Крылатское.ру | Новости | Человейник, едальня и корнер. Яндекс и Институт русского языка выделили слова, которые употребляют только в столичном регионе
Аналитики Яндекса совместно с экспертами Института русского языка им. В.В. Виноградова составили список диалектных слов (слова, употребляемые только жителями той или иной местности – прим. ред.), которые используются жителями в разных регионах России. Для москвичей и жителей Подмосковья свойственно четыре необычных слова, среди которых человейник и едальня.
«Мы попробовали составить список таких слов — не претендующий на полноту, но хотя бы дающий представление о региональном разнообразии русского языка. Для этого использовали данные блог-платформы
Яндекс.Дзен: изучили статьи и комментарии 6 млн пользователей из всех регионов России, в общей сложности — 11 млрд словоупотреблений. А потом вместе с лингвистами из Института русского языка им.
В. В. Виноградова РАН отобрали самые интересные слова и дали им определения», — отмечают в Яндексе.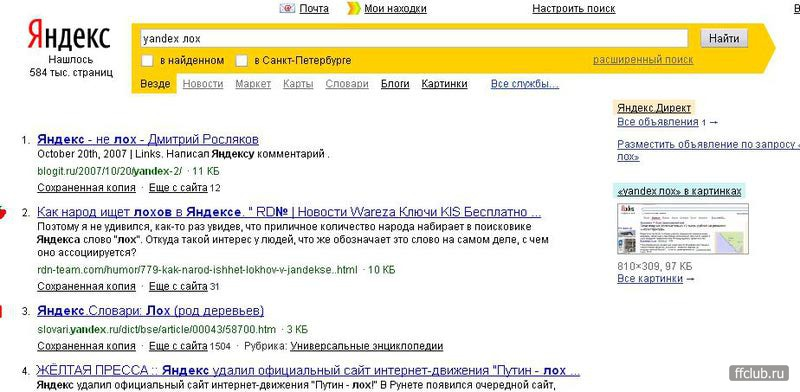
В результате, в список вошли удивительные, по своему произношению, и в то же время очень точные по смыслу слова, которые свойственны именно жителям тех или иных регионов.
Так, например, в Москве и Московской области специалисты выделили четыре, что сравнительно немного, нетипичных слова, которые совершенно не свойственны для жителей других российских регионов. Слово «человейник», что в буквальном смысле означает большой многоквартирный дом, употребляют в обиходе только москвичи и жители Подмосковья.
В исследовании не отмечается, что стало причиной появления этого слова, хоть и приводится пример его использования. Как правило, используется оно при описании жилых домов многоэтажной постройки, возведенных по реновации. Именно такие дома, или человейники, в последние несколько лет стали появляться во многих столичных районах, а также городах Подмосковья.
Еще одно не типичное для жителей других регионов России, но свойственное для москвичей, стало слово «едальня», что означает любое заведение общепита, будь то кафе, бар или дорогой ресторан. При этом, как и слово человейник, оно используется, как правило, в уничижительном смысле. По всей видимости, его появление связано с наличием в Москве и области большого количество разных
«забегаловок», которые, по большей части, не отличаются друг от друга.
При этом, как и слово человейник, оно используется, как правило, в уничижительном смысле. По всей видимости, его появление связано с наличием в Москве и области большого количество разных
«забегаловок», которые, по большей части, не отличаются друг от друга.
Третье слово, которое выделили в Яндексе, также имеет отношение к торговле и отчасти общепиту. Речь идет о слове «корнер» — отдельный павильон, торговая точка или стенд в большом магазине или торговом центре. Однако данное понятие чаще встречается в разговорах у жителей не только Москвы и Московской области, но и Томской области.
А вот слово «обплеваться», то есть испытать или выразить крайнее недовольство, часто употребляют как москвичи, так и жители Пензенской, Рязанской, Самарской, Саратовской и Тульской областей. В других регионах оно особенно не употребляется.
Впрочем, отмечают в Яндексе, это не означает, что жители других регионов не испытывают в повседневной жизни недовольства. Дело в том, что у них в регионе есть свое собственное слово,
описывающее те же эмоции.
С полным списком слов можно ознакомиться по ссылке.
«Яндекс» как угроза — Ведомости
Благоприятный инвестклимат в России – это некая бюрократическая фикция, которой можно пожертвовать, если речь идет о контроле над стратегическими национальными компаниями. Это в очередной раз подтвердила история «Яндекса», капитализация которого резко и сильно обвалилась из-за законопроекта малоизвестного депутата Госдумы.
Падение в пятницу котировок «Яндекса», крупнейшей российской интернет-компании, стало самым значительным в 2019 г.: на 17% на американской NASDAQ, на 20% на Мосбирже; за день компания потеряла $1,5 млрд капитализации. Причиной стало обсуждение в четверг в Госдуме законопроекта, внесенного депутатом «Единой России» Антоном Горелкиным. Он предлагает запретить иностранцам владеть более чем 20% долей или акций в «значимых» IT-компаниях по аналогии с законом о СМИ, подписанным Владимиром Путиным в 2014 г.
Он предлагает запретить иностранцам владеть более чем 20% долей или акций в «значимых» IT-компаниях по аналогии с законом о СМИ, подписанным Владимиром Путиным в 2014 г.
Инвесторы отреагировали на новость очень нервно, хотя судьба идеи формально остается неопределенной: законопроект еще не принят даже в первом чтении, после которого он может измениться до неузнаваемости. Да и сам Горелкин до сих пор не был заметным законотворцем или лоббистом, это первый его самостоятельный законопроект. Другое дело, что его поддержали фракция «Единая Россия», Роскомнадзор, ФАС, а также, как говорят источники The Bell и Bloomberg, Кремль.
Путин, конечно, может ездить в гости к «Яндексу», верить, что через несколько лет Россия войдет в число мировых лидеров в области искусственного интеллекта, поручать создать «максимально комфортные условия» для частных инвестиций в технологические стартапы. Но эти слова, получается, ничего не значат, когда речь заходит о безопасности страны, которой противопоставляется ее технологическое развитие. Ради нацбезопасности можно пренебречь «деталями», включая мнение частных IT-компаний, которые выступили резко против законопроекта, предупредив, что это фактически будет означать запрет на иностранные инвестиции в российские IT-компании и если не убьет отрасль, то загонит ее на глобальную периферию.
Ради нацбезопасности можно пренебречь «деталями», включая мнение частных IT-компаний, которые выступили резко против законопроекта, предупредив, что это фактически будет означать запрет на иностранные инвестиции в российские IT-компании и если не убьет отрасль, то загонит ее на глобальную периферию.
Горелкин не видит тут проблемы: сегодня котировки упали – завтра подрастут, написал он в своем телеграм-канале «Душитель интернета». Но обвал котировок флагмана российской цифровой индустрии – это общая оценка инвестклимату и институтам, которые призваны его улучшать, триггером падения может выступить любой собирательный Горелкин, чьи инициативы отвечают охранительной конъюнктуре. Инвестклимат измеряется в правительстве и Кремле не объемом инвестиций, новыми предприятиями и рабочими местами, а местом в различных иностранных рейтингах, которые стали удобными бюрократическими показателями для отчетности в конечном счете перед тем же Путиным. Сегодня мы в них упали – завтра подрастем. Видимо, такая логика и здесь уместна.
Видимо, такая логика и здесь уместна.
Кратко о том, какое значение имеет слово Яндекс
Современный Интернет сложно представить без специальных поисковых систем, которые ежедневно пополняются миллионами новых интернет-страниц со всего мира, предоставляя определенную группу страниц, в зависимости от их тематического содержания. До появления поисков приходилось записывать определенные имена страниц, после чего каждый раз набирать их в браузере. Но все меняется, и Интернет в частности. С появлением поисковой системы «Яндекс» русскоязычный сегмент Интернета получил доступ к нужной информации на русском языке. Но что означает слово «Яндекс»? В данной статье речь идет как раз об этом.
Что такое «Яндекс»?
«Яндекс» – это специальная поисковая система, созданная в далеком 1997 году. На тот момент времени практически не существовало поисковых систем, тем более, для русскоговорящего сегмента глобальной сети Интернет. Раньше людям приходилось узнавать у знакомых адреса страниц, на которых находились списки интернет-сайтов, или же самому по смысловому значению вписывать на английском языке какие-нибудь адреса. Не факт, что данный подбор адресов мог увенчаться успехом.
Не факт, что данный подбор адресов мог увенчаться успехом.
Ежедневно создаются миллионы интернет-страниц. Каждая из них содержит контент определенной тематики, например, музыку. Теперь представьте себе, что вы сидите за компьютером, у вас открыт браузер, вы знаете о существовании подобной странички, но не можете ничего больше делать, как хаотично вбивать различные адреса, и не факт, что желаемый результат будет на русском языке. Как известно, нынче Интернет состоит на 70% из сайтов, где размещается информация на английском языке, на момент 1997 года этот процент был близок к 100.
Создание русскоязычной поисковой системы было неким прорывом для всего СНГ, от чего популярность «Яндекса» держится и по сей день, хоть в мире существует множество других поисковых систем, не уступающих как по функционалу, так и по количеству искомой информации. Но, вопрос в том, что означает слово «Яндекс» не каждый его пользователь знает. В данной статье мы подробно расскажем об истории этого чудного слова, изменившего русский Интернет.
Что означает слово «Яндекс» и откуда оно берет свое начало?
Не многие знают, но поисковая система представляет собой определенный каталог из интернет-страниц, а не просто программу, которая при нажатии кнопки «Поиск» рыщет весь Интернет на сходство слов в поиске и на сайте. Совсем все не так. При создании своей интернет-странички человек может ее зарегистрировать на каком-нибудь поисковике, но может и отказаться от этого, из-за чего сайт нельзя будет увидеть при поиске, доступ к нему будет осуществляться лишь при введении его адреса в браузере.
Итак, «Яндекс», как и все другие поисковые системы, – это большой каталог сайтов, среди которых уже поисковик выбирает сайты, где встречаются искомые словосочетания. В переводе на английский каталог будет писаться как index. У данного слова множество переводов, но сейчас речь идет именно о одном из них, ведь именно из-за данного слова поисковая система так и называется.
Изначально создатели хотели назвать поисковую систему Yet another indexer, т. е как еще один каталог. Название было слишком саркастичное, ведь на тот момент было множество поисковиков на английском, но ни одного для русскоговорящих стран. Теперь в голове может сложиться уже ответ на вопрос, почему «Яндекс» так назвали. Вышеуказанное название было сокращено до Yet another, но подобный вариант все равно не нравился создателям, после чего было решено сделать аббревиатуру «YT» и лишь потом конвертировать всего лишь в одну русскую букву «Я», а потом заменить ею первую букву в слове «index». Так и получилось «Яндекс».
