Что такое индексация — самый полный гайд
Часто происходит путаница в терминологии: под индексацией иногда подразумевают сканирование сайта или совокупность и сканирования и индексации. В этом нет большой ошибки, часто путаницу вносят сами мануалы поисковых систем. Иногда в текстах Яндекса и Гугла можно увидеть использование термина индексация в разных контекстах, например:
Индексация сайта простыми словами
Так что же такое индексация: если кратко, то индексация (или индексирование, indexing) – один из процессов работы поисковых систем по построению поисковой базы в результате которого содержимое страниц попадает в индекс поисковой системы.
Для большей ясности приведу терминологию, а потом опишу все процессы.
Терминология
Планировщик (Scheduler) – программа, которая выстраивает маршрут обхода интернета роботами исходя из характеристик страниц, таких как частота обновления документов, востребованность этих страниц, цитируемость.
Crawler, Spider (Паук) Googlebot, YandexBot
- Основной робот, обходящий контент в порядке общей очереди.
- Быстрый робот (быстроробот или быстробот). Робот, который использует свежий индекс, на основе группы заданных хабовых страниц с важной, часто обновляемой информацией, например, с новостями популярных СМИ.
Сканирование (Crawling) – процесс загрузки страниц краулером в результате чего они попадают в хранилище, в виде сохраненных копий.
Краулинговый спрос: это то, как часто и в каком объеме робот бы хотел сканировать конкретные страницы.
Краулинговый лимит: ограничения скорости сканирования на стороне сайта, связанные с производительностью сайта или заданным вручную ограничением.
Краулинговый бюджет – это совокупность краулингового спроса и доступной скорости сканирования сайта (краулингового лимита). Простыми словами – это то сколько робот хочет и может скачать страниц.
Сохраненная копия – необработанная копия документа на момент последнего сканирования.
Поисковый индекс – информация со страниц, приведенная в удобный для работы поисковых алгоритмов формат. Список всех терминов и словопозиций где и на каких страницах они упоминаются. Информация хранится в базе в виде инвертированного индекса. Схематический пример:
Индексация – процесс загрузки, анализа содержимого документа документа с последующим включением в поисковый индекс.
Поисковая база – это совокупность поискового индекса, сохраненных страниц и служебной информации о документах, таких как заголовки, типы и кодировка документов, коды ответов страниц, мета теги и др.
Как происходит сканирование сайта
Так как ресурсы поисковых систем не безграничны, планировщик составляет очередь обхода страниц, исходя критериев их полезности, востребованности, популярности и др.
- Доля полезных/мусорных страниц на сайте, дубликаты
- Спамные и малополезные страницы
- Наличие бесконечной генерации страниц, например, некорректной фасетной навигации
- Популярность страниц
- Насколько актуальные версии страниц сайта, содержащиеся в поисковой базе
Робот в постоянном режиме скачивает страницы и помещает их в хранилище, заменяя старые версии. Мы можем увидеть их в виде сохраненных копий. Далее уже происходит индексация страниц.
Как проходит индексация сайта
Индексацию можно условно разбить на следующие процессы:
- Загрузка и разбор страницы по элементам: текст, мета-теги, микроразметка, изображения, видео и другой контент и служебные данные.

- Анализ страницы по определенным параметрам, например: разрешена ли она к индексации, сканированию, является ли неглавной копией другой страницы, содержит ли страница малополезный, спамный контент и др.
- Если страница успешно прошла все проверки, она добавляется в индекс.
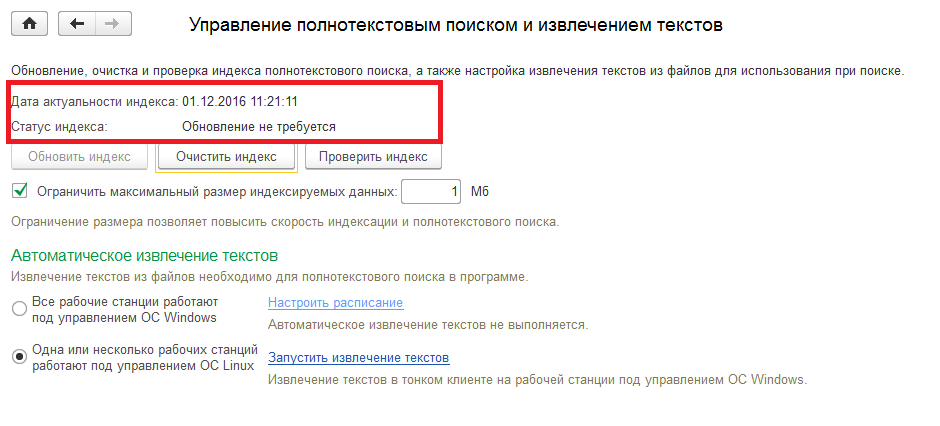
Как проходит индексация сайта в Яндексе
Все описанное в предыдущем пункте справедливо и для Яндекса и для Google. Какие есть особенности индексации у Яндекса?
У Google обновление поисковой базы – непрерывный процесс. В Яндексе обновление происходит во время Апдейтов, примерно раз в три дня. О том что произошло обновление можно узнать по уведомлениям в Яндекс.Вебмастере
Как проверить индексацию
Есть разные способы для проверки статуса индексации сайтов и отдельных его страниц:
- Вебмастер Яндекса
- Панель Google Search Console
- API панели для вебмастеров Yandex/Google
- SEO-сервисы, например Rush Analytics
- Плагины и расширения для браузеров
- Поисковые операторы ПС
- GA/Метрика
- Серверные логи
Выбор сервиса зависит от поисковой системы, а также задачи: узнать сколько страниц всего в индексе, получить список проиндексированных страниц или проверить статус индексации конкретной страницы или списка страниц. Подробнее расписано ниже.
Как узнать сколько страниц проиндексировано на сайте
Расширения для браузера
Быстрые способы проверить статус индексации сайта – расширения и букмарклеты для браузера, например RDS-бар
Сервисы для анализа сайтов
Так же можно проверить с помощью сервисов, таких как pr-cy.ru
Яндекс.Вебмастер и Google Search Console
Если есть доступы к панелям вебмастеров, можно получить количество проиндексированных страниц в панелях вебмастеров:
Яндекс Вебмастер – http://webmaster.yandex.ru
Google Search Console – https://search. google.com/search-console/
google.com/search-console/
С помощью специализированных программ для SEO, например Allsubmitter, Netpeak Checker.
Это может понадобиться когда нужна пакетная проверка параметров чужих сайтов.
Пример проверки числа проиндексированных страниц в Netpeak Checker.
Проверка индексации сайтов в Яндекс:
Проверка индексации сайтов в Google:
Пример проверки индексации сайтов в Яндекс и Google в Allsubmitter.
Как выгрузить список проиндексированных страниц сайта в Яндексе и Google
Яндекс Вебмастер
Внизу страницы ссылки на скачивание файла – cуществует ограничение в 50 000 страниц.
Google Search Console: в отчете Покрытие – выбираем нужные типы страниц
Переходим в нужный отчет и скачиваем список страниц в удобном формате. Google отдает только 1 000 страниц.
Поисковые операторы Яндекса
Запрос для поиска страниц в пределах одного домена – url:www.site.ru/* | url:site.ru/* | url:site.ru | url:www.site.ru.
Запрос для поиска с учетом всех поддоменов – site:site.ru
Список операторов и инструкцию по работе с ними можно посмотреть в справке Яндекса.
Ограничение: можно получить только 1000 результатов. Нужны специальные инструменты чтобы скопировать список страниц SERP: расширения браузера, букмарклеты или программы для парсинга выдачи.
Поисковые операторы Google
Запрос для поиска страниц в пределах одного сайта – site:site.ru
Получение списка страниц входа из систем веб-аналитики
Списки страниц входа из органики Яндекса в системах аналитики Яндекс.Метрика и Google.Analytics. Страницы по которым идут переходы с органической выдачи с большой вероятностью индексируются, но для точности рекомендуется проверять индексацию собранных страниц – индекс не статичен и страницы могут выпадать из индекса.
Список страниц по которым сайт показывается в выдаче в Яндекс.Вебмастере
Для выгрузки большого списка страниц из Яндекс.Вебмастера потребуется специальный скрипт.
Плагин для API Google Webmasters: Google Search Analytics for Sheets
Отображает страницы по которым были показы сайта в выдаче.
Преимущества выгрузки списка страниц через API в том что можно получить десятки тысяч страниц, которые с большой вероятностью проиндексированы, в отличие от веб-интерфейса где установлено ограничение по выгрузкам в 1000 страниц.
Серверные логи сайта
Получить список страниц которые посещает робот можно из логов, например с помощью программы SEO Log File Analyser от создателей Screaming Frog.
Как проверить индексацию конкретной страницы в Яндексе и Google
Сервис Яндекс.Вебмастер: Индексирование -> Проверить статус URL
Проверка с помощью оператора: пример запроса url:https://site.com/page/
Сервис Google Search Console: инструмент “Покрытие”
Нужно ввести в указанной на скрине строке поиска URL-адрес своего сайта и откроется отчет о статусе страницы.
Проверка с помощью оператора: пример запроса site:https://habr.com/ru/news/t/468361/
После отмены оператора info остался оператор site, но он выдает не всегда точные данные, можно сократить список результатов с помощью указания уникального текста проверяемой страницы.
Как массово проверить индексацию списка страниц
Для проверки можно использовать SEO-сервисы, например Rush Analytics.
Это позволяет массово проверить индексацию до десятков-сотен тысяч страниц
Как проверить разрешена индексация/сканирование страницы в Robots.txt
В Яндексе
Проверить доступна ли роботам страница или содержит запрет можно через. Инструменты -> Анализ robots. txt
txt
В Google
Инструмент проверки файла robots.txt
Важно: если файл robots.txt отдает 404 ошибку, боты считают что разрешено сканирование всего сайта без ограничений. Если файл отдает ошибку 5хх, то Googlebot считает это полным запретом на сканирование сайта, но если ошибка отдается более 30 дней – считает что разрешено сканировать весь сайт без ограничений. Яндекс любые серверные ошибки считает отсутствием файла robots.txt и отсутствием ограничений на обход и индексацию сайта.
Как узнать динамику числа проиндексированных страниц
С помощью специализированных сервисов, например: https://be1.ru/
С помощью Яндекс Вебмастера: в разделе Индексирование -> Страницы в поиске.
С помощью Google Search Console: в отчете Покрытие.
Почему число проиндексированных страниц может отличаться в разных сервисах?
Нужно понимать что проиндексированные страницы и страницы в поиске это разные сущности. Не все проиндексированные страницы будут включены в поиск и не все страницы в поиске будут показываться через операторы поиска – операторы лишь выводят результаты пустого поиск по сайту а не список всех страниц. Но этого в большинстве случаев достаточно чтобы оценить порядок числа проиндексированных страниц сайта.
Запрет индексации страниц
Запрет индексации с помощью Meta Noindex/X-Robots-Tag
Для гарантированного исключения попадания страниц в индекс можно использовать атрибут Noindex Мета Тега Robots или HTTP-заголовка X-Robots-Tag. Подробнее про этот атрибут можно прочитать тут.
Важно: Использование запрета индексации в через Meta/X-Robots-Tag Noindex вместе с запретом в Robots.txt
При добавлении директивы Noindex в мета-тег Robots и http-заголовок X-Robots-Tag, чтобы ее прочитать, робот должен просканировать страницу, поэтому она должна быть разрешена в файле Robots. txt. Следовательно для точечного запрета индексации страниц иногда требуется снять запрет в robots.txt или добавить директиву Allow, чтобы робот смог переобойти эти страницы.
txt. Следовательно для точечного запрета индексации страниц иногда требуется снять запрет в robots.txt или добавить директиву Allow, чтобы робот смог переобойти эти страницы.
Несмотря на вышеописанное, запрет в robots.txt в большинстве случаев все таки приведет к тому, что страницы не будут индексироваться, но его нельзя использовать для закрытия персональных данных или страниц с конфиденциальной информацией.
Как запретить индексацию страницы в robots.txt
Стоит сразу упомянуть что запрет в robots.txt не является надежным методом закрытия страниц от индексации.
В файле robots.txt указываются основные директивы для запрета или разрешения обхода/индексации отдельных страниц или разделов сайта.
Важно: Многие ошибочно считают что директива Disallow в Robots.txt служит для запрета индексации страниц, это не совсем так. Основная цель файла Robots.txt – управление трафиком поисковых роботов на сайте, а не индексацией / переиндексацией и разные поисковые системы по разному интерпретируют запрет.
Многие вебмастера не понимают почему после запрета страницы в robots.txt она продолжает находиться в индексе и приносить трафик. Запрет посещения и обновления страницы роботом не означает, что он обязан удалить уже присутствующую в индексе страницу. К тому же для индексации не всегда обязательно физически сканировать страницу, информацию о ней можно собирать из различных источников, например, из анкоров входящих ссылок.
Почему заблокированные в robots.txt страницы отображаются в выдаче?
В Яндексе и Google различается механизм обработки директив файла Robots.txt. Для Google директива Disallow в robots.txt запрещает лишь обход страниц, но не их индексацию из-за чего часто появляются страницы со статусом:
Для запрета индексации в Google через файл Robots.txt ранее использовалась незадокументированная директива Noindex в Robots.txt, но с сентября 2019 года Google перестал поддерживать ее. Yandex” search_bot
Yandex” search_bot
Запрет сканирования, индексации с помощью кодов ответа сервера 3хх/4хх
Чтобы гарантированно запретить роботам скачивать страницы, можно отдавать ботам при сканировании страниц коды:
- 301 редирект: особенно подходит для запрета дубликатов и склейки их с основными страницами;
- 403 Forbidden: доступ запрещен;
- 404 Not Found: не найдено;
- 410 Gone: удалено;
Удаление страниц из индекса
Удаление страниц или каталогов через Search Console
Инструмент не запрещает страницы к индексации или сканированию – он лишь временно скрывает страницы из поисковой выдачи. Рекомендуется использовать только для экстренного удаления страниц, случайно попавших в выдачу, после этого уже физически удалить их или запретить сканирование/индексацию.
Ускоренное удаление из индекса страниц в Яндексе
На сайт должны быть подтверждены права. Можно удалить только страницы, которые недоступны для робота: запрещенные в robots.txt или отдавать код 3хх, 4хх.
Для удаления из индекса Яндекса страниц чужого сайта можно воспользоваться формой – https://webmaster.yandex.ru/tools/del-url/.
Требования к URL-адресам такие же: запрет в robots.txt или коды ответа 301, 403, 404, 410 и т.п.
Как добавить страницы в индекс Яндекса или Google
Роботы постоянно ходят по ссылкам на сайтах. Для ускорения добавления существуют инструменты:
- Sitemap.xml. Добавьте и регулярно обновляйте актуальный список страниц в сайтмапах сайта.
- В Яндексе: инструменты -> переобход страниц
- В Google: Проверка URL -> Запросить индексирование
Как проверить обход / сканирование сайта поисковыми системами
Яндекс:
Общее количество загруженных (просканированных) Яндексом страниц можно увидеть на главной странице вебмастера.
Динамику обхода страниц можно увидеть на странице Индексирование -> Статистика обхода.
Google: отчет: статистика сканирования сайта.
Также можно проверить обход сайта всеми поисковыми роботами с помощью анализа серверных логов сайта (Access logs). Например, через программу SEO Log File Analyser.
Как часто происходит индексация сайта
Поисковые боты постоянно равномерно загружают страницы сайта, далее выкладывая их в обновленный индекс: Google обновляет индекс в постоянном режиме, Яндекс во время апдейтов поисковой базы, примерно раз в три дня.
Частота сканирования и переиндексации каждого отдельного сайта различается, и зависит от факторов:
- объем контента/страниц сайта
- краулинговый спрос поисковой системы для текущего сайта
- настройки скорости сканирования в вебмастерах
- скорость работы сайта
Как улучшить и ускорить индексацию сайта
Рекомендации для увеличения охвата страниц индексом поисковых систем:
- качественный уникальный контент, востребованный пользователями
- все основные страницы должны быть в валидных сайтмапах sitemap.xml
- оптимизация вложенности страниц
- оптимизация краулингового спроса/бюджета
- хорошая скорость сайта
- закрывать лишние страницы, чтобы не тратить на них ресурсы роботов
- внутренняя перелинковка
- создание ротарора на сайте (Ловец ботов)
Как ограничить скорость сканирования сайта
Обычно если требуется ограничить нагрузку, которую создают роботы, то у сайта большие проблемы и это негативно скажется на его индексации. Боты стараются быть “хорошими” юзерами и сканируют сайт равномерно, стараясь не перегружать сервера.
То что сайт от этого испытывает проблемы с нагрузкой, в 90% случаев может быть сигналом к смене хостинга/сервера или оптимизации производительности CMS. Но в случае крайней необходимости все таки можно задать рекомендуемую скорость сканирования сайта.
Для ограничения скорости обхода сайта можно воспользоваться инструментами Яндекс.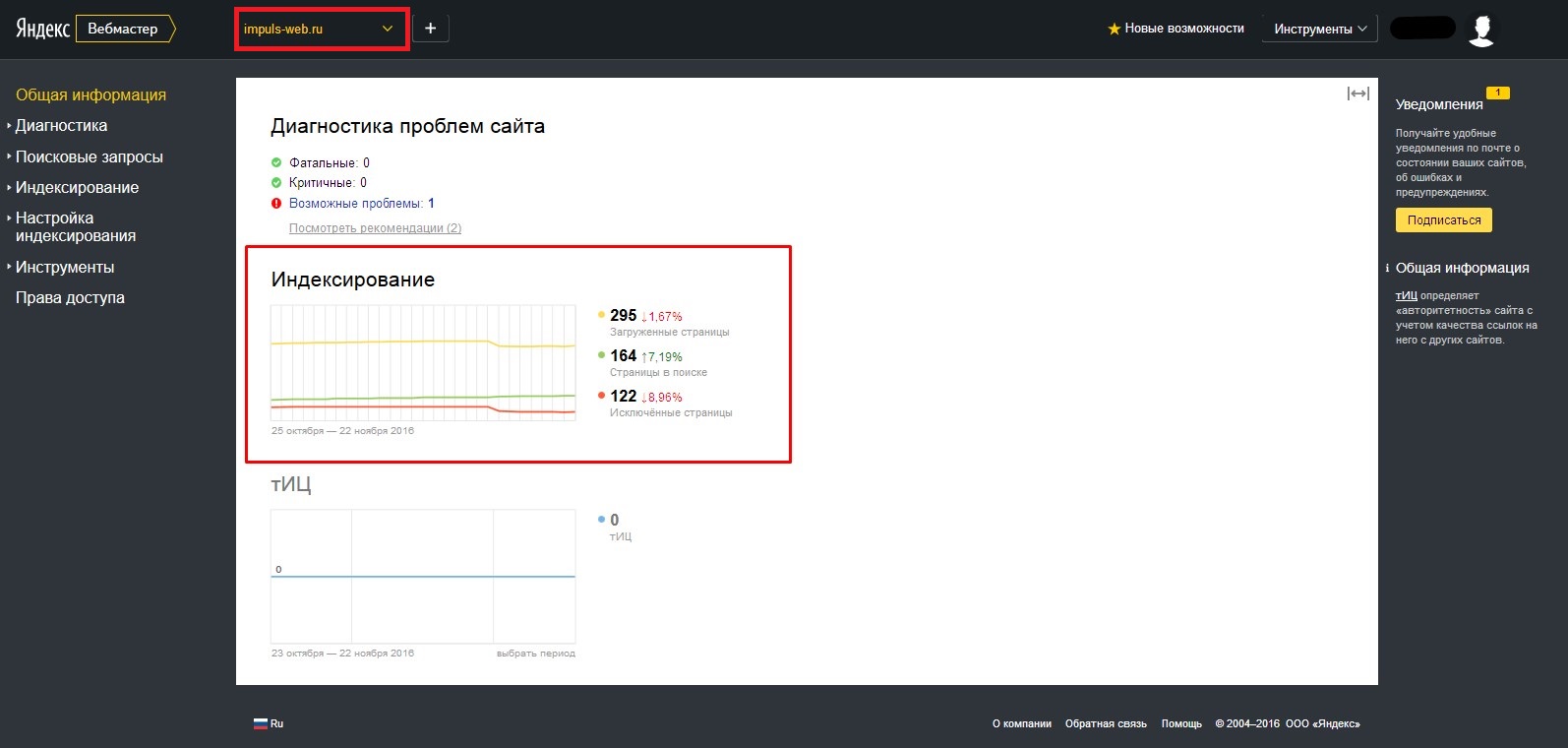 Вебмастер и Google
Вебмастер и Google
Яндекс:
Google:
В старой версии консоли можно было временно ограничить максимальную скорость сканирования сайта
В обновленной консоли такой возможности нет, но можно отправить сообщение о проблеме с активностью GoogleBot’а на сайте – https://www.google.com/webmasters/tools/googlebot-report
Как работает индексация базы данных?
Зачем это нужно?
Когда данные хранятся на дисковых устройствах хранения, они хранятся в виде блоков данных. Доступ к этим блокам осуществляется полностью,что делает их операцией доступа к атомарному диску. Дисковые блоки структурированы почти так же, как и связанные списки; оба содержат Раздел для данных, указатель на местоположение следующего узла (или блока), и оба не должны храниться последовательно.
Из — за того, что ряд записей может быть отсортирован только по одному полю, мы можем утверждать, что поиск по полю, которое не сортируется, требует линейного поиска, который требует N/2 обращений к блокам (в среднем), где N -количество блоков, которые охватывает таблица. Если это поле является неключевым (т. е. не содержит уникальных записей), то поиск всего табличного пространства должен осуществляться по N блочным доступам.
В то время как с отсортированным полем можно использовать двоичный поиск, который имеет доступ к блоку log2 N . Кроме того, поскольку данные сортируются по неключевому полю, то rest таблицы не нужно искать повторяющиеся значения, как только будет найдено более высокое значение. Таким образом, увеличение производительности является существенным.
Что такое индексация?
Индексация-это способ сортировки нескольких записей по нескольким полям. Создание индекса для поля в таблице создает другую структуру данных, которая содержит значение поля и указатель на запись, к которой оно относится. Затем эта индексная структура сортируется, позволяя выполнять двоичный поиск по ней.
Затем эта индексная структура сортируется, позволяя выполнять двоичный поиск по ней.
Недостатком индексации является то, что эти индексы требуют дополнительного места на диске, поскольку индексы хранятся вместе в таблице с использованием механизма MyISAM, этот файл может быстро достичь пределов размера базовой файловой системы, если индексируется много полей в одной таблице.
Как это работает?
Во-первых, давайте набросаем пример схемы таблицы базы данных;
Field name Data type Size on disk id (Primary key) Unsigned INT 4 bytes firstName Char(50) 50 bytes lastName Char(50) 50 bytes emailAddress Char(100) 100 bytes
Примечание: char был использован вместо varchar, чтобы обеспечить точный размер значения на диске. Этот образец базы данных содержит пять миллионов строк и неиндексирован. Теперь будет проанализирована производительность нескольких запросов. Это запрос с использованием идентификатора (отсортированное ключевое поле) и запрос с использованием firstName (неключевое несортированное поле).
Пример 1 — сортированные и несортированные поля
Учитывая наш пример базы данных из r = 5,000,000 записей фиксированного размера, дающих длину записи R = 204 байта, и они хранятся в таблице с использованием движка MyISAM, который использует размер блока по умолчанию B = 1,024 байт. Коэффициент блокировки таблицы будет равен bfr = (B/R) = 1024/204 = 5 записям на дисковый блок. Общее количество блоков, необходимых для хранения таблицы, составляет N = (r/bfr) = 5000000/5 = 1,000,000 блоков.
Линейный поиск по полю id потребует в среднем N/2 = 500,000 обращений к блоку, чтобы найти значение, учитывая, что поле id является ключевым полем. Но поскольку поле id также сортируется, двоичный поиск может быть проведен, требуя в среднем log2 1000000 = 19. блочных обращений. Мы сразу видим, что это радикальное улучшение.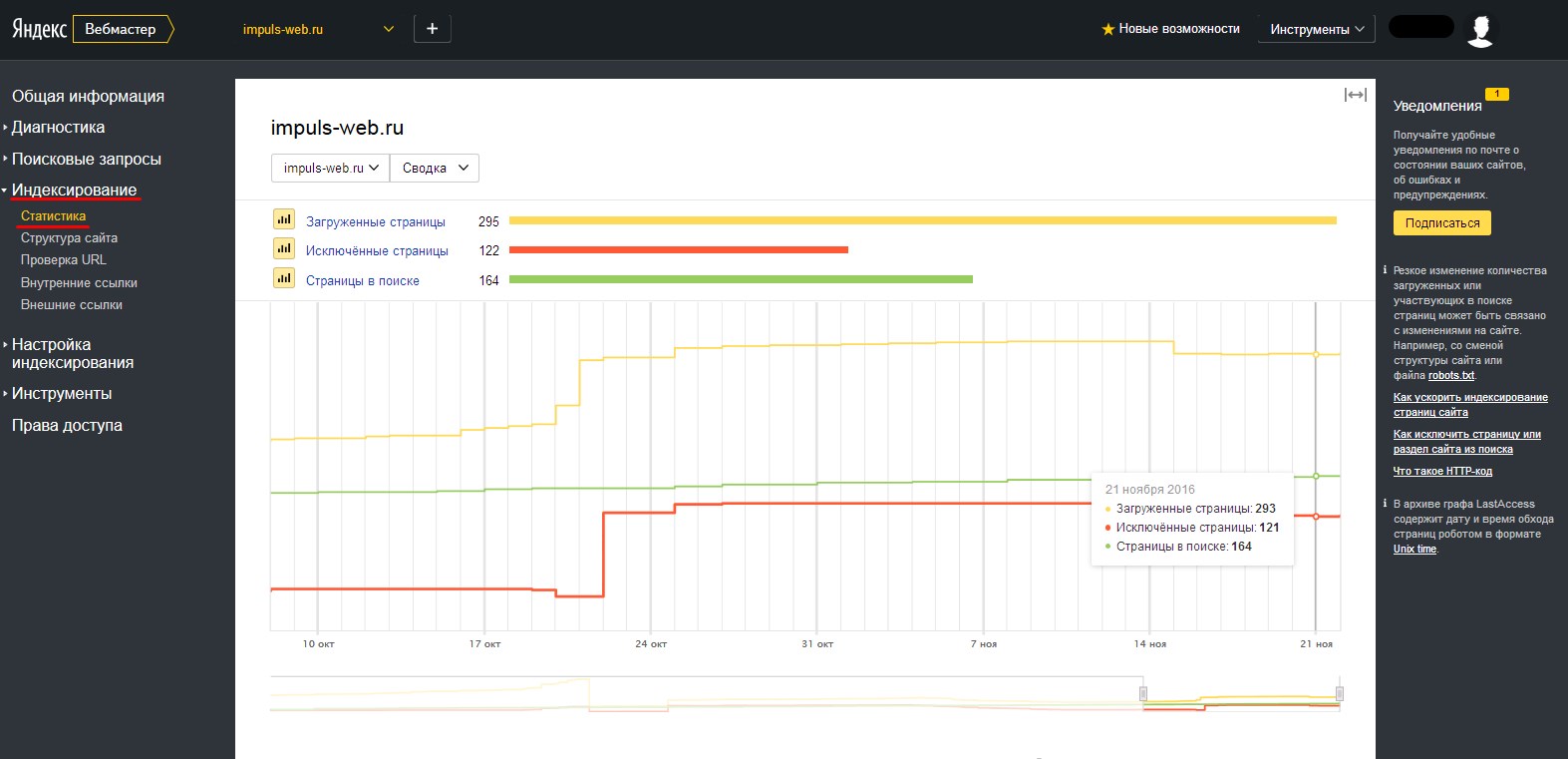 93 = 20
93 = 20
Теперь поле firstName не сортируется и не является ключевым полем, поэтому двоичный поиск невозможен, а значения не уникальны, и поэтому таблица потребует поиска до конца для точного доступа к блоку N = 1,000,000 . Именно эту ситуацию и стремится исправить индексация.
