Как посмотреть robots.txt сайта, который вам интересен?
От автора: хотите составить для своего проекта файл с указаниями для робота, но не знаете как? Сегодня разберемся, как посмотреть robots.txt сайта и изменить его под свои нужды.
В интернете каждый день появляются готовые решения по той или иной проблеме. Нет денег на дизайнера? Используйте один из тысяч бесплатных шаблонов. Не хотите нанимать сео-специалиста? Воспользуйтесь услугами какого-нибудь известного бесплатного сервиса, почитайте сами пару статей.
Уже давно нет необходимости самому с нуля писать тот же самый robots.txt. К слову, это специальный файл, который есть практически на любом сайте, и в нем содержатся указания для поисковых роботов. Синтаксис команд очень простой, но все равно на составление собственного файла уйдет время. Лучше посмотреть у другого сайта. Тут есть несколько оговорок:
Сайт должен быть на том же движке, что и ваш. В принципе, сегодня в интернете куча сервисов, где можно узнать название cms практически любого веб-ресурса.
Это должен быть более менее успешный сайт, у которого все в порядке с поисковым трафиком. Это говорит о том, что robots.txt составлен нормально.
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееИтак, чтобы посмотреть этот файл нужно в адресной строке набрать: доменное-имя.зона/robots.txt
Все неверятно просто, правда? Если адрес не будет найден, значит такого файла на сайте нет, либо к нему закрыт доступ. Но в большинстве случаев вы увидите перед собой содержимое файла:

В принципе, даже человек не особо разбирающийся в коде быстро поймет, что тут написать. Команда allow разрешает что-либо индексировать, а disallow – запрещает. User-agent – это указание поисковых роботов, к которым обращены инструкции. Это необходимо в том случае, когда нужно указать команды для отдельного поисковика.
Что делать дальше?
Скопировать все и изменить под свой сайт. Как изменять? Я уже говорил, что движки сайтов должны совпадать, иначе изменять что-либо бессмысленно – нужно переписывать абсолютно все.
Итак, вам необходимо будет пройтись по строкам и определить, какие разделы из указанных присутствуют на вашем сайте, а какие – нет. На скриншоте выше вы видите пример robots.txt для wordpress сайта, причем в отдельном каталоге есть форум. Вывод? Если у вас нет форума, все эти строки нужно удалить, так как подобных разделов и страниц у вас просто не существует, зачем тогда их закрывать?
Самый простой robots.txt может выглядеть так:
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Allow: /wp-content/uploads/
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Allow: /wp-content/uploads/ |
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееВсе вы наверняка знаете стандартную структуру папок в wordpress, если хотя бы 1 раз устанавливали этот движок. Это папки wp-admin, wp-content и wp-includes. Обычно все 3 закрывают от индексации, потому что они содержат чисто технические файлы, необходимые для работы движка, плагинов и шаблонов.
Каталог uploads открывают, потому что в нем содержаться картинки, а их обыно индексируют.
В общем, вам нужно пройтись по скопированному robots.txt и просмотреть, что из написанного действительно есть на вашем сайте, а чего нет. Конечно, самому определить будет трудно. Я могу лишь сказать, что если вы что-то не удалите, то ничего страшного, просто лишняя строчка будет, которая никак не вредит (потому что раздела нет).
Так ли важна настройка robots.txt?

