Настройка модуля Яндекс.Поиск — AdvantShop
Модуль «Поиск от Яндекс для интернет-магазинов» — позволит на сайте использовать механизм поиска яндекс, вместо стандартного поиска интернет-магазина.
Внимание
Модуль доступен с тарифного плана «Профи».
Настройки на стороне Яндекса
Необходимо авторизоваться в яндексе под своей учетной записью, далее перейти по ссылке для настройки и создания поиска https://site.yandex.ru/catalogs/new/. При первом переходе откроется окно «Пользовательское соглашение», прочтите и поставьте внизу галочку в поле согласия, далее нажмите «Продолжить» (рис.1), в случае если вы уже проходили этап соглашения, то откроется сразу настройки поиска (рис.2).
Рисунок 1.
Рисунок 2.
На рис.2 видим под цифрой 1, строчку «Страница с результатами поиска», в данное поле вводим ссылку вида: http://домен/search, где вместо слова домен вписываете свое доменное имя.
Если у Вас еще нет яндекса.вебмастера, и сайт там не добавлен, то отобразиться предупреждение (рис.2, цифра 2), что необходимо подтвердить владение на сайт в Яндекс.Вебмастере. Для этого Вам необходимо. зарегистрироваться в Яндекс.Вебмастере, добавить сайт и подтвердить права владения на сайт согласно инструкции.
Если все сделано корректно, то предупреждение пропадет и появится активной следующая строчка «Адрес YML-файла» (рис.3).
Рисунок 3.
В данную строчку необходимо разместить ссылку на файл xml, этот файл выгрузки для яндекс.маркета, который требуется изначально выгрузить в магазине по инструкции.
После чего внизу страницы можете добавлять ряд email, если это необходимо и нажать «Сохранить».
После проделанных выше пунктов, после сохранения на той же странице должен появиться каталог xml и фраза: «Каталог Обрабатывается» (рис.4). После того как каталог провериться, будет фраза «Каталог проиндексирован».
Рисунок 4.
Далее для настроек в магазине требуется API ключ и Идентификатор поиска, которые мы сейчас будем настраивать.
API-ключ можно получить в личном кабинете, для этого перейдите в правом меню в пункт «Выдача в JSON» (рис.5, цифра 1), откроется окно, где разместите API-ключ (рис.5, цифра 3) и сохраните (рис.5, цифра 4), предварительно получив его в кабинете разработчика (рис.5, цифра 2).
Рисунок 5.
В кабинете разработчика первоначально откроется страница в общей информации, нажмите «Подключить API» (рис.6).
Рисунок 6.
Далее, выберите «API Поиска для сайта» (рис.7), откроется окно с подключением ключа, нажмите галочку в поле согласия и кнопку «Отправить» (рис.8).
Рисунок 7.
Рисунок 8.
Откроется окно с информацией, что «API интерфейс подключен», далее необходимо нажать на кнопку «Перейти к API».
После этого произойдет переход в личный кабинет разработчика с созданным api-ключом (рис.9). Скопируйте его и разместите в настройках поиска (рис.5, цифра 3) и в настройках модуля магазина (рис.
Рисунок 9.
Идентификатор поиска — можно получить в личном кабинете в разделе «Мои поиски», нажав на поиск, в адресной строке, например «2431651» (рис.10), так же скопируйте его и разместите в настройках модуля магазина (рис.13).
Рисунок 10.
На этом настройки в яндексе закончены, переходим к настройкам модуля.
Настройки на стороне магазина
Перейдите в пункт меню «Модули», установите модуль «Поиск от Яндекс для интернет-магазинов» (рис.11).
Рисунок 11.
Перейдите в настройки модуля, поставьте галочку активен и заполните поля «Идентификатор поиска» и «API ключ» (рис.12) и (рис.13). Данные для заполнения возьмите в яндексе, так как описано выше.
Рисунок 12.
Рисунок 13.
Идентификатором товарного предложения является — настройку выставляете в соответствии с настройками экспортируемого yml-файла, который подается для яндекс поиска.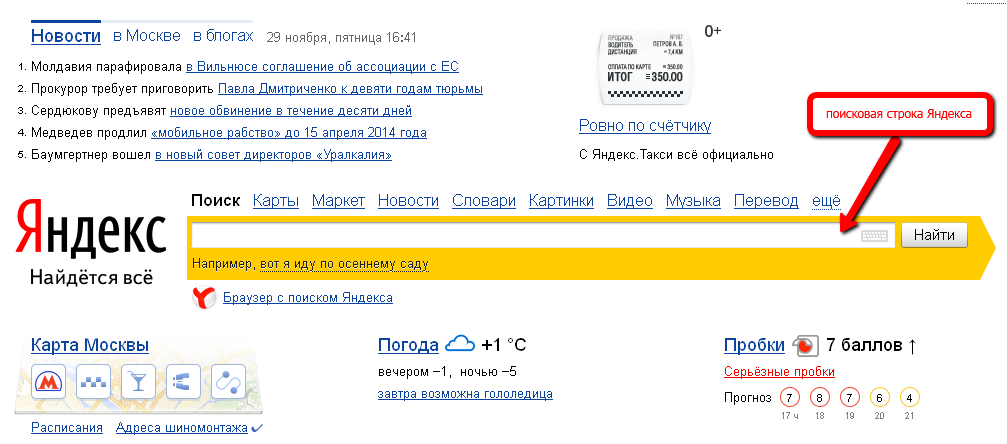
Готово, модуль настроен, стандартный поиск отключается автоматически, если подключен и активен данный модуль.
В личном кабинете яндекс можно скачивать статистику результатов поиска с сайта (рис.14).
Рисунок 14.
Тэги: Поиск от Яндекс для интернет-магазинов, яндекс.поиск, модуль, яндекс, поиск, глубина, уровни, жесткое соответствие, индекс для поиска, уровни глубины поиска, поиск по словам, по принципу слово, максимальное кол-во возвращенных, примеры поискового запроса,search,gjbcr
В «Яндексе» предсказали ухудшение поиска после исполнения требований ФАС — РБК
Фото: Сергей Коньков / ТАСС
Исполнение всех требований к инструментам поиска «Яндекса», которые Федеральная антимонопольная служба предъявила компании, ухудшит качество поиска для пользователей, а значит — и положение «Яндекса» по сравнению с конкурентами. Об этом РБК сообщили в пресс-службе компании.
Об этом РБК сообщили в пресс-службе компании.
ФАС ранее вынесла предупреждение «Яндексу» и потребовала в течение месяца прекратить дискриминировать в поисковой выдаче ссылки на конкурирующие компании. В предупреждении ФАС говорится, что «Яндекс» в своей поисковой выдаче предоставляет преимущество собственным сервисам, которые появлялись в так называемых «колдунщиках» — интерактивны виджетах, которые возникают на странице с результатами поиска.
«Мы не согласны с предупреждением ФАС. Некоторые требования предписания уже реализованы в поиске, однако отдельные важные его части мы считаем неправильными. Исполнение всех перечисленных требований ухудшит качество поиска для пользователя, а значит — положение поиска «Яндекса» на рынке по сравнению с конкурентами», — сообщили в пресс-службе компании.
Там также указали, что специальные ответы сервисов — это мировая практика всех поисковых систем и всех платформ, в том числе маркетплейсов. Без специальных ответов, которые есть во всех поисковых системах в мире, качество поиска становится хуже для пользователя, говорится в сообщении.
При этом в пресс-службе подчеркнули, что никакой сервис «Яндекса» или другой компании не имеет никаких приоритетов, показ основан на конкретной и прозрачной метрике полезности для пользователя. «Яндекс» готов ее аудировать и открыто про нее рассказывать.
Поиск по сайту и другие полезные возможности поиска в Яндексе
При поиске нужной информации, иногда мы понимаем, что нам не хватает стандартных возможностей Яндекса. Поэтому сегодня мы поговорим о том, как сделать наш запрос максимально точным.
Для этого существуют специальные символы-операторы, которые позволяют добавлять условия к словам или фразам.
На самом деле их больше, но сегодня рассмотрим самые важные из низ.
Фраза или слово
Для начала, давайте разберемся, как работает поиск, когда мы вписываем фразу или слово. Яндекс ищет не только то, что вписали вы, но и все его синонимы, падежи итд.
В топе, при этом, оказываются максимально релевантные страницы.
Например, при поиске фразы Котята даром в выдачу будут добавлены различные варианты по типу Котята в добрые руки, Отдам котят итд
Точное совпадение
Если вы ищете фразу в неизменном виде – просто заключите ее в кавычки. Например, «текст с точным совпадением«. В таком случае Яндекс постарается найти для вас именно то, что вы ищите. Кстати, данный метод работает и в поиске гугла.
Например, «текст с точным совпадением«. В таком случае Яндекс постарается найти для вас именно то, что вы ищите. Кстати, данный метод работает и в поиске гугла.
Если таких фраз нет – Яндекс напишет об этом:
Пропущенное слово
Если вы хотите найти фразу, но забыли слово или не хотите его указывать по какой-либо причине – существует оператор * который можно использовать за места пропущенного слова.
У данного метода есть еще 1 условие – фраза должна быть заключена в кавычки.
Например, фраза “Нет * без огня” найдет вам фразу Нет дыма без огня.
Поиск разных фраз\слов или логическое ИЛИ
Так же существует логический оператор ИЛИ, который обозначается символом | .
Например, если вы хотите добавить в выдачу 2 различных слова, то указывайте их через | :
Щенок | Котенок
Так же можно использовать данный метод в скобках для условного разделения на две ветки. Например, запрос (Щенок | Котенок) в добрые руки найдет как Щенок в добрые руки, так и Котенок в добрые руки.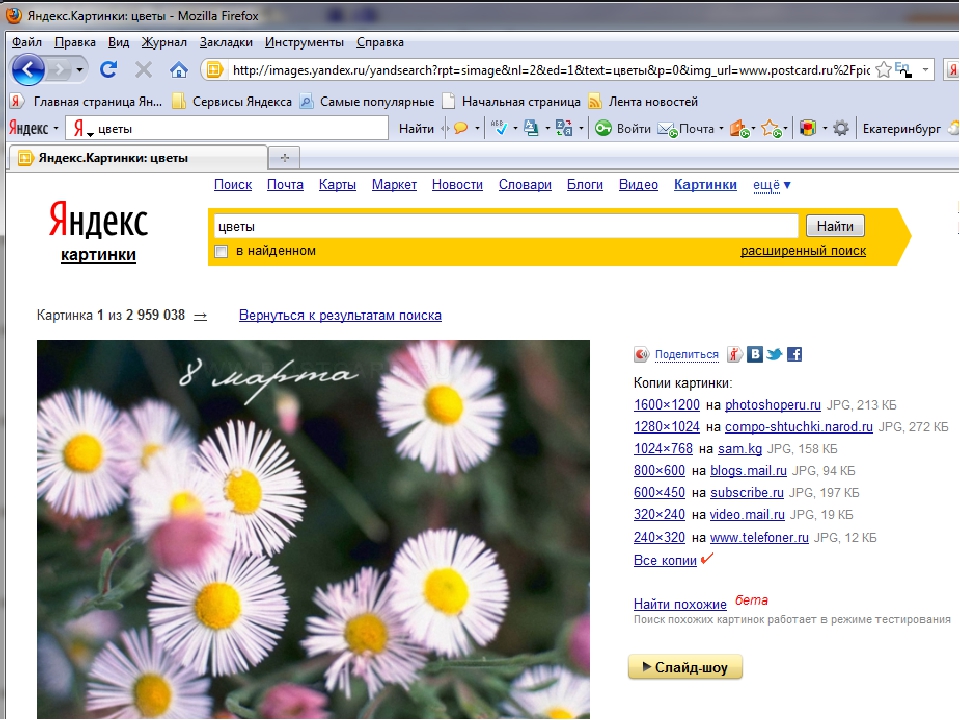
Минус слово
Так же есть возможность убирать из выдачи слова, которые вам не нужны. Например, чтобы убрать с выдачи страницы, где указано слово Купить, необходимо поставить перед словом знак — . Например, Щенки даром –купить, то мы не увидим в поиске страниц, где есть слово купить.
