Заработок на разработке сайтов, фриланс, своя страничка в интернете, заработать в Интернете на написании сайтов, веб мастер, вебмастер, веб программист, вебпрограммист.
Заработок в Интернет. Удаленная работа на дому. Все о надомной работе.
Неразрывный дефис html: seodon.ru | Спецсимволы HTML
Опубликовано: 27.02.2011 Последняя правка: 16.12.2015
На этой странице вы найдете полные таблицы спецсимволов HTML для создания сайта — математические, денежные символы, стрелки, буквы латинского, греческого и кириллического алфавитов и многое другое. Спецсимволы HTML (мнемоники) — это конструкции SGML ссылающиеся на определенные символы из символьного набора документа. В основном они используются для указания символов, которых нет на стандартной компьютерной клавиатуре либо которые не поддерживает кодировка HTML-страницы (Windows-1251, UTF-8 и т.д.) или конкретный шрифт.
Чтобы разместить символ необходимо указать его мнемонику или код. Обратите внимание на то, что спецсимволы чувствительны к регистру, поэтому указывайте их точно так, как показано. К тому же некоторые из них (довольно немногие) могут не поддерживаться отдельными версиями
популярных браузеров, в этом случае вместо символа вы увидите незакрашенный квадратик. Поэтому перед использованием спецсимволов рекомендуется проверить их на эту поддержку.
Гипертекстовый язык HTML является приложением SGML.
Знак зарегистрированной торговой марки (registered)
ª
ª
ª
Женский порядковый числитель
º
º
º
Мужской порядковый числитель
℘
℘
℘
Заглавная латинская P, мощность, функция Вейерштрасса
ℑ
ℑ
ℑ
Черная заглавная латинская I, мнимая часть комплексного числа
ℜ
ℜ
ℜ
Черная заглавная латинская R, вещественная часть комплексного числа
ℵ
ℵ
ℵ
Символ Алеф, мощность множества (кардинальное число множества)
µ
µ
µ
Знак микро
Карточные символы
Символ
Мнемоника
Код
Описание
♠
♠
♠
Пики
♣
♣
♣
Крести, трилистник
♥
♥
♥
Червы, валентинка
♦
♦
♦
Бубны
Указатели рукой
Символ
Мнемоника
Код
Описание
☚
☚
Рука указывающая влево
☛
☛
Рука указывающая вправо
☜
☜
Контур руки указывающей влево
☝
☝
Контур руки указывающей вверх
☞
☞
Контур руки указывающей вправо
☟
☟
Контур руки указывающей вниз
Прочие символы
Символ
Мнемоника
Код
Описание
·
·
·
Точка посередине
¡
¡
¡
Перевернутый восклицательный знак
¿
¿
¿
Перевернутый вопросительный знак
¦
¦
¦
Разорванная вертикальная линия
§
§
§
Параграф, абзац
¶
¶
¶
Возврат каретки, абзац
†
†
†
Крест, кинжал
‡
‡
‡
Двойной кинжал
•
•
•
Маленький черный кружок
‰
‰
‰
Промилле
′
′
′
Минуты, фут
″
″
″
Секунды, дюйм
‾
‾
‾
Верхняя черта
⌈
⌈
⌈
Левая скобка загнутая сверху
⌉
⌉
⌉
Правая скобка загнутая сверху
⌊
⌊
⌊
Левая скобка загнутая снизу
⌋
⌋
⌋
Правая скобка загнутая снизу
〈
⟨
〈
Левая угловая скобка
〉
⟩
〉
Правая угловая скобка
◊
◊
◊
Ромб
✓
✓
Галочка
HTML Символьные объекты.
Уроки для начинающих. W3Schools на русском
Зарезервированные символы в HTML должны быть заменены символьными объектами (или сущностями).
Символы, которых нет на вашей клавиатуре, также могут быть заменены объектами.
HTML Символьные объекты (сущности)
Некоторые символы зарезервированы в HTML.
Если вы используете знаки «меньше чем» (<) или «больше чем» (>) в вашем тексте, браузер может смешивать их с тегами.
Символьные объекты используются для отображения зарезервированных символов в HTML.
Символьный объект выглядит так:
&entity_name;
OR
entity_number;
Для отображения знака меньше (<) необходимо написать: < или <
Преимущество использования названия объекта:
название объекта легко запомнить. Недостаток использования названия объекта: Браузеры могут не поддерживать все названия символьных объектов, но поддержка чисел хорошая.
Неразрывный пробел
Общим символьным объектом, используемым в HTML, является неразрывный пробел:
Неразрывный пробел — это пробел, который не продолжится в новой строке.
Два слова, разделенные неразрывным пробелом, будут слипаться (не переходить на новую строку). Это удобно, когда разрыв слов может быть разрушительным.
Примеры:
Другое распространенное использование неразрывного пробела — это предотвращение усечения браузерами пробелов в HTML-страницах.
Если вы напишите в своем тексте 10 пробелов, браузер удалит 9 из них. Чтобы добавить реальные пробелы в ваш текст, вы можете использовать символьный объект .
Неразрывный дефис (‑) позволяет использовать символ дефиса (‑), который не будет разрываться.
Примечание: Названия объектов чувствительны к регистру.
Объединение диакритических знаков
Диакритический знак — это «глиф», добавленный к букве.
Некоторые диакритические знаки, такие как важность ( ̀) и ударение ( ́) называются акцентами.
Диакритические знаки могут появляться как над, так и под буквой, внутри буквы и между двумя буквами.
Диакритические знаки могут использоваться в соединении с буквенно-цифровыми символами для создания символа, который отсутствует в наборе символов (кодировке), используемом на странице.
Вот несколько примеров:
Знак
Символ
Конструкция
Результат
̀
a
à
à
́
a
á
á
̂
a
â
â
̃
a
ã
ã
̀
O
Ò
Ò
́
O
Ó
Ó
̂
O
Ô
Ô
̃
O
Õ
Õ
Вы увидите больше HTML символов в следующей главе этого учебника на нашем сайте W3Schools на русском.
Нет разрыва строки после дефиса
Вы также можете сделать ее «столяр как-то» вставить » и`у+2060 слово Столяр и».
Если принять-кодировка допускает, сам символ Юникода может быть **вставляется непосредственно в выходной HTML.
В противном случае, оно может быть сделано с помощью кодирования сущности. Е. Г. присоединиться к красно-коричневый текст, Используйте:
или (десятичный эквивалент):
. Еще один полезный символ и»У+FЭФФ нулевой ширины-брейк Space«[ 1 ]:
и (десятичный эквивалент):
<суп> [1]: Обратите внимание, что, хотя этот способ все еще работает в основных браузерах, таких как Chrome, он имеет устарел, так как Unicode 3.2.
в </SUP и ГТ;
Сравнение с «столяр как-то» с «неразрывный от U+2011 дефис и»:
Слово Joiner может быть использован для всех других персонажей, а не просто черточки.
Когда использовать слово «столяр», большинство рендеров будет растрировать текст одинаково. На Chrome, Firefox и в IE, и опера, оказание нормальные дефисы, например:
. (Степень различия зависит от браузера и шрифтов-зависимые. Е. Г. при использовании декларации шрифта » иАриалв лице», Firefox и ИЕ11 показывают относительно большие различия, в то время как Chrome и Opera показывают небольшие вариации.)
Сравнение с «столяр путь» С в <промежуток класс=С1></службы> (Усс . С1 {белый-пространство:без переноса;}) и в <заведующий отделением экологии транспортных></заведующий отделением экологии транспортных>:
Слово Joiner может быть использован для ситуаций, когда использование HTML-тегов ограничено, например, формы на сайтах и форумах.
На Спектре оформление и содержание, Большинство считают слово столяр, чтобы быть ближе к контенту, по сравнению с теги.
<суп>
&бык; как проверено на ОС Windows 8.1 Core 64-разрядные используя:
<БР>&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&бык; т. е. 11.0.9600.18205
<БР>&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&бык; в Firefox 43.0.4
<БР>&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&бык; хром 48.0.2564.109 (официальный выпуск) М (32-бит)
<БР>&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&ампер;усилитель; nbsp;&бык; Опера 35. 0.2066.92
в </SUP и ГТ;
вёрстка текста для публикации на сайте
Как часто вы заходили на сайт в поисках информации и тут же закрывали страницу, потому что материалы ресурса невозможно читать? Слова сливаются в кашу, строчки набегают друг на друга, а взгляд спотыкается о союзы, болтающиеся в конце строки.
Качественные иллюстрации, которые подчеркивают тему статьи, привлекают внимание и заставляют вчитаться в текст. Опрятная, аккуратная вёрстка текста работает на этот же результат, причем для достижения этого результата не потребуется много вложений. Несколько усовершенствований — и материалы будут легче восприниматься читателями и индексироваться поисковиками.
Абзацы и подзаголовки
Первое, что необходимо сделать, если вы готовите к публикации длинный текст — разбить материал на логические части. Озаглавьте каждую часть и оберните каждый заголовок в теги h3, h4 и т.д. — это нравится поисковым системам и облегчает работу над общим стилем статьи.
Разделите каждую часть на абзацы. Деление длинного текста на части задают графику всей статье, акцентируют внимание на логике повествования, дают отдых глазам и цепляют внимание подзаголовками при чтении по диагонали.
Один и тот же текст в двух вёрстках. Какой вариант читается легче?
Мы предлагаем разработку сайтов с помощью CMS или «с нуля». «Нулевые» сайты не опираются на громоздкие и ограниченные CMS, поэтому скорость загрузки страниц выше в 1.5‑2 раза, мы измеряли. В рамках сайта «с нуля» можно сделать всё. Или почти всё.
Помимо этого мы готовы проконсультировать Клиента по вопросу выбора площадки для хостинга сайта, обсудив и прокомментировав все плюсы и минусы планируемого решения.
Сайт — не сайт, если для пользователей поисковых систем он остается невидимым. Мы консультируем наших Клиентов по вопросам продвижения сайта в Сети: регистрации в поисковых системах, SEO‑оптимизации и т.д. Или берем на себя часть этих хлопот. Наш опыт показывает, что текст, написанный профессионалом, — наиболее простой путь опубликовать интересную статью на сайте. А правильно сверстать текст мы вам поможем.
Создание сайта
Мы предлагаем разработку сайтов с помощью CMS или «с нуля». «Нулевые» сайты не опираются на громоздкие и ограниченные CMS, поэтому скорость загрузки страниц выше в 1.5‑2 раза, мы измеряли. В рамках сайта «с нуля» можно сделать всё. Или почти всё.
Развертывание сайта на площадке хостера
Мы готовы проконсультировать Клиента по вопросу выбора площадки для хостинга сайта, обсудив и прокомментировав все плюсы и минусы планируемого решения.
Продвижение в Сети
Сайт — не сайт, если для пользователей поисковых систем он остается невидимым. Мы консультируем наших Клиентов по вопросам продвижения сайта в Сети: регистрации в поисковых системах, SEO‑оптимизации и т.д. Или берем на себя часть этих хлопот.
Консультации пользователей
Консультации сотрудников Клиента по вопросам обновления сайта. Наш опыт показывает, что текст, написанный профессионалом, — наиболее простой путь опубликовать интересную статью на сайте. А правильно сверстать текст мы вам поможем.
Висящие предлоги и союзы
Строка текста, которая заканчиваться одно‑ или двухбуквенными предлогами, союзами и частицами, тяжело читается и смотрится обрезанной. Чтобы избежать этого, двухбуквенные конструкции склеивают неразрывным пробелом со следующим словом. Неразрывный пробел запрещает браузеру переносить предложения на новую строку в месте склейки.
See the Pen nbsp-example by ItCntr (@itcntr) on CodePen.
15 бусинок, 2 июня и 12 км/ч
Правило похоже на предыдущее. Величины и их размерности, предметы и их количество пишут на одной строке, не допуская «подвисания» числительных. Для этого обе графемы склеивают неразрывным пробелом.
See the Pen Moscow Summer by ItCntr (@itcntr) on CodePen.
Неразрывный дефис
Неразрывный дефис ‑ используется, когда нужно запретить разделение дефисных конструкций на две части при переходе с одной строки на другую. В эту категорию попадают, например, составные имена собственные, для которых перенос неуместен в принципе.
See the Pen IT Center by ItCntr (@itcntr) on CodePen.
Тире вместо дефиса
Замена тире дефисом — типографская и грамматическая ошибка, которую заманчиво совершать день за днём: знак дефиса присутствует на любой клавиатуре, а тире нет. Тем не менее если в тексте присутствует длинное тире, его прописывают через код — и проклеивают с предыдущим словом неразрывным пробелом. Исключение составляют случаи, когда тире стоит в начале строки и обозначает прямую речь. В этом случае тире склеивают неразрывным пробелом со следующим словом.
See the Pen Yoda asks by ItCntr (@itcntr) on CodePen.
See the Pen copy-trade by ItCntr (@itcntr) on CodePen.
Кавычки
Кавычки повторяют судьбу длинного тире: правильных кавычек на компьютерной клавиатуре нет, поэтому их проставляют вручную числовыми или буквенными кодами. Кроме того, внешний вид кавычек меняется от языка к языку.
Для текста на русском языке внутренние кавычки оформляются кавычками‑лапками: „”, их коды „, ”, внешние — кавычками‑елочками «» с кодами «, »
Та же пара для англоязычного текста: внутренние кавычки “”, внешние кавычки: ‘’.
See the Pen Nimbus 2000 by ItCntr (@itcntr) on CodePen.
Вместо послесловия
Когда формальные правила вёрстки выполнены, посмотрите на текст как на картинку и оцените графику веб‑страницы. Для этого уменьшите масштаб страницы браузера до 40‑50%. Оцените, как перетекают предложения в абзаце? Как абзацы взаимодействуют друг с другом? Если текст выглядит слишком плотно, поиграйтесь межстрочным интервалом и размером шрифта.
А затем сравните свёрстанную страницу с тем, что было в самом начале. Вам понравится результат.
#www#типографика
Расстановка дефисов, минусов, тире и кавычек / Хабр
Вопросы правильной расстановки дефисов, длинного и короткого тире, знака минуса, кавычек-елочек и кавычек-лапок уже неоднократно поднимались в интернете и на Хабре в частности (см. ссылки ниже). Однако по-прежнему, студенты и аспиранты в своих курсовых и дипломных, диссертациях и авторефератах не уделяют достаточного внимания типографике.
В данной заметке я привожу две таблицы с основными правилами расстановки указанных знаков и отбивок между ними при верстке текстов в системе LaTeX, в которой готовится значительная часть квалификационных работ по физико-математическим специальностям.
Со временем возможно появятся похожие таблички с правилами расстановки пробелов, знаков препинания и по оформлению текста в целом.
Дефисы, минусы и тире
Название
LaTeX
HTML
Примеры употребления (LaTeX)
Дефис (hyphen)
-
-
+7~495~555-55-55
доктор физико-математических наук
док-во существования и единственности
кто-либо, где-то
во-первых, по-русски(точнее, здесь должен стоять неразрывный дефис)
гибридный метод частица-частица\,--\,частица-сетка
Длинное тире (em-dash)
---
— ALT+0151
Отбивается пробелами (от предыдущего символа — неразрывным ~):
Знание~--- сила
Самарский~А.\,А., Николаев~Е.\,С. Методы решения сеточных уравнений.~--- М.: Наука, 1978.
