛИЦА ПРИМЕР 17.TBL1
BMC50519I ROWAVG ОБРАБОТЧИВАЕТ КАРТУ PCTPAGES
BMC50520I 27 1 20 1
BMC50290I DB2 REAL-TIME-STATISTICS -RESET STATS- ФУНКЦИЯ ДЛЯ УТИЛИТЫ ЗАГРУЗКИ УСПЕШНО ДЛЯ ВСЕХ ОБЪЕКТОВ
BMC50387W ТРЕБУЕТСЯ КОПИЯ ИЗОБРАЖЕНИЯ. ТАБЛИЧНОЕ ПРОСТРАНСТВО AMUEX17D.EX17TS СОСТОЯНИЕ УСТАНОВЛЕНА «ОЖИДАНИЕ КОПИРОВАНИЯ»
BMC50004I ФАЗА УТИЛЬТЕРМА ЗАВЕРШЕНА. ПРОШЕДШЕЕ ВРЕМЯ = 00:00:00
0BMC50006I ВЫПОЛНЕНИЕ УТИЛИТЫ ЗАВЕРШЕНО, КОД ВОЗВРАТА = 4 (PDF) ПОДХОД СТЕГАНОГРАФИИ ГИБРИДНОГО ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ПРОСТРАНСТВЕННЫХ ХАРАКТЕРОВ UNICODE И НУЛЕВОЙ ШИРИНЫ
Международный журнал по информационным технологиям и безопасности, № 1 (т.9), 2017
[11] И. Банерджи, С. Бхаттачарья и Г. Саньял, «Стеганография нового текста посредством генерации специального кода
», в Трудах Международной конференции по системности, кибернетике и
информатике (ICSCI- 2011), Хайдарабад, Индия, 2011.
[12] А. Аль-Азави и М.А. Фадхил, «Стеганография арабского текста с использованием расширений кашида
с кодом Хаффмана», Прикладная наука, том. 10, pp. 436-439, 2010.
[13] А. Гутуб и М. Фаттани, «Новый метод стеганографии арабского текста с использованием буквенных точек
, и расширений», Всемирная академия наук, инженерии и технологий, вып.27, pp. 28-
31, 2007.
[14] Д. Хуанг и Х. Ян, «Изменения межсловного расстояния, представленные синусоидальными волнами для текстовых изображений водяных знаков
», IEEE Transactions on Circuits and Systems for Video
Техника, т. 11, pp. 1237-1245, 2001.
[15] YM Alginahi, MN Kabir и O. Tayan, «Улучшенный подход с нанесением водяных знаков на основе Кашиды
для арабских текстовых документов» в Electronics, Computer and Computing
(ICECCO), Международная конференция 2013 г., 2013 г., стр.301-304.
[16] С. Кингслин и Н. Кавита, «Оценочный подход к текстовым стеганографическим методам
«, Индийский журнал науки и технологий, вып. 8, 2015.
[17] Р. Санией и К. Фаэз, «Безопасность арифметического сжатия текста на основе
Метод стеганографии», Международный журнал электротехники и вычислительной техники, вып.
3, стр. 797, 2013.
[18] Р. С. Р. Прасад и К. Алла, «Новый подход к стеганографии текста на телугу», 2011 г.
Симпозиум IEEE по беспроводным технологиям и приложениям (ISWTA), 2011 г., стр.60-65.
[19] Л. Пор, Б. Делина, К. Ли, С. Чен и А. Сюй, «Скрытие информации: новый подход в стеганографии текста
», Международная конференция WSEAS. Ход работы. Математика и
Компьютеры в науке и технике, 2008.
[20] К. Беннетт, «Лингвистическая стеганография: обзор, анализ и проблемы надежности
, скрывающих информацию в тексте», 2004 г.
[21] А. Одех и К.М. Эллейти, «Стеганография в тексте путем слияния ZWC и символа Space
», 2012 г.
[22] Д. Чжан и Х. Чжун, «Метод скрытия текста с использованием многоосновной системы обозначений
с высокой способностью встраивания», в «Обработке изображений и сигналов» (CISP), 2014 г. 7-й Международный конгресс
, 2014 г. , стр. 622-627.
[23] Л. Ю. Пор, К. Вонг и К. О. Чи, «UniSpaCh: текстовый метод скрытия данных с использованием
символов пробела Unicode», Journal of Systems and Software, vol. 85, pp. 1075-1082, 2012.
[24] A. T. Abbasi, S.Н. Накви, А. Хан и Б. Ахмад, «Стеганография текста на урду: использование
отдельных букв», 2015 г.
[25] И. Стоянов, А. Милева и И. Стоянович, «Новое кодирование свойств in Text
Стеганография документов Microsoft Word, 2014.
[26] С. Рой и М. Манасмита, «Новый подход к форматированной текстовой стеганографии», в
Proceedings of the 2011 International Conference on Communication, Computing &
Безопасность, 2011, стр.511-516.
Поддержка Unicode для ‘string is space’ и ‘string trim’
Автор: Ян Нийтманс <[email protected]>
Состояние: Окончательный
Тип: Проект
Голосовать: Готово
Создано: 08-окт-2012
Постистория:
Обсуждения-Кому: Список ядра Tcl
Ключевые слова: Tcl
Tcl-Версия: 8.6
Tcl-Branch: tip-318-update
Этот TIP фактически является пересмотром [318], поскольку он пытается
определить, раз и навсегда, для каких символов строка является пробелом должна
вернуть 1 и какие символы string trim следует обрезать.
