«Что такое url ?» – Яндекс.Кью
Скажем так. В DarkNet очень много разнообразной информации, которой по большей части не найдешь в «чистом» интернете. Там есть как плюсы, так и минусы. Но минусов к сожалению гораздо больше.
Множество форумов педофилов, живодёров, убийц, террористов, угонщиков и тд которые обмениваются между собой опытом и информацией. Большой оборот детской порнографии, жестокого обращения с людьми и животными. Разнообразие шок контента.
В другой его части во всю торгуют незаконными услугами. К этому относится продажа поддельных паспортов, разного рода документов, продажа ворованных кредиток. Торговля наркотиками, оружием, запретными хим веществами которые могут быть использованы во зло.
Перечислять плохую сторону DarkNet можно бесконечно. Из его плюсов можно назвать разве что информацию которая под запретом у СМИ. Это разного рода журналисты которые делятся компроматом на высокопоставленных людей. Движения которые под запретом в какой либо стране. А так же продажа некоторых вещей которые нельзя купить в своей стране по определённым причинам, но которые жизненно необходимы, к примеру запрещенные лекарства.
Главный плюс и минус это анонимность. Для хорошей стороны DarkNet это однозначно плюс, люди могут делится правдой между собой и при этом не оказаться за решеткой. Но другая сторона медали это плохая сторона DarkNet, где водятся аморально разложенные личности, и ты будешь только рад если анонимность пропадёт и таких людей в лучшем случае посадят.
Но анонимность для всех.
Должен ли существовать DarkNet? Я думаю да. Аморальности в мире меньше не станет. К сожалению больных и тупых людей в мире куда больше разумных. DarkNet лишь отражает всю суть человека как зеркало. DarkNet лишь способ общения, способ поделиться информацией и предоставить свои услуги. Это не DarkNet плохой, это люди такие. Пропадёт DarkNet, люди найдут другое место, и так же продолжат делиться аморальными вещами. Такие люди были во все времена, даже когда не было интернета.
С другой стороны это место нужно борцам за справедливость, и к сожалению нельзя сделать так, что бы остались лишь хорошие.
Этот комментарий я написал в ознакомительных целях, и настоятельно не рекомендую пользоваться DarkNet. Это не то место где можно что то легко добыть, это не то место где можно доверять первому встречному. Вы можете потерять деньги, нервы а главное своё время, так что не лезьте туда.
URL — Википедия с видео // WIKI 2
Унифицированный указатель ресурса (от англ. Uniform Resource Locator, сокр. URL [ˌjuː ɑːr ˈel]) — система унифицированных адресов электронных ресурсов, или единообразный определитель местонахождения ресурса (файла)[1].
Используется как стандарт записи ссылок на объекты в Интернете (Гипертекстовые ссылки во «всемирной паутине» www).
Для обозначения электронного адреса используют аббревиатуру «URL» по ГОСТ Р 7.0.5-2008.
Энциклопедичный YouTube
1/5
Просмотров:714 555
276 597
42 139
101 532
61 891
✪ LEGENDS ONLY: MATH HOFFA VS METHOD MAN
✪ 도메인(URL)이란? 무료 도메인 구입하고 내 사이트에 연결하기! 임시 E-Mail 인증, HTTPS 적용 꿀팁 포함
✪ Internet Tips: Understanding URLs
✪ Uniform Resource Locator (URL)
Содержание
История
URL был изобретён Тимом Бернерсом-Ли в 1990 году в стенах Европейского совета по ядерным исследованиям (фр. Conseil Européen pour la Recherche Nucléaire, CERN) в Женеве, Швейцария. URL стал фундаментальной инновацией в Интернете. Изначально URL предназначался для обозначения мест расположения ресурсов (чаще всего файлов) во Всемирной паутине. Сейчас URL применяется для обозначения адресов почти всех ресурсов Интернета. Стандарт URL закреплён в документе RFC 3986. Сейчас URL позиционируется как часть более общей системы идентификации ресурсов URI, сам термин URL постепенно уступает место более широкому термину
В 2009 году Тим Бернерс-Ли высказал мнение об избыточности двойного слеша // в начале URL, после указания сетевого протокола[2][3].
Структура URL
Изначально локатор URL был разработан как система для максимально естественного указания на местонахождения ресурсов в сети. Локатор должен был быть легко расширяемым и использовать лишь ограниченный набор ASCII‐символов (к примеру, в URL никогда не применяется пробел). В связи с этим возникла следующая традиционная форма записи URL:
<схема>:[//[<логин>[:<пароль>]@]<хост>[:<порт>]][/<URL‐путь>][?<параметры>][#<якорь>]
В этой записи:
- схема
- схема обращения к ресурсу; в большинстве случаев имеется в виду сетевой протокол
- логин
- имя пользователя, используемое для доступа к ресурсу
- пароль
- пароль указанного пользователя
- хост
- полностью прописанное доменное имя хоста в системе DNS или IP-адрес хоста в форме четырёх групп десятичных чисел, разделённых точками; числа — целые в интервале от 0 до 255.
- порт
- порт хоста для подключения
- URL-путь
- уточняющая информация о месте нахождения ресурса; зависит от протокола.
- параметры
- строка запроса с передаваемыми на сервер (методом GET) параметрами. Начинается с символа
?, разделитель параметров — знак&. Пример:?параметр_1=значение_1&параметр_2=значение_2&параметр3=значение_3 - якорь
- идентификатор «якоря» (англ.)русск. с предшествующим символом
#. Якорем может быть указан заголовок внутри документа или атрибут id (англ.)русск. элемента. По такой ссылке браузер откроет страницу и переместит окно к указанному элементу. Например, ссылка на этот раздел статьи:https://ru.wikipedia.org/wiki/URL#Структура_URL
Схемы (протоколы) URL
Общепринятые схемы (протоколы) URL включают:
- ftp — протокол передачи файлов FTP
- http — протокол передачи гипертекста HTTP
- rtmp — проприетарный протокол потоковой передачи данных Real Time Messaging Protocol, в основном используется для передачи потокового видео и аудио с веб-камер через Интернет.
- rtsp — потоковый протокол реального времени.
