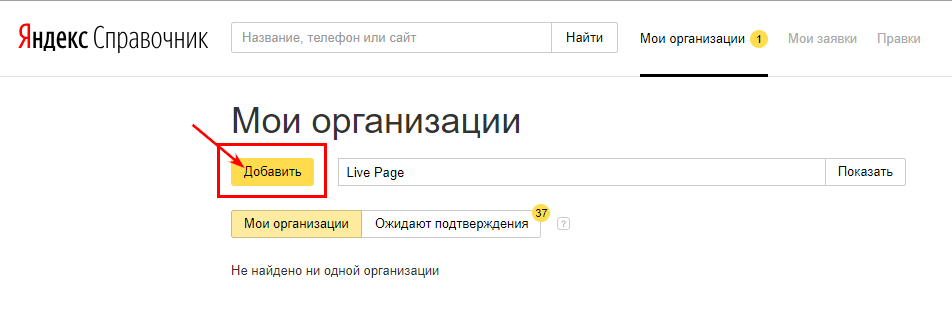
Что нашлось у «Яндекса» – Секрет фирмы – Коммерсантъ
Создателей портала «Яндекс» вполне можно считать ортодоксами российского онлайнового бизнеса. Они стояли у его истоков и поначалу двигали рынок на голом энтузиазме. Тогда Аркадий Волож, генеральный директор компании, отдавал себе отчет в том, что быстрых прибылей это дело не сулит. В 2000 году авторы yandex.ru сумели удачно пристроить свое детище и получить более $5 млн на развитие. И хотя о возврате в обозримом будущем этих денег речь не идет в силу весьма слабой развитости интернет-бизнеса в России, недавно «Яндекс» стал первым российским порталом, которому удалось выйти на самоокупаемость.
СЕКРЕТ ФИРМЫ: Как вы додумались до поисковой системы? Вспомнили, что все крупные западные порталы с них начинались?
АРКАДИЙ ВОЛОЖ:
 В науке я занимался поиском и анализом данных, диссертацию тоже писал на эту тему. Потом случился закон о кооперации, но жизнь осталась двойной, только место НИИ в моей жизни заняла торговля компьютерами. Я стал директором российско-американской компании CompTek, созданной в 1989 году и существующей до сих пор. А научной работой я продолжил заниматься в небольшой программистской компании «Аркадия».
В науке я занимался поиском и анализом данных, диссертацию тоже писал на эту тему. Потом случился закон о кооперации, но жизнь осталась двойной, только место НИИ в моей жизни заняла торговля компьютерами. Я стал директором российско-американской компании CompTek, созданной в 1989 году и существующей до сих пор. А научной работой я продолжил заниматься в небольшой программистской компании «Аркадия».В нашем софтверном проекте был очень известный программист Аркадий Барковский, который позже уехал в США. Аркадий занимался компьютерной лингвистикой. Мы, как два Аркадия, создали фирму с очевидным названием. Из сочетания наших с ним профессиональных интересов родилась идея искать информацию с учетом морфологии русского языка. В начале 1990-х годов мы сделали широко известный в узких кругах продукт — поиск по международной классификации изобретений с учетом словоформ русского языка. Вообще, «Аркадия» специализировалась на создании различных программ поиска. Некоторое время они неплохо продавались, однако впоследствии мы вынуждены были прекратить их производство.
СФ: Почему?
АВ: Потому что основными покупателями патентных программ тогда были бюджетные организации, а в начале 90-х бюджет страны заметно поиздержался, и за наши программы перестали платить. Кроме того, мы поняли, что программы для пользователей — не наш профиль, наше дело — разработка технологий. В результате «Аркадия» стала маленьким отделом в CompTek. Закрывать фирму нам было жалко, потому что все понимали, что разработки в общем-то уникальные. А зарплата пяти сотрудникам большую компанию, каковой являлась CompTek, не разоряла.
В 1996 году, когда, собственно, в России появился интернет, мы запустили рекламную акцию, суть которой заключалась в том, чтобы продемонстрировать, какая у нас есть замечательная технология поиска, на больших текстовых массивах. Мы сделали поиск по российскому сегменту интернета, и любой человек мог зайти на страничку yandex.ru и посмотреть, как работает технология. Объем всего Рунета тогда составлял пять гигабайт — меньше, чем жесткий диск современного компьютера.
СФ: Получается, что «Яндекс» существует столько же, сколько и Рунет?
АВ: На самом деле история «Яндекса» как отдельной компании началась в марте 2000 года. До этого было что угодно — отдел в компании, сайт в интернете, технология поиска,- но не самостоятельная фирма. А в 1999 году в США расцвел индекс NASDAQ, и российские инвесторы тоже стали бегать по рынку и говорить, что сейчас самое время уже что-нибудь сделать и заработать денег. Дескать, надо брать, если дают, и развиваться как можно быстрее. На фоне общего ажиотажа мы нашли инвестора, после чего выделили отдел CompTek в самостоятельную компанию «Яндекс», переписали на нее права на технологии, доменные имена и товарные знаки.
СФ: А откуда взялось название?
АВ: Само слово «яндекс» появилось за пару лет до самого «Яндекса» как название технологии — «языковой индекс». Придумал это название Илья Сегалович, главный разработчик «Яндекса», появившийся в компании после того, как Барковский уехал в Америку.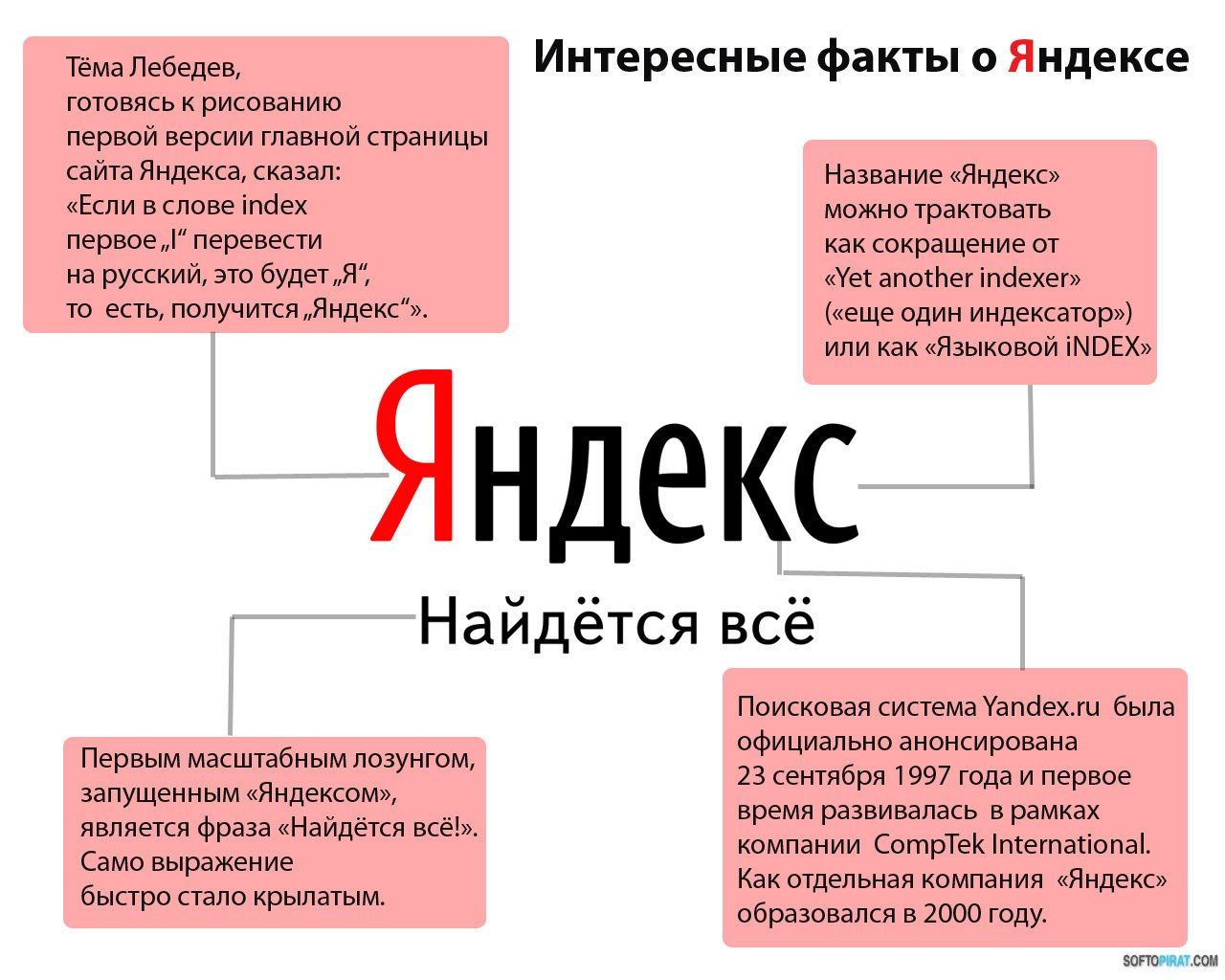 В свое время мы с Сегаловичем сидели за одной партой в школе, затем пути разошлись, а потом сошлись таким вот интересным образом. Он предложил с десяток названий, включая Yet Another index (YAndex). Мы «увидели» в нем русскую букву «Я», которая цепляла.
В свое время мы с Сегаловичем сидели за одной партой в школе, затем пути разошлись, а потом сошлись таким вот интересным образом. Он предложил с десяток названий, включая Yet Another index (YAndex). Мы «увидели» в нем русскую букву «Я», которая цепляла.
АВ: Где-то полгода, с октября 1999-го до февраля 2000 года, у нас был период, если можно так сказать, жениховства. Разные инвесторы покупали разные команды, работавшие в Интернете: кто-то покупал «Рамблер», кто-то Mail.ru… Нашим инвестором стал инвестиционный фонд ru-Net holdings.
СФ: Он получил контрольный пакет?
АВ: Нет. Вообще-то в Рунете это было стандартной схемой, но нам удалось оставить контроль за собой. Инвестор получил 35,72% акций за $5,28 млн. Я при этом перестал быть директором большой компании CompTek и стал директором маленькой компании «Яндекс». К тому времени мы не были первой компанией в Рунете — пятой, может быть, или одной из пяти.
СФ: И что получил инвестор?
АВ: Сейчас — долю в крупнейшей компании русского сегмента сети. Мы так и говорили: «Вы инвестируете в будущую первую компанию Рунета». Будущее, конечно, не запротоколируешь, поэтому можно сказать иначе: они получили долю в компании, работающей на растущем рынке. Со своей стороны, нам инвесторы помогли не только деньгами, но и кадрами. В частности, был такой очень квалифицированный специалист Бернар Люке, работавший до этого в Nestle. Он нам объяснил, к примеру, что рекламироваться на телевидении надо немедленно, потому что через год телереклама подорожает вдвое. Мы бы и сами это поняли, возможно, но не сразу, а время было дорого.
 После первых пятисекундных роликов с логотипом ресурса, которые появились на экранах в январе 2000 года, был снят полнометражный ролик с весьма простым сюжетом. Бритоголовый амбал подходил к интеллигентному юноше и страшным голосом спрашивал: «Закурить не найдется?» Ответом был адрес «Яндекса» и слоган «Найдется все», сохранившийся без изменения до сих пор. Пикантность ролика заключалась в том, что бандита играл Артемий Лебедев, создатель одноименной дизайн-студии, человек в интернете легендарный. Кстати, дизайн «Яндексу» сделала именностудия Лебедева. Господин Волож утверждает, что причиной такого заказа было только необходимое разделение труда, но дизайн «от Лебедева» в русском интернете — своего рода знак качества.
После первых пятисекундных роликов с логотипом ресурса, которые появились на экранах в январе 2000 года, был снят полнометражный ролик с весьма простым сюжетом. Бритоголовый амбал подходил к интеллигентному юноше и страшным голосом спрашивал: «Закурить не найдется?» Ответом был адрес «Яндекса» и слоган «Найдется все», сохранившийся без изменения до сих пор. Пикантность ролика заключалась в том, что бандита играл Артемий Лебедев, создатель одноименной дизайн-студии, человек в интернете легендарный. Кстати, дизайн «Яндексу» сделала именностудия Лебедева. Господин Волож утверждает, что причиной такого заказа было только необходимое разделение труда, но дизайн «от Лебедева» в русском интернете — своего рода знак качества.В конце 2000 года стартовала рекламная кампания «Все вопросы- к ‘Яндексу'». Для этой кампании было придумано 13 вопросов вроде «С кем вы, мастеракультуры?», «Что делать?», «Что день грядущий мне готовит?» и т. д.
Осенью 2001 года «Яндекс» участвовал в проекте ОРТ «Последний герой», а в октябре-декабре 2002 -го — в «Фабрике звезд».
В результате «Яндекс» стал чуть ли не синонимом справочника. Во всяком случае, когда адвокатское бюро МГКА «Арбитражсудправо» зарегистрировало домен yandex.com и «Яндекс» в судебном порядке потребовал этот домен ему вернуть (успешно), ответчик ссылался на то, что «яндекс» — слово общеупотребительное, и потому авторским правом не защищается.
СФ: Первых инвестиций вам хватило?
АВ: Да. Это были не только первые, но и единственные инвестиции. Больше и не требуется — с августа 2002 года мы вышли на самоокупаемость, так что теперь уже ничего не тратим, а только зарабатываем. У нас даже остался «денежный запас» — мы не все израсходовали.
СФ: Падение NASDAQ на вас как-то повлияло?
АВ: Никак. Деньги были выделены, дополнительных вложений мы не просили. Изменилось только давление со стороны инвесторов. Раньше нас постоянно подгоняли, заставляли расширяться и укрупняться как можно быстрее. Но ведь из компании в 13 человек трудно за год создать структуру, в которой трудилось бы уже 100 сотрудников — хотя бы потому, что сложно за короткий срок найти такое количество профессионалов. Основная проблема — это новизна самой отрасли. Интернет только создается, и никаких «специалистов по интернету» просто не существует. Люди становятся грамотными специалистами уже в процессе работы. Но нас торопили, говорили: кто быстрее растет, тому и карты в руки. В частности, основной идеей наших инвесторов было создание различных сервисов. Они считали, что поисковая система — это хорошо, но мало. Главное, что нужно,- это портал. И вот мы достаточно быстро стали обрастать различными проектами. К примеру, наш сервис «Народ» был сделан за две недели.
