Robots.txt – важные этапы при создании и проверке
Почему это важноRobots.txt – это текстовый файл с набором инструкций для поисковых роботов, который управляет правилами индексации сайтов. С его помощью можно обозначить для поисковых систем, какие страницы стоит проиндексировать в первую очередь (например, раздел «Новости компании», так как он часто обновляется) и какие страницы закрыты для индексирования (например, результаты внутреннего поиска, так как это может привести к дублированию данных в поисковой системе и ухудшению показателей ранжирования сайта). Подробней о дубликатах данных читайте в Рыбе «Дублируемый контент – как вовремя найти и обезвредить дубли».
Файл Robots.txt должен находиться в корне сайта и быть доступен по адресу:
http://site.ru/robots.txt
Если у вашего сайта несколько поддоменов (это сайты 3-го уровня, например: http://ru.site.com), то для каждого поддомена следует писать свой robots.
Robots.txt – простой текстовый файл. Внимание: имя файла должно содержать только маленькие буквы (то есть имена «Robots.txt» и «ROBOTS.TXT» — неправильные). Ещё одно ограничение robots.txt – размер файла. У Google это до 500 кб, у Яндекса до 32 кб. Если ваш robots.txt превышает эти размеры, то он может работать некорректно.
Более подробные требования к оформлению файла прописаны в справках поисковых систем: для Google и для «Яндекс».
Какие директивы существуют?Директива «User-agent»Директива, указывающая, для какого поискового робота написаны правила.
Примеры использования:
User-agent: * – для всех поисковых роботов
User-agent: Yandex – для поискового робота Yandex
User-agent: Googlebot – для поискового робота Google
User-agent: Yahoo – для поискового робота Yahoo
Рекомендуется использовать:
User-agent: *
Ниже мы рассмотрим примеры директив, как и для чего стоит их использовать.
Директива, запрещающая индексацию определённых файлов, страниц или категорий.
Эта директива применяется при необходимости закрыть дублирующие страницы (например, если это интернет-магазин, то страницы сортировки товаров, или же, если это новостной портал, то страницы печати новостей).
Также данная директива применима к «мусорным для поисковых роботов страницам». Такие страницы, как: «регистрация», «забыли пароль», «поиск» и тому подобные, – не несут полезности для поискового робота.
Примеры использования:
Disallow: /*sort – при помощи спец символа «*», мы даём понять поисковому роботу, что любой url, содержащий «SORT», будет исключён из индекса поисковой системы. Таким образом, в интернет-магазине мы сразу избавимся от всех страниц сортировки (учтите, что в некоторых CMS системах построение url сортировок может отличаться).
Disallow: /*print.php

Disallow: */telefon/ – в данном случае мы исключаем категорию «телефон», то есть url, содержащие «/telefon/».
Пример исключённых в данном случае url:
Пример не исключённых url в данном случае:
Disallow: /search – в данном случае мы исключим все страницы поиска, url которых начинаются с «/search». Давайте рассмотрим на примере исключенных страниц поиска:
Примеры не исключённых url в данном случае:
Disallow: / – закрыть весь сайт от индексации.
Директива, разрешающая индексировать страницы (по умолчанию поисковой системе открыт весь сайт для индексации). Данная директива используется с директивой «Disallow».
Важно: директива «allow» всегда должна быть выше директивы «disallow».
Пример №1 использования директив:
Allow: /user/search
Disallow: *search
В данном случае мы запрещаем поисковому роботу индексировать страницы «поиска по сайту», за исключением страниц «поиска пользователей».
Пример №2 использование директив:
Allow: /nokia
Disallow: *telefon
В данном случае, если url-структура страниц такого типа:
Мы закрываем все телефоны от индексации, за исключением телефонов «nokia».
Такая методика, как правило, редко используется.
Директива «sitemap»Данная директива указывает поисковому роботу путь к карте сайта в формате «XML».
Директива должна содержать в себе полный путь к файлу.
Sitemap: http://site.ru/sitemap.xml
Рекомендации по использованию данной директивы: проверьте правильность указанного адреса.
Директива «Host»
Данная директива позволяет указать главное зеркало сайта. Ведь для поисковой системы это два разных сайта.
Host: www.site.ru
Либо:
Host: site.ru
Пример полноценного robots. txt
txt
User-Agent: *
Disallow: /cgi-bin
Disallow: /*sort=*
Sitemap: http://www.site.ru/sitemap.xml
Host: www.site.ru
Корректность работы файла проверяется согласно правилам поисковых систем, в которых указаны правильные и актуальные директивы (ПС могут обновлять требования, поэтому важно следить за тем, чтобы ваш robots.txt оставался актуальным). Конечную проверку файла можно провести с помощью верификатора. В Google – это
Инструкция robots.txt – важный момент в процессе оптимизации сайта. Файл позволяет указать поисковому роботу, какие страницы не следует индексировать. Это, в свою очередь, позволяет ускорить индексации нужных страниц, отчего повышается общая скорость индексации сайта.
Необходимо помнить, что robots.txt – это не указания, а только рекомендации поисковым системам.
Robots.txt — Словарь— PromoPult.ru
Robots.txt размещается в корневой папке сайта и доступен по адресу вида https://somesite.ru/robots.txt
Этот стандарт утвержден Консорциумом Всемирной паутины W3C в 1994 году. Использование Robots.txt является добровольным как для владельцев сайтов, так и для поисковиков.
Назначение файла Robots.txt
Основная задача — управление поведением поисковых машин на сайте.
Приходя на сайт, робот сразу загружает содержимое Robots.txt. Если файл отсутствует, робот будет индексировать все документы из корневой и вложенных папок (если они не закрыты от индексации другими методами). В результате могут возникнуть следующие проблемы:
В результате могут возникнуть следующие проблемы:
- в индекс попадают лишние страницы и конфиденциальные документы (например, профили пользователей), которые не должны участвовать в поиске;
- до основного важного контента робот может не добраться, так его ресурс и время на сайте ограничены.
Обрабатывая файл, роботы получают инструкции: индексировать, индексировать частично, запрещено к индексации.
Как правило, от индексации закрывают следующие документы и разделы:
- административную панель,
- системные файлы,
- кэшированные данные,
- страницы загрузки,
- поиск, фильтры и сортировки,
- корзины товаров,
- личные кабинеты,
- формы регистрации.
Что содержит Robots.txt
User-agent
Правило, указывающее, каким роботам оно предназначается. Если не указывать все роботы, а только прописать знак *, это будет значить, что правило действительно для любого известного робота, посетившего сайт.
User-agent: Yandex
Правило для робота Google:
User-agent: Googlebot
Disallow
Правило, указывающее роботам, какую информацию индексировать запрещено. Это могут быть отдельные документы, разделы сайта или сайт целиком (в том случае, если он еще находится в разработке).
Правило, запрещающее индексировать весь сайт:
Disallow: /
Запрет обхода страниц, находящихся в определенном каталоге:
Disallow: /catalogue
Запрет обхода конкретной страницы (указать URL):
Disallow: /user-data.html
Allow
Данная директива разрешает индексировать содержимое сайта. Может потребоваться, когда нужно выборочно разрешить к индексации какой-либо контент. Обычно используется в комбинации с Disallow.
Правило, запрещающее индексировать все, кроме указанных страниц:
User-agent: Googlebot Allow: /cgi-bin Disallow: /
Host
Данная директива сообщает роботу о главном зеркале сайта. С марта 2018 года «Яндекс» полностью отказался от этой директивы, поэтому ее можно не прописывать в Robots. Однако важно, чтобы на всех не главных зеркалах сайта теперь стоял 301-й постраничный редирект.
С марта 2018 года «Яндекс» полностью отказался от этой директивы, поэтому ее можно не прописывать в Robots. Однако важно, чтобы на всех не главных зеркалах сайта теперь стоял 301-й постраничный редирект.
Crawl-delay
Правило задает скорость обхода сайта. В секундах задается минимальный период времени между окончанием загрузки одной страницы и началом загрузки следующей. Необходимо при сильной нагрузке на сервер, когда робот не успевает обрабатывать страницы.
Установка тайм-аута в две секунды:
User-agent: Yandex Crawl-delay: 2.0
Clean-param
Правило задается для динамических страниц GET-параметром или страниц с рекламными метками (идентификатор сессии, пользователей и т. д.), чтобы робот не индексировал дублирующуюся информацию.
Запрет индексации страниц с рекламной меткой — параметром ref:
User-agent: Yandex Disallow: Clean-param: ref /video/how_to_look.ru
Sitemap
Правило сообщает роботам, что все URL сайта, обязательные для индексации, находятся в файле Sitemap. xml. Прописывается путь к этой карте сайта. При каждом новом визите робот будет обращаться к этому файлу и вносить в индекс новую информацию, если она появилась на сайте.
xml. Прописывается путь к этой карте сайта. При каждом новом визите робот будет обращаться к этому файлу и вносить в индекс новую информацию, если она появилась на сайте.