- https — специальная реализация протокола HTTP, использующая шифрование (как правило, SSL или TLS)
- gopher — протокол Gopher
- mailto — адрес электронной почты
- news — новости Usenet
- nntp — новости Usenet через протокол NNTP
- irc — протокол IRC
- smb — протокол SMB/CIFS
- prospero — служба каталогов Prospero Directory Service
- telnet — ссылка на интерактивную сессию Telnet
- wais — база данных системы WAIS
- xmpp — протокол XMPP (часть Jabber)
- file — имя локального файла
- data — непосредственные данные (Data: URL)
- tel — звонок по указанному телефону
Экзотические схемы URL:
- afs — глобальное имя файла в файловой системе Andrew File System
- cid — идентификатор содержимого для частей MIME
- mid — идентификатор сообщений для электронной почты
- mailserver — доступ к данным с почтовых серверов
- nfs — имя файла в сетевой файловой системе NFS
- tn3270 — эмуляция интерактивной сессии Telnet 3270
- z39.50 — доступ к службам ANSI Z39.50
- skype — протокол Skype
- smsto — открытие редактора SMS в некоторых мобильных телефонах
- ed2k — файлообменная сеть eDonkey, построенная по принципу P2P
- market — Android-маркет
- steam — протокол Steam
- bitcoin — криптовалюта Биткойн
- ob — OpenBazaar
- tg — Telegram
Схемы URL в браузерах:
- view-source — просмотр исходного кода указанной веб-страницы в различных браузерах.
- В разных браузерах используются разные ключевые слова для доступа к служебным и сервисным страницам:
Кодирование URL
Стандарт URL использует набор символов US-ASCII. Это имеет серьёзный недостаток, поскольку разрешается использовать лишь латинские буквы, цифры и несколько знаков пунктуации. Все другие символы необходимо перекодировать. Например, перекодироваться должны буквы кириллицы, буквы с диакритическими знаками, лигатуры, иероглифы. Перекодирующая кодировка описана в стандарте RFC 3986 и называется URL-encoding, URLencoded или percent‐encoding.
Пример кодирования можно видеть в русскоязычной Википедии, использующей в URL русский язык. Например, строка вида:
https://ru.wikipedia.org/wiki/Википедия
кодируется как:
https://ru.wikipedia.org/wiki/%D0%92%D0%B8%D0%BA%D0%B8%D0%BF%D0%B5%D0%B4%D0%B8%D1%8F
Реализация
В → D0 и 92 → %D0%92 и → D0 и B8 → %D0%B8 к → D0 и BA → %D0%BA и → D0 и B8 → %D0%B8, и т. д.
! | * | ' | ( | ) | ; | : | @ | & | | + | $ | |
Что такое URL адреса, чем отличаются абсолютные и относительные ссылки для сайта
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня хочу затронуть тему формирования уникальных URL адресов в интернете и рассказать про принципы создания относительных и абсолютных ссылок.
Конечно же, тема формирования Урлов или их более расширенной версии URI (ури) довольно сложна, если копать глубоко и пытаться добраться до истины.
Но нам этого и не нужно, ибо достаточно понимать структуру URL в ее прикладном применении.

Ну и также, я думаю, будет полезно понимать, для чего и как можно создавать относительные ссылки для своего ресурса, а не использовать для этих целей абсолютные, когда в этом нет явной необходимости.
Урл адреса — что это и как они влияют на индексацию сайта
Итак, давайте посмотрим что такое URL, зачем он нужен и из каких частей состоит. Как вы знаете, поисковые системы производят индексацию сайтов ни как единого целого, а как совокупность отдельных страниц. Они потом будут участвовать в ранжировании по различным поисковым запросам (читайте подробнее о подборе ключевых слов в Вордстате на основе статистики запросов Яндекса.
URL и URI
Ну так вот, любой документ (вебстраница) в сети интернет имеет свой уникальный адрес URL, который расшифровывается как Uniform Resource Locator (определитель местонахождения ресурса). Он, равно как и протокол HTTP, а еще и как язык Html с валидатором W3C, был разработан и создан одним и тем же человеком — Тимом Бернерсом-Ли (отцом основателем проекта Всемирная паутина WWW — World Wide Web).
По большому счету URL является частным случаем другого идентификатора под названием URI (Uniform Resource Identifier — унифицированный идентификатор ресурса), но нам с вами все эти тонкости, скорее всего, будут не нужны (излишни) при работе со своим сайтом. Давайте попробуем в общих чертах разобраться с тем, что это такое и из каких частей он состоит, а потом перейдем к относительным и абсолютным ссылкам.
URL адрес — это способ однозначно указать на что-то в интернете. Он используется не только для работы с сайтами (что это?) по протоколу http (еще и по ftp), но нас, конечно же, будет интересовать именно применение этого идентификатора к Web (протоколы http и https). Урл в этом случае будет выглядеть примерно так (чуть ниже я приведу общую блок-схему его построения, но пока хотелось бы начать с простого частого примера):
https://ktonanovenkogo.ru/papka/fail.html
В этом примере адреса часть с «http» обозначает протокол передачи данных или же, если следовать терминологии спецификации, схему (ибо тот же mailto не является протоколом передачи данных, в отличии от http или ftp, но тоже используется в Урл адресах). Далее в приведенном примере следует «ktonanovenkogo.ru» (или же это может быть «www.ktonanovenkogo.ru») — это так называемое доменное имя или же имя узла (хоста).
WWW и другие зеркала сайта, которые нужно склеить
В Web-е есть специфика обозначения доменного имени в URL адресе сайта, которое может быть с WWW или без WWW. Для того, чтобы успешно можно было раскрутить свой сайт, очень важно склеить эти два зеркала вашего сайта с WWW или без него через 301 редирект. Зачастую, склейку зеркал за вас может выполнить хостер, но это обязательно нужно будет проверить.
Т.е. для поисковиков сайты с WWW или без оного являются абсолютно разными и без их склейки, ссылочная масса будет делиться между ними в неизвестной вам пропорции. WWW в адресе по своей сути — это некий атавизм, который делает ваше доменное имя второго уровня доменом третьего.
Тоже справедливо и при переезде сайта на защищенный протокол https с http — для поисковиков это будет уже другой сайт.
Ничего плохого в использовании WWW в URL сайта нет, но нужно четко определить главное зеркало (через Яндекс Вебмастер и через Гугл Вебмастер, а также через прописывание директивы Host в файл robots.txt вашего сайта), которое будет индексироваться поисковиками и которое будет участвовать в ранжировании.
У меня, например, главное зеркало — это «ktonanovenkogo.ru», т.е. «без атавизма», и если вы добавите к любому моему Урлу эту чудо-приставку, то произойдет автоматическое перенаправление на адрес «без WWW».
https://www.ktonanovenkogo.ru/papka/fail.html
Склеить можно не только описанные выше зеркала, но и любые другие доменные имена, принадлежащие вам. Например, если возможно различное написание латинскими буквами какого-либо известного бренда, то покупаются все возможные домены (варианты написания с ошибками, в разных доменных зонах и т.п.) и склеиваются между собой. Тогда, при обращении к сайту по любому из возможных URL адресов, будет открываться главное зеркало.