Но ведь из компании в 13 человек трудно за год создать структуру, в которой трудилось бы уже 100 сотрудников — хотя бы потому, что сложно за короткий срок найти такое количество профессионалов. Основная проблема — это новизна самой отрасли. Интернет только создается, и никаких «специалистов по интернету» просто не существует. Люди становятся грамотными специалистами уже в процессе работы. Но нас торопили, говорили: кто быстрее растет, тому и карты в руки. В частности, основной идеей наших инвесторов было создание различных сервисов. Они считали, что поисковая система — это хорошо, но мало. Главное, что нужно,- это портал. И вот мы достаточно быстро стали обрастать различными проектами. К примеру, наш сервис «Народ» был сделан за две недели.
Когда осенью 2000 года NASDAQ рухнул, давление спало. И у нас началась нормальная размеренная жизнь. Стали спокойно делать проекты, зная, что пришли сюда не на пару месяцев, а собираемся работать на рынке и через 20 лет.
«Яндекс» — это прежде всего люди
АВ: Компания, в которой сейчас работают порядка ста человек, обходится нам примерно в $150 тыс.
 в месяц. Зарабатываем мы… Вот за ноябрь прошлого года, например,- больше $200 тыс., хотя это конец года, конечно.
в месяц. Зарабатываем мы… Вот за ноябрь прошлого года, например,- больше $200 тыс., хотя это конец года, конечно.
СФ: На что тратятся эти $150 тыс.?
АВ: В основном на зарплату, включая заказы, которые мы размещаем на стороне (например, модерация каталога, некоторые программистские разработки, техническое обслуживание серверов). Немного уходит на закупку техники, на помещение, на различные накладные расходы. Компания «Яндекс» — это в основном люди. Нам не нужна бумага для публикации, не нужны типографии, а каналы связи у нас свои.
СФ: Что значит свои? Вы их купили или сами проложили?
АВ: Если отвлечься от интернета как канала передачи данных (корпоративные сети, телефония и тому подобное), то очень грубо контентная (содержательная) часть всемирной паутины выглядит следующим образом. Есть три сущности: медийные площадки, магистрали и инфраструктура доступа. Мы — самостоятельная медийная площадка. У нас собственный хостинг (все серверы стоят в нашем помещении), к которому мы подключаем полтора десятка магистральщиков. Для этого у нас есть собственные каналы, ведущие к центрам обмена трафиком (информационным потоком). Сейчас таких каналов три, доделывается четвертый. Далее наш контент через провайдеров доступа попадает к пользователям.
У нас собственный хостинг (все серверы стоят в нашем помещении), к которому мы подключаем полтора десятка магистральщиков. Для этого у нас есть собственные каналы, ведущие к центрам обмена трафиком (информационным потоком). Сейчас таких каналов три, доделывается четвертый. Далее наш контент через провайдеров доступа попадает к пользователям.
СФ: Зато у вас, наверное, дорогая техника?
АВ: Техника как раз у нас самая стандартная и поэтому стоит недорого. Считайте сами. Сейчас у нас 160 серверов. Стоимость каждого, если довольно грубо считать,- $3 тыс. Срок амортизации составляет три-четыре года. Плюс необходимо расширяться процентов на 30-50 в год, поскольку трафик растет очень быстро.
«Пользователь интересен тому, кто платит деньги»
СФ: Все услуги, которые предлагает «Яндекс», являются бесплатными. На чем деньги зарабатываете?
АВ: Есть общепринятая модель существования массовых бесплатных сервисов — рекламная. При такой модели сервис оплачивают не те, кто им пользуется, а те, кому пользующиеся интересны. Мы любим пользователя, холим и лелеем его, оказываем ему всевозможные услуги и привлекаем его, а уже он интересен тому, кто платит деньги. У «Яндекса» — совершенно такая модель. Мы живем на доходы от рекламы, она нам приносит сегодня 95% всех средств.
При такой модели сервис оплачивают не те, кто им пользуется, а те, кому пользующиеся интересны. Мы любим пользователя, холим и лелеем его, оказываем ему всевозможные услуги и привлекаем его, а уже он интересен тому, кто платит деньги. У «Яндекса» — совершенно такая модель. Мы живем на доходы от рекламы, она нам приносит сегодня 95% всех средств.
СФ: Баннеры?
АВ: Вот и вы тоже попались на эту удочку. Когда говорят о рекламе в интернете, всем сразу приходят на ум именно баннеры. Это действительно самая простая модель — у вас есть аудитория, вы повесили на страничке баннер, и все его видят. Аналог такой модели — растяжка или постер на улице, реклама в журнале, бегущая строка на телевидении. Такой рекламы у нас примерно треть — в денежном выражении. Но это совершенно неприцельная реклама. Типичный ее заказчик — компании из «большой десятки» рекламодателей России, которые относятся к области высоких технологий. МТС, «Вымпелком», «Мегафон», например. Есть, разумеется, рекламодатели из сегмента FMCG — Coca-Cola, PepsiCo, Nestle и т. д. Это заказчики, которым нужна вся аудитория.
Есть, разумеется, рекламодатели из сегмента FMCG — Coca-Cola, PepsiCo, Nestle и т. д. Это заказчики, которым нужна вся аудитория.
Есть и такие, которым вся не нужна. Именно поэтому у поисковых систем есть другой способ зарабатывать деньги. Это контекстная реклама в разных ее видах. Самая простая ее разновидность — реклама в каталоге. У нас есть каталог сайтов по разным темам, и можно разместить рекламу внутри какой-то категории. Это уже определенная степень прицельности. Но небольшая, и поэтому такая реклама — тоже не основная разновидность.
СФ: Какая же тогда основная?
АВ: Главное преимущество поискового сервиса для рекламодателя — то, что люди приходят туда с конкретными потребностями. Больше того, эти потребности у них явно выражены. Они открытым текстом пишут в строке запроса, чего они в данный момент хотят. И происходит это три миллиона раз в день. Три миллиона желаний в день в среднем от миллиона человек. И среди этих запросов около трети — товарно ориентированные. Кроме того, не бывает ведь так, чтобы один человек интересовался только мобильными телефонами, а другой — только зимними шинами. Человек в каждый момент разный. На работе я директор компании, дома — отец семейства, на дороге — автолюбитель. А поисковая система, по сути, удовлетворяет желание клиента: определяет, что ему в данный момент нужно, и может показывать рекламу ровно того самого, что человек сейчас ищет. Эта реклама гораздо более качественная и гораздо более действенная.
Кроме того, не бывает ведь так, чтобы один человек интересовался только мобильными телефонами, а другой — только зимними шинами. Человек в каждый момент разный. На работе я директор компании, дома — отец семейства, на дороге — автолюбитель. А поисковая система, по сути, удовлетворяет желание клиента: определяет, что ему в данный момент нужно, и может показывать рекламу ровно того самого, что человек сейчас ищет. Эта реклама гораздо более качественная и гораздо более действенная.
СФ: Как вы определяете действенность рекламы?
АВ: Очень просто. Например, можно замерить количество нажатий на ссылку или баннер (CTR — Click-through Rate, соотношение между количеством показов рекламы и количеством пользователей, которые перешли на рекламируемый сайт). У целевой рекламы CTR будет раз в восемь примерно выше.
СФ: Но не все же люди сделают покупку?
АВ: Конечно, не все. Можно, например, обнаженную девушку на баннере нарисовать, на него тоже нажимать будут. Но потом увидят, что пришли в магазин, и уйдут. Главное как раз то, что люди, которые переходят по ссылке, рекламируемой целевым образом, соответственно настроены. Они с большей вероятностью сделают покупку. Интересно, что и пользователи не воспринимают такую рекламу как что-то навязчивое — скорее как дополнительную информацию по своему запросу.
Но потом увидят, что пришли в магазин, и уйдут. Главное как раз то, что люди, которые переходят по ссылке, рекламируемой целевым образом, соответственно настроены. Они с большей вероятностью сделают покупку. Интересно, что и пользователи не воспринимают такую рекламу как что-то навязчивое — скорее как дополнительную информацию по своему запросу.
СФ: Правда?
АВ: Да. У нас есть сервис для пользователей с оченьмедленными линиями связи, там вообще не показываются баннеры, никакие, чтобы сэкономить время загрузки. И пользователи, как оказалось, были недовольны, что не видят рекламы по своему запросу.
Контекстная реклама (реклама, которая показывается, только если в запросе заданы определенные слова — контекст) является основным преимуществом поисковых машин. Благодаря высокой эффективности и небольшой стоимости такой рекламы она пользуется большим спросом у малого и среднего бизнеса, ориентированного на «продающую», а не имиджевую рекламу. Контекстная реклама является на сегодня основным хлебом поисково-справочных машин.
Контекстная реклама является на сегодня основным хлебом поисково-справочных машин.
«Нам и в интернете хорошо»
СФ: «Яндекс» приобрел популярность не только и не столько благодаря предоставлению возможностей широкого поиска в Рунете и, собственно, разрекламированности проекта, но и за счет создания различных бесплатных сервисов. У вас их более 20. Насколько они успешны с финансовой точки зрения?
АВ: Пожалуй, самый успешный проект — это «Яндекс.Маркет», который приносит нам сейчас 20-25% прибыли. Что он собой представляет? В интернете вся информация перемешана и никак не структурирована. Если вы ищете в «Яндексе», например, зимние шины, то найдете и магазин с ними, и представительскую страницу компании-производителя, и художественные произведения с этими словами, и форумы какие-нибудь, где употребили это словосочетание. Так вот, в «Яндекс.Маркете» содержится только информация о различных товарах, которую каждую ночь нам присылают около 200 интернет-магазинов. Это сотни тысяч позиций. Вы набираете в строке поиска на общей странице название какого-нибудь товара, и справа от результатов поиска появляются ссылки на этот товар с информацией о ценах в разных интернет-магазинах. При переходе по ссылке вы сразу попадаете на страничку товара, где уже есть кнопка «Купить». Если «выпавших» на общую страницу предложений вам недостаточно, вы можете кликнуть на содержащуюся под ними ссылку «Все предложения» и попасть в «Яндекс.Маркет».
СФ: А вы что с этого получаете?
АВ: Нам платят магазины за каждый переход к ним на сайт за покупкой. А взамен они получают поток покупателей, которым нужен именно их товар.
СФ: И много платят?
АВ: Как посмотреть. По десять центов за один «клик» по ссылке, но не меньше $40 в месяц. На первый взгляд, немного. Но тут ведь что хорошо? Что это большое количество небольших рекламодателей. Это не один большой клиент, которого надо уговаривать, поить чаем и всячески обхаживать, чтобы он правильно распределил рекламный бюджет. Здесь мы имеем сервис с формально описанными правилами, который нужен людям. За счет того, что есть большое количество небольших контрагентов, бизнес получается очень стабильным. И, что важно, понятным. Понятно, что хорошего он приносит пользователям, и что — рекламодателям, понятно, где между ними находимся мы. Для справочной системы в интернете мне такая модель кажется на сегодня самой удачной. Вот давайте попробуем написать слово «шины»?
Здесь мы имеем сервис с формально описанными правилами, который нужен людям. За счет того, что есть большое количество небольших контрагентов, бизнес получается очень стабильным. И, что важно, понятным. Понятно, что хорошего он приносит пользователям, и что — рекламодателям, понятно, где между ними находимся мы. Для справочной системы в интернете мне такая модель кажется на сегодня самой удачной. Вот давайте попробуем написать слово «шины»?
СФ: Давайте.
АВ: Так. Вот результаты поиска, вот ссылка на товары, а вот статистика: «Запросов за месяц: шины: 46730». 46 тысяч раз кто-то попросил шины. Вы можете себе представить, что по улицам ходят люди и спрашивают, где тут шины? А у нас постоянно спрашивают. Понятно, что это надо срочно кому-то продавать.
СФ: И как вы это продаете?
АВ: Отдел продаж звонит и говорит: «Здравствуйте, вы торгуете шинами? У нас за последний месяц шины спросили 46730 раз. Скажите, пожалуйста, что нам посоветовать нашим пользователям? Если хотите, можем перенаправить их к вам».
Скажите, пожалуйста, что нам посоветовать нашим пользователям? Если хотите, можем перенаправить их к вам».
СФ: Какие еще есть дополнительные источники получения прибыли?
АВ: Ну например, продажа программных разработок, организация нашего поиска по сайту клиента, но эта деятельность приносит всего 5% прибыли. Пока мы экспериментируем с другими способами получения дохода, но ведь и контекстная реклама тоже когда-то была экспериментом. В июне 2001 года стартовал проект «Яндекс.Директ» (система для онлайн-заказа рекламы), оборот которого в первый месяц составил $800, а сейчас — уже десятки тысяч долларов. Иногда совместно с оффлайновыми брэндами мы реализуем проекты, ограниченные во времени, такие, например, как «Яндекс.Пиво» или «Яндекс.Лето». Недавно мы запустили систему «Яндекс.Деньги», через которую человек может заплатить за различные товары и услуги. Она сейчас очень успешно развивается.
СФ: Что значит успешно?
АВ: Она очень быстро растет. Это оказалось именно то, что нужно. Теоретически вы ходите на работу и домой, а все остальное — ваше свободное время. И стоять в очереди на оплату мобильного телефона или квартиры вы не обязаны, это трата вашего времени. Соответственно, если вы вызовете курьера, который конвертирует ваши рубли в электронные деньги, то дальнейшие платежи вы можете делать, даже не вставая с кресла. Это такой протокол передачи денег от вас к продавцу. Все, что от вас будет требоваться,- периодически вызывать курьера для пополнения так называемого кошелька.
Это оказалось именно то, что нужно. Теоретически вы ходите на работу и домой, а все остальное — ваше свободное время. И стоять в очереди на оплату мобильного телефона или квартиры вы не обязаны, это трата вашего времени. Соответственно, если вы вызовете курьера, который конвертирует ваши рубли в электронные деньги, то дальнейшие платежи вы можете делать, даже не вставая с кресла. Это такой протокол передачи денег от вас к продавцу. Все, что от вас будет требоваться,- периодически вызывать курьера для пополнения так называемого кошелька.
СФ: Но есть же карточки и оплата по ним?
АВ: Кредитные карточки, придуманные 30-40 лет назад, когда никакого интернета не было, создавались под другую технологию. Оплата по карте подтверждалась подписью — биомеханический идентификатор, который от вас неотделим. Даже отпечатки пальцев можно фальсифицировать и использовать отдельно от владельца, а подпись — нет. В интернете подписи нет, поэтому жена, сын или, не дай бог, злоумышленник могут воспользоваться вашей картой. И доказать, что вы ею не пользовались, будет трудно.