е как еще один каталог. Название было слишком саркастичное, ведь на тот момент было множество поисковиков на английском, но ни одного для русскоговорящих стран. Теперь в голове может сложиться уже ответ на вопрос, почему «Яндекс» так назвали. Вышеуказанное название было сокращено до Yet another, но подобный вариант все равно не нравился создателям, после чего было решено сделать аббревиатуру «YT» и лишь потом конвертировать всего лишь в одну русскую букву «Я», а потом заменить ею первую букву в слове «index». Так и получилось «Яндекс».
Основные конкуренты
Как уже говорилось в заголовке о том, что означает слово «Яндекс» — поисковая система – это специальный каталог сайтов, который ищет ответы на заданные вопросы в своем же каталоге, но не у других поисковиков, хоть такие решения тоже существуют. В последнее время у данной поисковой системы существует лишь один крупный конкурент в русскоязычном сегменте – это Mail.ru. Как бы то ни было, но «Яндекс» все равно остается лидером. Если брать глобальные масштабы, то сильных конкурентов достаточно много, среди которых Google, Yahoo и другие немалоизвестные поисковые системы.
Если брать глобальные масштабы, то сильных конкурентов достаточно много, среди которых Google, Yahoo и другие немалоизвестные поисковые системы.
В заключение
Надеемся, что данная статья помогла вам найти ответ о том, что означает слово «Яндекс», и вы теперь чуточку лучше знаете историю современного Интернета.
Также не стоит забывать о том, что каждый создатель интернет-странички может зарегистрировать ее в «Яндексе». Абсолютно бесплатно.
Банчить, колымить и просрота: «Яндекс» назвал диалектные слова Томской области
Дмитрий Кандинский / vtomske.ru
Ко Дню русского языка 6 июня «Яндекс» опубликовал исследование про слова, которые используются только в некоторых частях страны. Лингвистам удалось установить, что в Томской области употребляют такие слова, как «просрота», «банчить», «вехотка», которые почти нигде больше не встречаются.
При составлении списков слов лингвисты использовали данные блог-платформы «Яндекс.Дзен»: изучили статьи и комментарии шести миллионов пользователей из всех регионов России, в общей сложности — 11 миллиардов словоупотреблений. Лингвисты из Института русского языка имени Виноградова РАН помогли отобрать самые интересные слова и дать им определения. Некоторые слова оказались характерными сразу для нескольких регионов.
Лингвисты из Института русского языка имени Виноградова РАН помогли отобрать самые интересные слова и дать им определения. Некоторые слова оказались характерными сразу для нескольких регионов.
По данным специалистов, только в Томской области употребляют слова «просрота» (просроченные товары) и
Слово «банчить» (торговать) можно встретить как в Томской области, так и в Оренбургской и Свердловская областях. В четырех регионах России, включая Томск, мочалку часто называют вехоткой. Под следиками в Томской, Новосибирской областях и Алтайском крае имеют в виду вязаные тапочки.
Слова «еслив» и «еслиф» (оно же — если) употребляют в Алтайском, Красноярском краях, Иркутской, Томской, Новосибирской областях и в Кузбассе. Жители Томской, Амурской областей, Красноярского и Приморского краев комнату или квартиру гостиничного типа называют гостинкой.
По данным лингвистов, только в Томской области и в Хакасии говорят калымить или колымить, имея в виду тяжелую работу. Известное слово «мультифора» (файлик) используют жители нескольких сибирских регионов.
В Москве и Томской области могут сказать корнер. Это отдельный павильон, торговая точка или стенд в большом магазине или торговом центре. Томичи и их соседи по Сибири могут сказать на разновес вместо на развес. Слово «огребаться» (пострадать, быть наказанным) можно услышать во многих регионах Сибири и в Хабаровском крае.
Три региона (Томская область, Красноярский край и Чувашия), по данным лингвистов, говорят секционка. Это секция из нескольких квартир с общим санузлом, комната в такой секции или дом с такими секциями. Жители нескольких регионов СФО говорят строжиться, что означает вести себя строго, сердиться. В Новосибирской и Томской областях можно встретить слово «шурушки». Это штучки, вещички, детальки, мелкие предметы.
Это штучки, вещички, детальки, мелкие предметы.
Еще одно местное для Сибири слово — «повдоль», которое употребляют вместо слова «вдоль». Вместо разбаловать в Томске и еще нескольких регионах говорят
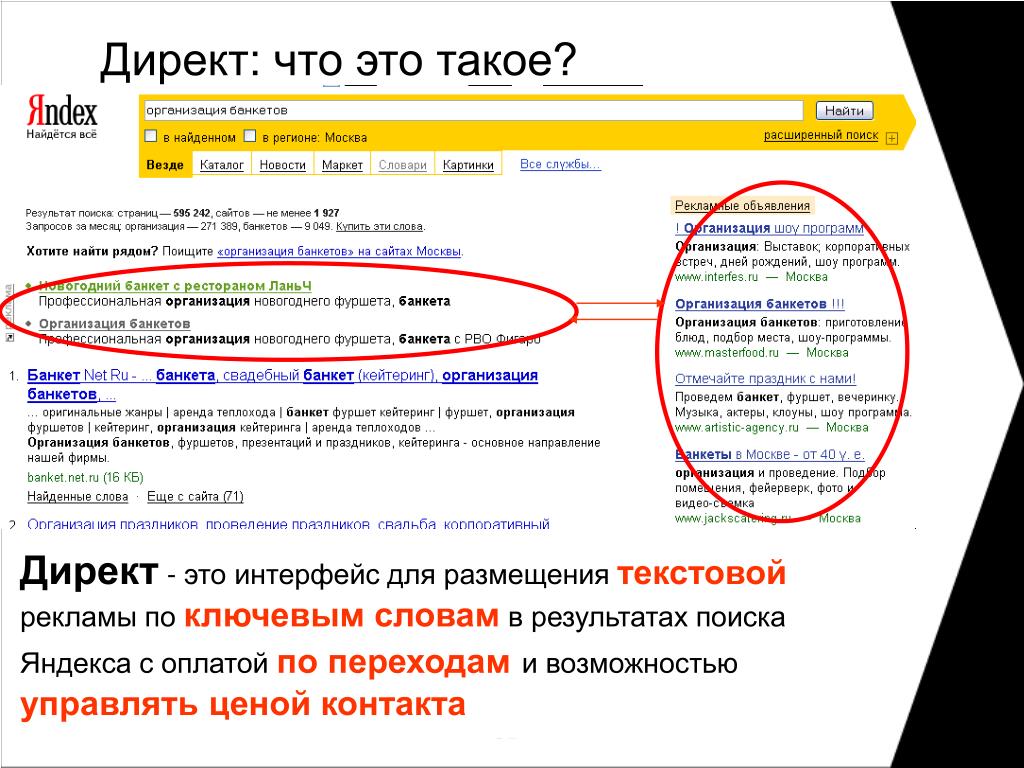
Список стоп-слов Яндекс.Директа
Стоп-слова в Яндекс.Директе — это служебные части речи и местоимения, а также любые слова, не несущие дополнительного смысла, которые автоматически исключаются из запроса пользователя при отборе объявлений для показа. Например, при запросе пользователя “Как и когда купить слона” для показа будут отобраны объявления, у которых в ключевых словах присутствует фраза “Купить слона”. “Как”, “и”, “когда” будут в этом случае являться стоп-словами.
Не путайте стоп-слова и минус-слова. Минус-слова — это слова, по запросам с которыми рекламное объявление показываться не будет. Минус-слова можно указать на уровне кампании, группы объявлений или ключевой фразы. Например, если мы укажем минус-слово «скачать» на уровне кампании, то ни одно из объявлений кампании не будет показываться по любым поисковым запросам пользователя, содержащим «скачать».
Мне понадобилось определить какие слова Яндекс.Директ считает стоп-словами. Сначала я задумал использовать для этой задачи список всех предлогов, союзов, междометий и местоимений. Но оказалось, что не все слова этих частей речи используются Директом в качестве стоп-слов. Например, союз «со» и предлог «между» к стоп-словам не относятся. Проверить это просто: если в сервис прогноза бюджета добавить предлог «в» и нажать «Посчитать», то сервис сообщит об ошибке:
А попытка рассчитать бюджет для предлога «между» закончится успехом:
Другой способ определить стоп-слова — с помощью Вордстата. Количество показов по фразам «небо земля» и «небо и земля» одинаковое. Это означает, что союз «и» не учитывается при показе объявлений в Директе:
Количество показов по фразам «небо земля» и «небо и земля» одинаковое. Это означает, что союз «и» не учитывается при показе объявлений в Директе:Вордстат при расчете количества показов для фразы, состоящей только из стоп-слова, возвращает 0. В этом он отличается от сервиса прогноза бюджета (который, напомню, выдает ошибку).
Но Вордстат возвратит тот же ноль и при запросе любого слова, у которого вообще нет показов:
Так что использовать Вордстат для определения стоп-слов не совсем надежно, поэтому я решил использовать сервис прогноза бюджета, он позволяет массово загружать несколько фраз и уведомляет о том какие именно слова не позволяют рассчитать бюджет:
Итак, я взял свой список предлогов, союзов, междометий и местоимений и начал опрашивать все слова в сервисе прогноза бюджета, но внезапно оказалось, что глагол «есть» — это тоже стоп-слово:
Значит список стоп-слов Яндекса не ограничивается одними лишь служебными словами и местоимениями. После этого открытия мне ничего не оставалось кроме как взять список кириллических униграмм (однословников) с OpenCorpora и прогнать их все в сервисе прогноза бюджета.
После этого открытия мне ничего не оставалось кроме как взять список кириллических униграмм (однословников) с OpenCorpora и прогнать их все в сервисе прогноза бюджета.Следующим открытием было то, что ограничиваться одними лишь кириллическими словами было ошибкой: Поэтому в список слов для проверки были добавлены англоязычные униграммы. Найти англоязычный корпус оказалось не так легко, но всё же удалось получить 5000 наиболее популярных англоязычных лемм.