Например, на рег.ру можно посмотреть свободные для регистрации потенциальные зеркала или освобождающиеся домены (можете вводить предполагаемое имя домена прямо в приведенную ниже форму):
Откуда берутся лишние URL-адреса (дубли страниц) вашего сайта в индексе поисковиков
Но вернемся к нашим баранам. Та часть URL, которая расположена за третьим слешем (/) — в нашем примере это «papka/fail.html» — называется путем до конкретного объекта (документа или файла). В нашем случае это документ «fail.html», который лежит в каталоге «papka», который в свою очередь лежит в корневой папке (корень в Урле всегда соответствует третьему слешу слева).
Но это еще не все, что может быть записано в адресе. Посредством URL различные CMS (системы управления контентом) передают так называемые GET параметры, которые добавляются в самый его конец после простановки знака вопроса, например, так:
https://www.ktonanovenkogo.ru/papka/fail.html?print=yes
Вся беда в том, что для поисковых систем два таких URL адреса (с и без Get параметров) являются абсолютно разными веб документами и каждый из них будет проиндексирован поисковиками.
К одному и тому же Урлу может добавляться вашей Cms сколько угодно много различных Get параметров и все это будет проиндексировано Яндексом и Гуглом, если вы не создадите соответствующие запреты в файле robots.txt, ссылка на статью про который приведена чуть выше. В противном случае поисковики вас могут пессимизировать за большое количество дублированного контента (одного и того же содержимого, доступного по разным адресам).
Также, например, к главной странице моего ресурса можно обратиться по двум разным Урлам:
https://ktonanovenkogo.ru
https://ktonanovenkogo.ru/index.php
(даже по трем — еще и https://ktonanovenkogo.ru/) и в любом случае откроется главная страница. Это довольно плохо, т.к. поисковики найдут у меня три разных страницы (имеющих с их точки зрения разные URL адреса), но с одинаковым содержанием, что им, ох как не нравится.
Поэтому у меня сделано так, что при вводе любого из приведенных чуть выше Урлов будет выполнено перенаправление на URL вида «https://ktonanovenkogo.ru/». Делается это, как правило, с помощью 301 редиректа в файле .htaccess, либо напрямую в настройках сервера вами самими, либо вашим хостером.
Гораздо больше информации про зеркала сайта и их склейку читайте в приведенной по ссылке публикации.
Структура Урл адреса и перекодировка в URL-encoded
Вообще, полную блок-схему URL адреса можно представить так:
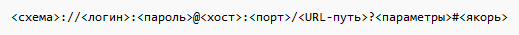
В реальности, как правило, не используют логин, пароль и порт, хотя для доступа на платные сайты может понадобиться их указание:
http://login:[email protected]/platniy-dostup.html
Также довольно часто устанавливают пароли для входа на Ftp сервер, где так же может использовать не стандартный порт, а отличный от используемого по умолчанию для этого протокола. Тогда для доступа к ресурсам такого Ftp сервера потребуется вводить подобный URL:
ftp://login:[email protected]:6789/samoe-nujnoe/cimus
Про GET параметры, которые могут прописываться в этом адресе после знака вопроса, мы уже говорили и упоминали, что следует обязательно запрещать к индексации страницы, в Урлах которых имеются подобные параметры (выше приведена ссылка на статью про роботс, где все это подробно расписано).
Урл адреса в виде хеш-ссылок, открывающие страницу в нужном месте
Но кроме всех этих вещей, которые могут входить в состав URL, на приведенной чуть выше блок-схеме вы можете видеть так называемый якорь, который добавляется в самом конце после разделяющего символа решетки «#» (Урлы, содержащие якоря, обычно называют хеш ссылками).
Якоря заранее проставляются внутри Html кода документа (страницы) с помощью добавление атрибута в нужный Html тег (абзаца, заголовка или другой подходящий), а затем, добавив название этого якоря к URL адресу страницы через символ решетки «#», вы сможете перейти не на начало этой вебстраницы, а сразу к тому месту, где был проставлен якорь (все современные веб браузеры автоматически прокрутят страницу до нужного места).
Выглядеть хеш-ссылка может так (в тексте страницы проставлен якорь «url-1»):
https://ktonanovenkogo.ru/vokrug-da-okolo/chto-takoe-url-adresa-url-uri-absolyutnye-i-otnositelnye-ssylki.html#url-1
Про работу с гиперссылками в Html, и в том числе про организацию навигации на странице с помощью хеш ссылок (якорей), читайте в этих статьях.
Какие символы можно использовать в URL адресах?
Еще стоит сказать о различных кодировках, которые используются в URL адресах. Без перекодирования в них можно использовать только ограниченное количество символов. Обычно советуют ограничиться набором из символов: [0-9],[a-z],[A-Z],[_],[-].
Вообще, во избежании ошибок, я бы советовал задавать название файлов и Урлов страниц своего сайта в нижнем регистре, ибо для юникс подобных систем (на которых работает большинство веб серверов) символы в верхнем и нижнем регистре являются разными (в отличии от Windows). Из-за разных регистров может возникнуть никому не нужная путаница.
Использование каких-либо других символов (включая русские) в урлах допустимо, но при этом будет происходить
Что опечаливает, так это неудобоваримый вид URL адресов с символами, например, кириллицы, которые получаются после перекодировки. Каждый символ кириллицы кодируется с помощью двух байт в Юникоде (UTF-8), записанных в шестнадцатеричном виде и разделенных знаком процента «%». Например, такой Урл:
https://ktonanovenkogo.ru/кто на новенького/
после перекодировки станет таким:
http//ktonanovenkogo.ru/%BA%D1%82%D0%BE%20%D0%BD%D0% B0%20%D0%BD%D0%BE%D0%B2%D0%B5%D0%BD%D1%8C%D0%BA%D0 %BE%D0%B3%D0%BE
В общем, получается не очень здорово и с этим неудобоваримым видом URL на национальных кодировках планируют разбираться и бороться, но движется это дело не ахти как быстро.
В связи со всем вышесказанным я бы советовал при использовании ЧПУ на своих CMS не делать адреса страниц на русском, а использовать транслитерацию, тем более, что по мнению многих продвиженцев так будет лучше в плане Seo оптимизации под Яндекс и Google.ru.