User-agent: Yandex Allow: / sitemap: https://somesite.ru/sitemaps.xml
Как создать файл Robots.txt
Файл создается в текстовом редакторе с присвоением имени robots.txt. В этом файле прописываются инструкции с учетом озвученных выше правил. Далее файл загружается в корневую директорию сайта.
Для блога или новостного сайта можно скачать стандартный robots.txt с сайта движка или форума разработчиков, подкорректировав под свои особенности.
Как проверить Robots.txt
Проверка валидности файла Robots.txt проводится с помощью инструментов веб-мастеров Google и «Яндекса».
См. также
VSPM-6B2413 Universal Robots Kit | Промышленная обработка изображений
VSPM-6B2413 Universal Robots Kit | Промышленная обработка изображений | SICKТип:VSPM-6B2413 Universal Robots Kit
Артикул: 1097255
Технический паспорт изделия Русский Cesky Dansk Deutsch English Español Suomi Français Italiano 日本語 – Японский 한국어 – Корейский Nederlands Polski Portugues Svenska Türkçe Traditional Chinese Китайский
Copy shortlinkТехнические характеристики
Загрузки
Принадлежности
Сценарии применения
Видео
Комплект поставки
Обслуживание и поддержка
Таможенные данные
Интерфейсы
Ethernet ✔ , TCP/IP Скорость передачи данных 100 Mbit/s EtherNet/IP™ ✔ Скорость передачи данных 100 Mbit/s Пользовательские интерфейсы Веб-сервер Конфигурационное ПО SOPAS ET Сохранение и вызов данных Журнал на 30 изображений, Сохранение изображений на ПК, Сохрнение изображений по FTP Связь по протоколу Ethernet Web-API Цифровой вход 4 входа (24 V) Конфигурируемые входы Внешний триггер, Вход энкодера, внешнее обучение, Выбор памяти эталонных объектов Цифровой выход 3 переключающих выхода, 24 В (тип B) Конфигурируемые выходы Выход программируется логически, дополнительные возможности сохранения изображений по FTP Выходной ток ≤ 100 mA Стандартные выходы Объект не зарегистрирован, всё в порядке, ошибка детали Максимальная частота энкодера 40 kHz Управление внешней подсветкой 5 V TTL Расширение модуля ввода-вывода 5 входов для выбора объекта, 16 выходов
Технические чертежи
Габаритный чертеж Стандарт
Зона обзора
Вид подключения
схема соединений M12, 12-конт.

схема соединений Ethernet

Пожалуйста, подождите…
Ваш запрос обрабатывается, это может занять несколько секунд.
Google обновил инструмент проверки файлов robots.txt
Google сообщил об обновлении инструмента проверки файла robots.txt в сервисе Webmaster Tools. Усовершенствованную версию инструмента можно найти в разделе «Сканирование:«Файл robots.txt — один из ключевых компонентов поисковой оптимизации сайтов, однако иногда он приносит больше вреда, чем пользы. В частности, этот самый файл может блокировать для роботов поисковых систем обход (сканирование) важных страниц сайта. Кроме того, robots.txt может препятствовать индексированию сайта в целом», — пишет редактор издания Search Engine Journal Мэтт Саузерн (Matt Southern).
Кроме того, robots.txt может препятствовать индексированию сайта в целом», — пишет редактор издания Search Engine Journal Мэтт Саузерн (Matt Southern).
Целью обновления инструмента Google как раз таки и является упрощение обнаружения и исправления ошибок в файле robots.txt, а также облегчение поиска директив, блокирующих индивидуальные URL-адреса, внутри единого большого файла.
Возможности модернизированного инструмента
Новая версия инструмента тестирования файла robots.txt в Google Webmaster Tools позволяет проверять новые URL-адреса на предмет их запрещённости к сканированию поисковыми роботами. Вебмастерам больше не придётся искать нужную строчку в длинном и сложном списке директив — инструмент сам подсветит указание для робота, нуждающееся в пересмотре и принятии окончательного решения.
Владельцы сайтов могут внести изменения в файл и тут же их протестировать: для этого надо всего-навсего загрузить обновлённую версию robots.txt на сервер.
Кроме того, модернизированная версия инструмента позволяет просматривать предыдущие версии файла robots.txt и проверять, когда и в связи с чем у сканирующих роботов Google возникли проблемы с доступом к определённым страницам сайта. По словам представителя команды Webmaster Tools Асафа Арнона (Asaph Arnon), Googlebot может взять паузу в сканировании сайта, если, к примеру, обнаружит внутреннюю ошибку сервера 500 для файла robots.txt.
Google советует дважды проверять файл robots.txt во избежание пропуска ошибок или важных предупреждений сервиса о нарушениях в сканировании и индексировании ресурса. Вебмастера также могут совмещать использование инструмента проверки файла robots.txt с другим функционалом Webmaster Tools: например, с обновлённым инструментом «Просмотреть как Googlebot», предоставляющим информацию об HTTP-ответе сервера, дате и времени сканирования, проблемах с доступом к картинкам, мобильному контенту, JavaScript и CSS файлам.
Что такое robots.
 txt и как его настроить
txt и как его настроитьЗнание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
- дубли страниц;
- служебные файлы;
- файлы, которые бесполезны для посетителей;
- страницы с неуникальным контентом.
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Главное правило называется User-agent. В нем мы создаем кодовое слово для роботов. Если робот видит такое слово, он понимает, что это правило для него.
Пример:
User-agent: Yandex
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
В последнее время эту строчку я заполняю так:
User-agent: *
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Allow: /category/
Даем рекомендацию, чтобы индексировались категории.
Disallow: /
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
- * – звездочка означает любую последовательность символов (либо отсутствие символов).
- $ – знак доллара является своеобразной точкой, которая прерывает последовательность символов.
Disallow: /category/$ # закрываем только страницу категорий Disallow: /category/* # закрываем все страницы в папке категории
Sitemap
Данная директива нужна для того, чтобы сориентировать робота, если он заплутает. Мы показываем роботу дорогу к Sitemap.
Мы показываем роботу дорогу к Sitemap.
Пример:
Sitemap: http://site.ru/sitemap.xml
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Crawl-delay: 10
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
User-agent: * Disallow: /
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.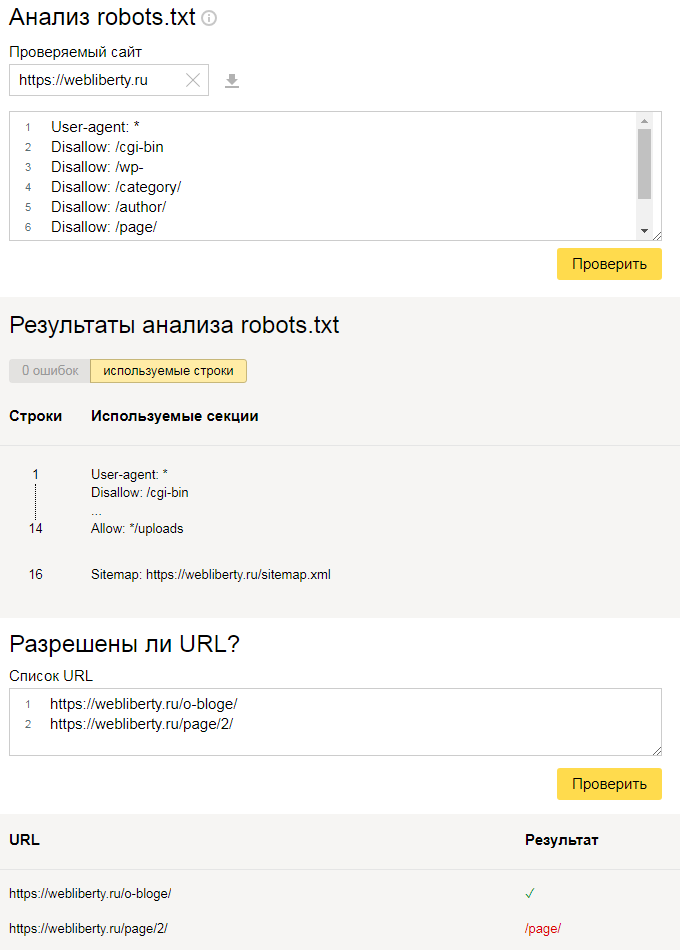 txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
Есть потрясающий инструмент, который позволит вам включиться в творческую работу с директивами и прописать правильный robots.txt – инструмент от Яндекс.Вебмастера.
Переходим в инструмент, вводим домен и содержимое вашего файла.
Нажимаем «Проверить» и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
Вводим список адресов, которые нас интересуют, и нажимаем «Проверить». Инструмент сообщит нам, разрешены ли для индексации данные адреса страниц, а в столбце «Результат» будет видно, почему страница индексируется или не индексируется.