Конечно, необходимо иметь этот файл и хотя бы основные каталоги через него закрыть. Но критично ли важно его составление? Как показывает практика, нет. Я лично вижу сайты на одних движках с абсолютно разным robots.txt, которые одинаково успешно продвигаются в поисковых системах.
Я не спорю, что можно совершить какую-то ошибку. Например, закрыть изображения или оставить открытым ненужный каталог, но чего-то супер страшного не произойдет. Во-первых, потому что поисковые системы сегодня умнее и могут игнорировать какие-то указание из файла. Во-вторых, написаны сотни статей о настройке robots.txt и уж что-то можно понять из них.
Я видел файлы, в которых было 6-7 строчек, запрещающих индексировать пару каталогов. Также я видел файлы с сотней-другой строк кода, где было закрыто все, что только можно. Оба сайта при этом нормально продвигались.
В wordpress есть так называемые дубли. Это плохо. Многие борятся с этим с помощью закрытия подобных дублей так:
Disallow: /wp-feed Disallow: */trackback Disallow: */feed Disallow: /tag/ Disallow: /archive/
Disallow: */trackback Disallow: */feed Disallow: /tag/ Disallow: /archive/ |
Это лишь некоторые из дублей, создаваемых wordpress. Могу сказать, что так можно делать, но защиты на 100% ожидать не стоит. Я бы даже сказал, что вообще не нужно ее ожидать и проблема как раз в том, о чем я уже говорил ранее:
Поисковые системы все равно могут забрать в индекс такие вещи.
Тут уже нужно бороться по-другому. Например, с помощью редиректов или плагинов, которые будут уничтожать дубли. Впрочем, это уже тема для отдельной статьи.
Где находится robots.txt?
Этот файл всегда находится в корне сайта, поэтому мы и можем обратиться к нему, прописав адрес сайта и название файла через слэш. По-моему, тут все максимально просто.
В общем, сегодня мы рассмотрели вопрос, как посмотреть содержимое файла robots.txt, скопировать его и изменить под свои нужды. О настройке я также напишу еще 1-2 статьи в ближайшее время, потому что в этой статье мы рассмотрели не все. Кстати, также много информации по продвижению сайтов-блогов вы можете найти в нашем курсе. А я на этом пока прощаюсь с вами.
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееХотите узнать, что необходимо для создания сайта?
Посмотрите видео и узнайте пошаговый план по созданию сайта с нуля!
Смотретьwebformyself.com
Файл robots.txt — способы анализа и проверки robots.txt
Создание файла
Описание. Файл robots.txt — это документ со служебной информацией. Он предназначен для поисковых роботов. В нем записывают, какие страницы можно индексировать, какие — нет и каким именно краулерам. Например, англоязычный Facebook разрешает доступ только боту Google. Файл robots.txt любого сайта можно посмотреть в браузере по ссылке www.site.ru/robots.txt.
Он не является обязательным элементом сайта, но его наличие желательно, потому что с его помощью владельцы сайта управляют поисковыми роботами. Задавайте разные уровни доступа к сайту, запрет на индексацию всего сайта, отдельных страниц, разделов или файлов. Для ресурсов с высокой посещаемостью ограничивайте время индексации и запрещайте доступ роботов, которые не относятся к основным поисковым системам. Это уменьшит нагрузку на сервер.
Создание. Создают файл в текстовом редакторе Notepad или подобных. Следите за тем, чтобы размер файла не превышал 32 КБ. Выбирайте для файла кодировку ASCII или UTF-8. Учтите, что файл должен быть единственным. Если сайт создан на CMS, то он будет генерироваться автоматически.
Разместите созданный файл в корневой директории сайта рядом с основным файлом index.html. Для этого используют FTP доступ. Если сайт сделан на CMS, то с файлом работают через административную панель. Когда файл создан и работает корректно, он доступен в браузере.
При отсутствии robots.txt поисковые роботы собирают всю информацию, относящуюся к сайту. Не удивляйтесь, когда увидите в выдаче незаполненные страницы или служебную информацию. Определите, какие разделы сайта будут доступны пользователям, остальные — закройте от индексации.
Проверка. Периодически проверяйте, все ли работает корректно. Если краулер не получает ответ 200 ОК, то он автоматически считает, что файла нет, и сайт открыт для индексации полностью. Коды ошибок бывают такими:
-
3хх — ответы переадресации. Робота направляют на другую страницу или на главную. Создавайте до пяти переадресаций на одной странице. Если их будет больше, робот пометит такую страницу как ошибку 404. То же самое относится и к переадресации по принципу бесконечного цикла;
-
4хх — ответы ошибок сайта. Если краулер получает от файла robots.txt 400-ую ошибку, то делается вывод, что файла нет и весь контент доступен. Это также относится к ошибкам 401 и 403;
-
5хх — ответы ошибок сервера. Краулер будет «стучаться», пока не получит ответ, отличный от 500-го.
Правила создания
Начинаем с приветствия. Каждый файл должен начинаться с приветствия User-agent. С его помощью поисковики определят уровень открытости.
| Код | Значение |
| User-agent: * | Доступно всем |
| User-agent: Yandex | Доступно роботу Яндекс |
| User-agent: Googlebot | Доступно роботу Google |
| User-agent: Mail.ru | Доступно роботу Mail.ru |
Добавляем отдельные директивы под роботов. При необходимости добавляйте директивы для специализированных поисковых ботов Яндекса.
| YandexBot | Основной робот |
| YandexImages | Яндекс.Картинки |
| YandexNews | Яндекс.Новости |
| YandexMedia | Индексация мультимедиа |
| YandexBlogs | Индексация постов и комментариев |
| YandexMarket | Яндекс.Маркет |
| YandexMetrika | Яндекс.Метрика |
| YandexDirect | Рекламная сеть Яндекса |
| YandexDirectDyn | Индексация динамических баннеров |
| YaDirectFetcher | Яндекс.Директ |
| YandexPagechecker | Валидатор микроразметки |
| YandexCalendar | Яндекс.Календарь |
У Google собственные боты:
| Googlebot | Основной краулер |
| Google-Images | Google.Картинки |
| Mediapartners-Google | AdSense |
| AdsBot-Google | Проверка качества рекламы |
|
AdsBot-Google-Mobile |
Проверка качества рекламы на мобильных устройствах |
| Googlebot-News | Новости Google |
Сначала запрещаем, потом разрешаем. Оперируйте двумя директивами: Allow — разрешаю, Disallow — запрещаю. Обязательно укажите директиву disallow, даже если доступ разрешен ко всему сайту. Такая директива является обязательной. В случае ее отсутствия краулер может не верно прочитать остальную информацию. Если на сайте нет закрытого контента, оставьте директиву пустой.
Работайте с разными уровнями. В файле можно задать настройки на четырех уровнях: сайта, страницы, папки и типа контента. Допустим, вы хотите закрыть изображения от индексации. Это можно сделать на уровне:
- папки — disallow: /images/
- типа контента — disallow: /*.jpg
| Нет | Да |
| Disallow: Yandex |
User-agent: Yandex Disallow: / |
| Disallow: /css/ /images/ |
Disallow: /css/ Disallow: /images/ |
Пишите с учетом регистра. Имя файла укажите строчными буквами. Яндекс в пояснительной документации указывает, что для его ботов регистр не важен, но Google просит соблюдать регистр. Также вероятна ошибка в названиях файлов и папок, в которых учитывается регистр.
Укажите 301 редирект на главное зеркало сайта. Раньше для этого использовалась директива Host, но с марта 2018 г. она больше не нужна. Если она уже прописана в файле robots.txt, удалите или оставьте ее на свое усмотрение; роботы игнорируют эту директиву.
Для указания главного зеркала проставьте 301 редирект на каждую страницу сайта. Если редиректа стоят не будет, поисковик самостоятельно определит, какое зеркало считать главным. Чтобы исправить зеркало сайта, просто укажите постраничный 301 редирект и подождите несколько дней.
Пропишите директиву Sitemap (карту сайта). Файлы sitemap.xml и robots.txt дополняют друг друга. Проверьте, чтобы:
- файлы не противоречили друг другу;
- страницы были исключены из обоих файлов;
- страницы были разрешены в обоих файлах.
Указывайте комментарии через символ #. Все, что написано после него, краулер игнорирует.
Проверка файла
Проводите анализ robots.txt с помощью инструментов для разработчиков: через Яндекс.Вебмастер и Google Robots Testing Tool. Обратите внимание, что Яндекс и Google проверяют только соответствие файла собственным требованиям. Если для Яндекса файл корректный, это не значит, что он будет корректным для роботов Google, поэтому проверяйте в обеих системах.
Если вы найдете ошибки и исправите robots.txt, краулеры не считают изменения мгновенно. Обычно переобход страниц осуществляется один раз в день, но часто занимает гораздо большее время. Проверьте через неделю файл, чтобы убедиться, что поисковики используют новую версию.
Проверка в Яндекс.Вебмастере
Сначала подтвердите права на сайт. После этого он появится в панели Вебмастера. Введите название сайта в поле и нажмите проверить. Внизу станет доступен результат проверки.
Дополнительно проверяйте отдельные страницы. Для этого введите адреса страниц и нажмите «проверить».
Проверка в Google Robots Testing Tool
Позволяет проверять и редактировать файл в административной панели. Выдает сообщение о логических и синтаксических ошибках. Исправляйте текст файла прямо в редакторе Google. Но обратите внимание, что изменения не сохраняются автоматически. После исправления robots.txt скопируйте код из веб-редактора и создайте новый файл через блокнот или другой текстовый редактор. Затем загрузите его на сервер в корневой каталог.
Запомните
-
Файл robots.txt помогает поисковым роботам индексировать сайт. Закрывайте сайт во время разработки, в остальное время — весь сайт или его часть должны быть открыты. Корректно работающий файл должен отдавать ответ 200.
-
Файл создается в обычном текстовом редакторе. Во многих CMS в административной панели предусмотрено создание файла. Следите, чтобы размер не превышал 32 КБ. Размещайте его в корневой директории сайта.
-
Заполняйте файл по правилам. Начинайте с кода “User-agent:”. Правила прописывайте блоками, отделяйте их пустой строкой. Соблюдайте принятый синтаксис.
-
Разрешайте или запрещайте индексацию всем краулерам или избранным. Для этого укажите название поискового робота или поставьте значок *, который означает «для всех».
-
Работайте с разными уровнями доступа: сайтом, страницей, папкой или типом файлов.
-
Включите в файл указание на главное зеркало с помощью постраничного 301 редиректа и на карту сайта с помощью директивы sitemap.
-
Для анализа robots.txt используйте инструменты для разработчиков. Это Яндекс.Вебмастер и Google Robots Testing Tools. Сначала подтвердите права на сайт, затем сделайте проверку. В Google сразу отредактируйте файл в веб-редакторе и уберите ошибки. Отредактированные файлы не сохраняются автоматически. Загружайте их на сервер вместо первоначального robots.txt. Через неделю проверьте, используют ли поисковики новую версию.
Материал подготовила Светлана Сирвида-Льорентэ.
www.ashmanov.com
Инструменты проверки файла robots.txt | www.wordpress-abc.ru
Вступление
Если у вас есть желание закрыть некоторые материалы своего сайта от поисковых и других ботов, используется три метода:
Во-первых, создаётся файл robots.txt в котором специальными записями закрываются/открываются части контента. Важно, что файл robots.txt запрещает роботам сканировать URL сайта;
Во-вторых, на HTML(XHTML) страницах или в HTTP заголовке прописывается мета–тег robots с атрибутами noindex (не показывает страницу в поиске) и/или nofollow (не разрешает боту обходить ссылки страницы). Синтаксис мета тега robots:
<meta name="robots" content="noindex, nofollow" />Важно, что мета–тег robots работает, если есть доступ ботов к сканированию страниц, где мета тег прописан. То есть они не закрыты файлом
robots.txt.
В-третьих, можно создавать закрытые разделы сайта.
При составлении файла robots.txt полезно проверять правильность его составления. Для этого предлагаю посмотреть следующие инструменты проверки файла robots.txt.
Инструменты проверки файла robots.txt
Напомню, что в классическом варианте в файле robots.txt создаются отдельные директивы для агента пользователя Yandex (user-agent: yandex) и других поисковых ботов сети, включая Googleboot (user-agent: *).
Инструмент проверки №1
Google в возможностях Searh Console оставил инструмент проверки файла robots.txt. Вот ссылка на него: https://www.google.com/webmasters/tools/robots-testing-tool
Вот скрин:

Для использования инструмента вам нужно зарегистрироваться инструментах веб–мастеров Google и добавить в них свой ресурс (сайт). Если вы всё это сделали, просто выберете сайт для проверки.
После выбора сайту откроется инструмент проверки файла robots.txt. Внизу читаем ошибки и предупреждения. Если их нет, то смотрим ещё ниже и видим сам инструмент проверки.

В форме проверки указываете проверяемый URL, выбираете бота Google (по умолчанию Googleboot) и жмёте кнопку «Проверить».
Результат проверки будет показан на этой же станице в виде зелёной надписи «Доступен» или красной надписи «Не доступен». Всё просто и понятно.
Инструмент проверки №2
По логике составления файла robots.txt о которой я напомнил выше, такой же инструмент проверки должен быть в веб–инструментах Яндекс для ботов Yandex. Смотрим. Действительно, в вашем аккаунте Яндекс Веб–мастер выбираете заранее добавленный ресурс (свой сайт).
В меню «Инструменты» есть вкладка «Анализ robots.txt», где проверяется весь файл robots на ошибки и проверяются отдельные URL сайта на закрытие в файле robots.

Независимые инструменты проверки файла robots.txt
Встаёт логичный вопрос, можно ли проверить файл robots.txt и его работу независимо от инструментов веб мастеров? Наверняка можно.
Во-первых, чтобы просмотреть доступность своего файла robots впишите в браузер его адрес. Он должен открыться и нормально читаться. Проверку можно сделать в нескольких браузерах.
Адрес файла должен быть:
http(s)://ваш_домен/robots.txt
Во-вторых, используйте для проверки файла следующие инструменты:
Websiteplanet.com

https://www.websiteplanet.com/ru/webtools/robots-txt/
Дотошный инструмент, выявляет ошибки и предупреждения, которые не показывают сами боты.
Seositecheckup.com