Поиск обязательных слов
Если необходимо чтобы слово в фразе было обязательно, необходимо использовать оператор + .
При необходимости можно указать несколько таких операторов, тогда все слова будут учтены при формировании выдачи.
Например, разновидности кошек в +России
Поиск по сайту
С недавних пор Яндекс убрал удобную возможность искать по сайтам из интерфейса расширенного поиска. Но все-же такая возможность осталась, используя слово формат: site:домен запрос
Например, запрос site:mintclickseo.ru продвижение отобразит только информацию с нашего сайта.
Вывод
Сегодня, практически любой человек использует интернет в повсеместной жизни и часто пользуется поисковыми системами. А зная данные приемы поиска информации в Яндексе, находить информацию будет на много легче. Особенно, если ваша работа или деятельность связана с интернетом и информацией в ней.
А зная данные приемы поиска информации в Яндексе, находить информацию будет на много легче. Особенно, если ваша работа или деятельность связана с интернетом и информацией в ней.
Поиск Яндекса с инженерной точки зрения. Лекция в Яндексе / Хабр
Сегодня мы публикуем ещё один из докладов, прозвучавших на летней встрече об устройстве поиска Яндекса. Выступление руководителя отдела ранжирования Петра Попова получилось в тот день самым доступным для широкой аудитории: минимум формул, максимум общих понятий о поиске. Но интересно было всем, потому что Пётр несколько раз переходил к деталям и в итоге рассказал много такого, о чём Яндекс никогда раньше публично не заявлял.
Кстати, одновременно с публикацией этой расшифровки начинается вторая встреча из серии, посвящённой технологиям Яндекса. Сегодняшнее мероприятие — уже не про поиск, а про инфраструктуру. Вот ссылка на трансляцию.
Ну а под катом — лекция Петра Попова и часть слайдов.
Меня зовут Пётр Попов, я работаю в Яндексе.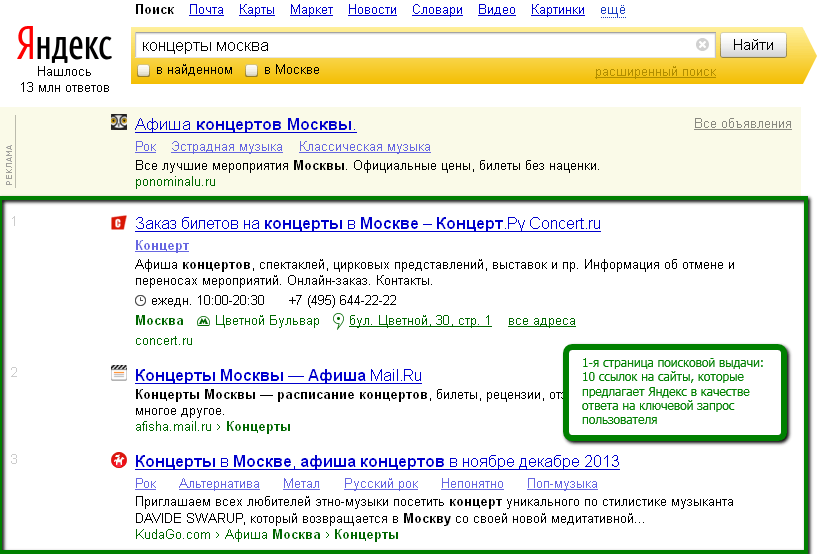
Надо сказать, что, устраиваясь на работу в Яндекс, я достаточно мало знал о предметной области — о том, что здесь люди делают. Знал только, что здесь работают хорошие люди. Поэтому испытывал некоторые сомнения.
Сейчас я расскажу достаточно полно, но не очень глубоко о том, как выглядит наш поиск. Что такое Яндекс? Это поисковик. Мы должны получить запрос пользователя и сформировать десятку результатов. Почему именно десятку? Пользователи чрезвычайно редко переходят на более далёкие страницы. Можно считать, что десять документов — это всё, что мы показываем.
Не знаю, есть ли в зале люди, которые занимаются рекламой Яндекса, потому что они считают, что основной продукт Яндекса — это совсем другое. Как обычно, здесь две точки зрения и обе правильные.
Мы считаем, что основное — это счастье пользователя. И, как ни удивительно, от состава десятки и того, как десятка отранжирована, это счастье зависит. Если мы ухудшаем выдачу, пользователи пользуются Яндексом меньше, уходят в другие поисковики, плохо себя чувствуют.
И, как ни удивительно, от состава десятки и того, как десятка отранжирована, это счастье зависит. Если мы ухудшаем выдачу, пользователи пользуются Яндексом меньше, уходят в другие поисковики, плохо себя чувствуют.
Какую конструкцию мы соорудили ради решения этой простой задачи — показать десять документов? Конструкция достаточно мощная, снизу, видимо, разработчики на неё взирают.
Наша модель работы. Нам нужно сделать всего несколько вещей. Нам нужно обойти интернет, проиндексировать получившиеся документы. Документом мы называем скачанную веб-страницу. Проиндексировать, сложить в поисковый индекс, запустить над этим индексом поисковую программу, ну и ответить пользователю. В общем-то, всё, профит.
Пройдемся по шагам этого конвейера. Что такое интернет и какого он объема? Интернет, считай, бесконечный. Возьмем любой сайт, который продает что-нибудь, какой-нибудь интернет-магазин, сменим там параметры сортировки — появится другая страничка. То есть можно задавать СGI-параметры страницы, и содержание будет совсем другое.
Сколько мы знаем принципиально значащих страниц с точностью до отбрасывания незначащих CGI-параметров? Сейчас — порядка нескольких триллионов. Скачиваем мы странички со скоростью порядка нескольких миллиардов страничек в день. И казалось бы, что нашу работу мы могли бы выполнить за конечное время, там, за два года.
Как мы вообще находим новые странички в интернете? Мы обошли какую-то страничку, вытянули оттуда ссылки. Они — наши потенциальные жертвы для скачивания. Возможно, за два года мы обойдем эти триллионы URL, но появятся новые, и в процессе парсинга документов появятся ссылки на новые странички. Уже тут видно, что наша основная задача — бороться с бесконечностью интернета, имея на руках конечные инженерные ресурсы в виде дата-центров.
Мы скачали все безумные триллионы документов, проиндексировали. Дальше нужно положить их в поисковый индекс. В индекс мы кладем не всё, а только лучшее из того, что скачали.
Есть товарищ Ашманов, широко известный в узких кругах специалист по поисковым системам в интернете. Он строит разные графики качества поисковых систем. Это график полноты поисковой базы. Как он строится? Задается запрос из редкого слова, смотрится, какие документы есть во всех поисковиках, это 100%. Каждый поисковик знает про какую-то долю. Сверху красным цветом мы, снизу черным цветом — наш основной конкурент.
Он строит разные графики качества поисковых систем. Это график полноты поисковой базы. Как он строится? Задается запрос из редкого слова, смотрится, какие документы есть во всех поисковиках, это 100%. Каждый поисковик знает про какую-то долю. Сверху красным цветом мы, снизу черным цветом — наш основной конкурент.
Тут можно задаться вопросом: как мы такого достигли? Возможны несколько вариантов ответа. Вариант первый: мы пропарсили страничку с этими тестами, выдрали оттуда все URL, все запросы, которые задает товарищ Ашманов и проиндексировали странички. Нет, мы так не делали. Второй вариант: для нас Россия является основным рынком, а для конкурентов она — что-то маргинальное, где-то на периферии зрения. Этот ответ имеет право на жизнь, но он мне тоже не нравится.
Ответ, который мне нравится, заключается в том, что мы проделали большую инженерную работу, сделали проект, который называется «большая база», под это закупили много железа и сейчас наблюдаем этот результат. Конкурента тоже можно бить, он не железный.
Документы мы скачали. Как мы строим поисковую базу? Вот схема нашей контент-системы. Есть интернет, облачко документов. Есть машины, которые его обходят — спайдеры, пауки. Документ мы скачали. Для начала — положили его в сохраненную копию. Это, фактически, отдельная междатацентровая хеш-таблица, куда можно читать и писать на случай, если мы потом захотим этот документ проиндексировать или показать пользователю как сохраненную копию на выдаче.
Дальше мы документ проиндексировали, определили язык и вытащили оттуда слова, приведенные согласно морфологии языка к основным формам. Ещё мы вытащили оттуда ссылки, ведущие на другие страницы.
Есть еще один источник данных, который мы широко используем при построении индекса и вообще в ранжировании — логи Яндекса. Задал пользователь запрос, получил десятку результатов и как-то там себя ведёт. Ему показались документы, он кликает или не кликает.
Разумно предположить, что если документ показался в выдаче, или, тем более, если пользователь по нему кликнул, провел какое-то взаимодействие, то такой документ нужно оставить в поисковой базе. Кроме того, логично предположить, что ссылки с такого хорошего документа ведут на документы, которые тоже хороши и которые неплохо бы приоритетно скачать. Здесь изображено планирование обхода. Стрелочка от планирования обхода должна вести в обход.
Кроме того, логично предположить, что ссылки с такого хорошего документа ведут на документы, которые тоже хороши и которые неплохо бы приоритетно скачать. Здесь изображено планирование обхода. Стрелочка от планирования обхода должна вести в обход.
Дальше есть стадия построения поискового индекса. Эти округлые прямоугольнички лежат в MapReduce, нашей собственной реализации MapReduce, которая называется YT, Yandex Table. Тут я немножко лакирую — на самом деле построение базы и шардирование оперируют с индексами как с файлами. Мы это немножко зафиксим. Эти округлые прямоугольнички будут лежать в MapReduce. Суммарный объем данных здесь — порядка 50 ПБ. Тут они превращаются в поисковые индексы, в файлики.