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
User-agent: * Disallow: /cgi-bin # папка на хостинге Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ # Все служебные файлы можно закрыть другим образом: Disallow: /wp- Disallow: /xmlrpc.php # файл WordPress API Disallow: /*? # поиск Disallow: /?s= # поиск Allow: /*.css # стили Allow: /*.js # скрипты Sitemap: https://site.ru/sitemap.xml # путь к карте сайта (надо прописать свой сайт)
Правильный robots.txt для Joomla
User-agent: * Disallow: /administrator/ Disallow: /bin/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /layouts/ Disallow: /libraries/ Disallow: /logs/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Sitemap: https://site.
 ru/sitemap.xml
ru/sitemap.xmlЗдесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Правильно настроенный файл robots.txt способен оказать позитивное влияние на продвижение сайта. Если вы хотите избавиться от мусора и навести порядок на сайте, файл robots.txt готов прийти на помощь.
Файл Robots txt — настройка, как создать и проверить: пример robots txt на сайте, директивы
Текстовый файл, записывающий специальные инструкции для поискового робота, ограничивающие доступ к содержимому на http сервере, находящийся в корневой директории веб-сайта и имеющий путь относительно имени самого сайта (/robots.txt ).
Robots.txt — как создать правильный файл robots.txtФайл robots.txt позволяет управлять индексацией вашего сайта. Закрыть какой-либо раздел можно директивой disallow, открыть — allow. Проверка и анализ robots.txt.
Выгрузить в xls, файл, индексация, сайт, директива, яндекс, настройка, запрет, проверка, пример, генератор, анализ, страница, правильный, закрыть, создать, добавить, проверить, задать, запретить, сделать, robots, txt, host, закрытый, где, disallow
Robots. txt — текстовый файл, содержащий инструкции для поисковых роботов, как нужно индексировать сайт.
txt — текстовый файл, содержащий инструкции для поисковых роботов, как нужно индексировать сайт.
В 2011 году случилось сразу несколько громких скандалов, связанных с нахождением в поиске Яндекса нежелательной информации.
Сначала в выдаче Яндекса оказалось более 8 тысяч SMS-сообщений, отправленных пользователями через сайт компании «МегаФон». В результатах поиска отображались тексты сообщений и телефонные номера, на которые они были отправлены.
Заместитель генерального директора «МегаФона» Валерий Ермаков заявил, что причиной публичного доступа к данным могло стать наличие у клиентов «Яндекс.Бара», который считывал информацию и отправлял поисковому роботу Яндекса.
У Яндекса было другое объяснение:
«Еще раз можем подтвердить, что страницы с SMS с сайта МегаФона были публично доступны всем поисковым системам… Ответственность за размещение информации в открытом доступе лежит на том, кто её разместил или не защитил должным образом.
Особо хотим отметить, что никакие сервисы Яндекса не виноваты в утечке данных с сайта МегаФона. Ни Яндекс.Бар, ни Яндекс.Метрика не скачивают содержимое веб-страниц. Если страница закрыта для индексации в файле robots.txt или защищена логином и паролем, то она недоступна и поисковым роботам, то есть информация, размещенная на ней, никогда не окажется в какой-либо поисковой системе».
 ..
..Вскоре после этого пользователи нашли в Яндексе несколько тысяч страниц со статусами заказов в онлайн-магазинах книг, игр, секс-товаров и т.д. По ссылкам с результатов поиска можно было увидеть ФИО, адрес и контактные данные клиента магазина, IP-адрес, наименование его покупки, дату и время заказа. И снова причиной утечки стал некорректно составленный (или вообще отсутствующий) файл robots.txt.
Чтобы не оказаться в подобных ситуациях, лучше заранее составить правильный robots.txt файл для сайта. Как сделать robots. txt в соответствии с рекомендациями поисковых систем, расскажем ниже.
txt в соответствии с рекомендациями поисковых систем, расскажем ниже.
Настройка robots.txt начинается с создания текстового файла с именем «robots.txt». После заполнения этот файл нужно будет сохранить в корневом каталоге сайта, поэтому лучше заранее проверить, есть ли к нему доступ.
Основные директивы robots.txtВ простейшем файле robots.txt используются следующие директивы:
- User-agent
DisallowAllow
Здесь указываются роботы, которые должны следовать указанным инструкциям. Например, User-agent: Yandex означает, что команды будут распространяться на всех роботов Яндекса. User-agent: YandexBot – только на основного индексирующего робота. Если в данном пункте мы поставим *, правило будет распространяться на всех роботов.
Директива DisallowЭта команда сообщает роботу user-agent, какие URL не нужно сканировать. При составлении файла robots.txt важно помнить, что эта директива будет относиться только к тем роботам, которые были перед этим указаны в директиве user-agent. Если подразумеваются разные запреты для разных роботов, то в файле нужно указать отдельно каждого робота и директиву disallow для него.
При составлении файла robots.txt важно помнить, что эта директива будет относиться только к тем роботам, которые были перед этим указаны в директиве user-agent. Если подразумеваются разные запреты для разных роботов, то в файле нужно указать отдельно каждого робота и директиву disallow для него.
Как закрыть части сайта с помощью директивы Disallow:
- Если нужно закрыть от сканирования весь сайт, необходимо использовать косую черту (
/):Disallow: / -
Если нужно закрыть от сканирования каталог со всем его содержимым, необходимо ввести его название и косую черту в конце:Disallow: /events/ -
Если нужно закрыть страницу, необходимо указать название страницы после косой черты:Disallow: /file.html
Разрешает роботу сканировать сайт или отдельные URL.
В примере ниже robots.txt запрещает роботам Яндекса сканировать весь сайт за исключением страниц, начинающихся с «events»:
User-agent: Yandex
Allow: /events
Disallow: /
Спецсимволы в директивахДля директив Allow и Disallow используются спецсимволы «*» и «$».
Звездочка (*) подразумевает собой любую последовательность символов. Например, если нужно закрыть подкаталоги, начинающиеся с определенных символов:Disallow: /example*/-
По умолчанию символ * ставится в конце каждой строки. Если нужно закончить строку определенным символом, используется спецсимвол $. Например, если нужно закрытьURL, заканчивающиеся наdoc:Disallow: /*.doc$ -
Спецсимвол # используется для написания комментариев и не учитывается роботами.

Директива Host в robots.txt используется, чтобы указать роботу на главное зеркало сайта.
Пример:
https://www.glavnoye-zerkalo.ru является главным зеркалом сайта, и для всех сайтов из группы зеркал необходимо прописать в robots.txt:
User-Agent: *
Disallow: /forum
Disallow: /cgi-bin
Host: https://www.glavnoye-zerkalo.ru
Правила использования директивы Host:
- В файле robots.txt может быть только одна директива
Host. Робот всегда ориентируется на первую директиву, даже если их указано несколько. - Если зеркало доступно по защищенному каналу, нужно добавить протокол HTTPS,
- Должно быть указано одно доменное имя и номер порта в случае необходимости.

Если директива Host прописана неправильно, роботы ее проигнорируют.
Директива Crawl-delayДиректива Crawl-delay задает для робота промежуток времени, с которым он должен загружать страницы. Пригодится в случае сильной нагрузки на сервер.
Например, если нужно задать промежуток в 3 секунды между загрузкой страниц:
User-agent: *
Disallow: /search
Crawl-delay: 3
Директива Clean-paramПригодится для сайтов, страницы которых содержат динамические параметры, которые не влияют на их содержимое (например, идентификаторы сессий). Директива позволяет роботам не перезагружать дублирующуюся информацию, что положительно сказывается на нагрузке на сервер.
Использование кириллицыПри составлении файла robots.txt нельзя использовать кириллические символы. Допускается использование Punycode для доменов.
Как проверить robots. txt
txtДля проверки файла robots.txt можно использовать Яндекс.Вебмастер (Анализ robots.txt) или Google Search Console (Инструмент проверки файла Robots.txt).
Как добавить файл robots.txt на сайт
Как только файл robots.txt написан и проверен, его нужно сохранить в виде текстового файла с названием robots.txt и загрузить в каталог верхнего уровня сайта или в корневой каталог.
Как проверить файл robots.txt в Яндекс и Google: пошаговая инструкция
Первым делом необходимо проверить доступность файла robots.txt. Переходим и смотрим его визуально https://robotstxt.ru/robots.txt, открывается ли он.
Дальше нам необходимо проверить его техническую доступность, заходим в сервис проверки ответа сервера Яндекса.
Вводим путь к вашему файлу robots.txt и нажимаем проверить.
Должен отображаться ответ сервера 200. Если вы видите другие цифры, то значит robots. txt не доступен и поисковая система не сможет его прочитать.
txt не доступен и поисковая система не сможет его прочитать.
Как проверить в Яндекс?