https://seositecheckup.com/tools/robotstxt-test
Англоязычный инструмент проверки файла robots.txt на ошибки. Регистрация не требуется. Хотя навязывается сервисом. Результаты в виде диаграммы.
Стоит отметить, что с июня сего года (2019) правила для составления файла robots.txt стали стандартом и распространяются на всех ботов. Так что выявленные ошибки для бота Google, будут ошибками и для бота Yandex.
Technicalseo.com
https://technicalseo.com/tools/robots-txt/
Протестируйте и подтвердите ваш robots.txt с помощью этого инструмента тестирования. Проверьте, заблокирован ли URL-адрес, какой оператор его блокирует и для какого агента пользователя. Вы также можете проверить, запрещены ли ресурсы для страницы (CSS, JavaScript, IMG).
en.ryte.com
https://en.ryte.com/free-tools/robots-txt/
Просто вписывает адрес своего файла и делаете проверку. Показывает предупреждения по синтаксису файла.
Вывод про инструменты проверки файла robots.txt
По-моему, лучшие инструменты проверки файла robots.txt находятся в инструментах веб–мастеров. Они ближе к источнику и более чувствительны к изменениям правил.
Кстати, есть проверка файла robots.txt в инструментах веб–мастеров Mail поисковика (https://webmaster.mail.ru/) и была у поисковика Bing.
Еще статьи
Похожие посты:
www.wordpress-abc.ru
Настройка robots.txt – как узнать, какие страницы необходимо закрывать от индексации
Файл robots.txt представляет собой набор директив (набор правил для роботов), с помощью которых можно запретить или разрешить поисковым роботам индексирование определенных разделов и файлов вашего сайта, а также сообщить дополнительные сведения. Изначально с помощью robots.txt реально было только запретить индексирование разделов, возможность разрешать к индексации появилась позднее, и была введена лидерами поиска Яндекс и Google.
Структура файла robots.txt
Сначала прописывается директива User-agent, которая показывает, к какому поисковому роботу относятся инструкции.
Небольшой список известных и частоиспользуемых User-agent:
- User-agent:*
- User-agent: Yandex
- User-agent: Googlebot
- User-agent: Bingbot
- User-agent: YandexImages
- User-agent: Mail.RU
Далее указываются директивы Disallow и Allow, которые запрещают или разрешают индексирование разделов, отдельных страниц сайта или файлов соответственно. Затем повторяем данные действия для следующего User-agent. В конце файла указывается директива Sitemap, где задается адрес карты вашего сайта.
Прописывая директивы Disallow и Allow, можно использовать специальные символы * и $. Здесь * означает «любой символ», а $ – «конец строки». Например, Disallow: /admin/*.php означает, что запрещается индексация индексацию всех файлов, которые находятся в папке admin и заканчиваются на .php, Disallow: /admin$ запрещает адрес /admin, но не запрещает /admin.php, или /admin/new/ , если таковой имеется.
Если для всех User-agent использует одинаковый набор директив, не нужно дублировать эту информацию для каждого из них, достаточно будет User-agent: *. В случае, когда необходимо дополнить информацию для какого-то из user-agent, следует продублировать информацию и добавить новую.
Пример robots.txt для WordPress:
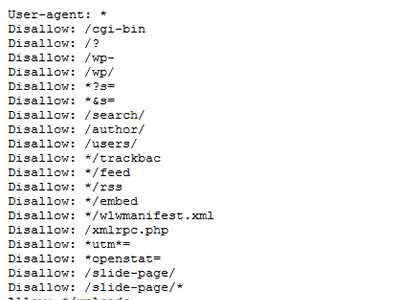
*Примечание для User agent: Yandex
-
Для того чтобы передать роботу Яндекса Url без Get параметров (например: ?id=, ?PAGEN_1=) и utm-меток (например: &utm_source=, &utm_campaign=), необходимо использовать директиву Clean-param.
-
Ранее роботу Яндекса можно было сообщить адрес главного зеркала сайта с помощью директивы Host. Но от этого метода отказались весной 2018 года.
-
Также ранее можно было сообщить роботу Яндекса, как часто обращаться к сайту с помощью директивы Crawl-delay. Но как сообщается в блоге для вебмастеров Яндекса:
- Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay.
- Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Вместо этой директивы в Яндекс. Вебмастер добавили новый раздел «Скорость обхода».
Проверка robots.txt
Старая версия Search console
Для проверки правильности составления robots.txt можно воспользоваться Вебмастером от Google – необходимо перейти в раздел «Сканирование» и далее «Просмотреть как Googlebot», затем нажать кнопку «Получить и отобразить». В результате сканирования будут представлены два скриншота сайта, где изображено, как сайт видят пользователи и как поисковые роботы. А ниже будет представлен список файлов, запрет к индексации которых мешает корректному считыванию вашего сайта поисковыми роботами (их необходимо будет разрешить к индексации для робота Google).
Обычно это могут быть различные файлы стилей (css), JavaScript, а также изображения. После того, как вы разрешите данные файлы к индексации, оба скриншота в Вебмастере должны быть идентичными. Исключениями являются файлы, которые расположены удаленно, например, скрипт Яндекс.Метрики, кнопки социальных сетей и т.д. Их у вас не получится запретить/разрешить к индексации. Более подробно о том, как устранить ошибку «Googlebot не может получить доступ к файлам CSS и JS на сайте», вы читайте в нашем блоге.
Новая версия Search console
В новой версии нет отдельного пункта меню для проверки robots.txt. Теперь достаточно просто вставить адрес нужной страны в строку поиска.
В следующем окне нажимаем «Изучить просканированную страницу».
Далее нажимаем ресурсы страницы
В появившемся окне видно ресурсы, которые по тем или иным причинам недоступны роботу google. В конкретном примере нет ресурсов, заблокированных файлом robots.txt.
Если же такие ресурсы будут, вы увидите сообщения следующего вида:
Рекомендации, что закрыть в robots.txt
Каждый сайт имеет уникальный robots.txt, но некоторые общие черты можно выделить в такой список:
- Закрывать от индексации страницы авторизации, регистрации, вспомнить пароль и другие технические страницы.
- Админ панель ресурса.
- Страницы сортировок, страницы вида отображения информации на сайте.
- Для интернет-магазинов страницы корзины, избранное. Более подробно вы можете почитать в советах интернет-магазинам по настройкам индексирования в блоге Яндекса.
- Страница поиска.
Это лишь примерный список того, что можно закрыть от индексации от роботов поисковых систем. В каждом случае нужно разбираться в индивидуальном порядке, в некоторых ситуациях могут быть исключения из правил.
Заключение
Файл robots.txt является важным инструментом регулирования отношений между сайтом и роботом поисковых систем, важно уделять время его настройке.
В статье большое количество информации посвящено роботам Яндекса и Google, но это не означает, что нужно составлять файл только для них. Есть и другие роботы – Bing, Mail.ru, и др. Можно дополнить robots.txt инструкциями для них.
Многие современные cms создают файл robots.txt автоматически, и в них могут присутствовать устаревшие директивы. Поэтому рекомендую после прочтения этой статьи проверить файл robots.txt на своем сайте, а если они там присутствуют, желательно их удалить. Если вы не знаете, как это сделать, обращайтесь к нам за помощью.
1ps.ru
Анализ файлов robots.txt крупнейших сайтов / Habr
Robots.txt указывает веб-краулерам мира, какие файлы можно или нельзя скачивать с сервера. Он как первый сторож в интернете — не блокирует запросы, а просит не делать их. Интересно, что файлы robots.txt проявляют предположения веб-мастеров, как автоматизированным процессам следует работать с сайтом. Хотя бот легко может их игнорировать, но они указывают идеализированное поведение, как следует действовать краулеру.По существу, это довольно важные файлы. Так что я решил скачать файл robots.txt с каждого из 1 миллиона самых посещаемых сайтов на планете и посмотреть, какие шаблоны удастся обнаружить.
Я взял список 1 млн крупнейших сайтов от Alexa и написал маленькую программу для скачивания файла robots.txt с каждого домена. После скачивания всех данных я пропустил каждый файл через питоновский пакет urllib.robotparser и начал изучать результаты.