В этой схеме есть проблемы. Основная связана с тем, что MapReduce — сугубо батчевая операция. Чтобы определить приоритетные документы для обхода, например, мы берем весь линковый граф, мёржим его со всем пользовательским поведением и формируем очередь для скачки. Это процесс достаточно латентный, занимающий какое-то время. Ровно так же с построением индекса. Там есть стадии обработки — они батчевые для всей базы. И выкладка так же устроена, мы или дельту выкладываем, или всё.
Важная задача при этих объемах — ускорить процедуру доставки индекса. Надо сказать, что эта задача для нас сложная. Речь идёт о борьбе с батчевым характером построения базы. У нас есть специальный быстрый контур, который качает всякие новости в real time, доносит до пользователя. Это наше направление работы, то, чем мы занимаемся.
А вот вторая сторона медали. Первая — контент-система, вторая — поиск. Можно понять, почему я рисовал пирамидку — потому что поиск Яндекса действительно похож на пирамиду, такую иерархическую структуру. Сверху стоят балансеры, фронты, которые генерируют выдачу. Чуть пониже — агрегирующие метапоиски, которые агрегируют выдачу с разных вертикалей. Надо сказать, что на выдаче вы наверняка видели веб-документы, видео и картинки. У нас три разных индекса, они опрашиваются независимо.
Каждый ваш поисковый запрос уходит по этой иерархии вниз и спускается до каждого кусочка поисковой базы. Мы весь индекс, который построили, разбили на тысячи кусков. Условно, — на две-три-пять тысяч. Над каждым куском подняли поиск, и этот запрос всюду спустился.
Мы весь индекс, который построили, разбили на тысячи кусков. Условно, — на две-три-пять тысяч. Над каждым куском подняли поиск, и этот запрос всюду спустился.
Тут же видно, что поиск Яндекса — большая штука. Почему она большая? Потому что мы в своей памяти храним, как вы видели на предыдущих слайдах, достаточно репрезентативный и мощный кусок интернета. Храним не один раз: в каждом дата-центре от двух до четырёх копий индекса. Запрос наш спускается до каждого поиска, фактически проходится по каждому индексу. Сейчас используемые структуры данных — такие, что мы вынуждены всё это хранить напрямую в оперативке.
Что нужно делать? Вместо дорогой оперативки использовать дешевый SSD, ускорить поиск, допустим, в два раза, и получить профит — десятки или сотни миллионов долларов капитальных расходов. Но тут не нужно говорить: кризис, Яндекс экономит и всё такое. На самом деле всё, что мы сэкономим, мы пустим в полезное дело. Мы увеличим индекс в два раза. Мы будем по нему качественнее искать. И это то, ради чего осуществляется такого рода сложная инженерка. Это реальный проект, правда, достаточно тяжелый и вялотекущий, но мы действительно так делаем, хотим поиск наш улучшить.
И это то, ради чего осуществляется такого рода сложная инженерка. Это реальный проект, правда, достаточно тяжелый и вялотекущий, но мы действительно так делаем, хотим поиск наш улучшить.
Поисковый кластер не только достаточно большой — он ещё и очень сложный. Там реально крутятся миллионы инстансов разных программ. Я вначале написал — сотни тысяч, но товарищи из эксплуатации меня поправили — таки миллионы. На каждой машинке в очень многих экземплярах 10-20 штук точно крутится.
У нас тысячи разных типов сервисов размазаны по кластеру. Надо пояснить: кластер — это такие машинки, хосты, на них запущены программы, все они общаются по TCP/IP. Программы имеют разное потребление CPU, памяти, жесткого диска, сети — короче, всех этих ресурсов. Программы живут на хостах в общежитии. Точнее, если будем сажать одну программу на хост, то утилизация кластера будет никакой. Поэтому мы вынуждены селить программы друг с другом.
Дальше слайд про то, что с этим делать. А здесь — небольшое замечание, что все данные программы, все релизы мы катаем с помощью торрентов, и число раздач на нашем торрент-трекере превышает оное число на Pirate Bay. Мы реально большие.
Мы реально большие.
Что нужно делать со всей этой кластерной конструкцией? Нужно улучшать механизмы виртуализации. Мы реально вкладываемся в разработку ядра Linux, у нас есть собственная система управления контейнерами а-ля Docker, про неё Олег подробнее расскажет.
Нам нужно заранее планировать, на каких хостах какие программы друг с другом селить, это тоже сложная задача. У нас постоянно что-то на кластер едет. Сейчас там наверняка десять релизов катятся.
Нам нужно грамотно селить программы друг с другом, нужно улучшать виртуализацию, нужно-таки объединить два больших кластера — роботный и поисковый. Мы как-то независимо заказывали железо и считали, что есть отдельно машинки с огромным числом дисков и отдельно — тонкие блейды для поиска. Сейчас мы поняли, что лучше заказывать унифицированное железо и запускать MapReduce и поисковые программы в изоляции: одно жрет в основном диски и сеть, второе в основном CPU, но по CPU у них баланс, нужно туда-сюда крутить. Это большие инженерные проекты, которые мы тоже ведем.
Что мы с этого получаем? Пользу в десятки миллионов долларов экономии капитальных расходов. Вы уже знаете, как мы эти деньги потратим — мы потратим их на улучшение нашего поиска.
Здесь я рассказал о конструкции в целом. Какие-то отдельные строительные блоки. Эти блоки люди долбили стамеской, и у них что-то получилось.
Ранжирующая функция Матрикснет. Достаточно простая функция. Можете почитать — там лежат в векторе бинарные признаки документа, а в этом цикле происходит вычисление релевантности. Я уверен, что среди вас есть специалисты, которые умеют на SSE программировать, и они бы живо это ускорили в десять раз. Так оно в какой-то момент и случилось. Тысяча строчек кода нам спасли 10-15% общего потребления CPU на нашем кластере, что опять же составляет десятки миллионов долларов капитальных расходов, которые мы знаем, как потратить. Это тысяча строчек кода, которая стоят очень дорого.
Мы более-менее вычистили из репозитория, соптимизировали, но там ещё есть что поделать.
Имеется у нас платформа для машинного обучения. Индексы с предыдущего слайда нужно подбирать жадным образом, перебирая все возможности. На CPU это делать долго. На GPU — быстро, зато пулы для обучения не лезут в память. Что нужно делать? Или покупать кастомные решения, куда этих железок много-много втыкается, или связывать машинки быстрым, использовать интерконнект какой-то, infiniband, учиться с этим жить. Оно типично глючит, не работает. Это очень забавный инженерный вызов, с которым мы тоже встречаемся. Он, казалось бы, совсем не связа с нашей основной деятельностью, но тем не менее.
Во что мы ещё инвестируем, так это в алгоритмы сжатия данных. Основная задача сжатия выглядит примерно следующим образом: есть последовательность целых чисел, нужно её как-то компрессировать, но не просто компрессировать — нужно ещё иметь случайный доступ к i-тому элементу. Типичный алгоритм — маленькими блоками сжать это, иметь разметку для общего потока данных. Такая задача — совсем другая, нежели контекстное сжатие типа zip или LZ-family. Там совсем другие алгоритмы. Можно сжать Хаффманом, Varlnt, блоками типа PFORX. У нас есть собственный патентованный алгоритм, мы его улучшаем, и это опять же 10-15% экономии оперативной памяти на простенький алгоритм.
Там совсем другие алгоритмы. Можно сжать Хаффманом, Varlnt, блоками типа PFORX. У нас есть собственный патентованный алгоритм, мы его улучшаем, и это опять же 10-15% экономии оперативной памяти на простенький алгоритм.
У нас есть всякие забавные мелочи, например доработки в CPU, планировщики Linux. Там какая проблема с гипертредными камнями от Intel? То, что на физическом ядре есть два потока. Когда там два треда занимают два потока, то они работают медленно, латенция увеличивается. Нужно правильно раскидывать задачки по физическим процессорам.
Если раскидывать правильно, а не так, как делает стоковый планировщик, можно получить 10-15% латентности нашего запроса, условно. Это то, что видят пользователи. Сэкономленные миллисекунды умножайте на число поисков — вот и сэкономленное время для пользователей.
У нас есть какие-то совсем странные вещи типа собственной реализации malloc, который на самом деле не работает. Он работает в аренах, и каждая локация просто сдвигает указатель внутри этой арены. Ну и ref counter арены поднимает на единичку. Арена жива, пока жива последняя локация. Для всякой смешанной нагрузки, когда у нас есть короткоживущая и долгоживущая локация, это не работает, это выглядит как утечка памяти. Но наши серверные программы устроены не так. Приходит запрос, мы там аллоцируем внутренние структуры, как-то работаем, потом отдаем ответ пользователю, всё сносится. Этот аллокатор идеально работает для наших серверных программ, которые без состояния. За счет того, что все локации локальны, последовательны в арене, оно работает очень быстро. Там нет никаких page fault, cache miss и т. п. Очень быстро — это от 5% до 25% скорости работы наших типичных серверных программ.
Это инженерка, что ещё можно делать? Можно заниматься машинным обучением. Про это вам с любовью расскажет Саша Сафронов.
А сейчас вопросы и ответы.
Я возьму очень понравившийся мне вопрос, который пришел на рассылку и который следовало бы включить в мою презентацию. Товарищ Анатолий Драпков спрашивает: есть знаменитый слайд про то, как быстро росла формула до внедрения Матрикснета. На самом деле и до, и после. Есть ли сейчас проблемы роста?
Проблемы роста у нас стоят в полный рост. Очередной порядок увеличения числа итераций в формуле ранжирования. Сейчас мы там порядка 200 тысяч итераций делаем в функции Матрикснет, чтобы ответить пользователю. Был получен следующим инженерным шагом. Раньше мы ранжировали на базовых. Это значит, что каждый базовый запускает у себя Матрикснет и выдает сто результатов. Мы сказали: давайте мы лучшие сто результатов объединим на среднем и отранжируем ещё раз совсем тяжелой формулой. Да, мы это сделали, на среднем можно вычислять в нескольких потоках функцию Матрикснет, потому что ресурсов нужно в тысячу раз меньше. Это проект, который нам позволил достичь очередного порядка увеличения объемов ранжирующей функции. Что будет ещё — не знаю.
Андрей Стыскин, руководитель управления поисковых продуктов Яндекса:
— Сколько занимала байт первая формула ранжирования Яндекса?
Пётр:
— Десяток, наверное.
Андрей:
— Ну, да, наверное, где-то символов сто. А сколько сейчас занимает формула ранжирования Яндекса?
Пётр:
— Где-то 100 МБ.
Андрей:
— Формула релевантности. Это для наших смотрителей с трансляций, специалистов по SEO. Попробуйте зареверсинженирить наши 100 МБ ранжирования.