Знак минуса (minus sign)
$-$
− ALT+8722
$3-2=1$
абсолютный ноль~--- это около $-273{,}15$ по Цельсию
Общепринятых правил употребления разделителей в «прочих „диапазонах“» я не нашел,
потому приведенные выше правила для этого случая вывел для себя сам, пользуясь здравым
смыслом и ориентируясь на современные книжные издания высокого качества (изд-во РХД).
Источники и дополнительные ссылки
С. М. Львовский «Набор и вёрстка в LaTeX» (Глава 3. Набор текста — § 1. Специальные типографические знаки — п. 1.1. Дефисы, минусы и тире)
А. А. Лебедев «Ководство» (§ 158. Короткое тире)
А. А. Лебедев «Ководство» (§ 97. Тире, минус и дефис, или Черты русской типографики)
А. А. Лебедев «Ководство» (§ 62. Экранная типографика)
Чёрточки: только ли тире, минус и дефис? / Типографика / Хабрахабр (21 февраля 2008)
Кавычки
Название
LaTeX
HTML
Употребление (LaTeX)
Замечание
Кавычки-«елочки»
<< >>
« » ALT+0171 ALT+0187
В~языке программирования С элементы многомерных массивов располагаются в памяти <<по строкам>>, а в Фортране~--- <<по столбцам>>.
<<Не надо,~--- сказал я.~--- Не надо мерять на деньги>>.~--- <<Да нет, я~пошутил>>,~--- сказал бородатый (А.~Стругацкий, Б.~Стругацкий)
<<А~может быть, трансгрессировать его?>>~--- <<Ну-ну,~--- сказал горбоносый.~--- Это тебе не диван. Ты не Кристобаль Хунта, да и я тоже\ldots>> (А.~Стругацкий, Б.~Стругацкий)
В русскоязычных текстах принято использовать именно этот тип кавычек
Точка и запятая ставятся после закрывающей кавычки, а восклицательный и вопросительный знаки и многоточие — перед ней
Кстати, кавычки не являются частью так называемых «веб-ссылок»
Кавычки-„лапки“ («9-9 – 6-6»)
\glqq \grqq
„ “ ALT+0132 ALT+0147 или ALT+8222 ALT+8220
<<Подробнее об этом вы можете прочитать в~книге А. \,А.~Самарского и~А.\,В.~Гулина \glqq Численные методы\grqq>>,~--- сказал лектор.
В русскоязычных текстах этот тип кавычек принято употреблять в качестве внутренних
Источники и дополнительные ссылки
С. М. Львовский «Набор и вёрстка в LaTeX» (Глава 3. Набор текста — § 1. Специальные типографические знаки — п. 1.2. Кавычки)
А. А. Лебедев «Ководство» (§ 143. Знаки препинания в нестандартных ситуациях)
А. А. Лебедев «Ководство» (§ 104. Кавычки)
А. А. Лебедев «Ководство» (§ 62. Экранная типографика)
Штрихи, штришки и штришочки / Типографика / Хабрахабр (16 мая 2008)
Оформление цитат на сайтах / Типографика / Хабрахабр (22 марта 2008)
Upd. Хабраюзеры neGODnick и monolith рекомендуют
пакет extdash (входит в коллекцию ncctools; см. тж. пакет ncc-latex), в котором вводятся команды, обеспечивающие возможность переноса составных слов, и команды растяжимых полупробелов,
раздел «The Russian Language» документации к babel, описывающий дополнительные варианты тире и дефисов, в том числе кириллическое длинное тире.
И еще пара полезных ссылок от того же
neGODnick
:
Как ставить тире в ворде. Как сделать длинное тире в Ворде
При наборе текстовых документов очень часто возникает необходимость сделать длинное тире. Но, на клавиатуре нет клавиши, которая бы отвечала за данный символ. Поэтому многие пользователи не знают, как это делается.
В данной статье мы рассмотрим сразу 4 способа, которые можно использовать для вставки длинного тире в документ Word. При этом данные способы одинаково актуальны, как для новых Word 2007, 2010, 2013 и 2016, так и для старого Word 2003.
Способ № 1. Использование комбинации клавиш CTRL+ALT+«минус».
Пожалуй самым простым и надежным способом сделать длинное тире в Ворде является комбинация клавиш CTRL+ALT+«минус». Пользоваться данной комбинацией клавиш очень просто. Установите курсор в том месте, где нужно сделать длинное тире, зажмите клавиши CTRL и ALT, и нажмите на кнопку «минус» на дополнительном блоке клавиш (в правой части клавиатуры). В результате в выбранном вами месте будет поставлено длинное тире.
Если нужно вставить не длинное тире, а короткое, то используйте туже комбинацию клавиш, только без ALT. То есть нажимайте просто CTRL+«минус» на дополнительном блоке клавиш.
Способ № 2. Использование комбинации клавиш ALT+X.
О комбинации клавиш ALT+X мы уже рассказывали в . Но, данную комбинацию клавиш можно использовать и для вставки длинного тире. Для этого нужно ввести число «2014» в том месте, где должно быть длинное тире, и после этого нажать комбинацию ALT+X. В результате число «2014» исчезнет, а вместо него появится длинное тире.
Если нужно сделать более короткое тире или дефис, то вместо «2014» используйте число «2013» или «2012».
Способ № 3. Использование клавиши ALT.
Еще один вариант, это ввод кода символа с зажатой клавишей ALT. Для этого установите курсор в том месте, где вы бы хотели сделать длинное тире, после этого зажмите клавишу ALT и не отпуская ее введите число «0151» на дополнительном блоке клавиш (правая часть клавиатуры).
Преимуществом данного способа является, то что он работает не только в Ворде, но и во многих других текстовых редакторах.
Способ № 4. Вставка длинного тире вручную.
Самый медленный и сложный способ, это вставка длинного тире вручную. В Word 2007, 2010, 2013 и 2016 для этого нужно перейти на вкладку «Вставка», нажать на кнопку «Символ» и выбрать вариант «Другие символы».
В Word 2003 для этого нужно открыть меню «Вставка» и выбрать пункт «Символ».
После этого откроется окно со списком всех доступных символов. Здесь нужно перейти на вкладку «Специальные символы».
После чего выбрать длинное тире и нажать на кнопку «Вставить».
Таким образом вы сделаете длинное тире в той точке документа Ворд, где был установлен ваш курсор.
Часто возникает вопрос при написании каких либо статей или курсовых, как поставить тире в ворде или в любом текстовом редакторе. Где находится дефис знают все, поэтому очень часто его и применяют. Хотя определенных правил на это счет нет, но все же лучше использовать тире.
Оказывается, существует 3 разных видов тире (длинное (-), средне (–) и «электронное» (-)) и как минимум 5 способов для их вставки. В данной статье мы разберем не только ситуации для программы Microsoft Word, но также некоторые способы можно будет применять в любом текстовом или HTML документе.
Пять различных способов вставки — выбирайте удобный
1. Автозамена в Word.
Программа Microsoft Office Word по-умолчанию заменяет дефис на тире в следующей ситуации: вы набираете, например, такой текст «Глагол — это » и в тот момент, когда после слова «это» вы поставили пробел, то дефис заменится на тире. То есть, получится: «Глагол — это » .
Автозамена происходит когда у дефиса по бокам пробел, но если это просто слово, где он используется, например слово «где-нибудь», то, конечно же, автозамена не сработает.
2. Использование шестнадцатеричных кодов.
Если автозамены не произошло, то поставить тире можно самостоятельно с помощью набранных цифр и сочетаний клавиш.
В ворде просто набираем цифру 2014 и нажимаем сочетание клавиш alt + x (икс). Цифра 2014 заменится на длинное тире. Цифра 2013 заменится на тире по-короче, а 2012 еще на меньшее.
3. Способ вставки тире для любых текстовых редакторов.
Зажмите клавишу Alt и набираете с помощью цифровой клавиатуры цифры 0151, отпустите клавишу Alt. В том месте куда вы поставили курсор появится знак длинного тире.
Такой способ подойдет даже если вы набираете текст не в программе Microsoft Word, а в любом html-редакторе.
4. Использование горячих клавиш.
Если у вас имеется на клавиатуре дополнительная «цифровая» клавиатура, то вы можете нажать сочетание клавиш Сtrl и «-» (Сtrl и знак минуса) или сочетание клавиш ctrl + alt + «-» (большое тире).
5. Через меню «Вставка символа».
Заходим в меню «Вставка» программы Word
Справа находим кнопку «Символ»
Кликнув по ней выпадет вкладка, на которой нужно выбрать «Другие символы»
Нам откроется окошко с множеством разных символов
Чтобы среди них не искать тире, можно просто перейти на вкладку «Специальные знаки». Выбрать там длинное тире, нажать «вставить» и оно поставиться в вашем документе.
Как оказывается все очень просто. Надеемся что данная статья поможет вам писать ваши тексты еще правильнее.
Большинство пользователей ПК работают с текстовыми редакторами. У каждого из них своя специфика по стилю и интенсивности использования. Кому-то нужен грамотный литературный текст, а кто-то просто передает мысли. Сразу отметим, что в Ворде для ввода дефиса применяются либо несколько клавиш, либо автоматическая настройка вставки длинного тире. При эпизодическом употреблении знака удобнее использовать сочетание клавиш. Если он используется часто, чтобы что-то заменить, то лучше настроить автоматическую вставку. Есть минимум пять способов вставить в Ворд длинное тире.
Первый способ
Он заключается в применении клавиш. Пользователь просто жмет на кнопку клавиатуры с нужной буквой или символом. Для быстрого проведения различных действий в компьютерных программах предусмотрены горячие клавиши. Чтобы вставить длинное тире в Ворде, нужно нажать кнопки Ctrl и Alt. Удерживая их, жмут на значок » – » в правой части клавиатуры. Перед этим проверяют, горит ли индикатор возле кнопки Numlock. Эта функция должна работать.
Второй способ
Этот метод предполагает использование цифрового кода. Печатают цифры 2014. Нажимают левый Alt на клавиатуре и не отпуская жмут Х. Так тоже можно ввести неразрывный дефис в Word.
Третий способ
По принципу он похож на второй. Нужно нажать быструю клавишу Alt, не отпускать и набрать 0151 на цифровой части клавиатуры, убрать палец. Как и в первом способе должна работать функция Numlock.
Четвертый способ
Допустим, пользователь не помнит комбинацию клавиш. Тогда ему надо кликнуть в меню текстового редактора по вкладке «Вставка», затем нажать на «Символ». Во всплывшем окне выбирается пункт «Другие символы». Появится ещё одно окно. В его поле «Шрифт» устанавливается пункт «Обычный текст», а в поле «Набор» — «Знаки пунктуации». Среди появившихся знаков будет несколько тире.
Пятый способ
То есть, напечатать длинное тире в Word довольно просто. Но, если его нужно много раз применять как замену другого символа, то процедура будет неудобной. В таком случае настраивают автозамену. Для этого проделывается тоже, что и в четвертом способе. Затем нужно выделить дефис и кликнуть на кнопку «Автозамена». В поле слева вводятся символы для автоматической замены на длинное тире.
Таким образом, создатели текстового редактора позаботились об удобной вставке интересующего нас пунктуационного знака. Чтобы делать это регулярно, следует запомнить комбинацию клавиш Ctrl + Alt + «Минус» или указанные коды. Четвертый способ неудобный и им нужно пользоваться, если пользователь не знает других. Для настройки замены символов длинным дефисом нужно применять пятый способ.
Правильное использование дефиса и тире зачастую создает путаницу среди писателей, наборщиков и типографов. Этот вопрос, рано или поздно, касается каждого человека — мы пишем и читаем, а неверное использование этих знаков препинания делает текст некрасиво оформленным и искажает вложенную в него смысловую нагрузку. Ответ на вопрос, что такое дефис и тире, разница в их написании и визуальное отличие знаков, помогут каждому более грамотно использовать неповторимый русский язык.
Дефис: длинное тире
Функция дефиса — разделение слова на части . Графически этот орфографический знак короче тире приблизительно в 3 раза.
Как правильно употреблять дефис в русском языке, помогут объемные и полные исключений правила, которые сводятся к перечислению множества частных случаев :
Другие случаи использование дефиса:
Запись частей слова в лингвистических текстах. Например: приставка при- , окончание —ют .
Обозначение важных частей или слогов слова: при-ло-же-ние-е .
В художественных повестях обозначают важность слова произносимого героем: «Внимание, еще раз говорю вни-ма-ни-е… ».
Когда ставится тире в предложении?
Употребление тире в предложениях, также как и дефис, имеет свои правила пунктуации. Наряду с использованием в тексте запятой, которую часто ошибочно ставят в неположенных для этого местах, применение тире имеет следующие особенности :
Между подлежащим и сказуемым.
Выражение предлежащего и сказуемого в именительном падеже: Собака — лучший друг человека .
Подлежащее в именительном падеже, а сказуемое выражено в неопределенной форме: Жизнь прожить — не поле перебежать .
Перед частицами или обобщающим словом.
Частицы это , вот и т.п.: Твердость — это лучшее качество данного материала .
Перед обобщающими словами: Вдумчивость, внимательность и усердность — лучшие качества школьника.
Обозначение количественных пределов.
Временной предел: Варить на медленном огне в течение 20 — 25 минут.
Пространственный предел: Перелет Москва — Тула .
В вышерасположенной таблице описаны случаи, которые наиболее часто встречаются при использовании тире в русском языке.
Также этот знак применяют:
После союзов, для выражения неожиданности: Лег в постель и — моментально заснул .
Между однородными членами: Кто молодец — я молодец !
Обозначение диалогов прямой речи: — Да, я согласен с вами, — сказал Ленин .
Как поставить дефис в ворде?
Практически все пользователи, работающие с операционной системой Windows, для набора текста используют текстовые редакторы Word или OpenOffice.
Рассмотрим, как в первом варианте поставить дефис в тексте:
Дефисоминус . На клавиатуре есть только один символ обозначающий «чёрточку». Расположен он, выше букв «З» и «Х», справа от числа «0». Многие не понимают его истинного значения и часто ставят этот знак в качестве минуса, тире, переноса, дефиса. На самом деле этот символ, своими размерами, стоит ниже минуса и дефиса. Как он обычно и используется? Для тире ставят два — три дефисоминуса подряд. Некрасиво, но если нет технической возможности — подойдет и так.
Неразрывный дефис . Мы выяснили, что для обозначения в документе дефиса используют символ дефосоминус (-) или, как говорят в народе, знак «минус». Но есть простой способ, о котором мало кто знает — использование специальных клавиш для создания неразрывного дефиса (тире). Что для этого нужно сделать? Нажать комбинацию Ctrl+«минус» . Обратите внимание: раскладка клавиатуры должна стоять на английском языке и знак «минус» нажимается на цифровой клавиатуре справа.
Как поставить тире в ворде?