В разработке…
Как проверить в Google?
Благодаря данному инструменту любой вебмастер и оптимизатор может посмотреть, открыты ли в robots.txt конкретные URL и файлы для индексирования роботами поисковой системы Google?
Допустим, на вашем сайте есть картинка, которую вы не желаете видеть в результатах выдачи Гугла по картинкам. В инструменте Robots Testing Tool вы узнаете, закрыт ли доступ к изображению боту Googlebot-Image.
Здесь нужно прописать URL-адрес, по которому располагается изображение. Далее инструмент обработает robots.txt таким же способом, что и робот Гугла по картинкам, чтобы выяснить, запрещен ли указанный УРЛ для индексирования.
Инструкция по проверке
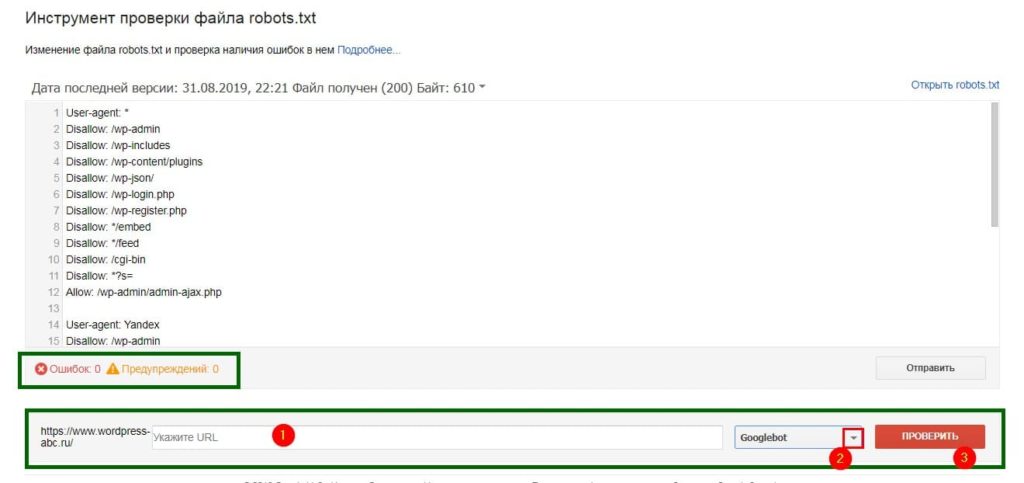
- Зайдите в Google Search Console и укажите свой сайт.
- Выберите инструмент проверки и проверьте инструкции, прописанные в файле Robots. Любые логические и синтаксические ошибки будут подчеркнуты, а их общее количество можно узнать внизу окна редактирования.
- В самом низу страницы найдите поле, предназначенное для указания необходимого URL-адреса.
- В меню, которое откроется справа, выберите бота.
- Кликните “Проверить”.
- После проверки инструмент покажет статус адреса: “Доступен” либо “Недоступен”. Если статус “Доступен”, значит роботам Гугла не запрещено включать в поиск изображение, а если “Недоступен”, то картинка не будет участвовать в поиске.
- Если нужно, сделайте необходимые исправления в меню и проверьте роботс снова. Имейте ввиду, что все изменения не вносятся в файл robots.txt вашего веб-ресурса автоматически.
- Сделайте копию измененного содержания и вставьте ее в robots на вашем сервере.
Что нужно знать
- Никакие изменения в редакторе не сохраняются на сервере в автоматическом режиме. Нужно скопировать измененный код и внести его в файл роботс.
- Инструмент для проверки Robots показывает
результаты только для юзер-агентов Google и роботов данной поисковой системы. При этом сотрудники компании не могут давать никаких гарантий, что роботы
других поисковиков будут учитывать содержание файла так же, как и Гугл.
 При этом сотрудники компании не могут давать никаких гарантий, что роботы
других поисковиков будут учитывать содержание файла так же, как и Гугл.
При этом сотрудники компании не могут давать никаких гарантий, что роботы
других поисковиков будут учитывать содержание файла так же, как и Гугл.Как отправить измененный robots.txt в Google?
В инструменте проверки роботса есть кнопка “Проверить”, благодаря которой ускоряется обход и включение в индекс нового robots.txt. Для передачи его в поисковую систему Google необходимо:
1. В правом нижнем углу редактора файла Robots кликнуть на кнопку “Проверить”. Так вы откроете диалоговое окно передачи.
2. Для выгрузки из инструмента кода файла, который был изменен, нажмите кнопку “Загрузить”.
3. Загрузите новый Robots в корневую папку сайта. Необходимо, чтобы URL файла выглядел следующим образом: /robots.txt.
На заметку. Если у вас нет доступа к админке, из-за чего нет возможности загружать файлы в корневой каталог домена, свяжитесь с его администратором.
Допустим, главная страница вашего веб-ресурса находится по
адресу subdomain. site.ru/site/example.
Тогда есть вероятность, что вы не сможете обновить файл robots, расположенный по адресу subdomain.site.ru/robots.txt.
Тогда напишите владельцу домена с просьбой изменить файл.
site.ru/site/example.
Тогда есть вероятность, что вы не сможете обновить файл robots, расположенный по адресу subdomain.site.ru/robots.txt.
Тогда напишите владельцу домена с просьбой изменить файл.
4. Нажмите “Проверить”. Так вы узнаете, применяется ли новая версия Robots, которую вы хотите, чтобы роботы просканировали.
5. Кликните “Отправить в Google” для отправки поисковой машине сигнала, что файл был изменен и его необходимо проверить.
6. Удостоверьтесь в том, что измененный файл был успешно проверен роботами. Для этого необходимо обновить страницу “Инструмент проверки файла robots.txt”. После этого обновится окно редактирование, где отобразится новый код файла. В меню, открывающемся над текстовым редактором, вы узнаете, когда Googlebot первый раз увидел актуальную версию роботса.
Заключение
Следуя инструкциям выше, вы будете уверены в том, что настроили Robots.txt правильно и поисковые системы сканируют файл так, как вам нужно.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Почему CAPTCHA стали такими сложными
В какой-то момент прошлого года постоянные запросы Google доказать, что я человек, стали становиться все более агрессивными. Все чаще и чаще за простой, немного слишком милой кнопкой с надписью «Я не робот» следовали требования доказать это — путем выбора всех светофоров, пешеходных переходов и витрин в сетке изображений. Вскоре светофоры утонули в далекой листве, пешеходные переходы искривлены и повернуты за угол, вывески на фасаде магазина расплывчаты и на корейском языке.Есть что-то однозначно удручающее в том, что вас просят определить пожарный гидрант и что с ним не удается справиться.
Эти тесты называются CAPTCHA, аббревиатура от полностью автоматизированного общедоступного теста Тьюринга, чтобы отличить компьютеры и людей друг от друга, и они уже достигли такого плато непостижимости. В начале 2000-х простых изображений текста было достаточно, чтобы сбить с толку большинство спам-ботов. Но десять лет спустя, после того как Google купил программу у исследователей Карнеги-Меллона и использовал ее для оцифровки Google Книг, тексты пришлось все больше искажать и скрывать, чтобы не отставать от улучшенных программ оптического распознавания символов — программ, которые окольными путями, все эти люди, решающие капчи, помогали совершенствоваться.
Но десять лет спустя, после того как Google купил программу у исследователей Карнеги-Меллона и использовал ее для оцифровки Google Книг, тексты пришлось все больше искажать и скрывать, чтобы не отставать от улучшенных программ оптического распознавания символов — программ, которые окольными путями, все эти люди, решающие капчи, помогали совершенствоваться.
Все эти навесы, которые могут быть, а могут и не быть витринами? Это финал гонки вооружений человечества с машинами.
Поскольку CAPTCHA — такой элегантный инструмент для обучения ИИ, любой конкретный тест может быть только временным, что с самого начала признали его изобретатели. Со всеми этими исследователями, мошенниками и обычными людьми, решающими миллиарды головоломок на пороге возможностей ИИ, в какой-то момент машины должны были пройти мимо нас. В 2014 году Google противопоставил один из своих алгоритмов машинного обучения людям, решая наиболее искаженные текстовые CAPTCHA: компьютер прошел тест правильно 99. 8 процентов времени, в то время как люди получали всего 33 процента.
8 процентов времени, в то время как люди получали всего 33 процента.
Затем Google перешел на NoCaptcha ReCaptcha, которая отслеживает пользовательские данные и поведение, позволяя некоторым людям пройти через них, нажав кнопку «Я не робот», и предоставляет другим метки изображений, которые мы видим сегодня. Но машины снова догоняют. Все эти навесы, которые могут быть витринами, а могут и не быть? Это финал гонки вооружений человечества с машинами.