Итоговый список получился таким:
| a |
| about |
| all |
| am |
| an |
| and |
| any |
| are |
| as |
| at |
| be |
| been |
| but |
| by |
| can |
| could |
| do |
| for |
| from |
| has |
| have |
| i |
| if |
| in |
| is |
| it |
| me |
| my |
| no |
| not |
| of |
| on |
| one |
| or |
| so |
| that |
| the |
| them |
| there |
| they |
| this |
| to |
| was |
| we |
| what |
| which |
| will |
| with |
| would |
| you |
| а |
| будем |
| будет |
| будете |
| будешь |
| буду |
| будут |
| будучи |
| будь |
| будьте |
| бы |
| был |
| была |
| были |
| было |
| быть |
| в |
| вам |
| вами |
| вас |
| весь |
| во |
| вот |
| все |
| всё |
| всего |
| всей |
| всем |
| всём |
| всеми |
| всему |
| всех |
| всею |
| всея |
| всю |
| вся |
| вы |
| да |
| для |
| до |
| его |
| едим |
| едят |
| ее |
| её |
| ей |
| ел |
| ела |
| ем |
| ему |
| емъ |
| если |
| ест |
| есть |
| ешь |
| еще |
| ещё |
| ею |
| же |
| за |
| и |
| из |
| или |
| им |
| ими |
| имъ |
| их |
| к |
| как |
| кем |
| ко |
| когда |
| кого |
| ком |
| кому |
| комья |
| которая |
| которого |
| которое |
| которой |
| котором |
| которому |
| которою |
| которую |
| которые |
| который |
| которым |
| которыми |
| которых |
| кто |
| меня |
| мне |
| мной |
| мною |
| мог |
| моги |
| могите |
| могла |
| могли |
| могло |
| могу |
| могут |
| мое |
| моё |
| моего |
| моей |
| моем |
| моём |
| моему |
| моею |
| можем |
| может |
| можете |
| можешь |
| мои |
| мой |
| моим |
| моими |
| моих |
| мочь |
| мою |
| моя |
| мы |
| на |
| нам |
| нами |
| нас |
| наса |
| наш |
| наша |
| наше |
| нашего |
| нашей |
| нашем |
| нашему |
| нашею |
| наши |
| нашим |
| нашими |
| наших |
| нашу |
| не |
| него |
| нее |
| неё |
| ней |
| нем |
| нём |
| нему |
| нет |
| нею |
| ним |
| ними |
| них |
| но |
| о |
| об |
| один |
| одна |
| одни |
| одним |
| одними |
| одних |
| одно |
| одного |
| одной |
| одном |
| одному |
| одною |
| одну |
| он |
| она |
| оне |
| они |
| оно |
| от |
| по |
| при |
| с |
| сам |
| сама |
| сами |
| самим |
| самими |
| самих |
| само |
| самого |
| самом |
| самому |
| саму |
| свое |
| своё |
| своего |
| своей |
| своем |
| своём |
| своему |
| своею |
| свои |
| свой |
| своим |
| своими |
| своих |
| свою |
| своя |
| себе |
| себя |
| собой |
| собою |
| та |
| так |
| такая |
| такие |
| таким |
| такими |
| таких |
| такого |
| такое |
| такой |
| таком |
| такому |
| такою |
| такую |
| те |
| тебе |
| тебя |
| тем |
| теми |
| тех |
| то |
| тобой |
| тобою |
| того |
| той |
| только |
| том |
| томах |
| тому |
| тот |
| тою |
| ту |
| ты |
| у |
| уже |
| чего |
| чем |
| чём |
| чему |
| что |
| чтобы |
| эта |
| эти |
| этим |
| этими |
| этих |
| это |
| этого |
| этой |
| этом |
| этому |
| этот |
| этою |
| эту |
| я |
| мені |
| наші |
| нашої |
| нашій |
| нашою |
| нашім |
| ті |
| тієї |
| тією |
| тії |
| теє |
Список не претендует на полную точность и вполне вероятно, что существуют еще какие-то стоп-слова.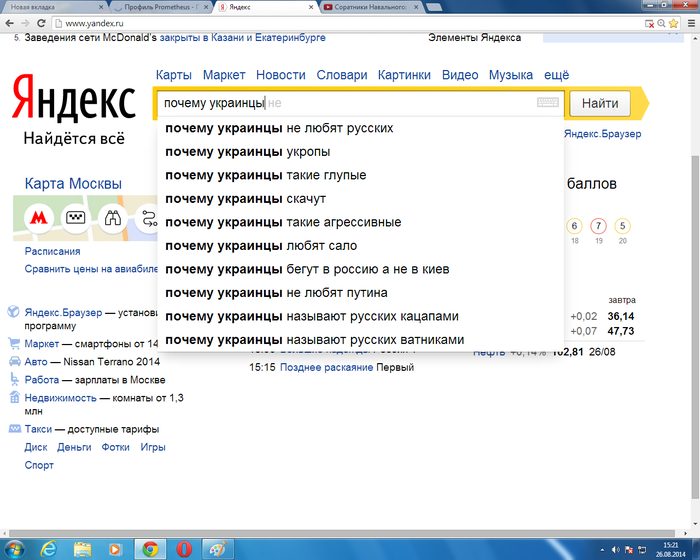 Учитывая, что у Яндекса есть турецкий поиск, то должны быть специфичные для этого языка стоп-слова.
Учитывая, что у Яндекса есть турецкий поиск, то должны быть специфичные для этого языка стоп-слова.
Немного интересных и необъяснимых аномалий:
- В список стоп-слов Яндекс.Директа входит слово «наса» (предполагаю, что это что-то вроде склонения слова «нас»).
Но Вордстат не считает его стоп-словом:
Количество показов для фраз «астронавт скотт келли» и «астронавт наса скотт келли» будет разным:
Но сервис прогноза бюджета не пропускает обе эти фразы и оставляет первую из них:
А рассчитать бюджет по фразе «что такое наса» сервис вообще не даст, так как она полностью состоит из стоп-слов (чтобы посчитать нужно добавлять плюсы перед словами):
Судя по тому, что количество показов для фраз «астронавт скотт келли» и «астронавт наса скотт келли» всё-таки разное, «наса» не является стоп-словом в том плане, что оно учитывается при показе объявлений, а уведомление об ошибке в сервисе прогноза бюджета — это баг Яндекса.
- Есть странные стоп-слова: «оне», «емъ», «комья», «томах», «имъ».

Но судя по разнице в количестве показов это всё стоп-слова только для валидатора сервиса прогноза бюджета:
Скорее всего, это тоже баг Яндекса.
- Есть некоторые слова, которые в Вордстате имеют количество показов больше 0, но прогноз бюджета Яндекс.Директа говорит о том, что слово является стоп-словом. Например, слово «будете» — это стоп-слово для сервиса прогноза бюджета:
Но не стоп-слово для Вордстата:
Если взять фразы «будете пить колу» и «пить колу», то количество показов у них различается, а значит «будете» всё же учитывается при показе объявлений:
Таких «псевдо-стоп-слов» (которые стоп-словами не являются, но на них ругается валидатор сервиса прогноза бюджета) я обнаружил довольно-таки много:
| будете |
| будучи |
| едим |
| едят |
| ел |
| ела |
| ем |
| емъ |
| ест |
| ешь |
| имъ |
| комья |
| наса |
| оне |
| сама |
| сами |
| самим |
| самими |
| самих |
| само |
| самого |
| самом |
| самому |
| саму |
| томах |
| тою |
| этою |
| am |
| could |
| me |
| them |
| мені |
| наші |
| нашої |
| нашій |
| нашою |
| нашім |
| ті |
| тієї |
| тією |
| тії |
| теє |
Фактически, эти слова учитываются при показе объявлений и стоп-словами не являются. Я включил их в список стоп-слов, так как завязывался на получение данных из API Яндекс.Директа с помощью метода CreateNewForecast. Этот метод не позволяет создать новый расчет если фраза состоит только из стоп-слов, поэтому мне нужно было точно знать список стоп-слов, которые не принимает метод. Использовать ли полный список или список без этих слов-аномалий — это зависит от решаемой задачи.
UPD: Благодаря Татьяне Михальченко и Олегу Саламаха список пополнился украинскими стоп-словами.
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.
Использование операторов для ключевых слов в Яндекс.Директе — ppc.world
Операторы — это определенные символы, расставляя которые, вы уточняете ключевые слова и избегаете нецелевых показов. Сам термин «операторы» используется только для символов Яндекс.Директа.
Что будет, если игнорировать операторы?
Если вы хотите дерзнуть и не использовать операторы для ряда ключевых фраз , то будьте готовы к тому, что реклама, в которой присутствуют данные фразы, будет показываться с любыми дополнительными словами, в любой словоформе ( изменение окончания слов), союзы и предлоги в данном случае учитываться не будут. При таком раскладе помните: все слова из ключевой фразы должны содержаться в поисковом запросе. В общем и целом мы бы порекомендовали вам не пренебрегать операторами, знать их и активно использовать: это поможет отсечь нецелевые показы и повысить эффективность ваших кампаний.
При таком раскладе помните: все слова из ключевой фразы должны содержаться в поисковом запросе. В общем и целом мы бы порекомендовали вам не пренебрегать операторами, знать их и активно использовать: это поможет отсечь нецелевые показы и повысить эффективность ваших кампаний.
Оператор +
Данный оператор принудительно учитывает предлоги и союзы. Если вы хотите, чтобы ваша реклама показывалась по запросу «Корм для собак», то нужно использовать оператор перед союзом: Корм +для собак.
Операторы группировки: «()» и «|»
Рассмотрим на примере: если вы хотите использовать 2 ключевые фразы — «корм для собак» и «корм для грызунов», то будет удобнее сгруппировать слова «собака» и «грызуны» со словом «корм». Использовать операторы с оставшимися словами, в данном случае, не нужно, поскольку они одинаковы. Основное преимущество создания одного запроса из нескольких фраз — конечно же экономия времени.
Оператор «»
Данный оператор позволяет показывать рекламное объявление по заданной фразе без дополнительных слов. Например, если мы заключаем в кавычки фразу «Купить Iphone 6», это значит, что объявление будет показываться только в том случае, если пользователь в строке поиска введёт запрос «Купить Iphone 6» . Если пользователь введёт запрос «Купить Iphone 6 с доставкой», ваше рекламное объявление показано не будет.
Как правило, оператор «» используется для высокочастотных запросов, поскольку к ним довольно сложно подобрать все варианты минус-слов. Обратите внимание, при использовании данного оператора охват уменьшится, потому что далеко не все пользователи вводят именно тот запрос, который вы используете в качестве ключевой фразы, заключенной в кавычки.
Оператор «!»Данный оператор позволяет вам показываться по заданной форме слова, то есть фиксирует окончания слова. Например, у вас есть фраза купить !кий, в данном случае мы будем показываться по запросу со словом «кий», а не со словом «киев» ( слово «кий» именно так звучит во множественном числе). Данный пример не случаен, ведь слово «кий» во множественном числе пишется как столица Украины — город Киев. Это значит, что если во фразе купить кий используем восклицательный знак, реклама не будет показываться по всем запросам, содержащим слово«киев».
Например, у вас есть фраза купить !кий, в данном случае мы будем показываться по запросу со словом «кий», а не со словом «киев» ( слово «кий» именно так звучит во множественном числе). Данный пример не случаен, ведь слово «кий» во множественном числе пишется как столица Украины — город Киев. Это значит, что если во фразе купить кий используем восклицательный знак, реклама не будет показываться по всем запросам, содержащим слово«киев».
Данный оператор позволяет вам фиксировать порядок слов в ключевой фразе. Как правило, он используется в тех случаях, когда именно порядок слов важен. Например: Дешевый рейс [Париж-Москва]. В этом примере именно направление рейса имеет значение, кампания настроена для тех пользователей, которые ищут билеты из Парижа в Москву, а не наоборот.
Можно ли использовать несколько операторов сразу?
Конечно, можно. Иногда даже нужно. Например, вернувшись к нашему примеру с ключевой фразой купить кий, мы можем зафиксировать окончания двух слов фразы с помощью оператора восклицательный знак: «!купить !кий». Но не забывайте, что при таком раскладе реклама будет показываться только в том случае, если пользователь введет именно такой запрос — без дополнительных слов и с такими же окончаниями.