Всех кто полагает, что при помощи тире, минуса и дефиса можно решить все проблемы пунктуации в Word — сильно ошибаются. Но об этом ниже. Сейчас поговорим о тире и как его можно поставить в ворде.
Существуют два вида тире:
Длинное тире — используется в русской типографии.
Короткое тире — его еще называют «средним», используется в западной типографии.
Точно также, существуют три способа (третий самый простой) вставки тире в текст:
Вставка тире при помощи ставки символа .
Устанавливаем курсор в то место, где нужно поставить знак тире:
Выбираем пункт меню Вкладка . Во вкладке ищем надпись Символ .
В появившемся окне выбираем кнопку Другие символы , ищем длинное тире и кликаем Вставить .
Вставка тире посредствам сочетания специальных клавиш:
Длинное тире . Нажимаем клавишу ALT и набираем в цифровом блоке клавиатуры Numpad справа 0151 и отпускаем Alt.
Короткое тире . Аналогично предыдущему пункту, набираем ALT+0150. В обоих случаях раскладка клавиатуры должна быть включена на английский язык.
Автоматическая программная вставка, включена по умолчанию во всех версиях:
Пишем слово.
Нажимаем пробел.
Ставим знак минуса (короткое тире)
Нажимаем пробел снова.
Пишем следующее слово.
Нажимаем клавишу продела еще раз и после этого тире превращается в дефис.
Практика: короткое или длинное тире
Что на практике? Реалии таковы, что около 95% пользователей в качестве тире используют короткий (западный) вариант. Связанно это c двумя особенностями :
Внешний вид . Отечественный вариант многим кажется очень длинным и постоянно бросается в глаза.
Автоматическая замена . Сочетание специальных клавиш — это хорошо. Но не каждый знает о них, а кто знает — введение символов долгое и неблагодарное. С другой стороны, после того как пользователь введет дефисоминус, сделает пробел и напишет следующее слов: происходит автоматическая замена символа на короткое тире.
9 видов горизонтальных чёрточек
Рассмотрим все существующие в типографии горизонтальные чёрточки , от самого короткого дефисоминуса, до самой длинной — горизонтальной черты.
Дефисоминус . Самый короткий, используется как дефис или минус.
Дефис . Для разделения слов на части.
Минус . В математических выражениях.
Цифровая чёрточка . Например, для записи телефонного номера.
Перенос . Перенос слова на следующую строку.
Маркер списка . Используется в ненумерованных списках.
Короткое тире . Стандарт тире использованного во всем мире.
Длинное тире . Русский стандарт тире.
Горизонтальная черта . Аналог длинного тире, который используется на западе в диалогах.
Теперь, во время набора сложного текста или при оформлении праздничной открытки, ни у кого не должно возникнуть сложностей в использовании таких символов как дефис и тире. Разница очевидна: дефис выступает как орфографический знак и ставится в середине словосочетания, тире — пунктуальный знак который ставится между словами.
Видео-урок: как отличать дефис от тире?
В этом ролике Эдуард Краснов проведет короткий ликбез, научить отличать дефис от тире:
Каждый пользователь Хабра, хоть раз напечатавший здесь «пробел-дефис-пробел», может видеть, как дефис магическим образом заменяется на длинное тире. Это сработала автозамена, похожая на ту, что имеется в ворде и других текстовых процессорах.
Что такое длинное тире
Тире, или попросту черточка (dash), бывает трех основных сортов, если не заморачиваться:
Дефис, самая короткая, вводится с клавиатуры.
Длинное тире или EM DASH — это черточка шириной в латинскую M. Вот как в этой фразе.
Среднее тире или EN DASH — черточка шириной в латинскую N. Вот такая: –
Если же заморачиваться, черточек этих существует изрядное множество, со своими традициями, гуру и холиварами. Ну как без них.
По роду деятельности мне приходится иметь дело с типографикой , и чтобы оформлять текст правильно и сразу, не полагаясь на милость железного мозга, нужно уметь вводить с клавиатуры символы, которые ввести нельзя. В частности, то самое длинное тире, которое часто используется в оформлении прямой речи.
Но, как мы знаем: если нельзя, но очень хочется, то можно. Долгое время сидел на Windows, и пользовался для быстрого ввода отсутствующих на клавиатуре символов известной комбинацией: зажатый + серия нажатий на малой (цифровой) клавиатуре. Например, длинное тире вставлялось набором 0151 с зажатым альтом. (Способ работал безотказно на всенародно любимой Хрюше, как сейчас — не знаю, подскажите в каментах.)
Несколько лет назад, когда принял окончательное решение переезжать на Linux, в полный рост встала проблема быстрого ввода типографских символов. Это не только тире, это разного рода типографские кавычки — «елочки» и „лапки”, а еще градусы водки Цельсия °, приближенное равенство ≈ и прочие нужные штуки.
Как водится, полез в интернеты поискать решение. Как водится, нашлось оно сразу.
Клавиша Compose
Этот способ поисковики выдали в большом количестве. Что это такое?
Метод Compose позволяет, нажав и отпустив специально назначенную клавишу, ввести кодовую последовательность символов и получить на экране фантик соответствующий символ.
Например, нажав 1, а потом 2, мы получаем ½. Чтобы получить рекомое длинное тире, следует нажать дефис три раза, и так далее. Учи кодовую таблицу, бро требует запоминания кодовых комбинаций , когда интуитивных, когда не очень.
На роль Compose можно назначить, например, левый Win, он же Super. Или правый, кому как удобно. Впрочем, через какое-то время я почувствовал: некая неуютность метода, ощущаемая вначале, никак не желает рассасываться со временем. Вспоминал стремительный метод выстукивания по цифрам и слегка ностальгировал.
Level 3
Напомню, дело было несколько лет назад. В потоке поисковой выдачи несколько раз встречались упоминания о таинственном третьем уровне, но что это такое, выгуглить сходу не удалось.
И оставался я счастливым нажимателем Compose, пока однажды не полез в дебри настроек клавиатуры моего линукса и не споткнулся там о… слово «level 3»! Оба-на…
(Или оно уже было переведено на русский?.. не помню. Не важно. И — не буду утомлять лирикой, сразу к делу.)
У клавиатуры есть уровни. Первый уровень — когда ты просто нажал клавишу. Например, нажав «А», напечатаешь «а»; нажав «2» — напечатаешь «2».
Второй уровень — когда ты нажал клавишу, зажимая шифт. Тогда, нажав «А», ты напечатаешь «А»; нажав «2» — напечатаешь «@» (в латинской раскладке) или «»» в русской.
Задействовав третий уровень, ты получишь возможность печатать и другие символы, только зажимать надо уже не шифт, а специально назначенную тобой клавишу-модификатор. Для меня удобно переключаться на третий уровень правым Alt. Легко и просто вводить часто используемые кавычки-елочки и длинные тире одной рукой.
Но и это не все! Зажав одновременно шифт и клавишу Level3, мы получим четвертый уровень и еще немножко символов, которые не поместились в логичные, интуитивно ожидаемые места третьего.
Чтобы задействовать эту плюшку, пользователям Linux надо не забыть включить «дополнительные типографские символы» в «разных параметрах совместимости». Ну и, понятно, выбрать клавишу для выбора третьего уровня (или третьего ряда, в зависимости от перевода, level 3, в общем). После чего можно посмотреть и распечатать карту задействованных символов там же в настройках.
А ведь есть и пятый уровень — но с ним пытливый читатель разберется сам; непытливому же оно и не надо вовсе, как мне нашептывает имха.
Фича есть во всех основных DE (пользователям Gnome 3 придется установить твикер). А как же Windows? Оказывается, и там есть такая возможность. Ключевое слово для поиска — «раскладка Бирмана».
Сам я, по понятным причинам, эту софтину не проверял. Буду благодарен толковым комментариям знающих. Внесу.
Итого
И пользователи Linux, и пользователи Windows могут настроить себе раскладку Бирмана, либо задействовать метод Compose, либо и то, и другое, как говаривал Винни-Пух.
Теперь мы можем запросто вводить символы «»-°≈½⅓¼←→, числа в квадрате², в кубе³, и прочую светотень.
И да́же мо́жем невозбра́нно расставля́ть ударе́ния ѓд́е́ п́о́п́а́л́о́!
Upd1:
Камрад подсказывает : конфигурация символов третьего уровня находится в файле /usr/share/X11/xkb/symbols/typo.
Метод Compose для пользователей Windows советует камрад : проект WinCompose на Гитхабе.
Upd2:
Для андроида есть несколько клавиатур, имеющих что-то вроде третьего уровня. По длинному тапу всплывает окошко, в котором можно выбрать дополнительные символы. Я поначалу использовал Hacker»s Keyboard , потом пересел на ее мод Full Keyboard русскоязычного автора.
Оформление дипломной работы в LibreOffice 3.0
Дефис, минус, тире и длинное тире
«Вставка → Специальные символы»
Существует четыре похожие знака: дефис, минус, тире и длинное тире. Здесь они упомянуты в порядке увеличения их длины при начертании.
Правила применения и оформления этих знаков очень разнообразны, поэтому будут рассмотрены только некоторые.
Дефис служит для связи частей слов, для разделения слов, а также в качестве знака переноса. Дефис ничем не отбивается [1, c.97].
В правилах русской пунктуации и в отечественной типографике упоминается единый знак «тире». В терминах компьютерных технологий (пришедших из английской типографики) он соответствует так называемому «длинному тире».
Тире не должно быть в начале строки, за исключением случая перед началом прямой речи и использования тире в качестве маркеров пунктов перечисления в списках.
Тире отбивается пробелами по следующим правилам:
После тире, стоящих в начале абзаца (при прямой речи или в списках), ставится неразрывной пробел обычного размера.
Тире, обозначающее диапазон значений, границы которого заданы числами (1941—1945, XVI—XVII) пробелами не отбивают.
Вокруг всех остальных тире предписывается ставить узкие (2 пункта) пробелы, причём перед тире пробел должен быть неразрывным.
Тире, идущее за запятой или точкой, по академическим правилам набирается без пробела, однако в современных шрифтах такой набор выглядит некрасиво и от этого требования практически отказались.
Короткое тире обычно ставится между цифрами, например: 2–3 кг. Оно не отбивается от предыдущего и последующего знаков [1, c. 97].
Кавычки
«Вставка → Специальные символы»
«Сервис → Параметры автозамены → Национальные»
Кавычки — парный знак препинания, который употребляется для выделения прямой речи, цитат, отсылок, названий литературных произведений, газет, журналов, предприятий, а также отдельных слов, если они включаются в текст не в своём обычном значении, используются в ироническом смысле, предлагаются впервые или, наоборот, как устаревшие, и т. п.
По своему рисунку различают следующие виды кавычек:
В русском языке традиционно применяются французские «ёлочки», а для кавычек внутри кавычек и при письме от руки — немецкие «лапки».
Правильно: Пушкин писал Дельвигу: «Жду „Цыганов“ и тотчас тисну».
Неправильно: ««Цыганы» мои не продаются вовсе», — сетовал Пушкин.
Во вкладке «Сервис → Параметры автозамены → Национальные» можно настроить автозамену кавычек.
Диакритические знаки
«Вставка → Специальные символы»
Диакритические знаки — элементы письменности, модифицирующие начертание знаков и обычно набираемые отдельно. Например: Motӧrhead, Mötley Crüe. Буквы ӧ, ü являются диакритическими знаками.
Ударение
При помощи диакритических знаков можно поставить знак ударения. Для этого нужно установить курсор после символа, над которым необходимо поставить ударение. Далее в меню «Вставка → Специальные символы» выбрать символ ударения «U+0300» или «U+0301».
Вставка неразрывного дефиса (Microsoft Word)
Обратите внимание: Эта статья написана для пользователей следующих версий Microsoft Word: 2007, 2010, 2013, 2016, 2019 и Word в Office 365. Если вы используете более раннюю версию (Word 2003 или более раннюю), этот совет может не работать для вы .Чтобы ознакомиться с версией этого совета, написанного специально для более ранних версий Word, щелкните здесь: Вставка неразрывного дефиса.
Когда Word вычисляет длину строки и переносит текст на следующую строку, он пытается разбить строку на пробел или дефис — тире.Иногда, однако, вы можете не захотеть, чтобы Word разрывал строку на тире. Например, тире используются в телефонных номерах, и вы можете не захотеть, чтобы линия прерывалась в середине телефонного номера.
Ответ на эту дилемму — использовать неразрывные дефисы вместо обычных дефисов, если вы не хотите, чтобы Word разрывал строку по дефису. Для этого удерживайте клавиши Ctrl и Shift при вводе тире (это то же самое, что вводить Ctrl и подчеркивание).В этом случае Word не разорвет линию.
Вы также можете вставить неразрывный дефис, выполнив следующие действия:
Отображение вкладки «Вставка» на ленте.
Щелкните инструмент «Символ» (в группе «Символы»), а затем щелкните «Дополнительные символы». Word отображает диалоговое окно «Символ».
Щелкните вкладку «Специальные символы». (См. Рисунок 1.)
WordTips — ваш источник экономичного обучения работе с Microsoft Word.
(Microsoft Word — самая популярная программа для обработки текстов в мире.)
Этот совет (29) применим к Microsoft Word 2007, 2010, 2013, 2016, 2019 и Word в Office 365. Вы можете найти версию этого совета для старого интерфейса меню Word здесь: Вставка неразрывного дефиса .
Автор Биография
Аллен Вятт
Аллен Вятт — всемирно признанный автор, автор более чем 50 научно-популярных книг и многочисленных журнальных статей. Он является президентом Sharon Parq Associates, компании, предоставляющей компьютерные и издательские услуги. Узнать больше о Аллене …
Выборочная отмена
Вы когда-нибудь задумывались, почему нельзя отменить только одно изменение, сделанное несколькими минутами ранее? Короткий ответ — то, что могло бы получиться…
Узнайте больше
Исправление нечетного поведения сортировки
При сортировке данных, содержащих как числа, так и текст, вы можете не получить в точности ожидаемый результат. Знать …
Узнайте больше
Подсчет сотрудников по классам
Excel очень хорошо умеет считать, даже если они должны соответствовать определенным критериям. Этот совет показывает, как можно …
Узнайте больше
Что такое Smart Cut and Paste
Как правило, редактирование упрощается благодаря функции, которую Word называет умным вырезанием и вставкой.Если хотите, можете повернуть …
Узнайте больше
Выбор текстового блока
В
Word есть интересный способ выделения прямоугольного блока текста без привязки к тому, что может быть …
Узнайте больше
Что такое дефисы и тире
Word предоставляет вам три типа дефисов и два типа дефисов, которые вы можете использовать в своих документах. Понимание …
Узнайте больше
неразрывный дефис — HTML / CSS
Привет.Я обнаружил следующее, пытаясь узнать, существует ли такая вещь, как неразрывный дефис. Судя по всему, у Unicode есть — но это не хорошо поддерживается, особенно в старых браузерах. Кто-то где-то сказал:
В качестве альтернативы вы можете использовать CSS, чтобы объявить класс, имеющий:
..nowrap {white-space: nowrap}
…. а затем заключить составное слово в < / span> (или любой другой подходящий встроенный тег). Вы также можете попробовать {white-space: pre}…
Я не был уверен, где разместить это, потому что часть вопроса касается символьного объекта , который, по-видимому, НЕ определен в html? Однако как насчет идеи CSS без упаковки? На одной из моих страниц www.TheBicyclingGuitarist.net/newstuff.htm я отдаю должное некоторым людям из comp.infosystems.www.authoring.site-design. Я хочу, чтобы дефис между сайтом и дизайном был неразрывным.