Учитывая, что индексная запись содержит только индексированное поле и указатель на исходную запись, само собой разумеется, что она будет меньше многополевой записи, на которую она указывает. Таким образом, сам индекс требует меньше дисковых блоков, чем исходная таблица, которая, следовательно, требует меньше обращений к блокам для итерации. Схема для индекса в поле firstName описана ниже;
Field name Data type Size on disk firstName Char(50) 50 bytes (record pointer) Special 4 bytes
Примечание: указатели в MySQL имеют длину 2, 3, 4 или 5 байт в зависимости от размера таблицы.
Пример 2 — индексация
Дан наш пример базы данных из r = 5,000,000 записей с длиной индексной записи R = 54 байта и использованием размера блока по умолчанию B = 1,024 байта. Коэффициент блокировки индекса будет равен bfr = (B/R) = 1024/54 = 18 записям на дисковый блок. Общее количество блоков, необходимых для хранения индекса, составляет N = (r/bfr) = 5000000/18 = 277,778 блоков.
Теперь поиск с использованием поля firstName может использовать индекс для повышения производительности. Это позволяет осуществлять двоичный поиск индекса со средним значением log2 277778 = 18.08 = 19 блочных обращений. Чтобы найти адрес фактической записи, которая требует дополнительного блочного доступа для чтения, доведя общее количество до 19 + 1 = 20 блочных обращений, это далеко от 1 000 000 блочных обращений, необходимых для поиска firstName совпадений в неиндексированной таблице.
Когда его следует использовать?
Учитывая, что создание индекса требует дополнительного дискового пространства (277 778 дополнительных блоков из приведенного выше примера, увеличение ~28%) и что слишком большое количество индексов может вызвать проблемы, связанные с ограничениями размера файловых систем, необходимо тщательно продумать выбор правильных полей для индексации.
Поскольку индексы используются только для ускорения поиска соответствующего поля в записях, само собой разумеется, что индексирование полей, используемых только для вывода, было бы просто пустой тратой дискового пространства и времени обработки при выполнении операции вставки или удаления, и поэтому их следует избегать. Кроме того, учитывая природу бинарного поиска, важна мощность или уникальность данных. Индексация по полю с мощностью 2 разделила бы данные пополам, в то время как мощность 1000 возвратила бы приблизительно 1000 записей. При такой низкой мощности эффективность сводится к линейной сортировке, и оптимизатор запросов будет избегать использования индекса, если мощность меньше 30% от числа записей, что фактически делает индекс пустой тратой пространства.
Как работает индексация приложений в App Store и Google Play? — Маркетинг на vc.ru
ASO (App Store Optimization) помогает улучшить видимость приложения и увеличить органический трафик из поиска. Сторы сканируют страницу приложения и показывают ее по выявленным ключевым словам. Это называется индексацией. Важно, что алгоритмы App Store и Google Play индексируют ключи по-разному.
{«id»:196259,»url»:»https:\/\/vc.ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play»,»title»:»\u041a\u0430\u043a \u0440\u0430\u0431\u043e\u0442\u0430\u0435\u0442 \u0438\u043d\u0434\u0435\u043a\u0441\u0430\u0446\u0438\u044f \u043f\u0440\u0438\u043b\u043e\u0436\u0435\u043d\u0438\u0439 \u0432 App Store \u0438 Google Play?»,»services»:{«facebook»:{«url»:»https:\/\/www. facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play&title=\u041a\u0430\u043a \u0440\u0430\u0431\u043e\u0442\u0430\u0435\u0442 \u0438\u043d\u0434\u0435\u043a\u0441\u0430\u0446\u0438\u044f \u043f\u0440\u0438\u043b\u043e\u0436\u0435\u043d\u0438\u0439 \u0432 App Store \u0438 Google Play?»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play&text=\u041a\u0430\u043a \u0440\u0430\u0431\u043e\u0442\u0430\u0435\u0442 \u0438\u043d\u0434\u0435\u043a\u0441\u0430\u0446\u0438\u044f \u043f\u0440\u0438\u043b\u043e\u0436\u0435\u043d\u0438\u0439 \u0432 App Store \u0438 Google Play?»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play&text=\u041a\u0430\u043a \u0440\u0430\u0431\u043e\u0442\u0430\u0435\u0442 \u0438\u043d\u0434\u0435\u043a\u0441\u0430\u0446\u0438\u044f \u043f\u0440\u0438\u043b\u043e\u0436\u0435\u043d\u0438\u0439 \u0432 App Store \u0438 Google Play?»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041a\u0430\u043a \u0440\u0430\u0431\u043e\u0442\u0430\u0435\u0442 \u0438\u043d\u0434\u0435\u043a\u0441\u0430\u0446\u0438\u044f \u043f\u0440\u0438\u043b\u043e\u0436\u0435\u043d\u0438\u0439 \u0432 App Store \u0438 Google Play?&body=https:\/\/vc.
facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play&title=\u041a\u0430\u043a \u0440\u0430\u0431\u043e\u0442\u0430\u0435\u0442 \u0438\u043d\u0434\u0435\u043a\u0441\u0430\u0446\u0438\u044f \u043f\u0440\u0438\u043b\u043e\u0436\u0435\u043d\u0438\u0439 \u0432 App Store \u0438 Google Play?»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play&text=\u041a\u0430\u043a \u0440\u0430\u0431\u043e\u0442\u0430\u0435\u0442 \u0438\u043d\u0434\u0435\u043a\u0441\u0430\u0446\u0438\u044f \u043f\u0440\u0438\u043b\u043e\u0436\u0435\u043d\u0438\u0439 \u0432 App Store \u0438 Google Play?»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play&text=\u041a\u0430\u043a \u0440\u0430\u0431\u043e\u0442\u0430\u0435\u0442 \u0438\u043d\u0434\u0435\u043a\u0441\u0430\u0446\u0438\u044f \u043f\u0440\u0438\u043b\u043e\u0436\u0435\u043d\u0438\u0439 \u0432 App Store \u0438 Google Play?»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041a\u0430\u043a \u0440\u0430\u0431\u043e\u0442\u0430\u0435\u0442 \u0438\u043d\u0434\u0435\u043a\u0441\u0430\u0446\u0438\u044f \u043f\u0440\u0438\u043b\u043e\u0436\u0435\u043d\u0438\u0439 \u0432 App Store \u0438 Google Play?&body=https:\/\/vc.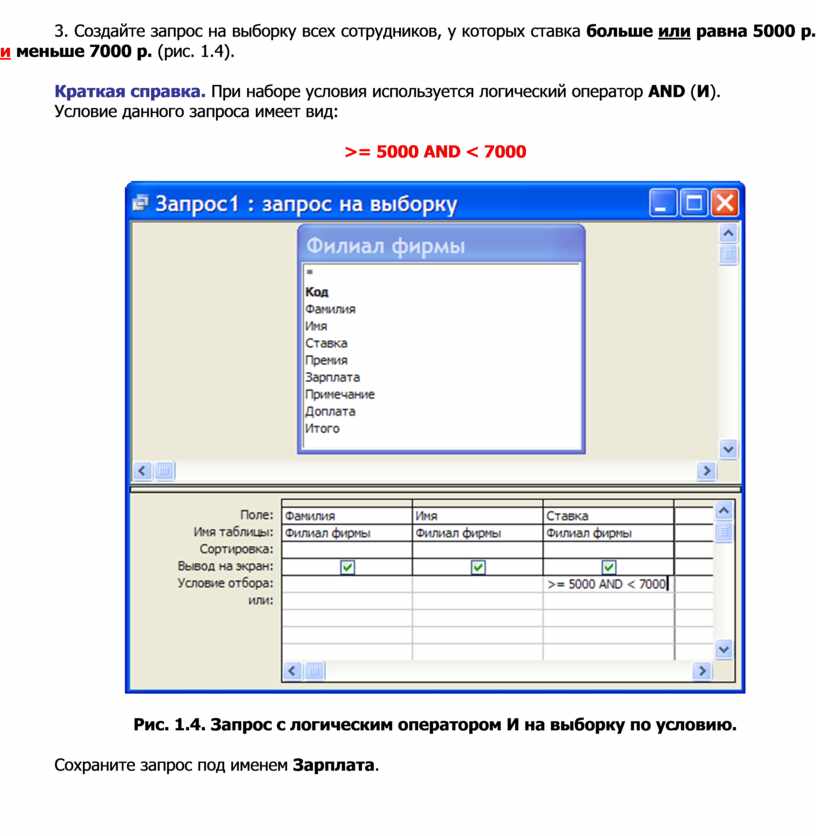 ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
ru\/marketing\/196259-kak-rabotaet-indeksaciya-prilozheniy-v-app-store-i-google-play»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
1632 просмотров
В этом материале мы рассмотрим факторы, которые влияют на индексацию и обсудим все нюансы процесса.
Содержание
Индексация в App Store и Google Play: разница в алгоритмах
В Google Play алгоритмы сканируют релевантные ключи не только в «родных» метаданных, но и в метаданных других локализаций, категориях, тегах, отзывах и даже почтовом адресе разработчика.
В App Store ключевые слова и их комбинации индексируются только из метаданных: заголовок, подзаголовок, поле с ключами, имя разработчика, внутренние покупки. Полное описание не индексируется вообще. При этом в одной стране может индексироваться несколько локализаций сразу.
Разные элементы оказывают разное влияние на ранжирование
Индексируемые элементы: нюансы
Название. В App Store можно использовать 30 символов. В Google Play – 50. Подберите наиболее релевантные ключи, чтобы закрепиться в топе.
В App Store можно использовать 30 символов. В Google Play – 50. Подберите наиболее релевантные ключи, чтобы закрепиться в топе.
Подзаголовок и краткое описание. У вас есть 30 символов для подзаголовка в App Store и 80 – для описания в Google Play.
Поле с ключами. Оно есть только в App Store. Используйте 100 символов. Не ставьте пробел после запятой. Старайтесь включать запросы, создающие комбинации со словами из названия. В App Store в принципе достаточно использовать ключ один раз в любом из полей (название, подзаголовок, ключевые слова), чтобы оно проиндексировалось. Не нужно дублировать слова.
Полное описание. В Google Play можно рассчитывать на 4000 символов. Мы рекомендуем обходиться 2000-2500. Это оптимальное количество. При оптимизации описания в Google Play рекомендуем проверять его на классификацию контента с помощью Natural Language API. После анализа вы увидите, каким категориям Google присвоил контент и его коэффициент «уверенности». При экспериментах с описанием старайтесь держать этот показатель не ниже 0.8 — чем выше, тем лучше. В App Store такое же количество знаков, но описание не индексируется. Можно использовать ключевые слова для продвижения в веб-поиске.
Алгоритм в App Store индексирует ключевые слова с момента подачи приложения на проверку.
Имя разработчика. Ваше ранжирование улучшится, если вы добавите в имя разработчика несколько ключевых слов. Важный момент: если вы несколько лет были с одним именем, а потом решили его поменять, есть вероятность обвала позиций и снижения показов в подборках. Из-за этого может просесть трафик.
Важный момент: если вы несколько лет были с одним именем, а потом решили его поменять, есть вероятность обвала позиций и снижения показов в подборках. Из-за этого может просесть трафик.
Встроенные покупки. В App Store они тоже отображаются в результатах поиска. Каждый IAP может иметь заголовок в 30 символов и описание – в 45. Лучший способ оптимизировать его для поиска – использовать релевантные ключевые слова в названии IAP. При этом оно должно точно передавать суть покупки.
Текстовый редактор | CheckasoПочта разработчика. Влияние этого элемента на индексацию в Google Play совсем незначительно, но игнорировать не стоит.
URL приложения. Впишите несколько ключевых слов в URL для лучшей индексации в Google Play. Не забудьте проверить адрес перед публикацией – потом вы не сможете его изменить.
В App Store выдача приложений теперь ограничена 250 позициями.
Отзывы. Google Play имеет тенденцию ставить приложения с хорошим средним рейтингом выше. К тому же его алгоритмы сканируют отзывы, чтобы определить возможные ключевые слова. Также отзывы имеют значение для SEO приложений обоих сторов.
Теги. Теги помогают Google Play понять, о чем приложения, чтобы группировать их, предлагая пользователю релевантный контент. Можно добавить до 5 тегов. Они должны описывать содержание и функциональность приложения. С марта 2020 года теги стали отображаться в результатах поиска рядом с именем разработчика, количеством загрузок и оценками.
Теги помогают Google Play понять, о чем приложения, чтобы группировать их, предлагая пользователю релевантный контент. Можно добавить до 5 тегов. Они должны описывать содержание и функциональность приложения. С марта 2020 года теги стали отображаться в результатах поиска рядом с именем разработчика, количеством загрузок и оценками.
По каким словам индексируют алгоритмы?
Алгоритмы сами определяют по каким словам индексировать. Они учитывают текстовые элементы на странице приложения, сочетая слова между собой и образовывая вариации ключевых запросов. Количество таких ключей может доходить до десятков тысяч.
Учитывая дополнительные локали, число может быть еще больше. Это простая математика. Допустим, вы используете 26 слов по 6 символов каждый. Если взять каждое их них и составить с ним все возможные вариации из двух, трех и четырех слов, то получатся тысячи ключей.
Сейчас Google Play блокирует игры, в метаданных которых используются слова про карантин. А App Store запрещает приложения, связанные с коронавирусом. Они могут быть опубликованы только официальными представителями здравоохранения или государства.
Лайфхаки от ASO специалистов
Мы внимательно изучили чат профессионального ASO сообщества и выделили любопытные лайфхаки.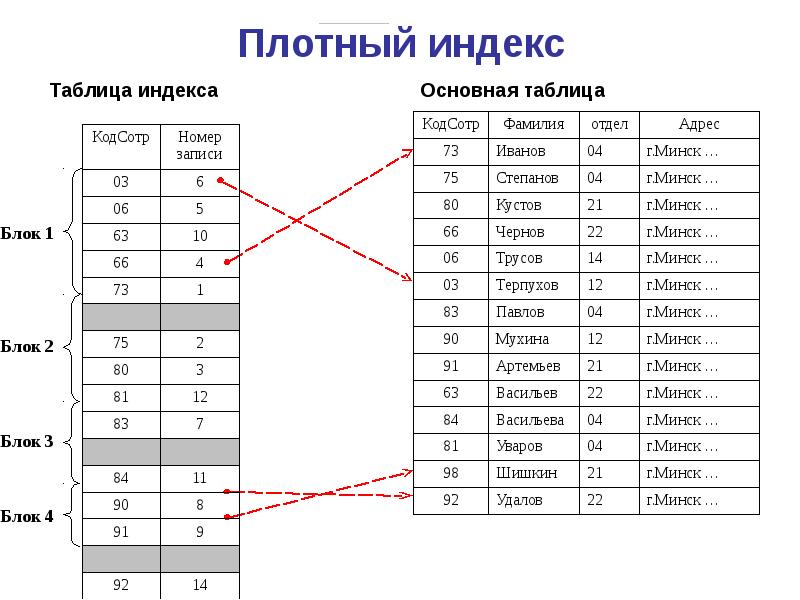 Все они основаны на личном опыте специалистов. Зачастую нюансы работы алгоритмов именно так и выясняются – с помощью экспериментов и наблюдений.
Все они основаны на личном опыте специалистов. Зачастую нюансы работы алгоритмов именно так и выясняются – с помощью экспериментов и наблюдений.
- Если у вас новое приложение и оно не начинает индексироваться в поиске – скачайте его, открыв по прямой ссылке. Тогда может появиться индексация. Проблема в том, что Google Play иногда не замечает приложения сразу после релиза, поэтому ему нужно помочь. При этом неизвестно, по каким именно ключам и на какие позиции вы попадете.
- Google Play борется с переспамом в метаданных (использование больше трех раз). Ваши позиции не станут выше, если вы повторите ключ много раз.
- В App Store символы в ключевых словах не воспринимаются, как пробелы. То есть запросы «photo editor» и «photo editor:» будут иметь разную поисковую выдачу. Диакритики тоже индексируются по-разному: «factura fácil» и «factura facil». При этом необязательно вписывать эти спецсимволы в метаданные, чтобы проиндексироваться. Высока вероятность, что стор сам проиндексирует по ключам со спецсимволами, главное – сами слова. Но ранжирование обычно лучше именно по тому варианту ключевого запроса, которое вписано.
- Есть много сведений, подтверждающих, что Google Play индексирует тексты на скриншотах тоже.
Как быстро приложение начнет индексироваться по ключевым запросам?
Индексация в App Store
Обычно результаты индексации можно наблюдать уже на следующий день после обновления текстовых элементов. Если это публикация нового приложения, то первые две недели у приложения будет «буст» ранжирования. То есть высокие позиции по проиндексированным ключевым запросам. Так App Store помогает новичкам.
Если это публикация нового приложения, то первые две недели у приложения будет «буст» ранжирования. То есть высокие позиции по проиндексированным ключевым запросам. Так App Store помогает новичкам.
Ловите лайфхак. Можно давать название приложению по формуле «популярный ключ + уникальная релевантная фраза». После публикации Apple ставит название приложения в поисковые подсказки. Когда пользователь начинает набирать популярный ключ, в числе подсказок появляется и название приложения. Если оно релевантно запросу, пользователь на него кликает, повышая популярность той уникальной фразы. Поскольку имя этого приложения с ней полностью совпадает, приложение оказывается на первом месте по этому уникальному запросу.
Так работает буст Apple в первые дни: по первому слову из названия появляется новая подсказка с названием приложения. Подсказка висит на втором месте по первому слову около трех дней (некоторые выпадают раньше). Затем она либо закрепится в списке подсказок и приложение будет получать трафик, либо выпадет.
Индексация в Google Play
В Google Play искусственный интеллект анализирует намного больше факторов ранжирования, поэтому сроки индексации назвать сложно. В среднем нужна неделя, чтобы оценить результаты и принимать новые решения. Если приложение не имеет веса (хотя бы какой-то установочной массы), то индексации может и не произойти.
Рекламные кампании в Google Ads помогают «раскачать» приложение. Также помогает разогнать индексацию по ключевым запросам запуск A/B тестирований с текстовыми элементами. Изменения в Google Play происходят не быстро, но постоянная работа над улучшением всегда приводит к желаемым результатам.
Также помогает разогнать индексацию по ключевым запросам запуск A/B тестирований с текстовыми элементами. Изменения в Google Play происходят не быстро, но постоянная работа над улучшением всегда приводит к желаемым результатам.
P.S.
Если материал показался вам полезным – подписывайтесь. Так вы не пропустите наши ASO-гайды, новости мобайла, кейсы и инструкции по эффективному продвижению приложений. Узнать о нашей платформе больше можно здесь.
ВЛИЯНИЕ ИНДЕКСОВ НА ПРОИЗВОДИТЕЛЬНОСТЬ 1С:ПРЕДПРИЯТИЕ 8 | Gilev.ru
— Ну у вас и запросы! — сказала база данных и повисла…
Краткий ответ на вопрос заголовка заключается в том, что это позволит выполнять запросы быстро и уменьшать негативное влияние блокировок на производительность в многопользовательском режиме.
Что такое индекс?
Подобно содержанию в книге, индекс в базе данных позволяет быстро искать конкретные сведения в таблице.
Сначала поговорим про индексы в MS SQL Server.
Индексы представляют собой структуру, позволяющую выполнять ускоренный доступ к строкам таблицы на основе значений одного или более ее столбцов.
Индекс содержит ключи, построенные из одного или нескольких столбцов таблицы или представления, и указатели, которые сопоставляются с местом хранения заданных данных.
Индексы сокращают объем данных, которые необходимо считать, чтобы возвратить результирующий набор.
Хотя индекс и связан с конкретным столбцом (или столбцами) таблицы, все же он является самостоятельным объектом базы данных.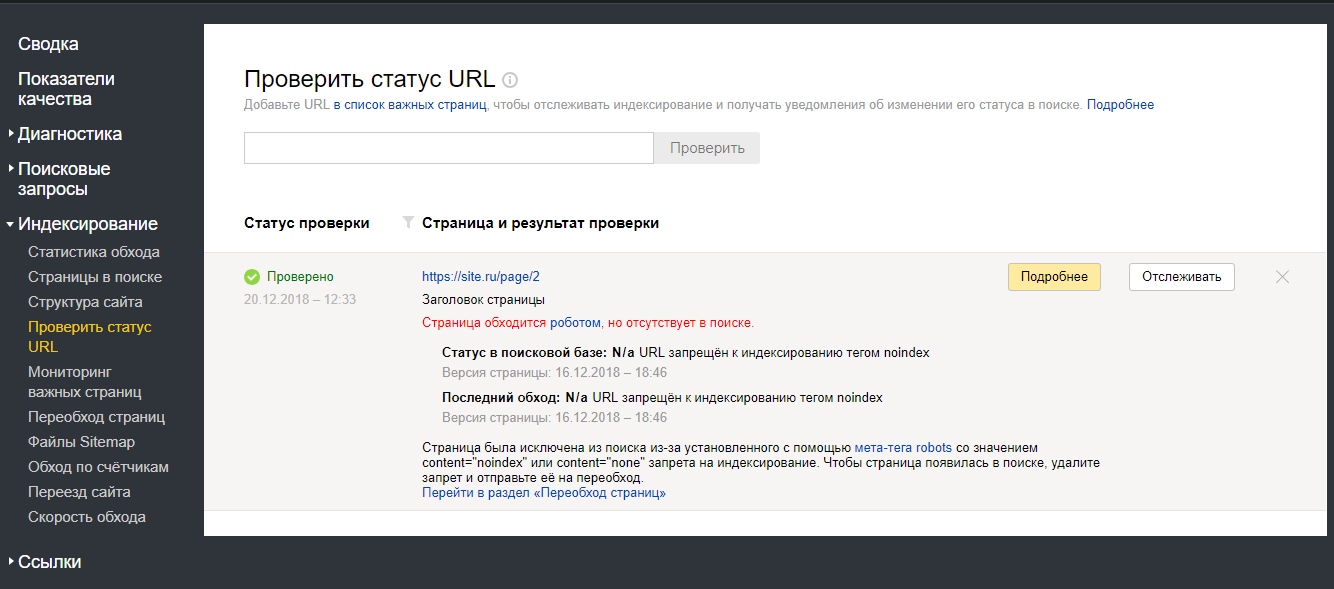
Просто объекта «Индекс» в платформе 1С:Предприятие 8 нет.
Индексы таблиц в базе данных 1С:Предприятие создаются неявным образом при создании объектов конфигурации, а также при тех или иных настройках объектов конфигурации.
- Неявным образом индексы создаются с учетом типов полей ключа данных — набора полей, однозначно определяющих данные. Для объектных типов данных (Справочник, Документ, ПланСчетов и др.) — это «Ссылка»; для регистров, подчиненных регистратору (РегистрНакопления, РегистрБухгалтерии, РегистрСведений, подчиненный регистратору и др.) — «Регистратор»; для регистров сведений, неподчиненных регистратору — поля, соответствующие изменениям, входящим в основной отбор регистра; для констант — идентификатор объекта метаданных Константы.
- индексируются данные в «соответствии»
Явным способом включением свойства «Индексировать» реквизитов и измерений с значение «Индексировать» и «Индексировать с доп. Упорядочиванием». Вариант ««Индексировать с доп. Упорядочиванием»» включает обычно колонку «код» или «наименование» в индекс.
Еще одним явным способом можно считать добавление объекта метаданных в объект метаданных «критерий отбора».
Можно указать индекс для таблицы значений и в запросах для временных таблиц.
ВЫБРАТЬ
Код,
Наименование
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ Справочник.Номенклатура
ИНДЕКСИРОВАТЬ ПО Код
В любом случае, надо понимать, что говоря об индексах, мы фактически подразумеваем индексы СУБД, которая используется для 1С:Предприятие. Исключению составляют объекты типа Таблица значений, когда индексы находятся в RAM (оперативной памяти).
Физическая сущность индексов в MS SQL Server.
Физически данные хранятся на 8Кб страницах. Сразу после создания, пока таблица не имеет индексов, таблица выглядит как куча (heap) данных. Записи не имеют определенного порядка хранения.
Когда вы хотите получить доступ к данным, SQL Server будет производить сканирование таблицы (table scan). SQL Server сканирует всю таблицу, что бы найти искомые записи.
SQL Server сканирует всю таблицу, что бы найти искомые записи.
Отсюда становятся понятными базовые функции индексов:
— увеличение скорости доступа к данным,
— поддержка уникальности данных.
Несмотря на достоинства, индексы так же имеют и ряд недостатков. Первый из них – индексы занимают дополнительное место на диске и в оперативной памяти. Каждый раз когда вы создаете индекс, вы сохраняете ключи в порядке убывания или возрастания, которые могут иметь многоуровневую структуру. И чем больше/длиннее ключ, тем больше размер индекса. Второй недостаток – замедляются операции вставки, обновления и удаления записей.
В среде MS SQL Server реализовано несколько типов индексов:
- некластерные индексы;
- кластерные (или кластеризованные) индексы;
- уникальные индексы;
- индексы с включенными столбцами
- индексированные представления
- полнотекстовый
- XML
Некластерный индекс
Некластерные индексы – не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки.
Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя:
- информацию об идентификационном номере файла, в котором хранится строка;
- идентификационный номер страницы соответствующих данных;
- номер искомой строки на соответствующей странице;
- содержимое столбца.
Некластерных индексов может быть несколько для одной таблицы.
Некластеризованный индекс по таблице, не имеющей кластеризованного индекса
Некластеризованный индекс по таблице, имеющей кластеризованный индекс
Кластерный (кластеризованный) индекс
Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту.
Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту.
Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными. Если в таблице определен некластерный индекс, то сервер должен сначала обратиться к индексу, а затем найти нужную строку в таблице. При использовании кластерных индексов следующая порция данных располагается сразу после найденных ранее данных. Благодаря этому отпадают лишние операции, связанные с обращением к индексу и новым поиском нужной строки в таблице.