Относительные и абсолютные ссылки на сайте
Давайте начнем с абсолютных ссылок, т.к. в этом случае ничего особенного, сверх того, что мы уже обсудили в данной статье, говорить и не придется. Т.о. абсолютная ссылка должна соответствовать тем требованиям, которые мы предъявляем к URL адресу — должен указываться протокол передачи данных, доменное имя сайта (хоста) и путь до нужного web документа. Все.
В Html абсолютная ссылка формируется с помощью специальных тегов A (гиперссылки), т.е. для ее проставления мы просто должны будем окружить открывающим и закрывающим тегами гиперссылки нужное место в тексте документа (фразу или картинку) и прописать в открывающем теге A в атрибуте «Href» абсолютный путь до того документа, на который должен будет попасть посетитель при переходе по ней:
<a href="https://ktonanovenkogo.ru/vokrug-da-okolo/programs/phpmyadmin-skachat-ustanovka-nastrojka.html">ПхпМайАдмин</a>
Все очень просто.
Чем хороши относительные ссылки и как их можно получить
Однако, абсолютные гиперссылки обычно используют только в тех случаях, когда хотят сослаться на внешние сайты, а для внутренних переходов большинство вебмастеров (умных и прозорливых, не таких как я 🙂 ) стараются использовать относительные ссылки. И это есть несколько причин:
- Относительные ссылки по определению более короткие и не загромождают, не утяжеляют код сайта (ведь в этом деле важна любая мелочь).
- Кроме того, при переезде на другой домен или при смене протокола на https вам не придется менять все ссылки на сайте.
- К тому же, некоторые конструкции интернет проекта можно будет очень быстро и безболезненно перенести на другой ресурс, не изменяя при этом внутренние относительные ссылки.
Итак, если судить по названию, то адрес web документа, на который они ссылаются, должен быть прописан относительно того документа вашего сайта, из кода которого и будет проставлена данная относительная ссылка (пляшем от печки). Второй вариант их простановки заключается в использования в качестве точки отсчета корневой папки. Вот именно эти два способа создания относительных ссылок мы сейчас и рассмотрим.
Создаем относительные ссылки относительно документа, из которого они проставляются
Самый простой и короткий вариант записи относительного пути (имеется в виду значения атрибута Href тега гиперссылки) получится в том случае, когда оба web документа: донор (с которого она проставляется) и акцептор (файл или web документ, на который она ведет), находятся в одной папке на сервере.
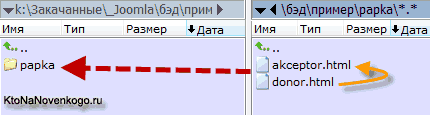
Тогда относительная ссылка будет представлять из себя лишь название web документа акцептора:
<a href="akceptor.html">анкор</a>
Теперь давайте предположим, что документ акцептор лежит в папке, которая расположена в одной директории с документом донором.
Как в этом случае будет выглядеть относительная ссылка? Все тоже довольно просто:
<a href="papka/akceptor.html">анкор</a>
Пока, думаю, что все понятно — прописываем путь до файла или документа акцептора (название папки, а через прямой слеш «/» имя файла или документа). Т.е. нам для того, чтобы попасть от донора к акцептору, нужно будет открыть папку, название которой мы и указываем в относительной ссылке.
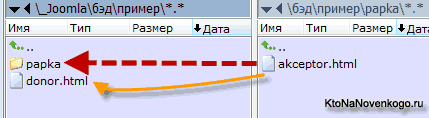
Теперь давайте рассмотрим противоположную ситуацию, когда внутри папки лежит сам документ донор, с которого нужно проставить относительную ссылку на документ или файл акцептор, который уже лежит на уровень выше:

Для того, чтобы нам от документа донора пройти к файлу (или документу) акцептору, потребуется подняться из этой папки на уровень выше. Для этого предусмотрен специальный элемент — две точки подряд, а затем через прямой слеш прописывается дальнейший путь к акцептору. Поэтому для приведенного выше примера относительный путь будет иметь вид:
<a href="../akceptor.html">Что такое URL адреса</a>
Если вам понадобится подняться на два уровня вверх, то запись будет иметь вид:
<a href="../../akceptor.html">Что такое Урл</a>
Ну, а если после этого для прописывания относительного пути до акцептора вам нужно будет еще войти в какую-либо папку на втором верхнем (относительно документа донора) уровне:

Тогда относительная ссылка, проставленная из Html кода документа донора, может иметь следующий вид:
<a href="../../primer-2/akceptor.html">Сложная конструкция пути</a>
Таких спусков в папки и подъемов на уровень вверх может быть сколь угодно много, главное, чтобы вы сами не запутались.
Создание ссылки относительно корневой папки
Все рассмотренные выше ссылки мы писали относительно того документа донора, с которого проставляется гиперссылка, но можно в качестве точки отсчета взять корневую папку сайта. Корень в обозначении относительных путей выглядит как одиночный прямой слеш «/».
Т.о. переход на главную страницу будет выглядеть довольно просто, но экстравагантно:
<a href="/">анкор</a>
Любую относительную ссылку, прописанную относительно корня сайта, можно представить как абсолютную, но с убранной частью стоящей слева от третьего слеша.
Например, абсолютный путь может выглядеть так:
<a href="https://ktonanovenkogo.ru/wp-content/uploads/html-tegi.html">анкор</a>
А относительный до того же самого файла будет уже несколько короче:
<a href="/wp-content/uploads/html-tegi.html">Текст</a>
Как сослаться на папку в относительном и абсолютном виде
Хочу обратить ваше внимание на один нюанс, который стоит учитывать при создании как абсолютных, так и относительных ссылок. Если вы хотите сослаться на папку, то обязательно ставьте в конце такой гиперссылки (после ее названия) прямой слеш «/». Т.е., если я хочу открыть содержимое папки, то мне следует написать:
<a href="/wp-content/uploads/">анкор</a>
А не такую:
<a href="/wp-content/uploads">текст</a>
Во втором случае, при обработке, сервер будет сначала пытаться найти файл с именем «uploads» (именно такой без каких-либо расширений) и не найдя его уже потом будет искать такую папку. Поэтому, написав сразу же слеш после названия нужной вам папки, вы не будете отнимать лишние ресурсы у вашего сервера на поиски того, чего там нет.
Также следует знать, что при обращении в относительной или абсолютной ссылке к папке, веб сервер отобразит так называемый индексный файл, который лежит в ней и который, как правило, называется либо index.html, либо index.php. Если индексного файла в папке не будет, то при неправильно настроенной на сервере безопасности вы увидите листинг ее содержимого, что может привести к снижению безопасности вашего ресурса.