Но не забывайте, что при таком раскладе реклама будет показываться только в том случае, если пользователь введет именно такой запрос — без дополнительных слов и с такими же окончаниями.
Подпишитесь, чтобы получать полезные материалы о платном трафике
Как создавать группы объявлений в Яндекс.Директ и делать группировку ключевых слов | Блог YAGLA
Как составлять объявления в Яндекс.Директе, чтобы попадать в потребность пользователя по поисковому запросу? Можно «штамповать» уникальные объявления под каждый ключевик. А можно поступить иначе — сделать группировку ключевых слов и создать группы объявлений.
В этой статье вы узнаете:
- В чем отличия данной методики;
- По какому принципу и с помощью каких инструментов группировать ключевые слова;
- Пошаговый алгоритм создания групп объявлений в интерфейсе Яндекс.Директ.
Всё это мы рассмотрим на конкретном примере.
Зачем группировать ключевые слова
На этапе сбора семантики мы собираем базисы и «вытаскиваем» из них максимум целевых запросов. У кого-то получаются сотни, а у кого-то тысячи в зависимости от продукта. Составлять объявления под каждый ключевик бессмысленно. Можно, конечно, автоматически подставлять запрос пользователя в заголовок в надежде повысить CTR и снизить цену клика.
У кого-то получаются сотни, а у кого-то тысячи в зависимости от продукта. Составлять объявления под каждый ключевик бессмысленно. Можно, конечно, автоматически подставлять запрос пользователя в заголовок в надежде повысить CTR и снизить цену клика.
Однако такой рецепт кликабельности давно стал мифом, так как:
- Большинство фраз — низкочастотники и ультранизкочастотники. Яндекс против тотального использования схемы «1 запрос = 1 объявление», так как она ведет к перегрузке серверов. Ультиматум — статус «Мало показов»;
- Всё идет к тому, что рекламодатели в Яндексе будут «бороться» не за ключевики, а за аудиторию, за конкретную потребность какого-либо сегмента ЦА. Она может выражаться разными словами. Это мы увидим далее на примере.
Выход — смысловая группировка семантики.
Допустим, у вас 10 базисов ключевых слов. Из них вы сгенерировали 300 фраз. Часть — ВЧ-ключевики — можно настроить один к одному (1 запрос = 1 объявление), а всё остальное — сгруппировать по смысловой релевантности. Это означает, что в одну группу вы собираете запросы, которые характеризуют одну конкретную потребность.
Это означает, что в одну группу вы собираете запросы, которые характеризуют одну конкретную потребность.
Если вы опасаетесь, что группировка повысит ставки, то напрасно, так как:
- Яндекс распознает синонимы;
- Пользователи стали умнее и уже не ведутся на подсветку запроса жирным в заголовке объявления.
Как группировать ключевые слова
Чаще всего в одной группе 2-5 фраз. Не рекомендуем делать больше, так как затем под них сложнее писать релевантные объявления. В следствие этого падает CTR и растет цена за клик.
Рассмотрим методику на примере продажи входных дверей. Вот несколько групп:
- Запросы, где пользователи интересуются деревянными входными дверями:
«Деревянные входные двери на заказ»;
«Заказать деревянную входную дверь»;
«Изготовление деревянных входных дверей»;
«Изготовление деревянных входных дверей +на заказ»;
«Изготовление деревянных входных дверей +на заказ недорого»;
- Запросы по металлическим входным дверям:
«Заказать металлическую входную дверь»;
«Заказать железную входную дверь»;
«Металлическая входная дверь на заказ»;
«Железная входная дверь на заказ»;
- Запросы со словом «изготовление», но без указания типа — деревянные или металлические:
«Изготовление входных дверей недорого»;
«Изготовление входных дверей»;
«Изготовление входных дверей на заказ»;
«Входные двери изготовление на заказ»;
- Запросы, которые содержат «на заказ»:
«Купить входную дверь на заказ»;
«Купить входную дверь заказать»;
«Входные двери на заказ недорого»;
«Входные двери на заказ производство»;
и т. д.
д.
По какому принципу мы объединяем ключевики? Смотрим смысловое соответствие. Его суть в следующем: есть слово-локомотив — это общее свойство или признак для группы. Под него подтягиваются все остальные.
Поэтому фразы «Изготовление входных дверей на заказ» и «Входные двери изготовление на заказ» попали в третью группу, где главное слово — «изготовление», а «Купить входную дверь на заказ» и «Входные двери на заказ недорого» — в четвертую, по признаку «На заказ».
Каким способом мы группируем ключевики? Если семантики немного, можно вручную. Для большого объема проводим кластеризацию с помощью таких платных инструментов, как Key Collector, Rush Analytics, PPC Help, Мегалемма. Как и любой автоматический метод, они не дают 100% точности обработки данных, поэтому стоит проверять результаты на смысловое соответствие.
Итак, мы сгруппировали ключевики, теперь переходим к объявлениям.
Что такое группы объявлений в Яндекс.Директ и для чего они нужны
Отразить все преимущества товара / услуги в одном объявлении сложно. Нужно знать, какие точно «выстрелят». Для этого ставим гипотезы. Оптимально проверять по 2 варианта на группу, чтобы избежать лишних заморочек.
Функционал Яндекса берет на себя работу по тестированию и сам определяет лучший вариант из группы исходя из CTR. Система поочередно показывает по одинаковым запросам объявления с указанием разных характеристик продукта. Половина пользователей увидит первый вариант, другая — второй.
Когда наберется достаточно статистики по кликам, более кликабельная версия получит преимущество в показах. В итоге ЦА будет чаще видеть рекламу, которая точно попадает в её потребность.
В пределах группы соблюдайте правила:
- Один заголовок объявления на группу;
- Он соответствует запросу или содержит максимум слов из него.
Нет смысла пробовать разные заголовки. Кликабельность зависит от того, насколько высоко это соответствие.
Кликабельность зависит от того, насколько высоко это соответствие.
Как вариант, можно использовать шаблоны Яндекс.Директ. Они позволяют автоматически подставлять в заголовок часть запроса пользователя, например, название модели. Но это подойдет только для товаров, у которых много модификаций.
Возьмем узкую тематику — светодиодные светильники, направление «панели Кристалайт», группа «Кристалайт двусторонний». Вот ключевики группы:
- Кристалайт двусторонний A1;
- Кристалайт двусторонний A2;
- Кристалайт двусторонний A3;
- Кристалайт двусторонний A4.
Включаем в заголовок и описание шаблон: «Кристалайт двусторонний А#1#». В итоге при поиске в Яндексе светильника А2 пользователь видит объявление именно по этой модели:
По запросу «Кристалайт двусторонний A1» аналогично:
Для нашего примера по входным дверям это не подойдет, поэтому далее мы рассматриваем общий алгоритм.
Как создать группу объявлений
Когда кампания настроена, нажимаем кнопку:
Для примера берем группу по деревянным входным дверям. Задаем название:
Пишем запросы в разделе «Ключевые фразы и минус-фразы», поле «Подобрать фразы»:
Добавьте фразы в группу, как показано на скриншоте:
Добавляем условия подбора аудитории в блоках «Ретаргетинг и подбор аудитории» и «Профиль пользователя»:
Чтобы показывать конкретные объявления специфической аудитории, настраиваем также регионы показа (здесь уже на уровне группы) и корректировки ставок.
Следующий шаг — объявления. Придумываем заголовок и описание для первой версии:
Настраиваем необходимые параметры:
Остальные объявления группы добавляем любым из способов:
Допустим, в втором варианте можно сделать другое описание. Например: Собственное производство. Широкий выбор отделок. Оплата в офисе или онлайн.
Например: Собственное производство. Широкий выбор отделок. Оплата в офисе или онлайн.
Когда объявления готовы, отправляем их на модерацию.
Итак, наша группа на данный момент включает два объявления. Какое из них увидят пользователи? Самое кликабельное, что покажет только практика.
Как построить эффективный аккаунт в Яндекс.Директ
Мы рассмотрели вариант, как эффективнее организовать ключевые слова и объявления и добиться бОльшей релевантности рекламы для потенциальных клиентов.
Вкратце это работает так:
1) Разбиваем семантику на смысловые группы;
2) Пишем и настраиваем под каждую группу по 2 варианта объявлений с одним заголовком, но с разными текстами;
3) Оба объявления показываются поочередно в ответ на запросы конкретной группы;
4) Яндекс выбирает наиболее эффективный вариант объявления исходя из CTR и отдает ему предпочтение при показах;
5) Целевой пользователь видит объявление, которое максимально соответствует его запросу.
В итоге мы приходим к такой схеме аккаунта:
Схема лучше работает, когда у вас максимум 5 ключевиков и 2 версии объявлений.
Высоких вам конверсий!
А о том, как провести конкурентный анализ семантики, объявлений и посадочных страниц читайте здесь.
Логотип и символ Яндекса, значение, история, PNG
Логотип Яндекса PNG
Первый логотип Яндекса (1996 г.) был вдохновлен логотипом компании CompTek, в которой была создана поисковая система Яндекс. История эмблемы на данный момент насчитывает как минимум пять обновлений.
Значение и история
1996-1997
Логотипы CompTek и Яндекс представляли собой прямоугольник с тонким черным контуром.Прямоугольник был разбит на две части. В левой части были видны черные буквы на белом фоне, а в правой части — белые буквы на красном фоне.
В случае логотипа CompTek название компании было разбито на «Comp» и «TEK». В случае с Яндексом в первом поле помещалась буква «я» («ya») кириллицей, а во втором поле — буква «ndex» латиницей.
В случае с Яндексом в первом поле помещалась буква «я» («ya») кириллицей, а во втором поле — буква «ndex» латиницей.
По сравнению с родительским логотипом, «Яндекс» имел более яркий красный оттенок.Буквы стали немного тоньше.
Вы можете задаться вопросом, почему имя поисковой системы включает буквы из двух разных скриптов. Оказывается, изначально слово «Яндекс» было составлено как аббревиатура, означающая «еще один индексатор». Слово использовалось как название новой технологии и было дано латинскими буквами, потому что информация о ней сохранялась в компьютерном файле (и «Яндекс» было названием этого файла).
Когда проект перерос в поисковую систему, его создатели решили приблизить аббревиатуру к русским корням.Итак, они написали первые буквы кириллицей, которая используется в русском алфавите.
1997-1999
Новая эмблема была разработана в 1997 году дизайнерской фирмой Art. Студия Лебедева, которая с тех пор отвечает за эволюцию логотипа. Этот логотип использовался при официальном запуске поисковой системы 23 сентября 1997 года.
Этот логотип использовался при официальном запуске поисковой системы 23 сентября 1997 года.
Этот сохранил конструкцию из двух ящиков. Теперь в дизайне появилась некоторая глубина: поле слева казалось немного ближе к читателю, а правый прямоугольник, казалось, сдвинулся назад.Убрали красную пломбу. Первые буквы были выделены красным, а остальная часть слова — черным. Буквы были полужирными, «я» было немного крупнее остальных.