Джейсон Полакис, профессор информатики в Университете Иллинойса в Чикаго, лично отмечает недавнее увеличение сложности CAPTCHA.В 2016 году он опубликовал статью, в которой использовал стандартные инструменты распознавания изображений, в том числе собственный поиск Google по обратным изображениям, для решения CAPTCHA Google с изображениями с точностью 70%. Другие исследователи справились с задачами Google Audio CAPTCHA, используя собственные программы распознавания звука.
По словам Полакиса, сегодня машинное обучение примерно так же хорошо, как люди, справляется с базовыми задачами распознавания текста, изображений и голоса. На самом деле, алгоритмы, вероятно, лучше справляются с этим: «Мы находимся на этапе, когда усложнение программного обеспечения в конечном итоге делает его слишком сложным для многих людей.Нам нужна альтернатива, но конкретного плана пока нет ».
На самом деле, алгоритмы, вероятно, лучше справляются с этим: «Мы находимся на этапе, когда усложнение программного обеспечения в конечном итоге делает его слишком сложным для многих людей.Нам нужна альтернатива, но конкретного плана пока нет ».
Проблема со многими из этих тестов не обязательно в том, что боты слишком умны, а в том, что люди их отстой
Литература по CAPTCHA изобилует фальстартами и странными попытками найти что-то, кроме текста или распознавания изображений, в чем люди универсально хороши, а машины с которыми борются. Исследователи пытались попросить пользователей классифицировать изображения людей по выражению лица, полу и этнической принадлежности.(Вы можете себе представить, насколько хорошо это прошло.) Были предложения по пустяковым CAPTCHA и CAPTCHA, основанным на детских стихах, распространенных в области, где якобы вырос пользователь. Такие культурные CAPTCHA нацелены не только на ботов, но и на людей, работающих на зарубежных фермах CAPTCHA, решающих головоломки за доли цента. Люди пытались заблокировать распознавание изображений, прося пользователей идентифицировать, скажем, свиней, но при этом создавая карикатуры на свиней и давая им солнцезащитные очки. Исследователи попросили пользователей идентифицировать объекты в пятнах, похожих на Magic Eye.В 2010 году исследователи предложили использовать CAPTCHA для индексации древних петроглифов, поскольку компьютеры не очень хорошо расшифровывают жесты оленей, нацарапанные на стенах пещер.
Люди пытались заблокировать распознавание изображений, прося пользователей идентифицировать, скажем, свиней, но при этом создавая карикатуры на свиней и давая им солнцезащитные очки. Исследователи попросили пользователей идентифицировать объекты в пятнах, похожих на Magic Eye.В 2010 году исследователи предложили использовать CAPTCHA для индексации древних петроглифов, поскольку компьютеры не очень хорошо расшифровывают жесты оленей, нацарапанные на стенах пещер.
Недавно были предприняты попытки разработать похожие на игры CAPTCHA, тесты, которые требуют, чтобы пользователи поворачивали объекты на определенные углы или перемещали части головоломки в нужное положение, с инструкциями, которые даются не в тексте, а в символах или подразумеваются контекстом игрового поля. Есть надежда, что люди поймут логику головоломки, но компьютеры, не имеющие четких инструкций, будут поставлены в тупик.Другие исследователи пытались использовать тот факт, что у людей есть тела, используя камеры устройств или дополненную реальность для интерактивного доказательства человечности.
Проблема многих из этих тестов не обязательно в том, что боты слишком умны, а в том, что люди с ними плохо справляются. И дело не в том, что люди глупы; дело в том, что люди очень разнообразны по языку, культуре и опыту. Как только вы избавитесь от всего этого, чтобы провести тест, который может пройти любой человек , без предварительной подготовки или особых размышлений, у вас останутся грубые задачи, такие как обработка изображений, именно то, что будет делать индивидуальный ИИ. хорош в.
«Тесты ограничены человеческими возможностями», — говорит Полакис. «Дело не только в наших физических возможностях, вам нужно что-то, что [может] кросс-культурное, кросс-языковое. Вам нужен вызов, который подходит для кого-то из Греции, кого-то из Чикаго, кого-то из Южной Африки, Ирана и Австралии одновременно. И он должен быть независимым от культурных сложностей и различий. Вам нужно что-то, что легко для обычного человека, оно не должно быть привязано к определенной подгруппе людей и в то же время должно быть трудным для компьютеров. Это очень ограничивает то, что вы на самом деле можете сделать. И это должно быть что-то, что человек может делать быстро и не слишком раздражает ».
Это очень ограничивает то, что вы на самом деле можете сделать. И это должно быть что-то, что человек может делать быстро и не слишком раздражает ».
Выяснение того, как исправить эти викторины с расплывчатыми изображениями, быстро приведет вас к философской территории: какое универсальное человеческое качество можно продемонстрировать машине, но которое не может имитировать никакая машина? Что значит быть человеком?
Но, возможно, наша человечность измеряется не тем, как мы выполняем задачу, а тем, как мы перемещаемся по миру — или, в данном случае, через Интернет.Игровые CAPTCHA, видео CAPTCHA, любой тест CAPTCHA, который вы изобрели, в конечном итоге будет сломан, говорит Шуман Гхосемаджумдер, который ранее работал в Google по борьбе с мошенничеством с кликами, прежде чем стать техническим директором компании Shape Security, занимающейся обнаружением ботов. Вместо тестов он предпочитает так называемую «непрерывную аутентификацию», по сути наблюдая за поведением пользователя и ища признаки автоматизации. «Настоящий человек не очень хорошо контролирует свои двигательные функции, поэтому он не может двигать мышью одним и тем же способом более одного раза при нескольких взаимодействиях, даже если они очень стараются», — говорит Гхосемаджумдер.«Хотя бот будет взаимодействовать со страницей, не двигая мышью или очень точно перемещая мышь, человеческие действия имеют« энтропию », которую трудно подделать, — говорит Гхосемаджумдер.
«Настоящий человек не очень хорошо контролирует свои двигательные функции, поэтому он не может двигать мышью одним и тем же способом более одного раза при нескольких взаимодействиях, даже если они очень стараются», — говорит Гхосемаджумдер.«Хотя бот будет взаимодействовать со страницей, не двигая мышью или очень точно перемещая мышь, человеческие действия имеют« энтропию », которую трудно подделать, — говорит Гхосемаджумдер.
Команда Google, занимающаяся CAPTCHA, думает в том же духе. Последняя версия reCaptcha v3, анонсированная в конце прошлого года, использует «адаптивный анализ рисков» для оценки трафика в зависимости от того, насколько он кажется подозрительным; Затем владельцы веб-сайтов могут решить бросить вызов сомнительным пользователям, например запрос пароля или двухфакторную аутентификацию.Google не сказал бы, какие факторы влияют на эту оценку, кроме того, что Google наблюдает, как выглядит группа «хорошего трафика» на сайте, по словам Сай Хормаи, менеджера по продукту в команде CAPTCHA, и использует это для определения « плохое движение. » Исследователи безопасности говорят, что это, скорее всего, сочетание файлов cookie, атрибутов браузера, шаблонов трафика и других факторов. Одним из недостатков новой модели обнаружения ботов является то, что она может сделать навигацию в Интернете, сводя к минимуму слежку, раздражающим занятием, поскольку такие вещи, как VPN и расширения для защиты от отслеживания, могут пометить вас как подозрительных и проблемных.
» Исследователи безопасности говорят, что это, скорее всего, сочетание файлов cookie, атрибутов браузера, шаблонов трафика и других факторов. Одним из недостатков новой модели обнаружения ботов является то, что она может сделать навигацию в Интернете, сводя к минимуму слежку, раздражающим занятием, поскольку такие вещи, как VPN и расширения для защиты от отслеживания, могут пометить вас как подозрительных и проблемных.
«Я думаю, люди понимают, что существует приложение для моделирования обычного человека-пользователя … или глупых людей».
Аарон Маленфант, руководитель группы инженеров Google CAPTCHA, говорит, что отказ от тестов Тьюринга призван обойти конкуренцию, которую люди продолжают проигрывать. «По мере того как люди вкладывают все больше и больше средств в машинное обучение, эти задачи будут становиться все сложнее и сложнее для людей, и именно поэтому мы запустили CAPTCHA V3, чтобы опередить эту кривую.Маленфант говорит, что через пять-десять лет проблемы с CAPTCHA, скорее всего, вообще не будут жизнеспособны. Вместо этого большая часть Интернета будет иметь постоянный секретный тест Тьюринга, работающий в фоновом режиме.
Вместо этого большая часть Интернета будет иметь постоянный секретный тест Тьюринга, работающий в фоновом режиме.