И доказать, что вы ею не пользовались, будет трудно.
СФ: Нужна другая технология?
АВ: Да. И эта технология — электронные деньги. Пока заплатить можно не за все, но за многое. Можно заплатить за телефон или за интернет, а можно, например, на журнал подписаться.
СФ: А несетевые проекты не собираетесь пока запускать? Как, например, ваш конкурент «Рамблер», который на базе региональной телесети «АСТ-Прометей» создал недавно начавший вещать телеканал «Рамблер ТелеСеть»?
АВ: Нет, нам и в интернете хорошо. Мы не испытываем затруднений с заработком на этой площадке. Да и возможностей еще столько, что для придумывания чего-то нового из сети уходить вовсе не обязательно.
«Отрасль просела, а мы выросли»
СФ: Как вы оцениваете свою долю рынка?
АВ: Трудно оценить долю на рынке, объемы которого пока никто всерьез не изучает. Но я думаю, что еще полгода-год, и рынок интернет-рекламы начнут измерять. Рынок радиорекламы в прошлом году имел объем около $50 млн, и Gallup Media его измерял. Рынок интернет-рекламы сейчас имеет объем около $10 млн. Немного подрастет и тоже попадет под наблюдение.
Рынок радиорекламы в прошлом году имел объем около $50 млн, и Gallup Media его измерял. Рынок интернет-рекламы сейчас имеет объем около $10 млн. Немного подрастет и тоже попадет под наблюдение.
СФ: Но все же компания сейчас стоит меньше, чем до кризиса интернет-компаний?
АВ: Сейчас, я думаю, уже столько же. Отрасль действительно сильно просела, но мы выросли. Так что если инвестор захочет продать свои акции, то деньги он вернет. Другое дело, что нас не особенно интересует акционерная стоимость компании, поскольку мы — компания не публичная, наши акции на бирже не котируются. Стоимость определяется количеством денег, которые за компанию готов заплатить потенциальный покупатель, а такого нет — мы несобираемся продаваться. У меня есть расчеты, сделанные одним инвестиционным аналитиком, которые обосновывают цену компании в пределах от $15 млн до $30 млн. Но, повторяю, это ни о чем не говорит. Задача наращивать курс акций перед нами не стоит.
СФ: А какая стоит?
АВ: Наша задача очень простая: сделать нормальный, окупаемый бизнес с понятной бизнес-моделью и очевидной полезностью людям. Если это получится, то у инвесторов не будет проблемы ликвидности инвестиций, и вообще — если у вас в руках есть реально работающая вещь, с ней можно много чего хорошего сделать.
Владимир Ермилов
Почему яндекс назвали яндексом | websiteforyou.su
Содержание
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Если вы еще не знакомы, то хочу представить вам один из самых популярных онлайн сервисов рунета под названием Яндекс. Существует он аж с 1996 года и на заре своего становления это была исключительно только поисковая система.
Давайте вопрос что такое Яндекс сегодня чуток отложим, а поговорим о том, откуда появилось такое странное название. Почему именно Яндекс? По этому поводу существует несколько трактовок и все они отвечают на поставленный вопрос.
Правда только одна из них отражает реальный ход размышлений автора этого сверхпопулярного сейчас слова, коим был один из отцов-основателей этой поисковой системы — Илья Сегалович (к сожалению, ушедший от нас в середине прошлого года).
Почему Yandex называется Яндексом?
На приведенном фото он крайний слева. Рядом с ним стоит его соратник и второй основательно Яндекса — Аркадий Волож. Ну, а справа стоят Сергей Брин и Ларри Пейдж — основатели поисковой системы Гугл. Это фото сделано в начале нашего века, когда компания Google планировала купить наш отечественный поисковик и ее руководители приезжали в Россию для переговоров, но сделка так и не состоялась.
Итак, перед Ильей стояла нелегкая задача — выбрать название для будущего поисковика (еще не доступного в то время через интернет) и при этом не ударить лицом в грязь. За основу было взято ключевое для поиска слово index (читайте про то, как работают поисковики и как важен для них индекс, и что это вообще такое).
Было принято решение, что словообразующей фразой станет yet another indexer, что в переводе означает еще один индексатор. В общем, довольно-таки скромно и без всяких заявок на будущий ошеломляющий успех. Английский язык тогда в России был фетишем и, естественно, что поисковая система первоначально получила название именно на латинице: YANDEX (Yet Another iNDEXer).
Однако, основной фишкой Яндекса в то время (да и сейчас тоже) являлось то, что он ищет ответы в интернете с учетом русской морфологии. Кроме него в то время это делал только Рамблер, который сейчас уже не является полноценным поисковиков. В общем, отцы-основатели решили, что нужно добавить в начале русскую букву Я вместо английской Y и получилось ЯNDEX. Это уже можно было интерпретировать, как Языковой INDEX.
В то время его главная страница выглядела так (дизайн Темы Лебедева):
В 2008 году мода на написание названий компаний латинскими буквами сошла на нет и ЯNDEX стал называться просто Яндексом.
Есть еще несколько трактовок, почему Яндекс называется именно Яндексом, и несмотря на то, что они вполне логичны и лаконичны, появились они уже после утверждения официального названия. Одну из них я уже упоминал — Языковый iNDEX.
Ну, а вторая гласит, что если взять в слове index первую букву I и перевести состоящее из нее слово с английского на русский, то как раз и получится местоимение Я — отсюда и ЯNDEX. Версия красивая, но несколько отличная от произошедшего в реальности.
Что такое Яндекс и что он представляет из себя сегодня?
Как я уже упоминал, на заре своего становления этот онлайн сервис был исключительно поисковой системой. Он и сейчас ею является, причем его доля на рынке рунете весьма весомая и составляет более шестидесяти процентов.
Но время текло и все менялось. С каждым новым годом существования Яндекс обрастал все новыми и новыми сервисами и возможностями. Некоторые из них дошли до нашего времени неизменными, некоторые изменились, объединились или даже закрылись, как, например, Народ.
Сейчас, если Вы ищите товар, то наверняка обращаетесь к Яндекс.Маркету, чтобы подобрать оптимальный по цене и отзывам магазин. Если едите куда-то, то переходите на сервис Яндекс Карт с отображением дорожной обстановки (пробок).
Для многих этот онлайн сервис стал порталом, с которого они ежедневно начинаю свой серфинг по интернету. Это особенно удобно потому, что главная страница Яндекса, подобно рабочему столу в Виндовс, имеет возможность добавления виджетов, настройки внешнего вида за счет использования тем, а также с нее доступны все остальные сервисы этого мега-портала.
Так что же такое Яндекс? Одним словом и не ответишь. Давайте я перечислю все сервисы собранные под его крылом, о которых мне довелось подробно писать. Наверное, так будет гораздо проще и нагляднее.
- Как получить паспорт Яндекса — в отличии от Гугла, зеркало рунета изначально приняло решение об использовании своей главной (стартовой) страницы для удобства пользователей.
Ну, и по аналогии с Гугл аккаунтом был введен Паспорт, который действителен на всей территории всех владений этой поисковой системы.
В общем, если у вас есть свой сайт с ежесуточной посещаемостью большей или равной 300 уникальных посетителей в сутки, то регистрируйтесь в Профит Партнере(официальном центре обслуживания партнеров РСЯ) и зарабатывайте, получайте призы и партнерские вознаграждения. Без балды — это реальный способ заработать.
По функционалу новая инкарнация Yandex Mail не сильно уступает последнему, а в некоторых аспектах даже превосходит. Например, имеется бесплатная возможность получения почты для домена, что в Гугле сейчас стало стоить малую копеечку (почта для домена в Гугл Аппс).
Да, все это не так агрессивно реализовано, как у поисковой системы Вебальта, но что-то общее имеется.
Думаю, что теперь, хотя бы в общих чертах, вам стало ясно, что такое Yandex и насколько он велик и могуч. Спасибо.
Содержание статьи
- Откуда взялось название Яндекс
- Как появился Яндекс
- Откуда и как произошло название нашей страны — Россия
В сети можно прочитать разные версии происхождения названия Яндекс. Так, наиболее логичным, но не вполне верным, является мнение, что имя интернет-компании Яндекс первоначально было образовано от словосочетания языковой индекс. Такая версия кажется вполне правдоподобной в том свете, что будущие основатели Яндекса стали первыми программистами, написавшими конкурентоспособный софт для поиска документов на русском языке. Кстати, наработки компании CompTek (прародителя Яндекса) и по сей день используются ведущими российскими компаниями.
История создания названия Яндекс
Само название Яндекс зародилось в стенах компании CompTek, где и были написаны первые поисковые алгоритмы, послужившие основой для запуска поисковика №1 в России. Название Яндекс было придумано основателями компании Ильей Сегаловичем и Аркадием Воложем. В попытке найти наиболее звучное, запоминающееся и лаконичное название были выбраны части слов из английского словосочетания yet another indexer, что буквально означает еще один индексатор. Индексатором в поисковых технологиях называется программа, бродящая по просторам интернета и считывающая текстовую информацию со страниц сайтов. Обработанные массивы информации помещаются в индекс – базу уже просмотренных и сохраненных программой-индексатором страниц. При помощи поисковых алгоритмов ранжирования пользователю дается ссылка на интересующую его информацию, исходя из поискового запроса, который он ввел на главной странице поисковика или в омнибокс своего браузера.
Первоначальное использование названия Яндекс
В самом начале название Яндекс было использовано для программного продукта, позволяющего находить интересующую информацию на жестком диске компьютера. Технология была примерно такой же, какой ее видит пользователь, вводящий запрос в строку поиска ОС Windows или при использовании разного рода профессиональных справочников, приобретаемых на дисках. Легкость восприятия слова Яндекс на слух, его звучность и оригинальность повлияли на то, что 23 сентября 1997 года под этим названием была анонсирована новая поисковая интернет-система Яндекс, кстати, вовсе не единственная на тот момент в России. В память о первых наработках в области поиска и о самом рождении поисковика компания Яндекс ежегодно проводит конференцию Yet another Conference, название которой является аллюзией на расшифровку имени компании.
Сегодня Яндекс — слово из повседневного обихода пользователя интернета. В Сети часто встречается А что, Яндекс уже отменили?, Одиночество — это когда с днем рождения первым поздравляет Яндекс, Все вопросы к Яндексу. Многим уже кажется, что так было всегда. В некотором роде это правда — Яндекс действительно появился одновременно с массовым интернетом, когда доступ в сеть перестал быть уделом избранных технических специалистов. Но само слово Яндекс — искусственное, имеет своих авторов и свою историю.
В 1993 году Аркадий Волож, будущий генеральный директор будущей компании Яндекс, и Илья Сегалович, будущий директор по технологиям компании, разрабатывали, как потом выяснилось, главную технологию — поиск неструктурированной информации с учетом русского языка.
Источник: gepeek.ru
Как пишется Яндекс на английском языке
Поисковая система Яндекс — самый популярный поисковик российского сегмента глобальной сети. Как и многие другие поисковые системы, она предоставляет своим пользователям большое количество интернет-сервисов: почта, облачное хранилище, онлайн-карты, видео, платежная система и многое другое. Исходя из этого, у многих пользователей возникает вопрос — как именно на английском языке пишется слово «Яндекс».
Откуда взялось название Яндекс
Фразу Yet Another indexer, что в переводе с английского языка звучит как «еще один индексатор», придумал будущий директор компании Яндекс Илья Сегалович и Аркадий Волож (гендиректор). В то время слово выглядело как «Яndex». Перед тем, как к нему прийти Илья выписывал различные варианты для названия своей новоиспеченной поисковой системы. Ему сразу же стало понятно, что англоязычное слово search (поиск) в произношении на русский манер звучит, мягко говоря, не очень. Поэтому ему достаточно быстро пришла на ум фраза «yet another index». Немного позже Яндекс в адресной строке записывали просто Yandex. Так система пишется на английском языке и сегодня.
Дизайн и логотип Яндекс
С самых ранних этапов появления компании и поисковой системы Yandex владельцы сотрудничали со студией Артемия Лебедева. Специалисты разрабатывали для Яндекс большую часть дизайна сайта. Больше всего для компании сделал Рома Воронежский — дизайнер студии. Дизайн разрабатывали и другие специалисты области, например, для проекта «Лето» от Яндекс дизайн был создан организацией «Болоtov.ru». Последнее время компания все чаще обходится без услуг Артемия Лебедева.
Логотип Яндекса, который практически не изменился и сегодня, появился еще в 1996 году. Впервые он фигурировал в Яndex.CD и Яndex.Site. Это произошло еще од появления самого поисковика. Логотип также был разработан студией Лебедева. В 3.0 версии логотип отбросил первую букву кириллицы (Яndex) и стал выглядеть как Yandex. Видимо первая буква «Я» у разработчиков была как кость в горле, ведь практически любой язык программирования понимает только латиницу. На английском языке Яндекс пишется — Yandex.
Нюансы при поиске в Яндекс
В поисковой системе Яндекс есть возможность настраивать поиск. Эта функция реализуется за счет гибкости языка при запросе. При поиске можно задавать область действия, например, включив в строку запроса А ~~ Г. В этом случае система найдет все результаты, где присутствует первый оператор (А), но исключит все результаты со вторым (Г). Другой оператор & найдет список ключевых слов в тексте, а двойной амперсанд будет искать «ключи» во всем документе.
Восклицательный знак в роли оператора поможет отключить морфологию определенного слова или фразы. Таким образом, если формы слова будут совпадать с другими, поисковая система выдаст дополнительные страницы. И наоборот, оператор «!!» уберет ненужные слова из результатов.
Сайты, которые не проходят индексацию в Яндекс
Есть несколько причин, по которым поисковая система Yandex не индексирует сайты и не показывает их в результаты в поиске.
- Сайты, которые крадут информацию или контент с других ресурсов.
- Редиректы — сайты, единственной целью которых является перенаправлять посетителей на другие ресурсы.
- Сайт, чей контент был сгенерирован программно, набор бессмысленного текста.
- И другие.
Как писать Яндекс на английском в почтовом адресе
Компания Яндекс предоставляет всем своим зарегистрированным пользователям бесплатный почтовый адрес. Более того, при входе в систему этот адрес по умолчанию является логином.