Естественно, в таблице может быть определен только один кластерный индекс. Кластерный индекс может включать несколько столбцов.
Необходимо избегать создания кластерного индекса для часто изменяемых столбцов, поскольку сервер должен будет выполнять физическое перемещение всех данных в таблице, чтобы они находились в упорядоченном состоянии, как того требует кластерный индекс. Для интенсивно изменяемых столбцов лучше подходит некластерный индекс.
При создании в таблице первичного ключа (PRIMARY KEY) сервер автоматически создает для него кластерный индекс, если его не существовало ранее или если при определении ключа не был явно указан другой тип индекса.
Когда же в таблице определен еще и некластерный индекс, то его указатель ссылается не на физическое положение строки в базе данных, а на соответствующий элемент кластерного индекса, описывающего эту строку, что позволяет не перестраивать структуру некластерных индексов всякий раз, когда кластерный индекс меняет физический порядок строк в таблице.
Уникальный индекс
Уникальность значений в индексируемом столбце гарантируют уникальные индексы. При их наличии сервер не разрешит вставить новое или изменить существующее значение таким образом, чтобы в результате этой операции в столбце появились два одинаковых значения.
Уникальный индекс является своеобразной надстройкой и может быть реализован как для кластерного, так и для некластерного индекса. В одной таблице может существовать один уникальный кластерный и множество уникальных некластерных индексов.
Уникальные индексы следует определять только тогда, когда это действительно необходимо. Для обеспечения целостности данных в столбце можно определить ограничение целостности UNIQUE или PRIMARY KEY, а не прибегать к уникальным индексам. Их использование только для обеспечения целостности данных является неоправданной тратой пространства в базе данных. Кроме того, на их поддержание тратится и процессорное время.
1С:Предприятие 8 активно использует кластерные уникальные индексы. Это означает, что можно получить ошибку не уникального индекса.
Если не уникальность заключается в датах с нулевыми значениями, то проблема решается созданием базы с параметром смещения равным 2000.
«Рыба» скрипта для определения не уникальных записей:
SELECT COUNT(*) Counter, <перечисление всех полей соответствующего индекса> from <имя таблицы>
GROUP BY <перечисление всех полей соответствующего индекса>
HAVING Counter > 1
Понятие первичного и внешнего ключа
Первичный ключ (primary key) – это набор столбцов таблицы, значения которых уникально определяют строку.
Внешний ключ (foreign key) . Внешним ключом называется поле таблицы, предназначенное для хранения значения первичного ключа другой таблицы с целью организации связи между этими таблицами. Внешний ключ в таблице может ссылаться и на саму эту таблицу. Такие внешние ключи, в основном, используются для хранения древовидной структуры данных в реляционной таблице. СУБД поддерживают автоматический контроль ссылочной целостности на внешних ключах.
1С не использует внешние ключи. Ссылочная целостность обеспечивается логикой приложения.
Ограничения индексов
Индекс может быть создан на основании нескольких полей. В этом случае существует ограничение – длина ключа индекса не должна превышать 900 байтов и не более 16 ключевых столбцов. На практике это означает что при создании индекса, включающего более 16 полей, индекс усекается. Это может оказать влияние на производительность при количестве субконто составного типа более 4х.
В актуальных релизах платформы выполнена оптимизация данного случая и используется хэш по ключу полей, но это медленней «полноценных» индексов.
Статистика индексов
Microsoft SQL Server собирает статистику по индексам и полям данных, хранимых в базе. Эта статистика используется оптимизатором запроса SQL Server при выборе оптимального плана исполнения запросов на выборку или обновление данных.
При создании индекса оптимизатор запросов автоматически сохраняет данные статистики о проиндексированых столбцах.
Просмотр статистики — sp_helpstats.
Фрагментация индексов
Чрезмерная фрагментация создает проблемы для больших операций ввода-вывода. Фрагментация не должна превышать 25%. От снижения фрагментации индексов могут выиграть операции сканирования больших диапазонов данных. Для этого рекомендуется выполнять периодическую дефрагментацию индексов. Обратите внимание, что при дефрагментации индексов (по умолчанию) автоматически обновляется статистика.
Смотреть степень фрагментированности индексов можно штатными средствами СУБД или в разрезе объектов метаданных можно например с помощью бесплатного онлайн-сервиса http://www.gilev.ru/sqlsize/
Оптимизация размещения индексов
При объеме таблиц не позволяющем им «разместиться» в оперативной памяти сервера, на первое место выходит скорость дисковой подсистемы (I/O). И здесь можно обратить внимание возможность размещать индексы в отдельных файлах расположенных на разных жестких дисках.
Подробное описание действий http://technet.microsoft.com/ru-ru/library/ms175905.aspx
Использование индекса из другой файловой группы повышает производительность некластерных индексов в связи с параллельностью выполнения процессов ввода/вывода и работы с самим индексом.
Для определения размеров можно использовать выше упомянутую обработку.
Влияние индексов на блокировки
Отсутствие необходимого индекса для запроса означает перебор всех записей таблицы, что в свою очередь приводит к избыточным блокировкам, т.е. блокируются лишние записи. Кроме того, чем дольше выполняется запрос из-за отсутствующих индексов, тем больше время удержания блокировок.
Другая причина блокировок — малое количество записей в таблицах. В связи с этим SQL Server, при выборе плана выполнения запроса, не использует индексы, а обходит всю таблицу(Table Scan), блокируя целиком. Для того, чтобы избежать подобных блокировок, необходимо увеличить количество записей в таблицах до 1500-2000. В этом случае сканирование таблицы становится долее дорогостоящей операцией и SQL Server начинает использовать индексы. Конечно это можно сделать не всегда, ряд справочников как «Организации», «Склады», «Подразделения» и т.п. обычно имеют мало записей. В этих случаях индексирование не будет улучшать работу.
Эффективность индексов
Мы уже отметили в заголовке статьи, что нас интересуют влияние индексов на быстродействие запросов. Итак, индексы наиболее подходят для задач следующего типа:
- Запросы, которые указывают «узкие» критерии поиска. Такие запросы должны считывать лишь небольшое число строк, отвечающих определенным критериям.
- Запросы, которые указывают диапазон значений. Эти запросы также должны считывать небольшое количество строк.
- Поиск, который используется в операциях связывания. Колонки, которые часто используются как ключи связывания, прекрасно подходят для индексов.
- Поиск, при котором данные считываются в определенном порядке. Если результирующий набор данных должен быть отсортирован в порядке кластеризованного индекса, то сортировка не нужна, поскольку результирующий набор данных уже заранее отсортирован. Например, если кластеризованный индекс создан по колонкам lastname (фамилия), firstname (имя), а для приложения требуется сортировка по фамилии и затем по имени, то здесь нет необходимости добавлять инструкцию ORDER BY.
Правда при всей полезности индексов, есть одно очень важное НО – индекс должен быть «эффективно используемым» и должен позволять находить данные с использованием меньшего числа операций ввода-вывода и объема системных ресурсов. И наоборот, неиспользуемые (редко используемые) индексы скорее ухудшают скорость записи данных (поскольку каждая операция, изменяющая данные, должна также обновлять страницы индексов) и создают избыточный объем базы.
Покрывающим (для данного запроса), называется индекс в котором есть все необходимые поля для этого запроса. Например, если индекс создан по колонкам a, b и c, а оператор SELECT запрашивает данные только из этих колонок, то требуется доступ только к индексу.
Для того, что бы определить эффективность индекса, мы можем приблизительно оценить с помощью бесплатного онлайн-сервиса http://www.gilev.ru/querytj/ показывающий «план исполнения запроса» и используемые индексы.
Политики индексирования в Azure Cosmos DB
- Чтение занимает 14 мин
В этой статье
ПРИМЕНИМО К: API SQL
В Azure Cosmos DB каждый контейнер имеет политику индексирования, определяющую, как должны индексироваться элементы контейнера.In Azure Cosmos DB, every container has an indexing policy that dictates how the container’s items should be indexed. Политика индексирования по умолчанию, задаваемая для только что созданных контейнеров, индексирует каждое свойство каждого элемента и применяет диапазонные индексы для любых строк или чисел.The default indexing policy for newly created containers indexes every property of every item and enforces range indexes for any string or number. Это позволяет получить хорошую производительность запросов без необходимости думать об индексировании и управлении индексами.This allows you to get good query performance without having to think about indexing and index management upfront.
В некоторых ситуациях полезно переопределить автоматическое поведение в соответствии с конкретными требованиями.In some situations, you may want to override this automatic behavior to better suit your requirements. Политику индексирования контейнера можно настроить, задав ее режим индексирования, а также включить или исключить пути к свойствам.You can customize a container’s indexing policy by setting its indexing mode, and include or exclude property paths.
Примечание
Метод обновления политик индексации, описанный в этой статье, применим только к API-интерфейсу SQL (Core) Azure Cosmos DB.The method of updating indexing policies described in this article only applies to Azure Cosmos DB’s SQL (Core) API. Дополнительные сведения об индексировании в API Azure Cosmos DB для MongoDBLearn about indexing in Azure Cosmos DB’s API for MongoDB
Режим индексированияIndexing mode
Azure Cosmos DB поддерживает два режима индексирования:Azure Cosmos DB supports two indexing modes:
- Целостность. индекс обновляется синхронно по мере создания, обновления или удаления элементов.Consistent: The index is updated synchronously as you create, update or delete items. Это означает, что согласованность запросов чтения будет согласована, настроенной для учетной записи.This means that the consistency of your read queries will be the consistency configured for the account.
- Нет: индексирование в контейнере отключено.None: Indexing is disabled on the container. Это часто используется, когда контейнер используется в качестве чистого хранилища значений ключа без необходимости в вторичных индексах.This is commonly used when a container is used as a pure key-value store without the need for secondary indexes. Его также можно использовать для повышения производительности операций с массовыми операциями.It can also be used to improve the performance of bulk operations. После выполнения операций с массовыми операциями в режиме индексирования можно задать значение consistent, а затем отслеживать его с помощью IndexTransformationProgress до завершения.After the bulk operations are complete, the index mode can be set to Consistent and then monitored using the IndexTransformationProgress until complete.
Примечание
Azure Cosmos DB также поддерживает режим отложенной индексации.Azure Cosmos DB also supports a Lazy indexing mode. Отложенное индексирование выполняет обновления индекса с более низкоприоритетным уровнем, когда обработчик не выполняет никаких других действий.Lazy indexing performs updates to the index at a much lower priority level when the engine is not doing any other work. Это может привести к несогласованным или неполным результатам запроса.This can result in inconsistent or incomplete query results. Если вы планируете запрашивать контейнер Cosmos, не выбирайте отложенное индексирование.If you plan to query a Cosmos container, you should not select lazy indexing. Новые контейнеры не могут выбрать Отложенное индексирование.New containers cannot select lazy indexing. Чтобы запросить исключение, обратитесь в службу поддержки Azure (за исключением случаев, когда вы используете учетную запись Azure Cosmos в режиме без сервера , который не поддерживает Отложенное индексирование).You can request an exemption by contacting Azure support (except if you are using an Azure Cosmos account in serverless mode which doesn’t support lazy indexing).
По умолчанию для политики индексирования задано значение automatic .By default, indexing policy is set to automatic. Это достигается путем задания automatic свойству в политике индексирования значения true .It’s achieved by setting the automatic property in the indexing policy to true. Задание этого свойства true позволяет Azure CosmosDB автоматически индексировать документы по мере их написания.Setting this property to true allows Azure CosmosDB to automatically index documents as they are written.
Размер индексаIndex size
В базе данных Azure Cosmos DB общий использованный объем хранилища зависит от размера данных и размера индекса.In Azure Cosmos DB, the total consumed storage is the combination of both the Data size and Index size. Ниже приведены некоторые функции размера индекса.The following are some features of index size:
- Размер индекса зависит от политики индексирования.The index size depends on the indexing policy. Если все свойства индексируются, размер индекса может быть больше, чем размер данных.If all the properties are indexed, then the index size can be larger than the data size.
- При удалении данных индексы сжимаются почти непрерывно.When data is deleted, indexes are compacted on a near continuous basis. Однако при небольших операциях удаления данных вы можете не заметить немедленного уменьшения размера индекса.However, for small data deletions, you may not immediately observe a decrease in index size.
- Размер индекса может временно увеличиваться при разбиении физических секций.The Index size can temporarily grow when physical partitions split. Место в индексе освобождается после завершения разбиения секции.The index space is released after the partition split is completed.
Включение и исключение путей к свойствамIncluding and excluding property paths
Пользовательская политика индексации может указывать пути к свойствам, которые явно включены или исключены из индексирования.A custom indexing policy can specify property paths that are explicitly included or excluded from indexing. Оптимизируя Количество индексируемых путей, можно значительно сократить задержку и ЕДИНИЦу оплаты операций записи.By optimizing the number of paths that are indexed, you can substantially reduce the latency and RU charge of write operations. Эти пути определяются методом, описанным в разделе Обзор индексирования со следующими дополнениями.These paths are defined following the method described in the indexing overview section with the following additions:
- путь, ведущий к скалярному значению (строке или номеру), заканчивается на
/?a path leading to a scalar value (string or number) ends with/? - элементы из массива обрабатываются вместе с помощью
/[]нотации (а не и/0/1т. д.).elements from an array are addressed together through the/[]notation (instead of/0,/1etc.) /*подстановочный знак можно использовать для сопоставления с любыми элементами, расположенными под узломthe/*wildcard can be used to match any elements below the node
Снова выполнив тот же пример:Taking the same example again:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 }
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
headquartersemployeesпуть:/headquarters/employees/?theheadquarters‘semployeespath is/headquarters/employees/?locationscountryпуть/locations/[]/country/?thelocations‘countrypath is/locations/[]/country/?путь к любому элементу
headquartersв разделе/headquarters/*the path to anything underheadquartersis/headquarters/*
Например, можно включить /headquarters/employees/? путь.For example, we could include the /headquarters/employees/? path. Этот путь обеспечит индексирование свойства Employees, но не будет индексировать дополнительный вложенный код JSON в этом свойстве.This path would ensure that we index the employees property but would not index additional nested JSON within this property.
Стратегия включения и исключенияInclude/exclude strategy
Любая политика индексации должна включать корневой путь /* как либо включенный, либо Исключенный путь.Any indexing policy has to include the root path /* as either an included or an excluded path.
Включите корневой путь для выборочного исключения путей, которые не нужно индексировать.Include the root path to selectively exclude paths that don’t need to be indexed. Это рекомендуемый подход, так как он позволяет Azure Cosmos DB заранее индексировать любое новое свойство, которое может быть добавлено в модель.This is the recommended approach as it lets Azure Cosmos DB proactively index any new property that may be added to your model.
Исключите корневой путь для выборочного включения путей, которые необходимо проиндексировать.Exclude the root path to selectively include paths that need to be indexed.
Для путей с обычными символами, включающими буквенно-цифровые символы и символ _ (подчеркивание), не нужно заключать строку пути вокруг двойных кавычек (например, «/Пас/?»).For paths with regular characters that include: alphanumeric characters and _ (underscore), you don’t have to escape the path string around double quotes (for example, «/path/?»). Для путей с другими специальными символами необходимо экранировать строку пути, заключенную в двойные кавычки (например, «/ » path-ABC » /?»).For paths with other special characters, you need to escape the path string around double quotes (for example, «/»path-abc»/?»). Если в пути предполагается наличие специальных символов, можно избежать последовательного переключения всех путей в целях безопасности.If you expect special characters in your path, you can escape every path for safety. Функционально, это не имеет никакой разницы при экранировании всех путей и только тех, которые имеют специальные символы.Functionally, it doesn’t make any difference if you escape every path Vs just the ones that have special characters.
По
_etagумолчанию свойство System исключено из индексирования, если только ETag не добавлен в включаемый путь для индексирования.The system property_etagis excluded from indexing by default, unless the etag is added to the included path for indexing.Если режим индексирования установлен в значение consistent, системные свойства
idи_tsбудут автоматически индексироваться.If the indexing mode is set to consistent, the system propertiesidand_tsare automatically indexed.
При включении и исключении путей можно столкнуться со следующими атрибутами:When including and excluding paths, you may encounter the following attributes:
kindможет иметь значениеrangeилиhash.kindcan be eitherrangeorhash. Поддержка хэш-индексов ограничена фильтрами равенства.Hash index support is limited to equality filters. Функциональность индекса диапазона предоставляет все функции хэш-индексов, а также эффективные операции сортировки, фильтры диапазонов, системные функции.Range index functionality provides all of the functionality of hash indexes as well as efficient sorting, range filters, system functions. Мы всегда рекомендуем использовать индекс диапазона.We always recommend using a range index.precisionчисло, определенное на уровне индекса для включенных путей.precisionis a number defined at the index level for included paths. Значение указывает на-1максимальную точность.A value of-1indicates maximum precision. Рекомендуется всегда задавать для этого параметра значение-1.We recommend always setting this value to-1.dataTypeможет иметь значениеStringилиNumber.dataTypecan be eitherStringorNumber. Указывает типы свойств JSON, которые будут индексироваться.This indicates the types of JSON properties which will be indexed.
Если этот параметр не указан, эти свойства будут иметь следующие значения по умолчанию:When not specified, these properties will have the following default values:
| Имя свойстваProperty Name | Значение по умолчаниюDefault Value |
|---|---|
kind | range |
precision | -1 |
dataType | String и NumberString and Number |
В этом разделе приведены примеры политик индексации для включения и исключения путей.See this section for indexing policy examples for including and excluding paths.
Приоритет включения или исключенияInclude/exclude precedence
Если включенные пути и исключенные пути конфликтуют, приоритет имеет более точный путь.If your included paths and excluded paths have a conflict, the more precise path takes precedence.
Приведем пример:Here’s an example:
Включаемый путь: /food/ingredients/nutrition/*Included Path: /food/ingredients/nutrition/*
Исключенный путь: /food/ingredients/*Excluded Path: /food/ingredients/*
В этом случае включенный путь имеет приоритет над исключенным путем, так как он более точен.In this case, the included path takes precedence over the excluded path because it is more precise. На основе этих путей все данные в food/ingredients пути или вложенные в них будут исключены из индекса.Based on these paths, any data in the food/ingredients path or nested within would be excluded from the index. Исключением могут быть данные внутри включаемого пути: /food/ingredients/nutrition/* , который будет индексироваться.The exception would be data within the included path: /food/ingredients/nutrition/*, which would be indexed.
Ниже приведены некоторые правила для приоритета включенных и исключаемых путей в Azure Cosmos DB.Here are some rules for included and excluded paths precedence in Azure Cosmos DB:
Более глубокие пути более точны, чем более узкие пути.Deeper paths are more precise than narrower paths. Например:
/a/b/?более точно, чем/a/?.for example:/a/b/?is more precise than/a/?./?Более точнее, чем/*.The/?is more precise than/*. Например/a/?, более точнее/a/*, чем так,/a/?имеет приоритет.For example/a/?is more precise than/a/*so/a/?takes precedence.Путь
/*должен содержать либо включенный путь, либо Исключенный путь.The path/*must be either an included path or excluded path.
Пространственные индексыSpatial indexes
При определении пространственного пути в политике индексации необходимо определить, какой индекс type следует применить к этому пути.When you define a spatial path in the indexing policy, you should define which index type should be applied to that path. К пространственным индексам могут относиться следующие типы:Possible types for spatial indexes include:
По умолчанию Azure Cosmos DB не создает пространственные индексы.Azure Cosmos DB, by default, will not create any spatial indexes. Если вы хотите использовать встроенные функции пространственного SQL, необходимо создать пространственный индекс для обязательных свойств.If you would like to use spatial SQL built-in functions, you should create a spatial index on the required properties. В этом разделе приведены примеры политик индексации для добавления пространственных индексов.See this section for indexing policy examples for adding spatial indexes.
Составные индексыComposite indexes
Для запросов, имеющих ORDER BY предложение с двумя или более свойствами, требуется составной индекс.Queries that have an ORDER BY clause with two or more properties require a composite index. Кроме того, можно определить составной индекс, чтобы повысить производительность многих запросов на равенство и диапазонов.You can also define a composite index to improve the performance of many equality and range queries. По умолчанию составные индексы не определяются, поэтому при необходимости следует добавлять составные индексы .By default, no composite indexes are defined so you should add composite indexes as needed.
В отличие от включенных или исключенных путей, нельзя создать путь с /* подстановочным знаком.Unlike with included or excluded paths, you can’t create a path with the /* wildcard. Каждый составной путь имеет неявную /? в конце пути, который не нужно указывать.Every composite path has an implicit /? at the end of the path that you don’t need to specify. Составные пути ведут к скалярному значению, и это единственное значение, включенное в составной индекс.Composite paths lead to a scalar value and this is the only value that is included in the composite index.
При определении составного индекса необходимо указать:When defining a composite index, you specify:
Два или более пути свойств.Two or more property paths. Последовательность, в которой определяются пути к свойствам, имеет значение.The sequence in which property paths are defined matters.
Порядок (по возрастанию или по убыванию).The order (ascending or descending).
Примечание
При добавлении составного индекса запрос будет использовать существующие индексы диапазона до завершения добавления нового составного индекса.When you add a composite index, the query will utilize existing range indexes until the new composite index addition is complete. Таким образом, при добавлении составного индекса вы можете не сразу приступить к улучшению производительности.Therefore, when you add a composite index, you may not immediately observe performance improvements. Ход преобразования индекса можно отслеживать с помощью одного из пакетов SDK.It is possible to track the progress of index transformation by using one of the SDKs.
УПОРЯДОЧИТЬ по запросам для нескольких свойств:ORDER BY queries on multiple properties:
Следующие рекомендации используются при использовании составных индексов для запросов с ORDER BY предложением с двумя или более свойствами:The following considerations are used when using composite indexes for queries with an ORDER BY clause with two or more properties:
Если пути составного индекса не соответствуют последовательности свойств в
ORDER BYпредложении, составной индекс не поддерживает запрос.If the composite index paths do not match the sequence of the properties in theORDER BYclause, then the composite index can’t support the query.Порядок составных путей индексов (по возрастанию или по убыванию) должен также совпадать с параметром
orderвORDER BYпредложении.The order of composite index paths (ascending or descending) should also match theorderin theORDER BYclause.Составной индекс также поддерживает
ORDER BYпредложение с противоположным порядком для всех путей.The composite index also supports anORDER BYclause with the opposite order on all paths.
Рассмотрим следующий пример, где составной индекс определяется для свойств Name, Age и _ts.Consider the following example where a composite index is defined on properties name, age, and _ts:
| Составной индексComposite Index | Образец ORDER BY запросаSample ORDER BY Query | Поддерживается составным индексом?Supported by Composite Index? |
|---|---|---|
(name ASC, age ASC) | SELECT * FROM c ORDER BY c.name ASC, c.age asc | Yes |
(name ASC, age ASC) | SELECT * FROM c ORDER BY c.age ASC, c.name asc | No |
(name ASC, age ASC) | SELECT * FROM c ORDER BY c.name DESC, c.age DESC | Yes |
(name ASC, age ASC) | SELECT * FROM c ORDER BY c.name ASC, c.age DESC | No |
(name ASC, age ASC, timestamp ASC) | SELECT * FROM c ORDER BY c.name ASC, c.age ASC, timestamp ASC | Yes |
(name ASC, age ASC, timestamp ASC) | SELECT * FROM c ORDER BY c.name ASC, c.age ASC | No |
Необходимо настроить политику индексирования, чтобы можно было обслуживать все необходимые ORDER BY запросы.You should customize your indexing policy so you can serve all necessary ORDER BY queries.
запросы с фильтрами по нескольким свойствам.Queries with filters on multiple properties
Если запрос имеет фильтры по двум или более свойствам, может оказаться полезным создать составной индекс для этих свойств.If a query has filters on two or more properties, it may be helpful to create a composite index for these properties.
Например, рассмотрим следующий запрос с фильтром равенства и диапазоном.For example, consider the following query which has both an equality and range filter:
SELECT *
FROM c
WHERE c.name = "John" AND c.age > 18
Этот запрос будет более эффективным, что займет меньше времени и потребляет меньше единиц запросов, если он способен использовать составной индекс в (name ASC, age ASC) .This query will be more efficient, taking less time and consuming fewer RU’s, if it is able to leverage a composite index on (name ASC, age ASC).
Запросы с несколькими фильтрами диапазонов также можно оптимизировать с помощью составного индекса.Queries with multiple range filters can also be optimized with a composite index. Однако каждый отдельный составной индекс может оптимизировать только один фильтр диапазона.However, each individual composite index can only optimize a single range filter. Фильтры диапазонов включают > , < ,, <= >= и != .Range filters include >, <, <=, >=, and !=. Фильтр диапазона должен быть определен последним в составном индексе.The range filter should be defined last in the composite index.
Рассмотрим следующий запрос с фильтром равенства и двумя фильтрами диапазона:Consider the following query with an equality filter and two range filters:
SELECT *
FROM c
WHERE c.name = "John" AND c.age > 18 AND c._ts > 1612212188
Этот запрос будет более эффективным с составным индексом в (name ASC, age ASC) и (name ASC, _ts ASC) .This query will be more efficient with a composite index on (name ASC, age ASC) and (name ASC, _ts ASC). Однако запрос не будет использовать составной индекс, (age ASC, name ASC) так как свойства с фильтрами равенства должны быть определены первыми в составном индексе.However, the query would not utilize a composite index on (age ASC, name ASC) because the properties with equality filters must be defined first in the composite index. Два отдельных составных индекса являются обязательными, а не одним составным индексом, (name ASC, age ASC, _ts ASC) так как каждый составной индекс может оптимизировать только один фильтр диапазона.Two separate composite indexes are required instead of a single composite index on (name ASC, age ASC, _ts ASC) since each composite index can only optimize a single range filter.
При создании составных индексов для запросов с фильтрами для нескольких свойств используются следующие рекомендации.The following considerations are used when creating composite indexes for queries with filters on multiple properties
- Выражения фильтра могут использовать несколько составных индексов.Filter expressions can use multiple composite indexes.
- Свойства в фильтре запроса должны соответствовать значениям в составном индексе.The properties in the query’s filter should match those in composite index. Если свойство находится в составном индексе, но не включено в запрос в качестве фильтра, то запрос не будет использовать составной индекс.If a property is in the composite index but is not included in the query as a filter, the query will not utilize the composite index.
- Если запрос содержит дополнительные свойства в фильтре, которые не были определены в составном индексе, то для оценки запроса будет использоваться сочетание составного индекса и индекса диапазона.If a query has additional properties in the filter that were not defined in a composite index, then a combination of composite and range indexes will be used to evaluate the query. Для этого потребуется меньше единиц запросов, чем при использовании индексов диапазона.This will require fewer RU’s than exclusively using range indexes.