В своей книге « Самый гуманный человек » Брайан Кристиан принимает участие в конкурсе по тесту Тьюринга как человек-фольга и обнаруживает, что на самом деле довольно сложно доказать свою человечность в разговоре. С другой стороны, создатели ботов обнаружили, что это легко пройти, не будучи самым красноречивым или умным собеседником, а уклоняясь от вопросов, шутя без смысла, делая опечатки или в случае с ботом, который выиграл соревнование Тьюринга в 2014 году. , утверждающий, что он 13-летний украинский мальчик, плохо владеющий английским языком.В конце концов, человеку свойственно ошибаться. Возможно, подобное будущее ожидает CAPTCHA, наиболее широко используемый тест Тьюринга в мире — новая гонка вооружений, чтобы не создавать ботов, которые превосходят людей по маркировке изображений и синтаксическому анализу текста, а ботов, которые делают ошибки, пропускают кнопки, отвлекаются. и переключать вкладки. «Я думаю, что люди понимают, что существует приложение для моделирования обычного человека-пользователя … или глупых людей», — говорит Гхосемаджумдер.
и переключать вкладки. «Я думаю, что люди понимают, что существует приложение для моделирования обычного человека-пользователя … или глупых людей», — говорит Гхосемаджумдер.
тестов CAPTCHA тоже могут сохраняться в этом мире. В 2017 году компания Amazon получила патент на схему, включающую оптические иллюзии и логические головоломки, которые людям очень трудно расшифровать.Этот тест называется тестом Тьюринга через неудачу, единственный способ пройти — получить неправильный ответ.
Встречайте роботов, которые могут прибыть в ближайший к вам аэропорт
«Доброе утро. Добро пожаловать в British Airways. Куда я могу вас отвезти?» Четкий женский голос может принадлежать любой женщине, работающей в BA, но это робот, курсирующий по лондонскому аэропорту Хитроу. Перевозчик испытывает пару автономных роботов, которые могут направлять пассажиров вокруг Терминала 5. Это один из последних примеров увеличения автоматизации в аэропортах, включая современные интеллектуальные машины, которые взаимодействуют с пассажирами.
Терминал 5 является самым загруженным в аэропорту Хитроу, в 2018 году он обслужил около 32,8 миллиона пассажиров на 210 723 рейсах. В следующем году BA установила на этом объекте 80 автоматических машин для сдачи пакетов; он также экспериментировал с беспилотными грузовыми автомобилями. По словам перевозчика, автоматизация терминала позволила сократить количество очередей и сделать поездки более быстрыми и плавными.
Чтобы сделать новых роботов более удобными, они оба были названы Билл в честь капитана Э. Х. «Билла» Лоуфорда, который летал на U.Первый международный регулярный пассажирский рейс К. из Мидлсекса в Париж в 1919 году.
«Мы всегда ищем новые и инновационные способы использования автоматизации, чтобы помочь нашим клиентам быстрее и удобнее путешествовать по аэропорту и за его пределами», говорит Рикардо Видаль, руководитель отдела инноваций BA. «Эти умные роботы — последнее новшество, позволяющее нам освободить наших сотрудников для решения насущных проблем и предложить индивидуальные услуги, которые, как мы знаем, ценят наши клиенты. В будущем я предполагаю, что парк роботов будет работать бок о бок. встаньте на сторону наших сотрудников, предлагая поистине безупречный опыт путешествий.»
В будущем я предполагаю, что парк роботов будет работать бок о бок. встаньте на сторону наших сотрудников, предлагая поистине безупречный опыт путешествий.»
Роботы в аэропорту Хитроу могут общаться с пассажирами на нескольких языках и предоставлять информацию о рейсах в режиме реального времени.
Пара роботов высотой по пояс от лондонской компании BotsAndUs может общаться с пассажирами на нескольких языках и предоставлять информацию в режиме реального времени. Информация о рейсах. Они также могут направлять людей к стойкам обслуживания, стойкам регистрации негабаритного багажа, самообслуживанию, сдаче сумок, кафе и другим объектам в терминале. Машины основаны на роботе компании Bo, который имеет 11-дюймовый дисплей и датчики, включая 3D-лидары, ультразвуковые, инфракрасные и визуальные.Он может автономно перемещаться и избегать препятствий и оснащен литий-ионным аккумулятором, обеспечивающим восемь часов работы при полной зарядке.
«Автоматизация уже существенно изменила работу аэропортов во всех сферах деятельности — от обслуживания пассажиров до перемещения багажа, безопасности и многого другого», — говорит Андрей Данеску, соучредитель и генеральный директор BotsAndUs. «То, что мы видим в качестве следующего ключевого шага, — это объединить все это вместе, чтобы они могли общаться и сотрудничать друг с другом, предлагая беспроблемный и безопасный опыт от автостоянки до посадки на рейс.»
«То, что мы видим в качестве следующего ключевого шага, — это объединить все это вместе, чтобы они могли общаться и сотрудничать друг с другом, предлагая беспроблемный и безопасный опыт от автостоянки до посадки на рейс.»
Мировое развертывание
Хитроу — не единственный аэропорт, пытающийся внедрить роботов. Они появились в аэропортах в таких местах, как Ла-Гуардия, Мюнхен и Сеул. Роботы или автономные машины являются частью пилотных проектов в 40% авиакомпаний и согласно исследованию Air Transport IT Insights за 2019 год, опубликованному отраслевой ассоциацией SITA, составляют основные программы у 14% перевозчиков. следующие три года.Игроки отрасли испытывают различные виды машин, которые служат разным целям.
Автоматизация уже значительно изменила работу аэропортов во всех сферах деятельности — от обслуживания пассажиров до перемещения багажа, обеспечения безопасности и многого другого.
Андрей Данеску
соучредитель и генеральный директор BotsAndUs
Ожидается, что в течение десятилетия эта тенденция будет набирать обороты, особенно по мере того, как все больше роботов используется для повседневных задач. Ожидается, что к 2030 году роботы заменят процессы регистрации, согласно отчету, опубликованному в этом году U.К. — компания по управлению запасами Vero Solutions. Новые технологии для улучшения обслуживания в аэропортах в настоящее время проходят испытания, и пассажиры скоро увидят сквозные преобразования во всем опыте полета.
Ожидается, что к 2030 году роботы заменят процессы регистрации, согласно отчету, опубликованному в этом году U.К. — компания по управлению запасами Vero Solutions. Новые технологии для улучшения обслуживания в аэропортах в настоящее время проходят испытания, и пассажиры скоро увидят сквозные преобразования во всем опыте полета.
В Японии, ведущем производителе роботов для автоматизации производства, по крайней мере шесть аэропортов уже проводили или планируют испытания роботов. К ним относятся роботы, которые могут убирать залы и предоставлять услуги буксировки в аэропорту Нарита недалеко от Токио, где в преддверии Олимпийских игр в 2020 году наблюдался всплеск путешественников.
Также обслуживая столицу, аэропорт Ханэда недавно представил 12 новых роботов-уборщиков в четырех моделях, а также экспериментирует с автономными автобусами. Международный аэропорт Осаки Кансай экспериментировал с KATE, мобильным киоском регистрации, разработанным SITA, который может автоматически перемещаться в густонаселенные районы аэропорта, чтобы сократить время ожидания.
Роботы также внедряются за пределами крупных городов Японии из-за нехватки рабочих рук и стареющего населения. В апреле 2019 года в аэропорту Фудзи Сидзуока к юго-западу от Токио был запущен Reborg-Z — робот-гид и охранный робот с камерой на 360 градусов и большим дисплеем.Он может рассказать пассажирам, как передвигаться на японском, китайском, корейском и английском языках, и может использовать технологию искусственного интеллекта для распознавания лиц, а также признаков чрезвычайной ситуации, таких как крик. Reborg-Z также имеет датчики огня и дыма и может связываться с другими подразделениями Reborg-Z, а также сотрудниками службы безопасности.
«Мы получили положительные отзывы от клиентов, потому что наши роботы работают очень стабильно», — говорит Морихиса Шинья, представитель ALSOK, чьи роботы патрулируют офисные здания и торговые центры Токио.«Пассажиры также хорошо отреагировали, и они фактически используют дисплей роботов для получения информации».
Японский SoftBank тем временем продвигает роботов-гуманоидов в качестве развлечения и проводников. Тысячи единиц его робота Pepper были развернуты в магазинах, банках и других учреждениях в Японии и за рубежом. Он также работает в ресторанах аэропортов в Лос-Анджелесе, Вашингтоне, округ Колумбия, и Монреале, болтает с потенциальными клиентами и предлагает блюда.
Тысячи единиц его робота Pepper были развернуты в магазинах, банках и других учреждениях в Японии и за рубежом. Он также работает в ресторанах аэропортов в Лос-Анджелесе, Вашингтоне, округ Колумбия, и Монреале, болтает с потенциальными клиентами и предлагает блюда.
«Часть нашей цели с Pepper — привлечь путешественников в наш ресторан, чтобы расслабиться и расслабиться перед вылетом», — говорит Лина Мизерек, представитель HMSHost, который управляет закусочными.«Pepper добавляет развлечения нашим гостям и помогает еще больше увеличить посещаемость ресторана от путешественников, которые в противном случае могли бы пойти прямо к своим воротам».