Крис Уотсон он же «Велосипедный гитарист»
27 30653
Пт, 12 ноября 2004 г., 18:19:08 GMT, Велосипедный гитарист написал:
Привет.Я обнаружил следующее, пытаясь узнать, существует ли такая вещь , как неразрывный дефис . Судя по всему, Unicode имеет — но это не очень хорошо поддерживается , особенно в старых браузерах. Кто-то где-то сказал:
В качестве альтернативы вы можете использовать CSS для объявления класса, имеющего:
.nowrap {white-space: nowrap}
Вы можете это сделать. Есть и другие решения. Я использую материал, у которого , чтобы оставаться в одной строке . Конечно, W3C-валидатор продолжает предупреждать, что не является допустимым элементом в HTML4.01. Если вы столкнулись с этим ворчанием валидатора, просто напишите свой собственный DTD. Я сделал. Теперь мне очень нравится валидатор ;-).
– PretLetters Webontwerp Zweefvliegen DTD
Пт, 12 ноября 2004 г., 18:19:08 GMT, «Велосипедный гитарист» написал:
Привет.Я обнаружил следующее, когда пытался узнать, существует ли такая вещь, как неразрывный дефис . Судя по всему, Unicode имеет — но это не очень хорошо поддерживается , особенно в старых браузерах. Кто-то где-то сказал:
В качестве альтернативы вы можете использовать CSS для объявления класса, имеющего:
.nowrap {white-space: nowrap}
… а затем обернуть составное слово в (или любой другой подходящий встроенный тег). Вы также можете попробовать {white-space: pre}…
Я не был уверен, где разместить это, потому что часть вопроса касается символьного объекта , который, по-видимому, НЕ определен в html? Однако как насчет идеи CSS без упаковки? На одной из моих страниц www.TheBicyclingGuitarist.net/newstuff.htm я отдаю должное некоторым людям из comp.infosystems.www.authoring.site-design. Я хочу, чтобы дефис между сайтом и дизайном был неразрывным.
Использование пустого пространства CSS: nowrap, похоже, хорошо работает в браузерах, у которых все последние версии .Однако есть небольшой фактор путаницы: спецификация CSS2 говорит, что пробел применяется только к элементам уровня блока. Для white-space: pre это разумно, для white-space: nowrap — глупо. Но разработчики браузеров, похоже, решили проигнорировать эту строку спецификации и сделать что-нибудь разумное. (AFAIK)
— Стивен Полей
http://www.xs4all.nl/~sbpoley/webmatters/
Стивен Поли писал:
Использование пустого пространства CSS: nowrap, кажется, хорошо работает в браузерах, у которых все последние . Да, если включен CSS. Однако есть небольшой фактор путаницы: спецификация CSS2 говорит, что пробел применяется только к элементам уровня блока.
Давно говорили, что это была ошибка, и, вероятно, не хотел этого сказать. Но из-за процессов W3C рекомендация W3C в настоящее время является спецификацией CSS2, но W3C действительно _значает_, что всем следует использовать черновик CSS 2.1 («Предлагаемая рекомендация»).
Формулировка значения свойства также расплывчата, особенно если вы думаете о названии white-space.Дефисы не являются пробелом в курсе .
— — часть вопроса касается сущности персонажа, которая явно НЕ определена в html?
Конструкция — определенно определена в HTML как обозначающая символ NON-BREAKING HYPHEN U + 2011. (Это не символьная сущность, а ссылка на символа.Терминология кажется постоянно запутанной, хотя .)
Но спецификации HTML очень расплывчаты относительно требуемой обработки символов. Несомненно, U + 2011 имеет определенную семантику в Unicode, но требуется ли пользовательским агентам HTML для соблюдения всей семантики символов Unicode ? В спецификациях HTML сказано, как ни странно: «В HTML есть два типа дефисов: простой дефис и мягкий дефис ». http://www.w3.org/TR/html4/struct/text.html#hyphenation
Позже он уточняет, что «простой дефис» означает U + 002D или широко известный «Ascii-дефис» или HYPHEN. -MINUS, чтобы использовать имя Unicode.Этот символ имеет, по определению Unicode, неоднозначную семантику, как предполагает его официальное название Unicode .
Таким образом, очевидно, что настоящий дефис, HYPHEN U + 2010, _не_ дефис в HTML, , и не неразрывный дефис. Верно? А может и нет. Возможно, человек, написавших спецификацию HTML, просто не особо задумывались о семантике символов в целом. Они просто написали короткое, отрывочное и вводящее в заблуждение описание, которое вращается вокруг мягкого дефиса (и упоминает «простой дефис» только для контраста).
Следовательно, тот факт, что несколько браузеров поддерживают неразрывный дефис, не может считаться ошибкой. Более того, это в основном проблема шрифта. Чтобы удовлетворял минимальным требованиям в обработке (что касается рендеринга документов HTML ), браузер просто должен отображать символ, обрабатывая его как обычный графический символ (в отличие от его окончательной обработки «простого дефиса» как разрешающего разрыв строки после него).
В пятницу, 12 ноября 2004 г., Юкка К. Корпела написал:
Конструкция — определенно определена в HTML как обозначающая символ NON-BREAKING HYPHEN U + 2011. (Это не символ , а ссылка на символ. Тем не менее, терминология кажется постоянно запутанной.) Вы тоже это заметили … Но спецификации HTML очень расплывчаты относительно требуемой обработки символов .Конечно, U + 2011 имеет определенную семантику в Unicode, но должны ли пользовательские агенты HTML соблюдать всю семантику символов Unicode? Я думаю, что ответ на этот вопрос — «не совсем». Есть некоторые правила Unicode , которые предназначены для использования в обычном тексте, но не имеют очевидной применимости в исходном «коде» для языка разметки, например, . В спецификациях HTML сказано, как ни странно: «В HTML есть два типа дефисов: простой дефис и мягкий дефис .« http://www.w3.org/TR/html4/struct/text.html#hyphenation Это восходит к RFC1866, не так ли? И разработчики браузеров не восприняли всерьез. указывает, что «простой дефис» означает U + 002D, или хорошо известный «дефис Ascii», или ДЕФИС-МИНУС для использования имени Unicode. Этот символ , по определению Unicode, имеет неоднозначную семантику, поскольку его официальное имя Unicode предлагает. RFC2070 ссылается на iso-10646, а не на Unicode как таковой, но разработки действительно сделали это различие довольно несущественным.По крайней мере, , мы можем надеяться, что они есть. Таким образом, очевидно, что настоящий дефис, HYPHEN U + 2010, _не_ дефис в HTML, , и не неразрывный дефис. Верно? А может и нет. Возможно, человек, написавших спецификацию HTML, просто не особо задумывались о семантике символов в целом. Можно сказать так … Следовательно, тот факт, что несколько браузеров поддерживают неразрывный дефис , не может считаться ошибкой.
И, наоборот, авторы не могут * полагаться * на поведение браузера в этом отношении.
Алан Дж. Флавелл (fl*****@ph.gla.ac.uk) написал: : Пт, 12 ноября 2004 г., Юкка К. Корпела писал:
:> Конструкция — определенно определена в HTML, поскольку обозначает символ :> NON-BREAKING HYPHEN U + 2011. (Это не символьная сущность :>, а символьная ссылка. Терминология кажется постоянно :> запутанной.)
: Вы тоже это заметили …
:> Но спецификации HTML очень расплывчаты. требуемый :> обработка символов.Несомненно, U + 2011 имеет определенную семантику в :> Unicode, но должны ли пользовательские агенты HTML соблюдать всю семантику :> символов Unicode?
: Думаю, ответ «не совсем». Есть несколько правил Unicode :, которые должны действовать в обычном тексте, но не имеют : какой-либо очевидной применимости в исходном «коде» для языка разметки, например, :.
Разумеется, они не применимы ни в каком тексте, кроме случаев, когда приложение выбирает их применимость.
Если вы используете vi для создания файла readme в Юникоде, который содержит арабских символов, то будет ли программист, выводящий файл на консоль, ожидать, что увидит, что арабский идет слева направо или справа налево? (Предполагая, что консоль знала, как обрабатывать кодировку / набор символов в первую очередь ).
Если html-файл, содержащий в основном английский текст, включает абзац, в котором использует символы в диапазоне от U + 0600 до U + 06FF (арабский), то должен ли браузер быть «достаточно умным», чтобы отображать это справа налево?
Каким-то образом, когда браузер распознает разные символы как разных видов дефисов и, следовательно, по-разному форматирует текст, вместо того, чтобы требовать разметки, чтобы сообщить ему, что делать, мне кажется неправильным, но это просто моя импульсивная реакция $ 0 .02 стоит.
Барбара де Зотэ писала:
Есть и другие решения. Я использую то, что должно оставаться в одной строке . Конечно, W3C-валидатор продолжает предупреждать о том, что не является допустимым элементом в HTML4.01. Если вас застукал из-за этого ворчания валидатора, просто напишите свой собственный DTD. Я сделал. Валидатор мне очень понравился ;-).
Вы не должны * никогда * использовать ни при каких обстоятельствах в HTML, даже если вы пишете свое собственное DTD.Это презентационный элемент, поэтому в HTML нет места . Это также проприетарный элемент, созданный либо Netscape, либо IE (я не могу вспомнить какой), что делает его еще хуже.
Вы должны использовать имена семантических классов, которые представляют содержимое, а не то, как он выглядит. . При написании разметки вы должны подумать о том, * почему * контент не должен иметь разрывов или других презентационных функций, а не о том, как он выглядит. Например, со страницы «Велосипедного гитариста», где (а) он не хотел бы, чтобы это закрывалось, в следующем:
комп.infosystems.www.authoring.site-design
Обычно я бы рекомендовал использовать U + 2011 (-, & # x2011; или -), , хотя, очевидно, поддержка старых браузеров является проблемой, но, что более важно, , потому что это — это название группы новостей, в которой используется ДЕФИС-МИНУС, и это имя необходимо понимать, если оно было скопировано и вставлено в программу чтения новостей. Таким образом, использование неразрывного дефиса на самом деле неверно. Я проверил это и написал эту группу новостей, используя неразрывный дефис , а затем скопировал в свою программу чтения новостей.Группу найти не удалось, но как только я заменил ее на обычный дефис, все заработало.
Следовательно, в этом случае кажется, что использование неразрывного дефиса является фактически презентационным, а не семантическим, поэтому я бы разметил это значение следующим образом:
class =» news «> comp.infosystems.www.authoring.site-design
Это имеет то преимущество, что также предоставляет ссылку, которую пользователь может использовать для подписки на группа новостей.
Поскольку это также код, который может использоваться программой чтения новостей для подписки на эту группу новостей, вы также можете разметить его в или даже в в зависимости от контекста, но будет уместно только в том случае, если вы просили читателя ввести текст в свою программу чтения новостей. В этот случай кажется наиболее подходящим.
comp.infosystems.www.authoring.site-design
Если хотите, вы также можете объединить ссылку и , но только один должен иметь.
Наконец, просто примените стиль к .news {...}
- Lachlan Hunt http://lachy.id.au/ http://GetFirefox.com/ Откройте для себя заново Интернет http: / /SpreadFirefox.com/ Зажигание Интернета
Сб, 13 ноя 2004, 03:04:59 GMT, Лахлан Хант писал:
Барбара де Зоте писала:
Есть и другие решения. Я использую то, что должно оставаться в одной строке . Конечно, W3C-валидатор постоянно предупреждает, что - это , недопустимый элемент в HTML4.01. Если вы столкнулись с этим ворчанием валидатора , просто напишите свой собственный DTD. Я сделал. Валидатор очень мне нравится ;-).
Вы не должны * никогда * использовать ни при каких обстоятельствах в HTML, даже если вы пишете свое собственное DTD. Это презентационный элемент, поэтому в HTML нет места . Это также проприетарный элемент, созданный либо Netscape, либо IE (я не могу вспомнить какой), что делает его еще хуже.
Вы должны использовать имена семантических классов, которые представляют содержимое, а не то, как он выглядит. .
Я знаю, и мне наплевать. Иногда можно зайти слишком далеко. Коротко, легко запомнить. Я не вижу причин не использовать его. Нет, любой, кто говорит мне, что является презентационным и / или частным элементом, тоже не является причиной . Иногда я просто использую ват, это практично. или class = "nobreak">? Я предпочитаю первое. Я ненавижу CSS-суп так же сильно, как и тег .
- PretLetters Webontwerp Zweefvliegen DTD
Барбара де Зоте написала:
в субботу, 13 ноября 2004 г., 03:04:59 GMT, Лахлан Хант написал:
* Никогда * не используйте < nobr> ни при каких обстоятельствах в HTML
вы должны использовать имена семантических классов, которые представляют, что такое контент , а не то, как он выглядит. Я знаю, и мне наплевать.
Ну, оставь свои плохие привычки при себе. Не советуйте никому использовать . Иногда можно зайти слишком далеко. Коротко, легко запомнить. Я не вижу причин не использовать его. Нет, кто-то говорит мне, что это презентационный элемент или проприетарный элемент, тоже не повод. Иногда я просто использую ват, это практично. или class = "nobreak">? Я предпочитаю первое. class = "nobreak", на мой взгляд, так же плохо, как и , он ничего не говорит о том, * почему * он так стилизован.Единственное отличие состоит в том, что, по крайней мере, диапазон действителен, поэтому я всегда выбираю его, а не nobr, но , поскольку они редко, если вообще когда-либо, являются единственными вариантами, я всегда использовал бы что-то более семантическое. Я ненавижу CSS-суп так же сильно, как и тег-суп.
Использование - это суп из тегов, так что это просто лицемерие. Хотя я никогда раньше не слышал о CSS-супе, но я предполагаю, что если бы вы не придумали , он бы относился к CSS, заполненному презентационными именами классов и идентификаторами (которые я видел много), а не стилей для семантических элементов, классов и идентификаторов , как и должно быть выполнено таблиц стилей.
- Lachlan Hunt http://lachy.id.au/ http://GetFirefox.com/ Откройте для себя заново Интернет http://SpreadFirefox.com/ Зажигая Интернет
Сб, 13 ноя 2004, 08:59:47 GMT, Лахлан Хант писал:
Барбара де Зоте писала:
В субботу, 13 ноября 2004 г., 03:04:59 GMT, Лахлан Хант писал:
Вы должны * никогда * не используйте ни при каких обстоятельствах в HTML
. Вы должны использовать имена семантических классов, которые представляют, что такое контент , а не то, как он выглядит.Я знаю, и мне наплевать.
Ну, оставь свои плохие привычки при себе. Не советуйте никому использовать .