Интуитивно понятно, что строка — это пространство и обрезка струны должна относиться к тому же
как пробел, но в настоящее время это не так, даже после
реализация [318]. Стандарт юникода расширен до версии 6.2 (на
на момент написания этой статьи), но также у Java и .NET есть свои взгляды на то, что
пробел должен быть. Попробуем поучиться у них.
Определение набора пространства Tcl
Символ NUL выполняет функцию разделителя строк, который может быть
рассматривается в той же группе, что и LINE SEPARATOR (U + 2028) и PARAGRAPH
СЕПАРАТОР (U + 2029).Это очень полезный персонаж для раздевания. У него даже было
свойство Whitespace в Unicode 2.0. Проблема с учетом этого
символ в качестве пробела заключается в том, что его видимое представление не указано, это
даже не должно встречаться в обычном тексте. Следовательно, его нет в пространстве Tcl.
set «, но очень полезно оставить его без обрезки струны .
Стандарт Unicode изменился со временем, что привело к появлению пробелов.
удаляется (устарело) и добавляется. Строка .Метод Trim () в .NET
3.5 пустое пространство нулевой ширины (U + 200B) и неразрывное пространство нулевой ширины (U + FEFF)
из строк, но более поздние версии .NET этого больше не делают. Пространство «Tcl»
set «не должен зависеть от этого: если символы в будущем Unicode устарели
версии, и из-за того, что свойства Whitespace изменены, они не будут
быть удаленным из «набора пространства Tcl». Но если новые пробельные символы
добавленные в будущих стандартах Unicode, они будут добавлены в «набор пространств Tcl»
Кроме того, на струну влияет пробел и обрезка струны .
3 символа, которые находятся в «наборе пробелов Tcl», но отсутствуют в текущем
Набор пробелов Unicode обсуждается сейчас.
Наиболее очевидным является неразрывный пробел нулевой ширины (U + FEFF), который очень полезен
удаляемый символ, так как теперь он используется как метка порядка байтов (BOM). Она имеет
нет видимого представления и — фактически — никакого смысла в Tcl, поскольку
Tcl уже внутри UTF-8. Это не должно происходить где-либо еще в
строка, но в прошлом это могло быть неразрывное пространство нулевой ширины.Это было
свойство White_Space в Unicode 2.0, но более поздние версии Unicode делают
нет; использование спецификации в качестве пробела устарело.
Когда использование пробела было объявлено устаревшим для (U + FEFF), был помещен другой символ
вперед в качестве замены для него: объединитель слов (U + 2060). Поскольку у этого персонажа нет
видимое представление и не имеет никакого значения в начале или в конце
строки, имеет смысл включить ее также в «набор пространств Tcl»,
больше, потому что его предшественник имел свойство White_Space .
Наконец, пространство нулевой ширины (U + 200B) имело свойство White_Space в
Юникод 3.0. В текущих диаграммах Unicode он по-прежнему указан как
пробел, хотя свойство White_Space было удалено позже. Поэтому это
также должен быть в «наборе пробелов Tcl».
В этом документе предлагается:
Для набора ASCII строка — это пробел, остается как есть. обрезка струн будет изменен, чтобы обрезать все символы, для которых строка является пробелом возвращает 1, дополненную символом NUL.Это означает, что NUL, VT и FF
будет добавлено в набор. Это потенциальная несовместимость .
Для символов вне ASCII, Unicode White_Space http://www.unicode.org/Public/6.2.0/ucd/PropList.txt формирует
основа того, что строка является пробелом и обрезка струны считают
Космос. Но в набор добавляется 3 символа: ноль с пробелом (U + 200B),
средство объединения слов (U + 2060) и неразрывный пробел нулевой ширины (U + FEFF) (т.е.,
Спецификация).
Команды обрезки струны слева, и , справа, , также будут
модифицированы, так как они отслеживают струнной обрезки .
Для набора ASCII единственное изменение — добавление 3 символов к обрезка струн . Для Unicode изменений больше, но все добавлено
символы либо используются редко, либо интуитивно ожидается, что они будут обрезаны
по обрезка струны . Я не думаю, что это повлияет на какой-либо код.
этим изменением он, вероятно, исправит больше ошибок, чем сломает какие-либо
существующий код.
NUL можно добавить к строке — это пробел , но это будет
противоречить тому, что делает функция isspace () в POSIX .
NUL можно исключить из набора обрезки струны .
Дополнительные символы, которые я считал частью набора:
здесь разрешен перерыв (U + 0082)
здесь нет перерыва (U + 0083)
соединитель нулевой ширины (U + 200C)
ноль с несоединением (U + 200D)
Это явно полезные символы, которые нужно удалить, так как в них нет
значение и отсутствие видимого появления в начале или конце строки.Но
они не являются пробелами, поэтому две команды будут расходиться.
Эталонная реализация доступна в репозитории ископаемых Tcl на tip-318-update ветка https://core.tcl-lang.org/tcl/timeline?r=tip-318-update.
Этот документ размещен в открытом доступе.
System To To — в пространстве для юникода
Ой! Это изображение не соответствует нашим правилам в отношении содержания.Чтобы продолжить публикацию, пожалуйста, удалите его или загрузите другое изображение.
Ой! Это изображение не соответствует нашим правилам в отношении содержания.Чтобы продолжить публикацию, пожалуйста, удалите его или загрузите другое изображение.
Ой! Это изображение не соответствует нашим правилам в отношении содержания.Чтобы продолжить публикацию, пожалуйста, удалите его или загрузите другое изображение.
Ой! Это изображение не соответствует нашим правилам в отношении содержания.Чтобы продолжить публикацию, пожалуйста, удалите его или загрузите другое изображение.
Ой! Это изображение не соответствует нашим правилам в отношении содержания.Чтобы продолжить публикацию, пожалуйста, удалите его или загрузите другое изображение.