Проблемы роста
Роботы, обслуживающие пассажиров, не всегда подходят для авиакомпаний или аэропортов. Спенсер — робот-гуманоид, на разработку и программирование которого ушло три года с участием нескольких европейских университетов, французского Национального центра научных исследований (CNRS) и аэропорта Амстердама Схипхол.В рамках проекта, совместно финансируемого Европейской комиссией, голландский перевозчик KLM опробовал Spencer в 2016 году, заставив его сканировать посадочные талоны и проводить пассажиров к выходам на посадку. Не вышло.
Пеппер — робот-гуманоид, который может развлекать и направлять пассажиров в аэропортах.
Люди по-прежнему предпочитают человеческое обслуживание клиентов автоматизации почти во всех аспектах авиаперелетов, согласно онлайн-опросу более 2000 путешественников из США, проведенному в 2019 году компанией OAG, глобальным поставщиком данных о поездках. Выяснилось, что «только 19% видят ценность в интерактивных роботах для консьерж-услуг и туристической информации.«
Существует распространенное заблуждение, что системы искусственного интеллекта уже могут понимать и реагировать на все ситуации, и пассажиры могут быть разочарованы, когда роботы не могут выполнить их запросы, — отмечает Норм Роуз, старший аналитик по технологиям и корпоративным путешествиям в Phocuswright, исследовании индустрии путешествий. Фирма. Успешное внедрение робототехники в аэропортах будет зависеть от плавного и эффективного перехода от робота к человеку. Роботы также должны начинаться с простых задач.
«Как мы видели в технологическом ландшафте, автоматизация наиболее эффективна, когда она дополняет человеческих услуг или предоставляет простые услуги, которые могут заменить основные задачи человека », — говорит Роуз.«Если ваша работа — ждать у ворот и направлять людей в нужное место, ваша работа будет заменена».
Погрузка и разгрузка багажа — еще одна задача, которую можно автоматизировать, — говорит Роуз, указывая в качестве примера на прототип робота для обработки ящиков от Boston Dynamics. В исследовании 2019 года, в котором прогнозируется, что к 2030 году роботы заменят до 20 миллионов рабочих мест на производстве, аналитическая фирма Oxford Economics назвала обработку багажа в аэропортах примером того, как роботы играют более важную роль в экономике услуг.Но хотя технология готова, стоимость пока непомерно высока.
«Роботы должны стать более распространенными, чтобы снизить стоимость и рассмотреть возможность замены наземных операторов», — говорит Роуз, добавляя, что автоматизация изменит услуги аэропорта и в других отношениях. «Если у меня сложный билет и рейс отменен, скорее всего, мне все равно понадобится агент-человек, хотя предоставление этому агенту технологии с поддержкой ИИ для оптимизации процесса перебронирования может быть еще одним примером применения ИИ в путешествии, хотя и не сексуально, как робот.»
Анализатор Robots.txt
Инструменты SEO
Инструменты, которые помогут вам создать и продвигать свой веб-сайт.
Расширения FirefoxВеб-инструменты Если вам нужна обратная связь или у вас есть какие-либо животрепещущие вопросы, задавайте их на форуме сообщества, чтобы мы могли их решить.
Обзор
Обзор содержания сайта.Включает карту сайта, глоссарий и контрольный список для быстрого старта.
SEO
Содержит информацию о ключевых словах, SEO на странице, построении ссылок и социальном взаимодействии.
КПП
Советы по покупке трафика в поисковых системах.
Отслеживание
Узнайте, как отслеживать свой успех с помощью обычных объявлений SEO и PPC. Включает информацию о веб-аналитике.
Доверие
Создание заслуживающего доверия веб-сайта — это залог того, что на него можно ссылаться и продавать его клиентам.
Монетизация
Узнайте, как зарабатывать деньги на своих веб-сайтах.
Аудио и видео
Ссылки на полезную аудио и видео информацию. Мы будем создавать новые SEO-видео каждый месяц.
Интервью
Эксклюзивные интервью только для участников.
Скидки
купонов и предложений, которые помогут вам сэкономить деньги на продвижении ваших сайтов.
Карта сайта
Просмотрите все наши учебные модули, на которые есть ссылки на одной странице.
Введите URL своего файла robots.txt
или вставьте его содержимое сюда
Связанная информация о файле Robots.txt
Получите конкурентное преимущество сегодня
Ваши ведущие конкуренты годами инвестируют в свою маркетинговую стратегию.
Теперь вы можете точно знать, где они ранжируются, выбирать лучшие ключевые слова и отслеживать новые возможности по мере их появления.
Изучите рейтинг своих конкурентов в Google и Bing сегодня с помощью SEMrush.
Введите конкурирующий URL-адрес ниже, чтобы быстро получить доступ к их истории эффективности обычного и платного поиска — бесплатно.
Посмотрите, где они занимают место, и побейте их!
- Исчерпывающие данные о конкурентах: исследований эффективности в обычном поиске, AdWords, объявлениях Bing, видео, медийных объявлениях и многом другом.
- Сравните через каналы: используйте чью-то стратегию AdWords, чтобы стимулировать рост вашего SEO, или используйте их стратегию SEO, чтобы инвестировать в платный поиск.
- Глобальный охват: Отслеживает результаты Google по более чем 120 миллионам ключевых слов на многих языках на 28 рынках
- Исторические данные о производительности: восходит к прошлому десятилетию, до того, как существовали Panda и Penguin, поэтому вы можете искать исторические штрафы и другие потенциальные проблемы с рейтингом.
- Без риска: Бесплатная пробная версия и низкая ежемесячная плата.
Ваши конкуренты, исследуют ваш сайт
Найдите новые возможности сегодня
Японский магазин использует робота для проверки людей в масках | Япония
Магазин в Японии нанял робота, чтобы гарантировать, что покупатели носят маски, поскольку страна готовится к возможной третьей волне коронавирусной инфекции.
Robovie, разработанный Международным научно-исследовательским институтом передовых телекоммуникаций в Киото, может выбрать клиентов, которые не носят масок, и вежливо попросить их скрыться. Он также может вмешаться, когда им не удается дистанцироваться от общества, пока они стоят в очереди, чтобы заплатить.
Судебный процесс, начавшийся на прошлой неделе в клубном магазине профессиональной футбольной команды Сересо Осака, продлится как минимум до конца месяца.
Разработчики Robovie, которые стоят за множеством роботизированных инноваций, надеются, что эксперимент уменьшит тесный контакт между покупателями и персоналом, добавляя, что они полагают, что большинство людей будут чувствовать себя менее смущенными, если их попросит прикрыть робот, чем другой человек. существование.
Оборудованный предварительно загруженной информацией о планировке магазина, Robovie использует камеру и датчики для наблюдения за перемещениями людей и лазеры для измерения расстояния между ними, сообщает информационное агентство Kyodo.
Когда это не принуждение к социальному дистанцированию и ношению масок — профилактическая мера, которая является общепринятой в Японии, — Robovie также направляет покупателей по магазину.
В то время как Япония избежала большого количества случаев заболевания и смертей, наблюдаемых в некоторых других странах, недавний рост ежедневных инфекций Covid-19 привел к призыву принять новые меры по предотвращению переполнения больниц с приближением зимы.
Он сообщил о 1441 новом случае в воскресенье, что немного меньше рекордных 1737 случаев заражения, зарегистрированных накануне, при этом Токио, Осака и другие города и регионы сообщают о рекордном ежедневном росте за выходные.
По данным общественного вещателя NHK, с начала пандемии в стране подтверждено 119 420 случаев заболевания и 1 908 случаев смерти.
Премьер-министр Ёсихидэ Суга заявил, что нет никаких планов по переосмыслению кампании субсидированного внутреннего туризма или объявлению второго чрезвычайного положения.
На самом северном главном острове Хоккайдо, популярном среди туристов месте, в течение четырех дней подряд было зарегистрировано более 200 случаев заболевания, в том числе более десятка случаев на соседнем острове Ришири, в которых местные жители обвиняют посетителей, использующих Схема проезда Go To, которая субсидирует праздники.
Опрос, проведенный Kyodo на выходных, показал, что 84% респондентов были обеспокоены последней вспышкой болезни, при этом более 68% заявили, что правительство должно уделять приоритетное внимание ответным мерам общественного здравоохранения над экономикой.
Половина опрошенных заявили, что они против распространенных слухов о продлении срока действия схемы Go To после конца января.
Предварительная проверка Robots.txt — searchVIU
Предварительная проверка Robots.txt — searchVIUУбедитесь, что изменения в файле robots.txt привели к желаемому результату и что трафик или прибыль не потеряны.