Вы можете говорить то, что хотите. Я могу сказать то, что хочу сказать. Вы не можете помешать мне сказать то, что я хочу сказать. Это не то, как это работает в группах новостей .
Иногда можно зайти слишком далеко. Коротко, легко запомнить. Я не вижу причин не использовать его. Нет, любой, кто говорит мне, что это презентационный элемент и / или проприетарный элемент, тоже не является причиной. Иногда я просто использую ват, это практично. или class = "nobreak">? Я предпочитаю первое.
class = "nobreak", на мой взгляд, так же плохо, как и , он ничего не говорит о том, * почему * он так оформлен.
Проблема в том, что если вы добавите [white-space: nowrap] (hmpf, кто когда-либо придумал пробелы в первую очередь?) К значимым классам, например ..name для личных имен, которые вы не хотите разбивать на несколько строк, придется повторять снова и снова.Если вы поместите его в класс .nobreak, , вы можете «переработать» этот класс и использовать его с различными другими классами ID и селекторами. Немного уменьшает размер таблицы стилей. Единственная разница в том, что по крайней мере диапазон действителен, Но в том-то и дело: мой :-) Проверка - хорошая привычка видеть, не сделали ли вы ошибок в разметке , но я думаю, что для чего-то еще она переоценена. Это ничего не делает для вас . Браузеру все равно, если вы используете , но он хочет, чтобы вы закрыли этот элемент.Таким образом, проверка для проверки того, является ли закрывающим тегом для всех непустых элементов, в порядке. Так же, как и проверка правильного использования [alt] с , например. , поэтому я всегда предпочитаю nobr, но поскольку они редко, если вообще , являются единственными вариантами, я всегда буду использовать что-то более семантическое. Я могу это понять. Тем не менее, я не вижу большой разницы между и или . Указывает, что содержимое внутри этого элемента должно оставаться вместе семантически.Не только потому, что « красиво выглядит». Если вы читаете вслух, сделайте вдох перед тем, как начать с части , содержащейся в , потому что вы не можете снова остановиться для вдоха до . Таким образом, для меня является семантическим, а не репрезентативным. Я думаю, что некоторые элементы, которые использовались в HTML strict, выбраны несколько произвольно. Например: зачем оставлять и и отказываться от ? (Не отвечайте на это; это реторика.Я видел обсуждение раньше) Почему реализует и и запрещает .
Я хочу, чтобы существовал такой элемент, как . Я использую в основном с именами . Личные имена, адреса. Вам не нужен перерыв между 's и Gravenhage. Семантически вы этого не хотите. Между Лахланом и Хантом тоже не останавливаешься, чтобы перевести дух . Они идут вместе. Если бы было больше элементов, таких как , я бы, вероятно, не использовал .Теперь все, что я говорю своему браузеру , это «эй, это все вместе. Не разбивай это ». И я, , не могу сказать почему. Но опять же, я не могу сказать, почему что-то должно иметь .
Я ненавижу CSS-суп так же сильно, как и тег-суп.
Использование - это тег суп,
Нет. Это элемент HTML. Это не значит, что использовать его для супа. Особенно , так как я считаю его семантическим. , так что это лицемерие.Хотя я никогда раньше не слышал о CSS-супе, но я предполагаю, что если вы его не выдумали, Нет, я не придумывал. Как вы знаете, существует больше групп новостей, чем те, что входят в иерархию ciwa *. , что он будет относиться к CSS, заполненному именами презентационных классов и идентификаторами (которых я видел много), Он ссылается (IIRC) на страницу, где фактическая разметка была заменена загрузками div с причудливыми именами классов, такими как 'main_header' :-) Добавление случайных поможет создать CSS-суп. , а не стили для семантических элементов, классов и идентификаторов, что соответствует тому, как должны выполняться таблицы стилей.
О, но разве вы не видите. Я согласен с этим. Я люблю CSS и пытаюсь постоянно расширять свои познания в CSS. Тем не менее, иногда я просто думаю: нет, не иметь возможности делать это (больше) неправильно. Как в примере с . Я действительно думаю, что предназначен быть таким же семантическим элементом, как и презентационным (например,
и
предназначены быть семантическими,
, но их эффект также является презентационным - в графических браузерах их размер шрифта варьируется). – PretLetters Webontwerp Zweefvliegen DTD
В субботу, 12 ноября 2004 г., Малкольм Дью-Джонс написал:
: Я думаю, что ответ на этот вопрос «не совсем». Есть некоторые правила Unicode :, которые предназначены для использования в обычном тексте, но не имеют: какой-либо очевидной применимости в исходном «коде» для языка разметки , например.
Разумеется, они не применимы ни в каком тексте, за исключением случаев, когда приложение выбирает их применимость. Мне это кажется тавтологией! Если вы используете vi для создания файла readme в Юникоде Но «приложение» здесь - это HTML, и здесь действуют правила HTML. Давайте не будем отвлекаться на обсуждение текстовых редакторов. Агенты клиента (браузеры и другие типы клиентов) не должны составлять свои собственные правила по любому из вопросов, которые кодифицированы соответствующими спецификациями взаимодействия .В тех местах, где в спецификации говорится, что применима семантика Unicode, это должно быть концом дела . Если html-файл, содержащий в основном английский текст, включает параграф , в котором используются символы в диапазоне от U + 0600 до U + 06FF (арабский) , тогда должен ли браузер быть «достаточно умным», чтобы отображать это справа до слева? http://www.w3.org/TR/html401/struct/dirlang.html#h-8.2
Если документ содержит символы с письмом справа налево и если агент пользователя отображает эти символы, агент пользователя должен использовать двунаправленный алгоритм .
Немного любопытная формулировка: браузер не -обязательно- должен поддерживать отображения символов RTL, но если это так, то он -обязательно- реализует алгоритм двунаправленного текста . Почему-то браузер распознает разные символы как разных видов дефисов и, следовательно, по-разному форматирует текст , вместо того, чтобы требовать разметки, чтобы сообщить ему, что делать, кажется мне неправильным
Хммм. Разметка HTML (в первую очередь) не должна сообщать что-либо, «что делать », а скорее заявлять агентам клиента, «что это за штука », чтобы они могли делать с ней все, что уместно.
Несколько случаев, когда HTML, кажется, сообщает агенту клиента, что делать (например, ,
,
), некоторые считают аномалиями в исходном определении HTML .
всего наилучшего
Лахлан Хант написал:
Вы не должны * никогда * использовать ни при каких обстоятельствах в HTML. Вот и снова. Это несколько раз обсуждалось на разных форумах, включая список www-html, и кажется, что подход W3C поддерживает использование специальных символов Unicode.Поэтому вместо того, чтобы говорить a / b , мы должны использовать a / b или эквивалент , используя сами символы в кодировке UTF-8. Помимо того, что - это странный и неуклюжий способ делать простые вещи, он в основном не работает в текущих браузерах . Кроме того, он делегирует задачи разметки на _нижний_ уровень, , а именно на уровень персонажа.
Похоже, вы говорите, что вместо этого нам следует использовать CSS, что на более практично в данной ситуации, но еще более неудобно: нам нужно , чтобы изобрести множество классов, которые вам понравятся, и использовать a / b на ..expression {пробел: nowrap; } Вы должны использовать имена семантических классов, которые представляют содержимое , а не то, как оно выглядит. a / b говорит, что a / b - это единица информации, в которой все символа принадлежат друг другу. Это, безусловно, более семантическое, чем подход W3C , который перемещает нас на уровень персонажа. При написании разметки вы должны подумать о * почему * в контенте не должно быть разрывов Я? Существует огромное количество ситуаций, когда разрывы строк нежелательны.Нужно ли придумывать классы для всех? Настоящая проблема - это то, что они называют «правилами разрыва строки Unicode», которые справедливо позволяют произвольно переносить строки после разных символов. Если нам нужно классифицировать всех выражений, в которых есть специальные символы внутри строк, все становится довольно неестественным. Почему консорциуму Unicode разрешено принимать громоздкое решение о том, что разрыв строки после "/" разрешен (за исключением ряда случаев - правила _ действительно_ беспорядочные), но нам не разрешено просто сказать "нет, не надо" не сломаться здесь "? комп.infosystems.www.authoring.site-design
Обычно я бы рекомендовал использовать U + 2011 (-, & # x2011; или -), хотя, очевидно, поддержка старых браузеров является проблемой, Это не проблема. Он просто не работает в большинстве браузеров. Но, в принципе, одним из возможных решений был бы неразрывный дефис. Не намного лучше и не намного хуже, чем . , но что более важно, потому что это имя группы новостей, в которой использует ДЕФИС-МИНУС, и это имя нужно понимать, если оно было скопировано и вставлено в программу чтения новостей. Вы правы. Аналогичные соображения могут относиться даже к : использование & nbsp; - который повсеместно поддерживается браузерами, но который все еще может вызывать проблемы при операциях вырезания и вставки, например, поскольку по определению является символом, отличным от символа пробела.
Использование позволяет избежать проблемы. Так же как и вместе с white-space: nowrap, _if_ CSS используется, но это более неуклюжий и менее структурированный подход . Следовательно, в этом случае кажется, что использование неразрывного дефиса является фактически презентационным, а не семантическим, Ну, это семантически и семантически неверно в том смысле, что в фактическом имени нет этого символа. class="news"> comp.infosystems.www.authoring.site-design
Это имеет то преимущество, что предоставление ссылки, по которой пользователь может использовать для подписки на группу новостей. На самом деле такие ссылки имеют довольно ограниченную полезность по нескольким причинам, и ссылки через группы Google с использованием http: URL более практичны. Но я отвлекся. В данном случае кажется наиболее подходящим.
Имя компьютерного кода? Я думаю, что это пограничный случай, и я думаю, что вы просто очень свободно интерпретируете семантику , чтобы избежать неизбежного вывода: в подавляющем большинстве случаев реальная альтернатива - это , который по определению лишен семантики _все_ .Так что вы, вероятно, захотите предложить, чтобы атрибуты класса давали некоторую семантику семантически пустым элементам.
«Барбара де Зоте» написала в году.
новости: opshedepfdx5vgts @ dunnet-q4wppud9:
Сб, 13 ноября 2004 г. 08:59:47 GMT, Лахлан Хант написал:
Используя < nobr> is tag суп,
No.Это элемент HTML. Это не значит, что использовать его для супа. Тем более, что считаю это семантическим.
Я бы не назвал это элементом _HTML_. Это часть другого неназванного языка , который понимают многие браузеры :)
Юкка К. Корпела писал:
Лахлан Хант писал:
Вы не должны * никогда * использовать ни при каких обстоятельствах в HTML И снова.Это несколько раз обсуждалось на разных форумах, включая список www-html, и кажется, что подход W3C поддерживает использование специальных символов Unicode. Поэтому вместо того, чтобы говорить a / b , мы должны использовать a / b или эквивалент , используя сами символы в кодировке UTF-8. Помимо того, что - это странный и неуклюжий способ делать простые вещи, он в основном не работает в текущих браузерах . Кроме того, он делегирует задачи разметки на _нижний_ уровень, , а именно на уровень персонажа.
Похоже, вы говорите, что вместо этого нам следует использовать CSS, что на более практично в данной ситуации, но еще более неудобно: нам нужно , чтобы изобрести множество классов, которые вам понравятся, и использовать a / b с .expression {white-space: nowrap; }
Да, верно. Я не вижу в этом проблемы. Если позаботится о том, чтобы количество различных классов не стало неуправляемым, а классы созданы только для тех ситуаций, когда существующей семантики элемента недостаточно, это правильный способ разметки семантического документа. . a / b говорит, что a / b - это единица информации, в которой все символа принадлежат друг другу. Похоже, вы просто пытаетесь применить семантику к элементу, который определен как чисто презентационный. Это, безусловно, более семантическое, чем подход W3C, который перемещает нас вниз на до уровня персонажа. Это зависит от обстоятельств. Некоторые ситуации могут быть более подходящими для разметки с использованием элементов, а другие лучше оставить на уровне персонажа. Я не могу придумать каких-либо конкретных примеров, но уверен, что в таких обстоятельствах могут быть другие.
При написании разметки вы должны думать о * почему * содержимое не должно иметь разрывов
Нужно ли мне?
Да, это правильный способ использования языка семантической разметки. Существует огромное количество ситуаций, когда разрывы строк нежелательны. Нужно ли придумывать классы для всех? Также существует огромное количество ситуаций, когда мне может понадобиться жирный текст. Лучше использовать для всех из них, или я должен правильно пометить их , указав, что это за каждый из них? Настоящая проблема заключается в том, что они называют «правилами разрыва строки Unicode», которые справедливо позволяют произвольно переносить строки после разных символов.Если нам нужно классифицировать всех выражений, в которых есть специальные символы внутри строк, все становится довольно неестественным. Почему консорциуму Unicode разрешено принимать громоздкое решение о том, что разрыв строки после "/" разрешен (за исключением ряда случаев - правила _ действительно_ беспорядочные), но нам не разрешено просто сказать "нет, не надо" не сломаться здесь "? Вы можете сказать это, это просто нужно сказать на уровне презентации . Уровень разметки просто говорит, что это такое, из чего, можно определить, почему и как это представить.
comp.infosystems.www.authoring.site-design
Обычно я бы рекомендовал использовать U + 2011 (â € ', & # x2011; или -), хотя, очевидно, поддержка старых браузеров является проблемой,
Это не проблема. Он просто не работает в большинстве браузеров.
Ну, я бы назвал это проблемой, но на самом деле я просто сослался на точку зрения , сделанную по поводу ее использования Велосипедным гитаристом в его / ее первоначальном вопросе . Но, в принципе, одним из возможных решений был бы неразрывный дефис. Не намного лучше и не намного хуже, чем . В этом случае я согласен.
, но что более важно, потому что это имя группы новостей, в которой используется ДЕФИС-МИНУС, и это имя нужно понимать, если оно было скопировано и вставлено в программу чтения новостей .
Вы правы. Аналогичные соображения могут относиться даже к : использование & nbsp; - который повсеместно поддерживается браузерами, но который все еще может вызывать проблемы при операциях вырезания и вставки, например, поскольку по определению является символом, отличным от символа пробела.
Да, это так, и его следует рассматривать как отдельный символ. Однако, исходя из опыта , копирование неразрывного пробела и вставка в некоторые, но не во все программы , оно действительно рассматривается как обычное пространство, поэтому не похоже, что вызывает столько проблем.
Следовательно, в этом случае кажется, что использование неразрывного дефиса является фактически презентационным, а не семантическим,
Ну, это семантически и семантически неверно в том смысле, что фактическое имя не имеет у меня нет этого персонажа.
С Преимущество также предоставления ссылки, по которой пользователь может использовать для подписки на группу новостей.
На самом деле такие ссылки имеют довольно ограниченную полезность по нескольким причинам, и ссылки через группы Google с использованием http: URL более практичны. Но я отвлекся.
Я нахожу новости: URI более полезны, поскольку при нажатии на один из них автоматически запустит мою программу чтения новостей и откроет группу, но я полагаю, что, вероятно, было бы более практично предоставить оба, и каким-то образом четко укажет на разницу пользователям.