с 1999 по 2004 год
В случае CompTek двухчастная структура оказалась выгодной. Поскольку название компании было трудно произносить (и запоминать) из-за группы согласных (mpt), было вполне естественно, что слово было разбито на две значимые части, чтобы его было легче понять и запомнить.Слово «Яндекс», напротив, было довольно легко произносить. Кроме того, его нельзя было разбить на значимые части — скорее, это было единое целое. Итак, двухчастная структура не подошла — Яндекс, очевидно, нуждался в другом подходе.
Поскольку поисковая машина в Интернете имела огромный успех, возникла потребность в логотипе, который был бы более профессиональным и отличительным, чем старый. И снова дизайн был разработан в ст. Студия Лебедева. Логотип 1999 года стал классикой. Хотя с тех пор было несколько обновлений, общий стиль знаков отличия остался неизменным.
И снова дизайн был разработан в ст. Студия Лебедева. Логотип 1999 года стал классикой. Хотя с тех пор было несколько обновлений, общий стиль знаков отличия остался неизменным.
В логотипе 1999 года отсутствуют какие-либо прямоугольники и другие элементы, кроме самих букв. Первая буква (кириллица), которая теперь была значительно выше всех остальных, была выделена красным. Текст «ndex» был черным. В дизайне использовались шрифты с засечками.
2004-2008
Модификация была очень тонкой и включала только детали глифов. Буквы стали немного тоньше и менее пышными.
2008-2016
На этот раз все буквы на логотипе были написаны кириллицей и шрифтом без засечек.
2016-2021
Помимо основного логотипа, был разработан целый набор версий по парадигме склонения слова в русском языке.
2021 — Сегодня
Редизайн 2021 года представил обновленный и обновленный визуальный стиль Яндекса, который полностью основан на предыдущих версиях логотипа компании, но имеет более сильный характер, что отражается в более широких и устойчивых формах букв в надписи. Цветовая палитра осталась прежней — знаковый красный для первой буквы и черный для всех остальных. Линии на новом логотипе стали толще и смелее, что сделало надписи более уверенными и профессиональными.
Цветовая палитра осталась прежней — знаковый красный для первой буквы и черный для всех остальных. Линии на новом логотипе стали толще и смелее, что сделало надписи более уверенными и профессиональными.
Английская версия
Основным логотипом Яндекса всегда был русский, так как в этой стране поисковик генерирует не менее 51 всего поискового трафика. Однако, поскольку русские знаки различия были бы непонятны и неразборчивы для англоязычного сообщества, была разработана глобальная версия.
Он очень похож по стилю, но выглядит немного более игриво, чем оригинал, потому что две верхние планки на «Y» имеют разную длину. Единственный глиф, присутствующий в обеих версиях, — это буква «е», которая выглядит очень похоже.
Логотип Яндекс Деньги
Логотип сервиса онлайн-платежей состоит из трех частей: основного логотипа Яндекса, слова «Деньги» более тонкими буквами и (по желанию) желтого кошелька. В русскоязычной версии слово «Деньги» заменено его переводом.
Логотип Яндекс Музыка
Помимо основного логотипа, вы можете увидеть слово «Музыка» и красную ноту в желтом круге.
Логотип Яндекс Такси
Структура и общий подход такие же, как у Яндекс Деньги и Музыка. Можно использовать значок с пятью черными квадратами внутри желтого пузыря речи.
Что такое Яндекс?
Яндекс — интернет-корпорация номер один в России, которую часто сравнивают с Google.Компания, основанная в 2000 году, предоставляет своим пользователям поисковые системы, новостные ленты и почтовые службы.
95 языков в App Store
Яндекс.Переводчик
Бесплатный переводчик, который может работать офлайн и переводить текст с фотографий
• Переводите на любую пару из 90 языков, когда вы онлайн.
• Переводите с французского, немецкого, итальянского, русского, испанского, турецкого и других языков на английский в автономном режиме: загрузите эти языки бесплатно и включите автономный режим в настройках.
• Произносите слова или фразы на русском, английском или турецком языках, чтобы перевести их на любой из этих языков, или пусть приложение прочитает вам перевод.
• Учите новые слова и их значения с помощью примеров использования в словаре приложения (доступно для большинства поддерживаемых в настоящее время языков).
• Сделайте снимок меню, дорожного знака, страницы книги или выберите фотографию с текстом из альбома «Фотопленка», чтобы просмотреть его перевод прямо поверх изображения (доступно только при подключении к сети).
• Переводите целые сайты прямо в приложении или в Safari.
• Читайте книги, новости или статьи на иностранном языке вместе с Яндекс.Переводчиком на iPad в режиме Split View.
• Читайте транслитерированный арабский, армянский, фарси, грузинский, греческий, иврит, корейский, японский или китайский пиньинь.
• Оцените экономящую время функцию интеллектуального набора текста и автоматическое определение языка.
• Сохраняйте переводы в Избранном и просматривайте историю переводов в любое время.
• Говорите на Apple Watch, чтобы увидеть, как ваши слова переведены на их экране.
Поддерживаемые в настоящее время языки: африкаанс, албанский, амхарский, арабский, армянский, азербайджанский, баскский, башкирский, белорусский, бенгальский, болгарский, бирманский, боснийский, каталонский, кебуанский, китайский, чувашский, хорватский, чешский, датский, голландский, эльфийский ( Синдарин), английский, эсперанто, эстонский, фарси, финский, французский, галисийский, грузинский, немецкий, греческий, гуджарати, гаитянский креольский, иврит, горно-марийский, хинди, венгерский, исландский, индонезийский, ирландский, итальянский, японский, яванский, каннада , Казахский, кхмерский, корейский, киргизский, латинский, латышский, лаосский, литовский, люксембургский, македонский, малагасийский, малайзийский, малаялам, мальтийский, маори, маратхи, марийский, монгольский, непальский, норвежский, папиаменто, польский, португальский, пенджаби, румынский , Русский, сербский, шотландский, сингальский, словацкий, словенский, испанский, сунданский, суахили, шведский, тагальский, таджикский, тамильский, татарский, телугу, тайский, турецкий, удмуртский, украинский, урду, узбекский, вьетнамский, валлийский, коса, якутский , Идиш, зулусский.
Поиск в России: лингвистический тест Google v Яндекс
Как англоговорящие, большинство из нас не задумывается о роли лингвистики в мире SEO и SEM. Мы фокусируемся и анализируем многие другие аспекты способности поисковых систем предоставлять пользователям отличные результаты поиска, одновременно определяя пользователей, на которых контекстные рекламодатели пытаются нацелить таргетинг.
Способность поисковой системы полностью понимать данный язык сильно влияет на то, насколько хорошо она выполняет свою задачу.Поскольку мы привыкли к английскому языку и Yahoo, Bing и Google, мы можем не думать о чешском языке и Seznam или о том, что поисковой системе, основанной на английском, не так просто выйти на иностранный рынок только на основе языковых навыков.
Большинство знакомо с Google как с ведущей глобальной поисковой системой. В последние годы Google улучшил свои возможности, чтобы предложить пользователям и рекламодателям лучший опыт работы с региональными версиями. Тем не менее, как выразился Джанлука Фиорелли, «региональные гуглы не работают.В оценках Фиорелли отмечается, что отсутствие у Google обновлений в региональных версиях, геотаргетинг и возможности понимания языка могут способствовать получению результатов поиска ниже среднего.
Тем не менее, как выразился Джанлука Фиорелли, «региональные гуглы не работают.В оценках Фиорелли отмечается, что отсутствие у Google обновлений в региональных версиях, геотаргетинг и возможности понимания языка могут способствовать получению результатов поиска ниже среднего.
Когда поисковая система изо всех сил пытается правильно понять язык, на котором она работает, и непреднамеренно пропускает отметку в том, что хочет пользователь или возвращает релевантные страницы, она также упускает ваши возможности для контекстной рекламы. Рекламодатели и наркоманы SEM хотят получить самые лучшие знания о способностях поисковой системы не только давать отличные результаты поиска, но, что еще более важно, помогать платным рекламодателям идентифицировать своих клиентов.
Однако некоторым может не хватать языковых навыков, чтобы проверить такие проблемы, или они могут вообще не осознавать, что они существуют. По этой причине многие просто переводят и проводят кампанию AdWords за границей, надеясь получить те же результаты, что и на сайте Google. com. В качестве альтернативы, маркетологи в поисковой сети могут также запустить одну и ту же кампанию в региональном Google и другом местном игроке.
Так часто бывает с Google.ru и Яндексом, ведущей поисковой системой в России, на долю которой приходится 62% рынка. По большей части, простые и понятные запросы дают аналогичные результаты в этих двух поисковых системах.Однако, среди ряда других причин, недостатки русского языка в Google.ru влияют на его способность предоставлять те же результаты поиска, которые пользователи получают на Яндексе. Во многих случаях Google.ru не адаптирует свои результаты с учетом местных особенностей, что приводит к языковым проблемам, когда дело доходит до получения результатов поиска, соответствующих намерениям пользователя. В конечном итоге это также влияет на то, какая реклама будет показываться российской целевой аудитории.
Я провел серию тестов на Google.ru и Яндексе, чтобы лучше отобразить различия между двумя поисковыми системами. Проблемы, связанные с намерением пользователя и языком, включают орфографические ошибки, спряжение глаголов, адаптацию существительных и транслитерацию. Поэтому я использую пример из каждой категории, чтобы проверить лингвистические возможности Google.ru и Яндекс.
Проблемы, связанные с намерением пользователя и языком, включают орфографические ошибки, спряжение глаголов, адаптацию существительных и транслитерацию. Поэтому я использую пример из каждой категории, чтобы проверить лингвистические возможности Google.ru и Яндекс.
Тест 1: орфографические ошибки
В первом туре я решил проверить два русских слова с разным значением и написанием, которые звучат очень похоже при произнесении. Когда я говорю, я все еще не могу различить русское слово, обозначающее лук ?? ? а русское слово для луга ?? ? , но, как видите, разница в одной букве.
Чтобы проверить языковые способности поисковой системы, я ввел ошибку в слове «луковый суп», что означает, что по правилам русской грамматики лук превращается в прилагательное. Я ввел «луговый суп» (?? ? ???? ???) вместо «луковый суп» (?? ? ???? ???).
Яндекс прошел тест, и я получил все результаты поиска рецептов лукового супа. Яндекс изменил прилагательное на правильное написание, дав мне релевантные результаты для рецептов и статьи в Википедии о французском луковом супе.
Яндекс изменил прилагательное на правильное написание, дав мне релевантные результаты для рецептов и статьи в Википедии о французском луковом супе.
Яндекс также предложил правильное написание, которое при нажатии приводило меня на страницу с большим количеством рекламы и даже лучшими результатами.
С другой стороны, Google попытался дать мне результаты 2012 года по «луговому супу». Многие ссылки вели меня к рецептам грибных супов, которые, как я узнал, могут быть своего рода супом с названием, связанным с зеленью и полем. Тем не менее, не многие люди ищут это и неправильно написали бы правильный запрос для лукового супа.