Поэтому каждый пользователь должен знать, как писать слово Яндекс на английском языке. К примеру, [email protected], [email protected] и так далее.
Искусственный интеллект в поиске. Как Яндекс научился применять нейронные сети, чтобы искать по смыслу, а не по словам
Сегодня мы анонсировали новый поисковый алгоритм «Палех». Он включает в себя все те улучшения, над которыми мы работали последнее время.
Например, поиск теперь впервые использует нейронные сети для того, чтобы находить документы не по словам, которые используются в запросе и в самом документе, а по смыслу запроса и заголовка.
Уже много десятилетий исследователи бьются над проблемой семантического поиска, в котором документы ранжируются, исходя из смыслового соответствия запросу. И теперь это становится реальностью.
В этом посте я постараюсь немного рассказать о том, как у нас это получилось и почему это не просто ещё один алгоритм машинного обучения, а важный шаг в будущее.
Искусственный интеллект или машинное обучение?
Почти все знают, что современные поисковые системы работают с помощью машинного обучения. Почему об использовании нейронных сетей для его задач надо говорить отдельно? И почему только сейчас, ведь хайп вокруг этой темы не стихает уже несколько лет? Попробую рассказать об истории вопроса.
Поиск в интернете — сложная система, которая появилась очень давно. Сначала это был просто поиск страничек, потом он превратился в решателя задач, и сейчас становится полноценным помощником. Чем больше интернет, и чем больше в нём людей, тем выше их требования, тем сложнее приходится становиться поиску.
Эпоха наивного поиска
Сначала был просто поиск слов — инвертированный индекс. Потом страниц стало слишком много, их стало нужно ранжировать. Начали учитываться разные усложнения — частота слов,
tf-idf.
Эпоха ссылок
Потом страниц стало слишком много на любую тему, произошёл важный прорыв — начали учитывать ссылки, появился
PageRank.
Эпоха машинного обучения
Интернет стал коммерчески важным, и появилось много жуликов, пытающихся обмануть простые алгоритмы, существовавшие в то время. Произошёл второй важный прорыв — поисковики начали использовать свои знания о поведении пользователей, чтобы понимать, какие страницы хорошие, а какие — нет.
Где-то на этом этапе человеческого разума перестало хватать на то, чтобы придумывать, как ранжировать документы. Произошёл следующий переход — поисковики стали активно использовать машинное обучение.
Один из лучших алгоритмов машинного обучения изобрели в Яндексе — Матрикснет. Можно сказать, что ранжированию помогает коллективный разум пользователей и «мудрость толпы». Информация о сайтах и поведении людей преобразуется во множество факторов, каждый из которых используется Матрикснетом для построения формулы ранжирования. Фактически, формулу ранжирования пишет машина (получалось около 300 мегабайт).
Но у «классического» машинного обучения есть предел: оно работает только там, где очень много данных. Небольшой пример. Миллионы пользователей вводят запрос [вконтакте], чтобы найти один и тот же сайт. В данном случае их поведение является настолько сильным сигналом, что поиск не заставляет людей смотреть на выдачу, а подсказывает адрес сразу при вводе запроса.
Но люди сложнее, и хотят от поиска всё больше. Сейчас уже до 40% всех запросов уникальны, то есть не повторяются хотя бы дважды в течение всего периода наблюдений. Это значит, что у поиска нет данных о поведении пользователей в достаточном количестве, и Матрикснет лишается ценных факторов. Такие запросы в Яндексе называют «длинным хвостом», поскольку все вместе они составляют существенную долю обращений к нашему поиску.
Эпоха искусственного интеллекта
И тут время рассказать о последнем прорыве: несколько лет назад компьютеры становятся достаточно быстрыми, а данных становится достаточно много, чтобы использовать нейронные сети. Основанные на них технологии ещё называют машинным интеллектом или искусственным интеллектом — потому что нейронные сети построены по образу нейронов в нашем мозге и пытаются эмулировать работу некоторых его частей.
Машинный интеллект гораздо лучше старых методов справляется с задачами, которые могут делать люди: например, распознаванием речи или образов на изображениях. Но как это поможет поиску?
Как правило, низкочастотные и уникальные запросы довольно сложны для поиска – найти хороший ответ по ним заметно труднее. Как это сделать? У нас нет подсказок от пользователей (какой документ лучше, а какой — хуже), поэтому для решения поисковой задачи нужно научиться лучше понимать смысловое соответствие между двумя текстами: запросом и документом.
Легко сказать
Строго говоря, искусственные нейросети – это один из методов машинного обучения. Совсем недавно им была посвящена
лекция в рамках Малого ШАДа. Нейронные сети показывают впечатляющие результаты в области анализа естественной информации — звука и образов. Это происходит уже несколько лет. Но почему их до сих пор не так активно применяли в поиске?
Простой ответ — потому что говорить о смысле намного сложнее, чем об образе на картинке, или о том, как превратить звуки в расшифрованные слова. Тем не менее, в поиске смыслов искусственный интеллект действительно стал приходить из той области, где он уже давно король, — поиска по картинкам.
Несколько слов о том, как это работает в поиске по картинкам. Вы берёте изображение и с помощью нейронных сетей преобразуете его в вектор в N-мерном пространстве. Берете запрос (который может быть как в текстовом виде, так и в виде другой картинки) и делаете с ним то же самое. А потом сравниваете эти вектора. Чем ближе они друг к другу, тем больше картинка соответствует запросу.
Ок, если это работает в картинках, почему бы не применить эту же логику в web-поиске?
Дьявол в технологиях
Сформулируем задачу следующим образом. У нас на входе есть запрос пользователя и заголовок страницы. Нужно понять, насколько они соответствует друг другу по смыслу. Для этого необходимо представить текст запроса и текст заголовка в виде таких векторов, скалярное умножение которых было бы тем больше, чем релевантнее запросу документ с данным заголовком. Иначе говоря, мы хотим обучить нейронную сеть таким образом, чтобы для близких по смыслу текстов она генерировала похожие векторы, а для семантически несвязанных запросов и заголовков вектора должны различаться.
Сложность этой задачи заключается в подборе правильной архитектуры и метода обучения нейронной сети. Из научных публикаций известно довольно много подходов к решению проблемы. Вероятно, самым простым методом здесь является представление текстов в виде векторов с помощью алгоритма word2vec (к сожалению, практический опыт говорит о том, что для рассматриваемой задачи это довольно неудачное решение).
Дальше — о том, что мы пробовали, как добились успеха и как смогли обучить то, что получилось.
DSSM
В 2013 году исследователи из Microsoft Research описали свой подход, который получил название
Deep Structured Semantic Model.
На вход модели подаются тексты запросов и заголовков. Для уменьшения размеров модели, над ними производится операция, которую авторы называют word hashing. К тексту добавляются маркеры начала и конца, после чего он разбивается на буквенные триграммы. Например, для запроса [палех] мы получим триграммы [па, але, лех, ех]. Поскольку количество разных триграмм ограничено, то мы можем представить текст запроса в виде вектора размером в несколько десятков тысяч элементов (размер нашего алфавита в 3 степени). Соответствующие триграммам запроса элементы вектора будут равны 1, остальные — 0. По сути, мы отмечаем таким образом вхождение триграмм из текста в словарь, состоящий из всех известных триграмм. Если сравнить такие вектора, то можно узнать только о наличии одинаковых триграмм в запросе и заголовке, что не представляет особого интереса. Поэтому теперь их надо преобразовать в другие вектора, которые уже будут иметь нужные нам свойства семантической близости.
После входного слоя, как и полагается в глубоких архитектурах, расположено несколько скрытых слоёв как для запроса, так и для заголовка. Последний слой размером в 128 элементов и служит вектором, который используется для сравнения. Выходом модели является результат скалярного умножения последних векторов заголовка и запроса (если быть совсем точным, то вычисляется косинус угла между векторами). Модель обучается таким образом, чтобы для положительны обучающих примеров выходное значение было большим, а для отрицательных — маленьким. Иначе говоря, сравнивая векторы последнего слоя, мы можем вычислить ошибку предсказания и модифицировать модель таким образом, чтобы ошибка уменьшилась.
Мы в Яндексе также активно исследуем модели на основе искусственных нейронных сетей, поэтому заинтересовались моделью DSSM. Дальше мы расскажем о своих экспериментах в этой области.
Теория и практика
Характерное свойство алгоритмов, описываемых в научной литературе, состоит в том, что они не всегда работают «из коробки». Дело в том, что «академический» исследователь и исследователь из индустрии находятся в существенно разных условиях. В качестве отправной точки (baseline), с которой автор научной публикации сравнивает своё решение, должен выступать какой-то общеизвестный алгоритм — так обеспечивается воспроизводимость результатов. Исследователи берут результаты ранее опубликованного подхода, и показывают, как их можно превзойти. Например, авторы оригинального DSSM сравнивают свою модель по метрике
NDCGс алгоритмами
BM25и
LSA. В случае же с прикладным исследователем, который занимается качеством поиска в реальной поисковой машине, отправной точкой служит не один конкретный алгоритм, а всё ранжирование в целом. Цель разработчика Яндекса состоит не в том, чтобы обогнать BM25, а в том, чтобы добиться улучшения на фоне всего множества ранее внедренных факторов и моделей. Таким образом, baseline для исследователя в Яндексе чрезвычайно высок, и многие алгоритмы, обладающие научной новизной и показывающие хорошие результаты при «академическом» подходе, оказываются бесполезны на практике, поскольку не позволяют реально улучшить качество поиска.
В случае с DSSM мы столкнулись с этой же проблемой. Как это часто бывает, в «боевых» условиях точная реализация модели из статьи показала довольно скромные результаты. Потребовался ряд существенных «доработок напильником», прежде чем мы смогли получить результаты, интересные с практической точки зрения. Здесь мы расскажем об основных модификациях оригинальной модели, которые позволили нам сделать её более мощной.
Большой входной слой
В оригинальной модели DSSM входной слой представляет собой множество буквенных триграмм. Его размер равен 30 000. У подхода на основе триграмм есть несколько преимуществ. Во-первых, их относительно мало, поэтому работа с ними не требует больших ресурсов. Во-вторых, их применение упрощает выявление опечаток и ошибок в словах. Однако, наши эксперименты показали, что представление текстов в виде «мешка» триграмм заметно снижает выразительную силу сети. Поэтому мы радикально увеличили размер входного слоя, включив в него, помимо буквенных триграмм, ещё около 2 миллионов слов и словосочетаний. Таким образом, мы представляем тексты запроса и заголовка в виде совместного «мешка» слов, словесных биграмм и буквенных триграмм.
Использование большого входного слоя приводит к увеличению размеров модели, длительности обучения и требует существенно больших вычислительных ресурсов.
Тяжело в обучении: как нейронная сеть боролась сама с собой и научилась на своих ошибках
Обучение исходного DSSM состоит в демонстрации сети большого количества положительных и отрицательных примеров. Эти примеры берутся из поисковой выдачи (судя по всему, для этого использовался поисковик Bing). Положительными примерами служат заголовки кликнутых документов выдачи, отрицательными — заголовки документов, по которым не было клика. У этого подхода есть определённые недостатки. Дело в том, что отсутствие клика далеко не всегда свидетельствует о том, что документ нерелевантен. Справедливо и обратное утверждение — наличие клика не гарантирует релевантности документа. По сути, обучаясь описанным в исходной статье образом, мы стремимся предсказывать аттрактивность заголовков при условии того, что они будут присутствовать в выдаче. Это, конечно, тоже неплохо, но имеет достаточно косвенное отношение к нашей главной цели — научиться понимать семантическую близость.
Во время своих экспериментов мы обнаружили, что результат можно заметно улучшить, если использовать другую стратегию выбора отрицательных примеров. Для достижения нашей цели хорошими отрицательными примерами являются такие документы, которые гарантированно нерелевантны запросу, но при этом помогают нейронной сети лучше понимать смыслы слов. Откуда их взять?
Первая попытка
Сначала в качестве отрицательного примера просто возьмём заголовок случайного документа. Например, для запроса [палехская роспись] случайным заголовком может быть «Правила дорожного движения 2016 РФ». Разумеется, полностью исключить то, что случайно выбранный из миллиардов документ будет релевантен запросу, нельзя, но вероятность этого настолько мала, что ей можно пренебречь. Таким образом мы можем очень легко получать большое количество отрицательных примеров. Казалось бы, теперь мы можем научить нашу сеть именно тому, чему хочется — отличать хорошие документы, которые интересуют пользователей, от документов, не имеющих к запросу никакого отношения. К сожалению, обученная на таких примерах модель оказалась довольно слабой. Нейронная сеть – штука умная, и всегда найдет способ упростить себе работу. В данном случае, она просто начала выискивать одинаковые слова в запросах и заголовках: есть — хорошая пара, нет — плохая. Но это мы и сами умеем делать. Для нас важно, чтобы сеть научилась различать неочевидные закономерности.
Ещё одна попытка
Следующий эксперимент состоял в том, чтобы добавлять в заголовки отрицательных примеров слова из запроса. Например, для запроса [палехская роспись] случайный заголовок выглядел как [Правила дорожного движения 2016 РФ роспись]. Нейронной сети пришлось чуть сложнее, но, тем не менее, она довольно быстро научилась хорошо отличать естественные пары от составленных вручную. Стало понятно, что такими методами мы успеха не добьемся.
Успех
Многие очевидные решения становятся очевидны только после их обнаружения. Так получилось и на этот раз: спустя некоторое время обнаружилось, что лучший способ генерации отрицательных примеров — это заставить сеть «воевать» против самой себя, учиться на собственных ошибках. Среди сотен случайных заголовков мы выбирали такой, который текущая нейросеть считала наилучшим. Но, так как этот заголовок всё равно случайный, с высокой вероятностью он не соответствует запросу. И именно такие заголовки мы стали использовать в качестве отрицательных примеров. Другими словами, можно показать сети лучшие из случайных заголовков, обучить её, найти новые лучшие случайные заголовки, снова показать сети и так далее. Раз за разом повторяя данную процедуру, мы видели, как заметно улучшается качество модели, и всё чаще лучшие из случайных пар становились похожи на настоящие положительные примеры. Проблема была решена.
Подобная схема обучения в научной литературе обычно называется hard negative mining. Также нельзя не отметить, что схожие по идее решения получили широкое распространение в научном сообществе для генерации реалистично выглядящих изображений, подобный класс моделей получил название Generative Adversarial Networks.