Обязательно закройте эту уязвимость, если обнаружите.
Кстати, обращение к главной странице сайта тоже по своей сути есть обращение к папке (корневой), и при этом будет запущен индексный файл лежащий в корне (в моем случае это index.php). Так вот, если вы обращаетесь к папке, то для снижения нагрузки на сервер лучше прописывать после доменного имени прямой слеш:
<a href="https://ktonanovenkogo.ru/">Абсолютная ссылка на главную</a>
Вот оно чё, Михалыч!
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Использую для заработка
Рубрика: ВебмастеруЧто такое URI, URL, URN и чем они различаются
Пост из серии: всегда хотел это понять, но значимость его была настолько мала, что всегда находился повод этого не делать 🙂
А вы задавались вопросом: URL — что это?
Всегда с таким сталкиваюсь, но до сих пор не желал понять в чем различие между терминами URI, URL, URN.
По началу, данная статья была результатом перевода «в лоб», в результате чего по ней разгорелись довольно нешуточные комментарии.
Позже, я решил переосмыслить чужие доводы и отчасти переписал первоисточник, стараясь внести ясность в повествование.

Вы когда-нибудь обращали внимание на адресную строку в Вашем браузере?
Что это? URI, URL или URN?
Многие из нас не делают различий между URI, URL, URN, а кое-кто даже и не слышал терминов URI и URN, все просто пользуются термином URL.
Давайте вместе попытаемся разобраться в этом.
Расшифровка аббревиатур
URL — Uniform Resource Locator (унифицированный определитель местонахождения ресурса)
URN — Unifrorm Resource Name (унифицированное имя ресурса)
URI — Uniform Resource Identifier (унифицированный идентификатор ресурса)
Внимание! Далее в мелочах кроется истина, и пока ничего не понятно, — какая-то каша, но, едем дальше.
В чем различия
URL: Исторически возник самым первым из понятий и закрепился как синоним термина веб-адрес. URL определяет местонахождение ресурса в сети и способ его (ресурса) извлечения.
Это позволяет нам полностью узнать: как, кому и где можно достать требуемый ресурс, вводя понятия схемы, данных авторизации и местонахождения.
URN: Неизменяемая последовательность символов определяющая только имя некоторого ресурса. Смысл URN в том, что им единоразово и уникально именуется какая-либо сущность в рамках конкретного пространства имен (контекста), либо без пространства имен, в общем (что не желательно). Таким образом, URN способен преодолеть недостаток URL связанный с возможным будущим изменением и перемещением ссылок, однако, теперь для того, чтобы знать местонахождение URN ресурса необходимо обращаться к системе разрешения имен URN, в которой он должен быть зарегистрирован.
URI: Это лишь обобщенное понятие (множество) идентификации ресурса, включающее в нашем случае как URL, так и URN, как по отдельности, так и совместно. Т.е. мы можем считать, что: URI = URL или URI = URN или URI = URL + URN
Подведем итоги
URI — это абстракция концепции идентификации,
а URL и URN — это конкретные реализации — полного адреса ресурса и уникального контекстного имени соответственно.
P.S.
Да простят меня собеседники, но, чтобы не вводить в заблуждение читателей, мной была удалена часть спорных комментариев.
путь, фрагмент, запрос и авторизация / Хабр
URL’ы не должны были стать тем, чем стали: мудрёным способом идентифицировать сайт в интернете для пользователя. К сожалению, мы не смогли стандартизировать URN, который мог бы стать более полезной системой наименования. Считать, что современная система URL достаточно хороша — это как боготворить командную строку DOS и говорить, что все люди просто должны научиться пользоваться командной строкой. Оконные интерфейсы были придуманы, чтобы пользоваться компьютерами стало проще, и чтобы сделать их популярнее. Такие же мысли должны привести нас к более хорошему методу определения сайтов в Вебе.— Дейл Догэрти,
1996
Есть несколько вариантов определения слова «интернет». Один из них — это система компьютеров, соединенных через компьютерную сеть. Такая версия интернета появилась в 1969 году с созданием ARPANET. Почта, файлы и чат работали в этой сети еще до создания HTTP, HTML и веб-браузера.
В 1992 году Тим Бернерс-Ли создал три штуки, благодаря которым родилось то, что мы считаем интернетом: протокол HTTP, HTML и URL. Его целью было воплотить понятие гипертекста в реальности. Гипертекст, в двух словах — это возможность создавать документы, которые ссылаются друг на друга. В те годы идея гипертекста считалась панацеей из научной фантастики, заодно с гипермедиа, и любыми другими словами с приставкой «гипер».
Ключевым требованием гипертекста была возможность ссылаться из одного документа на другой. В то время для хранения документов использовалась куча форматов, а доступ осуществлялся по протоколу вроде Gopher или FTP. Тиму нужен был надежный способ ссылаться на файл, так, чтобы в ссылке был закодирован протокол, хост в интернете и местонахождение на этом хосте. Этим способом стал URL, впервые официально задокументированный в RFC в 1994 году.
В начальной презентации World-Wide Web в марте 1992 Тим Бернерс-Ли описал его как «универсальный идентификатор документов» (Universal Document Identifier или UDI). Множество других форматов также рассматривались в качестве такого идентификатора:
protocol: aftp host: xxx.yyy.edu path: /pub/doc/README
PR=aftp; H=xx.yy.edu; PA=/pub/doc/README;
PR:aftp/xx.yy.edu/pub/doc/README
/aftp/xx.yy.edu/pub/doc/README)
Этот документ также объясняет, почему пробелы должны кодироваться в URL (%20):
В UDI избегают использование пробелов: пробелы — это запрещенные символы. Это сделано потому, что часто появляются лишние пробелы когда строки оборачиваются системами вроде mail, или из-за обычной необходимости выровнять ширину колонки, а так же из-за преобразования различных видов пробелов во время конвертации кодов символов и при передаче текста от приложения к приложению.
Важно понимать, что URL был просто сокращенным способом обратиться к комбинации схемы, домена, порта, учетных данных и пути, которые ранее нужно было определять из контекста для каждой из систем коммуникации.
scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
Эта позволило обращаться к разным системам из гипертекста, но сегодня, возможно, такая форма уже избыточна, так как практически все передается через HTTP. В 1996 браузеры уже добавляли http:// и www. за пользователей автоматически (что делает рекламу с этими кусками URL по-настоящему бессмысленной).