Найдено в yangteacher.ru/robots.txt
Среди моих любимых питомцев — сайты, которые позволяют индексировать содержимое только боту Google и банят всех остальных. Например, файл robots.txt сайта Facebook начинается со следующих строк:
Notice: Crawling Facebook is prohibited unless you have express written permission. See: http://www.facebook.com/apps/site_scraping_tos_terms.phphttp://www.facebook.com/apps/site_scraping_tos_terms.php)Это слегка лицемерно, потому что сам Facebook начал работу с краулинга профилей студентов на сайте Гарвардского университета — именно такого рода активность они сейчас запрещают всем остальным.
Требование письменного разрешения перед началом краулинга сайта плюёт в лицо идеалам открытого интернета. Оно препятствует научным исследованиям и ставит барьер для развития новых поисковых систем: например, поисковику DuckDuckGo запрещено скачивать страницы Facebook, а поисковику Google можно.
В донкихотском порыве назвать и посрамить сайты, которые проявляют такое поведение, я написал простой скрипт, который проверяет домены и определяет тех, которые внесли Google в белый список тех, кому разрешено индексировать главную страницу. Вот самые популярные из этих доменов:

(В оригинальной статье указаны также аналогичные списки китайских, французских и немецких доменов — прим. пер.)
Я включил в таблицу пометку, позволяет ли сайт ещё DuckDuckGo индексировать свою заглавную страницу, в попытке показать, насколько тяжело приходится в наши дни новым поисковым системам.
У большинства из доменов в верхней части списка — таких как Facebook, LinkedIn, Quora и Yelp — есть одно общее. Все они размещают созданный пользователями контент, который представляет собой главную ценность их бизнеса. Это один из их главных активов, и компании не хотят отдавать его бесплатно. Впрочем, ради справедливости, такие запреты часто представляются как защита приватности пользователей, как в этом заявлении технического директора Facebook о решении забанить краулеры или глубоко в файле robots.txt от Quora, где объясняется, почему сайт забанил Wayback Machine.
Далее по списку результаты становятся более противоречивыми — например, мне не совсем понятно, почему census.gov позволяет доступ к своему контенту только трём основным поисковым системам, но блокирует DuckDuckGo. Логично предположить, что данные государственных переписей принадлежат народу, а не только Google/Microsoft/Yahoo.
Хотя я не фанат подобного поведения, но вполне могу понять импульсивную попытку внести в белый список только определённые краулеры, если учесть количество плохих ботов вокруг.
Я хотел попробовать ещё кое-что: определить самые плохие веб-краулеры в интернете, с учётом коллективного мнения миллиона файлов robots.txt. Для этого я подсчитал, сколько разных доменов полностью банят конкретный useragent — и отранжировал их по этому показателю:
В списке боты нескольких определённых типов.
Первая группа — краулеры, которые собирают данные для SEO и маркетингового анализа. Эти фирмы хотят получить как можно больше данных для своей аналитики — генерируя заметную нагрузку на многие сервера. Бот Ahrefs даже хвастается: «AhrefsBot — второй самый активный краулер после Googlebot», так что вполне понятно, почему люди хотят заблокировать этих надоедливых ботов. Majestic (MJ12Bot) позиционирует себя как инструмент конкурентной разведки. Это значит, что он скачивает ваш сайт, чтобы снабдить полезной информацией ваших конкурентов — и тоже на главной странице заявляет о «крупнейшем в мире индексе ссылок».
Вторая группа user-agents — от инструментов, которые стремятся быстро скачать веб-сайт для персонального использования в офлайне. Инструменты вроде WebCopier, Webstripper и Teleport — все они быстро скачивают полную копию веб-сайта на ваш жёсткий диск. Проблема в скорости многопоточного скачивания: все эти инструменты очевидно настолько забивают трафик, что сайты достаточно часто их запрещают.
Наконец, есть поисковые системы вроде Baidu (BaiduSpider) и Yandex, которые могут агрессивно индексировать контент, хотя обслуживают только языки/рынки, которые не обязательно очень ценны для определённых сайтов. Лично у меня оба эти краулера генерируют немало трафика, так что я бы не советовал блокировать их.
Это знак времени, что файлы, которые предназначены для чтения роботами, часто содержат объявления о найме на работу разработчиков программного обеспечения — особенно специалистов по SEO.
В каком-то роде это первая в мире (и, наверное, единственная) биржа вакансий, составленная полностью из описаний файлов robots.txt. (В оригинальной статье представлены тексты всех 67 вакансий из файлов robots.txt — прим. пер.).
Есть некоторая ирония в том, что Ahrefs.com, разработчик второго среди самых забаненных ботов, тоже поместила в своём файле robots.txt объявление о поиске SEO-специалиста. А ещё у pricefalls.com объявление о работе в файле robots.txt следует после записи «Предупреждение: краулинг Pricefalls запрещён, если у вас нет письменного разрешения».
Весь код для этой статьи — на GitHub.
habr.com
Оптимизация сайта. Как написать и проверить robots.txt для WordPress.
Приветствую, уважаемые читатели блога PAMMAP.RU.
В этой статье я постараюсь ответить на следующие вопросы:
Зашел я недавно в Яндекс.Вебмастер, чтобы посмотреть, что делает поисковый робот Яндекса на моем сайте. Как подключить свой сайт к Яндекс.Вебмастер Вы можете посмотреть если перейдете по ссылке. И увидел, что в поиск попадает много ненужных страниц, которые там совершенно не нужны. Казалось бы, что плохого, когда в индексе поисковика много страниц, а плохое есть.
- это появление в поиске страниц, которые не несут никакой полезной информации для пользователя, и скорее всего пользователь на них все равно не зайдет, а если зайдет, то ненадолго.
- это появление в поиске копий одной и той же страницы с разными адресами. (Дублирование контента)
- это тратится драгоценное время на индексацию ненужных страниц поисковыми роботами. Поисковый робот вместо того чтобы заниматься нужным и полезным контентом будет тратить время на бесполезное блуждание по сайту. А так как роботы не индексируют весь сайт целиком и сразу (сайтов много и всем нужно уделить внимание), то важные страницы, которые Вы хотите увидеть в поиске, вы можете увидеть очень не скоро.
- возрастает нагрузка на сервер.
Было решено закрыть доступ для поисковых роботов к некоторым страницам сайта. В этом нам поможет файл robots.txt.
Зачем нужен robots.txt.
robots.txt – это обычный текстовый файл, в котором прописаны инструкции для поисковых роботов. Первое что делает поисковый робот при попадании на сайт, это ищет файл robots.txt. Если файл robots.txt не найден или он пустой, то поисковый робот будет бродить по всем доступным страницам и каталогам сайта (включая системные каталоги), в попытке проиндексировать содержимое. И не факт, что он проиндексирует нужную Вам страницу, если вообще доберется до нее.
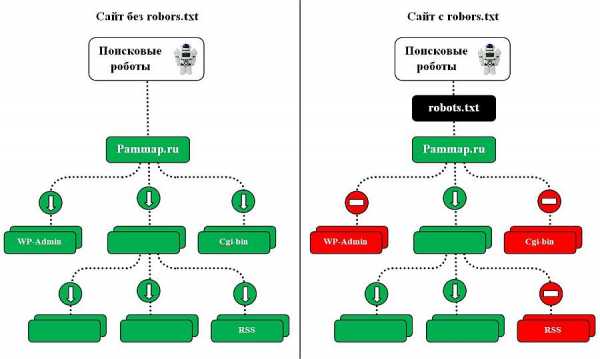
С помощью robots.txt мы можем указать поисковым роботам, на какие страницы можно заходить и как часто, а куда ходить не стоит. Инструкции могут быть указаны, как для всех роботов, так и для каждого робота в отдельности. Страницы, которые закрыты от поисковых роботов, не будут появляться в поисковиках. Если этого файла нет, то его обязательно необходимо создать.
Файл robots.txt должен находиться на сервере, в корне вашего сайта. Файл robots.txt можно посмотреть на любом сайте в Интернет, для этого достаточно после адреса сайта добавить /robots.txt . Для сайта PAMMAP.RU адрес, по которому можно посмотреть robots.txt будет выглядеть так: pammap.ru/robots.txt.