- Если свойство имеет фильтр диапазона (,,
><<=,>=или!=), то это свойство должно быть определено последним в составном индексе.If a property has a range filter (>,<,<=,>=, or!=), then this property should be defined last in the composite index. Если запрос содержит более одного фильтра диапазона, может оказаться полезным использовать несколько составных индексов.If a query has more than one range filter, it may benefit from multiple composite indexes. - При создании составного индекса для оптимизации запросов с несколькими фильтрами
ORDERсоставной индекс не будет оказывать влияния на результаты.When creating a composite index to optimize queries with multiple filters, theORDERof the composite index will have no impact on the results. Это необязательное свойство.This property is optional.
Рассмотрим следующие примеры, где составной индекс определяется по имени, возрасту и метке свойства.Consider the following examples where a composite index is defined on properties name, age, and timestamp:
| Составной индексComposite Index | Образец запросаSample Query | Поддерживается составным индексом?Supported by Composite Index? |
|---|---|---|
(name ASC, age ASC) | SELECT * FROM c WHERE c.name = "John" AND c.age = 18 | Yes |
(name ASC, age ASC) | SELECT * FROM c WHERE c.name = "John" AND c.age > 18 | Yes |
(name ASC, age ASC) | SELECT COUNT(1) FROM c WHERE c.name = "John" AND c.age > 18 | Yes |
(name DESC, age ASC) | SELECT * FROM c WHERE c.name = "John" AND c.age > 18 | Yes |
(name ASC, age ASC) | SELECT * FROM c WHERE c.name != "John" AND c.age > 18 | No |
(name ASC, age ASC, timestamp ASC) | SELECT * FROM c WHERE c.name = "John" AND c.age = 18 AND c.timestamp > 123049923 | Yes |
(name ASC, age ASC, timestamp ASC) | SELECT * FROM c WHERE c.name = "John" AND c.age < 18 AND c.timestamp = 123049923 | No |
(name ASC, age ASC) and (name ASC, timestamp ASC) | SELECT * FROM c WHERE c.name = "John" AND c.age < 18 AND c.timestamp > 123049923 | Yes |
Запросы с фильтром и ORDER BYQueries with a filter and ORDER BY
Если запрос фильтрует одно или несколько свойств и имеет различные свойства в предложении ORDER BY, может быть полезно добавить свойства в фильтр в ORDER BY предложение.If a query filters on one or more properties and has different properties in the ORDER BY clause, it may be helpful to add the properties in the filter to the ORDER BY clause.
Например, добавив свойства в фильтр в ORDER BY предложение, можно переписывать следующий запрос, чтобы использовать составной индекс:For example, by adding the properties in the filter to the ORDER BY clause, the following query could be rewritten to leverage a composite index:
Запрос с использованием индекса диапазона:Query using range index:
SELECT *
FROM c
WHERE c.name = "John"
ORDER BY c.timestamp
Запрос с использованием составного индекса:Query using composite index:
SELECT *
FROM c
WHERE c.name = "John"
ORDER BY c.name, c.timestamp
Одни и те же оптимизации запросов могут быть обобщены для ORDER BY запросов с фильтрами, учитывая, что отдельные составные индексы могут поддерживать только один фильтр диапазона.The same query optimizations can be generalized for any ORDER BY queries with filters, keeping in mind that individual composite indexes can only support, at most, one range filter.
Запрос с использованием индекса диапазона:Query using range index:
SELECT *
FROM c
WHERE c.name = "John" AND c.age = 18 AND c.timestamp > 1611947901
ORDER BY c.timestamp
Запрос с использованием составного индекса:Query using composite index:
SELECT *
FROM c
WHERE c.name = "John" AND c.age = 18 AND c.timestamp > 1611947901
ORDER BY c.name, c.age, c.timestamp
Кроме того, можно использовать составные индексы для оптимизации запросов с помощью системных функций и УПОРЯДОЧЕНия:In addition, you can use composite indexes to optimize queries with system functions and ORDER BY:
Запрос с использованием индекса диапазона:Query using range index:
SELECT *
FROM c
WHERE c.firstName = "John" AND Contains(c.lastName, "Smith", true)
ORDER BY c.lastName
Запрос с использованием составного индекса:Query using composite index:
SELECT *
FROM c
WHERE c.firstName = "John" AND Contains(c.lastName, "Smith", true)
ORDER BY c.firstName, c.lastName
При создании составных индексов для оптимизации запроса с помощью фильтра и предложения следует учитывать следующие моменты ORDER BY .The following considerations apply when creating composite indexes to optimize a query with a filter and ORDER BY clause:
- Если не определить составной индекс для запроса с фильтром по одному свойству и отдельным
ORDER BYпредложением с другим свойством, запрос будет выполняться.If you do not define a composite index on a query with a filter on one property and a separateORDER BYclause using a different property, the query will still succeed. Однако стоимость единицы запроса может быть сокращена с помощью составного индекса, особенно если свойство вORDER BYпредложении имеет большую кратность.However, the RU cost of the query can be reduced with a composite index, particularly if the property in theORDER BYclause has a high cardinality. - Если запрос фильтрует свойства, они должны быть включены в
ORDER BYпредложение первыми.If the query filters on properties, these should be included first in theORDER BYclause. - Если запрос фильтруется по нескольким свойствам, фильтры равенства должны быть первыми свойствами в
ORDER BYпредложении.If the query filters on multiple properties, the equality filters must be the first properties in theORDER BYclause. - Если запрос фильтруется по нескольким свойствам, то для составного индекса можно использовать не более одного фильтра диапазона или системной функции.If the query filters on multiple properties, you can have a maximum of one range filter or system function utilized per composite index. Свойство, используемое в фильтре диапазона или системной функции, должно быть определено последним в составном индексе.The property used in the range filter or system function should be defined last in the composite index.
- Все вопросы, касающиеся создания составных индексов для
ORDER BYзапросов с несколькими свойствами, а также запросы с фильтрами по нескольким свойствам, по-прежнему применяются.All considerations for creating composite indexes forORDER BYqueries with multiple properties as well as queries with filters on multiple properties still apply.
| Составной индексComposite Index | Образец ORDER BY запросаSample ORDER BY Query | Поддерживается составным индексом?Supported by Composite Index? |
|---|---|---|
(name ASC, timestamp ASC) | SELECT * FROM c WHERE c.name = "John" ORDER BY c.name ASC, c.timestamp ASC | Yes |
(name ASC, timestamp ASC) | SELECT * FROM c WHERE c.name = "John" AND c.timestamp > 1589840355 ORDER BY c.name ASC, c.timestamp ASC | Yes |
(timestamp ASC, name ASC) | SELECT * FROM c WHERE c.timestamp > 1589840355 AND c.name = "John" ORDER BY c.timestamp ASC, c.name ASC | No |
(name ASC, timestamp ASC) | SELECT * FROM c WHERE c.name = "John" ORDER BY c.timestamp ASC, c.name ASC | No |
(name ASC, timestamp ASC) | SELECT * FROM c WHERE c.name = "John" ORDER BY c.timestamp ASC | No |
(age ASC, name ASC, timestamp ASC) | SELECT * FROM c WHERE c.age = 18 and c.name = "John" ORDER BY c.age ASC, c.name ASC,c.timestamp ASC | Yes |
(age ASC, name ASC, timestamp ASC) | SELECT * FROM c WHERE c.age = 18 and c.name = "John" ORDER BY c.timestamp ASC | No |
Запросы с фильтром и статистическим выражениемQueries with a filter and an aggregate
Если запрос фильтрует одно или несколько свойств и имеет агрегатную системную функцию, может быть полезно создать составной индекс для свойств в системной функции Filter и Aggregate.If a query filters on one or more properties and has an aggregate system function, it may be helpful to create a composite index for the properties in the filter and aggregate system function. Эта оптимизация применяется к системным функциям Sum и AVG .This optimization applies to the SUM and AVG system functions.
Ниже приведены рекомендации по созданию составных индексов для оптимизации запроса с помощью фильтра и агрегатной системной функции.The following considerations apply when creating composite indexes to optimize a query with a filter and aggregate system function.
- Составные индексы необязательны при выполнении запросов со статистическими выражениями.Composite indexes are optional when running queries with aggregates. Однако стоимость единицы запроса в секунду может значительно снизиться с помощью составного индекса.However, the RU cost of the query can often be significantly reduced with a composite index.
- Если запрос фильтруется по нескольким свойствам, фильтры равенства должны быть первыми свойствами составного индекса.If the query filters on multiple properties, the equality filters must be the first properties in the composite index.
- Можно использовать не более одного фильтра диапазона для каждого составного индекса, и оно должно находиться в свойстве агрегатной системной функции.You can have a maximum of one range filter per composite index and it must be on the property in the aggregate system function.
- Свойство в системной функции Aggregate должно быть определено последним в составном индексе.The property in the aggregate system function should be defined last in the composite index.
- Значение
order(ASCилиDESC) не имеет значения.Theorder(ASCorDESC) does not matter.
| Составной индексComposite Index | Образец запросаSample Query | Поддерживается составным индексом?Supported by Composite Index? |
|---|---|---|
(name ASC, timestamp ASC) | SELECT AVG(c.timestamp) FROM c WHERE c.name = "John" | Yes |
(timestamp ASC, name ASC) | SELECT AVG(c.timestamp) FROM c WHERE c.name = "John" | No |
(name ASC, timestamp ASC) | SELECT AVG(c.timestamp) FROM c WHERE c.name > "John" | No |
(name ASC, age ASC, timestamp ASC) | SELECT AVG(c.timestamp) FROM c WHERE c.name = "John" AND c.age = 25 | Yes |
(age ASC, timestamp ASC) | SELECT AVG(c.timestamp) FROM c WHERE c.name = "John" AND c.age > 25 | No |
<преобразование индекса>изменение политики индексированияModifying the indexing policy
Политику индексирования контейнера можно обновить в любое время с помощью портал Azure или одного из поддерживаемых пакетов SDK.A container’s indexing policy can be updated at any time by using the Azure portal or one of the supported SDKs. Обновление политики индексирования активирует преобразование старого индекса в новый, который выполняется в сети и на месте (поэтому дополнительное пространство для хранения данных во время операции не потребляется).An update to the indexing policy triggers a transformation from the old index to the new one, which is performed online and in-place (so no additional storage space is consumed during the operation). Старая политика индексирования эффективно преобразуется в новую политику, не влияя на доступность записи, доступность чтения или пропускную способность, подготовленную в контейнере.The old indexing policy is efficiently transformed to the new policy without affecting the write availability, read availability, or the throughput provisioned on the container. Преобразование индекса — это асинхронная операция, а время, необходимое для выполнения, зависит от подготовленной пропускной способности, количества элементов и их размера.Index transformation is an asynchronous operation, and the time it takes to complete depends on the provisioned throughput, the number of items and their size.
Важно!
Преобразование «индекс» — это операция, использующая единицы запросов.Index transformation is an operation that consumes Request Units. Единицы запросов, потребляемые преобразованием индекса, в настоящее время не взимается, если используются бессерверные контейнеры.Request Units consumed by an index transformation aren’t currently billed if you are using serverless containers. Счета за эти единицы запроса будут выставляться после общедоступной доступности на сервере.These Request Units will get billed once serverless becomes generally available.
На запись доступности во время любых преобразований индекса не влияет.There is no impact to write availability during any index transformations. Преобразование «индекс» использует подготовленный метод отправки, но с более низким приоритетом, чем операции CRUD или запросы.The index transformation uses your provisioned RUs but at a lower priority than your CRUD operations or queries.
При добавлении нового индекса влияния на чтение доступности не возникает.There is no impact to read availability when adding a new index. Запросы будут использовать новые индексы только после завершения преобразования индекса.Queries will only utilize new indexes once the index transformation is complete. Во время преобразования индекса обработчик запросов будет продолжать использовать существующие индексы, поэтому во время преобразования индексирования вы научитесь выполнять аналогичные операции чтения до начала изменения индексирования.During the index transformation, the query engine will continue to use existing indexes, so you’ll observe similar read performance during the indexing transformation to what you had observed before initiating the indexing change. При добавлении новых индексов также возникает риск неполного или несоответствия результатов запроса.When adding new indexes, there is also no risk of incomplete or inconsistent query results.
При удалении индексов и немедленном выполнении запросов, использующих фильтрацию по удаленным индексам, не гарантируется согласованность или полнота результатов запроса.When removing indexes and immediately running queries that filter on the dropped indexes, there is not a guarantee of consistent or complete query results. Если удалить несколько индексов и сделать это в одном изменении одной политики индексирования, то обработчик запросов будет выполнять согласованные и полные результаты в рамках преобразования «индекс».If you remove multiple indexes and do so in one single indexing policy change, the query engine provides consistent and complete results throughout the index transformation. Однако при удалении индексов с помощью нескольких изменений политики индексирования обработчик запросов не будет предоставлять согласованные или полные результаты до завершения всех преобразований индекса.However, if you remove indexes through multiple indexing policy changes, the query engine will not provide consistent or complete results until all index transformations complete. Большинство разработчиков не удаляют индексы, а затем сразу же пытаются выполнить запросы, использующие эти индексы, так что на практике такая ситуация маловероятно.Most developers do not drop indexes and then immediately try to run queries that utilize these indexes so, in practice, this situation is unlikely.
Примечание
Там, где это возможно, всегда следует попытаться сгруппировать несколько изменений индексирования в одно изменение одной политики индексирования.Where possible, you should always try to group multiple indexing changes into one single indexing policy modification
Политики индексирования и TTLIndexing policies and TTL
Для использования функции срока жизни (TTL) требуется индексирование.Using the Time-to-Live (TTL) feature requires indexing. Это означает следующее.This means that:
- невозможно активировать TTL для контейнера, для которого задан режим индексирования
none,it is not possible to activate TTL on a container where the indexing mode is set tonone, - невозможно задать для режима индексирования значение None в контейнере, где активирован TTL.it is not possible to set the indexing mode to None on a container where TTL is activated.
В сценариях, где не требуется индексировать свойства, но требуется TTL, можно использовать политику индексирования с режимом индексирования, для которого задано значение consistent , нет включенных путей и /* как единственный исключаемый путь.For scenarios where no property path needs to be indexed, but TTL is required, you can use an indexing policy with an indexing mode set to consistent, no included paths, and /* as the only excluded path.
Дальнейшие действияNext steps
Дополнительные сведения об индексировании см. по следующим ссылкам:Read more about the indexing in the following articles:
Частично индексация элементов в поиске контента и других средствах электронного поиска — Microsoft 365 Compliance
- Чтение занимает 11 мин
В этой статье
Поиск по обнаружению электронных данных, который вы запустите из центра соответствия требованиям Microsoft 365, автоматически включает частично индексные элементы в предполагаемые результаты поиска при выполнении поиска.An eDiscovery search that you run from the Microsoft 365 compliance center automatically includes partially indexed items in the estimated search results when you run a search. Частично индексация элементов — это элементы почтовых ящиков Exchange и документы на сайтах SharePoint и OneDrive для бизнеса, которые по каким-то причинам не были полностью индексироваться для поиска.Partially indexed items are Exchange mailbox items and documents on SharePoint and OneDrive for Business sites that for some reason weren’t completely indexed for search. В Exchange частично индексация элемента обычно содержит файл (типа файла, который нельзя индексировать), который присоединен к сообщению электронной почты.In Exchange, a partially indexed item typically contains a file (of a file type that can’t be indexed) that is attached to an email message. Вот некоторые другие причины, по которым элементы не могут индексироваться для поиска и возвращаются в качестве частично индексных элементов при запуске поиска по обнаружению электронных обнаружений:Here are some other reasons why items can’t be indexed for search and are returned as partially indexed items when you run an eDiscovery search:
Тип файла не распознан или не поддерживается для индексирования.The file type is unrecognized or unsupported for indexing.
Сообщения имеют присоединенный файл без допустимой обработки, например файлов изображений; это самая распространенная причина частично индексации элементов электронной почты.Messages have an attached file without a valid handler, such as image files; this is the most common cause of partially indexed email items.
Тип файла поддерживает индексирование, но произошла ошибка индексирования определенного файла.The file type is supported for indexing but an indexing error occurred for a specific file.
В сообщение электронной почты вложено слишком много файлов.Too many files attached to an email message.
Размер файла, вложенного в сообщение электронной почты, превышает допустимый.A file attached to an email message is too large.
Файл зашифрован с помощью технологий, разработанных не корпорацией Майкрософт.A file is encrypted with non-Microsoft technologies.
Файл защищен паролем.A file is password-protected.
Примечание
Большинство организаций имеют менее 1% контента по объему и менее 12% по размеру, который частично индексировали.Most organizations have less than 1% of content by volume and less than 12% by size that is partially indexed. Разница между объемом и размером заключается в том, что более крупные файлы с большей вероятностью содержат содержимое, которое не может быть полностью проиндексироваться.The reason for the difference between volume and size is that larger files have a higher probability of containing content that can’t be completely indexed.
Для юридических расследований организации может потребоваться просмотреть частично индексные элементы.For legal investigations, your organization may be required to review partially indexed items. Вы также можете указать, следует ли включать частично индексируемые элементы при экспорте результатов поиска на локальный компьютер или при подготовке результатов для анализа с помощью advanced eDiscovery.You can also specify whether to include partially indexed items when you export search results to a local computer or when you prepare the results for analysis with Advanced eDiscovery. Дополнительные сведения см. в статьи Исследование частично индексных элементов в eDiscovery.For more information, see Investigating partially indexed items in eDiscovery.
Типы файлов, которые не поддерживают поискFile types not indexed for search
Файлы определенных типов, например файлы точечных рисунков или MP3-файлы, содержат контент, не подходящий для индексирования.Certain types of files, such as Bitmap or MP3 files, don’t contain content that can be indexed. В результате серверы индексации поиска в Exchange и SharePoint не выполняют полнотексовую индексацию этих типов файлов.As a result, the search indexing servers in Exchange and SharePoint don’t perform full-text indexing on these types of files. Файлы таких типов считаются неподдерживаемыми.These types of files are considered to be unsupported file types. Кроме того, бывают типы файлов, для которых полнотекстовое индексирование отключено (по умолчанию или администратором).There are also file types for which full-text indexing has been disabled, either by default or by an administrator. Неподтвердимые и отключенные типы файлов помечены как неиндексы в поиске контента.Unsupported and disabled file types are labeled as unindexed items in Content Searches. Как уже говорилось ранее, частично индексные элементы могут быть включены в набор результатов поиска при запуске поиска, экспорте результатов поиска на локальном компьютере или подготовке результатов поиска для предварительного поиска.As previously stated, partially indexed items can be included in the set of search results when you run a search, export the search results to a local computer, or prepare search results for Advanced eDiscovery.
Список поддерживаемых и отключенных форматов файлов см. в следующих статьях:For a list of supported and disabled file formats, see the following topics:
Сообщения и документы с частично индексными типами файлов могут быть возвращены в результатах поискаMessages and documents with partially indexed file types can be returned in search results
Не каждое сообщение электронной почты с частично индексным вложением файла или каждый частично индексируется документ SharePoint автоматически возвращается в виде частично индексируется.Not every email message with a partially indexed file attachment or every partially indexed SharePoint document is automatically returned as a partially indexed item. Это потому, что другие свойства сообщений или документов, такие как свойство Subject в сообщениях электронной почты и свойства Title или Author для документов индексироваться и доступны для поиска.That’s because other message or document properties, such as the Subject property in email messages and the Title or Author properties for documents are indexed and available to be searched. Например, поиск по ключевому слову «финансовый» возвращает элементы с частично индексным вложением файлов, если это ключевое слово отображается в теме сообщения электронной почты или в имени файла или заголовке документа.For example, a keyword search for «financial» will return items with a partially indexed file attachment if that keyword appears in the subject of an email message or in the file name or title of a document. Однако если ключевое слово отображается только в тексте файла, сообщение или документ будут возвращены в качестве частично индексного элемента.However, if the keyword appears only in the body of the file, the message or document would be returned as a partially indexed item.
Аналогичным образом сообщения с частично индексируемыми вложениями файлов и документами частично индексируемых типов файлов включаются в результаты поиска, когда другие свойства сообщения или документа, индексируемые и подируемые для поиска, соответствуют критериям поиска.Similarly, messages with partially indexed file attachments and documents of a partially indexed file type are included in search results when other message or document properties, which are indexed and searchable, meet the search criteria. К свойствам сообщений, индексируемым для поиска, относятся даты отправки и получения, отправитель и получатель, имя файла вложения и текст сообщения.Message properties that are indexed for search include sent and received dates, sender and recipient, the file name of an attachment, and text in the message body. К свойствам документов, индексируемым для поиска, относятся даты создания и изменения.Document properties indexed for search include created and modified dates. Поэтому, даже если вложение сообщения может быть частично индексным элементом, сообщение будет включено в регулярные результаты поиска, если значение других свойств сообщения или документа соответствует критериям поиска.So even though a message attachment may be a partially indexed item, the message will be included in the regular search results if the value of other message or document properties matches the search criteria.
Список свойств электронной почты и документов, которые можно найти с помощью функции Поиска в Центре обеспечения соответствия требованиям & безопасности, см. в статье Keyword queries and search conditions for eDiscovery.For a list of email and document properties that you can search for by using the Search feature in the Security & Compliance Center, see Keyword queries and search conditions for eDiscovery.
Частично индексные элементы, включенные в результаты поискаPartially indexed items included in the search results
Организации может потребоваться определить и выполнить дополнительный анализ частично индексных элементов, чтобы определить, какие они, какие они содержатся и имеют ли они отношение к конкретному расследованию.Your organization might be required to identify and perform additional analysis on partially indexed items to determine what they are, what they contain, and whether they’re relevant to a specific investigation. Как поясняется ранее, частично индексные элементы в поисковых расположениях контента автоматически включаются в расчетные результаты поиска.As previously explained, the partially indexed items in the content locations that are searched are automatically included with the estimated search results. Вы можете включить эти частично индексируемые элементы при экспорте результатов поиска или подготовке результатов поиска для предварительного поиска.You have the option to include these partially indexed items when you export search results or prepare the search results for Advanced eDiscovery.
Помните о частично проиндексациях элементов:Keep the following in mind about partially indexed items:
При запуске поиска по обнаружению электронных данных общее число и размер частично индексных элементов Exchange (возвращаемого поисковым запросом) отображаются в статистике поиска на странице вылетов и помечены как неиндексы.When you run an eDiscovery search, the total number and size of partially indexed Exchange items (returned by the search query) are displayed in the search statistics on the flyout page, and labeled as unindexed items. Статистические данные о частично индексациях элементов, отображаемой на странице вылетов, не включают частично индексные элементы в SharePoint или OneDrive.Statistics about partially indexed items displayed on the flyout page don’t include partially indexed items in SharePoint or OneDrive.
Если в результате поиска, который вы экспортируете, был поиск определенных местоположений контента или всех местоположений контента в организации, экспортируются только неиндексы из местоположений контента, содержащих элементы, которые соответствуют критериям поиска.If the search that you’re exporting results from was a search of specific content locations or all content locations in your organization, only the unindexed items from content locations that contain items that match the search criteria will be exported. In other words, if no search results are found in a mailbox or site, then any unindexed items in that mailbox or site won’t be exported.In other words, if no search results are found in a mailbox or site, then any unindexed items in that mailbox or site won’t be exported. Причина этого заключается в том, что экспорт частично индексных элементов из большого числа местоположений в организации может повысить вероятность ошибок экспорта и увеличить время, необходимое для экспорта и скачивания результатов поиска.The reason for this is that exporting partially indexed items from lots of locations in the organization might increase the likelihood of export errors and increase the time it takes to export and download the search results.
Чтобы экспортировать частично индексируемые элементы из всех местоположений контента для поиска, настройте поиск, чтобы вернуть все элементы (удалив ключевые слова из поискового запроса), а затем экспортировать только частично индексируемые элементы при экспорте результатов поиска (щелкнув только элементы, которые имеют неознаемый формат, шифруются или не индексируются по другим причинам в параметрах Output).To export partially indexed items from all content locations for a search, configure the search to return all items (by removing any keywords from the search query) and then export only partially indexed items when you export the search results (by clicking Only items that have an unrecognized format, are encrypted, or weren’t indexed for other reasons under Output options).
Если вы решите включить все элементы почтовых ящиков в результаты поиска или если поисковый запрос не указывает ключевые слова или указывает только диапазон дат, частично индексированные элементы не могут быть скопированы в PST-файл, содержащий частично индексированные элементы.If you choose to include all mailbox items in the search results, or if a search query doesn’t specify any keywords or only specifies a date range, partially indexed items might not be copied to the PST file that contains the partially indexed items. Это происходит потому, что все элементы, в том числе частично индексируются, будут автоматически включены в регулярные результаты поиска.This is because all items, including any partially indexed items, will be automatically included in the regular search results.
Частично проиндексировать элементы недоступны для предварительного просмотра.Partially indexed items aren’t available to be previewed. Чтобы просмотреть частично индексируемые элементы, возвращаемые поиском, необходимо экспортировать результаты поиска.You have to export the search results to view partially indexed items returned by the search.
Кроме того, при экспорте результатов поиска и включении частично индексируемых элементов в экспорт, частично индексируемые элементы из элементов SharePoint экспортируются в папку с именем Uncrawlable.Additionally, when you export search results and include partially indexed items in the export, partially indexed items from SharePoint items are exported to a folder named Uncrawlable. При экспорте частично индексных элементов Exchange они экспортируются по-разному в зависимости от того, соответствуют ли частично индексируемые элементы запросу поиска и конфигурации параметров экспорта.When you export partially indexed Exchange items, they are exported differently depending on whether or not the partially indexed items matched the search query and the configuration of the export settings.
В следующей таблице показано поведение экспорта индексируемого и частично индексируемого элементов и включен ли каждый из них для различных параметров конфигурации экспорта.The following table shows the export behavior of indexed and partially indexed items and whether or not each is included for the different export configuration settings.
| Конфигурация экспортаExport configuration | Индексные элементы, которые соответствуют запросу поискаIndexed items that match search query | Частично индексные элементы, которые соответствуют запросу поискаPartially indexed items that match search query | Частично индексировать элементы, которые не соответствуют запросу поискаPartially indexed items that don’t match search query |
|---|---|---|---|
| Экспортировать только индексированные элементы.Export only indexed items | ExportedExported | Экспорт (входит в индексируемую номенклатуру, экспортируемую)Exported (included with the indexed items that are exported) | Не экспортируетсяNot exported |
| Экспорт только частично индексируемой номенклатурыExport only partially indexed items | Не экспортируетсяNot exported | Экспорт (в качестве частично индексных элементов)Exported (as partially indexed items) | Экспорт (в качестве частично индексных элементов)Exported (as partially indexed items) |
| Экспорт индексируются и частично индексируются элементыExport indexed and partially indexed items | ExportedExported | Экспорт (входит в индексируемую номенклатуру, экспортируемую)Exported (included with the indexed items that are exported) | Экспорт (в качестве частично индексных элементов)Exported (as partially indexed items) |
Частично индексные элементы, исключенные из результатов поискаPartially indexed items excluded from the search results
Если элемент частично проиндексировали, но он не соответствует критериям запроса поиска, он не будет включен в качестве частично индексного элемента в результатах поиска.If an item is partially indexed but it doesn’t meet the search query criteria, it won’t be included as a partially indexed item in the search results. Другими словами, элемент исключается из результатов поиска.In other words, the item is excluded from the search results. Допустим, вы выполняете поиск, не указывая никаких ключевых слов и свойств, чтобы просмотреть весь контент.For example, let’s say you run a search and don’t include any keywords or properties because you want to include all content. Но вы задаете для запроса условие диапазона дат.But you include a date range condition for the query. Если частично индексированный элемент выпадает за пределы этого диапазона дат, он не будет включен в качестве частично индексного элемента.If a partially indexed item falls outside of that date range, it won’t be included as a partially indexed item. Диапазоны дат являются эффективным способом исключения частично индексных элементов из результатов поиска.Date ranges are an effective way to exclude partially indexed items from your search results.