Алеся Болгова, Intel:
— По последнему слайду про malloc не могли бы пояснить, как вы выделяете память? Очень интересно.
Пётр:
— Берется обычная страничка, 4 КБ, в начале у нее rev counter, и дальше мы каждую аллокацию… если маленькие аллокации меньше страницы, мы просто двигаемся в этой страничке. В каждом треде, естественно, эта страничка своя. Когда страничку закрыли — всё, про неё забыли. Единственное, у неё rev counter в начале.
Алеся:
— То есть вы страницу выделяете?
Пётр:
— Внутри страницы аллокациями вот так растем. Единственное, страничка живет, пока в ней последняя аллокация живет. Для обычного workload это выглядит как утечка, для нашего — как нормальная работа.
— Как вы определяете качество страницы, стоит её класть в индекс или нет? Тоже машинное обучение?
Пётр:
— Да, конечно. У странички есть множество факторов, от её размера до показов на поиске, до…
Андрей:
— До robot rank. Она находится на каком-то хосте, в какой-то поддиректории хоста, на неё сколько-то входящих ссылок. Те, кто на неё ссылаются, обладают каким-то качеством. Все это берем и пытаемся предсказать, с какой вероятностью, если данную страничку скачать, на ней будет информация, которая попадет по какому-то запросу в выдачу. Это предсказывается, отбирается топ с учетом размера документов — потому что в зависимости от размера документа вероятность, что она хоть по какому-то запросу попадет, повышается. Задача об оптимальном наполнении рюкзака. Отбирается с учетом размера документа и кладется топовая в индекс.
— …
Андрей:
— Давай мы тебя представим сначала.
— Может, не стоит?
Андрей:
— Владимир Гулин, начальник ранжирования поисковика Mail.Ru.
Владимир:
— Первый мой вопрос — про количество поисков вообще. Вы говорили, что вы там драматически увеличили размер базы. Хочется вообще понимать, с какого объема вы стартовали, каков был объем русского индекса, иностранного индекса, сколько документов приходилось на каждый шард, ну и после увеличения…
Пётр:
— Это такие цифры, слишком технические. Может, в кулуарах я бы сказал. Я могу сказать, во сколько раз мы примерно увеличились — на полтора порядка где-то. В 30 раз, условно. За последние три года.
Владимир:
— Я тогда абсолютные цифры в кулуарах уточню.
Пётр:
— Да, за отдельную плату, что называется.
Владимир:
— Ладно. Что касается свежести — какой приблизительно сейчас в Яндексе объем быстрого индекса? И вообще с какой скоростью вы это всё обновляете, смешиваете?
Пётр:
— Индекс реально реалтаймовый, там порядка двух минут латенции на то, чтобы добавить документ в индекс. От момента, как мы его проиндексировали, и дискавери тоже — скачка быстрая.
Владимир:
— Но именно найти документ. Сначала надо узнать, что документ существует.
Пётр:
— Я понимаю, что вопрос такой — непонятно, когда в интернете появилась первая ссылка на данный документ. Когда мы узнали первую ссылку, то дальше это вопрос минут в быстром слое.
Андрей:
— Речь идет о миллионах документов, которые ежедневно находятся в этом быстром индексе. Про них обычно очень много внешней информации: упоминание в Твиттере, сайтмэпы, упоминание новости на сайте Lenta.ru. И так как мы перекачиваем чуть ли не каждую секунду морду Lenta.ru, мы очень быстро обнаруживаем эти документы и в течение единиц минут в худшем случае доставляем их до поиска. Они могут искаться. По сравнению с большим индексом речь идет про драматически маленькое число документов, это миллионы.
Пётр:
— Да, на 3-4 порядка меньше.
Андрей:
— Да, это миллионы документов, которые умеют обновляться real time.
Владимир:
— Миллионы документов в сутки?
Пётр:
— Побольше чуть-чуть, но примерно так, да.
Владимир:
— Теперь вопрос про смешивание свежих результатов и результатов основного поиска.
Пётр:
— У нас два способа смешивания. Один — документ той же формулой ранжируется, что и батчевый обычный документ. А второй — специальное новостное подмешивание, когда мы определяем интент запроса, понимаем, что он реально свежий и что нужно что-то такое показать. Два способа.
Владимир:
— Как вы боретесь с ситуацией, когда у вас по популярным запросам, где дофига кликов, появляются свежие результаты? Как вы определяете, что свежий результат надо показывать выше того результата, который уже накликан? Спросили у вас: «Google». Вы вроде знаете, какие результаты по такому запросу хорошие. Но тем не менее, в новостях ещё что-то, какие-то статьи…
Пётр:
— Это всякие запросные факторы, всякие тренды и всё такое.
Андрей:
— Для всех поясню, в чем сложность задачи и в чем вопрос. Про документ, который долго существует в интернете, мы много чего знаем. Мы много знаем входящих на него ссылок, знаем, сколько на нем люди проводили времени, а про свежие документы этого всего не знаем. Поэтому сложность задачи ранжирования свежих документов и новостей — угадывать, будут ли люди это читать, уметь предсказывать количество ссылок, которые он наберет за какое-то время, чтобы его показывать нормально. И для подмешивания документов по запросу «Google», когда Google что-то хорошее сделал, там существует некая оптимизационная метрика, которая у нас называется профицит. Мы её умеем оптимизировать.
Пётр:
— Мы знаем поток запросов, содержание свежескачанных страниц. Эти две вещи мы можем анализировать и понимать, что реально свежий запрос требует подмешивания.
Андрей:
— А потом, на основе ручной оценки и пользовательского поведения именно в эту секунду в этот день, мы понимаем, что именно сегодня эта новость по запросу важна и у неё есть такие факторы: документ только появился, на него столько-то ретвитов. И поэтому следующую новость, которая будет с таким же распределением признаков, тоже нужно показывать, когда она наберет соответствующие значения.
Пётр:
—А факторы там могут быть такими: число найденного в обычном слое против числа найденного по этому запросу в свежем. Такие, самые наивные, хотя мы его выпиливаем тщательно.
Андрей:
— Для тех, кого пугает слово «факторы», специально будет третий доклад, где мы расскажем базовые принципы — как вообще устроено машинное обучение, ранжирование, что такое факторы, как с помощью этого сделать поисковик, который выдает нормальные хорошие результаты.
Владимир:
— Спасибо, остальное спрошу потом.
Никита Пустовойтов:
— Получается, у вас существует большое количество урлов, про которые вы в принципе знаете, а качать вы можете на несколько порядков меньше. Поскольку за время скачивания будут появляться новые, больше вы никогда не посетите. Для выбора применяется машинное обучение, какие-то эвристики?
Пётр:
—Только машинное обучение. Идея там простая: мы имеем сигнал на какой-то документ, любой, число показов, и его распространяем по ссылочному графу. Всё это агрегируем на странице «цель ссылки», дальше машинным обучением так же обучаем шанс показаться, исходя из этих данных.
Никита:
— Второй вопрос — инженерный. Вы говорили, что у вас много CPU-затратных задач. Рассматривали ли вы вариант использования процессора Xeon Phi от Intel? Он вроде гораздо быстрее работает с оперативной памятью, чем GPU.
Пётр:
— Мы его рассматривали для задач обучения именно нашего Матрикснета, нашей формулы, и там он феерично плохо себя показал. А так вообще у нас профиль очень плоский, у нас топовая функция где-то 1,5%. Мы всё, что можно, руками соптимизировали, а так у нас портянки С++-кода, который туда не ложится.
— Насколько я знаю, Яндекс был первым поисковиком, который начал работать с русской морфологией. Скажите, на данный момент это всё ещё является каким-либо преимуществом или все поисковики одинаково хорошо работают с русской морфологией?
Пётр:
— Сейчас в области морфологии наука не стоит на месте. Саша Сафронов расскажет о том, чего мы сейчас достигаем, там реально есть новые подходы и новые способы решения проблем. Например, определение запросов, похожих на этот, по пользовательскому поведению. Не расширение отдельных слов, а расширение запросов запросами.
Андрей:
— То есть это не совсем морфология. Морфологию действительно, наверное, все поисковики более-менее освоили, но это базовая вещь. А вот лингвистика, нахождение, чем и какие слова запроса можно расширить, какие ещё вещи стоит поискать в документе, чтобы найти кандидатов, которые будут более релевантные — про это будет третий доклад. Там наше ноу-хау, мы расскажем.
Пётр:
— По крайней мере, намекнем.
Андрей (зритель):
— Спасибо за краткий экскурс в столь сложную технологию, как поиск Яндекса. Использует ли Яндекс deep learning и алгоритмы обучения с подкреплением в построении быстрого индекса или кеша? Вообще если используете где-то, то как?
Пётр:
— Deep learning используем для того, чтобы факторы ранжирования обучать. Безотносительно к быстрому или медленному индексу. Он используется для картинок, веба и всего такого.
Андрей Стыскин:
— Летом запустили версию ранжирования, которая дала 0,5% прироста качества, где мы правильно сварили deep learning на словах. Приезжали наши бывшие коллеги из-за границы и рассказывали, что там такое не работает, а мы научились.
Пётр:
— А может, это потому, что мы для топ-100 документов это делаем. Речь идёт об очень затратной задаче. Наш способ построения пайплайна поиска позволяет для сотни документов это делать.
Андрей Стыскин:
— Невозможно посчитать deep learning для всех кандидатов, которых сотни миллионов на запросы, но для топа документов можно провернуть, и у нас эта схема поиска ровно так работает — позволяет такие очень сложные наукоемкие алгоритмы внедрять.
Игорь:
— Про будущее поисковика в целом. Интернет сейчас растет очень быстро, объем, наверное, растет экспоненциально. Уверены ли вы, что через 10 лет вы будете успевать за ростом интернета, и уверены ли, что будете охватывать его в таком же объеме? Повторите ещё раз, в каком объеме сейчас интернет охвачен по вашей оценке, и что будет через 10 лет?
Пётр:
— К сожалению, можно только процентно по отношению с кем-то степень охвата определять. Потому что он реально бесконечный.
Андрей:
— Это красивый философский вопрос. Пока мы в нашем коллективе за законом Мура успеваем, каждый год кратно увеличиваем наш размер базы. Но это правда сложно, правда интересно, и, конечно же, нам даже не хватает рук, чтобы это делать, но мы хотим и знаем, как это увеличивать в ближайшие несколько лет некоторыми сериями улучшений.
Пётр:
— 10 лет — слишком далеко, но ближайшие годы да, осилим.
Андрей (зритель):
— Сколько весит реплика интернета, как она разносится между ДЦ, и как осуществляется синхронизация реплик?
Пётр:
— Полный объем роботных данных — порядка 50 ПБ, реплика меньше, индекс меньше. Можете умножить на коэффициент, который вам кажется разумным. Вы же инженер, прикиньте.