Файл robots.txt , обычно у каждого сайта имеет свои особенности и бездумное копирование чужого файла, может создать проблемы с индексированием вашего сайта поисковыми роботами. Поэтому нужно четко понимать назначение файла robots.txt и назначение инструкций (директив), которые мы будем использовать, при его создании.
Директивы файла robots.txt.
Разберем основные инструкции (директивы), которые мы будем использовать при создании файла robots.txt.
User-agent: — указываем имя робота, для которого будут работать все нижеприведенные инструкции. Если инструкции нужно использовать для всех роботов, то в качестве имени используем * (звездочку)
Например:
User-agent:*
#инструкции действуют на всех поисковых роботов
User-agent: Yandex
#инструкции действуют только на поискового робота Яндекс
Имена самых популярных поисковиков Рунета это Googlebot (для Google) и Yandex (для Яндекса). Имена остальных поисковиков, если интересно, можно найти на просторах Интернет, но создавать для них отдельные правила, мне кажется, нет необходимости.
Disallow – запрещает для поисковых роботов доступ к некоторым частям сайта или сайту целиком.
Например:
Disallow /wp-includes/
#запрещает роботам доступ в wp-includes
Disallow /
# запрещает роботам доступ ко всему сайту.
Allow – разрешает для поисковых роботов доступ к некоторым частям сайта или сайту целиком.
Например:
Allow /wp-content/
#разрешает роботам доступ в wp-content
Allow /
#разрешает роботам доступ ко всему сайту.
Sitemap: — можно использовать для указания пути к файлу с описанием структуры вашего сайта (карты сайта). Она нужна для ускорения и улучшения индексации сайта поисковыми роботами.
Например:
Sitemap: //pammap.ru/sitemap_index.xml
Host: — Если у вашего сайта есть зеркала (копии сайта на другом домене). Например pammap.ru и www.pammap.ru. С помощью файла Host можно указать главное зеркало сайта. В поиске будет участвовать только главное зеркало.
Например:
Host: pammap.ru
Также можно использовать спецсимволы. * # и $
*(звездочка) – обозначает любую последовательность символов.
Например:
Disallow /wp-content*
#запрещает роботам доступ в /wp-content/plugins, /wp-content/themes и.т.д.
$(знак доллара) – По умолчанию в конце каждого правила предполагается наличие *(звездочка) чтобы отменить симовол *(звездочка) можно использовать символ $(знак доллара).
Например:
Disallow /example$
#запрещает роботам доступ в /example но не запрещает в /example.html
#(знак решетки) – можно использовать для комментариев в файле robots.txt
Подробнее с этими директивами, а также несколькими дополнительными, можно ознакомиться на сайте Яндекса.
Как написать robots.txt для WordPress.
Теперь приступим к созданию файла robots.txt. Так как наш блог работает на WordPress, то разберем процесс создания robots.txt для WordPress более подробно.
Вначале нужно определиться, что мы хотим разрешить поисковым роботам, а что запретить. Я для себя решил оставить только самое необходимое, это записи, страницы и разделы. Все остальное будем закрывать.
Какие папки есть в WordPress и что необходимо закрыть мы можем увидеть, если посмотрим в директорию нашего сайта. Я сделал это через панель управления хостингом на сайте reg.ru, и увидел следующую картину.
Разберемся с назначением каталогов и решим, что можно закрыть.
/cgi-bin (каталог скриптов на сервере – в поиске он нам не нужен.)
/files (каталог с файлами для загрузки. Здесь, например, лежит архивный файл с таблицей Excel для подсчета прибыли, о которой я писал в статье «Как посчитать прибыль от инвестиций в ПАММ счета«. В поиске этот каталог нам не нужен.)
/playlist(этот каталог я сделал для себя, для плейлистов на IPTV – в поиске не нужен.)
/test (этот каталог я создал для экспериментов, в поиске этот каталог не нужен)
/wp-admin/ (админка WordPress, в поиске она нам не нужна)
/wp-includes/ (системная папка от WordPress, в поиске она нам не нужна)
/wp-content/ (из этого каталога нам нужен только /wp-content/uploads/ в этом каталоге находятся картинки с сайта, поэтому каталог /wp-content/ мы запретим, а каталог с картинками разрешим отдельной инструкцией.)
Также нам не нужны в поиске следующие адреса:
Архивы – адреса вида //pammap.ru/2013/ и похожие.
Метки — в адресе меток содержится /tag/
RSS фиды — в адресе всех фидов есть /feed
Записи автора — в адресе есть /author/ (тем более, что автор всего один)
На всякий случай закрою адреса с PHP на конце так, как многие страницы доступны, как с PHP на конце, так и без. Это, как мне кажется, позволит избежать дублирования страниц в поиске.
Также закрою адреса с /GOTO/ я их использую для перехода по внешним ссылкам, в поиске им точно делать нечего.
И напоследок, уберем из поиска короткие адреса, вида //pammap.ru/?p=209 и поиск по сайту //pammap.ru/?s=, а также комментарии (адреса в которых содержится /?replytocom= )
А вот что у нас должно остаться:
/images (в этот каталог я закидываю некоторые картинки, пускай этот каталог роботы посещают)
/wp-content/uploads/ — содержит картинки от сайта.
Статьи, страницы и разделы, которые содержат понятные, читаемые адреса.
Например: //pammap.ru/portfel/ или Мои инвестиции
А теперь придумаем инструкции для robots.txt. Вот, что у меня получилось:
#Указываем, что эти инструкции будут выполнять все роботы
User-agent: *
#Разрешаем роботам бродить по каталогу uploads.
Allow: /wp-content/uploads/
#Запрещаем папку со скриптами
Disallow: /cgi-bin/
#Запрещаем папку files
Disallow: /files/
#Запрещаем папку playlist
Disallow: /playlist/
#Запрещаем папку test
Disallow: /test/
#Запрещаем все, что начинается с /wp- , это позволит закрыть сразу несколько папок, имена которых начинаются с /wp- , эта команда вполне может помешать индексации страниц или записей которые начинаются с /wp-, но давать таких имен я не планирую.
Disallow: /wp-*
#Запрещаем адреса, в которых содержится /?p= и /?s=. Это короткие ссылки и поиск.
Disallow: /?p=
Disallow: /?s=
#Запрещаем все архивы до 2099 года.
Disallow: /20
#Запрещаем адреса с расширением PHP на конце.
Disallow: /*.php
#Запрещаем адреса, которые содержат /goto/. Можно было не прописывать, но на всякий случай вставлю.
Disallow: /goto/
#Запрещаем адреса меток
Disallow: /tag/
#Запрещаем статьи по автору.
Disallow: /author/
#Запрещаем все фиды.
Disallow: */feed
#Запрещаем индексацию комментариев.
Disallow: /?replytocom=
#Ну и напоследок прописываем путь к нашей карте сайта.
Sitemap: //pammap.ru/sitemap_index.xml
Написать файл robots.txt для WordPress можно с помощью обычного блокнота. Создадим файл и запишем в него следующие строки.
User-agent: *
Allow: /wp-content/uploads/
Disallow: /cgi-bin/
Disallow: /files/
Disallow: /playlist/
Disallow: /test/
Disallow: /wp-*
Disallow: /?p=
Disallow: /?s=
Disallow: /20
Disallow: /*.php
Disallow: /goto/
Disallow: /tag/
Disallow: /author/
Disallow: */feed
Disallow: /?replytocom=
Sitemap: //pammap.ru/sitemap_index.xml
Вначале я планировал сделать один общий блок правил для всех роботов, но Яндекс работать с общим блоком отказался. Пришлось сделать для Яндекса отдельный блок правил. Для этого просто скопировал общие правила, изменил имя робота и указал роботу главное зеркало сайта, с помощью директивы Host.
User-agent: Yandex
Allow: /wp-content/uploads/
Disallow: /cgi-bin/
Disallow: /files/
Disallow: /playlist/
Disallow: /test/
Disallow: /wp-*
Disallow: /?p=
Disallow: /?s=
Disallow: /20
Disallow: /*.php
Disallow: /goto/
Disallow: /tag/
Disallow: /author/
Disallow: */feed
Disallow: /?replytocom=
Sitemap: //pammap.ru/sitemap_index.xml
Host: pammap.ru
Указать главное зеркало сайта можно также через Яндекс.Вебмастер, в разделе «Главное зеркало»