Я не считаю, что вопрос «могут ли люди понять значение URL» имеет смысл. Я просто думаю, что морально неприемлемо заставлять бабушку или дедушку вникать в то, что в конечном итоге является нормами файловой системы UNIX.— Исраэль дель Рио,
1996
Слэш, отделяющий путь в URL, знаком любому, кто использовал компьютер за последние пятьдесят лет. Сама иерархическая файловая система была представлена в системе MULTICS. Ее создатель в свою очередь ссылается на двухчасовую беседу с Альбертом Эйнштейном, которая состоялась в 1952 году.
В MULTICS использовался символ «больше» (>) для разделения компонентов файлового пути. Например:
>usr>bin>local>awk
Это совершенно логично, но, к сожалению, ребята из Unix решили использовать > для обозначения перенаправления, а для разделения пути взяли слэш (/).
Неправильно. Теперь я четко вижу, что мы не согласны друг с другом. Вы и я.…
Как человек, я хочу сохранить за собой право использовать разные критерии для разных целей. Я хочу иметь возможность давать имена самим работам, и конкретным переводам и конкретным версиям. Я хочу более богатого мира чем тот, что вы предлагаете. Я не хочу ограничивать себя вашей двухуровневой системой «документов» и «вариантов».
— Тим Бернерс-Ли,
1993
Половины URL-адресов, на которые ссылается Верховный Суд США, уже не существует. Если вы читаете академическую работу в 2011 году, и написана она была в 2001 году, то с большой вероятностью любой URL там будет нерабочим.
В 1993 году многие страстно верили, что URL отомрет, и на замену ему придет URN. Uniform Resource Name — это постоянная ссылка на любой фрагмент, который, в отличие от URL, никогда не изменится и не сломается. Тим Бернерс-Ли описал его как «срочную необходимость» еще в 1991.
Простейший способ создать URN — это использовать криптографический хэш содержания страницы, например:urn:791f0de3cfffc6ec7a0aacda2b147839. Однако, этот метод не удовлетворяет критериям веб-сообщества, так как невозможно выяснить, кто и как будет конвертировать этот хэш обратно в реальный контент. Такой способ также не учитывает изменений формата, которые часто происходят в файле (например, сжатие файла), которые не влияют на содержание.
В 1996 Киф Шэйфер и несколько других специалистов предложили решение проблемы поломанных URL. Ссылка на это решение сейчас не работает. Рой Филдинг опубликовал предложение реализации в июле 1995 года. Ссылка тоже поломана.
Я смог найти эти страницы через Google, который по сути сделал заголовки страниц современным аналогом URN. Формат URN был окончательно оформлен в 1997 году, и практически не использовался с тех пор. У него интересная реализация. Каждый URN состоит из двух частей: authority, который может преобразовать определенный тип URN, и конкретный идентификатор документа в понятном для authority формате. Например, urn:isbn:0131103628 будет обозначать книгу, формируя постоянную ссылку, которая (надеюсь) будет конвертирована в набор URL’ов вашим локальным преобразователем isbn .
Учитывая мощность поисковых движков, возможно, что лучшим на сегодня форматом URN могла бы стать простая возможность файлов ссылаться на свой прошлый URL. Мы можем позволить поисковым движкам индексировать эту информацию, и ссылаться на наши страницы корректно:
<!-- On http://zack.is/history -->
<link rel="past-url" href="http://zackbloom.com/history.html">
<link rel="past-url" href="http://zack.is/history.html">Формат application/x-www-form-urlencoded — это аномальный монстр во многих отношениях, результат многих лет случайностей реализаций и компромиссов, которые привели к необходимому для интероперабельности набору требований. Но это точно не образец хорошей архитектуры.— WhatWG URL Spec
Если вы использовали веб какое-то время, то вам знакомы параметры запросов. Они находятся после пути и нужны для кодирования параметров вроде ?name=zack&state=mi. Может показаться странным, что запросы используют символ амперсанда (&), который в HTML используется для кодирования специальных символов. Если вы писали на HTML, то скорее всего столкнулись с необходимостью кодировать амперсанды в URL, превращая http://host/?x=1&y=2 в http://host/?x=1&y=2 или http://host?x=1&y=2 (конкретно эта путаница существовала всегда).
Возможно, вы также замечали, что куки (cookies) используют похожий, но все же иной формат: x=1;y=2, и он никак не конфликтует с символами HTML. W3C не забыл про эту идею и рекомендовал всем поддерживать как ;, так и & в параметрах запросов еще в 1995 году.
Изначально эта часть URL использовалась исключительно для поиска индексов. Веб изначально был создан (и его финансирование было основано на этом) как метод совместной работы физиков, занимающихся элементарными частицами. Это не означает, что Тим Бернерс-Ли не знал, что он создает систему коммуникации с по-настоящему широким применением. Он не добавлял поддержку таблиц несколько лет, не смотря на то, что таблицы, наверное, пригодились бы физикам.
Так или иначе, физикам нужен был способ кодирования и связывания информации, и способ поиска этой информации. Для этого Тим Бернерс-Ли создал тег <ISINDEX>. Если <ISINDEX> присутствовал на странице, то браузер знал, что по этой странице можно делать поиск. Браузер показывал поисковую строку и позволял пользователю делать запрос на сервер.
Запрос представлял собой набор ключевых слов, отделенных друг от друга плюсами (+):
http://cernvm/FIND/?sgml+cmsКак это обычно случается в интернете, тег стали использовать для всего подряд, в том числе как поле ввода числа для вычисления квадратного корня. Вскоре предложили принять тот факт, что такое поле слишком специфично, и нужен тег общего характера <input>.
В том предложении использовался символ плюса для отделения компонентов запроса, но в остальном все напоминает современный GET-запрос:
http://somehost.somewhere/some/path?x=xxxx+y=yyyy+z=zzzzДалеко не все одобрили это. Некоторые считали, что нужен способ указать поддержку поиска по ту сторону ссылки:
<a HREF="wais://quake.think.com/INFO" INDEX=1>search</a>
Тим Бернерс-Ли думал, что нужен способ определения строго типизированных запросов:
<ISINDEX TYPE="iana:/www/classes/query/personalinfo">
Изучая прошлое, готов с определенной долей уверенности сказать: я рад, что победило более общее решение.