Хотя для такого решения, наверное, стоит принять во внимание целевую аудиторию сайта . Технически мыслящая группа из пользователей компьютеров может найти новости: URI проще и / или более вероятно, что поймут, как получить доступ к новой группе с помощью других средств, если необходимо , но нетехническая группа пользователей этого не сделает, так что больше всего выиграют от ссылки на группы Google.
В этом случае кажется наиболее подходящим.
Имя компьютерного кода? Я думаю, что это пограничный случай, и я думаю, что вы просто очень свободно интерпретируете семантику
Да, это была очень свободная интерпретация, однако очень слабо определен в спецификации .Он просто заявляет, что это фрагмент кода компьютера , и я очень вольно интерпретировал это как контент, который может быть обработан каким-либо значимым образом на компьютере. В этом случае он может быть обработан для подписки или публикации в группе новостей. Я знаю, что это не самая лучшая причина или лучшее объяснение моей причины , и я уверен, что многие не согласятся с этим. , чтобы избежать неизбежного вывода: в подавляющем большинстве случаев реальной альтернативой является , которому по определению недостает семантики _all_ . Как и , в каком-то смысле вы правы. Однако во многих случаях просто требует лучшего использования большего количества семантических элементов и классов там, где это необходимо.
Итак, вы, вероятно, захотите предложить, чтобы атрибуты класса давали некоторую семантику семантически пустым элементам.
Классы могут использоваться для предоставления семантики, определенной автором, даже для семантически пустых элементов. Но следует избегать семантически пустых элементов , где это возможно.
- Lachlan Hunt http: // lachy.id.au/ http://GetFirefox.com/ Откройте для себя Интернет заново http://SpreadFirefox.com/ Зажигая Интернет
Лахлан Хант написал:
a / b говорит, что a / b - это единица информации, в которой все символа принадлежат друг другу. Похоже, вы просто пытаетесь применить семантику к элементу , который определен как чисто презентационный.
Это потому, что вы уже так решили. Подумайте о rmdir / foo по сравнению с rmdir / foo . Разница чисто презентационная? Это то, что думает консорциум Unicode , когда он позволяет разделить первое выражение как rmdir / foo
Это, безусловно, больше семантики, чем подход W3C, который перемещает нас на уровень символов.
Это зависит от обстоятельств. Некоторые ситуации могут быть более подходящими для обозначения с использованием элементов, а другие лучше оставить на уровне персонажа.
Перемещение на уровень символа означает, что презентационные функции были встроены в текстовое содержимое документа. Разве это не хуже, чем , включив его в разметку вокруг контента? Конечно, ситуация может измениться, если мы будем рассматривать проблемы разрыва строки как потенциально принадлежащие логической структуре или семантике . Также существует огромное количество ситуаций, когда мне может понадобиться полужирный текст . Не совсем. Игнорирование заголовков, ячеек таблиц и тому подобного, а также с учетом только встроенного выделения, скорее всего, причина для текста , выделенного жирным шрифтом, - это сильный акцент. Не слишком ли грубая концепция - вопрос интересный, но он соответствует элементу . За исключением небольшого количества особых случаев, - это просто вульгарный способ написания (и следует винить в этом оригинальных дизайнеров HTML - они_ решили сделать логическую альтернативу пять раз как пока имя физической альтернативы). Я считаю новости: URI более полезны, поскольку при нажатии на один из автоматически запускается моя программа чтения новостей. Он не будет запускать программу чтения новостей, если браузер не настроен на использование программы - и это обычно _не_ обрабатывается при любых настройках по умолчанию.
В этом случае кажется наиболее подходящим.
Имя компьютерного кода? Я думаю, что это пограничный случай, и я думаю, что вы просто очень свободно интерпретируете семантику
Да, это была очень свободная интерпретация, однако очень свободно определен в спецификации .
Мы согласны с этим, хотя, возможно, для разных значений «очень». Но причина вашего выбора заключалась в том, что вы чувствовали, что вам _ нужен_ _ любой_ элемент , который вы можете рассматривать как логичный. То есть, пытаясь избежать и , вы бы подобрали практически все, даже элемент , о котором вы бы иначе и не мечтали.
Но это не обязательно плохой выбор. Он просто заявляет, что это фрагмент компьютерного кода , и я очень вольно интерпретировал это как контент, который может быть обработан каким-либо значимым образом на компьютере. Это будет означать, что что-то есть , не так ли? Конечно, вы можете передать любой текст в компьютер и обработать его осмысленным образом.
Но имя группы новостей может быть помечено как <код>, потому что это «компьютерный код » в том смысле, что оно было _определено_ отдельно для использования в качестве входных в компьютерное программное обеспечение, как идентификатор группы. Это станет более очевидным , возможно, если вы подумаете, как часто имена групп новостей должны быть искажены из выражений естественного языка, из которых они были получены , например.грамм. убирая акценты.
С практической точки зрения, некоторые программы автоматического перевода (BabelFish) обрабатывают текст внутри как буквальную строку, которая остается неизменной при переводе . И это очень естественно и очень желательно, поскольку если у нас есть, скажем, какой-то текст о Unix, в котором упоминается команда cat , , тогда мы не хотим, чтобы этот «кот» превратился в «чат». при переводе на французский .
, чтобы избежать неизбежного вывода: в подавляющем большинстве случаев реальной альтернативой является , которому по определению не хватает _всей семантики.
Как и , в каком-то смысле вы правы.
Нет. Даже если вы считаете чисто презентационным, отметка чего-либо говорит _больше_, чем отметка . Так же, как говорит больше, чем . Пример , грубо говоря, говорит: «Здесь у нас есть элемент с неопределенным значением , но предпочтительный визуальный рендеринг выделен жирным шрифтом». В нем не сказано , что это за значение, но он может дать подсказку. Классы могут использоваться для предоставления семантики, определенной автором, даже для семантически пустых элементов.
Какой автор определил семантику? Имя класса не имеет значения; это просто строка. У автора может быть что-то в голове, и кто-то , читающий исходный код, может получить подсказку, если он знает естественный язык , из которого было взято имя. Но это отличается от подсказки, предоставленной (или , даже если вы считаете это только презентационным), как определено _markup language_. Понимаете ли вы, что автор определил семантику class = "lauseke" или?
Подобные соображения могут относиться даже к использованию & nbsp; - который повсеместно поддерживается браузерами, но который все еще может вызывать проблемы при операциях вырезания и вставки, например, поскольку по определению является символом, отличным от символа пробела.
Использование позволяет избежать проблемы.
Если важно наличие неразрывного пробела, разве не важно скопировать его ?
- Анри Сивонен hs******@iki.fi http://iki.fi/hsivonen/ Mozilla Web Author FAQ: http://mozilla.org/docs/web-developer/ faq.html
Велосипедный гитарист написал:
Привет. Я обнаружил следующее, когда пытался узнать, существует ли такая вещь, как неразрывный дефис .Судя по всему, Unicode имеет - но это не очень хорошо поддерживается , особенно в старых браузерах. Кто-то где-то сказал:
В качестве альтернативы вы можете использовать CSS для объявления класса, имеющего:
.nowrap {white-space: nowrap}
... а затем обернуть составное слово в (или любой другой подходящий встроенный тег). Вы также можете попробовать {white-space: pre} ...
Я не был уверен, где разместить это, потому что часть вопроса касается символьного объекта , который, по-видимому, НЕ определен в html? Однако как насчет идеи CSS без упаковки? На одной из моих страниц www.TheBicyclingGuitarist.net/newstuff.htm Я отдаю должное некоторым людям из comp.infosystems.www.authoring.site-design. Я хочу, чтобы дефис между сайтом и дизайном был неразрывным.
Я не понимаю. В Mozilla дефисы (& minus ;, ISO 8859-1 -, 0x2D) неразрывны.
-
Дэвид Э. Росс
Я использую Mozilla в качестве своего веб-браузера, потому что мне нужен браузер, который соответствует веб-стандартам.См. .
Дэвид Росс написал:
Я не понимаю. В Mozilla дефисы (& minus ;, ISO 8859-1 -, 0x2D) неразрывны.
Ссылка на объект & минус; обозначает знак минус, который вообще не является дефисом .
ISO 8859-1 здесь не имеет значения.
Ссылка на символ - обозначает символ дефиса-минус (дефис Ascii), а 0x2D - это обычный способ упоминания его шестнадцатеричного кода в нескольких стандартах.
Правила разрыва строки Unicode допускают разрыв строки после символа дефиса-минус , и IE (и Opera) применяет этот принцип. Проблема, которую мы обсуждаем , заключается в том, что такие перерывы часто нежелательны.
Правила не подразумевают, что программа _ должна_ разбивать строку после символа дефиса с минусом в каком-либо конкретном случае. Но IE (и Opera) довольно механически после него ломается.
Использование - это суп из тегов, так что это просто лицемерие.
Ваш любимый сам по себе лицемерный клуб, посвященный неделе, это не больше суп из тегов, чем заменители PI, такие как BR или HR, или атрибуты mystery-meat , такие как WIDTH и HEIGHT. - | ) Pi Cabernet, - (Meno Internet. |) http://bednarz.nl/
: >> Конечно, он более семантический, чем подход W3C, который перемещает нас на : >> вниз на уровень персонажа. :> :> Это зависит от обстоятельств. Некоторые ситуации могут быть более подходящими для обозначения :> с использованием элементов, а другие лучше оставить на уровне персонажа.
: перемещение на уровень символа означает, что презентационные функции были : встроены в текстовое содержимое документа.Разве это не хуже, чем : встраивание его в разметку вокруг контента?
Спасибо за эти слова. Это было то, к чему я пытался добраться.
Независимо от желаемой семантики html, мне все еще кажется, что назад мне кажется, что «логика низкого уровня» отдельных символов, используемых в документе, может иметь больший контроль над представлением, чем логика высокого уровня "языка разметки, используемого средством , которое очень сильно связано с деталями представления документа. В другой части этой беседы я сказал:
Конечно, они не применимы ни в каком тексте, за исключением случаев, когда приложение выбирает их как применимые.
и Алан Дж. Флавелл ответили Мне это кажется тавтологией!
Я имел в виду, что стандарт Unicode, по моему мнению, не должен определять ничего, кроме отображения значений символов на имя символов и приемлемый глиф для него. Все остальное должно обрабатываться через логику более высокого уровня .Точные детали, соответствующие этой более высокой логике , будут зависеть от используемых технологий, а не от Unicode. По крайней мере, , таково мое мнение после того, как я увидел, насколько сложной стала вся проблема Unicode по сравнению с простой простой простой исходной идеей решения проблем с набором символов путем определения нового стандартного набора символов , который просто определял гораздо больше символов чем старый стандартный набор символов ascii , и включил это, просто потребовав от компьютеров и программного обеспечения использовать больше бит на символ.
Ну хорошо, по разным причинам символы должны иметь возможность указывать определенные вещи, такие как разрывы строк, но даже этот уровень информации форматирования в наборе символов должен быть отключен, за исключением для определения наборов зарезервированные значения, доступные приложениям для использования по своему усмотрению (и очевидно, что некоторые из этих значений будут иметь «хорошо известную семантику»).
Почему-то исходное обсуждение, казалось, затрагивало эти идеи, это все .
Эрик Б. Беднарз написал:
Лахлан Хант пишет:
Использование - это суп из тегов, так что это просто лицемерие. Не говоря уже о вашем любимом лицемерном клубе, посвященном неделе,
Понятия не имею, о каком "клубе" вы говорите. Я стараюсь избегать лицемерия , и если да, не могли бы вы объяснить, чтобы я мог сам исправить ? это не больше суп из тегов, чем заменители PI, такие как BR или HR, или атрибуты mystery-meat , такие как WIDTH и HEIGHT.
В отличие от , эти элементы и атрибуты действительно существуют в спецификациях HTML. Хотя, если вы хотите сказать, что они тоже презентационные, то я бы в чем-то согласился.
Это правда, что в некоторых случаях эти элементы и атрибуты могут считаться презентационными, особенно учитывая плохо структурированный дизайн элементов и
, который, я уверен, обсуждался уже раз прежде. . Однако, если они используются правильно, они могут быть разумно семантическими , и их использование определенно не так плохо, как .
- Lachlan Hunt http://lachy.id.au/ http://GetFirefox.com/ Откройте для себя заново Интернет http://SpreadFirefox.com/ Зажигая Интернет
В понедельник, 14 ноября 2004 г., Малкольм Дью-Джонс написал:
Я имел в виду, что стандарт юникода, по моему мнению, не должен определять ничего, кроме сопоставления значений символов с именем символов и приемлемым глифом для него. . Я думаю, что часть iso-10646 предназначена именно для этого.Как вы помните, изначально было двумя отдельными пушами, пытающимися решить проблему i18n : iso-10646 и Unicode, и что они как бы соединяли вместе. Это было в начале 1990-х, примерно , IIRC. Но стыки все еще видны в ряде мест.
Спецификация Unicode выходит далеко за рамки простого присвоения символам кодовых точек. Он не только кодирует символы (в терминах отображения регистра, направленности, комбинирования свойств и т. Д.).), но также определяет количество символов, предназначенных для выполнения функций управления без соответствия любому отображаемому глифу (соединитель нулевой ширины и соединитель без соединения, управление направленностью и т. д.). Они определены в основном для использования в текстовых данных; их применимость в конкретных приложениях , таких как язык разметки, менее очевидна и требует кодификации с помощью языка разметки (как это действительно происходит в некоторой степени в HTML).
Вы могли бы подумать, что это было нецелесообразно - выполнялось на неправильном уровне протокола и т. Д.- и наверняка у вас будет немало аргументов в вашу пользу, но я боюсь, что мы должны принять Unicode, как сейчас , что бы мы ни думали о таких деталях. Все остальное должно обрабатываться логикой более высокого уровня. Точные детали , соответствующие этой более высокой логике, будут зависеть от используемых технологий , а не от Unicode.
Думаю, тот же ответ. HTML мог бы сказать, что такие символы, как объединитель нулевой ширины , формат направленного всплывающего сообщения и т. Д.не имел дела в исходном документе HTML, и что такие вопросы должны были решаться на уровне разметки или представления; но HTML этого не сказал - на самом деле наоборот. Лучше или хуже.
Лахлан Хант писал:
В отличие от , эти элементы и атрибуты действительно существуют в спецификациях HTML . Хотя, если вы хотите сказать, что они тоже презентационные, то я бы в чем-то согласился.
Это правда, что в некоторых случаях эти элементы и атрибуты могут считаться презентационными, особенно учитывая плохо структурированный дизайн элементов и
, который, я уверен, уже обсуждался раз прежде. Однако, если они используются правильно, они могут быть разумно семантическими , и их использование определенно не так плохо, как .
UA не выдают летающую обезьяну, если разметка действительна, правильное использование не вызывает проблем, не позволяет нескольким UA применять нелепые правила нарушения юникода , а настраиваемый DTD решает ошибки при проверке .
Так что вы аргументируете, почему это «плохо»?
– Спартаникус
Лахлан Хант пишет:
Эрик Б. Беднарц писал:
Не считая вашего любимого лицемерного клуба недели,
Я понятия не имею, о каком "клубе" вы говорите.