Часто бывает очень много URL-адресов, особенно на крупных веб-сайтах или веб-сайтах с большим количеством динамического контента.Это означает, что Google больше не сканирует все URL-адреса и не может индексировать важные подстраницы. Чтобы оптимально использовать «краулинговый бюджет», в таких случаях часто имеет смысл исключить страницы через robots.txt.
Следует убедиться, что никакие релевантные страницы не исключены.
Перед фактическим изменением файла robots.txt мы сканируем веб-сайт с новой версией, хранящейся у нас, и сравниваем сканирование с последним сканированием веб-сайта в реальном времени. Таким образом, мы можем, среди прочего, проверить следующие структурные факторы:
- Можно ли дополнительно проиндексировать контент с помощью кликов или показов — если нет, то какие?
- Были ли пропущены важные страницы распространения, и контент с кликами или показами больше не связан с внутренними ссылками?
- Есть ли страницы, на которые есть внешние ссылки, которые больше не могут сканировать робот Googlebot?
- Отставали ли релевантные страницы во внутренней структуре ссылок?
На нашем веб-сайте мы используем файлы cookie.Некоторые из них очень важны, а другие помогают нам улучшить этот веб-сайт и улучшить ваш опыт.
Предпочтение конфиденциальностиЗдесь вы найдете обзор всех используемых файлов cookie.Вы можете дать свое согласие на использование целых категорий или отобразить дополнительную информацию и выбрать определенные файлы cookie.
| Имя | Borlabs Cookie |
|---|---|
| Провайдер | Владелец этого сайта |
| Назначение | Сохраняет предпочтения посетителей, выбранные в поле cookie файла cookie Borlabs. |
| Имя файла cookie | borlabs-cookie |
| Срок действия cookie | 1 год |
| Имя | Диспетчер тегов Google |
|---|---|
| Провайдер | Google LLC |
| Назначение | Cookie от Google, используемый для управления расширенными скриптами и обработкой событий. |
| Политика конфиденциальности | https://policies.google.com/privacy?hl=en |
| Имя файла cookie | _ga, _gat, _gid |
| Срок действия cookie | 2 года |
| Имя | Контактные формы |
|---|---|
| Провайдер | Hubspot Inc. |
| Назначение | Пользователь связался с searchVIU. |
| Политика конфиденциальности | https: //legal.hubspot.ru / политика конфиденциальности |
| Хост (ы) | hsforms.net |
| Имя файла cookie | __cfduid |
| Срок действия cookie | 1 месяц |
Настройте своих роботов.txt файл
На файлыRobots.txt ссылаются поисковые системы для индексации содержания вашего веб-сайта. Они могут быть полезны для предотвращения возврата в результатах поисковой системы определенного контента, например, предложения контента, скрытого за формой.
Обратите внимание: Google и другие поисковые системы не могут задним числом удалять страницы из результатов поиска после реализации метода файла robots.txt. Хотя это говорит ботам не сканировать страницу, поисковые системы все равно могут индексировать ваш контент, если, например, есть входящие ссылки на вашу страницу с других веб-сайтов.Если ваша страница уже проиндексирована и вы хотите, чтобы она была удалена из поисковых систем задним числом, вы, вероятно, захотите использовать метод метатега «Без индекса».
Как работают файлы robots.txt
Ваш файл robots.txt сообщает поисковым системам, как сканировать страницы, размещенные на вашем веб-сайте. Два основных компонента вашего файла robots.txt:
- User-agent: Определяет поисковую систему или веб-бота, к которому применяется правило. Звездочка (*) может использоваться как подстановочный знак с User-agent для включения всех поисковых систем.
- Disallow: Советует поисковой системе не сканировать и не индексировать файл, страницу или каталог.
Чтобы узнать больше о том, как настроить файлы robots.txt для результатов поиска Google, ознакомьтесь с документацией для разработчиков Google. Вы также можете использовать инструмент генератора robots.txt для создания файла.
Обратите внимание: для блокировки файла в файловом менеджере настройте файл так, чтобы он размещался в одном из ваших доменов. Затем вы можете добавить URL-адрес файла в файл robots.txt файл.
Обновите файл robots.txt в HubSpot
В своей учетной записи HubSpot щелкните значок настроек Настройки на главной панели навигации.
В меню левой боковой панели перейдите к Website > Pages .
Используйте раскрывающееся меню Изменение , чтобы выбрать домен для обновления.
- Щелкните вкладку SEO & Crawlers .
- Прокрутите вниз до Роботов.tx t и внесите изменения в свой файл robots.txt в текстовое поле.
Обратите внимание: , если вы используете на своем веб-сайте модуль поиска HubSpot, звездочка в поле агента пользователя заблокирует сканирование вашего сайта функцией поиска. Вам нужно будет включить HubSpotContentSearchBot в качестве пользовательского агента в файл robots.txt, чтобы функция поиска могла сканировать ваши страницы.
Целевые страницы Блог Настройки учетной записи Страницы веб-сайта
6 гостиничных брендов — лидеры в области робототехники
В гостиничной индустрии иногда кажется, что будущее наступило.Почему? Многие ведущие гостиничные бренды начали использовать роботов, чтобы улучшить качество обслуживания гостей. Фактически, некоторые из них уже некоторое время тестируют его. И это привело к появлению роботов-посыльных, роботов-дворецких и роботов-консьержей в отелях.
Почему отели используют роботов?Все отельеры хотят оставить у своего гостя положительные воспоминания. Еще лучше, если этот гость вернется или поделится своим опытом с другими. Как роботы могут в этом помочь?
Проще говоря, гостиничные роботы обеспечивают конкурентное преимущество над конкурентами.
Роботы могут высвободить время персонала. и помогут персонализировать пребывание гостя. Фактически, их использование практически безгранично — ограничивающими факторами являются только воображение и стоимость.
Вот лучшие отели, использующие роботов на сегодняшний день.
Робот-консьерж HiltonВ 2016 году Hilton и IBM объединились для создания Конни, робота-резидента в отеле McLean в Вирджинии. Конни (названная в честь основателя Hilton Конрада) — консьерж. Робот рассказывает гостям о близлежащих достопримечательностях, ресторанах и отелях.Работая на суперкомпьютере IBM Watson AI, Конни выглядит настолько привлекательно, насколько это возможно для робота.
Робот-дворецкий AloftВ 2014 году Aloft Hotels стала первым гостиничным брендом, использующим роботизированные технологии, представив A.L.O — робота-дворецкого или Botlr — в своем филиале в Купертино. Робот может объехать весь отель, чтобы доставить товар. Его основная цель заключалась в том, чтобы удивить гостя доставкой в номер.
Робот-доставщик Crowne PlazaЕще одним первопроходцем в области робототехники стала компания Crowne Plaza, расположенная в Сан-Хосе, в Кремниевой долине.Робот под названием Dash предназначен для доставки закусок, туалетных принадлежностей и других удобств отеля. При вызове Dash пробирается через отель, используя уникальное соединение Wi-Fi. И, к удивлению многих гостей, он звонит по телефону и сообщает о своем прибытии. Он даже может контролировать собственное энергопотребление и при необходимости возвращаться к точке зарядки.
Роботы на стойке регистрации Henn na HotelПричудливый и футуристический: так лучше всего можно описать отель Henn na в городке Сасебо, недалеко от Нагасаки, Япония.В этом отеле впереди роботы. Когда вы входите, на стойке регистрации вас встречает робот-велоцираптор. Затем он просит вас зарегистрироваться на сенсорном экране. Когда вы попадете в свою комнату, вы откроете дверь с распознаванием лиц. Робот в комнате (по имени Чури Сан) управляет отоплением и освещением, сообщает вам погоду и многое другое.
Yotel Hotels «Робот для перевозки багажа»Гостиничные роботы Yotel не похожи на своих конкурентов. Робот в нью-йоркском отеле, ласково названном Yobot, автоматически собирает и хранит багаж гостей.Yobot может обрабатывать около 300 единиц багажа в день. Таким образом, гости могут быстро пройти регистрацию заезда и иметь настолько ограниченный контакт с другими людьми, насколько они того пожелают. Однако настоящая цель этой технологии — высвободить сотрудников для выполнения других обязанностей — сэкономить время и деньги.
Hotel Сервисный робот EMC2В отеле EMC2 в Чикаго работают два робота-сотрудника, Клео и Лео. Одетые так, чтобы произвести впечатление (с бирками с именами и фалдами) ростом около трех футов, они вызвали настоящий фурор. Клео и Лео удовлетворяют потребности гостей, доставляя все, что им нужно: дополнительное полотенце, закуску, зубную щетку.В общем, они заменяют их, когда их человеческие аналоги недоступны.
Исключили из списка гостиничные бренды, использующие роботизированные технологии? Дайте нам знать в комментариях или присоединяйтесь к нам на Facebook!
Если вы когда-нибудь говорили: «Ух, сегодня пятница! — Ой, подождите, я работаю на мероприятиях ». |