Работа над тегом <INPUT> началась в январе 1993 года, она основывалась на более старом типе SGML. Было решено (пожалуй, к сожалению), что тегу <SELECT> нужна своя, более широкая структура:
<select name=FIELDNAME type=CHOICETYPE [value=VALUE] [help=HELPUDI]>
<choice>item 1
<choice>item 2
<choice>item 3
</select>Если вам любопытно, то да, была идея повторно использовать элемент <li> вместо создания нового <option>. Однако, были и другие предложения. В одном из них происходила замена переменных, что напоминает современный Angular:
<ENTRYBLANK TYPE=int LENGTH=length DEFAULT=default VAR=lval>
Prompt </ENTRYBLANK>
<QUESTION TYPE=float DEFAULT=default VAR=lval> Prompt </QUESTION>
<CHOICE DEFAULT=default VAR=lval>
<ALTERNATIVE VAL=value1> Prompt1
...
<ALTERNATIVE VAL=valuen> Promptn
</CHOICE>В этом примере проверяется тип input’ов на основе указания type, а значения VAR доступны на странице для замены строк в URL, примерно так:
http://eager.io/apps/$appIdДополнительные предложения использовали @ вместо = для разделения компонентов запроса:
name@value+name@(value&value)Марк Андриссен предложил метод, основанный на том, что он уже реализовал в Mosaic:
name=value&name=value&name=value
Всего два месяца спустя Mosaic добавил поддержку method=POST в формы, и так родились современные HTML-формы.
Конечно, компания Netscape Марка Андриссена создала еще и формат куки (с другим разделителем). Их предложение было болезненно недальновидным, оно привело к попытке создания заголовка Set-Cookie2, и создало фундаментальные структурные проблемы, с которыми нам все еще приходится иметь дело в продукте Eager.
Часть URL после символа ‘#’ известна как «фрагмент» (fragment). Фрагменты были частью URL со времен первой спецификации, они использовались для создания ссылки на конкретное место на загруженной странице. Например, если у меня есть якорь на сайте:
<a name="bio"></a>
Я могу сделать на него ссылку:
http://zack.is/#bio
Эта концепция постепенно была расширена до всех элементов (а не только якорей), и перешла на атрибут id вместо name:
<h2>Bio</h2>
Тим Бернерс-Ли решил использовать этот символ, основываясь на связи с форматом почтовых адресов в США (не смотря на то, что сам Тим — британец). По его словам:
Как минимум в США в почтовых адресах часто используют знак номера для указания номера квартиры или комнаты в здании. 12 Acacia Av #12 означает «Здание 12 на Акация Авеню, и в этом здании квартира 12». Этот символ казался естественным для такой цели. Сегодня http://www.example.com/foo#bar означает «На ресурсе http://www.example.com/foo конкретный вид, известный как bar”.
Оказывается, первичная система гипертекста, созданная Дугласом Энгельбартом, также использовала «#» для таких целей. Это может быть совпадением или случайным «заимствованием идеи».
Фрагменты специально не включаются в HTTP-запросы, то есть они живут исключительно в браузере. Такая концепция оказалась ценной, когда пришло время реализовывать клиентскую навигацию (до изобретения pushState). Фрагменты также были очень полезными, когда пришло время задуматься о сохранении состояния в URL без отправки на сервер. Что это значит? Давайте разберемся:
Кротовые холмики и горы
Есть целый стандарт, такой же мерзкий как SGML, созданный для передачи электронных данных, другими словами — для форм и отправки форм. Единственное, что мне известно: он выглядит как фортран задом наперед без пробелов.— Тим Бернерс-Ли,
1993
Есть ощущение, разделяемое многими, что организации, отвечающие за стандарты интернета ничего особо не делали с момента окончательного принятия HTTP 1.1. и HTML 4.01 в 2002 до тех пор, пока HTML 5 не стал по-настоящему популярным. Этот период также известен (только для меня) как Темный Век XHTML. В реальности люди, занимающиеся стандартами, были безумно заняты. Просто они занимались тем, что в итоге оказалось не слишком ценным.
Одним из направлений было создание Семантического Веба. Была мечта: создать Фреймворк Описания Ресурсов (Resource Description Framework). (прим. ред.: бегите от любой команды, которая хочет сделать фреймворк). Такой фреймворк позволял бы универсально описывать мета-информацию о содержании. Например, вместо того, чтобы делать красивую веб-страницу про мой Корвет Стингрэй, я бы сделал RDF-документ с описанием размеров, цвета и количества штрафов за превышение скорости, которые мне выписали за все время езды.
Это, конечно, совсем не плохая идея. Но формат был основан на XML, и это большая проблема курицы и яйца: нужно задокументировать весь мир, и нужны браузеры, которые умеют делать полезные штуки с этой документацией.
Но эта идея хотя бы родила условия для философских споров. Один из лучших подобных споров длился как минимум десять лет, он известен под искусным кодовым именем ‘httpRange-14’.
Целью httpRange-14 было ответить на фундаментальный вопрос «чем является URL?». Всегда ли URL ссылается на документ или он может ссылаться на все, что угодно? Может ли URL ссылаться на мою машину?
Они не пытались ответить на этот вопрос хоть сколько-нибудь удовлетворительно. Вместо этого они фокусировались на том, как и когда можно использовать редирект 303 чтобы сообщить пользователю, что по ссылке нет документа, и перенаправить его туда, где документ есть. И на том, когда можно использовать фрагменты (часть после ‘#’), чтобы направлять пользователей на связанные данные.
Прагматичному современному человеку эти вопросы могут показаться смешными. Многие из нас привыкли, что если URL получается использовать для чего-то, то значит его можно использовать для этого. И люди или будут использовать ваш продукт, или нет.
Но Семантический Веб заботился только о семантике.
Эта конкретная тема обсуждалась 1 июля 2002 года, 15 июля 2002 года, 22 июля 2002 года, 29 июля 2002 года, 16 сентября 2002 года, и как минимум еще 20 раз в течение 2005 года. Обсуждение закончилось благодаря тому самому ‘решению httpRange-14’ в 2005 году, и к нему вернулись снова из-за жалоб в 2007 и 2011, а запрос новых решений был открыт в 2012. Вопрос долго обсуждался группой pedantic web, у которой очень подходящее название. Единственное, чего так и не произошло — никакие из этих семантических данных так и не были добавлены в веб в какой-либо URL.
Авторизация
Как вы знаете, в URL можно включить логин и пароль:
http://zack:[email protected]
Браузер кодирует эти данные в формат Base64 и посылает в виде заголовка:
Authentication: Basic emFjazpzaGhoaGho
Base64 используется только для того, чтобы можно было передавать запрещенные в заголовках символы. Он никак не скрывает логин и пароль.
Это было проблемой, особенно до распространения SSL. Любой человек, который следит за вашим соединением, мог с легкостью увидеть пароль. Предлагали много альтернатив, в том числе Kerberos, который был и остается популярным протоколом безопасности.