Теперь, когда файл robots.txt для WordPress создан, нам его необходимо загрузить на сервер, в корневой каталог нашего сайта. Это можно сделать любым удобным для Вас способом.
Также для создания и редактирования robots.txt можно воспользоваться плагином WordPress SEO. Подробнее об этом полезном плагине я напишу позже. В этом случае файл robots.txt на рабочем столе можно не создавать, а просто вставить код файла robots.txt в соответствующий раздел плагина.

Как проверить robots.txt
Теперь, когда мы создали файл robots.txt, его нужно проверить. Для этого заходим в панель управления Яндекс.Вебмастер. Далее заходим в раздел “Настройка индексирования”, а далее “анализ robots.txt” . Здесь нажимаем кнопку «Загрузить robots.txt с сайта», после этого в соответствующем окне должно появиться содержимое вашего robots.txt.

Затем нажимаем «добавить» и в появившемся окне вводим различные url с вашего сайта, которые вы хотите проверить. Я ввел несколько адресов, которые должны быть запрещены и несколько адресов, которые должны быть разрешены.
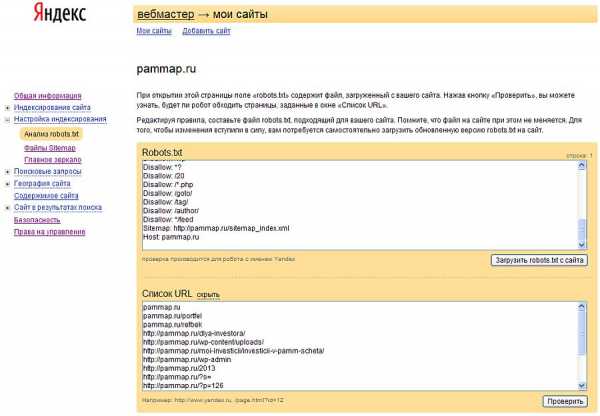
Нажимаем кнопку «Проверить», после этого Яндекс выдаст нам результаты проверки файла robots.txt. Как видим, наш файл проверку удачно прошел. То, что должно быть запрещено для поисковых роботов, у нас запрещено. То, что должно быть разрешено, у нас разрешено.

Такую же проверку можно провести для робота Google, через GoogleWebmaster, но она не сильно отличается от проверки через Яндекс, поэтому я ее описывать не буду.
Вот и все. Мы создали robots.txt для WordPress и он отлично работает. Остается только иногда поглядывать за поведением поисковых роботов на нашем сайте. Чтобы вовремя заметить ошибку и в случае необходимости внести изменения в файл robots.txt. Страницы которые были исключены из индекса и причину исключения можно посмотреть в соответствующем разделе Яндекс.ВебМастер (или GoogleWebmaster).
Актуальную версию моего файла robots.txt всегда можно посмотреть по ссылке pammap.ru/robots.txt
Удачных Инвестиций и успехов во всех ваших делах.
С уважением Сергей,
Автор блога Pammap.ru
pammap.ru
что на сайте стоит спрятать от робота – блог SEO студии Mary-ly
Файл Robots.txt: что на сайте стоит спрятать от робота – блог SEO студии Mary-lyRobots.txt помогает сократить нагрузку на сайт и оптимизировать процесс его индексации.
Расскажу об особенностях составления командного файла для роботов поисковиков



Доступен электронный вариант статьи, нажимай на кнопку.
| Скачать статью |

Поисковые боты регулярно сканируют страницы сайта…
а потом используют полученную информацию для индексации.
Но в случае, когда поисковые боты (или пауки) сканируют все без исключения страницы, мы получаем не возможность подняться в поисковой выдаче, а проблемы в виде перегрузки сайта и его зависания. Кроме того, далеко не всю информацию стоит раскрывать сторонним пользователям.Для того, чтобы направить ботов на путь истинный и запретить им посещать не требующие индексации страницы ресурса, существует специальный командный файл Robots.txt.
Его задача — объяснить роботам на их же языке, какие файлы необходимо сканировать, а какие следует обходить стороной.