Во время тестирования других орфографических ошибок и Google.ru, и Яндекс могут обрабатывать случайные запросы, но когда такие языковые проблемы сохраняются, носитель языка, такой как Яндекс, легче поймет намерения пользователя.
Тест 2: Спряжение глаголов
русских глаголов могут принимать разные формы, адаптируясь к временным, совершенным и несовершенным аспектам. В зависимости от подлежащего предложения глагол также может иметь до шести различных спряжений в настоящем и будущем времени.
В зависимости от подлежащего предложения глагол также может иметь до шести различных спряжений в настоящем и будущем времени.
Чтобы проверить спряжение глаголов, я ввел запрос «Я иду на первое свидание», используя несовершенную форму «I» глагола «идти». Обе поисковые системы относительно хорошо понимали намерения пользователя, но были некоторые очевидные различия в количестве возвращаемых спряжений глаголов.
Яндекс получил 49 миллионов результатов поиска по этому запросу. Он распознал намерение пользователя и различные спряжения глаголов, в результате чего на Яндексе возвращалось больше страниц по этому запросу.Как видно ниже, Яндекс включает шесть различных форм этого глагола, предлагая пользователям советы о том, как вести себя на первом свидании и куда идти.
Для этого теста результаты поисковой выдачи Google.ru были только для формата «я» и «вы-неформальный» формат глагола «идти». Другие спряжения глаголов не появлялись, когда я просматривал различные результаты на странице.__n7v64ey.jpg)
Google.ru дал мне 526 000 результатов поиска по сравнению с 49 миллионами Яндекс. Однако меня все же удивило развитие Google здесь.Google значительно улучшил свою способность распознавать различные спряжения глаголов. Не так давно на Google.ru были результаты точного совпадения только для определенного формата глагола. Тем не менее, очевидно, что Google есть место для улучшения, потому что две формы глагола против шести предоставят пользователю и рекламодателю другой опыт работы с Google по сравнению с Яндексом.
Тест 3: Адаптация существительного
Русское существительное бывает мужского, женского или нейтрального рода, и это может означать несколько разных окончаний для каждого пола плюс вариации единственного и множественного числа.Исходя из этого, существительное может иметь шесть возможных окончаний как для единственного, так и для множественного числа. Еще больше усложняет ситуацию то, что из этих правил есть исключения, которые россиянам просто необходимо запомнить.
И Google, и Яндекс хорошо разбираются в этом и в распространенных запросах, возвращая соответствующие результаты. Это улучшение для Google. Раньше, когда пользователь вводил, например, «Переезд в Канаду», он получал точное совпадение только с существительным, оканчивающимся на Канада. Теперь Google возвращает несколько форм существительного Canada.
Чтобы проверить способность поисковой системы понимать морфологию существительных, я выбрал слово «ложь» или «ложь». В своем единственном формате его можно записать тремя разными способами, в зависимости от случая — ???? — ??? — ?????.
Я ввел второй формат в поисковые строки в Яндексе и Гугле. Обе поисковые системы в основном давали мне результаты по фильмам со словом «ложь» в названии, но я получил разные результаты для Яндекс и Google.
Как видно ниже, Яндекс дал мне все три формата слова «ложь», и первым результатом является запись в вики о более базовом формате слова.
Google.ru очень четко понял запрос и дал примерно аналогичные результаты Яндекс. Однако, как вы видите ниже, он дал мне только точные результаты. Мне не было показано ни одной рекламы в Google.
Однако, как вы видите ниже, он дал мне только точные результаты. Мне не было показано ни одной рекламы в Google.
Тест 4: Транслитерация
В рамках четвертого теста я хотел проверить лингвистическую способность соответствующих поисковых систем распознавать поисковые запросы местных жителей по слову «яблоко», потому что это бренд, но также и обычный фрукт. Русские часто транслитерируют поисковые запросы крупных международных брендов.Это означает, что они возьмут исходное слово и букву и озвучат его по-русски. Например, иногда они будут искать Gucci, а иногда — транслитерацию ?????.
На основании нескольких тестов я знаю, что и Google.ru, и Яндекс знают, что россияне ищут таким образом многие крупные бренды. При этом я хотел протестировать каждую поисковую систему по слову «яблоко», чтобы увидеть, не запутает ли поиск фрукта.
Яндекс знал, что мне нужен фрукт, а не компьютер или iPhone.Все результаты были связаны с яблоками, а не с компанией.
Google.ru предположил, что я говорю о компании, как это делается на Google.com. Русская версия здесь не адаптирована к русскому языку, как это видно из результатов Apple, Apple Store и iCloud, приведенных ниже.
Хотя этот пример очень конкретен, он показывает, как Яндекс распознает местные нюансы, которых нет у Google.ru. В США такие результаты были бы хороши, потому что пользователь должен указать, ищет ли он компанию или фрукт из-за названия бренда и популярности.В России это явно другая история, потому что люди не обязательно ассоциируют русское слово «яблоко» с брендом, производителем iPhone / Mac.
Вывод:
Яндекс понимает русский язык намного лучше, чем Google.ru. Хотя Google Россия недавно добился положительных результатов в улучшении результатов поисковой выдачи, ему еще предстоит пройти долгий путь, прежде чем он догонит Яндекс. Для англоговорящего эти различия могут показаться незначительными, но для русскоговорящего и рекламодателя это имеет значение, поскольку оказывает большое влияние на пользовательский опыт и цифровую рекламу.
Как видно из публикации, результаты платного поиска в Google и Яндексе различаются, поэтому рекомендуется проводить PPC-кампании как в Google, так и в Яндексе. Однако также важно иметь представление о типах органических результатов, которые возвращают эти поисковые системы, которые повлияют на то, как компания использует Google и Яндекс в своих российских маркетинговых кампаниях (PPC).
Некоторые рекламодатели могут подумать, что, просто скопировав кампанию с Google.com на Google.ru, они получат те же результаты.Тем не менее, это не так. Как мы видели в этом посте, Google.ru еще предстоит проделать большую работу, прежде чем его можно будет считать на том же уровне, что и Google.com. Поэтому любой бизнес, проводящий кампании PPC, должен ожидать, что их ключевые слова будут вызывать разные впечатления в России.
Изображение функции с Flickr
Теги
Русский поиск (1) яндекс (26)Новый алгоритм поиска Яндекса на основе AI Палех
Яндекс недавно объявил о своем новом поисковом алгоритме Palekh, который улучшает понимание Яндексом смысла каждого поискового запроса за счет использования глубоких нейронных сетей в качестве фактора ранжирования среди других.В конечном итоге новый алгоритм помогает Яндексу улучшить результаты поиска по всем направлениям, особенно по длинным поисковым запросам.
Как известно большинству читателей State of Digital, поисковые запросы с длинным хвостом классифицируются по поисковым запросам, которые поисковая система обрабатывает очень редко. Существует корреляция между редкостью запроса и его длиной. Как правило, чем короче запрос, тем он более распространен и чем длиннее, тем реже. Такие запросы часто носят разговорный характер и подробно описывают что-то, когда пользователь не знает точной фразы или слова, но пытается объяснить это поисковой системе.Например, написать описание фильма, не зная названия, типа «фильм о парне, выращивающем картошку на какой-то планете».
Эти запросы с длинным хвостом заставляют поисковые системы полностью понимать цель запроса, чтобы предлагать наиболее релевантные результаты поиска. Поисковые системы более легко предлагают результаты поиска на основе сходства слов в запросе схожести и релевантности слов в результатах. Проблема с запросами с длинным хвостом заключается в том, что они не так легко совпадают с релевантными синонимами слов, и по этим редким запросам гораздо меньше данных.
Тем не менее, запросы с длинным хвостом и результаты поиска могут быть лучше всего сопоставлены, обнаружив и сопоставив сходство значений. Яндекс решил использовать передовой искусственный интеллект, чтобы улучшить способ поиска совпадений между запросами и результатами за счет лучшего понимания цели запроса, а не сходства самих слов.
Как компания, специализирующаяся на машинном обучении, Яндекс исторически встраивал машинное обучение в 70% своих продуктов и услуг, начиная с поиска.Совсем недавно с Палехом поисковая команда Яндекса научила свои нейронные сети видеть связи между запросом и документом, даже если они не содержат общих слов.
Этот новый алгоритм был назван в честь российского города Палех из-за жар-птицы на его гербе с длинным хвостом. Яндекс назвал все свои поисковые алгоритмы в честь городов России и выбрал Палех на основании символа длинного хвоста и влияния этого алгоритма на запросы с длинным хвостом.
В этом блоге рассказывается о динамике машинного обучения, лежащей в основе последнего поискового алгоритма Яндекса в Палехе, и о том, что отличает его от других способов использования глубоких нейронных сетей для ранжирования в веб-поиске.
Что такое машинное обучение? Что такое нейронные сети?Машинное обучение — это именно то, что нужно — машинное обучение от самого себя путем установления связей на основе шаблонов входных данных. Как говорит Яндекс, «машина, которая может обучаться, — это машина, которая может принимать собственные решения на основе алгоритмов ввода, эмпирических данных и опыта». После того, как цель установлена, модели обучаются для достижения этой цели на основе обучающих выборок. Машина учится создавать правила, которые со временем улучшаются по мере обработки большего количества данных.На результаты алгоритма влияют миллионы факторов, которые оказываются намного сложнее, чем способность человека обрабатывать или программировать.
Нейронные сети — это метод машинного обучения, созданный по образцу нейронов в человеческом мозгу, который стремится решать проблемы, как это сделал бы человеческий мозг. Нейронные сети основаны на действительных числах и могут быть обучены обнаружению взаимосвязей в наборе данных после обработки входных данных и распознавания шаблонов. Их можно обучить анализу изображений, звука или текста и применять для различных целей, таких как распознавание изображений, перевод текста или ранжирование в веб-поиске.
Как Яндекс научил свои нейронные сети лучше понимать запросы?Яндекс обучил свои нейронные сети с помощью модели семантического сопоставления, которая сводит информацию к числам, группирует их по значению контента, проецирует группы на семантическую карту, а затем находит совпадения между группами на основе их близости на карте. Обычно семантическое отображение обнаруживает связи между двумя разными объектами, помещая их в одно семантическое пространство и подтверждая их связи на основе близости их друг к другу.В этом случае ранжирования веб-страницы двумя объектами, проверяемыми на наличие соединений, являются поисковые запросы и документы или заголовок просканированных страниц.
Прежде чем что-либо произошло с отображением, команде поиска сначала нужно было обучить алгоритм, предоставив ему примеры пар запросов и соответствующих заголовков веб-страниц. Этот обучающий набор предоставил нейронным сетям базовое представление о том, какие связи должна установить поисковая команда Яндекса.