Как и с другими примерами нашей истории, простую базовую авторизацию было проще всего реализовать разработчикам браузеров (Mosaic). Так базовая авторизация стала первым и единственным решением до тех пор, пока разработчики не получили инструменты для создания собственных систем аутентификации.
Веб-приложение
В мире веб-приложений странно представить, что основой веба является гиперссылка. Это метод соединения одного документа с другим, который со временем оброс стилями, возможностью запуска кода, сессиями, аутентификацией и в конечном итоге стал общей социальной компьютерной системой, которую пытались (безуспешно) создать так много исследователей 70-х годов.
Вывод такой же, как и у любого современного проекта или стартапа: только распространение имеет смысл. Если вы сделали что-то, что люди используют, даже если это некачественный продукт, то они помогут вам превратить его в то, чего хотят сами. И с другой стороны, конечно, если никто не пользуется продуктом, то его техническое совершенство не имеет значения. Существует бесчисленное количество инструментов, на которые ушли миллионы часов работы, но ими пользуется ровно ноль человек.
| URL | Унифицированный указатель ресурсов Вычислительная техника »Сети — и многое другое … | Оцените это: | |||||||||
| URL | 9000af7a Univers Академия и наука »Университеты | Оцените: | |||||||||
| URL | Вы заболели Интернет» Чат | Оцените это: | |||||||||
| URL | UR Lame Интернет »Чат | Оцените его: | |||||||||
| URL | Underground Racing League | Оцените: | |||||||||
| URL | UR in Love Интернет »Чат | Оцените: | |||||||||
| URL | You aRe Loco Разное | Оцените: | |||||||||
| URL | Universal Republic of Love Разное »Приколы | Оцените: | |||||||||
| Оцените: | |||||||||||
| URL | U aRe Last Sports 45 | ||||||||||
| URL | 90 004 Оцените его: | ||||||||||
| URL | Universal Reader Line | Business» Продукты Оцените: | |||||||||
| URL | Единое расположение требований Бизнес »Общий бизнес | Оцените: | |||||||||
| Оцените: | |||||||||||
| URL | Пользователь действительно потерян Разное 17 | 000000000 | 000 | Оцените: | |||||||
| URL | Единый язык регистрации Вычисления »Общие вычисления | Оцените это: | |||||||||
| URL | Продукты питания и продукты питания Разное | Оцените: | |||||||||
| URL | Обычно Rad Libbys Разное »Funnies | URL | Unicorn Rainbow Leap Разное »Funnies | Оцените его: | |||||||
| URL | Универсальный локатор ресурсов 8 | 000000 Разное 90 017 Оцените его: | |||||||||
| URL | веб-адрес Разное »Несекретный | Оцените его: | |||||||||
| Оцените: | |||||||||||
| URL | Неизвестно Место ссылки Академические и научные» Библиотеки | : | |||||||||
| URL | Ultimate Rap League Сообщество »Музыка | Оценить: | |||||||||
| URL | Универсальный локатор Универсальный ресурс »Производство 9000 5 | Оцените: |
php — Что означает / #! / В URL?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- Реклама Обратитесь к разработчикам и технологам со всего мира
Что такое кодирование URL и как оно работает?

Введение
URL-адрес (унифицированный указатель ресурса) — это адрес ресурса во всемирной паутине. URL-адреса имеют четко определенную структуру, которая была сформулирована в RFC 1738 Тимом Бернерсом-Ли, изобретателем всемирной паутины.
Каждый URL-адрес подтверждает общий синтаксис , который выглядит так —
схема: [// [пользователь: пароль @] хост [: порт]] путь [? Запрос] [ Некоторые части синтаксиса URL, например [user: password @] устарели и редко используются по соображениям безопасности.Ниже приведен пример URL-адреса, который вы чаще всего видите в Интернете —
https://www.google.com/search?q=hello+world В первоначальный RFC, определяющий синтаксис унифицированных указателей ресурсов (URL), было внесено множество улучшений. Текущий RFC, определяющий универсальный синтаксис URI, — RFC 3986. Этот пост содержит информацию из последнего документа RFC.
Кодировка URL (процентное кодирование)
URL-адрес состоит из ограниченного набора символов, принадлежащих набору символов US-ASCII.Эти символы включают цифры (0-9), буквы (A-Z, a-z) и несколько специальных символов ( "-" , "." , "_" , "~" ).
управляющих символов ASCII (например, возврат, вертикальная табуляция, горизонтальная табуляция, перевод строки и т. Д.), Небезопасные символы, такие как пробел , \ , <, > , {, } и т. Д., А также любой символ вне кодировки ASCII нельзя размещать непосредственно в URL-адресах.
Кроме того, есть некоторые символы, которые имеют особое значение в URL-адресах.Эти символы называются зарезервированными символами. Некоторые примеры зарезервированных символов ? , /, # , : и т. Д. Любые данные, передаваемые как часть URL-адреса, будь то в строке запроса или сегменте пути, не должны содержать эти символы.
Итак, что нам делать, когда нам нужно передать какие-либо данные в URL-адресе, содержащие эти запрещенные символы? Ну мы их кодируем!
Кодирование URLКодирование URL-адресов преобразует зарезервированные, небезопасные и не-ASCII символы в URL-адресах в формат, который повсеместно принят и понятен всеми веб-браузерами и серверами.Сначала он преобразует символ в один или несколько байтов. Затем каждый байт представлен двумя шестнадцатеричными цифрами, которым предшествует знак процента (
%) - (например,% xy). Знак процента используется как escape-символ.
также называется процентным кодированием, поскольку оно использует знак процента (% ) в качестве escape-символа.
Пример кодирования URL
Пробел: Один из наиболее частых символов в кодировке URL, с которыми вы, вероятно, столкнетесь, - это пробел .Значение ASCII пробела символа в десятичном виде составляет 32 , которое при преобразовании в шестнадцатеричное получается равным 20 . Теперь мы просто ставим перед шестнадцатеричным представлением знак процента (% ), который дает нам значение в кодировке URL - % 20 .
Справочник по кодировке символов ASCII
Следующая таблица представляет собой ссылку на символы ASCII в их соответствующей кодированной форме URL.
Обратите внимание, что кодирование буквенно-цифровых символов ASCII не требуется.Например, вам не нужно кодировать символ
'0'в% 30, как показано в следующей таблице. Его можно передавать как есть. Но кодировка по-прежнему действительна согласно RFC. Все символы, которые можно безопасно передавать внутри URL-адресов, выделены в таблице зеленым цветом.
В следующей таблице используются правила, определенные в RFC 3986 для кодирования URL.