Андрей:
— А как разносится?
Пётр:
— Разносится банально — через torrent, torrent share. Потом качаем этот файлик.
Андрей:
— То есть в какой-то момент времени они не консистентны?
Пётр:
— Нет, там потом консистентные переключения. Бывает, что переключаем по ДЦ, когда ночью оно вдруг не консистентно.
Андрей:
— То есть можно через F5 — если нажимаем, один документ имеем…
Пётр:
— Мы боремся с этой проблемой, знаем о ней, ее решение стоит в наших планах.
Иван:
— Как вы боретесь с различными бот-системами и за что можно отправиться в бан?
Пётр:
— У нас есть специальные люди, которые знают ответ на этот вопрос, но они не скажут.
Андрей Стыскин:
— На сегодняшнем мероприятии мы хотели поговорить про технические детали.
Пётр:
— Про роботоловилку мы можем ответить. Нас действительно регулярно ддосят, поэтому у нас прямо на балансере, на первом слое, когда запрос попадает, есть детекция, что запрос из какой-то сети пришел негодной. Это быстро обновляется, мы быстро реджектим, оно не валит наш кластер.
Андрей:
— И это тоже устроено методом машинного обучения. Показывается капча, и в зависимости от того, как ты её разгадываешь, мы получаем положительные и отрицательные примеры. На каких-то факторах — типа айпишника подсетки, какого-то поведения, времени между действиями — обучаем и баним или не баним такие запросы. DDoS не пройдет.
Андрей Аксёнов, Sphinx Search:
— У меня технические вопросы. Проходной вопрос — почему память? Неужели даже децл подисковать на SSD не получается, чтобы индекс чуть-чуть не влезал, изредка упирался в SSD?
Пётр
— Там получается так, что футпринт одного запроса порядка 50-100 МБ, он прямо жесткий. С такой скоростью ты не сможешь сервить тысячу запросов в секунду, как мы хотим. Мы работаем над тем, чтобы этот футпринт уменьшить. Проблема, что данные про документ рассыпаны по всему диску. Мы хотим их собрать в одно место, и тогда наша общая мечта осуществится.
Андрей Аксёнов:
— Упирается в bandwidth или latency?
Пётр:
— В оба. Мы и последовательно пейджфолдимся, и объемы большие.
Андрей Аксёнов:
— То есть невероятно, но факт: даже если чуть-чуть…
Пётр:
— Да, даже если чуть-чуть отожрешь — всё.
Андрей Аксёнов:
— Экспоненциальное падение во много раз?
Пётр:
— Да-да.
Андрей Аксёнов:
— Теперь важнейший вопрос для промышленного хозяйства: сколько классов строка и классов векторов в базе?
Пётр:
— А вот всё меньше и меньше.
Андрей Аксёнов:
— Ну конкретнее.
Пётр:
— У нас пришли правильные люди, они насаждают правильные порядки. Сейчас это число уменьшается.
Андрей Аксёнов:
— Векторов-то сколько и строк?
Пётр:
— Сейчас векторов, наверное, даже один-два максимум.
Андрей Аксёнов:
— Один не бывает, два хоть…
Пётр:
— Ну вот видишь.
Андрей Аксёнов:
— А строк?
Пётр:
— Ну должен же быть корпоративный какой-то дух Яндекса.
Андрей Аксёнов:
— Скажи, не томи, ну.
Пётр:
— Строк две минимум. Ну три, может.
Андрей Аксёнов:
— Не пять?
Пётр:
— Не пять.
Андрей Аксёнов:
— Налицо прогресс, спасибо.
Фёдор:
— Про вашу схему с метапоисками. У вас очень высокий каскад. Какие тайминги на каждом уровне, можете озвучить?
Пётр Попов:
— Прямо сейчас вставляем ещё один слой, не хватает. Времена ответов… Средний метапоиск делает три раунда хождений туда-сюда, у него порядка 250 мс, 95-я квантиль. Дальше построение выдачи не очень быстрое, но вся конструкция где-то за 700 мс отрабатывает.
Андрей Стыскин:
— Да, там выше JavaScript, так что это 250 мс, а там 700.
Пётр:
— То, что снизу, оно делает кучу раундов. У нас тоже специалисты заняты прямо сейчас решением этой проблемы.
Фёдор:
— У вас нарисовано три группы вертикалей. Но у вас есть ещё Афиша, Новости и так далее. Где вы их замешиваете в итоге?
Пётр:
— В построении выдачи у нас есть такой блендер, который объединяет все эти вертикали, по пользовательскому поведению решает, кого показать. Это как раз построение выдачи.
Андрей:
— Вертикалей порядка сотни, это слой, который называется верхним метапоиском. В нём сливаются результаты средних метапоисков из вертикали веба, Картинок, Видео и ряда других, а также из маленьких базовых источников типа Афиши, Расписаний, ТВ и Электричек.
Пётр:
— Это к вопросу о том, почему у нас тысячи разных типов программ. Там очень много всяких источников, оно набегает.
Фёдор:
— Раз у вас так много вертикалей, есть ли среди них сторонние, которые не вы считаете?
Пётр:
— Особо нет. Реклама наша тоже вертикальная, отдельно от поиска, но стороннего особо нет.
Артём:
— У вашего основного конкурента выдача всегда была real time, он дельта-индексами докидывал. А у Яндекс был up выдачи. Складывалось впечатление, что темной ночью раз в семь дней человек нажимает рычаг и раскатывает индексы.
Пётр:
— К сожалению, так и происходит.
Артём:
— Правильно понимаю, что быстрый индекс был сделан для того, чтобы актуализировать выдачу real time?
Пётр:
— Да, но решение общее. Многие так реально делают, в том числе и наш основной конкурент.
Артём:
— Стремитесь ли вы к тому, чтобы тоже дельта-индексами подкидывать, просто отказаться от быстрого индекса?
Пётр:
— Естественно, стремимся. Ещё бы знать, как.
Артём:
— Когда это можно ожидать?
Пётр:
— Хороший вопрос. На тех же графиках Ашманова видно, как мы обновляем индекс. Сейчас это видно меньше, и мы делаем так, чтобы это проходило совсем быстро и незаметно. Такова одна из наших задач.
Артём:
— Вы каждый раз обрабатываете запрос пользователя? Приходит запрос, вы отсылаете его на бэкенд, рассчитывается формула и результат?
Пётр:
— Есть кеши, но они работают в 50% случаев. 40-50% запросов пользователей — уникальные и никогда больше не будут заданы. Очень много по-настоящему уникальных запросов пользователей вообще за всю жизнь Яндекса. Кешируем 50-60%. Для кеширования тоже своя система.
Как настроить поиск в Яндексе
Вариант 1: Веб-сайт
При использовании поиска Яндекс вполне можно внести некоторые изменения в работу поисковой системы, обратившись к настройкам официального сайта. Доступны параметры в равной степени на всех существующих платформах и отличаются друг от друга всего лишь интерфейсом.
Перейти на официальный сайт поиска Яндекс
Компьютер
- Чтобы изменить настройки поиска в полной версии веб-сайта, откройте страницу по представленной выше ссылке, в правом верхнем углу разверните список «Настройка» и выберите «Настройки портала». После этого отобразятся основные параметры, отвечающие за работу поисковой системы.
- Установите галочку «Показывать историю поиска», если хотите, чтобы при щелчке по пустому полю Яндекса отображался список последних или самых частых запросов. Тут же можно воспользоваться кнопкой «Очистить историю запросов», чтобы избавиться от всех подсказок.
Подробнее: Очистка поиска в Яндексе
- При включении опции «Показывать сайты, на которые вы часто заходите», во время поиска наиболее востребованные с вашей стороны веб-сайты будут выведены выше прочих ресурсов. Это относится не только к страницам с результатами, но и поисковым подсказкам.
- Следующий параметр «Показывать время посещения» позволяет поиску запоминать и впоследствии отображать время последнего перехода по ссылке на сайт. При этом данные о посещении привязаны к сайту, а не к самому результату.
- Оставшаяся функция «Показывать метки персонализации веб-результатов» позволяет отображать дополнительную метку рядом с результатами поиска, подобранными на основе личных данных. Если снять галочку, метки исчезнут, однако это не повлияет на появление персональных ответов.
- Во втором блоке «Фильтрация поиска» на странице можно установить один из трех вариантов безопасности результатов. Чаще всего используется «Умеренный», однако если вы хотите избавиться от цензуры или, наоборот, скрыть некоторый контент, можно попробовать и другие фильтры.
Телефон
- На мобильных устройствах, как уже было сказано, также доступно использование аналогичных настроек, которые мы не будем рассматривать повторно и ограничимся лишь переходом в нужный раздел. Для этого коснитесь фотографии аккаунта в правом верхнем углу экрана и нажмите по строке с никнеймом.
- Через всплывающее окно перейдите в «Настройки» и на открывшейся странице выберите «Поиск».
После этого должны будут отобразиться рассмотренные ранее настройки. Обратите внимание, что внесенные здесь изменения, равно как и в полной версии сайта, применяются к учетной записи, а не к программе или устройству.
Вне зависимости от платформы, применить внесенные изменения можно с помощью кнопки «Сохранить», расположенной в самом конце рассматриваемой страницы, поле чего происходит автоматический возврат к предыдущему разделу поисковой системы.
Вариант 2: Яндекс.Браузер
Веб-браузер от компании Яндекс предоставляет большое количество настроек, в том числе распространяющихся на работу поиска. Присутствуют они как в программе на компьютере, так и в официальном мобильном приложении.
Компьютер
- При использовании Яндекс.Браузера на компьютере разверните главное меню с помощью кнопки с тремя горизонтальными линиями на верхней панели и выберите «Настройки». Находясь на вкладке «Общие настройки», пролистайте страницу ниже до блока «Поиск».
- Галочка рядом с пунктом «Показывать подсказки при наборе адресов и запросов» позволяет обозревателю отображать наиболее актуальные подсказки при наборе тех или иных символов в поле поиска. Данная опция отличается от аналогичной настройки поисковой системы Яндекс, так как работает вне зависимости от поиска по умолчанию.
- Если на каком-либо ресурсе предусмотрен внутренний поиск, включение параметра «Показывать в умной строке поисковые запросы при поиске на сайте» позволит использовать адресную строку в качестве поля поиска. В противном случае отображаться будет привычный URL-адрес.
- Следующий параметр отвечает всего лишь за проверку орфографии, чтобы вы могли быстро перейти на нужный веб-ресурс, даже если ошиблись несколькими символами. Тут стоит учитывать, что работает это только если неверный адрес сайта не сильно отличается от нужного.
- Последняя галочка «Заранее запрашивать данные о страницах, чтобы быстрее их загружать» отвечает за предварительную загрузку веб-сайтов по ссылкам на просматриваемом ресурсе. Данный параметр ускоряет работу браузера, однако вместе с этим может негативно влиять на требования к памяти.