Поскольку компьютеры лучше работают с числами, а не со словами, Яндекс преобразовал миллиарды поисковых запросов и просканированные страницы в числа.Затем эти числа нужно было систематизировать, чтобы в них был смысл. Произвольный набор слов не имеет реального понятия или значения. Только очень конкретные наборы слов имеют смысл вместе, и существуют миллионы возможных контекстов. Алгоритм находит небольшие подмножества слов, которые наполнены смыслом, но это все равно приводит к миллионам возможностей, поэтому числа должны быть сгруппированы. Таким образом, используя метод, называемый уменьшением размерности, матрица сжимает длинный список слов в группу из 300 и затем помещает его в 300-мерный вектор.Слова могут быть совершенно разными, но если они попадают в один и тот же вектор, есть похожее значение. То же самое и с заголовками просканированных страниц.
Эти семантические векторы затем используются для поиска совпадений на основе их близости. Каждый запрос и заголовок проверяются, чтобы увидеть, насколько близка проекция размерности заголовка к запросу на карте. Так же, как слова выглядят похожими на поисковую систему, векторы тоже.
Чтобы упростить объяснение, предположим, что мы имеем дело с двумерным пространством, поэтому числа затем рассматриваются как точки на координатной плоскости.Затем заданный запрос и заголовок веб-страницы отображаются на координатной плоскости. Затем можно измерить расстояние между точками запроса и заголовком веб-страницы, чтобы решить, насколько документ релевантен запросу. Чем ближе две точки, тем более релевантный запрос к документу.
Почему это особенно полезно для запросов с длинным хвостом?Помещая запрос в семантический вектор с заголовком веб-страницы, поисковая система понимает, что запрос и заголовок веб-страницы имеют смысл, даже если в них нет похожих слов.Раньше алгоритмы были более ограничены поиском сходства на основе синонимов и понятий. Например, туфли и ботинки или концепт такого бренда, как каяк, и настоящий каяк. Однако, как люди, мы знаем, что запросы с длинным хвостом могут не включать слова, которые соответствуют аналогичным словам или понятиям. Используя нейронные сети, поисковая система может находить сходства, выходящие за рамки слов и значений. Из-за того, что запросы с длинным хвостом обычно требуют результатов, основанных на значении, и для этих редких запросов данных меньше, семантическое сопоставление заполняет пробел.
Чем отличается подход Яндекса от других?Яндекс также включает другие цели для обучения своих нейронных сетей. Эти цели включают в себя прогнозирование продолжительных кликов, CTR и модели «щелкни или не щелкни». Вместо одной из лучших моделей нейронных сетей Яндекс включает пять. Сравнивая преимущества включения всех своих моделей, поисковая команда Яндекса замечает гораздо более точные результаты поиска. Используя все предыдущие факторы ранжирования и лучшую модель нейронной сети, Яндекс добился улучшения результатов длиннохвостых запросов на 1%.Применяя все предыдущие факторы ранжирования и пять моделей нейронных сетей, это улучшение удваивается и приводит к увеличению точности длинных запросов на 2%.
Что Яндекс планирует с этим делать в будущем?Яндекс научил свои нейронные сети видеть заголовки документов, но поисковая команда в настоящее время работает также над проверкой текстового содержимого. При этом поисковая система Яндекса сможет выдавать еще более точные результаты после более подробного изучения того, соответствует ли содержание просканированных страниц заданному запросу.На сегодняшний день другие поисковые системы с аналогичной технологией проверяют только заголовки.
Яндекс также работает над реализацией модели с большим количеством сканируемых страниц. В настоящее время модель проверяет сотни документов, которые уже отфильтрованы в первые результаты поиска Яндекса. Команда поиска Яндекса работает над оптимизацией модели на более раннем этапе поиска, чтобы в конечном итоге она охватила миллиарды документов. Чем больше документов сможет включить Яндекс, тем точнее будут результаты поиска.
В дополнение к общему повышению точности результатов поиска Яндекса это, как правило, поможет Яндексу лучше понимать разговорные запросы в будущем.
Что это значит для SEO?По мере того, как Яндекс улучшает свою способность обрабатывать разговорные запросы, остальным SEO-специалистам и онлайн-маркетологам также необходимо адаптироваться к этому. Как всегда в случае с SEO, имеет значение несколько факторов ранжирования, и трудно сказать, какие из них имеют наибольшее значение. Однако в конечном итоге качественный контент для пользователя всегда был в центре внимания поисковой команды Яндекса. Палех этого не изменит. Специалисты по SEO все же должны учитывать, что нужно пользователю, не сосредотачиваясь на отдельных ключевых словах и не практикуя наполнение ключевыми словами.Пока веб-мастера предоставляют контент, который поможет пользователям Яндекса, машинное обучение Яндекса его распознает.
Пользователи Яндекса могут быть уверены, что передовая технология машинного обучения Яндекса будет и дальше предоставлять им все более релевантные результаты поиска, чем больше данных будет обрабатываться. Поскольку поисковая команда Яндекса успешно обучила Палех, пользователи могут рассчитывать на взаимодействие с окном поиска Яндекса с гораздо более сложными запросами.
Теги
AI (9) искусственный интеллект (6) поисковая система (5) SEO (450) яндекс (26)Яндекс с открытым исходным кодом CatBoost, библиотека машинного обучения для повышения градиента — TechCrunch
В настоящее время искусственный интеллект обеспечивает все большее количество вычислительных функций, и сегодня сообщество разработчиков получает еще один импульс искусственного интеллекта благодаря Яндекс.Сегодня российский поисковый гигант, который, как и его американский аналог Google, расширил множество других бизнес-направлений, от мобильных устройств до карт и т. Д., Объявил о запуске CatBoost, библиотеки машинного обучения с открытым исходным кодом, основанной на повышении градиента — ветвь машинного обучения, специально разработанная, чтобы помочь «обучить» системы, когда у вас очень скудный объем данных, и особенно когда не все данные могут быть сенсорными (например, аудио, текст или изображения), но включают транзакционные или исторические данные, тоже.
CatBoost сегодня дебютирует в двух направлениях. (Я, кстати, думаю, что «кошка» — это сокращение от «категории», а не ваш кошачий друг, хотя Яндекс наслаждается игрой слов. Если вы посетите сайт CatBoost, вы поймете, что я имею в виду.)
Во-первых, Яндекс заявляет, что начинает использовать новую структуру в своих собственных сервисах, чтобы заменить MatrixNet, алгоритм машинного обучения, который до сих пор использовался в компании для всего, от задач ранжирования, прогнозирования погоды и т. Д. Яндекс.службы такси (которые сейчас выделяются в совместное предприятие с Uber на российском рынке с оборотом 3,7 млрд долларов) и рекомендации. Переход с MatrixNet на CatBoost происходит сейчас и будет продолжаться в ближайшие месяцы.
Во-вторых, Яндекс предлагает библиотеку CatBoost как бесплатную услугу, выпущенную под лицензией Apache, для всех, кто нуждается или хочет использовать технологию повышения градиента в своих программах. «Это вершина многолетней работы», — сказал в интервью Миша Биленко, руководитель отдела машинного интеллекта и исследований Яндекса.«Мы сами использовали множество инструментов машинного обучения с открытым исходным кодом, поэтому давать что-то взамен — хорошая карма». Он упомянул переход Google к Tensorflow с открытым исходным кодом еще в 2015 году, а также создание и развитие Linux как два источника вдохновения.
Биленко добавил, что «нет планов» коммерциализировать CatBoost или закрыть его каким-либо другим собственным способом. «Это не вопрос конкурентов», — сказал он. «Мы были бы рады, если бы конкуренты использовали его в качестве основы».
Конечно, по мере того, как Яндекс продолжает расти, он уже давно ищет способы повысить свой международный авторитет за пределами русскоязычного мира.Подобные шаги подчеркивают не только приверженность компании сообществу разработчиков ПО с открытым исходным кодом, но и ее надежду на то, что она будет в центре его развития как среди крупных технологических компаний, так и среди более широкого сообщества разработчиков.
Так же, как Google продолжал расширять и обновлять Tensorflow, идея состоит в том, что сегодняшняя версия CatBoost — это первая итерация, которая будет обновляться и развиваться дальше, сказал мне Биленко. Сегодня библиотека имеет три основных функции:
«Снижение переобучения», которое, по словам Яндекса, помогает вам добиться лучших результатов в программе обучения.Он «основан на запатентованном алгоритме построения моделей, который отличается от стандартной схемы повышения градиента».
«Поддержка категориальных функций», в которой результаты обучения улучшаются, позволяя использовать нечисловые коэффициенты, «вместо того, чтобы предварительно обрабатывать данные или тратить время и усилия на преобразование их в числа».
Он также использует интерфейс API, который позволяет использовать CatBoost из командной строки или через API для Python или R, включая инструменты для анализа формул и визуализации обучения.
Хотя существует ряд других библиотек, которые помогают с повышением градиента или другими решениями для обучения систем машинного обучения (например, XGBoost), Биленко утверждал, что преимущества CatBoost и других фреймворков, предлагаемых крупными компаниями, такими как Яндекс, заключаются в следующем. что они прошли «боевую проверку» на точность.
«Грязный секрет большого количества кода машинного обучения в том, что он требует довольно обширной настройки», — сказал он. «Нашему требуется немного, и он обеспечивает довольно хорошую производительность прямо из коробки.Это ключевое отличие ».
Влияет ли скрытое семантическое индексирование на исследование ключевых слов?
Узнайте, оказывает ли скрытое семантическое индексирование такое влияние на ваше SEO, и что вам следует делать, чтобы улучшить исследование ключевых слов
Прежде чем писать этот пост, я заметил широкие дискуссии о скрытом семантическом индексировании (LSI) и его влиянии на SEO. Некоторые источники утверждают, что для повышения рейтинга крайне важно выбрать так называемые ключевые слова LSI. Другие говорят, что LSI не влияет на позиции вашего сайта.Прочитав разные мнения по этой теме, я понял, что есть много людей, которые не знают, что на самом деле представляет собой LSI.
Загрузите наш индивидуальный ресурс для участников — успешное руководство по поисковой оптимизации
Это руководство из семи шагов по SEO является одним из самых популярных и справедливо. Если вы все сделаете правильно, SEO может стать фантастическим и относительно недорогим способом привлечь на ваш сайт качественных посетителей, которые хотят вести с вами дела.
Получите доступ к руководству по успешной поисковой оптимизации
Если вас интересуют тенденции SEO, вы наверняка слышали о скрытой семантической индексации.Обсуждаемые многими влиятельными лицами, ключевые слова LSI считаются почти панацеей. Если вы хотите узнать, оказывает ли LSI такое влияние на ваше SEO, и что вам следует сделать, чтобы улучшить исследование ключевых слов, эта статья для вас.
Что такое скрытое семантическое индексирование?
Чтобы выяснить, как (и влияет ли) LSI на поисковый рейтинг, давайте определим, что означает скрытое семантическое индексирование. Это метод, использующий математическую технику для определения отношений между словами и понятиями, содержащимися в фрагменте контента.Поскольку такое описание мало что говорит обычному пользователю, позвольте мне дать более практическое описание.