Аналогичным образом, если при экспорте результатов поиска будут включены частично индексные элементы, не будут экспортироваться частично индексные элементы, исключенные из результатов поиска.Similarly, if you choose to include partially indexed items when you export the results of a search, partially indexed items that were excluded from the search results won’t be exported.
Исключением из этого правила является создание удержания на основе запроса, связанного с делом об обнаружении электронных данных.One exception to this rule is when you create a query-based hold that’s associated with an eDiscovery case. Если создается удержание электронных данных на основе запроса, все частично индексные элементы помещаются в удержание.If you create a query-based eDiscovery hold, all partially indexed items are placed on hold. Это включает частично индексные элементы, которые не соответствуют критериям запроса поиска, и частично индексные элементы, которые могут не соответствовать состоянию диапазона дат.This includes partially indexed items that don’t match the search query criteria and partially indexed items that might fall outside of a date range condition. Дополнительные сведения о создании удержаний электронных данных на основе запросов см. в статью Создание удержания для электронных данных.For more information about creating query-based eDiscovery holds, see Create an eDiscovery hold.
Ограничения индексации сообщенийIndexing limits for messages
В следующей таблице описываются ограничения индексации, которые могут привести к возвращению сообщения электронной почты в качестве частично индексного элемента в поисковой операции по обнаружению электронных сообщений в Microsoft 365.The following table describes the indexing limits that might result in an email message being returned as a partially indexed item in an eDiscovery search in Microsoft 365.
Список ограничений индексации для документов SharePoint см. в раздел Ограничения поиска для SharePoint Online.For a list of indexing limits for SharePoint documents, see Search limits for SharePoint Online.
| Ограничение индексацииIndexing limit | ПримечанияMaximum value | ОписаниеDescription |
|---|---|---|
| Максимальный размер вложения (за исключением файлов Excel)Maximum attachment size (excluding Excel files) | 150 МБ150 MB | Максимальный размер вложения электронной почты, который будет размыкать для индексации.The maximum size of an email attachment that will parse for indexing. Любое вложение, которое больше этого предела, не будет разобрано для индексации, а сообщение с вложением будет помечено как частично индексироваться.Any attachment that’s larger than this limit won’t be parsed for indexing, and the message with the attachment will be marked as partially indexed. Примечание: Parsing — это процесс, в котором служба индексации извлекает текст из вложения, удаляет ненужные символы, такие как пунктуация и пробелы, а затем делит текст на слова (в процессе, называемом маркеризацией), которые затем хранятся в индексе.Note: Parsing is the process where the indexing service extracts text from the attachment, removes unnecessary characters like punctuation and spaces, and then divides the text into words (in a process called tokenization), that are then stored in the index. |
| Максимальный размер файлов ExcelMaximum size of Excel files | 4 МБ4 MB | Максимальный размер файла Excel, расположенного на сайте или присоединенного к сообщению электронной почты, которое будет разобрано для индексации.The maximum size of an Excel file located on a site or attached to an email message that will be parsed for indexing. Любой файл Excel, размером больше этого ограничения, не будет разобран, а файл или сообщение электронной почты с вложением файла будут помечены как неиндексы.Any Excel file that’s larger than this limit won’t be parsed, and the file or the email the message with the file attachment will be marked as unindexed. |
| Максимальное количество вложенийMaximum number of attachments | 250250 | Максимальное количество файлов, присоединенных к сообщению электронной почты, которое будет разобрано для индексации.The maximum number of files attached to an email message that will be parsed for indexing. Если в сообщении более 250 вложений, первые 250 вложений размыкаются и индексированы, а сообщение помечено как частично индексироваться, так как у него были дополнительные вложения, которые не были разобрано.If a message has more than 250 attachments, the first 250 attachments are parsed and indexed, and the message is marked as partially indexed because it had additional attachments that weren’t parsed. |
| Максимальная глубина вложенияMaximum attachment depth | 3030 | Максимальное количество вложенных вложений, которые размыкаются.The maximum number of nested attachments that are parsed. Например, если к сообщению электронной почты прикреплено другое сообщение, а прикрепленное сообщение имеет прикрепленный документ Word, документ Word и прикрепленное сообщение будут индексироваться.For example, if an email message has another message attached to it and the attached message has an attached Word document, the Word document and the attached message will be indexed. Это поведение будет продолжаться до 30 вложенных вложений.This behavior will continue for up to 30 nested attachments. |
| Максимальное количество прикрепленных изображенийMaximum number of attached images | 00 | Изображение, прикрепленное к сообщению электронной почты, пропускается размерщиком и не индексироваться.An image that’s attached to an email message is skipped by the parser and isn’t indexed. |
| Максимальное время, затраченное на разбиение элементаMaximum time spent parsing an item | 30 секунд30 seconds | Не более 30 секунд тратится на размыв элемента для индексации.A maximum of 30 seconds is spent parsing an item for indexing. Если время разметки превышает 30 секунд, элемент помечен как частично индексация.If the parsing time exceeds 30 seconds, the item is marked as partially indexed. |
| Максимальная производительность размерщикаMaximum parser output | 2 миллиона символов2 million characters | Максимальное количество текстового вывода из индексного проиндексировать.The maximum amount of text output from the parser that’s indexed. Например, если размерщик извлек 8 миллионов символов из документа, индексироваться будут только первые 2 миллиона символов.For example, if the parser extracted 8 million characters from a document, only the first 2 million characters are indexed. |
| Максимальные маркеры аннотацииMaximum annotation tokens | 2 миллиона2 million | При индексации сообщения электронной почты каждое слово обозначается различными инструкциями по обработке, которые указывают, как это слово должно индексироваться.When an email message is indexed, each word is annotated with different processing instructions that specify how that word should be indexed. Каждый набор инструкций по обработке называется маркером аннотации.Each set of processing instructions is called an annotation token. Для поддержания качества службы в Office 365 существует ограничение в 2 миллиона маркеров аннотации для сообщения электронной почты.To maintain the quality of service in Office 365, there is a limit of 2 million annotation tokens for an email message. |
| Максимальный размер тела в индексеMaximum body size in index | 67 миллионов символов67 million characters | Общее количество символов в теле сообщения электронной почты и всех его вложений.The total number of characters in the body of an email message and all its attachments. При индексации сообщения электронной почты весь текст в теле сообщения и во всех вложениях соединен в одну строку.When an email message is indexed, all text in the body of the message and in all attachments is concatenated into a single string. Максимальный размер индексации этой строки — 67 миллионов символов.The maximum size of this string that is indexed is 67 million characters. |
| Максимально уникальные маркеры в телеMaximum unique tokens in body | 1 миллион1 million | Как объяснялось ранее, маркеры являются результатом извлечения текста из контента, удаления знаков препинания и пробелов, а затем деления его на слова (называемые маркеры), которые хранятся в индексе.As previously explained, tokens are the result of extracting text from content, removing punctuation and spaces, and then dividing it into words (called tokens) that are stored in the index. Например, фраза содержит "cat, mouse, bird, dog, dog" 5 маркеров.For example, the phrase "cat, mouse, bird, dog, dog" contains 5 tokens. Но только 4 из них являются уникальными маркерами.But only 4 of these are unique tokens. Существует ограничение в 1 миллион уникальных маркеров для каждого сообщения электронной почты, что позволяет предотвратить слишком большой размер индекса с помощью случайных маркеров.There is a limit of 1 million unique tokens per email message, which helps prevent the index from getting too large with random tokens. |
Дополнительные сведения о частично индексациях элементовMore information about partially indexed items
Как уже говорилось ранее, так как индексация свойств сообщений и документов и их метаданных может привести к возвращению результатов поиска по ключевым словам, если это ключевое слово появится в индексных метаданных.As previously stated, because message and document properties and their metadata are indexed, a keyword search might return results if that keyword appears in the indexed metadata. Тем не менее этот элемент может быть не включен в результаты, если ключевые слова встречаются только в содержимом неподдерживаемых типов.However, that same keyword search might not return the same item if the keyword only appears in the content of an item with an unsupported file type. В этом случае элемент будет возвращен в качестве частично индексного элемента.In this case, the item would be returned as a partially indexed item.
Если частично индексация элемента включена в результаты поиска, так как он соответствует критериям запроса поиска (и не был исключен), он не будет включен в качестве частично индексного элемента в расчетную статистику поиска.If a partially indexed item is included in the search results because it met the search query criteria (and wasn’t excluded), then it won’t be included as a partially indexed item in the estimated search statistics. Кроме того, при экспорте результатов поиска он не будет включен с частично индексируемой номенклатурой.Also, it won’t be included with partially indexed items when you export search results.
Несмотря на то, что тип файла поддерживается для индексации и индексироваться, могут быть ошибки индексации или поиска, из-за которые файл будет возвращен в качестве частично индексного элемента.Although a file type is supported for indexing and is indexed, there can be indexing or search errors that will cause a file to be returned as a partially indexed item. Например, поиск очень большого файла Excel может быть частично успешным (так как индексация первых 4 МБ) может привести к сбою из-за превышения предельного размера файла.For example, searching a very large Excel file might be partially successful (because the first 4 MB are indexed), but then fails because the file size limit is exceeded. В этом случае не исключено, что один и тот же файл возвращается с результатами поиска и частично индексироваться.In this case, it’s possible that the same file is returned with the search results and as a partially indexed item.
Файлы, зашифрованные с помощью технологий шифрования Майкрософт и присоединенные к сообщению электронной почты, которое соответствует критериям поиска, можно просмотреть и расшифровать при экспорте.Files that are encrypted with Microsoft encryption technologies and are attached to an email message that matches the criteria of a search can be previewed and will be decrypted when exported. В это время частично индексироваться файлы, зашифрованные с помощью технологий шифрования Майкрософт (и хранимые в SharePoint или OneDrive для бизнеса).At this time, files that are encrypted with Microsoft encryption technologies (and stored in SharePoint or OneDrive for Business) are partially indexed.
Сообщения электронной почты, зашифрованные с помощью S/MIME, частично индексироваться.Email messages encrypted with S/MIME are partially indexed. Это также касается зашифрованных сообщений с вложенными файлами или без них.This includes encrypted messages with or without file attachments.
Сообщения электронной почты, защищенные с помощью Azure Rights Management, индексются и будут включены в результаты поиска, если они соответствуют запросу поиска.Email messages protected using Azure Rights Management are indexed and will be included in the search results if they match the search query. Защищенные правами сообщения электронной почты расшифровываются и могут просматриваться и экспортироваться.Rights-protected email messages are decrypted and can be previewed and exported. Эта функция требует, чтобы вам была назначена роль расшифровки RMS, которая по умолчанию назначена группе ролей диспетчера электронных данных.This functionality requires that you are assigned the RMS Decrypt role, which is assigned by default to the eDiscover Manager role group.
См. такжеSee also
Изучение частично индексных элементов в eDiscoveryInvestigating partially indexed items in eDiscovery
Процесс индексации роботами поисковых систем, как увеличить скорость индексации сайта
Каждый процесс, происходящий в поисковых системах, уникален и интересен. Зная архитектуру поисковой системы, можно понимать причины «выпадения» сайта из выдачи или повышения позиций. Рассмотрим каждый процесс в отдельности.
Процесс индексации
Индексация – это процесс, во время которого поисковые роботы посещают сайты, собирая с их страниц разнообразную информацию и занося ее в специальные базы данных. Потом эти данные обрабатываются, и строится индекс – выжимка из документов. Именно по индексу поисковая система ищет и выдает ссылки на сайты, исходя из запросов пользователей.
Рассмотрим процесс индексации на примере поисковой системы Яндекс.
В поисковой системе есть 2 типа роботов: быстрый и основной. Задача основного робота – индексация всего контента, а быстрого – занесение в базы данных самой свежей информации. Планировщик поискового робота составляет маршруты посещения и передает его «пауку», который ходит по выбранным страницам и выкачивает из них информацию. Если во время индексации в документах обнаруживаются новые ссылки, они добавляются в общий список.
При первом посещении «паук» проверяет состояние ресурса. Если его характеристики подходят под требования Яндекса, сайт заносится в базу. При повторном посещении «пауком» уже проиндексированной страницы происходит обновление содержащейся на ней информации.
Документы в индекс попадают следующими способами: автоматически, когда поисковый робот сам переходит по внешним и внутренним ссылкам, ибо если владелец сайта сам добавил URL через специальную форму или через установленную на сайте Яндекс.Метрику. Этот сервис передает URL страниц на индексацию Яндексу. При необходимости в интерфейсе Метрики можно отключить данную опцию.
Скорость индексации и обновления страниц сайта
В идеале, как только создана новая страница, она должна быть сразу же проиндексирована. Однако большие объемы информации затрудняют индексацию новых страниц и обновление старых. Роботы поисковых систем постоянно обновляют базу данных, но, чтобы она была доступна пользователям, ее необходимо переносить на «базовый поиск». База данных переносится туда не полностью. Исключаются зеркала сайтов, страницы, содержащие поисковый спам, и другие ненужные, по мнению поисковика, документы.
Глобально базы поисковых систем обновляются роботами примерно раз в неделю.
Однако для некоторых типов информации такая скорость обновления неприемлема. Примером может служить индексация новостных сайтов. Размещенные новости должны быть доступны в поисковой системе практически сразу после их добавления. Для того, чтобы увеличить скорость индексации часто обновляемых страниц, и существует специальный быстрый робот, который посещает новостные сайты несколько раз в день.
Понять, что сайт посетил быстрый робот, можно сразу по двум признакам: если в поисковой выдаче рядом с URL сайта показывается время последнего обновления и если в числе проиндексированных страниц сохранены две копии одного и того же документа.
Поисковые роботы стремятся проиндексировать как можно больше информации, однако существует ряд факторов, которые накладывают ограничения на процесс индексации. Так, например, возможность попадания в индекс напрямую зависит от авторитетности ресурса, уровня вложенности страниц, наличия файла sitemap.xml, отсутствия ошибок, мешающих нормальной скорости индексации сайта. Основными инструментами управления индексацией сайтов являются robots.txt, мета-теги, теги, атрибуты noindex и nofollow.
На сегодняшний день могут индексироваться следующие типы документов:
1. PDF, Flash (Adobe Systems).
2. DOC/DOCX, XLS/XLSX, PPT/PPTX (MS Office).
3. ODS, ODP, ODT, ODG (Open Office).
4. RTF, TXT.
Robots.txt — это текстовый файл, в котором можно задавать параметры индексирования как для всех роботов поисковых систем сразу, так и по отдельности. Тег и метатег noindex отвечают за индексацию текста или самой страницы, а nofollow – за индексацию ссылок. В одной из следующих глав мы подробно разберем настройку этих элементов сайта.
Помимо обычных текстов, размещенных на сайтах, все современные поисковые системы умеют индексировать и документы в закрытых форматах, хотя существуют некоторые ограничения на типы данных, размещенных в этих файлах. Так, в PDF индексируется только текстовое содержимое. Во flash-документе индексируется текст, который размещен только в определенных блоках, в то время как документы больше 10 Мб не индексируются вовсе.
Роботы поисковых систем
Среди всех существующих поисковых роботов выделяют 4 основных типа:
1. Индексирующий робот;
2. Робот по изображениям;
3. Робот по зеркалам сайта;
4. Робот, проверяющий работоспособность сайта или страницы.
Определить, какой робот зашел на сайт, можно с помощью лог-файла, который обычно доступен либо в админке, либо на ftp. Все существующие роботы представляются по одной схеме, но каждый имеет свое название. Например: «Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)» — основной индексирующий робот поисковой системы Яндекс.
Некоторые посторонние роботы могут маскироваться под роботов Яндекса путем указания соответствующего user-agent. Вы можете проверить подлинность робота с помощью идентификации, основанной на обратных DNS-запросах.
Индексирующий робот обнаруживает и индексирует страницы, чтобы создать базу для основного поиска.
Робот по изображениям заносит в индекс графическую информацию, которая в дальнейшем отображается в выдаче соответствующего сервиса, например, Яндекс.Картинки или Картинки Google.
Робот, определяющий зеркала, проверяет зеркала сайтов, прописанных в файле robots.txt. Если они идентичны, то в результатах выдачи поисковой системы будет только один сайт – главное зеркало.
Специальный робот проверяет доступность сайта, добавленного через форму «Добавить URL» в Яндекс.Вебмастере.
Существуют и другие типы индексирующих роботов: индексаторы видео и пиктограмм (иконок) сайтов; робот, проверяющий работоспособность сайтов в Яндекс.Каталоге; индексатор «быстрого» контента на площадках типа Яндекс.Новостей и др.
Важно понимать, что процесс индексации сайта является длительным, за ним следует процесс обновления индексных баз, который также требует временных затрат. Поэтому результат внесенных на сайте изменений будет виден только через 1-2 недели.
Вернуться назад: Как устроены поисковые системыЧитать далее: Представление сайтов внутри поисковых систем
Как работает индексирование | Учебник Chartio
Что делает индексирование?
Индексирование — это способ упорядочить неупорядоченную таблицу, чтобы максимально повысить эффективность запроса при поиске.
Когда таблица не проиндексирована, порядок строк, скорее всего, не будет определен запросом как оптимизированный каким-либо образом, и поэтому вашему запросу придется выполнять линейный поиск по строкам. Другими словами, запросы должны будут перебирать каждую строку, чтобы найти строки, соответствующие условиям.Как вы понимаете, это может занять много времени. Просматривать каждую строку не очень эффективно.
Например, приведенная ниже таблица представляет собой полностью неупорядоченную таблицу в вымышленном источнике данных.
| идентификатор компании | шт. | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 16 | 12 | 1,31 |
| 10 | 12 | 1,15 |
| 12 | 24 | 1,3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1,35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1,36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
Если бы мы выполнили следующий запрос:
ВЫБРАТЬ
Идентификатор компании,
единицы,
себестоимость единицы продукции
ИЗ
index_test
КУДА
company_id = 18
База данных должна будет выполнять поиск по всем 17 строкам в том порядке, в котором они появляются в таблице, сверху вниз, по одной. Таким образом, чтобы найти все возможные экземпляры company_id номер 18, база данных должна просмотреть всю таблицу на предмет появления 18 в столбце company_id .
Это будет занимать все больше и больше времени по мере увеличения размера таблицы. По мере увеличения сложности данных может в конечном итоге случиться так, что таблица с миллиардом строк будет соединена с другой таблицей с миллиардом строк; теперь запрос должен перебирать вдвое большее количество строк, что требует вдвое больше времени.
Вы можете видеть, как это становится проблематичным в нашем постоянно насыщенном данными мире. Таблицы увеличиваются в размере, а время поиска увеличивается.
Запрос к неиндексированной таблице, если он представлен визуально, будет выглядеть так:
Индексирование настраивает столбец, в котором находятся условия поиска, в отсортированном порядке, что помогает оптимизировать производительность запроса.
С индексом в столбце company_id таблица, по сути, «выглядела бы» так:
| идентификатор компании | шт. | unit_cost |
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1,15 |
| 11 | 24 | 1,15 |
| 11 | 24 | 1,15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1,3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1,31 |
| 18 | 18 | 1,34 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 18 | 18 | 1.34 |
| 20 | 6 | 1,31 |
| 21 | 18 | 1,36 |
Теперь база данных может искать company_id number 18 и возвращать все запрошенные столбцы для этой строки, а затем переходить к следующей строке. Если номер comapny_id следующей строки также равен 18, то он вернет все столбцы, запрошенные в запросе. Если в следующей строке company_id равен 20, запрос знает, что нужно прекратить поиск, и запрос будет завершен.
Как работает индексирование?
На самом деле таблица базы данных не переупорядочивается каждый раз при изменении условий запроса, чтобы оптимизировать производительность запроса: это было бы нереально. На самом деле происходит то, что индекс заставляет базу данных создавать структуру данных. Тип структуры данных, скорее всего, является B-деревом. Несмотря на то, что B-Tree имеет множество преимуществ, главное преимущество для наших целей состоит в том, что его можно сортировать. Когда структура данных отсортирована по порядку, это делает наш поиск более эффективным по очевидным причинам, которые мы указали выше.
Когда индекс создает структуру данных для определенного столбца, важно отметить, что никакой другой столбец не сохраняется в структуре данных. Наша структура данных для приведенной выше таблицы будет содержать только числа company_id . Единицы и unit_cost не будет храниться в структуре данных.
Как база данных узнает, какие еще поля в таблице нужно возвращать?
Индексы базы данных также будут хранить указатели, которые являются просто справочной информацией для размещения дополнительной информации в памяти.В основном индекс содержит company_id и домашний адрес этой конкретной строки на диске памяти. Фактически индекс будет выглядеть так:
| идентификатор компании | указатель |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
С этим индексом запрос может искать только те строки в столбце company_id , которые имеют 18, а затем с помощью указателя может перейти в таблицу, чтобы найти конкретную строку, в которой находится этот указатель.Затем запрос может перейти в таблицу, чтобы получить поля для столбцов, запрошенных для строк, которые соответствуют условиям.
Если бы поиск был представлен визуально, это выглядело бы так:
Резюме
- Индексирование добавляет структуру данных со столбцами для условий поиска и указателем
- Указатель — это адрес на диске памяти строки с остальной информацией
- Структура данных индекса отсортирована для повышения эффективности запросов
- Запрос ищет конкретную строку в индексе; индекс относится к указателю, который найдет остальную информацию.
- Индекс уменьшает количество строк, в которых должен выполнять поиск запрос, с 17 до 4.
Убийцы производительности SQL-запросов — понимание плохой индексации базы данных
На производительность SQL Server влияет множество факторов. Наиболее частыми убийцами производительности SQL Server являются плохой дизайн базы данных, плохая индексация, плохой дизайн запросов, невозможность повторного использования планов выполнения, частая перекомпиляция запросов, чрезмерная фрагментация и многое другое. При наличии этих факторов на вашем компьютере даже добавление дополнительных аппаратных ресурсов может не помочь, поскольку эти убийцы производительности SQL Server могут использовать все доступные ресурсы.Плохая индексация — один из главных факторов, убивающих производительность, и мы сосредоточимся на них в этой статье.
Что такое индексы?
Индекс используется для ускорения поиска данных и выполнения SQL-запросов. Индексы базы данных уменьшают количество страниц данных, которые необходимо прочитать, чтобы найти конкретную запись.
Самая большая проблема при индексировании — определить правильные для каждой таблицы.
Мы начнем с объяснения кластеризованных и некластеризованных индексов.
Таблица без кластеризованного индекса называется кучей из-за ее неупорядоченной структуры. Данные в таблице кучи не сортируются, обычно записи добавляются одна за другой, так как они вставляются в таблицу. Их также можно изменить с помощью механизма базы данных, но опять же, без определенного порядка. Когда вы вставляете много строк в таблицу кучи, новые записи записываются на страницы данных без определенного порядка. Поиск записи в таблице кучи можно сравнить с поиском определенного листа в куче листьев.Это неэффективно и требует времени.
Куча может иметь один или несколько некластеризованных индексов или вообще не иметь индексов.
Некластеризованный индекс создается только из страниц индекса, содержащих указатели строк (указатели) для записей на страницах данных. Он не содержит страниц данных, таких как кластерные индексы.
Кластерный индекс упорядочивает данные таблицы, поэтому запросы к данным запрашиваются быстрее и эффективнее. Кластеризованный индекс состоит как из страниц индекса, так и из страниц данных, в то время как таблица кучи не имеет страниц индекса; он состоит только из страниц данных.Другими словами, это не просто индекс, то есть указатель на строку данных, которая содержит значение ключа, но также содержит данные таблицы. Данные в кластеризованной таблице сортируются с использованием значений столбцов, из которых состоит кластеризованный индекс.
Найти запись в таблице с правильным кластеризованным индексом так же быстро и легко, как найти имя в алфавитно упорядоченном списке. Общая рекомендация для всех таблиц SQL — иметь правильный кластерный индекс
.В то время как в таблице может быть только один кластеризованный индекс, таблица может иметь до 999 некластеризованных индексов
Индексы могут быть созданы с использованием T-SQL.
CREATE TABLE [Person]. [Address] ( [AddressID] [int] IDENTITY (1,1) NOT FOR REPLICATION NOT NULL, [AddressLine1] [nvarchar] (60) NOT NULL, ) [AddressLine2] [nvarchar] (60) NULL, [City] [nvarchar] (30) NOT NULL, ОГРАНИЧЕНИЕ [PK_Address_AddressID] ПЕРВИЧНЫЙ КЛЮЧ КЛАСТЕРИРОВАН ( [AddressID] ASC ] ВКЛ. |
Когда вы выполняете оператор select для кластеризованной таблицы, в которой создается восходящий кластеризованный индекс, результаты будут упорядочены по возрастанию столбца кластеризованного ключа.В этом примере это столбец AddressID.
Та же таблица, но с кластеризованным индексом по убыванию, вернет результаты, отсортированные по убыванию столбца AddressID. Чтобы создать кластерный индекс по убыванию, просто замените ASC на DESC в приведенном выше коде, чтобы синтаксис ограничения стал.
ОГРАНИЧЕНИЕ [PK_Address_AddressID] ПЕРВИЧНЫЙ КЛЮЧ КЛАСТЕРИРОВАН ( [AddressID] DESC ) |
Оператор select в этой таблице возвращает столбец AddressID, отсортированный по убыванию.
Код T-SQL для создания таблицы с некластеризованным индексом:
СОЗДАТЬ ТАБЛИЦУ [Person]. [Address4] ( [AddressID] [int] IDENTITY (1,1) НЕ ДЛЯ ПОВТОРЕНИЯ НЕ NULL, [AddressLine1] [nvarchar] (60) NOT NULL, [AddressLine2] [nvarchar] (60) NULL, [City] [nvarchar] (30) NOT NULL) СОЗДАТЬ НЕКЛЮЧЕНЫЙ ИНДЕКС [IX_Address_StateProvinceID4] НА [Человек].[Address4] ( [AddressID] ASC ) ON [PRIMARY] |
Когда вы выполняете оператор select для таблицы кучи с теми же столбцами и данными, возвращаемые результаты будут неупорядоченными.