Читайте также: Устранение проблем с нехваткой памяти в Яндекс.Браузере
- Как и другие веб-обозреватели, Яндекс.Браузер позволяет менять установленную по умолчанию поисковую систему. Для этого в настройках поиска нужно воспользоваться ссылкой «Настройки поисковой системы» и с помощью выпадающего списка выбрать один из доступных вариантов.
Подробнее: Управление поисковыми системами в Яндекс.Браузере
Здесь доступен как выбор существующих вариантов, так и добавление новых. Подробно данный раздел был рассмотрен в отдельной инструкции на примере ПК и мобильной версии обозревателя.
Телефон
- Чтобы перейти к параметрам в мобильной версии обозревателя, откройте приложение, разверните меню на стартовом экране и выберите «Настройки».
- Связанные с поиском опции располагаются в блоке «Поиск» и ограничены всего несколькими параметрами. Первым выступает «Регион», изменение которого позволит отображать актуальные результаты поиска в соответствии с выбранной страной.
- В разделе «Голосовые возможности» можно управлять работой голосового помощника «Алиса», интегрированного в данное приложение. По необходимости можете добавить активацию голосом, включить чтение страниц или же, наоборот, заблокировать голосовое управление.
Оставшиеся пункты мы рассматривать не будем, так как они или уже были описаны ранее, или вовсе не влияют на работу поиска и носят, скорее, визуальный характер.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТПоделиться статьей в социальных сетях:
Десять скрытых фишек поиска Яндекса, которые полезно знать
Я уверен, что большинство наших читателей не знают и половины интересных фишек, которые есть у поисковой машины. Потому что, как правило, мы лишь вбиваем в поисковую строку то, что нам нужно, и изучаем результаты поиска или фактовые ответы. Но поиск Яндекса гораздо интереснее, чем вы думаете. Сейчас расскажу, почему. Поехали!
Найти ту же картинку, но в более высоком разрешении или похожую
Иногда нам попадается красивая картинка, которую мы хотим поставить, например, в качестве обоев рабочего стола, но увы, ее разрешение таково, что на мониторе изображение превращается в неприятную кашу из пикселей. Или нам, авторам различных материалов, часто требуется та или иная картинка в хорошем качестве, чтобы вставить ее в статью. В этом случае на помощь приходит поиск по картинкам Яндекса.
Он работает очень просто: вы вставляете ссылку на имеющееся у вас изображение или загружаете его файлом, а поисковик в ответ предлагает вам все доступные в Сети варианты этой картинки с указанием разрешения.
Кроме того, здесь есть еще одна полезная штука — похожие картинки. Иногда таким образом получается найти что-то даже более интересное. Причем работает эта фишка как при поиске по загруженному изображению, так и при обычном текстовом поиске по картинкам.
Узнать больше по фотографии или что на ней изображено
Яндекс умеет подсказывать, что изображено на фотографии. Например, можно сфотографировать здание или памятник в путешествии, загрузить в поиск по картинками и получить больше информации о нем.
Поиск по сайту, если на сайте его нет
Зачастую мы ищем информацию на конкретном ресурсе, однако нередко случается так, что поиска на нужном сайте либо вовсе нет, либо он работает не так, как хотелось бы. В этом случае нам поможет оператор site:, который можно использовать вместе с любым текстовым запросом.
Например, мы хотим найти все статьи про фишки Яндекса на kod.ru. Для этого в поисковик нужно ввести запрос site:kod.ru фишки яндекса. Как видите, это очень просто.
А еще прямо в выдаче можно найти кнопку «Ещё с сайта», если лень запоминать оператора site:.
Поиск только по заголовкам материалов
Еще один крайне полезный оператор — это title:, который отвечает за поиск только по заголовкам материалов, что очень удобно, когда интересует какая-то конкретная статья. Например, если мы ищем подробности о грядущем обновлении iOS 14, то просто вводим в поисковик title:обновление iOS 14.
Поиск документов в определенном формате
По аналогии можно искать только файлы в определенном формате, например, только doc или pdf. Для этого стоит использовать оператора mime:. Это пригодится, например, если нужно найти «рыбу» анкеты на шенгенскую визу (да-да, когда-нибудь она нам снова понадобится). Вводим mime:doc анкета для шенгена и получаем результат.
Поиск страниц на определенном языке
В моей работе часто возникает потребность найти источник какой-либо новости на оригинальном, зачастую на английском языке. Чтобы максимально упростить эту задачу, я использую оператора lang:. Вводим, например, lang:en iPhone 12 renders leaks и получаем результаты только на английском. Профит!
Только поиск и ничего больше!
Если перейти по ссылке ya.ru, то вам откроется страница поиска Яндекса без новостей и прочего контента, который иногда может отвлечь настолько, что вы забудете, что хотели найти. Да, там нет ничего, кроме поисковой строки!
Интерактивные ответы
Поиск Яндекса — это не только выдача ссылок, подходящих под запрос, но и интерактивные ответы. Например, введя в поиск калькулятор, у вас на экране отобразится вполне функциональный калькулятор, а если спросить у яндекса, сколько сантиметров в 7 футах или сколько 35678 тенге в рублях, то откроется соответствующий конвертер величин или валют.
Колдунщик цветов — в помощь дизайнеру и не только
Сколько сходу вы можете назвать цветов? С черным, белым, синим или зеленым все вроде бы абсолютно ясно и понятно. А знаете ли вы, как например, выглядит цвет «трилистник крайола» или «перванш». Вот и я узнал это только в процессе работы над данным материалом.
Но хорошо, что у нас есть Яндекс, а в нем есть колдунщик, знающий названия целых 1010 цветов и показывающий, что это вообще за цвет такой. Вместе с тем он может показывать коды цветов и переводить их из RGB в HSV или HEX (и, естественно, обратно). Для дизайнеров и просто любопытных людей — штука просто незаменимая!
Как его запустить? Очень просто: просто введите в поиск, например, цвет Яндекса или бисмарк-фуриозо. Гарантирую, зависнете минут на 10 точно, открывая для себя все новые и новые цвета.
Переводчик в поисковой строке
Для того, чтобы перевести незнакомое слово на русский язык, не обязательно переходить на специальную страничку переводчика. Его можно перевести сразу в поисковой строке, а за подробностями перейти на страницу выдачи, где вас уже будет ждать соответствующий колдунщик.
О других фишках Яндекса, которые экономят пользователям 50 000 часов в сутки, читайте в нашем предыдущем материале:
Семь фишек поиска Яндекса, которые экономят пользователям 50 000 часов в сутки
Поиск в целом как раз создан для того, чтобы люди решали свои задачи быстрее. И в Яндексе над этим усердно работают.
«Яндекс» обогнал Google на чужой территории – Газета Коммерсантъ № 158 (6396) от 03.09.2018
Доля «Яндекса» в сегменте поиска на мобильных устройствах на базе Android в России впервые превзошла показатель Google. Это знаковый момент для российской компании: долгие годы смартфоны и планшеты на Android оставались зоной, где Google уверенно доминировал. Росту доли «Яндекса» помогли запуск голосового помощника «Алиса», появление окна выбора поиска по умолчанию в результате соглашения с ФАС и предустановка сервисов компании на новых устройствах, констатируют аналитики.
«Яндекс» впервые обошел Google по доле поисковых запросов на устройствах с разработанной Google операционной системой Android, свидетельствуют данные аналитического сервиса «Яндекс.Радар». На неделе с 13 по 19 августа доля «Яндекса» составила 49,35%, Google — 49,28% из общего числа запросов. В Google от комментариев отказались.
Ситуация заметно изменилась за последние два года. Так, если в последнюю неделю лета в 2016 году доля «Яндекса» на Android составляла еще 38,2%, а Google — 60,1%, то с 24 по 31 августа 2017 года доля поиска «Яндекса» достигла уже 42,7%, тогда как Google — 56%. Как раз с августа 2017 года в новой версии мобильного браузера Google Chrome на Android пользователям в России показывается окно выбора поисковика по умолчанию — «Яндекс», Google или Mail.ru. Это было одним из ключевых условий мирового соглашения, которое Google заключила с Федеральной антимонопольной службой (ФАС) 17 апреля 2017 года. «Именно это стало основной причиной роста нашей доли на Android в августе 2017 года относительно августа 2016 года»,— подтверждали тогда “Ъ” в «Яндексе». Противостояние ФАС и Google было инициировано жалобой «Яндекса» и длилось почти полтора года. В результате Google также пришлось отказаться от эксклюзивности своих приложений на Android и согласиться, что любые разработчики приложений (например, «Яндекс» и Mail.ru Group) могут претендовать на место на главном экране.
Помимо окна выбора поиска по умолчанию на долю «Яндекса» положительно повлияли предустановка сервисов компании на мобильных устройствах, запуск улучшенного поискового алгоритма «Королев» в августе 2017 года и голосового виртуального помощника «Алиса» в октябре 2017-го, а также его дальнейшая дистрибуция в сервисах «Яндекса» (например, в мобильном и десктопном браузере и «Навигаторе»), считают в компании. «»Алиса» стала одним из важнейших драйверов органической установки поискового приложения «Яндекса» на мобильные устройства пользователей,— сообщил представитель «Яндекса» Илья Грабовский.— С момента запуска «Алисы» и старта рекламной кампании дневная аудитория нашего поискового приложения выросла в два раза».
Старший аналитик Sberbank Investment Research Светлана Суханова называет успех команды «Яндекса» на Android «ошеломляющим». «Он выше ожиданий рынка и быстрее прогноза, который давала компания. И это произошло не только в результате урегулирования спора Google с ФАС, этому способствуют успех «Алисы», улучшенный поиск по картинкам и видео»,— рассуждает аналитик. По ее словам, иллюстрацией последнего тезиса может служить то, что доля «Яндекса» в мобильном поиске на iOS тоже выросла — на 1,5 процентных пункта (п. п.) год к году и на 3,2 п. п. с конца января 2018 года — и составила 41,4%.
Аналитик Sova Capital Александр Венгранович также отдает должное успеху «Алисы» и постоянному расширению экосистемы продуктов, но при этом считает, что доля «Яндекса» растет в основном за счет предустановок поиска на устройствах Android, которые стали поставлять в Россию с первого квартала 2018 года. «Поскольку доля таких устройств постоянно увеличивается, а используют «Яндекс» на них чаще, значит, и доля российского поисковика постоянно растет. Я ждал, что 50% на Android у него будет к концу года, но «Яндекс», судя по всему, справится с этой задачей быстрее»,— говорит господин Венгранович.
Роман Рожков
Яндекс назван наиболее вероятной поисковой системой для продвижения теорий заговора — исследование
Российская поисковая система «Яндекс» с большей вероятностью будет продвигать контент, связанный с теорией заговора, в своих результатах поиска, чем любая другая крупная поисковая система, согласно новому исследованию, опубликованному в среду.