Разные цели
В качестве положительных примеров исследователи из Microsoft Research использовались клики по документам. Однако, как уже было сказано, это достаточно ненадежный сигнал о смысловом соответствии заголовка запросу. В конце концов, наша задача состоит не в том, чтобы поднять в поисковой выдаче самые посещаемые сайты, а в том, чтобы найти действительно полезную информацию. Поэтому мы пробовали в качестве цели обучения использовать другие характеристики поведения пользователя. Например, одна из моделей предсказывала, останется ли пользователь на сайте или уйдет. Другая – насколько долго он задержится на сайте. Как оказалось, можно заметно улучшить результаты, если оптимизировать такую целевую метрику, которая свидетельствует о том, что пользователь нашёл то, что ему было нужно.
Профит
Ок, что это нам дает на практике? Давайте сравним поведение нашей нейронной модели и простого текстового фактора, основанного на соответствии слов запроса и текста — BM25. Он пришёл к нам из тех времён, когда ранжирование было простым, и сейчас его удобно использовать за базовый уровень.
В качестве примера возьмем запрос [келлская книга] и посмотрим, какое значение принимают факторы на разных заголовках. Для контроля добавим в список заголовков явно нерелевантный результат.
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| келлская книга википедия | 0.91 | 0.92 |
| ученые исследуют келлскую книгу вокруг света | 0.88 | 0.85 |
| book of kells wikipedia | 0 | 0.81 |
| ирландские иллюстрированные евангелия vii viii вв | 0 | 0.58 |
| икеа гипермаркеты товаров для дома и офиса ikea |
0 | 0.09 |
Все факторы в Яндексе нормируются в интервал [0;1]. Вполне ожидаемо, что BM25 имеет высокие значения для заголовков, которые содержат слова запроса. И вполне предсказуемо, что этот фактор получает нулевое значение на заголовках, не имеющих общих слов с запросом. Теперь обратите внимание на то, как ведет себя нейронная модель. Она одинаково хорошо распознаёт связь запроса как с русскоязычным заголовком релевантной страницы из Википедии, так и с заголовком статьи на английском языке! Кроме того, кажется, что модель «увидела» связь запроса с заголовком, в котором не упоминается келлская книга, но есть близкое по смыслу словосочетание («ирландские евангелия»). Значение же модели для нерелевантного заголовка существенно ниже.
Теперь давайте посмотрим, как будут себя вести наши факторы, если мы переформулируем запрос, не меняя его смысла: [евангелие из келлса].
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| келлская книга википедия | 0 | 0.85 |
| ученые исследуют келлскую книгу вокруг света | 0 | 0.78 |
| book of kells wikipedia | 0 | 0.71 |
| ирландские иллюстрированные евангелия vii viii вв | 0.33 |
0.84 |
| икеа гипермаркеты товаров для дома и офиса ikea | 0 | 0.10 |
Для BM25 переформулировка запроса превратилась в настоящую катастрофу — фактор стал нулевым на релевантных заголовках. А наша модель демонстрирует отличную устойчивость к переформулировке: релевантные заголовки по-прежнему имеют высокое значение фактора, а нерелевантный заголовок — низкое. Кажется, что именно такое поведение мы и ожидали от штуки, которая претендует на способность «понимать» семантику текста.
Ещё пример. Запрос [рассказ в котором раздавили бабочку].
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| фильм в котором раздавили бабочку | 0.79 | 0.82 |
| и грянул гром википедия | 0 | 0.43 |
| брэдбери рэй википедия | 0 | 0.27 |
| машина времени роман википедия | 0 | 0.24 |
| домашнее малиновое варенье рецепт заготовки на зиму | 0 | 0.06 |
Как видим, нейронная модель оказалась способна высоко оценить заголовок с правильным ответом, несмотря на полное отсутствие общих слов с запросом. Более того, хорошо видно, что заголовки, не отвечающие на запрос, но всё же связанные с ним по смыслу, получают достаточно высокое значение фактора. Как будто наша модель «прочитала» рассказ Брэдбери и «знает», что это именно о нём идёт речь в запросе!
А что дальше?
Мы находимся в самом начале большого и очень интересного пути. Судя по всему, нейронные сети имеют отличный потенциал для улучшения ранжирования. Уже понятны основные направления, которые нуждаются в активном развитии.
Например, очевидно, что заголовок содержит неполную информацию о документе, и хорошо бы научиться строить модель по полному тексту (как оказалось, это не совсем тривиальная задача). Далее, можно представить себе модели, имеющие существенно более сложную архитектуру, нежели DSSM — есть основания предполагать, что таким образом мы сможем лучше обрабатывать некоторые конструкции естественных языков. Свою долгосрочную цель мы видим в создании моделей, способных «понимать» семантическое соответствие запросов и документов на уровне, сравнимом с уровнем человека. На пути к этой цели будет много сложностей — тем интереснее будет его пройти. Мы обещаем рассказывать о своей работе в этой области. Cледите за следующими публикациями.
Парк Чаир. Кореиз-Гаспра | Официальный сайт гостиницы Парк-Отель «Глория»
Главная » Достопримечательности рядом » Парк Чаир. Кореиз-ГаспраМежду Кореизом и поселком Гаспра находится одно из самых живописных, самых романтичных мест крымского полуострова – парк Чаир. Если вы отдыхаете в гостинице в Мисхоре, то добраться сюда будет несложно – есть прямое сообщение по автотрассе, можно добраться на автомобиле или автобусе.
Первое, что вызывает много вопросов – откуда взялось такое диковинное название парка? Все просто, на самом деле «чаир» с крымско-татарского в буквальном смысле означает «горный луг» — название, идеально соответствующее объекту.
Чаир – очень большой парк, площадь которого составляет 23 гектара. На необъятной площади произрастает огромное количество различных растений – как традиционных для полуострова (а природа Крыма очень богата и разнообразна), так и привнесенных. Специалисты-ботаники насчитывают тут около трех сотен хвойных и вечнозеленых растений, в том числе и тех, что прибыли сюда с других континентов. Так что тут можно полюбоваться на кипарисы, магнолии и гортензии. Что особенно интересно, посещение парка приносит удовольствие в любой сезон – просто в одно время можно полюбоваться буйным цветением, а в другое время – оценить великолепие природы и богатство парка.
Среди растений, которые произрастают в парке Чаир, есть и свои долгожители – тут присутствуют трехсотлетние и даже пятисотлетние гиганты, правда, высаживались они не искусственно – они остались тут с той поры, когда на месте парка еще был дикий лес.
Возникновение парка не было спонтанным – он вырос естественным путем, так как в этом регионе издавна выращивались сады, поднимающиеся вдоль склонов от моря к горам. Постепенно они вытесняли лес. Развитие парк получил благодаря Великому князю Николаю Николаевичу, который до 1917 года владел поместьем и дачей «Чаир». Теперь тут обосновался санаторий, а парк Чаир открыт для посещения всеми заинтересованными. Так что в нем ежегодно бывают гости из разных стран и городов: обычно это отдыхающие из Ялты или те, кто живет в гостинице в Мисхоре.
Парк воспевается в песнях, не раз был описан в художественной литературе. Памятник садово-парковой архитектуры и историческое достояние этих мест, он привлекает не только своей самобытностью – это замечательное место для отдыха в жаркий день. Пребывание тут живительно действует на людей – воздух, насыщенный морскими ароматами и запахом хвои, благотворно влияет на нервную систему и органы дыхания, так что парк исцеляет и душу, и тело.
Ди́рект или дире́кт — как правильно? | Образование | Общество
Отвечает Есения Павлоцки, лингвист-морфолог, эксперт института филологии, массовой информации и психологии Новосибирского государственного педагогического университета.
Слово директ не так давно вошло в наш активный словарный запас. Это связано с популярностью таких сервисов, как Яндекс.Директ и Direct Messages в ряде соцсетей. Чаще всего подразумевается директ в Инстаграме.
Яндекс.Директ — это система контекстной рекламы, а Direct Messages — это, говоря по-простому, личные сообщения в соцсетях. Оба наименования происходят от английского direct — прямой, непосредственный, а также управлять, наводить.
Яндекс.Директ имеет такое название, потому что контекстная реклама направлена прямо на определенную целевую аудиторию, а Direct Messages — потому что сообщения направляются напрямую конкретному адресату.
Система Direct Messages в Инстаграме как лексическая единица уже трансформировалась в нарицательное существительное директ — его уже давно пишут кириллицей и всё реже с большой буквы. Теперь директ — это синоним ЛС, то есть личные сообщения. Ударение в этом слове все ставят по-разному. Точнее, есть люди, которые говорят дире́кт, но есть и те, кто без тени сомнений произносит ди́рект.
Ставить вопрос о том, как правильно, здесь просто нельзя. Ударение в слове директ в языке-источнике падает на второй слог, однако не все слова при заимствовании имеют то же ударение, что в языке-источнике, — такого правила нет. Слово заимствуется, а потом какое-то время проявляет себя, демонстрируя свои особенности. В случае с директом говорить о словарном, нормативном закреплении какого-то варианта слишком рано.
Однако нельзя и объяснить, откуда взялось ударение ди́рект. Нет никаких очевидных слов-аналогов, к которым оно могло бы тяготеть, противостоя английскому ударению заимствованного direct (дире́кт). Более того, у нас даже есть слово дире́ктор, которое должно подталкивать нас к ударению дире́кт.
Все это позволяет думать, что в ударении ди́рект проявилась сленговая природа, истоком которой была элементарная ошибка — неправильное чтение транскрипции английского слова рядом популярных блогеров. Вероятно, именно ошибка стала модным произношением, которое люди принимают за, условно говоря, правильное — то есть такое, какое якобы есть в языке-источнике.
Несмотря на то, что орфоэпическую закономерность нельзя заставить проявляться в каком-либо направлении, учитывая все детали этого вопроса, с оговоркой можно сказать, что дире́кт — все-таки правильнее, потому что это ударение нейтральное. А основанное на неправильном чтении английского варианта наше слово ди́рект все же отдает сленговостью.
Пока только на этом основании мы можем утверждать, что правильно — дире́кт. Однако, повторюсь, требуется время для того, чтобы слово окончательно прижилось и продемонстрировало стабильное ударение.
Смотрите также:
«Подлец» и «Мерзавец» — Ивановский государственный химико-технологический университет
“khimik” 26(1971) 2009 Table of ContentsЕсть старая легенда происхождения слов подлец и мерзавец.
Согласно древнерусскому преданию, зимой в Древней Руси казнили таким способом: в мороз к столбу привязывали провинившегося человека и обливали его холодной водой. Воду лили постоянно, пока человек не покрывался толстым слоем льда и умирал. Так вот… Подлецом называли того, кто подливал воду, а мерзавцем — того, кто замерзал… Научных подтверждений версии, связанной с этим экзотическим видом казни, мы не обнаружили, а о происхождении данных слов можем сказать следующее.
Когда-то слово подлец обозначало всего лишь человека неблагородного происхождения. Слово по происхождению польское и означало «простой, незнатный человек». Так, известная пьеса А. Островского «На всякого мудреца довольно простоты» в польских театрах шла под названием «Записки подлеца».
Этимология слова мерзавец восходит к слову мерзкий праславянской формы, от которой в числе прочего произошли: др.-русск. мьрзъкъ, ст.-слав. мръзъкъ, русск. мерзкий, укр. мерзенний, сербохорв. мр̏зак, мр̏зка «противный, -ая», словенск. mŕzǝk, mŕzkа «отвратительный, -ая», чешск. и словацк. mrzký «скверный, гадкий». Родственно мёрзнуть, мороз; сравним: албанск. mardhem «дрожу от холода», чешск. ostuditi «возбудить отвращение» (см. студить, стыд), немецк. Schauder «дрожь, озноб; ужас, отвращение».
Холод даже у северных народов приятных ассоциаций не вызывает, поэтому «мерзавцем» стали называть холодного, бесчувственного, равнодушного, черствого, бесчеловечного… в общем крайне неприятного субъекта. Слова «отморозки» и «мразь», кстати, родом оттуда же. Мерзавец — человек, действия которого не греют душу, а, напротив — вызывают омерзение; человек, душа которого омерзела (по аналогии с хладеющим трупом).
Здесь же следует упомянуть просторечное мерзавчик — «самая маленькая мера, допустимая при продаже водки (раньше = 1/200 ведра)», также произошедшее от прилагательного мерзкий. Название может быть объяснено губительным действием содержимого бутылки на человеческий организм.
Соучредитель российской поисковой компании «Яндекс» впал в кому.
МОСКВА (Рейтер). Соучредитель и технический директор ведущей на российском рынке поисковой компании «Яндекс» впал в кому после лечения от рака Nasdaq- зарегистрированная компания заявила в четверг.
Логотип компании можно увидеть на здании штаб-квартиры компании Яндекс в Москве 14 июня 2012 года. REUTERS / Максим Шеметов
Илья Сегалович, 48 лет, основал Яндекс в 1997 году вместе с генеральным директором компании Аркадием Воложом.
«Он создал вдохновленную и невероятную команду талантливых инженеров, которые сейчас составляют основу компании», — сказал Волож журналистам во время конференц-звонка после того, как компания ранее опубликовала свои последние результаты.
Дуэт придумал название «Яндекс» — где «Ya» означает русский эквивалент английского местоимения «I» — поскольку Сегалович экспериментировал с производными слов, описывающих суть технологии. Полное название изначально расшифровывалось как «Еще один iNDEX», но сегодня оно является синонимом поиска в Интернете в русскоязычных странах.
Яндекс привлек 1,4 миллиарда долларов в результате первичного публичного размещения акций с превышением лимита подписки в Нью-Йорке в 2011 году, и в настоящее время его рыночная стоимость составляет 10 миллиардов долларов.
Аналитик, попросивший не называть его имени, сказал, что трудно сказать, повлияет ли болезнь Сегаловича на будущее компании.
«Каждый случай индивидуален, но риск там наверняка … Посмотрите, что случилось с Apple после смерти Джобса», — сказал аналитик, имея в виду Стива Джобса, легендарного соучредителя Apple Inc.Критики говорят, что после его смерти темпы инноваций американской фирмы замедлились, что сказывается на результатах.
Яндекс занял 61,7% российского поискового рынка во втором квартале, опередив Google и российского конкурента Mail.Ru Group, заявило в четверг и добавило, что теперь ожидается рост доходов на 34–38%. в год, по сравнению с предыдущим прогнозом на 30-35 процентов.
В апреле Яндекс повысил прогноз с 28 до 32 процентов после того, как его продажи в первом квартале выросли на 36 процентов.