Помимо использования кода T-SQL для создания индекса, вы можете использовать SQL Server Management Studio. Чтобы создать индекс для существующей таблицы:
- Разверните узел Tables в обозревателе объектов
- Разверните таблицу, в которой вы хотите создать индекс, и щелкните ее правой кнопкой мыши
- Щелкните правой кнопкой мыши Индексы
- Выбрать Новый индекс
Выберите Кластерный индекс или Некластерный индекс вариант
- Если вы выбрали параметр Кластерный индекс , отобразится следующее диалоговое окно.Имя индекса создается автоматически, но оно не очень информативное, поэтому рекомендуется изменить его и добавить имена столбцов кластеризованного индекса, например ClusteredIndex_AddressID
Нажмите Добавить
Выберите столбцы, которые вы хотите использовать в качестве кластеризованного индекса
- Нажмите ОК . Выбранные столбцы будут перечислены в списке Ключевые столбцы индекса список
- Если вы хотите, чтобы кластерный индекс был уникальным, установите флажок Уникальный
- Используйте другие вкладки для настройки параметров индекса, параметров хранения и расширенных свойств
После успешного создания индекса он будет указан в узле Индексы для конкретной таблицы
Шаги аналогичны для создания некластеризованного индекса
Другой вариант создания кластерного индекса для существующей таблицы с помощью SQL Server Management Studio:
- Щелкните правой кнопкой мыши таблицу и выберите Design
- Щелкните правой кнопкой мыши сетку проекта и выберите Indexes / Keys
Нажмите Добавить .По умолчанию столбец идентификаторов добавляется в порядке возрастания
.Чтобы выбрать другой столбец, нажмите кнопку с многоточием в строке Столбцы и выберите другой столбец и порядок сортировки
- В столбце Создать как кластеризованный выберите Да для кластеризованного индекса. Оставьте № , чтобы создать некластеризованный индекс
- Опять же, рекомендуется изменить автоматически созданное имя в строке Identity — (Name) на более информативное
- Нажмите Закрыть
- Нажмите Сохранить в меню SQL Server Management Studio, чтобы сохранить индекс
Куча или кластерная таблица SQL?
При поиске определенной записи в таблице кучи SQL Server должен просмотреть все строки таблицы.Это может быть приемлемо для таблицы с небольшим количеством записей.
Поскольку строки в таблице кучи неупорядочены, они идентифицируются идентификатором строки (RID), который состоит из номера файла, номера страницы и номера слота строки.
Не рекомендуется использовать таблицу кучи, если вы собираетесь хранить в таблице большое количество записей. Выполнение SQL-запроса к таблице с миллионами записей без кластерного индекса требует много времени. Кроме того, если вам нужно получить отсортированный список результатов, проще определить кластерный индекс по возрастанию или убыванию, как показано в приведенных выше примерах, чем сортировать несортированный набор результатов, извлеченный из таблицы кучи.То же самое касается группировки, фильтрации по диапазону значений.
В этой статье мы показали, как создавать кластеризованные и некластеризованные индексы с использованием опций T-SQL и SQL Server Management Studio, и указали на основные различия между кластеризованной таблицей и таблицей кучи. В следующей части этой статьи мы объясним, что считается плохой практикой индексирования, и дадим рекомендации по созданию индексов.
Милена — специалист по SQL Server с более чем 20-летним опытом работы в ИТ.Она начала с компьютерного программирования в средней школе и продолжила обучение в университете.Она работает с SQL Server с 2005 года и имеет опыт работы с SQL 2000 по SQL 2014.
Ее любимые темы SQL Server — это аварийное восстановление SQL Server, аудит и мониторинг производительности.
Посмотреть все сообщения Милены «Милли» Петрович
Последние сообщения Милены Петрович (посмотреть все)Отслеживание и настройка запросов с использованием индексов SQL Server
В предыдущих статьях этой серии (см. Полное содержание статьи внизу) мы обсудили внутреннюю структуру таблиц и индексов SQL Server, рекомендации, которым следует следовать при разработке правильного индекса, группу операций, которые вы можете выполнять с индексы SQL Server, способы разработки эффективных кластерных и некластеризованных индексов и, наконец, различные типы индексов SQL Server, помимо классификации кластерных и некластеризованных индексов.В этой статье мы обсудим, как настроить производительность неверных запросов с помощью индексов SQL Server.
До этого момента, получив полное представление о концепции, структуре, дизайне и типах индекса SQL Server, мы готовы разработать наиболее эффективный индекс SQL Server, от которого оптимизатор запросов SQL Server всегда будет извлекать выгоду, ускоряя извлечение данных. обрабатывает наши запросы, что является основной целью создания индекса, с минимальным количеством операций дискового ввода-вывода и минимальным использованием системных ресурсов.
Перед проектированием индекса, который помогает обработчику запросов быстро находить данные и как можно реже касаться базовой таблицы, вы должны хорошо понимать базовую структуру данных и их использование, тип запросов, считывающих эти данные, и частоту запросы выполняются. Как администратор базы данных вы можете использовать различные инструменты и сценарии, чтобы предоставить владельцам системы список предлагаемых индексов, которые могут повысить производительность их системных запросов.Но в зависимости от своего понимания поведения системы они должны предоставить окончательное подтверждение создания таких индексов только после проверки производительности запроса в среде разработки до и после создания предлагаемого индекса.
Администраторы баз данных должны балансировать между созданием слишком большого количества индексов и слишком малого количества индексов. Например, нет необходимости индексировать каждый столбец индивидуально или включать столбец во множество перекрывающихся индексов. Они также должны учитывать, что индекс, который повысит производительность запросов SELECT, также замедлит различные операции DML, такие как запросы INSERT, UPDATE и DELETE.
Еще одна вещь, которую следует учитывать, — это настройка самого индекса, поскольку индекс, который нормально работал с вашими запросами в прошлом, может не соответствовать запросам сейчас из-за частых изменений в схеме таблицы и самих данных. Это может потребовать удаления индекса и создания более эффективного. В следующей статье мы подробно обсудим, как получить информацию об использовании индекса, и решим, нужно ли нам сохранить или удалить этот индекс. С другой стороны, индекс может страдать от проблем фрагментации только из-за очень частого изменения данных, что может быть решено с помощью различных задач обслуживания индекса, подробно обсуждаемых в последней статье этой серии.
Давайте начнем нашу демонстрацию, чтобы понять концепцию настройки производительности на практике. Мы создадим новую базу данных IndexDemoDB, содержащую три таблицы; таблица STD_Info, содержащая информацию о студентах, таблица Courses, содержащая список доступных курсов, и, наконец, таблица STD_Evaluation, которая содержит оценки зарегистрированных студентов на доступных курсах. Таблица STD_Evaluation содержит два внешних ключа; идентификатор студента, который ссылается на таблицу STD-Info, и идентификатор курса, который ссылается на таблицу курсов.Приведенный ниже сценарий T-SQL используется для создания базы данных и таблиц, как описано:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 21 22 23 24 25 26 | СОЗДАТЬ БАЗУ ДАННЫХ IndexDemoDB GO СОЗДАТЬ ТАБЛИЦУ STD_Info (STD_ID INT IDENTITY (1,1) ПЕРВИЧНЫЙ КЛЮЧ, STD_Name VARCHAR (50), CH_Add_BirthDate)GO CREATE TABLE Курсы (Course_ID INT IDENTITY (1,1) PRIMARY KEY, Course_Name VARCHAR (50), Course_MaxGrade INT ) GO STABLE EV_ID INT IDENTITY (1,1),STD_ID INT, Course_ID INT, STD_Course_Grade INT, CONSTRAINT FK_STD_Evaluation_STD_Info ИНОСТРАННЫЙ КЛЮЧ (STD_ID_ID) FOREIGN KEY (STD_ID_ID) FOREIGN KEY (STD_ID)ССЫЛКИ Курсы (Course_ID) ) |
После создания базы данных и таблиц без индекса или ключа, определенного в таблице STD_Evaluation, мы заполним каждую таблицу 100 КБ записями, используя ApexSQL Generate, как показано ниже:
Настройка простого запроса
Чтение из таблицы, не имеющей индекса, похоже на поиск слова в книге путем изучения каждой отдельной страницы в этой книге.Если вы попытаетесь выполнить приведенный ниже запрос SELECT для извлечения данных из таблицы STD_Evaluation после включения статистики TIME и IO и включения плана выполнения, используя оператор T-SQL ниже:
SET STATISTICS TIME ON SET STATISTICS IO ON GO SELECT * FROM [dbo]. [STD_Evaluation] WHERE STD_ID <1530 |
Из плана выполнения, сгенерированного после выполнения запроса, вы увидите, что SQL Server выполнит операцию Table Scan для этой таблицы, проверив все строки таблицы, чтобы проверить, достигают ли эти строки условия WHERE, как показано в плане выполнения ниже. :
Вы также можете видеть из статистики TIME и IO, что запрос выполняется в пределах 655 мс , потребляя 94 мс из времени ЦП, как показано ниже:
Наличие указателя в начале книги позволит читателю быстрее найти свою цель.То же самое относится к таблицам SQL Server; наличие индекса в таблице ускоряет процесс извлечения данных, предоставляя клиенту запрошенные данные за более короткое время, конечно, если индекс спроектирован правильно.
Если мы посмотрим на поверхность предыдущего запроса SELECT и решим добавить индекс в столбец STD_ID, упомянутый в предложении WHERE этого запроса, используя оператор CREATE INDEX T-SQL ниже:
СОЗДАТЬ НЕЗАКЛЮЧЕННЫЙ ИНДЕКС IX_STD_Evaluation_STD_ID НА [STD_Evaluation] (STD_ID) |
Затем выполните тот же оператор SELECT:
ВЫБРАТЬ * ИЗ [dbo].[STD_Evaluation] ГДЕ STD_ID <1530 |
Из плана выполнения, созданного после выполнения запроса, вы увидите, что SQL Server снова выполняет операцию сканирования таблицы, чтобы получить данные из этой таблицы без учета созданного индекса, как показано в плане выполнения ниже:
Проверяя ВРЕМЯ и статистику ввода-вывода запроса, вы увидите, что необходимое время и время ЦП, затраченное на выполнение запроса, не очень далеко от предыдущего оператора SELECT без индексов, с небольшими улучшениями, как показано ниже:
Наличие индекса, созданного для этой таблицы, не означает, что SQL Server обязательно будет его использовать.В некоторых ситуациях SQL Server обнаруживает, что сканирование базовой таблицы происходит быстрее, чем использование индекса, особенно когда таблица небольшая или запрос возвращает большинство записей таблицы.
Давайте еще раз посмотрим на предыдущий план выполнения, вы увидите зеленое сообщение от SQL Server, которое рекомендует индекс для повышения производительности этого запроса на 77,75%. Щелкните правой кнопкой мыши этот план выполнения и выберите параметр Missing Index Details , чтобы отобразить предлагаемый индекс, как показано ниже:
То же предложение индекса можно также найти, запросив sys.dm_db_missing_index_details динамическое представление управления, которое возвращает подробную информацию об отсутствующих индексах, за исключением пространственных индексов, как показано ниже:
ВЫБРАТЬ * ИЗ sys.dm_db_missing_index_details |
В предыдущем запросе будет предложен тот же индекс покрытия с STD_ID, который используется в предложении WHERE запроса в качестве ключа индекса, а остальные возвращенные столбцы в операторе SELECT, столбцы EV_ID, Course_ID и STD_Course_Grade в качестве неключевых столбцов. в предложении INCLUDE оператора создания индекса, показанного ниже:
Мы отбросим неверный индекс, созданный ранее, и создадим новый индекс, предложенный SQL Server, используя сценарий T-SQL ниже:
ИСПОЛЬЗОВАТЬ [IndexDemoDB] GO DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO СОЗДАТЬ НЕЗАКЛЮЧЕННЫЙ ИНДЕКС [IX_STD_Evaluation_STD .[STD_Evaluation] ([STD_ID]) ВКЛЮЧИТЬ ([EV_ID], [Course_ID], [STD_Course_Grade]) GO |
Если вы попытаетесь выполнить тот же оператор SELECT:
ВЫБРАТЬ * ИЗ [dbo]. [STD_Evaluation] ГДЕ STD_ID <1530 |
Затем проверьте план выполнения, созданный после выполнения запроса, вы увидите, что SQL Server выполнит операцию поиска индекса для извлечения данных пользователю, как показано ниже:
Статистика TIME и IO покажет, что время, необходимое для выполнения запроса, уменьшилось с 655 мс до 554 мс, примерно на 15% улучшения после добавления индекса, а потребляемое время ЦП уменьшилось с 94 мс до 31 мс, примерно с 67% улучшение при использовании index.Вы можете представить себе улучшение, которое можно получить в случае больших таблиц, как показано ниже:
Предыдущий некластеризованный индекс создается над таблицей кучи. Мы отбросим ранее созданный некластеризованный индекс, создадим кластерный индекс в столбце EV_ID, а затем снова создадим некластеризованный индекс, используя сценарий T-SQL ниже:
DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO СОЗДАТЬ КЛАСТЕРИРОВАННЫЙ ИНДЕКС IX_Evaluation_EV_ID ON [STD_Evaluation] ([EV_ID]) GO _Evaluation_EV_ID.[STD_Evaluation] ([STD_ID])ВКЛЮЧИТЬ ([EV_ID], [Course_ID], [STD_Course_Grade]) |
Напомним, что мы упоминали в предыдущих статьях этой серии, что некластеризованный индекс будет автоматически перестроен при создании кластерного индекса для таблицы, чтобы указывать на кластерный ключ вместо указания на базовую таблицу. Если мы снова выполним тот же оператор SELECT:
ВЫБРАТЬ * ИЗ [dbo].[STD_Evaluation] ГДЕ STD_ID <1530 |
Вы увидите, что будет создан тот же план выполнения без каких-либо изменений по сравнению с предыдущим, как показано ниже:
Кроме того, статистика ВРЕМЕНИ и ввода-вывода покажет, что время, необходимое для выполнения запроса, и время ЦП, потребляемое запросом, чем-то похоже на предыдущий результат, с небольшим улучшением в сокращении операций ввода-вывода, выполняемых для извлечения данных, из-за для работы с небольшой таблицей, как показано ниже:
Вы также можете подумать о замене некластеризованного индекса кластеризованным индексом в столбце STD_ID, учитывая, что кластерный индекс не содержит предложения INCLUDE.Если мы отбросим все индексы, доступные в этой таблице, и заменим его только одним кластеризованным индексом, используя сценарий T-SQL ниже:
DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO DROP INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] GO CREATE CLUSTERED INDEX_ IX_Evaluation [STD_Evaluation] |
Затем выполните тот же оператор SELECT:
ВЫБРАТЬ * ИЗ [dbo].[STD_Evaluation] ГДЕ STD_ID <1530 |
Из сгенерированного плана выполнения вы увидите, что для получения запрошенных данных будет выполнена операция Clustered Index Seek , как показано ниже:
Без заметного улучшения статистики ВРЕМЕНИ и ввода-вывода, генерируемой при выполнении запроса, в случае нашей небольшой таблицы, как показано ниже:
Настройка сложного запроса
Давайте теперь попробуем настроить выполнение более сложного запроса, который возвращает имя студента, название курса, максимальную оценку за курс и, наконец, оценку студента в этом классе, объединив три ранее созданных таблицы вместе на основе общих столбцов между каждыми двумя таблицами, с учетом того, что таблица STD_Evaluation не имеет индекса , как показано в инструкции SELECT ниже:
SELECT ST.[STD_Name], C. [Course_Name], C. [Course_MaxGrade], EV. [STD_Course_Grade] ОТ [dbo]. [STD_Info] ST ПРИСОЕДИНИТЬСЯ [dbo]. [STD_Evaluation] EV ON ST.STD_ID = EV. [STD_ID] JOIN [dbo]. [Courses] C ON C.Course_ID = EV.Course_ID ГДЕ ST. [STD_ID]> 1500 И C.Course_ID> 320 |
Если вы проверите план выполнения, созданный после выполнения запроса, вы увидите, что из-за того, что STD_Evaluation не имеет индекса, SQL Server будет сканировать все записи таблицы STD_Evaluation для поиска строк, соответствующих условию предложения WHERE, путем выполнение операции сканирования таблицы.Кроме того, в плане выполнения будет отображаться зеленое сообщение, показывающее предлагаемый индекс от SQL Server для повышения производительности запроса, как показано ниже:
Щелкните правой кнопкой мыши этот план выполнения и выберите параметр «Сведения об отсутствующем индексе», чтобы отобразить предлагаемый индекс. Оператор T-SQL, который используется для создания нового индекса, с процентом улучшения производительности, который здесь составляет 82%, будет отображаться в появившемся окне, как показано ниже:
Статистика ВРЕМЕНИ и ввода-вывода, сгенерированная при выполнении предыдущего запроса, показывает, что SQL Server выполняет 310 логических операций чтения в течение 65 мс и потребляет 16 мс из времени ЦП для извлечения данных, как показано ниже:
То же предложение индекса можно также найти, запросив sys.dm_db_missing_index_details динамическое представление управления, которое возвращает подробную информацию об отсутствующих индексах, за исключением пространственных индексов, как показано ниже:
Производительность запроса также можно настроить с помощью комбинации инструментов SQL Server Profiler и Database Engine Tuning Advisor . Щелкните правой кнопкой мыши запрос, который вам удалось настроить, и выберите параметр Trace Query в SQL Server Profiler , как показано ниже:
Будет отображен новый сеанс SQL Server Profiler.Когда вы выполняете настраиваемый запрос, статистика запроса будет захвачена в открытом сеансе SQL Server Profiler, как показано на снимке ниже:
Сохраните предыдущую трассировку, чтобы использовать ее в качестве рабочей нагрузки для помощника по настройке ядра СУБД. В меню Tools среды SQL Server Management Studio выберите параметр Database Engine Tuning Advisor , как показано ниже:
В открывшемся окне помощника по настройке ядра СУБД подключитесь к целевому SQL-серверу, базе данных, из которой запрос будет извлекать данные, и, наконец, выделите файл рабочей нагрузки, содержащий трассировку запроса, затем щелкните
как показано ниже:После успешного завершения операции анализа в созданном отчете будут отображаться рекомендации, включающие индексы и статистику, которые могут повысить производительность запроса, с предполагаемым процентом улучшения.В нашем случае тот же ранее предложенный индекс будет отображаться в отчете с рекомендациями, как показано ниже:
Если мы возьмем оператор CREATE INDEX, предоставленный из предыдущего плана выполнения или из отчета помощника по настройке ядра СУБД, и создадим предложенный индекс для повышения производительности запроса, как в операторе T-SQL ниже:
ИСПОЛЬЗОВАТЬ [IndexDemoDB] GO СОЗДАТЬ НЕКЛЮЧЕНЫЙ ИНДЕКС [IX_STD_Evaluation_Course_ID] ON [dbo].[STD_Evaluation] ([STD_ID], [Course_ID]) ВКЛЮЧИТЬ ([STD_Course_Grade]) GO |
Затем выполните тот же оператор SELECT:
ВЫБРАТЬ СТ. [STD_Name], C. [Course_Name], C. [Course_MaxGrade], EV. [STD_Course_Grade] ОТ [dbo]. [STD_Info] ST JOIN [dbo]. [STD_Evaluation] EV НА ST.STD_ID = EV. [STD_ID] СОЕДИНЕНИЕ [dbo].[Курсы] C ON C.Course_ID = EV.Course_ID ГДЕ ST. [STD_ID]> 1500 И C.Course_ID> 320 |
Из сгенерированного плана выполнения вы увидите, что предыдущая медленная операция сканирования таблицы изменилась на быструю операцию поиска индекса, как показано ниже:
Статистика TIME и IO также показывает, что после создания предложенного индекса SQL Server выполняет только 3 операции логического анализа , по сравнению с 310 логическими операциями чтения перед созданием индекса, с примерно улучшением 91% , в пределах 40 мс , по сравнению с с 65 мс, необходимыми для выполнения запроса перед созданием индекса, с примерно 39% улучшением и потреблением нет процессорного времени по сравнению с 16 мс, затраченными до создания индекса, как четко показано ниже:
Предыдущий некластеризованный индекс создается над таблицей кучи.Мы отбросим ранее созданный некластеризованный индекс, создадим кластерный индекс в столбце EV_ID, а затем снова создадим некластеризованный индекс, используя сценарий T-SQL ниже:
ИСПОЛЬЗОВАТЬ [IndexDemoDB] GO DROP INDEX [IX_STD_Evaluation_Course_ID] ON [dbo]. [STD_Evaluation] GO EVID 9_Evaluation [STD_Evaluation] [9_Evaluation] GO_EEX5000 [9_Evaluation] (GO_EEX5000 9_USTERED) [GO_EX5_INDER 9_Evaluation] СОЗДАТЬ НЕКЛАССНЫЙ ИНДЕКС [IX_STD_Evaluation_Course_ID] ON [dbo].[STD_Evaluation] ([STD_ID], [Course_ID]) ВКЛЮЧИТЬ ([STD_Course_Grade]) GO |
Если вы снова выполните тот же оператор SELECT:
ВЫБРАТЬ СТ. [STD_Name], C. [Course_Name], C. [Course_MaxGrade], EV. [STD_Course_Grade] ОТ [dbo]. [STD_Info] ST JOIN [dbo]. [STD_Evaluation] EV НА ST.STD_ID = EV. [STD_ID] СОЕДИНЕНИЕ [dbo].[Курсы] C ON C.Course_ID = EV.Course_ID ГДЕ ST. [STD_ID]> 1500 И C.Course_ID> 320 |
Будет сгенерирован тот же план выполнения, как показано ниже:
Кроме того, статистика TIME и IO покажет небольшое увеличение количества логических чтений и времени, необходимого для выполнения запроса, поскольку мы работаем с небольшой таблицей, как показано ниже:
В предыдущих статьях этой серии мы упоминали, что порядок сортировки столбцов в ключе индекса должен соответствовать тому же порядку столбцов в запросе, который будет охватывать индекс.Чтобы понять причину с практической точки зрения, давайте рассмотрим два следующих ниже примера.
В ранее созданном индексе порядок сортировки столбцов STD_ID и Course_ID соответствует порядку сортировки по умолчанию ASC . Если мы изменим запрос SELECT для сортировки возвращаемых строк на основе столбцов STD_ID и Course_ID DESC , что полностью противоположно порядку столбцов в индексе, как показано в запросе T-SQL ниже:
SELECT ST.[STD_Name], C. [Course_Name], C. [Course_MaxGrade], EV. [STD_Course_Grade] ОТ [dbo]. [STD_Info] ST ПРИСОЕДИНИТЬСЯ [dbo]. [STD_Evaluation] EV ON ST.STD_ID = EV. [STD_ID] JOIN [dbo]. [Courses] C ON C.Course_ID = EV.Course_ID ГДЕ ST. [STD_ID]> 1500 И C.Course_ID> 320 ORDER BY ST. [STD_ID ] DESC, C. [Course_ID] DESC |
Из сгенерированного плана выполнения вы увидите, что ничего не изменится, за исключением Scan Direction некластеризованного индекса, который будет Backward , который можно просмотреть в окне свойств узла поиска индекса.Это означает, что вместо того, чтобы читать индекс сверху вниз, SQL Server будет читать данные из этого индекса снизу вверх без необходимости повторной сортировки данных, как четко показано ниже:
С минимальными накладными расходами при обратном чтении статистика показана ниже:
Все будет иначе, если изменить запрос для извлечения строк в порядке, очень далеком от порядка сортировки в ключе индекса.Например, если мы изменим запрос SELECT для извлечения данных, отсортированных на основе столбца STD_ID в порядке ASC и на основе столбца Course_ID в порядке DESC, как показано в инструкции T-SQL ниже:
ВЫБРАТЬ СТ. [STD_Name], C. [Course_Name], C. [Course_MaxGrade], EV. [STD_Course_Grade] ОТ [dbo]. [STD_Info] ST JOIN [dbo]. [STD_Evaluation] EV НА ST.STD_ID = EV. [STD_ID] СОЕДИНЕНИЕ [dbo].[Курсы] C ON C.Course_ID = EV.Course_ID ГДЕ ST. [STD_ID]> 1500 И C.Course_ID> 320 ЗАКАЗ ПО ST. [STD_ID] ASC, C. [Course_ID] DESC |
SQL Server не может извлечь выгоду из порядка сортировки столбцов в индексе, поскольку он очень далек от запрошенного порядка в запросе, но все же может извлечь выгоду из индекса для извлечения данных с помощью операции поиска индекса, тогда он должен отсортируйте строки, возвращенные из индекса, используя дорогостоящую операцию Sort , как показано в сгенерированном плане выполнения ниже:
Из статистики TIME видно, что дорогостоящая операция сортировки заметно замедлит выполнение запроса.Вот почему мы постоянно говорим, что действительно важно соответствовать порядку сортировки столбцов в индексе и запросу, который получит выгоду от этого индекса. Дополнительные временные затраты на операцию сортировки четко показаны ниже:
Здесь важно отметить, что индексирование столбцов по отдельности может быть не оптимальным решением для повышения производительности запроса. Предположим, что мы планируем проиндексировать столбцы STD_ID и Course_ID, которые используются в условиях WHERE и JOIN в предыдущем запросе, с учетом того, что таблица STD_Evaluation не имеет индекса , созданного на нем, используя сценарий T-SQL ниже:
СОЗДАТЬ НЕЗАКЛЮЧЕННЫЙ ИНДЕКС [IX_STD_Evaluation_STD_ID] ВКЛ [dbo].[STD_Evaluation] ([STD_ID]) GO СОЗДАТЬ НЕЗАКЛЮЧЕННЫЙ ИНДЕКС [IX_STD_Evaluation_Course_ID] ON [dbo]. [STD_Evaluation] (Course_ID) GO |
Если вы выполните тот же оператор SELECT:
ВЫБРАТЬ СТ. [STD_Name], C. [Course_Name], C. [Course_MaxGrade], EV. [STD_Course_Grade] ОТ [dbo]. [STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID = EV. [STD_ID] JOIN [dbo]. [Courses] C ON C.Course_ID = EV.Course_ID ГДЕ ST. [STD_ID]> 1500 И C. Course_ID> 320 |
Из плана выполнения, созданного после выполнения запроса, вы увидите, что созданные индексы не покрывают предыдущий запрос, который требует от SQL Server выполнения дополнительной операции Key Lookup для получения остальных столбцов, которые не являются включены в созданные индексы из базовой таблицы, как показано ниже:
А дорогостоящие затраты на операцию поиска ключа будут переведены в дополнительные ВРЕМЯ затраты, как показано в статистике ниже:
В этой статье мы реализовали практические советы и рекомендации по созданию индексов, упомянутые в предыдущих статьях этой серии.Staty настроен на следующую статью, в которой мы проверим информацию об индексах, чтобы сохранить полезные индексы и отбросить плохие.