Терминология Robots.txt
Правила, которые необходимо прописать в файле Robots.txt, включают обязательные и дополнительные поля, а также специальные команды, содержащие ссылки или названия файлов и папок, и специальные символы, помогающие поисковым роботам понять, что делать.


Каждая строка файла содержит так называемую директорию. К основным директориям, которые обязательно должны присутствовать в Robots.txt, относятся:
Указывает, к ботам какой поисковой системы обращены следующие ниже правила. Роботы каждой системы имеют своё общее имя, например, Yandexbot, YandexImage, YandexVideo и др. (так называются «пауки» Яндекса), Googlebot, GoogleImages и др. (Гугла), Mail.ru (одноимённого поисковика), Bingbot (Bing), Slurp (Yahoo!) и т. д. Если правила относятся ко всем поисковым системам, в этом поле следует писать символ *. Директория располагается над остальными правилами.
Правила этой директории могут закрыть от индексации отдельные документы и папки сайта. Даже если вы не знаете, зачем нужен запрет и какие страницы необходимо скрывать, уверена, вы знаете, какую информацию требуется защитить от сторонних пользователей. Это могут быть данные о паролях и личном кабинете, данные админки и т. д. Вот для такой информации и существует директория Disallow. Обычно идёт следом за User-agent, может занимать несколько строк по количеству запретов.
User-agent и Disallow — обязательные составляющие robots.txt. Есть и дополнительные директории, которые, хоть и не являются необходимыми, но помогают оптимизировать настройку индексации. В их числе:
антипод Disallow, в задачах которого принудить ботов открыть и проиндексировать отдельные файлы и папки сайта. Такая просьба «Не проходите мимо». Может находиться под User-agent или Disallow. Как и в случае с запретами, директория Allow может занимать сразу несколько строк.
показывает поисковым ботам место расположения карты сайта. Наиболее распространённый вид команды данной директории — http://yoursite/sitemap_index.xml или http://yoursite/sitemap.xml. Может располагаться на любой строке robots.txt.
устанавливает время, которое должно проходить до следующего сканирования. Смысл — уменьшение частоты индексации с целью снижения нагрузки на сайт. Команда директории указывается в секундах, целых или десятичных с точкой в качестве разделителя (2.0, 0.7). Директорию использовали роботы Яндекса, Mail.ru, Yahoo! и Bing, в прошлом году Яндекс отказался от неё по причине наиболее частых ошибок при составлении robots.txt.
Другие директории, с помощью которых можно прописать правила для поисковых роботов, используются реже и не сильно влияют на индексацию и разгрузку сайта.
 С первым символом мы уже познакомились:
С первым символом мы уже познакомились:* адресует команды файла Robots.txt всем роботам поисковых систем, также он используется в командах для того, чтобы показать, что вместо него в строке могут быть любые другие знаки, литеры и символы.
Пример:
User-agent: Yandexbot
Allow: *.pdf — переводится, как «Роботы Яндекса, обязательно просканируйте все документы, в названии которых присутствует .pdf»

Специальные символы robots.txt





Символ / без дополнений означает весь сайт. В сочетании с Disallow он блокирует весь сайт, а с Allow требует проиндексировать всё, что на нём есть.
Символ $ используется для указания, что на последующие знаки правило не распространяется. Можно сказать, что $ завершает команду.Пример:
User-agent: *
Disallow: *.pdf$ — означает, что всем роботам запрещено индексировать любые документы, заканчивающиеся на .pdf.
Символ # ставится перед комментариями автора файла Robots.txt. В настоящее время практически не используются, так как роботы чаще всего не обращают на них внимания.
символы robots.txt
Учтите, если вы не укажите никакой команды для директивы Allow, это будет означать, что нет ни одного файла, который требуется индексировать, иными словами, запрет на индексацию.Точно такой же запрет можно установить, если указать в директиве Disallow символ / без каких-либо дополнений.
Совместное использование принудительно разрешающих (Allow) и запрещающих (Disallow) директив, приводит к тему, что роботы будут выполнять правила последовательно в соответствии с указаниями. Например, чтобы запретить ботам Гугла сканировать все документы, кроме тех, название которых заканчивается на .js, следует указать:
User-agent: GoogleBot
Allow: *.js$
Disallow: /



В зависимости от того, какую версию вебмастера (новую или старую) вы используете, проверка осуществляется либо в разделе «Сканирование» с помощью сервиса «Посмотреть как Googlebot» (для старой версии), либо простым вводом ссылки на сайт в поисковую строку. После запуска проверки выводится список закрытых для сканирования файлов и папок.



Для того, чтобы проверить Robots.txt с помощью инструментов Яндекса, достаточно просто ввести адрес сайта в специальное поле на странице
https://webmaster.yandex.ru/
tools/robotstxt/.
Способы проверки корректности заполнения файла Robots.txt
Что необходимо скрыть от ботов
Для облегчения нагрузки на сайт, а также чтобы скрыть некоторую «секретную» информацию, которая не предназначена для посторонних глаз, я рекомендую запрещать доступ к:


· файлам админки;
· данным личных кабинетов, формам регистрации и авторизации;
· корзине, формам заказа, данным о доставке;
· файлам .ajax и .json;
· документам папки cgi;
· поисковому функционалу;
· служебным страницам;
· плагинам;
· UTM-меткам;
· дублирующим разделам и страницам.

Доступен электронный вариант статьи, нажимай на кнопку.
| Скачать статью |
 Не забывайте, что боты поисковых систем не обязаны следовать правилам файла Robots.txt. Он не является обязательным для них, скорее носит рекомендательный характер. В ряде случаев поисковые «пауки» могут в обход правил сканировать закрытые страницы или игнорировать те, которые вы просите проиндексировать. Такое происходит далеко не всегда, поэтому всё же не стоит пренебрегать возможностью настроить процесс индексации.
Не забывайте, что боты поисковых систем не обязаны следовать правилам файла Robots.txt. Он не является обязательным для них, скорее носит рекомендательный характер. В ряде случаев поисковые «пауки» могут в обход правил сканировать закрытые страницы или игнорировать те, которые вы просите проиндексировать. Такое происходит далеко не всегда, поэтому всё же не стоит пренебрегать возможностью настроить процесс индексации.Создание файла Robots.txt требует специфических знаний и опыта. Для небольших сайтов можно использовать универсальные команды, которые нетрудно найти в рекомендациях некоторых специалистов. Если же есть необходимость составить более сложный перечень команд и самостоятельно справиться не удаётся, можно обратиться к профессиональным SEO-специалистам, в надёжности которых вы уверены. Обычно такая услуги стоит небольших денег, зато позволяет сэкономить время и избежать многих ошибок.
mary-ly.ru