Я заранее догадывался, что настоящим результатом «супа из тегов» было простое отсутствие NOBR в спецификациях W3C.
это не больше тегов, чем заменители PI, такие как BR или HR, или атрибуты mystery-meat , такие как WIDTH и HEIGHT.
В отличие от , эти элементы и атрибуты действительно существуют в спецификациях HTML.
Ну, кому до половых органов крысы. Это правда, что в некоторых случаях эти элементы и атрибуты могут считаться презентационными, особенно учитывая плохо структурированный дизайн элементов и
, Что ж, словарь HTML, который является настолько грубым инструментом, является причиной того, что иногда презентационная разметка лучше, чем ничего (например, ).грамм. для все, что выделено курсивом в обычной типографике, но не соответствует соответствующему типу элемента в HTML, все равно богаче SPAN - или ничего). Можно спорить о достоинствах таких вопросов , пока коровы не вернутся домой.
BR, однако, вовсе не касается * описательной разметки * (в SGML: тегах). Он сообщает приложению что-то * сделать * (например, взорвать, воспроизвести музыку , отобразить новую строку; в SGML: инструкции по обработке - хотя один из , вероятно, также может утверждать, что ссылка на символ должна выполнять трюк : синтаксический анализатор сворачивает символы пробелов HTML и разрешенные ссылки на символов для CR / LF передаются в приложение для буквального рендеринга .Это - как и все, что связано с SGML в HTML - не имеет ничего общего с веб-браузерами или, конечно, с реальной жизнью в целом. Однако, если они используются правильно, они могут быть достаточно семантическими , и их использование определенно не так плохо, как .
Я до сих пор не вижу, что плохого в NOBR (или WBR, если на то пошло). В худшем случае ничего не происходит.
Давайте посмотрим на слегка измененную версию вашего более раннего утверждения, и представим, что двойной дефис / минус был длинным тире.
| Эти элементы и атрибуты - в отличие от NOBR - действительно существуют в | Спецификации HTML.
Если вы соблюдаете правила поведения UA и правила разрыва строк Unicode, вы поймете, что вам на помощь нужна презентационная разметка:
| Эти элементы и атрибуты - в отличие от | NOBR - действительно существуют в | Спецификации HTML.
В, 14.11.2004 в 23:10, yf***@vtn1.victoria.tc.ca (Малкольм Дью-Джонс) сказал:
Независимо от того, какой может быть желательная семантика html, мне все равно кажется обратным, что "низкий логика уровня »отдельных символов , используемых в документе, могла бы иметь больший контроль над представлением , чем« логика высокого уровня »языка разметки, используемого инструментом, который очень сильно озабочен деталями представления документа. На самом деле, это обратное для HTML, чтобы очень сильно интересоваться деталями представления документа. HTML был предназначен не для этого. Я имел в виду, что стандарт юникода, по моему мнению, не должен определять ничего, кроме отображения значений символов на имена символов и приемлемый глиф для него. Я категорически не согласен. Это может быть приемлемо для символьных данных в вашем HTML, но это нарушает ввод данных в формы. По крайней мере, таково мое мнение после того, как я увидел, насколько сложной стала вся проблема Unicode,
Это не просто Unicode, и он не «стал» сложным; это всегда было сложных.Вы смотрите на это с точки зрения индоевропейского языка и не видите всех проблем.
- Шмуэль (Сеймур Дж.) Мец, SysProg и JOAT
Массовая незапрашиваемая электронная почта, в отношении которой может быть возбужден судебный иск. Я оставляю за собой право публично публиковать или высмеивать любые оскорбительные электронные письма. Ответ на домен Patriot dot net user shmuel + новости, чтобы связаться со мной. Не отвечать на sp******@library.lspace.org
:> Независимо от того, какой может быть желательная семантика html, она все равно :> мне кажется наоборот что «логика низкого уровня» отдельных символов :>, используемых в документе, может иметь больший контроль над представлением :>, чем «логика высокого уровня» языка разметки, используемого :> инструментом, который очень сильно касается деталей презентации :> документа.
: На самом деле, HTML очень сильно занимается : деталями представления документа. HTML : предназначался не для этого.
Я сказал, что HTML использовался _tool_, который занимается презентацией.
Такие инструменты принимают обширные решения по презентации на основе html, а способность инструментов принимать правильные решения по презентации в различных средах всегда была основной целью html. :> Я имел в виду, что стандарт юникода, на мой взгляд, не должен :> определять что-либо, кроме отображения значений символов на символы :> name и приемлемый глиф для него.
: Совершенно не согласен. Это может быть приемлемо для символьных данных в : ваш HTML, но это нарушает ввод данных в формы.
Как нарушает ввод данных в формы?
:> По крайней мере, таково мое мнение после того, как я увидел, насколько сложной стала вся проблема :> Unicode,
: Это не просто Unicode, и он не «стал» сложным; это всегда было : сложное. Вы смотрите на это с точки зрения индоевропейского : языка и не видите всех проблем.
Верно, я. Различные языковые проблемы не должны рассматриваться на уровне символьных данных именно потому, что некоторые проблемы человеческого языка не легко отображают в символьные данные. Попытка сделать это просто делает все излишне сложным для языков, которые достаточно хорошо соответствуют такой простой системе.
Эти другие проблемы следует решать с помощью протокола более высокого уровня.
Если бы юникод оставался простым, то мы все использовали бы его для всех языков западного стиля много лет назад, и все усилия, которые сейчас затрачиваются на , вместо этого были бы использованы для работы над системами, которые, естественно, работают больше для других языков. западные языки.
Однако, как уже указывалось, решения приняты, и у нас есть , чтобы жить с ними.
В, 16.11.2004 в 22:40, yf***@vtn1.victoria.tc.ca (Малкольм Дью-Джонс) сказал:
Я сказал, что HTML использовался _tool_, который занимается презентацией . А вода мокрая. Ваша точка зрения? Как нарушает ввод данных в формы? Потому что он не может представить данные так, как ожидает пользователь, когда пользователь вводит данные Unicode, которые предназначены для воздействия на представление . Верно, я. Различные языковые проблемы не следует решать на уровне символьных данных именно потому, что некоторые человеческие языковые проблемы нелегко сопоставить с символьными данными. Проблемы, решаемые Unicode, легко отображаются. Эти другие проблемы должны решаться протоколом более высокого уровня. Нет. То, что вы хотите, разрушит взаимодействие между приложениями. Если бы юникод оставался простым, мы бы все использовали его для всех языков западного стиля много лет назад,
Почему? И какое значение имеет его принятие, если оно не включает в себя истинную интернационализацию ?
- Шмуэль (Сеймур Дж.) Metz, SysProg и JOAT
Незапрашиваемая массовая электронная почта, в отношении которой может быть возбуждено судебное дело. Я оставляю за собой право публично публиковать или высмеивать любые оскорбительные электронные письма. Ответ на домен Patriot dot net user shmuel + новости, чтобы связаться со мной. Не отвечать на sp******@library.lspace.org
Эта дискуссия закрыта
Ответы на это обсуждение отключены.
Как ввести неразрывный дефис в Windows
Необходимо соединить два слова или числа с помощью дефиса - и не разделять их снова в конце строки или страницы? Узнайте здесь , как ввести неразрывный дефис в Windows .
Во-первых, голландский отец и голландский сын отжимают фасоль
Примерно в 1828 году Каспар и Коенрад ван Хаутен изобрели гидравлический пресс.
Если вы бросите в него обжаренные какао-бобы, пресс отделит жир бобов - масло какао - от твердых частиц. Это проложило путь для горячего шоколада (порошка) и шоколадных плиток (больше какао-масла, чем в бобах), как мы их знаем.
Теперь, имея это в виду ... как насчет способа написать какао-боб , не разделяя два слова в конце строки или страницы?
Как ввести неразрывный дефис в Windows
На Mac? Как вставить неразрывный дефис (-) на Mac
Использование карты символов (универсальная и немного громоздкая)
Необходимое время: 3 минуты.
Чтобы вставить неразрывный дефис в любой текст в Windows с помощью карты символов:
Откройте приложение «Карта символов».
Шаги : Откройте меню Start и введите символьная карта , затем щелкните Character Map в результатах поиска.
Выберите Lucida Sans Unicode под шрифтом : .
Другие шрифты : Большинство шрифтов не содержат неразрывного дефиса, но вы, конечно, можете выбрать любой шрифт, который есть.
Проверить Расширенный вид .
Введите неразрывный дефис под Искать: .
Выделите символ U + 2011 Неразрывный дефис .
Щелкните Выберите из Символов для копирования: .
Теперь нажмите Копировать .
Теперь вставьте неразрывный дефис там, где вы хотите его использовать.
Еще меньше ломки? Как войти в неразрывное пространство в Windows
Использование сочетания клавиш Office для неразрывных дефисов
Для ввода символа дефиса, после которого строка или страница не будут разрываться в Word, Excel и других приложениях MS Office:
Нажмите Ctrl Shift _ (подчеркивание). Пользовательское сочетание неразрывных дефисов : вы можете изменить сочетание клавиш для неразрывного дефиса в приложениях Office; см. ниже.
Альтернатива : Вы также можете вставить неразрывный дефис с помощью диалогового окна Symbol :
Поместите текстовый курсор туда, где вы хотите поставить неразрывный дефис.
Откройте вкладку Вставьте на ленте.
Выбрать Символ | Дополнительные символы… в разделе Символы .
Перейдите на вкладку Специальные символы .
Дважды щелкните - Неразрывный дефис .
Использование шестнадцатеричного кода Unicode для неразрывного пробела и Word или WordPad
Вы также можете вставить неразрывный дефис в Word или WordPad, используя его кодовую точку Unicode.
Чтобы вставить непрерывный пробел с использованием Unicode:
Поместите текстовый курсор туда, где должен появиться неразрывный дефис. Копировать и вставить : Вы также можете выделить и скопировать дефис, конечно, после того, как вы вставили его, чтобы вставить в другое место.
Тип 2011 .
Немедленно нажмите Alt X , чтобы заменить код.
Использование копирования и вставки
Чтобы скопировать неразрывный дефис для публикации в любом месте, используйте кнопку ниже:
Как ввести неразрывный дефис в Windows: FAQ
Есть ли альтернативный код для неразрывного дефиса?
Нет, неразрывный дефис нельзя вводить
Могу ли я изменить сочетание клавиш для неразрывных дефисов?
Да, вы можете настроить ярлык для неразрывного дефиса в приложениях Office:
Откройте вкладку Специальные символы в диалоговом окне Office Symbol .(См. Выше.)
Выделите - Неразрывный дефис .
Нажмите Сочетание клавиш… .
Щелкните в Нажмите новую комбинацию клавиш: поле .
Теперь нажмите комбинацию клавиш, которую вы хотите использовать для неразрывных дефисов.
Щелкните Назначить .
Щелкните Закройте .
Теперь нажмите Закройте еще раз.
Могу ли я использовать автозамену Word для ввода неразрывного дефиса?
Да.
Для настройки приложений Office автоматически заменяйте определенную комбинацию символов неразрывным дефисом:
Откройте вкладку Специальные символы диалогового окна Symbol ; см. выше.
Выделите - Неразрывный дефис .
Теперь щелкните Автозамена… .
Проверить Заменять текст при вводе .
Теперь введите комбинацию символов, которую вы хотите заменить неразрывным дефисом под Заменить: . Пример : Вы можете, например, использовать что-то вроде _- . Дефис уже есть : обратите внимание (и проверьте), что неразрывный дефис уже был введен под с: .
Щелкните Добавить .
Теперь нажмите OK и Закройте
Могу ли я ввести неразрывный дефис с помощью панели Emoji или экранной клавиатуры?
Нет, на клавиатуре эмодзи, а также на экранной и сенсорной клавиатурах неразрывный дефис отсутствует.
Есть ли HTML-объект для неразрывного дефиса?
Хотя для неразрывного дефиса нет именованного HTML-объекта, его можно ввести с помощью Unicode:
HTML-код
& # 8209;
шестнадцатеричный код HTML
& # x2011;
(Как ввести неразрывный дефис, протестированный в Windows 10; обновлено в сентябре 2021 г.)
TT4T - Разное
Слово
Подсчитать
каждый
инструмент считает слова по-своему.См. Таблицу ниже:
Тип
текста
Слово
Открыть
Офис
Trados
диджей
Ву
Wordfast
SDLX
Транзит
Нумерация * E.г .: 1. Внимание
1
0
0
0
0
0
0
Пули * E.г .: • Внимание
1
0
0
0
0
0
0
Номера E.г .: 20
1
1
0
0
0
1
0
Символы ( долл. США, % , и )
1
0
0
0
0
1
0
Сокращения ( i.е. ; например ; так далее.)
1
1
1
каждый
письмо
1
каждый
письмо
1
с переносом
слова
1
каждая
слово
каждый
слово
1
каждый
слово
1
каждый
слово
Ненавистные числа E.г .: 555-555-5555
1
каждый номер
каждый номер
1
0
1
0
* Как
количество инструментов, например, «1». или "•".
Дополнительно,
Word не считает текст в текстовых полях, записях указателя, заголовках;
Dj Vu делает.Дежавю дважды импортирует текстовое поле Word.
Примечание:
Данные были собраны из многих и противоречивых источников. У нас есть
никогда не проверял их все.
Там
некоторые сторонние программы, которые можно использовать для подсчета слов: PractiCount,
WebBudget XT,
и т. д. - но всегда есть проблемы с используемыми критериями
посчитать их.
Шон
Келли разработала макрос для полного подсчета слов в Word
(включая текстовые поля, заголовок, нижний колонтитул и т. д.): http://www.shaunakelly.com/word/CompleteWordCount/index.html
Верх
- Главная / Заявление об ограничении ответственности
[css-text] Предотвратить разрыв строки после явных дефисов · Проблема № 3434 · w3c / csswg-drafts · GitHub
Спасибо за изучение моей проблемы!
Я только что уточнил, что в 806cd4e
Я думаю, что этот коммит содержит опечатку: - визуальное обозначение . Меня также несколько беспокоит то, что это только начинает определять, что такое «возможность расстановки переносов» , а не , а не то, что - это .Возможно, явное противопоставление механизма «расстановки переносов» с поведением разрыва строки было бы здесь полезным дополнением, так же как и явное недвусмысленное предложение, которое буквально начинается со слов «Возможность расстановки переносов - это…».
Для таких слов, как электронная почта или футболка, UA уже разрешено быть достаточно умным и решить, что дефис после единственной буквы не означает исключительную возможность или какую-либо аналогичную эвристику.
Чтобы уточнить, не зависит ли это от hyphenate-limit-chars , который был предложен в teleconf? Насколько я понимаю, это свойство контролирует только «возможности расстановки переносов», и поэтому, как новое определение, может повлиять только на то, будет ли электронное письмо переноситься через дефис на электронное письмо и письмо , но не на то, будет ли электронное письмо разбиваться на части. .
fantasai: Кажется действительно странным, что вы воспринимаете фразу с дефисом как обсуждаемую, запретить взлом в долгосрочной перспективе - это необычно строго. Я вижу, что нельзя разбивать точку, которая не является дефисом, но разбивать дефис, я не думаю, что вы захотите подавить.
fantasai: футболку можно не сломать, если на другой стороне меньше 2 знаков. Вы можете контролировать это для расстановки переносов в L4. fantasai: длительный разрыв маловероятен, потому что каждая половина слишком коротка
и др.