Содержание
Ахмад Ясин (Ahmad Yaseen) — инженер Microsoft по большим данным с глубокими знаниями и опытом в областях SQL BI, администрирования баз данных SQL Server и разработки.Он является сертифицированным специалистом по решениям Microsoft в области управления данными и аналитикой, сертифицированным партнером по решениям Microsoft в области администрирования и разработки баз данных SQL, партнером разработчика Azure и сертифицированным инструктором Microsoft.
Кроме того, он публикует свои советы по SQL во многих блогах.
Посмотреть все сообщения от Ahmad Yaseen
Последние сообщения от Ahmad Yaseen (посмотреть все) Объяснение индексов базы данных— Essential SQL
Индекс базы данных позволяет запросу эффективно извлекать данные из базы данных. Индексы связаны с конкретными таблицами и состоят из одного или нескольких ключей. Из таблицы может быть построено более одного индекса. Ключи — это причудливый термин для значений, которые мы хотим найти в индексе.Ключи основаны на столбцах таблиц. Сравнивая ключи с индексом, можно найти одну или несколько записей в базе данных с одинаковым значением.
Поскольку индекс значительно ускоряет извлечение данных, важно, чтобы для каждой таблицы были определены правильные индексы. Отсутствующие индексы не будут замечены для небольших баз данных, но будьте уверены, когда ваши таблицы увеличатся в размере, запросы будут занимать гораздо больше времени.
Сила индекса базы данных
Однажды я работал с базой данных, для выполнения ряда операций которой потребовалось около восьми дней.Посмотрев на самые длительные запросы и запустив их через генератор плана запросов, мы поняли, что база данных может выиграть от нового индекса. Оптимизатор подсчитал, что стоимость запроса упадет с 300 000 операций до 30! Мы внедрили индекс, и вся операция заняла от восьми дней до двух часов. Излишне говорить, что мы были очень рады увеличению производительности.
А как насчет примера?
В этом примере рассмотрим указатель на обратной стороне книги. Пользоваться им довольно просто.Просто найдите интересующую вас тему, отметьте и пролистайте эти страницы в своей книге.
Ключи к этому указателю — это тематические слова, на которые мы ссылаемся. Записи указателя состоят из номеров ключей и страниц. Клавиши расположены в алфавитном порядке, что позволяет нам очень легко сканировать указатель, находить запись, отмечать страницы, а затем перелистывать книгу на нужные страницы.
Рассмотрим альтернативу. В книге без указателя тематические слова могут быть указаны внизу каждой страницы.При использовании такой системы, чтобы найти интересующий вас предмет, вам придется пролистать всю книгу. Это делает поиск предметов очень медленным!
Только до тех пор, пока вы не дойдете до самого конца книги, вы сможете узнать, что просмотрели каждую страницу по этому предмету.
Сила индекса заключается в том, что он позволяет вам получить более или менее прямой доступ к интересующим вас страницам книги. Фактически, это экономит часы перелистывания страниц!
Колода карт
Считайте, что у вас есть колода из 52 карт: четыре масти, от туза до короля.Если колода перетасовывается в случайном порядке, и я просил вас выбрать восьмерку червей, вам придется пролистывать каждую карту по отдельности, пока не найдете ее. В среднем вам придется пройти половину колоды, а это 26 карт.
А теперь представьте, что мы разделили карты на четыре стопки по мастям, каждая стопка перемешалась случайным образом. Теперь, если бы я попросил вас выбрать восьмерку червей, вы сначала выбрали бы стопку червей, на которую в среднем нужно было бы найти две, а затем пролистали 13 карт.В среднем, чтобы найти семь флипов, всего девять. Это на семнадцать флипов (26-9) быстрее, чем сканирование всей колоды.
Мы могли бы пойти еще дальше и разделить отдельные стопки на две группы (одна от туза до 6, другая от 7 до короля). В этом случае средний поиск уменьшится до 6.
Это мощность индекса. Разделяя и сортируя наши данные по ключам, мы можем использовать метод накопления, чтобы резко сократить количество переворотов, необходимых для поиска наших данных.
Индексы B + Tree используются базами данных
Структура, которая используется для хранения индекса базы данных, называется B + Tree. B + Tree работает аналогично стратегии сортировки карт, о которой мы говорили ранее. В дереве B + ключевые значения разделены на множество меньших стопок. Как следует из названия, сваи, технически называемые узлами, соединены древовидным способом. Что делает B + Tree шипящим, так это то, что для каждой кучи в дереве очень легко и быстро провести сравнение с найденным значением и перейти к следующей куче.Каждая стопка резко уменьшает количество элементов, которые нужно сканировать; на самом деле экспоненциально так.
Таким образом, прогуливаясь по узлам, делая сравнения по пути, мы можем избежать сканирования тысяч записей всего за несколько простых сканирований узлов. Надеюсь, эта диаграмма поможет проиллюстрировать идею…
В приведенном выше примере рассмотрим, что вам нужно получить запись, соответствующую пару «ключ-значение 15». Для этого выполняются следующие сравнения:
- Было определено, что 15 меньше 40, поэтому мы переходим ветвь «До значений <40».
- Поскольку 15 больше 10, но меньше 30, мы переходим по ветви «К значениям> = 10 и <16».
С древовидной структурой B + можно иметь тысячи записей, представленных в дереве, которое имеет относительно мало уровней в своих ветвях. Поскольку количество поисков напрямую связано с высотой дерева, обязательно убедитесь, что все ветви имеют одинаковую высоту. Это распределяет данные по всему дереву, что делает более эффективным поиск данных в любом диапазоне.
Поскольку данные в базе данных постоянно обновляются, важно, чтобы дерево B + сохраняло баланс. Каждый раз, когда записи добавляются, удаляются или обновляются ключи, специальные алгоритмы перемещают данные и значения ключей от блока к блоку, чтобы гарантировать, что ни одна часть дерева не находится более чем на один уровень выше другой.
На самом деле изучение B + Tree очень технически и математически. Если вас интересуют мелкие детали, я бы начал со статьи в Википедии. В реальном примере каждый узел (темно-синий) будет содержать много ключевых значений (светло-синий).Фактически, каждый узел имеет размер блока диска, который традиционно является наименьшим объемом данных, который может быть прочитан с жесткого диска.
Это довольно сложный предмет. Надеюсь, мне было легко понять. Я действительно хотел бы знать. Пожалуйста, оставьте комментарий.
Помните! Я хочу напомнить вам, что если у вас есть другие вопросы, на которые вы хотите ответить, оставьте комментарий или напишите мне в Твиттере. Я здесь, чтобы помочь тебе.
Как создавать и оптимизировать индексы SQL Server для повышения производительности
Индексы имеют первостепенное значение для достижения хорошей производительности базы данных и приложений.Плохо спроектированные индексы и их отсутствие являются основными источниками низкой производительности SQL Server. В этой статье описывается подход к оптимизации индекса SQL-сервера для повышения производительности запросов.
Индекс — это копия информации из таблицы, которая ускоряет извлечение строк из таблицы или представления. Две основные характеристики индекса:
- Меньше, чем таблица — это позволяет SQL Server быстрее выполнять поиск по индексу, поэтому, когда запрос попадает в конкретный столбец в нашей таблице и если этот столбец имеет индекс, SQL Server может выбрать поиск по индексу. вместо поиска по всей таблице, потому что индекс намного меньше, и поэтому его можно сканировать быстрее
- Предварительно отсортировано — это также означает, что поиск может выполняться быстрее, потому что все уже предварительно отсортировано, например, если мы ищем некоторую строку, которая начинается с буквы «Z», SQL Server достаточно умен, чтобы начать поиск с внизу индекса, потому что он знает, где будут критерии поиска
Доступные типы индексов
В целом SQL Server поддерживает множество типов индексов, но в этой статье мы предполагаем, что читатель имеет общее представление о типах индексов, доступных в SQL Server, и перечислит только наиболее часто используемые, которые имеют наибольшее влияние на оптимизацию индекса SQL Server.Общее описание всех типов индексов см. В разделе Типы индексов.
- Clustered — определяет, как данные записываются на диск, например. если таблица не имеет кластеризованного индекса, данные могут быть записаны в любом порядке, что затрудняет доступ к ним SQL Server, однако, если он присутствует, кластерный индекс сортирует и сохраняет строки данных таблицы или представления, обычно в в алфавитном порядке по порядку номеров. Итак, если у нас есть поле идентификатора с кластеризованным индексом, данные будут записаны на диск на основе номера этого идентификатора.Может быть только один способ, которым SQL Server может упорядочить данные физически на диске, и поэтому нам разрешен только один кластеризованный индекс для каждой таблицы. Важно знать, что кластеризованный индекс автоматически создается с первичным ключом.
- Некластеризованный — это наиболее распространенный тип в SQL Server, обычно более одного в одной таблице. Максимальное количество некластеризованных индексов зависит от версии SQL Server, но это число, например, в SQL Server 2016 до 999 на таблицу.В отличие от кластеризованных индексов, которые фактически организуют данные, некластеризованный индекс немного отличается. Лучшей аналогией было бы думать об этом как о книге. Если мы переходим к самому концу книги, обычно есть часть для индексации, которая содержит огромный список тем и указывает, на какой странице они находятся. Типичный сценарий: читатель находит тему / термин и указывает, например, к главе на странице 256. Если читатель переходит на эту страницу, искомая информация оказывается прямо там. Дело в том, чтобы найти его очень быстро, без необходимости просматривать всю книгу в поисках содержимого, и это в основном то, что делает некластеризованный индекс.
- Columnstore — преобразует данные, которые обычно хранятся в столбцах, и преобразует их в строки, что позволяет ядру базы данных выполнять поиск более быстро.Они являются стандартом для хранения и запросов к большим таблицам фактов хранилищ данных.
- Spatial — этот тип индекса обеспечивает возможность более эффективно выполнять определенные операции с пространственными объектами, такими как геометрия и география. Они несколько необычны за пределами специализированных ГИС-систем.
- XML — в соответствии с названием этот тип индекса связан с типом данных XML, и они преобразуют данные XML в табличный формат, что опять же позволяет выполнять поиск по ним быстрее.Есть два типа: первичный и вторичный. Первичный индекс необходим для создания вторичного индекса.
- Полнотекстовый — обеспечивает эффективную поддержку сложных поисков слов и запросов на английском языке в данных символьных строк. Это единственный тип индекса, который позволяет нам выполнять запросы другого типа и находить слова, которые похожи друг на друга или разные формы слова, поэтому, например, если выполняется поиск по единственному слову, индекс также вернет множественное число указанного слова
Создание индекса
Итак, теперь, когда мы получили некоторые базовые знания и общее представление о том, какие индексы используются, давайте посмотрим несколько реальных примеров оптимизации индекса SQL Server с использованием SQL Server Management Studio (SSMS) для создания индекса и, что наиболее важно, более подробно рассмотрим некоторые из них. преимущества производительности индексов.
Перво-наперво нам нужно создать тестовую таблицу и вставить в нее некоторые данные. В следующем примере используется база данных AdventureWorks2014, но вы можете использовать любую базу данных еще и потому, что мы создаем новую таблицу, которую впоследствии можно будет удалить. Выполните приведенный ниже код, чтобы создать новую копию существующей таблицы Person.Address :
ВЫБРАТЬ * INTO Person.AddressIndexTest ОТ Person.Address a;
Мы только что создали новую таблицу под названием Person.AddressIndexTest , и, выполнив запрос, указанный выше, мы скопировали в него 19614 записей, но в отличие от исходной таблицы, вновь созданная таблица не имеет абсолютно никаких индексов:
Поскольку в этой таблице нет индексов, если мы откроем ApexSQL Plan и посмотрим на план выполнения, это будет полное сканирование таблицы (сканирование всех строк из таблицы), строка за строкой, возвращая результат, который указанное в операторе Select:
Теперь давайте запросим новые данные в SSMS и посмотрим, как мы можем анализировать информацию, возвращаемую в таблице результатов.Перед анализом запросов и тестированием производительности рекомендуется использовать следующий код:
КОНТРОЛЬНАЯ ТОЧКА;
ИДТИ
DBCC DROPCLEANBUFFERS;
DBCC FREESYSTEMCACHE ('ВСЕ');
GO CHECKPOINT и DBCC DROPCLEANBUFFERS просто создают чистое состояние системы. Он будет удалять как можно больше из кеша, потому что при тестировании производительности настоятельно рекомендуется каждый раз начинать с чистого состояния памяти. Таким образом, мы знаем, что какие-либо изменения в производительности не были вызваны кешированием некоторых данных, которые не были кэшированы при предыдущих запусках.
Другой частью того же запроса будет оператор Select, в котором мы возвращаем один столбец из только что созданной таблицы. Но, обернувшись вокруг оператора Select, давайте добавим SET STATISTICS IO для отображения информации, касающейся объема дисковой активности, генерируемой самими операторами T-SQL. Итак, когда мы выполняем оператор, он, конечно, вернет некоторые данные, но интересная часть — это когда мы переключаемся на вкладку Messages , где мы можем увидеть, как таблица была запрошена изнутри:
Как видно, выполняется 339 логических операций чтения и столько же операций упреждающего чтения.Здесь важно знать, что представляют собой эти двое:
- чтения с упреждающим чтением — это когда данные считываются с диска и затем копируются в память (кеш) AKA активность диска
- логических чтений — это когда данные считываются из кеша AKA memory activity
Более простой способ получить ту же информацию — получить фактический план выполнения только оператора Select в ApexSQL Plan, а затем переключиться на вкладку чтения ввода-вывода.Не забывайте всегда очищать кеш, иначе вы можете увидеть ноль операций упреждающего чтения. Почему? Поскольку мы уже выполнили оператор Select один раз в SSMS, и после этого SQL Server обращается к данным из кеша:
Теперь давайте создадим индекс для таблицы, а затем снова запустим тот же запрос, и количество чтений должно быть меньше. Самый простой способ создать индекс — перейти в обозреватель объектов, найти таблицу, щелкнуть ее правой кнопкой мыши, перейти к Новый индекс и затем щелкнуть команду Некластеризованный индекс :
Это откроет окно Новый индекс , в котором мы можем нажать кнопку Добавить в правом нижнем углу, чтобы добавить столбец к этому индексу:
В этом примере нам нужно добавить в индекс только один столбец, и это тот, который указан в инструкции Select.Итак, выберите столбец таблицы AddressID и нажмите кнопку OK , чтобы продолжить:
Вернемся к новой индексной таблице. На вкладке Ключевые столбцы индекса должен быть столбец, который мы только что добавили (если это не так, переключите страницу, и он появится). SQL Server автоматически выбрал имя для индекса, и при необходимости его можно изменить, но почему бы не использовать значения по умолчанию. Чтобы завершить создание индекса, просто нажмите кнопку OK еще раз:
Как только это будет сделано, давайте запустим тот же самый запрос и снова посмотрим на операции ввода-вывода:
На этот раз мы получили 1 физическое, 13 логических и 11 операций упреждающего чтения, что значительно меньше, чем раньше.Обратите внимание, что мы получили тот же результат, но с гораздо меньшей активностью диска и доступом к кешу при добавлении одного индекса, и SQL Server выполнил запрос этого запроса, но сделал значительно меньше работы. Это почему? Что ж, мы можем взглянуть на несколько вещей, чтобы это объяснить. Сначала перейдем в обозреватель объектов, щелкните правой кнопкой мыши нашу таблицу и выберите Properties :
Это откроет окно свойств таблицы, и если мы переключимся на страницу Storage , появится элемент Data space , который представляет размер данных в таблице в мегабайтах (в данном случае 2.68 МБ), и в первый раз, когда мы выполнили запрос без индекса, SQL Server должен был прочитать каждую строку в таблице, но индекс составляет всего 0,367 МБ. Итак, после того, как мы создали индекс, SQL Server мог выполнить тот же запрос, только прочитав индекс, потому что в этом случае индекс в 7,3 раза меньше, чем фактическая таблица:
Мы также можем посмотреть статистику. Статистика играет важную роль в мире производительности баз данных. После создания индекса SQL Server автоматически создает статистику.Вернитесь в обозреватель объектов, разверните таблицу, разверните папку Statistics и щелкните правой кнопкой мыши статистику с тем же именем, что и ранее созданный индекс, и выберите Properties :
Опять же, это откроет окно свойств статистики, в котором мы можем переключиться на страницу Details , под которой мы видим, что индекс разбит на разные диапазоны:
Вы увидите сотни таких диапазонов в статистике по таблицам, и благодаря им SQL Server знает, находятся ли искомые значения в самом начале, в середине или в конце индекса, и поэтому ему не нужно читать весь индекс.Обычно он начинается с некоторого процента до конца и просто читается до конца.
Итак, эти два фактора: индекс обычно меньше таблицы и тот факт, что статистика ведется по индексу, позволяет SQL Server находить конкретные данные, которые мы ищем, используя меньше ресурсов и быстрее. Имейте в виду, что индексы обеспечивают повышение производительности при чтении данных из базы данных, но они также могут привести к снижению производительности при записи данных.Почему? Просто потому, что при вставке данных в таблицу SQL Server должен будет обновить как значения таблицы, так и значения индекса, увеличивая ресурсы записи. Общее практическое правило — знать, как часто таблица читается и как часто производится запись. Таблицы, которые в основном предназначены только для чтения, могут иметь много индексов, а таблицы, в которые выполняется запись, должны иметь меньше индексов.
Индекс Columnstore
Индекс columnstore — это технология для хранения, извлечения и управления данными с использованием столбчатого формата данных, называемого columnstore.Создание индекса columnstore аналогично созданию обычного индекса. Разверните таблицу в обозревателе объектов, щелкните правой кнопкой мыши папку индекса, и вы увидите два элемента: кластеризованный и некластеризованный индекс хранилища столбцов:
Обе команды открывают одно и то же диалоговое окно нового индекса. Поэтому вместо того, чтобы показывать тот же процесс создания индексов другого типа, давайте посмотрим на существующие индексы Columnstore в нашей пробной базе данных. Теперь мне нравится выполнять запрос снизу к целевой базе данных, и он возвращает список всех индексов для всех пользовательских таблиц из этой базы данных:
ЕГЭ AdventureWorks 2014
ИДТИ
ВЫБЕРИТЕ DB_NAME () как Database_Name,
sc.имя AS Schema_Name,
o.name AS Table_Name,
i.name AS Index_Name,
i.type_desc AS Тип_индекса
ИЗ sys.indexes i
ВНУТРЕННЕЕ СОЕДИНЕНИЕ sys.objects o ON i.object_id = o.object_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ sys.schemas sc ON o.schema_id = sc.schema_id
ГДЕ i.name НЕ ПУСТО
И o.type = 'U'
ЗАКАЗАТЬ ПО ИМЕНИ,
Я печатаю; В таблице результатов отображается имя базы данных, имя схемы, имя таблицы, имя индекса и, что наиболее важно, тип индекса.Прокручивая список индексов вниз, найдите тот, который говорит о некластеризованном хранилище столбцов, и, как мы видим из приведенного ниже примера, он прикреплен к таблице SalesOrderDetail :
Затем давайте запустим запрос Select в ApexSQL Plan и снова не забудьте добавить контрольную точку для очистки буферов:
КОНТРОЛЬНАЯ ТОЧКА;
ИДТИ
DBCC DROPCLEANBUFFERS;
DBCC FREESYSTEMCACHE ('ВСЕ');
ИДТИ
УСТАНОВИТЬ СТАТИСТИКУ IO ON;
ВЫБЕРИТЕ sod.SalesOrderID,
дерьмо.CarrierTrackingNumber
ОТ Sales.SalesOrderDetail sod OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX);
ВЫКЛЮЧИТЬ СТАТИСТИКУ IO; В первый раз мы запустим его с возможностью игнорировать индекс columnstore. Идея заключается в том, чтобы увидеть, какую производительность мы получаем, игнорируя индекс, и, как показано ниже, мы получили: число сканирований 1, 1246 логических чтений, 3 физических чтения и 1242 чтения с упреждающим чтением:
Мы уже знаем, что представляют собой эти операции ввода-вывода, но давайте просто закомментируем вариант игнорирования индекса columnstore и посмотрим, что произойдет:
Итак, на этот раз будет использоваться индекс, и вместо активности диска и памяти, которые мы имели ранее, на этот раз мы получили 218 логических операций чтения, 3 физических чтения и 422 чтения с упреждающим чтением:
Таким образом, мы снизились с 1200 операций упреждающего чтения до 400, что означает, что SQL Server выполняет на 66% меньше работы.
- LOB читает — вы увидите их при чтении разных типов данных
Как это работает? Индекс columnstore принимает данные, которые обычно хранятся в столбцах, а вместо этого сохраняет их в строках. В этом случае мы искали информацию, хранящуюся в двух столбцах: SalesOrderID и CarrierTrackingNumber , но таблица SalesOrderDetail имеет 9 дополнительных столбцов. Без индекса columnstore SQL Server должен прочитать все детали каждой строки, чтобы найти те две, которые мы указали.Но с индексом columnstore данные хранятся в строках, а не в столбцах, и поэтому SQL Server должен только читать соответствующие строки и, кроме того, может игнорировать большой процент строк, что в конечном итоге дает нам значительное увеличение оптимизации индекса SQL Server, просто вызывая SQL Server делать меньше работы.
Изучить планы выполнения
Числа могут сбивать с толку, даже если мы знаем, что они обозначают. У ApexSQL Plan есть опция сравнения, которая позволяет сравнивать данные бок о бок, но мне нравится изучать планы выполнения и смотреть на несколько вещей, которые разбивают вещи, чтобы легко понять, что хорошо, а что плохо. даже для начинающего пользователя.
Итак, что я обычно делаю, так это редактирую текст запроса и выполняю два оператора Select в одном запросе, из которого один имеет возможность исключить индекс, а другой — это то, что SQL Server обычно выбирает для выполнения запроса. Таким образом, если мы наведем указатель мыши на первый оператор Select, появится всплывающая подсказка с кодом T-SQL. Как показано ниже, это заставляет план выполнения игнорировать индекс columnstore. Кроме того, он показывает общую стоимость запроса относительно пакета, которая в данном случае составляет 50%.Ниже мы также видим, что он сканирует кластерный индекс полностью или только в диапазоне:
Если мы перейдем к обычному оператору Select, обратите внимание, что стоимость запроса составляет всего 13,6%, что на 36,4% меньше. Глядя на план выполнения, мы также можем убедиться, что на этот раз использовался индекс columnstore. Кроме того, если мы просто посмотрим на столбцы, представляющие визуальный индикатор общей стоимости, стоимости ЦП и затрат ввода-вывода, мы увидим повышение производительности по этому запросу при наличии одного индекса:
Индексы Columnstore были введены в SQL Server 2014 с основным ограничением при добавлении индекса columnstore в таблицу, так как таблица станет доступной только для чтения.К счастью, Microsoft удалила это ограничение в SQL Server 2016, и, начиная с этой версии и более новых, у нас есть функции чтения и записи.
Я надеюсь, что эта статья была для вас информативной, и благодарю вас за то, что вы ее прочитали.
Дополнительные сведения о настройке индекса SQL Server см. В статьях о том, как оптимизировать производительность запросов SQL Server — часть 1 и часть 2.
Полезные ссылки
19 марта 2018 г.Добавление точечного запроса с разными требованиями к индексированию
Добавление точечного запроса с разными требованиями к индексированиюВыбор индекса для запроса диапазона по цене произведено ясный выбор производительности, когда все возможные полезные индексы были считается.Теперь предположим, что этот запрос также должен выполняться для заголовков :
выберите цену из названий где title = "Глядя на лук-порей"
Вы знаете, что существует очень мало повторяющихся заголовков, поэтому это запрос возвращает только одну или две строки.
Рассматривая этот и предыдущий запросы, в таблице 13-3 показаны четыре возможных стратегии индексации и оценка затрат на использование каждого индекса. Оценки для номеров страниц индекса и данных были сгенерированы с использованием фактора заполнения 75 процентов с sp_estspace :
sp_estspace заголовки, 1000000, 75
Значения были округлены для облегчения сравнения.
Возможно выбор индекса | Индексные страницы | Диапазон запроса по цена | Точечный запрос по заголовку | |
|---|---|---|---|---|
1 | Некластеризовано по заголовку Кластер цена | 36 800 650 | Кластерный индекс, около 26 600 страниц (135 000 *.19) с вводом / выводом 16K: 3,125 ввода / вывода | Некластеризованный индекс, 6 операций ввода-вывода |
2 | Сгруппировано по заголовку Некластеризованный на цена | 3 770 6 076 | Сканирование таблицы, 135000 страниц с вводом / выводом 16K: 17500 операций ввода / вывода | Кластерный индекс, 6 входов / выходов |
3 | Некластеризованный на название , цена | 36 835 | Несовпадающее сканирование индекса, о 35,700 страниц с вводом / выводом 16K: 4500 вводов / выводов | Некластеризованный индекс, 5 входов / выходов |
4 | Некластеризованный на цена , титул | 36 835 | Сканирование индекса соответствия, около 6800 страниц (35,700 *.19) с вводом / выводом 16K: 850 вводов / выводов | Несовпадающее сканирование индекса, около 35 700 страницы с вводом / выводом 16K: 4500 вводов / выводов |
Изучение цифр в Таблице 13-3 показывает, что:
Для запрос диапазона по цене , вариант 4 лучший; варианты 1 и 3 приемлемы для ввода / вывода 16K.
Для запроса баллов по заголовкам , варианты индексации 1, 2 и 3 превосходны.
Лучшая стратегия индексации для комбинации этих двух запросы — использовать два индекса:
Вариант 4, для Диапазон запросов по цене .
Вариант 2, для точечных запросов на заголовок , поскольку кластеризованный индекс требует очень мало места.
Вам может потребоваться дополнительная информация, которая поможет вам определить какую стратегию индексирования использовать для поддержки нескольких запросов. Типичный соображения:
Какая частота каждый запрос? Сколько раз в день или в час выполняется запрос?
Каковы требования ко времени ответа? Является одним из них особенно критично по времени?
Каковы требования к времени отклика для обновлений? Замедляет ли создание более одного индекса обновление?
Типичный диапазон значений? Шире или уже диапазон цен, например от 20 до 50 долларов, часто используется? Как разные диапазоны влияют на выбор индекса?
Есть большой кеш данных? Эти запросы критичны достаточно, чтобы обеспечить кеш-память на 35 000 страниц для некластеризованного составного индексы в выборе индекса 3 или 4? Привязка этого индекса к собственному кешу обеспечит очень быструю работу.
Какие еще запросы и какие еще аргументы поиска используются? Часто ли эта таблица соединяется с другими таблицами?
Лучшие практики для запросов и индексирования
Вместе с переходом на Oak в AEM 6 были внесены некоторые серьезные изменения в способ управления запросами и индексами. В Jackrabbit 2 весь контент был проиндексирован по умолчанию и его можно было свободно запрашивать. В Oak индексы должны создаваться вручную под узлом oak: index .Запрос можно выполнить без индекса, но для больших наборов данных он будет выполняться очень медленно или даже прерваться.