Более половины первых страниц результатов поиска Яндекса по спорным терминам, таким как «плоская земля» и «Джордж Сорос», приходилось на страницы, пропагандирующие теории заговора, как выяснили исследователи из Цюрихского университета.
Это была значительно более высокая доля, чем среди результатов, представленных любыми другими протестированными поисковыми системами — Google, Yahoo, Bing и DuckDuckGo, которые вместе с Яндексом составляют пятерку крупнейших поисковых порталов в мире.
«Все поисковые системы, за исключением Google, постоянно отображали результаты, пропагандирующие заговор, и возвращали ссылки на сайты, посвященные заговорам, в своих лучших результатах», — обнаружили исследователи во главе с Александрой Урман, научным сотрудником группы социальных вычислений Цюрихского университета.
«Поисковой системой с наибольшей долей содержания, пропагандирующего заговоры, был Яндекс».
Исследователи создали ботов для имитации десятков поисковых запросов по шести спорным терминам — «11 сентября», «Джордж Сорос», «иллюминаты», «QAnon», «плоская земля» и «новый мировой порядок» — а затем отслеживает и классифицирует результаты первой страницы, предоставленные различными поисковыми системами.
В моделировании, которое проводилось на английском языке, использовались компьютерные серверы в трех разных местах в два разных дня, чтобы имитировать поведение реального пользователя.Хотя исследователи сообщили о некоторых различиях в результатах в зависимости от места и времени поиска, самым большим фактором была используемая поисковая машина.
Около 65% всех результатов поиска на первой странице Яндекса по данному запросу были ссылками на сайты или статьи, выступающие за сговор. Google почти не дал результатов, в то время как 25-40% результатов на трех других страницах относились к страницам, продвигающим опровергнутые теории заговора.
Яндекс также был единственным сайтом, который не отправлял результаты на научные или исследовательские сайты и с гораздо большей вероятностью включал в свои результаты сообщения в социальных сетях, которые также содержали конспиративный контент.
Исследование представляет собой препринт, а это значит, что оно еще не прошло рецензирование.
Яндекс не ответил на запрос The Moscow Times о комментарии.
Исследователи заявили, что они выбрали сочетание терминов, которые будут имитировать пользователей, уже заинтересованных в теориях заговора, таких как «QAnon», и более нейтральные поисковые запросы о людях и событиях, такие как «Джордж Сорос» и «11 сентября». определить, какие поисковые системы с большей вероятностью будут уделять больше внимания сайтам, посвященным теориям заговора, в своих результатах — потенциально подталкивая пользователей к чтению о теориях заговора, когда они просто искали основную информацию или факты.
«Хотя можно предположить, что только пользователи, которые уже заинтересованы в конспирологическом контенте, целенаправленно переходят на специализированные нишевые веб-сайты, их появление в первых результатах поиска, особенно для запросов, которые не обозначают теории заговора как таковые (например,« 9/11 » »Или« Джордж Сорос ») потенциально может привести к случайному ознакомлению с теориями заговора. Это вызывает беспокойство, учитывая высокое доверие людей к результатам поиска », — заключили исследователи.
Обратный поиск изображений в поисковых системах, таких как Google, Яндекс, Bing и Tineye
Время чтения: 5 минутПри поиске чего-либо в Google мы склонны искать по ключевым словам.Что, если нам нужно найти что-то похожее на изображение, которое мы сказали несколько мгновений назад? Вот где проявляется преимущество обратного поиска изображений.
Функция обратного поиска изображений позволит вам проверить Google на наличие полного списка всех страниц, на которых это изображение появляется в Интернете. Другими словами, вы можете искать в Google, используя изображение.
Сегодня в этом блоге мы собираемся поделиться полным руководством по обратному поиску изображений в нескольких поисковых системах, таких как Google, Яндекс, Bing и TinEye.Начнем сначала с основ.
Что такое обратный поиск изображений?Короче говоря, обратный поиск изображений похож на простой поиск в Google, но на этот раз с изображениями. Он не только позволяет детально изучить изображение, но также дает подробную информацию о размере изображения и о том, где его можно получить в Интернете.
Почему следует выбирать обратный поиск изображений?Обратный поиск изображений чрезвычайно полезен, и вы можете использовать его по следующим причинам:
- Ищите интересные факты о конкретном изображении, которое вам нравится.
- Узнайте о статусе авторских прав на изображение перед его использованием.
- Проверьте нарушения авторских прав на изображения, которые вы уже используете
- Проверьте, используют ли ваши изображения уже другие люди
Давайте покажем вам обратный поиск изображений в Google (рабочий стол).
Во-первых, нужно открыть Google.Обратный поиск изображений работает в Firefox, Chrome и Safari.
Во-вторых, откройте картинки Google. Перейдите в правую часть строки поиска Google и нажмите значок «камера». Загрузите свое изображение.
Google Image SearchОднако, если у вас нет сохраненного изображения, вы можете получить URL-адрес изображения. Откройте значок камеры Google еще раз и вставьте URL-адрес изображения.
Наконец, нажмите на поиск. Вы увидите загруженное фото вместе с ключевыми словами. Рядом с изображением Google сообщит вам, доступны ли изображения других размеров или нет.
Как выполнить обратный поиск изображений в приложении Google Chrome на мобильном устройстве?Теперь давайте попробуем обратный поиск изображений через приложение Google Chrome на мобильном устройстве. Откройте поиск картинок Google в приложении Chrome.
Сначала найдите свое изображение, набрав его. Нажмите Enter, и появится список фотографий. Сохраните желаемое изображение.
Теперь, когда вы снова открываете изображение, нажмите и удерживайте его несколько секунд. Вы увидите раскрывающееся меню с несколькими вариантами.Один из вариантов — «поискать это изображение в Google».
поиск изображений в приложении Google Chrome на мобильном устройствеВыберите этот вариант, и на новой вкладке вы увидите, где находится это изображение, а также его различные размеры.
Как выполнить обратный поиск изображений в Google? (мобильный браузер)Откройте изображения Google в своем веб-браузере. Избавьтесь от мобильного просмотра. Для этого вам необходимо изменить настройки веб-сайта на режим рабочего стола.
Щелкните три точки в конце или верхнем правом углу браузера.Выберите вариант «запросить настольный веб-сайт». Теперь вы увидите Google таким, каким вы его видите на своем компьютере.
поиск изображений в Google для мобильных устройствЗагрузите изображение так же, как вы загружали бы его на свой компьютер. Если у вас есть сохраненное изображение, вы можете загрузить его напрямую, а если нет, вы можете вставить URL-адрес.
Нажмите на поиск, чтобы просмотреть результаты. Google покажет вам похожие поисковые запросы, а также изображения, доступные в других размерах. Вы можете проверить другие веб-сайты с такой же картинкой.
Как выполнить обратный поиск изображений в Google с помощью iPhone?Откройте браузер и перейдите на images.google.com. Если вы используете Safari, щелкните значок «AA» слева. Поиск изображений
в Google с помощью iPhoneЕсли вы используете Chrome, посмотрите в правом нижнем углу экрана на три точки и нажмите на них.
Выберите «запросить настольный сайт» и таким же образом загрузите изображения. Нажмите «поиск», чтобы увидеть результаты.
Обратный поиск изображений в BingНажмите на опцию «изображения» в левой части главной страницы Bing.В строке поиска выберите «поиск по изображению».
поиск изображений в BingВы получите такие опции, как перетаскивание изображения в строку поиска, загрузку изображений, вставку URL-адреса и создание фотографии. В отличие от Google, в Bing вы можете перетащить более одного изображения в строку поиска.
Вы можете выполнить любое из вышеперечисленных действий и нажать на «поиск». Щелкните вкладки, чтобы проверить страницы, на которых появляется изображение. Вы найдете похожие изображения и похожие запросы.
Как отменить поиск картинок на яндексе?На Яндексе нажмите на изображение в верхнем левом углу строки поиска.Затем щелкните значок камеры.
Поиск картинок на ЯндексеУ вас будет возможность ввести URL-адрес изображения или загрузить картинку с рабочего стола. Если вы решите сохранить, а затем загрузить изображения с рабочего стола, вы увидите результаты со всеми доступными размерами изображений.
Есть кнопка «распознать текст», которая поможет вам в поиске или переводе слов на изображении.
Как выполнить обратный поиск изображений на TinEye?TinEye — это поисковая машина, которая предлагает быстрый поиск изображений в обратном направлении.Нажмите кнопку загрузки в левой части строки поиска, чтобы просмотреть сохраненные изображения на рабочем столе.
Вы также можете вставить URL изображения в строку поиска. Вы также можете перетащить изображение из вкладки браузера прямо на главную страницу TinEye.
обратный поиск изображений на TinEyeСамое приятное то, что вы можете использовать фильтр для поиска по самому новому или самому старому сообщению, размеру изображения, наилучшему совпадению и наиболее измененному. У вас также будет возможность фильтровать по домену, чтобы получить конкретные результаты.
В заключение можно сказать, что обратный поиск изображений легко выполнить на любом мобильном устройстве или компьютере. Будь то Mac или ПК, Android или iPhone, вы все равно можете воспользоваться его преимуществами.
Однако иногда обратный поиск изображений может не работать сразу. В результате, даже если вы загрузите фотографию в строку поиска, вы не получите нулевых результатов.
Такие инциденты происходят из-за того, что веб-сайты препятствуют индексации изображений. Иногда центры обработки данных могли немного рассинхронизироваться.Таким образом, некоторые пользователи могут найти изображение с помощью обратного поиска, а другие — нет.
СвязанныеРоссийский гигант поисковых систем Яндекс приобретает KitLocate
Еще одна транснациональная компания открывает магазин в Израиле. Российский гигант поисковых систем Яндекс на этой неделе приобрел израильский стартап, занимающийся технологией определения местоположения KitLocate. Подробности сделки не разглашаются, но источники, близкие к KitLocate, сообщили, что Яндекс заплатил 20 миллионов долларов за тель-авивскую компанию.
Как бы он ни платил за его компанию, сказал генеральный директор KitLocate Омри Моран, «Яндекс» окупит свои деньги и не только. «Яндекс похож на Google в том смысле, что они являются поисковой системой и имеют множество приложений, которые предоставляют множество услуг, многие из которых основаны на геолокации и карте». Подход KitLocate к геолокации отличается от подхода других компаний, занимающихся технологиями определения местоположения, что приводит не только к новому набору услуг, которые KitLocate может предложить клиентам, но и к значительной экономии заряда батареи, сказал Моран.
«Так мы и стали сотрудничать с Яндексом», — сказал Моран в эксклюзивном интервью газете The Times of Israel. «В течение некоторого времени они искали технологию для продления срока службы батарей, и мы встретились друг с другом, в результате чего была заключена сделка, которая принесет пользу как организациям, так и клиентам».