Улучшенный прогноз отражает «хорошие показатели основного бизнеса» и поток доходов от сделки с Mail.ru, в рамках которой последний будет использовать свою технологию контекстной рекламы, сказал финансовый директор Александр Шульгин.
Продажи во втором квартале выросли на 35 процентов до 9,2 миллиарда рублей (284 миллиона долларов) за счет доходов от текстовой рекламы, которые составили 88 процентов от общей суммы. Медийная реклама, второй по величине источник доходов, выросла на 31 процент.
Чистая прибыль компании выросла на 47 процентов до 2,9 миллиарда рублей, а скорректированная прибыль до вычета процентов, налогов, износа и амортизации увеличилась на 40 процентов до 4,3 миллиарда рублей.
Акции Яндекса к 16:00 по Гринвичу торговались с повышением на 2,3% до 31,51 доллара, что ниже предыдущего максимума сессии в 33,15 доллара.
(1 доллар = 32,3817 российских рублей)
Репортаж Марии Киселевой и Анастасии Тетеревлевой; Редактирование Меган Дэвис и Грега Малиха
Когда Яндекс начал работать.История компании Яндекс
Вы можете прочитать онлайн разные версии происхождения названия Яндекс. Итак, наиболее логичным, но не совсем верным является мнение, что название интернет-компании Яндекс изначально образовалось от словосочетания «языковой указатель». Эта версия кажется вполне правдоподобной в свете того, что будущие основатели «Яндекса» были первыми программистами, написавшими конкурентоспособную программу для поиска документов на русском языке. Кстати, достижения CompTek (прародителя Яндекса) до сих пор используют ведущие российские компании.
История создания имени Яндекс
Само название «Яндекс» зародилось в стенах CompTek, где были написаны первые поисковые алгоритмы, послужившие основой для запуска поисковой системы №1 в России. Название Яндекс придумали основатели компании Илья Сегалович и Аркадий Волож. Пытаясь найти наиболее звучное, запоминающееся и лаконичное название, части слов были выбраны из английской фразы «еще один индексатор», что дословно означает «еще один индексатор».Индексатор в поисковых технологиях — это программа, которая перемещается по Интернету и считывает текстовую информацию со страниц сайтов. Обработанные массивы информации помещаются в индекс — базу данных уже просмотренных и сохраненных индексатором страниц. Используя алгоритмы поискового ранжирования, пользователю предоставляется ссылка на интересующую его информацию на основе поискового запроса, который он ввел в поисковой системе домашней страницы или омнибоксе вашего браузера.
Первоначальное использование имени Яндекс
В самом начале имя Яндекс использовалось для программного продукта, позволяющего находить интересующую информацию на жестком диске вашего компьютера.Технология была примерно такой же, как то, что видит пользователь при вводе запроса в строку поиска Windows или при использовании всевозможных профессиональных каталогов, купленных на дисках. Легкость восприятия слова Яндекс на слух, его звучность и оригинальность повлияли на то, что 23 сентября 1997 года под этим названием появилась новая поисковая машина Яндекс, кстати, не единственная на тот момент в России. . В память о первых разработках в области поиска и рождении поисковой системы Яндекс ежегодно проводит конференцию «Еще одна конференция», название которой является намеком на расшифровку названия компании.
Сегодня я расскажу об истории успеха основателя Яндекса Аркадия Воложа. И это сразу после статьи об основателе Google.
Хотя Яндекс всегда был для меня на первом месте, так как этот поисковик мне удобнее использовать . Как насчет вас? Делитесь в комментариях. Яндекс — есть все! Слоган всем известный и наверное заслуженный. На данный момент Яндекс — самая популярная поисковая система в России, в мире Яндекс на двадцатом месте.Яндекс, созданный нашими соотечественниками Аркадий Волож и Илья Сегалович в 1997 году, быстро завоевал любовь и популярность среди пользователей Рунета.
НО большое количество сервисов, на данный момент их более 50, делают Яндекс практически незаменимым для пользователей Интернета.
Каждый из нас хоть раз использовал Яндекс Маркет или Яндекс Трафик, Яндекс Поиск или Яндекс Карты. Сооснователя Яндекса Илья Сегалович уже нет с нами, он умер в 2013 году в возрасте 48 лет от рака.
Итак, с чего начался Яндекс и вообще откуда взялось такое название. Яндекс родился в конце 80-х — начале 90-х.
Это были времена перестройки, времена, когда мир стал для нас более открытым, появилась возможность общаться со специалистами из других стран, и все новое и прогрессивное легко развивалось и продвигалось.
В те времена Аркадий Волаж — программист и математик, работавший в Институте проблем управления, одновременно стал соучредителем кооператива, который занимается автоматизацией рабочих мест.С этого момента начинается история Аркадия Волажа как предпринимателя.
Основатель Яндекс. Аркадий Волож. Биография
Немного о биографии Аркадия Волажа. Аркадий из Казахстана, из городка Гурьев, сейчас его зовут Атырау. Родился в 1964 году.
.Отец работал геологом, был доктором геолого-минеральных наук. Мама преподавала в музыкальной школе. Аркадий Волаж получил высшее образование в Москве в Российском государственном институте нефти и газа, окончил факультет прикладной математики.
После окончания института начал работать в Государственном институте проблем управления. Здесь он впервые начал заниматься проблемами электронной автоматизированной обработки больших объемов информации.
Здесь он встречает американца Роберта Стабблбайна , который брал уроки английского языка. Им в голову приходит идея создать компьютерную компанию.
CompTec и Аркадия. Как родился ЯндексТак появляется CompTec. Однако, занимаясь бизнесом, Волаж продолжает создавать программы для обработки больших объемов информации.
Он приходит к выводу, что программа должна учитывать особенности русского языка, в связи с тем, что слова могут иметь множество форм.
Помогает ему в этой задаче. Аркадий Борковский , который в то время также занимался проблемами компьютерной лингвистики. Вместе они организовывают компанию Аркадия.
Волаж приглашает своего друга-программиста Илью Сегаловича в свою новую компанию. Их первым проектом был классификатор изобретателей с расширенными возможностями внутреннего поиска.
Эту программу могут использовать учреждения, которым необходимо работать с патентами. Но, к сожалению, у Аркадии не было крупных заказов и встал вопрос о ее закрытии.
Но дальновидный Волаж решает присоединить Аркадию со всеми ее разработками к другой своей компании, которая тогда успешно развивалась Comptec . И не прогадал!
Работа в поисковой системе ЯндексИлья Сегалович вместе с другими программистами стал дальше работать над своей поисковой системой.Осталось придумать название.
Постепенно родилсяЯндекс, что означает «еще один индексатор» (еще один индексатор). Тогда Волаж предложил заменить комбинацию букв Ya на русскую букву I, так родился Яндекс.
Название устраивало всех, тем более что его можно было понять как языковый указатель, подчеркивающий особенности нового индексатора.
Однако Яндекс был еще далек от привычного и любимого нами. Это была просто умная поисковая система, привязанная к определенному продукту.
Но его изюминкой было то, что он принял во внимание морфологию русского языка, поэтому, если поисковая машина встретила слово, которого не было в его словаре, он мог предсказать, в каких формах могло бы это слово, на основе изменений слов в вашем словаре.
Это был 1996 год, Интернет в России активно развивался, и сотрудники ComTec не могли не воспользоваться этим. ComTec представляет на выставке Netcom в 1996 году новый продукт для интернет-сайтов Яндекс.сайт, который впоследствии превратился в Яндекс.
Сервер в настоящее время используется. Перед компанией стоит вопрос о создании собственной поисковой системы. В то время они использовали систему AltaVista в русскоязычном Интернете.
Итак, 23 сентября 1997 года на московской выставке компьютерных технологий Softtool уже состоялась презентация Яндекс как новой поисковой системы Yandex.ru.
С этого момента начинается триумфальное шествие Яндекса по русскоязычному Интернету.Яндекс постоянно развивается, вводя все больше и больше удобных функций.
Уже в 1998 году на Яндексе появилась контекстная реклама. И, наконец, в 2000 году был создан Яндекс, генеральным директором которого стал Аркадий Волаж.
Яндекс Директ
Development продолжает контекстную рекламу в Яндекс. В 2001 году был запущен Яндекс.Директ — сервис, позволяющий пользователям автоматически размещать контекстную рекламу.
И всего за год существования Яндекс.Прямой сервис, этим сервисом воспользовались около 2500 пользователей.
Каждый из нас, это, конечно, относится к предпринимателям Рунета, продвигающим партнерские программы, продавцам информационного бизнеса, продающим информационные продукты, и торговым посредникам, которые могут использовать контекстную рекламу для рекламы своего Интернет-бизнеса.
Информационно-деловой курс Powerful Direct Алексея Полевского, бесплатный авто-семинар по настройке кампании в Яндекс Директ Алексея Полевского и его бесплатные видео-уроки по работе в системе Яндекс Директ.
Другой известный специалист системы настройки рекламной кампании Яндекс Директ — Это инфобизнесмен.
У него есть автоматический вебинар по заработку в партнерских программах, где он знакомит с основами Яндекс.Директа, бесплатным курсом по информационному бизнесу и бесплатной pdf-книгой Яндекс Директ.
Большой популярностью пользовалась книга Константина Живенкова «Тайны». эффективная реклама Яндекс Директ. «
Конечно, помимо этого, есть и другие авторы, информационные бизнесмены, которые выпускали информационные продукты, связанные с работой с Яндексом.Директ — Василий Татаркин, Дмитрий Печеркин, но они прошли через Яндекс.Директ, потому что они специалисты по продвижению интернет-проектов, партнерским продажам информационных продуктов и перепродажам.
Еще есть специалист в Рунете, который специализируется на обучении партнерскому маркетингу через продажи через Яндекс.Директ. Это Александр Аристаров.
Вы можете скачать бесплатный вебинар «Как заработать 224 000 рублей в месяц на партнерских программах» или пройти тренинг aristarov «Заработок на партнерских программах в Яндекс.Прямой. «
С 2002 года Яндекс начинает приносить прибыль своим акционерам. Следующий шаг в развитии Яндекс — выход за пределы России.
Наряду с офисами в Санкт-Петербурге, Казани открывается украинское представительство Яндекса с офисами в Одессе, Симферополе (тогда украинском), Киеве.
А потом еще в Белоруссии и Казахстане. В эти годы в жесточайшей конкуренции с иностранными конкурентами Яндекс успевает не сдавать свои позиции.
Во многом благодаря внедрению новых сервисов, таких как Яндекс Карты, Яндекс Плакат, ориентированных не только на российских пользователей в целом, но и конкретно на жителей конкретного города.
Мне лично он очень понравился. В 2008 году Яндекс выходит за пределы ближнего зарубежья и открывает представительство в Калифорнии.
Яндекс поддерживает российскую науку, создавая основу для развития новых технологий в нашей стране. Проводит олимпиады для студентов и школьников.
Организует бесплатные курсы, рассчитанные на два года, которые назвали школой анализа данных. Новые принципы поиска, Matrixnet и Spectrum, внедренные Яндексом, позволяют сделать поиск еще более точным даже при отсутствии четко сформулированного запроса.С 2011 года акции Яндекса торгуются на Нью-Йоркской фондовой бирже.
Яндекс в Турции
Интересным и очень важным шагом в развитии Яндекса можно считать его турецкий проект. В 2011 году был открыт портал yandex.com.tr.
турецких пользователя смогли использовать сервисы Яндекса: Яндекс Почта, Яндекс Карты, Поиск Яндекса на турецком языке. Когда я делаю парсер ключевых слов в Яндекс Wordstat с помощью программы, иногда встречаются турецкие слова.
Следующая веха в истории Яндекса — запуск Яндекс Браузера. Применяется в России, Украине и Турции. Что ж, будем ждать еще новостей от Яндекса!
Если статья была вам полезна, нажимайте на кнопки социальных сетей ниже. Чтобы быть в курсе самых важных новостей, подписывайтесь на.
П.С. Если вы задумываетесь о создании сайта, вам поможет курс «Сайт с нуля». При покупке по ссылкам из Блога Андрея Хвостова я верну вам 30% их комиссии денег .Скачать бесплатные видеоуроки « ТОП 5 способов заработка в Интернете»
Посмотрите бесплатный вебинар «Инфобизнес изнутри». Если вы хотите узнать Как заработать на партнерских программах и информационных продуктах , скачайте бесплатный видеокурс Владислава Челпаченко.
Поисковая система Яндекс давно стала одной из самых востребованных поисковых систем среди жителей России и стран СНГ. В начале 2013 года она входила в четверку лучших поисковых запросов планеты.Но мало кто знает, как и кем был создан Яндекс.
Создание Яндекса происходило в несколько этапов:
- CompTek
- Аркадия;
- Яндекс — поисковая система;
- Компания Яндекс.
Comptek
Хотя сама поисковая машина была анонсирована 23 сентября 1997 года, история ее создания восходит к 1988 году. Окончив факультет прикладной информатики, Аркадий Волож принят на работу в Институт проблем управления АН СССР. , где он работает над возможностью обработки больших объемов данных.Здесь он знакомится со своим американским студентом Робертом Стабблином, который проходит стажировку в том же институте. Парень помогает Аркадию с изучением английского языка. Результатом их общения стало появление компании CompTek, специализирующейся на продаже персональных компьютеров.
Аркадия
Параллельно с развитием компании Волож рассматривал возможность создания сервиса, позволяющего искать информацию. Для реализации и развития своих идей вместе с компьютерным лингвистом Аркадием Борковским в 1989 году они создали компанию «Аркадия».Четыре года спустя Arcadia и CompTek объединились. Незадолго до этого к ним присоединился еще один разработчик известного поисковика, программист Илья Сегалович, школьный друг Аркадия. Именно он стал одним из «отцов» имени будущего поисковика.
Яндекс — поисковик
Эволюция Яндекса началась в 1995 году, когда было решено создать программу для поиска информации в Интернете, но пока только на определенных сайтах. В это время Аркадий Волож создал Яндекс.То, чем Яндекс стал для нас сейчас, впервые увидел свет 23 сентября 1997 года на московской выставке Softool. Он не стал первым подобным продуктом русского происхождения, но благодаря хорошей адаптации к особенностям русского языка быстро завоевал расположение пользователей. Дальнейший путь Яндекса — это череда модернизаций, направленных на оптимизацию его работы, что, естественно, повлияло на отношение к нему пользователей.