В этой статье описывается, когда и когда создавать индексы, а также когда они не нужны, уловки, позволяющие избегать использования запросов, когда они не нужны, а также советы по оптимизации индексов и запросов для максимально оптимального выполнения.
Кроме того, не забудьте прочитать документацию Oak по написанию запросов и индексов. Помимо того, что индексы являются новой концепцией в AEM 6, существуют синтаксические различия в запросах Oak, которые необходимо учитывать при переносе кода из предыдущей установки AEM.
Когда использовать запросы
Дизайн репозитория и таксономии
При разработке таксономии репозитория необходимо учитывать несколько факторов. К ним, среди прочего, относятся элементы управления доступом, локализация, наследование свойств компонентов и страниц.
При разработке таксономии, которая решает эти проблемы, также важно учитывать «проходимость» схемы индексирования. В этом контексте проходимость — это способность таксономии, которая позволяет предсказуемо получать доступ к контенту на основе его пути.Это сделает систему более производительной, которую легче поддерживать, чем систему, которая требует выполнения большого количества запросов.
Кроме того, при разработке таксономии важно учитывать, важен ли порядок. В случаях, когда явное упорядочение не требуется и ожидается большое количество узлов-родственников, предпочтительно использовать неупорядоченный тип узла, например стропу : папка или дуб: неструктурированный . В случаях, когда требуется заказ, более подходящими будут nt: неструктурированный и строп: OrderedFolder .
Запросы компонентов
Поскольку запросы могут быть одной из самых сложных операций, выполняемых в системе AEM, рекомендуется избегать их выполнения в компонентах. Выполнение нескольких запросов каждый раз при отображении страницы часто может снизить производительность системы. Есть две стратегии, которые можно использовать, чтобы избежать выполнения запросов при рендеринге компонентов: обход узлов и предварительная выборка результатов .
Узлы перемещения
Если репозиторий спроектирован таким образом, что позволяет заранее знать местоположение требуемых данных, код, который извлекает эти данные из необходимых путей, может быть развернут без необходимости выполнять запросы для его поиска.
Примером этого может быть рендеринг контента, который соответствует определенной категории. Один из подходов — организовать контент с помощью свойства категории, которое можно запросить для заполнения компонента, отображающего элементы в категории.
Лучшим подходом было бы структурировать этот контент в таксономии по категориям, чтобы его можно было получить вручную.
Например, если контент хранится в таксономии, подобной:
/ content / myUnstructuredContent / parentCategory / childCategory / contentPiece
узел / content / myUnstructuredContent / parentCategory / childCategory может быть просто извлечен, его дочерние элементы могут быть проанализированы и использованы для визуализации компонента.
Кроме того, когда вы имеете дело с небольшим или однородным набором результатов, может быть быстрее пройти через репозиторий и собрать необходимые узлы, чем создавать запрос, возвращающий тот же набор результатов. Как правило, следует избегать запросов, если это возможно.
Предварительная загрузка результатов
Иногда содержание или требования к компоненту не позволяют использовать обход узла как метод получения требуемых данных.В этих случаях требуемые запросы должны быть выполнены до того, как компонент будет отрисован, чтобы обеспечить оптимальную производительность для конечного пользователя.
Если результаты, необходимые для компонента, могут быть вычислены во время его создания и не ожидается, что содержимое изменится, запрос может быть выполнен, когда автор применит настройки в диалоговом окне.
Если данные или контент будут меняться регулярно, запрос может выполняться по расписанию или через прослушиватель для обновлений базовых данных.Затем результаты можно записать в общую папку в репозитории. Любые компоненты, которым нужны эти данные, могут затем извлекать значения из этого единственного узла без необходимости выполнять запрос во время выполнения.
Оптимизация запросов
При выполнении запроса, не использующего индекс, будут регистрироваться предупреждения об обходе узла. Если это запрос, который будет выполняться часто, следует создать индекс. Чтобы определить, какой индекс использует данный запрос, рекомендуется инструмент Explain Query.Для получения дополнительной информации можно включить ведение журнала DEBUG для соответствующих API поиска.
ПРИМЕЧАНИЕ
После изменения определения индекса его необходимо перестроить (переиндексировать). В зависимости от размера индекса это может занять некоторое время.
При выполнении сложных запросов могут быть случаи, когда разбиение запроса на несколько меньших запросов и соединение данных через код постфактум более производительно. В этих случаях рекомендуется сравнить производительность двух подходов, чтобы определить, какой вариант лучше подходит для рассматриваемого варианта использования.
AEM позволяет писать запросы одним из трех способов:
Несмотря на то, что все запросы перед запуском преобразуются в SQL2, накладные расходы на преобразование запросов минимальны, и поэтому наибольшее беспокойство при выборе языка запросов вызывает удобочитаемость и уровень комфорта со стороны команды разработчиков.
ПРИМЕЧАНИЕ
При использовании QueryBuilder он будет определять счетчик результатов по умолчанию, что в Oak медленнее по сравнению с предыдущими версиями Jackrabbit. Чтобы компенсировать это, вы можете использовать параметр guessTotal.
Инструмент запроса «Объяснение»
Как и в случае с любым языком запросов, первым шагом к оптимизации запроса является понимание того, как он будет выполняться. Чтобы включить это действие, вы можете использовать инструмент Explain Query, который является частью панели управления операциями. С помощью этого инструмента можно подключить и объяснить запрос. Будет показано предупреждение, если запрос вызовет проблемы с большим репозиторием, а также со временем выполнения и индексами, которые будут использоваться. Инструмент также может загружать список медленных и популярных запросов, которые затем можно объяснить и оптимизировать.
Ведение журнала DEBUG для запросов
Чтобы получить дополнительную информацию о том, как Oak выбирает, какой индекс использовать и как механизм запросов фактически выполняет запрос, можно добавить конфигурацию ведения журнала DEBUG для следующих пакетов:
- org.apache.jackrabbit.oak.plugins.index
- org.apache.jackrabbit.oak.query
- com.day.cq.search
Не забудьте удалить этот регистратор, когда закончите отладку запроса, так как он будет выводить много активности и в конечном итоге может заполнить ваш диск файлами журнала.
Для получения дополнительной информации о том, как это сделать, см. Документацию по ведению журнала.
Статистика индекса
Lucene регистрирует JMX-компонент, который предоставляет подробную информацию об индексированном содержимом, включая размер и количество документов, присутствующих в каждом из индексов.
Вы можете получить к нему доступ, войдя в консоль JMX по адресу https: // server: port / system / console / jmx
После входа в консоль JMX выполните поиск Lucene Index Statistics , чтобы найти его.Другую статистику индекса можно найти в MBean-компоненте IndexStats .
Для получения статистики запросов взгляните на MBean с именем Oak Query Statistics .
Если вы хотите копаться в своих индексах с помощью такого инструмента, как Luke, вам нужно будет использовать консоль Oak, чтобы выгрузить индекс из NodeStore в каталог файловой системы. Инструкции о том, как это сделать, см. В документации Lucene.
Вы также можете извлечь индексы в вашей системе в формате JSON.Для этого вам необходимо получить доступ к https: // server: port / oak: index.tidy.-1.json
Пределы запросов
В процессе разработки
Установить низкие пороги для дуба .queryLimitInMemory (например, 10000) и дуба. queryLimit Читает (например, 5000) и оптимизирует дорогостоящий запрос при обнаружении исключения UnsupportedOperationException с сообщением «Запрос прочитал более x узлов…»
Это помогает избежать ресурсоемких запросов (т. Е. Не поддержанных каким-либо индексом или менее покрывающих индексов).Например, запрос, считывающий 1 миллион узлов, приведет к увеличению количества операций ввода-вывода и отрицательно повлияет на общую производительность приложения. Любой запрос, который не выполняется из-за вышеуказанных ограничений, должен быть проанализирован и оптимизирован.
После развертыванияДля версий AEM 6.0–6.2 вы можете настроить порог обхода узла с помощью параметров JVM в стартовом скрипте AEM, чтобы предотвратить перегрузку среды большими запросами.
Рекомендуемые значения:
-
-Док.queryLimitInMemory = 500000 -
-Doak.queryLimitReads = 100000
В AEM 6.3 указанные выше 2 параметра являются предварительно настроенными OOTB и могут быть сохранены через OSGi QueryEngineSettings.
Дополнительная информация доступна по адресу: https://jackrabbit.apache.org/oak/docs/query/query-engine.html#Slow_Queries_and_Read_Limits
Советы по созданию эффективных индексов
Должен ли я создать индекс?
Первый вопрос, который следует задать при создании или оптимизации индексов, — действительно ли они необходимы в данной ситуации.Если вы собираетесь запускать рассматриваемый запрос только один раз или только изредка и в непиковое время для системы посредством пакетного процесса, возможно, лучше вообще не создавать индекс.
После создания индекса каждый раз, когда индексированные данные обновляются, индекс также должен обновляться. Поскольку это влияет на производительность системы, индексы следует создавать только тогда, когда они действительно необходимы.
Кроме того, индексы полезны только в том случае, если данные, содержащиеся в индексе, достаточно уникальны, чтобы гарантировать это.Рассмотрим указатель в книге и темы, которые он охватывает. При индексировании набора тем в тексте обычно встречаются сотни или тысячи записей, что позволяет быстро перейти к подмножеству страниц, чтобы быстро найти информацию, которую вы ищете. Если бы в этом указателе было всего две или три записи, каждая из которых указала бы на несколько сотен страниц, указатель был бы не очень полезен. Та же концепция применима к индексам базы данных. Если есть только пара уникальных значений, индекс будет не очень полезен.При этом индекс также может стать слишком большим, чтобы быть полезным. Чтобы посмотреть статистику индекса, см. Статистику индекса выше.
Lucene или индексы собственности?
индексы Lucene были введены в Oak 1.0.9 и предлагают некоторые мощные оптимизации по сравнению с индексами свойств, которые были введены при первоначальном запуске AEM 6. При принятии решения о том, использовать ли индексы Lucene или индексы свойств, примите во внимание следующее:
- Индексы Lucene предлагают гораздо больше возможностей, чем индексы свойств.Например, индекс свойств может индексировать только одно свойство, в то время как индекс Lucene может включать многие. Для получения дополнительной информации обо всех функциях, доступных в индексах Lucene, обратитесь к документации.
- Индексы Lucene асинхронны. Хотя это дает значительный прирост производительности, он также может вызвать задержку между записью данных в репозиторий и обновлением индекса. Если жизненно важно, чтобы запросы возвращали 100% точные результаты, потребуется индекс свойств.
- В силу асинхронности индексы Lucene не могут применять ограничения уникальности. Если это необходимо, то необходимо будет создать индекс собственности.
Как правило, рекомендуется использовать индексы Lucene, если нет острой необходимости в использовании индексов свойств, чтобы получить преимущества более высокой производительности и гибкости.
Индексирование Solr
AEM также по умолчанию поддерживает индексирование Solr. Это в основном используется для поддержки полнотекстового поиска, но его также можно использовать для поддержки любого типа запроса JCR.Solr следует учитывать, когда у экземпляров AEM нет ресурсов ЦП для обработки количества запросов, необходимых в развертываниях с интенсивным поиском, таких как веб-сайты, управляемые поиском, с большим количеством одновременных пользователей. В качестве альтернативы, Solr может быть реализован в виде подхода на основе поискового робота, чтобы использовать некоторые из более продвинутых функций платформы.
ИндексыSolr могут быть настроены для запуска встроенными на сервере AEM для сред разработки или могут быть выгружены на удаленный экземпляр для улучшения масштабируемости поиска в производственной и промежуточной средах.Хотя разгрузка поиска улучшит масштабируемость, она приведет к задержке и по этой причине не рекомендуется, если не требуется. Для получения дополнительной информации о том, как настроить интеграцию Solr и как создавать индексы Solr, см. Документацию Oak Queries and Indexing.
ПРИМЕЧАНИЕ
В то время как использование интегрированного подхода поиска Solr позволило бы выгрузить индексацию на сервер Solr. Если более продвинутые функции сервера Solr используются посредством подхода, основанного на поисковом роботе, потребуются дополнительные работы по настройке.Headwire создала коннектор с открытым исходным кодом, чтобы ускорить внедрение этих типов.
Обратной стороной этого подхода является то, что, хотя по умолчанию запросы AEM будут учитывать списки ACL и, таким образом, скрывать результаты, к которым у пользователя нет доступа, перенос поиска на сервер Solr не будет поддерживать эту функцию. Если поиск должен осуществляться таким образом, необходимо проявлять особую осторожность, чтобы гарантировать, что пользователям не будут представлены результаты, которые они не должны видеть.
Возможные варианты использования, в которых этот подход может быть подходящим, — это случаи, когда данные поиска из нескольких источников могут нуждаться в агрегировании.Например, у вас может быть сайт, размещенный на AEM, а также второй сайт, размещенный на сторонней платформе. Solr можно настроить для сканирования содержимого обоих сайтов и сохранения их в агрегированном индексе. Это позволит выполнять поиск по сайтам.
Рекомендации по проектированию
В документации Oak для индексов Lucene перечислено несколько соображений, которые следует учитывать при разработке индексов:
Если запрос использует другие ограничения пути, используйте
AssessmentPathRestrictions.Это позволит запросу возвращать подмножество результатов по указанному пути, а затем фильтровать их на основе запроса. В противном случае запрос будет искать все результаты, соответствующие параметрам запроса в репозитории, а затем фильтровать их на основе пути.Если в запросе используется сортировка, укажите явное определение свойства для свойства сортировки и установите для него
упорядоченныйравнымtrue. Это позволит упорядочить результаты в индексе и сэкономить на дорогостоящих операциях сортировки во время выполнения запроса.Помещайте в индекс только то, что необходимо. Добавление ненужных функций или свойств приведет к росту индекса и снижению производительности.
В индексе свойств наличие уникального имени свойства помогло бы уменьшить размер индекса, но для индексов Lucene следует использовать миксины
nodeTypesиnodeTypeилимиксинабудет более производительным, чем запросnt: base.При использовании этого подхода определитеindexRulesдляnodeTypes, о которых идет речь.Если ваши запросы выполняются только по определенным путям, создайте эти индексы по этим путям. Индексы не обязательно должны находиться в корне репозитория.
Рекомендуется использовать единый индекс, когда все индексируемые свойства связаны, чтобы позволить Lucene оценить как можно больше ограничений свойств изначально.Кроме того, запрос будет использовать только один индекс даже при выполнении соединения.
CopyOnRead
В случаях, когда NodeStore хранится удаленно, можно включить опцию CopyOnRead . Эта опция приведет к тому, что удаленный индекс будет записан в локальную файловую систему при чтении. Это может помочь повысить производительность запросов, которые часто выполняются по этим удаленным индексам.
Это можно настроить в консоли OSGi с помощью службы LuceneIndexProvider и включено по умолчанию, начиная с версии Oak 1.0,13.
Удаление индексов
При удалении индекса всегда рекомендуется временно отключить индекс, задав для свойства type значение disabled , и провести тестирование, чтобы убедиться, что ваше приложение работает правильно, прежде чем фактически удалять его. Обратите внимание, что индекс не обновляется, когда он отключен, поэтому он может не иметь правильного содержимого, если он снова включен, и может потребоваться переиндексировать.
После удаления индекса свойств в экземпляре TarMK необходимо выполнить сжатие, чтобы освободить все использованное дисковое пространство.Для индексов Lucene фактическое содержимое индекса находится в BlobStore, поэтому потребуется сборка мусора хранилища данных.
При удалении индекса в экземпляре MongoDB стоимость удаления пропорциональна количеству узлов в индексе. Поскольку удаление большого индекса может вызвать проблемы, рекомендуется отключить индекс и удалить его только во время периода обслуживания с помощью такого инструмента, как oak-mongo.js . Обратите внимание, что этот подход не следует использовать для обычного содержимого узлов, так как он может привести к несогласованности данных.
Переиндексация
В этом разделе описаны только приемлемые причины для переиндексации индексов Oak.
Помимо причин, изложенных ниже, инициирование переиндексации индексов Oak , а не , изменит поведение или устранит проблемы, а также непременно увеличит нагрузку на AEM.
Следует избегать повторной индексации индексов Oak, если не указаны причины, указанные в таблицах ниже.
ПРИМЕЧАНИЕ
Перед просмотром приведенных ниже таблиц, чтобы определить, полезна ли переиндексация, ** всегда ** проверяйте:
- запрос правильный
- запрос преобразуется в ожидаемый индекс (с использованием запроса объяснения)
- процесс индексации завершен
Изменения конфигурации индексов дуба
Единственные приемлемые условия без ошибок для повторной индексации индексов Oak — это изменение конфигурации индекса Oak.
К повторной индексации всегда следует подходить с должным учетом ее влияния на общую производительность AEM и выполнять ее в периоды низкой активности или периодов обслуживания.
Следующие подробные сведения о возможных проблемах вместе с решениями:
Изменение определения индекса собственности
Применяется для / если:
Симптомы:
- Узлы, существующие до обновления определения индекса свойств, отсутствуют в результатах
Как проверить:
- Определите, были ли отсутствующие узлы созданы / изменены до развертывания обновленного определения индекса.
- Проверить свойства
jcr: createdилиjcr: lastModifiedлюбых отсутствующих узлов относительно времени изменения индекса
Как решить проблему:
Переиндексировать люценовый индекс
В качестве альтернативы прикоснитесь (выполните безопасную операцию записи) к отсутствующим узлам
- Требуется ручное управление или индивидуальный код
- Требует, чтобы был известен набор отсутствующих узлов
- Требует изменения любого свойства на узле
Изменение определения индекса Lucene
Применяется для / если:
Симптомы:
- Индекс Lucene не содержит ожидаемых результатов
- Результаты запроса не отражают ожидаемое поведение определения индекса
- План запроса не сообщает ожидаемый результат на основе определения индекса
Как проверить:
- Убедитесь, что определение индекса было изменено, используя статистику индекса Lucene JMX Mbean (LuceneIndex), метод
diffStoredIndexDefinition.
- Убедитесь, что определение индекса было изменено, используя статистику индекса Lucene JMX Mbean (LuceneIndex), метод
Как решить проблему:
Ошибочные и исключительные ситуации
В следующей таблице описаны единственные допустимые ошибочные и исключительные ситуации, когда повторное индексирование индексов Oak решит проблему.
Если в AEM возникла проблема, которая не соответствует критериям, описанным ниже, не выполняйте повторную индексацию , а не , поскольку это не решит проблему.
Следующие подробные сведения о возможных проблемах вместе с решениями:
Отсутствует двоичный файл индекса Lucene
Применяется для / если:
Симптомы:
- Индекс Lucene не содержит ожидаемых результатов
Как проверить:
- Файл журнала ошибок содержит исключение о том, что двоичный файл индекса Lucene отсутствует
Как решить проблему:
Выполнить обходную проверку репозитория; например:
http: // localhost: 4502 / system / console / repositorycheck
при просмотре репозитория определяет, отсутствуют ли другие двоичные файлы (кроме файлов lucene)
Если двоичные файлы, отличные от индексов lucene, отсутствуют, восстановите из резервной копии
В противном случае переиндексируйте все индексов люцена
Примечание:
Это состояние указывает на неверно сконфигурированное хранилище данных, которое может привести к ЛЮБОМУ двоичному файлу (например,двоичные файлы активов), чтобы они исчезли.
В этом случае выполните восстановление до последней удачной версии репозитория, чтобы восстановить все недостающие двоичные файлы.
Двоичный файл индекса Lucene поврежден
Применяется для / если:
Симптомы:
- Индекс Lucene не содержит ожидаемых результатов
Как проверить:
Как решить проблему:
Удалите локальную копию индекса lucene
- Остановка AEM
- Удалите локальную копию индекса lucene по адресу
crx-quickstart / repository / index - Перезапустите AEM
Если это не решает проблему, а исключения
AsyncIndexUpdateсохраняются, то:- Переиндексировать индекс ошибок
- Также подайте заявку в службу поддержки Adobe
Как переиндексировать
Переиндексация Индексы собственности
Переиндексация индексов собственности Lucene
Используйте дубовую дорожку.jar для повторной индексации индекса Lucene Property.
Установите для свойства async-reindex значение true в индексе свойства lucene
-
[дуб: queryIndexDefinition] @ reindex-async = true
-
ПРИМЕЧАНИЕ
В предыдущем разделе суммированы и сформулированы рекомендации по повторной индексации Oak из документации Apache Oak в контексте AEM.
Предварительное извлечение текста — это процесс извлечения и обработки текста из двоичных файлов непосредственно из хранилища данных с помощью изолированного процесса и непосредственного подвергания извлеченного текста последующим повторным индексам индексов Oak.
- Предварительное извлечение текста из дуба рекомендуется для повторного / индексирования индексов Lucene в репозиториях с большими объемами файлов (двоичных файлов), содержащих извлекаемый текст (например, PDF-файлы, Word Docs, PPT, TXT и т. Д.), Которые подходят для полнотекстового поиска. поиск по развернутым индексам Oak; например
/ дуб: index / damAssetLucene. - Предварительное извлечение текста принесет пользу только при повторном индексировании индексов Lucene, а НЕ индексах свойств Oak, поскольку индексы свойств не извлекают текст из двоичных файлов.
- Предварительное извлечение текста имеет большое положительное влияние при полнотекстовом переиндексировании двоичных файлов с большим количеством текста (PDF, Doc, TXT и т. Д.), Когда репозиторий изображений не будет иметь такой же эффективности, поскольку изображения не содержать извлекаемый текст.
- Предварительное извлечение текста выполняет извлечение текста, связанного с полнотекстовым поиском, сверхэффективным способом и предоставляет его процессу повторного / индексирования Oak таким образом, чтобы его можно было использовать с максимальной эффективностью.
Повторная индексация существующего люценового индекса с включенной бинарной экстракцией
- Обработка повторной индексации всего контента-кандидата в репозитории; когда двоичных файлов для извлечения полного текста много или они сложны, на AEM возлагается повышенная вычислительная нагрузка для выполнения извлечения полного текста.Предварительное извлечение текста переводит «дорогостоящую вычислительную работу» извлечения текста в изолированный процесс, который напрямую обращается к хранилищу данных AEM, избегая накладных расходов и конфликтов ресурсов в AEM.
Поддержка развертывания нового люценового индекса в AEM с включенным двоичным извлечением
- Когда новый индекс (с включенным двоичным извлечением) развертывается в AEM, Oak автоматически индексирует все возможное содержимое при следующем запуске асинхронного полнотекстового индекса. По тем же причинам, которые описаны выше при повторной индексации, это может привести к чрезмерной нагрузке на AEM.
Предварительное извлечение текста нельзя использовать для нового содержимого, добавляемого в репозиторий, и в этом нет необходимости.
Новое содержимое, добавленное в репозиторий, будет естественно и постепенно индексироваться процессом асинхронного полнотекстового индексирования (по умолчанию каждые 5 секунд).
При нормальной работе AEM, например, при загрузке ресурсов через веб-интерфейс или программном приеме ресурсов, AEM будет автоматически и поэтапно выполнять полнотекстовый индекс нового двоичного содержимого. Поскольку объем данных является инкрементным и относительно небольшим (примерно объем данных, который может быть сохранен в репозитории за 5 секунд), AEM может выполнять полнотекстовое извлечение из двоичных файлов во время индексирования без влияния на общую производительность системы.
Вы будете повторно индексировать lucene-индекс, который выполняет полнотекстовое двоичное извлечение, или развертываете новый индекс, который будет полнотекстовым индексом двоичных файлов существующего контента
Содержимое (двоичные файлы), из которого следует предварительно извлечь текст, должно находиться в репозитории
Окно обслуживания для создания файла CSV И для выполнения окончательной переиндексации
Дуб версия: 1.0.18+, 1.2.3+
дуб-пробег.jarversion 1.7.4+
Папка / общий ресурс файловой системы для хранения извлеченного текста, доступная из индексируемых экземпляров AEM
- Конфигурация OSGi для предварительного извлечения текста требует, чтобы в файловой системе был путь к извлеченным текстовым файлам, поэтому они должны быть доступны непосредственно из экземпляра AEM (локальный диск или монтирование общего файлового ресурса)
Создать список содержимого для предварительного извлечения
Выполните шаг 1 (a-b) во время периода обслуживания / периода низкого использования, поскольку во время этой операции выполняется обход хранилища узлов, что может привести к значительной нагрузке на систему.
1а. Выполните oak-run.jar --generate , чтобы создать список узлов, текст которых будет предварительно извлечен.
1б. Список узлов (1a) сохраняется в файловой системе в виде файла CSV
. Обратите внимание, что выполняется обход всего хранилища узлов (как указано в путях в команде oak-run) каждый раз, когда выполняется --generate , и создается новый CSV-файл . Файл CSV — это , а не , который повторно используется между дискретными выполнениями процесса предварительного извлечения текста (шаги 1-2).
Предварительное извлечение текста в файловую систему
Шаг 2 (a-c) может быть выполнен во время нормальной работы AEM, если он взаимодействует только с хранилищем данных.
2а. Выполните oak-run.jar --tika , чтобы предварительно извлечь текст для двоичных узлов, перечисленных в файле CSV, созданном в (1b)
2б. Процесс, инициированный в (2a), обращается напрямую к двоичным узлам, определенным в CSV в хранилище данных, и извлекает текст.
2с. Извлеченный текст сохраняется в файловой системе в формате, доступном для процесса повторной индексации Oak (3a)
Предварительно извлеченный текст идентифицируется в CSV по двоичному отпечатку пальца.Если двоичный файл одинаков, один и тот же предварительно извлеченный текст может использоваться во всех экземплярах AEM. Поскольку AEM Publish обычно является подмножеством AEM Author, предварительно извлеченный текст из AEM Author также может использоваться для повторного индексации AEM Publish (при условии, что AEM Publish имеет доступ файловой системы к извлеченным текстовым файлам).
Предварительно извлеченный текст может постепенно добавляться с течением времени. Предварительное извлечение текста будет пропускать извлечение для ранее извлеченных двоичных файлов, поэтому рекомендуется сохранить предварительно извлеченный текст на случай, если повторное индексирование должно произойти снова в будущем (при условии, что извлеченное содержимое не слишком велико.Если это так, оцените сжатие содержимого в промежуточный период, так как текст хорошо сжимается).
Повторное индексирование индексов Oak, получение полного текста из файлов извлеченного текста
Выполните повторную индексацию (шаги 3a-b) во время периода обслуживания / низкого использования, поскольку во время этой операции выполняется обход хранилища узлов, что может привести к значительной нагрузке на систему.
3а. Повторное индексирование индексов Lucene вызывается в AEM
3б. Конфигурация OSGi хранилища данных Apache Jackrabbit Oak PreExtractedTextProvider (настроенная так, чтобы указывать на извлеченный текст по пути файловой системы) инструктирует Oak извлекать полнотекстовый текст из извлеченных файлов и избегает прямого обращения к данным, хранящимся в репозитории, и их обработки.
.