Вкратце, метод скрытого семантического индексирования не только записывает ключевые слова, содержащиеся в контенте, но также исследует текст в целом. Это позволяет вам анализировать, какие другие фрагменты контента содержат те же слова. Хотя алгоритм не понимает значения терминов, весь шаблон позволяет ему справляться с контекстной природой языка. Этот метод напоминает то, как человек классифицирует документы, просматривая их содержимое.
Конечно, у LSI есть существенные недостатки:
- Метод не учитывает порядок слов и отбрасывает все предлоги и союзы. Считается, что
- слов имеют только одно значение.
- Значение текста может не совпадать со значением слов. Ирония и лежащие в ее основе идеи не признаются.
Влияет ли скрытое семантическое индексирование на SEO?
Итак, у нас есть алгоритм, который может определять содержание страниц и обеспечивать более глубокое понимание связи между языком и контекстом.Означает ли это, что поисковые системы используют его для определения наиболее релевантных результатов и ответов на конкретные поисковые запросы? Что ж, хотя многие статьи в Интернете говорят «да», некоторые мнения экспертов заставили меня усомниться в том, что это так.
Во-первых, в наши дни нет доказательств того, что поисковые системы используют LSI. Google никогда не признавал этого факта, а Яндекс даже публично заявлял, что не использует алгоритм LSI. Да, латентно-семантическое индексирование раньше помогало поисковым системам видеть различия в значениях слова, но это было в конце 1980-х годов.Каковы шансы, что информация все еще актуальна?
Скрытое семантическое индексирование — не единственный алгоритм, применимый для выявления семантически связанных тем. Я имею в виду, что LSI — это всего лишь один метод из списка других, таких как Word2Vec, GloVe и т. Д. Так же, как «iPhone» — это не имя для всех доступных смартфонов, LSI не следует рассматривать как алгоритм Google, влияющий на SEO только потому, что это алгоритм, который существует. Вот почему бессмысленно предполагать, что поисковые системы предпочитают старые технологии и методы новым.
Вот что Билл Славски говорит по этой теме:
«Google пытается индексировать синонимы и другие значения слов. Но для этого не используется технология LSI. Называя это LSI, люди вводят в заблуждение. Google предлагает замену синонимов и уточнение запросов на основе синонимов как минимум с 2003 года, но это не означает, что он использует LSI. Это все равно что сказать, что вы используете смарт-телеграф для подключения к мобильной сети. Для отправки сообщений на дальние расстояния использовался телеграф, но это не телефон.Технологии меняются и развиваются, и Google разработал собственную семантическую технологию, которая не является LSI, хотя обе они основаны на семантике ».
А как насчет «ключевых слов LSI»?
Если вы выполните поиск по запросу «ключевые слова LSI» в Google, он предоставит вам 892 000 результатов по этой теме. Вы найдете генераторы ключевых слов LSI, руководства по внедрению этих ключевых слов в свой контент и советы по улучшению SEO с помощью LSI. В конце концов, неопытные пользователи будут уверены, что мистические слова LSI повлияют на их рейтинг.
Они ошибаются? И да, и нет. Почему да? Мы уже пришли к выводу, что поисковые системы не используют технологию LSI, поэтому название «ключевые слова LSI» не имеет смысла. Почему бы и нет? Говоря о «ключевых словах LSI», люди имеют в виду тематически связанные слова, а иногда и синонимы. Действительно, эти слова имеют значение с точки зрения того, как поисковые системы видят и оценивают ваш контент.
Что дальше?
Несмотря на то, что скрытое семантическое индексирование не имеет ничего общего с вашим веб-сайтом, потребность в помощи поисковым системам в понимании вашего контента и ранжировании его по релевантным запросам все еще существует.Связанные слова — это те слова (кроме ваших ключевых слов), которые могут дать вам желаемый результат.
Как найти родственные слова
Если вы хотите улучшить возможность сканирования своего сайта, включение тематически связанных слов и синонимов является эффективным методом. Как я уже упоминал, есть два типа слов, которые следует выбирать с учетом тематики контента, а не только целевого ключевого слова:
- Слова, которые означают то же, что и ваше ключевое слово. Если ваше ключевое слово — «идея», синонимами будут: «значение», «тема», «концепция» и т. Д.
- Связанные слова, то есть термины и фразы, семантически связанные с запросом. Если ключевое слово — «SEO», родственными словами будут: «исследование ключевых слов», «поисковая выдача», «профиль ссылок» и т. Д.
Исследования
Такие слова довольно легко найти, если знать, где их искать. Первый способ всегда удобен, и вы его уже знаете. Это поиск в Google. При поиске по своей теме прокрутите страницу вниз и увидите следующее поле:
Поскольку Google уже связывает эти фразы с темой, стоит использовать некоторые из этих фраз для своей страницы.
Конечно, список достаточно короткий, и важно продолжить поиск с помощью других инструментов, таких как Serpstat , Moz или Ahrefs . Если вы выберете Serpstat, введите целевое ключевое слово или фразу, перейдите в раздел «Исследования SEO> Связанные ключевые слова», и служба предоставит вам список фраз, семантически связанных с вашим ключевым словом:
Самое главное, что список состоит не только из фраз, содержащих ваше основное ключевое слово, но и из всех связанных слов, которые люди обычно ищут по теме.Вы можете фильтровать фразы по объему поиска, цене за клик или мощности соединения и выбирать наиболее подходящие для ваших целей.
Как их реализовать
Хотя родственные слова не являются вашими ключевыми словами, по-прежнему довольно легко злоупотреблять ими и подвергаться наказанию за это. Помните, что пользовательский опыт — один из самых важных факторов ранжирования.
Если тексты просто засоряют глаза аудитории и содержат мало полезной информации, пользователи могут покинуть вашу страницу слишком быстро.Даже если в вашем контенте много связанных слов, показатель отказов резко возрастет, и ваши позиции упадут. Следовательно, существуют некоторые «правила», когда дело доходит до внедрения связанных слов в ваш контент, чтобы улучшить (а не разрушить) вашу стратегию SEO:
- Очень осторожно используйте синонимы и родственные фразы.
- Используйте фиксированное соотношение выбранных фраз и других слов в тексте.
- Думайте о естественной речи. Когда текст будет готов, прочтите его еще раз и спросите себя: «Могу ли я сказать так в реальной жизни?» Если ответ положительный, продолжайте.
- Добавьте их в свой мета-заголовок и описание. Поскольку использование ключевых слов несколько раз в заголовке и описании — не лучшая идея, связанные слова помогут вам расширить ваши возможности.
Подведение итогов
Конечно, использование термина LSI не вредит вашему SEO, но вся суета вокруг «ключевых слов LSI» и самой концепции вызывает множество вопросов. Вот почему, чтобы никого не сбить с толку и не подорвать доверие клиентов, прекратите делать что-то «только потому, что мы можем».’
Когда дело доходит до того, что мы называем ключевыми словами LSI, но то, что мы должны называть просто связанными словами, они не являются панацеей. Они достаточно полезны, но не решат ваших проблем с SEO. Помните, что добавление связанных слов не обязательно означает улучшение общего рейтинга вашего сайта. Они помогут ему получить релевантные результаты, что еще более важно.
Инна Яцына — менеджер по бренду и сообществу в Serpstat , универсальной SEO-платформе. Инна имеет опыт в цифровом и контент-маркетинге, а также в SEO.Она любит писать полезные сообщения, помогать людям, читать, путешествовать и любит животных (особенно собак).Search Giant Яндекс стремится создать альтернативную веб-экосистему; Особый интерес в Индии вызывает магазин приложений
«Яндекс» — популярная поисковая система и компания, предоставляющая онлайн-услуги, с набором онлайн-сервисов, которые конкурируют с подобными Google по своим предложениям. Яндекс, занимающий более 60% рынка поисковых систем в России, предлагает почту, облачное хранилище, аналитику, платежные сервисы, рекламную платформу, браузер и, с недавних пор, магазин приложений.После проведения одного из самых прибыльных IPO 2012 года Яндекс сосредоточил свое внимание на международной экспансии. На мобильном саммите представители Яндекса поделились с нами своими текущими планами международной экспансии и, в частности, планами в отношении Индии.
Яндекс Store
Яндекс Store — это альтернативный магазин приложений для платформы Android. Магазин скоро будет выпущен, и он уже может похвастаться впечатляющими 40000
приложениями.По словам Яндекса, выпуск магазина приложений завершает экосистему мобильных вычислений, которую пользователь может захотеть использовать. «Мы пытаемся предложить этот пакет операторам связи и OEM-производителям в качестве альтернативы существующей экосистеме, чтобы предоставить пользователю такой же полный опыт, как и при использовании обычного варианта. Мы считаем, что это такой же хороший опыт, как и другие пакеты, если не лучше ».
С ростом числа телефонов на базе Android, выпускаемых без аккредитации Google, экосистема Яндекса кажется очевидной альтернативой.
Международная экспансия
В современном мире в поиске в Интернете доминирует Google, и для поисковой компании, которая должна расширяться на международном уровне с почти такими же предложениями, как у лидера рынка, Яндекс имеет практичный, но уникальный подход.
«Яндекс стал очень популярной поисковой системой в России и странах СНГ благодаря действительно хорошей технологии и пониманию значения слов в запросах пользователей, сделанных из разных частей России.Например, если кто-то в Санкт-Петербурге ищет море, он, скорее всего, имеет в виду Балтийское море. Если пользователь из Сочи (2000 миль от Петербурга) делает то же самое, он, скорее всего, имеет в виду Черное море. Итак, мы можем понять, что они означают для одного и того же слова. «
» В прошлом году мы начали нашу международную экспансию, запустив некоторые из наших услуг в Турции. Мы запустили поиск здесь, и для нас это была первая страна, которая не говорила по-русски, поэтому пришлось начинать с нуля. Пока дела идут хорошо, и в Турции на Яндекс приходится около 2% поискового трафика.Это может показаться не таким уж большим, но это определенно начало. Наш подход к международной экспансии основан на странах, которые не предлагают высокой конкуренции на рынке поиска. Если бы мы продвигали наши услуги в США, тогда было бы что-то странное, не так ли? » Сказал представитель.
«В Турции у нас хорошо получилось подойти к поиску с лингвистической точки зрения. Это сработало, но мы должны признать, что это непростая задача. Мы наняли местных жителей и сделали сознательную попытку сделать это Яндекс. Турция, а не очередное отделение Яндекса Россия.
«Сказав это, я не могу определить это как нашу международную стратегию, но это то, что мы сделали в Турции, и это сработало для нас. Но сделать это для нас было тяжело. Сделать это в других странах означало бы начать все сначала, и это будет нелегко. Поэтому было бы неправильно сказать, что это наша стратегия ». добавил представитель.
Что касается своих планов в отношении Индии, они отказались поделиться им с нами, но упомянули, что их присутствие на саммите мобильных устройств было направлено на продвижение магазина Яндекс для разработчиков приложений.«Я не могу назвать вам несколько приложений, сделанных в Индии, в магазине, но уверяю вас, что из 40000 приложений, по крайней мере, одно создано индийцами», — смеется представитель.