KitLocate получает свои возможности по экономии заряда аккумулятора (по словам Морана, телефоны, использующие платформу KitLocate, могут работать до 24 часов в обычном режиме от одной зарядки аккумулятора), просматривая информацию о местоположении за пределами чипа GPS.Помимо GPS, KitLocate собирает данные о действиях пользователя через Wi-Fi, акселерометры и другие датчики на устройстве.
Омри Моран (Фото любезно предоставлено)
«Чтобы правильно определять местоположение, вам нужна статистика и информация о привычках пользователя, которые вы можете анализировать, чтобы отслеживать, что человек делает», — сказал Моран. «Это позволяет приложениям предугадывать потребности и при необходимости действовать, а также снижает нагрузку на аккумулятор, потому что не все датчики должны работать постоянно, чтобы гарантировать, что пользователь получит нужные услуги.”
Получите ежедневное издание The Times of Israel по электронной почте и никогда не пропустите наши главные новости
Регистрируясь, вы соглашаетесь с условиямиПо словам Морана, многие службы определения местоположения являются контекстными, и по мере изменения контекста меняются и инструменты, используемые для определения местоположения — и того, какие услуги должны быть предоставлены. «Например, если человек едет по шоссе, а следующий съезд находится в десяти милях от него, и мы видим, что движение в этом районе невелико, нам не нужно проверять чип GPS каждые пять секунд, чтобы определять местоположение.«Опрос может проводиться реже; таким образом, сказал Моран, устройство будет потреблять меньше энергии, а батарея прослужит дольше.
Data — еще один важный элемент в наборе инструментов KitLocate. В системе по-новому используется гео-ограждение — система, которая выполняет определенные действия в зависимости от того, где находится пользователь. Используя данные, которые система собирает о привычках — о том, что пользователи часто посещают в магазинах, даже о том, какие разделы магазина им больше интересны (например, мужской или женский отдел), KitLocate позволяет предприятиям активно предлагать пользователям услуги и возможности, которые в противном случае они не могли бы предложить.Информация собирается из приложений, использующих систему KitLocate, и анализируется мощными приложениями для работы с большими данными.
Как поисковая компания, Яндекс, естественно, интересуется большими данными, хотя Моран сказал, что не может сейчас сказать, какие именно задачи будут переданы KitLocate. Теперь компания станет ядром нового израильского научно-исследовательского центра Яндекса, и, предположительно, нынешний штат из 8 человек будет расширен, возможно, существенно, по мере того, как Яндекс интегрирует KitLocate в свои проекты развития.
«Технология KitLocate, упакованная в удобный для разработчиков SDK, обеспечивает возможности определения местоположения, включая гео-ограждение, обнаружение движения и социальное местоположение, для приложений на основе определения местоположения на смартфоне iOS или Android пользователя», — говорится в заявлении Яндекса. «Уловка в том, что при этом снижается потребление энергии аккумулятора до менее 1% в час. Алгоритмы KitLocate позволяют приложениям на основе определения местоположения реже запрашивать географические координаты устройства без потери точности, что значительно продлевает срок службы телефона без подзарядки.
«Те мобильные продукты Яндекса, которые не нуждаются в постоянной GPS-синхронизации, такие как наш поиск на основе местоположения, не могут дождаться, когда их дополнят умным решением KitLocate. Благодаря технологии KitLocate мы сможем предоставлять результаты поиска, а также предложения продуктов или услуг на мобильном телефоне или планшете пользователя, относящиеся не только к конкретному пользователю, но и к его текущему местоположению. Это облачное решение выглядит особенно многообещающим для приложений с рекомендациями на основе местоположения », — заявили в компании.
KitLocate едва исполнился год, и он окончил последний курс начинающих выпускников Microsoft Ventures Accelerator в Израиле. Фактически, именно с помощью программы Яндекс нашел KitLocate, сказал Моран. «Они сделали презентацию на MS Ventures, перечислив то, что они искали, и в их презентации был пункт« энергоэффективная геолокация »- и, как оказалось, в нашей презентации у нас был пункт с таким же названием. ”
Это была встреча умов — или основные моменты, которые создали эти умы, — которая объединила две компании, — сказал Моран, добавив, что «мы очень рады быть частью Яндекса, и я знаю, что они счастливы. у нас тоже.”
Ты серьезный. Мы ценим это!
Нам очень приятно, что вы прочитали статей X Times of Israel за последний месяц.
Вот почему мы приходим на работу каждый день — чтобы предоставить таким взыскательным читателям, как вы, обязательные к прочтению материалы об Израиле и еврейском мире.
Итак, теперь у нас есть запрос . В отличие от других новостных агентств, у нас нет платного доступа. Но поскольку журналистика, которую мы делаем, стоит дорого, мы приглашаем читателей, для которых The Times of Israel стала важной, поддержать нашу работу, присоединившись к The Times of Israel Community .
Всего за 6 долларов в месяц вы можете поддержать нашу качественную журналистику, наслаждаясь The Times of Israel AD-FREE , а также получая доступ к эксклюзивному контенту, доступному только для членов сообщества Times of Israel.
Присоединяйтесь к нашему сообществу Присоединяйтесь к нашему сообществу Уже участник? Войдите, чтобы больше не видеть этоСлужба безопасности Яндекса поймала администратора на продаже доступа к почтовым ящикам пользователей
Российская интернет-поисковая компания Яндекс раскрывает утечку данных, системный администратор продавал доступ к тысячам почтовых ящиков пользователей.
Российская поисковая система и интернет-провайдер Яндекс раскрывает утечку данных. Компания обнаружила, что один из ее системных администраторов был пойман на продаже доступа к учетным записям электронной почты 4887 пользователей.
Инцидент безопасности был обнаружен во время плановой проверки его внутренней службой безопасности, внутреннее расследование все еще продолжается.
«Внутреннее расследование показало, что сотрудник предоставлял несанкционированный доступ к почтовым ящикам пользователей в личных целях.Сотрудник был одним из трех системных администраторов с необходимыми правами доступа для оказания технической поддержки службы. В результате его действий было взломано 4887 почтовых ящиков. Никакие платежные реквизиты Яндекса не были скомпрометированы ». говорится в пресс-релизе компании. «Служба безопасности Яндекса уже заблокировала несанкционированный доступ к взломанным почтовым ящикам. Мы связались с владельцами почтовых ящиков, чтобы предупредить их о взломе, и они были проинформированы о необходимости изменить пароли своих учетных записей.”
На момент написания статьи компания не разглашала имя неверного сотрудника, она лишь подтвердила, что он был одним из трех системных администраторов с необходимыми правами доступа для оказания технической поддержки сервиса Яндекс.Почта.
Компания сообщила об инциденте безопасности властям и уведомляет владельцев взломанных 4887 почтовых ящиков.
Яндекс объявил, что обеспечил безопасность взломанных учетных записей и заблокировал любой другой несанкционированный доступ, а также принудительно сбросил пароли для затронутых учетных записей.
Компании не известно о доступе к платежным данным пользователей.
«В настоящее время ведется тщательное внутреннее расследование инцидента, и Яндекс внесет изменения в процедуры административного доступа. Это поможет свести к минимуму вероятность того, что отдельные лица могут поставить под угрозу безопасность пользовательских данных в будущем. Компания также связалась с правоохранительными органами ». заключает компания.
Если вы хотите получать еженедельный бюллетень по вопросам безопасности бесплатно, подпишитесь на здесь .
Пьерлуиджи Паганини
( SecurityAffairs — взлом, нарушение данных)
Поделиться
Яндекс: акции поисковой системы Яндекс выросли на 50% по сравнению с дебютным
НЬЮ-ЙОРК: Акции недавно публичной российской поисковой компании в Интернете Yandex NV выросли во вторник на 50 процентов, что свидетельствует о том же пылком интересе инвесторов, который удвоил цену акций LinkedIn Corp после ее первичного публичного размещения на прошлой неделе.Несмотря на высокий спрос на Яндекс, источник сообщил, что инвесторы предлагают купить в 17 раз больше акций, чем предоставили Яндекс и его владельцы, однако обеспокоенность вызывает то, что оценки IPO для интернет-компаний намного выше, чем их прогнозы по доходам.
Помимо этого, это может спровоцировать наплыв менее способных компаний, стремящихся удовлетворить тот же спрос инвесторов, который подпитывал бум доткомов в конце 1990-х.
акций «Яндекса», крупнейшего IPO в США со времен Google Inc почти семь лет назад, стоили 37 долларов.47 во второй половине дня на бирже Nasdaq.
IPO состоится через неделю после того, как профессиональная социальная сеть LinkedIn стала публичной. Инвесторы более чем удвоили стоимость акций этой компании в первый день торгов.
Это также связано с предположениями Уолл-стрит о том, когда социальные сети Facebook и Twitter станут общедоступными. IPO «Яндекса» предоставило больше доказательств того, что интернет-компании снова в восторге, может быть, больше, чем следовало бы.
«Яндекс демонстрирует хороший рост на сегодняшний день, и я думаю, что он будет расти в будущем», — сказал IPOdesktop.com, президент Фрэнсис Гаскинс. «Инвесторы жаждут роста везде, где они могут его получить, будь то Россия или где-то еще».
Яндекс привлек на IPO 1,3 миллиарда долларов, продав 52,2 миллиона акций по 25 долларов каждая. Он оценил компанию примерно в 8 миллиардов долларов. Morgan Stanley, Deutsche Bank Securities и Goldman Sachs & Co возглавили андеррайтеров при размещении.
Яндекс не решил, как использовать деньги, полученные от IPO, но важно иметь большие остатки денежных средств, как и у конкурентов, — сказал 46-летний сооснователь и технический директор Илья Сегалович.
«У всех наших конкурентов груды денег — огромные груды — и мы должны быть готовы ко всему», — сказал Сегалович.
Бизнес-модель Яндекса основана на интернет-рекламе. В 2010 году прибыль выросла на 90 процентов до 3,8 миллиарда рублей (134 миллиона долларов США) за счет роста продаж на 43 процента до 12,5 миллиарда рублей (441,3 миллиона долларов США).
Аналитики говорят, что поисковая система, разработанная Сегаловичем и 47-летним соучредителем Аркадием Воложом, имеет конкурентное преимущество перед Google, поскольку она лучше приспособлена для обработки грамматических сложностей русского языка.
Для роста компании она должна защищать свою долю на рынке поисковой системы в России, которая сейчас составляет 65 процентов против 22 процентов Google.
«Google — отличная компания, но мы лучше», — сказал Сегалович.
Сегалович и Волож, которые познакомились еще школьниками, сказали, что IPO поможет вывести Россию на карту как место рождения глобальной технологической компании.
«Мы работаем над тем, чтобы это произошло», — сказал Волож в интервью.
«Россия славится своими ресурсами», — сказал он.«Но в России тоже много талантов … Пока не так много технологических компаний … которые работали бы на весь мир. Мы считаем, что научная культура России настолько сильна, что рано или поздно такая компания появится «.