Компания Яндекс
2000 год становится знаковым для создателей Яндекс.В это время появляется одноименная компания, должность генерального директора в которой занимает Аркадий Волож, а Илья Сегалович становится директором по технологиям и развитию. Кроме того, у Яндекса есть такие знакомые нам приложения, как Яндекс.Почта, Яндекс.Окарта, Яндекс.Новости и др.
За 10 лет Яндекс стал самым популярным российским интернет-порталом. Вскоре у него появится английская версия и возможность поиска на татарском и украинском языках. Затем Яндекс получает такие удобные сервисы, как Яндекс.Работа, Яндекс. Карты и Яндекс. Пробки и некоторые другие.
Дизайн Яндекса требуется Студии Артемия Лебедева. Дизайнеры занимаются не только дизайном самой поисковой системы, но и разрабатывают внешний вид сайта, полиграфическую продукцию компании. Наверное, самым плодотворным специалистом студии можно назвать Романа Воронежского, но в проектировании принимали участие все лучшие специалисты студии. Не обошлось и без сотрудничества с другими компаниями. Первая версия Яндекс.Игрушки разработала «Город-Инфо»; на Яндекс.Лет работали сотрудники Bolotov.ru. Сегодня наблюдается определенная тенденция к привлечению дизайнеров из сторонних компаний.
История имен Яндекса
Впервые слово Яндекс было выпущено в 1993 году, так называемое приложение для поиска информации на жестком диске. Существует четыре гипотезы происхождения названия. Наиболее правдоподобно первое предположение. В соответствии с ним слово «яндекс» является сокращением словосочетания «еще один индексатор», что переводится как «еще один индексатор».«Возможно, название появилось в результате замены 1-й буквы в слове« индекс »или произошло от словосочетания« языковой указатель ». Самой странной является версия Артемия Лебедева, который заметил сходство со словом« яндекс », в «янь» символизирует мужское начало. Через некоторое время, чтобы подчеркнуть отечественное происхождение бренда, было принято решение заменить первые две буквы согласной «Я», а позже название было полностью русифицировано.
Сейчас Яндекс — успешная и динамично развивающаяся компания.Огромный труд, вложенный в него создателями, окупился с лихвой и принес не только значительную прибыль, но и признание пользователей. Сегодня Яндекс — лучшая поисковая машина в российском Интернете.
Аркадий Юрьевич Волож , ныне генеральный директор «Яндекса», родился 11 февраля 1964 года в городе Гурьев (ныне Атырау) Казахской ССР. В 1986 году окончил Московский институт нефти и газа им. И.М. Губкина по специальности «прикладная математика». Позже Волож работал в Институте проблем управления (ИПУ) АН СССР и проводил исследования по обработке больших объемов информации.
В 1988 году Волож основал компанию CompTek и оставался ее генеральным директором до 2000 года. CompTek по-прежнему успешно работает на российском рынке в качестве дистрибьютора программного обеспечения и телекоммуникационного оборудования.
Параллельно с руководством CompTek Volozh писал программу, которая могла искать информацию в больших объемах текста. В 1989 году вместе со специалистом в области компьютерной лингвистики Аркадием Борковским основал компанию «Аркадия», в которой были разработаны информационно-поисковые системы «Классификация товаров и услуг» и «Международная классификация изобретений».
В 1993 году «Аркадия» была объединена с CompTek, и в том же году была разработана программа для поиска информации на жестком диске под названием «Яндекс». В 1995 году было решено использовать компании-разработчики программного обеспечения в Интернете, хотя официально поисковая система Yandex.ru была анонсирована только 23 сентября 1997 года на выставке информационных технологий Softool.
Возможности поисковой системы Яндекс.ру расширялись по мере роста российского сегмента сети Интернет.В 2000 году Яндекс основал акционеров CompTek, генеральным директором стал Аркадий Волож. Также в 2000 году были открыты следующие сервисы: Яндекс.Почта, Яндекс.Книги, Яндекс.Новости, Яндекс.Продукты, Яндекс.Гуру, Яндекс.Окарта и.
В 2009 году Яндекс запустил поисковую программу Снежинск, основанную на Matrixnet — методе машинного обучения. Это позволило пользователям из 1250 городов России получать результаты локального поиска. В 2010 году доля Яндекса в поисковых запросах Рунета превысила 60%, а 19 мая 2010 года компания вышла на международный уровень, запустив свою англоязычную версию на яндексе.com поисковая система. В этом же году был запущен один из ключевых сервисов — Яндекс.Карты, а в 2011 году — еще один сервис — Яндекс.Фабрика.
Аркадий Волож постоянно совмещает менеджмент Яндекса (ему принадлежит 19,77% акций с правом голоса) с работой в различных сферах, связанных с информационными технологиями. В 1998 году возглавил комитет. доступа к беспроводным сетям Российской ассоциации документальной электросвязи, также известной как РАНС.РУ. На этой должности Волож принял участие в дерегулировании частот беспроводного доступа и внес значительный вклад в легализацию IP-телефонии в нашей стране.
С 2007 года Аркадий Волож возглавляет кафедру анализа данных на базе компании Яндекс Факультета инноваций и высоких технологий Московского физико-технического университета. Газета «Коммерсантъ» в 2010 году поставила Волож на первое место в рейтинге топ-менеджеров в номинации «Медиабизнес».
Аркадий Волож женат, имеет троих детей.
Яндекс делает очередной развод в Google В России запускает Яндекс.Браузер на iOS и Android — TechCrunch
Яндекс, известный как «Google России» за доминирование в поиске и последующее расширение облачных сервисов, таких как карты, онлайн-хранилище и приложения, сегодня представляет еще один сервис, который даст ему более прочную точку опоры в быстрорастущих странах. мобильный рынок: дебютирует специальный мобильный браузер, в котором будет единое поле для URL-адресов и поиска, функции распознавания голоса и многое другое. Но Яндекс все еще не запускает полноценную мобильную платформу в стиле Android, чтобы завершить картину.
«Нет планов» по разработке мобильной операционной системы, — сказал мне представитель компании. «Для нас это не имеет смысла. Это совсем другой бизнес. В любом случае, у нас [теперь] есть все для нашей собственной мобильной экосистемы на Android: поиск, такие приложения, как Mail и Maps, 3D UI (Yandex.Shell), магазин приложений, а теперь и браузер ».
Яндекс.Браузер для мобильных устройств появился после того, как в прошлом году Яндекс запустил в октябре 2012 года специализированный браузер для настольных ПК с одноименным названием. Сейчас у этого браузера около 8 миллионов пользователей в России, что составляет 5-6% рынка.
Мобильная версия будет запущена, по словам компании, «позже в этом году».
Этот шаг происходит в то время, когда Яндекс уже является сильным игроком на рынке мобильных устройств. Мало того, что его карты и другие приложения уже популярны среди пользователей iOS и Android (и у него есть сделка с Apple, чтобы помочь использовать свой собственный картографический продукт на устройствах iOS в русскоязычных странах, как часть постепенного отдаления последней компании от Google) , но Яндекс уже выполняет около половины всех поисковых запросов на Android-устройствах.Это важный показатель и, возможно, более значимый, чем то, где Яндекс позиционирует прямо сейчас на iOS: Android — это платформа, на которой он концентрирует большую часть своей энергии, потому что он является самым быстрорастущим в России по ряду недорогих и высоких -окончить трубку.
«Согласно нашей статистике, около 49% поисковых запросов на Яндексе приходится на Android, но мы, конечно, хотим большего», — отмечает представитель. Ему принадлежит около 60% доли в онлайн-поиске в России, вместе с другими крупными игроками, включая Google.
В то время как Яндекс сосредоточил и продолжает концентрировать свои усилия на русскоязычных рынках и, в меньшей степени, в Турции, новые мобильные сервисы, где условия игры остаются открытыми, предоставили Яндексу возможность протестировать и опробовать экспортировать больше услуг на английском языке. В этом ключе компания запускает Яндекс.Браузер для мобильных устройств как для русскоязычных, так и для англоязычных пользователей.
(Злополучное, но полное потенциала приложение Wonder в США является одним из примеров того, как это не всегда работает.)
Подобно онлайн-браузеру, мобильный браузер построен на базе WebKit (Blink на Android). И, как и Chrome, он позволяет пользователям объединять URL-адреса и поисковые запросы в одно поле, которое Яндекс называет «Smartbox». Это заставит пользователя сначала использовать поиск Яндекса в браузере.
Интересно, что хотя Яндекс довольно жестко конкурирует с Google в России и на других рынках, где работает Яндекс, за пределами этого поисковый гигант становится основным партнером. Как отмечает Яндекс, в английской версии мобильного браузера по умолчанию будет использоваться поиск в Google (за исключением Китая, где по умолчанию используется Baidu.«Это потому, что мы хотим сделать браузер действительно удобным для людей за пределами России, СНГ и Турции», — говорит представитель. Пользователи также могут установить поиск по умолчанию на Bing или Yahoo в английской версии.
Это не коммерческие сделки, но если и когда Яндекс получит больше пользователей в браузере, «мы подумаем о некоторых альтернативных способах его монетизации, например о моделях распределения доходов для поисковых систем и веб-сайтов, предустановленных на странице запуска браузера». На домашних рынках основной поток доходов браузера будет поступать от поисковой рекламы.
Другие функции, которые появятся в будущем, также будут включать «интеграцию с социальными сетями, синхронизацию между мобильной и настольной версиями браузера и улучшенное взаимодействие с пользователем», — заявляет компания. И, как вы можете видеть на некоторых снимках экрана в этом посте, похоже, что также будет некоторая интеграция голосового поиска и, возможно, других функций.
Как начать поиск в русскоязычном Интернете
По мере того, как напряженность в отношениях между Украиной и Россией продолжает накаляться, необходимость журналистов вникать в русскоязычный Интернет или Рунет и проверять сообщения становится все более актуальной.Но поиск источников, изображений и историй из России и Восточной Европы может оказаться сложной задачей, если вы не знаете языка.
Различия в проведении исследования русских источников заключаются не только в самом языке, но и в наборе инструментов, поскольку часто существуют более совершенные альтернативы таким сервисам, как Google Maps и Facebook для поиска в Рунете.
В дополнение к предоставлению ресурса для не говорящих по-русски по навигации в незнакомом разделе Интернета, это руководство показывает, что существуют особые проблемы при поиске и проверке материалов для историй на разных языках и в разных регионах.Большинство из этих рекомендаций в равной степени применимо, когда вы проводите исследования на турецком, арабском или любом другом языке с активной базой онлайн-пользователей.
Расширьте свой набор инструментовУ большинства журналистов есть несколько онлайн-инструментов, которые они используют для исследования и проверки, такие как Google Maps для проверки местоположения, а также Facebook и Twitter для поиска историй и людей. Эти инструменты по-прежнему достаточно хорошо работают для историй в большинстве стран из-за их почти повсеместного распространения, но часто есть более эффективные альтернативы.
Российский аналог Google — Яндекс, который, помимо прочего, предоставляет поисковую систему, агрегатор новостей, поиск изображений и картографический сервис. Хотя о функции поиска нет ничего особенного, Яндекс Карты — отличный сервис, который часто превосходит Google Карты в России, Украине и Беларуси. Выбрав бинокль в нижнем левом углу экрана, вы можете включить режим «Панорама» — ответ Яндекса на Google Street View.
Синие области на карте показывают доступные изображения улиц для Яндекс Панорамы
Яндекс сделал множество снимков в сверхвысоком разрешении с воздушных шаров в некоторых крупных городах, что позволяет получить перспективу между видом улицы с земли и снимком со спутника.
Санкт-Петербург, вид с воздушного шара. Каждый синий значок воздушного шара указывает на дополнительные доступные изображения с этой точки зрения
Интеллектуальный поискКак и при поиске материалов для рассказа на английском языке, наиболее распространенными поисковыми фразами, которые вы будете вводить в Twitter, Instagram и другие веб-сайты, являются названия мест. Если вы ищете информацию о пожаре или стрельбе в клубе, имеет смысл поискать в Twitter название клуба, его адрес и город, чтобы найти аккаунты свидетелей, фотографии, видео и т. Д.Эта практика, очевидно, будет работать на большинстве других языков, но некоторые службы могут обрабатывать этот поиск лучше, чем другие.
В русском языке, как и в других языках, прилагательные и существительные, составляющие географические названия, не остаются статичными, как в английском языке. При описании того, что происходит в Большом театре, слово «Большой» никогда не меняется в английском языке, но так же, как «он» может измениться на «он», слово «Большой» изменит свое окончание на русском языке в зависимости от его роли в предложении. .
Если вы ищете учетные записи свидетелей в Твиттере, поиск по слову «Большой» на русском языке не покажет вам, что кто-то о чем-то говорит в Большом театре, рядом с Большим театром, за Большим театром, и скоро.В отличие от Twitter, эта проблема не возникает при использовании поиска Google, поскольку он распознает изменяющиеся формы слов на русском и других языках и будет включать их все в ваши поисковые запросы.
Если вам не удается найти материалы почти на любом языке в Twitter, попробуйте вставить ключевое слово в Wiktionary.org, а затем скопируйте / вставьте варианты ключевого слова из «Declension» (для существительных и прилагательных) или «Conjugation» (для глаголов) раздел. Этот метод дает вам более десятка форм слова «Большой», чтобы расширить область поиска.
Таблица склонения всех возможных форм слова «большой» с ключевыми словами для использования в алгоритмах поиска
Искать в нужном местеДаже с идеальными ключевыми словами для поиска все будет напрасно, если вы будете искать не в нужных местах. Подавляющее большинство россиян не используют Twitter, и только около 10 миллионов имеют учетные записи в Facebook, но более 60 миллионов имеют учетные записи в российском клоне Facebook «Вконтакте» (ВКонтакте).
Услуга также чрезвычайно популярна в остальной части Восточной Европы, Центральной Азии и на Кавказе.Как подробно описано в руководстве по российским социальным сетям, довольно легко выполнять поиск в ВКонтакте, не используя много русского языка, а его функции поиска при отслеживании определенных групп людей намного мощнее, чем у Facebook.
Домашняя страница Вконтакте, или ВК, самой популярной социальной сети в Восточной Европе и некоторых частях Центральной Азии и Кавказа
Феномен ВКонтакте, которого нет в большинстве стран Западной Европы и Америки, — это популярность местных групп для распространения и проверки информации.Часто лучший способ найти и проверить материалы в Восточной Европе — это отследить страницу группы в городе или районе, на которой могут присутствовать тысячи участников. В случае пожара в отдаленном районе Сибири или авиакатастрофы на Украине самый быстрый способ найти фотографии, видео и свидетельства очевидцев — это посетить страницы этих местных групп.