Дело не в том, являются ли части составного слова, написанного через дефис, короче порогового значения. В общем, большинство составных слов, содержащих дефис, воспринимаются как единое целое (и при произнесении вслух изменяются атомарно). Личные имена и ключевые слова в коде с дефисом - два хороших примера, которые можно добавить к моей скудной выборке из трех часто употребляемых английских слов. Но я думаю, что вариант использования намного шире и не является «странным» или «необычным». Хранение составных частей вместе позволяет не отвлекать или вводить в заблуждение читателя (ошибочный запах, ложный запах или садовая дорожка) и повышает удобочитаемость.Некоторые советы по стилю собраны ниже (не все актуальные):
Ссылки на избранные руководства по стилю и авторитетные источники
Канадский стиль: 2. Расстановка переносов: составление слов и разделение слов
Во многих случаях ударение делается только на один слог в составе. На протяжении многих лет существовала тенденция к тому, что английское составное слово начиналось как два отдельных слова, затем переносилось через дефис и, наконец, при отсутствии структурных препятствий для объединения, превращалось в одно слово, написанное без пробела или дефиса.
2.17: Слово деление
Чтобы обеспечить четкое и недвусмысленное представление, старайтесь как можно больше не разделять слова в конце строки. Если разделение слов необходимо, вам следует руководствоваться пониманием и удобочитаемостью текста. Принятая практика резюмируется ниже:
(i) Избегайте вводящих в заблуждение разрывов, которые могут заставить читателя спутать одно слово с другим, как в только чтение и пожать грушу . (j) По возможности разделяйте составные части только дефисом ( военно-полевой суд , не военный суд ).Составное, написанное одним словом, следует разделить между его элементами ( теплица , парусник ).
Чикагское руководство по стилю, 17-е издание
2: Подготовка рукописи, редактирование рукописей и корректура
2.13: Расстановка переносов
В текстовом процессоре должна быть отключена функция расстановки переносов. Единственные дефисы, которые должны появляться в рукописи, - это дефисы, которые будут появляться независимо от того, где они появились на странице (например,г., в сложных формах). Не беспокойтесь, если такой дефис попадает в конец строки или если правое поле сильно неровно.
2.96: Обозначение дефисов и тире
Дефисы в конце строки должны быть помечены, чтобы различать мягкие (т. Е. Условные или необязательные) и жесткие дефисы. Мягкие дефисы - это дефисы, которые используются только для разрыва слова в конце строки; жесткие дефисы являются постоянными (например, в тупике) и должны оставаться независимо от того, где появляется слово или термин, расставленный через дефис.
2.112: Вычитка разрывов слов
Когда речь идет о понятном, но нестандартном переносе слова для строки, которая в противном случае была бы слишком свободной или слишком плотной, нестандартный разрыв (например, перенос уже перенесенного через дефис термина) может быть предпочтительным.
7: Правописание, особая трактовка слов и составных слов
7.36–7.47: Word Division
7,40: Делящиеся соединения, префиксы и суффиксы
Перенесенные через дефис или замкнутые составные слова и слова с префиксами или суффиксами лучше всего разделять на естественные разрывы.
бедняков / бедняков (, а не )
7.42: Разделение имен собственных и имен личных
Существительные собственные, состоящие более чем из одного элемента, особенно личные имена, следует по возможности разделять между элементами, а не внутри каких-либо элементов.
Heitor Villa- / Lobos ( или лучше Heitor / Villa-Lobos)
7.81–7.89: составные части и расстановка переносов
7,81: Переносить или не переносить через дефис 7.82: Определенные соединения
7,83: Тенденция к закрытым соединениям
При частом использовании открытые или написанные через дефис соединения имеют тенденцию становиться закрытыми ( на линии до онлайн до онлайн ).
7.84: Дефисы и удобочитаемость
Дефис может облегчить чтение, показывая структуру и, часто, произношение. Слова, которые в противном случае могли бы быть неправильно прочитаны, такие как recreation или co-op , следует переносить через дефис.Дефисы также могут устранить двусмысленность. Например, дефис в очень нужная одежда показывает, что одежда очень нужна, а не в изобилии.
Руководство по стилю Microsoft: 7. Практические вопросы стиля: разрывы строк
Старайтесь держать заголовки в одной строке. Если двухстрочный заголовок неизбежен, разорвите строки, чтобы первая строка была длиннее. Не разбивайте заголовки, расставляя слова через дефис, и избегайте разбиения заголовка между частями слова, написанного через дефис.Не имеет значения, разрывается ли строка до или после союза, но избегайте разрывов между двумя словами, которые являются частью глагольной фразы.
Стиль Microsoft
Закладки, перекрестные ссылки, и подписи
Не в стиле Microsoft
Закладки, перекрестные ссылки и подписи
Старайтесь не нарушать имена и параметры функций. Если расстановка переносов необходима, разделяйте эти имена между словами, составляющими функцию или параметр, а не внутри самого слова.
Современный английский язык Гарнера: заголовок: необычное использование
Во-вторых, разрывы строк должны как можно точнее отражать логические и грамматические разрывы. Иногда перерыв может привести к ошибке. … Даже если ошибка невозможна, лучше не отделять предлог от его объекта между строками, например, или от глагола в инфинитиве. Аналогичным образом, важность расстановки фразовых прилагательных через дефис становится очевидной в конце заголовка.
Техническое сообщение: Приложение: Справочник: Часть C: Редактирование и корректура ваших документов: Дефисы
Используйте дефис, чтобы разделить слово в конце строки.
Встретимся в павильоне ion через час.
Однако по возможности избегайте таких разрывов строк; они замедляют читателя.
Illustrator CC: Краткое руководство по Visual: 20. Стиль и тип редактирования: применение переносов
Независимо от текущих настроек расстановки переносов вам нужно будет «внимательно следить» за текстом, расставленным через перенос, и, при необходимости, исправлять неудобные перерывы с помощью мягкого возврата или команды «Без перерыва».Чтобы предотвратить разрыв определенного слова в конце строки, такого как составное слово (например, «однострочный»), чтобы воссоединить слово с неудобным переносом через дефис (например, «кортеж по признаку пола»)…
Руководство по стилю GPO: 6. Правила составления
Составное слово - это объединение двух или более слов с дефисом или без него. Он передает идею единицы, которая не так ясно или быстро передается в несвязанной последовательности составных слов. Дефис - это знак препинания, который не только объединяет, но и разделяет составные слова; он способствует пониманию, удобочитаемости и обеспечивает правильное произношение.Когда составные слова должны быть разделены в конце строки, такое разделение должно производиться с сохранением префиксов и сочетаний форм более чем одного слога.
С переносом или без переноса
StackOverflow. Английский язык и использование. Следует ли разрешать переносу составных слов через строки?
StackOverflow: английский язык и использование: нормально ли разделять слова через дефис в разных строках? [дубликат]
Использование неразрывных и дополнительных переносов
Используйте неразрывный дефис , неразрывный дефис или неразрывный
дефис , чтобы не разбивать фразы или термины в конце строки.С неразрывными дефисами,
все выражение или термин переносится на следующую строку вместо разрыва. Необязательный дефис имеет противоположный эффект. Это позволяет разбивать слова на указанных позициях.
Чтобы вставить неразрывный дефис , выполните следующие действия:
1. Поместите курсор в то место, куда вы хотите вставить неразрывный дефис.
2. Выполните одно из следующих действий:
А.1. На вкладке Вставить в группе Символы щелкните значок Символ раскрывающийся список, затем щелкните Другие символы ... :
А.2. В диалоговом окне Symbol на Special Characters На вкладке выберите Неразрывный дефис :
А.3. Щелкните Вставить и закройте диалоговое окно Символ .
B. Нажмите Ctrl + Shift + _ (подчеркивание).
Необязательный перенос управляет переносом слов в определенных местах текста. Для
Например, если длинное слово переносится на следующую строку и оставляет широкое пространство, необязательный дефис может быть
вставляется в это конкретное слово, так что первая часть появляется в первой строке. Если слово
позже перемещен на другую позицию из-за редактирования, необязательный дефис игнорируется. Если дальнейшее редактирование переместится
слово обратно в зону переноса, дефис появляется снова.
Чтобы вставить дополнительный дефис , выполните следующие действия:
1. Поместите курсор в то место, где вы хотите вставить дополнительный дефис.
2. Выполните одно из следующих действий:
А.1. На вкладке Вставить в группе Символы щелкните значок Символ раскрывающийся список, затем щелкните Другие символы ... . В диалоговом окне Symbol на Специальные символы Вкладка , выберите Необязательный дефис :
А.2. Щелкните Вставить и закройте диалоговое окно Символ .
B. Нажмите Ctrl + - (минус).
См. Также этот совет на французском языке:
Utilization de tyrets d'union insécable et tyrets d'union conditionnel.
- - неразрывный дефис (u + 2011) скопировать и вставить
-
U + 2011 скопировать и вставить
Эта кодовая точка впервые появилась в версии 1.1 стандарта Unicode® и принадлежит
в блок «Общая пунктуация», который идет от 0x2000 до 0x206F.
Вы можете безопасно добавить этот символ в свой html-код с помощью объекта: & # x2011;
Вы можете использовать кнопку u + 2011 copy pc, расположенную ниже.
Easy u + 2011 copy paste:
| U + 2012 ->
Метаданные Unicode
В следующей таблице показаны определенные метаданные, известные об этом персонаже. Имя u + 2011 представляет собой смайлик с неразрывным дефисом.
поле
значение
Кодовая точка (шестнадцатеричная)
2011, u2011
Возраст символа
Unicode 1.1
1 Устаревшее имя (Unicode).0)
-
Официальное имя (Unicode 9.0)
НЕПРЕРЫВНЫЙ ДЕФИС
разрешенное имя
неразрывный дефис
блок
Общая пунктуация опечатки
u + 0211, u + 1201
Есть альтернативное написание, которое можно найти в дикой природе для символа Unicode 2011, например
u 2011, (u + 2011) или u +2011. Вы также можете найти u-2011, u * 2011, un + 2011, u2011, u = 2011 или c + 2011.Вы также можете записать его с помощью u 2011 unicode, u plus 2011, uncode 2011 или unicode + 2011.
Его двунаправленный класс - «ON»: другие нейтральные символы (все остальные символы, включая СИМВОЛ ЗАМЕНЫ ОБЪЕКТА)
Глифы и символы в вашем browser
В следующей таблице Unicode представлены различные версии глифа, соответствующие символам Unicode u + 2011, которые доступны на вашем компьютере.
Чтобы легко вводить этот символ, вы можете загрузить и установить клавиатуру Unicode General Punctuation.
Образцы шрифтов используются ниже, чтобы показать, есть ли у символа глиф в этом шрифте или нет.
Кодировки (преобразователь символов Unicode)
Следующий преобразователь таблицы символов для + u2011 позволяет увидеть значение символа в различных кодировках
 Поэтому перед использованием спецсимволов рекомендуется проверить их на эту поддержку.
Поэтому перед использованием спецсимволов рекомендуется проверить их на эту поддержку. Уроки для начинающих. W3Schools на русском
Уроки для начинающих. W3Schools на русском






 С1 {белый-пространство:без переноса;}
С1 {белый-пространство:без переноса;} 0.2066.92
в </SUP и ГТ;
0.2066.92
в </SUP и ГТ;
 А правильно сверстать текст мы вам поможем.
А правильно сверстать текст мы вам поможем. А правильно сверстать текст мы вам поможем.
А правильно сверстать текст мы вам поможем.


 Однако по-прежнему, студенты и аспиранты в своих курсовых и дипломных, диссертациях и авторефератах не уделяют достаточного внимания типографике.
Однако по-прежнему, студенты и аспиранты в своих курсовых и дипломных, диссертациях и авторефератах не уделяют достаточного внимания типографике. ~137--138
~137--138
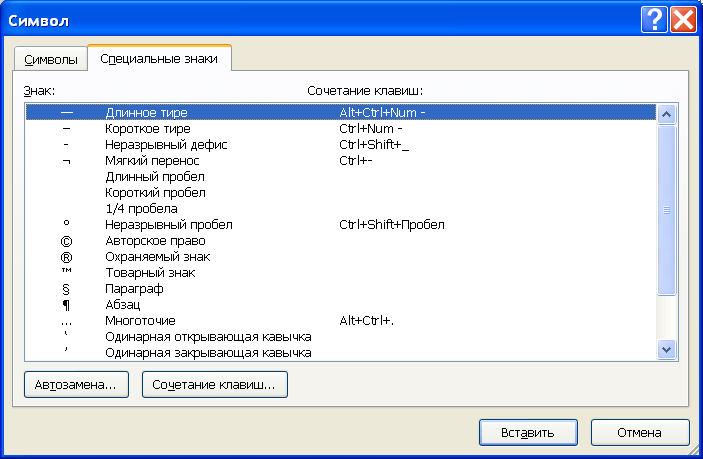
 \,А.~Самарского и~А.\,В.~Гулина \glqq Численные методы\grqq>>,~--- сказал лектор.
\,А.~Самарского и~А.\,В.~Гулина \glqq Численные методы\grqq>>,~--- сказал лектор.
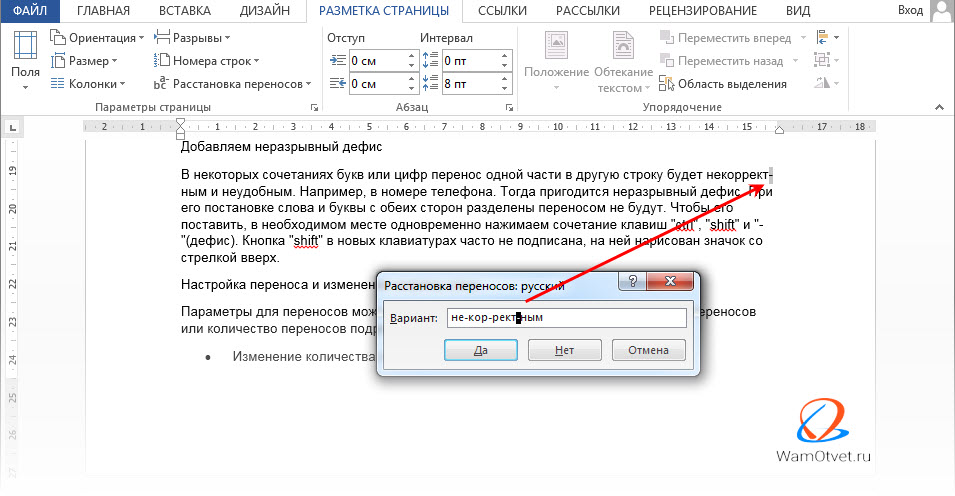 В результате в выбранном вами месте будет поставлено длинное тире.
В результате в выбранном вами месте будет поставлено длинное тире.