VK также отличается от Facebook и других западных сетей обилием информации о военной службе, часто в виде публичных групп для разных воинских частей.Поиск этих групп относительно прост, и вы можете искать пользователей с определенными видами военной службы, работы или образования, как в прошлом, так и в настоящем.
Как и во всех социальных исследованиях, будут полезные источники, у которых нет учетных записей в социальных сетях, и информация, предоставленная некоторыми источниками в социальных сетях, может быть неверной. Также стоит изучить другие сети, такие как «Одноклассники», у которого 40 миллионов российских пользователей, и «Мой Мир» (25 миллионов), чтобы расширить сеть.
Узнайте больше об этих и других сетях в полной версии этого руководства на Global Voices.
Хотя это резюме было специально для русскоязычных ресурсов, те же уроки можно применить почти к каждому региону для поиска новостей и проверки материалов. Например, с китайскими источниками вам нужно ориентироваться в Weibo, а общедоступные группы Telegram часто являются лучшим способом найти новые материалы, связанные с Сирией. Инструменты и методы, которые журналисты используют для публикаций, например, в США, Великобритании, Германии и Франции, будут достаточно хорошо работать и в других странах, но для поиска наиболее актуальных и заслуживающих внимания материалов необходимо применять универсальный подход. заменить на регионально ориентированный.
Соучредитель топовой поисковой системы России в коме
МОСКВА. Крупнейшая поисковая система России Яндекс заявила в четверг, что ее соучредитель Илья Сегалович находится на аппарате жизнеобеспечения в коме.
Генеральный директор «Яндекса» Аркадий Волож сообщил ранее в тот же день в блоге компании, что Сегалович, лечившийся от рака, скончался. Но через несколько часов компания исправила заявление.
В нем говорилось, что первые известия о его смерти исходили от семьи, но дальнейшая информация указывала на то, что Сегалович находился на аппарате жизнеобеспечения без функции мозга. Компания заявила, что ждет более подробной информации.
Сегалович, 48 лет, создал Яндекс в 1997 году вместе со своим школьным другом Воложем.Компания добилась успеха в России: на нее приходится 62 процента рынка поисковых систем по сравнению с 25,6 процентами Google.
Сегалович придумал название двигателя, производное от еще одного индекса, и был его главным техническим директором.
Волож похвалил его «энциклопедические знания технологий и четкое видение продукта».
Почему, когда я выбираю установку Firefox без яндекса, я получаю Firefox с яндексом? | Форум поддержки Firefox
WestEnd сказал
На сайте загрузки Mozilla Firefox AFAIK нет яндекс.Так откуда вы берете эту версию?
У русского Firefox от Mozilla в качестве поисковой системы по умолчанию используется Яндекс.
OP получает его от Mozilla, если вы смотрели видео. Вы можете подумать, что во всех регионах Firefox поисковой системой по умолчанию должен быть Google.
Mozilla на самом деле больше хотела уйти от Google, что и сделала Mozilla еще в ноябре 2014 года, больше не делая Google глобальной поисковой системой по умолчанию в Firefox.
Перенесемся в Firefox 57.0 в ноябре 2017 года, когда Mozilla вернулась к использованию Google по умолчанию в США, Канаде, Гонконге и Тайване, потому что им нужна была возможность заменить Yahoo в тех регионах, где Yahoo был по умолчанию.
Firefox Features Google as Default Search Provider in the U.S., Canada, Hong Kong and Taiwan
Затем 7 марта поисковая система Yahoo была удалена как один из вариантов по умолчанию, который поставлялся с Firefox (для пользователей, использующих Firefox 52 ESR, 57, 58, 59.0 и новее) и позже и были заменены новыми поисковыми системами в зависимости от локали.
Вы можете увидеть причины ухода из Yahoo на https://support.mozilla.org/en-US/forums/contributors/712925
» WestEnd [[# answer-1205548 | сказал]] » <цитата> На сайте загрузки Mozilla Firefox AFAIK нет яндекс. Так откуда вы берете эту версию? В русском браузере Firefox от Mozilla по умолчанию используется Яндекс.OP получает его от Mozilla, если вы смотрели видео. Вы можете подумать, что во всех регионах Firefox поисковой системой по умолчанию должен быть Google. Mozilla на самом деле хотела больше уйти от Google, что и сделала [https://blog.mozilla.org/blog/2014/11/19/promoting-choice-and-innovation-on-the-web/ Mozilla еще в ноябре 2014], больше не делая Google глобальной поисковой системой по умолчанию в Firefox. Перенесемся в Firefox 57.0 в ноябре 2017 года, когда Mozilla вернулась к использованию Google по умолчанию в U.S., Канада, Гонконг и Тайвань, потому что им нужна была возможность заменить Yahoo в тех регионах, где Yahoo использовался по умолчанию.
Firefox Features Google as Default Search Provider in the U.S., Canada, Hong Kong and TaiwanЗатем, 7 марта, поисковая система Yahoo была удалена как один из вариантов по умолчанию, который поставлялся с Firefox (для пользователей, использующих Firefox 52 ESR, 57, 58, 59.0 и более поздних версий) и более поздних версий, и заменен новыми поисковыми системами в зависимости от локали.Вы можете увидеть причины ухода из Yahoo на https://support.mozilla.org/en-US/forums/contributors/712925
Изменено Джеймсом
Расположение головного офиса, конкуренты, финансы, сотрудники
Сотрудничество имеет решающее значение для создания платформы MaaS будущего19 марта 2021 г.
0 Александр Высоцкий, директор по публичной политике Яндекс.Такси, объясняет, почему правительствам следует использовать опыт и ноу-хау частных технологических компаний для внедрения эффективных решений MaaS по всему миру.Много было сказано о позитивном преобразующем потенциале мобильности как услуги (MaaS), но лучший способ облегчить ее внедрение все еще обсуждается во всем мире. Пандемия изменила наше отношение к транспорту, но не избавила нас от необходимости в MaaS. Рабочее решение должно содержать данные по запросу в реальном времени, которые охватывают весь транспортный сектор, от частных такси до общественных автобусов и личных транспортных средств, предоставляя пользователям возможность оплачивать несколько видов транспорта на платформе.Будущие платформы MaaS также, вероятно, отойдут от бесконтактных платежей, которые большинство горожан знают сегодня, когда они используют проездные карты или мобильные телефоны, чтобы проходить через турникеты на станциях поездов и метро. Вместо этого они, вероятно, примут технологию бесконтактной проверки пассажиров нового поколения (с использованием биометрии или других бесконтактных технологий), что потребует от городов дорогостоящей модернизации существующей транспортной инфраструктуры. Эти проекты и связанные с ними инвестиции необходимо планировать на долгосрочную перспективу.Чтобы прочитать статью MaaS полностью, заполните форму ниже. Нажимая «Отправить», вы подтверждаете, что принимаете наши условия и политику конфиденциальности. Имя похожие темы похожие темы Комментарий Содержание Russell Publishing Ltd. Этот веб-сайт использует файлы cookie для включения, оптимизации и анализа операций сайта, а также для предоставления персонализированного контента и позволяет вам подключаться к социальным сетям. Нажимая «Я согласен», вы даете согласие на использование файлов cookie для несущественных функций и соответствующей обработки персональных данных.Вы можете изменить свой файл cookie и связанные с ним настройки обработки данных в любое время через наши «Настройки файлов cookie». Пожалуйста, ознакомьтесь с нашей Политикой использования файлов cookie, чтобы узнать больше об использовании файлов cookie на нашем веб-сайте. Обзор конфиденциальности Этот веб-сайт использует файлы cookie, чтобы улучшить вашу работу во время навигации по веб-сайту. Из этих файлов cookie файлы cookie, которые относятся к категории «Необходимые», хранятся в вашем браузере, поскольку они столь же важны для работы основных функций веб-сайта. Для других типов файлов cookie «Реклама и таргетинг», «Аналитика» и «Эффективность» они помогают нам анализировать и понимать, как вы используете этот веб-сайт.Эти файлы cookie будут храниться в вашем браузере только с вашего согласия. У вас также есть возможность отказаться от этих различных типов файлов cookie. Но отказ от некоторых из этих файлов cookie может повлиять на ваш опыт просмотра. Вы можете настроить доступные ползунки на «Включено» или «Отключено», затем нажмите «Сохранить и принять». Просмотрите нашу страницу с Политикой использования файлов cookie. Всегда включен Необходимые файлы cookie абсолютно необходимы для правильной работы веб-сайта. В эту категорию входят только файлы cookie, которые обеспечивают основные функции и функции безопасности веб-сайта.Эти файлы cookie не хранят никакой личной информации. Cookie-файлы Cookielawinfo-checkbox-Advertising-targeting Файл cookie устанавливается в соответствии с GDPR, чтобы записать согласие пользователя на использование файлов cookie в категории «Реклама и таргетинг». Cookielawinfo-checkbox-analytics Этот файл cookie устанавливается плагином GDPR Cookie Consent WordPress. Файл cookie используется для запоминания согласия пользователя на использование файлов cookie в категории «Аналитика». Cookielawinfo-checkbox-необходимо Этот файл cookie устанавливается подключаемым модулем GDPR Cookie Consent.Файл cookie используется для хранения согласия пользователя на использование файлов cookie в категории «Необходимые». Cookielawinfo-checkbox-performance Этот файл cookie устанавливается плагином GDPR Cookie Consent WordPress. Файл cookie используется для запоминания согласия пользователя на использование файлов cookie в категории «Производительность». PHPSESSID Этот файл cookie является родным для приложений PHP. Файл cookie используется для хранения и идентификации уникального идентификатора сеанса пользователя с целью управления сеансом пользователя на веб-сайте. Файл cookie является сеансовым и удаляется при закрытии всех окон браузера.View_cookie_policy Файл cookie устанавливается плагином GDPR Cookie Consent и используется для хранения информации о том, согласился ли пользователь на использование файлов cookie. Он не хранит никаких личных данных. zmember_logged Этот файл cookie сеанса обслуживается нашей системой членства / подписки и определяет, можете ли вы видеть контент, доступный только зарегистрированным пользователям. __cfduid Файл cookie устанавливается CloudFare. Файл cookie используется для идентификации отдельных клиентов за общим IP-адресом и применения настроек безопасности для каждого клиента.Он не соответствует никакому идентификатору пользователя в веб-приложении и не хранит никакой личной информации. представление Файлы cookie производительности включают в себя файлы cookie, которые обеспечивают расширенные функции веб-сайта, такие как кеширование. Эти файлы cookie не хранят никакой личной информации. Cookie-файлы cf_ob_info Этот файл cookie устанавливается сетью доставки контента Cloudflare и вместе с файлом cookie cf_use_ob используется для определения того, следует ли продолжать обслуживание «Всегда в сети» до истечения срока действия файла cookie.cf_use_ob Этот файл cookie устанавливается сетью доставки контента Cloudflare и используется для определения того, следует ли продолжать обслуживание «Всегда в сети» до истечения срока действия файла cookie. free_subscription_only Этот файл cookie сеанса обслуживается нашей системой членства / подписки и контролирует, к каким типам контента вы можете получить доступ. ls_smartpush Этот файл cookie устанавливается сервером Litespeed и позволяет серверу сохранять настройки для повышения производительности сайта. next-i18next one_signal_sdk_db Этот файл cookie устанавливается push-уведомлениями OneSignal и используется для хранения пользовательских настроек в связи с их статусом разрешения на уведомления.YSC аналитика Файлы cookie аналитики собирают информацию об использовании вами контента и в сочетании с ранее собранной информацией используются для измерения, понимания и составления отчетов об использовании вами этого веб-сайта. Cookie-файлы печенье Этот файл cookie устанавливается LinkedIn. Целью файлов cookie является включение функций LinkedIn на странице. GPS Этот файл cookie устанавливается YouTube и регистрирует уникальный идентификатор для отслеживания пользователей в зависимости от их географического положения. язык Этот файл cookie устанавливается LinkedIn и используется для хранения языковых предпочтений пользователя для предоставления контента на этом сохраненном языке при следующем посещении пользователем веб-сайта.lidc Lissc nQ_cookieId nQ_visitId vuid Мы встраиваем видео с нашего официального канала Vimeo. Когда вы нажимаете кнопку воспроизведения, Vimeo удаляет сторонние файлы cookie, чтобы включить воспроизведение видео и узнать, как долго зритель смотрел видео. Этот файл cookie не отслеживает людей. wow.anonymousId wow.schedule вау. сессия wow.utmvalues Этот файл cookie устанавливается Spotler и сохраняет значения UTM для сеанса. Значения UTM — это особые текстовые строки, которые добавляются к URL-адресам, которые позволяют Communigator отслеживать URL-адреса и значения UTM при нажатии на них._ga Этот файл cookie устанавливается Google Analytics и используется для расчета данных о посетителях, сеансах и кампаниях, а также для отслеживания использования сайта в аналитическом отчете сайта. Он хранит информацию анонимно и присваивает случайно сгенерированный номер для идентификации уникальных посетителей. _gat Эти файлы cookie устанавливаются Google Universal Analytics для регулирования скорости запросов и ограничения сбора данных на сайтах с высокой посещаемостью. _gid Этот файл cookie устанавливается Google Analytics и используется для хранения информации о том, как посетители используют веб-сайт, и помогает в создании аналитического отчета о том, как работает веб-сайт.Собранные данные, включая количество посетителей, источник, откуда они пришли, и страницы, посещенные в анонимной форме. advanced_ads_page_impressions advanced_ads_pro_server_info Этот файл cookie устанавливается Advanced Ads и определяет географическое местоположение, роль и возможности пользователя. Он используется для очистки кеша в Advanced Ads Pro, когда используются соответствующие условия посетителя. advanced_ads_pro_visitor_referrer bscookie IDE Этот файл cookie устанавливается Google DoubleClick и хранит информацию о том, как пользователь использует веб-сайт, и любую другую рекламу перед посещением веб-сайта.Это используется для показа пользователям релевантной для них рекламы в соответствии с профилем пользователя. li_sugr UserMatchHistory Этот файл cookie устанавливается Linkedin и используется для отслеживания посетителей на нескольких веб-сайтах с целью представления релевантной рекламы на основе предпочтений посетителей.